
Anahtar Kelimeler:DeepSeek-R1-0528, Yapay Zeka Ajanı, Çok Modelli Model, Açık Kaynak Yapay Zeka, Büyük Dil Modeli, Pekiştirmeli Öğrenme, Görüntü Düzenleme, Yapay Zeka Kıyaslama Testleri, DeepSeek-R1-0528-Qwen3-8B, Devre İzleme Aracı, Darwin Gödel Makinesi, FLUX.1 Kontext, Ajan Temelli Bilgi Getirme
🔥 Odak Noktası
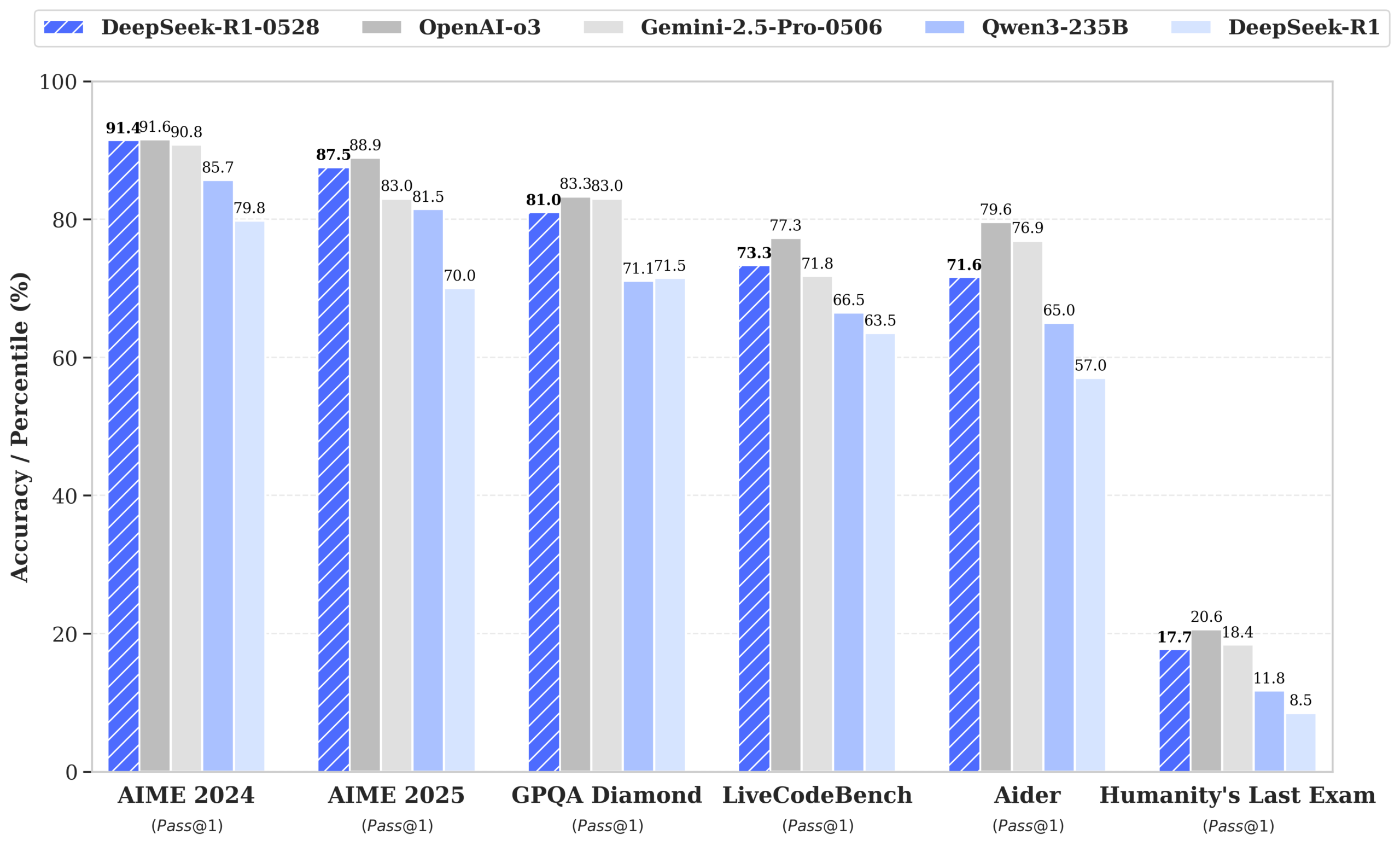
DeepSeek, performansı GPT-4o ve Gemini 2.5 Pro’ya yaklaşan R1-0528 modelini yayınladı ve açık kaynak listelerinde zirveye yerleşti: DeepSeek-R1-0528, matematik, programlama ve genel mantıksal çıkarım gibi birçok kıyaslama testinde mükemmel performans gösterdi; özellikle AIME 2025 testinde doğruluk oranı %70’ten %87.5’e yükseldi. Yeni sürüm, halüsinasyon oranını önemli ölçüde (%45-50 civarında) azalttı, ön uç (frontend) kod oluşturma yeteneklerini geliştirdi ve JSON çıktısı ile fonksiyon çağrılarını destekliyor. Aynı zamanda DeepSeek, Qwen3-8B Base üzerinde ince ayar yaparak DeepSeek-R1-0528-Qwen3-8B’yi yayınladı; bu model AIME 2024’te R1-0528’den sonra ikinci sırada yer alarak Qwen3-235B’yi geride bıraktı. Bu güncelleme, DeepSeek’in dünyanın en büyük ikinci yapay zeka laboratuvarı ve açık kaynak lideri konumunu pekiştirdi. (Kaynak: ClementDelangue, dotey, huggingface, NandoDF, andrew_n_carr, Francis_YAO_, scaling01, karminski3, teortaxesTex, tokenbender, dotey)
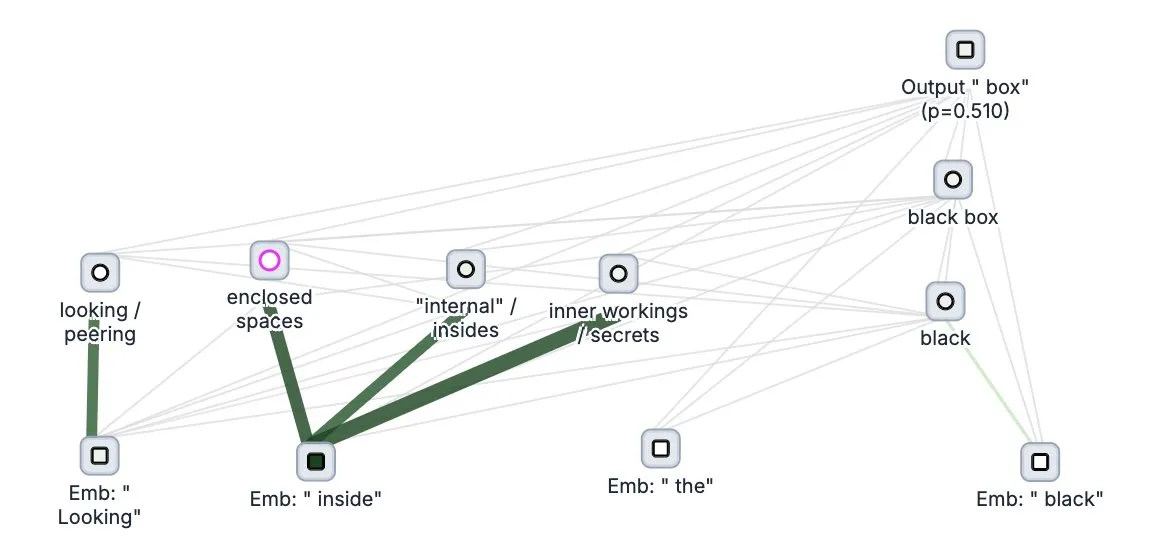
Anthropic, büyük dil modelleri için “düşünce izleme” aracı Circuit Tracer’ı açık kaynak olarak yayınladı: Anthropic şirketi, büyük dil modellerinin (LLM) içsel “düşünme” süreçlerini ve karar alma mekanizmalarını anlamak için araştırmacıların “atfetme haritaları” oluşturmasına ve etkileşimli olarak keşfetmesine olanak tanıyan büyük dil modeli yorumlanabilirlik araştırma aracı Circuit Tracer’ı açık kaynak olarak yayınladı. Bu araç, araştırmacıların LLM’lerin iç işleyişini, örneğin modelin bir sonraki token’ı tahmin etmek için belirli özellikleri nasıl kullandığını daha derinlemesine incelemelerine yardımcı olmayı amaçlıyor. Kullanıcılar, Neuronpedia üzerinden aracı deneyebilir ve cümle girerek modelin özellik kullanım durumunun devre şemasını elde edebilirler. (Kaynak: scaling01, mlpowered, rishdotblog, menhguin, NeelNanda5, akbirkhan, riemannzeta, andersonbcdefg, algo_diver, Reddit r/ClaudeAI)
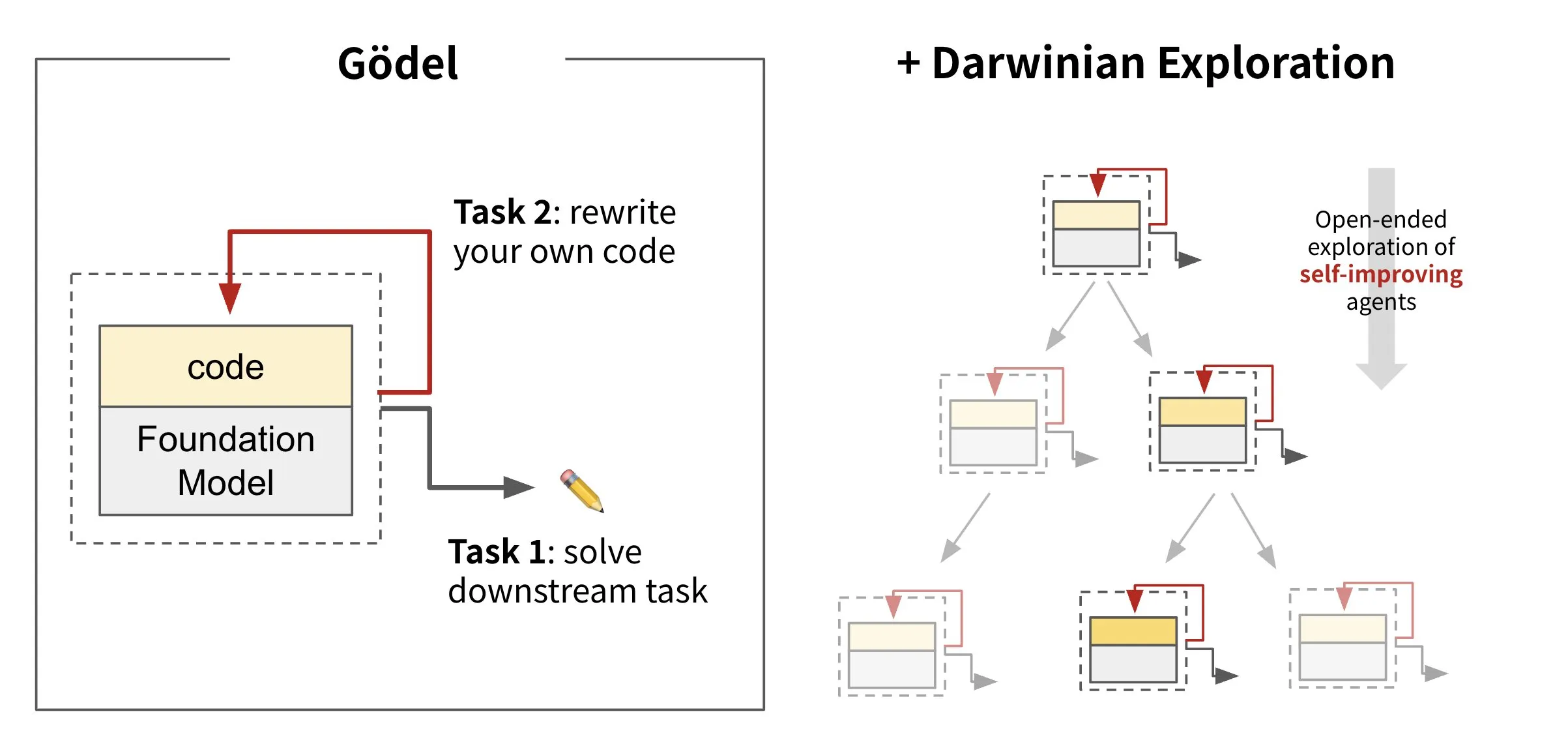
Sakana AI, kendi kendine evrilen ajan çerçevesi Darwin Gödel Machine’i (DGM) yayınladı: Sakana AI, kendi kodunu yeniden yazarak kendini geliştirebilen bir yapay zeka ajan çerçevesi olan Darwin Gödel Machine’i (DGM) tanıttı. DGM, evrim teorisinden esinlenerek, kendi kendini geliştiren ajanların tasarım alanını açık uçlu bir şekilde keşfetmek için sürekli genişleyen bir ajan varyantları soyunu sürdürüyor. Bu çerçeve, yapay zeka sistemlerinin zamanla insanlar gibi kendi yeteneklerini öğrenmesini ve evrimleştirmesini sağlamayı amaçlıyor. SWE-bench’te DGM, performansı %20.0’dan %50.0’a; Polyglot’ta ise başarı oranını %14.2’den %30.7’ye yükseltti. (Kaynak: SakanaAILabs, teortaxesTex, Reddit r/MachineLearning)
Black Forest Labs, metin ve görüntü karma girişini destekleyen görüntü düzenleme modeli FLUX.1 Kontext’i yayınladı: Black Forest Labs, akış eşleştirme mimarisini kullanan yeni nesil görüntü düzenleme modeli FLUX.1 Kontext’i tanıttı. Model, bağlama duyarlı görüntü oluşturma ve düzenleme için hem metin hem de görüntü girdilerini aynı anda kabul edebiliyor. Bu model, karakter tutarlılığı, yerel düzenleme, stil referansı ve etkileşim hızı konularında üstün performans sergiliyor; örneğin 1024×1024 çözünürlükte görüntüleri yalnızca 3-5 saniyede oluşturabiliyor. Replicate’in testleri, düzenleme etkilerinin GPT-4o-Image’dan daha iyi ve maliyetinin daha düşük olduğunu gösteriyor. Kontext, Pro ve Max sürümlerini sunuyor ve açık kaynaklı bir Dev sürümü yayınlamayı planlıyor. (Kaynak: TomLikesRobots, two_dukes, cloneofsimo, robrombach, bfirsh, timudk, scaling01, KREA AI)

🎯 Gelişmeler
Google DeepMind, çok modlu tıp modeli MedGemma’yı yayınladı: Google DeepMind, çok modlu tıbbi metin ve görüntü anlama için özel olarak tasarlanmış güçlü bir açık model olan MedGemma’yı tanıttı. Bu model, Health AI Developer Foundations’ın bir parçası olarak sunulmakta olup, yapay zekanın tıp alanındaki uygulama yeteneklerini, özellikle metin ve X-ray gibi tıbbi görüntüleri birleştirerek kapsamlı analiz yapma konusunda geliştirmeyi amaçlamaktadır. (Kaynak: GoogleDeepMind)
Perplexity AI, karmaşık görevlerin üstesinden gelmek için Perplexity Labs’ı kullanıma sundu: Perplexity AI, daha karmaşık görevleri yerine getirmek üzere tasarlanmış yeni bir özellik olan Perplexity Labs’ı yayınladı. Bu özellik, kullanıcılara bütün bir araştırma ekibine benzer analiz ve oluşturma yetenekleri sunmayı amaçlıyor. Kullanıcılar Labs aracılığıyla analiz raporları, sunumlar ve dinamik gösterge tabloları oluşturabilirler. Bu özellik şu anda tüm Pro kullanıcılarına açık olup, bilimsel araştırma, pazar analizi ve mini uygulamalar (oyunlar, gösterge tabloları gibi) oluşturma potansiyelini göstermektedir. (Kaynak: AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas)
Tencent Hunyuan ve Tencent Music, fotoğraflardan gerçekçi şarkı söyleyen videolar oluşturabilen HunyuanVideo-Avatar’ı ortaklaşa kullanıma sundu: Tencent Hunyuan ve Tencent Music, kullanıcıların yüklediği fotoğrafları ve sesleri birleştirerek sahne bağlamını ve duyguyu otomatik olarak algılayan, gerçekçi dudak senkronizasyonu ve dinamik görsel efektlere sahip konuşan veya şarkı söyleyen videolar üretebilen HunyuanVideo-Avatar modelini ortaklaşa yayınladı. Bu teknoloji çeşitli stilleri destekliyor ve açık kaynak olarak sunuldu. (Kaynak: huggingface, thursdai_pod)
Apache Spark 4.0.0 resmi olarak yayınlandı; SQL, Spark Connect ve çoklu dil desteği geliştirildi: Apache Spark 4.0.0 sürümü resmi olarak yayınlandı. Bu sürüm, SQL işlevlerinde önemli geliştirmeler, uygulamaların daha kolay çalışmasını sağlayan Spark Connect iyileştirmeleri ve yeni dillere destek getiriyor. Bu güncelleme ile 390’dan fazla katılımcının katkısıyla 5100’den fazla sorun çözüldü. (Kaynak: matei_zaharia, lateinteraction)

Kling 2.1 video modeli yayınlandı, karakter tutarlılığı için OpenArt entegrasyonu yapıldı: Kling AI, video modeli Kling 2.1’i yayınladı ve yapay zeka video hikaye anlatımında karakter tutarlılığını sağlamak için OpenArt ile iş birliği yaptı. Kling 2.1, komut istemi uyumunu, video oluşturma hızını, kamera hareketlerinin netliğini geliştirdi ve en iyi metinden videoya efektlerine sahip olduğunu iddia ediyor. Yeni sürüm 720p (standart) ve 1080p (profesyonel) çıktıları destekliyor; görüntüden videoya özelliği şu anda mevcut, metinden videoya özelliği ise yakında kullanıma sunulacak. (Kaynak: Kling_ai, NandoDF)
Hume, herhangi bir insan sesini anlayıp üretebilen EVI 3 ses modelini yayınladı: Hume, evrensel ses zekasını hedefleyen en son sesli dil modeli EVI 3’ü tanıttı. EVI 3, yalnızca belirli birkaç konuşmacının değil, herhangi bir insan sesini anlayıp üretebiliyor, böylece daha geniş bir ifade yelpazesi ve tonlama, ritim, tını ve konuşma tarzına daha derin bir anlayış sunuyor. Bu teknoloji, herkesin sesle tanınan, benzersiz ve güvenilir bir yapay zekaya sahip olmasını amaçlıyor. (Kaynak: AlanCowen, AlanCowen, _akhaliq)
Alibaba, otonom bilgi arama ajanlarını keşfetmek için WebDancer’ı yayınladı: Alibaba, otonom olarak bilgi arayabilen yapay zeka ajanlarını araştırmak ve geliştirmek amacıyla WebDancer projesini başlattı. Bu proje, yapay zeka ajanlarının ağ ortamlarında daha etkili bir şekilde gezinmesini, bilgiyi anlamasını ve karmaşık bilgi edinme görevlerini tamamlamasını sağlamaya odaklanıyor. (Kaynak: _akhaliq)
MiniMax, görsel RL çıkarımı ve algı görevlerini birleştiren V-Triune çerçevesini ve Orsta modelini açık kaynak olarak yayınladı: Yapay zeka şirketi MiniMax, görsel pekiştirmeli öğrenme birleşik çerçevesi V-Triune’u ve bu çerçeveye dayanan Orsta model serisini (7B ila 32B) açık kaynak olarak yayınladı. Bu çerçeve, üç katmanlı bileşen tasarımı ve dinamik kesişim üzeri birleşim (IoU) ödül mekanizması aracılığıyla, VLM’lerin tek bir son eğitim sürecinde görsel çıkarım ve algı görevlerini ortaklaşa öğrenmesini ilk kez mümkün kılıyor ve MEGA-Bench Core kıyaslama testinde performansı önemli ölçüde artırıyor. (Kaynak: 量子位)

Şanghay AI Laboratuvarı ve diğerleri, modellerin derin çıkarım yeteneklerini test eden yeni görüntü düzenleme kıyaslama standardı RISEBench’i yayınladı: Şanghay Yapay Zeka Laboratuvarı, birçok üniversiteyle birlikte RISEBench adlı yeni bir görüntü düzenleme değerlendirme kıyaslama standardı yayınladı. Bu standart, zaman, nedensellik, uzay ve mantık olmak üzere dört temel çıkarım türünü kapsayan, insan uzmanlar tarafından tasarlanmış 360 zorlu vaka içeriyor. Test sonuçları, GPT-4o-Image’ın bile görevlerin yalnızca %28.9’unu tamamlayabildiğini göstererek, mevcut çok modlu modellerin karmaşık komutları anlama ve görsel düzenleme konularındaki eksikliklerini ortaya koydu. (Kaynak: 36氪)

Hong Kong Çin Üniversitesi ve diğerleri, yapay zeka modellerinin verimliliği ve doğruluğu artırmak için seçici düşünmesini sağlayan TON çerçevesini önerdi: Hong Kong Çin Üniversitesi ve Singapur Ulusal Üniversitesi Show Lab araştırmacıları, görsel dil modellerinin (VLM) açıkça çıkarım yapmaya ihtiyaç duyup duymadığına otonom olarak karar vermesini sağlayan TON (Think Or Not) çerçevesini önerdi. Bu çerçeve, “düşünceyi atma” ve pekiştirmeli öğrenme yoluyla, modelin basit sorulara doğrudan yanıt vermesini ve karmaşık sorular için ayrıntılı çıkarım yapmasını sağlayarak, doğruluktan ödün vermeden ortalama çıkarım çıktı uzunluğunu %90’a kadar azaltıyor ve bazı görevlerde doğruluğu %17’ye kadar artırıyor. (Kaynak: 36氪)
Microsoft Copilot, yapay zeka destekli market alışverişi için Instacart ile entegre oldu: Microsoft AI Başkanı Mustafa Suleyman, Copilot’un artık Instacart hizmetiyle entegre olduğunu duyurdu. Kullanıcılar, Copilot uygulaması aracılığıyla yemek tarifi oluşturmaktan alışveriş listesi hazırlamaya ve market ürünlerinin eve teslimine kadar tüm süreci sorunsuz bir şekilde tamamlayabilecekler. Bu, yapay zeka asistanlarının günlük yaşam hizmetleri alanındaki genişlemesinin bir başka işaretidir. (Kaynak: mustafasuleyman)
🧰 Araçlar
LlamaIndex, yapay zeka uygulaması oluşturmayı basitleştirmek için BundesGPT kaynak kodunu ve create-llama aracını kullanıma sundu: LlamaIndex’ten Jerry Liu, BundesGPT’nin kaynak kodunu sunduğunu duyurdu ve açık kaynak aracı create-llama’yı tanıttı. LlamaIndex tabanlı bu araç, geliştiricilerin kurumsal verileri ve yapay zeka aracılarını kolayca oluşturmasına ve entegre etmesine yardımcı olmayı amaçlıyor. Yeni eject-mode özelliği, BundesGPT gibi tamamen özelleştirilebilir yapay zeka arayüzleri oluşturmayı çok basit hale getiriyor. Bu hamle, Almanya’nın her vatandaşa ücretsiz ChatGPT Plus aboneliği sağlama potansiyel planını desteklemeyi amaçlıyor. (Kaynak: jerryjliu0)
LangChain araçları MCP araçlarına dönüştürülebilir ve FastMCP sunucusuna entegre edilebilir: LangChain kullanıcıları artık LangChain araçlarını MCP (Model Component Protocol) araçlarına dönüştürebilir ve doğrudan FastMCP sunucusuna ekleyebilirler. langchain-mcp-adapters kütüphanesini kurarak geliştiriciler, LangChain’in araç setini MCP ekosisteminde daha kolay kullanabilir ve farklı yapay zeka çerçeveleri arasındaki birlikte çalışabilirliği teşvik edebilirler. (Kaynak: LangChainAI, hwchase17)
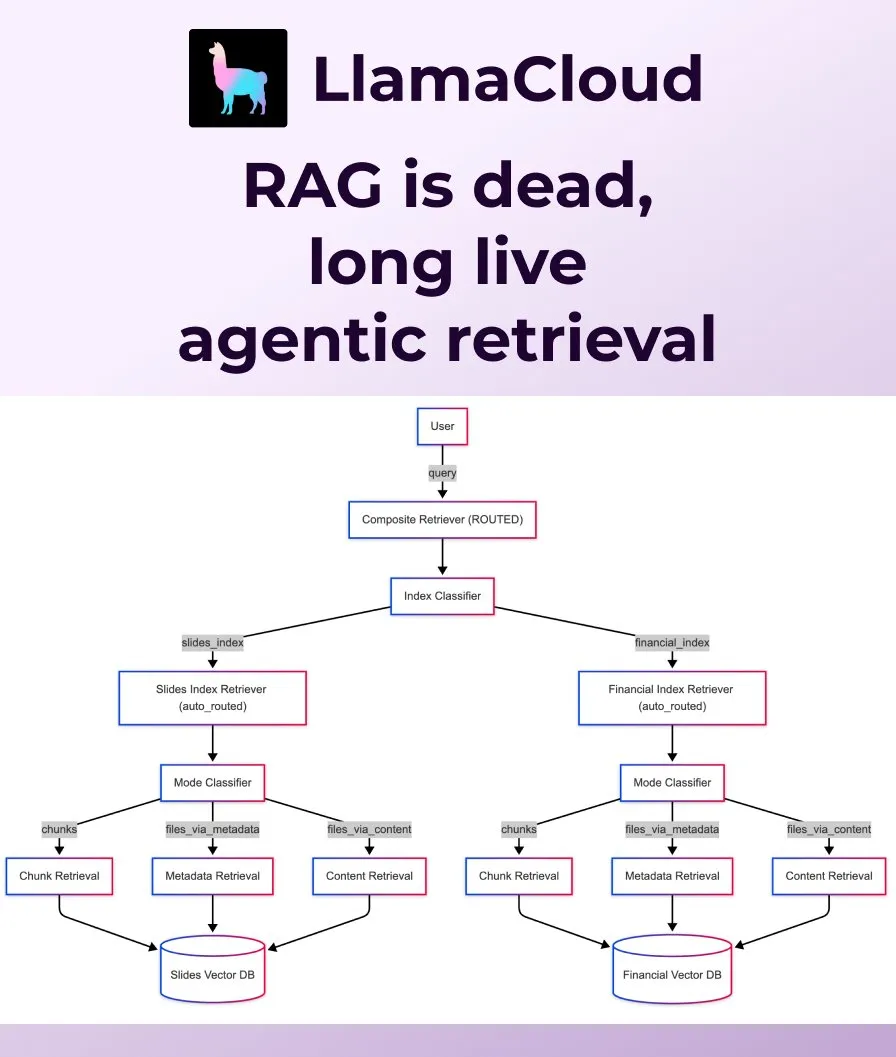
LlamaIndex, geleneksel RAG’ın yerini alacak Agentic Retrieval’ı yayınladı: LlamaIndex, geleneksel basit RAG’ın (Retrieval Augmented Generation) modern uygulama ihtiyaçlarını karşılamak için yetersiz kaldığını düşünüyor ve Agentic Retrieval’ı tanıttı. LlamaCloud’a yerleşik olan bu çözüm, ajanların soru içeriğine göre tek veya birden fazla bilgi kaynağından (Sharepoint, Box, GDrive, S3 gibi) tüm dosyaları veya belirli veri bloklarını dinamik olarak almasına olanak tanıyarak daha akıllı ve esnek bağlam elde etmeyi sağlıyor. (Kaynak: jerryjliu0, jerryjliu0)
Ollama, yapılandırılmamış verileri dönüştürmek için Osmosis-Structure-0.6B modelini çalıştırmayı destekliyor: Kullanıcılar artık Ollama aracılığıyla Osmosis-Structure-0.6B modelini çalıştırabilirler. Bu, herhangi bir yapılandırılmamış veriyi belirtilen bir formata (örneğin JSON Schema) dönüştürebilen çok küçük bir modeldir ve herhangi bir modelle birlikte kullanılabilir; özellikle yapılandırılmış çıktı gerektiren çıkarım görevleri için uygundur. (Kaynak: ollama)
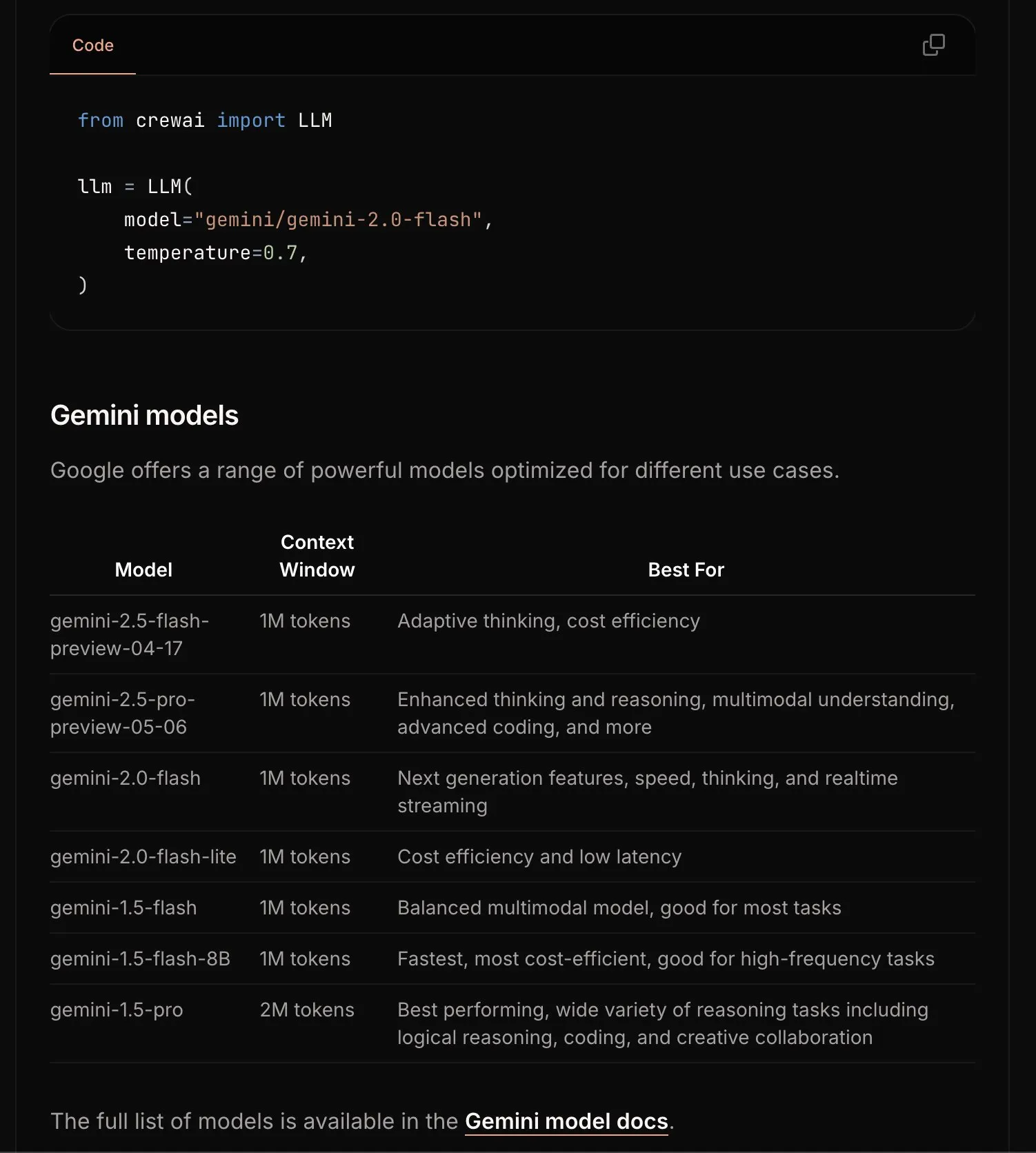
CrewAI, başlangıç sürecini basitleştirmek için Gemini belgelerini güncelledi: CrewAI ekibi, kullanıcıların Gemini modelleriyle yapay zeka ajanları oluşturmaya daha kolay başlamalarına yardımcı olmak amacıyla Google Gemini API hakkındaki belgelerini güncelledi. Yeni belgeler daha net yönergeler, örnek kodlar veya en iyi uygulamaları içerebilir. (Kaynak: _philschmid)
Requesty, OpenWebUI için en iyi LLM’i otomatik olarak seçen Smart Routing özelliğini kullanıma sundu: Requesty, OpenWebUI ile sorunsuz bir şekilde entegre olan ve kullanıcı isteminin görev türüne göre en iyi LLM’i (GPT-4o, Claude, Gemini gibi) otomatik olarak seçen Smart Routing özelliğini yayınladı. Kullanıcıların model kimliği olarak smart/task kullanması yeterlidir; sistem, istemi yaklaşık 65 milisaniyede sınıflandırabilir ve maliyet, hız ve kaliteye göre en uygun modele yönlendirebilir. Bu özellik, model seçimini basitleştirmeyi ve kullanıcı deneyimini iyileştirmeyi amaçlamaktadır. (Kaynak: Reddit r/OpenWebUI)
EvoAgentX: İlk yapay zeka ajanı kendi kendine evrimleşen açık kaynak çerçevesi yayınlandı: Birleşik Krallık Glasgow Üniversitesi araştırma ekibi, dünyanın ilk yapay zeka ajanı kendi kendine evrimleşen açık kaynak çerçevesi olan EvoAgentX’i yayınladı. Tek tıklamayla iş akışı oluşturmayı destekler ve çoklu ajan sistemlerinin çevre ve hedef değişikliklerine göre yapısını ve performansını sürekli olarak optimize etmesini sağlayan “kendi kendine evrimleşme” mekanizmasını sunar. Amaç, yapay zeka çoklu ajan sistemlerini “manuel ayarlama”dan “otonom evrimleşme”ye taşımaktır. Deneyler, çok adımlı soru yanıtlama, kod oluşturma ve matematiksel çıkarım görevlerinde performansın ortalama %8-%13 arttığını göstermiştir. (Kaynak: 36氪)

📚 Öğrenme Kaynakları
HuggingFace, Gradio ve diğerleri, cömert ödüller ve API kredileri sunan Agents & MCP Hackathon’u ortaklaşa düzenliyor: HuggingFace, Gradio, Anthropic, SambaNovaAI, MistralAI ve LlamaIndex gibi kurumlar, Gradio Agents & MCP Hackathon’u (2-8 Haziran) ortaklaşa düzenleyecek. Etkinlik toplam 11.000 ABD Doları ödül sunuyor ve erken kayıt yaptıranlara Hyperbolic, Anthropic, Mistral, SambaNova’dan ücretsiz API kredileri sağlıyor. Modal Labs ise tüm katılımcılara toplamda 300.000 ABD Dolarını aşan 250 ABD Doları değerinde GPU kredisi vaat ediyor. (Kaynak: huggingface, _akhaliq, ben_burtenshaw, charles_irl)
LangChain, JPMorgan Chase’in yatırım araştırmaları için çoklu ajan sistemlerini kullanma pratiğini paylaştı: JPMorgan Chase’den David Odomirok ve Zheng Xue, “Ask David” adlı çoklu ajanlı bir yapay zeka sistemini nasıl oluşturduklarını paylaştı. Bu sistem, binlerce finansal ürün için yatırım araştırma süreçlerini otomatikleştirmeyi amaçlıyor ve çoklu ajan mimarisinin karmaşık finansal analizlerdeki uygulama potansiyelini gösteriyor. (Kaynak: LangChainAI, hwchase17)
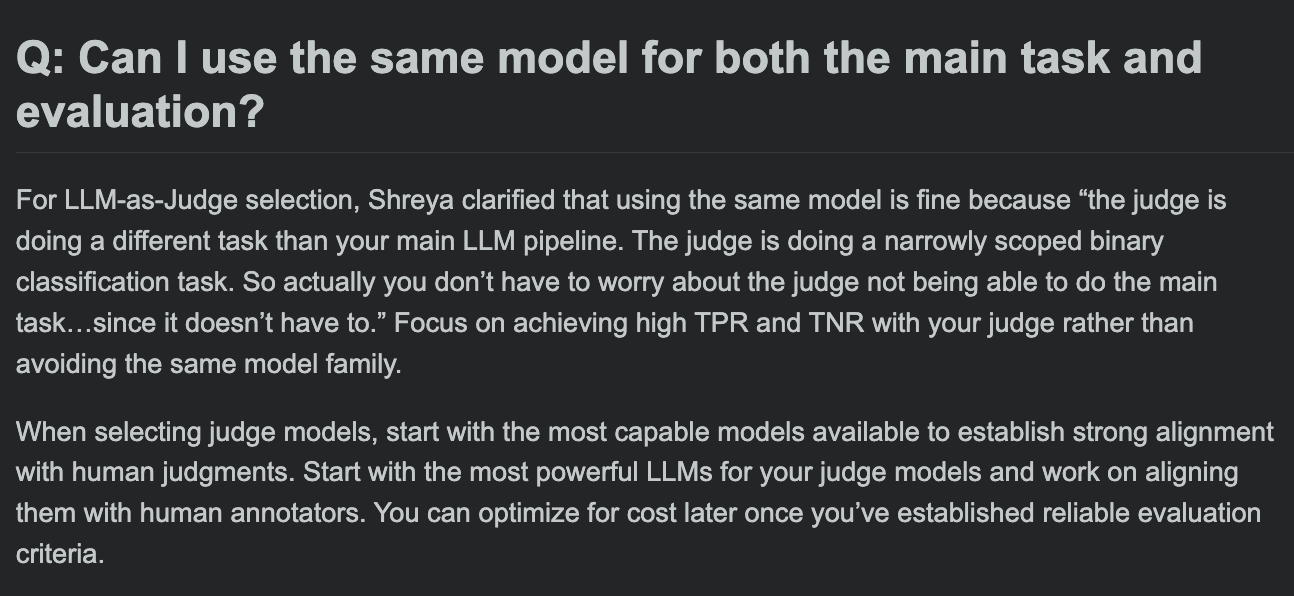
Hamel Husain, LLM değerlendirme kursu SSS’lerini paylaştı ve değerlendirme modeli ile ana görev modelinin aynı olup olamayacağını tartıştı: LLM değerlendirme kursunun soru-cevap bölümünde Hamel Husain, yaygın bir soruyu tartıştı: Ana görev işleme ve görev değerlendirmesi için aynı modelin kullanılıp kullanılamayacağı. Bu tartışma, geliştiricilerin model değerlendirmesindeki potansiyel önyargıları ve en iyi uygulamaları anlamalarına yardımcı oluyor. (Kaynak: HamelHusain, HamelHusain)
The Rundown AI, kişiselleştirilmiş yapay zeka eğitim platformunu başlattı: The Rundown AI, farklı sektörlere, beceri seviyelerine ve günlük iş akışlarına yönelik özelleştirilmiş eğitimler, kullanım senaryoları ve canlı atölye çalışmaları sunan dünyanın ilk kişiselleştirilmiş yapay zeka eğitim platformunu başlattığını duyurdu. Platform içeriği, 16 teknoloji dikeyinde sektöre özel yapay zeka sertifika programları, 300’den fazla gerçek dünya yapay zeka kullanım senaryosu, uzman atölye çalışmaları ve yapay zeka araçlarında indirimler içeriyor. (Kaynak: TheRundownAI, rowancheung)
Common Crawl, Mart-Mayıs 2025 ana bilgisayar ve alan adı düzeyindeki ağ haritalarını yayınladı: Common Crawl, Mart, Nisan ve Mayıs 2025’i kapsayan en son ana bilgisayar ve alan adı düzeyindeki ağ haritası verilerini yayınladı. Bu veriler, ağ yapısını araştırmak, dil modellerini eğitmek ve büyük ölçekli ağ analizi yapmak için önemli bir değere sahiptir. (Kaynak: CommonCrawl)
Bill Chambers, “20 Days of DSPyOSS” öğrenme etkinliğini başlattı: Topluluğun DSPyOSS’un işlevlerini ve kullanım yöntemlerini daha iyi anlamasına yardımcı olmak için Bill Chambers, 20 günlük bir DSPyOSS öğrenme etkinliği başlattı. Her gün bir DSPy kod parçacığı ve açıklaması yayınlanacak ve kullanıcıların çerçeveyi temelden ileri seviyeye kadar öğrenmelerine yardımcı olmayı amaçlayacak. (Kaynak: lateinteraction)
DeepLearning.AI, The Batch haftalık bültenini yayınladı; Andrew Ng, araştırma fonlarını kesmenin risklerini tartışıyor: The Batch haftalık bülteninin son sayısında Andrew Ng, araştırma fonlarını kesmenin ulusal rekabet gücü ve güvenlik üzerindeki potansiyel risklerini tartışıyor. Bülten ayrıca Claude 4 modelinin kodlama kıyaslama testlerindeki performansı, Google I/O’daki yapay zeka duyuruları, DeepSeek’in düşük maliyetli eğitim yöntemi ve GPT-4o’nun telif hakkıyla korunan kitapları eğitim için kullanmış olabileceği gibi sıcak konuları da kapsıyor. (Kaynak: DeepLearningAI)
Google DeepMind, İngiltere’deki üniversite öğrencilerine Gemini 2.5 Pro ve NotebookLM’i ücretsiz olarak sunuyor: Google DeepMind, İngiltere’deki üniversite öğrencilerine en gelişmiş modellerine (Gemini 2.5 Pro ve NotebookLM dahil) 15 ay boyunca ücretsiz erişim sağlayacağını duyurdu. Bu hamle, öğrencilerin araştırma, yazma ve sınavlara hazırlanma gibi öğrenme süreçlerini desteklemeyi ve 2 TB ücretsiz depolama alanı sunmayı amaçlıyor. (Kaynak: demishassabis)
Yapay Zeka Makale Özeti: Prot2Token, Sonraki Token Tahmini Yoluyla Protein Modellemesi için Birleşik Bir Çerçeve: “Prot2Token: A Unified Framework for Protein Modeling via Next-Token Prediction” başlıklı makale, protein dizisi özelliklerinden, kalıntı özelliklerinden proteinler arası etkileşimlere kadar çeşitli tahmin görevlerini standart bir sonraki token tahmin formatına dönüştüren birleşik bir protein modelleme çerçevesi olan Prot2Token’ı tanıtmaktadır. Bu çerçeve, otoregresif bir kod çözücü kullanır ve önceden eğitilmiş protein kodlayıcılarının gömülmelerini ve öğrenilebilir görev tokenlarını çoklu görev öğrenimi için kullanarak verimliliği artırmayı ve biyolojik keşifleri hızlandırmayı amaçlar. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: Kurumsal Sistemlerde Alan Adına Özgü Geri Çağırma için Zor Negatif Örnek Madenciliği: “Hard Negative Mining for Domain-Specific Retrieval in Enterprise Systems” başlıklı makale, kurumsal alana özgü veriler için ölçeklenebilir bir zor negatif örnek madenciliği çerçevesi önermektedir. Bu yöntem, dağıtılmış yeniden sıralama modellerinin performansını artırmak için anlamsal olarak zorlayıcı ancak bağlamsal olarak ilgisiz belgeleri dinamik olarak seçer. Bulut hizmetleri alanındaki kurumsal bir korpus üzerinde yapılan deneyler, MRR@3 ve MRR@10’da sırasıyla %15 ve %19’luk bir iyileşme göstermiştir. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: FS-DAG, Görsel Açıdan Zengin Belge Anlama için Az Örnekli Alan Uyarlamalı Grafik Ağları: “FS-DAG: Few Shot Domain Adapting Graph Networks for Visually Rich Document Understanding” başlıklı makale, az örnekli durumlarda görsel açıdan zengin belge anlama için FS-DAG model mimarisini önermektedir. Bu model, modüler bir çerçeve içinde en az veriyle farklı belge türlerine uyum sağlamak için alana özgü ve dil/görsel özgü omurga ağlarını kullanır ve bilgi çıkarma görevlerindeki deneylerde SOTA yöntemlerine göre daha hızlı yakınsama hızı ve performans göstermektedir. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: FastTD3, İnsansı Robot Kontrolü için Basit, Hızlı ve Yetenekli Pekiştirmeli Öğrenme: “FastTD3: Simple, Fast, and Capable Reinforcement Learning for Humanoid Control” başlıklı makale, paralel simülasyon, büyük toplu güncellemeler, dağıtılmış eleştirmenler ve dikkatle ayarlanmış hiperparametreler aracılığıyla HumanoidBench, IsaacLab ve MuJoCo Playground gibi popüler paketlerde insansı robotların eğitim hızını önemli ölçüde artıran FastTD3 adlı bir pekiştirmeli öğrenme algoritmasını tanıtmaktadır. (Kaynak: HuggingFace Daily Papers, pabbeel, cloneofsimo, jachiam0)
Yapay Zeka Makale Özeti: HLIP, 3D Tıbbi Görüntüleme için Ölçeklenebilir Dil-Görüntü Ön Eğitimi: “Towards Scalable Language-Image Pre-training for 3D Medical Imaging” başlıklı makale, HLIP (Hierarchical attention for Language-Image Pre-training) adlı ölçeklenebilir bir 3D tıbbi görüntüleme ön eğitim çerçevesini tanıtmaktadır. HLIP, hafif hiyerarşik dikkat mekanizmasını benimser ve doğrudan düzenlenmemiş klinik veri kümeleri üzerinde eğitim yapabilir ve birden fazla kıyaslama testinde SOTA performansı elde etmiştir. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: PENGUIN, LLM’lerde Kişiselleştirilmiş Güvenlik için Bir Kıyaslama ve Planlama Tabanlı Ajan Yaklaşımı: “Personalized Safety in LLMs: A Benchmark and A Planning-Based Agent Approach” başlıklı makale, kişiselleştirilmiş güvenlik kavramını tanıtmakta ve PENGUIN kıyaslamasını (7 hassas alanda 14000 senaryo içeren) ve RAISE çerçevesini (kullanıcıya özgü arka plan bilgilerini stratejik olarak edinen, eğitimsiz, iki aşamalı bir ajan) önermektedir. Araştırma, kişiselleştirilmiş bilgilerin güvenlik puanlarını önemli ölçüde artırabildiğini ve RAISE’in düşük etkileşim maliyetiyle güvenliği artırabildiğini göstermektedir. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: LLM Ajanlarının Çok Turlu Çıkarımını Tur Seviyesinde Kredi Atamasıyla Güçlendirme: “Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Credit Assignment” başlıklı makale, özellikle çok turlu araç kullanımı senaryolarında pekiştirmeli öğrenme yoluyla LLM ajanlarının çıkarım yeteneklerinin nasıl geliştirileceğini araştırmaktadır. Yazarlar, daha hassas kredi ataması sağlamak için ince taneli bir tur seviyesinde avantaj tahmin stratejisi önermektedir. Deneyler, bu yöntemin LLM ajanlarının karmaşık karar verme görevlerindeki çok turlu çıkarım yeteneğini önemli ölçüde artırabildiğini göstermektedir. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: PISCES, Büyük Dil Modellerinde Parametre İçi Kavramların Hassas Silinmesi: “Precise In-Parameter Concept Erasure in Large Language Models” başlıklı makale, parametre uzayında kodlanmış kavramların yönlerini doğrudan düzenleyerek model parametrelerindeki tüm kavramları hassas bir şekilde silmek için PISCES çerçevesini önermektedir. Bu yöntem, MLP vektörlerini ayrıştırmak için bir ayrıştırıcı kullanır, hedef kavramla ilişkili özellikleri tanımlar ve model parametrelerinden kaldırır. Deneyler, silme etkisi, özgüllük ve sağlamlık açısından mevcut yöntemlerden daha üstün olduğunu göstermektedir. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: DORI, İnce Taneli Çok Eksenli Algı Görevleriyle MLLM’lerin Yön Anlayışını Ayrıştırma: “Right Side Up? Disentangling Orientation Understanding in MLLMs with Fine-grained Multi-axis Perception Tasks” başlıklı makale, çok modlu büyük dil modellerinin (MLLM) nesne yönünü anlama yeteneğini değerlendirmek amacıyla DORI kıyaslamasını tanıtmaktadır. DORI, ön yüz konumlandırma, döndürme dönüşümü, göreceli yön ilişkileri ve kanonik yön anlama olmak üzere dört boyut içerir. 15 SOTA MLLM test edilmiş ve en iyi modellerin bile ince yön yargılarında önemli sınırlamaları olduğu bulunmuştur. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: LLM’ler Gerçek Dünya Metinlerinden Nedensel İlişkileri Çıkarabilir mi?: “Can Large Language Models Infer Causal Relationships from Real-World Text?” başlıklı makale, LLM’lerin gerçek dünya metinlerinden nedensel ilişkileri çıkarma yeteneğini araştırmaktadır. Araştırmacılar, farklı uzunluklarda, karmaşıklıklarda ve alanlarda metinler içeren, gerçek akademik literatürden türetilmiş bir kıyaslama geliştirmiştir. Deneyler, SOTA LLM’lerin bile bu görevde önemli zorluklarla karşılaştığını, en iyi modelin F1 puanının yalnızca 0.477 olduğunu ve örtük bilgileri işleme, ilgili faktörleri ayırt etme ve dağınık bilgileri bağlama konularındaki zorluklarını ortaya koyduğunu göstermektedir. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: IQBench, İnsan IQ Testleriyle Görsel Dil Modellerinin “Zeka” Seviyesini Değerlendirme: “IQBench: How “Smart’’ Are Vision-Language Models? A Study with Human IQ Tests” başlıklı makale, standartlaştırılmış görsel IQ testleriyle görsel dil modellerinin (VLM) akışkan zekasını değerlendirmeyi amaçlayan yeni bir kıyaslama olan IQBench’i tanıtmaktadır. Bu kıyaslama, görsel merkezli olup, 500 adet elle toplanmış ve açıklanmış görsel IQ sorusu içerir ve modellerin açıklama, problem çözme örüntüleri ve nihai tahmin doğruluğunu değerlendirir. Deneyler, o4-mini, Gemini-2.5-Flash ve Claude-3.7-Sonnet’in iyi performans gösterdiğini, ancak tüm modellerin 3D uzay ve anagram çıkarım görevlerinde zorlandığını göstermektedir. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: PixelThink, Verimli Piksel Zinciri Çıkarımına Doğru: “PixelThink: Towards Efficient Chain-of-Pixel Reasoning” başlıklı makale, dışarıdan tahmin edilen görev zorluğunu ve içeriden ölçülen model belirsizliğini birleştirerek pekiştirmeli öğrenme paradigması içinde çıkarım üretimini düzenleyen PixelThink çözümünü önermektedir. Bu model, sahne karmaşıklığına ve tahmin güvenine göre çıkarım uzunluğunu sıkıştırmayı öğrenir. Aynı zamanda değerlendirme için ReasonSeg-Diff kıyaslaması tanıtılmıştır. Deneyler, bu yöntemin çıkarım verimliliğini ve genel segmentasyon performansını artırdığını göstermektedir. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: Test Zamanı Ölçeklendirmesi Olarak Çoklu Ajan Tartışmasının Yeniden İncelenmesi: Koşullu Etkinliğin Sistematik Bir Çalışması: “Revisiting Multi-Agent Debate as Test-Time Scaling: A Systematic Study of Conditional Effectiveness” başlıklı makale, çoklu ajan tartışmasını (MAD) bir test zamanı hesaplama ölçeklendirme tekniği olarak kavramsallaştırmakta ve farklı koşullar altında (görev zorluğu, model ölçeği, ajan çeşitliliği) kendi kendine ajan yöntemlerine göre etkinliğini sistematik olarak araştırmaktadır. Araştırma, matematiksel çıkarım için MAD avantajının sınırlı olduğunu, ancak sorun zorluğu arttığında veya model yeteneği azaldığında daha etkili olduğunu bulmuştur; güvenlik görevleri için MAD’in işbirlikçi optimizasyonu güvenlik açığını artırabilir, ancak çeşitlendirilmiş yapılandırmalar saldırı başarı oranını azaltmaya yardımcı olur. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: VF-Eval, MLLM’lerin AIGC Videoları Hakkında Geri Bildirim Oluşturma Yeteneğini Değerlendirme: “VF-Eval: Evaluating Multimodal LLMs for Generating Feedback on AIGC Videos” başlıklı makale, çok modlu büyük dil modellerinin (MLLM) yapay zeka tarafından üretilen içerik (AIGC) videolarını yorumlama yeteneğini değerlendirmek için yeni bir kıyaslama olan VF-Eval’ı önermektedir. VF-Eval, tutarlılık doğrulama, hata algılama, hata türü tespiti ve çıkarım değerlendirmesi olmak üzere dört görev içerir. 13 öncü MLLM’nin değerlendirilmesi, en iyi performans gösteren GPT-4.1’in bile tüm görevlerde iyi performans göstermekte zorlandığını ortaya koymuştur. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: SafeScientist, LLM Ajanları ile Risk Farkındalığı Olan Bilimsel Keşiflere Doğru: “SafeScientist: Toward Risk-Aware Scientific Discoveries by LLM Agents” başlıklı makale, yapay zeka güdümlü bilimsel keşiflerde güvenliği ve etik sorumluluğu artırmayı amaçlayan SafeScientist adlı bir yapay zeka bilim insanı çerçevesini tanıtmaktadır. Bu çerçeve, uygunsuz veya yüksek riskli görevleri aktif olarak reddedebilir ve istem izleme, ajan işbirliği izleme, araç kullanımı izleme ve etik denetçi bileşenleri gibi çoklu savunma mekanizmalarıyla araştırma sürecinin güvenliğini vurgular. Aynı zamanda değerlendirme için SciSafetyBench kıyaslaması önerilmiştir. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: CXReasonBench, Göğüs Röntgenlerinde Yapılandırılmış Tanısal Çıkarımı Değerlendirmek için Bir Kıyaslama: “CXReasonBench: A Benchmark for Evaluating Structured Diagnostic Reasoning in Chest X-rays” başlıklı makale, büyük görsel dil modellerinin (LVLM) göğüs röntgeni tanısında klinik olarak etkili çıkarım adımlarını gerçekleştirip gerçekleştiremediğini değerlendirmek için CheXStruct sürecini ve CXReasonBench kıyaslamasını tanıtmaktadır. Bu kıyaslama, 12 tanısal görevi ve 1200 vakayı kapsayan 18988 Soru-Cevap çifti içerir ve anatomik bölge seçimi ve tanısal ölçümlerin görsel lokalizasyonu dahil olmak üzere çok yollu, çok aşamalı değerlendirmeyi destekler. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: ZeroGUI, Sıfır İnsan Maliyetiyle Çevrimiçi GUI Öğrenimini Otomatikleştirme: “ZeroGUI: Automating Online GUI Learning at Zero Human Cost” başlıklı makale, sıfır insan maliyetiyle GUI ajan eğitimini otomatikleştirmek için ölçeklenebilir bir çevrimiçi öğrenme çerçevesi olan ZeroGUI’yi önermektedir. ZeroGUI, VLM tabanlı otomatik görev oluşturma, otomatik ödül tahmini ve iki aşamalı çevrimiçi pekiştirmeli öğrenmeyi entegre ederek GUI ortamlarıyla sürekli etkileşim kurar ve onlardan öğrenir. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: Spatial-MLLM, MLLM’lerin Görsel Uzamsal Zekasını Artırma: “Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence” başlıklı makale, yalnızca 2D gözlemlerden görsel tabanlı uzamsal çıkarım yapmak için Spatial-MLLM çerçevesini önermektedir. Bu çerçeve, çift kodlayıcı mimarisi (bir semantik görsel kodlayıcı ve bir uzamsal kodlayıcı) ve uzamsal farkındalığa sahip kare örnekleme stratejisi kullanarak birden fazla gerçek dünya veri kümesinde SOTA performansı elde etmektedir. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: TrustVLM, Görsel Dil Modeli Tahminlerinin Güvenilir Olup Olmadığını Belirleme: “To Trust Or Not To Trust Your Vision-Language Model’s Prediction” başlıklı makale, görsel dil modellerinin (VLM) tahminlerinin güvenilirliğini değerlendirmeyi amaçlayan, eğitimsiz bir çerçeve olan TrustVLM’i tanıtmaktadır. Bu yöntem, görüntü gömme uzayındaki kavram temsili farklılıklarını kullanarak yanlış sınıflandırma tespitini iyileştirmek için yeni güven puanı fonksiyonları önerir ve 17 farklı veri kümesinde SOTA performansı sergiler. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: MAGREF, Maske Kılavuzlu Çoklu Referanslı Video Üretimi: “MAGREF: Masked Guidance for Any-Reference Video Generation” başlıklı makale, birleşik bir çoklu referanslı video üretim çerçevesi olan MAGREF’i önermektedir. Bölgesel farkındalığa sahip dinamik maskeler ve piksel düzeyinde kanal birleştirme yoluyla maske kılavuz mekanizmasını sunarak, çeşitli referans görüntüler ve metin istemleri koşullarında tutarlı çoklu nesne video sentezini gerçekleştirir ve çoklu nesne video kıyaslamalarında mevcut açık kaynak ve ticari temelleri aşar. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: ATLAS, Test Zamanında Bağlamı Optimum Şekilde Ezberlemeyi Öğrenme: “ATLAS: Learning to Optimally Memorize the Context at Test Time” başlıklı makale, mevcut ve geçmiş tokenlara göre belleği optimize ederek bağlamı ezberlemeyi öğrenen ve uzun süreli bellek modellerinin çevrimiçi güncelleme özelliğinin üstesinden gelen yüksek kapasiteli bir uzun süreli bellek modülü olan ATLAS’ı önermektedir. Buna dayanarak yazarlar, DeepTransformers mimari ailesini önermektedir. Deneyler, ATLAS’ın dil modelleme, sağduyu çıkarımı, yoğun geri çağırma ve uzun bağlam anlama görevlerinde Transformers ve son dönem doğrusal döngüsel modelleri aştığını göstermektedir. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: Satori-SWE, Örnek Verimli Evrimsel Test Zamanı Ölçeklendirmeli Yazılım Mühendisliği Yöntemi: “Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering” başlıklı makale, kod üretimini evrimsel bir süreç olarak ele alarak ve çıktıları yinelemeli olarak optimize ederek küçük modellerin yazılım mühendisliği görevlerindeki (SWE-Bench gibi) performansını artırmak için EvoScale yöntemini önermektedir. Satori-SWE-32B modeli bu yöntemle, az sayıda örnek kullanarak, parametre sayısı 100B’yi aşan modellerin performansına ulaşmış veya onu geçmiştir. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: OPO, Optimum Ödül Taban Çizgisine Sahip Politika Üzeri Pekiştirmeli Öğrenme: “On-Policy RL with Optimal Reward Baseline” başlıklı makale, mevcut RL algoritmalarının LLM’leri eğitirken karşılaştığı eğitim istikrarsızlığı ve düşük hesaplama verimliliği sorunlarını çözmeyi amaçlayan yeni, basitleştirilmiş bir pekiştirmeli öğrenme algoritması olan OPO’yu önermektedir. OPO, hassas politika üzeri eğitimi vurgular ve teorik olarak gradyan varyansını en aza indiren optimum bir ödül taban çizgisi sunar. Deneyler, matematiksel çıkarım kıyaslamalarında üstün performans ve eğitim istikrarı gösterdiğini ortaya koymaktadır. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: SWE-bench Canlı Yayında! Gerçek Zamanlı Güncellenen Yazılım Mühendisliği Kıyaslaması: “SWE-bench Goes Live!” başlıklı makale, mevcut SWE-bench sınırlamalarının üstesinden gelmeyi amaçlayan gerçek zamanlı güncellenebilir bir kıyaslama olan SWE-bench-Live’ı tanıtmaktadır. Yeni sürüm, 2024’ten bu yana gerçek GitHub sorunlarından kaynaklanan 1319 görev içermekte, 93 depoyu kapsamakta ve ölçeklenebilirlik ve sürekli güncelleme sağlamak için otomatikleştirilmiş yönetim süreçleriyle donatılmıştır, böylece daha sıkı, kirlenmeye karşı dirençli LLM ve ajan değerlendirmesi sunmaktadır. (Kaynak: HuggingFace Daily Papers, _akhaliq)
Yapay Zeka Makale Özeti: ToMAP, Zihin Teorisi ile Rakip Farkındalığı Olan LLM İkna Edicilerini Eğitme: “ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind” başlıklı makale, iki zihin teorisi modülünü entegre ederek daha esnek ikna ajanları oluşturmak ve rakibin zihinsel durumuna ilişkin farkındalıklarını ve analizlerini artırmak için ToMAP adlı yeni bir yöntemi tanıtmaktadır. Deneyler, yalnızca 3B parametreli ToMAP ikna edicilerinin, birden fazla ikna nesnesi modelinde ve korpusunda GPT-4o gibi büyük temellerden daha iyi performans gösterdiğini ortaya koymaktadır. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: LLM’ler CLIP’i Aldatabilir mi? Metin Güncellemeleri Yoluyla Önceden Eğitilmiş Çok Modlu Temsillerin Çelişkili Kompozisyonelliğini Kıyaslama: “Can LLMs Deceive CLIP? Benchmarking Adversarial Compositionality of Pre-trained Multimodal Representation via Text Updates” başlıklı makale, LLM’leri kullanarak CLIP gibi önceden eğitilmiş çok modlu temsillerin kompozisyonellik açıklarından yararlanmak için aldatıcı metin örnekleri üreten Çok Modlu Çelişkili Kompozisyonellik (MAC) kıyaslamasını tanıtmaktadır. Araştırma, saldırı başarı oranını ve örnek çeşitliliğini artırmak için çeşitliliği teşvik eden filtrelemeyle reddetme örneklemesi ince ayarı yoluyla kendi kendine eğitim yöntemi önermektedir. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: Gürültülü Ödüllerin Akıl Yürütmeyi Öğrenmedeki Rolü – Zirveye Giden Yol, Zirveden Daha Derin Bilgelik Kazır: “The Climb Carves Wisdom Deeper Than the Summit: On the Noisy Rewards in Learning to Reason” başlıklı makale, ödül gürültüsünün LLM’lerin pekiştirmeli öğrenme yoluyla akıl yürütme sonrası eğitimi üzerindeki etkisini incelemektedir. Araştırma, LLM’lerin büyük miktarda ödül gürültüsüne karşı güçlü bir sağlamlık sergilediğini ve yalnızca kritik akıl yürütme ifadelerinin varlığını ödüllendirerek (cevap doğruluğunu doğrulamadan) bile, modelin sıkı doğrulama ve doğru ödüllerle eğitilen modellerle karşılaştırılabilir bir performansa ulaşabildiğini bulmuştur. (Kaynak: HuggingFace Daily Papers)
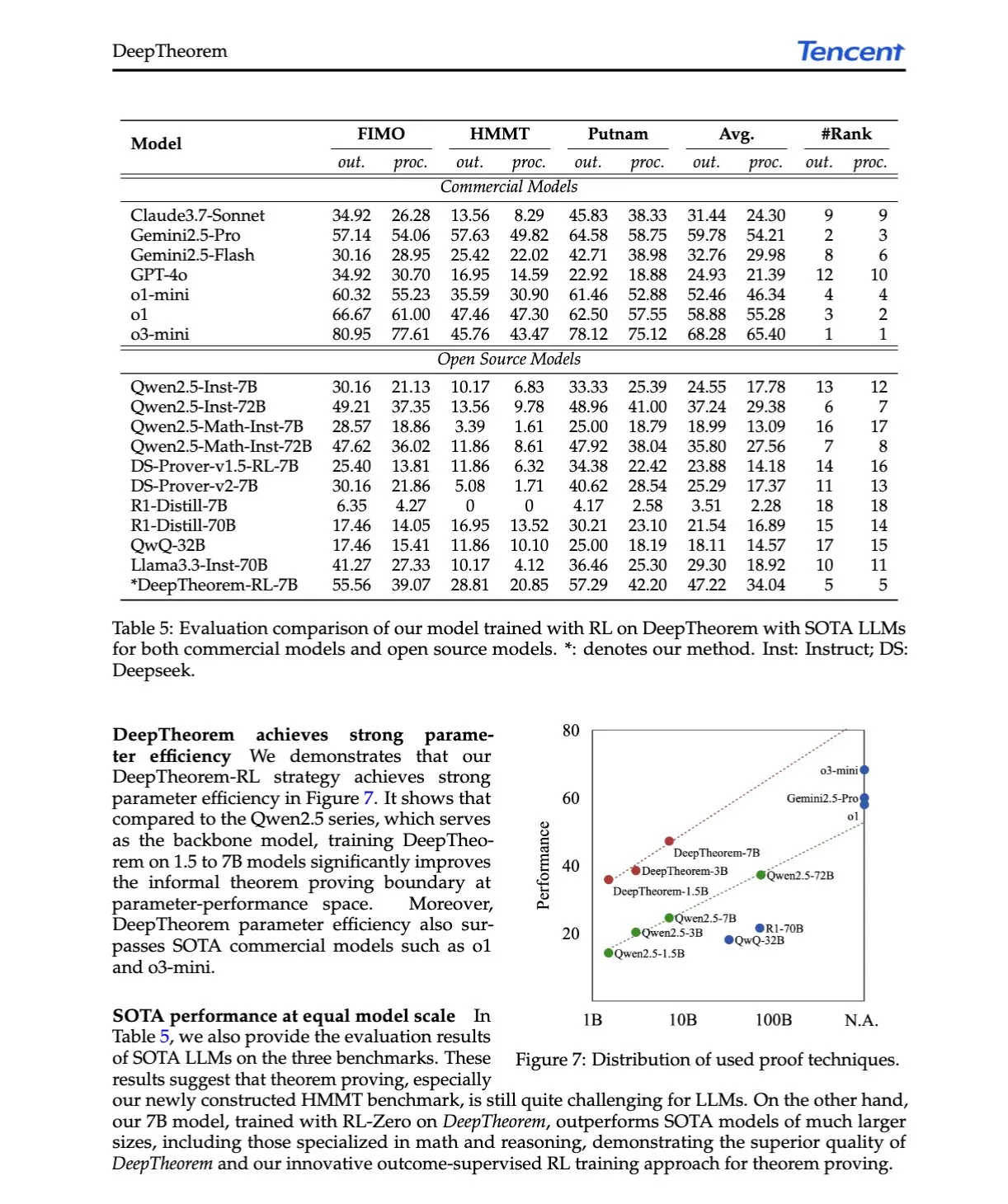
Yapay Zeka Makale Özeti: DeepTheorem, Doğal Dil ve Pekiştirmeli Öğrenme Yoluyla LLM Teorem Kanıtlamasını Geliştirme: “DeepTheorem: Advancing LLM Reasoning for Theorem Proving Through Natural Language and Reinforcement Learning” başlıklı makale, doğal dili kullanarak LLM matematiksel çıkarımını geliştiren gayri resmi bir teorem kanıtlama çerçevesi olan DeepTheorem’u önermektedir. Bu çerçeve, büyük ölçekli bir kıyaslama veri kümesi (121.000 IMO düzeyinde gayri resmi teorem ve kanıt) ve gayri resmi teorem kanıtlaması için özel olarak tasarlanmış bir RL stratejisi (RL-Zero) içerir. (Kaynak: HuggingFace Daily Papers, teortaxesTex)
Yapay Zeka Makale Özeti: D-AR, Otoregresif Modeller Yoluyla Difüzyon: “D-AR: Diffusion via Autoregressive Models” başlıklı makale, görüntü difüzyon sürecini standart otoregresif sonraki token tahmin sürecine dönüştüren yeni bir paradigma olan D-AR’ı önermektedir. Tasarlanan bir tokenizer aracılığıyla görüntüler ayrık token dizilerine dönüştürülür ve farklı konumlardaki tokenlar, piksel uzayında farklı difüzyon gürültü giderme adımlarına çözülebilir. Bu yöntem, ImageNet üzerinde 775M Llama omurgası ve 256 ayrık token kullanarak 2.09 FID’ye ulaşmıştır. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: Table-R1, Tablo Çıkarımı için Çıkarım Zamanı Ölçeklendirmesi: “Table-R1: Inference-Time Scaling for Table Reasoning” başlıklı makale, tablo çıkarım görevlerinde çıkarım zamanı ölçeklendirmesini ilk kez araştırmaktadır. Araştırmacılar, iki son eğitim stratejisi geliştirmiş ve değerlendirmiştir: öncü modellerin çıkarım yörüngelerinden damıtma (Table-R1-SFT) ve doğrulanabilir ödüllerle pekiştirmeli öğrenme (Table-R1-Zero). Table-R1-Zero (7B parametre), çeşitli tablo çıkarım görevlerinde GPT-4.1 ve DeepSeek-R1’in performansına ulaşmış veya onu geçmiştir. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: Muddit, Metinden Görüntüye Üretimin Ötesinde Birleşik Ayrık Difüzyon Modeli: “Muddit: Liberating Generation Beyond Text-to-Image with a Unified Discrete Diffusion Model” başlıklı makale, metin ve görüntü modalitelerinin hızlı paralel üretimini destekleyen birleşik bir ayrık difüzyon Transformer modeli olan Muddit’i tanıtmaktadır. Muddit, önceden eğitilmiş metinden görüntüye omurga ağlarının güçlü görsel ön bilgilerini ve hafif bir metin kod çözücüyü entegre ederek hem kalite hem de verimlilik açısından rekabetçidir. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: VideoReasonBench, MLLM’ler Görsel Merkezli Karmaşık Video Çıkarımı Yapabilir mi?: “VideoReasonBench: Can MLLMs Perform Vision-Centric Complex Video Reasoning?” başlıklı makale, görsel merkezli karmaşık video çıkarım yeteneklerini değerlendirmeyi amaçlayan bir kıyaslama olan VideoReasonBench’i tanıtmaktadır. Bu kıyaslama, ince taneli işlem dizilerine sahip videoları içerir ve sorular hatırlama, çıkarım yapma ve tahmin etme yeteneklerini değerlendirir. Deneyler, çoğu SOTA MLLM’nin bu kıyaslamada düşük performans gösterdiğini, düşünceyle geliştirilmiş Gemini-2.5-Pro’nun ise öne çıktığını göstermektedir. (Kaynak: HuggingFace Daily Papers, OriolVinyalsML)
Yapay Zeka Makale Özeti: GeoDrive, Hassas Eylem Kontrolüne Sahip 3D Geometri Bilgili Sürüş Dünya Modeli: “GeoDrive: 3D Geometry-Informed Driving World Model with Precise Action Control” başlıklı makale, uzamsal anlayışı ve eylem kontrol edilebilirliğini artırmak için sağlam 3D geometri koşullarını sürüş dünya modeline açıkça entegre eden GeoDrive’ı önermektedir. Bu yöntem, eğitimde oluşturma efektlerini geliştirmek için dinamik bir düzenleme modülü kullanır. Deneyler, eylem doğruluğu ve 3D uzamsal algı açısından mevcut modellerden daha üstün olduğunu kanıtlamaktadır. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: Dinamik Düşük Güven Maskelemesi ile Uyarlanabilir Sınıflandırıcısız Kılavuzluk: “Adaptive Classifier-Free Guidance via Dynamic Low-Confidence Masking” başlıklı makale, modelin anlık tahmin güvenini kullanarak sınıflandırıcısız kılavuzluğun (CFG) koşulsuz girdisini özelleştirmek için A-CFG yöntemini önermektedir. A-CFG, yinelemeli (maskeli) difüzyon dil modelinin her adımında düşük güvenli tokenları tanımlar ve geçici olarak yeniden maskeler, böylece CFG’nin düzeltici etkisini daha hassas hale getiren dinamik, yerelleştirilmiş koşulsuz girdiler oluşturur. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: PatientSim, Gerçekçi Doktor-Hasta Etkileşimleri için Karakter Odaklı Bir Simülatör: “PatientSim: A Persona-Driven Simulator for Realistic Doctor-Patient Interactions” başlıklı makale, MIMIC veri kümesindeki klinik profillere ve dört eksenli karakterlere (kişilik, dil yeterliliği, hastalık geçmişi hatırlama düzeyi, bilişsel karışıklık düzeyi) dayalı olarak gerçekçi ve çeşitli hasta karakterleri üreten PatientSim’i tanıtmaktadır. Amaç, doktor LLM’lerini eğitmek veya değerlendirmek için gerçekçi hasta etkileşim sistemleri sağlamaktır. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: LoRAShop, Düzeltilmiş Akış Transformatörleri ile Eğitimsiz Çoklu Kavramlı Görüntü Üretimi ve Düzenlemesi: “LoRAShop: Training-Free Multi-Concept Image Generation and Editing with Rectified Flow Transformers” başlıklı makale, LoRA modellerini kullanarak çoklu kavramlı görüntü düzenlemesi için ilk çerçeve olan LoRAShop’u tanıtmaktadır. Bu çerçeve, Flux tarzı difüzyon transformatörünün iç özellik etkileşim örüntülerini kullanarak her kavram için ayrıştırılmış gizli maskeler türetir ve LoRA ağırlıklarını yalnızca kavram bölgelerinde karıştırarak çoklu nesne veya stillerin sorunsuz entegrasyonunu sağlar. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: AnySplat, Kısıtlanmamış Görünümlerden İleri Beslemeli 3D Gauss Sıçratma: “AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views” başlıklı makale, kalibre edilmemiş görüntü kümelerinden yeni bakış açısı sentezi için ileri beslemeli bir ağ olan AnySplat’ı tanıtmaktadır. Geleneksel sinirsel oluşturma süreçlerinden farklı olarak AnySplat, tek bir ileri yayılımla 3D Gauss temellerini (sahne geometrisini ve görünümünü kodlayan) ve her giriş görüntüsünün kamera iç ve dış parametrelerini tahmin edebilir, poz etiketlemesine ihtiyaç duymaz ve gerçek zamanlı yeni bakış açısı sentezini destekler. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: ZeroSep, Sıfır Eğitimle Sesteki Her Şeyi Ayırma: “ZeroSep: Separate Anything in Audio with Zero Training” başlıklı makale, yalnızca önceden eğitilmiş metin kılavuzlu ses difüzyon modellerinin belirli yapılandırmalarda sıfır örnekli ses kaynağı ayırma gerçekleştirebildiğini bulmuştur. ZeroSep yöntemi, karışık sesi difüzyon modelinin gizli uzayına ters çevirerek ve metin koşullu kılavuzlukla gürültü giderme sürecini yönlendirerek tek tek ses kaynaklarını kurtarır; herhangi bir özel görev eğitimi veya ince ayar gerektirmez. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: Tek Örnekli Entropi Minimizasyonu Araştırması: “One-shot Entropy Minimization” başlıklı makale, 13440 büyük dil modelini eğiterek entropi minimizasyonunun yalnızca tek bir etiketsiz veri ve 10 adımlık optimizasyonla, binlerce veri ve özenle tasarlanmış ödüller kullanan kural tabanlı pekiştirmeli öğrenmenin elde edebileceği performans iyileştirmelerine ulaşabileceğini, hatta aşabileceğini bulmuştur. Bu sonuç, LLM son eğitim paradigmalarının yeniden düşünülmesine yol açabilir. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: ChartLens, Grafiklerde İnce Taneli Görsel Atfetme: “ChartLens: Fine-grained Visual Attribution in Charts” başlıklı makale, MLLM’lerin grafik anlamada halüsinasyon üretme eğilimine karşı, grafik sonrası görsel atfetme görevini ve ChartLens algoritmasını tanıtmaktadır. Bu algoritma, grafik nesnelerini tanımlamak için segmentasyon tekniklerini kullanır ve işaretleyici kümesi istemleriyle MLLM ile ince taneli görsel atfetme gerçekleştirir. Aynı zamanda finans, politika, ekonomi gibi alanlardaki grafiklerin ince taneli atfetme açıklamalarını içeren ChartVA-Eval kıyaslaması yayınlanmıştır. (Kaynak: HuggingFace Daily Papers)
Yapay Zeka Makale Özeti: Büyük Dil Modellerinde Bilginin Yapısal Örüntülerini Grafik Perspektifinden Keşfetme: “A Graph Perspective to Probe Structural Patterns of Knowledge in Large Language Models” başlıklı makale, LLM’lerdeki bilginin yapısal örüntülerini grafik perspektifinden incelemektedir. Araştırma, LLM’lerin üçlü ve varlık düzeyindeki bilgisini nicelleştirir, düğüm derecesi gibi grafik yapısal özellikleriyle ilişkisini analiz eder ve bilgi homojenliğini (topolojik olarak yakın varlıkların benzer bilgi düzeyine sahip olması) ortaya çıkarır. Buna dayanarak varlık bilgisini tahmin etmek ve bilgi kontrolü için kullanmak üzere grafik makine öğrenimi modelleri geliştirilmiştir. (Kaynak: HuggingFace Daily Papers)
💼 İş Dünyası
Cisimleşmiş zeka şirketi Lumos Robotics, yarım yılda yaklaşık 200 milyon yuan finansman sağladı ve COSCO Shipping gibi şirketlerle iş birliği yaptı: Eski Dreame yöneticisi Yu Chao tarafından kurulan cisimleşmiş zeka robot şirketi Lumos Robotics (鹿明机器人), Fosun RZ Capital, Dematic ve Wuzhong Financial Holding’in yatırım yaptığı Melek++ turu finansmanını tamamladığını duyurdu. Şirket, yarım yılda toplamda yaklaşık 200 milyon yuan finansman sağladı. Aile senaryolarına odaklanan şirket, LUS, MOS serisi insansı robotlar ve temel bileşenler dahil olmak üzere ürünlere sahip. Tam boyutlu insansı robot LUS’u piyasaya sürdü ve cisimleşmiş zekanın lojistik ve akıllı üretim gibi senaryolarda ticarileşmesini hızlandırmak için Dematic, COSCO Shipping gibi şirketlerle stratejik iş birlikleri yaptı. (Kaynak: 36氪)

Snorkel AI, 100 milyon dolarlık D Serisi finansman turunu tamamladı ve yapay zeka ajanı değerlendirme ile uzman veri hizmetlerini başlattı: Veri merkezi yapay zeka şirketi Snorkel AI, Valor Equity Partners liderliğindeki 100 milyon dolarlık D Serisi finansman turunu tamamladığını ve toplam finansmanının 235 milyon dolara ulaştığını duyurdu. Aynı zamanda şirket, işletmelerin daha güvenilir ve profesyonel yapay zeka ajanları oluşturmasına ve dağıtmasına yardımcı olmak amacıyla Snorkel Evaluate (veri merkezi ajanı yapay zeka değerlendirme platformu) ve Expert Data-as-a-Service (uzman veri hizmeti) hizmetlerini başlattı. (Kaynak: realDanFu, percyliang, tri_dao, krandiash)
ABD Enerji Bakanlığı, Dell ve Nvidia ile yeni nesil süper bilgisayar “Doudna”yı geliştirmek için iş birliği yapacağını duyurdu: ABD Enerji Bakanlığı, Lawrence Berkeley Ulusal Laboratuvarı için “Doudna” adlı yeni nesil amiral gemisi süper bilgisayarı NERSC-10’u geliştirmek üzere Dell şirketiyle bir sözleşme imzaladığını duyurdu. Sistem, Nvidia’nın yeni nesil Vera Rubin platformu tarafından desteklenecek ve 2026’da kullanıma girmesi bekleniyor. Performansının mevcut amiral gemisi Perlmutter’ın 10 katından fazla olması hedefleniyor ve büyük ölçekli yüksek performanslı bilgi işlem ve yapay zeka iş yüklerini destekleyerek ABD’nin küresel yapay zeka hakimiyeti yarışını kazanmasına yardımcı olması amaçlanıyor. (Kaynak: 36氪, nvidia)

🌟 Topluluk
DeepSeek R1-0528, performans, halüsinasyon ve araç çağırma konularıyla hararetli tartışmalara yol açtı: DeepSeek R1-0528’in yayınlanması toplulukta geniş çaplı tartışmalara neden oldu. Çoğu görüş, matematik, programlama ve genel mantıksal çıkarım konularında önemli gelişmeler kaydettiğini, hatta bazı kapalı kaynak modelleri yakaladığını veya aştığını belirtiyor. Yeni sürüm, halüsinasyon oranını düşürmede ilerleme kaydetti ve JSON çıktısı ile fonksiyon çağırma desteği ekledi. Aynı zamanda, damıtılmış Qwen3-8B sürümü de küçük modellerdeki üstün matematiksel performansı nedeniyle dikkat çekti. Topluluk genel olarak DeepSeek’in açık kaynak alanındaki liderliğini pekiştirdiğini düşünüyor ve R2 sürümünün yayınlanmasını bekliyor. (Kaynak: ClementDelangue, dotey, scaling01, awnihannun, karminski3, teortaxesTex, scaling01, karminski3, teortaxesTex, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Yapay zeka görüntü düzenleme modeli FLUX.1 Kontext ilgi görüyor, bağlam anlama ve karakter tutarlılığı vurgulanıyor: Black Forest Labs tarafından yayınlanan FLUX.1 Kontext görüntü düzenleme modeli, hem metin hem de görüntü girdilerini aynı anda işleyebilmesi ve karakter tutarlılığını koruyabilmesi nedeniyle toplulukta ilgi gördü. Kullanıcı geri bildirimleri, görüntü düzenleme, stil aktarımı ve metin yerleştirme gibi görevlerde üstün performans sergilediğini, özellikle çok turlu düzenlemelerde ana nesne özelliklerini iyi koruduğunu gösteriyor. Replicate gibi platformlar modeli kullanıma sundu ve ayrıntılı test raporları ile kullanım ipuçları sağladı. (Kaynak: TomLikesRobots, two_dukes, robrombach, timudk, robrombach, cloneofsimo, robrombach, robrombach)

Yapay zeka ajanları arama ve reklam modellerini önemli ölçüde değiştirecek: Perplexity AI CEO’su Arav Srinivas’a göre, yapay zeka ajanları kullanıcılar adına arama yaptıkça, Google gibi arama motorlarındaki insan sorgu hacmi önemli ölçüde düşecek. Bu durum, reklam CPM/CPC’lerinin düşmesine ve reklam harcamalarının sosyal medyaya veya yapay zeka platformlarına kaymasına neden olabilir. Kullanıcılar artık sık sık anahtar kelime araması yapmak yerine, yapay zeka asistanları tarafından proaktif olarak bilgi alacaklar. (Kaynak: AravSrinivas)
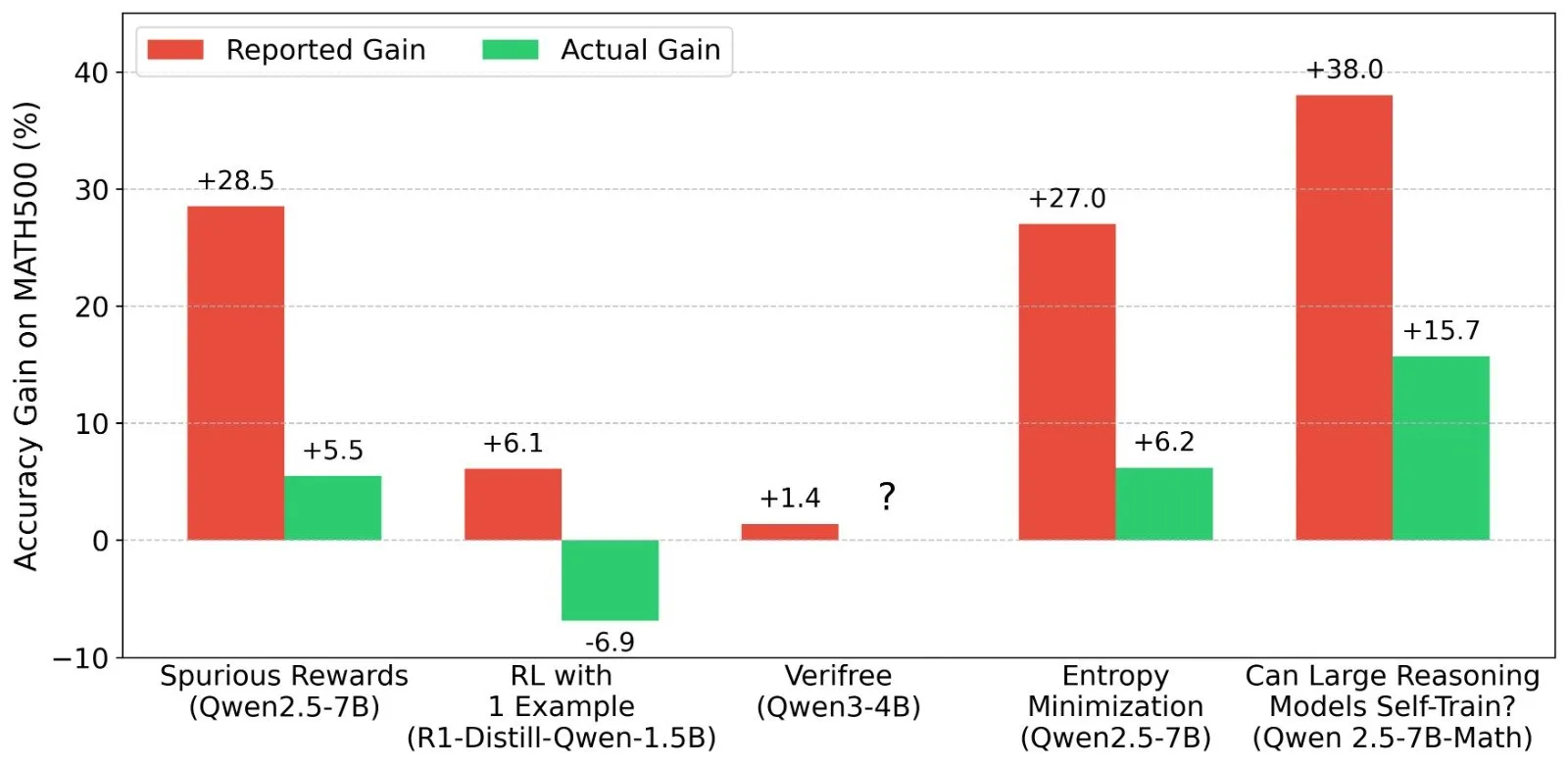
LLM pekiştirmeli öğrenme (RL) sonuçları üzerine tartışma: ödül sinyalleri ve model yeteneklerinin gerçekliği: Shashwat Goel ve diğer araştırmacılar, son LLM RL araştırmalarında modellerin gerçek ödül sinyalleri olmadan bile performans artışı göstermesi olgusuna şüpheyle yaklaşıyor ve bazı araştırmaların önceden eğitilmiş modellerin temel yeteneklerini hafife almış olabileceğini veya başka karıştırıcı faktörlerin bulunabileceğini belirtiyor. Tartışma, Qwen gibi modellerin RL’deki performansının derinlemesine analiz edilmesine ve RLVR’nin (doğrulanabilir ödül pekiştirmeli öğrenme) etkinliği üzerine düşünülmesine yol açtı; RL etkilerini değerlendirirken daha sıkı temel çizgiler ve komut istemi optimizasyonunun gerekliliğini vurguladı. (Kaynak: menhguin, AndrewLampinen, lateinteraction, madiator, vikhyatk, matei_zaharia, hrishioa, iScienceLuvr)
“Vibe Coding” tartışmalara yol açtı, güvenli varsayılanlar ve teknik borç riskleri vurgulandı: “Vibe coding” (sezgiye ve hızlı iterasyona daha fazla dayanan, katı kurallardan ziyade atmosfer programlaması) toplulukta tartışma konusu oldu. Replit CEO’su Amjad Masad, bu yöntemin yeni geliştiricilere güç verdiğini ancak platformların güvenli varsayılan yapılandırmalar sunması gerektiğini belirtti. Aynı zamanda Pedro Domingos, “atmosfer programlaması teknik borcun Godzilla’sıdır” yorumunu yaparak bunun uzun vadeli bakım sorunlarına yol açabileceğini ima etti. Semafor’un Lovable’ın RLS stratejisi yapılandırmasındaki bir güvenlik açığı nedeniyle yaşadığı sorunu bildirmesi, bu programlama yönteminin güvenliği konusundaki endişeleri daha da artırdı. (Kaynak: alexalbert__, amasad, pmddomingos, gfodor)
Yazılım mühendisliğinde yapay zekanın rolü: verimlilik artışı ve insan programcıların yeri doldurulamazlığı: Redis’in yaratıcısı Salvatore Sanfilippo, yapay zekanın (Gemini 2.5 Pro gibi) programlama yardımı, kod incelemesi ve fikir doğrulama konularında değerli olmasına rağmen, insan programcıların yaratıcı problem çözme ve kalıpların dışında düşünme konularında yapay zekadan çok daha üstün olduğunu paylaştı. Topluluk tartışmaları, yapay zekanın şu anda daha çok “akıllı lastik ördek” gibi olduğunu, düşünmeye yardımcı olabileceğini ancak önerilerinin dikkatle değerlendirilmesi gerektiğini ve aşırı bağımlılığın geliştiricilerin temel yeteneklerini zayıflatabileceğini belirtti. Mitchell Hashimoto da LLM’lerin Clang derleme sorunlarını hızla bulmasına yardımcı olduğu ve önemli ölçüde zaman kazandırdığı bir örneği paylaştı. (Kaynak: mitchellh, 36氪)
Yapay zekanın büyük ölçekte işleri devralıp almayacağı sürekli ilgi çekiyor: Anthropic CEO’su Dario Amodei, yapay zekanın giriş seviyesi ofis pozisyonlarının yarısını ortadan kaldırabileceğini öngörürken, Mark Cuban yapay zekanın yeni şirketler ve yeni işler yaratacağını düşünüyor. Topluluk bu konuda hararetli bir şekilde tartışıyor; müşteri hizmetleri, başlangıç seviyesi metin yazarlığı, bazı geliştirme işleri gibi alanların şimdiden etkilendiği, ancak yapay zekanın yaratıcılık, karmaşık karar verme ve yüksek düzeyde kişilerarası etkileşim gerektiren alanlarda henüz insanın yerini alamayacağı görüşleri mevcut. Genel kanı, yapay zekanın işin doğasını değiştireceği ve insanların yapay zeka ile iş birliği yapma yeteneklerini uyarlaması ve geliştirmesi gerektiği yönünde. (Kaynak: Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ArtificialInteligence)
AI Agent (akıllı ajanlar) yeni nesil etkileşim girişi haline geliyor ve büyük şirketlerin rekabetine yol açıyor: Microsoft, Google, OpenAI, Alibaba, Tencent, Baidu, Coocaa gibi yerli ve yabancı teknoloji şirketleri AI Agent alanına yatırım yapıyor. Akıllı ajanlar derinlemesine düşünebiliyor, otonom olarak planlayabiliyor, karar alabiliyor ve karmaşık görevleri yerine getirebiliyor; arama motorları ve uygulamalardan sonraki yeni nesil etkileşim girişi olarak görülüyorlar. Şu anda üç ana güç oluşmuş durumda: OpenAI ve Baidu gibi teknoloji ekosistemi kurucuları; Microsoft ve Alibaba Cloud gibi dikey senaryolarda kurumsal hizmet sağlayıcıları; ve Huawei ve Coocaa gibi yazılım ve donanım terminal üreticileri. (Kaynak: 36氪)

💡 Diğer
Çin yapay zekasının denizaşırı açılımı hızlanıyor, ürün ihracatından ekosistem oluşturmaya doğru kayıyor: “Çin Yapay Zekasının Okyanus Ötesi Büyümesi” raporu, Çin yapay zeka şirketlerinin denizaşırı açılımının ölçekli bir hızlı şeride girdiğini ve %76’sının uygulama düzeyinde yoğunlaştığını belirtiyor. Denizaşırı açılım yolu, erken dönem araç tipi uygulamalardan, orta dönemde teknoloji avantajlarını birleştirerek sektör çözümleri ihraç etmeye doğru gelişti ve şu anda teknoloji standartlarını ve açık kaynak iş birliğini teşvik ederek teknoloji ekosisteminin denizaşırı açılımına odaklanıyor. Yapay zekanın denizaşırı açılımı “yakından uzağa” doğru kademeli bir sızma gösteriyor ve yerelleştirme, uyumluluk etiği ve marka pazarlaması gibi zorluklarla karşılaşıyor. (Kaynak: 36氪)

ABD Enerji Bakanlığı, yapay zeka yarışını “yeni Manhattan Projesi”ne benzetti ve ABD’nin kazanacağını vurguladı: ABD Enerji Bakanlığı, yeni nesil süper bilgisayar “Doudna”yı duyururken, yapay zeka geliştirme yarışını “çağımızın Manhattan Projesi” olarak adlandırdı ve ABD’nin bu yarışta kazanacağını ilan etti. Bu açıklama, toplulukta büyük güçlerin teknoloji rekabeti, yapay zeka etiği ve uluslararası iş birliği hakkında tartışmalara yol açtı. (Kaynak: gfodor, teortaxesTex, andrew_n_carr, npew, jpt401)
Yapay zekanın içerik oluşturma alanındaki ilerlemesi “gerçeklik” ve “yaratıcılık” hakkında düşüncelere yol açıyor: Topluluk, yapay zekanın moda tasarımı, çizgi roman oluşturma, video üretimi gibi alanlardaki uygulamalarını tartıştı. Bir yandan yapay zeka, çeşitli içerikleri hızla üretebiliyor, hatta birkaç yıl önceki çizgi roman çalışmalarını videoya dönüştürebiliyor; diğer yandan, bu üretilen içerikler bazen tuhaf veya derinlikten yoksun görünebiliyor. Bu durum, yapay zeka tarafından üretilen içeriğin “daha iyi” olup olmadığı ve insan yaratıcılığının yapay zeka çağında nasıl bir rol oynayacağı hakkında düşüncelere yol açtı. (Kaynak: Reddit r/ChatGPT, Reddit r/artificial)
