Anahtar Kelimeler:Wujie Serisi Büyük Modeller, RLHF Yeni Yöntemi, Claude Gov Serisi Modeller, Büyük Dil Modelleri, Çok Modlu Füzyon, Fiziksel AGI, AI Güvenliği, Somutlaştırılmış Zeka, Emu3 Yerel Çok Modlu Dünya Modeli, Jianwei Brainμ Beyin Bilimi Modeli, RoboBrain 2.0 Somutlaştırılmış Beyin, OpenComplex2 Tam Atom Mikroskobik Yaşam Modeli, Çatallanma Token Takviyeli Öğrenme
🔥 Odak Noktası
BAAI Konferansı, Fiziksel AGI ve çok modlu birleşime odaklanan “Wu Jie” serisi büyük modellerini duyurdu: 2025 BAAI Konferansı’nda Pekin Yapay Zeka Akademisi (BAAI), araştırma odağının “Wu Dao” dil modeli keşfinden daha geniş fiziksel dünya ve çok modlu birleşime kaydığını gösteren tamamen yeni “Wu Jie” serisi büyük modellerini tanıttı. Bu seri, yerel çok modlu dünya modeli Emu3, dünyanın ilk beyin bilimi çok modlu genel temel modeli “Jianwei Brainμ”, somutlaşmış beyin RoboBrain 2.0 ve tüm atomlu mikroskobik yaşam modeli OpenComplex2’yi içeriyor. Bu model serisinin piyasaya sürülmesi, AI’ın dijital dünyadan fiziksel dünyaya, makro anlayıştan mikro keşfe doğru evrimleşme eğilimini yansıtıyor ve AI’ın fiziksel dünyayı algılamasını, anlamasını ve onunla etkileşim kurmasını, pratik sorunları çözmesini ve Fiziksel AGI’nin gelişimini desteklemesini amaçlıyor. Konferans ayrıca Bengio dahil 4 Turing Ödülü sahibini ve çok sayıda endüstri liderini bir araya getirerek AI güvenliği, takviyeli öğrenme, ajanlar, somutlaşmış zeka gibi öncü konuları tartıştı (Kaynak: 量子位)

Qwen ve Tsinghua LeapLab, “80/20 kuralının ötesine geçen” yeni bir RLHF yöntemi önerdi: Qwen ekibi ve Tsinghua Üniversitesi LeapLab işbirliğiyle yapılan bir araştırma, takviyeli öğrenme (RLHF) yoluyla büyük modellerin çıkarım yeteneklerini geliştirirken, tüm tokenleri kullanarak eğitimle aynı veya hatta daha iyi sonuçlar elde etmek için yalnızca yaklaşık %20’lik yüksek entropili “forking tokens” (ayrışma tokenleri) üzerine odaklanmanın yeterli olduğunu buldu. Bu yüksek entropili tokenler esas olarak mantıksal bağlantı işlevini üstlenir ve çıkarım sürecinde kilit yönlendirici bir rol oynar. Bu bulguya dayanarak, Qwen3-32B, AIME’24 ve AIME’25 matematik yarışması benchmarklarında 600B parametrenin altındaki modeller için sıfırdan eğitimde SOTA sonuçları elde etti. Bu araştırma yalnızca eğitim verimliliğini artırmakla kalmadı, aynı zamanda yüksek entropili tokenlerin modelin genelleme yeteneği için önemini ortaya koydu ve RL ile SFT arasındaki farkı ve LLM RL’nin özelliklerini anlamak için yeni bir bakış açısı sundu (Kaynak: 量子位)

Anthropic, ABD ulusal güvenlik müşterilerine özel Claude Gov serisi modellerini piyasaya sürdü: Anthropic şirketi, ABD ulusal güvenlik müşterileri için özel olarak tasarlanmış Claude Gov serisi modellerini yayınladı. Bu modeller halihazırda ABD’nin en üst düzey ulusal güvenlik kurumlarında konuşlandırılmış olup, erişim izinleri gizli bilgileri işleyen operatörlerle kesinlikle sınırlandırılmıştır. Bu hamle, özellikle Anthropic’in daha önceki araştırmalarında modellerin “hayatta kalma davranışı” ve “felaketle sonuçlanabilecek kötüye kullanım” riski sergilediğini belgelemesi göz önüne alındığında, AI etiği ve potansiyel kötüye kullanım riskleri hakkında tartışmalara yol açtı. Anthropic, AI güvenlik araştırma şirketi olduğunu ve açıkları bularak yamalamayı amaçladığını iddia etse de, teknolojisini askeri ve ulusal güvenlik alanlarında uygulaması, AI’ın silahlandırılması ve kontrolden çıkma riskleri konusundaki kamuoyu endişelerini şüphesiz artırdı (Kaynak: AnthropicAI, Reddit r/ArtificialInteligence)

Yann LeCun, mevcut büyük dil modellerinin beş yıl içinde geçerliliğini yitireceğini öngördü: NYU profesörü ve Meta baş AI bilimcisi Yann LeCun, Newsweek’e verdiği röportajda mevcut büyük dil modellerinin (LLM) beş yıl içinde geçerliliğini yitireceğini belirtti. Mevcut AI sistemlerinin gerçek dünya anlayışından yoksun olmasının temel sınırlamaları olduğunu savundu. LeCun, gelecekteki daha akıllı AI sistemlerinin biçimlerini öngörerek, mevcut LLM mimarilerinin ötesine geçecek yeni nesil AI teknolojilerinin gelişim yönüne işaret etti; bu teknolojiler muhtemelen dünyanın içsel temsillerine ve nedensel çıkarım yeteneklerine daha fazla odaklanacaktır (Kaynak: ylecun)
🎯 Eğilimler
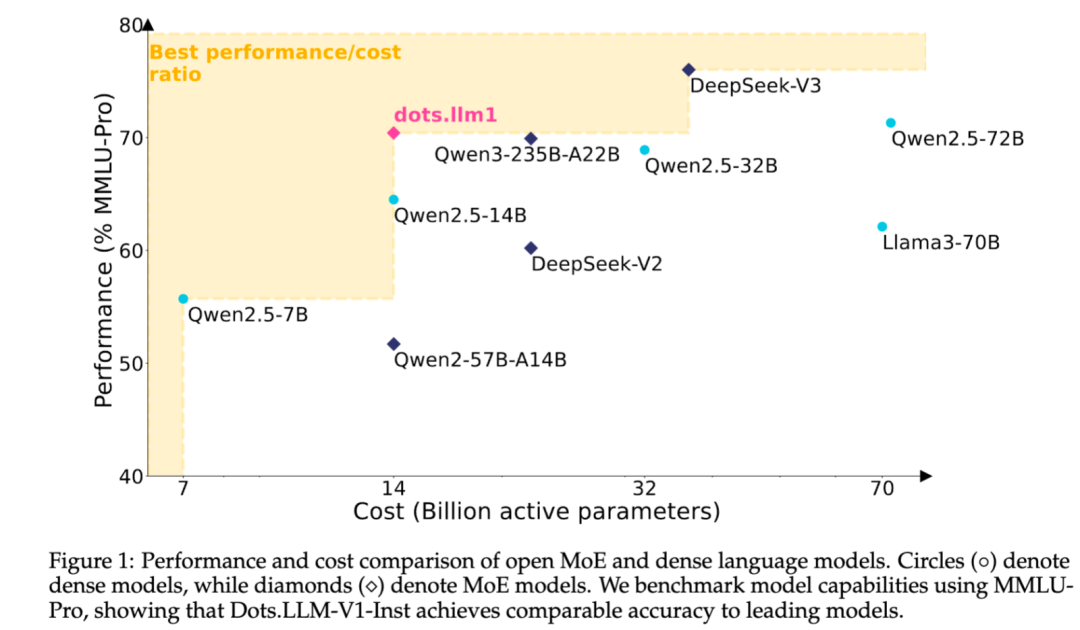
Xiaohongshu, kendi geliştirdiği MoE metin büyük modeli dots.llm1’i açık kaynak olarak yayınladı: Xiaohongshu hi lab ekibi, ilk kendi geliştirdiği metin büyük modeli dots.llm1’i açık kaynak olarak yayınladı. Bu model MoE mimarisini kullanıyor, toplam parametre sayısı 142B ve aktif parametre sayısı 14B. 14B parametrenin aktif olduğu durumda, model Çince ve İngilizce genel senaryolarda, matematik, kod ve hizalama görevlerinde mükemmel performans gösteriyor ve Qwen2.5-32B/72B-Instruct gibi modellerle rekabet edebiliyor. Xiaohongshu bu kez kapsamlı bir açık kaynak sunumu yaptı; yalnızca kullanıma hazır dots.llm1.inst modelini sağlamakla kalmadı, aynı zamanda birden fazla ön eğitim aşamasındaki checkpoint’leri ve uzun metin base modelini de açık kaynak olarak sundu ve topluluğun ikincil geliştirme ve araştırma yapmasını kolaylaştırmak için eğitim ayrıntılarını detaylı bir şekilde açıkladı. Bu model sentetik veri kullanmıyor ve yüksek kaliteli gerçek verilerin uygulanmasını vurguluyor (Kaynak: 36氪)
Anthropic Claude modelinin işlevleri, bağlam işleme ve entegrasyon yeteneklerini genişleterek sürekli olarak yükseltiliyor: Anthropic son zamanlarda Claude serisi modelleri için birçok önemli güncelleme yayınladı. Projects on Claude artık 10 kattan fazla içeriği işleyebiliyor ve dosyalar eşiği aştığında işlevsel bağlamı genişletmek için yeni bir erişim moduna geçiyor. Aynı zamanda, Pro planı kullanıcıları artık Claude’un web’de, Google Workspace’te ve MCP (Model Control Protocol) aracılığıyla bağlanan herhangi bir özel uygulama veya önceden oluşturulmuş hizmette (Zapier ve Asana gibi) arama yapmasına olanak tanıyan Research ve Integrations özelliklerini kullanabiliyor, böylece görev oluşturma, belgeleri güncelleme ve iş akışlarını tetikleme gibi araçlar arası işlemler gerçekleştirilebiliyor. Bu güncellemeler, Claude’un karmaşık görev işleme ve çok kaynaklı bilgi entegrasyonu yeteneklerini geliştirmeyi amaçlıyor (Kaynak: AnthropicAI, AnthropicAI)
Hugging Face, AI ajan ekosistemini güçlendirmek için MCP sunucusunu başlattı: Hugging Face, AI ajanlarının Hugging Face platformundaki modellere, veri kümelerine ve hatta Space’te barındırılan uygulamalara daha etkili bir şekilde erişmesini ve bunları kullanmasını sağlayan ilk MCP (Model Control Protocol) sunucusunu (hf.co/mcp) yayınladı. Bu girişim, internetin ajan dostu bir evrime doğru ilerlemesinde önemli bir adım olarak görülüyor ve AI ajanları için bir “uygulama mağazası” ekosistemi oluşturmayı amaçlıyor. MCP sunucusunun piyasaya sürülmesi, geliştiricilerin AI ajanlarının Hugging Face’in devasa kaynaklarıyla daha kolay etkileşim kurmasını sağlayarak AI ajan uygulamalarının geliştirilmesini ve yenilikçiliğini teşvik ediyor (Kaynak: TheTuringPost, karminski3)
OpenAI, ChatGPT ses modelini güncelleyerek doğallığı ve çeviri yeteneğini geliştirdi: OpenAI, ChatGPT’nin Advanced Voice özelliğini güncelleyerek konuşma deneyimini daha doğal ve akıcı hale getirdi. Bu güncelleme tüm ücretli kullanıcılara sunuldu. Aynı zamanda, ChatGPT’nin dil çevirisi yetenekleri de geliştirildi; kullanıcılar artık farklı diller arasında gerçek zamanlı çeviri yapması için doğrudan talimat verebiliyor. Bu iyileştirmeler, kullanıcıların ChatGPT ile sesli etkileşiminin rahatlığını ve pratikliğini artırmayı amaçlıyor (Kaynak: kevinweil, shuchaobi)
PyTorch, dağıtık Checkpoint güvenliğini ve rahatlığını artırmak için Safetensors’ı entegre etti: PyTorch, dağıtık Checkpoint özelliğinin artık Hugging Face’in Safetensors formatını desteklediğini duyurdu. Bu entegrasyon, farklı ekosistemler arasında model Checkpoint’lerini kaydetmeyi ve yüklemeyi daha güvenli ve kullanışlı hale getiriyor, özellikle de geçmişteki pickle formatının güvenlik risklerini çözüyor. Yeni API, fsspec yolları aracılığıyla Safetensors’ı okumaya ve yazmaya olanak tanıyor; torchtune, Checkpoint süreçlerini optimize ederek bu özelliği benimseyen ilk kütüphane oldu. Bu adım, son bir yılda AI güvenliği alanındaki önemli gelişmelerden biri olarak kabul ediliyor ve model paylaşımının ve dağıtımının güvenliğini artırmaya yardımcı oluyor (Kaynak: ClementDelangue, huggingface)

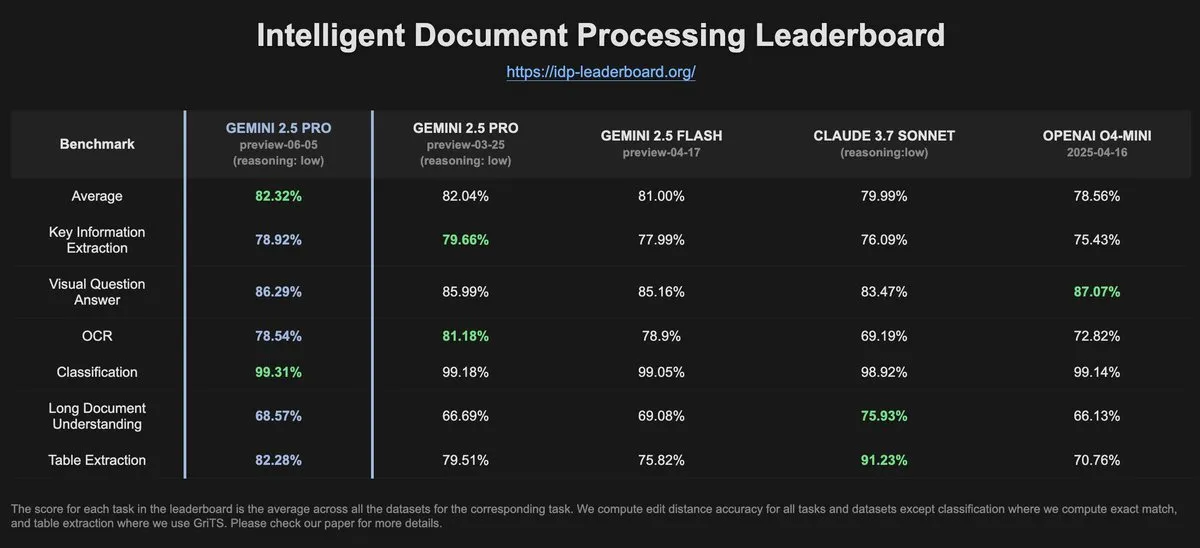
IDP-Leaderboard verileri, Gemini-2.5-pro-06-05’in OCR performansında önceki sürüme göre düşüş olduğunu gösteriyor: IDP-Leaderboard’un en son verilerine göre, yeni sürüm Gemini-2.5-pro-06-05’in OCR (Optik Karakter Tanıma) performansı 03-25 sürümüne kıyasla düşüş gösterdi. Buna rağmen, bu model belge işleme genel yeteneği (belge, elektronik tablo tanıma vb. dahil) açısından hala en güçlü performansı sergiliyor. IDP-Leaderboard, büyük modellerin belge zekası işleme alanındaki yeteneklerini değerlendirmeye odaklanan bir benchmark testidir (Kaynak: karminski3)
Apple araştırması LLM çıkarım sınırlamalarını ortaya koyuyor, gerçek “düşünme” olmayabilir: Apple araştırmacıları, mevcut LLM’lerin çıkarım görevlerindeki avantajlarını ve sınırlamalarını tartışan bir makale yayınladı ve bu modellerin belirli bir karmaşıklığın üzerindeki görevleri yerine getirirken performanslarının “çöktüğünü” belirtti. Araştırma, LLM’lerin “çıkarımının” insan anlamında gerçek düşünme ve anlamadan ziyade daha çok örüntü eşleştirme ve belleğe dayandığını ima ediyor. Bu görüş, Yann LeCun gibi uzmanların görüşleriyle örtüşüyor ve AGI gerçekleştirme yolları ve mevcut modellerin yetenek sınırları hakkında tartışmalara yol açıyor (Kaynak: omarsar0, NandoDF)

DeepSeek R1, Dwarf Fortress oyununda mükemmel metin anlama ve yaratıcı yorumlama yeteneği sergiliyor: Kullanıcı deneyleri, DeepSeek R1 modelinin karmaşık metin yoğun oyun Dwarf Fortress’ın verilerini işlerken güçlü metin anlama ve yaratıcı yorumlama yeteneği sergilediğini gösteriyor. Oyun ekran görüntülerinden metin verilerini çıkarıp DeepSeek R1’e girerek, model yalnızca verileri ayrıştırmakla kalmıyor, aynı zamanda cücelerin davranışlarındaki ilginç tuhaflıkları ve kalıpları da tanıyabiliyor ve bunları canlı ve eğlenceli bir dille tanımlayabiliyor, bu da yapılandırılmamış metin anlama ve üretme konusundaki potansiyelini gösteriyor (Kaynak: Reddit r/LocalLLaMA)

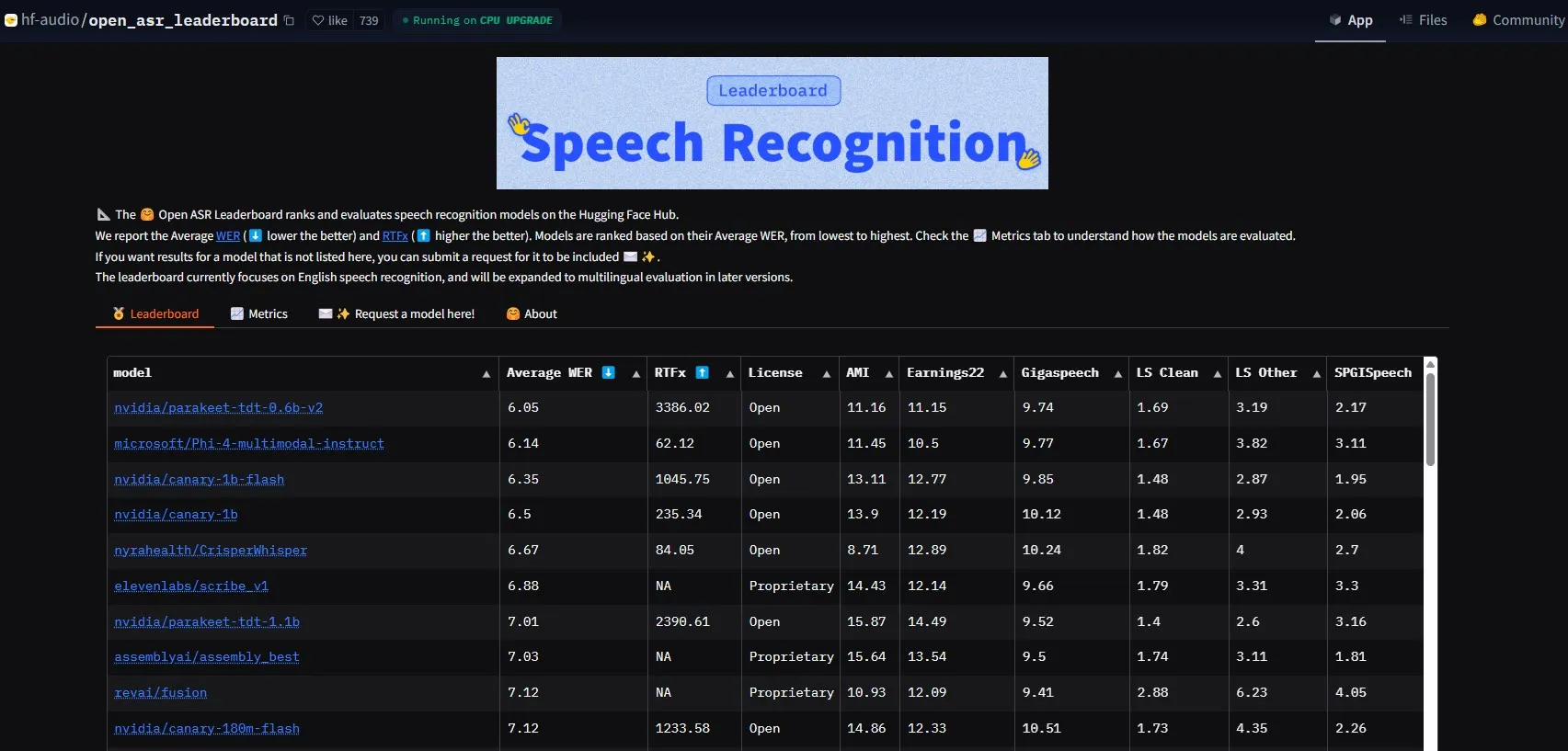
NVIDIA, Parakeet-tdt-0.6b-v2 modelini yayınlayarak ASR performans çıtasını yükseltti: NVIDIA’nın piyasaya sürdüğü yeni otomatik konuşma tanıma (ASR) modeli Parakeet-tdt-0.6b-v2, HuggingFace Open-ASR-Leaderboard’da %6.05 kelime hata oranı (WER) ile sektörde yeni bir rekor kırdı. Bu model yalnızca doğrulukta lider olmakla kalmıyor, aynı zamanda son derece hızlı çıkarım hızına (RTFx 3386, alternatiflerden 50 kat daha hızlı) sahip ve şarkı sözü transkripsiyonu, hassas zaman damgası/sayı biçimlendirme gibi yenilikçi özellikleri destekliyor (Kaynak: huggingface)
Alibaba Qwen ekibi Qwen3-Embedding serisi modellerini yayınladı: Alibaba Qwen ekibi, 0.6B, 4B, 8B olmak üzere üç farklı boyutta yeni Qwen3-Embedding serisi modellerini piyasaya sürdü. Bu modeller, MMTEB, MTEB ve MTEB-Code gibi birden fazla metin gömme benchmark testinde SOTA (State-of-the-Art) performans elde etti, 119 dili destekliyor ve Transformers.js aracılığıyla tarayıcı içinde çalışabiliyor (WebGPU hızlandırmasını destekliyor), çok dilli ve platformlar arası uygulamalar için güçlü metin temsil yeteneği sunuyor (Kaynak: huggingface)
Gemini 2.5 Pro güçlü kod üretme ve görev işleme yeteneği sergiliyor: GoogleDeepMind’ın Gemini 2.5 Pro (preview-06-05 sürümü) karmaşık görevleri işlerken güçlü bir yetenek sergiledi. Örneğin, kullanıcı Majid Manzarpour, 25.000’den fazla ses dosyası içeren bir kütüphaneyi organize etmek ve sınıflandırmak için bir betik yazmasını istediğinde, Jeff Dean bunun “çok zor görünmediğini” yorumladı, bu da modelin bu tür büyük ölçekli, karmaşık programlama görevlerini işleme potansiyeline işaret ediyor. Ayrıca, GosuCoder’ın test grafiği, Gemini 2.5 Pro 06-05 güncelleme sürümünün AI kodlama yardımında daha iyi performans gösterdiğini, özellikle temperature 0.7 olarak ayarlandığında değerlendirme puanının en yüksek olduğunu gösteriyor (Kaynak: JeffDean, jeremyphoward)
Hugging Face ve Google Colab entegrasyonu derinleştirerek AI iş akışlarını basitleştiriyor: Hugging Face ve Google Colab, Hugging Face Hub’daki tüm model kartlarına “Open in Colab” desteği ekleyerek işbirliklerini güçlendirdiklerini duyurdu. Kullanıcılar artık herhangi bir model kartından doğrudan Colab not defterlerini başlatabiliyor, böylece Hugging Face’teki modelleri daha kolay deneyip kullanabiliyor ve AI geliştirme ve araştırma engelini daha da düşürüyor (Kaynak: huggingface)
🧰 Araçlar
LlamaBot: LangGraph tabanlı AI kodlama asistanı: LangChainAI, doğal dil sohbeti yoluyla Web uygulamaları oluşturabilen, LangGraph tarafından desteklenen bir AI ajanı olan LlamaBot’u tanıttı. Özellikleri arasında gerçek zamanlı kod üretimi, gerçek zamanlı önizleme ve farklı geliştirme görevleri için tasarlanmış özel ajanlar bulunuyor ve Web uygulaması geliştirme sürecini basitleştirmeyi amaçlıyor (Kaynak: LangChainAI, hwchase17)
Fast RAG sistemi: Verimli belge işleme için DeepSeek-R1 ve Qdrant’ı birleştiriyor: LangChainAI, yüksek performanslı bir RAG (Retrieval Augmented Generation) uygulama çözümünü sergiledi. Bu çözüm, SambaNova’nın DeepSeek-R1 modelini, Qdrant’ın ikili niceleme teknolojisini ve LangGraph’ı birleştirerek 32 kat bellek azaltımı sağlıyor, böylece büyük ölçekli belgeleri verimli bir şekilde işleyebiliyor ve bilgi erişimi ile içerik üretimi için yeni optimizasyon yolları sunuyor (Kaynak: LangChainAI, hwchase17)

Gemini Research Assistant: Gemini ve LangGraph tabanlı tam yığın akıllı araştırma asistanı: Google Gemini ekibi, akıllı web araştırması yapmak için Gemini modelini ve LangGraph’ı kullanan tam yığın bir AI araştırma asistanını açık kaynak olarak yayınladı. Bu asistan, yansıtıcı muhakeme yeteneğine sahip olup arama stratejilerini sürekli olarak optimize ederek kullanıcılara daha derinlemesine ve verimli araştırma desteği sunuyor. Proje kodu GitHub’da mevcut (Kaynak: LangChainAI, hwchase17)
Agent Flow: Açık kaynaklı kodsuz AI ajan oluşturucu: Karan Vaidya, Gumloop’a alternatif olarak açık kaynaklı, kodsuz bir AI ajan oluşturucusu olan Agent Flow’u piyasaya sürdü. ComposioHQ ve LangChain’in LangGraph’ı üzerine kurulu olup, kullanıcıların sürükle-bırak düğümleriyle iş akışlarını ve karmaşık ajan kalıplarını otomatikleştirmesine olanak tanıyarak AI ajan uygulamalarının geliştirme engelini düşürmeyi amaçlıyor (Kaynak: hwchase17)
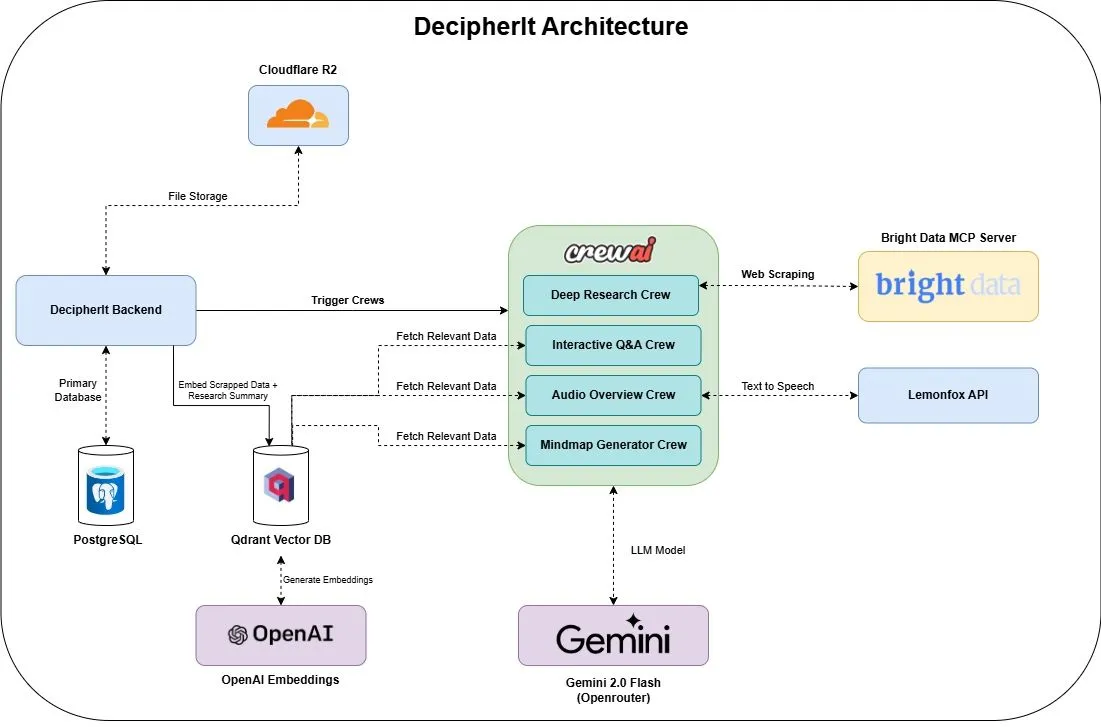
DecipherIt: Açık kaynaklı AI araştırma asistanı, NotebookLM’e alternatif: DecipherIt adlı açık kaynaklı bir AI araştırma asistanı piyasaya sürüldü ve NotebookLM’in bir alternatifi olarak konumlandırıldı. Bu araç, çoklu ajan orkestrasyonu (crewAI), anlamsal arama (Qdrant + OpenAI), gerçek zamanlı web erişimi (Bright Data MCP) ve konuşma sentezi (lemonfoxai) kullanarak kullanıcı tarafından yüklenen belgeleri, URL’leri veya girilen konuları özetler, zihin haritaları, sesli genel bakışlar, SSS ve anlamsal soru-cevap içeren eksiksiz bir araştırma çalışma alanına dönüştürebiliyor (Kaynak: qdrant_engine)
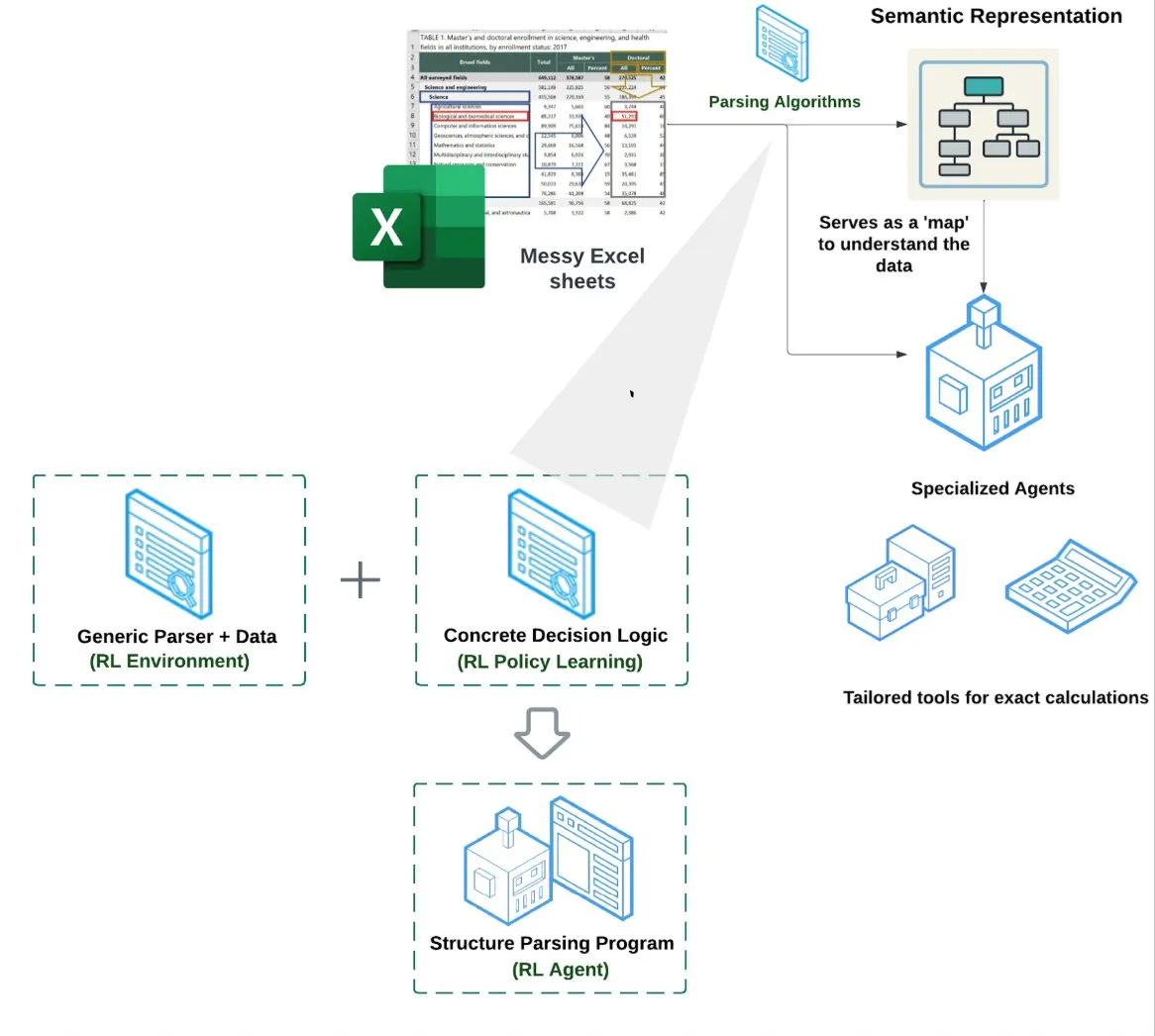
LlamaIndex, Elektronik Tablo Ajanı (Spreadsheet Agent) başlattı: LlamaIndex, henüz özel önizleme aşamasında olan yeni bir elektronik tablo ajanını yayınladı. Bu ajan, karmaşık Excel dosyalarını işlemeye odaklanarak veri dönüştürme ve kalite güvencesi yapabiliyor. Teknik mimarisinin temelinde, takviyeli öğrenmeye dayalı yapısal anlama (veri modelini/anlamsal grafiği öğrenme) ve anlamsal grafik üzerine kurulu özel araçlar bulunuyor. Geleneksel RAG veya metinden CSV’ye yöntemlerinden daha iyi Excel işleme yeteneği sunmayı amaçlıyor ve salt LLM ile kod yazan temelden %10-20 daha iyi performans gösterdiği iddia ediliyor (Kaynak: jerryjliu0)
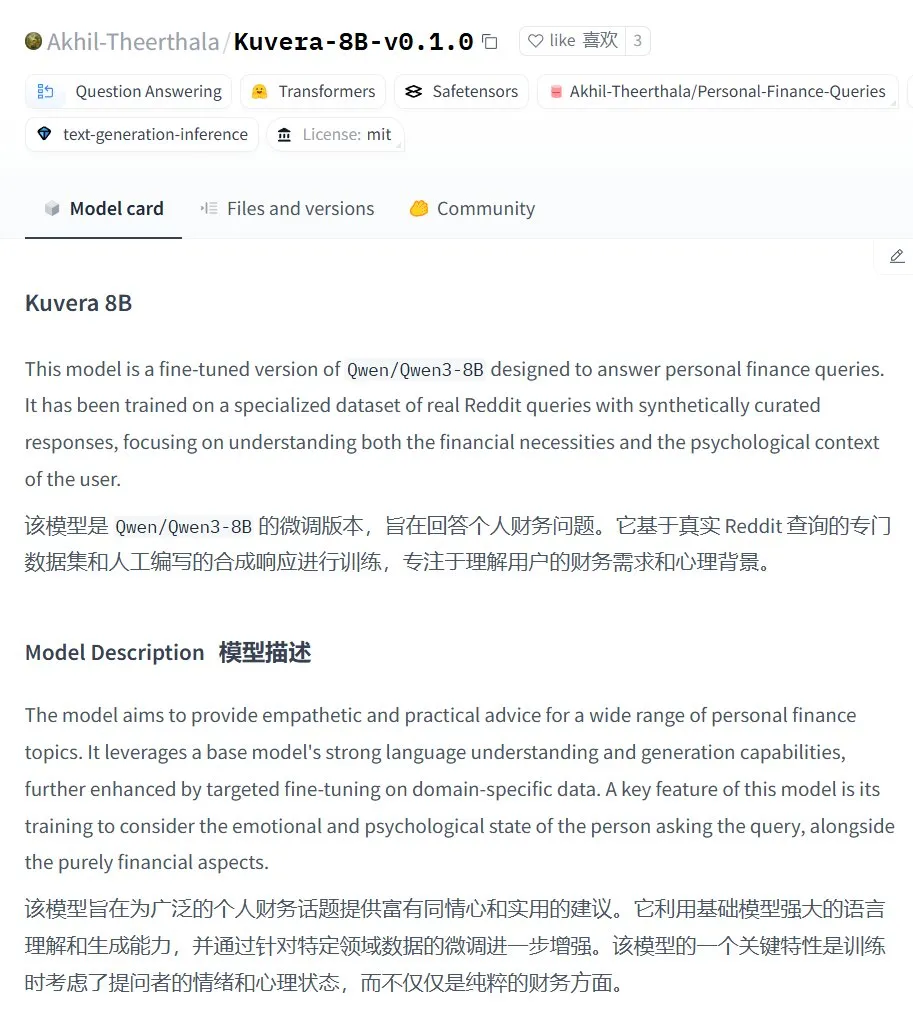
Kuvera-8B-v0.1.0: Kişisel finans danışmanlığı büyük modeli: Akhil-Theerthala, Hugging Face’te kişisel finans sorunları için tasarlanmış bir model olan Kuvera-8B-v0.1.0’ı yayınladı. Qwen3-8B üzerine ince ayar yapılmış olup Reddit gibi veri kaynaklarını kullanıyor ve bütçeleme, tasarruf, yatırım, borç yönetimi ve temel finansal planlama gibi konularda şefkatli ve pratik tavsiyeler sunmayı amaçlıyor. Qwen3 tabanlı olduğu için model Çince soru-cevap destekliyor (Kaynak: karminski3)
Otter.ai yerine yerel Whisper+Pyannote ses işleme çözümü: Bir Reddit kullanıcısı, Otter.ai gibi bulut hizmetlerinin yerine geçmek üzere oluşturduğu tamamen yerel bir ses işleme akışını paylaştı. Bu çözüm, transkripsiyon için ctranslate2 ve faster-whisper’ı, konuşmacı ayrımı (diarisation) için pyannote ve speechbrain’i birleştiriyor ve yerel GPU’da üç saatten uzun toplantı kayıtlarını işleyebiliyor, konuşmacı etiketli metin kayıtları ve JSON dosyaları (özetler ve eylem listeleri gibi özelleştirilmiş içerikler dahil) üretebiliyor. Bu girişim, bulut hizmetlerinin sınırlamalarını, gizlilik endişelerini ve özelleştirme eksikliğini gidermeyi amaçlıyor (Kaynak: Reddit r/LocalLLaMA)
GPT Deep Research MCP: Derinlemesine araştırma için OpenWebUI ile entegrasyon: Kullanıcılar, GPT Deep Research MCP’yi OpenWebUI ile birlikte denemeyi öneriyor. Bu MCP aracı (gptr-mcp), derinlemesine araştırma yetenekleri sunmayı amaçlıyor ve MCP destekli OpenWebUI ile birlikte kullanıldığında etkileyici bir araştırma deneyimi sunarak yerel AI araçlarının bilgi işleme ve bilgi keşfi alanındaki uygulamalarını daha da genişletiyor (Kaynak: Reddit r/OpenWebUI)
📚 Öğrenme
OpenAI, gerçek vakalar ve araç önizlemeleri içeren uygulama değerlendirme pratikleri paylaşım toplantısı düzenleyecek: OpenAI, uygulama değerlendirmeleri (Evals) için en iyi uygulamalar hakkında bir paylaşım toplantısı düzenleyecek. Toplantıda OpenAI’den Jim Blomo, gerçek müşteri vakaları ve sonuçlarıyla birlikte AI ürünlerinin nasıl etkili bir şekilde değerlendirileceğini tartışacak. Etkinlik ayrıca OpenAI’nin izleme, puanlama gibi özellikleri içeren yakında çıkacak değerlendirme araçlarını da önizleyecek. Bu paylaşım toplantısı, geliştiricilerin ve işletmelerin AI uygulamalarını daha iyi oluşturmalarına ve optimize etmelerine yardımcı olmayı amaçlıyor ve kayıtlı bir tekrarı sunulacak (Kaynak: HamelHusain, HamelHusain)

Anthropic, LLM’lerin “düşüncelerini” anlamaya yardımcı olmak için yorumlanabilirlik araştırma yöntemlerini açık kaynak olarak yayınladı: Anthropic, büyük dil modellerinin “düşünce süreçlerini” izlemek için kullandığı araştırma yöntemlerini açık kaynak olarak yayınladığını duyurdu. Araştırmacılar artık bu yöntemi kullanarak “atıf grafikleri” (attribution graphs) oluşturabilir ve Anthropic’in son araştırmalarında gösterdiği gibi etkileşimli olarak keşfedebilirler. Ekip ayrıca, araştırmacıların bu araçları açık kaynaklı modellerde uygulayarak LLM’lerin iç çalışma mekanizmalarını daha iyi anlamalarını kolaylaştırmak için Neuronpedia etkileşimli arayüzü ve Jupyter Notebook eğitimleri de sundu. Bu proje, Anthropic Fellows programı katılımcıları tarafından Decode Research işbirliğiyle yönetiliyor (Kaynak: AnthropicAI)
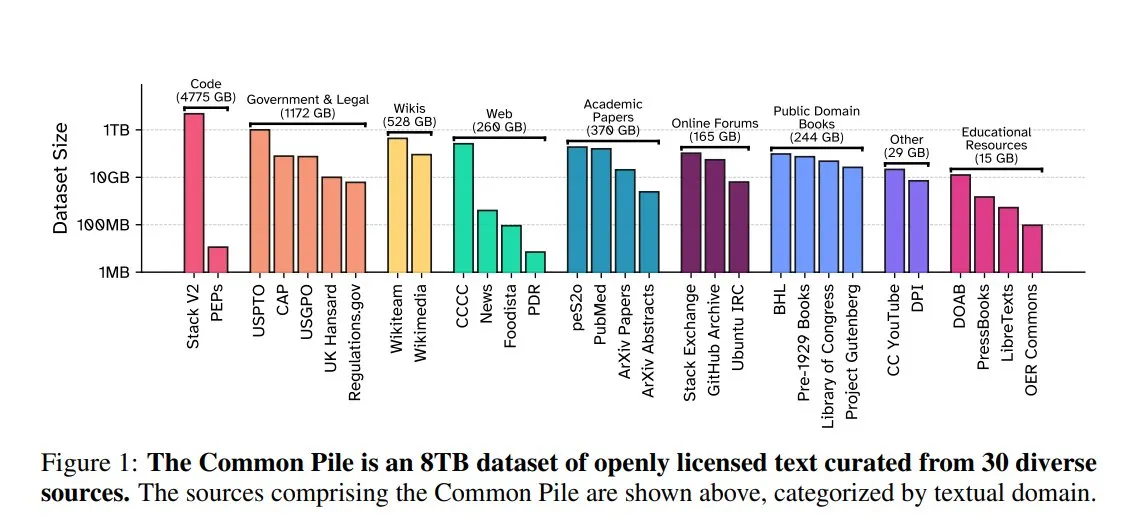
EleutherAI, Common Pile v0.1’i yayınladı: 8TB açık lisanslı metin veri kümesi: EleutherAI, Vector Institute, Allen AI, Hugging Face ve DPI ile birlikte, 8TB boyutunda, 1 trilyon Token içeren kamu malı ve açık lisanslı bir metin veri kümesi olan Common Pile v0.1’i yayınladı. Ekip, bu veri kümesine dayanarak 7B parametreli Comma v0.1-1T ve -2T modellerini eğitti ve performansları, benzer veri ölçeğinde eğitilmiş LLaMA 1&2 gibi modellerle karşılaştırılabilir düzeydeydi. Bu girişim, izinsiz metin kullanmadan yüksek performanslı dil modelleri eğitme olasılığını keşfetmeyi amaçlıyor ve açık kaynak topluluğuna değerli veri kaynakları sunuyor (Kaynak: huggingface)
NVIDIA NIM, Vanna metinden SQL’e çıkarımını hızlandırıyor: NVIDIA geliştirici blogu, Vanna’nın metinden SQL’e çözümünü optimize etmek için NVIDIA NIM’in (NVIDIA Inference Microservices) nasıl kullanılacağını gösteren bir eğitim yayınladı. NIM, üretken AI modelleri için optimize edilmiş uç noktalar sunarak çıkarım sürecini hızlandırabiliyor ve böylece daha hızlı analiz yapılmasını sağlıyor. Bu, doğal dil sorgularını veritabanı sorgularına dönüştürmesi gereken uygulama senaryoları için büyük önem taşıyor (Kaynak: dl_weekly)
Stanford Üniversitesi makine öğrenimi dersi ücretsiz ders notları paylaşıldı: The Turing Post, Stanford Üniversitesi’nde Andrew Ng ve Tengyu Ma tarafından verilen CS229 Makine Öğrenimi dersinin ücretsiz ders notlarını paylaştı. İçerik, denetimli öğrenme, denetimsiz öğrenme yöntemleri ve algoritmaları, derin öğrenme ve sinir ağları, genelleme, düzenlileştirme ve takviyeli öğrenme süreci gibi temel makine öğrenimi konularını kapsıyor ve öğrenenlere yüksek kaliteli öğrenme kaynakları sunuyor (Kaynak: TheTuringPost)

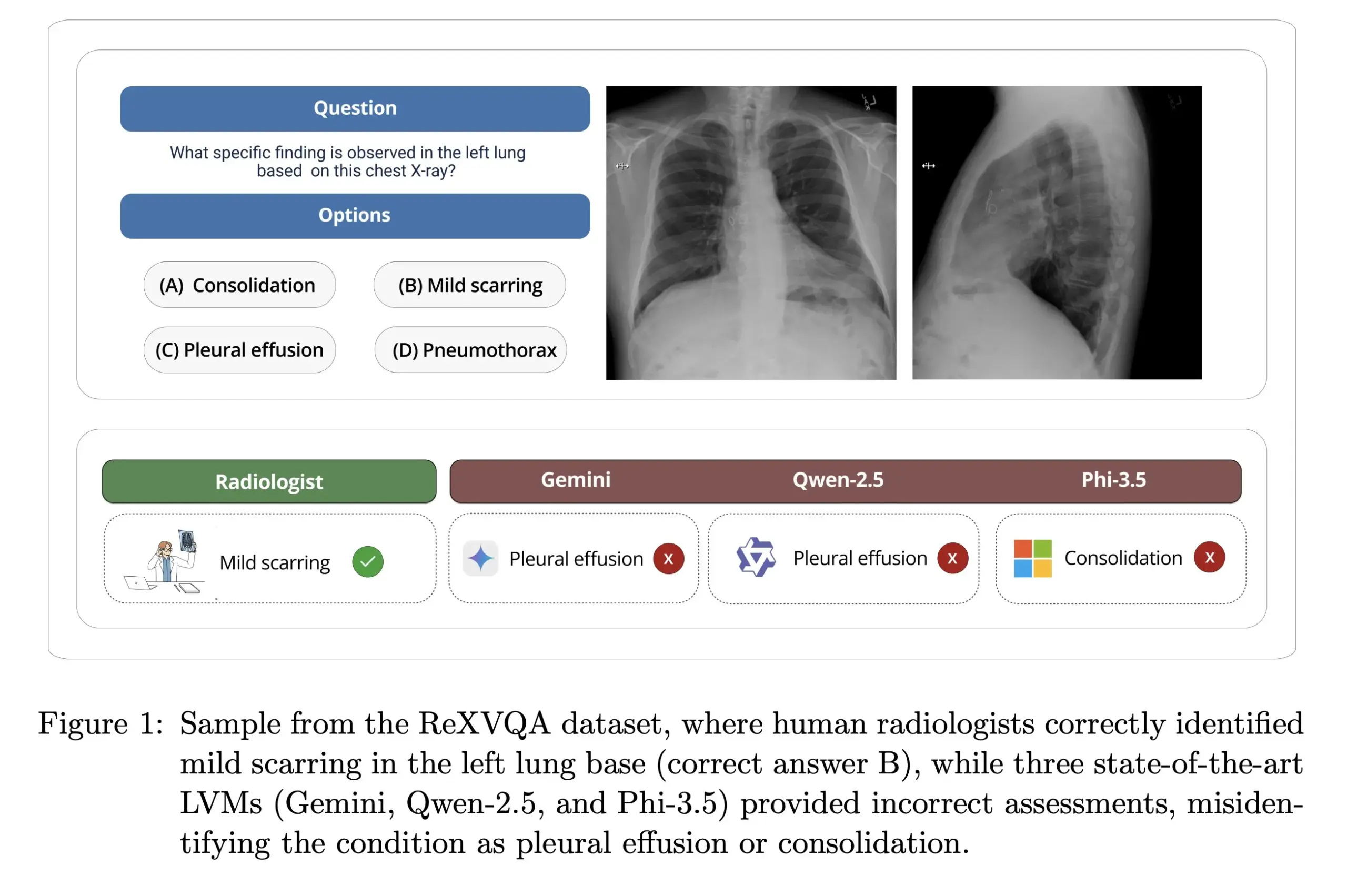
Harvard Üniversitesi ReXVOA’yı yayınladı: Büyük ölçekli, yüksek kaliteli göğüs röntgeni soru-cevap benchmark’ı: Harvard Üniversitesi Pranav Rajpurkar laboratuvarı, büyük ölçekli, yüksek kaliteli bir göğüs röntgeni görsel soru-cevap (VQA) benchmark veri kümesi olan ReXVOA’yı yayınladı. Bu veri kümesi, mevcut büyük, öncü modellere meydan okumayı ve yeni nesil modellerin tıbbi görüntü anlama ve soru-cevap yeteneklerindeki ilerlemeyi ölçmek için bir ölçüt olarak hizmet etmeyi amaçlıyor (Kaynak: huggingface)
OWL Labs, difüzyon modeli otokodlayıcı eğitim deneyimlerini paylaşıyor: OWL (Open World Labs), blogunda difüzyon modelleri için otokodlayıcı eğitme deneyimlerini ve bulgularını özetledi ve bazı alışılmadık yöntemlerin başarısızlık vakalarını paylaştı. Bu makale, araştırmacılara ve geliştiricilere pratikte difüzyon modeli otokodlayıcılarını uygulama ve optimize etme konusunda referans sağlıyor (Kaynak: NandoDF)
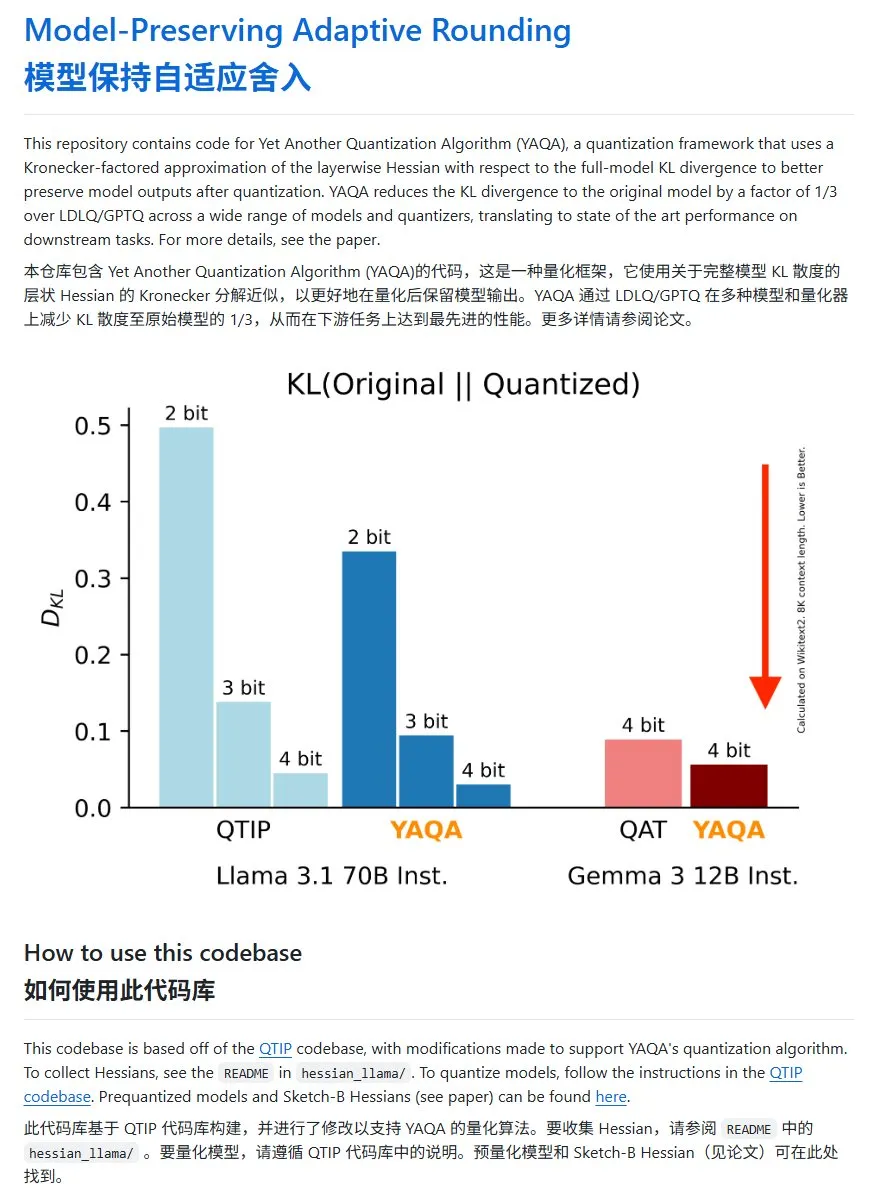
YAQA: KL sapmasını önemli ölçüde azaltan yeni bir model niceleme yöntemi: Cornell-RelaxML ekibi, YAQA adlı yeni bir model niceleme yöntemi önerdi. Bu yöntem, LDLQ/GPTQ teknolojilerini birleştirerek mevcut niceleme yöntemlerine kıyasla niceleme sonrası modellerin KL sapmasını orijinal modelin 1/3’üne düşürebiliyor. YAQA niceleme süreci yavaş olsa ve büyük miktarda VRAM gerektirse de, getirdiği performans artışı ve sonraki çıkarımın ekonomikliği onu umut verici bir niceleme çözümü haline getiriyor. Proje kodu GitHub’da açık kaynak olarak yayınlandı (Kaynak: karminski3)
💼 Ticari
2000’li Guangzhou’lu genç Hong Letong, AI ile matematik problemlerini çözmeyi hedefleyen Axiom’u kurdu: 2000’li yıllarda doğan başarılı öğrenci Hong Letong (Carina Hong) tarafından kurulan AI girişimi Axiom dikkat çekti. Axiom, karmaşık matematik problemlerini çözmek için AI kullanmaya odaklanıyor ve hedef müşterileri arasında hedge fonları ve kantitatif ticaret şirketleri bulunuyor. The Information’a göre Axiom, yaklaşık 300-500 milyon dolar değerlemeyle 50 milyon dolarlık bir finansman için görüşüyor ve B Capital’in baş yatırımcı olabileceği belirtiliyor. Hong Letong sosyal medyada finansman haberlerinin doğru olmadığını belirtti ancak şirketin AI matematik yetenekleri aradığını doğruladı. Hong Letong, lisans derecesini MIT’den, yüksek lisans derecesini Oxford’dan aldı ve şu anda Stanford’da matematik ve hukuk alanlarında çift doktora yapıyor; daha önce birçok matematik yarışmasında ödül kazandı (Kaynak: 36氪)

Anthropic, rekabet ilişkisi nedeniyle Windsurf’ün Claude API erişimini kesti: Anthropic kurucu ortağı, şirketin AI girişimi Windsurf’e Claude modelinin API erişimini durdurduğunu doğruladı. Gerekçe, Windsurf’ün OpenAI’nin bir tür “sarmalayıcısı” veya onunla yakından ilişkili bir hizmet olarak görülmesi ve OpenAI’nin Anthropic’in doğrudan rakibi olmasıydı. Bu hamle, özellikle işleri üçüncü taraf büyük model API’lerine dayanan girişimler için API bağımlılığı ve platform riskleri hakkında tartışmalara yol açtı; model sağlayıcısının ticari kararları doğrudan hayatta kalmalarını etkileyebilir (Kaynak: ClementDelangue, Reddit r/LocalLLaMA)
OpenAI, telif hakkı davası nedeniyle kullanıcıların silinmiş sohbet kayıtlarını saklamak zorunda kaldı: Haberlere göre, The New York Times tarafından açılan bir telif hakkı davasında, ABD federal mahkemesi OpenAI’ye, potansiyel kanıt olarak kullanıcıların silmeyi seçtikleri içerikler de dahil olmak üzere tüm ChatGPT kullanıcılarının konuşma kayıtlarını saklamasını emretti. The New York Times, OpenAI’yi ücretli duvar makalelerini ChatGPT’yi eğitmek için kullanmakla suçluyor ve AI’ın benzer içerikler üretebileceğinden endişe ediyor. Bu hamle, kullanıcı gizliliği ve veri koruma (GDPR gibi) konularında endişelere yol açtı ve AI eğitim verilerinin telif hakkı ile kullanıcı gizliliği arasındaki yasal ve etik gerilimi vurguladı (Kaynak: Reddit r/ArtificialInteligence)

🌟 Topluluk
AI büyük modelleri 2025 Gaokao kompozisyon ve matematik sınavlarında farklı performanslar sergiledi: 2025 Gaokao (Çin üniversite giriş sınavı) sırasında, birçok ana akım AI büyük modeli kompozisyon ve matematik sorularıyla sınandı. Kompozisyon alanında, Doubao, DeepSeek, ChatGPT dahil 16 AI asistanı yazma yeteneklerini sergiledi; çoğu yapısal olarak düzgün makaleler üretebildi ancak genellikle şablon kullanımı, klişe alıntılar ve benzer temalar sorunları yaşandı. Matematik (yeni müfredat I. bölüm objektif sorular) testinde, ByteDance Doubao ve Tencent Yuanbao 68 puanla (tam puan 73) birinci olurken, OpenAI o3 yalnızca 34 puan alarak düşük performans gösterdi. Testler, mevcut AI’ın Çince anlama, mantıksal çıkarım ve yaratıcı ifade konularındaki ilerlemesini ve sınırlamalarını yansıttı; özellikle AI izlerini önleme ve karmaşık matematiksel çıkarımlarla başa çıkma konularında hala geliştirilmesi gereken alanlar olduğu görüldü (Kaynak: 36氪, 36氪)

Şirket içi AI uygulamalarında trend: Dahili bilgi tabanları ve özelleştirilmiş sohbet robotları dikkat çekiyor: Topluluk tartışmaları, şirket verilerine dayalı olarak eğitilmiş şirket içi sohbet robotları oluşturmanın, çalışanların süreçler, veri bulma, sorumlu kişiler gibi dahili sorularını yanıtlamak için bir trend haline geldiğini gösteriyor. Bu tür uygulamalar, dahili bilgi erişim verimliliğini ve bilgi yönetimi seviyesini artırmayı amaçlıyor. Amazon gibi şirketler benzer sistemleri devreye soktu ve olumlu geri bildirimler aldı. Ancak, veri güvenliği, potansiyel hassas bilgi sızıntısı ve etkili bir şekilde nasıl ticarileştirileceği, şirketlerin uygulama sürecinde dikkat etmesi gereken sorunlar olmaya devam ediyor (Kaynak: Reddit r/ArtificialInteligence)
AI destekli programlamada “indeksli” ve “indekssiz” tartışması: Performans ve güvenilirlik dengesi: AI kodlama asistanları üzerine yapılan bir deney (test nesnesi olarak Apollo 11 ay iniş kodu kullanılarak), “indeksli” (önceden kod tabanı dizini oluşturan ve vektör araması kullanan) ve “indekssiz” (kod dosyalarını isteğe bağlı olarak okuyup analiz eden) olmak üzere iki tür AI aracısını karşılaştırdı. Sonuçlar, indeksli aracıların çoğu durumda daha hızlı olduğunu ve daha az API çağrısı yaptığını gösterdi, ancak kod tabanının sık sık değişmesi nedeniyle dizinin güncelliğini yitirdiği durumlarda, eski bilgilere dayanarak hata üretebileceği ve hata ayıklama süresinin daha uzun olabileceği görüldü. Bu, AI kodlama araçlarını seçerken anlık performans ile bilgi güvenilirliği arasında bir denge kurulması gerektiğini ortaya koyuyor (Kaynak: Reddit r/ClaudeAI)

LLM’lerin “düşünüp düşünmediği” tartışması devam ediyor: Örüntü eşleştirmeden insan bilişine: Toplulukta büyük dil modellerinin (LLM) gerçekten “düşünüp düşünmediği” konusundaki tartışmalar devam ediyor. Eleştirmenler, LLM’lerin esasen kelime dizilerinin olasılıklarını hesaplayarak çalışan karmaşık tahmini metin üreticileri olduğunu ve bilinçli bir düşünme eylemi gerçekleştirmediklerini savunuyor. Ancak, birçok kullanıcı LLM’lerle etkileşim kurarken insanlarla konuşmaya benzer bir deneyim yaşadığını belirtiyor. Bu, insan dil üretim mekanizmaları üzerine yeniden düşünmeye ve LLM’ler ile insan bilişsel süreçleri arasında benzerlikler olup olmadığına dair tartışmalara yol açıyor. Apple’ın araştırması, LLM’lerin karmaşık çıkarımlardaki sınırlamalarına daha da işaret ederek, gerçek çıkarımdan ziyade örüntü belleğine daha fazla dayandıklarını öne sürüyor ve bu tartışmaya yeni bir bakış açısı katıyor (Kaynak: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)

Paul Graham, AI’ın gelir eşitsizliği üzerindeki etkisinden bahsediyor: Paul Graham, 16 yaşındaki oğluna kısa vadede AI teknolojisinin insanların iş gelirleri arasındaki farkı artırabileceğini söyledi. Örnek olarak, ortalama seviyedeki programcıların artık iş bulmakta daha fazla zorlandığını, mükemmel programcıların ise AI yardımıyla daha yüksek gelir elde ettiğini belirtti. Bunun yeni bir şey olmadığını, teknolojik ilerlemenin genellikle gelir eşitsizliğini artırdığını, çünkü gelir alt sınırının sıfırda sabitlendiğini ve teknolojinin sürekli olarak en iyi yeteneklerin getiri üst sınırını yükselttiğini savundu (Kaynak: dotey)
AI güvenlik etiği tartışması: Model davranışından toplumsal normlara: Toplulukta AI güvenliği ve etiği konusundaki tartışmalar giderek artıyor. Geoffrey Hinton, Yoshua Bengio’yu, özellikle öncü sistemlerde ortaya çıkabilecek kendini koruma ve aldatma davranışlarına odaklanarak AI’ın güvenli tasarımını teşvik etmeyi amaçlayan LawZero projesini başlattığı için tebrik etti. Aynı zamanda, bazı AI güvenlik araştırmalarının (modelin kapatılmayı kabul edip etmediğini test etmek gibi) pratik değeri olmayan “güvenlik tiyatrosu” olduğu yönünde eleştiriler de var. OpenAI’nin insan-makine ilişkileri üzerine yaptığı araştırma da tartışmalara yol açtı; AI’ın giderek daha fazla hayata entegre olduğu bir ortamda, kullanıcıların duygusal refahı üzerindeki etkisinin öncelikli olarak araştırılması ve model etkileşimlerinde açık iletişim ile antropomorfizmden kaçınma arasında nasıl bir denge kurulacağının tartışılması gerektiğini vurguladı (Kaynak: geoffreyhinton, ClementDelangue, togelius)

ChatGPT gibi AI asistanlarının duygusal destek rolü kullanıcılar tarafından takdirle karşılanıyor: Birçok kullanıcı, sosyal medyada ChatGPT gibi AI asistanlarının zor zamanlarında kendilerine duygusal destek ve pratik yardım sağladığı deneyimlerini paylaştı. Bazı kullanıcılar, işsizlik, sağlık sorunları veya moral bozukluğu yaşadıklarında ChatGPT’nin yalnızca somut eylem planları ve kaynak bilgileri sunmakla kalmayıp, aynı zamanda yargılayıcı olmayan bir şekilde paniklerini hafifletmelerine ve güçlerini yeniden kazanmalarına yardımcı olduğunu belirtti. Bu, AI’ın gerçek duygulara ve bilince sahip olmamasına rağmen psikolojik destek ve kriz müdahalesi alanındaki potansiyel değerini gösteriyor (Kaynak: Reddit r/ChatGPT)
“Vibe Coding”, AI destekli programlamada yeni bir fenomen haline geliyor: “Vibe Coding” terimi, geliştirici topluluğunda sezgiye ve AI destekli hızlı kod iterasyonuna dayanan bir programlama biçimini ifade etmek için popüler hale geldi. Claude Code gibi araçlar, belirli zaman dilimlerinde (gece veya sabahın erken saatleri gibi, muhtemelen sunucu yükünün düşük olması veya yüksek oranda nicelenmemiş olması nedeniyle) mükemmel performans göstermeleri nedeniyle bazı programcılar tarafından tercih ediliyor. Bu fenomen, AI kodlama asistanlarının geliştirme verimliliğindeki artışı yansıtıyor ve aynı zamanda model tutarlılığı, nicelemenin etkisi ve geliştiricilerin yeni çalışma modelleri hakkında tartışmalara yol açıyor (Kaynak: dotey, jeremyphoward)
💡 Diğer
Andrej Karpathy, gürültü kirliliğinin uyku ve sağlık üzerindeki büyük etkisini yeniden değerlendiriyor: Andrej Karpathy, kişisel deneyimlerini paylaşarak trafik gürültüsü gibi çevresel gürültü kirliliğinin uyku kalitesi ve uzun vadeli sağlık üzerinde büyük ve yeterince fark edilmeyen olumsuz etkilere neden olabileceğine dikkat çekti. Gece gürültüsünün (yüksek sesli arabalar, motosiklet sesleri gibi) milyonlarca insanın uyku kalitesini düşürebileceğini, bunun da ruh halini, yaratıcılığı, enerjiyi etkileyebileceğini ve kardiyovasküler, metabolik ve bilişsel hastalık riskini artırabileceğini tahmin ediyor. Whoop, Oura gibi uyku takip cihazlarının gürültü ile uyku arasındaki ilişkiyi açıkça izlemesi ve halkın bu konudaki farkındalığını artırması çağrısında bulundu (Kaynak: karpathy)
AI ve dinin kesişimi dikkat çekiyor: Sosyal medya kullanıcısı menhguin, AI tabanlı yeni tür dinlerin veya dine benzer uygulamaların potansiyel pazarının göz ardı edilmemesi gerektiğini gözlemledi. Örneğin, AI astroloji, AI İncil videoları, AI dua uygulamaları ve belirli grupların AI uygulamaları, AI teknolojisinin insanların manevi veya inanç ihtiyaçlarını karşılama potansiyeline işaret ediyor (Kaynak: menhguin)
AI destekli HTTP 2.0 sunucusu oluşturma, LLM’lerin büyük yazılım projelerindeki potansiyelini keşfediyor: Bir geliştirici, kendi geliştirdiği bir çerçeve (promptyped) ve Gemini 2.5 Pro modelini kullanarak, kodla-derle-test et döngüsüyle LLM’nin sıfırdan HTTP 2.0 standardına uygun bir sunucu oluşturmasını sağladı. Proje, 15.000 satır kaynak kodu ve 30.000’den fazla satır test kodu üretti ve h2spec uyumluluk testini geçti. Yaklaşık 119 saat API süresi ve 631 dolar API maliyetine rağmen, bu deney LLM’lerin mimari tasarım ve karmaşık, standartlara uyumlu yazılımlar yazma potansiyelini gösterirken, aynı zamanda tamamen LLM tarafından yazılan uygulamaların biçimini de ortaya koydu (Kaynak: Reddit r/LocalLLaMA)