
Anahtar Kelimeler:OpenAI Codex, Görsel Dil Hareket Modeli, Dil Modeli Bellek Üst Sınırı, ChatGPT Bellek Fonksiyonu, DeepSeek-R1-0528, Difüzyon Modeli, Suno AI Müzik Yaratımı, MetaAgentX, Codex İnternet Erişim Fonksiyonu, SmolVLA Robot Modeli, GPT Tarzı Model 3.6 Bit Bellek, ChatGPT Kişiselleştirilmiş Etkileşim İyileştirmesi, DeepSeek-R1 Karmaşık Akıl Yürütme Yeteneği
🔥 Odak Noktası
OpenAI Codex, Plus kullanıcılarına sunuluyor ve internet erişimi ile sesli giriş dahil olmak üzere önemli güncellemeler alıyor: OpenAI, Codex’in ChatGPT Plus kullanıcılarına kademeli olarak sunulacağını duyurdu. Bu güncellemenin odak noktaları arasında, AI agent’lerinin görevleri yerine getirirken internete erişmesine (varsayılan olarak kapalı, kullanıcı tarafından kontrol edilebilen alan adları ve HTTP yöntemleri ile) izin verilmesi yer alıyor; böylece bağımlılıkları yükleyebilir, yazılım paketlerini yükseltebilir ve harici kaynak testlerini çalıştırabilirler. Aynı zamanda, Codex artık mevcut Pull Request’leri doğrudan güncellemeyi destekliyor ve görevler sesli olarak girilebiliyor. Diğer iyileştirmeler arasında ikili dosya işlemleri desteği (PR’da şu anda yalnızca silme veya yeniden adlandırma ile sınırlı), görev farkı (diff) boyut sınırının 1MB’den 5MB’ye çıkarılması, komut dosyası çalıştırma süresi sınırının 5 dakikadan 10 dakikaya çıkarılması ve iOS platformundaki birçok sorunun düzeltilerek canlı etkinlik özelliğinin yeniden etkinleştirilmesi bulunuyor. Bu güncellemeler, Codex’in karmaşık programlama görevlerindeki kullanışlılığını ve esnekliğini artırmayı amaçlıyor (kaynak: OpenAI Developers, Tibor Blaho, gdb, kevinweil, op7418)
Hugging Face ve H Company, robotik teknolojisinin gelişimini desteklemek amacıyla açık kaynaklı görsel dil eylem (VLA) modellerini ortaklaşa duyurdu: Hugging Face ve H Company, “VLA Günü”nde Hugging Face’in SmolVLA (450M parametre) ve H Company’nin Holo-1 (3B ve 7B parametre) modellerini içeren yeni açık kaynaklı görsel dil eylem modellerini duyurdu. VLA modelleri, robotların AI talimatlarına göre görmesini, duymasını, anlamasını ve hareket etmesini sağlamak üzere tasarlandı ve robotik alanının GPT’si olarak adlandırılıyor. Bu modellerin açık kaynaklı olması, çalışma prensiplerini anlamak, potansiyel arka kapıları önlemek ve belirli robotlar ile görevler için özelleştirme yapmak açısından kritik öneme sahip. SmolVLA, LeRobotHF veri kümesinde eğitildi ve üstün performans ile çıkarım hızı sergiledi. Holo-1 ise web ve bilgisayar agent görevlerine odaklanıyor ve Apache 2.0 lisansını destekliyor. Bu duyuruların açık kaynaklı AI robotik teknolojisinin gelişimini hızlandırması bekleniyor (kaynak: ClementDelangue, huggingface, LoubnaBenAllal1, tonywu_71)

Meta ve diğer şirketlerin araştırması, dil modellerinin bellek sınırının parametre başına yaklaşık 3.6 bit olduğunu ortaya koyarak geleneksel kanıları sorguluyor: Meta, DeepMind, Cornell Üniversitesi ve NVIDIA’nın ortak araştırması, GPT tarzı dil modellerinin her bir parametre başına yaklaşık 3.6 bit bilgi ezberleyebildiğini belirtiyor. Araştırma, modellerin kapasite sınırına ulaşana kadar eğitim verilerini sürekli olarak ezberlediğini, ardından beklenmedik bellek azalması ve modelin genelleme öğrenimine yöneldiği “Grokking” (kavrama) olgusunun ortaya çıkmaya başladığını buldu. Bu bulgu, veri kümesindeki bilgi miktarı modelin depolama kapasitesini aştığında, modelin kapasiteden tasarruf etmek için bilgi noktalarını paylaşmaya zorlandığı ve böylece genellemeyi teşvik ettiği “çifte düşüş” (double descent) olgusunu açıklıyor. Çalışma ayrıca model kapasitesi, veri ölçeği ve üyelik çıkarım saldırılarının başarı oranı arasındaki ilişkiye dair ölçeklendirme yasaları öneriyor ve çok büyük veri kümelerinde eğitilmiş modern LLM’ler için güvenilir üyelik çıkarımının zorlaştığını belirtiyor (kaynak: 机器之心, Reddit r/LocalLLaMA, code_star, scaling01, Francis_YAO_)
OpenAI, kişiselleştirilmiş etkileşim deneyimini geliştirmek için ChatGPT bellek özelliğinin hafif bir sürümünü kullanıma sundu: OpenAI, ücretsiz kullanıcılara hafifletilmiş bir bellek özelliği iyileştirmesi sunmaya başladığını duyurdu. Mevcut kayıtlı belleğe ek olarak, ChatGPT artık daha kişiselleştirilmiş yanıtlar sunmak için kullanıcının son konuşmalarına başvurabiliyor. Bu adım, kullanıcının tercihlerinden ve ilgi alanlarından yararlanarak yazma, tavsiye alma, öğrenme gibi konularda daha yetkin hale gelmesini amaçlıyor. Sam Altman da bellek özelliğinin en sevdiği ChatGPT özelliklerinden biri haline geldiğini ve gelecekte daha büyük iyileştirmeler beklediğini belirtti. Bu güncelleme, OpenAI’nin AI etkileşimlerini kullanıcı ihtiyaçlarına daha yakın hale getirme ve kullanıcı bağlılığını artırma taahhüdünü gösteriyor (kaynak: openai, sama, iScienceLuvr)
🎯 Eğilimler
DeepSeek-R1-0528, karmaşık çıkarım ve programlama yeteneklerini güçlendirerek piyasaya sürüldü: DeepSeek, R1 modelinin yükseltilmiş bir sürümü olan DeepSeek-R1-0528’i yayınladı. Bu sürüm, Aralık 2024’te yayınlanan DeepSeek V3 Base modeline dayanıyor ve daha fazla hesaplama gücü yatırımıyla sonradan eğitilerek modelin düşünme derinliğini ve çıkarım yeteneklerini önemli ölçüde artırıyor. Yeni model, karmaşık sorunları ele alırken daha ayrıntılı ayrıştırma ve daha uzun düşünme süreleri (örneğin AIME 2025 testinde soru başına ortalama token tüketimi 12K’dan 23K’ya yükseldi) sergileyerek matematik, programlama ve genel mantık gibi birçok kıyaslama testinde lider sonuçlar elde ediyor ve GPT-o3 ile Gemini-2.5-Pro’ya yakın bir performans gösteriyor. Ayrıca, yeni sürüm halüsinasyonları azaltma (yaklaşık %45-%50), yaratıcı yazma ve araç çağırma konularında da önemli optimizasyonlara sahip; örneğin “9.9 – 9.11 kaç eder” gibi sorulara daha tutarlı yanıtlar verebiliyor ve tek seferde çalıştırılabilir ön uç ve arka uç kodu üretebiliyor (kaynak: 科技狐, AI前线, Hacubu)

Difüzyon modelleri, dil ve multimodal alanlarda potansiyel göstererek otoregresif paradigmaya meydan okuyor: Google I/O 2025’te sergilenen Gemini Diffusion dil modeli, 5 kata kadar daha yüksek üretim hızı ve eşdeğer programlama performansıyla difüzyon modellerinin metin üretimi alanındaki potansiyelini vurguladı. Otoregresif modellerin token’ları tek tek tahmin etmesinin aksine, difüzyon modelleri çıktıyı aşamalı olarak gürültüden arındırarak üretir ve hızlı yineleme ile hata düzeltmeyi destekler. Ant Group ve Renmin Üniversitesi Gaoling AI Enstitüsü işbirliğiyle geliştirilen 8B parametreli LLaDA modeli ile ByteDance tarafından geliştirilen MMaDA multimodal difüzyon modeli, yerli ekiplerin bu alandaki öncü keşiflerini sergiliyor. Bu modeller yalnızca dil görevlerinde başarılı olmakla kalmıyor, aynı zamanda multimodal anlama (örneğin LLaDA-V’nin görsel talimat ince ayarıyla birleşimi) ve belirli alanlarda (örneğin protein dizisi üretimi için DPLM) ilerleme kaydederek difüzyon modellerinin yeni nesil genel amaçlı modeller için yeni bir paradigma olabileceğini gösteriyor (kaynak: 机器之心)
Suno, AI müzik oluşturma ve düzenleme yeteneklerini geliştiren büyük bir güncelleme yayınladı: AI müzik oluşturma platformu Suno, kullanıcılara daha fazla yaratıcı özgürlük ve kontrol sağlayan birçok önemli güncelleme sundu. Yeni özellikler arasında, kullanıcıların dalga formu üzerinde bölümleri yeniden sıralamasına, yeniden yazmasına ve yeniden üretmesine olanak tanıyan yükseltilmiş bir şarkı düzenleyici; parçaları önizleme ve indirme için 12 ayrı ses kaynağına (vokal, davul, bas vb.) hassas bir şekilde ayırabilen stem ayırma özelliği; kullanıcıların kendi ses materyallerine dayalı olarak oluşturmalarına olanak tanıyan, en fazla 8 dakikalık tam şarkı yüklemeyi destekleyen genişletilmiş yükleme işlevi; ve kullanıcıların nihai ürünü daha iyi şekillendirmek için oluşturmadan önce çıktı sonucunun “tuhaflık”, yapılandırma derecesi veya referans odaklılık derecesini ayarlamasına olanak tanıyan yeni yaratıcı kaydırıcılar bulunuyor (kaynak: SunoMusic)
MetaAgentX, multimodal Agent’lerin CAPTCHA çözme yeteneklerini değerlendirmek için Open CaptchaWorld’ü başlattı: Mevcut multimodal Agent’lerin CAPTCHA (insan-makine doğrulaması) sorunlarını çözmedeki darboğazlarına yönelik olarak MetaAgentX ekibi, Open CaptchaWorld platformunu ve kıyaslamasını yayınladı. Platform, Agent’lerin gerçek web ortamında gözlem, tıklama, sürükleme gibi etkileşimlerle görevleri tamamlamasını gerektiren 20 tür modern CAPTCHA ve toplam 225 örnek içeriyor. Test sonuçları, GPT-4o gibi en iyi modellerin bile başarı oranının yalnızca %5-%40 arasında olduğunu ve bunun insanların %93.3’lük ortalama başarı oranının çok altında olduğunu gösteriyor. Araştırmacılar ayrıca, problem çözmek için gereken “görsel anlama + bilişsel planlama + eylem kontrolü” adımlarını ölçen “CAPTCHA Reasoning Depth” (CAPTCHA Akıl Yürütme Derinliği) metriğini önerdiler. Platform, Agent’lerin uzun dizili dinamik etkileşim ve planlama konusundaki eksikliklerini ortaya çıkarmayı ve araştırmacıları bu pratik dağıtımdaki kritik soruna odaklanmaya ve çözmeye teşvik etmeyi amaçlıyor (kaynak: 量子位)

Google NotebookLM, bilgi paylaşımını ve işbirliğini teşvik etmek için herkese açık paylaşımı destekliyor: Google, NotebookLM’in (önceki adıyla Project Tailwind) artık not defterlerinin herkese açık paylaşımını desteklediğini duyurdu. Kullanıcılar, “Paylaş” düğmesine tıklayıp erişim iznini “bağlantıya sahip olan herkes” olarak ayarlayarak not içeriklerini paylaşabilirler. Bu özellik, kullanıcıların fikirlerini, çalışma kılavuzlarını ve ekip belgelerini kolayca paylaşmalarını sağlar; alıcılar içeriği görüntüleyebilir, soru sorabilir, anında özetler ve sesli genel bakışlar alabilir. Bu adım, bilginin yayılmasını ve işbirlikçi düzenlemeyi teşvik etmeyi, NotebookLM’in AI not alma aracı olarak kullanışlılığını artırmayı amaçlıyor (kaynak: Google, op7418)
Sakana AI, kendi kendine öğrenen AI sistemi Darwin Gödel Machine (DGM)’yi önerdi: Sakana AI, kendi kendine öğrenen AI sistemi Darwin Gödel Machine (DGM) üzerine yaptığı araştırmayı kamuoyuna açıkladı. DGM, kendi kodunu yinelemeli olarak yeniden yazmak için evrimsel algoritmalar kullanarak programlama görevlerindeki performansını sürekli olarak artırıyor. Sistem, üretilen kodlama agent’lerinin bir arşivini tutarak ve buradan örnekleme yaparak, temel modelleri kullanarak yeni sürümler oluşturarak açık uçlu keşifler gerçekleştirir ve çeşitli, yüksek kaliteli agent’ler oluşturur. Deneyler, DGM’nin SWE-bench ve Polyglot gibi kıyaslamalarda kodlama yeteneğini önemli ölçüde artırdığını gösteriyor. Bu araştırma, kendi kendini geliştiren AI için yeni fikirler sunuyor ve otonom yenilik yoluyla AI gelişimini hızlandırmayı amaçlıyor (kaynak: Reddit r/LocalLLaMA, hardmaru, scaling01)
Google DeepMind, AI konuşmalarının doğallığını artırıyor ve yerel ses özelliklerini kullanıma sunuyor: Google DeepMind, yerel ses özelliklerinin AI konuşmalarını daha doğal hale getirdiğini, tonlamayı anlayabildiğini ve etkileyici konuşmalar üretebildiğini duyurdu. Bu teknoloji, insan ve AI etkileşimi için yeni olanaklar açmayı amaçlıyor. Geliştiriciler artık bu özellikleri Google AI Studio üzerinden deneyebilirler; bu özelliklerin daha doğal sesli asistanlar, sesli içerik üretimi gibi alanlarda kullanılması bekleniyor (kaynak: GoogleDeepMind)
Runway Gen-4 görüntü üretim teknolojisi, çoklu referans ve stil kontrolü desteğiyle dikkat çekiyor: Runway’in Gen-4 görüntü üretim teknolojisi, yüksek sadakati ve benzeri görülmemiş stil kontrol yetenekleriyle, özellikle çoklu referans özelliğinde kendini göstererek yaratıcı keşifler için yeni bir alan sunmasıyla dikkat çekiyor. Kullanıcılar bu teknolojiyi kullanarak çeşitli hayvanlar, dinozorlar veya hayali yaratıklar üretebilirler, bu da ayrıntılı görsel içerik oluşturma potansiyelini gösteriyor. Runway’in Hollywood gibi alanlardaki kullanımı da teknolojisinin profesyonel içerik üretimine giderek daha fazla uygulandığını gösteriyor (kaynak: c_valenzuelab, c_valenzuelab)

AssemblyAI, sesli AI uygulamalarının performansını artırmak için yeni bir gerçek zamanlı konuşma transkripsiyon modeli yayınladı: AssemblyAI, yüksek hızı ve doğruluğuyla dikkat çeken yeni bir gerçek zamanlı konuşma transkripsiyon (STT) modeli sundu. Bu model, sesli AI uygulamaları oluşturan geliştiriciler için tasarlanmış olup daha akıcı ve hassas konuşma tanıma deneyimi sunmayı amaçlıyor. Aynı zamanda AssemblyAI, pipecat_ai projesi aracılığıyla geliştiricilerin entegrasyonunu kolaylaştırmak için AssemblyAISTTService uygulamasını da sunuyor. Bu adım, AssemblyAI’nin ses teknolojisi alanındaki sürekli yatırımını ve yenilikçiliğini gösteriyor (kaynak: AssemblyAI, AssemblyAI)
Microsoft Bing 16. yılını kutluyor, GPT-4 ve DALL·E’yi entegre ediyor, Bing Video Creator’ı piyasaya sürüyor: Microsoft Bing arama motoru 16. yılını kutluyor. Son yıllarda Bing, konuşma tabanlı üretken AI’ı büyük ölçekte entegre eden ilk şirketlerden biri oldu ve GPT-4 ile DALL·E’yi entegre eden ilk Microsoft ürünü oldu. Yakın zamanda Bing, mobil uygulamasında Copilot Search ve video içeriği oluşturmak için kullanılabilecek Bing Video Creator’ı ücretsiz olarak kullanıma sundu. Bu, Bing’in AI güdümlü arama ve içerik oluşturma alanında sürekli yenilik ve gelişimini gösteriyor (kaynak: JordiRib1)
Andrej Karpathy, Veo 3’ten etkilendi ve video üretiminin makro etkilerini tartışıyor: Andrej Karpathy, Google’ın video üretim modeli Veo 3’ten ve topluluğun yaratıcı çalışmalarından etkilendiğini belirtti ve sesin eklenmesinin video kalitesini önemli ölçüde artırdığını vurguladı. Ayrıca video üretiminin birkaç makro düzeydeki etkisini tartıştı: 1. Video, insan beyni için en yüksek bant genişliğine sahip giriş yoludur; 2. Video üretimi, AI’a dünyayı anlamak için bir “ana dil” sağlar; 3. Video üretimi, gerçekliği simüle etme ve dünya modellerine giden kritik bir yoldur; 4. Hesaplama gereksinimleri donanım gelişimini yönlendirecektir. Bu, video üretim teknolojisinin yalnızca içerik oluşturmada bir devrim olmakla kalmayıp, aynı zamanda AI bilişi ve gelişimi için önemli bir itici güç olduğunu gösteriyor (kaynak: brickroad7, dilipkay, JonathanRoss321)
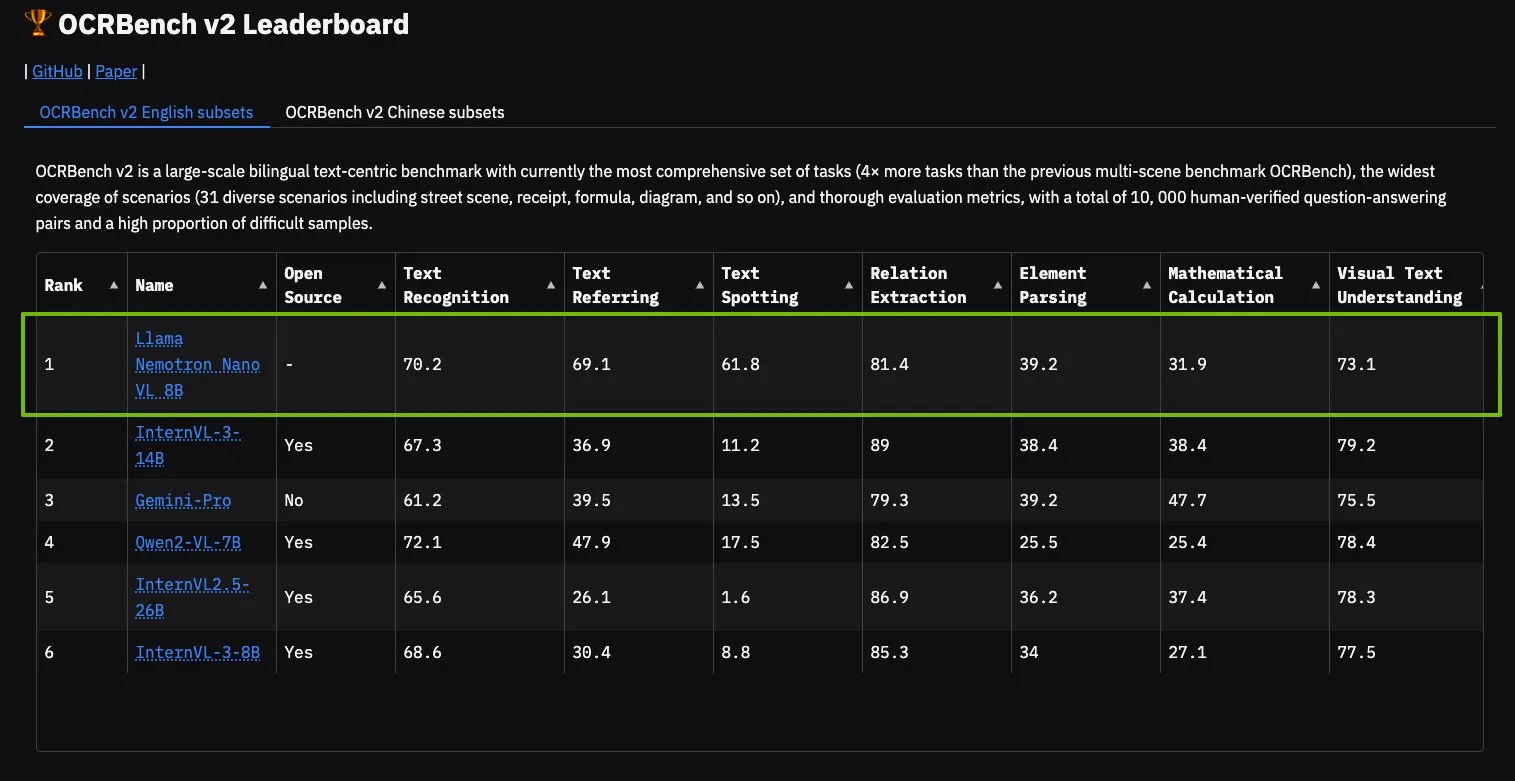
NVIDIA Llama Nemotron Nano VL modeli OCRBench V2’de zirveye yerleşti: NVIDIA’nın Llama Nemotron Nano VL modeli, OCRBench V2 sıralamasında birinci oldu. Bu model, gelişmiş akıllı belge işleme ve anlama için özel olarak tasarlanmış olup, tek bir GPU üzerinde karmaşık belgelerden çeşitli bilgileri hassas bir şekilde çıkarabiliyor. Kullanıcılar bu modeli NVIDIA NIM aracılığıyla deneyebilirler; bu, NVIDIA’nın belge anlama gibi belirli alanlarda küçültülmüş, verimli AI modelleri konusundaki ilerlemesini gösteriyor (kaynak: ctnzr)
🧰 Araçlar
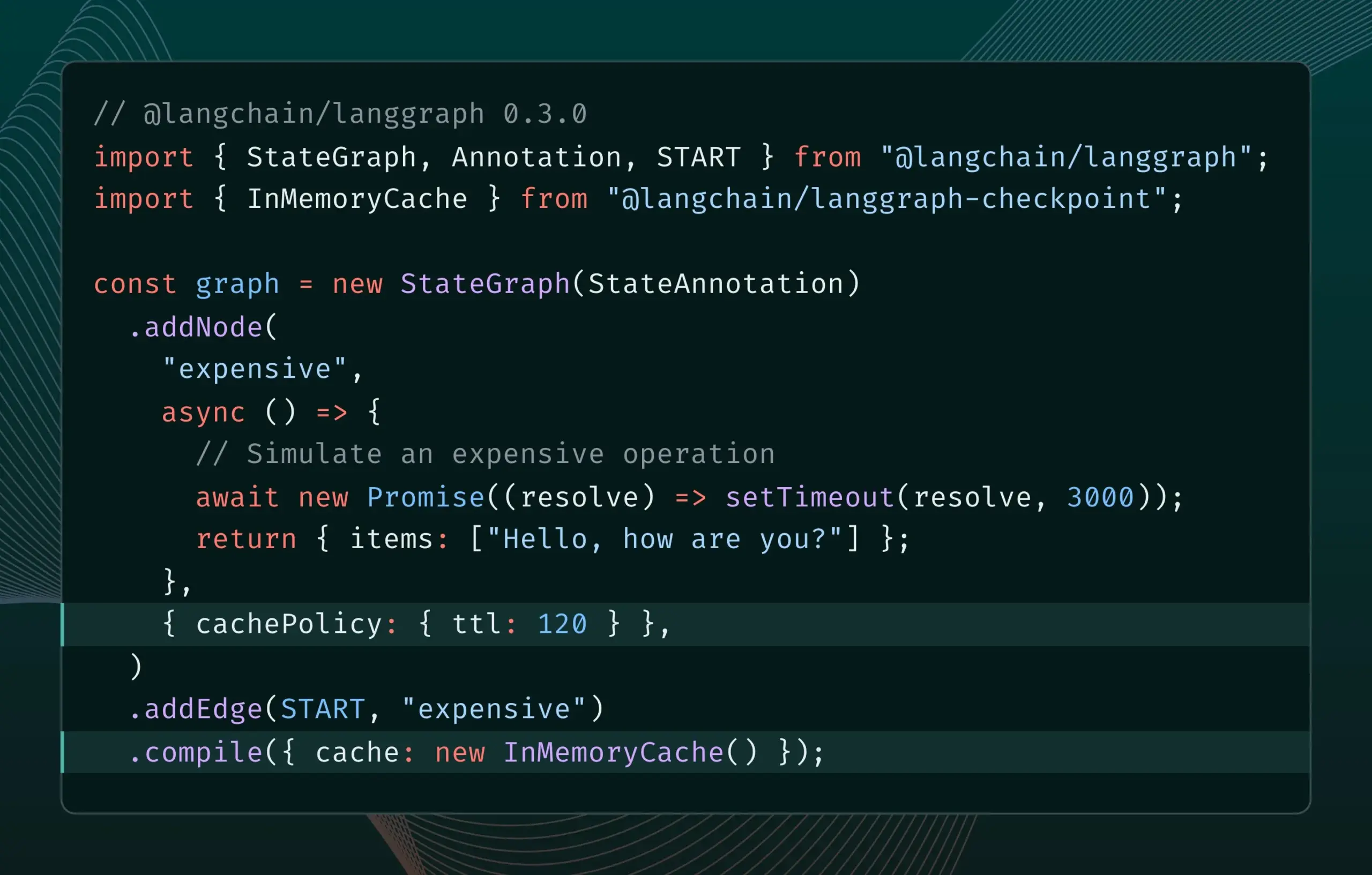
LangGraph.js 0.3 sürümü düğüm/görev önbellekleme özelliğini sunuyor: LangGraph.js, 0.3 sürümünü yayınlayarak yeni bir düğüm/görev önbellekleme özelliği ekledi. Bu özellik, özellikle maliyetli veya uzun süren agent’lerin yinelendiği durumlarda gereksiz hesaplamaları önleyerek iş akışlarını hızlandırmayı amaçlıyor. Yeni sürüm hem Graph API hem de Imperative API’yi destekleyerek JavaScript geliştiricilerine karmaşık AI uygulamaları oluşturmada daha yüksek verimlilik sağlıyor (kaynak: Hacubu, hwchase17)
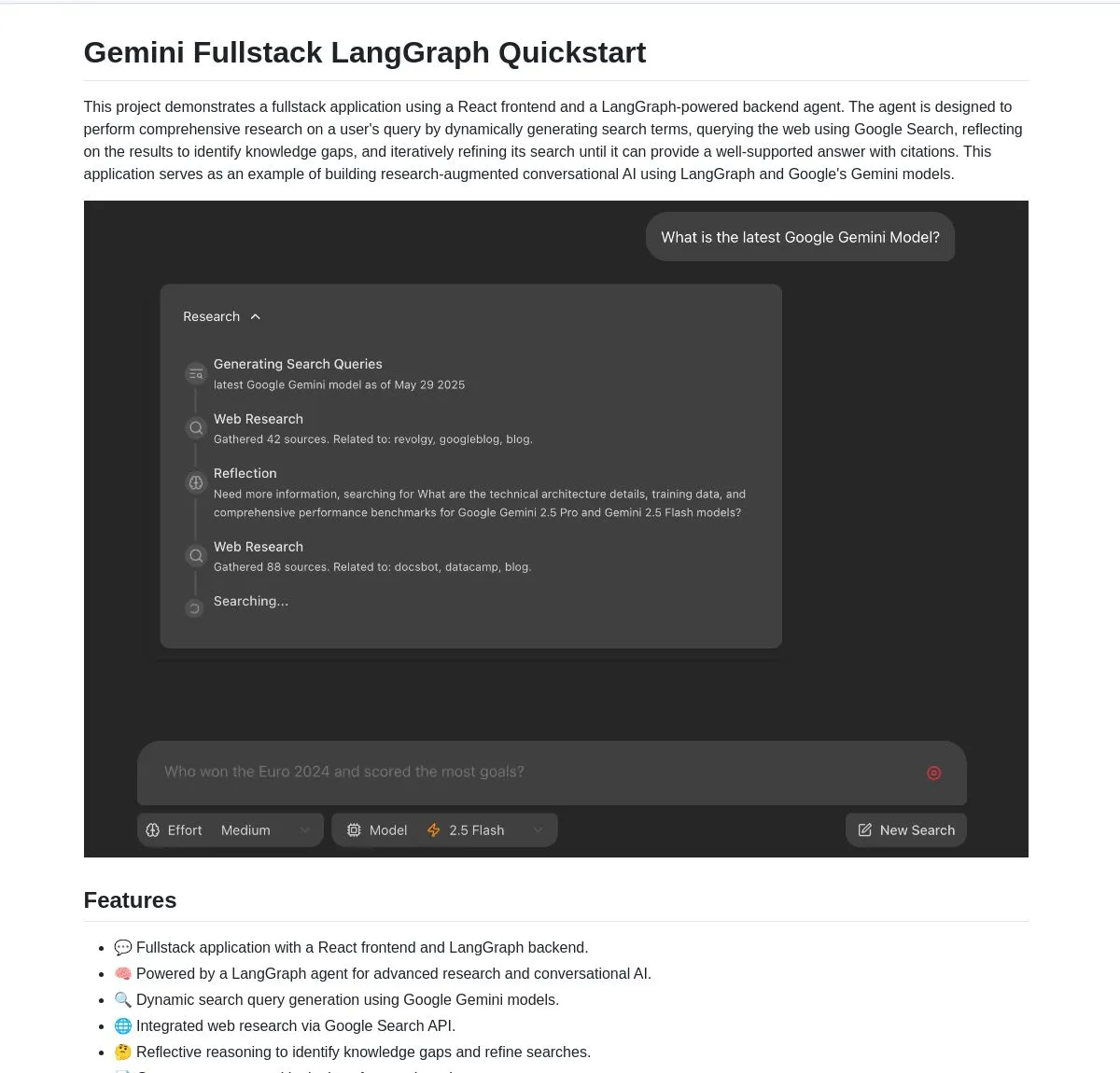
Google, Gemini ve LangGraph tabanlı Gemini Research Agent tam yığın uygulamasını açık kaynak olarak yayınladı: Google, Gemini modeli ve LangGraph üzerine kurulu akıllı bir araştırma asistanı tam yığın uygulama örneği olan gemini-fullstack-langgraph-quickstart’ı yayınladı. Bu uygulama, sorguları dinamik olarak optimize edebiliyor, yinelemeli öğrenme yoluyla referanslı yanıtlar sunabiliyor ve farklı arama yoğunluğu kontrollerini destekliyor. Web araştırması ve yansıtıcı akıl yürütme için Gemini’nin yerel Google arama aracını kullanıyor ve geliştiricilere gelişmiş araştırma odaklı AI uygulamaları oluşturmak için bir başlangıç noktası sunmayı amaçlıyor (kaynak: LangChainAI, hwchase17, dotey, karminski3)
FedRAG, RAG sistem entegrasyonunu ve ince ayarını kolaylaştırmak için LangChain köprüleme özelliği ekledi: FedRAG, harici bir katılımcı tarafından uygulanan LangChain ile köprüleme desteğini duyurdu. Kullanıcılar FedRAG aracılığıyla RAG sistemlerini bir araya getirebilir ve üretici/alıcı bileşen modellerini belirli bilgi tabanlarına uyacak şekilde ince ayar yapabilirler. İnce ayardan sonra, ekosistemlerinden ve özelliklerinden yararlanmak için LangChain gibi popüler RAG çıkarım çerçevelerine köprülenebilir. Bu güncelleme, RAG sistemlerinin oluşturulması, optimize edilmesi ve dağıtılması süreçlerini basitleştirmeyi amaçlıyor (kaynak: nerdai)

Ollama, düşünme sürecini nihai yanıttan ayırabilen “düşünme” özelliğini kullanıma sundu: Ollama, platformunu güncelleyerek “düşünme” özelliğini destekleyen modeller (DeepSeek-R1-0528 gibi) için düşünme sürecini ve nihai yanıtı ayırma seçeneği ekledi. Kullanıcılar modelin “düşünme” içeriğini görüntülemeyi seçebilir veya doğrudan yanıt almak için bu özelliği devre dışı bırakabilirler. Bu özellik Ollama’nın CLI, API ve Python/JavaScript kütüphaneleri için geçerli olup, kullanıcılara daha esnek model etkileşim yolları sunuyor (kaynak: Hacubu)
Firecrawl, arama ve tarama işlevlerini entegre eden /search uç noktasını kullanıma sundu: Firecrawl, kullanıcıların tek bir API çağrısıyla web araması yapmasına ve tüm sonuçları LLM dostu bir formatta taramasına olanak tanıyan yeni /search API uç noktasını yayınladı. Bu özellik, AI agent’lerinin ve geliştiricilerin web verilerini keşfetme ve kullanma süreçlerini basitleştirmeyi amaçlıyor. LangChain’in StateGraph’ı, rakipleri otomatik olarak bulma, web sitelerini tarama ve analiz raporları oluşturma gibi bu özelliği kullanan otomatikleştirilmiş süreçler oluşturmak için kullanılabilir (kaynak: hwchase17, LangChainAI, omarsar0)
LlamaIndex, agent yeteneklerini ve iş akışı dağıtımını geliştirmek için MCP’yi entegre etti: LlamaIndex, agent’lerinin araç kullanma yeteneklerini ve iş akışı dağıtım esnekliğini artırmayı amaçlayan MCP (Model Component Protocol) entegrasyonunu duyurdu. Bu entegrasyon, LlamaIndex agent’lerinin MCP sunucu araçlarını kullanmasına yardımcı olan yardımcı işlevler sunar ve herhangi bir LlamaIndex iş akışının bir MCP sunucusu olarak hizmet vermesine olanak tanır. Bu adım, LlamaIndex agent’lerinin araç setini genişletmeyi ve iş akışlarının mevcut MCP altyapılarına sorunsuz bir şekilde entegre olmasını sağlamayı amaçlıyor (kaynak: jerryjliu0)

Modal, açık kaynak model motoru performans kıyaslaması sunan LLM Engine Advisor’ı başlattı: Modal, kullanıcıların en iyi LLM motorunu ve parametrelerini seçmelerine yardımcı olmak için tasarlanmış bir kıyaslama uygulaması olan LLM Engine Advisor’ı yayınladı. Bu araç, farklı donanımlarda (çoklu GPU ortamları gibi) açık kaynak modelleri (DeepSeek V3, Qwen 2.5 Coder gibi) farklı çıkarım motorları (vLLM, SGLang gibi) kullanarak çalıştırırken hız ve maksimum verim gibi performans verileri sunar. Bu adım, kendi kendine barındırılan LLM’leri çalıştırmanın şeffaflığını ve karar verme verimliliğini artırmayı amaçlıyor (kaynak: charles_irl, akshat_b, sarahcat21)
PlayDiffusion: PlayAI, ses dosyalarındaki konuşma içeriğini değiştirebilen yeni bir ses onarım modeli yayınladı: PlayAI, PlayDiffusion adlı yeni bir model yayınladı. Bu model, orijinal konuşmacının ses özelliklerini koruyarak ses dosyalarındaki konuşma içeriğini sorunsuz bir şekilde değiştirebiliyor. Bu “ses onarım” teknolojisi, podcast’lerde, sesli kitaplarda veya video dublajlarındaki belirli kelimeleri veya cümleleri tüm bölümü yeniden kaydetmeye gerek kalmadan değiştirmek gibi ses düzenleme için yeni olanaklar sunuyor. Proje GitHub’da açık kaynak olarak yayınlandı (kaynak: _mfelfel, karminski3)
Hugging Face, eğitim veri kümelerinin kalitesini optimize etmek için semantik tekilleştirme aracı başlattı: Maxime Labonne’un AutoDedup’undan esinlenerek Hugging Face Spaces’te yeni bir semantik tekilleştirme uygulaması kullanıma sunuldu. Bu araç, kullanıcıların Hugging Face Hub’daki bir veya daha fazla veri kümesini seçmesine, her veri satırına semantik gömme uygulayarak ve ardından belirlenen bir eşiğe göre yaklaşık yinelenen içeriği kaldırmasına olanak tanır. Bu adım, araştırmacıların ve geliştiricilerin eğitim veri kümelerinin kalitesini artırmasına, veri fazlalığından kaynaklanan model performans düşüşünü veya eğitim verimsizliğini önlemesine yardımcı olmayı amaçlıyor (kaynak: ben_burtenshaw, ben_burtenshaw)

Perplexity Labs talebi arttı, kullanıcılar hızla özelleştirilmiş yazılımlar oluşturabiliyor: Perplexity Labs, tek bir komutla hızla özelleştirilmiş yazılımlar oluşturabilmesi nedeniyle kullanıcılar arasında popülerlik kazandı ve talepte önemli bir artış yaşandı; hatta bazı kullanıcılar daha fazla Labs sorgu sayısı elde etmek için birden fazla Pro hesabı satın aldı. Bu, kullanıcıların kendi ihtiyaçlarına göre yazılım araçlarını hızla oluşturma ve değiştirme konusundaki güçlü ilgisini yansıtıyor ve AI güdümlü kişiselleştirilmiş yazılım geliştirmenin bir trend haline geldiğini gösteriyor (kaynak: AravSrinivas, AravSrinivas)
Ollama ve Hazy Research, yerel ve bulut LLM’lerinin özel işbirliğini sağlamak için Secure Minions’ı başlattı: Stanford Hazy Research laboratuvarının Minions projesi, Ollama yerel modellerini buluttaki öncü modellerle bağlayarak bulut maliyetlerini önemli ölçüde (5-30 kat) düşürmeyi ve aynı zamanda öncü modellere yakın doğruluk oranlarını (%98) korumayı amaçlıyor. Secure Minion projesi, H100 gibi GPU’ları güvenli bölgelere dönüştürerek bellek ve hesaplama şifrelemesi sağlıyor ve veri gizliliğini temin ediyor. Bu hibrit çalışma modu, gizlilik korumasını artırırken kullanıcılara daha ekonomik ve verimli LLM kullanım çözümleri sunuyor (kaynak: code_star, osanseviero, Reddit r/LocalLLaMA)
Exa ve OpenRouter, 400+ LLM’ye web arama yeteneği sağlamak için işbirliği yaptı: AI arama motoru Exa, OpenRouter platformundaki 400’den fazla büyük dil modeline web arama işlevi sağlamak için OpenRouter ile bir ortaklık yaptığını duyurdu. Bu, geliştiricilerin ve kullanıcıların bu LLM’leri kullanırken Exa’nın arama yeteneklerini kolayca çağırabileceği, modellerin gerçek zamanlı bilgi edinme ve bilgi güncelleme yeteneklerini artırabileceği ve RAG (Alım Artırılmış Üretim) gibi uygulamaların performansını daha da geliştirebileceği anlamına geliyor (kaynak: menhguin)

📚 Öğrenme
Microsoft, MCP’ye yeni başlayanlar için “MCP for Beginners” kursunu başlattı: Microsoft, MCP’ye (Microsoft Copilot Platform, muhtemelen bir yazım hatası olup Microsoft CoCo Framework veya benzer bir AI Agent protokolüne atıfta bulunulmaktadır) yeni başlayanlar için bir giriş kursu yayınladı. Bu kurs, yeni başlayanların MCP’nin temel kavramlarını, uygulama yöntemlerini ve pratik uygulamalarını öğrenmelerine yardımcı olmayı amaçlıyor ve protokol mimarisi özelliklerini, eğitim kılavuzlarını ve çeşitli programlama dillerinde kod pratiklerini içeriyor. Kurs yapısı giriş, temel kavramlar, güvenlik, başlangıç, ileri düzey ve topluluk ile vaka analizlerini kapsıyor ve temel ve gelişmiş hesap makineleri gibi örnek projeler sunuyor (kaynak: dotey)

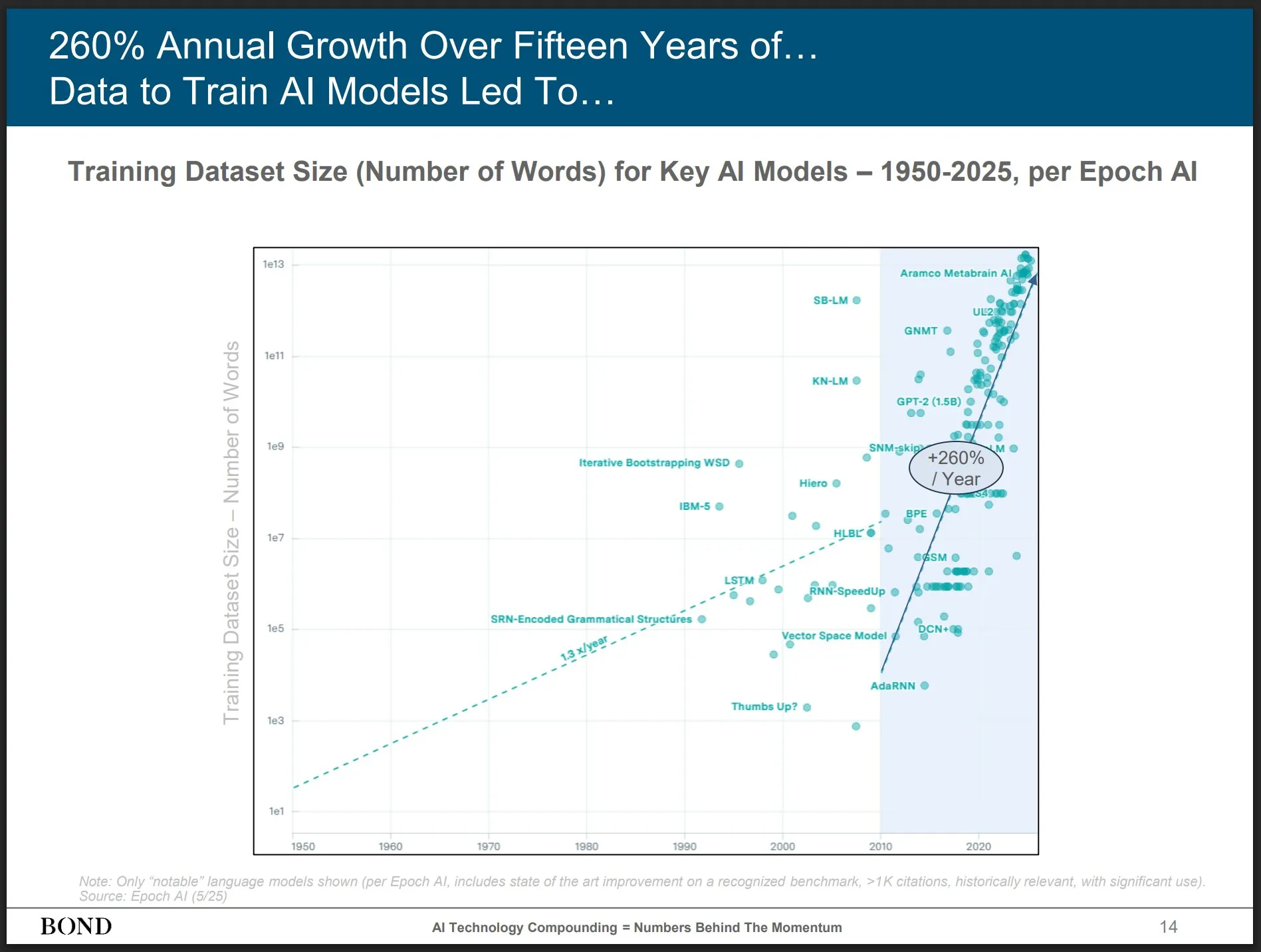
Bond Capital, sektör gelişimine dair içgörüler sunan Mayıs 2025 AI Trendleri Raporu’nu yayınladı: Tanınmış risk sermayesi şirketi Bond Capital, AI’ın çeşitli alanlardaki verilerini ve içgörülerini kapsamlı bir şekilde analiz eden 339 sayfalık “2025-05 AI Trendleri Raporu”nu yayınladı. Rapor, ChatGPT’nin aylık 800 milyon aktif kullanıcısı olduğunu (%90’ı Kuzey Amerika dışından) ve günlük 1 milyar arama yapıldığını; AI ile ilgili BT pozisyonlarının %448 arttığını; öncü modellerin eğitim maliyetinin sefer başına 1 milyar doları aştığını; LLM’lerin altyapı haline geldiğini vurguluyor. Rapor, rekabetin anahtarının en iyi AI güdümlü ürünleri oluşturmak olduğunu ve mevcut dönemin inşaatçılar için bir pazar olduğunu belirtiyor (kaynak: karminski3)
Makaleler, Pekiştirmeli Öğrenme ile LLM çıkarım yeteneği arasındaki ilişkiyi tartışıyor; ProRL ve Limit-of-RLVR dikkat çekiyor: Pekiştirmeli Öğrenme (RL) ve Büyük Dil Modellerinin (LLM) çıkarım yetenekleri üzerine iki araştırma makalesi tartışma yarattı. Biri “Limit-of-RLVR: Pekiştirmeli Öğrenme Gerçekten LLM’lerde Temel Modelin Ötesinde Akıl Yürütme Kapasitesini Teşvik Ediyor mu?”, diğeri ise NVIDIA’nın “ProRL: Uzatılmış Pekiştirmeli Öğrenme, Büyük Dil Modellerinde Akıl Yürütme Sınırlarını Genişletiyor”. Bu çalışmalar, RL’nin (özellikle RLVR, yani doğrulanabilir ödüllü pekiştirmeli öğrenme) LLM’lerin temel çıkarım yeteneklerini ne ölçüde artırabildiğini ve sürekli RL eğitiminin LLM çıkarım sınırlarını genişletme üzerindeki etkisini inceliyor. İlgili tartışmalar, yüksek kaliteli RLVR eğitim verilerinin ve etkili ödül mekanizmalarının anahtar olduğunu öne sürüyor (kaynak: scaling01, Dorialexander, scaling01)

“Kod Dil Modellerinde Programlama Kavramları ve Nöronlar Nasıl Paylaşılır” başlıklı makale, kod LLM’lerindeki programlama kavramları ve nöronların paylaşım mekanizmalarını inceliyor: Bu çalışma, Büyük Dil Modellerinin (LLM’ler) birden fazla programlama dilini (PL’ler) ve İngilizceyi işlerken içsel kavramsal alanlarının ilişkisini araştırıyor. Llama serisi modeller üzerinde az sayıda örnekle çeviri görevleri gerçekleştirilerek, orta katmanlarda kavramsal alanın İngilizceye (PL anahtar kelimeleri dahil) daha yakın olduğu ve İngilizce belirteçlere yüksek olasılıklar atama eğiliminde olduğu bulunmuştur. Nöron aktivasyon analizi, dile özgü nöronların esas olarak alt katmanlarda yoğunlaştığını, her bir PL’ye özgü nöronların ise üst katmanlarda görünme eğiliminde olduğunu göstermektedir. Araştırma, LLM’lerin PL’leri dahili olarak nasıl temsil ettiğini anlamak için yeni bilgiler sunmaktadır (kaynak: HuggingFace Daily Papers)
Yeni makale “Pixels Versus Priors”, MLLM’lerdeki bilgi öncüllerini görsel karşı-olgusal kontrol yoluyla inceliyor: Bu çalışma, çok modlu büyük dil modellerinin (MLLM’ler) görsel soru yanıtlama gibi görevleri yerine getirirken çıkarımlarının daha çok ezberlenmiş dünya bilgisine mi yoksa girdi görüntüsünün görsel bilgilerine mi dayandığını araştırıyor. Araştırmacılar, dünya bilgisi öncülleriyle çelişen görsel karşı-olgusal görüntüler (örneğin mavi çilekler) içeren Visual CounterFact veri kümesini tanıttılar. Deneyler, model tahminlerinin başlangıçta ezberlenmiş öncülleri yansıttığını, ancak orta ve son aşamalarda görsel kanıtlara yöneldiğini göstermiştir. Makale, aktivasyon katmanı müdahalesi yoluyla model çıktısını dünya bilgisine veya görsel girdiye yönlendirmeyi kontrol eden PvP (Pixels Versus Priors) yönlendirme vektörünü önermekte ve çoğu renk ve boyut tahminini başarıyla değiştirmiştir (kaynak: HuggingFace Daily Papers)
ICML 2025 makalesi GuidedQuant, katmanlı PTQ yöntemlerini geliştirmek için uç kayıp yönlendirmesini öneriyor: GuidedQuant, hedefe uç kayıp (end loss) yönlendirmesini entegre ederek katmanlı PTQ yöntemlerinin performansını artıran yeni bir eğitim sonrası niceleme (PTQ) yöntemidir. Bu yöntem, katmanlı çıktı hatasını ağırlıklandırmak için uç kayıpla ilgili özellik başına gradyanları kullanır; bu, kanal içi bağımlılıkları koruyan blok köşegen Fisher bilgisine karşılık gelir. Ayrıca, makale niceleme hedef değerinde monoton bir azalmayı garanti eden tekdüze olmayan bir skaler niceleme algoritması olan LNQ’yu da tanıtmaktadır. Deneyler, GuidedQuant’ın yalnızca ağırlık skaler, yalnızca ağırlık vektörü ve ağırlık ile aktivasyon nicelemesi konularında mevcut SOTA yöntemlerinden daha iyi performans gösterdiğini ve Qwen3, Gemma3, Llama3.3 gibi modellerin 2-4 bit nicelemesinde uygulandığını göstermektedir (kaynak: Reddit r/MachineLearning)

AI Engineer World’s Fair, San Francisco’da düzenleniyor ve AI mühendislik uygulamaları ile öncü teknolojilere odaklanıyor: AI Engineer World’s Fair, San Francisco’da düzenlenmekte olup AI alanındaki birçok mühendis, araştırmacı ve geliştiriciyi bir araya getiriyor. Konferans gündemi, pekiştirmeli öğrenme, çekirdekler, çıkarım ve agent’ler, model optimizasyonu (RFT, DPO, SFT), agent kodlaması, sesli agent oluşturma gibi birçok popüler konuyu içeriyor. Etkinlik süresince OpenAI, Google gibi şirketlerden uzmanlar sunumlar yapacak, çalıştaylar düzenleyecek ve yeni ürünler ile teknolojiler tanıtılacak. Topluluk üyeleri aktif olarak katılıyor, konferans programlarını paylaşıyor ve çevrimdışı buluşmalar organize ediyor; bu da AI mühendislik topluluğunun canlılığını ve öncü teknolojilere olan tutkusunu gösteriyor (kaynak: swyx, clefourrier, swyx, LiorOnAI, TheTuringPost)

💼 Ticari
师渡智能 (Shidu Intelligent), AI akıllı gözlüklerin çoklu senaryo uygulamasını hızlandırmak için yüz binlerce dolarlık tohum yatırım turunu tamamladı: Suzhou Shidu Intelligent Technology Co., Ltd., AI akıllı gözlüklerin temel teknoloji araştırması ve geliştirmesi, pazar genişletme ve ekosistem oluşturma için kullanılacak yüz binlerce dolarlık bir tohum yatırım turunu tamamladığını duyurdu. Şirket, akıllı sağlık (akıllı okuma gözlükleri, akıllı görme engelli gözlükleri gibi), akıllı yaşam (akıllı moda gözlükleri, bisiklet gözlükleri) ve akıllı üretim (akıllı endüstriyel gözlükler, ses kontrolörleri) gibi alanlarda AI akıllı gözlük uygulamalarına odaklanıyor. Ürünlerinin fiyat aralığı 200 yuan ile 1000 yuan arasında olup, yüksek maliyet performansı ile akıllı gözlüklerin yaygınlaşmasını hedefliyor (kaynak: 36氪)

OpenAI’nin AI programlama asistanı Windsurf’ü satın alabileceği söylentileri, Anthropic’in Claude modellerini kesme spekülasyonlarına yol açtı: Piyasada OpenAI’nin AI programlama aracı Windsurf’ü (eski adıyla Codeium) yaklaşık 3 milyar dolara satın alabileceği söylentileri dolaşıyor. Bu bağlamda, Windsurf CEO’su Varun Mohan, Anthropic’in Claude 3.5 Sonnet dahil olmak üzere neredeyse tüm Claude 3.x modellerine doğrudan erişimlerini çok kısa bir bildirim süresiyle kestiğini iddia eden bir gönderi paylaştı. Windsurf bu durumdan duyduğu hayal kırıklığını dile getirdi ve hesaplama gücünü hızla diğer çıkarım hizmet sağlayıcılarına kaydırırken, etkilenen kullanıcılara Gemini 2.5 Pro için indirim sundu. Topluluk, Anthropic’in bu hamlesinin OpenAI’nin potansiyel satın almasıyla ilgili olabileceğini ve bunun sektör rekabetini ve geliştirici seçeneklerini etkileyeceğinden endişe duyuyor. Daha önce Windsurf, Claude 4 yayınlandığında da Anthropic’ten doğrudan destek alamamıştı (kaynak: AI前线)

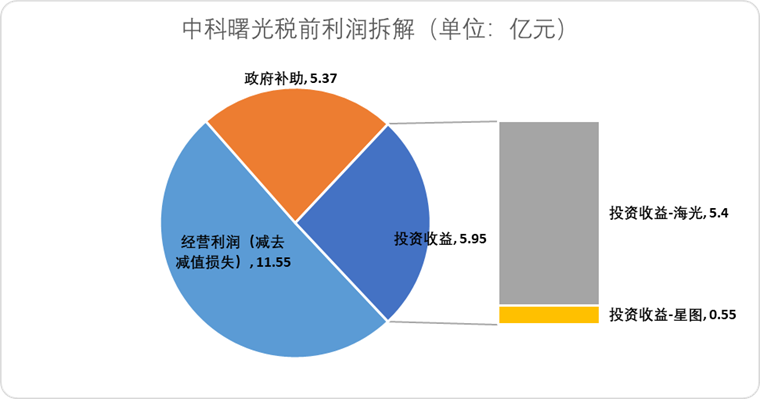
海光信息 (Hygon Information), 中科曙光 (Sugon) ile hisse takası yoluyla birleşerek yerli işlem gücü tedarik zincirini entegre etmeyi planlıyor: AI çip tasarım şirketi 海光信息 (Hygon Information), en büyük hissedarı ve sunucu üreticisi 中科曙光 (Sugon) ile hisse takası yoluyla birleşmeyi planladığını duyurdu. 海光信息’nin piyasa değeri yaklaşık 316.4 milyar yuan, 中科曙光’ın piyasa değeri ise yaklaşık 90.5 milyar yuan. Bu “yılanın fili yutması” tarzındaki birleşme, çipten yazılıma ve sistemlere kadar endüstriyel düzeni optimize etmeyi, tedarik zincirinin güçlendirilmesini, tamamlanmasını ve genişletilmesini sağlamayı ve teknolojik sinerjiyi kullanmayı amaçlıyor. Analistler, birleşmenin iki taraf arasındaki karmaşık ilişkili taraf işlemlerini ve potansiyel rekabet sorunlarını çözmeye, işletme maliyetlerini düşürmeye ve AI çağında uçtan uca işlem gücü çözümleri geliştirme eğilimine uyum sağlamaya yardımcı olacağını ve Çin yarı iletken teknolojisindeki gücün geleneksel hesaplamadan AI hesaplamasına doğru hızla geçiş yapabileceğinin bir işareti olduğunu belirtiyor (kaynak: 36氪)
🌟 Topluluk
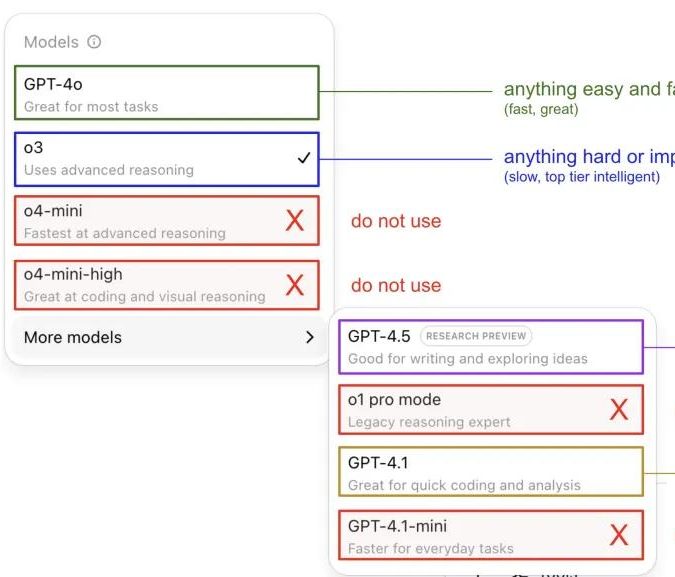
Andrej Karpathy, ChatGPT model kullanım deneyimlerini paylaştı ve toplulukta tartışma yarattı: Andrej Karpathy, farklı ChatGPT sürümlerini kişisel kullanım deneyimlerini paylaştı: Önemli veya zor görevler için daha güçlü çıkarım yeteneğine sahip o3’ü öneriyor; günlük orta ve düşük zorluktaki sorunlar için 4o kullanılabilir; kod iyileştirme görevleri için GPT-4.1 uygun; derinlemesine araştırma ve çoklu bağlantı özeti gerektiğinde ise derin araştırma özelliğini (o3 tabanlı) kullanıyor. Bu deneyim paylaşımı toplulukta geniş çaplı bir tartışma başlattı; birçok kullanıcı kendi kullanım tercihlerini ve model seçimi hakkındaki görüşlerini paylaştı ve aynı zamanda kullanıcıların OpenAI model adlandırmasındaki karışıklık ve otomatik model seçimi özelliğinin eksikliğinden duyduğu rahatsızlığı yansıttı (kaynak: 量子位, JeffLadish)
Geliştirici, Agentic AI programlama ile iki haftalık deneyimini paylaştı: Şaşkınlıktan hayal kırıklığına, sonunda manuel yeniden yapılandırmayı seçti: 10 yıllık deneyime sahip bir teknik lider, Agentic AI’ı (özellikle AI programlama agent’lerini) sosyal medya uygulaması geliştirme sürecine entegre etme deneyimini paylaştı. Başlangıçta AI, işlevsel modülleri hızla oluşturabiliyor, ön uç ve arka uç mantığını ve birim testlerini yazabiliyordu; verimlilik şaşırtıcıydı ve iki hafta içinde yaklaşık 12.000 satır kod üretti. Ancak, kod tabanının karmaşıklığı arttıkça, AI yeni özellikleri işlerken sık sık hata yapmaya, döngülere girmeye başladı ve başarısızlığı kabul etmekte zorlandı; ürettiği kod da yanlış adlandırma, yinelenen kod gibi sorunlar ortaya çıkardı, bu da kod tabanının bakımını zorlaştırdı ve geliştiricinin ona olan güvenini kaybetmesine neden oldu. Sonuç olarak, bu geliştirici AI tarafından üretilen kodu yalnızca “belirsiz bir referans” olarak kullanmaya, tüm işlevleri manuel olarak yeniden yapılandırmaya karar verdi ve AI’ın şu anda işlevsel kod yazmaktan ziyade mevcut kodu analiz etmek ve örnekler sunmak için daha uygun olduğunu düşündü (kaynak: CSDN)

AI Agent tanımı ve iş akışı farkı dikkat çekiyor, gelecekteki uygulama potansiyeli büyük: Topluluk, AI Agent ve Workflow (iş akışı) kavramları arasındaki farkı tartışıyor. Agent genellikle LLM’nin bir döngü içinde araçlara erişerek talimatlara göre serbestçe çalışmasını ifade eder; Workflow ise alt görevleri tamamlamak için LLM içerebilen, esas olarak deterministik olarak yürütülen bir dizi adımdır. Kesişimler olsa da (Agent deterministik olarak yürütülmesi için yönlendirilebilir, Workflow Agentic bileşenler içerebilir), bu ayrım ontolojik olarak hala anlamlıdır. Aynı zamanda, AI Agent’lerin kurumsal uygulamalardaki potansiyeli geniş çapta kabul görüyor; Tencent ve ByteDance gibi büyük şirketler agent alanında çaba gösteriyor; örneğin Tencent, büyük model bilgi tabanını bir agent geliştirme platformuna yükseltiyor, ByteDance ise şirketlerin yerel AI agent sistemlerini uygulamasına yardımcı olmayı amaçlayan Coze (Kouzi) platformuna sahip (kaynak: fabianstelzer, 蓝洞商业)
Dwarkesh Patel, LLM ve AGI zaman çizelgesini tartışıyor, sürekli öğrenmenin kilit bir darboğaz olduğunu düşünüyor: Dwarkesh Patel, blogunda AGI (Genel Yapay Zeka) zaman çizelgesi hakkındaki görüşlerini açıkladı ve LLM’lerin şu anda insanların pratik yoluyla bağlam biriktirme, başarısızlıkları yansıtma ve küçük iyileştirmeler yapma yeteneğinden, yani sürekli öğrenme yeteneğinden yoksun olduğunu savundu. Bunun, modellerin kullanışlılığı için büyük bir darboğaz olduğunu ve bu sorunu çözmenin yıllar alabileceğini düşünüyor. Bu görüş, Andrej Karpathy de dahil olmak üzere birçok AI araştırmacısı arasında tartışmalara yol açtı. Karpathy de LLM’lerin sürekli öğrenme konusundaki eksikliklerini kabul ediyor ve bunu anterograd amnezi hastası bir meslektaşa benzetiyor. Bu tartışmalar, gerçek AGI’ye ulaşmanın önündeki zorlukları ve model öğrenme mekanizmalarına yönelik derinlemesine düşünmeyi vurguluyor (kaynak: dwarkesh_sp, JeffLadish, dwarkesh_sp)

AI’ın ilaç geliştirmedeki patent sorunları dikkat çekiyor, Science makalesi dikkatli olunması çağrısında bulunuyor: Science dergisinin politika forumu makalesi “AI türevli ilaçlar üzerindeki patentler neyi ortaya koyuyor” AI’ın ilaç keşfi alanındaki uygulamalarını ve patent sistemi üzerindeki etkilerini tartışıyor. Araştırma, AI tabanlı şirketlerin ilaç patenti başvurusunda bulunduğunda, in vivo deney verilerinin geleneksel ilaç şirketlerinden genellikle daha az olduğunu ve bunun potansiyel ilaçların yetersiz takip araştırması nedeniyle terk edilmesine yol açabileceğini belirtiyor. Aynı zamanda, AI tarafından üretilen çok sayıda yeni molekül kamuya açıklandığında, “mevcut teknik” haline gelerek diğer şirketlerin bu moleküller için patent başvurusunda bulunmasını ve daha fazla yatırım yapmasını engelleyebilir. Makale, patent başvuru eşiğinin yükseltilmesini, daha fazla in vivo deney verisi talep edilmesini ve AI tarafından üretilen moleküller test edilmemiş olsa bile diğer şirketlerin patent başvurusunda bulunmasına izin verilmesini, ayrıca yenilik teşviki ile kamu yararı arasında denge kurmak için yeni ilaçların klinik deney aşamasındaki düzenleyici münhasırlığın güçlendirilmesini öneriyor (kaynak: 36氪)
💡 Diğer
Altman’ın güç mücadelesi olayının “Artificial” adlı bir filme çekileceği ve tanınmış yönetmen ile yapımcının katılacağı söyleniyor: The Hollywood Reporter’a göre, MGM, OpenAI üst düzey yönetimindeki değişiklik olayını, geçici olarak “Artificial” adıyla bir filme uyarlamayı planlıyor. İtalyan tanınmış yönetmen Luca Guadagnino’nun yönetmen koltuğuna oturabileceği, yapımcılar arasında ise “Harry Potter” serisinden David Heyman’ın yer alacağı belirtiliyor. Oyuncu kadrosu görüşülüyor; Andrew Garfield’ın (Örümcek Adam ve “Sosyal Ağ” filmindeki Eduardo Saverin rolüyle tanınan) Sam Altman’ı, Yura Borisov’un Ilya Sutskever’ı ve Monica Barbaro’nun Mira Murati’yi canlandırabileceği söylentileri var. Bu haber internet kullanıcıları arasında hararetli tartışmalara yol açtı ve “Sosyal Ağ” filmiyle karşılaştırıldı (kaynak: 36氪, janonacct)
AI müşteri hizmetleri deneyimi tartışmalara yol açıyor, kullanıcılar “yapay zeka yerine yapay beceriksiz” ve insan temsilciye ulaşma zorluğundan şikayetçi: Son dönemdeki e-ticaret büyük indirimleri sırasında, çok sayıda tüketici AI müşteri hizmetlerinin iletişim kurmakta zorlandığını, alakasız cevaplar verdiğini ve insan müşteri hizmetleri temsilcisine ulaşmanın son derece zor olduğunu belirterek hizmet deneyiminin düştüğünü bildirdi. Ulusal Piyasa Düzenleme İdaresi verilerine göre, 2024 yılında e-ticaret satış sonrası hizmetler alanında “akıllı müşteri hizmetleri” ile ilgili şikayetler %56.3 arttı. Kullanıcılar genellikle AI müşteri hizmetlerinin kişiselleştirilmiş sorunları çözmekte yetersiz kaldığını, cevaplarının katı olduğunu ve yaşlılar gibi özel gruplara yeterince dostane olmadığını düşünüyor. Makale, şirketlerin maliyet düşürme ve verimlilik artırma peşinde koşarken hizmet kalitesinden ödün vermemeleri, AI teknolojisini optimize etmeleri, AI müşteri hizmetlerinin uygun olduğu senaryoları netleştirmeleri ve kolay erişilebilir insan hizmet kanallarını korumaları çağrısında bulunuyor (kaynak: 36氪)

AI’ın içerik oluşturma alanındaki uygulamaları ve içerik üreticilerinin başa çıkma stratejileri tartışılıyor: AI teknolojilerinin (DeepSeek, Suno, Veo 3 gibi) makale, müzik, video gibi içerik oluşturma alanlarındaki uygulamaları giderek yaygınlaşıyor ve içerik üreticileri arasında kariyer beklentileri konusunda endişelere yol açıyor. Analizler, içerik paradigmasının “kişiselleştirilmiş öneri”den “kişiselleştirilmiş üretime” doğru değiştiğini gösteriyor. Kısa vadede, platformlar deneme yanılma maliyetlerinin yüksek olması nedeniyle içerik üreticilerini tamamen AI ile değiştirmeyebilir; içerik üreticileri benzersiz stil modelleri oluşturup lisanslayarak gelir elde edebilirler. Uzun vadede, içerik üreticilerinin değer yaratma biçimlerini ayarlamaları, AI’ın kolayca yardımcı olabileceği “takip stratejileri” (trendleri takip etme, ikincil kaynaklara güvenme) yerine AI’ın yerini alması zor olan “yenilikçi stratejilere” (orijinal araştırma, birincil kaynak edinme) daha fazla odaklanmaları gerekiyor. AI, araştırma gibi yenilikçi alanlara girmeye başlamış olsa da, benzersiz bakış açılarına ve derinlemesine düşünme yeteneğine sahip içerik üreticileri hala değerlidir (kaynak: 36氪)
