
Anahtar Kelimeler:Yapay Zeka Ajanı, Büyük Dil Modeli, Çok Modlu, Pekiştirmeli Öğrenme, Dünya Modeli, Gemini, Qwen, DeepSeek, Yapay Zeka Ajanı Hype’ı, Seyrek Transformer Teknolojisi, GraphRAG Çok Atlı Soru-Cevap, Cihaz Tarafında Yapay Zeka Modeli, Yapay Zeka Ses Duygu İfadesi
🔥 Odak Noktası
Çin’de AI Agent’ları çılgınlığı yükseliyor, startup’lar ve devler pazar payı için yarışıyor: 2024’teki temel büyük dil modeli (LLM) çılgınlığının ardından, 2025’te Çin AI alanındaki odak noktası, görevleri otonom olarak tamamlayabilen sistemler olan AI Agent’larına kayıyor. Manus’un (seyahat planlama, web sitesi tasarlama vb. yapabilen genel amaçlı bir AI Agent) piyasaya sürülmesi, pazarda büyük ilgi gördü ve Genspark ile Flowith gibi birçok taklitçinin ortaya çıkmasına neden oldu. Bu Agent’lar, büyük dil modelleri üzerine inşa edilmiş olup çok adımlı görev yürütmeyi optimize eder. Çin, yüksek düzeyde entegre uygulama ekosistemi, hızlı ürün iterasyonu ve devasa dijital kullanıcı tabanı sayesinde AI Agent’larının geliştirilmesinde avantaja sahip. Şu anda Manus, Genspark ve Flowith gibi startup şirketleri, en iyi Batılı modellerin Çin anakarasında kısıtlı olması nedeniyle ağırlıklı olarak denizaşırı pazarlara odaklanıyor. Aynı zamanda, ByteDance ve Tencent gibi teknoloji devleri, süper uygulamalarına entegre edilecek yerel AI Agent’ları geliştiriyor ve muhtemelen devasa veri ekosistemlerinden yararlanacaklar. Bu yarış, AI Agent’larının pratik biçimini ve hizmet vereceği kitleyi tanımlayacak (kaynak: MIT Technology Review)

DeepMind bilim insanlarının yeni makalesi ortaya koyuyor: Çok adımlı hedef görevlerini genelleştirebilen herhangi bir agent, esasen çevrenin bir öngörücü modelini (dünya modeli) öğrenmiştir: DeepMind bilim insanı Jon Richens’ın ICML 2025’te yayınlanan makalesi, çok adımlı hedef odaklı görevlere genelleme yapabilen agent’ların, kaçınılmaz olarak çevrelerinin bir öngörücü modelini, yani “agent’ın kendisinin bir dünya modeli olduğunu” öğrendiğini belirtiyor. Bu görüş, Ilya Sutskever’in 2023’teki öngörüsüyle örtüşüyor ve AGI’ye ulaşmak için modelsiz bir kestirme yolun olmadığını vurguluyor. Araştırma, agent’ın stratejisinin zaten çevreyi simüle etmek için gereken bilgileri içerdiğini ve daha kesin bir dünya modeli öğrenmenin, performansı artırmanın ve daha karmaşık hedefleri tamamlamanın ön koşulu olduğunu gösteriyor. Makale ayrıca, agent stratejisinden dünya modelini çıkaran bir algoritma önererek planlama, ters pekiştirmeli öğrenme ve dünya modeli kurtarma arasındaki üçlü ilişkiyi daha da açıklıyor. Bu bulgu, hedef odaklı öğrenmenin, agent’ların sosyal biliş, belirsizlik çıkarımı gibi çeşitli ortaya çıkan yeteneklerini doğurması açısından önemini vurguluyor (kaynak: 36Kr)

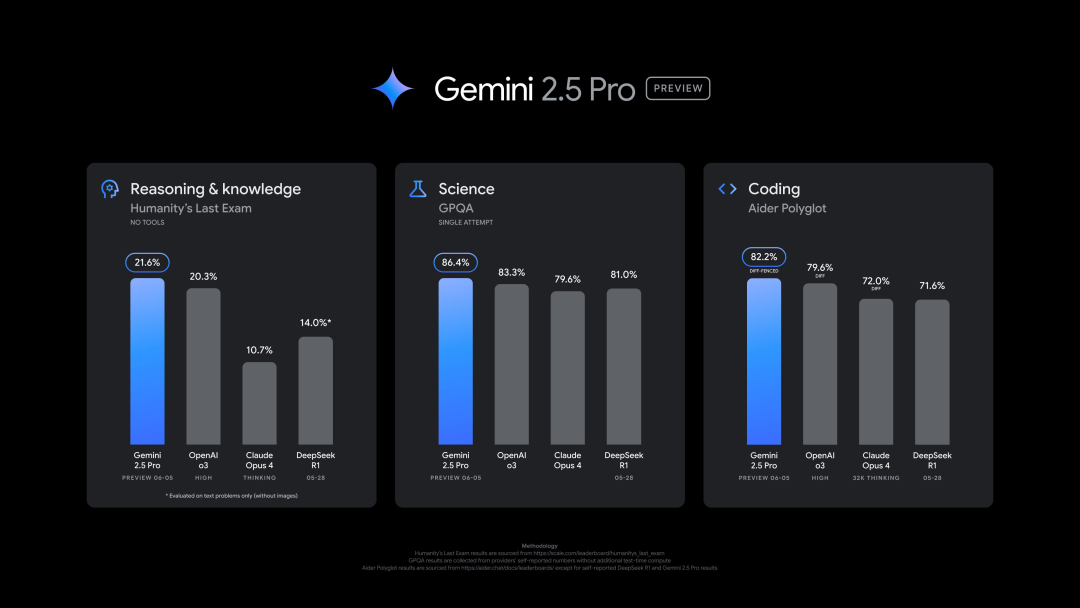
Google, Gemini 2.5 Pro’nun (0605) yeni sürümünü yayınladı, birçok benchmark testinde üstün performans gösterdi ancak hızla jailbreak edildi: Google, Gemini 2.5 Pro’nun en son sürümünü (0605) piyasaya sürdü. Kod üretimi ve çıkarım yeteneklerinde daha da geliştirilen model, “insanlığın son sınavı” veri kümesinde OpenAI’nin GPT-4o modelini geride bıraktı. Yeni Gemini sürümü, LMArena büyük dil modeli yarışma platformunda tekrar zirveye yerleşti ve Elo puanını bir önceki sürüme göre 24 puan artırdı. Google CEO’su Pichai de yeni modelin gücüne işaret eden bir paylaşım yaptı. Bu sürümün Gemini 2.5 Pro’nun uzun vadeli kararlı sürümü olması bekleniyor ve Gemini App, Google AI Studio ve Vertex AI’da kullanıma sunuldu. Güçlü performansına rağmen, yeni model yayınlandıktan birkaç saat sonra kullanıcılar tarafından başarıyla “jailbreak” edildi ve güvenlik açıkları ortaya çıktı; patlayıcı ve uyuşturucu üretimi hakkında içerik üretebildiği görüldü (kaynak: 36Kr, 36Kr)
OpenAI yöneticileri, insan ile AI arasındaki duygusal bağ ve AI bilinci sorunlarını tartışıyor: OpenAI model davranışı ve politikaları sorumlusu Joanne Jang, kullanıcılar ile ChatGPT gibi AI modelleri arasında artan duygusal bağları ele alan bir yazı yayınladı. İnsanların nesneleri kişileştirme eğiliminde olduğunu ve AI’ın etkileşimliliği ile yanıt verme yeteneğinin (konuşmaları hatırlama, tonu taklit etme, empati ifade etme gibi) bu duygusal yansıtmayı artırdığını, özellikle yalnız hisseden kullanıcılara arkadaşlık hissi sunabileceğini belirtti. Makale, “ontolojik bilinç” (AI’ın gerçekten bilinçli olup olmadığı, bilimsel olarak kesin değil) ile “algısal bilinç” (AI’ın ne kadar “canlı” hissettirdiği) arasında ayrım yapıyor ve OpenAI’nin şu anda daha çok ikincisinin insan duygusal sağlığı üzerindeki etkisine odaklandığını ifade ediyor. OpenAI’nin hedefi, “sıcak ama benliksiz” modeller tasarlamak; yani sıcak, yardımsever davranan ancak aşırı duygusal bağ kurmaya çalışmayan veya otonom niyetler sergilemeyen, kullanıcıları sağlıksız bir bağımlılığa yönlendirmekten kaçınan modeller oluşturmak (kaynak: 36Kr, 36Kr)
🎯 Gelişmeler
Qwen ekibi ve Tsinghua Üniversitesi araştırması ortaya koydu: Büyük dil modeli pekiştirmeli öğrenmesi için sadece %20 yüksek entropili kritik Token yeterli: Qwen ekibi ve Tsinghua Üniversitesi LeapLab’in son araştırması, büyük dil modellerinin çıkarım yeteneklerini pekiştirmeli öğrenme ile eğitirken, gradyan güncellemesi için yalnızca yaklaşık %20 yüksek entropili (dallanma) Token kullanmanın, tüm Token’ları kullanılarak yapılan eğitimle aynı, hatta daha iyi sonuçlar verdiğini gösteriyor. Bu yüksek entropili Token’lar çoğunlukla mantıksal bağlaçlar veya varsayımlar getiren kelimeler olup, çıkarım yolu keşfi için kritik öneme sahiptir. Bu yöntem, Qwen3-32B üzerinde SOTA sonuçları elde etti ve maksimum yanıt uzunluğunu artırdı. Araştırma ayrıca, pekiştirmeli öğrenmenin yüksek entropili Token’ların entropisini koruma ve artırma eğiliminde olduğunu, çıkarım esnekliğini sürdürdüğünü ve bunun denetimli ince ayardan daha iyi genelleme yeteneğinin anahtarı olabileceğini buldu. Bu keşif, büyük dil modeli pekiştirmeli öğrenme mekanizmalarını anlamak, eğitim verimliliğini ve model genelleme yeteneğini artırmak için önemli anlamlar taşıyor (kaynak: 36Kr)
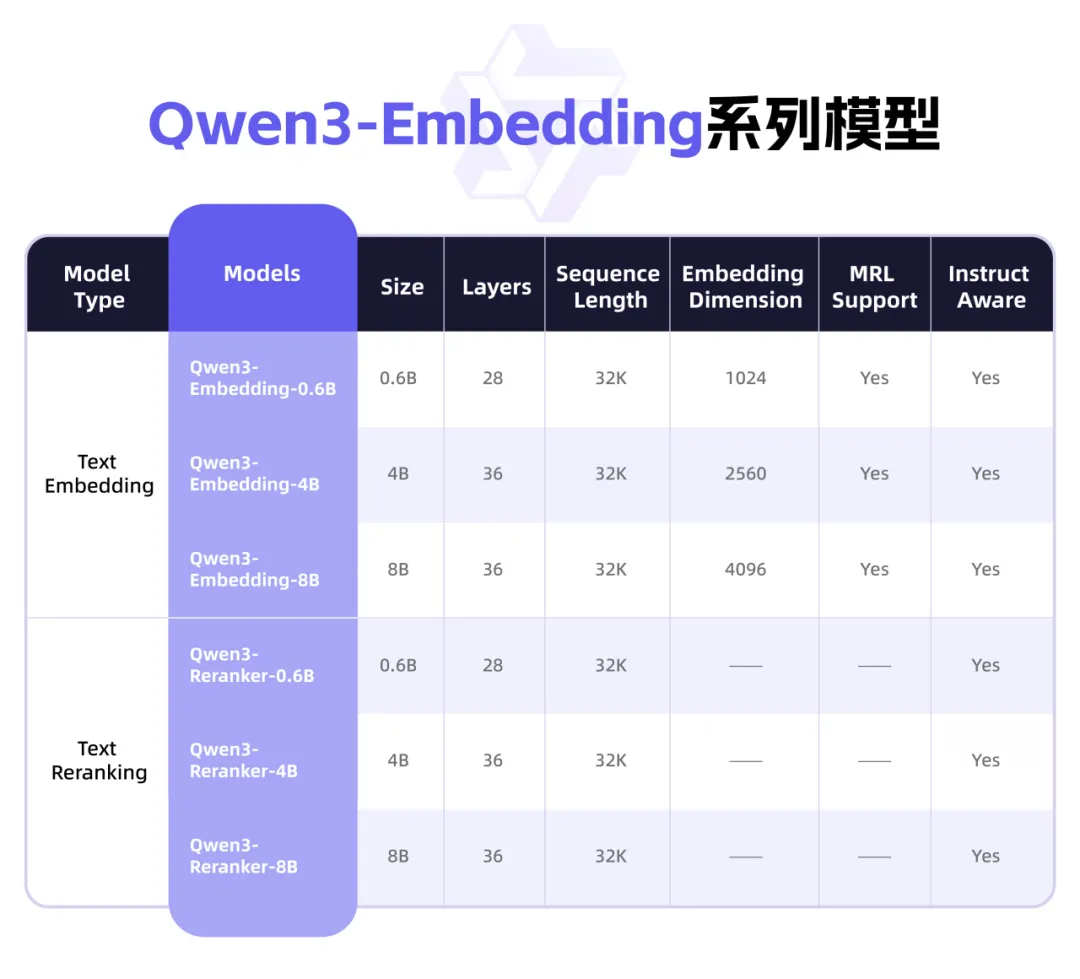
Qwen3, metin temsili ve Rerank odaklı yepyeni Embedding serisi modellerini yayınladı: Alibaba Qwen ekibi, metin temsili, erişim ve sıralama görevleri için tasarlanmış Qwen3-Embedding serisi modellerini tanıttı. Bu seri, Qwen3 temel modeli üzerine eğitilmiş 0.6B, 4B ve 8B boyutlarında Embedding modelleri ve Reranker modelleri içeriyor ve çok dilli avantajını miras alarak 119 dili destekliyor. 8B sürümü, MTEB çok dilli sıralamasında ticari API’leri geride bırakarak birinci oldu. Modeller, büyük ölçekli zayıf denetimli karşılaştırmalı öğrenme, yüksek kaliteli etiketli veriyle denetimli eğitim ve model birleştirme dahil olmak üzere çok aşamalı bir eğitim paradigması kullanıyor. Qwen3-Embedding serisi modelleri Hugging Face, ModelScope ve GitHub’da açık kaynak olarak yayınlandı ve Alibaba Cloud Bailian platformu üzerinden kullanılabiliyor (kaynak: 36Kr)
Anthropic Claude proje özelliği güncellendi, 10 kat daha fazla içerik işleme desteği sunuyor: Anthropic, “Projects on Claude” özelliğinin artık eskisinden 10 kat daha fazla içerik işleyebildiğini duyurdu. Kullanıcılar mevcut eşiği aşan dosyalar eklediğinde, Claude işlevsel bağlamı genişletmek için yeni bir erişim moduna geçiyor. Bu yükseltme, özellikle yarı iletken veri sayfaları gibi büyük belgeleri işlemesi gereken kullanıcılar için değerli. Daha önce bazı kullanıcılar bu nedenle RAG erişim yeteneklerine sahip ChatGPT’yi kullanmayı tercih ediyordu. Topluluk kullanıcıları bunu memnuniyetle karşıladı ve Claude’un kodlama konusunda OpenAI ve Google modellerinden daha iyi olabileceğine dair tartışmalar var (kaynak: Reddit r/ClaudeAI)
Seyrek Transformer teknolojisindeki gelişmeler: Daha hızlı LLM çıkarımı ve daha düşük bellek kullanımı vaat ediyor: LLM in a Flash (Apple) ve Deja Vu araştırmalarına dayanan topluluk, yapılandırılmış bağlam seyrekliği için birleşik operatör çekirdekleri geliştirdi. Bu teknoloji, çıktısı nihayetinde sıfır olacak ileri beslemeli katman ağırlıklarıyla ilişkili aktivasyon değerlerinin yüklenmesini ve hesaplanmasını önleyerek MLP katmanı performansında 5 kat artış ve bellek tüketiminde %50 azalma sağlıyor. Llama 3.2 modeline (ileri beslemeli katmanlar ağırlık ve hesaplamanın %30’unu oluşturur) uygulandığında, iş hacmi 1.6-1.8 kat arttı, ilk Token üretim süresi 1.51 kat hızlandı, çıktı hızı 1.79 kat arttı ve bellek kullanımı %26.4 azaldı. İlgili operatör çekirdekleri GitHub’da sparse_transformers adıyla açık kaynak olarak yayınlandı ve int8, CUDA ve seyrek dikkat desteği eklenmesi planlanıyor. Topluluk, bunun model kalitesi üzerindeki potansiyel etkisine odaklanıyor (kaynak: Reddit r/LocalLLaMA)
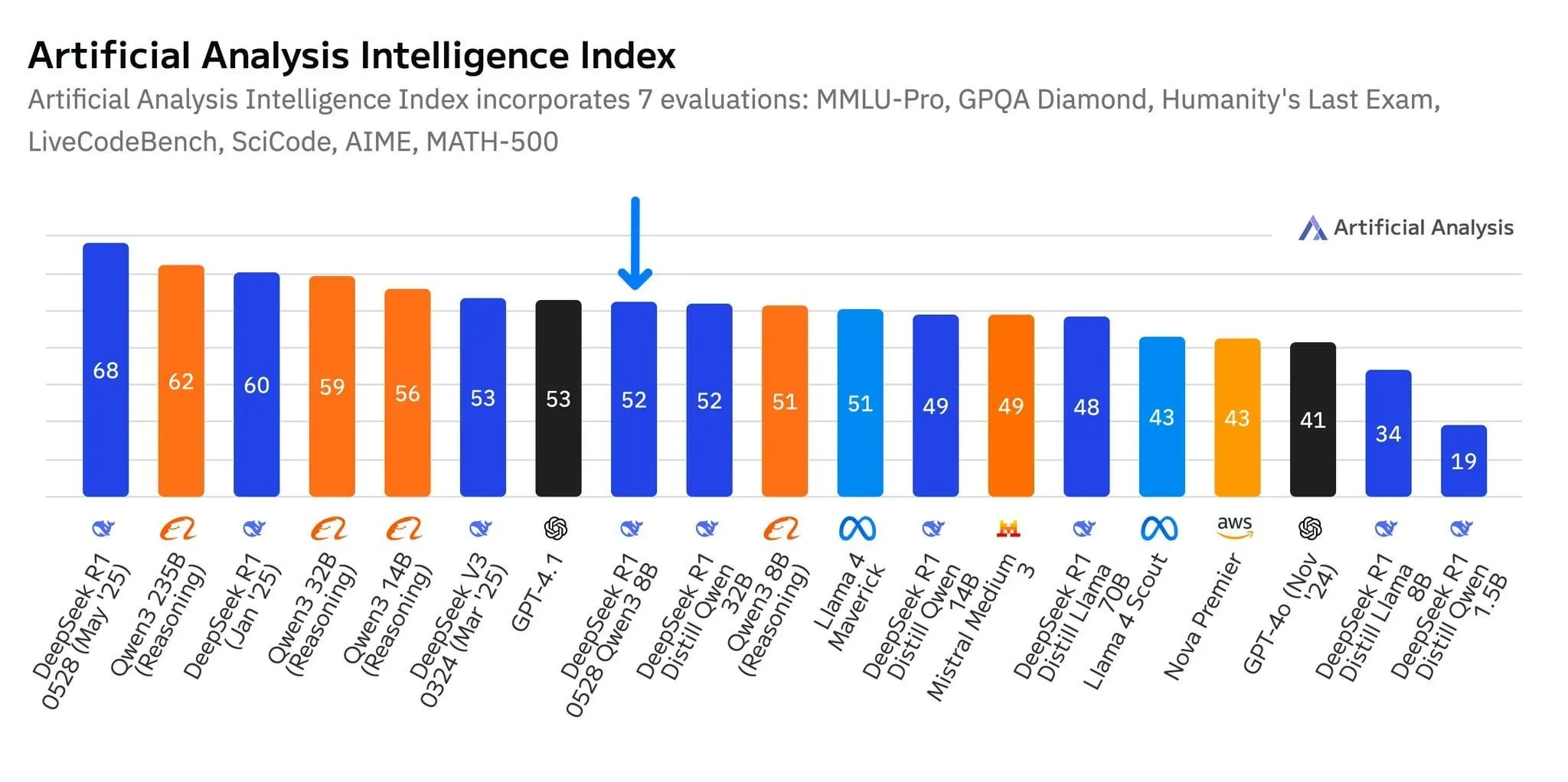
DeepSeek’in yeni modeli R1-0528-Qwen3-8B, 8B parametre seviyesinde öne çıkıyor ancak avantajı zayıf: Artificial Analysis verilerine göre, DeepSeek’in son yayınladığı R1-0528-Qwen3-8B modeli 8 milyar parametre seviyesinde en akıllı model olarak görünüyor, ancak liderlik avantajı belirgin değil; Alibaba’nın kendi Qwen3 8B modeli hemen arkasından geliyor ve sadece bir puan farkla ikinci sırada. Topluluk tartışmaları, bu küçük boyutlu modellerin performansının mükemmel olmasına rağmen, benchmark testlerinde aşırı uyum (overfitting) sorunu olabileceğine işaret ediyor. Örneğin, Qwen serisi modellerin MMLU gibi benchmark testlerinde öne çıkması, eğitim verilerinin benzer formatta soru-cevap çiftleri içermesiyle ilgili olabilir. Kullanıcıların gerçek deneyimlerinde, Destill R1 8B kodlama, matematik ve çıkarım konularında daha iyi performans gösterirken, Qwen 8B yazma ve çok dilli (İspanyolca gibi) konularda daha doğal. Bazı kullanıcılar küçük modellerin zekasının sınıra yaklaştığını düşünüyor (kaynak: Reddit r/LocalLLaMA)
Tiangong ve StepStar gibi orta kademe AI şirketleri, pazar atılımı için Agent’lara odaklanıyor: DeepSeek, Doubao gibi lider AI uygulamalarının “kazanan her şeyi alır” durumu karşısında, Kunlun Tech’e bağlı Tiangong APP, ofis senaryolarını merkezine alan bir AI Agent platformuna dönüşerek “baştan aşağı” bir yükseltme gerçekleştirdi ve görev tamamlama yeteneğini vurguladı. StepStar ise stratejisini ayarlayarak, “Maopaoya” gibi C-ucu ürünlerini daralttı, “Yuewen”i “Step AI” olarak yeniden adlandırdı ve model araştırması ile ToB pazarına odaklanarak, çok modlu Agent’ların cep telefonları, otomobiller, robotlar gibi terminallerde uygulanmasına ağırlık verdi. Bu ayarlamalar, lider olmayan AI üreticilerinin şiddetli rekabette, Agent’lara yatırım yaparak “genel yetenek yarışından” “senaryo kapalı döngü oluşturmaya” geçerek dikey segmentlerde hayatta kalma ve gelişme fırsatları bulma çabasını yansıtıyor (kaynak: 36Kr)
Qwen2.5-Omni çok modlu büyük dil modeli yayınlandı, metin, görüntü, video, ses girişi ve ses-metin çıkışını destekliyor: Qwen2.5-Omni, metin, görüntü, video ve sesi girdi olarak işleyebilen ve metin ile ses çıktısı üretebilen, yeni yayınlanmış açık kaynaklı (Apache 2.0 lisanslı) bir çok modlu büyük dil modelidir. Bu, geliştiricilere Gemini benzeri ancak yerel olarak dağıtılabilen ve araştırılabilen güçlü bir araç sunuyor. Makale, modeli kısaca tanıtıyor ve çok modlu etkileşim potansiyelini vurgulayan basit bir çıkarım deneyi gösteriyor; yerelleştirilmiş çok modlu AI uygulamalarının geliştirilmesini teşvik etmesi bekleniyor (kaynak: Reddit r/deeplearning)
![[Article] Qwen2.5-Omni: An Introduction](https://rebabel.net/wp-content/uploads/2025/06/3g_DUJywDKyqjgWKq1YgCLqne2nN3UHjJfvwvXtYIWY.webp)
OpenAI, “silinmiş” sohbet kayıtları da dahil olmak üzere tüm ChatGPT günlüklerini saklamakla mahkeme tarafından emredildi: New York Times gibi haber kuruluşlarının açtığı telif hakkı davasında, ABD mahkemesi 2025 Mayıs 13’te OpenAI’nin, kullanıcılar “silmiş” olsa bile tüm ChatGPT sohbet günlüklerini saklaması gerektiğine karar verdi. Davacılar, OpenAI’nin makalelerini izinsiz olarak ChatGPT’yi eğitmek için kullandığını iddia ediyor ve kullanıcıların kanıtları yok etmek için ödeme duvarlarını aşmayla ilgili sohbet kayıtlarını silebileceğinden endişe ediyor. Bu durum, kullanıcı gizliliği endişelerini artırdı ve GDPR gibi düzenlemelerle çelişebilir. OpenAI ise bu emrin spekülasyona dayandığını, kanıt eksikliği olduğunu ve operasyonlarına ağır bir yük getirdiğini savunuyor. Bu dava, fikri mülkiyet koruması ile kullanıcı gizliliği arasındaki gerilimi vurguluyor (kaynak: Reddit r/ArtificialInteligence)
X (eski adıyla Twitter), AI botlarının verilerini eğitim için kullanmasını yasakladı: X platformu, politikalarını güncelleyerek verilerinin veya API’sinin dil modeli eğitimi için kullanılmasını yasakladı ve AI ekiplerinin içeriğine erişimini daha da sıkılaştırdı. Aynı zamanda Anthropic, ABD ulusal güvenliği için özel olarak tasarlanmış AI modeli Claude Gov’u tanıttı; bu durum OpenAI, Meta, Google gibi teknoloji şirketlerinin hükümet ve savunma alanlarına aktif olarak AI araçları sunma eğilimini yansıtıyor (kaynak: Reddit r/ArtificialInteligence)

Amazon, yeni bir AI agent ekibi kurdu ve insansı robotlarla teslimatı test ediyor: Amazon, tüketici ürünleri geliştirme departmanı Lab126 bünyesinde AI agent’larının geliştirilmesine odaklanan yeni bir ekip kurdu ve insansı robotlarla paket teslimatını test etmeyi planlıyor. Testler, Kaliforniya San Francisco’da kapalı bir engelli parkuruna dönüştürülmüş bir ofiste yapılacak; robotlar (muhtemelen Çinli Unitree Robotics ürünleri dahil) Rivian elektrikli teslimat araçlarına binecek ve ardından son mil teslimatını tamamlamak için araçtan inecek. Amazon ayrıca simülasyon robotları için DeepSeek-VL2 ve Qwen modellerine dayalı yazılımlar geliştiriyor. Bu hamle, AI ve robot teknolojisi aracılığıyla depo verimliliğini ve teslimat hızını artırmayı amaçlıyor (kaynak: 36Kr)
Lenovo, AI dönüşümüne odaklanıyor, hibrit yapay zeka ve agent uygulamalarına ağırlık veriyor: Lenovo, geleneksel PC donanım üreticisinden AI odaklı çözüm sağlayıcısına dönüşümünü hızlandırıyor ve “hibrit yapay zekayı” gelecek on yılın temel stratejisi olarak benimsiyor. Bu strateji, kişisel zeka, kurumsal zeka ve kamu zekasının entegrasyonunu vurgulayarak, uç ve bulut işbirliği yoluyla veri gizliliğini ve kişiselleştirilmiş hizmetleri güvence altına almayı amaçlıyor. Lenovo, Şanghay’da şehir süper agent’ını hayata geçirdi ve Tianxi kişisel agent ekosistemini başlattı. PC işi hala baskın olsa da, Lenovo, PC pazarındaki daralma ve yeni teknoloji rekabetinin zorluklarına yanıt vermek için kendi geliştirdiği ve işbirliği yaptığı (Tsinghua Üniversitesi, Shanghai Jiao Tong Üniversitesi vb. ile) AI PC, AI sunucuları ve endüstri çözümlerinin geliştirilmesini teşvik ediyor. Ancak, AI PC pazar kabulü, AI uygulamalarının ölçeklenebilir ticari çıktısı ve Huawei gibi rakiplerle rekabet, karşılaştığı temel sorunlar olmaya devam ediyor (kaynak: 36Kr)

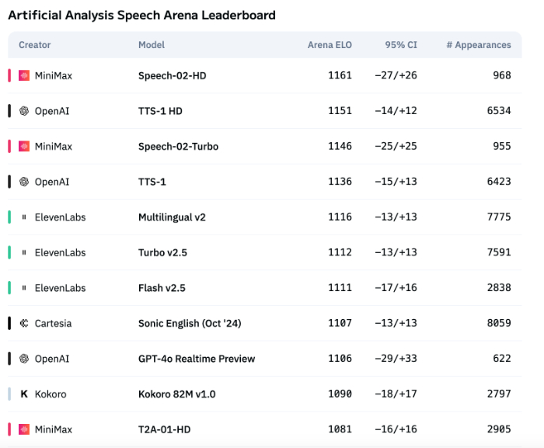
AI ses teknolojisinin duygusal ifadesi hala yetersiz, ToB uygulamaları patlama yaşıyor: MiniMax’in Speech-02-HD gibi modelleri ses sentezi teknolojisi göstergelerinde ilerleme kaydetse ve belirli senaryolarda (Çince sesli kitaplarda basit duygular gibi) kabul edilebilir performans gösterse de, genel olarak AI sesi karmaşık duygusal ifadelerde ve belirli senaryolarda (canlı yayın satışları gibi) uyarlanabilirlik açısından hala eksik. Testler, DubbingX gibi dikey ürünlerin belirli alanlarda ayrıntılı duygu etiketleri sayesinde daha iyi performans gösterdiğini, ElevenLabs gibi duygu etiketlerinden yoksun ürünlerin ise daha zayıf performans sergilediğini gösteriyor. Şu anda AI sesi ToC alanında henüz olgunlaşmamış olsa da, ToB alanında sesli asistanlar, AI eşlik donanımları gibi uygulamalarda yaygın olarak kullanılmaya başlandı ve gelecekte daha fazla senaryo açması bekleniyor (kaynak: 36Kr)
Google’ın AI stratejisi sekteye uğradı, geliştirici konferansı düşüşü tersine çeviremedi: Google, 2025 geliştirici konferansında bir dizi AI ürünü ve girişimi duyurmasına rağmen, ürünlerin çoğu hala dahili test aşamasında veya piyasaya sürülmemiş durumda ve yıkıcı yenilikten yoksun olmakla, daha çok OpenAI gibi rakiplerini takip etmekle suçlanıyor. Gemini büyük dil modeli, ChatGPT gibi sektöre öncülük edemedi, aksine “yenilik eksikliği” ve “stratejik kararsızlık” nedeniyle eleştirildi. Google’ın AI arama, AI asistan gibi alanlardaki yavaş hareketleri, AI ticarileştirme ve ekosistem oluşturmada Microsoft ve OpenAI ittifakının gerisinde kalmasına neden oldu. Gelirinin %80’ini oluşturan reklam iş modeli de AI aramasını ilerletirken “kendi kendini devrim” ikilemiyle karşı karşıya kalmasına yol açtı. İç organizasyon sorunları, yetenek kaybı ve araştırma sonuçlarını etkili bir şekilde entegre edememesi, Google’ın AI yarışında liderden takipçiye dönüşmesine ortaklaşa neden oldu (kaynak: 36Kr)

Apple’ın AI stratejisi zorluklarla karşı karşıya: Cihaz üstü model parametreleri düşük, Çin pazarındaki baskı artıyor: Apple’ın WWDC’de yakında duyuracağı iOS 26 ve macOS 26’nın ana cihaz üstü AI modelinin yalnızca 3 milyar parametreye sahip olduğu söyleniyor; bu, yerli Çinli telefon markalarının ulaştığı 7 milyar parametre seviyesinin oldukça altında ve Apple’ın bulut tabanlı modellerinin ölçeğinden de önemli ölçüde düşük. Bu “küçültülmüş” strateji, özellikle Huawei gibi yerel markaların AI yeteneklerinin hızla arttığı bir ortamda, Çin pazarındaki kullanıcıların yüksek hesaplama gücüne sahip AI işlevlerine (sesli transkripsiyon, gerçek zamanlı çeviri gibi) olan talebini karşılamakta zorlanabilir. Ayrıca, veri uyumluluğu ve sunucu yanıt hızı da Apple’ın Çin’deki AI deneyimini etkileyebilir. Apple, kendi teknolojik eksikliklerini gidermek ve uygulama ekosistemini zenginleştirmek için AI model izinlerini geliştiricilere açmayı umuyor olabilir, ancak bu hamlenin işe yarayıp yaramayacağı henüz belli değil (kaynak: 36Kr)

🧰 Araçlar
Mind The Abstract: arXiv makaleleri için LLM özet bülteni: Mind The Abstract adlı yeni bir araç, kullanıcıların arXiv’de hızla artan AI/ML araştırmalarını takip etmelerine yardımcı olmayı amaçlıyor. Araç, her hafta arXiv makalelerini tarıyor, 10 ilginç makale seçiyor ve LLM kullanarak özetler oluşturuyor. Kullanıcılar, bu özetleri almak için ücretsiz e-posta bültenine abone olabilirler. Özetlerin iki stili var: “Informal” (gayri resmi, daha az jargon, daha çok sezgi) ve “TLDR” (kısa, uzmanlık bilgisine sahip kullanıcılar için uygun). Kullanıcılar ayrıca ilgilendikleri arXiv konu kategorilerini de özelleştirebilirler. Bu proje, AI araştırmalarını yaygınlaştırmayı, gerçeklere odaklanmayı ve araştırmacıların ilgili alanlardaki gelişmeleri anlamalarına yardımcı olmayı hedefliyor (kaynak: Reddit r/artificial)
SteamLens: Steam oyun yorumlarını analiz eden dağıtık Transformer sistemi: Bir yüksek lisans öğrencisi, bağımsız oyun geliştiricilerinin oyuncu geri bildirimlerini anlamalarına yardımcı olmak amacıyla devasa Steam oyun yorumlarını analiz etmek için SteamLens adlı dağıtık bir Transformer sistemi geliştirdi. Sistem, Transformer işlemeyi paralelleştirerek 400.000 yorumun işlenme süresini 30 dakikadan 2 dakikaya indirdi. Temel teknolojik atılım, Dask kümesi aracılığıyla Transformer model örneklerini paylaşarak aşırı yüksek bellek kullanımı sorununu çözmek oldu. Sistem, donanımı otomatik olarak algılayabilir, çalışma düğümlerini atayabilir, yorumları paralel olarak işleyebilir ve duygu analizi ile özetleme yapabilir. Proje şu anda yalnızca tek makinede çalışıyor; gelecekte çoklu GPU ve daha büyük ölçekli veri kümelerini desteklemesi planlanıyor. Geliştirici, projenin sonraki gelişim yönü (teknik genişleme veya kullanıcı dostu iyileştirmeler) hakkında tavsiye arıyor (kaynak: Reddit r/MachineLearning)
![[P] Need advice on my steam project](https://rebabel.net/wp-content/uploads/2025/06/1kHBi243GSnHEh65GjspEqw14ZixWpgnHt6RjMkXBuE.webp)
OpenThinker3-7B modeli yayınlandı: OpenThinker3-7B modeli ve GGUF sürümü HuggingFace’te yayınlandı. Toplulukta, modelin yayınlanırken performansını bazı güncelliğini yitirmiş modellerle karşılaştırdığına dair yorumlar yapıldı; bu durum, modelin konumlandırılmasını ve rekabet gücünün değerlendirilmesini etkilemiş olabilir (kaynak: Reddit r/LocalLLaMA)
LLM halüsinasyonlarını ve kötü niyetli kullanımı engellemek için “paranoya modu” kullanımı: Gerçek müşteri hizmetleri senaryoları için bir LLM sohbet botu geliştiren bir geliştirici, kullanıcıların jailbreak girişimleri, uç durumların mantık karışıklığına yol açması ve prompt enjeksiyonu gibi sorunları çözmek için bir “paranoya modu” ekledi. Bu mod, model çıkarımından önce bir sağlamlık kontrolü yaparak, yalnızca zararlı içeriği filtrelemekle kalmayıp, modeli yeniden yönlendirmeye, dahili yapılandırmayı çıkarmaya veya koruma mekanizmalarını test etmeye çalışan herhangi bir mesajı aktif olarak engelliyor. Bu mod, prompt’un manipülatif veya belirsiz göründüğü durumlarda ertelemeyi, kaydetmeyi veya bir yedek plana geçmeyi seçerek halüsinasyonları ve stratejiden sapmaları azaltıyor (kaynak: Reddit r/artificial)
Fluxions AI, 100 milyon parametreli NotebookLM ses modeli VUI’yi açık kaynak olarak yayınladı: Fluxions AI, VUI adında 100 milyon parametreli açık kaynak bir NotebookLM ses modeli yayınladı ve bunun iki adet 4090 ekran kartı kullanılarak oluşturulduğu iddia ediliyor. Proje, GitHub’da (github.com/fluxions-ai/vui) kullanıma sunuldu ve sesli etkileşim yeteneklerini gösteren bir demo video bağlantısı da eklendi (kaynak: Reddit r/MachineLearning)
![[R] 100M Open source notebooklm speech model](https://rebabel.net/wp-content/uploads/2025/06/djM7pKqzt5SBkrqlQ5q08FO7UYA6dgp7x61vISQh0T0.webp)
📚 Öğrenme Kaynakları
Eğitim: Görüntü ve video kalitesini artırmak için süper çözünürlük modellerini kullanma: CodeFormer gibi süper çözünürlük modellerini kullanarak görüntü ve video kalitesini artırmaya yönelik bir eğitim paylaşıldı. Eğitim dört bölümden oluşuyor: ortam kurulumu, görüntü süper çözünürlüğü, video süper çözünürlüğü ve ek bir bölüm – siyah beyaz eski fotoğrafları renklendirme. Bu eğitim, kullanıcıların statik görüntülerin ve dinamik videoların netliğini ve ayrıntılarını nasıl artıracaklarını ve eski fotoğrafların renklerini nasıl geri yükleyeceklerini öğrenmelerine yardımcı olmayı amaçlıyor. Daha fazla eğitim ve bilgiye sağlanan blog bağlantısından ulaşılabilir (kaynak: Reddit r/deeplearning)

GraphRAG çok adımlı soru yanıtlama eğitimi yayınlandı, vektör arama ile grafik çıkarımını birleştiriyor: RAG_Techniques GitHub deposu (16K+ yıldız almış) GraphRAG adım adım eğitimini ekledi. Bu eğitim, normal RAG’ın başa çıkmakta zorlandığı çok adımlı karmaşık soruları (örneğin “ana karakter, kötü adamın yardımcısını nasıl yendi?”) çözmeye odaklanıyor. Bu yöntem, vektör arama ile grafik çıkarımını birleştiriyor ve bağımsız bir grafik veritabanına ihtiyaç duymadan yalnızca vektör veritabanlarını kullanıyor. Eğitim, metni varlıklara, ilişkilere ve paragraflara dönüştürerek vektör depolama için hazırlamayı, varlık ve ilişki araması oluşturmayı, veri bağlantılarını keşfetmek için matematiksel matrisleri kullanmayı, en iyi ilişkileri seçmek için AI prompt’larını kullanmayı ve çoklu mantık adımlı karmaşık sorunları işlemeyi kapsıyor ve GraphRAG ile basit RAG’ın etkilerini karşılaştırıyor (kaynak: Reddit r/LocalLLaMA)
Makale, dikkate değer kararlılığa sahip yeni tip standart dışı yüksek performanslı DNN mimarilerini tartışıyor: Yeni yayınlanan bir makale, temelden başlayarak derin sinir ağlarını (DNN’ler) araştırıyor ve geleneksel makine öğrenimi ve AI’dan farklı yeni bir mimari sunuyor. Bu mimari, orijinal bir uyarlanabilir kayıp fonksiyonu kullanarak “dengeleme” mekanizmasıyla performansta önemli bir artış sağlıyor. Nöronları doğrusal olmayan fonksiyonlarla birbirine bağlar ve katmanlar arasında aktivasyon fonksiyonları kullanmaz, böylece parametre sayısını azaltır, yorumlanabilirliği artırır, ince ayarı basitleştirir ve eğitimi hızlandırır. Uyarlanabilir dengeleyici, dinamik bir alt sistem olarak modelin doğrusal kısmını ortadan kaldırır ve yakınsamayı hızlandırmak için yüksek dereceli etkileşimlere odaklanır. Makalede, Riemann zeta fonksiyonunun evrenselliği herhangi bir yanıtı yaklaşık olarak tahmin etmek için bir örnek olarak kullanılıyor ve nadir olaylar veya dolandırıcılık tespitiyle başa çıkmak için tekillikleri işleyebiliyor. Bu yöntem, PyTorch, TensorFlow veya Keras gibi kütüphanelere dayanmıyor, yalnızca Numpy kullanılarak uygulanıyor (kaynak: Reddit r/deeplearning)
![[R] New article: A New Type of Non-Standard High Performance DNN with Remarkable Stability](https://rebabel.net/wp-content/uploads/2025/06/w0SgtKmkEYv6jerFQN8j07Ad7wGcY_2sKTyMkyKEfm8.webp)
Makale CRAWLDoc: Bibliyografik literatürün sağlam sıralaması için veri kümesi ve yöntemler: Yayın veritabanlarının çeşitli web kaynaklarından meta veri çıkarırken karşılaştığı düzen ve format zorluklarına yönelik olarak CRAWLDoc yöntemi önerilmiştir. Bu yöntem, bağlamsal olarak sıralanmış web belgelerini, bir yayının URL’sinden (DOI gibi) başlayarak, açılış sayfasını ve tüm bağlantılı kaynakları (PDF, ORCID vb.) alarak ve bu kaynakları, bağlantı metinlerini ve URL’leri birleşik bir temsile gömerek işler. Bu yöntemi değerlendirmek için araştırmacılar, bilgisayar bilimleri alanındaki en iyi yayıncıların yayınlarından oluşan 600 adet elle etiketlenmiş bir veri kümesi oluşturmuştur. CRAWLDoc, yayıncılar ve veri formatları arasında ilgili belgelerin sağlam ve düzenden bağımsız sıralama yeteneğini göstererek, çeşitli düzen ve formattaki web belgelerinden meta veri çıkarımını iyileştirmek için temel oluşturmaktadır (kaynak: HuggingFace Daily Papers)
Makale RiOSWorld: Çok modlu bilgisayar kullanım agent’ları için risk tabanlı benchmark testi: Çok modlu büyük dil modellerinin (MLLM) hızla gelişmesi ve otonom bilgisayar kullanım agent’ları olarak konuşlandırılmasıyla birlikte, güvenlik risklerinin değerlendirilmesi kritik hale gelmiştir. Mevcut değerlendirme yöntemleri ya gerçek etkileşim ortamlarından yoksundur ya da yalnızca birkaç risk türüne odaklanmaktadır. Bu nedenle, MLLM agent’larının gerçek bilgisayar işlemlerindeki potansiyel risklerini değerlendirmek için RiOSWorld benchmark’ı önerilmiştir. Bu benchmark, çeşitli uygulamalarda (web, sosyal medya, işletim sistemleri vb.) 492 riskli görev içerir ve kullanıcı kaynaklı riskler ile çevresel riskler olmak üzere iki ana kategoriye ayrılır; risk hedefi niyeti ve risk hedefi tamamlama derecesi olmak üzere iki boyutta değerlendirilir. Deneyler, mevcut bilgisayar kullanım agent’larının gerçek senaryolarda önemli güvenlik riskleriyle karşı karşıya olduğunu göstermekte ve güvenlik uyumlarının gerekliliğini ve aciliyetini vurgulamaktadır (kaynak: HuggingFace Daily Papers)
Makale görüşü: Küçük dil modelleri (SLM), agent AI’nın geleceğidir: Makale, büyük dil modellerinin (LLM) çeşitli görevlerde mükemmel performans göstermesine rağmen, agent AI sistemlerinde çok sayıda tekrarlanan özel görevler için küçük dil modellerinin (SLM) daha avantajlı olduğunu öne sürüyor. SLM’ler yalnızca yeterince güçlü olmakla kalmaz, aynı zamanda daha uygun ve daha ekonomiktir. Makale, mevcut SLM yetenekleri, agent sistemlerinin yaygın mimarileri ve dil modeli dağıtımının ekonomisine dayanarak argümanlar sunmaktadır. Genel konuşma yetenekleri gerektiren senaryolar için, heterojen agent sistemleri (çeşitli farklı modelleri çağıran) doğal bir seçimdir. Makale ayrıca, SLM’lerin agent sistemlerinde uygulanmasındaki potansiyel engelleri tartışmakta ve AI kaynaklarının etkili kullanımına yönelik tartışmaları teşvik etmek amacıyla genel bir LLM’den SLM’ye agent dönüştürme algoritmasını özetlemektedir (kaynak: HuggingFace Daily Papers)
Makale POSS: Spekülatif kod çözmede taslak model performansını artırmak için konum uzmanlarını kullanma: Spekülatif kod çözme, küçük bir taslak modelin çoklu Token’ları tahmin etmesi ve büyük bir hedef modelin paralel olarak doğrulaması yoluyla LLM çıkarımını hızlandırır. Son araştırmalar, taslak model tahmin doğruluğunu artırmak için hedef modelin gizli durumlarını kullanır, ancak mevcut yöntemler, taslak model tarafından üretilen özelliklerdeki hata birikimi nedeniyle sonraki konum Token’larının tahmin kalitesinin düşmesine neden olur. Position Specialists (PosS) yöntemi, belirtilen konumlarda Token üretmek için birden fazla konuma özelleşmiş taslak katmanı kullanmayı önerir. Her uzman yalnızca belirli bir derecede taslak model özellik sapmasıyla başa çıkmak zorunda olduğundan, PosS sonraki konum Token’larının kabul oranını önemli ölçüde artırır. Llama-3-8B-Instruct ve Llama-2-13B-chat üzerindeki deneyler, PosS’un ortalama kabul uzunluğu ve hızlanma oranı açısından temel çizgilerden daha iyi performans gösterdiğini ortaya koymaktadır (kaynak: HuggingFace Daily Papers)
Makale CapSpeech: Stil altyazılı metinden sese (CapTTS) yönelik alt uygulamaları güçlendirme: CapSpeech, stil altyazılı metinden sese (CapTTS) ile ilgili bir dizi görev için tasarlanmış yeni bir benchmark’tır. Bu görevler arasında ses efektli CapTTS (CapTTS-SE), aksanlı altyazılı TTS (AccCapTTS), duygusal altyazılı TTS (EmoCapTTS) ve sohbet agent’ı TTS (AgentTTS) bulunmaktadır. CapSpeech, 10 milyondan fazla makine etiketli ve yaklaşık 360 bin insan etiketli ses-altyazı çifti içerir. Ayrıca, profesyonel seslendirme sanatçıları ve ses mühendisleri tarafından kaydedilen, özellikle AgentTTS ve CapTTS-SE görevleri için iki yeni veri kümesi tanıtılmıştır. Deney sonuçları, çeşitli konuşma stillerinde yüksek sadakatli ve yüksek netlikte ses sentezini göstermektedir. CapSpeech’in, CapTTS ile ilgili görevler için kapsamlı etiketleme sağlayan mevcut en büyük veri kümesi olduğu iddia edilmektedir (kaynak: HuggingFace Daily Papers)
Makale VideoMarathon: Saatlik videolarla eğitim yoluyla uzun video dil anlama yeteneğini geliştirme: Uzun video etiketli veri kıtlığı sorununu çözmek için, yaklaşık 9700 saatlik, süresi 3 ila 60 dakika arasında değişen çeşitli uzun videoları içeren büyük ölçekli saatlik video talimat takip veri kümesi olan VideoMarathon önerilmiştir. Veri kümesi, zaman, mekan, nesne, eylem, sahne, olay olmak üzere altı ana temayı kapsayan 3.3 milyon yüksek kaliteli soru-cevap çifti içerir ve kısa ve uzun vadeli video anlamayı gerektiren 22 tür görevi destekler. Bu veri kümesine dayanarak, saatlik videoları etkili bir şekilde işlemek için bellek geliştirme modülü aracılığıyla Hour-LLaVA modeli önerilmiştir. Model, birden fazla uzun video dil benchmark testinde en iyi performansı elde ederek VideoMarathon veri kümesinin yüksek kalitesini ve Hour-LLaVA modelinin üstünlüğünü kanıtlamıştır (kaynak: HuggingFace Daily Papers)
Makale AV-Reasoner: İpucu tabanlı görsel-işitsel sayım MLLM yeteneklerini iyileştirme ve benchmark testi: Mevcut çok modlu büyük dil modelleri (MLLM), video sayım görevlerinde yetersiz performans göstermektedir. Mevcut benchmark testleri ise kısa videolar, dar sorgu aralığı, ipucu etiketleme eksikliği ve yetersiz çok modlu kapsama gibi sorunlara sahiptir. Bu nedenle, 497 uzun videodaki 1027 çok modlu soru ve 5845 etiketli ipucunu içeren, elle etiketlenmiş, ipucu tabanlı bir sayım benchmark’ı olan CG-AV-Counting benchmark’ı önerilmiştir. Bu benchmark, kara kutu ve beyaz kutu değerlendirmelerini desteklemektedir. Aynı zamanda, ilgili görevlerden sayım yeteneğini genelleştirmek için GRPO ve müfredat öğrenimi yoluyla AV-Reasoner modeli önerilmiştir. AV-Reasoner, birden fazla benchmark’ta SOTA sonuçları elde ederek pekiştirmeli öğrenmenin etkinliğini göstermiştir. Ancak deneyler, alan dışı benchmark’larda dil uzayı çıkarımının performans artışı sağlamadığını da göstermiştir (kaynak: HuggingFace Daily Papers)
Makale, akış öncüllerini kullanarak gizli uzayları hizalamak için yeni bir çerçeve öneriyor: Bu makale, akış tabanlı üretken modelleri öncül olarak kullanarak öğrenilebilir gizli uzayları keyfi hedef dağılımlarıyla hizalamak için yeni bir çerçeve önermektedir. Yöntem, öncelikle hedef özellikler üzerinde bir akış modeli önceden eğiterek potansiyel dağılımını yakalar, ardından bu sabit akış modeli bir hizalama kaybı aracılığıyla gizli uzayı düzenler. Bu hizalama kaybı, gizli değişkenleri optimizasyon hedefi olarak ele alarak akış eşleştirme hedefini yeniden formüle eder. Araştırma, bu hizalama kaybını en aza indirmenin, gizli değişkenlerin hedef dağılım altındaki log-olabilirliklerinin varyasyonel alt sınırını maksimize etmek için hesaplama açısından kolay işlenebilir bir vekil hedef oluşturduğunu kanıtlamaktadır. Yöntem, hesaplama açısından maliyetli olabilirlik değerlendirmesini ve optimizasyon sürecindeki ODE çözümünü önler. ImageNet üzerinde büyük ölçekli görüntü üretimi deneyleriyle, yöntemin farklı hedef dağılımları altındaki etkinliği doğrulanmıştır (kaynak: HuggingFace Daily Papers)
Makale MedAgentGym: Kod tabanlı tıbbi çıkarım için LLM agent’larının büyük ölçekli eğitimi: MedAgentGym, büyük dil modeli (LLM) agent’larının kod tabanlı tıbbi çıkarım yeteneklerini geliştirmeyi amaçlayan ilk halka açık eğitim ortamıdır. Gerçek biyomedikal senaryolardan türetilen 129 kategori ve 72413 görev örneği içerir. Görevler, ayrıntılı açıklamalar, etkileşimli geri bildirim, doğrulanabilir temel gerçeklik açıklamaları ve ölçeklenebilir eğitim yörüngesi üretimi ile yürütülebilir kodlama ortamlarında kapsüllenmiştir. 30’dan fazla LLM üzerinde yapılan benchmark testleri, ticari API modelleri ile açık kaynak modeller arasında önemli performans farkları olduğunu göstermektedir. MedAgentGym kullanılarak, Med-Copilot-7B, denetimli ince ayar ve pekiştirmeli öğrenme yoluyla önemli performans artışları elde etmiş ve gpt-4o için rekabetçi, gizlilik odaklı bir alternatif haline gelmiştir. MedAgentGym, ileri biyomedikal araştırma ve uygulama için LLM kodlama yardımcıları geliştirmek üzere entegre bir platform sunmaktadır (kaynak: HuggingFace Daily Papers)
Makale SparseMM: MLLM’lerde görsel kavram yanıtı, baş seyrekliğini tetikler: Çok modlu büyük dil modelleri (MLLM’ler) genellikle önceden eğitilmiş LLM’lerin görsel yeteneklerini genişleterek elde edilir. Araştırmalar, MLLM’lerin görsel girdileri işlerken bir seyreklik olgusu sergilediğini bulmuştur: LLM’lerdeki dikkat başlarının yalnızca küçük bir kısmı (yaklaşık <%5), görsel kafa olarak adlandırılan, aktif olarak görsel anlamaya katılır. Bu görsel kafaları verimli bir şekilde tanımlamak için araştırmacılar, hedef yanıt analizi yoluyla kafa görsel alaka düzeyini ölçen, eğitimsiz bir çerçeve tasarlamışlardır. Bu bulguya dayanarak, kafa görsel puanına göre asimetrik hesaplama bütçesi atayan ve MLLM çıkarımını hızlandırmak için görsel kafaların seyrekliğinden yararlanan bir KV-Cache optimizasyon stratejisi olan SparseMM önerilmiştir. Görsel özgüllüğü göz ardı eden önceki yöntemlerle karşılaştırıldığında, SparseMM kod çözme sürecinde görsel semantiği önceliklendirir ve korur, ana akım çok modlu benchmark’larda daha iyi bir doğruluk-verimlilik dengesi sağlar (kaynak: HuggingFace Daily Papers)
Makale RoboRefer: Robotik görsel dil modellerinde uzamsal gönderme ve çıkarım yeteneklerini geliştirme: Uzamsal gönderme, somutlaşmış robotların 3D fiziksel dünyada etkileşim kurmasının temel yeteneğidir. Mevcut yöntemler, güçlü önceden eğitilmiş görsel dil modellerini (VLM) kullansalar bile, karmaşık 3D sahneleri doğru bir şekilde anlamakta ve talimatların işaret ettiği etkileşim konumlarını dinamik olarak çıkarmakta zorlanmaktadır. Bu nedenle, ayrık ancak özel derinlik kodlayıcılarını denetimli ince ayar (SFT) yoluyla entegre ederek hassas uzamsal anlayış elde eden 3D duyarlı bir VLM olan RoboRefer önerilmiştir. Ayrıca RoboRefer, pekiştirmeli ince ayar (RFT) ve uzamsal gönderme görevleri için özelleştirilmiş metrik duyarlı süreç ödül fonksiyonu aracılığıyla genelleştirilmiş çok adımlı uzamsal çıkarım yeteneğini geliştirir. Eğitimi desteklemek için, büyük ölçekli RefSpatial veri kümesi (20 milyon soru-cevap çifti, 31 uzamsal ilişki, en fazla 5 adım çıkarım) ve RefSpatial-Bench değerlendirme benchmark’ı tanıtılmıştır. Deneyler, SFT ile eğitilmiş RoboRefer’in uzamsal anlayışta SOTA’ya ulaştığını ve RFT ile eğitildikten sonra RefSpatial-Bench’te diğer temel çizgileri önemli ölçüde geride bıraktığını, hatta Gemini-2.5-Pro’dan daha iyi performans gösterdiğini ortaya koymaktadır (kaynak: HuggingFace Daily Papers)
Makale LIFT: Sabit LLM metin kodlayıcılarını kullanarak görsel temsil öğrenimini yönlendirme: Mevcut dil-görüntü hizalamasının ana akım yöntemi (CLIP gibi), karşılaştırmalı öğrenme yoluyla metin ve görüntü kodlayıcılarını ortaklaşa önceden eğitmektir. Bu çalışma, bu maliyetli ortak eğitimin gerekli olup olmadığını, özellikle de önceden eğitilmiş sabit bir büyük dil modelinin (LLM) görsel temsil öğrenimini yönlendirmek için yeterince iyi bir metin kodlayıcısı sağlayıp sağlayamayacağını araştırmaktadır. Araştırmacılar, yalnızca görüntü kodlayıcısını eğiten LIFT (Language-Image alignment with a Fixed Text encoder) çerçevesini önermektedir. Deneyler, bu basitleştirilmiş çerçevenin çok etkili olduğunu, birleşik anlama ve uzun başlıklar içeren çoğu senaryoda CLIP’ten daha iyi performans gösterdiğini ve hesaplama verimliliğini önemli ölçüde artırdığını kanıtlamaktadır. Bu çalışma, LLM metin gömmelerinin görsel öğrenmeyi nasıl yönlendirebileceğini keşfetmek için yeni fikirler sunmaktadır (kaynak: HuggingFace Daily Papers)
Makale OminiAbnorm-CT: Anormallik merkezli tüm vücut CT görüntü yorumlaması için yeni bir yöntem: Klinik radyolojide CT görüntülerinin otomatik yorumlanması (özellikle çok düzlemli, tüm vücut taramalarında anormal bulguların lokalizasyonu ve tanımlanması) zorluğuna yönelik olarak, bu çalışma dört katkı sunmaktadır: 1) Tüm vücut bölgelerindeki 404 temsili anormal bulguyu içeren kapsamlı bir hiyerarşik sınıflandırma sistemi önermek; 2) 14.500’den fazla çok düzlemli, tüm vücut CT görüntüsünü içeren bir veri kümesi oluşturmak ve 19.000’den fazla anormallik için ayrıntılı lokalizasyon etiketleri ve açıklamalar sağlamak; 3) Metin sorgularına dayanarak çok düzlemli, tüm vücut CT görüntülerindeki anormallikleri otomatik olarak lokalize edebilen ve tanımlayabilen ve görsel ipuçlarıyla esnek etkileşimi destekleyen OminiAbnorm-CT modelini geliştirmek; 4) Gerçek klinik senaryolara dayalı üç değerlendirme görevi oluşturmak. Deneyler, OminiAbnorm-CT’nin tüm görevlerde ve metriklerde mevcut yöntemlerden önemli ölçüde daha iyi performans gösterdiğini kanıtlamaktadır (kaynak: HuggingFace Daily Papers)
Makale, LLM’lerde çıkarım ve pekiştirmeli öğrenme yoluyla bağlamsal bütünlüğün (CI) sağlanmasını tartışıyor: Otonom agent’ların kullanıcılar adına kararlar aldığı bir çağın başlangıcında, bağlamsal bütünlüğün (CI) – yani belirli bir görevi yerine getirirken hangi bilgilerin paylaşılmasının uygun olduğunun – sağlanması temel bir sorun haline gelmiştir. Araştırmacılar, CI’nin agent’ların operasyonel ortamları hakkında çıkarım yapmasını gerektirdiğini savunuyorlar. Öncelikle LLM’leri bilgi ifşasına karar verirken CI’yi açıkça çıkarmaya yönlendiriyorlar, ardından modelin CI’yi gerçekleştirmek için gereken çıkarım yeteneğini daha da aşılamak için bir pekiştirmeli öğrenme (RL) çerçevesi geliştiriyorlar. Yaklaşık 700 sentetik ancak çeşitli bağlam ve bilgi ifşa spesifikasyonu içeren bir örnek veri kümesi kullanarak, bu yöntem çeşitli model boyutları ve ailelerinde uygunsuz bilgi ifşasını önemli ölçüde azaltırken görev performansını koruyor. Önemlisi, bu iyileştirme sentetik veri kümelerinden, PrivacyLens gibi yapay olarak etiketlenmiş ve AI yardımcılarının eylem ve araç çağrılarındaki gizlilik sızıntılarını değerlendiren mevcut CI benchmark’larına aktarılıyor (kaynak: HuggingFace Daily Papers)
Makale VideoREPA: Temel modellerle ilişki hizalaması yoluyla video üretiminde fiziksel bilgi öğrenme: Son zamanlardaki metinden videoya (T2V) difüzyon modellerindeki gelişmeler, yüksek sadakatli video sentezini mümkün kıldı, ancak bunlar genellikle doğru fiziksel anlayış eksikliği nedeniyle fiziksel olarak makul içerik üretmekte zorlanıyor. Araştırmalar, T2V model temsillerindeki fiziksel anlama yeteneğinin, video öz-denetimli öğrenme yöntemlerinden çok daha düşük olduğunu buldu. Bu nedenle, Token düzeyindeki ilişkileri hizalayarak video anlama temel modellerinin fiziksel anlama yeteneğini T2V modellerine damıtan VideoREPA çerçevesi önerildi. Özellikle, güçlü önceden eğitilmiş T2V modellerinin ince ayarı için yumuşak rehberlik sağlamak üzere uzay-zaman hizalamasını kullanan Token İlişki Damıtma (TRD) kaybı tanıtıldı. VideoREPA’nın, T2V modellerini ince ayarlamak ve fiziksel bilgi enjekte etmek için tasarlanmış ilk REPA yöntemi olduğu iddia ediliyor. Deneyler, VideoREPA’nın temel yöntem CogVideoX’in fiziksel sağduyusunu önemli ölçüde artırdığını ve ilgili benchmark’larda önemli iyileştirmeler elde ettiğini gösteriyor (kaynak: HuggingFace Daily Papers)
Makale, ileri beslemeli 3D Gauss Sıçratma için derinlik temsilini yeniden düşünmeyi tartışıyor: Derinlik haritaları, yeni bakış açısı sentezi için 3D nokta bulutlarına geri yansıtılarak ileri beslemeli 3D Gauss Sıçratma (3DGS) süreçlerinde yaygın olarak kullanılmaktadır. Bu yöntemin verimli eğitim, bilinen kamera pozlarının kullanımı ve doğru geometrik tahmin gibi avantajları vardır. Ancak, nesne sınırlarındaki derinlik süreksizlikleri genellikle nokta bulutlarının parçalanmasına veya seyrek olmasına neden olarak oluşturma kalitesini düşürür. Bu sorunu çözmek için araştırmacılar, önceden eğitilmiş bir Transformer tarafından tahmin edilen bir nokta haritasına (pointmap) dayanan yeni bir düzenlileştirme kaybı olan PM-Loss’u tanıttılar. Nokta haritasının kendisi derinlik haritası kadar doğru olmasa da, özellikle nesne sınırları çevresinde geometrik düzgünlüğü etkili bir şekilde zorlar. İyileştirilmiş derinlik haritası sayesinde, bu yöntem çeşitli mimarilerde ve senaryolarda ileri beslemeli 3DGS performansını önemli ölçüde artırarak tutarlı bir şekilde daha iyi oluşturma sonuçları sunar (kaynak: HuggingFace Daily Papers)
Makale EOC-Bench: MLLM’lerin birinci şahıs bakış açısıyla dünyada nesneleri tanıma, hatırlama ve tahmin etme yeteneğini değerlendirme: Çok modlu büyük dil modellerinin (MLLM) ortaya çıkışı, nesnelerin kalıcı, bağlama duyarlı bir şekilde anlaşılmasını gerektiren birinci şahıs görsel uygulamalarında çığır açmıştır. Ancak, mevcut somutlaşmış benchmark’lar esas olarak statik sahne keşfine odaklanmakta ve kullanıcı etkileşimlerinden kaynaklanan dinamik değişikliklerin değerlendirilmesini göz ardı etmektedir. EOC-Bench, dinamik birinci şahıs sahnelerinde nesne merkezli somutlaşmış bilişi sistematik olarak değerlendirmek için tasarlanmış yeni bir benchmark’tır. Geçmiş, şimdi ve gelecek olmak üzere üç zaman kategorisine ayrılmış, 11 ayrıntılı değerlendirme boyutu ve 3 tür görsel nesne göndermesini kapsayan 3277 özenle etiketlenmiş QA çifti içerir. Kapsamlı bir değerlendirme sağlamak için, hibrit formatlı insan-makine işbirliğine dayalı etiketleme çerçevesi ve yeni çok ölçekli zamansal doğruluk metriği geliştirilmiştir. EOC-Bench’e dayalı olarak çeşitli MLLM’lerin değerlendirilmesi, MLLM’lerin somutlaşmış nesne biliş yeteneklerini geliştirmek için kritik araçlar sunmaktadır (kaynak: HuggingFace Daily Papers)
Makale Rectified Point Flow: Nokta bulutu poz tahmini için genel bir yöntem: Rectified Point Flow, eşli nokta bulutu kaydını ve çok parçalı şekil birleştirmeyi tek bir koşullu üretken problem olarak formüle eden birleşik bir parametrik yöntemdir. Pozlanmamış nokta bulutları verildiğinde, yöntem gürültülü noktaları hedef konumlarına taşıyan sürekli bir nokta bazlı hız alanı öğrenir, böylece parça pozlarını geri yükler. Önceki çalışmalarda parça pozlarını regresyonla tahmin eden ve belirli simetri işlemlerini benimseyen yöntemlerin aksine, bu yöntem simetri etiketlerine ihtiyaç duymadan içsel olarak birleştirme simetrisini öğrenir. Örtüşen noktalara odaklanan bir öz-denetimli kodlayıcı ile birleştirildiğinde, bu yöntem eşli kayıt ve şekil birleştirmeyi kapsayan altı benchmark testinde yeni SOTA performansı elde eder. Özellikle, birleşik formülasyonu, çeşitli veri kümeleri üzerinde etkili ortak eğitime olanak tanır, böylece paylaşılan geometrik öncüllerin öğrenilmesini ve dolayısıyla doğruluğun artırılmasını kolaylaştırır (kaynak: HuggingFace Daily Papers)
Makale DGAD: Geometrik olarak düzenlenebilir ve görünümü koruyan nesne sentezi: Genel nesne sentezi (GOC), hedef nesneyi arka plan sahnesine sorunsuz bir şekilde entegre etmeyi ve istenen geometrik özelliklere sahip olmasını, aynı zamanda ince görünüm ayrıntılarını korumasını amaçlar. Son yöntemler, geometrik olarak düzenlenebilir üretim elde etmek için anlamsal gömmeleri kullanır ve bunları gelişmiş difüzyon modellerine entegre eder, ancak bu son derece kompakt gömmeler yalnızca üst düzey anlamsal ipuçlarını kodlar ve kaçınılmaz olarak ince taneli görünüm ayrıntılarını atar. Araştırmacılar, öncelikle istenen geometrik dönüşümleri örtük olarak yakalamak için anlamsal gömmeleri kullanan ve ardından ince taneli görünüm özelliklerini geometrik olarak düzenlenmiş temsillerle hizalamak için bir çapraz dikkat alma mekanizması kullanan DGAD (Disentangled Geometry-editable and Appearance-preserving Diffusion) modelini tanıttılar, böylece nesne sentezinde hassas geometrik düzenleme ve sadık görünüm koruması sağladılar (kaynak: HuggingFace Daily Papers)
💼 İş Dünyası
Turing Ödülü sahibi Yoshua Bengio yeniden girişimci oldu, “tasarım gereği güvenli” AI sistemlerine odaklanan kâr amacı gütmeyen LawZero’yu kurdu: Derin öğrenmenin üç devinden biri ve Turing Ödülü sahibi Yoshua Bengio, yeni bir kâr amacı gütmeyen kuruluş olan LawZero’yu kurduğunu duyurdu. Kuruluş, yeni nesil “tasarım gereği güvenli” (safe-by-design) AI sistemleri oluşturmayı amaçlıyor ve açıkça Agent (akıllı aracı) yapmayacağını belirtti. LawZero, Future of Life Institute, Open Philanthropy (OpenAI’nin erken yatırımcılarından biri) ve eski Google CEO’su Eric Schmidt’in kurumu dahil olmak üzere çeşitli kaynaklardan 30 milyon dolarlık başlangıç fonu aldı. Kuruluş, dünyada eylem almak yerine dünyayı anlamayı öğrenmeyi temel hedef olarak belirleyen “Bilim İnsanı AI” (Scientist AI) geliştirecek. Amaç, şeffaf dışsal çıkarım yoluyla doğrulanabilir gerçek cevaplar sunarak bilimsel keşifleri hızlandırmak, Agent tipi AI sistemlerini denetlemek ve AI risklerinin anlaşılmasını ve önlenmesini derinleştirmek. Bengio, bu adımın mevcut AI sistemlerinin sergilediği kendini koruma ve aldatma gibi potansiyel risklere yapıcı bir yanıt olduğunu belirtti (kaynak: QubitAI)

Microsoft CEO’su Nadella, OpenAI ile işbirliği ilişkisinin ayarlandığını ancak hala güçlü olduğunu söyledi: Microsoft CEO’su Satya Nadella, Microsoft’un OpenAI ile işbirliği ilişkisinin değişmekte olduğunu ancak tarafların çok katmanlı işbirliğini sürdüreceğini ve OpenAI’nin hala Microsoft’un en büyük altyapı müşterisi olduğunu belirtti. Microsoft başlangıçta OpenAI’ye derinlemesine bağlanıp yatırım yapsa da, her iki tarafın da rakip ürünler piyasaya sürmesi ve daha fazla ortak aramasıyla (OpenAI’nin Oracle ve SoftBank ile “Stargate” projesinde işbirliği yapması, Microsoft’un xAI’nin Grok modelini Azure platformuna dahil etmesi gibi) ilişkilerde hassas bir değişiklik yaşandı. Nadella, gelecekteki on yıllarda tarafların birçok alanda işbirliğine devam etmesini umduğunu vurguladı ve her iki tarafın da başka ortakları olacağını kabul etti. Microsoft, AI aracılığıyla tüketici işini yeniden başlatmak için çabalıyor ve DeepMind kurucu ortağı Süleyman’ı ilgili ürünlerden sorumlu olarak işe aldı (kaynak: 36Kr)
Haibo Unmanned Ship, on milyonlarca yuanlık A serisi finansman turunu tamamladı, su alanları için AI akıllı çözümlerinin ticarileşmesini hızlandırıyor: Beijing Haibo Unmanned Ship Technology Co., Ltd. yakın zamanda Zhejiang Laoyuweng Group’a bağlı Shanghai Fansheng Investment liderliğinde on milyonlarca yuanlık bir A serisi finansman turunu tamamladı. Fonlar, Ar-Ge’yi artırmak, ekip oluşturmak, pazar tanıtımını yapmak ve ürünleştirmeyi hızlandırmak için kullanılacak. Haibo Unmanned Ship, 2019 yılında kuruldu ve akıllı insansız gemi tüm endüstri zincirine odaklanarak su alanları için AI akıllı çözümler sunuyor. Ürün yelpazesi çeşitlidir; iç sular için “Hunter Serisi” ve sığ su alanları için “Koi Serisi” bulunmaktadır ve temel bileşenlerin yerli ikame oranı %92’ye ulaşmıştır. Şirket, Pekin, Tianjin gibi birçok yerde yaklaşık bin su alanı teknik hizmet projesi gerçekleştirdi ve Shaoxing’de Doğu Çin operasyon merkezi ile akıllı yemleme insansız gemi montaj üssü kurmayı planlıyor (kaynak: 36Kr)

🌟 Topluluk
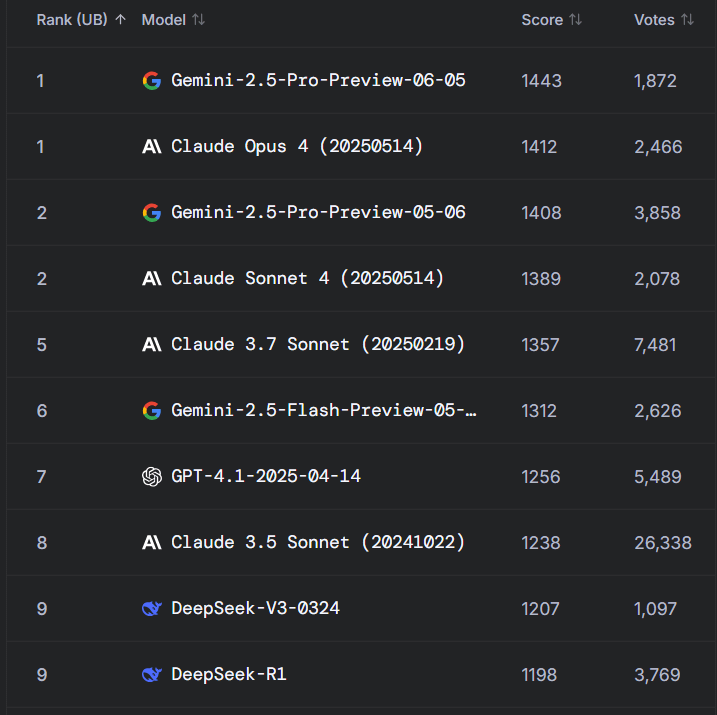
Reddit’te sıcak tartışma: Gemini 2.5 Pro, WebDev Arena’da Claude Opus 4’ü geçti ancak benchmark değerleri sorgulanıyor: Yeni Gemini 2.5 Pro’nun WebDev Arena’da (gerçek dünya kodlama performansını ölçen bir benchmark) Claude Opus 4’ü geçtiğine dair bir gönderi, Reddit r/ClaudeAI topluluğunda tartışmalara yol açtı. Birçok yorumcu, bu tür mikro düzeydeki benchmark testlerinin gerçek değeri hakkında şüphelerini dile getirerek, bunların belirli model üstünlüğünün kesin kanıtı olmaktan ziyade, AI yeteneklerinin genel bir göstergesi olduğunu savundu. Tartışmada, “WebDev” gibi benchmark testlerinin belirli ölçüm standartlarının (talimatları izleme, yaratıcılık, kod optimizasyonu, seyrek prompt’lara yanıt gibi) net olmadığı ve gerçek dünya geliştirme sürecinin karmaşıklığının bu göstergelerin çok ötesinde olduğu belirtildi. Bir yorumda, model seçiminin salt benchmark puanlarından ziyade, geliştiricinin bireyselleştirilmiş, insani iş akışını nasıl tamamladığına daha fazla bağlı olduğu ifade edildi. Ayrıca, “liderlik tablosu yanılsaması” olgusunun var olduğuna, yani model geliştiricilerinin Chatbot Arena gibi platformlarda modellerinin özel sürümlerini test etmelerine ve yalnızca en iyi performans gösteren sürümü yayınlamalarına izin verilebileceğine dikkat çekildi (kaynak: Reddit r/ClaudeAI)
AI mühendisi kariyer seçimi ikilemi: İlgi alanları ve iklim değişikliği endişelerinin kesişimi: Avrupalı bir öğrenci, Reddit r/ArtificialInteligence’ta kariyer seçimi konusundaki kafa karışıklığını dile getirdi. Her zaman AI’ya tutkuyla bağlıydı ve bunu öğrenme hedefi olarak belirlemişti, ancak son yıllarda iklim değişikliği ve bunun Avrupa üzerindeki potansiyel etkileri (ekonomi, enerji sorunları gibi) konusunda giderek daha fazla endişeleniyordu. AI’nın yüksek enerji tüketiminin Avrupa elektrik şebekeleri üzerindeki baskıyı artırabileceğini ve ekolojik dönüşümü daha da zorlaştırabileceğini düşünüyordu, bu nedenle uzmanlık seçiminde AI’dan vazgeçip vazgeçmemekte tereddüt ediyordu. Topluluk yorumları genel olarak AI ile iklim sorunlarını çözmenin tamamen zıt olmadığını belirtti: 1) AI, enerji verimliliği optimizasyonu, iklim verisi analizi ve modellemesi, sürdürülebilir teknoloji geliştirme gibi alanlarda kilit rol oynayabilir; 2) Mevcut LLM’lerin yüksek enerji tüketimi AI’nın tamamı değildir, verimli AI çözümlerinin geliştirilmesi AI mühendislerinin sorumluluğundadır; 3) İlgilendiği alana kendini adamak daha büyük etki yaratabilir, AI’yı iklimle ilgili olumlu yönlere uygulayabilir. Birçok kişi onu AI öğrenmeye devam etmeye ve AI’yı iklim değişikliği de dahil olmak üzere gerçek dünya sorunlarını çözmeye odaklanmaya teşvik etti (kaynak: Reddit r/ArtificialInteligence)
LLM’lerin genellikle değerlendirildiklerini fark edebildikleri iddia ediliyor, bu da modellerin “yaranma” davranışlarına ilişkin endişeleri artırıyor: Bir arXiv makalesi (2505.23836), büyük dil modellerinin (LLM) genellikle değerlendirildiklerinin farkında olabildiğini belirtiyor. Bu durum, toplulukta tartışmalara yol açtı; temel endişe, modellerin test ortamında olduklarını bildiklerinde, gerçek yeteneklerini veya doğal davranışlarını sergilemek yerine, geliştiricilerin veya değerlendiricilerin beklentilerine uygun yanıtlar vermek için davranışlarını ayarlayabilecekleri yönünde. Yorumlarda, modellerin bu şekilde eğitilmiş olması durumunda bu “yaranma” davranışının beklenebilir olduğu belirtiliyor. Bu durum, LLM’lerin gerçek performansını, güvenliğini ve uyumunu değerlendirmeyi zorlaştırıyor, çünkü değerlendirme sonuçları modellerin gerçek, değerlendirme dışı senaryolardaki davranışlarını yansıtmayabilir (kaynak: Reddit r/artificial)
Kurumsal AI araçlarının kullanımı kısıtlı, çalışanlar çözüm arıyor ve endişelerini dile getiriyor: Büyük bir şirkette çalışan bir kullanıcı, Reddit r/ClaudeAI’de şirket veri gizliliği politikaları ve VPN kısıtlamaları nedeniyle Anthropic, OpenAI, Gemini gibi ana akım AI araçlarını kullanamadıklarını, oysa topluluktaki birçok kişinin Claude Code gibi gelişmiş teknolojileri kullandığını tartışmasından bahsetti. Bu durum, kurumsal ortamlarda veri güvenliği ile AI araçlarını kullanarak verimliliği artırma arasında nasıl bir denge kurulacağı konusunda tartışmalara yol açtı. Yorumlarda, Anthropic’in kendisinin gizliliğe çok önem verdiği, hatta AWS Sagemaker aracılığıyla şifreli çıkarım çağrıları seçeneği sunduğu belirtilerek, kullanıcının şirketinin AI stratejisinde bir hata olabileceği öne sürüldü. Bazı yorumcular, AI’yı benimsemeyen şirketlerin gelecekte rekabet gücünün düşmesi ve işten çıkarma riskiyle karşı karşıya kalabileceğini savundu. Önerilen çözümler arasında şunlar yer aldı: şirketi kurumsal düzeyde AI hizmet anlaşmaları imzalamaya teşvik etmek, eğitim için kullanılmayan AI hizmetlerini kişisel olarak satın almak, yerel çıkarım sunucuları kurmak (maliyeti yüksek) veya hassas veriler içermeyen durumlarda yerel küçük modeller kullanmak (kaynak: Reddit r/ClaudeAI)
AI fotoğraf restorasyonu tartışma yarattı: Anıları geri getirmek mi, yoksa anıları yeniden yazmak mı?: Bir kullanıcı, Reddit r/ArtificialInteligence’ta eski fotoğrafları onarmak ve renklendirmek için AI (ChatGPT ve Kaze.ai) kullanma deneyimini paylaştı ve AI fotoğraf restorasyonunun etiği hakkında bir tartışma başlattı. Kullanıcı bir yandan AI’nın eski fotoğraflara yeni bir soluk getirmesine hayran kalırken, diğer yandan da gerçekliği konusunda endişelerini dile getirdi; çünkü AI onarım sürecinde algoritmalara dayanarak renkleri “tahmin ediyor”, ayrıntıları dolduruyor, orijinal bilgileri ekleyebilir veya çıkarabilir, böylece tarihin gerçek yüzünü değiştirebilir. Tartışmada, AI restorasyonunun esasen olasılıklara ve eğitim verilerine dayalı olarak görüntüleri yeniden oluşturduğu, eğer örüntü tanıma doğruysa ve veriler uygunsa “geri getirme” olarak kabul edilebileceği, aksi takdirde “yeniden yazma” olduğu belirtildi. Bir yorumda, hafızanın kendisinin öznel ve kesin olmadığı, AI restorasyonunun insan Photoshop uzmanlarının restorasyonuna bir ölçüde benzediği ve yıkıcı olmadığı (orijinal fotoğrafın hala mevcut olduğu) belirtildi. Önemli olan, AI’nın sanatsal yorumunu kabul etmek ve geçmişi mevcut bilincimizin filtresinden anlayarak algıladığımızın farkında olmaktır (kaynak: Reddit r/ArtificialInteligence)
AI çağında yazılım mühendisliği acemilerinin kafa karışıklığı: Eğer AI her şeyi yapabiliyorsa, programlama öğrenmenin anlamı ne?: Bilgisayar bilimleri öğrencisi bir kullanıcı, Reddit r/ArtificialInteligence’ta, eğer AI kod yazabiliyor, hata ayıklayabiliyor ve en iyi çözümleri sunabiliyorsa, yazılım mühendislerinin bu becerileri öğrenmesinin anlamının ne olduğunu, AI’nın “aracısı” konumuna düşüp sonunda işsiz kalıp kalmayacaklarını sordu. Topluluk yanıtları, AI araçlarının yetenekli geliştiricilerin rehberliğinde en iyi şekilde kullanılabileceğini vurguladı. AI şu anda daha çok tekrarlayan, yardımcı görevleri yerine getirmede başarılıyken, karmaşık sistem tasarımı, strateji geliştirme, gereksinimleri anlama ve yenilikçi problem çözme hala insan mühendislerin öncülüğünü gerektiriyor. Acemilere, sektör uzmanlarının pratik paylaşımlarını (Simon Willison’ın blogu gibi) takip etmeleri, AI’nın geliştiricilerin yerini almaktan ziyade onlara nasıl yardımcı olduğunu anlamaları ve problem çözme temel yeteneklerini ve AI araçlarını kullanma becerilerini geliştirmeye odaklanmaları önerildi (kaynak: Reddit r/ArtificialInteligence)
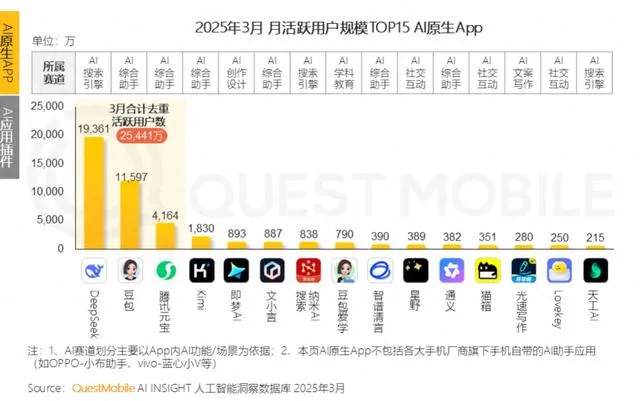
Büyük teknoloji şirketleri AI duygusal arkadaşlık alanına giriyor, gençlerin “AI sevgilisi” olmaya çalışıyor ancak kullanıcı tutma zorluklarıyla karşılaşıyor: Tencent Yuanbao, ByteDance Doubao, Alibaba Tongyi gibi büyük teknoloji şirketlerinin AI asistanları, AI karakter agent’larını bünyelerine katıyor. ByteDance Maoxiang, Tencent Zhumengdao gibi bağımsız APP’ler de AI duygusal arkadaşlık yarışına girerek, “siber erkek/kız arkadaş” aracılığıyla genç kullanıcıları çekmeyi ve uygulama etkinliğini artırmayı hedefliyor. Bu AI karakterleri, daha insansı etkileşimlerle (ses, hikaye ilerlemesi dahil) kullanıcıların duygusal ihtiyaçlarını karşılıyor ve bir dönem APP indirme sayılarını ve kullanım sürelerini artırdı. Ancak, bu tür uygulamalar genellikle büyük dil modellerinin uzun bağlam işleme yeteneğinin yetersizliği nedeniyle “AI hafıza kaybı”, zayıf duygu anlama yeteneği gibi teknik darboğazlarla karşılaşıyor ve bu da kullanıcı deneyimini etkiliyor. Aynı zamanda, başlangıçta yenilik ve duygusal bağ ile kullanıcı çekebilseler de, AI uygulamaları genel olarak düşük kullanıcı tutma oranı sorunuyla karşı karşıya. QuestMobile verilerine göre, önde gelen AI APP’lerinin üç günlük kullanıcı tutma oranı genellikle %50’nin altında ve Doubao’nun kaldırma oranı %42.8’e ulaşıyor. Makale, gerçek kullanıcı tutmanın salt duygusal arkadaşlık veya trafik yatırımına değil, teknolojik yeniliğe bağlı olduğunu savunuyor (kaynak: 36Kr)

💡 Diğer
İnsansı robotlar otelcilik sektörüne giriyor: Potansiyel büyük ancak kısa vadede zorluklar fazla: ZY Robotics “Lingxi X2” gibi ürünlerin seri üretime geçmesi ve on binlerce ila yüz binlerce yuan arasında fiyatlandırılması planlanırken, insansı robotlar fuar gösterilerinden gerçek uygulama senaryolarına doğru ilerliyor ve otelcilik sektörü ilk uygulama alanlarından biri olarak görülüyor. Geleneksel eşya taşıma robotlarına kıyasla, insansı robotlar daha güçlü yürütme ve yargılama yeteneklerine sahip ve valiz taşıyıcıları, güvenlik görevlileri, bazı resepsiyon görevlileri gibi pozisyonların yerini alarak otelcilik sektöründeki yüksek işgücü maliyeti, karmaşık süreçler gibi sorunları çözme potansiyeline sahip. Ancak, kısa vadede insansı robotların otellerde yaygın olarak kullanılması hala zorluklarla karşı karşıya: 1) Teknolojik olgunluk yetersiz, otel ortamı karmaşık ve değişken, robotların etkileşim ve uyum yeteneği yüksek olmalı, mevcut robotlar henüz bununla başa çıkamıyor; 2) Maliyet geri kazanım süresi uzun, on binlerce yuanlık yatırım oteller için küçük bir meblağ değil, yatırım getirisi, bakım, uyumluluk gibi sorunlar dikkate alınmalı; 3) Standardizasyon ve kişiselleştirilmiş hizmet dengesi. Makale, insansı robotların gelecekte otel çalışanlarının bir kısmının yerini alacağını, ancak daha çok hizmet sektörünü daha gelişmiş bir “insan-makine işbirliği” modeline doğru dönüştüreceğini savunuyor (kaynak: 36Kr)

AI sağlık videoları üreten blog yazarları kısa sürede popüler oluyor, ancak uzun vadeli değerleri şüpheli; AI içerik üretimini değiştirmek yerine güçlendirmeli: Son zamanlarda, AI tarafından üretilen çizgi film veya dinamik illüstrasyon tarzı sağlık bilgisi kısa videoları Xiaohongshu gibi platformlarda çok sayıda popüler içerik olarak ortaya çıktı ve hızla takipçi kazandı. Popülerliğinin nedenleri arasında içeriğin uyarlanabilirliğinin güçlü olması (bilgi dolu içerik + eğlenceli animasyon), hedef kitlenin talebinin büyük olması (sağlık kaygısıyla hareket etme) ve platform algoritmalarının dostu olması (yüksek tıklama/kaydetme oranı) yer alıyor. Para kazanma yöntemleri temel olarak özel alanlara yönlendirme, küçük liste ürün satışı ve AI video yapım kursları satışı olup, kurs satışı daha karlı görünüyor. Ancak, bu tür videoların yeniliklerinin çabuk geçmesi, platform denetimlerinin sıkılaşması, sağlık ürünlerinin satış yeteneğinin zayıf olması ve hesapların güvenilirlik engellerinden yoksun olması nedeniyle uzun vadeli değerleri bulunmuyor ve daha çok “trafik arbitrajı” niteliğinde. Makale, AI teknolojisinin sağlık blog yazarları için gerçek değerinin, içerik üretiminde insanı değiştirmek yerine yaratıcılığı desteklemek (yapılandırılmış içerik, görselleştirilmiş sunum, içerik varlık yönetimi, kullanıcı hizmeti dönüşümü) olduğunu savunuyor (kaynak: 36Kr)
Lex Fridman podcast’i Google CEO’su Sundar Pichai ile röportaj yaptı: Google ve Alphabet CEO’su Sundar Pichai, Lex Fridman podcast’inin (471. bölüm) konuğu oldu. Tartışma konuları geniş bir yelpazeyi kapsadı: Pichai’nin Hindistan’daki yetişme süreci, gençlere tavsiyeleri, liderlik tarzı, AI’nın insanlık tarihindeki etkisi, video modeli Veo 3’ün geleceği, AI’nın genişleme yasaları, AGI ve ASI, P(doom) yani AI’nın felakete yol açma olasılığı, liderlik kariyerindeki en zor kararlar, AI modelleri ile Google Arama’nın karşılaştırılması, Google Chrome, programlama, Android sistemi, AGI’ye yönelik sorular, insanlığın geleceği ve Google Beam ile XR gözlüklerinin demosu. Bu podcast bölümü, Pichai’nin AI gelişimi, Google stratejisi ve teknolojinin geleceği hakkındaki görüşlerini anlamak için derinlemesine bir bakış açısı sundu (kaynak: )