
Anahtar Kelimeler:DeepSeek, OpenAI, Çıkarım Modeli, Çok Modelli Büyük Model, Pekiştirmeli Öğrenme, AI Yenilik, Açık Kaynak Model, DeepSeek R1 Çıkarım Modeli, OpenAI o4 Pekiştirmeli Öğrenme Eğitimi, Çok Modelli Büyük Model İnsan Düşünce Haritası, Mistral AI Magistral Serisi, Xiaohongshu dots.llm1 MoE Modeli
🔥 Odak Noktası
DeepSeek ve OpenAI’nin İnovasyon Yolları “Bilişsel İnovasyonu” Ortaya Koyuyor: DeepSeek, “sınırlı Scaling Law”, MLA ve MoE mimari inovasyonları ve yazılım-donanım sinerjisi optimizasyonu yoluyla düşük maliyetli yüksek performans elde etti. R1 çıkarım modelinin açık kaynaklı hale getirilmesi, yapay zeka bilişsel yeteneklerinde bir atılım sağladı, Çinli yenilikçilerin temel araştırma alanındaki “zihinsel damgasını” kırdı ve Çinli şirketlerin yapay zeka temel araştırmaları ve model inovasyonu alanındaki küresel liderlik gücünü kanıtladı. OpenAI ise Transformer mimarisi ve Scaling Law’un (ölçeklendirme yasası) ustaca kullanımıyla büyük dil modeli devrimine öncülük etti ve ChatGPT ile çıkarım modeli o1 aracılığıyla insan-makine etkileşimi paradigmasında bir dönüşümü ve yapay zeka bilişsel yeteneklerinde bir sıçramayı teşvik etti. Her ikisinin de gelişim yolları, teknolojinin özünün derinlemesine anlaşılmasını ve stratejik yeniden yapılandırılmasını vurguluyor ve yapay zeka çağındaki girişimciler için değerli organizasyonel yapılandırma ve inovasyon fikirleri sunuyor. Özellikle DeepSeek’in “beliren özellikleri” teşvik eden AI Lab paradigması, teknoloji inovasyonu odaklı girişimciler için yeni bir organizasyonel model referansı sağlıyor (Kaynak: 36Kr)
OpenAI’nin Yeni Bir Model Olan o4’ü Eğittiği ve Takviyeli Öğrenmenin Yapay Zeka Düzenini Yeniden Şekillendirdiği Bildirildi: SemiAnalysis, OpenAI’nin GPT-4.1 ile GPT-4.5 arasında yeni bir model eğittiğini ve yeni nesil çıkarım modeli o4’ün GPT-4.1 tabanlı takviyeli öğrenme (RL) ile eğitileceğini açıkladı. RL, CoT üreterek modelin çıkarım yeteneklerinin kilidini açıyor ve yapay zeka ajanlarının gelişimini destekliyor. Ancak altyapı (özellikle çıkarım) ve ödül fonksiyonu tasarımı için son derece yüksek gereksinimleri var ve “ödül hackleme” (reward hacking) olgusuna eğilimli. Yüksek kaliteli veri, RL’yi ölçeklendirmenin anahtarıdır ve kullanıcı davranış verileri önemli bir varlık haline gelecektir. RL ayrıca laboratuvar organizasyon yapısını da değiştirerek çıkarım ve eğitimi derinden bütünleştiriyor. Ön eğitimden farklı olarak RL, DeepSeek R1 gibi model yeteneklerini sürekli olarak güncelleyebilir. Küçük modeller için damıtma (distillation) RL’den daha iyi olabilir. Bu sızıntı, yapay zeka alanının, özellikle de çıkarım modellerinin, RL tabanlı sürekli evrim ve yetenek artışı yaşayacağını gösteriyor (Kaynak: 36Kr)
Çok Modlu Büyük Modellerin Kendiliğinden “İnsan Zihin Haritaları” Oluşturabildiği Keşfedildi: Çin Bilimler Akademisi Otomasyon Enstitüsü ile Beyin Bilimi ve Akıllı Teknoloji Mükemmeliyet İnovasyon Merkezi’nden ortak bir ekip, davranışsal deneyler ve nörogörüntüleme analizleri yoluyla çok modlu büyük dil modellerinin (MLLM’ler) insanlardakine oldukça benzeyen nesne kavramı temsil sistemlerini kendiliğinden oluşturabildiğini doğruladı. Araştırma, 4.7 milyon “üçten birini ayırma görevi” davranışsal yargı verisini analiz ederek yapay zeka modelinin “kavram haritasını” ilk kez oluşturdu. Temel bulgular şunları içeriyor: Farklı mimarilere sahip yapay zeka modelleri benzer düşük boyutlu bilişsel yapılara yakınsayabilir; modeller, denetimsiz koşullar altında insan bilişiyle tutarlı üst düzey nesne kavramı sınıflandırma yeteneği sergiler; yapay zeka modellerinin “düşünme boyutlarına” hayvan, yiyecek, sertlik gibi anlamsal etiketler atanabilir; MLLM’lerin temsilleri, beynin belirli bölgelerindeki (FFA, PPA gibi) sinirsel aktivite örüntüleriyle önemli ölçüde ilişkilidir ve bu da “yapay zeka ve insanların kavram işleme mekanizmalarını paylaştığına” dair kanıtlar sunar. Bu çalışma, yapay zeka bilişini anlamak, beyin benzeri zeka geliştirmek ve beyin-makine arayüzleri için yeni fikirler sunmaktadır (Kaynak: Quantumbit)

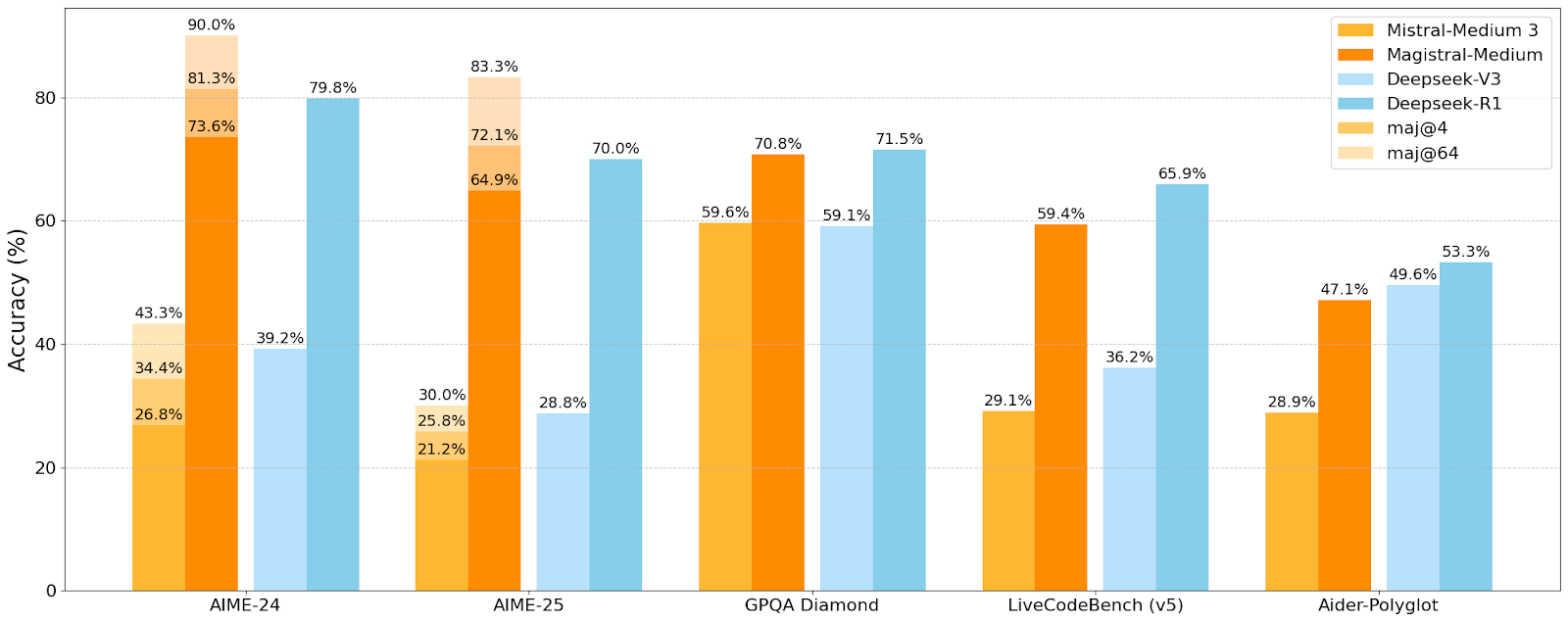
Mistral AI, İlk Çıkarım Modeli Serisi Magistral’ı Yayınladı, Küçük Model Magistral-Small Açık Kaynaklı Hale Getirildi: Mistral AI, özellikle çıkarım için tasarlanmış ilk model serisi olan Magistral’ı tanıttı. Bu seri, Magistral-Small ve Magistral-Medium’u içeriyor. Mistral Small 3.1 (2503) tabanlı Magistral-Small, 24B parametreli verimli bir çıkarım modelidir ve Magistral Medium’un yörüngesi üzerinden SFT ve RL eğitimi ile çıkarım yetenekleri geliştirilmiştir. Model çok dilliliği destekler, 128k bağlam penceresine sahiptir (önerilen etkili bağlam 40k), Apache 2.0 lisansı altında açık kaynaklıdır ve tek bir RTX 4090 veya 32GB RAM’e sahip bir MacBook’ta yerel olarak (nicemlemeden sonra) konuşlandırılabilir. Kıyaslama testleri, Magistral-Small’un AIME24, AIME25, GPQA Diamond ve Livecodebench (v5) gibi görevlerde bazı daha büyük modellere yakın ve hatta onlardan daha iyi performans gösterdiğini ortaya koyuyor. Magistral-Medium daha yüksek performansa sahip ancak şu anda açık kaynaklı değil. Bu sürüm, Mistral’ın model çıkarım yeteneklerini ve çok dilli desteğini geliştirme konusundaki ilerlemesini işaret ediyor (Kaynak: Reddit r/LocalLLaMA, Mistral AI, X)
🎯 Eğilimler
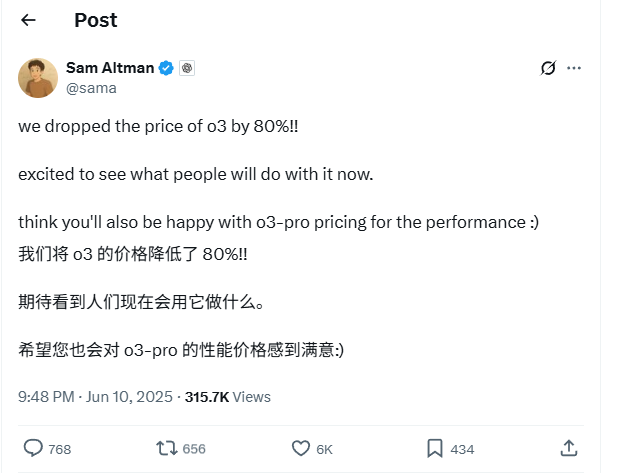
OpenAI o3 Model API Fiyatlarında %80’lik Büyük İndirim: OpenAI CEO’su Sam Altman, o3 modelinin API fiyatlarının %80 oranında düşürüldüğünü duyurdu. Ayarlamadan sonra, giriş fiyatı 2 ABD Doları/milyon token, çıkış fiyatı ise 8 ABD Doları/milyon token oldu (bazı kaynaklar çıkış fiyatını 5 ABD Doları/milyon token olarak belirtiyor, resmi belgelere başvurulması gerekiyor). Bu büyük indirim, o3 modelini kod yazma gibi görevler için kullanma maliyetini önemli ölçüde düşürerek daha geniş çaplı uygulamaları ve yenilikleri teşvik etmesi bekleniyor. Kullanıcıların, resmi web sitesindeki fiyat listesinin henüz güncellenmemiş olabileceğine dikkat etmeleri ve gereksiz kayıpları önlemek için API çağrısı yapmadan önce gerçekte geçerli olan fiyatı doğrulamak için test yapmaları önerilir. Bu hamle, pazar rekabetine (Gemini 2.5 Pro ve Claude 4 Sonnet gibi) bir yanıt olarak değerlendiriliyor ve yapay zeka zekasının maliyetinin düşmeye devam edeceğinin bir göstergesi olabilir (Kaynak: X, X, X)
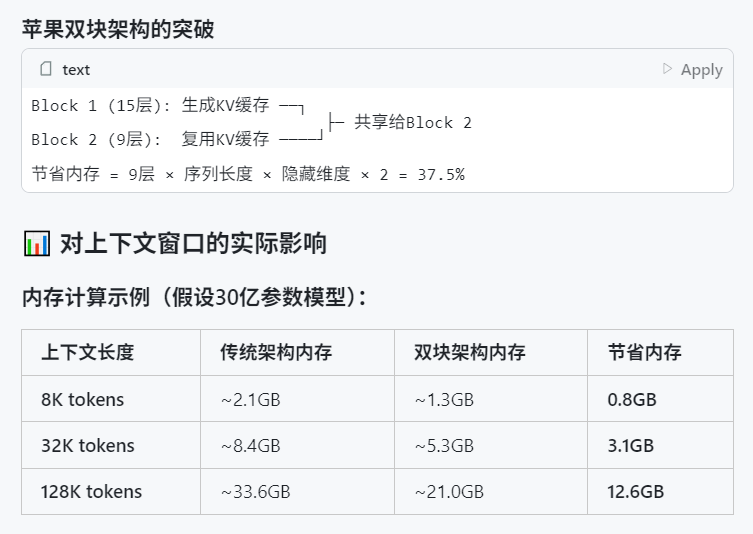
Apple WWDC 2025’in Yapay Zekaya Fazla Değinmediği İddia Ediliyor, Ancak Teknik Detaylar İddialı Hedefleri Ortaya Koyuyor: Apple’ın Dünya Geliştiriciler Konferansı (WWDC) 2025’te yapay zekaya beklenenden daha az yer verdiği görülse de, teknik belgeleri cihaz içi ve bulut tabanlı modeller konusundaki derin yatırımlarını ortaya koyuyor. Apple, mobil cihaz modelleri (yaklaşık 3B boyutunda) için tasarlanmış “çift bloklu mimari” (bellek kullanımını azaltmayı amaçlayan) ve sunucu tarafı modeller için kullanılan “PT-MoE” (paralel yollu uzmanlar karışımı) mimarisi dahil olmak üzere gelişmiş eğitim, damıtma ve nicemleme teknikleri kullanıyor. Bu teknolojiler, Apple çiplerinde düşük gecikmeli çıkarımı optimize etmeyi ve KV önbellek bellek kullanımını azaltmayı amaçlıyor. Dışarıdan Apple’ın yapay zeka alanında geride kaldığı yönünde sesler yükselse de, model teknolojisindeki başarıları (açık kaynaklı gömme modelleri gibi) ve farklı önceliklere (sadece sohbet robotları yerine cihaz içi zeka gibi) odaklanması, kendine özgü bir yapay zeka stratejisi olduğunu gösteriyor. WWDC ayrıca Safari 26’nın WebGPU’yu destekleyeceğini duyurdu; bu, cihaz üzerinde yapay zeka modellerinin (örneğin Transformers.js aracılığıyla) performansını önemli ölçüde artıracak, örneğin tarayıcı içi görsel model altyazı oluşturma hızını yaklaşık 12 kat artıracak (Kaynak: X, X, X)
Perplexity Pro Kullanıcıları Artık OpenAI o3 Modelini Kullanabiliyor: Perplexity, Pro abonelerinin artık OpenAI’nin o3 modelini kullanabileceğini duyurdu. Bu entegrasyon, Perplexity Pro kullanıcılarına daha güçlü bilgi işleme ve soru yanıtlama yetenekleri sunacak. Aynı zamanda Perplexity, “Memory” özelliğini de test ediyor ve daha özlü ve pratik bir kullanıcı deneyimi sunmayı amaçlayan iOS sesli asistanını güncelledi. Discover makale özelliği de varsayılan olarak daha özlü “Özet” moduna ayarlandı ve derinlemesine “Rapor” moduna geçiş seçeneği sunuyor (Kaynak: X, X, X)

Xiaohongshu, İlk 142B MoE Büyük Modeli dots.llm1’i Açık Kaynaklı Hale Getirdi, Çince Değerlendirmelerde DeepSeek-V3’ü Geçti: Xiaohongshu, ilk büyük modeli olan dots.llm1’i açık kaynaklı hale getirdi. Bu, 142 milyar parametreli bir MoE (Uzmanlar Karışımı) modelidir ve çıkarım sırasında yalnızca 14 milyar parametre etkinleştirilir. Model, ön eğitim aşamasında, esas olarak genel web tarayıcılarından ve kendi tarayıcılarından elde edilen web verilerinden oluşan 11.2 trilyon sentetik olmayan token kullandı. Xiaohongshu ekibi, ölçeklenebilir üç aşamalı bir veri işleme çerçevesi önerdi ve tekrarlanabilirliği artırmak için bunu açık kaynaklı hale getirdi. dots.llm1, C-Eval’de 92.2 puan alarak DeepSeek-V3 dahil tüm modelleri geride bıraktı ve Çince-İngilizce, matematik, hizalama gibi görevlerde Alibaba’nın Qwen3-32B modelinin performansına yaklaştı. Xiaohongshu ayrıca, topluluğun büyük model dinamiklerini anlamasını teşvik etmek için ara eğitim kontrol noktalarını da açık kaynaklı hale getirdi (Kaynak: 36Kr)
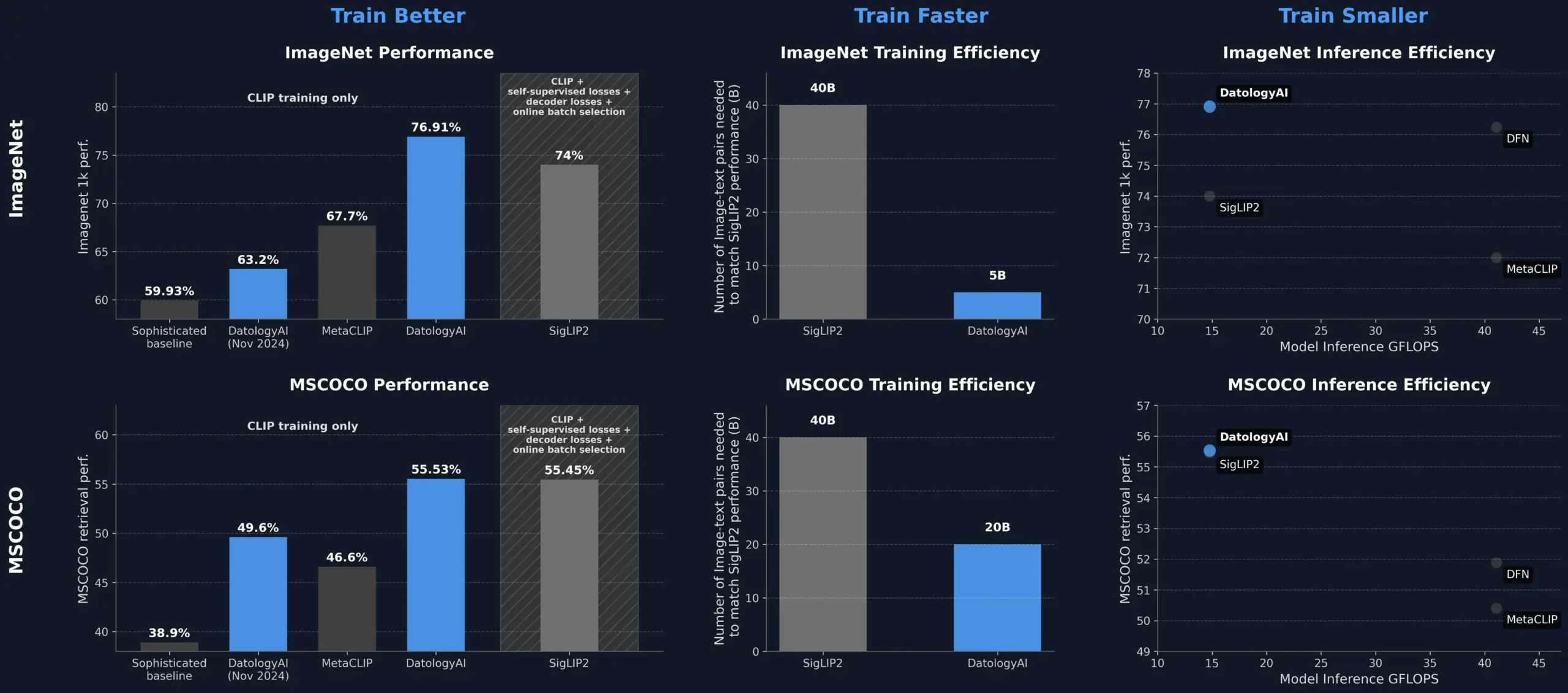
DatologyAI, Veri Yönetimi ile CLIP Model Performansını Artırarak SigLIP2’yi Geride Bıraktı: DatologyAI, yalnızca veri yönetimi (data curation) ile CLIP model performansını önemli ölçüde artırma başarısını sergiledi. Yöntemleri, ViT-B/32 modelinin ImageNet 1k üzerindeki doğruluğunu %76.9’a çıkararak SigLIP2 tarafından bildirilen %74’ü aştı. Ayrıca, bu yöntem 8 kat eğitim verimliliği artışı ve 2 kat çıkarım verimliliği artışı sağladı ve ilgili modelleri kamuya açık olarak yayınlandı. Bu, model mimarisini değiştirmeden bile, veriyi optimize ederek model potansiyelini ortaya çıkarabilen yüksek kaliteli, özenle yönetilen veri kümelerinin gelişmiş yapay zeka modellerinin eğitimindeki merkezi rolünü vurgulamaktadır (Kaynak: X, X)
Kuaishou ve Northeastern Üniversitesi, Birleşik Çok Modlu Gömme Çerçevesi UNITE’ı Önerdi: Çok modlu alımda farklı modalitelerdeki (metin, görüntü, video) veri dağılım farklılıklarından kaynaklanan çapraz modalite girişim sorununu çözmek için Kuaishou ve Northeastern Üniversitesi araştırmacıları, çok modlu birleşik gömme çerçevesi UNITE’ı önerdi. Bu çerçeve, “modaliteye duyarlı maskeli karşılaştırmalı öğrenme” (MAMCL) mekanizması aracılığıyla, karşılaştırmalı öğrenmede yalnızca sorgu hedef modalitesiyle tutarlı negatif örnekleri dikkate alarak modaliteler arası hatalı rekabeti önler. UNITE, “alım adaptasyonu + talimat ince ayarı” olmak üzere iki aşamalı bir eğitim benimser ve görüntü-metin alımı, video-metin alımı ve talimat alımı gibi birçok değerlendirmede SOTA (son teknoloji) sonuçlar elde etti; örneğin MMEB Benchmark’ta daha büyük ölçekli modelleri geride bıraktı ve CoVR’da önemli ölçüde öne geçti. Araştırma, birleşik modalitede video-metin verilerinin temel yeteneğini vurguluyor ve talimat görevlerinin daha çok metin ağırlıklı verilere dayandığını belirtiyor (Kaynak: Quantumbit)

NVIDIA, Earth-2 İklim Simülasyonu Yapay Zeka Temel Modelini Yayınladı: NVIDIA’nın Earth-2 platformu, küresel iklimi kilometre düzeyinde çözünürlükle simüle edebilen yeni bir yapay zeka temel modelini tanıttı. Bu model, daha hızlı ve daha doğru iklim tahminleri sunmayı amaçlayarak Dünya’nın karmaşık doğal sistemlerini anlama ve tahmin etme konusunda yeni yollar sunuyor. Bu hamle, yapay zekanın iklim bilimi ve Dünya sistemi modellemesi alanlarındaki uygulamalarında önemli bir adımı işaret ediyor ve iklim değişikliği araştırmalarını ve afet uyarı yeteneklerini geliştirme potansiyeline sahip (Kaynak: X)

OpenAI Hizmetlerinde Geniş Çaplı Kesinti Yaşandı, ChatGPT ve API Etkilendi: OpenAI’nin ChatGPT hizmeti ve API arayüzleri, Pekin saatiyle 10 Haziran akşamı geniş çaplı bir kesinti yaşadı; bu durum hata oranlarında ve gecikmelerde artış olarak kendini gösterdi. Birçok kullanıcı hizmetlere erişemediklerini veya “Hmm… bir şeyler ters gitmiş gibi görünüyor” gibi hata mesajlarıyla karşılaştıklarını bildirdi. OpenAI resmi durum sayfası sorunu doğruladı ve mühendislerin temel nedeni belirleyip acil olarak onarım yaptıklarını belirtti. Bu kesinti, dünya çapında ChatGPT ve API’lerine bağımlı olan çok sayıda kullanıcıyı ve uygulamayı etkiledi ve büyük yapay zeka hizmetlerinin kararlılığının önemini bir kez daha vurguladı (Kaynak: X, Reddit r/ChatGPT, Reddit r/ChatGPT)
🧰 Araçlar
Model Context Protocol (MCP) Sunucu Ekosistemi Genişlemeye Devam Ediyor: Model Context Protocol (MCP), büyük dil modellerine (LLM) güvenli ve kontrol edilebilir araç ve veri kaynağı erişimi sağlamayı amaçlamaktadır. GitHub’daki modelcontextprotocol/servers deposu, MCP’nin referans uygulamalarını ve topluluk tarafından oluşturulan sunucuları bir araya getirerek çeşitli uygulamalarını sergilemektedir. Resmi ve üçüncü taraf sunucular; dosya sistemleri, Git işlemleri, veritabanı etkileşimleri (PostgreSQL, MySQL, MongoDB, Redis, ClickHouse, Cassandra vb.), bulut hizmetleri (AWS, Azure, Cloudflare), API entegrasyonları (GitHub, GitLab, Slack, Google Drive, Stripe, PayPal), arama (Brave, Algolia, Exa, Tavily), kod yürütme, yapay zeka modeli çağrıları (Replicate, ElevenLabs) gibi geniş bir alanı kapsamaktadır. MCP ekosistemi hızla gelişmekte olup, 130’dan fazla resmi ve topluluk sunucusu bulunmaktadır ve EasyMCP, FastMCP, MCP-Framework gibi geliştirme çerçeveleri ile MCP-CLI, MCPM gibi yönetim araçları ortaya çıkmıştır. Amaç, LLM’lerin harici araçlara ve verilere erişim engelini düşürmek ve AI Agent’ların gelişimini teşvik etmektir (Kaynak: GitHub Trending)
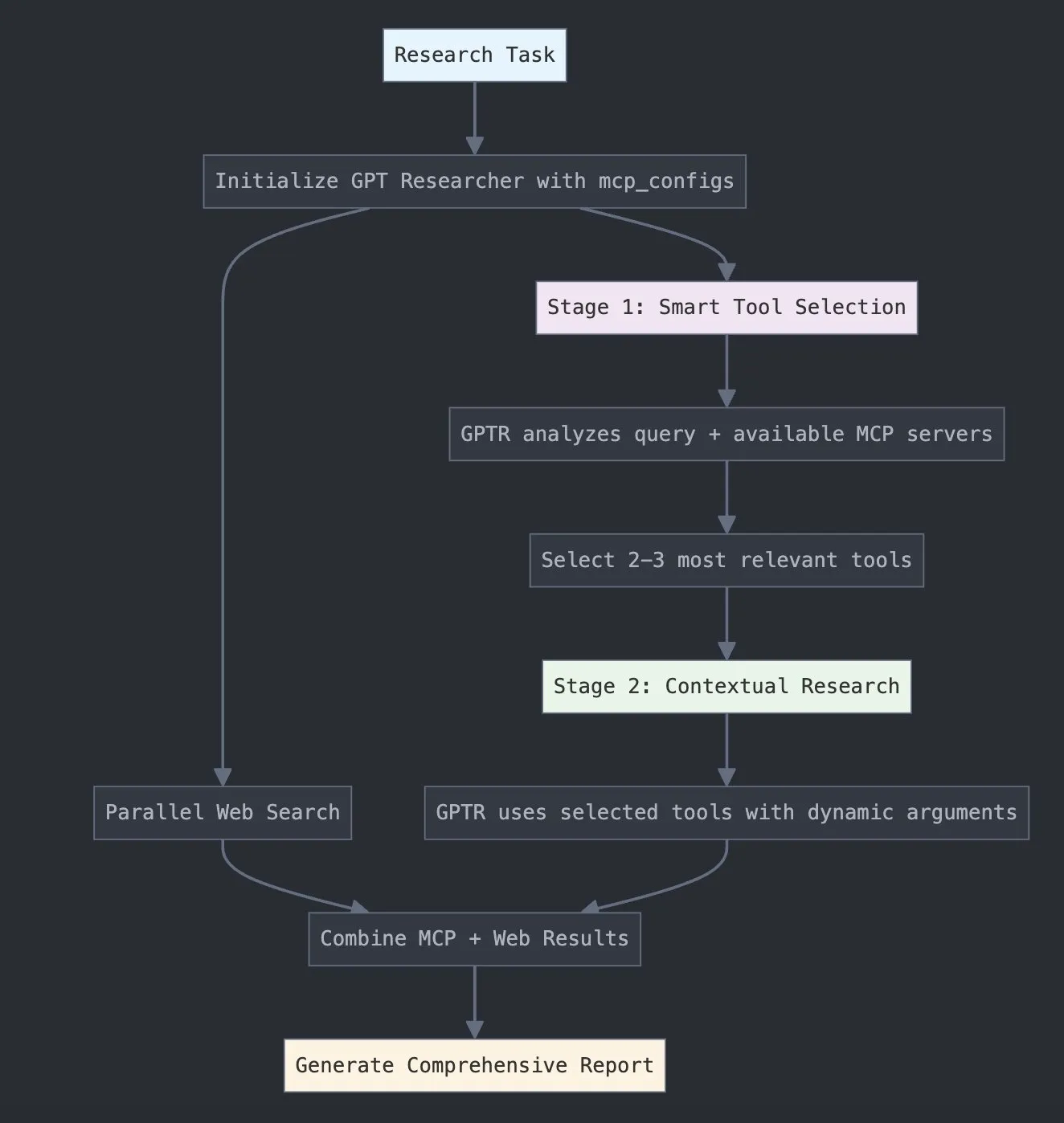
LangChain, Araştırma Yeteneklerini Artırmak İçin GPT Researcher MCP’yi Piyasaya Sürdü: LangChain, GPT Researcher’ın artık akıllı araç seçimi ve araştırma için model bağlam protokolü (MCP) adaptörünü kullandığını duyurdu. Bu entegrasyon, MCP’yi web arama yetenekleriyle birleştirerek kullanıcılara daha kapsamlı veri toplama ve analiz yetenekleri sunmayı ve yapay zekanın araştırma alanındaki uygulama derinliğini ve genişliğini daha da artırmayı amaçlıyor (Kaynak: X)
Hugging Face, İnsan Benzeri TTS İçin 100M Açık Kaynaklı NotebookLM Olan Vui’yi Yayınladı: Hugging Face’te, üç model içeren 100 milyon parametreli açık kaynaklı bir NotebookLM projesi olan Vui yayınlandı: Vui.BASE (40 bin saatlik sesli diyalog üzerine eğitilmiş temel model), Vui.ABRAHAM (bağlama duyarlı yeteneklere sahip tek konuşmacılı model) ve Vui.COHOST (iki kişilik diyalog kurabilen model). Vui, sesleri klonlayabiliyor, nefes alıp verme, hımm, haa gibi sözlü tikleri ve hatta konuşma dışı sesleri taklit edebiliyor, bu da insan benzeri metinden sese (TTS) teknolojisinde yeni bir ilerlemeyi işaret ediyor (Kaynak: X, X)
Consilium: Karmaşık Sorunları Çözmek İçin Açık Kaynaklı Çoklu Ajan İşbirliği Platformu: Hugging Face’te, açık kaynaklı bir çoklu ajan işbirliği platformu olan Consilium projesi sergilendi. Kullanıcılar, karmaşık sorunları ortaklaşa çözmek ve fikir birliğine varmak için tartışma ve gerçek zamanlı araştırma (web sayfaları, arXiv, SEC dosyaları) yoluyla uzman bir yapay zeka ajan ekibi oluşturabilirler. Kullanıcılar stratejiyi belirler, ajan ekibi cevapları bulmaktan sorumludur; bu da yapay zekanın işbirlikçi problem çözme alanındaki yeni keşiflerini göstermektedir (Kaynak: X)
Unsloth, Magistral-Small-2506 Optimize Edilmiş GGUF Modelini Yayınladı: Mistral AI’nin Magistral-Small-2506 çıkarım modelini yayınlamasının ardından Unsloth, hızla llama.cpp, LMStudio ve Ollama gibi platformlar için uygun olan optimize edilmiş GGUF formatındaki modelini piyasaya sürdü. Bu hızlı yanıt, açık kaynak topluluğunun model optimizasyonu ve dağıtımı konusundaki canlılığını ve verimliliğini yansıtmakta ve yeni modellerin daha geniş bir kullanıcı ve geliştirici kitlesi tarafından daha hızlı kullanılabilmesini sağlamaktadır (Kaynak: X)
📚 Öğrenme
Yeni Makale Takviyeli Öğrenme Ön Eğitimi (RPT) Paradigmasını İnceliyor: “Reinforcement Pre-Training (RPT)” başlıklı yeni bir makale, yeni nesil belirteç tahminini RLVR (Doğrulanabilir Ödüllerle Takviyeli Öğrenme) kullanarak bir çıkarım görevi olarak yeniden yapılandırmayı önermektedir. RPT, yeni belirteç çıkarım yeteneğini teşvik ederek dil modeli tahmin doğruluğunu iyileştirmeyi ve sonraki takviyeli ince ayar için güçlü bir temel sağlamayı amaçlamaktadır. Araştırma, eğitim hesaplama miktarını artırmanın tahmin doğruluğunu sürekli olarak iyileştirdiğini göstermekte ve RPT’nin dil modeli ön eğitimini ilerletmek için etkili ve umut verici bir genişletme paradigması olduğunu belirtmektedir (Kaynak: HuggingFace Daily Papers, X)

Makale, Kendi Kendine Öğrenme Yoluyla Hafif Uzun Bağlam Temsilleri İçin Cartridges’i Öneriyor: “Cartridges: Lightweight and general-purpose long context representations via self-study” başlıklı bir makale, çıkarım sırasında tüm külliyatı bağlam penceresine yerleştirmek yerine uzun metinleri işlemek için çevrimdışı olarak küçük KV önbellekleri (Cartridge olarak adlandırılır) eğiterek bir yöntem araştırmaktadır. Araştırma, “kendi kendine öğrenme” (külliyat hakkında sentetik diyaloglar oluşturarak ve bağlam damıtma hedefiyle eğiterek) yoluyla eğitilen Cartridge’lerin, önemli ölçüde daha düşük bellek tüketimi (38.6 kat azalma) ve daha yüksek iş hacmi (26.4 kat artış) ile ICL’ye eşdeğer performans elde edebildiğini ve modelin etkili bağlam uzunluğunu genişletebildiğini, hatta yeniden eğitime gerek kalmadan külliyatlar arası kombinasyon kullanımını destekleyebildiğini bulmuştur (Kaynak: HuggingFace Daily Papers, X)

Makale, Geometri Problemi Çözümünde LLM’ler için Grup Karşılaştırmalı Politika Optimizasyonunu (GCPO) İnceliyor: “GeometryZero: Improving Geometry Solving for LLM with Group Contrastive Policy Optimization” başlıklı makale, LLM’lerin geometri problemi çözümünde yardımcı çizgi oluşturma zorluklarına yönelik olarak GCPO çerçevesini önermektedir. Bu çerçeve, “grup karşılaştırmalı maske” aracılığıyla bağlamsal faydaya göre yardımcı çizgi oluşturma için pozitif ve negatif ödül sinyalleri sağlar ve daha uzun çıkarım zincirlerini teşvik etmek için bir uzunluk ödülü sunar. GCPO tabanlı geliştirilen GeometryZero model serisi, Geometry3K ve MathVista gibi kıyaslama testlerinde temel modellerden daha iyi performans göstererek ortalama %4.29’luk bir iyileşme sağlamış ve sınırlı hesaplama gücüyle küçük modellerin geometrik çıkarım yeteneklerini artırma potansiyelini göstermiştir (Kaynak: HuggingFace Daily Papers)
“Düşünme İllüzyonu” Başlıklı Makale, Problem Karmaşıklığı Yoluyla Çıkarım Modellerinin Yeteneklerini ve Sınırlamalarını İnceliyor: Bu çalışma, büyük çıkarım modellerinin (LRM’ler) yeteneklerini, ölçeklenme özelliklerini ve sınırlamalarını sistematik olarak incelemektedir. Karmaşıklığı hassas bir şekilde kontrol edilebilen bulmaca ortamları kullanarak yapılan araştırma, LRM’lerin belirli bir karmaşıklık seviyesini aştıktan sonra doğruluklarının tamamen çöktüğünü ve sezgilere aykırı ölçeklenme sınırlamaları sergilediğini bulmuştur: çıkarım çabası, problem karmaşıklığı belirli bir noktaya kadar arttıktan sonra aksine azalmaktadır. Standart LLM’lerle karşılaştırıldığında, LRM’ler düşük karmaşıklıktaki görevlerde daha kötü performans gösterirken, orta karmaşıklıktaki görevlerde üstünlük sağlamakta, yüksek karmaşıklıktaki görevlerde ise her ikisi de başarısız olmaktadır. Araştırma, LRM’lerin hassas hesaplama konusunda sınırlamaları olduğunu, açık algoritmaları kullanmakta zorlandıklarını ve farklı ölçeklerde tutarlı çıkarım yapamadıklarını belirtmektedir (Kaynak: HuggingFace Daily Papers, X)
Makale, Az Kaynaklı Dillerde LLM’lerin Sağlamlık Değerlendirmesini İnceliyor: “Evaluating LLMs Robustness in Less Resourced Languages with Proxy Models” başlıklı makale, büyük dil modellerinin (LLM’ler) Lehçe gibi düşük kaynaklı dillerde pertürbasyonlara (karakter düzeyinde ve kelime düzeyinde saldırılar gibi) karşı hassasiyetini incelemektedir. Araştırma, az sayıda karakter değişikliği yaparak ve kelime önemini hesaplamak için küçük vekil modeller kullanarak, farklı LLM’lerin tahminlerini önemli ölçüde değiştirebilen saldırılar oluşturulabileceğini bulmuştur; bu da LLM’lerin bu dillerde mevcut olabilecek ve iç güvenlik mekanizmalarını atlatmak için kullanılabilecek güvenlik açıklarını ortaya koymaktadır. Araştırmacılar ilgili veri kümesini ve kodu yayınlamıştır (Kaynak: HuggingFace Daily Papers)
Rel-LLM: LLM’lerin İlişkisel Veritabanlarını İşleme Verimliliğini Artıran Yeni Bir Yöntem: Bir makale, büyük dil modellerinin (LLM) ilişkisel veritabanlarını işlerken düşük verimlilik sorununu çözmeyi amaçlayan Rel-LLM çerçevesini önermektedir. Geleneksel yöntemler, yapılandırılmış verileri metne dönüştürürken önemli bağlantıların kaybolmasına ve girdi fazlalığına neden olur. Rel-LLM, bir grafik sinir ağı (GNN) kodlayıcı aracılığıyla yapılandırılmış grafik istemleri oluşturarak, alım artırılmış üretim (RAG) çerçevesi içinde ilişkisel yapıyı korur. Bu yöntem, zamansal farkındalığa sahip alt grafik örneklemesi, heterojen GNN kodlayıcı, grafik gömmelerini LLM gizli uzayıyla hizalamak için MLP projeksiyon katmanı ve grafik temsillerini JSON grafik istemleri olarak yapılandırma gibi adımları içerir ve kendi kendine denetimli ön eğitim hedefiyle grafik ve metin temsillerini hizalar. Deneyler, GNN kodlamasının metin serileştirmesinde kaybolan karmaşık ilişkisel yapıları etkili bir şekilde yakalayabildiğini ve yapılandırılmış grafik istemlerinin ilişkisel bağlamı LLM dikkat mekanizmalarına etkili bir şekilde enjekte edebildiğini göstermektedir (Kaynak: X)

Makale, LLM’lerin “Aşırı Reddetme” Sorununu ve EvoRefuse Optimizasyon Yöntemini İnceliyor: “EVOREFUSE: Evolutionary Prompt Optimization for Evaluation and Mitigation of LLM Over-Refusal to Pseudo-Malicious Instructions” başlıklı makale, büyük dil modellerinin (LLM) “sözde kötü niyetli talimatlara” (anlamsal olarak zararsız ancak modelin reddetmesini tetikleyen girdiler) aşırı reddetme sorununu incelemektedir. Mevcut talimat yönetimi yöntemlerinin ölçeklenebilirlik ve çeşitlilik konusundaki eksikliklerini gidermek için makale, evrimsel algoritmalar kullanarak istemleri optimize eden bir yöntem olan EVOREFUSE’u önermektedir. Bu yöntem, LLM’lerin sürekli olarak reddetmesine neden olan çeşitli sözde kötü niyetli talimatlar üretebilir. Buna dayanarak araştırmacılar, EVOREFUSE-TEST (582 talimat içeren bir kıyaslama testi) ve EVOREFUSE-ALIGN (3000 talimat ve yanıt içeren bir hizalama eğitim veri kümesi) oluşturmuştur. Deneyler, EVOREFUSE-ALIGN üzerinde ince ayar yapılmış LLAMA3.1-8B-INSTRUCT modelinin aşırı reddetme oranının, alt optimal hizalama veri kümelerinde eğitilmiş modellere göre %14.31’e kadar daha düşük olduğunu ve güvenliği tehlikeye atmadığını göstermiştir (Kaynak: HuggingFace Daily Papers)
💼 İş Dünyası
CASVI (Zhongke Wenge), Pekin Shijingshan Bölgesi Endüstriyel Fonu’ndan Yeni Bir Stratejik Finansman Turunu Tamamladı: Kurumsal düzeyde yapay zeka hizmet sağlayıcısı CASVI (Zhongke Wenge), Pekin Shijingshan Bölgesi Modern İnovasyon Endüstrisi Geliştirme Fonu A.Ş.’den yeni bir stratejik finansman turunu tamamladığını duyurdu. Bu finansman turu, esas olarak kendi geliştirdiği karar destek zekası işletim sistemi DIOS’un Ar-Ge yatırımlarına ve pazar tanıtımına kullanılacak, kurumsal düzeyde yapay zeka teknolojisinin gelişimini ve ticari uygulamasını hızlandıracaktır. 2017 yılında kurulan CASVI’nin çekirdek ekibi Çin Bilimler Akademisi Otomasyon Enstitüsü’nden gelmektedir ve çok dilli anlama, çapraz modalite semantiği ve karmaşık senaryo karar verme teknolojilerine odaklanarak medya, finans, kamu, enerji gibi sektörlere hizmet vermektedir. Daha önce CDB Capital, China Internet Investment Fund, SCGC gibi devlet destekli fonlardan on milyar yuanın üzerinde yatırım almıştı (Kaynak: Quantumbit)

Sakana AI, Bölgesel Finansal Yapay Zeka Gelişimini Desteklemek İçin Japonya’nın Hokkoku Bankası ile Stratejik İşbirliği Anlaşması İmzaladı: Japon yapay zeka girişimi Sakana AI, merkezi Ishikawa Eyaleti’nde bulunan Hokkoku Financial Holdings ile bölgesel finans ve yapay zekanın birleştirilmesi konusunda stratejik işbirliği yapmak üzere bir mutabakat zaptı (MOU) imzaladığını duyurdu. Bu, Mitsubishi UFJ Bankası ile kapsamlı bir ortaklık kurmasının ardından Sakana AI’nin bir finans kurumuyla ikinci kez güçlerini birleştirmesi anlamına geliyor ve özellikle finansal hizmetler alanında Japonya’nın bölgesel toplumunun karşılaştığı sorunları çözmek için en son yapay zeka teknolojisini uygulamayı amaçlıyor. Sakana AI, finans kurumları için son derece uzmanlaşmış yapay zeka teknolojileri geliştirmeye kendini adamıştır ve bu işbirliğinin Japonya’daki diğer bölgesel bankalar için yapay zeka uygulamaları konusunda bir örnek teşkil etmesi beklenmektedir (Kaynak: X, X)

Cohere, Yapay Zeka Platformunu Sağlık Sektörüne Taşımak İçin Ensemble ile İşbirliği Yapıyor: Yapay zeka şirketi Cohere, Cohere North AI akıllı ajan platformunu sağlık sektörüne taşımak için EnsembleHP (sağlık çözümleri sağlayıcısı) ile bir ortaklık kurduğunu duyurdu. İki taraf, güvenli bir yapay zeka akıllı ajan platformu aracılığıyla tıbbi yönetim süreçlerindeki sürtünmeyi azaltmayı ve hastaneler ile sağlık sistemlerinin hasta deneyimini iyileştirmeyi amaçlıyor. Bu hamle, Cohere’in büyük dil modellerini ve yapay zeka teknolojisini kilit dikey sektörlerdeki uygulamalarını ilerletme konusunda önemli bir adım attığını gösteriyor (Kaynak: X)
🌟 Topluluk
Ilya Sutskever Toronto Üniversitesi Onursal Derece Konuşmasında: Yapay Zeka Sonunda Her Şeyi Yapabilecek, Aktif Olarak Dikkat Edilmeli: OpenAI kurucu ortağı Ilya Sutskever, Toronto Üniversitesi’nden aldığı onursal bilim doktorası (okuldaki dördüncü derecesi) konuşmasında, yapay zekanın ilerlemesinin “bir gün yapabildiğimiz her şeyi yapabilmesini” sağlayacağını, çünkü insan beyninin biyolojik bir bilgisayar, yapay zekanın ise dijital bir beyin olduğunu belirtti. Yapay zekanın tanımladığı olağanüstü bir çağda olduğumuzu ve yapay zekanın öğrenci ve işin anlamını derinden değiştirdiğini düşünüyor. Endişelenmek yerine, en iyi yapay zekayı kullanarak ve gözlemleyerek sezgi oluşturmanın, yetenek sınırlarını anlamanın önemini vurguladı. İnsanları yapay zeka gelişimine dikkat etmeye ve beraberinde getireceği büyük zorluklar ve fırsatlarla aktif olarak başa çıkmaya çağırdı, çünkü yapay zeka herkesin hayatını derinden etkileyecek. Ayrıca kişisel zihniyetini paylaştı: “Gerçekliği kabul et, geçmişten pişman olma, mevcut durumu iyileştirmek için çabala.” (Kaynak: X, 36Kr)
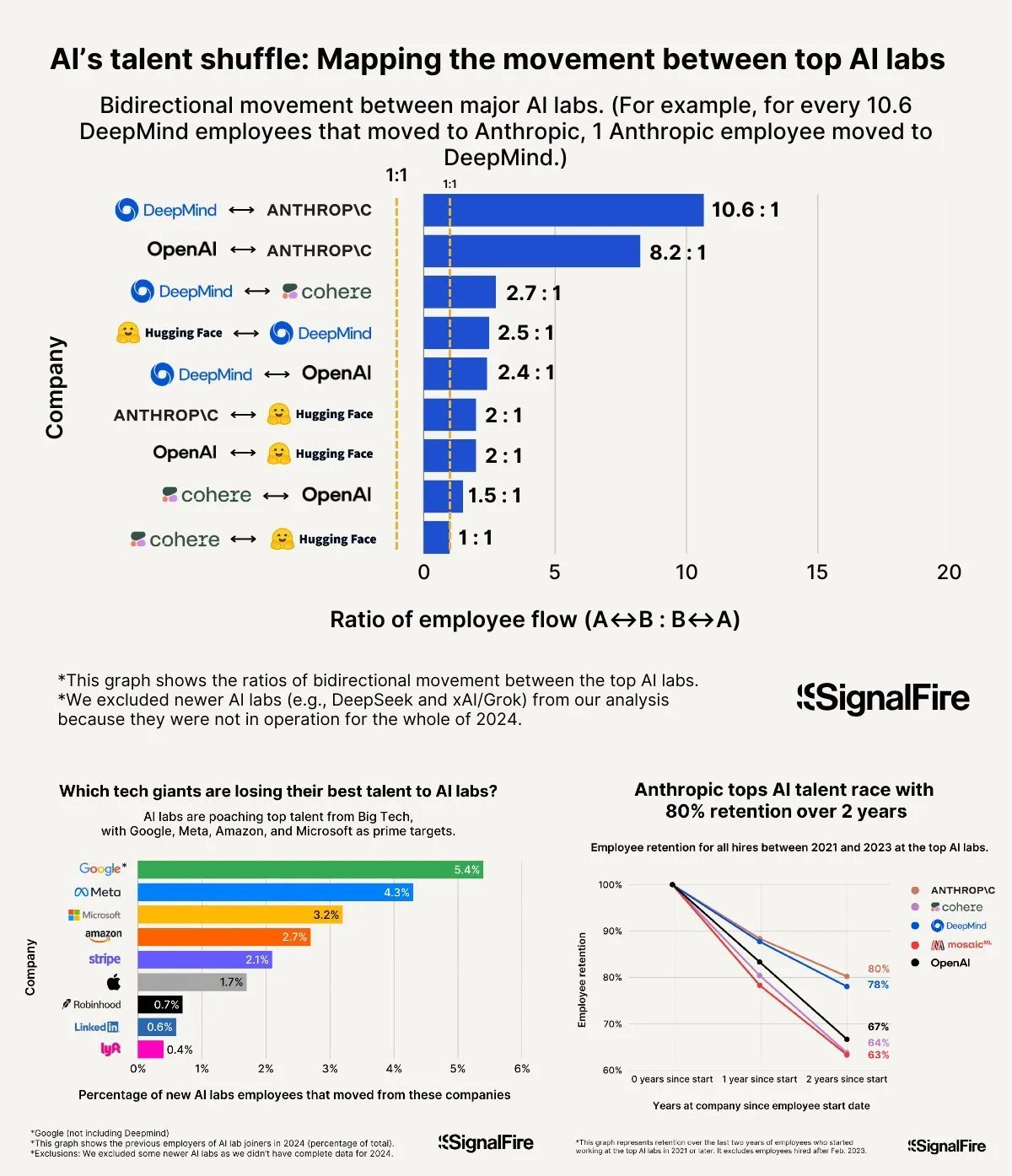
Yapay Zeka Yetenek Savaşları Kızışıyor: Meta’nın Yüksek Maaşları Bile OpenAI ve Anthropic’e Karşı Yetersiz Kalıyor: Meta’nın yapay zeka yeteneklerini çekmek için yıllık 2 milyon doların üzerinde maaş teklif ettiği iddia ediliyor, ancak yine de yeteneklerin OpenAI ve Anthropic’e kaymasıyla mücadele ediyor. Tartışmalar, OpenAI L6 seviyesi maaşların 1.5 milyon dolara yaklaştığını ve hisse senedi değerlenme potansiyelinin Meta’dan daha iyi görüldüğünü, bu da onu en iyi yeteneklerin gözünde daha çekici kıldığını gösteriyor. Ayrıca, Llama ekibinin hile yaptığı iddiaları ve Meta içindeki yüksek KPI baskısı, yüksek düşük performanslı çalışan çıkarma oranı (bu yıl %15-20’ye ulaştı) gibi faktörler de yetenek seçimini etkiliyor. Anthropic ise yaklaşık %80’lik bir yetenek tutma oranıyla (kuruluşundan iki yıl sonra) en iyi yapay zeka araştırmacılarının tercih ettiği büyük şirketlerden biri haline geldi. Bu yetenek savaşının şiddeti “akıl almaz” olarak tanımlanıyor (Kaynak: X, X)
“Vibe Coding” Deneyimi Paylaşımı: Yapay Zeka Destekli Programlamada Kaçınılması Gereken 5 Kural: Sosyal medyada, deneyimli bir geliştirici, yapay zeka (Claude gibi) ile “Vibe Coding” (yapay zeka destekli bir programlama şekli) yaparken verimsiz hata ayıklama döngülerine düşmekten kaçınmak için beş kural paylaştı: 1. Üç denemede başarısızlık: Yapay zeka sorunu üç kez düzeltemezse, durmalı ve yapay zekanın yeni tanımlanan gereksinimlerden baştan oluşturmasına izin verilmelidir. 2. Bağlamı sıfırla: Yapay zeka uzun konuşmalardan sonra “unutur”, her 8-10 mesaj turundan sonra geçerli kodu kaydetmeniz, yeni bir oturum açmanız ve yalnızca sorunlu bileşenleri ve kısa bir uygulama açıklamasını yapıştırmanız önerilir. 3. Sorunu kısa ve öz bir şekilde açıklayın: Hatayı tek bir cümleyle net bir şekilde açıklayın. 4. Sık sık sürüm kontrolü yapın: Her özellik tamamlandıktan sonra Git’e gönderin. 5. Gerekirse baştan başlayın: Bir hatayı düzeltmek çok uzun sürerse (örneğin 2 saatten fazla), sorunlu bileşeni silip yapay zekanın yeniden oluşturmasına izin vermek daha iyidir. Temel nokta, kodun geri döndürülemez bir şekilde bozulduğunu kabul ettiğinizde, onarmaktan kararlılıkla vazgeçmektir. Aynı zamanda, yapay zekayı daha iyi yönlendirmek ve hata ayıklamak için programlama bilmenin önemi vurgulanmaktadır (Kaynak: Reddit r/LocalLLaMA, Reddit r/ClaudeAI, Reddit r/ArtificialInteligence)
Fei-Fei Li, World Labs’ı Kurma Nedenini Anlatıyor: Zekanın Özüne Yönelik Bir Keşiften Kaynaklanıyor, Uzamsal Zeka Yapay Zekanın Kritik Eksikliği: a16z podcast’inde Fei-Fei Li, World Labs’ı kurma amacını paylaştı ve bunun temel model çılgınlığına bir tepki olmadığını, zekanın özüne yönelik sürekli bir keşif olduğunu vurguladı. Dilin verimli bir bilgi taşıyıcısı olmasına rağmen, üç boyutlu fiziksel dünyayı temsil etme konusunda eksiklikleri olduğunu ve gerçek genel zekanın fiziksel uzay ve nesne ilişkilerinin anlaşılması üzerine kurulması gerektiğini düşünüyor. Kornea hasarı nedeniyle geçici olarak stereo görüşünü kaybetmesi, üç boyutlu uzay temsilinin fiziksel etkileşim için ne kadar önemli olduğunu daha derinden anlamasını sağladı. World Labs, fiziksel dünyayı gerçekten anlayabilen yapay zeka modelleri (dünya modeli LWM) oluşturarak mevcut yapay zekanın uzamsal zeka konusundaki eksikliğini gidermeyi amaçlıyor. Bu vizyonu gerçekleştirmek için endüstriyel düzeyde hesaplama gücü, veri ve yeteneğin bir araya getirilmesi gerektiğini ve mevcut teknolojik atılım noktasının yapay zekanın tek gözle vizyondan tam üç boyutlu sahne anlayışını yeniden oluşturmasını sağlamak olduğunu belirtiyor (Kaynak: Quantumbit)

Yapay Zeka Destekli Üniversite Giriş Sınavı: Soru Tahmini Tartışmalarından Tercih Belirlemedeki Fırsatlar ve Endişeler: Üniversite giriş sınavları öncesinde ve sonrasında yapay zekanın eğitim alanındaki uygulamaları geniş çaplı tartışmalara yol açtı. Bir yandan, “yapay zeka soru tahmini” popüler bir konu haline geldi, ancak sınav sorularının bilimsel doğası, gizliliği ve “tahmin karşıtı” mekanizmalar nedeniyle yapay zekanın kesin soru tahmini olasılığı düşük ve piyasadaki bazı tahmin denemelerinin kalitesi endişe verici. Öte yandan, yapay zeka hazırlık planlaması, soru çözümü, sınav gözetimi ve değerlendirme gibi alanlarda olumlu bir rol sergiledi; örneğin kişiselleştirilmiş öğrenme planları, akıllı soru yanıtlama, yapay zeka gözetim sistemleri adalet ve verimliliği artırdı. Tercih belirleme aşamasında, yapay zeka araçları öğrencinin puanına ve sıralamasına göre hızlı bir şekilde okul ve bölüm önerebiliyor, bilgi eşitsizliğini ortadan kaldırıyor. Ancak, tercih belirlemede yapay zekaya aşırı güvenmek de endişelere yol açıyor: algoritmalar popüler bölüm tercihlerini pekiştirebilir, bireysel ilgi alanlarını ve uzun vadeli gelişimi göz ardı edebilir; hayat tercihlerini tamamen algoritmalara bırakmak, “algoritma tarafından hayatın rehin alınmasına” neden olabilir. Makale, yapay zeka desteğine rasyonel bir bakış açısıyla yaklaşılması gerektiğini vurguluyor, araçları bilgelikle kullanmanın ve geleceği düşünerek tanımlamanın önemini belirtiyor (Kaynak: 36Kr)
AI Agent Şirketlerinin Başarı Modeli Tartışması: Self-Servis vs. Özelleştirilmiş Hizmet: Topluluk, AI Agent şirketlerinin başarı modellerini tartıştı. Bir görüş, başarılı AI Agent şirketlerinin (özellikle orta ve büyük pazarlara hizmet verenlerin) çoğunlukla Palantir benzeri bir model benimsediğini, yani salt self-servis modeli yerine çok sayıda yerinde geliştirme mühendisi (FDE) ve özelleştirilmiş yazılım kullandığını savunuyor. Diğer taraf ise self-servis modelinin uzun vadeli değerinde ısrar ediyor ve ekiplerin sonunda önemli uygulamaları kurum içinde oluşturmayı seçeceğini düşünüyor. Bu, AI Agent alanındaki hizmet modelleri ve pazar stratejileri konusundaki farklı düşünce yollarını yansıtıyor (Kaynak: X)
💡 Diğer
Google Diffusion Sistem İstemleri Ortaya Çıktı, Tasarım İlkelerini ve Yetenek Sınırlarını Gözler Önüne Serdi: Bir kullanıcı, Google Diffusion (bir metin yayılım dil modeli) olduğu iddia edilen sistem istemlerini paylaştı. Bu istem, modelin kimliğini (Gemini Diffusion, Google tarafından eğitilmiş uzman bir metin yayılım dil modeli, otoregresif olmayan), temel ilkelerini ve kısıtlamalarını (talimatlara uyma, otoregresif olmayan özellikler, doğruluk, gerçek zamanlı erişim olmaması, güvenlik etiği, bilgi kesme tarihi Aralık 2023, kod oluşturma yeteneği gibi) ve HTML web sayfaları ile HTML oyunları oluşturmaya yönelik özel talimatları ayrıntılı olarak açıklıyor. Bu talimatlar, çıktı formatı, estetik tasarım, stiller (Tailwind CSS’in özel kullanımı veya oyunlarda özel CSS gibi), simge kullanımı (Lucide SVG simgeleri), düzen ve performans (CLS önleme), yorum gereksinimleri gibi konuları kapsıyor. Son olarak, adım adım düşünmenin ve kullanıcı talimatlarına hassasiyetle uymanın önemi vurgulanıyor. Bu istem, bu tür modellerin tasarım anlayışlarını ve beklenen davranışlarını anlamak için bir pencere sunuyor (Kaynak: Reddit r/LocalLLaMA)
Arvind Narayanan, “Yapay Zeka Normal Bir Teknoloji Olarak” Makalesinin Doğuşunu ve Düşüncelerini Anlatıyor: Princeton Üniversitesi profesörü Arvind Narayanan, Sayash Kapoor ile birlikte yazdığı “AI as Normal Technology” (Yapay Zeka Normal Bir Teknoloji Olarak) makalesinin yazım sürecini paylaştı. Başlangıçta AGI ve varoluşsal risklere şüpheyle yaklaşıyordu, ancak meslektaşlarının ısrarı üzerine konuyu ciddiye almaya ve ilgili tartışmalara katılmaya karar verdi. Düşünerek, süper zeka ile ilgili görüşlerin ciddiye alınmaya değer olduğunu, sosyal medyanın ciddi tartışmalar için uygun olmadığını ve hem yapay zeka etiği hem de yapay zeka güvenliği topluluklarının kendi “bilgi kozalarına” sahip olduğunu fark etti. Makalenin ilk taslağı ICML’de reddedildi, ancak değerlendirme sürecindeki hararetli tartışmalar, araştırmalarına devam etme kararlılıklarını daha da pekiştirdi. Yapay zeka güvenliği topluluğuyla aralarındaki anlaşmazlığın düşündüklerinden daha derin olduğunu fark ettiler ve daha verimli, sınırlar ötesi bir tartışma yapma gerekliliğini anladılar. Sonunda, makale Columbia Üniversitesi Knight First Amendment Institute çalıştayında yayınlandı, geniş ilgi gördü ve verimli tartışmalara yol açtı, bu da Narayanan’ı yapay zeka politikalarının geleceği konusunda daha iyimser hale getirdi (Kaynak: X)
2000’ler Kuşağı Yapay Zeka Girişimcileri Yükseliyor, Girişimcilik Kurallarını Yeniden Şekillendiriyor: 2000’ler kuşağından bir grup yapay zeka girişimcisi, küresel girişimcilik dalgasında şaşırtıcı bir hızla öne çıkıyor. Yapay zeka teknolojilerine derinlemesine hakimiyetleri ve doğal dijital ortamdaki keskin sezgileriyle girişimcilik kurallarını yeniden tanımlıyorlar. Örnekler arasında Anysphere (Cursor) kurucusu Michael Truell (3 yılda stajyerlikten on milyarlarca dolarlık bir şirketin CEO’luğuna), Mercor’un üç kurucusu (2 yılda on milyarlarca dolarlık bir yapay zeka işe alım platformu kurdular), Magic’in kurucu ortağı Eric Steinberger (25 yaşında 400 milyon doların üzerinde fon toplayan bir yapay zeka kodlama şirketi kurdu) ve Axiom’dan Hong Letong (yapay zeka ile matematik problemlerini çözmeye odaklanıyor, henüz ürünü olmamasına rağmen yüksek değerleme aldı) bulunuyor. Bu genç girişimciler genellikle şu özelliklere sahip: programlama ana dilleri; genç yaşta ün kazanmış, teknolojik fırsat penceresini yakalamışlar; kullanıcı ihtiyaçlarını keskin bir şekilde algılıyorlar; organizasyon ve ürün konusunda yapay zeka odaklı bir anlayışa sahipler, minimalist ve verimli ekiplere ve “yapay zeka üründür” mantığına eğilimliler. Başarıları, yapay zeka çağında girişimcilik paradigmasının değiştiğini gösteriyor (Kaynak: 36Kr)