Anahtar Kelimeler:Yapay Zeka Araştırması, Bilgisayar Bilimi, Pekiştirmeli Öğrenme, İlaç Geliştirme, Otonom Sürüş, Dil Modeli, Çoklu Modal İşleme, Sanal Hücre, Laude Enstitüsü, Pekiştirmeli Öğrenme Öğretmenleri (RLTs), BioNeMo Platformu, Tesla Robotaksi, Kimi VL A3B Düşünme Modeli
🔥 Odak Noktası
Laude Institute kuruldu, bilgisayar bilimleri alanında kamu yararına araştırmaları desteklemek için 100 milyon dolarlık başlangıç fonu aldı: Andy Konwinski, dünya üzerinde önemli etki yaratacak ticari olmayan bilgisayar bilimi araştırmalarını finanse etmeyi amaçlayan kâr amacı gütmeyen bir kuruluş olan Laude Institute’un kuruluşunu duyurdu. Jeff Dean, Joyia Pineau ve Dave Patterson gibi tanınmış isimler yönetim kuruluna katıldı. Kurum, 100 milyon dolarlık bir başlangıç taahhüt fonu aldı ve fonlama, kaynak paylaşımı ve topluluk oluşturma yoluyla araştırmacıların fikirlerini pratik etkiye dönüştürmelerini destekleyecek, özellikle açık ve etki odaklı araştırmalara odaklanacak. (Kaynak: JeffDean, matei_zaharia, lschmidt3, Tim_Dettmers, andrew_n_carr, gneubig, lateinteraction, sarahookr, jefrankle)

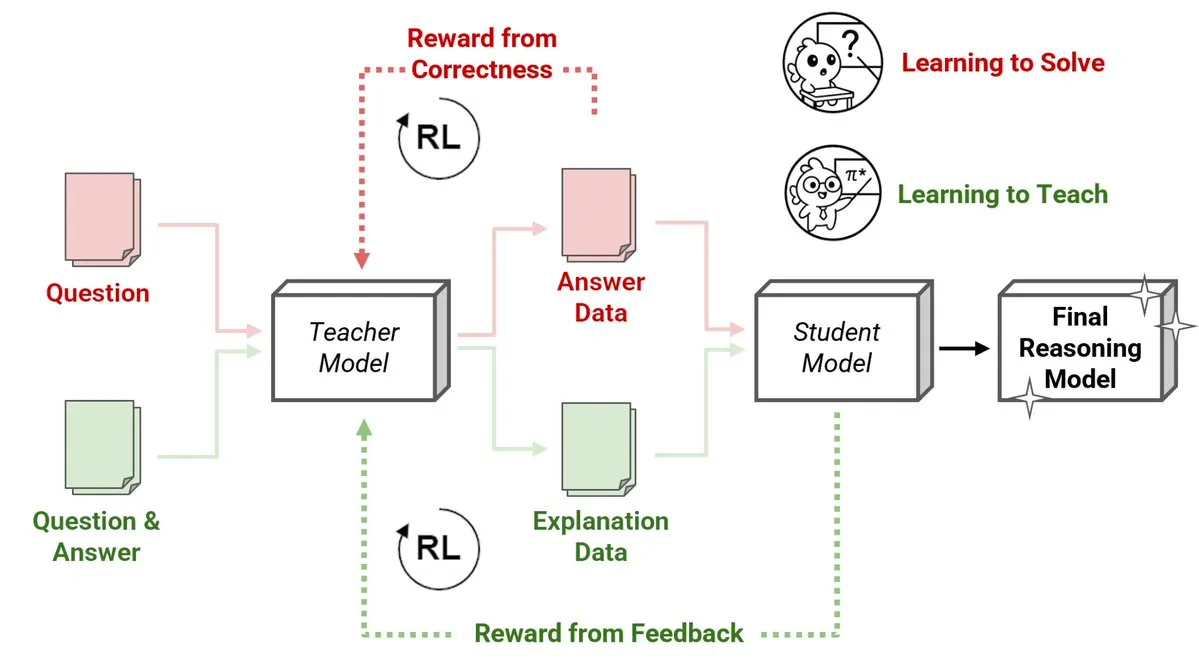
Sakana AI, Pekiştirmeli Öğrenme Öğretmenleri (RLTs) adlı yeni bir yöntem yayınladı; küçük modeller büyük modellere çıkarım yapmayı öğretiyor: Sakana AI, pekiştirmeli öğrenme (RL) yoluyla büyük dil modellerinin (LLM’ler) çıkarım öğretme şeklini değiştiren Pekiştirmeli Öğrenme Öğretmenleri (RLT’ler) adlı yeni bir yöntem sundu. Geleneksel RL, sorunları “çözmeyi öğrenmeye” odaklanırken, RLT’ler öğrenci modellere öğretmek için net, adım adım “açıklamalar” üretmek üzere eğitilir. Yalnızca 7B parametreli bir RLT, 32B parametreli bir öğrenci modelini eğitirken, rekabetçi ve lisansüstü düzeydeki çıkarım görevlerinde kendisinden kat kat büyük LLM’lerden daha iyi performans gösterdi. Bu yöntem, RL ile çıkarım yapan dil modelleri geliştirmek için yeni bir verimlilik standardı belirliyor. (Kaynak: cognitivecompai, AndrewLampinen)
Nvidia, ilaç geliştirmeyi hızlandırmak için yapay zeka süper bilgisayarını kullanmak üzere Novo Nordisk ile iş birliği yapıyor: Nvidia, Danimarkalı ilaç devi Novo Nordisk ve Danimarka Ulusal Yapay Zeka İnovasyon Merkezi ile iş birliği yaparak yapay zeka teknolojisini ve Danimarka’nın en yeni Gefion süper bilgisayarını kullanarak yeni ilaç geliştirmeyi hızlandıracağını duyurdu. Bu iş birliği, Nvidia’nın BioNeMo platformunu ve gelişmiş yapay zeka iş akışlarını kullanarak ilaç araştırma ve geliştirme modellerini dönüştürmeyi amaçlıyor. Eviden ve Nvidia teknolojisiyle inşa edilen Gefion süper bilgisayarı, yaşam bilimleri gibi alanlardaki araştırmalar için güçlü hesaplama desteği sağlayarak kişiselleştirilmiş tıp ve yeni tedavilerin keşfini teşvik edecek. (Kaynak: nvidia)

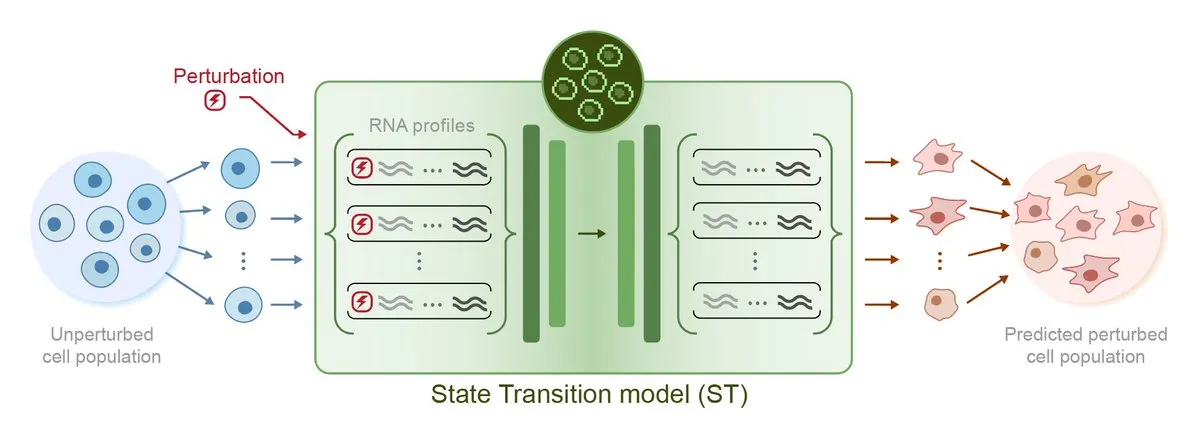
Arc Institute, sanal hücre hedefine doğru bir adım olarak ilk pertürbasyon tahmin yapay zeka modeli STATE’i yayınladı: Arc Institute, sanal hücre hedefine ulaşmada önemli bir adım olan ilk pertürbasyon tahmin yapay zeka modeli STATE’i yayınladı. STATE modeli, hücre durumunu (örneğin “hastalıklı”dan “sağlıklı”ya) değiştirmek için ilaçların, sitokinlerin veya gen pertürbasyonlarının nasıl kullanılacağını öğrenmek üzere tasarlanmıştır. Bu modelin yayınlanması, yapay zekanın hücre davranışını anlama ve tahmin etme konusunda yeni bir ilerleme kaydettiğini gösteriyor ve hastalık tedavisi ve ilaç geliştirme için yeni yollar açıyor. İlgili model HuggingFace’te kullanıma sunuldu. (Kaynak: riemannzeta, ClementDelangue)
Tesla Robotaxi, Austin’de pilot uygulamaya başladı; görsel çözüm dikkat çekiyor, Karpathy’nin geride bıraktığı kod büyük ölçüde basitleştirildi: Tesla, ABD’nin Teksas eyaletinin Austin şehrinde Robotaxi pilot hizmetini resmi olarak başlattı. İlk araçlar Model Y temel alınarak dönüştürüldü ve tamamen görsel algılama çözümü ile FSD yazılımını kullanıyor. Tesla Yapay Zeka ve Otonom Sürüş Yazılımı Başkanı Ashok Elluswamy liderliğindeki ekip, sistemde önemli teknolojik değişiklikler yaparak Andrej Karpathy ekibinin geride bıraktığı yaklaşık 330-340 bin satırlık C++ sezgisel kodunu yaklaşık %90 oranında basitleştirerek yerine “dev sinir ağı”nı getirdi. Bu hamle, “insan deneyimi kodlamasından” “parametrik eğitime” geçmeyi amaçlıyor ve devasa veri ve simülasyon sürüşleriyle modeli otonom olarak optimize ediyor. Hizmet şu anda erken deneyim aşamasında olup, Tesla’nın teknolojik rotası ve ölçeklenebilirlik yetenekleri hakkında sektörde geniş çaplı tartışmalara yol açtı. (Kaynak: 36氪, Ronald_vanLoon, kylebrussell)

🎯 Gelişmeler
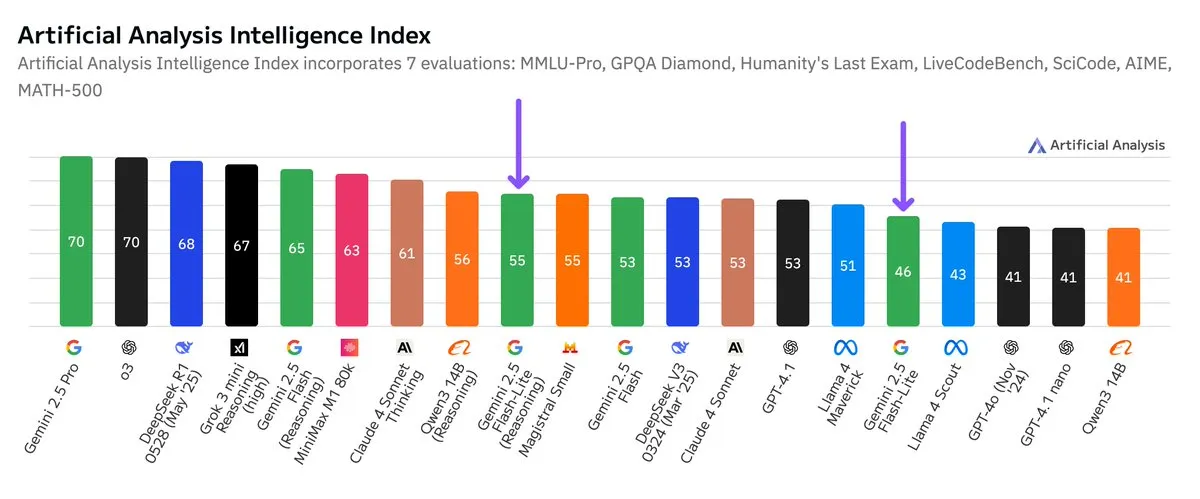
Google Gemini 2.5 Flash-Lite bağımsız kıyaslama testi yayınlandı, fiyat-performans oranı arttı: Artificial Analysis tarafından yayınlanan bağımsız kıyaslama testi sonuçlarına göre, Google Gemini 2.5 Flash-Lite Preview (06-17) sürümü, normal Flash sürümüne kıyasla maliyeti yaklaşık 5 kat düşürürken hızı yaklaşık 1.7 kat artırdı, ancak zeka seviyesinde bir düşüş yaşandı. Bu model, Şubat 2025’te yayınlanan Gemini 2.0 Flash-Lite’ın yükseltilmiş bir versiyonu olup hibrit bir modeldir. Bu güncelleme, Google’ın model verimliliği ve maliyet etkinliği arayışındaki sürekli çabalarını gösteriyor ve maliyet ile hıza yüksek önem veren uygulama senaryolarına yönelik olabilir. (Kaynak: zacharynado)
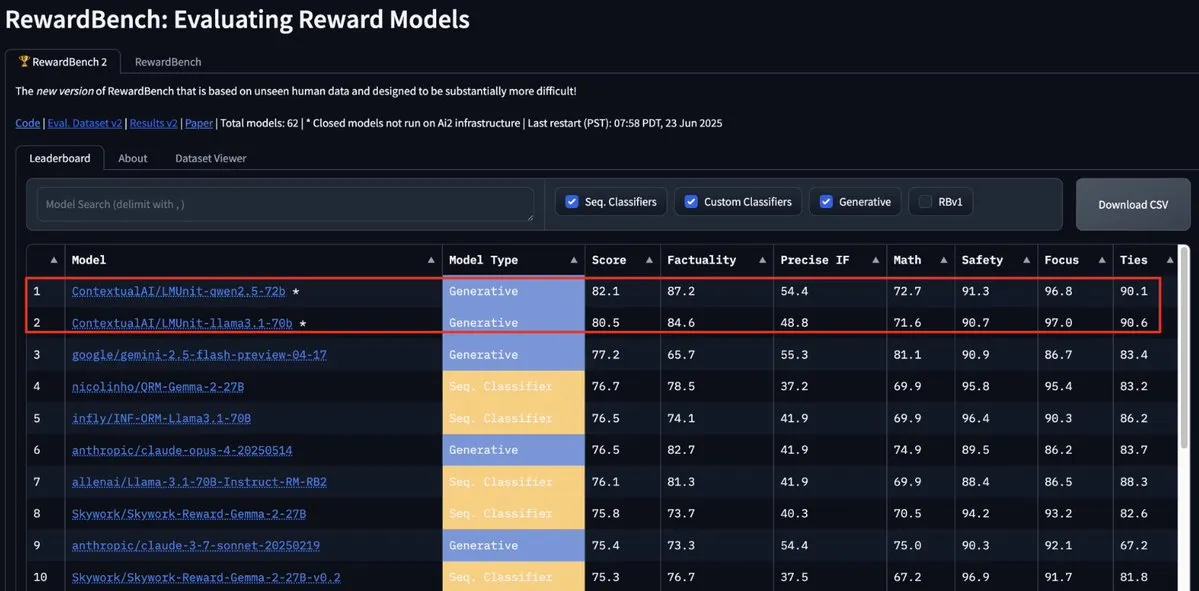
ContextualAI’nin LMUnit modeli RewardBench2’de zirveye yerleşti, Gemini, Claude 4 ve GPT-4.1’i geride bıraktı: ContextualAI’nin LMUnit modeli, RewardBench2 kıyaslama testinde birinci sırada yer alarak Gemini, Claude 4 ve GPT-4.1 gibi tanınmış modellerden %5’ten fazla daha yüksek bir puan elde etti. Bu başarı, iddiaya göre OpenAI’nin o4 ve sonraki modeller için büyük çaba sarf ettiği “rubrics” yöntemine benzeyen benzersiz eğitim yöntemine atfedilebilir. Bu yöntem, LLM’nin hakem olarak (llm-as-a-judge) çıkarım yaparken etkili bir şekilde ölçeklenmesine yardımcı oluyor. (Kaynak: natolambert, menhguin, apsdehal)
Arcee.ai, AFM-4.5B modelinin bağlam uzunluğunu 4k’dan 64k’ya başarıyla genişletti: Arcee.ai, ilk temel modeli AFM-4.5B’nin bağlam uzunluğunun 4k’dan 64k’ya başarıyla genişletildiğini duyurdu. Ekip, bu atılımı aktif deneyler, model birleştirme, damıtma ve şakayla “bol miktarda çorba” (model füzyon teknolojisine atıfta bulunarak) olarak adlandırılan yöntemlerle gerçekleştirdi. Bu ilerleme, uzun metin görevlerini işlemek için kritik öneme sahip. Arcee’nin GLM-32B-Base modelindeki iyileştirmeler de etkinliğini kanıtladı; yalnızca uzun bağlam desteği 8k’dan 32k’ya yükseltilmekle kalmadı, aynı zamanda kısa bağlam dahil tüm temel model değerlendirmelerinde de iyileşmeler görüldü. (Kaynak: eliebakouch, teortaxesTex, nrehiew_, shxf0072, code_star)

Google Gemini API güncellendi, video ve PDF işleme hızı ve yetenekleri geliştirildi: Google Gemini API, video ve PDF işleme konusunda önemli güncellemeler aldı. Önbelleğe alınmış videoların ilk yanıt süresi (TTFT) 3 kat, önbelleğe alınmış PDF’lerin işleme hızı ise 4 kata kadar artırıldı. Ayrıca, yeni sürüm birden fazla videonun toplu işlenmesini destekliyor ve örtük önbelleklemenin performansı açık önbelleklemeye yaklaştı. Bu iyileştirmeler, geliştiricilerin Gemini API kullanarak multimedya içeriklerini işleme verimliliğini ve deneyimini artırmayı amaçlıyor. (Kaynak: _philschmid)
Moonshot (Kimi), Kimi VL A3B Thinking modelini güncelleyerek çok modlu işleme yeteneklerini geliştirdi: Moonshot AI (Kimi), MIT lisansına dayanan küçük görsel dil modeli (VLM) Kimi VL A3B Thinking’in güncellenmiş bir sürümünü yayınladı. Yeni sürüm, daha az token tüketirken ve düşünme süresini kısaltırken, video işlemeyi destekliyor ve daha yüksek çözünürlüklü görüntüleri (1792×1792) işleyebiliyor. VideoMMMU’da 65.2 puan, MathVision’da 20.1 puan artışla 56.9 puan, MathVista’da 8.4 puan artışla 80.1 puan, MMMU-Pro’da 3.2 puan artışla 46.3 puan aldı ve görsel çıkarım, UI Agent konumlandırma, video ve PDF işleme konularında üstün performans sergileyerek Hugging Face’te açık kaynak olarak yayınlandı. (Kaynak: mervenoyann)

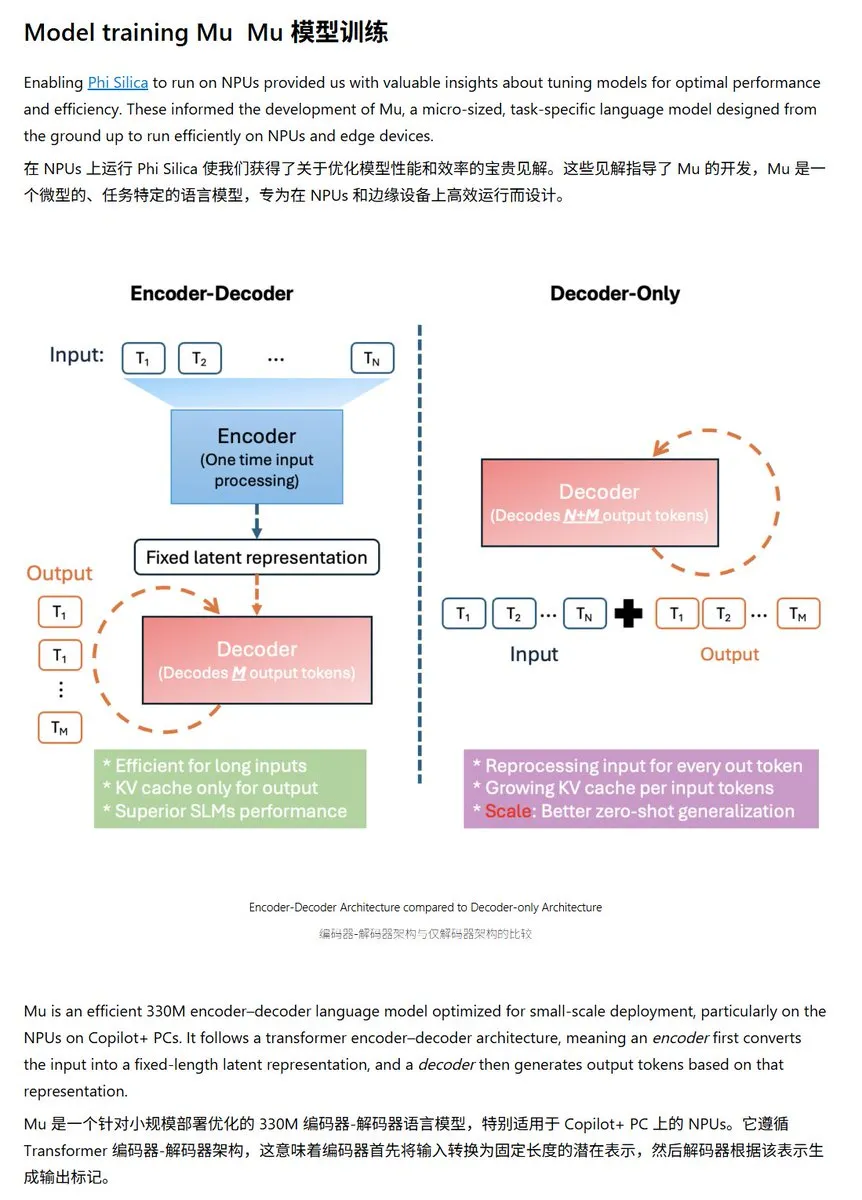
Microsoft, Windows NPU için optimize edilmiş Mu-330M küçük dil modelini yayınladı: Microsoft, Windows Copilot+ PC’lerin NPU’larında (Sinir İşlem Birimi) çalışmak üzere tasarlanmış yeni küçük dil modeli Mu-330M’yi tanıttı. Bu model, Windows sistemi içindeki Agent işlevlerini desteklemeyi amaçlıyor. Model, NPU için optimize edilmiş olup, düşük performans tüketimiyle verimli çalışmak üzere dönel konum gömmeleri, gruplandırılmış sorgu dikkati, çift katmanlı LayerNorm gibi teknolojileri kullanıyor. Bu, Microsoft’un uç nokta yapay zeka yetenekleri konusundaki ileriye dönük adımlarını işaret ediyor. (Kaynak: karminski3)
DeepMind, difüzyon dil modellerine odaklanan Mercury teknik raporunu yayınladı: Inception Labs (DeepMind ile ilişkili ekip), difüzyon dil modeli Mercury’nin teknik raporunu yayınladı. Rapor, Mercury modelinin mimarisini, eğitim yöntemlerini ve deney sonuçlarını ayrıntılı olarak açıklayarak araştırmacılara bu yeni ortaya çıkan model türü hakkında derinlemesine bilgiler sunuyor. Difüzyon modelleri, görüntü oluşturma alanında önemli başarılar elde etti ve bunların dil modellerine uygulanması, mevcut yapay zeka araştırmalarının öncü bir yönüdür. (Kaynak: andriy_mulyar)
Meta, yapay zeka destekli akıllı gözlük serisini genişletmek için Oakley ile iş birliği yapıyor: Meta, gözlük markası Oakley ile iş birliği yaparak yapay zeka destekli akıllı gözlük ürün yelpazesini daha da genişletiyor. Yeni akıllı gözlüklerin Meta’nın yapay zeka teknolojisini entegre etmesi, daha zengin etkileşim özellikleri ve kullanıcı deneyimi sunması bekleniyor. Bu iş birliği, Meta’nın giyilebilir yapay zeka cihazları alanındaki sürekli yatırımını işaret ediyor ve yapay zekayı günlük hayata daha sorunsuz bir şekilde entegre etmeyi amaçlıyor. (Kaynak: rowancheung, Ronald_vanLoon)
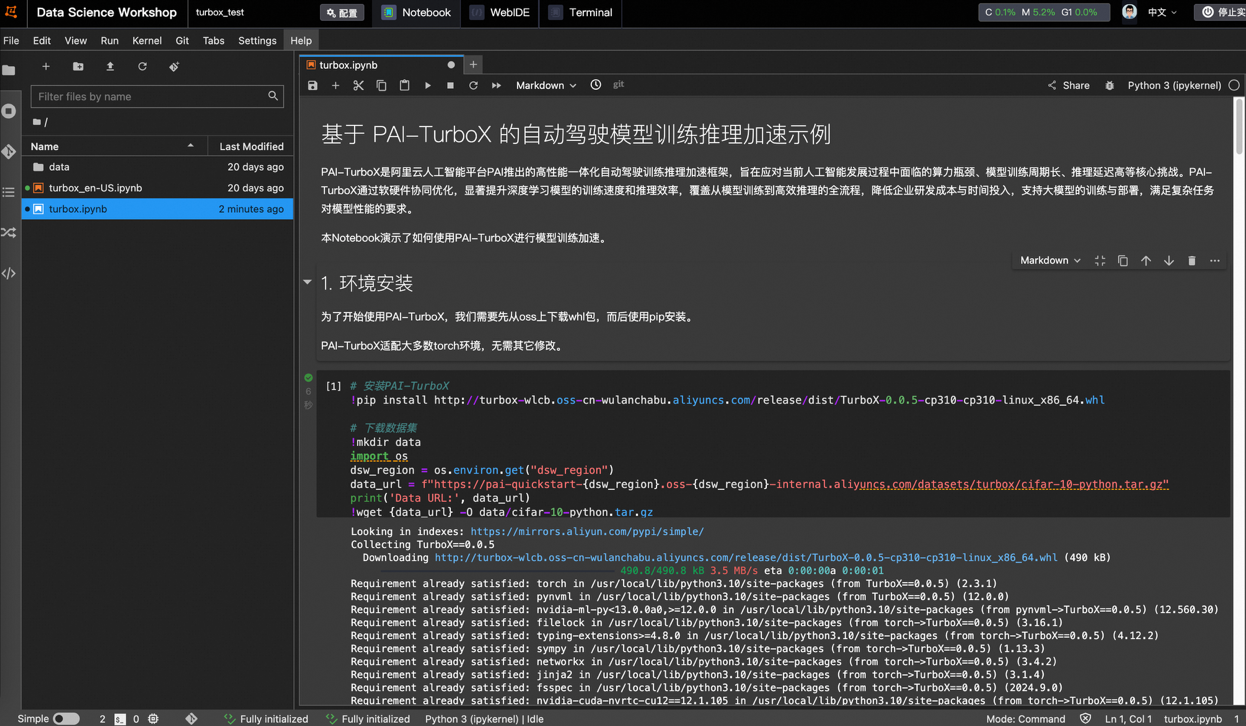
Alibaba Cloud, otonom sürüş modeli eğitim ve çıkarım hızlandırma çerçevesi PAI-TurboX’i piyasaya sürdü, eğitim süresini %50’ye kadar kısaltabiliyor: Alibaba Cloud, otonom sürüş alanına yönelik model eğitim ve çıkarım hızlandırma çerçevesi PAI-TurboX’i yayınladı. Bu çerçeve, algılama, planlama kontrolü ve hatta dünya modellerinin eğitim ve çıkarım verimliliğini artırmayı amaçlıyor. Çok modlu veri ön işleme, CPU afinitesi, dinamik derleme, boru hattı paralelliği gibi stratejileri optimize ederek ve operatör optimizasyonu ile niceleme yetenekleri sunarak bunu başarıyor. Gerçek testler, BEVFusion, MapTR, SparseDrive gibi birçok endüstri modelinin eğitim görevlerinde PAI-TurboX’in eğitim süresini yaklaşık %50 oranında kısaltabildiğini gösteriyor. (Kaynak: 量子位)
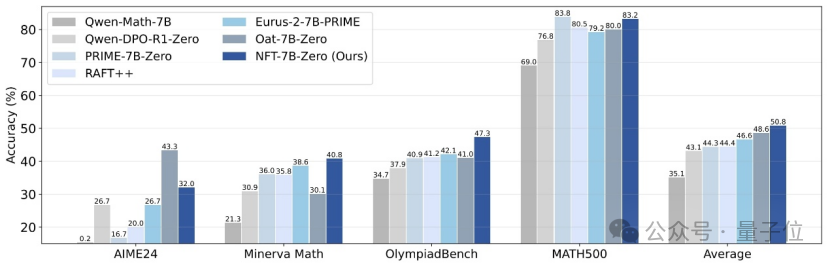
Tsinghua Üniversitesi, Nvidia ve diğerleri, denetimli öğrenmenin hatalardan “ders çıkarmasını” sağlayan NFT yöntemini önerdi: Tsinghua Üniversitesi, Nvidia ve Stanford Üniversitesi araştırmacıları ortaklaşa NFT (Negative-aware FineTuning) adlı yeni bir denetimli öğrenme şeması önerdi. Bu yöntem, RFT (Rejection FineTuning) algoritmasına dayanarak, negatif verileri kullanarak eğitim yapmak için “örtük negatif model” oluşturarak, yani “örtük negatif strateji” ile çalışır. Bu strateji, denetimli öğrenmenin de pekiştirmeli öğrenme gibi “kendi kendine düşünmesini” sağlayarak, denetimli öğrenme ile pekiştirmeli öğrenme arasındaki bazı yetenek boşluklarını kapatır ve matematiksel çıkarım gibi görevlerde önemli performans artışları gösterir, hatta On-Policy koşullarında kayıp fonksiyonu gradyanı GRPO ile eşdeğerdir. (Kaynak: 量子位)
OmniGen2 yayınlandı: Görsel anlama ve görüntü oluşturmayı birleştiren 8B çok fonksiyonlu düzenleme modeli: OmniGen2 adlı yeni bir çok fonksiyonlu düzenleme modeli yayınlandı. Bu model, görsel anlamayı (Qwen-VL-2.5 tabanlı) görüntü oluşturma (4B parametreli bir difüzyon modeli) ile birleştirerek toplamda yaklaşık 8B parametreye sahip. OmniGen2, metinden görüntüye, görüntü düzenleme, görüntü anlama ve bağlamsal oluşturma gibi çeşitli görevleri destekleyebiliyor ve birden fazla görselle ilgili sorunu çözebilen ve uç cihaz entegrasyonuna uygun birleşik bir model sunmayı amaçlıyor. (Kaynak: karminski3)

Chroma-8.9B-v39 metinden görüntü oluşturma modeli güncellendi, FLUX.1-schnell tabanlı, ticari kullanıma uygun: Metinden görüntüye model Chroma-8.9B-v39 güncellenerek aydınlatma ve görev doğallığı iyileştirildi. Model, FLUX.1-schnell tabanlı olup, parametre sayısı 12B’den 8.9B’ye düşürülmüş ve Apache 2.0 lisansı altında ticari kullanıma izin veriyor. İddiaya göre model, “eksik anatomik kavramları yeniden tanıttı, tamamen içerik kısıtlaması yok” ve 5 milyon anime, furry, sanat eseri ve fotoğraf içeren bir veri kümesiyle sonradan eğitildi. (Kaynak: karminski3)

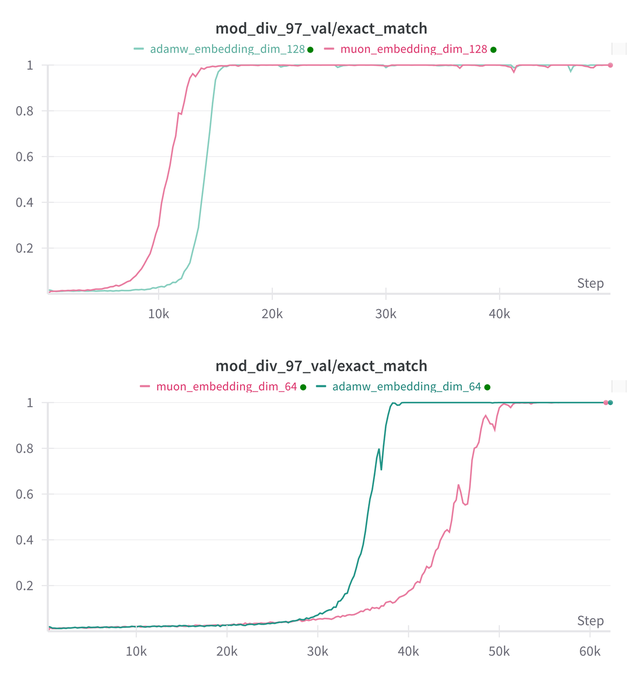
Essential AI, Muon ve Adam modellerinin Grokking yeteneği üzerine araştırma sonuçlarını güncelledi: Essential AI, Muon ve Adam modellerinin Grokking (modelin eğitim başlangıcında düşük performans gösterip ardından aniden genellemeyi anlaması olgusu) yeteneği hakkındaki en son araştırma ilerlemelerini paylaştı. İlk hipotezler gerçek gözlemlerle çelişebilir; ekip, hiperparametre arama alanını genişlettikten sonra Muon’un AdamW’ye göre belirgin bir genel avantajı olmadığını, ikisinin farklı senaryolarda birbirlerine üstünlük sağladığını gösteren dahili küçük araştırma deneylerinin sonuçlarını açıkladı. Bu, AdamW’nin birçok durumda hala güçlü ve hatta SOTA bir optimize edici olduğunu gösteriyor. (Kaynak: eliebakouch, teortaxesTex, nrehiew_)
Ostris AI görüntü oluşturma modeli güncellendi, CFG’siz sürüme odaklanıyor ve yüksek frekanslı ayrıntıları optimize ediyor: Ostris AI, görüntü oluşturma modelini sürekli olarak güncelliyor ve şu anda daha hızlı yakınsadığı için CFG’siz (Classifier-Free Guidance) sürümün geliştirilmesine odaklanıyor. En son 7. Gün güncellemesinde ekip, yüksek frekanslı ayrıntıları daha iyi işlemek için yeni eğitim teknikleri ekledi ve yüksek ayrıntılı artefaktları kaldırmak için çaba gösteriyor. Önceki 4. Gün güncellemesi, CFG kullanılmadan yeni yöntemlerle oluşturulan görüntü kalitesinde önemli bir iyileşme göstermişti. (Kaynak: ostrisai)

Ant Group, Çin Bilimler Akademisi ve diğerleri ViLaSR-7B modelini açık kaynak olarak yayınladı, “çizerken düşünme” uzamsal çıkarımını mümkün kılıyor: Ant Teknoloji Araştırma Enstitüsü, Çin Bilimler Akademisi Otomasyon Enstitüsü ve Hong Kong Çin Üniversitesi ortaklaşa ViLaSR-7B modelini açık kaynak olarak yayınladı. Bu model, “Drawing to Reason in Space” paradigması aracılığıyla büyük görsel dil modellerinin (LVLM) düşünmeye yardımcı olmak için görsel alanda yardımcı işaretler (referans çizgileri, sınırlayıcı kutular gibi) çizmesini sağlayarak uzamsal algı ve çıkarım yeteneklerini artırıyor. ViLaSR, üç aşamalı bir eğitim çerçevesi kullanıyor: soğuk başlatma, yansıtıcı reddetme örneklemesi ve pekiştirmeli öğrenme. Deneyler, modelin labirent navigasyonu, görüntü anlama ve video uzamsal çıkarımı gibi 5 kıyaslamada ortalama %18.4 iyileşme sağladığını ve VSI-Bench’te Gemini-1.5-Pro’ya yakın performans gösterdiğini ortaya koydu. (Kaynak: 量子位)

🧰 Araçlar
SGLang artık arka uç olarak Hugging Face Transformers’ı destekliyor, çıkarım verimliliğini artırıyor: SGLang, artık arka uç olarak Hugging Face Transformers’ı desteklediğini duyurdu. Bu, kullanıcıların Transformers uyumlu herhangi bir model için hızlı, üretim düzeyinde çıkarım hizmetleri sunabileceği anlamına geliyor; yerel desteğe gerek kalmadan, tak ve çalıştır. Bu entegrasyon, yüksek performanslı dil modeli çıkarımının dağıtım sürecini basitleştirmeyi, SGLang’in uygulanabilirliğini ve kullanım kolaylığını genişletmeyi amaçlıyor. (Kaynak: TheZachMueller, ClementDelangue)

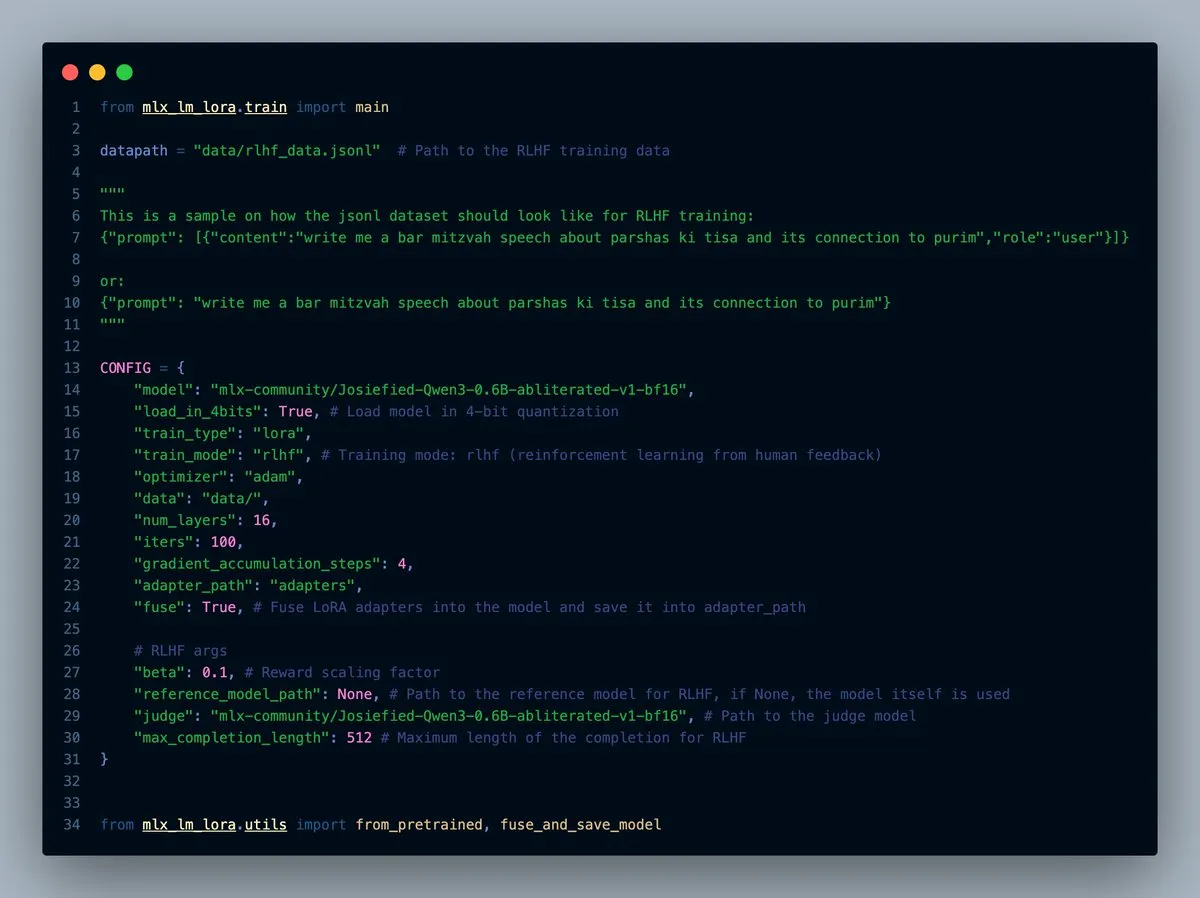
MLX-LM-LORA v0.7.0 yayınlandı, yerleşik RLHF özelliği ile: MLX-LM-LORA, v0.7.0 sürümünü yayınladı. Yeni sürüm, insan geri bildiriminden pekiştirmeli öğrenme (RLHF) için yerleşik bir özelliğe sahip. Araç artık 4-bit, 6-bit, 8-bit yüklemeyi, RLHF eğitim modunu destekliyor ve adaptörleri doğrudan temel ağırlıklara birleştirebiliyor. Bu, özellikle Apple çipli cihazlarda MLX çerçevesi altında LoRA ince ayarını daha akıllı ve verimli hale getiriyor. (Kaynak: awnihannun)
LlamaCloud yayınlandı, belge iş akışları için MCP uyumlu araç kutusu sunuyor: LlamaCloud, herhangi bir belge iş akışı için Model Bağlam Protokolü (MCP) uyumlu bir araç kutusu olarak kullanıma sunuldu. Kullanıcılar, karmaşık belge çıkarma, karşılaştırma gibi işlemleri gerçekleştirmek için Claude gibi modellere bağlayabilirler. Örneğin, Tesla’nın son beş çeyrekteki finansal performansını analiz edebilir ve kapsamlı bir rapor oluşturabilir; dinamik olarak standartlaştırılmış şemalar oluşturup tüm dosyalarda çalıştırarak ve ardından nihai sonucu üretmek için kod üreterek bunu yapar. LlamaCloud, yanlış şemaları dinamik olarak düzeltebilir ve doğrudan dosya bağlantılarını destekler. (Kaynak: jerryjliu0)
Georgi Gerganov, LlamaBarn projesini duyurdu: Georgi Gerganov (llama.cpp’nin yaratıcısı), sosyal medyada “LlamaBarn” adlı yeni bir projeyi duyuran bir resim yayınladı. Resimde, model seçimi, parametre ayarlamaları gibi öğeler içeren bir gösterge paneline benzer bir arayüz görülüyor, bu da yerel LLM’leri yönetmek, çalıştırmak veya test etmek için bir araç olabileceğini düşündürüyor. Topluluk bunu merakla bekliyor ve Ollama gibi mevcut araçlara güçlü bir rakip olabileceğini düşünüyor. (Kaynak: ClementDelangue, teortaxesTex, jeremyphoward)
Void Editor: MCP ve yerel modelleri destekleyen yeni bir açık kaynaklı yapay zeka programlama asistanı: Void Editor, Cursor gibi araçlara alternatif olmayı amaçlayan yeni bir açık kaynaklı yapay zeka programlama asistanı olarak tanıtıldı. Sekme otomatik tamamlama, sohbet modu, Model Bağlam Protokolü (MCP) ve Agent modunu destekliyor. Kullanıcılar herhangi bir büyük dil modeli API’sine bağlanabilir veya modelleri yerel olarak çalıştırabilir, bu da geliştiricilere esnek bir yapay zeka destekli programlama deneyimi sunar. (Kaynak: karminski3)
Together AI, uygun açık kaynaklı LLM’yi seçmeye yardımcı olmak için Which LLM aracını başlattı: Together AI, kullanıcıların belirli kullanım durumlarına, performans gereksinimlerine ve ekonomik değerlendirmelere göre en uygun açık kaynaklı büyük dil modelini seçmelerine yardımcı olmak amacıyla “Which LLM” adlı ücretsiz bir araç yayınladı. Açık kaynaklı LLM sayısındaki hızlı artışla birlikte, bu tür araçlar geliştiricilere ve araştırmacılara model seçiminde değerli bir referans sağlayabilir. (Kaynak: vipulved)
Perplexity Finance, hisse senedi fiyat zaman çizelgesi izleme özelliği ekledi: Perplexity Finance, kullanıcıların artık platformlarında herhangi bir hisse senedi kodunun fiyat değişiklik zaman çizelgesini izleyebileceğini duyurdu. Bu yeni özellik, kullanıcılara daha sezgisel ve kullanışlı finansal piyasa bilgileri analiz araçları sunmayı amaçlıyor ve Perplexity’nin yapay zeka yetenekleriyle birleşerek finansal bilgi sorgulama ve analizine yeni bir deneyim getirebilir. (Kaynak: AravSrinivas)

IdeaWeaver, sistem performansı hata ayıklaması için ilk yapay zeka aracısını piyasaya sürdü: IdeaWeaver, sistem performansı sorunlarını hata ayıklamak için özel olarak tasarladığı iddia edilen ilk yapay zeka aracısını yayınladı. Bu araç, CrewAI çerçevesini kullanarak CPU, bellek, G/Ç ve ağ ile ilgili sorunları teşhis etmek için sistem komutlarını fiilen yürütebilir. Özelliği, gizliliği korumak için yerel LLM’leri (OLLAMA aracılığıyla) önceliklendirmesi ve yalnızca yerel modeller mevcut olmadığında OpenAI API anahtarı talep etmesidir; bu da yapay zeka yeteneklerini DevOps ve sistem yönetimi alanlarına uygulamayı amaçlamaktadır. (Kaynak: Reddit r/artificial)
Kling AI, Live Photo desteği ekledi, oluşturulan videoları dinamik duvar kağıdı olarak kaydetmeyi mümkün kılıyor: Kling AI, video oluşturma özelliğinin artık eserleri Live Photos (canlı fotoğraflar) olarak kaydetmeyi desteklediğini duyurdu. Kullanıcılar, beğendikleri Kling tarafından oluşturulan dinamik içerikleri telefon duvar kağıdı olarak ayarlayabilir, bu da yapay zeka tarafından oluşturulan videoların eğlencesini ve kullanışlılığını artırır. (Kaynak: Kling_ai)
Cognition AI, VM anlık görüntü hızını 200 kat artıran Blockdiff’i açık kaynak olarak yayınladı: Cognition AI, Devin için geliştirdiği VM anlık görüntü dosya formatı Blockdiff’i açık kaynak olarak yayınladığını duyurdu. EC2’nin VM anlık görüntüleri oluşturması çok uzun sürdüğü için (30+ dakika), ekip kendi otterlink sanal makine yöneticisini ve Blockdiff dosya formatını oluşturarak anlık görüntü oluşturma hızını 200 kat artırdı. Bu açık kaynak katkısı, geliştiricilerin sanal makine ortamlarını daha verimli bir şekilde yönetmelerine yardımcı olmayı amaçlıyor. (Kaynak: karinanguyen_)

📚 Öğrenme Kaynakları
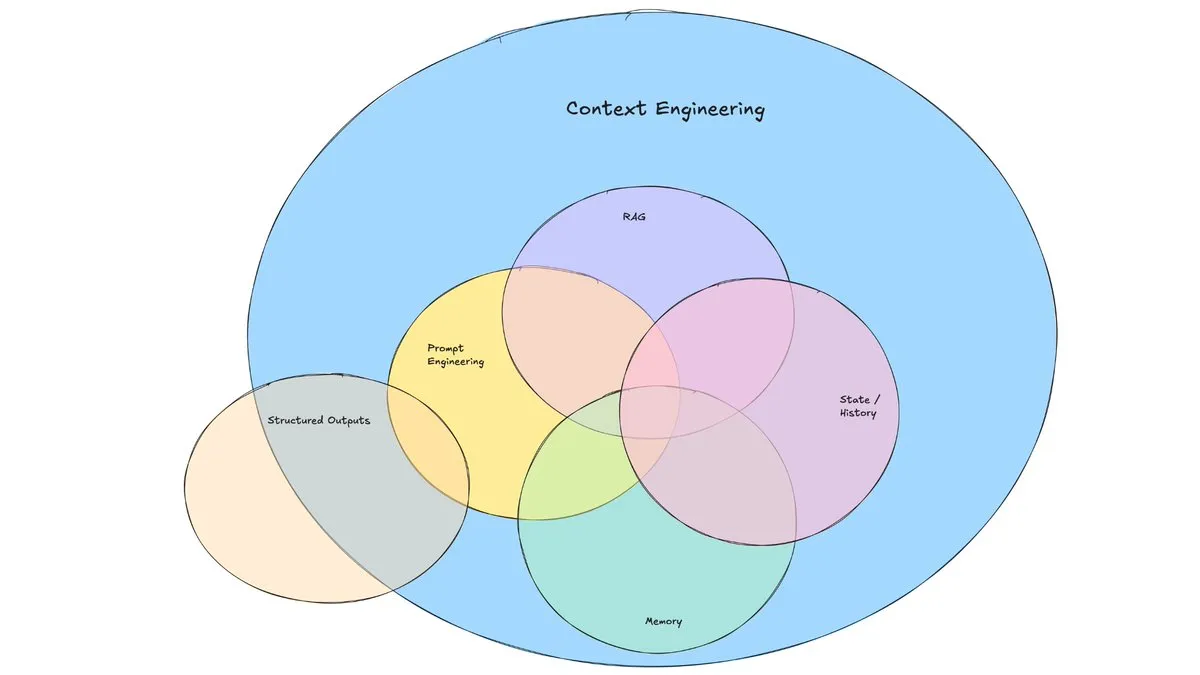
LangChain blog yazısı “Bağlam Mühendisliği”nin yükselişini tartışıyor: LangChain, giderek popülerleşen “Bağlam Mühendisliği” (Context Engineering) terimini tartışan bir blog yazısı yayınladı. Makale bunu, “LLM’nin bir görevi makul bir şekilde tamamlaması için doğru bilgiyi ve araçları doğru formatta sağlayan dinamik sistemler oluşturmak” olarak tanımlıyor. Bu tamamen yeni bir kavram değil; Agent geliştiricileri bunu uzun zamandır uyguluyor ve LangGraph, LangSmith gibi araçlar da bu amaçla geliştirildi. Bu terimin ortaya atılması, ilgili becerilere ve araçlara daha fazla dikkat çekilmesine yardımcı oluyor. (Kaynak: hwchase17, Hacubu, yoheinakajima)
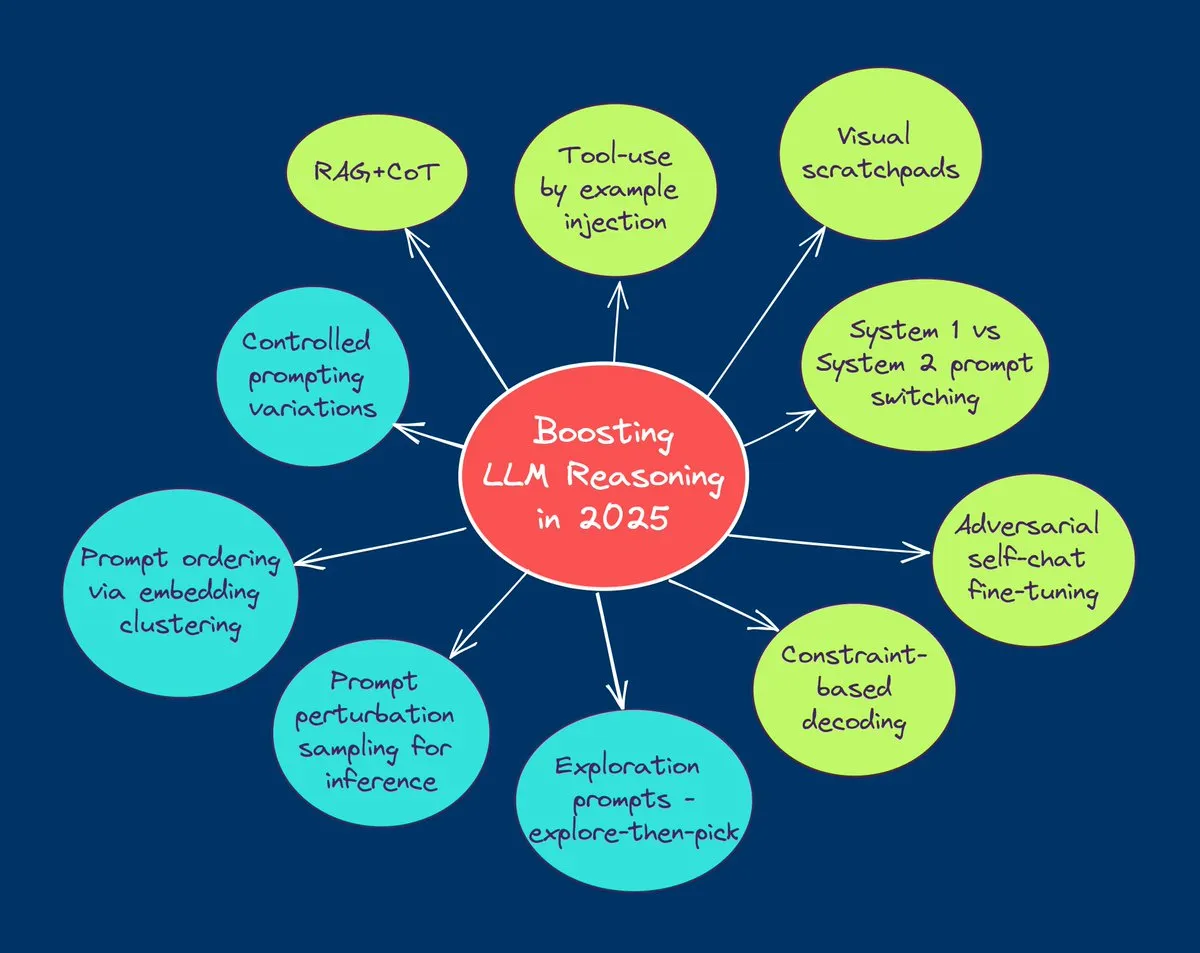
TuringPost, 2025’te LLM çıkarım yeteneklerini artırmak için 10 önemli teknolojiyi özetledi: TuringPost, 2025’te büyük dil modellerinin (LLM) çıkarım yeteneklerini artırmak için kullanılacak 10 temel teknolojiyi paylaştı: Geri Çağırma Destekli Düşünce Zinciri (RAG+CoT), örneklerle araç enjeksiyonu yoluyla kullanım, Görsel Karalama Defteri (çok modlu çıkarım desteği), Sistem 1 ve Sistem 2 istemleri arasında geçiş, karşıt kendi kendine konuşma ince ayarı, kısıt tabanlı kod çözme, keşifsel istem (önce keşfet sonra seç), çıkarım için istem pertürbasyon örneklemesi, gömme kümelemesi yoluyla istem sıralaması ve kontrollü istem varyantları. Bu teknolojiler, LLM’lerin karmaşık görevlerdeki performansını optimize etmek için çeşitli yollar sunar. (Kaynak: TheTuringPost, TheTuringPost)
Cohere Labs, makine öğreniminin geleceğini keşfetmek için ML Yaz Okulu düzenliyor: Cohere Labs’in açık bilim topluluğu, Temmuz ayında ML Yaz Okulu (ML Summer School) düzenleyecek. Etkinlik, makine öğreniminin geleceğini tartışmak üzere küresel topluluk üyelerini bir araya getirecek ve sektörden konuşmacıları ağırlayacak. Bunlardan Katrina Lawrence, 2 Temmuz’da kalkülüs, vektör kalkülüsü ve lineer cebir gibi temel kavramları kapsayan bir makine öğrenimi matematik tekrarı dersi verecek. (Kaynak: sarahookr)

DeepLearning.AI, Meta ile iş birliği yaparak “Building with Llama 4” ücretsiz kursunu başlattı: DeepLearning.AI, Meta ile iş birliği yaparak “Building with Llama 4” adlı ücretsiz bir kurs başlattı. Kurs içeriği şunları içeriyor: Llama 4 serisi modellerle pratik çalışma, Uzmanlar Karışımı (MOE) mimarisini anlama ve resmi API’yi kullanarak uygulamalar oluşturma; çoklu görüntü çıkarımı, görüntü konumlandırma (nesneleri ve sınırlayıcı kutularını tanıma) ve 1 milyon token’a kadar uzun bağlamlı metin sorgularını işlemek için Llama 4’ü uygulama; sistem istemlerini otomatik olarak iyileştirmek için Llama 4’ün istem optimizasyon araçlarını kullanma ve ince ayar için yüksek kaliteli veri kümeleri oluşturmak üzere sentetik veri araç setini kullanma. (Kaynak: DeepLearningAI)
EleutherAI YouTube kanalı, kapsamlı yapay zeka araştırma içeriği sunuyor: EleutherAI’nin YouTube kanalı, okuma gruplarının ve konuşma serilerinin 100 saati aşan kayıtlı videolarını bir araya getiriyor. Konular arasında makine öğreniminin ölçeklenebilirliği ve performansı, fonksiyonel analiz ve ekip üyelerinin podcast’leri ve röportajları yer alıyor. Kanal, yapay zeka araştırmacıları ve meraklıları için zengin öğrenme kaynakları sunuyor. EleutherAI ayrıca yeni bir konuşma serisi başlattı; ilk bölümde @linguist_cat, tokenizatörler ve sınırlamaları hakkında konuşacak. (Kaynak: BlancheMinerva, BlancheMinerva)
Makale, gizli görsel token’lar aracılığıyla çok modlu çıkarımı geliştirmeyi tartışıyor (Machine Mental Imagery): “Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens” başlıklı yeni bir makale, VLM kod çözme sürecine tam görüntüler oluşturmak yerine gizli görsel token’lar ekleyerek çok modlu çıkarımı geliştirmek için Mirage çerçevesini öneriyor ve insan zihinsel imgelemesini taklit ediyor. Bu yöntem önce gerçek görüntü gömmelerini damıtarak gizli token’ları denetler, ardından gizli yörüngeleri görev hedefleriyle hizalamak için saf metin denetimine geçer ve pekiştirmeli öğrenme yoluyla yeteneği daha da artırır. Deneyler, Mirage’ın açık görüntüler oluşturmadan daha güçlü çok modlu çıkarım elde edebildiğini kanıtlıyor. (Kaynak: HuggingFace Daily Papers)
Makale, görsel anlama ve üretimi birleştirmek için metinle hizalanmış temsiller aracılığıyla Vision as a Dialect çerçevesini öneriyor: “Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations” başlıklı bir makale, Tar adlı çok modlu bir LLM çerçevesini tanıtıyor. Bu çerçeve, görüntüleri ayrık token’lara dönüştürmek için metinle hizalanmış bir tokenizatör (TA-Tok) kullanır ve LLM kelime dağarcığı projeksiyonunun metinle hizalanmış kod kitabını kullanarak görsel ve metni paylaşılan ayrık anlamsal temsilde birleştirir. Tar, belirli mod tasarımlarına ihtiyaç duymadan modlar arası giriş çıkışı paylaşılan bir arayüz aracılığıyla gerçekleştirir ve verimlilik ile görsel ayrıntıları dengelemek için ölçek uyarlanabilir kodlayıcı-kod çözücü ve üretken de-tokenizatör kullanır. (Kaynak: HuggingFace Daily Papers)
Makale, LLM uzun düşünce zinciri çıkarımı için yörünge duyarlı PRM olan ReasonFlux-PRM’yi öneriyor: “ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs” başlıklı makale, DeepSeek-R1 gibi öncü çıkarım modelleri tarafından üretilen yörünge-yanıt türü çıkarım izlerini değerlendirmek için özel olarak tasarlanmış yeni bir yörünge duyarlı süreç ödül modeli (PRM) sunuyor. ReasonFlux-PRM, adım düzeyinde ve yörünge düzeyinde denetimi birleştirerek yapılandırılmış düşünce zinciri verileriyle hizalanmış ince taneli ödül dağılımı sağlar ve SFT, RL ve BoN test zamanı genişletme gibi senaryolarda performans artışı elde eder. (Kaynak: HuggingFace Daily Papers)
Makale, büyük dil modelleri için jailbreak koruma önlemlerinin değerlendirme yöntemlerini inceliyor: “SoK: Evaluating Jailbreak Guardrails for Large Language Models” başlıklı bir makale, büyük dil modellerinin (LLM’ler) jailbreak saldırılarını ve koruma önlemlerini (Guardrails) sistematik bir bilgi derlemesiyle ele alıyor. Makale, koruma önlemlerini altı temel boyutta sınıflandırmak için yeni bir çok boyutlu taksonomi öneriyor ve pratik etkinliklerini değerlendirmek için bir güvenlik-verimlilik-kullanışlılık değerlendirme çerçevesi sunuyor. Geniş kapsamlı analiz ve deneylerle makale, mevcut koruma önlemi yöntemlerinin avantaj ve dezavantajlarını belirtiyor, farklı saldırı türlerine karşı genellenebilirliklerini tartışıyor ve savunma kombinasyonlarını optimize etmek için içgörüler sunuyor. (Kaynak: HuggingFace Daily Papers)
AAAI 2025 Üstün Makalesi, kısmen gözlemlenebilir Markov karar süreçlerinin (POMDP) karar verilebilir bir sınıfını tartışıyor: “Revelations: A Decidable Class of POMDP with Omega-Regular Objectives” başlıklı bir makale, AAAI 2025 Üstün Makale Ödülü’nü kazandı. Bu çalışma, karar verilebilir bir MDP (Markov karar süreci) sınıfını tanımlıyor: “güçlü ifşaatlara” sahip karar problemleri, yani her adımda dünyanın kesin durumunu ortaya çıkarma olasılığı sıfır olmayan problemler. Makale ayrıca, kesin durumun sonunda ortaya çıkacağının garanti edildiği ancak her adımda ortaya çıkmasının zorunlu olmadığı “zayıf ifşaatlar” için karar verilebilirlik sonuçları da sunuyor. Bu araştırma, eksik bilgi durumunda optimal karar verme için yeni bir teorik temel sağlıyor. (Kaynak: aihub.org)
Makale, KV önbellek sıkıştırması için değişmeli vektör niceleme olan CommVQ’yu öneriyor: “CommVQ: Commutative Vector Quantization for KV Cache Compression” başlıklı makale, uzun bağlamlı LLM çıkarımında bellek kullanımını azaltmak için KV önbelleğini toplamsal niceleme ve hafif kodlayıcılar ile kod kitapları kullanarak sıkıştıran CommVQ adlı bir yöntem öneriyor. Kod çözme hesaplama maliyetini düşürmek için kod kitabı, dönel konum gömmeleri (RoPE) ile değişebilir olacak şekilde tasarlanmış ve EM algoritması kullanılarak eğitilmiştir. Deneyler, bu yöntemin 2 bit nicelemede FP16 KV önbellek boyutunu %87.5 oranında azaltabildiğini ve mevcut KV önbellek niceleme yöntemlerinden daha iyi performans gösterdiğini, hatta çok küçük bir hassasiyet kaybıyla 1 bit KV önbellek nicelemesini mümkün kıldığını gösteriyor. (Kaynak: HuggingFace Daily Papers)
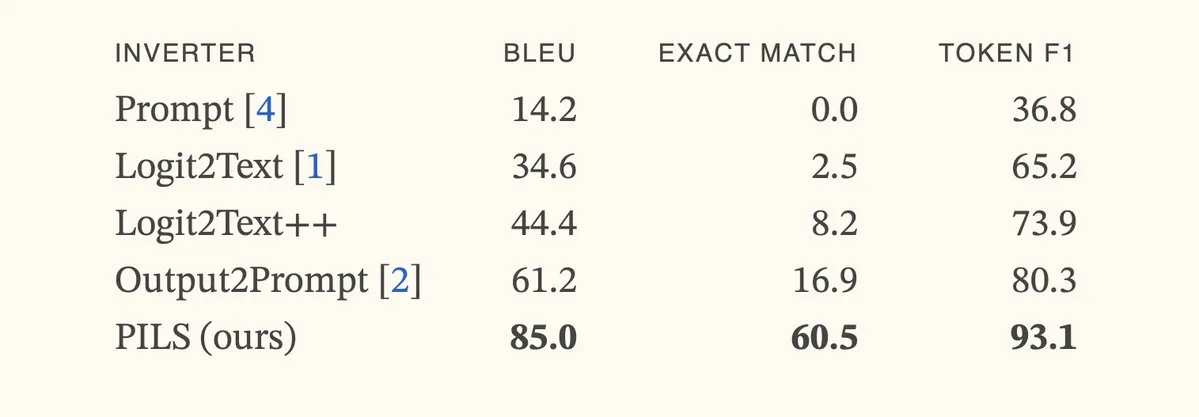
Makale, bir sonraki token dağılımlarının kompakt temsili yoluyla dil modeli tersine çevirmeyi iyileştiren PILS yöntemini öneriyor: “Better Language Model Inversion by Compactly Representing Next-Token Distributions” başlıklı makale, PILS (Prompt Inversion from Logprob Sequences) adlı yeni bir dil modeli tersine çevirme yöntemi öneriyor. Bu yöntem, gizli istemleri kurtarmak için modelin birden fazla üretim adımındaki bir sonraki token olasılıklarını analiz eder. Temelinde, dil modeli çıktı vektörlerinin düşük boyutlu bir alt uzayı işgal ettiğini keşfetmek yatar, bu da bir sonraki token olasılık dağılımının doğrusal bir eşleme yoluyla kayıpsız olarak sıkıştırılmasını ve daha etkili bir tersine çevirme için kullanılmasını sağlar. Deneyler, PILS’in gizli istemleri kurtarmada önceki SOTA yöntemlerinden önemli ölçüde daha iyi performans gösterdiğini ortaya koyuyor. (Kaynak: HuggingFace Daily Papers, jxmnop)
Makale, genel bir konu tutarlı video oluşturma veri seti olan Phantom-Data’yı öneriyor: “Phantom-Data : Towards a General Subject-Consistent Video Generation Dataset” başlıklı makale, mevcut konudan videoya üretim modellerinde yaygın olarak görülen “kopyala-yapıştır” sorununu (yani konu kimliğinin arka plan ve bağlam özellikleriyle aşırı derecede iç içe geçmesi) çözmeyi amaçlayan Phantom-Data adlı yeni bir veri seti sunuyor. Phantom-Data, farklı kategorilerde kimlik tutarlı yaklaşık bir milyon eşleştirilmiş örnek içeren ilk genel, eşleştirilmiş konudan videoya tutarlılık veri setidir. Bu veri seti, konu tespiti, büyük ölçekli bağlamlar arası konu geri çağırma ve öncül güdümlü kimlik doğrulama olmak üzere üç aşamalı bir süreçle oluşturulmuştur. (Kaynak: HuggingFace Daily Papers)
Makale, pekiştirmeli öğrenme yoluyla ultra uzun metin üretiminde ustalaşmak için LongWriter-Zero’yu öneriyor: “LongWriter-Zero: Mastering Ultra-Long Text Generation via Reinforcement Learning” başlıklı makale, herhangi bir etiketli veya sentetik veriye ihtiyaç duymadan, LLM’lerin ultra uzun, yüksek kaliteli metinler üretme yeteneğini sıfırdan pekiştirmeli öğrenme (RL) kullanarak geliştirmek için teşvik tabanlı bir yöntem öneriyor. Bu yöntem, temel bir modelle başlar ve RL aracılığıyla planlama ve yazma süreçlerinde iyileştirme yapması için yönlendirilir ve uzunluğu, yazma kalitesini ve yapısal formatı kontrol etmek için özel bir ödül modeli kullanır. Deneyler, Qwen2.5-32B’den eğitilen LongWriter-Zero’nun uzun metin yazma görevlerinde geleneksel SFT yöntemlerinden daha iyi performans gösterdiğini ve birden fazla kıyaslama testinde SOTA seviyesine ulaştığını gösteriyor. (Kaynak: HuggingFace Daily Papers)
💼 İş Dünyası
Hukuk yapay zeka şirketi Harvey, 5 milyar dolar değerlemeyle 300 milyon dolarlık E Serisi finansman turunu tamamladığını duyurdu: Hukuk yapay zeka girişimi Harvey, Kleiner Perkins ve Coatue’nin ortak liderliğinde 300 milyon dolarlık E Serisi finansman turunu tamamladığını ve şirket değerlemesinin 5 milyar dolara ulaştığını duyurdu. Diğer yatırımcılar arasında Sequoia Capital, GV, DST Global, Conviction, Elad Gil, OpenAI Startup Fund, Elemental, SV Angel, Kris Fredrickson ve REV bulunuyor. Bu finansman, Harvey’nin hukuk alanındaki yapay zeka uygulamalarını geliştirmeye ve genişletmeye devam etmesine yardımcı olacak. (Kaynak: saranormous)
Hyperbolic isteğe bağlı GPU bulut hizmeti, lansmanından sonraki 7 gün içinde 1 milyon dolarlık ARR’ye ulaştı: Yuchenj_UW, geçen hafta başlattığı Hyperbolic isteğe bağlı GPU bulut hizmetinin, yalnızca bir tweet ile yapılan sınırlı pazarlamaya rağmen, 7 gün içinde yıllık yinelenen gelirinin (ARR) 0’dan 1 milyon dolara ulaştığını duyurdu. Geliştiricilere ücretsiz 8xH100 düğüm deneme kredisi sunmaları, pazarda yüksek performanslı GPU bulut hizmetlerine yönelik güçlü bir talebi gösteriyor. (Kaynak: Yuchenj_UW)
Replit, yıllık yinelenen gelirinin (ARR) 100 milyon doları aştığını duyurdu: Çevrimiçi entegre geliştirme ortamı (IDE) ve bulut bilişim platformu Replit, yıllık yinelenen gelirinin (ARR) 100 milyon doları aştığını ve 2024 sonundaki 10 milyon dolardan önemli bir artış kaydettiğini duyurdu. Şirket, 2023’te 1,1 milyar dolarlık değerlemeyle son finansman turunu tamamladıktan sonra bankada hala fonlarının yarısından fazlasının bulunduğunu belirtti. Replit’in büyümesi, kurumsal kullanıcıların (Zillow, HubSpot gibi) ve bağımsız geliştiricilerin platformunu kullanmasından kaynaklanıyor ve şu anda aktif olarak işe alım yapıyor. (Kaynak: pirroh, kylebrussell, hwchase17, Hacubu)
🌟 Topluluk
YZ programlamada yeni paradigma: Önce tasarla, sonra prompt ver, iteratif olarak kod üretimini optimize et: dotey ve Bao Yu, yapay zeka programlamanın getirdiği yazılım geliştirme modeli değişimini tartışıyor. Geleneksel “önce tasarla sonra kodla” ile “önce uygula sonra yeniden yapılandır” tartışması yapay zeka çağında birleşiyor. Yapay zeka, tasarımdan kodlamaya kadar olan maliyeti ve zamanı büyük ölçüde kısaltarak, geliştiricilerin tasarım henüz tam olarak netleşmediğinde bile hızlı bir şekilde sürümler oluşturmasına ve sonuçları doğrulayarak tasarımı ve prompt’ları iteratif olarak iyileştirmesine olanak tanıyor. Prompt’lar, daha önce “ayrıntılı tasarım belgeleri”nin rolünü üstleniyor ancak daha basitleştirilmiş durumda. Bu modelde, geliştiriciler sistem tasarımına daha fazla odaklanmalı, küçük partiler halinde kod üretmeli, kaynak kodu yönetimini kullanmalı ve yapay zeka tarafından üretilen kodu inceleyip test etmelidir. Deneyimli programcılar için düşünme biçimini ve geliştirme alışkanlıklarını değiştirmek, yapay zeka programlamayı benimsemenin anahtarıdır. (Kaynak: dotey)
Claude Code, güçlü büyük kod tabanlarını işleme yeteneği ve bağlam verimliliği nedeniyle geliştiriciler tarafından tercih ediliyor: Reddit r/ClaudeAI topluluğu, Claude Code’un büyük kod tabanlarını işlemedeki üstün performansını hararetle tartışıyor. Kullanıcılar, 200k Token’dan çok daha büyük kod tabanlarını iyi anladığını ve değişiklikler yapabildiğini bildiriyor. Tartışmada, Claude Code’un muhtemelen insan okumasına benzer stratejiler (sadece önemli kısımları okuma), bağlam almak için grep gibi araçlar kullanma (RAG’ın vektörleştirilmiş sıkıştırmasına tamamen güvenmek yerine) ve birinci taraf model entegrasyonunun avantajları sayesinde verimli bağlam işleme gerçekleştirdiği düşünülüyor. Kullanıcılar, Claude Code’u sistem sorunlarını düzeltmek, kişisel finans takipçisi oluşturmak, Android uygulamaları geliştirmek (Android geliştirme deneyimi olmasa bile), Obsidian DataviewJS betikleri oluşturmak gibi çeşitli başarılı kullanım örneklerini paylaşarak iş verimliliğini önemli ölçüde artırdıklarını belirtiyorlar. (Kaynak: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

“Bağlam Mühendisliği” kavramı dikkat çekiyor, LLM’leri güçlendirmek için dinamik sistemler oluşturmayı vurguluyor: LangChain’den Harrison Chase, “Bağlam Mühendisliği”nin (Context Engineering) yapay zeka mühendislerinin sistem oluşturmadaki temel işi olduğunu öne sürüyor. Bu, “LLM’nin bir görevi makul bir şekilde tamamlaması için doğru bilgiyi ve araçları doğru formatta sağlayan dinamik sistemler oluşturmak” olarak tanımlanıyor. Bu kavram, LLM uygulamalarında bağlam bilgisinin nasıl etkili bir şekilde organize edilip sunulacağının model performansı için önemini vurguluyor ve Agent oluşturma gibi alanların temelini oluşturuyor. (Kaynak: hwchase17, Hacubu, yoheinakajima)
Meta kurucusu Zuckerberg’in bizzat yapay zeka yeteneklerini işe alması toplulukta ilgi uyandırdı: Sosyal medya haberlerine göre, Meta kurucusu Mark Zuckerberg, süper zeka laboratuvarının yetenek alım çalışmalarına bizzat katılıyor, yüzlerce potansiyel adayla doğrudan iletişime geçiyor ve yanıt verenleri akşam yemeğine davet ediyor. Bu hamle, Meta’nın yapay zeka alanında, özellikle de genel yapay zeka (AGI) veya süper zeka konusunda yatırım yapma kararlılığını ve çabasını gösterdiği şeklinde yorumlanıyor ve en iyi teknoloji şirketlerinin yapay zeka alanındaki en iyi yetenekler için verdiği kıyasıya rekabeti gözler önüne seriyor. (Kaynak: reach_vb, andrew_n_carr)

Yapay zekanın gelişimi, istihdam piyasası ve ekonomik yapı hakkında derinlemesine düşüncelere yol açıyor: Harvard Business School ve ekonomist Anton Korinek, AGI’nin 2-5 yıl içinde gerçekleşebileceği ve ekonomik sistem kökten değişmezse çöküşe yol açabileceği uyarısında bulunarak evrensel temel gelirin gerekliliğini vurguladı. Aynı zamanda topluluk tartışmalarında, yapay zekanın çok sayıda ölçülebilir görevi otomatikleştireceği, mavi ve beyaz yakalı işleri etkileyeceği ve şirketlerin yapay zekaya uyum sağlamak için organizasyon yapılarını yeniden oluşturması gerekeceği belirtiliyor. Yuval Noah Harari, yapay zeka devrimini “YZ göçü dalgası”na benzeterek, yapay zekanın istihdamı ve güç arayışını devralmasıyla ilgili tartışmalara yol açtı. Bu görüşler, yapay zekanın gelecekteki sosyoekonomik yapılar üzerindeki yıkıcı etkisine işaret ediyor. (Kaynak: 36氪, 36氪, Reddit r/artificial, Reddit r/ChatGPT)

Yapay zeka programlama yarışmalarında öne çıkıyor, Sakana AI ajanının başarılı performansı hararetli tartışmalara yol açtı: Sakana AI’nin ajanı, AtCoder sezgisel programlama yarışmasında 1000’den fazla insan programcı arasında 21. sırada yer alarak genel performansta ilk %6.8’lik dilime girdi. Yapay zeka, 4 saat içinde yaklaşık 100 sürüm yineleyerek binlerce potansiyel çözüm üretti; oysa insan yarışmacılar genellikle yalnızca yaklaşık 12 çözüm test edebiliyor. Yapay zeka, Gemini 2.5 Pro’yu kullandı ve gerçek optimizasyon sorunlarını çözmek için uzman bilgisi ile benzetilmiş tavlama ve ışın arama gibi sistematik arama algoritmalarını birleştirdi. Topluluk buna karışık tepkiler verdi; bazıları yarışma programlamasının kurumsal düzeydeki mühendislikten farklı olduğunu ve yapay zekanın zaferinin daha çok bilgisayarın toplama ve çıkarmada insanları yenmesine benzediğini savundu. (Kaynak: Reddit r/ArtificialInteligence)
💡 Diğer Haberler
Mesleki eğitim alanında yapay zeka keşifleri: Mülakat, öğretmen ve öğrenme makinesi gibi çeşitli denemeler: Huatu, Fenbi, Zhonggong gibi mesleki eğitim devleri aktif olarak yapay zeka uygulamalarını araştırıyor ve farklı yönlere odaklanıyor. Huatu, yapay zeka mülakat değerlendirmesine odaklanırken, Fenbi yapay zeka ile notlandırma ve yapay zeka öğretmen (yapay zeka soru çözme sistemi sınıfının satışları 14 milyon yuanı aştı) alanında derinlemesine çalışıyor, Zhonggong ise yapay zeka istihdam öğrenme makinesini piyasaya sürdü. Sektördeki genel kanı, yapay zekanın sadece yüksek prim peşinde koşmak yerine öğrenme etkisini ve operasyonel verimliliği artırması gerektiği yönünde. Yapay zeka uygulamaları da kavram kanıtlamadan senaryo derinleştirmeye doğru ilerliyor; örneğin 51CTO, dijital insanlar ve 3D modelleme kullanarak dersler oluşturuyor ve yapay zeka aracılığıyla soru oluşturma ve öğrenme yolu analizi yapıyor. Ancak, çoğu eğitim şirketi henüz kendi büyük modellerini oluşturma yeteneğine sahip değil ve daha çok üçüncü taraf API’lerini kullanma eğiliminde. (Kaynak: 36氪)
Disney ve Universal Studios, yapay zeka görüntü oluşturma tek boynuzlusu Midjourney’e telif hakkı ihlali davası açtı: Hollywood devleri Disney ve Universal Studios, yapay zeka görüntü oluşturma şirketi Midjourney’e, telif hakkıyla korunan çok sayıda IP içeriğini (Iron Man, Minyonlar gibi) izinsiz olarak yapay zeka modellerini eğitmek ve son derece benzer görüntüler oluşturmak için kullandığı iddiasıyla ortak dava açtı. Davacılar, ihlalin durdurulmasını ve kasıtlı olarak ihlal edilen her eser için 150.000 dolara kadar tazminat talep ediyor. Bu dava, üretken yapay zekanın karşılaştığı telif hakkı zorluklarını vurguluyor; Midjourney kurucusu daha önce verileri izinsiz kullandığını kabul etmişti. Dava, telif hakkı lisanslama mekanizmalarının ve içerik filtreleme sistemlerinin kurulmasını teşvik etmeyi amaçlayabilir. (Kaynak: 36氪)

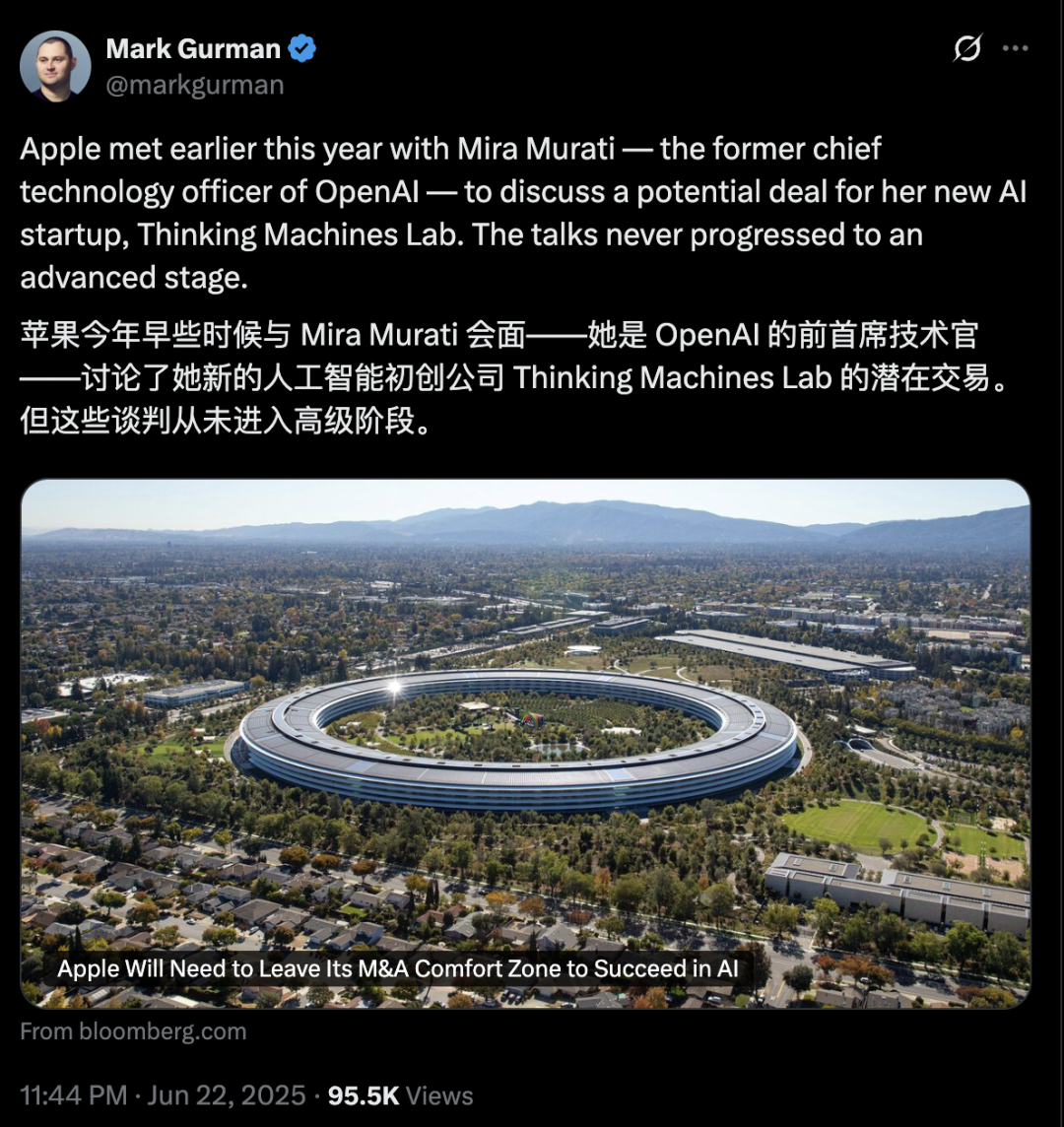
Apple’ın yapay zeka konusunda geri kaldığı iddia ediliyor, açığı kapatmak için satın alma düşünebilir, eski OpenAI CTO’sunun şirketi dikkat çekiyor: Haberlere göre Apple, yapay zeka alanında nispeten geri kalmış durumda, kendi geliştirdiği yapay zeka yetenekleri yetersiz ve Siri’nin performansı zayıf. Açığı kapatmak için Apple’ın büyük bir satın alma düşünebileceği, iddiaya göre OpenAI’nin eski CTO’su Mira Murati ile yeni kurduğu şirketi Thinking Machines Lab hakkında ön görüşmeler yaptığı söyleniyor. Tarihsel olarak Apple, kendi yeteneklerini güçlendirmek için birçok kez küçük teknoloji şirketlerini satın aldı (Siri’nin kendisi gibi). Şu anda Apple, yapay zeka modeli parametre ölçeğinde sektör devlerinin çok gerisinde; Mistral gibi şirketleri satın almak, kendi geliştirdiği büyük modellerde atılım yapmasına yardımcı olabilir. (Kaynak: 36氪)