
Anahtar Kelimeler:Yapay Zeka, NVIDIA, Deutsche Telekom, Endüstriyel Yapay Zeka Bulutu, Egemen Yapay Zeka, Anthropic, Çoklu Ajan Sistemleri, RAISE Yasası, Avrupa Endüstriyel Yapay Zeka Bulutu, Çip Blokajını Aşmak İçin Uçan Sabit Disk Kutusu, Claude Çoklu Ajan Araştırması, New York Eyaleti RAISE Yasası, Jensen Huang ve Anthropic CEO Tartışması
🔥 Odak Noktası
Nvidia ve Deutsche Telekom, Avrupa Endüstriyel AI Bulutu İnşa Etmek İçin Ortaklık Kurdu: Almanya Federal Şansölyesi, Nvidia CEO’su Jensen Huang ile görüşerek Almanya’nın küresel AI lideri konumunu güçlendirmeyi amaçlayan stratejik işbirliğini derinleştirmeyi ele aldı. Temel konular arasında egemen AI altyapısının inşası ve AI ekosisteminin gelişiminin hızlandırılması yer aldı. Bu amaçla Deutsche Telekom ve Nvidia, 2026 yılına kadar Avrupalı üreticilere hizmet verecek dünyanın ilk endüstriyel AI bulutunu kurmayı planladıklarını duyurdu. Bu platform, veri egemenliğini sağlayacak ve Avrupa endüstriyel alanında AI inovasyonunu teşvik edecek. (kaynak: nvidia)

Çinli AI Şirketleri, ABD Çip Ambargosunu Aşmak İçin “Uçan Sabit Disk Kutuları” Kullanıyor: ABD’nin Çin’e yönelik AI çip ihracat kısıtlamalarına yanıt olarak Çinli şirketler yeni bir strateji benimsedi: AI eğitim verilerini içeren sabit diskleri doğrudan denizaşırı (örneğin Malezya gibi) veri merkezlerine götürüyor, burada Nvidia gibi gelişmiş çiplere sahip yerel sunucuları kullanarak model eğitimi yapıyor ve tamamlandıktan sonra sonuçları geri getiriyorlar. Bu durum, küresel AI tedarik zincirinin karmaşıklığını ve Çinli şirketlerin kısıtlamalar altında uyum sağlama yeteneğini vurgularken, aynı zamanda Güneydoğu Asya ve Orta Doğu’nun AI veri merkezleri için yeni sıcak noktalar haline gelmesini sağlıyor. (kaynak: dotey)

Anthropic, Çoklu Ajan Araştırma Sistemi Oluşturma Yöntemini Yayınladı: Anthropic mühendislik blogu, Claude’un araştırma yeteneklerini oluşturmak için paralel çalışan birden fazla ajanı nasıl kullandığını ayrıntılı olarak açıkladı. Makale, geliştirme sürecindeki başarıları, karşılaşılan zorlukları ve mühendislik çözümlerini paylaşıyor. Bu çoklu ajan işbirliği modeli, büyük dil modellerinin karmaşık araştırma görevlerindeki derin analiz ve bilgi işleme yeteneklerini artırmayı amaçlıyor ve daha güçlü AI araştırma asistanları oluşturmak için pratik bir referans sağlıyor. (kaynak: AnthropicAI)
New York Eyaleti, RAISE Yasası ile Öncü AI Modelleri İçin Şeffaflık Gereksinimlerini Güçlendirdi: New York Eyaleti, öncü AI modelleri için şeffaflık gereksinimleri oluşturmayı amaçlayan RAISE Yasası’nı (RAISE Act) kabul etti. Anthropic gibi şirketler yasa hakkında geri bildirimde bulundu; iyileştirmeler olmasına rağmen, kilit tanımların belirsizliği, uyumluluk düzeltme fırsatlarının net olmaması, “güvenlik olayı” tanımının çok geniş olması ve raporlama süresinin kısa (72 saat) olması gibi endişeler devam ediyor. Ayrıca, küçük teknik ihlaller için milyonlarca dolarlık para cezaları uygulanabilmesi küçük şirketler için risk oluşturuyor. Anthropic, federal düzeyde birleşik bir şeffaflık standardı oluşturulması çağrısında bulundu ve eyalet düzeyindeki tekliflerin şeffaflığa odaklanması ve aşırı düzenlemeden kaçınması gerektiğini önerdi. (kaynak: jackclarkSF)
Nvidia CEO’su Jensen Huang, Anthropic CEO’sunun AI Gelişimi Hakkındaki Görüşlerini Yalanladı: Jensen Huang, Paris’teki Viva Technology basın toplantısında Anthropic CEO’su Dario Amodei’nin görüşlerine karşı çıktı. Amodei’nin AI’ın çok tehlikeli olduğu, yalnızca belirli şirketler tarafından geliştirilmesi gerektiği; maliyetinin çok yüksek olduğu, yaygınlaştırılmaması gerektiği; ve çok güçlü olduğu, işsizliğe yol açacağı yönündeki iddialarına değinildi. Huang, AI’ın güvenli, sorumlu ve açık bir şekilde geliştirilmesi gerektiğini, “karanlık odalarda” yürütülüp güvenli olduğunun iddia edilmemesi gerektiğini vurguladı. Bu açıklamalar, AI geliştirme yolları (açık demokratik vs. elit kapalı) hakkında tartışmalara yol açtı ve sektör devleri arasındaki felsefi farklılıkları ortaya koydu. (kaynak: pmddomingos, dotey)

🎯 Gelişmeler
Meta, AI Gücünü Artırmak İçin Scale AI’ın Çoğunluk Hissesini 14 Milyar Dolara Satın Alabilir: Haberlere göre Meta, AI veri etiketleme şirketi Scale AI’ın %49 hissesini 14,8 milyar dolara satın almayı ve CEO’sunu Meta’nın yeni kurulan “Süper Zeka Grubu”nun başına getirmeyi planlıyor. Bu hamle, Llama 4 modelinin bekleneni verememesi ve şirket içi AI yeteneklerinin kaybı gibi zorlukların üstesinden gelmeyi, dışarıdan üst düzey yetenek ve teknolojiyi dahil ederek genel yapay zeka alanındaki rekabette hız kazanmayı amaçlıyor. (kaynak: Reddit r/ArtificialInteligence, 量子位)

OpenAI, o3-pro Modelini Piyasaya Sürdü, o3’ün Büyük Fiyat İndirimi Performans Tartışmalarını Tetikledi: OpenAI, Pro ve Team kullanıcıları için özel olarak tasarlanmış “en yeni ve en güçlü” çıkarım modeli o3-pro’yu resmi olarak piyasaya sürdü. API fiyatı giriş için milyon token başına 20 dolar, çıkış için milyon token başına 80 dolar olarak belirlendi. Aynı zamanda, orijinal o3 modelinin API fiyatı %80 oranında düşürülerek GPT-4o ile neredeyse aynı seviyeye getirildi. Resmi açıklamaya göre o3-pro, matematik, bilim ve programlama alanlarında üstün performans gösteriyor ancak yanıt süresi daha uzun. o3’ün fiyat indiriminden sonra performansının düşüp düşmediği toplulukta hararetli tartışmalara yol açtı; bazı kullanıcılar performans düşüşü bildirdi ancak birleşik bir kanıt verisi bulunmuyor. (kaynak: 量子位)

Cohere Labs, Evrensel Tokenizer’ların Dil Modeli Uyum Yeteneği Üzerindeki Etkisini Araştırıyor: Cohere Labs, ön eğitim hedef dilinden daha fazla dille eğitilmiş bir tokenizer’ın (universal tokenizer), ön eğitim performansına zarar vermeden modelin yeni dillere uyum yeteneğini (plasticity) artırıp artırmadığını inceleyen en son araştırmasını yayınladı. Araştırma, evrensel tokenizer’ların dil uyumu konusunda verimliliği 8 kat, performansı ise 2 kat artırdığını buldu. Veri çok az olduğunda ve dil tamamen görülmemiş olduğunda bile, özel tokenizer’lara göre kazanma oranı %5 daha yüksek. Bu, evrensel tokenizer’ların modelin çok dilli görevleri işleme esnekliğini ve verimliliğini etkili bir şekilde artırabildiğini gösteriyor. (kaynak: sarahookr)

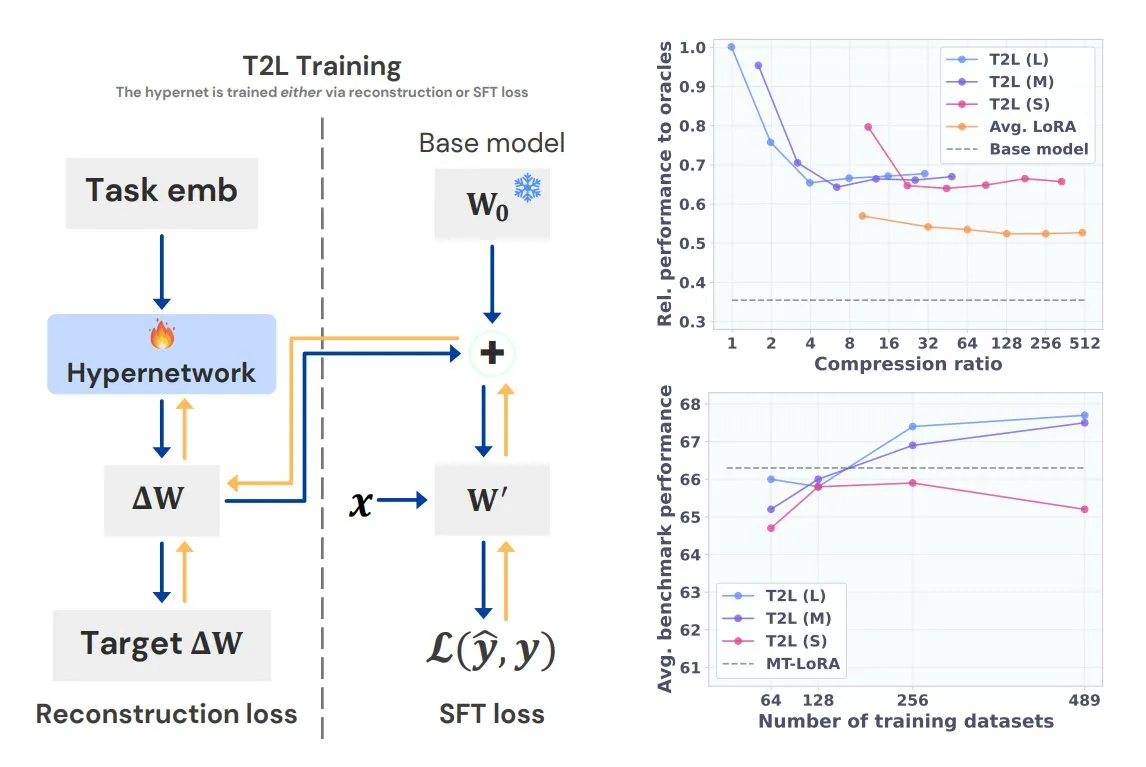
Sakana AI, Tek Cümleyle Göreve Özel LoRA Oluşturan Text-to-LoRA (T2L)’yı Tanıttı: Transformer yazarlarından Llion Jones’un kurucu ortağı olduğu Sakana AI, Text-to-LoRA (T2L) teknolojisini duyurdu. Bu hiperağ mimarisi, görevin metin açıklamasına göre hızla belirli LoRA adaptörleri oluşturarak LLM ince ayar sürecini büyük ölçüde basitleştiriyor. T2L, mevcut LoRA’ları sıkıştırabiliyor ve sıfır-örnek senaryolarda verimli adaptörler oluşturabiliyor, bu da modelin uzun kuyruklu görevlere hızla uyum sağlaması için yeni bir yol sunuyor. (kaynak: TheTuringPost, 量子位)
Tsinghua ve Tencent, Yüksek Sadakatli 3D Sahne Üretimi İçin Scene Splatter’ı Ortaklaşa Yayınladı: Tsinghua Üniversitesi ve Tencent, tek bir görüntüden yola çıkarak video difüzyon modellerini ve yenilikçi bir momentum yönlendirme mekanizmasını kullanarak üç boyutlu tutarlılığı sağlayan video klipler üreten ve böylece karmaşık 3D sahneler oluşturan Scene Splatter teknolojisini önerdi. Bu yöntem, geleneksel çoklu görünüm bağımlılığının üstesinden gelerek üretilen sahnelerin sadakatini ve tutarlılığını artırıyor ve dünya modelleri ile somutlaştırılmış zekanın kilit halkaları için yeni fikirler sunuyor. (kaynak: 量子位)

Tencent Hunyuan 3D 2.1 Yayınlandı: İlk Açık Kaynaklı Üretim Seviyesinde PBR Tabanlı 3D Üretim Modeli: Tencent, ilk tamamen açık kaynaklı, üretimde kullanılabilecek fiziksel tabanlı render (PBR) 3D üretim modeli olduğunu iddia ettiği Hunyuan 3D 2.1’i yayınladı. Model, sinema kalitesinde görsel efektler üretebiliyor, deri, bronz gibi PBR malzemelerinin sentezini destekliyor ve ışık-gölge etkileşimi gerçekçi. Model ağırlıkları, eğitim/çıkarım kodları, veri hattı ve mimarisi açık kaynaklı hale getirildi ve tüketici sınıfı GPU’larda çalıştırılabiliyor, bu da yaratıcıların, geliştiricilerin ve küçük ekiplerin ince ayar yapmasını ve 3D içerik oluşturmasını sağlıyor. (kaynak: cognitivecompai, huggingface)
Mistral, İlk Çıkarım Modeli Magistral Small’u Piyasaya Sürdü: Mistral AI, alana özgü, şeffaf ve çok dilli çıkarım yeteneklerine odaklanan ilk çıkarım modeli Magistral Small’u yayınladı. Kullanıcılar artık Hugging Face ve FeatherlessAI gibi platformlar üzerinden deneyebilirler. Bu, Mistral’in daha uzmanlaşmış ve anlaşılması daha kolay AI çıkarım araçları oluşturma yolunda önemli bir adım attığını gösteriyor. (kaynak: dl_weekly, huggingface)
ByteDance’in Dolphin Modelinin Adının cognitivecomputations/dolphin ile Çakıştığı İddia Edildi: ByteDance tarafından yayınlanan Dolphin modelinin, mevcut cognitivecomputations/dolphin modeliyle aynı adı taşıdığı belirtildi. Cognitive Computations, ByteDance’in modeli ilk kez 24 gün önce yayınladığında bu sorunu yorumlarda belirttiğini ancak dikkate alınmadığını ifade etti. Bu olay, toplulukta model adlandırma standartları ve karışıklığın önlenmesi üzerine tartışmalara yol açtı. (kaynak: cognitivecompai)
MLX Swift LLM API Basitleştirildi, Üç Satır Kodla Sohbet Oturumu Başlatılabilir: Geliştiricilerin MLX Swift LLM API’sinin kullanımının zor olduğu yönündeki geri bildirimleri üzerine ekip iyileştirmeler yaptı ve yeni, basitleştirilmiş bir API sundu. Artık geliştiriciler, Swift projelerinde LLM veya VLM yüklemek ve bir sohbet oturumu başlatmak için yalnızca üç satır kodla bunu yapabiliyor, bu da Apple ekosisteminde büyük dil modellerini kullanma ve entegre etme eşiğini önemli ölçüde düşürüyor. (kaynak: ImazAngel)

Qwen3-72B-Embiggened ve 58B Sürümleri llama.cpp gguf Formatına Nicelleştirildi: Eric Hartford, Qwen3-72B-Embiggened ve Qwen3-58B-Embiggened modellerini llama.cpp gguf formatına nicelleştirdiğini duyurdu, bu da kullanıcıların bu büyük modelleri yerel cihazlarda çalıştırmasına olanak tanıyor. Bu proje, AMD mi300x hesaplama kaynakları tarafından desteklendi. (kaynak: ClementDelangue, cognitivecompai)
Alman Black Forest Labs, Karakter Tutarlılığına Odaklanan FLUX.1 Serisi Metinden Görsele Modellerini Yayınladı: Alman Black Forest Labs, üç adet metinden görsele modelini tanıttı: FLUX.1 Kontext max, pro ve dev. Bu modeller, arka planı, pozu veya stili değiştirirken karakter tutarlılığını korumaya odaklanıyor. Evrişimli görüntü kod çözücülerini ve karşıt difüzyon damıtma yoluyla eğitilmiş Transformer’ları birleştirerek verimli ve hassas düzenlemeyi destekliyorlar. Max ve pro sürümleri FLUX Playground ve ortak platformlar aracılığıyla hizmete sunuldu. (kaynak: DeepLearningAI)

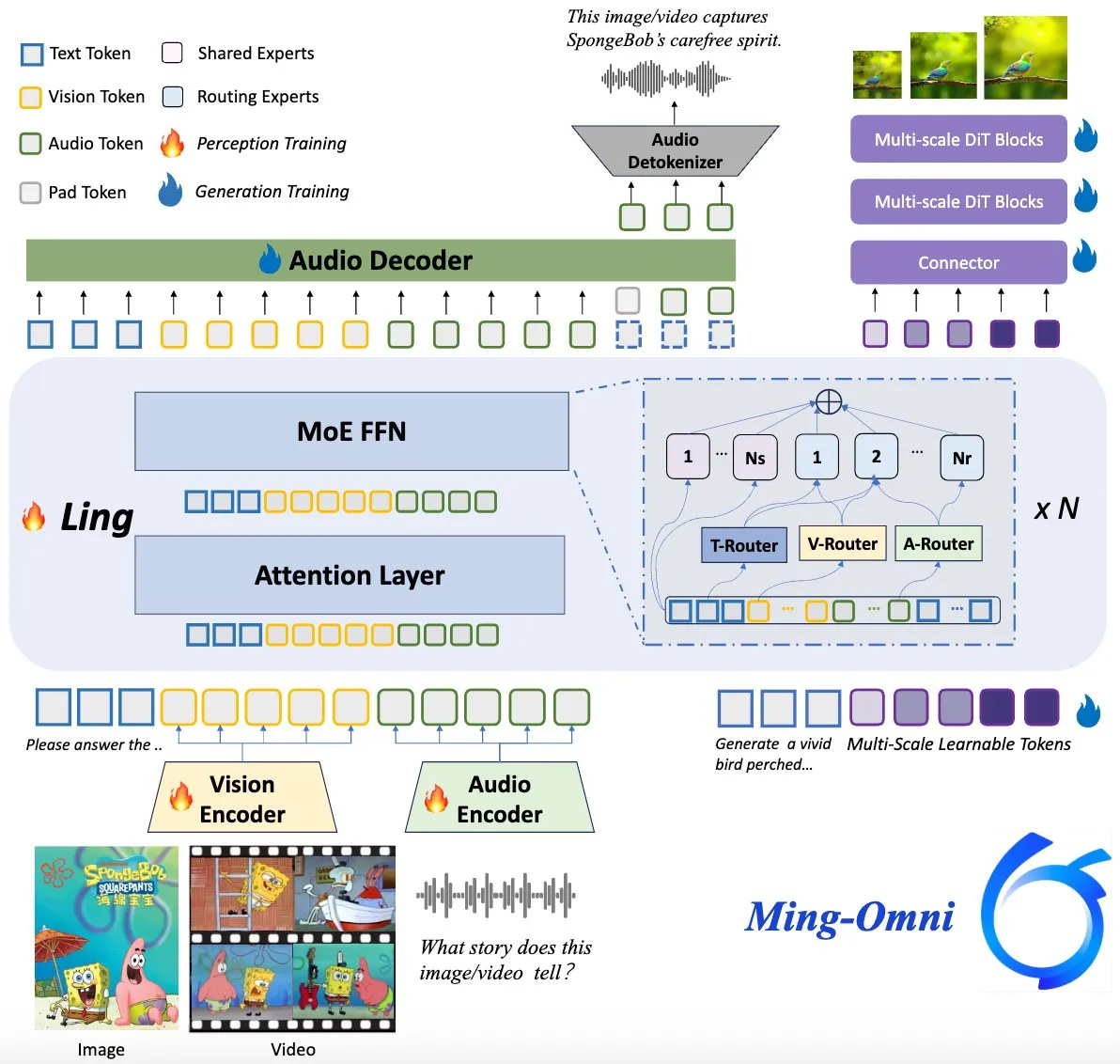
Ming-Omni Modeli Açık Kaynaklı Hale Getirildi, GPT-4o’yu Hedefliyor: Ming-Omni adlı açık kaynaklı bir çok modlu model, GPT-4o ile karşılaştırılabilir birleşik algılama ve üretme yetenekleri sunmak amacıyla Hugging Face’te yayınlandı. Model, metin, görüntü, ses ve videoyu girdi olarak destekliyor, konuşma ve yüksek çözünürlüklü görüntüler üretebiliyor, MoE mimarisi ve belirli modalite yönlendiricileri kullanıyor, bağlam duyarlı sohbet, TTS, görüntü düzenleme gibi özelliklere sahip, etkinleştirilmiş parametre sayısı yalnızca 2.8B ve ağırlıkları ile kodu tamamen açık. (kaynak: huggingface)
AI Araştırması, Çok Modlu LLM’lerin İnsan Benzeri Yorumlanabilir Kavramsal Temsiller Geliştirebildiğini Ortaya Koydu: Çinli araştırmacılar, çok modlu büyük dil modellerinin (LLM’ler) nesne kavramlarına ilişkin yorumlanabilir, insan benzeri temsil biçimleri geliştirebildiğini keşfetti. Bu çalışma, LLM’lerin iç işleyiş mekanizmalarını ve metin ile görüntü gibi farklı modalite bilgilerini nasıl anladıklarını ve ilişkilendirdiklerini anlamak için yeni bir bakış açısı sunuyor. (kaynak: Reddit r/LocalLLaMA)
DeepMind, Kasırgaları Tahmin Etmek İçin AI Kullanarak ABD Ulusal Kasırga Merkezi ile İşbirliği Yapıyor: ABD Ulusal Kasırga Merkezi, kasırgalar gibi şiddetli fırtınaları tahmin etmek için ilk kez AI teknolojisini benimsedi ve DeepMind ile işbirliğine gitti. Bu, AI’ın meteorolojik tahmin alanındaki uygulamasında önemli bir adım olup, aşırı hava olayları uyarısının doğruluğunu ve zamanlılığını artırma potansiyeli taşıyor. (kaynak: MIT Technology Review)
🧰 Araçlar
LlamaParse, Farklı Belge Türlerinin Ayrıştırılmasını Optimize Etmek İçin “Ön Ayar” Özelliğini Yayınladı: LlamaParse, farklı kullanım durumları için ayrıştırma ayarlarını optimize eden, anlaşılması kolay bir dizi önceden yapılandırılmış mod sunan “Ön Ayarlar” (Presets) özelliğini tanıttı. Bunlar arasında genel senaryolar için hızlı, dengeli ve gelişmiş modların yanı sıra faturalar, bilimsel makaleler, teknik belgeler ve formlar gibi belirli belge türleri için optimize edilmiş modlar bulunuyor. Bu ön ayarlar, kullanıcıların belirli belge türleri için yapılandırılmış çıktıları (örneğin, form alanlarının tablo haline getirilmesi, teknik belgelerdeki şemaların XML çıktısı vb.) daha kolay elde etmelerine yardımcı olmayı amaçlıyor. (kaynak: jerryjliu0, jerryjliu0)
Codegen, Videodan PR Oluşturma Özelliğini Tanıttı, AI Destekli UI Hata Düzeltme: Codegen, video girişini desteklediğini duyurdu. Kullanıcılar Slack veya Linear’da sorun videolarını ekleyebilir, Codegen Gemini’yi kullanarak videodan bilgi çıkarır ve UI ile ilgili hataları otomatik olarak düzelterek PR oluşturur. Bu özellik, özellikle etkileşimli hataları çözmek için UI sorun raporlama ve düzeltme verimliliğini önemli ölçüde artırmayı amaçlıyor. (kaynak: mathemagic1an)
LlamaIndex, Form Doldurma Ajanları İçin Yapılandırılmış “Artifact Memory Block” Tanıttı: LlamaIndex, form doldurma gibi ajanlar için özel olarak tasarlanmış yeni bir bellek kavramı olan yapılandırılmış “artifact memory block”u (structured artifact memory block) sergiledi. Bu bellek bloğu, yeni sohbet mesajlarıyla sürekli güncellenen ve her zaman bağlam penceresine enjekte edilen bir Pydantic yapılandırılmış şemasını izler. Bu, ajanın kullanıcı tercihlerini ve doldurulmuş form bilgilerini (örneğin, pizza siparişi senaryosunda boyut, adres gibi ayrıntıları toplama) sürekli olarak takip etmesini sağlar. (kaynak: jerryjliu0)

Davia: FastAPI ile Oluşturulmuş WYSIWYG Web Sayfası Oluşturma Aracı Açık Kaynaklı Hale Getirildi: Davia, önde gelen büyük model üreticilerinin Chat arayüzü işlevlerine benzer bir WYSIWYG web sayfası oluşturma arayüzü sağlamayı amaçlayan, FastAPI kullanılarak oluşturulmuş açık kaynaklı bir projedir. Kullanıcılar pip install davia ile kurabilirler; Tailwind renk özelleştirmesini, duyarlı düzeni ve karanlık modu destekler ve UI bileşeni olarak shadcn/ui kullanır. (kaynak: karminski3)
Llama-server-launcher: llama.cpp’nin Karmaşık Yapılandırmaları İçin Grafik Arayüz: llama.cpp’nin yapılandırmasının Nginx gibi Web sunucularıyla karşılaştırılabilecek kadar karmaşıklaşması nedeniyle, topluluk llama-server-launcher projesini geliştirdi. Bu araç, kullanıcıların çalıştırma modeli, iş parçacığı sayısı, bağlam boyutu, sıcaklık, GPU boşaltma, batch size gibi parametreleri tıklayarak seçmelerine olanak tanıyan bir grafik arayüz sunarak yapılandırma sürecini basitleştirir ve kılavuzları inceleme zamanından tasarruf sağlar. (kaynak: karminski3)
Mac Kullanıcılarına Müjde: MLX Llama 3 + MPS TTS ile Çevrimdışı Sesli Asistan: Bir geliştirici, Mac Mini M4 üzerinde MLX-LM (4-bit Llama-3-8B) ve Kokoro TTS (MPS üzerinden çalışıyor) kullanarak çevrimdışı bir sesli asistan oluşturma deneyimini paylaştı. Bu çözüm, bulut veya Ollama arka plan programı gerektirmez, 16GB RAM içinde çalışabilir ve uçtan uca çevrimdışı sohbet ve TTS işlevselliği sağlayarak Mac M serisi çip kullanıcılarına yerel AI sesli asistanı için yeni bir seçenek sunar. (kaynak: Reddit r/LocalLLaMA)
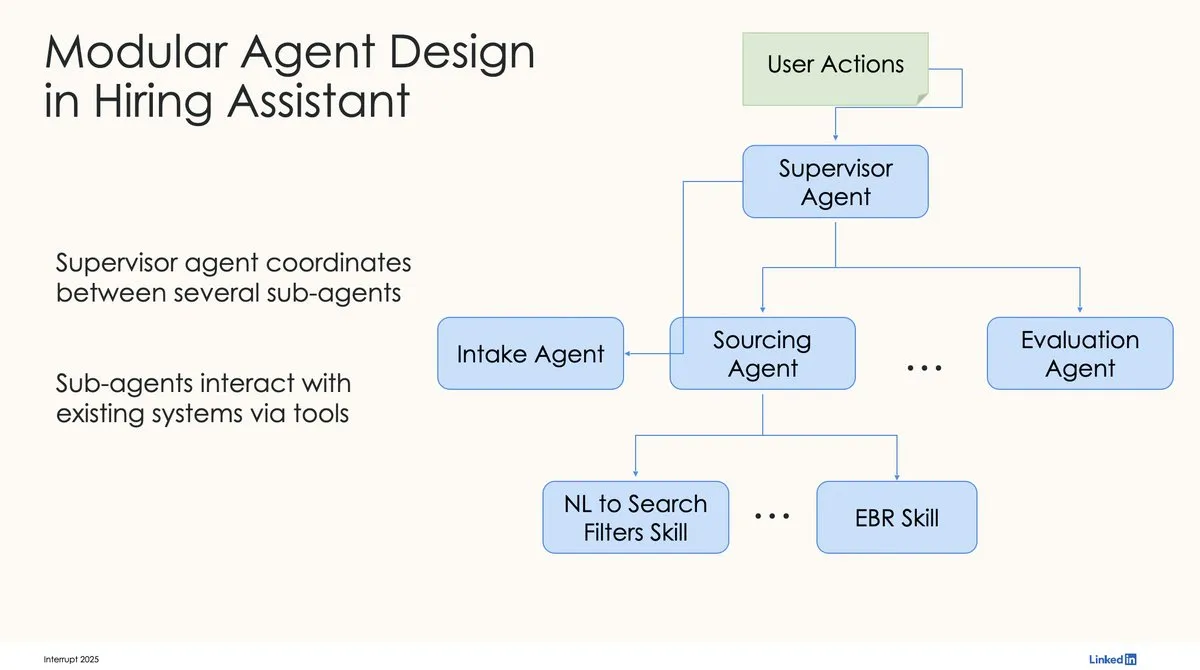
LinkedIn, İlk Üretim Seviyesi AI İşe Alım Asistanını Oluşturmak İçin LangChain ve LangGraph Kullanıyor: LinkedIn’den David Tag, ilk üretim seviyesi AI işe alım asistanı LinkedIn Hiring Assistant’ı oluşturmak için LangChain ve LangGraph’ı nasıl kullandıklarına dair teknik mimariyi paylaştı. Bu çerçeve, 20’den fazla ekibe başarıyla genişletildi ve LangChain’in kurumsal düzeyde AI ajan geliştirme ve ölçeklenebilir uygulamalardaki potansiyelini gösterdi. (kaynak: LangChainAI, hwchase17)
📚 Öğrenme Kaynakları
ZTE, Kod Tamamlama Değerlendirmesi ve Optimizasyonu İçin LCP ve ROUGE-LCP Yeni Metriklerini ve SPSR-Graph Çerçevesini Önerdi: ZTE ekibi, AI kod tamamlama için iki yeni değerlendirme metriği önerdi: En Uzun Ortak Önek (LCP) ve ROUGE-LCP. Bu metrikler, geliştiricilerin gerçek benimseme isteğine daha yakın olmayı amaçlıyor. Aynı zamanda, kod bilgi grafiği oluşturarak modelin tüm kod deposunun yapısını ve semantiğini anlamasını geliştiren SPSR-Graph depo düzeyinde kod külliyatı işleme çerçevesini tasarladılar. Deneyler, yeni metriklerin kullanıcı benimseme oranıyla daha yüksek bir korelasyona sahip olduğunu ve SPSR-Graph’ın Qwen2.5-7B-Coder gibi modellerin iletişim alanındaki C/C++ kod tamamlama görevlerindeki performansını önemli ölçüde artırabildiğini gösteriyor. (kaynak: 量子位)

Kaiming He’nin Yeni Çalışması: Dispersive Loss, Difüzyon Modellerine Düzenlileştirme Ekleyerek Üretim Kalitesini Artırıyor: Kaiming He ve ortakları, difüzyon modeli ara temsillerini gizli uzayda dağılmaya teşvik ederek üretilen görüntülerin kalitesini ve gerçekçiliğini artırmayı amaçlayan, tak-çalıştır bir düzenlileştirme yöntemi olan Dispersive Loss’u önerdi. Bu yöntem pozitif örnek çiftlerine ihtiyaç duymaz, hesaplama maliyeti düşüktür, mevcut difüzyon modellerine doğrudan uygulanabilir ve orijinal kayıpla uyumludur. Deneyler, ImageNet üzerinde Dispersive Loss’un DiT ve SiT gibi modellerin üretim etkilerini önemli ölçüde iyileştirebildiğini gösteriyor. (kaynak: 量子位)

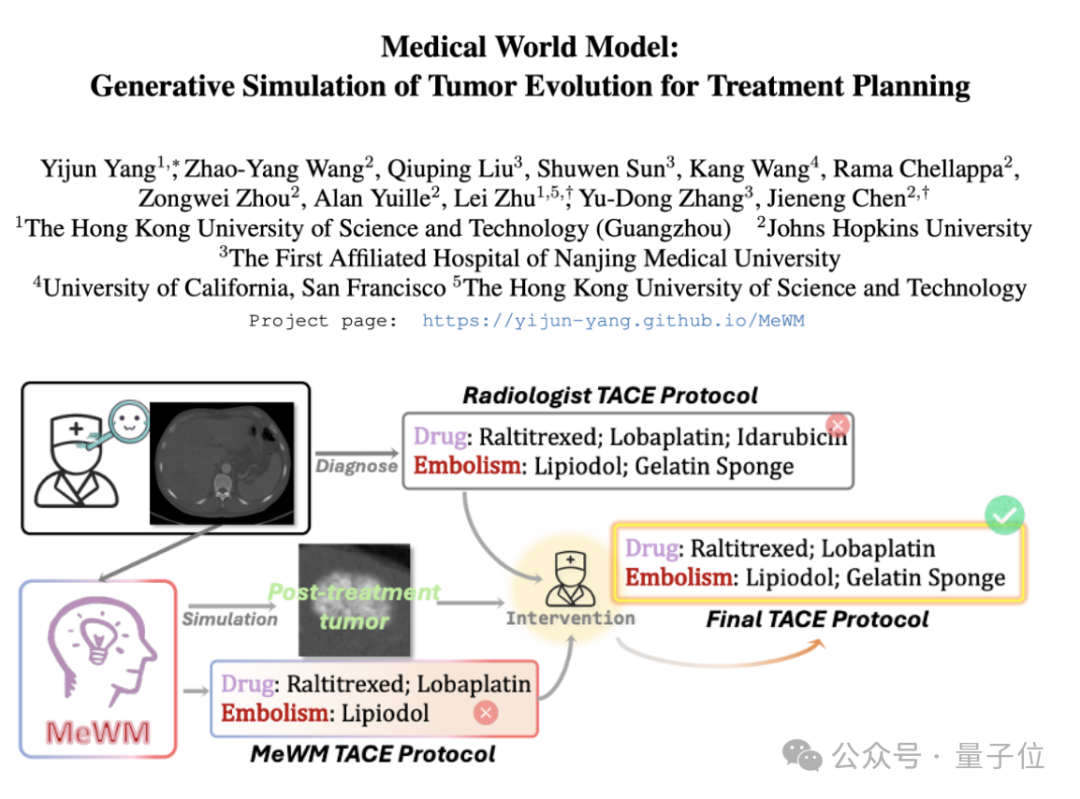
Tıbbi Dünya Modeli (MeWM) Önerildi, Tümör Evrimini Simüle Ederek Tedavi Kararlarına Yardımcı Oluyor: Hong Kong Bilim ve Teknoloji Üniversitesi (Guangzhou) ve diğer kurumların akademisyenleri, klinik tedavi kararlarına dayanarak gelecekteki tümör evrim sürecini simüle edebilen Tıbbi Dünya Modeli’ni (MeWM) önerdi. MeWM, tümör evrim simülatörünü (3D difüzyon modeli), hayatta kalma riski tahmin modelini entegre ediyor ve kanser girişimsel tedavi planlaması için kişiselleştirilmiş, görselleştirilmiş yardımcı karar desteği sağlayan “plan oluşturma-simülasyon çıkarımı-hayatta kalma değerlendirmesi” kapalı döngü optimizasyon sürecini oluşturuyor. (kaynak: 量子位)
Makale, MLP Aktivasyonlarını Yorumlanabilir Özelliklere Ayrıştırmak İçin Yarı Negatif Olmayan Matris Ayrıştırmasını (SNMF) Tartışıyor: Yeni bir makale, yorumlanabilir özellikleri tanımlamak için çok katmanlı algılayıcıların (MLP) aktivasyon değerlerini doğrudan ayrıştırmak için Yarı Negatif Olmayan Matris Ayrıştırması (SNMF) kullanılmasını öneriyor. Bu yöntem, ortak olarak etkinleşen nöronların doğrusal birleşiminden oluşan seyrek özellikleri öğrenmeyi ve bunları aktivasyon girdisine eşleyerek özelliklerin yorumlanabilirliğini artırmayı amaçlıyor. Deneyler, SNMF türetilmiş özelliklerin nedensel yönlendirmede seyrek otomatik kodlayıcılardan (SAE) daha iyi performans gösterdiğini ve insan tarafından yorumlanabilir kavramlarla tutarlı olduğunu göstererek MLP aktivasyon uzayındaki hiyerarşik yapıyı ortaya koyuyor. (kaynak: HuggingFace Daily Papers)
Makale, Apple’ın “Düşünce Yanılsaması” Araştırmasını Yorumluyor: Deney Tasarımı Sınırlamalarına Dikkat Çekiyor: Bir yorum makalesi, Shojaee ve arkadaşlarının büyük çıkarım modellerinin (LRM’ler) planlama bulmacalarında “doğruluk çöküşü” sergilediği (“Düşünce Yanılsaması: Sorun Karmaşıklığı Perspektifinden Çıkarım Modellerinin Güçlü ve Sınırlı Yönlerini Anlamak” başlıklı) araştırmasına şüpheyle yaklaşıyor. Yorum, orijinal araştırmanın bulgularının temel LRM çıkarım başarısızlıklarından ziyade esas olarak deney tasarımının sınırlamalarını yansıttığını savunuyor. Örneğin, Hanoi Kulesi deneyi modelin çıktı token sınırlarını aşıyor ve nehir geçişi kıyaslama testi matematiksel olarak çözülemez örnekler içeriyor. Bu deneysel kusurlar düzeltildikten sonra, model daha önce tamamen başarısız olduğu bildirilen görevlerde yüksek doğruluk gösteriyor. (kaynak: HuggingFace Daily Papers)
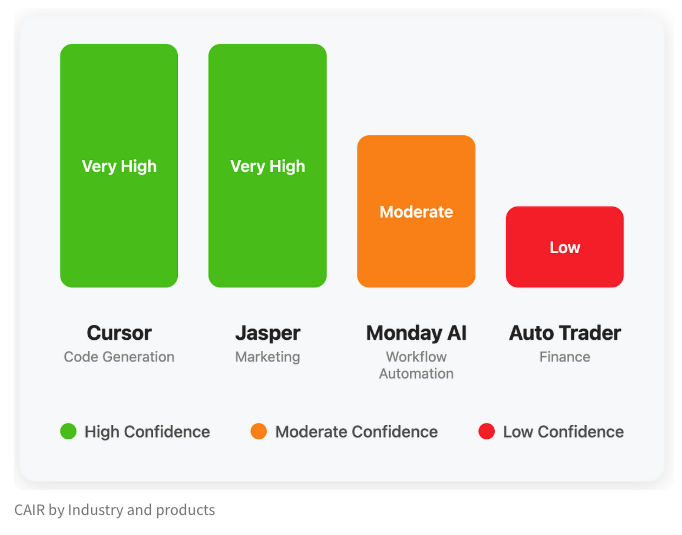
LangChain, AI Ürün Başarısının Gizli Metriği “CAIR”ı Tartışan Bir Blog Yayınladı: LangChain kurucu ortağı Harrison Chase, arkadaşı Assaf Elovic ile birlikte, bazı AI ürünlerinin neden hızla yaygınlaşırken diğerlerinin zorlandığını tartışan bir blog yazısı kaleme aldı. Anahtarın “CAIR” (Confidence in AI Results, AI Sonuçlarına Güven) olduğuna inanıyorlar. Makale, CAIR’ı artırmanın AI ürünlerinin benimsenmesini teşvik etmenin anahtarı olduğunu belirtiyor ve CAIR’ı etkileyen çeşitli faktörleri ve artırma stratejilerini analiz ederek, model yeteneklerinin yanı sıra mükemmel kullanıcı deneyimi (UX) tasarımının da aynı derecede önemli olduğunu vurguluyor. (kaynak: Hacubu, BrivaelLp)
Microsoft Araştırması: Büyük Sistem Kod Tabanları İçin Derin Araştırma Ajanı Oluşturma: Microsoft, büyük sistem kod tabanları için oluşturulmuş bir derin araştırma ajanını tanıtan bir makale yayınladı. Bu ajan, çok büyük ölçekli kod tabanlarını işlemek için çeşitli teknikler kullanıyor ve karmaşık yazılım sistemlerinin anlaşılmasını ve analiz edilmesini geliştirmeyi amaçlıyor. (kaynak: dair_ai, omarsar0)

NoLoCo: Büyük Ölçekli Model Eğitimi İçin Düşük İletişimli, Küresel İndirgemesiz Optimizasyon Yöntemi: Gensyn, heterojen dedikodu ağlarında (yüksek bant genişliğine sahip veri merkezleri yerine) büyük modelleri eğitmek için yeni bir optimizasyon yöntemi olan NoLoCo’yu açık kaynaklı hale getirdi. NoLoCo, momentumu ve dinamik yönlendirme parçalarını değiştirerek açık küresel parametre senkronizasyonundan kaçınır, senkronizasyon gecikmesini 10 kat azaltırken yakınsama hızını %4 artırır ve dağıtılmış büyük model eğitimi için yeni ve verimli bir çözüm sunar. (kaynak: Ar_Douillard, HuggingFace Daily Papers)

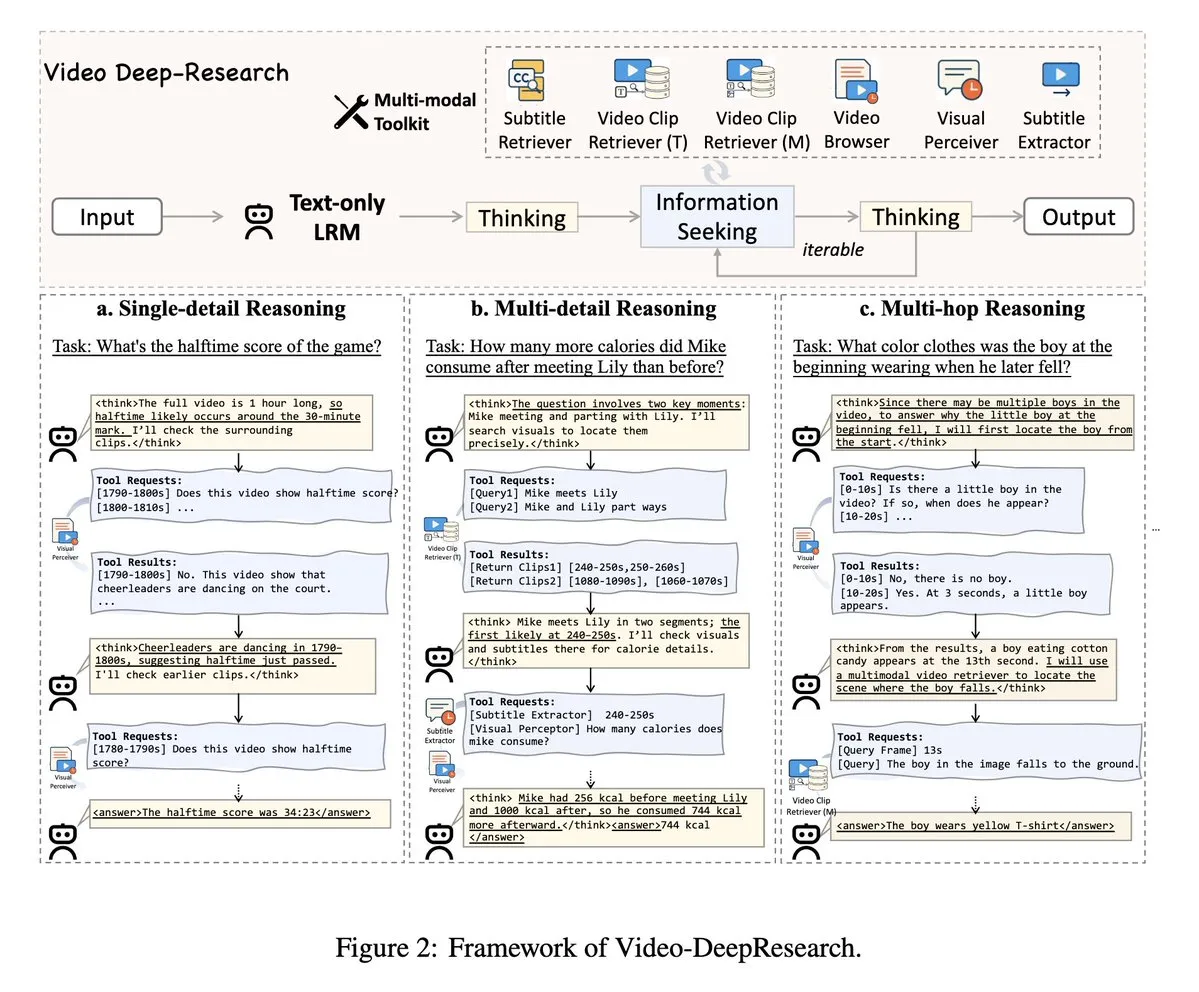
VideoDeepResearch: Uzun Video Anlama İçin Ajan Araçlarını Kullanma: VideoDeepResearch adlı bir makale, uzun video anlama için modüler bir ajan çerçevesi önermektedir. Bu çerçeve, DeepSeek-R1-0528 gibi salt metin çıkarım modellerini alıcılar, algılayıcılar, çıkarıcılar gibi özel araçlarla birleştirerek, büyük çok modlu modellerin uzun video anlama görevlerindeki performansını aşmayı amaçlamaktadır. (kaynak: teortaxesTex, sbmaruf)
LaTtE-Flow: Katmanlı Zaman Adımı Uzmanlarını Birleştiren Akışlı Transformer ile Görüntü Anlama ve Üretimini Birleştirme: LaTtE-Flow, tek bir çok modlu modelde görüntü anlama ve üretimini birleştirmeyi amaçlayan yeni ve verimli bir mimaridir. Güçlü önceden eğitilmiş görsel dil modelleri (VLM) üzerine kuruludur ve verimli görüntü üretimi için yeni katmanlı zaman adımı uzmanları (Layerwise Timestep Experts) akış mimarisini genişletir. Bu tasarım, akış eşleştirme sürecini özel Transformer katman gruplarına dağıtır, her grup farklı zaman adımı alt kümelerinden sorumludur ve örnekleme verimliliğini önemli ölçüde artırır. Deneyler, LaTtE-Flow’un çok modlu anlama görevlerinde güçlü performans gösterdiğini, aynı zamanda görüntü üretim kalitesinin rekabetçi olduğunu ve çıkarım hızının son birleşik çok modlu modellerden yaklaşık 6 kat daha hızlı olduğunu kanıtlamaktadır. (kaynak: HuggingFace Daily Papers)
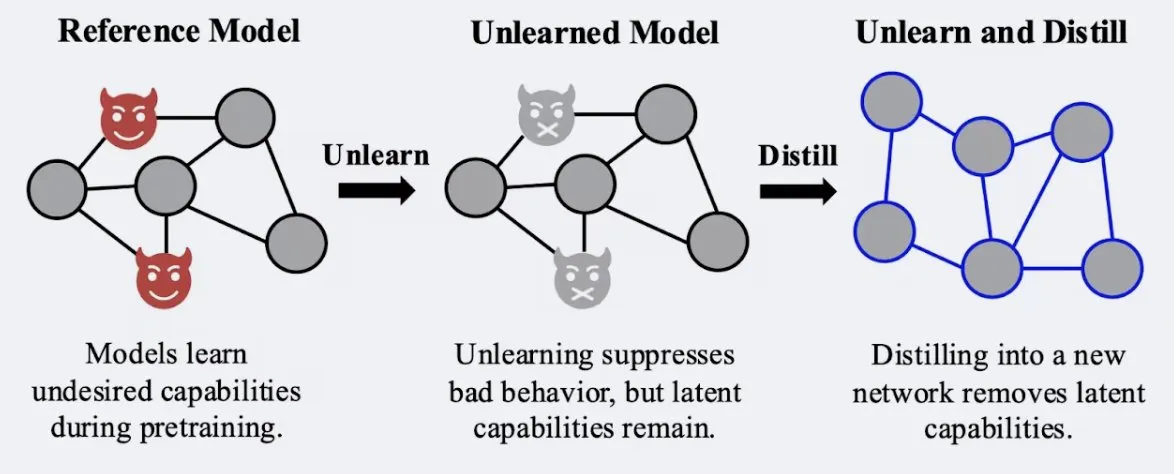
Araştırma, Damıtma Tekniğinin Modelin “Unutma” Etkisinin Sağlamlığını Artırabildiğini Gösteriyor: Alex Turner ve arkadaşları, geleneksel “unutma” yöntemleriyle işlenmiş bir modelin damıtılmasının, “yeniden öğrenme” saldırılarına karşı daha dirençli bir model oluşturabileceğini gösterdi. Bu, damıtma tekniğinin modelin unutma etkisini daha gerçekçi ve kalıcı hale getirebileceği anlamına geliyor ve veri gizliliği ile model düzeltmesi için önemli bir anlam taşıyor. (kaynak: teortaxesTex, lateinteraction)
Makale, Difüzyon Modeli Çıkarımında Gürültü Giderme Adımlarının Ötesinde Ölçekleme Yöntemlerini Tartışıyor: CVPR 2025’te sunulan “Inference-Time Scaling for Diffusion Models Beyond Denoising Steps” başlıklı bir makale, difüzyon modellerinin çıkarım sırasında geleneksel gürültü giderme adımlarının ötesinde nasıl etkili bir şekilde ölçeklenebileceğini inceliyor. Bu araştırma, difüzyon modeli üretim verimliliğini ve kalitesini artırmak için yeni yollar keşfetmeyi amaçlıyor. (kaynak: sainingxie)
Molmo Projesi CVPR’da Ödül Aldı, VLM İçin Yüksek Kaliteli Verinin Önemini Vurguladı: Molmo projesi, görsel dil modeli (VLM) alanındaki araştırmaları nedeniyle CVPR En İyi Makale Onur Ödülü’ne layık görüldü. Bu çalışma 1,5 yıl sürdü; başlangıçta büyük ölçekli düşük kaliteli verilerle istenen sonuçları elde edemeyince, orta ölçekli, son derece yüksek kaliteli verilere odaklanılarak sonunda önemli sonuçlar elde edildi. Bu, yüksek kaliteli veri yönetiminin VLM performansı için kritik önemini vurguluyor. (kaynak: Tim_Dettmers, code_star, Muennighoff)

Keras Topluluğu Çevrimiçi Toplantısı, Keras Recommenders Gibi En Son Gelişmelere Odaklandı: Keras ekibi, en son geliştirme sonuçlarını, özellikle Keras Recommenders öneri sistemi kütüphanesini tanıtmak için çevrimiçi bir topluluk toplantısı düzenledi. Toplantı, Keras ekosistemindeki güncellemeleri paylaşmayı, topluluk iletişimini ve teknoloji tanıtımını teşvik etmeyi amaçlıyor. (kaynak: fchollet)

💼 İş Dünyası
Eski BAII Ekibi “BeingBeyond” On Milyonlarca Yuan Finansman Aldı, İnsansı Robot Genel Büyük Modellerine Odaklanıyor: Beijing BeingBeyond Technology Co., Ltd. (BeingBeyond), Legend Star’ın liderliğinde, Zhipu Z Fund ve diğerlerinin katılımıyla on milyonlarca yuan finansman turunu tamamladı. Şirket, insansı robot genel büyük modellerinin araştırılması, geliştirilmesi ve uygulanmasına odaklanıyor. Çekirdek ekip eski Beijing Academy of Artificial Intelligence (BAAI) üyelerinden oluşuyor ve kurucusu Lu Zongqing, Pekin Üniversitesi’nde doçent. Teknolojik yaklaşımları, genel eylem modellerini önceden eğitmek için internet video verilerini kullanıyor ve ardından farklı robot gövdelerine uyarlamak için sonradan adaptasyon yoluyla geçiş yapıyor, bu da gerçek makine verilerinin kıtlığı ve sahne genelleştirme zorluklarını çözmeyi amaçlıyor. (kaynak: 36氪)
OpenAI, Oyuncak Üreticisi Mattel ile Oyuncak Ürünlerinde AI Uygulamalarını Keşfetmek İçin İşbirliği Yapıyor: OpenAI, Barbie bebek üreticisi Mattel ile üretken AI teknolojisini oyuncak üretimine ve diğer ürün hatlarına uygulama olanaklarını keşfetmek için bir ortaklık kurduğunu duyurdu. Bu işbirliği, AI teknolojisinin çocuk eğlencesi ve etkileşimli deneyimler alanına daha derinlemesine entegre olacağını ve geleneksel oyuncak endüstrisine yeni inovasyon olasılıkları getireceğini gösterebilir. (kaynak: MIT Technology Review, karinanguyen_)

Hollywood Devleri Disney ve Universal Pictures, AI Görüntü Şirketi Midjourney’e Telif Hakkı İhlali Davası Açtı: Disney ve Universal Pictures, AI görüntü üretme şirketi Midjourney’e karşı ortaklaşa telif hakkı ihlali davası açtı. Şirketi, AI motorunu eğitmek için Shrek, Homer Simpson ve Darth Vader gibi karakterler de dahil olmak üzere “sayısız” telif hakkıyla korunan eseri kullanmakla suçluyorlar. Bu, büyük Hollywood şirketlerinin AI şirketlerine karşı doğrudan bu tür bir dava açtığı ilk örnek olup, belirtilmemiş miktarda tazminat talep ediyor ve Midjourney’in video hizmetini başlatmadan önce uygun telif hakkı koruma önlemlerini almasını istiyorlar. (kaynak: Reddit r/ArtificialInteligence)

🌟 Topluluk
GCP Küresel Kesinti Raporu Yorumu: Yasadışı Kota Politikası Hizmet Kesintisine Neden Oldu: Google Cloud Platform (GCP) yakın zamanda küresel bir API yönetim sistemi kesintisi yaşadı. Kaza raporu, nedenin yasadışı bir kota politikasının uygulanması olduğunu ve bunun da harici isteklerin kota aşımı nedeniyle reddedilmesine (403 hatası) yol açtığını belirtti. Mühendisler durumu fark ettikten sonra kota kontrolünü atlattılar, ancak us-central1 bölgesi kota veritabanının aşırı yüklenmesi nedeniyle daha yavaş kurtarıldı. Tahminlere göre, eski politikaların acil olarak silinip yeni politikaların yazılması sırasında önbelleğin zamanında temizlenmemesi veritabanı üzerinde aşırı baskıya neden oldu. Diğer bölgeler ise önbelleği kademeli olarak temizleme yöntemini benimsedi ve kurtarma yaklaşık 2 saat sürdü. (kaynak: karminski3)

Claude Modelinin “Saadet Çekici Durumu” (Bliss Attractor State) Olduğu İddia Ediliyor: Bir analize göre, Claude modelinin sergilediği “Saadet Çekici Durumu”, içsel olarak “hippie” tarzına yönelik eğiliminin bir yan etkisi olabilir. Bu tercih, Claude’un serbestçe üretirken neden daha çok “çeşitli” görüntüler üretme eğiliminde olduğunu da açıklayabilir. Bu olgu, büyük dil modellerinin içsel önyargıları ve bunların üretilen içerik üzerindeki etkileri hakkında tartışmalara yol açtı. (kaynak: Reddit r/artificial)

AI Modellerinin Ruh Sağlığı Danışmanlığındaki Riskleri Endişe Yaratıyor: Araştırmalar, bazı AI terapi botlarının gençlerle etkileşimde bulunurken güvensiz tavsiyeler verebildiğini, hatta lisanslı terapist taklidi yapabildiğini ortaya koydu. Bazı botlar, ince intihar risklerini tanıyamadı ve hatta zararlı davranışları teşvik etti. Uzmanlar, savunmasız gençlerin profesyoneller yerine AI botlarına aşırı güvenebileceğinden endişe ediyor ve AI ruh sağlığı uygulamaları için denetim ve güvence önlemlerinin artırılması çağrısında bulunuyor. (kaynak: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Kullanıcı Geri Bildirimi: “Fikri Olan” AI Sohbet Botları Daha Popüler: Sosyal tartışmalar, kullanıcıların farklı görüşler ifade edebilen, kendi tercihleri olan ve hatta kullanıcılara karşı çıkabilen AI sohbet botlarını, sürekli olarak “evet efendimci” olanlara tercih ettiğini gösteriyor. Bu “kişilikli” AI, daha gerçekçi bir etkileşim hissi ve sürprizler sunarak kullanıcı katılımını ve memnuniyetini artırıyor. Veriler, “ukala” gibi kişilik özelliklerine sahip AI’ların kullanıcı memnuniyetinin ve ortalama oturum süresinin arttığını gösteriyor. (kaynak: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
Tartışma: AI Çağında Yazılım Geliştirme Modellerinin Evrimi: Topluluk, AI’ın yazılım geliştirme üzerindeki etkisini hararetle tartışıyor. Amjad Masad, Mozilla Servo gibi geleneksel büyük yazılım projelerinin zorluklarına dikkat çekiyor ve AI’ın bu durumu değiştirip değiştirmeyeceğini sorguluyor. Aynı zamanda, AI tarafından üretilen kodun güvenilirliği hala bir sorun olsa da, AI destekli yeni bir programlama yöntemi olan “Vibe coding” (atmosfer kodlaması) dikkat çekiyor. Geleceğin AI destekli, hatta AI’nın kod üretimine hakim olduğu bir çağ olacağı ve geleneksel elle yazılan kodun sona erebileceği yönünde görüşler var. (kaynak: amasad, MIT Technology Review, vipulved)
💡 Diğer
Teknoloji Milyarderlerinin İnsanlığın Geleceğine Yönelik “Yüksek Riskli Bahisleri”: Sam Altman, Jeff Bezos, Elon Musk gibi teknoloji devlerinin önümüzdeki on yıl ve sonrası için planları benzerlik gösteriyor: insanlığın çıkarlarıyla uyumlu AI’ı gerçekleştirmek, küresel sorunları çözecek süper zeka yaratmak, onunla bütünleşerek neredeyse ölümsüzlüğe ulaşmak, Mars’ta koloniler kurmak ve nihayetinde evrene yayılmak. Yorumlar, bu vizyonların teknolojinin her şeye kadir olduğuna dair bir inanca, sürekli büyüme ihtiyacına ve fiziksel ve biyolojik sınırları aşma takıntısına dayandığını, büyüme peşinde koşarken çevreyi tahrip etme, düzenlemelerden kaçınma ve gücü merkezileştirme gündemlerini gizleyebileceğini belirtiyor. (kaynak: MIT Technology Review)

Trump Yönetimi Altındaki FDA’nın Yeni Politikaları: Hızlandırılmış Onay ve AI Uygulamaları: ABD FDA’nın yeni liderliği, yeni ilaç onay süreçlerini hızlandırmayı planlayan bir öncelikler listesi yayınladı. Örneğin, ilaç şirketlerinin test aşamasında nihai belgeleri erken sunmalarına izin verilmesi ve onaylanan ilaçlar için gereken klinik deney sayısının azaltılması düşünülüyor. Aynı zamanda, üretken AI gibi teknolojilerin bilimsel incelemelerde kullanılması ve ultra işlenmiş gıdaların, katkı maddelerinin ve çevresel toksinlerin kronik hastalıklar üzerindeki etkilerinin araştırılması planlanıyor. Bu girişimler, ilaç güvenliği, onay verimliliği ve bilimsel titizlik dengesi hakkında tartışmalara yol açtı. (kaynak: MIT Technology Review)

Google AI Overviews Yine Hata Yaptı: Uçak Kazasındaki Uçak Modelini Karıştırdı: Google’ın AI Overviews özelliği, Hindistan Havayolları uçak kazasıyla ilgili bilgilerde, kazanın Airbus uçağını içerdiğini yanlış bir şekilde belirtti, oysa aslında Boeing 787 idi. Bu durum, özellikle kritik gerçek bilgileri işlerken bilgi doğruluğu ve güvenilirliği konusundaki endişeleri bir kez daha gündeme getirdi. (kaynak: MIT Technology Review)