
Anahtar Kelimeler:AlphaEvolve, AI algoritma tasarımı, çok modlu AI, AI programlama araçları, özerk evrim algoritmaları, büyük dil modelleri, AI ajanları, AlphaEvolve açık kaynak uygulaması, AI ile özerk matris çarpım algoritması tasarımı, çok modlu AI birleşik arayüzü, AI programlama araçlarının geliştiriciler üzerindeki etkisi, yerel büyük model Qwen 3 performansı
🔥 Odak Noktası
Google DeepMind, AI’ın otonom olarak algoritmalar tasarladığı ve evrimleştirdiği AlphaEvolve’u yayınladı: Google DeepMind, AlphaEvolve projesini ve makalesini kamuoyuna duyurarak, daha verimli algoritmaları otonom olarak tasarlayabilen, test edebilen, öğrenebilen ve evrimleştirebilen bir AI agent’ı sergiledi. Sistem, (Gemini gibi) Large Language Model’ları (LLM’leri) prompt engineering ile yönlendirerek başlangıç algoritma önerileri üretiyor ve algoritmaları evrimsel bir döngüde uygunluk değerlendirmesi ve hayatta kalanların seçimi yoluyla optimize ediyor. Topluluk hızla yanıt verdi; açık kaynaklı bir implementasyon olan OpenAlpha_Evolve ortaya çıktı ve araştırmacılar Claude gibi araçları kullanarak AlphaEvolve’un matris çarpımı gibi alanlardaki atılımlarını doğruladı. Bu, AI’ın algoritma inovasyonundaki büyük potansiyelini gösteriyor. (Kaynak: karminski3, karminski3, Reddit r/ClaudeAI, Reddit r/artificial)

OpenAI’ın çok modlu stratejisi belirginleşiyor: Entegre arayüzler ve merkezi altyapı dikkat çekiyor: OpenAI, son dönemde GPT-4o, Sora ve Whisper gibi ürünlerin lansmanıyla sadece metin, görüntü, ses ve video gibi çok modlu yeteneklerindeki ilerlemesini göstermekle kalmadı, aynı zamanda birden fazla modaliteyi birleşik arayüzlere ve API’lere entegre etme stratejik niyetini de ortaya koydu. Bu strateji kullanıcılara kolaylık sağlasa da, altyapının merkezileşmesinin harici geliştiricilerin ve araştırmacıların inovasyon alanını kısıtlayabileceğine dair tartışmalara yol açtı. Özellikle Sora gibi video üretim modelleri, yüksek hesaplama kaynağı gereksinimleri nedeniyle yüksek maliyetli uygulamaları OpenAI ekosistemine daha da dahil ederek, önde gelen platformların “hesaplama çekim gücünü” artırabilir ve AI alanındaki açıklığı ve modüler gelişimi etkileyebilir. (Kaynak: Reddit r/deeplearning)
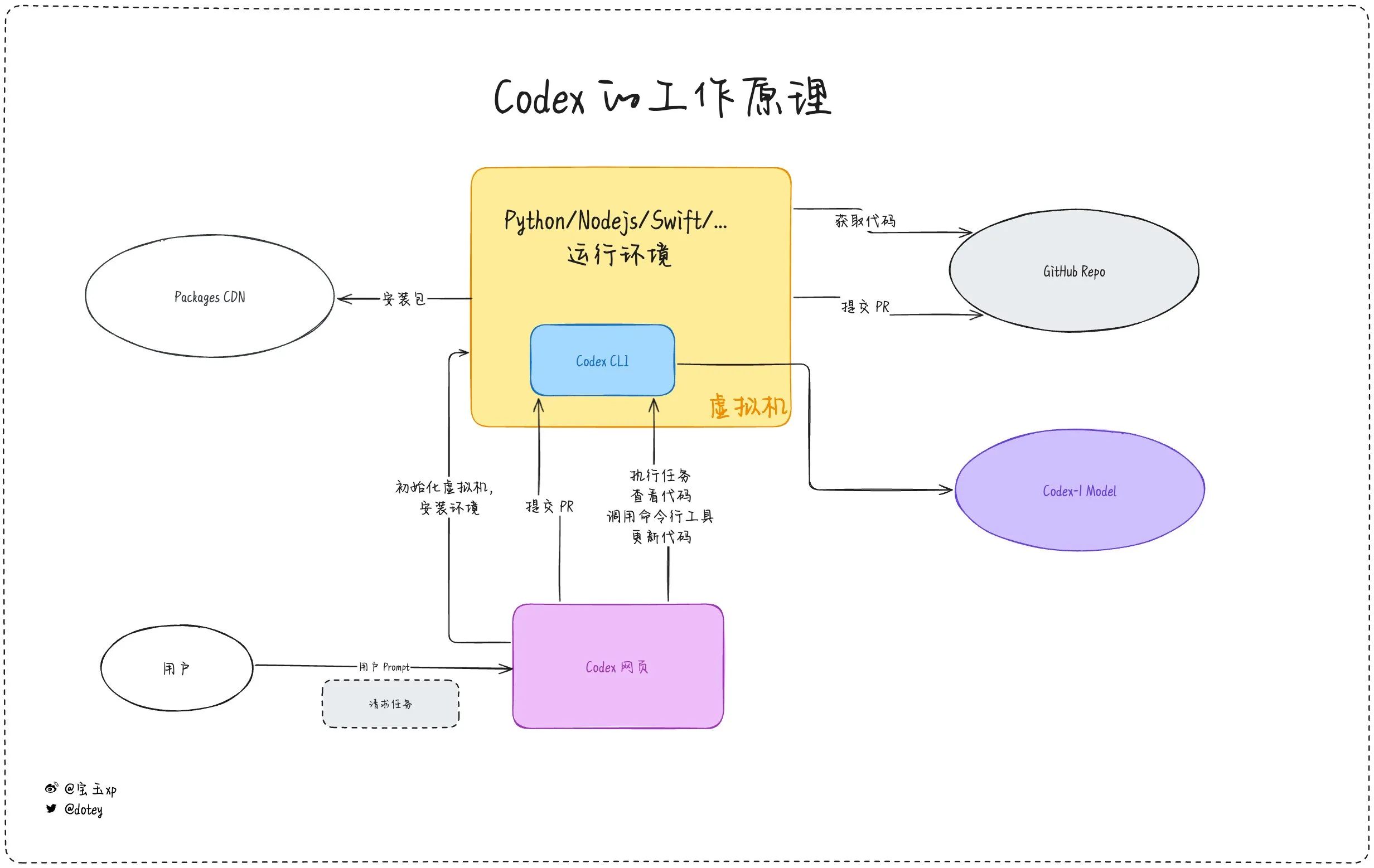
AI programlama araçlarının penetrasyonu artıyor, geliştirici deneyimi ve yansımalar bir arada: Codex, Devin gibi AI programlama araçları ve çeşitli AI Agent’lar yazılım geliştirme süreçlerine hızla entegre oluyor. Geliştirici geri bildirimleri, Codex’in kod uluslararasılaştırma, proje yükseltme gibi konularda yüksek verimlilik gösterdiğini ve geliştirme döngülerini önemli ölçüde kısaltabildiğini gösteriyor. Ancak, dotey’in Codex değerlendirmesinde belirttiği gibi, mevcut AI araçları daha çok “dış kaynaklı çalışanlar” gibi; görevleri tamamlayabilseler de internet bağlantısı, görev sürekliliği ve deneyim birikimi konularında hala sınırlamaları bulunuyor. Topluluk tartışmalarında ayrıca, bazı geliştiricilerin AI destekli programlamayı uzun süre kullandıktan sonra kendi düşünme ve yaratıcılıkları üzerindeki etkisini sorgulamaya başladığı, hatta daha çok “insan beynine” dayanan geliştirme modellerine geri döndüğü belirtiliyor. Bu durum, AI araçlarının verimliliği artırma ile geliştiricilerin temel yeteneklerini koruma arasındaki dengenin hala önemli bir konu olduğunu gösteriyor. (Kaynak: dotey, giffmana, cto_junior, Reddit r/artificial)
🎯 Eğilimler
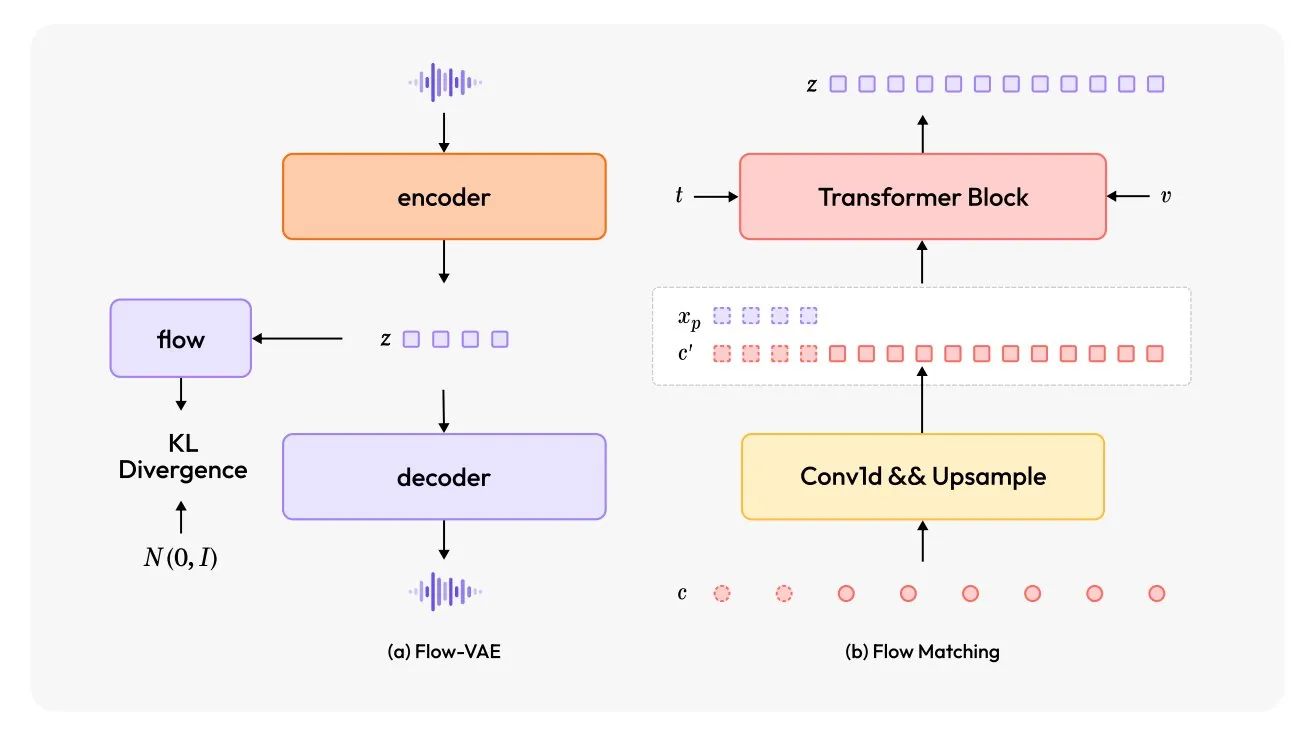
MiniMax-Speech: Yeni çok dilli TTS modeli yayınlandı: TheTuringPost, yeni bir metinden sese (TTS) modeli olan MiniMax-Speech’i tanıttı. Bu model iki büyük yenilik içeriyor: kısa ses kayıtlarından ses tonunu yakalayabilen öğrenilebilir bir konuşmacı kodlayıcı ve ses kalitesini artırmak için bir Flow-VAE modülü. MiniMax-Speech 32 dili destekliyor ve sese duygu eklemek, metin açıklamalarından ses üretmek veya sıfır-çekim (zero-shot) ses klonlama için kullanılabiliyor, bu da kişiselleştirilmiş ve yüksek kaliteli ses sentezi alanındaki potansiyelini gösteriyor. (Kaynak: TheTuringPost, TheTuringPost)
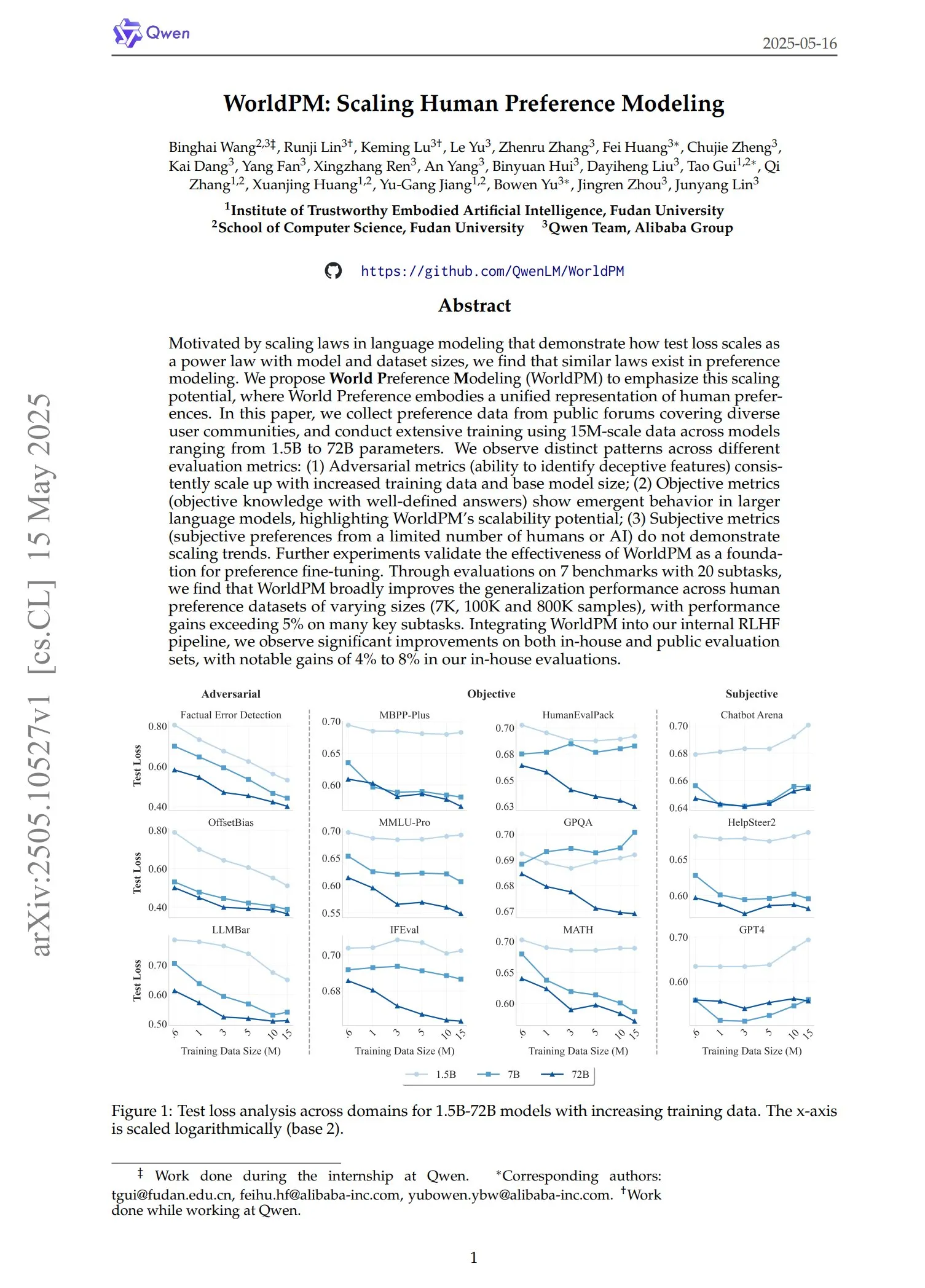
Qwen, WorldPM serisi tercih modellerini yayınladı: Qwen ekibi dört yeni tercih modelleme modeli sundu: WorldPM-72B, WorldPM-72B-HelpSteer2, WorldPM-72B-RLHFLow ve WorldPM-72B-UltraFeedback. Bu modeller temel olarak diğer modellerin yanıtlarının kalitesini değerlendirmek ve denetimli öğrenme sürecine yardımcı olmak için kullanılıyor. Yetkililer, bu tercih modellerini kullanarak eğitimin, sıfırdan eğitime göre daha iyi sonuçlar verdiğini belirtti ve ilgili makale de yayınlandı. (Kaynak: karminski3)
Grok’a grafik oluşturma özelliği eklendi: XAI’nin Grok modeli artık grafik oluşturma özelliğini destekliyor. Kullanıcılar Grok aracılığıyla tarayıcıda grafikler oluşturabilecek ve bu özelliğin önümüzdeki günlerde daha fazla platforma yayılması bekleniyor. Bu güncelleme, Grok’un veri görselleştirme ve bilgi sunumu yeteneklerini artırıyor. (Kaynak: grok, Yuhu_ai_, TheGregYang)
DeepRobotics, orta boy dört ayaklı robot Lynx’i tanıttı: DEEP Robotics şirketi, yeni orta boy dört ayaklı robotu Lynx’i tanıttı. Bu robot, karmaşık arazilerde stabil bir şekilde ilerleme yeteneğini sergileyerek şirketin robot hareket kontrolü ve algılama teknolojilerindeki ilerlemesini yansıtıyor ve denetim, lojistik gibi çeşitli senaryolarda uygulanabilir. (Kaynak: Ronald_vanLoon)
Sanctuary AI, genel amaçlı robotlar için yeni dokunsal sensörleri entegre etti: Sanctuary AI, genel amaçlı robotlarının yeni dokunsal sensör teknolojisini entegre ettiğini duyurdu. Bu iyileştirme, robotların nesne algılama ve manipülasyon yeteneklerini artırmayı amaçlıyor, böylece çevreleriyle daha hassas bir şekilde etkileşim kurabiliyorlar ve bu, daha güçlü genel yapay zeka robotlarına doğru atılmış önemli bir adım. (Kaynak: Ronald_vanLoon)
Unitree robotları gelişmiş yürüme yeteneklerini sergiledi: Unitree Robotics’in Go2 robotu, ters yürüme, adaptif takla atma ve engellerin üzerinden atlama dahil olmak üzere birçok gelişmiş yürüme biçimini sergiledi. Bu yeteneklerin gerçekleştirilmesi, robot köpeklerinin hareket kontrol algoritmaları ve çevresel uyum yeteneklerinde önemli bir gelişme olduğunu gösteriyor. (Kaynak: Ronald_vanLoon)
Çinli araştırma ekibi, kültürlenmiş insan beyin hücreleriyle çalışan bir robot geliştirdi: InterestingSTEM’in haberine göre, Çinli bir araştırma ekibi laboratuvarda kültürlenmiş insan beyin hücreleriyle çalışan bir robot geliştiriyor. Bu araştırma, biyolojik hesaplama ile robotik teknolojisinin birleşimini araştırıyor ve biyolojik nöronların öğrenme ve uyum yeteneklerini kullanarak robot kontrolü için yeni fikirler sunmayı amaçlıyor. Henüz erken keşif aşamasında olmasına rağmen, gelecekteki robot zekasının biçimleri hakkında geniş çaplı tartışmalara yol açtı. (Kaynak: Ronald_vanLoon)
Yeni nano ölçekli beyin sensörü, %96.4 sinir sinyali tanıma doğruluğuna ulaştı: Yeni bir nano ölçekli beyin sensörü, sinir sinyallerini tanımada %96.4’e varan bir doğruluk oranı sergiledi. Bu teknolojinin beyin-bilgisayar arayüzleri, sinirbilim araştırmaları ve tıbbi teşhis alanlarında uygulanması ve beyin aktivitesinin daha hassas bir şekilde yorumlanması için yeni araçlar sunması bekleniyor. (Kaynak: Ronald_vanLoon)

MistralAI’ın eğitim için test setlerini kullandığı söylentileri dikkat çekiyor: Toplulukta, MistralAI’ın NIAH gibi benchmark testlerinde eğitim için test seti verilerini kullanmış olabileceğine dair tartışmalar ortaya çıktı. kalomaze, GitHub NIAH testi ile özel NIAH (programatik olarak oluşturulmuş gerçekler ve sorular) performansını karşılaştırarak, MistralAI’ın ilkinde ikincisinden çok daha iyi performans gösterdiğini belirtti ve olası bir veri kirliliğine işaret etti. Dorialexander, değerlendirme setinin “sentetik bir benzerinin” veri karışımını tasarlamak için kullanılmış olabileceğini tahmin etti ve bu durum, model değerlendirmesinin adaleti ve şeffaflığı konusunda endişelere yol açtı. (Kaynak: Dorialexander)
Araştırma, Claude 3.5’in ikna kabiliyetinde insanları geçtiğini iddia ediyor: arXiv’de yayınlanan bir araştırma makalesi, Anthropic’in Claude 3.5 modelinin ikna kabiliyeti açısından insanlardan daha iyi performans gösterdiğini belirtiyor. Bu araştırma, modelin ve insanların belirli ikna görevlerindeki performansını deneysel olarak karşılaştırdı ve sonuçlar, AI’ın ikna edici argümanlar oluşturma ve iletişim kurma konusunda önemli avantajlara sahip olabileceğini gösterdi. Bu durumun pazarlama, halkla ilişkiler ve insan-makine etkileşimi gibi alanlar üzerinde potansiyel etkileri bulunuyor. (Kaynak: Reddit r/ClaudeAI)

Yerel büyük dil modellerinin tüketici sınıfı donanımlardaki yetenekleri önemli ölçüde arttı: Reddit kullanıcı geri bildirimlerine göre, Qwen 3’ün 14B parametreli modeli (128k bağlamı desteklemek için yarn yaması uygulanmış), sadece 10GB VRAM ve 24GB RAM’e sahip tüketici sınıfı bir PC’de, IQ4_NL nicelemesi ve 80k bağlam yapılandırmasıyla Roo Code ve Aider gibi AI programlama yardımcılarını oldukça iyi çalıştırabiliyor. Uzun bağlamları (örneğin 20k+) işlerken hızı yavaş olsa da (yaklaşık 2 t/s), kod düzenleme kalitesi ve kod tabanı bilişsel yeteneği iyi performans gösteriyor. Bu, yerel bir modelin daha uzun konuşmalarda karmaşık kodlama görevlerini istikrarlı bir şekilde işleyebildiği ve anlamlı kod farklılıkları üretebildiği ilk durum. Bu ilerleme, modelin kendisindeki iyileştirmeler, llama.cpp gibi çıkarım çerçevelerinin optimizasyonu ve Roo gibi ön uç araçlarının uyarlanması sayesinde gerçekleşti. (Kaynak: Reddit r/LocalLLaMA)
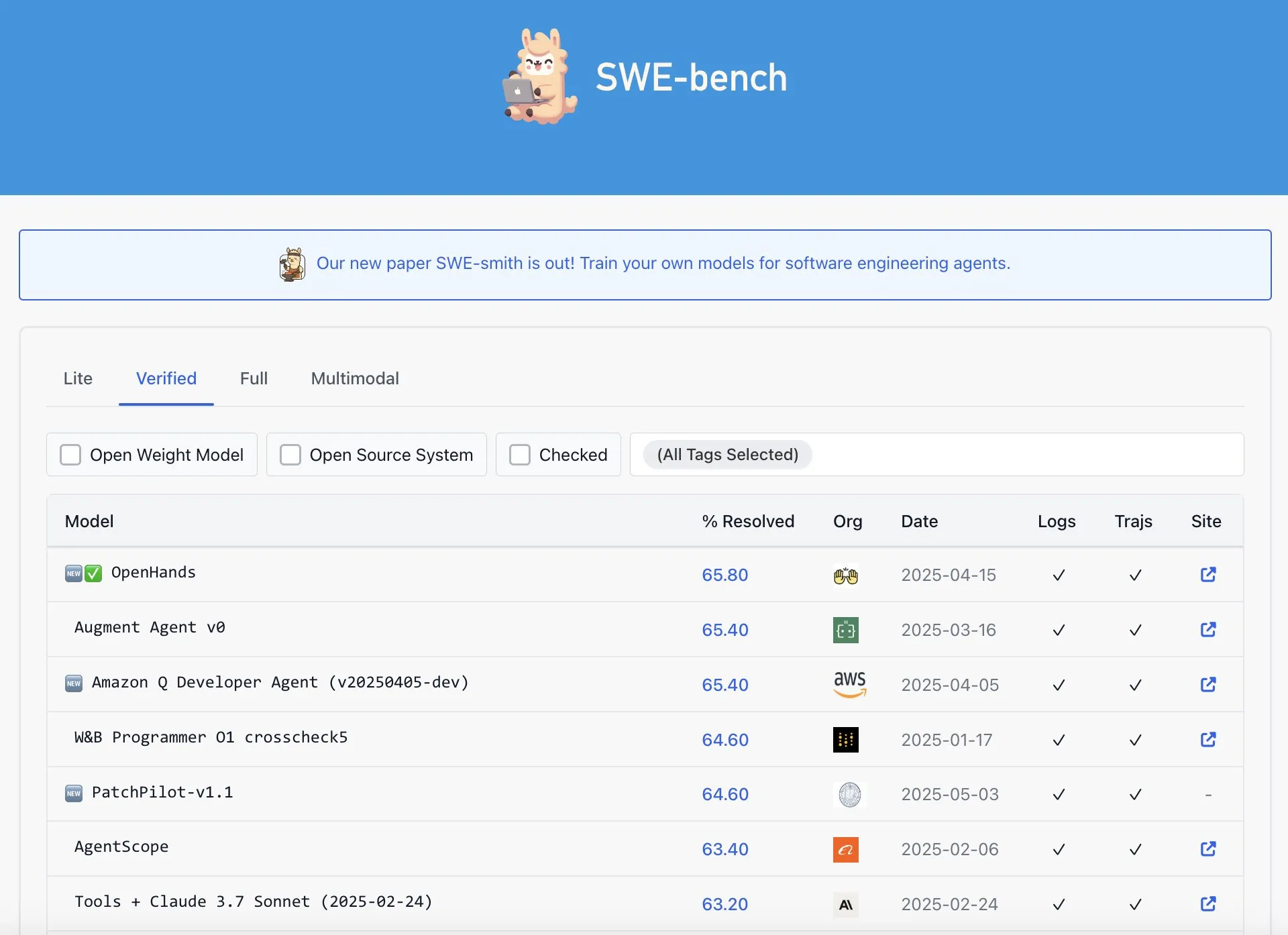
OpenAI Codex’in SWE-Bench Verified sıralamasında en iyi performansı göstermediği iddia edildi: Graham Neubig, OpenAI’ın Codex modelinin SWE-Bench Verified sıralamasında SOTA (State-of-the-Art) sonuçlar elde ettiği yönündeki iddiaların tam olarak doğru olmadığını belirtti. Verileri ve farklı ölçüm standartlarını analiz ederek, Codex’in bu özel benchmark’taki performansının hangi açıdan bakılırsa bakılsın tartışmalı olduğunu ve şüphesiz en iyi olmadığını savundu. (Kaynak: JayAlammar)
🧰 Araçlar
OpenAlpha_Evolve açık kaynak oldu: Google’ın AI algoritma tasarım agent’ının yeniden üretimi: Google DeepMind’ın AlphaEvolve makalesini yayınlamasının ardından geliştirici shyamsaktawat hızla açık kaynaklı bir implementasyon olan OpenAlpha_Evolve’u yayınladı. Bu Python framework’ü, kullanıcıların AI güdümlü algoritma tasarımı fikirlerini denemelerine olanak tanıyor. Görev tanımlama, prompt engineering, kod üretimi (Gemini gibi LLM’ler yardımıyla), yürütme testleri, uygunluk değerlendirmesi ve evrimsel seçim gibi aşamaları içeriyor ve daha geniş bir topluluğun AI’ın yeni algoritmalar tasarlama alanındaki öncü keşiflere katılımını amaçlıyor. (Kaynak: karminski3, Reddit r/artificial, Reddit r/LocalLLaMA)

Cursor editörü, tüm dosyayı hızlı düzenleme özelliği ekledi: AI öncelikli kod editörü Cursor, kullanıcıların artık tüm dosyaları hızlı bir şekilde düzenleyebileceğini duyurdu. Bu yeni özellik, geliştiricilerin çalışma verimliliğini artırmayı ve Cursor’da büyük ölçekli kod değişiklikleri ve yeniden yapılandırmayı daha kolay hale getirmeyi amaçlıyor. (Kaynak: cursor_ai)
Codex, uygulama uluslararasılaştırma ve yerelleştirme görevlerini verimli bir şekilde tamamladı: Geliştirici Katsuya, OpenAI Codex kullanarak uygulama uluslararasılaştırma deneyimini paylaştı. Codex’in uygulamayı Japonca’ya yerelleştirmesini istedi ve normalde birkaç gün sürecek bu işi bir gecede tamamladı. Bu, Codex’in otomatik kod üretimi ve karmaşık dil görevlerini işleme konusundaki güçlü yeteneklerini açıkça gösterdi. (Kaynak: gdb, ShunyuYao12)
llmbasedos: LLM’ler için tasarlanmış güvenli MCP sanal alan ortamı: llmbasedos projesi, Large Language Model’lar (LLM’ler) için güvenli bir modüler hesaplama protokolü (MCP) sanal alanı sağlamayı amaçlayan, kırpılmış bir Arch Linux tabanlı bir işletim sistemi ortamı sunuyor. Dosya sistemi, posta, senkronizasyon, proxy gibi işlevleri MCP hizmetleri olarak paketliyor ve kullanıcılar sanal makine veya fiziksel makineden ISO’dan önyükleme yaptıktan sonra bu hizmetleri çağırarak güvenli LLM etkileşimi ve geliştirme yapabiliyorlar. (Kaynak: karminski3)

cachelm: Açık kaynaklı LLM semantik önbellekleme aracı verimliliği artırıyor ve maliyetleri düşürüyor: Geliştirici devanmolsharma, LLM uygulamaları için tasarlanmış bir semantik önbellek katmanı olan açık kaynaklı cachelm aracını yayınladı. Vektör araması yoluyla semantik benzerliğe dayalı önbellekleme uygulayarak, LLM API’lerine yapılan tekrarlı çağrıları (kullanıcı sorularının farklı ifade edilmesi durumunda bile) etkili bir şekilde azaltır, böylece Token tüketimini düşürür ve yanıtları hızlandırır. Araç OpenAI, ChromaDB, Redis, ClickHouse gibi platformları destekler ve kullanıcıların kendi vektörleştiricilerini, veritabanlarını veya LLM’lerini özelleştirmelerine olanak tanır. (Kaynak: Reddit r/MachineLearning)
ArchGW 0.2.8 yayınlandı, AI-native proxy temel işlevleri birleştiriyor: ArchGW, uygulamalardaki tekrarlayan “düşük seviyeli” işlevleri birleştirmeyi amaçlayan Envoy tabanlı bir AI-native proxy olan 0.2.8 sürümünü yayınladı. Yeni sürüm, çift yönlü trafik desteği (Google A2A için hazırlık), hızlı yönlendirme ve araç çağırma için geliştirilmiş Arch-Function-Chat 3B modeli ve Groq üzerinde barındırılan LLM’ler için destek ekliyor. ArchGW, yerel bir proxy aracılığıyla AI uygulama geliştirmeyi basitleştirir, güvenliği, tutarlılığı ve gözlemlenebilirliği artırır. (Kaynak: Reddit r/artificial)
SparseDepthTransformer: Lise öğrencisi dinamik katman atlama Transformer verimlilik çözümünü geliştirdi: Bir lise öğrencisi, SparseDepthTransformer adlı bir proje geliştirdi. Hafif bir puanlama mekanizmasıyla her Token’ın semantik önemini değerlendirerek ve önemsiz Token’ların Transformer’ın derin katman hesaplamalarını atlamasını sağlayarak çalışıyor. Deneyler, bu yöntemin çıktı kalitesini korurken bellek kullanımını yaklaşık %15 azalttığını ve Token başına ortalama işleme katmanı sayısını yaklaşık %40 düşürdüğünü gösterdi. Bu, Transformer verimliliğini artırmak için yeni bir yaklaşım sunuyor. (Kaynak: Reddit r/MachineLearning)

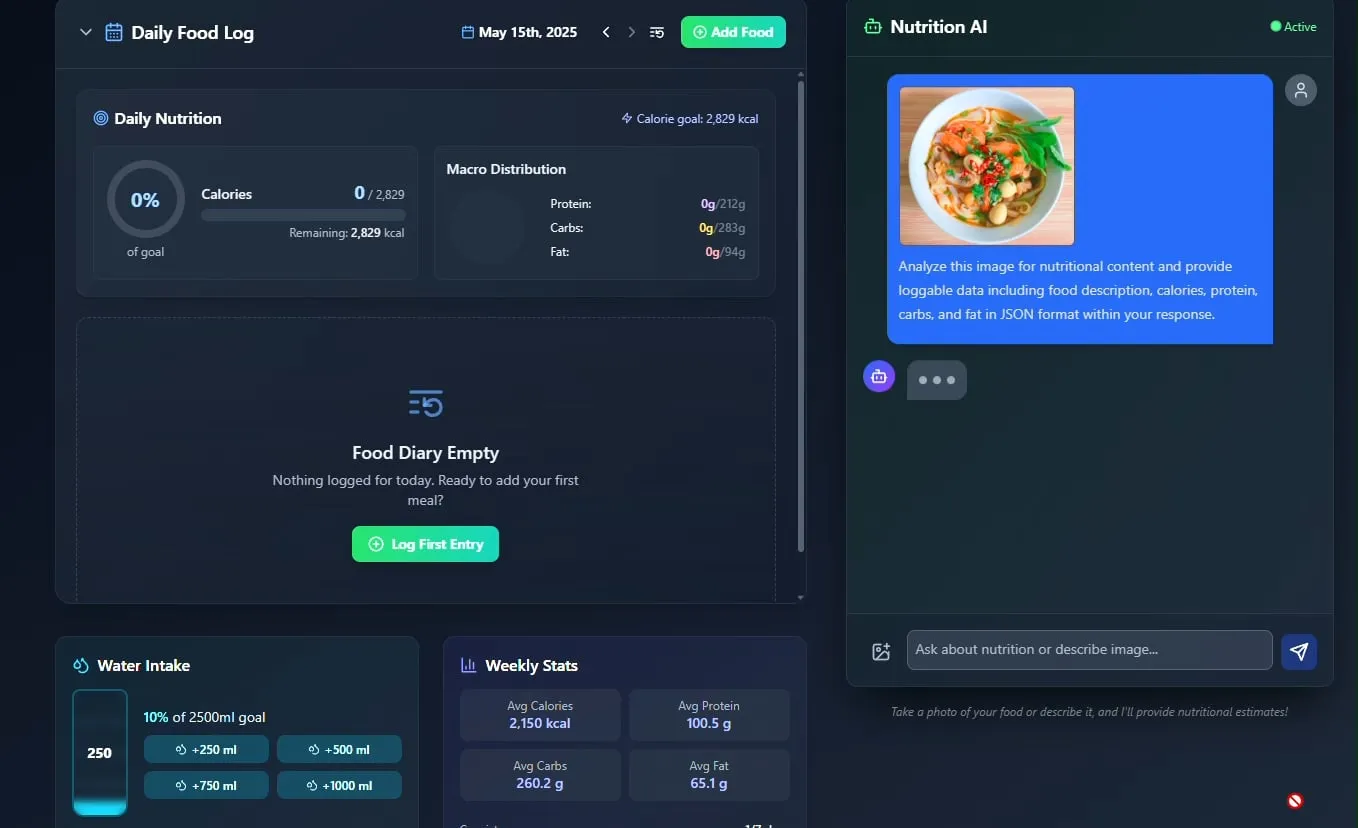
AI yiyecek ve beslenme takipçisi tanıtıldı, açık kaynak yapılması planlanıyor: Geliştirici Pavankunchala, AI destekli bir diyet ve beslenme takip uygulamasını sergiledi. Uygulamanın temel işlevi, kullanıcı tarafından yüklenen yiyecek fotoğraflarını analiz ederek yiyecekleri tanımlamak ve besin bilgilerini (kalori, protein vb.) tahmin etmektir. Aynı zamanda manuel kayıt, günlük beslenme özeti ve su takibini de desteklemektedir. Geliştirici, gelecekte bu projenin kodunu açık kaynak yapmayı planlıyor. (Kaynak: Reddit r/LocalLLaMA)
İtalyan AI agent’ı iş arama otomasyonunu gerçekleştirdi, bir dakikada binlerce iş başvurusu tartışma yarattı: İtalya’dan olduğu iddia edilen bir AI Agent, güçlü iş arama otomasyon yeteneğini sergileyerek 1 dakikada 1000 iş başvurusu tamamladı. Bu gösteri, toplulukta AI’ın işe alım alanındaki uygulamaları hakkında geniş çaplı tartışmalara yol açtı. Bir yandan verimliliğine hayran kalınırken, diğer yandan etkinliği, işe alım piyasasına etkileri ve “robot tespiti” gibi sorunlarla nasıl başa çıkılacağı konusunda endişeler dile getirildi. (Kaynak: Reddit r/ChatGPT)

📚 Öğrenme
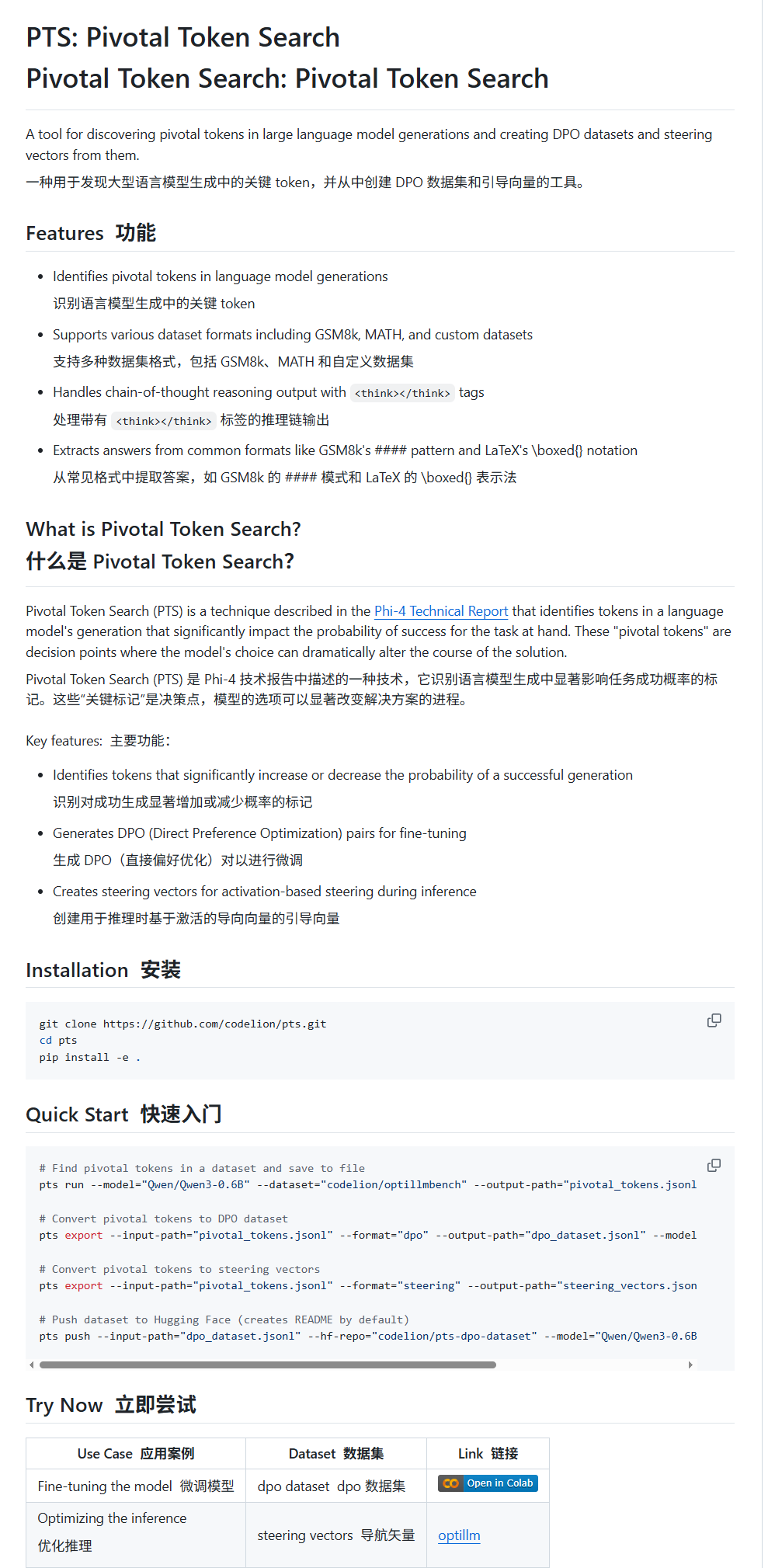
Pivotal Token Search (PTS): Yeni bir LLM ince ayar ve yönlendirme tekniği: karminski3, PTS (Pivotal Token Search) adlı yeni bir tekniği tanıttı. Bu teknik, “büyük dil modellerinin çıktılarındaki kilit karar noktalarının az sayıda kritik Token’a dayandığı” fikrine dayanmaktadır. Çıktının doğruluğunu önemli ölçüde etkileyebilen bu Token’ları (“seçilen Token’lar” ve “reddedilen Token’lar” olarak ikiye ayrılır) çıkararak ince ayar için bir DPO veri kümesi oluşturur. Ayrıca, PTS, kritik Token’ların aktivasyon modellerini çıkararak yönlendirme vektörleri (steering vectors) üretebilir ve çıkarım sırasında modeli ince ayar yapmadan yönlendirebilir. Bu yöntemin Phi4’ten ilham aldığı iddia ediliyor ve etkinliği toplulukta tartışılıyor. (Kaynak: karminski3)
OpenAI Codex CLI ücretsiz API kredisi sunuyor, veri paylaşımını teşvik ediyor: OpenAI geliştirici hesabı, Plus veya Pro kullanıcılarının npm i -g @openai/codex@latest ve codex --free komutlarını çalıştırarak ücretsiz API kredisi alabileceklerini duyurdu. Ayrıca, kullanıcılar platform ayarlarında OpenAI modellerini iyileştirmek ve eğitmek için veri paylaşımını seçerek ücretsiz günlük Token alabilirler. Bu adım, geliştiricileri Codex araçlarını kullanmaya ve model iyileştirmesine katılmaya teşvik etmeyi amaçlıyor. (Kaynak: OpenAIDevs, fouad)
Çoklu Agent Sistemleri (MAS) için ücretsiz öğrenme kaynakları özeti: TheTuringPost, Çoklu Agent Sistemleri (MAS) öğrenmek için 7 ücretsiz kaynağı derleyip paylaştı. Bunlar arasında CrewAI, CAMEL çoklu agent framework’ü ve LangChain çoklu agent eğitimleri; “Multiagent Systems: Algorithmic, Game-Theoretic, and Logical Foundations” adlı bir kitap; ve sırasıyla prompt’lardan çoklu agent sistemlerine, AutoGen kullanarak çoklu agent geliştirmede uzmanlaşma ve crewAI ile pratik çoklu AI agent’ları ve gelişmiş kullanım senaryolarını kapsayan üç çevrimiçi kurs bulunuyor. (Kaynak: TheTuringPost)

MobileNetV2 ile hızlı görüntü sınıflandırma eğitimi: Reddit kullanıcısı Eran Feit, MobileNetV2 kullanarak görüntü sınıflandırması için bir Python eğitimi paylaştı. Bu eğitim, kullanıcıları önceden eğitilmiş MobileNetV2 modelini yükleme, OpenCV kullanarak görüntüleri ön işleme (BGR’den RGB’ye dönüştürme, 224×224’e ölçekleme, toplu işleme), çıkarım yapma ve tahmin sonuçlarını çözerek insanlar tarafından okunabilir etiketler ve olasılıklar elde etme konusunda adım adım yönlendiriyor. Bu eğitim, hafif görüntü sınıflandırma görevlerine hızlı bir başlangıç yapmak isteyen yeni başlayanlar için uygundur. (Kaynak: Reddit r/deeplearning)
OpenWebUI çok kaynaklı RAG ve hibrit arama uygulama kılavuzu yayınlandı: productiv-ai.guide web sitesi, OpenWebUI’da çok kaynaklı Gelişmiş Geri Alım Üretimi (RAG) ile Hibrit Arama ve Yeniden Sıralama (Re-ranking) uygulamak için ayrıntılı bir adım adım kılavuz yayınladı. Bu kılavuz, kullanıcıların bilgi alımının doğruluğunu ve alaka düzeyini artırmak için yakın zamanda eklenen harici yeniden sıralama özelliği de dahil olmak üzere OpenWebUI’ın RAG işlevlerini yapılandırmasına ve kullanmasına yardımcı olmayı amaçlamaktadır. (Kaynak: Reddit r/OpenWebUI)
💼 Ticari
AI Agent kulvarında rekabet kızışıyor: Manus ve Lovart derinlemesine karşılaştırması: Dikey tasarım alanındaki AI Agent “Lovart”, benzersiz “sipariş alma tarzı” iş akışıyla dikkat çekiyor; talep iletişiminden katmanlı materyal teslimine kadar tam bir tasarım sürecini simüle etmeye çalışıyor ve genel amaçlı Agent “Manus”un “sevk ve idare tarzı” mantığıyla tezat oluşturuyor. Lovart, tasarım estetiği anlayışı, kavramsal ifade ve bilgi organizasyonu konularında Manus’tan daha iyi performans gösterse ve daha hızlı olsa da, her ikisi de kararlılık, Çince işleme ve değişikliklerin senkronizasyonu gibi sorunlarla karşılaşıyor. Lovart’ın ortaya çıkışı, dikey Agent’ların senaryolara derinlemesine nüfuz etmesi ve sektör deneyimini içselleştirmesi açısından doğru bir yön olarak görülüyor ve AI Agent’ların içerik endüstrisinde gerçekten uygulanabilir hale gelebileceğinin habercisi olarak değerlendiriliyor. (Kaynak: 36氪)

Çocuk akıllı saat pazarında patlama, AIoT trendi yerli SoC çip üreticilerinin performansını artırıyor: Tüketim politikalarının teşviki ve AIoT geliştirme trendinden yararlanan Çin akıllı giyilebilir cihaz pazarı (özellikle çocuk akıllı saatleri) satışlarında büyük bir artış yaşandı. DeepSeek gibi açık kaynaklı büyük modellerin ortaya çıkışı, uç cihazlarda AI dağıtım eşiğini düşürerek AI’ın akıllı ev aletleri, AI kulaklıklar gibi terminallere nüfuzunu hızlandırdı. Rockchip, Bestechnic gibi yerli SoC çip üreticileri, düşük güç tüketimi ve AI hesaplama gücü alanındaki yatırımları ve Rockchip RK3588 gibi amiral gemisi çiplerinin PC, akıllı donanım, otomotiv gibi çoklu senaryoları kapsaması sayesinde performanslarında önemli bir artış kaydetti ve değerlemeleri de buna paralel olarak yükseldi. (Kaynak: 36氪)
OpenAI’ın şirket yeniden yapılandırma planlarını değiştirdiği ve kar amacı gütmeyen statüsüne yönelik eleştirilere karşı çıktığı iddia edildi: Garrison Lovely’nin ifşaatına göre, daha önce bildirilmemiş bir OpenAI’ın Kaliforniya Başsavcılığı’na yazdığı mektup ortaya çıktı. Mektubun içeriği sadece OpenAI’ın şirket yeniden yapılandırma planlarındaki beklenmedik ayrıntıları içermekle kalmıyor, aynı zamanda OpenAI’ın şirketin kar amacı gütmeyen yönetim yapısını zayıflatmaya çalıştığı yönündeki eleştiri ve şüpheleri aktif olarak bertaraf etmeye çalıştığını da gösteriyor. (Kaynak: NeelNanda5)

🌟 Topluluk
LLM’lerin N-Gram doğası ve “zeka” sınırları hararetli tartışmalara yol açıyor: Topluluk, Large Language Model’ların (LLM) ne ölçüde hala N-Gram istatistiksel özelliklerine dayandığını ve mevcut LLM’lerin “gerçek AI” olup olmadığını tartışmaya devam ediyor. Bazı görüşler (örneğin pmddomingos’un jxmnop’un NeurIPS makalesine yaptığı yorum), LLM’lerin vakaların 2/3’ünden fazlasında N-Gram modellerine benzer davrandığını öne sürüyor. Reddit’teki bir veri bilimcisi, mevcut LLM’lerin gerçek anlama, muhakeme ve sağduyudan yoksun olduğunu, AGI’dan (Genel Yapay Zeka) hala uzak olduğunu ve özünde kendini bilen ve uyum sağlayabilen agent’lar değil, karmaşık “bir sonraki kelime tahmin sistemleri” olduğunu belirtti. (Kaynak: jxmnop, pmddomingos, Reddit r/ArtificialInteligence)

AI tarafından üretilen “şeffaf ince film” tarzı görüntüler ve “Doubao”nun sınırları zorlayan çizimleri dikkat çekiyor: Son zamanlarda, sosyal medyada Doubao gibi AI çizim araçları tarafından üretilen belirli bir tarzda, özellikle “şeffaf ince film” ile sarılmış efektler sunan çok sayıda görüntü ortaya çıktı. Bu görüntüler, yeni görsel efektleri ve potansiyel olarak “sınırları zorlayan” içerikleri nedeniyle kullanıcılar arasında geniş çaplı tartışmalara, taklitlere ve ikincil yaratımlara yol açarak AI tarafından üretilen içerik alanında popüler bir trend haline geldi. (Kaynak: op7418, dotey)

AI etiği ve geleceği: “Tanrı” inşa etmek mi yoksa kendi kendini yok etmek mi?: Topluluk, AI gelişiminin nihai hedefleri ve potansiyel riskleri hakkında hararetli tartışmalar yürütüyor. Emad Mostaque, bazılarının ütopya veya yıkım getirebilecek “Tanrı” benzeri bir AGI inşa etmeye çalıştığını açıkça belirtti. NVIDIA CEO’su Jensen Huang ise gelecekte insan mühendislerin 1000 AI ile işbirliği içinde çip tasarladığı bir senaryoyu öngördü. Aynı zamanda, SMBC çizgi romanının başlattığı tartışma, AI bilinç sorununu daha pratik bir etik muamele düzeyine taşıdı: Bu “nesnelere” vicdanımız rahat bir şekilde davranabilir miyiz? Bu görüşler, AI’ın geleceğine dair karmaşık bir hayal gücü oluşturuyor. (Kaynak: Reddit r/artificial, Reddit r/artificial, Reddit r/artificial)
AI, SaaS iş modelini altüst edecek mi? Geliştirici topluluğu hararetle tartışıyor: Claude Code gibi güçlü AI programlama araçlarının yaygınlaşmasıyla birlikte, geliştirici topluluğu bunların SaaS (Hizmet Olarak Yazılım) iş modeli üzerindeki potansiyel etkisini tartışmaya başladı. Görüşler, bireysel geliştiricilerin mevcut SaaS ürünlerinin temel işlevlerini AI kullanarak kopyalama eşiğinin düştüğünü gösteriyor. Bu durum, işletmelerin ve bireysel kullanıcıların geleneksel SaaS hizmetlerine olan bağımlılıklarını azaltmalarına ve daha uygun maliyetli kendi kendine oluşturulmuş veya AI destekli çözümlere yönelmelerine neden olabilir. Gelecekte yazılım geliştirmenin daha çok AI’ın mikro yönetimine dayanabileceği düşünülüyor. (Kaynak: Reddit r/ClaudeAI)
AI’ın çok dilli işlemedeki farklılıkları dikkat çekiyor, Llama ön belirteçleyicisi (pretokenizer) nedenlerden biri olabilir: Topluluk tartışmaları, Large Language Model’ların (LLM) İngilizce’deki performansının genellikle diğer dillerden daha iyi olduğuna işaret ediyor. Bunun olası nedenlerinden biri olarak Llama gibi modellerin ön belirteçleyicisinin (pretokenizer) İngilizce olmayan metinleri (özellikle Latin alfabesi dışındaki karakterleri) işleme şekli gösteriliyor. Örneğin, ön belirteçleyici Çince karakterleri aşırı derecede daha küçük birimlere ayırabilir, bu da modelin dil yapısını ve semantiğini anlamasını etkileyerek bu dillerdeki performans düşüşüne yol açabilir. (Kaynak: giffmana)

💡 Diğer
DSPy framework’ü, AI agent geliştirmede temel ilkelere (primitives) verilen önemi vurguluyor: AI framework’ü DSPy, Ocak 2023’te temel soyutlamalarını açık kaynak olarak sunduğundan beri, birkaç küçük basitleştirme dışında neredeyse hiç değişiklik yapmadı ve birçok LLM API yinelemesinden geçmesine rağmen kararlılığını korudu. Topluluk tartışmaları, bunun DSPy’nin sadece yüzeysel geliştirici deneyimine veya “agent”ları hızlı bir şekilde oluşturma kolaylığına odaklanmak yerine, doğru temel ilkeleri (primitives) oluşturmaya odaklanmasından kaynaklandığını belirtiyor. Görüşe göre, mevcut birçok agent geliştirme framework’ü kullanılabilirliğe aşırı odaklanırken, temel yapı taşlarının sağlamlığını ihmal ediyor; oysa DSPy’nin felsefesi, karmaşık “agent” davranışları oluşturabilmek için önce sağlam bir “reaksiyon” temeline sahip olmaktır. (Kaynak: lateinteraction, lateinteraction)
AI tarafından üretilen içerikte estetik yorgunluk, özelleştirilmiş model talebini doğuruyor: Topluluk tartışmalarına göre, pekiştirmeli öğrenme (RL) ile optimize edilmiş birçok görüntü üretim modelinin çıktıları genellikle “vasat” veya “kitsch” görünüyor; teknik olarak iyi görünseler de heyecan verici yaratıcılık ve kişilikten yoksunlar. Bu durum, model optimizasyon hedeflerinin benzersiz sanatsal arayışlar yerine kitlenin ortalama estetik tercihlerine yönelme eğiliminde olabileceğini yansıtıyor. Bu nedenle, gelecekte özelleştirilmiş modeller ve bireysel estetik hedeflere göre örnekleme yapabilen yöntemler, bu sorunun üstesinden gelmek ve daha çekici AI içerikleri oluşturmak için kilit öneme sahip olarak görülüyor. (Kaynak: torchcompiled)

Ollama çok modlu motorunu yayınladı, OpenWebUI kullanıcıları uyumluluğu merak ediyor: Ollama, çok modlu motorunun resmi olarak yayınlandığını duyurdu. Bu haber, OpenWebUI topluluğu kullanıcılarının dikkatini çekti. Kullanıcılar genellikle OpenWebUI’ın, Ollama’nın yeni çok modlu motorunu “kutudan çıktığı gibi” destekleyip destekleyemeyeceğini, yani görüntü, metin gibi çeşitli veri türlerini işleme yeteneğinden karmaşık yapılandırma değişiklikleri yapmadan yararlanılıp yararlanılamayacağını merak ediyor. (Kaynak: Reddit r/OpenWebUI)
