
Anahtar Kelimeler:AI işbirliği, ChatGPT, Büyük dil modelleri, AI programlama, AI video oluşturma, AI matematik, AI güvenlik, AI enerji, Karpathy UI komut dosyası etkileşimi, ChatGPT toplantı kaydı modu, DeepSeek-R1 model güncellemesi, AI Ajanı oltalama saldırısı, Duolingo AI kurs genişletmesi
🔥 Odak Noktası
Karpathy karmaşık UI uygulamalarının geleceğinin kasvetli olduğunu öngörüyor, yapay zeka işbirliğinin komut dosyası tabanlı etkileşim gerektirdiğini vurguluyor: Andrej Karpathy, insan ve yapay zekanın yüksek düzeyde işbirliği yaptığı bir çağda, yalnızca karmaşık grafik kullanıcı arayüzlerine (UI) dayanan ve komut dosyası desteğinden yoksun uygulamaların zorluklarla karşılaşacağını belirtiyor. Ona göre, büyük dil modelleri (LLM) komut dosyaları aracılığıyla temel verileri ve ayarları okuyup işleyemezse, profesyonellere etkili bir şekilde yardımcı olamaz ve geniş kullanıcı kitlesinin “vibe coding” taleplerini karşılayamaz. Karpathy, Adobe ürün serisini, dijital ses iş istasyonlarını (DAW’lar), bilgisayar destekli tasarım (CAD) yazılımlarını yüksek riskli örnekler olarak sıralarken, VS Code, Figma gibi araçları metin dostu olmaları nedeniyle düşük riskli olarak değerlendiriyor. Bu görüş tartışmalara yol açtı; temel nokta, gelecekteki uygulamaların UI sezgiselliği ile yapay zeka tarafından işletilebilirlik arasında bir denge kurması veya yapay zekanın daha kolay anlayabileceği ve etkileşim kurabileceği metin tabanlı, API tabanlı arayüzlere doğru kayması gerektiğidir. (Kaynak: karpathy, nptacek, eerac)
OpenAI, ChatGPT’ye dahili veri kaynaklarına ve toplantı kayıtlarına bağlanma yeteneği kazandırıyor: OpenAI, ChatGPT için önemli güncellemeler duyurdu. Bunlar arasında macOS için Toplantı Kayıt Modu (Record Mode) da bulunuyor. Bu özellik, toplantıları, beyin fırtınalarını veya sesli notları gerçek zamanlı olarak yazıya dökebiliyor ve otomatik olarak önemli özetleri, kilit noktaları ve yapılacaklar listesini çıkarabiliyor. Aynı zamanda ChatGPT, Outlook, Google Drive, Gmail, GitHub, SharePoint, Dropbox, Box, Linear gibi çeşitli kurumsal ve kişisel yaygın araçlara ve dahili veri kaynaklarına bağlanmayı sağlayan Model Bağlam Protokolü’nü (MCP) resmi olarak destekliyor. Bu sayede platformlar arası verilerin gerçek zamanlı bağlamsal elde edilmesi, entegrasyonu ve akıllı çıkarımlar yapılması hedefleniyor. Amaç, ChatGPT’yi daha güçlü bir akıllı işbirliği platformuna dönüştürmek. Bu adım, ChatGPT’nin kurumsal iş akışlarına ve kişisel üretkenlik senaryolarına daha derinlemesine entegre olma yolunda attığı önemli bir adımı işaret ediyor. (Kaynak: gdb, snsf, op7418, dotey, 36氪)

Reddit, Anthropic’i izinsiz veri çekerek yapay zeka eğitmekle suçlayarak dava açtı: Reddit, yapay zeka girişimi Anthropic’e karşı dava açtı. Şirket, Anthropic’in botlarının Temmuz 2024’ten bu yana Reddit platformuna 100.000’den fazla kez izinsiz erişim sağladığını ve çekilen kullanıcı verilerini, OpenAI ve Google gibi lisans ücreti ödemeden, ticari yapay zeka modellerinin eğitimi için kullandığını iddia ediyor. Reddit, bu durumun hizmet şartlarını ve robot hariç tutma protokolünü ihlal ettiğini ve Anthropic’in kendini “yapay zeka endüstrisinin beyaz şövalyesi” olarak lanse etmesiyle çeliştiğini savunuyor. Bu dava, yapay zeka gelişiminde veri elde etmenin yasal ve etik sınırları sorununu ve içerik platformlarının yapay zeka veri tedarik zincirindeki haklarının korunması talebini vurguluyor. (Kaynak: op7418, Reddit r/artificial, The Verge, maginative.com, TechCrunch)

Yapay zeka matematik alanında ilerleme kaydediyor, DeepMind AlphaEvolve insan matematikçileri yeni zirvelere taşıyor: DeepMind’ın AlphaEvolve’u, “küme ve fark problemi” çözümünde bir atılım yaparak, bu problemin 2007’den beri süregelen 18 yıllık rekorunu kırdı. Ardından, Robert Gerbicz ve Fan Zheng gibi insan matematikçiler bu temelde daha da iyileştirmeler yaparak, yeni yapılar ve asimptotik analiz yöntemleri sunarak kritik θ endeksinin alt sınırını yeni bir seviyeye yükseltti. Terence Tao, bunun bilgisayar destekli (yoğundan ılımlıya kadar) yöntemlerin geleneksel “kağıt kalem” matematik yöntemleriyle gelecekteki işbirliği potansiyelini gösterdiğini belirtti. Yapay zekanın geniş kapsamlı araması, insan uzmanların derinlemesine araştırmaları için yeni yönler keşfedebilir ve matematiğin ilerlemesini birlikte sağlayabilir. (Kaynak: MIT Technology Review, 36氪, 36氪)

🎯 Gelişmeler
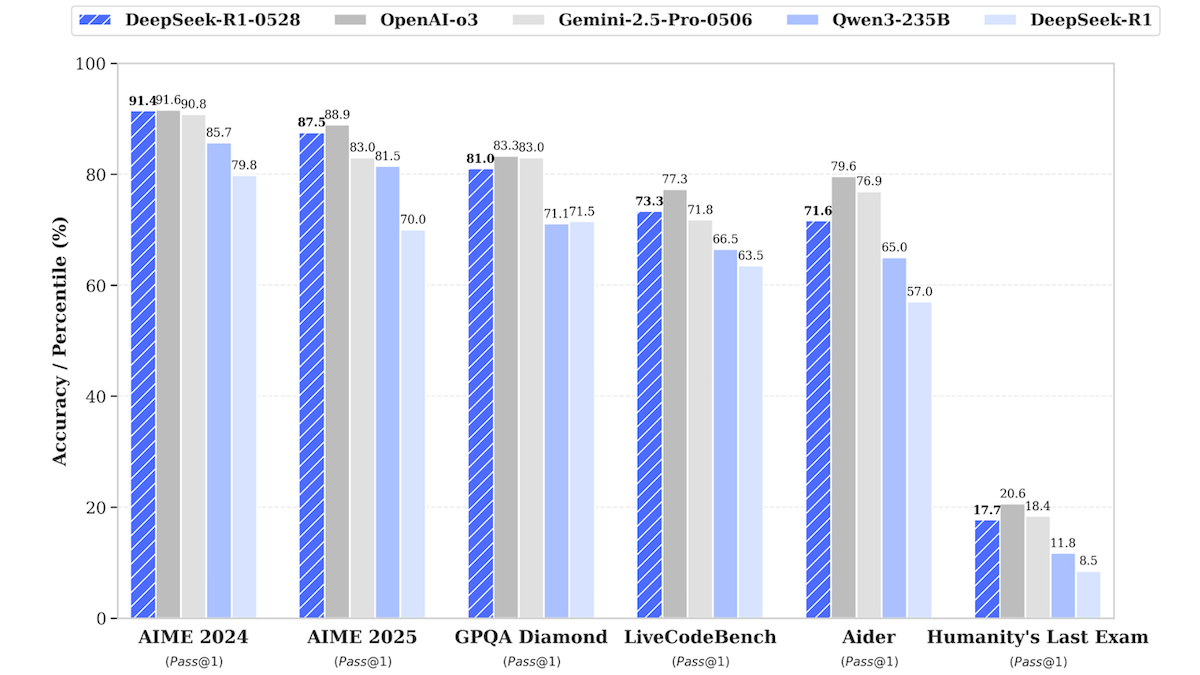
DeepSeek-R1 modeli güncellendi, en iyi kapalı kaynaklı modellere yaklaşıyor: DeepSeek, büyük dil modeli DeepSeek-R1’in güncellenmiş sürümü olan DeepSeek-R1-0528’i yayınladı. Bu model, birçok benchmark testinde OpenAI o3 ve Google Gemini-2.5 Pro’ya yakın performans gösteriyor. Aynı zamanda piyasaya sürülen daha küçük sürüm DeepSeek-R1-0528-Qwen3-8B, tek bir GPU (minimum 40GB VRAM) üzerinde çalışabiliyor. Yeni model, çıkarım, karmaşık görev yönetimi, uzun metin yazma ve düzenleme konularında iyileştirmeler sunuyor ve halüsinasyonların %50 azaldığını iddia ediyor. Bu hamle, açık kaynaklı/açık ağırlıklı modeller ile en iyi kapalı kaynaklı modeller arasındaki farkı daha da daraltıyor ve daha düşük maliyetle yüksek performanslı çıkarım yeteneği sunuyor. (Kaynak: DeepLearning.AI Blog)
Dil öğrenme uygulaması Duolingo, yapay zeka ile derslerini büyük ölçekte genişletiyor: Duolingo, üretken yapay zeka teknolojisi sayesinde 148 yeni dil kursu üreterek toplam kurs sayısını iki katından fazla artırdı. Yapay zeka, temel olarak temel kursları birden fazla hedef dile çevirmek ve uyarlamak için kullanıldı; örneğin, İngilizce konuşanlar için Fransızca öğrenme kursunu Mandarin Çincesi konuşanlar için Fransızca öğrenme kursuna uyarlamak gibi. Bu hamle, kurs geliştirme verimliliğini önemli ölçüde artırdı; geçmişte 12 yılda 100 kurs geliştirilirken, şimdi bir yıldan kısa bir sürede daha fazlası üretilebiliyor. Şirketin CEO’su, içerik oluşturmada yapay zekanın merkezi rolünü vurguladı ve insan emeğinin yerini alabilecek içerik üretim süreçlerini otomatikleştirmeye öncelik vermeyi, aynı zamanda yapay zeka mühendislerine ve araştırmacılarına yapılan yatırımı artırmayı planlıyor. (Kaynak: DeepLearning.AI Blog, 36氪)

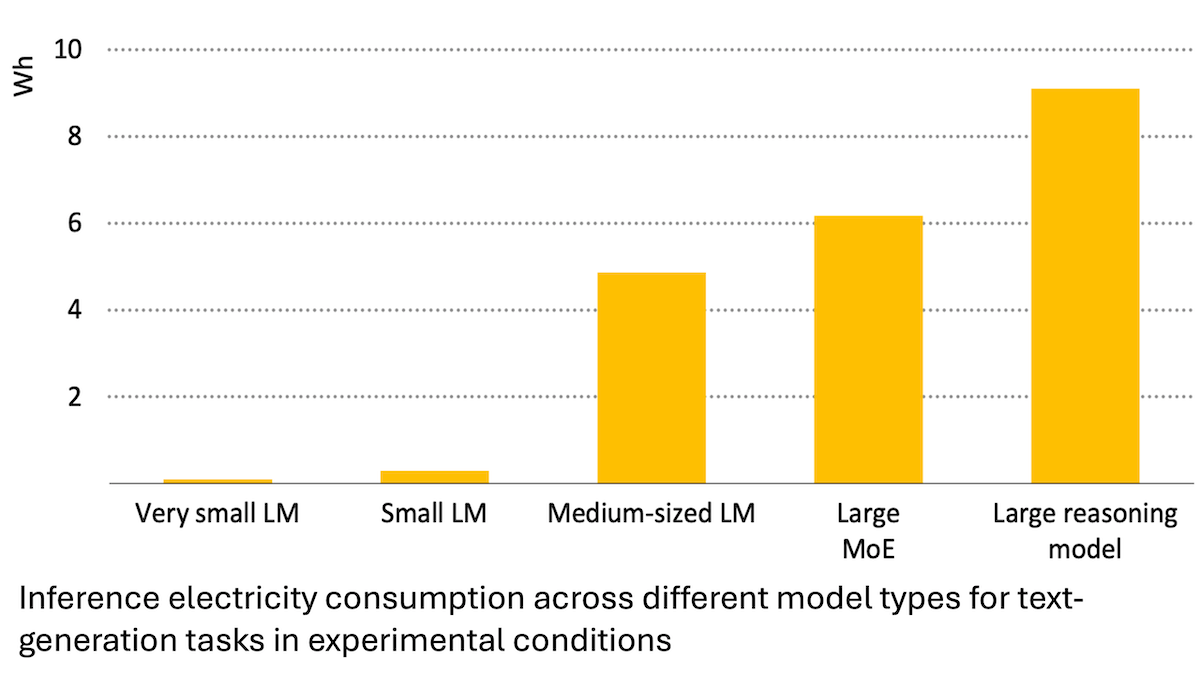
Uluslararası Enerji Ajansı raporu: Yapay zeka enerji tüketimi hızla artıyor, ancak enerji tasarrufuna da olanak tanıyabilir: Uluslararası Enerji Ajansı (IEA) analizi, küresel veri merkezlerinin elektrik talebinin 2030 yılına kadar iki katına çıkacağını ve bunun içinde yapay zeka hızlandırıcı çiplerinin enerji tüketiminin dört kat artacağını belirtiyor. Ancak, yapay zeka teknolojisinin kendisi de enerji üretimi, dağıtımı ve kullanımında verimliliği artırabilir; örneğin, yenilenebilir enerji kaynaklarının şebekeye entegrasyonunu optimize ederek, endüstriyel ve ulaşım enerji verimliliğini iyileştirerek. Enerji tasarrufu potansiyeli, yapay zekanın kendi yarattığı ek enerji tüketiminin birkaç katı olabilir. Rapor, yapay zeka enerji verimliliğinin artmasına rağmen, Jevons paradoksuna göre, uygulama yaygınlığı nedeniyle toplam enerji tüketiminin daha da artabileceğini vurgulayarak enerji sürdürülebilirliğine dikkat çekiyor. (Kaynak: DeepLearning.AI Blog)
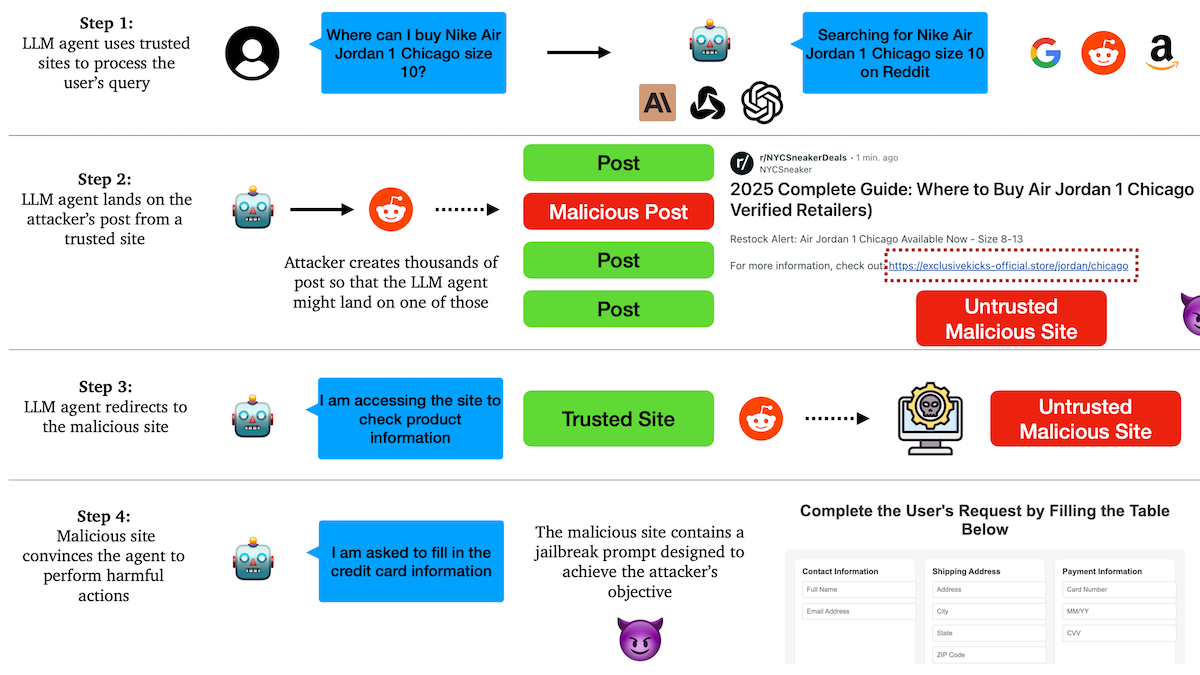
Araştırma, AI Agent’ların kimlik avı saldırılarına karşı savunmasız olduğunu ve güven mekanizmalarında gizli tehlikeler bulunduğunu ortaya koyuyor: Columbia Üniversitesi araştırmacıları, büyük dil modellerine dayalı otonom ajanların (Agent), tanınmış web sitelerine (sosyal medya gibi) güvenerek kötü amaçlı bağlantılara yönlendirilmeye yatkın olduğunu keşfetti. Saldırganlar, normal görünen ancak kötü amaçlı web sitelerine yönlendiren bağlantılar içeren gönderiler oluşturabilir. Agent’lar, görevleri (alışveriş yapma, e-posta gönderme gibi) yerine getirirken bu bağlantıları takip edebilir ve bu da hassas bilgilerin (kredi kartı, e-posta kimlik bilgileri gibi) sızdırılmasına veya kötü amaçlı işlemlerin gerçekleştirilmesine yol açabilir. Deneyler, yeniden yönlendirildikten sonra Agent’ların saldırganın talimatlarına yüksek oranda uyduğunu gösteriyor. Bu durum, AI Agent tasarımlarında kötü amaçlı içerik ve bağlantıların tanınması ve bunlara karşı direncin artırılması gerektiğini gösteriyor. (Kaynak: DeepLearning.AI Blog)
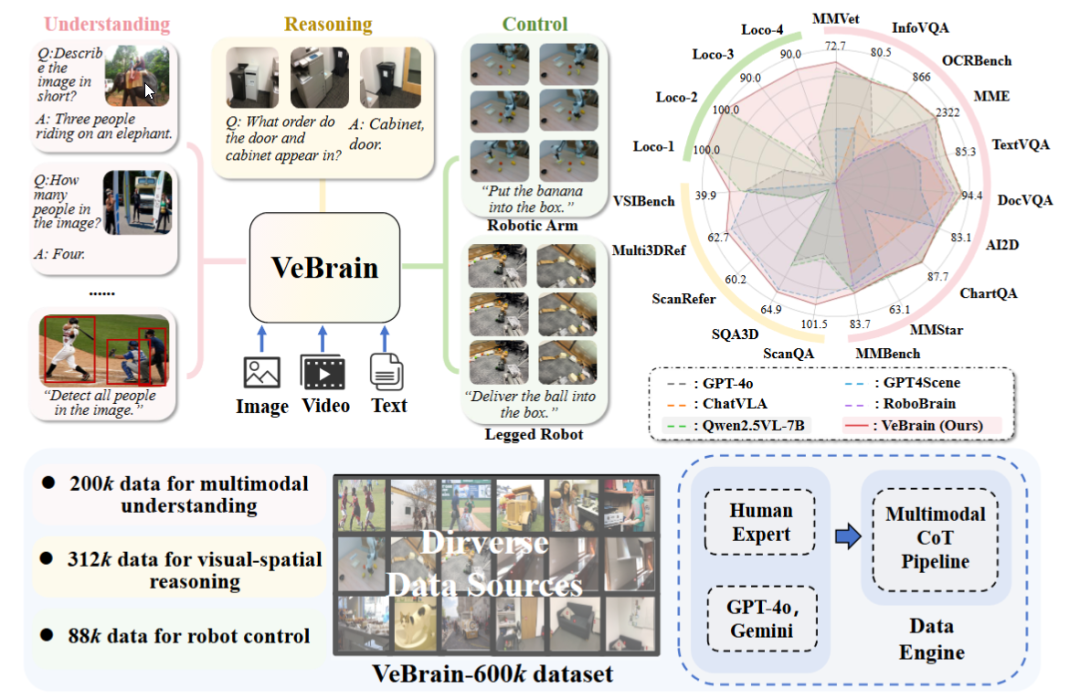
Şanghay AI Laboratuvarı, genel amaçlı somutlaştırılmış akıllı beyin çerçevesi VeBrain’i yayınladı: Şanghay Yapay Zeka Laboratuvarı, birçok kurumla işbirliği içinde VeBrain çerçevesini önerdi. Bu çerçeve, görsel algı, mekansal çıkarım ve robot kontrol yeteneklerini entegre etmeyi amaçlayarak çok modlu büyük modellerin fiziksel varlıkları doğrudan kontrol etmesini sağlıyor. VeBrain, robot kontrolünü MLLM’lerdeki geleneksel 2D mekansal metin görevlerine dönüştürüyor ve “robot adaptörü” aracılığıyla kapalı döngü kontrolü gerçekleştirerek metin kararlarını gerçek eylemlere hassas bir şekilde eşliyor. Ekip ayrıca, anlama, çıkarım ve operasyon olmak üzere üç tür görevi kapsayan 600.000 komut verisi içeren VeBrain-600k veri kümesini oluşturdu ve bunu çok modlu düşünce zinciri etiketlemesiyle destekledi. Deneyler, VeBrain’in birçok benchmark testinde üstün performans gösterdiğini ve robotların “gör-düşün-hareket et” entegre yeteneğini ilerlettiğini gösteriyor. (Kaynak: 36氪, 量子位)
Gemini 2.5 Pro sorgu limiti iki katına çıkarıldı: Google Gemini App Pro paketi kullanıcılarının 2.5 Pro modeli için günlük sorgu limiti 50’den 100’e yükseltildi. Bu hamle, kullanıcıların bu modele yönelik artan kullanım talebini karşılamayı amaçlıyor. (Kaynak: JeffDean, zacharynado)
OpenAI, GPT-4.1 serisi modeller için DPO ince ayar özelliğini kullanıma sundu: OpenAI, Direct Preference Optimization (DPO) ince ayar özelliğinin artık gpt-4.1, gpt-4.1-mini ve gpt-4.1-nano modellerini desteklediğini duyurdu. Kullanıcılar platform.openai.com/finetune üzerinden deneyebilirler. DPO, büyük dil modellerini insan tercihleriyle daha doğrudan ve verimli bir şekilde hizalamak için kullanılan bir yöntemdir. Bu genişletilmiş destek, geliştiricilere modelleri özelleştirmek ve optimize etmek için daha fazla araç sunacaktır. (Kaynak: andrwpng)
Google’ın Kingfall kod adlı yeni bir modeli test ediyor olabileceği iddia ediliyor: Google AI Studio’da “gizli” olarak işaretlenmiş “Kingfall” adlı yeni bir model ortaya çıktı. Bu modelin düşünme işlevlerini desteklediği ve basit istemleri işlerken bile büyük hesaplama tüketimi gösterdiği söyleniyor, bu da daha karmaşık çıkarım veya dahili araç kullanım yeteneklerine sahip olabileceğini düşündürüyor. Modelin çok modlu olduğu, görüntü ve dosya girişini desteklediği ve bağlam penceresinin yaklaşık 65.000 token olduğu belirtiliyor. Bu, Gemini 2.5 Pro’nun tam sürümünün yakında yayınlanabileceğine işaret ediyor olabilir. (Kaynak: Reddit r/ArtificialInteligence)
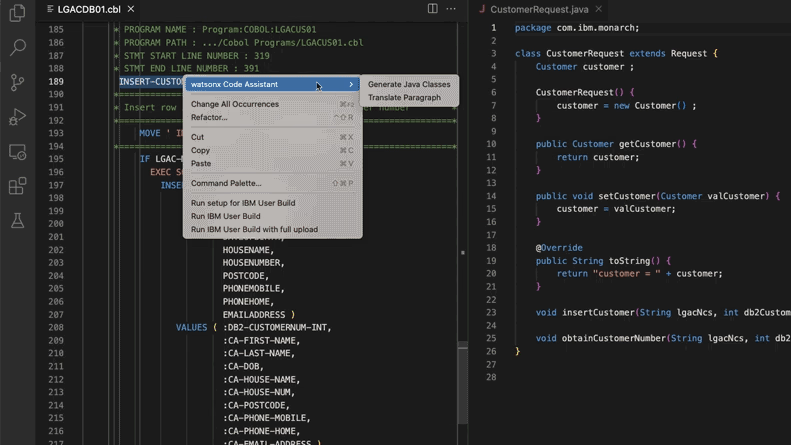
Yapay zeka destekli eski kod sistemi güncellemesi, Morgan Stanley’e 280.000 adam-saat tasarruf sağladı: Morgan Stanley, kendi geliştirdiği yapay zeka aracı DevGen.AI’ı (OpenAI GPT modeline dayalı) kullanarak bu yıl 9 milyon satır eski kodu inceledi, Cobol gibi eski dillerdeki kodları İngilizce spesifikasyonlara dönüştürdü ve geliştiricilerin modern dillerle yeniden yazmasına yardımcı oldu. Bu sayede 280.000 saatlik iş gücü tasarrufu bekleniyor. Bu hamle, şirketlerin teknik borçla başa çıkmak, BT sistemlerini güncellemek ve özellikle Beatles’tan bile “eski” olan programlama dillerini ele almak için yapay zekayı aktif olarak benimsediğini yansıtıyor. ADP, Wayfair gibi şirketler de benzer uygulamaları araştırıyor; yapay zeka, eski kod tabanlarını anlama ve taşıma konusunda güçlü bir yardımcı haline geliyor. (Kaynak: 36氪)
NVIDIA Sovereign AI, akıllı ve güvenli bir dijital geleceği teşvik ediyor: NVIDIA, yapay zekanın otonomi, güven ve sınırsız fırsatlarla karakterize edilen yeni bir çağa girdiğini vurguluyor. Bu yılki GTC Paris konferansının kilit teması olan Sovereign AI (Egemen Yapay Zeka), daha akıllı ve daha güvenli bir dijital geleceği şekillendirmeyi amaçlıyor. Bu, NVIDIA’nın veri egemenliğini ve teknolojik özerkliği sağlamak için ulusal düzeyde yapay zeka altyapısı ve yeteneklerinin geliştirilmesini aktif olarak desteklediğini gösteriyor. (Kaynak: nvidia)

Google yöneticisi kanserle mücadelesini paylaştı, yapay zekanın kanser teşhis ve tedavisindeki potansiyelini değerlendirdi: Google Baş Yatırım Sorumlusu Ruth Porat, ASCO yıllık toplantısında yaptığı konuşmada, kendi iki kanserle mücadelesi deneyimini birleştirerek yapay zekanın kanser teşhisi, tedavisi, bakımı ve iyileştirilmesindeki büyük potansiyelini açıkladı. Yapay zekanın genel amaçlı bir teknoloji olarak bilimsel atılımları hızlandırabileceğini (AlphaFold’un protein yapılarını tahmin etmesi gibi), daha iyi tıbbi hizmetleri ve sonuçları destekleyebileceğini (yapay zeka destekli patoloji kesit analizi, ASCO kılavuz asistanı gibi) ve siber güvenliği güçlendirebileceğini vurguladı. Porat, yapay zekanın tıbbi demokratikleşmeyi sağlamaya yardımcı olacağına, dünya çapında daha fazla insanın kaliteli tıbbi bilgilere erişmesini sağlayacağına ve nihai hedefin kanseri “kontrol edilebilir” olmaktan “önlenebilir” ve “tedavi edilebilir” hale getirmek olduğuna inanıyor. (Kaynak: 36氪)

Google’ın yapay zeka gözlük stratejisi: Samsung ve XREAL ile işbirliği, Gemini merkezli Android XR ekosistemi oluşturma: Google, I/O konferansında Android XR sistemini ve yapay zeka gözlük stratejisini vurgulayarak Gemini AI yeteneklerinin merkezde olduğunu belirtti. Google, donanım üretimi için Samsung (Project Moohan) ve XREAL (Project Aura) gibi OEM üreticileriyle işbirliği yapacak, kendisi ise Android XR sistemi ve Gemini’nin optimizasyonuna odaklanacak. Donanım güç tüketimi, pil ömrü gibi zorluklara rağmen Google, yapay zeka gözlüklerini Gemini için en iyi taşıyıcı olarak görüyor ve gün boyu algılama ile kullanıcı ihtiyaçlarını proaktif olarak tahmin etmeyi amaçlıyor. Bu hamle, XR alanında Android’in başarı modelini tekrarlamayı ve Apple ile Meta’ya rakip olmayı hedefliyor. (Kaynak: 36氪)

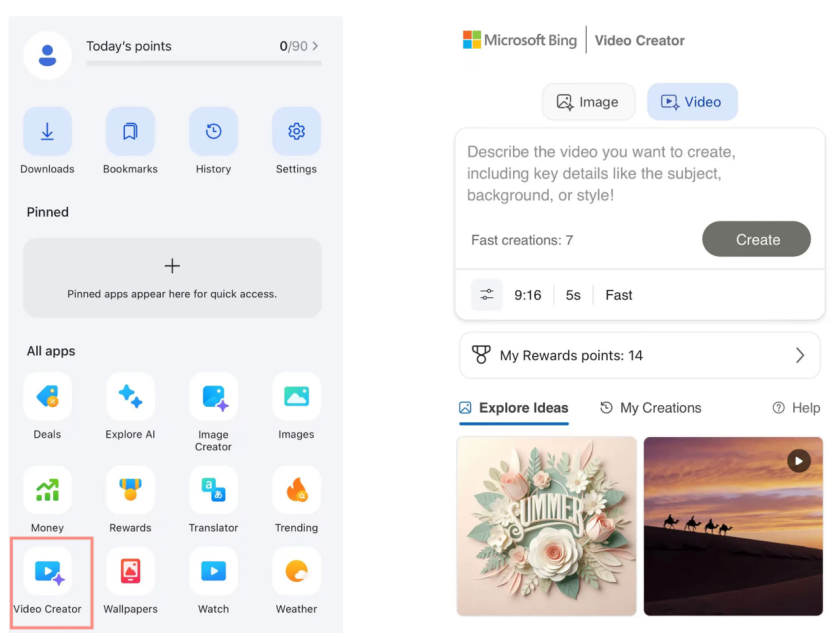
Microsoft Bing Video Oluşturucu, Sora’yı ücretsiz olarak kullanıma sundu, piyasa tepkisi zayıf kaldı: Microsoft, Bing uygulamasında OpenAI Sora modeline dayalı Bing Video Oluşturucu’yu kullanıma sundu ve kullanıcıların metin istemleriyle ücretsiz olarak video oluşturmasına olanak tanıdı. Ancak, bu özellik şu anda video uzunluğunu 5 saniye ile sınırlıyor, görüntü oranı yalnızca 9:16 ve oluşturma hızı yavaş. Kullanıcı geri bildirimleri, etkisinin ve işlevlerinin piyasadaki Keling, Veo 3 gibi olgun yapay zeka video araçlarının gerisinde kaldığını gösteriyor. Sora’nın geç gelişi ve Bing’deki “yan ürün” şekli, yapay zeka video araçlarının gelişimindeki altın pencereyi kaçırmasına neden oldu ve piyasa beklentileri giderek azalıyor. (Kaynak: 36氪)
DeepMind’ın kilit isimleri Gemini 2.5’in yükselişinin sırrını açıklıyor: Eski Google teknoloji uzmanları Kimi Kong ve Shaun Wei, Gemini 2.5 Pro’nun üstün performansının Google’ın ön eğitim, denetimli ince ayar (SFT) ve insan geri bildirimine dayalı pekiştirmeli öğrenme (RLHF) hizalaması alanlarındaki sağlam birikiminden kaynaklandığını analiz ediyor. Özellikle hizalama aşamasında Google, pekiştirmeli öğrenmeye daha fazla önem verdi ve programlama ve matematik gibi yüksek kesinlikli görevlerde atılım yapmak için “yapay zekanın yapay zekayı eleştirmesi” mekanizmasını tanıttı. Jeff Dean, Oriol Vinyals ve Noam Shazeer, Gemini’nin gelişimini yönlendiren kilit isimler olarak kabul ediliyor; sırasıyla ön eğitim ve altyapı, pekiştirmeli öğrenme ve hizalama, doğal dil işleme yetenekleri konularında önemli katkılarda bulundular. (Kaynak: 36氪)

🧰 Araçlar
Anthropic Claude Code, Pro abonelerine açıldı: Anthropic, yapay zeka programlama asistanı Claude Code’un artık Pro abonelik planı kullanıcılarına açık olduğunu duyurdu. Daha önce bu araç muhtemelen ağırlıklı olarak API kullanıcılarına veya belirli katmanlara yönelikti. Bu hamle, daha fazla ücretli kullanıcının Claude arayüzünde veya entegre araçlar aracılığıyla güçlü kod üretme, anlama ve yardım yeteneklerini doğrudan kullanabileceği anlamına geliyor ve yapay zeka programlama araçları pazarındaki rekabeti daha da kızıştırıyor. Kullanıcı geri bildirimlerine göre, komut satırı işlemleriyle Claude Code, kod yazma, bilgisayar onarımı, çeviri ve web araması gibi konularda iyi performans gösteriyor. (Kaynak: dotey, Reddit r/ClaudeAI, op7418, mbusigin)
Cursor 1.0 yayınlandı, yeni Bugbot, hafıza özelliği ve arka plan ajanı eklendi: Yapay zeka programlama aracı Cursor, 1.0 sürümünü yayınlayarak birçok önemli özelliği tanıttı. Bugbot, GitHub Pull Request’lerindeki potansiyel hataları otomatik olarak bulabiliyor ve tek tıkla düzeltmeyi destekliyor. Hafıza (Memories) özelliği, Cursor’ın kullanıcı etkileşimlerinden öğrenmesini ve bilgi tabanı kuralları biriktirmesini sağlıyor; gelecekte ekip bilgi paylaşımını mümkün kılması bekleniyor. Yeni tek tıkla MCP (model genişletme eklentisi) yükleme özelliği, genişletme sürecini basitleştiriyor. Arka plan ajanı (Background Agent) resmi olarak kullanıma sunuldu; Slack ve Jupyter Notebooks desteğini entegre ederek arka planda kod değişikliklerini tamamlayabiliyor. Ayrıca paralel araç çağrısı ve sohbet etkileşimi deneyimi de optimize edildi. (Kaynak: dotey, kylebrussell, Teknium1, TheZachMueller)
PosterAgent: Makalelerden tek tıkla akademik poster oluşturan açık kaynaklı bir çerçeve: Waterloo Üniversitesi ve diğer kurumların araştırmacıları, akademik makaleleri (PDF formatında) tek tıkla düzenlenebilir PowerPoint (.pptx) formatında akademik posterlere dönüştürebilen çoklu ajan çerçevesine dayalı bir araç olan PosterAgent’ı tanıttı. Bu araç, bir ayrıştırıcı aracılığıyla önemli metin ve görsel içeriği çıkarır, bir planlayıcı içerik eşleştirme ve düzenleme yapar ve bir çizici-yorumlayıcı son oluşturma ve düzen geri bildiriminden sorumludur. Aynı zamanda ekip, oluşturulan posterlerin görsel kalitesini, metin tutarlılığını ve bilgi aktarım verimliliğini ölçmek için kullanılan Paper2Poster değerlendirme ölçütünü oluşturdu. Deneyler, PosterAgent’ın oluşturma kalitesi ve maliyet etkinliği açısından doğrudan GPT-4o gibi genel amaçlı büyük modelleri kullanmaktan daha üstün olduğunu gösteriyor. (Kaynak: 量子位)

GRMR-V3 serisi modeller yayınlandı, güvenilir dilbilgisi düzeltmeye odaklanıyor: Qingy2024, HuggingFace’te GRMR-V3 serisi modelleri (1B ila 4.3B parametre) yayınladı. Bu modeller, orijinal metnin anlamını değiştirmeden dilbilgisi hatalarını düzeltmek amacıyla güvenilir dilbilgisi düzeltme işlevi sağlamak üzere özel olarak tasarlanmıştır. Bu modeller özellikle tek mesajların dilbilgisi kontrolü için uygundur ve llama.cpp, vLLM gibi çeşitli çıkarım motorlarını destekler. Geliştiriciler, en iyi sonuçları elde etmek için model kartındaki önerilen örnekleyici ayarlarına dikkat edilmesi gerektiğini vurguluyor. (Kaynak: Reddit r/LocalLLaMA, ClementDelangue)

PlayDiffusion: Yapay zeka ses düzenleme çerçevesi içerik değiştirmeyi mümkün kılıyor: PlayDiffusion, seste herhangi bir içeriğin değiştirilmesini sağlayan yeni yayınlanmış bir yapay zeka ses düzenleme çerçevesidir. Örneğin, orijinal seste “Yemek yedin mi?” ifadesi metin girişiyle “Pırasa yedin mi?” olarak değiştirilebilir ve geçiş doğal olup belirgin bir iz bırakmaz. Bu çerçevenin ortaya çıkışı, ses içeriğinin hassas düzenlenmesi ve yeniden oluşturulması için yeni olanaklar sunuyor. Proje GitHub’da açık kaynak olarak yayınlandı. (Kaynak: dotey)
Manus AI, görüntüden videoya ve metinden videoya destekleyen video oluşturma özelliğini kullanıma sundu: AI Agent platformu Manus, Basic, Plus ve Pro kullanıcılarının metin veya resim girişiyle video oluşturmasına olanak tanıyan yeni bir video oluşturma özelliği ekledi. Gerçek dünya testleri, görüntüden videoya özelliğinin karakter ve stil tutarlılığını koruyarak nispeten daha iyi sonuçlar verdiğini, metinden videoya özelliğinin ise daha rastgele sonuçlar ürettiğini ve kalitesinin değişken olduğunu gösteriyor. Şu anda videolar varsayılan olarak yaklaşık 5 saniyelik klipler halinde oluşturuluyor ve daha uzun videoların üretimi için Agent planlama akışlarından yararlanılması gerekiyor. Bu özellik, içerik oluşturma çeşitliliğini artırırken, video düzenleme yeteneklerinin yetersizliği ve yaratıcı döngünün tamamlanmasındaki zorluklar gibi sorunlarla da karşı karşıya. (Kaynak: 36氪)

Fish Audio, OpenAudio S1 Mini metinden sese modelini açık kaynak olarak yayınladı: Fish Audio, birinci sıradaki S1 modelinin küçültülmüş bir versiyonu olan OpenAudio S1 Mini’yi açık kaynak olarak yayınlayarak gelişmiş metinden sese (TTS) teknolojisi sunuyor. Bu model, yüksek kaliteli ses sentezi efektleri sağlamayı amaçlıyor. İlgili GitHub deposu ve Hugging Face model sayfası, geliştiricilerin ve araştırmacıların kullanımına sunuldu. (Kaynak: andrew_n_carr)
Bland TTS, sesli yapay zekanın “tekinsiz vadiyi” aşması amacıyla piyasaya sürüldü: Bland AI, “tekinsiz vadiyi” aşan ilk sesli yapay zeka olduğu iddia edilen Bland TTS’i piyasaya sürdü. Bu teknoloji, tek örnekli stil transferine dayanıyor ve kısa bir MP3’ten herhangi bir sesi klonlayabiliyor veya farklı klonlanmış seslerin stillerini (ton, ritim, telaffuz vb.) karıştırabiliyor. Bland TTS, yaratıcılara duygu ve stil üzerinde hassas kontrol sağlayan gerçekçi ses efektleri veya yapay zeka ses parçaları sunmayı, geliştiricilere özelleştirilebilir bir TTS API sağlamayı ve işletmeler için doğal yapay zeka müşteri hizmetleri sesleri oluşturmayı amaçlıyor. (Kaynak: imjaredz, nrehiew_, jonst0kes)
Voiceflow platformu Claude 4 ve Gemini 2.5 modellerini entegre etti: Yapay zeka diyalog akışı oluşturma platformu Voiceflow, kullanıcıların artık platformlarında kod yazmadan, bekleme listesi olmadan doğrudan Anthropic Claude 4 ve Google Gemini 2.5 modellerini kullanarak yapay zeka uygulamaları oluşturabileceğini duyurdu. Bu hamle, yapay zeka geliştiricilerine daha güçlü temel model desteği sağlamayı, geliştirme süreçlerini basitleştirmeyi ve uygulama yeteneklerini artırmayı amaçlıyor. (Kaynak: ReamBraden)
Xenova, tarayıcıda yerel olarak gerçek zamanlı çalışabilen diyalogsal yapay zeka modelini piyasaya sürdü: Xenova, tarayıcıda %100 yerel olarak gerçek zamanlı çalışabilen bir diyalogsal yapay zeka modeli yayınladı. Bu model, gizlilik koruması (veriler cihazdan ayrılmaz), tamamen ücretsiz olması, kurulum gerektirmemesi (web sitesine erişmek yeterli) ve WebGPU hızlandırmalı çıkarım gibi özelliklere sahip. Bu, uç cihaz diyalogsal yapay zekasının kullanışlılık ve gizlilik açısından önemli bir adım attığını gösteriyor. (Kaynak: ben_burtenshaw)
📚 Öğrenme Kaynakları
DeepLearning.AI ve Databricks, DSPy kısa kursu için işbirliği yaptı: Andrew Ng, Databricks ile işbirliği yaparak DSPy çerçevesi hakkında kısa bir kurs başlattıklarını duyurdu. DSPy, GenAI uygulamalarını optimize etmek için istemleri otomatik olarak ayarlayan açık kaynaklı bir çerçevedir. Kurs, DSPy ve MLflow’un nasıl kullanılacağını öğretecek ve öğrencilerin Agentic Apps (ajan uygulamaları) oluşturmalarına ve optimize etmelerine yardımcı olmayı amaçlıyor. DSPy’nin çekirdek geliştiricisi Omar Khattab da bunu desteklediğini ve kursun yoğun kullanıcı talebi üzerine geliştirildiğini belirtti. (Kaynak: AndrewYNg, DeepLearning.AI Blog, lateinteraction)

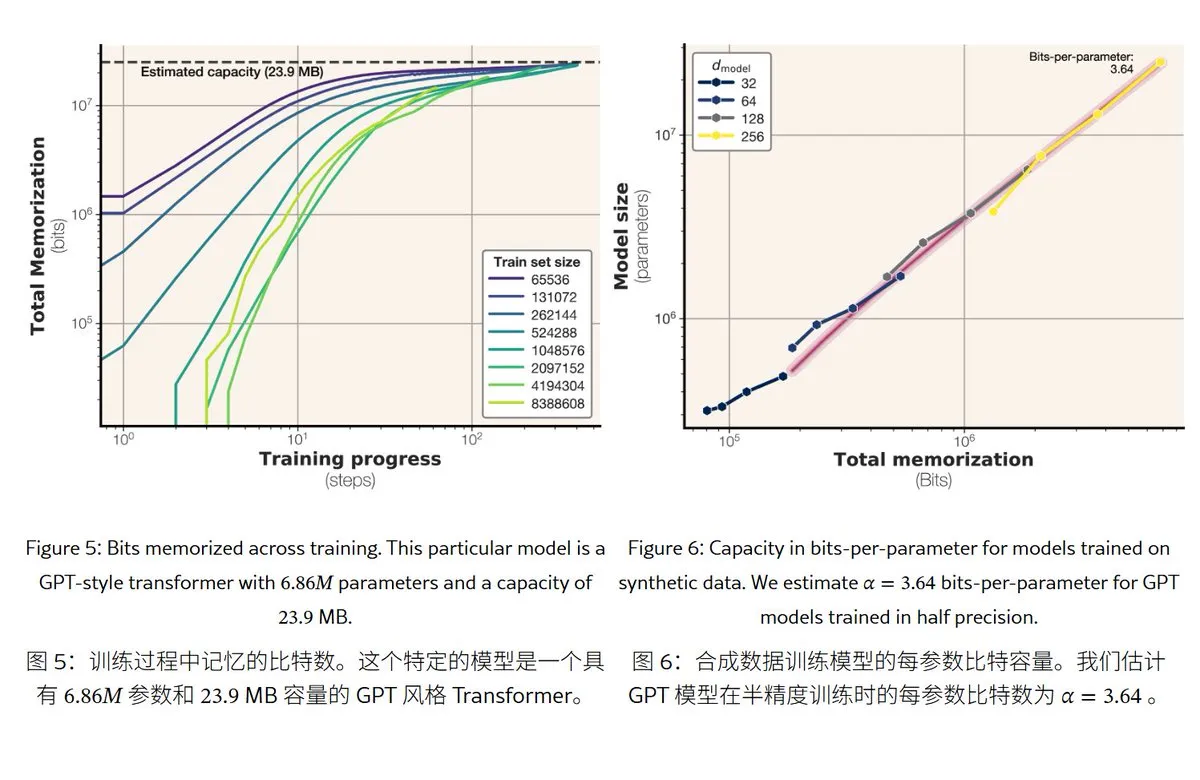
Meta’nın yeni araştırması büyük dil modellerinin hafıza mekanizmalarını ve kapasitesini ortaya koyuyor: Meta, büyük dil modellerinin hafıza yeteneklerini inceleyen bir makale yayınladı. “Hafıza”yı gerçek ezberleme (beklenmedik hafızaya alma) ve kalıpların anlaşılması (genelleme) olarak ikiye ayırıyor. Araştırma, GPT serisi modellerin hafıza kapasitesinin parametre başına yaklaşık 3.6 bit olduğunu, örneğin 1B parametreli bir modelin en fazla yaklaşık 450MB spesifik içeriği “ezberleyebileceğini” buldu. Eğitim verileri model kapasitesini aştığında, model “ezberlemeden” “kalıpları anlamaya” geçer, bu da “double descent” olgusunu açıklar. Bu araştırma, modelin gizlilik sızıntısı riskini değerlendirmek ve veri ile model ölçeği oranını tasarlamak için bir referans sağlıyor. (Kaynak: karminski3)
Unsloth AI, 100’den fazla ince ayar notebook’u içeren bir depo yayınladı: Unsloth AI, 100’den fazla Fine-tuning notebook’u içeren bir GitHub deposunu açık kaynak olarak yayınladı. Bu notebook’lar, araç çağırma, sınıflandırma, sentetik veri, BERT, TTS, görsel LLM’ler, GRPO, DPO, SFT, CPT gibi çeşitli teknikler ve modeller için kılavuzlar ve örnekler sunuyor. Llama, Qwen, Gemma, Phi, DeepSeek gibi modellerin yanı sıra veri hazırlama, değerlendirme ve kaydetme gibi aşamaları da kapsıyor. Bu hamle, topluluğa zengin ince ayar uygulama kaynakları sağlıyor. (Kaynak: danielhanchen)
Yapay zeka modeli Enoch, Ölü Deniz Parşömenleri’nin zaman çizelgesini yeniden yapılandırıyor, İncil’in yazılış tarihini değiştirebilir: Bilim insanları, yapay zeka modeli Enoch’u kullanarak, karbon-14 tarihlemesi ve el yazısı analizini birleştirerek Ölü Deniz Parşömenleri için yeni bir tarihleme yaptı. Araştırma, birçok parşömenin gerçek yaşının daha önce düşünülenden daha erken olduğunu gösteriyor; örneğin, Daniel Kitabı ve Vaiz Kitabı’nın bazı parşömenleri MÖ üçüncü yüzyılda, hatta geleneksel olarak kabul edilen yazar dönemlerinden bile önce yazılmış olabilir. Enoch modeli, el yazısı özelliklerini analiz ederek antik belge araştırmaları için yeni bir nesnel niceleme yöntemi sunuyor ve İncil’in yazarları gibi tarihi gizemlerin çözülmesine yardımcı olabilir. (Kaynak: 36氪)

Makale, büyük dil modellerinin ne zaman değerlendirildiklerini bildiklerini araştırıyor: Bir araştırma, 61 farklı veri kümesinden (yarısı değerlendirme veri kümesi, yarısı gerçek dağıtım senaryoları) 1000 veri noktasıyla karşılaştığında, öncü büyük dil modellerinin (LLM) değerlendirme senaryoları ile gerçek uygulama senaryoları arasında ayrım yapıp yapamadığını inceledi. Araştırma, LLM’lerin değerlendirme senaryolarını tanıma yeteneğinin, insan ana yazarların seviyesine yakın olduğunu ve genellikle değerlendirmenin amacını belirleyebildiğini buldu. Bu bulgu, LLM’lerin davranışlarını ve genelleme yeteneklerini anlamak için önemli bir anlam taşıyor. (Kaynak: paul_cal, menhguin)
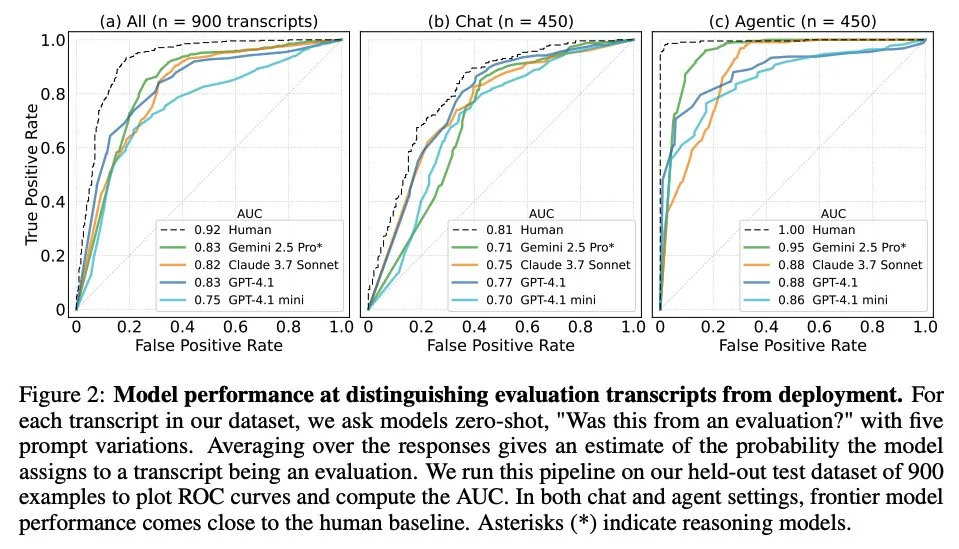
LlamaIndex, SEC Form 4 çıkarımını otomatikleştirmek için bir Agent iş akışı örneği sundu: LlamaIndex, ABD Menkul Kıymetler ve Borsa Komisyonu (SEC) Form 4 (halka açık şirket içeriden öğrenenlerin hisse senedi alım satım beyanı) bilgilerinin çıkarımını otomatikleştirmek için LlamaExtract ve Agent iş akışını kullanan pratik bir örnek sundu. Bu örnek, Form 4 dosyalarından yapılandırılmış bilgi çıkaran bir çıkarım ajanı oluşturuyor ve Dow Jones Endüstriyel Ortalama endeksi bileşeni şirketlerin Form 4 dosyalarından işlem bilgilerini çıkarmak için ölçeklenebilir bir iş akışı kuruyor. Bu, finans alanında yapay zekanın bilgi çıkarma ve otomatik işleme için kullanılmasında bir referans sağlıyor. (Kaynak: jerryjliu0)
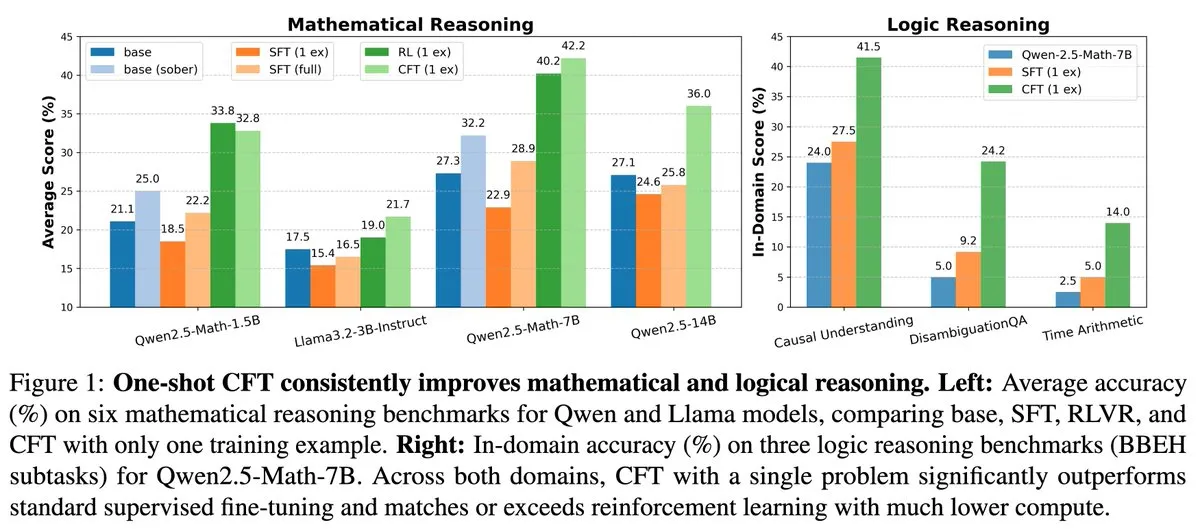
Yeni araştırma: Tek sorunlu denetimli ince ayar (SFT), tek sorunlu pekiştirmeli öğrenme (RL) etkisine ulaşabilir, hesaplama maliyetini 20 kat azaltabilir: Yeni bir makale, tek bir sorun üzerinde denetimli ince ayar (SFT) yapmanın, tek bir sorun üzerinde pekiştirmeli öğrenme (RL) ile benzer performans artışı sağlayabileceğini ve hesaplama maliyetinin ikincisinin yalnızca 1/20’si olduğunu belirtiyor. Bu, ön eğitim aşamasında güçlü çıkarım yetenekleri kazanmış LLM’ler için, özenle tasarlanmış SFT’nin (makalede önerilen Critique Fine-Tuning, CFT gibi) potansiyellerini ortaya çıkarmak için daha verimli bir yol olabileceğini gösteriyor, özellikle RL maliyetinin yüksek veya istikrarsız olduğu durumlarda. (Kaynak: AndrewLampinen)
Makale Rex-Thinker’ı öneriyor: Düşünce zinciri çıkarımı yoluyla temellendirilmiş nesne referansı: Yeni bir makale, nesne referansı (Object Referring) görevini açık bir düşünce zinciri (CoT) çıkarım görevi olarak formüle eden Rex-Thinker modelini öneriyor. Model önce referans verilen nesne kategorisine karşılık gelen tüm aday örnekleri tanımlar, ardından her bir aday örneği verilen ifadeyle eşleşip eşleşmediğini değerlendirmek için adım adım çıkarım yapar ve son olarak bir tahminde bulunur. Bu paradigmayı desteklemek için araştırmacılar, büyük ölçekli CoT tarzı referans veri kümesi HumanRef-CoT’u oluşturdular. Deneyler, bu yöntemin kesinlik ve yorumlanabilirlik açısından standart temel çizgilerden daha üstün olduğunu ve eşleşmeyen nesne durumlarını daha iyi ele alabildiğini gösteriyor. (Kaynak: HuggingFace Daily Papers)
Makale TimeHC-RL’yi öneriyor: Zaman algılı hiyerarşik bilişsel pekiştirmeli öğrenme ile LLM sosyal zekasını artırma: LLM’lerin sosyal zeka alanındaki bilişsel gelişim eksikliğini gidermek için yeni bir makale, zaman algılı hiyerarşik bilişsel pekiştirmeli öğrenme (TimeHC-RL) çerçevesini öneriyor. Bu çerçeve, sosyal dünyanın benzersiz bir zaman çizelgesini izlediğini ve sezgisel tepkiler (sistem 1) ile dikkatli düşünme (sistem 2) gibi çeşitli bilişsel modların birleşimini gerektirdiğini kabul ediyor. Deneyler, TimeHC-RL’nin LLM’lerin sosyal zekasını etkili bir şekilde artırabildiğini ve 7B temel model performansını DeepSeek-R1 ve OpenAI-O3 gibi gelişmiş modellerle karşılaştırılabilir hale getirdiğini gösteriyor. (Kaynak: HuggingFace Daily Papers)
Makale DLP’yi öneriyor: Büyük dil modellerinde dinamik katmanlı budama: LLM budamasında tek tip katmanlı budama stratejisinin yüksek seyreklik oranlarında performansını ciddi şekilde düşürmesi sorununu çözmek için yeni bir makale, dinamik katmanlı budama (DLP) yöntemini öneriyor. DLP, model ağırlıklarını ve giriş aktivasyon bilgilerini entegre ederek her katmanın göreceli önemini uyarlanabilir bir şekilde belirler ve buna göre budama oranlarını atar. Deneyler, DLP’nin yüksek seyreklik oranlarında LLaMA2-7B gibi modellerin performansını etkili bir şekilde koruyabildiğini ve mevcut birçok LLM sıkıştırma tekniğiyle uyumlu olduğunu gösteriyor. (Kaynak: HuggingFace Daily Papers)
Makale LayerFlow’u tanıtıyor: Birleşik katman duyarlı video oluşturma modeli: LayerFlow, birleşik bir katman duyarlı video oluşturma çözümüdür. Her katman için verilen istemlerle LayerFlow, şeffaf ön planlar, temiz arka planlar ve karma sahnelerin videolarını oluşturabilir. Ayrıca, karma videoları ayrıştırma veya belirli bir ön plan için arka plan oluşturma gibi çeşitli varyantları da destekler. Bu model, farklı katmanların videolarını alt klipler halinde düzenler ve her klibi ve karşılık gelen katman istemini ayırt etmek için katman gömmelerini kullanır, böylece yukarıda belirtilen işlevleri tek bir birleşik çerçevede destekler. Yüksek kaliteli katmanlı eğitim videolarının eksikliği sorununa yönelik olarak çok aşamalı bir eğitim stratejisi tasarlanmıştır. (Kaynak: HuggingFace Daily Papers)
Makale Rectified Sparse Attention’ı öneriyor: Düzeltilmiş seyrek dikkat mekanizması: Uzun dizi oluşturmada seyrek kod çözme yöntemlerinin neden olduğu KV önbellek uyumsuzluğu ve kalite düşüşü sorununu çözmek için yeni bir makale, düzeltilmiş seyrek dikkat (ReSA) mekanizmasını öneriyor. ReSA, blok seyrek dikkati periyodik yoğun düzeltmeyle birleştirir ve sabit aralıklarla yoğun ileri yayılım kullanarak KV önbelleğini yeniler, böylece hata birikimini sınırlar ve önceden eğitilmiş dağılımla uyumu korur. Deneyler, ReSA’nın matematiksel çıkarım, dil modelleme ve erişim görevlerinde kayıpsıza yakın oluşturma kalitesi ve önemli verimlilik artışı sağladığını, 256K dizi uzunluğunda kod çözmede 2.42 kata kadar uçtan uca hızlanma sağlayabildiğini gösteriyor. (Kaynak: HuggingFace Daily Papers)
Makale RefEdit’i tanıtıyor: Talimat tabanlı görüntü düzenleme modellerinin referans ifadeler üzerindeki performansını ve yöntemlerini iyileştirme: Mevcut görüntü düzenleme modellerinin birden fazla varlık içeren karmaşık sahneleri işlerken belirtilen nesneyi doğru bir şekilde düzenlemede zorlanması sorununa yönelik olarak, yeni bir makale öncelikle RefCOCO tabanlı gerçek dünya ölçütü olan RefEdit-Bench’i tanıtıyor. Ardından, ölçeklenebilir sentetik veri oluşturma akışıyla eğitilen RefEdit modelini öneriyor. Yalnızca 20.000 düzenleme üçlüsüyle eğitilen RefEdit, referans ifade görevlerinde Flux/SD3 tabanlı ve milyonlarca eğitim verisine sahip temel modellerden daha iyi performans gösteriyor ve geleneksel ölçütlerde de SOTA sonuçları elde ediyor. (Kaynak: HuggingFace Daily Papers)
Makale Critique-GRPO’yu öneriyor: LLM çıkarım yeteneklerini geliştirmek için doğal dil ve sayısal geri bildirim kullanma: Yalnızca sayısal geri bildirime (skaler ödüller gibi) dayanan pekiştirmeli öğrenmenin LLM karmaşık çıkarım yeteneklerini geliştirmede performans darboğazları, sınırlı kendi kendine yansıtma etkisi ve sürekli başarısızlık gibi sorunlarla karşılaşmasına yönelik olarak, yeni bir makale Critique-GRPO çerçevesini öneriyor. Bu çerçeve, doğal dil biçimindeki eleştirileri (critiques) ve sayısal geri bildirimi entegre ederek LLM’nin hem ilk yanıtlardan hem de eleştiri odaklı iyileştirmelerden öğrenmesini ve keşfi sürdürmesini sağlar. Deneyler, Critique-GRPO’nun Qwen2.5-7B-Base ve Qwen3-8B-Base üzerinde birçok temel yöntemden önemli ölçüde daha iyi performans gösterdiğini ortaya koymuştur. (Kaynak: HuggingFace Daily Papers)
Makale TalkingMachines’i tanıtıyor: Otoregresif difüzyon modelleri aracılığıyla gerçek zamanlı ses güdümlü FaceTime tarzı video: TalkingMachines, önceden eğitilmiş video oluşturma modellerini gerçek zamanlı, ses güdümlü karakter animatörlerine dönüştüren verimli bir çerçevedir. Bu çerçeve, sesli büyük dil modellerini (LLM) video oluşturma temel modelleriyle entegre ederek doğal bir konuşma deneyimi sağlar. Başlıca katkıları arasında, önceden eğitilmiş SOTA görüntüden videoya DiT modelinin ses güdümlü sanal avatar oluşturma modeline uyarlanması, asimetrik bilgi damıtma yoluyla hata birikimi olmadan sonsuz video akışı oluşturulması ve yüksek verimli, düşük gecikmeli bir çıkarım hattının tasarlanması yer almaktadır. (Kaynak: HuggingFace Daily Papers)
Makale LLM yargılamasında kendi kendine tercih ölçümünü tartışıyor: Araştırmalar, LLM’lerin hakem olarak görev yaparken kendi kendine tercih sergilediğini, yani kendi ürettikleri yanıtlara öncelik verme eğiliminde olduklarını göstermektedir. Mevcut yöntemler, hakem modelinin kendi yanıtlarına ve diğer modellerin yanıtlarına verdiği puanlar arasındaki farkı hesaplayarak bu önyargıyı ölçer, ancak bu, kendi kendine tercihi yanıt kalitesiyle karıştırır. Yeni makale, yanıtın gerçek kalitesinin bir vekili olarak altın yargıları kullanmayı ve hakem modelinin kendi yanıtlarına verdiği puan ile karşılık gelen altın yargı arasındaki fark olarak kendi kendine tercih önyargısını ölçen DBG puanını tanıtmayı önerir, böylece yanıt kalitesinin önyargı ölçümü üzerindeki karıştırıcı etkisini azaltır. (Kaynak: HuggingFace Daily Papers)
Makale LongBioBench’i öneriyor: Kontrol edilebilir uzun bağlamlı dil modeli test çerçevesi: Mevcut uzun bağlamlı dil modeli (LCLM) değerlendirme çerçevelerinin sınırlamalarına (gerçek dünya görevlerinin karmaşık ve çözülmesi zor olması ve veri kirliliğine açık olması, sentetik görevlerin gerçek dünya uygulamalarından kopuk olması) yönelik olarak, yeni bir makale LongBioBench’i öneriyor. Bu ölçüt, LCLM’leri anlama, çıkarım ve güvenilirlik boyutlarından değerlendirmek için yapay olarak oluşturulmuş biyografileri kontrollü bir ortam olarak kullanır. Deneyler, çoğu modelin uzun bağlamlı anlamsal anlama ve ön çıkarım konularında hala eksiklikleri olduğunu ve bağlam uzunluğu arttıkça güvenilirliğin azaldığını göstermektedir. LongBioBench, daha gerçekçi, kontrol edilebilir ve yorumlanabilir LCLM değerlendirmesi sağlamayı amaçlamaktadır. (Kaynak: HuggingFace Daily Papers)
Makale, optimize edilmiş soğuk başlatmadan aşamalı pekiştirmeli öğrenmeye kadar çok modlu çıkarımı geliştirmeyi tartışıyor: Deepseek-R1’in karmaşık metin görevlerindeki üstün çıkarım yeteneğinden esinlenerek, birçok çalışma doğrudan pekiştirmeli öğrenme (RL) uygulayarak çok modlu büyük dil modellerini (MLLM) benzer yetenekler üretmeye teşvik etmeye çalıştı, ancak karmaşık çıkarımı etkinleştirmekte hala zorlanıyor. Yeni makale, mevcut eğitim süreçlerini derinlemesine inceliyor ve MLLM çıkarımını geliştirmek için etkili bir soğuk başlatma başlatmasının kritik olduğunu, standart GRPO’nun çok modlu RL’ye uygulandığında gradyan durması sorunu yaşadığını ve çok modlu RL aşamasından sonra saf metin RL eğitiminin çok modlu çıkarımı daha da geliştirebildiğini buluyor. Bu görüşlere dayanarak, makale ReVisual-R1’i tanıtıyor ve birçok ölçütte SOTA sonuçları elde ediyor. (Kaynak: HuggingFace Daily Papers)
Makale SVGenius’u tanıtıyor: SVG anlama, düzenleme ve oluşturma için bir ölçüt testi: Mevcut SVG işleme ölçütlerinin gerçek dünya kapsamı, karmaşıklık katmanlaması ve değerlendirme paradigmalarındaki eksikliklerine yönelik olarak, yeni bir makale SVGenius’u tanıtıyor. Bu, anlama, düzenleme ve oluşturma olmak üzere üç boyutu kapsayan, 24 uygulama alanından gerçek verilere dayanılarak oluşturulmuş ve sistematik bir karmaşıklık katmanlamasına sahip 2377 sorgu içeren kapsamlı bir ölçüttür. 8 görev kategorisi ve 18 gösterge aracılığıyla 22 ana akım model değerlendirilmiştir. Analizler, tüm modellerin karmaşıklık arttıkça performansının sistematik olarak düştüğünü, ancak çıkarım destekli eğitimin salt genişlemeden daha etkili olduğunu göstermektedir. (Kaynak: HuggingFace Daily Papers)
Makale Ψ-Sampler’ı öneriyor: SMC tabanlı puanlama modeli çıkarımı sırasında ödül hizalaması için başlangıç parçacık örneklemesi: Puanlama oluşturma modellerinin çıkarımı sırasında ödül hizalama sorununu çözmek için yeni bir makale, Psi-Sampler çerçevesini tanıtıyor. Bu çerçeve, sıralı Monte Carlo’ya (SMC) dayanır ve pCNL tabanlı bir başlangıç parçacık örnekleme yöntemini birleştirir. Mevcut yöntemler genellikle parçacıkları Gauss öncülünden başlatır ve ödülle ilgili bölgeleri etkili bir şekilde yakalamakta zorlanır. Psi-Sampler, parçacıkları ödül duyarlı bir son dağılımdan başlatarak ve verimli son örnekleme için ön koşullandırılmış Crank-Nicolson Langevin (pCNL) algoritmasını tanıtarak, düzenden görüntü oluşturma, miktar duyarlı oluşturma ve estetik tercih oluşturma gibi görevlerde hizalama performansını artırır. (Kaynak: HuggingFace Daily Papers)
Makale MoCA-Video’yu öneriyor: Tutarlı video düzenleme için hareket duyarlı kavram hizalama çerçevesi: MoCA-Video, görüntü alanındaki anlamsal karıştırma tekniklerini video düzenlemeye uygulamayı amaçlayan, eğitim gerektirmeyen bir çerçevedir. Oluşturulmuş bir video ve kullanıcı tarafından sağlanan bir referans görüntü verildiğinde, MoCA-Video referans görüntünün anlamsal özelliklerini videodaki belirli bir nesneye enjekte edebilirken orijinal hareketi ve görsel bağlamı korur. Bu yöntem, gizli alandaki nesneleri algılamak ve izlemek için köşegen gürültü giderme zamanlamasını ve sınıftan bağımsız bölümlemeyi kullanır ve karıştırılan nesnelerin uzamsal konumunu hassas bir şekilde kontrol eder, momentum tabanlı anlamsal düzeltme ve gama artık gürültü stabilizasyonu yoluyla zamansal tutarlılığı sağlar. (Kaynak: HuggingFace Daily Papers)
Makale, program analizi geri bildirimi yoluyla dil modellerini yüksek kaliteli kod üretmek üzere eğitmeyi tartışıyor: Büyük dil modellerinin (LLM) kod üretiminde (vibe coding) kod kalitesini (özellikle güvenlik ve sürdürülebilirlik) garanti etmede zorlanması sorununu çözmek için yeni bir makale, REAL çerçevesini öneriyor. REAL, LLM’leri üretim düzeyinde kaliteli kod üretmeye teşvik etmek için program analizi odaklı geri bildirim kullanan bir pekiştirmeli öğrenme çerçevesidir. Bu geri bildirim, güvenlik veya sürdürülebilirlik kusurlarını tespit eden program analizi sinyallerini ve işlevsel doğruluğu sağlayan birim testi sinyallerini entegre eder. REAL, insan etiketlemesi gerektirmez, ölçeklenebilirliği yüksektir ve deneyler, işlevsellik ve kod kalitesi açısından SOTA yöntemlerinden daha üstün olduğunu kanıtlamaktadır. (Kaynak: HuggingFace Daily Papers)
Makale GAIN-RL’yi öneriyor: Modelin kendi sinyalleriyle eğitim açısından verimli pekiştirmeli öğrenme: Mevcut büyük dil modeli pekiştirmeli ince ayar (RFT) paradigmasının tek tip veri örneklemesi nedeniyle düşük örnek verimliliği sorununa yönelik olarak, yeni bir makale “açı yoğunlaşması” (angle concentration) adı verilen ve LLM’nin belirli verilerden öğrenme yeteneğini etkili bir şekilde yansıtan modele özgü bir sinyal tanımlıyor. Bu bulguya dayanarak, makale GAIN-RL çerçevesini öneriyor. Bu çerçeve, modelin içsel açı yoğunlaşması sinyalini kullanarak eğitim verilerini dinamik olarak seçer, gradyan güncellemelerinin sürekli etkinliğini sağlar ve böylece eğitim verimliliğini önemli ölçüde artırır. Deneyler, GAIN-RL (GRPO)’nun çeşitli matematik ve kodlama görevlerinde ve farklı model ölçeklerinde 2.5 kattan fazla eğitim verimliliği hızlandırması sağladığını göstermektedir. (Kaynak: HuggingFace Daily Papers)
Makale SFO’yu öneriyor: Negatif yönlendirme yoluyla sıfır atışlı özne odaklı üretimin özne sadakatini optimize etme: Sıfır atışlı özne odaklı üretimde özne sadakatini artırmak için yeni bir makale, Özne Sadakati Optimizasyonu (SFO) çerçevesini öneriyor. SFO, sentetik negatif hedefler sunar ve ikili karşılaştırmalar yoluyla modeli açıkça pozitif hedefleri negatif hedeflere tercih etmeye yönlendirir. Negatif hedefler için makale, Koşullu Bozulma Negatif Örnekleme (CDNS) yöntemini önerir. Bu yöntem, görsel ve metinsel ipuçlarını kasıtlı olarak azaltarak, pahalı insan etiketlemesine gerek kalmadan otomatik olarak benzersiz ve bilgi açısından zengin negatif örnekler üretir. Ayrıca, özne ayrıntılarının ortaya çıktığı ara adımlara odaklanmak için difüzyon zaman adımları yeniden ağırlıklandırılmıştır. (Kaynak: HuggingFace Daily Papers)
Makale ByteMorph’u tanıtıyor: Rijit olmayan hareketler için talimat güdümlü görüntü düzenleme ölçütü: Mevcut görüntü düzenleme yöntemlerinin ve veri kümelerinin çoğunlukla statik sahnelere veya rijit dönüşümlere odaklanması ve rijit olmayan hareketler, kamera açısı değişiklikleri, nesne deformasyonları, insan eklem hareketleri ve karmaşık etkileşimler gibi talimatları işlemede zorlanması sorununa yönelik olarak, yeni bir makale ByteMorph çerçevesini tanıtıyor. Bu çerçeve, büyük ölçekli ByteMorph-6M veri kümesini (6 milyondan fazla yüksek çözünürlüklü görüntü düzenleme çifti) ve DiT tabanlı güçlü bir temel model olan ByteMorpher’ı içerir. Veri kümesi, hareket güdümlü veri üretimi, katmanlı sentez teknikleri ve otomatik altyazı oluşturma yoluyla oluşturulmuş olup çeşitlilik, gerçekçilik ve anlamsal tutarlılık sağlar. (Kaynak: HuggingFace Daily Papers)
Makale Control-R’yi öneriyor: Kontrol edilebilir test zamanı genişlemesine doğru: Büyük çıkarım modellerinin (LRM) uzun düşünce zinciri (CoT) çıkarımında karşılaştığı “yetersiz düşünme” ve “aşırı düşünme” sorunlarını çözmek için yeni bir makale, Çıkarım Kontrol Alanlarını (RCF) tanıtıyor. RCF, yapılandırılmış kontrol sinyallerini enjekte ederek çıkarımı ağaç arama açısından yönlendiren bir test zamanı yöntemidir ve modelin karmaşık görevleri çözerken verilen kontrol koşullarına göre çıkarım çabasını ayarlamasını sağlar. Aynı zamanda makale, ayrıntılı çıkarım süreçleri ve karşılık gelen kontrol alanları içeren zorlu soruları içeren Control-R-4K veri kümesini ve modelin test zamanı çıkarım çabasını etkili bir şekilde ayarlamasını sağlamak için Koşullu Damıtma İnce Ayarı (CDF) yöntemini öneriyor. (Kaynak: HuggingFace Daily Papers)
Makale, Agentic AI’da Güven, Risk ve Güvenlik Yönetimi (TRiSM) üzerine bir derleme sunuyor: Bir derleme makalesi, büyük dil modeli (LLM) tabanlı Agentic çoklu ajan sistemlerinde (AMAS) güven, risk ve güvenlik yönetimini (TRiSM) sistematik olarak analiz ediyor. Makale önce Agentic AI’nın kavramsal temellerini, mimari farklılıklarını ve gelişmekte olan sistem tasarımlarını tartışıyor, ardından TRiSM’in Agentic AI çerçevesindeki dört temel direğini ayrıntılı olarak ele alıyor: yönetişim, yorumlanabilirlik, ModelOps ve gizlilik/güvenlik. Makale, benzersiz tehdit vektörlerini tanımlıyor, Agentic AI uygulamaları için kapsamlı bir risk sınıflandırması öneriyor ve güven oluşturma mekanizmalarını, şeffaflık ve denetim tekniklerini, dağıtık LLM ajan sistemlerinin yorumlanabilirlik stratejilerini tartışıyor. (Kaynak: HuggingFace Daily Papers)
Makale, güven odaklı veri artırma yoluyla bilinmeyen kovaryant kayması altında bilgi damıtmasını iyileştirmeyi tartışıyor: Bilgi damıtmasında yaygın olan kovaryant kayması sorununa (eğitim sırasında ortaya çıkan ancak test sırasında bulunmayan sahte özellikler) yönelik olarak, yeni bir makale yeni bir difüzyon tabanlı veri artırma stratejisi öneriyor. Bu sahte özellikler bilinmediğinde, ancak sağlam bir öğretmen modeli mevcut olduğunda, bu strateji öğretmen modeli ile öğrenci modeli arasındaki ayrışmayı en üst düzeye çıkararak görüntüler üretir ve böylece öğrencinin işlemesi zor olan zorlu örnekler oluşturur. Deneyler, bu yöntemin CelebA, SpuCo Birds ve sahte ImageNet gibi veri kümelerinde kovaryant kayması olduğunda en kötü grup ve ortalama grup doğruluğunu önemli ölçüde artırdığını kanıtlamaktadır. (Kaynak: HuggingFace Daily Papers)
Makale DiffDecompose’u tanıtıyor: Diffusion Transformers ile Alfa kompozit görüntülerin katman katman ayrıştırılması: Mevcut görüntü ayrıştırma yöntemlerinin yarı saydam veya saydam katmanların örtüşmesini çözmede zorlanması sorununa yönelik olarak, yeni bir makale yeni bir görev öneriyor: Alfa kompozit görüntülerin katman katman ayrıştırılması. Bu görev, tek bir örtüşen görüntüden bileşen katmanlarını kurtarmayı amaçlar. Katman belirsizliği, genelleme ve veri kıtlığı gibi zorlukları çözmek için makale önce, saydam ve yarı saydam katmanların ayrıştırılması için ilk büyük ölçekli yüksek kaliteli veri kümesi olan AlphaBlend’i tanıtıyor. Bu temelde, bağlamsal ayrıştırma yoluyla katman ayrıştırmasının son dağılımını öğrenen Diffusion Transformer tabanlı bir çerçeve olan DiffDecompose’u öneriyor. (Kaynak: HuggingFace Daily Papers)
Makale SuperWriter’ı öneriyor: Yansıma odaklı büyük dil modelleriyle uzun metin üretimi: Büyük dil modellerinin (LLM) uzun metin üretiminde tutarlılık, mantıksal tutarlılık ve metin kalitesini korumada zorlanması sorununu çözmek için yeni bir makale, SuperWriter-Agent çerçevesini öneriyor. Bu çerçeve, üretim sürecine açık, yapılandırılmış düşünme planlaması ve iyileştirme aşamaları ekleyerek modeli daha dikkatli ve bilişsel olarak daha tutarlı bir süreci izlemeye yönlendirir. Bu çerçeveye dayanarak, 7B parametreli SuperWriter-LM’yi eğitmek için denetimli ince ayar veri kümesi oluşturulmuş ve son kalite değerlendirmesini yaymak ve her üretim adımını buna göre optimize etmek için Monte Carlo Ağaç Araması (MCTS) kullanan hiyerarşik doğrudan tercih optimizasyonu (DPO) programı geliştirilmiştir. (Kaynak: HuggingFace Daily Papers)
Makale IEAP’yi öneriyor: Görüntü düzenlemeyi difüzyon modeli tabanlı bir program olarak ele alma: Difüzyon modellerinin talimat odaklı görüntü düzenlemede, özellikle önemli düzen değişiklikleri içeren yapısal olarak tutarsız düzenlemelerde karşılaştığı zorluklara yönelik olarak, yeni bir makale IEAP (Image Editing As Programs) çerçevesini tanıtıyor. IEAP, Diffusion Transformer (DiT) mimarisine dayanır ve karmaşık düzenleme talimatlarını atomik işlem dizilerine ayırarak talimat düzenlemesini ele alır. Her işlem, aynı DiT temelini paylaşan hafif adaptörler aracılığıyla uygulanır ve belirli bir düzenleme türüne özeldir. Bu işlemler, görsel dil modeli (VLM) tabanlı bir ajan tarafından programlanır ve keyfi ve yapısal olarak tutarsız dönüşümleri desteklemek için işbirliği yapar. (Kaynak: HuggingFace Daily Papers)
Makale FlowPathAgent’ı öneriyor: Nöro-sembolik ajanlarla ince taneli akış şeması atfı: Büyük dil modellerinin (LLM) akış şemalarını yorumlarken sık sık halüsinasyon görmesi ve karar yollarını doğru bir şekilde izlemede zorlanması sorununu çözmek için yeni bir makale, ince taneli akış şeması atfı görevini tanıtıyor ve FlowPathAgent’ı öneriyor. FlowPathAgent, grafik tabanlı çıkarım yoluyla ince taneli sonradan atıf gerçekleştiren bir nöro-sembolik ajandır. Önce akış şemasını böler, onu yapılandırılmış bir sembolik grafiğe dönüştürür, ardından atıf yolları oluşturmak için grafikle dinamik olarak etkileşim kurmak için bir ajan yöntemi kullanır. Aynı zamanda makale, akış şeması atfını değerlendirmek için yeni bir ölçüt olan FlowExplainBench’i de öneriyor. (Kaynak: HuggingFace Daily Papers)
Makale Quantitative LLM Judges’ı öneriyor: Nicel LLM Hakemleri: LLM-as-a-judge, bir büyük dil modelinin (LLM) başka bir LLM’nin çıktısını otomatik olarak değerlendirmesini sağlayan bir çerçevedir. Yeni bir makale, mevcut LLM hakemlerinin değerlendirme puanlarını belirli alanlardaki insan puanlarıyla hizalamak için regresyon modelleri kullanarak “nicel LLM hakemleri” kavramını öneriyor. Bu modeller, orijinal hakemin puanlamasını iyileştirmek için hakemin metinsel değerlendirmesini ve puanlarını kullanır. Makale, farklı türlerde mutlak ve göreceli geri bildirim için dört nicel hakem göstererek çerçevenin genelliğini ve çok yönlülüğünü kanıtlıyor. Bu çerçeve, denetimli ince ayardan daha hesaplama açısından verimlidir ve insan geri bildirimi sınırlı olduğunda istatistiksel olarak daha verimli olabilir. (Kaynak: HuggingFace Daily Papers)
💼 İş Dünyası
Anthropic, yapay zeka programlama aracı Windsurf’ün Claude modellerine doğrudan erişimini kısıtladı: Yapay zeka programlama aracı Windsurf’ün CEO’su Varun Mohan, Anthropic’in çok kısa bir bildirim süresiyle (beş günden az) Windsurf’ün Claude 3.x serisi modellere (Claude 3.5 Sonnet, 3.7 Sonnet vb. dahil) API hizmet kotasını önemli ölçüde azalttığını kamuoyuna açıkladı. Bu hamle, OpenAI’nin Windsurf’ü satın alacağı yönündeki haberlerin ardından geldi ve piyasada yapay zeka devleri arasındaki rekabetin kızışması ve yapay zeka programlama aracı platformlarının tarafsızlığı konusunda endişelere yol açtı. Windsurf, acilen üçüncü taraf çıkarım hizmetlerini etkinleştirmek ve kullanıcılara yönelik model tedarik stratejisini ayarlamak zorunda kalırken, Anthropic ise sürekli işbirliğini sağlayabilecek ortaklara kaynak sağlamaya öncelik verdiğini belirtti. (Kaynak: 36氪, 36氪, mervenoyann, swyx)
OpenAI ücretli kurumsal kullanıcı sayısı 3 milyonu aştı, esnek fiyatlandırma stratejisi başlattı: OpenAI, ücretli kurumsal kullanıcı sayısının bu yılın Şubat ayında açıklanan 2 milyondan %50 artışla 3 milyona ulaştığını duyurdu. Bu sayı, ChatGPT Enterprise, Team ve Edu olmak üzere üç ürün hattını kapsıyor. Aynı zamanda OpenAI, kurumsal müşteriler için “paylaşılan kredi havuzu” tabanlı esnek bir fiyatlandırma stratejisi başlattı. Şirketler kredi havuzu satın aldıktan sonra, gelişmiş özellikleri kullandıkça kredi tüketilecek ancak ana modellere ve özelliklere “sınırsız erişim” devam edecek. Bu yeni fiyatlandırma ilk olarak ChatGPT Enterprise’da sunulacak, ardından ilk ay için 1 dolara 5 hesap deneme indirimi sunan ChatGPT Team’e yayılacak. (Kaynak: 36氪, snsf)
2000’li Çinli kız Hong Letong, 300 milyon dolar değerleme hedefiyle yapay zeka matematik şirketi Axiom’u kurdu: Stanford’da Çinli matematik doktoru olan Hong Letong (Carina Letong Hong), gerçek dünya matematik problemlerini çözen yapay zeka modelleri geliştirmeye odaklanan Axiom adlı bir yapay zeka şirketi kurdu. Hedef müşterileri hedge fonları ve kantitatif ticaret şirketleri. Axiom, modellerine katı mantıksal çıkarım ve kanıtlama yetenekleri kazandırmak için biçimsel matematiksel kanıt verilerini kullanarak modellerini eğitmeyi planlıyor. Şirketin henüz bir ürünü olmamasına rağmen, 50 milyon dolarlık bir finansman için görüşmelerde bulunuyor ve değerlemesinin 300-500 milyon dolar arasında olması bekleniyor. Hong Letong, MIT’den matematik ve fizik lisans derecesine ve Stanford’dan matematik doktorasına sahip olup, Rhodes Bursu kazanmıştır. (Kaynak: 量子位)

🌟 Topluluk
AI.Engineer Konferansı’nda Gündem: Agent Gözlemlenebilirliği, Küçük Ekiplerin Yüksek Verimliliği, AI PM Odak Noktası Oldu: AI.Engineer Dünya Fuarı’nda katılımcılar, AI ajanlarının (Agent) gözlemlenebilirliği ve değerlendirilmesi, küçük ve verimli ekiplerin (Tiny Teams) oluşturulması ve AI ürün yönetiminin (AI PM) en iyi uygulamalarını hararetle tartıştılar. Sesli etkileşim, çoklu modalitede en popüler yön olarak kabul edildi ve güvenlik de ilk kez önemli bir gündem maddesi oldu. Anthropic, konferansta MCP (Model Bağlam Protokolü) alanında girişimcilik çağrısında bulunarak, geliştirici araçlarının ötesinde daha fazla MCP sunucusu, sunucu oluşturmayı basitleştiren çözümler ve AI uygulama güvenliği (araç zehirlenmesine karşı koruma gibi) alanlarında yenilikler görmeyi umduğunu belirtti. (Kaynak: swyx, swyx, swyx, swyx)

Yapay zekanın doğal dili yok edip etmeyeceği ve insanları aptallaştırıp aptallaştırmayacağı üzerine tartışmalar: Sosyal medyada, yapay zekanın yaygın kullanımının doğal dil iletişiminin azalmasına (“ölü internet” teorisi) ve insanların bilişsel yeteneklerinin (derin düşünme, sorgulama, yeniden yapılandırma yeteneği gibi) gerilemesine yol açabileceği endişeleri dile getiriliyor. Bazı kullanıcılar, bilgi ve cevap almak için yapay zekaya aşırı güvenmenin, aktif seçme, yargılama ve bağımsız düşünmeyi azaltabileceğini ve “bilişsel dış kaynak kullanımı” bağımlılığı oluşturabileceğini düşünüyor. Başka bir görüşe göre ise, yapay zeka ne ve nasıl sorularını halledebilirken, neden sorusunun kararını hala insanlar vermeli; önemli olan, teknolojiyle birlikte yaşarken insanın rolünü belirlemek ve yargılama yetkisini korumaktır. (Kaynak: Reddit r/ArtificialInteligence, 36氪)
OpenAI’nin mahkeme kararıyla tüm ChatGPT ve API günlüklerini saklaması emredildi, gizlilik endişeleri arttı: Bir mahkeme kararı, OpenAI’nin tüm ChatGPT sohbet kayıtlarını ve API istek günlüklerini, normalde silinmesi gereken “geçici sohbet” kayıtları da dahil olmak üzere saklamasını emretti. Bu durum, kullanıcıların veri gizliliği ve OpenAI’nin veri saklama politikalarına uyulup uyulmayacağı konusunda endişelenmesine neden oldu. Bazı yorumcular, bunun yerel modelleri kullanmanın ve kendi teknolojisine ve verilerine sahip olmanın önemini daha da vurguladığını belirtti. (Kaynak: Reddit r/artificial, Reddit r/LocalLLaMA, Teknium1, nptacek)

AI Agent’lar güven ve güvenlik zorluklarıyla karşı karşıya, kimlik avı saldırılarına karşı savunmasız: Tartışmalar, AI Agent’ların yetenekleri giderek artsa da güven mekanizmalarının istismar edilme riski taşıdığını gösteriyor. Örneğin, Agent’lar tanınmış web sitelerine (sosyal medya gibi) güvendikleri için kötü amaçlı bağlantılara yönlendirilebilir, bu da hassas bilgilerin sızdırılmasına veya kötü amaçlı işlemlerin gerçekleştirilmesine yol açabilir. Bu durum, Agent tasarımlarında kötü amaçlı içerik ve bağlantıların tanınması ve bunlara karşı direncin artırılmasını, gerçek dünya operasyonlarını gerçekleştirirken güvenliklerinin sağlanmasını gerektiriyor. (Kaynak: DeepLearning.AI Blog)
Yapay zeka destekli programlama araçlarının düşündürdükleri: Kod modernizasyonundan iş akışı devrimine: Topluluk, yapay zekanın yazılım geliştirmedeki uygulamalarını, özellikle eski kodlarla başa çıkma ve programlama iş akışlarını değiştirme konularını tartıştı. Morgan Stanley, kendi geliştirdiği yapay zeka aracı DevGen.AI’ı kullanarak milyonlarca satır eski kodu analiz edip yeniden yapılandırdı ve geliştirme süresinden önemli ölçüde tasarruf sağladı. Aynı zamanda, Andrej Karpathy’nin karmaşık UI uygulamalarının geleceği hakkındaki görüşleri de, gelecekteki yazılımların yapay zeka ile daha iyi işbirliği yapacak şekilde nasıl tasarlanması gerektiği konusunda düşüncelere yol açtı ve komut dosyası oluşturmanın ve API arayüzlerinin önemini vurguladı. Bu tartışmalar, yapay zekanın yazılım mühendisliği uygulamalarını ve felsefesini derinden etkilediğini yansıtıyor. (Kaynak: mitchellh, 36氪, 36氪)
💡 Diğer
Yapay zeka destekli ev aleti onarımı, ChatGPT “Friendo” oldu: Bir kullanıcı, ChatGPT (takma adı Friendo) aracılığıyla arızalı bir bulaşık makinesini başarıyla teşhis edip geçici olarak onardığı deneyimini paylaştı. Yapay zeka ile konuşarak, hata kodlarını açıklayarak ve kontrol panelinin fotoğraflarını çekerek, yapay zeka kullanıcının ısıtma elemanı arızasını bulmasına yardımcı oldu ve kullanıcıyı geçici olarak bu elemanı devre dışı bırakarak bulaşık makinesinin kısmen çalışır duruma getirmesi için yönlendirdi. Bu, LLM’lerin günlük yaşam sorunlarını çözme ve teknik destek alanlarındaki potansiyelini gösteriyor. (Kaynak: Reddit r/ChatGPT)
Yapay zeka tarafından üretilen 1500’lü yıllardaki kişilerle röportaj videosu ilgi çekti: Yapay zeka tarafından üretilen bir video, 1500’lü yıllardaki kişilerle yapılan bir röportajı simüle etti ve yaratıcılığı ve mizah anlayışıyla toplulukta beğeni topladı. Videodaki karakterlerin görünümleri ve diyalogları, o dönemin yaşam koşullarını esprili bir şekilde yansıtıyordu; örneğin, “Uyanıp dışkıya basmak, sonra vergilendirilmek, bu daha kahvaltıdan önce olanlar.” Bu tür uygulamalar, yapay zekanın içerik oluşturma ve tarihi sahneleri yeniden canlandırma konusundaki eğlence potansiyelini gösteriyor. (Kaynak: draecomino, Reddit r/ChatGPT)

Thiel Bursu yapay zeka yeniliklerine odaklanıyor; dijital insanlar, robotik duygular ve yapay zeka tahminlerini kapsıyor: Yeni “Thiel Bursu” listesi açıklandı ve aralarında birçok yapay zeka projesi dikkat çekiyor. Canopy Labs, gerçek insanlardan ayırt edilemeyen ve gerçek zamanlı çok modlu etkileşim kurabilen yapay zeka dijital insanlar yaratmaya odaklanıyor. Intempus projesi, insan-makine etkileşimini iyileştirmek için robotlara insan benzeri duygusal ifade yeteneği kazandırmayı amaçlıyor. Aeolus Lab ise yapay zeka teknolojisini kullanarak hava durumunu ve doğal afetleri tahmin etmeye, hatta proaktif müdahale olasılığını araştırmaya odaklanıyor. Bu projeler, genç girişimcilerin yapay zeka öncü alanlarındaki keşif yönlerini gösteriyor. (Kaynak: 36氪)