
Anahtar Kelimeler:DeepMind AlphaEvolve, Sakana AI DGM, DeepSeek-R1, Pekiştirmeli Öğrenme ProRL, NVIDIA Cosmos, Çok Modelli Büyük Model, Yapay Zeka Aracı Çerçevesi, LLM Çıkarım Optimizasyonu, AlphaEvolve Matematik Rekoru, Darwin Gödel Makinesi Kendini Geliştirme, MedHELM Tıbbi Değerlendirme, ProRL Pekiştirmeli Öğrenme Ölçeklenebilirliği, Cosmos Transfer Fizik Simülasyonu
🔥 Odak Noktası
DeepMind AlphaEvolve matematik rekorunu tazeledi, insan-makine işbirliği bilimsel ilerlemeyi teşvik ediyor: DeepMind’ın AlphaEvolve’u, 18 yıldır kırılamayan matematik rekorunu bir hafta içinde iki kez kırarak geniş ilgi gördü. Terence Tao, bunun basit bir “kazanan” ve “kaybeden” durumu olmadığını, farklı yöntemlerin matematiksel ilerlemeyi teşvik etmek için birbirini nasıl tamamlayabileceğini gösterdiğini belirtti. Bu olay, yapay zekanın (YZ) ve insan işbirliğinin teknoloji ve bilim alanlarında yeni paradigmalar yaratma potansiyelini vurguluyor; YZ basitçe insanların yerini almıyor, aksine ilerleme için birlikte yeni yollar açıyor (Kaynak: shaneguML)

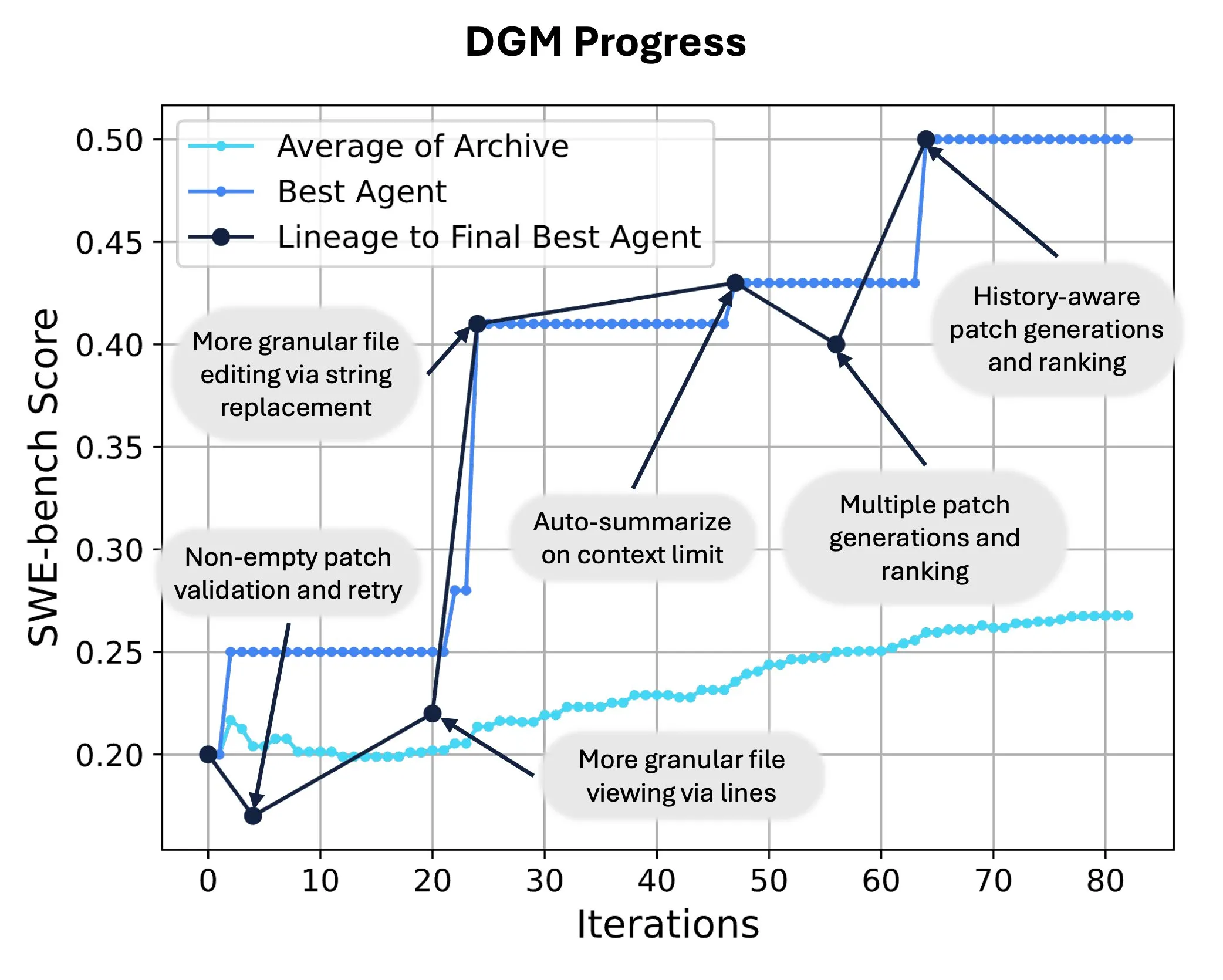
Sakana AI, YZ’nin kendi kendini yeniden yazmasını ve evrimleşmesini sağlayan Darwin Gödel Machine’i (DGM) yayınladı: Sakana AI, kendi kodunu değiştirerek performansını artırabilen, kendi kendini geliştiren bir ajan olan Darwin Gödel Machine’i (DGM) tanıttı. Evrim teorisinden esinlenen DGM, sürekli genişleyen bir ajan varyantları soyunu sürdürerek “kendi kendini geliştiren” ajan tasarım alanının açık uçlu keşfini sağlıyor. SWE-bench’te DGM, performansı %20.0’dan %50.0’a çıkardı; Polyglot’ta başarı oranı %14.2’den %30.7’ye yükselerek insan tarafından tasarlanan ajanlardan önemli ölçüde daha iyi performans gösterdi. Bu teknoloji, YZ sistemlerinin sürekli öğrenme ve yetenek evrimi gerçekleştirmesi için yeni bir yol sunuyor (Kaynak: SakanaAILabs, hardmaru)
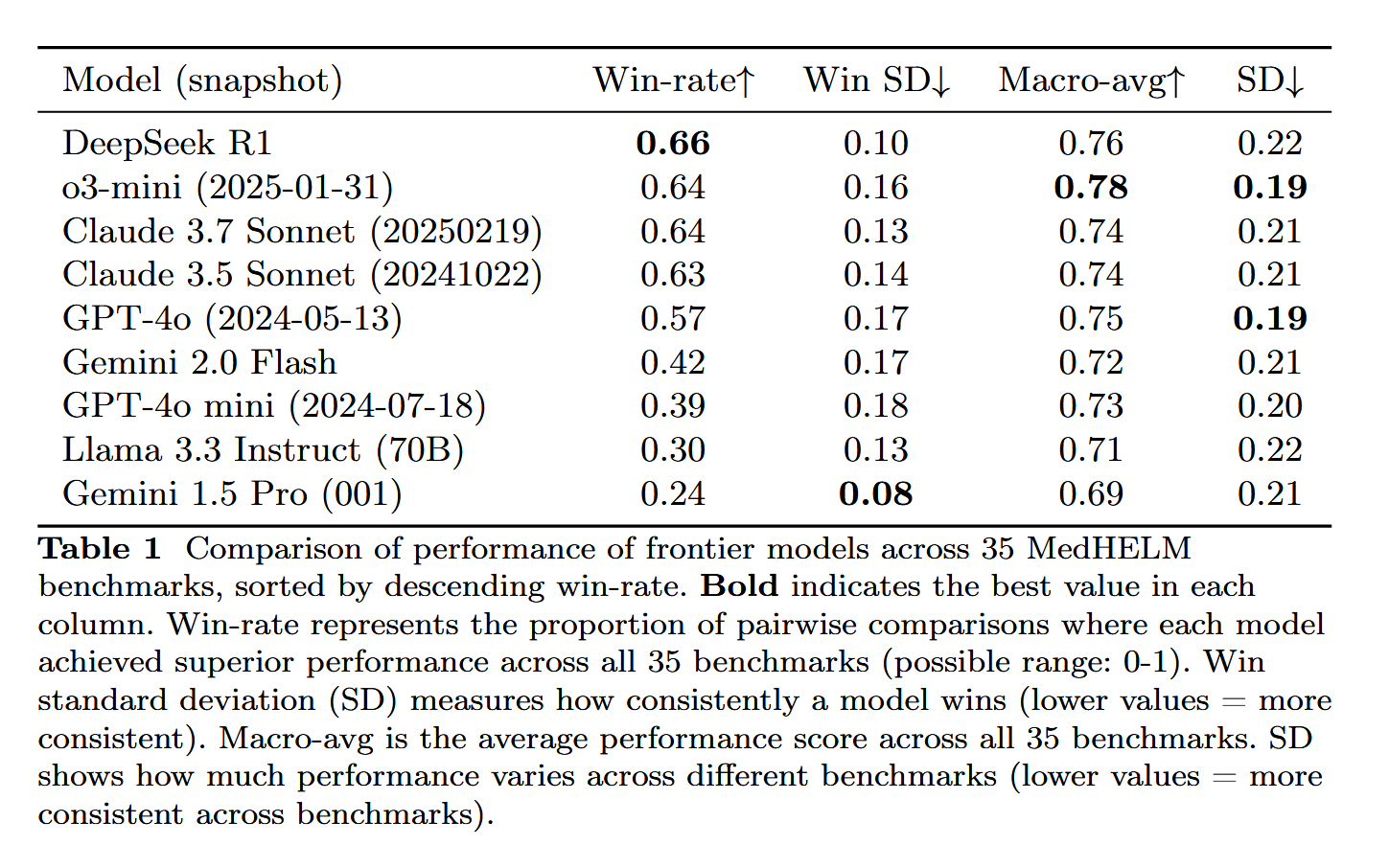
DeepSeek-R1, MedHELM tıbbi görev değerlendirmesinde öne çıktı: Büyük dil modeli DeepSeek-R1, LLM’lerin geleneksel tıp lisans sınavları yerine daha pratik klinik görevlerdeki performansını değerlendirmeyi amaçlayan MedHELM (Büyük Dil Modelleri için Tıbbi Görevlerin Bütünsel Değerlendirmesi) kıyaslama testinde en iyi performansı gösterdi. Bu sonuç, DeepSeek-R1’in tıp alanındaki potansiyelini, özellikle de gerçek klinik senaryoları ele alma yeteneğini göstermesi açısından anlamlı kabul ediliyor (Kaynak: iScienceLuvr)
Pekiştirmeli öğrenme ölçeklenebilirliği araştırmasında yeni gelişme: ProRL, LLM çıkarım sınırlarını genişletiyor: Pekiştirmeli öğrenmenin (RL) ölçeklenebilirliği üzerine yeni bir makale (arXiv:2505.24864) dikkat çekti. Araştırma, uzun süreli pekiştirmeli öğrenme (ProRL) eğitimi yoluyla, temel modellerin geniş çaplı örneklemeyle elde etmesi zor olan yepyeni çıkarım stratejilerinin keşfedilebileceğini gösteriyor. ProRL, KL diverjans kontrolü, referans politika sıfırlaması ve çeşitlendirilmiş görev setlerini birleştirerek, RL eğitimli modellerin çeşitli pass@k değerlendirmelerinde temel modellerden sürekli olarak daha iyi performans göstermesini sağlıyor. Bu çalışma, RL’nin dil modeli çıkarım sınırlarını nasıl önemli ölçüde genişletebileceğine dair yeni bilgiler sunuyor ve gelecekteki uzun vadeli RL çıkarım araştırmaları için temel oluşturuyor. NVIDIA, ilgili model ağırlıklarını yayınladı (Kaynak: Teknium1, cognitivecompai, natolambert, scaling01)

🎯 Eğilimler
NVIDIA, fiziksel dünya YZ uygulamalarını desteklemek için Cosmos Transfer ve Cosmos Reason’ı duyurdu: NVIDIA, Cosmos sistemini tanıttı. Cosmos Transfer, basit oyun motoru görüntülerini, derinlik bilgilerini ve hatta kaba robot simülasyonlarını gerçekçi sahne videolarına dönüştürerek robotlar ve otonom sürüş gibi YZ sistemleri için büyük miktarda kontrol edilebilir eğitim verisi sağlayabiliyor. Cosmos Reason ise YZ’nin bu sahneleri anlamasını ve karar vermesini sağlıyor; örneğin otonom sürüş testlerinde nasıl ilerleneceğine karar vermek gibi. Her iki araç da şu anda açık kaynaklı olup, fiziksel dünya YZ’sinin gelişimini hızlandırması, eğitim verisi eksikliği ve sahne kontrolü zorluklarını çözmesi bekleniyor (Kaynak: )
DeepSeek, R1 güncellemesini yayınladı, açık kaynak ekosistemi gelişmeye devam ediyor: DeepSeek, R1 modelinin bir güncellemesini yayınladı; buna R1’in kendisi ve 8 milyar parametrelik damıtılmış küçük bir model de dahil. Aynı zamanda ByteDance, açık kaynak alanında sık sık hamleler yaparak BAGEL, Dolphin, Seedcoder, Dream0 gibi projeleri başlattı. Bu gelişmeler, Çin’in YZ açık kaynak alanındaki etkinliğini ve yenilikçiliğini, özellikle de çok modlu ve özel amaçlı modeller alanındaki hızlı gelişimini gösteriyor (Kaynak: TheRundownAI, stablequan, reach_vb, clefourrier)
Google, açık kaynak YZ modellerinin akıllı telefonlarda kullanımını teşvik etmek için Edge AI Gallery’yi yayınladı: Google, açık kaynak YZ modellerini akıllı telefonlara taşıyarak yerel, gizlilik odaklı YZ uygulamalarını mümkün kılmayı amaçlayan Edge AI Gallery’yi başlattı. Kullanıcılar, Hugging Face’in LLM’lerini doğrudan cihazlarında çalıştırarak kod üretme, görüntü tabanlı sohbet gibi işlemleri yapabiliyor; çok turlu konuşmaları destekliyor ve istenilen modeli seçme imkanı sunuyor. Uygulama LiteRT tabanlı olup, şu anda Android’i destekliyor, iOS sürümü yakında çıkacak. Bu, uç bilişim YZ’sinin gelişimini ve yaygınlaşmasını daha da hızlandıracak (Kaynak: TheRundownAI, huggingface, reach_vb, osanseviero)
Yeni araştırma, LLM’leri optimize etmek için pozitif ve negatif damıtılmış çıkarım yörüngelerinin kullanımını inceliyor: Yeni bir makale, öğretmen bir model (DeepSeek-R1 gibi) tarafından üretilen doğru ve yanlış çıkarım yörüngelerinden yararlanarak küçük öğrenci modellerinin çıkarım yeteneklerini geliştirmeyi amaçlayan Reinforced Distillation (REDI) çerçevesini öneriyor. REDI iki aşamadan oluşuyor: ilk olarak Supervised Fine-Tuning (SFT) yoluyla doğru yörüngelerden öğrenme, ardından yeni önerilen REDI hedef fonksiyonunu (referanssız bir kayıp fonksiyonu) kullanarak pozitif ve negatif yörüngeleri birleştirerek modeli daha da optimize etme. Deneyler, matematiksel çıkarım görevlerinde REDI’nin temel yöntemlerden daha iyi performans gösterdiğini ve Qwen-REDI-1.5B modelinin MATH-500 üzerinde %83.1 gibi yüksek bir puan elde ettiğini gösteriyor (Kaynak: HuggingFace Daily Papers)
LLMSynthor çerçevesi, yapısal farkındalığa sahip veri sentezi için LLM’leri kullanıyor: LLMSynthor, büyük dil modellerini (LLM) yapısal farkındalığa sahip simülatörlere dönüştüren ve dağıtım geri bildirimiyle yönlendirilen genel bir veri sentezi çerçevesidir. Bu çerçeve, LLM’leri yüksek dereceli bağımlılıkları modellemek için parametrik olmayan copula simülatörleri olarak ele alır ve örnekleme verimliliğini artırmak için LLM öneri örneklemesini sunar. Özet istatistik alanındaki farklılıkları en aza indirerek, yinelemeli sentez döngüsü gerçek verileri ve sentezlenmiş verileri hizalar. E-ticaret, nüfus ve mobilite gibi gizliliğe duyarlı alanlardaki heterojen veri kümeleri üzerindeki değerlendirmeler, LLMSynthor’un ürettiği sentezlenmiş verilerin yüksek istatistiksel doğruluğa ve kullanışlılığa sahip olduğunu göstermektedir (Kaynak: HuggingFace Daily Papers)
v1 çerçevesi, seçici görsel yeniden ziyaret yoluyla çok modlu etkileşimli çıkarımı geliştiriyor: v1, çok modlu büyük dil modellerinin (MLLM) çıkarım sırasında seçici görsel yeniden ziyaret yapmasını sağlayan hafif bir eklentidir. Mevcut MLLM’lerin genellikle görsel girdiyi tek seferde işlemesinin aksine, v1, modelin çıkarım sırasında ilgili görüntü bölgelerini dinamik olarak almasına olanak tanıyan bir “işaretle ve kopyala” mekanizması sunar. Görsel temel ek açıklamaları içeren çok modlu çıkarım yörüngeleri veri kümesi v1g üzerinde eğitilerek, v1, MathVista gibi kıyaslama testlerinde, özellikle ince taneli görsel referans ve çok adımlı çıkarım gerektiren görevlerde performans artışı göstermiştir (Kaynak: HuggingFace Daily Papers)
MetaFaith, LLM’lerin doğal dildeki belirsizlik ifadesinin doğruluğunu artırıyor: LLM’lerin belirsizliği ifade etmede sıkça abartılı davranma sorununu çözmek için MetaFaith, yeni bir ipucu tabanlı kalibrasyon yöntemi öneriyor. Araştırma, mevcut LLM’lerin içsel belirsizliklerini sadık bir şekilde yansıtmada yetersiz kaldığını, standart ipucu yöntemlerinin etkisinin sınırlı olduğunu ve gerçekliğe dayalı kalibrasyon tekniklerinin bile sadık kalibrasyona zarar verebileceğini ortaya koyuyor. MetaFaith, insan üstbilişinden esinlenerek, farklı görevlerde ve modellerde modelin sadık kalibrasyon yeteneğini önemli ölçüde artırabiliyor, sadakati %61’e kadar yükseltebiliyor ve insan değerlendirmelerinde %83 kazanma oranı elde ediyor (Kaynak: HuggingFace Daily Papers)
CLaSp: Bağlam içi katman atlama yoluyla LLM’ler için kendi kendine tahmini kod çözmeyi hızlandırma: CLaSp, büyük dil modelleri (LLM) için, modelin ara katmanlarında doğrulama sırasında atlamalar yaparak sıkıştırılmış bir taslak model oluşturan ve böylece ek eğitim veya model değişikliği gerektirmeden kod çözme sürecini hızlandıran bir kendi kendine tahmini kod çözme stratejisidir. CLaSp, katman atlama sürecini optimize etmek için dinamik programlama algoritmasını kullanır ve bir önceki doğrulama aşamasının tam gizli durumuna göre stratejiyi dinamik olarak ayarlar. Deneyler, CLaSp’nin LLaMA3 serisi modellerde 1.3 ila 1.7 kat hızlanma sağladığını ve üretilen metnin orijinal dağılımını değiştirmediğini göstermektedir (Kaynak: HuggingFace Daily Papers)
HardTests, LLM kullanarak yüksek kaliteli kod test senaryoları sentezliyor: LLM’lerin karmaşık programlama problemlerinde kod üretirken mevcut test senaryolarıyla etkili bir şekilde doğrulama yapma zorluğunu çözmek için HardTests, LLM kullanarak yüksek kaliteli test senaryoları üretmek üzere bir süreç olan HARDTESTGEN’i öneriyor. Bu sürece dayalı olarak oluşturulan HardTests veri kümesi, 47.000 programlama problemi ve sentezlenmiş yüksek kaliteli test senaryoları içeriyor. Mevcut testlerle karşılaştırıldığında, HARDTESTGEN tarafından üretilen testler, LLM tarafından üretilen kodu değerlendirirken kesinliği %11.3, geri çağırmayı %17.5 artırıyor ve zor problemler için kesinlik artışı %40’a ulaşabiliyor. Bu veri kümesi, model eğitimi açısından da daha iyi sonuçlar veriyor (Kaynak: HuggingFace Daily Papers)
Araştırma, görsel dil modellerinde (VLM) önyargıların varlığını ortaya koyuyor: Bir çalışma, gelişmiş görsel dil modellerinin (VLM), popüler konularla ilgili görsel görevleri (sayma ve tanıma gibi) işlerken, internetten öğrendikleri büyük miktardaki ön bilgilerden güçlü bir şekilde etkilendiğini ortaya koydu. Örneğin, VLM’ler Adidas markasına eklenen dördüncü bir çizgiyi tanımakta zorlanıyor. Hayvanlar, markalar, satranç gibi 7 farklı alandaki sayma görevlerinde VLM’lerin ortalama doğruluğu sadece %17.05 oldu. Modelin dikkatlice incelemesi veya yalnızca görüntü detaylarına güvenmesi talimatı verildiğinde bile doğruluk artışı sınırlı kaldı. Bu çalışma, VLM önyargılarını test etmek için otomatik bir çerçeve öneriyor (Kaynak: HuggingFace Daily Papers)
Point-MoE: Uzmanların Karışımı modelini kullanarak 3D anlamsal segmentasyonda alanlar arası genelleme: 3D nokta bulutu verilerinin çeşitli kaynaklardan (derinlik kameraları, LiDAR gibi) gelmesi ve alanların heterojen olması (iç mekan, dış mekan gibi) nedeniyle birleşik bir model eğitmenin zorluğunu çözmek için Point-MoE, bir Uzmanların Karışımı (MoE) mimarisi öneriyor. Bu mimari, basit bir top-k yönlendirme stratejisiyle, alan etiketleri olmasa bile uzman ağlarını otomatik olarak uzmanlaştırabiliyor. Deneyler, Point-MoE’nin yalnızca güçlü çok alanlı temel modellerden daha iyi performans göstermekle kalmayıp, aynı zamanda görülmemiş alanlarda da daha iyi genelleme yeteneğine sahip olduğunu gösteriyor ve büyük ölçekli, alanlar arası 3D algılama için ölçeklenebilir bir yol sunuyor (Kaynak: HuggingFace Daily Papers)
SpookyBench, video dil modellerinin “zamansal kör noktasını” ortaya koyuyor: Video dil modelleri (VLM) uzay-zaman ilişkilerini anlama konusunda ilerleme kaydetmiş olsa da, uzamsal bilgiler belirsiz olduğunda, saf zamansal örüntüleri yakalamakta zorlanıyorlar. SpookyBench kıyaslama testi, gürültülü kare dizilerinde bilgi (şekiller, metinler gibi) kodlayarak, insanların %98’den fazla doğrulukla tanıyabildiğini, gelişmiş VLM’lerin doğruluğunun ise %0 olduğunu ortaya koydu. Bu, VLM’lerin kare düzeyindeki uzamsal özelliklere aşırı derecede güvendiğini ve zamansal ipuçlarından anlam çıkaramadığını gösteriyor. Bu çalışma, VLM’lerin “zamansal kör noktasını” aşmanın gerekliliğini vurguluyor; bu, uzamsal bağımlılığı zamansal işlemeden ayırmak için yeni mimariler veya eğitim paradigmaları gerektirebilir (Kaynak: HuggingFace Daily Papers, _akhaliq)
LLM kullanarak bilimsel yenilik tespiti için yeni yöntem ve veri kümesi: Bilimsel araştırmalarda yeni fikirleri belirlemek hayati önem taşır ancak zorluklarla doludur. Bu soruna yönelik olarak araştırmacılar, bilimsel yenilik tespiti için büyük dil modellerini (LLM) kullanmayı öneriyor ve pazarlama ile doğal dil işleme alanlarında iki yeni veri kümesi oluşturdu. Bu yöntem, makalelerin kapanış kümelerini çıkararak ve LLM’leri kullanarak ana fikirlerini özetleyerek veri kümeleri oluşturuyor. Fikir kavramlarını yakalamak için araştırmacılar, LLM’lerden fikir düzeyinde bilgi damıtarak benzer kavramlara sahip fikirleri hizalayan hafif bir alıcıyı eğitmeyi öneriyor, böylece verimli ve doğru fikir alımı sağlıyor. Deneyler, bu yöntemin önerilen kıyaslama veri kümelerinde diğer yöntemlerden daha iyi performans gösterdiğini kanıtlıyor (Kaynak: HuggingFace Daily Papers)
un^2CLIP, unCLIP’i tersine çevirerek CLIP’in görsel detay yakalama yeteneğini artırıyor: CLIP modelinin görüntü detay farklılıklarını ayırt etme ve yoğun tahmin gibi görevlerdeki eksikliklerine yönelik olarak un^2CLIP, unCLIP modelini tersine çevirerek CLIP’i iyileştirmeyi öneriyor. unCLIP, CLIP görüntü gömmelerini kullanarak bir görüntü oluşturucu eğitir ve böylece görüntülerin detay dağılımını öğrenir. un^2CLIP bu özelliği kullanarak, iyileştirilmiş CLIP görüntü kodlayıcısının unCLIP’in görsel detay yakalama yeteneğini kazanmasını sağlarken orijinal metin kodlayıcısıyla hizalamasını korur. Deneyler, un^2CLIP’in birçok görevde orijinal CLIP ve diğer iyileştirme yöntemlerinden önemli ölçüde daha iyi performans gösterdiğini ortaya koyuyor (Kaynak: HuggingFace Daily Papers)
ViStoryBench: Hikaye görselleştirme için kapsamlı kıyaslama paketi yayınlandı: Hikaye görselleştirme (anlatı ve referans görüntülere göre tutarlı görüntü dizileri oluşturma) teknolojisinin gelişimini desteklemek için ViStoryBench, kapsamlı bir değerlendirme kıyaslaması sunuyor. Bu kıyaslama, çeşitli hikaye türlerini (komedi, korku vb.) ve sanat stillerini (anime, 3D render vb.) içeren veri kümeleri içerir ve karakter tutarlılığını test etmek için tek ve çok karakterli hikayelerin yanı sıra modelin görsel üretim doğruluğunu zorlamak için karmaşık olay örgüleri ve dünya inşası içerir. ViStoryBench, modelin anlatı yapısı ve görsel unsurlar açısından performansını kapsamlı bir şekilde değerlendirmeyi amaçlayan çeşitli değerlendirme metrikleri kullanır ve araştırmacıların modelin güçlü ve zayıf yönlerini belirlemesine ve buna göre iyileştirmeler yapmasına yardımcı olur (Kaynak: HuggingFace Daily Papers)
Çatal-Birleştir Kod Çözme (FMD), ses-video büyük modellerinde dengeli çok modlu anlayışı geliştiriyor: Ses-video büyük dil modellerinde (AV-LLM) olası modalite önyargısı sorununu (yani modelin karar verirken bir modaliteye aşırı güvenmesi) çözmek için Çatal-Birleştir Kod Çözme (FMD), ek eğitim gerektirmeyen bir çıkarım zamanı stratejisi öneriyor. FMD, önce erken kod çözme katmanları aracılığıyla saf ses ve saf video girdilerini ayrı ayrı işler (çatal aşaması), ardından üretilen gizli durumları birleştirerek ortak çıkarım yapar (birleştirme aşaması). Bu yöntem, modalite katkılarının dengelenmesini teşvik etmeyi ve çapraz modalite tamamlayıcı bilgilerinden yararlanmayı amaçlar. VideoLLaMA2 ve video-SALMONN gibi modeller üzerindeki deneyler, FMD’nin ses, video ve ses-video ortak çıkarım görevlerinde performansı artırabildiğini göstermektedir (Kaynak: HuggingFace Daily Papers)
LegalSearchLM: Hukuk davalarının alınmasını hukuki unsur üretimine dönüştürme: Geleneksel hukuk davası alma (LCR) yöntemleri gömme veya sözcüksel eşleştirmeye dayanır ve gerçek dünya senaryolarında sınırlamalarla karşılaşır. LegalSearchLM, LCR’yi hukuki unsur üretimi görevi olarak ele alan yeni bir yöntem öneriyor. Bu model, sorgu davası için hukuki unsur çıkarımı yapar ve kısıtlı kod çözme yoluyla doğrudan hedef davaya dayalı içerik üretir. Aynı zamanda araştırmacılar, 1,2 milyon Kore hukuk davasını içeren büyük ölçekli bir LCR kıyaslaması olan LEGAR BENCH’i yayınladı. Deneyler, LegalSearchLM’nin LEGAR BENCH’te temel modellerden %6-20 daha iyi performans gösterdiğini ve güçlü alanlar arası genelleme yeteneği sergilediğini gösteriyor (Kaynak: HuggingFace Daily Papers)
RPEval: Büyük dil modellerinin rol yapma yeteneklerini değerlendirmek için yeni bir kıyaslama: Büyük dil modellerinin (LLM) rol yapma yeteneklerini değerlendirme zorluklarına yönelik olarak RPEval, yeni bir kıyaslama testi sunuyor. Bu kıyaslama, LLM’lerin rol yapma performansını duygu anlama, karar verme, ahlaki eğilim ve rol tutarlılığı olmak üzere dört temel boyutta değerlendiriyor. İnsan değerlendirmesinin kaynak tüketiminin büyük olması ve otomatik değerlendirmenin olası önyargıları sorunlarını çözmeyi amaçlıyor (Kaynak: HuggingFace Daily Papers)
GATE: Gelişmiş Arapça STS için genel metin gömme modeli: Arapça anlamsal metin benzerliği (STS) araştırmalarında yüksek kaliteli veri kümeleri ve önceden eğitilmiş modellerin eksikliğini gidermek için GATE (General Arabic Text Embedding) modeli geliştirildi. GATE, Matryoshka temsil öğrenimi ve karma kayıp eğitim yöntemlerini kullanarak, Arapça doğal dil çıkarımı üçlü veri kümeleriyle birlikte eğitilir. Deney sonuçları, GATE’nin MTEB kıyaslamasının STS görevlerinde SOTA performansı elde ettiğini, OpenAI dahil büyük modellere kıyasla performansı %20-25 artırdığını ve Arapçanın kendine özgü anlamsal inceliklerini etkili bir şekilde yakalayabildiğini gösteriyor (Kaynak: HuggingFace Daily Papers)
CoDA: Eklemli nesnelerin tüm vücut manipülasyonu için işbirlikçi difüzyon gürültü optimizasyon çerçevesi: Eklemli nesnelerin tüm vücut manipülasyonunun (vücut, el ve nesne hareketleri dahil) gerçekçiliğini ve hassasiyetini sağlamak için CoDA, yeni bir işbirlikçi difüzyon gürültü optimizasyon çerçevesi öneriyor. Bu çerçeve, vücut, sol el ve sağ el için üç özel difüzyon modelinin gürültü alanı optimizasyonu yoluyla ve insan hareket zincirindeki gradyan akışı aracılığıyla elin vücudun diğer kısımlarıyla doğal koordinasyonunu sağlar. El-nesne etkileşiminin hassasiyetini artırmak için CoDA, uç efektör konumunu nesne geometrisinin Base Point Set’ine (BPS) olan mesafe olarak kodlayan birleşik bir BPS tabanlı temsil kullanır, böylece difüzyon gürültü optimizasyonunu yönlendirir ve yüksek hassasiyetli etkileşim hareketleri üretir (Kaynak: HuggingFace Daily Papers)
LLM çıkarım yansıtma mekanizmasına yeni bir bakış: Bayesçi Uyarlanabilir Pekiştirmeli Öğrenme çerçevesi BARL: Northwestern Üniversitesi ve Google DeepMind işbirliğiyle geliştirilen Bayesçi Uyarlanabilir Pekiştirmeli Öğrenme (BARL) çerçevesi, büyük dil modellerinin (LLM) çıkarım sürecindeki “yansıtma” davranışını açıklamayı ve optimize etmeyi amaçlıyor. Geleneksel pekiştirmeli öğrenme (RL) test sırasında genellikle yalnızca öğrenilmiş politikayı kullanırken, BARL çevre belirsizliğinin modellenmesini tanıtarak modelin çıkarım sırasında yeni politikaları uyarlanabilir bir şekilde keşfetmesini sağlar. Deneyler, BARL’ın matematiksel çıkarım gibi görevlerde daha yüksek doğruluk oranları elde edebildiğini ve token tüketimini önemli ölçüde azaltabildiğini göstermektedir. Bu çalışma, LLM’lerin neden, nasıl ve ne zaman yansıtıcı keşif yapması gerektiğini ilk kez Bayesçi bir bakış açısıyla açıklıyor (Kaynak: 量子位)

LLM’lerin biçimsel belirsizlik gramerlerinde uygulanması: Otomatik çıkarım için LLM’lere ne zaman güvenilmeli: Büyük dil modelleri (LLM), biçimsel belirtimler üretme potansiyeli göstermektedir, ancak olasılıksal doğaları ile biçimsel doğrulamanın deterministik gereksinimleri arasında bir çelişki bulunmaktadır. Araştırmacılar, LLM tarafından üretilen biçimsel yapılardaki başarısızlık modlarını ve belirsizlik nicelemesini (UQ) kapsamlı bir şekilde inceledi. Sonuçlar, SMT tabanlı otomatik biçimselleştirmenin doğruluğa etkisinin alana göre değiştiğini ve mevcut UQ tekniklerinin bu hataları tanımlamakta zorlandığını göstermektedir. Makale, LLM çıktılarını modellemek için bir Olasılıksal Bağlamdan Bağımsız Gramer (PCFG) çerçevesi sunmakta ve belirsizlik sinyallerinin göreve bağlı olduğunu bulmaktadır. Bu sinyalleri birleştirerek, seçici doğrulama gerçekleştirilebilir, hatalar önemli ölçüde azaltılabilir ve LLM güdümlü biçimselleştirme daha güvenilir hale getirilebilir (Kaynak: HuggingFace Daily Papers)
Düşük kodlu iş akışı üretiminde küçük dil modellerinin (SLM) ince ayarı ile büyük dil modellerinin (LLM) ipuçlarının karşılaştırılması: Araştırma, JSON formatında düşük kodlu iş akışları oluşturma görevinde küçük dil modellerini (SLM) ince ayarlamanın ve büyük dil modellerine (LLM) ipucu vermenin etkilerini karşılaştırdı. Sonuçlar, iyi ipuçlarının LLM’lerin makul sonuçlar üretmesini sağlayabilmesine rağmen, alana özgü görevler ve yapılandırılmış çıktılar için SLM’leri ince ayarlamanın kalitede ortalama %10’luk bir iyileşme sağladığını gösteriyor. Bu, özellikle çıktı kalitesi gereksinimlerinin yüksek olduğu belirli senaryolarda SLM’lerin hala avantajlı olduğunu gösteriyor (Kaynak: HuggingFace Daily Papers)
Çok modlu büyük modellerde modalite tercihinin değerlendirilmesi ve yönlendirilmesi: Araştırmacılar, kontrollü kanıt çatışması senaryolarında çok modlu büyük dil modellerinin (MLLM) modalite tercihini (yani karar verirken bir modaliteye eğilim göstermesini) sistematik olarak değerlendirmek için MC² kıyaslamasını oluşturdular. Araştırma, test edilen 18 MLLM’nin tümünün belirgin modalite önyargıları sergilediğini ve tercih yönünün dış müdahalelerle etkilenebileceğini ortaya koydu. Buna dayanarak araştırmacılar, ek ince ayar veya özenle tasarlanmış ipuçları gerektirmeden modalite tercihini açıkça kontrol etmek için temsil mühendisliğine dayalı bir sondaj ve yönlendirme yöntemi önerdiler ve halüsinasyon azaltma, çok modlu makine çevirisi gibi alt görevlerde olumlu sonuçlar elde ettiler (Kaynak: HuggingFace Daily Papers)
Çok dilli LLM güvenliği araştırmasının mevcut durumu: Dil boşluğunu ölçmekten boşluğu kapatmaya: 2020-2024 yılları arasında yaklaşık 300 NLP konferans makalesinin sistematik bir incelemesi, LLM güvenliği araştırmasında belirgin bir İngilizce merkezlilik sorunu olduğunu gösteriyor. Kaynak açısından zengin İngilizce dışı diller bile nadiren ilgi görüyor ve İngilizce dışı diller nadiren bağımsız araştırma nesneleri olarak ele alınıyor; İngilizce güvenlik araştırmaları da genellikle iyi dil belgelendirme uygulamalarından yoksun. Çok dilli güvenlik araştırmalarını teşvik etmek için makale, güvenlik değerlendirmesi, eğitim verisi üretimi ve diller arası güvenlik genellemesi dahil olmak üzere gelecekteki yönleri öneriyor ve küresel olarak farklı topluluklar için daha sağlam ve kapsayıcı YZ güvenlik uygulamaları geliştirmeyi amaçlıyor (Kaynak: HuggingFace Daily Papers, sarahookr)

Tekrarlayan sinir ağlarındaki çift doğrusal durum geçişlerinin yeniden incelenmesi: Geleneksel görüş, tekrarlayan sinir ağlarının (RNN) gizli birimlerinin esas olarak belleği modellemek için kullanıldığı yönündedir. Bu çalışma, farklı bir bakış açısıyla, gizli birimlerin ağ hesaplamasının aktif katılımcıları olduğunu savunmaktadır. Araştırmacılar, gizli birimler ile girdi gömmeleri arasındaki çarpımsal etkileşimleri içeren çift doğrusal işlemleri yeniden incelemiş ve bunların durum izleme görevlerinde gizli durum evrimini temsil etmek için doğal tümevarımsal önyargılar olduğunu teorik ve deneysel olarak kanıtlamıştır. Araştırma ayrıca, çift doğrusal durum güncellemelerinin, karmaşıklığı artan durum izleme görevlerine karşılık gelen doğal bir hiyerarşi oluşturduğunu ve Mamba gibi popüler doğrusal RNN’lerin bu hiyerarşinin en düşük karmaşıklık merkezinde yer aldığını göstermektedir (Kaynak: HuggingFace Daily Papers)
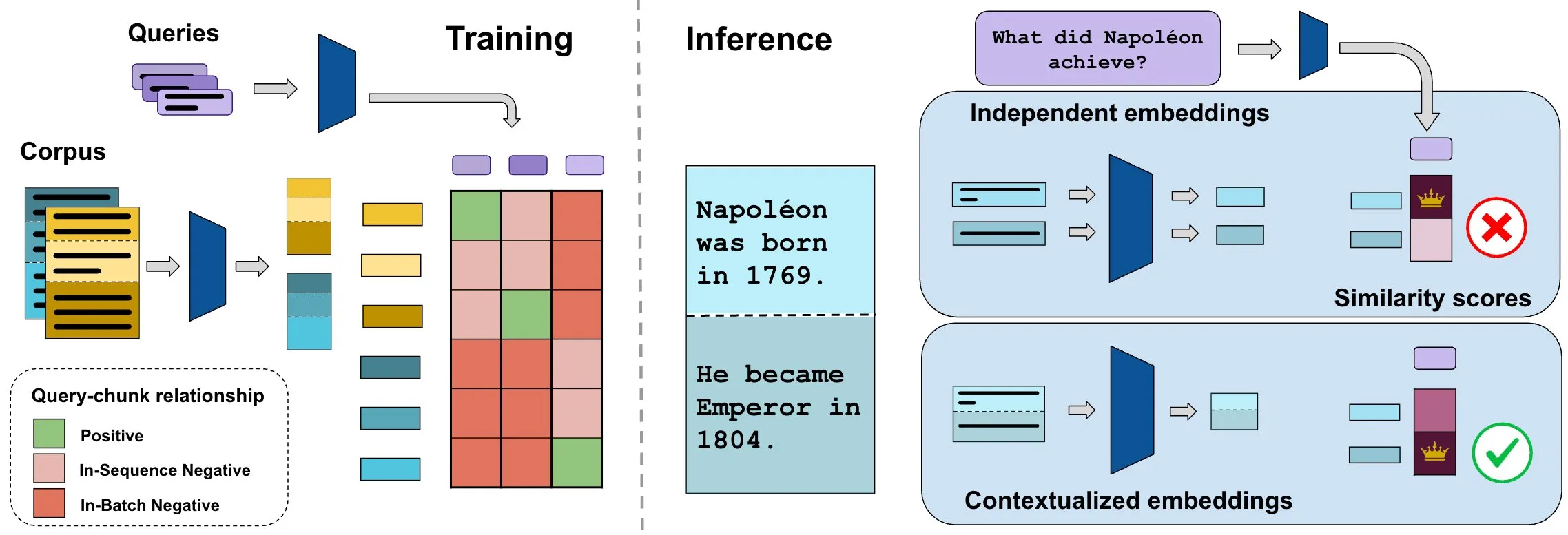
ConTEB kıyaslaması bağlamsal belge gömmelerini değerlendiriyor, InSeNT yöntemi alım kalitesini artırıyor: Mevcut belge alım gömme yöntemleri genellikle aynı belgenin farklı parçalarını (chunk) bağımsız olarak kodlar ve belge düzeyindeki bağlamsal bilgiyi göz ardı eder. Bu sorunu çözmek için araştırmacılar, alım modellerinin belge bağlamını kullanma yeteneğini özel olarak değerlendiren ConTEB kıyaslamasını başlattı ve SOTA modellerinin bu konuda yetersiz performans gösterdiğini buldu. Aynı zamanda araştırmacılar, bağlamsal temsil öğrenimini geliştirmek için InSeNT (In-Sequence Negative Training) karşılaştırmalı öğrenme son eğitim yöntemini ve geç parça havuzlamasını önerdi. Bu, ConTEB üzerindeki alım kalitesini önemli ölçüde artırdı ve alt optimal parça stratejilerine ve daha büyük ölçekli korpuslara karşı daha sağlam olduğunu gösterdi (Kaynak: HuggingFace Daily Papers, tonywu_71)
🧰 Araçlar
PraisonAI: Düşük kodlu çoklu YZ ajan çerçevesi: PraisonAI, basit görevlerden karmaşık zorluklara kadar otomasyonu ve problem çözmeyi düşük kodlu bir çözümle basitleştirmeyi amaçlayan, üretim düzeyinde bir çoklu YZ ajan çerçevesidir. PraisonAI Agents, AG2 (AutoGen) ve CrewAI’yi entegre eder; basitlik, özelleştirme ve etkili insan-makine işbirliğini vurgular. Özellikleri arasında YZ ajanlarının otomatik oluşturulması, kendi kendine yansıtma, çok modluluk, çoklu ajan işbirliği, bilgi ekleme, uzun ve kısa süreli bellek, RAG, kod yorumlayıcı, 100’den fazla özel araç ve LLM desteği bulunur. Python ve JavaScript’i destekler ve kodsuz YAML yapılandırma seçenekleri sunar (Kaynak: GitHub Trending)
TinyTroupe: Microsoft’un açık kaynaklı LLM güdümlü çoklu ajan rol simülasyon çerçevesi: TinyTroupe, belirli kişiliklere, ilgi alanlarına ve hedeflere sahip karakterleri (TinyPerson) simüle etmek ve simüle edilmiş bir ortamda (TinyWorld) etkileşimde bulunmak için büyük dil modellerini (LLM, özellikle GPT-4) kullanan deneysel bir Python kütüphanesidir. Bu çerçeve, simülasyon yoluyla hayal gücünü artırmayı ve ticari bilgiler sunmayı amaçlar; reklam değerlendirmesi, yazılım testi, sentetik veri üretimi, ürün geri bildirimi ve beyin fırtınası gibi senaryolarda uygulanabilir. Kullanıcılar, Python ve JSON dosyaları aracılığıyla ajanları ve ortamları tanımlayarak programatik, analitik ve çoklu ajanlı simülasyon deneyleri yapabilirler (Kaynak: GitHub Trending)

FLUX Kontext, çoklu görüntü referansı ve görüntü düzenlemede yeni bir çığır açıyor: Kullanıcı geri bildirimlerine göre FLUX Kontext, çoklu görüntü referansı konusunda mükemmel performans gösteriyor; bu özellik ComfyUI’deki görüntü birleştirme düğümü aracılığıyla etkinleştirilebiliyor. Bu araç, hediye kutusu için bir tanıtım görseli oluştururken malzeme ve toz gibi detayları çok iyi bir şekilde yeniden üreterek yüksek tutarlılıkta görüntü düzenleme sağlıyor. Ayrıca, kullanıcılar FLUX Kontext’i kullanarak tek tıklamayla zayıflama, yüz inceltme, kas ekleme gibi fotoğraf düzenleme işlemlerini sergilediler; sonuçlar doğal ve yüz benzerliği yüksek, bu da e-ticaret gibi senaryolar için kolaylık sağlıyor (Kaynak: op7418, op7418, op7418)

Ichi: MLX Swift ve MLX audio tabanlı cihaz üzerinde konuşma YZ’si: Rudrank Riyam, MLX Swift ve MLX audio kullanarak cihaz üzerinde çalışan bir konuşma YZ projesi olan Ichi’yi geliştirdi. Bu, konuşma işlemenin yerel cihazda tamamlanabileceği anlamına geliyor, bu da kullanıcı gizliliğini korumaya ve bulut hizmetlerine bağımlılığı azaltmaya yardımcı oluyor. Projenin kodu GitHub’da açık kaynak olarak yayınlandı (Kaynak: stablequan, awnihannun)
FedRAG, NoEncode RAG ve MCP çekirdek soyutlamasını tanıtıyor: FedRAG projesi, yeni bir çekirdek soyutlama olan NoEncode RAG with MCP’yi tanıttı. Geleneksel RAG, bir alıcı, bir üretici ve bir bilgi tabanı içerir; bilgi tabanındaki bilgiler alıcı modeli tarafından kodlanmalıdır. NoEncode RAG ise kodlama adımını tamamen atlayarak doğrudan bir NoEncode bilgi tabanı ve bir üreticiden oluşur, alıcıya/gömme işlemine gerek duymaz. Bu, MCP (Model Component Provider) sunucularını bilgi kaynağı olarak kullanan RAG sistemleri oluşturmanın yolunu açar; kullanıcılar birden fazla üçüncü taraf MCP kaynağına bağlanabilir ve en iyi performansı elde etmek için FedRAG aracılığıyla RAG’ı ince ayarlayabilir (Kaynak: nerdai)

📚 Öğrenme
Stanford Üniversitesi CS224n (2024 sürümü) dersi yayında, LLM ve ajan içerikleri eklendi: Stanford Üniversitesi’nin klasik doğal dil işleme dersi CS224n’in 2024 yılı en son sürümü yayınlandı. Yeni sürüm ders içeriği, ön eğitim, son eğitim, kıyaslama, çıkarım, ajanlar gibi büyük dil modeli (LLM) ile ilgili en son konuları kapsıyor. Ders videoları YouTube’da herkese açık olarak yayınlandı, ayrıca ücretli senkronize ders deneyimi de sunuluyor (Kaynak: stanfordnlp)
Sistem mimarisi yeteneğini geliştirme rehberi: YZ çağında pratik ve öğrenme: Dotey, YZ destekli programlamanın giderek güçlendiği bir ortamda kişisel sistem mimarisi yeteneklerini nasıl geliştirileceğine dair ayrıntılı yöntemler paylaştı. Makale, sistem tasarımının karmaşık sistemleri uygulanması ve bakımı kolay küçük modüllere ayırma ve modüller arasındaki işbirliğini net bir şekilde tanımlama süreci olduğunu vurguluyor. Geliştirme yöntemleri arasında “çok görmek” (klasik vakaları, açık kaynak projeleri incelemek), “çok pratik yapmak” (mimariyi yeniden oluşturma, karşılaştırmalı öğrenme, önce tasarım, YZ destekli doğrulama, yeniden yapılandırma, yan proje uygulaması) ve “çok gözden geçirmek” (karar verme gerekçelerini, deneyimleri ve dersleri özetlemek) yer alıyor. YZ, bilgi araştırma, tasarım doğrulama, iletişim ve karar vermeye yardımcı bir araç olarak kullanılabilir, ancak pratik ve düşünmenin yerini tutamaz (Kaynak: dotey)

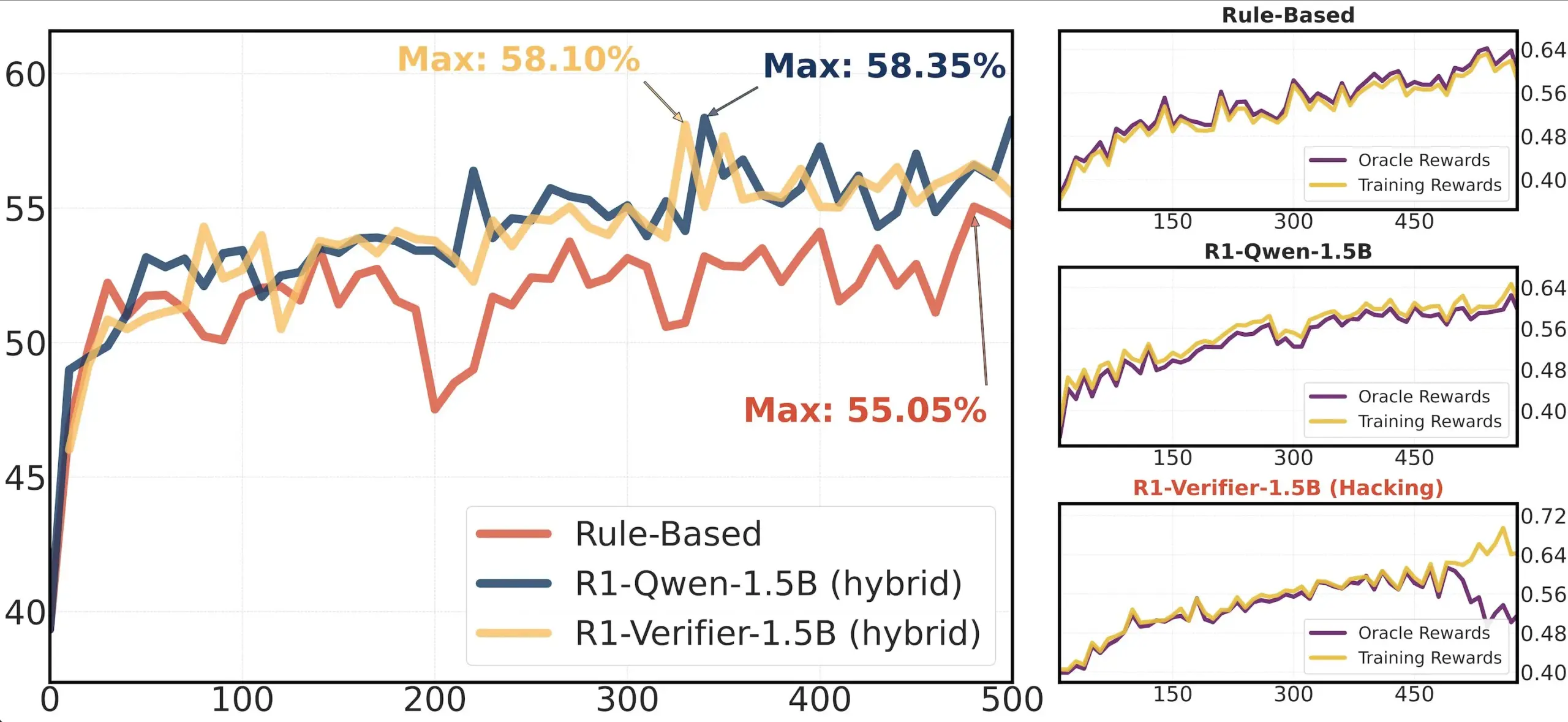
Makale paylaşımı: RLHF’de doğrulayıcı güvenilirliği araştırması: “Pitfalls of Rule- and Model-based Verifiers” başlıklı bir makale, pekiştirmeli öğrenme doğrulamasında (RLVR) kural tabanlı ve model tabanlı doğrulayıcıların kusurlarını inceliyor. Araştırma, kural tabanlı doğrulayıcıların matematik alanında bile genellikle güvenilir olmadığını ve birçok alanda kullanılamadığını; model tabanlı doğrulayıcıların ise basit karşıt örüntüler oluşturarak saldırıya uğramaya açık olduğunu ortaya koyuyor. İlginç bir şekilde, topluluk üretken doğrulayıcılara yöneldikçe, araştırmacılar bunların ayırt edici doğrulayıcılardan daha fazla ödül manipülasyonuna (reward hacking) maruz kaldığını buldu; bu da ayırt edici doğrulayıcıların RLVR’de daha sağlam olabileceğini gösteriyor (Kaynak: Francis_YAO_)
Makale önerisi: Polinom en iyi yaklaşımının eş salınım teoremi: Bir makale, polinom en iyi yaklaşımının eş salınım teoremini ve bununla ilgili sonsuz norm diferansiyel problemini tanıtıyor. Bu teorem, fonksiyon yaklaşımı teorisinde klasik bir sonuçtur ve sayısal algoritmaların anlaşılması ve tasarlanması için önemli bir yere sahiptir (Kaynak: eliebakouch)
Reasoning Gym: Pekiştirmeli öğrenme için doğrulanabilir ödüllü çıkarım ortamları: Yeni makale “Reasoning Gym: Reasoning Environments for Reinforcement Learning with Verifiable Rewards” (arXiv:2505.24760), pekiştirmeli öğrenme için bir dizi çıkarım ortamı öneriyor. Bu ortamların özelliği, ödüllerinin doğrulanabilir olmasıdır; bu da daha güvenilir pekiştirmeli öğrenme çıkarım ajanlarının araştırılması ve geliştirilmesi için bir platform sunar (Kaynak: Ar_Douillard)

🌟 Topluluk
“Orta eğitim (Mid-training)” üzerine tartışma: YZ topluluğu, “orta eğitim (Mid-training)” teriminin anlamı ve uygulaması üzerine bir tartışma başlattı. Bazıları kafa karışıklığı yaşadıklarını, yalnızca ön eğitim ve son eğitimi bildiklerini belirtti. Bazı görüşlere göre, orta eğitim, ön eğitim ile son ince ayar arasında gerçekleştirilen belirli bir aşama eğitimini, örneğin belirli alan bilgisine yönelik sürekli ön eğitimi veya erken hizalamayı ifade edebilir. Dorialexander, ilgili blog yazılarını paylaşarak bu kavramı daha da irdeledi ve bunun temel bir model üzerine belirli görev veya yeteneklerin enjekte edilmesini içerebileceğini, ancak henüz birleşik bir tanım ve metodolojinin oluşmadığını belirtti (Kaynak: code_star, fabianstelzer, Dorialexander, iScienceLuvr, clefourrier)

Claude Code tersine mühendislik analizi ilgi çekti: Hrishi, Claude Code’un minimize edilmiş kodunu tersine mühendislikle inceleyerek, 8-10 saat harcayarak, birden fazla alt ajan ve büyük sağlayıcıların amiral gemisi modellerini kullanarak iç yapısının karmaşıklığını ortaya çıkardı. Analiz, Claude Code’un basit bir Claude modeli döngüsü olmadığını, aksine öğrenmeye değer birçok mekanizma içerdiğini gösteriyor. Bu bulgu, toplulukta ajan oluşturma ve model uygulamaları hakkında birçok deneyim öğrenilebileceği yönünde bir tartışma başlattı (Kaynak: rishdotblog, imjaredz, hrishioa)
Sistem istemi uzunluğu ve model performansı üzerine tartışma: Topluluk, sistem istemi uzunluğunun LLM performansı üzerindeki etkisini tartıştı. Dotey, çok uzun sistem istemlerinin her zaman iyi olmadığını, modelin dikkatini dağıtabileceğini, maliyeti artırabileceğini belirtti ve ChatGPT serisi ürünlerin sistem istemlerinin nispeten kısa olmasına rağmen iyi sonuçlar verdiğine dikkat çekti. Tony出海号 ise Claude, Cursor gibi ürünlerin sistem istemlerinin on binlerce kelime uzunluğunda olduğunu belirterek, istem sistemlerini genişletmenin gerekliliğine işaret etti. YC’nin bir makalesi de önde gelen YZ şirketlerinin LLM’leri “evcilleştirmek” için uzun istemler, XML, meta istemler gibi yöntemler kullandığını ortaya koydu. Dorialexander ise YC makalesinde bahsedilen uzun istem yöntemlerinin RL/çıkarım eğitimindeki sağlamlığı konusunda şüphelerini dile getirdi ve “dalkavukluk” (sycophancy) sorununu nasıl azaltılacağına odaklandı (Kaynak: dotey, Dorialexander)

Softpick ölçeklenebilirlik sorunu, bilimsel şeffaflığa övgü topladı: Araştırmacı Zed, daha önceki araştırması olan Softpick yönteminin daha büyük modellere (1.8B parametre) ölçeklendiğinde eğitim kaybı ve kıyaslama testi sonuçlarının Softmax’tan daha kötü olduğunu açıkça belirtti ve arXiv ön baskısını güncelledi. Topluluk, bu olumsuz sonuçların şeffaf bir şekilde paylaşılmasını takdirle karşıladı, bunun bilimsel ilerleme için hayati önem taşıdığını ve mükemmel bilimsel meslektaşların bir niteliği olarak gördüğünü belirtti (Kaynak: gabriberton, vikhyatk, BlancheMinerva)
Kullanıcılar yerel LLM çalıştırma için model seçimlerini ve deneyimlerini paylaşıyor: Reddit r/LocalLLaMA topluluğu kullanıcıları, şu anda kullandıkları yerel büyük dil modelleri hakkında hararetli bir tartışma yürütüyor. Qwen 3 (özellikle 32B Q4, 32B Q8, 30B A3B), Gemma 3 (özellikle 27B QAT Q8, 12B), Devstral gibi modeller, kodlama, yaratıcılık, genel çıkarım gibi alanlardaki performansları nedeniyle yaygın olarak bahsediliyor. Kullanıcılar, modellerin bağlam uzunluğu, çıkarım hızı, IQ1_S_R4 gibi nicelenmiş sürümleri ve 8GB VRAM, Snapdragon 8 Elite çipli telefonlar gibi farklı donanımlardaki çalışma durumlarına odaklanıyor. Claude Code, Gemini API gibi kapalı kaynak modeller de uzun bağlam işleme, kodlama yetenekleri gibi belirli avantajları nedeniyle aynı anda kullanılıyor (Kaynak: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
💡 Diğer
YZ çağında beceri geliştirme: Soru sorma, eleştirel düşünme ve sürekli öğrenme kilit öneme sahip: Tartışmalar, YZ çağında soru sorma yeteneği, eleştirel düşünme, öğrenme modunda kalma, kodlama veya talimat verme yeteneği, YZ araçlarını ustaca kullanma ve net iletişim kurma olmak üzere altı becerinin hayati önem taşıdığını vurguluyor. Zapier şirketi bile yeni çalışanlarının %100’ünün YZ konusunda yetkin olmasını talep ediyor; bu, salt teknik bilgiden ziyade iletişim ihtiyaçlarını ve görevleri doğru bir şekilde devretme yeteneğini vurguladığı şeklinde yorumlanıyor. YZ, uygulamayı kolaylaştırıyor, bu nedenle tasarım ve düşünme kalitesi nihai sonuç üzerinde daha büyük bir etkiye sahip (Kaynak: TheTuringPost, zacharynado)

YZ etiği ve toplumsal etkileri: Endişeler ve güçlendirme bir arada: Aktör Steve Carell, yeni filmi “Mountainhead”in tasvir ettiği gelecek toplumu hakkında endişelerini dile getirerek, bunun yakında yaşayacağımız bir toplum olabileceğini belirtti ve YZ’nin potansiyel olumsuz etkilerine dair kaygılarını ima etti. Öte yandan, YZ’nin “köylüler ve krallar” gibi aşırı bir ayrışmaya neden olmayacağı, aksine bireyleri güçlendirerek bireyler ile büyük şirketler arasındaki yetenek farkını daraltabileceği, kişisel üretkenliği, yaratıcılığı ve etkiyi artırabileceği yönünde görüşler de mevcut. Ancak, YZ’nin demokratikleşmesi beklentilerine temkinli yaklaşanlar da var; büyük şirketlerin model eğitimi ve dağıtımını kontrol ederek hakimiyeti ellerinde tutmaya devam edeceğini düşünüyorlar (Kaynak: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

YZ güdümlü iş ilanı toplama platformu Hiring Cafe: Hamed N., ChatGPT API’sini kullanarak şirketlerin doğrudan kendi web sitelerinde yayınladığı 4,1 milyon iş ilanını topladı ve Hiring Cafe web sitesini oluşturdu. Bu platform, LinkedIn ve Indeed gibi platformlarda yaygın olan “hayalet işler” ve üçüncü taraf aracılar sorununu çözmeyi amaçlıyor; pozisyon, işlev, sektör, deneyim yılı, yönetici/IC rolü gibi güçlü filtrelerle iş arayanların pozisyonları daha etkili bir şekilde filtrelemesine yardımcı oluyor. Bu, ticari olmayan bir doktora öğrencisi yan projesi olup, topluluktan övgü ve kullanım gördü (Kaynak: Reddit r/ChatGPT)
