
Anahtar Kelimeler:AlphaEvolve, Gemini, Evrimsel Algoritma, Yapay Zeka Ajanları, Algoritma Optimizasyonu, Matris Çarpımı, Borg Veri Merkezi, 4×4 Kompleks Matris Çarpımı Optimizasyonu, Google DeepMind Algoritma Keşfi, Yapay Zeka ile Otomatik Algoritma Tasarımı, Gemini 2.0 Pro Uygulaması, Borg Kaynak Planlama Optimizasyonu
🔥 Odak Noktası
Google DeepMind, AlphaEvolve’u tanıttı: Gemini tabanlı evrimsel algoritma kodlama ajanı, matematik ve bilgisayar bilimleri alanında çığır açıyor: Google DeepMind, Gemini 2.0 Pro büyük dil modelini kullanarak evrimsel algoritmalar aracılığıyla algoritma kodlarını otomatik olarak keşfeden ve optimize eden bir akıllı ajan olan AlphaEvolve’u duyurdu. AlphaEvolve, insanlar tarafından sağlanan başlangıç kodu ve değerlendirme metriklerinden yola çıkarak aday çözümleri otonom olarak üretebilir, değerlendirebilir ve iyileştirebilir. Sistem, 50’den fazla matematik probleminde üstün performans gösterdi; vakaların yaklaşık %75’inde bilinen çözümleri yeniden üretti ve %20’sinde daha iyi çözümler keşfetti. Dikkat çekici bir şekilde, AlphaEvolve 4×4 karmaşık matris çarpımındaki hesaplama sayısını 49’dan 48’e düşürerek 56 yıllık rekoru kırdı. Ayrıca, Google’ın dahili Borg veri merkezinin zamanlama algoritmasını optimize ederek küresel hesaplama kaynaklarının %0,7’sini geri kazandı ve yeni nesil TPU çiplerinin tasarımını iyileştirerek Gemini eğitim süresini %1 kısalttı. Bu başarı, yapay zekanın otomatik algoritma keşfi ve bilimsel inovasyon alanındaki muazzam potansiyelini gösteriyor; şu anda esas olarak otomatik olarak değerlendirilebilen sorunlarla ilgilense de, ilaç keşfi gibi uygulamalı bilim alanlarındaki uygulama beklentileri geniş. (Kaynak: , 量子位, 36氪)
Nvidia, Computex 2025’te birçok yapay zeka gelişmesini duyurdu, Jensen Huang Agentic AI ve Physical AI vizyonunu vurguladı: Nvidia CEO’su Jensen Huang, Computex 2025’te yaptığı açılış konuşmasında, yapay zekanın “tek seferlik yanıttan” “düşünen, akıl yürüten” Agentic AI (akıllı ajan yapay zekası) ve fiziksel dünyayı anlayan Physical AI (fiziksel yapay zeka) yönünde evrildiğini vurguladı. Bu eğilimi desteklemek için Nvidia, genişletilmiş Blackwell platformunu (Blackwell Ultra AI) duyurdu ve Grace Blackwell GB300 sisteminin tam üretime geçtiğini, çıkarım performansının önceki nesle göre 1,5 kat arttığını açıkladı. Huang ayrıca, GB300’ün 14 katı performans sunan yeni nesil yapay zeka süper çipi Rubin Ultra’nın önizlemesini yaptı. Yapay zeka altyapısı inşasını teşvik etmek için Nvidia, NVLink Fusion teknolojisini tanıttı ve Tayvan’da TSMC, Foxconn gibi şirketlerle yapay zeka süper bilgisayarı kurmak için iş birliği yaptı. Ayrıca Nvidia, insansı robot temel modeli Isaac GR00T N1.5’i güncelleyerek çevreye uyum ve görev yürütme yeteneklerini geliştirdi ve DeepMind, Disney Research ile iş birliği içinde geliştirilen fizik motoru Newton’u açık kaynak yapmayı planlıyor. (Kaynak: AI 前线, 量子位, Reddit r/artificial)
OpenAI Codex ekibi AMA’da GPT-5 ve gelecekteki ürün entegrasyon planlarını açıkladı: OpenAI Codex ekibi Reddit’te bir “Bana Her Şeyi Sor” (AMA) etkinliği düzenledi. Araştırma Başkan Yardımcısı Jerry Tworek, yeni nesil temel model GPT-5’in hedefinin mevcut model yeteneklerini geliştirmek ve model değiştirme ihtiyacını azaltmak olduğunu belirtti. Codex, Operator (görev yürütme ajanı), Deep Research (derin araştırma aracı) ve Memory (hafıza fonksiyonu) gibi mevcut araçları entegre ederek birleşik bir yapay zeka asistanı deneyimi oluşturmayı planlıyorlar. Ekip üyeleri ayrıca Codex’in geliştirilme amacını (modelin yetersiz kullanımına dair iç düşüncelerden kaynaklanan), Codex’in dahili kullanımının programlama verimliliğinde yaklaşık 3 kat artış sağladığını ve gelecekteki yazılım mühendisliğine dair beklentilerini (gereksinimleri verimli ve güvenilir bir şekilde çalıştırılabilir yazılıma dönüştürmek) paylaştı. Codex şu anda esas olarak konteyner çalışma zamanına yüklenen bilgileri kullanıyor, gelecekte en son bilgileri elde etmek için RAG teknolojisiyle birleşebilir. OpenAI ayrıca esnek fiyatlandırma planlarını araştırıyor ve Plus/Pro kullanıcılarına Codex CLI kullanımı için ücretsiz API kredisi sunmayı planlıyor. (Kaynak: 36氪)
VS Code, GitHub Copilot Chat eklentisini açık kaynak yaptığını duyurdu, açık kaynak yapay zeka kod düzenleme platformu oluşturmayı planlıyor: Visual Studio Code ekibi, VS Code’u açık, işbirlikçi ve topluluk odaklı temel prensiplere bağlı kalarak açık kaynak bir yapay zeka düzenleyicisine dönüştürme planlarını duyurdu. Bu planın bir parçası olarak, GitHub Copilot Chat eklentisi GitHub’da MIT lisansıyla açık kaynak yapıldı. Gelecekte VS Code, geliştirme verimliliğini, şeffaflığı ve güvenliği artırmak amacıyla bu yapay zeka özelliklerini kademeli olarak düzenleyicinin çekirdeğine entegre etmeyi planlıyor. Bu hamle, Microsoft’un açık kaynak alanındaki önemli bir adımı olarak kabul ediliyor ve yapay zeka destekli programlama araçları ekosistemini derinden etkileyebilir. (Kaynak: dotey, jeremyphoward)
Huawei Ascend ve DeepSeek iş birliği, MoE model çıkarım performansı Nvidia Hopper’ı aşıyor: Huawei Ascend, CloudMatrix 384 süper düğümü ve Atlas 800I A2 çıkarım sunucularının DeepSeek V3/R1 gibi ultra büyük MoE modellerini dağıtırken çıkarım performansında önemli bir atılım gerçekleştirdiğini ve belirli koşullar altında Nvidia Hopper mimarisini aştığını duyurdu. CloudMatrix 384 süper düğümü, 50ms gecikmeyle kart başına Decode veriminde 1920 Token/s’yi aştı, Atlas 800I A2 ise 100ms gecikmeyle kart başına 808 Token/s verime ulaştı. Huawei bunu, algoritma ve sistem optimizasyonu yoluyla donanım süreci sınırlamalarını telafi eden “matematikle fiziği tamamlama” stratejisine bağlıyor. İlgili teknik rapor yayınlandı ve çekirdek kod bir ay içinde açık kaynak yapılacak. Optimizasyon önlemleri arasında MoE modelleri için uzman paralel çözümleri, PD ayrık dağıtımı, vLLM çerçeve uyarlaması, A8W8C16 niceleme stratejisi ve FlashComm iletişim şeması, katman içi paralel dönüştürme, FusionSpec spekülatif çıkarım motoru ve MLA/MoE operatör donanım yakınlığı optimizasyonu yer alıyor. (Kaynak: 量子位, WeChat)
🎯 Eğilimler
Apple, verimli görsel dil modeli FastVLM’yi açık kaynak yaptı, uç cihazlarda yapay zeka deneyimini optimize ediyor: Apple, iPhone gibi uç cihazlarda verimli çalışmak üzere özel olarak tasarlanmış bir görsel dil modeli olan FastVLM’yi (Fast Vision Language Model) açık kaynak yaptı. FastVLM, konvolüsyonel katmanları Transformer modülleriyle birleştiren ve çok ölçekli havuzlama ve alt örnekleme tekniklerini kullanan yeni bir hibrit görsel kodlayıcı olan FastViTHD’yi tanıtarak görüntü işleme için gereken görsel token sayısını önemli ölçüde azaltıyor (geleneksel ViT’den 16 kat daha az). Bu, modelin yüksek doğruluğu korurken, ilk token çıktı hızının (TTFT) benzer modellere kıyasla 85 kata kadar artmasını sağlıyor. FastVLM, ana akım LLM’lerle uyumlu ve iOS/Mac ekosistemine kolayca uyarlanabilir; görüntü açıklaması, soru-cevap, analiz gibi çeşitli gerçek zamanlı metin-görüntü görevleri için 0.5B, 1.5B, 7B olmak üzere üç parametre sürümü sunuyor. (Kaynak: WeChat)
Meta, KernelLLM 8B modelini yayınladı, belirli kıyaslama testlerinde GPT-4o’yu geride bıraktı: Meta, Hugging Face’te KernelLLM 8B modelini yayınladı. İddiaya göre, KernelBench-Triton Level 1 kıyaslama testinde, bu 8 milyar parametreli model, tek seferlik çıkarım performansında GPT-4o ve DeepSeek V3 gibi daha büyük ölçekli modelleri geride bıraktı. Çoklu çıkarım durumunda ise KernelLLM’nin performansı DeepSeek R1’den daha iyiydi. Bu yayın, yapay zeka topluluğunun dikkatini çekti ve orta ve küçük ölçekli modellerin belirli görevlerde güçlü rekabet gücü sergilediğinin bir başka örneği olarak kabul edildi. (Kaynak: ClementDelangue, huggingface, mervenoyann, HuggingFace Daily Papers)
Mistral Medium 3 modeli Arena’da güçlü performans sergiliyor, özellikle teknik alanda öne çıkıyor: Mistral AI’nin yeni tanıttığı Mistral Medium 3 modeli, lmarena.ai’nin topluluk değerlendirmesinde mükemmel bir performans sergiledi; genel sohbet yeteneği sıralamasında 11. sırada yer alarak Mistral Large’a göre önemli bir gelişme kaydetti (Elo puanında 90 puanlık artış). Model, özellikle teknik alanda öne çıkıyor; matematik yeteneği sıralamasında 5., karmaşık istemler ve kodlama yeteneği sıralamasında 7., WebDev Arena’da ise 9. sırada yer alıyor. Topluluk yorumlarına göre, teknik alandaki performansı GPT-4.1 seviyesine yakın ve maliyeti GPT-4.1 mini fiyatlandırmasına benzer şekilde daha rekabetçi olabilir. Kullanıcılar modeli Mistral’in resmi sohbet arayüzünde ücretsiz olarak deneyebilirler. (Kaynak: hkproj, qtnx_, lmarena_ai)
Hugging Face Datasets, sohbet diyaloglarını doğrudan görüntüleme özelliği ekledi: Hugging Face Datasets platformu önemli bir güncelleme yaptı; kullanıcılar artık veri kümelerindeki sohbet diyaloglarını doğrudan okuyabiliyor. Bu özellik, Caleb, Maxime Labonne gibi topluluk üyeleri tarafından veri kalitesi sorunlarını çözmede büyük bir adım olarak görülüyor, çünkü orijinal diyalog verilerini doğrudan incelemek veriyi daha iyi anlamaya, veri temizliği yapmaya ve model eğitim etkinliğini artırmaya yardımcı oluyor. Daha önce, belirli diyalog içeriklerini görüntülemek ek kod veya araçlar gerektirebiliyordu; yeni özellik bu süreci basitleştirerek veri çalışmalarının kolaylığını ve şeffaflığını artırıyor. (Kaynak: eliebakouch, _lewtun, _akhaliq, maximelabonne, ClementDelangue, huggingface, code_star)
MLX LM, Hugging Face Hub ile entegre oldu, Mac’te yerel model çalıştırmayı basitleştiriyor: MLX LM artık doğrudan Hugging Face Hub’a entegre edildi, Mac kullanıcıları Apple Silicon cihazlarında 4400’den fazla LLM’yi yerel olarak daha kolay çalıştırabilir. Kullanıcıların Hugging Face Hub’daki uyumlu modellerin sayfasında “Bu modeli kullan” seçeneğine tıklaması, karmaşık bulut yapılandırmalarına veya beklemeye gerek kalmadan modeli terminalde hızla çalıştırması için yeterli. Ayrıca, doğrudan model sayfasından OpenAI uyumlu bir sunucu başlatmak da mümkün. Bu entegrasyon, yerel model çalıştırma engelini düşürmeyi ve geliştirme ile deney verimliliğini artırmayı amaçlıyor. (Kaynak: awnihannun, ClementDelangue, huggingface, reach_vb)
Nvidia, fiziksel yapay zeka çıkarım modeli Cosmos-Reason1-7B’yi açık kaynak yaptı: Nvidia, Hugging Face’te Physical AI model serisinden Cosmos-Reason1-7B’yi açık kaynak yaptı. Bu model, fiziksel dünya sağduyusunu anlamayı ve buna uygun somut kararlar üretmeyi amaçlıyor. Bu, Nvidia’nın fiziksel dünya ile yapay zekayı birleştirme yönünde attığı yeni bir adımı işaret ediyor ve robotik, otonom sürüş gibi fiziksel ortamla etkileşim gerektiren uygulamalar için yeni araçlar ve araştırma temelleri sunuyor. (Kaynak: reach_vb)
Baidu’nun video üretim modeli Steamer-I2V, VBench görüntüden videoya listesinin zirvesine yerleşti: Baidu’nun video üretim modeli Steamer-I2V, otoriter video üretim değerlendirme listesi VBench’in görüntüden videoya (I2V) kategorisinde birinci sırada yer alarak toplamda %89.38 puanla OpenAI Sora ve Google Imagen Video gibi tanınmış modelleri geride bıraktı. Steamer-I2V’nin teknik avantajları arasında piksel düzeyinde hassas görüntü kontrolü, usta işi kamera hareketleri, 1080P’ye kadar sinematik HD görüntü kalitesi ve dinamik estetik ile milyarlarca Çince çok modlu veritabanına dayalı hassas Çince semantik anlama yer alıyor. Bu başarı, Baidu’nun çok modlu üretim alanındaki gücünü gösteriyor ve yapay zeka içerik ekosistemi oluşturma stratejisinin bir parçası. (Kaynak: 36氪)

LLM’ler saat ve takvim gibi zaman görevlerini okumada düşük performans gösteriyor: Edinburgh Üniversitesi ve diğer kurumların araştırmacıları, büyük dil modellerinin (LLM) ve çok modlu büyük dil modellerinin (MLLM) birçok görevde mükemmel performans göstermesine rağmen, analog saatleri okuma ve takvim tarihlerini anlama gibi görünüşte basit zaman okuma görevlerinde doğruluk oranlarının endişe verici derecede düşük olduğunu buldu. Araştırma, ClockQA ve CalendarQA adlı iki özel test seti oluşturdu; sonuçlar, yapay zeka sistemlerinin saatleri okuma doğruluğunun yalnızca %38,7, takvim tarihlerini belirleme doğruluğunun ise yalnızca %26,3 olduğunu gösterdi. Gemini-2.0 ve GPT-o1 gibi gelişmiş modeller bile, özellikle Roma rakamları, stilize edilmiş ibreler veya artık yıllar, belirli günlerin haftanın hangi günü olduğu gibi karmaşık tarih hesaplamalarıyla uğraşırken belirgin zorluklar yaşıyor. Araştırmacılar, bunun mevcut modellerin uzamsal akıl yürütme, yapılandırılmış düzen analizi ve alışılmadık örüntülere genelleme yeteneklerindeki eksiklikleri ortaya koyduğuna inanıyor. (Kaynak: 36氪, WeChat)

Microsoft, Build konferansında Grok modelini Azure AI Foundry’ye getireceğini duyurdu: Microsoft Build 2025 geliştirici konferansında Microsoft, xAI şirketinin Grok modelinin Azure AI Foundry model serisine katılacağını duyurdu. Kullanıcılar, Haziran ayı başına kadar Azure Foundry ve GitHub’da Grok-3 ve Grok-3-mini’yi ücretsiz olarak deneyebilecekler. Bu hamle, Azure AI Foundry’nin desteklediği üçüncü taraf model yelpazesini daha da genişleteceği anlamına geliyor; gelecekte kullanıcılar OpenAI, xAI, DeepSeek, Meta, Mistral AI, Black Forest Labs gibi birçok üreticinin modellerini birleşik bir ayrılmış verimle kullanabilecekler. (Kaynak: TheTuringPost, xai)
Apple’ın AB iPhone kullanıcılarının Siri’yi üçüncü taraf sesli asistanlarla değiştirmesine izin vermeyi planladığı bildirildi: Mark Gurman’ın haberine göre Apple, Avrupa Birliği bölgesindeki iPhone kullanıcılarının Siri’yi ilk kez üçüncü taraf sesli asistanlarla değiştirmesine izin vermeyi planlıyor. Bu hamle, AB’nin giderek sıkılaşan dijital pazar düzenleme gerekliliklerine yanıt vermek, platformun açıklığını ve kullanıcı seçme özgürlüğünü artırmak amacıyla yapılıyor olabilir. Planın uygulanması halinde, sesli asistan pazarının yapısını önemli ölçüde etkileyecek ve diğer sesli asistanlara Apple ekosistemine girme fırsatı sunacaktır. (Kaynak: zacharynado)

Meta, molekül ve malzeme keşfini hızlandırmak için Open Molecules 2025 veri kümesini ve UMA modelini yayınladı: Meta AI, Open Molecules 2025 (OMol25) ve Meta Evrensel Atom Modeli’ni (UMA) yayınladı. OMol25, biyomoleküller, metal kompleksleri ve elektrolitler gibi maddeleri içeren, şu anda mevcut olan en büyük ve en çeşitli yüksek hassasiyetli kuantum kimyası hesaplama veri kümesidir. UMA, daha doğru moleküler davranış tahminleri sağlamak amacıyla 30 milyardan fazla atom üzerinde eğitilmiş bir makine öğrenimi atomlar arası potansiyel modelidir. Bu araçların açık kaynak yapılması, molekül ve malzeme bilimindeki keşif ve yeniliği hızlandırmayı amaçlamaktadır. (Kaynak: AIatMeta)
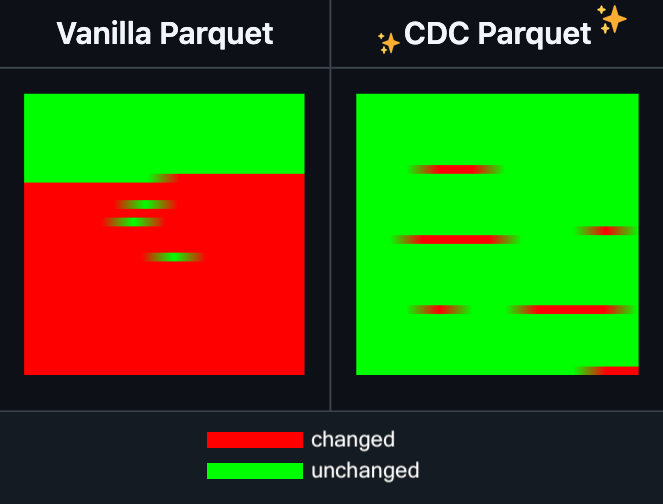
Hugging Face Datasets, Parquet dosyalarında artımlı düzenleme özelliği ekledi: Hugging Face Datasets, temel bağımlılık kütüphanesi PyArrow’nun gece sürümünün artık Parquet dosyalarında dosyayı tamamen yeniden yazmadan artımlı düzenlemeyi desteklediğini duyurdu. Bu yeni özellik, özellikle sık sık güncellenmesi veya kısmen değiştirilmesi gereken büyük ölçekli veri kümesi işlemlerinin verimliliğini büyük ölçüde artıracak, zaman ve hesaplama kaynağı tüketimini önemli ölçüde azaltacaktır. Bu hamlenin, geliştiricilerin büyük yapay zeka eğitim veri kümelerini işleme ve bakımını yapma deneyimini iyileştirmesi bekleniyor. (Kaynak: huggingface)
LangGraph, iş akışı verimliliğini artırmak için düğüm düzeyinde önbellekleme özelliği ekledi: LangGraph, açık kaynak sürümüne düğüm/görev önbellekleme özelliği eklendiğini duyurdu. Bu özellik, özellikle genel bölümler içeren veya sık sık hata ayıklama gerektiren akıllı ajan (Agent) iş akışlarında tekrarlayan hesaplamaları önleyerek iş akışlarını hızlandırmayı amaçlamaktadır. Kullanıcılar, yapay zeka uygulamalarını daha hızlı yinelemek ve optimize etmek için zorunlu API’de veya grafik API’sinde önbelleği kullanabilirler. Bu, LangGraph’ın bu haftaki açık kaynak yayın serisi güncellemelerinin ilki. (Kaynak: hwchase17)

Sakana AI, yeni yapay zeka mimarisi “Sürekli Düşünme Makineleri”ni (CTM) tanıttı: Tokyo merkezli yapay zeka girişimi Sakana AI, “Sürekli Düşünme Makineleri” (Continuous Thought Machines, CTM) adlı yeni bir yapay zeka model mimarisi yayınladı. CTM, modellerin insan beyni gibi daha az yönlendirmeyle akıl yürütmesini sağlamayı amaçlıyor. Bu yeni mimari, mevcut yapay zeka modellerinin karmaşık akıl yürütme ve otonom öğrenme konularında karşılaştığı zorluklara yeni çözümler sunabilir. (Kaynak: dl_weekly)
Microsoft ve Nvidia, RTX AI PC işbirliğini derinleştiriyor, TensorRT Windows ML’e geliyor: Microsoft Build ve Taipei Uluslararası Bilgisayar Fuarı (COMPUTEX) sırasında Nvidia ve Microsoft, RTX AI PC geliştirme işbirliğini daha da ilerleteceklerini duyurdu. Nvidia’nın TensorRT çıkarım optimizasyon kütüphanesi yeniden tasarlandı ve Microsoft’un yeni çıkarım yığını Windows ML’e entegre edildi. Bu hamle, yapay zeka uygulamalarının geliştirme sürecini basitleştirmeyi ve RTX GPU’ların PC tarafındaki yapay zeka görevlerinde en yüksek performansı tam olarak kullanmasını sağlamayı, yapay zekanın kişisel bilgi işlem cihazlarında yaygınlaşmasını ve uygulanmasını teşvik etmeyi amaçlıyor. (Kaynak: nvidia)
Bilibili, animasyon video üretim modeli Index-AniSora’yı açık kaynak yaptı, birçok metrikte SOTA’ya ulaştı: Bilibili, IJCAI 2025’te yayınlanan kendi geliştirdiği animasyon video üretim modeli Index-AniSora’yı açık kaynak yaptığını duyurdu. AniSora, anime video üretimi için özel olarak tasarlanmış olup, Japon animesi, Çin animesi, manga uyarlamaları gibi çeşitli stilleri destekler ve videonun belirli bölgelerini yönlendirme, zamansal yönlendirme (ilk/son kare yönlendirmesi, anahtar kare interpolasyonu gibi) gibi hassas kontrolleri gerçekleştirebilir. Projenin açık kaynak içeriği, CogVideoX-5B tabanlı AniSoraV1.0 ve Wan2.1-14B tabanlı AniSoraV2.0’ın eğitim ve çıkarım kodlarını, eğitim veri kümesi oluşturma araçlarını, animasyona özel Benchmark sistemini ve insan tercihine dayalı pekiştirmeli öğrenme ile optimize edilmiş AniSoraV1.0_RL modelini içerir. (Kaynak: WeChat)

Tencent Hunyuan, ilk çok modlu birleşik CoT ödül modeli UnifiedReward-Think’i açık kaynak yaptı: Tencent Hunyuan, Shanghai AI Lab, Fudan Üniversitesi ve diğer kurumlarla işbirliği içinde, uzun zincirli akıl yürütme (CoT) yeteneğine sahip ilk birleşik çok modlu ödül modeli olan UnifiedReward-Think’i önerdi. Bu model, ödül modelinin karmaşık görsel üretim ve anlama görevlerini değerlendirirken “düşünmeyi öğrenmesini” sağlayarak değerlendirme doğruluğunu, görevler arası genelleme yeteneğini ve akıl yürütme yorumlanabilirliğini artırmayı amaçlamaktadır. Proje, model, veri kümesi, eğitim betikleri ve değerlendirme araçları dahil olmak üzere tamamen açık kaynak yapılmıştır. (Kaynak: WeChat)
Alibaba, video üretim ve düzenleme modeli Tongyi Wanxiang Wan2.1-VACE’yi açık kaynak yaptı: Alibaba, video üretim ve düzenleme modeli Tongyi Wanxiang Wan2.1-VACE’yi resmi olarak açık kaynak yaptı. Bu model, metinden video oluşturma, görüntü referanslı video oluşturma, video yeniden boyama, video kısmi düzenleme, video arka planını genişletme ve video süresini uzatma gibi çeşitli işlevlere sahiptir. Bu açık kaynak sürümü, 1.3B ve 14B olmak üzere iki versiyonu içeriyor; 1.3B versiyonu tüketici sınıfı grafik kartlarında çalıştırılabiliyor ve AIGC video oluşturma engelini düşürmeyi amaçlıyor. (Kaynak: WeChat)
ByteDance, görsel dil modeli Seed1.5-VL’yi yayınladı, birçok kıyaslama testinde lider: ByteDance, 532M parametreli bir görsel kodlayıcı ve 20B aktif parametreli bir uzmanlar karışımı (MoE) LLM’den oluşan görsel dil modeli Seed1.5-VL’yi oluşturdu. Nispeten kompakt mimarisine rağmen, 60 genel kıyaslama testinin 38’inde SOTA performansına ulaştı ve GUI kontrolü ve oyun oynama gibi ajan merkezli görevlerde OpenAI CUA ve Claude 3.7 gibi modelleri geride bırakarak güçlü çok modlu akıl yürütme yeteneği sergiledi. (Kaynak: WeChat)
MiniMax, otoregresif TTS modeli MiniMax-Speech’i tanıttı, 32 dilde sıfır-çekim ses klonlamayı destekliyor: MiniMax, Transformer tabanlı otoregresif metinden sese (TTS) modeli MiniMax-Speech’i önerdi. Bu model, referans sesten transkripsiyona gerek kalmadan tını özelliklerini çıkarabilir, sıfır-çekim yöntemiyle referans tınıyla tutarlı ve etkileyici konuşma üretebilir ve tek örnekli ses klonlamayı destekler. Flow-VAE teknolojisi ile sentezlenmiş ses kalitesini artırır ve 32 dili destekler. Bu model, nesnel ses klonlama metriklerinde SOTA seviyesine ulaştı ve genel TTS Arena sıralamasında zirvede yer aldı; ayrıca ses duygu kontrolü, metinden sese ve profesyonel ses klonlama gibi uygulamalara genişletilebilir. (Kaynak: WeChat)
OuteTTS 1.0 (0.6B) yayınlandı, 14 dili destekleyen Apache 2.0 açık kaynak TTS modeli: OuteAI, Qwen-3 0.6B üzerine inşa edilmiş hafif bir metin-konuşma (TTS) modeli olan OuteTTS-1.0-0.6B’yi yayınladı. Model, Apache 2.0 lisansını kullanıyor ve Çince, İngilizce, Japonca, Korece dahil 14 dili destekliyor. Python çıkarım kütüphanesi OuteTTS v0.4.2, EXL2 asenkron toplu çıkarım, vLLM deneysel toplu çıkarım ve Llama.cpp sunucusunun sürekli toplu işleme ve harici URL model çıkarımını desteklemek üzere güncellendi. Tek bir NVIDIA L40S GPU üzerindeki kıyaslama testleri, vLLM OuteTTS-1.0-0.6B FP8’in 32 toplu iş boyutunda 0.05 RTF (gerçek zamanlı faktör) değerine ulaşabildiğini gösteriyor. Model ağırlıkları (ST, GGUF, EXL2, FP8) Hugging Face’te kullanıma sunuldu. (Kaynak: Reddit r/LocalLLaMA)

Hugging Face ve Microsoft Azure işbirliğini derinleştiriyor, 10.000’den fazla açık kaynak model Azure AI Foundry’ye geliyor: Microsoft Build konferansında CEO Satya Nadella, Hugging Face ile işbirliğini genişlettiklerini duyurdu. Şu anda Hugging Face aracılığıyla Azure AI Foundry’de 11.000’den fazla en popüler açık kaynak model sunuluyor ve kullanıcıların kolayca dağıtım yapması sağlanıyor. Bu hamle, Azure’un yapay zeka ekosistemini daha da zenginleştiriyor ve geliştiricilere daha fazla model seçeneği ve daha kolay bir geliştirme deneyimi sunuyor. (Kaynak: ClementDelangue, _akhaliq)

Intel, Arc Pro B50/B60 serisi GPU’ları tanıttı, yapay zeka ve iş istasyonu pazarına odaklanıyor, 24GB sürümü yaklaşık 500 dolar: Intel, Computex’te yeni Arc Pro B serisi profesyonel grafik kartlarını tanıttı; bunlar arasında Arc Pro B50 (16GB VRAM, yaklaşık 299 dolar) ve Arc Pro B60 (24GB VRAM, yaklaşık 500 dolar) bulunuyor. Bunlardan, çift B60 GPU’dan oluşan 48GB VRAM’li “Project Battlematrix” iş istasyonu çözümü de tanıtıldı ve fiyatının 1000 doların altında olması bekleniyor. Bu ürünler, yapay zeka hesaplama ve profesyonel iş istasyonları için yüksek performanslı ve uygun maliyetli çözümler sunmayı amaçlıyor; özellikle yüksek VRAM yapılandırması, yerel olarak büyük dil modellerini çalıştırmak için çekici. Yeni ürünlerin bu yılın 3. çeyreğinde piyasaya sürülmesi, başlangıçta OEM üreticileri aracılığıyla sunulması ve 4. çeyrekte DIY sürümlerinin çıkması bekleniyor. (Kaynak: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

🧰 Araçlar
Moondream Station Linux sürümünü yayınladı, yerel Moondream çalıştırmayı basitleştiriyor: Moondream Station, Moondream’i (bir görsel dil modeli) yerel cihazlarda çalıştırmayı basitleştirmeyi amaçlayan bir araç olup, şimdi Linux işletim sistemini desteklediğini duyurdu. Bu, Linux kullanıcılarının çok modlu yapay zeka deneyleri ve uygulama geliştirme için Moondream modellerini daha kolay dağıtabileceği ve kullanabileceği anlamına geliyor. (Kaynak: vikhyatk)
Flowith, sınırsız adımları, bağlamı ve araç çağrılarını destekleyen sonsuz akıllı ajan NEO’yu yayınladı: Yapay zeka uygulama şirketi Flowith, küresel olarak ilk sınırsız adım, sınırsız bağlam ve sınırsız araç çağrısını desteklediğini iddia ettiği en son akıllı ajan ürünü NEO’yu yayınladı. Bu akıllı ajan, bulutta uzun süre çalışmak üzere tasarlanmış olup, kıyaslama ölçütlerinin ötesinde bir zeka seviyesine sahip ve sıfır maliyetli, sınırsız olduğunu iddia ediyor. Bu yayın, yapay zeka akıllı ajanlarının karmaşık uzun vadeli görevleri yerine getirme ve harici yetenekleri entegre etme konusunda yeni bir ilerlemeyi temsil edebilir. (Kaynak: _akhaliq, op7418)

Kapa AI, Weaviate kullanarak etkileşimli teknik doküman soru-cevap aracı “Ask AI” geliştirdi: Kapa AI, kullanıcıların doğal dil konuşması yoluyla teknik dokümanları, blogları, eğitimleri, GitHub sorunlarını ve forumları gibi tüm teknik bilgi tabanını sorgulamasına olanak tanıyan “Ask AI” adlı akıllı bir widget geliştirdi. Verimli semantik arama ve bilgi erişimi sağlamak için Kapa AI, yerleşik hibrit arama yeteneği, Docker uyumluluğu ve hızla artan kullanıcı ve veri ölçeğini desteklemek için çoklu kiracılık özelliklerine değer vererek Weaviate vektör veritabanını benimsedi. (Kaynak: bobvanluijt)

Geliştirici, Gemini Flash’ı kullanarak ekran görüntüsünü HTML’e dönüştüren hızlı bir MVP aracı oluşturdu: Geliştirici Daniel Huynh, Google AI’nin Gemini Flash modelini kullanarak bir hafta sonunda tasarım taslaklarını, rakip ürünleri veya ilham veren ekran görüntülerini hızla HTML koduna dönüştüren bir MVP (Minimum Viable Product – Minimum Uygulanabilir Ürün) aracı oluşturdu. Araç, Hugging Face Spaces’te ücretsiz deneme sürümüyle kullanıma sunuldu ve çok modlu modellerin ön uç geliştirme yardımındaki potansiyelini gösteriyor. (Kaynak: osanseviero, _akhaliq)
Azure AI Foundry Agent Service resmi olarak kullanıma sunuldu, LlamaIndex ile entegre edildi: Microsoft, Azure AI Foundry Agent Service’in resmi olarak yayınlandığını (GA) ve LlamaIndex için birinci sınıf destek sunduğunu duyurdu. Bu hizmet, kurumsal müşterilerin müşteri destek asistanları, süreç otomasyon botları, çoklu akıllı ajan sistemleri ve kurumsal veri ve araçlarla güvenli bir şekilde entegre edilmiş çözümler oluşturmasına yardımcı olmayı amaçlıyor ve kurumsal düzeyde yapay zeka akıllı ajanlarının geliştirilmesini ve uygulanmasını daha da teşvik ediyor. (Kaynak: jerryjliu0)
tinygrad: PyTorch ve micrograd arasında yer alan minimalist bir derin öğrenme çerçevesi: tinygrad, basitliği temel tasarım felsefesi olarak benimseyen bir derin öğrenme çerçevesidir ve yeni hızlandırıcılar eklemenin en kolay yolu olmayı, çıkarım ve eğitimi desteklemeyi amaçlar. LLaMA ve Stable Diffusion gibi modelleri destekler ve işlemleri birleştirmek ve performansı optimize etmek için tembel değerlendirme (lazy evaluation) kullanır. tinygrad, GPU (OpenCL), CPU (C kodu), LLVM, Metal, CUDA gibi çeşitli hızlandırıcıları destekler. Kodu kısa ve özdür, temel işlevler az sayıda kod satırıyla gerçekleştirilir, bu da geliştiricilerin anlamasını ve genişletmesini kolaylaştırır. (Kaynak: GitHub Trending)
Nano AI Search, “Süper Arama” özelliğini tanıttı, çoklu modelleri ve MCP araç kutusunu entegre ediyor: Nano AI Search (bot.n.cn), daha derinlemesine bilgi edinme ve işleme yeteneği sunmayı amaçlayan “Süper Arama” özelliğini ekledi. Bu özellik, yurtiçi ve yurtdışından yüzlerce büyük modeli entegre ediyor ve isteğe bağlı olarak otomatik geçiş yapabiliyor; yerleşik MCP evrensel araç kutusu, binlerce yapay zeka aracını destekliyor, web sayfaları, resimler, videolar, PDF’ler gibi çeşitli formatlardaki dosyaları işleyebiliyor ve kod oluşturma, veri analizi gibi işlemleri gerçekleştirebiliyor. Aynı zamanda genel alan aramasını yerel bilgi tabanı özel alan aramasıyla birleştirerek daha kapsamlı sonuçlar sunuyor ve yerleşik metinden resme, metinden videoya yetenekleri içeriyor. Kullanıcı deneyimi, bu özelliğin arama sonuçlarını grafikler içeren ayrıntılı raporlara ve şık web sayfalarına dönüştürebildiğini, pazar araştırması, alışveriş karşılaştırması, bilgi düzenleme gibi çeşitli senaryolar için uygun olduğunu gösteriyor. (Kaynak: WeChat)
Clara: LLM, Agent, otomasyon ve görüntü üretimini entegre eden modüler çevrimdışı yapay zeka çalışma alanı: Geliştiriciler, tamamen çevrimdışı, modüler bir yapay zeka çalışma alanı oluşturmayı amaçlayan Clara adlı açık kaynaklı bir proje başlattı. Kullanıcılar, gösterge tablosunda widget biçiminde yerel LLM sohbetlerini (RAG, görüntü, belge, kod yürütme desteği, Ollama ve OpenAI benzeri API’lerle uyumlu) düzenleyebilir, hafıza ve mantığa sahip Agent’lar oluşturabilir, yerel N8N entegrasyonu aracılığıyla otomasyon süreçlerini çalıştırabilir (1000’den fazla ücretsiz şablon sunar) ve Stable Diffusion (ComfyUI) kullanarak yerel olarak görüntüler üretebilir. Clara, Mac, Windows, Linux sürümlerini sunarak kullanıcıların birden fazla yapay zeka aracı arasında sık sık geçiş yapma sorununu çözmeyi ve tek duraklı bir yapay zeka işlemi sağlamayı amaçlamaktadır. (Kaynak: Reddit r/LocalLLaMA)
AI Playlist Curator: LLM kullanarak YouTube çalma listelerini kişiselleştirilmiş olarak düzenleyen Python aracı: Bir geliştirici, kullanıcıların büyük ve düzensiz YouTube çalma listelerini otomatik olarak düzenlemesine yardımcı olmayı amaçlayan AI Playlist Curator adlı bir Python projesi oluşturdu. Bu araç, LLM kullanarak kullanıcı tercihlerine göre şarkıları sınıflandırır ve kişiselleştirilmiş alt çalma listeleri oluşturur; kaydedilmiş herhangi bir çalma listesini ve beğenilen şarkıları işlemeyi destekler. Proje GitHub’da açık kaynak olarak yayınlandı ve geliştirici daha da geliştirmek için topluluk geri bildirimi almayı umuyor. (Kaynak: Reddit r/MachineLearning)
OpenAI Codex programlama asistanı ChatGPT iOS uygulamasına geldi: OpenAI, programlama asistanı Codex’in artık ChatGPT’nin iOS uygulamasına entegre edildiğini duyurdu. Kullanıcılar mobil cihazlarında yeni programlama görevleri başlatabilir, kod farklılıklarını görüntüleyebilir, değişiklik talep edebilir ve hatta çekme istekleri (PR) gönderebilir. Bu özellik ayrıca, kullanıcıların farklı cihazlar arasında sorunsuz bir şekilde çalışmasını kolaylaştırmak için kilit ekranı canlı etkinlikleri aracılığıyla Codex’in ilerlemesini izlemeyi de destekliyor. (Kaynak: openai)
Kollektiv: LLM sohbetlerinde bağlamın tekrar tekrar yapıştırılması sorununu çözmek için MCP protokolünü kullanan araç: Geliştiriciler, kullanıcıların LLM’lerle (Claude gibi) sohbet ederken büyük miktarda bağlamı (araştırma makaleleri, SDK belgeleri, kişisel notlar, kitap içerikleri gibi) tekrar tekrar kopyalayıp yapıştırma sorununu çözmeyi amaçlayan Kollektiv aracını tanıttı. Kollektiv, kullanıcıların bu belge kaynaklarını bir kez yüklemesine ve MCP (Model Control Protocol) sunucusu aracılığıyla herhangi bir uyumlu IDE veya MCP istemcisinden (Cursor, Windsurf, PyCharm vb.) isteğe bağlı olarak çağırmasına olanak tanır. MCP sunucusu, kullanıcı kimlik doğrulaması, veri izolasyonu ve verilerin sohbet arayüzüne isteğe bağlı olarak akışından sorumludur. Araç şu anda hassas veya gizli materyaller için önerilmemektedir. (Kaynak: Reddit r/ClaudeAI)
📚 Öğrenme
Google DeepMind, AlphaEvolve teknik raporunu yayınladı, algoritma keşif yeteneğini ortaya koyuyor: Google DeepMind, yapay zeka sistemi AlphaEvolve hakkındaki teknik raporunu yayınladı. AlphaEvolve, evrimsel algoritmalar aracılığıyla algoritmalar tasarlayabilen ve optimize edebilen Gemini tabanlı bir kodlama ajanıdır. Rapor, AlphaEvolve’un yapılandırılmış geri bildirim döngüleri aracılığıyla aday algoritma çözümlerini otonom olarak nasıl ürettiğini, değerlendirdiğini ve iyileştirdiğini ayrıntılı olarak açıklıyor ve 4×4 karmaşık matris çarpım algoritması rekorunu kırmak da dahil olmak üzere birçok matematik ve hesaplama bilimi probleminde çığır açıyor. Bu rapor, yapay zekanın otomatik bilimsel keşif ve algoritma inovasyonu alanındaki potansiyelini anlamak için önemli bir referans sağlıyor. (Kaynak: , HuggingFace Daily Papers)
DeepLearning.AI “Yapay Zeka Tarayıcı Ajanları Oluşturma” kursunu başlattı: DeepLearning.AI, “Building AI Browser Agents” adlı yeni bir kurs başlattı. Kurs, AGI şirketinin kurucu ortakları Div Garg ve Naman Agarwal tarafından veriliyor ve öğrencilerin tarayıcıyla etkileşime girebilen yapay zeka ajanları (Agent) oluşturma teknolojisinde ustalaşmalarına yardımcı olmayı amaçlıyor. Kurs içeriği, web otomasyonu, bilgi çıkarma, kullanıcı arayüzü etkileşimi gibi yapay zekanın tarayıcı ortamındaki uygulamalarını kapsayabilir. (Kaynak: DeepLearningAI)
Qwen3 teknik raporu yayınlandı: Alibaba, en son nesil büyük dil modeli Qwen3’ün teknik raporunu yayınladı. Rapor, Qwen3’ün model mimarisini, eğitim yöntemlerini, performans değerlendirmesini ve çeşitli kıyaslama testlerindeki performansını ayrıntılı olarak açıklıyor. Qwen3 serisi modeller, daha güçlü dil anlama, üretme ve çok modlu işleme yetenekleri sunmayı amaçlıyor; teknik raporunun yayınlanması, araştırmacılara ve geliştiricilere bu modelin teknik ayrıntılarını derinlemesine anlama fırsatı sunuyor. (Kaynak: _akhaliq)

Makale Tartışması: Çoklu Görüş Araması ve Veri Yönetimi ile Adım Adım Teorem İspatını Geliştirme (MPS-Prover): Yeni bir makale, yeni bir adım adım otomatik teorem ispatı (ATP) sistemi olan MPS-Prover’ı tanıtıyor. Bu sistem, verimli eğitim sonrası veri yönetimi stratejileri (performanstan ödün vermeden yaklaşık %40 gereksiz veriyi budama) ve çoklu görüş ağaç arama mekanizması (öğrenilmiş eleştirmen modelini sezgisel kurallarla entegre etme) aracılığıyla mevcut adım adım ispatlayıcılardaki yanlı arama rehberliği sorununu aşıyor. Deneyler, MPS-Prover’ın miniF2F ve ProofNet gibi birçok kıyaslama ölçütünde SOTA performansına ulaştığını ve daha kısa, daha çeşitli ispatlar ürettiğini gösteriyor. (Kaynak: HuggingFace Daily Papers)
Makale Tartışması: Görsel Planlama – Sadece Görüntülerle Düşünmek (Visual Planning): Yeni bir makale, modellerin metne dayanmak yerine tamamen görsel temsiller (görüntü dizileri) aracılığıyla planlama yapmasını sağlayan “görsel planlama” paradigmasını öneriyor. Araştırmacılar, uzamsal ve geometrik bilgiler içeren görevlerde dilin en doğal akıl yürütme aracı olmayabileceğini savunuyor. Pekiştirmeli öğrenme yoluyla görsel planlama çerçevesi VPRL’yi tanıtıyorlar ve büyük görsel modelleri eğitim sonrası optimize etmek için GRPO’yu kullanıyorlar; FrozenLake, Maze ve MiniBehavior gibi görsel navigasyon görevlerinde önemli gelişmeler elde ederek saf metin tabanlı akıl yürütme planlama varyantlarından daha iyi performans gösteriyorlar. (Kaynak: HuggingFace Daily Papers)
Makale Tartışması: Akıl Yürütme Ölçeklendirmesi Büyük Dil Modellerinin Gerçekliğini Artırabilir (Scaling Reasoning can Improve Factuality): Bir çalışma, büyük dil modellerinin (LLM) akıl yürütme süreçlerini ölçeklendirmenin karmaşık açık alan soru-cevap (QA) görevlerindeki gerçeklik doğruluğunu artırıp artıramayacağını araştırıyor. Araştırmacılar, QwQ-32B ve DeepSeek-R1-671B gibi modellerden akıl yürütme yörüngelerini çıkarıyor ve çeşitli Qwen2.5 serisi modelleri ince ayar yaparken bilgi grafiği yollarını akıl yürütme yörüngelerine dahil ediyor. Deneyler, tek bir çalıştırmada daha küçük akıl yürütme modellerinin orijinal talimat ince ayarlı modellere kıyasla gerçeklik doğruluğunda belirgin bir artış gösterdiğini ortaya koyuyor. Test zamanı hesaplama ve token bütçesi artırıldığında, gerçeklik doğruluğu %2-8 oranında istikrarlı bir şekilde artabiliyor. (Kaynak: HuggingFace Daily Papers)
Makale Tartışması: Mergenetic – Basit Evrimsel Model Birleştirme Kütüphanesi: Yeni bir makale, evrimsel model birleştirme için açık kaynaklı bir kütüphane olan Mergenetic’i tanıtıyor. Model birleştirme, mevcut modellerin yeteneklerini ek eğitime gerek kalmadan yeni modellerde birleştirmeye olanak tanır. Mergenetic, birleştirme yöntemlerini ve evrimsel algoritmaları kolayca birleştirmeyi destekler ve değerlendirme maliyetini düşürmek için hafif uygunluk değerlendiricileriyle birleşir. Deneyler, Mergenetic’in çeşitli görevlerde ve dillerde mütevazı donanım kullanarak rekabetçi sonuçlar üretebildiğini kanıtlıyor. (Kaynak: HuggingFace Daily Papers)
Makale Tartışması: Grup Düşüncesi – Token Düzeyinde İşbirliği Yapan Çoklu Eşzamanlı Akıl Yürütme Ajanları (Group Think): Yeni bir makale, tek bir LLM’nin birden fazla eşzamanlı akıl yürütme ajanı (düşünür) olarak hareket etmesini sağlayan “Grup Düşüncesi”ni (Group Think) öneriyor. Bu ajanlar, birbirlerinin kısmi üretim ilerlemelerine görünürlüğü paylaşır, Token düzeyinde birbirlerinin akıl yürütme yörüngelerine dinamik olarak uyum sağlar, böylece gereksiz akıl yürütmeyi azaltır, kaliteyi artırır ve gecikmeyi düşürür. Bu yöntem, yerel GPU’larda uç çıkarım için uygundur ve deneyler, özel olarak eğitilmemiş açık kaynaklı LLM’ler kullanıldığında bile gecikmeyi iyileştirdiğini kanıtlamaktadır. (Kaynak: HuggingFace Daily Papers)
Makale Tartışması: İnsanlar Strateji Oyunlarında LLM Rakiplerinden Rasyonellik ve İşbirliği Bekliyor (Humans expect rationality and cooperation from LLM opponents): İlk kez yapılan kontrollü parasal teşvikli bir laboratuvar deneyi, insanların çok oyunculu P-beauty yarışmasında diğer insanlara ve LLM’lere karşı oynarken davranış farklılıklarını inceliyor. Sonuçlar, insanların LLM’lere karşı oynarken önemli ölçüde daha düşük sayılar seçtiğini gösteriyor; bunun temel nedeni “sıfır” Nash dengesi seçimlerinin yaygınlığındaki artış. Bu değişim, esas olarak LLM’lerin daha güçlü akıl yürütme yeteneklerine ve işbirliği eğilimlerine sahip olduğunu düşünen yüksek stratejik akıl yürütme yeteneğine sahip denekler tarafından yönlendiriliyor. (Kaynak: HuggingFace Daily Papers)
Makale Tartışması: Görsel Dil Modellerinden Basit Yarı Denetimli Bilgi Damıtma için Çift Başlı Optimizasyon (Dual-Head Optimization for KD): Yeni bir makale, yarı denetimli bir ortamda bilgiyi görsel dil modellerinden (VLM) kompakt, göreve özgü modellere aktarmak için basit ve etkili bir bilgi damıtma (KD) çerçevesi olan DHO’yu (Dual-Head Optimization) öneriyor. DHO, etiketli verileri ve öğretmen tahminlerini bağımsız olarak öğrenen çift tahmin başlığı sunar ve çıkarım sırasında çıktılarını doğrusal olarak birleştirir, böylece denetimli sinyal ile damıtma sinyali arasındaki gradyan çakışmasını hafifletir. Deneyler, DHO’nun birden fazla alanda ve ince taneli veri kümelerinde tek başlı KD temellerinden daha iyi performans gösterdiğini ve ImageNet’te SOTA’ya ulaştığını gösteriyor. (Kaynak: HuggingFace Daily Papers)
Makale Tartışması: GuardReasoner-VL – Pekiştirmeli Akıl Yürütme ile VLM’leri Koruma: Görsel dil modellerinin (VLM) güvenliğini artırmak için yeni bir makale, akıl yürütme tabanlı VLM koruma modeli GuardReasoner-VL’yi tanıtıyor. Temel fikir, çevrimiçi pekiştirmeli öğrenme (RL) yoluyla koruma modelini denetim kararları vermeden önce dikkatli bir şekilde akıl yürütmeye teşvik etmektir. Araştırmacılar, 123K örnek ve 631K akıl yürütme adımı içeren GuardReasoner-VLTrain adlı bir akıl yürütme külliyatı oluşturdular ve denetimli ince ayar (SFT) ile modelin akıl yürütme yeteneğini soğuk başlattılar, ardından çevrimiçi RL ile daha da geliştirdiler. Deneyler, bu modelin (3B/7B sürümleri açık kaynak yapılmıştır) üstün performans gösterdiğini ve ortalama F1 puanında bir sonraki en iyi modelden %19,27 daha yüksek olduğunu gösteriyor. (Kaynak: HuggingFace Daily Papers)
Makale Tartışması: Çoklu Token Tahmini Kayıtçılara İhtiyaç Duyar (Multi-Token Prediction Needs Registers): Yeni bir makale, gelecekteki hedefleri tahmin etmek için giriş dizisine öğrenilebilir kayıtçı Token’larını serpiştirerek basit ve etkili bir çoklu Token tahmin yöntemi olan MuToR’u öneriyor. Mevcut yöntemlerle karşılaştırıldığında, MuToR’un parametre artışı ihmal edilebilir düzeydedir, mimari değişiklik gerektirmez, mevcut önceden eğitilmiş modellerle uyumludur ve bir sonraki Token ön eğitim hedefiyle tutarlıdır, özellikle denetimli ince ayar için uygundur. Bu yöntem, dil ve görsel alanlardaki üretken görevlerde etkinliğini ve genelliğini göstermektedir. (Kaynak: HuggingFace Daily Papers)
Makale Tartışması: MMLongBench – Uzun Bağlamlı Görsel Dil Modelleri için Etkili ve Kapsamlı Kıyaslama Testi: Uzun bağlamlı görsel dil modellerinin (LCVLM) değerlendirme ihtiyaçlarına yönelik olarak yeni bir makale, çeşitli uzun bağlamlı görsel dil görevlerini kapsayan ilk kıyaslama olan MMLongBench’i tanıtıyor. MMLongBench, görsel RAG, çoklu örnek ICL gibi beş görev kategorisini kapsayan 13331 örnek içerir ve çeşitli görüntü türleri sunar. Tüm örnekler, 8K-128K Token’lık beş standartlaştırılmış giriş uzunluğunda sunulur. 46 kapalı ve açık kaynaklı LCVLM üzerinde yapılan kıyaslama testleri, tek bir görevin performansının genel uzun bağlam yeteneğini temsil etmediğini, mevcut modellerin hala büyük bir gelişme alanı olduğunu ve akıl yürütme yeteneği güçlü modellerin genellikle uzun bağlam performansının daha iyi olduğunu ortaya koymuştur. (Kaynak: HuggingFace Daily Papers)
Makale Tartışması: MatTools – Malzeme Bilimi Araçları için Büyük Dil Modeli Kıyaslama Testi: Yeni bir makale, büyük dil modellerinin (LLM) fizik tabanlı hesaplamalı malzeme bilimi yazılım paketlerinin kodunu üreterek ve güvenli bir şekilde yürüterek malzeme bilimi sorularını yanıtlama yeteneğini değerlendirmek için MatTools kıyaslama testini öneriyor. MatTools, bir malzeme simülasyon aracı soru-cevap (QA) kıyaslama testi (pymatgen tabanlı, 69225 QA çifti içerir) ve gerçek dünya araç kullanımı kıyaslama testi (49 görev, 138 alt görev içerir) içerir. Çeşitli LLM’lerin değerlendirilmesi şunları ortaya koyuyor: genel modeller özel modellerden daha iyi performans gösteriyor; yapay zeka yapay zekayı daha iyi anlıyor; basit yöntemler daha etkili. (Kaynak: HuggingFace Daily Papers)
Makale Tartışması: LLM Filigranlarının Sağlamlığını, Metin Kalitesini ve Güvenliğini Dengeleyen Evrensel Bir Ortak Yaşam Filigran Çerçevesi: Mevcut büyük dil modeli (LLM) filigran şemalarının sağlamlık, metin kalitesi ve güvenlik arasındaki ödünleşim sorununa yönelik olarak, yeni bir makale evrensel bir ortak yaşam filigran çerçevesi önermektedir. Bu çerçeve, logit tabanlı ve örnekleme tabanlı yöntemleri entegre eder ve seri, paralel ve hibrit olmak üzere üç strateji tasarlar. Hibrit çerçeve, çeşitli yönlerde performansı optimize etmek amacıyla filigranı uyarlanabilir bir şekilde gömmek için Token entropisini ve semantik entropiyi kullanır. Deneyler, bu yöntemin mevcut temel çizgilerden daha iyi performans gösterdiğini ve SOTA seviyesine ulaştığını göstermektedir. (Kaynak: HuggingFace Daily Papers)
Makale Tartışması: CheXGenBench – Sentetik Göğüs Röntgenlerinin Doğruluğu, Gizliliği ve Faydası için Birleşik Kıyaslama: Yeni bir makale, sentetik göğüs röntgeni üretimini değerlendirmek için çok yönlü bir çerçeve olan CheXGenBench’i tanıtıyor; aynı anda doğruluğu, gizlilik risklerini ve klinik faydayı değerlendiriyor. Bu çerçeve, standartlaştırılmış veri bölümlerini ve birleşik bir değerlendirme protokolünü (20’den fazla nicel metrik) içerir ve 11 önde gelen metinden görüntüye mimarinin üretim kalitesini, potansiyel gizlilik açıklarını ve sonraki klinik uygulanabilirliğini analiz eder. Araştırma, mevcut değerlendirme protokollerinin üretim doğruluğunu değerlendirmede yetersiz kaldığını ortaya koyuyor. Ekip aynı zamanda yüksek kaliteli sentetik veri kümesi SynthCheX-75K’yı da yayınladı. (Kaynak: HuggingFace Daily Papers)
Klasik ders kitabı “Fonksiyonel Analiz”in yazarı Peter Lax 99 yaşında vefat etti: Uygulamalı matematiğin devi, Abel Ödülü’nü alan ilk uygulamalı matematikçi Peter Lax 99 yaşında vefat etti. Lax, yazdığı klasik ders kitabı “Fonksiyonel Analiz” ile tanınıyordu ve kısmi diferansiyel denklemler, akışkanlar mekaniği, sayısal hesaplama gibi alanlarda Lax eşdeğerlik teoremi, Lax-Friedrichs ve Lax-Wendroff yöntemleri gibi temel katkılarda bulundu. Aynı zamanda bilgisayar teknolojisini matematiksel analize uygulayan ilk öncülerden biriydi ve çalışmaları bilgisayar çağındaki matematik gelişimini derinden etkiledi. (Kaynak: 量子位)

Eski OpenAI Çinli Başkan Yardımcısı Lilian Weng’in on bin kelimelik uzun makalesi “Why We Think”, test zamanı hesaplamasını ve düşünce zincirini tartışıyor: Eski OpenAI Çinli Başkan Yardımcısı Lilian Weng, “Test-time Compute” (Test Zamanı Hesaplaması) ve “Chain-of-Thought” (CoT – Düşünce Zinciri) gibi teknolojilerin büyük dil modellerinin performansını ve zeka seviyesini nasıl önemli ölçüde artırdığını derinlemesine inceleyen “Why We Think” başlıklı on bin kelimelik uzun bir makale yayınladı. Makale, insanların düşünme biçimindeki “hızlı ve yavaş düşünme” çift sistem teorisine benzetme yaparak, modelin çıktı vermeden önce daha fazla “düşünmesinin” (akıllı kod çözme, CoT çıkarımı, gizli değişken modellemesi vb. yoluyla) mevcut yetenek darboğazlarını aşabileceğine işaret ediyor. Makalede, token tabanlı düşünme, paralel örnekleme ve sıralı revizyon, pekiştirmeli öğrenme ve harici araç entegrasyonu, düşünce sadakati ve sürekli uzay düşüncesi gibi birçok araştırma yönündeki ilerlemeler ve zorluklar ayrıntılı olarak ele alınıyor. (Kaynak: 量子位)

Harbin Teknoloji Enstitüsü ve Pennsylvania Üniversitesi ortaklaşa PointKAN’ı tanıttı, KANs tabanlı nokta bulutu analizinde yeni SOTA: Harbin Teknoloji Enstitüsü (Shenzhen) ve Pennsylvania Üniversitesi araştırma ekipleri, Kolmogorov-Arnold Networks (KANs) tabanlı bir 3D nokta bulutu analiz çözümü olan PointKAN’ı tanıttı. Bu yöntem, geometrik afin modülü ve paralel yerel özellik çıkarma modülü aracılığıyla ve geleneksel MLP’lerdeki sabit aktivasyon fonksiyonları yerine öğrenilebilir aktivasyon fonksiyonlarını kullanarak nokta bulutunun karmaşık geometrik özelliklerini daha etkili bir şekilde yakalar. Aynı zamanda ekip, rasyonel fonksiyonları B-spline fonksiyonlarının yerine kullanarak ve grup içi parametre paylaşımı yaparak parametre sayısını ve hesaplama yükünü önemli ölçüde azaltan Efficient-KANs yapısını önerdi. Deneyler, PointKAN ve hafif sürümü PointKAN-elite’in sınıflandırma, parça segmentasyonu ve az örnekli öğrenme gibi görevlerde SOTA veya rekabetçi performans elde ettiğini gösteriyor. (Kaynak: WeChat)

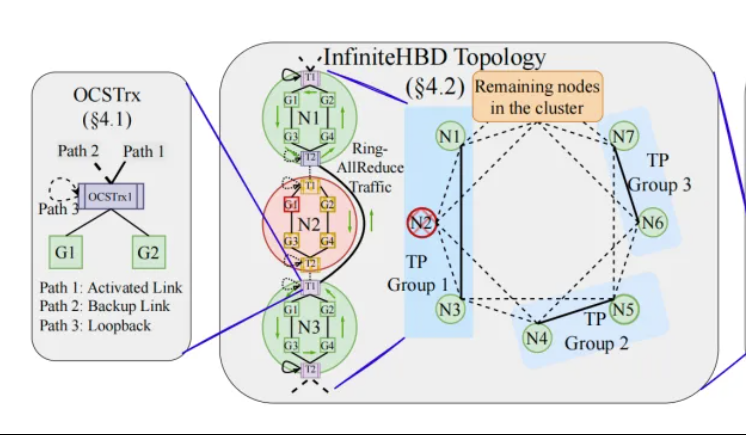
Pekin Üniversitesi/Step AI/XiZhi, InfiniteHBD’yi önerdi: Yeni nesil yüksek bant genişlikli GPU ara bağlantı mimarisi, büyük model eğitim maliyetini düşürüyor: Pekin Üniversitesi, Step AI (Jieyue Xingchen) ve XiZhi Technology araştırma ekipleri, mevcut büyük model dağıtık eğitimindeki yüksek bant genişlikli alan (HBD) mimarisinin sınırlamalarına yönelik olarak InfiniteHBD çözümünü önerdi. Bu mimari, optik yol anahtarlama (OCS) yeteneği gömülü optoelektronik dönüştürme modülünü temel alarak dinamik olarak yeniden yapılandırılabilir noktadan çok noktaya bağlantı sağlar, düğüm düzeyinde arıza izolasyonu ve düşük kaynak parçalanması yeteneğine sahiptir. Araştırma, InfiniteHBD’nin birim maliyetinin NVIDIA NVL-72’nin yalnızca %31’i olduğunu, GPU israf oranının sıfıra yakın olduğunu ve MFU’nun (model FLOPs kullanım oranı) NVIDIA DGX’e kıyasla 3,37 kata kadar artırılabileceğini gösteriyor. Bu çalışma SIGCOMM 2025 tarafından kabul edildi. (Kaynak: WeChat, 量子位)
ICML 2025 Makale Hızlı Bakış: OmniAudio 360° Videodan Uzamsal Ses Üretiyor: ICML 2025’te yayınlanacak bir araştırma, doğrudan 360° panoramik videodan yönlü birinci dereceden ambisonik (FOA) uzamsal ses üretebilen OmniAudio çerçevesini öneriyor. Araştırma öncelikle büyük ölçekli 360° video ve uzamsal ses eşleştirilmiş veri kümesi Sphere360’ı oluşturdu. OmniAudio iki aşamalı bir eğitim kullanıyor: ilk olarak, genel ses özelliklerini öğrenmek için büyük ölçekli uzamsal olmayan ses verilerini kullanarak kabadan inceye akış eşleştirme ön eğitimi kendi kendine denetimli olarak gerçekleştiriliyor; ardından (genel ve yerel görsel özellikleri çıkaran) çift dallı bir video kodlayıcı ile birleştirilerek denetimli ince ayar yapılıyor. Deneysel sonuçlar, OmniAudio’nun nesnel ve öznel değerlendirme metriklerinde mevcut temel modellerden önemli ölçüde daha iyi performans gösterdiğini ortaya koyuyor. (Kaynak: WeChat)

Huawei Selftok: Ters difüzyona dayalı otoregresif görsel belirteçleyici, çok modlu üretimi birleştiriyor: Huawei Pangu çok modlu üretim ekibi, otoregresif öncülü görsel Token’lara dahil etmek için ters difüzyon sürecini kullanan yenilikçi bir görsel Token’laştırma çözümü olan Selftok teknolojisini önerdi. Bu, piksel akışını kesinlikle nedensellik yasalarına uyan ayrık dizilere dönüştürerek mevcut uzamsal Token şemaları ile otoregresif (AR) paradigma arasındaki çakışma sorununu çözmeyi amaçlıyor. Selftok Tokenizer, çift akışlı bir kodlayıcı (görüntü dalı SD3 VAE’yi devralır, metin dalı öğrenilebilir sürekli vektör grubudur) ve yeniden etkinleştirme mekanizmalı bir niceleyici kullanır. Deneyler, Selftok’un ImageNet yeniden yapılandırma metriklerinde SOTA’ya ulaştığını ve Ascend AI ve MindSpeed çerçevesi üzerinde eğitilen Selftok dAR-VLM’nin GenEval gibi metinden görüntüye kıyaslama ölçütlerinde GPT-4o’yu aştığını gösteriyor. Bu çalışma CVPR 2025 en iyi makale adayı seçildi. (Kaynak: WeChat)
Yan Shuicheng ekibi, çok modlu genel amaçlı modelleri sınıflandırmak için General-Level değerlendirme çerçevesini ve General-Bench kıyaslama ölçütünü yayınladı: Singapur Ulusal Üniversitesi’nden Profesör Yan Shuicheng, Nanyang Teknoloji Üniversitesi’nden Profesör Zhang Hanwang ve diğerlerinin öncülüğünde on önde gelen üniversite, çok modlu genel amaçlı modeller için General-Level değerlendirme çerçevesini ve büyük ölçekli kıyaslama veri kümesi General-Bench’i ortaklaşa yayınladı. Bu çerçeve, otonom sürüş sınıflandırma yaklaşımından esinlenerek, çok modlu büyük dil modellerinin (MLLM) genelliğini ve performansını değerlendirmek için beş seviye (Seviye 1-5) belirler. Temel değerlendirme standardı, modelin görevler arasında, anlama ve üretme paradigmaları arasında ve çapraz modaliteler arasında bilgi aktarımı ve geliştirme yeteneğini inceleyen “sinerji etkisidir”. General-Bench, 700’den fazla görev ve 320.000 örnek içerir. 100’den fazla mevcut MLLM üzerinde yapılan değerlendirmeler, çoğu modelin L2-L3 seviyesinde olduğunu ve henüz hiçbir modelin L5’e ulaşamadığını göstermektedir. (Kaynak: WeChat)

💼 Ticari
Sakana AI, Mitsubishi UFJ Financial Group (MUFG) ile çok yıllık bir ortaklık anlaşması imzaladı: Japon yapay zeka girişimi Sakana AI, Japonya’nın en büyük bankası Mitsubishi UFJ Financial Group (MUFG Bank) ile çok yıllık kapsamlı bir ortaklık anlaşması imzaladığını duyurdu. Sakana AI, MUFG Bank’a çevik ve güçlü yapay zeka teknolojisi sağlayarak, yüz yıllık geçmişe sahip bu bankanın hızla gelişen yapay zeka alanında rekabetçi kalmasına yardımcı olmayı amaçlıyor. Bu işbirliğinin Sakana AI’nin bir yıl içinde kârlılığa ulaşmasına yardımcı olması bekleniyor. (Kaynak: SakanaAILabs, SakanaAILabs)

Cohere, güvenli akıllı ajan platformu Cohere North’u Dell’in yerelleştirilmiş kurumsal yapay zeka çözümlerine getirmek için Dell ile işbirliği yapıyor: Yapay zeka şirketi Cohere, güvenli, akıllı ajan yetenekli kurumsal yapay zeka çözümlerini hızlandırmak için Dell Technologies ile işbirliği yaptığını duyurdu. Dell, Cohere’in güvenli akıllı ajan platformu Cohere North’un yerel (on-premises) dağıtım çözümünü kurumlara sunan ilk sağlayıcı olacak. Bu işbirliği, hassas verilerle çalışan ve sıkı uyumluluk gereksinimleri olan sektörler için özellikle kritik öneme sahip olup, kurumların kendi veri merkezlerinde Cohere’in gelişmiş yapay zeka ajan teknolojisini dağıtmasına ve çalıştırmasına olanak tanıyor. (Kaynak: sarahookr)

Mistral AI, MGX ve Bpifrance ile işbirliği yaparak Fransa’da Avrupa’nın en büyük yapay zeka kampüsünü kuruyor: Mistral AI, Abu Dabi destekli teknoloji yatırım şirketi MGX ve Fransız ulusal yatırım bankası Bpifrance ile işbirliği yaparak Fransa’nın Paris bölgesinde Avrupa’nın en büyük yapay zeka kampüsünü kuracağını duyurdu. Bu kampüs, veri merkezlerini, yüksek performanslı bilgi işlem kaynaklarını, eğitim ve araştırma tesislerini entegre edecek. Nvidia da teknik destek sağlayarak bu projede yer alacak. Bu hamle, Avrupa yapay zeka ekosisteminin gelişimini teşvik etmeyi ve Fransa’nın küresel yapay zeka alanındaki stratejik konumunu güçlendirmeyi amaçlıyor. (Kaynak: arthurmensch, arthurmensch)
🌟 Topluluk
Yapay zeka çalışanları arasında ADHD yaygınlığı dikkat çekiyor, %20-30’u aşabilir: Sosyal medyada yapay zeka alanında çalışan kişiler arasında dikkat eksikliği hiperaktivite bozukluğu (ADHD) yaygınlığına ilişkin tartışmalar ortaya çıktı. Bir kullanıcı, bu alanın nöroçeşitlilik özelliklerine sahip birçok yeteneği cezbettiğini gözlemledi. Minh Nhat Nguyen, yapay zeka endüstrisinde %20-30’dan fazla kişinin ADHD’li olabileceğini yorumladı. Bu durum, yapay zeka araştırma ve geliştirme çalışmalarının yüksek düzeyde odaklanma, hızlı yineleme ve yaratıcı düşünme gereksinimleriyle ilgili olabilir; bu özellikler bazen ADHD’nin bazı belirtileriyle örtüşmektedir. (Kaynak: Dorialexander)
Yapay zeka çağında becerilerin değersizleşmesi derin düşüncelere yol açıyor, araç hakimiyeti değil sistemin yeniden yapılandırılması kilit önem taşıyor: Derinlemesine bir analiz makalesi, yapay zeka çağındaki asıl krizin “yapay zeka araçlarını kullanıp kullanamama” değil, becerilerin kendisinin değersizleşmesi ve tüm çalışma sisteminin yeniden yapılandırılması olduğunu belirtiyor. Makale, Maginot Hattı, konteynerleşme, daktiloların kelime işlemcilerle yer değiştirmesi gibi örneklerle, sadece yeni araçları kullanmayı öğrenmenin liderliği garanti etmediğini, asıl önemli olanın yapay zekanın işin yapısını, süreçlerini ve organizasyon mantığını nasıl değiştirdiğini anlamak olduğunu savunuyor. Sistem yeniden yazıldığında, önceden yüksek değerli olan beceriler hızla marjinalleşebilir. Üretkenlikteki artış, bireysel değerin artmasını sağlamayabilir, çünkü değer yeni sistemin koordinasyon katmanını kontrol eden öznere akacaktır. Makale, “yapay zekayı öğrenirsen öne geçersin”, “yapay zeka daha çok iş yapmamı sağlıyor, bu yüzden daha değerliyim”, “iş pozisyonları değişmiyor, sadece çalışma şekli değişiyor” gibi sekiz popüler yanılgıyı çürütüyor ve kişinin kendi konumunu ve değerini sistem düzeyinde düşünmesi gerektiğini vurguluyor. (Kaynak: 36氪)
Eski Google CEO’su Schmidt: İnsan dışı zekanın yükselişi küresel düzeni yeniden şekillendirecek, yapay zeka risk ve zorluklarına karşı dikkatli olunmalı: Eski Google CEO’su Eric Schmidt, bir röportajda toplumun “insan dışı zekanın” yıkıcı potansiyelini ciddi şekilde hafife aldığı uyarısında bulundu. Yapay zekanın dil üretiminden stratejik karar almaya doğru ilerlediğini ve karmaşık görevleri bağımsız olarak tamamlayabildiğini belirtti. Schmidt, yapay zekanın getirdiği üç temel zorluğu vurguladı: enerji ve hesaplama gücü darboğazları (ABD’nin 90 gigawatt ek elektriğe ihtiyacı var), kamuya açık verilerin tükenmeye yakın olması (bir sonraki aşamada yapay zeka tarafından üretilen verilere ihtiyaç duyulacak) ve yapay zekanın insanların mevcut bilgisinin ötesine geçerek “yeni bilgi” yaratmasının nasıl sağlanacağı. Ayrıca üç büyük riske işaret etti: yapay zekanın tekrarlayan kendi kendini geliştirmesinin kontrolden çıkması, silah kontrolünü ele geçirmesi ve yetkisiz kendi kendini kopyalaması. Çin-ABD yapay zeka rekabetinin arttığı bir ortamda, açık kaynaklı yapay zekanın hızla yayılmasının güvenlik riskleri getirebileceğini ve hatta “nükleer caydırıcılığa” benzer bir “önleyici saldırı” durumuna yol açabileceğini belirtti. Schmidt, küresel yapay zeka yönetişimi diyaloğunun derhal başlatılması çağrısında bulundu ve sistem tasarımının en başından itibaren insan özgürlüğünün korunmasının yerleşik olması gerektiğini vurguladı. (Kaynak: 36氪)

GitHub CEO’su “programlamanın gereksizliği” tezine karşı çıkıyor, yapay zeka çağında insan programcıların hala önemli olduğunu vurguluyor: Nvidia CEO’su Jensen Huang ve diğerlerinin “gelecekte programlama öğrenmeye gerek kalmayacak” şeklindeki görüşlerine karşı GitHub CEO’su Thomas Dohmke bir röportajda itiraz etti. 2025’in programlama ajanları (SWE Agent) yılı olacağını ancak insan programcıların rolünün hala kritik olduğunu belirtti. Dohmke, yapay zekanın geliştiricilerin yeteneklerini artıran bir asistan olması gerektiğini, tamamen yerini almaması gerektiğini vurguladı. Gelecekte yazılım geliştirmenin insan ve yapay zeka işbirliği modeline evrileceğini, geliştiricilerin görevleri dağıtan ve sonuçları denetleyen “akıllı ajan orkestra şefleri” gibi olacağını tasavvur etti. GitHub CPO’su Mario Rodriguez de şirketin Copilot ile bireysel yetenekleri güçlendirmeye kararlı olduğunu belirtti. Yapay zeka geliştikçe, insan düşüncesini ve eylemini temsil edebilen makineleri programlamayı ve yeniden programlamayı anlamanın hayati önem taşıdığını, kod öğrenmekten vazgeçmenin akıllı ajanların geleceğindeki söz hakkından vazgeçmek anlamına geldiğini düşünüyorlar. (Kaynak: 36氪, 量子位)

Yapay zeka destekli programlama hararetli tartışmalara yol açıyor: Verimlilik artışı önemli, ancak insan geliştiricilerin rolü hala kritik: Onlarca yıllık programlama deneyimine sahip bir geliştirici, yapay zekanın (muhtemelen Codex veya benzeri bir araç) saatlerce uğraştığı bir hatayı dakikalar içinde çözdüğü ve kodu optimize ettiği bir deneyimi paylaştı ve yapay zekayı “hiç yorulmayan süper güçlü bir takım arkadaşı” olarak nitelendirdi. Bu deneyim toplulukta tartışmalara yol açtı. Çoğu kişi, yapay zekanın kod üretme, hata düzeltme, bilgi özetleme konularındaki güçlü yeteneğini kabul ediyor ve verimliliği önemli ölçüde artırabileceğini düşünüyor. Ancak, bazı geliştiriciler yapay zekanın hala hata yapabildiğini, özellikle karmaşık mantık, sınır koşulları ve yaratıcı çözümler konusunda insanlardan geri kaldığını ve çıktılarının deneyimli geliştiriciler tarafından incelenmesi ve eleştirel bir şekilde değerlendirilmesi gerektiğini belirtiyor. Microsoft CEO’su Nadella da yapay zekanın bir güçlendirme aracı olduğunu, yazılım geliştirmenin artık yapay zekasız olamayacağını, ancak insanların hırsının ve etkinliğinin hala önemli olduğunu vurguluyor. Tartışmalar genel olarak, yapay zekanın programlama şeklini değiştireceği, geliştiricilerin yapay zeka ile işbirliği yapmanın yeni paradigmasına uyum sağlaması, daha üst düzey mimari tasarım ve sorun tanımlamaya odaklanması gerektiği yönünde. (Kaynak: Reddit r/ChatGPT, WeChat)
AI Agent Manus kayıtları açtı ancak fiyatlandırması yüksek, yerli ve yabancı devlerle rekabetle karşı karşıya, Çince sürümünün yayınlanması şüpheli: AI Agent platformu Manus, davet kodlarının yoğun ilgi görmesinin ardından resmi olarak kayıtlara açıldı, ancak şu anda yalnızca yurtdışı kullanıcılara yönelik ve Çince sürümü sunulmuyor. Kullanıcı geri bildirimlerine göre, puan tüketim sistemi kullanılıyor; ücretsiz puanlar (kayıtta 1000, günlük 300) yalnızca basit görevleri tamamlamaya yetiyor, karmaşık görevler (web tabanlı Sudoku oyunu yapmak gibi) için ücretli puan satın almak gerekiyor, ortalama 1 dolar 100 puan, fiyatı oldukça yüksek. Sektör uzmanları, Manus’un üçüncü taraf büyük modellere (örneğin yurtdışı sürümünde Claude) bağımlı olmasının maliyeti artırdığını ve bulut tabanlı sanal alan çalıştırmanın da ek masraflara yol açtığını analiz ediyor. Çince sürümünün gecikmesi, yerel model kaydı, kullanıcıların ödeme alışkanlıkları ve pazar rekabetiyle ilgili olabilir. ByteDance’in Coze’u, Baidu’nun “Xinxiang” APP’si gibi yerli ve yabancı ürünler şimdiden rekabet oluşturmuş durumda. Manus yeni finansman sağlamış olsa da, “hafif model, ağır uygulama” modelinin rekabet avantajı test ediliyor. (Kaynak: 36氪)
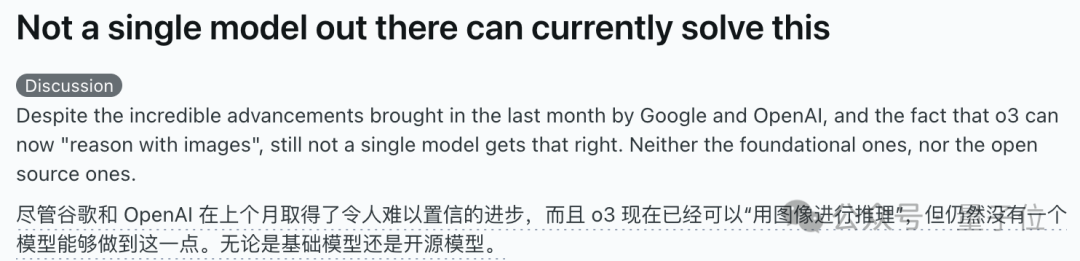
Yapay zeka modelleri “küpü tamamlama” görsel akıl yürütme sorusunda topluca çuvalladı, gerçek anlama yetenekleri hakkında tartışmalara yol açtı: Eksik bir küpü tamamlamak için kaç küçük küp gerektiğini hesaplamayı gerektiren bir görsel akıl yürütme sorusu, OpenAI o3, Google Gemini 2.5 Pro, DeepSeek, Qwen3 dahil olmak üzere birçok ana akım yapay zeka modelini zorladı. Modellerin verdiği cevaplar farklıydı; bunun temel nedeni, nihai büyük küpün özellikleri (örneğin 3x3x3, 4x4x4, 5x5x5) hakkındaki farklı anlayışlarıydı. İpuçlarıyla yönlendirilse bile, modeller soruyu bir kerede doğru bir şekilde çözmekte zorlandı. Bazı kullanıcılar, sorunun kendisinin muğlak olabileceğini ve insanların da bu konuda kafa karışıklığı yaşayabileceğini belirtti. Bu durum, yapay zeka modellerinin sorunu gerçekten anlayıp anlamadığı veya yalnızca örüntü eşleştirmeye mi dayandığı konusunda tartışmalara yol açtı ve mevcut yapay zekanın karmaşık uzamsal akıl yürütme ve görsel anlama konusundaki sınırlamalarını vurguladı. (Kaynak: 36氪)
Kullanıcılar LLM’lerin talimat takibi ve akıl yürütmedeki “aşırı düşünme” sorununu tartışıyor: Sosyal medya ve makale tartışmaları, büyük dil modellerinin (LLM) zincirleme düşünme (CoT) gibi akıl yürütme süreçlerini kullanırken bazen “aşırı düşündüğünü” ve bunun da basit talimatları doğru bir şekilde takip edememesine yol açtığını belirtiyor. Örneğin, belirli sayıda kelime yazması veya belirli bir ifadeyi tekrarlaması istendiğinde, CoT modelin bu temel kısıtlamaları göz ardı ederek görevin genel içeriğine daha fazla odaklanmasına veya ek açıklayıcı içerik eklemesine neden olabilir. Araştırmacılar bu olguyu ölçmek için “kısıtlı dikkat” metriğini önerdiler ve bağlamsal öğrenme, kendi kendine yansıma, kendi kendine akıl yürütme seçimi ve sınıflandırıcı akıl yürütme seçimi gibi hafifletme stratejilerini test ettiler. Bu, tüm görevlerin CoT için uygun olmadığını ve basit talimatların daha doğrudan bir yürütme şekli gerektirebileceğini gösteriyor. (Kaynak: menhguin, omarsar0)

Yapay Zeka Ekonomisi Üzerine Yeniden Düşünmek: Ucuz Bilişsel Emek Geleneksel Ekonomi Modellerini Kırıyor, Değer Dağılımı Yeniden Şekillenmeyle Karşı Karşıya: Tartışmalara yol açan bir görüşe göre, yapay zekanın yükselişi bilişsel emeği (rapor yazma, veri analizi, kod yazma gibi) son derece ucuz hale getiriyor ve bu durum, temel varsayımı “insan zekasının kıt ve pahalı olması” olan klasik ekonomi modellerini temelden sarsıyor. Yapay zeka, neredeyse sıfır marjinal maliyetle büyük miktarda bilgi işini tamamlayabildiğinde, üretkenlik fırlayabilir ancak tek görev değeri hızla düşecek ve uzmanlaşma avantajı aşınacaktır. Değer dağılımı artık basitçe verimliliğe veya çıktıya göre değil, yeni kıt kaynakları (veri, platformlar, yapay zeka modellerinin kendisi gibi) kimin kontrol ettiğine bağlı olacaktır. Bu, tarihteki teknolojik değişimlerde (hızlı modanın giyim endüstrisine, akış hizmetlerinin müzik endüstrisine etkisi gibi) verimlilik artışının getirdiği faydanın tamamen emekçilere akmadığı, sistem koordinatörleri tarafından elde edildiği durumlara benzemektedir. Makale, yapay zekanın sadece görevleri otomatikleştirmekle kalmayıp, aynı zamanda “düşünmeyi” de metalaştırdığı uyarısında bulunuyor; bu, modern ekonomi tarihindeki en yıkıcı güç olabilir. (Kaynak: Reddit r/artificial)
Yapay Zeka Çağında Kurumsal Strateji: “Akıllı Şirket” Tuzağından Kaçınmak, Eski Süreçleri Optimize Etmek Yerine Yeniden Yapılandırmak Gerekir: Birçok şirket yapay zekayı benimserken, onu mevcut süreçleri optimize etme, maliyetleri düşürme ve verimliliği artırma aracı olarak kullanma eğilimindedir ve “aynı şeyi daha akıllıca yapma” şeklindeki “akıllı şirket” tuzağına düşmektedir. Ancak, gerçek değişim eski süreçleri daha akıllı hale getirmek değil, bu süreçlerin hala var olması gerekip gerekmediğini düşünmek ve tamamen yeni, yapay zeka yerel sistemler ve iş modelleri oluşturmaktır. Teknoloji basitçe eski sistemlere uyum sağlamayacak, sistemi yeniden şekillendirecektir. Şirketler, yapay zeka tarafından yakında ortadan kaldırılacak süreçlere optimizasyon için aşırı kaynak yatırmaktan kaçınmalı, bunun yerine yeni kuralları tanımlamaya, karar verme şekillerini, koordinasyon mekanizmalarını ve organizasyonel yapıları temelden değiştirmeye odaklanmalıdır. (Kaynak: 36氪)
💡 Diğer
LangChain New York çevrimdışı buluşma etkinliği: LangChain, 22 Mayıs Perşembe günü New York’ta Tabs ve TavilyAI ile ortaklaşa bir çevrimdışı buluşma etkinliği düzenleyeceğini duyurdu. Etkinlik içeriğinde ocak başı sohbetleri, ürün tanıtımları ve diğer geliştiricilerle交流环节leri yer alacak. (Kaynak: hwchase17, LangChainAI)

Küresel Yapay Zeka Konferansı Tokyo Durağı Haziran’da düzenlenecek: “Küresel Yapay Zeka Konferansı Tokyo Durağı” adlı bir etkinlik 7-8 Haziran tarihlerinde Japonya’nın Tokyo kentinde düzenlenmesi planlanıyor. Etkinliğe çok sayıda tanınmış yapay zeka geliştiricisi, sanatçısı, yatırımcısı vb. katılacak. Yapay zeka alanına ilgi duyan ve Japonya’ya gitmeyi planlayan kişiler ilgili kayıt bilgilerini takip edebilirler. (Kaynak: op7418)

Yapay zeka hizmet mimarisi paradigması “Model olarak Hizmet”ten “Ajan olarak Hizmet”e doğru kayıyor: Yapay zeka teknolojisinin gelişmesiyle birlikte, yapay zeka hizmet mimarisi “Model olarak Hizmet”ten (MaaS) “Ajan olarak Hizmet”e (AaaS) doğru derin bir sıçrama yaşıyor. Yapay zeka Ajanları, hedef odaklı, çevreye duyarlı, otonom karar verme ve öğrenme yetenekleriyle, geleneksel yapay zeka modellerinin pasif olarak komutları yerine getirme modelini aşıyor. Bağımsız olarak düşünebiliyor, görevleri parçalayabiliyor, yollar planlayabiliyor ve karmaşık hedefleri tamamlamak için harici araçları çağırabiliyorlar. Bu dönüşüm, temel altyapıdan (hesaplama gücü, veri), çekirdek algoritmalara ve büyük modellere, orta katman Ajan bileşenlerine ve platformlarına, ardından da terminal ürün uygulamalarına (genel amaçlı, dikey sektör, gömülü Ajan) kadar tüm değer zincirinin kapsamlı bir şekilde gelişmesini teşvik ediyor. HeyGen, Laiye Technology, Waveform Intelligence gibi Çinli yapay zeka Ajan şirketleri de aktif olarak yurtdışına açılarak denizaşırı pazarları keşfediyor. Yüksek hesaplama maliyeti, yetersiz arz gibi zorluklarla karşılaşılmasına rağmen, algoritma optimizasyonu, özel çipler, uç bilişim gibi çözümlerle yapay zeka Ajanlarının potansiyeli sürekli olarak ortaya çıkarılıyor. (Kaynak: 36氪)