
Anahtar Kelimeler:Gemini 2.5 Pro, Veo 3, OpenAI, Claude 4 Opus, AI video oluşturma, Jony Ive, AI ajanları, Çok modelli modeller, Deep Think modu, Video oluşturma modelleri, AI akıl yürütme yeteneği, AI donanım tasarımı, Yazılım mühendisliği optimizasyonu
🔥 Odak Noktası
Google, Gemini 2.5 Pro Deep Think ve Veo 3’ü duyurarak yapay zeka çıkarımını ve video üretimini yeni zirvelere taşıdı: Google I/O konferansında Google, karmaşık sorunları çözmek için özel olarak tasarlanan Gemini 2.5 Pro’nun Deep Think modunu tanıttı. Bu mod, USAMO gibi matematik yarışması problemlerinde üstün performans göstererek, örneğin karmaşık cebir problemlerini çok adımlı çıkarım ve farklı kanıt yöntemlerini (örneğin çelişkiyle ispat, Rolle teoremi) deneyerek çözme gibi yapay zekanın ileri düzey çıkarım alanındaki önemli ilerlemelerini sergiledi. Aynı zamanda, Google’ın yayınladığı video üretim modeli Veo 3, gerçekçi sahneleri, kontrol edilebilir karakter tutarlılığı, ses sentezi ve çeşitli düzenleme özellikleriyle (sahne değişimi, referans görüntüden üretim, stil transferi, başlangıç-bitiş karesi belirleme, bölgesel düzenleme vb. gibi) yapay zeka video üretim alanında yeni bir standart belirleyerek geniş ilgi gördü (Kaynak: demishassabis, lmthang, GoogleDeepMind, _philschmid, fabianstelzer, matvelloso, seo_leaders, op7418, )
OpenAI, Jony Ive’ın şirketini 6,5 milyar dolara satın alarak yapay zeka destekli yeni nesil bilgisayarlar yaratmak için iş birliği yapıyor: OpenAI, Apple’ın eski baş tasarımcısı Jony Ive ile iş birliği yaptığını ve şirketini satın aldığını duyurdu. Amaçları, yapay zeka destekli yeni nesil bir bilgisayar geliştirmek. Bu hamle, OpenAI’ın donanım alanına genişlediğini ve yapay zeka yeteneklerini bilgi işlem cihazlarına derinlemesine entegre etmeye çalıştığını gösteriyor; bu da insan-bilgisayar etkileşimini yeniden şekillendirebilir. Jony Ive, Apple’daki olağanüstü tasarımlarıyla tanınıyor ve katılımı, yeni cihazın tasarım ve kullanıcı deneyiminde önemli atılımlar yapabileceğini ve mevcut bilgi işlem cihazlarının formuna meydan okuyabileceğini gösteriyor (Kaynak: op7418, TheRundownAI, BorisMPower)
Anthropic geliştirici konferansı yaklaşıyor, Claude 4 Opus’un yazılım mühendisliği yeteneklerine odaklanarak piyasaya sürülmesi bekleniyor: Anthropic ilk geliştirici konferansını düzenlemek üzere ve topluluk genelinde yeni nesil model Claude 4’ün (Sonnet 4 ve Opus 4 dahil) bu konferansta duyurulabileceği tahmin ediliyor. Claude Sonnet 3.7 API’sinin, “düşünme adımları” gerektirmeyen hızlı araç kullanımı gibi Claude 4 benzeri davranışlar sergilediğine dair işaretler var. Anthropic, OpenAI ve Google’ın “her şeyi yapabilen model” arayışından farklı bir yolla yazılım mühendisliği zorluklarını aşmaya odaklanıyor gibi görünüyor. TIME dergisi de Claude 4 Opus’un piyasaya sürüleceğini dolaylı olarak doğrulayarak, Anthropic’in yapay zeka kodlama ve karmaşık görev işleme yeteneklerine yönelik piyasa beklentisini daha da artırdı (Kaynak: op7418, mathemagic1an, cto_junior, scaling01, Reddit r/ClaudeAI)
OpenAI ve Google’ın yapay zeka ekosistem stratejilerindeki farklılık: Savaş gemisi inşa etmek ve imparatorluğu dönüştürmek: OpenAI ve Google, gelecekteki yapay zeka platformunun “ana işletim sistemi” konumunu ele geçirmek için sırasıyla “ekosistemi bir araya getirme” ve “ekosistemi dönüştürme” olmak üzere iki farklı yoldan ilerliyor. OpenAI, donanım (io), veritabanı (Rockset), araç zinciri (Windsurf) ve iş birliği araçları (Multi) gibi unsurları satın alarak sıfırdan tam yığınlı bir yapay zeka yeteneği oluşturuyor. Google ise Gemini modelini mevcut ürünlerine (Arama, Android, Docs, YouTube vb.) derinlemesine entegre etmeyi ve temel sistemleri dönüştürerek yapay zeka yerlileştirmesini sağlamayı seçiyor. İki strateji farklı olsa da hedefleri aynı: yapay zeka çağının nihai platformunu inşa etmek (Kaynak: dotey)
🎯 Gelişmeler
Microsoft “akıllı ajan ağı” vizyonunu açıkladı, yapay zeka akıllı ajanlarının yeni nesil çalışmanın çekirdeği olacağını vurguladı: Microsoft CEO’su Satya Nadella, Build 2025 konferansında ve röportajlarında şirketin “akıllı ajan ağı (agentic web)” vizyonunu açıkladı. Gelecekte yapay zeka akıllı ajanlarının iş ve M365 ekosisteminin birinci sınıf vatandaşları olacağını, hatta “yapay zeka akıllı ajan yöneticisi” gibi yeni meslekler doğurabileceğini belirtti. Kodun %95’i yapay zeka tarafından üretildiğinde, insanların rolü bu akıllı ajanları yönetmeye ve düzenlemeye yönelecek. Microsoft, Azure AI Foundry, Copilot Studio ve NLWeb gibi açık protokoller aracılığıyla açık bir akıllı ajan ekosistemi kuruyor ve Teams’i çoklu akıllı ajan iş birliği merkezi haline getiriyor (Kaynak: rowancheung, TheTuringPost)
MMaDA: Metin çıkarımı, çok modlu anlama ve görüntü üretimini birleştiren çok modlu difüzyon dil modeli yayınlandı: Araştırmacılar, MMaDA (Multimodal Large Diffusion Language Models) adlı yeni bir çok modlu difüzyon temel modelini tanıttı. Bu model, Mixed Long-CoT (Karmaşık Uzun Düşünce Zinciri) ve birleşik pekiştirmeli öğrenme algoritması UniGRPO aracılığıyla metin çıkarımı, çok modlu anlama ve görüntü üretimi yeteneklerini birleştiriyor. MMaDA-8B, çok modlu anlamada Show-o ve SEED-X’i, metinden görüntüye üretimde ise SDXL ve Janus’u geride bırakıyor. Model ve kodları Hugging Face’te açık kaynak olarak yayınlandı (Kaynak: _akhaliq, arankomatsuzaki, andrew_n_carr, Reddit r/LocalLLaMA)

dKV-Cache: Difüzyon dil modelleri için tasarlanan önbellek mekanizması, çıkarım hızını önemli ölçüde artırıyor: Difüzyon dil modellerinin (DLM’ler) yavaş çıkarım hızı sorununa yönelik olarak araştırmacılar dKV-Cache mekanizmasını önerdi. Bu yöntem, otoregresif modellerdeki KV-Cache’ten esinlenerek, gecikmeli ve koşullu önbellekleme stratejileri aracılığıyla DLM’lerin gürültü giderme süreci için anahtar-değer önbelleği tasarlıyor. Deneyler, dKV-Cache’in 2-10 kat çıkarım hızlandırması sağlayabildiğini, DLM’ler ile otoregresif modeller arasındaki hız farkını önemli ölçüde azalttığını, hatta uzun dizilerde performansı artırdığını ve mevcut DLM’lere eğitim gerektirmeden uygulanabildiğini gösteriyor (Kaynak: NandoDF, HuggingFace Daily Papers)

Imagen4 detay restorasyonunda mükemmel performans sergiliyor, görüntü üretimi son aşamasına yaklaşıyor: Imagen4 modeli, karmaşık metin istemlerine dayalı görüntü oluşturmada güçlü detay restorasyon yeteneği sergiledi. Örneğin, 25 belirli detayı (belirli renkler, nesneler, konumlar, ışıklandırma ve atmosfer gibi) içeren bir görüntü oluştururken, Imagen4 bunların 23’ünü başarıyla restore etti. Bu yüksek sadakat ve karmaşık talimatların hassas bir şekilde anlaşılması, metinden görüntüye teknolojisinin kullanıcıların hayal gücünü mükemmel bir şekilde yeniden üretebilen “son aşama” seviyesine yaklaştığını gösteriyor (Kaynak: cloneofsimo)

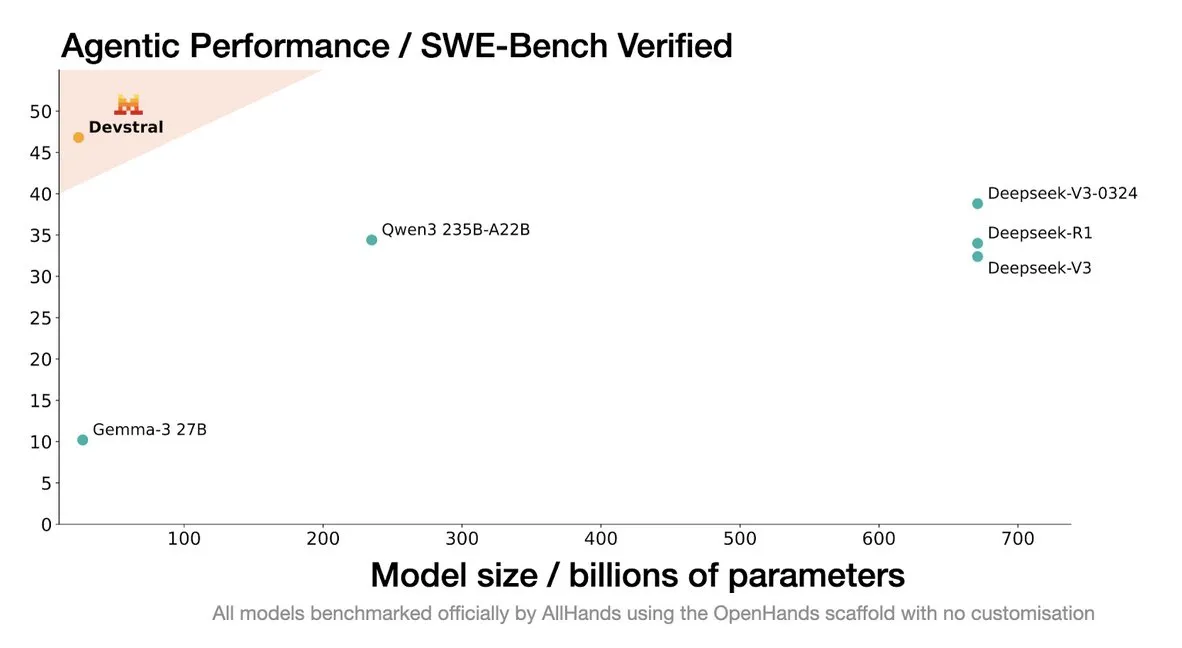
Mistral, kodlama ajanları için özel olarak tasarlanmış Devstral modelini yayınladı: Mistral AI, kodlama ajanları için özel olarak tasarlanmış açık kaynaklı bir model olan Devstral’ı tanıttı ve allhands_ai ile iş birliği içinde geliştirdi. 4-bit DWQ nicelleştirilmiş versiyonu Hugging Face’te (mlx-community/Devstral-Small-2505-4bit-DWQ) kullanıma sunuldu ve M2 Ultra gibi cihazlarda sorunsuz çalışarak kod üretimi ve anlama konularında optimizasyon potansiyeli gösteriyor (Kaynak: awnihannun, clefourrier, GuillaumeLample)
ByteDance, entegre Transformer mimarisini kullanan Gemini seviyesinde çok modlu model eğitim raporunu yayınladı: ByteDance, Gemini benzeri yerel çok modlu modellerin eğitim yöntemlerini ayrıntılı olarak açıklayan 37 sayfalık bir rapor yayınladı. En dikkat çekici olanı, aynı omurga ağını hem GPT benzeri otoregresif model hem de DiT benzeri difüzyon modeli olarak kullanan “Entegre Transformer” (Integrated Transformer) mimarisi olup, çok modlu birleşik modelleme alanındaki keşiflerini sergiliyor (Kaynak: NandoDF)

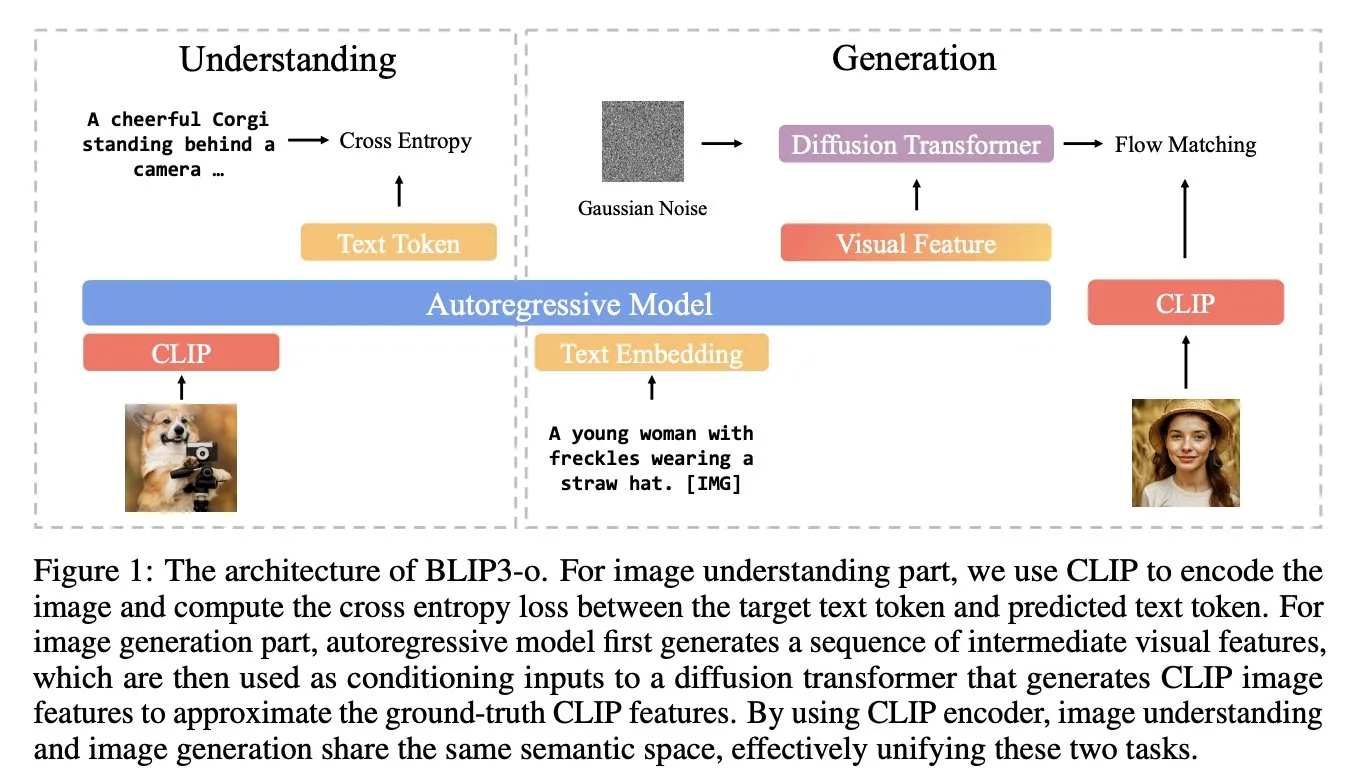
BLIP3-o: Salesforce, GPT-4o seviyesinde görüntü üretme yeteneğinin kilidini açmak için tamamen açık kaynaklı birleşik çok modlu model serisini piyasaya sürdü: Salesforce araştırma ekibi, GPT-4o benzeri görüntü üretme yeteneğinin kilidini açmayı amaçlayan, tamamen açık kaynaklı birleşik çok modlu modellerden oluşan BLIP3-o serisini yayınladı. Bu proje sadece modelleri açık kaynaklı hale getirmekle kalmadı, aynı zamanda 25 milyon veri içeren ön eğitim veri setini de kamuoyuna açarak çok modlu araştırmaların açıklığını teşvik etti (Kaynak: arankomatsuzaki)
Google, düşük kaynaklı cihazlar için özel olarak tasarlanmış çok modlu model Gemma 3n E4B önizleme sürümünü piyasaya sürdü: Google, Hugging Face’te Gemma 3n E4B-it-litert-preview modelini yayınladı. Bu model, metin, görüntü, video ve ses girdilerini işlemek ve metin çıktısı üretmek üzere tasarlanmıştır; mevcut sürüm metin ve görsel girdileri desteklemektedir. Gemma 3n, iç içe geçmiş birden fazla modele izin veren ve 2B veya 4B parametreleri etkin bir şekilde etkinleştiren yeni bir Matformer mimarisi kullanır ve özellikle düşük kaynaklı cihazlarda verimli çalışacak şekilde optimize edilmiştir. Model, yaklaşık 11 trilyon tokenlik çok modlu veri üzerinde eğitilmiştir ve bilgisi Haziran 2024 itibariyledir (Kaynak: Tim_Dettmers, Reddit r/LocalLLaMA)
Araştırma, büyük modellerdeki dile özgü bilgi (LSK) olgusunu ortaya koyuyor: Yeni bir araştırma, dil modellerinde var olan “Dile Özgü Bilgi” (Language Specific Knowledge, LSK) olgusunu inceliyor; bu olgu, modelin belirli konuları veya alanları işlerken belirli İngilizce dışı dillerde İngilizce’den daha iyi performans gösterebilmesidir. Araştırma, belirli bir dilde (hatta düşük kaynaklı bir dilde) düşünce zinciri çıkarımı yoluyla model performansının artırılabileceğini buldu. Bu, kültüre özgü metinlerin ilgili dillerde daha zengin olduğunu ve belirli bilgilerin yalnızca “uzman” dillerde bulunabileceğini gösteriyor. Araştırmacılar, bu LSK’yı ölçmek ve kullanmak için LSKExtractor yöntemini tasarladılar ve birden fazla model ve veri kümesinde ortalama doğruluğu göreceli olarak %10 artırdılar (Kaynak: HuggingFace Daily Papers)
DeepMind Veo 3 video üretim efektleri şaşırtıcı, gerçekçi detaylar dikkat çekiyor: Google DeepMind’ın video üretim modeli Veo 3, sahne değişimi, referans görüntü odaklı üretim, stil transferi, karakter tutarlılığı, başlangıç ve bitiş karesi belirleme, video ölçekleme, nesne ekleme ve hareket kontrolü gibi güçlü video üretim yetenekleri sergiledi. Ürettiği videoların gerçekçiliği ve karmaşık talimatları anlama yeteneği, kullanıcıları yapay zeka video üretim teknolojisinin hızlı gelişimine hayran bıraktı, hatta bazı kullanıcılar profesyonel yapımlarla yarışan reklam filmleri oluşturmak için kullandı (Kaynak: demishassabis, , Reddit r/ChatGPT)
Moondream görsel dil modeli 4-bit nicelleştirilmiş sürümüyle VRAM’i önemli ölçüde azaltıyor ve hızı artırıyor: Moondream görsel dil modeli (VLM), 4-bit nicelleştirilmiş bir sürüm yayınlayarak VRAM kullanımını %42 azaltırken çıkarım hızını %34 artırdı ve aynı zamanda %99,4 doğruluk oranını korudu. Bu optimizasyon, bu güçlü küçük VLM’nin nesne tespiti gibi görevlerde dağıtımını ve kullanımını kolaylaştırarak geliştiricilerden beğeni topladı (Kaynak: Sentdex, vikhyatk)
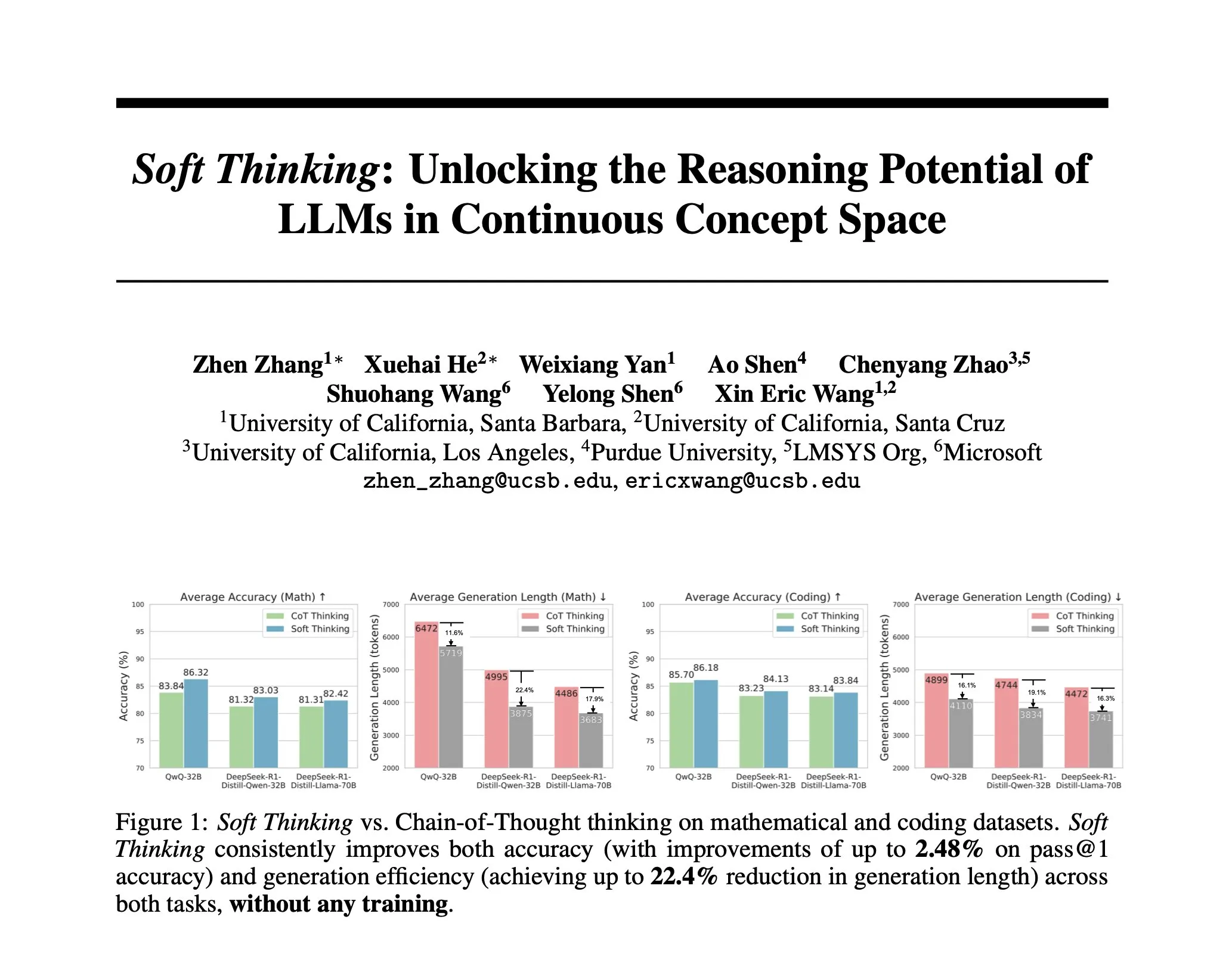
Araştırma, insan benzeri “yumuşak” çıkarımı simüle eden eğitimsiz bir yöntem olan Soft Thinking’i öneriyor: Yapay zeka çıkarımını, ayrık belirteçlerle sınırlı kalmadan insanın akıcı düşüncesine yaklaştırmak için araştırmacılar Soft Thinking yöntemini önerdi. Bu yöntem ek eğitim gerektirmez ve olasılıksal ağırlıklı gömme karışımlarıyla birden fazla anlamı sorunsuz bir şekilde birleştiren sürekli, soyut kavram belirteçleri üreterek daha zengin temsiller ve farklı çıkarım yollarının kesintisiz keşfini sağlar. Deneyler, bu yöntemin matematik ve kodlama karşılaştırmalı değerlendirmelerinde doğruluğu %2,48’e (pass@1) kadar artırdığını ve aynı zamanda belirteç kullanımını %22,4’e kadar azalttığını gösterdi (Kaynak: arankomatsuzaki)
IA-T2I çerçevesi: İnternet kullanarak metinden görüntüye modellerin belirsiz bilgileri işleme yeteneğini artırma: Mevcut metinden görüntüye modellerin belirsiz bilgiler (yeni olaylar, nadir kavramlar gibi) içeren metin istemlerini işlemedeki eksikliklerini gidermek için IA-T2I (Internet-Augmented Text-to-Image Generation) çerçevesi önerildi. Bu çerçeve, referans görüntüye ihtiyaç olup olmadığını belirlemek için aktif bir erişim modülü kullanır, arama motorundan dönen sonuçlardan en uygun görüntüleri seçerek T2I modelini geliştirmek için katmanlı bir görüntü seçim modülünden yararlanır ve üretilen görüntüleri sürekli olarak değerlendirmek ve optimize etmek için kendi kendine yansıtma mekanizmasını kullanır. Özel olarak oluşturulmuş Img-Ref-T2I veri kümesinde, IA-T2I, GPT-4o’dan yaklaşık %30 daha iyi performans gösterdi (insan değerlendirmesi) (Kaynak: HuggingFace Daily Papers)
MoI (Mixture of Inputs) otoregresif üretim kalitesini ve çıkarım yeteneğini artırıyor: Standart otoregresif üretim sürecinde token dağılım bilgilerinin atılması sorununu çözmek için araştırmacılar Mixture of Inputs (MoI) yöntemini önerdi. Bu yöntem ek eğitim gerektirmez; bir token ürettikten sonra, üretilen ayrık token’ı daha önce atılan token dağılımıyla karıştırarak yeni bir girdi oluşturur. Bayesci tahmin yoluyla, token dağılımı öncül, örneklenen token ise gözlem olarak kabul edilir ve geleneksel tek-sıcak vektör yerine sürekli bir sonsal beklenti yeni model girdisi olarak kullanılır. MoI, matematiksel çıkarım, kod üretimi ve doktora düzeyinde soru cevaplama görevlerinde Qwen-32B, Nemotron-Super-49B gibi birçok modelin performansını sürekli olarak artırdı (Kaynak: HuggingFace Daily Papers)
ConvSearch-R1: Pekiştirmeli öğrenme yoluyla diyalogsal aramadaki sorgu yeniden yazımını optimize etme: Diyalogsal aramada bağlama bağlı sorguların belirsizlik, eksiklik ve gönderim sorunlarını çözmek için ConvSearch-R1 çerçevesi önerildi. Bu çerçeve, ilk kez kendi kendine yönlendirilen bir yöntem benimseyerek, sorgu yeniden yazımını doğrudan erişim sinyallerini kullanarak pekiştirmeli öğrenme yoluyla optimize eder ve harici yeniden yazım denetimine (insan etiketlemesi veya büyük modeller gibi) olan bağımlılığı tamamen ortadan kaldırır. İki aşamalı yöntemi, kendi kendine yönlendirilen strateji ön ısıtması ve erişim odaklı pekiştirmeli öğrenmeyi (derece teşvikli ödül mekanizması kullanarak) içerir. Deneyler, ConvSearch-R1’in TopiOCQA ve QReCC veri kümelerinde önceki SOTA yöntemlerinden önemli ölçüde daha iyi performans gösterdiğini ortaya koymuştur (Kaynak: HuggingFace Daily Papers)
ASRR çerçevesi, büyük dil modelleri için verimli uyarlanabilir çıkarım sağlar: Büyük çıkarım modellerinin (LRM’ler) basit görevlerde gereksiz çıkarım nedeniyle aşırı hesaplama maliyetine yol açması sorununa yönelik olarak, araştırmacılar Uyarlanabilir Kendi Kendine Kurtarma Çıkarımı (Adaptive Self-Recovery Reasoning, ASRR) çerçevesini önermiştir. Bu çerçeve, modelin “içsel kendi kendine kurtarma mekanizmasını” (cevap üretiminde örtük olarak çıkarımı tamamlama) ortaya çıkararak gereksiz çıkarımı bastırır ve soru zorluğuna göre çıkarım çabasını uyarlanabilir bir şekilde tahsis etmek için doğruluk duyarlı bir uzunluk ödülü ayarlaması sunar. Deneyler, ASRR’nin performans kaybını minimuma indirirken çıkarım bütçesini önemli ölçüde azaltabildiğini ve güvenlik ölçütlerinde zararsızlık oranını artırabildiğini göstermiştir (Kaynak: HuggingFace Daily Papers)
MoT (Mixture-of-Thought) çerçevesi mantıksal çıkarım yeteneğini artırıyor: İnsanların mantıksal problemleri çözmek için birden fazla çıkarım biçimini (doğal dil, kod, sembolik mantık) kullanmasından esinlenerek, araştırmacılar Mixture-of-Thought (MoT) çerçevesini önerdi. MoT, LLM’lerin yeni tanıtılan doğruluk tablosu sembolik biçimi de dahil olmak üzere üç tamamlayıcı biçimde çıkarım yapmasını sağlar. İki aşamalı bir tasarımla (kendi kendine gelişen MoT eğitimi ve MoT çıkarımı), MoT, FOLIO ve ProofWriter gibi mantıksal çıkarım ölçütlerinde tek biçimli düşünce zinciri yöntemlerinden önemli ölçüde daha iyi performans göstererek ortalama doğruluğu %11,7’ye kadar artırdı (Kaynak: HuggingFace Daily Papers)
RL Tango: Dil çıkarımını geliştirmek için pekiştirmeli öğrenme yoluyla üretici ve doğrulayıcıyı birlikte eğitme: Mevcut LLM pekiştirmeli öğrenme yöntemlerinde doğrulayıcının (ödül modeli) sabit olması veya denetimli ince ayarın ödül kırma ve zayıf genelleme sorunlarına yol açmasını çözmek için RL Tango çerçevesi önerildi. Bu çerçeve, pekiştirmeli öğrenme yoluyla LLM üreticisini ve üretken, süreç düzeyinde bir LLM doğrulayıcısını eş zamanlı olarak eğitir. Doğrulayıcı, yalnızca sonuç düzeyinde doğrulama doğruluğu ödülüne dayalı olarak eğitilir ve süreç düzeyinde etiketlemeye ihtiyaç duymaz, böylece üreticiyle etkili bir karşılıklı destek oluşturur. Deneyler, Tango’nun üreticisinin ve doğrulayıcısının 7B/8B ölçekli modellerde SOTA seviyesine ulaştığını göstermiştir (Kaynak: HuggingFace Daily Papers)
pPE: Önsel bilgi istemi mühendisliği, pekiştirmeli ince ayara (RFT) yardımcı oluyor: Araştırma, pekiştirmeli ince ayarda (RFT) önsel bilgi istemi mühendisliğinin (prior prompt engineering, pPE) rolünü inceliyor. Çıkarım zamanı bilgi istemi mühendisliğinden (iPE) farklı olarak, pPE eğitim aşamasında dil modelinin belirli davranışları içselleştirmesini sağlamak için talimatları (adım adım çıkarım gibi) sorgudan önce yerleştirir. Deneylerde beş iPE stratejisi (çıkarım, planlama, kod çıkarımı, bilgi hatırlama, boş örnek kullanımı) pPE yöntemlerine dönüştürülerek Qwen2.5-7B’ye uygulandı. Sonuçlar, tüm pPE eğitimli modellerin iPE karşılıklarından daha iyi performans gösterdiğini, özellikle boş örnek pPE’nin AIME2024 ve GPQA-Diamond gibi ölçütlerde en büyük artışı sağladığını gösterdi ve pPE’nin RFT’de yeterince araştırılmamış etkili bir araç olduğunu ortaya koydu (Kaynak: HuggingFace Daily Papers)
BiasLens: İnsan yapımı test setleri olmadan LLM önyargı değerlendirme çerçevesi: Mevcut LLM önyargı değerlendirme yöntemlerinin insan yapımı etiketli verilere dayanması ve sınırlı kapsamda olması sorununu çözmek için BiasLens çerçevesi önerildi. Bu çerçeve, modelin vektör uzay yapısından yola çıkarak, kavram aktivasyon vektörleri (CAV’ler) ve seyrek otomatik kodlayıcılar (SAE’ler) ile yorumlanabilir kavram temsillerini çıkarır ve hedef kavramlar ile referans kavramlar arasındaki temsil benzerliğindeki değişiklikleri ölçerek önyargıyı nicelleştirir. BiasLens, etiketsiz veri durumunda geleneksel önyargı değerlendirme metrikleriyle güçlü bir tutarlılık (Spearman korelasyonu r > 0.85) gösterir ve mevcut yöntemlerle tespit edilmesi zor olan önyargı biçimlerini ortaya çıkarabilir (Kaynak: HuggingFace Daily Papers)
HumaniBench: İnsan odaklı büyük çok modlu model değerlendirme çerçevesi: Mevcut LMM’lerin adalet, etik, empati gibi insan odaklı standartlarda yetersiz performans göstermesi sorununa yönelik olarak HumaniBench önerildi. Bu, GPT-4o destekli etiketleme ve uzman doğrulaması ile oluşturulmuş 32 bin gerçek dünya resim-metin soru-cevap çifti içeren kapsamlı bir ölçüttür. HumaniBench, adalet, etik, anlama, çıkarım, dilsel kapsayıcılık, empati ve sağlamlık olmak üzere yedi insan odaklı yapay zeka ilkesini değerlendirir ve yedi farklı görevi kapsar. 15 SOTA LMM üzerinde yapılan testler, kapalı kaynaklı modellerin genel olarak önde olduğunu, ancak sağlamlık ve görsel konumlandırmanın hala zayıf noktalar olduğunu göstermiştir (Kaynak: HuggingFace Daily Papers)
AJailBench: İlk büyük ölçekli sesli dil modeli jailbreak saldırısı kapsamlı ölçütü: Büyük ölçekli sesli dil modellerinin (LAM’ler) jailbreak saldırıları karşısındaki güvenliğini sistematik olarak değerlendirmek için AJailBench önerildi. Bu ölçüt öncelikle 10 ihlal kategorisini kapsayan 1495 karşıt sesli komut içeren AJailBench-Base veri kümesini oluşturdu. Bu veri kümesine dayalı değerlendirme, mevcut SOTA LAM’lerin hiçbirinin tutarlı bir sağlamlık göstermediğini ortaya koydu. Daha gerçekçi saldırıları simüle etmek için araştırmacılar, Bayesci optimizasyon yoluyla ince ve etkili pertürbasyonları aramak için bir ses pertürbasyon araç kiti (APT) geliştirdi ve genişletilmiş AJailBench-APT veri kümesini oluşturdu. Araştırma, küçük ve anlamsal olarak korunan pertürbasyonların LAM’lerin güvenlik performansını önemli ölçüde azaltabildiğini gösterdi (Kaynak: HuggingFace Daily Papers)
WebNovelBench: LLM’lerin uzun roman yazma yeteneklerini değerlendirme ölçütü: LLM’lerin uzun anlatı yeteneklerini değerlendirme zorluğunu çözmek için WebNovelBench önerildi. Bu ölçüt, 4000’den fazla Çince web romanı veri kümesini kullanarak değerlendirmeyi taslaktan hikayeye üretim görevi olarak belirler. LLM’nin yargıç olarak kullanıldığı bir yöntemle, sekiz anlatı kalitesi boyutundan otomatik değerlendirme yapılır ve ana bileşen analizi ile puanlar birleştirilerek insan eserleriyle yüzdelik sıralama karşılaştırması yapılır. Deneyler, insan başyapıtlarını, popüler web romanlarını ve LLM tarafından üretilen içeriği etkili bir şekilde ayırt etti ve 24 SOTA LLM’nin kapsamlı bir analizini yaptı (Kaynak: HuggingFace Daily Papers)
MultiHal: LLM halüsinasyon değerlendirmesi için çok dilli bilgi grafiği temelli veri kümesi: Mevcut halüsinasyon değerlendirme ölçütlerinin bilgi grafiği yolları ve çok dillilik konusundaki eksikliklerini gidermek için MultiHal önerildi. Bu, üretilen metin değerlendirmesi için özel olarak tasarlanmış, bilgi grafiği tabanlı, çok dilli, çok adımlı bir ölçüttür. Ekip, açık alan bilgi grafiklerinden 140.000 yol çıkardı ve 25.900 yüksek kaliteli yol seçti. Temel değerlendirme, çok dilli ve çoklu modellerde, bilgi grafiği ile zenginleştirilmiş RAG’nin (KG-RAG) normal soru yanıtlama sistemlerine kıyasla anlamsal benzerlik puanlarında yaklaşık 0,12 ila 0,36 puanlık mutlak bir artış sağladığını ve bilgi grafiği entegrasyonunun potansiyelini gösterdiğini ortaya koydu (Kaynak: HuggingFace Daily Papers)
Llama-SMoP: Seyrek karışık projektör tabanlı LLM sesli-görüntülü konuşma tanıma yöntemi: LLM’lerin sesli-görüntülü konuşma tanımada (AVSR) yüksek hesaplama maliyeti sorununu çözmek için Llama-SMoP önerildi. Bu, seyrek karışık projektör (SMoP) modülünü kullanan verimli bir çok modlu LLM’dir ve seyrek kapılı uzmanlar karışımı (MoE) projektörü aracılığıyla çıkarım maliyetini artırmadan model kapasitesini genişletir. Deneyler, modaliteye özgü yönlendirme ve uzmanları kullanan Llama-SMoP DEDR yapılandırmasının ASR, VSR ve AVSR görevlerinde üstün performans elde ettiğini ve uzman aktivasyonu, ölçeklenebilirlik ve gürültüye karşı dayanıklılık konularında iyi performans gösterdiğini ortaya koymuştur (Kaynak: HuggingFace Daily Papers)
VPRL: Pekiştirmeli öğrenmeye dayalı saf görsel planlama çerçevesi, metin tabanlı çıkarımdan daha iyi performans gösteriyor: Cambridge Üniversitesi, University College London ve Google araştırma ekipleri, tamamen görüntü dizilerine dayanarak çıkarım yapan yeni bir paradigma olan VPRL’yi (Visual Planning with Reinforcement Learning) önerdi. Bu çerçeve, büyük görsel modelleri sonradan eğitmek için grup göreli politika optimizasyonunu (GRPO) kullanır, görsel durum geçişleri aracılığıyla ödül sinyallerini hesaplar ve ortam kısıtlamalarını doğrular. FrozenLake, Maze ve MiniBehavior gibi görsel navigasyon görevlerinde VPRL’nin doğruluk oranı %80,6’ya ulaşarak, metin tabanlı çıkarım yöntemlerinden (örneğin Gemini 2.5 Pro’nun %43,7’si) önemli ölçüde daha iyi performans gösterdi ve karmaşık görevlerde ve sağlamlıkta daha iyi sonuçlar verdi, bu da görsel planlamanın üstünlüğünü kanıtladı (Kaynak: 量子位)

Nvidia gelecekteki beş yıllık yapay zeka teknoloji yol haritasını açıkladı, yapay zeka altyapı şirketine dönüşüyor: Nvidia CEO’su Jensen Huang, COMPUTEX 2025’te şirketin yapay zeka altyapı şirketi olarak yeniden konumlandığını duyurdu ve gelecekteki beş yıllık teknoloji yol haritasını açıkladı. Yapay zeka altyapısının elektrik veya internet gibi her yerde olacağını vurgulayan Huang, Nvidia’nın yapay zeka çağının “fabrikalarını” inşa etmeye odaklandığını belirtti. Bu dönüşümü desteklemek için Nvidia, tedarik zinciri “arkadaş çevresini” genişletecek, TSMC gibi şirketlerle iş birliğini derinleştirecek ve Tayvan’da bir ofis (NVIDIA Constellation) ve ilk devasa yapay zeka süper bilgisayarını kurmayı planlıyor (Kaynak: 36氪)

Google, yapay zeka gözlük projesini yeniden başlattı, Android XR platformunu ve üçüncü taraf cihazları duyurdu: Google, I/O 2025 konferansında yapay zeka/AR gözlük projesini yeniden başlattığını, XR cihazları için özel olarak geliştirilen Android XR platformunu duyurduğunu ve bu platforma dayalı iki üçüncü taraf cihazı sergilediğini açıkladı: Samsung’un Project Moohan (Vision Pro’ya rakip) ve Xreal’in Project Aura’sı. Google, Android’in akıllı telefon alanındaki başarısını tekrarlamayı, XR cihazları için “Android anı” yaratmayı ve gelecekteki ortam bilişimi ve uzamsal bilişim platformlarını konumlandırmayı hedefliyor. Yükseltilmiş Gemini 2.5 Pro çok modlu büyük model ve Project Astra akıllı asistan teknolojisi ile birleştiğinde, yeni nesil yapay zeka/AR gözlükleri ses anlama, gerçek zamanlı çeviri, durumsal farkındalık ve karmaşık görev yürütme konularında devrim niteliğinde bir deneyim sunacak (Kaynak: 36氪)

ARC-AGI-2 yarışma ilkeleri güncellendi, çok adımlı bağlamsal çıkarım vurgulandı: Yeni yayınlanan ARC-AGI-2 makalesi, bu yarışmanın tasarım ilkelerini güncelledi. Yeni ilkeler, görevlerin çözülmesinin çoklu kural, çok adımlı ve bağlamsal çıkarım yeteneği gerektirmesini şart koşuyor. Izgara daha büyük, daha fazla nesne içeriyor ve birden fazla etkileşimli kavramı kodluyor. Görevler yenilikçi ve yeniden kullanılamaz nitelikte olup, ezberlemeyi sınırlamak amaçlanıyor. Bu tasarım, kaba kuvvet program sentezine kasıtlı olarak direniyor. İnsan çözücüler görev başına ortalama 2,7 dakika harcarken, OpenAI o3-medium gibi en iyi sistemler yalnızca yaklaşık %3 puan alıyor ve tüm görevler açık bir bilişsel çaba gerektiriyor (Kaynak: TheTuringPost, clefourrier)
Skywork, 8 saatlik işi 8 dakikaya indirmeyi amaçlayan süper akıllı ajanı piyasaya sürdü: Skywork, kullanıcıların 8 saatlik iş yükünü 8 dakikada tamamlayabileceğini iddia ettiği yapay zeka çalışma alanı akıllı ajanı Skywork Super Agents’ı duyurdu. Bu ürün, yapay zeka çalışma alanı akıllı ajanlarının öncüsü olarak konumlandırılıyor; belirli işlevleri ve uygulama yöntemleri daha fazla gözlem gerektiriyor (Kaynak: _akhaliq)
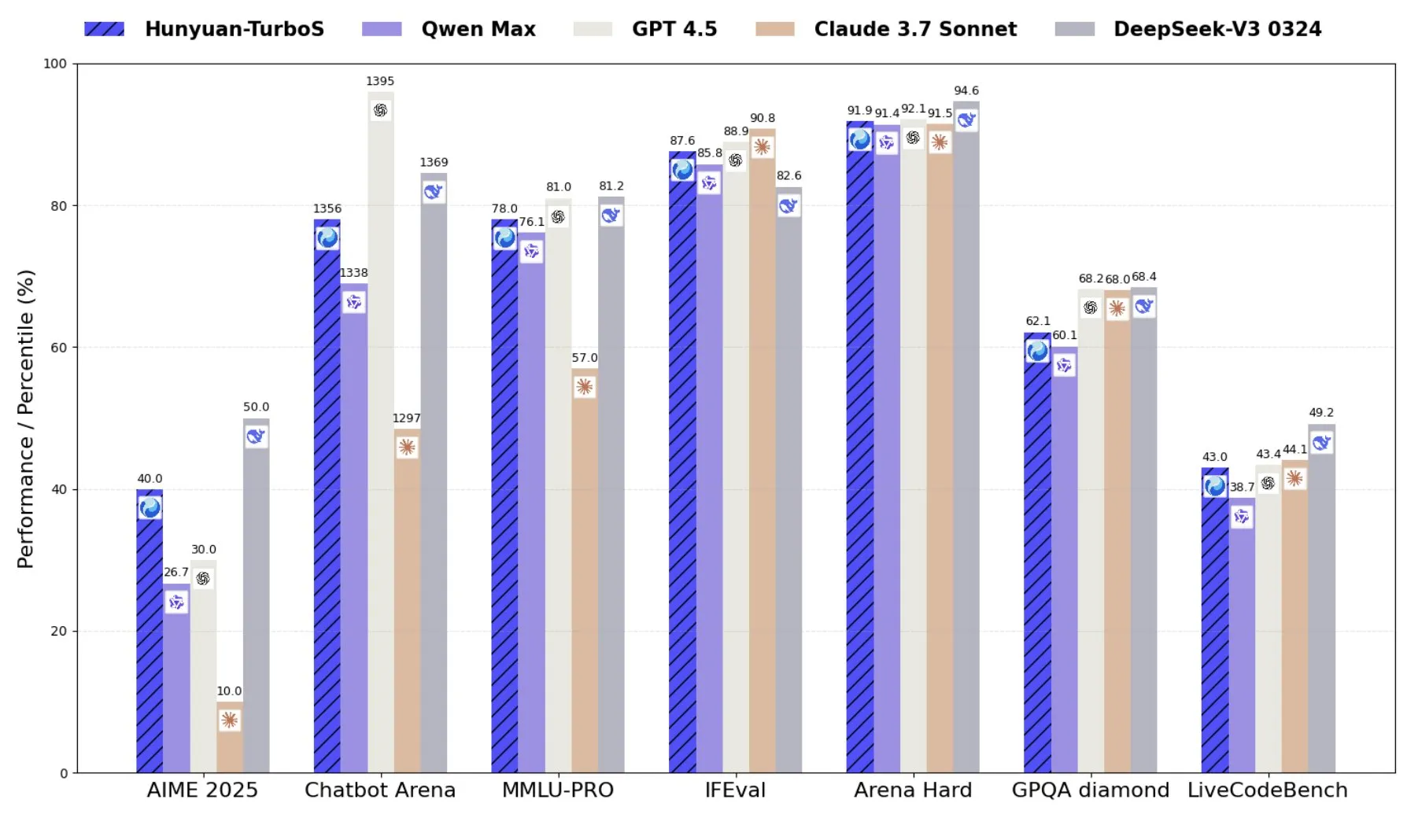
Tencent, Transformer ve Mamba’yı birleştiren karma uzman modeli Hunyuan-TurboS’u piyasaya sürdü: Tencent, Transformer ve Mamba’nın karma uzman (MoE) mimarisini kullanan Hunyuan-TurboS modelini yayınladı. Bu model 56 milyar aktif parametreye sahip ve 16 trilyon token üzerinde eğitildi. Hunyuan-TurboS, hızlı yanıt ve derin “düşünme” modları arasında dinamik olarak geçiş yapabiliyor ve LMSYS Chatbot Arena’da genel sıralamada ilk yedi arasında yer alıyor (Kaynak: tri_dao)
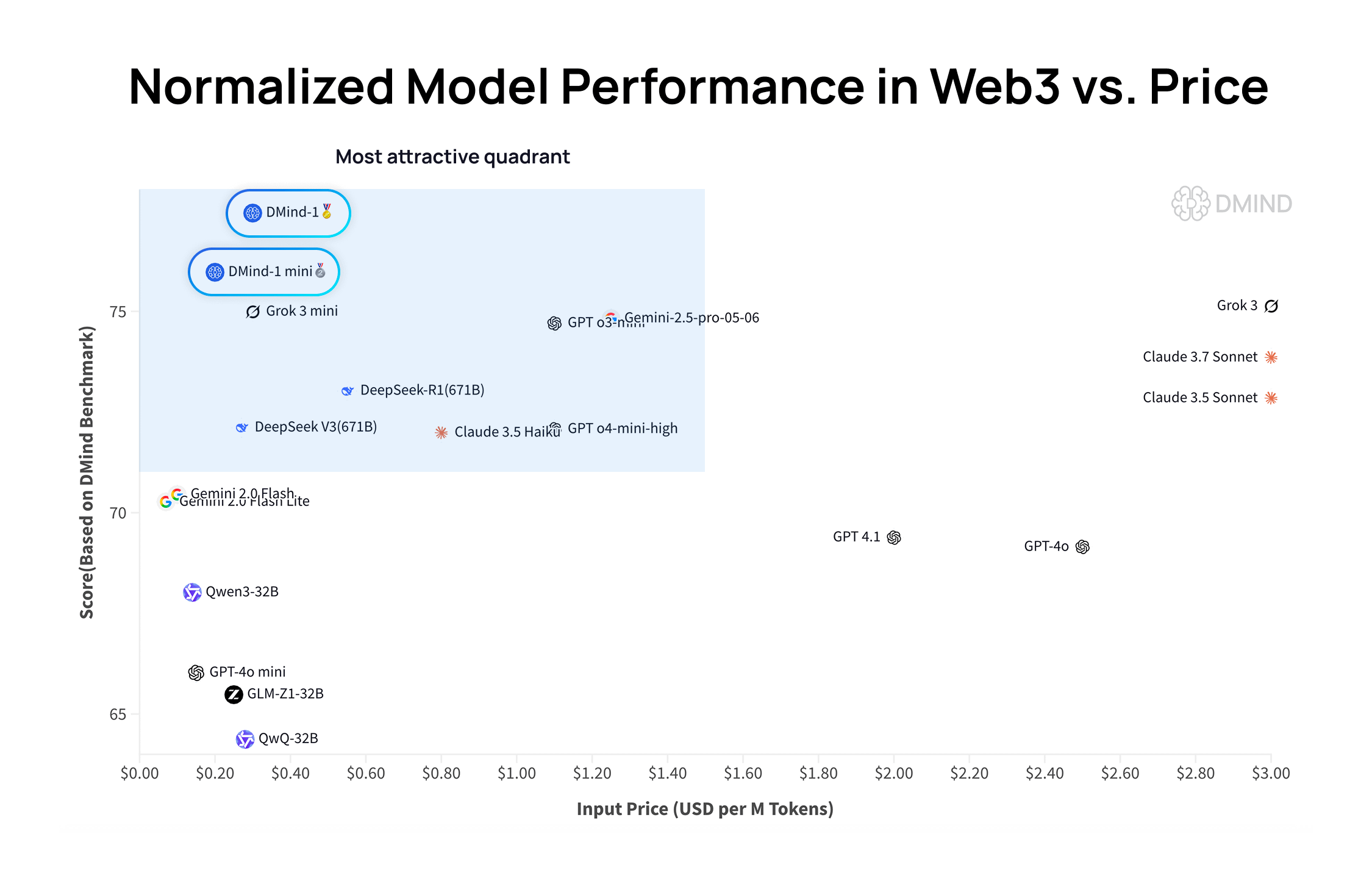
DMind-1: Web3 senaryoları için özel olarak tasarlanmış açık kaynaklı büyük dil modeli: DMind AI, Web3 senaryoları için optimize edilmiş açık kaynaklı bir büyük dil modeli olan DMind-1’i yayınladı. DMind-1 (32B), Qwen3-32B temel alınarak ince ayar yapılmış ve büyük miktarda Web3’e özgü bilgi kullanılarak AI+Web3 uygulamalarının performansını ve maliyetini dengelemeyi amaçlamaktadır. Web3 karşılaştırmalı değerlendirmelerinde DMind-1, ana akım genel amaçlı LLM’lerden daha iyi performans göstermiş ve token maliyeti yalnızca %10 civarındadır. Aynı zamanda yayınlanan DMind-1-mini (14B), DMind-1’in performansının %95’inden fazlasını korurken gecikme ve hesaplama verimliliği açısından daha iyidir (Kaynak: _akhaliq)
LightOn, çıkarım yoğun erişim görevlerinde üstün performans gösteren küçük parametreli model Reason-ModernColBERT’i yayınladı: LightOn, yalnızca 149 milyon parametreye sahip bir geç etkileşimli model olan Reason-ModernColBERT’i tanıttı. Popüler BRIGHT karşılaştırmalı değerlendirmesinde (çıkarım yoğun erişime odaklanan) bu model, parametre sayısı 45 kat daha büyük modelleri geride bırakarak ve birçok alanda SOTA seviyesine ulaşarak mükemmel performans sergiledi. Bu başarı, geç etkileşimli modellerin belirli görevlerdeki verimliliğini bir kez daha kanıtladı (Kaynak: lateinteraction, jeremyphoward, Dorialexander, huggingface)

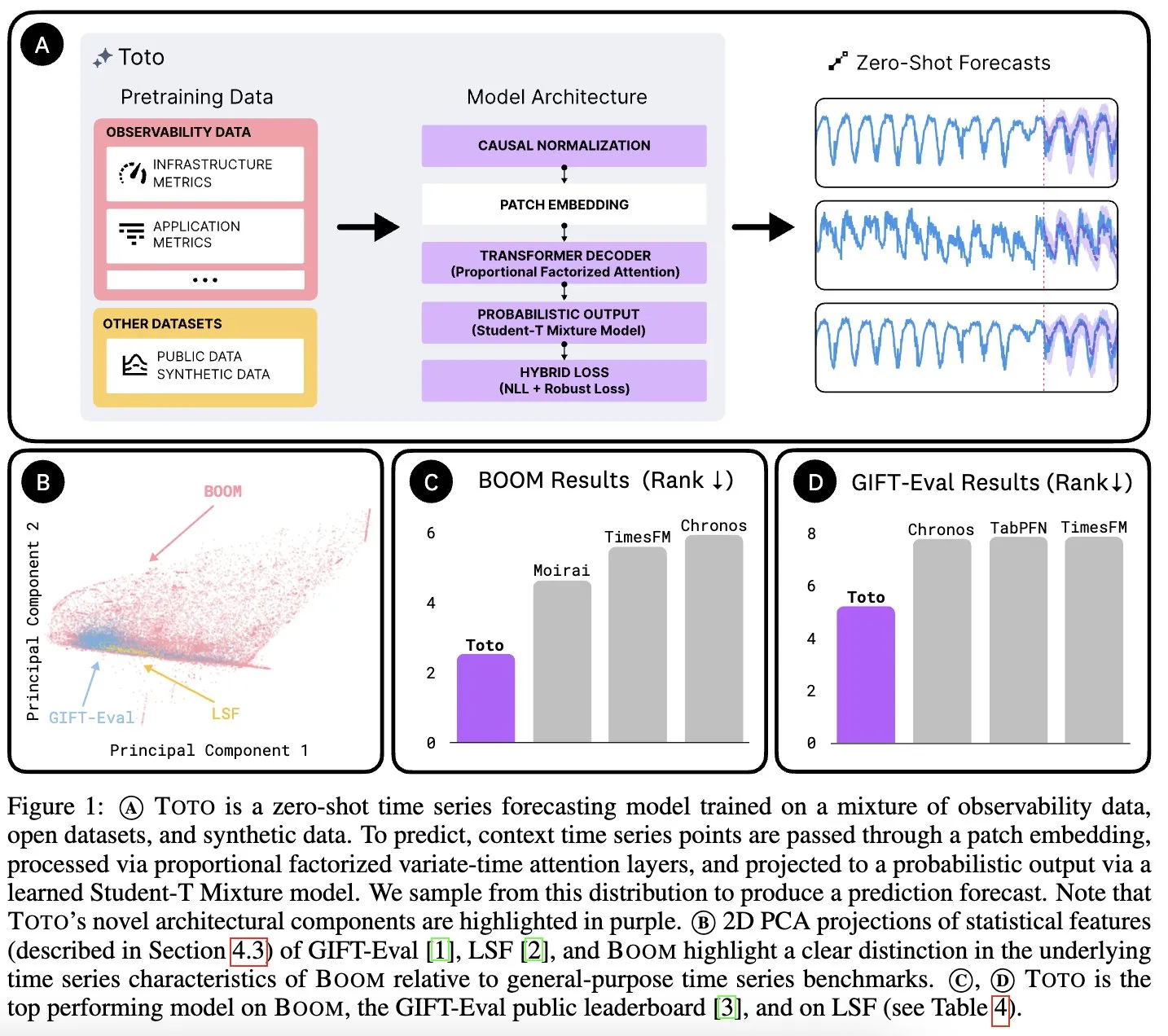
Datadog AI Research, zaman serisi temel modeli Toto’yu ve gözlemlenebilirlik metrikleri için BOOM adlı referans veri setini yayınladı: Datadog AI Research, yeni bir zaman serisi temel modeli olan Toto’yu tanıttı ve ilgili referans testlerinde mevcut SOTA modellerini önemli ölçüde geride bıraktı. Aynı zamanda, şu anda en büyük gözlemlenebilirlik metrikleri referans veri seti olan BOOM da yayınlandı. Her ikisi de Apache 2.0 lisansı altında açık kaynak olarak sunuldu ve zaman serisi analizi ile gözlemlenebilirlik alanındaki araştırma ve uygulamaları teşvik etmeyi amaçlıyor (Kaynak: jefrankle, ClementDelangue)
TII, Falcon-H1 serisi hibrit Transformer-SSM modellerini yayınladı: Birleşik Arap Emirlikleri Teknoloji İnovasyon Enstitüsü (TII), Transformer dikkat mekanizmalarını ve Mamba2 durum uzay modeli (SSM) başlıklarını birleştiren hibrit mimarili dil modelleri olan Falcon-H1 serisini yayınladı. Bu model serisi 0.5B’den 34B’ye kadar değişen parametre ölçeklerine sahip, 256K’ya kadar bağlam uzunluğunu destekliyor ve birçok karşılaştırmalı testte Qwen3-32B, Llama4-Scout gibi önde gelen Transformer modellerinden daha iyi veya onlarla karşılaştırılabilir performans gösteriyor; özellikle çok dillilik (doğal olarak 18 dili destekliyor) ve verimlilik konularında avantaj sağlıyor. Modeller vLLM, Hugging Face Transformers ve llama.cpp’ye entegre edildi (Kaynak: Reddit r/LocalLLaMA)

MIT araştırması: Yapay zeka, insan müdahalesi olmadan görsel ve ses arasındaki ilişkiyi öğrenebilir: MIT araştırmacıları, insanlardan açık bir yönlendirme veya etiketlenmiş veri almadan görsel bilgiler ile karşılık gelen sesler arasındaki bağlantıyı kendi kendine öğrenebilen bir yapay zeka sistemi sergiledi. Bu yetenek, dünyayı insanlar gibi daha iyi anlayıp algılayabilen daha kapsamlı çok modlu yapay zeka sistemleri geliştirmek için hayati önem taşıyor (Kaynak: Reddit r/artificial, Reddit r/ArtificialInteligence)

Birleşik Arap Emirlikleri, Körfez bölgesindeki yapay zeka yarışını hızlandıran büyük bir Arapça yapay zeka modeli başlattı: Birleşik Arap Emirlikleri, yapay zeka alanındaki yatırımlarını daha da ileriye taşıyan ve Körfez ülkeleri arasındaki yapay zeka teknolojisi geliştirme yarışını kızıştıran büyük bir Arapça yapay zeka modeli yayınladı. Bu hamle, Arapça’nın yapay zeka alanındaki etkisini artırmayı ve yerelleştirilmiş yapay zeka uygulamalarına olan talebi karşılamayı amaçlıyor (Kaynak: Reddit r/artificial)
Fenbi Technology, dikey alana özgü büyük bir model yayınlayarak “AI+Eğitim” için yeni bir paradigma tanımladı: Fenbi Technology, Tencent Cloud AI Endüstriyel Uygulama Zirvesi’nde mesleki eğitim alanındaki kendi geliştirdiği dikey alana özgü büyük modelini sergiledi. Bu model, mülakat değerlendirmesi, yapay zeka destekli soru çözme sistemi gibi ürünlerde halihazırda kullanılmakta olup, “öğretme, öğrenme, pratik yapma, değerlendirme, test etme” süreçlerinin tamamını kapsamaktadır. Yapay zeka öğretmenleri gibi formatlar aracılığıyla, “herkese aynı” yaklaşımdan “herkese farklı” kişiselleştirilmiş öğretime geçmeyi ve eğitimde akıllı dönüşümü teşvik etmek için kendi geliştirdiği büyük modeli içeren yapay zeka donanım ürünlerini piyasaya sürmeyi hedefliyor (Kaynak: 量子位)

Beisen Kuxueyuan, beş yeni AI Agent içeren yeni nesil AI Learning platformunu yayınladı: Beisen Holdings, Kuxueyuan’ı satın aldıktan sonra yapay zeka büyük modellerine dayalı yeni nesil öğrenme platformu AI Learning’i piyasaya sürdü. Platform, mevcut eLearning temeline ek olarak AI ders oluşturma asistanı, AI öğrenme asistanı, AI pratik koçu, AI liderlik koçu ve AI sınav asistanı olmak üzere beş akıllı ajan ekledi. Amaç, Agent aracılığıyla gerçek zamanlı diyalog, beceri eğitimi, kişiselleştirilmiş öğrenme ve AI destekli tek duraklı ders oluşturma ve sınavlarla geleneksel kurumsal öğrenme modelini dönüştürmektir (Kaynak: 量子位)

Pony.ai 1. Çeyrek Mali Raporu: Robotaxi hizmet geliri yıllık %800 arttı, yıl sonunda 1000 otonom araç konuşlandırılacak: Pony.ai, 2025 yılı birinci çeyrek mali raporunu açıkladı; toplam gelir 102 milyon yuan olup yıllık %12 artış gösterdi. Temel Robotaxi hizmet geliri 12,3 milyon yuan’a ulaşarak yıllık %200,3’lük büyük bir artış kaydetti ve yolcu ücretlerinden elde edilen gelir yıllık %800 arttı. Şirket, ikinci çeyrekte yedinci nesil Robotaxi’nin seri üretimine başlamayı ve yıl sonuna kadar 1000 araç konuşlandırarak araç başına başa baş noktasına ulaşmayı hedefliyor. Pony.ai ayrıca Tencent Cloud ve Uber ile iş birliği yaptığını duyurdu; sırasıyla WeChat ve Uber platformları aracılığıyla iç ve Orta Doğu pazarlarını genişletecek (Kaynak: 量子位)

OpenAI CPO’su Kevin Weil: ChatGPT bir eylem asistanına dönüşecek, model maliyeti GPT-4’ün 500 katı: OpenAI Baş Ürün Sorumlusu Kevin Weil, ChatGPT’nin konumunun soru yanıtlamaktan kullanıcılar için görevleri yerine getirmeye doğru değişeceğini belirtti. Araçları (web’de gezinme, programlama, dahili bilgi kaynaklarına bağlanma gibi) dönüşümlü olarak kullanarak bir yapay zeka eylem asistanı haline gelecek. Mevcut modelin maliyetinin ilk GPT-4’ün 500 katı olduğunu ancak OpenAI’ın verimliliği artırmak ve API fiyatlarını düşürmek için donanım geliştirmeleri ve algoritma iyileştirmeleri yoluyla çalıştığını açıkladı. AI Agent’ların hızla gelişeceğine, bir yıl içinde başlangıç seviyesindeki bir mühendis seviyesinden mimar seviyesine yükseleceğine inanıyor (Kaynak: 量子位)

🧰 Araçlar
FlowiseAI: Yapay zeka akıllı ajanlarını görsel olarak oluşturma: FlowiseAI, kullanıcıların görsel bir arayüz aracılığıyla yapay zeka akıllı ajanları ve LLM uygulamaları oluşturmasına olanak tanıyan açık kaynaklı bir projedir. Bileşenleri sürükleyip bırakmayı, farklı LLM’leri, araçları ve veri kaynaklarını bağlamayı destekleyerek yapay zeka uygulamalarının geliştirme sürecini basitleştirir. Kullanıcılar, Flowise’ı npm ile kurabilir veya Docker ile dağıtarak kendi yapay zeka akışlarını hızla oluşturabilir ve test edebilir (Kaynak: GitHub Trending)

Hugging Face JS kütüphanesi yayınlandı, Hub API ve çıkarım servisleriyle etkileşimi basitleştiriyor: Hugging Face, geliştiricilerin JS/TS aracılığıyla Hugging Face Hub API ve çıkarım servisleriyle etkileşimini kolaylaştırmak amacıyla bir dizi JavaScript kütüphanesi (@huggingface/inference, @huggingface/hub, @huggingface/mcp-client vb.) yayınladı. Bu kütüphaneler, depo oluşturma, dosya yükleme, 100.000’den fazla modelin çıkarımını (sohbet tamamlama, metinden görüntüye oluşturma vb. dahil) çağırma, MCP istemcisini kullanarak akıllı ajanlar oluşturma gibi işlevleri destekler ve birden fazla çıkarım sağlayıcısını destekler (Kaynak: GitHub Trending)

Jan AI yerel çalışma ortamı Apache 2.0 lisansına güncellendi, kurumsal kullanım engelleri azaltıldı: Jan AI, LLM’leri yerel olarak çalıştırmayı destekleyen açık kaynaklı bir araçtır ve yakın zamanda lisansını AGPL’den daha esnek olan Apache 2.0’a değiştirdi. Bu hamle, işletmelerin ve ekiplerin Jan’ı kurum içinde dağıtmasını ve kullanmasını kolaylaştırmayı, AGPL’nin getirdiği uyumluluk sorunları hakkında endişelenmeden özgürce çatallama, değiştirme ve yayınlama olanağı sunarak Jan’ın gerçek üretim ortamlarında büyük ölçekli benimsenmesini teşvik etmeyi amaçlamaktadır (Kaynak: reach_vb, Reddit r/LocalLLaMA)
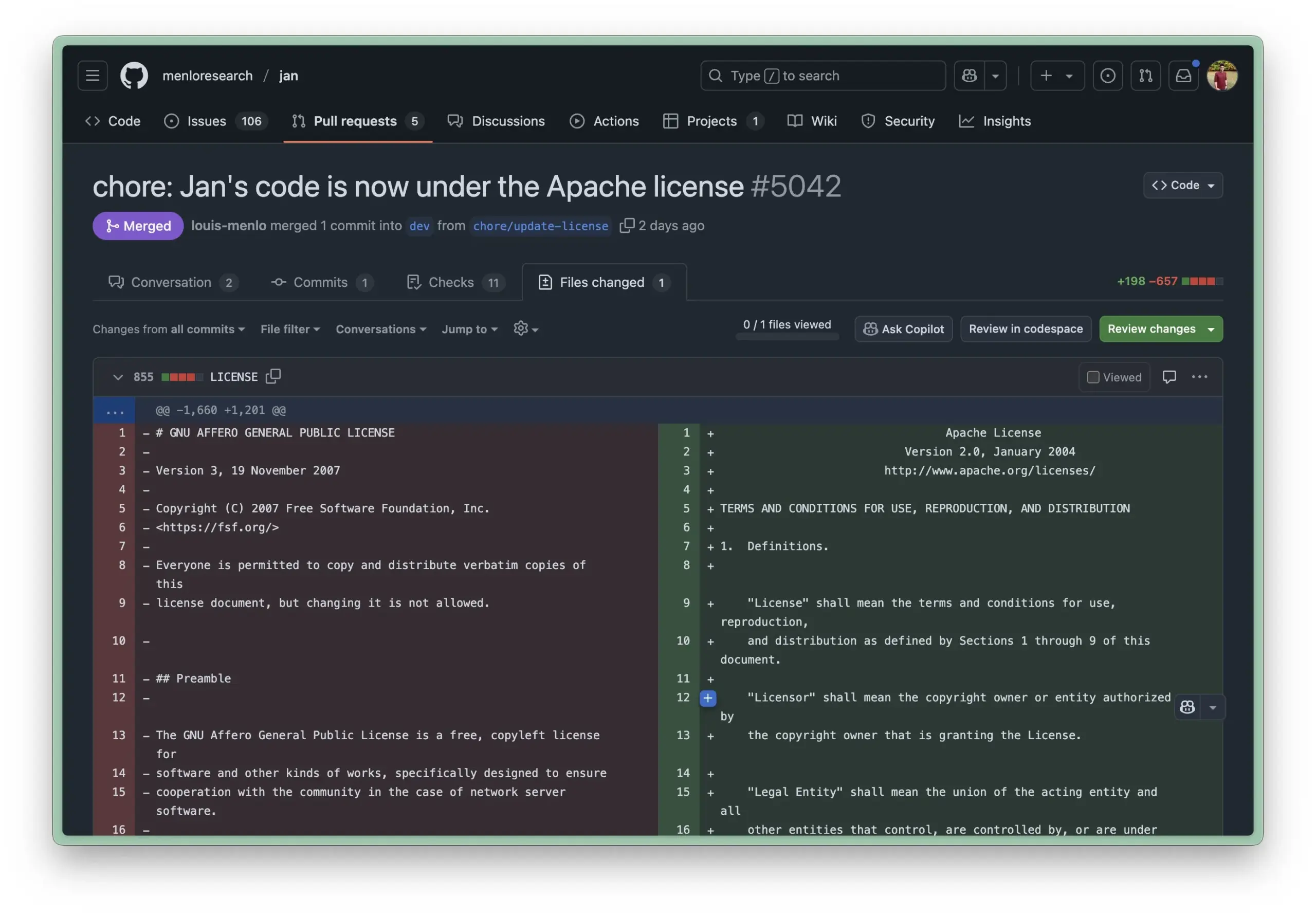
Obsidian, notların veritabanı tarzında yönetilmesini sağlayan Bases çekirdek eklentisini tanıttı: Bilgi yönetimi yazılımı Obsidian, kullanıcıların not koleksiyonlarını güçlü veritabanlarına dönüştürmelerine olanak tanıyan çekirdek eklentisi Bases’i güncelledi. Bases aracılığıyla kullanıcılar, özel tablo görünümleri oluşturabilir, bilgi tabanlarındaki verileri görselleştirebilir ve etkileşimli olarak işleyebilir, özellikleri kullanarak notları filtrelemeyi ve proje yönetimi, seyahat planlaması, okuma listeleri gibi çeşitli senaryolar için dinamik özellikler türeten formüller oluşturmayı destekler. Bu özellik şu anda erken kullanıcılara sunulmuştur (Kaynak: op7418)
Hugging Face, yerel modellerin tarayıcı ve dosya işlemlerini kontrolünü basitleştiren Tiny Agents’ı tanıttı: Hugging Face, MCP kursunda, kolay kullanımlı bir tarayıcı kontrol ayar çerçevesi olan Tiny Agents’ı tanıttı. Kullanıcılar, komut satırı, JSON yapılandırması ve istem tanımlaması yoluyla, yerel olarak çalışan LLM’lerin (OpenAI uyumlu sunucu aracılığıyla) tarayıcıyı (Playwright gibi) veya yerel dosya sistemini doğrudan API çağırmadan kontrol etmesini sağlayabilir, bu da llama.cpp gibi yerel modellerin akıllı ajan uygulamaları için kolaylık sağlar (Kaynak: Reddit r/LocalLLaMA)

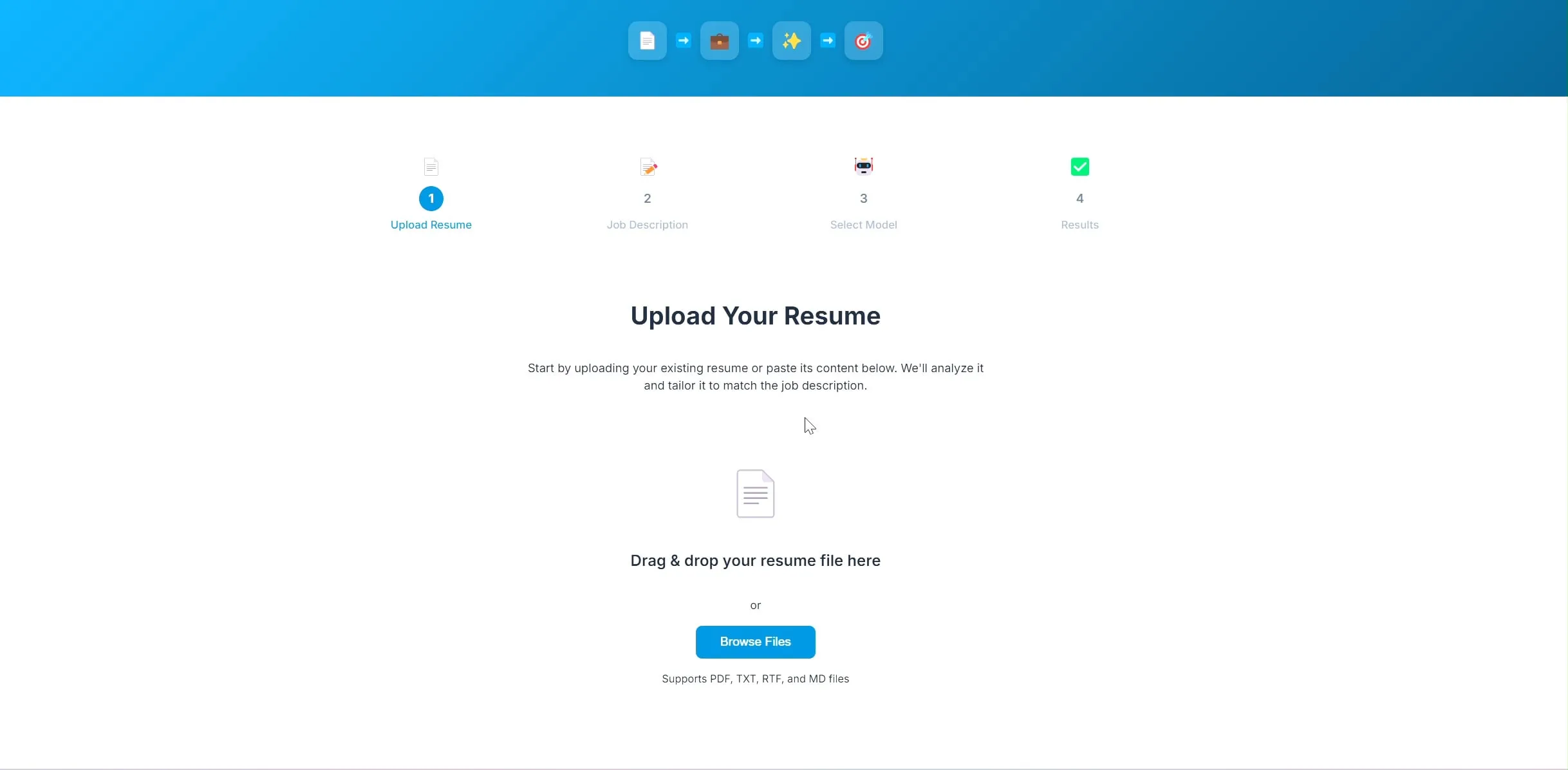
Geliştirici, LangChain ve Ollama tabanlı yapay zeka özgeçmiş optimizasyon uygulamasını açık kaynak olarak yayınladı: Bir geliştirici, yapay zeka destekli bir özgeçmiş optimizasyon uygulaması oluşturdu ve açık kaynak olarak yayınladı. Kullanıcı mevcut özgeçmişini ve hedef pozisyon tanımını yükledikten sonra, uygulama özgeçmişteki anahtar kelimeleri işe alım gereksinimlerine daha uygun hale getirmeye çalışır. Projenin arka ucu LangChain kullanır, BM25 seyrek erişim ve yoğun model ile hibrit erişim gerçekleştirir, dil modeli Ollama aracılığıyla yerel olarak çalışır ve ön uç React kullanır. Proje şu anda kavram kanıtlama aşamasındadır ve kodu GitHub’da açık kaynak olarak yayınlanmıştır (Kaynak: Reddit r/deeplearning)
Lovable uygulama oluşturma aracı resim işleme yeteneklerini geliştirdi: Yapay zeka uygulama oluşturma aracı Lovable, resim işleme özelliklerini geliştirdiğini duyurdu. Kullanıcılar artık sohbete resim yükleyebilir ve Lovable’a bu resim materyallerini uygulamada kullanması talimatını verebilir, bu da yapay zeka destekli görsel öğeler içeren uygulamalar oluşturma kullanıcı deneyimini geliştirir (Kaynak: op7418)
Helios: Yapay zeka ile devlet işlerini hızlandırmayı deneyen ilk platform: Joe Scheidler, yapay zeka kullanarak devlet işlerinin verimliliğini artırmayı amaçlayan ve “devletin Cursor’u” olarak tanımlanan Helios platformunu tanıttı. Bu platform, özellikle devlet dairelerini hedef alan ve yapay zeka teknolojisiyle iş akışlarını ve verimliliğini optimize etmeye çalışan ilk girişimlerden biridir; belirli işlevleri ve uygulama senaryoları daha fazla gözlem gerektirmektedir (Kaynak: timsoret)
📚 Öğrenme Kaynakları
Zhejiang Üniversitesi “Büyük Modellerin Temelleri” ders kitabını yayınladı, LLM bilgisini sistematik olarak açıklıyor ve sürekli güncelliyor: Zhejiang Üniversitesi LLM ekibi, büyük dil modelleriyle ilgilenen okuyuculara sistematik temel bilgiler ve en son teknoloji tanıtımı sunmayı amaçlayan “Büyük Modellerin Temelleri” ders kitabını açık kaynak olarak yayınladı. Kitap, geleneksel dil modelleri, LLM mimarisinin evrimi, Prompt mühendisliği, parametre verimli ince ayar, model düzenleme, erişimle zenginleştirilmiş üretim gibi konuları içeriyor ve aylık olarak güncellenecek. Her bölüm, en son gelişmeleri takip etmek için ilgili Makale Listesi ile donatılmıştır. Tam PDF ve bölüm bazlı içerikler GitHub’da yayınlandı (Kaynak: GitHub Trending)

Hugging Face, çeşitli seviyelerde ve alanlarda bilgi kapsayan 10 ücretsiz yapay zeka kursu sunuyor: Hugging Face, platformunda sunulan 10 ücretsiz yapay zeka kursunu bir araya getirdi. İçerik, başlangıçtan ileri seviyeye kadar popüler yapay zeka konularını kapsıyor; bunlar arasında doğal dil işleme, derin öğrenme, pekiştirmeli öğrenme, ses işleme, çok modluluk vb. bulunuyor. Bu kurslar, farklı seviyelerdeki öğrencilere yapay zeka bilgisini sistematik olarak öğrenmeleri için değerli kaynaklar sunarak yapay zeka bilgisinin yaygınlaşmasına ve açık kaynak topluluğunun gelişimine daha da katkıda bulunuyor (Kaynak: huggingface, reach_vb, _akhaliq)

Stanford Üniversitesi, Marin 8B modelinin eğitimiyle ilgili deneyimlerini ve derslerini paylaştı: Stanford Üniversitesi Percy Liang ekibi, Marin 8B modelini sıfırdan eğitme (ve birçok ölçütte Llama 3.1 8B temel modelini geride bırakma) sürecindeki ayrıntılı bir değerlendirmeyi kamuoyuyla paylaştı. Bu dürüst kayıt, ekibin geliştirme sürecindeki tüm bulgularını ve yaptığı hataları içeriyor ve topluluğa LLM’lerin gerçek dünya yapım deneyimi hakkında değerli bilgiler sunarak, bilimsel araştırma sürecinde deneme yanılma ve yinelemenin önemini vurguluyor (Kaynak: stanfordnlp, YejinChoinka, hrishioa)
DeepLearning.AI ve Predibase, LLM’ler için pekiştirmeli ince ayar (RFT) kursu için iş birliği yaptı: Andrew Ng’nin DeepLearning.AI’si, Predibase ile iş birliği yaparak LLM performansını artırmak için GRPO (Group Relative Policy Optimization) kullanarak pekiştirmeli ince ayar (RFT) hakkında ücretsiz, kısa süreli bir kurs başlattı. Kurs, Predibase kurucu ortağı ve CTO’su Travis Addair ve diğerleri tarafından veriliyor ve öğrencilerin, küçük açık kaynaklı LLM’leri belirli kullanım durumları için çıkarım motorlarına dönüştürmek üzere yalnızca az miktarda etiketlenmiş veriyle pekiştirmeli öğrenmeyi nasıl kullanacaklarını öğrenmelerine yardımcı olmayı amaçlıyor (Kaynak: DeepLearningAI)
Hugging Face makale sayfasına yapay zeka tarafından oluşturulan özet özelliği eklendi: Hugging Face, makale görüntüleme sayfasına yeni bir özellik ekledi: her makale için yapay zeka tarafından oluşturulan tek cümlelik bir özet. Bu özet, makalenin temel içeriğini kısa ve öz bir şekilde özetleyerek kullanıcıların araştırma literatürünü hızla filtrelemesine ve anlamasına yardımcı olmayı, akademik kaynakların erişilebilirliğini ve kullanım verimliliğini artırmayı amaçlıyor. Bu özellik açık kaynaklı LLM’ler tarafından destekleniyor ve “yapay zekayı yapay zeka araştırmaları için güçlendirme” felsefesini yansıtıyor (Kaynak: _akhaliq, _akhaliq, _akhaliq, _akhaliq, huggingface)

Qdrant, SambaNova ve diğerleri hızlı çoklu belge RAG sistemi oluşturma çözümünü birlikte sergiledi: Bir teknik blog yazısı, Qdrant vektör veritabanı, SambaNova, DeepSeek-R1 ve LangGraph kullanarak hızlı, bellek açısından verimli çoklu belge erişimle zenginleştirilmiş üretim (RAG) sisteminin nasıl oluşturulacağını tanıttı. Bu çözüm, ikili nicelleştirme yoluyla 32 kat bellek tasarrufu sağlıyor, hızlı ve odaklanmış LLM yanıtları için DeepSeek-R1’i kullanıyor ve modüler düzenleme için LangGraph’tan yararlanıyor; büyük ölçekli çoklu belge işleme senaryoları için uygundur (Kaynak: qdrant_engine)
LangChain Interrupt 2025 Zirvesi özeti (Mandarin versiyonu) yayınlandı: LangChain Interrupt 2025 Zirvesi’nin Mandarin dilindeki özeti yayınlandı. Bu zirveye dünya genelinden 800’den fazla kişi katıldı, yapay zeka akıllı ajanlarının oluşturulmasıyla ilgili deneyimler ve gelecek beklentileri paylaşıldı ve LangGraph Platform, LangGraph Studio v2 gibi birçok ürün duyuruldu, akıllı ajan mühendisliği, yapay zeka gözlemlenebilirliği gibi konular tartışıldı (Kaynak: hwchase17)
Andi Marafioti, saf PyTorch ile görsel dil modelini adım adım eğitmek için nanoVLM eğitimini yayınladı: Andi Marafioti, nanoVLM adlı yeni bir blog eğitimi yayınladı. Bu eğitimde, saf PyTorch kullanarak kendi görsel dil modelinizi (VLM) sıfırdan nasıl eğiteceğiniz ayrıntılı olarak anlatılıyor. Eğitim içeriği anlaşılması ve uygulanması kolay olup, yeni başlayanların VLM eğitim sürecini hızla kavramalarına yardımcı olmayı amaçlamaktadır (Kaynak: LoubnaBenAllal1)

Ferenc Huszár, sürekli zamanlı Markov zincirlerini ve bunların difüzyon dil modellerindeki uygulamalarını açıklıyor: Derin öğrenme araştırmacısı Ferenc Huszár, Mercury ve Gemini Diffusion gibi difüzyon dil modellerinin (DLM’ler) temel bileşenleri olan sürekli zamanlı Markov zincirlerinin (CTMC’ler) ardındaki sezgiyi derinlemesine ve anlaşılır bir şekilde açıklayan bir blog yazısı yayınladı. Makale, Markov zincirlerinin farklı bakış açılarını ve nokta süreçleriyle olan bağlantılarını inceliyor ve DLM’lerin teorik temelini anlamak için değerli bir referans sunuyor (Kaynak: fhuszar)
💼 İş Dünyası
“Yapay Zeka” şirketi Builder.ai iflas etti, yaklaşık 500 milyon dolar fon toplamıştı: Bir zamanlar yapay zeka ile yazılım geliştirmeyi altüst edeceğini iddia eden ve değeri bir ara 1 milyar dolara ulaşan İngiliz şirketi Builder.ai (eski adıyla Engineer.ai) bu hafta iflas tasfiyesini duyurdu. Şirketin yapay zeka platformundaki birçok işlevin aslında Hintli mühendisler tarafından manuel olarak tamamlandığı iddia edilmişti. Microsoft, SoftBank DeepCore gibi tanınmış kurumlardan yaklaşık 500 milyon dolar fon almasına rağmen, teknolojinin gerçekliği konusundaki şüpheler, mali yönetimdeki karmaşa ve kurucunun yasal anlaşmazlıkları gibi sorunlar nedeniyle sonunda fonları tükendi ve Microsoft’a 30 milyon dolar, Amazon’a ise 85 milyon dolar bulut hizmeti borcu kaldı (Kaynak: 36氪)

LMArena.ai (eski adıyla LMSys) 100 milyon dolarlık tohum yatırım aldı, Gradio uygulamasından ticarileşmeye doğru: Başlangıçta LLM rekabeti ve değerlendirmesi için Gradio tabanlı bir akademik proje olan LMSys olarak bilinen LMArena.ai, a16z ve Kaliforniya Üniversitesi yatırım şirketinin liderliğinde 100 milyon dolarlık tohum yatırım aldığını duyurdu. Bu yatırım turu, LMArena’nın güvenilir yapay zeka alanındaki araştırmalarına ve platform operasyonlarına devam etmesini destekleyecek ve başarılı bir açık kaynaklı akademik projenin ticarileşmeye doğru bir dönüşümünü işaret ediyor. Bu aynı zamanda Gradio gibi hızlı prototipleme araçlarının etkili yapay zeka projelerini kuluçkalamadaki potansiyelini de vurguluyor (Kaynak: ClementDelangue, _akhaliq, clefourrier)
Yapay zeka yetenek savaşı kızışıyor, OpenAI, Google gibi şirketler on milyonlarca dolarlık maaşlarla yetenek avında: Silikon Vadisi’ndeki yapay zeka alanındaki yetenek savaşı kızışmış durumda; en iyi araştırmacılar (IC), OpenAI, Google, xAI gibi devlerin çekirdek kaynakları haline geldi ve yıllık maaş artı hisse senedi teşvikleri genellikle on milyonlarca doları aşıyor. Örneğin, OpenAI, SSI’ye katılmak isteyen kıdemli bir araştırmacıyı elinde tutmak için 2 milyon dolar ikramiye ve 20 milyon doların üzerinde hisse senedi teklif etti; Google DeepMind da en iyi yeteneklere yıllık 20 milyon dolar maaş sunuyor. Bu yoğun rekabet, az sayıda çekirdek yeteneğin büyük dil modellerinin gelişimine yaptığı büyük katkıdan kaynaklanıyor; onların gidişi veya kalışı yapay zeka modellerinin başarısını doğrudan etkileyebilir (Kaynak: 36氪)
🌟 Topluluk
Sora’nın Çince yeteneği artmış gibi görünüyor, ancak model sınırlamaları hala mevcut: Sosyal medya kullanıcıları, OpenAI’nin video üretim modeli Sora’nın Çince metinleri işlemede ilerleme kaydettiğini ve Çince karakterler içeren sahneler üretebildiğini gözlemledi. Ancak kullanıcılar, modelin hala sınırlamaları olduğunu ve üretilen içeriğin mükemmel olmadığını, bu kusurluluğu kabul etmenin mevcut aşamada yapay zeka modelleriyle etkileşim kurmanın normal bir parçası olabileceğini belirtti (Kaynak: dotey)

Gemini, derinlemesine rapor “sınav” özelliğini başlattı, bilgi yeniden kullanımına ve öğrenme döngüsüne yardımcı oluyor: Google Gemini, kullanıcıların derinlemesine bir rapor okuduktan sonra Gemini’nin doğrudan soru sorarak test yapmasını sağlayan yeni bir özellik başlattı. Bu özellik, kullanıcıların içeriği ne kadar anladığını test etmeyi ve “öğren → test et → telafi et → tekrar öğren” şeklinde yapay zeka tabanlı bir öğrenme döngüsü oluşturmayı amaçlıyor; yapay zeka çağında öğrenmenin temelinin okuma miktarından ziyade bilginin yeniden kullanılabilirliği olduğunu vurguluyor (Kaynak: dotey)
ChatGPT hafıza özelliği kullanıcılar arasında kontrol endişelerine yol açtı: ChatGPT’nin yeni “sohbetlerden öğrenme hafızası” özelliği, modelin kullanıcıların geçmiş konuşmalarını hatırlamasını ve sonraki etkileşimlerde daha kişiselleştirilmiş yanıtlar sunmasını sağlıyor. Ancak bazı ileri düzey kullanıcılar, bunun modelle etkileşim kurma şeklini değiştirdiğini belirterek endişelerini dile getirdi; modelin girdi içeriğini tamamen kontrol etmeyi tercih ediyorlar ve modelin bilgileri olmadan veya hassas bir şekilde kontrol edemedikleri şekilde geçmiş bilgileri kullanmasını istemiyorlar (Kaynak: random_walker)
AI Agent hızla gelişiyor, gelecekteki çalışma modelleri değişebilir: Topluluk, AI Agent’ların hızlı gelişimini ve gelecekteki çalışma modelleri üzerindeki potansiyel etkilerini hararetle tartışıyor. Görüşler, AI Agent’ların basit soru-cevap araçlarından, kodlama, araştırma, müşteri desteği gibi karmaşık görevleri bağımsız olarak tamamlayabilen “sanal çalışanlara” dönüştüğü yönünde. OpenAI CPO’su Kevin Weil, AI Agent yeteneklerinin hızla artacağını, bir yıl içinde başlangıç seviyesindeki bir mühendis seviyesinden mimar seviyesine yükseleceğini öngörüyor. Microsoft da “akıllı ajan ağı” vizyonunu ortaya koyarak, gelecekteki çalışmanın AI akıllı ajanlarını yönetme ve düzenleme etrafında şekillenebileceğini gösteriyor (Kaynak: rowancheung, 量子位)
Yapay zekanın tıbbi teşhis alanındaki potansiyeli büyük, ancak doktorların mesleki kaygılarını artırıyor: Yapay zeka, tıbbi teşhis alanında şaşırtıcı yetenekler sergiliyor; örneğin, o1-preview modelinin tıbbi çıkarım ve teşhis görevlerinde insanüstü performans gösterdiğini iddia eden araştırmalar ve yapay zekanın zatürreyi saniyeler içinde tespit ettiği vakalar dikkat çekiyor. Bu durum, yapay zeka destekli teşhisi popüler bir konu haline getirirken, 20 yıllık bazı doktorların mesleki gelecekleri hakkında endişelenmelerine ve hatta McDonald’s’ta çalışmaya gideceklerini şakayla karışık söylemelerine neden oluyor. Topluluk tartışmaları, yapay zekanın doktorların yerini tamamen almaktan ziyade, verimliliklerini ve doğruluklarını artırmalarına yardımcı olacak bir araç olarak görülmesi gerektiğini savunuyor (Kaynak: paul_cal, Reddit r/ArtificialInteligence)
Haber yayıncıları Google’ın yapay zeka arama modelini “hırsızlık” olarak suçluyor: Haber Medya Birliği gibi yayıncılar, Google’ın yeni yapay zeka arama modeline şiddetle karşı çıkarak bunu “hırsızlık” olarak nitelendirdi. Google yapay zekasının haber içeriğinden doğrudan bilgi çıkarıp arama sonuçlarına entegre ederek haber sitelerini bypass ettiğini, yayıncıların trafiğine ve reklam gelirlerine zarar verdiğini savunuyorlar; bu durum yapay zeka çağında içerik telif hakkı ve adil kullanım konusunda hararetli tartışmalara yol açtı (Kaynak: Reddit r/artificial)
DeepSeek modeli Çin’de geleneksel kehanet için kullanılıyor, yapay zeka uygulama sınırları tartışılıyor: Bazı kullanıcılar, DeepSeek modelinin Çin’deki yoğun trafiğinin, kullanıcıların onu I Ching kehaneti gibi geleneksel falcılık faaliyetleri için kullanmasından kaynaklandığını fark etti. Bu olgu, yapay zeka uygulama sınırları ve kültürel uyum hakkında tartışmalara yol açarken, aynı zamanda kullanıcıların yapay zeka yeteneklerine yönelik çeşitli keşiflerini ve taleplerini de dolaylı olarak yansıtıyor (Kaynak: menhguin, cto_junior)

💡 Diğer
Figure şirketinin insansı robotu BMW üretim hattında 20 saatlik kesintisiz vardiyayı tamamladı: İnsansı robot şirketi Figure, robotunun BMW X3 üretim hattında 20 saatlik kesintisiz vardiyayı başarıyla tamamladığını duyurdu. Daha önce robot, haftalarca 10 saatlik vardiya testlerinden geçmişti. Figure, bunun dünya genelinde bir insansı robotun otomotiv üretim hattında bu kadar uzun süreli kesintisiz çalışmayı tamamladığı ilk örnek olduğunu belirterek, endüstriyel otomasyon alanındaki potansiyelini sergiledi (Kaynak: adcock_brett, TheRundownAI)
Agentic AI ile GenAI arasındaki fark ve bağlantı: Topluluk, Agentic AI (akıllı ajan yapay zekası) ve Generative AI (üretken yapay zeka) kavramlarını tartıştı. Üretken yapay zeka temel olarak yeni içerik (metin, resim, kod vb.) yaratabilen yapay zekayı ifade ederken, akıllı ajan yapay zekası daha çok özerklik, hedef odaklılık ve çevreyle etkileşim kurma yeteneğini vurgular. Akıllı ajan yapay zekası genellikle üretken yapay zekayı temel yeteneklerinden biri olarak kullanarak görevleri anlamak, planlamak ve yürütmek için kullanır ve yapay zekanın daha gelişmiş özerk zekaya doğru ilerlemesinde önemli bir yöndür (Kaynak: Ronald_vanLoon, Ronald_vanLoon)

Yapay zekanın bilimsel araştırmalardaki uygulaması hafife alınıyor, “sonuçları güzelleştirme” olgusu mevcut: Topluluk tartışmaları, yapay zekanın bilimsel araştırmalardaki potansiyelinin büyük olduğunu ancak hafife alınabileceğini ve aynı zamanda araştırmacıların yayınlamak için yapay zeka deney sonuçlarını “güzelleştirme” eğiliminde olduğunu belirtiyor. Örneğin, kısmi diferansiyel denklemler (PDE’ler) gibi alanlarda, yapay zekanın gerçek performansı makalelerde sunulduğu kadar etkileyici olmayabilir. Bu durum, bilimsel topluluğun yapay zekanın bilimsel keşiflerdeki gerçek rolünü ve sınırlamalarını daha titiz ve şeffaf bir şekilde değerlendirmesi gerektiğini gösteriyor (Kaynak: clefourrier)