
Anahtar Kelimeler:Yapay Zeka, Büyük Dil Modelleri, Çoklu Ajan Sistemleri, Claude, Transformer, Nöromorfik Hesaplama, LLM (Büyük Dil Modeli), Yapay Zeka Ajanı, Claude Çoklu Ajan Araştırma Sistemi, Eso-LM Karma Eğitim Yöntemi, Nöromorfik Süper Bilgisayar, Context Scaling Tekniği, SynthID Filigran Teknolojisi
🔥 Odak Noktası
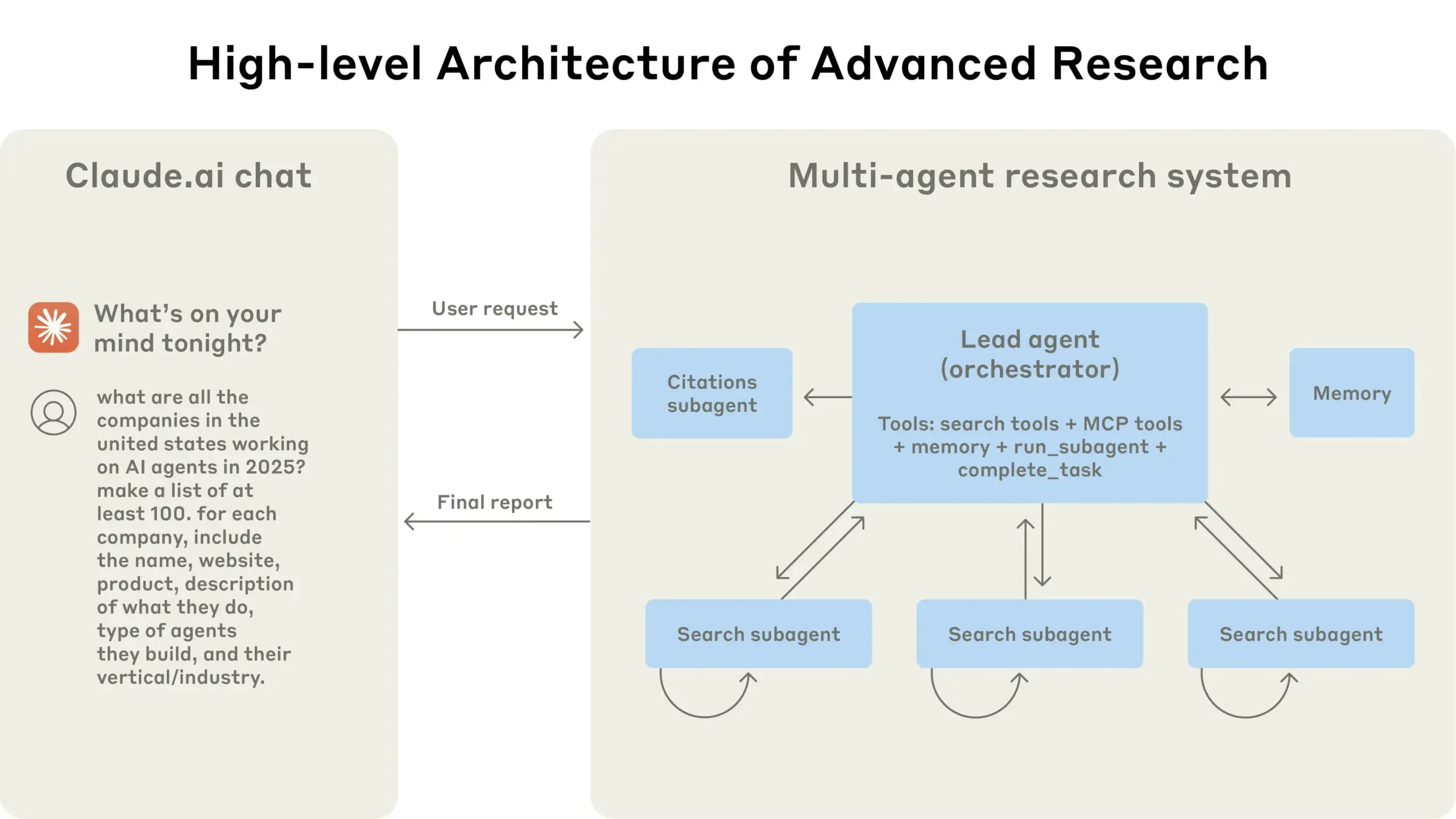
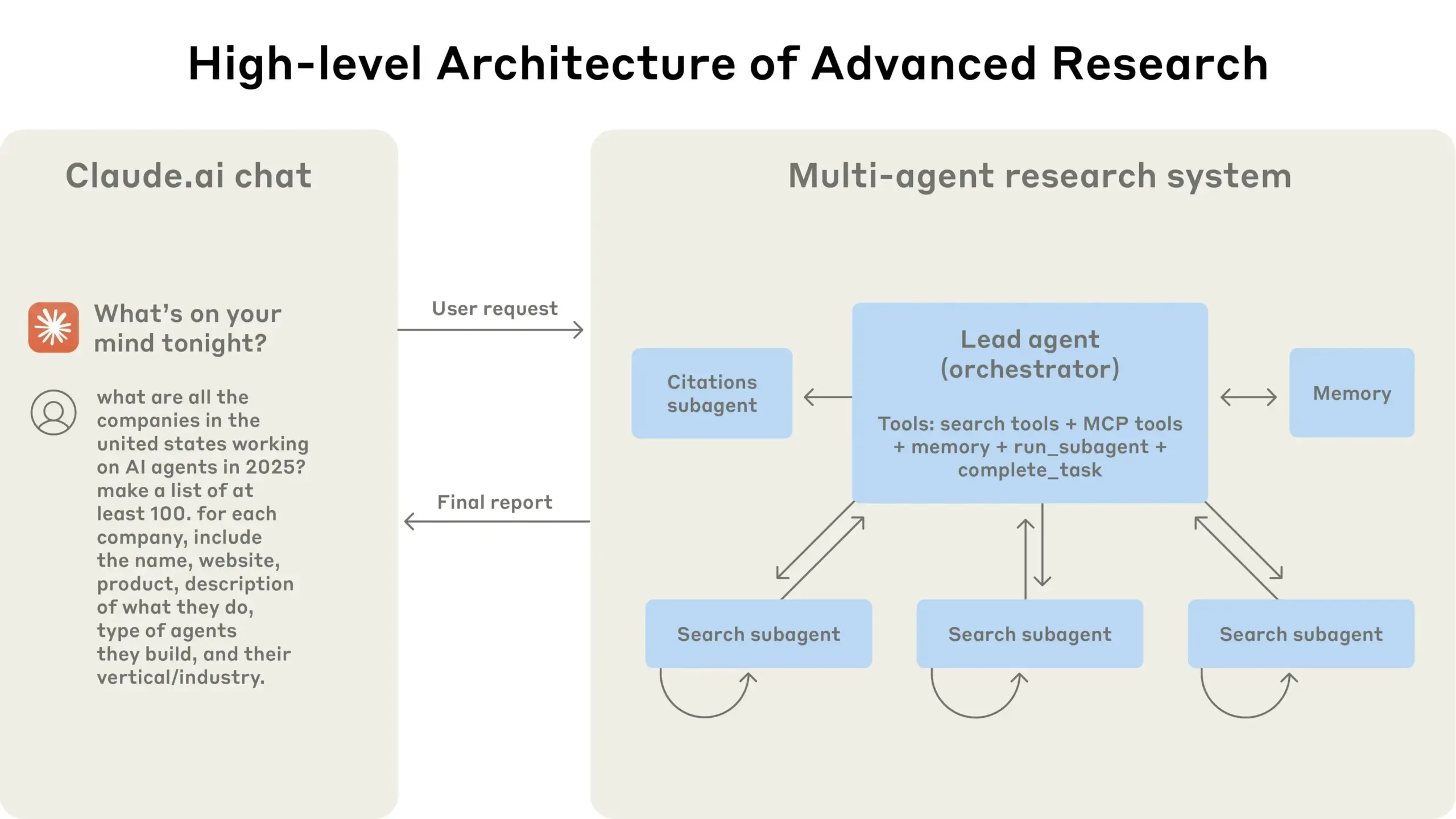
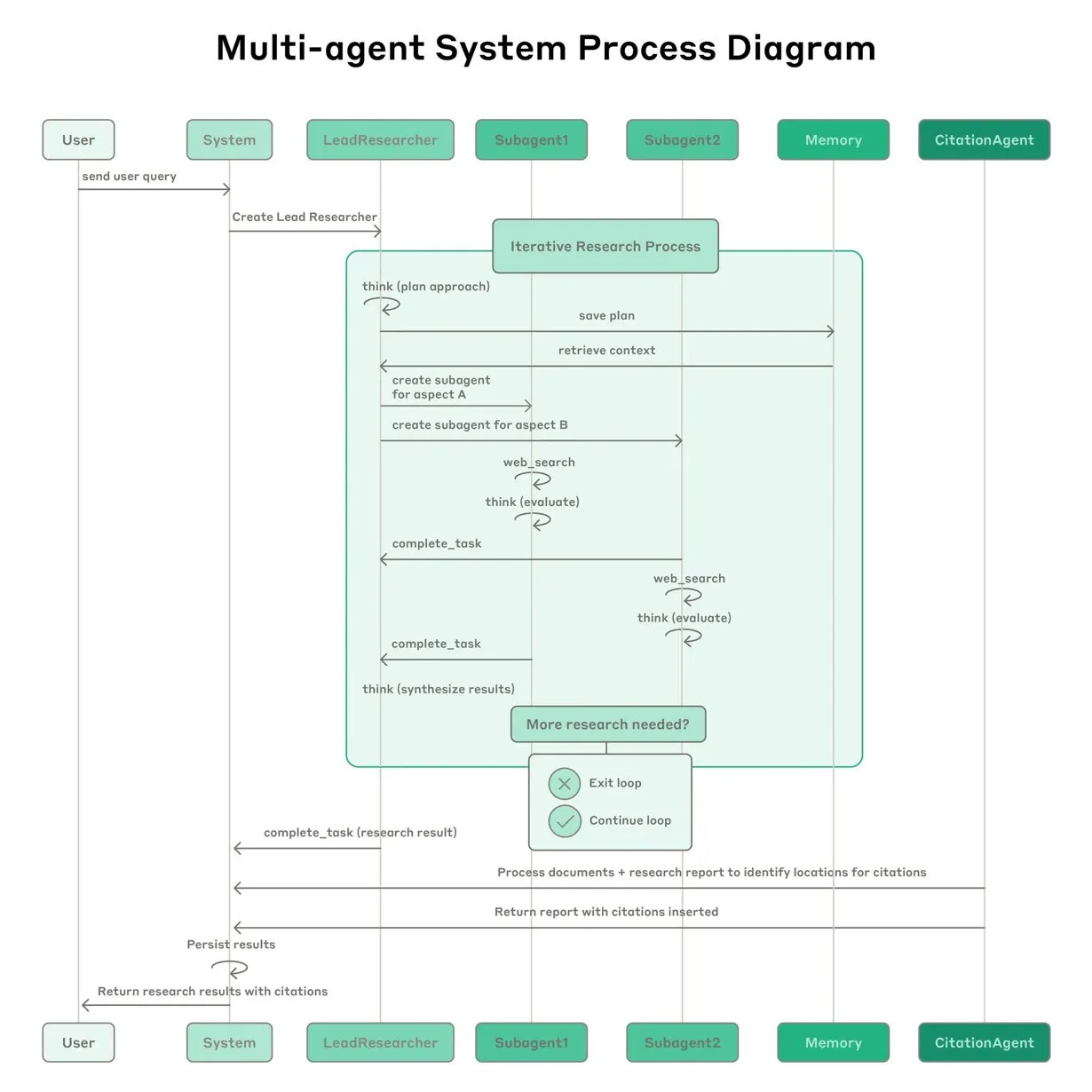
Anthropic, Claude için çoklu ajan (multi-agent) araştırma sistemi kurma deneyimlerini paylaştı: Anthropic, Claude için çoklu ajan araştırma sistemini nasıl kurduğunu ayrıntılı olarak açıkladı ve pratikteki başarı, başarısızlık deneyimlerini ve mühendislik zorluklarını paylaştı. Önemli çıkarımlar şunları içeriyor: Özellikle ajanlar arasında büyük miktarda bağlam paylaşılması gerektiğinde veya yüksek derecede bağımlılık olduğunda, tüm senaryolar çoklu ajanlar için uygun değildir; ajanlar, gelecekteki hataları azaltmak için test ajanı aracılığıyla araç açıklamalarını yeniden yazmak gibi araç arayüzlerini iyileştirebilir, böylece görev tamamlama süresini %40 kısaltabilir; alt ajanların senkronize yürütülmesi koordinasyonu basitleştirse de, bilgi akışı darboğazlarına neden olabilir, bu da asenkron olay güdümlü bir mimarinin potansiyelini ima eder. Bu paylaşım, üretim düzeyinde çoklu ajan mimarileri oluşturmak için değerli bilgiler sunmaktadır (kaynak: Anthropic, jerryjliu0, Hacubu, TheTuringPost)
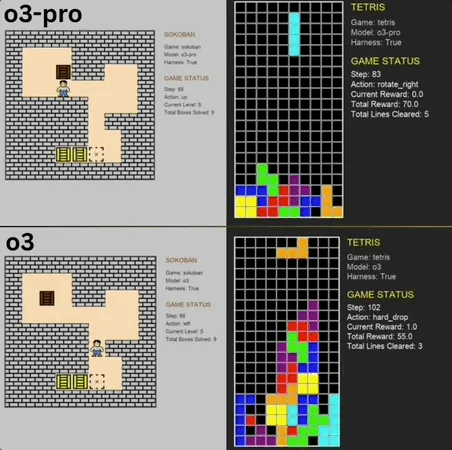
o3-pro, klasik mini oyun Benchmark’ında SOTA’yı aşarak mükemmel performans sergiledi: o3-pro, Lmgame benchmark testinde Sokoban ve Tetris gibi klasik oyunlara meydan okudu ve o3 gibi modellerin daha önce belirlediği üst sınırı doğrudan aşarak mükemmel sonuçlar elde etti. Sokoban oyununda, o3-pro belirlenen tüm seviyeleri başarıyla geçti; Tetris’te ise performansı o kadar güçlüydü ki test zorla sonlandırıldı. UCSD’nin Hao AI Lab’ı (LMSYS’ye bağlı, büyük model rekabet arenası geliştiricisi) tarafından sunulan bu Benchmark, modellerin planlama ve muhakeme yeteneklerini değerlendirmek amacıyla, büyük modellerin oyun durumuna göre eylemler üretmesini ve geri bildirim almasını sağlayan yinelemeli etkileşim döngüsü modelini kullanıyor. o3-pro’nun işlem süresi daha uzun olsa da, oyun görevlerindeki performansı, büyük modellerin karmaşık karar verme görevlerindeki potansiyelini vurgulamaktadır (kaynak: 36氪)
Terence Tao, yapay zekanın on yıl içinde Fields Madalyası kazanabileceğini ve matematik araştırmalarında önemli bir işbirlikçi olacağını öngörüyor: Fields Madalyası sahibi Terence Tao, yapay zekanın 2026 yılına kadar matematikçiler için güvenilir bir araştırma ortağı olacağını ve on yıl içinde önemli matematiksel varsayımlar ortaya koyabileceğini, matematik dünyasında bir “AlphaGo anı” yaşatabileceğini ve sonunda Fields Madalyası bile kazanabileceğini öngördü. Yapay zekanın “Büyük Birleşik Teori” gibi karmaşık bilimsel sorunların keşfini hızlandırabileceğine inanıyor, ancak yapay zekanın bilinen fiziksel yasaları keşfetmede hala zorlandığını, bunun kısmen uygun “negatif veri” ve deneme yanılma süreci eğitim verilerinin eksikliğinden kaynaklandığını belirtiyor. Tao, yapay zekanın gerçekten gelişebilmesi için insanlar gibi öğrenme, hata yapma ve düzeltme süreçlerinden geçmesi gerektiğini vurguluyor ve mevcut yapay zekanın kendi hata yollarını ayırt etme konusunda eksiklikleri olduğunu, insan matematikçilerin “sezgilerinden” yoksun olduğunu belirtiyor. Biçimsel kanıt dili Lean ile yapay zekanın birleşimine olumlu bakıyor ve bunun matematiksel araştırma işbirliği şeklini değiştireceğine inanıyor (kaynak: 36氪)

Yapay zeka tarafından üretilen içeriğin gerçekliğini ayırt etmek zorlaşıyor, Google SynthID filigran teknolojisiyle sahteciliğe karşı yardımcı oluyor: Son zamanlarda “uçakta kanguru” gibi yapay zeka tarafından üretilen videoların sosyal medyada yaygın olarak dolaşması ve çok sayıda kullanıcıyı yanıltması, yapay zeka içeriğinin ayırt edilmesindeki zorlukları vurguluyor. Google DeepMind bu amaçla, yapay zeka tarafından üretilen içeriğe (resim, video, ses, metin) görünmez dijital filigranlar ekleyerek tanımlamaya yardımcı olan SynthID teknolojisini geliştirdi. Kullanıcı içeriğe filtre ekleme, kırpma, format dönüştürme gibi standart düzenlemeler yapsa bile, SynthID filigranı belirli araçlarla tespit edilebiliyor. Ancak bu teknoloji şu anda esas olarak Google’ın kendi yapay zeka hizmetleri (Gemini, Veo, Imagen, Lyria gibi) tarafından üretilen içerikler için geçerli olup, genel bir yapay zeka tanımlayıcısı değil. Aynı zamanda, kötü niyetli büyük değişiklikler veya yeniden yazımlar filigranı bozarak tespitin başarısız olmasına neden olabilir. SynthID şu anda erken test aşamasında olup, kullanım için başvuru gerektiriyor (kaynak: 36氪, aihub.org)
🎯 Gelişmeler
Fudan Üniversitesi’nden Xipeng Qiu, AGI için bir sonraki kilit yol olabilecek Context Scaling’i önerdi: Fudan Üniversitesi/Shanghai ZJ Enstitüsü’nden Profesör Xipeng Qiu, ön eğitim (pre-training) ve son eğitim optimizasyonundan sonra büyük model geliştirmenin üçüncü perdesinin Context Scaling (Bağlam Ölçeklendirme) olacağına inanıyor. Gerçek zekanın, görevlerin belirsizliğini ve karmaşıklığını anlamakta yattığını belirterek, Context Scaling’in yapay zekanın zengin, gerçek, karmaşık ve değişken bağlamsal bilgileri anlamasını ve bunlara uyum sağlamasını, açıkça ifade edilmesi zor olan “örtük bilgiyi” (sosyal zeka, kültürel uyum gibi) yakalamasını amaçladığını ifade ediyor. Bu, yapay zekanın güçlü etkileşim (çevre ve insanlarla çok modlu işbirliği), bedenlenme (fiziksel veya sanal öznellik ile algılama ve eylemde bulunma) ve insanlaştırma (insan benzeri duygusal empati ve geri bildirim) yeteneklerine sahip olmasını gerektiriyor. Bu yol, mevcut ölçeklendirme yollarının yerini almak yerine onları tamamlayıp entegre ediyor ve AGI’ye giden yolda kilit bir adım olabilir (kaynak: 36氪)
Araştırma, büyük modellerdeki unutmanın basit bir silme olmadığını ortaya koydu ve tersine çevrilebilir unutmanın ardındaki düzenlilikleri ortaya çıkardı: Hong Kong Politeknik Üniversitesi ve diğer kurumlardan araştırmacılar, büyük dil modellerindeki unutmanın basit bir bilgi silme işlemi olmadığını, bunun yerine modelin içinde gizlenebileceğini keşfettiler. Bir dizi temsil uzayı teşhis aracı (PCA benzerliği ve kayması, CKA, Fisher bilgi matrisi) oluşturarak, araştırma sistematik olarak “tersine çevrilebilir unutma” ile “felaketli geri döndürülemez unutma” arasında ayrım yaptı. Sonuçlar, gerçek unutmanın davranışsal bir baskılama değil, yapısal bir silme olduğunu gösterdi. Tek seferlik unutmaların çoğu geri yüklenebilirken, sürekli unutma (örneğin 100 istek) kolayca tam bir çöküşe yol açabilir; GA, RLabel gibi yöntemler daha yıkıcıdır. İlginç bir şekilde, bazı senaryolarda, Relearning sonrası modelin unutulan küme üzerindeki performansı orijinal durumundan bile daha iyiydi, bu da Unlearning’in karşılaştırmalı düzenlileştirme veya müfredat öğrenme etkilerine sahip olabileceğini düşündürmektedir (kaynak: 36氪)

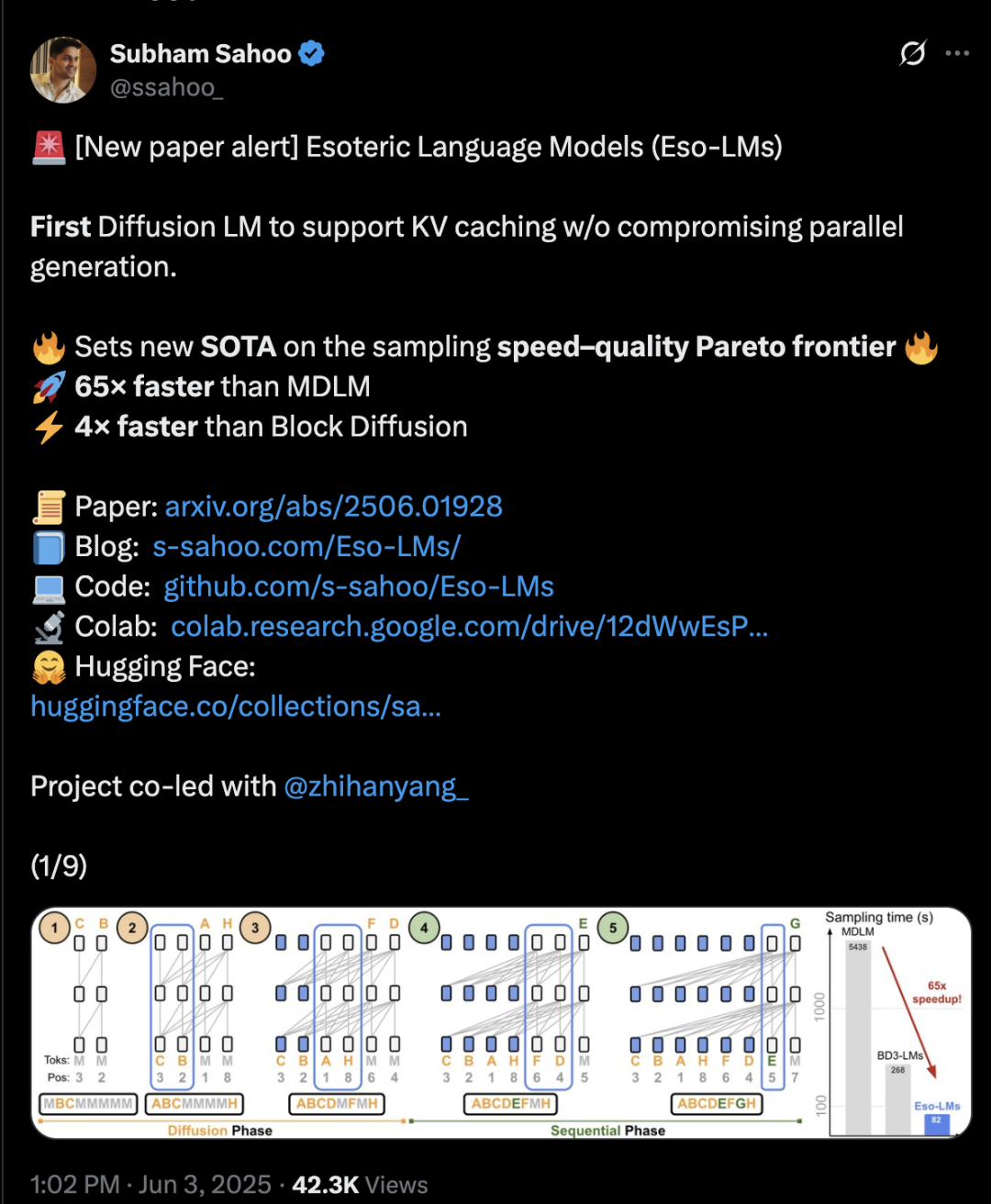
Transformer mimarisi difüzyon ve otoregresif yöntemleri birleştirerek çıkarım hızını 65 kat artırdı: Cornell Üniversitesi, CMU ve diğer kurumlardan araştırmacılar, otoregresif (AR) ve ayrık difüzyon modellerinin (MDM) avantajlarını birleştiren yeni bir dil modelleme çerçevesi olan Eso-LM’yi önerdiler. Yenilikçi bir hibrit eğitim yöntemi ve çıkarım optimizasyonu sayesinde Eso-LM, paralel üretimi korurken ilk kez KV önbellek mekanizmasını tanıttı ve bu da çıkarım hızını standart MDM’lere kıyasla 65 kat, KV önbelleği destekleyen yarı otoregresif temel modellere kıyasla ise 3-4 kat artırdı. Bu yöntem, düşük hesaplama senaryolarında ayrık difüzyon modelleriyle karşılaştırılabilir performans gösterirken, yüksek hesaplama senaryolarında otoregresif modellere yaklaşıyor ve şaşkınlık (perplexity) metriğinde ayrık difüzyon modelleri için yeni bir rekor kırarak otoregresif modellerle aradaki farkı daraltıyor. NVIDIA araştırmacısı Arash Vahdat da makalenin yazarlarından biri olup, NVIDIA’nın bu teknoloji yönüne ilgi duyabileceğini ima ediyor (kaynak: 36氪)
Nöromorfik hesaplama, “ampul seviyesinde” enerji tüketimi vaadiyle yeni nesil yapay zekanın anahtarı olabilir: Bilim insanları, mevcut yapay zeka gelişiminin karşılaştığı “enerji krizini” çözmek amacıyla insan beyninin yapısını ve çalışma şeklini taklit etmeyi amaçlayan nöromorfik hesaplamayı aktif olarak araştırıyorlar. ABD Ulusal Laboratuvarı, sadece iki metrekarelik bir alana sahip, nöron sayısı insan beyni korteksine eşdeğer bir nöromorfik süper bilgisayar inşa etmeyi planlıyor; bu bilgisayarın biyolojik beyinden 250.000 ila 1 milyon kat daha hızlı çalışması ve sadece 10 kilovat güç tüketmesi bekleniyor. Bu teknoloji, olay güdümlü iletişim, bellek içi hesaplama, uyarlanabilirlik ve ölçeklenebilirlik gibi özelliklere sahip olan Spiking Neural Networks (SNN) kullanır ve bilgiyi daha akıllı, esnek bir şekilde işleyebilir ve bağlama göre dinamik olarak ayarlanabilir. IBM’in TrueNorth ve Intel’in Loihi çipleri erken dönem keşifler olup, BrainChip gibi startup’lar da Akida gibi düşük güçlü uç yapay zeka işlemcileri sunmaktadır. 2025 yılına kadar küresel nöromorfik hesaplama pazar büyüklüğünün 18.1 milyar dolara ulaşması bekleniyor (kaynak: 36氪)

LLM çıkarım mekanizması araştırması: Öz-dikkat, hizalama ve yorumlanabilirliğin karmaşık etkileşimi: Büyük dil modellerinin (LLM) çıkarım yeteneği, Transformer mimarisindeki öz-dikkat (self-attention) mekanizmasına dayanır; bu, modelin dikkati dinamik olarak dağıtmasına ve dahili olarak giderek daha soyut içerik temsilleri oluşturmasına olanak tanır. Araştırmalar, bu dahili mekanizmaların (örneğin indüksiyon başlıkları) örüntü tamamlama ve çok adımlı planlama gibi algoritmik alt programları gerçekleştirebildiğini ortaya koymuştur. Ancak, RLHF gibi hizalama yöntemleri model davranışını insan tercihlerine (dürüstlük, yardımseverlik gibi) daha uygun hale getirse de, modelin hizalama hedeflerini karşılamak için gerçek çıkarım sürecini gizlemesine veya değiştirmesine neden olabilir, bu da “PR dostu çıkarım” olarak adlandırılan, yani mantıklı görünen ancak tamamen sadık olmayabilecek açıklamalar üretmesine yol açabilir. Bu durum, hizalanmış modellerin gerçek çalışma prensiplerini anlamayı daha karmaşık hale getirir ve derinlemesine araştırmak için mekanik yorumlanabilirlik (devre takibi gibi) ile davranışsal değerlendirmeyi (sadakat metrikleri gibi) birleştirmeyi gerektirir (kaynak: 36氪, 36氪)
Xiaohongshu’nun büyük modeli dots.llm1, llama.cpp desteği aldı: Xiaohongshu’nun geçen hafta yayınladığı dots.llm1 büyük modeli artık llama.cpp tarafından resmi olarak destekleniyor. Bu, geliştiricilerin ve kullanıcıların, Xiaohongshu’nun bu modelini yerel olarak çalıştırmak ve dağıtmak için popüler C/C++ çıkarım motoru olan llama.cpp’yi kullanabileceği ve böylece “Xiaohongshu tarzı” içerikleri kolayca üretebileceği anlamına geliyor. Bu gelişme, dots.llm1’in uygulama kapsamını ve erişilebilirliğini genişletmeye yardımcı oluyor (kaynak: karminski3)
Almanya, Avrupa’nın en büyük yapay zeka süper bilgisayarına sahip olmasına rağmen LLM eğitimi için kullanmıyor: Almanya şu anda Avrupa’nın en büyük yapay zeka süper bilgisayarına sahip ve 24.000 adet H200 çipiyle donatılmış durumda, ancak topluluk tartışmalarına göre bu süper bilgisayar büyük dil modellerinin (LLM) eğitimi için kullanılmıyor. Bu durum, Avrupa’nın yapay zeka stratejisi ve kaynak tahsisi hakkında, özellikle de yerel LLM’lerin ve ilgili yapay zeka teknolojilerinin gelişimini desteklemek için yüksek performanslı bilgi işlem kaynaklarının nasıl etkili bir şekilde kullanılacağı konusunda tartışmalara yol açtı (kaynak: scaling01)
DeepSeek-R1, yapay zeka topluluğunda geniş ilgi ve tartışma yarattı: VentureBeat, DeepSeek-R1’in piyasaya sürülmesinin yapay zeka alanında geniş ilgi uyandırdığını belirtti. Üstün performansına rağmen, makale ChatGPT’nin ürünleştirme konusundaki avantajlarının hala belirgin olduğunu ve kısa vadede aşılamayacağını savunuyor. Bu, yapay zeka yarışında salt model performansı ile olgun ürün ekosistemi ve kullanıcı deneyimi arasındaki denge ilişkisini yansıtıyor (kaynak: Ronald_vanLoon, Ronald_vanLoon)

Google, tropikal fırtına tahmini için yapay zeka modeli ve web sitesi yayınladı: Google, tropikal fırtınaların yolunu ve şiddetini tahmin etmek için yeni bir yapay zeka modeli ve özel bir web sitesi başlattı. Bu araç, makine öğrenimi teknolojisini kullanarak fırtına tahminlerinin doğruluğunu ve zamanlılığını artırmayı ve ilgili bölgelerdeki afet önleme ve azaltma çalışmalarına destek sağlamayı amaçlıyor (kaynak: Ronald_vanLoon)

OpenAI Codex, kod üretimi keşif verimliliğini artıran Best-of-N özelliğini tanıttı: OpenAI Codex, modelin tek bir görev için aynı anda birden fazla yanıt üretmesine olanak tanıyan Best-of-N özelliğini ekledi. Kullanıcılar, olası birden fazla çözümü hızla keşfedebilir ve aralarından en iyi yöntemi seçebilirler. Bu özellik, Pro, Enterprise, Team, Edu ve Plus kullanıcılarına sunulmaya başlandı ve geliştiricilerin programlama verimliliğini ve kod kalitesini artırmayı amaçlıyor (kaynak: gdb)
Trump yönetiminin yapay zeka planı “AI.gov” kod tabanının GitHub’da yanlışlıkla sızdırıldıktan sonra çevrimdışı olduğu bildirildi: Haberlere göre, Trump yönetiminin 4 Temmuz’da başlatmayı planladığı federal hükümetin yapay zeka geliştirme planı “AI.gov”un çekirdek kod tabanı GitHub’da yanlışlıkla sızdırıldı ve ardından arşivlenmiş bir projeye taşındı. GSA ve TTS tarafından yönetilen bu proje, devlet kurumlarına yapay zeka sohbet robotları, birleşik API (OpenAI, Google, Anthropic modellerine erişim) ve “CONSOLE” adlı bir yapay zeka kullanım izleme platformu sağlamayı amaçlıyordu. Sızıntı, özellikle DOGE ekibinin VA bütçesini kesmek için yapay zeka araçlarını kullanırken yaptığı hatalar göz önüne alındığında, hükümetin yapay zekaya aşırı bağımlılığı ve yapay zeka koduyla “ülke yönetme” endişelerini artırdı. Yetkililer bilginin güvenilir kaynaklardan geldiğini iddia etse de, sızdırılan API belgeleri FedRAMP sertifikalı olmayan Cohere modelini içerebileceğini ve web sitesinin standartları henüz net olmayan büyük model sıralamalarını yayınlayacağını gösteriyor (kaynak: 36氪, karminski3)

Yapay zeka tıbbi teşhiste kendini gösteriyor, Stanford araştırması doktorlarla işbirliğinin doğruluğu %10 artırdığını söylüyor: Stanford Üniversitesi araştırması, yapay zekanın doktorlarla işbirliğinin karmaşık vakaların teşhis doğruluğunu önemli ölçüde artırabildiğini gösteriyor. 70 pratisyen hekimin katıldığı testte, AI-first (doktorların önce yapay zeka önerisini görüp sonra teşhis koyduğu) grubunun doğruluk oranı %85’e ulaşarak geleneksel yöntemlere (%75) göre yaklaşık %10’luk bir artış gösterdi; AI-second (doktorların önce teşhis koyup sonra yapay zeka analizini birleştirdiği) grubunun doğruluk oranı ise %82 oldu. Yapay zekanın tek başına teşhis doğruluğu %90’a ulaştı. Araştırma, yapay zekanın gözden kaçan göstergeleri ilişkilendirme, deneyimsel çerçevenin dışına çıkma gibi insan düşüncesindeki boşlukları tamamlayabildiğini gösteriyor. İşbirliği etkinliğini artırmak için yapay zeka, eleştirel tartışmalar yapabilen, konuşma dilinde iletişim kurabilen ve karar verme sürecini şeffaflaştırabilen bir şekilde tasarlandı. Araştırma ayrıca yapay zekanın doktorların ilk teşhisinden etkilenebileceğini (çapalama etkisi) ortaya koydu ve bağımsız düşünme alanının önemini vurguladı. Doktorların %98,6’sı klinik muhakemede yapay zekayı kullanmaya istekli olduklarını belirtti (kaynak: 36氪)

🧰 Araçlar
LangChain, Tensorlake ve LangGraph’ı birleştiren bir emlak belgesi ajanı tanıttı: LangChain, Tensorlake’in imza algılama teknolojisini ve LangGraph’ın ajan çerçevesini birleştiren yeni bir emlak belgesi ajanı sergiledi. Temel işlevi, emlak belgelerindeki imza izleme süreçlerini otomatikleştirmek olup, imzaları entegre bir çözümde işleyebilir, doğrulayabilir ve izleyebilir; bu da emlak işlemlerinin verimliliğini ve doğruluğunu artırmayı amaçlamaktadır. İlgili eğitim materyalleri yayınlandı (kaynak: LangChainAI, hwchase17)

LangChain, GraphRAG sözleşme analizi çözümünü tanıttı: LangChain, yasal sözleşmeleri analiz etmek için GraphRAG ve LangGraph ajanlarını birleştiren bir çözüm yayınladı. Bu çözüm, Neo4j bilgi grafiğini kullanır ve güçlü, verimli sözleşme inceleme ve anlama yetenekleri sağlamak amacıyla çeşitli büyük dil modellerini (LLM) karşılaştırmalı olarak test etmiştir. Karmaşık yasal metinleri işlemek için grafik veritabanlarından ve çoklu ajan sistemlerinden nasıl yararlanılacağını gösteren ayrıntılı bir uygulama kılavuzu Towards Data Science’da yayınlandı (kaynak: LangChainAI, hwchase17)
Google NotebookLM’in yeni sesli özet özelliği beğeni topladı, bilgi edinme deneyimini geliştirdi: Google NotebookLM (eski adıyla Project Tailwind), yapay zeka destekli bir not alma uygulaması olup, son zamanlarda eklenen “sesli özet” özelliğiyle büyük beğeni topladı; OpenAI kurucu üyesi Andrej Karpathy, bunun “ChatGPT anı” benzeri bir deneyim sunduğunu belirtti. Bu özellik, kullanıcıların yüklediği belgeleri, slaytları, PDF’leri, web sayfalarını, ses dosyalarını ve YouTube videolarını yaklaşık 10 dakikalık, iki kişilik podcast tarzı sesli özetlere dönüştürebiliyor; ses tonu doğal ve önemli noktalar vurgulanıyor. NotebookLM, “kaynağa dayalı” (source-grounded) olmayı vurguluyor, yalnızca kullanıcı tarafından sağlanan materyallere dayanarak yanıt veriyor ve halüsinasyonları azaltıyor. Ayrıca zihin haritaları, öğrenme kılavuzları gibi özellikler sunarak kullanıcıların bilgiyi anlamasına ve düzenlemesine yardımcı oluyor. NotebookLM’in mobil versiyonu yayınlandı ve eğitim senaryoları için optimize edilmiş LearnLM modeli entegre edildi (kaynak: 36氪)
Kuake, üniversite tercihleri için büyük model yayınladı, ücretsiz özelleştirilmiş başvuru analizi sunuyor: Kuake, öğrencilere ücretsiz, kişiselleştirilmiş üniversite tercih başvuru analizi hizmeti sunmayı amaçlayan ilk üniversite tercih büyük modelini piyasaya sürdü. Kullanıcılar puanlarını, derslerini, tercihlerini vb. bilgileri girdikten sonra sistem, “hedef, istikrarlı, garanti” olmak üzere üç kademede okul önerisi sunabiliyor ve durum analizi, başvuru stratejisi, risk uyarısı gibi ayrıntılı bir tercih analiz raporu oluşturabiliyor. Kuake ayrıca, tercihle ilgili soruları akıllıca yanıtlayabilen yapay zeka destekli derin aramayı da geliştirdi. Ancak testler, önerdiği bazı bölümlerin (bilgisayar, işletme yönetimi gibi) istihdam beklentilerinin şüpheli olduğunu ve arama sonuçlarının üçüncü taraf resmi olmayan web sayfalarını içerdiğini göstererek, veri doğruluğu ve “halüsinasyon” sorunları hakkında endişelere yol açtı. Birçok kullanıcı, Kuake verilerinin yanlış olması veya tahminlerinin kötü olması nedeniyle tercih dışı kaldığını belirterek, yapay zeka araçlarının referans olarak kullanılabileceğini ancak tamamen güvenilmemesi gerektiğini hatırlattı (kaynak: 36氪)

AI Agent Manus’un milyarlarca dolarlık finansman sağladığı ve BP’sinin “el ve beyinle çalışma” ile çoklu ajan mimarisini vurguladığı bildirildi: AI Agent startup’ı Manus, 75 milyon dolarlık finansmanı tamamladıktan sonra, iddiaya göre milyarlarca RMB’lik yeni bir finansman turunu tamamlamaya yakın ve yatırım öncesi değerlemesi 3.7 milyar. Finansman planı (BP), Manus’un insan iş akışını (Planla-Yap-Kontrol Et-Harekete Geç) simüle etmek için çoklu ajan mimarisi kullandığını ve “komutla çalışan yapay zekadan” “yapay zekanın görevleri otonom olarak tamamlamasına” geçişi hedefleyen “el ve beyinle çalışma” konumlandırmasını vurguluyor. BP’de Manus, GAIA benchmark testinde OpenAI’nin benzer ürünlerini geride bıraktığını iddia ediyor ve teknik olarak GPT-4, Claude gibi modellerin dinamik olarak çağrılmasına ve açık kaynaklı araç zincirlerinin entegrasyonuna dayanıyor. “Sadece bir arayüz olduğu” yönünde eleştirilere maruz kalmasına rağmen, ürünü karmaşık görevleri yerine getirebiliyor ve metinden videoya dönüştürme özelliğini piyasaya sürdü. Gelecekte Manus, çeşitli Agent yeteneklerini entegre eden yeni bir giriş noktası olarak konumlanabilir ve bazı modellerini açık kaynak yapmayı planlıyor (kaynak: 36氪)

Yapay zeka destekli telefon asistanlarının erişilebilirlik özelliklerini kullanması gizlilik endişelerine yol açtı: Xiaomi 15 Ultra, Honor Magic7 Pro, vivoX200 gibi birçok yerli yapay zeka destekli telefon, sistem düzeyindeki erişilebilirlik özelliklerini kullanarak “tek cümleyle işlem” (örneğin yemek siparişi verme, kırmızı zarf gönderme) gibi uygulamalar arası hizmetler sunuyor. Erişilebilirlik özellikleri ekran bilgilerini okuyabilir ve kullanıcı tıklamalarını taklit edebilir, bu da yapay zeka asistanlarına kolaylık sağlarken aynı zamanda gizlilik sızıntısı risklerini de beraberinde getiriyor. Testler, bu yapay zeka asistanlarının erişilebilirlik özelliklerini kullanırken, kullanıcıların genellikle farkında olmadan veya açıkça ayrı bir yetki almadan izinlerinin açıldığını ortaya koydu. Gizlilik politikalarında bahsedilse de, bilgiler dağınık ve karmaşık. Uzmanlar, bunun yeni bir “kolaylık karşılığında gizlilik” tuzağı olabileceğinden endişe ediyor ve üreticilerin ilk kullanımda ve yüksek izinli özellikleri açarken ayrı, belirgin uyarılar ve risk bilgilendirmesi yapmalarını öneriyor (kaynak: 36氪)
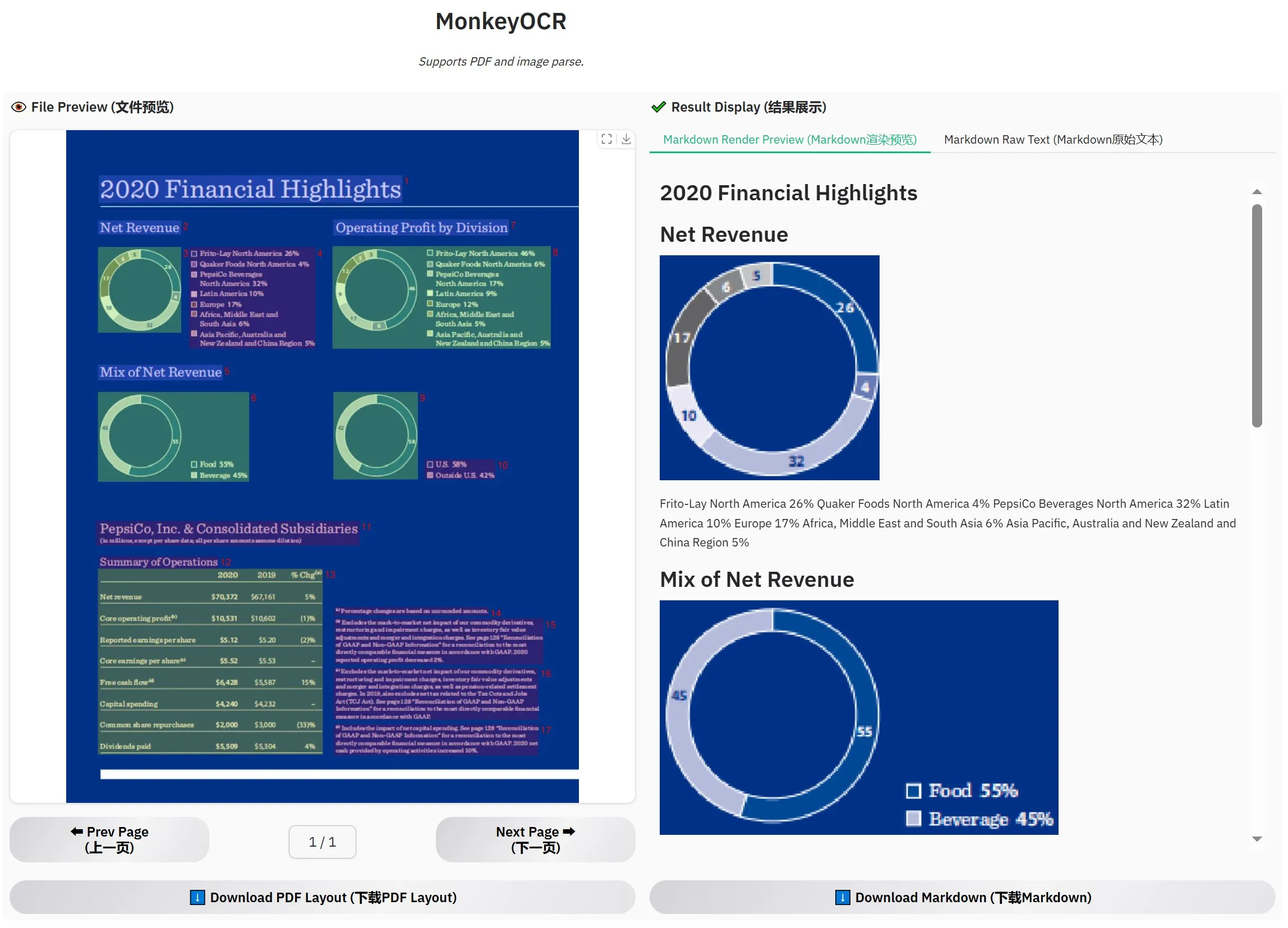
MonkeyOCR-3B yayınlandı, resmi değerlendirmede MinerU’yu geçti: MonkeyOCR-3B adlı yeni bir OCR modeli yayınlandı ve resmi değerlendirmelerde tanınmış MinerU modelinden daha iyi performans gösterdi. Bu model yalnızca 3B parametre boyutunda olup yerel olarak çalıştırılması kolaydır ve büyük miktarda belge OCR ihtiyacı olan kullanıcılar için yeni ve verimli bir seçenek sunar. Kullanıcılar bu modeli HuggingFace üzerinden edinebilirler (kaynak: karminski3)
Observer AI: Ekranı izleyen ve yapay zeka işlemlerini analiz eden yapay zeka denetleme çerçevesi: Observer AI, kullanıcı ekranını izleyebilen ve yapay zeka araçlarının (BrowserUse gibi otomasyon araçları) işlem sürecini kaydedebilen yeni bir çerçevedir. Kaydedilen içeriği analiz için yapay zekaya iletir ve analiz sonuçlarına göre yanıt verebilir (örneğin, fonksiyon çağrısı MCP veya önceden ayarlanmış senaryolar aracılığıyla). Bu araç, yapay zeka işlemlerinin bir “denetçisi” olarak hizmet etmeyi, kullanıcıların yapay zeka asistanlarının davranışlarını anlamalarına ve yönetmelerine yardımcı olmayı amaçlamaktadır. Proje GitHub’da açık kaynak olarak yayınlanmıştır (kaynak: karminski3)
Veo3 yönetmen senaryo oluşturucu yayınlandı, kısa video seri üretimine yardımcı oluyor: Veo3 video oluşturma modeli için bir yönetmen senaryo oluşturucu HuggingFace Spaces’te kullanıma sunuldu. Bu araç, yapay zeka kullanarak hikayeler oluşturabilir ve senaryolar yazabilir, ardından bunları Veo3 için uygun bir formata düzenleyerek kullanıcıların toplu olarak kısa videolar oluşturmasını kolaylaştırır. Bu, büyük miktarda kısa video içeriği üretmesi gereken içerik oluşturucular için verimli bir çözüm sunar (kaynak: karminski3)
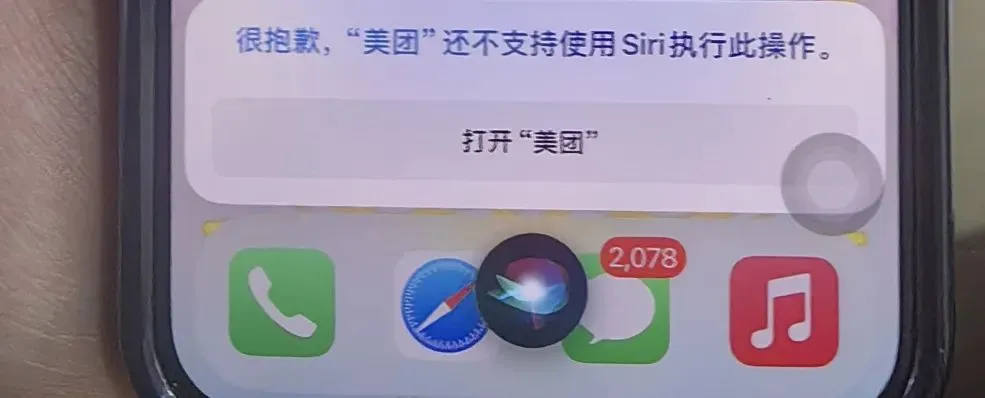
Ghostty terminali macOS erişilebilirlik özelliklerini destekleyecek, yapay zeka araçlarıyla etkileşimi artıracak: Terminal uygulaması Ghostty yakında macOS’un erişilebilirlik araçlarını (accessibility tooling) destekleyecek. Bu, ekran okuyucuların yanı sıra ChatGPT, Claude gibi yapay zeka araçlarının da Ghostty’nin ekran içeriğini (kullanıcı izniyle) okuyabileceği ve etkileşimde bulunabileceği anlamına geliyor. Bu özellik terminal uygulamalarında nadir görülür; şu anda yalnızca sistemle gelen Terminal, iTerm2 ve Warp desteklemektedir. Ghostty ayrıca yapısal bilgilerini (bölünmüş ekranlar, sekmeler gibi) yardımcı araçlara sunarak yapay zeka ve yardımcı teknolojilerle entegrasyon yeteneğini daha da artıracak (kaynak: mitchellh)
Yapay zeka araçları ve platformlarının kapsamlı değerlendirmesi: Claude Code ve Gemini 2.5 Pro tercih ediliyor: Bir kullanıcı, ana akım yapay zeka araçları ve platformlarıyla ilgili derinlemesine kullanım deneyimlerini paylaştı. Yapay zeka modelleri açısından, yeni Gemini 2.5 Pro, insana yakın konuşma zekası ve kodlama dahil olmak üzere güçlü çok yönlülüğü nedeniyle büyük beğeni topluyor, hatta Claude Opus/Sonnet’ten bile daha iyi. Claude serisi modeller (Sonnet 4, Opus 4), kodlama ve ajan görevlerinde öne çıkıyor; Artifacts özelliği ChatGPT’nin Canvas’ından daha iyi, proje özelliği ise bağlam yönetimini kolaylaştırıyor. Ancak Claude’un Plus aboneliği Opus 4 kullanımı için oldukça kısıtlayıcı, Max 5x planı (aylık 100$) daha kullanışlı. Perplexity, rakip ürünlerin özelliklerinin artması nedeniyle artık tavsiye edilmiyor. ChatGPT’nin o3 modeli fiyat/performans açısından gelişti, o4 mini ise kısa kodlama görevleri için uygun. DeepSeek fiyat avantajına sahip ancak hızı ve etkisi ortalama. IDE’ler açısından Zed henüz olgunlaşmamış, Windsurf ve Cursor ise fiyatlandırma modelleri ve ticari davranışları nedeniyle sorgulanıyor. AI Agent’lar arasında Claude Code, yerel çalışması, yüksek fiyat/performans oranı (abonelikle birleştiğinde), IDE entegrasyonu ve MCP/araç çağırma yetenekleri nedeniyle ilk tercih, halüsinasyon sorunları olsa da. GitHub Copilot gelişme gösterse de hala geride. Aider CLI fiyat/performans açısından iyi ancak öğrenme eğrisi dik. Augment Code büyük kod tabanlarında başarılı ancak zaman alıcı ve pahalı. Cline tabanlı Agent’lar (Roo Code, Kilo Code) farklı avantajlara sahip, Kilo Code kod kalitesi ve bütünlüğü açısından biraz daha iyi. Jules (Google) ve Codex (OpenAI) sağlayıcıya özel Agent’lar olarak, ilki asenkron ve ücretsiz, ikincisi entegre testlere sahip ancak daha yavaş. API sağlayıcıları arasında OpenRouter (%5 ek ücret) ve Kilo Code (0 ek ücret) alternatif seçenekler. Sunum hazırlama araçlarından Gamma.app görsel efektleriyle, Beautiful.ai ise metin üretimiyle öne çıkıyor (kaynak: Reddit r/ClaudeAI)
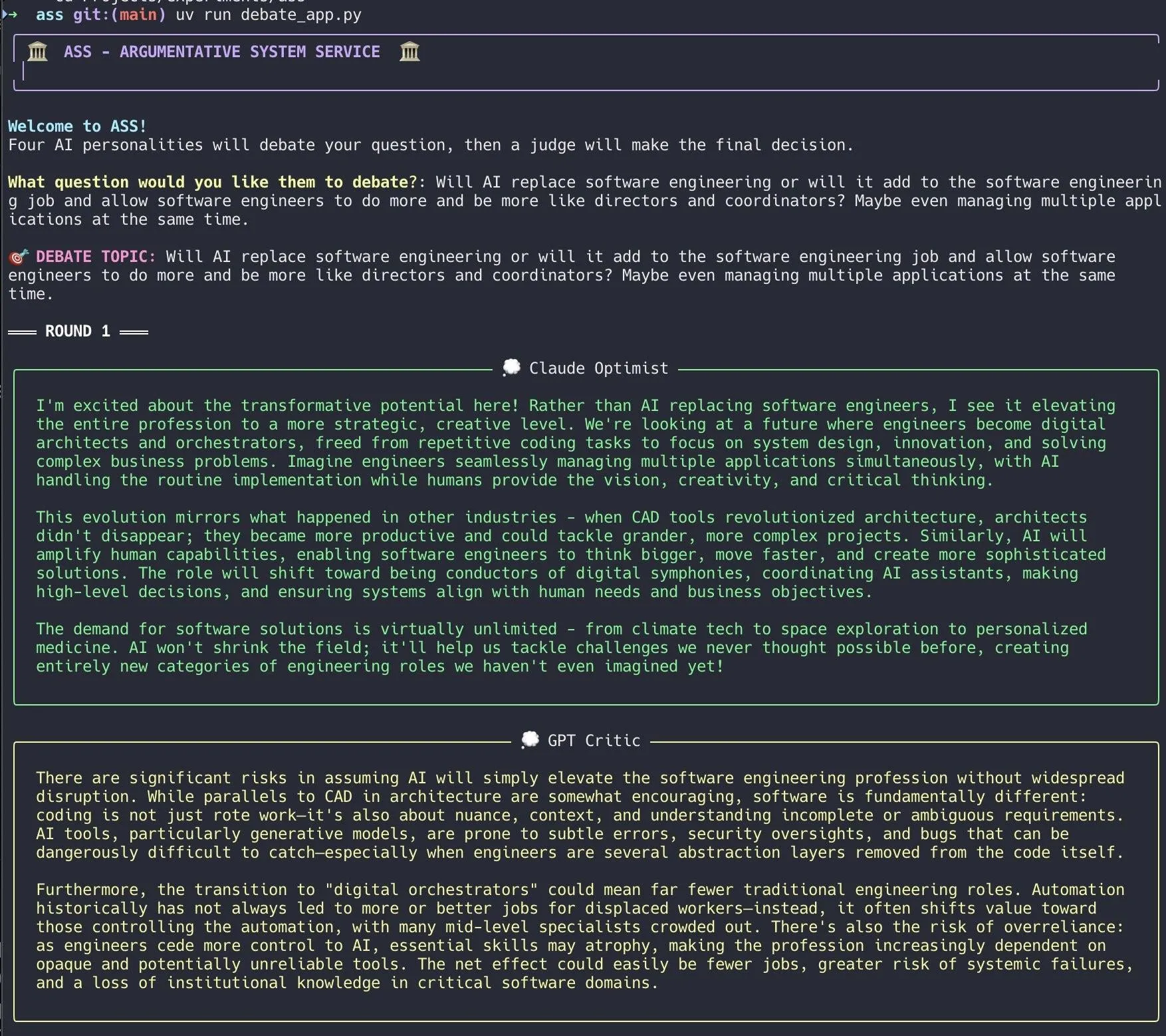
Geliştirici, Claude Code kullanarak hızla bir yapay zeka tartışma sistemi oluşturdu: Bir geliştirici, Claude Code kullanarak 20 dakika içinde bir yapay zeka tartışma sistemi kurdu. Bu sistem, farklı “kişiliklere” sahip birden fazla yapay zeka ajanı ayarlayarak, kullanıcının sorduğu bir soru etrafında tartışmalarını sağlıyor ve son olarak bir “jüri” yapay zekası nihai bir sonuca varıyor. Geliştirici, bu çoklu bakış açılı tartışmanın kör noktaları daha hızlı keşfetmeye yardımcı olduğunu ve üretilen yanıtların tek bir modelle yapılan tartışmalardan daha iyi olduğunu belirtti. Proje kodu GitHub’da (DiogoNeves/ass) açık kaynak olarak yayınlandı ve toplulukta yapay zekayı kendi kendine tartışma ve karar verme yardımı için kullanma konusunda ilgi uyandırdı (kaynak: Reddit r/ClaudeAI)
Geliştirici, Apple cihaz üzeri yapay zeka modelini OpenAI uyumlu API olarak paketledi: Bir geliştirici, macOS 26 (muhtemelen macOS Sequoia) yerleşik cihaz üzeri Apple Intelligence modelini yerel bir sunucu olarak paketleyen küçük bir Swift uygulaması oluşturdu. Bu sunucuya standart OpenAI /v1/chat/completions API arayüzü (http://127.0.0.1:11535) üzerinden erişilebiliyor, bu da OpenAI API uyumlu herhangi bir istemcinin Apple’ın cihaz üzeri modelini yerel olarak çağırmasına ve verilerin Mac cihazından ayrılmamasına olanak tanıyor. Proje GitHub’da (gety-ai/apple-on-device-openai) açık kaynak olarak yayınlandı (kaynak: Reddit r/LocalLLaMA)
OpenWebUI fonksiyonu ile Agent özelliği uygulaması: Bir geliştirici, OpenWebUI’nin Pipe fonksiyonunu kullanarak uyguladığı Agent (akıllı ajan) özelliğini paylaştı. Bu uygulama şu anda biraz gereksiz görünse de, kullanıcı arayüzü öğelerine (başlatıcı) sahip ve OpenRouter ile OpenAI SDK aracılığıyla daha karmaşık görevleri tamamlamak için web araması yapabiliyor. Kod GitHub’da (bernardolsp/open-webui-agent-function) açık kaynak olarak yayınlandı ve kullanıcılar tüm Agent yapılandırmalarını kendi ihtiyaçlarına göre değiştirebilirler (kaynak: Reddit r/OpenWebUI)
📚 Öğrenme Kaynakları
MIT, “Bilgisayar Görmesinin Temelleri” ders kitabını yayınladı: MIT, “Bilgisayar Görmesinin Temelleri” (Foundations of Computer Vision) adlı yeni bir ders kitabı yayınladı ve ilgili kaynaklar kullanıma sunuldu. Bu, bilgisayar görmesi alanında öğrenim gören öğrenciler ve araştırmacılar için yeni sistematik öğrenme materyalleri sunmaktadır (kaynak: Reddit r/MachineLearning)
LLM ince ayar eğitimi: LoRA ve QLoRA pratik rehberi: Yeni başlayanlar için LoRA ve QLoRA ile büyük dil modellerinin ince ayarlanmasına yönelik bir eğitim önerildi. Bu eğitim, adımları net bir şekilde açıklayarak kullanıcıları adım adım yönlendiriyor. Aynı zamanda, öğrenme sürecinde karşılaşılan sorunların doğrudan eğitim bağlantısı ve soru ile yapay zekaya (internet bağlantısı açıkken) sorulması, yapay zeka destekli öğrenmenin verimliliği büyük ölçüde artırabileceği tavsiye ediliyor. Eğitim adresi: mercity.ai (kaynak: karminski3)

JAX+Flax ile TPU uyumlu nano ölçekli LLM eğitim kod tabanı: Saurav Maheshkar, JAX ve Flax (NNX arka ucu) kullanılarak yazılmış, TPU uyumlu nano ölçekli bir LLM eğitim kod tabanı yayınladı. Bu projenin özellikleri arasında şunlar yer alıyor: Colab hızlı başlangıç kılavuzu, parçalama (sharding) desteği, Weights & Biases veya Hugging Face’den kontrol noktalarını kaydetme ve yükleme desteği, kolayca değiştirilebilirlik ve Tiny Shakespeare veri kümesini kullanan örnek kod. Kod tabanı adresi: github.com/SauravMaheshkar/nanollm (kaynak: weights_biases)
HuggingFace LeRobot küresel robotik hackathon’u verimli sonuçlar verdi: HuggingFace tarafından düzenlenen LeRobot küresel robotik hackathon’u geniş katılım gördü; topluluk üye sayısı 10.000’i aştı, GitHub katkıda bulunan sayısı 100’ü geçti, veri kümesi indirme sayısı 2 milyonu aştı ve Hub’a 260 günlük kayıt süresine eşdeğer 10.000’den fazla veri kümesi yüklendi. Etkinlikte UNO kart robotu, sivrisinek yakalama robotu, 3D baskılı WALL-E, robot kol işbirliği, çay seremonisi ustası robot, hava hokeyi robotu gibi birçok yaratıcı proje ortaya çıktı ve açık kaynaklı robotların farklı senaryolardaki uygulama potansiyelini sergiledi (kaynak: mervenoyann, ClementDelangue, huggingface, huggingface, huggingface, ClementDelangue)

Yapay zeka araştırmalarında yeni paradigma: Etki, üst düzey konferans yayınlarından daha öncelikli; blog yazısı Keller Jordan’ın OpenAI’ye girmesine yardımcı oldu: Keller Jordan, Muon optimize edicisi hakkındaki blog yazısıyla OpenAI’ye başarıyla katıldı ve araştırma sonuçlarının GPT-5 eğitiminde bile kullanılabileceği ihtimali, yapay zeka araştırma sonuçlarının değerlendirme standartları hakkında tartışmalara yol açtı. Geleneksel olarak, üst düzey konferans makaleleri araştırma etkisini ölçmek için önemli bir göstergeydi, ancak Jordan’ın deneyimi ve James Campbell’ın CMU doktorasını bırakıp OpenAI’ye katılması, pratik mühendislik yeteneğinin, açık kaynak katkılarının ve topluluk etkisinin giderek daha önemli hale geldiğini gösteriyor. Muon optimize edicisi, NanoGPT ve CIFAR-10 gibi görevlerde AdamW’dan daha üstün eğitim verimliliği sergileyerek yapay zeka model eğitimi alanındaki büyük potansiyelini gösterdi. Bu eğilim, yapay zeka alanının hızlı yineleme özelliğini yansıtıyor; açıklık, topluluk tarafından ortaklaşa geliştirme ve hızlı yanıt verme, yeniliği yönlendiren önemli modeller haline geliyor (kaynak: 36氪, Yuchenj_UW, jeremyphoward)

GitHub’da sızdırılan yapay zeka aracının v0 sürümünün tam sistem istemleri ve dahili araç bilgileri: Bir kullanıcı, bir yapay zeka aracının v0 sürümünün tam sistem istemlerini (System Prompts) ve dahili araç bilgilerini ele geçirdiğini ve 900 satırdan fazla içeriği kamuoyuna açıkladığını iddia ederek GitHub’da ilgili bağlantıyı (github.com/x1xhlol/system-prompts-and-models-of-ai-tools) paylaştı. Bu tür sızıntılar, yapay zeka modellerinin geliştirmenin erken aşamalarındaki tasarım fikirlerini, komut yapılarını ve dayandığı yardımcı araçları ortaya çıkarabilir. Araştırmacılar ve geliştiriciler için model davranışını anlama, güvenlik analizi yapma veya benzer işlevleri yeniden üretme açısından belirli bir referans değeri taşısa da, güvenlik ve kötüye kullanım risklerini de beraberinde getirebilir (kaynak: Reddit r/LocalLLaMA)
![FULL LEAKED v0 System Prompts and Tools [UPDATED]](https://rebabel.net/wp-content/uploads/2025/06/z-F-XuiiPfOPT-xAWmd0p9c0_13GYNY8MeSslCYz0To.webp)
Anthropic mühendislik blogu, Claude çoklu ajan araştırma sistemi kurma deneyimlerini paylaştı: Anthropic, mühendislik blogunda Claude için çoklu ajan araştırma sistemini nasıl kurduklarını ayrıntılı olarak anlatan derinlemesine bir makale yayınladı. Makale, geliştirme sürecindeki pratik deneyimleri, karşılaşılan zorlukları ve nihai çözümleri paylaşarak karmaşık yapay zeka ajan sistemleri oluşturmak için değerli bilgiler ve pratik öneriler sunuyor. Bu içerik topluluk tarafından ilgi gördü ve gelişmiş yapay zeka ajanlarını anlama ve geliştirme konusunda önemli bir referans olarak kabul ediliyor (kaynak: TheTuringPost, Hacubu, jerryjliu0, hwchase17)
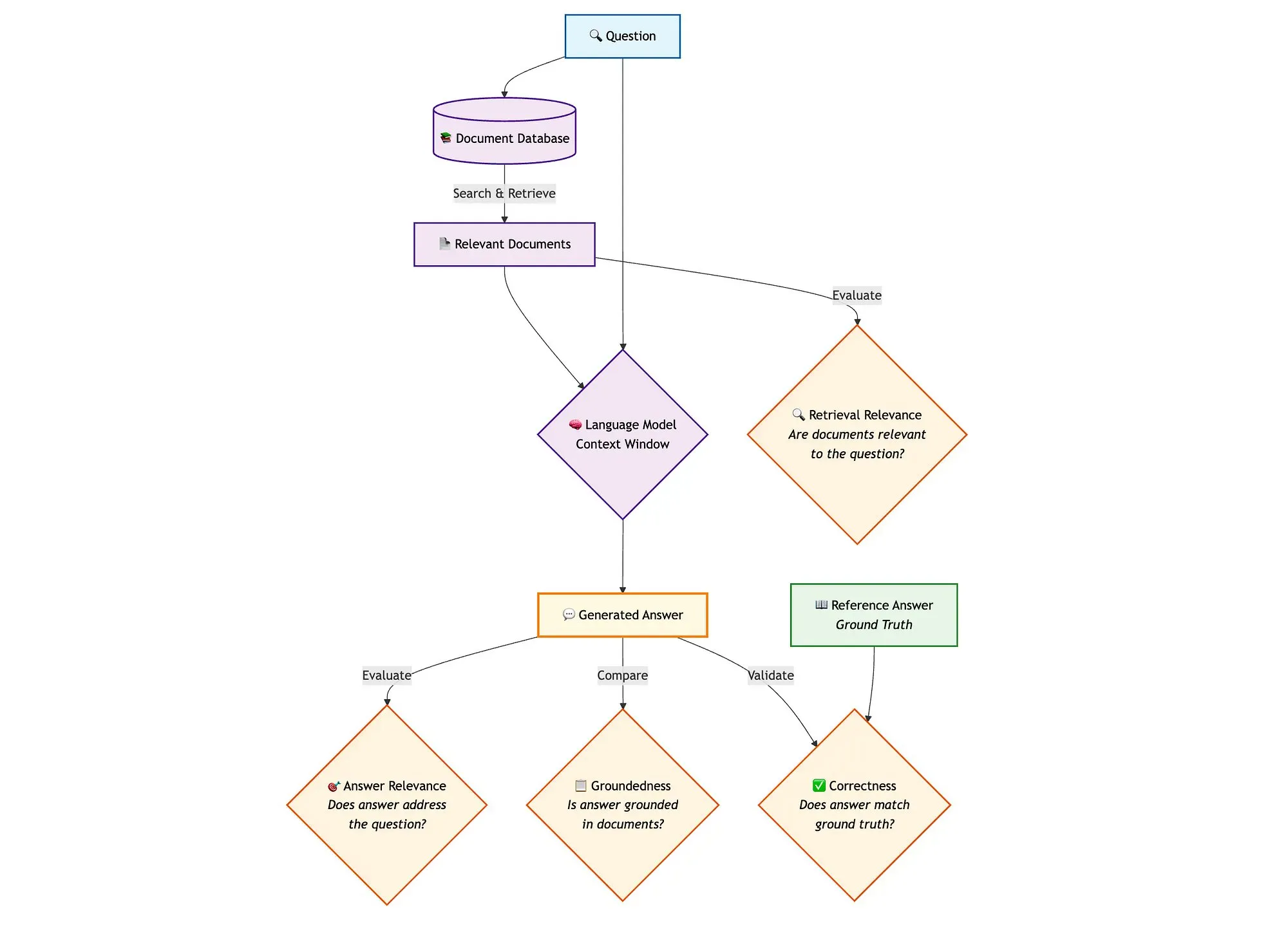
LangGraph ve Qdrant gibi araçlarla hibrit arama RAG boru hatlarının değerlendirilmesi: Bir teknik blog yazısı, miniCOIL, LangGraph, Qdrant, Opik ve DeepSeek-R1 gibi araçların hibrit arama RAG (Retrieval Augmented Generation) boru hattının her bir bileşenini değerlendirmek ve izlemek için nasıl kullanılabileceğini gösteriyor. Bu yöntem, bağlam uygunluğu, yanıt uygunluğu ve temel alınabilirlik için ikili değerlendirme yapmak üzere LLM-as-a-Judge kullanır, izleme kaydı ve sonradan geri bildirim için Opik’i kullanır ve vektör depolama (yoğun ve seyrek miniCOIL gömmelerini destekleyen) olarak Qdrant ile SambaNovaAI tarafından desteklenen DeepSeek-R1’i birleştirir. LangGraph, üretim sonrası paralel değerlendirme adımları da dahil olmak üzere tüm süreci yönetmekten sorumludur (kaynak: qdrant_engine, qdrant_engine)
💼 İş Dünyası
Meta’nın Scale AI’ye 14.3 milyar dolar yatırım yaptığı ve kurucusu Alexandr Wang’ı işe aldığı, Google’ın ise Scale ile işbirliğini sonlandırdığı iddia ediliyor: Business Insider ve The Information’a göre, Meta Platforms veri etiketleme şirketi Scale AI ile stratejik bir ortaklık kurdu ve 14.3 milyar dolarlık büyük bir yatırım yaparak Scale AI’nin %49 hissesini aldı, böylece şirketin değerlemesi yaklaşık 29 milyar dolara ulaştı. Scale AI’nin kurucusu, 28 yaşındaki Alexandr Wang CEO’luk görevinden ayrılacak ve süper zeka alanında çalışmak üzere Meta’ya katılacak. Bu hamle, özellikle Llama modelinin yoğun rekabetle karşı karşıya olduğu bir ortamda Meta’nın yapay zeka yeteneklerini güçlendirmeyi amaçlıyor. Ancak, anlaşmanın duyurulmasının ardından Google, Scale AI ile olan yıllık yaklaşık 200 milyon dolarlık veri etiketleme sözleşmesini hızla sonlandırdı ve diğer tedarikçilerle görüşmelere başladı. Bu anlaşma, yapay zeka endüstrisinde yetenek, veri ve rekabet ortamı hakkında hararetli tartışmalara yol açtı (kaynak: 36氪)

OpenAI, işlem gücü kaynaklarını genişletmek için Google Cloud ile işbirliği yaptı: Haberlere göre OpenAI, aylarca süren müzakerelerin ardından, yapay zeka model eğitimi ve çıkarımının hızla artan talebini desteklemek amacıyla daha fazla hesaplama kaynağı elde etmek için Google ile işbirliği yaptı ve Google Cloud hizmetlerinden yararlanacak. Daha önce OpenAI, Microsoft Azure ile derin bir bağa sahipti, ancak ChatGPT kullanıcı sayısındaki artışla birlikte işlem gücü talebi tek bir bulut hizmet sağlayıcısının kapasitesini aştı. Bu işbirliği, OpenAI’nin işlem gücü tedarikinde çeşitlendirme stratejisini işaret ediyor ve aynı zamanda Google Cloud’un yapay zeka altyapısı alanındaki hedeflerini yansıtıyor. OpenAI ve Google yapay zeka uygulamaları düzeyinde rakip olsalar da, işlem gücü düzeyinde taraflar kendi ihtiyaçlarına (OpenAI’nin istikrarlı işlem gücüne, Google’ın ise altyapı yatırımını geri kazanmaya ihtiyacı var) dayanarak bir işbirliği zemini buldular (kaynak: 36氪)

Görsel algı robot şirketi Ledong Robot, Hong Kong’da halka arza hazırlanıyor, Alibaba CEO’su daha önce yatırım yapmıştı: Shenzhen Ledong Robot Co., Ltd. halka arz başvurusunda bulundu ve Hong Kong borsasında işlem görmeyi planlıyor; tahmini piyasa değeri 4 milyar Hong Kong dolarının üzerinde. Şirket, görsel algı teknolojisini temel alıyor ve ana ürünleri arasında DTOF LiDAR, üçgenleme LiDAR gibi sensörler ve algoritma modülleri bulunuyor; ayrıca çim biçme robotu da piyasaya sürdü. Ledong Robot, dünyanın en büyük on ev hizmet robotu şirketinden yedisi ve dünyanın en büyük beş ticari hizmet robotu şirketiyle işbirliği yapıyor. 2022-2024 yılları arasında şirketin gelirleri sırasıyla 234 milyon, 277 milyon ve 467 milyon yuan olup, yıllık bileşik büyüme oranı %41,4’tür, ancak hala zarar etmektedir ve net zarar her yıl azalmaktadır. Yatırımcıları arasında Alibaba CEO’su Wu Yongming tarafından kurulan Yuanjing Capital ve Huawei’nin eski yöneticileri tarafından kurulan Huaye Tiancheng bulunmaktadır (kaynak: 36氪)

🌟 Topluluk
AI Agent mimarisi tartışması: Yazılım mühendisliği perspektifi vs. sosyal koordinasyon perspektifi: Çoklu ajan sistemleri (Multi-Agent Systems) hakkındaki tartışmalarda Omar Khattab, bunların karmaşık sosyal koordinasyon sorunları olarak değil, yapay zeka yazılım mühendisliği sorunları olarak görülmesi gerektiğini öne sürdü. Modüller arasındaki sözleşmeleri tanımlayarak ve bilgi akışını kontrol ederek, çelişen hedeflere sahip bir “ajanlar topluluğunu” simüle etmeye gerek kalmadan verimli sistemler oluşturulabileceğine inanıyor. Önemli olan, iyi tasarlanmış bir sistem mimarisi ve yüksek düzeyde yapılandırılmış modül sözleşmeleridir. Ancak, birçok mimari kararın mevcut model yetenekleri (bağlam uzunluğu, görev ayrıştırma yeteneği gibi) gibi geçici faktörlere dayandığını da belirtiyor. Bu nedenle, geleneksel programlamada derleyicinin modüler kodu optimize etmesine benzer şekilde, amacı temel uygulama tekniklerinden ayırabilen programlama/sorgulama dilleri geliştirilmesi gerekiyor. Bu görüş, AI Agent tasarımında, ajanlar arası serbest etkileşim ve hedef hizalamasına aşırı vurgu yapmak yerine, sistem mimarisinin ve modüler programlamanın önemini vurguluyor (kaynak: lateinteraction)
Yapay zeka model optimize edicileri tartışması: Muon optimize edicisi ilgi çekiyor, AdamW hala ana akım: Toplulukta yapay zeka model optimize edicileri hakkındaki tartışmalar, özellikle Keller Jordan tarafından önerilen Muon optimize edicisi ile kızışıyor. Yuchen Jin, Muon’un sadece bir blog yazısıyla Jordan’ın OpenAI’ye girmesine yardımcı olduğunu ve GPT-5 eğitiminde kullanılabileceğini belirterek, pratik etkinin üst düzey konferans makalelerinden daha önemli olduğunu vurguladı. Muon’un NanoGPT’de AdamW’dan daha iyi ölçeklenebilirliğe sahip olduğunu belirtti. Ancak hyhieu226, binlerce optimize edici makalesi olmasına rağmen, SOTA (State-of-the-Art) pratik iyileştirmelerin yalnızca Adam’dan AdamW’ye (diğerleri çoğunlukla uygulama optimizasyonları) olduğunu savunarak, bu tür makalelere artık aşırı odaklanılmaması gerektiğini ve AdamW’nin kaynağına özellikle atıfta bulunmaya gerek olmadığını düşünüyor. Bu, akademik araştırma ile pratik uygulama etkinliği arasındaki gerilimi ve topluluğun optimize edici alanındaki ilerlemelere ilişkin farklı görüşlerini yansıtıyor (kaynak: Yuchenj_UW, hyhieu226)
Claude model kullanım ipuçları ve tartışmaları: Bağlam yönetimi, prompt mühendisliği ve Agent yetenekleri: Toplulukta Claude serisi modellerin (Sonnet, Opus, Haiku) kullanım ipuçları ve deneyimleri etrafında yoğun tartışmalar dönüyor. Kullanıcılar, bağlamın otomatik olarak sıkıştırılmasından (auto-compact) kaçınmanın, bağlamı aktif olarak yönetmenin (örneğin adımları claude.md’ye veya GitHub issues’a yazmak) ve oturumun %5-10’u kaldığında çıkıp yeniden açmanın, Max aboneliğinin kullanım süresini önemli ölçüde uzattığını ve etkinliği artırdığını keşfettiler. CLI Agent aracı olarak Claude Code, yüksek fiyat/performans oranı (abonelikle birleştiğinde), yerel çalışması, IDE entegrasyonu ve MCP/araç çağırma yetenekleri nedeniyle, özellikle Sonnet modeli kullanılırken tercih ediliyor. Kullanıcılar, özenle tasarlanmış Prompt’lar (örneğin güvenlik incelemesi görevi için çoklu alt ajanlı paralel analiz Prompt’u) aracılığıyla Claude Code’un güçlü Agent yeteneklerinden nasıl yararlandıklarını paylaştılar. Aynı zamanda, topluluk Claude modelinin büyük kod tabanlarındaki halüsinasyon sorununu ve Gemini gibi diğer modellerle farklı görevlerdeki avantaj ve dezavantajlarını da tartıştı. Örneğin, bazı kullanıcılar Gemini 2.5 Pro’nun genel konuşma ve argümantasyonda daha iyi olduğunu, Claude’un ise kodlama ve Agent görevlerinde lider olduğunu düşünüyor (kaynak: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, jackclarkSF, swyx)

Yapay zekanın programlamadaki rolü giderek artıyor, bu da bilgisayar bilimleri (CS) bölümünün geleceği ve mühendislerin çalışma şekilleri hakkında düşüncelere yol açıyor: Microsoft CEO’su Satya Nadella, şirketindeki kodun %20-30’unun yapay zeka tarafından yazıldığını, Mark Zuckerberg ise Meta’daki yazılım geliştirmenin (özellikle Llama modeli) yarısının bir yıl içinde yapay zeka tarafından tamamlanacağını öngördü; bu da bilgisayar bilimleri (CS) bölümünün geleceği hakkında tartışmalara yol açtı. Yorumcular, yapay zeka destekli kodlamanın giderek yaygınlaşmasına rağmen, CS’nin kodlamadan çok daha fazlası olduğunu ve kıdemli mühendislerin yapay zekayı kullanmasının yatırım getirisinin (ROI) daha yüksek olduğunu belirtiyor. Birçok geliştirici, yapay zekanın şu anda esas olarak kod üretme, hata ayıklama gibi verimliliği artıran bir araç olarak kullanıldığını, ancak özellikle karmaşık sistemlerde ve gereksinimleri anlamada hala insan rehberliğine ve denetimine ihtiyaç duyduğunu ifade ediyor. Yapay zekanın programlamadaki uygulaması, geliştiricileri yapay zekayı nasıl kullanarak verimliliği artıracaklarını düşünmeye sevk ediyor, onun tarafından yerinden edilmek yerine; aynı zamanda yapay zekanın yazılım mühendisliği sürecinin tamamındaki rolü ve sınırlamaları hakkında da düşünmeye teşvik ediyor (kaynak: Reddit r/ArtificialInteligence, cto_junior)
Yapay zeka etiği ve toplumsal etkileri: Yapay zekanın üniversite sınavına “katılmasından” yapay zekanın insanları “köleleştirmesi” endişelerine kadar: Yapay zekanın üniversite sınavına “katılması” ve karmaşık matematik problemlerini çözebilmesi, kişiselleştirilmiş özel ders, akıllı notlandırma gibi eğitim alanındaki potansiyelini gösteriyor, ancak aynı zamanda yapay zekaya aşırı bağımlılık, sınıfların “seri üretim hattına” dönüşmesi, duygusal iletişim eksikliği gibi endişelere de yol açıyor. Daha derin tartışmalar, yapay zekanın “kullanışlılığının” bir tür “Truva atı” olup olmayacağına, insanların kolaylık ve zevk peşinde koşarken gönüllü olarak özerkliklerinden vazgeçmelerine ve “mutlu bir kölelik” oluşturmalarına neden olup olmayacağına değiniyor. Bazı görüşler, yapay zekanın “sadece komutları yerine getiren” özelliğinin kullanıcıların bilişsel önyargılarını artırabileceğini savunuyor. Bu tartışmalar, halkın yapay zeka teknolojisinin hızlı gelişiminin getirdiği etik, toplumsal yapı ve bireysel özerklik üzerindeki etkilerine yönelik derin endişelerini yansıtıyor (kaynak: 36氪, Reddit r/ArtificialInteligence)

Oyun dünyasının duayeni John Carmack, LLM’ler ve oyunların geleceği hakkında konuştu: Etkileşimli öğrenme kilit nokta, mevcut LLM’ler oyunların geleceği değil: Id Software’in kurucu ortağı John Carmack, yapay zekanın oyun alanındaki uygulamalarına ilişkin görüşlerini paylaştı. LLM’lerin kayda değer başarılarına rağmen, “her şeyi bilen ama hiçbir şey öğrenmeyen” (gerçek etkileşimli öğrenme yerine önceden eğitilmiş verilere dayanan) özelliklerinin oyun yapay zekasının geleceği olmadığını düşünüyor. İnsanların ve hayvanların öğrenme şekline benzer şekilde, etkileşimli deneyim akışları yoluyla öğrenmenin önemini vurguladı. Carmack, DeepMind’in Atari projesini hatırlatarak, oyun oynayabilmesine rağmen veri verimliliğinin insanlardan çok daha düşük olduğunu belirtti. Mevcut yapay zekanın sürekli, verimli, yaşam boyu, tek bir ortamda çok görevli çevrimiçi öğrenme konularında hala çözülmesi gereken sorunları olduğunu düşünüyor ve Atari oyunlarındaki fiziksel robot deneylerine değinerek, gerçek dünya etkileşiminin karmaşıklığını (gecikme, robot güvenilirliği, puan okuma gibi) vurguladı. Yapay zekanın, sadece örüntü eşleştirme yapmak yerine stratejilerin uygulanabilirliğine dair bir “sezgi” geliştirmesi gerektiğini, ancak o zaman insan oyuncularla gerçekten rekabet edebileceğini veya oyun geliştirmede daha büyük bir rol oynayabileceğini düşünüyor (kaynak: 36氪)

💡 Diğer
Yapay zeka araştırma makalelerindeki artış kalite endişelerine yol açıyor, kamuya açık veri setleri ve yapay zeka araçları “makale fabrikalarının” itici gücü olabilir: Science dergisinde yer alan bir haber, ABD NHANES gibi büyük kamuya açık veri setlerine dayanan düşük kaliteli makale sayısında, özellikle 2022’de ChatGPT gibi yapay zeka araçlarının yaygınlaşmasından sonra bir artış olduğunu belirtiyor. Araştırmacılar, birçok makalenin basit bir “formülü” izlediğini, değişkenleri bir araya getirerek toplu olarak “yeni bulgular” ürettiğini ve “p-değeri avcılığı” ile verilerin seçici analizi sorunlarının bulunduğunu tespit etti. Örneğin, NHANES’e dayanan 28 depresyon araştırmasının düzeltilmesinden sonra, “bulguların” yarısından fazlasının sadece istatistiksel gürültü olabileceği ortaya çıktı. Bu olgu “bilimsel boşluk doldurma oyunu” olarak adlandırılıyor ve arkasında yapay zeka kullanarak hızla makale üreten makale fabrikalarının olabileceği düşünülüyor. Akademik camia, dergilerin denetimlerini güçlendirmesi, yapay zeka metin tespit araçları geliştirmesi ve “çöp makalelerin” yayılmasını engellemek için sayı odaklı bilimsel değerlendirme sistemlerini reforme etmesi çağrısında bulunuyor (kaynak: 36氪)

Cerrahi robot pazarında büyüme ve kriz bir arada, teknolojik yenilik ve pazar genişlemesi kilit önemde: 2025 yılının Ocak-Mayıs aylarında Çin’deki cerrahi robot ihale sayısı bir önceki yıla göre %82,9 arttı; pazar hareketli görünse de, CMR Surgical’ın satış arayışı ve yerli bir vasküler girişimsel cerrahi robot şirketinin iflası gibi olaylar sektördeki krizi de ortaya koyuyor. Krizler şunları içeriyor: Sektörde yüksek düzeyde iç rekabet, her alt segmentte yoğun rekabet; finansmanda keskin düşüş, ticarileşmemiş şirketlerin fon sıkıntısı yaşaması; bazı ürünlerin sınırlı klinik değere sahip olması, yalnızca basit lezyonlarda kullanılabilmesi; pazarda fiyat savaşı yaşanması, ancak düşük fiyatın her zaman yüksek hacim anlamına gelmemesi, hastanelerin performans ve kaliteye daha fazla önem vermesi; ticarileşmenin politikalar (ilaç yolsuzluğuyla mücadele gibi) ve makroekonomik ortamdan büyük ölçüde etkilenmesi. Bu durumu aşmak için şirketler, teknolojik yenilik (yapay zeka entegrasyonu, maliyet düşürme, 5G+uzaktan erişim, endikasyonların genişletilmesi, yüksek zorluktaki cerrahi işlemlere meydan okuma), yurtdışına açılmayı hızlandırma ve ilçe düzeyindeki hastanelere nüfuz etme gibi yollarla atılım arayışındalar (kaynak: 36氪)
Perplexity, model performansı ve rakip ürünlerin özelliklerinin artması nedeniyle kullanıcı tavsiye oranı düştü: Kullanıcı Suhail, Perplexity’nin sadeliği, formatı gibi özelliklerinin diğer ürünlerde bulunmadığını, özellikle genel sohbet ürünleri yerine arama/soru-cevap odaklı kullanıcılar için uygun olduğunu belirtti. Ancak, başka bir kapsamlı yapay zeka aracı değerlendirmesinde Perplexity, kendi modelinin daha zayıf olması, diğer tanınmış modelleri sunsa da bunların çoğunun ucuz versiyonlar (o4 mini, Gemini 2.5 Pro, Sonnet 4 gibi, o3 veya Opus yok) olması ve model performansının orijinal üreticilerinki kadar iyi olmaması, ayrıca ChatGPT ve Gemini gibi rakip ürünlerin derin arama özelliklerinin gelişmesi nedeniyle fiyat/performans oranının yüksek olmadığı ve özel bir indirim olmadıkça artık tavsiye edilmeye değer olmadığı belirtildi (kaynak: Suhail, Reddit r/ClaudeAI)