
Anahtar Kelimeler:OpenAI GDPval kıyaslaması, Claude Opus 4.1, GPT-5, AI değerlendirmesi, ekonomik görev performansı, AI modeli ekonomik etki değerlendirmesi, Claude Opus 4.1 vs GPT-5, GDPval kıyaslama testi, AI pratik uygulama yeteneği, çoklu sektör AI performans karşılaştırması
🔥 Spotlight
OpenAI GDPval Benchmark Released: Claude Opus 4.1 Outperforms GPT-5 : OpenAI released the new GDPval benchmark to evaluate AI models’ performance on real-world economic tasks across 9 industries and 44 occupations. Initial results show that Anthropic’s Claude Opus 4.1 achieved or surpassed human expert level in nearly half of the tasks, outperforming GPT-5. OpenAI acknowledged Claude’s superior aesthetic performance, while GPT-5 led in accuracy. This marks a shift in AI evaluation towards measuring real economic impact and reveals the rapid advancement of AI capabilities. (Source: OpenAI, menhguin, MillionInt, _sholtodouglas, polynoamial, menhguin, aidan_mclau, sammcallister, menhguin, andy_l_jones, tokenbender, scaling01, scaling01, scaling01, scaling01, scaling01, scaling01, alexwei_, scaling01, scaling01, scaling01, gdb, teortaxesTex, snsf, dilipkay, scaling01, scaling01, jachiam0, jachiam0, sama, ClementDelangue, AymericRoucher, shxf0072, Reddit r/artificial, 36氪, 36氪, 36氪)

AI and Wikipedia’s “Doom Spiral” for Vulnerable Languages : AI models learn languages by scraping internet text, and Wikipedia is often the largest online data source for vulnerable languages. However, a flood of low-quality AI-translated content is entering these smaller Wikipedia versions, leading to widespread errors. This creates a “garbage in, garbage out” vicious cycle, potentially making AI translations of these languages even more unreliable and thus accelerating the decline of vulnerable languages. The Greenlandic Wikipedia has been proposed for closure due to “gibberish” caused by AI tools. This highlights the potential negative impact of AI on cultural diversity and language preservation. (Source: MIT Technology Review, MIT Technology Review)

OpenAI’s Top Researcher Song Yang Jumps to Meta : Song Yang, head of OpenAI’s strategic exploration team and a key contributor to diffusion models, has moved to Meta’s MSL team, reporting to Chief Scientist Zhao Shengjia. Song Yang is a child prodigy who entered Tsinghua University at 16 and became known at OpenAI for achievements such as consistency models, being regarded as one of the “strongest brains” in the industry. This move is another significant event in Meta’s continuous poaching of OpenAI talent, sparking industry attention on AI talent competition and research directions. (Source: 36氪, dotey, jeremyphoward, teortaxesTex)

China Telecom Tianyi AI Releases High-Quality Dataset with Over 10 Trillion Tokens : China Telecom Tianyi AI has released a high-quality general large model corpus dataset with a total storage of 350TB and over 10 trillion tokens, along with specialized datasets covering 14 key industries. This dataset has been meticulously annotated and optimized, including multimodal industry data, aiming to enhance AI model performance and generalization capabilities. China Telecom emphasizes that high-quality datasets are the core fuel for AI development, and relying on the Xingchen MaaS platform, it has built a “data-model-service” closed loop, committed to promoting inclusive AI development and localized innovation, having successfully trained trillion-parameter large models. (Source: 量子位)

China’s Guoxing Aerospace Achieves Normalized Commercial Operation of World’s First Space Computing Constellation : China’s Guoxing Aerospace has successfully launched and achieved normalized commercial operation of its space computing constellation, marking a shift from “can be done” to “usable” for space computing. The constellation consists of the first batch of “Xingsuan” satellites, aiming to build a space-based computing infrastructure of 2800 computing satellites with a total computing power exceeding 100,000 P, supporting the operation of billion-parameter models. This success involved deploying a road recognition model to an in-orbit satellite, completing the entire process from image acquisition and model inference to result transmission, marking the first in-orbit operation of a traffic industry algorithm and providing a new paradigm for the spatial extension of global AI infrastructure. (Source: 量子位)

China Restricts Nvidia Chip Procurement, Accelerating Semiconductor Self-Sufficiency : China has banned major tech companies from purchasing Nvidia chips, a move indicating that China has made sufficient progress in the semiconductor sector to reduce reliance on US-designed chips. This highlights US vulnerability in Taiwan’s semiconductor manufacturing and China’s increasing self-sufficiency. For example, the DeepSeek-R1-Safe model has been trained on 1000 Huawei Ascend chips. Nvidia’s Jensen Huang also previously noted that 50% of global AI researchers are from China. (Source: AndrewYNg, Plinz)

🎯 Trends
ChatGPT Pulse Launched, Ushering in an Era of Proactive Intelligence : OpenAI has launched a preview of ChatGPT Pulse for Pro users, a feature that transforms ChatGPT from a passive Q&A tool into a proactive intelligent assistant. Pulse generates personalized daily briefings in the background based on user chat history, feedback, and connected applications (e.g., calendar, Gmail), presented as cards, aiming to provide a finite, non-addictive information experience. Sam Altman called it his “favorite feature,” foreshadowing ChatGPT’s future shift towards highly personalized and proactive services. (Source: Teknium1, openai, dejavucoder, natolambert, gdb, jam3scampbell, jam3scampbell, scaling01, sama, sama, scaling01, nickaturley, kevinweil, dotey, raizamrtn, BlackHC, op7418, 36氪, 36氪, 36氪, 36氪, 量子位)

Google Releases Gemini Robotics 1.5 Series, Enabling “Cross-Species” Robot Learning : Google DeepMind released the Gemini Robotics 1.5 series models (including Gemini Robotics 1.5 and Gemini Robotics-ER 1.5), aiming to equip robots with stronger “think-then-act” capabilities and cross-embodiment learning skills. Gemini Robotics-ER 1.5 acts as the “brain” for planning and decision-making, while Gemini Robotics 1.5 acts as the “cerebellum” for executing actions, with both working collaboratively. This series of models excels in embodied reasoning and cross-embodiment learning, capable of transferring actions learned from one robot to another, potentially advancing the development of general-purpose robots. (Source: Teknium1, nin_artificial, dejavucoder, crystalsssup, scaling01, jon_lee0, BlackHC, Google, demishassabis, shaneguML, demishassabis, JeffDean, 36氪, 36氪)

Google Releases Gemini 2.5 Flash Series Model Updates : Google has released the latest updates to its Gemini 2.5 Flash and Flash-Lite models, which show improvements in intelligence, cost-effectiveness, and token efficiency. Flash-Lite’s intelligence index increased by 8 points in inference mode and 12 points in non-inference mode, with higher token efficiency and faster inference speed. These updates result in better model performance in instruction following, multimodal understanding, and translation, with Flash models being more efficient in Agent tool usage. (Source: scaling01, osanseviero, Google, osanseviero, andrew_n_carr)
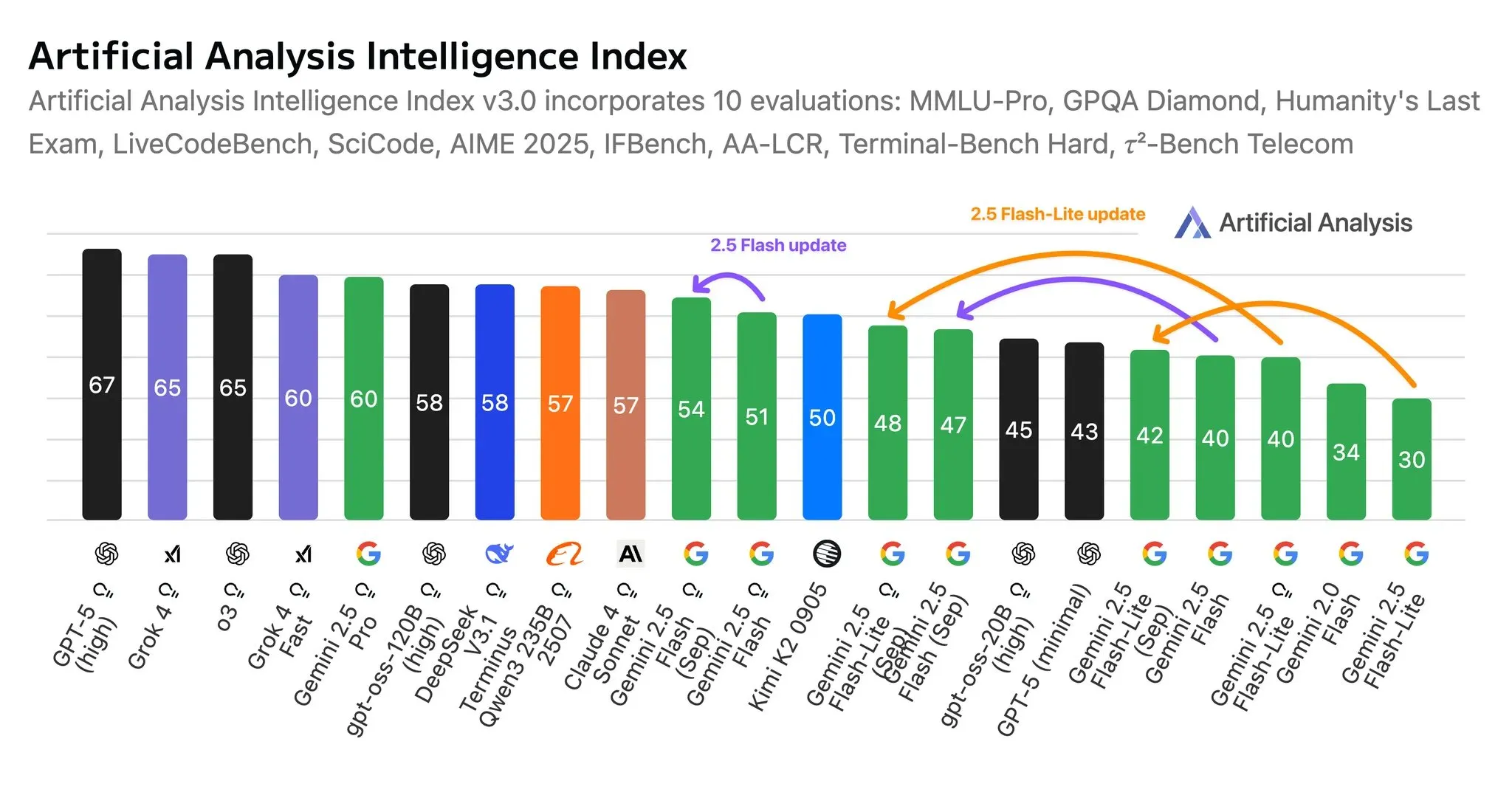
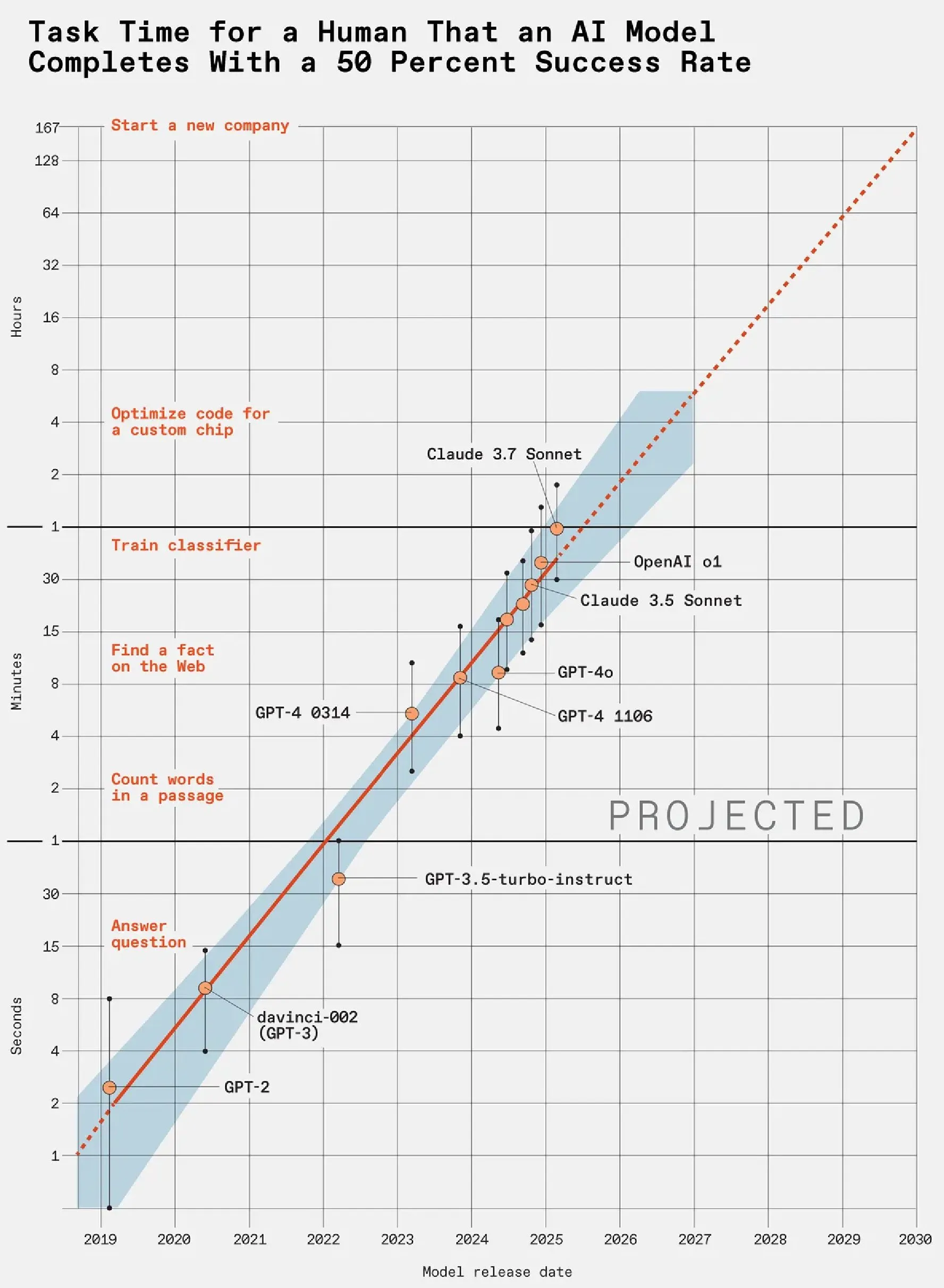
AI Capability Improvement Astounding: LLM Capabilities Double Every 7 Months : A METR study on LLM benchmarks, measuring the time LLMs take to complete human tasks, found that LLM capabilities double every 7 months. GPT-5 can now consistently complete complex tasks that would take humans several hours. Following this trend, by 2030, LLMs could potentially handle work that would take humans a year to complete, such as starting new companies. This foreshadows a disruptive impact of AI on the labor market in the coming years. (Source: karminski3)
Video Models Show Potential for General Visual Intelligence : Video models are experiencing a “GPT moment,” demonstrating general capabilities from simple perception to visual reasoning. Models like Veo3 already possess zero-shot capabilities, able to solve complex tasks within the visual stack. Research indicates that video models are general “spatiotemporal reasoners,” and are expected to become a key path to general visual intelligence in the future, especially in robotics, where they can solve “most difficult” problems such as semantics, planning, and common sense. (Source: shaneguML, BlackHC, AndrewLampinen, teortaxesTex)

AI Agents Transition from “Assistants” to “Managers,” Deeply Integrating into the Physical World : Renowned futurist Bernard Marr predicts that by 2026, AI Agents will transition from passive assistants to proactive managers, capable of autonomously handling daily tasks and coordinating complex projects. AI will no longer be confined to the digital world but will deeply integrate into the physical world through forms like autonomous driving, humanoid robots, and IoT, changing how humans interact with their environment. Major Chinese tech companies like Tencent, Alibaba, and Baidu are also actively deploying enterprise-grade AI Agents, emphasizing their task execution and delivery capabilities rather than just conversational abilities, aiming to make them new business growth drivers. (Source: 36氪, 36氪, omarsar0)
Industrial Robots Shift from “Solo Operations” to “Super Production Teams” : Industrial embodied AI robots are expanding from single processes to full-workflow collaboration, forming “super production teams.” For example, a production line composed of 8 industrial embodied AI robots from Weiyi Zhizao can produce 4 different products, achieving minute-level switching and hour-level adjustments. These robots can think like humans, take over tasks, and improve production efficiency and flexibility. AI vision technology has become a core driving force, pushing industrial robots from “execution tools” towards “embodied intelligence,” providing a Chinese solution for the digital and intelligent transformation of manufacturing. (Source: 36氪)

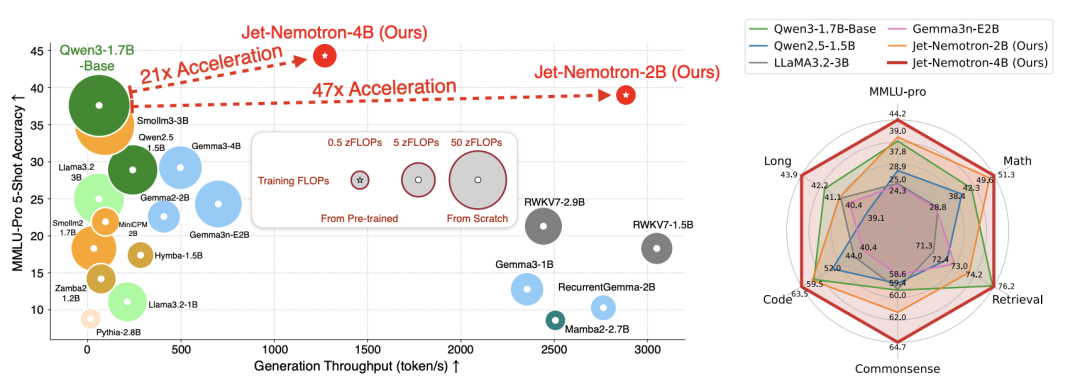
Grok-4-fast’s Efficiency Gains Potentially Linked to NVIDIA Jet-Nemotron Algorithm : Grok-4-fast’s impressive performance in cost reduction and efficiency improvement may be related to NVIDIA’s Jet-Nemotron algorithm. The algorithm, using the PortNAS framework, starts with a pre-trained full attention model and optimizes the attention mechanism, achieving an approximately 53x increase in LLM inference speed while maintaining performance comparable to top open-source models. Jet-Nemotron-2B demonstrates higher accuracy than Qwen3-1.7B-Base on MMLU-Pro, is 47 times faster, and has smaller memory requirements, potentially significantly reducing model costs. (Source: 36氪)
NVIDIA Cosmos Reason Model Downloads Exceed 1 Million : The NVIDIA Cosmos Reason model has surpassed 1 million downloads on HuggingFace and ranks highly on the physical reasoning leaderboard. This model aims to teach AI Agents and robots to think like humans, provided as easily deployable microservices, and represents a significant achievement for NVIDIA in advancing AI Agents and robotics technology. (Source: huggingface, ClementDelangue)

Meta Releases Code World Model (CWM) to Advance Code Generation Research : Meta FAIR has released the Code World Model (CWM), a 32-billion-parameter research model designed to explore how world models can transform code generation and code reasoning. CWM is open-sourced under a research license, encouraging the community to build upon it and signaling new research directions in code generation. (Source: ylecun)
Google Releases EmbeddingGemma, a Lightweight Text Embedding Model : Google has launched EmbeddingGemma, a lightweight, open text embedding model with only 300M parameters, yet achieving SOTA performance in MTEB benchmarks. It outperforms models twice its size and is ideal for fast, efficient on-device AI applications. (Source: _akhaliq)

Alibaba Tongyi Qianwen Unveils Multimodal and Large-Scale Expansion Roadmap : Alibaba’s Tongyi Qianwen has unveiled an ambitious roadmap, heavily betting on unified multimodal models and extreme-scale expansion. Goals include extending context length from 1M to 100M tokens, reaching trillion- or even ten-trillion-level parameters, expanding test-time computation to 1M, and data volume to 100 trillion tokens. Furthermore, it will drive infinite-scale synthetic data generation and expanded Agent capabilities, embodying the philosophy of “scale is everything.” (Source: menhguin, karminski3)

AI-Assisted Healthcare Enters Clinical Application Phase : AI applications in healthcare are transitioning from cutting-edge experimental products to routine tools. For instance, JD Health has launched “AI Hospital 1.0” and upgraded its “Jingyi Qianxun 2.0” medical large model, achieving AI-driven “medical examination, diagnosis, and pharmacy” closed-loop services, covering guided consultation, inquiry, examination, medication purchase, and health management. AI smart stethoscopes can now assist in diagnosing heart disease, and AI-powered image reading has made breakthroughs in areas like lung nodules and cerebral hemorrhage, achieving diagnostic accuracy exceeding 96%. AI is fully entering clinical applications, enhancing the efficiency and precision of medical services. (Source: 36氪, 36氪, 量子位, Ronald_vanLoon, Reddit r/ArtificialInteligence)

Meta AI App Launches AI-Generated Short Videos “Vibes” : The Meta AI App has launched a new feature called “Vibes,” a dynamic feed focused on AI-generated short videos. This move signifies Meta’s further strategic deployment in AI content creation, aiming to provide users with new, AI-driven short video experiences. (Source: dejavucoder, _tim_brooks, EigenGender)
Breakthrough in AI-Generated Genomes Achieved : Arc Institute announced three new discoveries, including the world’s first functional AI-generated genome. This breakthrough leverages Evo 2, a biological ML model released in collaboration between Arc and NVIDIA, enabling scientists to design and write large-scale changes into the human genome, correcting DNA repeats that cause genetic diseases, and potentially accelerating gene therapy and biomaterials research. (Source: dwarkesh_sp, riemannzeta, zachtratar, kevinweil, Reddit r/artificial)
Apple Introduces SimpleFold, a Lightweight AI for Protein Folding Prediction : Apple researchers have developed SimpleFold, a new AI based on flow matching models for protein folding prediction. It discards computationally expensive components found in traditional diffusion methods, using only general Transformer blocks to directly convert random noise into protein structure predictions. SimpleFold-3B performs excellently in standard benchmarks, achieving 95% of the performance of leading models, with higher deployment and inference efficiency, potentially lowering the computational barrier for protein structure prediction and accelerating drug discovery. (Source: Reddit r/ArtificialInteligence, HuggingFace Daily Papers)

Deep Integration of Industrial AI and Physical AI : Alibaba has partnered with NVIDIA to integrate the complete NVIDIA Physical AI software stack into the Alibaba Cloud platform. Physical AI aims to bring artificial intelligence from screens into the physical world, optimizing AI-generated content by integrating physical laws to make it more consistent with real-world logic. Its core technologies include world models, physical simulation engines, and embodied intelligence controllers, aiming to achieve AI’s complete understanding of 3D space, real-time physical computation, and concrete actions. This collaboration is expected to drive widespread AI applications in robotics, logistics, automotive, manufacturing, and other industries, transforming AI from an information processing tool into an intelligent system capable of understanding and manipulating the physical world. (Source: 36氪)

Hunyuan3D-Omni Framework for AI-Generated 3D Assets Released : Hunyuan3D-Omni is a unified framework for controllable 3D asset generation, based on Hunyuan3D 2.1. It supports not only image and text conditions but also accepts point clouds, voxels, bounding boxes, and skeletal poses as conditional signals, enabling precise control over geometry, topology, and pose. The model employs a single cross-modal architecture to unify all signals and is trained with a progressive, difficulty-aware sampling strategy, improving generation accuracy and robustness. (Source: HuggingFace Daily Papers)
Tencent Announces Hunyuan Image 3.0, Claimed to be the Strongest Open-Source Text-to-Image Model : Tencent has announced that it will release Hunyuan Image 3.0 on September 28th, claiming it to be the world’s most powerful open-source text-to-image model. This announcement has garnered widespread community attention and anticipation, especially regarding its application prospects in tools like ComfyUI. (Source: ostrisai, Reddit r/LocalLLaMA)

Llama.cpp Adds Qwen3 Reranker Support : Llama.cpp has merged support for the Qwen3 reranker, a feature that outputs similarity scores for query-document pairs via a reranking model (cross-encoder), significantly improving the recall performance of retrieval pipelines like RAG. Users will need to use the new GGUF files to get correct results. (Source: Reddit r/LocalLLaMA)![Llama.cpp新增Qwen3 reranker支持](https://external-preview.redd.it/gjtn51bKTEhntL8tK6567mzxkqg8KV6qsi2OUMPMyfI.png?auto=webp&s