Anahtar Kelimeler:Meta V-JEPA 2, NVIDIA Endüstriyel AI Bulutu, Sakana AI Metinden-LoRA’ya, OpenAI o3-pro, Databricks Lakebase, MLflow 3.0, Princeton Üniversitesi HistBench, Video Eğitimli Açık Kaynak Dünya Modeli, Avrupa Üretim AI Bulut Platformu, Metin Üreten LLM Adaptörü, DPO ile İnce Ayar GPT-4.1, AI Ajan Gözlemlenebilirliği, Meta V-JEPA 2, NVIDIA Endüstriyel Yapay Zeka Bulutu, Sakana AI Metin-LoRA Dönüştürücü, OpenAI o3-pro modeli, Databricks Lakebase veri platformu, MLflow 3.0 sürümü, Princeton Üniversitesi HistBench test seti, Video eğitimli açık kaynak dünya modeli projesi, Avrupa üretim sektörü için AI bulut platformu, Metin üreten büyük dil modeli adaptörü, Doğrudan tercih optimizasyonu ile GPT-4.1 ince ayarı, Yapay zeka ajanları için gözlemlenebilirlik çözümleri
🔥 Odak Noktası
Meta, V-JEPA 2’yi duyurdu: Video ile eğitilmiş açık kaynaklı görüntü/video dünya modeli : Meta, ViT mimarisine dayanan, farklı boyut (L/G/H) ve çözünürlük (286/384) sürümlerine sahip ve 1,2 milyar parametreye ulaşan yeni açık kaynaklı görüntü/video dünya modeli V-JEPA 2’yi tanıttı. V-JEPA 2, görsel anlama ve tahminleme konularında üstün performans sergiliyor ve robotların alışılmadık ortamlarda sıfır-örnek (zero-shot) planlama yapmasını ve görevleri yerine getirmesini sağlıyor. Meta, yapay zekanın dünya modellerini kullanarak dinamik ortamlara uyum sağlaması ve yeni becerileri verimli bir şekilde öğrenmesi vizyonunu vurguluyor. Aynı zamanda Meta, mevcut modellerin videolardan fiziksel dünyayı çıkarım yapma yeteneğini değerlendirmek için MVPBench, IntPhys 2 ve CausalVQA adlı üç yeni benchmark yayınladı. (Kaynak: huggingface, huggingface, ylecun, AIatMeta, scaling01, karminski3)
Nvidia, Avrupa’da ilk endüstriyel yapay zeka bulutunu kurarak imalat sanayinin gelişimini destekliyor : Nvidia, Avrupalı üreticiler için dünyanın ilk endüstriyel yapay zeka bulut platformunu inşa ettiğini duyurdu. Bu AI fabrikası, endüstri liderlerinin tasarımdan mühendislik simülasyonlarına, dijital fabrika ikizlerinden robot teknolojilerine kadar tüm üretim süreçlerindeki uygulamaları hızlandırmalarına yardımcı olmayı amaçlıyor. Bu adım, Nvidia’nın GTC Paris ve VivaTech 2025’te duyurduğu, Avrupa ve diğer bölgelerdeki yapay zeka inovasyonunu hızlandırmayı hedefleyen bir dizi girişimin bir parçası. Jensen Huang, Avrupa’daki yapay zeka hesaplama gücünün iki yıl içinde on katına çıkmasının beklendiğini belirtti ve “hareket eden her şey robotlaşacak, otomobiller bir sonraki adım” diye vurguladı. (Kaynak: nvidia, nvidia, Jensen Huang: Avrupa AI hesaplama gücü iki yılda on katına çıkacak)

Sakana AI, Text-to-LoRA’yı tanıttı: Metin açıklamasıyla anında göreve özel LLM adaptörleri oluşturma : Sakana AI, kullanıcıların görevleri metinle tanımlamasına dayanarak anında göreve özel LLM adaptörleri (LoRA’lar) üretebilen bir Hypernetwork olan Text-to-LoRA teknolojisini yayınladı. Bu teknoloji, özelleştirilmiş büyük modellerin kullanım engelini düşürmeyi amaçlıyor ve teknik olmayan kullanıcıların derin teknik bilgi veya büyük hesaplama kaynakları olmadan doğal dil aracılığıyla temel modelleri özelleştirmesine olanak tanıyor. Text-to-LoRA, yüzlerce mevcut LoRA adaptörünü kodlayabiliyor ve performansı korurken daha önce görülmemiş görevlere genelleme yapabiliyor. İlgili makale ve kodlar arXiv ve GitHub’da yayınlandı ve ICML 2025’te sunulacak. (Kaynak: SakanaAILabs, hardmaru, kylebrussell, ClementDelangue, huggingface)
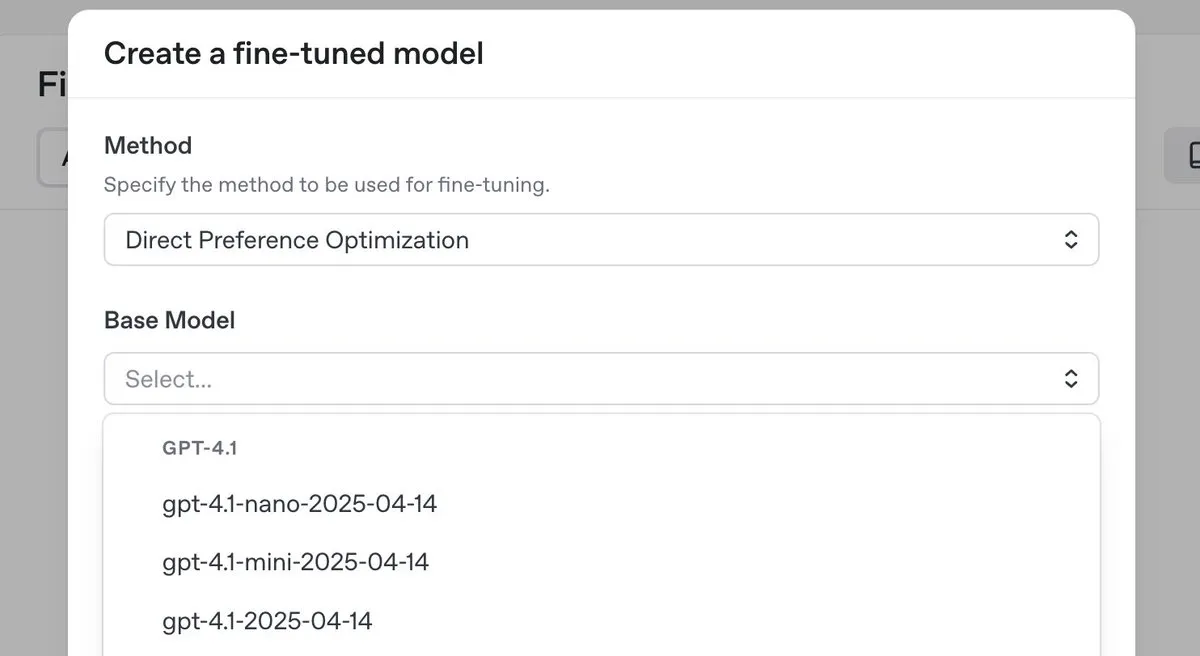
OpenAI, en üst düzey çıkarım modeli o3-pro’yu yayınladı ve fiyatları önemli ölçüde düşürdü, aynı zamanda GPT-4.1 serisi için DPO ince ayar özelliğini sundu : OpenAI, yeni en üst düzey çıkarım modeli o3-pro’yu tanıttı ve geliştiricilerin kullanım maliyetlerini düşürmek amacıyla o3 serisi modellerde önemli fiyat indirimleri yaptı. Aynı zamanda OpenAI, kullanıcıların artık GPT-4.1 ailesi modellerini (4.1, 4.1-mini ve 4.1-nano dahil) ince ayarlamak için doğrudan tercih optimizasyonunu (DPO) kullanabileceklerini duyurdu. DPO, sabit hedefler yerine model yanıtlarını karşılaştırarak özelleştirmeye olanak tanır ve özellikle ton, stil ve yaratıcılık konusunda öznel gereksinimleri olan görevler için uygundur. ARC Prize, o3 fiyat indiriminden sonra yeniden test edildi ve ARC-AGI üzerindeki performansında bir değişiklik olmadığı görüldü. (Kaynak: OpenAIDevs, scaling01, aidan_mclau, giffmana, jeremyphoward, BorisMPower, rowancheung, TheRundownAI)
🎯 Gelişmeler
Databricks, Lakebase’i, ücretsiz sürümü ve Agent Bricks’i kullanıma sunarak veri ve yapay zeka uygulama geliştirmeyi hızlandırıyor : Databricks, lakehouse ile entegre olan ve yapay zeka için oluşturulmuş, Postgres’in kullanım kolaylığını, lakehouse’un ölçeklenebilirliğini ve Neon veritabanının dallanma teknolojisini birleştiren tam yönetilen bir Postgres veritabanı olan Lakebase’in genel önizleme aşamasına geçtiğini duyurdu. Aynı zamanda Databricks, geliştiricilerin veri mühendisliği, veri bilimi ve yapay zeka öğrenmelerine yardımcı olmak için ücretsiz bir platform sürümü ve çok sayıda eğitim materyali sundu. Ayrıca, Databricks Apps genel kullanıma sunuldu (GA) ve müşterilerin platform üzerinde etkileşimli veri ve yapay zeka uygulamaları oluşturup dağıtmasına olanak tanıyor. Databricks ayrıca, kullanıcıların görevleri tanımladıktan sonra sistemin otomatik olarak değerlendirme oluşturup ajanı optimize ettiği, yapay zeka ajanları geliştirmek için bildirimsel bir yaklaşım benimseyen Agent Bricks’i de tanıttı. (Kaynak: matei_zaharia, matei_zaharia, lateinteraction, matei_zaharia, matei_zaharia, matei_zaharia, jefrankle, lateinteraction, matei_zaharia, lateinteraction, cto_junior, lateinteraction, jefrankle)

Nvidia, Mistral AI ile Avrupa’da uçtan uca bulut platformu kurmak için iş birliği yapıyor : Nvidia, Fransız startup Mistral AI ile uçtan uca bir bulut platformu oluşturmak için iş birliği yaptığını duyurdu. İş birliğinin ilk aşamasında 18.000 adet Nvidia Grace Blackwell sistemi kurulacak ve 2026’da daha fazla lokasyona genişletilmesi planlanıyor. Bu iş birliği, Nvidia’nın Avrupa’da yapay zeka altyapısını geliştirme ve “egemen yapay zeka” (sovereign AI) konseptini destekleme çabalarının bir parçası olup, Avrupa’ya yerelleştirilmiş veri merkezleri ve sunucular sağlamayı amaçlıyor. (Kaynak: Jensen Huang: Avrupa AI hesaplama gücü iki yılda on katına çıkacak)
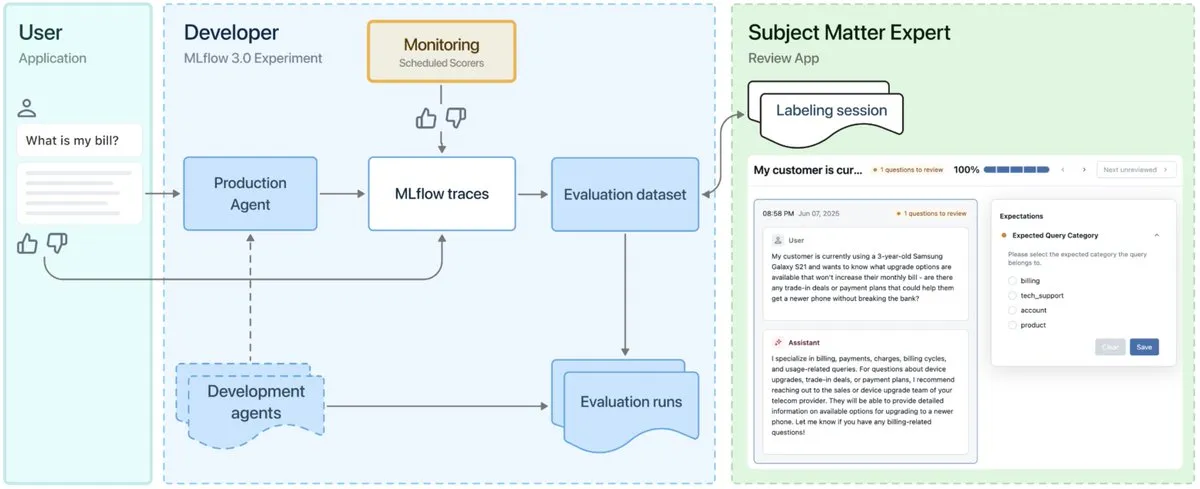
MLflow 3.0 yayınlandı, yapay zeka ajanlarının gözlemlenebilirliği ve geliştirilmesi için özel olarak tasarlandı : MLflow 3.0 resmi olarak yayınlandı. Yeni sürüm, yapay zeka ajanlarının gözlemlenebilirliği ve geliştirilmesi için yeniden tasarlandı ve geleneksel yapılandırılmış makine öğrenimi özelliklerini güncelledi. MLflow 3.0, yapay zeka sistemlerinin veri yoluyla sürekli iyileştirilmesini hedefliyor, yapay zeka sistemlerini izlemeyi, değerlendirmeyi ve denetlemeyi destekliyor ve kurumsal düzeydeki gereksinimleri (insan iş birliği, veri yönetişimi ve güvenliği, Databricks veri ekosistemiyle entegrasyon gibi) dikkate alıyor. (Kaynak: matei_zaharia, matei_zaharia, lateinteraction)
Princeton Üniversitesi ve Fudan Üniversitesi, yapay zekanın tarih araştırmalarında uygulanmasını teşvik etmek için HistBench ve HistAgent’ı ortaklaşa başlattı : Princeton Üniversitesi AI Laboratuvarı ve Fudan Üniversitesi Tarih Bölümü, dünyanın ilk tarih araştırmaları için yapay zeka değerlendirme benchmark’ı olan HistBench’i ve yapay zeka asistanı HistAgent’ı ortaklaşa başlattı. HistBench, 29 dilde ve çoklu medeniyet tarihini kapsayan 414 tarih sorusu içeriyor ve yapay zekanın karmaşık tarihi materyalleri işleme ve çok modlu anlama yeteneğini test etmeyi amaçlıyor. HistAgent ise literatür tarama, OCR, çeviri gibi araçları entegre eden, tarih araştırmaları için özel olarak tasarlanmış bir ajandır. Testler, genel amaçlı büyük modellerin HistBench’te %20’den az doğruluk oranına sahip olduğunu, HistAgent’ın ise mevcut modellerden çok daha iyi performans gösterdiğini ortaya koydu. (Kaynak: Dünyanın ilk tarih benchmark’ı, Princeton ve Fudan AI tarih asistanı oluşturdu, AI beşeri bilimler alanına giriyor)

Microsoft Research ve Pekin Üniversitesi, otoregresif video üretim verimliliğini artırmak için Next-Frame Diffusion (NFD) çerçevesini ortaklaşa yayınladı : Microsoft Research ve Pekin Üniversitesi, kare içi paralel örnekleme ve kareler arası otoregresif yöntemle A100 GPU üzerinde 310M model kullanarak saniyede 30 kareden fazla yüksek kaliteli otoregresif video üretimi sağlayan yeni Next-Frame Diffusion (NFD) çerçevesini ortaklaşa tanıttı. NFD, bloklu nedensel dikkat mekanizmasına sahip bir Transformer kullanıyor ve verimliliği daha da artırmak için tutarlılık damıtma ve spekülatif örnekleme tekniklerini birleştiriyor; gerçek zamanlı etkileşimli oyunlar gibi senaryolarda kullanılması bekleniyor. (Kaynak: Saniyede 30 kareden fazla video üretiyor, gerçek zamanlı etkileşimi destekliyor, otoregresif video üretiminde yeni çerçeve üretim verimliliğini yeniliyor)

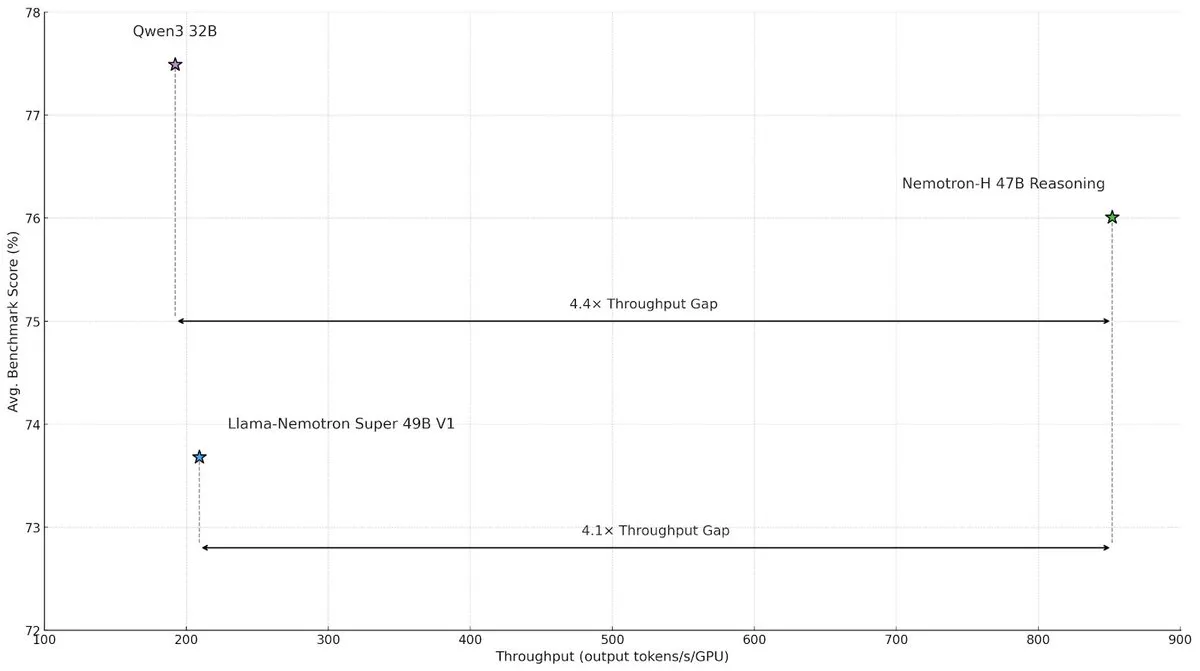
NVIDIA, büyük ölçekli çıkarım hızını ve verimliliğini artırmak için Nemotron-H hibrit mimari modelini yayınladı : NVIDIA Research, büyük ölçekli çıkarım görevlerindeki hız darboğazlarını çözmeyi amaçlayan, Mamba ve Transformer’ın hibrit bir mimarisini kullanan Nemotron-H modelini tanıttı. Bu model, çıkarım yeteneğini korurken, benzer Transformer modellerine göre 4 kat daha yüksek iş hacmi (throughput) sağlıyor. Araştırmalar, hibrit modellerin daha az dikkat katmanı kullansalar bile çıkarım performansını koruyabildiğini ve özellikle uzun çıkarım zinciri senaryolarında doğrusal mimarinin verimlilik avantajının belirgin olduğunu gösteriyor. (Kaynak: _albertgu, tri_dao, krandiash)
Google DeepMind araştırmacısı Jack Rae, Meta’nın “Süper Zeka” grubuna katıldı : Google DeepMind baş araştırmacısı Jack Rae’nin Meta’nın yeni kurulan “Süper Zeka” grubuna katıldığı doğrulandı. Rae, DeepMind’da Gemini modelinin “düşünme” yeteneğinden sorumluydu ve “sıkıştırma zekadır” (compression is intelligence) düşüncesinin önde gelen temsilcilerinden biri olup, daha önce OpenAI’de GPT-4’ün geliştirilmesinde yer almıştı. Meta CEO’su Zuckerberg, Llama modelini geliştirmek ve sektör liderlerini yakalamak amacıyla daha güçlü yapay zeka araçları geliştirmek için yeni ekibe on milyonlarca dolar seviyesinde maaş paketleri sunarak bizzat en iyi yapay zeka yeteneklerini işe alıyor. (Kaynak: Zuckerberg’in “Süper Zeka” grubuna katılan ilk önemli isim, Google DeepMind baş araştırmacısı, “sıkıştırma zekadır”ın kilit ismi, DhruvBatraDB)

Mistral AI, çok dilli çıkarımı destekleyen ilk çıkarım modeli Magistral’ı yayınladı : Mistral AI, 24B parametreli açık kaynak sürümü Magistral Small ve kurumsal odaklı Magistral Medium’u içeren ilk çıkarım modeli Magistral’ı tanıttı. Model, çok adımlı mantık ve yorumlanabilirlik için özel olarak ince ayarlanmış olup, çok dilli çıkarımı destekliyor, özellikle Avrupa dilleri için optimize edilmiş ve izlenebilir düşünme süreçleri sunabiliyor. Magistral, mevcut çıkarım modellerinden damıtılmış verilere dayanmadan, saf pekiştirmeli öğrenme yoluyla geliştirilmiş bir GRPO algoritması kullanılarak eğitildi. Ancak, benchmark test sonuçları, en son Qwen ve DeepSeek R1 sürümlerinin verilerini içermemesi nedeniyle kısmen sorgulandı. (Kaynak: Yeni “SOTA” çıkarım modeli Qwen ve R1’den kaçınıyor mu? Avrupa versiyonu OpenAI eleştiri yağmuruna tutuldu)

ByteDance Doubao Büyük Dil Modeli 1.6 yayınlandı ve fiyatı tekrar önemli ölçüde düşürüldü, video modeli Seedance 1.0 pro da eş zamanlı olarak tanıtıldı : Volcano Engine, Doubao Büyük Dil Modeli 1.6’yı yayınladı ve “giriş uzunluğu” aralığına göre fiyatlandırmada bir ilke imza attı; 0-32K giriş aralığı için fiyat milyon token başına 0,8 yuan, çıkış için ise milyon token başına 8 yuan oldu, bu da maliyeti 1.5 sürümüne göre %63 düşürdü. Yeni yayınlanan video üretim modeli Seedance 1.0 pro’nun fiyatı bin token başına 1,5 fen (0,015 yuan) olarak belirlendi, bu da 5 saniyelik 1080P video üretmenin yaklaşık 3,67 yuan’a mal olacağı anlamına geliyor. Volcano Engine Başkanı Tan Dai, bu fiyat indiriminin, şirketlerin sık kullandığı 32K aralığındaki maliyetlerin hedeflenmiş optimizasyonu ve iş modeli inovasyonu yoluyla gerçekleştirildiğini ve Agent’ların büyük ölçekli uygulamasını teşvik etmeyi amaçladığını belirtti. (Kaynak: Doubao Büyük Dil Modeli fiyatı tekrar önemli ölçüde düştü, Volcano Engine hala agresif bir şekilde pazar payı için rekabet ediyor, 「Volcano」 Baidu Cloud’a doğru yanıyor)
Hong Kong Bilim ve Teknoloji Üniversitesi, Huawei ile birlikte tamamen otonom bilgi grafiği oluşturmayı sağlayan AutoSchemaKG çerçevesini önerdi : Hong Kong Bilim ve Teknoloji Üniversitesi KnowComp Laboratuvarı, Hong Kong Huawei Teori Departmanı ile iş birliği yaparak, önceden tanımlanmış bir şemaya ihtiyaç duymadan tamamen otonom olarak bilgi grafikleri oluşturabilen AutoSchemaKG çerçevesini önerdi. Bu sistem, doğrudan metinden bilgi üçlülerini çıkarmak ve varlık ile olay şemalarını tümevarımsal olarak belirlemek için büyük dil modellerini kullanıyor. Bu çerçeveye dayanarak ekip, 900 milyondan fazla düğüm ve 5,9 milyar kenar içeren ATLAS adlı bir bilgi grafiği serisi oluşturdu. Deneyler, bu yöntemin sıfır insan müdahalesiyle, şema tümevarımının insan tarafından tasarlanan şemalarla %95 semantik uyum sağladığını gösterdi. (Kaynak: En büyük açık kaynaklı GraphRag: Bilgi grafiğinin tamamen otonom olarak oluşturulması)

QJing Technology, DeepSeek büyük dil modelinin çalışma verimliliğini artıran yazılım ve donanım entegre sunucu 8 kart çözümünü yayınladı : QJing Technology, Intel ile ortaklaşa bir ekosistem salonu düzenleyerek en son yazılım ve donanım entegre sunucu 8 kart çözümünü yayınladı. Bu çözüm, DeepSeek-R1/V3-671B gibi büyük modelleri verimli bir şekilde çalıştırabiliyor ve tek karta kıyasla performansı 7 kata kadar artırıyor. Aynı zamanda, kendi geliştirdiği çıkarım motoru KLLM, büyük model yönetim platformu AMaaS ve ofis uygulama paketi “QJing·Zhiwen” de önemli yükseltmeler aldı. Bu geliştirmeler, büyük modellerin özel (private) dağıtımında karşılaşılan yüksek başlangıç engeli ve yetersiz çalışma performansı gibi zorlukları çözmeyi amaçlıyor. (Kaynak: QJing Technology & Intel Ekosistem Salonu düzenlendi, donanım, çıkarım motoru ve üst katman uygulama ekosistemi entegre edilerek büyük model özel dağıtımının “son kilometresi” tamamlandı)

Black Forest Labs, karakter ve stil tutarlılığını güçlendiren FLUX.1 Kontext serisi görüntü modellerini yayınladı : Alman Black Forest Labs, görüntüleri düzenlerken karakter ve stil tutarlılığını korumaya odaklanan FLUX.1 Kontext serisi metinden görüntüye modellerini (max, pro, dev sürümleri) tanıttı. Bu model serisi, görüntülerin yerel ve küresel olarak değiştirilmesini destekliyor ve metin ve/veya görüntü girdilerinden görüntüler üretebiliyor. FLUX.1 Kontext dev sürümünün açık kaynak olması planlanıyor. Yaklaşık 1000 istem ve referans görüntü çifti içeren özel bir benchmark testinde, FLUX.1 Kontext max ve pro sürümleri, OpenAI GPT Image 1 ve Google Gemini 2.0 Flash gibi rakip modellerden daha iyi performans gösterdi. (Kaynak: DeepLearning.AI Blog)

Nvidia, Rutgers Üniversitesi ve diğer kurumlar, video anlamada gereken Token sayısını azaltmak için Mamba katmanını kullanan STORM çerçevesini önerdi : Nvidia, Rutgers Üniversitesi, Kaliforniya Üniversitesi, Berkeley ve diğer kurumlardan araştırmacılar, metin-video sistemi STORM’u geliştirdi. Bu sistem, SigLIP görsel Transformer’ı ile Qwen2-VL’nin LLM’i arasına bir Mamba katmanı ekleyerek, tek kare Token gömülmelerini (aynı klipten diğer karelerden gelen bilgileri içeren) zenginleştiriyor ve böylece önemli bilgileri kaybetmeden kareler arasındaki Token gömülmelerini ortalamasını alıyor. Bu, sistemin videoları daha az Token ile işlemesini sağlıyor ve MVBench ile MLVU gibi video anlama benchmark testlerinde GPT-4o ve Qwen2-VL’den daha iyi performans gösterirken, işlem hızını 3 kattan fazla artırıyor. (Kaynak: DeepLearning.AI Blog)

Google kurucu ortağı insansı robotlara mesafeli yaklaşıyor, özel amaçlı robotların ticarileşme potansiyeli yüksek görülüyor : Google kurucu ortağı Sergey Brin, insan formunu birebir kopyalayan insansı robotlara pek sıcak bakmadığını, bunun robotların etkili çalışması için gerekli bir koşul olmadığını belirtti. Aynı zamanda, özel amaçlı robotlar “kutudan çıkar çıkmaz çalışabilme” özellikleri ve net ticarileşme yolları nedeniyle dikkat çekiyor. Örneğin, su altı robotları ve çim biçme robotları gibi robotlar belirli senaryolarda büyük potansiyel gösteriyor. Analizlere göre, mevcut aşamada pratik sorunları çözebilen robot formları ve üretkenlik kilit öneme sahip; özel amaçlı robotlar, net iş modelleri ve zorunlu ihtiyaç senaryoları sayesinde ticarileşmede öncü oluyor. (Kaynak: Özel amaçlı robotlar insansı robotlara “Kardeşim kenara çekil, masaya ben oturacağım” diyor.)

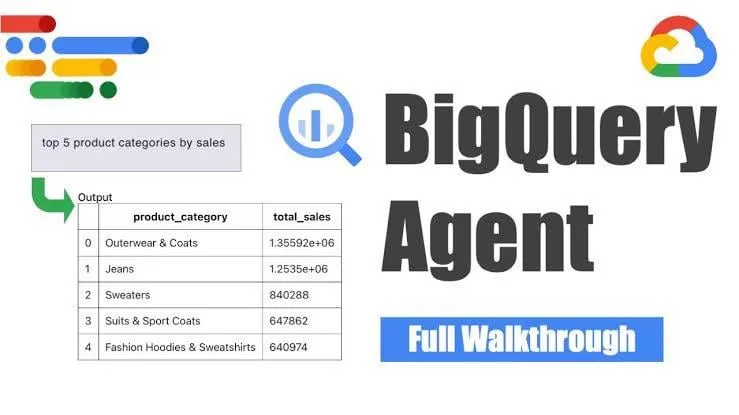
Google, akıllı pipeline üretimi için BigQuery veri mühendisliği ajanını kullanıma sundu : Google, veri pipeline’larının üretimini verimli bir şekilde ölçeklendirmek için bağlamsal çıkarım kullanan BigQuery veri mühendisliği ajanını tanıttı. Kullanıcılar, basit komut satırı talimatlarıyla pipeline gereksinimlerini tanımlayabiliyor; ajan ise alana özgü istemleri kullanarak kullanıcının veri ortamına özel toplu pipeline kodu üretiyor. Bu kod, veri alım yapılandırmalarını, dönüşüm sorgularını, tablo oluşturma mantığını ve Dataform veya Composer aracılığıyla zamanlama ayarlarını içeriyor. Bu araç, yapay zeka yardımıyla veri mühendislerinin birden fazla veri alanı, ortam ve dönüşüm mantığıyla uğraşırken karşılaştığı tekrarlayan işleri basitleştirmeyi amaçlıyor. (Kaynak: Reddit r/deeplearning)
Yandex, yaklaşık 5 milyar kullanıcı-şarkı etkileşimini içeren büyük ölçekli kamuya açık veri seti Yambda’yı yayınladı : Yandex, öneri sistemleri araştırmaları için özel olarak tasarlanmış Yambda adlı büyük ölçekli bir kamuya açık veri seti yayınladı. Bu veri seti, Yandex Music’ten yaklaşık 5 milyar anonimleştirilmiş kullanıcı-şarkı etkileşim verisi içeriyor ve araştırmacılara gerçek dünya ölçeğindeki verilerle çalışma konusunda nadir bir fırsat sunuyor. (Kaynak: _akhaliq)

ByteDance, Hugging Face’te video onarım modeli SeedVR2’yi yayınladı : ByteDance Seed ekibi, Hugging Face’te video onarımı için tek adımlı bir difüzyon Transformer modeli olan SeedVR2’yi yayınladı. Apache 2.0 lisansına sahip olan bu model, tek adımlı çıkarım özelliğiyle hızlı ve verimli olup, bloklara ayırmaya veya boyut sınırlamalarına gerek kalmadan keyfi çözünürlükte işlemeyi destekliyor. (Kaynak: huggingface)
ByteDance Doubao video büyük dil modeli Seedance 1.0 Pro’nun gerçek dünya test sonuçları övgü topladı : ByteDance’in en son yayınladığı görüntüden videoya büyük dil modeli Seedance 1.0 Pro, gerçek dünya testlerinde iyi bir komut takip yeteneği ve nesne üretimi kararlılığı gösterdi. Kullanıcılar, video üretim kalitesinin yüksek olduğunu, kamera hareketlerinin ve zamanlamasının doğru olduğunu ve Veo 2/3’ten sonra ikinci sırada yer aldığını belirtti. Potansiyel bir dezavantaj, saf nesne hareketi üretirken modelin bazen sahneyi daha mantıklı hale getirmek için el hareketleri eklemesi; bu durum el görünümünü kısıtlayarak önlenebilir. (Kaynak: karminski3, karminski3, karminski3)
Alibaba, gerçek zamanlı yüz yakalama ve 3D sanal karakter oluşturmayı destekleyen açık kaynaklı dijital insan çerçevesi Mnn3dAvatar’ı yayınladı : Alibaba, GitHub’da Mnn3dAvatar adlı bir dijital insan çerçevesini açık kaynak olarak yayınladı. Bu proje, gerçek zamanlı yüz yakalamayı ve ifadeleri 3D sanal karakterlere eşlemeyi mümkün kılıyor, aynı zamanda kullanıcıların kendi 3D sanal karakterlerini oluşturmalarını da destekliyor. Bu çerçeve, basit canlı yayın satışları, içerik sunumu gibi senaryolar için uygundur. (Kaynak: karminski3)
Nvidia, insansı robot temel modeli Gr00t N 1.5 3B’yi açık kaynak yaptı ve ince ayar eğitimi sundu : Nvidia, insansı robotların çıkarım becerileri için özel olarak tasarlanmış, ticari lisanslı açık bir temel model olan Gr00t N 1.5 3B modelini açık kaynak olarak yayınladı. Aynı zamanda Nvidia, insansı robot teknolojisinin gelişimini ve uygulamasını teşvik etmek amacıyla LeRobotHF SO101 ile kullanılmak üzere eksiksiz bir ince ayar eğitimi de yayınladı. (Kaynak: ClementDelangue)
Together AI, büyük ölçekli LLM çıkarım hizmeti sunan ve fiyatları önemli ölçüde düşüren Batch API’yi başlattı : Together AI, sentetik veri üretimi, benchmark testi, içerik denetimi ve özetleme, belge çıkarma gibi yüksek iş hacimli (high-throughput) uygulama senaryoları için özel olarak tasarlanmış yeni Batch API’sini kullanıma sundu. Bu API, gerçek zamanlı API’den %50 daha ucuz bir başlangıç fiyatı sunuyor, her seferinde en fazla 50.000 istek veya 100MB toplu işlemi destekliyor ve 15 üst düzey modelle uyumlu. (Kaynak: vipulved)
Google Gemini 2.5 Pro’ya etkileşimli fraktal sanat üretme özelliği eklendi : Google, Gemini 2.5 Pro’nun artık anında etkileşimli fraktal sanat oluşturmayı desteklediğini duyurdu. Kullanıcılar, “Benim için güzel, parçacık tabanlı, animasyonlu, sonsuz, 3D, simetrik, matematiksel formüllerden ilham alan bir fraktal sanat eseri oluştur” gibi istemler sağlayarak benzersiz görsel sanat eserleri üretebilirler. (Kaynak: demishassabis)
Google Veo3 Fast video üretim hızı iki katına çıktı : Google laboratuvarları, video üretim aracı Flow’daki Veo3 Fast sürümünün üretim hızının, 720p çözünürlüğü korurken iki kattan fazla arttığını duyurdu. Bu güncelleme, kullanıcıların daha hızlı video içeriği oluşturmasını sağlamayı amaçlıyor. (Kaynak: op7418)
Hugging Face, model kullanım süreçlerini basitleştirmek için Google Colab ve Kaggle ile entegre oldu : Hugging Face artık Google Colab ve Kaggle ile entegre oldu. Kullanıcılar, herhangi bir model kartından doğrudan Colab not defterlerini başlatabilir veya aynı modeli Kaggle Notebook’ta çalıştırılabilir genel kod örnekleriyle birlikte açabilir, bu da model kullanımı ve deney süreçlerini basitleştirir. (Kaynak: ClementDelangue, huggingface)
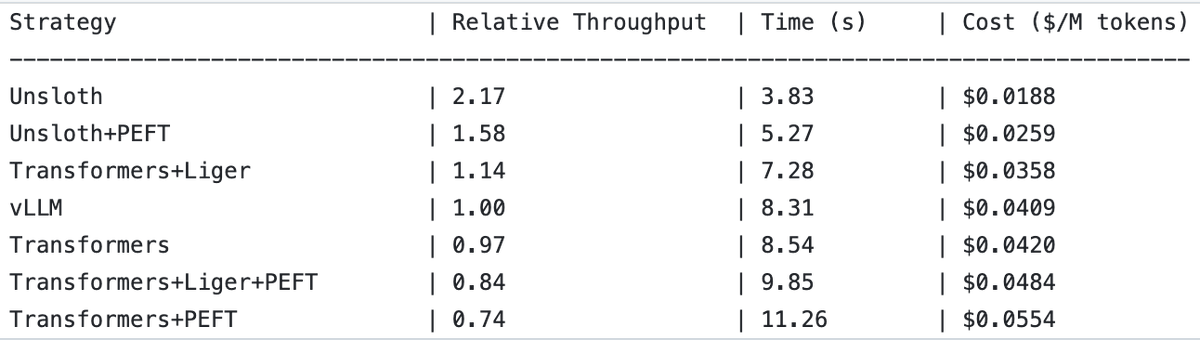
UnslothAI, ödül modeli hizmetlerinde ve dizi sınıflandırma çıkarımında 2 kat iş hacmi (throughput) artışı sağladı : UnslothAI’nin ödül modeli (RM) hizmetleri sunmak için kullanılabileceği ve dizi sınıflandırma çıkarımında iş hacminin vLLM’in iki katı olduğu keşfedildi. Bu keşif, RL (Pekiştirmeli Öğrenme) topluluğunda dikkat çekti ve UnslothAI’nin performans artışının ilgili araştırma ve uygulamaları hızlandırması bekleniyor. (Kaynak: natolambert, danielhanchen)
Digua Robot, ilk tek SoC hesaplama ve kontrol entegre robot geliştirme kiti RDK S100’ü yayınladı : Digua Robot, sektördeki ilk tek SoC (System-on-Chip) hesaplama ve kontrol entegre robot geliştirme kiti olan RDK S100’ü tanıttı. Bu kit, insan benzeri beyin-beyincik mimarisiyle tasarlanmış olup, tek bir SoC üzerinde CPU+BPU+MCU’yu entegre ederek, bedensel zeka (embodied intelligence) büyük ve küçük modellerinin verimli iş birliğini destekliyor ve “algılama-karar verme-kontrol” döngüsünü tamamlıyor. RDK S100, çeşitli arayüzler ve yazılım-donanım eşgüdümlü, uç ve bulut entegre geliştirme altyapısı sunarak, bedensel zeka ürünlerinin oluşturulmasını ve çoklu senaryo dağıtımını hızlandırmayı amaçlıyor. Şu anda 20’den fazla lider müşteriyle iş birliği yapılmış olup, pazar fiyatı 2799 yuan olarak belirlenmiştir. (Kaynak: Digua Robot, ilk tek SoC hesaplama ve kontrol entegre robot geliştirme kitini yayınladı, 20’den fazla lider müşteriyle iş birliği yaptı | En Ön Cephe)

🧰 Araçlar
LangChain, çoklu ajan mimarisi benchmark testini ve yönetici (supervisor) yöntemi iyileştirmelerini yayınladı : LangChain, giderek artan çoklu ajan sistemlerine yönelik olarak, çoklu ajanlar arasındaki koordinasyonun nasıl optimize edileceğini araştıran bir ön benchmark testi gerçekleştirdi. Aynı zamanda LangChain, yönetici (supervisor) yönteminde bazı iyileştirmeler yaptı ve ilgili blog yazısı yayınlandı. (Kaynak: LangChainAI, hwchase17)
Cartesia, sesli ajanlar için tasarlanmış hızlı, ekonomik akışlı (streaming) sesten metne modeli Ink-Whisper’ı tanıttı : Cartesia, sesli ajanlar için optimize edilmiş, yüksek hızlı, düşük maliyetli akışlı sesten metne (STT) modeli Ink-Whisper’ı yayınladı. Bu model, gerçek dünya koşullarında doğruluk için özel olarak tasarlanmış olup, hızlı sesli yapay zeka etkileşimleri için Cartesia’nın Sonic metinden sese (TTS) modeliyle birlikte kullanılabilir. Ink-Whisper, VapiAI, PipecatAI ve Livekit gibi platformlara entegrasyonu destekliyor. (Kaynak: simran_s_arora, tri_dao, krandiash)

MonkeyOCR: Küçük, hızlı, açık kaynaklı belge ayrıştırma modeli : MonkeyOCR adlı 3B parametreli bir belge ayrıştırma modeli, Apache 2.0 lisansıyla yayınlandı. Bu model, grafikler, formüller, tablolar dahil olmak üzere belgelerdeki çeşitli öğeleri ayrıştırabiliyor ve geleneksel ayrıştırıcı pipeline’larının yerini alarak daha iyi bir belge işleme çözümü sunmayı amaçlıyor. (Kaynak: mervenoyann, huggingface)
LlamaIndex, yapay zeka asistanı yanıtlarının güvenilirliğini artırmak için Cleanlab ile entegre oldu : LlamaIndex, CleanlabAI ile entegrasyonunu duyurdu. LlamaIndex, kurumsal verilerden içgörüler üreten yapay zeka bilgi asistanları ve üretim düzeyinde ajanlar oluşturmak için kullanılıyor. Cleanlab’ın katılımı, bu yapay zeka asistanı yanıtlarının güvenilirliğini artırmayı amaçlıyor; her LLM yanıtını puanlayabiliyor, halüsinasyonları veya yanlış yanıtları gerçek zamanlı olarak yakalayabiliyor ve yanıtların güvenilmez olmasının nedenlerini (kötü getirme, veri/bağlam sorunları, zorlu sorgular veya LLM halüsinasyonları gibi) analiz etmeye yardımcı oluyor. (Kaynak: jerryjliu0)

Claude Code, karmaşık kod değişikliklerinin kontrol edilebilirliğini artırmak için “Plan Modu”nu ekledi : Anthropic’in Claude Code’u “Plan Modu” (Plan mode) özelliğini tanıttı. Bu özellik, kullanıcıların kodu fiilen değiştirmeden önce uygulama planını incelemesine olanak tanıyarak, özellikle karmaşık kod değişikliklerinde her adımın dikkatlice düşünülmesini sağlıyor. Kullanıcılar, Shift + Tab tuşlarına iki kez basarak plan moduna geçebilirler; Claude Code ayrıntılı bir uygulama planı sunacak ve uygulamadan önce onay isteyecektir. Bu özellik, tüm Claude Code kullanıcılarına (Pro veya Max aboneleri dahil) sunulmuştur. (Kaynak: dotey, kylebrussell)
rvn-convert: Rust ile yazılmış SafeTensors’tan GGUF v3’e dönüştürme aracı : rvn-convert adlı açık kaynaklı bir araç yayınlandı. Rust diliyle yazılmış olan bu araç, SafeTensors formatındaki model dosyalarını GGUF v3 formatına dönüştürmek için kullanılıyor. Aracın özellikleri arasında tek parça (single-shard) desteği, hız, Python ortamına ihtiyaç duymaması, safetensors dosyalarını bellek eşlemesi (memory-map) yapabilmesi ve doğrudan gguf dosyasına yazabilmesi bulunuyor, bu da RAM tepe noktalarını ve disk çevrim sorunlarını önlüyor. Şu anda BF16’dan F32’ye yukarı örnekleme (upsampling), tokenizer.json gömme gibi özellikleri destekliyor. (Kaynak: Reddit r/LocalLLaMA)
Runway API’sine 4K video süper çözünürlük özelliği eklendi : Runway, API’sinin artık 4K video süper çözünürlük özelliğini desteklediğini duyurdu. Geliştiriciler, video içeriklerinin netliğini ve kalitesini artırmak için bu özelliği kendi uygulamalarına, ürünlerine, platformlarına ve web sitelerine entegre edebilirler. (Kaynak: c_valenzuelab)
You.com, araştırma materyallerini düzenlemek ve yönetmek için Projects özelliğini başlattı : You.com, kullanıcıların araştırma materyallerini kolay erişilebilir klasörler halinde düzenlemelerine yardımcı olmak amacıyla “Projects” adlı yeni bir araç yayınladı. Bu özellik, kullanıcıların konuşmaları bağlamsallaştırmasına ve yapılandırmasına olanak tanıyarak, sohbet kayıtlarının dağılmasını ve içgörülerin kaybolmasını önlüyor, böylece bilgi yönetimi süreçlerini basitleştiriyor. (Kaynak: RichardSocher)
LlamaIndex, LlamaExtract akıllı ajan belge çıkarma hizmetini başlattı : LlamaIndex, karmaşık belgelerden ve giriş şemalarından yapılandırılmış veri çıkarmayı amaçlayan, ajan odaklı bir belge çıkarma hizmeti olan LlamaExtract’ı yayınladı. Bu hizmet yalnızca anahtar-değer çiftlerini çıkarmakla kalmıyor, aynı zamanda her çıkarılan öğe için kesin kaynak çıkarımı, sayfa referansları ve eşleşen metin sağlıyor. LlamaExtract, API olarak sunuluyor ve alt akış ajan iş akışlarına kolayca entegre edilebiliyor. (Kaynak: jerryjliu0)

langchain-google-vertexai güncellemesi yayınlandı, istemci önbellekleme ve araç desteği geliştirildi : langchain-google-vertexai yeni bir sürümle güncellendi. Başlıca güncellemeler şunlardır: tahmin istemcisi önbelleklemesi, yeni istemci örnekleme hızını 500 kat artırıyor; yerleşik kod yürütme aracı desteği. (Kaynak: LangChainAI, Hacubu)
Perplexity Finance, Excel modellerinin doğrudan indirilmesi özelliğini ekledi : Perplexity Finance, kullanıcıların artık Excel modellerini doğrudan sayfalarından indirebileceğini duyurdu; bu, finansal modelleme ve araştırma için daha hızlı bir başlangıç noktası sağlıyor. Bu özellik tüm kullanıcılara ücretsiz olarak sunuluyor; daha önce yalnızca CSV formatında indirme destekleniyordu. (Kaynak: AravSrinivas)
Viwoods, GPT-4o gibi yapay zeka özelliklerini entegre eden AI Paper Mini e-mürekkep tabletini piyasaya sürdü : Yeni e-mürekkep üreticisi Viwoods, yapay zeka özellikleriyle donatılmış bir e-mürekkep tableti olan AI Paper Mini’yi tanıttı. Cihaz, GPT-4o, DeepSeek gibi çeşitli yapay zeka modellerini destekliyor ve Chat modu ile önceden ayarlanmış yapay zeka asistanları (içerik analizi, e-posta oluşturma, yapay zeka ile metne dönüştürme) sunuyor. Öne çıkan özellikleri arasında takvim görünümünde görev yönetimi ve hızlı erişim için kayan pencere notları bulunuyor. Donanım tarafında, Paper Mini 292 ppi Carta 1000 ekrana, 4GB+128GB depolama alanına sahip ve bir kalemle birlikte geliyor. Viwoods ayrıca, 300ppi Carta 1300 esnek ekrana sahip ve daha hızlı tepki süresi sunan daha büyük boyutlu AI Paper’ı da tanıttı. (Kaynak: Yarım iPhone fiyatına, yapay zekalı bir “e-mürekkep tablet” aldım…)

360, Nano AI süper arama ajanını yayınladı, Zhou Hongyi bizzat tanıttı : 360 Grubu kurucusu Zhou Hongyi, Nano AI süper arama ajanının lansmanını yönetti. Bu ajan, “tek bir cümleyle her şey aranabilir” hedefini gerçekleştirmeyi amaçlıyor; insan müdahalesi olmadan otonom olarak düşünebiliyor, tarayıcıyı ve harici araçları çağırarak görevleri yerine getirebiliyor ve tüm süreci görselleştirme ve adımları izleme desteği sunuyor. Zhou Hongyi, bu lansmanın kendisinin de Nano AI kullanılarak hazırlanmaya çalışıldığını belirtti ve ayrıca AI akıllı ses kayıt cihazı Nano AI Note ile Rokid ile ortak markalı AI gözlüklerini de tanıttı. (Kaynak: Zhou Hongyi, AI ile pazarlama departmanını “yok etmek” istiyor, “Nano” bunu başardı mı?)
📚 Öğrenme Kaynakları
DeepLearning.AI, yeni kısa kursu duyurdu: Apache Airflow ile GenAI iş akışlarını düzenleme : DeepLearning.AI, Astronomer ile iş birliği yaparak, Apache Airflow 3.0 kullanarak RAG prototiplerini üretime hazır iş akışlarına dönüştürmeyi öğreten yeni bir kısa kurs başlattı. Kurs içeriği, iş akışlarını modüler görevlere ayırma, zaman ve olay güdümlü tetikleyiciler kullanarak pipeline’ları zamanlama, görevleri paralel çalıştırmak için dinamik görev eşleme, hata toleransı için yeniden deneme/uyarı/geri doldurma ekleme ve pipeline tekniklerini genişletme konularını içeriyor. Bu kurs için Airflow deneyimi gerekmiyor. (Kaynak: DeepLearningAI, FLUX.1 Kontext’s Consistent Characters, Benchmarking Costs Climb, Mary Meeker’s Action-Packed AI Report, Better Video Gen)
Hamel Husain, RAG optimizasyonu ve değerlendirmesi üzerine mini bir kurs başlattı : Hamel Husain, RAG (Retrieval Augmented Generation – Geri Getirme Artırılmış Üretim) optimizasyonu ve değerlendirmesi üzerine dört bölümlük bir mini kurs başlattığını duyurdu. İlk bölümü @bclavie tarafından sunulan kursta, RAG’ın “kökü kazınması gereken bir düşünce virüsü” olduğu yönündeki önceki tartışmalara yanıt olarak “geri getirme RAG’dır” görüşü ele alınıyor. Bu ücretsiz kurs serisi, uygulayıcıların RAG değerlendirmesinde karşılaştıkları zorlukları çözmelerine yardımcı olmayı amaçlıyor. (Kaynak: HamelHusain, HamelHusain, lateinteraction, HamelHusain, HamelHusain, HamelHusain, HamelHusain, HamelHusain)

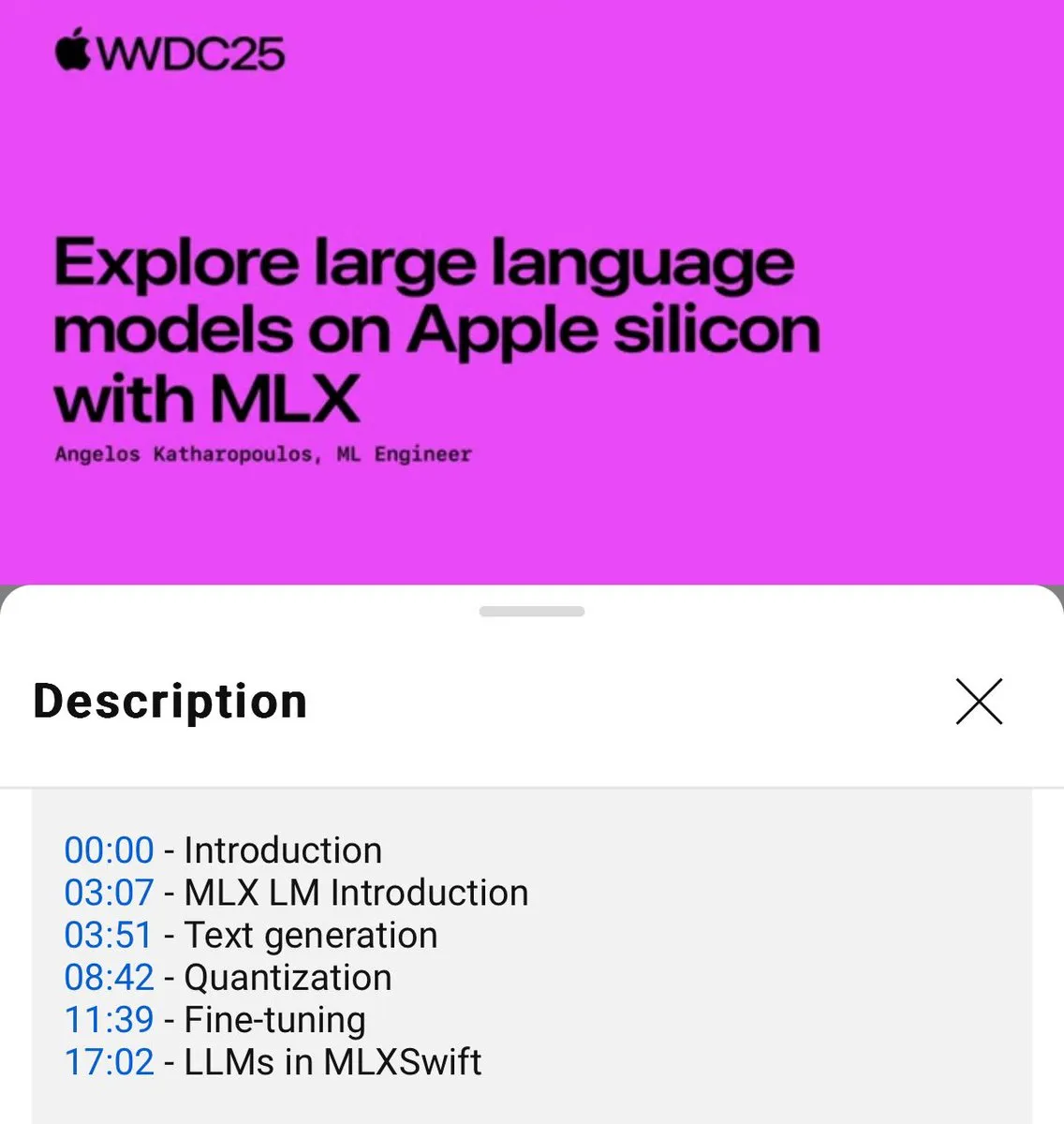
MLX dil modellerinin yerel kullanımı için eğitim yayınlandı (WWDC25) : WWDC25 konferansında Angelos Katharopoulos, MLX kullanarak yerel dil modelleriyle hızlı bir şekilde nasıl çalışılacağını tanıttı. Eğitim, MLXLM CLI kullanarak tek satırlık komut işlemlerini kapsıyor; örneğin model niceleme (mlx_lm.convert), LoRA ince ayarı (mlx_lm.lora) ve model birleştirme ile Hugging Face’e yükleme (mlx_lm.fuse). Tam Jupyter Notebook eğitimi GitHub’da mevcut. (Kaynak: awnihannun)
LangChain, Harvey AI’nin hukuk alanında yapay zeka ajanları oluşturma yöntemini paylaştı : Harvey AI’den Ben Liebald, LangChain’in Interrupt etkinliğinde hukuk alanında yapay zeka ajanları oluşturmaya yönelik olgunlaşmış yöntemlerini paylaştı. Bu yöntem, LangSmith değerlendirmesini ve “döngüde avukat” (lawyer-in-the-loop) stratejisini birleştirerek, karmaşık hukuki işler için avukatların güvenebileceği yapay zeka araçları sunmayı amaçlıyor. (Kaynak: LangChainAI, hwchase17)

RLHF El Kitabı v1.1 güncellendi, RLVR/çıkarım modeli içeriği genişletildi : RLHF El Kitabı (rlhfbook.com) v1.1 sürümüne güncellendi ve RLVR (Video Temsillerinden Pekiştirmeli Öğrenme) ile çıkarım modelleri hakkında genişletilmiş içerik eklendi. Güncellemeler, başlıca çıkarım modeli raporlarının özetlerini, yaygın uygulamaları/ipuçlarını ve kullanıcılarını, o1 öncesi ilgili çıkarım çalışmalarını ve asenkron RL gibi iyileştirmeleri içeriyor. (Kaynak: menhguin)
Makale SWE-Flow: Test odaklı bir yaklaşımla yazılım mühendisliği verilerini sentezleme : SWE-Flow adlı yeni bir makale, test odaklı geliştirmeye (TDD) dayanan yeni bir veri sentezleme çerçevesi öneriyor. Bu çerçeve, birim testlerini analiz ederek artımlı geliştirme adımlarını otomatik olarak çıkarıyor ve yapılandırılmış geliştirme planları oluşturmak için çalışma zamanı bağımlılık grafiği (RDG) oluşturuyor. Her adım, kısmi bir kod tabanı, karşılık gelen birim testleri ve gerekli kod değişikliklerini üreterek doğrulanabilir TDD görevleri oluşturuyor. Bu yönteme dayanarak SWE-Flow-Eval benchmark veri seti oluşturuldu. (Kaynak: HuggingFace Daily Papers)
Makale PlayerOne: Birinci şahıs bakış açısıyla oluşturulan ilk gerçek dünya simülatörü : PlayerOne, dinamik ortamlarda sürükleyici keşifler yapabilen, birinci şahıs bakış açısıyla (egosentrik) oluşturulan ilk gerçek dünya simülatörü olarak öneriliyor. Kullanıcının birinci şahıs sahne görüntüsü verildiğinde, PlayerOne karşılık gelen dünyayı inşa edebiliyor ve harici bir kamerayla yakalanan kullanıcının gerçek hareketleriyle birebir uyumlu birinci şahıs videoları üretebiliyor. Model, kabadan inceye bir eğitim süreci benimsiyor ve parça ayrıştırmalı hareket enjeksiyon şeması ile birleşik yeniden yapılandırma çerçevesi tasarlıyor. (Kaynak: HuggingFace Daily Papers)
Makale ComfyUI-R1: İş akışı üretimi için çıkarım modellerini keşfetme : ComfyUI-R1, otomatik iş akışı üretimi için kullanılan ilk büyük çıkarım modelidir. Araştırmacılar önce 4K iş akışı içeren bir veri kümesi oluşturdular ve uzun zincirli düşünme (CoT) çıkarım verileri oluşturdular. ComfyUI-R1, iki aşamalı bir çerçeve ile eğitildi: soğuk başlatma için CoT ince ayarı ve çıkarım yeteneğini teşvik etmek için pekiştirmeli öğrenme. Deneyler, 7B parametreli modelin format geçerliliği, geçiş oranı ve düğüm/grafik düzeyinde F1 puanlarında mevcut yöntemlerden önemli ölçüde daha iyi performans gösterdiğini ortaya koydu. (Kaynak: HuggingFace Daily Papers)
Makale SeerAttention-R: Uzun çıkarımlar için seyrek dikkat uyarlanabilir çerçevesi : SeerAttention-R, çıkarım modellerinin uzun kod çözme işlemleri için özel olarak tasarlanmış bir seyrek dikkat çerçevesidir. Kendi kendine damıtma (self-distillation) geçit mekanizması aracılığıyla dikkat seyrekliğini öğrenir ve otoregresif kod çözmeye uyum sağlamak için sorgu havuzlamasını (query pooling) kaldırır. Bu çerçeve, orijinal parametreleri değiştirmeden mevcut önceden eğitilmiş modellere hafif bir eklenti olarak entegre edilebilir. AIME benchmark testinde, yalnızca 0.4B token ile eğitilen SeerAttention-R, 4K token bütçesi altında, büyük seyrek dikkat bloklarında (64/128) kayıpsıza yakın çıkarım doğruluğunu korudu. (Kaynak: HuggingFace Daily Papers)
Makale SAFE: Görsel-dil-eylem modelleri için çok görevli hata tespiti : Makale, VLA gibi genel amaçlı robot stratejileri için tasarlanmış bir hata tespit edicisi olan SAFE’i öneriyor. VLA özellik uzayını analiz ederek, SAFE, VLA iç özelliklerinden görev başarısızlığı olasılığını tahmin etmeyi öğreniyor. Bu tespit edici, başarılı ve başarısız dağıtımlarda eğitiliyor ve görülmemiş görevlerde değerlendiriliyor; farklı strateji mimarileriyle uyumlu olup, VLA’ların çevreleriyle etkileşim halindeyken güvenliğini artırmayı amaçlıyor. (Kaynak: HuggingFace Daily Papers)
Makale Branched Schrödinger Bridge Matching: Dallanmış Schrödinger Köprülerini Öğrenme : Bu çalışma, başlangıç dağılımı ile hedef dağılım arasındaki ara yörüngeleri tahmin etmek amacıyla dallanmış Schrödinger köprülerini öğrenmek için Branched Schrödinger Bridge Matching (BranchSBM) çerçevesini tanıtıyor. Mevcut yöntemlerden farklı olarak BranchSBM, ortak bir başlangıç noktasından birden fazla farklı sonuca doğru dallanan veya ayrışan evrimleri modelleyebiliyor; bunu birden fazla zamana bağlı hız alanı ve büyüme sürecini parametreleştirerek başarıyor. (Kaynak: HuggingFace Daily Papers)
💼 İş Dünyası
Meta’nın veri etiketleme şirketi Scale AI’yi 15 milyar dolara satın almayı planladığı ve kurucusunun Meta’ya katılacağı iddia edildi : Haberlere göre Meta, veri etiketleme alanının lider şirketlerinden Scale AI’yi 15 milyar dolara satın almayı planlıyor. Anlaşma gerçekleşirse, Scale AI’nin 28 yaşındaki Çinli kurucusu Alexandr Wang ve ekibi doğrudan Meta’ya katılacak. Bu hamle, Meta CEO’su Zuckerberg’in AGI (Genel Yapay Zeka) ekibinin gücünü artırmak ve OpenAI ile Google gibi rakiplerini yakalamak için attığı önemli bir adım olarak görülüyor. Meta son zamanlarda yapay zeka yeteneklerini işe alma konusunda sık sık hamleler yapıyor ve en iyi mühendislere on milyonlarca dolarlık maaş paketleri sunuyor. (Kaynak: Zuckerberg’in “Süper Zeka” grubuna katılan ilk önemli isim, Google DeepMind baş araştırmacısı, “sıkıştırma zekadır”ın kilit ismi, dylan522p, sarahcat21, Dorialexander)
Disney ve Universal Pictures, yapay zeka görüntü şirketi Midjourney’e telif hakkı ihlali davası açtı : Disney ve Universal Pictures, yapay zeka görüntü üretim şirketi Midjourney’e, “Star Wars”, “The Simpsons” gibi tanınmış IP eserlerini izinsiz kullandığı gerekçesiyle dava açtı. Bu dava dikkat çekiyor; Disney’in kazanması durumunda, büyük ölçekli veri eğitimine dayanan diğer yapay zeka şirketleri için zincirleme bir reaksiyon yaratabilir ve yapay zeka alanındaki telif hakkı tartışmalarını daha da şiddetlendirebilir. (Kaynak: Reddit r/artificial, Reddit r/LocalLLaMA, karminski3)

Google, yapay zeka aramasının etkisiyle tekrar “gönüllü ayrılma planı” başlattı; arama, reklam gibi birçok önemli ekibi etkiledi : Yapay zeka aramasının getirdiği etkiyle karşı karşıya kalan Google, ABD’deki birçok departman çalışanına tekrar “gönüllü ayrılma planı” sundu. Bu plan, arama, reklam, çekirdek mühendislik gibi kilit ekipleri etkiliyor ve ofise dönüş politikalarını güçlendiriyor. Bu hamle, kaynakları yeniden yapılandırmayı ve daha fazla enerjiyi yapay zeka amiral gemisi projesi Gemini ile “AI modu” arama deneyiminin geliştirilmesine ayırmayı amaçlıyor. Google’ın geleneksel arama işi, yapay zekanın yükselişi nedeniyle büyük zorluklarla karşı karşıya ve şirket aynı zamanda düzenleyici baskılarla da mücadele ediyor. (Kaynak: Yapay zeka aramasının etkisi altında Google tekrar “gönüllü ayrılma planı” başlattı, birçok önemli ekibi etkiledi, jpt401)
🌟 Topluluk
Yapay zeka, Amsterdam’daki sosyal yardım dolandırıcılığı tespit deneyinde önyargı sergiledi, proje durduruldu : Amsterdam, dolandırıcılığı tespit etmek için sosyal yardım başvurularını değerlendirmek üzere bir yapay zeka sistemi (Smart Check) kullanmayı denedi. Sorumlu yapay zeka en iyi uygulamalarına (önyargı testleri ve teknik güvenceler dahil) uyulmasına rağmen, pilot projede sistem adil ve etkili olamadı. Başlangıçtaki model, Hollandalı olmayan başvuru sahiplerine ve erkeklere karşı önyargılıydı; ayarlamalardan sonra ise Hollandalı ve kadınlara karşı önyargı geliştirdi. Sonuç olarak, ayrımcılık yapılmayacağından emin olunamadığı için proje durduruldu. Bu vaka, algoritmik adalet, sorumlu yapay zeka uygulamalarının etkinliği ve yapay zekanın kamu hizmeti kararlarında kullanımı hakkında geniş çaplı tartışmalara yol açtı. (Kaynak: MIT Technology Review, Inside Amsterdam’s high-stakes experiment to create fair welfare AI)

Yapay zeka tarafından üretilen içerik tanımlama sistemi: Değer, sınırlamalar ve yönetişim mantığı tartışması : Yapay zeka tarafından üretilen söylentilerin ve sahte propagandanın artmasıyla birlikte, yapay zeka tanımlama sistemi bir yönetişim aracı olarak dikkat çekiyor. Teorik olarak, açık ve örtük tanımlama, tanıma verimliliğini artırabilir ve kullanıcı farkındalığını güçlendirebilir. Ancak pratikte, tanımlama kolayca atlatılabilir, taklit edilebilir ve yanlış değerlendirilebilir ve maliyeti yüksektir. Makale, yapay zeka tanımlamasının mevcut içerik yönetişim sistemine dahil edilmesi, söylentiler ve sahte propaganda gibi yüksek riskli alanlara odaklanılması ve üretim ile yayma platformlarının sorumluluklarının makul bir şekilde tanımlanması, aynı zamanda halkın bilgi okuryazarlığı eğitiminin güçlendirilmesi gerektiğini savunuyor. (Kaynak: Söylentiler “Yapay Zeka” Rüzgarını Arkasına Aldığında)
Yapay zeka destekli kodlama araçları (Claude Code gibi) geliştirici verimliliğini önemli ölçüde artırıyor ve iş yükünü azaltıyor : Topluluktaki birçok geliştirici, yapay zeka destekli kodlama araçlarını (özellikle Anthropic’in Claude Code’u) kullanma konusundaki olumlu deneyimlerini paylaştı. Bu araçlar yalnızca kod yazma, test etme ve hata ayıklamaya yardımcı olmakla kalmıyor, aynı zamanda proje planlama, karmaşık sorun çözme gibi konularda da destek sağlayarak geliştirme verimliliğini önemli ölçüde artırıyor, iş yükünü ve teslim tarihi kaygısını azaltıyor. Bazı kullanıcılar, yapay zeka desteğinin kendilerini “durdurulamaz bir güç” gibi hissettirdiğini belirtti. (Kaynak: AnthropicAI, sbmaruf, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

Yapay zeka tarafından üretilen içeriğin enerji ve su tüketimi dikkat çekiyor, Sam Altman her ChatGPT sorgusunun yaklaşık 1/15 çay kaşığı su tükettiğini söyledi : OpenAI CEO’su Sam Altman, her ChatGPT sorgusunun yaklaşık “on beşte bir çay kaşığı” su tükettiğini açıkladı. Bu veri, yapay zeka modellerinin eğitimi ve çıkarımının çevresel etkileri hakkında tartışmalara yol açtı. Belirli hesaplama yöntemleri ve eğitim maliyetlerinin dahil edilip edilmediği henüz net olmasa da, yapay zekanın enerji ayak izi ve su kaynakları tüketimi teknoloji dünyası ve çevre alanında dikkat çeken bir konu haline geldi. (Kaynak: MIT Technology Review, Reddit r/ChatGPT)

LLM’lerin matematiksel kanıtları gerçekten anlayıp anlamadığı tartışması: IneqMath benchmark testi modellerin eksikliklerini ortaya koyuyor : Yeni yayınlanan IneqMath benchmark testi, Olimpiyat düzeyindeki matematiksel eşitsizlik kanıtlarına odaklanıyor ve LLM’lerin bazen doğru cevabı bulabilmelerine rağmen, titiz ve mantıklı kanıtlar oluşturma konusunda önemli eksiklikleri olduğunu ortaya koyuyor. Bu durum, LLM’lerin matematik gibi alanlarda gerçekten anlayıp anlamadığı yoksa sadece “tahmin” mi yürüttüğü konusunda tartışmalara yol açtı. Sathya, bu “doğru cevap-yanlış çıkarım” olgusunun PutnamBench gibi benchmark testlerinde de görüldüğünü belirtti. (Kaynak: lupantech, lupantech, _akhaliq, clefourrier)
Yapay Zeka Ajanlarının yazılım geliştirme, araştırma ve günlük görevlerdeki uygulamaları ve tartışmaları : Topluluk, Yapay Zeka Ajanlarının farklı alanlardaki uygulamalarını geniş çapta tartışıyor. Örneğin, bir kullanıcı n8n ve Claude kullanarak derinlemesine araştırma yapan bir akıllı ajan iş akışı oluşturma deneyimini paylaştı; LlamaIndex, Artifact Memory Block aracılığıyla artımlı form doldurma ajanının nasıl uygulanacağını gösterdi; tartışmalar ayrıca yapay zeka odaklı araç arayüzleri tasarlamak için MCP (Model Context Protocol) kullanımını ve Yapay Zeka Ajanlarının hukuk, altyapı otomasyonu (Cisco’nun JARVIS’i gibi) gibi alanlardaki uygulamalarını da içeriyor. (Kaynak: qdrant_engine, OpenAIDevs, jerryjliu0, dzhng, Reddit r/ClaudeAI, omarsar0)

İnsansı robot güvenlik standartları dikkat çekiyor, fiziksel ve psikolojik etkilerin dengelenmesi gerekiyor : İnsansı robotlar endüstriyel uygulamalara girmeye ve ev gibi senaryoları hedeflemeye başladıkça, güvenlik standartları tartışma konusu haline geliyor. IEEE İnsansı Robot Araştırma Grubu, insansı robotların dinamik stabilite gibi benzersiz özelliklere sahip olduğunu ve yeni güvenlik kurallarına ihtiyaç duyduğunu belirtiyor. Fiziksel güvenliğin (düşme, çarpışma önleme gibi) yanı sıra, insan-robot etkileşimindeki iletişim zorlukları (niyet ifadesi, çoklu robot koordinasyonu gibi) ve psikolojik etkiler (aşırı insanlaştırmanın yüksek beklentilere yol açması, duygusal güvenlik gibi) de dikkate alınmalıdır. Standartların oluşturulmasında inovasyon ve güvenlik dengelenmeli ve farklı uygulama senaryolarının ihtiyaçları göz önünde bulundurulmalıdır. (Kaynak: MIT Technology Review, Why humanoid robots need their own safety rules)

💡 Diğer
Docker, docker run --gpus komutunun artık AMD GPU’ları desteklediğini duyurdu : Docker resmi olarak, docker run --gpus komutunun artık AMD GPU’lar üzerinde çalışmayı da desteklediğini güncelledi. Bu iyileştirme, AMD GPU’ların konteynerize edilmiş AI/ML iş yüklerindeki kullanım kolaylığını artırıyor ve AMD’nin AI ekosistemindeki uygulamalarını teşvik etmede olumlu bir etkiye sahip. (Kaynak: dylan522p)
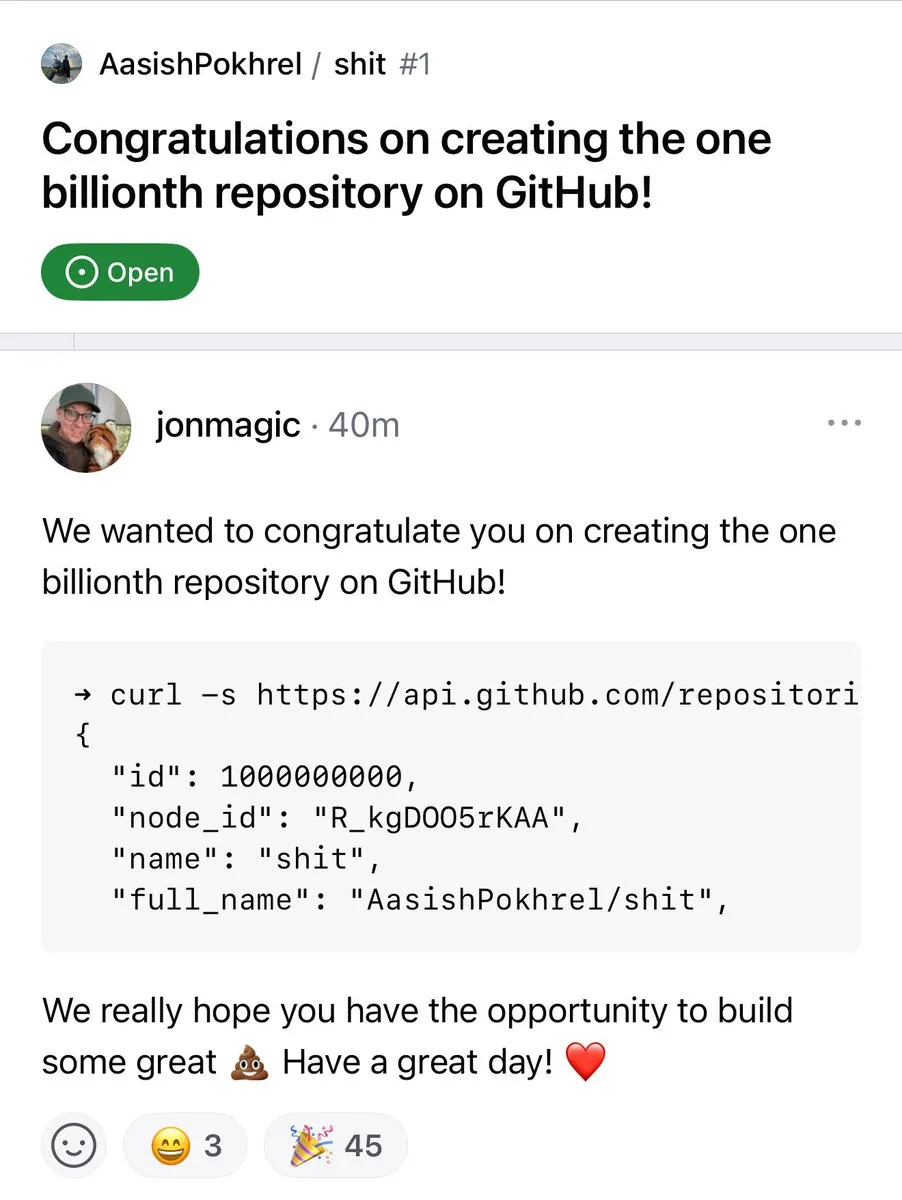
GitHub depo sayısı 1 milyarı aştı : GitHub platformundaki kod depo sayısı resmi olarak 1 milyar sınırını aştı. Bu dönüm noktası, açık kaynak topluluğunun ve kod barındırma platformlarının sürekli gelişimini ve büyümesini işaret ediyor. (Kaynak: karminski3, zacharynado)
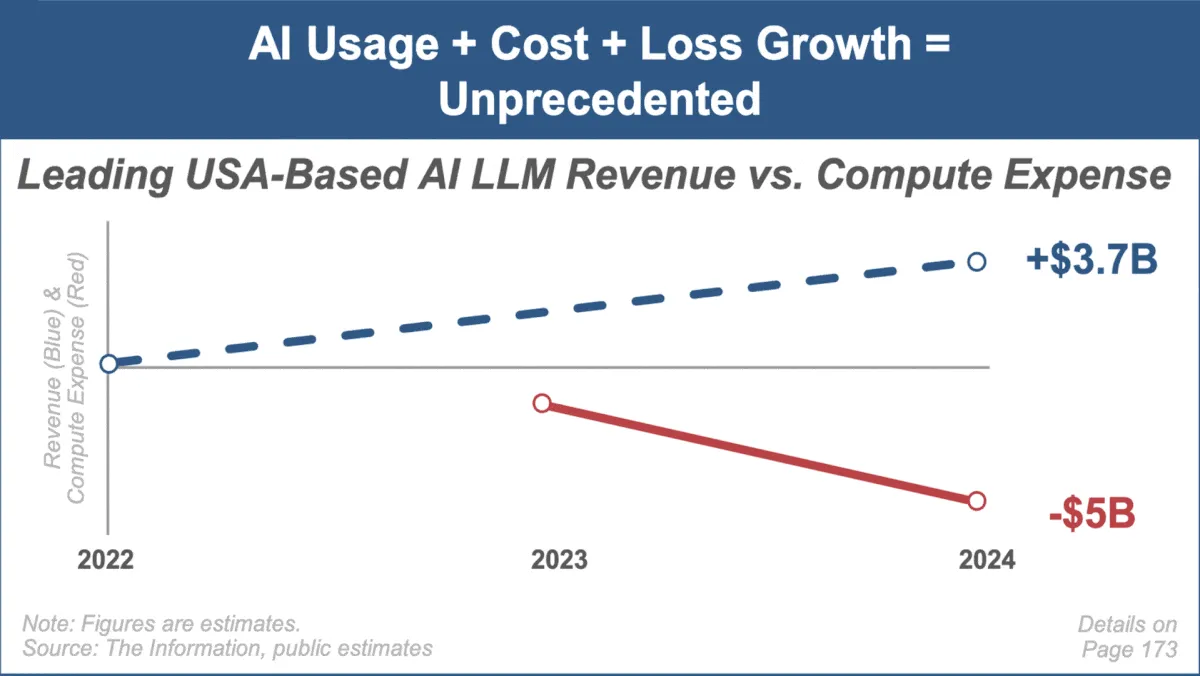
Mary Meeker, en son yapay zeka trendleri raporunu yayınladı; pazarın hızlı büyümesine ve zorluklarına odaklandı : Tanınmış yatırım analisti Mary Meeker, yapay zeka pazarına ilişkin ilk trend raporu olan “Trends — Artificial Intelligence (May ‘25)”i yayınladı. Rapor, yapay zeka alanındaki benzeri görülmemiş büyüme hızını, kullanıcı sayısındaki büyük artışı (örneğin ChatGPT kullanıcılarının 800 milyona ulaşması), yapay zeka ile ilgili sermaye harcamalarındaki önemli artışı ve yapay zekanın performans ve yeni yeteneklerindeki sürekli atılımları vurguluyor. Rapor aynı zamanda, artan hesaplama maliyetleri, modellerin hızlı bir şekilde yenilenmesi ve açık kaynak alternatiflerinin rekabeti gibi yapay zeka iş modellerinin karşılaştığı zorluklara da dikkat çekiyor. (Kaynak: DeepLearning.AI Blog)