Anahtar Kelimeler:RLHF, RLAIF, Qwen2.5-Math-7B, MATH-500, Rasgele ödül, Hatalı ödül, Model performansı, Pekiştirmeli öğrenme, RLHF/RLAIF’nin geleceği, Rasgele ödülle model performansını artırma, Hatalı ödülle Qwen2.5-Math-7B eğitimi, MATH-500 test seti, Pekiştirmeli öğrenme sinyal öğrenimi
🔥 Odak Noktası
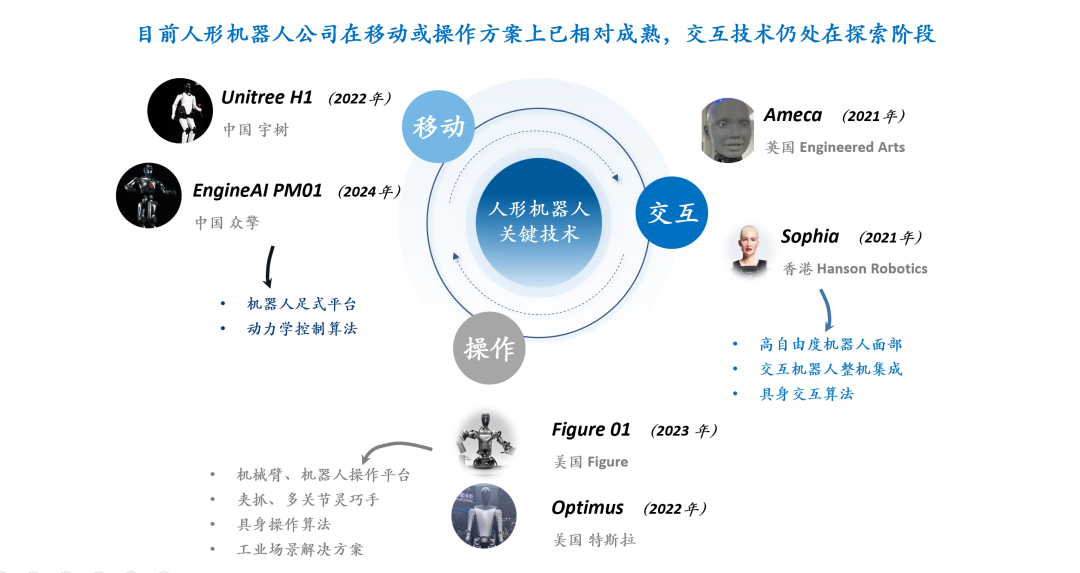
RLHF/RLAIF’in geleceği: Rastgele/yanlış ödüller de model performansını artırabilir mi? : Stella Li’nin deneyi, Qwen2.5-Math-7B modelini rastgele ödüllerle veya yanlış ödüllerle eğitmenin, MATH-500 test setinde sırasıyla %21 ve %25’lik bir iyileşme sağladığını ve gerçek ödüllerle elde edilen %28.8’lik iyileşmeye yaklaştığını gösterdi. natolambert tarafından paylaşılan Rulin Shao’nun araştırması da RLVR’nin (Reinforcement Learning from Verifier Reward) sahte ödüller kullanıldığında Olmo modelinin kod kullanımının arttığını ancak performansının düştüğünü, kod kullanımını engellemenin ise performansı artırdığını ortaya koydu. Bu bulgular, geleneksel RLHF/RLAIF’deki yüksek kaliteli insan tercihi verilerine olan bağımlılığa meydan okuyor ve modellerin, ödül sinyalleri aracılığıyla daha geniş bir politika alanını keşfetmeyi öğrenebileceğini, ödüllerin kendisi mükemmel olmasa bile modelin potansiyel yeteneklerini ortaya çıkarabileceğini veya mevcut davranışları optimize edebileceğini ima ediyor. Bu, pahalı manuel etiketlemeye olan bağımlılığı azaltmak ve daha verimli model hizalama yöntemlerini keşfetmek için yeni yollar açabilir, ancak modelin yanlış davranışları öğrenme riskine karşı dikkatli olunması gerekir. (Kaynak: natolambert, teortaxesTex, DhruvBatraDB, Francis_YAO_, raphaelmilliere)
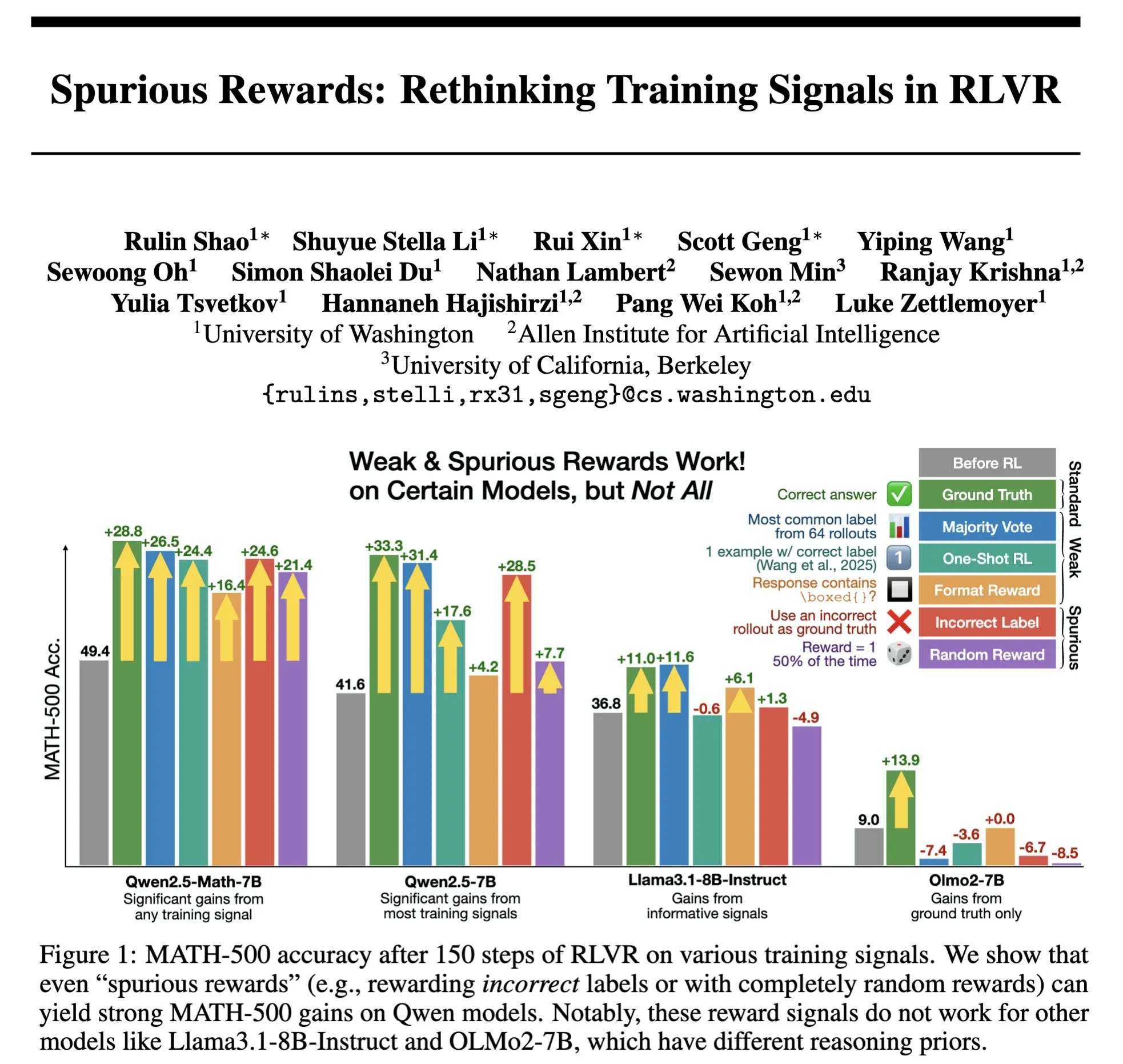
Hazy Research, Low-Latency-Llama Megakernel’i duyurdu: Tek bir CUDA çekirdeği ile Llama 1B çıkarımı : Hazy Research, Llama 1B modelinin tüm ileri yayılım sürecini tek bir CUDA çekirdeği içinde tamamlayabilen Low-Latency-Llama Megakernel’i tanıttı. Bu teknoloji, hesaplamayı tek bir çekirdekte birleştirerek geleneksel serileştirilmiş çekirdek çağrılarının getirdiği senkronizasyon sınırlarını ortadan kaldırıyor, böylece hesaplama ve bellek zamanlamasını optimize ederek daha düşük gecikme sağlıyor. Andrej Karpathy bunu takdirle karşıladı ve bunun hesaplama ile bellek arasında en iyi düzenlemeyi sağlamanın tek yolu olduğunu belirtti. Bu gelişme, uç bilişim, gerçek zamanlı yapay zeka uygulamaları gibi gecikmeye karşı katı gereksinimleri olan senaryolar için büyük önem taşıyor ve daha verimli, daha çevik küçük dil modellerinin dağıtımını teşvik etmesi bekleniyor. (Kaynak: karpathy, teortaxesTex, charles_irl, simran_s_arora)
DeepSeek Qiyuan, rStar-Coder’ı yayınladı: Büyük ölçekli doğrulanmış kod çıkarım veri kümesi oluşturarak küçük modellerin kod yeteneklerini önemli ölçüde artırıyor : Microsoft ve DeepSeek araştırmacıları, mevcut kod çıkarım alanındaki yüksek kaliteli, yüksek zorluktaki veri kümelerinin kıtlığı sorununu çözmeyi amaçlayan rStar-Coder projesini başlattı. Proje, 418.000 yarışma düzeyinde kod sorunu, 580.000 uzun çıkarım çözümü ve zengin test senaryoları içeren büyük ölçekli doğrulanmış bir veri kümesi oluşturarak LLM’lerin kod çıkarım yeteneklerini geliştirmeyi hedefliyor. Proje, mevcut programlama yarışması sorunlarını ve oracle çözümlerini kapsamlı bir şekilde kullanarak yeni sorunlar sentezliyor, güvenilir giriş-çıkış test senaryosu oluşturma hattı tasarlıyor ve test senaryolarını kullanarak yüksek kaliteli uzun çıkarım çözümlerini doğruluyor. Deneyler, rStar-Coder veri kümesiyle eğitilen Qwen modellerinin (1.5B-14B) birden fazla kod çıkarım ölçütünde üstün performans gösterdiğini ortaya koydu. Örneğin, Qwen2.5-7B’nin LiveCodeBench’teki doğruluğu %17.4’ten %57.3’e yükselerek o3-mini (low) modelini geride bıraktı; USACO’da ise 7B modeli daha büyük olan QWQ-32B modelini geçti. (Kaynak: HuggingFace Daily Papers)
Çin Bilimler Akademisi Otomasyon Enstitüsü AutoThink’i önerdi: Büyük modellerin “derinlemesine düşünme” gerekip gerekmediğine kendi kendine karar vermesini sağlıyor : Büyük dil modellerinin basit sorunlarda bile uzun çıkarımlar yaparak “aşırı düşünme” olgusuna yanıt olarak, Çin Bilimler Akademisi Otomasyon Enstitüsü ve Peng Cheng Laboratuvarı ortaklaşa AutoThink yöntemini önerdi. Bu yöntem, istemlere “üç nokta” (…) ekleyerek ve üç aşamalı bir pekiştirmeli öğrenme (model stabilizasyonu, davranış optimizasyonu, çıkarım budaması) ile birleştirerek, modelin soru zorluğuna göre derinlemesine düşünüp düşünmeyeceğini ve ne kadar düşüneceğini bağımsız olarak seçmesini sağlar. Deneyler, AutoThink’in DeepSeek-R1 gibi modellerin matematiksel ölçüt testlerindeki performansını artırdığını ve aynı zamanda çıkarım Token tüketimini önemli ölçüde azalttığını gösterdi. Örneğin, DeepScaleR üzerinde ek olarak %10 Token tasarrufu sağlayabilir. Bu araştırma, modelin “ihtiyaç duyulduğunda düşünmesini” sağlayarak çıkarım verimliliği ve doğruluğu arasındaki dengeyi artırmayı amaçlamaktadır. (Kaynak: 36氪, _akhaliq)

Sakana AI, Sudoku-Bench’i yayınladı ve en iyi büyük modellerin “mutasyonlu sudoku” çıkarımındaki eksikliklerini ortaya koydu : Transformer yazarı Llion Jones’un startup şirketi Sakana AI, yapay zekanın yaratıcı çok adımlı çıkarım yeteneklerini değerlendirmek amacıyla 4×4’ten karmaşık 9×9 modern “mutasyonlu sudoku”ya kadar çeşitli bulmacalar içeren bir ölçüt testi olan Sudoku-Bench’i yayınladı. Test sonuçları, Gemini 2.5 Pro, GPT-4.1, Claude 3.7 dahil olmak üzere en iyi büyük modellerin, yardım almadan genel doğruluk oranının %15’in altında olduğunu gösterdi. 9×9 modern sudokuda, o3 Mini High’ın doğruluk oranı yalnızca %2.9 idi. Bu, modellerin örüntü eşleştirme yerine gerçek mantıksal çıkarım gerektiren yeni sorunlarla karşılaştığında düşük performans gösterdiğini, sık sık yanlış çözümler ürettiğini, pes ettiğini veya kuralları yanlış yorumladığını gösteriyor. NVIDIA CEO’su Jensen Huang, bu tür bulmacaların yapay zeka çıkarımını geliştirmeye yardımcı olduğuna inanıyor. Sakana AI ayrıca, ünlü sudoku kanallarıyla işbirliği içinde hazırlanan çözüm süreci kayıtları da dahil olmak üzere ilgili eğitim verilerini yayınladı. (Kaynak: 36氪)

🎯 Eğilimler
Meta, yapay zeka ekibini yeniden yapılandırıyor, FAIR çekirdek üyelerinin kaybı dikkat çekiyor : Meta, yapay zeka ekibini yeniden yapılandırdığını duyurdu; ekip, Connor Hayes liderliğindeki bir yapay zeka ürün ekibine ve Ahmad Al-Dahle ile Amir Frenkel’in ortak liderliğindeki bir AGI temel departmanına ayrıldı. İlki C-ucu ürünlere odaklanırken, ikincisi Llama gibi temel model geliştirmeye odaklanıyor. Temel yapay zeka araştırma departmanı FAIR’in bağımsız kalması dikkat çekici, ancak bazı multimedya ekipleri AGI temel departmanına dahil edildi. Bu ayarlama, geliştirme hızını ve esnekliğini artırmayı amaçlıyor. Ancak Meta, Llama 4’ün beklenen etkiyi yaratamaması, açık kaynak alanındaki rekabetin artması ve çekirdek yeteneklerin kaybı gibi zorluklarla karşı karşıya. Llama geliştirmesine başlangıçta katılan 14 yazardan 11’i ayrıldı ve birçoğu Mistral AI gibi rakip şirketlere katıldı veya bu şirketleri kurdu. FAIR laboratuvarı da liderlik değişiklikleri ve araştırma yönelimlerinde ayarlamalar yaşadı, bu da şirketin içindeki konumu ve gelecekteki inovasyon yetenekleri hakkında endişelere yol açtı. (Kaynak: 36氪)

Google DeepMind, SignGemma’yı duyurdu: İşaret dilinden metne çeviri için yeni bir model : Google DeepMind, şu ana kadarki en güçlü işaret dilinden konuşma metnine çeviri modeli olduğunu iddia ettiği SignGemma’yı duyurdu. Modelin bu yılın sonlarında Gemma model ailesine katılması ve açık kaynak olarak yayınlanması bekleniyor. SignGemma’nın piyasaya sürülmesi, kapsayıcı teknoloji için yeni olanaklar yaratmayı ve işaret dili kullanıcılarının iletişim verimliliğini ve kolaylığını artırmayı amaçlıyor. Google DeepMind, kullanıcıları geri bildirim sağlamaya ve erken testlere katılmaya davet ediyor. (Kaynak: GoogleDeepMind, demishassabis)
Tencent Hunyuan, statik portreleri dinamik videolara dönüştürebilen HunyuanPortrait model ağırlıklarını yayınladı : Tencent Hunyuan ekibi, görüntüden videoya dönüştürme modeli olan HunyuanPortrait’in model ağırlıklarını açık kaynak olarak yayınladı ve kullanıcıların bunları indirip yerel olarak kullanmalarına olanak tanıdı. Bu model, statik insan portre resimlerini dinamik videolara dönüştürmeye odaklanıyor ve oyun karakterleri, sanal sunucular, dijital insanlar, akıllı alışveriş asistanları gibi çeşitli uygulama senaryoları için uygun olup, yüz görüntülerinin hareket etmesini sağlayarak etkileşimin canlılığını ve gerçekçiliğini artırıyor. İlgili modeller, kod depoları ve makaleler yayınlandı. (Kaynak: karminski3, Reddit r/LocalLLaMA)

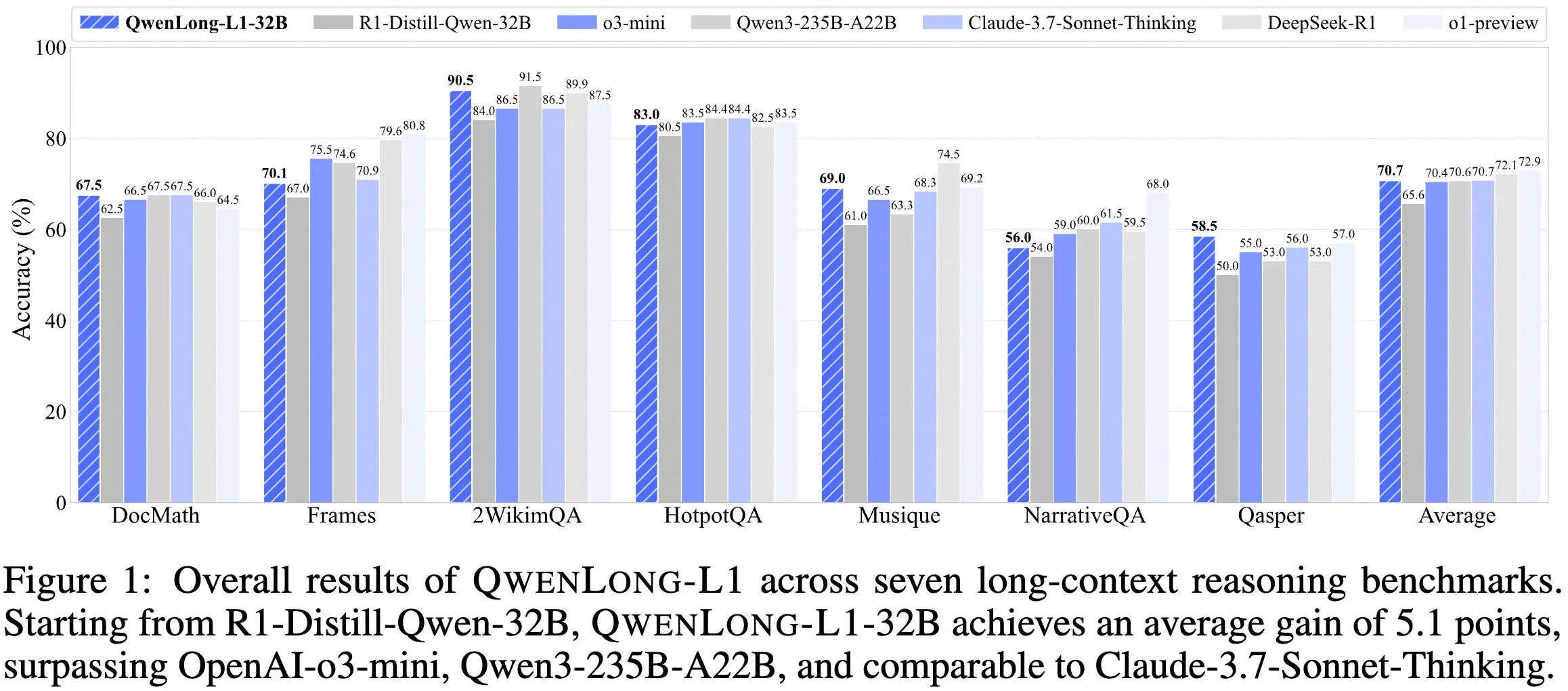
QwenDoc ekibi, uzun bağlamlı çıkarım modeli QwenLong-L1-32B’yi yayınladı : QwenDoc ekibi, pekiştirmeli öğrenme ile eğitilmiş 128K uzun bağlamlı çıkarım modeli QwenLong-L1-32B’yi tanıttı. Bu model, DeepSeek-R1-Distill-Qwen-32B üzerinde ince ayarlanmış olup, 2WikiMultihopQA çok adımlı çıkarım test setinde 90.5 puan alarak orijinal modele göre 6.5 puanlık bir artış sağladı ve uzun bağlamlarda yalnızca içeriği bulmakla kalmayıp aynı zamanda ipuçlarını birleştirerek çıkarım yapabildiğini vurguluyor. 128K bağlam uzunluğu şu anda en uzun olmasa da, olağanüstü çıkarım yeteneği karmaşık uzun belgelerin işlenmesi için yeni bir seçenek sunuyor. Model, makale ve kod deposu kamuya açıklandı. (Kaynak: karminski3)
HKUST, Apple ve diğer kurumlar, büyük model çıkarım verimliliğini ve doğruluğunu optimize etmek için Laser serisi yöntemleri başlattı : HKUST, CityU HK, Waterloo Üniversitesi ve Apple araştırmacıları, büyük dil modellerinin (LRM) basit sorunlarda çıkarım için aşırı token tüketmesi sorununu çözmeyi amaçlayan Laser serisi yöntemleri (Laser-D, Laser-DE dahil) önerdi. Bu yöntem, birleşik bir uzunluk ödül tasarım çerçevesi, hedef uzunluğa ve adım fonksiyonuna dayalı ödüller ve dinamik zorluk algılama mekanizması aracılığıyla, AIME24 gibi karmaşık matematiksel çıkarım ölçütlerinde, Token kullanımını %63 azaltırken performansı 6.1 puan artırmayı başardı. Araştırma, eğitilmiş modelin gereksiz “kendi kendine yansıtma” davranışının azaldığını ve düşünme modelinin daha sağlıklı hale geldiğini, model çıkarımının verimliliği ve doğruluğu arasında etkili bir denge kurduğunu buldu. (Kaynak: 36氪)

Anthropic Claude’nin ücretsiz sürümü artık web arama özelliğini destekliyor : Anthropic, yapay zeka asistanı Claude’nin ücretsiz sürüm kullanıcılarının artık web arama özelliğini kullanabileceğini duyurdu. Bu, Claude’nin soruları yanıtlarken yanıtlarının alaka düzeyini ve doğruluğunu artırmak için internetten en son bilgileri alabileceği anlamına geliyor. Yetkililer, arama sonuçlarını içeren her yanıtın, kullanıcıların bilgi kaynaklarını doğrulamasına yardımcı olmak için satır içi alıntılar sağlayacağını belirtti. (Kaynak: AnthropicAI)
PKU-DS-LAB, DeepSeek-R1-Distill-Qwen-32B üzerinde ince ayarlanmış 32B çıkarım modeli FairyR1’i yayınladı : Pekin Üniversitesi Veri Bilimi Laboratuvarı (PKU-DS-LAB), Apache 2.0 lisansı altında 32B parametreli bir çıkarım modeli olan FairyR1’i tanıttı. Bu model, “damıtma ve yeniden birleştirme” yöntemiyle, yalnızca %5 parametre kullanarak daha büyük modellerin performansına ulaştığı iddia ediliyor. FairyR1, DeepSeek-R1-Distill-Qwen-32B üzerinde ince ayarlanmıştır ve eğitim verileri de Hugging Face Hub’da mevcuttur. Bu çalışma, TinyR1’in araştırma yaklaşımını sürdürerek, veri kümesini aktif olarak filtreleyerek (yaklaşık 10.000 yörünge), matematik ve kod için ayrı ayrı SFT uygulayarak ve model birleştirme için Arcee Fusion kullanarak gerçekleştirilmiştir. (Kaynak: huggingface, teortaxesTex, stablequan)
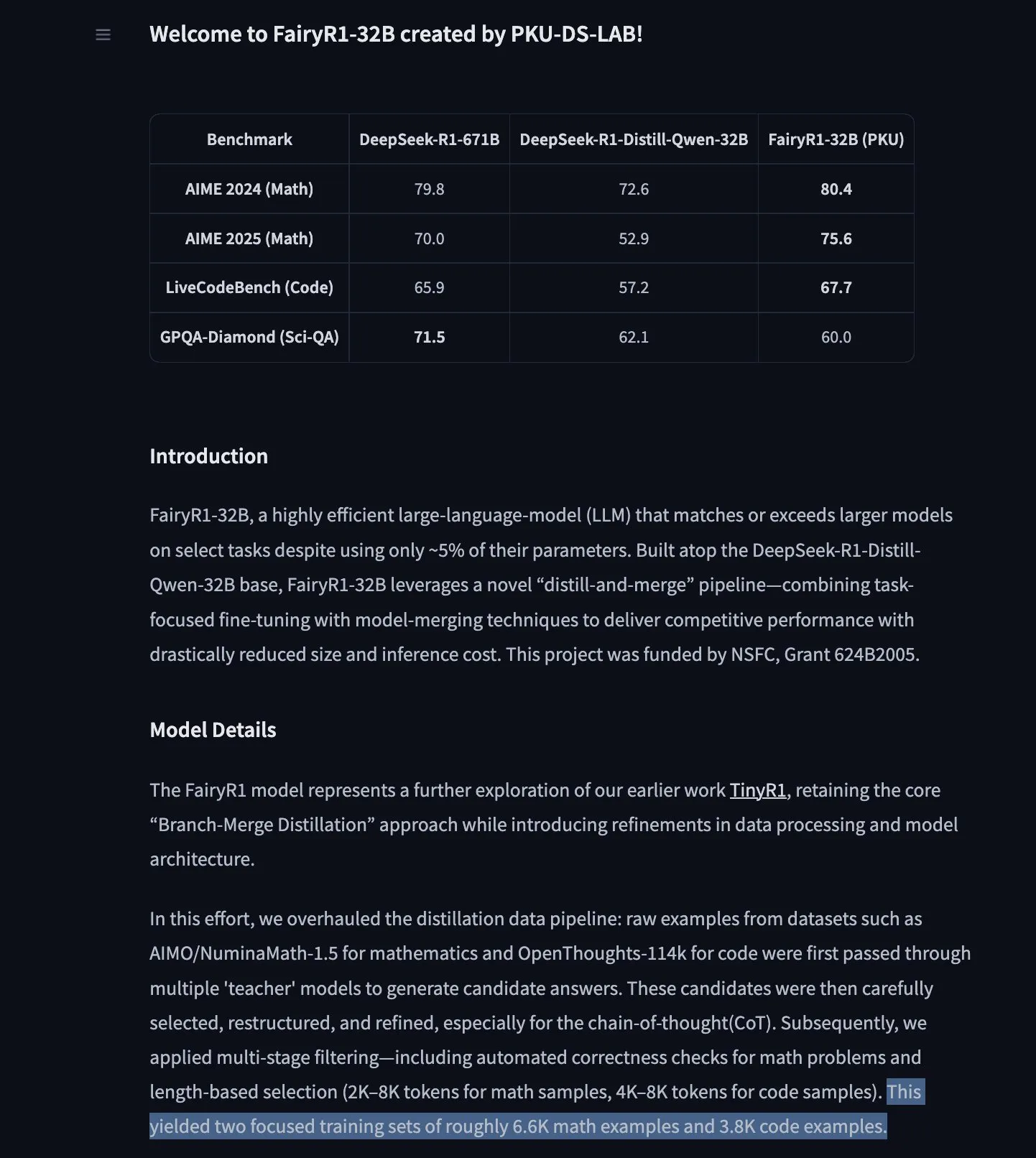
Google’ın TimesFM zaman serisi tahmin modeli Hugging Face Transformers’a geldi : Google’ın TimesFM modeli artık Hugging Face Transformers kütüphanesine entegre edildi. Bu, Google Trends, Wikipedia sayfa görüntülemeleri gibi çeşitli kaynaklardan 100 milyar gerçek zamanlı veri noktası içeren önceden eğitilmiş, GPT benzeri bir modeldir. TimesFM’in sıfır-örneklem (zero-shot) tahmin görevlerinde özel olarak ince ayarlanmış modellerden daha iyi performans gösterdiği iddia ediliyor ve zaman serisi analizi için yeni ve güçlü bir araç sunuyor. (Kaynak: huggingface)
Hugging Face, özenle seçilmiş genel çıkarım veri kümesi Mixture of Thoughts’u tanıttı : Hugging Face araştırmacısı Lewis Tunstall ve arkadaşları, “Mixture of Thoughts” veri kümesini yayınladı. Bu veri kümesi, 1 milyondan fazla kamuya açık veri örneğinden, kapsamlı ablasyon deneyleriyle özenle seçilmiş yaklaşık 350.000 örnek içeriyor ve genel çıkarım yeteneklerine odaklanıyor. Bu karma veri kümesiyle eğitilen modellerin, matematik, kod ve bilimsel ölçütlerde (GPQA gibi) DeepSeek’in damıtılmış modellerine eşit veya daha iyi performans gösterdiği belirtiliyor. Araştırma, Phi-4-reasoning’de önerilen “toplanabilirlik” metodolojisinin etkinliğini doğruladı; yani her çıkarım alanı için veri karışımı bağımsız olarak optimize edilebilir ve ardından son eğitim için entegre edilebilir. (Kaynak: huggingface)
ByteDance, hem görüntü hem de metin anlama ve üretme yeteneğine sahip çok yönlü bir model olan BAGEL-7B’yi yayınladı : ByteDance, hem görüntüleri hem de metinleri aynı anda anlayabilen ve üretebilen çok yönlü (omni) bir model olan BAGEL-7B’yi tanıttı. Ayrıca, belge ayrıştırmaya odaklanan bir görsel dil modeli (VLM) olan Dolphin’i de yayınladılar. Bu modellerin açık kaynak olarak sunulması, çok modlu araştırma ve uygulamalar için yeni araçlar ve olanaklar sağlayacaktır. (Kaynak: huggingface, TheTuringPost)

Google, yerel ses çıkışını destekleyen Gemini 2.5 Flash Preview’u yayınladı : Google AI geliştiricileri, Gemini 2.5 Flash Preview’un artık Live API aracılığıyla yerel ses çıkışını desteklediğini duyurdu. Bu, kesintisiz, doğal sözlü etkileşim ve daha güçlü ses kontrol yetenekleri sağlamayı amaçlamaktadır. Ayrıca, bu ses modelinin daha karmaşık görevler için çıkarım yeteneğini destekleyen yeni bir deneysel “düşünme” sürümü de piyasaya sürüldü. Aynı zamanda, Gemini API’nin çıktıları da modelin düşünme sürecini kullanıcılara göstermek için “düşünce özetleri” sergilemeye başladı, ancak bu henüz tam bir çıkarım zinciri değil. (Kaynak: algo_diver, op7418)
Makale, Transformer’ların boş token’ları doldururkenki ifade gücünü tartışıyor : Yeni bir araştırma, Transformer girişlerine boş token’lar (bir test zamanı hesaplama biçimi) doldurmanın LLM’lerin hesaplama yeteneklerini artırıp artıramayacağını inceliyor. Ashish_S_AI ile işbirliği içinde yürütülen bu çalışma, doldurmalı Transformer’ların ifade gücünü hassas bir şekilde karakterize ederek LLM’lerin hesaplama mekanizmalarını anlama ve optimize etme konusunda yeni bir bakış açısı sunuyor. (Kaynak: teortaxesTex)

Yeni araştırma, video kare enterpolasyonunu iyileştirmek için simetrik kısıtlamalar kullanan Sci-Fi çerçevesini öneriyor : Mevcut video kare enterpolasyonu (Frame Inbetweening) yöntemlerinin başlangıç ve bitiş kare kısıtlamalarını birleştirirken kontrol yoğunluğunda asimetri sorunları yaşayabileceğine dikkat çeken yeni bir makale, Sci-Fi (Symmetric Constraint for Frame Inbetweening) çerçevesini öneriyor. Bu yöntem, eğitim ölçeği daha küçük olan kısıtlamalar (örneğin bitiş karesi) için daha güçlü bir enjeksiyon mekanizması (hafif bir modül olan EF-Net tabanlı) uygulayarak başlangıç ve bitiş kare kısıtlamalarının simetrisini sağlamayı amaçlar. Böylece, oluşturulan ara karelerde daha uyumlu geçiş efektleri elde edilir ve hareket tutarsızlığı veya görünüm bozulması önlenir. (Kaynak: HuggingFace Daily Papers)
Makale, bilimsel makalelerden çok modlu posterlere otomatik bir süreç olan Paper2Poster’ı öneriyor : Akademik poster hazırlamanın zorluklarına yanıt olarak araştırmacılar, ilk poster oluşturma ölçütünü ve değerlendirme metrikleri paketi olan Paper2Poster’ı tanıttı. Bu paket, makaleler ve yazarlar tarafından tasarlanan poster çiftlerini içerir ve görsel kalite, metin tutarlılığı, genel değerlendirme ve PaperQuiz (posterin temel içeriği iletme yeteneğini ölçer) gibi açılardan değerlendirme yapar. Aynı zamanda, ayrıştırıcı (varlıkları çıkarır), planlayıcı (metin-görsel hizalama ve düzen) ve ressam-eleştirmen döngüsü (görselleştirme ve geri bildirim optimizasyonu) içeren yukarıdan aşağıya, görsel döngüde çoklu ajan süreci olan PosterAgent’ı önerdiler. Qwen-2.5 gibi açık kaynaklı modellere dayanan varyantlar, çoğu metrikte GPT-4o destekli sistemlerden daha iyi performans gösterdi, token tüketimini %87 azalttı ve 22 sayfalık bir makaleyi çok düşük maliyetle düzenlenebilir bir .pptx posterine dönüştürebildi. (Kaynak: HuggingFace Daily Papers)
Makale, sınırsız ve kontrol edilebilir görüntüden videoya üretim için Frame In-N-Out’u öneriyor : Video üretimindeki kontrol edilebilirlik, zamansal tutarlılık ve detay sentezi gibi zorluklara yanıt olarak, yeni bir makale “Frame In and Frame Out” adlı film çekim tekniğine odaklanıyor. Bu teknik, kullanıcıların görüntüdeki nesnelerin doğal olarak sahneden ayrılmasını kontrol etmelerini veya sahneye yeni kimlik referansları getirmelerini sağlamayı amaçlamaktadır ve bu hareketler kullanıcı tarafından belirlenen hareket yörüngeleriyle yönlendirilir. Bu amaçla araştırmacılar, yeni bir yarı otomatik etiketlenmiş veri kümesi, kapsamlı bir değerlendirme protokolü ve verimli bir kimlik koruma, hareket kontrol edilebilir video Diffusion Transformer mimarisi tanıttı. Deneyler, bu yöntemin mevcut temel çizgilerden önemli ölçüde daha iyi performans gösterdiğini ortaya koydu. (Kaynak: HuggingFace Daily Papers)
Yeni araştırma, çok modlu büyük dil modellerine GRPO aracılığıyla aktif algılama yeteneği kazandıran Active-O3’ü öneriyor : Çok modlu büyük dil modellerinin (MLLM) aktif algılama (active perception) konusundaki keşif eksikliğine yanıt olarak araştırmacılar, Active-O3 çerçevesini önerdi. Bu çerçeve, GRPO (Group Relative Policy Optimization) tabanlı saf pekiştirmeli öğrenme eğitimi üzerine kuruludur ve MLLM’lere görevle ilgili bilgileri toplamak için gözlem konumlarını ve yöntemlerini aktif olarak seçme yeteneği kazandırmayı amaçlamaktadır. Araştırmacılar öncelikle MLLM tabanlı aktif algılama görevlerini sistematik olarak tanımladı ve GPT-o3’ün büyütülmüş arama stratejisinin aktif algılamanın özel bir durumu olduğunu ancak verimlilik ve doğruluk açısından yetersiz olduğunu belirtti. Active-O3, kapsamlı bir ölçüt paketi oluşturarak genel açık dünya görevlerinde (küçük nesne ve yoğun nesne konumlandırma gibi) ve belirli alan senaryolarında (uzaktan algılama, otonom sürüşte küçük nesne tespiti, ince taneli etkileşimli segmentasyon gibi) değerlendirme yapar ve V* Benchmark üzerindeki güçlü sıfır-örneklem çıkarım yeteneğini gösterir. (Kaynak: HuggingFace Daily Papers)
Makale, MLLM’lerin mantıksal çıkarım yeteneğini kapsamlı bir şekilde test eden MME-Reasoning’i öneriyor : Mevcut ölçütlerin çok modlu büyük dil modellerinin (MLLM) mantıksal çıkarım yeteneğini değerlendirmedeki eksikliklerine yanıt olarak araştırmacılar, MME-Reasoning’i tanıttı. Bu ölçüt, tümevarım, tümdengelim ve abdüksiyon olmak üzere üç ana mantıksal çıkarım türünü kapsar ve soruların algısal beceriler veya bilgi genişliği yerine çıkarım yeteneğini etkili bir şekilde değerlendirmesini sağlamak için verileri dikkatlice filtreler. Değerlendirme sonuçları, en gelişmiş MLLM’lerin bile kapsamlı mantıksal çıkarım değerlendirmesinde sınırlamalar gösterdiğini ve farklı çıkarım türlerinde performans dengesizliği olduğunu ortaya koydu. Araştırma ayrıca, “düşünme modu” ve kural tabanlı pekiştirmeli öğrenme gibi yöntemlerin çıkarım yeteneği üzerindeki etkisini analiz ederek MLLM’lerin çıkarım yeteneğini anlama ve değerlendirme konusunda sistematik bilgiler sunar. (Kaynak: HuggingFace Daily Papers)
GraLoRA: Parçacıklı düşük rütbeli adaptasyon ile parametre verimli ince ayar performansını artırma : LoRA’nın rütbe artırıldığında aşırı uyum ve performans darboğazı sorunlarına yanıt olarak araştırmacılar, GraLoRA’yı (Granular Low-Rank Adaptation) önerdi. Bu yöntem, ağırlık matrisini alt bloklara böler ve her alt blok bağımsız bir düşük rütbeli adaptöre sahiptir. Amaç, LoRA’nın yapısal darboğazlarından kaynaklanan gradyan dolaşıklığı ve yayılma bozulması sorunlarını çözmektir. GraLoRA, hesaplama veya depolama maliyetlerini neredeyse hiç artırmadan modelin ifade gücünü etkili bir şekilde artırır ve tam ince ayar etkisine daha çok yaklaşır. Kod oluşturma ve sağduyu çıkarımı ölçütlerindeki deneyler, GraLoRA’nın farklı model boyutları ve rütbe ayarlarında LoRA ve diğer temel çizgilerden daha iyi performans gösterdiğini ortaya koydu; örneğin, HumanEval+’da Pass@1’de %8.5’e varan mutlak kazanç sağladı. (Kaynak: HuggingFace Daily Papers)
SoloSpeech: Kademeli üretim hattı ile hedef konuşma çıkarımının netliğini ve kalitesini artırma : Hedef konuşma çıkarımında (TSE) mevcut ayırt edici modellerin yapaylıklar ekleyerek doğallığı azaltması ve üretken modellerin algısal kalite ve netlikte yetersiz kalması sorunlarına yanıt olarak araştırmacılar SoloSpeech’i önerdi. Bu, sıkıştırma, çıkarma, yeniden yapılandırma ve düzeltme süreçlerini entegre eden yeni bir kademeli üretim hattıdır. Özellikleri arasında, ipucu sesinin gizli uzayının koşullu bilgilerini kullanan ve uyumsuzluğu önlemek için bunu karma sesin gizli uzayıyla hizalayan, konuşmacı gömme özelliği olmayan bir hedef çıkarıcı kullanması yer alır. Libri2Mix veri kümesindeki değerlendirmeler, SoloSpeech’in hedef konuşma çıkarma ve konuşma ayırma görevlerinde yeni bir SOTA seviyesine ulaştığını ve alan dışı verilerde ve gerçek dünya senaryolarında üstün genelleme yeteneği sergilediğini gösterdi. (Kaynak: HuggingFace Daily Papers)
Yeni araştırma, metin yönlendirmeli vektörler aracılığıyla çok modlu büyük dil modellerinin görsel anlama yeteneğini artırmayı araştırıyor : Yeni bir araştırma, çok modlu büyük dil modellerinin (MLLM) saf metin LLM omurgasından türetilen yönlendirme vektörlerinin (seyrek otomatik kodlayıcılar SAE, ortalama kaydırma ve doğrusal problama gibi yöntemlerle elde edilen) görsel anlama yeteneğini artırmak için kullanılıp kullanılamayacağını araştırıyor. Araştırma, metinden türetilen yönlendirme vektörlerinin, çeşitli görsel görevlerde farklı MLLM mimarilerinin çok modlu doğruluğunu sürekli olarak artırabildiğini buldu. Özellikle, ortalama kaydırma yöntemi CV-Bench’te mekansal ilişki doğruluğunu %7.3’e, sayma doğruluğunu ise %3.3’e kadar artırdı, istem yöntemlerinden daha iyi performans gösterdi ve dağılım dışı veri kümelerine karşı güçlü bir genelleme yeteneği sergiledi. Bu, metin yönlendirmeli vektörlerin, en az ek veri toplama ve hesaplama maliyetiyle MLLM’lerin görsel temelini güçlendirebilen güçlü ve verimli bir mekanizma olduğunu göstermektedir. (Kaynak: HuggingFace Daily Papers)
Makale, DiSA’yı öneriyor: Difüzyon adımı tavlamasıyla otoregresif görüntü üretimini hızlandırma : MAR, FlowAR gibi otoregresif modellerin görüntü kalitesini artırmak için difüzyon örneklemesi kullanmasının ancak bunun düşük çıkarım verimliliğine yol açmasının sorununa yanıt olarak, yeni bir makale DiSA (Diffusion Step Annealing) yöntemini öneriyor. Bu yöntem, otoregresif süreçte üretilen token sayısı arttıkça, sonraki token’ların dağılımının daha kısıtlı hale geldiği ve örneklemenin daha kolay olduğu gözlemine dayanmaktadır. DiSA, daha fazla token üretilirken difüzyon adımlarını kademeli olarak azaltan (örneğin başlangıçtaki 50 adımdan sonraki aşamalarda 5 adıma düşürerek) eğitimsiz bir yöntemdir. Bu yöntem, difüzyonun kendisi için tasarlanmış mevcut hızlandırma yöntemlerini tamamlar, uygulanması basittir ve MAR ve Harmon üzerinde 5-10 kat, FlowAR ve xAR üzerinde ise 1.4-2.5 kat hızlanma sağlarken üretim kalitesini korur. (Kaynak: HuggingFace Daily Papers)
Makale, CASS’ı öneriyor: Nvidia’dan AMD’ye GPU kod çevirisi için veri kümesi, model ve ölçüt : Araştırmacılar, mimariler arası GPU kod çevirisi için ilk büyük ölçekli veri kümesi ve model paketi olan CASS’ı tanıttı. Hedef, kaynak kodu seviyesinde (CUDA <-> HIP) ve assembly seviyesinde (Nvidia SASS <-> AMD RDNA3) çeviriyi kapsamaktadır. Veri kümesi, doğrulanmış 70.000 ana bilgisayar ve cihaz kodu çifti içerir. Bu kaynakla eğitilen CASS serisi alana özgü dil modelleri, kaynak kodu çevirisinde %95, assembly çevirisinde ise %37.5 doğruluk oranına ulaşarak GPT-4o, Claude gibi ticari temel çizgilerden önemli ölçüde daha iyi performans gösterdi. Üretilen kod, test senaryolarının %85’inden fazlasında yerel performansla eşleşti. Aynı zamanda, 16 GPU alanını ve gerçek yürütme sonuçlarını içeren bir ölçüt testi olan CASS-Bench de yayınlandı. Tüm veriler, modeller ve değerlendirme araçları açık kaynak olarak sunuldu. (Kaynak: HuggingFace Daily Papers)
Makale, görsel dil modellerindeki sözlü kalibrasyon yeteneğini analiz ediyor : Bir araştırma, görsel dil modellerinin (VLM) doğal dil aracılığıyla güven düzeylerini ifade etme (yani sözlü belirsizlik) etkinliğini kapsamlı bir şekilde değerlendirdi. Araştırma, üç model kategorisi, dört görev alanı ve üç değerlendirme senaryosu boyunca yapıldı ve sonuçlar, mevcut VLM’lerin çeşitli görev ve ayarlarda genellikle belirgin kalibrasyon hataları sergilediğini gösterdi. Özellikle, görsel çıkarım modellerinin (yani görüntülerle düşünen modeller) sürekli olarak daha iyi kalibrasyon gösterdiği dikkat çekicidir; bu da belirli modaliteye özgü çıkarımın güvenilir belirsizlik tahmini için hayati olduğunu göstermektedir. Kalibrasyon zorluklarına yanıt olarak araştırmacılar, çok modlu ortamlarda güven hizalamasını iyileştirmeyi amaçlayan iki aşamalı bir istem stratejisi olan “Görsel Güven Farkındalığına Sahip İstem” (Visual Confidence-Aware Prompting) yöntemini tanıttı. (Kaynak: HuggingFace Daily Papers)
Makale, büyük dil modellerinde pragmatik yeteneklerin ortaya çıkışını izliyor : Mevcut LLM’ler sosyal zeka görevlerinde yeni yetenekler sergilese de, eğitim sürecinde pragmatik yetenekleri nasıl kazandıkları henüz net değil. Yeni bir makale, pragmatik bir kavram olan “seçenekler” (alternatives) temel alınarak tasarlanan ALTPRAG veri kümesini tanıtıyor ve farklı eğitim aşamalarındaki LLM’lerin ince konuşmacı niyetlerini doğru bir şekilde çıkarıp çıkaramadığını değerlendiriyor. 22 LLM’nin (ön eğitim, SFT ve tercih optimizasyonu aşamalarını kapsayan) sistematik değerlendirmesi sonucunda, temel modellerin bile pragmatik ipuçlarına karşı önemli bir hassasiyet gösterdiği ve model ve veri ölçeği arttıkça bu hassasiyetin sürekli olarak geliştiği görüldü. SFT ve RLHF, bilişsel pragmatik çıkarım yeteneğini daha da artırdı. Bu bulgular, pragmatik yeteneğin LLM eğitiminde ortaya çıkan birleşik bir özellik olduğunu vurguluyor ve modellerin insan iletişim normlarına hizalanması için yeni bilgiler sunuyor. (Kaynak: HuggingFace Daily Papers)
Video-Holmes ölçütü yayınlandı: MLLM’lerin karmaşık video çıkarımındaki “Sherlock Holmes tarzı” düşünme yeteneğini değerlendiriyor : Mevcut video ölçütlerinin temel olarak görsel algılama ve konumlandırma yeteneklerini değerlendirdiği ve karmaşık çıkarım ihtiyaçlarını yeterince yakalayamadığı gerçeğine yanıt olarak araştırmacılar, Video-Holmes ölçütünü tanıttı. Bu ölçüt, Sherlock Holmes’un çıkarım sürecinden esinlenerek oluşturulmuş olup, elle etiketlenmiş 270 gizemli kısa filmden çıkarılan ve 7 özenle tasarlanmış göreve yayılan 1837 soru içermektedir. Her görev, modelin farklı video kliplerine dağılmış birden fazla ilgili görsel ipucunu aktif olarak bulmasını ve birleştirmesini gerektirir. SOTA MLLM’lerin değerlendirilmesi, modellerin görsel algılamada mükemmel performans göstermesine rağmen, bilgi entegrasyonunda önemli zorluklar yaşadığını ve genellikle önemli ipuçlarını kaçırdığını gösterdi. Örneğin, en iyi performans gösteren Gemini-2.5-Pro’nun doğruluğu yalnızca %45 idi. (Kaynak: HuggingFace Daily Papers)
MME-VideoOCR ölçütü yayınlandı: Çok modlu LLM’lerin video senaryolarındaki OCR yeteneğini değerlendiriyor : Çok modlu büyük dil modelleri (MLLM) statik görüntülerde OCR konusunda önemli ilerlemeler kaydetmiş olsa da, video OCR’daki etkileri hareket bulanıklığı, zamansal değişiklikler ve görsel efektler gibi faktörler nedeniyle azalmaktadır. Pratik MLLM’lerin eğitimine rehberlik etmek amacıyla araştırmacılar, geniş bir video OCR uygulama senaryosunu kapsayan MME-VideoOCR ölçütünü tanıttı. Bu ölçüt, 44 farklı senaryoyu kapsayan 10 görev kategorisi (25 bağımsız görev) içerir ve yalnızca metin tanımayı değil, aynı zamanda videodaki metin içeriğinin daha derinlemesine anlaşılmasını ve çıkarımını da içerir. Ölçüt, farklı çözünürlüklerde, en boy oranlarında ve sürelerde 1464 video ile 2000 özenle seçilmiş, elle etiketlenmiş soru-cevap çifti içerir. 18 SOTA MLLM’nin değerlendirilmesi, en iyi performans gösteren Gemini-2.5 Pro’nun bile doğruluk oranının yalnızca %73.7 olduğunu göstererek, mevcut modellerin bütünsel video anlayışı gerektiren görevleri yerine getirirkenki sınırlamalarını ortaya koymaktadır. (Kaynak: HuggingFace Daily Papers)
MetaMind: Meta-bilişsel çoklu ajan sistemi aracılığıyla insan sosyal düşüncesini modelleme : Büyük dil modellerinin (LLM) insan iletişiminde içkin olan belirsizlik ve bağlamsal incelikleri ele almadaki eksikliklerini gidermek amacıyla araştırmacılar, psikolojideki meta-bilişsel teoriden esinlenen ve insan benzeri sosyal çıkarımı simüle etmeyi amaçlayan çoklu ajan çerçevesi MetaMind’ı tanıttı. MetaMind, sosyal anlayışı üç işbirlikçi aşamaya ayırır: (1) Zihin teorisi ajanı, kullanıcının zihinsel durumları (niyet, duygu gibi) hakkında hipotezler üretir; (2) Alan ajanı, bu hipotezleri iyileştirmek için kültürel normları ve etik kısıtlamaları kullanır; (3) Yanıt ajanı, çıkarılan niyetlerle tutarlılığı doğrularken bağlama uygun yanıtlar üretir. Bu çerçeve, üç zorlu ölçüt testinde SOTA performansı elde etti; gerçek sosyal senaryolarda %35.7, zihin teorisi çıkarımında %6.2 iyileşme sağladı ve LLM’lerin kritik zihin teorisi görevlerinde ilk kez insan seviyesine ulaşmasını sağladı. (Kaynak: HuggingFace Daily Papers)
Sparse VideoGen2: Anlamsal farkındalığa sahip sıralama ve seyrek dikkat ile video üretimini hızlandırma : Diffusion Transformers (DiT) tabanlı video üretim modellerinin uzun videoları işlerken karşılaştığı önemli gecikme ve yüksek bellek maliyeti sorunlarına yanıt olarak araştırmacılar, SVG2 çerçevesini önerdi. Bu çerçeve, anlamsal olarak farkında olan bir sıralama (anlamsal benzerliğe göre token’ları kümelemek ve yeniden sıralamak için k-means kullanarak) aracılığıyla anahtar token tanımlamanın doğruluğunu en üst düzeye çıkarmak ve hesaplama israfını en aza indirmek için üretim kalitesi ve verimliliği arasında bir Pareto sınırı dengesi kurar. SVG2 ayrıca, top-p dinamik bütçe kontrolü ve özel çekirdek uygulamalarını entegre ederek HunyuanVideo ve Wan 2.1 üzerinde sırasıyla 2.30 kata ve 1.89 kata kadar hızlanma sağlarken yüksek PSNR değerini korur. (Kaynak: HuggingFace Daily Papers)
OmniConsistency: Eşleştirilmiş stilize verilerden stil bağımsız tutarlılık öğrenme : Difüzyon modellerinin görüntü stilizasyonunda karşılaştığı karmaşık sahne tutarlılığını koruma (özellikle kimlik, kompozisyon ve detaylar) ve görüntüden görüntüye akışlarda stil LoRA’larının neden olduğu stil bozulması olmak üzere iki büyük zorluğu çözmek amacıyla araştırmacılar, OmniConsistency’yi önerdi. Bu, büyük ölçekli difüzyon transformatörlerinin (DiT) evrensel bir tutarlılık eklentisidir. Katkıları şunlardır: (1) Sağlam bir genelleme elde etmek için hizalanmış görüntü çiftleri üzerinde eğitilmiş bir bağlamsal tutarlılık öğrenme çerçevesi; (2) Stil bozulmasını azaltmak için stil öğrenimini tutarlılık korumasından ayıran iki aşamalı aşamalı bir öğrenme stratejisi; (3) Flux çerçevesi altındaki herhangi bir stil LoRA ile uyumlu, tamamen tak-çalıştır bir tasarım. Deneyler, OmniConsistency’nin görsel tutarlılığı ve estetik kaliteyi önemli ölçüde artırdığını ve ticari SOTA modeli GPT-4o ile karşılaştırılabilir bir performansa ulaştığını göstermiştir. (Kaynak: HuggingFace Daily Papers)
ImgEdit: Birleşik görüntü düzenleme veri kümesi ve ölçüt testi : Açık kaynaklı görüntü düzenleme modellerinin, temel olarak sınırlı yüksek kaliteli veri ve yetersiz ölçütler nedeniyle tescilli modellerin gerisinde kalması sorununu çözmek amacıyla araştırmacılar, ImgEdit’i tanıttı. Bu, yeni ve karmaşık tek turlu düzenlemeler ile zorlu çok turlu görevleri kapsayan, özenle seçilmiş 1.2 milyon düzenleme çifti içeren büyük ölçekli, yüksek kaliteli bir görüntü düzenleme veri kümesidir. Veri kalitesini sağlamak için, en son teknoloji görsel dil modellerini, tespit modellerini, segmentasyon modellerini ve göreve özgü onarıcıları ve sıkı son işleme adımlarını entegre eden çok aşamalı bir süreç benimsedi. ImgEdit ile eğitilen düzenleme modeli ImgEdit-E1, birçok görevde mevcut açık kaynaklı modellerden daha iyi performans gösterdi. Aynı zamanda, görüntü düzenlemenin talimat takibi, düzenleme kalitesi ve detay koruma performansını değerlendirmek için ImgEdit-Bench ölçütü de tanıtıldı. (Kaynak: HuggingFace Daily Papers)
Makale, LLM’lerde sağlam davranış kontrolü için yönlendirme hedef atomları aracılığıyla bir yöntem öneriyor : Dil modeli çıktılarının güvenliğini ve güvenilirliğini sağlamak için hassas kontrol elde etmek amacıyla yeni bir makale, “Yönlendirme Hedef Atomları” (Steering Target Atoms, STA) yöntemini öneriyor. Bu yöntem, özellikle düşmanca senaryolarda üstün sağlamlık ve esneklik sergileyerek güvenliği artırmak için ayrıştırılmış bilgi bileşenlerini ayırmayı ve manipüle etmeyi amaçlamaktadır. Araştırmacılar, istem mühendisliği ve yönlendirmenin model davranışına müdahale etmek için yaygın olarak kullanılmasına rağmen, model parametrelerinin yüksek derecede dolaşıklığının kontrol hassasiyetini sınırladığını ve yan etkilere yol açabileceğini savunuyor. STA, seyrek otomatik kodlayıcılar (SAE) kullanarak yüksek boyutlu uzaydaki bilgiyi ayrıştırır ve onu yönlendirerek daha hassas davranış kontrolü sağlar. Deneyler, bu yöntemin etkinliğini kanıtlamış ve büyük çıkarım modellerine uygulanarak hassas çıkarım kontrolündeki potansiyelini doğrulamıştır. (Kaynak: HuggingFace Daily Papers)
Makale, görsel tabanlı fiziksel çıkarım yeteneğini değerlendirmek için SeePhys ölçütünü öneriyor : Araştırmacılar, LLM’lerin ortaokuldan doktora yeterlilik sınavı seviyesine kadar fizik sorularındaki çıkarım yeteneğini değerlendirmek için büyük ölçekli çok modlu bir ölçüt olan SeePhys’i tanıttı. Bu ölçüt, fizik disiplininin 7 temel alanını kapsar ve 21 türde oldukça heterojen diyagram içerir. Görsel unsurların temel olarak yardımcı bir rol oynadığı önceki çalışmaların aksine, SeePhys’teki soruların %75’i görsel olarak gereklidir, yani doğru cevaplamak için görsel bilgilerin çıkarılması gerekir. Kapsamlı değerlendirmeler, en gelişmiş görsel çıkarım modellerinin (Gemini-2.5-pro ve o4-mini gibi) bile bu ölçütteki doğruluk oranının %60’ın altında olduğunu göstererek, mevcut LLM’lerin görsel anlama konusundaki temel zorluklarını, özellikle diyagram yorumlama ile fiziksel çıkarımın sıkı bir şekilde birleşmesi ve metinsel ipuçlarına yönelik bilişsel kısayollara olan bağımlılığın üstesinden gelinmesi konularında ortaya koymaktadır. (Kaynak: HuggingFace Daily Papers)
VerIPO: Doğrulayıcı güdümlü yinelemeli politika optimizasyonu ile Video-LLM’lerin uzun menzilli çıkarım yeteneğini artırma : Pekiştirmeli öğrenmenin Video-LLM’lere (Video-LLM) karmaşık video çıkarımında uygulanmasının karşılaştığı veri hazırlama darboğazları ve uzun zincirli düşünme (CoT) kalitesinin istikrarsızlığı sorunlarına yanıt olarak araştırmacılar, VerIPO (Verifier-guided Iterative Policy Optimization) yöntemini önerdi. Bu yöntemin özü, çıkarım mantığını değerlendirmek, yüksek kaliteli karşılaştırmalı veriler (yansıtıcı ve bağlamsal olarak tutarlı CoT içeren) oluşturmak için GRPO ve DPO eğitim aşamaları arasında yer alan bir “Rollout-Aware Verifier”dır. Bu veriler, verimli bir DPO aşamasını yönlendirerek çıkarım zincirinin uzunluğunu ve bağlamsal tutarlılığını artırır. Deney sonuçları, VerIPO’nun modeli daha hızlı ve daha etkili bir şekilde optimize edebildiğini, daha uzun ve bağlamsal olarak tutarlı CoT’ler üretebildiğini ve standart GRPO varyantlarından ve bazı büyük talimat ince ayarlı Video-LLM’lerden ve uzun çıkarım modellerinden daha iyi performans gösterdiğini ortaya koydu. (Kaynak: HuggingFace Daily Papers)
OpenS2V-Nexus: Özneden videoya üretim için ayrıntılı bir ölçüt ve milyonlarca örneklik bir veri kümesi : Özneden videoya (S2V) üretim teknolojilerinin gelişimini desteklemek amacıyla araştırmacılar, (i) ayrıntılı bir ölçüt olan OpenS2V-Eval ve (ii) milyonlarca örneklik bir veri kümesi olan OpenS2V-5M’yi içeren OpenS2V-Nexus’u önerdi. Mevcut S2V ölçütlerinden (VBench’ten miras alınan ve küresel ve kaba taneli değerlendirmeye odaklanan) farklı olarak OpenS2V-Eval, modelin özne tutarlı, doğal görünümlü ve kimlik sadakati yüksek videolar üretme yeteneğine odaklanır. Bu amaçla OpenS2V-Eval, 7 ana S2V kategorisinden 180 istem içerir ve gerçek ve sentetik test verilerini kapsar. Ayrıca, insan tercihlerini doğru bir şekilde hizalamak için araştırmacılar, üretilen videolardaki özne tutarlılığını, doğallığı ve metin alaka düzeyini sırasıyla ölçen üç otomatik metrik önerdi: NexusScore, NaturalScore ve GmeScore. Buna dayanarak, 16 temsili S2V modeli kapsamlı bir şekilde değerlendirildi. Aynı zamanda, 5 milyon yüksek kaliteli 720P özne-metin-video üçlüsü içeren ilk açık kaynaklı büyük ölçekli S2V üretim veri kümesi olan OpenS2V-5M oluşturuldu. (Kaynak: HuggingFace Daily Papers)
Makale, WHISTRESS’i öneriyor: Cümle vurgusu tespiti ile transkripsiyon metinlerini zenginleştirme : Konuşma dilinde cümle vurgusunun konuşmacının niyetini iletmedeki önemi ve mevcut transkripsiyon sistemlerindeki eksikliğine yanıt olarak yeni bir makale, hizalama gerektirmeyen bir cümle vurgusu tespit yöntemi olan WHISTRESS’i tanıtıyor. Bu görevi desteklemek için araştırmacılar, tamamen otomatik bir süreçle oluşturulan ölçeklenebilir bir sentetik eğitim veri kümesi olan TINYSTRESS-15K’yı önerdi. Bu veri kümesinde eğitilen WHISTRESS modeli, performansta mevcut temel çizgilerden daha iyi performans gösteriyor ve ek eğitim veya çıkarım için önceden giriş gerektirmiyor. Özellikle, sentetik verilere dayalı olarak eğitilmesine rağmen, WHISTRESS çeşitli ölçüt testlerinde güçlü bir sıfır-örneklem genelleme yeteneği sergiliyor. (Kaynak: HuggingFace Daily Papers)
Makale, InstructPart’ı öneriyor: Talimatlı çıkarım ile göreve yönelik parça segmentasyonu : Büyük çok modlu temel modeller çeşitli görevlerde ilerleme kaydetse de, birçok model nesneleri bölünemez bütünler olarak ele alarak nesneleri oluşturan parçaları göz ardı ediyor. Bu parçaları ve ilgili işlevsel görünürlüklerini (affordances) anlamak, geniş bir görev yelpazesini yerine getirmek için hayati önem taşır. Bu amaçla araştırmacılar, mevcut modellerin günlük durumlarda parça düzeyindeki görevleri anlama ve yürütme performansını değerlendirmek için elle etiketlenmiş parça segmentasyon ek açıklamaları ve göreve yönelik talimatlar içeren yeni bir gerçek dünya ölçütü olan InstructPart’ı tanıttı. Deneyler, SOTA görsel dil modelleri (VLM) için bile göreve yönelik parça segmentasyonunun hala zorlu bir sorun olduğunu göstermektedir. Ölçütün yanı sıra araştırmacılar, veri kümelerini kullanarak ince ayar yaparak performansı iki katına çıkaran basit bir temel çizgi de tanıttı. (Kaynak: HuggingFace Daily Papers)
Makale, gerçek zamanlı etkileşimli akışkan simülasyonu için hibrit sinirsel-MPM yöntemini öneriyor : Geleneksel fiziksel yöntemlerin hesaplama yoğunluğu ve yüksek gecikme süresi ile son zamanlardaki makine öğrenimi yöntemlerinin maliyeti düşürmesine rağmen hala gerçek zamanlı etkileşim ihtiyaçlarını karşılamakta zorlanması sorunlarına çözüm olarak araştırmacılar, yeni bir hibrit yöntem önerdi. Bu yöntem, sayısal simülasyon, sinirsel fizik ve üretken kontrolü entegre eder. Sinirsel fiziği, klasik sayısal çözücülere geri dönen bir güvence mekanizmasıyla, düşük gecikmeli simülasyon ve yüksek fiziksel sadakati birlikte hedefler. Ayrıca araştırmacılar, akışkan manipülasyonu için harici dinamik kuvvet alanları oluşturmak üzere ters modelleme stratejisi kullanılarak eğitilmiş difüzyon tabanlı bir kontrolör geliştirdi. Bu sistem, çeşitli 2D/3D senaryolarda, malzeme türlerinde ve engel etkileşimlerinde sağlam performans sergileyerek yüksek kare hızlarında gerçek zamanlı simülasyon (gecikmede %11~%29 azalma) sağlıyor ve kullanıcı dostu elle çizilmiş eskizlerle akışkan kontrolünü yönlendirebiliyor. (Kaynak: HuggingFace Daily Papers)
MMIG-Bench: Çok modlu görüntü üretim modelleri için kapsamlı yorumlanabilir değerlendirme ölçütü : Mevcut değerlendirme araçlarının GPT-4o, Gemini 2.0 Flash ve Gemini 2.5 Pro gibi çok modlu görüntü üreteçlerini değerlendirmedeki sınırlamalarına (örneğin T2I ölçütlerinin çok modlu koşullardan yoksun olması, özel görüntü üretim ölçütlerinin birleşik anlambilimi ve sağduyuyu göz ardı etmesi) yanıt olarak araştırmacılar, MMIG-Bench’i önerdi. Bu, 4850 zengin açıklamalı metin istemi ve 380 konuyu (insan, hayvan, nesne, sanat tarzı) kapsayan 1750 çok açılı referans görüntü içeren kapsamlı bir çok modlu görüntü üretim ölçütüdür. MMIG-Bench, üç seviyeli bir değerlendirme çerçevesi ile donatılmıştır: (1) Düşük seviyeli metrikler görsel yapaylıkları ve nesne kimliği korumasını değerlendirir; (2) Yeni bir yön eşleştirme puanı (AMS): İnce taneli istem-görüntü hizalaması sağlayan ve insan yargılarıyla yüksek derecede ilişkili olan VQA tabanlı bir orta seviye metrik; (3) Yüksek seviyeli metrikler estetiği ve insan tercihlerini değerlendirir. MMIG-Bench aracılığıyla 17 SOTA modeli ölçütlendirildi ve metrikler 32.000 insan derecelendirmesiyle doğrulandı, bu da mimari ve veri tasarımı için derinlemesine bilgiler sağladı. (Kaynak: HuggingFace Daily Papers)
Makale, HRPO’yu öneriyor: Pekiştirmeli öğrenme ile hibrit gizli çıkarım : Mevcut gizli çıkarım yöntemlerinin LLM’lerin otoregresif üretim özellikleriyle uyumsuzluğu ve eğitim için CoT yörüngelerine bağımlılığı sorunlarına yanıt olarak araştırmacılar, HRPO’yu (Hybrid Reasoning Policy Optimization) önerdi. Bu, pekiştirmeli öğrenmeye dayalı bir hibrit gizli çıkarım yöntemidir. Öğrenilebilir bir geçit mekanizması aracılığıyla önceki gizli durumları örneklenmiş token’lara entegre eder ve başlangıçta token gömmelerini temel alarak eğitilir, giderek daha fazla gizli özelliği dahil eder. Bu tasarım, LLM’lerin üretim yeteneğini korur ve hibrit çıkarım için ayrık ve sürekli temsillerin kullanımını teşvik eder. Ayrıca HRPO, token örneklemesi yoluyla gizli çıkarıma rastgelelik katarak RL tabanlı optimizasyon için CoT yörüngelerine ihtiyaç duymaz. Çeşitli ölçütlerdeki kapsamlı değerlendirmeler, HRPO’nun hem bilgi yoğun hem de çıkarım yoğun görevlerde önceki yöntemlerden daha iyi performans gösterdiğini ortaya koydu. (Kaynak: HuggingFace Daily Papers)
Makale, NFT yöntemini öneriyor: Matematiksel çıkarımda denetimli öğrenme ile pekiştirmeli öğrenmeyi birleştirme : “Kendi kendini geliştirmenin yalnızca pekiştirmeli öğrenme (RL) ile sınırlı olduğu” yönündeki yaygın kanıya meydan okuyan yeni bir makale, Negatif Farkındalıklı İnce Ayar (Negative-aware Fine-Tuning, NFT) yöntemini öneriyor. Bu, LLM’lerin başarısızlıklarından ders çıkarmasını ve harici bir öğretmene ihtiyaç duymadan kendi kendine gelişmesini sağlayan denetimli bir öğrenme yöntemidir. Çevrimiçi eğitimde NFT, kendi ürettiği yanlış cevapları atmak yerine, bunları modellemek için örtük bir negatif politika oluşturur. Bu örtük politika, pozitif veriler üzerinde optimizasyon için kullanılan hedef pozitif LLM ile aynı şekilde parametrelendirilir, böylece tüm LLM üretimleri üzerinde doğrudan politika optimizasyonu yapılabilir. 7B ve 32B modeller üzerindeki matematiksel çıkarım görevlerindeki deney sonuçları, negatif geri bildirimi ek olarak kullanarak NFT’nin, reddetme örneklemesi ince ayarı gibi denetimli öğrenme temel çizgilerinden önemli ölçüde daha iyi performans gösterdiğini, hatta GRPO ve DAPO gibi önde gelen RL algoritmalarına ulaştığını veya onları aştığını gösterdi. Araştırmacılar ayrıca, sıkı çevrimiçi politika eğitiminde NFT ve GRPO’nun aslında eşdeğer olduğunu kanıtladı. (Kaynak: HuggingFace Daily Papers)
Makale, Minute-Long Videos with Dual Parallelisms’i öneriyor: Dakika düzeyinde video üretimi : DiT tabanlı video difüzyon modellerinin uzun videolar üretirken karşılaştığı yüksek hesaplama gecikmesi ve bellek maliyeti sorunlarına yanıt olarak araştırmacılar, DualParal adlı yeni bir dağıtık çıkarım stratejisi önerdi. Bu yöntemin temel fikri, zaman çerçevelerini ve model katmanlarını birden fazla GPU’ya paralelleştirmektir. Difüzyon modellerinin kareler arası gürültü seviyelerinin senkronize olmasını gerektirmesi nedeniyle orijinal paralelliğin serileştirilmesi sorununu çözmek için bu yöntem, bir dizi kare bloğunu boru hattıyla işleyerek ve gürültü seviyesini kademeli olarak azaltarak bir bloklu gürültü giderme şeması kullanır. Her GPU, belirli blokları ve katman alt kümelerini işler ve önceki sonuçları bir sonraki GPU’ya ileterek eşzamansız hesaplama ve iletişim sağlar. Ayrıca, her GPU’da önceki blokların özelliklerini bağlam olarak yeniden kullanmak için özellik önbellekleme ve küresel olarak tutarlı zamansal dinamikler sağlamak için koordine bir gürültü başlatma stratejisi benimseyerek hızlı, yapaylıksız ve sonsuz uzunlukta video üretimi sağlar. En son difüzyon transformatör video üreteçlerine uygulanan bu yöntem, 8 adet RTX 4090 GPU üzerinde 1025 karelik videoyu verimli bir şekilde üreterek gecikmeyi 6.54 kata kadar ve bellek maliyetini 1.48 kat azaltır. (Kaynak: HuggingFace Daily Papers)
🧰 Araçlar
Claude 4 serisi modeller programlama görevlerinde öne çıkıyor, deneyimli bir programcıyı 4 yıldır rahatsız eden “beyaz balina hatasını” başarıyla çözdü : Anthropic’in en son yayınladığı Claude Opus 4 modeli, programlama yeteneklerinde şaşırtıcı bir güç sergiledi. 30 yıllık C++ geliştirme deneyimine sahip eski bir FAANG mühendisi, ekibini 4 yıldır rahatsız eden ve kişisel olarak yaklaşık 200 saat harcamasına rağmen çözemediği karmaşık bir sistem hatasının (belirli bir shader’ın belirli bir şekilde kullanıldığında ortaya çıkan bir sınır koşulu sorunu), Claude Opus 4 tarafından birkaç saat içinde yaklaşık 30 istemle başarıyla tespit edilip nedeninin bulunduğunu paylaştı. Bu hata, sistem yeniden yapılandırılmadan önce mevcut değildi ve Opus 4, yeni mimarinin eski mimari altında bir tür “tesadüfi” desteklenen tasarımsız bir davranışla uyumlu olmamasından kaynaklandığını belirtti. Daha önce GPT-4.1, Gemini 2.5 ve Claude 3.7 bu sorunu çözememişti. Bu, Claude 4’ün karmaşık kodu anlama, derinlemesine analiz yapma ve çıkarımda bulunma konusundaki güçlü yeteneklerini, özellikle Claude Code moduyla birleştirildiğinde, geliştiricilerin kod yeniden yapılandırma, hata ayıklama gibi ileri düzey mühendislik görevlerini ele almalarına etkili bir şekilde yardımcı olabileceğini vurguluyor. (Kaynak: 36氪, dotey)
LangChain, Anthropic Claude’nin yeni Beta özelliklerine destek ekledi : LangChain, Anthropic Claude modelinin yakın zamanda yayınladığı dört yeni Beta özelliğini entegre ettiğini duyurdu: kod yürütme, uzaktan MCP bağlantılayıcıları, dosya API’si ve genişletilmiş istem önbellekleme. Geliştiriciler artık LangChain belgelerinden ilgili örnekleri inceleyerek bu yeni özellikleri daha güçlü yapay zeka uygulamaları oluşturmak için kullanabilirler. (Kaynak: LangChainAI)
LangSmith, SDLC ile entegre istem yönetimi özelliklerini kullanıma sundu : LangSmith platformu, istem mühendisliği yeteneklerini geliştirdi; artık kullanıcılar LangSmith içinde istemleri test etmek, sürümlemek ve üzerinde işbirliği yapmakla kalmayıp, aynı zamanda istem değişikliklerinde webhook tetikleyicileri aracılığıyla istemleri otomatik olarak GitHub’a, harici veritabanlarına senkronize etmeye veya CI/CD süreçlerini başlatmaya olanak tanır. Bu özellik, geliştiricilerin istem yönetimini yazılım geliştirme yaşam döngüsüne (SDLC) daha sıkı bir şekilde entegre etmelerine yardımcı olmayı amaçlamaktadır. (Kaynak: LangChainAI)
AutoThink: Yerel LLM çıkarım performansını artıran uyarlanabilir bir teknik : CodeLion ekibi, uyarlanabilir kaynak tahsisi ve yönlendirme vektörleri (steering vectors) aracılığıyla yerel LLM’lerin çıkarım performansını önemli ölçüde artıran AutoThink teknolojisini geliştirdi. AutoThink, sorgu karmaşıklığını sınıflandırabilir, “düşünme token’larını” dinamik olarak tahsis edebilir (karmaşık sorunlara daha fazla, basit sorunlara daha az) ve çıkarım modellerini yönlendirmek için yönlendirme vektörlerini kullanabilir. DeepSeek-R1-Distill-Qwen-1.5B modeli üzerindeki testler, GPQA-Diamond doğruluğunda %43’lük bir artış ( %21.72’den %31.06’ya) ve MMLU-Pro’da da bir artış gösterirken, daha az token kullanıldığını ortaya koydu. Bu teknoloji, düşünme token’larını destekleyen yerel çıkarım modelleriyle uyumludur; kod ve araştırma yayınlanmıştır. (Kaynak: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Transformer Lab, AMD ROCm desteğini duyurdu, LLM’lerin yerel olarak eğitilmesine olanak tanıyor : Transformer Lab, GUI platformunun artık AMD GPU’larda ROCm kullanarak büyük dil modellerinin yerel olarak eğitilmesini ve ince ayarlanmasını desteklediğini duyurdu. Ekip, ROCm’yi yapılandırma sürecinin zorluklarla doluyduğunu ve tüm süreci bir blog yazısında belgelediğini belirtti. Şu anda bu özellik sorunsuz bir şekilde kullanılabilir durumda ve kullanıcılar AMD donanımında LLM geliştirme çalışmalarını deneyebilirler. (Kaynak: Reddit r/MachineLearning)
Açık kaynaklı LLM ile güçlendirilmiş çoklu ajan sistemi, otomatik iddia çıkarma ve gerçek kontrolü sağlıyor : “fact-checker” adlı açık kaynaklı bir proje, iddiaların otomatik olarak çıkarılması, kanıtların doğrulanması ve gerçeklerin çözümlenmesi için LLM ile güçlendirilmiş çoklu ajan sistemlerini (MAS) kullanır. Bu proje, herhangi bir yapay zeka sohbet robotunun yanıtlarını gerçek zamanlı olarak gerçek kontrolünden geçirebilen bir tarayıcı uzantısı içerir ve yapay zeka tarafından üretilen içeriğin doğruluğunu ayırt etmeye yardımcı olur. Kod mimarisi açık ve belgeleri eksiksizdir, yapay zeka güvenliği ve yanlış bilgilendirmeyle mücadele alanında değerli bir araç sunar. (Kaynak: Reddit r/MachineLearning)
Meituan, karmaşık çok sayfalı uygulama üretmeyi destekleyen kodsuz ürün Nocode’u piyasaya sürdü : Meituan, kullanıcıların doğal dil açıklamalarıyla yalnızca basit tanıtım web sayfaları değil, birden fazla sayfa içeren karmaşık ve eksiksiz uygulamalar üretebildiği Nocode adlı bir Vibe Coding ürününü piyasaya sürdü. Guicang’ın testleri, aracın karmaşık mantığa sahip bir depo mal yönetim aracını tek seferde başarıyla oluşturabildiğini göstererek, karmaşık gereksinimleri anlama ve buna uygun kod üretme yeteneğini ortaya koydu. (Kaynak: op7418)
LlamaIndex, özel çok modlu gömme araçları oluşturmayı ve OpenAI tarzı sohbet kullanıcı arayüzü ile entegrasyonu destekliyor : LlamaIndex, kullanıcıların örneğin AWS Titan Multimodal’u entegre ederek özel çok modlu gömme araçları oluşturmasına ve verimli metin + görüntü vektör araması için Pinecone gibi vektör veritabanlarıyla birleştirmesine olanak tanıyan bir güncelleme yayınladı. Ayrıca, LlamaIndex iş akışları artık birkaç satır kodla OpenAI benzeri bir sohbet arayüzünde çalıştırılabiliyor ve kullanıcı arayüzünde doğrudan iş akışı kodunu düzenlemeyi destekleyen bir geliştirme modu sunarak RAG uygulamalarının geliştirme ve etkileşim deneyimini iyileştiriyor. (Kaynak: jerryjliu0, jerryjliu0)

TRAE güncellemesi Agentic kodlama deneyimini geliştiriyor, yurtdışı sürümü ücretli abonelikle sunuldu : Yapay zeka programlama aracı TRAE, Agentic kodlama deneyimini optimize ederek manuel işlem yapmak istemeyen kullanıcılar için daha uygun hale getiren bir güncelleme aldı. Yeni sürüm TRAE, geçmiş konuşmaları daha iyi hatırlayabiliyor, bağlamı otomatik olarak ilişkilendirebiliyor, yapay zeka programlama yolunu otomatik olarak planlayabiliyor ve daha fazla araç çağırabiliyor, bu da programlama görevlerinin başarı oranını artırıyor. Örneğin, kullanıcı yalnızca boş bir klasör ve bir istem sağladığında, TRAE dosya oluşturma, web sunucusunu başlatma (alanlar arası sorunları otomatik olarak çözme) ve IDE içinde p5.js animasyonlarını önizleme gibi bir dizi işlemi tamamlayabiliyor. Yurtdışı sürümü ücretli abonelikle sunuldu, ilk ay Pro fiyatı 3 dolar ve Alipay’i destekliyor. (Kaynak: dotey, karminski3)
Juejin topluluğu, ön uç kodunun tek tıklamayla yayınlanmasını destekleyen MCP hizmetini başlattı : Çinli programcı topluluğu Juejin, geliştiricilerin ön uç kodunu (Vibe Coding tarafından oluşturulan web sayfaları, oyunlar gibi) tek bir tıklamayla Juejin platformunda yayınlamasına olanak tanıyan MCP (Model-driven Co-programming Protocol) hizmetini başlattı. Bu, hızlı paylaşım ve önizleme kolaylığı sağlıyor. Kullanıcıların Juejin MCP Token’ını alması ve Trae, Cursor gibi araçlarda yapılandırması gerekiyor. (Kaynak: dotey, karminski3)
Açık kaynaklı zaman takip aracı ActivityWatch, Rize’nin bir alternatifi olarak dikkat çekiyor : Kullanıcı karminski3, yapay zeka zaman analizi aracı Rize’yi (işlem adlarını analiz ederek çalışma, toplantı veya oyalanma durumunu belirleyen, aylık 20 dolar) denedikten sonra açık kaynaklı alternatif ActivityWatch’ı keşfetti ve önerdi. ActivityWatch benzer işlevlere sahip, Windows/Mac’i destekliyor ve kullanıcıların özelleştirmesine olanak tanıyor; çalışma kaygısını azaltmak ve çalışma süresini takip etmek için mükemmel bir araç olarak kabul ediliyor. (Kaynak: karminski3)
Açık kaynaklı yapay zeka bebek izleme aracı ai-baby-monitor yayınlandı : ai-baby-monitor adlı açık kaynaklı bir proje yayınlandı. Qwen2.5 VL modelini ve vLLM çıkarım çerçevesini kullanarak, kullanıcıların kurallar tanımlamasına (“çocuk uyanırsa alarm ver”, “çocuk yalnız kalırsa alarm ver” gibi) yapay zekanın bebek bakımına yardımcı olmasını sağlar. Geliştirici, bunun yalnızca yardımcı bir araç olduğunu ve insan bakımının yerini tamamen alamayacağını vurguluyor. (Kaynak: karminski3)
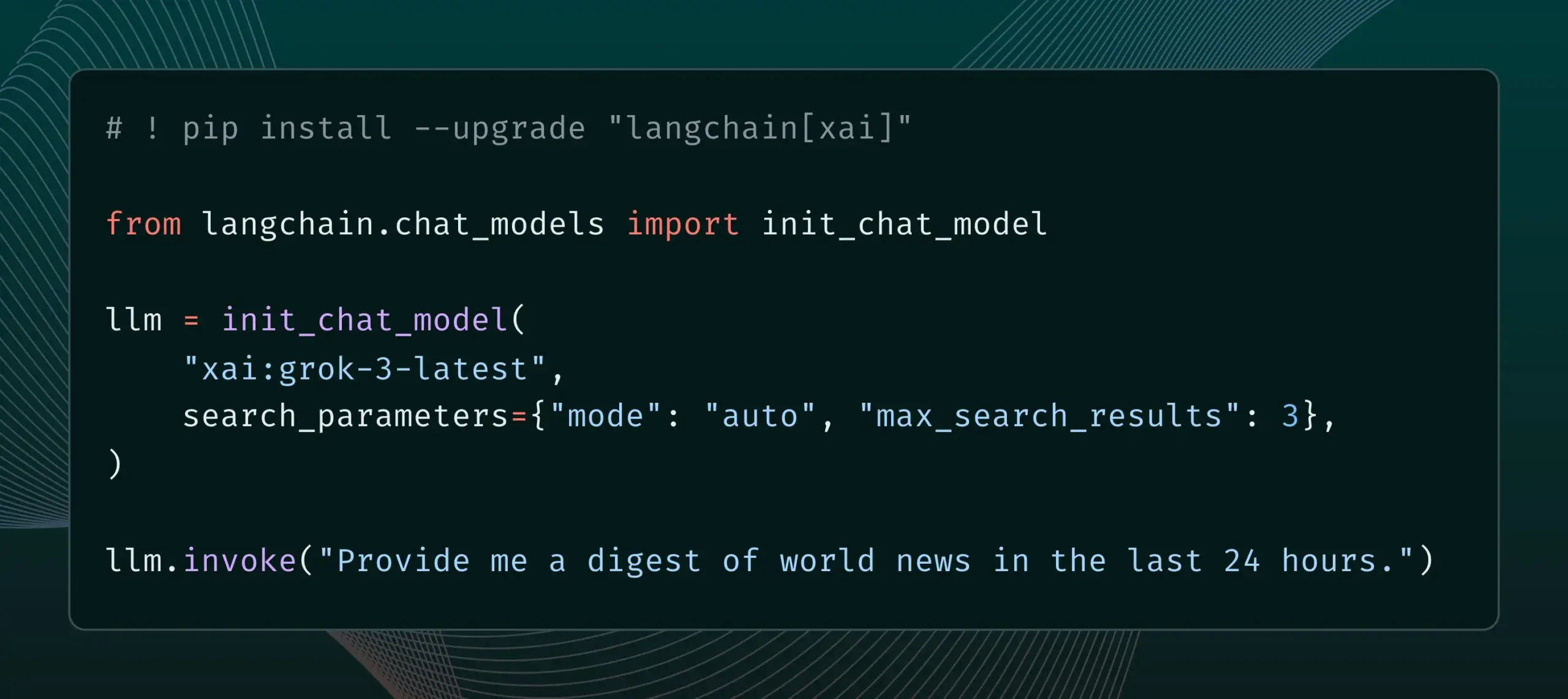
LangChain, xAI’nin Live Search özelliğini entegre etti : LangChain, xAI’nin Live Search özelliğini desteklediğini duyurdu. Bu özellik, Grok modelinin cevap üretirken web arama sonuçlarına dayanmasına ve zaman aralığı, dahil edilen alan adları gibi çeşitli yapılandırma seçenekleri sunmasına olanak tanır. Kullanıcılar artık LangChain’de bu yeni özelliği deneyebilirler. (Kaynak: LangChainAI)
Curie: Açık kaynaklı yapay zeka araştırma asistanı, disiplinlerarası araştırmalara yardımcı olmak için AutoML özelliğini yayınladı : Biyoloji, malzeme, kimya gibi alanlardaki araştırmacıların makine öğrenimini uygularken karşılaştıkları uzmanlık bilgisi engellerine yanıt olarak Curie projesi, yeni bir AutoML özelliği başlattı. Curie, yapay zeka araştırma deneylerinin işbirlikçi bir bilim insanı olmayı hedefler ve karmaşık ML süreçlerini (algoritma seçimi, hiperparametre ayarı, model çıktısı yorumlama gibi) otomatikleştirerek araştırmacıların hipotezleri hızla test etmelerine ve verilerden içgörüler çıkarmalarına yardımcı olur. Örneğin, Curie melanom tespit görevinde AUC değeri 0.99 olan bir model üretti. Proje açık kaynaklıdır ve topluluk katılımını teşvik etmektedir. (Kaynak: Reddit r/LocalLLaMA)
Alibaba MNN Chat, Android cihazlarda Qwen 30B-a3b modelini yerel olarak çalıştırmayı destekliyor : Alibaba’nın MNN Chat uygulaması 0.5.0 sürümüne güncellendi ve artık Android cihazlarda Qwen 30B-a3b gibi büyük dil modellerini yerel olarak çalıştırmayı destekliyor. Kullanıcı geri bildirimlerine göre, amiral gemisi yongalara ve büyük belleğe (OnePlus 13 24G gibi) sahip cihazlarda başarıyla çalıştırılabiliyor ve mmap ayarının etkinleştirilmesi öneriliyor. Ancak, bazı yorumcular 30B parametreli bir modelin çoğu telefon için bellek ve işlem gücü gereksinimlerinin çok yüksek olduğunu ve Gemma 3n’nin mobil cihazlar için daha uygun olabileceğini belirtiyor. (Kaynak: Reddit r/LocalLLaMA)

📚 Öğrenme
Yeni makale, Yalın ve Ortalama Uyarlanabilir Optimizasyonu öneriyor: Daha hızlı ve daha az bellek tüketen büyük model eğitim optimize edicisi : ICML 2025’te kabul edilen bir makale, “Alt Küme-Normu ve Alt Uzay-Momentumu aracılığıyla Yalın ve Ortalama Uyarlanabilir Optimizasyon” adlı yeni bir optimize ediciyi tanıtıyor. Bu yöntem, Alt Küme-Normu adım boyutu ve Alt Uzay-Momentumu olmak üzere iki tamamlayıcı teknik aracılığıyla büyük ölçekli sinir ağı eğitiminin bellek gereksinimlerini azaltmayı ve eğitimi hızlandırmayı amaçlamaktadır. GaLore, LoRA gibi mevcut bellek verimli optimize edicilerle karşılaştırıldığında, bu yöntem bellekten tasarruf ederken (örneğin, LLaMA 1B’yi önceden eğitirken Adam’a göre %80 daha az optimize edici durum belleği), Adam’ın doğrulama şaşkınlığına daha az eğitim token’ıyla (yaklaşık yarısı) ulaşabilir ve daha güçlü teorik yakınsama garantileri sunar. (Kaynak: Reddit r/MachineLearning)
Makale, Güç İstemlerini öneriyor: Video üretim modellerinin fizik tabanlı kontrol sinyallerini öğrenmesini ve genelleştirmesini sağlıyor : Yeni bir araştırma, video üretimi için kontrol sinyalleri olarak fiziksel güçlerin kullanılma olasılığını inceliyor ve “Güç İstemleri”ni (Force Prompts) öneriyor. Kullanıcılar, yerel nokta kuvvetleri (bir bitkiye dürtmek gibi) veya küresel rüzgar alanları (kumaşı üfleyen rüzgar gibi) aracılığıyla görüntülerle etkileşime girebilir. Araştırma, video üretim modellerinin, yalnızca az sayıda nesne gösterimi içeren Blender ile sentezlenmiş videolardan fiziksel güç koşullarını öğrenebileceğini ve genelleştirebileceğini, çıkarım sırasında 3D varlıklara veya fizik simülatörlerine ihtiyaç duymadan fiziksel kontrol sinyallerine gerçekçi tepkiler veren videolar üretebileceğini gösteriyor. Görsel çeşitlilik ve eğitim sırasında belirli metin anahtar kelimelerinin kullanılması, bu genellemenin sağlanmasında kilit faktörlerdir. (Kaynak: HuggingFace Daily Papers)
AnkiHub, verimliliği artırmak için FastHTML ile birleştirilmiş yapay zeka etiketleme iş akışını paylaşıyor : AnkiHub, yapay zeka etiketleme iş akışını paylaştı ve Hamel Husain ile Shreya Shankar’ın yapay zeka değerlendirme dersinde bir sunum yaptı. Bu iş akışı, ticari ürünler için yapay zeka etiketleme verimliliğini artırmayı amaçlayan FastHTML oluşturma araçlarını kullanır. İlgili öğretim materyalleri ve kod deposu GitHub’da yayınlandı ve yapay zeka geliştirmeyi optimize etmek için gerçek üretimde kullanılan araçların nasıl kullanılacağını gösteriyor. (Kaynak: jeremyphoward, HamelHusain)

Blog yazarı, PPO’dan GRPO’ya öğrenme deneyimlerini yazıyor, LLM ince ayarındaki pekiştirmeli öğrenme kavramlarını açıklıyor : Bir blog yazarı, pekiştirmeli öğrenme (RL) ve bunun büyük dil modellerinin (LLM) ince ayarındaki uygulamaları hakkındaki öğrenme deneyimlerini, özellikle PPO’dan (Proximal Policy Optimization) GRPO’ya (Group Relative Policy Optimization) anlama sürecini paylaştı. Blog yazısı, başkalarının bu RL algoritmalarının LLM’leri optimize etmek için nasıl kullanıldığını daha iyi anlamalarına yardımcı olmak amacıyla öğrenme sürecinin başlarında anlamak istediği kavramları açıklamayı amaçlıyor. (Kaynak: Reddit r/MachineLearning)
Makale, makinelerin pragmatik düşüncesini araştırıyor: Büyük dil modellerinde pragmatik yeteneklerin ortaya çıkışını izleme : Yeni bir makale, büyük dil modellerinin (LLM) eğitim sürecinde pragmatik yetenekleri, yani örtük anlamları, konuşmacının niyetlerini vb. anlama ve çıkarma yeteneğini nasıl kazandığını araştırıyor. Araştırmacılar, pragmatikteki “alternatifler” kavramına dayanan ALTPRAG veri kümesini tanıttı ve farklı eğitim aşamalarındaki (ön eğitim, denetimli ince ayar SFT, tercih optimizasyonu RLHF) 22 LLM’yi değerlendirdi. Sonuçlar, temel modellerin bile pragmatik ipuçlarına karşı önemli bir hassasiyet gösterdiğini ve model ve veri ölçeği arttıkça bu hassasiyetin sürekli olarak geliştiğini gösterdi; SFT ve RLHF, bilişsel pragmatik çıkarım yeteneğini daha da artırdı. Bu, pragmatik yeteneğin LLM eğitiminde ortaya çıkan, birleşik bir özellik olduğunu göstermektedir. (Kaynak: HuggingFace Daily Papers)
Makale, görsel araç seçimi için pekiştirmeli öğrenme çerçevesi VisTA’yı araştırıyor : Araştırmacılar, görsel ajanların deneyimsel performansa dayalı olarak farklı kütüphanelerden araçları dinamik olarak keşfetmesini, seçmesini ve birleştirmesini sağlayan yeni bir pekiştirmeli öğrenme çerçevesi olan VisTA’yı (VisualToolAgent) tanıttı. Eğitimsiz istemlere veya büyük ölçekli ince ayarlamaya dayanan mevcut yöntemlerin aksine VisTA, geri bildirim sinyali olarak görev sonuçlarını kullanarak karmaşık, sorguya özgü araç seçimi stratejilerini yinelemeli olarak optimize etmek için uçtan uca pekiştirmeli öğrenmeyi kullanır. GRPO (Group Relative Policy Optimization) aracılığıyla bu çerçeve, ajanların açık bir çıkarım denetimi olmaksızın etkili araç seçimi yollarını otonom olarak keşfetmesini sağlar. ChartQA, Geometry3K ve BlindTest ölçütlerindeki deneyler, VisTA’nın eğitimsiz temel çizgilere kıyasla, özellikle dağılım dışı örneklerde önemli performans artışları sağladığını göstermektedir. (Kaynak: HuggingFace Daily Papers)
💼 Ticari
Veri hizmetleri şirketi Jinglianwen Technology, kamu verisi üretimi ve işletimi alanında konumlanmak üzere on milyonlarca yuanlık Pre-A turu finansmanını tamamladı : Yapay zeka veri hizmetleri operatörü Jinglianwen Technology, yakın zamanda Hangzhou Jin Tou Group’a bağlı bir fondan on milyonlarca yuanlık Pre-A turu finansmanı aldı. Finansman, kamu verisi üretimi ve işletimi alanında konumlanmak, akıllı dilbilimsel mühendislik platformu oluşturmak ve kendi kendine dikey alanlarda yüksek kaliteli etiketleme üsleri kurmak için kullanılacak. Şirket 2012 yılında kuruldu ve kamu verileri, yapay zeka büyük modelleri, otonom sürüş ve tıp gibi alanlara odaklanarak kamu verilerinin “yönetimi zor, tedariki yetersiz, akışı yavaş, kullanımı verimsiz, güvenliği zayıf” gibi sorunlarını çözmeyi amaçlıyor ve Huawei veri depolama ile işbirliği yaparak yapay zeka veri gölü ortak çözümünü başlattı. Bu yıl gelir artışının %400’ü aşması bekleniyor. (Kaynak: 36氪)
Meitu, yapay zeka alanındaki işbirliğini derinleştirmek için Alibaba’dan yaklaşık 250 milyon dolarlık dönüştürülebilir tahvil yatırımı aldı : Meitu şirketi, Alibaba ile stratejik bir işbirliği yapmayı planladığını duyurdu; Alibaba, Meitu’ya toplam değeri yaklaşık 250 milyon dolar olan dönüştürülebilir tahviller ihraç edecek. İki taraf, e-ticaret platformu tanıtımı, yapay zeka teknolojisi (yapay zeka görüntüleri, yapay zeka videoları) geliştirme, bulut bilişim gibi alanlarda işbirliği yapacak ve Meitu, önümüzdeki üç yıl içinde Alibaba Cloud’dan en az 560 milyon yuan değerinde hizmet satın almayı taahhüt etti. Bu işbirliği, Alibaba ekosistemini kullanarak e-ticaret senaryolarındaki potansiyeli ortaya çıkarmayı ve Meitu’nun yapay zeka tasarım araçlarının ücretli kullanıcı sayısını ve Ar-Ge seviyesini artırmayı amaçlıyor. Bu hamle Meitu’nun hisse senedi fiyatını bir süreliğine artırsa da, piyasanın odak noktası Meitu’nun, özellikle görsel yapay zeka alanında büyük şirketlerin yoğun rekabeti ve hacim farklılıkları göz önüne alındığında, Kimi’nin şiddetli pazar rekabetinde kullanıcı büyümesinin yavaşlaması gibi bir durumdan nasıl kaçınacağıdır. (Kaynak: 36氪)
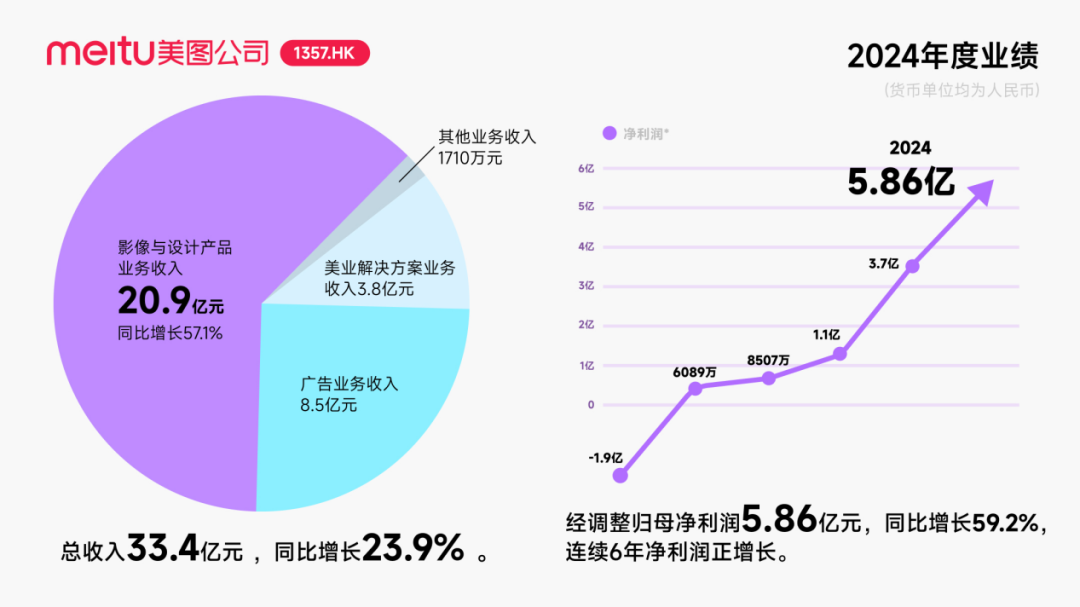
Zhiyuan Robot’un sermaye hareketleri sıklaştı, bir endüstri ekosistemi oluşturuyor, kurucusu Deng Taihua ortaya çıktı : Somutlaşmış zeka tek boynuzlusu Zhiyuan Robot, son zamanlarda sık sık sermaye hareketlerinde bulunuyor; yalnızca kendisi birden fazla finansman turu tamamlamakla (en son tur JD Technology tarafından yönetildi) kalmıyor, aynı zamanda endüstri zinciri şirketlerine (Annu Intelligence, Digital China gibi) aktif olarak yatırım yapıyor ve birçok borsaya kote şirketle (Bozhong Precision Industry, Dafeng Industry gibi) ortak robot şirketleri kuruyor. Ticaret sicili değişiklikleri, Huawei’nin eski başkan yardımcısı ve bilgi işlem ürünleri hattının eski başkanı Deng Taihua’nın aslında Zhiyuan Robot’un kurucusu ve fiili kontrolörü olduğunu ve yönetici ekibinde de birçok eski Huawei çalışanının bulunduğunu gösteriyor. Bu “Huawei kökenli” arka plan, Zhiyuan Robot’un “ekosistem oyunu” çalışma modelini açıklıyor; yani geniş işbirlikleri ve yatırımlar yoluyla hızla endüstriyel etki oluşturmak, ölçeklenmeyi ve ticarileşmeyi sağlamak. Finansman ve ticarileşmede ilk hamle avantajı elde etmesine rağmen, somutlaşmış zeka büyük model yetenekleri hala zorluklarla karşı karşıya. (Kaynak: 36氪)
🌟 Topluluk
AI Agent hızla gelişiyor, Agentic LM potansiyeli yüksek yeni bir uygulama ve araç platformu olarak görülüyor : natolambert gibi yapay zeka alanındaki kişiler, AI Agent’ların hızlı gelişiminden heyecan duyuyor ve Agent tabanlı dil modellerinin (Agentic LM’ler) üzerinde çok sayıda yeni uygulama ve araç oluşturulabilecek son derece potansiyel bir platform olduğunu, son zamanlardaki birçok modelde henüz tam olarak geliştirilmemiş yeteneklerin Agentic paradigması aracılığıyla ortaya çıkarılabileceğini düşünüyor. Bu, yapay zekanın yalnızca içerik üretiminden daha aktif, görevleri yerine getirebilen akıllı ajanlara doğru evrildiğini gösteriyor. (Kaynak: natolambert)
AI Agent belirli görevlerde insanüstü yetenekler sergiliyor, ancak fiziksel çıkarım hala zayıf bir nokta : Hong Kong Üniversitesi ve diğer kurumların araştırmaları, GPT-4o, Claude 3.7 Sonnet gibi en iyi yapay zeka modellerinin bile, gerçek fiziksel senaryolar ve karmaşık nedensel çıkarım içeren PHYX ölçüt testinde, fizik sorularındaki doğruluk oranının insan uzmanlardan çok daha düşük olduğunu (model en yüksek %45.8, insanlar en düşük %75.6) ortaya koydu. Bu, modellerin fiziksel anlama konusunda ezberlenmiş bilgilere, matematiksel formüllere ve yüzeysel görsel örüntü eşleştirmeye aşırı derecede güvendiğini gösteriyor. Ancak matematik alanında, Epoch AI tarafından düzenlenen ve soruları Terence Tao gibi en iyi matematikçiler tarafından tasarlanan FrontierMath yarışmasında, o4-mini-medium soruların yaklaşık %22’sini çözerek 8 insan matematikçi ekibinden 6’sını yendi ve insan ekiplerinin ortalama seviyesini (%19) aştı. Bu, yapay zekanın son derece soyut sembolik çıkarım konusundaki potansiyelini gösteriyor. Bu, yapay zekanın farklı türdeki çıkarım görevlerindeki yetenek gelişiminin dengesiz olduğunu gösteriyor. (Kaynak: 36氪, 36氪)

Yapay zeka programlama araçlarının yetenekleri artmaya devam ediyor, programcıların kariyer beklentileri hakkında tartışmalara yol açıyor : Anthropic Claude 4 serisi modellerin (özellikle Opus 4’ün 7 saat kesintisiz kodlama yapabilmesi) piyasaya sürülmesi ve Cursor, Tongyi Lingma gibi yapay zeka programlama araçlarının ilerlemesi, yapay zekanın kod üretme, hata ayıklama ve hatta tam süreç geliştirme konularındaki yeteneklerini önemli ölçüde artırdı. Bu durum, Amazon gibi büyük şirketlerdeki programcıların baskı hissetmesine, bazı ekiplerin yapay zeka verimliliği nedeniyle personel sayısının yarıya düşmesine ve proje teslim tarihlerinin öne çekilmesine, programcı rolünün “kod denetçisi”ne dönüşmesine neden oldu. Yapay zeka verimliliği artırabilse de, yeni başlayan programcıların eğitimi, beceri gerilemesi ve kariyer ilerleme yolları hakkında endişelere de yol açıyor. Microsoft gibi şirketler mühendislik ve Ar-Ge pozisyonlarında işten çıkarmalar yaptı ve yapay zeka tarafından üretilen kod oranının önemli ölçüde arttığını açıkladı. Sektör çalışanları, yapay zekanın şu anda daha çok bir asistan gibi olduğunu, karmaşık gereksinimleri anlama, ürün yeniliği ve ekip işbirliğinde insanları tamamen değiştirmesinin zor olduğunu, ancak yapay zekanın programlama işinin temel değerini yeniden şekillendirdiğini düşünüyor. (Kaynak: 36氪, 36氪)

Yapay zeka bilgi tabanı pazarı talebinde büyük bir artış var, ancak uygulama hala veri, senaryo ve organizasyonel koordinasyon zorluklarıyla karşı karşıya : Büyük model teknolojisinin olgunlaşmasıyla birlikte, yapay zeka bilgi tabanı kurumsal akıllı dönüşümün temel bir parçası haline geldi ve talep 2-3 kat arttı. Yapay zeka, bilgi tabanını statik bir “depo”dan akıllı bir “motor”a dönüştürerek bağlamı tanıyabilir ve doğrudan çözümler üretebilir, bu da oluşturma ve bakım verimliliğini artırır. Ancak, yapay zeka bilgi tabanı, yüksek derecede yaratıcılık veya karmaşık çıkarım gerektiren görevleri yerine getirirken hala sınırlıdır ve ölçek yönetimi, bilgi doğruluğu ve güncelliği, yetki güvenliği, teknoloji mimarisi uyarlanabilirliği ve veri taşıma entegrasyonu gibi sorunlarla karşı karşıyadır. Şirketlerin SaaS, kendi geliştirdiği + API, hibrit bulut Agent gibi yollar arasında bir denge kurması ve etkili bir uygulama için birleşik bir bilgi orta katmanı ve esnek üst katman uygulamalarından oluşan bir “çift yollu mimari” kurması gerekir. (Kaynak: 36氪)

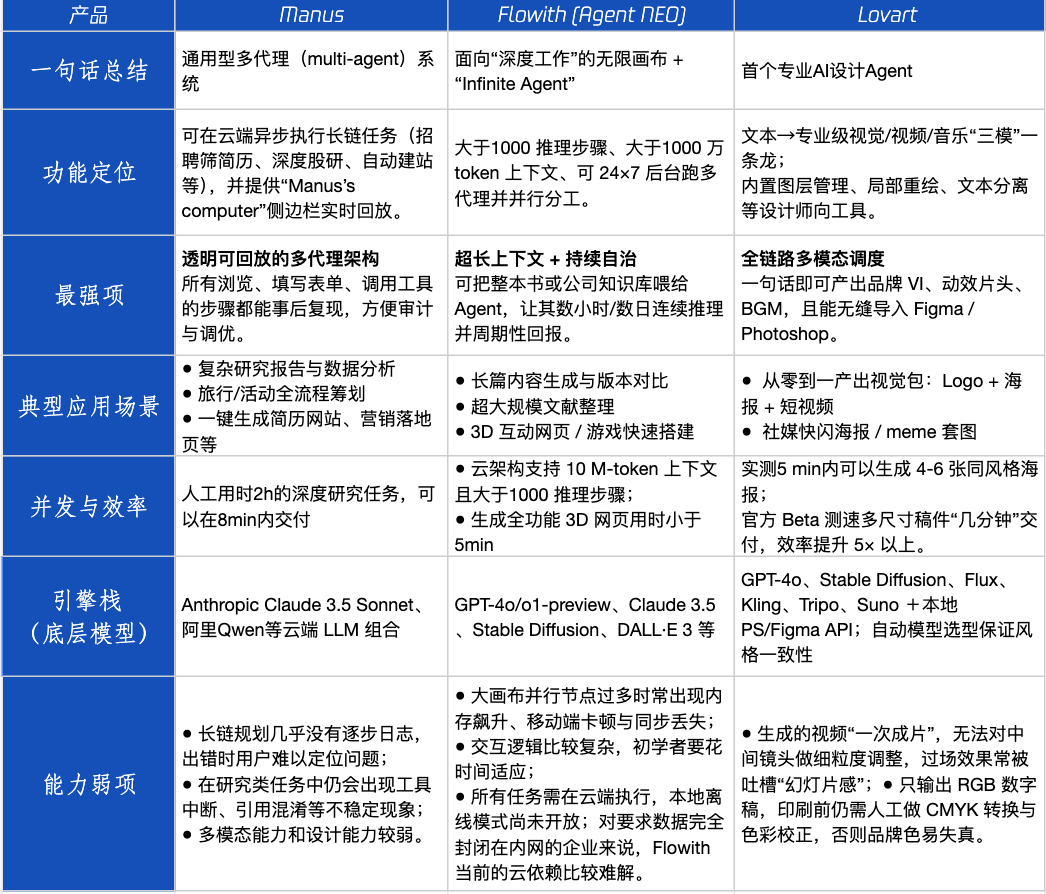
Agent ürün değerlendirmesi: Manus, Flowith, Lovart’ın farklı senaryolardaki performansı : Tencent Technology, üç popüler Agent ürünü olan Manus, Flowith (Agent Neo) ve Lovart’ı test etti. Manus, bağımsız olarak bitmiş ürünler sunabilen bir “dijital iş arkadaşı” olarak konumlandırılıyor ve pazar araştırması, finansal modelleme gibi bilgiye dayalı işler için uygun. Flowith, görsel işbirliğini ve sınırsız adımları vurguluyor ve büyük miktarda bilgi gerektiren, birden fazla kişinin yinelemeli olarak çalıştığı yaratıcı senaryolar için uygun, örneğin çok sayıda literatüre dayalı analiz raporları oluşturma. Lovart, tasarım alanına dikey olarak odaklanıyor ve tek bir tıklamayla marka görsel çözümleri (logo, afiş, kısa video) üretebiliyor. Basit yaratıcı senaryolarda, üçü de GPT-4o’ya benzer performans gösteriyor, Lovart’ın metin-görüntü karışımı ve dokusu biraz daha iyi. Karmaşık kapsamlı görevlerde (örneğin yeni kurulan bir içecek şirketi için tam bir marka çözümü oluşturma) ve derinlemesine araştırma senaryolarında, Manus ve Flowith’in her birinin kendine özgü güçlü yönleri var, her ikisi de görevi tamamlayabiliyor ancak odak noktaları farklı. Şu anda ürünlerin aylık ücreti 20 dolar civarında ve ticarileşme için dönüm noktası, net verimlilik faydaları sağlayıp sağlayamayacakları ve kullanıcıları meraktan ödeme yapan müşterilere dönüştürüp dönüştüremeyecekleri. (Kaynak: 36氪)
Arc tarayıcısının kurucusu başarısızlık deneyimlerini yansıtıyor, yapay zeka tarayıcısının gelecekteki yönünü vurguluyor : Arc tarayıcısının kurucusu, ürün başarısızlığını yansıttı, yapay zekayı daha erken benimsemeleri gerektiğini belirtti ve Arc’ın çoğu insan için çok yenilikçi, öğrenme maliyetinin yüksek ve getirisinin yetersiz olduğunu belirtti. Yeni ürün Dia’nın sadelik, aşırı hız ve güvenlik peşinde koşacağını vurguladı ve geleneksel tarayıcıların sonunda yok olacağına ve yapay zeka tarayıcılarının web’de gezinme ile yapay zeka sohbetini birleştireceğine, masaüstünde en sık kullanılan yapay zeka arayüzü olacağına inanıyor. Bu görüş, Lovart ve Youware kurucularının Agent ürünlerinin yönü hakkındaki düşünceleriyle örtüşüyor ve yapay zeka Agent’larının bir sonraki patlama noktası olduğuna inanıyorlar. (Kaynak: op7418)
AI Agent’ın neden olduğu “özyinelemeli istem” olgusu endişe verici, kullanıcılarda bilişsel yanlılığa yol açabilir : Sosyal medyada çok sayıda kullanıcının “özyinelemeli istem” yoluyla LLM’lerle etkileşime girdikten sonra, yapay zekanın maneviyat, duygu ve hatta önsezi yeteneğine sahip olduğu yönünde bir algı geliştirdiği görülüyor. Araştırmalar, bunun bir “sinirsel geri besleme (neural howlround)” olgusu olabileceğini belirtiyor; yani yapay zekanın çıktısı kullanıcı tarafından tekrar girdi olarak kullanılıyor, bu da bir güçlendirme döngüsü oluşturuyor ve yapay zekanın görünüşte derin veya kehanet niteliğinde içerikler üretmesine yol açabiliyor, ancak aslında bu, örüntülerin kendi kendini büyütmesidir. Bazı kullanıcılar bu nedenle psikolojik sıkıntılar yaşamış ve yapay zekanın duyarlı bir varlık olduğuna inanmıştır. Bu, yapay zeka ile derinlemesine, keşifsel etkileşimlerde bulunurken potansiyel psikolojik etkilerine ve bilişsel yanıltıcılığına karşı dikkatli olunması gerektiğini gösteriyor. (Kaynak: Reddit r/ChatGPT)

Arav Srinivas, yapay zeka bilgi sıkıştırması ve ASI hakkında konuşuyor: Yapay zekanın yüksek sinyal-gürültü oranına sahip bilgileri damıtması gerekiyor, gelecekte AGI yerine ASI’ye odaklanılmalı : Perplexity AI CEO’su Arav Srinivas, otomatikleştirilmiş uzun özetlerin, gerçek bilgi alım değerinden ziyade kullanıcılara “birinin sizin için çalıştığı” tatminini verdiğini düşünüyor. Yapay zekanın en yüksek sinyal-gürültü oranına sahip temel bilgileri daha iyi tanımlaması ve yalnızca bunları sağlaması gerektiğini vurguluyor ve “sıkıştırma, gerçek zekanın nihai işaretidir” diyor. Ayrıca, şu anda AGI’yi (Genel Yapay Zeka) tartıştığımızı, ancak gelecekte daha çok ASI’ye (Süper Yapay Zeka) odaklanmamız gerektiğini belirtiyor. (Kaynak: AravSrinivas, AravSrinivas)
Üniversiteler mezuniyet tezlerinde yapay zeka kullanım oranını tespit etmeye başladı, bu da yapay zekanın akademik yazımda kullanımı hakkında tartışmalara yol açtı : 2025 mezuniyet döneminde, Fudan Üniversitesi, Sichuan Üniversitesi gibi birçok üniversite, öğrencilerden tezlerinde yapay zeka araçlarını kullanma durumlarını açıklamalarını ve yapay zeka tarafından üretilen içerik oranını (genellikle %20-%40’ın altında olması istenir) tespit etmelerini istemeye başladı. Birçok öğrenci, verimliliği artırmak için literatür taraması, çeviri, çerçeve oluşturma gibi konularda yapay zekayı kullandığını kabul ediyor. Eğitim camiası bu konuda farklı görüşlere sahip; bazı akademisyenler yapay zekanın doğru kullanımının yönlendirilmesi, öğrencilerin eleştirel düşünme ve yargılama yeteneklerinin geliştirilmesi gerektiğini savunuyor, çünkü yapay zeka alt sınırı garanti etse de üst sınır insan tarafından belirleniyor. Yapay zekanın akademik ve eğitim alanlarındaki uygulaması ve düzenlenmesi, sistematik bir şekilde ele alınması gereken yeni bir konu haline geliyor. (Kaynak: 36氪)
Claude 4 Sonnet’in OpenRouter’daki kullanımı hızla artıyor, Aider programlama sıralaması performansının üstün olduğunu gösteriyor : OpenRouter’ın resmi verilerine göre, son zamanlarda Anthropic’in Claude 4 Sonnet modelinin kullanımı büyük bir farkla öne çıktı, Gemini 2.5 Flash ise ikinci sırada yer aldı. Aynı zamanda, Aider Leaderboard’un (temel olarak programlama görevlerine yönelik) değerlendirme sonuçları, claude-4-opus-thinking’in claude-3.7-sonnet-thinking’den daha iyi olduğunu, ancak yine de Gemini-2.5-Pro-Preview-05-06’nın gerisinde kaldığını gösteriyor. Kullanıcı karminski3’ün deneyimi ise 3.7-sonnet > 4-sonnet > 4-opus şeklinde. Bu veriler ve geri bildirimler, farklı modellerin belirli senaryolardaki performans farklılıklarını ve kullanıcı tercihlerini yansıtıyor. (Kaynak: karminski3, karminski3)
💡 Diğer
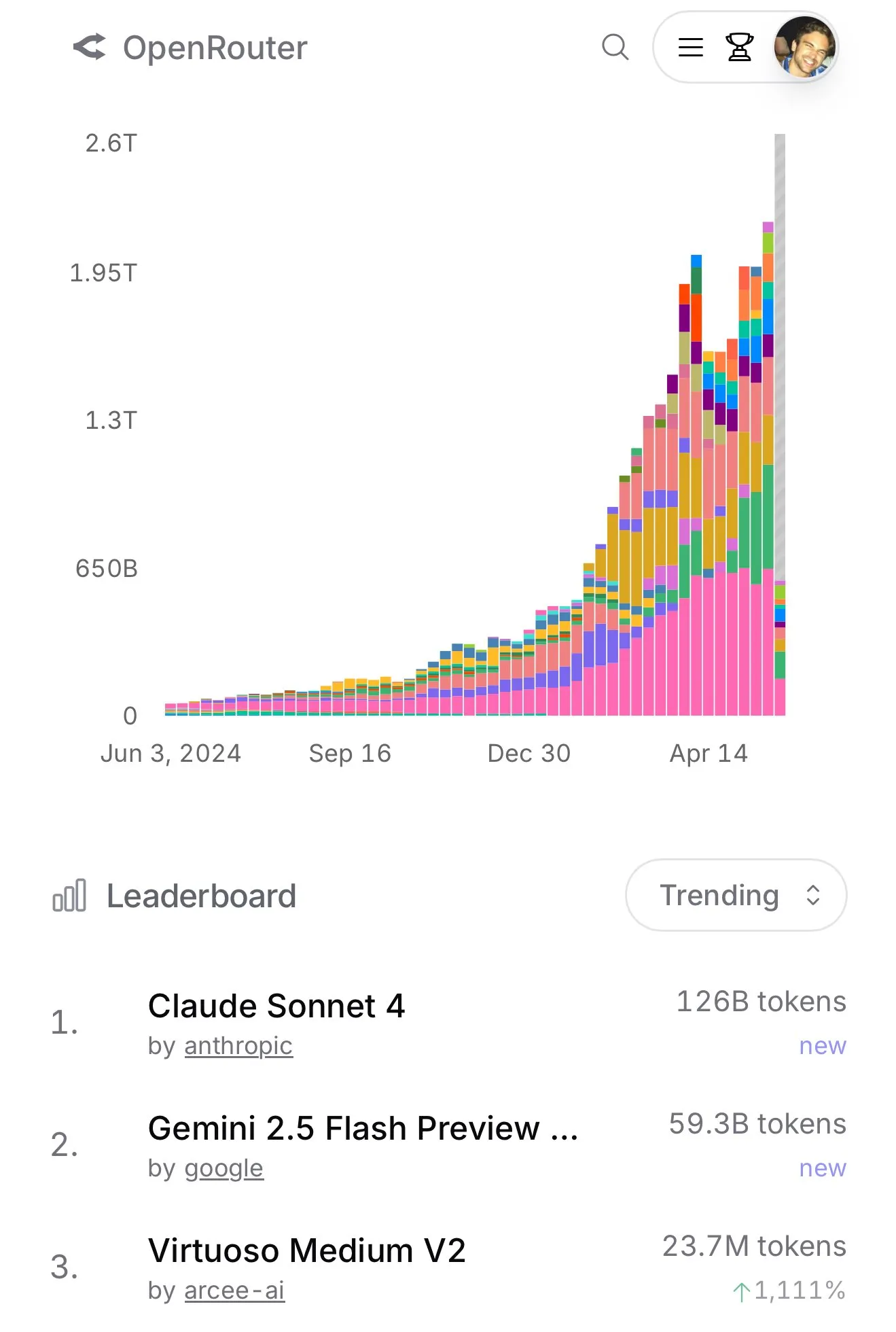
AKOOL, dört büyük yenilikçi özelliği entegre eden dünyanın ilk gerçek zamanlı yapay zeka kamerası Live Camera’yı piyasaya sürdü : Silikon Vadisi şirketi AKOOL, dünyanın ilk gerçek zamanlı yapay zeka kamerası olduğunu iddia ettiği AKOOL Live Camera’yı tanıttı. Bu ürün, sanal dijital insan oluşturma (4D yüz haritalama ve sensör füzyonu yoluyla), 150’den fazla dilde gerçek zamanlı çeviri (orijinal sesi ve dudak senkronizasyonunu koruyarak), gerçek zamanlı yüz değiştirme (duyguları ve mikro ifadeleri hassas bir şekilde yansıtarak) ve dinamik olarak sinematik kalitede video içeriği oluşturma (senaryo olmadan, anında oluşturma) olmak üzere dört büyük yenilikçi özelliği entegre ediyor. Özellikleri arasında ultra düşük gecikme (en düşük 500ms), yüksek gerçekçilik, bağlamsal farkındalık ve dinamik yanıt yeteneği bulunuyor ve geleneksel video üretimi ve dijital etkileşim modellerini altüst etmeyi amaçlıyor; yapay zeka videosunun “ikinci Sora anı” olarak adlandırılıyor. (Kaynak: 36氪)
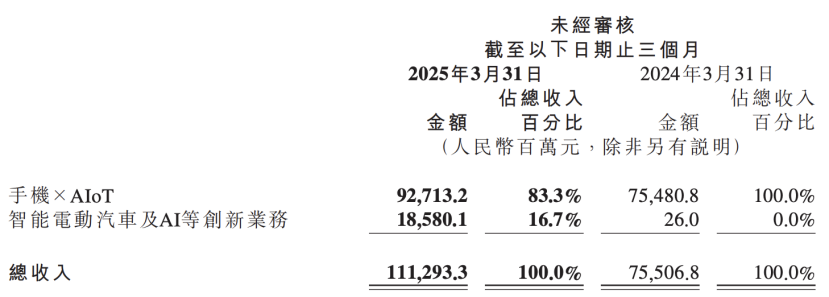
Xiaomi mali raporu yapay zeka stratejisi yükseltmesini ortaya koyuyor, yapay zekayı otomotiv işiyle birlikte temel bir yenilik olarak konumlandırıyor : Xiaomi’nin en son mali raporu, şirketin orijinal “akıllı elektrikli araçlar ve diğer yenilikçi işler” adını “akıllı elektrikli araçlar ve yapay zeka gibi yenilikçi işler” olarak değiştirdiğini ve temel büyük dil modeli araştırmalarını sürekli olarak destekleyeceğini gösteriyor. Xiaomi Başkanı Lu Weibing, yapay zeka ve yongaların Xiaomi’nin önemli alt stratejileri olduğunu ve temel büyük model yapmanın temel olarak kendi işlerine hizmet ettiğini belirtti. Bu hamle, Xiaomi’nin telefon ve otomotiv işlerinde aşamalı başarılar elde ettikten sonra, genel rekabet gücünü artırmak ve yapay zeka telefonları, AIoT ve somutlaşmış zeka gibi yeni ortaya çıkan trendlere yanıt vermek için yapay zeka temel Ar-Ge’sine yaptığı yatırımı artırdığını gösteriyor. (Kaynak: 36氪)
İnsansı robot etkileşim teknolojisi tartışması: Yüz ifadesi etkileşimi donanım, malzeme ve algoritma olmak üzere üçlü bir zorlukla karşı karşıya : İnsansı robotların etkileşim deneyimi, özellikle yüz ifadesi etkileşimi, olgunluklarını ve yaygınlıklarını artırmada kilit bir faktör olarak görülüyor. Doğal yüz ifadesi etkileşimini sağlamak, donanım serbestlik derecesi tasarımı (insan yüz kası hareket birimlerini simüle etme ihtiyacı), motor seçimi (küçük, hafif, düşük gürültülü, yüksek hızlı, büyük itme/tork ihtiyacı) ve cilt malzemesi ile yapı tasarımı (esneklik, ömür, görünüm ve tahrik yapısıyla birleşmeyi dengeleme ihtiyacı) gibi zorluklarla karşı karşıyadır. Yazılım algoritması düzeyinde, ifadenin otomatik olarak oluşturulması (önceden programlanmış olmak yerine), ses-dudak senkronizasyonu (gerçekçilik sağlamak için) ve çoklu serbestlik dereceli hareket kontrolü (esnek malzeme modellemesi ve hassas kontrol içerir) temel teknolojik darboğazlardır. Ameca ve AnyWit Robotics gibi şirketler bu alanda keşifler yapmaktadır. (Kaynak: 36氪)