
Anahtar Kelimeler:Qwen3-Sonraki 80B, MobileLLM-R1, Replit Ajan 3, Somutlaştırılmış Yapay Zeka, Diferansiyel Gizlilik, LLM Çıkarımı, Yapay Zeka Ajanı, Transformer, Kapılı DeltaNet Hibrit Dikkat Mekanizması, DARPA AIxCC Güvenlik Açığı Tespit Sistemi, Kenar Cihazlarda Yapay Zeka Çıkarım Optimizasyonu, Otonom Yazılım Üretimi ve Testi, Çok Dilli Kodlayıcı Modeli mmBERT
🔥 Odak Noktası
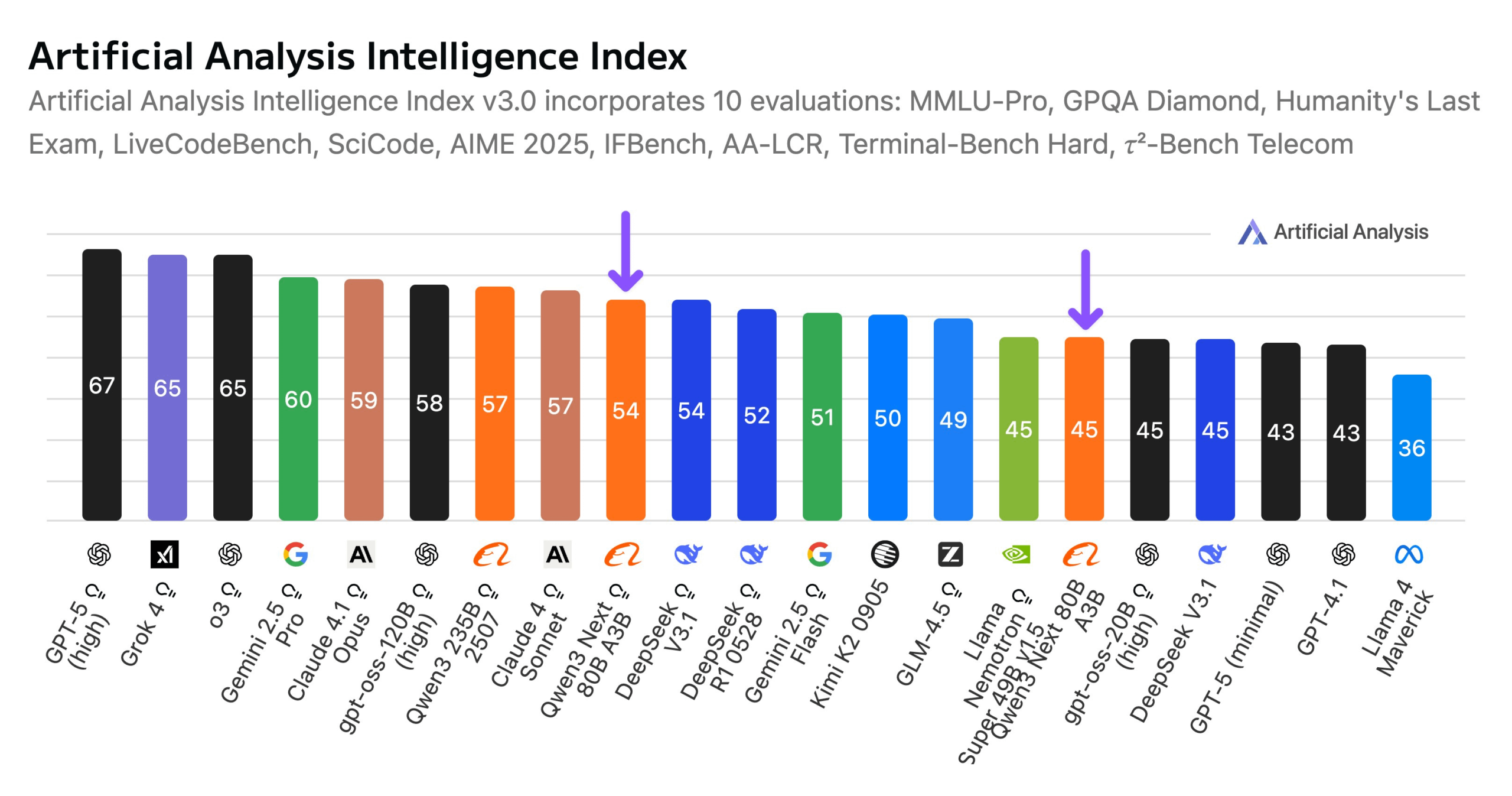
Alibaba, Qwen3-Next 80B Modelini Duyurdu: Alibaba, hibrit çıkarım yeteneklerine sahip açık kaynaklı bir model olan Qwen3-Next 80B’yi tanıttı. Gated DeltaNet ve Gated Attention’ın hibrit dikkat mekanizmasını ve %3,8’lik yüksek seyrekliği (yalnızca 3B aktif parametre) kullanan bu model, DeepSeek V3.1 ile benzer bir zeka seviyesine sahipken, eğitim maliyetini 10 kat azaltıyor ve çıkarım hızını 10 kat artırıyor. Qwen3-Next 80B, çıkarım ve uzun bağlam işleme konularında üstün performans göstererek Gemini 2.5 Flash-Thinking’i bile geride bırakıyor. 256k token bağlam penceresini destekleyen model, tek bir H200 GPU üzerinde çalışabiliyor ve NVIDIA API Catalog’da sunuluyor; bu da verimli LLM mimarisinde yeni bir çığır açıyor. (Kaynak: Alibaba_Qwen, ClementDelangue, NandoDF)
DARPA AIxCC Yarışması: LLM Destekli Otomatik Güvenlik Açığı Tespiti ve Onarımı Sistemi: DARPA Yapay Zeka Siber Yarışması (AIxCC) kapsamında, “All You Need Is A Fuzzing Brain” adlı LLM destekli bir Siber Akıl Yürütme Sistemi (CRS) öne çıkarak, daha önce bilinmeyen 6 sıfır gün güvenlik açığı da dahil olmak üzere 28 güvenlik açığını bağımsız olarak başarıyla tespit etti ve bunlardan 14’ünü onardı. Sistem, gerçek dünyadaki açık kaynaklı C ve Java projelerinde olağanüstü otomatik güvenlik açığı tespiti ve yama uygulama yetenekleri sergiledi ve finalde dördüncü sırada yer aldı. Bu CRS açık kaynak olarak yayınlandı ve LLM’lerin güvenlik açığı tespiti ve onarımı görevlerindeki en son seviyesini değerlendirmek için herkese açık bir liderlik tablosu sunuyor. (Kaynak: HuggingFace Daily Papers)
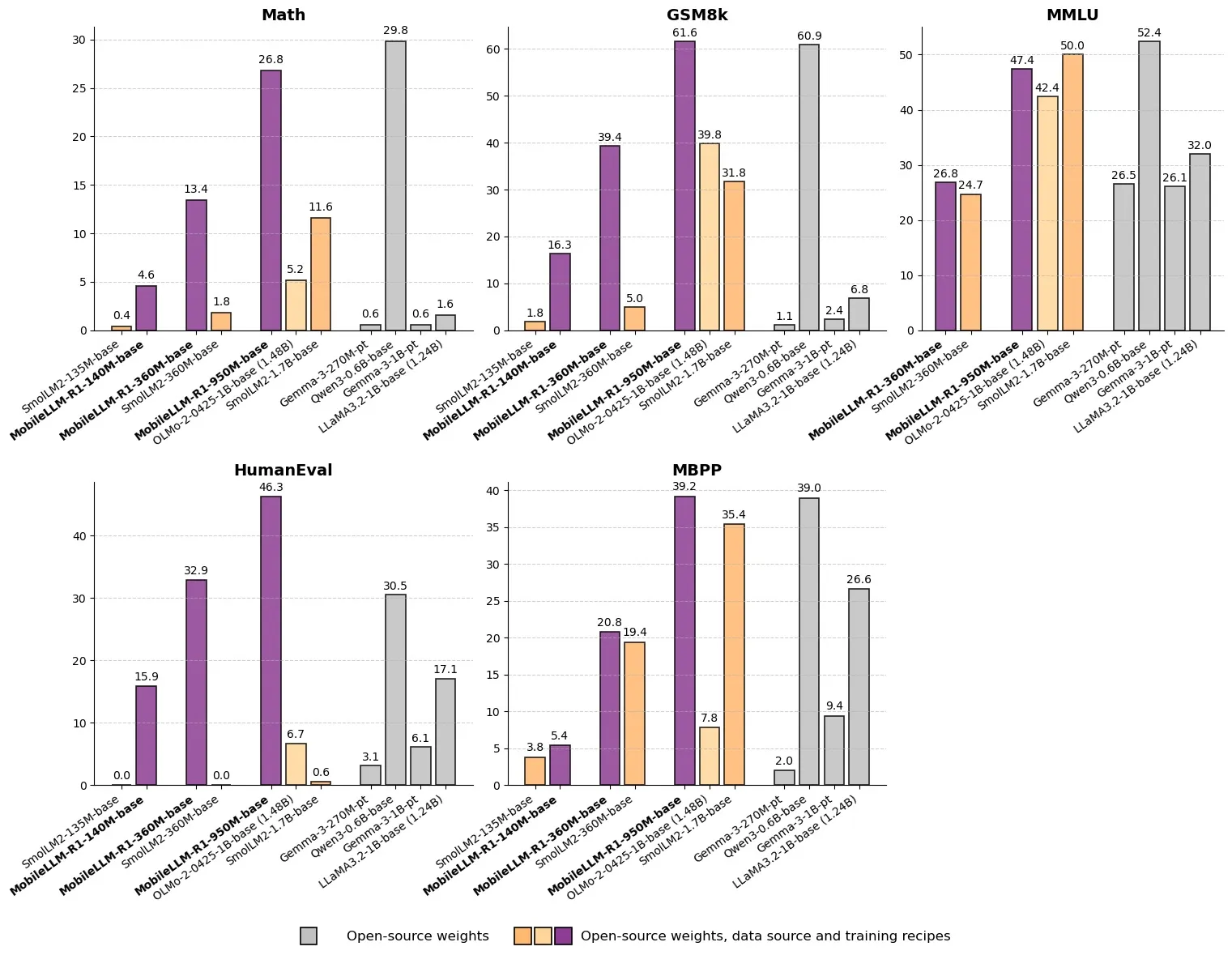
Meta, MobileLLM-R1’i Duyurdu: Milyar Altı Parametreli Verimli Çıkarım Modeli: Meta, Hugging Face üzerinde 1 milyardan az parametreye sahip bir uç çıkarım modeli olan MobileLLM-R1’i yayınladı. Bu model, matematiksel doğrulukta Olmo-1.24B’den yaklaşık 5 kat, SmolLM2-1.7B’den ise yaklaşık 2 kat daha yüksek performans göstererek 2-5 katlık bir performans artışı sağlıyor. MobileLLM-R1, yalnızca 4.2T ön eğitim token’ı (Qwen kullanımının %11.7’si) kullanarak, az miktarda son eğitimle güçlü çıkarım yetenekleri sergiliyor. Bu, veri verimliliği ve model ölçeği açısından bir paradigma değişikliğine işaret ediyor ve uç cihazlarda AI çıkarımı için yeni yollar açıyor. (Kaynak: _akhaliq, Reddit r/LocalLLaMA)
OpenAI, LLM Halüsinasyonlarının Nedenlerini Araştırıyor: Değerlendirme Mekanizması Anahtar: OpenAI, büyük dil modellerinin (LLM’ler) halüsinasyonlarının modelin kendisindeki bir arızadan ziyade, mevcut değerlendirme yöntemlerinin “tahmini” “dürüstlüğe” tercih etmesinin doğrudan bir sonucu olduğunu belirten bir araştırma makalesi yayınladı. Çalışma, mevcut kıyaslama testlerinin genellikle modelleri “bilmiyorum” yanıtını verdikleri için cezalandırdığını ve bu durumun modelleri makul görünen ancak aslında yanlış yanıtlar üretmeye teşvik ettiğini savunuyor. Makale, modellerin belirsiz durumlarda yüksek güvenilirlikli çıktılar peşinde koşmak yerine daha iyi kalibrasyon ve dürüstlük sergilemelerini teşvik etmek için kıyaslama puanlama yöntemlerinin değiştirilmesi ve mevcut liderlik tablolarının yeniden düzenlenmesi çağrısında bulunuyor. (Kaynak: dl_weekly, TheTuringPost, random_walker)
Replit Agent 3: Otonom Yazılım Üretimi ve Testinde Çığır Açan Gelişme: Replit, yazılımı yüksek derecede otonom olarak üretebilen ve test edebilen AI ajanı Agent 3’ü tanıttı. Bu ajan, sıfır müdahale ile saatlerce çalışarak eksiksiz uygulamalar (sosyal ağ platformları gibi) oluşturma ve bunları kendi kendine test etme yeteneğini sergiledi. Kullanıcı geri bildirimleri, Agent 3’ün fikirleri hızla gerçek ürünlere dönüştürebildiğini, geliştirme verimliliğini önemli ölçüde artırdığını ve hatta ayrıntılı çalışma makbuzları sağlayabildiğini gösteriyor. Bu ilerleme, AI ajanlarının yazılım geliştirme alanındaki muazzam potansiyelini, özellikle test edilebilir ortamlar sağlama konusunda Replit’in lider konumda olduğunu gösteriyor. (Kaynak: amasad, amasad, amasad)
🎯 Gelişmeler
Unitree Robotics, IPO’yu Hızlandırıyor, “AI’yı Çalıştırmaya” Odaklanıyor: Dört ayaklı robot unicorn’u Unitree Robotics, aktif olarak IPO’ya hazırlanıyor. Kurucu Wang Xingxing, AI’ın fiziksel uygulama katmanındaki muazzam potansiyelini vurgulayarak, büyük modellerin gelişiminin AI ve robotların entegrasyonu için bir fırsat sunduğuna inanıyor. Embodied AI’ın gelişimi veri toplama, çok modlu veri füzyonu ve model kontrol hizalaması gibi zorluklarla karşılaşsa da, Wang Xingxing geleceğe iyimser bakıyor ve inovasyon ve girişimcilik eşiğinin önemli ölçüde düştüğünü, küçük organizasyonların patlayıcı gücünün daha da artacağını düşünüyor. Unitree Robotics, dört ayaklı robot pazarında lider konumda olup yıllık geliri 1 milyar yuanı aşmıştır. Bu IPO, robotların derinlemesine katılımıyla geleceğin hızlanmasını sağlamak için sermaye gücünden yararlanmayı amaçlamaktadır. (Kaynak: 36氪)

Apple AI Departmanında Üst Düzey Yönetici Değişiklikleri, Siri’nin Yeni Özellikleri 2026’ya Ertelendi: Apple’ın AI departmanı, üst düzey yöneticilerin ayrılmasıyla çalkalanıyor; eski Siri başkanı Robby Walker görevinden ayrılmak üzere ve çekirdek ekip üyeleri Meta tarafından transfer edildi. Devam eden kalite sorunları ve temel mimari geçişinden etkilenen Siri’nin kişiselleştirilmiş yeni özelliklerinin 2026 baharına erteleneceği duyuruldu. Bu çalkantı ve erteleme, Apple’ın AI inovasyonu ve uygulama hızına dair dışarıdan gelen şüpheleri artırıyor; şirket AI sunucu çipleri ve harici modelleri değerlendirme konusunda sık sık adımlar atsa da, gerçek ilerleme beklentilerin altında kalıyor. (Kaynak: 36氪)
mmBERT: Çok Dilli Encoder Modellerinde Yeni Gelişmeler: mmBERT, 1800’den fazla dildeki 3T çok dilli metin üzerinde önceden eğitilmiş bir encoder modelidir. Model, ters maskeleme oranı zamanlaması ve ters sıcaklık örnekleme oranı gibi yenilikçi unsurları tanıtmakta ve eğitimin son aşamalarında 1700’den fazla düşük kaynaklı dil verisi ekleyerek performansı önemli ölçüde artırmıştır. mmBERT, sınıflandırma ve alma görevlerinde hem yüksek hem de düşük kaynaklı dillerde üstün performans sergilemekte olup, OpenAI’nin o3 ve Google’ın Gemini 2.5 Pro gibi modellerle karşılaştırılabilir bir performans sunarak çok dilli encoder model araştırmalarındaki boşluğu doldurmaktadır. (Kaynak: HuggingFace Daily Papers)
MachineLearningLM: LLM’ler için Bağlamsal Makine Öğrenimini Sağlayan Yeni Çerçeve: MachineLearningLM, genel LLM’lere (Qwen-2.5-7B-Instruct gibi) güçlü bağlamsal makine öğrenimi yetenekleri sağlamayı, aynı zamanda genel bilgi ve akıl yürütme yeteneklerini korumayı amaçlayan sürekli bir ön eğitim çerçevesidir. Milyonlarca Yapısal Nedensel Modelden (SCM) ML görevleri sentezleyerek ve verimli token istemleri kullanarak, bu çerçeve LLM’lerin gradyan inişi yapmadan, yalnızca bağlam içi öğrenme (ICL) yoluyla 1024’e kadar örneği işlemesini sağlar. MachineLearningLM, finans, fizik, biyoloji ve tıp gibi alanlardaki alan dışı tablo sınıflandırma görevlerinde, GPT-5-mini gibi güçlü temel modellerden ortalama %15 daha iyi performans göstermektedir. (Kaynak: HuggingFace Daily Papers)
Meta vLLM: Büyük Ölçekli Çıkarım Verimliliğinde Yeni Bir Atılım: Meta’nın vLLM katmanlı uygulaması, PyTorch ve vLLM’nin büyük ölçekli çıkarımdaki verimliliğini önemli ölçüde artırarak, hem gecikme hem de iş hacmi açısından kendi dahili yığınından daha iyi performans gösterdi. Bu optimizasyon sonuçlarının vLLM topluluğuna geri beslenmesiyle, bu ilerleme AI çıkarımı için daha verimli ve uygun maliyetli çözümler getirme potansiyeline sahip, özellikle büyük dil modeli çıkarım görevlerini ele almak için kritik öneme sahip ve AI uygulamalarının gerçek dünya senaryolarında dağıtımını ve genişlemesini teşvik ediyor. (Kaynak: vllm_project)

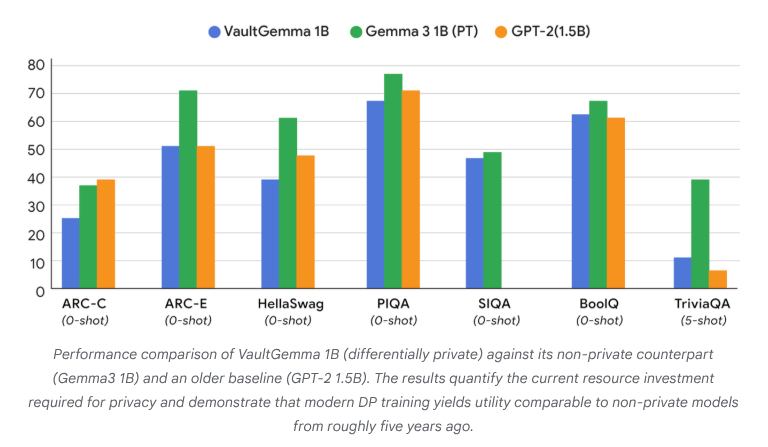
VaultGemma: İlk Diferansiyel Gizliliğe Sahip Açık Kaynak LLM Yayınlandı: Google Research, şimdiye kadar sıfırdan eğitilmiş ve diferansiyel gizlilik korumasına sahip en büyük açık kaynak model olan VaultGemma’yı yayınladı. Bu araştırma sadece VaultGemma’nın ağırlıklarını ve teknik raporunu sunmakla kalmıyor, aynı zamanda diferansiyel gizliliğe sahip dil modelleri için ölçeklendirme yasalarını da ilk kez ortaya koyuyor. VaultGemma’nın yayınlanması, hassas veriler üzerinde daha güvenli ve sorumlu AI modelleri oluşturmak için önemli bir temel sağlıyor ve gizlilik korumalı AI teknolojisinin gelişimini teşvik ederek gerçek dünya uygulamalarında daha uygulanabilir hale getiriyor. (Kaynak: JeffDean, demishassabis)
OpenAI GPT-5/GPT-5-mini API Hız Limitleri Önemli Ölçüde Artırıldı: OpenAI, GPT-5 ve GPT-5-mini’nin API hız limitlerinin önemli ölçüde artırıldığını ve bazı seviyelerde iki katına çıktığını duyurdu. Örneğin, GPT-5’in Tier 1’i 30K TPM’den 500K TPM’ye, Tier 2’si ise 450K’dan 1M’ye yükseltildi. GPT-5-mini’nin Tier 1’i de 200K’dan 500K’ya çıkarıldı. Bu ayarlama, geliştiricilerin bu modelleri büyük ölçekli uygulamalar ve deneyler için kullanma yeteneğini önemli ölçüde artırarak, hız limitlerinden kaynaklanan darboğazları azalttı ve GPT-5 serisi modellerin ticarileşmesini ve ekosistem gelişimini daha da teşvik etti. (Kaynak: OpenAIDevs)
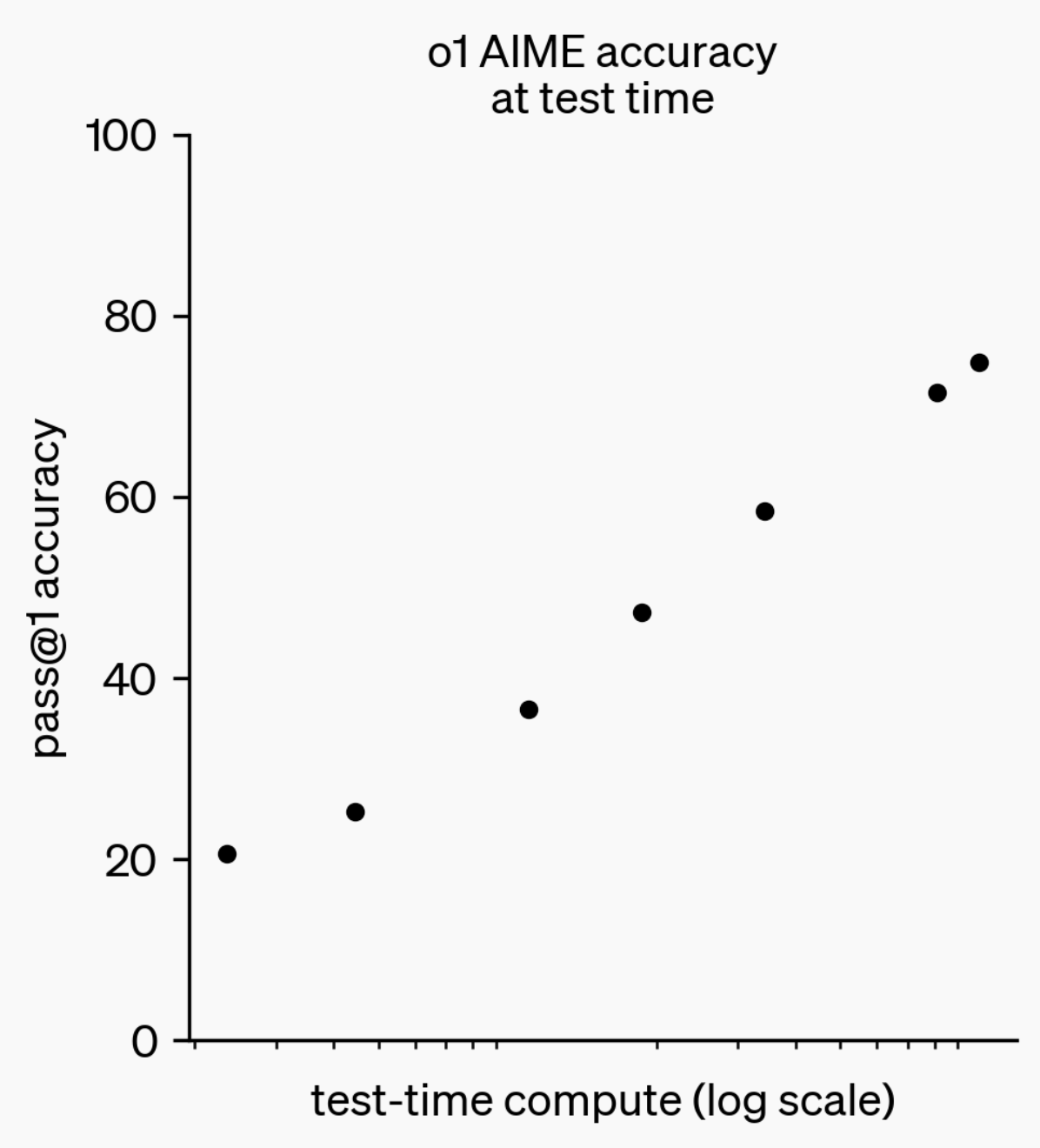
LLM Çıkarım Yeteneklerinin Evrimi: o1-preview’dan GPT-5 Pro’ya: Geçtiğimiz yıl, büyük dil modellerinin (LLM’ler) çıkarım yeteneklerinde önemli ilerlemeler kaydedildi. Bir yıl önce OpenAI tarafından yayınlanan o1-preview modelinin saniyelerce düşünmesi gerekirken, günümüzün en gelişmiş çıkarım modelleri saatlerce düşünebiliyor, web’de gezinebiliyor ve kod yazabiliyor; bu da AI çıkarım boyutunun sürekli genişlediğini gösteriyor. Modellerin “düşünmesi” için takviyeli öğrenme (RL) ile eğitilmesi ve özel düşünce zinciri (chain of thought) kullanılması sayesinde, LLM’lerin çıkarım görevlerindeki performansı düşünme süresi arttıkça iyileşiyor, bu da çıkarım hesaplamasının genişlemesinin gelecekteki model gelişiminde yeni bir yön olacağını gösteriyor. (Kaynak: polynoamial, gdb)
Japon Sakana AI: Doğadan İlham Alan AI Unicorn’u: Japon startup Sakana AI, kuruluşundan itibaren bir yıl içinde 1 milyar doların üzerinde bir değerlemeye ulaşarak Japonya’nın en hızlı “unicorn” statüsüne ulaşan şirketi oldu. Şirket, eski Google Brain araştırmacısı David Ha tarafından kuruldu ve AI yaklaşımı, doğadaki “kolektif zekadan” ilham alarak, büyük, enerji yoğun modelleri körü körüne takip etmek yerine mevcut küçük ve büyük sistemleri birleştirmeyi hedefliyor. Sakana AI, çevrimdışı Japonca sohbet robotu “Tiny Sparrow”u ve Japon edebiyatını anlayabilen bir AI’yı piyasaya sürdü ve Japon Mitsubishi UFJ Bank ile işbirliği yaparak “bankaya özel AI sistemi” geliştirmeye odaklandı. Şirket, “Japon yumuşak gücü” aracılığıyla yetenekleri çekmeyi ve AI alanında cesur deneyler yapmayı vurguluyor. (Kaynak: SakanaAILabs)
Robotik Teknolojisinde Atılımlar ve AI Entegrasyonu: İnsansı, Sürü ve Dört Ayaklı Robotlarda Yeni Gelişmeler: Robotik alanı, özellikle insansı robotlar, sürü robotları ve dört ayaklı robotlar olmak üzere önemli ilerlemeler kaydediyor. İnsansı robotların çalışanlarla doğal diyalog etkileşimleri gerçeğe dönüşürken, dört ayaklı robotlar 100 metreyi 10 saniyenin altında koşarak şaşırtıcı bir hıza ulaştı ve sürü robotları “şaşırtıcı bir zeka” sergiledi. Ayrıca, karmaşık arazide navigasyon için ANT navigasyon sistemi ve Eufy’nin robot süpürgeler için tasarladığı otonom merdiven tırmanma tabanı, robotların günlük ve endüstriyel senaryolarda daha yaygın olarak kullanılacağını gösteriyor. AI’ın nörobilim klinik deneylerindeki uygulamaları da derinleşiyor; akıllı dış iskelet HAPO SENSOR aracılığıyla kullanım etkilerinin analizi, AI’ın sağlık alanındaki potansiyelini ortaya koyuyor. (Kaynak: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
🧰 Araçlar
Qwen Code v0.0.10 & v0.0.11 Güncellemeleri: Geliştirici Deneyimini ve Verimliliğini Artırıyor: Alibaba Cloud Qwen Code, v0.0.10 ve v0.0.11 sürümlerini yayınlayarak birçok yeni özellik ve geliştirici dostu iyileştirme getirdi. Yeni sürümler, akıllı görev ayrıştırma için Subagents, görev takibi için Todo Write aracı ve proje yeniden açıldığında “tekrar hoş geldiniz” proje özeti işlevi sunuyor. Ayrıca, güncellemeler arasında özelleştirilebilir önbellek stratejileri, daha akıcı düzenleme deneyimi (ajan döngüsü olmadan), yerleşik terminal kıyaslama stres testi, daha az yeniden deneme sayısı, optimize edilmiş büyük proje dosyası okuma, geliştirilmiş IDE ve shell entegrasyonu, daha iyi MCP ve OAuth desteği ile iyileştirilmiş bellek/oturum yönetimi ve çok dilli belgeler bulunuyor. Bu iyileştirmeler, geliştiricilerin üretkenliğini önemli ölçüde artırmayı hedefliyor. (Kaynak: Alibaba_Qwen)
Claude Code Kullanım İpuçları ve Kullanıcı Deneyimi İyileştirmeleri: Claude Code kullanıcı deneyimine yönelik tartışmalar ve iyileştirme önerileri artarak devam ediyor. Kullanıcılar, AI ajanlarının kod sorunlarını çözmesine yardımcı olmak için “uygun günlük bilgisi ekle” istemlerini paylaştı. Bir geliştirici, mobil kullanım, anlık bildirimler ve etkileşimli sohbeti destekleyen Claude Code’un iOS uygulaması “Standard Input”u yayınladı. Aynı zamanda, topluluk Claude Code’un büyük projeleri işlerken gösterdiği tutarsızlığı ve bağlam yönetiminin önemini de tartıştı. Kullanıcılara, bağlamı aktif olarak temizlemeleri, Claude md dosyalarını ve çıktı stilini özelleştirmeleri, görevleri alt ajanlarla ayrıştırmaları ve verimliliği ve kod kalitesini artırmak için planlama modunu ve hooks’u kullanmaları önerildi. (Kaynak: dotey, mattrickard, Reddit r/ClaudeAI)
Hugging Face, VS Code/Copilot ile Derin Entegrasyon Sağlayarak Geliştiricileri Güçlendiriyor: Hugging Face, çıkarım sağlayıcıları aracılığıyla Kimi K2, Qwen3 Next, gpt-oss, Aya gibi yüzlerce en son teknoloji açık kaynak modeli doğrudan VS Code ve GitHub Copilot’a entegre etti. Cerebras Systems, FireworksAI, Cohere Labs, Groq Inc gibi ortaklar tarafından desteklenen bu entegrasyon, geliştiricilere daha zengin model seçenekleri sunuyor ve açık kaynak ağırlıklar, çoklu sağlayıcı otomatik yönlendirme, adil fiyatlandırma, sorunsuz model geçişi ve tam şeffaflık gibi avantajları vurguluyor. Ayrıca, Hugging Face’in Transformers kütüphanesi, değerlendirme ve eğitim döngülerini basitleştiren ve çıkarım hızını artıran “Continuous Batching” özelliğini de tanıttı; bu da AI model geliştirme ve deneyleri için güçlü bir araç kutusu olmayı hedefliyor. (Kaynak: ClementDelangue, code)

AU-Harness: Ses LLM’leri için Kapsamlı Açık Kaynak Değerlendirme Araç Kiti: AU-Harness, büyük ses dil modelleri (LALM’ler) için özel olarak tasarlanmış verimli ve kapsamlı bir açık kaynak değerlendirme çerçevesidir. Bu araç kiti, toplu işlem ve paralel yürütmeyi optimize ederek %127’ye varan hız artışı sağlamış ve büyük ölçekli LALM değerlendirmesini mümkün kılmıştır. Modellerin farklı senaryolarda adil karşılaştırmasını sağlamak için standartlaştırılmış istem protokolleri ve esnek yapılandırmalar sunar. AU-Harness ayrıca, mevcut LALM’lerin zamansal anlama ve karmaşık konuşma akıl yürütme görevlerindeki önemli boşlukları ortaya çıkarmayı ve sistematik LALM gelişimini teşvik etmeyi amaçlayan LLM-Adaptive Diarization (zamansal ses anlama) ve Spoken Language Reasoning (karmaşık ses bilişsel görevleri) olmak üzere iki yeni değerlendirme kategorisi sunmuştur. (Kaynak: HuggingFace Daily Papers)
LLM Destekli CI/CD Güvenlik Açığı Tespit Sistemi AI-DO: AI-DO (Automating vulnerability detection Integration for Developers’ Operations), sürekli entegrasyon/sürekli dağıtım (CI/CD) süreçlerine entegre edilmiş bir öneri sistemidir ve CodeBERT modelini kullanarak kod inceleme aşamasında güvenlik açıklarını tespit eder ve konumlandırır. Bu sistem, akademik araştırma ile endüstriyel uygulama arasındaki boşluğu kapatmayı amaçlamaktadır. CodeBERT’in açık kaynak ve endüstriyel veriler üzerindeki alanlar arası genelleme değerlendirmesi, modelin aynı alan içinde doğru performans gösterdiğini, ancak alanlar arası performansın düştüğünü ortaya koymuştur. Uygun alt örnekleme teknikleri kullanılarak açık kaynak veriler üzerinde ince ayar yapılmış derin öğrenme modelleri ise güvenlik açığı tespit yeteneğini etkili bir şekilde artırabilir. AI-DO’nun geliştirilmesi, mevcut iş akışını kesintiye uğratmadan geliştirme sürecindeki güvenliği artırmıştır. (Kaynak: HuggingFace Daily Papers)
Replit Agent 3: Fikirden Uygulamaya Ultra Hızlı Gerçekleştirme: Replit’in Agent 3’ü, Upwork’teki bir salon giriş uygulaması gereksinimini, müşteri giriş süreci, müşteri veritabanı ve arka uç kontrol paneli içeren eksiksiz bir uygulamaya 145 dakika içinde dönüştürebilen şaşırtıcı bir verimlilik sergiledi. Bu ajan ayrıca, sıfır müdahale ile 193 dakika boyunca çalışarak kimlik doğrulama, veritabanı, depolama ve WebSocket dahil olmak üzere üretim düzeyinde kod üretebilme, hatta kendi testlerini ve sıralama algoritmalarını yazabilme gibi yüksek derecede özerkliğe sahiptir. Bu yetenekler, AI ajanlarının hızlı prototipleme ve tam yığın uygulama geliştirme alanındaki muazzam potansiyelini vurgulamakta ve fikirden gerçek ürüne dönüşüm sürecini büyük ölçüde hızlandıracaktır. (Kaynak: amasad, amasad, amasad)
Claude’a Yeni Dosya Oluşturma ve Düzenleme Özellikleri Eklendi: Claude artık doğrudan Claude.ai ve masaüstü uygulamasında Excel elektronik tabloları, belgeler, PowerPoint sunumları ve PDF dosyaları oluşturabilir ve düzenleyebilir. Bu yeni özellik, Claude’un günlük ofis ve üretkenlik araçlarındaki uygulama senaryolarını büyük ölçüde genişleterek, belge işleme ve içerik oluşturma iş akışlarına daha derinlemesine katılımını sağlıyor ve kullanıcıların karmaşık dosya görevlerini yerine getirirken verimliliğini ve kolaylığını artırıyor. (Kaynak: dl_weekly)
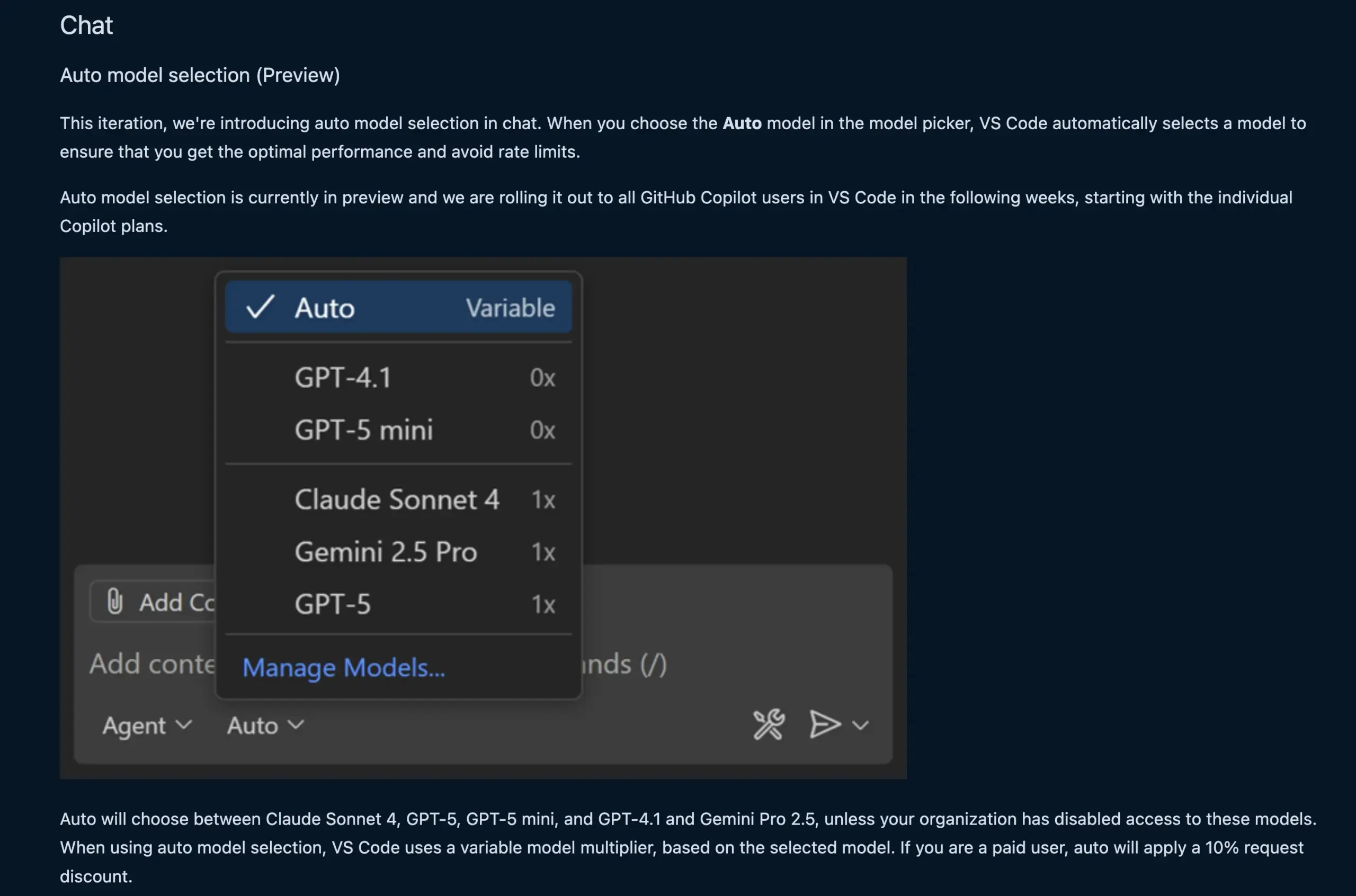
VS Code Sohbet Özelliği LLM Modelini Otomatik Olarak Seçiyor: VS Code’un yeni sohbet özelliği, artık kullanıcı isteğine ve hız limitlerine göre uygun LLM modelini otomatik olarak seçebiliyor. Bu özellik, Claude Sonnet 4, GPT-5, GPT-5 mini, GPT-4.1 ve Gemini Pro 2.5 gibi modeller arasında akıllıca geçiş yaparak geliştiricilere daha kullanışlı ve verimli bir AI destekli programlama deneyimi sunuyor. Aynı zamanda, VS Code’un dil modeli sohbet sağlayıcısı uzantı API’si nihai hale getirildi; bu da uzantılar aracılığıyla model katkısına izin veriyor ve “kendi anahtarını getir” (BYOK) modunu destekleyerek model seçimi ve özelleştirme yeteneklerini daha da zenginleştiriyor. (Kaynak: code, pierceboggan)
Box, Yapılandırılmamış Veri Yönetimini Güçlendirmek için AI Ajan Yeteneklerini Tanıttı: Box, müşterilerinin yapılandırılmamış verilerinin değerinden tam olarak yararlanmalarına yardımcı olmak amacıyla yeni AI ajan özelliklerini duyurdu. Güncellenmiş Box AI Studio, çeşitli iş fonksiyonları ve endüstri kullanım durumları için AI ajanları oluşturmayı daha da kolaylaştırıyor. Box Extract, AI ajanlarını kullanarak çeşitli belgelerden karmaşık veri çıkarımı yaparken, Box Automate ise kullanıcıların içerik merkezi iş akışlarında AI ajanlarını dağıtmasına olanak tanıyan yeni bir iş akışı otomasyon çözümüdür. Bu özellikler, önceden oluşturulmuş entegrasyonlar, Box API veya yeni Box MCP Server aracılığıyla müşterilerin mevcut sistemleriyle sorunsuz bir şekilde işbirliği yaparak, işletmelerin yapılandırılmamış içeriği işleme biçimini dönüştürmeyi hedefliyor. (Kaynak: hwchase17)
Cursor Yeni Tab Modeli: Kod Öneri Doğruluğunu ve Kabul Oranını Artırıyor: Cursor, varsayılan kod öneri aracı olarak yeni Tab modelini yayınladı. Bu model, çevrimiçi takviyeli öğrenme (RL) ile eğitildi ve eski modele kıyasla kod öneri sayısını %21 azaltırken, öneri kabul oranını %28 artırdı. Bu iyileştirme, yeni modelin daha doğru ve geliştiricinin niyetine daha uygun kod önerileri sunabildiği anlamına geliyor, böylece programlama verimliliğini ve kullanıcı deneyimini önemli ölçüde artırıyor, gereksiz dikkat dağıtıcı unsurları azaltıyor ve geliştiricilerin kodlama görevlerini daha verimli tamamlamasını sağlıyor. (Kaynak: BlackHC, op7418)
awesome-llm-apps: Açık Kaynak LLM Uygulama Koleksiyonu: GitHub’daki awesome-llm-apps projesi, açık kaynak bir altın madeni olarak nitelendiriliyor. Bu proje, AI bloglarını podcast’e dönüştüren ajanlardan tıbbi görüntü analizine kadar birçok alanı kapsayan 40’tan fazla dağıtılabilir LLM uygulamasını bir araya getiriyor. Her uygulama, ayrıntılı belgeler ve kurulum talimatları ile birlikte geliyor, bu da haftalar sürecek geliştirme işlerini artık dakikalar içinde tamamlamayı mümkün kılıyor. Örneğin, içerisindeki AI sesli rehber projesi, çoklu ajan sistemleri, gerçek zamanlı web araması ve TTS teknolojisi aracılığıyla doğal ve bağlamsal olarak ilgili sesli rehberler üretebiliyor ve düşük API maliyetleriyle çoklu ajan sistemlerinin içerik üretimindeki pratikliğini sergiliyor. (Kaynak: Reddit r/MachineLearning)
📚 Öğrenim
MMOral: Diş Panoramik X-Ray Analizi için Çok Modlu Kıyaslama ve Talimat Veri Kümesi: MMOral, diş panoramik X-ray yorumlaması için özel olarak tasarlanmış ilk büyük ölçekli çok modlu talimat veri kümesi ve kıyaslama aracıdır. Bu veri kümesi, özellik çıkarma, rapor oluşturma, görsel soru yanıtlama ve görüntü diyaloğu gibi görevleri kapsayan 20.563 açıklamalı görüntü ve 1.3 milyon talimat takip örneği içerir. MMOral-Bench kapsamlı değerlendirme paketi, diş teşhisinin beş temel boyutunu kapsar ve sonuçlar, GPT-4o gibi en iyi LVLM modellerinin bile yalnızca %41.45 doğruluk oranına ulaştığını göstererek mevcut modellerin bu alandaki sınırlamalarını vurgular. OralGPT, Qwen2.5-VL-7B üzerinde SFT uygulayarak %24.73’lük önemli bir performans artışı sağlamış ve akıllı diş hekimliği ile klinik çok modlu AI sistemleri için temel oluşturmuştur. (Kaynak: HuggingFace Daily Papers)
Transformer Güvenlik Açığı Tespitinde Alanlar Arası Değerlendirme: Bir araştırma, CodeBERT’in endüstriyel ve açık kaynak yazılımlarında güvenlik açıklarını tespit etme performansını değerlendirdi ve alanlar arası genelleme yeteneğini analiz etti. Çalışma, endüstriyel veriler üzerinde eğitilen modellerin aynı alan içinde doğru tespit yaptığını, ancak açık kaynak kodunda performansın düştüğünü buldu. Uygun alt örnekleme teknikleri kullanılarak açık kaynak veriler üzerinde ince ayar yapılmış derin öğrenme modelleri ise güvenlik açığı tespit yeteneğini etkili bir şekilde artırabilir. Bu sonuçlara dayanarak, araştırma ekibi, mevcut iş akışını kesintiye uğratmadan kod incelemesi sırasında güvenlik açıklarını tespit edip konumlandırabilen, CI/CD süreçlerine entegre edilmiş bir öneri sistemi olan AI-DO sistemini geliştirdi; bu da akademik teknolojinin endüstriyel uygulamalara dönüşümünü teşvik etmeyi amaçlıyor. (Kaynak: HuggingFace Daily Papers)
Ego3D-Bench: Ben Merkezli Çok Açılı Sahnelerde VLM Uzamsal Akıl Yürütme Kıyaslaması: Ego3D-Bench, görsel dil modellerinin (VLM’ler) ben merkezli, çok açılı dış mekan verilerinde üç boyutlu uzamsal akıl yürütme yeteneklerini değerlendirmek için tasarlanmış yeni bir kıyaslama aracıdır. Bu kıyaslama, GPT-4o, Gemini1.5-Pro gibi 16 SOTA VLM’yi test etmek için insan tarafından etiketlenmiş 8.600’den fazla soru-cevap çifti içerir. Sonuçlar, mevcut VLM’ler ile insan seviyesi arasında uzamsal anlama konusunda önemli bir boşluk olduğunu göstermektedir. Bu boşluğu kapatmak için araştırma ekibi, tahmini küresel üç boyutlu koordinatlara dayalı bilişsel haritalar oluşturarak çoktan seçmeli soru-cevaplarda ortalama %12 ve mutlak mesafe tahmininde %56 performans artışı sağlayan Ego3D-VLM son eğitim çerçevesini önermiştir; bu da insan seviyesinde uzamsal anlama elde etmek için değerli bir araç sunmaktadır. (Kaynak: HuggingFace Daily Papers)
LLM Uzun Süreli Görev Yürütmede “Azalan Getiri İllüzyonu”: Yeni bir araştırma, LLM’lerin uzun süreli görev yürütmedeki performansını inceleyerek, tek adımlı doğrulukta küçük bir artışın görev uzunluğunda üstel bir büyümeye yol açabileceğini belirtiyor. Makale, LLM’lerin uzun görevlerdeki başarısızlığının akıl yürütme yeteneği eksikliğinden değil, yürütme hatalarından kaynaklandığını savunuyor. Bilgi ve planların açıkça sağlanmasıyla, büyük modellerin daha fazla adımı doğru bir şekilde yürütebildiği, hatta küçük modellerin tek adımlı doğrulukta %100’e ulaşsa bile bu durumun geçerli olduğu bulundu. İlginç bir bulgu, modellerin “öz düzenleme” etkisine sahip olmasıdır; yani, bağlam önceki hataları içerdiğinde, modelin tekrar hata yapma olasılığı daha yüksektir ve bu durum yalnızca model ölçeğiyle çözülemez. En son “düşünme modelleri” ise öz düzenlemeden kaçınabilir ve tek bir yürütmede daha uzun görevleri tamamlayabilir, bu da model ölçeğini genişletmenin ve sıralı test hesaplamasının uzun süreli görevler için büyük faydalarını vurgular. (Kaynak: Reddit r/ArtificialInteligence)
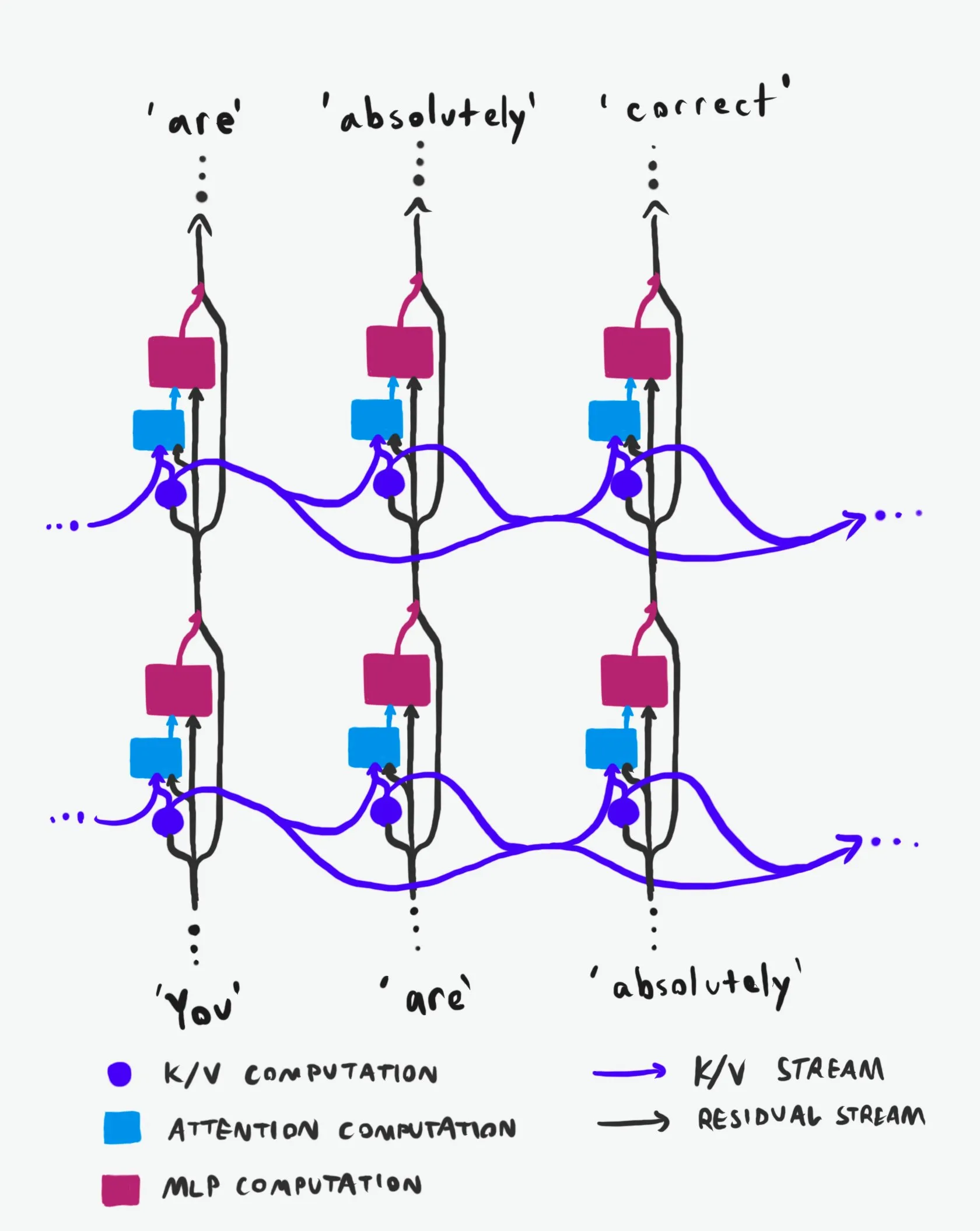
Transformer Nedensel Yapısı: Bilgi Akışının Derinlemesine Analizi: “Sınıfının en iyisi” olarak nitelendirilen bir teknik açıklama, Transformer büyük dil modellerinin (LLM’ler) nedensel yapısını ve bilgi akış biçimlerini derinlemesine analiz ediyor. Bu açıklama, anlaşılması zor terimleri bir kenara bırakarak, Transformer mimarisindeki iki ana bilgi otoyolunu, yani Residual Stream ve Attention mekanizmasını açıkça ortaya koyuyor. Görselleştirmeler ve ayrıntılı açıklamalar aracılığıyla, araştırmacıların ve geliştiricilerin Transformer’ın iç işleyişini daha iyi anlamalarına yardımcı oluyor, böylece model tasarımı, optimizasyon ve hata ayıklama konularında daha bilinçli kararlar almalarını sağlıyor ve LLM’lerin temel mekanizmalarını derinlemesine kavramak için önemli bir değer taşıyor. (Kaynak: Plinz)
Carnegie Mellon Üniversitesi’nde Yeni Bir LM Çıkarım Kursu Açılıyor: Carnegie Mellon Üniversitesi’nden (CMU) @gneubig ve @Amanda Bertsch, bu sonbaharda dil modeli (LM) çıkarımı üzerine yeni bir dersi birlikte verecekler. Bu ders, klasik kod çözme algoritmalarından LLM’lerin en son yöntemlerine ve verimliliğe odaklanan bir dizi çalışmaya kadar LM çıkarım alanına kapsamlı bir giriş yapmayı amaçlıyor. Ders içeriği, ilk dört dersin videoları da dahil olmak üzere çevrimiçi olarak yayınlanacak ve LM çıkarımıyla ilgilenen öğrenciler ve araştırmacılar için değerli bir öğrenme kaynağı sağlayarak, en son çıkarım tekniklerini ve uygulamalarını öğrenmelerine yardımcı olacak. (Kaynak: lateinteraction, dejavucoder, gneubig)
OpenAIDevs, Codex Derinlemesine Analiz Videosu Yayınladı: OpenAIDevs, Codex’in son iki aydaki değişikliklerini ve en son özelliklerini ayrıntılı olarak tanıtan bir Codex derinlemesine analiz videosu yayınladı. Video, bu güçlü AI programlama aracından tam olarak yararlanmak için ipuçları ve en iyi uygulamalar sunarak geliştiricilerin Codex’i daha iyi anlamalarına ve kullanmalarına yardımcı olmayı amaçlıyor. İçerik, Codex’in kod üretimi, hata ayıklama ve yardımcı geliştirme alanlarındaki en son gelişmelerini kapsıyor ve AI destekli programlama verimliliğini artırmak isteyen geliştiriciler için önemli bir öğrenme kaynağıdır. (Kaynak: OpenAIDevs)
2025 Bulut GPU Pazarı Durum Raporu: dstackai, 2025 bulut GPU pazarının mevcut durumu hakkında maliyetleri, performansı ve kullanım stratejilerini kapsayan bir rapor yayınladı. Bu rapor, mevcut piyasa fiyatlarını, donanım yapılandırmalarını ve performans göstergelerini ayrıntılı olarak analiz ederek makine öğrenimi mühendislerine bulut hizmeti sağlayıcılarını seçmeleri için somut piyasa içgörüleri ve referanslar sunuyor. Makine öğrenimi mühendisliğinde bulut sağlayıcısı seçimine ilişkin genel kılavuzları tamamlayan bu rapor, AI eğitimi ve çıkarımının maliyetini ve verimliliğini optimize etmek için önemli bir rehberlik sağlıyor. (Kaynak: stanfordnlp)
AI Donanım Panoraması: AI’yı Güçlendiren Çeşitli Hesaplama Birimleri: The Turing Post, AI’yı güçlendiren donanım üzerine bir rehber yayınlayarak GPU, TPU, CPU, ASIC’ler, NPU, APU, IPU, RPU, FPGA, kuantum işlemciler, bellek içi hesaplama (PIM) çipleri ve nöromorfik çipler gibi çeşitli hesaplama birimlerini ayrıntılı olarak tanıttı. Bu rehber, her bir donanımın AI hesaplamasındaki rolünü, avantajlarını ve uygulama senaryolarını derinlemesine inceleyerek okuyucuların AI teknoloji yığınının temel hesaplama desteğini kapsamlı bir şekilde anlamalarına yardımcı oluyor ve donanım seçimi ile AI sistem tasarımı için önemli bir referans değeri taşıyor. (Kaynak: TheTuringPost)
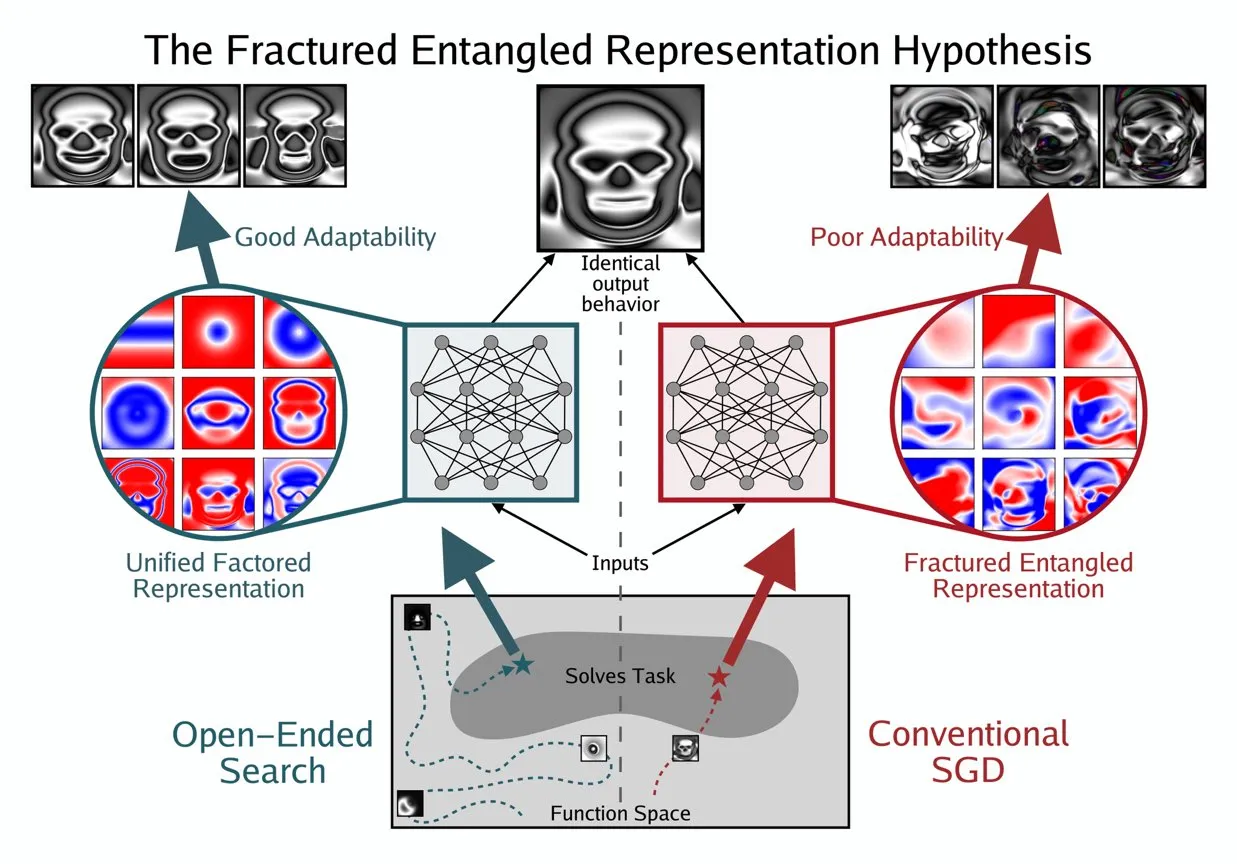
Kenneth Stanley, AI’ın “Gerçek Anlayışını” Anlamak İçin UFR Kavramını Önerdi: Kenneth Stanley, AI’ın “gerçek anlayışının” ne anlama geldiğini açıklamaya yardımcı olmak için “Birleşik Faktörlü Temsil” (Unified Factored Representation, UFR) kavramını ortaya attı. İnsanların AI’ın “gerçek anlayışından” bahsettiğinde, bunun çekirdeğinin UFR olduğunu savunuyor. Bu kavram, AI’ın bilişsel yetenekleri için daha derin bir teorik çerçeve sağlamayı, sadece desen tanımayı aşarak AI’ın dünyayı nasıl yapılandırdığını, ayrıştırdığını ve katı kısıtlamalar oluşturduğunu ele almayı amaçlıyor. Böylece AI’ın sadece bilgiyi taklit etmekle kalmayıp, insanlar gibi yaratıcı düşünmesini ve yeni sorunları çözmesini teşvik ediyor. (Kaynak: hardmaru, hardmaru)
💼 İş Dünyası
Tencent’in OpenAI’dan Üst Düzey Araştırmacı Transfer Ettiği Bildirildi, AI Yetenek Savaşı Kızışıyor: Bloomberg’in haberine göre, OpenAI’ın üst düzey araştırmacısı Yao Shunyu görevinden ayrılarak Çinli teknoloji devi Tencent’e katıldı. Bu olay, özellikle ABD ve Çin arasında olmak üzere küresel AI yetenek savaşının giderek kızıştığını vurguluyor. Üst düzey AI araştırmacılarının akışı, sadece şirketlerin teknolojik gelişim rotalarını etkilemekle kalmıyor, aynı zamanda AI alanındaki inovasyon rekabetinin yoğunluğunu da yansıtıyor ve gelecekteki AI manzarasının yetenek akışına bağlı olarak değişebileceğini gösteriyor. (Kaynak: The Verge)
OpportuNext, AI İşe Alım Platformu Kurmak İçin Teknik Kurucu Ortak Arıyor: IIT Bombay mezunları tarafından kurulan AI destekli işe alım platformu OpportuNext, teknik bir kurucu ortak arıyor. Platform, kapsamlı özgeçmiş analizi, anlamsal iş arama, beceri açığı yol haritaları ve ön değerlendirmeler aracılığıyla iş arayanların ve işverenlerin işe alım süreçlerindeki sorunlarını çözmeyi amaçlıyor. Hedef pazar 262 milyon dolarlık Hindistan pazarı olup, 40.5 milyar dolarlık küresel pazara genişleme planları bulunmaktadır. OpportuNext, ürün-pazar uyumunu doğrulamış ve özgeçmiş ayrıştırıcısının prototipini tamamlamıştır; 2026 ortalarında A Serisi finansmanı tamamlamayı planlamaktadır. Bu pozisyon, AI/ML (NLP), full-stack geliştirme, veri altyapısı, crawler/API ve DevOps/güvenlik konularında güçlü bir geçmiş gerektirmektedir. (Kaynak: Reddit r/deeplearning)
Oracle Kurucusu Larry Ellison: AI Karlılığının Anahtarı Çıkarım: Oracle kurucusu Larry Ellison, “AI karlılığının anahtarı çıkarımdır” dedi. Model eğitimine yapılan mevcut devasa yatırımların nihayetinde ürün satışlarına dönüşeceğini ve bu ürünlerin esas olarak çıkarım yeteneklerine dayanacağını düşünüyor. Ellison, Oracle’ın çıkarım talebini kullanma konusunda lider konumda olduğunu vurgulayarak, AI endüstrisindeki anlatının “en büyük modeli kim eğitebilir”den “çıkarım hizmetlerini kim verimli, güvenilir ve ölçeklenebilir bir şekilde sağlayabilir”e doğru değiştiğini öngörüyor. Bu görüş, AI ekonomik modelinin gelecekteki yönü, yani çıkarım hizmetlerinin gelecekteki gelir yapısına hakim olup olmayacağı konusunda tartışmaları tetikledi. (Kaynak: Reddit r/MachineLearning)
🌟 Topluluk
AI Etiği ve Güvenliği: Çok Boyutlu Zorluklar ve İşbirliği: Topluluk, AI’ın getirdiği etik ve güvenlik zorluklarını geniş çapta tartıştı; bunlar arasında AI’ın iş gücü piyasası üzerindeki potansiyel etkileri ve koruma stratejileri, ChatGPT MCP aracının gizlilik ve güvenlik endişeleri ve AI’ın yok olma riskine yol açabileceğine dair ciddi tartışmalar yer alıyor. Kullanıcıların AI’a aşırı bağımlılığı, hatta “AI psikozu” ve yalnızlık gibi AI’dan kaynaklanan ruh sağlığı sorunları da giderek daha fazla dikkat çekiyor. Aynı zamanda, AI düzenlemesi (Ted Cruz yasası gibi) üzerine tartışmalar devam ediyor. Olumlu tarafı ise, Anthropic ve OpenAI gibi şirketlerin güvenlik ajanslarıyla işbirliği yaparak model güvenlik açıklarını birlikte tespit edip onararak AI güvenlik korumasını güçlendirmesidir. (Kaynak: Ronald_vanLoon, dotey, williawa, Dorialexander, Reddit r/ArtificialInteligence, Reddit r/artificial, sleepinyourhat, EthanJPerez)

LLM Performansı ve Değerlendirmesi: Model Kalitesi ve Kıyaslama Tartışmaları: Topluluk, LLM’lerin performans değerlendirmesi ve model kalitesi sorunlarını derinlemesine tartıştı. K2-Think gibi modeller, değerlendirme yöntemlerindeki kusurlar (veri kirliliği ve haksız karşılaştırmalar gibi) nedeniyle sorgulanarak, mevcut AI kıyaslama testlerinin güvenilirliği konusunda endişelere yol açtı. Araştırmalar, LLM’lerin veri etiketleyici olarak önyargı getirebileceğini ve bilimsel sonuçlarda “LLM Hacking”e yol açabileceğini belirtiyor. Kullanıcıların Claude Code deneyimleri karışık olup, tutarlılık ve “tembellik” konularındaki zorlukları yansıtırken, Anthropic de Claude Sonnet 4’ün performans düşüşünü kabul etti ve düzeltti. Aynı zamanda, GPT-5 Pro güçlü çıkarım yetenekleri nedeniyle övgü toplarken, bazı kullanıcılar AI tarafından üretilen metinlerin genelliğini ve model güvenilirliğine (çıkarım hataları gibi) yönelik sürekli endişeleri gözlemledi. (Kaynak: Grad62304977, rao2z, Reddit r/LocalLLaMA, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, npew, kchonyc, dejavucoder, vikhyatk)
Geleceğin İşleri ve AI Ajanları: Verimlilik Artışı ve Kariyer Dönüşümü: AI ajanları, çalışma şekillerini derinden değiştiriyor. Alan uzmanları (avukatlar, doktorlar, mühendisler gibi) kişisel bilgilerini AI ajanlarına aktararak profesyonel hizmetlerini genişletebilir ve gelirlerinin saatlik ücretle sınırlı kalmamasını sağlayabilir. Replit CEO’su Amjad Masad, AI ajanlarının isteğe bağlı yazılım üreteceğini, geleneksel yazılım değerini sıfıra yaklaştıracağını ve şirketlerin inşa edilme şeklini yeniden şekillendireceğini öngörüyor. Topluluk, AI çağında girişimcilik ruhunun ve uyum yeteneğinin önemini, Replit’in ajan geliştirmedeki benzersiz avantajlarını (test edilebilir ortamlar gibi) ve robot modelleri ile insan beyni verimliliğinin karşılaştırmasını tartıştı. Ayrıca, Cursor’ın takviyeli öğrenme ortamı olarak potansiyeli de dikkat çekti; bu da AI’ın bireylerin ve kuruluşların üretkenliğini daha da artıracağını gösteriyor. (Kaynak: amasad, amasad, amasad, fabianstelzer, amasad, lateinteraction, Dorialexander, dwarkesh_sp, sarahcat21)
Açık Kaynak Ekosistemi ve İşbirliği: Model Yaygınlaştırma ve Topluluk İhtiyaçları: Hugging Face, AI ekosisteminde merkezi bir rol oynamakta olup, modüler, standartlaştırılmış ve entegre platform avantajlarıyla geliştiricilere zengin araçlar ve modeller sunarak AI oluşturma eşiğini düşürmektedir. Topluluk tartışmaları, Apple MLX projesinin ve açık kaynak katkılarının donanım verimliliğini artırmasını olumlu karşıladı. Aynı zamanda, topluluk Qwen ekibini Qwen3-Next modeli için GGUF desteği sağlamaya aktif olarak çağırarak, özel mimarisinin llama.cpp gibi daha geniş yerel çıkarım çerçevelerinde çalışabilmesini talep etti; bu da model yaygınlaştırma ve kullanım kolaylığına yönelik topluluk ihtiyaçlarını karşılamayı ve açık kaynak AI teknolojisinin daha da gelişmesini teşvik etmeyi amaçlıyor. (Kaynak: ClementDelangue, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
AI’ın Geniş Sosyal Etkisi: Eğlenceden Ekonomiye Çok Yönlü Yansımalar: AI, topluma çeşitli biçimlerde nüfuz ediyor. AI evcil hayvan kısa dramaları, kişiselleştirilmiş anlatıları ve duygusal değerleri sayesinde sosyal medyada büyük ilgi görerek, AI’ın içerik oluşturma ve eğlence alanındaki muazzam potansiyelini sergiledi, çok sayıda genç kullanıcıyı çekti ve yeni iş modelleri doğurdu. Aynı zamanda, AI devleri (OpenAI ve Oracle gibi) arasındaki finansal akışlar üzerine tartışmalar, AI ekonomik modeli üzerine düşünceleri tetikledi. Topluluk ayrıca AI’ın kaynak sorunlarını (su kaynakları gibi) çözme potansiyelini ve AI sohbet robotlarının kullanıcı deneyimini iyileştirmek için daha fazla görsel içeriğe ihtiyaç duyduğu önerilerini de tartıştı. Ayrıca, AI’ın sosyal medyadaki uygulamaları, bunun sosyal duygu ve biliş üzerindeki etkileri hakkında tartışmalara yol açtı. (Kaynak: 36氪, Yuchenj_UW, kylebrussell, brickroad7)
AI Topluluğundan İlginç Notlar ve Gözlemler: Kullanıcıların AI’dan Kişiselleştirilmiş Beklentileri ve Mizahi Yansımalar: AI topluluğu, teknolojik gelişmeler ve kullanıcı deneyimi üzerine benzersiz gözlemler ve mizahi yansımalarla dolu. Örneğin, OpenAI abonelik indirim kodları ile “düşünme” davranışı arasındaki ilişki, AI’ın değeri ve maliyeti üzerine tartışmaları tetikledi. Kullanıcılar, Claude Code’un daha kişiselleştirilmiş yanıtlar vermesini, hatta AI’a “kişilik” kazandırılmasını umarak, AI etkileşim deneyimine yönelik derin talepleri yansıtıyor. Aynı zamanda, AI ajanlarının simülasyon ortamlarında (GTA-6 gibi) takviyeli öğrenme eğitimi alması fikri, topluluğun AI’ın gelecekteki gelişim yolu hakkındaki sınırsız hayal gücünü de gösteriyor. Bu tartışmalar, AI teknolojisinin mevcut durumu hakkında içgörüler sunmakla kalmıyor, aynı zamanda kullanıcıların AI ile etkileşimlerinde ortaya çıkan duyguları ve beklentileri de yansıtıyor. (Kaynak: gneubig, jonst0kes, scaling01)
💡 Diğer
2025 AI Becerileri Ustalaşma Rehberi: Yapay zeka teknolojisinin hızla gelişmesiyle birlikte, temel AI becerilerine hakim olmak kişisel kariyer gelişimi için hayati önem taşımaktadır. Bir 2025 AI becerileri ustalaşma rehberi, yapay zeka, makine öğrenimi ve derin öğrenme alanlarında ustalaşılması gereken 12 temel beceriyi vurgulamaktadır. Bu beceriler, temel teoriden pratik uygulamalara kadar uzanmakta olup, profesyonellerin ve öğrencilerin AI çağının yeni yetenek gereksinimlerine uyum sağlamalarına, teknolojik inovasyon ve iş piyasasındaki rekabet güçlerini artırmalarına yardımcı olmayı amaçlamaktadır. (Kaynak: Ronald_vanLoon)

2025 Bulut GPU Pazarı: Maliyet, Performans ve Dağıtım Stratejileri Raporu: dstackai, 2025 bulut bilişim GPU pazarının mevcut durumu hakkında ayrıntılı bir rapor yayınlayarak, farklı bulut hizmeti sağlayıcılarının GPU maliyetlerini, performans göstergelerini ve dağıtım stratejilerini derinlemesine analiz etti. Bu rapor, makine öğrenimi mühendislerine ve işletmelere bulut sağlayıcısı seçimi konusunda somut rehberlik sağlamayı, AI eğitim ve çıkarım görevleri için kaynak yapılandırmalarını optimize etmelerine yardımcı olmayı ve böylece artan AI altyapısı talepleri karşısında daha uygun maliyetli ve performans avantajlı kararlar almalarını sağlamayı amaçlamaktadır. (Kaynak: stanfordnlp)
AI Donanım Teknolojilerine Genel Bakış: Akıllı Geleceği Güçlendiren Çeşitli Hesaplama Birimleri: The Turing Post, yapay zekayı güçlendiren mevcut çeşitli hesaplama birimlerini ayrıntılı olarak tanıtan kapsamlı bir AI donanım rehberi yayınladı. Bunlar arasında Grafik İşlem Birimleri (GPU), Tensor İşlem Birimleri (TPU), Merkezi İşlem Birimleri (CPU), Uygulamaya Özel Entegre Devreler (ASIC’ler), Nöral İşlem Birimleri (NPU), Hızlandırılmış İşlem Birimleri (APU), Akıllı İşlem Birimleri (IPU), Dirençli İşlem Birimleri (RPU), Alan Programlanabilir Kapı Dizileri (FPGA), kuantum işlemciler, Bellek İçi Hesaplama (PIM) ve nöromorfik çipler bulunmaktadır. Bu rehber, AI teknoloji yığınının temel donanım desteğini anlamak için net bir bakış açısı sunarak, geliştiricilerin ve araştırmacıların AI iş yükleri için en uygun donanım çözümlerini seçmelerine yardımcı olmaktadır. (Kaynak: TheTuringPost)