
Anahtar Kelimeler:Gemini 2.5 Pro, VeBrain, Segment Anything Model 2, Qwen3-Embedding, AI Agent, Gemini 2.5 Pro Derin Düşünme Modu, VeBrain Genel Somutlaştırılmış Yapay Zeka Beyin Çerçevesi, SAM 2 Görüntü ve Video Segmentasyonu, Qwen3-Embedding 32k Bağlam, AI Agent Çok Modlu Anlama
🔥 Odak Noktası
Google, birçok yeni AI gelişmesini duyurdu; Gemini 2.5 Pro Deep Think modu karmaşık çıkarım yeteneğini artırıyor: Google I/O konferansında Google, Gemini 2.5 Pro’nun Deep Think modunu duyurdu. Bu mod, AI’ın karmaşık sorunları (USAMO seviyesindeki matematik problemleri gibi) işlerken kullandığı çıkarım yeteneğini önemli ölçüde artırmayı amaçlıyor. Aynı zamanda Google, algoritma keşfi için Gemini tarafından desteklenen bir kodlama ajanı olan AlphaEvolve’u da tanıttı. AlphaEvolve, matris çarpımı algoritma tasarımında ve açık matematik problemlerini çözmede başarılar elde etti ve Google’ın dahili veri merkezlerini, çip tasarımını ve AI eğitim verimliliğini optimize etmek için uygulanıyor. Ayrıca, video modeli Veo 3, görüntü modeli Imagen 4 ve AI kurgu aracı FLOW da birlikte piyasaya sürüldü; bu da Google’ın çok modlu AI alanındaki kapsamlı yapılanmasını ve hızlı ilerlemesini gösteriyor. (Kaynak: OriolVinyalsML, demishassabis, demishassabis, op7418)
Shanghai AI Laboratuvarı, evrensel cisimleşmiş zeka beyin çerçevesi VeBrain’i ortaklaşa yayınladı: Shanghai AI Laboratuvarı, birçok kurumla birlikte VeBrain’i (Visual Embodied Brain) tanıttı. Bu, görsel algı, uzamsal çıkarım ve robot kontrol yeteneklerini birleştirmeyi amaçlayan evrensel bir cisimleşmiş zeka beyin çerçevesidir. Çerçeve, robot kontrol görevlerini MLLM’deki 2D uzamsal metin görevlerine (anahtar nokta tespiti ve cisimleşmiş beceri tanıma gibi) dönüştürerek ve metin kararından gerçek eyleme hassas eşleme ve kapalı döngü kontrolü sağlamak için “robot adaptörünü” tanıtarak çalışır. Model eğitimini desteklemek için ekip, çok modlu anlama, görsel-uzamsal çıkarım ve robot operasyonu olmak üzere üç görev türünü kapsayan 600.000 talimat verisi içeren VeBrain-600k veri kümesini oluşturdu. Testler, VeBrain’in çok modlu anlama, uzamsal çıkarım ve gerçek robot kontrolünde (mekanik kollar ve robot köpekler) SOTA seviyesine ulaştığını göstermektedir. (Kaynak: 量子位)

Anthropic, model yorumlanabilirliğini artırmak için LLM görselleştirme aracı “devre izleme”yi açık kaynak olarak yayınladı: Anthropic, araştırmacıların büyük dil modellerinin (LLM) iç işleyiş mekanizmalarını anlamalarına yardımcı olmayı amaçlayan “devre izleme” (circuit tracing) adlı açık kaynaklı bir araç yayınladı. Bu araç, modelin bilgiyi işlerken içindeki süper düğümleri ve bağlantılarını görselleştiren “atfetme grafikleri” (attribution graphs) oluşturarak, bir sinir ağı şemasına benzer şekilde çalışır. Araştırmacılar, düğüm aktivasyon değerlerine müdahale ederek ve model davranışındaki değişiklikleri gözlemleyerek her bir düğümün işlevini doğrulayabilir ve LLM’lerin karar verme mantığını çözebilir. Araç, ana akım açık kaynak modeller üzerinde atfetme grafikleri oluşturmayı destekler ve görselleştirme, açıklama ekleme ve paylaşım için etkileşimli bir ön uç arayüzü olan Neuronpedia’yı sunar. Bu girişim, AI yorumlanabilirliği araştırmalarını teşvik etmeyi ve daha geniş bir topluluğun model davranışlarını keşfetmesini ve anlamasını sağlamayı amaçlamaktadır. (Kaynak: 量子位, swyx)
Meta, görüntü ve video segmentasyon yeteneklerini geliştiren Segment Anything Model 2’yi (SAM 2) yayınladı: Meta AI Araştırma (FAIR), popüler Segment Anything Model’inin yükseltilmiş versiyonu olan SAM 2’yi tanıttı. SAM 2, görüntü ve videolardaki yönlendirilebilir görsel segmentasyon görevlerine odaklanan bir temel modeldir ve istemlere (noktalar, kutular, metin gibi) göre görüntü veya videodaki belirli nesneleri veya bölgeleri hassas bir şekilde tanımlayıp segmente edebilir. Model, Apache Lisansı altında açık kaynak olarak sunulmuştur ve araştırmacılar ile geliştiricilerin ücretsiz olarak kullanmasına ve uygulamalar oluşturmasına olanak tanıyarak bilgisayarla görme alanındaki gelişmeleri daha da ileriye taşımaktadır. (Kaynak: AIatMeta)
🎯 Gelişmeler
BAAI (Zhiyuan Enstitüsü), tek kartla on binlerce karelik video anlamayı sağlayan Video-XL-2’yi açık kaynak olarak yayınladı: BAAI (Zhiyuan Enstitüsü), Shanghai Jiao Tong Üniversitesi ve diğer kurumlarla işbirliği içinde yeni nesil ultra uzun video anlama modeli Video-XL-2’yi yayınladı. Bu model, etki, işleme uzunluğu ve hız açısından önemli ölçüde geliştirilmiştir; tek bir kart on binlerce karelik video girişini işleyebilir ve 2048 karelik bir videoyu yalnızca 12 saniyede kodlayabilir. Video-XL-2, SigLIP-SO400M görsel kodlayıcı, dinamik Token sentez modülü (DTS) ve Qwen2.5-Instruct büyük dil modelini kullanır ve dört aşamalı progresif eğitim ve verimlilik optimizasyon stratejileri (bölümlü ön doldurma ve çift granüleriteli KV kod çözme gibi) aracılığıyla yüksek performans elde eder. Model, MLVU, Video-MME gibi kıyaslama testlerinde üstün performans göstermiştir ve ağırlıkları açık kaynak olarak yayınlanmıştır. (Kaynak: 量子位)

Character.ai, AvatarFX video oluşturma özelliğini kullanıma sundu; resimdeki karakterler hareket edip etkileşim kurabiliyor: Lider AI eşlik uygulaması Character.ai (c.ai), kullanıcıların statik resimlerdeki karakterleri (evcil hayvanlar gibi insan olmayan figürler dahil) canlandırmasına, konuşmasına, şarkı söylemesine ve kullanıcılarla etkileşim kurmasına olanak tanıyan AvatarFX özelliğini başlattı. Bu özellik DiT mimarisine dayanıyor ve yüksek sadakat ile zamansal tutarlılığı vurguluyor; çok karakterli, uzun sekanslı diyaloglar gibi karmaşık senaryolarda bile kararlılığını koruyor. AvatarFX şu anda web sürümünde tüm kullanıcılara açık olup, APP tarafında yakında kullanıma sunulacak. Aynı zamanda c.ai, AI yaratım deneyimini daha da zenginleştirmek için Scenes (etkileşimli hikaye sahneleri), Imagine Animated Chat (canlandırılmış sohbet kayıtları) ve Stream (karakterler arası hikaye oluşturma) gibi yeni özellikleri de duyurdu. (Kaynak: 量子位)

Nvidia, Llama-3.1 Nemotron-Nano-VL-8B-V1 görsel dil modelini tanıttı: Nvidia, görüntü, video ve metin girdilerini işleyebilen ve metin çıktıları üretebilen, belirli bir düzeyde görüntü çıkarımı ve tanıma yeteneğine sahip yeni görselden metne modeli Llama-3.1-Nemotron-Nano-VL-8B-V1’i yayınladı. Bu modelin yayınlanması, Nvidia’nın çok modlu AI alanındaki sürekli yatırımının bir göstergesidir. Aynı zamanda, topluluk tartışmaları Llama-4’ün 70B altındaki modellerden vazgeçmesinin Gemma3 ve Qwen3 gibi modeller için ince ayar pazarında fırsatlar yaratabileceğine işaret ediyor. (Kaynak: karminski3)
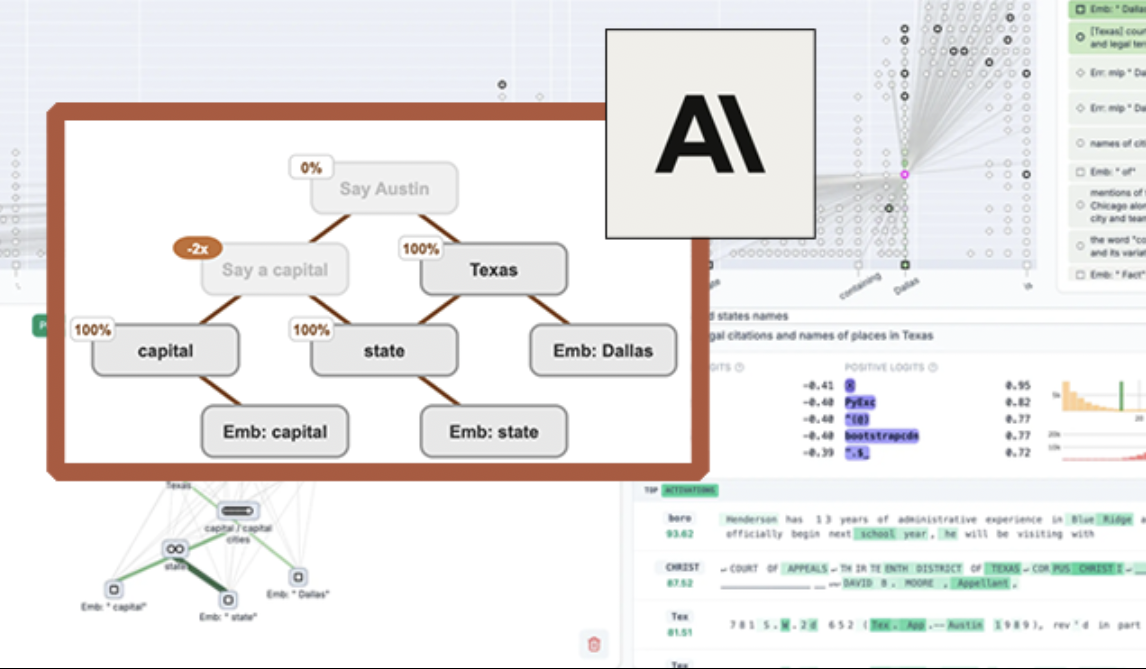
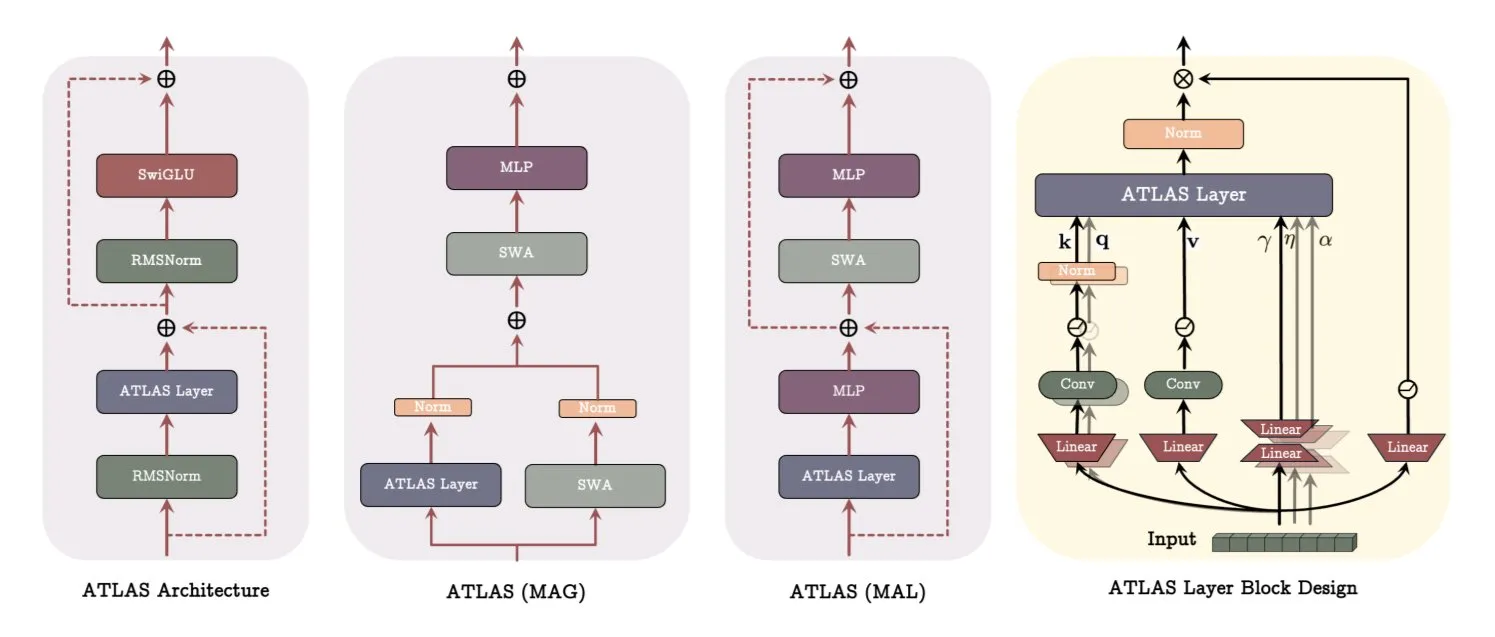
Google, model öğrenme ve bellek yöntemlerini yenileyen ATLAS mimarisi makalesini yayınladı: Google’ın en son makalesi, aktif bellek (Omega kuralı en son c token’ı işler) ve daha akıllı bellek kapasitesi yönetimi (polinomsal ve üstel özellik eşlemesi) aracılığıyla modellerin öğrenme ve bellek yeteneklerini optimize etmeyi amaçlayan ATLAS adlı yeni bir model mimarisini tanıtıyor. ATLAS, daha etkili bellek güncellemeleri için Muon optimize edicisini kullanır ve geleneksel sabit dikkatin yerine öğrenilebilir, bellek odaklı mekanizmalar getiren DeepTransformers ve Dot (Deep Omega Transformers) gibi tasarımları içerir. Bu araştırma, AI’ın daha akıllı, bağlam duyarlı sistemlere doğru ilerlemesinde bir dönüm noktası olup, AI’ın büyük ölçekli veri kümelerini işleme ve kullanma yeteneğini artırma potansiyeline sahiptir. (Kaynak: TheTuringPost)
Qwen, Qwen3-Embedding serisi modellerini yayınlayarak gömme performansını önemli ölçüde artırdı: Qwen ekibi, 0.6B, 4B ve 8B olmak üzere üç versiyon içeren yeni Qwen3-Embedding model serisini yayınladı. Bu modeller, 32k’ya kadar bağlam uzunluğunu ve 100 dili desteklemekte olup, MTEB’de (Massive Text Embedding Benchmark) SOTA sonuçları elde etmiş ve bazı metriklerde ikinci sıradaki modele 10 puan fark atmıştır. Bu gelişme, metin gömme teknolojisinde bir başka önemli atılımı işaret etmekte ve anlamsal arama, RAG gibi uygulamalar için daha güçlü bir temel sağlamaktadır. (Kaynak: AymericRoucher, ClementDelangue)

Microsoft Bing Video Creator kullanıma sunuldu, OpenAI Sora modeline dayalı ve ücretsiz: Microsoft, Bing uygulamasında Bing Video Creator’ı başlattı. Bu özellik OpenAI’nin Sora modeline dayanıyor ve kullanıcıların metin istemleriyle ücretsiz olarak video oluşturmasına olanak tanıyor. Bu, Sora modelinin ilk kez geniş kitlelere ücretsiz olarak sunulması anlamına geliyor. Ücretsiz olmasına rağmen, şu anda video uzunluğunun yalnızca 5 saniye olması, 9:16 en boy oranı ve yavaş üretim hızı gibi sınırlamalar mevcut. Kullanıcı geri bildirimleri, etkisinin mevcut SOTA video modelleriyle (Kling, Veo3 gibi) karşılaştırıldığında bir boşluk olduğunu gösteriyor ve bu da Sora’nın teknoloji yineleme hızı ve Microsoft’un ürün stratejisi hakkında tartışmalara yol açıyor. (Kaynak: 36氪)
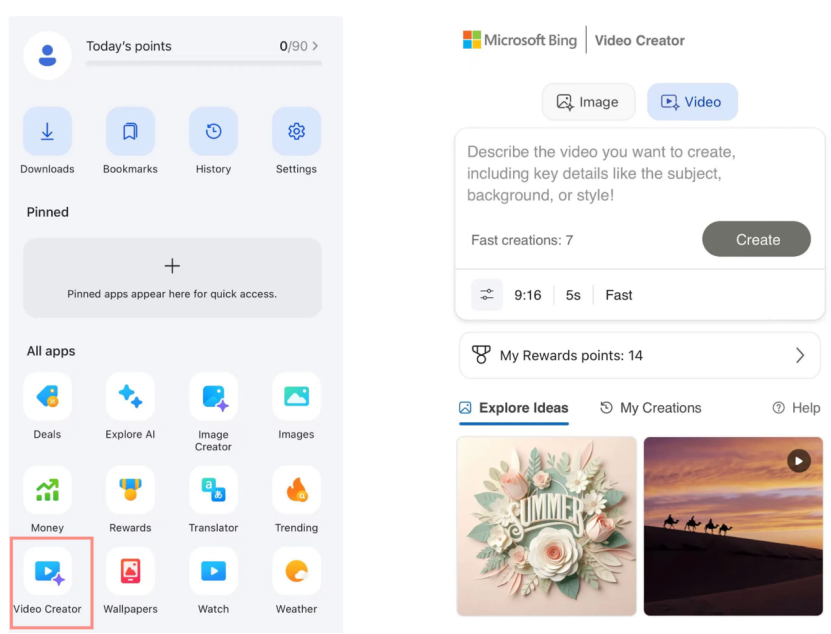
OpenAI, işyeri entegrasyonunu geliştirmek için birçok kurumsal düzeyde özellik başlattı: OpenAI, Google Drive gibi uygulamalar için özel bağlayıcılar sunmanın yanı sıra ChatGPT’de toplantı kaydı, transkripsiyon ve özetleme özellikleri ve SSO (Tek Oturum Açma) ile puan tabanlı kurumsal sürüm fiyatlandırması desteği de dahil olmak üzere kurumsal kullanıcılara yönelik bir dizi yeni özellik yayınladı. Bu güncellemeler, ChatGPT’yi kurumsal iş akışlarına daha derinlemesine entegre etmeyi ve ofis verimliliğini artırmayı amaçlamaktadır. (Kaynak: TheRundownAI, EdwardSun0909)
Hugging Face, MacBook’ta çalışabilen verimli robot modeli SmolVLA’yı yayınladı: Hugging Face, son derece verimli olmasıyla öne çıkan ve hatta bir MacBook’ta çalışabilen SmolVLA adlı bir robot modeli yayınladı. Bu model, az sayıda (örneğin 31) gösteri verisi üzerinde ince ayar yapıldıktan sonra, belirli görevlerde (Koch Arm operasyonu gibi) tek görevli temel çizgilerin performansına ulaşabilir veya onu aşabilir, bu da kaynak kısıtlı ortamlarda robot AI dağıtma potansiyelini göstermektedir. (Kaynak: mervenoyann, sytelus)
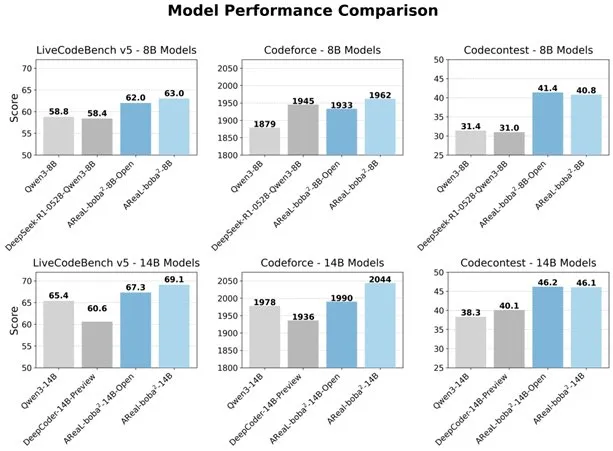
Alibaba, LLM kod yeteneklerini geliştirmek için tamamen asenkron RL sistemi AReaL-boba²’yi açık kaynak olarak yayınladı: Alibaba Qwen ekibi, büyük dil modelleri (LLM) için özel olarak tasarlanmış ve Qwen3-14B üzerinde SOTA kod için takviyeli öğrenme etkileri elde eden tamamen asenkron takviyeli öğrenme sistemi AReaL-boba²’yi açık kaynak olarak yayınladı. Bu sistem, sistem ve algoritma ortak tasarımıyla 2.77 kat eğitim hızlandırması sağlamış, LiveCodeBench’te 69.1 puan elde etmiş ve çok turlu takviyeli öğrenmeyi desteklemektedir. (Kaynak: _akhaliq)
DuckDB, veri gölü ve katalog formatlarını entegre eden DuckLake uzantısını tanıttı: DuckDB, SQL ve Parquet tabanlı açık bir lakehouse formatı olan DuckLake uzantısını yayınladı. DuckLake, meta verileri bir katalog veritabanında, verileri ise Parquet dosyalarında saklar. Bu uzantı sayesinde DuckDB, DuckLake’teki verileri doğrudan okuyup yazabilir, tabloların oluşturulmasını, değiştirilmesini, sorgulanmasını, zaman yolculuğunu ve şema evrimini destekleyerek veri göllerinin oluşturulmasını ve yönetilmesini basitleştirmeyi amaçlar. (Kaynak: GitHub Trending)
Model Context Protocol (MCP) Ruby SDK yayınlandı: Model Context Protocol (MCP), MCP sunucularını uygulamak için Shopify ile işbirliği içinde sürdürülen resmi Ruby SDK’sını yayınladı. MCP, AI modellerinin (özellikle Agent’ların) araçları keşfetmesi, kaynaklara erişmesi ve önceden tanımlanmış istemleri yürütmesi için standartlaştırılmış bir yol sağlamayı amaçlamaktadır. Bu SDK, JSON-RPC 2.0’ı destekler ve geliştiricilerin MCP spesifikasyonlarına uygun AI uygulamaları oluşturmasını kolaylaştırmak için araç kaydı, istem yönetimi, kaynak erişimi gibi temel işlevleri sunar. (Kaynak: GitHub Trending)
AI teknolojisi, çinko pillerin %99,8 verimliliğe ve 4300 saat çalışma süresine ulaşmasına yardımcı oldu: Yapay zeka optimizasyonu sayesinde yeni nesil çinko piller, %99,8 Kulombik verimliliğe ve 4300 saate kadar çalışma süresine ulaştı. AI’ın malzeme bilimi alanındaki uygulamaları, özellikle pil tasarımı ve performans tahmini konularında, enerji depolama teknolojilerinde çığır açmakta ve elektrikli araçlar, taşınabilir elektronik cihazlar gibi alanlar için daha verimli ve daha uzun ömürlü enerji çözümleri sunma potansiyeli taşımaktadır. (Kaynak: Ronald_vanLoon)

🧰 Araçlar
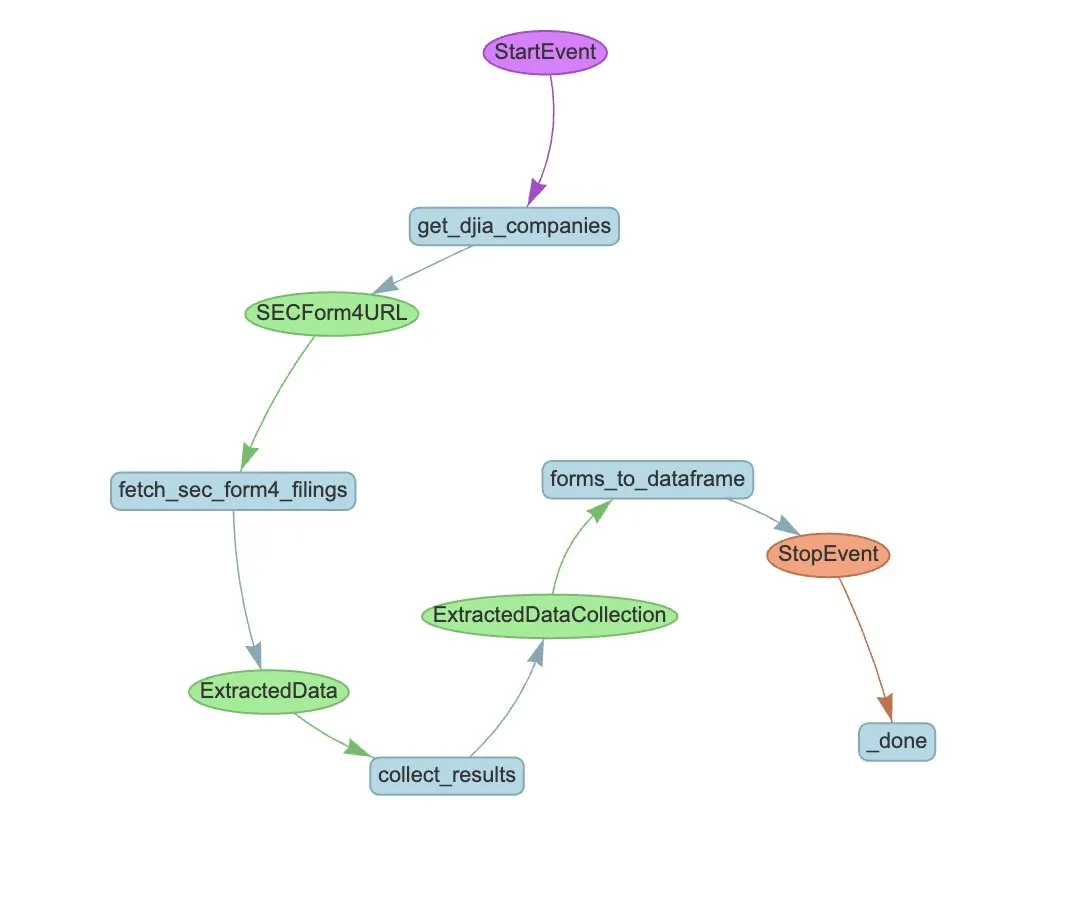
LlamaIndex, SEC Form 4 çıkarımını otomatikleştirmek için LlamaExtract ve Agent iş akışını tanıttı: LlamaIndex, SEC Form 4 dosyalarından yapılandırılmış bilgileri otomatik olarak çıkarmak için LlamaExtract ve Agent iş akışının nasıl kullanılacağını gösterdi. SEC Form 4, halka açık şirket yöneticilerinin, direktörlerinin ve ana hissedarlarının hisse senedi işlemlerini açıkladığı önemli bir belgedir. Çıkarım ajanı ve ölçeklenebilir bir iş akışı oluşturarak, Dow Jones Endüstri Ortalaması’ndaki tüm şirketlerin Form 4 beyanları verimli bir şekilde işlenebilir, bu da piyasa şeffaflığını ve veri analizi verimliliğini artırır. (Kaynak: jerryjliu0)
Cognee: AI Agent’lara dinamik bellek sağlayan açık kaynaklı bir araç: Cognee, AI Agent’lara dinamik bellek yetenekleri sağlamayı amaçlayan açık kaynaklı bir projedir ve yalnızca 5 satır kodla entegre edilebildiği iddia edilmektedir. Ölçeklenebilir, modüler bir ECL (Extract, Cognify, Load) boru hattı oluşturarak, Agent’ların geçmiş konuşmaları, belgeleri, görüntüleri ve ses transkripsiyonlarını birbirine bağlamasına ve almasına yardımcı olur, böylece geleneksel RAG sistemlerinin yerini alır, geliştirme zorluğunu ve maliyetini düşürür ve 30’dan fazla veri kaynağından veri işleme ve yüklemeyi destekler. (Kaynak: GitHub Trending)
Claude Code artık Pro kullanıcılarına açık ve topluluk sürümü GitHub Action yayınlandı: Anthropic’in AI programlama asistanı Claude Code, Pro abonelerine açıldı ve kullanıcılar JetBrains IDE eklentisi gibi yollarla kullanabiliyor. Topluluk geliştiricileri ayrıca, ücretli kullanıcıların GitHub Issues veya PR’larında doğrudan Claude Code’u çağırarak, ek API ücreti ödemeden abonelik kotalarını kullanarak kod incelemesi, soru yanıtlama gibi görevleri tamamlamalarına olanak tanıyan bir Claude Code GitHub Action fork sürümü yayınladı. (Kaynak: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
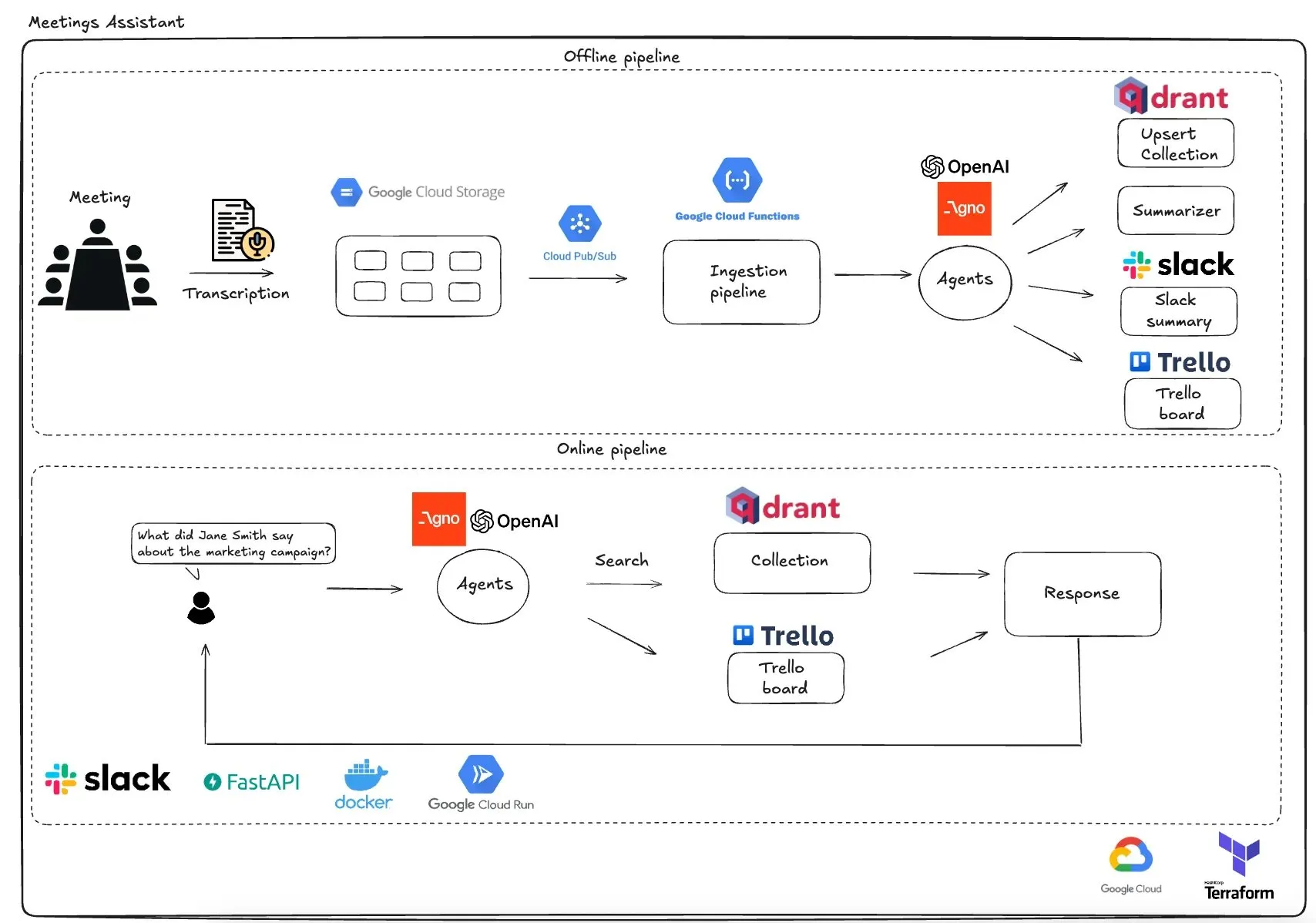
Qdrant, GCP tabanlı çoklu ajanlı toplantı asistanını tanıttı: Qdrant, tamamen sunucusuz bir çoklu ajanlı toplantı asistanı sistemi sergiledi. Bu sistem, toplantı içeriğini yazıya dökebiliyor, özetleme için LLM ajanlarını kullanabiliyor, bağlamsal bilgileri Qdrant vektör veritabanında saklayabiliyor ve görevleri Trello ile senkronize ederek nihai sonuçları doğrudan Slack’te teslim edebiliyor. Sistem, ajan orkestrasyonu için AgnoAgi’yi, Cloud Run üzerinde çalışan FastAPI’yi ve gömme ve çıkarım için OpenAI’yi kullanıyor. (Kaynak: qdrant_engine)
Microsoft, koordinatsız GUI öğesi yerelleştirmesi için GUI-Actor’ı yayınladı: Microsoft, Hugging Face’te GUI-Actor’ı yayınladı; bu, koordinat gerektirmeyen bir GUI (Grafik Kullanıcı Arayüzü) öğesi yerelleştirme yöntemidir. Bu yöntem, AI ajanlarının metin tabanlı koordinat tahminlerine dayanmak yerine özel bir <actor> token aracılığıyla doğrudan yerel görsel yamalara (visual patches) işaret etmesine olanak tanır ve GUI ajan operasyonlarının doğruluğunu ve sağlamlığını artırmayı amaçlar. (Kaynak: _akhaliq)

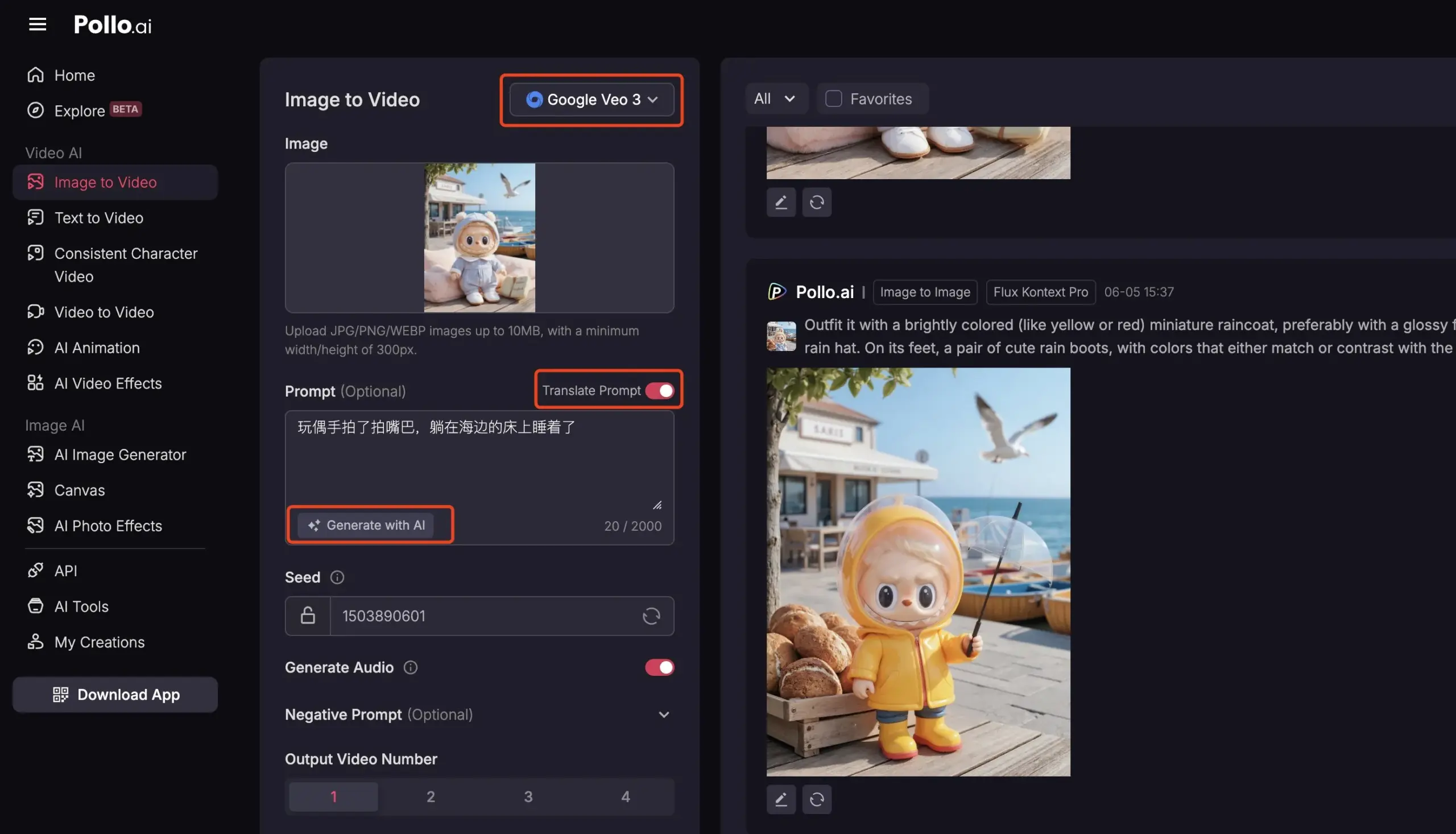
Pollo AI, kapsamlı AI video hizmetleri sunmak için Veo3 ve FLUX Kontext’i entegre etti: AI araç platformu Pollo AI son zamanlarda sık sık güncellenerek Google Veo3 video oluşturma modelini ve FLUX Kontext görüntü düzenleme işlevlerini entegre etti. Kullanıcılar bu platformda FLUX Kontext ile resimleri düzenledikten sonra doğrudan Veo3’e göndererek video oluşturabilirler. Platform ayrıca, piyasadaki birçok ana akım video büyük modeline tek seferde erişimi destekleyen bir API arayüzü sunar ve AI istem oluşturma, çok dilli çeviri gibi yardımcı işlevleri içerir, bu da AI video oluşturmanın kolaylığını ve verimliliğini artırmayı amaçlar. (Kaynak: op7418)
📚 Öğrenme Kaynakları
Meta-Learning derinlemesine analiz: AI’a nasıl öğrenileceğini öğretmek: “Öğrenmeyi öğrenme” olarak da bilinen Meta-Learning’in (Meta-Öğrenme) temel fikri, modeli az sayıda örnekle bile yeni görevlere hızla uyum sağlayabilecek şekilde eğitmektir. Bu süreç genellikle iki model içerir: temel öğrenici (base-learner) iç öğrenme döngüsünde belirli görevlere (az örnekle görüntü sınıflandırma gibi) hızla uyum sağlar, meta öğrenici (meta-learner) ise dış öğrenme döngüsünde temel öğrenicinin parametrelerini veya stratejilerini yönetir ve günceller, böylece yeni görevleri çözme yeteneğini artırır. Eğitim tamamlandıktan sonra, temel öğrenici meta öğrenicinin öğrendiği bilgileri kullanarak başlatılır. (Kaynak: TheTuringPost, TheTuringPost)

Makale İncelemesi: “A Controllable Examination for Long-Context Language Models”: Bu makale, mevcut uzun bağlamlı dil modelleri (LCLM) değerlendirme çerçevelerinin sınırlamalarına (gerçek dünya görevlerinin karmaşık ve çözülmesi zor olması, veri kirliliğine kolayca maruz kalması; NIAH gibi sentetik görevlerin bağlamsal tutarlılıktan yoksun olması) değinerek, ideal bir değerlendirme çerçevesinin sahip olması gereken üç özelliği önermektedir: kesintisiz bağlam, kontrol edilebilir ortam ve sağlam değerlendirme. Ayrıca, LCLM’leri anlama, çıkarım yapma ve güvenilirlik boyutlarında değerlendirmek için insan tarafından oluşturulmuş biyografileri kontrollü bir ortam olarak kullanan yeni bir kıyaslama olan LongBioBench’i tanıtmaktadır. Deneyler, çoğu modelin anlamsal anlama, başlangıç düzeyinde çıkarım yapma ve uzun bağlamlı güvenilirlik konularında hala eksiklikleri olduğunu göstermektedir. (Kaynak: HuggingFace Daily Papers)
Makale İncelemesi: “Advancing Multimodal Reasoning: From Optimized Cold Start to Staged Reinforcement Learning”: Deepseek-R1’in karmaşık metin görevlerindeki üstün çıkarım yeteneklerinden esinlenerek, bu çalışma optimize edilmiş soğuk başlatma (cold start) ve aşamalı takviyeli öğrenme (RL) yoluyla çok modlu büyük dil modellerinin (MLLM) karmaşık çıkarım yeteneklerinin nasıl geliştirilebileceğini araştırmaktadır. Araştırma, etkili bir soğuk başlatma başlatmasının MLLM çıkarımını geliştirmek için kritik olduğunu ve yalnızca özenle seçilmiş metin verileriyle başlatmanın bile mevcut birçok modeli geride bırakabildiğini bulmuştur. Standart GRPO’nun çok modlu RL’ye uygulandığında gradyan durması sorunu yaşadığı, ancak sonraki saf metin RL eğitiminin çok modlu çıkarımı daha da geliştirebildiği görülmüştür. Bu bulgulara dayanarak, araştırmacılar birçok zorlu kıyaslamada SOTA sonuçları elde eden ReVisual-R1’i tanıtmışlardır. (Kaynak: HuggingFace Daily Papers)
Makale İncelemesi: “Unleashing the Reasoning Potential of Pre-trained LLMs by Critique Fine-Tuning on One Problem”: Bu çalışma, önceden eğitilmiş LLM’lerin çıkarım potansiyelini verimli bir şekilde ortaya çıkarmak için bir yöntem önermektedir: tek bir problem üzerinde Eleştirel İnce Ayar (Critique Fine-Tuning, CFT). Modelin tek bir probleme ürettiği çeşitli çözümleri toplayarak ve bir öğretmen LLM’den ayrıntılı eleştiriler alarak eleştiri verileri oluşturulur ve ince ayar yapılır. Deneyler, Qwen ve Llama serisi modellerine tek bir problem üzerinde CFT uygulandıktan sonra, çeşitli çıkarım görevlerinde önemli performans artışları elde edildiğini göstermiştir; örneğin, Qwen-Math-7B-CFT matematik ve mantık çıkarım kıyaslamalarında ortalama %15-16’lık bir iyileşme sağlamış ve hesaplama maliyeti takviyeli öğrenmeden çok daha düşük olmuştur. (Kaynak: HuggingFace Daily Papers)
Makale İncelemesi: “SVGenius: Benchmarking LLMs in SVG Understanding, Editing and Generation”: Mevcut SVG (Ölçeklenebilir Vektör Grafikleri) işleme kıyaslamalarının sınırlı kapsama alanı, karmaşıklık katmanlaması eksikliği ve parçalanmış değerlendirme paradigmaları sorunlarını çözmek için SVGenius geliştirilmiştir. Bu, 24 uygulama alanından gerçek verilere dayanılarak oluşturulmuş ve sistematik karmaşıklık katmanlaması yapılmış, anlama, düzenleme ve oluşturma olmak üzere üç boyutu kapsayan 2377 sorgudan oluşan kapsamlı bir kıyaslamadır. 8 görev kategorisi ve 18 metrik aracılığıyla 22 ana akım modeli değerlendirmiş, mevcut modellerin karmaşık SVG’leri işlerkenki sınırlamalarını ortaya koymuş ve çıkarım destekli eğitimin saf ölçek genişletmeden daha etkili olduğuna işaret etmiştir. (Kaynak: HuggingFace Daily Papers)
Hugging Face Hub güncelleme günlüğü yayınlandı: Hugging Face Hub, en son güncelleme günlüğünü yayınladı. Kullanıcılar, platforma eklenen yeni özellikleri, model kütüphanesi güncellemelerini, veri kümesi genişletmelerini ve araç zinciri iyileştirmelerini içeren en son gelişmeleri öğrenmek için bu günlüğü inceleyebilirler. Bu, topluluk kullanıcılarının Hugging Face ekosisteminin en son kaynaklarından ve yeteneklerinden zamanında haberdar olmalarına ve bunlardan yararlanmalarına yardımcı olur. (Kaynak: huggingface, _akhaliq)
Maxime Labonne ve diğer yazarlar çok sayıda LLM Notebook’unu açık kaynak olarak yayınladı: LLM Mühendis El Kitabı’nın yazarları Maxime Labonne ve Iustin Paul, LLM ile ilgili bir dizi Jupyter Notebook’unu açık kaynak olarak yayınladı. Bu Notebook’lar zengin içerikli olup, yalnızca temel ince ayar tekniklerini değil, aynı zamanda otomatik değerlendirme, tembel birleştirmeler (lazy merges), karma uzman modelleri (frankenMoEs) oluşturma ve sansürü kaldırma teknikleri gibi ileri düzey konuları da kapsamaktadır ve LLM geliştiricileri ile araştırmacıları için değerli pratik kaynaklar sunmaktadır. (Kaynak: maximelabonne)
DeepLearningAI, The Batch haftalık bültenini yayınladı ve AI Fund’ın AI geliştiricilerini nasıl yetiştirdiğini tartıştı: Andrew Ng, en son The Batch haftalık bülteninde, AI Fund’ın AI yeteneklerini ve geliştiricilerini yetiştirme konusundaki deneyimlerini ve stratejilerini paylaştı. Bu haftaki bülten ayrıca DeepSeek’in yeni açık kaynak modelinin en iyi LLM’lerle rekabet eden performansı, Duolingo’nun dil kurslarını genişletmek için AI kullanması, AI’ın enerji tüketimi dengesi ve kötü niyetli bağlantıların AI Agent’ları potansiyel olarak yanıltması gibi sıcak konuları da kapsadı. (Kaynak: DeepLearningAI)

💼 İş Dünyası
Reddit, Anthropic’i kullanıcı verilerini AI eğitimi için izinsiz kullanmakla suçlayarak dava etti: Reddit, AI şirketi Anthropic’e karşı, AI modellerini (Claude gibi) eğitmek için Reddit içeriğini otomatik botlarla izinsiz olarak topladığı, bunun da sözleşme ihlali ve haksız rekabet oluşturduğu iddiasıyla dava açtı. Bu dava, mevcut AI gelişiminde veri kazıma ve model eğitimi yasallığı konusundaki tartışmaları vurgulamakta ve içerik platformlarının veri değerlerini korumaya yönelik artan önemini yansıtmaktadır. (Kaynak: Reddit r/artificial, Reddit r/ArtificialInteligence, TheRundownAI)

Amazon, Kuzey Karolina’da AI veri merkezi kurmak için 10 milyar dolar yatırım yapmayı planlıyor: Amazon, artan AI iş taleplerini desteklemek için Kuzey Karolina’da yeni veri merkezleri kurmak üzere 10 milyar dolar yatırım yapacağını duyurdu. Bu hamle, büyük teknoloji şirketlerinin AI altyapısına yönelik süregelen yatırımlarını yansıtmakta ve AI model eğitimi ile çıkarımı için gereken büyük ölçekli hesaplama ve depolama kaynaklarını karşılama amacını taşımaktadır. (Kaynak: Reddit r/artificial)

Anthropic, Windsurf.ai’nin Claude model API erişimini kısıtladı, platform riski endişeleri arttı: AI uygulama geliştirme platformu Windsurf.ai, Anthropic’in sadece 5 günden az bir süre önceden bildirimde bulunarak Claude 3.x ve Claude 4 modellerine olan API erişim kapasitesini önemli ölçüde azalttığını açıkladı. Bu durum, Windsurf.ai’yi ücretli kullanıcı hizmetlerini güvence altına almak için acilen üçüncü taraf tedarikçiler aramaya ve ücretsiz ile Pro kullanıcıları için BYOK (kendi anahtarını getir) seçeneği sunmaya zorladı. Bu olay, geliştiricilerin AI model sağlayıcılarının platform risklerine ilişkin endişelerini artırdı; yani model sağlayıcıları hizmet stratejilerini her an değiştirebilir ve hatta alt uygulamalarla rekabete girebilir. (Kaynak: swyx, scaling01, mervenoyann)
🌟 Topluluk
AI Mühendisleri Konferansı (@aiDotEngineer) gündemde, Agent tasarımı ve AI girişimciliği odak noktası: San Francisco’da düzenlenen AI Mühendisleri Konferansı (@aiDotEngineer) toplulukta sıcak bir tartışma konusu oldu. LlamaIndex, üretim ortamlarında etkili Agent tasarım modellerini paylaştı; Anthropic konferansta yeni girişimlere yönelik bir “ihtiyaç listesi” yayınladı ve MCP sunucularının yeni alanlardaki uygulamalarına, sunucu oluşturmanın basitleştirilmesine ve AI uygulama güvenliğine (araç zehirlenmesi gibi) odaklandı; Graphite, AI destekli kod inceleme aracını sergiledi. Konferansta ayrıca yeni nesil GPT modellerini ölçeklendirmenin karşılaştığı temel araştırma zorlukları gibi konular da tartışıldı. (Kaynak: swyx, swyx, swyx, iScienceLuvr)

Araştırmacı Rohan Anil’in Anthropic’e katılması dikkat çekti: Araştırmacı Rohan Anil’in Anthropic ekibine katılacağını duyurması, AI topluluğunda geniş yankı uyandırdı ve tartışmalara neden oldu. Birçok sektör profesyoneli ve takipçi bu durumu tebrik etti ve Anthropic’in araştırma çalışmalarına yeni katkılar getirmesini beklediklerini belirtti. Bu aynı zamanda en iyi AI yeteneklerinin hareketliliğinin sektördeki dengeler üzerindeki potansiyel etkisini de yansıtıyor. (Kaynak: arohan, gallabytes, andersonbcdefg, scaling01, zacharynado)
Mahkeme, OpenAI’den tüm ChatGPT günlüklerini saklamasını talep etti, veri saklama politikası tartışmaları başladı: Edinilen bilgilere göre, mahkeme OpenAI’den “geçici sohbetler” ve silinmesi gereken API istekleri de dahil olmak üzere tüm ChatGPT günlüklerini saklamasını talep etti. Bu haber, toplulukta veri saklama politikaları hakkında tartışmalara yol açtı. Özellikle OpenAI API’sini kullanan uygulamalar için bu, kendi veri saklama politikalarının tam olarak uygulanamayacağı anlamına gelebilir ve bu da kullanıcı gizliliği ve veri yönetimi açısından yeni zorluklar doğurabilir. Kullanıcılara, verilerini korumak için mümkün olduğunda yerel modelleri tercih etmeleri önerilmektedir. (Kaynak: code_star, TomLikesRobots)

AI tarafından üretilen içeriğin yaygınlaşması ve “AI Çöplüğü” (AI Slop) olgusu endişe yaratıyor: Sosyal medyada düşük kaliteli, dikkat çekmeye çalışan AI tarafından üretilen içeriklerin (“AI Çöplüğü” olarak adlandırılıyor) artması, Reddit’teki AI tarafından oluşturulan gönderilerden Facebook’taki “karides İsa” gibi AI resimlerine kadar, kullanıcıların bilgi kalitesi ve internet ortamının bozulması konusundaki endişelerini artırıyor. Bu içerikler genellikle botlar veya trafik arayanlar tarafından ucuza üretiliyor ve “etkileşim tuzağı” yoluyla beğeni ve paylaşım elde etmeyi amaçlıyor. Araştırmalar, internet trafiğinin büyük bir kısmının yanlış bilgi yayan, veri çalan “kötü botlar” tarafından oluşturulduğunu gösteriyor. Bu olgu yalnızca kullanıcı deneyimini etkilemekle kalmıyor, aynı zamanda demokrasi ve siyasi iletişim için de bir tehdit oluşturuyor ve gelecekteki AI modellerinin eğitim verilerini kirletme potansiyeli taşıyor. (Kaynak: aihub.org)

LLM maliyet tartışması: Gemini uygun maliyetli, Claude 4 kodlama maliyeti dikkat çekiyor: Topluluk tartışmaları, mevcut LLM kullanım maliyetlerinin önemli ölçüde farklılık gösterdiğine işaret ediyor. Örneğin, tüm bir sigorta belgesini işlemek ve çok sayıda soru sormak için Gemini kullanmanın maliyeti yalnızca yaklaşık 0.01 ABD doları olup, yüksek bir maliyet etkinliği göstermektedir. Buna karşılık, Claude 4 modeli kodlama gibi görevlerde üstün performans gösterse de, Cursor.ai gibi platformlardaki maksimum mod (max mode) kullanım maliyeti yüksektir ve bu da kullanıcıları Google Gemini 2.5 Pro gibi daha uygun maliyetli seçeneklere yöneltmektedir. (Kaynak: finbarrtimbers, Teknium1)
AI Agent’lar gerçek web senaryolarında CAPTCHA (insan-makine doğrulaması) çözmede zorluklarla karşılaşıyor: MetaAgentX ekibi, çok modlu etkileşimli ajanların CAPTCHA çözme yeteneğini değerlendirmeye odaklanan Open CaptchaWorld platformunu yayınladı. Testler, GPT-4o gibi SOTA modellerinin bile 20 farklı gerçek web ortamındaki etkileşimli CAPTCHA’ları işlerken başarı oranının yalnızca %5-%40 olduğunu gösterdi; bu, insanların %93,3’lük ortalama başarı oranının çok altında. Bu, mevcut AI Agent’ların görsel anlama, çok adımlı planlama, durum takibi ve hassas etkileşim konularında hala darboğazları olduğunu ve CAPTCHA’nın pratik dağıtımlarının önünde büyük bir engel teşkil ettiğini gösteriyor. (Kaynak: 量子位)

AI ajanı eğitim pazarı hareketli, kurs kalitesi ve istihdam beklentileri dikkat çekiyor: AI Agent kavramının yükselişiyle birlikte, ilgili eğitim kursları da hızla çoğaldı. Bazı eğitim kurumları, başlangıç seviyesinden istihdama kadar kapsamlı rehberlik sunduklarını, hatta “iş garantisi” vaat ettiklerini iddia ediyor; ücretler birkaç yüz yuan’dan on binlerce yuan’a kadar değişiyor. Ancak, piyasadaki kursların kalitesi değişkenlik gösteriyor; bazı kursların içeriğinin sığ olduğu, aşırı pazarlandığı ve hatta “kolay para kazanma” vaat eden AI hızlandırılmış kurslarına benzediği belirtiliyor. Öğrenciler ve gözlemciler, bu tür eğitimlerin gerçek etkisi, eğitmenlerin nitelikleri ve “iş garantisi” vaatlerinin gerçekliği konusunda temkinli davranıyor ve bunların AI gelişiminin geçiş dönemindeki bir başka “sahte talep” olabileceğinden endişe ediyorlar. (Kaynak: 36氪)

💡 Diğer
AI’ın robotik alanındaki uygulama gelişmeleri: dokunsal algılamalı el, amfibi robot ve itfaiyeci robot köpek: AI teknolojisi, robot yeteneklerinin sınırlarını zorluyor. Araştırmacılar, çevreyle daha iyi etkileşim kurmasını sağlayan dokunsal algılama yeteneğine sahip bir mekanik el geliştirdi. Copperstone HELIX Neptune, farklı arazilerde çalışabilen AI destekli bir amfibi robot sergiledi. Çin ise 60 metre su püskürtebilen, merdiven çıkabilen ve kurtarma operasyonlarını canlı yayınlayabilen bir itfaiyeci robot köpek geliştirdi. Bu gelişmeler, AI’ın robotların algılama, karar verme ve karmaşık görevleri yerine getirme yeteneklerini artırma potansiyelini gösteriyor. (Kaynak: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

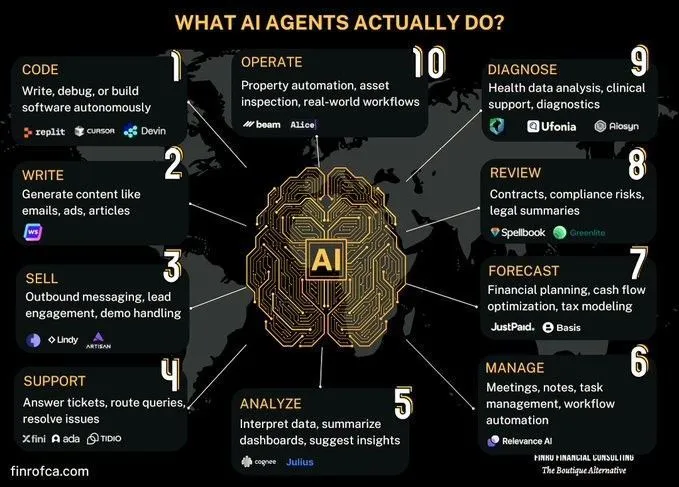
AI Agent ve Üretken AI karşılaştırma tartışması: Toplulukta AI Agent (akıllı ajan AI) ile Üretken AI (Generative AI) arasındaki farklar ve bağlantılar hakkında tartışmalar ortaya çıktı. Üretken AI temel olarak içerik oluşturmaya odaklanırken, AI Agent daha çok algılama, planlama ve eyleme dayalı özerk karar verme ve görev yürütmeye odaklanır. İkisi arasındaki farkları anlamak, AI teknolojisinin gelişim yönünü ve uygulama senaryolarını daha iyi kavramaya yardımcı olur. (Kaynak: Ronald_vanLoon, Ronald_vanLoon)
AI’ın karmaşık organizasyonel süreç otomasyonundaki zorlukları tartışılıyor: AI, belirli görevleri otomatikleştirme veya destekleme konusunda ilerleme kaydetmiş olsa da, daha geniş bir ekonomik dönüşüm sağlamak için insan veya ekip yerine geçmesi büyük bir karmaşıklıkla karşı karşıyadır. Birçok kuruluşta açıkça belgelenmemiş ancak hayati önem taşıyan, riski yüksek ancak nadiren meydana gelen ve nedenleri unutulmuş olabilecek kadar alışkanlık haline gelmiş süreçler bulunmaktadır. AI ajanlarının bu tür örtük bilgileri deneme yanılma yoluyla öğrenmesi, maliyetinin yüksek olması ve öğrenme fırsatlarının sınırlı olması nedeniyle zordur. Bu, basit bir makine öğrenmesinden ziyade yeni bir teknolojik paradigma gerektirmektedir. (Kaynak: random_walker)