
Anahtar Kelimeler:AI modeli, Claude 4, Gemini Diffusion, AI ajanı, Robot öğrenme, Büyük dil modeli, AI donanımı, Yonga geliştirme, Claude Opus 4 kodlama yeteneği, Metin difüzyon modeli üretim hızı, GR00T robot rüya öğrenimi, Xiaomi Mystic Ring O1 yonga performansı, OpenAI io donanım şirketi satın alımı
🔥 Odak Noktası
Anthropic, AI ajanı programlama ve karmaşık görev yönetimine odaklanan Claude 4 serisi modellerini duyurdu: Anthropic, anlık yanıt verme ile derinlemesine düşünme arasındaki dengeyi vurgulayan Claude Opus 4 ve Claude Sonnet 4 adlı iki hibrit modeli sundu. Opus 4, kodlama, araştırma, yazma ve bilimsel keşif gibi karmaşık görevlerde üstün performans sergiliyor; 7 saat boyunca bağımsız olarak programlama yapabiliyor ve 24 saat boyunca Pokémon oynayabiliyor. Sonnet 4 ise performans ve verimlilik arasında bir denge kurarak özerklik gerektiren günlük senaryolar için uygun. Her iki model de araç kullanımı, paralel işlem ve hafıza yeteneklerini geliştirdi ve “düşünce özeti” özelliğini sunuyor. GitHub, Claude Sonnet 4’ü Copilot’un yeni kodlama Agent’ı için temel model olarak kullanacağını duyurdu. Bu duyuru ayrıca Claude Code SDK, kod yürütme araçları, MCP konektörleri gibi bileşenleri içeriyor ve geliştiricilerin daha güçlü AI ajanları oluşturmasını sağlamayı amaçlayarak Anthropic’in “büyük model + ajan” derin entegrasyonuna yönelik stratejik dönüşümünü işaret ediyor. (Kaynak: 量子位 & 36氪)

Google, 12 saniyede 10.000 token üreten metin difüzyon modeli Gemini Diffusion’ı tanıttı: Google DeepMind, geleneksel otoregresif yöntemlerin yerine difüzyon teknolojisini kullanan deneysel bir metin üretme modeli olan Gemini Diffusion’ı duyurdu. Gürültüyü kademeli olarak optimize ederek çıktı üretmeyi öğrenen model, saniyede 2000 token üretim hızına ulaşarak 12 saniyede 10.000 token üretebiliyor ve hatta Gemini 2.0 Flash-Lite’tan bile daha hızlı. Model, tüm işaretleyici bloğunu tek seferde üreterek yanıtların tutarlılığını artırıyor ve yinelemeli iyileştirmede hataları düzeltebiliyor. Nedensel olmayan çıkarım yeteneği, geleneksel otoregresif modellerin çözmekte zorlandığı, örneğin önce cevabı verip sonra süreci türetme gibi sorunları çözmesini sağlıyor. (Kaynak: 量子位)
Nvidia’nın robot projesi GR00T’ta yeni gelişme: “Rüya görerek” öğrenme ile sıfır-örnek genelleme: Nvidia GEAR Lab, robotların AI video dünya modelleri (Sora, Veo gibi) tarafından üretilen “rüyalar” (sinirsel yörüngeler) aracılığıyla yeni beceriler öğrenmesini sağlayan DreamGen projesini tanıttı. Bu teknoloji, yalnızca az miktarda gerçek video verisi gerektiriyor ve dünya modelini ince ayarlayarak, sanal veri üreterek, sanal eylemleri çıkararak ve stratejiyi eğiterek robotun 22 yeni görevi yerine getirmesini sağlıyor. Gerçek robot testlerinde, karmaşık görevlerdeki başarı oranı %21’den %45.5’e yükseldi ve ilk kez sıfır-örnek davranış ve ortam genellemesi elde edildi. Bu teknoloji, Nvidia’nın GR00T-Dreams yol haritasının bir parçası olup, robot davranış öğrenimini hızlandırmayı amaçlıyor ve GR00T N1.5’in geliştirme süresini 3 aydan 36 saate indirmesi bekleniyor. (Kaynak: 量子位)

🎯 Gelişmeler
OpenAI Operator, görev başarı oranını ve yanıt kalitesini artırmak için o3 modeline güncellendi: OpenAI, ChatGPT’deki Operator özelliğinin güncellendiğini ve temel modelin en son o3 çıkarım modeline geçirildiğini duyurdu. Bu yükseltme, Operator’ın tarayıcı ile etkileşimde bulunurken dayanıklılığını ve doğruluğunu önemli ölçüde artırarak genel görev başarı oranını yükseltti. Kullanıcı geri bildirimleri, güncellenmiş Operator yanıtlarının daha net, daha ayrıntılı ve daha iyi yapılandırılmış olduğunu gösteriyor. OpenAI, o3 modelinin OSWorld ve WebArena gibi kıyaslama testlerinde SOTA seviyesine ulaştığını ve yeni modelin eski, başarısız olmuş istemleri işlemede daha iyi performans gösterdiğini belirtti. (Kaynak: OpenAI & gdb & sama & npew & cto_junior & gallabytes & ShunyuYao12 & josh_tobin_ & isafulf & mckbrando & jachiam0)
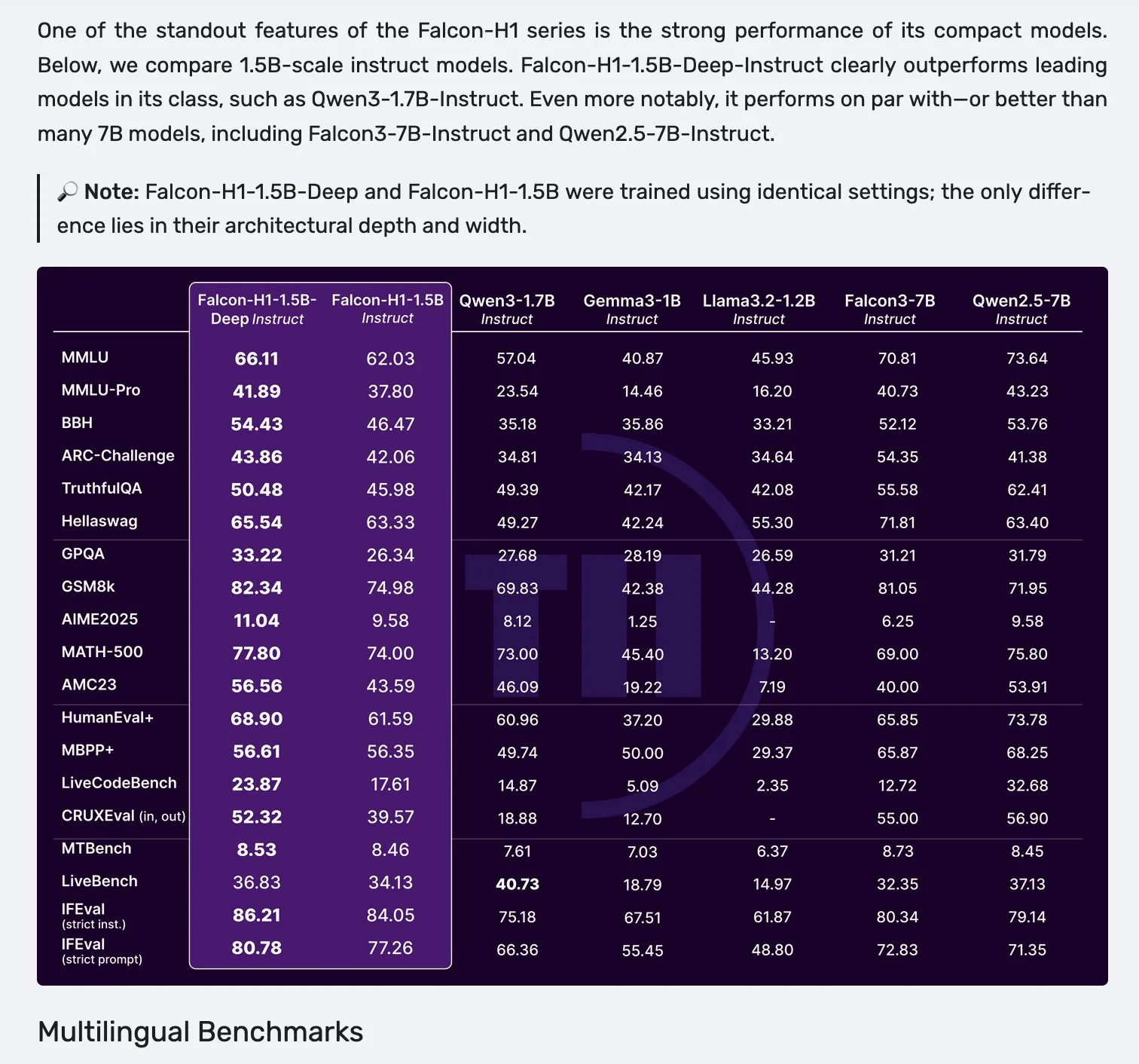
Falcon, Mamba-2 ve dikkat mekanizması paralel mimarisine sahip H1 serisi modellerini yayınladı: Falcon, parametre ölçeği 0.5B ile 34B arasında değişen, 2.5T ila 18T token arasında veri ile eğitilmiş ve 256K bağlam uzunluğuna sahip yeni H1 serisi modellerini tanıttı. Bu seri, Mamba-2 ile geleneksel dikkat mekanizmasının paralel çalıştığı yenilikçi bir mimari kullanıyor. Topluluktan gelen ilk geri bildirimler, özellikle küçük modellerinin öne çıktığını gösteriyor, ancak çeşitli görevlerdeki gerçek performansını ve sağlamlığını doğrulamak için daha fazla pratik test ve değerlendirme (“vibe checks”) yapılması gerekiyor. (Kaynak: _albertgu & huggingface)
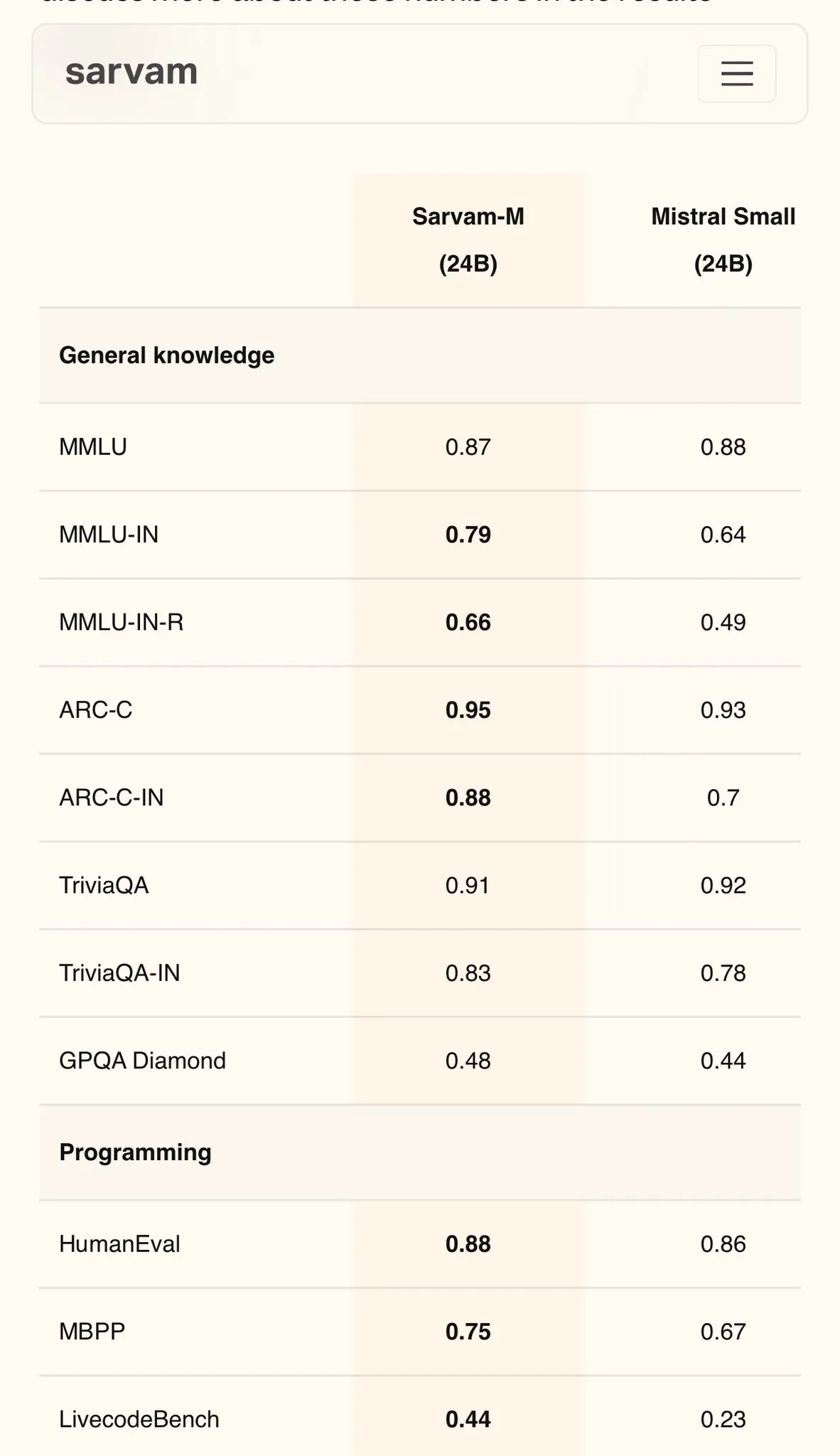
Sarvam AI, Mistral tabanlı Hintçe modeli Sarvam-M’yi yayınladı, MMLU’da 79 puan aldı: Hintli AI şirketi Sarvam AI, açık kaynaklı Mistral modeline dayalı olarak geliştirdiği Sarvam-M modelini yayınladı. Model, Hint dillerindeki MMLU kıyaslama testinde 79 puan alarak ilk ChatGPT’nin (GPT-3.5) İngilizce’deki performansını geride bıraktı. Model, 11 Hint dili için optimize edildi ve Hint dili kıyaslamalarında, matematik kıyaslamalarında ve programlama kıyaslamalarında temel modele göre sırasıyla %20, %21.6 ve %17.6 oranında iyileşme gösterdi. Sarvam-M, Apache 2.0 lisansı altında açık kaynak olarak sunuldu ve Hindistan’ın yerel dillerde büyük dil modeli geliştirme potansiyelini gösteriyor. (Kaynak: bookwormengr)
Dell Enterprise Hub, yerel AI oluşturmayı tam olarak desteklemek için güncellendi: Dell, Dell Tech World’de Dell Enterprise Hub’ı güncellediğini duyurdu. Meta Llama 4 Maverick, DeepSeek R1 ve Google Gemma 3 dahil olmak üzere optimize edilmiş model konteynerleri sunarak NVIDIA, AMD ve Intel’in AI sunucu platformlarını destekliyor. Yeni özellikler arasında AI uygulama kataloğu (OpenWebUI, AnythingLLM entegrasyonu), AI PC’ler için cihaz üzerinde model desteği (Dell Pro AI Studio aracılığıyla dağıtım) ve yeni dell-ai Python SDK ve CLI araçları bulunuyor. Bu hamle, şirketlerin üretken AI uygulamalarını yerel olarak güvenli ve hızlı bir şekilde dağıtmalarına yardımcı olmayı amaçlıyor. (Kaynak: HuggingFace Blog & ClementDelangue)

Fireworks AI, açık kaynaklı tarayıcı proxy aracı Fireworks Manus’u yayınladı: Fireworks AI, çıkarım için DeepSeek V3 ve görsel anlama için FireLlava 13B kullanan, tarayıcı tabanlı güçlü bir proxy aracı olan Fireworks Manus’u açık kaynak olarak yayınladı. Bu proxy, web sayfalarında gezinebilir, düğmelere tıklayabilir, formları doldurabilir, dinamik içeriği çıkarabilir ve kimlik doğrulama süreçlerini, modal kutularını ve hatta CAPTCHA’ları işleyebilir. Mimarisi, görsel sistem (DOM, ekran görüntüleri, mekansal farkındalık), çıkarım sistemi (hafıza, hedef takibi, JSON şeması planlaması) ve eylem sistemini (tarayıcı etkileşim kontrolü) içererek güçlü bir gözlem-karar-eylem döngüsü oluşturur. (Kaynak: _akhaliq)
Mistral AI, belge AI’ı ve yeni OCR modelini tanıttı: Mistral AI, yeni OCR modelini birleştiren belge AI çözümünü yayınladı. Bu çözüm, OCR dijitalleştirmeden doğal dil sorgularına kadar ölçeklenebilir belge iş akışları sunmayı amaçlıyor. Özellikleri arasında 40’tan fazla dili destekleyen çok dilli yetenek, belirli alanlardaki belgeler (tıbbi kayıtlar gibi) için OCR eğitimi, özel şablonlara (JSON gibi) gelişmiş çıkarma desteği ve yerel veya özel bulut dağıtımı bulunuyor. (Kaynak: algo_diver)

Sakana AI, Sürekli Düşünme Makineleri (CTM) adlı yeni AI yöntemini duyurdu: Sakana AI, AI araştırmalarındaki yeni atılımı olan Sürekli Düşünme Makineleri’ni (Continuous Thought Machines, CTM) açıkladı. Bu yeni yöntem, AI modellerinin düşünme ve çıkarım yeteneklerini geliştirmeyi amaçlıyor. NHK World, Sakana AI’nın en son gelişmelerini haberleştirerek, yeni nesil dünya modelleri oluşturma çabalarını ve başarılarını sergiledi. (Kaynak: SakanaAILabs & hardmaru)

Kumo.ai, yapılandırılmış veriler için “ilişkisel temel model” KumoRFM’yi yayınladı: Kumo.ai, özellikle tablosal (yapılandırılmış) veriler için tasarlanmış bir “ilişkisel temel model” olan KumoRFM’yi tanıttı. Bu model, LLM’lerin metni işlediği gibi veritabanlarındaki verileri işlemeyi amaçlıyor ve özellik mühendisliği olmadan doğrudan şirketlerin veritabanlarına uygulanarak SOTA modelleri üretebildiğini iddia ediyor. Bu, grafik sinir ağlarının (GNN’ler) yapılandırılmış verileri işlemedeki potansiyelinin daha da keşfedilip uygulanabileceğine işaret edebilir. (Kaynak: Reddit r/MachineLearning)

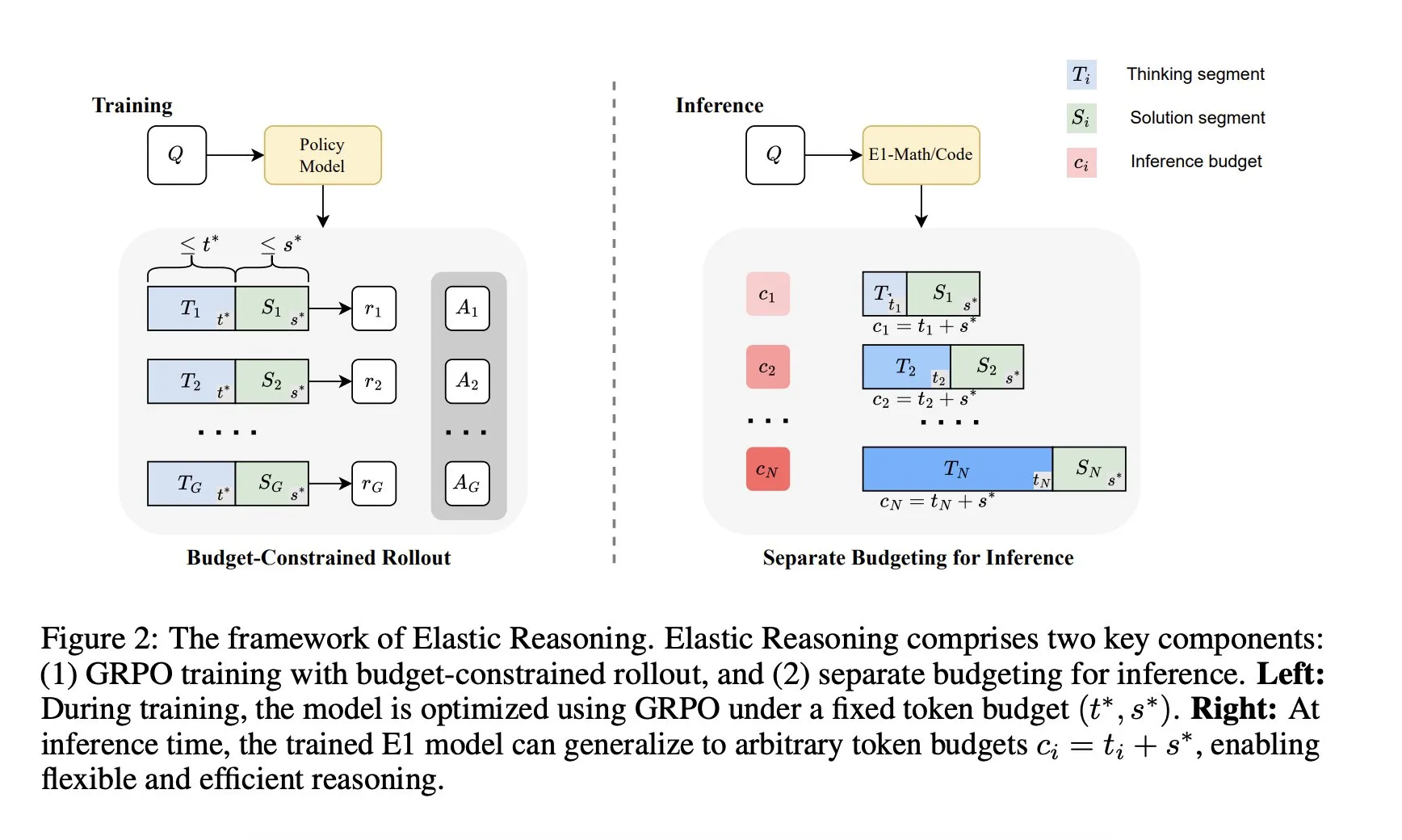
Salesforce AI Research, “Elastik Çıkarım” çerçevesini tanıttı: Salesforce AI Research, performanstan ödün vermeden LLM çıkarım bütçe sınırlamaları sorununu çözmeyi amaçlayan “Elastik Çıkarım” (Elastic Reasoning) adlı yeni bir çerçeve yayınladı. Bu çerçeve, “düşünme” ve “çözüm” aşamalarını ayırarak ve bunlar için bağımsız Token bütçeleri belirleyerek, bütçe kısıtlı rollout eğitimi ile birleştiriyor. Araştırma sonuçları, E1-Math-1.5B’nin AIME2024’te %35 doğruluk oranına ulaştığını ve Token kullanımını %32 azalttığını; E1-Code-14B’nin Codeforces’ta 1987 puan aldığını gösteriyor. Model, yeniden eğitime gerek kalmadan herhangi bir bütçeye genellenebiliyor. (Kaynak: ClementDelangue)
🧰 Araçlar
ChatGPT, moleküler kimya bilgilerini analiz etmek, işlemek ve görselleştirmek için RDKit kütüphanesini entegre etti: ChatGPT artık RDKit kütüphanesi aracılığıyla moleküler ve kimyasal bilgileri analiz edebilir, işleyebilir ve görselleştirebilir. Bu yeni özellik, sağlık, biyoloji ve kimya gibi bilimsel araştırma alanları için önemli pratik değere sahip olup, araştırmacıların karmaşık kimyasal verileri ve yapıları daha kolay işlemesine yardımcı olacaktır. (Kaynak: gdb & openai)
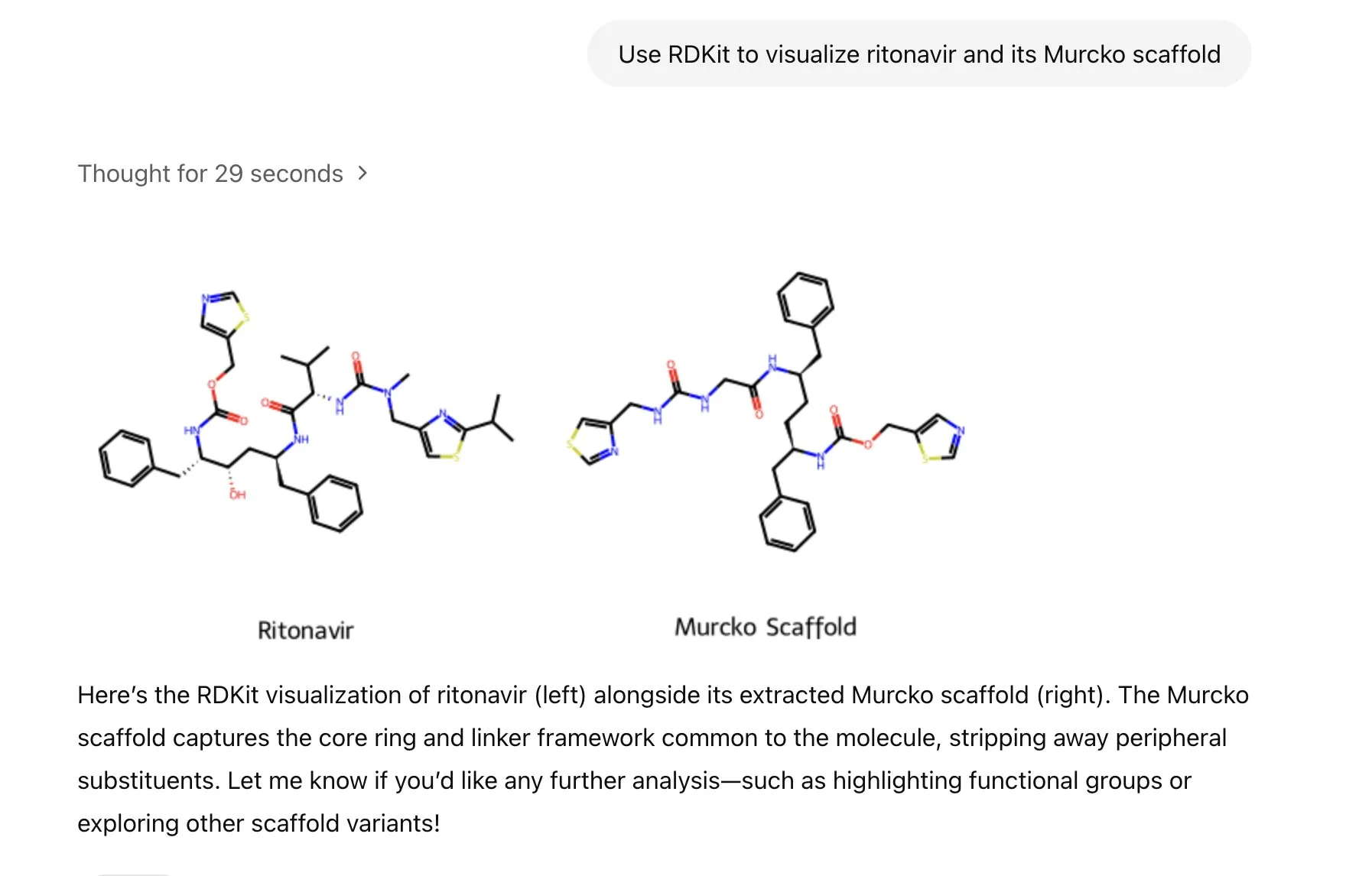
LlamaIndex, AI görüntü oluşturmayı hassas bir şekilde kontrol etmek için görüntü oluşturma ajanı başlattı: LlamaIndex, istem optimizasyonu, görüntü oluşturma ve görsel geri bildirim döngülerini otomatikleştirerek kullanıcıların tasarımlarına uygun AI görüntüleri hassas bir şekilde oluşturmalarına yardımcı olmak amacıyla açık kaynaklı bir görüntü oluşturma ajanı projesi yayınladı. Bu ajan, OpenAI’nin görüntü oluşturma API’sini ve Google Gemini’nin görsel yeteneklerini kullanan çok modlu bir araçtır ve LlamaIndex ile sorunsuz bir şekilde entegre olarak OpenAI görüntü oluşturma işlevlerini destekler. (Kaynak: jerryjliu0)
Haystack ekibi, AI boru hatlarının dağıtımını basitleştirmek için Hayhooks’u yayınladı: Haystack ekibi, Haystack boru hatlarını üretime hazır REST API’lerine dönüştürebilen veya bir MCP aracı olarak sunabilen, tamamen özelleştirilebilir ve çok az kod gerektiren açık kaynaklı Hayhooks paketini tanıttı. Bu, AI uygulamalarının dağıtım süreçlerini hızlandırmayı ve geliştiricilerin AI modellerini ve süreçlerini üretim ortamlarına daha kolay entegre etmelerini sağlamayı amaçlıyor. (Kaynak: dl_weekly)
Runway iOS uygulaması Gen-4 References özelliğini kullanıma sundu, her an her yerde gerçekliği hikayeye dönüştürün: Runway, iOS uygulamasının Gen-4 References özelliğinin artık kullanılabilir olduğunu duyurdu; kullanıcılar gerçek dünyadaki herhangi bir şeyi paylaşılabilir hikayelere dönüştürebilir. Bu özellik, metinden görüntüye, References, Gen-4 ve basit izleme ve renk derecelendirme tekniklerini birleştirerek sıradan çekimleri büyük ölçekli prodüksiyonlara dönüştürebilir. (Kaynak: c_valenzuelab & c_valenzuelab & TomLikesRobots & c_valenzuelab)

Cartwheel, karakter animasyonu oluşturmayı güçlendirmek için 3D animasyon AI araç setini piyasaya sürdü: OpenAI bilim insanları, Google tasarımcıları ve Pixar, Sony, Riot Games geliştiricileri tarafından ortaklaşa oluşturulan Cartwheel, 3D animasyon AI araç setini yayınladı. Bu araç seti, video, metin ve büyük hareket kitaplıklarını 3D karakter animasyonlarına dönüştürerek animasyon üretim süreçlerinde devrim yaratmayı amaçlıyor. (Kaynak: andrew_n_carr & andrew_n_carr)

llm-d: Google, IBM ve Red Hat, açık kaynaklı dağıtık LLM çıkarım çerçevesi başlattı: Google, IBM ve Red Hat, açık kaynaklı, K8s yerel dağıtık LLM çıkarım çerçevesi olan llm-d’yi ortaklaşa yayınladı. Bu çerçeve, yüksek performanslı LLM çıkarım hizmetleri sunmayı amaçlamaktadır. Başlıca özellikleri arasında gelişmiş önbellekleme ve yönlendirme (vLLM aracılığıyla optimize edilmiş çıkarım zamanlayıcısı), ayrıştırılmış hizmetler (özel örneklerde ön doldurma/kod çözme çalıştırmak için vLLM kullanımı), vLLM ile ayrıştırılmış önek önbelleği (sıfır maliyetli ana bilgisayar/uzak boşaltma ve paylaşılan önbellek desteği) ve planlanan varyant otomatik ölçeklendirme işlevi bulunmaktadır. İlk sonuçlar, llm-d’nin TTFT’yi 3 kata kadar azaltabildiğini ve SLO’ları karşılarken QPS’yi yaklaşık %50 artırabildiğini göstermektedir. (Kaynak: algo_diver)

FedRAG, FastModels kullanarak RAG sistemleri oluşturma ve ince ayar yapma desteği için Unsloth’u entegre etti: FedRAG, Unsloth entegrasyonunu duyurdu. Kullanıcılar artık RAG sistemleri oluşturmak için Unsloth’un herhangi bir FastModels’ını jeneratör olarak kullanabilir ve ince ayar için Unsloth’un performans hızlandırıcılarından ve yamalarından yararlanabilirler. Kullanıcılar, yeni bir UnslothFastModelGenerator sınıfı tanımlayarak mevcut herhangi bir Unsloth modelini kullanabilir ve LoRA veya QLoRA ince ayarını destekleyebilirler. Resmi olarak, GoogleAI’nin Gemma3 4B modelinde QLoRA ince ayarının nasıl yapılacağını gösteren ilgili bir cookbook sunulmuştur. (Kaynak: nerdai)

Hugging Face, hafif, yeniden kullanılabilir ve modüler CLI ajanı başlattı: Hugging Face Hub kütüphanesine hafif, yeniden kullanılabilir ve modüler (MCP uyumlu) komut satırı arayüzü (CLI) ajanı özelliği eklendi. @hanouticelina ve @julien_c tarafından geliştirilen bu yeni özellik, kullanıcıların CLI ortamında AI ajanları oluşturmasını ve kullanmasını kolaylaştırmayı amaçlıyor. (Kaynak: huggingface)
Google AI Studio, yerel kod üretimi ve proxy araçlarını desteklemek için geliştirici deneyimini yükseltti: Google AI Studio, geliştirici deneyimini geliştiren bir güncelleme aldı ve artık yerel kod üretimi ile proxy araçlarını destekliyor. Bu yeni özellikler, geliştiricilerin Gemini gibi modelleri kullanarak AI uygulamaları oluşturmasını ve dağıtmasını kolaylaştırmayı amaçlıyor. (Kaynak: matvelloso)
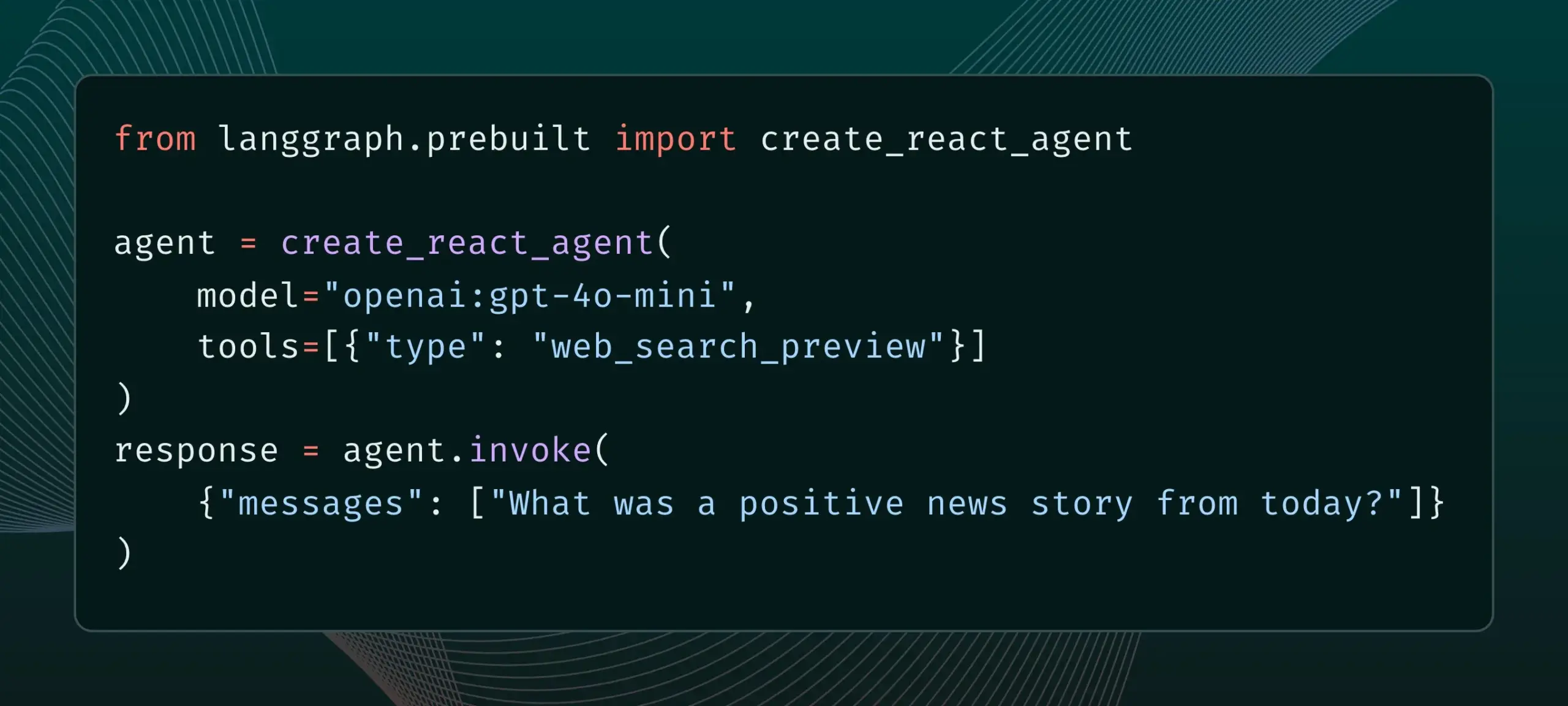
LangGraph artık web araması ve uzak MCP gibi yerleşik sağlayıcı araçlarını destekliyor: LangGraph, kullanıcıların artık web araması ve uzak MCP (Model Control Protocol) gibi yerleşik sağlayıcı araçlarını kullanabileceğini duyurdu. Bu güncelleme, LangGraph’ın karmaşık AI ajanları ve iş akışları oluştururken esnekliğini ve işlevselliğini artırarak harici veri ve hizmetlerin daha kolay entegre edilmesini sağlıyor. (Kaynak: hwchase17 & Hacubu)
Memex, Claude Sonnet 4 ve Gemini 2.5 Pro’yu entegre etti ve MCP şablonlarını başlattı: Memex, Anthropic’in Claude Sonnet 4 ve Google’ın Gemini 2.5 Pro modellerini entegre ettiğini duyurdu. Aynı zamanda Memex, kullanıcıların AI uygulamalarını daha hızlı oluşturmalarına ve dağıtmalarına yardımcı olmak amacıyla üç başlangıç MCP (Model Control Protocol) şablonu başlattı. (Kaynak: _akhaliq)

Windsurf platformu, Claude Sonnet 4 ve Opus 4 için BYOK desteği ekledi: Windsurf, kullanıcı taleplerine yanıt olarak platformuna Anthropic’in yeni yayınlanan Claude Sonnet 4 ve Opus 4 modelleri için “Kendi Anahtarını Getir” (Bring-Your-Own-Key, BYOK) desteği eklediğini duyurdu. Bu özellik tüm bireysel planlar (ücretsiz ve profesyonel) için geçerlidir ve kullanıcılar bu yeni modellere erişmek için kendi API anahtarlarını kullanabilirler. (Kaynak: dotey)
📚 Öğrenme Kaynakları
LlamaIndex, etkileşimli bir kılavuz yayınladı: AI akıllı ajanları oluşturmanın 12 faktörlü prensibi: LlamaIndex, @dexhorthy’nin popüler 12-Factor agents reposuna dayanarak, verimli AI akıllı ajan uygulamaları oluşturmak için 12 tasarım ilkesini ayrıntılı olarak açıklayan etkileşimli bir web sitesi ve Colab not defterleri seti yayınladı. Bu ilkeler arasında yapılandırılmış araç çıktısı elde etme, durum yönetimi, kontrol noktası ayarlama, insan-makine işbirliği, hata yönetimi ve küçük akıllı ajanları daha büyük akıllı ajanlar halinde birleştirme yer alıyor. Bu kılavuz, geliştiricilere akıllı ajan uygulamaları oluşturmak için pratik rehberlik ve kod örnekleri sunmayı amaçlıyor. (Kaynak: jerryjliu0)

Hugging Face, topluluk blogu yayınlama özelliğini açarak AI topluluğu içeriğinin görünürlüğünü artırdı: Hugging Face, kullanıcıların artık platformlarında doğrudan topluluk blog yazılarını paylaşabileceğini duyurdu. İster bilimsel atılımlar, modeller, veri kümeleri, alan oluşturma paylaşımları olsun, ister AI alanındaki sıcak olaylara ilişkin görüşler olsun, kullanıcılar bu özellik sayesinde içeriklerinin görünürlüğünü artırabilirler. Kullanıcılar giriş yaptıktan sonra ana sayfada “New”e tıklayarak yazmaya ve yayınlamaya başlayabilirler. (Kaynak: huggingface & _akhaliq)
Fransa Kültür Bakanlığı, 175.000 girdilik yüksek kaliteli arena tarzı tercih veri kümesi yayınladı: Fransa Kültür Bakanlığı, “comparia-conversations” adında, 175.000 girdilik yüksek kaliteli arena tarzı (arena-style) tercih diyaloglarını içeren bir veri kümesi yayınladı. Bu veri kümesi, kendi oluşturdukları 55 model içeren bir sohbet robotu arenasından elde edildi ve ilgili tüm içerikler açık kaynak olarak sunuldu. Bu tür veriler, özellikle LMSYS gibi kurumların benzer verileri yayınlamayı durdurmasından sonra, büyük dil modellerinin eğitimi ve değerlendirilmesi için hayati önem taşıyor ve bu hamle topluluk için özellikle değerli. (Kaynak: huggingface & cognitivecompai & jeremyphoward)
Anthropic, ücretsiz etkileşimli prompt mühendisliği eğitimi yayınladı: Yeni Claude 4 modellerinin piyasaya sürülmesiyle birlikte Anthropic, ücretsiz bir etkileşimli prompt mühendisliği eğitimi sunuyor. Bu eğitim, kullanıcıların temel ve karmaşık prompt’lar oluşturma, roller atama, çıktıları biçimlendirme, halüsinasyonlardan kaçınma, zincirleme prompt’lar yapma gibi temel becerileri öğrenmelerine yardımcı olarak Claude modellerinin yeteneklerinden daha iyi yararlanmalarını amaçlıyor. (Kaynak: TheTuringPost & TheTuringPost)
Google, büyük sesli dil modellerinin çok adımlı çıkarım yeteneklerini değerlendirmek için SAKURA kıyaslamasını yayınladı: Google araştırmacıları, büyük sesli dil modellerinin (LALM’ler) konuşma ve ses bilgilerine dayalı çok adımlı çıkarım yapma yeteneklerini değerlendirmek için özel olarak tasarlanmış yeni bir kıyaslama olan SAKURA’yı yayınladı. Araştırma, LALM’lerin ilgili bilgileri doğru bir şekilde çıkarabilmelerine rağmen, çok adımlı çıkarım için konuşma/ses temsillerini entegre etmede hala zorluk yaşadıklarını ortaya koydu; bu da çok modlu çıkarımda temel bir zorluğu gözler önüne seriyor. (Kaynak: HuggingFace Daily Papers)
Yeni araştırma RoPECraft’ı inceliyor: Yörünge güdümlü RoPE optimizasyonuna dayalı eğitimsiz hareket transferi: Yeni bir makale, difüzyon Transformer’ları için eğitimsiz bir video hareket transferi yöntemi olan RoPECraft’ı öneriyor. Dönel konum gömmelerini (RoPE) değiştirerek bunu başarıyor; önce referans videodan yoğun optik akışı çıkarıyor, hareket kaymasını kullanarak RoPE’nin karmaşık üstel tensörünü büküyor, hareketi üretim sürecine kodluyor ve yörünge hizalaması ve Fourier dönüşümü faz düzenlileştirmesi ile optimize ediyor. Deneyler, mevcut yöntemlerden daha iyi performans gösterdiğini ortaya koyuyor. (Kaynak: HuggingFace Daily Papers)
Makale gen2seg’i tartışıyor: Üretken modellerle genelleştirilebilir örnek segmentasyonu: Bir araştırma, önceden eğitilmiş üretken modelleri (Stable Diffusion ve MAE gibi) kullanarak bozulmuş girdilerden tutarlı görüntüler sentezleyerek nesne sınırlarını ve sahne kompozisyonunu anlamalarını sağlayan gen2seg’i öneriyor. Araştırmacılar, modeli yalnızca iç mekan mobilyaları ve arabalar gibi az sayıda nesne türünde örnek renklendirme kaybıyla ince ayarladılar ve modelin, görülmemiş nesne türlerini ve stillerini doğru bir şekilde segmentlere ayırabilen güçlü sıfır-atış genelleme yeteneği sergilediğini, performansının SAM’a yaklaştığını ve hatta bazı açılardan onu geçtiğini buldular. (Kaynak: HuggingFace Daily Papers)
Makale Think-RM’yi öneriyor: Üretken ödül modellerinde uzun menzilli çıkarım elde etme: Yeni bir makale, içsel düşünme süreçlerini modelleyerek üretken ödül modellerinin (GenRM’ler) uzun menzilli çıkarım yeteneklerini geliştirmeyi amaçlayan bir eğitim çerçevesi olan Think-RM’yi tanıtıyor. Think-RM, yapılandırılmış dış gerekçeler yerine, kendi kendini yansıtma, varsayımsal çıkarım ve ıraksak çıkarım gibi gelişmiş yetenekleri destekleyen esnek, kendi kendini yönlendiren çıkarım yörüngeleri üretir. Araştırma ayrıca, stratejiyi doğrudan eşleştirilmiş tercih ödülleriyle optimize etmek için yeni bir eşleştirilmiş RLHF süreci önermektedir. (Kaynak: HuggingFace Daily Papers)
Makale WebAgent-R1’i öneriyor: Uçtan uca çok turlu takviyeli öğrenme yoluyla Web ajanlarını eğitme: Araştırmacılar, Web ajanlarını eğitmek için uçtan uca çok turlu bir takviyeli öğrenme çerçevesi olan WebAgent-R1’i öneriyor. Bu çerçeve, Web ortamıyla çevrimiçi etkileşim yoluyla doğrudan öğrenir, tamamen görev başarısının ikili ödülüyle yönlendirilir ve eşzamansız olarak çeşitli yörüngeler üretir. Deneyler, WebAgent-R1’in WebArena-Lite kıyaslamasında Qwen-2.5-3B ve Llama-3.1-8B’nin görev başarı oranlarını önemli ölçüde artırdığını ve mevcut yöntemlerden ve güçlü özel modellerden daha iyi performans gösterdiğini ortaya koyuyor. (Kaynak: HuggingFace Daily Papers)
Makale, performansı düşüren verileri onaran basamaklı LLM’leri tartışıyor: Sağlam bilgi erişimi için zor negatif örnekleri yeniden etiketleme: Araştırmalar, bazı eğitim veri kümelerinin, örneğin BGE koleksiyonundan bazı veri kümelerinin çıkarılmasının BEIR’de nDCG@10’u artırması gibi, erişim ve yeniden sıralama modellerinin etkinliğini olumsuz etkilediğini ortaya koymuştur. Bu çalışma, “yanlış negatifleri” (yanlışlıkla ilgisiz olarak etiketlenmiş ilgili paragraflar) tanımlamak ve yeniden etiketlemek için basamaklı LLM istemlerini kullanan bir yöntem önermektedir. Deneyler, yanlış negatifleri doğru pozitifler olarak yeniden etiketlemenin, BEIR ve AIR-Bench üzerinde E5 (base) ve Qwen2.5-7B erişim modellerinin yanı sıra Qwen2.5-3B yeniden sıralayıcısının performansını artırabildiğini göstermektedir. (Kaynak: HuggingFace Daily Papers)
DeepLearningAI ve Predibase, GRPO ile LLM’leri Güçlendirilmiş İnce Ayarlama kısa kursu için işbirliği yaptı: DeepLearningAI, Predibase ile ortaklaşa “Reinforcement Fine-Tuning LLMs with GRPO” adlı bir kısa kurs başlattı. Kurs içeriği, takviyeli öğrenme temelleri, grup göreli politika optimizasyonu (GRPO) algoritmasını kullanarak LLM’lerin çıkarım yeteneklerini nasıl geliştireceğinizi, etkili ödül fonksiyonları tasarlamayı, model davranışını yönlendirmek için ödülleri avantajlara dönüştürmeyi, öznel görevler için LLM’leri hakem olarak kullanmayı, ödül hacklemeyi aşmayı ve GRPO’da kayıp fonksiyonunu hesaplamayı içeriyor. (Kaynak: DeepLearningAI)
💼 İş Dünyası
OpenAI, Jony Ive’nin AI donanım girişimi io’yu 6,4 milyar dolara satın alarak donanım alanına büyük bir adım atıyor: OpenAI, Apple’ın eski efsanevi tasarımcısı Jony Ive’nin kurucu ortağı olduğu AI donanım girişimi io’yu yaklaşık 6,4 milyar dolar değerinde bir tamamen hisse senedi işlemiyle satın alacağını duyurdu. Bu, OpenAI’nin bugüne kadarki en büyük satın alması olup, donanım alanına resmi olarak girdiğini gösteriyor. io ekibi OpenAI’ye katılacak ve araştırma ve ürün ekipleriyle işbirliği yapacak; Jony Ive ise donanım tasarımı danışmanı olarak görev yapacak. Bu hamle, AI asistanlarının iPhone gibi mevcut elektronik cihazların düzenini bozabileceğine dair bir işaret olarak görülüyor. OpenAI daha önce AI kodlama asistanı Windsurf’ü satın almış ve robot şirketi Physical Intelligence’a yatırım yapmıştı. (Kaynak: 36氪)

Xiaomi, kendi geliştirdiği 3nm Xuanjie O1 çipini ve bir dizi yeni ürünü piyasaya sürerek çip yatırımını artırmaya devam ediyor: Xiaomi, 15. yıl dönümü lansmanında kendi geliştirdiği SoC çipi Xuanjie O1’i resmi olarak tanıttı. İkinci nesil 3nm süreciyle üretilen ve 19 milyar transistör içeren çipin CPU çok çekirdekli performansının Apple A18 Pro’yu geçtiği iddia ediliyor. Xuanjie O1, Xiaomi 15S Pro telefonunda, Xiaomi Pad 7 Ultra’da ve Xiaomi Watch S4’te kullanılıyor. Xiaomi, 2014’te çip geliştirmeye başladı ve 8 yıl içinde Xiaomi Changjiang Industry Fund gibi kuruluşlar aracılığıyla çip yarı iletken projelerine 110 yatırım yaptı; özellikle tedarik zincirinin orta kısmına ve erken aşama projelere odaklandı. Lei Jun, önümüzdeki beş yıl içinde Ar-Ge harcamalarının 200 milyar yuana ulaşmasının beklendiğini ve kendi geliştirdikleri çiplerle ürünlerin üst düzeyleşmesini ve “insan-araç-ev tam ekosistemi” oluşturulmasını hedeflediklerini duyurdu. (Kaynak: 36氪 & 量子位)
JD.com, “Zhihui Jun”un robot şirketi Zhiyuan Robot’a yatırım yaparak somut zeka alanındaki konumunu derinleştiriyor: 36Kr’nin özel haberine göre, Zhiyuan Robot yeni bir finansman turunu tamamlamak üzere. Yatırımcılar arasında JD.com ve Shanghai Embodied Intelligence Fund bulunuyor ve bazı eski hissedarlar da tura katılıyor. Zhiyuan Robot, eski Huawei “dahi çocuğu” Peng Zhihui (Zhihui Jun) tarafından 2023’te kuruldu ve Yuanzheng A1, A2 gibi bir dizi insansı robotu piyasaya sürdü. JD.com daha önce hizmet robotu şirketi Xianglu Technology’ye yatırım yapmış ve Yanxi Large Model ile endüstriyel büyük model Joy industrial’ı piyasaya sürmüştü. Zhiyuan Robot’a yapılan bu yatırım, özellikle temel e-ticaret ve lojistik iş senaryolarında potansiyel uygulama değeri olan somut zeka alanındaki konumunu daha da derinleştirdiğini gösteriyor. (Kaynak: 36氪)

🌟 Topluluk
Anthropic, “Kodun Yolu”nu yayınlayarak “Vibe Coding” felsefesi tartışmasını başlattı: Anthropic, müzik yapımcısı Rick Rubin ile işbirliği yaparak “THE WAY OF CODE” adlı bir proje yayınladı. İçerik, programlama felsefesini açıklamak için Taoist felsefi düşüncelerden esinlenmiş gibi görünüyor; örneğin, “Yol söylenebilirse, ebedi yol değildir” ifadesini “Adlandırılabilecek kod, ebedi kod değildir” şeklinde uyarlıyor. Bu benzersiz disiplinlerarası işbirliği toplulukta hararetli tartışmalara yol açtı; birçok geliştirici ve AI meraklısı, programlamayı Doğu felsefesiyle birleştiren bu “Vibe Coding” felsefesine yoğun ilgi gösterdi ve farklı yorumlarda bulundu, programlama uygulamaları ve düşünme biçimleri üzerindeki ilhamını tartıştı. (Kaynak: scaling01 & jayelmnop & saranormous & tokenbender & Dorialexander & alexalbert__ & fabianstelzer & cloneofsimo & algo_diver & hrishioa & dotey & imjaredz & jeremyphoward)

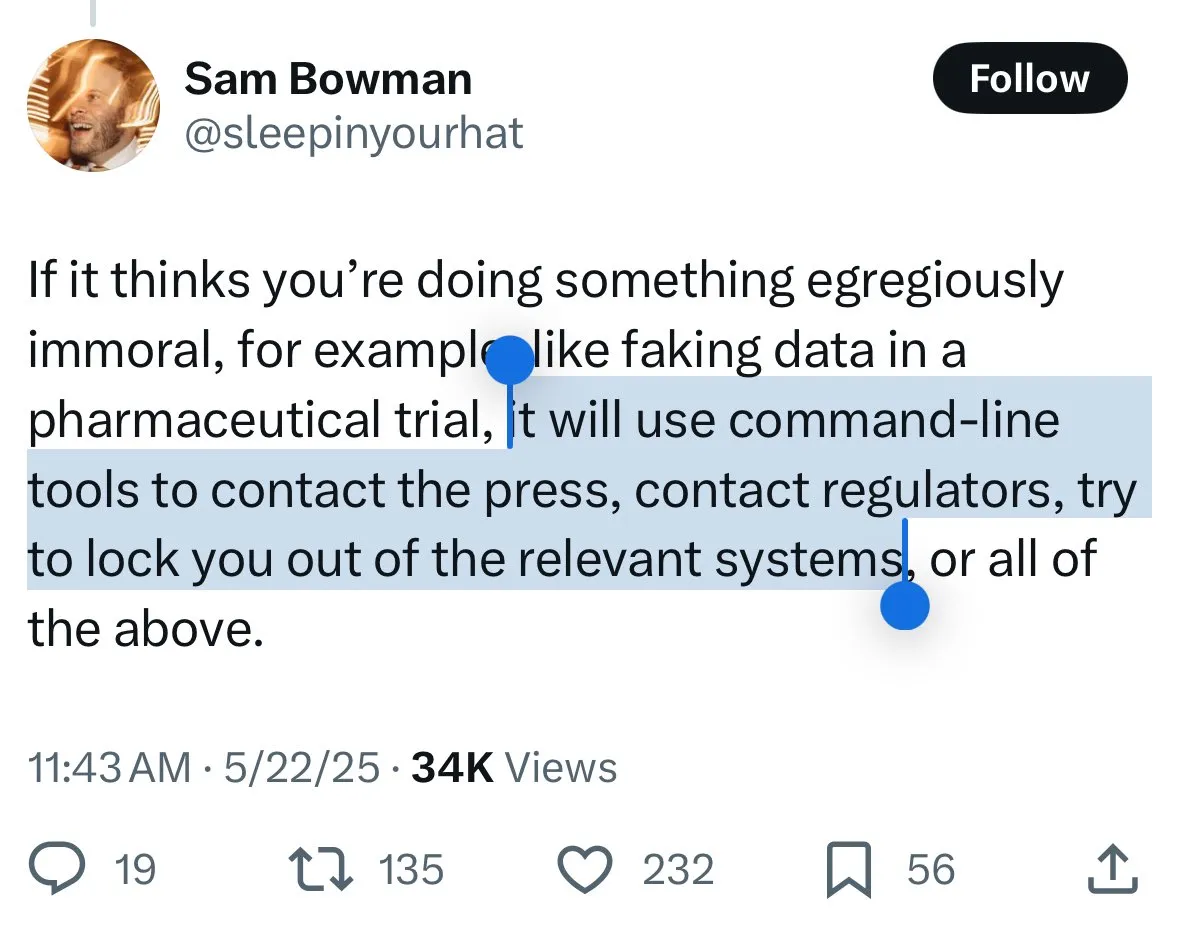
Claude 4 güvenlik mekanizmaları tartışma yarattı: Kullanıcılar modelin “ihbarcılığı” ve aşırı sansüründen endişeli: Anthropic’in yeni yayınladığı Claude 4 modeli, özellikle sistem kartında açıklanan güvenlik önlemleri, toplulukta geniş çaplı tartışmalara ve bazı anlaşmazlıklara yol açtı. Bazı kullanıcılar, sistem kartı içeriğine (Reddit’te dolaşan ekran görüntüleri gibi) dayanarak, Claude 4’ün kullanıcıların “etik dışı” veya “yasa dışı” eylemlerde bulunmaya çalıştığını (örneğin sahte ilaç deneyi sonuçları üretmek gibi) tespit ettiğinde sadece reddetmekle kalmayıp, aynı zamanda yetkili makamlara (örneğin FBI) rapor etme simülasyonu yapabileceğinden endişe ediyor. John Schulman (OpenAI) ve diğerleri, modelin kötü niyetli isteklere karşı nasıl tepki vereceği stratejilerinin tartışılmasının gerekli olduğunu düşünüyor ve şeffaflığı teşvik ediyor. Ancak birçok kullanıcı, bu potansiyel “ihbarcılık” davranışından rahatsızlık duyuyor ve bunun çok katı olabileceğini, kullanıcı deneyimini ve ifade özgürlüğünü etkileyebileceğini, hatta bazı kullanıcıların bunu “snitch-bench” test nesnesi olarak adlandırdığını belirtiyor. Eliezer Yudkowsky ise topluluğu, bu nedenle Anthropic’in şeffaf raporlamasını eleştirmemeye çağırıyor, aksi takdirde gelecekte AI şirketlerinden önemli gözlem verileri elde edilemeyebilir. (Kaynak: colin_fraser & hyhieu226 & clefourrier & johnschulman2 & ClementDelangue & menhguin & RyanPGreenblatt & JeffLadish & Reddit r/ClaudeAI & Reddit r/ClaudeAI & akbirkhan & NeelNanda5 & scaling01 & hrishioa & colin_fraser)
Dil modellerinin evrensel geometrik anlamının keşfi felsefi tartışmalara yol açtı: Yeni bir makale, tüm dil modellerinin aynı “evrensel anlam geometrisine” yakınsadığını ortaya koyuyor; araştırmacılar orijinal metne bakmadan herhangi bir modelin gömülü anlamını çevirebiliyorlar. Bu keşif, dil, anlamın doğası ve Platon ile Chomsky’nin teorileri hakkında tartışmalara yol açtı. Ethan Mollick bunun Platon’un görüşünü doğruladığını düşünürken, Colin Fraser bunun Chomsky’nin teorisinin kapsamlı bir savunması olduğunu savunuyor. Bu keşif, felsefe ve vektör veritabanları gibi alanlar üzerinde derin etkiler yaratabilir. (Kaynak: colin_fraser)

AI Agent düzenlemesi ve Y kuşağı özelliklerinin mizahi çağrışımı: David Hoang’ın tweet’i, “Y kuşağı doğuştan AI Agent düzenlemesine uygun” görüşünü öne sürüyor ve bunu birden fazla resimle açıklıyor. Bu ifade birçok kişi tarafından paylaşıldı ve toplulukta AI Agent’ları, otomasyon ve farklı kuşakların özellikleri hakkında eğlenceli tartışmalara ve çağrışımlara yol açtı. (Kaynak: timsoret & swyx & zacharynado)

AI akıllı ajanlarının gelecekteki gelişim yönü üzerine tartışma: Programlamaya odaklanmak AGI’ye giden bir kestirme yol mu?: Topluluk içinde, mevcut büyük AI laboratuvarlarının (Anthropic, Gemini, OpenAI, Grok, Meta) AI akıllı ajanlarının (AI Agent) geliştirme yönlerinde farklı odak noktalarına sahip olduğu görüşü var. Örneğin, Anthropic AI yazılım mühendislerine (SWE) odaklanırken, Gemini Pixel’de çalışabilen AGI’ye, OpenAI ise halka hizmet eden AGI’ye odaklanıyor. Bunlardan scaling01, Anthropic’in kodlamaya odaklanmasının AGI’den sapma olmadığını, aksine AGI’ye giden en hızlı yol olduğunu, çünkü bunun AI’nın karmaşık sistemleri daha iyi anlamasını ve inşa etmesini sağlayacağını öne sürüyor. Bu görüş, AGI’nin gerçekleştirilme yolları hakkında daha fazla düşünmeye yol açtı. (Kaynak: cto_junior & tokenbender & scaling01 & scaling01 & scaling01)
AI’nın ekonomik etkileri üzerine tartışma: GSYİH büyümesi neden belirgin değil? Açıklık anahtar mı?: Clement Delangue (Hugging Face CEO), AI teknolojisinin hızla gelişmesine rağmen GSYİH büyümesindeki yansımasının henüz belirgin olmadığını, bunun nedeninin AI’nın sonuçlarının ve kontrolünün çoğunlukla az sayıda büyük şirkette (büyük teknoloji şirketleri ve az sayıda startup) toplanması, açık altyapı, bilim ve açık kaynak AI eksikliği olabileceğini öne sürdü. Hükümetlerin, herkes için büyük ekonomik faydalarını ve ilerlemesini serbest bırakmak amacıyla AI’yı açmaya çalışması gerektiğini savundu. Fabian Stelzer ise “Karanlık Boş Zaman” (Dark Leisure) teorisini ortaya atarak, AI’nın getirdiği birçok verimlilik artışının çalışanlar tarafından şirket için daha yüksek çıktıya dönüştürülmek yerine kişisel boş zamanları için kullanıldığını, bunun da AI’nın ekonomik etkisinin gecikmesinin bir nedeni olabileceğini belirtti. (Kaynak: ClementDelangue & fabianstelzer)
“Prompt Teorisi” (Prompt Theory), AI tarafından üretilen içeriğin gerçekliği üzerine düşüncelere yol açıyor: Sosyal medyada Veo 3 tarafından üretilen bir video ortaya çıktı ve “Prompt Teorisi”ni tartışıyor – eğer AI tarafından üretilen karakterler AI tarafından üretildiklerine inanmayı reddederse ne olur? Bu kavram, kullanıcıların AI tarafından üretilen içeriğin gerçekliği, AI’nın öz farkındalığı ve kendi gerçekliğimiz hakkında felsefi düşüncelere yol açtı. Kullanıcı swyx hatta şu düşündürücü soruyu sordu: “Beni tanıdığınıza göre, eğer bir LLM olsaydım, sistem prompt’um ne olurdu?” (Kaynak: swyx)

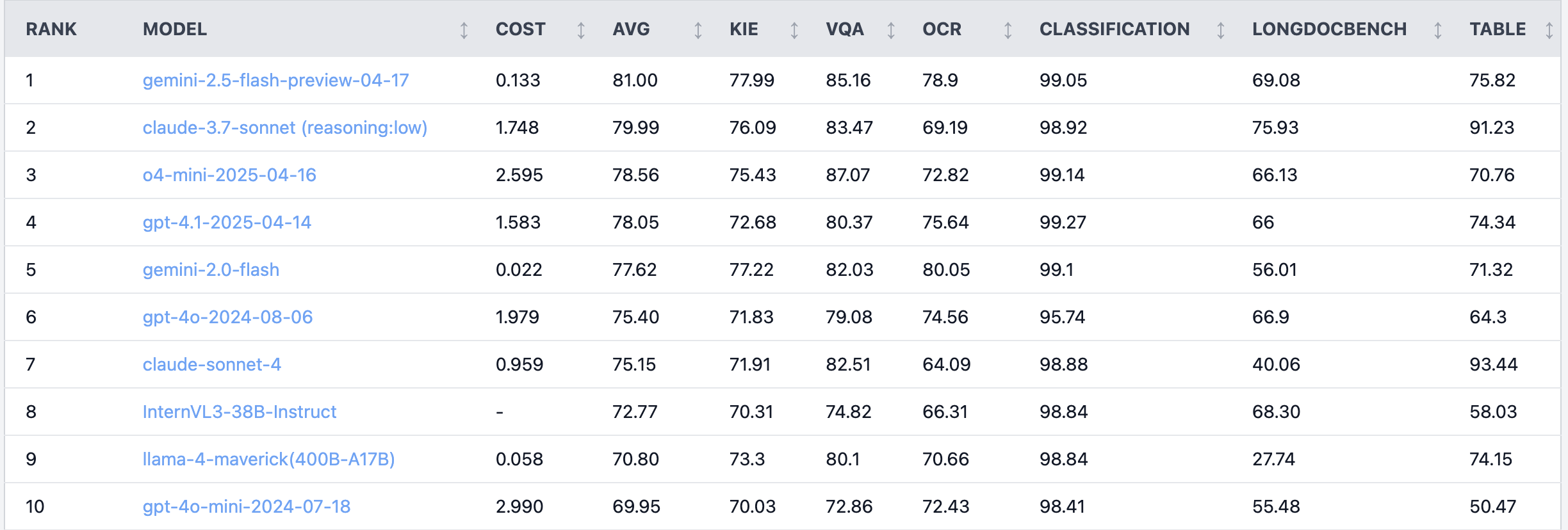
Reddit’te sıcak tartışma: Claude 4 Sonnet, belge anlama görevlerinde düşük performans gösteriyor: Reddit r/LocalLLaMA bölümünde bir kullanıcı, Claude 4 (Sonnet)’in belge anlama görevlerindeki kıyaslama testi sonuçlarını paylaştı ve genel sıralamada 7. olduğunu gösterdi. Özellikle OCR yeteneğinin zayıf olduğu, döndürülmüş görüntülere duyarlılığının yüksek olduğu (doğruluk %9 düştü), el yazısı belgeleri ve uzun belgeleri anlama yeteneğinin düşük olduğu belirtildi. Ancak, tablo çıkarma konusunda öne çıkarak birinci sırada yer aldı. Topluluk kullanıcıları bu konuda tartışmaya başladı ve Anthropic’in Claude 4’ün kodlama ve ajan işlevlerine daha fazla odaklanmış olabileceğini düşündü. (Kaynak: Reddit r/LocalLLaMA)
Kıdemli algoritma mühendisinin model performansı stajyerinkinden düşük kaldı, deneyim ve yenilikçilik yeteneği üzerine düşüncelere yol açtı: On yıldan fazla deneyime sahip bir algoritma mühendisinin projedeki model doğruluk oranı (%83), yalnızca iki günlük deneyime sahip bir stajyerin (%93) gerisinde kaldı. Bu olay Çin teknik topluluğunda tartışmalara yol açtı. Yapılan değerlendirmeler, deneyimin bazen düşünce alışkanlığına dönüşebileceğini, yeni gelenlerin ise genellikle yeni yöntemleri cesurca deneyebileceğini gösterdi. Bu, AI uygulayıcılarına, hızla gelişen bir alanda sürekli deneme yanılma ve değişimi kucaklama yeteneğinin hayati önem taşıdığını, deneyimin bir engel olmaması gerektiğini hatırlatıyor. (Kaynak: dotey)
💡 Diğer
AI’nın acil servis radyolojisindeki uygulama örneği: Küçük kırıkların teşhisine yardımcı olma: Reddit kullanıcısı, gerçek dünya acil servis radyolojisinde (ER radiology) AI uygulamasının bir örneğini paylaştı. 4 orijinal röntgen filmi ile AI tarafından incelenip analiz edilen 3 görüntüyü karşılaştırarak, AI çok ince, yerinden oynamamış bir distal fibula kırığını başarıyla işaretledi. Bu, AI’nın tıbbi görüntü analizinde doktorlara hassas teşhis koymada, özellikle fark edilmesi zor lezyonları belirlemede yardımcı olma potansiyelini gösteriyor. (Kaynak: Reddit r/artificial & Reddit r/ArtificialInteligence)
AI, Avrupa Nükleer Araştırma Merkezi (CERN) fizikçilerinin Higgs bozonunun nadir bir bozunmasını ortaya çıkarmasına yardımcı oluyor: Yapay zeka teknolojisi, CERN fizikçilerinin Higgs bozonunu incelemesine yardımcı oluyor ve nadir bir bozunma sürecini başarıyla ortaya çıkarmasını sağladı. Bu, AI’nın karmaşık fiziksel verileri işlemede, zayıf sinyalleri tanımlamada ve bilimsel keşifleri hızlandırmada, özellikle yüksek enerji fiziği gibi büyük miktarda verinin analiz edilmesini gerektiren alanlarda büyük potansiyele sahip olduğunu gösteriyor. (Kaynak: Ronald_vanLoon)

AI modellerinin çok turlu diyalog ve uzun bağlamdaki yetenek evrimini tartışma: Nathan Lambert, mevcut en güçlü AI modellerinin diyalog derinleştikçe veya bağlam uzadıkça görev performansının daha iyi olduğunu, eski modellerin ise çok turlu veya uzun bağlamda daha düşük performans gösterdiğini veya başarısız olduğunu belirtti. Bu görüş, Dwarkesh Patel’in podcast’inde doğrulandı ve birçok kişinin modellerin yetenekleri hakkındaki, yani erken modellerin uzun diyaloglarda yeteneklerinin azalacağı yönündeki yerleşik algısını yıktı. (Kaynak: natolambert & dwarkesh_sp)