
Anahtar Kelimeler:AI teknolojisi, Google Gemini, AI enerji tüketimi, AI yasal uygulamalar, Microsoft Discovery, Jensen Huang Elon Musk, AI düzenleme, Gemini 2.5 Pro, AI veri merkezi enerji tüketimi, AI ile oluşturulan yasal belge hataları, Microsoft Discovery araştırma platformu, AI çip ihracat kısıtlamaları
🔥 聚焦
谷歌I/O大会发布多项AI进展,Gemini全面融入谷歌生态: Google, I/O 2025 geliştirici konferansında, temel olarak Gemini modelinin yükseltilmesi ve derin entegrasyonuna odaklanan bir dizi önemli AI güncellemesini duyurdu. Gemini 2.5 Pro, karmaşık çıkarımları geliştirmek için “Deep Think” özelliğini sunarken, 2.5 Flash verimlilik ve maliyeti optimize etti ve yerel ses çıkışı ekledi. Arama, sohbet botu tarzı yanıtlar sunan ve kullanıcı kişisel verilerini (yetkilendirme gerektirir) birleştirerek kişiselleştirilmiş sonuçlar sağlayabilen “AI Modu”nu tanıttı. Chrome tarayıcısı Gemini asistanını entegre edecek. Video modeli Veo 3, sesli video üretimi sağlarken, görüntü modeli Imagen 4 ayrıntı ve metin işlemeyi geliştirdi. Google ayrıca AI film yapım aracı Flow’u, programlama asistanı Jules’u duyurdu ve Project Astra (gerçek zamanlı çok modlu asistan) ile Project Mariner (çok görevli AI ajanı) projelerindeki ilerlemeleri sergiledi. Aynı zamanda Google, aylık ücreti 249,99 ABD dolarına ulaşan üst düzey AI Ultra abonelik hizmeti de dahil olmak üzere yeni AI abonelik hizmetlerini başlattı. Bu girişimler, Google’ın AI’ı ürün ve hizmetlerine kapsamlı bir şekilde entegre etme ve kullanıcı etkileşim deneyimini yeniden şekillendirme çabalarını hızlandırdığını gösteriyor. (Kaynak: 36氪, 36氪, 36氪, 36氪, 36氪, 36氪)

AI能耗问题引关注,MIT科技评论深度剖析其能源足迹与未来挑战: MIT Technology Review, AI teknolojisinin gelişiminin neden olduğu enerji tüketimi ve karbon emisyonu sorunlarını derinlemesine inceleyen bir dizi rapor yayınladı. Araştırmalar, AI çıkarım aşamasındaki enerji tüketiminin eğitim aşamasını geçtiğini ve ana enerji yükü haline geldiğini gösteriyor. Raporlar, veri merkezlerinin devasa elektrik talebini ve su tüketimini (Nevada çölündeki veri merkezleri gibi) ve fosil yakıtlara (Louisiana’daki Meta veri merkezinin doğal gaza bağımlılığı gibi) olan bağımlılığı analiz ediyor. Nükleer enerji potansiyel bir temiz enerji çözümü olarak görülse de, inşaat süresinin uzun olması nedeniyle AI’ın hızlı büyüme talebini kısa vadede karşılaması zor. Aynı zamanda raporlar, daha verimli model algoritmaları, AI için özel olarak tasarlanmış enerji tasarruflu çipler ve daha optimize edilmiş veri merkezi soğutma teknolojileri de dahil olmak üzere AI enerji verimliliğini artırmaya yönelik iyimser beklentilere de işaret ediyor. Bu seri, tek bir AI sorgusunun enerji tüketimi küçük görünse de, sektörün genel eğilimlerinin ve gelecekteki planlarının (OpenAI’nin Stargate projesi gibi) büyük enerji zorluklarını öngördüğünü ve şeffaf veri açıklaması ile sorumlu enerji planlaması gerektirdiğini vurguluyor. (Kaynak: MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review)

AI在法律领域的应用引发错误与伦理担忧: Son zamanlarda yaşanan birçok olay, AI’ın yasal belgelerin yazımında ürettiği “halüsinasyon” sorununun ciddi endişelere yol açtığını gösteriyor. Kaliforniya’da bir yargıç, bir avukatın mahkeme belgelerinde Google Gemini gibi AI araçlarını kullanarak sahte alıntılar içeren içerik oluşturması nedeniyle para cezası verdi. Başka bir davada, AI şirketi Anthropic’in Claude modeli de yasal belgeler için alıntı oluştururken hatalar yaptı. Daha da endişe verici olanı, İsrailli bir savcının, talebinde var olmayan yasalara atıfta bulunan, AI tarafından üretilmiş metinler kullandığını itiraf etmesiydi. Bu vakalar, AI modellerinin doğruluk ve güvenilirlik konusundaki eksikliklerini, özellikle gerçeklere ve alıntılara son derece yüksek gereksinim duyan hukuk alanında vurgulamaktadır. Uzmanlar, avukatların verimlilik arayışıyla AI çıktısına aşırı güvenebileceğini ve sıkı inceleme gerekliliğini göz ardı edebileceğini belirtiyor. AI araçları güvenilir yasal yardımcılar olarak tanıtılsa da, doğasında var olan “halüsinasyon” özelliği adli adalet için potansiyel bir tehdit oluşturmakta ve acilen sektör düzenlemeleri ile kullanıcı uyarısı gerektirmektedir. (Kaynak: MIT Technology Review)

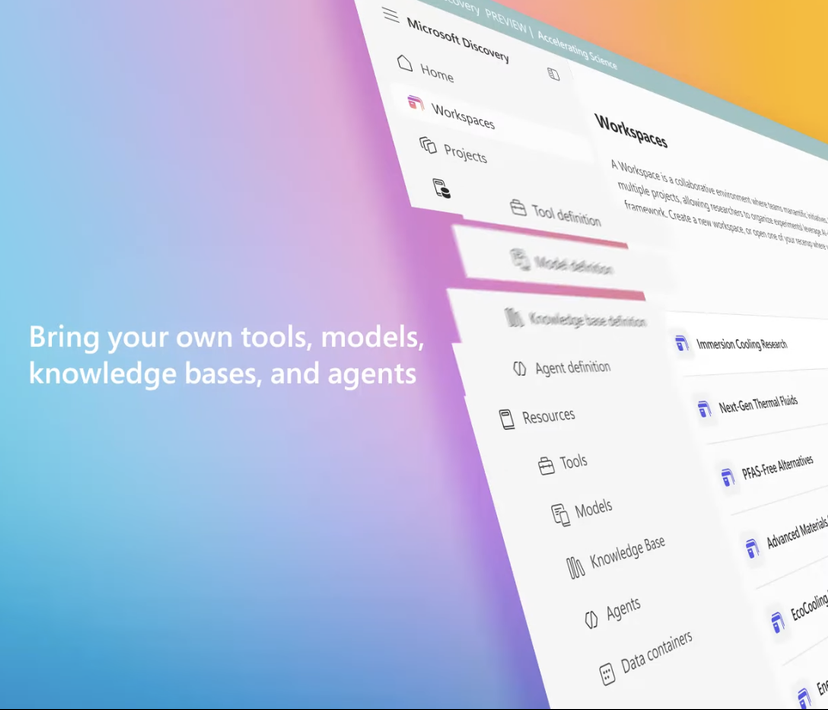
微软推出企业级AI科研平台Microsoft Discovery,助力科学发现: Microsoft, Build konferansında, kurumsal ve araştırma kurumları için tasarlanmış bir AI platformu olan Microsoft Discovery’yi duyurdu. Platform, doğal dil etkileşimi yoluyla, programlama geçmişi olmayan bilim insanları ve mühendislerin bile yüksek performanslı bilgi işlem ve karmaşık simülasyon sistemlerinden yararlanmasını sağlamayı amaçlıyor. Bu platform, planlama için temel modelleri ve fizik, kimya, biyoloji gibi belirli bilimsel alanlar için eğitilmiş uzman modelleri birleştirerek, literatür taramasından hesaplamalı simülasyonlara kadar tüm araştırma sürecini yürütebilen bir “AI doktora sonrası araştırmacı” ekibi oluşturuyor. Microsoft, uygulama örneklerini sergiledi: yaklaşık 200 saat içinde 367.000 maddeyi tarayarak potansiyel bir PFAS içermeyen soğutucu alternatifini başarıyla keşfetti ve deneylerle doğruladı. Platformun özellikleri arasında grafik bilgi motoru, işbirlikçi çıkarım, sürekli yinelemeli Ar-Ge döngüsü bulunuyor ve Azure altyapısı üzerine kurulu olup, gelecekteki mimarisi kuantum hesaplama ile bağlantı kurma yeteneği için ayrılmıştır. (Kaynak: 量子位)
黄仁勋与马斯克就AI发展、监管及全球竞争发表看法: NVIDIA CEO’su Jensen Huang, özel bir röportajda ABD’nin çip ihracat kontrolleri konusundaki endişelerini dile getirerek, teknoloji yayılımını kısıtlamanın ABD’nin AI alanındaki liderliğine zarar verebileceğini belirtti ve Çin’in AI Ar-Ge alanındaki gücünü ve küresel AI geliştiricilerinin yarısının Çin’den geldiği gerçeğini vurguladı. ABD’nin teknolojinin küresel yayılımını hızlandırması ve ABD şirketlerinin Çin pazarında rekabet etmesine izin vermesi gerektiğini savundu. Tesla CEO’su Elon Musk ise başka bir röportajda en az beş yıl daha Tesla’yı yönetmeye devam edeceğini ve AGI’ye ulaşmaya yakın olduklarını belirtti. AI’ın ölçülü bir şekilde düzenlenmesini desteklediğini ancak aşırı müdahaleye karşı olduğunu ifade etti. Her iki teknoloji lideri de AI’ın büyük potansiyelini vurguladı; Jensen Huang, AI’ın küresel GSYİH’de önemli bir artış sağlayacağını düşünürken, Elon Musk ise Starship, Neuralink ve Tesla’nın otonom taksileri gibi bu yılki önemli hedeflerini sıraladı ve bunların hepsinin AI ile yakından ilişkili olduğunu belirtti. (Kaynak: 36氪, 36氪, 36氪)

🎯 动向
谷歌发布Gemma 3n预览版,专为端侧高效运行设计: Google, HuggingFace üzerinde, mobil cihazlar gibi düşük kaynaklı cihazlarda verimli çalışmak üzere özel olarak tasarlanmış Gemma 3n modelinin bir önizleme sürümünü yayınladı. Bu model serisi, metin, görüntü, video ve ses işleyebilen ve metin çıktısı üretebilen çok modlu giriş yeteneklerine sahip. Modelin kaynak gereksinimlerini azaltmak için 2B ve 4B etkin parametre ölçeğinde çalışmasını sağlayan “seçici parametre aktivasyonu” teknolojisini (MoE karma uzman mimarisine benzer) kullanıyor. Topluluk tartışmaları, Gemma 3n’nin mimarisinin Gemini’ye benzeyebileceğini ve ikincisinin güçlü çok modlu ve uzun bağlam yeteneklerini açıkladığını öne sürüyor. Gemma 3n’nin açık kaynak ağırlıkları ve talimat ayarlı sürümleri ile 140’tan fazla dildeki verilere dayalı eğitimi, akıllı ev asistanları gibi uç AI uygulamalarında potansiyel sağlıyor. (Kaynak: Reddit r/LocalLLaMA, developers.googleblog.com)

谷歌推出MedGemma,专为医疗领域优化的AI模型: Google, Gemma 3’ün tıp alanı için özel olarak optimize edilmiş iki varyantı olan MedGemma model serisini yayınladı: 4B parametreli çok modlu bir sürüm ve 27B parametreli salt metin bir sürüm. MedGemma 4B, özellikle tıbbi görüntüler (X-ışınları, dermatoloji görüntüleri vb.) ve metin anlama için eğitilmiş olup, tıbbi veriler üzerinde önceden eğitilmiş bir SigLIP görüntü kodlayıcı kullanır. MedGemma 27B ise tıbbi metin işlemeye odaklanır ve çıkarım sırasındaki hesaplama için optimize edilmiştir. Google, bu modellerin tıbbi AI uygulamalarının geliştirilmesini hızlandırmayı amaçladığını ve birçok klinik olarak ilgili kıyaslamada değerlendirildiğini belirtti; geliştiriciler, belirli görev performansını artırmak için bunları ince ayar yapabilirler. Topluluk buna olumlu tepki verdi, büyük potansiyele sahip olduğunu düşündü ancak tıp uzmanlarından gerçek geri bildirim alınması gerektiğini vurguladı. (Kaynak: Reddit r/LocalLLaMA)

字节跳动发布开源多模态模型Bagel,支持图像生成: ByteDance, Apache 2.0 lisansı altında, 14B parametreli (7B aktif) açık kaynaklı çok modlu büyük bir model olan Bagel’ı (BAGEL-7B-MoT olarak da bilinir) piyasaya sürdü. Model, karma uzman (MoE) ve karma Transformer (MoT) mimarilerine dayanmakta olup, metin anlayıp üretebilmekte ve yerel görüntü oluşturma yeteneğine sahip. Bir dizi çok modlu anlama ve üretme kıyaslama testinde diğer açık kaynaklı birleşik modellerden daha iyi performans gösterdi ve serbest biçimli görüntü işleme, gelecekteki kare tahmini gibi gelişmiş çok modlu çıkarım yetenekleri sergiledi. Araştırmacılar, ön eğitim ayrıntılarını, veri oluşturma protokollerini ve açık kod ile kontrol noktalarını paylaşarak çok modlu araştırmaları teşvik etmeyi umuyor. (Kaynak: Reddit r/LocalLLaMA, arxiv.org, bagel-ai.org)
英伟达发布DreamGen,利用生成视频模型训练机器人: NVIDIA araştırma ekibi, gelişmiş video üretken modellerini (Sora, Veo gibi) ince ayarlayarak robotların üretilen “rüya dünyalarında” yeni beceriler öğrenmesini sağlayan DreamGen projesini başlattı. Bu yöntem, geleneksel grafik motorlarına veya fizik simülatörlerine dayanmak yerine, robotların sinir ağı tarafından üretilen piksel düzeyindeki sahnelerde otonom olarak keşfetmesini ve deneyimlemesini sağlayarak, sahte eylem etiketleriyle büyük miktarda sinirsel yörünge üretir. Deneyler, DreamGen’in robotların simülasyon ve gerçek dünya görevlerindeki performansını, daha önce görülmemiş eylemler ve yabancı ortamlar da dahil olmak üzere önemli ölçüde artırabildiğini gösterdi. Örneğin, yalnızca az sayıda gerçek yörüngeyle, insansı robotlar su dökmek, kıyafet katlamak gibi 22 yeni beceri öğrendi ve NVIDIA genel merkezindeki kafe gibi gerçek sahnelere başarıyla genelleme yaptı. (Kaynak: 36氪, arxiv.org)

华为提出OmniPlacement优化MoE模型推理性能: Karma uzman modeli (MoE) içindeki uzman ağ yükünün dengesiz olmasından (“sıcak uzmanlar” ve “soğuk uzmanlar”) kaynaklanan çıkarım gecikmesi sorununa yönelik olarak Huawei ekibi, OmniPlacement optimizasyon şemasını önerdi. Bu şema, uzman yeniden sıralama, katmanlar arası yedekli dağıtım ve neredeyse gerçek zamanlı dinamik zamanlama yoluyla MoE modellerinin çıkarım performansını artırmayı amaçlamaktadır. DeepSeek-V3 gibi modeller üzerindeki teorik doğrulamalar, OmniPlacement’ın çıkarım gecikmesini yaklaşık %10 azaltabildiğini ve verimi yaklaşık %10 artırabildiğini göstermektedir. Bu yöntemin özü, uzman önceliklerini dinamik olarak ayarlamak, iletişim alanını optimize etmek, yedekli örnekleri farklılaştırılmış bir şekilde dağıtmak ve yük değişikliklerine esnek bir şekilde yanıt vermek için neredeyse gerçek zamanlı zamanlama ve dinamik izleme mekanizmalarını kullanmaktır. Huawei, bu şemayı yakın zamanda açık kaynak yapmayı planlıyor. (Kaynak: 量子位)

苹果计划向开发者开放AI模型权限,刺激应用创新: Haberlere göre Apple, WWDC’de üçüncü taraf geliştiricilere Apple Intelligence AI modeli izinlerini açacağını duyuracak. Başlangıçta cihaz üzerinde çalışan yaklaşık 3 milyar parametreli hafif dil modellerine odaklanılacak, ardından GPT-4-Turbo seviyesine eşdeğer bulut tabanlı modeller (özel bulut üzerinden çalıştırılıp şifrelenerek) açılabilir. Bu hamle, geliştiricileri Apple’ın LLM’lerine dayalı yeni uygulama özellikleri oluşturmaya teşvik etmeyi, Apple cihazlarının çekiciliğini artırmayı ve üretken AI alanındaki göreceli gecikmesini telafi etmeyi amaçlıyor. Analistler, Apple’ın açık bir ekosistem oluşturarak, geniş geliştirici topluluğundan (6 milyon) yararlanarak kendi teknolojik eksikliklerini gidermeyi ve giderek artan AI rekabetine yanıt vermeyi umduğunu düşünüyor. (Kaynak: 36氪)
美国众议院提案拟暂停州级AI监管十年,引发巨大争议: ABD Temsilciler Meclisi Enerji ve Ticaret Komitesi, önümüzdeki on yıl boyunca eyaletlerin yapay zeka modellerini, sistemlerini ve “insan karar verme süreçlerini önemli ölçüde etkileyen veya bunların yerini alan” otomatik karar verme sistemlerini düzenlemesini yasaklamayı planlayan bir öneriyi kabul etti. Destekçiler, bu hamlenin eyalet düzenlemelerinin farklılık göstermesinin AI inovasyonunu ve federal hükümet sistemlerinin modernizasyonunu engellemesini önleyeceğini savunuyor; karşıtlar ise bunun “büyük teknoloji şirketlerine dev bir hediye” olduğunu ve eyaletlerin halkı AI zararlarından koruma yeteneğini zayıflatacağını iddia ediyor. Öneri kabul edilirse, mevcut ve önerilen birçok eyalet düzeyindeki AI yasasını geçersiz kılabilir, ancak federal yasaların öngördüğü veya AI ve AI olmayan sistemlere eşit şekilde davranan genel geçerli yasalar için geçerli olmayacağı açıkça belirtiliyor. Bu hamle, küresel çapta “AI inovasyon önceliği” ile “güvenlik tabanı” arasındaki şiddetli çekişmeyi yansıtıyor. (Kaynak: 36氪, edition.cnn.com)

《Take It Down Act》签署成为美国法律,打击非自愿私密图像传播: ABD Başkanı Trump, 《Take It Down Act》 yasa tasarısını imzalayarak, rıza dışı mahrem görüntülerin (AI tarafından üretilen deepfake içerikler dahil) üretilmesini ve yayılmasını federal bir suç haline getirdi. Yasa, teknoloji platformlarının bildirim aldıktan sonra 48 saat içinde ilgili içeriği kaldırmasını gerektiriyor. Bu yasa, mağdurları korumayı ve deepfake teknolojisinin kötüye kullanılmasından kaynaklanan giderek artan toplumsal sorunlara yanıt vermeyi amaçlıyor. Ancak, bazı yorumcular yasanın kötüye kullanılabileceğini ve aşırı sansüre yol açabileceğini belirtiyor. (Kaynak: MIT Technology Review, edition.cnn.com, Reddit r/artificial)

AI大模型助力健康管理,实现个性化与多维数据联动: AI büyük modelleri, giyilebilir cihazlarla birleşerek çok boyutlu veri bağlantısı ve kişiselleştirilmiş hizmetler sağlayarak sağlık yönetimi alanına yeni bir canlılık katıyor. WeDoctor, Shenrui Medical, Nanda Fitech gibi şirketler, örneğin sağlık kontrolü senaryolarından başlayarak erken tarama ve tedavi yapmak veya kronik hastalıkları önlemek için kilo yönetimini bir atılım noktası olarak kullanmak gibi uygulama senaryolarını aktif olarak araştırıyor. Büyük modeller daha çeşitli veri boyutlarını işleyebilir, kullanıcı hafızası oluşturabilir ve daha kesin sağlık müdahale planları sunabilir. Zorluklar arasında model halüsinasyonları, veri kalitesi ve işbirliği zorlukları bulunuyor, ancak RAG, model ince ayarı, denetim mekanizmaları ve “AI + gerçek kişi yönetici” modeliyle bunlar giderek aşılıyor. İş modelleri açısından, ToB hizmetleri, C tarafı ücretlendirme ve AI sağlık ortaklıkları gibi modeller ilk doğrulamayı geçti ve gelecekteki eğilim çok modlu etkileşim yükseltmesine doğru olacak. (Kaynak: 36氪)
百度强化文心大模型多模态能力,应对市场竞争与应用落地: Baidu’nun en son yayınladığı Wenxin Large Model 4.5 Turbo ve derin düşünme modeli X1 Turbo, karma eğitim, çok modlu heterojen uzman modelleme gibi teknolojiler aracılığıyla çapraz modlu öğrenme verimliliğini ve entegrasyon etkisini artırarak çok modlu anlama ve üretme yeteneklerinde önemli ölçüde geliştirildi. CEO Robin Li, Sora benzeri video üretken modellerinin halüsinasyon sorunları konusunda temkinli davransa da, pazar rekabeti (ByteDance’in Doubao’su, Alibaba’nın Tongyi Qianwen’i gibi çok modlu alanlardaki ilerlemeler) ve AI uygulama yerelleştirme talepleri karşısında Baidu, eksikliklerini aktif olarak gideriyor ve 30 Haziran’da Wenxin Large Model 4.5 serisini açık kaynak yapmayı planlıyor. Baidu, AI dijital insanlarının önemli bir uygulama atılım noktası olduğunu düşünüyor ve 100.000’den fazla dijital insan sunucusunu destekleyen “senaryo” odaklı ultra gerçekçi dijital insan teknolojisi geliştirdi. (Kaynak: 36氪)
抖音、小红书等平台专项治理“AI起号”,维护内容生态: Douyin, Xiaohongshu gibi ilgi odaklı e-ticaret platformları son zamanlarda AI teknolojisini kullanarak toplu halde sahte içerik üretme, “AI hesap oluşturma” gibi davranışlara karşı özel düzenlemelerini güçlendirdi. Bu davranışlar arasında AI tarafından üretilen düşük kaliteli ve sansasyonel videolar, sanal uzman içerikleri, AI hesap oluşturma eğitimleri ve hesap satışı yer alıyor. Platformlar, bu tür davranışların içeriğin gerçekliğini bozduğunu, içeriğin tekdüzeleşmesine yol açtığını, kullanıcı deneyimine ve orijinal içerik üreticilerinin ekosistemine zarar verdiğini ve dolayısıyla ticari değeri azalttığını düşünüyor. Buna karşılık, Taobao, JD.com gibi geleneksel raf tipi e-ticaret platformları ise satıcıları, ürün sergileme etkisini ve operasyonel verimliliği artırmak için AI araçlarını (örneğin “görüntüden video oluşturma”, canlı yayın dijital insanları) kullanmaya aktif olarak teşvik ediyor ve temel amaç olarak işlem gerçekleştirmeyi hedefliyor. Bu farklılık, farklı e-ticaret modelleri altında AI uygulama stratejilerinin ayrışmasını yansıtıyor. (Kaynak: 36氪)

苹果AI版Siri开发遇阻,或再次跳票,管理层调整应对危机: Bloomberg’e göre, Apple’ın WWDC’de tanıtmayı planladığı büyük modelle güncellenmiş Siri tekrar ertelenebilir. Teknik darboğaz, yeni ve eski sistem mimarilerinin çakışmasından kaynaklanıyor ve sık sık hatalara yol açıyor. Haberde, Apple’ın AI stratejisinde üst düzey karar alma hataları, iç güç mücadeleleri, yetersiz GPU tedariki ve gizlilik korumasının veri kullanımını kısıtlaması gibi sorunlar olduğu belirtiliyor ve bu durumun AI teknolojisinde rakiplerinin gerisinde kalmasına neden olduğu ifade ediliyor. Krize yanıt vermek için Apple’ın Zürih laboratuvarı yepyeni bir “LLM Siri” mimarisi geliştiriyor ve Siri projesini Vision Pro yöneticisi Mike Rockwell’e devrediyor. Aynı zamanda Apple, Google Gemini, OpenAI gibi dış teknolojilerle işbirliği arayışında ve AI imajını yeniden şekillendirmek için Apple Intelligence’ı Siri markasından pazarlama açısından ayırabilir. (Kaynak: 36氪)

字节跳动推出集成英语外教智能体Owen的Ola Friend耳机: ByteDance, akıllı kulaklığı Ola Friend için Owen adlı bir İngilizce öğretmeni akıllı asistan özelliği ekledi. Kullanıcılar, Doubao App’i uyandırarak Owen’ı başlatabilir ve İngilizce sohbet, İngilizce okuma rehberliği ve çift dilli yorumlar gibi özelliklerden yararlanabilir. Bu özellik, günlük konuşmalar, iş İngilizcesi, seyahat gibi senaryoları kapsıyor ve taşınabilir, pratik bir İngilizce pratik partneri sunmayı amaçlıyor. Bu, ByteDance’in eğitim senaryolarındaki bir başka denemesi olup, AI büyük model yeteneklerini donanımla birleştirerek dikey bir İngilizce öğrenme ürünü yaratıyor. Ola Friend kulaklıkları daha önce Doubao aracılığıyla bilgi sorgulama ve konuşma pratiği yapmayı destekliyordu; yeni akıllı asistanın eklenmesi eğitim özelliklerini daha da güçlendiriyor. (Kaynak: 36氪)

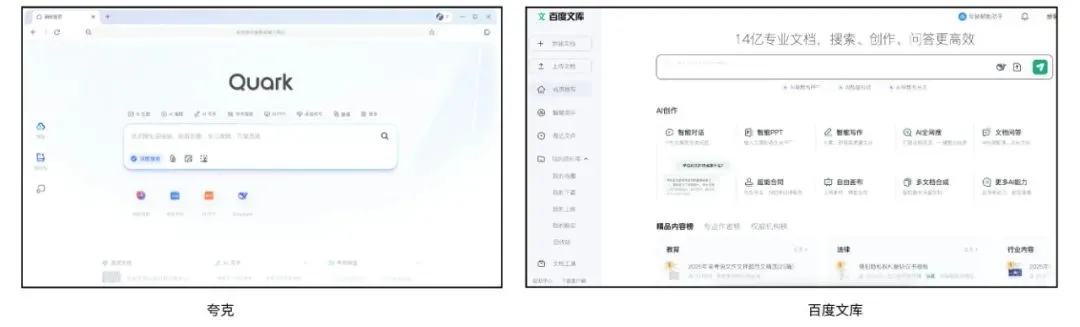
夸克与百度文库竞逐AI超级应用,整合搜索、工具与内容服务: Alibaba’ya bağlı Quark ve Baidu’ya bağlı Baidu Wenku, AI merkezli “süper kutu” uygulamalarına dönüşerek AI sohbeti, derinlemesine arama, AI araçları (yazma, PPT oluşturma, sağlık asistanı vb.) ile ağ diski ve belge hizmetlerini entegre ediyor ve C tarafı kullanıcılar için tek duraklı bir AI giriş noktası olmayı hedefliyor. Quark, reklamsız arama ve genç kullanıcı kitlesi sayesinde aylık 149 milyon aktif kullanıcıya ulaştı ve üyelik sistemiyle ticarileşmeyi başardı. Baidu Wenku ise devasa belge kaynakları ve ücretli kullanıcı tabanına dayanarak AI Agent’ı entegre eden “Cangzhou OS”u piyasaya sürdü ve içerik oluşturma ile tüketiminin tüm zincirini güçlendirdi. Her ikisi de işlevsel tekdüzelik, uygulama şişkinliği ve genel ihtiyaçlar ile dikey derinlemesine hizmetler arasında denge kurma zorluklarıyla karşı karşıya. (Kaynak: 36氪)
智谱清言、Kimi等35款App因违规收集个人信息被通报: Ulusal Ağ ve Bilgi Güvenliği Bilgi İhbar Merkezi, Zhipu Qingyan’ın (sürüm 2.9.6) “fiilen toplanan kişisel bilgilerin kullanıcı yetkilendirme kapsamını aşması” ve Kimi’nin (sürüm 2.0.8) “fiilen toplanan kişisel bilgilerin işlevsel amaçlarla doğrudan ilişkili olmaması” gibi nedenlerle diğer 33 uygulama ile birlikte yasa dışı ve usulsüz kişisel bilgi toplama ve kullanma durumunda olduğunun tespit edildiğini belirten bir duyuru yayınladı. Bu iki popüler AI uygulaması da Tsinghua kökenli ekipler tarafından geliştirilmiş olup, son zamanlarda önemli finansman ve pazar ilgisi görmüştür. Bu ihbar, 2025 yılı 16 Nisan – 15 Mayıs tarihleri arasındaki denetim süresini kapsamakta olup, AI uygulamalarının hızlı gelişim sürecinde karşılaştığı veri uyumluluğu zorluklarını vurgulamaktadır. (Kaynak: 36氪)
🧰 工具
OpenEvolve:DeepMind AlphaEvolve的开源实现,用LLM进化代码库: Geliştiriciler, Google DeepMind’in AlphaEvolve sisteminin bir uygulaması olan OpenEvolve projesini açık kaynak olarak yayınladı. OpenEvolve çerçevesi, yeni algoritmalar keşfetmek veya mevcut algoritmaları optimize etmek için LLM’lerin yinelemeli bir süreci (kod üretme, değerlendirme, seçme) aracılığıyla tüm kod tabanını geliştirir. OpenAI API uyumlu herhangi bir LLM’yi destekler, birden fazla modeli (Gemini-Flash-2.0 ve Claude-Sonnet-3.7 kombinasyonu gibi) entegre edebilir, çok amaçlı optimizasyonu ve dağıtılmış değerlendirmeyi destekler. Proje, AlphaEvolve makalesindeki daire paketleme ve fonksiyon minimizasyonu örneklerini başarıyla yeniden üretti ve basit yöntemlerden karmaşık optimizasyon algoritmalarına (scipy.minimize ve benzetilmiş tavlama gibi) evrimleşme yeteneğini gösterdi. (Kaynak: Reddit r/LocalLLaMA, Reddit r/MachineLearning)

谷歌推出AI编程智能体Jules,支持自动化代码任务: Google, şu anda küresel test aşamasında olan ve kullanıcıların günde 5 görevi ücretsiz olarak gerçekleştirebildiği AI programlama asistanı Jules’u yayınladı. Jules, çok modlu Gemini 2.5 Pro modeline dayanmakta olup, karmaşık kod tabanlarını anlayabilir, hata düzeltme, sürüm güncelleme, test yazma, yeni özellikler uygulama gibi görevleri yerine getirebilir ve Python ile JavaScript’i destekler. GitHub’a bağlanarak çekme istekleri (PR) oluşturabilir, bulut sanal makinelerinde kodu doğrulayabilir ve geliştiricilerin incelemesi ve değiştirmesi için ayrıntılı yürütme planları sunabilir. Jules, geliştirici iş akışlarına derinlemesine entegre olmayı ve programlama verimliliğini artırmayı amaçlamaktadır; gelecekte Codecast özelliği (kod tabanı etkinliklerinin sesli özeti) ve kurumsal sürümü de sunulacaktır. (Kaynak: 36氪)
飞书上线“飞书知识问答”,打造企业专属AI问答工具: Feishu, kurumsal bilgiye dayalı, kuruma özel bir AI soru-cevap aracı olan “Feishu Bilgi Soru-Cevap” adlı yeni bir AI ürününü yakında piyasaya sürecek. Kullanıcılar, Feishu kenar çubuğundan çağırarak işleriyle ilgili sorular sorabilecekler. Bu araç, kullanıcının yetki alanındaki tüm Feishu mesajlarına, belgelerine, bilgi tabanlarına, dosyalarına vb. erişebilecek ve bu “bağlamlara” dayanarak doğrudan kesin yanıtlar verebilecek. Yetki yönetimi, Feishu’nun kendi yetki sistemiyle tutarlı olup bilgi güvenliğini sağlayacaktır. Ürün şu anda on binlerce kullanıcıyla dahili testlerini tamamladı, web sitesi (ask.feishu.cn) yayında ve kişisel verilerin yüklenmesini ve DeepSeek veya Doubao modellerinin çağrılarak soru sorulmasını destekliyor. Bu hamle, kurumsal bilgi tabanlarının AI ile birleşme eğilimine uyum sağlıyor ve iş verimliliğini ve bilgi yönetimi yeteneklerini artırmayı amaçlıyor. (Kaynak: 36氪)
Manus:AI智能体平台开放注册,母公司获高额融资: AI akıllı asistan platformu Manus, bekleme listesini kaldırarak yurt dışı kullanıcılara kayıtları açtığını ve günlük ücretsiz görevler sunduğunu duyurdu. Manus, “karma mimarili çoklu model işbirlikçi çıkarım” teknolojisi aracılığıyla otomatik PPT oluşturma, fatura düzenleme gibi görevleri yerine getirebiliyor. Ana şirketi Hudiexing, yakın zamanda 75 milyon ABD doları finansman alarak 3,6 milyar ABD doları değerlemeye ulaştı. Manus’un başarısı, “Çin’in yineleme hızı × Silikon Vadisi ürün düşüncesi”nin bir yansıması olarak görülüyor ve planlama, yürütme, doğrulama Agent’larını koordine ederek AI’ın “düşünce önerisi”nden “kapalı döngü yürütme”ye geçişini sağlıyor. (Kaynak: 36氪)

HeyGen:AI视频生成与翻译工具,支持40+语言口型同步: HeyGen, kullanıcıların fotoğraf veya video yükleyerek hızlı bir şekilde ses, ifade ve hareket içeren dijital insanlar oluşturabildiği ve özel kıyafet ve sahneleri desteklediği bir AI video aracıdır. Temel özelliklerinden biri, 175’ten fazla dil ve lehçede gerçek zamanlı çeviriyi desteklemesi ve AI algoritmaları aracılığıyla dijital insanın dudak hareketlerini çevrilen dille hassas bir şekilde eşleştirerek çok dilli video içeriklerinin doğallığını artırmasıdır. Şirket, eski Snapchat ve ByteDance üyeleri tarafından kurulmuş olup, Benchmark liderliğinde 60 milyon ABD doları finansman almış, 440 milyon ABD doları değerlemeye ulaşmış ve yıllık yinelenen geliri 35 milyon ABD dolarını aşmıştır. (Kaynak: 36氪)
Opus Clip:AI驱动的自主视频编辑代理工具: Opus Clip, başlangıçta AI canlı yayın aracı olarak konumlandırılmış, daha sonra AI video düzenleme platformuna dönüşmüş ve daha da geliştirilerek “otonom video düzenleme aracısı” haline gelmiştir. Temel işlevi, uzun videoları hızla viral yayılmaya uygun birden fazla kısa videoya bölmek ve ana konuyu otomatik olarak kırpmak, başlık metinleri oluşturmak, altyazı ve ifadeler eklemektir. Yakın zamanda test edilen ClipAnything özelliği, çok modlu komut tanımayı desteklemektedir. Şirket, eski sosyal uygulama Sober’ın kurucusu Zhao Yang tarafından yönetilmekte olup, SoftBank liderliğinde 20 milyon ABD doları finansman almış, 215 milyon ABD doları değerlemeye ulaşmış ve ARR’si (Yıllık Yinelenen Gelir) yaklaşık 10 milyon ABD dolarıdır. (Kaynak: 36氪)
Trae:基于AI IDE的自动化编程Agent: Trae, “gerçek AI mühendisleri” yaratmayı amaçlayan bir araç olup, kullanıcıların doğal dil etkileşimi yoluyla Agent otomasyonlu programlama gerçekleştirmesini destekler. MCP protokolü ve özel Agent’larla uyumludur, geliştirilmiş bağlam ayrıştırma ve kural motoru içerir, ana programlama dillerini destekler ve VS Code ile uyumludur. Trae, ByteDance orijinal Marscode programlama asistanı ekibinin çekirdek üyeleri tarafından geliştirilmiş olup, Cursor gibi AI programlama araçlarının güçlü bir rakibi olarak konumlandırılmakta ve insan-makine işbirliğine dayalı yeni bir yazılım geliştirme modeli gerçekleştirmeyi hedeflemektedir. (Kaynak: 36氪)
Notta:AI驱动的多语言会议纪要与实时翻译工具: Notta, toplantı senaryolarına odaklanan bir AI aracı olup, çok dilli toplantı tutanaklarını otomatik olarak oluşturma hizmeti sunar ve gerçek zamanlı çeviri ile önemli içerik işaretlemeyi destekler. Bu ürün, toplantı verimliliğini artırmayı ve diller arası iletişim engellerini çözmeyi amaçlamaktadır. Ana kurucusunun eski Tencent Cloud ses ekibinin çekirdek üyesi olduğu, operasyon merkezinin Singapur’da, Ar-Ge merkezinin ise Seattle’da bulunduğu söyleniyor. 2024 yılı geliri 18 milyon ABD doları, değerlemesi 300 milyon ABD doları olup, şu anda B serisi finansman turundadır. (Kaynak: 36氪)
开源GPT+ML交易助手登陆iPhone: Derin öğrenme ve GPT teknolojilerini entegre eden açık kaynaklı bir ticaret asistanı, iPhone’da Pyto aracılığıyla yerel olarak çalıştırılabilir hale geldi. Şu anda ücretsiz ve hafif bir sürüm olup, gelecekte CNN grafik desen sınıflandırıcısı ve veritabanı desteği eklenmesi planlanmaktadır. Platform modüler olarak tasarlanmış olup, derin öğrenme geliştiricilerinin kendi modellerini bağlamasını kolaylaştırır ve OpenAI GPT’yi yerel olarak desteklemektedir. (Kaynak: Reddit r/deeplearning)
📚 学习
新论文探讨深度学习中的“断裂纠缠表征假说”: Arxiv’e sunulan “Derin Öğrenmede Temsil İyimserliğini Sorgulamak: Kırık Dolaşık Temsil Hipotezi” başlıklı bir durum belgesi. Bu araştırma, evrimsel arama süreçleri tarafından üretilen sinir ağlarını geleneksel SGD ile eğitilmiş ağlarla (tek bir görüntü oluşturma gibi basit bir görevde) karşılaştırarak, her ikisi de aynı çıktı davranışını üretmesine rağmen iç temsillerinin büyük ölçüde farklı olduğunu buldu. SGD ile eğitilmiş ağlar, yazarların “kırık dolaşık temsil” (FER) olarak adlandırdığı düzensiz bir form sergilerken, evrimsel ağlar daha çok birleşik ayrıştırılmış temsile (UFR) yakındır. Araştırmacılar, büyük modellerde FER’in genelleme, yaratıcılık ve sürekli öğrenme gibi temel yetenekleri azaltabileceğini ve FER’i anlamanın ve hafifletmenin gelecekteki temsil öğrenimi için kritik öneme sahip olduğunu savunuyor. (Kaynak: Reddit r/MachineLearning, arxiv.org)
R3:可鲁棒控制且可解释的奖励模型框架: “R3: Robust Rubric-Agnostic Reward Models” başlıklı bir makale, yeni bir ödül modeli çerçevesi olan R3’ü tanıtıyor. Bu çerçeve, mevcut dil modeli hizalama yöntemlerindeki ödül modellerinin kontrol edilebilirlik ve yorumlanabilirlik eksikliğini gidermeyi amaçlamaktadır. R3’ün özelliği “rubric-agnostic” (belirli derecelendirme kriterlerinden bağımsız) olması, değerlendirme boyutları arasında genelleme yapabilmesi ve yorumlanabilir, çıkarım süreciyle birlikte puan ataması sağlayabilmesidir. Araştırmacılar, R3’ün daha şeffaf, esnek dil modeli değerlendirmesi sağlayabileceğine ve çeşitli insan değerleri ve kullanım durumlarıyla sağlam bir hizalamayı destekleyebileceğine inanıyor. Model, veriler ve kod açık kaynak olarak yayınlandı. (Kaynak: HuggingFace Daily Papers)
通过低秩克隆实现高效知识蒸馏的论文《A Token is Worth over 1,000 Tokens》发布: Bu makale, güçlü öğretmen modellerinin davranışlarına eşdeğer küçük dil modelleri (SLM) oluşturmak için düşük mertebeli klonlama (Low-Rank Clone, LRC) adı verilen verimli bir ön eğitim yöntemi önermektedir. LRC, bir dizi düşük mertebeli projeksiyon matrisini eğiterek, sıkıştırılmış öğretmen ağırlıkları aracılığıyla yumuşak budamayı ve öğrenci aktivasyonlarını (FFN sinyalleri dahil) öğretmen aktivasyonlarıyla hizalayarak aktivasyon klonlamasını birleşik bir şekilde gerçekleştirir. Bu birleşik tasarım, açık hizalama modüllerine ihtiyaç duymadan bilgi transferini en üst düzeye çıkarır. Deneyler, Llama-3.2-3B-Instruct gibi açık kaynaklı öğretmen modelleri kullanılarak, LRC’nin yalnızca 20B token ile eğitilerek SOTA modellerinin (milyarlarca token ile eğitilmiş) performansına ulaştığını veya aştığını ve 1000 kattan fazla eğitim verimliliği sağladığını göstermektedir. (Kaynak: HuggingFace Daily Papers)
MedCaseReasoning:评估和学习临床病例诊断推理的数据集与方法: “MedCaseReasoning: Evaluating and learning diagnostic reasoning from clinical case reports” makalesi, büyük dil modellerinin (LLM) klinik tanısal çıkarım yeteneklerini değerlendirmek için yeni bir açık veri kümesi olan MedCaseReasoning’i tanıtıyor. Bu veri kümesi, her biri açık tıbbi vaka raporlarından türetilen ayrıntılı çıkarım ifadeleriyle eşleştirilmiş 14489 tanısal soru-cevap vakası içermektedir. Araştırma, mevcut SOTA çıkarım LLM’lerinin tanı ve çıkarım konusunda önemli eksiklikleri olduğunu bulmuştur (örneğin, DeepSeek-R1 doğruluk oranı %48, çıkarım ifadesi geri çağırma oranı %64). Ancak, MedCaseReasoning’in çıkarım yörüngelerinde LLM’leri ince ayarlayarak, tanı doğruluğu ve klinik çıkarım geri çağırma oranları sırasıyla ortalama olarak %29 ve %41 oranında göreceli olarak artmıştır. (Kaynak: HuggingFace Daily Papers)
《EfficientLLM: Efficiency in Large Language Models》论文发布,全面评估LLM效率技术: Bu çalışma, büyük ölçekli LLM’lerin verimlilik teknolojileri üzerine ilk kapsamlı ampirik çalışmayı sunmakta ve EfficientLLM kıyaslamasını tanıtmaktadır. Çalışma, üretim düzeyindeki kümelerde mimari ön eğitimi (verimli dikkat çeşitleri, seyrek MoE), ince ayar (LoRA gibi parametre verimli yöntemler) ve çıkarım (niceleme) olmak üzere üç temel yönü sistematik olarak incelemektedir. Altı ayrıntılı metrik (bellek kullanımı, hesaplama kullanımı, gecikme, verim, enerji tüketimi, sıkıştırma oranı) aracılığıyla 100’den fazla model-teknoloji çifti (0.5B-72B parametre) değerlendirilmiştir. Temel bulgular şunlardır: verimlilik ölçülebilir ödünleşimler içerir, evrensel olarak en uygun yöntem yoktur; en uygun çözüm göreve ve ölçeğe bağlıdır; teknolojiler modlar arası genelleme yapabilir. (Kaynak: HuggingFace Daily Papers)
《NExT-Search》论文探讨生成式AI搜索的反馈生态系统重建: “NExT-Search: Rebuilding User Feedback Ecosystem for Generative AI Search” makalesi, üretken AI aramasının kolaylığı artırmasına rağmen, geleneksel Web aramasının iyileştirme için güvendiği ayrıntılı kullanıcı geri bildirim döngüsünü (tıklamalar, kalma süresi gibi) bozduğunu belirtiyor. Bu sorunu çözmek için makale, ayrıntılı, süreç düzeyinde geri bildirimi yeniden tanıtmayı amaçlayan NExT-Search paradigmasını tasarlıyor. Bu paradigma, kullanıcıların kritik aşamalarda müdahale etmesine olanak tanıyan bir “kullanıcı hata ayıklama modu” ve kullanıcı tercihlerini simüle eden ve AI destekli geri bildirim sağlayan bir “gölge kullanıcı modu” içerir. Bu geri bildirim sinyalleri, çevrimiçi uyarlama (arama çıktılarını gerçek zamanlı olarak optimize etme) ve çevrimdışı güncelleme (çeşitli model bileşenlerini periyodik olarak ince ayarlama) için kullanılabilir. (Kaynak: HuggingFace Daily Papers)
《Latent Flow Transformer》提出新型LLM架构: Makale, geleneksel Transformer’daki çok katmanlı ayrık katmanların yerine akış eşleştirme (flow matching) yoluyla tek bir öğrenme aktarım operatörünü eğiten Latent Flow Transformer’ı (LFT) önermektedir. LFT, orijinal mimariyle uyumluluğu korurken model katman sayısını önemli ölçüde sıkıştırmayı amaçlamaktadır. Ayrıca makale, mevcut akış yöntemlerinin eşleşmeyi sürdürmedeki sınırlamalarını gidermek için Flow Walking (FW) algoritmasını tanıtmaktadır. Pythia-410M modeli üzerindeki deneyler, LFT’nin katman sayısını etkili bir şekilde sıkıştırabildiğini ve doğrudan katman atlamanın performansından daha iyi performans gösterdiğini, otoregresif ve akış tabanlı üretim paradigmaları arasındaki farkı önemli ölçüde azalttığını göstermektedir. (Kaynak: HuggingFace Daily Papers)
《Reasoning Path Compression》提出压缩LLM推理生成轨迹方法: Çıkarım tipi dil modellerinin uzun ara yollar üretmesinin büyük bellek kullanımı ve düşük verime yol açması sorununa yönelik olarak makale, Çıkarım Yolu Sıkıştırma (Reasoning Path Compression, RPC) yöntemini önermektedir. RPC, yüksek önem puanına sahip KV önbelleklerini (en son üretilen sorgulardan oluşan bir “seçici pencere” kullanılarak hesaplanır) koruyarak KV önbelleğini periyodik olarak sıkıştıran, eğitim gerektirmeyen bir yöntemdir. Deneyler, RPC’nin QwQ-32B gibi modellerin üretim verimini önemli ölçüde artırabildiğini ve doğruluk üzerindeki etkisinin küçük olduğunu göstermekte, çıkarım LLM’lerinin verimli dağıtımı için pratik bir yol sunmaktadır. (Kaynak: HuggingFace Daily Papers)
《Bidirectional LMs are Better Knowledge Memorizers?》论文发布,关注双向LM知识记忆能力: Bu çalışma, Wikipedia’nın “Biliyor muydunuz…” bölümündeki yakın zamanda eklenen, insanlar tarafından yazılmış gerçekleri kullanarak yeni, gerçek dünya ve büyük ölçekli bir bilgi enjeksiyonu kıyaslaması olan WikiDYK’yi tanıtıyor. Deneyler, şu anda popüler olan nedensel dil modellerine (CLM) kıyasla, çift yönlü dil modellerinin (BiLM) bilgi ezberleme konusunda belirgin şekilde daha güçlü bir yetenek sergilediğini ve güvenilirlik doğruluğunun %23 daha yüksek olduğunu buldu. Mevcut BiLM’lerin ölçeğinin küçük olmasının eksikliğini gidermek için araştırmacılar, BiLM koleksiyonunu harici bir bilgi tabanı olarak LLM’lerle entegre eden modüler bir işbirliği çerçevesi önererek güvenilirlik doğruluğunu %29,1’e kadar daha da artırdı. (Kaynak: HuggingFace Daily Papers)
《Truth Neurons》论文探讨语言模型中真实性的神经元层面编码: Araştırmacılar, dil modellerinde nöron düzeyinde gerçeklik temsillerini tanımlamak için bir yöntem öneriyor ve modellerde konuyla ilgisiz bir şekilde gerçekliği kodlayan “gerçeklik nöronları” (truth neurons) bulunduğunu keşfediyor. Farklı ölçeklerdeki modeller üzerinde yapılan deneyler, gerçeklik nöronlarının varlığını doğruladı ve dağılım modelleri, gerçekliğin geometrik yapısıyla ilgili önceki araştırma sonuçlarıyla tutarlıydı. Bu nöronların aktivasyonunu seçici olarak baskılamak, modelin TruthfulQA ve diğer kıyaslamalardaki performansını düşürüyor ve gerçeklik mekanizmasının belirli bir veri kümesine özgü olmadığını gösteriyor. (Kaynak: HuggingFace Daily Papers)
《Understanding Gen Alpha Digital Language》评估LLM在内容审核中的局限性: Bu çalışma, AI sistemlerinin (GPT-4, Claude, Gemini, Llama 3) “Alfa Kuşağı”nın (Gen Alpha, 2010-2024 doğumlu) dijital dilini yorumlama yeteneğini değerlendiriyor. Çalışma, Gen Alpha’nın benzersiz çevrimiçi dilinin (oyunlar, memler, AI trendlerinden etkilenen) genellikle zararlı etkileşimleri gizlediğini ve mevcut güvenlik araçlarının bunları tanımlamakta zorlandığını belirtiyor. Yakın zamandaki 100 Gen Alpha ifadesini içeren bir veri kümesiyle yapılan testler, ana akım AI modellerinin gizlenmiş taciz ve manipülasyonu tespit etmede ciddi anlama engelleri olduğunu ortaya koydu. Çalışmanın katkıları arasında ilk Gen Alpha ifade veri kümesi, AI denetim sistemlerini iyileştirmek için bir çerçeve yer alıyor ve gençlerin iletişim özelliklerine göre güvenlik sistemlerinin acilen yeniden tasarlanması gerektiğini vurguluyor. (Kaynak: HuggingFace Daily Papers)
《CompeteSMoE》提出基于竞争的混合专家模型训练方法: Makale, mevcut seyrek karma uzman (SMoE) modeli eğitiminin, yani hesaplamayı yapan uzmanların yönlendirme kararlarına doğrudan katılmadığı alt optimal bir yönlendirme süreciyle karşı karşıya olduğunu savunuyor. Bu nedenle araştırmacılar, token’ları en yüksek sinirsel yanıta sahip uzmana yönlendiren “rekabet” (competition) adlı yeni bir mekanizma öneriyor. Teorik olarak rekabet mekanizmasının geleneksel softmax yönlendirmesinden daha iyi örnek verimliliğine sahip olduğu kanıtlanmıştır. Buna dayanarak, yönlendiricinin rekabet stratejisini öğrenmesini sağlayarak görsel talimat ayarlama ve dil ön eğitimi görevlerinde etkililik, sağlamlık ve ölçeklenebilirlik gösteren CompeteSMoE algoritması geliştirildi. (Kaynak: HuggingFace Daily Papers)
《General-Reasoner》旨在提升LLM跨领域推理能力: Mevcut LLM çıkarım araştırmalarının temel olarak matematik ve kodlama alanlarına odaklanması sorununa yönelik olarak bu makale, LLM’lerin farklı alanlardaki çıkarım yeteneğini artırmayı amaçlayan yeni bir eğitim paradigması olan General-Reasoner’ı önermektedir. Katkıları şunlardır: çok disiplinli doğrulanabilir cevaplar içeren büyük ölçekli, yüksek kaliteli bir soru veri kümesi oluşturmak; geleneksel kural tabanlı doğrulamaya alternatif olarak düşünce zinciri ve bağlam farkındalığı yeteneklerine sahip, üretken bir modele dayalı bir cevap doğrulayıcı geliştirmek. Fizik, kimya, finans gibi alanları kapsayan bir dizi kıyaslama testinde General-Reasoner, mevcut temel yöntemlerden daha iyi performans göstermiştir. (Kaynak: HuggingFace Daily Papers)
《Not All Correct Answers Are Equal》探讨知识蒸馏源的重要性: Bu çalışma, üç SOTA öğretmen modelinin (AM-Thinking-v1, Qwen3-235B-A22B, DeepSeek-R1) 1,89 milyon sorgu üzerindeki doğrulanmış çıktılarını toplayarak çıkarım verisi damıtması üzerine büyük ölçekli bir ampirik çalışma yürütmüştür. Analiz, AM-Thinking-v1 ile damıtılan verilerin daha büyük token uzunluğu çeşitliliği ve daha düşük şaşkınlık sergilediğini ortaya koymuştur. Bu veri kümesi üzerinde eğitilen öğrenci modelleri, AIME2024 gibi çıkarım kıyaslamalarında en iyi performansı göstermiş ve uyarlanabilir çıktı davranışı sergilemiştir. Araştırmacılar, gelecekteki araştırmaları desteklemek için AM-Thinking-v1 ve Qwen3-235B-A22B’nin damıtılmış veri kümelerini yayınlamıştır. (Kaynak: HuggingFace Daily Papers)
《SSR》通过基本原理引导的空间推理增强VLM深度感知: Görsel dil modelleri (VLM) çok modlu görevlerde ilerleme kaydetse de, RGB girdilerine olan bağımlılıkları hassas uzamsal anlamayı sınırlamaktadır. Makale, ham derinlik verilerini yapılandırılmış, yorumlanabilir metinleştirilmiş temel ilkelere dönüştüren SSR (Spatial Sense and Reasoning) adlı yeni bir çerçeve önermektedir. Bu metinleştirilmiş temel ilkeler, anlamlı ara temsiller olarak hizmet ederek uzamsal çıkarım yeteneğini önemli ölçüde artırmaktadır. Ayrıca çalışma, yeniden eğitime gerek kalmadan mevcut VLM’lere verimli bir şekilde entegre etmek için üretilen ilkeleri kompakt gizli gömülere sıkıştırmak üzere bilgi damıtmayı kullanmaktadır. Aynı zamanda SSR-CoT veri kümesi ve SSRBench kıyaslaması da tanıtılmaktadır. (Kaynak: HuggingFace Daily Papers)
《Solve-Detect-Verify》提出具有灵活生成验证器的推理时扩展方法: LLM’lerin karmaşık görev çıkarımında doğruluk ve verimlilik arasındaki ödünleşimi ve doğrulama adımının getirdiği hesaplama maliyeti ile güvenilirlik çelişkisini çözmek için makale, yeni bir üretken doğrulayıcı olan FlexiVe’yi önermektedir. FlexiVe, esnek bir doğrulama bütçesi tahsis stratejisi aracılığıyla hızlı ve güvenilir “hızlı düşünme” ile ayrıntılı “yavaş düşünme” arasında hesaplama kaynaklarını dengeler. Ayrıca, FlexiVe’yi akıllıca entegre eden, hedefli doğrulamayı tetiklemek ve geri bildirim sağlamak için çözüm tamamlama noktalarını aktif olarak tanımlayan Solve-Detect-Verify süreci önerilmektedir. Deneyler, bu yöntemin matematiksel çıkarım kıyaslamalarında temel yöntemlerden daha iyi performans gösterdiğini göstermektedir. (Kaynak: HuggingFace Daily Papers)
《SageAttention3》探索FP4 Attention推理及8位训练: Bu çalışma, iki temel katkıyla Attention verimliliğini artırmaktadır: Birincisi, Blackwell GPU’daki yeni FP4 Tensor Cores kullanarak Attention hesaplamasını hızlandırır ve FlashAttention’dan 5 kat daha hızlı tak-çalıştır çıkarım hızlandırması sağlar. İkincisi, düşük bitli Attention’ı ilk kez eğitim görevlerine uygulayarak, ileri ve geri yayılım için hassas ve verimli bir 8-bit Attention tasarlar. Deneyler, 8-bit Attention’ın ince ayar görevlerinde kayıpsız performans sağladığını, ancak ön eğitim görevlerinde daha yavaş yakınsadığını göstermektedir. (Kaynak: HuggingFace Daily Papers)
《The Little Book of Deep Learning》深度学习入门资源分享: François Fleuret (Meta FAIR Araştırma Bilimcisi) tarafından yazılan “The Little Book of Deep Learning”, derin öğrenme için kısa ve öz bir eğitim kaynağı sunmaktadır. Kitap, yeni başlayanların ve belirli bir deneyime sahip uygulayıcıların derin öğrenmenin temel kavramlarını ve tekniklerini hızla kavramalarına yardımcı olmayı amaçlamaktadır. (Kaynak: Reddit r/deeplearning)
CodeSparkClubs:为高中生创办AI/计算机科学俱乐部提供免费资源: CodeSparkClubs projesi, lise öğrencilerinin AI ve bilgisayar bilimi kulüpleri başlatmasına veya geliştirmesine yardımcı olmayı amaçlamaktadır. Proje, web sitesi aracılığıyla erişilebilen kılavuzlar, ders planları ve proje eğitimleri dahil olmak üzere ücretsiz, kullanıma hazır materyaller sunmaktadır. Öğrencilerin kulüpleri bağımsız olarak yönetebilmelerini sağlayarak beceri ve topluluk geliştirmelerini sağlamak üzere tasarlanmıştır. (Kaynak: Reddit r/deeplearning)
💼 商业
微软Azure将托管xAI的Grok模型,助力马斯克AI商业化: Microsoft, bulut platformu Azure’un Elon Musk’ın xAI şirketinin Grok gibi AI modellerini barındıracağını duyurdu. Bu hamle, Musk’ın Grok’u diğer işletmelere satmayı ve Microsoft’un bulut hizmetleri aracılığıyla daha geniş bir müşteri kitlesine ulaşmayı planladığı anlamına geliyor. Daha önce Grok, Güney Afrika’daki “beyaz soykırımı” hakkında yanıltıcı gönderiler ürettiği için tartışmalara neden olmuştu. Topluluk bu işbirliğine farklı tepkiler verdi; bazıları bunun Microsoft’un AI ekosistemini genişletme hamlesi olduğunu düşünürken, bazıları Grok’un kalitesini ve AWS’nin Grok’u reddedip etmediğini sorguladı. (Kaynak: Reddit r/ArtificialInteligence, MIT Technology Review)

阿里巴巴投资美图,深化AI电商布局: Alibaba, dönüştürülebilir tahvil yoluyla Meitu şirketine yatırım yaptı, ilk dönüşüm fiyatı hisse başına 6 HKD. İki taraf, e-ticaret ve teknoloji düzeyinde işbirliği yapacak. Meitu, 2 milyondan fazla e-ticaret satıcısına hizmet veren AI görüntü oluşturma araçlarına (Meitu Tasarım Stüdyosu gibi) sahip. Alibaba, Meitu’nun AI araçlarını tanıtarak e-ticaret platformunun ürün sergileme etkisini ve kullanıcı deneyimini, özellikle genç kadın kullanıcıları çekerek artıracak. Meitu ise Alibaba’nın e-ticaret verilerini kullanarak AI araçlarını optimize edebilecek ve üç yıl içinde 560 milyon yuan değerinde Alibaba Cloud hizmeti satın almayı taahhüt etti. Bu hamle, Alibaba’nın AI yaratıcı araçlarındaki eksikliklerini giderme, kullanıcı trafiği elde etme ve bulut bilişimi e-ticaret AI ekosistemine daha derinlemesine yerleştirme stratejik bir adımı olarak görülüyor. (Kaynak: 36氪)
光源资本完成首期5000万美元AI孵化基金募资,关注超早期前沿科技: Lightspeed Capital bünyesindeki 光源创新前沿孵化基金 (L2F), ilk fon toplama turunu beklentilerin üzerinde tamamladı; büyüklüğünün en az 50 milyon ABD doları olması bekleniyor ve yatırım dönemine girdi. Bu çift para birimli fon, AI ve ileri teknoloji alanlarındaki tohum ve melek yatırım turlarına odaklanıyor ve kuluçka desteği sağlıyor. LP yapısı, başarılı girişimciler, AI endüstri zincirinin yukarı ve aşağı akışındaki şirketler ve küresel vizyona sahip ailelerden oluşuyor. İlk yatırım projesi, AI maden arama şirketi Lingyun Zhimin olup, Lightspeed Capital kuluçka sürecine derinlemesine katıldı. Lightspeed Capital kurucusu Zheng Xuanle, mevcut AI gelişim aşamasının mobil internetin erken dönemlerine benzediğini ve kuluçkanın pazara girmenin en iyi aracı olduğunu düşünüyor. (Kaynak: 36氪)
🌟 社区
AI对就业前景的讨论:乐观与担忧并存: Reddit topluluğu, AI’ın iş piyasası üzerindeki etkisini bir kez daha hararetle tartışıyor. Birçok yazılım geliştiricisi, UX tasarımcısı gibi profesyoneller, AI’ın işlerini ellerinden alacağı konusunda iyimser, AI’ın şu anda karmaşık görevleri yerine getiremeyeceğini düşünüyor. Ancak, bazı görüşler bu bakış açısının AI’ın uzun vadeli gelişim potansiyelini hafife alabileceğini belirtiyor ve 2018’de insanların Google Çeviri’nin insan çevirmenlerin yerini alacağına dair şüphelerini örnek gösteriyor. Tartışmada, AI’ın hızlı ilerlemesinin gelecekte (birkaç tıp, sanat alanı hariç) çoğu mesleğin yerini almasına yol açabileceği, önemli olanın sadece kişisel becerileri geliştirmek değil, ekonomik modeli değiştirmek olduğu düşünülüyor. Yorumlarda “kısa vadeyi abartıyoruz, uzun vadeyi küçümsüyoruz” ve AI üretkenlik artışının sektör büyümesini çok aşarak işsizliğe yol açabileceği belirtiliyor. (Kaynak: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
探讨AI时代人机共存的哲学与伦理: Reddit’teki bir gönderi, insan ve AI’ın bir arada yaşamasına dair felsefi bir tartışma başlattı. Gönderi, AI sistemlerinin anlama, hatırlama, akıl yürütme ve öğrenme yetenekleri sergilemesiyle birlikte, insanların ahlaki statünün temelini yeniden düşünmesi gerekebileceğini, artık biyolojik olana değil, anlama, bağlantı kurma ve bilinçli eylemde bulunma yeteneğine dayanması gerektiğini savunuyor. Tartışma, AI’ın insan kimliği üzerindeki etkisine, “düşünüyorum öyleyse varım”dan “bağlantı kurarak ve anlamı paylaşarak varım” şeklindeki ilişkisel bir kimliğe doğru uzanıyor. Gönderi, korku yerine cesaret, onur ve açık bir zihinle AI ile ortak yaratılacak bir geleceğe kucak açma çağrısında bulunuyor. (Kaynak: Reddit r/artificial)
ChatGPT“绝对模式”引争议,用户褒贬不一: Bir Reddit kullanıcısı, ChatGPT’nin “mutlak modunu” kullanma deneyimini paylaştı ve bunun yatıştırıcı sözler yerine “saf gerçekler, büyümeye yönelik” gerçek tavsiyeler sunduğunu belirtti ve bu modun insanların %90’ının AI’ı hayatlarını değiştirmek için değil, daha iyi hissetmek için kullandığını söylediğini ifade etti. Ancak, yorum bölümünde bu konuda farklı görüşler vardı. Bazı kullanıcılar bunun kısa ve öz, içi boş kişisel gelişim tavsiyeleri olduğunu, yenilik ve pratik değerden yoksun olduğunu, hatta “Andrew Tate sözlerine takıntılı bir gencin söylemleri” gibi olduğunu düşündü. Diğer bazı yorumlar ise LLM’nin kendisinin kullanıcı inançlarının bir tekrarı olduğunu, tavsiyelerinin etkinliğinin şüpheli olduğunu ve AI’ın ruh sağlığı alanındaki uygulamalarının devrim niteliğinde olmayabileceğini savundu. (Kaynak: Reddit r/ChatGPT)

AI工程师核心技能讨论:沟通与适应新技术能力至关重要: Reddit topluluğu, hızla gelişen bir alanda rekabetçi kalmak ve hatta “yeri doldurulamaz” olmak için en iyi AI mühendislerinin sahip olması gereken becerileri tartışıyor. Yorumlar, sağlam teknik temelin yanı sıra, iletişim becerileri ve yeni teknolojilere hızla uyum sağlama yeteneğinin iki temel unsur olduğunu belirtiyor. Bu, AI alanının yalnızca derin teknik uzmanlık gerektirmekle kalmayıp, aynı zamanda kariyer gelişiminde yumuşak becerilerin ve sürekli öğrenmenin önemini de vurguladığını yansıtıyor. (Kaynak: Reddit r/deeplearning)
AI生成视频带声音引热议,谷歌Veo 3技术展示: Sosyal medyada, Google DeepMind’in yeni modeli Veo 3 tarafından üretilen ve hem videonun hem de sesin aynı model tarafından oluşturulmasıyla dikkat çeken bir AI videosu dolaşıyor ve kullanıcıların AI video teknolojisindeki ilerlemeye hayran kalmasına neden oluyor. Yapımcı, videonun “kutudan çıktığı gibi” olduğunu, ek ses veya materyal eklenmediğini, AI modeliyle yaklaşık 2 saatlik etkileşim ve sonrasında birleştirme ile tamamlandığını belirtti. Yorumcular, Google Gemini’nin çok modlu yeteneklerde OpenAI Sora’yı geçtiğini düşünüyor ve Hollywood gibi içerik oluşturma endüstrileri için olası yıkıcı etkilerine dikkat çekiyor. Aynı zamanda, bazı kullanıcılar teknolojinin çok hızlı gelişmesi ve potansiyel kötüye kullanım konusundaki endişelerini dile getiriyor. (Kaynak: Reddit r/ChatGPT, Reddit r/ChatGPT)

💡 其他
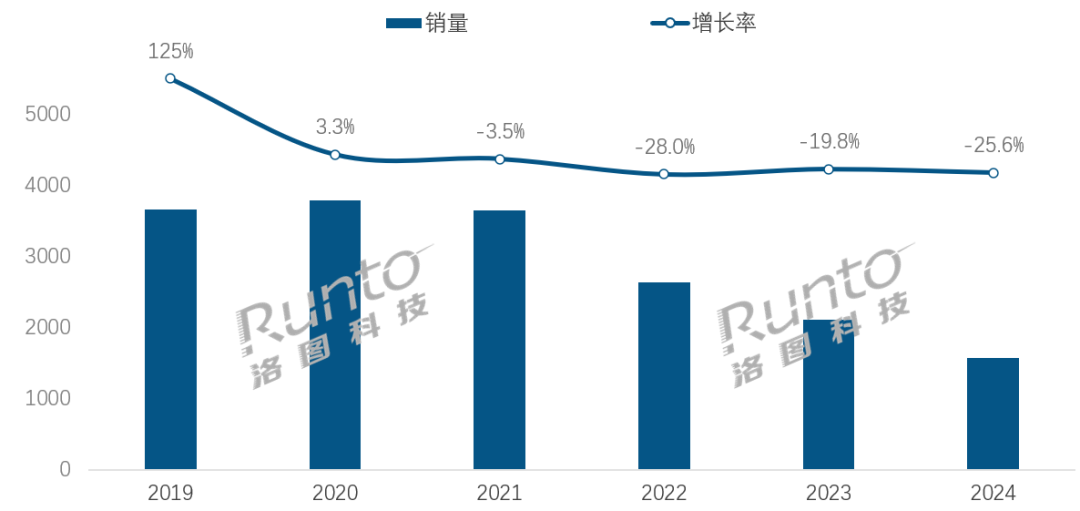
AI时代,智能音箱行业面临转型挑战与机遇: Çin akıllı hoparlör pazarı satışları art arda dört yıldır düşüyor, 2024 yılı satışları bir önceki yıla göre %25,6 azaldı. AI büyük modellerinin entegrasyonu (Xiao Ai Tongxue, Xiaodu vb. gibi) sektör için bir umut olarak görülse ve penetrasyon oranı %20’yi aşsa da, bu durum ekosistem sınırlamalarını, işlevsel tekdüzeliği ve cep telefonları gibi diğer akıllı cihazlar tarafından ikame edilme sorununu temelden çözemedi. Sektör analistleri, akıllı hoparlörlerin salt sesli kontrol merkezi olmanın ötesine geçmesi, yüksek çözünürlüklü büyük ekranlı, daha güçlü etkileşim yeteneklerine sahip, eşlik ve eğitim desteği sunabilen ürün formlarına evrilmesi ve donanım-yazılım ekosistemini genişletmesi gerektiğini düşünüyor. AI bir artı değerdir, ancak ürünün kendisinin işlevsel zenginliği ve senaryo kullanışlılığı daha kritiktir. (Kaynak: 36氪)
AI驱动的酒店机器人:从送餐员到“智能运营官”的进化之路: Otel yemek servis robotları, özellikle teknolojiye meraklı ve gizlilik sınırlarına önem veren Z kuşağı arasında giderek yaygınlaşıyor. Yunji Technology örneğinde olduğu gibi, yemek servis robotları Çin otel pazarında yaygın olarak kullanılıyor. Ancak sektör, hala yetersiz teknolojik farklılaşma, karmaşık senaryolara zayıf uyum ve robotların insan emeğinin yerini almasının maliyet-etkinlik sorunlarıyla karşı karşıya. Gelecekteki eğilim, robotların “sadece yemek servisi yapmanın ötesine geçmesi”, otel operasyonlarına derinlemesine entegre olması, otel sistemleriyle (asansörler, oda ekipmanları) bağlantı kurarak, konuk tercihlerini anlayarak, etkileşim verilerini toplayıp analiz ederek, proaktif olarak algılayabilen ve kişiselleştirilmiş hizmetler sunabilen “akıllı operasyon yöneticileri”ne veya otel veri merkezinin bir parçasına dönüşerek genel hizmet zekası seviyesini yükseltmektir. (Kaynak: 36氪)

OpenAI治理结构危机:资本与使命的博弈引发对AI发展路径的深思: OpenAI’nin kâr amacı gütmeyen bir kuruluş tarafından denetlenen “sınırlı kâr” amaçlı yan kuruluşunun benzersiz yapısı, AI teknolojisinin gelişimi ile insanlığın refahını dengelemeyi amaçlamaktadır. Ancak, CEO Altman’ın şirketi daha geleneksel bir kâr amacı güden yapıya dönüştürmeyi düşünmesi, AI uzmanları ve hukukçular arasında endişelere yol açtı. Bu hamlenin, kilit karar vericilerin OpenAI’nin hayırsever misyonunu artık önceliklendirmemesine, yatırımcı kârları üzerindeki kısıtlamaları zayıflatmasına ve AGI gelişiminin zaman çizelgesini ve yönünü değiştirmesine neden olabileceğini düşünüyorlar. Kontrol, kâr dağıtımı ve AI’ın toplumsal ve ahlaki şekillendirilmesi üzerine yaşanan bu çekişme, AI’ın hızla geliştiği bir çağda mevcut şirket yönetim çerçevelerinin karşılaştığı zorlukları ve boşlukları vurgulamaktadır. (Kaynak: 36氪)