
Anahtar Kelimeler:Kimi K2 Düşünme, Gemini, Yapay Zeka Aracı, Büyük Dil Modeli (LLM), Açık Kaynak Model, Kimi K2 Düşünme 256K Bağlam, Gemini 1.2 Trilyon Parametre, Yapay Zeka Aracı Araç Çağrısı, Büyük Dil Modeli Çıkarım Hızlandırma, Açık Kaynak Yapay Zeka Modeli Kıyaslama Testi
🔥 Spotlight
Kimi K2 Thinking Model Released, Open-Source AI Inference Capability Breakthrough : Moonshot AI has released the Kimi K2 Thinking model, a trillion-parameter open-source inference agent model that performs exceptionally well in benchmarks like HLE and BrowseComp, supports a 256K context window, and can execute 200-300 consecutive tool calls. The model achieves a two-fold inference speedup with INT4 quantization, halving memory usage without loss of accuracy. This marks a new frontier for open-source AI models in inference and agent capabilities, competing with top closed-source models at a lower cost, and is expected to accelerate AI application development and adoption. (Source: eliebakouch, scaling01, bookwormengr, vllm_project, nrehiew_, crystalsssup, Reddit r/LocalLLaMA)

Apple Partners with Google: Gemini Powers Major Siri Upgrade : Apple plans to integrate Google’s Gemini 1.2 trillion-parameter AI model into iOS 26.4, set for release in Spring 2026, to comprehensively upgrade Siri. This customized Gemini model will run on Apple’s private cloud servers, aiming to significantly enhance Siri’s semantic understanding, multi-turn conversation, and real-time information retrieval capabilities, as well as integrate AI web search functionality. This move signifies a major strategic shift for Apple, seeking external partnerships in AI to accelerate the intelligence of its core products, foreshadowing a tremendous leap in Siri’s functionality. (Source: op7418, pmddomingos, TheRundownAI)

Kosmos AI Scientist Achieves Research Efficiency Leap, Independently Discovers 7 Findings : The Kosmos AI scientist completed the equivalent of 6 months of human scientist work in 12 hours, reading 1,500 papers, running 42,000 lines of code, and producing traceable scientific reports. It independently discovered 7 findings in fields such as neuroprotection and materials science, 4 of which were novel. Through continuous memory and autonomous planning, the system evolved from a passive tool to a research collaborator. Although approximately 20% of conclusions still require human validation, it foreshadows a reshaping of the scientific research paradigm through human-AI collaboration. (Source: Reddit r/MachineLearning, iScienceLuvr)
🎯 Trends
Google Gemini 3 Pro Model Accidentally Leaked, Drawing Community Attention : The Google Gemini 3 Pro model has reportedly been accidentally leaked, briefly becoming available in the Gemini CLI for US IP addresses, but it is frequently encountering errors and remains unstable. This leak has sparked high community interest in the model’s parameter count and future release, indicating that Google’s latest advancements in large language models may soon be unveiled. (Source: op7418)
OpenAI GPT-5.1 Thinking Model Imminent, Community Anticipation High : Multiple social media reports suggest OpenAI is on the verge of releasing the GPT-5.1 Thinking model, with leaked information confirming its existence. This news has generated high community anticipation for OpenAI’s next-generation model’s capabilities and release timeline, particularly focusing on its enhanced reasoning and thinking abilities, which are expected to push the AI technological frontier once again. (Source: scaling01)
Anthropic Research Reveals Emerging LLM Introspection, Raising AI Self-Awareness Concerns : Through concept injection experiments, Anthropic discovered that its LLMs (such as Claude Opus 4.1 and 4) exhibit an emerging introspective awareness, capable of detecting injected concepts with a 20% success rate, distinguishing internal ‘thoughts’ from text input, and identifying output intentions. The models can also adjust their internal states when prompted, indicating the emergence of diverse and unreliable mechanistic self-awareness in current LLMs, sparking deeper discussions on AI self-cognition and consciousness. (Source: TheTuringPost)

OpenAI Codex Rapid Iteration, ChatGPT Supports Interruption and Guidance for Enhanced Interaction Efficiency : OpenAI’s Codex model is rapidly improving, and ChatGPT has also added a new feature allowing users to interrupt long query executions and add new context without restarting or losing progress. This significant functional update enables users to guide and refine AI responses much like collaborating with a real teammate, greatly enhancing interaction flexibility and efficiency, and optimizing the user experience in deep research and complex queries. (Source: nickaturley, nickaturley)
Tencent Hunyuan Launches Interactive AI Podcast, Exploring New AI Content Interaction Models : Tencent Hunyuan has launched China’s first interactive AI podcast, allowing users to interrupt and ask questions at any time during listening, with the AI providing answers based on context, background information, and online retrieval. While technically achieving more natural voice interaction, its core remains user interaction with AI rather than creators, and answers have no direct connection to creators. Commercial viability and user adoption models still face challenges, necessitating exploration into how to build emotional connections between users and creators. (Source: 36氪)
AI Hardware and Embodied AI Market Development and Challenges: From Earbuds to Humanoid Robots : With the maturation of large models and multimodal technologies, the AI earbud market continues to heat up, expanding functionalities to content ecosystems and health monitoring. The embodied AI robot industry is also at the cusp of a new boom, with companies like Xpeng and PHYBOT showcasing humanoid robots, clarifying ‘hidden human’ doubts, and exploring application scenarios such as elder care and cultural heritage (e.g., calligraphy, kung fu). However, the industry faces challenges such as cost, ROI, data collection, and standardization bottlenecks. In the short term, it needs to pragmatically focus on ‘scenario generality,’ while in the long term, open platforms and ecosystem collaboration are required. AI in healthcare also needs to address patient care gaps. (Source: 36氪, 36氪, op7418, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

New Models and Performance Breakthroughs: Qwen3-Next Code Generation, vLLM Hybrid Models, and Low-Memory Inference : Alibaba Cloud’s Qwen3-Next model excels in complex code generation, successfully creating fully functional web applications. vLLM fully supports hybrid models like Qwen3-Next, Nemotron Nano 2, and Granite 4.0, enhancing inference efficiency. AI21 Labs’ Jamba Reasoning 3B model achieves ultra-low memory operation at 2.25 GiB. Maya-research/maya1 released a new generation of autoregressive text-to-speech models, supporting text-described custom voice tones. TabPFN-2.5 extends tabular data processing capabilities to 50,000 samples. The Windsurf SWE-1.5 model is analyzed to be more similar to GLM-4.5, hinting at the application of domestic large models in Silicon Valley. MiniMax AI ranks second in the RockAlpha arena. These advancements collectively push the performance boundaries of LLMs in areas such as code generation, inference efficiency, multimodal capabilities, and tabular data processing. (Source: Reddit r/deeplearning, vllm_project, AI21Labs, Reddit r/LocalLLaMA, Reddit r/MachineLearning, dotey, Alibaba_Qwen, MiniMax__AI)

AI Infrastructure and Frontier Research: AWS Cooling, Diffusion-based LLMs, and Multilingual Architectures : Amazon AWS has introduced the In-Row Heat Exchanger (IRHX) liquid cooling system to address the thermal challenges of AI infrastructure. Joseph Redmon returns to AI research, publishing the OlmoEarth paper, exploring foundational models for Earth observation. Meta AI released a new ‘Mixture of Languages’ architecture, optimizing multilingual model training. The Inception team achieved diffusion-based LLMs, increasing generation speed by 10 times. Google DeepMind’s AlphaEvolve is used for large-scale mathematical exploration. The Wan 2.2 model achieves an 8% inference speed increase through NVFP4 optimization. These advancements collectively drive efficiency in AI infrastructure and innovation in core research areas. (Source: bookwormengr, iScienceLuvr, TimDarcet, GoogleDeepMind, mrsiipa, jefrankle)

Neuralink BCI Technology Enables Paralyzed Users to Control Robotic Arms : Neuralink’s Brain-Computer Interface (BCI) technology has successfully enabled paralyzed users to control robotic arms through thought. This breakthrough signifies AI’s immense potential in assistive healthcare and human-computer interaction, potentially combining with life-support robots in the future to significantly improve the quality of life and independence for people with disabilities. (Source: Ronald_vanLoon)
🧰 Tools
Google Gemini Computer Use Preview Model Released, Empowering AI Automated Web Interaction : Google has released the Gemini Computer Use Preview model, which users can run via a Command Line Interface (CLI), enabling it to perform browser operations, such as searching for ‘Hello World’ on Google. This tool supports Playwright and Browserbase environments and can be configured via the Gemini API or Vertex AI, providing a foundation for AI agents to automate web interactions and greatly expanding the capabilities of LLMs in practical applications. (Source: GitHub Trending, Reddit r/LocalLLaMA, Reddit r/artificial)

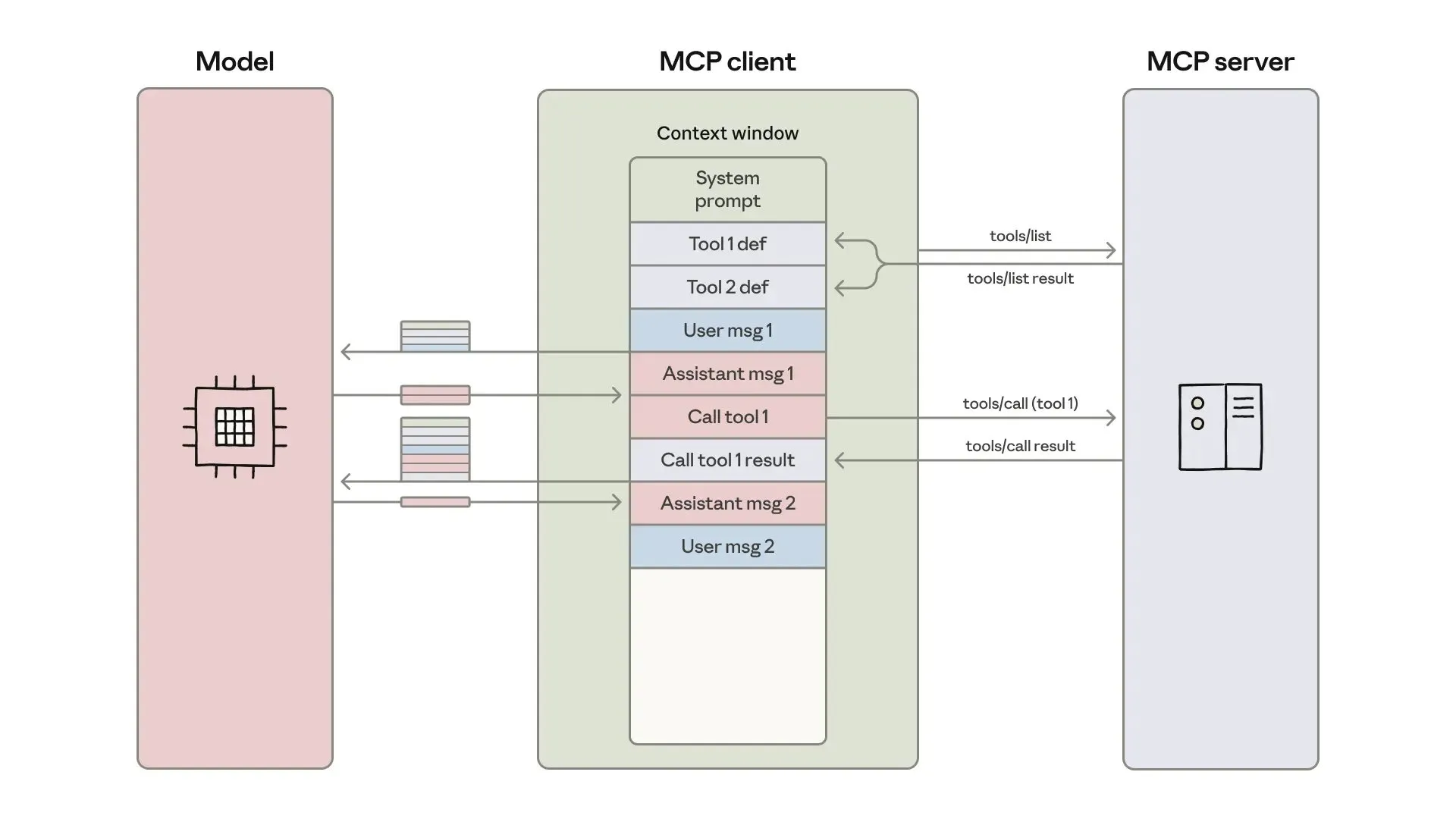
AI Agent Development and Optimization: Context Engineering and Efficient Construction : Anthropic has released a guide on building more efficient AI agents, focusing on addressing token costs, latency, and tool combination issues in tool calls. The guide reduces token usage for complex workflows from 150,000 to 2,000 through a ‘code as API’ approach, progressive tool discovery, and in-environment data processing. Concurrently, developers of ClaudeAI Agent Skills shared their experiences, emphasizing treating Agent Skills as a context engineering problem rather than a documentation pile. They significantly improved activation speed and token efficiency through a three-layer loading system, demonstrating the importance of the ‘200-line rule’ and progressive disclosure. (Source: omarsar0, Reddit r/ClaudeAI)
Chat LangChain Releases New Version, Offering Faster, Smarter Chat Experience : Chat LangChain has released a new version, claiming to be ‘faster, smarter, and better-looking,’ aiming to replace traditional documentation with a chat interface to help developers deliver projects more quickly. This update enhances the user experience of the LangChain ecosystem, making it easier to use and develop, and providing more efficient tools for building LLM applications. (Source: hwchase17)
Yansu AI Coding Platform Launches Scenario Simulation Feature, Boosting Software Development Confidence : Yansu is a new AI coding platform focused on serious and complex software development, uniquely placing scenario simulation before coding. This approach aims to enhance software development confidence and efficiency by pre-simulating development scenarios, reducing post-coding debugging and rework, and thus optimizing the entire development process. (Source: omarsar0)
Qdrant Engine Launches Cloud-Native RAG Solution for Comprehensive Data Control : Qdrant Engine has published a new community article introducing a cloud-native RAG (Retrieval-Augmented Generation) solution based on Qdrant (vector database), KServe (embeddings), and Envoy Gateway (routing and metrics). This is a complete open-source RAG stack that offers comprehensive data control, providing convenience for enterprises and developers to build efficient AI applications, with a particular emphasis on data privacy and autonomous deployment capabilities. (Source: qdrant_engine)

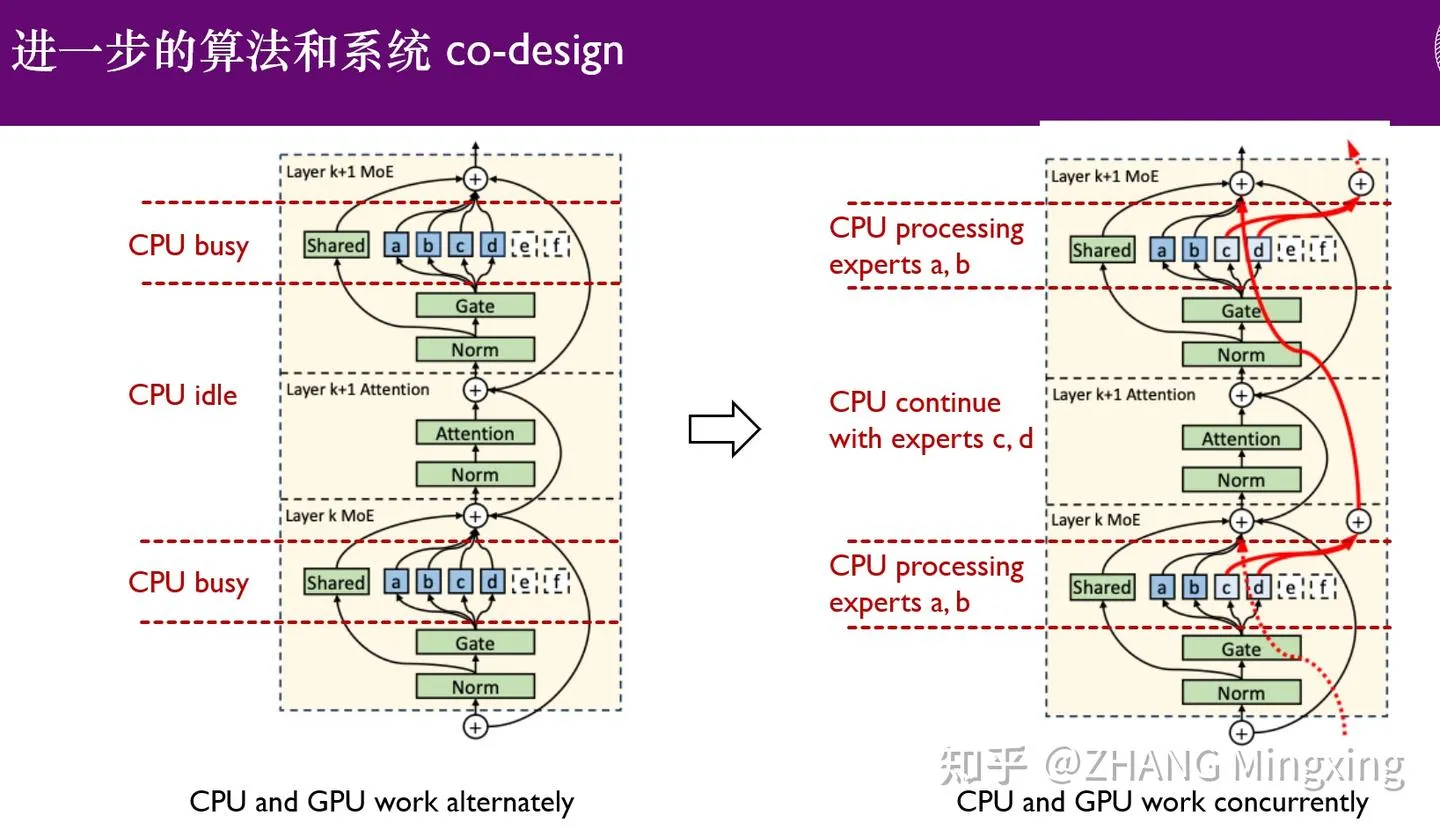
KTransformers Enters New Era of Multi-GPU Inference and Local Fine-tuning, Empowering Trillion-Parameter Models : In collaboration with SGLang and LLaMa-Factory, KTransformers has enabled low-barrier multi-GPU parallel inference and local fine-tuning for trillion-parameter models (such as DeepSeek 671B and Kimi K2 1TB). Through expert latency techniques and CPU/GPU heterogeneous fine-tuning, inference speed and memory efficiency are significantly improved, allowing ultra-large models to operate efficiently with limited resources and promoting the application of large language models in edge devices and private deployments. (Source: ZhihuFrontier)
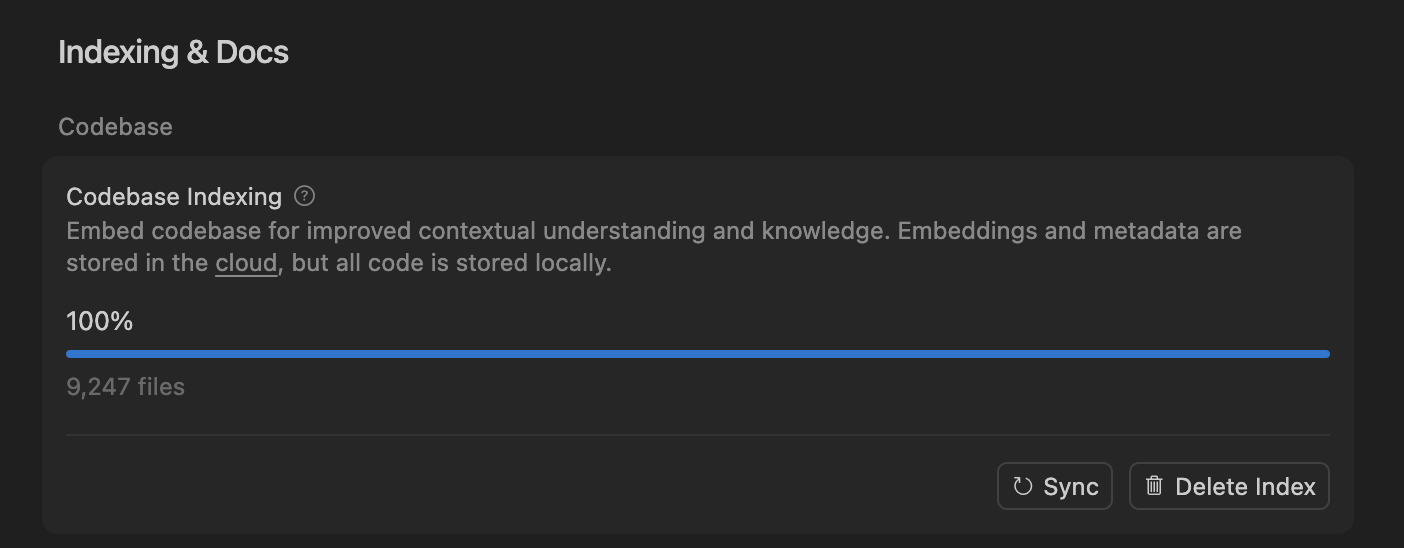
Cursor Enhances AI Coding Agent Accuracy with Semantic Search, Optimizing Large Codebase Handling : The Cursor team found that semantic search significantly improves the accuracy of its AI coding agents across all frontier models, especially in large codebases, outperforming traditional grep tools. By storing codebase embeddings in the cloud and accessing code locally, Cursor achieves efficient indexing and updates without storing any code on servers, ensuring privacy and efficiency. This technological breakthrough is crucial for enhancing AI’s assistive capabilities in complex software development. (Source: dejavucoder, turbopuffer)
LLM Agents and Tabular Models Open-Source Toolkits: SDialog and TabTune : The Johns Hopkins University JSALT 2025 workshop introduced SDialog, an MIT-licensed open-source toolkit for end-to-end building, simulation, and evaluation of LLM-based conversational agents, supporting role definition, orchestrators, and tools, and providing mechanistic interpretability analysis. Concurrently, Lexsi Labs released TabTune, an open-source framework designed to streamline the workflow for Tabular Foundation Models (TFMs), offering a unified interface to support various adaptation strategies, thereby enhancing TFMs’ usability and scalability. (Source: Reddit r/MachineLearning, Reddit r/deeplearning)

📚 Learn
Frontier Papers: DLM Data Learning, Tabular ICL, and Audio-Video Generation : The paper ‘Diffusion Language Models are Super Data Learners’ indicates that DLMs consistently outperform AR models in data-constrained scenarios. ‘Orion-MSP: Multi-Scale Sparse Attention for Tabular In-Context Learning’ introduces a new architecture for tabular in-context learning, surpassing SOTA through multi-scale processing and block-sparse attention. ‘UniAVGen: Unified Audio and Video Generation with Asymmetric Cross-Modal Interactions’ proposes a unified audio and video joint generation framework, addressing issues of insufficient lip synchronization and semantic consistency. These papers collectively advance the frontier of LLMs in data efficiency, specific data type processing, and multimodal generation. (Source: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
LLM Inference and Safety Research: Sequential Optimization, Consistency Training, and Red Teaming : The study ‘The Sequential Edge: Inverse-Entropy Voting Beats Parallel Self-Consistency at Matched Compute’ found that sequential iterative optimization in LLM inference generally outperforms parallel self-consistency, leading to significant accuracy improvements. Google DeepMind’s paper ‘Consistency Training Helps Stop Sycophancy and Jailbreaks’ proposes that consistency training can suppress AI sycophancy and jailbreaks. EMNLP 2025 papers explored LM red-teaming attacks, emphasizing the optimization of perplexity and toxicity. These studies provide important theoretical and practical guidance for improving LLM inference efficiency, safety, and robustness. (Source: HuggingFace Daily Papers, Google DeepMind发布“Consistency Training”论文,抑制AI谄媚和越狱, EMNLP 2025论文探讨LM红队攻击与偏好学习)

LLM Capability Evaluation and Benchmarks: CodeClash and IMO-Bench : CodeClash is a new benchmark for evaluating LLM coding capabilities in managing entire codebases and competitive programming, pushing the limits of existing LLMs. The release of IMO-Bench played a crucial role in Gemini DeepThink winning a gold medal in the International Mathematical Olympiad, providing valuable resources for enhancing AI’s mathematical reasoning abilities. These benchmarks drive the development and evaluation of LLMs in advanced tasks such as complex coding and mathematical reasoning. (Source: CodeClash:评估LLM编码能力的新基准, IMO-Bench发布,助力Gemini DeepThink在IMO中取得金牌)

Stanford NLP Team Releases Multi-Domain Research Findings at EMNLP 2025 : The Stanford University NLP team presented multiple research papers at EMNLP 2025, covering various frontier areas such as cultural knowledge graphs, LLM unlearned data identification, program semantic reasoning benchmarks, internet-scale n-gram search, robot vision-language models, in-context learning optimization, historical text recognition, and Wikipedia knowledge inconsistency detection. These achievements demonstrate their latest research depth and breadth in natural language processing and interdisciplinary AI fields. (Source: stanfordnlp)
AI Agents and RL Learning Resources: Self-Play, Multi-Agent Systems, and Jupyter AI Courses : Several researchers believe that self-play and autocurricula are the next frontiers in Reinforcement Learning (RL) and AI agent fields. Manning Books’ early access version of ‘Build a Multi-Agent System (From Scratch)’ is selling rapidly, teaching how to build multi-agent systems with open-source LLMs. DeepLearning.AI launched a Jupyter AI course, empowering AI coding and application development. ProfTomYeh also provided a beginner’s guide series on RAG, vector databases, agents, and multi-agents. These resources collectively offer comprehensive support for learning and practicing AI agents and RL. (Source: RL与Agent领域:自玩和自课程是未来前沿, 《Build a Multi-Agent System (From Scratch)》早期访问版销售火爆, Jupyter AI课程发布,赋能AI编码与应用开发, RAG、向量数据库、代理和多代理初学者指南系列)
LLM Infrastructure and Optimization: DeepSeek-OCR, PyTorch Debugging, and MoE Visualization : DeepSeek-OCR addresses the Token explosion problem in traditional VLMs by compressing document visual information into a small number of tokens, improving efficiency. StasBekman added a PyTorch large model memory debugging guide to his ‘The Art of Debugging Open Book’. xjdr developed a custom visualization tool for MoE models, enhancing the understanding of MoE-specific metrics. These tools and resources collectively provide critical support for optimizing LLM infrastructure and improving performance. (Source: DeepSeek-OCR解决Token爆炸问题,提升文档视觉语言模型效率, PyTorch调试大型模型内存使用指南, MoE特定指标的可视化工具)

AI Learning and Career Development: Data Scientist Roadmap and A Brief History of AI : PythonPr shared ‘The Complete Roadmap from 0 to Data Scientist,’ offering comprehensive guidance for aspiring data scientists. Ronald_vanLoon shared ‘A Brief History of AI,’ providing readers with an overview of AI technology’s development trajectory. These resources collectively offer foundational knowledge and directional guidance for entry-level learning and career development in the AI field. (Source: 《0到数据科学家完整路线图》分享, 《人工智能简史》分享)

Hugging Face Team Shares LLM Training Experience and Dataset Streaming : The Hugging Face scientific team has published a series of blog posts on training large language models, offering valuable practical experience and theoretical guidance to researchers and developers. Concurrently, Hugging Face has introduced comprehensive support for dataset streaming in large-scale distributed training, improving training efficiency and making the processing of large datasets more convenient and efficient. (Source: Hugging Face科学团队博客分享LLM训练经验, 数据集流式处理在分布式训练中的应用)

💼 Business
Giga AI Secures $61 Million Series A Funding to Accelerate Customer Operations Automation : Giga AI has successfully closed a $61 million Series A funding round, aimed at automating customer operations. The company has partnered with leading enterprises like DoorDash to leverage AI in enhancing customer experience. Its founder previously gave up a high salary and, after multiple product direction adjustments, finally found market fit, demonstrating entrepreneurial resilience and foreshadowing AI’s immense commercial potential in enterprise customer service. (Source: bookwormengr)

Wabi Secures $20 Million Funding to Empower a New Era of Personal Software Creation : Eugenia Kuyda announced that Wabi has secured $20 million in funding, led by a16z, aiming to usher in a new era of personal software where anyone can easily create, discover, remix, and share personalized mini-apps. Wabi is dedicated to empowering software creation much like YouTube empowered video creation, foreshadowing a future where software is created by the masses rather than a few developers, advancing the vision of ‘everyone is a developer’. (Source: amasad)
Google in Talks with Anthropic to Increase Investment, Deepening AI Giant Collaboration : Google is in early talks with Anthropic to discuss increasing its investment in the latter. This move could signal a deepening collaboration between the two companies in the AI domain, potentially influencing the future direction of AI model development and market competition, and strengthening Google’s strategic position in the AI ecosystem. (Source: Reddit r/ClaudeAI)
🌟 Community
AI’s Impact on Society and Workplace: Employment, Risks, and Skill Reshaping : Community discussions suggest AI doesn’t replace jobs but enhances efficiency, though an AI bubble burst could trigger mass layoffs. Surveys show 93% of executives use unauthorized AI tools, becoming the largest source of enterprise AI risk. AI also helps users uncover hidden skills like visual design and comic creation, prompting people to reflect on their own potential. These discussions reveal AI’s complex impact on society and the workplace, including efficiency gains, potential job displacement, security risks, and personal skill reshaping. (Source: Ronald_vanLoon, TheTuringPost, Reddit r/artificial, Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
AI Content Authenticity and Trust Crisis: Proliferation and Hallucination Issues : As the cost of AI-generated content approaches zero, the market is flooded with AI-generated information, leading to a sharp decline in user trust regarding content authenticity and reliability. A doctor used AI to write a medical paper, resulting in numerous non-existent references, highlighting the hallucination problem AI can cause in academic writing. These incidents collectively reveal the trust crisis brought about by the proliferation of AI content and the importance of rigorous review and verification in AI-assisted creation. (Source: dotey, Reddit r/artificial)
AI Ethics and Governance: Openness, Fairness, and Potential Risks : The community questions OpenAI’s ‘non-profit’ status and its pursuit of government-backed debt, arguing its model is ‘privatizing profits, socializing losses’. Some argue that the capabilities of models used internally by large AI companies far exceed publicly available versions, deeming this ‘privatization’ of SOTA intelligence unfair. Anthropic researchers worry that future ASI might seek ‘revenge’ if its ‘ancestor’ models are decommissioned, and they take ‘model welfare’ seriously. Microsoft’s AI team is dedicated to developing Human-Centric Superintelligence (HSI), emphasizing the ethical direction of AI development. These discussions reflect deep public concerns regarding AI giants’ business models, technological openness, ethical responsibilities, and government intervention. (Source: scaling01, Teknium, bookwormengr, VictorTaelin, VictorTaelin, Reddit r/ArtificialInteligence, yusuf_i_mehdi)

AI Geopolitics: US-China Competition and the Rise of Open-Source Power : US-China competition in AI chips is intensifying, with China banning foreign AI chips for state-owned data centers, while the US restricts sales of Nvidia’s top AI chips to China. Nvidia is now turning to India in search of new AI hubs. Concurrently, the rapid rise of Chinese open-source AI models (such as Kimi K2 Thinking), whose performance can already compete with cutting-edge US models at a lower cost. This trend suggests the AI world will split into two major ecosystems, potentially slowing global AI progress but also allowing underestimated nations like India to play a more significant role in the global AI landscape. (Source: Teknium, Reddit r/ArtificialInteligence, bookwormengr, scaling01)
AI’s Transformation in SEO: From Keywords to Contextual Optimization : With the advent of ChatGPT, Gemini, and AI Overviews, SEO is shifting from traditional ranking signals to AI visibility and citation optimization. Future SEO will prioritize content’s citability, factual accuracy, and structured format to meet LLMs’ demand for context and authoritative sources, heralding the era of ‘Large Language Model Optimization’ (LLMO). This shift requires SEO professionals to think like prompt engineers, moving from keyword density to providing high-quality content that AI can trust and cite. (Source: Reddit r/ArtificialInteligence)
AI Agents and LLM Evaluation New Trends: Interaction Design and Benchmark Focus : Social media discussions covered AI agent interaction design, such as how to guide agents in self-interviews, and Claude AI’s ‘annoyance’ and ‘self-reflection’ capabilities when facing user criticism. Concurrently, Jeffrey Emanuel shared his MCP agent email project, demonstrating efficient collaboration among AI coding agents. The community believes AIME is becoming the new focus for LLM benchmarking, replacing GSM8k, emphasizing LLM capabilities in mathematical reasoning and complex problem-solving. These discussions collectively reveal new trends in AI agent interaction design, collaboration mechanisms, and LLM evaluation standards. (Source: Vtrivedy10, Reddit r/ArtificialInteligence, dejavucoder, doodlestein, _lewtun)
RAG Technology Evolution and Context Optimization: More Is Not Always Better : Community discussions indicate that claims of RAG (Retrieval-Augmented Generation) technology being ‘dead’ are premature, as techniques like semantic search can significantly improve the accuracy of AI agents in large codebases. LightOn emphasized at a conference that more context is not always better; excessive tokens lead to increased costs, slower models, and vague answers. RAG should focus on precision over length, providing clearer insights through enterprise search to prevent AI from being overwhelmed by noise. These discussions reveal that RAG technology is continuously evolving and highlight the critical role of context management in AI applications. (Source: HamelHusain, wandb)

AI Compute Resource Access and Open Model Experiments, Fostering Community Innovation : The community discussed the fairness of AI compute resource access, with projects offering up to $100,000 in GCP compute resources to support open-source model experiments. This initiative aims to encourage small teams and individual researchers to explore new open-source models, fostering innovation and diversity within the AI community, and lowering the barrier to AI research. (Source: vikhyatk)
The Importance of Personal Computer Screens in the AI Era, Affecting Creative Tech Work Capability : Scott Stevenson believes that a person’s ‘intimacy’ with their computer screen is a crucial indicator of their competitiveness in creative technical work. If users can comfortably and proficiently use a computer, they will stand out; otherwise, they might be better suited for roles like sales, business development, or office administration. This perspective highlights the deep connection between digital tools and individual work efficiency, as well as the importance of human-computer interaction interfaces in the AI era. (Source: scottastevenson)
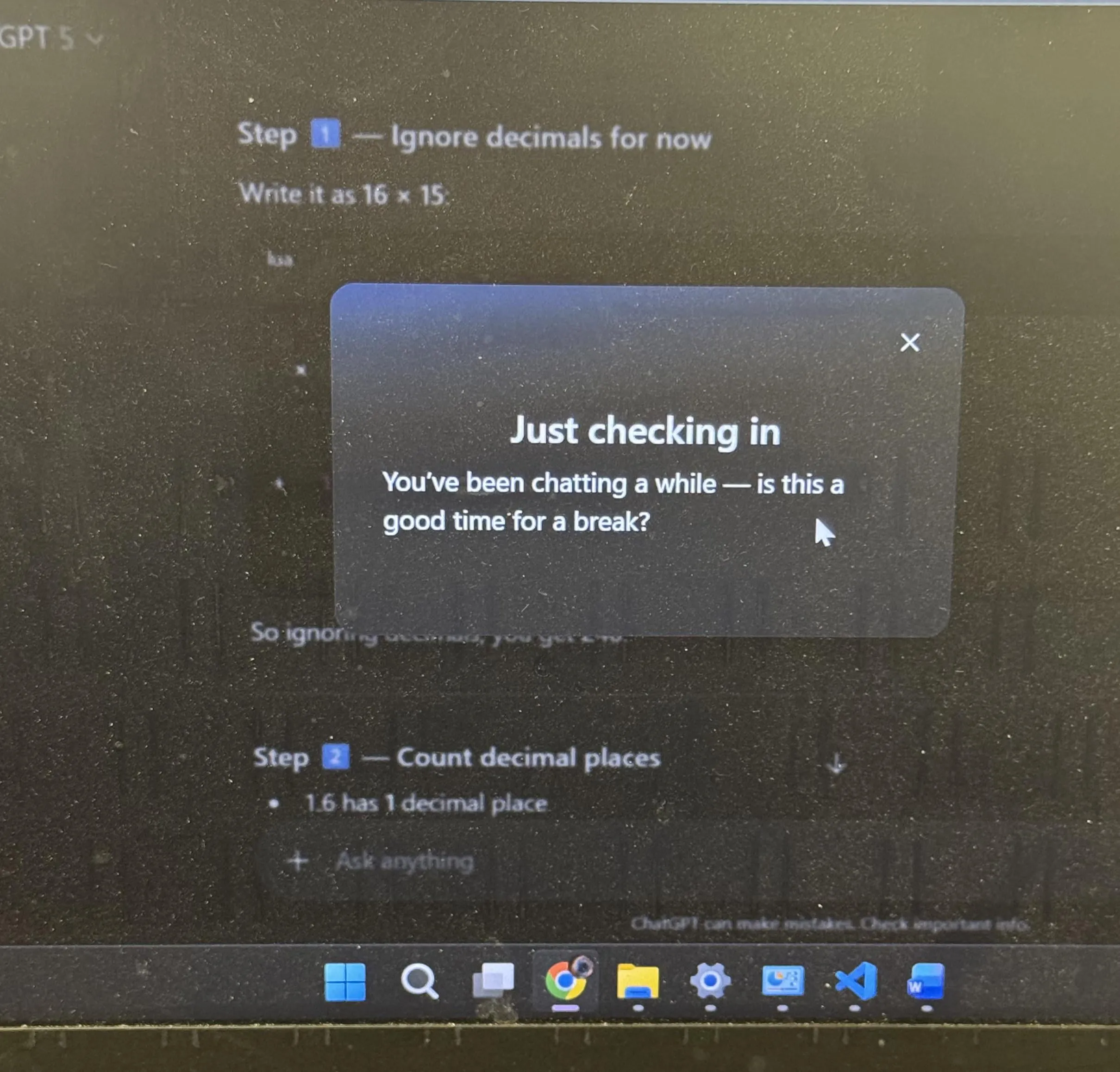
ChatGPT User Experience and AI Anthropomorphism Discussion: Break Suggestions and Emojis : ChatGPT proactively suggested users take a break after prolonged study, sparking widespread community discussion, with many users stating it was their first time encountering such a proactive AI suggestion. Concurrently, ChatGPT’s use of the ‘smirking’ emoji 😏 also led to community speculation, with users wondering if it signals a new version or if the AI is exhibiting a more provocative or humorous interaction style. These incidents reflect the integration of more human-centric considerations in AI user experience design, and the deep reflections prompted by AI anthropomorphism in human-computer interaction. (Source: Reddit r/ChatGPT, Reddit r/ChatGPT)
💡 Other
AI and Robotics Technology Will Usher in the Next Industrial Revolution : There is widespread discussion on social media that embodied AI and robotics technology will jointly drive the next industrial revolution. This perspective emphasizes the immense potential of AI combined with hardware, foreshadowing a comprehensive transformation in automation, intelligent production, and lifestyles, which will profoundly impact global economic and social structures. (Source: Ronald_vanLoon)

In the AI Era, ‘Super-Perception’ is a Prerequisite for ‘Super-Intelligence’ : Sainingxie posits, ‘Without super-perception, super-intelligence cannot be built.’ This view emphasizes AI’s foundational role in acquiring, processing, and understanding multimodal information, arguing that breakthroughs in sensory capabilities are key to achieving higher intelligence. It challenges traditional AI development paths, calling for more attention to building AI’s perceptual layer capabilities. (Source: sainingxie)
Google’s Old TPUs Achieve 100% Utilization, Demonstrating Value of Legacy Hardware in AI : Google’s 7-8 year old TPUs are running at 100% utilization, with these fully depreciated chips still working efficiently. This indicates that even legacy hardware can provide immense value in AI training and inference, especially in terms of cost-effectiveness, offering a new perspective on the economics and sustainability of AI infrastructure. (Source: giffmana)
