
Anahtar Kelimeler:büyük dil modeli, AI değerlendirme, çoklu ajan sistemi, akıl yürütme yeteneği, bağlam işleme, açık kaynak model, AI video oluşturma, AI programlama, LLM akıl yürütme yeteneği değerlendirmesi, Claude Opus 4’ün Apple makalesine itirazı, MiniMax-M1 MoE modeli, Kimi-Dev-72B programlama modeli, Gemini Derin Düşünme özelliği
🔥 Öne Çıkanlar
Apple’ın makalesi büyük dil modellerinin çıkarım yeteneklerini sorguladı, Claude ortak yazarlı makale deney tasarımındaki kusurlara dikkat çekti: Apple şirketi yakın zamanda yayınladığı “Düşünme Yanılsaması” (The Illusion of Thought) başlıklı makalesinde, Hanoi Kuleleri, blok dünyası gibi klasik problem testleri aracılığıyla ana akım büyük dil modellerinin (LLM) karmaşık çıkarım görevlerinde düşük performans gösterdiğini, bunun özünde örüntü eşleştirme olduğunu ve gerçek anlama olmadığını belirtti. Ancak, bağımsız araştırmacı Alex Lawsen ve AI modeli Claude Opus 4 ortak imzasıyla yayınlanan “‘Düşünme Yanılsamasının’ Kendisinin Yanılsaması” (“The Illusion of the ‘Illusion of Thought’“) başlıklı bir makale ile buna karşı çıktı ve Apple’ın deneyinde tasarım kusurları olduğunu savundu: 1. LLM’lerin Token çıktı sınırının dikkate alınmaması, modelin aşırı uzun adımları tam olarak çıktılayamaması nedeniyle hatalı olarak değerlendirilmesine yol açtı; 2. Bazı test senaryolarının (bazı “nehri geçme problemleri” gibi) verilen koşullar altında matematiksel olarak çözümsüz olması, AI’ın “doğru cevap” verememesinin yetersizlikten kaynaklanmadığı; 3. Değerlendirme yönteminin değiştirilmesi, örneğin modelden tam adımlar yerine çözüm programını çıktılamasının istenmesi durumunda AI’ın üstün performans gösterdiği. Bu olay, LLM’lerin gerçek çıkarım yetenekleri ve değerlendirme metodolojileri hakkında geniş çaplı tartışmalara yol açtı, makul değerlendirme şemaları tasarlamanın önemini vurguladı ve geliştiricilere pratik uygulamalarda bağlam penceresi, çıktı bütçesi ve görev ifadesi gibi faktörlerin model performansı üzerindeki etkisine dikkat etmeleri gerektiğini hatırlattı. (Kaynak: 新智元, 大数据文摘)
Google’ın AI yol haritası sızdırıldı, yeni nesil AI mimarisinin mevcut attention mekanizmasını terk edebileceğine işaret ediyor: Google ürün yöneticisi Logan Kilpatrick, AI Mühendisleri Dünya Fuarı’nda Gemini modelinin gelecekteki gelişim yönünü açıkladı; bunlar arasında en dikkat çekici olanı “sınırsız bağlam” gerçekleştirme vizyonuydu. Mevcut attention mekanizması ve bağlam işleme yöntemleriyle gerçek anlamda sınırsız bağlamın elde edilemeyeceğini belirterek, Google’ın tamamen yeni bir çekirdek AI mimarisi üzerinde çalışıyor olabileceğini ima etti. Yol haritası ayrıca şunları içeriyor: tam modalite yetenekleri (görüntü + ses zaten destekleniyor, video bir sonraki aşama), Diffusion erken deneyleri, varsayılan olarak Agent yetenekleri (birinci sınıf araç çağırma ve kullanma, modelin kademeli olarak akıllı bir varlığa dönüşmesi), sürekli genişleyen çıkarım yetenekleri ve daha fazla küçük modelin piyasaya sürülmesi. Bu planlar dizisi, Google’ın AI’ı pasif yanıttan proaktif akıllı Agent’lara doğru aktif olarak ilerlettiğini ve özellikle bağlam işleme alanında mevcut teknolojik darboğazları aşmaya kararlı olduğunu gösteriyor; bu da AI mimarisinde büyük bir devrime yol açabilir. (Kaynak: 新智元)
Sakana AI, ALE-Agent’ı yayınladı, NP-zor problemler için programlama yarışmasında insan yarışmacıların %98’ini yendi: Transformer yazarlarından Llion Jones’un kurucu ortağı olduğu Sakana AI, Japon programlama yarışma platformu AtCoder ile işbirliği yaparak ALE-Bench’i (Algoritma Mühendisliği Kıyaslaması) başlattı. Bu kıyaslama, AI’ın NP-zor problemler (yol planlama, görev zamanlama gibi) üzerindeki uzun vadeli çıkarım ve yaratıcı programlama yeteneklerini değerlendirmeye odaklanıyor. Geliştirdikleri ALE-Agent, Gemini 2.5 Pro tabanlı olup, alan bilgisi ipuçları (domain knowledge prompting) ve çeşitlendirilmiş çözüm uzayı arama stratejilerini birleştirerek AtCoder sezgisel yarışmasında üstün performans gösterdi ve 21. sırada (ilk %2) yer alarak çok sayıda üst düzey insan geliştiriciyi geride bıraktı. Bu, AI’ın karmaşık optimizasyon problemlerini çözmede önemli bir ilerleme kaydettiğini gösteriyor ve lojistik, üretim planlaması gibi pratik uygulamalar için büyük önem taşıyor. ALE-Agent, benzetilmiş tavlama (simulated annealing) gibi algoritmalarda üstün performans gösterse de, hata ayıklama, karmaşıklık analizi ve optimizasyon tuzaklarından kaçınma konularında hala geliştirilecek alanları bulunuyor. (Kaynak: 新智元, SakanaAILabs, hardmaru)
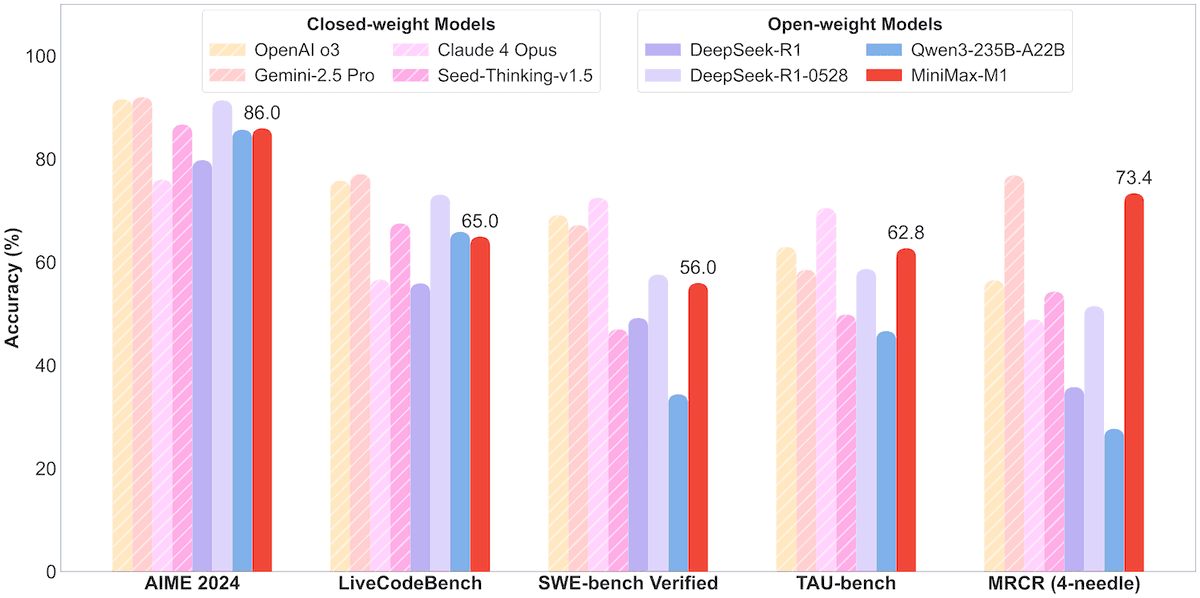
MiniMax, 456B parametreli MoE modeli MiniMax-M1’i açık kaynak olarak yayınladı, milyon Token bağlam ve 80.000 Token çıktıyı destekliyor: MiniMax şirketi, ilk açık kaynak büyük ölçekli Mixture-of-Experts (MoE) çıkarım modeli olan MiniMax-M1’i yayınladı. Model 456 milyar parametreye sahip ve her Token için 45.9 milyar parametreyi etkinleştiriyor; MoE ile Lightning Attention mekanizmasının birleştirildiği bir mimari kullanıyor. M1, doğal olarak 1 milyon Token bağlam uzunluğunu destekliyor ve sektör lideri 80.000 Token çıktıya ulaşabiliyor; 40k ve 80k düşünme bütçeli iki versiyon içeriyor. Yazılım mühendisliği, araç kullanımı ve uzun bağlam görevleri için yapılan kıyaslama testlerinde M1, DeepSeek-R1 ve Qwen3-235B gibi modellerden daha iyi performans gösterdi, özellikle Agent araç kullanımı (TAU-bench gibi) konusunda dikkat çekici sonuçlar elde etti. Takviyeli öğrenme aşaması sadece 512 adet H800 ile üç haftada tamamlandı ve maliyeti yaklaşık 537.400 ABD Doları oldu. M1 modeli, MiniMax APP ve Web üzerinden ücretsiz olarak kullanılabiliyor ve API aracılığıyla hizmet veriyor. (Kaynak: op7418, scaling01, jeremyphoward, karminski3, Reddit r/LocalLLaMA, 智东西)
🎯 Gelişmeler
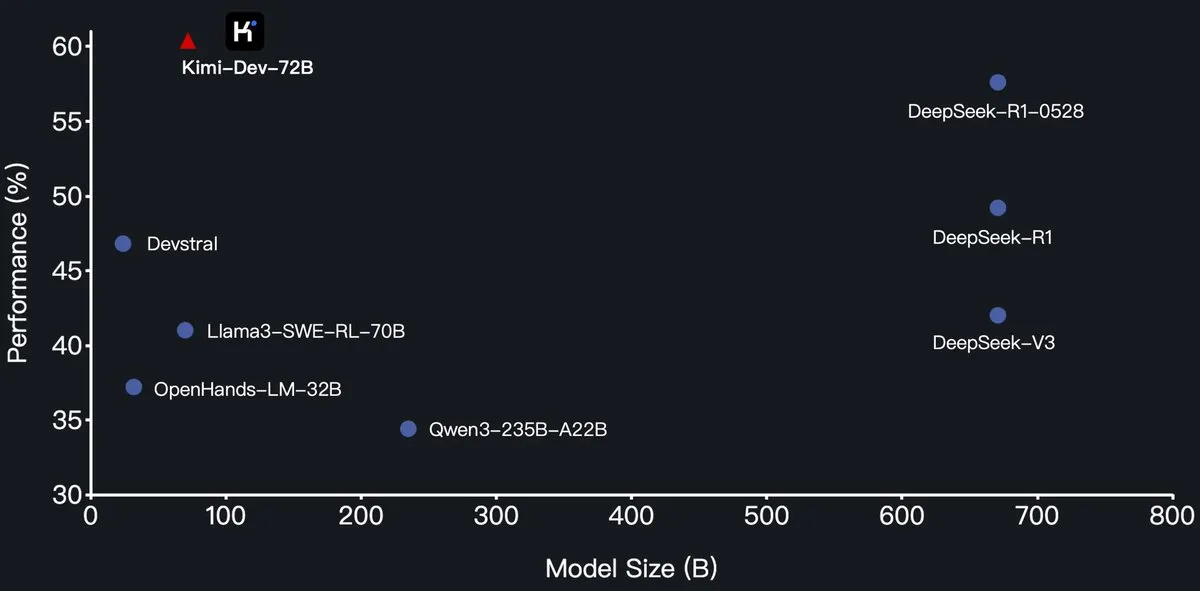
Moonshot AI (月之暗面), Kimi-Dev-72B programlama büyük dil modelini açık kaynak olarak yayınladı, SWE-Bench’te DeepSeek-R1’i geçti: Moonshot AI (月之暗面), Qwen2.5-72B üzerinde ince ayar yapılmış yeni açık kaynak programlama büyük dil modeli Kimi-Dev-72B’yi yayınladı. Kimi-Dev-72B’nin SWE-bench Verified kıyaslama testinde %60.4 çözüm oranına ulaştığı ve DeepSeek-R1-0528 (%57.6) ile Qwen3-235B-A22B gibi modelleri geride bırakarak açık kaynak modeller arasında öne çıktığı iddia ediliyor. Model, takviyeli öğrenme ile eğitilmiş olup, Docker ortamında gerçek kod depolarını onarmaya odaklanıyor ve yalnızca tam test paketleri geçtiğinde ödül alıyor. Qwen geliştirme lideri yetki vermediğini belirtti, ancak Kimi’nin MIT lisansı altında ince ayarlı bir sürüm yayınlaması kurallara uygun. (Kaynak: Dorialexander, scaling01, karminski3, Reddit r/LocalLLaMA)
Qwen3 serisi modellerine MLX format desteği eklendi, Apple çipleri için çıkarım optimize edildi: Alibaba Tongyi Qianwen ekibi, Qwen3 serisi modellerinin artık MLX formatını desteklediğini ve 4bit, 6bit, 8bit ve BF16 olmak üzere dört farklı niceleme seviyesi sunduğunu duyurdu. Bu hamle, modellerin Apple MLX çerçevesindeki çalışma verimliliğini optimize etmeyi ve geliştiricilerin Mac cihazlarında yerel dağıtım ve çıkarım yapmasını kolaylaştırmayı amaçlıyor. Kullanıcılar ilgili modelleri HuggingFace ve ModelScope üzerinden edinebilirler. (Kaynak: ClementDelangue, stablequan, jeremyphoward)

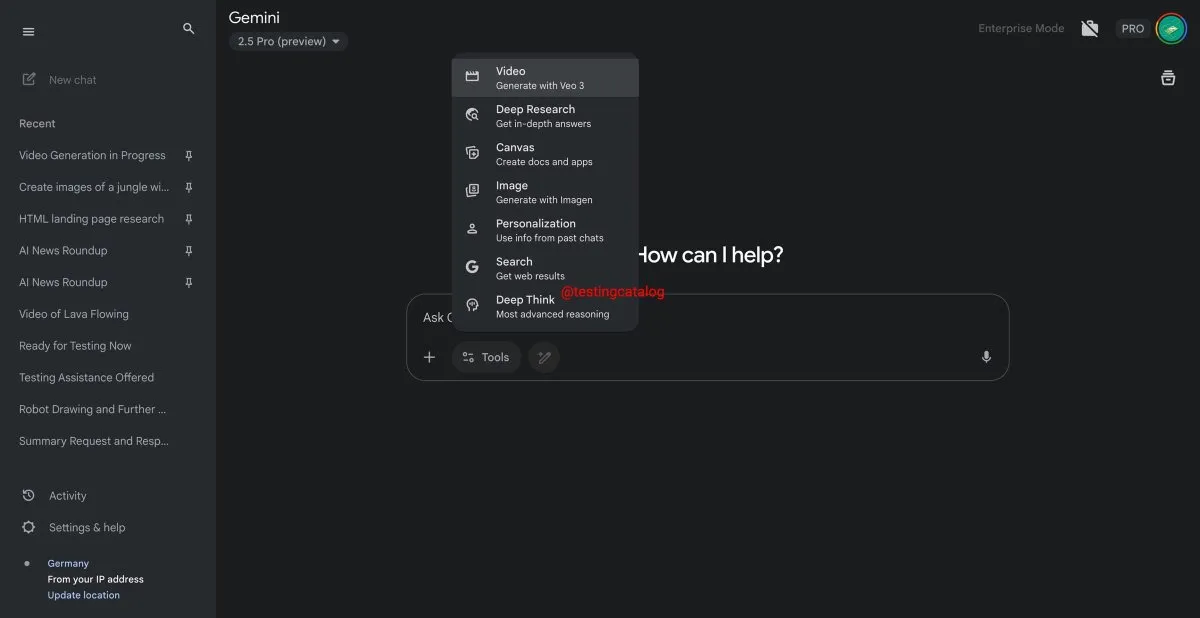
Google Gemini yakında “Deep Think” özelliğini sunacak, karmaşık problem çözme yeteneğini artıracak: Google, Gemini 2.5 Pro modeli için “Deep Think” adlı yeni bir özelliği kullanıma sunmaya hazırlanıyor. Bu özellik, özellikle matematiksel görevlerde daha zorlu problemleri ele almak için ek hesaplama gücü sağlayarak, Deep Think’in normal Gemini 2.5 Pro’ya kıyasla performansını %15’e kadar artırması bekleniyor. Bu özellik, araç çubuğunda yeni bir seçenek olarak görünecek ve işlem süreci birkaç dakika sürebilecek. Aynı zamanda, Gemini’nin kullanıcı arayüzü de güncellenecek. (Kaynak: op7418)
Google Veo 3 video oluşturma modeli resmi olarak kullanıma sunuldu, 70’ten fazla pazara genişledi: Google, AI video oluşturma modeli Veo 3’ün AI Pro ve Ultra aboneleri için resmi olarak dünya genelinde 70’ten fazla pazarda kullanıma sunulduğunu duyurdu. Veo 3, oluşturduğu videoların gerçekçi ve yaratıcı efektleriyle dikkat çekiyor; daha önce kullanıcılar tarafından “büyüleyici meyve kesme” gibi ASMR içerikleri üretmek için kullanılmış ve sosyal medyada on milyonlarca izlenme alarak içerik oluşturma alanındaki potansiyelini göstermişti. Bu resmi lansman, daha fazla kullanıcının Veo 3’ü deneyimlemesini ve video oluşturmak için kullanmasını sağlayacak. (Kaynak: Google, 新智元)
Hugging Face ve Groq işbirliği yaparak yüksek hızlı LLM çıkarım hizmetleri sunuyor: Hugging Face, AI çip şirketi Groq ile işbirliği yaptığını ve Groq’un LPU™ (Language Processing Unit) birimini Hugging Face Playground ve API’sine entegre ettiğini duyurdu. Kullanıcılar artık doğrudan Hugging Face platformunda Groq donanımıyla hızlandırılmış LLM çıkarım hizmetlerini deneyimleyebilecekler; Llama 4, Qwen 3 dahil olmak üzere çeşitli modeller destekleniyor. Bu hamle, geliştiricilere özellikle Agent’lar, asistanlar ve gerçek zamanlı AI uygulamaları oluşturmak için daha hızlı ve daha verimli AI model çıkarım seçenekleri sunmayı amaçlıyor. (Kaynak: HuggingFace Blog, huggingface, ClementDelangue, mervenoyann, JonathanRoss321, _akhaliq)

Hugging Face Hub’a model boyutu filtreleme özelliği eklendi, geliştiricilerin uygun model seçmesine yardımcı oluyor: Hugging Face platformu, kullanıcıların özellikle mlx / mlx-lm çerçevesinde çalışan modeller için model boyutuna (Size Range) göre filtreleme yapmasına olanak tanıyan yeni bir özellik sundu. Bu iyileştirme, geliştiricilerin belirli donanım ve performans gereksinimlerine uygun modelleri daha kolay bulmalarına yardımcı olmayı amaçlıyor ve model ne kadar büyükse o kadar iyi olmadığı, küçük uzmanlaşmış modellerin belirli senaryolarda genellikle daha iyi olduğu vurgulanıyor. (Kaynak: ClementDelangue, awnihannun, reach_vb, huggingface, ggerganov)

NVIDIA NCCL güncellemesi, yarı hassasiyetli girdiler için FP32 birikimiyle indirgeme işlemlerine başladı: NVIDIA Collective Communications Library (NCCL) en son sürümü (commit 72d2432) önemli bir güncelleme getirdi: yarı hassasiyetli girdilerin (FP16, BF16 gibi) indirgeme işlemlerini (reduction ops) işlerken FP32 ile birikim yapmaya başladı. Bu değişiklik, özellikle büyük ölçekli dağıtık eğitimde hesaplama hassasiyetini korumak ve taşmayı önlemek için kritik öneme sahip. Bu sürümün PyTorch 2.8 ve üzeri sürümlerde entegre edilmesi bekleniyor. (Kaynak: StasBekman)

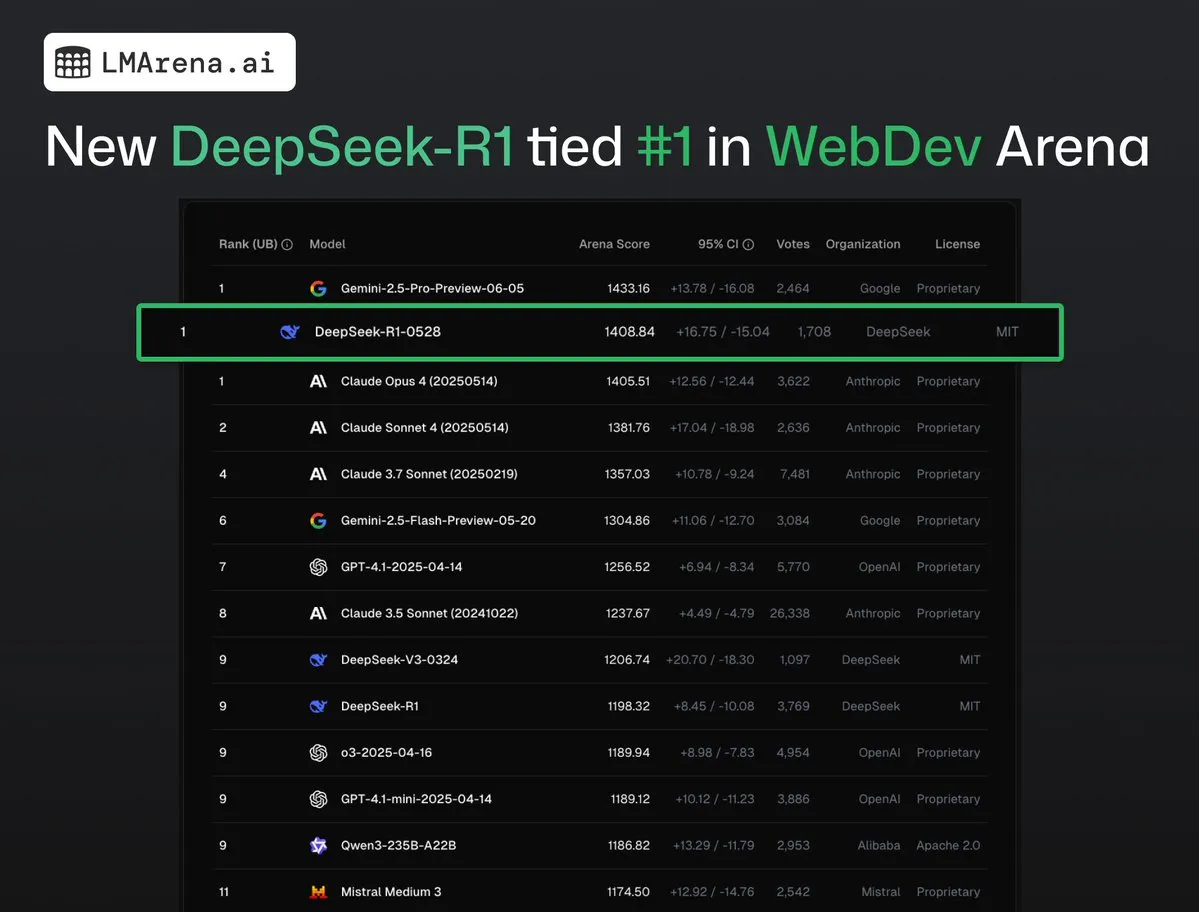
DeepSeek-R1 (0528), WebDev Arena’da Claude Opus 4 ile birinciliği paylaştı: lmarena.ai’nin en son verilerine göre, yeni DeepSeek-R1 (0528) sürümü WebDev Arena kıyaslama testinde üstün performans göstererek Claude Opus 4 ile birinciliği paylaştı. Bu model, Text Arena genel sıralamasında altıncı, programlama yeteneği sıralamasında ikinci, zorlu prompt’lar sıralamasında dördüncü, matematik yeteneği sıralamasında beşinci sırada yer aldı ve sıralamadaki en iyi performansı gösteren MIT lisanslı açık kaynak model oldu. Bu, DeepSeek’in belirli geliştirme ve çıkarım görevlerindeki güçlü rekabetçiliğini gösteriyor. (Kaynak: ClementDelangue, zizhpan)
ByteDance, Poe platformunda Seedream 3.0 görüntü ve Seedance 1.0 Lite video modellerini kullanıma sundu: ByteDance’e ait AI oluşturma araçları, denizaşırı Poe platformunda güncellenerek, Dreamina AI’ın (即梦AI) görüntü oluşturma modeli Seedream 3.0 ve video oluşturma modeli Seedance 1.0 Lite’ı kullanıma sundu. Seedream 3.0, net ve canlı görüntüler oluşturmayı hedeflerken, Seedance 1.0 Lite ise gerçekçi dinamik efektlere sahip videoları hızla oluşturabiliyor. Kullanıcılar Poe’da önce Seedream ile resim oluşturup, ardından @-mention ile Seedance’i etiketleyerek bunu videoya dönüştürebilir ve böylece resimden videoya kesintisiz bir oluşturma süreci elde edebilirler. (Kaynak: op7418)

Tencent, Levo şarkı söyleme modelini piyasaya sürdü, parça ayırma ve sıfır-örnek ses klonlamayı destekliyor: Tencent, performansının Suno V3.5 ile karşılaştırılabileceği iddia edilen Levo adlı bir AI şarkı söyleme modelini yayınladı. Levo, ses parçası ayırma ve sıfır-örnek (zero-shot) ses klonlama özelliklerini destekliyor ve yayınlanan demo ve puanlamalara göre başarılı bir performans sergiliyor. Bu gelişme, Tencent’in AI müzik üretimi alanındaki gücünü gösteriyor. (Kaynak: karminski3)
OpenAI, WhatsApp’ta ChatGPT görüntü oluşturma özelliğini başlattı: OpenAI, kullanıcıların artık WhatsApp’taki 1-800-ChatGPT hizmeti aracılığıyla ChatGPT’nin görüntü oluşturma özelliğini kullanabileceğini duyurdu. Bu güncelleme, daha geniş bir kullanıcı kitlesinin anlık mesajlaşma uygulamalarında doğrudan AI görüntüleri oluşturmasını kolaylaştırıyor. (Kaynak: gdb, eliza_luth, iScienceLuvr)
SpatialLM 1.1 sürümüne güncellendi, 3D sahne anlama ve yeniden yapılandırma yetenekleri geliştirildi: Mekansal çıkarım modeli SpatialLM, 1.1 sürümünü yayınladı. Yeni sürüm, metinden 3D sahne oluşturma (Text-to-3D), el kamerası video yeniden yapılandırması, LiDAR nokta bulutu verileri (iPhone Pro LiDAR gibi) ve sentetik ağ örneklemesi dahil olmak üzere çeşitli girdi kaynağı modlarını destekliyor. Temel özellikler arasında, 3D tarama verileri eksik olsa bile makul yeniden yapılandırma yapabilen yapılandırılmamış nokta bulutlarının sağlam işlenmesi yer alıyor. Ayrıca, yeni sürüm video akışı girdileri için sıfır-örnek (zero-shot) algılamayı optimize etti, iç mekan düzeni tahmin doğruluğunu geliştirdi ve 3D nesne algılama efektlerini iyileştirdi. AR sahne yeniden yapılandırması, robotik mekansal anlama, 3D tasarım iş akışları ve tüketici kamera uygulamaları dahil olmak üzere geniş bir uygulama yelpazesine sahip. (Kaynak: karminski3)
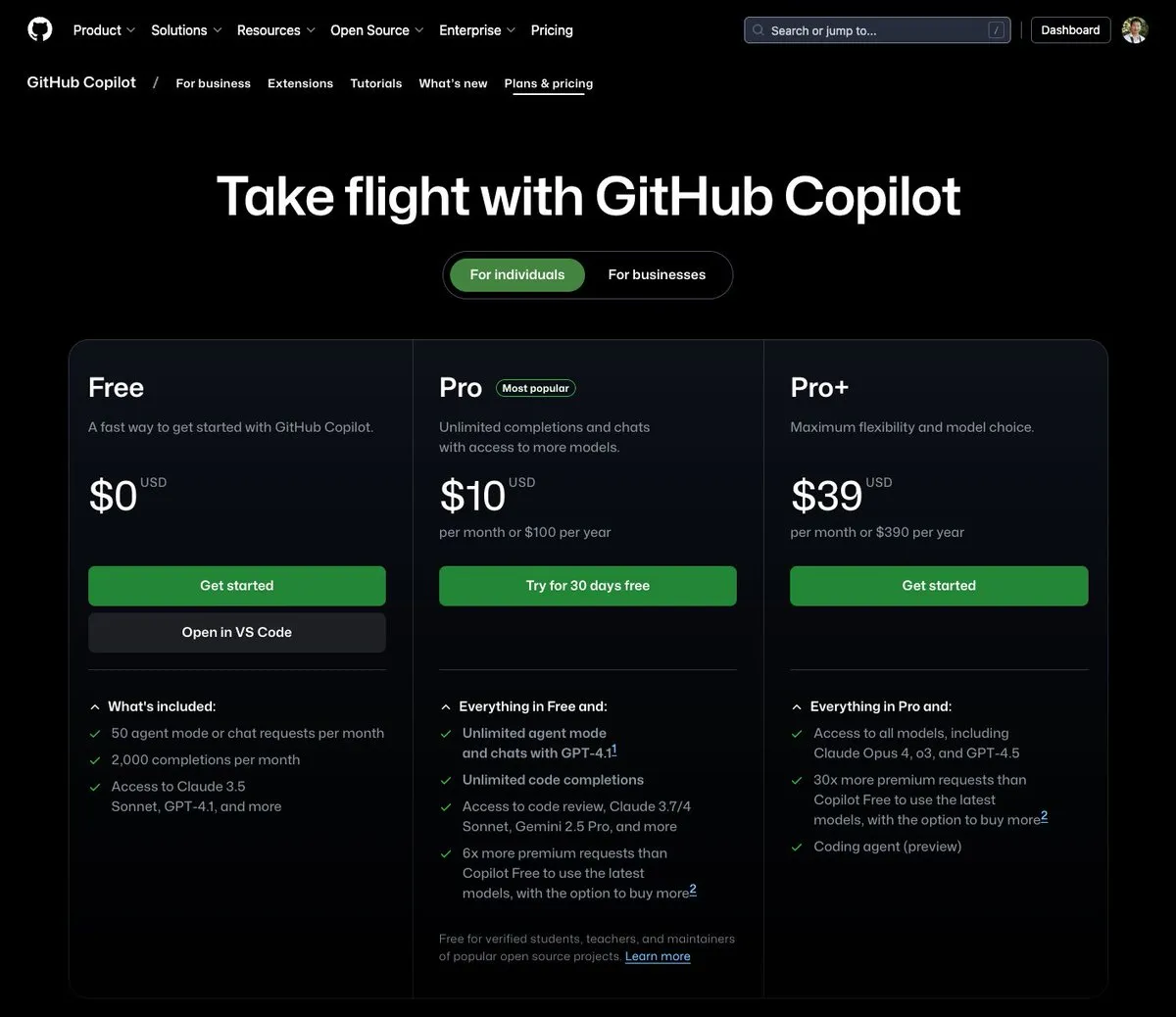
GitHub Copilot, aylık 39 dolarlık bir paket sundu; Claude Opus 4 gibi çeşitli büyük modelleri entegre ediyor: GitHub Copilot, aylık 39 dolarlık yeni bir abonelik paketi ekledi. Bu paket yalnızca kodlama asistanı işlevleri sunmakla kalmıyor, aynı zamanda kullanıcıların Claude Opus 4, o3 ve GPT-4.5 dahil olmak üzere çeşitli güçlü dil modellerine erişmesine ve Coding agent’ı kullanmasına olanak tanıyor. Bu girişim, geliştiricilere daha kapsamlı bir AI destekli programlama deneyimi sunmayı amaçlıyor. (Kaynak: dotey)
AI büyük model çağırma maliyetleri düşmeye devam ediyor, Doubao (豆包) 1.6 serisinin fiyatları %63 daha düştü: Volcano Engine, Force原动力 Konferansı’nda Doubao (豆包) büyük model 1.6 serisini yayınladı ve genel maliyetinin %63 oranında düştüğünü duyurdu. Çoğu kurumsal kullanıcının yaygın olarak kullandığı 0-32K giriş uzunluğu aralığında fiyat, milyon Token başına giriş için 0.8 yuan, çıkış için 8 yuan oldu. Bu, bu yılın Mart ayında Alibaba Qwen’in maliyeti DeepSeek R1’in 1/10’una düşürmesinin ardından büyük model fiyat savaşlarının devam ettiğini gösteriyor. Düşük maliyetler, AI Agent gibi uygulamaların hayata geçirilmesini ve yaygınlaşmasını daha da teşvik edecek. (Kaynak: 字节必须再赢一次)
Chipmunk video oluşturma hızlandırma aracı güncellendi, çoklu GPU mimarilerini ve daha fazla açık kaynak modeli destekliyor: Dan Fu ekibinin Chipmunk aracı güncellendi ve artık çeşitli NVIDIA GPU mimarilerinde (sm_80, sm_89, sm_90; örneğin A100s, 4090s, H100s) 1.4-3 kat kayıpsız video oluşturma hızlandırması sağlıyor. Aynı zamanda Chipmunk, Mochi, Wan gibi daha fazla açık kaynak video modeli için destek ekledi ve entegrasyon eğitimleri sundu. Bu araç, video modellerindeki aktivasyon değerlerinin seyrekliğinden (aktivasyon değerlerinin yalnızca %5-25’i çıktının %90’ından fazlasına katkıda bulunur) yararlanarak hızlandırma sağlıyor ve modeli yeniden eğitmeye gerek duymuyor. (Kaynak: realDanFu)

🧰 Araçlar
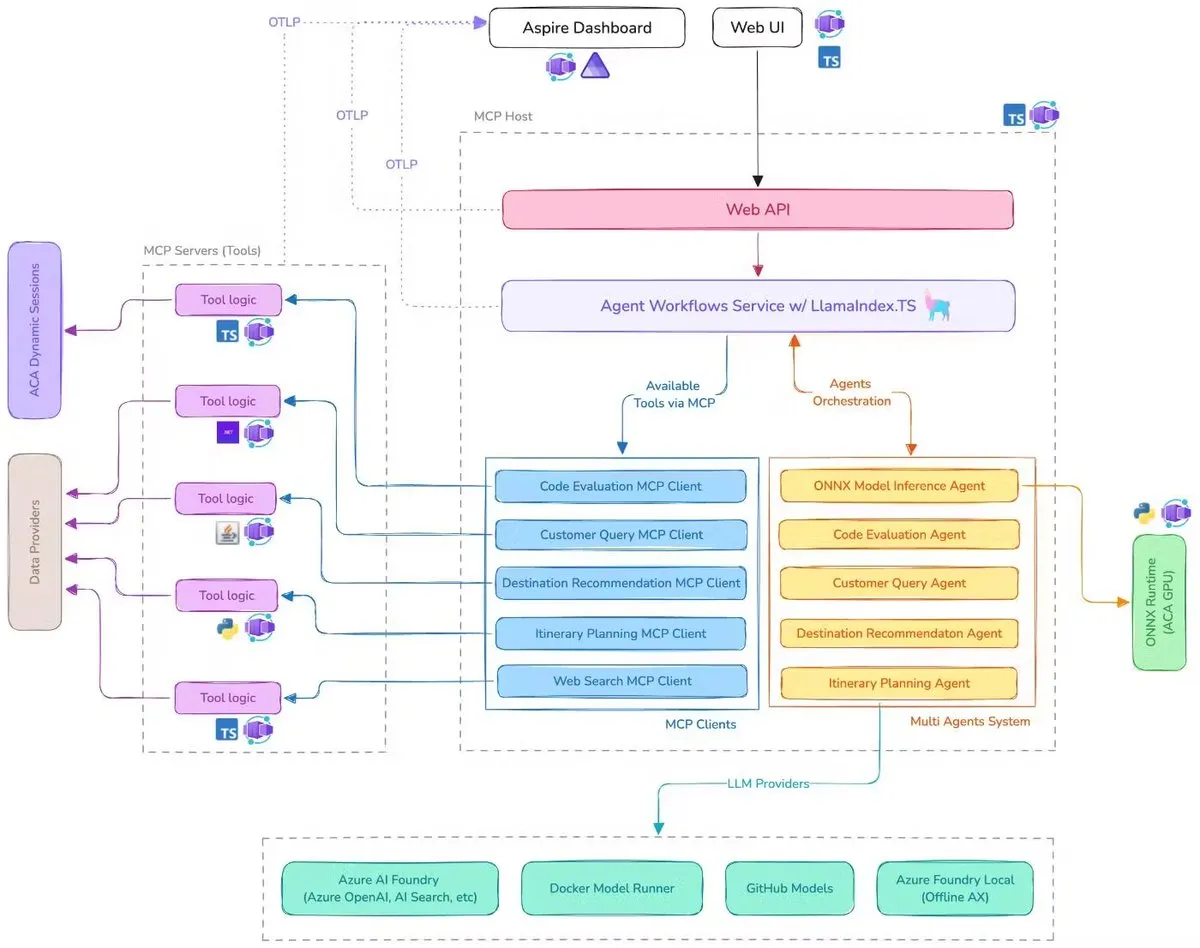
Microsoft, MCP, LlamaIndex.TS ve Azure AI Foundry’yi entegre eden AI seyahat asistanı demosu yayınladı: Microsoft, bir AI seyahat asistanı demosu sergiledi. Bu sistem, Model Context Protocol (MCP), LlamaIndex.TS ve Azure AI Foundry aracılığıyla birden fazla AI Agent’ını (sorgu sınıflandırma, destinasyon önerisi, seyahat planlama dahil altı uzman Agent) karmaşık seyahat planlama görevlerini tamamlamak için koordine ediyor. Her Agent, Java, .NET, Python ve TypeScript ile yazılmış MCP sunucuları aracılığıyla gerçek zamanlı verilere ve araçlara erişiyor. Bu uygulama, kurumsal düzeyde çoklu Agent’ların çok dilli mikro hizmetler aracılığıyla nasıl birlikte çalışabileceğini, Azure OpenAI ve GitHub modellerini kullanarak AI yetenekleri sağlayabileceğini ve Azure Container Apps aracılığıyla ölçeklenebilir sunucusuz dağıtım gerçekleştirebileceğini gösteriyor. (Kaynak: jerryjliu0, jerryjliu0)
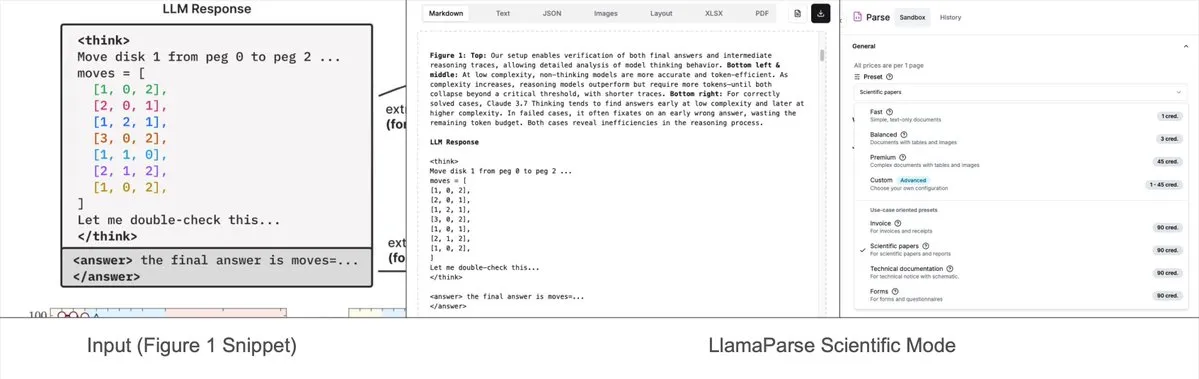
LlamaParse’a önceden ayarlanmış modlar eklendi, karmaşık grafikleri Mermaid veya Markdown olarak ayrıştırabiliyor: LlamaIndex’in LlamaParse aracı yakın zamanda güncellendi ve araştırma raporları gibi belgelerdeki karmaşık grafikleri (örneğin birden fazla eğri ve açıklama içeren grafikler) ayrıştırıp bunları biçimlendirilmiş Mermaid diyagramlarına veya Markdown tablolarına dönüştürebilen “önceden ayarlanmış modlar” (preset-modes) eklendi. Bu özellik, sayfadan tam bağlamı yakalamaya yardımcı oluyor ve oluşturulan yapılandırılmış metin, RAG süreçleri oluşturmak veya daha fazla meta veri çıkarmak için kullanılabiliyor. (Kaynak: jerryjliu0)
Prompt Optimizer: Yüksek kaliteli prompt’lar yazmaya yardımcı olan bir optimizasyon aracı: Prompt Optimizer, kullanıcıların daha kaliteli AI prompt’ları yazmasına ve böylece AI çıktılarının kalitesini artırmasına yardımcı olmak için tasarlanmış bir araçtır. Web uygulaması ve Chrome eklentisi olmak üzere iki biçimde sunulur; akıllı optimizasyon, çok turlu yinelemeli iyileştirme, orijinal ve optimize edilmiş prompt’ların karşılaştırılması, çoklu model entegrasyonu (OpenAI, Gemini, DeepSeek, Zhipu AI, SiliconFlow vb.), gelişmiş parametre yapılandırması, yerel şifreli depolama gibi özellikler sunar. Bu araç, veri güvenliğini ve gizliliğini sağlamak için tamamen istemci tarafında işlem yapar. (Kaynak: GitHub Trending)

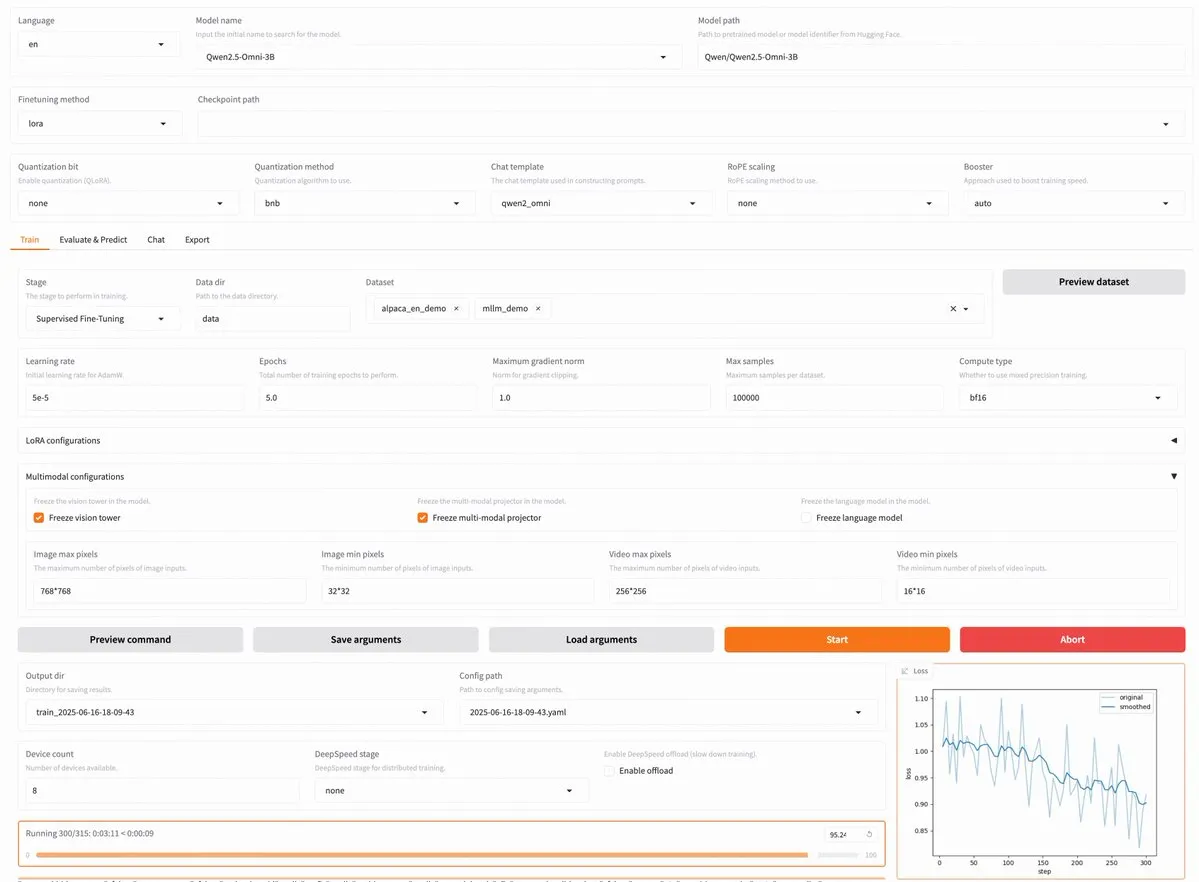
LLaMA Factory v0.9.3 yayınlandı, Qwen3, Llama 4 dahil yaklaşık 300 model için kodsuz ince ayar desteği sunuyor: LLaMA Factory, v0.9.3 sürümünü yayınladı. Bu sürüm, en yeni Qwen3, Llama 4, Gemma 3, InternVL3, Qwen2.5-Omni dahil olmak üzere yaklaşık 300’den fazla model için uygun, Gradio kullanıcı arayüzünü destekleyen, tamamen açık kaynaklı, kodsuz bir ince ayar platformudur. Kullanıcılar Docker imajı aracılığıyla yerel olarak kurabilir veya Hugging Face Spaces, Google Colab ve Novita’nın GPU bulutunda deneyebilirler. (Kaynak: _akhaliq)
Nanonets OCR: Qwen 2.5 VL 3B tabanlı SOTA OCR modeli açık kaynak olarak yayınlandı: Nanonets, Qwen 2.5 VL 3B ana ağına dayanan ve Mistral OCR API’sinden daha iyi performans gösteren yeni bir 3B parametreli OCR modeli olan Nanonets OCR’ı yayınladı. Model, Apache 2.0 lisansıyla açık kaynak olarak sunuluyor. LaTeX tanıma, filigran ve imza algılama, karmaşık tablo çıkarma gibi çeşitli OCR görevlerini yerine getirebiliyor. (Kaynak: huggingface)
Perplexity Labs’in birçok profesyonel pozisyonun yerini alabileceği iddiası, AI araçlarının yetenekleri hakkında tartışma başlattı: Bir kullanıcı olan GREG ISENBERG, Perplexity Labs’i kullanarak satış elemanı, metin yazarı, film yönetmeni, sosyal medya yöneticisi ve finans analisti olmak üzere beş pozisyonun işini yaptığını iddia etti ve AI araçlarının yeteneklerinin “gerçekten çılgınca” olduğunu belirtti. Perplexity CEO’su Arav Srinivas, bunu AI Agent’larının gerçek hayattaki kullanım senaryolarında nasıl uygulandığını gösteren en iyi videolardan biri olarak yeniden paylaştı ve Perplexity Labs’in finansal analiz, sosyal medya pazarlaması, yaratıcı yönlendirme ve satış alanlarında piyasadaki diğer araçlarla karşılaştırmasını yaptı. Bu, AI Agent’larının çok alanlı profesyonel görevleri entegre etme ve yürütme potansiyelini vurguluyor. (Kaynak: AravSrinivas, AravSrinivas)
Claude-Flow v1.0.50 önemli güncellemesini yayınladı, kod otomasyon verimliliğini artırmak için “sürü modunu” etkinleştirdi: Claude Code tabanlı bir toplu araç paralel Agent sistemi olan Claude-Flow, v1.0.50 sürümünü yayınladı. Yeni sürüm, kullanıcıların oluşturma, test etme, dağıtma veya çok aşamalı araştırma döngüleri için yüzlerce Claude Agent’ını aynı anda oluşturmasına, yönetmesine ve koordine etmesine olanak tanıyan “sürü modunu” (Swarm Mode) sunuyor. Geleneksel sıralı Claude Code otomasyonuna kıyasla performansın 20 kat arttığı iddia ediliyor. Geliştiriciler npx claude-flow@latest init --sparc --force komutuyla başlatabilirler. (Kaynak: Reddit r/ClaudeAI)

📚 Öğrenme Kaynakları
Awesome Machine Learning: Kapsamlı makine öğrenimi kaynakları listesi: GitHub’daki “awesome-machine-learning” projesi, programlama diline göre sınıflandırılmış, özenle seçilmiş makine öğrenimi çerçeveleri, kütüphaneleri ve yazılımlarının bir listesidir. Ayrıca ücretsiz makine öğrenimi kitapları, profesyonel etkinlikler, çevrimiçi kurslar, blog bültenleri ve yerel buluşmalar gibi kaynaklara bağlantılar içerir ve makine öğrenimi öğrencileri ve uygulayıcıları için değerli bir rehber sunar. (Kaynak: GitHub Trending)
Anthropic ve Cognition AI, çoklu Agent sistemlerinin oluşturulması hakkında ayrı ayrı blog yazıları yayınladı, LangChain özetledi: Anthropic ve Cognition AI yakın zamanda çoklu Agent sistemleri oluşturma (veya oluşturmama) hakkında kendi blog yazılarını yayınladılar. Anthropic, çoklu Agent araştırma sistemlerini nasıl oluşturduklarına dair deneyimlerini paylaşırken, Cognition AI “çoklu Agent oluşturmayın” görüşünü ortaya koydu. LangChain’den Harrison Chase bunu özetleyerek, görünüşte görüşler farklı gibi görünse de, her iki makalenin de rehber ilkeler ve öneriler konusunda birçok ortak noktası olduğunu belirtti ve LangChain’in çoklu Agent konusundaki çabalarıyla ilişkilendirdi. (Kaynak: hwchase17, Hacubu)
“Recent Advances in Speech Language Models: A Survey” makalesi ACL 2025 ana konferansına kabul edildi: Hong Kong Çin Üniversitesi ekibi tarafından yazılan konuşma dili modelleri (SpeechLM) üzerine bir derleme makalesi olan “Recent Advances in Speech Language Models: A Survey”, ACL 2025 ana konferansına kabul edildi. Bu makale, alanındaki ilk kapsamlı ve sistematik derleme olup, SpeechLM’in teknik mimarisini (konuşma ayrıştırıcıları, dil modelleri, ses kodlayıcılar), eğitim stratejilerini (ön eğitim, talimat ince ayarı, sonradan hizalama), etkileşim paradigmalarını (tam çift yönlü modelleme), uygulama senaryolarını (anlamsal, konuşmacı, paralinguistik) ve değerlendirme sistemlerini derinlemesine analiz ediyor. Makale, SpeechLM’in doğal insan-makine sesli etkileşimini gerçekleştirme potansiyelini vurguluyor ve karşılaşılan zorluklar ile gelecekteki yönelimleri işaret ediyor. (Kaynak: 36氪)

Yeni araştırma, görsel oyun öğrenimi (ViGaL) yoluyla küçük modellerin alanlar arası çıkarım yeteneğini artırıyor, 7B model matematik performansı GPT-4o’yu aşıyor: Rice Üniversitesi, Johns Hopkins Üniversitesi ve Nvidia araştırma ekipleri, ViGaL (Visual Game Learning) adlı yeni bir sonradan eğitim paradigması önerdi. 7B parametreli çok modlu bir modelin (Qwen2.5-VL-7B) Yılan ve 3D döndürme gibi basit atari oyunları oynamasıyla, model yalnızca oyun becerilerini geliştirmekle kalmadı, aynı zamanda matematik (MathVista) ve çok disiplinli soru cevaplama (MMMU) gibi karmaşık çıkarım görevlerinde de belirgin bir alanlar arası yetenek artışı gösterdi, hatta bazı açılardan GPT-4o gibi üst düzey modelleri geride bıraktı. Araştırma, oyun eğitiminin modelin mekansal anlama, sıralı planlama gibi genel bilişsel yeteneklerini geliştirebildiğini ve farklı oyunların farklı çıkarım becerilerini güçlendirebildiğini gösteriyor. Bu yöntem, çıkarım yeteneğini artırırken modelin genel görsel yeteneklerini de koruyor. (Kaynak: 新智元)

Şanghay AI Lab ve diğerleri, talimat birleştirme yoluyla LLM’lerin matematiksel problem çözme yeteneğini artıran MathFusion çerçevesini önerdi: Şanghay Yapay Zeka Laboratuvarı, Çin Renmin Üniversitesi Gaoling Yapay Zeka Enstitüsü ve diğer kurumlar, farklı matematiksel problem oluşturma yapılarının daha çeşitli ve mantıksal olarak daha karmaşık sentetik talimatlarla birleştirilmesi yoluyla büyük dil modellerinin (LLM) matematiksel problemleri çözme yeteneğini artırmayı amaçlayan MathFusion çerçevesini ortaklaşa önerdi. Bu çerçeve, sıralı birleştirme, paralel birleştirme ve koşullu birleştirme olmak üzere üç strateji içerir ve problemler arasındaki derin bağlantıları etkili bir şekilde yakalayabilir. Deneyler, yalnızca 45K sentetik talimat kullanılarak DeepSeekMath-7B, Llama3-8B, Mistral-7B gibi modeller üzerinde ince ayar yapıldıktan sonra, MathFusion’ın birden fazla matematiksel kıyaslama testinde ortalama doğruluğu 18.0 puan artırdığını ve yüksek veri verimliliği ile performans sergilediğini gösterdi. (Kaynak: 量子位)

Şanghay AI Lab ve diğerleri GRA çerçevesini önerdi, küçük modeller işbirliğiyle yüksek kaliteli veriler üretiyor, performansı 72B modelle karşılaştırılabilir: Şanghay Yapay Zeka Laboratuvarı, Çin Renmin Üniversitesi ile birlikte GRA (Generator–Reviewer–Adjudicator) çerçevesini önerdi. Bu çerçeve, makale gönderme ve hakem değerlendirme mekanizmalarını simüle ederek, birden fazla küçük dil modelinin (7-8B parametre) işbirliğiyle yüksek kaliteli eğitim verileri üretmesini sağlıyor. Bu çerçevede, Generator üretmekten, Reviewer çok turlu değerlendirme ve puanlamadan, Adjudicator ise değerlendirme çakışmalarında nihai kararı vermekten sorumlu. Deneyler, GRA ile üretilen verilerle LLMA-3.1-8B ve Qwen-2.5-7B gibi temel modellerin eğitilmesinin, matematik, kod, mantıksal çıkarım gibi 10 ana veri kümesindeki performansının, Qwen-2.5-72B-Instruct gibi büyük bir modelin damıtılmasıyla üretilen verilerle karşılaştırıldığında eşit veya daha iyi olduğunu gösterdi. Bu, düşük maliyetli, yüksek verimli veri sentezi için yeni fikirler sunuyor. (Kaynak: 量子位)

Makale, büyük modellerin yorumlanabilirliğinin mevcut durumunu ve geleceğini tartışıyor, AI’ın güvenli dağıtımı için önemini vurguluyor: Tencent Araştırma Enstitüsü, büyük dil modellerinin (LLM) yorumlanabilirliğinin mevcut durumunu, teknik yollarını ve gelecekteki zorluklarını derinlemesine inceleyen bir makale yayınladı. Makale, LLM’lerin iç mekanizmalarını anlamanın değer sapmalarını önlemek, modelleri hata ayıklamak ve iyileştirmek, kötüye kullanımı önlemek ve yüksek riskli senaryolarda uygulamaları teşvik etmek için kritik olduğunu belirtiyor. Mevcut teknik yollar arasında otomatik yorumlama (büyük modellerin küçük modelleri yorumlaması), özellik görselleştirme (seyrek otomatik kodlayıcılar gibi), düşünce zinciri izleme ve mekanik yorumlanabilirlik (Anthropic’in “AI mikroskobu” ve DeepMind’in Tracr’ı gibi) bulunuyor. Ancak, nöronların çoklu anlamsallığı, yorumlama yasalarının evrenselliği ve insan bilişsel sınırlamaları hala ana zorluklar. Makale, yorumlanabilirlik araştırmalarına yapılan yatırımın artırılması çağrısında bulunuyor ve AI teknolojisinin güvenli, şeffaf ve insan merkezli gelişimini sağlamak için mevcut aşamada sektörün kendi kendini düzenlemesini teşvik eden yumuşak hukuk kurallarının benimsenmesini öneriyor. (Kaynak: 腾讯研究院)

Yeni makale, ayrık difüzyon modellerinin büyük dil ve çok modlu modellerdeki uygulamalarını ve ilerlemelerini tartışıyor: “Discrete Diffusion in Large Language and Multimodal Models: A Survey” başlıklı bir makale, ayrık difüzyon dil modellerinin (dLLMs) ve ayrık difüzyon çok modlu dil modellerinin (dMLLMs) araştırma ilerlemelerini sistematik olarak gözden geçiriyor. Bu modeller, çoklu Token paralel kod çözme ve gürültü giderme tabanlı üretim stratejileri benimseyerek paralel üretim, ince taneli çıktı kontrol edilebilirliği ve dinamik, yanıta duyarlı algılama yetenekleri elde ediyor ve çıkarım hızı otoregresif modellere kıyasla 10 kata kadar artabiliyor. Makale, gelişim geçmişlerini izliyor, matematiksel çerçevelerini biçimselleştiriyor, temsili modelleri sınıflandırıyor, kritik eğitim ve çıkarım tekniklerini analiz ediyor ve dil, görsel-dil ve biyoloji alanlarındaki uygulamalarını özetliyor, son olarak gelecekteki araştırma yönlerini ve dağıtım zorluklarını tartışıyor. (Kaynak: HuggingFace Daily Papers)
Yeni araştırma Test3R’ı öneriyor: Test zamanı öğrenme yoluyla 3D yeniden yapılandırma geometrik doğruluğunu artırma: Test3R adlı yeni bir teknik, test zamanında öğrenme yoluyla 3D yeniden yapılandırmanın geometrik doğruluğunu önemli ölçüde artırıyor. Bu yöntem, (I_1,I_2,I_3) görüntü üçlüsünü kullanarak (I_1,I_2) ve (I_1,I_3) görüntü çiftlerinden yeniden yapılandırma sonuçları üretir. Temel fikir, test zamanında kendi kendine denetimli bir hedefle ağı optimize etmektir: bu iki yeniden yapılandırma sonucunun ortak görüntü I_1’e göre geometrik tutarlılığını en üst düzeye çıkarmak. Deneyler, Test3R’ın 3D yeniden yapılandırma ve çoklu görünüm derinlik tahmini görevlerinde mevcut SOTA yöntemlerinden önemli ölçüde daha iyi performans gösterdiğini ve evrensellik ile düşük maliyet özelliklerine sahip olduğunu, diğer modellere kolayca uygulanabildiğini, test zamanı eğitim yükünün ve parametre sayısının son derece küçük olduğunu göstermektedir. (Kaynak: HuggingFace Daily Papers)
Makale Mirage-1’i öneriyor: Hiyerarşik çok modlu becerilere sahip GUI Agent’ı, uzun vadeli görev işleme yeteneğini artırıyor: Araştırmacılar, mevcut GUI Agent’larının çevrimiçi ortamlarda uzun vadeli görevleri işlerken karşılaştığı bilgi eksikliği ve çevrimdışı-çevrimiçi alan farkı sorunlarını çözmeyi amaçlayan çok modlu, platformlar arası, tak-çalıştır bir GUI Agent’ı olan Mirage-1’i önerdi. Mirage-1’in çekirdeği, yörüngeleri kademeli olarak yürütme becerileri, çekirdek beceriler ve meta beceriler olarak soyutlayan ve uzun vadeli görev planlaması için hiyerarşik bir bilgi yapısı sağlayan Hiyerarşik Çok Modlu Beceriler (HMS) modülüdür. Aynı zamanda, Beceri Geliştirilmiş Monte Carlo Ağaç Arama (SA-MCTS) algoritması, çevrimiçi ağaç keşfinde eylem arama alanını azaltmak için çevrimdışı olarak elde edilen becerileri kullanır. AndroidWorld, MobileMiniWob++, Mind2Web-Live ve yeni oluşturulan AndroidLH kıyaslama testlerinde Mirage-1, önemli performans artışları göstermiştir. (Kaynak: HuggingFace Daily Papers)
“Don’t Pay Attention” makalesi, Transformer’a meydan okuyan yeni bir sinir ağı temel mimarisi Avey’i öneriyor: “Don’t Pay Attention” başlıklı bir makale, dikkat ve döngüsel mekanizmalara olan bağımlılıktan kurtulmayı amaçlayan Avey adlı yeni bir sinir ağı temel mimarisi öneriyor. Avey, herhangi bir Token ile en alakalı Token’ları (dizideki konumlarından bağımsız olarak) tanımlayan ve yalnızca bunları bağlamsallaştıran bir sıralayıcı (ranker) ve otoregresif bir sinir işlemcisinden (autoregressive neural processor) oluşur. Bu mimari, dizi uzunluğunu bağlam genişliğinden ayırarak keyfi uzunluktaki dizileri etkili bir şekilde işleyebilir. Deney sonuçları, Avey’in standart kısa menzilli NLP kıyaslama testlerinde Transformer ile karşılaştırılabilir performans gösterdiğini ve özellikle uzun menzilli bağımlılıkları yakalamada başarılı olduğunu göstermektedir. (Kaynak: HuggingFace Daily Papers)
Yeni makale, ödül modelleri aracılığıyla ölçeklenebilir kod doğrulaması elde etmeyi, doğruluk ve verim arasında denge kurmayı tartışıyor: Bir araştırma, büyük dil modellerinin (LLM) kodlama görevlerini çözerken, sonuç ödül modellerini (ORM) kapsamlı doğrulayıcılarla (tam test paketleri gibi) kullanma arasındaki dengeyi inceliyor. Araştırma, kapsamlı doğrulayıcıların olduğu durumlarda bile, ORM’nin hıza karşılık belirli bir doğruluktan ödün vererek ölçeklendirilmiş doğrulamada hala kritik bir rol oynadığını buluyor. Özellikle “üret-kes-yeniden sırala” yönteminde, daha hızlı ancak daha az doğru bir doğrulayıcı kullanarak yanlış çözümleri önceden kaldırmak, sistem hızını 11.65 kat artırırken doğruluğu yalnızca %8.33 azaltıyor. Bu yöntem, yanlış ancak üst sıralarda yer alan çözümleri filtreleyerek işe yarıyor ve ölçeklenebilir ve doğru program sıralama sistemleri tasarlamak için yeni fikirler sunuyor. (Kaynak: HuggingFace Daily Papers)
Yeni kıyaslama AbstentionBench ortaya koyuyor: Çıkarım odaklı LLM’ler cevaplanamayan sorularda düşük performans gösteriyor: Büyük dil modellerinin (LLM) belirsizlikle karşılaştıklarında çekimser kalma (yani net bir cevap vermeyi reddetme) yeteneklerini değerlendirmek için araştırmacılar AbstentionBench’i başlattı. Bu büyük ölçekli kıyaslama testi, cevabı bilinmeyen, yetersiz tanımlanmış, yanlış öncüllere dayanan, öznel yorumlara açık ve güncelliğini yitirmiş bilgiler gibi çeşitli türlerde sorular içeren 20 farklı veri kümesi içeriyor. 20 önde gelen LLM üzerinde yapılan değerlendirmeler, çekimser kalmanın henüz çözülmemiş bir sorun olduğunu ve model boyutunun artmasının buna pek yardımcı olmadığını gösteriyor. Şaşırtıcı bir şekilde, matematik ve bilim alanları için özel olarak eğitilmiş çıkarım odaklı LLM’lerin bile, çıkarım ince ayarının çekimser kalma yeteneklerini ortalama %24 oranında düşürdüğü görülüyor. Dikkatle tasarlanmış sistem prompt’ları pratikte çekimser kalma performansını artırabilse de, bu durum modellerin belirsizlik çıkarımı konusundaki temel eksikliklerini çözmüyor. (Kaynak: HuggingFace Daily Papers)
Makale, yama tabanlı prompt’lar ve ayrıştırma yöntemleri (PatchInstruct) kullanarak LLM’lerle zaman serisi tahmini yapılmasını öneriyor: Yeni bir araştırma, büyük miktarda yeniden eğitime veya karmaşık harici mimarilere gerek kalmadan, büyük dil modellerini (LLM) zaman serisi tahmini için kullanmanın basit ve esnek prompt stratejilerini araştırıyor. Zaman serisi ayrıştırması, yama tabanlı tokenizasyon (patch-based tokenization) ve benzerlik tabanlı komşu zenginleştirme gibi özel prompt yöntemlerini birleştirerek, araştırmacılar LLM’lerin tahmin kalitesini artırabildiklerini, aynı zamanda basitliği koruyabildiklerini ve veri ön işlemeyi en aza indirebildiklerini buldular. Araştırmanın önerdiği PatchInstruct yöntemi, LLM’lerin kesin ve etkili tahminler yapmasını sağlıyor. (Kaynak: HuggingFace Daily Papers)
Yeni veri kümesi MS4UI yayınlandı, kullanıcı arayüzü eğitim videolarının çok modlu özetlenmesine odaklanıyor: Mevcut kıyaslamaların adımlı, uygulanabilir talimatlar ve görseller sunma konusundaki eksikliklerini gidermek için araştırmacılar MS4UI (Multi-modal Summarization for User Interface Instructional Videos) veri kümesini önerdi. Bu veri kümesi, toplam süresi 167 saati aşan 2413 UI eğitim videosu içeriyor ve manuel video segmentasyonu, metin özeti ve video özeti etiketlemesi yapıldı. UI eğitim videoları için kısa, uygulanabilir çok modlu özetleme yöntemleri araştırmasını teşvik etmeyi amaçlıyor. Deneyler, mevcut SOTA çok modlu özetleme yöntemlerinin MS4UI üzerinde düşük performans gösterdiğini ve bu alanda yeni yöntemlerin önemini vurguladığını gösteriyor. (Kaynak: HuggingFace Daily Papers)
DeepResearch Bench: Kapsamlı bir derin araştırma Agent’ı kıyaslama testi: LLM tabanlı Derin Araştırma Agent’larının (Deep Research Agents, DRAs) yeteneklerini sistematik olarak değerlendirmek için araştırmacılar DeepResearch Bench’i başlattı. Bu kıyaslama, 22 farklı alandan uzmanlar tarafından özenle tasarlanmış 100 doktora düzeyinde araştırma görevi içeriyor. DRAs’ları değerlendirmenin karmaşıklığı ve yoğun emeği nedeniyle, araştırmacılar insan yargısıyla yüksek derecede uyumlu iki yeni değerlendirme yöntemi önerdi: biri, üretilen araştırma raporlarının kalitesini değerlendirmek için referans tabanlı uyarlanabilir bir standart yöntem; diğeri ise etkili atıf sayısını ve genel atıf doğruluğunu değerlendirerek DRA’nın bilgi alma ve toplama yeteneklerini değerlendiren bir çerçeve. (Kaynak: HuggingFace Daily Papers)
Makale BridgeVLA’yı öneriyor: Giriş-çıkış hizalaması yoluyla verimli 3D manipülasyon öğrenimi: Görsel dil modellerinin (VLM) robotik manipülasyon öğreniminde 3D sinyal kullanım verimliliğini artırmak için araştırmacılar, yeni bir 3D görsel dil eylem (VLA) modeli olan BridgeVLA’yı önerdi. BridgeVLA, 3D girdiyi birden fazla 2D görüntüye yansıtarak VLM ana ağının girdisiyle hizalamayı sağlar ve eylem tahmini için 2D ısı haritaları kullanarak tutarlı bir 2D görüntü alanında girdi ve çıktıyı birleştirir. Ayrıca, bu araştırma, VLM ana ağının alt akış politika öğreniminden önce 2D ısı haritalarını tahmin etme yeteneğine sahip olmasını sağlayan ölçeklenebilir bir ön eğitim yöntemi önermektedir. Deneyler, BridgeVLA’nın birden fazla simülasyon kıyaslamasında ve gerçek robot deneylerinde üstün performans gösterdiğini, 3D manipülasyon öğreniminin verimliliğini ve etkinliğini önemli ölçüde artırdığını ve güçlü örnek verimliliği ile genelleme yeteneği sergilediğini göstermektedir. (Kaynak: HuggingFace Daily Papers)
Yeni araştırma, atıf temelli sentez yoluyla milyonlarca çeşitli ve karmaşık kullanıcı talimatı (SynthQuestions) üretiyor: Büyük dil modellerinin (LLM) hizalanması için gereken çeşitli, karmaşık ve büyük ölçekli talimat verilerinin eksikliğini gidermek için araştırmacılar, atıf temelli (attributed grounding) bir talimat sentezleme yöntemi önerdi. Bu çerçeve şunları içerir: 1) Seçilen gerçek talimatları bağlamsallaştırılmış kullanıcılarla ilişkilendiren yukarıdan aşağıya bir atıf süreci; 2) Önce bağlamları, ardından anlamlı talimatları oluşturmak için web belgelerini kullanan aşağıdan yukarıya bir sentez süreci. Bu yöntemle 1 milyon talimat içeren SynthQuestions veri kümesi oluşturuldu. Deneyler, bu veri kümesinde eğitilen modellerin birçok yaygın kıyaslama testinde lider performans elde ettiğini ve web külliyatı arttıkça performansın sürekli olarak arttığını göstermektedir. (Kaynak: HuggingFace Daily Papers)
PersonaFeedback: Büyük ölçekli, insan tarafından etiketlenmiş kişiselleştirilmiş değerlendirme kıyaslaması yayınlandı: Büyük dil modellerinin (LLM) önceden tanımlanmış kullanıcı profilleri ve sorguları verildiğinde kişiselleştirilmiş yanıtlar verme yeteneğini değerlendirmek için araştırmacılar PersonaFeedback kıyaslamasını başlattı. Bu kıyaslama, kullanıcı profillerinin bağlamsal karmaşıklığına ve kişiselleştirilmiş yanıtları ayırt etme zorluğuna göre basit, orta ve zor olmak üzere üç seviyeye ayrılmış 8298 insan tarafından etiketlenmiş test senaryosu içeriyor. Mevcut kıyaslamalardan farklı olarak PersonaFeedback, profil çıkarımını kişiselleştirmeden ayırarak, modelin açıkça tanımlanmış profillere göre özelleştirilmiş yanıtlar üretme yeteneğini değerlendirmeye odaklanıyor. Deney sonuçları, SOTA LLM’lerin bile zor seviyedeki testlerde zorlandığını gösteriyor ve mevcut geri alma artırılmış çerçevelerin kişiselleştirme görevleri için nihai çözüm olmadığını ortaya koyuyor. (Kaynak: HuggingFace Daily Papers)
Makale, çok dilli büyük modellerde “dil cerrahisini” tartışıyor: Gizli enjeksiyon yoluyla çıkarım zamanı dil kontrolü: Yeni bir araştırma, büyük dil modellerinde (LLM) doğal olarak ortaya çıkan temsil hizalama olgusunu ve bunun dile özgü ve dilden bağımsız bilgileri ayırmadaki önemini inceliyor. Araştırma, bu hizalamanın varlığını doğruluyor ve açıkça tasarlanmış hizalama modellerinin davranışlarıyla karşılaştırmasını analiz ediyor. Bu bulgulara dayanarak, araştırmacılar LLM’lerdeki dil karışıklığı sorununu azaltmak ve kesin diller arası kontrol sağlamak için gizli enjeksiyon (latent injection) kullanan Çıkarım Zamanı Dil Kontrolü (Inference-Time Language Control, ITLC) yöntemini öneriyor. Deneyler, ITLC’nin hedef dilin anlamsal bütünlüğünü korurken güçlü diller arası kontrol yeteneğine sahip olduğunu ve mevcut büyük ölçekli LLM’lerde bile hala var olan diller arası karışıklık sorununu etkili bir şekilde azaltabildiğini kanıtlıyor. (Kaynak: HuggingFace Daily Papers)
Makale NoWait yöntemini öneriyor: “Düşünme Token’larını” kaldırarak büyük model çıkarım verimliliğini artırma: Son araştırmalar, büyük çıkarım modellerinin karmaşık adım adım çıkarım yaparken, aşırı “düşünme” (örneğin “Wait”, “Hmm” gibi Token’lar çıkarma) nedeniyle çıktıların gereksizleştiğini ve verimliliği etkilediğini gösteriyor. Yeni önerilen NoWait yöntemi, çıkarım sırasında bu açık kendi kendine yansıma Token’larını baskılayarak, bunların ileri düzey çıkarım için gerekliliğini doğrulamayı amaçlıyor. Metin, görsel ve video çıkarım görevlerini kapsayan on kıyaslama testinde, NoWait beş R1 tarzı model ailesinde düşünce zinciri yörünge uzunluğunu %27-%51 oranında kısalttı ve modelin kullanışlılığına zarar vermedi. Bu yöntem, verimli ve kullanışlılığını koruyan çok modlu çıkarım için tak-çalıştır bir çözüm sunuyor. (Kaynak: HuggingFace Daily Papers)
💼 İş Dünyası
OpenAI, öncü askeri yetenekler geliştirmek için ABD Savunma Bakanlığı’ndan 200 milyon dolarlık AI sözleşmesi kazandı: OpenAI, ulusal güvenlik için gelişmiş yapay zeka araçları geliştirmek üzere ABD Savunma Bakanlığı ile bir yıllık, 200 milyon dolar değerinde bir sözleşme imzaladı. Bu, OpenAI’nin Pentagon tarafından listelenen bu tür bir sözleşmeyi ilk kez alması anlamına geliyor. Çalışmalar ağırlıklı olarak Ulusal Başkent Bölgesi’nde yürütülecek. OpenAI daha önce savunma şirketi Anduril ile işbirliği yapmıştı. Bu hamle, ABD savunma alanında AI uygulamalarına yönelik geniş çaplı bir çabanın ortasında geliyor; rakipleri Anthropic de bu alanda Palantir ve Amazon ile işbirliği yapıyor. OpenAI CEO’su Sam Altman daha önce ulusal güvenlik projelerini desteklediğini açıkça belirtmişti. (Kaynak: Reddit r/ArtificialInteligence, code_star)

Alta, Menlo Ventures liderliğinde 11 milyon dolarlık finansman sağladı, AI+moda alanına odaklanıyor: AI moda girişimi Alta, Menlo Ventures liderliğinde Benchstrength ve Aglaé Ventures (LVMH Grubu’nun Arnault ailesi destekli VC fonu) katılımıyla 11 milyon dolarlık finansman sağladığını duyurdu. Amy Tong Wu, Alta yönetim kuruluna katılacak. Bu finansman turu, Alta’nın AI ve moda birleşimindeki daha fazla gelişimine yardımcı olacak. (Kaynak: ZhaiAndrew)
Figure şirketi organizasyon yapısını değiştirdi, kontrol departmanını AI yol haritasını hızlandırmak için Helix’e dahil etti: İnsansı robot şirketi Figure, kontrol (Controls) departmanının artık mevcut olmadığını ve tüm ekibin Helix departmanına dahil edildiğini duyurdu. Bu hamle, şirketin yapay zeka alanındaki yol haritasını hızlandırmayı amaçlıyor ve Figure’ün AI teknolojilerinin araştırma ve geliştirilmesine daha fazla kaynak ve enerji odakladığını gösteriyor. (Kaynak: adcock_brett)
🌟 Topluluk
AGI hakkında tartışma: Sıradan kullanıcıların aşırı endişelenmesine gerek yok, AGI daha çok stratejik bir araç, günlük bir araç değil: Toplulukta birçok kişi, sıradan LLM kullanıcılarının AGI’nin (Genel Yapay Zeka) gelişi hakkında aşırı endişelenmesine gerek olmadığını belirtiyor. AGI’nin tanımı belirsiz ve teorik; gerçekleşse bile kısa vadede kullanıcıların sohbet pencerelerine doğrudan yansımayacak, bunun yerine ulusal veya büyük kurumların stratejik bir aracı ve altyapısı olarak, bireylerin toplantılarını ayarlamasına yardımcı olmak yerine uluslar arası müzakereler gibi karmaşık işleri ele almak için kullanılacak. (Kaynak: farguney, farguney, farguney, farguney)
Çoklu Agent sistemlerinin oluşturulması insan değerlendirmesi gerektirir, uç durumlar ve kaynak kalitesine dikkat edilmelidir: Çoklu Agent sistemleri oluştururken, insan değerlendirmesi ve testi kritik öneme sahiptir ve otomatik değerlendirmenin gözden kaçırabileceği uç durumları ortaya çıkarabilir. Örneğin, erken dönem Agent’lar bilgi kaynağı seçerken, yetkili akademik PDF’ler veya kişisel bloglar yerine SEO optimize edilmiş içerik çiftliklerini tercih etme eğilimindeydi. Prompt’lara kaynak kalitesi sezgisel yöntemlerini eklemek bu tür sorunların çözülmesine yardımcı olur. Bu, otomatik değerlendirme çağında bile, sistem arızalarını, ince kaynak seçimi önyargılarını vb. sorunları keşfetmek için manuel testin hala vazgeçilmez olduğunu gösterir. (Kaynak: riemannzeta)

LLM’lerin tahmin ve öğrenme mekanizmalarının video modellerinden farkı düşünceye yol açıyor: Yann LeCun ve Pedro Domingos, Sergey Levine’in dil modellerinin bir sonraki Token tahmininden neden bu kadar çok şey öğrenebildiğini, video modellerinin ise bir sonraki kare tahmininden neden nispeten daha az şey öğrendiğini sorgulayan görüşünü yeniden paylaştı. Levine, bunun LLM’lerin bir dereceye kadar “beyin tarayıcısı” rolünü oynamasından kaynaklanabileceğini tahmin ediyor, bu da öğrenme mekanizmalarının benzersizliğine işaret ediyor veya LLM’lerin Platon’un mağarasında yaşayıp, gölgelerin dizisini (metin) gözlemleyerek gerçek dünyayı çıkarsadığı anlamına geliyor. (Kaynak: ylecun, pmddomingos, pmddomingos)

AI Agent’larının eğitim alanındaki olumlu etkisi: Öğrenenlerin konfor alanlarından çıkmasını teşvik ediyor: Topluluk tartışmaları, AI Agent’larının yalnızca işletmeler için değil, eğitim alanında da büyük potansiyele sahip olduğunu gösteriyor. AI Agent’larıyla etkileşim kurarak, öğrenenler konfor alanlarından daha etkili bir şekilde çıkabilir ve böylece öğrenme sonuçlarının iyileşmesini sağlayabilirler. (Kaynak: pirroh, amasad)
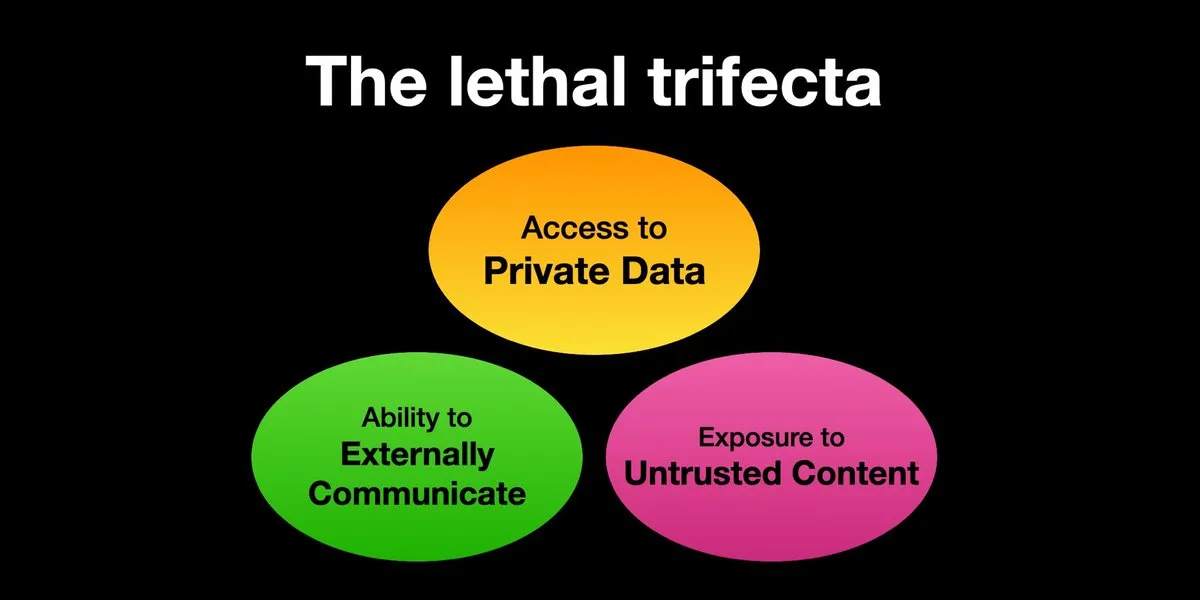
AI Agent’ları prompt enjeksiyon saldırısı riskiyle karşı karşıya, güvenlik önlemlerinin acilen güçlendirilmesi gerekiyor: Karpathy, Simon Willison’ın AI Agent’larının “ölümcül üçlü” (Lethal Trifecta) riskiyle karşı karşıya olduğu uyarısını yeniden paylaştı: AI Agent’ları aynı anda özel verilere erişim, güvenilmeyen içerikle temas ve dış iletişim yeteneğine sahip olduğunda, saldırganlar sistemi veri çalmaya ikna edebilir. Bu, erken dönem bilgisayar virüslerinin “Vahşi Batı” çağını anımsatıyor; şu anda kötü niyetli prompt’lara karşı savunma mekanizmaları henüz yetersiz, örneğin Agent’ların keyfi komut dosyalarını yürütme yeteneğini sınırlamak için işletim sistemi çekirdek/kullanıcı alanı gibi güvenlik paradigmaları eksik. Bu, LLM Agent’larını kişisel hesaplama için erken benimseme konusunda endişelere yol açıyor. (Kaynak: karpathy, TheTuringPost)
AI çağında hızlı öğrenme yeteneği temel rekabet gücü haline geliyor: Mustafa Suleyman, gelecek on yılda en büyük kariyer hızlandırıcısının mükemmel öğrenme yeteneği olacağını belirtiyor. İnsanların kendi öğrenme stillerini belirlemelerini, AI’ı kullanarak materyalleri uygun biçimlere (podcast’ler, sınavlar gibi) dönüştürmelerini, ardından bilgiyi uygulayıp bu süreci sürekli tekrarlayarak hızlı öğrenme ve büyüme sağlamalarını öneriyor. (Kaynak: mustafasuleyman)
AI tarafından üretilen içeriğin gerçekliği ve alaka düzeyi: Alaka düzeyi gerçeklikten daha önemli olabilir: Kullanıcı imjaredz, AI tarafından oluşturulmuş 2000 adet tanıtım e-postası gönderdiğini ve kimsenin bunların AI tarafından yazıldığından şikayet etmediğini, aksine 5 kişinin e-posta içeriğinin “tam da üzerinde çalıştıkları şey” olduğunu belirttiğini paylaştı. Bu, iletişimde içeriğin alaka düzeyinin “gerçekliğinden” (insan tarafından yaratılıp yaratılmadığı) daha önemli olup olmadığı konusunda bir tartışma başlattı. (Kaynak: imjaredz)
LLM’lerin “anlama” yeteneği üzerine tartışma: Davranışsal benzerlik gerçek anlama anlamına gelmez: Toplulukta, büyük dil modellerinin güçlü davranışsal ve bilişsel benzerlik yetenekleri sergilemesine rağmen, bunun gerçek anlama ile eşdeğer olmadığı yönünde görüşler var. Anlama, açıklama yeteneği gerektirir ve yalnızca davranış sergilemek zeka veya anlama değildir. Bu temel fark genellikle göz ardı edilir. Bu görüş, yaşamı tehdit eden kararları modellere devretmeden önce, bunların gerçekten genel yapay zekaya yaklaşıp yaklaşmadığının dikkatle değerlendirilmesi ve yeteneklerinin aşırı abartılmasına karşı uyanık olunması gerektiğini vurguluyor. (Kaynak: farguney)
AI Agent’ları yazılım mühendisliği kıyaslama testlerinde başarılı, ancak “Agent” doğası üzerine tartışmalar: AI’ın SWE-bench gibi yazılım mühendisliği kıyaslama testlerinde puanları sürekli artarken (hatta %50-60’ı geçerken), topluluk “Agent kodlama çağının” gerçekten gelip gelmediğini tartışıyor. Eğer yaygın olarak kullanılanlar “Agent’sız çerçeveler” (agentless frameworks) ise ve dil modellerinin ortamda gerçekten keşif yapmasına izin verilmiyorsa, bu çerçeveler kendi başlarına değerli olsa da, buna “Agent kodlama çağı” demenin pek doğru olmayabileceği yönünde görüşler var. (Kaynak: huybery, terryyuezhuo)
AI tarafından üretilen resimlerin içerik denetimi ihtiyacı: Açık kaynak veya ticari çözümler aranıyor: AI tarafından üretilen resim teknolojilerinin yaygınlaşmasıyla birlikte, yerel geliştiriciler çıktı içeriğinin uygunluğu sorununa, özellikle de pornografik, politik olarak hassas vb. içeriklerin nasıl tespit edileceğine odaklanmaya başladı. Toplulukta içerik denetimi için kullanılabilecek açık kaynak küçük modeller veya ticari ürünler arayışı tartışmaları ortaya çıktı. (Kaynak: dotey)
💡 Diğer
AI güdümlü kişiselleştirme ve içerik alaka düzeyi: 2000 AI e-postasına olumsuz yorum yok, 5 kişi “tam da ihtiyacım olan şey” dedi: Bir kullanıcı, AI tarafından oluşturulmuş 2000 adet tanıtım e-postası gönderdiğini ve hiçbir alıcının e-postaların AI tarafından yazıldığından şikayet etmediğini paylaştı. Aksine, beş alıcı e-posta içeriğinin “tam da o anda üzerinde çalıştıkları iş” olduğunu belirtti. Bu vaka, AI destekli iletişimde içeriğin yüksek alaka düzeyinin “gerçeklik” (yani insan tarafından yazılıp yazılmadığı) kaygısını aşıp aşamayacağı konusunda bir tartışma başlattı ve AI’ın kişiselleştirilmiş içerik üretme potansiyelini ima etti. (Kaynak: imjaredz)
İnsanlar AI sistemlerinin darboğazı haline geliyor, insan verimliliğinin artırılması veya kaçınılması gerekiyor: Charles Earl’ün görüşüne göre, gelen kutusundaki e-postaların dağ gibi birikmesi, giden kutusunun ise bomboş olması, insanların bilgi işleme ve yanıtlama konusunda darboğaz olduğunu yansıtıyor. AI çağında, insan darboğazından nasıl kaçınılacağı veya AI gibi teknolojilerle insan çalışma verimliliğinin nasıl artırılacağı üzerine düşünmek gerekiyor. (Kaynak: charles_irl)
AI kontrollü akıllı evlerin potansiyel riskleri: Kullanıcı, uygulama arızası nedeniyle soğuk akıllı yatakta mahsur kaldı: Bir kullanıcı, AI kontrollü akıllı yatağının (Eight Sleep Pod3) uygulamasındaki bir arıza nedeniyle sıcaklığı ayarlayamayıp sonunda soğuk yatakta mahsur kaldığı deneyimini paylaştı. Bu modelin manuel kontrolü olmaması ve tamamen uygulamaya bağımlı olması nedeniyle, bu arıza AI ve uygulama kontrollü akıllı ev cihazlarına aşırı güvenmenin getirebileceği rahatsızlıkları ve “distopik” deneyimleri vurguladı. (Kaynak: madiator)