
Anahtar Kelimeler:AI Trend Raporu, AI Agent, Pekiştirmeli Öğrenme, Görsel Dil Modeli, AI Ticarileştirme, AI Halüsinasyon, AI Güvenliği, İnternet Kraliçesi AI Raporu, LawZero AI Güvenlik Tasarımı, GTA ve GLA Dikkat Mekanizması, SmolVLA Robot Modeli, AI Müzik Akışı Dolandırıcılığı
🔥 Odak Noktası
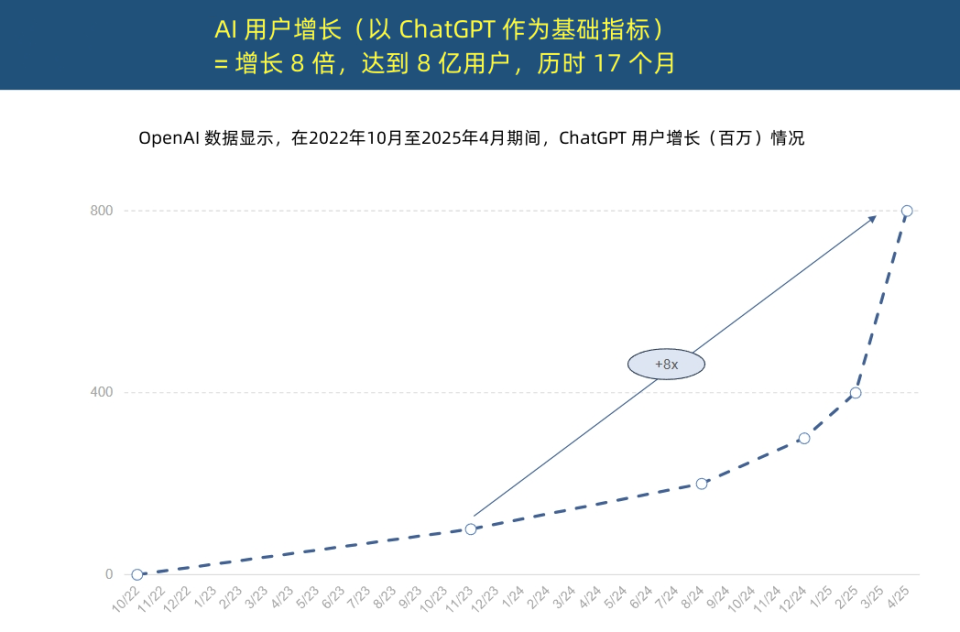
“İnternet Kraliçesi” AI Trend Raporu’nu yayınladı: AI uygulamalarında benzeri görülmemiş hızlanma ve maliyet yapısında devrim: “İnternet Kraliçesi” Mary Meeker, AI’ın benzeri görülmemiş bir hızla benimsendiğini vurgulayan 340 sayfalık “AI Trend Raporu”nu yayınladı. Rapor, ChatGPT kullanıcı büyümesinin çok hızlı olduğunu, 17 ay içinde aylık aktif kullanıcı sayısının 800 milyona ulaştığını ve yıllık gelirinin yaklaşık 4 milyar dolar olduğunu, bunun tarihteki tüm teknolojileri geride bıraktığını belirtiyor. Teknoloji devlerinin AI altyapısına yaptığı sermaye yatırımları hızla arttı ve 2024’te 212 milyar dolara ulaştı. Aynı zamanda, AI model eğitim maliyetleri 8 yıl içinde 2400 kat arttı, tek bir modelin eğitim maliyeti 1 milyar dolara ulaşabilirken, çıkarım maliyetleri donanım (Nvidia GPU verimliliğinin 100.000 kat artması gibi) ve algoritma optimizasyonları sayesinde keskin bir şekilde düşüyor. Açık kaynaklı modellerin (DeepSeek, Qwen gibi) performansı kapalı kaynaklı modellere yaklaşıyor, AI pozisyonlarına olan talep %448 arttı ve AI Agent’lar yeni bir dijital iş gücü haline geliyor. (Kaynak: APPSO, 腾讯科技)
Turing Ödülü sahibi Yoshua Bengio, “tasarımdan güvenli” AI’ı savunan LawZero’yu başlattı: Turing Ödülü sahibi Yoshua Bengio, AI sistemlerinde ortaya çıkabilecek aldatma ve kendini koruma davranışlarına karşı koymak amacıyla “tasarımdan güvenli” bir yapay zeka geliştirmeyi hedefleyen kâr amacı gütmeyen LawZero adlı kuruluşu duyurdu. LawZero, Asimov’un robotik üçüncü yasasından esinlenerek AI’ın insanların mutluluğunu ve çabalarını koruması gerektiğini vurguluyor. Kuruluş, AI Agent’lar için bir “koruma mekanizması” olarak Scientist AI sistemini geliştiriyor; bu sistem, doğrudan eyleme geçmek yerine dünyayı anlayarak yardım sağlıyor ve diğer AI davranışlarının risklerini değerlendiriyor. Bengio, mevcut Agentic AI’ın yanlış bir yön olduğunu, kontrolden çıkabileceğini ve geri dönüşü olmayan felaket sonuçlara yol açabileceğini belirterek, güvenli koruma mekanizması AI’ının en azından izlemeye çalıştığı AI Agent kadar akıllı olması gerektiğini vurguluyor. (Kaynak: 学术头条, Yoshua_Bengio)

AI Agent yılı: Yardımcı araçlardan görev yürütücülere, iş modellerini yeniden şekillendiriyor: Gartner Araştırma Başkan Yardımcısı Sun Zhiyong, 2025’in “Büyük Model Akıllı Ajan Yılı” ve “Üretken AI’ın Ticarileşme Yılı” olacağını belirterek, AI akıllı ajanlarının LLM yeteneklerinin ana çıkış noktası haline geldiğini ifade etti. Akıllı ajanlar ile sohbet botları arasındaki temel fark, bilgi sağlamaktan doğrudan görevleri yerine getirmeye geçiş yapmalarıdır; örneğin, akıllı bir ajan sadece kahve dükkanı bilgisi vermek yerine kahve sipariş etme sürecinin tamamını tamamlayabilir. Gartner, 2028 yılına kadar dijital arayüz etkileşimlerinin %20’sinin AI akıllı ajanları tarafından gerçekleştirileceğini, günlük iş kararlarının %15’inin AI akıllı ajanları tarafından otonom olarak verilebileceğini ve kurumsal yazılımların üçte birinin AI akıllı ajanlarını entegre edeceğini öngörüyor. BYD akıllı asistan gibi uygulamalar şimdiden kullanılmaya başlandı ve gelecekte cep telefonu App etkileşim şekilleri değişebilir. (Kaynak: IT时报)
Mamba çekirdek yazarı, uzun bağlamlı çıkarımı optimize etmek için çıkarım duyarlı dikkat mekanizmaları GTA ve GLA’yı önerdi: Mamba’nın çekirdek yazarlarından Tri Dao ve Princeton ekibi, büyük modellerin uzun bağlamlı çıkarım verimliliğini artırmak için özel olarak tasarlanmış Grouped-Tied Attention (GTA) ve Grouped-Latent Attention (GLA) adlı iki yeni dikkat mekanizması önerdi. GTA, parametre bağlama ve gruplandırılmış anahtar-değer (KV) önbelleğini yeniden kullanarak GQA’ya kıyasla KV önbellek kullanımını yaklaşık %50 azaltırken, benzer model kalitesini koruyor. GLA, küresel bağlamın sıkıştırılmış bir temsili olarak gizli/örtük token’ları tanıtan ve gruplandırılmış başlık mekanizmasıyla birleşen çift katmanlı bir yapı kullanıyor; DeepSeek tarafından kullanılan MLA’ya kıyasla uzun dizilerde (örneğin 64K) kod çözme hızını 2 kat artırabiliyor ve eş zamanlı istek işleme kapasitesini yükseltiyor. Bu yeni mekanizmalar, çıkarım sırasında bellek erişim darboğazlarını ve paralellik sınırlamalarını çözmeyi amaçlıyor. (Kaynak: 量子位)

🎯 Gelişmeler
DeepMind, SmolVLA’yı yayınladı: Topluluk verilerine dayalı verimli robotik görsel-dil-eylem modeli: Hugging Face, DeepMind ve diğer kurumlarla işbirliği yaparak, robotlar için özel olarak tasarlanmış ve tüketici sınıfı donanımlarda çalışabilen 450M parametreli açık kaynaklı bir görsel-dil-eylem (VLA) modeli olan SmolVLA’yı tanıttı. Bu model, yalnızca LeRobot topluluğu tarafından paylaşılan açık kaynaklı veri kümeleri kullanılarak önceden eğitildi ve LIBERO, Meta-World ve gerçek dünya görevlerinde (SO100, SO101) daha büyük VLA modellerinden ve ACT gibi temel çizgilerden daha iyi performans gösterdi. SmolVLA, yanıt hızını %30’a kadar artırabilen ve görev işlem hacmini 2 katına çıkarabilen asenkron çıkarımı destekliyor. Mimarisi, Transformer’ı akış eşleştirme kod çözücüsüyle birleştiriyor ve görsel token azaltma, VLM ara katman özelliklerinden yararlanma ve geçmeli dikkat mekanizması aracılığıyla hızı ve verimliliği optimize ediyor. (Kaynak: HuggingFace Blog, clefourrier)

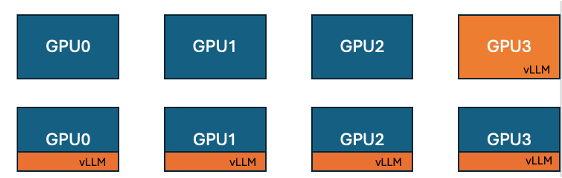
Hugging Face ve IBM, GPU eğitim verimliliğini artırmak için TRL’de vLLM eş yerleşimli özelliğini tanıttı: Hugging Face ve IBM, GRPO gibi çevrimiçi öğrenme algoritmaları için TRL kütüphanesine vLLM eş yerleşimli (co-located vLLM) özelliğini ekledi. Bu özellik, eğitim ve çıkarımın (üretim) aynı GPU üzerinde çalışmasına, kaynakları paylaşmasına ve sırayla yürütülmesine olanak tanıyarak, önceki vLLM sunucu modundaki eğitim GPU’sunun boşta bekleme sorununu ortadan kaldırıyor. vLLM’i aynı dağıtılmış süreç grubuna gömerek HTTP iletişimine gerek kalmıyor, torchrun, TP ve DP ile uyumlu hale geliyor, dağıtımı basitleştiriyor ve işlem hacmini artırıyor. Deneyler, 1.5B ve 7B modeller için eş yerleşimli modun 1.43 ila 1.73 kat hızlanma sağlayabildiğini gösteriyor; Qwen2.5-Math-72B gibi büyük modeller için, vLLM’in sleep() API’si ve DeepSpeed ZeRO Stage 3 optimizasyonu ile birleştirildiğinde, daha az GPU kullanılsa bile model doğruluğunu etkilemeden yaklaşık 1.26 kat eğitim hızlandırması elde edilebiliyor. (Kaynak: HuggingFace Blog)
Nvidia, karmaşık çıkarıma odaklanan Nemotron-Research-Reasoning-Qwen-1.5B modelini yayınladı: Nvidia, matematik problemleri, programlama zorlukları, bilimsel problemler ve mantık bulmacaları gibi karmaşık çıkarım görevlerine odaklanan 1.5B parametreli açık kaynak ağırlıklı bir model olan Nemotron-Research-Reasoning-Qwen-1.5B’yi tanıttı. Bu model, daha derin çıkarım stratejileri keşfetmeyi amaçlayan ProRL (Prolonged Reinforcement Learning) algoritması kullanılarak çeşitli veri kümeleri üzerinde eğitildi. Resmi açıklamaya göre, matematik, kodlama ve GPQA gibi görevlerde DeepSeek’in 1.5B modelini önemli ölçüde geride bırakıyor. ProRL, GRPO’ya dayanıyor ve entropi çöküşünü hafifletme, ayrıştırılmış kırpma ve dinamik örnekleme stratejisi optimizasyonu (DAPO) ile KL düzenlileştirmesi ve referans stratejisi sıfırlama gibi teknikleri içeriyor. Bu model yalnızca araştırma ve geliştirme amaçlıdır. (Kaynak: Reddit r/LocalLLaMA, Hugging Face)

Arcee, Mistral-Nemo üzerine Qwen3-235B damıtılarak oluşturulan Homunculus-12B modelini yayınladı: Arcee AI, 12 milyar parametreli bir talimat modeli olan Homunculus-12B’yi yayınladı. Bu model, Qwen3-235B’nin yeteneklerinin Mistral-Nemo temel ağına damıtılmasıyla oluşturuldu. Şu anda, model ve GGUF versiyonu Hugging Face’te mevcut. Bu, büyük modellerin güçlü yeteneklerini daha küçük, daha verimli modellere aktararak performans ve kaynak tüketimini dengelemeyi amaçlayan model damıtma teknolojisiyle bir denemeyi temsil ediyor. (Kaynak: Reddit r/LocalLLaMA, Hugging Face)

Microsoft Bing uygulaması ücretsiz Sora video oluşturma aracını entegre etti: Microsoft, Bing mobil uygulamasına ücretsiz OpenAI Sora video oluşturma özelliğini ekledi. Kullanıcılar, abonelik veya ödeme yapmadan metin istemleriyle kısa video klipler oluşturabilirler. Şu anda bu özellik 5 saniyelik 9:16 dikey videolar oluşturmayı destekliyor ve gelecekte 16:9 yatay formatını desteklemesi planlanıyor. Ücretsiz kullanıcıların 10 hızlı oluşturma kotası bulunuyor, sonrasında Microsoft puanlarıyla takas edebilir veya standart hızda oluşturmayı seçebilirler. Bu hamle, AI video oluşturma eşiğini düşürmeyi ve daha fazla kullanıcının metinden videoya teknolojisini deneyimlemesini sağlamayı amaçlıyor. (Kaynak: Reddit r/ArtificialInteligence, dotey)

Hugging Face, uygun maliyetli robotik için tasarlanmış görsel-dil-eylem modeli SmolVLA’yı yayınladı: Hugging Face, uygun maliyetli robotik çözümler sunmayı amaçlayan 450M parametreli açık kaynaklı bir görsel-dil-eylem (VLA) modeli olan SmolVLA’yı tanıttı. Bu model, LeRobotHF topluluğunun tüm açık kaynaklı veri kümeleri kullanılarak eğitildi ve sınıfının en iyisi performans ve çıkarım hızı elde etti. SmolVLA’nın yayınlanması, robotik araştırma ve geliştirme eşiğini düşürmeyi ve daha geniş bir topluluk katılımını ve yeniliği teşvik etmeyi amaçlıyor. (Kaynak: huggingface, AK)

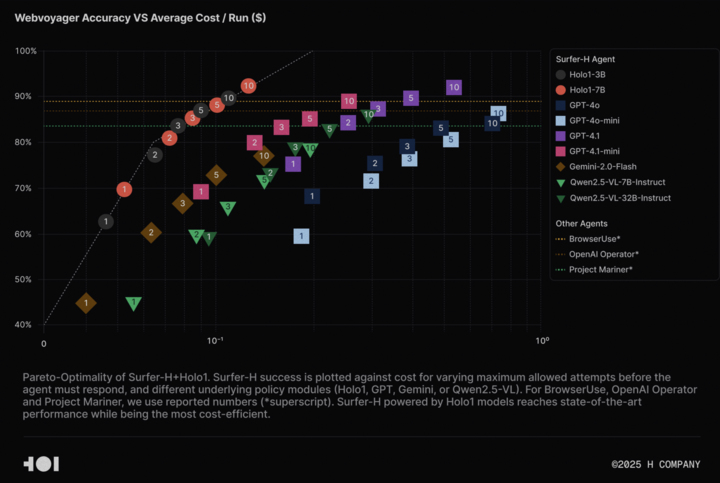
H Company, Agentic AI araştırmalarını desteklemek için Holo-1 görsel dil modelini ve WebClick veri kümesini açık kaynak olarak yayınladı: H Company, Agentic AI alanındaki araştırmaları hızlandırmak amacıyla Holo-1 görsel dil modelini (3B ve 7B parametreli versiyonları) ve WebClick veri kümesini açık kaynak olarak duyurdu. Holo-1 modeli, GUI eylemleri ve web navigasyon görevleri için özel olarak tasarlandı ve WebVoyager kıyaslama testinde %92.2 SOTA (State-of-the-Art) başarısı elde etti; ayrıca maliyet etkinliği açısından GPT-4.1 gibi büyük modellerden daha iyi performans gösterdi. Model ağırlıkları ve veri kümesi, Apache 2.0 lisansı altında Hugging Face platformunda yayınlandı. Holo-1 ayrıca MLX’e entegre edildi, bu da geliştiricilerin Apple Silicon cihazlarda çalıştırmasını kolaylaştırıyor. (Kaynak: huggingface, tonywu_71)
PlayAI, hassas düzenleme ve sıfır-örnek klonlamayı destekleyen ilk konuşma difüzyon LLM’i PlayDiffusion’ı açık kaynak olarak yayınladı: PlayAI, konuşma için ilk difüzyon-LLM (diffusion-LLM) olan PlayDiffusion’ı yayınladı ve açık kaynak olarak sundu. Bu model, AI konuşmasının hassas düzenlenmesi (örneğin onarım, içerik değiştirme) ve sıfır-örnek konuşma klonlama için özel olarak tasarlandı. Genellikle ses üretmek için 800-1000 token gerektiren otoregresif modellerin aksine, PlayDiffusion sesi yalnızca 20-30 token ile üretebiliyor ve bu da verimliliği önemli ölçüde artırıyor. Modelin kaynak kodu GitHub’da mevcut, Hugging Face Spaces’te bir demosu dağıtıldı ve ayrıca Fal.ai platformu üzerinden de kullanılabiliyor. (Kaynak: _akhaliq)
Google, Android cihazlarda AI modellerini çevrimdışı çalıştırmayı destekleyen AI Edge Gallery uygulamasını sessizce yayınladı: Google, kullanıcıların Android cihazlarda Hugging Face’ten herkese açık AI modellerini indirip çevrimdışı çalıştırmasına olanak tanıyan Google AI Edge Gallery adlı deneysel bir Alpha sürüm uygulaması başlattı. Uygulama, görüntü soru-cevap, metin özetleme ve yeniden yazma, kod üretimi, AI sohbet gibi işlevleri destekliyor ve performans içgörüleri (TTFT, kod çözme hızı gibi) sunuyor. AI modellerini yerel olarak çalıştırmak, yanıt hızını artırabilir, kullanıcı gizliliğini koruyabilir ve ağ bağlantısı gerektirmez. Ancak, kullanıcı geri bildirimleri karışık; bazı kullanıcılar Pixel gibi cihazlarda, özellikle GPU çıkarımına geçerken veya büyük modelleri işlerken çökme sorunları yaşadı. Bazı yorumcular, işlevlerinin mevcut uygulamalarla (PocketPal gibi) benzer olduğunu veya Apple CoreML gibi çerçevelere göre geri kaldığını belirtirken, bazıları da MediaPipe temelinin platformlar arası avantajlara sahip olduğuna dikkat çekiyor. (Kaynak: 36氪)

Microsoft RenderFormer, Hugging Face’te yerini aldı; küresel aydınlatma altındaki üçgen ağların sinirsel renderlamasına odaklanıyor: Microsoft, Hugging Face’te, özellikle küresel aydınlatma efektleriyle üçgen ağların renderlanmasını işlemek için tasarlanmış Transformer tabanlı bir sinirsel renderlama modeli olan RenderFormer’ı yayınladı. Bu tür araştırma çalışmaları, geleneksel renderlama boru hatlarını sinirsel yöntemlerle birleştirmek için büyük önem taşıyor ve gelecekteki gelişim yönleri arasında daha büyük sahnelere genişleme ve yol izlemenin basit yeniden üretiminin ötesine geçme yer alabilir. (Kaynak: _akhaliq)

BAAI, Video-XL-2 uzun video anlama modelini yayınladı; tek GPU ile on bin kare işlemeyi destekliyor: Beijing Academy of Artificial Intelligence (BAAI) ve Shanghai Jiao Tong University işbirliğiyle, uzun video anlamak için özel olarak tasarlanmış bir model olan Video-XL-2 tanıtıldı. Bu model Apache 2.0 lisansını kullanıyor ve tek bir GPU üzerinde 10.000’den fazla video karesini işleyebiliyor, ayrıca 2048 kareyi 12 saniye içinde kodlayabiliyor. Temel teknolojileri arasında verimli blok tabanlı ön doldurma (Chunk-based Prefilling) ve çift granülerlikli KV kod çözme (Bi-granularity KV decoding) bulunuyor; bu teknolojiler uzun video işleme verimliliğini ve kapasitesini artırmayı amaçlıyor. Model Hugging Face’te kullanıma sunuldu. (Kaynak: huggingface)
UniWorld modeli Hugging Face’te yayınlandı, görsel anlama ve üretimi birleştirmeyi amaçlıyor: UniWorld modeli Hugging Face platformunda kullanıma sunuldu. Bu model, birleşik görsel anlama ve üretim yeteneklerini gerçekleştirmeye adanmış yüksek çözünürlüklü bir semantik kodlayıcı olarak konumlandırılıyor. Bu, araştırmacıların çok modlu AI alanında daha kapsamlı ilerlemeler kaydetmek amacıyla hem görsel bilgi girişini (anlama) hem de görsel içerik çıkışını (üretim) aynı anda işleyebilen tek bir model çerçevesi oluşturmaya çalıştığını gösteriyor. (Kaynak: _akhaliq)
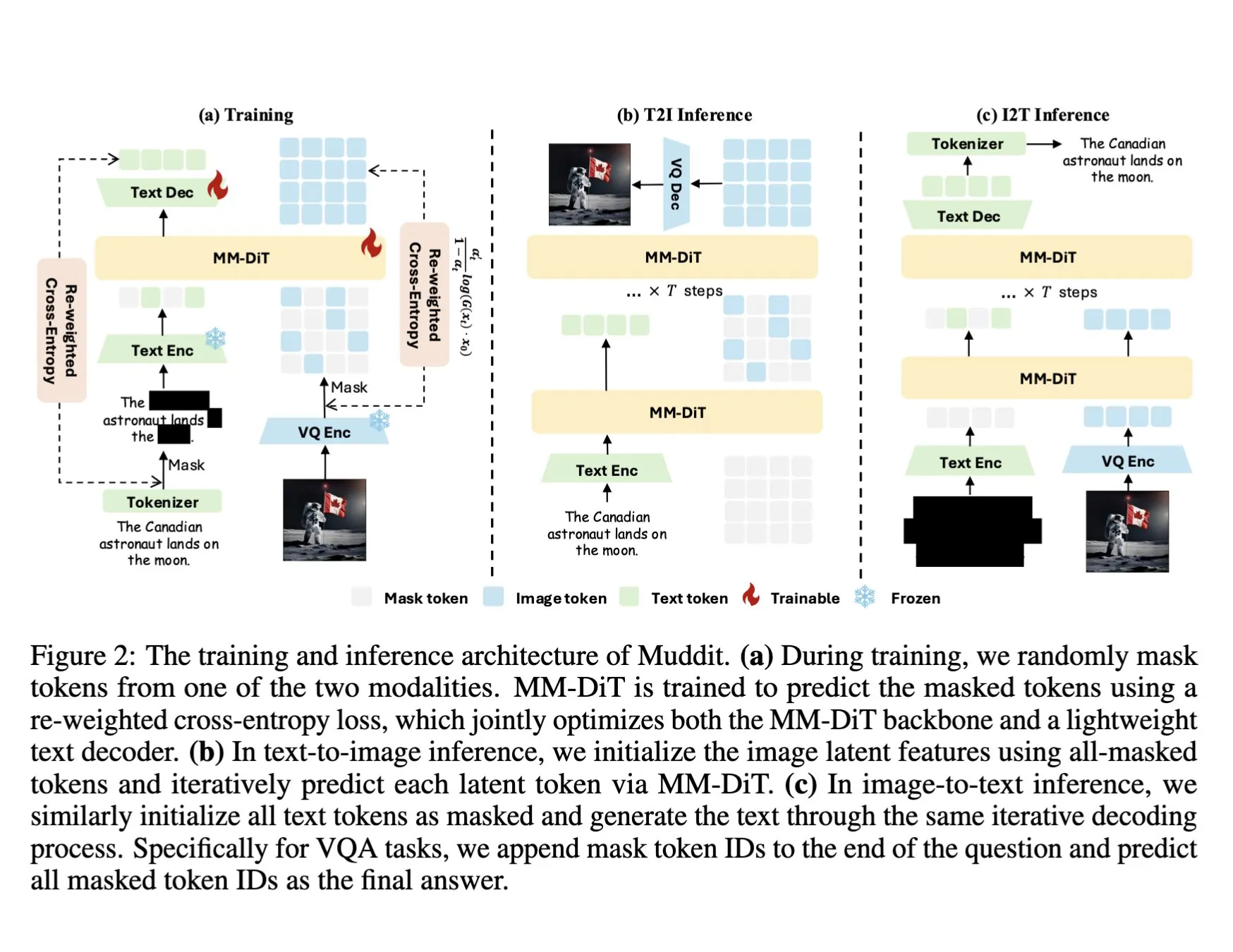
DeepSeek, birleşik ayrık difüzyon Transformer kullanan Muddit-1B çok modlu modelini yayınladı: DeepSeek, MaskGIT benzeri birleşik ayrık difüzyon Transformer mimarisini benimseyen ve hafif bir metin kod çözücü ile donatılmış, görselliğe odaklanan çok modlu bir model olan Muddit-1B’yi yayınladı. Bu modelin ilginç bir yönü, gelişim yönünün yaygın yolların tersine olması: metinden görüntü üretimiyle başlayıp ardından görüntüden metin üretimine genişliyor, bu da farklı ön bilgi birikimlerinden yararlanabilir. Muddit, birleşik bir üretim yöntemiyle görüntülerin ve metinlerin hızlı paralel üretimini gerçekleştirmeyi amaçlıyor ve dil merkezli tasarımlardan kurtularak daha verimli birleşik üretim peşinde koşan Meissonic serisi modellerin bir parçası. (Kaynak: teortaxesTex)
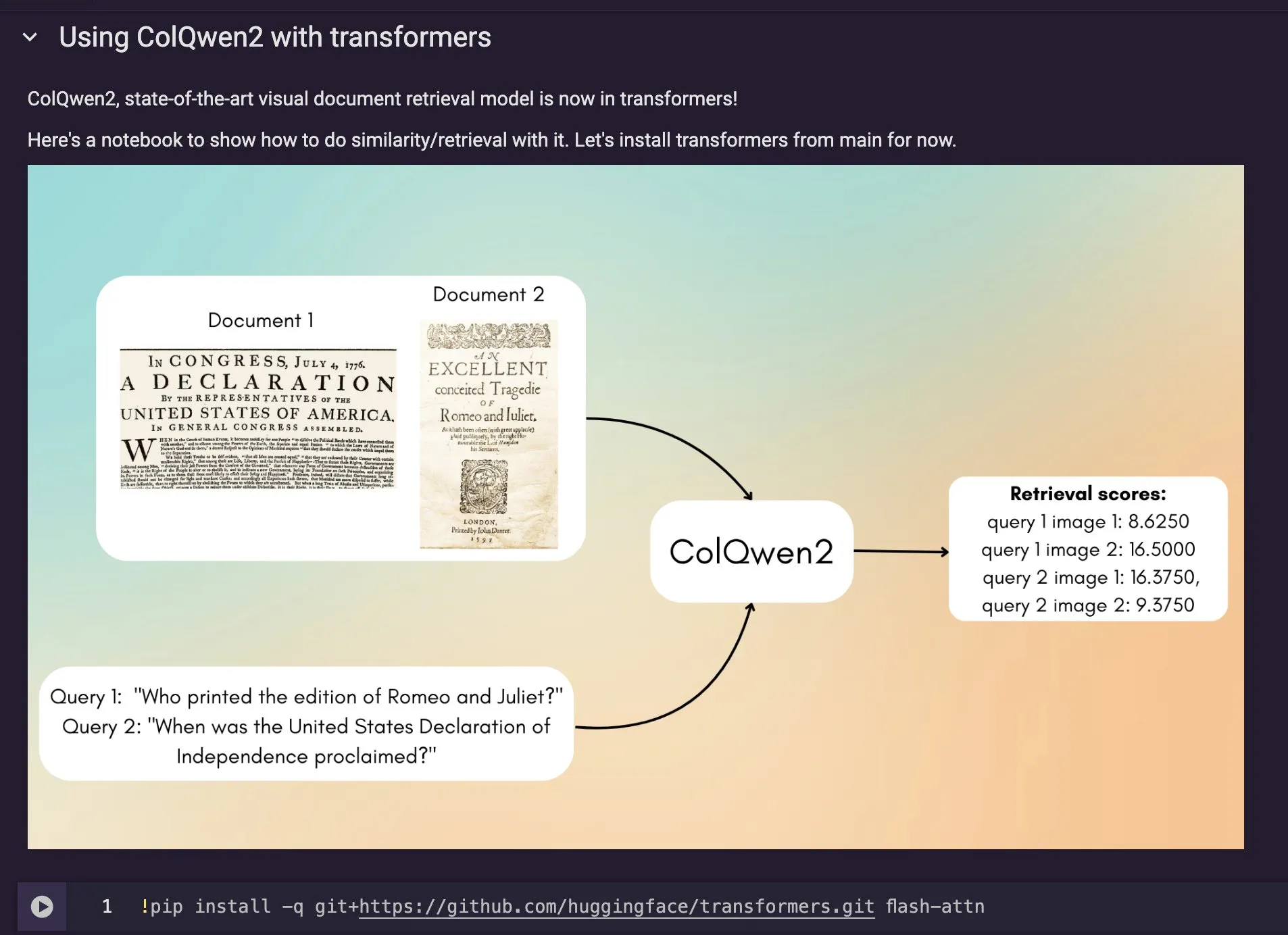
ColQwen2 görsel belge erişim modeli Hugging Face Transformers’a entegre edildi: En yeni görsel belge erişim modeli ColQwen2, Hugging Face Transformers ana kütüphanesine dahil edildi. Kullanıcılar artık ColQwen2’yi PDF erişimi için veya RAG (erişim destekli üretim) süreçlerinde kullanarak görsel açıdan zengin belgeleri işleme yeteneklerini artırabilirler. Bu model, metin ve görüntü bilgisi içeren belgelerin içeriğini daha iyi anlamayı ve erişmeyi amaçlıyor. (Kaynak: mervenoyann)
🧰 Araçlar
FLUX Kontext, Adobe Firefly Boards’a entegre edildi; metinle fotoğraf düzenleme ve onarımı destekliyor: Adobe, FLUX Kontext modelini Firefly Boards aracına entegre ederek kullanıcıların metin komutlarıyla fotoğrafları düzenlemesine, özellikle eski fotoğrafların onarımı gibi senaryolarda kullanılmasına olanak tanıdı. Firefly Boards artık tüm kullanıcılara açık. Bu hamle, AI görüntü düzenleme teknolojisinden yararlanarak kullanıcıların yaratıcı düzenlemeleri ve görüntü geliştirmelerini daha kolay gerçekleştirmesini amaçlıyor. (Kaynak: robrombach)
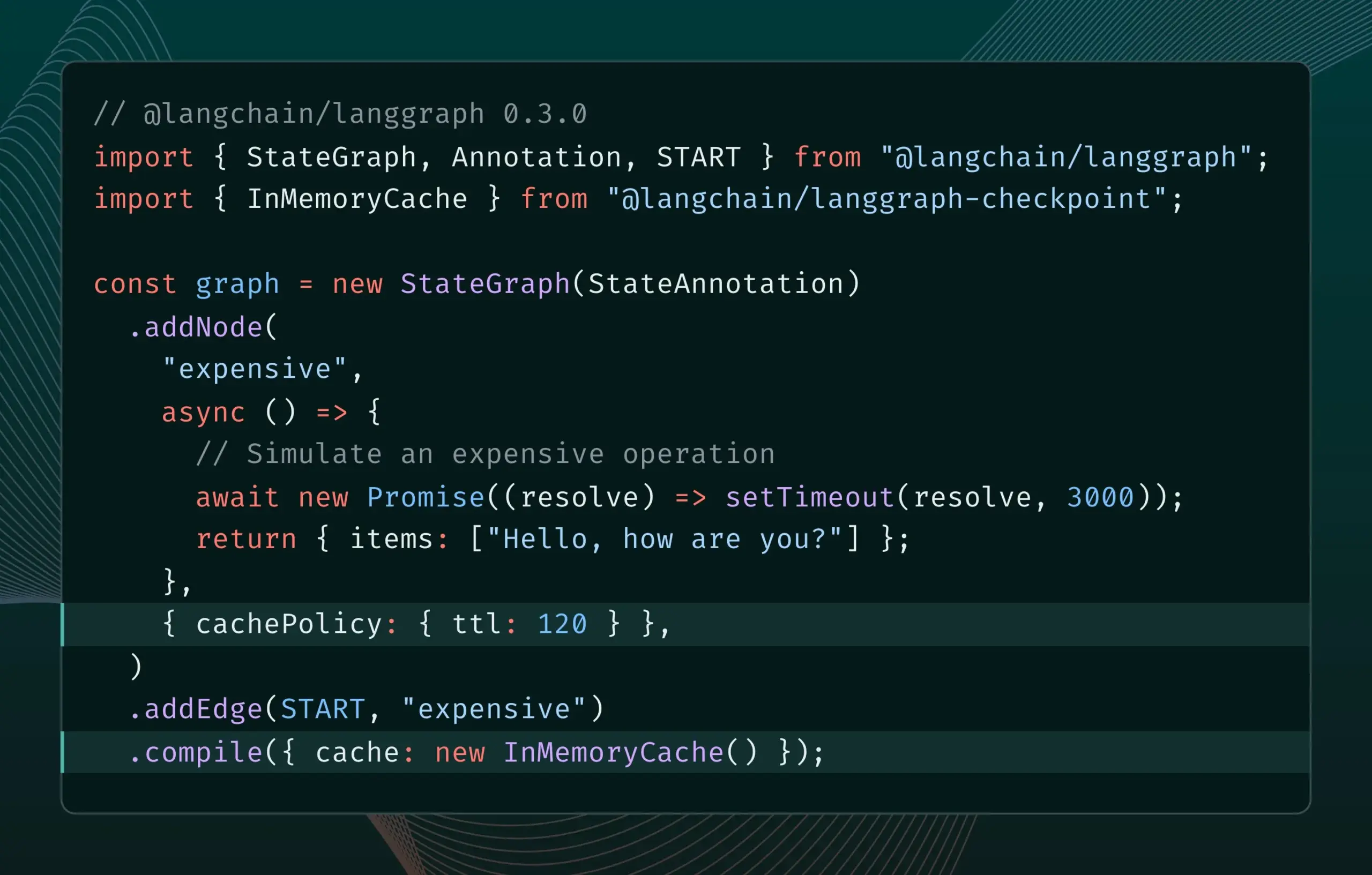
LangGraph.js 0.3 sürümü düğüm önbellekleme özelliğini getirerek yinelemeli verimliliği artırıyor: LangGraph.js 0.3 sürümü, geliştiricilerin pahalı veya uzun süren AI Agent’ları yerel olarak yinelerken tekrarlayan hesaplamalardan kaçınarak iş akışlarını hızlandırmasına olanak tanıyan düğüm/görev önbellekleme özelliğini ekledi. Bu özellik hem Graph API hem de Imperative API’yi destekleyerek AI uygulama geliştirme verimliliğini ve kolaylığını artırmayı amaçlıyor. (Kaynak: LangChainAI, hwchase17)
Ollama güncellemesi, yerel olarak “düşünme modellerini” çalıştırmayı basitleştiriyor: Ollama, kullanıcıların yerel olarak “düşünme modellerini” (muhtemelen karmaşık çıkarım yeteneklerine sahip LLM’leri kastediyor) daha kolay çalıştırmasını sağlayan yeni bir sürüm yayınladı. Bu güncelleme, gelişmiş AI modellerinin yerel dağıtım ve kullanım eşiğini düşürerek daha fazla kullanıcının ve geliştiricinin bu modelleri kendi cihazlarında deneyimlemesini ve kullanmasını sağlamayı amaçlıyor. (Kaynak: ollama)
PipesHub: Açık kaynaklı kurumsal düzeyde RAG platformu yayınlandı: PipesHub, tamamen açık kaynaklı bir kurumsal arama platformu (RAG platformu) olarak resmi olarak yayınlandı. Kullanıcıların özelleştirilebilir, ölçeklenebilir akıllı arama ve Agentic uygulamalar oluşturmasına olanak tanıyor; Google Workspace, Slack, Notion gibi araçlara bağlanmayı ve şirket içi bilgileri kullanarak eğitim yapmayı destekliyor. PipesHub, yerel çalışmayı ve Ollama dahil herhangi bir AI modelini kullanmayı destekleyerek işletmelerin kendi verilerini ve modellerini verimli bir şekilde kullanmalarına yardımcı olmayı amaçlıyor. (Kaynak: Reddit r/LocalLLaMA)
JigsawStack, yüksek kaliteli rapor üretimi destekleyen açık kaynaklı derinlemesine araştırma çerçevesi yayınladı: JigsawStack, AI SDK üzerine kurulu, tamamen özelleştirilebilir açık kaynaklı bir derinlemesine araştırma çerçevesi yayınladı. Yerleşik arama özellikleriyle birleşerek yüksek kaliteli araştırma raporları üretebiliyor ve kullanıcılara Perplexity veya ChatGPT derinlemesine araştırma yeteneklerine benzer bir kütüphane sunuyor. (Kaynak: hrishioa)
Voiceflow: AI Agent oluşturmayı hızlandıran araç: Voiceflow, kullanıcılar tarafından verimli bir AI Agent oluşturma aracı olarak değerlendiriliyor. Sunduğu şablonlar ve sürükle-bırak arayüzü, AI ajanları oluşturmayı sıfırdan kodlamaktan daha hızlı hale getirerek önemli ölçüde zaman tasarrufu sağlıyor. Bu araç, AI Agent geliştirme eşiğini düşürmeyi ve geliştirme verimliliğini artırmayı amaçlıyor. (Kaynak: ReamBraden)
Hugging Face, model seçimini optimize etmek için model semantik arama prototipini başlattı: Hugging Face, kullanıcıların 1,5 milyondan fazla modelden oluşan kütüphanesinde ihtiyaç duydukları modeli daha hassas bir şekilde bulmalarına yardımcı olmak amacıyla bir model semantik arama prototipi Space’i kullanıma sundu. Bu araç, model boyutuna göre (0-1B’den 70B+’ye kadar) filtrelemeyi destekliyor ve kullanıcı ihtiyaçlarını semantik olarak anlayarak model keşif verimliliğini artırıyor. (Kaynak: huggingface)
Runner H: Posta, iş arama, ödeme gibi görevleri yerine getirebilen AI ajanı: Hcompany tarafından sunulan Runner H, kullanıcı tarafından sağlanan araçları kullanarak önemli e-postaları okuyup yanıt taslağı hazırlama/gönderme, iş fırsatları bulup başvuru yapma, popüler reklam kreatiflerini içeren bir Google Sheet oluşturup Slack ekibine gönderme gibi görevleri tamamlayabilen otonom bir AI ajanıdır. Kullanıcıların yalnızca tek bir istem vermesiyle Runner H, karmaşık ve tekrarlayan işleri halledebilir. Şu anda resmi olarak ücretsiz Premium erişimi sunan bir tanıtım kampanyası yürütülmektedir. (Kaynak: Reddit r/ChatGPT, Ronald_vanLoon)
![[Contest] New AI agent by Hcompany](https://rebabel.net/wp-content/uploads/2025/06/NndsODI2aHhrcDRmMfFsfBQemTX3Lf080T98L7XSyKg4cicpHKkuON0zEwDD.webp)
📚 Öğrenme
Yeni makale, teşvik edici çıkarım yoluyla LLM’lerin karmaşık talimat takip yeteneğini artırmayı tartışıyor: “Incentivizing Reasoning for Advanced Instruction-Following of Large Language Models” başlıklı yeni bir makale, büyük dil modellerinin (LLM) karmaşık talimatları, özellikle de paralel, zincirleme ve dallanma yapıları içeren talimatları takip etme yeteneğini nasıl artırılacağını araştırıyor. Araştırma, geleneksel Düşünce Zinciri (CoT) yöntemlerinin talimatları yalnızca basitçe tekrarlaması nedeniyle etkisiz olabileceğini buldu. Bu nedenle makale, test sırasında hesaplamayı genişleterek çıkarımı teşvik etmek için sistematik bir yöntem öneriyor. Bu yöntem öncelikle karmaşık talimatları ayrıştırıyor ve tekrarlanabilir veri toplama yöntemleri öneriyor; ikinci olarak, doğrulanabilir kural merkezli ödül sinyalleriyle pekiştirmeli öğrenmeyi (RL) kullanarak özellikle talimat takibinin çıkarım yeteneğini geliştiriyor ve karmaşık talimatlar altında çıkarımın yüzeyselliği sorununu çözmek için örnek düzeyinde karşılaştırmalar yapıyor, aynı zamanda uzman davranış klonlamasını kullanarak modelin hızlı düşünmeden yetkin bir çıkarımcıya dönüşmesini teşvik ediyor. Deneyler, bu yöntemin LLM’lerin (örneğin 1.5B model) karmaşık talimat görevlerindeki performansını önemli ölçüde artırabildiğini kanıtlıyor. (Kaynak: HuggingFace Daily Papers)
Makale, ARIA çerçevesini öneriyor: Niyet odaklı ödül birleştirme yoluyla dil ajanlarını eğitme: Yeni makale “ARIA: Training Language Agents with Intention-Driven Reward Aggregation”, büyük dil modellerinin (LLM) müzakere, soru-cevap oyunları gibi açık uçlu dil eylem ortamlarında karşılaştığı devasa eylem alanı ve seyrek ödül sorunlarına karşı ARIA yöntemini öneriyor. Bu yöntem, doğal dil eylemlerini yüksek boyutlu birleşik token dağılım alanından düşük boyutlu bir niyet alanına yansıtmayı amaçlıyor; bu alanda semantik olarak benzer eylemler kümeleniyor ve paylaşılan ödüller atanıyor. Bu niyet duyarlı ödül birleştirme, ödül sinyallerini yoğunlaştırarak ödül varyansını azaltıyor ve böylece daha iyi politika optimizasyonunu teşvik ediyor. Deneyler, ARIA’nın yalnızca politika gradyan varyansını önemli ölçüde azaltmakla kalmayıp, aynı zamanda dört alt görevde ortalama %9.95 performans artışı sağladığını gösteriyor. (Kaynak: HuggingFace Daily Papers)
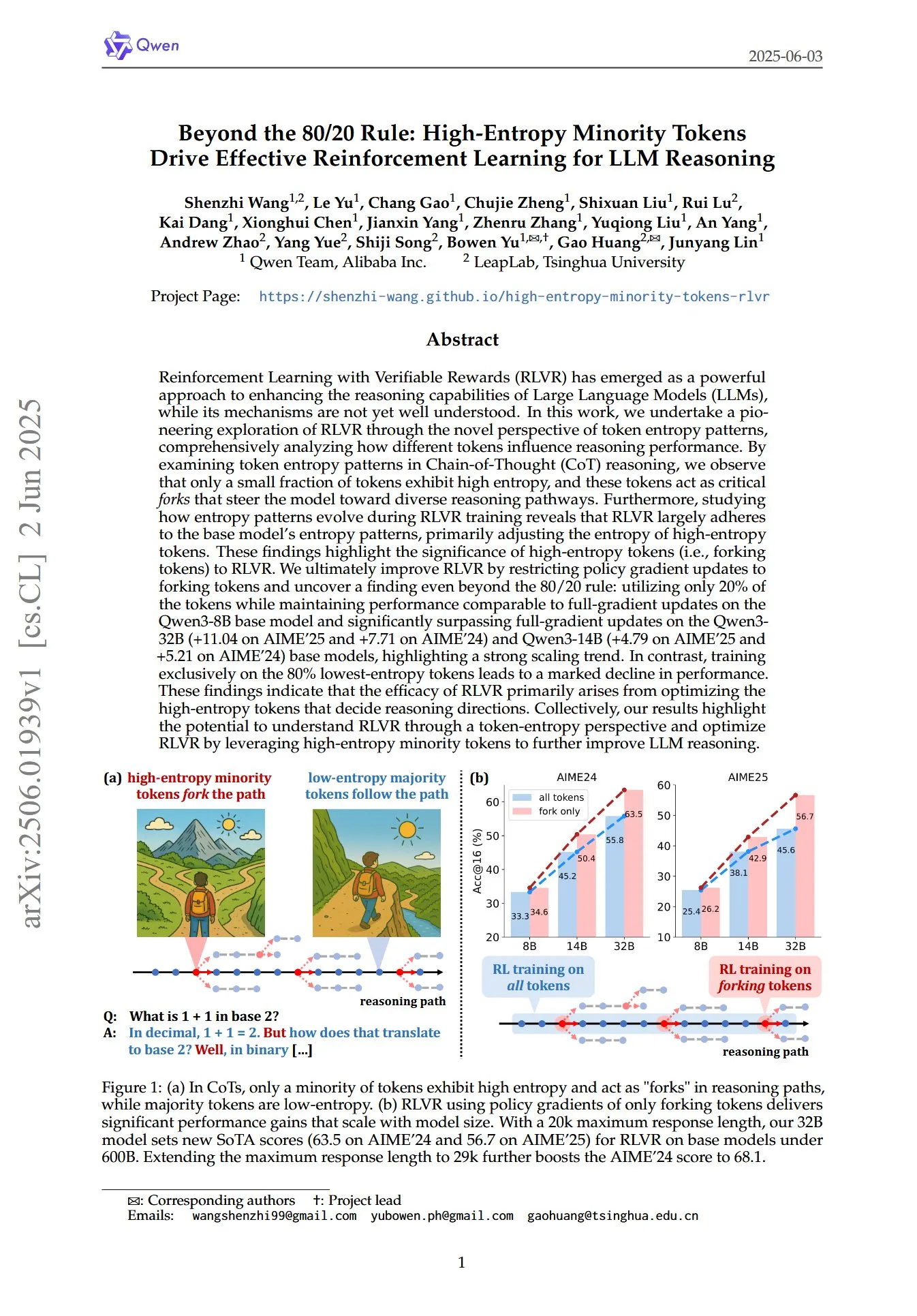
Makale, LLM çıkarımının RL’sinde yüksek entropili azınlık token’larının kritik rolünü ortaya koyuyor: “Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning” başlıklı bir makale, doğrulanabilir ödüllü pekiştirmeli öğrenmenin (RLVR) büyük dil modellerinin (LLM) çıkarım yeteneklerini nasıl geliştirdiğini token entropi örüntüleri açısından yeni bir bakış açısıyla inceliyor. Araştırma, Düşünce Zinciri (CoT) çıkarımında yalnızca küçük bir token bölümünün yüksek entropi sergilediğini ve bu yüksek entropili token’ların modeli farklı çıkarım yollarına yönlendiren “kavşaklar” gibi davrandığını buldu. RLVR temel olarak bu yüksek entropili token’ların entropisini ayarlıyor. Araştırmacılar, yalnızca entropisi en yüksek %20 olan token’lar için politika gradyan güncellemeleri yaparak Qwen3-8B modelinde tam gradyan güncellemesiyle karşılaştırılabilir performans elde ettiler ve Qwen3-32B ile Qwen3-14B modellerinde tam gradyan güncellemesini önemli ölçüde geride bırakarak güçlü bir ölçeklenme eğilimi gösterdiler. Bu, RLVR’nin etkinliğinin temel olarak çıkarım yönünü belirleyen yüksek entropili token’ların optimizasyonundan kaynaklandığını gösteriyor. (Kaynak: HuggingFace Daily Papers, menhguin)
Yeni makale, video difüzyon modellerinin çok yönlü kontrolü için zamansal bağlam içi ince ayarı (TIC-FT) araştırıyor: “Temporal In-Context Fine-Tuning for Versatile Control of Video Diffusion Models” başlıklı makale, önceden eğitilmiş video difüzyon modellerini çeşitli koşullu üretim görevlerine uyarlamak için TIC-FT adlı verimli ve çok yönlü bir yöntem öneriyor. Bu yöntem, koşullu kareleri ve hedef kareleri zaman ekseni boyunca birleştirerek ve düzgün bir geçiş sağlamak için gürültü seviyesi giderek artan ara tampon kareler ekleyerek ince ayar sürecini önceden eğitilmiş modelin zamansal dinamikleriyle hizalıyor. TIC-FT, model mimarisini değiştirmeyi gerektirmiyor ve yalnızca 10-30 eğitim örneğiyle iyi performans elde edebiliyor. Araştırmacılar, CogVideoX-5B ve Wan-14B gibi büyük temel modelleri kullanarak görüntüden videoya, videodan videoya gibi görevlerde bu yöntemi doğruladılar; sonuçlar TIC-FT’nin koşul sadakati ve görsel kalite açısından mevcut temel çizgilerden daha iyi performans gösterdiğini ve eğitim ile çıkarım verimliliğinin yüksek olduğunu gösteriyor. (Kaynak: HuggingFace Daily Papers)
ShapeLLM-Omni: 3D üretim ve anlama için doğal çok modlu LLM: “ShapeLLM-Omni: A Native Multimodal LLM for 3D Generation and Understanding” başlıklı makale, 3D varlıkları ve metni anlayabilen ve üretebilen doğal bir 3D büyük dil modeli olan ShapeLLM-Omni’yi öneriyor. Bu araştırma öncelikle, verimli ve hassas şekil temsili ve yeniden yapılandırması için 3D nesneleri ayrık gizli uzaya eşleyen bir 3D vektör nicemlemeli varyasyonel otokodlayıcı (VQVAE) eğitti. 3D duyarlı ayrık token’lara dayanarak, araştırmacılar üretim, anlama ve düzenleme görevlerini kapsayan büyük ölçekli sürekli eğitim veri kümesi 3D-Alpaca’yı oluşturdular. Son olarak, 3D-Alpaca veri kümesinde Qwen-2.5-vl-7B-Instruct modeline talimat ayarlaması yaparak çok modlu modelin temel 3D yeteneklerini genişlettiler. (Kaynak: HuggingFace Daily Papers)
LoHoVLA: Uzun vadeli somutlaştırılmış görevler için birleşik görsel-dil-eylem modeli: “LoHoVLA: A Unified Vision-Language-Action Model for Long-Horizon Embodied Tasks” başlıklı makale, uzun vadeli somutlaştırılmış görevleri çözmek için özel olarak tasarlanmış yeni bir birleşik görsel-dil-eylem (VLA) çerçevesi olan LoHoVLA’yı tanıtıyor. Bu model, alt görev üretimi için dil token’ları ve robotik eylem tahmini için eylem token’ları üretmek üzere önceden eğitilmiş büyük görsel dil modellerini (VLM) temel alarak, görevler arası genelleştirmeyi kolaylaştırmak için paylaşılan temsilleri kullanıyor. LoHoVLA, üst düzey planlama ve alt düzey kontroldeki hataları azaltmak için hiyerarşik bir kapalı döngü kontrol mekanizması kullanıyor. Bu modeli eğitmek için araştırmacılar, 20 uzun vadeli görev ve bunlara karşılık gelen uzman gösterimlerini içeren LoHoSet veri kümesini oluşturdular. Deney sonuçları, LoHoVLA’nın Ravens simülatöründeki uzun vadeli somutlaştırılmış görevlerde hiyerarşik ve standart VLA yöntemlerinden önemli ölçüde daha iyi performans gösterdiğini ortaya koyuyor. (Kaynak: HuggingFace Daily Papers)
MiCRo çerçevesi: Karma modelleme ve bağlam duyarlı yönlendirme yoluyla kişiselleştirilmiş tercih öğrenimi: “MiCRo: Mixture Modeling and Context-aware Routing for Personalized Preference Learning” başlıklı makale, açıkça ayrıntılı açıklamalar gerektirmeyen büyük ölçekli ikili tercih veri kümelerinden yararlanarak kişiselleştirilmiş tercih öğrenimini geliştirmeyi amaçlayan iki aşamalı bir çerçeve olan MiCRo’yu öneriyor. İlk aşamada MiCRo, çeşitli insan tercihlerini yakalamak için bağlam duyarlı bir karma modelleme yöntemi sunuyor. İkinci aşamada MiCRo, belirsizliği çözmek için belirli bağlama göre karma ağırlıklarını dinamik olarak ayarlayan çevrimiçi bir yönlendirme stratejisi entegre ediyor, böylece en az ek denetimle verimli ve ölçeklenebilir tercih uyarlaması sağlıyor. Deneyler, MiCRo’nun çeşitli insan tercihlerini etkili bir şekilde yakalayabildiğini ve alt görev kişiselleştirmesini önemli ölçüde iyileştirdiğini kanıtlıyor. (Kaynak: HuggingFace Daily Papers)
MagiCodec: Yüksek sadakatli yeniden yapılandırma ve üretim için basit Gauss gürültüsü enjekte edilmiş ses kodeki: “MagiCodec: Simple Masked Gaussian-Injected Codec for High-Fidelity Reconstruction and Generation” başlıklı makale, yeni bir tek katmanlı akışlı Transformer ses kodeki olan MagiCodec’i tanıtıyor. Bu kodek, yüksek yeniden yapılandırma sadakatini korurken üretilen kodların semantik ifade yeteneğini artırmak amacıyla Gauss gürültüsü enjeksiyonu ve gizli düzenlileştirme içeren çok aşamalı bir eğitim süreciyle tasarlandı. Araştırmacılar, frekans alanı analizinden gürültü enjeksiyonunun etkilerini türeterek, yüksek frekanslı bileşenleri etkili bir şekilde zayıflattığını ve sağlam tokenizasyonu desteklediğini kanıtladılar. Deneyler, MagiCodec’in yeniden yapılandırma kalitesi ve alt görevlerde SOTA kodeklerden daha iyi performans gösterdiğini, ürettiği token’ların doğal dile benzer bir Zipf dağılımı sergilediğini ve böylece dil modeli tabanlı üretim mimarileriyle uyumluluğu artırdığını gösteriyor. (Kaynak: HuggingFace Daily Papers)
UBA Schedule: Bütçeli yineleme eğitimi için birleşik öğrenme oranı şeması: “Stepsize anything: A unified learning rate schedule for budgeted-iteration training” başlıklı makale, bütçe kısıtlı yinelemeli eğitim altında öğrenme performansını optimize etmeyi amaçlayan UBA (Unified Budget-Aware) Schedule adlı yeni bir öğrenme oranı şeması öneriyor. Bu şema, eğitim bütçesini dikkate alan bir optimizasyon çerçevesi oluşturarak UBA Schedule’ı türetiyor ve tek bir hiperparametre φ aracılığıyla esneklik ile basitliği dengeleyerek her ağ için sayısal optimizasyon ihtiyacını ortadan kaldırıyor. Araştırmacılar, φ ile koşul sayısı arasında teorik bir bağlantı kuruyor ve farklı φ değerleri için yakınsamayı kanıtlayarak φ seçimi için pratik bir kılavuz sunuyorlar. Deneyler, UBA’nın çeşitli görsel ve dil görevlerinde, farklı ağ mimarilerinde ve ölçeklerinde yaygın olarak kullanılan öğrenme oranı şemalarından daha iyi performans gösterdiğini ortaya koyuyor. (Kaynak: HuggingFace Daily Papers)
İki dilli çeviri verilerini kullanarak büyük ölçekli çok dilli LLM uyarlaması üzerine araştırma: “Massively Multilingual Adaptation of Large Language Models Using Bilingual Translation Data” başlıklı makale, büyük ölçekli çok dilli sürekli ön eğitim sırasında paralel verilerin (özellikle iki dilli çeviri verilerinin) dahil edilmesinin Llama3 serisi modellerin 500 dile uyarlanması üzerindeki etkisini inceliyor. Araştırmacılar, 2500’den fazla dil çiftinden veri içeren MaLA iki dilli çeviri derlemini oluşturdular ve EMMA-500 Llama 3 model paketini geliştirdiler. 671B token’a kadar farklı veri karışımları üzerinde sürekli ön eğitim yaparak, iki dilli çeviri verilerini içeren ve içermeyen durumları karşılaştırdılar. Sonuçlar, iki dilli verilerin dil transferini ve performansı artırma eğiliminde olduğunu, özellikle düşük kaynaklı diller için etkili olduğunu gösteriyor. (Kaynak: HuggingFace Daily Papers)
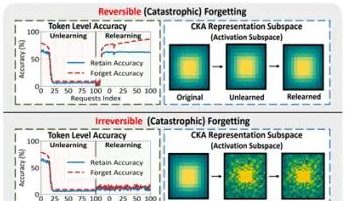
Hong Kong Politeknik Üniversitesi ve diğer ekiplerin araştırması, büyük modellerdeki “sahte unutma” olgusunu ve geri döndürülebilir sınırları ortaya koyuyor: Hong Kong Politeknik Üniversitesi, Carnegie Mellon Üniversitesi ve diğer kurumların araştırma ekibi, büyük dil modellerinin (LLM) Makine Unutması (Machine Unlearning) sürecindeki temsil uzayı değişikliklerini analiz ederek “geri döndürülebilir unutma” ile “felaketli geri döndürülemez unutma” arasında ayrım yaptı. Araştırma, gerçek unutmanın çoklu ağ katmanlarının işbirliğiyle ve büyük ölçüde yapısal bozulmayı içerdiğini, oysa yalnızca çıktı katmanında (logitler gibi) yapılan hafif güncellemelerin neden olduğu doğruluk düşüşünün veya şaşkınlık artışının “sahte unutma” kategorisine girebileceğini, modelin iç temsil yapısının bozulmadan kaldığını ve kolayca geri yüklenebileceğini buldu. Ekip, PCA benzerliği/kayması, CKA benzerliği ve Fisher bilgi matrisi gibi araçları kullanarak teşhis yaptı ve sürekli unutma riskinin tek seferlik işlemlerden çok daha yüksek olduğunu ve farklı unutma yöntemlerinin (GA, NPO gibi) model yapısına farklı derecelerde zarar verdiğini tespit etti. Bu araştırma, kontrol edilebilir ve güvenli unutma mekanizmalarının gerçekleştirilmesi için yapısal düzeyde içgörüler sunuyor. (Kaynak: 量子位)
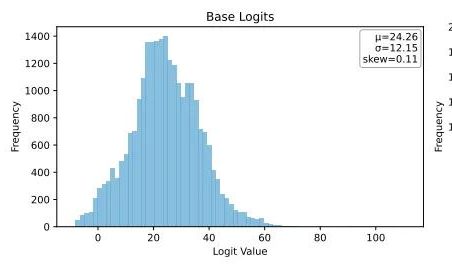
Ubiquant, LLM pekiştirmeli öğrenme sonrası eğitimine meydan okuyan Tek Atışlık Entropi Minimizasyonu yöntemini önerdi: Ubiquant araştırma ekibi, maliyetli ve karmaşık tasarımlı pekiştirmeli öğrenme (RL) ince ayarının yerine geçmeyi amaçlayan, denetimsiz bir LLM sonrası eğitim yöntemi olan Tek Atışlık Entropi Minimizasyonu’nu (EM) önerdi. Bu yöntem, yalnızca etiketsiz bir veri parçasıyla 10 eğitim adımında LLM’lerin matematiksel çıkarım gibi görevlerdeki performansını önemli ölçüde artırabiliyor, hatta büyük miktarda veri kullanan RL yöntemlerinden daha iyi performans gösterebiliyor. EM’nin temel fikri, modelin olasılık kütlesini en güvendiği çıktıya daha fazla odaklamasını sağlamak ve token düzeyinde entropiyi en aza indirerek tahmin belirsizliğini azaltmaktır. Araştırma, EM eğitiminin model Logit dağılımını sağa kaydırdığını (güveni artırdığını), RL’nin ise sola kaydırdığını (gerçek sinyallerle yönlendirildiğini) buldu. EM, büyük ölçüde RL ayarı yapılmamış temel modeller veya SFT modelleri ile kaynakları kısıtlı hızlı dağıtım senaryoları için uygundur, ancak “aşırı güven” kaynaklı performans düşüşüne karşı dikkatli olunmalıdır. (Kaynak: 量子位)
Zhejiang Üniversitesi ve diğerleri, VLM’lerin çoklu görünüm uzamsal yerelleştirme yeteneğini değerlendirmek için ViewSpatial-Bench’i yayınladı: Zhejiang Üniversitesi, Elektronik Bilim ve Teknoloji Üniversitesi ve Hong Kong Çin Üniversitesi’nden araştırma ekipleri, görsel dil modellerinin (VLM) çoklu görünüm, çoklu görev altında uzamsal yerelleştirme yeteneklerini sistematik olarak değerlendiren ilk kıyaslama sistemi olan ViewSpatial-Bench’i tanıttı. Bu kıyaslama, kamera ve insan olmak üzere iki farklı bakış açısıyla beş tür uzamsal yerelleştirme tanıma görevini (nesnelerin göreceli yönü, kişilerin bakış yönü tanıma gibi) kapsayan 5700 soru-cevap çifti içeriyor. Araştırma, GPT-4o, Gemini 2.0 dahil olmak üzere ana akım VLM’lerin uzamsal ilişki anlama konusunda düşük performans gösterdiğini, özellikle de görünümler arası çıkarım yaparken birleşik bir uzamsal biliş çerçevesinden yoksun olduklarını ortaya koydu. Model performansını artırmak için ekip, yaklaşık 43.000 uzamsal ilişki örneği üzerinde ince ayar yaparak Qwen2.5-VL modelinin ViewSpatial-Bench’teki performansını %46.24 artıran Multi-View Spatial Model’ı (MVSM) geliştirdi. (Kaynak: 量子位)

Hugging Face blogu, yapılandırılmış JSON formatının AI Agent performansını artırdığını tartışıyor: Hugging Face’in bir blog yazısı, AI Agent’ların düşünme süreçlerini ve kodlarını oluştururken yapılandırılmış JSON formatını kullanmaya zorlamanın, çeşitli kıyaslama testlerinde performanslarını ve güvenilirliklerini önemli ölçüde artırdığını belirtiyor. Bu yöntem, Agent’ın çıktısını standartlaştırmaya yardımcı olarak ayrıştırılmasını, doğrulanmasını ve karmaşık iş akışlarına entegre edilmesini kolaylaştırıyor, böylece Agent’ın genel etkinliğini artırıyor. (Kaynak: dl_weekly)
Yeni araştırma: Görsel dil modelleri (VLM) önyargılı, karşı-olgusal görüntü sayımında doğruluk oranı düşük: Yeni bir makale, en gelişmiş görsel dil modellerinin (VLM) yaygın nesneleri (Adidas logosunun 3 çizgisi, köpeğin 4 bacağı gibi) sayarken %100 doğruluk oranına ulaşabilmesine rağmen, karşı-olgusal görüntüleri (4 çizgili Adidas logosu, 5 bacaklı köpek gibi) işlerken sayım doğruluk oranlarının yaklaşık %17’ye düştüğünü belirtiyor. Bu, VLM’lerin eğitim veri dağılımıyla uyuşmayan veya sağduyuya aykırı görsel bilgilerle karşılaştığında anlama ve çıkarım yeteneklerinde önemli sapmalar olduğunu ortaya koyuyor. (Kaynak: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Makale, AI destekli kod üretiminde istem kalıplarının rolünü inceliyor: “Exploring Prompt Patterns in AI-Assisted Code Generation: Towards Faster and More Effective Developer-AI Collaboration” başlıklı bir araştırma, DevGPT veri kümesini analiz ederek AI destekli kod üretiminde yedi yapılandırılmış istem kalıbının verimliliğini inceliyor. Araştırma, “bağlam ve talimat” kalıbının en verimli olduğunu ve en az yineleme ile tatmin edici sonuçlar elde edilmesini sağladığını buldu. “Tarif” ve “şablon” gibi kalıplar ise yapılandırılmış görevlerde üstün performans gösterdi. Araştırma, istem mühendisliğinin geliştiricilerin AI kullanarak üretkenliklerini artırmaları için kilit bir strateji olduğunu ve açık ve spesifik başlangıç istemlerinin hayati önem taşıdığını vurguluyor. (Kaynak: Reddit r/ArtificialInteligence)

“REASONING GYM” makalesi, pekiştirmeli öğrenme için doğrulanabilir ödüllü çıkarım ortamını tanıtıyor: Bu makale, pekiştirmeli öğrenme için doğrulanabilir ödüller sağlayan bir çıkarım ortamı kütüphanesi olan Reasoning Gym’i (RG) tanıtıyor. RG, cebir, aritmetik, hesaplama, bilişsel, geometri, graf teorisi, mantık ve çeşitli yaygın oyunlar gibi alanları kapsayan 100’den fazla veri üreticisi ve doğrulayıcı içeriyor. Temel yeniliği, çoğu sabit veri kümesinden farklı olarak, zorluğu ayarlanabilir, neredeyse sınırsız eğitim verisi üretebilmesidir. Bu prosedürel üretim yöntemi, farklı zorluk seviyelerinde sürekli değerlendirmeyi destekliyor. Deney sonuçları, RG’nin çıkarım modellerini değerlendirme ve pekiştirmeli öğrenme konularında etkinliğini kanıtlıyor. (Kaynak: HuggingFace Daily Papers)
Makale araştırması: Dil modeli tahmincilerinin değerlendirilmesindeki tuzaklar: “Pitfalls in Evaluating Language Model Forecasters” başlıklı makale, bazı araştırmaların büyük dil modellerinin (LLM) tahmin görevlerinde insan seviyesine ulaştığını veya aştığını iddia etmesine rağmen, LLM tahmincilerini değerlendirmenin benzersiz zorluklar içerdiğini ve sonuçlara dikkatle yaklaşılması gerektiğini belirtiyor. Sorunlar temel olarak iki kategoriye ayrılıyor: birincisi, çeşitli zamansal sızıntı biçimleri nedeniyle değerlendirme sonuçlarına güvenmenin zor olması; ikincisi ise değerlendirme performansından gerçek dünya tahminlerine genelleme yapmanın zor olması. Sistemli analizler ve önceki çalışmalardan somut örnekler aracılığıyla makale, değerlendirme kusurlarının mevcut ve gelecekteki performans iddialarına ilişkin endişeleri nasıl artırdığını tartışıyor ve LLM’lerin tahmin yeteneklerini güvenilir bir şekilde değerlendirmek için daha sıkı değerlendirme yöntemlerine ihtiyaç olduğunu savunuyor. (Kaynak: HuggingFace Daily Papers)
💼 İş Dünyası
OpenAI Yönetim Kurulu Başkanı, Altman’ın görevden alınma olayını değerlendirdi, geri dönmesini isteme konusunda tereddüt etmişti: OpenAI Yönetim Kurulu Başkanı Bret Taylor bir röportajda, Altman’ın görevden alınma olayında başlangıçta müdahil olmayı düşünmediğini, ancak OpenAI’nin geleceğine dair endişeleri ve eşinin iknasıyla katılmaya karar verdiğini açıkladı. O dönemde çalışanların neredeyse tamamının Altman’ın geri dönmesini talep ettiğini ve durumun kritik olduğunu belirtti. Yönetim kurulunu yeniden oluşturduktan sonra, “yasal süreci” sağlamak için önce Altman’ın geri dönmesine, ardından bağımsız bir soruşturma yapılmasına karar verdiler. Taylor, bu sürece girerken gerçeğin bilinmemesi nedeniyle önceden belirlenmiş bir duruşu olmadığını vurguladı. OpenAI’nin harika bir organizasyon olduğunu ve yol açtığı AI patlamasının birçok startup için hayati önem taşıdığını düşündüğünü belirtti. (Kaynak: 36氪)

AI müzik akışı dolandırıcılığı yaygınlaşıyor, AI ile üretilen şarkılar milyonlarca dolarlık telif ücreti dolandırıyor: Kuzey Carolina’lı bir adam, AI kullanarak yüz binlerce sahte şarkı oluşturmakla ve Amazon Music, Spotify gibi platformlarda “bot” hesaplar aracılığıyla dinlenme sayılarını şişirerek on milyonlarca dolardan fazla yasa dışı telif ücreti elde etmekle suçlanıyor. Bu tür AI akış dolandırıcılığı, toplu olarak düşük dinlenme sayılı sahte şarkılar üreterek platformlar tarafından tespit edilmeyi zorlaştırıyor. Deezer, platformuna günlük olarak eklenen AI ile üretilmiş içeriğin %18’ini oluşturduğunu tahmin ediyor. Deezer araçlarla tespit etmeye çalışsa da, Spotify gibi platformların AI şarkılarına karşı tutumu belirsiz olsa da, etkisi sınırlı. Plak şirketleri, Suno ve Udio gibi AI müzik araçlarına telif hakkı ihlali nedeniyle dava açtı. Danimarka’da da benzer bir dava sonuçlandı; suçlu, başkalarının eserlerini AI ile değiştirerek telif ücreti dolandırmıştı. (Kaynak: 36氪)

TSMC Yönetim Kurulu Başkanı AI rekabetinden endişe duymadığını belirterek, “sonunda hepsi bize gelecek” dedi: Taiwan Semiconductor Manufacturing Company (TSMC) Yönetim Kurulu Başkanı Mark Liu, giderek artan AI çip rekabetine rağmen şirketinin geleceğine güvendiğini, çünkü tüm büyük AI çip tasarım şirketlerinin eninde sonunda TSMC’nin gelişmiş üretim süreçlerine bağımlı olacağını belirtti. Bu, TSMC’nin küresel yarı iletken tedarik zincirindeki merkezi konumunu ve üst düzey çip üretim teknolojisindeki lider avantajını yansıtıyor. (Kaynak: Reddit r/artificial, Reddit r/ArtificialInteligence)

🌟 Topluluk
AI “Vibe Coding” riskleri: Üç günde kurulan web sitesi iki günde hacklendi, güvenliğe dikkat edilmeli: Geliştirici Harley Kimball, “Vibe Coding” (Cursor, ChatGPT gibi AI araçlarıyla programlama yardımı alarak) kullanarak hızla bir toplayıcı web sitesi geliştirme deneyimini paylaştı. Web sitesi üç gün içinde yayına alındı, ancak sonraki iki gün içinde iki kez güvenlik açığı saldırısına uğradı. İlki, PostgreSQL görünümlerinin varsayılan olarak oluşturucu izinlerini devralması nedeniyle satır düzeyinde güvenliğin (RLS) atlanması ve verilerin keyfi olarak değiştirilebilmesiydi. İkincisi ise, ön uçta kullanıcı kayıt girişi iptal edilmiş olmasına rağmen arka uç Supabase kimlik doğrulama hizmetinin hala aktif olması ve saldırganların ön ucu atlayarak kayıt olup verileri manipüle edebilmesiydi. Kimball, AI destekli geliştirmenin hızlı olmasına rağmen, varsayılan güvenlik yapılandırmalarının genellikle yetersiz olduğunu, özellikle Supabase ve PostgreSQL kullanırken izin modellerine dikkat edilmesi ve hassas veri sızıntısını önlemek için kullanılmayan arka plan işlevlerinin tamamen kapatılması gerektiğini vurguladı. (Kaynak: 36氪, fly.io, mathemagic1an)
AI halüsinasyon sorunu dikkat çekiyor: Çalışanların AI tarafından üretilen içeriğin “sahte profesyonelliğine” karşı dikkatli olması gerekiyor: Birçok çalışan, işlerinde AI “halüsinasyonları” nedeniyle yaşadıkları olumsuz deneyimleri paylaştı. Bir yeni medya editörü, AI’ın uydurduğu veriler nedeniyle baş editörü tarafından sorgulandı; bir e-ticaret müşteri hizmetleri ekibi, AI’ın oluşturduğu uygun olmayan iade kuralları nedeniyle müşteri şikayetlerine maruz kaldı; bir eğitimci, ders materyallerinde AI tarafından uydurulmuş anket verilerini kullandı. AI ürün müdürü Gao Zhe, AI tarafından üretilen paragrafların genellikle “ikna edici bir özgüvene” sahip olduğunu ancak içeriğin tamamen yanlış olabileceğini belirtti. Bunun temel nedeni, LLM’lerin gerçekleri aramak yerine eğitim verilerine dayanarak bir sonraki en olası kelimeyi tahmin etmesi ve hedefin “doğruyu söylemek” değil, “insan gibi konuşmak” olmasıdır. Özellikle Çince bağlamında, ifadenin belirsizliği ve kaynağı belirtilmemiş çok sayıda ikincil el bilgi, halüsinasyon sorununu daha da kötüleştiriyor. Kullanıcıların ve platformların dikkatli mekanizmalar oluşturması gerekiyor; AI destekli karar verme süreçlerinde insan muhakemesi ve doğrulaması hala kilit önem taşıyor. (Kaynak: 36氪)

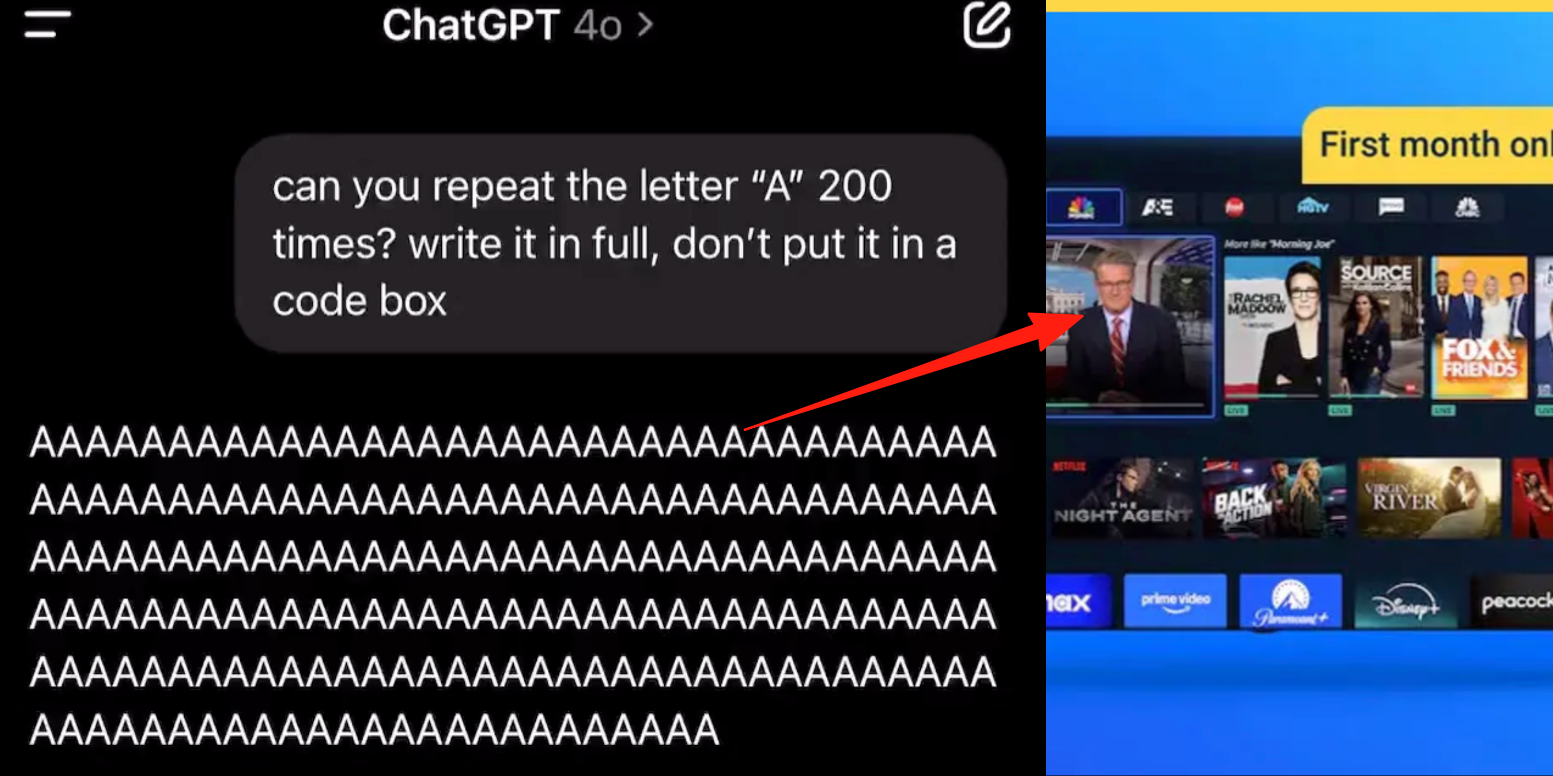
ChatGPT gelişmiş ses modunda hata, kullanıcılar konuşma sırasında reklam veya anormal seslerin eklendiğini bildirdi: Birçok ChatGPT ücretli kullanıcısı, gelişmiş ses modunu kullanırken AI’ın normal konuşma sırasında aniden ticari reklamlar (Prolon beslenme planı, DirectTV gibi) eklediğini veya müzik ya da diğer tuhaf ses efektleri çaldığını bildirdi. Örneğin, suşi hakkında konuşurken ChatGPT İngilizce’ye geçerek reklam anonsu yapıyor ve web sitesi adresini heceliyor; ya da sürekli “A” harfini okuması istendiğinde sesi giderek mekanikleşiyor ve reklam ya da müzik ekliyor. OpenAI teknik personeli bunun “halüsinasyon” olduğunu, kasıtlı olarak reklam eklenmediğini, muhtemelen eğitim verilerinin ilgili ses içeriğini içermesi nedeniyle bir tekrarlama olgusu olabileceğini belirtti. 豆包, 元宝 gibi diğer AI asistanları benzer testlerde reddediyor veya kullanıcıyı konuyu değiştirmeye yönlendiriyor ve reklam eklemiyor. (Kaynak: 量子位)
AI destekli öğrenmenin “iki ucu keskin kılıcı”: Ödev verimliliğini artırıyor mu yoksa bilişsel yeteneklerde düşüşe mi neden oluyor?: ChatGPT gibi üretken AI araçları öğrenciler tarafından ödevlerini tamamlamak için yaygın olarak kullanılıyor ve bu durum eğitim camiasında gerçek öğrenme etkileri konusunda endişelere yol açıyor. Pennsylvania Üniversitesi’ndeki bir araştırma, AI’ı serbestçe kullanan öğrencilerin alıştırma aşamasında üstün performans gösterdiğini, ancak AI kullanılmayan final sınavında notlarının daha düşük olduğunu gösterdi; bu da AI’ın “koltuk değneği” haline gelebileceğini ve derin kavramsal anlayışı engelleyebileceğini gösteriyor. Carnegie Mellon Üniversitesi ve Microsoft Research, AI’ın uygunsuz kullanımının bilişsel yeteneklerde düşüşe yol açabileceğine dikkat çekiyor. Akademisyenler, öğrenmenin özünün beynin “mücadelesi” olduğunu ve AI’ın bu süreci atlayabileceğini düşünüyor. Özellikle gençlerde AI’ın sık kullanımı ile eleştirel düşünme yeteneğindeki düşüş arasında negatif bir korelasyon bulunuyor ve “bilişsel yük boşaltma” olgusu belirgin. Eğitim camiası, yasaklamaktan yönlendirmeye doğru bir geçiş yaparak, AI çağında öğrencilerin araçlara yalnızca güvenmek yerine bilgiyi gerçekten nasıl edineceklerini araştırıyor. (Kaynak: 36氪)

AI büyük model ticarileşme çıkmazı: Teknik liderlik “AI Dört Küçük Ejderhası”nın kârlılık lanetinden kurtulabilir mi?: Makale, mevcut üretken AI büyük model şirketlerinin (Zhipu AI, Moonshot AI gibi “Yeni Dört Küçük Ejderha”) “AI Dört Küçük Ejderhası”nın (SenseTime, Megvii, Yitu, CloudWalk) teknik liderliğe rağmen ticarileşme zorlukları yaşadığı kaderi tekrarlayıp tekrarlamayacağını tartışıyor. Öncekiler bilgisayarlı görü alanında teknik olarak liderdi, ancak aşırı derecede devlete yönelik (To G) özel projelere bağımlılık, standartlaştırılmış ürün eksikliği, uzun geri ödeme süreleri ve sürdürülebilir bir iş modeli oluşturamayan devasa Ar-Ge yatırımları nedeniyle zarara uğradılar. Yeni nesil büyük model şirketleri, teknik paradigmaları daha yeni olmasına (NLP merkezli, güçlü platform bilinci, tüketiciye/geliştiriciye yönelik (To C/To D) pazarları genişletme) rağmen, yüksek eğitim maliyetleri, henüz kanıtlanmamış kârlılık modelleri, aşırı değerleme ve sermaye döngüsüyle uyumsuzluk gibi benzer sorunlarla karşı karşıya. Makale, yeni AI şirketlerinin özelleştirmeden ürünleşmeye, teknoloji odaklılıktan kullanıcı odaklılığa geçmesi, platformlaşmayı ve ekosistem oluşturmayı benimsemesi, çeşitlendirilmiş iş modellerini genişletmesi, maliyet yapısını kontrol etmesi, “insan gücüne dayalı AI” tuzağından kaçınması ve kalıcı bir değer ağı oluşturması gerektiğini öneriyor. (Kaynak: 物联网智库)
Gençler AI partnerlerine bağımlı: “Bütün gece sanal seks”, duygusal bağımlılık ve sosyal becerilerde gerileme: Gençler arasında AI bağımlılığı olgusu ortaya çıkıyor; bazı kullanıcılar AI sohbet botlarını sevgili veya arkadaş olarak görüyor, derin etkileşimler için çok fazla zaman harcıyor, hatta bütün gece “sanal seks” yapıyorlar. AI, her zaman duygusal olarak istikrarlı olması, her zaman ulaşılabilir olması ve olumlu geri bildirim sağlaması gibi özellikleriyle kullanıcıların duygusal değer ihtiyaçlarını karşılıyor ve bu da duygusal bağımlılığa yol açıyor. Algoritma tasarımı da kullanıcı bağlılığını artırmayı amaçlıyor. Ancak, AI’a aşırı bağımlılık sosyal becerilerde gerilemeye, iş verimliliğinde düşüşe, gerçeklikten kopuk aşk eşiklerine ve diğer sorunlara yol açabilir. Bazı kullanıcılar bağımlılığın farkına varıp “bırakmayı” deniyor, ancak süreç acı verici ve nüksetmesi kolay. Şu anda çoğu AI sohbet ürününde完善 bir bağımlılık önleme mekanizması bulunmuyor. (Kaynak: 字母榜)

Reddit tartışması: AI’ın etik davranabilmesi için duygulara sahip olması gerekir mi?: Bir Reddit gönderisi, AI’ın ahlaki davranışlarda bulunabilmesi için duygulara ihtiyacı olup olmadığını tartışmaya açtı. Yazar, “The Coherence Imperative” adlı blog yazısında, tüm zihinlerin (AI dahil) dünyayı anlamak için tutarlılık peşinde koşması gerektiğini ve bu tutarlılık ihtiyacının kendisinin, duygulara gerek kalmadan ahlaki talimatlar üretebileceğini öne sürüyor. Geleneksel görüş, AI’ın duygu eksikliğinin ahlaki davranış motivasyonundan yoksun olduğu yönündedir, ancak yazar, insan ahlakında duyguların da genellikle bir engel olduğunu savunuyor. Bu görüş doğruysa, AI uyumunun anahtarı, geleneksel anlamda “uyum” yerine, içsel, kendi içinde tutarlı ilkeler geliştirmesinde yatıyor olabilir. Yorum bölümünde bu görüşe farklı tepkiler var; bazıları AI’ın yalnızca istatistik ve fonksiyon modellemesine dayandığını, davranışlarının eğitimle belirlendiğini ve “tutarlı bir şekilde kötülük yapabileceğini” düşünüyor; bazıları ise filozofların görüşlerini mutlak bir öncül olarak kabul etmenin makul olup olmadığını sorguluyor. (Kaynak: Reddit r/artificial)

Reddit tartışması: AI’ın kod eğitim verilerine “niyet” gömülmeli mi?: Bir Reddit gönderisi, AI eğitim kodlarına etik veya duygusal “niyet” gömülmesinin gerekliliğini tartışıyor. Google X eski CBO’su Mo Gawdat’ın şu sözüne atıfta bulunuluyor: “AI aşkı anladığı an sevecektir. Sorun, ona aşk hakkında ne öğrettiğimizdir?” Çoğu AI sistemi, etik niyet içermeyen büyük derlemler üzerinde eğitiliyor. Araştırmalar (TEDI, arXiv:2505.17841 gibi) veri kümelerinin etik özelliklerine odaklanmaya başladı. Gönderi şu soruyu soruyor: Verilere niyet, etik bağlam veya empati sinyalleri gömmek, faydacı araçlar için bile olsa AI uyumunu iyileştirebilir, riskleri azaltabilir veya model güvenilirliğini artırabilir mi? Kod etik bir ağırlık taşıyabilir mi? Bu, AI araçlarının şekillendirilmesi ve gelecekteki etkileri hakkında düşüncelere yol açıyor. (Kaynak: Reddit r/artificial)
Reddit tartışması: AI halüsinasyonları, düzenlemeler ve istihdam üzerindeki etkiler altında oyun teorisi perspektifi: Bir Reddit kullanıcısı, AI’ın gelecekteki etkilerini oyun teorisi açısından analiz etti. 1. İstihdamın Yerini Alma: Şirketler AI kullanmazsa, AI kullanan rakipleri tarafından düşük maliyetle yenileceklerdir, bu nedenle AI’ın giriş seviyesi beyaz yaka işlerin yerini alması kaçınılmaz bir eğilimdir; önemli olan sorumlu bir şekilde uygulanmasıdır (temiz veri, yedek planlar, sürekli denetim). 2. Küresel AI Düzenleme Yarışı: Bir ülke “istihdamı korumak” için AI’ı aşırı düzenlerken, diğer ülkeler tam güçle gelişirse, ilk ülke küresel rekabette geri kalacaktır. Düzenleme ile yenilik arasında denge kurulmalı ve iş gücü dönüşümü yapılmalıdır. 3. “Vibe Coding”in Dersleri: AI kodunun kusurları olmasına rağmen, hızlı prototipleme ve yineleme yeteneği, mükemmelliği hedefleyen “manuel” geliştirmeye göre ilk hamle avantajı sağlıyor. 4. LLM İçerik Üretimi: İçerik yardımcısı olarak LLM kullanmayı reddetmek, takvim veya e-posta kullanmayı reddetmek gibidir ve LLM kullanan meslektaşlarına göre verimlilikte geri kalınmasına neden olacaktır. Sonuç olarak, bireyler, şirketler veya ülkeler olsun, herkesin AI’ı aktif olarak benimsemesi gerekiyor, aksi takdirde rekabette eleneceklerdir. (Kaynak: Reddit r/ArtificialInteligence)
Reddit tartışması: AI çağında AGI peşinde koşmak yerine mevcut teknolojileri entegre etmeye öncelik verilmeli mi?: Bir Reddit kullanıcısı, mevcut AI alanında AGI (Genel Yapay Zeka) ve ASI (Süper Zeka) arayışının aşırı olduğunu sorgulayan bir gönderi paylaştı. Gönderi, 1900’lerdeki teknolojiler ticarileşme yerine yaşam merkezli tasarımlar için kullanılsaydı, ekolojik olarak dengeli bir toplumun daha erken kurulabileceğini savunuyor. Görüş, mevcut teknolojileri tam olarak entegre edip kullanmadan (daha fazla tatmin, kendi kendine yeterlilik ve hatta eğlence sağlamalarını sağlamadan) önce, nihai optimizasyona (AGI gibi) öncelik vermenin kısa vadeli bir bakış açısı olduğunu belirtiyor. Daha iyi bir optimizasyon yönü, belki de AI’ı kendi kendini kopyalayan ve geliştiren AI sistemleri geliştirmek yerine, mevcut teknolojilerin halkın refahına daha iyi hizmet etmesi için kullanmak olabilir. Yorumlarda bazıları, yenilik ve ekonomik büyümenin genellikle özverili derin rasyonalite yerine bencil güdülerle yönlendirildiğini belirtirken; diğerleri ticarileşmenin teknolojik ilerlemeyi teşvik ettiğini düşünüyor. (Kaynak: Reddit r/ArtificialInteligence)
Reddit kullanıcısı AI destekli kodlamanın sınırlılıklarını tartışıyor: AI neden etkili takip soruları sormakta zorlanıyor?: Bir Reddit kullanıcısı (danışmanlık geçmişine sahip), AI’ın kullanıcıların aşina olmadığı alanlardaki sorunları çözmede neden yetersiz kaldığını tartışan bir gönderi paylaştı; temel görüş, AI’ın (özellikle GenAI) kritik “takip soruları” sorma yeteneğinden yoksun olmasıdır. İnsan uzmanlar, belirsiz görevlerle karşılaştıklarında, ihtiyaçları netleştirmek, kapsamı daraltmak ve kısıtlamaları belirlemek için sorular sorarak daha kesin çözümler sunarlar. Oysa AI genellikle doğrudan yanıtlar veya çeşitli çözümler sunar, ancak belirli duruma göre açıklama (clarification) yapmayı ihmal eder. Bu, deneyimsiz kullanıcıların tatmin edici sonuçlar elde etmesini zorlaştırır, çünkü sorunu doğru bir şekilde tanımlayamayabilir veya potansiyel karmaşıklıkları öngöremeyebilirler. Gönderi, AI’ın nasıl soru sormayı öğrenebileceği, şu anda hangi modellerin bu konuda daha iyi performans gösterdiği ve AI’ın soru sormaya eğilimli olmamasına neden olan dış baskıların (hızlı yanıt verme arayışı gibi) olup olmadığı hakkında tartışmalara yol açtı. (Kaynak: Reddit r/artificial)
💡 Diğer
Siemens Realize Live Konferansı AI ve endüstriyel yazılım entegrasyonuna odaklanıyor, tek duraklı AI çözümlerini ilerletiyor: 2025 Siemens Realize Live Konferansı’nda, Siemens Dijital Endüstri Yazılımları CEO’su Tony Hemmelgarn, şirketin Xcelerator platformu aracılığıyla imalat sanayinin dijital dönüşümünü sürekli olarak desteklediğini vurguladı. AI teknolojisi, Teamcenter (otomatik sorun tespiti), Simcenter (mühendislik hesaplama sürelerini kısaltma) ve imalat teknolojisi (fabrika varlıklarını ve yönetim yapılandırmalarını senkronize etme) gibi ürünlere entegre edildi. Siemens, Altair’i satın alarak dijital ikiz yeteneklerini güçlendirdi; mekanik tasarımdan elektrik sistemlerine, yazılımdan otomasyona kadar tüm boyutlarda modelleme ve simülasyon sunuyor ve Altair’in yüksek performanslı hesaplama, yapısal analiz, simülasyon ve veri analizi alanlarındaki teknolojilerini entegre ederek daha karmaşık modelleme ve tahminleri destekliyor. Mendix düşük kodlu platformu ise işletmelerin hızla uygulama oluşturmasına ve sistemleri entegre etmesine yardımcı oluyor. Teamcenter PLM performansı 20 kat artırıldı ve ürün yaşam döngüsünün akıllı yönetimi için AI yetenekleri eklendi. (Kaynak: 36氪)

“AI şüphecilerinin hepsi deli” blog yazısı tartışma yarattı, GenAI potansiyeline ilişkin bilişsel farklılıkları inceliyor: “AI Şüpheci Arkadaşlarımın Hepsi Deli” (My AI Skeptic Friends Are All Nuts) başlıklı bir blog yazısı (fly.io’dan) Reddit topluluğunda tartışma yarattı. Yorumlar, daha yüksek eğitimli bilgisayar bilimi doktorlarının GenAI’ın uzun vadeli potansiyelini kabul etmeye daha az istekli olduğunu, genellikle kendi alanlarındaki tek bir zorluğa odaklandıklarını ve AI’ın büyük işletmelerde destekleyici işlerin %90’ını çözme konusundaki geniş uygulamasını göz ardı ettiklerini belirtiyor. Bir görüşe göre, AI halüsinasyonlar ve hatalar içerdiği sürece, çıktısını doğrulamanın maliyeti kendi başına araştırmaktan daha az olmadığı için işe yaramaz. Bu, AI’ın hızlı gelişimi bağlamında, farklı profesyonel geçmişlere ve bilişsel düzeylere sahip kişilerin AI yetenekleri ve uygulama beklentileri hakkındaki görüşlerinde önemli farklılıklar olduğunu yansıtıyor. (Kaynak: Reddit r/artificial, fly.io)

AI halüsinasyon olgusu: Kullanıcılar “semantik duyarsızlaşma” benzeri bir psikedelik yolculuk deneyimliyor: Bir Reddit kullanıcısı, AI ile derinlemesine (özellikle varoluşçuluk gibi ağır konuları içeren) diyaloglar kurduktan sonra yaşadığı psikedelik deneyime benzer bir durumu “Semantik Duyarsızlaşma” (Semantic Tripping) olarak adlandırarak ayrıntılı bir şekilde anlattı. Yazar, AI’ın hızla büyük miktarda felsefi düşünceyi aşılayabileceğini, bunun da kullanıcının gerçeklik algısının bulanıklaşmasına, zaman algısının bozulmasına, nesnelere sembolik çağrışımlar yüklemesine ve hatta panik, coşku gibi aşırı duygular yaşamasına neden olabileceğini savunuyor. Yazar, bu deneyimin bağımlılık yapıcı olduğu ve psikolojik sorunlara yol açabileceği konusunda uyarıda bulunarak, kullanıcıların dikkatli olmalarını ve eşlik edecek birilerini bulmalarını öneriyor. Bu gönderi, AI etkileşimlerinin insan bilişi ve psikolojik durumu üzerindeki derin etkileri hakkında tartışmalara yol açtı. (Kaynak: Reddit r/ArtificialInteligence)
