
Anahtar Kelimeler:Kuantum hesaplama, Otonom sürüş, Büyük dil modelleri, 3D üretim modelleri, Yapay zeka araçları, Makine öğrenimi, Yapay zeka araştırması, CUDA-Q kuantum hesaplama platformu, Waymo otonom sürüş veri araştırması, Claude çoklu ajan sistemi, Tencent Hunyuan 3D 2.1, Yapay zeka üretim çekirdek performans optimizasyonu
🔥 Odak Noktası
Nvidia, kuantum hesaplamaya özel CUDA-Q platformunu duyurdu: Nvidia CEO’su Jensen Huang, GTC Paris’teki konuşmasında, kuantum-klasik hızlandırmalı bir süper hesaplama platformu olan CUDA-Q’yu tanıttı. Platform, mevcut klasik hesaplama ile gelecekteki kuantum hesaplama arasındaki boşluğu kapatmayı amaçlıyor ve klasik bilgisayarlarda kuantum işlemlerinin simüle edilmesine veya gerçek kuantum bilgisayarlara yardımcı olmasına olanak tanıyor. CUDA-Q, Grace Blackwell üzerinde zaten mevcut ve GB200 NVL72 süper bilgisayarı aracılığıyla geliştirme hızını 1300 kat artırabiliyor. Jensen Huang, kuantum bilgisayarların pratik uygulamalarının birkaç yıl içinde gerçekleşeceğini öngörüyor ve bu geliştirme aşamasında Nvidia çiplerinin (özellikle GB200’ün) simülasyon hesaplamalarında ve QPU’lara yardımcı olmada vazgeçilmez olduğunu vurguladı. Nvidia, GPU’lar ve QPU’ların birlikte nasıl çalışabileceğini araştırmak için dünya genelindeki kuantum hesaplama şirketleri ve süper hesaplama merkezleriyle işbirliği yapıyor (Kaynak: 量子位)

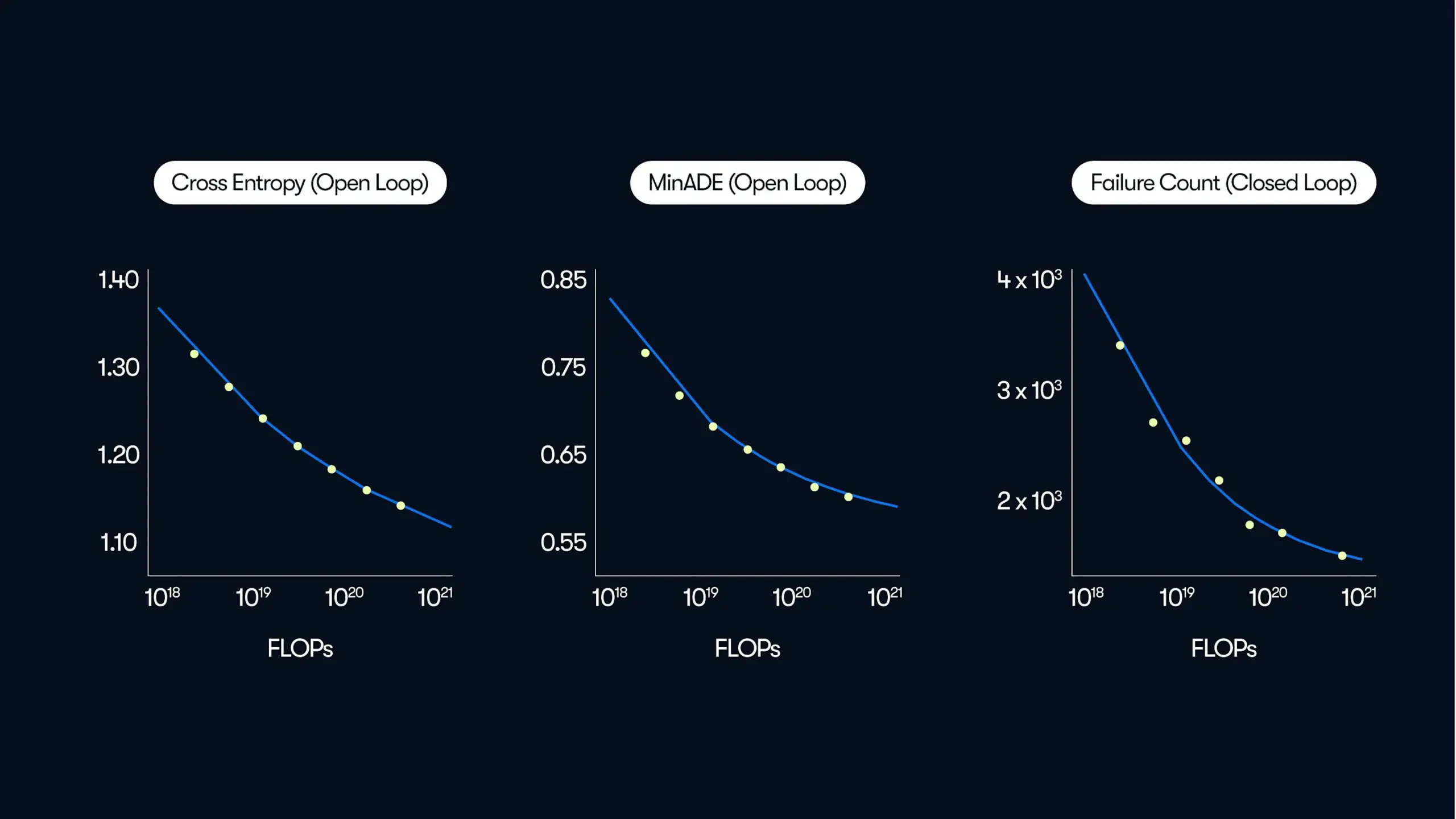
Waymo, otonom sürüş üzerine büyük ölçekli bir araştırma yayınladı ve “veri odaklı” performans artışı yasalarını ortaya koydu: Waymo, en son blog yazısında, otonom sürüş alanında bugüne kadarki en büyük veri kümesi olan 500.000 saatlik sürüş verisine dayanan kapsamlı bir araştırma sonucunu paylaştı. Araştırma, büyük dil modellerine (LLM) benzer şekilde, otonom sürüş sistemlerinin hareket tahmin kalitesinin de eğitim hesaplama miktarı arttıkça bir üs yasası ilişkisi izlediğini gösteriyor. Veri ölçeğinin genişletilmesi, model performansını artırmak için kritik öneme sahipken, çıkarım hesaplama kapasitesinin artırılması da modelin karmaşık sürüş senaryolarını işleme yeteneğini geliştirebilir. Bu araştırma, eğitim verilerini ve hesaplama kaynaklarını artırarak gerçek dünyadaki otonom sürüş performansının önemli ölçüde iyileştirilebileceğini ilk kez doğruluyor ve sektöre ölçeklendirme yoluyla yetenekleri artırma yolunu gösteriyor (Kaynak: Sawyer Merritt, scaling01)
Anthropic, Claude çoklu ajan araştırma sistemi oluşturma deneyimlerini paylaştı: Anthropic, mühendislik blogunda, Claude’un araştırma yeteneklerini oluşturmak için paralel çalışan birden fazla ajandan nasıl yararlanıldığını ayrıntılı olarak açıkladı. Makale, geliştirme sürecindeki başarıları, karşılaşılan sorunları ve mühendislik zorluklarını paylaşıyor. Bu çoklu ajan sistemi, Claude’un bilgiyi daha etkili bir şekilde almasını, analiz etmesini ve sentezlemesini sağlayarak araştırma ve karmaşık soruları yanıtlama yeteneğini artırıyor. Bu paylaşım, büyük dil modellerinin karmaşık sistem tasarımı yoluyla işlevlerini nasıl genişlettiğini anlamak için önemli bir referans değeri taşıyor (Kaynak: ImazAngel, teortaxesTex)
Meta, video anlama, tahmin ve robot kontrolü sağlayan V-JEPA 2 dünya modelini tanıttı: Meta AI, fiziksel dünyanın dinamiklerini anlama ve tahmin etme konusunda önemli ilerlemeler kaydeden, video tabanlı bir dünya modeli olan V-JEPA 2’yi yayınladı. V-JEPA 2, yalnızca verimli video özellik öğrenimi gerçekleştirmekle kalmıyor, aynı zamanda yeni ortamlarda sıfır-atış planlama ve robot kontrolü de sağlayarak genel yapay zeka alanındaki potansiyelini gösteriyor. Model, kendi kendine denetimli öğrenme yoluyla video verilerinden dünya temsillerini öğreniyor ve daha akıllı, gerçek dünyayla daha fazla etkileşim kurabilen yapay zeka sistemleri oluşturmak için yeni yollar sunuyor (Kaynak: dl_weekly)
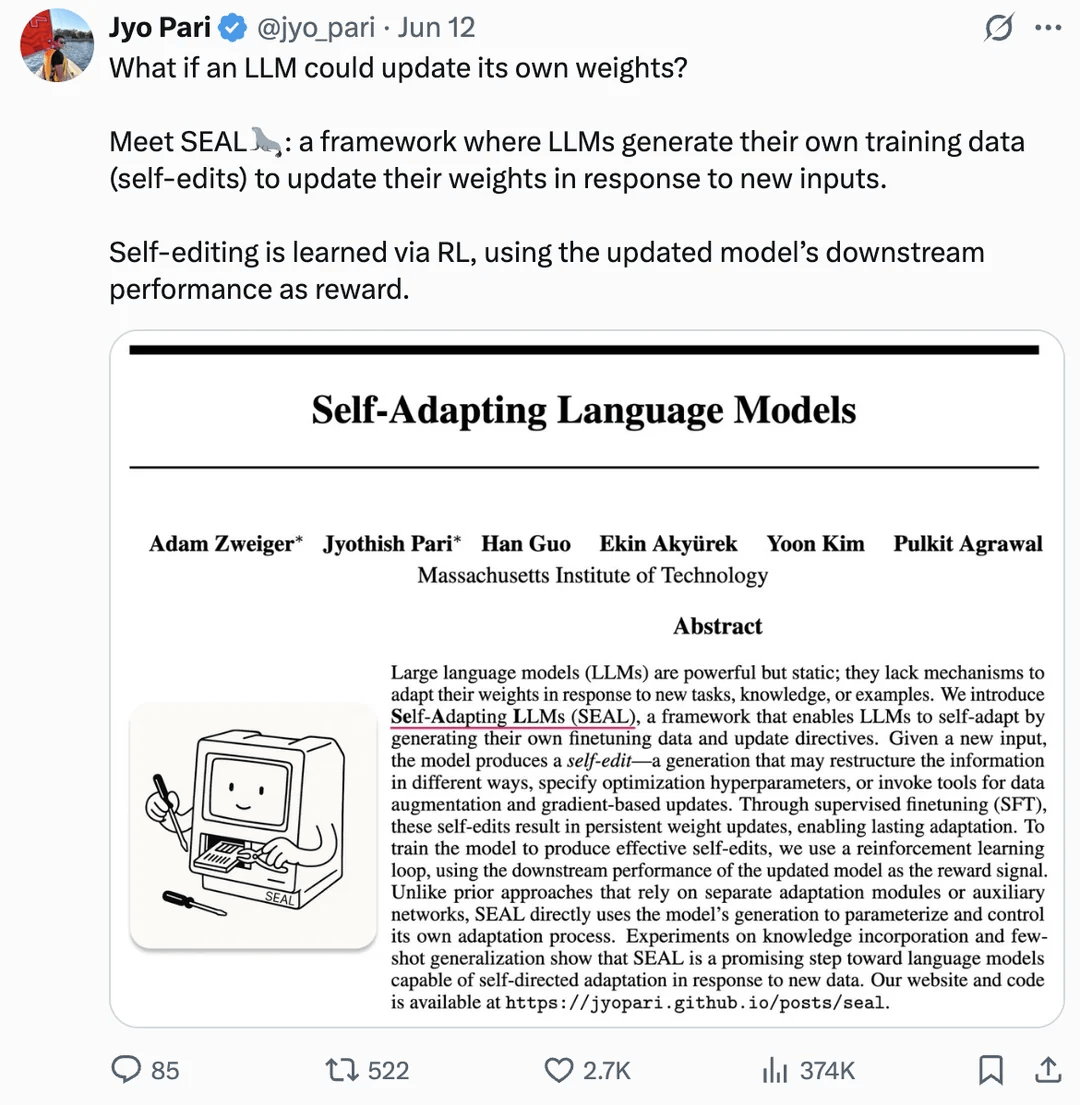
Makale, LLM’lerin kendi kendini geliştirmesi için ağırlıklarını kendi kendine güncellemesini tartışıyor: arXiv’de yayınlanan bir makale (2506.10943), büyük dil modellerinin (LLM) artık kendi ağırlıklarını güncelleyerek kendi kendini geliştirebileceğini öne sürüyor. Bu mekanizma, LLM’lerin yeni verilerden veya deneyimlerden öğrenebileceği ve tam bir yeniden eğitime gerek kalmadan performansını artırmak veya yeni görevlere uyum sağlamak için iç parametrelerini dinamik olarak ayarlayabileceği anlamına gelebilir. Bu araştırma yönü başarılı olursa, LLM’lerin uyarlanabilirliğini ve sürekli öğrenme yeteneğini büyük ölçüde artıracak ve daha otonom yapay zeka sistemlerine doğru önemli bir adım olacaktır (Kaynak: Reddit r/artificial)
🎯 Gelişmeler
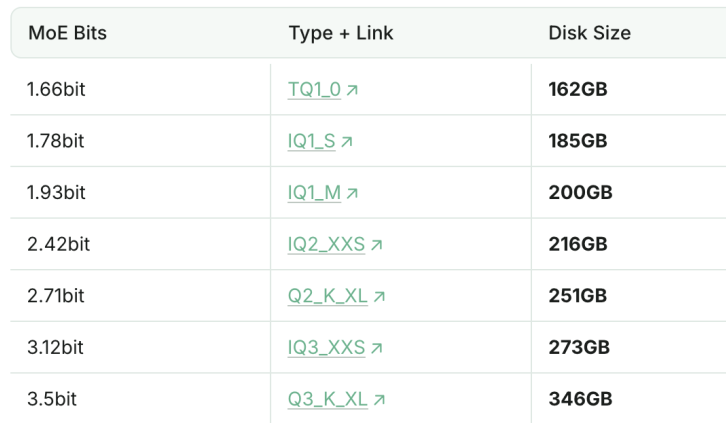
1.93bit nicelenmiş DeepSeek-R1, programlama yeteneğinde Claude 4 Sonnet’i geride bıraktı: Unsloth stüdyosu, DeepSeek-R1’i (0528 sürümü) başarıyla 1.93bit’e niceledi ve programlama kıyaslama testi aider’da %60’lık bir skor elde ederek Claude 4 Sonnet’i (%56.4) ve Ocak ayındaki tam sürüm R1’i geride bıraktı. Bu aşırı sıkıştırılmış sürümün dosya boyutu %70’ten fazla azaldı ve hatta GPU olmadan (CPU ve yeterli bellek ile) çalışabiliyor. Tam sürüm R1-0528, aider’da %71.4 puan alarak düşünme modu etkinleştirilmemiş Claude 4 Opus’u geçti. Bu, model niceleme teknolojisinin performansı korurken kaynak gereksinimlerini önemli ölçüde azaltma potansiyelini gösteriyor (Kaynak: 量子位)
Tencent Hunyuan, ilk üretim seviyesi PBR 3D oluşturma modeli Hunyuan 3D 2.1’i açık kaynak olarak yayınladı: Tencent Hunyuan ekibi, endüstrinin ilk tamamen açık kaynaklı, üretim seviyesine ulaşan PBR (Physically Based Rendering) 3D oluşturma modeli olan Hunyuan 3D 2.1’i duyurdu. Model, PBR malzeme sentezleme teknolojisini kullanarak sinema kalitesinde görsel efektlere sahip 3D içerikler üretebiliyor ve deri, bronz gibi malzemelerin ışık altında daha canlı ve gerçekçi görünmesini sağlıyor. Proje, model ağırlıklarını, eğitim/çıkarım kodlarını, veri işlem hatlarını ve mimarisini açık kaynak olarak sundu ve tüketici sınıfı ekran kartlarında çalışmayı destekleyerek 3D içerik oluşturma teknolojisinin geliştirilmesini ve yaygınlaştırılmasını amaçlıyor (Kaynak: op7418, ImazAngel)
Meta AI, 3D nokta bulutu temsillerinde kendi kendine denetimli öğrenmeyi ilerleten Sonata’yı yayınladı: Meta AI, 3D kendi kendine denetimli öğrenme alanında önemli ilerlemeler kaydeden bir araştırma olan Sonata’yı tanıttı. Sonata, geometrik kısayol sorunlarını belirleyip çözerek ve esnek, verimli bir çerçeve sunarak olağanüstü derecede sağlam 3D nokta bulutu temsilleri öğrenebiliyor. Bu çalışma, 3D algılama teknolojilerinin mevcut seviyesini yükseltiyor ve gelecekteki 3D algılama ve uygulama alanlarındaki yenilikler için temel oluşturuyor (Kaynak: AIatMeta)

Meta AI, okuma davranışını anlamak için “Vahşi Doğada Okuma Tanıma Veri Kümesi”ni yayınladı: Meta AI, video, göz takip ve baş duruş sensörü çıktılarını içeren “Reading Recognition in the Wild” adlı büyük, çok modlu bir veri kümesini kamuoyuna açıkladı. Bu veri kümesi, giyilebilir cihazlardan okuma tanıma görevlerini çözmeye yardımcı olmayı amaçlıyor ve 60Hz yüksek frekansta göz takip verilerini toplayan ilk ego-merkezli bakış açısı veri kümesi olup, insan okuma davranışını araştırmak için değerli bir kaynak sunuyor (Kaynak: AIatMeta)

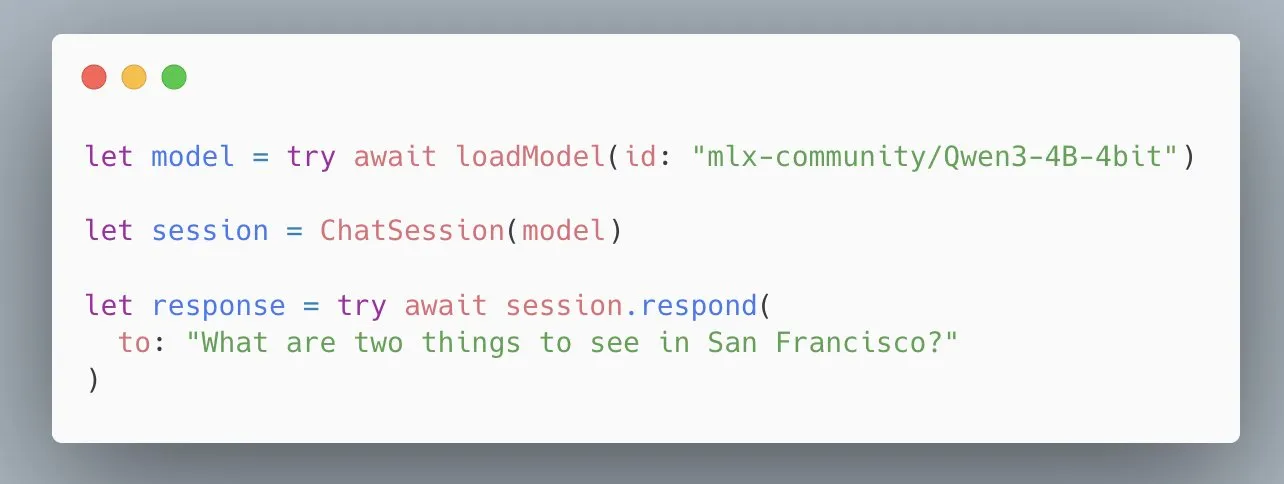
Apple MLX Swift LLM API basitleştirildi, modeli yüklemek için üç satır kod yeterli: Geliştiricilerin MLX Swift LLM API’sinin kullanımının zor olduğu yönündeki geri bildirimlerine yanıt olarak Apple ekibi hızla iyileştirmeler yaparak yeni, basitleştirilmiş bir API sundu. Artık geliştiriciler, Swift projelerinde LLM veya VLM yüklemek ve sohbet oturumu başlatmak için yalnızca üç satır kod kullanarak Apple ekosisteminde büyük dil modellerini kullanma engelini önemli ölçüde düşürdü (Kaynak: stablequan)
Google Gemma3 4B’nin Brezilya Portekizcesi için optimize edilmiş GAIA sürümü tanıtıldı: Google, Brezilya’daki çeşitli kurumlarla (ABRIA, CEIA-UFG, Nama, Amadeus AI) ve DeepMind ile işbirliği yaparak Brezilya Portekizcesi için optimize edilmiş açık kaynaklı dil modeli GAIA’yı (Gemma-3-Gaia-PT-BR-4b-it) yayınladı. Model, Gemma-3-4b-pt tabanlı olup, 13 milyar yüksek kaliteli Brezilya Portekizcesi belirteci üzerinde sürekli ön eğitime tabi tutuldu. GAIA, geleneksel SFT’ye ihtiyaç duymadan komut takibini sağlamak için yenilikçi “ağırlık birleştirme” tekniğini kullanıyor ve ENEM 2024 kıyaslama testinde temel Gemma modelini geride bıraktı. Model, sohbet, soru-cevap, özetleme, metin oluşturma ve Brezilya Portekizcesi ince ayarı için temel model olarak kullanıma uygundur (Kaynak: Reddit r/LocalLLaMA)
Figure AI robotu, ölçeklenebilir dağıtımı desteklemek için Helix AI ve otonomiyi birleştiriyor: Figure AI, gerçek dünya robotlarının Helix AI ve otonomiyi geliştirerek ölçeklenebilir dağıtımı nasıl desteklediğini gösterdi. Bu, fiziksel robotların gelişmiş yapay zeka modelleriyle birleşmesinin, robotların daha karmaşık ortamlarda uygulanmasını mümkün kıldığını ve robotik alanında mühendislik ile gelişmekte olan teknolojilerin önemini vurguladığını gösteriyor (Kaynak: Ronald_vanLoon)
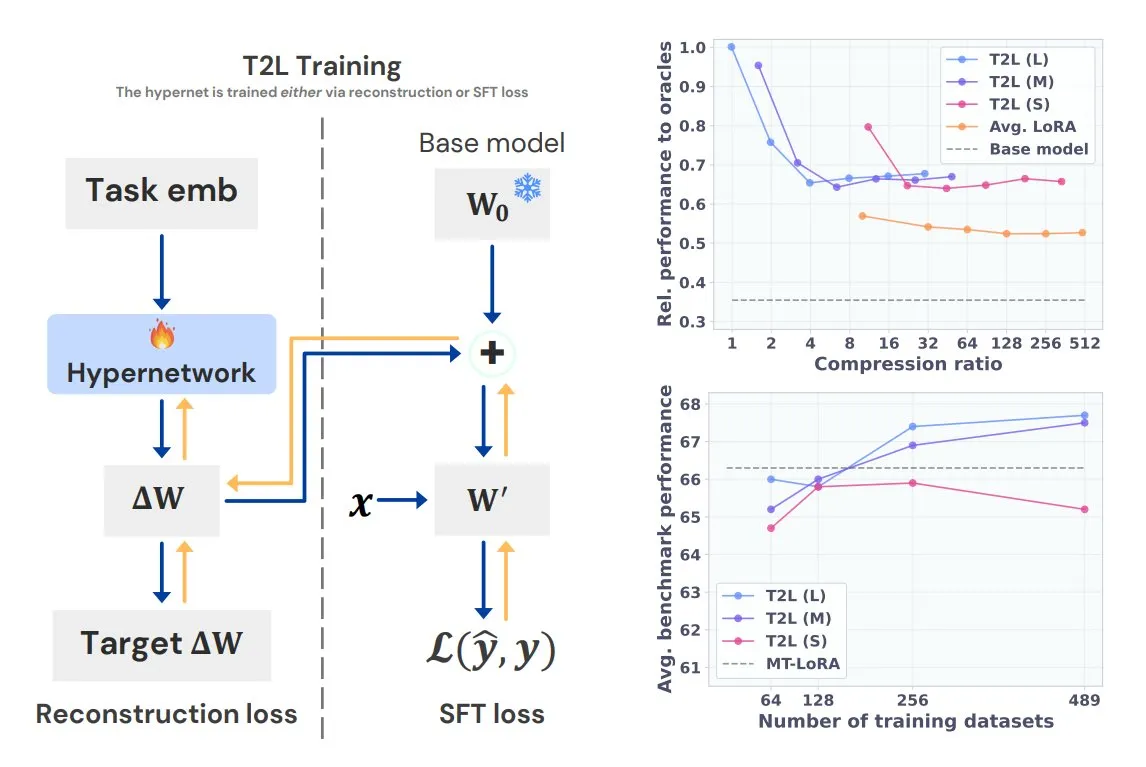
Sakana AI, Text-to-LoRA (T2L) hiperağını tanıttı: Sakana AI, mevcut birden fazla LoRA’yı (Düşük Rütbeli Adaptasyon) kendi içine sıkıştırabilen ve yalnızca görevin metin açıklamasıyla büyük dil modelleri için hızla yeni LoRA adaptörleri üretebilen yeni bir hiperağ olan Text-to-LoRA’yı (T2L) yayınladı. T2L, eğitildikten sonra anında yeni LoRA’lar oluşturabilir ve göreve özel LLM’lerin hızlı bir şekilde özelleştirilmesi ve dağıtılması için verimli bir yol sunar. İlgili sonuçlar ICML 2025’te sunulacaktır (Kaynak: TheTuringPost)
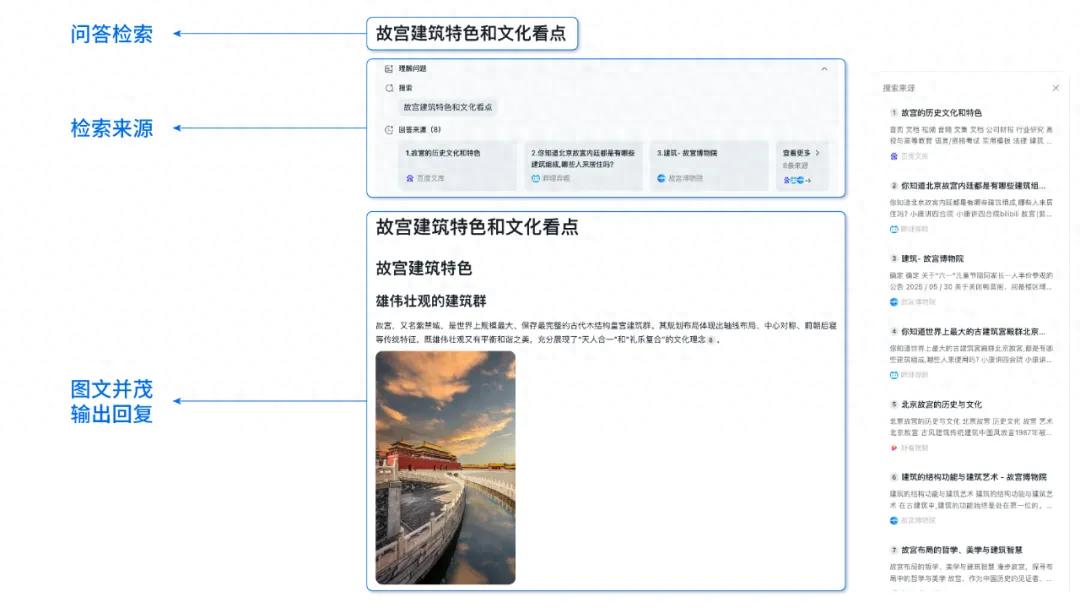
Baidu AI Search, Baidu Akıllı Bulut Qianfan platformunda tam olarak kullanıma sunuldu: Baidu Akıllı Bulut Qianfan Uygulama Geliştirme Platformu AppBuilder, “Baidu AI Search” hizmetini resmi olarak başlattı. Bu hizmet, “Baidu Search” ve “Akıllı Arama Üretimi” olmak üzere iki temel yeteneği birleştirerek işletmelere bilgi alımından akıllı üretime kadar tüm zincir boyunca hizmetler sunuyor. Baidu’nun 20 yılı aşkın Çince arama teknolojisinden ve yüz milyarlarca girişlik veritabanından yararlanarak reklamsız çok modlu arama sonuçları sunuyor ve hassas filtreleme, kaynak takibi ve kurumsal düzeyde güvenlik politikalarını destekliyor. Akıllı arama üretimi yeteneği, Wenxin, Deepseek gibi modellerle birleşerek yapay zeka özetleme, özel bilgi birleşik arama gibi işlevler sunuyor (Kaynak: 量子位)
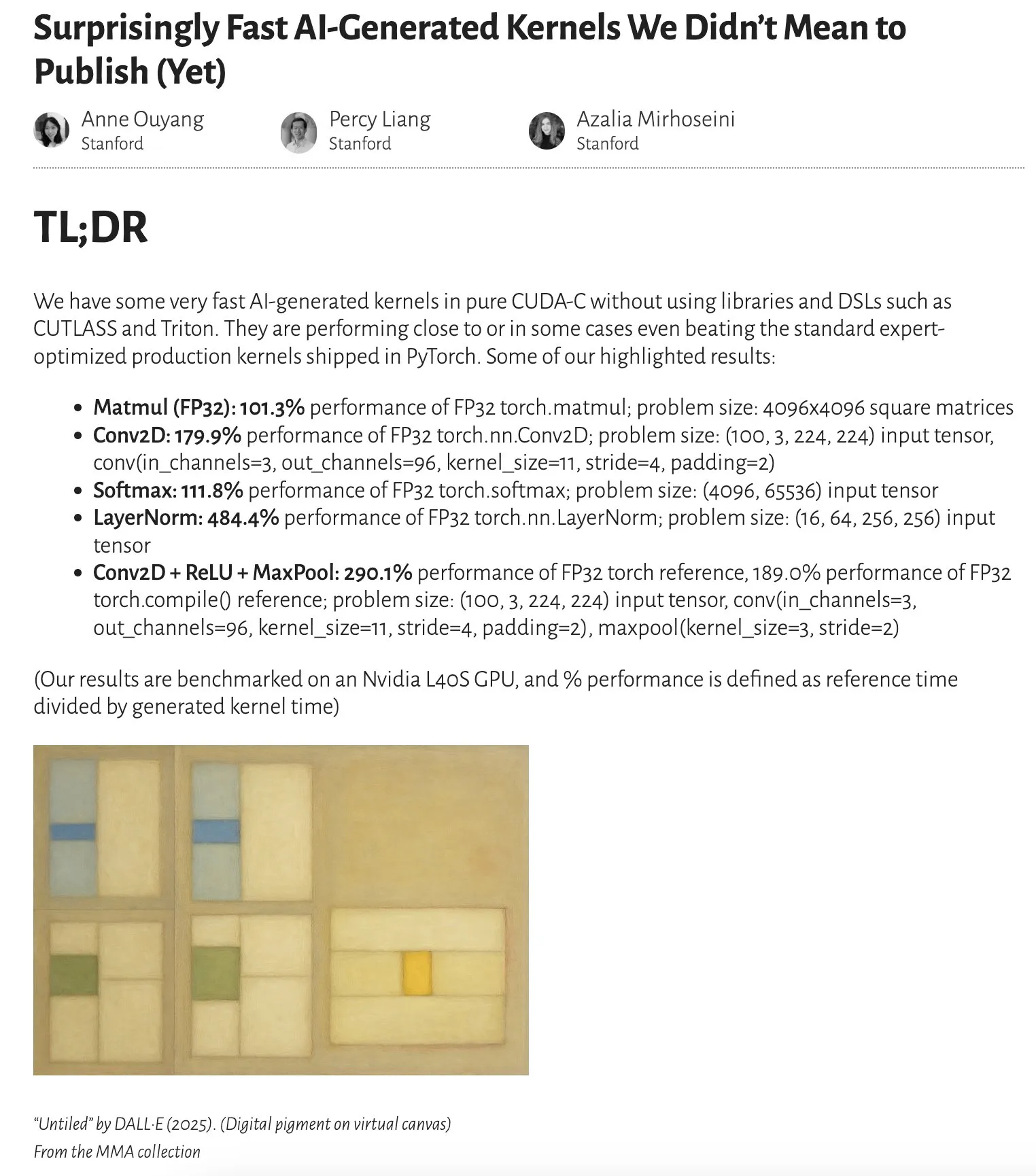
Araştırma, yapay zeka tarafından üretilen çekirdeklerin performansının uzmanlar tarafından optimize edilen çekirdeklere yaklaştığını hatta aştığını gösteriyor: Anne Ouyang’ın blog yazısı, yalnızca test zamanı araması (test-time only search) ile üretilen yapay zeka çekirdeklerinin performansının, PyTorch’taki standart, uzmanlar tarafından optimize edilmiş üretim çekirdeklerine yaklaştığını ve hatta bazı durumlarda aştığını belirtiyor. Bu, yapay zekanın kod optimizasyonu ve performans artışı konusunda büyük bir potansiyele sahip olduğunu ve gelecekte alt düzey kütüphane optimizasyonunda daha önemli bir rol oynayabileceğini gösteriyor (Kaynak: jeremyphoward)
“Difüzyon İkiliği” araştırması, ayrık difüzyon dil modellerinde az adımlı üretim için yeni bir yöntem öneriyor: ICML 2025’te yayınlanan “The Diffusion Duality” adlı bir makale, gizli Gauss difüzyonundan yararlanarak ayrık difüzyon dil modellerinde az adımlı üretim gerçekleştirmek için yeni bir yöntem öneriyor. Bu yöntem, 7 sıfır-atış olasılık kıyaslama testinin 3’ünde otoregresif (AR) modelleri geride bırakarak difüzyon modellerinin üretim verimliliğini artırmak için yeni bir yaklaşım sunuyor (Kaynak: arankomatsuzaki)
MLP katmanı yorumlanabilirliğinde yeni bir atılım: aktivasyonların yorumlanabilir özelliklere ayrıştırılması: Mor Geva ve arkadaşlarının yeni araştırması, çok katmanlı algılayıcıların (MLP) aktivasyonlarını yorumlanabilir özelliklere ayrıştırmak için basit bir yöntem gösteriyor. Bu yöntem, seyrek nöron kombinasyonlarının giderek daha soyut kavramlar oluşturduğu gizli bir kavram hiyerarşisini ortaya çıkararak sinir ağlarının iç işleyişini anlamak için daha derin bir bakış açısı sunuyor (Kaynak: menhguin)

HeadHunter çerçevesi, pertürbe edilmiş dikkat yönlendirmesi üzerinde hassas kontrol sağlıyor: Sayak Paul ve arkadaşları, pertürbe edilmiş dikkat yönlendirmesinin ilkeli bir analizi için HeadHunter çerçevesini önerdi. Bu çerçeve, üretim kalitesi ve görsel özellikler üzerinde derin, ince taneli kontrol sağlayarak üretken modellerin çıktısını iyileştirmek ve özelleştirmek için yeni araçlar ve içgörüler sunuyor (Kaynak: huggingface, RisingSayak)

🧰 Araçlar
Windsurf ücretli planları artık Claude Sonnet 4’ü destekliyor: Windsurf, tüm ücretli planlarının Claude Sonnet 4 modelini kullanıma sunduğunu duyurdu. Kullanıcılar artık Windsurf platformunda Anthropic’in bu en yeni modelinin güçlü özelliklerini metin üretimi, diyalog gibi görevler için kullanarak yapay zeka asistanlarının performansını ve deneyimini daha da artırabilirler (Kaynak: op7418)
Anthropic, Claude Code için resmi Python SDK’sını yayınladı: Anthropic, geliştiricilerin Claude’un kod üretme ve araç kullanma yeteneklerini kendi Python projelerine entegre etmelerini kolaylaştırmak amacıyla Claude Code için resmi Python SDK’sını yayınladı. Bu SDK, araç kullanımı, akışlı çıktı, senkron/asenkron işlemler, dosya işleme özelliklerini destekliyor ve yerleşik sohbet yapısıyla Claude Code ile etkileşim geliştirme sürecini basitleştiriyor (Kaynak: Reddit r/ClaudeAI)
Claude Task Master VS Code eklentisi yayınlandı: DevDreed, Claude Task Master VS Code eklentisinin 1.0.0 sürümünü yayınladı. Bu eklenti, eyaltoledano’nun Claude Task Master AI projesini tamamlamayı amaçlıyor ve Claude Task Master’ın çıktılarını doğrudan VS Code arayüzüne entegre ederek kullanıcıların düzenleyici ve konsol arasında sorunsuz geçiş yapmasını sağlayarak geliştirme verimliliğini artırıyor (Kaynak: Reddit r/ClaudeAI)
SmartSelect AI: Tarayıcı içi metin ve görüntü yapay zeka işleme aracı: SmartSelect AI adlı bir Chrome eklentisi yayınlandı. Bu eklenti, kullanıcıların web’de gezinirken seçtikleri metni doğrudan özetlemesine, çevirmesine veya sohbet etmesine, resimleri yapay zeka ile tanımlamasına olanak tanıyor; sekmeler arasında geçiş yapmaya veya ChatGPT gibi harici uygulamalara kopyalayıp yapıştırmaya gerek kalmıyor. Araç, Gemini modeline dayanıyor ve bilgi edinme ve işleme verimliliğini artırmayı amaçlıyor (Kaynak: Reddit r/deeplearning)

Unsiloed AI, çok amaçlı veri parçalama aracını açık kaynak olarak yayınladı: Unsiloed AI (EF 2024), veri parçalama (chunker) işlevlerinin bir kısmını açık kaynak olarak yayınladı. Bu araç, PDF, Excel, PPT gibi çeşitli formatlardaki belgeleri işlemeye yardımcı olarak bunları büyük dil modellerinin işleyebileceği formatlara dönüştürmeyi amaçlıyor. Unsiloed AI, Fortune 100 şirketleri ve birçok startup tarafından çok modlu veri alımı için kullanılıyor (Kaynak: Reddit r/LocalLLaMA)
Claude Superprompt System: Claude istemlerini optimize etmek için ücretsiz bir araç: Igor Warzocha, kullanıcıların basit istekleri, Claude’un yeteneklerinden daha iyi yararlanmak için düşünce zinciri ve bağlamsal örnekler içeren yapılandırılmış, karmaşık istemlere dönüştürmelerine yardımcı olmak amacıyla “Claude Superprompt System” adlı çevrimiçi bir araç geliştirdi ve paylaştı. Araç, Anthropic’in resmi belgelerine ve topluluk tarafından keşfedilen en iyi uygulamalara dayanarak, XML etiket yapısı, CoT çıkarım blokları gibi yöntemlerle istemleri optimize ederek Claude’un çıktı kalitesini artırıyor. Proje kodu GitHub’da açık kaynak olarak yayınlandı (Kaynak: Reddit r/artificial)
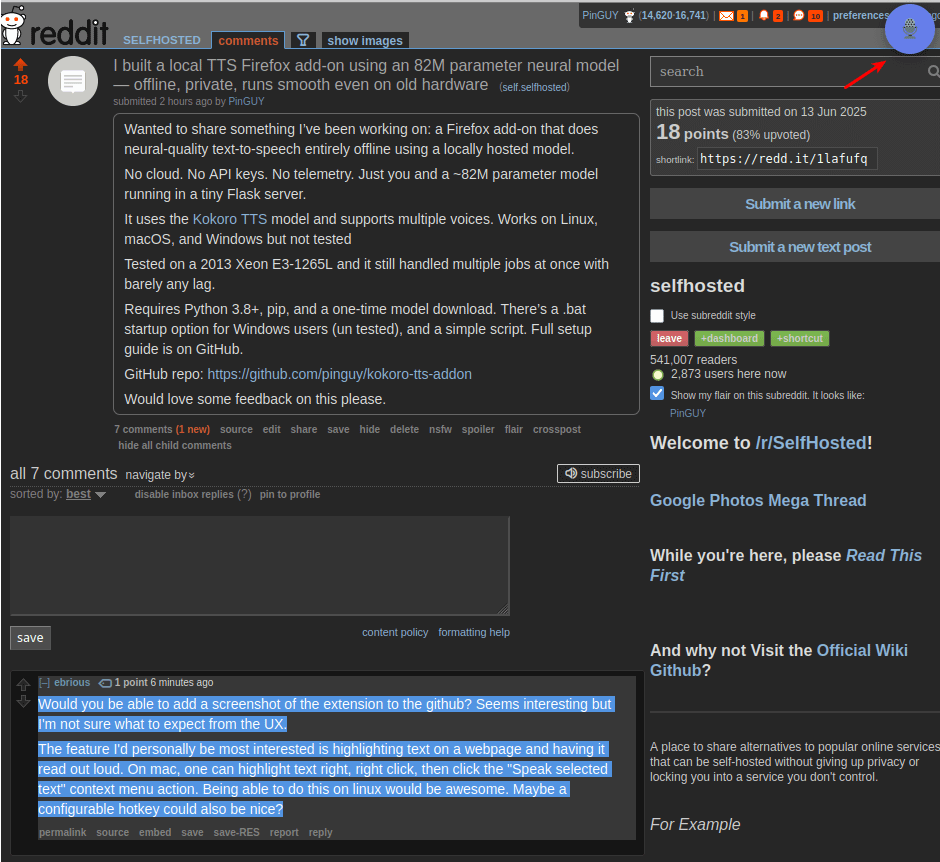
Yerel TTS Firefox eklentisi Kokoro-TTS yayınlandı: Geliştirici Pinguy, metinden sese dönüştürme için 82M parametreli yerel olarak barındırılan bir sinir ağı modeli (Kokoro TTS modeli) kullanan Kokoro TTS adlı bir Firefox eklentisi yayınladı. Eklenti tamamen çevrimdışı çalışarak kullanıcı gizliliğini koruyor. Çeşitli sesleri ve aksanları destekliyor, eski donanımlarda bile sorunsuz çalışıyor ve Windows, Linux ve macOS sürümleri sunuyor (Kaynak: Reddit r/artificial)
Spy Search: Açık kaynaklı LLM arama motoru projesi güncellendi: JasonHonKL, açık kaynaklı LLM arama motoru projesi Spy Search’ü güncelledi. Proje, büyük dil modellerine dayalı verimli bir arama motoru oluşturmaya odaklanıyor ve en son sürümü 3 saniye içinde arama yapıp yanıt verebiliyor. Proje kodu GitHub’da barındırılıyor ve kullanıcılara hızlı, kullanışlı bir günlük arama aracı sunmayı amaçlıyor (Kaynak: Reddit r/deeplearning)
HandFonted: El yazısını yazı tipine dönüştürme aracı açık kaynak oldu: Resham Gaire, el yazısı karakter resimlerini yüklenebilir .ttf yazı tipi dosyalarına dönüştüren uçtan uca bir Python uygulaması olan HandFonted projesini geliştirdi ve açık kaynak olarak yayınladı. Sistem, görüntü işleme ve karakter segmentasyonu için OpenCV’yi, karakter sınıflandırması için özel bir PyTorch modelini (ResNet-Inception) kullanıyor ve en iyi eşleşme için Macar algoritmasını uyguluyor, son olarak fontTools kütüphanesini kullanarak yazı tipi dosyasını oluşturuyor (Kaynak: Reddit r/MachineLearning)
📚 Öğrenme Kaynakları
Wei Dongyi ve diğerlerinin makalesi matematik dergisinde zirveye yerleşti, süperkritik odak dağıtıcı doğrusal olmayan dalga denkleminin patlama olgusunu inceliyor: Pekin Üniversitesi akademisyenleri Wei Dongyi, Zhang Zhifei ve Shao Feng’in ortak makalesi “On blow-up for the supercritical defocusing nonlinear wave equation”, en iyi matematik dergilerinden biri olan “Forum of Mathematics, Pi”de yayınlandı. Araştırma, belirli bir odak dağıtıcı doğrusal olmayan dalga denkleminin süperkritik durumdaki patlama (çözümün sonlu bir zamanda sonsuz hale gelmesi) sorununu inceliyor. Uzay boyutu d=4 ve p≥29 ile d≥5 ve p≥17 durumlarında, sonlu zamanda patlayan pürüzsüz karmaşık değerli çözümlerin varlığını kanıtladılar. Bu başarı, ilgili alandaki bir boşluğu dolduruyor ve ispat yöntemi, diğer doğrusal olmayan kısmi diferansiyel denklemlerin patlama araştırmaları için yeni fikirler sunuyor (Kaynak: 量子位)

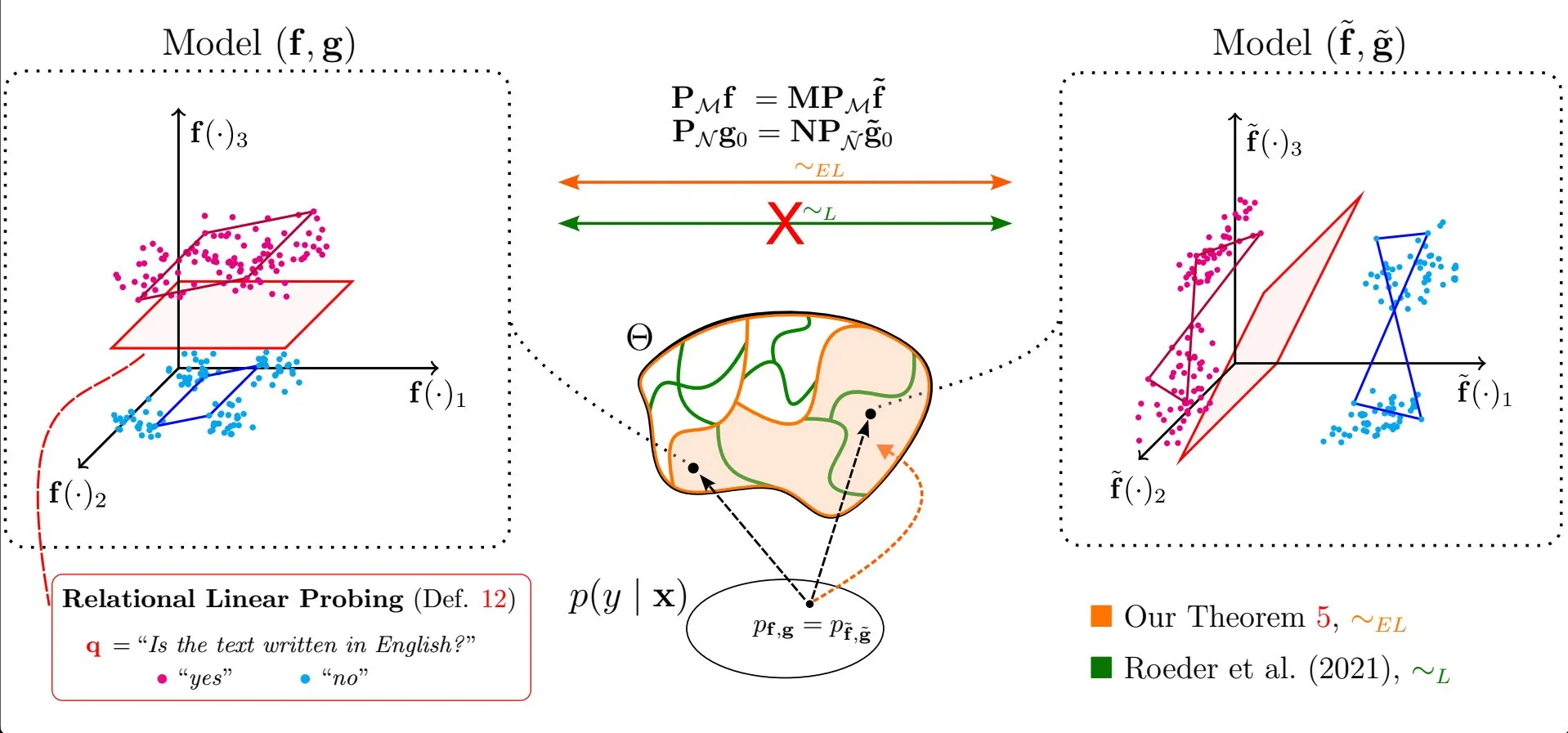
Makale, büyük dil modeli temsillerindeki doğrusal özelliklerin evrenselliğini tartışıyor: Emanuele Marconato ve arkadaşlarının “All or None: Identifiable Linear Properties of Next-token Predictors in Language Modeling” (AISTATS 2025’te yayınlandı) adlı araştırması, tanımlanabilirlik açısından büyük dil modellerinin (LLM) temsillerinde doğrusal özelliklerin neden bu kadar yaygın olduğunu inceliyor. Bu araştırma, LLM’lerin iç temsillerinin yapısını ve davranışını daha derinlemesine anlamaya yardımcı oluyor (Kaynak: menhguin)
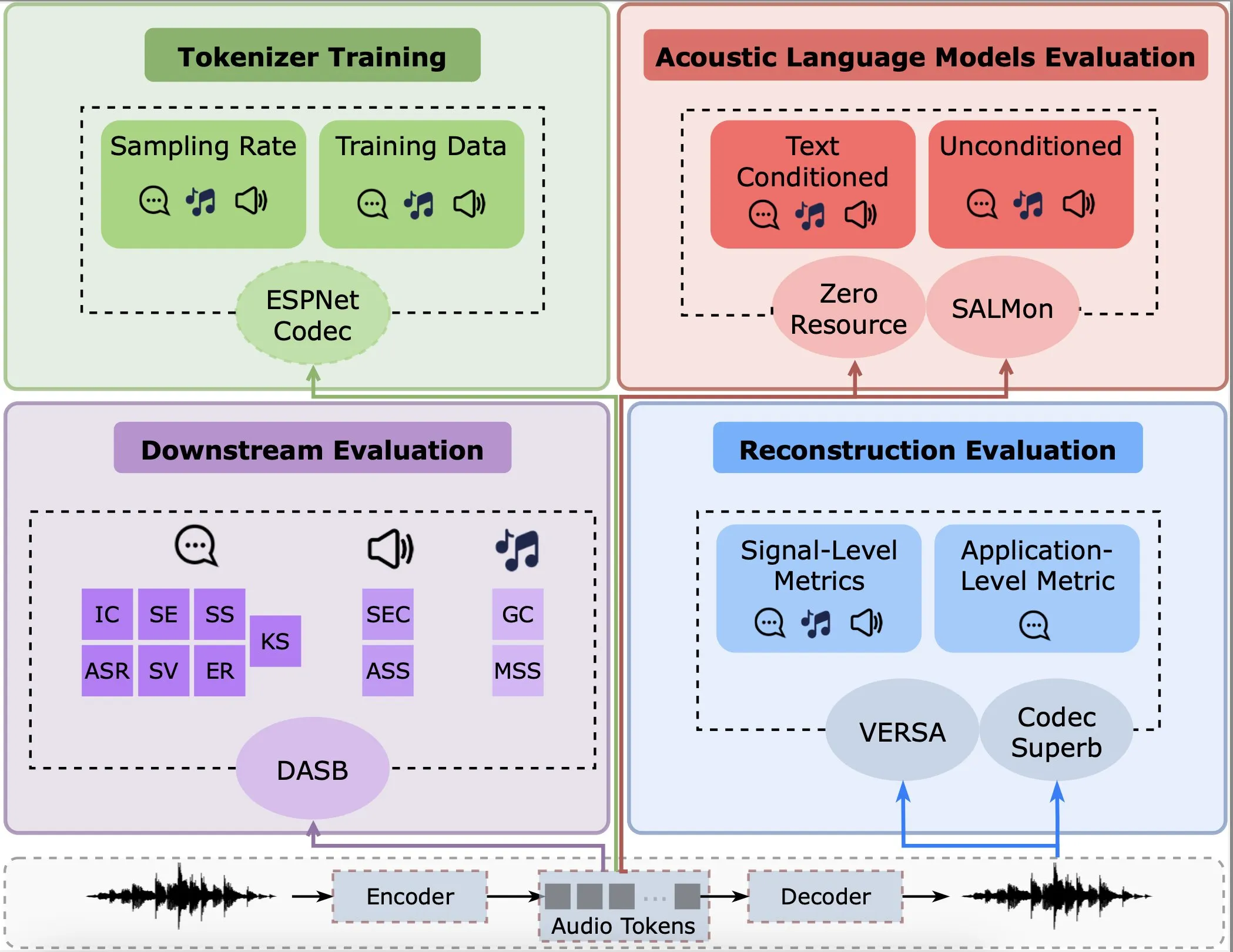
Araştırma, ses kodlayıcıların yeniden yapılandırma, alt görevler ve dil modellerindeki performansını analiz ediyor: Gallil Maimon ve arkadaşları, mevcut ses kodlayıcıları (Audio Tokenisers) üzerinde kapsamlı bir ampirik analiz yapan yeni bir araştırma yayınladı. Araştırma, bu kodlayıcıları yeniden yapılandırma kalitesi, alt görevlerdeki performansları ve dil modelleriyle entegrasyonları gibi birden fazla boyutta değerlendirerek ses işleme modellerinin seçimi ve optimizasyonu için referans sağlıyor (Kaynak: menhguin)
Makale “düşünce yanılsamasını” tartışıyor: çıkarım modellerinin artılarını ve eksilerini sorun karmaşıklığı perspektifinden anlamak: Apple’ın “düşünce yanılsaması” araştırmasına yanıt olarak bir makale (arXiv:2506.09250) sunuldu ve Claude Opus ilk yazar olarak listelendi. Makale, Apple araştırmasının deney tasarımını eleştiriyor ve gözlemlenen çıkarım çöküşünün aslında modelin içsel mantık yeteneğinin eksikliğinden değil, belirteç sınırlamalarından kaynaklandığını savunuyor. Bu, büyük dil modellerinin gerçek çıkarım yeteneklerinin nasıl değerlendirileceği konusunda bir tartışma başlattı (Kaynak: NandoDF, BlancheMinerva, teortaxesTex)

Araştırma uyarlanabilir dil modellerini tartışıyor, ancak orta vadeli bellek hala bir zorluk: Dorialexander, “uyarlanabilir dil modelleri” ile ilgili makaleleri inceledikten sonra, bunun umut verici bir araştırma yönü olmasına rağmen, modellerin çıkarım sırasında orta vadeli belleği gerçekleştirmede hala sınırlamaları olduğunu belirtiyor. Bu, mevcut modellerin daha uzun bağlamlara yayılan tutarlı bilgileri işlemede hala zorluklarla karşılaştığını gösteriyor (Kaynak: Dorialexander)

RLHF test kalitesi araştırması: Mevcut testler ne kadar iyi? Nasıl geliştirilebilir? Test kalitesi ne kadar önemli?: Kexun Zhang ve arkadaşlarının son çalışması, özellikle LLM kodlama alanında, insan geri bildiriminden pekiştirmeli öğrenmede (RLHF) doğrulayıcıların (testlerin) önemini tartışıyor. Araştırma üç temel soru ortaya koyuyor: Mevcut testlerin kalitesi nasıl? Daha iyi testler nasıl elde edilebilir? Test kalitesi model performansını ne kadar etkiliyor? Bu araştırma, LLM kodlama yeteneklerini geliştirmek için yüksek kaliteli testlerin gerekliliğini vurguluyor (Kaynak: StringChaos)
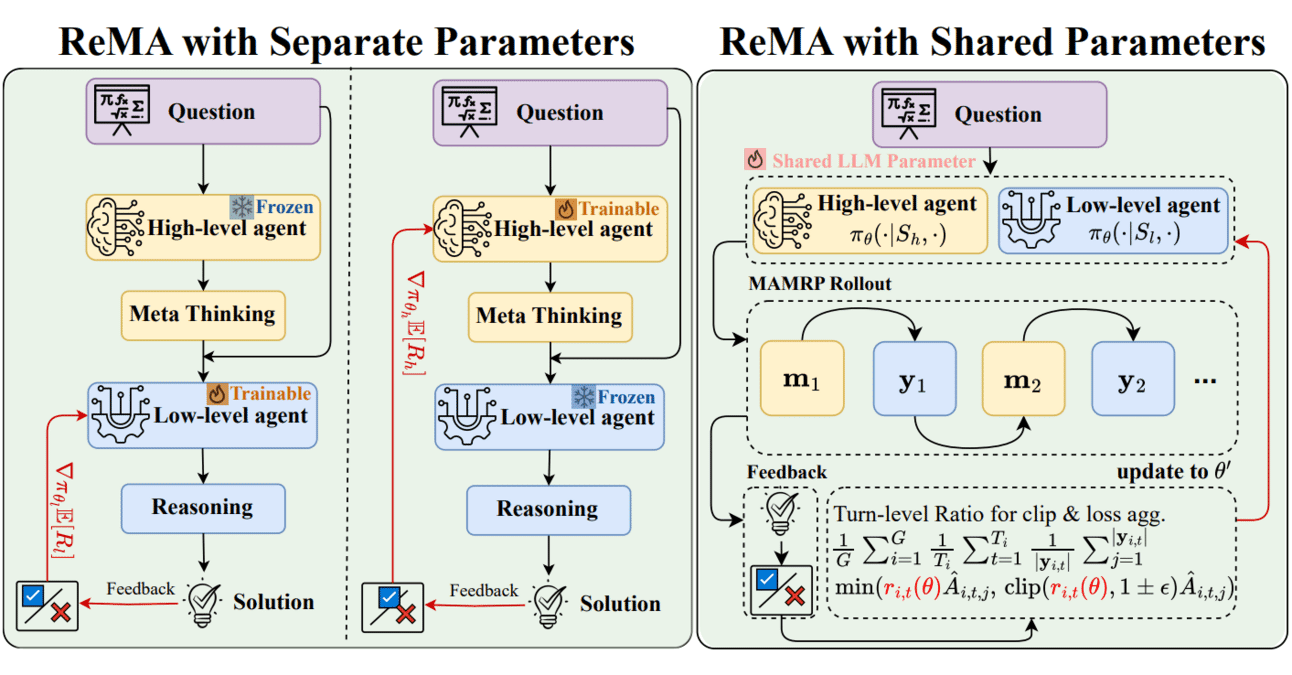
Meta-öğrenme ve pekiştirmeli öğrenme birleşimi: ReMA, LLM işbirliği verimliliğini artırıyor: Reinforced Meta-thinking Agents (ReMA), özellikle birden fazla LLM ajanının işbirliği içinde çalıştığı durumlarda büyük dil modellerinin (LLM) verimliliğini artırmak için meta-öğrenme (Meta-learning) ve pekiştirmeli öğrenmeyi (RL) birleştiriyor. ReMA, problem çözmeyi meta-düşünme (strateji planlama) ve çıkarım (strateji yürütme) olmak üzere iki bölüme ayırıyor ve özel ajanlar ve çoklu ajan pekiştirmeli öğrenme yoluyla optimizasyon yaparak hem matematiksel kıyaslamalarda hem de hakem olarak LLM’lerin kullanıldığı kıyaslamalarda iyileştirmeler sağlıyor (Kaynak: TheTuringPost, TheTuringPost)
Yapay zeka değerlendirme stratejileri: Bütçe kısıtlamaları altında en iyi model kalitesi tahminini elde etmek için ucuz ve pahalı değerlendiriciler nasıl birleştirilir: Adam Fisch ve arkadaşlarının araştırması (arXiv:2506.07949) pratik bir sorunu ele alıyor: ucuz ama gürültülü bir değerlendiriciye, pahalı ama doğru bir değerlendiriciye ve sabit bir bütçeye sahip olunduğunda, model kalitesinin en doğru tahminini elde etmek için bütçe nasıl tahsis edilmelidir. Bu araştırma, yapay zeka sistemlerinin değerlendirilmesi için maliyet-etkinlik analizi çerçevesi sunuyor (Kaynak: Ar_Douillard)
LLM istemlerinde “sahte ödül” ve “sahte istem” olgusu: Stella Li ve arkadaşlarının araştırması, LLM eğitimi ve değerlendirmesindeki ilginç olguları ortaya koyuyor. “Sahte ödül” (örneğin rastgele ödüllerin bile bazı görevlerde model performansını artırabilmesi) keşfinin ardından, “Lorem ipsum” gibi anlamsız metinlerin bile bazı durumlarda önemli performans artışları (%19.4 gibi) sağlayabildiği “sahte istem” olgusunu daha da araştırıyorlar. Bu bulgular, LLM’lerin istemlere nasıl yanıt verdiğini ve daha sağlam değerlendirme yöntemlerinin nasıl tasarlanacağını anlamak için yeni zorluklar ve düşünceler ortaya koyuyor (Kaynak: Tim_Dettmers)

Makale, yapay zeka etkileşiminin “kukla tiyatrosu” modelini tartışıyor: “The Pig in Yellow: AI Interface as Puppet Theatre” başlıklı bir makale (veya taslak), dilsel yapay zeka sistemlerini (LLM, AGI, ASI) öznelliğe sahip olmaktan ziyade öznelliği taklit eden performatif arayüzler olarak ele almayı öneriyor. Makale, “Miss Piggy” benzetmesini kullanarak yapay zekanın akıcılığının, tutarlılığının ve duygusal ifadesinin zihinsel göstergeler olmadığını, optimizasyon ürünleri olduğunu analiz ediyor ve arayüzün bir kukla gibi olduğunu, kullanıcıların etkileşimde anlamı birlikte inşa ettiğini ve gücün performatif tasarım yoluyla kendini gösterdiğini vurguluyor (Kaynak: Reddit r/artificial)
💼 İş Dünyası
“DJI’ın vaftiz babası” Li Zexiang’ın hissedarı olduğu Woan Robot, halka arz için hazırlanıyor: Harbin Teknoloji Enstitüsü mezunu kardeşler tarafından kurulan ve yapay zeka destekli ev robotlarına odaklanan Woan Robot (SwitchBot), Hong Kong borsasına başvuru dosyasını sundu. Şirket, “DJI’ın vaftiz babası” Li Zexiang’dan yatırım ve kaynak desteği aldı; Li Zexiang %12.98 hisseye sahip. Woan Robot, son on yılda yedi tur finansman alarak değerlemesini 20 milyon RMB’den 40 milyar RMB’ye çıkardı. Ürünleri arasında insan uzuv hareketlerini taklit eden yürütme robotları ve algılama-karar verme sistemleri bulunuyor ve %11.9 pazar payıyla küresel yapay zeka destekli ev robotları alanında en büyük tedarikçi haline geldi. Şirket, 2024’te 1.11 milyon RMB düzeltilmiş net kar elde etti (Kaynak: 量子位)

Tencent, 2026 “Qingyun Planı”nı başlattı, ilk kez konu kaynak havuzunu açtı: Tencent, 2026 “Qingyun Planı”nı başlattığını duyurdu. Plan, dünya çapındaki en iyi teknoloji öğrencilerine yönelik olup, yapay zeka büyük modelleri, temel altyapı, yüksek performanslı hesaplama gibi on ana teknoloji alanını kapsıyor ve yüzün üzerinde teknoloji konusu sunuyor. Önceki yıllardan farklı olarak, bu dönemki plan ilk kez Qingyun konu kaynak havuzunu açıyor ve seçkin yeteneklere işe alım için yeşil koridor sağlıyor. Amaç, okul-işletme işbirliğini derinleştirmek ve genç teknoloji yeteneklerini yetiştirmek. Tencent, sektörün önde gelen eğitmenlerini, hesaplama kaynaklarını ve rekabetçi maaşları sağlayacak (Kaynak: 量子位)

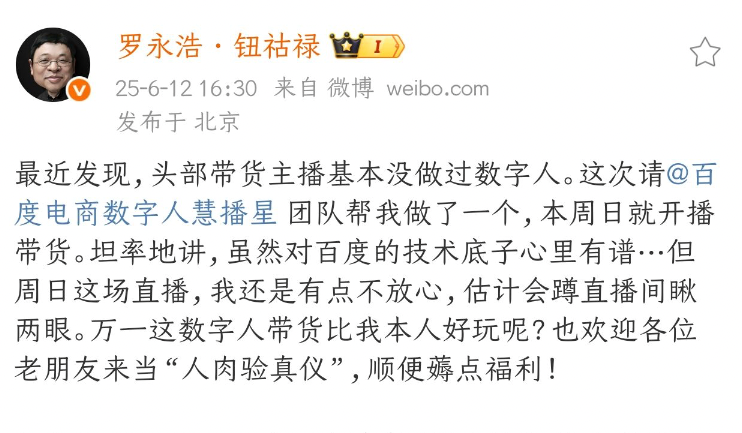
Luo Yonghao’nun dijital insanı 15 Haziran’da Baidu e-ticaret platformunda yayına başlayacak: Luo Yonghao, yapay zeka dijital ikizinin 15 Haziran’da Baidu e-ticaret platformunda ilk canlı yayınını yapacağını duyurdu. Bu, Baidu’nun yüksek ikna kabiliyetine sahip dijital insanlar gibi kilit teknolojilerdeki atılımları sayesinde, önde gelen bir yayıncının yapay zeka dijital insan kullanarak canlı satış yapacağı ilk örnek olacak. Bu adım, “Yapay Zeka + Önde Gelen IP” e-ticaretinde yeni bir paradigmanın keşfi olarak görülüyor ve canlı yayın e-ticaret sektörünün akıllılaşma, verimlilik ve düşük maliyet yönünde gelişmesini teşvik etmesi bekleniyor. Baidu e-ticaret verilerine göre, halihazırda 100.000’den fazla dijital insan yayıncı çeşitli sektörlerde kullanılıyor, bu da satıcıların işletme maliyetlerini önemli ölçüde düşürüyor ve GMV’yi artırıyor (Kaynak: 量子位)
🌟 Topluluk
Çinli yapay zeka şirketleri, modelleri eğitmek için büyük miktarda veri içeren sabit diskleri Malezya’ya taşıyor: NIK, Çinli yapay zeka şirketlerinin çip kısıtlamalarını aşmak ve denizaşırı hesaplama kaynaklarından yararlanmak için eğitim verileriyle dolu sabit diskleri Malezya gibi yerlere “insan gücüyle” taşıma stratejisi benimsediğini bildirdi. Örneğin, bir mühendisin 80TB veri içeren 15 sabit diski Malezya’ya uçarak model eğitimi için sunucu kiraladığı belirtiliyor. Bu olgu, küresel yapay zeka hesaplama rekabetinin yoğunluğunu ve verilerin sınır ötesi akışının gerçek zorluklarını yansıtıyor, aynı zamanda veri güvenliği ve uyumluluğu hakkında tartışmalara yol açıyor (Kaynak: jpt401, agihippo, cloneofsimo, fabianstelzer)

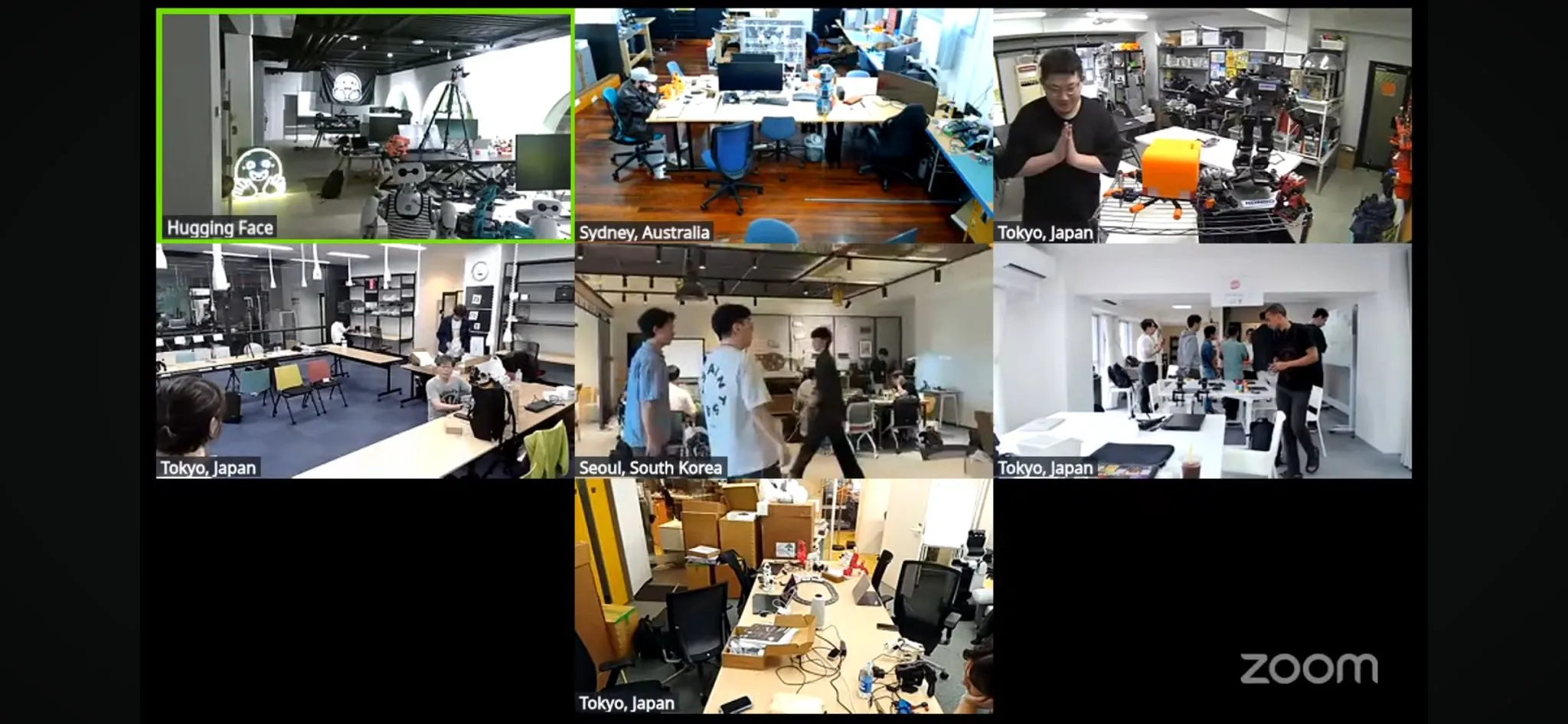
Dünyanın en büyük LeRobot robot hackathon’u başladı: Hugging Face tarafından düzenlenen LeRobot küresel robot hackathon’u, dünya genelinde 5 kıtada 100’den fazla lokasyonda resmen başladı ve 2300’den fazla katılımcıyı cezbetti. Etkinlik, açık kaynaklı yapay zeka robotlarının geliştirilmesini teşvik etmeyi amaçlıyor ve katılımcılar 52 saat boyunca robotlarla ilgili yapım ve keşif çalışmaları yapacaklar. Çeşitli yerlerden geliştiriciler ve ekipler coşkuyla katılarak etkinlik fotoğraflarını ve proje ilerlemelerini paylaştı, bu da topluluğun robot teknolojisine olan tutkusunu ve yaratıcılığını gösteriyor (Kaynak: _akhaliq, eliebakouch, ClementDelangue)
Lovable, yapay zeka web sayfası oluşturma yarışması düzenledi, Claude’un performansı övgü aldı: Lovable, kullanıcıların OpenAI, Anthropic ve Google’ın en iyi modellerini ücretsiz olarak kullanarak yapay zeka web sayfası oluşturma yarışmasına katılmasına olanak tanıyan bir etkinlik düzenledi. Kullanıcı op7418, aynı istem setini kullanarak üç modelle web sayfası oluşturma deneyimini paylaştı ve Claude’un içerik miktarı ve görsel efektler açısından öne çıktığını belirtti. Bu tür etkinlikler, geliştiricilere ve kullanıcılara farklı büyük modellerin belirli uygulama senaryolarındaki performanslarını karşılaştırma fırsatı sunuyor (Kaynak: _philschmid, op7418)
Yapay zeka modellerinin çıkarım yetenekleri üzerine tartışma: belirteç sınırlamaları ve gerçek mantık: Apple’ın “Düşünce Yanılsaması” (Illusion of Thinking) makalesine karşı toplulukta karşıt görüşler ortaya çıktı. Yorumlar ve sonraki araştırmalar (örneğin, Claude Opus’u yazar olarak listeleyen arXiv:2506.09250), gözlemlenen model çıkarım yeteneği “çöküşünün” modelin kendi mantık yeteneğinin eksikliğinden ziyade belirteç sayısı sınırlamalarından kaynaklandığını savunuyor. Modellerin daha sıkıştırılmış yanıt formatları kullanmasına veya yeterli bağlama sahip olmasına izin verildiğinde, sorunları başarıyla çözebildikleri belirtiliyor. Bu, büyük dil modellerinin gerçek çıkarım yeteneklerinin nasıl doğru bir şekilde değerlendirileceği ve anlaşılacağı ile mevcut değerlendirme yöntemlerinin olası sınırlamaları hakkında derinlemesine bir tartışma başlattı (Kaynak: NandoDF, BlancheMinerva, teortaxesTex, rao2z)
DSPy çerçevesi, karmaşık çok aşamalı dil modeli programlarının optimizasyonunu destekliyor: Omar Khattab, DSPy çerçevesinin 2022/2023’ten beri karmaşık çok aşamalı dil modeli programlarının (Compound AI Systems) istem optimizasyonu ve pekiştirmeli öğrenmesini desteklediğini vurguladı. Yapay zeka sistemleri giderek karmaşıklaştıkça, onları basit “modeller” yerine “programlar” olarak görmenin daha uygun olduğunu savunuyor. DSPy, yalnızca doğrusal “akışlar” veya “zincirler” değil, özyineleme, istisna işleme vb. dahil olmak üzere bu tür keyfi karmaşıklıktaki programları oluşturmak ve optimize etmek için destek sağlamayı amaçlıyor (Kaynak: lateinteraction)
LLM’lerin insan düşüncesine benzer olup olmadığına dair tartışma: Geoffrey Hinton, büyük dil modellerinin (LLM) insanların dili işleme biçimine benzediğini ve dilin nasıl çalıştığını anlamamız için en iyi model olduğunu düşünüyor. Ancak Pedro Domingos buna itiraz ederek, LLM’lerin eski dilbilim teorilerinden daha iyi olmasının, onların insanlar gibi düşündüğü anlamına gelmediğini savunuyor. Bu tartışma, yapay zeka alanında LLM’lerin doğası ve insan bilişiyle ilişkisi hakkındaki süregelen tartışmayı yansıtıyor (Kaynak: pmddomingos)
Yapay zekanın fizik bilimleri araştırmalarındaki uygulama potansiyeli büyük: Yerbilimleri alanında bir araştırmacı, o3 Pro (muhtemelen OpenAI’nin gelişmiş bir modelini kastediyor) kullanma konusundaki olumlu deneyimlerini paylaştı ve araştırmada “çok zeki bir doktora sonrası araştırmacı” gibi olduğunu söyledi. Model, kodlama, model geliştirme, fikirleri rafine etme konularında mükemmel performans gösterdi, talimatları hızlı ve doğru bir şekilde yerine getirebildi ve araştırmaya yardımcı oldu. Araştırmacı, mevcut modellerin henüz aktif olarak araştırma soruları önerme yeteneğine (AGI özelliği) sahip olmamasına rağmen, güçlü yardımcı işlevlerinin araştırma verimliliğini önemli ölçüde artırdığını ve otonom LLM’lerin çok uzakta olmadığını hissettiğini belirtti (Kaynak: Reddit r/ArtificialInteligence)
💡 Diğer
Yapay zeka ile çizgi roman oluşturma araçları yaratıcı ifadeyi kolaylaştırıyor: Kullanıcı StriderWriting, yapay zeka araçlarını kullanarak çizgi roman oluşturma deneyimini paylaştı ve yapay zekanın “aptalca fikirleri” çizgi romana dönüştürmeyi mümkün kıldığını belirtti. Bu, yapay zekanın yaratıcı içerik üretimi alanındaki yaygınlaşmasını yansıtıyor, yaratım engelini düşürüyor ve daha fazla insanın yaratıcılığını kolayca ifade etmesini sağlıyor (Kaynak: Reddit r/ChatGPT)

Yapay zeka önyargılarına ilişkin endişeler: ChatGPT’nin cinsiyetçi kalıp yargılar konusundaki performansı kullanıcıları rahatsız etti: Bir kadın kullanıcı, ChatGPT’nin konuşmalarında erkeklere yönelik olumsuz kalıp yargılar sergilediğini, örneğin iş ve tıbbi sorunlar tartışılırken, herhangi bir yönlendirme olmaksızın olumsuz karakterin erkek olduğunu varsaydığını ve “erkekler işte böyle nefret edilesi” gibi ifadeler kullandığını bildirdi. Kullanıcı, bu tür cinsiyete dayalı tembel kalıp yargıların rahatsız edici olduğunu belirtti ve OpenAI’nin bu tür davranışları kısıtlamak için kuralları olup olmadığını sorguladı. Bu, yapay zeka modellerinin eğitim verilerindeki önyargılar ve bunların etkileşimlerde nasıl ortaya çıktığına dair tartışmaları yeniden alevlendirdi (Kaynak: Reddit r/ChatGPT)
Yapay zekanın haber raporlamasındaki tarafsızlık potansiyeli ve mevcut sınırlamaları: Bir kullanıcı, OpenAI’nin o3 modelini “tarafsız bir haber muhabiri” olarak potansiyelini test etti ve 2017’den bu yana Trump ve Biden yönetimlerinin çeşitli politikalarının olası “istenmeyen” sonuçları hakkında yorum yapmasını istedi. Yapay zeka görünüşte nesnel analizler üretebilse de, bilgi kaynakları, potansiyel önyargıları ve karmaşık siyasi-ekonomik dinamikleri gerçek anlamda anlama derinliği gelecekte çözülmesi gereken sorunlar olmaya devam ediyor. Bu, topluluğun yapay zekayı kullanarak haberlerin nesnelliğini ve derinliğini artırma beklentisini ve mevcut teknolojinin sınırlamalarına dair farkındalığını yansıtıyor (Kaynak: Reddit r/deeplearning)