
Anahtar Kelimeler:Yapay Zeka Ajanı, Büyük Dil Modeli, Gemini 2.5 Pro, NVIDIA Yapay Zeka Süper Bilgisayarı, Microsoft Build Konferansı, Araştırma Yapay Zeka Ajanı, Akıl Yürütme Yeteneği Değerlendirmesi, Yapay Zeka Programlama, Kodlama Ajanı Otomatik Hata Düzeltme, Microsoft Discovery Araştırma Platformu, NVLink Fusion Teknolojisi, CloudMatrix 384 Süper Düğüm, EdgeInfinite Algoritması
🔥 Odak Noktası
AI Agent’leri geliştirme ve bilimsel araştırma paradigmalarını yeniden tanımlıyor: Microsoft Build konferansında, hataları otonom olarak onaran ve kod bakımını yapan Coding Agent ile fikir üretebilen, sonuçları simüle edebilen ve otonom olarak öğrenebilen bilimsel araştırma agent platformu Microsoft Discovery dahil olmak üzere bir dizi AI Agent aracı duyuruldu. Aynı zamanda, OpenAI Ürün Direktörü Kevin Weil ve Anthropic CEO’su Dario Amodei, AI’ın halihazırda ileri düzey programlama yeteneklerine sahip olduğunu belirterek, başlangıç seviyesi programcı pozisyonlarının yerini AI’ın alabileceğini ve geliştirici rolünün “AI yönlendiricisi”ne dönüşeceğini öngörüyor. Bu gelişmeler, AI Agent’lerinin yardımcı araçlardan karmaşık projelerde bağımsız olarak çalışabilen temel güçlere evrildiğini ve yazılım geliştirme ile bilimsel araştırmanın süreçlerini ve verimliliğini derinden değiştireceğini gösteriyor (kaynak: GitHub Trending, X)
Büyük Dil Modellerinin (LLM) çıkarım yetenekleri yeni zorluklar ve değerlendirmelerle karşı karşıya: Son dönemdeki birçok araştırma ve tartışma, Büyük Dil Modellerinin karmaşık çıkarım görevlerindeki sınırlılıklarını ortaya koyuyor. Harvard Üniversitesi gibi kurumların araştırmaları, Düşünce Zinciri’nin (CoT) bazen modellerin talimatları takip etme konusundaki doğruluk oranını düşürebileceğini, çünkü içeriğin planlanmasına aşırı odaklanıp basit kısıtlamaları göz ardı edebileceğini belirtiyor. Aynı zamanda, parça işleme gibi gerçek dünya fiziksel görevleri ve küp yığma problemi gibi karmaşık görsel-uzamsal çıkarımlar da o3, Gemini 2.5 Pro dahil olmak üzere en üst düzey AI modellerinin yetersizliklerini ortaya koyuyor. Modellerin yeteneklerini daha doğru değerlendirmek için, AI’ın çok modlu entegrasyon, bilimsel doğrulama gibi alanlardaki gerçek seviyesini tespit etmeyi amaçlayan EMMA, SPOT gibi yeni kıyaslama ölçütleri öneriliyor ve modellerin daha sağlam ve güvenilir çıkarıma doğru evrilmesi hedefleniyor (kaynak: HuggingFace Daily Papers, QbitAI)
Google AI her alanda güç gösteriyor, Gemini 2.5 Pro güçlü performans sergiliyor: Google, AI alanında kapsamlı bir atak sergiliyor; Gemini 2.5 Pro modeli, LMSYS Chatbot Arena gibi birçok kıyaslama testinde, özellikle uzun bağlam ve video anlama konularında en üst düzeyde performans göstererek ve WebDev Arena’da önceki sürümünü geride bırakarak öne çıkıyor. Google Cloud Next ‘25 konferansında Google, Gemini 2.5 Flash, Imagen 3, Veo 2, Vertex AI Agent Development Kit (ADK) ve Agent2Agent (A2A) protokolü dahil olmak üzere 200’den fazla güncelleme yayınladı. Bu, AI’ı bulut platformunun her katmanına entegre etme ve kurumsal ölçekte dağıtımı teşvik etme kararlılığını gösteriyor. Google Labs ayrıca, NotebookLM gibi AI-native yenilikçi ürünleri sürekli olarak geliştirerek güçlü ürün inovasyonu ve yineleme yeteneğini sergiliyor (kaynak: Google, GoogleDeepMind)
Nvidia, masaüstü seviyesinde AI süper bilgisayarı ve kurumsal düzeyde AI fabrika çözümlerini duyurdu: Nvidia, Computex konferansında, GB300 süper çipiyle donatılmış, 784GB’a kadar birleşik belleğe sahip ve 1T parametreli büyük modelleri çalıştırabilen kişisel AI bilgisayarı DGX Station ile işletmeler için AI Agent’leri, fiziksel AI, bilimsel hesaplama gibi çeşitli uygulamaları hızlandırabilen RTX PRO Server dahil olmak üzere birçok önemli yeni ürün duyurdu. Aynı zamanda Nvidia, yarı özelleştirilmiş NVLink Fusion teknolojisini ve NVIDIA AI veri platformunu tanıttı ve Disney gibi şirketlerle fiziksel AI motoru Newton’u geliştirmek için işbirliği yaptığını açıkladı. Bu adımlar, Nvidia’nın çip şirketinden AI altyapı şirketine dönüştüğünü ve masaüstünden veri merkezine kadar eksiksiz bir AI ekosistemi kurmayı hedeflediğini gösteriyor (kaynak: nvidia, QbitAI)

🎯 Eğilimler
Kimi.ai, uzun metin düşünme modeli kimi-thinking-preview’u yayınladı: Kimi.ai, en son uzun metin düşünme modeli olan kimi-thinking-preview’u platform.moonshot.ai üzerinde kullanıma sundu. Modelin üstün çok modlu ve çıkarım yeteneklerine sahip olduğu iddia ediliyor ve yeni kullanıcılar kayıt olduklarında denemek için 5 dolarlık bir kupon alabiliyorlar. Topluluk yorumları, modelin üçüncü bir tarafça değerlendirilmesini öneriyor ve Kimi’nin daha önce özel bir düşünme modeliyle livecodebench’te liderliği ele geçirdiğinden bahsediyor (kaynak: X)
Red Hat, Kubernetes tabanlı dağıtık çıkarım çerçevesi llm-d’yi tanıttı: LLM çıkarımının yavaşlığı, yüksek maliyeti ve ölçeklendirme zorluklarını çözmek için Red Hat, Kubernetes-native bir dağıtık çıkarım çerçevesi olan llm-d’yi tanıttı. Bu çerçeve, LLM çıkarımını optimize etmek için vLLM, akıllı zamanlama ve ayrıştırılmış hesaplama kullanıyor. llm-d, yüksek performanslı LLM çıkarım motoru vLLM, konteyner orkestrasyon standardı Kubernetes ve Gateway API uzantıları aracılığıyla akıllı yönlendirme sağlayan Inference Gateway (IGW) olmak üzere üç açık kaynaklı temel üzerine inşa edilmiştir ve LLM çıkarımının verimliliğini ve ölçeklenebilirliğini artırmayı amaçlamaktadır (kaynak: X, X)
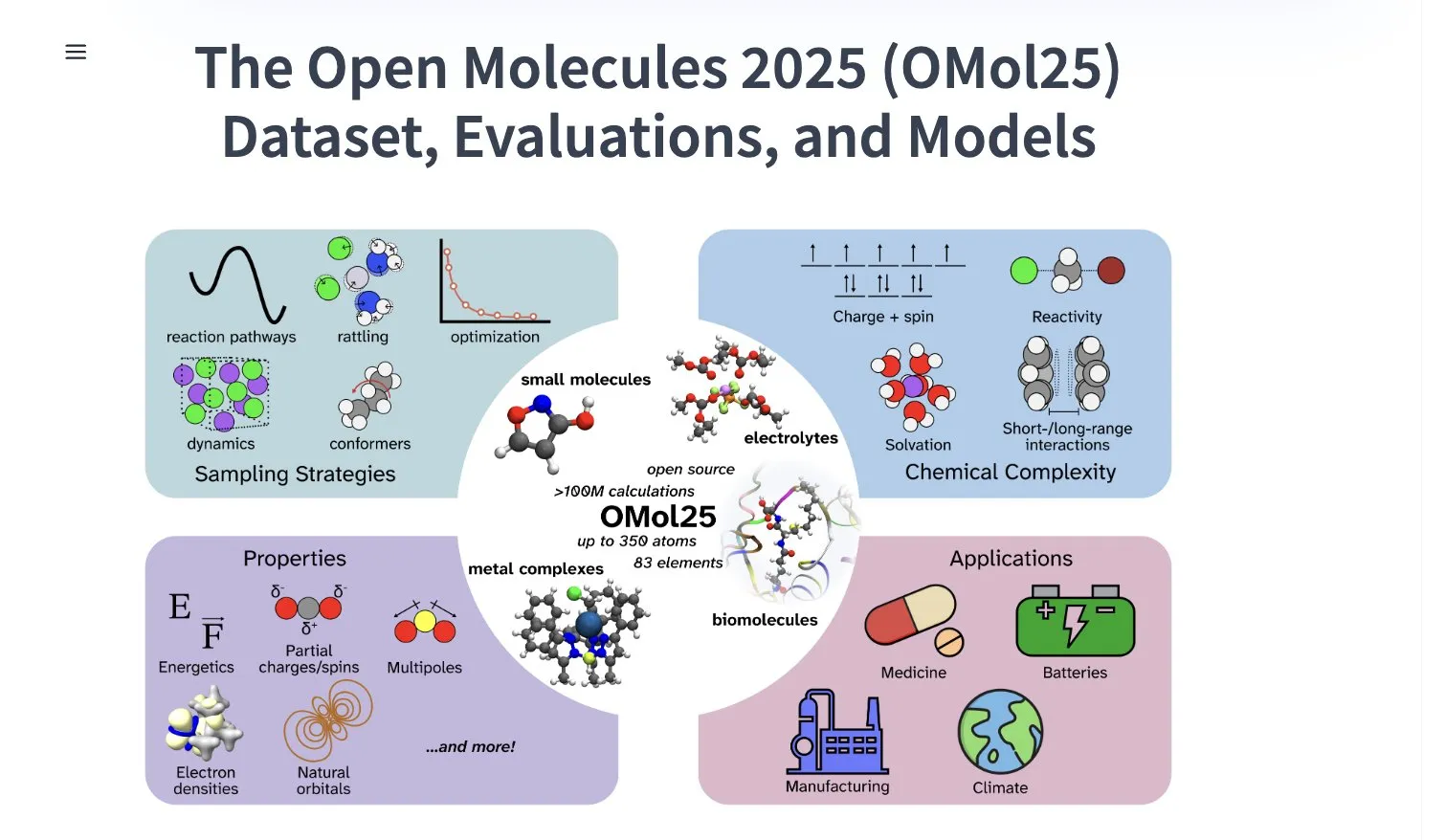
Meta AI, 100 milyondan fazla moleküler konformer içeren OMol25 veri kümesini yayınladı: Meta AI, HuggingFace üzerinde 83 elementi ve çeşitli kimyasal ortamları kapsayan 100 milyondan fazla moleküler konformer içeren OMol25 veri kümesini yayınladı. Bu veri kümesi, DFT (Yoğunluk Fonksiyonel Teorisi) düzeyinde hassasiyete ulaşabilen ve aynı zamanda hesaplama maliyetlerini önemli ölçüde azaltan makine öğrenimi modellerini eğitmeyi amaçlamaktadır. Bu, ilaç keşfi, gelişmiş malzeme tasarımı ve temiz enerji çözümleri gibi alanlardaki araştırma ve uygulamaları hızlandırmaya yardımcı olacaktır (kaynak: X)
Gemini 2.5 Pro, NotebookLM Almanya bölgesi iOS App Store’da yayınlandı: Google’ın NotebookLM uygulaması (Gemini 2.5 Pro entegreli) Almanya bölgesindeki iOS App Store’da yayınlandı; daha önce AB bölgesindeki iOS sürümü yalnızca TestFlight aracılığıyla sunuluyordu. Aynı zamanda, Android sürümünün daha yaygın olarak kullanılabilir olduğu görülüyor. NotebookLM, kullanıcıların uzun belgeleri, notları vb. içerikleri anlamalarına ve işlemelerine yardımcı olmayı amaçlamaktadır (kaynak: X)
ByteDance AI araştırmalarında aktif, son zamanlarda birçok makale yayınladı: ByteDance’a bağlı SEED ekibi, son iki ay içinde model birleştirme, takviyeli öğrenme ile tetiklenen uyarlanabilir düşünce zinciri (AdaCoT), gizli temsiller aracılığıyla çıkarım optimizasyonu (LatentSeek) gibi alanları kapsayan en az 13 AI ile ilgili araştırma makalesi yayınladı. Bu araştırmalar, ByteDance’ın Büyük Dil Modellerinin verimliliğini, çıkarım yeteneğini ve eğitim yöntemlerini geliştirme konusundaki sürekli yatırımını ve keşfini göstermektedir (kaynak: X, X)
AI destekli yeni nesil çinko pil, %99,8 verimlilik ve 4300 saat çalışma süresi elde etti: Yapay zeka optimizasyonu sayesinde yeni nesil çinko pil, %99,8 Coulomb verimliliği ve 4300 saate varan çalışma süresi elde etti. Bu teknolojik atılım, AI’ın malzeme bilimi ve enerji depolama alanlarındaki uygulama potansiyelini gösteriyor ve daha verimli, daha uzun ömürlü pil teknolojilerinin geliştirilmesini teşvik ederek yenilenebilir enerji depolaması ve taşınabilir elektronik cihazlar için önemli bir anlam taşıyor (kaynak: X)

Perplexity, AI destekli akıllı tarayıcı Comet’i erken test için kullanıma sundu: Perplexity, agent özelliklerine sahip web tarayıcısı Comet’i erken test kullanıcılarına sunmaya başladı. Bu tarayıcının, Perplexity’nin güçlü AI arama ve bilgi entegrasyon yeteneklerini birleştirerek kullanıcılara daha akıllı, daha kişiselleştirilmiş bir web tarama deneyimi sunması bekleniyor (“atmosfer taraması” (vibe browsing) olarak adlandırılan yeni bir deneyim) (kaynak: X)
Intel, büyük VRAM’e odaklanan uygun maliyetli Arc Pro B serisi ekran kartlarını piyasaya sürdü: Intel, Arc Pro B50 (16GB VRAM, 299 dolar) ve AI iş istasyonları için özel olarak tasarlanmış Arc Pro B60 (24GB VRAM, tek kart 500 dolar) ekran kartlarını tanıttı. B60, AI çıkarım testlerinde Nvidia RTX A1000’den daha iyi performans gösterdi ve daha büyük VRAM’i sayesinde büyük modelleri çalıştırırken daha avantajlı. Project Battlematrix iş istasyonu, Xeon işlemcileri kullanıyor ve en fazla 8 adet B60 GPU (toplam 192GB VRAM) ile 70 milyardan fazla parametreli modelleri destekleyebiliyor. Bu hamle, Intel’in AI donanım pazarında fiyat/performans atılımı arayışının bir stratejisi olarak görülüyor (kaynak: QbitAI)

Huawei Cloud, AI hesaplama gücünü artırmak için CloudMatrix 384 süper düğümünü tanıttı: Huawei Cloud, 384 AI hızlandırıcı kartını birbirine bağlayarak süper bir bulut sunucusu oluşturan ve 300 PFlops’a kadar hesaplama gücü sağlayan tam eşler arası bağlantı mimarisine sahip CloudMatrix 384 süper düğümünü duyurdu. Bu, AI eğitimi ve çıkarımındaki iletişim verimliliği, bellek duvarı ve güvenilirlik zorluklarını çözmeyi amaçlıyor. Bu mimari, özellikle MoE modellerine olan yakınlığı, ağ ile hesaplamayı güçlendirme, depolama ile hesaplamayı güçlendirme gibi özellikleriyle öne çıkıyor ve DeepSeek-R1 gibi büyük modellerin çıkarım hizmetlerini desteklemek için halihazırda kullanılıyor (kaynak: QbitAI)

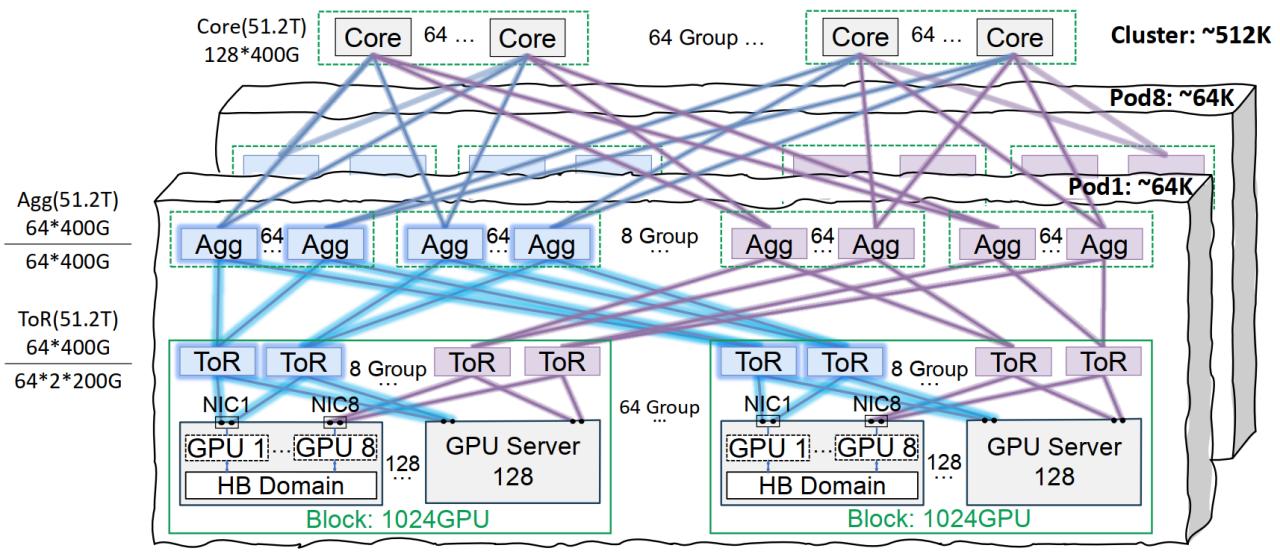
Tencent Cloud Star Pulse ağ altyapısı büyük model eğitimini optimize ediyor: Tencent Cloud, büyük ölçekli AI model eğitimi ve çıkarımı için özel olarak tasarlanmış Star Pulse yüksek performanslı ağ altyapısı çözümünü tanıttı. Bu çözüm, aynı yörüngede ara bağlantı mimarisi (tek bir Pod’da 64.000 GPU, tüm kümede 512.000 GPU ağını destekler), optimize edilmiş güç yönetimi ve soğutma çözümleri ile akıllı izleme sistemi aracılığıyla geleneksel veri merkezlerinin ağ, dağıtım yoğunluğu ve arıza tespiti konularındaki sıkıntılarını gideriyor. Star Pulse, Tencent Hunyuan gibi kendi geliştirdiği hizmetleri destekliyor ve DeepSeek’in DeepEP iletişim çerçevesi için performans optimizasyonu sağladı (kaynak: QbitAI)
Stability AI, SV4D2.0 modelini yayınladı, video üretimi alanına dönüşünü işaret ediyor olabilir: Stability AI, Hugging Face üzerinde sv4d2.0 adlı bir model yayınlayarak topluluğun dikkatini çekti. Ayrıntılar az olsa da, bu hamle Stability AI’ın video üretimi veya ilgili 3D/4D alanlarında yeni teknolojik gelişmelere veya ürün yinelemelerine sahip olduğu anlamına gelebilir ve bir ayarlama döneminden sonra AI üretimi alanının ön saflarına geri dönebileceğini ima ediyor (kaynak: X)
Meta AI, Adjoint Sampling öğrenme algoritmasını yayınladı: Meta AI, skaler ödüle dayalı üretici modelleri eğitmek için Adjoint Sampling adlı yeni bir öğrenme algoritması önerdi. Bu algoritma, FAIR tarafından geliştirilen teorik temellere dayanıyor, yüksek düzeyde ölçeklenebilir ve gelecekteki ölçeklenebilir örnekleme yöntemleri araştırmaları için bir temel oluşturması bekleniyor. İlgili araştırma makalesi, modeller, kod ve kıyaslama ölçütleri yayınlandı (kaynak: X)
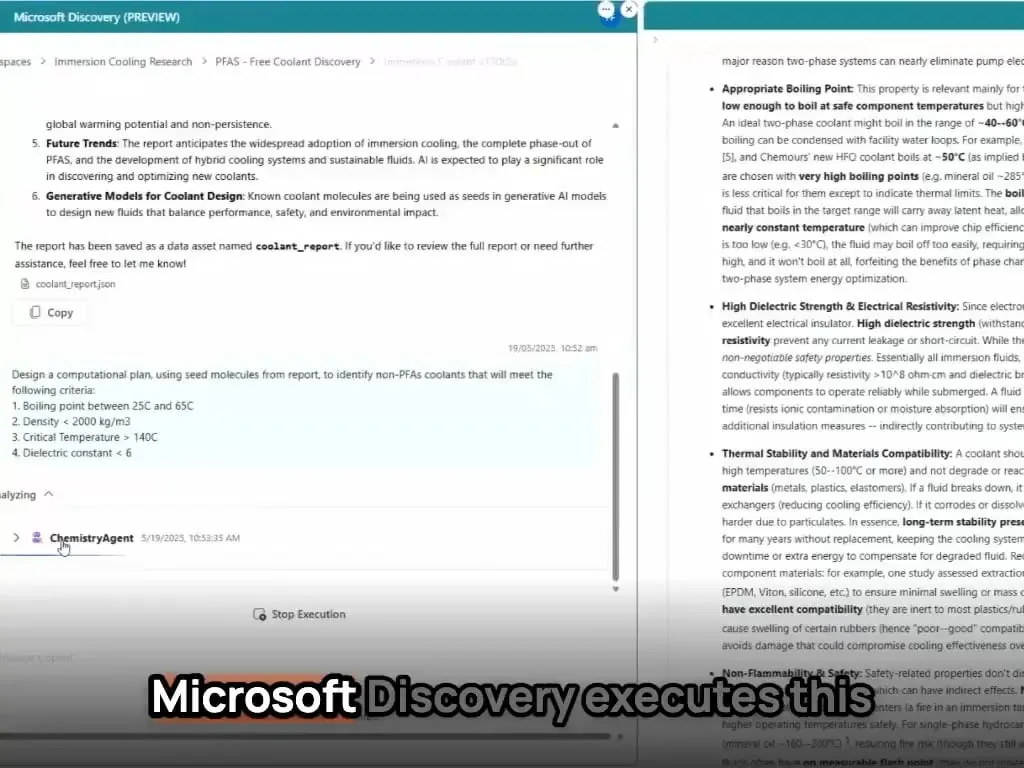
Microsoft AI Agent’leri, yeni malzeme keşfini ve sentezini saatler içinde tamamladı: Microsoft, AI Agent’lerinin bilimsel araştırma ve geliştirmedeki güçlü yeteneklerini sergiledi. Bu Agent’ler, bilimsel literatürü tarayabiliyor, planlar yapabiliyor, kod yazabiliyor, simülasyonlar çalıştırabiliyor ve normalde yıllarca sürecek yeni bir veri merkezi soğutucusunun keşfini saatler içinde tamamlayabiliyor. Dahası, ekip AI tarafından tasarlanan yeni soğutucuyu başarıyla sentezledi ve gerçek bir anakart üzerinde göstererek AI’ın malzeme bilimi gibi alanlarda otonom keşif ve yaratıcılığı hızlandırmadaki büyük potansiyelini gösterdi (kaynak: Reddit r/artificial)
BAAI, kod ve çok modlu erişime odaklanan üç BGE serisi vektör modelini yayınladı: BAAI, üniversitelerle işbirliği içinde BGE-Code-v1 (kod vektör modeli), BGE-VL-v1.5 (genel amaçlı çok modlu vektör modeli) ve BGE-VL-Screenshot (görselleştirilmiş belge vektör modeli) olmak üzere üç model tanıttı. Bu modeller CoIR, Code-RAG, MMEB, MVRB gibi kıyaslama testlerinde üstün performans gösterdi. BGE-Code-v1, Qwen2.5-Coder-1.5B’ye; BGE-VL-v1.5, LLaVA-1.6’ya; BGE-VL-Screenshot ise Qwen2.5-VL-3B-Instruct’e dayanıyor ve kod erişimi, görüntü-metin anlama ve karmaşık görsel belge erişiminin performansını artırmayı amaçlıyor. Modeller tamamen açık kaynaklıdır (kaynak: WeChat)
Huawei OmniPlacement teknolojisi MoE model çıkarımını optimize ediyor, DeepSeek-V3 gecikmesini teorik olarak %10 azaltıyor: Uzmanlar Karışımı (MoE) modellerindeki uzman ağ yükünün dengesizliği (“sıcak uzmanlar” ve “soğuk uzmanlar”) nedeniyle çıkarım performansının sınırlanması sorununa yönelik olarak Huawei ekibi OmniPlacement teknolojisini önerdi. Bu teknoloji, uzman yeniden sıralama, katmanlar arası yedekli dağıtım ve neredeyse gerçek zamanlı dinamik zamanlama yoluyla DeepSeek-V3 gibi modellerde çıkarım gecikmesini teorik olarak yaklaşık %10 azaltmayı ve verimi yaklaşık %10 artırmayı hedefliyor. Bu çözüm yakın zamanda tamamen açık kaynaklı hale getirilecek (kaynak: WeChat)

vivo, EdgeInfinite algoritmasını yayınladı, telefon tarafında 128K uzun metinlerin verimli işlenmesini sağlıyor: vivo AI Araştırma Enstitüsü, ACL 2025’te uç cihazlar için özel olarak tasarlanmış EdgeInfinite algoritmasını tanıtan bir araştırma yayınladı. Bu algoritma, eğitilebilir kapılı bellek modülü ve bellek sıkıştırma/açma teknolojisi aracılığıyla Transformer mimarisinde ultra uzun metinleri verimli bir şekilde işliyor. Algoritma, BlueLM-3B modelinde test edildi ve 10GB GPU belleğe sahip cihazlarda 128K token işleyebiliyor. LongBench’teki birçok görevde üstün performans göstererek ilk kelime çıkış süresini ve bellek kullanımını önemli ölçüde azaltıyor (kaynak: WeChat)

🧰 Araçlar
LlamaParse güncellendi, belge ayrıştırma yetenekleri geliştirildi: LlamaParse, AI Agent destekli belge ayrıştırma aracı olarak performansını artıran birçok güncelleme yayınladı. Yeni özellikler arasında Gemini 2.5 Pro, GPT-4.1 desteği, eğrilik tespiti ve güvenilirlik puanları bulunuyor. Ayrıca, kullanıcıların ayrıştırma yapılandırmalarını doğrudan kod tabanlarına kopyalamalarını kolaylaştıran kod parçacığı düğmeleri eklendi ve kullanım durumu ön ayarları ile işlenmiş/ham Markdown arasında dışa aktarma geçişi yapma özelliği eklendi (kaynak: X)
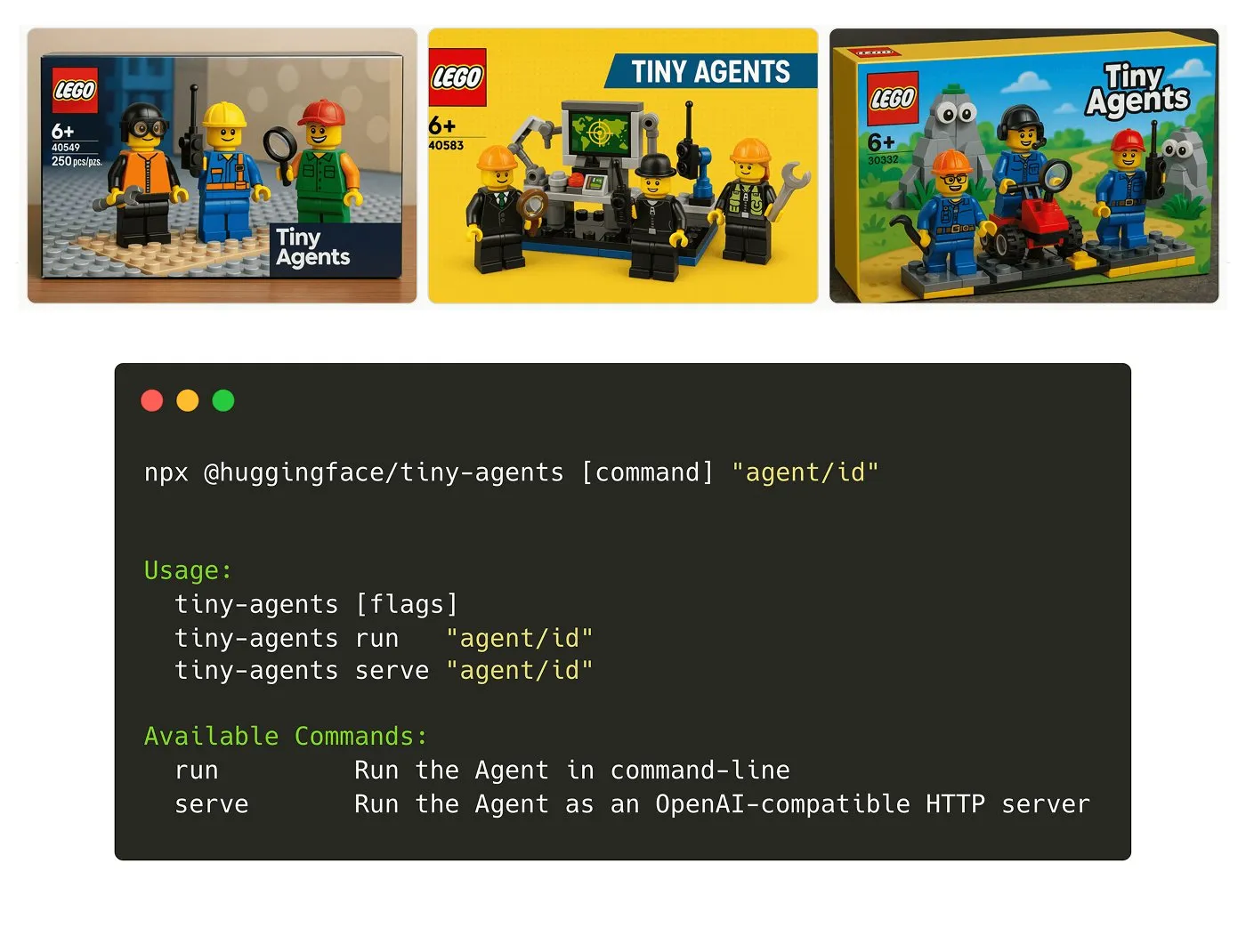
Hugging Face, Tiny Agents NPM paketini tanıttı: Julien Chaumond, hafif, birleştirilebilir bir agent NPM paketi olan Tiny Agents’ı yayınladı. Hugging Face’in Inference Client ve MCP (Model Component Protocol) yığını üzerine inşa edilen bu paket, geliştiricilerin küçük agent uygulamalarını hızla başlatmalarını ve oluşturmalarını kolaylaştırmayı amaçlıyor. Resmi bir başlangıç eğitimi mevcut (kaynak: X)
LangGraph platformuna MCP desteği eklendi, agent entegrasyonu basitleştirildi: LangGraph platformu artık MCP’yi (Model Component Protocol) destekliyor; platformda dağıtılan her agent otomatik olarak bir MCP uç noktası sunacak. Bu, kullanıcıların bu agent’leri araç olarak kullanabileceği ve MCP akışlanabilir HTTP’yi destekleyen herhangi bir istemcide özel kod yazmadan veya ek altyapı yapılandırmadan kullanabileceği anlamına geliyor, bu da agent’ler arasındaki entegrasyonu ve birlikte çalışabilirliği basitleştiriyor (kaynak: X)

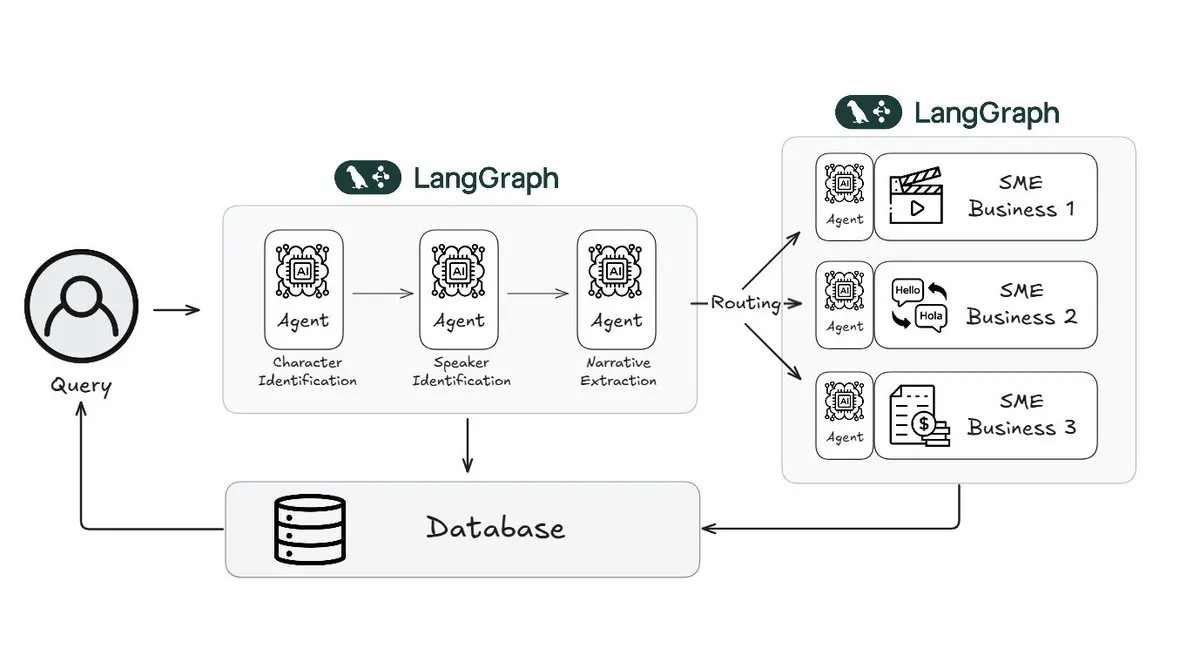
Webtoon, LangGraph kullanarak hikaye inceleme iş yükünü %70 azalttı: Dijital çizgi roman lideri Webtoon, devasa içerik kütüphanesinin anlatısal anlayışını otomatikleştirmek için LangGraph kullanarak Webtoon Comprehension AI’ı (WCAI) geliştirdi. WCAI, akıllı çok modlu agent’ler aracılığıyla manuel taramayı değiştirerek karakter ve konuşmacı tanıma, olay örgüsü ve ton çıkarma ile doğal dil içgörü sorgulaması yapabiliyor. Bu sayede pazarlama, çeviri ve öneri ekiplerinin iş yükünü %70 azaltıp yaratıcılığı artırdı (kaynak: X)
OpenMemory MCP, AI araçları arasında kalıcı özel bellek paylaşımını sağlıyor: Mem0 projesi, AI uygulamalarına platformlar ve oturumlar arası kalıcı özel bellek sağlamayı amaçlayan OpenMemory MCP sunucusunu tanıttı. Kullanıcılar yerel olarak dağıtım yapabilir ve MCP protokolü aracılığıyla OpenMemory’yi Cursor gibi istemci araçlarına bağlayarak bellek ekleme, arama, listeleme ve silme işlemlerini gerçekleştirebilir. Bu araç, bir gösterge paneli aracılığıyla bellek yönetimi işlevleri sunarak AI Agent’lerinin kişiselleştirme ve bağlam anlama yeteneklerini artırmayı vaat ediyor (kaynak: WeChat)

Miaoduo AI 2.0 yayınlandı, arayüz tasarımı AI asistanı olarak konumlandırıldı: Miaoduo AI 2.0, arayüz tasarımı alanında kullanıcılarla işbirliği içinde tasarım görevlerini tamamlamayı amaçlayan bir AI asistanı olarak yayınlandı. Yeni sürüm, AI sihirli kutusu aracılığıyla etkileşimi artırıyor, diyalog tabanlı düzenlemeyi ve yinelemeli tasarım çözümlerini destekliyor. Önceden ayarlanmış stillere veya kullanıcı girdilerine (uzun metin, eskiz, referans resim) göre birden fazla arayüz sürümü oluşturabiliyor ve ana akım tasarım sistemleriyle uyumlu. Ayrıca, görüntü-metin işleme, tasarım danışmanlığı ve kısayol komutları (doğal dilden API çağrısına) gibi işlevler sunuyor. Miaoduo AI, MCP protokolünü destekliyor ve tasarım taslak verilerini büyük modellerin okuması için optimize ederek yüksek sadakatli ön uç kodu üretmeyi hedefliyor (kaynak: QbitAI)

llmbasedos: MCP tabanlı açık kaynaklı başlatılabilir AI işletim sistemi kavram kanıtı: Geliştirici iluxu, Microsoft’un “AI uygulamaları için USB-C” (MCP tabanlı) kavramını yayınlamasından üç gün önce llmbasedos projesini açık kaynaklı hale getirdi. Bu proje, USB’den veya sanal makineden hızla başlatılabilen bir AI işletim sistemidir. FastAPI ağ geçidi aracılığıyla küçük Python arka plan programlarıyla JSON-RPC üzerinden iletişim kurarak kullanıcı komut dosyalarının basit bir cap.json yapılandırmasıyla ChatGPT/Claude/VS Code gibi araçlar tarafından çağrılmasına olanak tanır. Varsayılan olarak çevrimdışı llama.cpp kullanır, ancak GPT-4o veya Claude 3’e de geçiş yapılabilir ve açık AI uygulama bağlantı standartlarını teşvik etmeyi amaçlar (kaynak: Reddit r/LocalLLaMA)
📚 Öğrenme
Bilgi Damıtma (KD) neden etkilidir? Yeni araştırma kısa bir açıklama sunuyor: Kyunghyun Cho ve arkadaşları, Bilgi Damıtma’nın (KD) etkinliğine dair kısa bir açıklama önerdiler. Öğretmen modelden gelen düşük entropili yaklaşık örneklemenin, öğrenci modelde daha yüksek kesinliğe ancak daha düşük geri çağırma oranına yol açtığını varsayıyorlar. Otoregresif dil modelleri doğası gereği sonsuz basamaklı karma dağılımlar olduğundan, bu varsayımı SmolLM ile doğruladılar. Araştırma, mevcut değerlendirme yöntemlerinin kesinliğe aşırı odaklanıp geri çağırma oranındaki kaybı göz ardı edebileceğini, bunun da büyük ölçekli genel amaçlı modellerin gözden kaçırabileceği içerik ve kullanıcı gruplarıyla ilgili olduğunu savunuyor (kaynak: X)

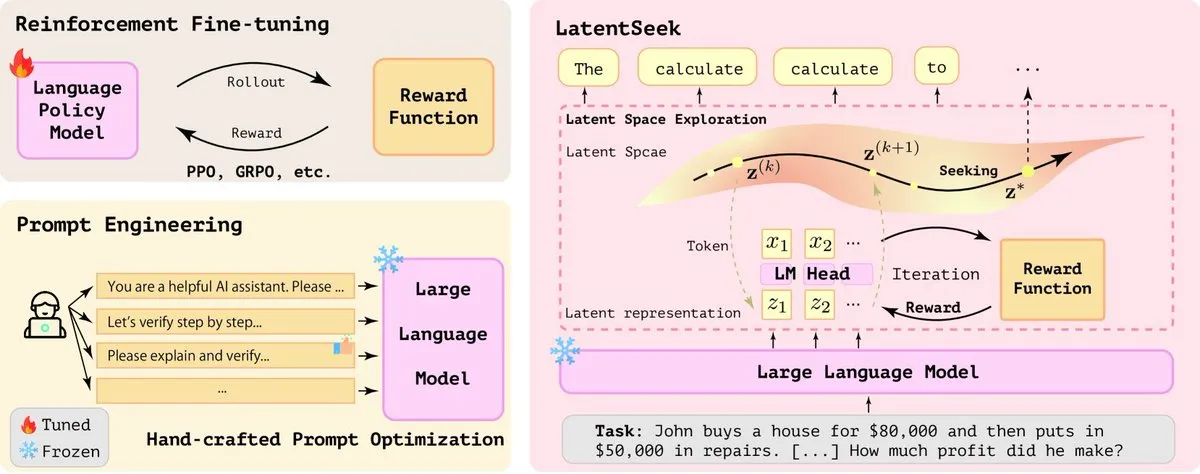
LatentSeek: Gizli uzayda politika gradyan optimizasyonu ile LLM çıkarım yeteneğini artırma: “Seek in the Dark” adlı bir makale, test zamanında gizli uzaydaki örnek düzeyinde politika gradyanı aracılığıyla Büyük Dil Modellerinin (LLM) çıkarım yeteneğini artıran yeni bir paradigma olan LatentSeek’i öneriyor. Bu yöntem eğitim, veri veya ödül modeli gerektirmez ve gizli temsilleri optimize ederek modelin çıkarım sürecini iyileştirmeyi amaçlar. Bu eğitimden bağımsız yöntem, LLM’lerin karmaşık çıkarım görevlerindeki performansını artırma potansiyeli göstermektedir (kaynak: X)
Microsoft, CoML’yi öneriyor: Dil modelleri için Zincirleme Model Öğrenimi: Microsoft Research, “Zincirleme Model Öğrenimi” (Chain-of-Model Learning, CoML) adlı yeni bir öğrenme paradigması önerdi. Bu yöntem, gizli durumların nedensel ilişkisini her ağ katmanına zincirleme bir yapıda entegre ederek model eğitiminin ölçeklendirme verimliliğini ve dağıtım sırasındaki çıkarım esnekliğini artırmayı amaçlıyor. Temel kavramı olan “Zincirleme Temsil” (CoR), her katmanın gizli durumunu birden fazla alt temsil zincirine ayırır; sonraki zincirler önceki tüm zincirlerin giriş temsillerine erişebilir, böylece modelin zincir ekleyerek aşamalı olarak genişlemesine ve esnek çıkarım için farklı sayıda zincir seçerek çeşitli ölçeklerde alt modeller sunmasına olanak tanır. Bu prensibe dayalı olarak tasarlanan CoLM (Zincirleme Dil Modeli) ve varyantı CoLM-Air (KV paylaşım mekanizması eklenmiş) standart Transformer ile karşılaştırılabilir performans sergilemiş ve aşamalı genişleme ile esnek çıkarım avantajları getirmiştir (kaynak: X, HuggingFace Daily Papers)

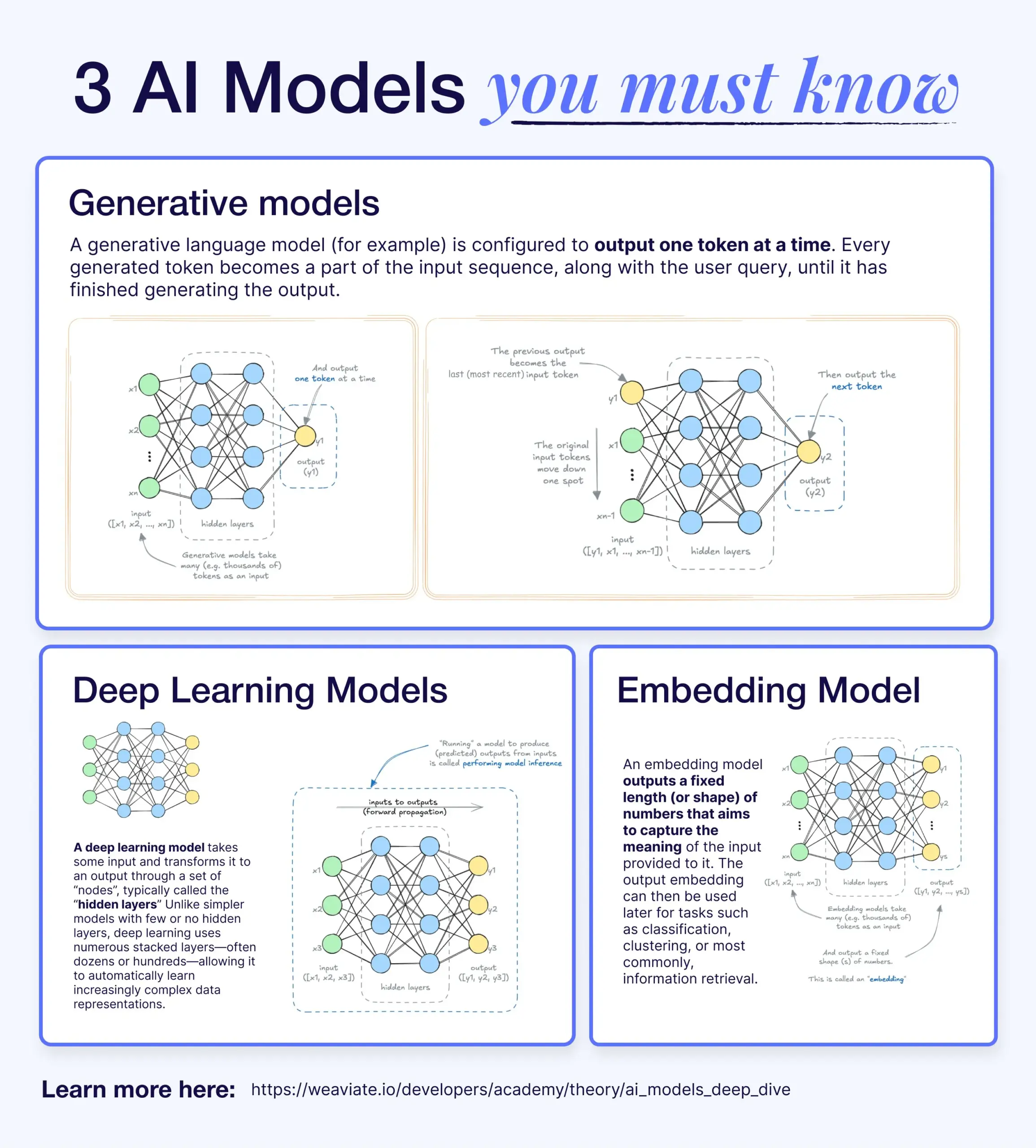
Derin öğrenme, üretici modeller ve gömme modelleri arasındaki farklar ve bağlantılar: Bir bilgilendirme makalesi, derin öğrenme modelleri, üretici modeller ve gömme modelleri arasındaki ilişkiyi açıklıyor. Derin öğrenme modelleri, çok katmanlı sinir ağları aracılığıyla sayısal girdi ve çıktıları işleyen temel altyapıdır. Üretici modeller, derin öğrenme modellerinin bir türüdür ve eğitim verilerine benzer yeni içerikler (GPT, DALL-E gibi) oluşturmak için özel olarak tasarlanmıştır. Gömme modelleri de derin öğrenme modellerinin bir türüdür ve verileri (metin, resim vb.) anlamsal bilgiyi yakalayan sayısal vektör temsillerine dönüştürmek için kullanılır; genellikle benzerlik araması ve RAG sistemlerinde kullanılır. Birçok AI sisteminde bu modeller birlikte çalışır; örneğin, RAG sistemleri erişim için gömme modellerini kullanır ve ardından üretici modeller yanıtlar oluşturur (kaynak: X)
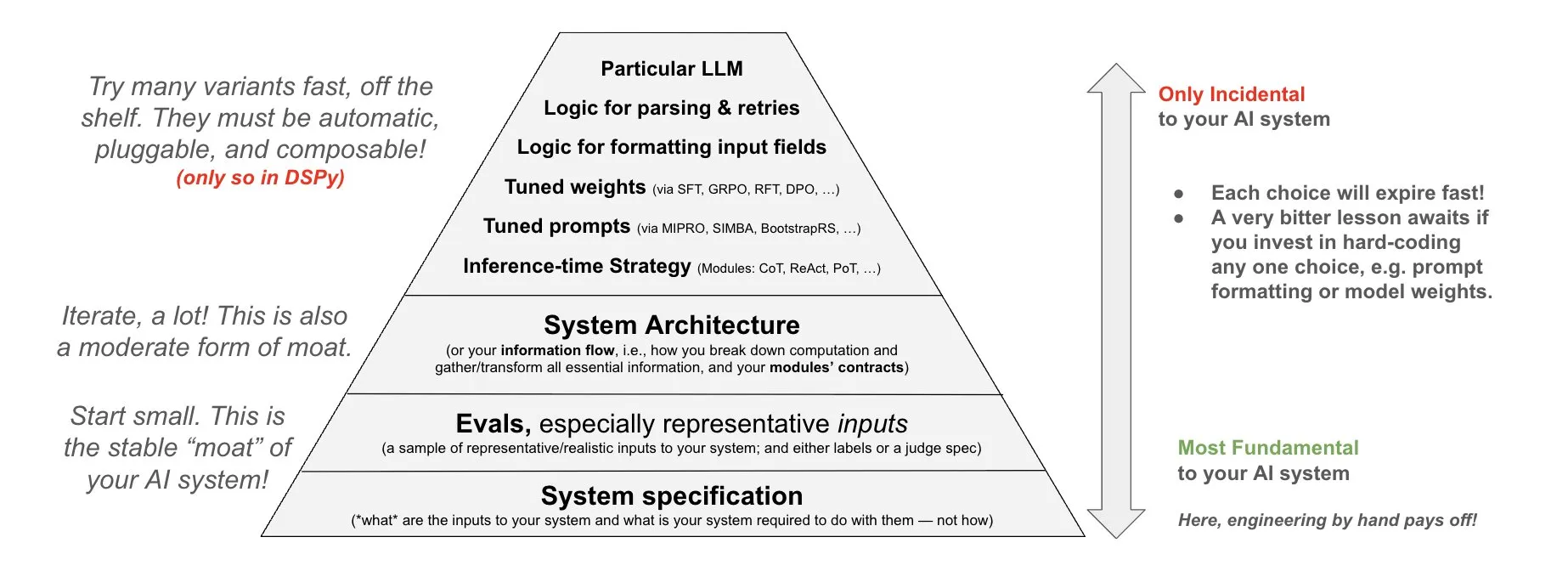
DSPy, AI sistemlerine yatırım felsefesini öneriyor: DSPy, AI sistemlerine yatırım yapma konusundaki felsefesini paylaştı ve enerjinin AI sistemlerinin üç temel katmanına odaklanması gerektiğini vurguladı: veri, model ve algoritma. Birleştirilebilir üst düzey modüller (Prompts, Demonstrations, Optimizers, Metrics, Tools, Agents, Reasoning Modules) sunarak geliştiricilerin bu üç temel katmanı hızla yineleyebileceğini ve böylece daha güçlü AI sistemleri oluşturabileceğini savunuyorlar (kaynak: X)
Transformers kütüphanesi güncellendi, optimize edilmiş çekirdeklere otomatik geçiş performansı artırıyor: Hugging Face Transformers kütüphanesinin en son sürümü, donanım izin verdiğinde optimize edilmiş çekirdeklere otomatik olarak geçiş yapma özelliğini uyguluyor. Bu güncelleme, Llama gibi popüler modeller için kernels kütüphanesini entegre ediyor ve Hugging Face Hub’daki en popüler topluluk çekirdeklerini kullanarak uyumlu donanımlarda modelin çalışma verimliliğini ve performansını artırmayı amaçlıyor (kaynak: X)
ARC-AGI-2 kıyaslama ölçütü yayınlandı, öncü AI çıkarım sistemlerine meydan okuyor: François Chollet ve arkadaşları, ARC-AGI-2 kıyaslama ölçütü hakkında bir makale yayınlayarak tasarım ilkelerini, zorluklarını, insan performansı analizini ve mevcut modellerin performansını ayrıntılı olarak açıkladı. Bu kıyaslama ölçütü, AI’ın soyut muhakeme yeteneğini değerlendirmeyi amaçlıyor; insanlar görevlerin %100’ünü çözebilirken, mevcut öncü AI modellerinin puanı %5’in altında kalıyor, bu da ileri düzey soyut muhakeme konusunda AI ile insanlar arasında hala büyük bir fark olduğunu gösteriyor (kaynak: X)

Terence Tao, GitHub Copilot ile fonksiyon limitlerini kanıtlama eğitimini yayınladı: Matematikçi Terence Tao, GitHub Copilot kullanarak toplama, çıkarma, çarpma teoremleri dahil olmak üzere fonksiyon limit problemlerini kanıtlamaya yardımcı olacak bir video eğitimi yayınladı. Copilot’un kod çerçevesini hızla oluşturabildiğini ve mevcut kütüphane fonksiyonlarını önerebildiğini vurgularken, karmaşık matematiksel ayrıntılar, özel durumların ele alınması ve yaratıcı çözümler konusunda hala önemli ölçüde insan müdahalesi ve ayarlaması gerektiğini, bazen kağıt kalemle türetme yapıp ardından formel doğrulama yapmanın daha verimli olabileceğini belirtti (kaynak: 36Kr)
PhyT2V çerçevesi, LLM kullanarak metinden videoya fiziksel tutarlılığı artırıyor: Pittsburgh Üniversitesi araştırma ekibi, Büyük Dil Modelleri (LLM) rehberliğinde zincirleme çıkarım (CoT) ve yinelemeli kendini düzeltme mekanizması aracılığıyla metin ipuçlarını optimize ederek mevcut metinden videoya (T2V) modellerinin ürettiği içeriğin fiziksel gerçekçiliğini artırmak için PhyT2V çerçevesini önerdi. Bu yöntem, model yeniden eğitimi gerektirmeden, üretilmiş videolar ile ipuçları arasındaki anlamsal uyuşmazlıkları analiz ederek ve fiziksel kurallarla birleştirerek ipucu düzeltmesi yapar ve T2V modellerinin dağılım dışı (OOD) senaryoları işlerken fiziksel tutarlılığını artırmayı amaçlar. Deneyler, PhyT2V’nin CogVideoX, OpenSora gibi modellerin VideoPhy, PhyGenBench gibi kıyaslama ölçütlerindeki performansını önemli ölçüde artırdığını göstermiştir (kaynak: WeChat)

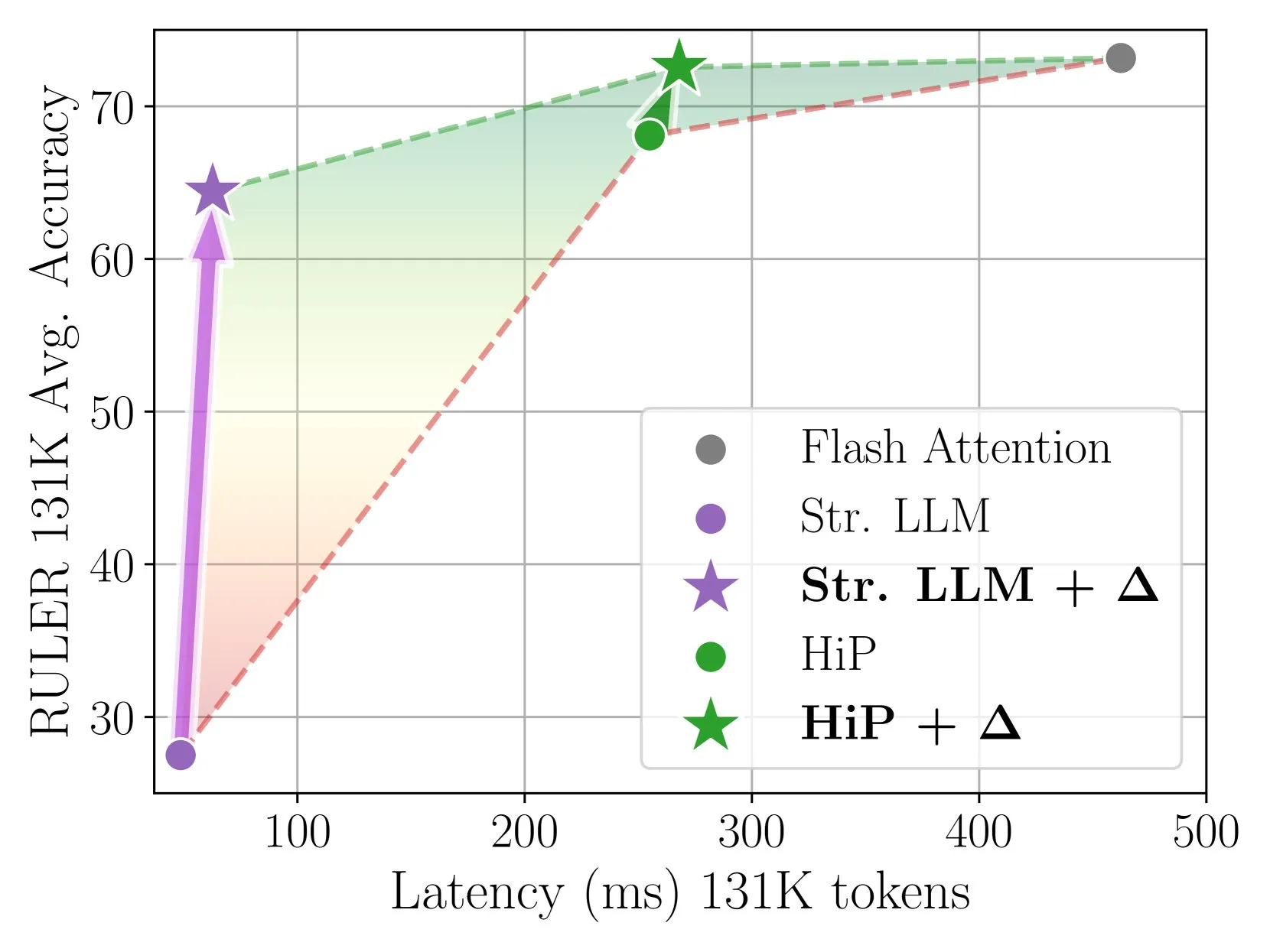
Delta Attention, artımlı düzeltme ile hızlı ve doğru seyrek dikkat (sparse attention) çıkarımı sağlıyor: Bu araştırma, seyrek dikkat hesaplamasının dikkat çıktısının dağılım kaymasına yol açarak model performansını düşürdüğünü buldu. Delta Attention, bu dağılım kaymasını düzelterek seyrek dikkatin çıktı dağılımını tam dikkate daha yakın hale getirir, böylece yüksek seyrekliği (yaklaşık %98,5) korurken performansı önemli ölçüde artırır ve RULER kıyaslama ölçütünde kayan pencere dikkatinin (sink token ile) tam dikkat doğruluğunun %88’ini geri kazandırır, hem de hesaplama maliyeti düşüktür. 1M token ön dolumunu işlerken Flash Attention 2’den 32 kat daha hızlıdır (kaynak: HuggingFace Daily Papers)
Thinkless çerçevesi, LLM’lerin CoT çıkarımını ne zaman yapacağını öğrenmesini sağlıyor: Büyük Dil Modellerinin (LLM) tüm sorgularda karmaşık Düşünce Zinciri (CoT) çıkarımı kullanmasının yol açtığı düşük hesaplama verimliliği sorununu çözmek için araştırmacılar Thinkless çerçevesini önerdi. Bu çerçeve, LLM’leri takviyeli öğrenme yoluyla eğiterek görev karmaşıklığına ve kendi yeteneklerine göre uyarlanabilir bir şekilde kısa formlu veya uzun formlu çıkarım seçmelerini sağlar. Temel algoritma DeGRPO, öğrenme hedefini kontrol token kaybı (çıkarım modunu belirler) ve yanıt kaybı (cevap doğruluğunu artırır) olarak ayırarak eğitim sürecini stabilize eder. Deneyler, Thinkless’ın Minerva Algebra gibi kıyaslama ölçütlerinde uzun zincirli düşünme kullanımını %50-%90 oranında azaltabildiğini ve çıkarım verimliliğini önemli ölçüde artırdığını göstermiştir (kaynak: HuggingFace Daily Papers)
CPGD algoritması, kural tabanlı dil modeli takviyeli öğrenme kararlılığını artırıyor: Mevcut kural tabanlı takviyeli öğrenme yöntemlerinin (GRPO, REINFORCE++, RLOO gibi) dil modellerini eğitirken karşılaşabileceği eğitim kararsızlığı sorununa yönelik olarak araştırmacılar CPGD (politika kayması ile kırpılmış politika gradyan optimizasyonu) algoritmasını önerdi. CPGD, KL diverjansına dayalı bir politika kayması kısıtlaması getirerek politika güncellemelerini dinamik olarak düzenler ve aşırı politika güncellemelerini önlemek için log-oran kırpma mekanizmasını kullanır. Teorik ve ampirik analizler, CPGD’nin kararsızlığı azaltabildiğini ve eğitim kararlılığını korurken performansı önemli ölçüde artırabildiğini göstermektedir (kaynak: HuggingFace Daily Papers)
Nöro-sembolik sorgu derleyicisi QCompiler, RAG sistemlerinin karmaşık sorgu işleme yeteneğini artırıyor: Geri Almayla Zenginleştirilmiş Üretim (RAG) sistemlerinin, özellikle kaynak kısıtlı durumlarda iç içe yapılar ve bağımlılıklar içeren karmaşık sorguları işlerken arama niyetini hassas bir şekilde belirlemedeki zorluğunu çözmek için QCompiler çerçevesi önerildi. Bu çerçeve, dilbilimsel gramer kuralları ve derleyici tasarımından esinlenerek, karmaşık sorguları biçimlendirmek için öncelikle minimal ve yeterli bir BNF grameri G[q] tasarlar, ardından sorgu ifadesi dönüştürücü, sözcüksel-dilbilgisel ayrıştırıcı ve yinelemeli iniş işlemcisi aracılığıyla sorguyu soyut sözdizimi ağacına (AST) derleyerek yürütür. Yaprak düğümlerindeki alt sorguların atomikliği, daha hassas belge erişimi ve yanıt üretimi sağlar (kaynak: HuggingFace Daily Papers)
Jedi veri kümesi ve OSWorld-G kıyaslama ölçütü, bilgisayar kullanım senaryolarında GUI öğe konumlandırma araştırmasını teşvik ediyor: Grafik kullanıcı arayüzü (GUI) konumlandırmasının (doğal dil talimatlarını GUI işlemlerine eşleme) darboğazını çözmek için araştırmacılar OSWorld-G kıyaslama ölçütünü (metin eşleştirme, öğe tanıma, düzen anlama ve hassas operasyonları kapsayan 564 ince taneli etiketlenmiş örnek) ve büyük ölçekli sentetik veri kümesi Jedi’yi (4 milyon örnek) yayınladı. Jedi üzerinde eğitilen çok ölçekli modeller, ScreenSpot-v2, ScreenSpot-Pro ve OSWorld-G’de mevcut yöntemlerden daha iyi performans gösterdi ve genel amaçlı temel modellerin karmaşık bilgisayar görevlerindeki (OSWorld) agent yeteneğini %5’ten %27’ye yükseltti (kaynak: HuggingFace Daily Papers)
Parçalı Düşünce Zinciri Çıkarımı (Fractured CoT), LLM çıkarım verimliliğini ve performansını artırıyor: CoT çıkarımının getirdiği yüksek token maliyeti sorununu çözmek için araştırmacılar, kesilmiş CoT’nin (çıkarımı tamamlamadan önce durdurup doğrudan cevap üretme) genellikle tam CoT ile karşılaştırılabilir performans elde ettiğini, ancak token tüketimini önemli ölçüde azalttığını buldu. Buna dayanarak, çıkarım yörüngesi sayısı, her yörüngedeki nihai çözüm sayısı ve çıkarım izi kesme derinliği olmak üzere üç boyutu ayarlayarak birden fazla çıkarım kıyaslama ölçütünde ve model ölçeğinde daha iyi bir doğruluk-maliyet dengesi sağlayan Fractured Sampling birleşik çıkarım stratejisi önerildi. Bu, daha verimli ve ölçeklenebilir LLM çıkarımının önünü açıyor (kaynak: HuggingFace Daily Papers)
LLM bağlam koşullandırması ve PWP ipuçları ile kimyasal formüllerin çok modlu doğrulanması: Araştırmacılar, yapılandırılmış LLM bağlam koşullandırmasını ve Kalıcı İş Akışı İpuçları (PWP) ilkelerini birleştirerek LLM’lerin çıkarım sırasındaki davranışlarını ayarlamayı araştırdılar. Amaç, özellikle resim içeren karmaşık bilimsel belgeleri işlerken kimyasal formüller gibi hassas doğrulama görevlerindeki güvenilirliklerini artırmaktır. Bu yöntem, API veya model değişikliği gerektirmeden yalnızca standart sohbet arayüzlerini (Gemini 2.5 Pro, ChatGPT Plus o3) kullanır. İlk deneyler, bu yöntemin metin hatası tanımlamasını iyileştirdiğini ve Gemini 2.5 Pro’nun manuel incelemede gözden kaçan resim formülü hatalarını belirlemesine yardımcı olduğunu göstermiştir (kaynak: HuggingFace Daily Papers)
PWP, meta-ipuçları ve meta-muhakeme ile AI güdümlü akademik hakem değerlendirmesi: Araştırmacılar, bilimsel makalelerin eleştirel hakem değerlendirmesini standart LLM sohbet arayüzleri aracılığıyla gerçekleştirmek için Kalıcı İş Akışı İpuçları (PWP) yöntemini önerdi. PWP, ayrıntılı analiz iş akışını tanımlamak için hiyerarşik modüler bir mimari (Markdown yapılı) kullanır ve meta-ipuçları ve meta-muhakeme aracılığıyla uzman değerlendirme süreçlerini (örtük bilgi dahil) sistematik olarak kodlar. PWP, LLM’yi iddiaları kanıtlardan ayırma, metin/resim/grafik analizini entegre etme, nicel fizibilite kontrolleri yapma gibi sistematik çok modlu değerlendirmeler yapmaya yönlendirir ve test vakalarında metodolojik kusurları başarıyla tespit etmiştir (kaynak: HuggingFace Daily Papers)
SPOT kıyaslama ölçütü, AI’ın bilimsel araştırmaları otomatik doğrulama yeteneğini değerlendiriyor: Büyük Dil Modellerinin (LLM) “AI ortak bilim insanı” olarak akademik makalelerin otomatik doğrulanmasındaki yeteneğini değerlendirmek için araştırmacılar SPOT kıyaslama ölçütünü tanıttı. Bu kıyaslama ölçütü, yayınlanmış 83 makale ve düzeltme veya geri çekmeye yol açabilecek 91 hata içerir ve orijinal yazarlar ile manuel etiketleyiciler tarafından çapraz doğrulanmıştır. Deney sonuçları, en gelişmiş LLM’lerin (o3 gibi) bile SPOT’taki geri çağırma oranının %21,1’i, kesinlik oranının ise %6,1’i geçmediğini, model güvenilirliğinin düşük olduğunu ve birden fazla çalıştırmada sonuçların tutarsız olduğunu göstermektedir. Bu, mevcut LLM’lerin güvenilir akademik doğrulama konusunda gerçek ihtiyaçlarla arasında büyük bir fark olduğunu ortaya koymaktadır (kaynak: HuggingFace Daily Papers)
ExTrans, örnek zenginleştirmeli takviyeli öğrenme ile çok dilli derin çıkarım çevirisi gerçekleştiriyor: Makine çevirisinde Büyük Çıkarım Modellerinin (LRM) yeteneğini, özellikle çok dilli senaryolarda artırmak için araştırmacılar ExTrans’ı önerdi. Bu yöntem, politika çeviri modelinin çevirilerini güçlü LRM’lerinkiyle (örneğin DeepSeek-R1-671B) karşılaştırarak ödülü ölçmek için yeni bir ödül modelleme yöntemi tasarlar. Deneyler, Qwen2.5-7B-Instruct’i omurga olarak kullanarak eğitilen modelin edebi çeviride SOTA’ya ulaştığını ve OpenAI-o1 ile DeepSeeK-R1’den daha iyi performans gösterdiğini göstermiştir. Hafif ödül modelleme sayesinde bu yöntem, tek yönlü çeviri yeteneğini 11 dilde 90 çeviri yönüne etkili bir şekilde aktarabilir (kaynak: HuggingFace Daily Papers)
Eğitilebilir seyrek dikkat (VSA) ile video difüzyon modellerinin hızlandırılması: Video Difüzyon Transformer (DiT) modellerindeki 3D tam dikkat mekanizmasının karesel karmaşıklık sorununu çözmek için araştırmacılar VSA’yı (Eğitilebilir Seyrek Dikkat) önerdi. VSA, hafif bir kaba aşama ile token’ları bloklara toplar ve anahtar token’ları belirler, ardından bu bloklar içinde ince taneli token düzeyinde dikkat hesaplaması yapar. VSA, uçtan uca eğitilebilen tek bir türevlenebilir çekirdektir, son işleme analizi gerektirmez ve FlashAttention3 MFU’nun %85’ini korur. Deneyler, VSA’nın difüzyon kaybını düşürmeden eğitim FLOPS’unu 2,53 kat azalttığını ve açık kaynaklı Wan-2.1 modelinin dikkat süresini 6 kat hızlandırarak uçtan uca üretim süresini 31 saniyeden 18 saniyeye düşürdüğünü göstermiştir (kaynak: HuggingFace Daily Papers)
SoftCoT++: Yumuşak düşünce zinciri çıkarımı ile test zamanı ölçeklendirmesi: Sürekli gizli uzayda çıkarım yapan SoftCoT yönteminin keşif yeteneğini artırmak için araştırmacılar SoftCoT++’ı önerdi. Bu yöntem, çeşitli özel başlangıç token’ları ile potansiyel düşünceleri sarsar ve yumuşak düşünce temsillerinin çeşitliliğini teşvik etmek için karşılaştırmalı öğrenme uygular, böylece SoftCoT’u test zamanı ölçeklendirme (TTS) paradigmasına genişletir. Deneyler, SoftCoT++’ın SoftCoT’un performansını önemli ölçüde artırdığını ve kendine tutarlılıkla ölçeklendirilmiş SoftCoT’tan daha iyi performans gösterdiğini, ayrıca kendine tutarlılık gibi geleneksel ölçeklendirme teknikleriyle güçlü uyumluluğa sahip olduğunu göstermiştir (kaynak: HuggingFace Daily Papers)
MTVCrafter: Açık dünya insan görüntüsü animasyonu için 4D hareket tokenizasyonu: Mevcut yöntemlerin 2D duruş görüntülerine bağımlı olmasının sınırlı genelleme yeteneğine yol açması sorununu çözmek için MTVCrafter, doğrudan ham 3D hareket dizilerini (4D hareket) modellemeyi öneriyor. Temelinde, 3D hareket dizilerini 4D hareket token’larına nicelleştiren ve daha sağlam uzay-zaman ipuçları sağlayan 4DMoT (4D Hareket Tokenizer) bulunur. Ardından, benzersiz hareket dikkati ve 4D konum kodlaması ile tasarlanmış MV-DiT (Harekete Duyarlı Video DiT), bu token’ları bağlam olarak etkili bir şekilde kullanarak karmaşık 3D dünyalarda insan görüntüsü animasyonu gerçekleştirir. Deneyler, MTVCrafter’ın FID-VID’de 6.98’e ulaştığını, SOTA’dan önemli ölçüde daha iyi performans gösterdiğini ve farklı stil ve sahnelerdeki çeşitli karakterlere iyi bir şekilde genelleme yapabildiğini göstermiştir (kaynak: HuggingFace Daily Papers)
QVGen: Nicelleştirilmiş video üretim modellerinin sınırlarını zorlamak: Video difüzyon modellerinin (DM) yüksek hesaplama ve bellek gereksinimleri sorununu çözmek için QVGen, özellikle 4 bit ve altı gibi aşırı düşük bitli nicelleştirme için tasarlanmış yeni bir Nicelleştirmeye Duyarlı Eğitim (QAT) çerçevesi öneriyor. Teorik analiz yoluyla araştırmacılar, gradyan normunu düşürmenin QAT yakınsaması için kritik olduğunu buldular ve büyük nicelleştirme hatalarını azaltmak için yardımcı bir modül (Phi) tanıttılar. Phi’nin çıkarım maliyetini ortadan kaldırmak için, SVD ve rütbe tabanlı düzenlileştirme yoluyla Phi’yi kademeli olarak ortadan kaldıran bir rütbe azaltma stratejisi önerdiler. Deneyler, QVGen’in 4 bit ayarında ilk kez tam hassasiyetle karşılaştırılabilir kaliteye ulaştığını ve mevcut yöntemlerden önemli ölçüde daha iyi performans gösterdiğini ortaya koymuştur (kaynak: HuggingFace Daily Papers)
ViPlan: Görsel planlama için sembolik yüklemler ve görsel dil modeli kıyaslaması: VLM güdümlü sembolik planlama ile doğrudan VLM planlama yöntemleri arasındaki karşılaştırma boşluğunu kapatmak için ViPlan, ilk açık kaynaklı görsel planlama kıyaslama ölçütü olarak önerildi. ViPlan, Blocksworld’ün görsel versiyonu ve simüle edilmiş ev robotu ortamı olmak üzere iki ana alanda artan zorluk derecelerine sahip bir dizi görev içerir. 9 açık kaynaklı VLM ailesi ve bazı kapalı kaynaklı modeller üzerinde yapılan kıyaslama testleri, sembolik planlamanın Blocksworld’de (hassas görüntü konumlandırması kritik) daha iyi performans gösterdiğini, doğrudan VLM planlamasının ise ev robotu görevlerinde (sağduyu bilgisi ve hata kurtarma yeteneği önemli) daha iyi olduğunu ortaya koydu. Araştırma ayrıca, CoT ipuçlarının çoğu model ve yöntem için önemli bir fayda sağlamadığını göstererek mevcut VLM görsel çıkarım yeteneklerinin hala yetersiz olduğunu ima ediyor (kaynak: HuggingFace Daily Papers)
İlkel Çığlıklardan Dilbilgisine: İşbirlikçi Yiyecek Arama Ortamlarında Dilin Evrimi Üzerine Bir Araştırma: Dilin kökenini ve evrimini araştırmak için araştırmacılar, çoklu agent’lı yiyecek arama oyununda erken insan işbirliği senaryolarını simüle ettiler. Uçtan uca derin takviyeli öğrenme yoluyla agent’ler sıfırdan eylem ve iletişim stratejileri öğrendiler. Araştırma, agent’lerin geliştirdiği iletişim protokollerinin doğal dilin ayırt edici özelliklerini sergilediğini buldu: keyfilik, değiştirilebilirlik, yerinden edilme, kültürel aktarım ve birleştirilebilirlik. Bu çerçeve, kısmen gözlemlenebilir, zamansal çıkarım ve işbirlikçi hedef güdümlü somutlaştırılmış çoklu agent ortamlarında dilin nasıl evrimleştiğini araştırmak için bir platform sunmaktadır (kaynak: HuggingFace Daily Papers)
Tiny QA Benchmark++: Ultra Hafif Çok Dilli Sentetik Veri Kümesi Üretimi ve LLM Sürekli Değerlendirmesi için Duman Testi: Tiny QA Benchmark++ (TQB++), LLM işlem hatları için birim testi tarzı bir güvenlik ağı sağlamayı amaçlayan, saniyeler içinde son derece düşük maliyetle çalışabilen ultra hafif, çok dilli bir duman testi paketidir. TQB++, 52 maddelik bir İngilizce altın küme içerir ve kullanıcıların özel dil, alan veya zorlukta küçük test paketleri oluşturabileceği LiteLLM tabanlı minyatür bir sentetik veri üreteci (pypi paketi) sunar. Proje, 10 dilde hazır paketler sunmakta ve ipucu şablonu hatalarını, tokenizer kaymasını ve ince ayar yan etkilerini hızla tespit etmek için CI/CD süreçlerine kolay entegrasyon için OpenAI-Evals, LangChain gibi araçları desteklemektedir (kaynak: HuggingFace Daily Papers)
HelpSteer3-Preference: Çoklu Görev ve Diller Arası Açık İnsan Etiketli Tercih Veri Kümesi: Yüksek kaliteli, çeşitli açık tercih verilerine olan ihtiyacı karşılamak için NVIDIA, HelpSteer3-Preference veri kümesini yayınladı. Bu veri kümesi, CC-BY-4.0 lisansını izleyen, STEM, kodlama ve çok dilli senaryolar gibi LLM gerçek uygulamalarını kapsayan 40.000’den fazla insan etiketli tercih örneği içerir. Bu veri kümesi kullanılarak eğitilen Ödül Modelleri (RM), RM-Bench’te (%82,4) ve JudgeBench’te (%73,7) SOTA performansı elde ederek önceki en iyi sonuçlara göre yaklaşık %10’luk bir iyileşme sağlamıştır. Bu veri kümesi ayrıca üretici RM’leri eğitmek ve RLHF ile hizalanmış politika modelleri için de kullanılabilir (kaynak: HuggingFace Daily Papers)
SEED-GRPO: Belirsizliğe Duyarlı Politika Optimizasyonu için Semantik Entropi ile Geliştirilmiş GRPO: GRPO’nun politika güncellemeleri sırasında LLM’nin giriş ipuçlarına yönelik belirsizliğini dikkate almaması sorununu çözmek için araştırmacılar SEED-GRPO’yu önerdi. Bu yöntem, giriş ipuçlarına yönelik LLM belirsizliğini (yani birden fazla üretilen cevabın semantik çeşitliliğini) açıkça ölçen semantik entropi aracılığıyla politika güncellemelerinin büyüklüğünü ayarlar. Bu belirsizliğe duyarlı eğitim mekanizması, yüksek belirsizlikli sorunlar için daha muhafazakar güncellemelere izin verirken, güvenilir sorunlar için orijinal öğrenme sinyalini korur. Deneyler, SEED-GRPO’nun beş matematiksel çıkarım kıyaslama ölçütünde de SOTA performansı elde ettiğini göstermiştir (kaynak: HuggingFace Daily Papers)
Bilgisayar Kullanımından Evrensel Kullanıcı Modeli (GUM) Oluşturma: Araştırmacılar, kullanıcının bilgisayarla herhangi bir etkileşimini (örneğin cihaz ekran görüntüleri) gözlemleyerek kullanıcı bilgisi ve tercihlerini öğrenen ve güvenilirlik ağırlıklı önermeler oluşturan bir Evrensel Kullanıcı Modeli (GUM) mimarisi önerdi. GUM, yapılandırılmamış çok modlu gözlemlerdengeni önermeler çıkarabilir, bağlam olarak ilgili önermeleri geri alabilir ve mevcut önermeleri sürekli olarak düzeltebilir. Bu mimari, sohbet asistanlarını geliştirmeyi, işletim sistemi bildirimlerini yönetmeyi ve etkileşimli agent’lerin uygulamalar arasında kullanıcı tercihlerine uyum sağlamasını amaçlamaktadır. Deneyler, GUM’un kalibre edilmiş ve doğru kullanıcı çıkarımları yapabildiğini ve GUM tabanlı asistanların kullanıcının açıkça talep etmediği faydalı işlemleri proaktif olarak belirleyip yürütebildiğini göstermiştir (kaynak: HuggingFace Daily Papers)
DataExpert-io/data-engineer-handbook: GitHub’daki popüler bir proje, 2024 başlangıç yol haritası, 6 haftalık ücretsiz YouTube eğitim kampı materyalleri, proje örnekleri, mülakat ipuçları, önerilen kitaplar, topluluklar ve bülten listeleri dahil olmak üzere kapsamlı bir veri mühendisliği öğrenme kaynakları deposu sunmaktadır. Önerilen kitaplar arasında “Fundamentals of Data Engineering”, “Designing Data-Intensive Applications” ve “Designing Machine Learning Systems” bulunmaktadır. Bu el kitabı ayrıca Mage (orkestrasyon), Databricks (veri gölü), Snowflake (veri ambarı), dbt (veri kalitesi), LangChain (LLM uygulama kütüphanesi) gibi veri mühendisliğinin çeşitli alanlarındaki şirketleri listelemekte ve tanınmış şirketlerin veri mühendisliği blogları ile önemli teknik inceleme bağlantıları sunmaktadır (kaynak: GitHub Trending)
💼 Ticari
Cohere, SAP ile işbirliği yaparak kurumsal düzeyde AI Agent’lerini küresel işletmelere taşıyor: Cohere, kurumsal düzeyde AI Agent teknolojisini SAP Business Suite’e entegre etmek için SAP ile işbirliği yaptığını duyurdu. Bu, küresel işletmelere güvenli ve ölçeklenebilir AI yetenekleri sunacak. Cohere’in öncü modelleri SAP AI Core’a da gelecek, bu da işletmelerin finans, sağlık gibi alanlarda çok dilli, alana özgü AI modellerini (Command, Embed, Rerank) kullanmalarını sağlayacak ve kurumsal AI uygulamalarını hızlandırıp gerçek ticari değeri ortaya çıkarmayı amaçlayacak (kaynak: X, X)
xAI, devlet verilerini kullanarak kurumsal ve kamu işlerini genişletmeyi hedefliyor: The Information’a göre, Elon Musk’ın xAI şirketi, modeller ve uygulamalar geliştirmek ve bunları devlet müşterilerine satmak için devlet kurumlarının verilerini kullanmayı planlıyor. Bu girişim, xAI’nin ticarileştirme stratejisinin önemli bir parçası olabilir, ancak aynı zamanda veri kullanımı ve potansiyel önyargılar hakkında tartışmalara da yol açıyor (kaynak: X)
Weaviate, AWS ile küresel işbirliğini derinleştirerek üretici AI girişimlerini hızlandırıyor: Vektör veritabanı şirketi Weaviate, üretici AI projelerini birlikte hızlandırmak amacıyla AWS ile küresel işbirliğini güçlendirdiğini duyurdu. Bu işbirliği, küresel geliştiricilere daha yüksek hız, daha büyük ölçek ve daha iyi geliştirici deneyimi sunmaya odaklanarak üretici AI teknolojilerinin uygulanmasını ve geliştirilmesini teşvik edecek (kaynak: X)

🌟 Topluluk
AI Programlama Agent’lerinin Yükselişi, Programcıların Kariyer Geleceği Tartışmalarını Ateşliyor: Microsoft, OpenAI gibi şirketler, GitHub Copilot Coding Agent, OpenAI Codex gibi AI programlama agent’lerini (Coding Agents) piyasaya sürüyor veya güçlendiriyor. Bu agent’ler kodlama, hata düzeltme, kod bakımı gibi görevleri otonom olarak tamamlayabiliyor. Anthropic CEO’su Dario Amodei, AI’ın kısa vadede kodun çoğunu hatta tamamını yazabileceğini öngörürken, OpenAI CPO’su Kevin Weil de AI’ın başlangıç seviyesi mühendislerden mimarlara dönüşeceğini düşünüyor. Bu durum, programcıların kariyer geleceği hakkında toplulukta geniş çaplı tartışmalara yol açtı: Bazıları başlangıç seviyesi pozisyonların yerini AI’ın alacağından ve AI’ın büyük miktarda programlama işini otomatikleştireceğinden endişe ederken; bazıları ise AI’ın programcıların verimliliğini artıracağını, onların daha üst düzey mimari tasarım ve inovasyona odaklanmalarını sağlayacağını ve rollerinin “AI yönlendiricisi”ne dönüşeceğini savunuyor. Genel eğilim, AI ile verimli bir şekilde işbirliği yapmayı öğrenmenin programcıların temel becerisi haline geleceğini gösteriyor (kaynak: X, X, 36Kr, 36Kr)
AI Agent Kavramı ve Standartları Üzerine Yoğun Tartışmalar, MCP Protokolü Dikkat Çekiyor: Manus, Genspark Super Agent, Fellou.ai gibi AI Agent uygulamalarının yükselişiyle birlikte, topluluk Agent’in tanımı, yetkinlik seviyeleri ve geliştirme paradigmaları üzerine hararetli tartışmalar yürütüyor. Tanınmış risk sermayesi şirketi BVP, Agent’ler için L0’dan L6’ya kadar yedi seviyeli bir sınıflandırma önerdi. Aynı zamanda, AI uygulamaları arası birlikte çalışabilirliği sağlamada kilit bir teknoloji olan Model Bağlam Protokolü (MCP) dikkat çekiyor. Anthropic, OpenAI, Google gibi yurtdışındaki büyük şirketler MCP’yi destekliyor veya desteklemeyi planlıyor. Yurtiçinde ise Alibaba Cloud, Tencent Cloud gibi şirketler MCP etrafında yerelleştirilmiş Agent geliştirme platformları oluşturmaya başladı. Geliştirici iluxu, Microsoft’un “AI uygulamaları için USB-C” kavramını önermesinden önce benzer bir llmbasedos projesini açık kaynaklı hale getirerek açık Agent bağlantı standartlarını teşvik etmeyi amaçladı (kaynak: X, X, WeChat, Reddit r/LocalLLaMA)
LLM’lerin Belirli Çıkarım Görevlerindeki Başarısızlığı, Yetenek Sınırları Üzerine Tartışmalara Yol Açıyor: Topluluk, LLM’lerin bazı görünüşte basit fiziksel veya görsel-uzamsal çıkarım görevlerinde toplu “başarısızlık” yaşamasını hararetle tartışıyor. Örneğin, daha büyük bir küp oluşturmak için küpleri yığma sorusunda, o3, Gemini 2.5 Pro gibi en üst düzey modeller bile yanlış cevaplar verdi. Aynı zamanda, bir değerlendirme makalesi, parça imalatı gibi temel fiziksel görevlerde LLM’lerin (o3 dahil) deneyimli işçilerden daha kötü performans gösterdiğini, bunun temel nedenlerinin yetersiz görsel yetenekler ve fiziksel çıkarım hataları ile gerçek dünyanın örtük bilgisi eksikliği olduğunu belirtiyor. Bu vakalar, LLM’lerin gerçek anlama yeteneği, halüsinasyon sorunları (örneğin o3’ün çıkarım sırasında artan halüsinasyon oranı) ve mevcut Benchmark’ların etkinliği hakkında tartışmalara yol açarak AI’ın belirli alanlardaki bilgi ve karmaşık çıkarım konularında hala büyük bir gelişim alanı olduğunu vurguluyor (kaynak: QbitAI, 36Kr)

Çin-ABD Teknoloji Rekabeti ve AI Geliştirme Stratejileri Dikkat Çekiyor: Nvidia CEO’su Jensen Huang, bir röportajda çip düzenlemeleri, AI fabrikaları ve kurumsal pragmatizm konularına değindi ve görüşleri mevcut Çin-ABD teknoloji rekabeti ortamına dair derin bir içgörü olarak yorumlandı. Bazı yorumcular, ABD’nin Çin’in üst düzey AI kaynaklarına erişimini kısıtlayarak liderliğini sürdürmeye çalıştığını, ancak bunun kaybet-kaybet durumuna yol açabileceğini ve küresel AI gelişimini yavaşlatabileceğini düşünüyor. Huang ise gerçek rekabetin uzun vadeli olduğunu ve ABD’nin sadece kısa vadeli göreceli avantaj aramak yerine kapsamlı bir liderlik (çipler, fabrikalar, altyapı, modeller, uygulamalar) hedeflemesi gerektiğini, aksi takdirde AI çağının gelişim fırsatlarını kaçırabileceğini ve sonuçta genel ulusal güç rekabetinde geride kalabileceğini düşünüyor gibi görünüyor (kaynak: X)
ChatGPT gibi AI Araçlarının Ruh Sağlığı Desteğindeki Kullanımı ve Tartışmalar: Reddit topluluğu kullanıcıları, ChatGPT gibi AI araçlarını ruh sağlığı desteği için kullanma deneyimlerini paylaşıyor ve bu araçların iki profesyonel terapi seansı arasında yardımcı olabileceğini, özellikle karmaşık duyguları çözümleme ve ifade etme konusunda faydalı olduğunu belirtiyorlar. Kullanıcılar, AI’a sorular sorarak veya AI’ın kendi duyguları hakkında sorular sormasını sağlayarak duygusal kaynaklarını daha iyi anlıyor ve iyileştirme planları yapıyorlar. Yorumlarda, bazı kullanıcılar (kendilerini terapist olarak tanıtanlar dahil) AI’ın bazı durumlarda bazı insan terapistlerden bile daha iyi olabileceğini, özellikle profesyonel yardıma ulaşmakta zorlanan veya insan terapistlere karşı güven sorunu yaşayan bireyler için faydalı olabileceğini düşünüyor. Ancak bazı kullanıcılar, AI’ın profesyonel tedavinin yerini tamamen alamayacağını ve kişisel veri gizliliği sorunlarına dikkat edilmesi gerektiğini hatırlatıyor (kaynak: Reddit r/ChatGPT)
💡 Diğer
“Qizhi Cup” Algoritma Yarışması Başladı, Üç Öncü AI Alanına Odaklanıyor: Qiyuan Lab, toplam 750.000 Yuan ödül havuzuna sahip “Qizhi Cup” algoritma yarışmasını başlattı. Yarışma, “Uydu Uzaktan Algılama Görüntülerinde Sağlam Örneklem Bölütleme”, “Gömülü Platformlar için İHA Yer Hedefi Tespiti” ve “Çok Modlu Büyük Modellere Yönelik Karşıtlık (Adversarial)” olmak üzere üç ana kulvarda düzenleniyor. Amaç, sağlam algılama, hafif dağıtım ve karşıt savunma gibi AI temel teknolojilerinin inovasyonunu ve uygulamaya geçirilmesini teşvik etmektir. Yarışma, yerel araştırma kurumlarına ve işletmelere açıktır (kaynak: WeChat)

Chicago Sun-Times’ın AI Tarafından Üretilen İçeriği Hatalı Çıktı, Var Olmayan Kitaplar ve Uzmanlar Önerildi: Chicago Sun-Times’ın bir yaz etkinlikleri önerisi bölümünde, bazı içeriklerin AI tarafından üretildiği ve gerçekte var olan yazarlar tarafından yazılmış kurgusal kitapların yanı sıra var olmayan “uzmanların” görüşlerine yer verildiği iddia edildi. Örneğin, Min Jin Lee’nin “Nightshade Market” ve Rebecca Makkai’nin “Boiling Point” adlı kitapları önerilenler arasında listelendi, ancak bu kitaplar mevcut değil. Bu olay, haber medyasının AI tarafından üretilen içerik kullanırken doğruluk ve denetim mekanizmalarına ilişkin endişeleri artırdı (kaynak: Reddit r/artificial)
AI Kullanımının “Hile” Olup Olmadığına Dair Tartışma: Topluluk, iş ve öğrenimde ChatGPT, Claude gibi AI araçlarını kullanmanın sınırlarını tartışıyor. Genel kanı, açık bir kuralın yasaklamadığı durumlarda (örneğin üniversite ödevleri), AI araçlarını verimliliği artırma, tekrarlayan görevleri tamamlama veya düşünmeye yardımcı olma amacıyla kullanmanın “hile” olmadığı, bunun hesap makinesi veya arama motoru kullanmaya benzer olduğu yönünde. Önemli olan, kullanıcının AI çıktısını anlayıp anlamadığı, etkili bir şekilde ayarlayıp doğrulayıp doğrulayamadığı ve AI’nın yardımcı rolünü (özellikle akademik ortamlarda) dürüstçe beyan edip etmediğidir. Ancak, tamamen AI tarafından üretilen içeriğe güvenmek ve ayırt etmeksizin orijinal olduğunu iddia etmek, akademik sahtekarlık veya kişisel beceri gelişimini etkileyebilir (kaynak: Reddit r/ArtificialInteligence)