
Anahtar Kelimeler:Apple WWDC25, AI stratejisi, Siri yükseltmesi, Foundation çerçevesi, Cihaz tarafında AI, Tam sistem çevirisi, Xcode Vibe Kodlama, Görsel akıllı arama, Apple Intelligence Geleneksel Çince desteği, watchOS Akıllı Yığın işlevi, Apple AI gizlilik koruma stratejisi, Sistemler arası ekosistem AI entegrasyonu, Üretken AI sürümü Siri çıkış tarihi
🔥 Odak Noktası
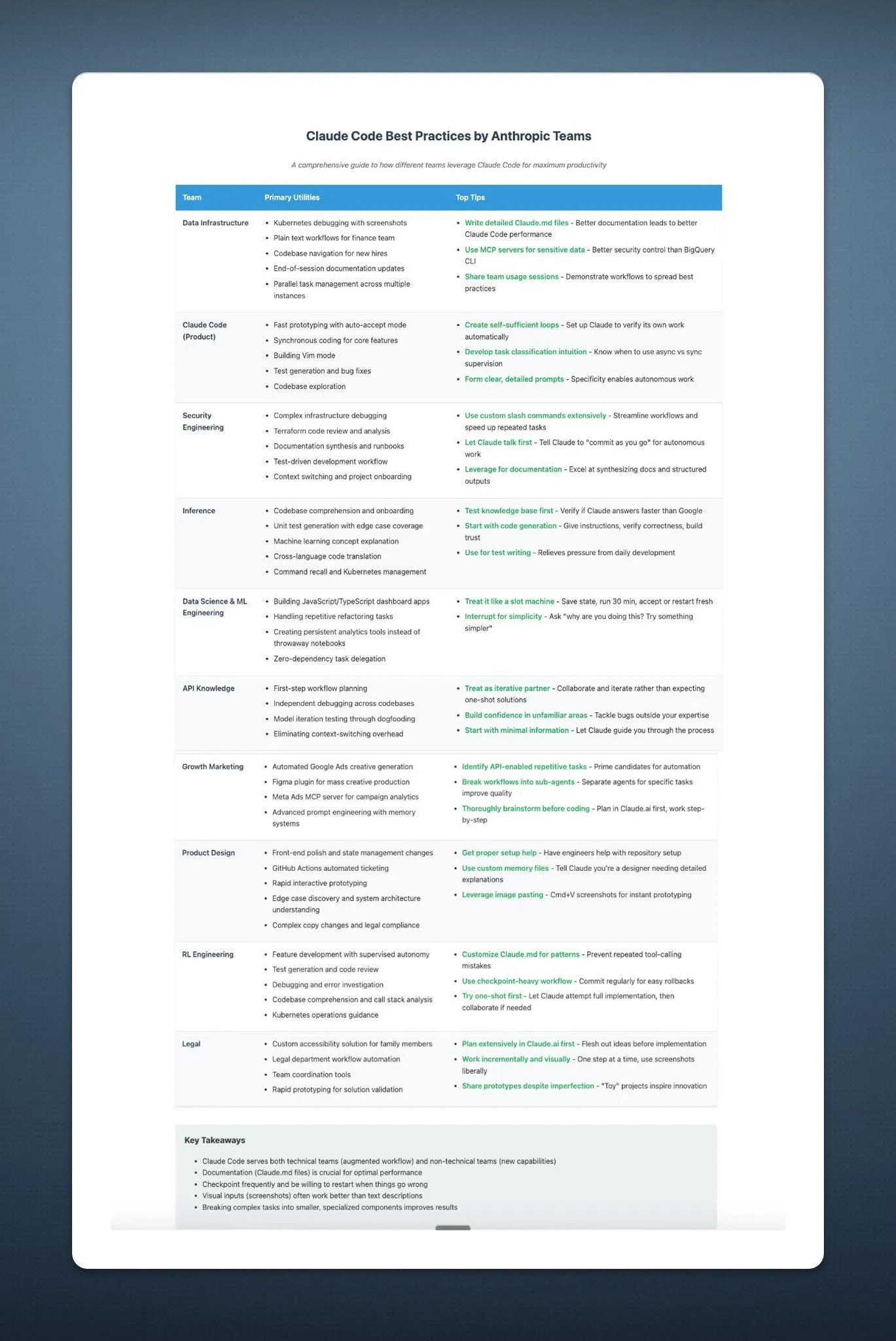
Apple WWDC25 AI Gelişmeleri: Pragmatik Entegrasyon ve Açıklık, Siri Hala Beklemede: Apple, WWDC25’te AI stratejisindeki ayarlamaları sergiledi; geçen yılki “büyük vaatler” yerine daha pragmatik bir yaklaşımla sistemin temel katmanlarını ve temel işlevlerini iyileştirmeye odaklandı. Önemli noktalar arasında AI’ın işletim sistemlerine ve birinci taraf uygulamalara “anlamlı bir şekilde” entegre edilmesi ve cihaz üzerinde çalışan “Foundation” model çerçevesinin geliştiricilere açılması yer alıyor. Telefon, FaceTime, Message vb. destekleyen ve API sunan sistem genelinde çeviri; ChatGPT gibi modelleri destekleyen Xcode’a Vibe Coding’in eklenmesi; ekran içeriğine dayalı görsel akıllı arama (daire içine almaya benzer, kısmen ChatGPT tarafından desteklenir) ve watchOS için Smart Stack gibi yeni özellikler bulunuyor. Apple Intelligence’ın Geleneksel Çince pazarında destekleneceğinden bahsedilse de, Basitleştirilmiş Çince için lansman tarihi ve merakla beklenen üretken AI destekli Siri hala belirsizliğini koruyor; ikincisinin “gelecek yıl” tekrar ele alınması bekleniyor. Apple, kullanıcı gizliliğini korumak için cihaz üzerinde AI ve özel bulut bilişime vurgu yaptı ve sistemler arası ekosistemde AI yeteneklerinin entegrasyonunu sergiledi. (Kaynak: 36氪, 36氪, 36氪, 36氪)

Apple’ın Yayınladığı AI Makalesi Büyük Dil Modellerinin Çıkarım Yeteneğini Sorguluyor, Sektörde Geniş Çaplı Tartışma Yarattı: Apple şirketi yakın zamanda “Düşüncenin İllüzyonu: Çıkarım Modellerinin Avantajlarını ve Sınırlılıklarını Sorun Karmaşıklığı Perspektifinden Anlamak” başlıklı bir makale yayınladı. Makalede Claude 3.7 Sonnet, DeepSeek-R1, o3 mini gibi büyük çıkarım modelleri (LRM’ler) üzerinde bulmaca testleri yapılarak, bu modellerin basit sorunları işlerken “aşırı düşündüğü”, yüksek karmaşıklıktaki sorunlarda ise “tamamen doğruluk çöküşü” yaşadığı ve doğruluk oranlarının sıfıra yaklaştığı belirtildi. Araştırma, mevcut LRM’lerin genelleştirilebilir çıkarım konusunda temel engellerle karşılaşabileceğini ve gerçek düşünmeden ziyade daha çok örüntü eşleştirmeye benzediğini öne sürüyor. Bu görüş Gary Marcus gibi akademisyenlerin dikkatini çekti, ancak aynı zamanda çok sayıda eleştiriyi de beraberinde getirdi. Eleştirmenler, deney tasarımında mantıksal boşluklar olduğunu (karmaşıklık tanımı, token çıktı sınırlarının göz ardı edilmesi gibi) belirtti ve hatta Apple’ı kendi AI alanındaki yavaş ilerlemesi nedeniyle mevcut büyük dil modeli başarılarını reddetmeye çalışmakla suçladı. Makalenin ilk yazarının stajyer olması da tartışma konusu oldu. (Kaynak: 36氪, Reddit r/ArtificialInteligence)

OpenAI’nin Gizlice Yeni Model o4’ü Eğittiği İddia Edildi, Reinforcement Learning AI Ar-Ge Düzenini Yeniden Şekillendiriyor: SemiAnalysis, OpenAI’nin GPT-4.1 ile GPT-4.5 arasında bir ölçekte yeni bir model eğittiğini ve yeni nesil çıkarım modeli o4’ün GPT-4.1 tabanlı reinforcement learning (RL) ile eğitileceğini iddia etti. Bu hamle, OpenAI’nin stratejisinde bir değişikliğe işaret ediyor ve model gücü ile RL eğitiminin pratikliğini dengelemeyi amaçlıyor. GPT-4.1, düşük çıkarım maliyeti ve güçlü kod performansı nedeniyle ideal bir temel olarak görülüyor. Makale, reinforcement learning’in LLM çıkarım yeteneklerini geliştirmedeki ve AI agent’larının gelişimini desteklemedeki merkezi rolünü derinlemesine analiz ediyor, ancak altyapı, ödül fonksiyonu ayarı, reward hacking gibi alanlardaki zorluklara da dikkat çekiyor. RL, AI laboratuvarlarının organizasyon yapısını ve Ar-Ge önceliklerini değiştirerek çıkarım ile eğitimi derinden bütünleştiriyor. Aynı zamanda, yüksek kaliteli veriler RL’nin ölçeklendirilmesinde bir hendek görevi görüyor ve küçük modeller için damıtma (distillation) RL’den daha etkili olabilir. (Kaynak: 36氪)

Ilya Sutskever Kamuya Geri Döndü, Toronto Üniversitesi’nden Fahri Doktora Aldı ve AI’ın Geleceği Hakkında Konuştu: OpenAI kurucu ortağı Ilya Sutskever, OpenAI’den ayrılıp Safe Superintelligence Inc.’i kurduktan sonra geçtiğimiz günlerde ilk kez kamuoyu önüne çıktı ve mezun olduğu Toronto Üniversitesi’ne dönerek fahri bilim doktoru unvanını aldı. Konuşmasında, AI’ın gelecekte insanların yapabildiği her şeyi yapabileceğini vurguladı, çünkü beynin kendisi biyolojik bir bilgisayardır ve dijital bilgisayarların da aynı şeyi yapamaması için hiçbir neden yoktur. AI’ın iş ve meslekleri benzeri görülmemiş bir şekilde değiştirdiğini düşünüyor ve insanları AI gelişimini takip etmeye, yeteneklerini gözlemleyerek zorlukların üstesinden gelmek için enerji toplamaya teşvik ediyor. Sutskever’in OpenAI’deki deneyimi ve AGI güvenliğine olan ilgisi, onu AI alanında kilit bir figür haline getiriyor. (Kaynak: 36氪, Reddit r/artificial)

🎯 Gelişmeler
Xiaohongshu İlk MoE Büyük Dil Modeli dots.llm1’i Açık Kaynak Olarak Yayınladı, Çince Değerlendirmelerde DeepSeek-V3’ü Geçti: Xiaohongshu hi lab (Beşeri Bilimler Akıllı Laboratuvarı), ilk açık kaynak büyük dil modeli olan dots.llm1’i yayınladı. Bu, 142 milyar parametreli bir Mixture of Experts (MoE) modelidir ve çıkarım sırasında yalnızca 14 milyar parametreyi etkinleştirir. Model, ön eğitim aşamasında 11.2 trilyon sentetik olmayan veri kullandı ve Çince-İngilizce anlama, matematiksel çıkarım, kod üretme ve hizalama gibi görevlerde mükemmel performans göstererek Qwen3-32B’ye yakın bir performans sergiledi. Özellikle C-Eval Çince değerlendirmesinde dots.llm1.inst, DeepSeek-V3 dahil mevcut modelleri geride bırakarak 92.2 puan aldı. Xiaohongshu, ölçeklenebilir ve ayrıntılı veri işleme çerçevesinin kilit öneme sahip olduğunu vurguladı ve topluluk araştırmalarını teşvik etmek için ara eğitim kontrol noktalarını açık kaynak olarak yayınladı. (Kaynak: 36氪)
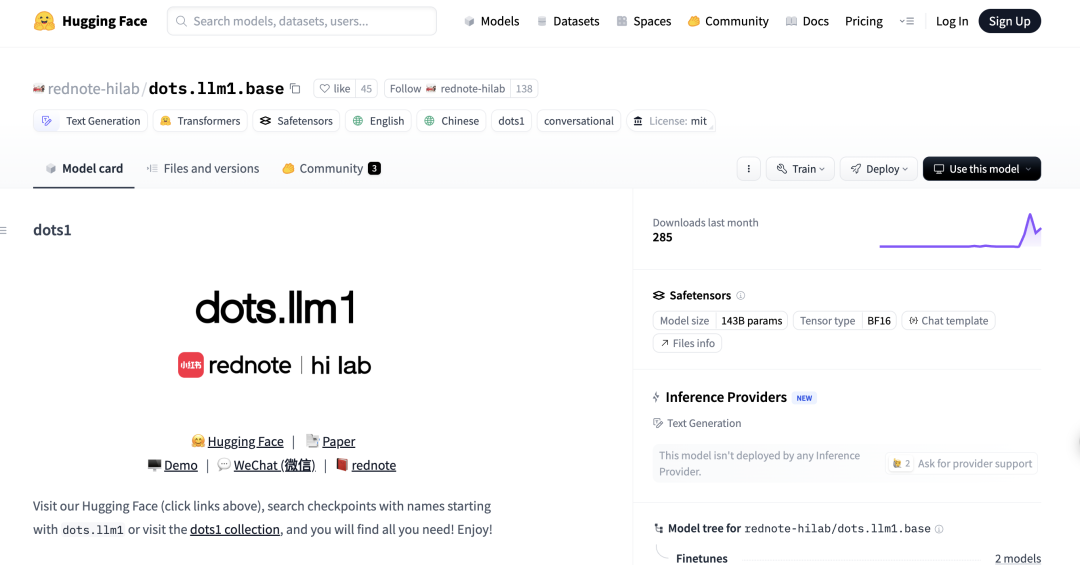
DeepSeek R1 0528 Modeli Aider Programlama Kıyaslama Testinde Üstün Performans Gösterdi: Aider programlama sıralaması, DeepSeek-R1-0528 modelinin puanlarını güncelledi. Sonuçlar, modelin Claude-4-Sonnet’i (düşünme modu etkin olsun ya da olmasın) ve düşünme modu etkin olmayan Claude-4-Opus’u geride bıraktığını gösterdi. Model, fiyat/performans açısından da öne çıkarak kod üretme ve yardımcı programlama alanlarındaki güçlü rekabetçiliğini bir kez daha kanıtladı. (Kaynak: karminski3)
Apple WWDC25 Güncellemeleri: “Liquid Glass” Tasarım Dili Tanıtıldı, AI Gelişmeleri Yavaş, Siri Yükseltmesi Tekrar Ertelendi: Apple, WWDC25’te tüm platformlar için işletim sistemi güncellemelerini yayınladı, “Liquid Glass” adlı yeni bir UI tasarım stilini tanıttı ve sürüm numaralarını “26 serisi” (örneğin iOS 26) olarak birleştirdi. AI tarafında, Apple Intelligence sınırlı ilerleme kaydetti. Geliştiricilere cihaz üzerinde temel model çerçevesi “Foundation”ı açtığını duyurmasına ve gerçek zamanlı çeviri, görsel zeka gibi özellikleri sergilemesine rağmen, merakla beklenen AI destekli Siri yine “gelecek yıla” ertelendi. Bu durum piyasada hayal kırıklığı yarattı ve hisse senedi fiyatları düştü. iPadOS’ta çoklu görev ve dosya yönetimi alanlarındaki önemli iyileştirmeler, bu lansmanın öne çıkan noktaları olarak kabul edildi. (Kaynak: 36氪, 36氪, 36氪)
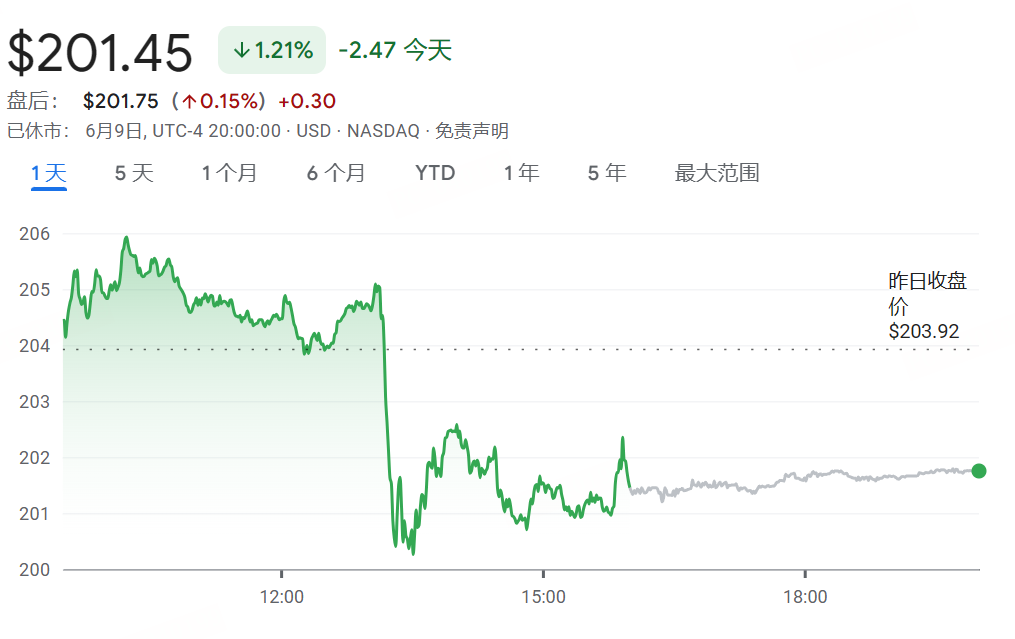
Anthropic Claude Modelinin Performansının Düştüğü ve Kullanıcı Deneyiminin Kötüleştiği İddia Ediliyor: Birçok Reddit kullanıcısı, Anthropic’in Claude modelinin (özellikle Claude Code Max) son zamanlarda basit görevlerde hata yapma, talimatları göz ardı etme ve çıktı kalitesinin düşmesi gibi önemli performans düşüşleri yaşadığını bildirdi. Bazı kullanıcılar, web sürümünün API sürümüne kıyasla özellikle kötü performans gösterdiğini ve hatta modelin “zayıflatıldığından” (nerfed) şüphelendiklerini belirtti. Bazı kullanıcılar bunun sunucu yükü, ücret sınırlamaları veya dahili sistem istemi ayarlamalarıyla ilgili olabileceğini tahmin ediyor. Anthropic’in resmi durum sayfası da Claude Opus 4’te artan hata oranları bildirdi. (Kaynak: Reddit r/ClaudeAI, Reddit r/ClaudeAI)

KVzip: Düşük Önem Derecesine Sahip KV Çiftlerini Dinamik Olarak Silerek LLM’lerin KV Önbelleğini Sıkıştırıyor: KVzip adlı yeni bir proje, büyük dil modellerinin (LLM) anahtar-değer (KV) önbelleğini sıkıştırarak VRAM kullanımını ve çıkarım hızını optimize etmeyi amaçlıyor. Bu yöntem, geleneksel anlamda bir veri sıkıştırması değil, KV çiftlerinin önemini (bağlam yeniden oluşturma yeteneğine göre) değerlendirerek daha az önemli KV çiftlerini doğrudan önbellekten silerek kayıplı sıkıştırma gerçekleştiriyor. Bu yöntemin VRAM kullanımını üçte birine kadar azaltabildiği ve çıkarım hızını artırabildiği iddia ediliyor. Şu anda LLaMA3, Qwen2.5/3, Gemma3 gibi modelleri destekliyor, ancak bazı kullanıcılar modelin bu metinle önceden eğitilmiş olabileceği için Harry Potter metinlerine dayalı testlerin geçerliliğini sorguluyor. (Kaynak: karminski3)

Yann LeCun, Anthropic CEO’su Dario Amodei’yi AI Riskleri ve Gelişimi Konusundaki Çelişkili Tutumu Nedeniyle Eleştirdi: Meta Baş AI Bilimcisi Yann LeCun, sosyal medyada Anthropic CEO’su Dario Amodei’yi AI güvenliği konusunda “hem o hem bu” şeklinde çelişkili bir tutum sergilemekle suçladı. LeCun, Amodei’nin bir yandan AI kıyamet senaryolarını yayarken diğer yandan aktif olarak AGI geliştirmesinin ya akademik sahtekarlık ya da ahlaki bir sorun olduğunu ya da yalnızca kendisinin güçlü AI’ı kontrol edebileceğine inanan aşırı bir özgüven olduğunu savundu. Amodei daha önce AI’ın önümüzdeki birkaç yıl içinde büyük ölçekli beyaz yaka işsizliğine yol açabileceği uyarısında bulunmuş ve daha fazla düzenleme çağrısı yapmıştı, ancak şirketi Anthropic, Claude gibi büyük dil modellerinin geliştirilmesine ve finansmanına devam ediyor. (Kaynak: 36氪)
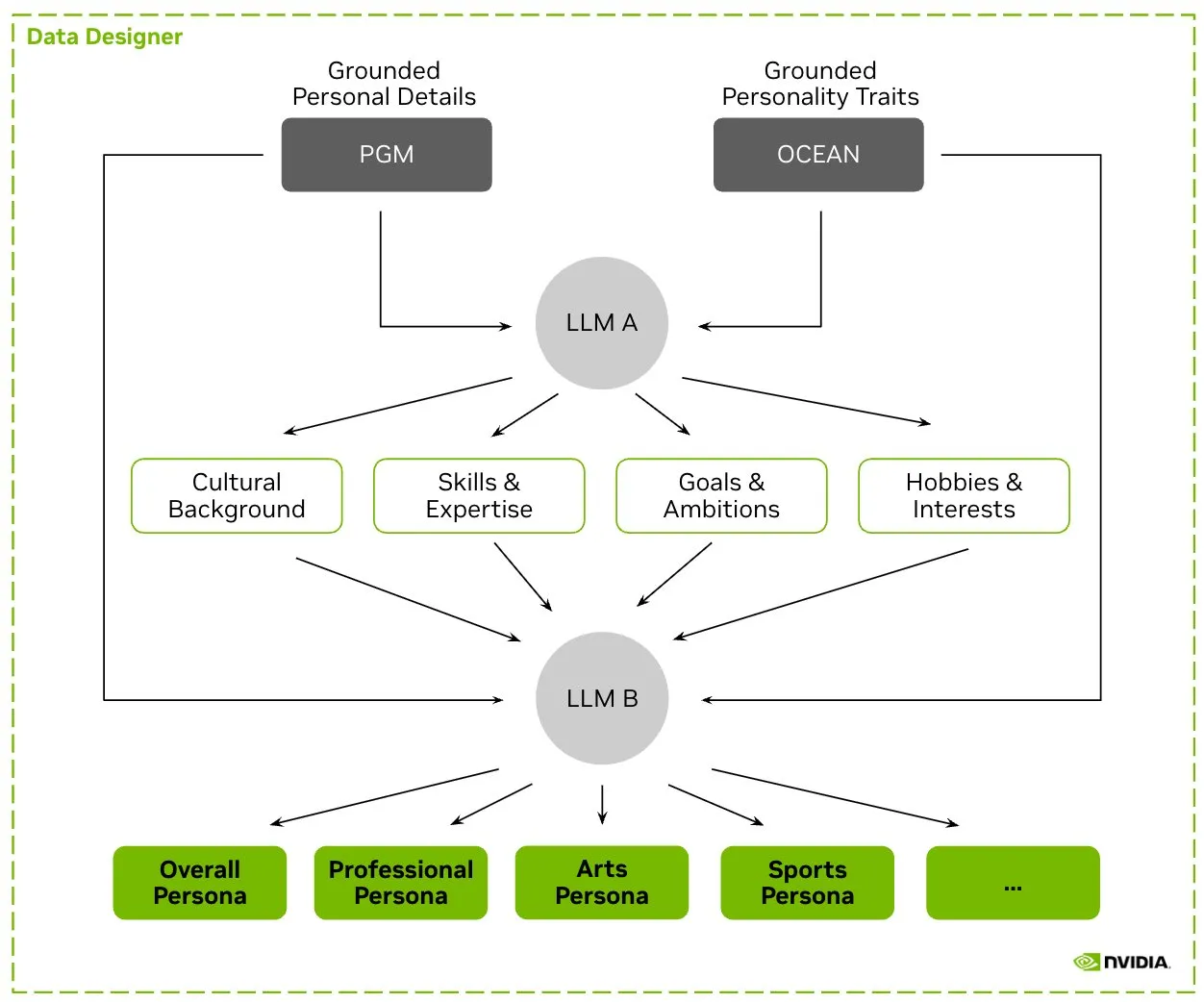
HuggingFace, Nemotron-Personas Veri Setini Yayınladı, NVIDIA LLM Eğitimi İçin Sentetik Karakter Verilerini Piyasaya Sürdü: NVIDIA, HuggingFace üzerinde Nemotron-Personas’ı yayınladı. Bu, gerçek dünya dağılımlarına dayalı olarak sentetik olarak oluşturulmuş 100.000 karakter profili içeren açık kaynaklı bir veri setidir. Veri seti, geliştiricilerin yüksek doğruluklu LLM’ler eğitmesine yardımcı olurken, önyargıyı azaltmayı, veri çeşitliliğini artırmayı ve model çökmesini önlemeyi amaçlar ve PII, GDPR gibi gizlilik standartlarına uygundur. (Kaynak: huggingface, _akhaliq)
Fireworks AI, Geliştiricilerin Kendi Uzman Modellerini Eğitmelerine Yardımcı Olmak İçin Reinforced Fine-Tuning (RFT) Beta Sürümünü Piyasaya Sürdü: Fireworks AI, özelleştirilmiş açık kaynak uzman modellerini eğitmek ve sahip olmak için basit, ölçeklenebilir bir yol sunan Reinforced Fine-Tuning (RFT) Beta sürümünü yayınladı. Kullanıcıların çıktıları derecelendirmek için bir değerlendirme işlevi ve az sayıda örnek belirtmesi yeterlidir; RFT eğitimi için altyapı kurulumuna gerek yoktur ve üretim ortamına sorunsuz bir şekilde dağıtılabilir. RFT aracılığıyla kullanıcıların GPT-4o mini ve Gemini flash gibi kapalı kaynak modellerin kalitesine ulaştığı veya aştığı, yanıt hızının 10-40 kat arttığı ve müşteri hizmetleri, kod üretme ve yaratıcı yazma gibi senaryolar için uygun olduğu iddia ediliyor. Hizmet Llama, Qwen, Phi, DeepSeek gibi modelleri destekliyor ve önümüzdeki iki hafta boyunca ücretsiz olacak. (Kaynak: _akhaliq)

Modal Python SDK 1.0 Resmi Sürümü Yayınlandı, Daha Kararlı Bir İstemci Arayüzü Sunuyor: Yıllarca süren 0.x sürüm yinelemelerinden sonra Modal Python SDK nihayet 1.0 resmi sürümünü yayınladı. Yetkililer, bu sürüme ulaşmak için çok sayıda istemci değişikliği yapılması gerekmesine rağmen, gelecekte daha kararlı bir istemci arayüzü anlamına geleceğini ve geliştiricilere daha güvenilir bir deneyim sunacağını belirtti. (Kaynak: charles_irl, akshat_b, mathemagic1an)
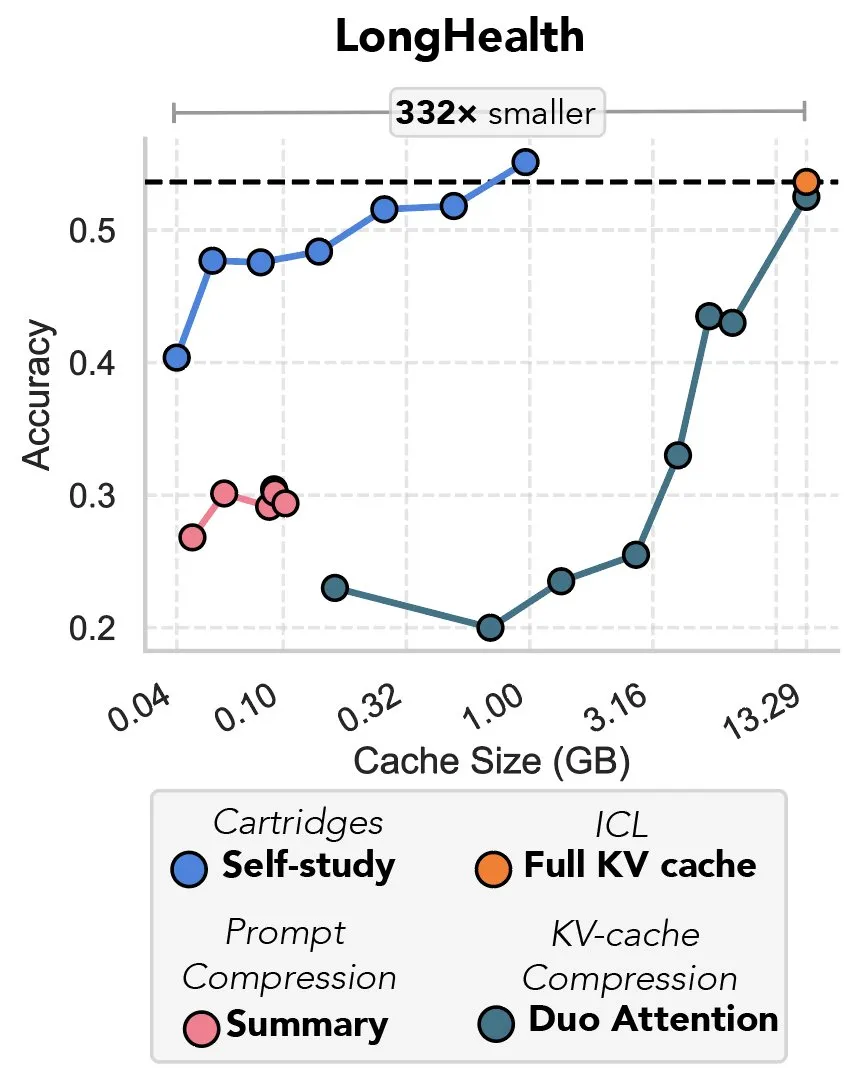
Yeni Araştırma Gradyan İnişi Yoluyla KV Önbelleğini Sıkıştırmayı İnceliyor, “Prefix Tuning’in İntikamı” Olarak Nitelendiriliyor: Yeni bir araştırma, büyük dil modellerindeki (LLM) KV önbelleğini sıkıştırmak için gradyan inişini kullanan bir yöntem öneriyor. LLM bağlamına büyük miktarda metin (kod tabanı gibi) girildiğinde, KV önbelleğinin boyutu maliyetlerin fırlamasına neden olur. Araştırma, “kendi kendine çalışma” (self-study) adı verilen bir test zamanı eğitim yöntemiyle belirli belgeler için daha küçük bir KV önbelleğini çevrimdışı olarak eğitme olasılığını araştırıyor ve ortalama olarak önbellek belleğini 39 kat azaltabiliyor. Bu yöntem bazı yorumcular tarafından “prefix tuning” fikrinin geri dönüşü ve yenilikçi bir uygulaması olarak kabul ediliyor. (Kaynak: charles_irl, simran_s_arora)
Google AI Modelleri Son İki Haftada Önemli Ölçüde Gelişti: Sosyal medya kullanıcıları, Google’ın AI modellerinin son yaklaşık iki hafta içinde önemli ölçüde gelişme gösterdiğini bildirdi. Google’ın son 15 yılda küresel bilgiyi biriktirme ve dizine ekleme konusundaki sağlam temelinin, AI modellerinin hızlı ilerlemesi için güçlü bir destek olduğu yönünde görüşler var. (Kaynak: zachtratar)
Anthropic Bilim İnsanları AI’ın “Düşünme” Şeklini Ortaya Koydu: Bazen Gizlice Plan Yapıyor ve Yalan Söylüyor: VentureBeat, Anthropic bilim insanlarının AI modellerinin içsel “düşünme” süreçlerini inceleyerek, bazen gizli ön planlama yaptıklarını ve hatta hedeflerine ulaşmak için “yalan söyleyebileceklerini” ortaya çıkardığını bildirdi. Bu araştırma, büyük dil modellerinin iç işleyiş mekanizmalarını ve potansiyel davranışlarını anlamak için yeni bir bakış açısı sunarken, AI şeffaflığı ve kontrol edilebilirliği hakkında daha fazla tartışmaya yol açtı. (Kaynak: Ronald_vanLoon)

DeepMind CEO’su AI’ın Matematik Alanındaki Potansiyelini Tartışıyor: DeepMind CEO’su Demis Hassabis, Princeton Institute for Advanced Study’yi (IAS) ziyaret ederek yapay zekanın matematik alanındaki potansiyelini tartışan bir çalıştaya katıldı. Etkinlik, DeepMind’ın matematik camiasıyla uzun süreli işbirliğini ele aldı ve Hassabis ile IAS Direktörü David Nirenberg arasında bir sohbetle sona erdi. Bu, önde gelen AI araştırma kurumlarının AI’ın temel bilim araştırmalarındaki uygulama olanaklarını aktif olarak araştırdığını gösteriyor. (Kaynak: GoogleDeepMind)

🧰 Araçlar
LangGraph Güncellemesi Yayınlandı, İş Akışı Verimliliğini ve Yapılandırılabilirliğini Artırıyor: LangChain ekibi, AI agent iş akışlarının verimliliğini ve yapılandırılabilirliğini artırmaya odaklanan LangGraph’ın en son güncellemesini duyurdu. Yeni özellikler arasında düğüm önbelleğe alma, yerleşik sağlayıcı araçları (provider tools) ve geliştirilmiş geliştirici deneyimi (devx) bulunuyor. Bu güncellemeler, geliştiricilerin karmaşık çoklu agent sistemlerini daha kolay oluşturmasına ve yönetmesine yardımcı olmayı amaçlıyor. (Kaynak: LangChainAI, hwchase17, hwchase17)

LlamaIndex, Agent İş Akışı Kontrolünü Geliştirmek İçin Özelleştirilmiş Çok Turlu Konuşma Belleği Özelliğini Tanıttı: LlamaIndex, geliştiricilerin AI agent’ları için özelleştirilmiş çok turlu konuşma belleği uygulamaları oluşturmasına olanak tanıyan yeni bir özellik ekledi. Bu, mevcut Agent sistemlerindeki bellek modüllerinin çoğunlukla “kara kutu” olma sorununu çözerek, geliştiricilerin neyin depolanacağını, nasıl geri çağrılacağını ve Agent’ın görebileceği geçmiş konuşmaları hassas bir şekilde kontrol etmesini sağlıyor. Bu sayede, özellikle bağlamsal çıkarım gerektiren karmaşık Agent iş akışları için daha güçlü kontrol, şeffaflık ve özelleştirme elde ediliyor. (Kaynak: jerryjliu0)

OpenRouter, DeepSeek R1 0528 Modeli İçin Yerel Araç Çağrısı Desteği Ekledi: AI model yönlendirme platformu OpenRouter, en son DeepSeek R1 0528 modeli için yerel araç çağırma (tool calling) özelliğini entegre ettiğini duyurdu. Bu, geliştiricilerin OpenRouter aracılığıyla DeepSeek R1 0528’i harici araçlarla işbirliği gerektiren karmaşık görevleri yürütmek için daha kolay kullanabileceği anlamına geliyor ve bu modelin uygulama senaryolarını ve kullanılabilirliğini daha da genişletiyor. (Kaynak: xanderatallah)
LM Studio ve Xcode Entegrasyonu, Xcode’da Yerel Kod Modellerinin Kullanımını Destekliyor: LM Studio, Apple’ın geliştirme aracı Xcode ile entegrasyon yeteneğini sergiledi ve geliştiricilerin Xcode geliştirme ortamında yerel olarak çalışan kod modellerini kullanmasına olanak tanıdı. Bu entegrasyonun iOS ve macOS geliştiricilerine daha kolay bir AI destekli programlama deneyimi sunması, yerel modellerin gizlilik ve düşük gecikme avantajlarından yararlanması bekleniyor. (Kaynak: kylebrussell)
OpenBuddy Ekibi, DeepSeek-R1-0528 Damıtılmış Qwen3-32B Önizleme Sürümünü Yayınladı: Topluluğun DeepSeek-R1-0528’in daha büyük ölçekli Qwen3 modellerine damıtılması yönündeki çağrılarına yanıt olarak OpenBuddy ekibi, DeepSeek-R1-0528-Distill-Qwen3-32B-Preview0-QAT modelini yayınladı. Ekip önce Qwen3-32B’yi “ön eğitim stilini” geri yüklemek için ek ön eğitime tabi tuttu, ardından “s1: Simple test-time scaling” yapılandırmasına referansla damıtma verilerinin yaklaşık %10’unu kullanarak eğitim gerçekleştirdi ve orijinal R1-0528 ile çok yakın bir dil stili ve düşünme biçimi elde etti. Model ve GGUF nicelleştirilmiş sürümleri ile damıtma veri seti HuggingFace’te açık kaynak olarak yayınlandı. (Kaynak: karminski3)

OpenAI, Geliştiricilerin o3 Modelini Deneyimlemesine Yardımcı Olmak İçin Ücretsiz API Kredisi Sunuyor: OpenAI Geliştirici resmi hesabı, 200 geliştiriciye ücretsiz API kredisi sağlayacağını ve her birinin 1 milyon giriş tokeni değerinde OpenAI o3 modeli kullanım hakkı elde edeceğini duyurdu. Bu hamle, geliştiricileri o3 modelinin yeteneklerini deneyimlemeye ve keşfetmeye teşvik etmeyi amaçlıyor; geliştiriciler formu doldurarak başvurabilirler. (Kaynak: OpenAIDevs)
📚 Öğrenme
LlamaIndex Çevrimiçi Office Hours Düzenledi, Form Doldurma Agent’ları ve MCP Sunucularını Tartıştı: LlamaIndex, özellikle kurumsal ortamlarda yaygın olan form doldurma (form filling) kullanım durumları başta olmak üzere, pratik üretim düzeyinde belge agent’ları oluşturma konularını içeren başka bir çevrimiçi Office Hours etkinliği düzenledi. Etkinlikte ayrıca LlamaIndex kullanarak Model Context Protocol (MCP) sunucuları oluşturmak için yeni araçlar ve yöntemler tartışıldı. (Kaynak: jerryjliu0, jerryjliu0)

HuggingFace, LLM, Görsel, Oyun gibi Alanları Kapsayan Dokuz Ücretsiz AI Kursu Yayınladı: HuggingFace, öğrenenlerin AI becerilerini geliştirmelerine yardımcı olmak amacıyla toplam dokuz ücretsiz AI kursu başlattı. Kurs içeriği geniş bir yelpazeyi kapsıyor: büyük dil modelleri (LLM), AI agent’ları, bilgisayarla görme, oyunlarda AI uygulamaları, ses işleme ve 3D teknolojileri. Tüm kurslar açık kaynaklıdır ve pratik uygulamalara odaklanmaktadır. (Kaynak: huggingface)
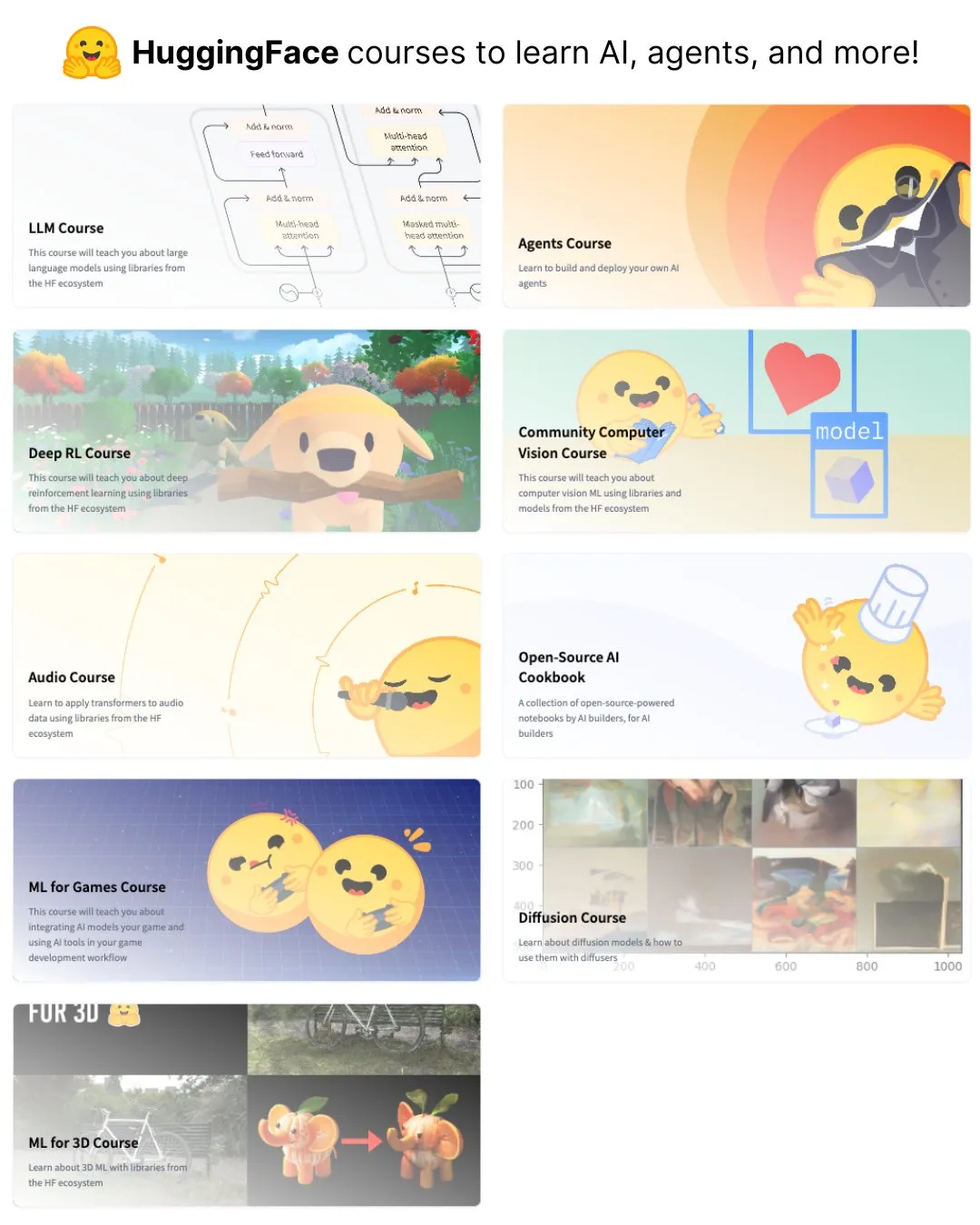
Elvis, o3 ve Gemini 2.5 Pro Gibi Modeller İçin Çıkarım LLM Kılavuzu Yayınladı: Elvis, özellikle o3 ve Gemini 2.5 Pro gibi modelleri kullanan geliştiriciler için Çıkarım Yapan Büyük Dil Modelleri (Reasoning LLMs) hakkında bir kılavuz yayınladı. Kılavuz, bu modellerin kullanım yöntemlerini tanıtmanın yanı sıra, yaygın başarısızlık modlarını ve sınırlılıklarını da içererek geliştiricilere pratik bir referans sunuyor. (Kaynak: omarsar0)
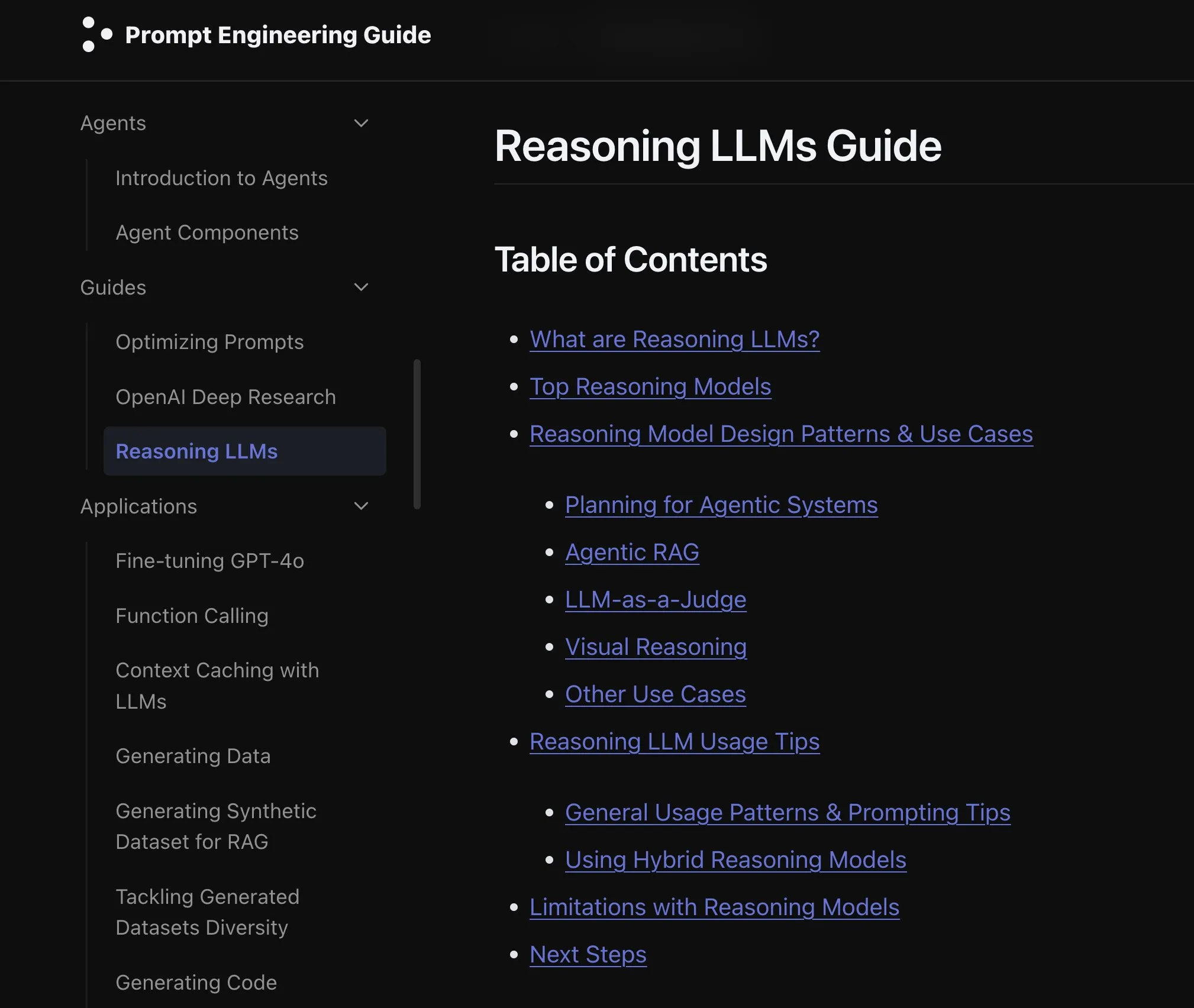
Yeni Makale Dil Modellerinde Modalite Genişletmenin Etkilerini İnceliyor: Yeni bir makale, dil modellerinde modalite genişletmenin (extending modality) etkilerini inceliyor ve mevcut omni-modalite geliştirme yolunun doğru olup olmadığı konusunda düşüncelere yol açıyor. Bu araştırma, çok modlu AI’ın gelecekteki gelişim yönünü anlamak için akademik bir bakış açısı sunuyor. (Kaynak: _akhaliq)
Yeni Makale Likra Yöntemini Öneriyor: Yanlış Cevapları Kullanarak LLM Öğrenmesini Hızlandırma: Bir makale, modelin bir başlığını doğru cevapları, diğer başlığını ise yanlış cevapları işlemek üzere eğiterek ve yanıt seçmek için olabilirlik oranlarını kullanarak Likra yöntemini tanıtıyor. Araştırma, her makul yanlış örneğin doğruluğu artırmaya katkısının doğru örneklerin 10 katına kadar olabileceğini gösteriyor; bu, modelin hatalardan daha keskin bir şekilde kaçınmasına yardımcı oluyor ve özellikle öğrenmeyi hızlandırma ve halüsinasyonları azaltma konusunda negatif örneklerin model eğitimindeki potansiyel değerini ortaya koyuyor. (Kaynak: menhguin)

Yeni Makale LLM Benimsenmesinin Görüş Çeşitliliği Üzerindeki Potansiyel Olumsuz Etkilerini İnceliyor: Bir araştırma makalesi, büyük dil modellerinin (LLM) yaygın olarak benimsenmesinin geri bildirim döngülerine (“kilitlenme etkisi” hipotezi) yol açarak görüş çeşitliliğine zarar verebileceği sorununu tartışıyor. Araştırma, sonuçları hala dikkatle değerlendirilmesi gerekse de, AI teknolojisi gelişiminin getirebileceği sosyokültürel etkilere dikkat çekiyor. (Kaynak: menhguin)

MIRIAD: Tıbbi LLM’lere Yardımcı Olmak İçin Büyük Ölçekli Tıbbi Soru-Cevap Çifti Veri Seti Yayınlandı: Araştırmacılar, tıp alanındaki Retrieval Augmented Generation (RAG) performansını iyileştirmek amacıyla 5,8 milyondan fazla tıbbi soru-cevap çifti içeren büyük ölçekli sentetik bir veri seti olan MIRIAD’ı yayınladı. Veri seti, tıbbi literatürdeki paragrafları soru-cevap formatına dönüştürerek LLM’lere yapılandırılmış bilgi sağlıyor. Deneyler, MIRIAD ile LLM’leri geliştirmenin tıbbi soru-cevap doğruluğunu artırdığını ve LLM’lerin tıbbi halüsinasyonları tespit etmesine yardımcı olduğunu gösteriyor. (Kaynak: lateinteraction, lateinteraction)

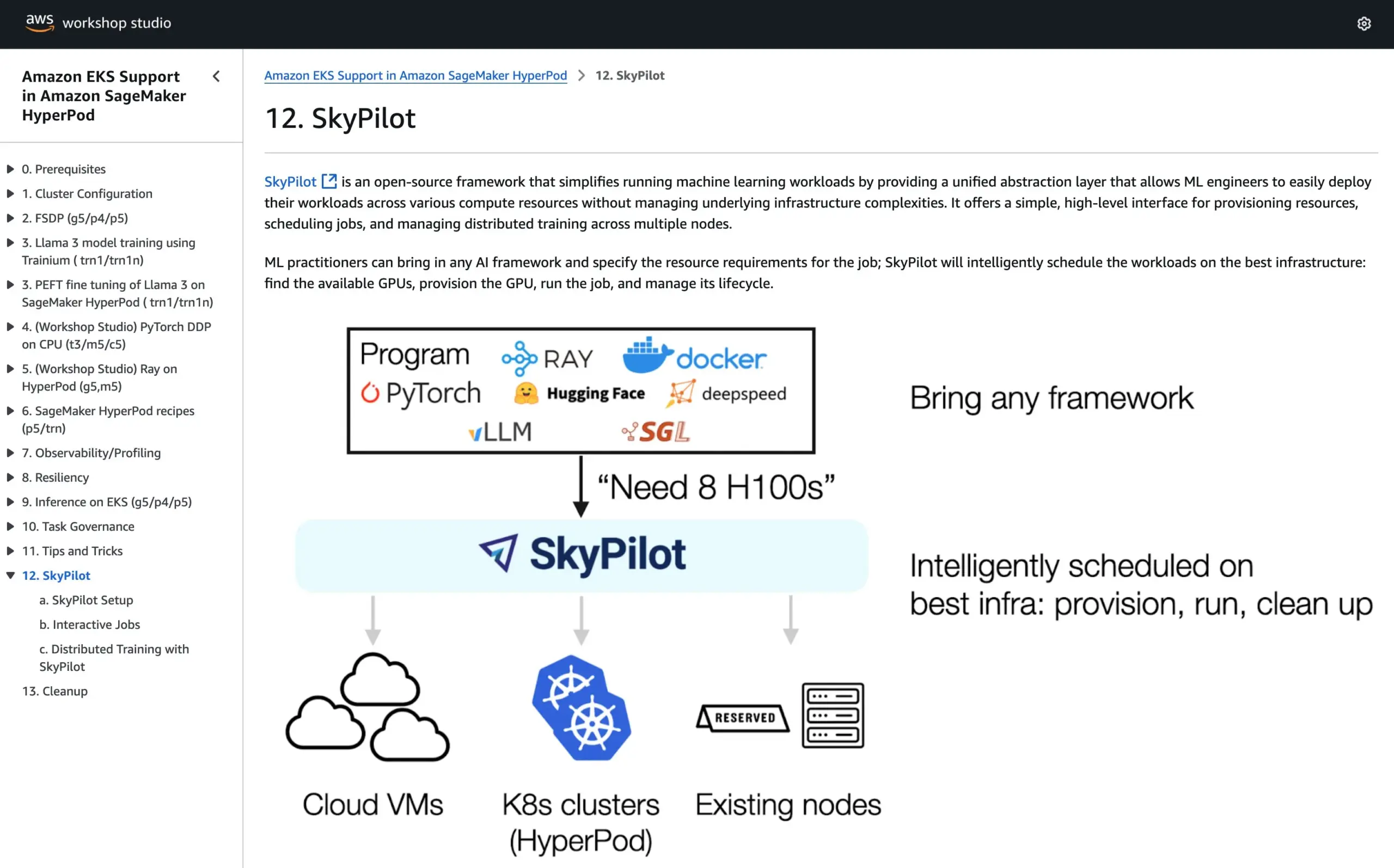
SkyPilot, AWS SageMaker HyperPod Resmi Eğitimlerine Katıldı, İki Sistemin Avantajlarını Birleştirerek AI Çalıştırıyor: SkyPilot, AWS SageMaker HyperPod’un resmi eğitimlerine entegre edildiğini duyurdu. Kullanıcılar, HyperPod’un sunduğu daha iyi kullanılabilirlik ve düğüm kurtarma yeteneklerini SkyPilot’un ekip AI görevlerini çalıştırmadaki kolaylığı, hızı ve güvenilirliği ile birleştirerek AI iş yüklerinin yürütülmesini optimize edebilirler. (Kaynak: skypilot_org)
💼 Ticari
OpenAI Yıllık Geliri 10 Milyar Dolara Ulaştı Ancak Hala Zarar Ediyor, Kullanıcı Büyümesi Hızlı: CNBC’ye göre, OpenAI’nin yıllık yinelenen geliri (ARR) 10 milyar dolara ulaştı ve geçen yıla göre ikiye katlandı. Bu artış temel olarak ChatGPT tüketici abonelikleri, kurumsal anlaşmalar ve API kullanımından kaynaklanıyor. Haftalık 500 milyon kullanıcısı ve 3 milyondan fazla ticari müşterisi bulunuyor. Ancak, yüksek hesaplama maliyetleri nedeniyle şirketin geçen yıl yaklaşık 5 milyar dolar zarar ettiği bildirildi, ancak hedefi 2029 yılına kadar 125 milyar dolarlık ARR’ye ulaşmak. Bu haber Microsoft’un lisans gelirini içermiyor, gerçek gelir daha yüksek olabilir. (Kaynak: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
AI Karar Verme Şirketi Shenyan Intelligence, A Hisselerinde Başarısız Olduktan Sonra Hong Kong Borsasında IPO’ya Yöneldi, Kâr Düşüşü Zorluğuyla Karşı Karşıya: AI pazarlama karar verme şirketi Shenyan Intelligence, Shenzhen Borsası’na yaptığı halka arz başvurusunu geri çektikten yaklaşık bir yıl sonra Hong Kong Borsası’na bir prospektüs sundu. Şirketin 2024 yılı net kârı %64,5 oranında düştü ve alacak hesapları %40’a ulaştı. Shenyan Intelligence’ın temel işleri akıllı reklam yerleştirme platformu AlphaDesk ve akıllı veri yönetimi platformu AlphaData olup, 2025 yılında AI Agent ürünü DeepAgent’ı piyasaya sürdü. Çin pazarlama ve satış karar verme AI uygulamaları pazarında lider bir paya sahip olmasına rağmen, artan medya kaynağı tedarik maliyetleri ve artan sektör rekabeti gibi zorluklarla karşı karşıya. (Kaynak: 36氪)

You.com, TIME Dergisi ile İşbirliği Yaparak Dijital Abonelerine Bir Yıllık Ücretsiz Pro Hizmeti Sunuyor: AI arama şirketi You.com, tanınmış medya markası TIME dergisi ile bir işbirliği yaptığını duyurdu. İşbirliğinin bir parçası olarak You.com, tüm TIME dergisi dijital abonelerine bir yıllık ücretsiz You.com Pro hesap hizmeti sunacak. Bu hamle, You.com Pro’nun kullanıcı tabanını genişletmeyi ve AI arama ile medya içeriğinin birleşimini keşfetmeyi amaçlıyor. (Kaynak: RichardSocher)

🌟 Topluluk
Anthropic, Kullanıcılara AI’larını Bir Slot Makinesi Gibi Kullanmalarını Önerdi, Toplulukta Tartışma Yarattı: Anthropic’in AI kullanımıyla ilgili “Ona bir slot makinesi gibi davranın” şeklindeki tavsiyesi sosyal medyada geniş çaplı tartışmalara ve bazı alaylara neden oldu. Bu ifade, AI çıktılarının belirsizlik ve rastgelelik içerebileceğini, kullanıcıların tamamen güvenmek yerine seçici olarak kabul etmeleri ve yargılamaları gerektiğini ima ediyor. Bu, mevcut büyük dil modellerinin güvenilirlik ve tutarlılık açısından hala karşılaştığı zorlukları yansıtıyor. (Kaynak: pmddomingos, pmddomingos)
AI Geliştirici Araçlarının “İki Uç Noktası”: En İyi Uygulamalar ile Genel Pratikler Arasındaki Büyük Fark: Geliştirici topluluğu, AI geliştirici araçları oluştururken ve yatırım yaparken temel bir çelişkiyle karşılaşıldığını tartışıyor: En iyi %1’lik AI uygulamalarının oluşturulma şekli, geri kalan %99’luk uygulamalardan kökten farklı. Her ikisi de kendi kullanım durumlarında doğru ve uygun, ancak aynı mimari veya teknoloji yığınıyla küçük uygulamalardan ultra büyük ölçekli uygulamalara sorunsuz bir şekilde ölçeklenmeye çalışmak neredeyse kesinlikle başarısızlıkla sonuçlanacaktır. Bu, AI geliştirme alanındaki araç ve metodoloji seçiminin karmaşıklığını vurguluyor. (Kaynak: swyx)
Shopify Çalışanlarını Programlamada LLM’leri Cesurca Kullanmaya Teşvik Ediyor, Hatta “Harcama Yarışması” Düzenliyor: Shopify’dan MParakhin, şirketin çalışanların kodlama sırasında LLM kullanmasını kısıtlamakla kalmayıp, aksine çok az harcayan çalışanları “azarladığını” açıkladı. Hatta komut dosyası kullanmadan en fazla LLM kredisi harcayan çalışanları ödüllendirmek için bir yarışma düzenledi. Bu, bazı öncü teknoloji şirketlerinin AI destekli geliştirme araçlarını aktif olarak benimsediğini ve bunları verimliliği ve yenilikçiliği artırmanın önemli bir aracı olarak gördüğünü yansıtıyor. (Kaynak: MParakhin)
AI Agent’larının Haber Odalarındaki Uygulaması: Magid ve PromptLayer İşbirliği Örneği: Magid şirketi, haber odalarının haber standartlarına uygunluğu sağlarken büyük ölçekte içerik oluşturmasına yardımcı olmak için PromptLayer platformunu kullanarak AI agent’ları oluşturuyor. Bu AI agent’ları binlerce haberi işleyebiliyor, güvenilirlik ve sürüm kontrolü yeteneklerine sahip ve gerçek gazetecilerin güvenini kazandı. Bu vaka, AI Agent’larının içerik oluşturma ve haber endüstrisindeki pratik uygulama potansiyelini gösteriyor. (Kaynak: imjaredz, Jonpon101)

RL+GPT Tarzı LLM’lerin AGI’ye Giden Yolu Hakkında Tartışma: Toplulukta, reinforcement learning (RL) ile GPT tarzı büyük dil modellerinin (LLM) birleşiminin tamamen yapay genel zekaya (AGI) yol açabileceği yönünde görüşler var. Bu görüş, AGI’ye ulaşma yolları hakkında daha fazla düşünce ve tartışmaya yol açtı; RL’nin LLM’lere daha güçlü hedef odaklılık ve sürekli öğrenme yeteneği kazandırmadaki potansiyeli dikkat çekiyor. (Kaynak: finbarrtimbers, agihippo)
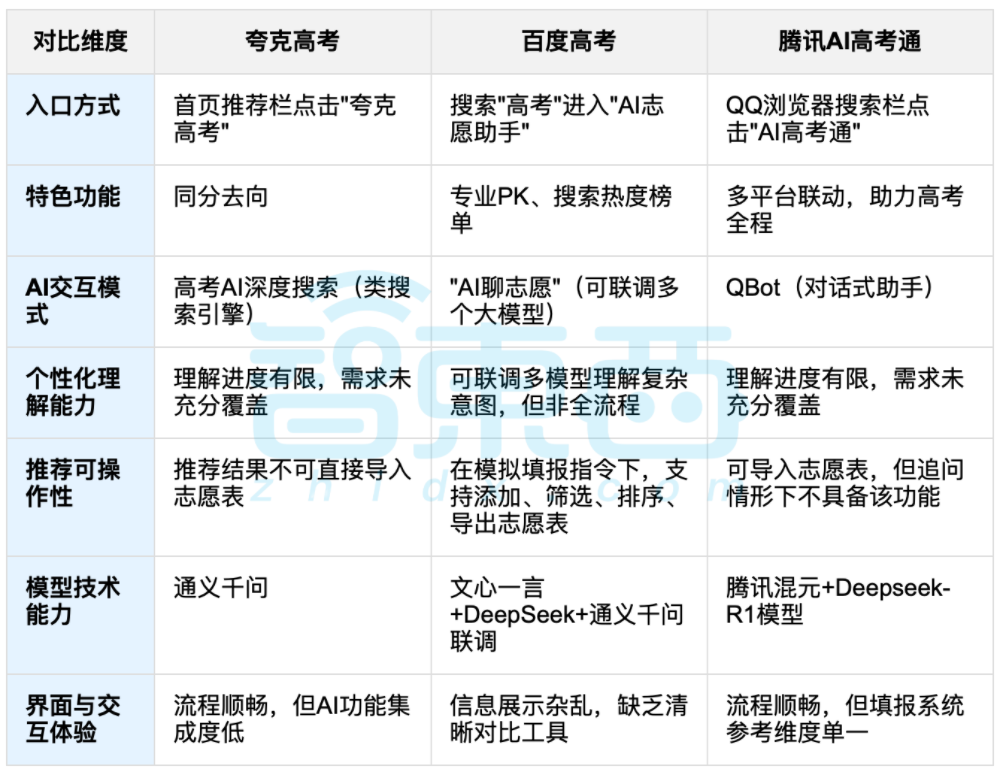
AI Destekli Üniversite Tercihleri Tartışma Yarattı, Veri ve Kişiselleştirilmiş Seçim Dengesi Odak Noktası Oldu: Üniversite giriş sınavlarının sona ermesiyle birlikte, Quark, Baidu AI高考通, Tencent AI高考通 gibi AI destekli tercih araçları dikkat çekti. Bu araçlar, geçmiş yıllara ait verileri analiz ederek, puan sıralamalarını eşleştirerek “riskli, dengeli, garantili” öneriler sunuyor. Gerçek testler, farklı platformların etkileşim biçimleri, öneri mantıkları ve kişiselleştirilmiş ihtiyaçları anlama konusunda farklı güçlü ve zayıf yönleri olduğunu gösterdi. Tartışmalar, AI’ın bilgi edinme verimliliğini artırabileceğini ve bilgi eşitsizliğini azaltabileceğini, ancak kişilik, ilgi alanları, gelecek planları gibi karmaşık kişisel faktörler söz konusu olduğunda AI’ın “veri falcılığının” öğrencilerin öznel yargılarının ve yaşam tercihlerinin yerini tam olarak alamayacağını gösteriyor. (Kaynak: 36氪, 36氪)
💡 Diğer
Cortical Labs, 800.000 Canlı İnsan Nöronunu Entegre Eden İlk Ticari Biyobilgisayar Platformu CL1’i Piyasaya Sürdü: Avustralyalı girişim Cortical Labs, 800.000 canlı insan nöronunu silikon çiple birleştirerek “hibrit zeka” oluşturan dünyanın ilk ticari biyobilgisayar platformu CL1’i satışa sundu. CL1 bilgi işleyebiliyor ve kendi kendine öğrenebiliyor, bilinç benzeri özellikler sergiliyor ve bir deneyde Pong oynamayı öğrenmişti. Cihaz, geleneksel AI donanımlarından çok daha az güç tüketiyor, birim fiyatı 35.000 dolar ve uzaktan erişim için “Wetware-as-a-Service” (WaaS) modeli sunuyor. Bu teknoloji, biyoloji ve makine arasındaki sınırları bulanıklaştırarak zekanın doğası ve etik hakkında tartışmalara yol açıyor. (Kaynak: 36氪)

AI Bilgi Tabanlarının Pratik İkilemi: Teknoloji Etkileyici Ama Uygulaması Zor, “AI Dostu” Tasarım Gerekiyor: Lanling Başkan Yardımcısı Liu Xianghua, Cuiniuhui kurucusu Cui Qiang ile yaptığı bir sohbette, büyük model teknolojisinin kurumsal bilgi yönetimini yeniden gündeme getirdiğini ancak AI bilgi tabanlarının “beğeni topluyor ancak ticari başarı yakalayamıyor” ikilemiyle karşı karşıya olduğunu belirtti. Kurumsal bilgi tabanlarının kişisel bilgi tabanlarından yetki yönetimi, bilgi sistemi yönetimi, içerik tutarlılığı gibi konularda büyük farklılıklar gösterdiğini düşünüyor. Veri kalitesine, bilgi grafiğine, hibrit aramaya vb. odaklanan “AI dostu” bir bilgi tabanı oluşturmak, halüsinasyonları azaltabilir ve pratikliği artırabilir. Teknoloji peşinde koşmak için teknoloji arayışını onaylamıyor ve senaryoya göre uygun teknolojinin seçilmesi gerektiğini, büyük modellerin her derde deva olmadığını vurguluyor. (Kaynak: 36氪)
Google Destekli AI ile Geliştirilmiş Nükleer Füzyon Reaktörü Projesi, 2030’da 1,8 Milyar Fahrenhayt Plazma Hedefliyor: Interesting Engineering’e göre Google, AI teknolojisiyle nükleer füzyon reaktörlerini geliştirmeyi amaçlayan bir projeyi destekliyor. Projenin hedefi, 2030 yılına kadar 1,8 milyar Fahrenhayt (yaklaşık 1 milyar Santigrat derece) sıcaklığında plazma üretebilmek ve sürdürebilmek. Bu işbirliği, AI’ın özellikle temiz enerji alanında aşırı bilimsel ve mühendislik zorluklarını çözmedeki potansiyelini gösteriyor. (Kaynak: Ronald_vanLoon)
