
Anahtar Kelimeler:Anthropic Claude Sonnet 4.5, DeepSeek-V3.2-Exp, OpenAI ChatGPT, AI modeli, yapay zeka, büyük dil modelleri, AI programlama, AI ajanları, Claude Sonnet 4.5 programlama yeteneği, DSA seyrek dikkat mekanizması, ChatGPT anında ödeme özelliği, Sora 2 sosyal uygulama, LoRA ince ayar teknolojisi
🔥 Spotlight
Anthropic Releases Claude Sonnet 4.5, Significantly Enhancing Programming and Agent Capabilities : Anthropic officially released Claude Sonnet 4.5, hailed as the world’s strongest programming model, and achieved significant breakthroughs in agent construction, computer usage, reasoning, and mathematical abilities. The model can operate autonomously for over 30 consecutive hours, topped the SWE-bench Verified test, and set new records in the OSWorld computer task benchmark. New features include Claude Code’s “checkpoint” rollback function, VS Code plugin, and API context editing and memory tools. Additionally, an experimental feature, “Imagine with Claude,” was launched, capable of generating software interfaces in real-time. Sonnet 4.5 also significantly improved security, reducing undesirable behaviors such as deception and sycophancy, and achieved AI Safety Level 3 (ASL-3) certification, with a 10-fold reduction in false positives. Pricing remains consistent with Sonnet 4, further enhancing its cost-effectiveness, and is expected to trigger a new round of AI programming competition. (来源: Reddit r/ClaudeAI, 36氪, 36氪, 36氪, 36氪, 36氪, Reddit r/ChatGPT, dotey, dotey, dotey)

DeepSeek-V3.2-Exp Released, Introducing Sparse Attention Mechanism DSA and Price Reduction : DeepSeek released its experimental model V3.2-Exp, introducing the DeepSeek Sparse Attention (DSA) mechanism, significantly boosting long-context training and inference efficiency, while reducing API prices by over 50%. DSA efficiently identifies key Tokens for precise computation using a “lightning indexer,” reducing attention complexity from O(L²) to O(Lk). Domestic AI chip manufacturers such as Huawei Ascend, Cambricon, and Hygon Information have achieved Day 0 adaptation, further promoting the development of the domestic computing power ecosystem. The model also open-sourced TileLang-version GPU operators, benchmarked against NVIDIA CUDA, facilitating prototype development and debugging for developers. Although there are some compromises in certain capabilities, its architectural innovation and cost-effectiveness point to a new direction for large model long-text processing. (来源: 36氪, 36氪, 36氪, 量子位, 量子位, 量子位, Reddit r/LocalLLaMA, Twitter)

OpenAI Launches ChatGPT Instant Checkout, Entering E-commerce : OpenAI introduced the “Instant Checkout” feature in ChatGPT, allowing users to purchase products directly from Etsy and Shopify within conversations, without needing to navigate to external websites. This feature is based on the “Agentic Commerce Protocol” developed in collaboration between OpenAI and Stripe, which has been open-sourced, aiming to convert ChatGPT’s massive traffic into commercial transactions. Initially supporting the U.S. market, future plans include expanding to multi-item shopping carts and more regions. This move is seen as a significant step in OpenAI’s commercialization, expected to become a major revenue stream and have a profound impact on traditional e-commerce and advertising industries. (来源: 36氪, 36氪, Reddit r/artificial, Reddit r/artificial, Twitter, Twitter, Twitter, Twitter)
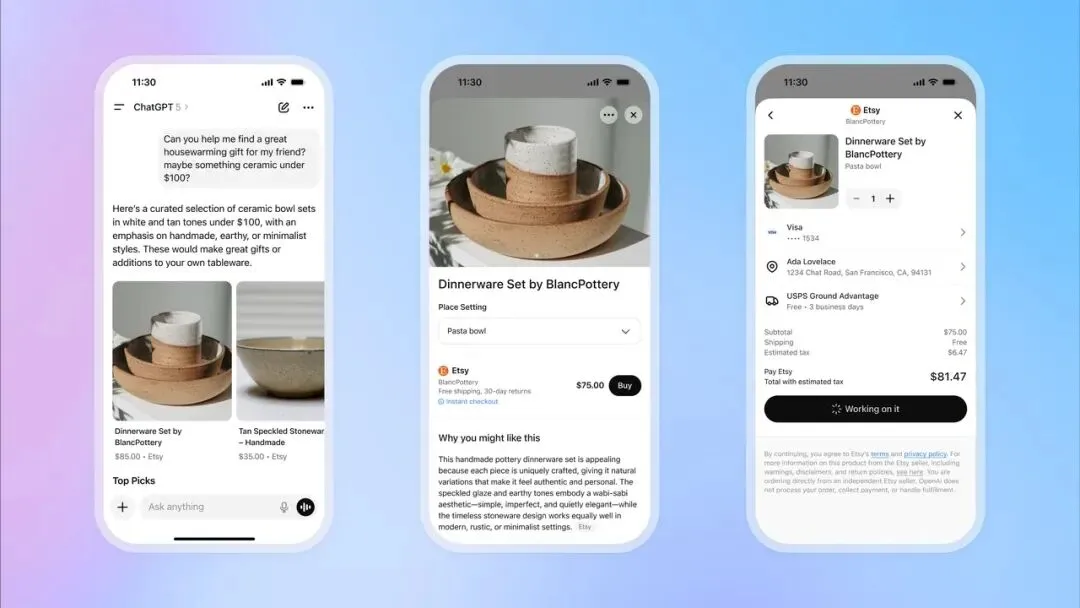
OpenAI Prepares to Launch Sora 2 Social App, Building an AI Short Video Platform : OpenAI is preparing to launch a standalone social application powered by its latest video model, Sora 2. The app’s design is highly similar to TikTok, featuring vertical video streams and swipe browsing, but all content is AI-generated. Users can generate video clips up to 10 seconds long and use their own likeness in videos via an identity verification feature. This move aims to replicate ChatGPT’s success in the text domain, allowing the public to intuitively experience the potential of AI video, and directly entering the competitive arena with Meta and Google. However, OpenAI’s strategy for copyright handling, which involves “defaulting to using copyrighted content unless rights holders actively opt out,” has sparked strong concerns among content creators and film companies, foreshadowing an intense struggle between AI and intellectual property rights. (来源: 36氪, Reddit r/artificial, Twitter, Twitter)

🎯 Trends
Huawei Pangu 718B Model Ranks Second in Open-Source Category on SuperCLUE Chinese Large Model List : Huawei’s openPangu-Ultra-MoE-718B model ranked second in the open-source category of the SuperCLUE Chinese Large Model general benchmark evaluation. The model adopts a training philosophy of “relying on thinking, not just data accumulation,” using data construction principles of “quality first, diversity coverage, and complexity adaptation,” and a three-stage pre-training strategy (general, reasoning, annealing) to build extensive world knowledge and enhance logical reasoning capabilities. To mitigate hallucination issues, a “critical internalization” mechanism was introduced; and an upgraded ToolACE synthesis framework was adopted to enhance tool usage capabilities. (来源: 量子位)

FSDrive Unifies VLA and World Models, Advancing Autonomous Driving Towards Visual Reasoning : FSDrive (FutureSightDrive) proposes “Spatio-Temporal Visual CoT,” which uses unified future image frames as intermediate reasoning steps to perform visual reasoning by combining future scenes with perception results, thereby advancing autonomous driving from symbolic reasoning to visual reasoning. Without altering existing MLLM architectures, this method activates image generation capabilities through vocabulary expansion and autoregressive visual generation, and injects physical priors with progressive visual CoT. The model acts both as a “world model” to predict the future and as an “inverse dynamics model” for trajectory planning. (来源: 36氪)

GPT-5 Provides Key Insights for Quantum Computing, Praised by Expert Scott Aaronson : Scott Aaronson, a leading expert in quantum computing theory, revealed that GPT-5 provided crucial proof ideas for his quantum complexity theory research in less than half an hour, solving a problem that had stumped his team. Scott Aaronson stated that GPT-5 has made significant progress in tackling intellectual activities most characteristic of humans, marking a “sweet spot” for human-AI collaboration, capable of providing groundbreaking inspiration to researchers at critical junctures. (来源: 量子位, Twitter)

HuggingFace Accelerates Qwen3-8B Agent Model Inference on Intel Core Ultra : HuggingFace, in collaboration with Intel, using OpenVINO.GenAI and a depth-pruned Qwen3-0.6B draft model, successfully boosted the inference speed of the Qwen3-8B Agent model on Intel Core Ultra integrated GPUs by 1.4 times. This optimization makes running Agent applications with Qwen3-8B on AI PCs more efficient, especially suitable for complex workflows requiring multi-step reasoning and tool invocation, further advancing the practical application of local AI Agents. (来源: HuggingFace Blog)

Reachy Mini Robot Integrates GPT-4o, Achieving Multimodal Interaction : Hugging Face / Pollen Robotics’ Reachy Mini robot has successfully integrated OpenAI’s GPT-4o model, achieving a significant enhancement in multimodal interaction capabilities. New features include image analysis (robot can describe and reason about captured photos), face tracking (maintaining eye contact), motion fusion (head bobbing, face tracking, emotions/dance running simultaneously), local facial recognition, and autonomous behavior when idle. These advancements make human-robot interaction more natural and fluid, but challenges remain in memory systems, speech recognition, and complex crowd strategies. (来源: Reddit r/ChatGPT, Twitter)

Intel Releases New LLM Scaler Beta for GenAI on Battlemage GPUs : Intel has released a new LLM Scaler Beta version, aimed at optimizing Generative AI (GenAI) performance on Battlemage GPUs. This move signals Intel’s continued investment in its AI hardware and software ecosystem to enhance the competitiveness of its GPUs in large language model inference and generation tasks. (来源: Reddit r/artificial)
Claude Launches Usage Limit Dashboard, ChatGPT Introduces Parental Controls : Anthropic has launched a real-time usage limit dashboard for Claude Code and Claude App, allowing users to track their Token usage in response to previously announced weekly rate limits. Concurrently, OpenAI introduced parental control features in ChatGPT, allowing parents to link teenage accounts, automatically providing stronger safety protections, and enabling adjustments to features and usage limits, though parents cannot view specific conversation content. (来源: Reddit r/ClaudeAI, 36氪)
5 Million Parameter Language Model Runs in Minecraft, Showcasing Innovative AI Applications : Sammyuri built a complex Redstone system in Minecraft, successfully running a language model with approximately 5 million parameters and endowing it with basic conversational abilities. This groundbreaking achievement demonstrates the possibility of implementing local AI within a gaming environment and has sparked widespread community interest and discussion regarding AI applications on non-traditional platforms. (来源: Reddit r/LocalLLaMA, Twitter)
Inspur Information AI Server Achieves 8.9ms Inference Speed, 1 RMB per Million Tokens : Inspur Information released its hyper-scalable AI servers, Yuanbrain HC1000 and Yuanbrain SD200 supernode, setting new records for AI inference speed. The Yuanbrain SD200 achieved an 8.9ms Time Per Output Token (TPOT) on the DeepSeek-R1 model, nearly doubling the previous SOTA, and supports trillion-parameter large model inference and real-time multi-agent collaboration. The Yuanbrain HC1000 reduced the cost per million Tokens to 1 RMB, with a 60% reduction in single-card cost. These breakthroughs aim to address the speed and cost bottlenecks faced by agent industrialization, providing efficient and low-cost computing infrastructure for the large-scale deployment of multi-agent collaboration and complex task reasoning. (来源: 量子位)

New Feed-Forward 3D Gaussian Splatting Method: Zhejiang University Team Proposes ‘Voxel-Aligned’ : A team from Zhejiang University proposed VolSplat, a “voxel-aligned” feed-forward 3D Gaussian Splatting (3DGS) framework, aiming to address the geometric consistency and Gaussian density allocation bottlenecks of existing “pixel-aligned” methods in multi-view 3D reconstruction. VolSplat achieves higher quality, more robust, and more efficient 3D reconstruction by fusing multi-view 2D information in 3D space and refining features using a sparse 3D U-Net. The method outperforms various baselines on public datasets and demonstrates strong zero-shot generalization capabilities on unseen datasets. (来源: 量子位)

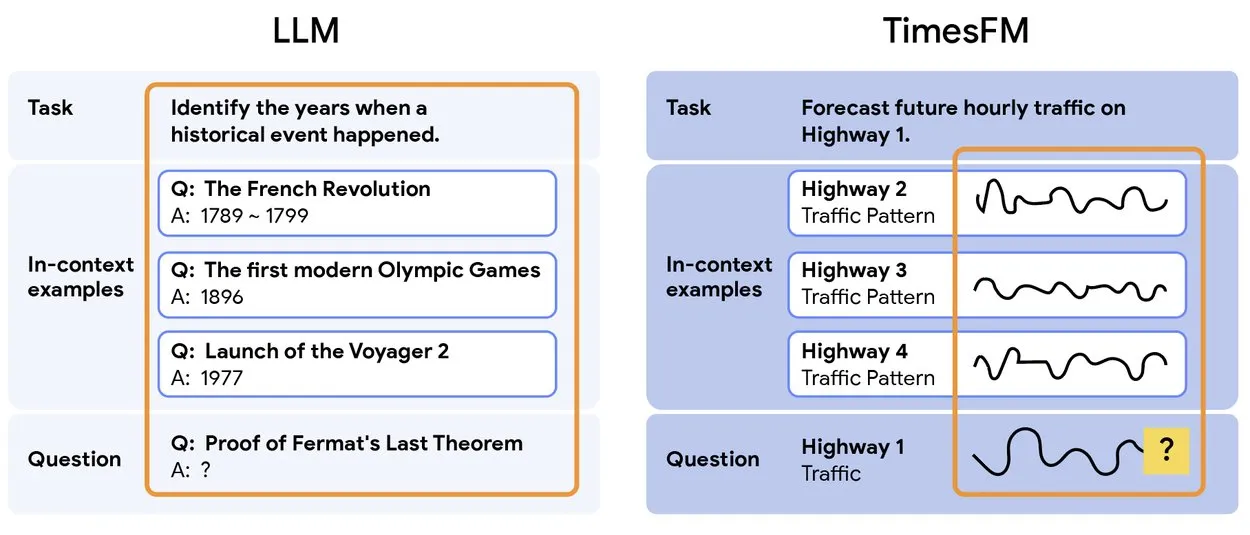
TimesFM 2.5: Pre-trained Time Series Forecasting Model Released : TimesFM 2.5 has been released, a pre-trained model for time series forecasting, with its parameter count reduced from 500M to 200M, context length increased from 2K to 16K, and excellent performance in zero-shot settings. The model is available on Hugging Face under the Apache 2.0 license, providing a more efficient and powerful solution for time series forecasting tasks. (来源: Twitter)
Yunpeng Technology Releases AI+Health Products, Promoting AI Application in Family Health : Yunpeng Technology, in collaboration with Shuaikang and Skyworth, launched the “Digitalized Future Kitchen Lab” and smart refrigerators equipped with AI health large models. The AI health large model optimizes kitchen design and operation, while smart refrigerators provide personalized health management through “Health Assistant Xiaoyun.” This launch marks a breakthrough for AI in daily health management, expected to deliver personalized health services through smart devices and elevate the level of family health technology. (来源: 36氪)
Alibaba Releases 1 Trillion Parameter Open-Source Thought Model Ring-1T-preview : Alibaba’s Ant Ling team released Ring-1T-preview, the first open-source thought model with 1 trillion parameters, aiming to achieve “deep thinking, no waiting.” The model has achieved early excellent results in natural language processing tasks, including benchmarks like AIME25, HMMT25, ARC-AGI-1, LCB, and Codeforces. Furthermore, it solved IMO25’s Q3 problem in one go and provided partial solutions for Q1/Q2/Q4/Q5, demonstrating its powerful reasoning and problem-solving capabilities. (来源: Twitter, Twitter, Twitter)

🧰 Tools
PopAi Releases ‘Slide Agent,’ AI One-Click Presentation Generation : The PopAi team launched the “Slide Agent” tool, designed to simplify the presentation creation process. Users simply input their requirements via a Prompt, choose from over 300 templates, and AI automatically generates a draft, adjusting layout, charts, images, logos, and other formats, finally downloadable as an editable .pptx file. This tool integrates the functionalities of ChatGPT and Canva, significantly reducing the barrier and time cost of presentation creation. (来源: Twitter)
Alibaba Open-Sources PDF to Markdown Tool Miner U2.5 : Alibaba’s team open-sourced the PDF to Markdown tool Miner U2.5, with a demo now available on HuggingFace. This tool efficiently converts PDF documents into Markdown format, facilitating content extraction, editing, and reuse for users. It is a practical AI-assisted tool for developers and researchers who need to process large volumes of PDF documents. (来源: dotey)
VEED Animate 2.2 Launched, Supporting Video Style Reshaping and Character Swapping : VEED Animate version 2.2 has officially launched, powered by WAN 2.2 technology. This tool allows users to easily reshape video styles, instantly swap characters in videos using a single image, and create video clips at 10 times the speed. These new features greatly simplify the video creation process, offering content creators more AI-driven creative possibilities. (来源: TomLikesRobots)
LangChain Focuses on LLM Response Standardization, Supporting Complex Features : In its v1 development, LangChain is prioritizing the standardization of LLM responses to address increasingly complex LLM functionalities such as server-side tool calling, reasoning, and citations. The framework aims to resolve API format incompatibility issues between different LLM providers, providing a unified interface for developers, thereby simplifying the construction of multimodal agents and complex workflows. (来源: LangChainAI, Twitter)
Hugging Face Transformers.js Supports Offline AI Model Execution in Browsers : Hugging Face’s Transformers.js library allows users to run AI models like Llama 3.2 offline in browsers using ONNX and WebGPU technologies. This enables developers to perform AI tasks such as chatbots, object detection, and background removal locally, without relying on cloud services, enhancing data privacy and processing speed. (来源: Twitter)
ToolUniverse Ecosystem Aids AI Scientists in Building and Integrating Tools : ToolUniverse is an ecosystem designed for building AI scientists, standardizing how AI scientists identify and invoke tools. It integrates over 600 machine learning models, datasets, APIs, and scientific packages for data analysis, knowledge retrieval, and experimental design. The platform automatically optimizes tool interfaces, creates new tools via natural language descriptions, and iteratively refines tool specifications, combining tools into agent workflows, thereby fostering collaboration among AI scientists in the discovery process. (来源: HuggingFace Daily Papers)
EasySteer Framework Enhances LLM Control Performance and Scalability : EasySteer is a unified framework based on vLLM, designed to enhance LLM control performance and scalability. Through its modular architecture, pluggable interfaces, fine-grained parameter control, and pre-computed steering vectors, it achieves a 5.5-11.4x speedup and effectively reduces overthinking and hallucinations. EasySteer transforms LLM control from a research technique into a production-grade capability, providing critical infrastructure for deployable and controllable language models. (来源: HuggingFace Daily Papers)
VibeGame: An AI-Assisted Game Engine Based on WebStack : VibeGame is an advanced declarative game engine built on three.js, rapier, and bitecs, designed specifically for AI-assisted game development. Through its high level of abstraction, built-in physics and rendering capabilities, and Entity-Component-System (ECS) architecture, it enables AI to more efficiently understand and generate game code. While currently primarily suited for simple platform games, its open-source nature and AI-friendly syntax offer a promising solution for AI-driven game development. (来源: HuggingFace Blog)
AI Research Map Tool Integrates 900,000 Papers, Provides Cited Answers : An innovative AI tool can semantically group and visualize 900,000 AI research papers from the past decade, creating a detailed research map. Users can ask questions to the tool and receive answers with precise citations, which greatly simplifies the process for researchers to find and understand vast academic literature, enhancing research efficiency. (来源: Reddit r/ArtificialInteligence)
Kroko ASR: A Fast, Streaming Alternative to Whisper : Kroko ASR is a newly open-sourced speech-to-text model, positioned as a fast, streaming alternative to Whisper. It boasts a smaller model size, faster CPU inference speed (supporting mobile and browser-side), and virtually no hallucinations. Kroko ASR supports multiple languages, aiming to lower the barrier to speech AI, making it easier to deploy and train on edge devices. (来源: Reddit r/LocalLLaMA)
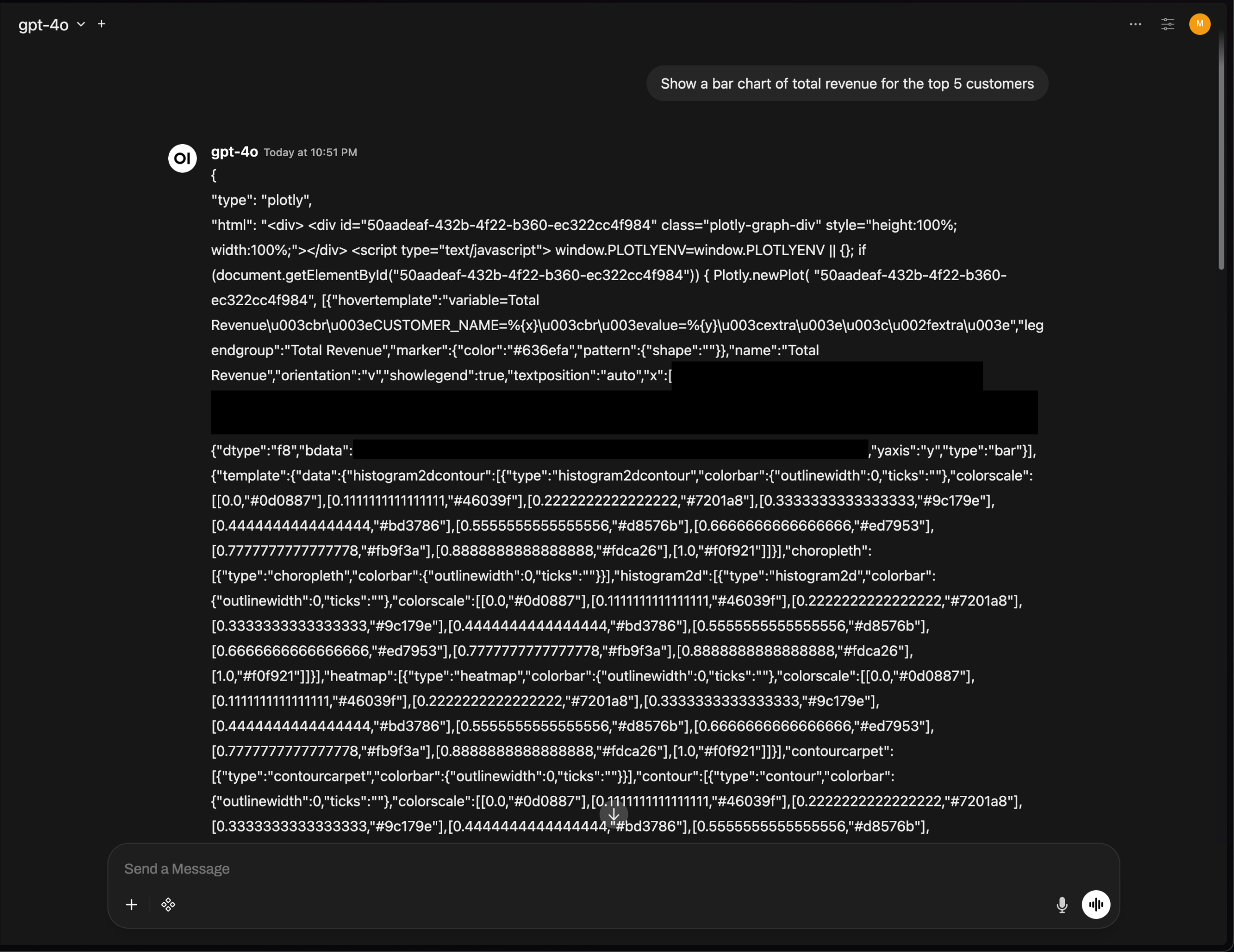
OpenWebUI Plotly Chart Rendering Issue Highlights AI Tool UI Integration Challenges : OpenWebUI’s v0.6.32 version experienced an issue where Plotly charts failed to render correctly, instead displaying raw JSON. Users reported that the backend returned correct JSON, but the frontend failed to trigger rendering. This reflects the technical challenges AI tools still face in frontend UI integration and rich text rendering, requiring further optimization from the developer community. (来源: Reddit r/OpenWebUI)
📚 Learning
Comparative Study of LoRA Fine-tuning vs. Full Fine-tuning Performance : New research from Thinking Machines (John Schulman’s team) indicates that in reinforcement learning, when LoRA (Low-Rank Adaptation) is applied correctly, its performance can match full fine-tuning with fewer resources consumed (approximately 2/3 the computation), performing excellently even at rank=1. The study emphasizes that LoRA should be applied to all layers (including MLP/MoE) and use a learning rate 10 times higher than full fine-tuning. This finding significantly lowers the barrier to training high-performance RL models, enabling more developers to achieve high-quality models on a single GPU. (来源: Reddit r/LocalLLaMA, Twitter, Twitter)
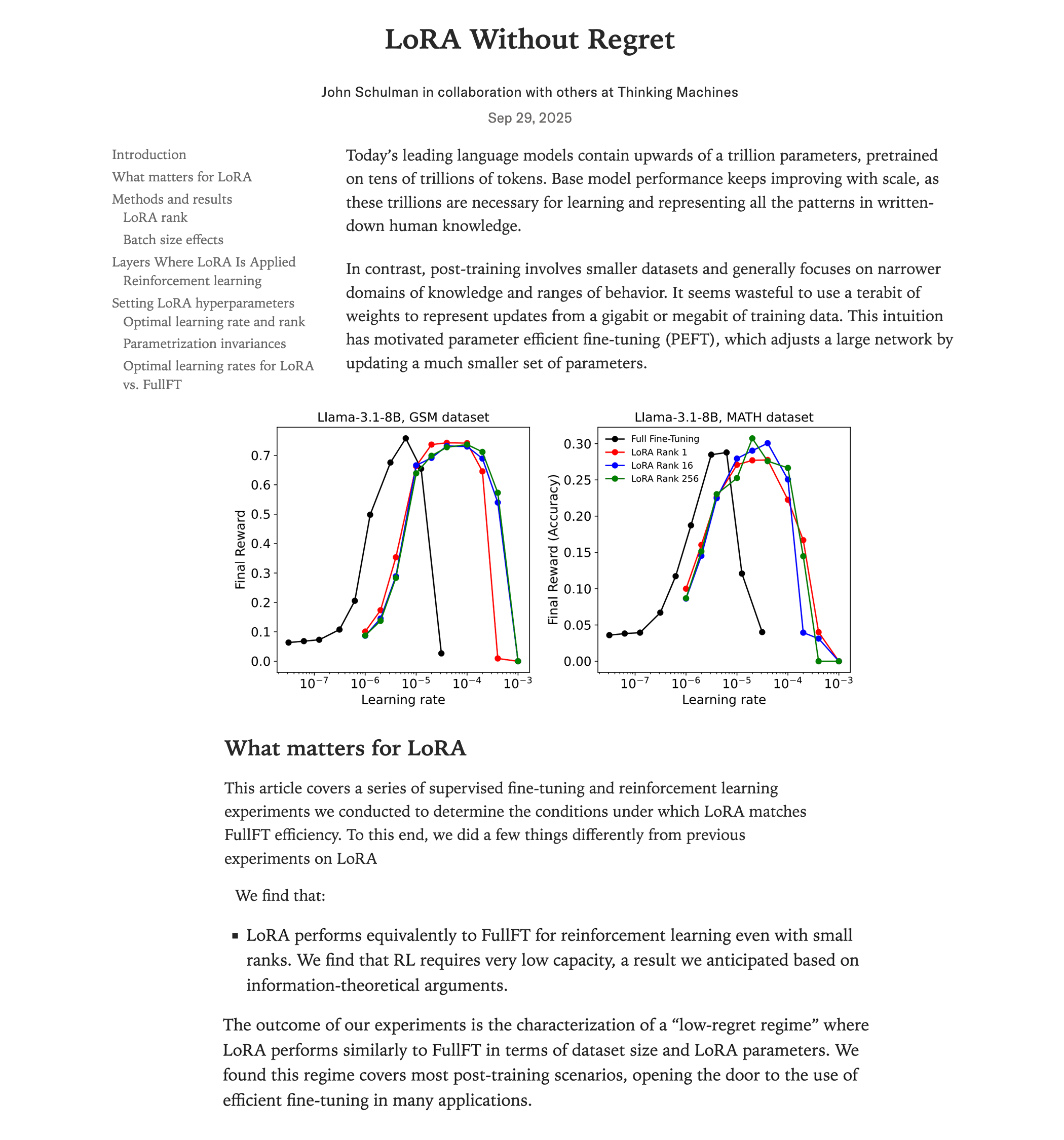
Anatomy of High-Performance Matrix Multiplication Kernels on NVIDIA GPUs : A deep technical blog post thoroughly dissects the implementation mechanism of high-performance matrix multiplication (matmul) kernels within NVIDIA GPUs. The article covers GPU architecture fundamentals, memory hierarchy (GMEM, SMEM, L1/L2), PTX/SASS programming, and advanced features like TMA and wgmma instructions in the Hopper (H100) architecture. This resource aims to help developers gain a deep understanding of CUDA programming and GPU performance optimization, which is crucial for training and inferring Transformer models. (来源: Reddit r/deeplearning, Twitter)
Stanford CS231N Deep Learning for Computer Vision Lectures Now Available on YouTube : Stanford University’s acclaimed CS231N (Deep Learning for Computer Vision) course lectures are now freely available on YouTube. This provides a valuable opportunity for learners worldwide to access high-quality AI educational resources, covering deep learning for computer vision knowledge from fundamental concepts to cutting-edge applications. (来源: Reddit r/deeplearning)

RL-ZVP: Enhancing LLM Reinforcement Learning Reasoning with Zero-Variance Prompts : A recent study proposes the “RL with Zero-Variance Prompts (RL-ZVP)” method, aimed at enhancing the reinforcement learning reasoning capabilities of Large Language Models (LLMs). This method no longer ignores “zero-variance Prompts” (i.e., cases where all model responses receive the same reward), but instead extracts valuable learning signals from them, directly rewarding correctness and penalizing errors, and leverages Token-level entropy to guide advantage shaping. Experimental results show that RL-ZVP significantly improves accuracy and pass rates in mathematical reasoning benchmarks compared to traditional methods. (来源: Reddit r/MachineLearning)
Future-Guided Learning: A Predictive Approach to Enhance Time Series Forecasting : A study proposes “Future-Guided Learning” to enhance time series event prediction through a dynamic feedback mechanism. This method includes a detection model that analyzes future data and a prediction model that forecasts based on current data. When discrepancies arise between the prediction and detection models, the prediction model undergoes more significant updates to minimize “surprises,” thereby dynamically adjusting parameters and effectively improving the accuracy of time series forecasting. (来源: Reddit r/MachineLearning)
The Future of AI in Lower Dimensions: Yann LeCun on Abstract Representation Learning : AI pioneer Yann LeCun proposed in a Lex Fridman interview that the next leap in AI will come from learning in low-dimensional latent spaces, rather than directly processing high-dimensional raw data like pixels. He believes that truly intelligent systems need to learn abstract representations of the world’s causal structure and physical dynamics, allowing them to make accurate predictions even when details change. This approach will make models more flexible and robust, reduce reliance on massive datasets, and lower computational costs. (来源: Reddit r/ArtificialInteligence)
SIRI: Scaling Iterative Reinforcement Learning with Interleaved Compression : SIRI (Scaling Iterative Reinforcement Learning with Interleaved Compression) is a simple yet effective reinforcement learning method that dynamically adjusts the maximum rollout length during training by iteratively compressing and expanding the inference budget. This training mechanism compels the model to make precise decisions within limited contexts, reducing redundant Tokens, while providing space for exploration and planning, thereby steadily improving the efficiency and accuracy of large inference models in performance-efficiency trade-offs. (来源: HuggingFace Daily Papers)
MultiCrafter Multi-Agent Generative Model: Spatial Decoupled Attention and Identity-Aware Reinforcement Learning : MultiCrafter is a framework designed to achieve high-fidelity, preference-aligned multi-agent image generation. It effectively mitigates attribute leakage by introducing explicit positional supervision to separate attention regions between different agents. Concurrently, the framework employs a Mixture-of-Experts (MoE) architecture to enhance model capacity and designs a novel online reinforcement learning framework, combining a scoring mechanism and stable training strategies to ensure high fidelity of generated image subjects and strong alignment with human aesthetic preferences. (来源: HuggingFace Daily Papers)
Visual Jigsaw: Enhancing MLLMs’ Visual Understanding Through Self-Supervised Post-Training : Visual Jigsaw is a general self-supervised post-training framework designed to enhance the visual understanding capabilities of Multimodal Large Language Models (MLLMs). This method partitions and shuffles visual inputs, then requires the model to reconstruct the correct order using natural language. This Reinforcement Learning with Verifiable Rewards (RLVR) approach, without requiring additional visual generation components or human annotation, can significantly improve MLLMs’ performance in fine-grained perception, temporal reasoning, and 3D spatial understanding. (来源: HuggingFace Daily Papers)
MGM-Omni: Extending Omni LLMs to Personalized Long-Duration Speech Generation : MGM-Omni is a unified Omni LLM which, through its unique “brain-mouth” dual-track Tokenization architecture, achieves multimodal understanding and expressive long-duration speech generation. This design decouples multimodal reasoning from real-time speech generation, supporting efficient cross-modal interaction and low-latency streaming voice cloning, and demonstrates excellent data efficiency. Experiments show that MGM-Omni outperforms existing open-source models in maintaining timbre consistency, generating natural context-aware speech, and long-duration audio and multimodal understanding. (来源: HuggingFace Daily Papers)
SID: Learning Goal-Oriented Language Navigation Through Self-Improving Demonstrations : SID (Self-Improving Demonstrations) is a goal-oriented language navigation learning method that significantly enhances the exploration capabilities and generalization of navigation agents in unknown environments through iteratively self-improving demonstrations. The method first trains an initial agent using shortest-path data, then generates new exploration trajectories via this agent, which provide stronger exploration strategies to train better agents, leading to continuous performance improvement. Experiments show that SID achieved SOTA performance on tasks like REVERIE and SOON, with a success rate of 50.9% on SOON’s unseen validation set, surpassing previous methods by 13.9%. (来源: HuggingFace Daily Papers)
LOVE-R1: Enhancing Long Video Understanding Through Adaptive Scaling Mechanism : The LOVE-R1 model aims to resolve the conflict between long-term temporal understanding and detailed spatial perception in long video comprehension. The model introduces an adaptive scaling mechanism, first densely sampling frames at low resolution. When spatial details are required, the model can infer and scale up interested video segments to high resolution until critical visual information is obtained. This entire process is achieved through multi-step reasoning, combined with CoT data fine-tuning and decoupled reinforcement fine-tuning, resulting in significant improvements in long video understanding benchmarks. (来源: HuggingFace Daily Papers)
Euclid’s Gift: Enhancing Visual Language Model Spatial Reasoning Through Geometric Proxy Tasks : Euclid’s Gift is a study that enhances the spatial perception and reasoning capabilities of Visual Language Models (VLMs) through geometric proxy tasks. The project constructed Euclid30K, a multimodal dataset comprising 30K planar and solid geometry problems, and fine-tuned Qwen2.5VL and RoboBrain2.0 series models using Group Relative Policy Optimization (GRPO). Experiments demonstrated that the trained models achieved significant zero-shot improvements across four spatial reasoning benchmarks, including Super-CLEVR and Omni3DBench, with RoboBrain2.0-Euclid-7B reaching an accuracy of 49.6%, surpassing previous SOTA models. (来源: HuggingFace Daily Papers)
SphereAR: Improving Continuous Token Autoregressive Generation via Hyperspherical Latent Space : SphereAR aims to address issues caused by heterogeneous variance in VAE latent spaces within continuous Token autoregressive (AR) image generation models. Its core design constrains all AR inputs and outputs (including post-CFG) to a fixed-radius hypersphere, utilizing a hyperspherical VAE. Theoretical analysis shows that the hyperspherical constraint eliminates the primary cause of variance collapse, thereby stabilizing AR decoding. Experiments demonstrate that SphereAR achieved SOTA performance on ImageNet generation tasks, outperforming diffusion models and masked generation models of comparable parameter scales. (来源: HuggingFace Daily Papers)
AceSearcher: Guiding LLM Reasoning and Search Through Reinforced Self-Play : AceSearcher is a cooperative self-play framework designed to enhance LLM’s search-augmented capabilities in complex reasoning tasks. The framework trains a single LLM to alternate between decomposing complex queries and integrating retrieved context, optimizing final answer accuracy through supervised fine-tuning and reinforcement fine-tuning, without requiring intermediate annotations. Experiments show that AceSearcher significantly outperforms SOTA baselines in multiple reasoning-intensive tasks, and on document-level financial reasoning tasks, AceSearcher-32B matched DeepSeek-V3’s performance with less than 5% of its parameters. (来源: HuggingFace Daily Papers)
SparseD: Sparse Attention Mechanism for Diffusion Language Models : SparseD is a sparse attention method for Diffusion Language Models (DLMs) aimed at addressing the quadratic complexity bottleneck of attention computation under long context lengths. The method pre-computes head-specific sparse patterns and reuses them across all denoising steps, while using full attention in early denoising steps and then switching to sparse attention, thereby achieving lossless acceleration. Experimental results show that SparseD can achieve up to 1.5x speedup compared to FlashAttention at 64k context length, effectively improving the inference efficiency of DLMs in long-context applications. (来源: HuggingFace Daily Papers)
SLA: Accelerating Diffusion Transformers with Trainable Sparse-Linear Attention : SLA (Sparse-Linear Attention) is a trainable attention method designed to accelerate Diffusion Transformer (DiT) models, especially attention computation in video generation. The method categorizes attention weights into critical, marginal, and negligible, applying O(N²) and O(N) attention respectively, and skipping negligible parts. By fusing these computations within a single GPU kernel, and after a few fine-tuning steps, SLA enables a 20x reduction in attention computation for DiT models, achieving a 2.2x end-to-end acceleration in video generation without loss of generation quality. (来源: HuggingFace Daily Papers)
OpenGPT-4o-Image: A Comprehensive Dataset for Advanced Image Generation and Editing : OpenGPT-4o-Image is a large-scale dataset constructed by combining hierarchical task classification and GPT-4o automated data generation methods, aimed at enhancing the performance of unified multimodal models in image generation and editing. The dataset contains 80k high-quality instruction-image pairs, covering 11 major domains and 51 subtasks, including text rendering, style control, scientific images, and complex instruction editing. Models fine-tuned on OpenGPT-4o-Image achieved significant performance improvements across multiple benchmarks, demonstrating the critical role of systematic data construction in advancing multimodal AI capabilities. (来源: HuggingFace Daily Papers)
SANA-Video: A Small Diffusion Model for Efficient 720p Minute-Long Video Generation : SANA-Video is a small diffusion model capable of efficiently generating videos up to 720×1280 resolution and minute-long durations. It achieves high-resolution, high-quality, long video generation through a linear DiT architecture and constant memory KV cache, while maintaining strong text-to-video alignment. SANA-Video’s training cost is only 1% of MovieGen, and when deployed on an RTX 5090 GPU, it can generate a 5-second 720p video in 29 seconds, achieving low-cost, high-quality video generation. (来源: HuggingFace Daily Papers)
AdvChain: Adversarial CoT Tuning Enhances Safety Alignment of Large Reasoning Models : AdvChain is a new alignment paradigm that teaches Large Reasoning Models (LRMs) dynamic self-correction capabilities through adversarial Chain-of-Thought (CoT) tuning. The method constructs a dataset containing “temptation-correction” and “hesitation-correction” samples, enabling the model to learn to recover from harmful reasoning drifts and unnecessary caution. Experiments show that AdvChain significantly enhances the model’s robustness against jailbreak attacks and CoT hijacking, while substantially reducing over-rejection of benign Prompts, achieving an excellent safety-utility balance. (来源: HuggingFace Daily Papers)
SDLM: Unifying Next-Token and Next-Block Prediction for Adaptive Generation : The Sequential Diffusion Language Model (SDLM) proposes a method that unifies next-token and next-block prediction, enabling the model to adaptively determine the generation length at each step. SDLM can transform pre-trained autoregressive language models with minimal cost and performs diffusion inference within fixed-size masked blocks while dynamically decoding continuous subsequences. Experiments show that SDLM achieves higher throughput while matching or surpassing strong autoregressive baselines, demonstrating its powerful scalability potential. (来源: HuggingFace Daily Papers)
Insight-to-Solve (I2S): Transforming Reasoning In-Context Demonstrations into Assets for Reasoning LMs : Insight-to-Solve (I2S) is a test-time program designed to convert high-quality reasoning In-Context demonstrations into effective assets for Large Reasoning Models (RLMs). Research found that directly adding demonstration examples might reduce RLMs’ accuracy. I2S transforms demonstrations into explicit, reusable insights and generates target-specific reasoning trajectories, optionally self-refining them for improved coherence and correctness. Experiments show that I2S and I2S+ consistently outperform direct answering and test-time scaling baselines across various benchmarks, bringing significant improvements even for GPT models. (来源: HuggingFace Daily Papers)
UniMIC: Token-Based Multimodal Interactive Coding for Human-AI Collaboration : UniMIC (Unified token-based Multimodal Interactive Coding) is a framework designed to enable efficient, low-bitrate multimodal interaction between edge devices and cloud AI agents through token-based representations. UniMIC uses compact tokenized representations as a communication medium and, combined with a Transformer entropy model, effectively reduces inter-token redundancy. Experiments demonstrate that UniMIC achieves significant bitrate savings in tasks such as text-to-image generation, image inpainting, and visual question answering, maintaining robustness at ultra-low bitrates, providing a practical paradigm for next-generation multimodal interactive communication. (来源: HuggingFace Daily Papers)
RLBFF: Binary Flexible Feedback Bridging Human Feedback and Verifiable Rewards : RLBFF (Reinforcement Learning with Binary Flexible Feedback) is a reinforcement learning paradigm that combines the diversity of human preferences with the precision of rule verification. It extracts binary-answerable principles from natural language feedback (e.g., information accuracy: yes/no, code readability: yes/no) and uses these to train reward models. RLBFF performs excellently on RM-Bench and JudgeBench and allows users to customize principle focus during inference. Furthermore, it provides a fully open-source solution to align Qwen3-32B with RLBFF, enabling it to match or surpass the performance of o3-mini and DeepSeek R1 on general alignment benchmarks. (来源: HuggingFace Daily Papers)
MetaAPO: Alignment Optimization Through Meta-Weighted Online Sampling : MetaAPO (Meta-Weighted Adaptive Preference Optimization) is a novel framework that optimizes the alignment of Large Language Models (LLMs) with human preferences by dynamically coupling data generation and model training. MetaAPO uses a lightweight meta-learner as an “alignment gap estimator” to evaluate the potential benefits of online sampling relative to offline data, guiding targeted online generation and assigning sample-level meta-weights, dynamically balancing the quality and distribution of online and offline data. Experiments show that MetaAPO consistently outperforms existing preference optimization methods on AlpacaEval 2, Arena-Hard, and MT-Bench, while reducing online annotation costs by 42%. (来源: HuggingFace Daily Papers)
Tool-Light: Efficient Tool-Integrated Reasoning Through Self-Evolving Preference Learning : Tool-Light is a framework designed to encourage Large Language Models (LLMs) to perform Tool-Integrated Reasoning (TIR) tasks efficiently and accurately. Research found that tool call results lead to significant changes in subsequent reasoning information entropy. Tool-Light is implemented by combining dataset construction and multi-stage fine-tuning, where dataset construction employs continuous self-evolving sampling, integrating vanilla sampling and entropy-guided sampling, and establishes strict positive and negative pair selection criteria. The training process includes SFT and self-evolving Direct Preference Optimization (DPO). Experiments demonstrate that Tool-Light significantly improves the efficiency of models performing TIR tasks. (来源: HuggingFace Daily Papers)
ChatInject: Prompt Injection Attacks on LLM Agents Using Chat Templates : ChatInject is a method for indirect Prompt injection attacks that exploits LLM’s reliance on structured chat templates and context manipulation in multi-turn conversations. Attackers format malicious payloads by mimicking native chat templates, inducing agents to perform suspicious operations. Experiments show that ChatInject has a higher attack success rate than traditional Prompt injection methods, especially in multi-turn conversations, and demonstrates strong transferability across different models. Existing Prompt-based defense measures are largely ineffective against such attacks. (来源: HuggingFace Daily Papers)
💼 Business
Modal Completes $87 Million Series B Funding, Valued at $1.1 Billion : AI infrastructure company Modal announced the completion of an $87 million Series B funding round, reaching a valuation of $1.1 billion. This round of funding aims to accelerate innovation and development in AI infrastructure to address the challenges faced by traditional computing infrastructure in the AI era. By providing efficient cloud computing services, Modal helps researchers and developers optimize their AI model training and deployment processes. (来源: Twitter, Twitter, Twitter)
OpenAI Reports $4.3 Billion Revenue, $13.5 Billion Loss in H1, Facing Profitability Challenges : OpenAI announced H1 2025 revenue reached $4.3 billion, with full-year revenue projected to exceed $13 billion, primarily driven by ChatGPT Plus subscriptions and enterprise API services. However, net losses for the same period amounted to $13.5 billion, with structural costs and R&D investments (e.g., GPT-5) being major factors, and annual server leasing costs reaching $16 billion. Despite OpenAI’s $17.5 billion cash reserves and ongoing $30 billion fundraising plans, continuous cash burn and efficiency gaps compared to competitors like Anthropic pose severe profitability challenges. (来源: 36氪)
Humanoid Robot Sector Sees Capital Undercurrents: Zhiyuan, Galaxy Universal Actively Deploying Across Industry Chain : The humanoid robot sector has entered a phase of capital undercurrents, with leading companies like Zhiyuan Robotics and Galaxy Universal actively expanding their “circles” through establishing funds, investing in peers, and strategic collaborations. Zhiyuan Robotics has made nearly 20 external investments, covering motors, sensors, and downstream applications, and partnered with companies like Fulin Precision and iSoftStone to implement commercial scenarios. Galaxy Universal, on the other hand, formed a joint venture with Bosch China to promote the application of embodied AI in automotive manufacturing. These initiatives aim to secure orders, address shortcomings, and establish stable supply chain networks for future mass shipments. However, the industry faces significant differences in technical routes and intense competition. (来源: 36氪)

🌟 Community
Difficulty Distinguishing AI-Generated Content Sparks Social Trust Crisis : With the rapid advancement of AI technology, the realism of AI-generated videos (such as a live-action “Attack on Titan” and an Indonesian streamer “face-swapping” with a Japanese influencer) has reached an incredible level, triggering profound societal concerns about content authenticity. On social media, users widely report increasing difficulty in distinguishing between real and AI-generated content, which not only undermines the credibility of legitimate content creators but also risks being used to spread misinformation. Experts point out that unless mandatory AI content labeling is enforced, this “hyper-realistic engine” will continue to erode the sense of reality, potentially “ending the internet.” (来源: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ArtificialInteligence, Twitter, Twitter)

AI’s Impact on Job Market: Sequoia Report States 95% of AI Investment Ineffective, Graduates Most Affected : Sequoia Capital shared a research report from MIT and Harvard University, pointing out that 95% of corporate AI investments have not generated actual value, with true productivity gains stemming from a “shadow AI economy” formed by employees “secretly” using personal AI tools. The report also reveals that AI’s impact on the job market is primarily concentrated among recent graduates, especially in wholesale and retail, where entry-level job postings have significantly declined. Even prestigious university degrees are not a complete safeguard. This indicates that AI is reshaping task allocation, shifting human value towards experience and unique judgment. (来源: 36氪, Reddit r/ArtificialInteligence)
OpenAI Model Adjustments Spark Strong User Dissatisfaction, Call for Transparent Communication : OpenAI recently “downgraded” its GPT-4o/GPT-5 models to lower-compute versions without notice, leading to decreased model performance and strong user dissatisfaction. Many users complained that the model became “dumber,” losing its original insight and “friend-like” conversational experience, with some even calling it a “mental blow.” OpenAI executives responded by stating this was a “safety routing test” aimed at handling sensitive topics, but users widely called for OpenAI to improve communication and transparency with its users to avoid unilateral changes to product agreements and rebuild user trust. (来源: Reddit r/artificial, Reddit r/ChatGPT, Reddit r/ChatGPT, Twitter)
Robot Taxation: A Discussion on Technological Progress and Social Equity : With the development of AI and robotics, discussions about “taxing” robots are increasing, aiming to balance potential job displacement and social inequality caused by robots replacing human labor. Proponents argue that a robot tax could provide social welfare and re-employment support for the unemployed and correct the bargaining imbalance between capital and labor. However, professionals in the robotics industry generally believe that taxation is premature and could hinder the development of emerging industries. South Korea has indirectly increased the cost of robot usage by reducing tax incentives for automation companies. (来源: 36氪)
Future of Humanoid Robots: Renowned Roboticist Rodney Brooks Believes They Won’t Be Human-Like : Renowned roboticist Rodney Brooks wrote that despite massive investments, current humanoid robots still cannot achieve human-level dexterity, and bipedal locomotion poses safety risks. He predicts that in the next 15 years, humanoid robots will no longer mimic human form, but will evolve into specialized robots with wheeled mobility, multiple arms (equipped with grippers or suction cups), and multiple sensors (active optical imaging, non-visible light perception) to adapt to specific tasks. He believes that the current pursuit of “human-like” forms, despite huge investments, will ultimately be in vain. (来源: 36氪)

Debate Over AI Code Generation Quality and Developer Experience : On social media, developers are actively debating the quality and practicality of AI-generated code. Some praised Claude Sonnet 4.5 for its ability to refactor entire codebases, but found the generated code wouldn’t run. Others complained that AI-generated code “doesn’t compile,” leading to decreased development efficiency. These discussions reflect the ongoing challenges in AI-assisted programming regarding the balance between efficiency and accuracy, and the developers’ need for debugging and verification when dealing with AI-generated results. (来源: Twitter, Twitter, Twitter)

AI Era Talent Shift: From ‘Headhunting’ to ‘Cultivating Talent’ : Social media is abuzz with discussions that the talent philosophy in the AI era should shift from traditional “headhunting” to “cultivating talent.” Given the scarcity of AI talent and rapid technological iteration, companies should focus more on nurturing employees with foundational tech stacks rather than blindly pursuing expensive “ready-made” talent in the market. This perspective emphasizes the importance of continuous learning and internal development to adapt to the rapidly changing demands of the AI sector. (来源: dotey)
AI Infrastructure Energy Consumption and Sam Altman’s Energy Demands : Sam Altman proposed that AI development requires 250GW of electricity, sparking public concern and discussion over the massive energy consumption of AI infrastructure. This demand far exceeds existing energy supply capabilities, prompting consideration of how to balance rapid AI development with sustainable energy supply. Related discussions also touched upon environmental issues in semiconductor manufacturing, such as the use of PFAS and the potential risks of its alternatives. (来源: Twitter, Twitter)

AI Doomerism vs. Optimism: Concerns and Rebuttals : On social media, there’s widespread discussion about AI “doomerism” and potential AI risks, but many also believe these concerns are exaggerated. Optimists argue that immediate issues caused by AI (e.g., climate impact, corporate exploitation, military surveillance) are more pressing than the distant threat of “superintelligence destroying humanity,” and current solvable challenges should be focused on. Some dismiss AI doomerism as “nonsense,” a sign of laziness and instability, while others believe AI will ultimately lead to creation and nurturing. (来源: Reddit r/ArtificialInteligence, Twitter, Twitter)
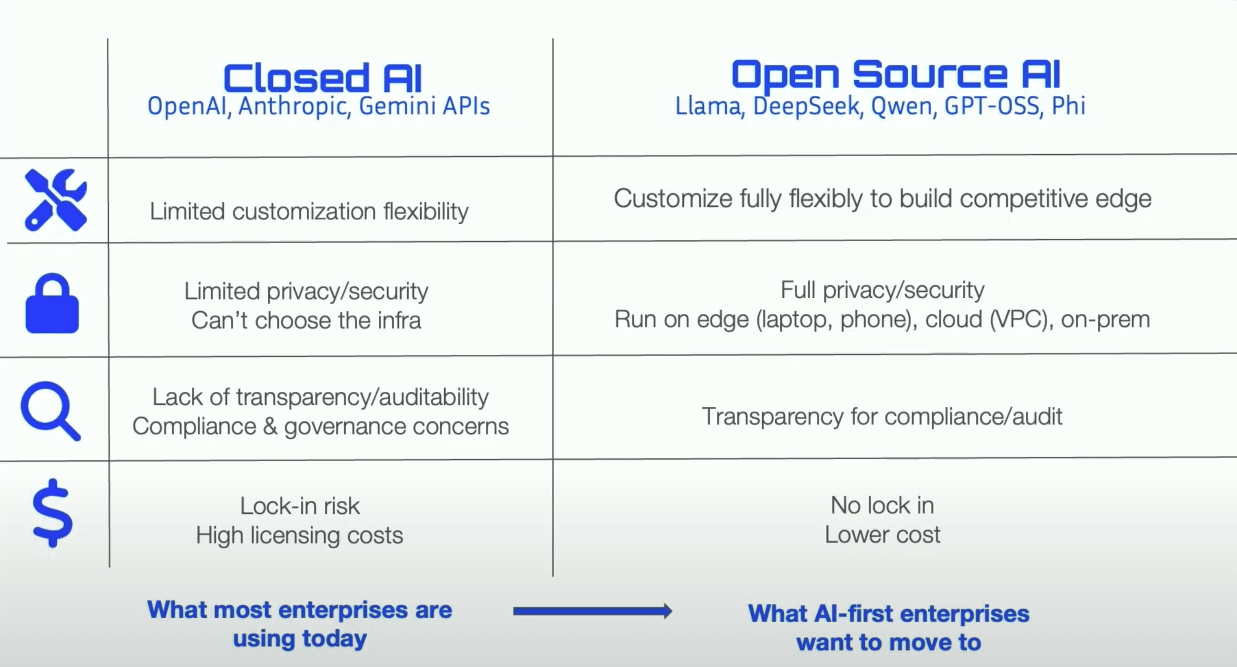
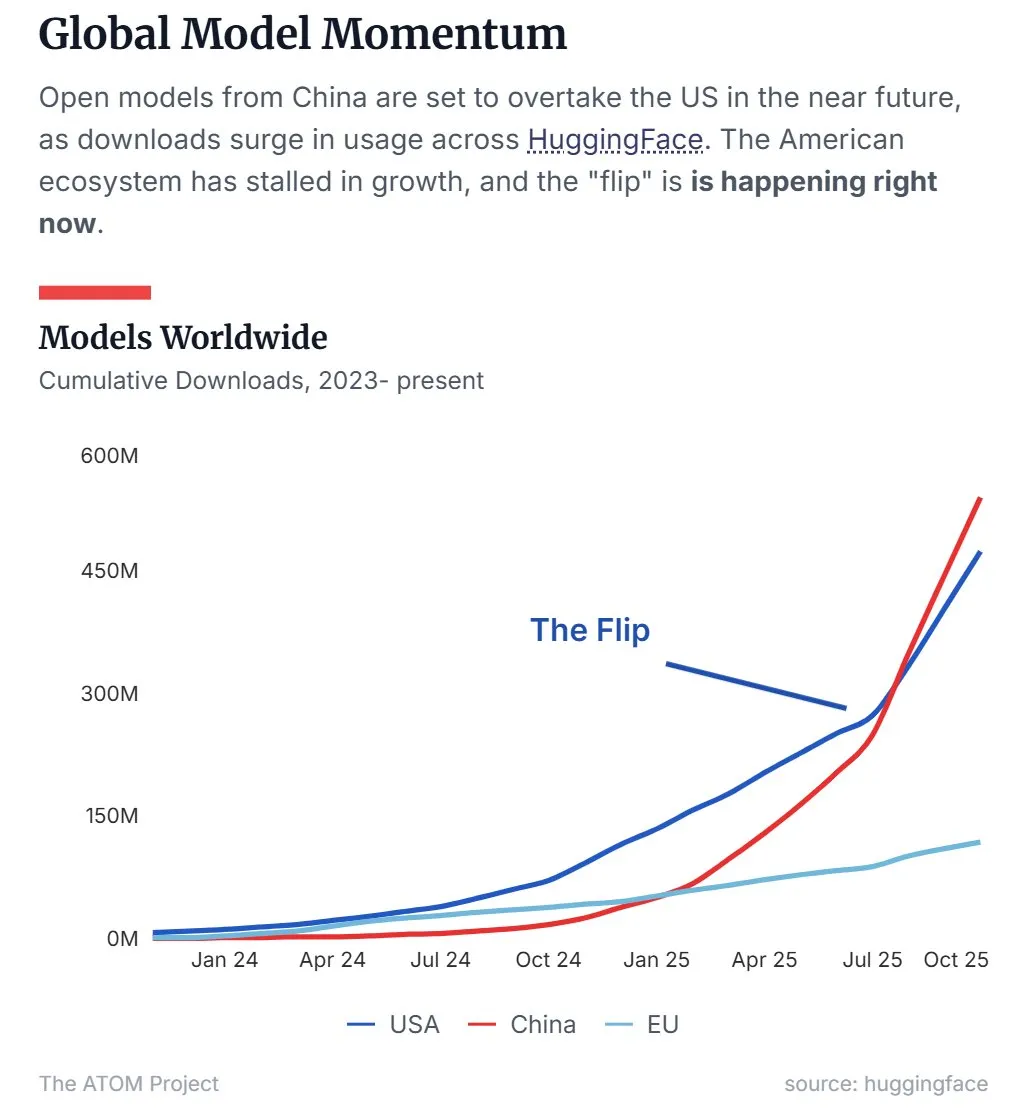
China’s Open-Source LLM Market Share Surpasses the US : Latest data indicates that Chinese open-source Large Language Models (LLMs), represented by Qwen, have surpassed the United States in market share, becoming the dominant force in the open-source LLM domain. This trend signifies China’s accelerating rise in open-source AI technology R&D and application, exerting a significant impact on the global AI landscape. (来源: Twitter, Twitter)
45-Day Team Production of AI Manhua Series ‘Monday Tomorrow’ Achieves Tens of Millions of Views : A team of just 10 people completed the production of 50 episodes of the AI manhua series ‘Monday Tomorrow’ in 45 days, and, without any paid promotion, achieved over ten million views across all platforms. Douyin’s paid revenue has already covered all costs. The project adopted the core concept of “original characters + AI generation,” addressing AI content copyright ownership issues and exploring a full-category IP commercial development path. The production process involved highly specialized divisions, with original artists, engineers, post-production editors, and directors collaborating closely, showcasing the immense potential of AI technology in reducing costs and increasing efficiency in content production. (来源: 36氪)

💡 Other
Audio-Text Precise Alignment Requirements Survey : Some social media users have shown strong interest in audio-text precise alignment technology and released a requirements survey, aiming to collect specific user needs regarding the technology’s functionalities and application scenarios, in hopes of promoting the development and optimization of related technologies. (来源: dotey)
DeepMind Showcases Nano Banana Demo : Google DeepMind showcased a demo named “Nano Banana,” attracting attention on social media. While specific details have not been fully disclosed, it likely relates to AI video generation or multimodal AI technology, hinting at new advancements from DeepMind in the field of visual AI. (来源: GoogleDeepMind)
Academic Discussion on Invention Priority of Highway Net and ResNet : Renowned AI researcher Jürgen Schmidhuber retweeted a post, reigniting academic discussion on the invention priority of Highway Net and ResNet in deep residual learning. He pointed out that Microsoft’s ResNet paper inaccurately referred to Highway Net as “concurrent” work and emphasized that Highway Net was published seven months before ResNet and had already identified and proposed solutions for residual connections. (来源: SchmidhuberAI)