
Anahtar Kelimeler:Büyük Dil Modelleri, Akıl Yürütme Yeteneği, Genel Yapay Zeka, Örüntü Eşleme, Düşünce Yanılsaması, Apple Araştırması, AI Dedektörü, AI Düzenlemesi, Log-Linear Dikkat Mekanizması, Huawei Pangu MoE Modeli, ChatGPT Gelişmiş Ses Modu, TensorZero Çerçevesi, Anthropic CEO Düzenleme Görüşü
🔥 Odak Noktası
Apple araştırması “düşünme yanılsamasını” ortaya koyuyor: Mevcut “muhakeme” modelleri gerçekten düşünmüyor, daha çok örüntü eşleştirmeye dayanıyor: Apple’ın yeni araştırma makalesi “Düşünmenin Yanılsaması: Muhakeme Modellerinin Güçlü ve Zayıf Yönlerini Sorun Karmaşıklığı Perspektifinden Anlamak” (The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models Through the Lens of Problem Complexity), mevcut “muhakeme” yeteneğine sahip olduğu iddia edilen büyük dil modellerinin (Claude, DeepSeek-R1, GPT-4o-mini vb. gibi) performansının gerçek anlamda mantıksal çıkarımdan ziyade verimli örüntü eşleştiricilere benzediğini belirtiyor. Araştırma, bu modellerin eğitim dağılımının dışındaki veya karmaşıklığı yüksek sorunlarla uğraşırken performanslarının önemli ölçüde düştüğünü, hatta basit sorunlarda bile “aşırı düşünme” nedeniyle hata yapabildiğini ve erken hataları düzeltmekte zorlandığını ortaya koydu. Çalışma, modellerin sözde “düşünme” süreçlerinin (düşünce zinciri gibi) yeni veya karmaşık görevlerle karşılaştığında genellikle başarısız olduğunu vurguluyor, bu da genel yapay zekaya (AGI) beklenenden daha uzak olabileceğimizi gösteriyor. (Kaynak: machinelearning.apple.com, TheTuringPost, mervenoyann, Reddit r/artificial, Reddit r/LocalLLaMA, Reddit r/MachineLearning)

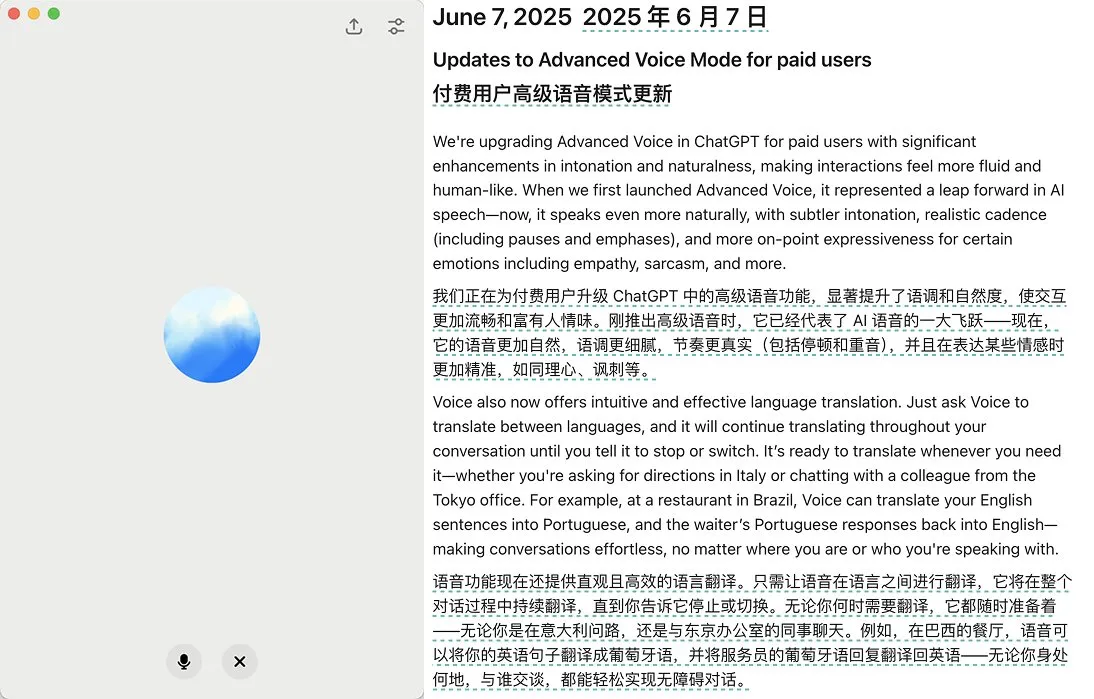
OpenAI, ChatGPT için gelişmiş ses modu güncellemesini yayınladı, doğallığı ve çeviri işlevlerini iyileştirdi: OpenAI, ChatGPT’nin ücretli kullanıcıları için gelişmiş ses modu (Advanced Voice Mode) için önemli bir güncelleme yayınladı. Yeni sürüm, sesin doğal akıcılığını önemli ölçüde artırarak yapay zeka asistanından ziyade insana benzemesini sağlıyor. Ayrıca güncelleme, dil çevirisi performansını ve komut takip etme yeteneğini de geliştirdi ve yeni bir çeviri modu ekledi; kullanıcılar, durdurulması istenene kadar ChatGPT’nin tüm konuşma boyunca her iki tarafın konuşmalarını sürekli olarak çevirmesini sağlayabilir. Bu güncelleme, sesli etkileşimi daha kolay ve doğal hale getirerek kullanıcı deneyimini iyileştirmeyi amaçlıyor. (Kaynak: juberti, Plinz, op7418, BorisMPower)
Yapay zeka dedektörlerinin etkisiz olduğu ve yapay zeka içeriğinin “gizlenmesine” yardımcı olabileceği iddia ediliyor: Sosyal medya ve teknoloji forumlarında, mevcut yapay zeka içerik tespit araçlarının yalnızca etkisiz olmakla kalmayıp, aynı zamanda yapay zeka tarafından üretilen içeriğin fark edilmesini daha da zorlaştırabileceğine dair yaygın tartışmalar ortaya çıktı. Birçok kullanıcı ve uzman, bu dedektörlerin içeriğin kaynağını gerçekten anlamak yerine, esas olarak dil kalıplarına ve belirli kelimelere (akademik terim “delve” gibi) dayalı olarak yargıda bulunduğunu düşünüyor. Yanlış pozitif riski (öğrenciler gibi gruplar için haksızlığa neden olabilir) ve yapay zeka modellerinin kendilerinin de tespitten kaçınmak için evrimleşmesi nedeniyle, bu araçların güvenilirliği ciddi şekilde sorgulanıyor. Yapay zeka dedektörlerinin varlığının, yapay zeka tarafından içerik üretilirken kolayca işaretlenebilecek belirli özelliklerden kaçınılmasını teşvik ederek, insan yazısına daha çok benzemesine neden olduğu yönünde görüşler var. (Kaynak: Reddit r/ArtificialInteligence, sytelus)

Anthropic CEO’su, yapay zeka şirketleri için şeffaflık ve sorumluluk denetiminin güçlendirilmesi çağrısında bulundu: Anthropic CEO’su, The New York Times’da yayınlanan bir görüş yazısında, yapay zeka şirketlerine yönelik denetimlerin gevşetilmemesi gerektiğini, özellikle şeffaflıklarının artırılması ve sorumluluklarının takip edilmesi gerektiğini vurguladı. Bu görüş, yapay zeka endüstrisinin hızla geliştiği ve yeteneklerinin her geçen gün arttığı bir ortamda özellikle önem taşıyor ve toplumun yapay zekanın potansiyel riskleri ve etik kaygılarına yanıt veriyor. Makale, yapay zeka teknolojisinin etkisinin arttıkça, gelişiminin kamu yararına uygun olmasını ve kötüye kullanımının önlenmesini sağlamanın hayati önem taşıdığını ve bunun için endüstri özdenetimi ile dış denetimin birlikte çalışması gerektiğini savunuyor. (Kaynak: Reddit r/artificial)

🎯 Gelişmeler
Jeff Dean yapay zekanın geleceğini öngörüyor: Özel donanım, model evrimi ve bilimsel uygulamalar: Google AI yöneticisi Jeff Dean, Sequoia Capital AI Ascent etkinliğinde yapay zekanın gelecekteki gelişimine ilişkin görüşlerini paylaştı. Özel donanımın (TPU gibi) yapay zeka ilerlemesi için önemini vurguladı ve model mimarilerinin evrimsel eğilimlerini tartıştı. Dean ayrıca, hesaplama altyapısının gelecekteki biçimlerini ve yapay zekanın bilimsel araştırma gibi alanlardaki muazzam uygulama potansiyelini öngördü ve yapay zekanın bilimsel keşifleri yönlendiren kilit bir araç olacağına inandığını belirtti. (Kaynak: TheTuringPost)

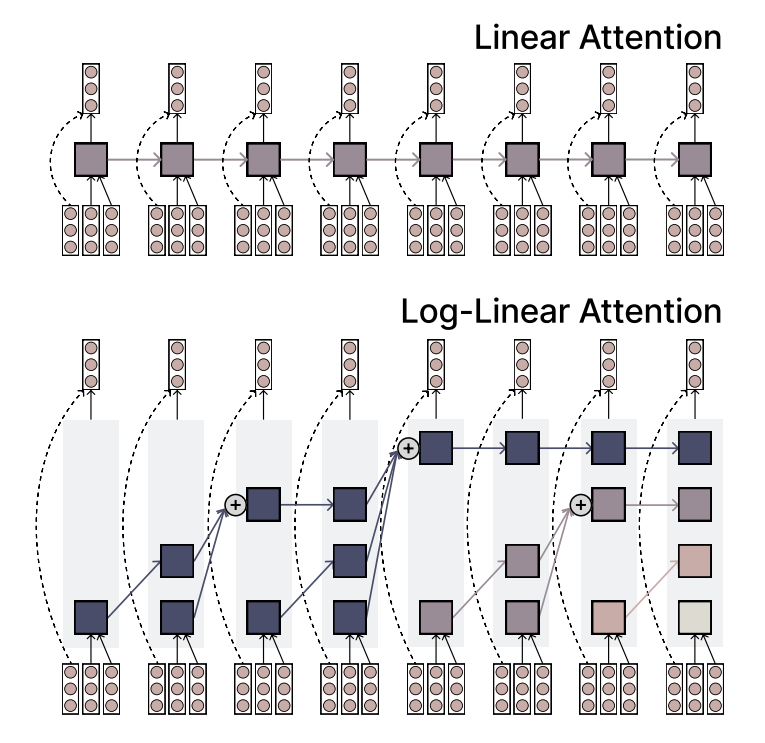
MIT, verimlilik ve ifade gücünü birleştiren Log-Linear Attention mekanizmasını önerdi: MIT araştırmacıları, Log-Linear Attention adlı yeni bir dikkat mekanizması önerdi. Bu mekanizma, doğrusal dikkatin (Linear Attention) yüksek verimliliği ile Softmax dikkatinin güçlü ifade yeteneğini birleştirmeyi amaçlıyor. Temel özelliği, az sayıda ancak dizi uzunluğuyla logaritmik olarak artan bellek yuvaları (memory slots) kullanmasıdır, böylece uzun dizileri işlerken düşük hesaplama karmaşıklığını korurken önemli bilgileri yakalar. (Kaynak: TheTuringPost)
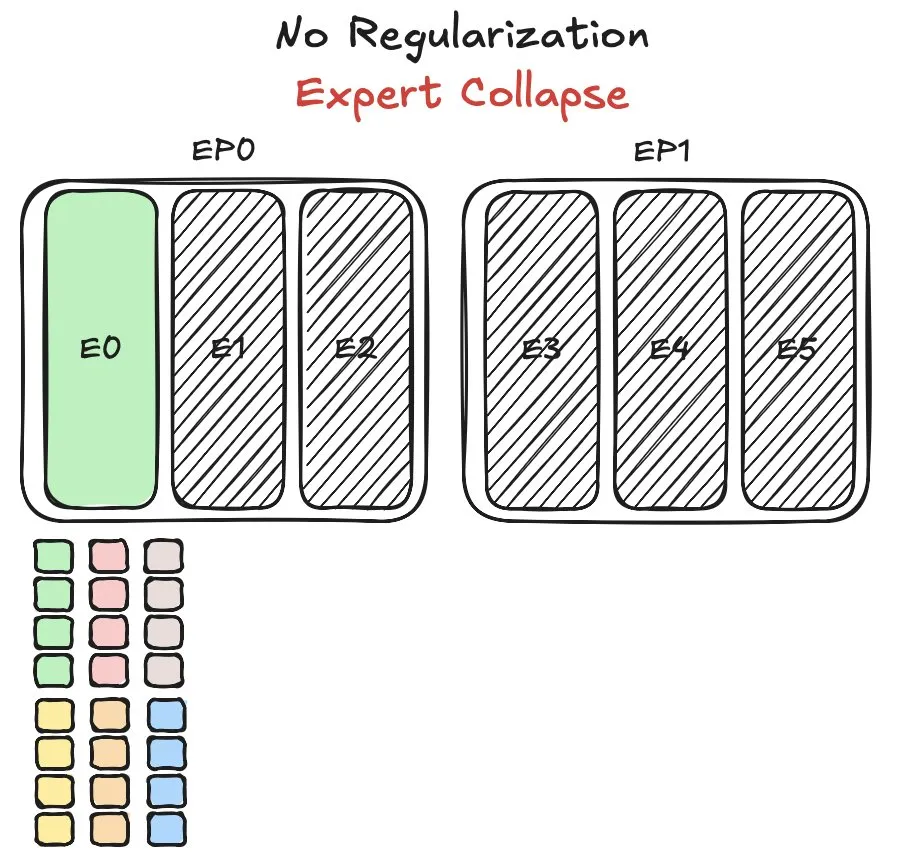
Huawei Pangu MoE modeli uzman yük dengeleme zorluklarıyla karşılaşıyor, yeni bir yöntem öneriyor: Huawei, karma uzman (MoE) modeli Pangu Ultra MoE’yi eğitirken, uzman yük dengeleme konusunda kritik bir sorunla karşılaştı. Uzman yük dengeleme, eğitim dinamikleri ve sistem verimliliği arasında bir denge kurmayı gerektirir. Huawei, bu soruna yönelik olarak MoE modelindeki farklı uzman modüllerinin görev dağılımını ve hesaplama yükünü optimize etmeyi amaçlayan yeni bir çözüm önerdi; bu da eğitim verimliliğini ve model performansını artırmayı hedefliyor. İlgili araştırma bir makalede yayınlandı. (Kaynak: finbarrtimbers)
NVIDIA, nesne tespiti odaklı Cascade Mask R-CNN Mamba Vision modelini yayınladı: NVIDIA, Hugging Face’te cascade_mask_rcnn_mamba_vision_tiny_3x_coco adlı yeni bir model yayınladı. Adından da anlaşılacağı gibi, bu model nesne tespiti görevleri için özel olarak tasarlanmıştır ve muhtemelen Cascade R-CNN mimarisini Mamba (bir durum uzay modeli) görsel teknolojisiyle birleştirerek nesne tespitinin doğruluğunu ve verimliliğini artırmayı amaçlamaktadır. (Kaynak: _akhaliq)
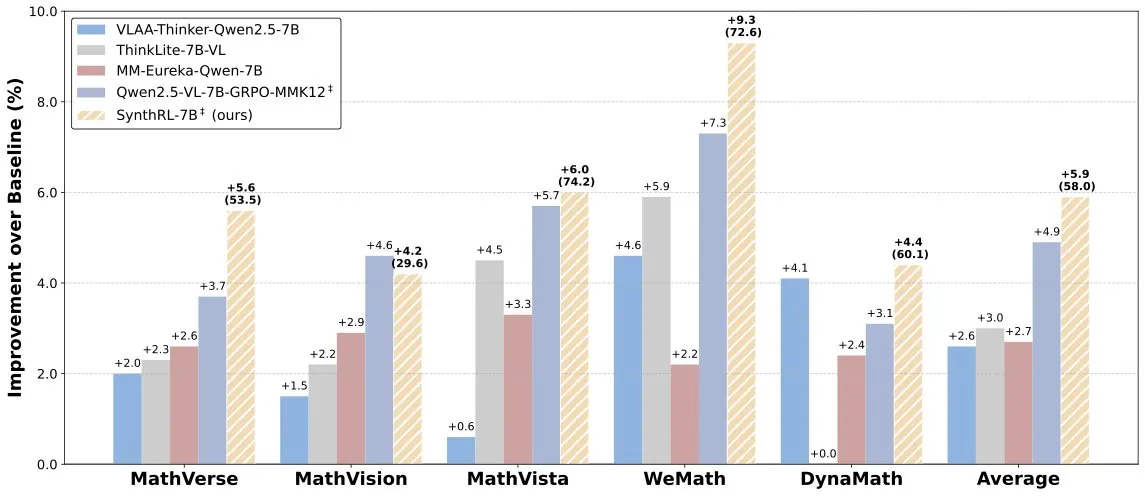
SynthRL modeli yayınlandı: Doğrulanabilir veri sentezi yoluyla ölçeklenebilir görsel muhakeme: Hugging Face’te, ölçeklenebilir görsel muhakeme yeteneğine odaklanan SynthRL modeli yayınlandı. Temel teknolojisi, doğrulanabilir veri sentezi yöntemleriyle daha zorlu görsel muhakeme görevi varyantları üretirken orijinal cevapların doğruluğunu korumaktır. Bu, modelin karmaşık görsel senaryolardaki anlama ve muhakeme seviyesini yükseltmeye yardımcı olur. (Kaynak: _akhaliq)
DeepSeek-R1 iyi performans gösterse de ChatGPT’nin ürün avantajı hala sağlam: VentureBeat, DeepSeek-R1 gibi yeni ortaya çıkan modellerin bazı açılardan mükemmel performans göstermesine rağmen, ChatGPT’nin ilk hamle avantajı, geniş kullanıcı tabanı, olgun ürün ekosistemi ve sürekli iterasyon yeteneği sayesinde ürün düzeyindeki lider konumunun kısa vadede aşılamayacağını belirtiyor. Yapay zeka yarışı sadece teknik parametrelerin bir karşılaştırması değil, aynı zamanda ürün deneyimi, ekosistem oluşturma ve iş modelinin kapsamlı bir mücadelesidir. (Kaynak: Ronald_vanLoon)

Qwen ekibi Qwen3-coder’ın geliştirilmekte olduğunu doğruladı: Qwen ekibinden Junyang Lin, Qwen3 serisinin kodlama yetenekleri geliştirilmiş versiyonu olan Qwen3-coder üzerinde çalıştıklarını doğruladı. Belirli bir zaman çizelgesi açıklanmamış olsa da, Qwen2.5’in yayınlanma döngüsüne bakıldığında, birkaç hafta içinde piyasaya sürülmesi bekleniyor. Topluluk, bu modelin kod üretimi, otonom/ajan iş akışı entegrasyonu alanlarında çığır açmasını ve çeşitli programlama dillerine iyi destek vermeye devam etmesini bekliyor. (Kaynak: Reddit r/LocalLLaMA)

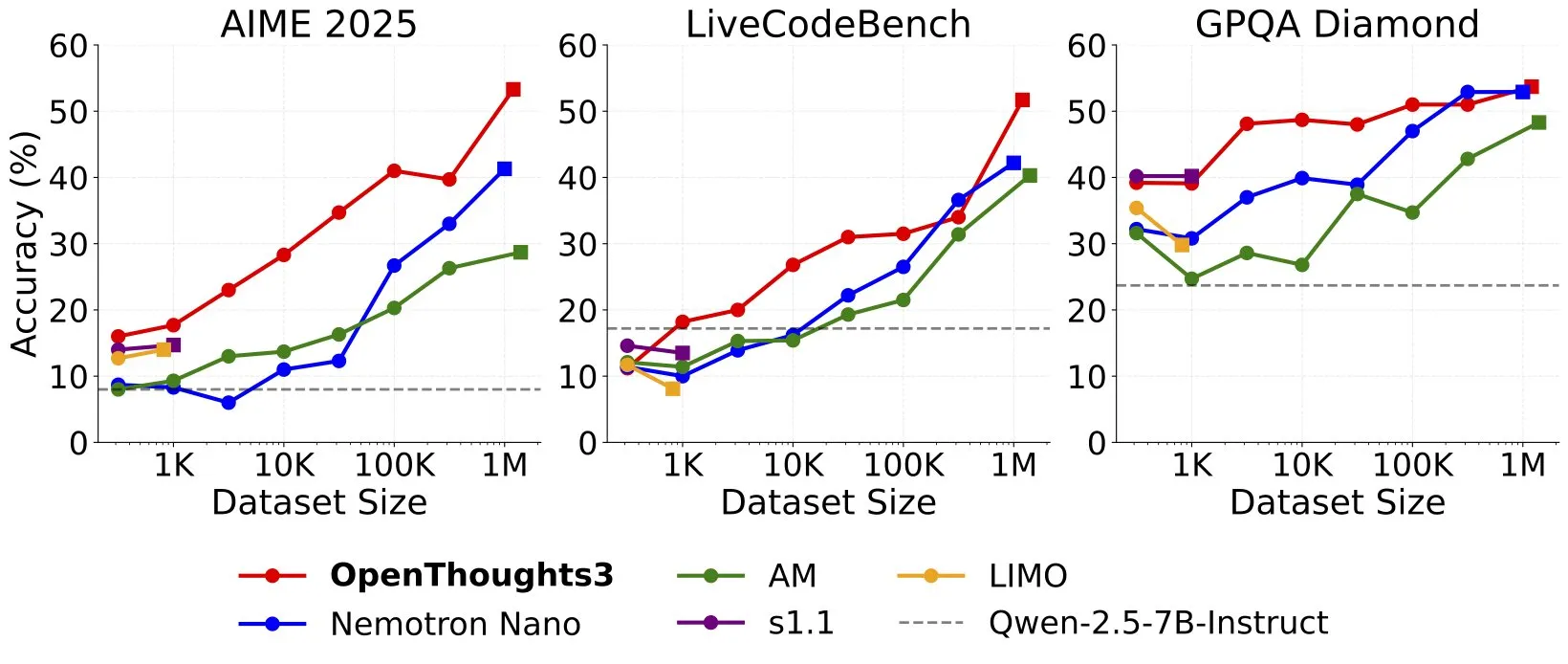
OpenThinker3-7B yayınlandı, SOTA açık kaynak veri 7B muhakeme modeli olduğu iddia ediliyor: Ryan Marten, açık verilerle eğitilmiş mevcut en gelişmiş 7B parametreli muhakeme modeli olduğunu iddia ettiği OpenThinker3-7B modelini duyurdu. İddiaya göre bu model, kod, bilim ve matematik değerlendirmelerinde DeepSeek-R1-Distill-Qwen-7B’den ortalama %33 daha yüksek performans gösteriyor. Aynı zamanda eğitim veri seti OpenThoughts3-1.2M de yayınlandı. (Kaynak: menhguin)
🧰 Araçlar
TensorZero: Açık kaynaklı LLMOps çerçevesi, LLM uygulama geliştirme ve dağıtımını optimize eder: TensorZero, üretim verilerini geri bildirim döngüleri aracılığıyla daha akıllı, daha hızlı ve daha ekonomik modellere dönüştürmeyi amaçlayan açık kaynaklı bir LLM uygulama optimizasyon çerçevesidir. LLM ağ geçidi (birden fazla model sağlayıcısını destekler), gözlemlenebilirlik, optimizasyon (istemler, ince ayar, RL), değerlendirme ve deney (A/B testi) gibi işlevleri entegre eder ve düşük gecikme süresi, yüksek verim ve GitOps’u destekler. Bu araç Rust ile yazılmıştır ve performans ile endüstriyel düzeyde uygulama gereksinimlerini vurgular. (Kaynak: GitHub Trending)

LangChain, SambaNova, Qdrant ve LangGraph’ı birleştiren yüksek performanslı RAG sistemini tanıttı: LangChain, yüksek performanslı bir geri getirme destekli üretim (RAG) uygulama çözümünü tanıttı. Bu çözüm, SambaNova’nın DeepSeek-R1 modelini, Qdrant’ın ikili niceleme teknolojisini ve LangGraph’ı birleştirerek 32 kat bellek azaltımı sağlayarak büyük ölçekli belgeleri verimli bir şekilde işleyebiliyor. Bu, daha ekonomik ve daha hızlı RAG uygulamaları oluşturmak için yeni olanaklar sunuyor. (Kaynak: hwchase17, qdrant_engine)
Google’ın tek tıkla eğitici video oluşturma uygulaması Sparkify, yüksek kaliteli örnekler sergiliyor: Google’ın tek tıkla eğitici videolar oluşturabilen Sparkify uygulaması, sergilediği örneklerin kalitesiyle dikkat çekiyor. Video içeriğinin genel tutarlılığı iyi, seslendirme doğal ve hatta bölünmüş ekran gösterimi gibi karmaşık efektleri bile gerçekleştirebiliyor, bu da yapay zekanın otomatik video içerik oluşturma alanındaki potansiyelini gösteriyor. (Kaynak: op7418)
Hugging Face ilk MCP sunucusunu kullanıma sundu, sohbet botu işlevlerini genişletiyor: Hugging Face, kullanıcıların sohbet kutusuna yapıştırarak kullanabileceği ilk MCP (Modular Chat Processor) sunucusunu (hf.co/mcp) yayınladı. MCP sunucusu, modüler işleme birimleri aracılığıyla daha zengin etkileşim deneyimleri sunarak sohbet botlarının işlevlerini geliştirmeyi amaçlıyor. Topluluk ayrıca Agentset MCP, GitHub MCP gibi diğer faydalı MCP sunucularının bir listesini de derledi. (Kaynak: TheTuringPost)
Chatterbox TTS’in etkisi ElevenLabs ile karşılaştırılabilir düzeyde, gptme’ye entegre edildi: TTS (metinden sese) aracı Chatterbox, mükemmel ses sentezi etkisiyle dikkat çekiyor; kullanıcı geri bildirimlerine göre etkisi ünlü ElevenLabs ile eşdeğer ve Kokoro’dan daha iyi. Chatterbox, referans örnekler aracılığıyla sesi özelleştirmeyi destekliyor ve şimdi gptme’nin TTS arka ucu olarak eklenerek kullanıcılara yüksek kaliteli ses çıkış seçenekleri sunuyor. (Kaynak: teortaxesTex, _akhaliq)
E-Library-Agent: Yerel kitaplar/belgeler için akıllı arama ve soru-cevap sistemi: E-Library-Agent, kişisel kitap veya makale koleksiyonlarını çıkarabilen, dizinleyebilen ve sorgulayabilen, kendi kendine barındırılan bir yapay zeka ajanıdır. Bu proje, ingest-anything’e dayanır ve LlamaIndex, Qdrant ve Linkup platformları tarafından desteklenir; yerel materyal çıkarma, bağlama duyarlı soru-cevap ve tek bir arayüz üzerinden ağ keşfi işlevlerini gerçekleştirerek kullanıcıların kişisel bilgi tabanlarını yönetmelerini ve kullanmalarını kolaylaştırır. (Kaynak: qdrant_engine)
Claude Code, güçlü kodlama yardım yetenekleri nedeniyle geliştiricilerden yüksek not alıyor: Reddit topluluğu kullanıcıları, özellikle oyun geliştirme (Godot C# projeleri gibi) gibi alanlarda yazılım geliştirmek için Anthropic’in Claude Code’unu kullanma konusundaki olumlu deneyimlerini paylaştı. Kullanıcılar, karmaşık sorunları çözme yeteneğinin diğer yapay zeka kodlama yardımcılarından (GitHub Copilot gibi) çok daha üstün olduğunu, bağlamı anlayabildiğini ve etkili kod üretebildiğini övdü; aylık 100 dolarlık ücretin bile buna değer olduğu düşünülüyor. Geliştiriciler, deneyimli programcıların Claude Code ile birleştiğinde son derece üretken olacağına inanıyor. (Kaynak: Reddit r/ClaudeAI)
ChatterUI yerel görsel model desteğini uyguluyor, ancak Android’de işlem yavaş: LLM sohbet istemcisi ChatterUI’nin ön sürümü, eklentiler ve yerel görsel modeller için destek ekledi (llama.rn aracılığıyla). Kullanıcılar, yerel uyumlu modeller için mmproj dosyalarını yükleyebilir veya görsel işlevleri destekleyen API’lere (Google AI Studio, OpenAI gibi) bağlanabilir. Ancak, llama.cpp’nin Android’de kararlı bir GPU arka ucuna sahip olmaması nedeniyle görüntü işleme hızı son derece yavaş (örneğin 512×512 görüntü 5 dakika sürüyor), iOS’ta performans nispeten daha iyi. (Kaynak: Reddit r/LocalLLaMA)
FLUX kontext, otomobil tanıtım görsellerinin arka planını değiştirmede mükemmel performans sergiliyor: Kullanıcı testleri, yapay zeka görüntü düzenleme aracı FLUX kontext’in otomobil tanıtım görsellerinin arka planını değiştirmede önemli ölçüde etkili olduğunu ortaya koydu. Örneğin, Xiaomi SU7’nin resmi resimlerinin arka planını değiştirmek (gün batımı kumsalı, yarış pisti gibi), araç yalnızca arka planı doğal bir şekilde birleştirmekle kalmıyor, aynı zamanda hareket halindeki araçlara akıllıca hareket bulanıklığı efekti ekleyerek görüntünün gerçekçiliğini ve görsel etkisini artırıyor. (Kaynak: op7418)

📚 Öğrenme Kaynakları
fastcore’un yeni özelliği flexicache: esnek önbellekleme dekoratörü: Jeremy Howard, fastcore kütüphanesindeki pratik bir yeni özellik olan flexicache‘i tanıttı. Bu, ‘mtime’ (dosya değişiklik zamanına dayalı) ve ‘time’ (zaman damgasına dayalı) olmak üzere iki yerleşik önbellekleme stratejisine sahip son derece esnek bir önbellekleme dekoratörüdür ve kullanıcıların az miktarda kodla yeni önbellekleme stratejileri özelleştirmesine olanak tanır. Bu özellik, Daniel Roy Greenfeld tarafından ayrıntılı olarak açıklanan bir makalede tanıtılmıştır ve kod yürütme verimliliğini artırmaya yardımcı olur. (Kaynak: jeremyphoward)
Transformer model eğitimi için MuP ve Muon’un birleştirilme potansiyeli tartışılıyor: Jingyuan Liu, Jeremy Bernstein’ın Muon ve spektral koşulları türetme üzerine yaptığı çalışmaları derinlemesine inceledi ve özellikle MuP (Maximal Update Parametrization) ve Muon’un (bir optimize edici) nasıl birlikte çalıştığına dair zarif türetme sürecine hayranlığını dile getirdi. Türetmeden yola çıkarak, MuP tabanlı model eğitimi için bir optimize edici olarak Muon kullanmanın doğal bir seçim olduğunu düşünüyor ve bunun Moonshot’ın Moonlight çalışmasındaki AdamW’nin hiperparametrelerinden Muon’a güncelleme RMS’sini eşleştirerek geçiş yapmaktan daha heyecan verici olabileceğini belirtiyor. Topluluk tartışmaları, MuP + Muon kombinasyonunun yıl sonuna kadar büyük teknoloji şirketleri tarafından ölçeklendirilerek uygulanabileceğini öne sürüyor. (Kaynak: jeremyphoward)

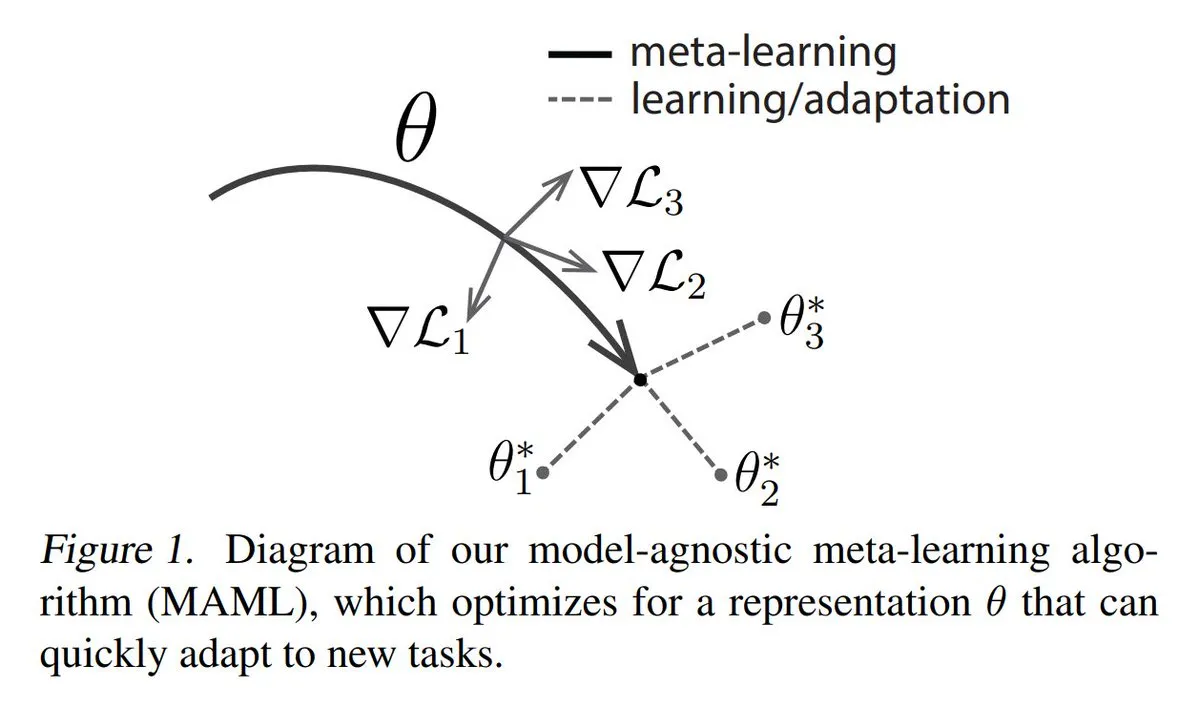
Meta-öğrenmenin (Meta-learning) üç ana yöntemi analiz ediliyor: Meta-öğrenme, yalnızca az sayıda örnekle bile modellerin yeni görevleri hızla öğrenmesini sağlamayı amaçlar. Yaygın yöntemler şunlardır: 1. Optimizasyon tabanlı/gradyan tabanlı: Az sayıda gradyan adımıyla görev üzerinde verimli bir şekilde ince ayar yapabilen model parametrelerini bulmak. 2. Metrik tabanlı: Modelin yeni ve eski örnekler arasındaki benzerliği daha iyi ölçmesine yardımcı olarak ilgili örnekleri etkili bir şekilde gruplandırmak. 3. Model tabanlı: Tüm model, yerleşik belleği veya dinamik mekanizmaları kullanarak hızla uyum sağlayacak şekilde tasarlanmıştır. TuringPost, temelden modern meta-öğrenme yöntemlerine kadar ayrıntılı bir açıklama sunmaktadır. (Kaynak: TheTuringPost)
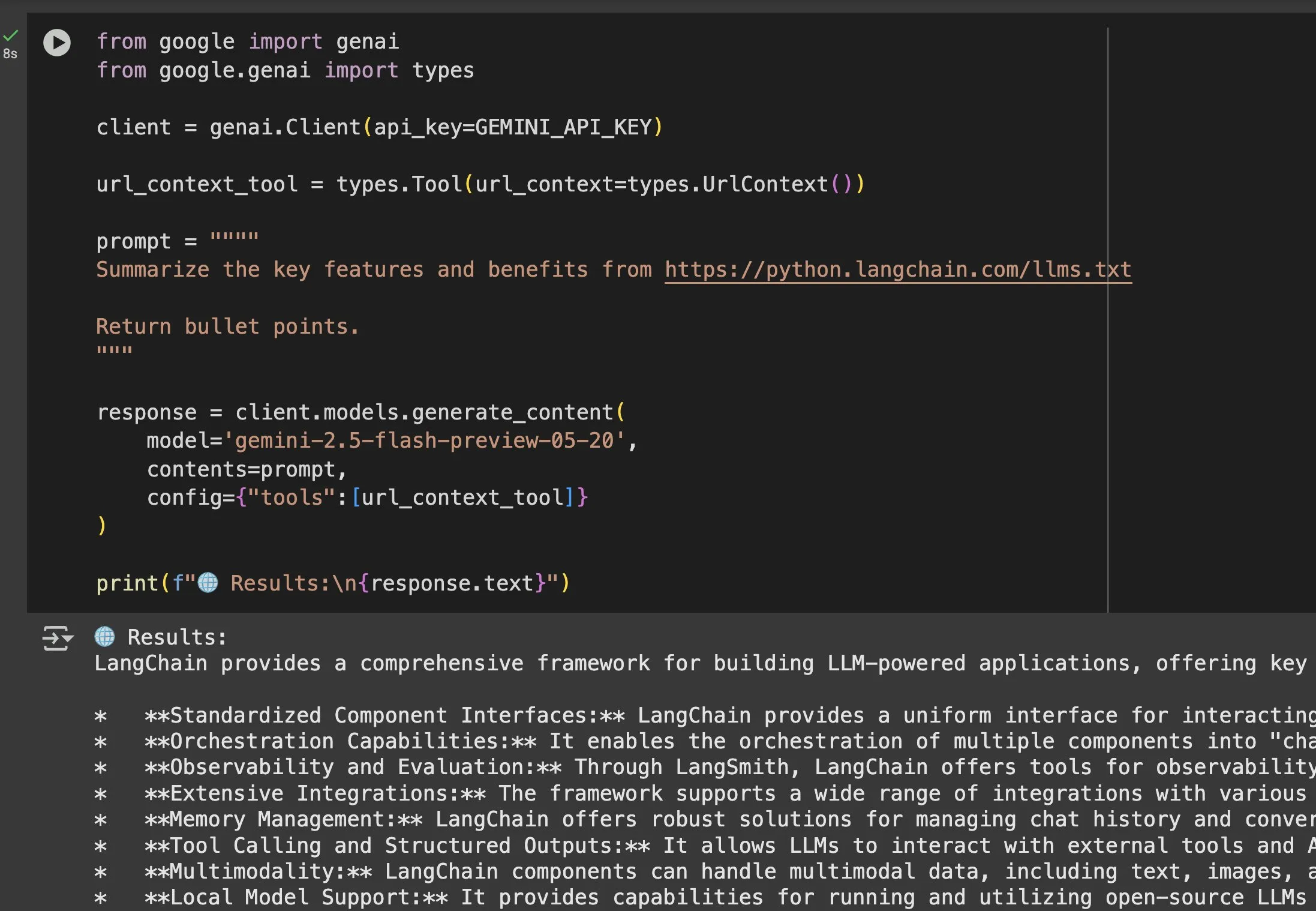
llms.txt dosyasının Gemini gibi modellerdeki uygulama değeri öne çıkıyor: Jeremy Phoward, llms.txt dosyasının pratikliğini vurguladı. Örneğin, Gemini artık URL’lerdeki içeriği anlayabiliyor; yalnızca isteme URL eklemek ve URL bağlam aracını yapılandırmak yeterli. Bu, istemcilerin (Gemini gibi) llms.txt uç noktasını okuyarak ihtiyaç duydukları bilgilerin nerede saklandığını tam olarak bilebileceği anlamına geliyor, bu da bilgilerin programatik olarak elde edilmesini ve kullanılmasını büyük ölçüde kolaylaştırıyor. (Kaynak: jeremyphoward)
EleutherAI, 8TB açık lisanslı metin veri kümesi Common Pile v0.1’i yayınladı: EleutherAI, 8TB açık lisanslı ve kamu malı metin içeren büyük bir veri kümesi olan Common Pile v0.1’i duyurdu. Bu veri kümesine dayanarak 7B parametreli dil modelleri eğittiler (sırasıyla 1T ve 2T token kullanarak) ve performansları LLaMA 1 ve LLaMA 2 gibi benzer modellerle karşılaştırılabilir düzeyde. Bu, tamamen uyumlu verilerle yüksek performanslı dil modelleri eğitme araştırması için değerli kaynaklar ve ampirik kanıtlar sunmaktadır. (Kaynak: clefourrier)

SelfCheckGPT: Referanssız bir LLM halüsinasyon tespit yöntemi: Bir blog yazısı, dil modellerindeki halüsinasyonları tespit etmek için LLM-as-a-judge (LLM’yi değerlendirici olarak kullanma) alternatif olarak SelfCheckGPT’yi inceliyor. Bu, referans metin gerektirmeyen, sıfır kaynaklı bir tespit yöntemidir ve LLM çıktılarının gerçekliğini değerlendirmek ve geliştirmek için yeni bir yaklaşım sunmaktadır. (Kaynak: dl_weekly)
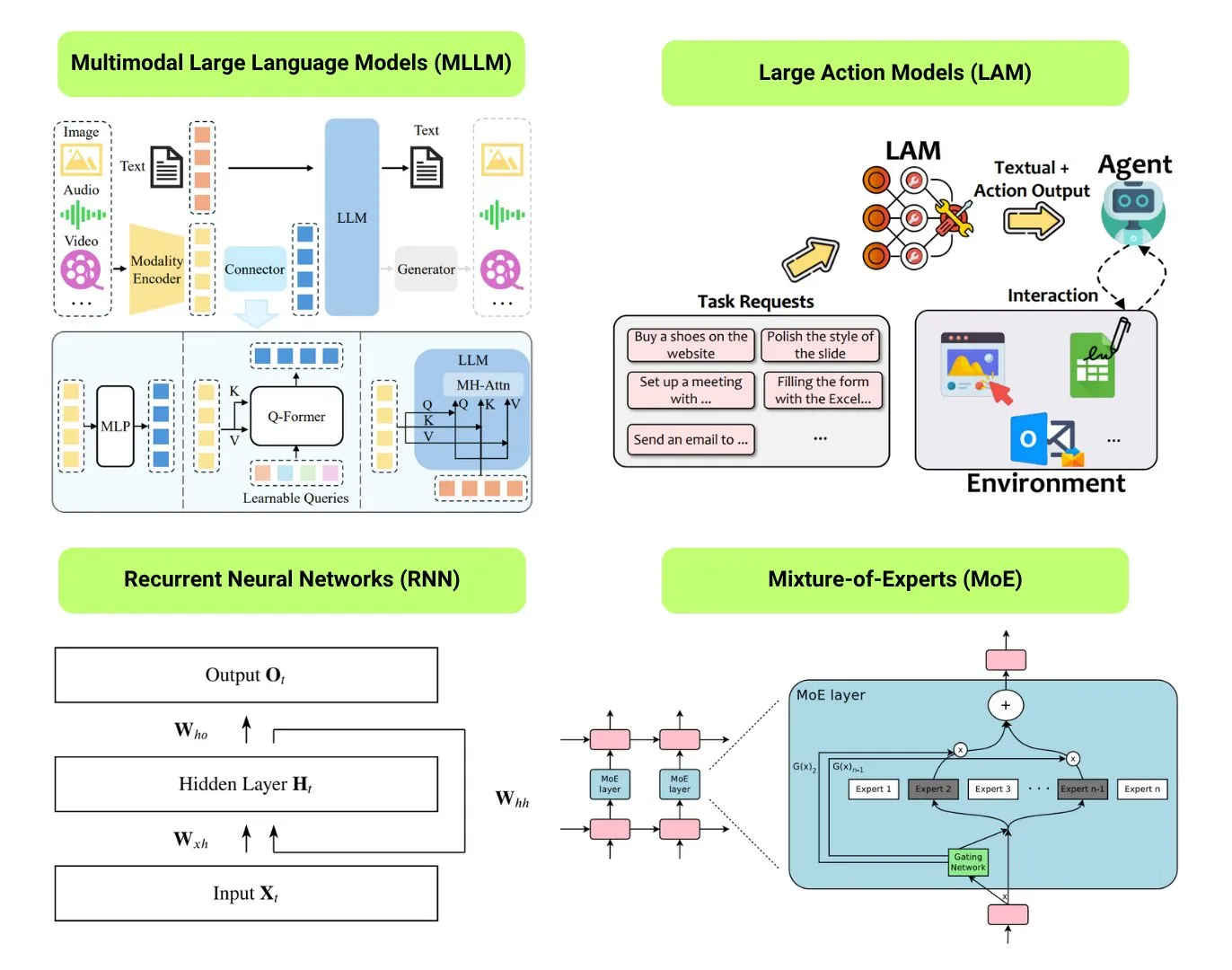
12 temel yapay zeka model türü derlendi: The Turing Post, LLM (Büyük Dil Modeli), SLM (Küçük Dil Modeli), VLM (Görsel Dil Modeli), MLLM (Çok Modlu Büyük Dil Modeli), LAM (Büyük Davranış Modeli), LRM (Büyük Muhakeme Modeli), MoE (Uzmanlar Karışımı Modeli), SSM (Durum Uzay Modeli), RNN (Tekrarlayan Sinir Ağı), CNN (Evrişimli Sinir Ağı), SAM (Her Şeyi Segmentlere Ayırma Modeli) ve LNN (Mantıksal Sinir Ağı) dahil olmak üzere 12 temel yapay zeka model türünü derledi. İlgili kaynaklar, bu model türlerinin açıklamalarını ve faydalı bağlantıları sunmaktadır. (Kaynak: TheTuringPost)
GitHub Popüler: Kubernetes The Hard Way Eğitimi: Kelsey Hightower’ın “Kubernetes The Hard Way” eğitimi GitHub’da ilgi görmeye devam ediyor. Bu eğitim, kullanıcıların otomatik komut dosyalarına güvenmek yerine Kubernetes kümesini manuel olarak adım adım kurarak temel bileşenlerini ve çalışma prensiplerini derinlemesine anlamalarına yardımcı olmayı amaçlamaktadır. Eğitim, Kubernetes’in temel bilgilerini öğrenmek isteyenlere yöneliktir ve ortam hazırlığından küme temizliğine kadar tüm süreci kapsamaktadır. (Kaynak: GitHub Trending)
GitHub Popüler: Ücretsiz GPT’ler ve İstemler Listesi: friuns2/BlackFriday-GPTs-Prompts deposu GitHub’da popülerleşiyor; bir dizi ücretsiz GPT modelini ve yüksek kaliteli istemleri topluyor ve düzenliyor, kullanıcılar Plus aboneliği olmadan kullanabilirler. Bu kaynaklar programlama, pazarlama, akademik araştırma, iş arama, oyun, yaratıcılık gibi birçok alanı kapsıyor ve bazı “Jailbreaks” tekniklerini içeriyor, GPT kullanıcılarına zengin, kullanıma hazır araçlar ve ilham kaynağı sunuyor. (Kaynak: GitHub Trending)

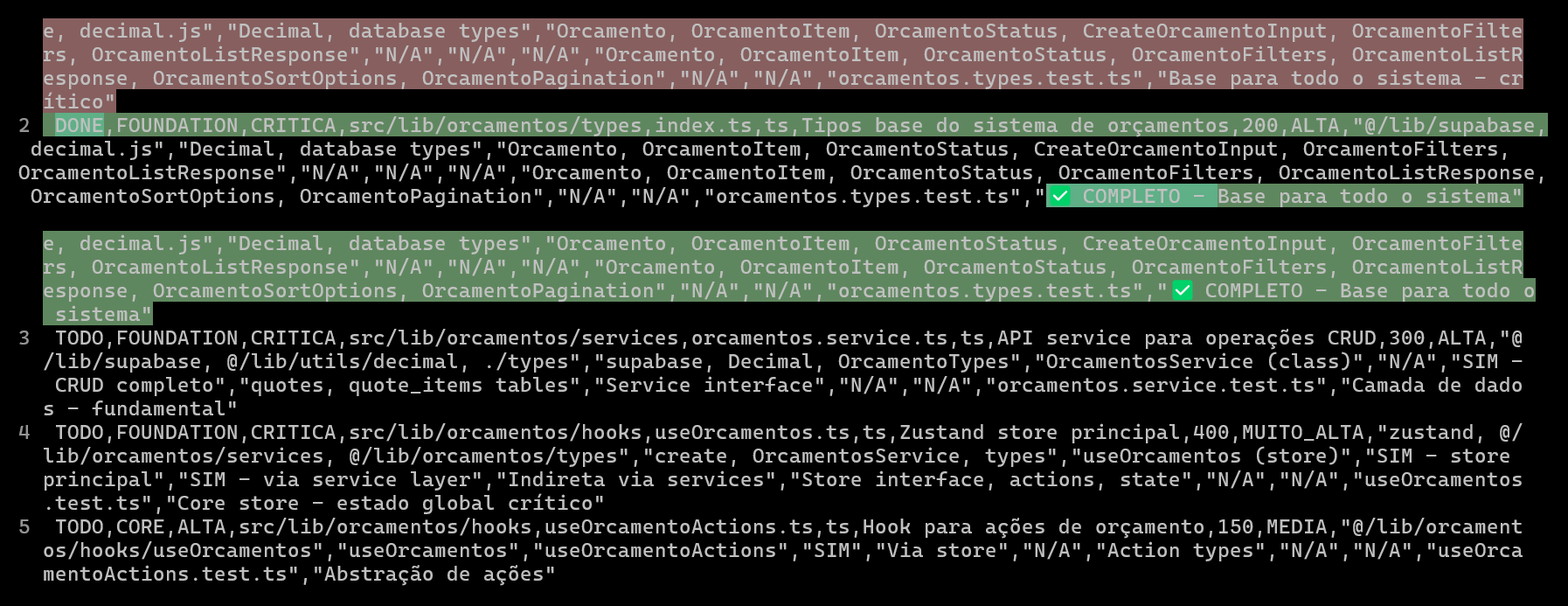
Yapay zeka kodlama projelerini CSV ile planlamak ve izlemek, kod kalitesini ve verimliliğini artırır: Bir geliştirici, bir ERP sistemi geliştirirken Claude Code kullanarak, her dosyanın kodlama ilerlemesini planlamak ve izlemek için ayrıntılı CSV dosyaları oluşturarak karmaşık işlevlerin geliştirme verimliliğini ve kod kalitesini önemli ölçüde artırdığını paylaştı. CSV dosyası durum, dosya adı, öncelik, kod satır sayısı, karmaşıklık, bağımlılıklar, işlev açıklaması, kullanılan Hook’lar, içe/dışa aktarılan modüller ve önemli “ilerleme notları” içeriyordu. Bu yöntem, yapay zekanın kodu daha odaklı bir şekilde oluşturmasını sağlıyor ve geliştiricinin projenin gerçek ilerlemesi ile orijinal plan arasındaki farkı net bir şekilde kavramasına olanak tanıyor. (Kaynak: Reddit r/ClaudeAI)
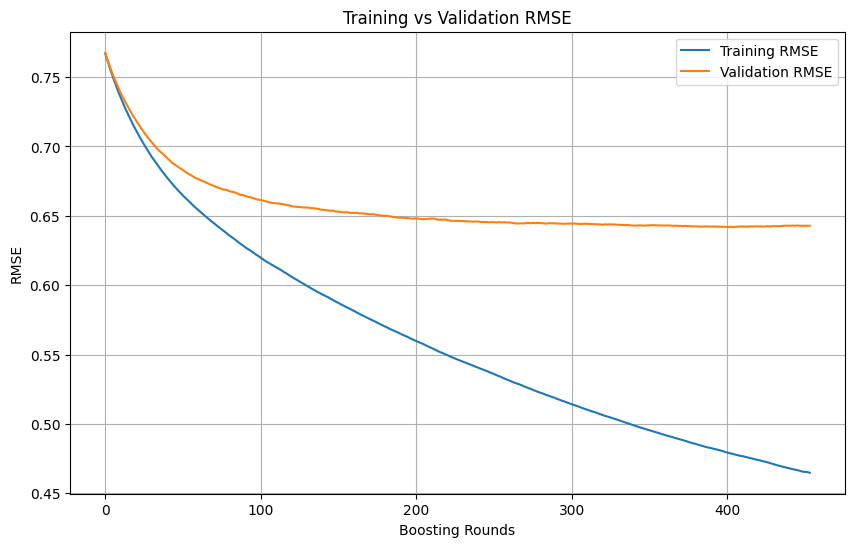
Makine öğrenimi eğitiminde aşırı uyumun belirlenmesi ve durdurma zamanlaması: Makine öğrenimi model eğitimi sürecinde, eğitim kaybı hızla düşmeye devam ederken doğrulama kaybı yavaşça düşer, hatta durur veya yükselirse, bu genellikle modelin aşırı uyum (overfitting) yaşadığını gösterir. Prensip olarak, doğrulama kaybı hala düşüyorsa eğitime devam edilebilir. Önemli olan, doğrulama setinin eğitim setinden bağımsız olmasını ve görevin gerçek veri dağılımını temsil etmesini sağlamaktır. Doğrulama kaybı düşmeyi durdurur veya yükselmeye başlarsa, eğitimi erken durdurmayı veya modelin genelleme yeteneğini iyileştirmek için düzenlileştirme gibi yöntemler uygulamayı düşünmek gerekir. (Kaynak: Reddit r/MachineLearning)
🌟 Topluluk
AI Engineer World’s Fair 2025, RL+Reasoning, Eval gibi konulara odaklanıyor: AI Engineer World’s Fair 2025 konferansının temaları, pekiştirmeli öğrenme + muhakeme (RL+Reasoning), değerlendirme (Eval), yazılım mühendisliği ajanları (SWE-Agent), yapay zeka mimarları ve ajan altyapısı gibi ileri düzey konuları kapsıyor. Katılımcılar, konferansın canlılık ve yenilikçi düşüncelerle dolu olduğunu, birçok kişinin yeni şeyler denemeye cesaret ettiğini, sürekli olarak kendilerini yeniden şekillendirdiğini ve yapay zeka alanına girdiğini belirtti. Konferans ayrıca yapay zeka mühendisleri için bir iletişim ve öğrenme platformu sağladı. (Kaynak: swyx, hwchase17, charles_irl, swyx)

Sam Altman’ın ideal yapay zekası: Küçük model + üstün muhakeme + devasa bağlam + evrensel araçlar: Sam Altman, idealindeki yapay zeka biçimini şöyle tanımladı: insanüstü muhakeme yeteneğine sahip, son derece küçük hacimli bir model, trilyonlarca seviyesinde bağlam bilgisine erişebilen ve akla gelebilecek her türlü aracı çağırabilen bir model. Bu görüş tartışmalara yol açtı; bazıları bunun mevcut büyük modellerin bilgi depolamaya dayalı durumuyla farklı olduğunu düşündü ve küçük modellerin devasa bağlamlarda bilgiyi ayrıştırma ve karmaşık muhakeme yapma fizibilitesini sorguladı, bilgi ve düşünme yeteneğinin verimli bir şekilde ayrılamayacağını savundu. (Kaynak: teortaxesTex)
Kodlama ajanları kod yeniden yapılandırma arzusunu tetikliyor, yapay zeka destekli programlamanın zorlukları ve fırsatları: Geliştiriciler, kodlama ajanlarının ortaya çıkmasının başkalarının kodunu yeniden yapılandırma “cazibesini” büyük ölçüde artırdığını ve yeni tehlikeler getirdiğini belirtiyor. Bir geliştirici, yaklaşık 10 dakikalık manuel çalışma gerektiren bir programlama görevini tamamlamak için yapay zeka yardımını kullanma deneyimini paylaştı; yapay zeka hızla çalışan kod üretebilse de, deneyimli bir programcının organizasyon ve stil düzeyine ulaşmak için hala önemli miktarda manuel yönlendirme ve yeniden yapılandırma gerekiyor. Bu, yapay zeka destekli programlamanın başlangıç/orta seviye kodu ileri seviye kod kalitesine yükseltme konusundaki zorluklarını vurguluyor. (Kaynak: finbarrtimbers, mitchellh)
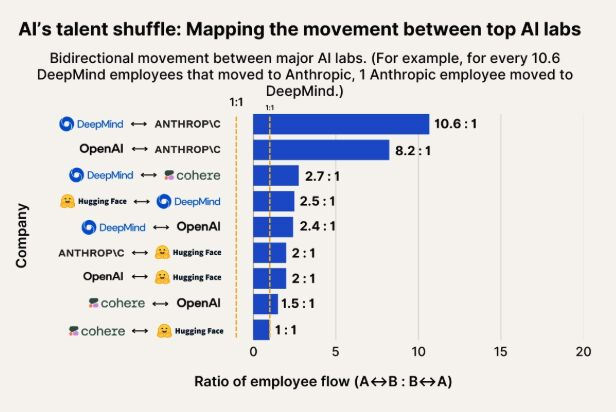
Yapay zeka yetenek akışı gözlemi: Anthropic, Google DeepMind ve OpenAI yetenekleri için önemli bir varış noktası haline geliyor: Yapay zeka yetenek akışını gösteren bir grafik, Anthropic’in Google DeepMind ve OpenAI’den gelen araştırmacıları çeken önemli bir şirket haline geldiğini gösteriyor. Topluluk bunun bilişsel algıyla uyumlu olduğunu belirtti ve bazı kullanıcılar Anthropic’in bazı “gizli silahları” veya benzersiz araştırma yönleri olabileceğini ve en iyi yetenekleri cezbettiğini tahmin etti. (Kaynak: bookwormengr, TheZachMueller)
İnsansı robotların yaygınlaşması güven ve toplumsal kabul zorluklarıyla karşı karşıya: Teknoloji yorumcusu Faruk Guney, ilk insansı robot dalgasının büyük bir güven açığı nedeniyle başarısız olabileceğini öngörüyor. Teknolojinin sürekli ilerlemesine rağmen, toplumun bu “kara kutu zekalarını” evlere kabul etmeye, refakat, ev işleri ve hatta çocuk bakımı gibi görevleri yerine getirmelerine henüz hazır olmadığını düşünüyor. Robotların şeffaf olmayan kararları, potansiyel gözetim riskleri ve insanlardan tamamen farklı “sevimli” görünümleri (Wall-E kadar değil), yaygın uygulamalarının önünde engeller olabilir. Ancak yeterli toplumsal tartışma, düzenleme, denetim ve güvenin yeniden inşasından sonra insansı robotların gerçek anlamda yaygınlaşması mümkün olabilir. (Kaynak: farguney, farguney)
Yapay zeka kişiselleştirilmiş tasarım: “Kusurlu” olan “mükemmel” olandan daha iyi: Bir geliştirici, yapay zeka ses platformunda 50 yapay zeka kişiselleştirilmiş imaj oluşturma deneyimini paylaştı. Sonuç olarak, aşırı tasarlanmış arka plan hikayeleri, mutlak mantıksal tutarlılık ve aşırı tekil kişilik özelliklerinin yapay zekayı mekanik ve gerçek dışı gösterdiği sonucuna varıldı. Başarılı yapay zeka kişilik şekillendirmesi, “3 katmanlı kişilik yığını” (temel özellikler + niteleyici özellikler + tuhaflıklar), uygun “kusurlu kalıplar” (ara sıra dil sürçmeleri, kendini düzeltme gibi) ve yerinde arka plan bilgileri (300-500 kelime, olumlu ve zorlu deneyimler, belirli tutkular ve uzmanlıkla ilgili kırılgan noktalar içeren) ile sağlanır. Bu “kusurlu” detaylar, yapay zekayı daha insancıl ve bağlantı kurulabilir hale getirir. (Kaynak: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
LLM’lerin “algı” ve “AGI” yeteneğine sahip olup olmadığı tartışması: Heyecan ve şüphe bir arada: Topluluk genel olarak LLM’lerin muazzam potansiyeli konusunda heyecanlı, bunların tarihi öneme sahip büyük icatlarla karşılaştırılabileceğini ve her şeyi değiştireceğini düşünüyor. Ancak, LLM’lerin “algı yeteneğine” sahip olup olmadığı, “haklara” ihtiyaç duyup duymadığı ve “insanlığı sona erdirip erdirmeyeceği” veya “AGI” getirip getirmeyeceği gibi iddialar konusunda birçok kişi hala şüpheci. LLM yeteneklerini ve araştırma sonuçlarını yorumlarken ayrıntılı ve dikkatli olunması gerektiği vurgulanıyor. (Kaynak: fabianstelzer)
💡 Diğer
Çoklu robotun otonom yürüme işbirliği tartışılıyor: Sosyal medyada çoklu robotların otonom yürüme konusundaki işbirliği keşifleri hakkında tartışmalar ortaya çıktı. Bu, robot yol planlaması, görev dağıtımı, bilgi paylaşımı ve çarpışmadan kaçınma gibi karmaşık teknolojileri içeriyor ve robotik, RPA (Robotik Süreç Otomasyonu) ve makine öğrenimi alanlarında sürekli ilgi gören bir araştırma yönüdür. (Kaynak: Ronald_vanLoon)
ULMFiT hiperparametrelerini optimize etmek için rastgele ormanları kullanma teknikleri: Jeremy Howard, ULMFiT’i (bir transfer öğrenme yöntemi) optimize ederken kullandığı bir tekniği paylaştı: çok sayıda ablasyon deneyi çalıştırarak ve tüm hiperparametreleri ve sonuç verilerini rastgele orman modeline besleyerek model performansını en çok etkileyen hiperparametreleri bulmak. Bu yöntem Weights & Biases tarafından ürünlerine entegre edildi ve hiperparametre ayarlaması için yeni fikirler sundu. (Kaynak: jeremyphoward)

Figure şirketinin insansı robotu 60 dakikalık lojistik görev işleme yeteneğini sergiliyor: Figure şirketi, Helix sinir ağı tarafından yönlendirilen insansı robotunun lojistik senaryolarındaki çeşitli görevleri otonom olarak tamamladığını gösteren 60 dakikalık bir video yayınladı. Bu gösteri, robotlarının karmaşık gerçek ortamlarda uzun süreli istikrarlı çalışma yeteneğini ve otonom karar verme seviyesini kanıtlamayı amaçlıyor. (Kaynak: adcock_brett)