
Anahtar Kelimeler:AI Programlama Ajanı, Codex, AlphaEvolve, AI Çıkarım Paradigması, MoE Modeli, AI Çipi, AI Eğitimi, AI Kısa Dizisi, OpenAI Codex-1 Modeli, Google DeepMind AlphaEvolve, ByteDance Seed1.5-VL, Qwen ParScale Teknolojisi, NVIDIA GB300 Sistemi
🔥 Odak
OpenAI, yeni model codex-1 tarafından desteklenen bulut tabanlı AI programlama ajanı Codex’i duyurdu: OpenAI, yazılım mühendisliği için optimize edilmiş, o3’ün özel olarak ayarlanmış bir sürümü olan codex-1’e dayanan bulut tabanlı AI programlama ajanı Codex’i kullanıma sundu. Codex, bulut tabanlı bir sandbox ortamında birden fazla görevi güvenli bir şekilde paralel olarak işleyebilir, GitHub ile entegre olarak kod kütüphanelerini doğrudan çağırabilir, böylece modülleri hızla oluşturabilir, kod tabanıyla ilgili soruları yanıtlayabilir, güvenlik açıklarını düzeltebilir, PR gönderebilir ve otomatik test ve doğrulama yapabilir. Geçmişte günler veya saatler süren görevler, Codex ile 30 dakika içinde tamamlanabilir. Araç, ChatGPT Pro, Enterprise ve Team kullanıcılarına sunulmuş olup, geliştiriciler için bir “10x mühendis” olmayı ve yazılım geliştirme süreçlerini yeniden şekillendirmeyi amaçlamaktadır. (Kaynak: 36氪)
Google DeepMind, AI’ın özerk evrimiyle matematik ve algoritma alanlarında çığır açan AlphaEvolve’u tanıttı: Google DeepMind’in AI sistemi AlphaEvolve, kendi kendini evrimleştirerek ve büyük dil modellerini eğiterek birçok matematik ve bilim alanında çığır açtı. 4×4 matris çarpım algoritmasını (56 yıl sonra ilk kez) geliştirdi, altıgen doldurma problemini optimize etti (16 yıl sonra ilk kez) ve “öpüşme sayısı problemi”nde ilerleme kaydetti. AlphaEvolve, algoritmaları özerk bir şekilde optimize edebiliyor, hatta Gemini modelinin eğitimini hızlandırmanın bir yolunu buldu ve Google’ın dahili hesaplama altyapısını optimize etmek için kullanılarak hesaplama kaynaklarından %0,7 tasarruf sağladı. Bu, AI’ın sadece sorunları çözmekle kalmayıp yeni bilgiler de keşfedebildiğini gösteriyor ve bilimsel araştırma paradigmalarını altüst ederek AI’ın bilim yaratmasını sağlama potansiyeli taşıyor. (Kaynak: 36氪)
Altman’ın Sequoia AI Zirvesi konuşması: AI üç yıl içinde gerçek dünyaya girecek, yaşamı ve işi yeniden şekillendirecek: OpenAI CEO’su Altman, Sequoia AI Zirvesi’nde 2025’te AI ajanlarının (özellikle kodlama alanında) pratik hale geleceğini, 2026’da AI’ın büyük bilimsel keşiflere yol açacağını ve 2027’de robotların fiziksel dünyaya girerek değer yaratacağını öngördü. OpenAI’ın erken keşiflerden ChatGPT’nin doğuşuna kadar olan yolculuğunu anlattı ve gelecekteki AI ürünlerinin, bireyin tüm yaşam deneyimlerini barındırabilen ve akıllı varsayılan arayüz haline gelen “çekirdek AI aboneliği” hizmetleri olacağını belirtti. OpenAI, çekirdek modellere ve uygulama senaryolarına odaklanacak ve “küçük ekip, büyük sorumluluk” organizasyonel verimliliğini sürdürecektir. (Kaynak: 36氪)
Nvidia Computex konuşması: Kişisel AI bilgisayarı üretime girdi, yeni nesil GB300 sistemi tanıtıldı, Tayvan’da AI süper bilgisayarı kurulması planlanıyor: Nvidia CEO’su Jensen Huang, Computex 2025’te kişisel AI bilgisayarı DGX Spark’ın tam üretime geçtiğini ve birkaç hafta içinde piyasaya sürüleceğini duyurdu; yeni nesil AI sistemi GB300 (72 adet Blackwell Ultra GPU ve 36 adet Grace CPU ile donatılmış) ise 3. çeyrekte piyasaya sürülecek. Nvidia, TSMC ve Foxconn ile birlikte Tayvan’da bir AI süper bilgisayar merkezi kuracak. Aynı zamanda Blackwell RTX Pro 6000 iş istasyonu serisi ve Grace Blackwell Ultra Superchip’i duyurdu ve Temmuz ayında robot eğitimi için Newton fizik motorunu açık kaynak olarak sunmayı planlıyor. Huang, AI’ın her yerde olacağını vurgulayarak devrimci etkisini yineledi. (Kaynak: 36氪)

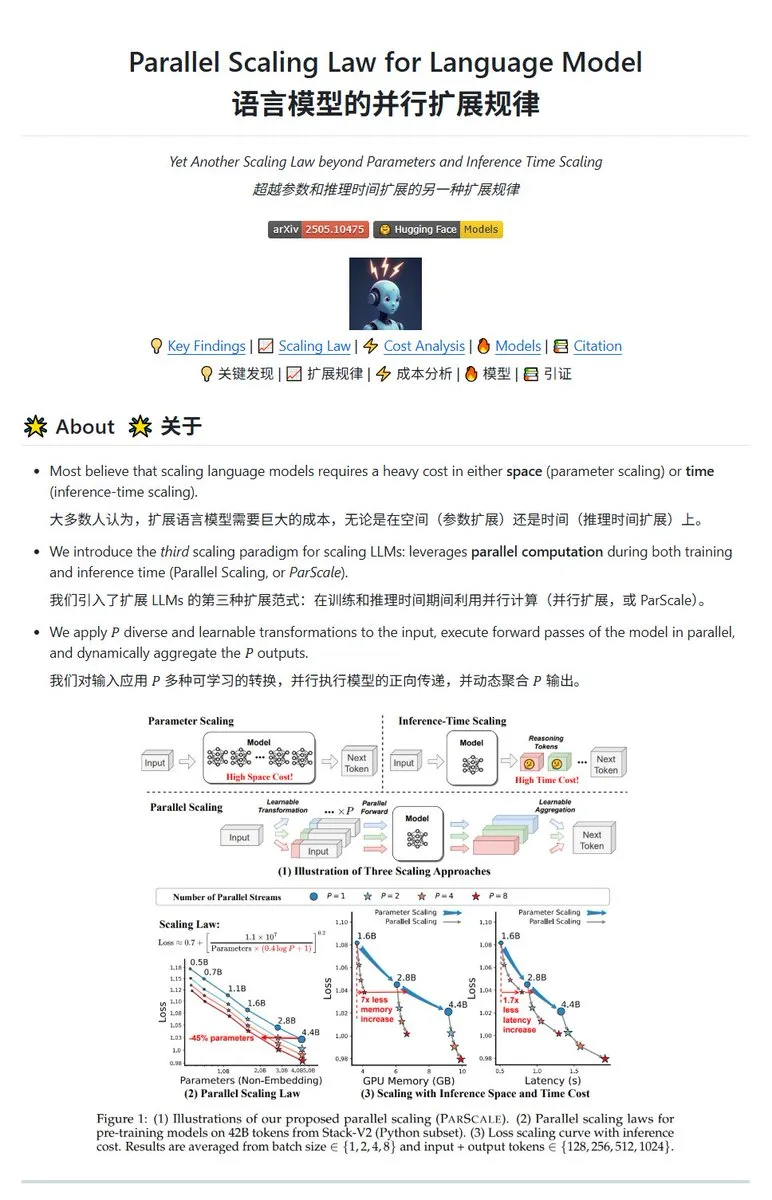
Qwen, ParScale paralel ölçeklendirme teknolojisini yayınladı, küçük modeller büyük model etkisi yaratabiliyor: Qwen ekibi, paralel çıkarım yoluyla model yeteneklerini artıran ParScale teknolojisini tanıttı. Bu yöntem, çıkarım için n paralel akış kullanır; her akış, girdiyi işlemek için öğrenilebilir farklılaştırılmış bir dönüşüm kullanır ve son olarak sonuçlar dinamik bir birleştirme mekanizmasıyla birleştirilir. Araştırmalar, P paralel akışın etkisinin, model parametre sayısını O(log P) kat artırmaya benzediğini göstermektedir; örneğin, 30B’lik bir model, 8 paralel akışla 42.5B’lik bir modelin etkisine ulaşabilir. Bu teknolojinin, bellek kullanımını önemli ölçüde artırmadan model performansını artırması veya paralelliği artırarak mevcut model boyutunu küçültmesi bekleniyor, ancak bu, hesaplama talebini artırma ve çıkarım hızını düşürme pahasına olabilir. (Kaynak: karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
🎯 Gelişmeler
Poe raporu: OpenAI ve Google AI yarışında lider, Anthropic zayıflık gösteriyor: Poe’nun en son kullanım raporu (Ocak-Mayıs 2025), AI pazarındaki büyük değişimleri gösteriyor. Metin üretimi alanında GPT-4o (%35,8) liderken, Gemini 2.5 Pro çıkarım yeteneğinde (%31,5) zirveye yerleşti. Görüntü üretimine Imagen3, GPT-Image-1 ve Flux serisi hakim. Video üretimi alanında Kling-2.0-Master beklenmedik bir çıkış yaparken, Runway’in pazar payı önemli ölçüde düştü. Ajanlar açısından o3 en iyi performansı sergiledi. Rapor, çıkarım yeteneğinin kilit bir savaş alanı haline geldiğini, Anthropic’in Claude modelinin pazar payının düştüğünü ve DeepSeek R1 kullanıcı oranının da zirveden gerilediğini belirtiyor. Şirketlerin, modellerin karmaşık görevlerdeki doğruluğuna ve güvenilirliğine dikkat etmesi ve AI modellerini esnek bir şekilde seçmesi gerekiyor. (Kaynak: 36氪)

Meta’nın amiral gemisi AI modeli Behemoth (Llama 4) lansmanı ertelendi, AI stratejisinde ayarlamaya yol açabilir: Bildirildiğine göre, Meta’nın Nisan ayında piyasaya sürmeyi planladığı 2 trilyon parametreli büyük modeli Behemoth (Llama 4), performansın beklentileri karşılamaması nedeniyle sonbahara veya daha sonraya ertelendi. Model, OpenAI, Google gibi rakiplerle rekabet etmek amacıyla 30T çok modlu token kullanılarak 32K GPU üzerinde önceden eğitilmişti. Geliştirme sürecindeki zorluklar, Llama 4 ekibinin performansına yönelik şirket içinde hayal kırıklığına yol açtı ve AI ürün ekibinde ayarlamalara neden olabilir. Aynı zamanda, Llama 1’in ilk 14 kişilik ekibinden 11 kişi ayrıldı. Meta yöneticileri, “ekibin %80’inin istifa ettiği” yönündeki söylentileri yalanlayarak, ayrılanların çoğunlukla Llama 1 makale ekibinden olduğunu vurguladı. Bu olay, Meta’nın AI yarışında bir darboğaza girip girmediğine dair dışarıdaki endişeleri artırdı. (Kaynak: 36氪)

ByteDance ve Google DeepMind, verimlilik ve üretim sistemi uygulamalarına odaklanan yeni MoE model araştırmasını yayınladı: ByteDance’in “MegaScale-MoE: Large-Scale Communication-Efficient Training of Mixture-of-Experts Models in Production” başlıklı makalesi, büyük ölçekli MoE modellerinin verimli eğitimi için özel olarak tasarlanmış bir üretim sistemini tanıtıyor. Operatör düzeyinde iletişimi hesaplamayla örtüştürerek Megatron-LM’den 1.88 kat daha fazla verimlilik elde ediyor ve veri merkezlerinde ürün modellerini (Internal-352B, 32 uzman, top-3 gibi) eğitmek için kullanılıyor. Google DeepMind, AI’ın kendi kendini evrimleştirmesi ve LLM’leri eğitmesi yoluyla matematik ve algoritma alanlarında çığır açan AlphaEvolve’u yayınladı; örneğin 4×4 matris çarpımını ve altıgen doldurma problemini geliştirerek AI’ın bilimsel keşiflerdeki potansiyelini gösterdi. (Kaynak: teortaxesTex, 36氪)

OpenAI, AI çıkarım paradigmasını tartışıyor ve performans artışındaki kilit rolünü vurguluyor: OpenAI araştırmacısı Noam Brown, AI gelişiminin büyük miktarda veriyle bir sonraki kelimeyi tahmin etmeye dayalı ön eğitim paradigmasından çıkarım paradigmasına geçtiğini belirtti. Ön eğitim maliyetli iken, çıkarım paradigması modelin “düşünme” süresini (çıkarım hesaplama miktarı) artırarak cevap kalitesini yükseltiyor, eğitim maliyeti değişmese bile. Örneğin, o serisi modeller, matematik yarışmalarında (AIME) ve doktora düzeyindeki bilimsel problemlerde (GPQA), daha uzun çıkarım süreleriyle GPT-4o’dan çok daha yüksek doğruluk oranları elde etti. OpenAI baş ekonomisti Ronnie Chatterji ise AI’ın kurumsal yapıyı nasıl yeniden şekillendirdiğini tartışarak, kilit noktanın şirketlerin AI’ı insan rollerini geliştirmek veya değiştirmek için nasıl entegre ettiği ve AI teknolojisinin değer zincirine nasıl yerleştirildiği olduğunu belirtti. (Kaynak: 36氪)

Google CEO’su Pichai “Google öldü” iddialarına yanıt verdi, AI odaklı arama evrimini ve altyapı avantajlarını vurguladı: Google CEO’su Sundar Pichai, bir röportajda “Google aramasının AI tarafından yerinden edileceği” endişelerine yanıt verdi. Google’ın “AI Özetleri” ve “AI Modu” gibi özelliklerle aramayı reaktif sorgulardan öngörücü, kişiselleştirilmiş akıllı asistanlara dönüştürdüğünü belirtti. Google’ın AI altyapısındaki (kendi geliştirdiği TPU’lar, büyük ölçekli veri merkezleri) ve model verimliliğindeki uzun vadeli yatırımlarının temel avantajları olduğunu ve gelişmiş modelleri uygun maliyetle sunabildiğini vurguladı. Pichai, AI’ın “tüm senaryolara uygun bir teknoloji platformu” olduğunu ve arama, YouTube, Cloud gibi temel işleri yeniden şekillendireceğini ve yeni biçimler doğuracağını düşünüyor. Ayrıca Çin AI’ının (DeepSeek gibi) rekabet gücünün göz ardı edilemeyeceğini belirtti ve elektriğin AI gelişimindeki kilit darboğaz olacağını söyledi. (Kaynak: 36氪)

Eğitim alanında AI uygulamaları geliştiren startup’ların bir özeti: Makale, 2025’te dikkat edilmesi gereken 13 AI eğitim startup’ını listeliyor. Bu şirketler, kişiselleştirilmiş öğrenme yolları, akıllı rehberlik sistemleri, otomatik puanlama ve sürükleyici içerik oluşturma gibi yöntemlerle öğretimi değiştiriyor. Örneğin, Merlyn ses kontrollü bir AI asistanı olup öğretmenlerin idari yükünü azaltıyor; Brisk Teaching, öğretim görevlerini basitleştiren bir Chrome eklentisi; Edexia, öğretmenlerin tarzını öğrenen bir AI puanlama platformu; Storytailor, bibliyoterapiyi AI ile birleştirerek kişiselleştirilmiş hikayeler yaratıyor; Brainly, AI destekli ödev yardımı sunuyor. Bu şirketler, verimliliği artırmaktan kişiselleştirilmiş öğrenme ve eğitimde eşitliği sağlamaya kadar AI’ın eğitim alanındaki geniş uygulama potansiyelini gösteriyor. (Kaynak: 36氪)
AI kısa dizileri teknik ve ticarileşme zorluklarıyla karşı karşıya, yapım etkisi beklentilerin altında: AI araçlarının kısa dizi yapım maliyetlerini düşürme ve üretim süresini kısaltma potansiyeli olmasına rağmen, sektör profesyonelleri AI kısa dizilerinin ana karakter tutarlılığı, dudak senkronizasyonu ve kamera dili doğallığı gibi konularda önemli teknik zorluklar yaşadığını tespit etti. Bu durum, birçok yapımın “PPT tarzı kısa dizi” gibi görünmesine neden oluyor. AI’ın gerçeküstü yaratıcılığı anlamadaki zorluğu, fantastik ve bilim kurgu türlerinin potansiyelini sınırlıyor. Mevcut AI teknolojisi, tam teşekküllü kısa dizilerden ziyade kısa filmler üretmek için daha uygun ve ticarileşme beklentileri belirsiz. Bona Film Grubu ve Huace Grubu gibi büyük film şirketleri kaynak avantajlarıyla öne çıkma olasılığı daha yüksekken, çoğu küçük yaratıcı, yüksek deneme-yanılma maliyetleri ve hızlı teknoloji yinelemesi nedeniyle eserlerinin hızla eskimesi gibi sorunlarla karşı karşıya. (Kaynak: 36氪)
MSI, NVIDIA GB10 süper çipini entegre eden, 6144 CUDA çekirdeği ve 128GB LPDDR5X bellek içeren AI PC’yi tanıttı: MSI, NVIDIA GB10 süper çipine sahip AI PC’si EdgeExpert MS-C931 S’i sergiledi. Bu çipin 6144 CUDA çekirdeği ve 128GB LPDDR5X belleğe sahip olduğu doğrulandı. Bu, ASUS, Dell ve Lenovo’nun ardından NVIDIA DGX Spark mimarisine dayalı kişisel AI bilgisayarı sunan bir başka üretici oldu. Bu tür ürünlerin piyasaya sürülmesi, yüksek performanslı AI hesaplama yeteneğinin giderek kişisel ve uç cihazlara yaygınlaştığını gösteriyor, ancak bazı yorumcular fiyatlandırmasının Mac Mini gibi ürünlerle rekabet etmesini zorlaştırabileceğini belirtiyor. (Kaynak: Reddit r/LocalLLaMA)
Qwen3-30B, VLLM üzerinde yüksek iş hacmi elde ederek veri kümesi yönetimi için uygun hale geldi: Qwen3-30B-A3B modeli, VLLM çerçevesi ve RTX 3090s ekran kartlarında mükemmel çıkarım hızı (5K t/s ön doldurma, 1K t/s üretim) sergileyerek veri kümesi filtreleme ve yönetimi gibi görevler için oldukça uygun hale geldi. QwQ’ya kıyasla hafif bir gerileme olsa da, hız avantajı onu veri işleme açısından daha pratik kılıyor. Mevcut ana sorun eğitim hızının son derece yavaş olması, ancak Hugging Face Transformers kütüphanesinde bu sorunu çözmeye çalışan bir PR bulunuyor ve gelecekte Qwen3-30B tabanlı geliştirilmiş veri kümeleriyle RpR modellerinin sunulması bekleniyor. (Kaynak: Reddit r/LocalLLaMA)
B站 (Bilibili), çeşitli 2D stilleri destekleyen açık kaynaklı animasyon video üretim modeli Index-AniSora’yı yayınladı: B站, AniSora teknoloji çerçevesine (IJCAI25 tarafından kabul edildi) dayanan, 2D video üretimi için özel olarak tasarlanmış açık kaynaklı Index-AniSora modelini tanıttı. Bu model, çizgi romanları tek tıklamayla animasyona dönüştürebilir ve anime serileri, Çin yapımı animasyonlar, manga uyarlamaları, VTuber’lar gibi çeşitli stilleri destekler. AniSora sistemi, on milyonlarca yüksek kaliteli metin-video çiftinden oluşan bir veri kümesi oluşturarak, birleşik bir difüzyon üretim çerçevesi geliştirerek ve zaman-mekan maskeleme mekanizması ekleyerek karakterlerin ağız hareketleri ve eylemleri üzerinde hassas kontrol sağlar. Aynı zamanda B站, animasyon videoları için bir değerlendirme ölçütü ve VLM tabanlı optimize edilmiş otomatik bir değerlendirme sistemi tasarladı. Açık kaynak içeriği AniSoraV1.0 (CogVideoX-5B tabanlı), AniSoraV2.0 (Wan2.1-14B tabanlı, Huawei 910B eğitimini destekler) ve ilgili veri kümesi oluşturma ve değerlendirme araçlarını içerecektir. (Kaynak: WeChat)

ByteDance, çok modlu görevlerde üstün performans gösteren görsel dil modeli Seed1.5-VL’yi yayınladı: ByteDance, 532M parametreli bir görsel kodlayıcı ve 20B aktif parametreli bir uzmanlar karışımı (MoE) LLM’den oluşan görsel dil modeli Seed1.5-VL’yi tanıttı. Bu model, 60 genel kıyaslama testinin 38’inde SOTA (son teknoloji) performansına ulaştı ve GUI kontrolü ve oyun oynama gibi ajan merkezli görevlerde OpenAI CUA ve Claude 3.7 gibi önde gelen sistemleri geride bırakarak güçlü çok modlu anlama ve çıkarım yetenekleri sergiledi. (Kaynak: WeChat)
Nous Research, 40B parametreli LLM’nin dağıtık ön eğitimini gerçekleştiren Psyche Network’ü tanıttı: Nous Research, DeepSeek V3 MLA mimarisine dayanan merkezi olmayan bir eğitim ağı olan Psyche Network’ü yayınladı ve ilk testinde 40 milyar parametreli büyük bir dil modelinin ön eğitimini gerçekleştirdi. Ağ, DisTrO optimize ediciyi ve özel bir eşler arası ağ yığınını kullanarak küresel olarak dağıtılmış GPU hesaplama gücünü birleştiriyor, bireylerin ve küçük grupların tek bir H/DGX üzerinde eğitim yapmasına ve 3090 GPU’larda çalışmasına olanak tanıyor. Bu girişim, teknoloji devlerinin hesaplama gücü tekelini kırmayı ve büyük ölçekli model eğitimini daha erişilebilir hale getirmeyi amaçlıyor. (Kaynak: 量子位)

🧰 Araçlar
Sim Studio: Açık kaynaklı AI ajanı iş akışı oluşturucu: Sim Studio, kullanıcıların çeşitli araçlara bağlanan LLM uygulamalarını hızla oluşturup dağıtabileceği sezgisel bir arayüz sunan, açık kaynaklı, hafif bir AI ajanı iş akışı oluşturma platformudur. Bulut tabanlı bir sürümü ve kendi kendine barındırma (Docker ortamı önerilir, Ollama gibi yerel modelleri destekler) seçenekleri mevcuttur. Teknoloji yığını Next.js, Bun, PostgreSQL, Drizzle ORM, Better Auth, Shadcn UI, Tailwind CSS, Zustand, ReactFlow ve Turborepo’yu içerir. (Kaynak: GitHub Trending)

Cherry Studio: Kapsamlı özelliklere sahip açık kaynaklı LLM ön yüz masaüstü uygulaması ilgi görüyor: Cherry Studio, RAG, web araması, yerel model (Ollama, LM Studio aracılığıyla bağlantı) ve bulut modeli (Gemini, ChatGPT gibi) erişimi gibi birçok özelliği entegre eden açık kaynaklı bir LLM ön yüz masaüstü uygulamasıdır. Kullanıcı geri bildirimlerine göre MCP (çoklu kontrol protokolü) desteği ve yönetimi Open WebUI ve LibreChat’ten daha iyi ve kurulumu kolay. Uygulama ayrıca Obsidian bilgi tabanına doğrudan bağlantıyı da destekliyor. Bazı kullanıcılar kaynağı konusunda endişelerini dile getirse de, kapsamlı özellik seti onu çekici bir seçenek haline getiriyor. (Kaynak: Reddit r/LocalLLaMA)

MLX-LM-LoRA: MLX modellerine LoRA ekleme ve çeşitli eğitim yöntemlerini destekleme: Açık kaynaklı mlx-lm-lora projesi, kullanıcıların Apple MLX çerçevesindeki modellere LoRA (Low-Rank Adaptation) modüllerini entegre etmelerini sağlar. Bu proje sadece LoRA eklemeyi desteklemekle kalmaz, aynı zamanda ORPO, DPO, CPO, GRPO gibi çeşitli hizalama eğitim yöntemlerini de içerir, böylece kullanıcılar modellerini kendi ihtiyaçlarına göre ince ayar yapabilir, özelleştirilmiş LoRA modülleri oluşturabilir ve bunları tercih ettikleri MLX modellerine uygulayabilirler. (Kaynak: karminski3)
DeepDrone: Qwen tabanlı AI kontrollü drone projesi açık kaynaklı hale getirildi: Bir geliştirici, Qwen büyük modelini temel alarak DeepDrone adlı bir AI kontrollü drone projesi oluşturdu ve bunu HuggingFace ve GitHub’da açık kaynak olarak yayınladı. Bu proje, büyük dil modellerinin otonom drone kontrolüne uygulanma potansiyelini gösteriyor ve AI’ın otomasyon ve potansiyel askeri uygulamaları hakkındaki tartışmaları ateşledi. (Kaynak: karminski3)
Qwen Web Dev: Tek bir komutla web sitesi oluşturma ve dağıtma: Alibaba Qwen ekibi, Qwen Web Dev aracının geliştirildiğini duyurdu; kullanıcılar artık yalnızca bir komut (prompt) aracılığıyla bir web sitesi oluşturabilir ve tek tıklamayla dağıtabilir. Bu araç, web geliştirme engelini düşürmeyi ve kullanıcıların fikirlerini daha kolay bir şekilde gerçek, erişilebilir web sitelerine dönüştürmelerini ve dünyayla paylaşmalarını sağlamayı amaçlamaktadır. (Kaynak: Alibaba_Qwen, huybery)
SuperGo.AI: Sekiz LLM modelini tek bir arayüzde birleştiren araç: AI meraklıları, SuperGo.AI adlı bir araç geliştirdi. Bu araç, sekiz farklı role sahip LLM’yi (AI Süper Beyin, AI Hayal Gücü, AI Ahlak, AI Evren vb.) tek bir arayüzde birleştiriyor. Bu AI rolleri birbirlerini algılayabilir ve etkileşimde bulunabilir; kullanıcılar karma yanıtlar almak için “Yaratıcı”, “Bilimsel” ve “Karma” modlarını seçebilirler. Araç, yeni bir çoklu AI işbirliği deneyimi sunmayı amaçlıyor ve şu anda herhangi bir ödeme duvarı bulunmuyor. (Kaynak: Reddit r/artificial)
Kokoro-JS: Sınırsız yerel metinden sese (TTS) dönüştürme: Kokoro-JS, tarayıcı tarafında yaklaşık 300MB’lık bir AI modelini indirerek %100 yerel olarak çalışan, %100 açık kaynaklı bir metinden sese dönüştürme aracıdır. Kullanıcının girdiği metin hiçbir sunucuya gönderilmez, bu da gizliliği ve çevrimdışı kullanılabilirliği garanti eder. Araç, sınırsız TTS işlevi sunmayı amaçlamaktadır. (Kaynak: Reddit r/LocalLLaMA)
📚 Öğrenme
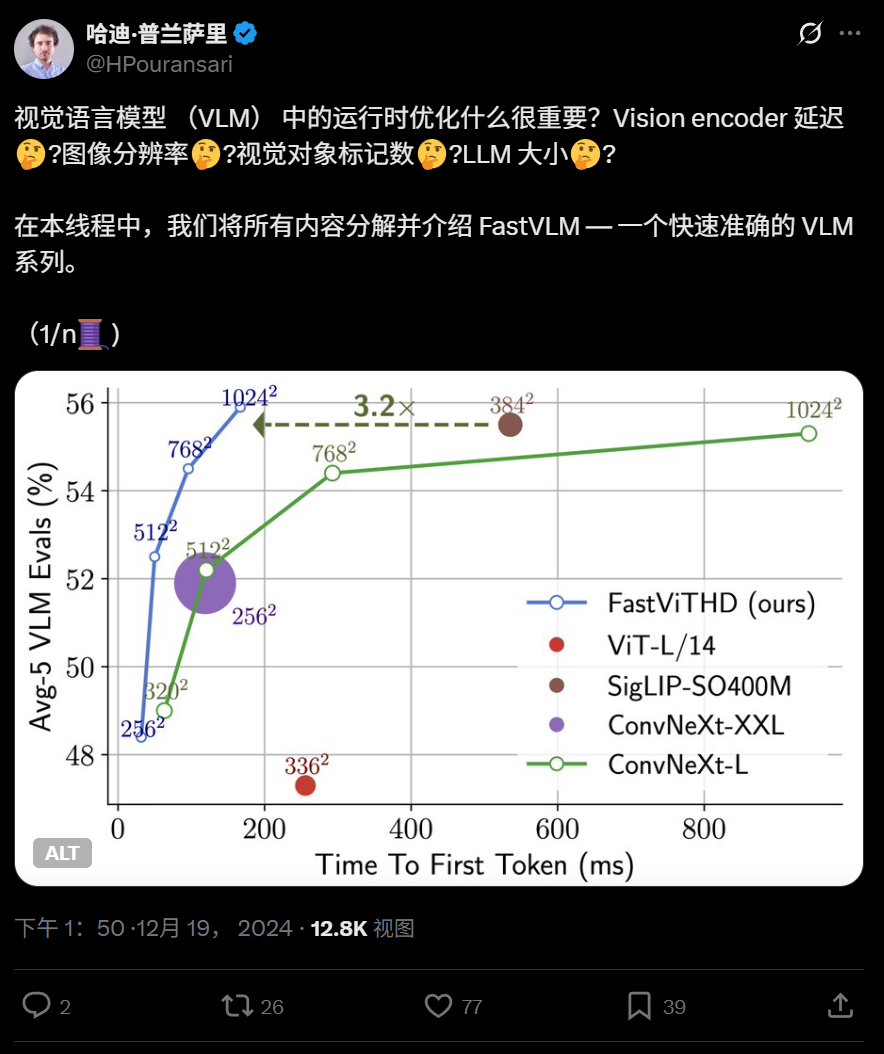
Apple, uç cihazlarda verimli çalışma için optimize edilmiş görsel dil modeli FastVLM’yi açık kaynak olarak sundu: Apple, iPhone gibi cihazlarda verimli çalışmak üzere özel olarak tasarlanmış bir görsel dil modeli olan FastVLM’yi açık kaynak olarak sundu. FastVLM, evrişimli katmanları Transformer modülleriyle birleştiren yeni bir hibrit görsel kodlayıcı olan FastViTHD’yi tanıtıyor ve çok ölçekli havuzlama ve alt örnekleme tekniklerini kullanarak görüntüleri işlemek için gereken görsel token sayısını önemli ölçüde azaltıyor (geleneksel ViT’den 16 kat daha az), ilk token çıkış hızını ise 85 kat artırıyor. Bu model, ana akım LLM’lerle uyumludur ve MLX çerçevesine dayalı iOS/macOS demo uygulamasıyla birlikte sunulmuştur; uç cihazlar ve gerçek zamanlı görüntü-metin görevleri için uygundur. (Kaynak: WeChat)
Harbin Teknoloji Enstitüsü ve Pennsylvania Üniversitesi, KAN tabanlı 3D nokta bulutu analizini geliştiren PointKAN’ı önerdi: Harbin Teknoloji Enstitüsü (Shenzhen) ve Pennsylvania Üniversitesi’nden araştırma ekipleri, Kolmogorov-Arnold Networks (KANs) tabanlı yeni bir 3D algılama mimarisi olan PointKAN’ı tanıttı. PointKAN, geleneksel MLP’lerdeki sabit aktivasyon fonksiyonlarının yerine öğrenilebilir aktivasyon fonksiyonları kullanarak karmaşık geometrik özellikleri öğrenme yeteneğini artırır. Geometrik afin modülü ve paralel yerel özellik çıkarma modülü içerir. Ekip ayrıca, temel fonksiyonlar olarak rasyonel fonksiyonları kullanan ve parametreleri gruplayarak paylaşan Efficient-KANs yapısını benimseyen PointKAN-elite sürümünü de önerdi. Bu, parametre sayısını ve hesaplama karmaşıklığını önemli ölçüde azaltırken, sınıflandırma, parça segmentasyonu ve az örnekle öğrenme görevlerinde SOTA (son teknoloji) performansı sergiledi. (Kaynak: 量子位)

Pittsburgh Üniversitesi, AI tarafından üretilen videoların fiziksel gerçekçiliğini artıran PhyT2V çerçevesini önerdi: Pittsburgh Üniversitesi Akıllı Sistemler Laboratuvarı, metinden videoya (T2V) modelleri tarafından üretilen içeriğin fiziksel tutarlılığını artırmayı amaçlayan PhyT2V çerçevesini geliştirdi. Bu yöntem, modeli yeniden eğitmeye veya büyük ölçekli harici verilere ihtiyaç duymadan, büyük dil modeli (LLM) güdümlü düşünce zinciri (CoT) ve yinelemeli kendi kendini düzeltme mekanizmaları aracılığıyla metin istemlerini çok turlu fiziksel kural analizi ve optimizasyonuna tabi tutar. PhyT2V, fiziksel kuralları, anlamsal uyuşmazlıkları tanımlayabilir ve düzeltilmiş istemler üretebilir, böylece ana akım T2V modellerinin (CogVideoX, OpenSora gibi) gerçekçi fiziksel senaryolarda (katılar, sıvılar, yerçekimi vb.) genelleme yeteneğini artırır. Özellikle dağıtım dışı senaryolarda etkisi belirgindir ve fiziksel sağduyu (PC) ile anlamsal uyum (SA) metriklerinde 2.3 kata kadar iyileşme sağlar. (Kaynak: WeChat)
LLM’lerdeki son araştırmalar: Çok modluluk, test zamanı hizalaması, Agent, RAG optimizasyonu ve daha fazlası: Bir haftalık LLM araştırma gelişmeleri şunları içeriyor: 1. Washington Üniversitesi, modeli değiştirmeden veya logitlere erişmeden test zamanında hizalama sağlayan QALIGN’ı önerdi; metin üretiminde MCMC aracılığıyla daha iyi hizalama sağlıyor. 2. UCLA, biyomedikal alan kodlayıcısının bağlam uzunluğunu 8192 token’a genişleten Clinical ModernBERT’i önceden eğitti. 3. Skoltech, harici bilgilere (varlık popülaritesi, soru türü) dayalı hafif, LLM’den bağımsız, uyarlanabilir bir RAG erişim yöntemi önerdi. 4. PSU, LLM çoklu Agent sistemlerinde otomatik hata atfetme sorununu tanımladı ve değerlendirme veri kümeleri ile yöntemler geliştirdi. 5. Fudan Üniversitesi, LLM’lerin talimat takip yeteneğini artırmak için çok boyutlu bir kısıtlama çerçevesi ve otomatik talimat oluşturma süreci önerdi. 6. a-m-team, DeepSeek-R1-671B ile karşılaştırılabilir matematiksel kodlama yeteneğine sahip AM-Thinking-v1 (32B) modelini açık kaynak olarak sundu. 7. Xiaomi, ön eğitimi ve son eğitimi optimize ederek çıkarım görevlerinde üstün performans gösteren MiMo-7B’yi tanıttı. 8. MiniMax, 32 dili sıfır vuruşlu ses klonlamayı destekleyen MiniMax-Speech otoregresif TTS modelini önerdi. 9. ByteDance, çok modlu görevlerde ve ajan merkezli görevlerde üstün performans gösteren Seed1.5-VL görsel dil modelini oluşturdu. 10. Dünyanın ilk 32B parametreli dil modeli INTELLECT-2, dağıtık pekiştirmeli öğrenme eğitimi gerçekleştirdi ve PRIME-RL çerçevesini önerdi. (Kaynak: WeChat)
AAAI 2025 çalıştayları sinirsel çıkarım, matematiksel keşifler ve AI’ın bilim ve mühendisliği hızlandırmasına odaklanıyor: AAAI 2025 çalıştayları, AI’ın bilim alanındaki uygulamalarını ele aldı. Bunlardan “Sinirsel Çıkarım ve Matematiksel Keşifler” çalıştayı, kara kutu sinir ağlarının matematiksel varsayımlar önermek ve yeni geometrik şekiller üretmek için kullanılabileceğini vurguladı, ancak sembolik düzeyde mantıksal çıkarıma ulaşamadığını belirtti ve disiplinler arası yaklaşımları savundu. Bir diğer “AI Bilim ve Mühendisliği Hızlandırmak İçin” çalıştayı (dördüncüsü, teması AI Biyobilimleri) ise tedavi tasarımı için temel modeller, ilaç keşfi için üretken modeller, laboratuvarda kapalı döngü antikor tasarımı, genomikte derin öğrenme ve biyolojik uygulamalarda nedensel çıkarım gibi konulara odaklandı ve üretken modellerin biyobilimlerdeki zorluklarını ve fırsatlarını tartıştı. (Kaynak: aihub.org)

Google ve Anthropic, AI yorumlanabilirliği araştırmalarında anlaşmazlık yaşıyor, mekanik yorumlanabilirlik zorluklarla karşı karşıya: AI’ın “kara kutu” özelliği, birçok kritik alanda uygulanmasını kısıtlıyor. Google DeepMind kısa süre önce, seyrek öz kodlayıcılar (SAE) gibi yöntemlerle AI’ın iç mekanizmalarını tersine mühendislikle anlamaya çalışan “mekanik yorumlanabilirlik” araştırmalarının önceliğini düşürdüğünü duyurdu. Bu yaklaşımın, nesnel bir referans eksikliği, kavramların tam olarak kapsanmaması, özelliklerin bozulması gibi birçok sorunla karşılaştığını ve mevcut SAE teknolojilerinin kritik görevlerde gerekli “kavramları” tanımlayamadığını belirtti. Buna karşılık Anthropic CEO’su Dario Amodei, bu alandaki araştırmaların güçlendirilmesi gerektiğini savundu ve önümüzdeki 5-10 yıl içinde “AI’ın nükleer manyetik rezonans görüntülemesinin” gerçekleştirilebileceği konusunda iyimser olduğunu ifade etti. Bu tartışma, AI davranışlarını anlama ve kontrol etmenin derin zorluklarını vurguluyor. (Kaynak: 36氪)

Pekin Üniversitesi/StepFun/SiPhotonics, maliyeti düşüren ve verimliliği artıran yeni nesil GPU yüksek bant genişliği alanı mimarisi InfiniteHBD’yi önerdi: Mevcut yüksek bant genişliği alanı (HBD) mimarilerinin ölçeklenebilirlik, maliyet ve hata toleransı konusundaki sınırlamalarına yönelik olarak Pekin Üniversitesi, StepFun (阶跃星辰) ve SiPhotonics (曦智科技) ekipleri InfiniteHBD mimarisini önerdi. Bu mimari, optik anahtar modülünü (OCSTrx) merkeze alarak, optoelektronik dönüşüm modülüne düşük maliyetli optik anahtarlama (OCS) yeteneği ekleyerek veri merkezi ölçeğinde dinamik olarak yeniden yapılandırılabilir K-Hop Ring topolojisi ve düğüm düzeyinde hata izolasyonu sağlar. InfiniteHBD’nin birim maliyeti NVL-72’nin yalnızca %31’i kadardır, GPU israf oranı neredeyse sıfırdır ve MFU (model FLOPs kullanım oranı) NVIDIA DGX’e kıyasla 3.37 kata kadar artış göstererek büyük ölçekli büyük model eğitimi için daha iyi bir çözüm sunar. Makale SIGCOMM 2025 tarafından kabul edildi. (Kaynak: WeChat)

OceanBase, PowerRAG’ı yayınlayarak AI’ı tamamen benimsedi ve Data×AI entegre veri temelini oluşturdu: OceanBase, geliştirici konferansında AI odaklı uygulama ürünü PowerRAG’ı yayınladı. Bu ürün, kullanıma hazır RAG geliştirme yetenekleri sunmayı ve veri, platform, arayüz ve uygulama katmanlarını birbirine bağlamayı amaçlıyor. CTO Yang Chuanhui, OceanBase’in AI stratejisini ayrıntılı olarak açıkladı: Data×AI yetenekleri oluşturmak ve entegre bir veritabanından entegre bir veri temeline doğru evrilmek. OceanBase, vektör yeteneklerini geliştirecek, birleşik erişimi iyileştirecek, kurumsal bilgi depolamasının dinamik olarak güncellenmesini sağlayacak, model sonrası eğitim ve ince ayarı derinlemesine entegre edecek ve Dify, FastGPT gibi ana akım Agent platformları ile MCP protokolüne uyum sağladı. Vektör performansı VectorDBBench testlerinde lider konumda yer aldı ve BQ niceleme algoritmasıyla bellek gereksinimlerini önemli ölçüde azalttı. (Kaynak: WeChat)

💼 İş Dünyası
Şanghay Devlet Yatırım Fonu, CoreTonic, Enflame, Biren Technology gibi AI çip şirketlerine yatırım yaptı: Şanghay Devlet Sermaye Yatırım Ltd. Şti. (Şanghay Devlet Yatırımı) yakın zamanda üç yarı iletken şirketi olan CoreTonic (芯耀辉), Enflame Technology (燧原科技) ve Biren Technology (壁仞科技) ile yatırım anlaşmaları imzaladı. Daha önce, öncü AI ana fonu Biren Technology’nin halka arz öncesi finansman turuna liderlik etmişti. Şanghay Devlet Yatırımı, temel modeller, hesaplama çipleri, somutlaşmış zeka gibi alanlara aktif olarak yatırım yapacağını belirtti. CoreTonic, özellikle Chiplet teknolojisi olmak üzere yarı iletken IP’lerine odaklanıyor ve kurucusu Zeng Keqiang daha önce Synopsys Çin’in başkan yardımcısıydı. Enflame Technology ve Biren Technology ise GPU çip tasarım şirketleridir. Bu hamle, Şanghay Devlet Yatırımı’nın AI endüstri zincirinin yukarı akışında, özellikle de hesaplama çipi alanında önemli bir odaklanma içinde olduğunu gösteriyor. (Kaynak: 36氪)
Sakana AI, bankacılığa özel AI geliştirmek için Mitsubishi UFJ Bank ile kapsamlı bir ortaklık anlaşması imzaladı: Japon AI girişimi Sakana AI, Mitsubishi UFJ Bank (MUFG) ile çok yıllık bir ortaklık anlaşması imzaladığını duyurdu. Sakana AI, MUFG için bankacılık operasyonlarına özel AI ajanları geliştirecek ve bankacılık operasyonlarının dönüşümünü ve AI’ın pratik uygulamasını teşvik etmeyi amaçlayacak. Aynı zamanda, Sakana AI’ın kurucu ortağı ve COO’su Ren Ito, bankanın AI stratejisini uygulamasına yardımcı olmak üzere MUFG’nin danışmanı olarak görev yapacak. Bu işbirliği, Sakana AI’ın Japon finans sektöründeki belirli sorunları çözmek için gelişmiş AI teknolojisini uygulamasında önemli bir adımı işaret ediyor. (Kaynak: SakanaAILabs, SakanaAILabs, SakanaAILabs, SakanaAILabs, SakanaAILabs)

01.AI kurucu ortağı Gu Xuemei girişim kurmak için ayrıldı, şirketin iş odağı B2B’ye kayıyor: 01.AI (零一万物) kurucu ortağı ve model ön eğitimi ile C-ucu ürünlerinden sorumlu olan Gu Xuemei, birkaç ay önce şirketten ayrıldı ve yakın zamanda kendi girişimini kurmaya hazırlanıyor. 01.AI olayı doğruladı ve katkılarından dolayı teşekkür etti. 2025’ten bu yana, 01.AI’ın iş odağı AI ToC uygulamaları ve model API’lerinden dijital insanlar, model özelleştirme ve dağıtım gibi B2B senaryolarına kaydı. Yerel ofis aracı “Wanzhi” (万知) gibi C-ucu ürünleri, beklenenden düşük kullanıcı sayısı nedeniyle faaliyetlerini durdurdu ve yurtdışı rol yapma ürünü Mona’nın ticarileşmesi de ideal değildi. Daha önce, kurucu ortak Dai Zonghong da kendi girişimini kurmak için ayrılmıştı. (Kaynak: 36氪)

🌟 Topluluk
AI makalelerinde AIGC tespiti tartışmalara yol açtı, doğruluğu sorgulanıyor, öğrencilerin mezuniyeti etkileniyor: Bu yıl birçok üniversite, öğrencilerin AI yazımını kötüye kullanmasını önlemek amacıyla mezuniyet tezi inceleme sürecine AIGC tespitini dahil etti. Ancak bu girişim geniş çaplı tartışmalara yol açtı. Öğrenciler, kendi yazdıkları içeriklerin sık sık AI tarafından üretilmiş olarak yanlış değerlendirildiğini, AI destekli düzenlemelerden sonra ise şüphe düzeyinin arttığını belirtiyor. Hatta bazı testler, “Tengwang Ge Xu” (滕王阁序) adlı klasik eserin AI tarafından üretilmiş olma olasılığının %99,2 olduğunu gösterdi. AIGC tespit araçları da AI tarafından destekleniyor ve çalışma prensipleri metnin dil özelliklerini AI yazım modelleriyle karşılaştırmaya dayanıyor, ancak doğrulukları şüpheli; OpenAI’nin erken dönem araçlarının doğruluk oranı sadece %26 idi. Bu belirsizlik sadece öğrencilere sıkıntı ve ek masraf (farklı tespit sitelerinin sonuçları farklı, intihal azaltma hizmetleri ücretli) getirmekle kalmıyor, aynı zamanda AI araçlarının doğası hakkında da düşüncelere yol açıyor: AI insan yazısını taklit ediyor, sonra da insan makalesinin AI’ya benzeyip benzemediğini tespit etmek için AI kullanılıyor; bu durum kendi içinde mantıksal bir çelişki barındırıyor. (Kaynak: 36氪)

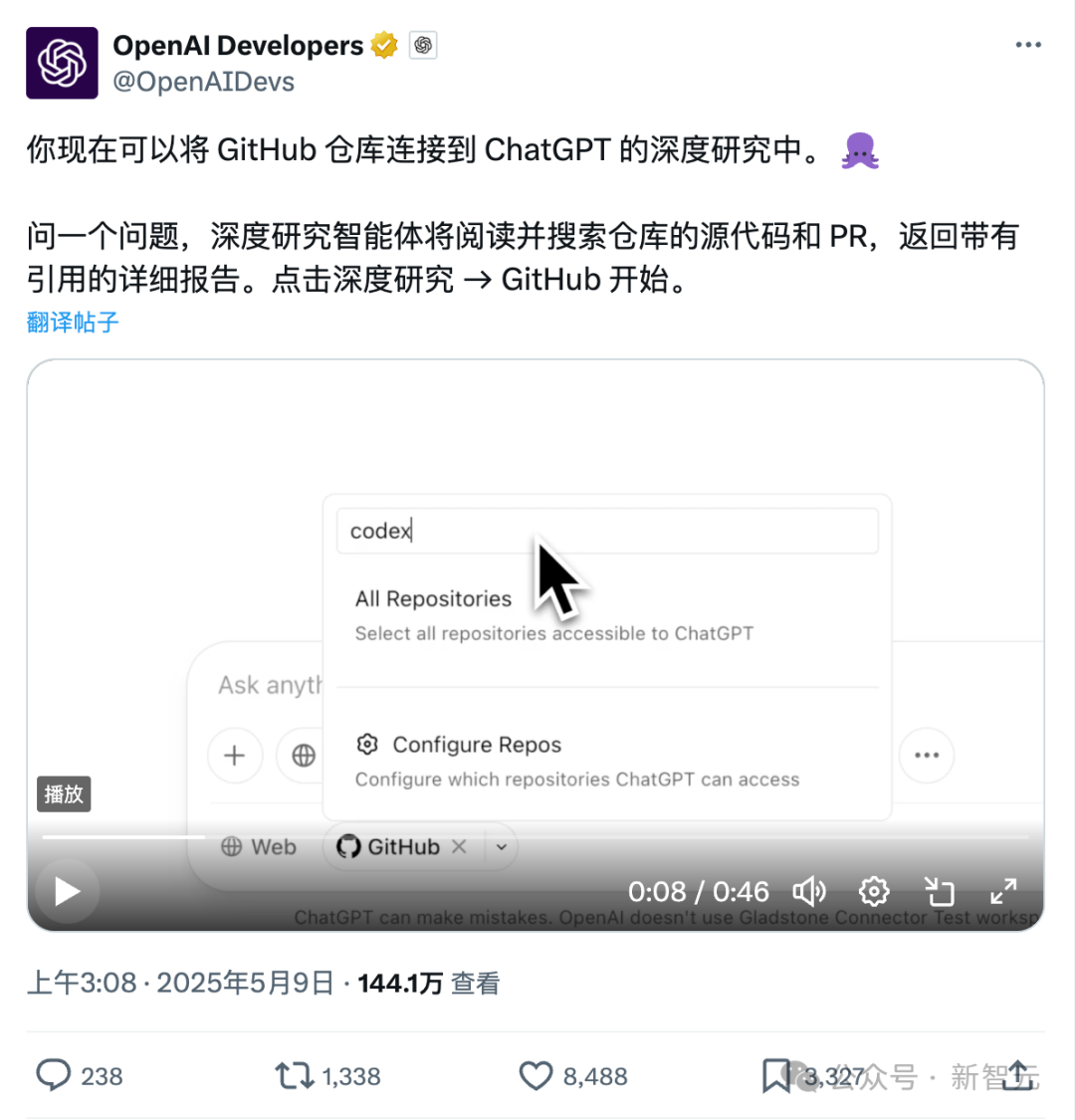
ChatGPT’nin Github’a doğrudan bağlanma yeni özelliği: Kod tabanlarını ve profesyonel belgeleri derinlemesine araştırma: ChatGPT’nin yakın zamanda kullanıma sunulan Deep Research özelliği, Github depolarına doğrudan bağlanma yeteneği ekledi. Kullanıcılar, ChatGPT’ye genel veya özel depolarına erişim yetkisi vererek derinlemesine kod analizi, işlevsel mimari özeti, teknoloji yığını tanımlama, kod kalitesi değerlendirmesi ve proje uygunluk analizi gibi işlemleri gerçekleştirebilir. Bu özellik yalnızca kodla sınırlı değil; kullanıcılar PDF, Word gibi çeşitli belgeleri Github depolarına yükleyerek ChatGPT’yi belirli alanlardaki materyallerin derinlemesine araştırılması için kullanabilirler, bu da sınırlı kapsamlı bir RAG+MCP kombinasyonunu etkin bir şekilde gerçekleştirir. Bu özellik şu anda Plus kullanıcılarına açık olup, araştırma kapsamını sınırlayarak araştırma raporlarının profesyonelliğini ve doğruluğunu artırması ve yanılsamaları azaltması beklenmektedir. (Kaynak: 36氪)
AI Agent pazarında rekabet kızışıyor, Manus tamamen kayda açıldı, ByteDance ve Baidu gibi büyük şirketler pazara giriyor: “Her şeye gücü yeten Agent” olarak bilinen Manus, 12 Mayıs’ta tamamen kayda açıldığını duyurdu; kullanıcılar beklemeden kullanım kotası alabilecek. Aynı zamanda, piyasada Manus’un 1,5 milyar dolar değerlemeyle yeni bir finansman turu yürüttüğü söylentileri dolaşıyor. Mart ayındaki lansmanından bu yana Manus, Agent tipi projelerde bir çılgınlık yarattı ancak trafik düşüşü ve rakip ürünlerin ortaya çıkması gibi zorluklarla da karşılaştı. ByteDance, Coze Space’i piyasaya sürdü, Baidu “Miaoda” (秒哒) ve “Xinxiang”ı (心响) kullanıma sundu ve tasarım Agent’ı Lovart da testlere başladı. Agent pazarı, erken kavram kanıtlamasından ürün işlevselliği, iş modelleri ve kullanıcı büyümesi gibi her yönden rekabete doğru ilerliyor. (Kaynak: 36氪)
AI destekli kodlama, geliştirici iş akışlarını değiştiriyor, üretkenliği artırıyor ancak aşırı bağımlılığa karşı dikkatli olunmalı: Reddit kullanıcıları, AI kod yardımcılarının özellikle büyük eski projelerle uğraşırken ve karmaşık kodları anlarken kodlama deneyimlerini nasıl önemli ölçüde değiştirdiğini paylaştı. AI araçları kodu satır satır açıklayabiliyor, öneriler sunabiliyor, potansiyel sorunları vurgulayabiliyor, dosyaları özetleyebiliyor, parçacıkları bulabiliyor ve yorumlar oluşturabiliyor; adeta 7/24 uzman rehberliğine sahip olmak gibi. Yorumlarda, AI’ın tekrarlayan kodlamayı tamamlayabildiği, verimliliği artırabildiği, yeni yöntemlere yönlendirebildiği, yorumlar ekleyebildiği ve hatta geliştiricilerin yeteneklerinin ötesindeki görevleri tamamlamasına yardımcı olarak günlerce süren işleri saatlere indirebildiği belirtildi. Ancak bu durum, geliştirici becerilerinin evrimi ve AI araçlarına bağımlılık hakkında da düşüncelere yol açtı. (Kaynak: Reddit r/artificial)
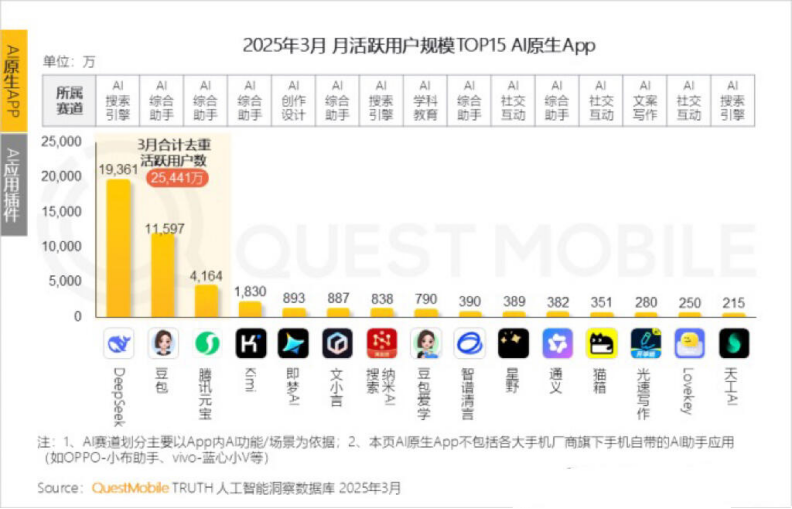
Kimi’nin aylık aktif kullanıcı sayısı düştü, Moonshot AI dikey alanlarda atılım ve sosyalleşme dönüşümü arayışında: Moonshot AI’ın (月之暗面) Kimi Chat adlı ürününün QuestMobile verilerine göre aylık aktif kullanıcı sayısı geçen yıl Ekim ayındaki 36 milyondan bu yıl Mart ayında 18,2 milyona düşerek dördüncü sıraya geriledi. Kullanıcı bağlılığını artırmak için Kimi, genel amaçlı büyük modelden dikey alanlara doğru genişliyor; örneğin finansal içerik arama kalitesini artırmak için Caixin Media ile işbirliği yapıyor, AI tıbbi arama alanına yatırım yapıyor ve Bilibili video içeriğini entegre ediyor. Aynı zamanda Kimi, sosyal platformlar aracılığıyla daha fazla C-ucu kullanıcıya ulaşmak için Xiaohongshu’da bir “check-in” meydan okuması başlattı. Kullanıcı arayüzü de çok modlu, Doubao benzeri ve topluluk odaklı bir yöne doğru ayarlanıyor. DeepSeek gibi rakiplerin ve büyük şirketlerin AI uygulamalarına akın etmesiyle karşı karşıya kalan Kimi’nin teknolojik liderlik konumu sarsıldı, ticarileşme baskısı arttı ve aktif olarak yeni büyüme noktaları arıyor. (Kaynak: 36氪)
AI’ın kendisinden birinci şahıs olarak bahsetmesi gerekip gerekmediği üzerine tartışma: Bir Reddit kullanıcısı, ChatGPT gibi LLM’lerin kendilerinden “ben” veya kullanıcıdan “sen” diye bahsetmesinin uygun olmayabileceğini, çünkü bunların özünde “insan” değil “nesne” olduklarını ve potansiyel tehlikeli veya etik sorunlara yol açmamak için kişileştirilmiş bir varlık oldukları izlenimini vermemek adına “ChatGPT size yardımcı olacaktır…” gibi üçüncü şahıs ifadeler kullanmalarını önerdi. Yorumlarda, bazıları üçüncü şahsın aksine öz farkındalık ima ettiğini düşünürken, bazıları da üçüncü şahsın kulağa aptalca ve rahatsız edici geldiğini belirtti. Bu tartışma, kullanıcıların AI’ın kimlik konumu ve insan-makine etkileşim biçimleri hakkındaki düşüncelerini yansıtıyor. (Kaynak: Reddit r/ArtificialInteligence)
💡 Diğer
MIT, veri ve araştırma güvenilirliği konusunda şüpheler olduğunu belirterek geniş yankı uyandıran bir AI makalesini acilen geri çekti: Massachusetts Teknoloji Enstitüsü (MIT), ekonomi bölümü doktora öğrencisi Aidan Toner-Rogers tarafından yazılan “Yapay Zeka, Bilimsel Keşif ve Ürün İnovasyonu” başlıklı makaleyi geri çekti. Makale, AI araçlarının önde gelen bilim insanlarının inovasyon verimliliğini önemli ölçüde artırabileceğini, ancak bilimsel araştırmalardaki “zengin-fakir” uçurumunu derinleştirebileceğini ve sıradan araştırmacıların mutluluğunu azaltabileceğini öne sürdüğü için büyük ilgi görmüş ve Nobel ödüllü profesörler dahil olmak üzere tanınmış akademisyenlerden övgü almıştı. MIT, araştırma bütünlüğü ihbarı aldıktan ve dahili bir soruşturma yürüttükten sonra, makalenin veri kaynağı, güvenilirliği, geçerliliği ve araştırmanın gerçekliği konusunda güvenini kaybettiğini belirterek arXiv ve The Quarterly Journal of Economics’ten makalenin kaldırılmasını talep etti. Yazar MIT’den ayrıldı ve ilgili profesörler de olayla ilgilerinin olmadığını belirten açıklamalar yaptı. İddialara göre yazar, soruşturma sırasında sahte alan adları satın alarak büyük şirketlerden geliyormuş gibi e-postalar göndermiş, bu durum fark edilince hakkında dava açılmış. (Kaynak: 36氪)

AI tarafından üretilen görsellerin internet dolandırıcılığında kullanılması kullanıcıları alarma geçirdi: Bir Reddit kullanıcısı, Facebook gibi sosyal medya platformlarında AI tarafından üretilen insan görsellerinin ürün tanıtımı için kullanıldığı örnekleri paylaştı. Bu görsellerdeki insanlar ve sahneler genellikle mantıksız unsurlar içeriyor (örneğin, modelin tuhaf bir şekilde kutuya girip çıkması, arka planda alakasız kişilerin belirmesi gibi), ancak karakter imajı tutarlılığı yüksek. Yorumcular, bu tür AI tarafından üretilen içeriklerin dolandırıcılıkta kullanıldığını belirterek kullanıcıları uyardı. Pleasant Green gibi blog yazarları da bu tür dolandırıcılıkları ifşa eden videolar hazırladı. (Kaynak: Reddit r/ChatGPT)
AI tarafından üretilen görsellerde stil taklidi ve komut istemi çıkarma tartışması: Kullanıcılar, AI modellerinin (DALL-E 3 gibi) belirli bir sanat stilini (örneğin, Pixar stilini Designer Toy stiliyle birleştiren Salvador Dalí) taklit ederek karakter portreleri oluşturmasını nasıl sağlayacaklarını tartıştılar ve karakter özellikleri, arka plan, ışıklandırma ve gölge gibi temel kavramları (gölgenin zihinsel bir yansıma olarak kullanılması gibi) vurgulayan ayrıntılı komut istemlerini paylaştılar. Ayrıca, bir kullanıcı, görsellerden stil parametrelerini çıkarmak ve bunları JSON formatında çıktılamak için bir komut istemi şablonu sundu; bu, kullanıcıların görsel stillerini tersine mühendislikle anlamalarına yardımcı olmayı amaçlıyor, ancak tam olarak yeniden oluşturmak hala zor. (Kaynak: dotey, dotey)
