
Anahtar Kelimeler:AlphaEvolve, Claude Sonnet, GPT-4.1, Meta FAIR, Qwen3, Phi-4-reasoning, AI düzenleme, Gemini destekli kodlama asistanı, Matris çarpımı algoritması optimizasyonu, Veri merkezi verimlilik optimizasyonu, Çok dilli çok modelli model, Merkezi olmayan AI eğitim ağı, Seed1.5-VL
🔥 Öne Çıkanlar
Google DeepMind, AlphaEvolve’u duyurdu: Gemini destekli kodlama ajanı algoritma keşfinde devrim yaratıyor: Google DeepMind, büyük dil modellerinin (LLM) yaratıcılığını otomatik değerlendiricilerle birleştirerek karmaşık algoritmaları keşfetmek ve optimize etmek üzere tasarlanan, Gemini destekli bir AI kodlama ajanı olan AlphaEvolve’u tanıttı. AlphaEvolve, daha hızlı matris çarpımı algoritmaları tasarlamada başarılı oldu, Erdős minimum örtüşme problemi ve öpüşme sayısı problemi gibi açık matematik problemlerini çözdü. Ayrıca Google içinde veri merkezi verimliliğini optimize etmek (ortalama %0.7 hesaplama kaynağı geri kazanımı), çip tasarımı ve Gemini’nin kendi eğitimini hızlandırmak için kullanılarak AI’ın bilimsel keşif ve mühendislik optimizasyonundaki büyük potansiyelini ortaya koydu. (Kaynak: GoogleDeepMind, DeepLearning.AI Blog)
Anthropic, Claude Sonnet ve Opus için yeni modeller yayınlamaya hazırlanıyor, çıkarım ve araç çağırma yeteneklerini güçlendiriyor: The Information’a göre Anthropic, önümüzdeki haftalarda Claude Sonnet ve Claude Opus’un yeni sürümlerini piyasaya sürmeyi planlıyor. Yeni modellerin temel özelliği, “düşünme modu” ve “araç kullanım modu” arasında esnek bir şekilde geçiş yapabilmesi. Harici araçları (uygulamalar, veritabanları gibi) kullanarak sorunları çözerken bir engelle karşılaşıldığında, model aktif olarak “çıkarım moduna” dönerek durumu yansıtıp kendini düzeltebiliyor. Kod üretimi açısından, yeni model üretilen kodu otomatik olarak test edebiliyor ve bir hata bulunursa duraklayıp, düşünüp düzeltebiliyor. Bu “düşün-eyleme geç-yansıt” kapalı döngüsünün, modelin karmaşık sorunları çözme yeteneğini ve güvenilirliğini önemli ölçüde artırması bekleniyor. (Kaynak: steph_palazzolo, dotey)

ABD Cumhuriyetçi Parti milletvekilleri, federal ve eyalet düzeyinde AI düzenlemelerinin 10 yıl süreyle yasaklanmasını önererek hararetli tartışmalara yol açtı: ABD Cumhuriyetçi Parti milletvekilleri, bütçe uzlaşma tasarısına, önümüzdeki on yıl boyunca federal ve eyalet hükümetlerinin yapay zeka modelleri, sistemleri veya otomatik karar verme sistemlerini düzenlemesini yasaklayan bir madde ekledi. Ayrıca AI’ın ticarileştirilmesi ve federal hükümetin IT sistemlerinde uygulanmasını desteklemek için 500 milyon dolar tahsis etmeyi planlıyorlar. Bu hamle, bazı teknoloji çevreleri tarafından AI inovasyonunu korumak ve düzenlemelerin boğucu etkisini önlemek için olumlu bir sinyal olarak görülse de, DeepFake’lerin yayılması, veri gizliliğinin kontrolden çıkması, AI etiği ve çevresel etkiler gibi potansiyel riskler konusunda endişelere yol açtı. Teklif kabul edilirse, mevcut ve gelecekteki AI mevzuatı üzerinde önemli bir etkisi olacak. (Kaynak: Reddit r/ArtificialInteligence, Yoshua_Bengio)

OpenAI, GPT-4.1 modelini yayınladı ve güvenlik değerlendirme merkezini hizmete açtı, kodlama ve talimat takip yeteneklerini vurguladı: OpenAI, kullanıcı talebi üzerine GPT-4.1 modelinin bugünden itibaren ChatGPT’de (Plus, Pro, Team kullanıcıları; Enterprise ve Education sürümleri daha sonra) kullanılabileceğini duyurdu. GPT-4.1, kodlama görevleri ve talimat takibi için optimize edildi, daha hızlı ve o3 ile o4-mini’nin günlük kodlama alternatifi olarak kullanılabilir. Aynı zamanda, GPT-4.1 mini, tüm kullanıcıların mevcut olarak kullandığı GPT-4o mini’nin yerini alacak. Ayrıca OpenAI, modellerinin güvenlik testi sonuçlarını ve metriklerini kamuya açıklamak için Güvenlik Değerlendirme Merkezi’ni (Safety Evaluations Hub) başlattı ve güvenlik iletişiminde şeffaflığı artırmak için düzenli olarak güncelleyecek. (Kaynak: openai, michpokrass)
Meta FAIR, moleküler keşif ve atomik modellemeye odaklanan birçok AI araştırma sonucu yayınladı: Meta AI (FAIR), moleküler özellik tahmini, dil işleme ve sinirbilim alanlarındaki en son açık kaynak sürümlerini duyurdu. Bunlar arasında büyük atomik sistemlerin simülasyonu için bir moleküler keşif veri kümesi olan Open Molecules 2025 (OMol25); malzeme ve moleküllerin atomik etkileşimlerini modellemek için yaygın olarak uygulanabilen bir makine öğrenimi atomlar arası potansiyel modeli olan Universal Model for Atoms (UMA); ve skaler ödüllere dayalı üretken modelleri eğitmek için ölçeklenebilir bir algoritma olan Adjoint Sampling bulunmaktadır. Ayrıca FAIR, Rothschild Vakfı Hastanesi ile yaptığı işbirliğiyle insanlar ve LLM’ler arasındaki dil gelişiminde önemli benzerlikler ortaya koydu. (Kaynak: AIatMeta)
🎯 Gelişmeler
ByteDance, 20B aktif parametre ile üstün performans gösteren Seed1.5-VL görsel-dil büyük modelini yayınladı: ByteDance, görsel-dil çok modlu büyük modeli Seed1.5-VL’yi tanıttı. Bu model, yalnızca 20B aktif parametreye sahip olmasına rağmen Gemini 2.5 Pro ile karşılaştırılabilir bir performans sergiliyor ve 60 halka açık değerlendirme kriterinden 38’inde SOTA (son teknoloji) sonuçlar elde etti. Seed1.5-VL, genel çok modlu anlama ve çıkarım yeteneklerini geliştirdi, özellikle görsel konumlandırma, çıkarım, video anlama ve çok modlu ajanlar alanlarında öne çıkıyor. Model, Volcano Engine’de API olarak kullanıma sunuldu; çıkarım giriş fiyatı 0.003 yuan/bin token, çıkış fiyatı ise 0.009 yuan/bin token. (Kaynak: 机器之心)

Qwen3 teknik raporu açıklandı: Düşünme ve düşünmeme modlarını birleştiriyor, büyük model küçük modeli damıtıyor: Alibaba, 0.6B ila 235B parametre arasında 8 model içeren Qwen3 serisi modellerinin teknik raporunu yayınladı. Temel yenilik, çift çalışma modunda yatıyor; model, görevin karmaşıklığına göre “düşünme modu” (karmaşık çıkarım) ve “düşünmeme modu” (hızlı yanıt) arasında otomatik olarak geçiş yapabiliyor ve “düşünme bütçesi” parametresi aracılığıyla hesaplama kaynaklarını dinamik olarak tahsis ediyor. Eğitim, üç aşamalı ön eğitim (genel bilgi, çıkarım geliştirme, uzun metin) ve dört aşamalı son eğitim (uzun düşünce zinciri soğuk başlatma, çıkarım takviyeli öğrenme, düşünme modu entegrasyonu, genel takviyeli öğrenme) kullanıyor. Aynı zamanda, öğretmen modelden (örneğin 235B) öğrenci modele (örneğin 30B) bilgi aktarımı sağlamak için “büyükten küçüğe” veri damıtma stratejisi benimsiyor. (Kaynak: 36氪)

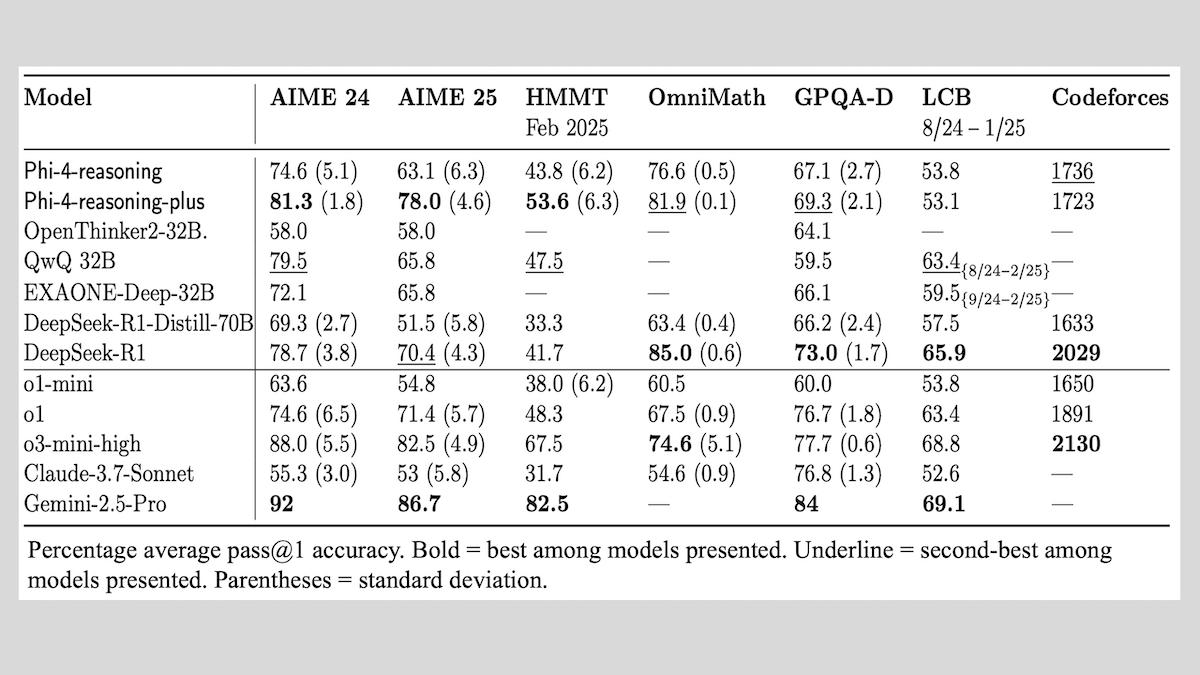
Microsoft, Phi-4-reasoning serisi modellerini yayınladı ve çıkarım modeli eğitimi deneyimlerini paylaştı: Microsoft, Phi-4-reasoning, Phi-4-reasoning-plus (her ikisi de 14B parametre) ve Phi-4-mini-reasoning (3.8B parametre) olmak üzere üç model tanıttı ve eğitim yöntemleri ile deneyimlerini kamuoyuyla paylaştı. Bu modeller, önceden eğitilmiş modellerin ince ayarlanmasıyla matematiksel çıkarım gibi yetenekleri geliştirmeye odaklanıyor. Örneğin, Phi-4-reasoning-plus, takviyeli öğrenme yoluyla matematik problemlerinde üstün performans gösterirken, Phi-4-mini-reasoning aşamalı olarak SFT ve RL ince ayarından geçiyor. Rapor, küçük model eğitiminde ortaya çıkabilecek kararsızlıkları ve başa çıkma stratejilerini, ayrıca büyük model RL eğitiminde veri seçimi ve ödül fonksiyonu tasarımıyla ilgili hususları paylaşıyor. Model ağırlıkları, MIT lisansı altında Hugging Face’te kullanıma sunuldu. (Kaynak: DeepLearning.AI Blog)
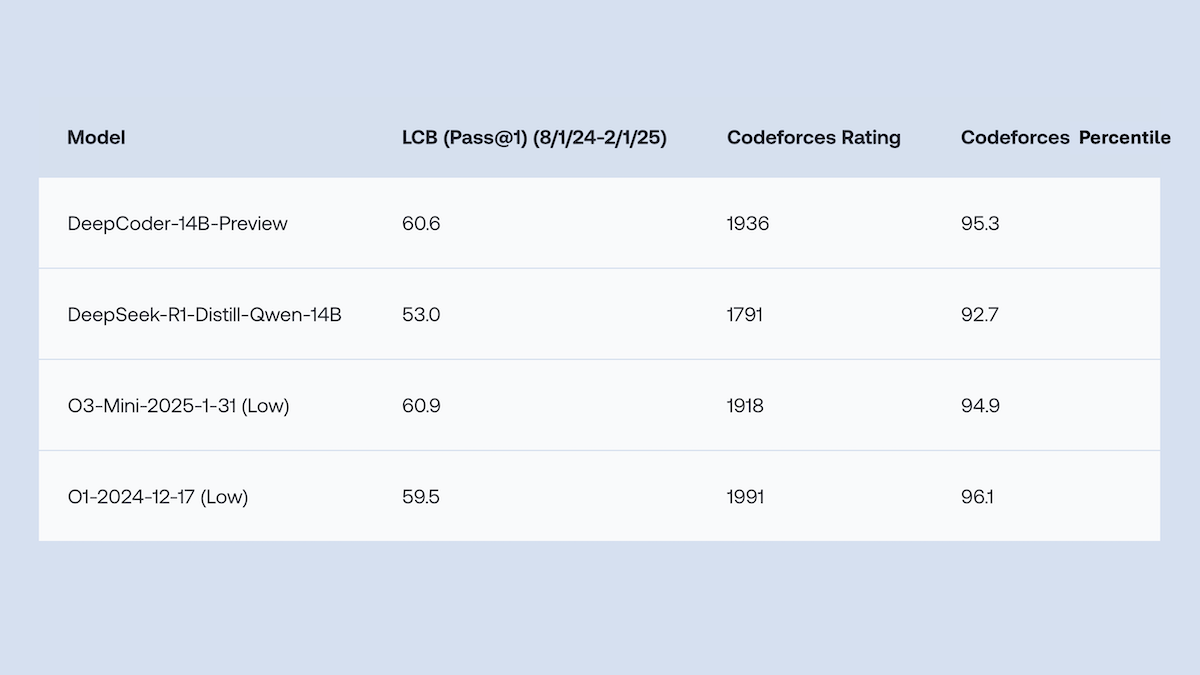
Together.AI ve Agentica, kod üretimi performansında o1 ile rekabet eden DeepCoder-14B-Preview’u açık kaynak olarak yayınladı: Together.AI ve Agentica ekipleri, 14B parametreli bir kod üretim modeli olan DeepCoder-14B-Preview’u yayınladı. Bu modelin performansı, birçok kodlama kriterinde DeepSeek-R1 ve OpenAI o1 gibi daha büyük modellerle karşılaştırılabilir düzeyde. Model, DeepSeek-R1-Distilled-Qwen-14B’nin ince ayarlanmasıyla geliştirildi ve basitleştirilmiş bir takviyeli öğrenme yöntemi (GRPO ve DAPO optimizasyonlarını birleştirerek) kullandı. Ayrıca RL kütüphanesi Verl’in paralel işleme yetenekleri geliştirilerek eğitim süresi önemli ölçüde kısaltıldı. Model ağırlıkları, kod, veri kümeleri ve eğitim günlükleri MIT lisansıyla açık kaynak olarak sunuldu. (Kaynak: DeepLearning.AI Blog)
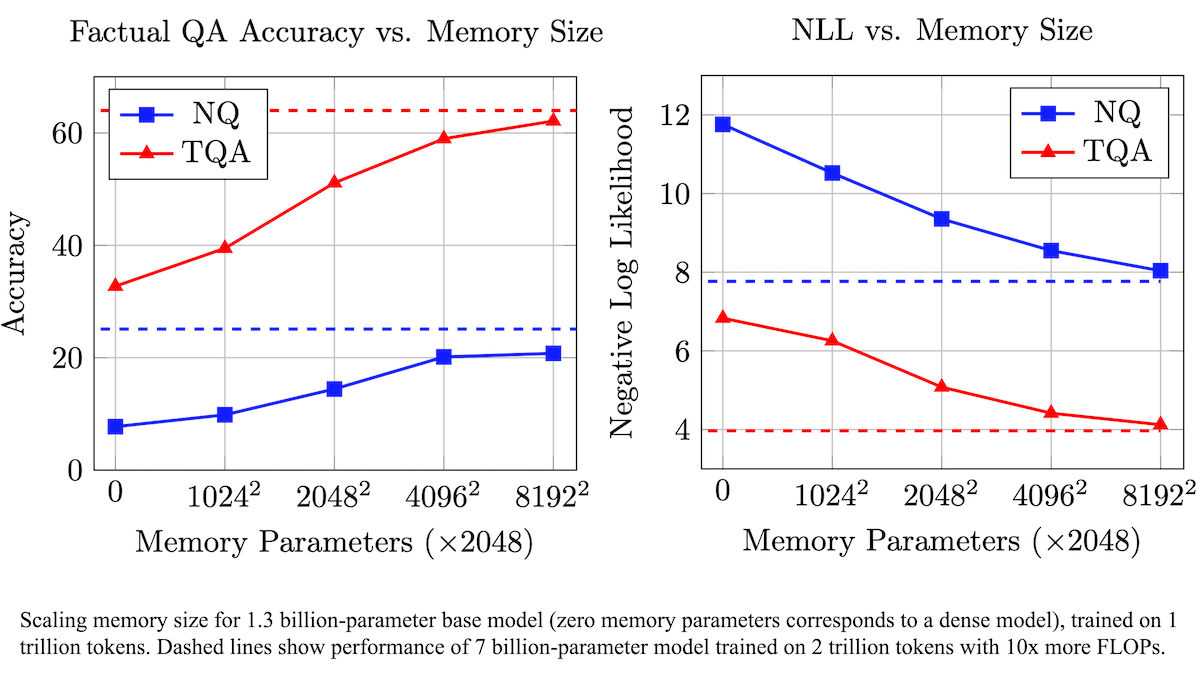
Meta, LLM’lerin gerçeklere dayalı doğruluğunu artırmak ve hesaplama gereksinimlerini azaltmak için eğitilebilir bir bellek katmanı önerdi: Meta araştırmacıları, Transformer mimarisine eğitilebilir bir bellek katmanı ekleyerek, büyük dil modellerinin gerçekleri hatırlama konusundaki doğruluğunu, hesaplama miktarını önemli ölçüde artırmadan geliştirdi. Bu yöntem, bilgiyi depolamak için anahtarları ve karşılık gelen değerleri öğrenerek çalışır ve anahtarları iki yarım anahtara bölme stratejisi kullanarak büyük ölçekli anahtar erişimindeki hesaplama darboğazını etkili bir şekilde çözer. Deneyler, bellek katmanıyla donatılmış 8B parametreli bir modelin, birden fazla soru-cevap veri kümesinde bellek katmanı olmayan benzer modellere göre daha iyi performans gösterdiğini ve ön eğitim verileri ile hesaplama miktarı gereksinimlerinde avantajlar sunduğunu gösterdi. (Kaynak: DeepLearning.AI Blog)
Alibaba, metin/görüntüden videoya üretim ve düzenlemeyi destekleyen Wan2.1 serisi video temel modellerini açık kaynak olarak yayınladı: Alibaba, Apache 2.0 lisansı altında 1.3B ve 14B parametre sürümlerini içeren kapsamlı bir açık kaynak video temel model paketi olan Wan2.1’i yayınladı. Wan2.1, metinden videoya, görüntüden videoya, video düzenleme, metinden görüntüye ve videodan sese gibi çeşitli görevlerde üstün performans sergiliyor ve özellikle Çince ve İngilizce metinlerin görsel üretimini destekliyor. T2V-1.3B modeli yalnızca 8.19GB VRAM gerektiriyor, tüketici sınıfı GPU’larda çalışabiliyor ve 4 dakika içinde 5 saniyelik 480P video üretebiliyor. Eşlik eden Wan-VAE, 1080P videoları verimli bir şekilde kodlayıp çözebiliyor ve zamansal bilgileri koruyor. (Kaynak: _akhaliq, Reddit r/LocalLLaMA)

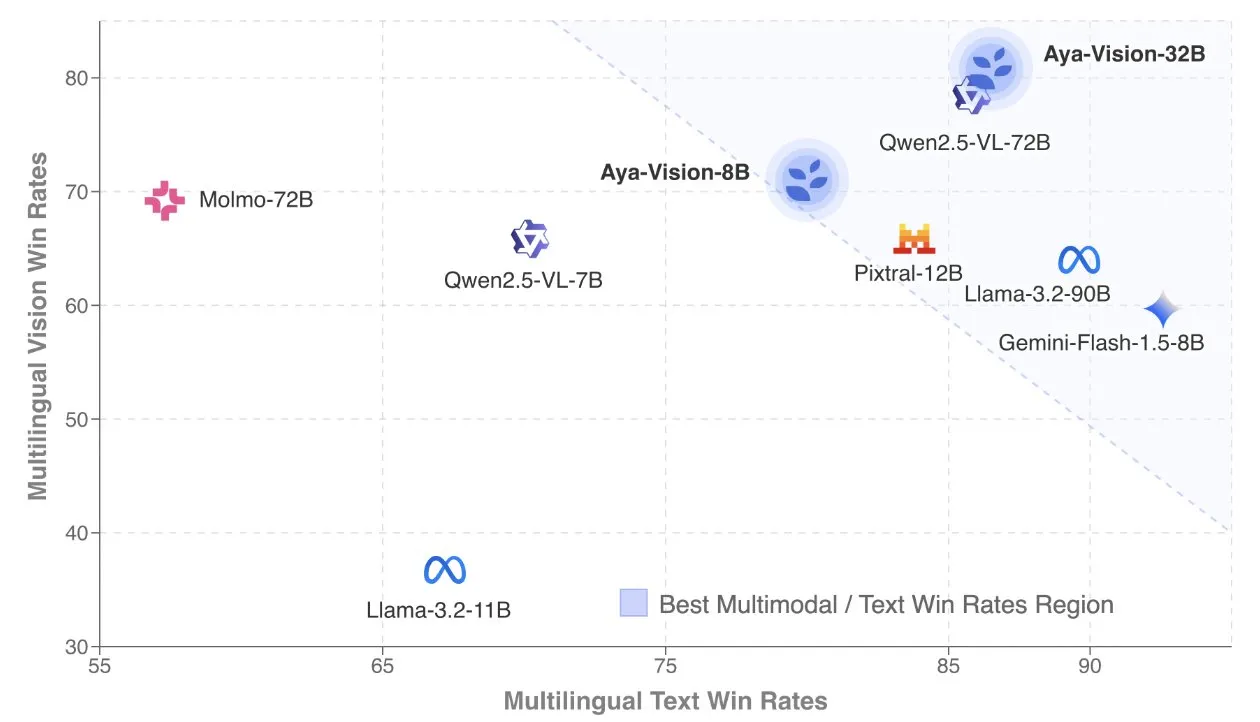
Cohere, çok dilli çok modlu modellere odaklanan Aya Vision teknik raporunu yayınladı: Cohere Labs, SOTA (son teknoloji) çok dilli çok modlu modeller oluşturma formülünü ayrıntılı olarak açıklayan Aya Vision teknik raporunu yayınladı. Aya Vision modelleri, 23 dilde çok modlu ve metin görevlerindeki yetenekleri birleştirmeyi amaçlıyor. Rapor, sentetik çok dilli veri çerçevelerini, mimari tasarımları, eğitim yöntemlerini, çapraz modlu model birleştirmeyi ve açık uçlu, çok dilli üretim görevlerinde kapsamlı değerlendirmeyi ele alıyor. 8B modeli, Pixtral-12B gibi daha büyük modellerden daha iyi performans gösterirken, 32B modeli daha verimli olup Llama3.2-90B gibi iki katından daha büyük modelleri geride bırakıyor. (Kaynak: sarahookr, Cohere Labs)
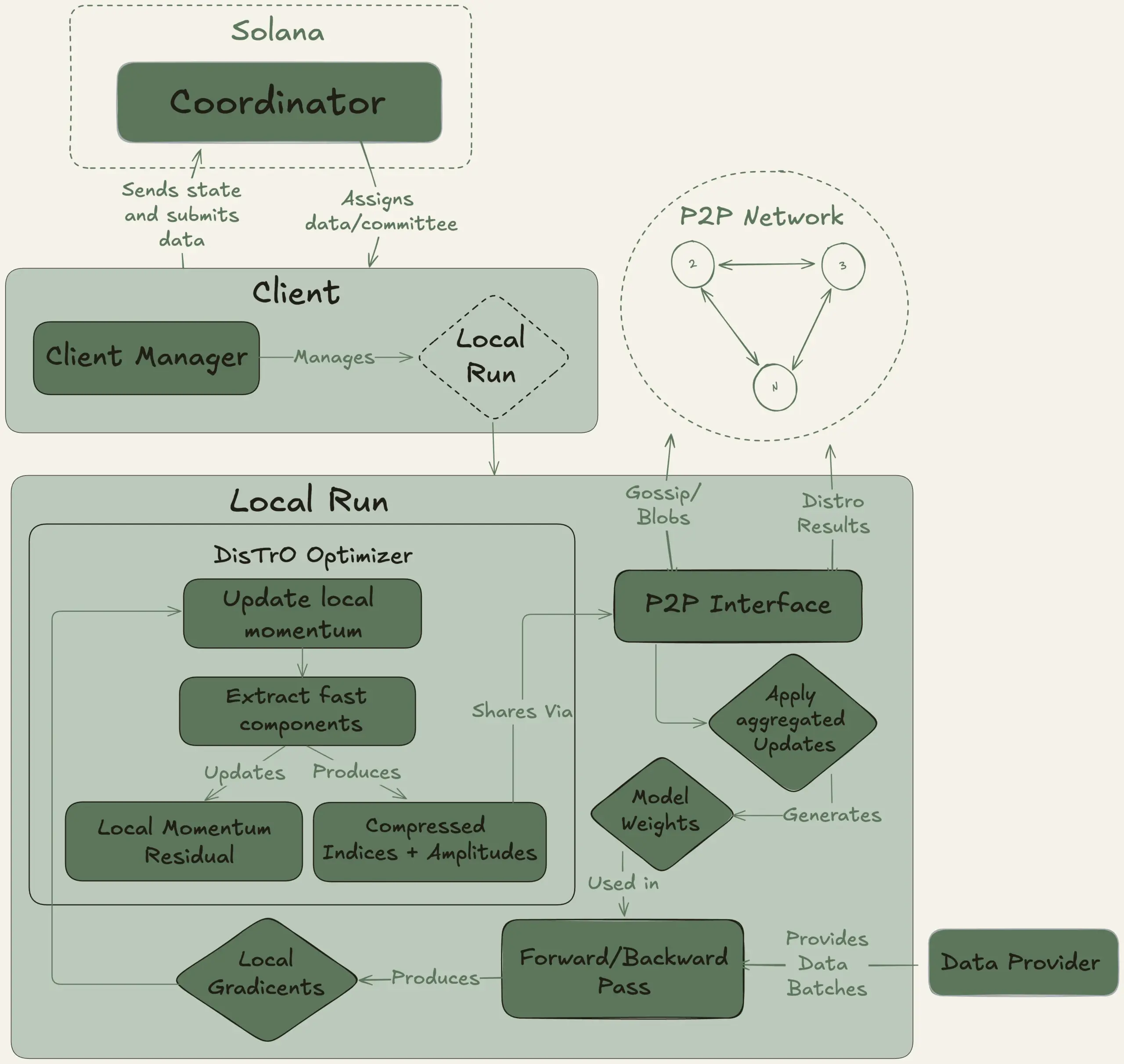
Nous Research, 40B parametreli büyük dil modelini merkezi olmayan bir şekilde eğitmek amacıyla Psyche projesini başlattı: Nous Research, bireylerin ve küçük toplulukların büyük ölçekli model geliştirmeye katılmasına olanak tanımak amacıyla küresel hesaplama gücünü bir araya getirerek güçlü AI modelleri eğitmeyi hedefleyen merkezi olmayan bir AI eğitim ağı olan Psyche ağını başlattığını duyurdu. Test ağı, MLA mimarisini kullanan 40B parametreli bir LLM’nin ön eğitimine başladı. Veri kümesi FineWeb (14T), FineWeb-2’nin bir kısmı (4T) ve The Stack v2’yi (1T) içeriyor ve toplamda yaklaşık 20T token’dan oluşuyor. Bu modelin eğitimi tamamlandıktan sonra, tüm kontrol noktaları (tavlanmamış ve tavlanmış sürümler dahil) ve veri kümeleri açık kaynak olarak sunulacak. (Kaynak: eliebakouch, Teknium1)
Stability AI, hızlı metinden sese üretim odaklı açık kaynak Stable Audio Open Small modelini yayınladı: Stability AI, Hugging Face’te Stable Audio Open Small modelini yayınladı. Bu model, hızlı metinden sese üretim için özel olarak tasarlanmış bir model olup, çekişmeli son eğitim (adversarial post-training) tekniklerini kullanmaktadır. Model, verimli ve açık kaynaklı bir ses üretim çözümü sunmayı amaçlamaktadır. (Kaynak: _akhaliq)
Google Gemini Advanced, GitHub ile entegre olarak kodlama yardım yeteneklerini güçlendirdi: Google, Gemini Advanced’in artık GitHub’a bağlandığını ve kodlama asistanı olarak yeteneklerini daha da geliştirdiğini duyurdu. Kullanıcılar, genel veya özel GitHub depolarına doğrudan bağlanarak Gemini’yi fonksiyonlar üretmek veya değiştirmek, karmaşık kodu açıklamak, kod tabanı hakkında sorular sormak, hata ayıklama yapmak gibi işlemler için kullanabilirler. İstem çubuğundaki “+” düğmesine tıklayıp “Kodu içe aktar” seçeneğini seçerek ve GitHub URL’sini yapıştırarak kullanmaya başlayabilirsiniz. (Kaynak: algo_diver)
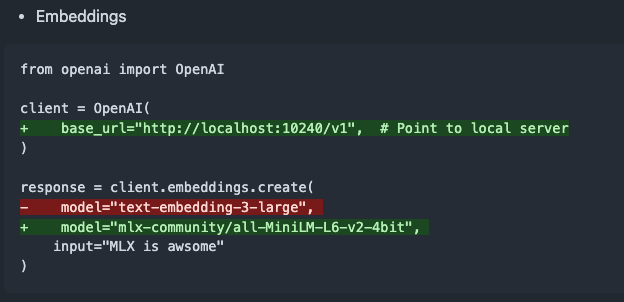
mlx-omni-server v0.4.0 yayınlandı, embeddings hizmeti ve daha fazla TTS modeli eklendi: mlx-omni-server, v0.4.0 sürümüne güncellendi ve mlx-embeddings aracılığıyla gömme (embedding) üretimini basitleştiren yeni bir /v1/embeddings hizmeti sunuyor. Aynı zamanda, daha fazla TTS modeli (kokoro, bark gibi) entegre edildi ve qwen3 gibi yeni modelleri desteklemek için mlx-lm yükseltildi. (Kaynak: awnihannun)
Together Chat’e PDF dosyası işleme özelliği eklendi: Together Chat, PDF dosyası yükleme ve işleme desteğini duyurdu. Mevcut sürüm temel olarak PDF’deki metin içeriğini ayrıştırıp işlenmek üzere modele iletiyor; gelecekte PDF’deki görüntü içeriğini okumak için OCR özelliğinin ekleneceği bir v2 sürümü planlanıyor. (Kaynak: togethercompute)
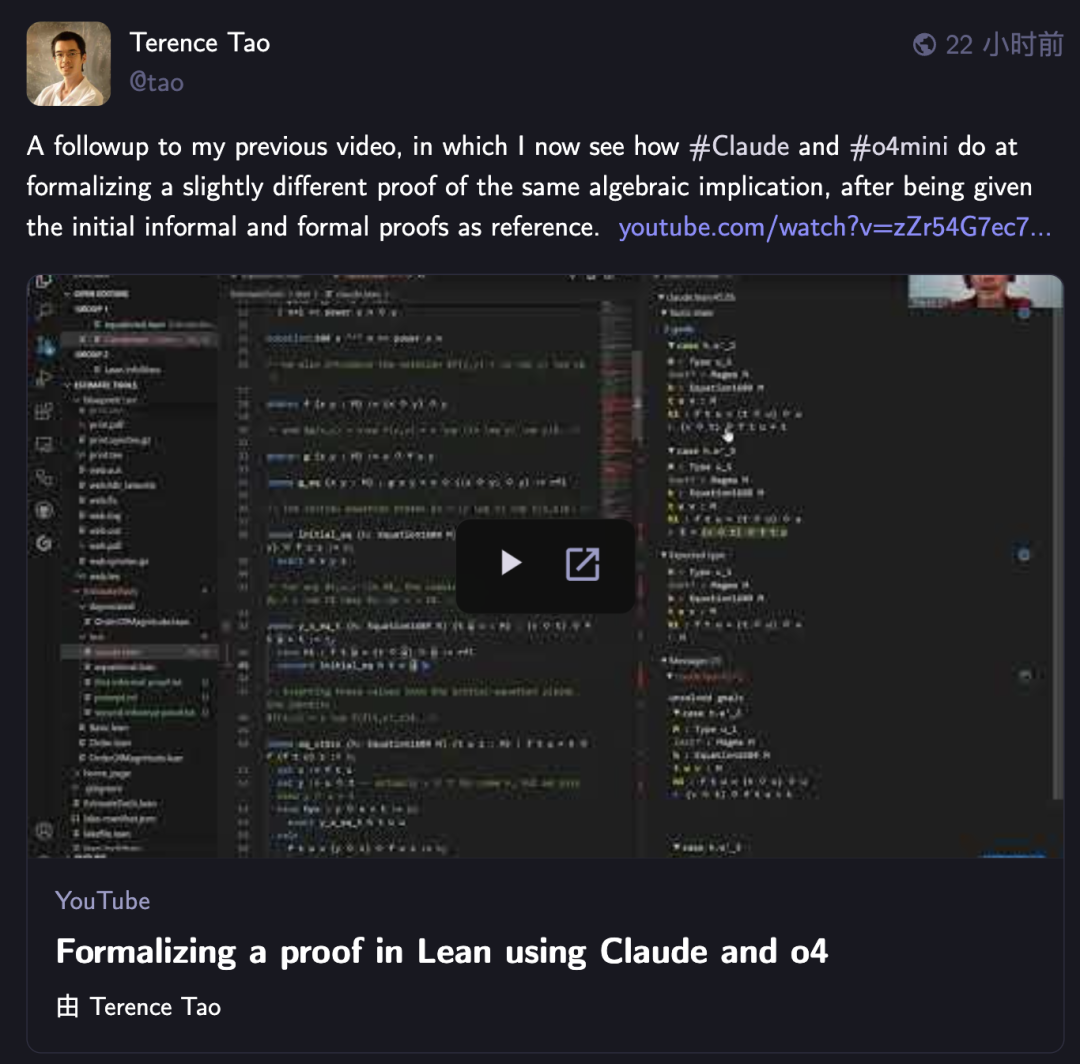
Terence Tao, AI ile matematiksel biçimsel kanıtlara tekrar meydan okudu, Claude o4-mini’den daha iyi performans gösterdi: Matematikçi Terence Tao, YouTube serisi videolarında, AI’ın Lean kanıt asistanında cebirsel çıkarım kanıtlarını biçimselleştirme yeteneğini test etti. Deneyde, Claude görevi yaklaşık 20 dakikada tamamlayabildi, ancak derleme sürecinde Lean’deki doğal sayıların 0’dan başlaması kuralını yanlış anlama ve simetri işleme sorunları ortaya çıksa da insan müdahalesiyle düzeltildi. Buna karşılık, o4-mini daha temkinli davrandı, üs fonksiyonu tanım sorununu tespit edebildi, ancak kritik kanıt adımında vazgeçerek görevi tamamlayamadı. Tao, otomasyona aşırı güvenmenin kanıtın genel yapısını kavramayı zayıflatabileceğini, en iyi otomasyon seviyesinin %0 ile %100 arasında olması gerektiğini ve anlayışı derinleştirmek için insan müdahalesinin korunması gerektiğini belirtti. (Kaynak: 36氪)
Altman röportajı: OpenAI’nin nihai hedefi temel bir AI abonelik hizmeti oluşturmak: OpenAI CEO’su Sam Altman, Sequoia Capital AI Ascent 2025 etkinliğinde, OpenAI’nin “Platonik idealinin” bir AI işletim sistemi geliştirmek ve kullanıcıların temel AI abonelik hizmeti haline gelmek olduğunu belirtti. Gelecekteki AI modellerinin, kullanıcıların tüm yaşam verilerini (trilyonlarca bağlam belirteci) işleyebileceğini ve derinlemesine kişiselleştirilmiş çıkarımlar yapabileceğini öngördü. Altman bunun henüz “PPT aşamasında” olduğunu kabul etti, ancak şirketin esneklik ve uyarlanabilirlikle gurur duyduğunu vurguladı. Ayrıca AI sesli etkileşim potansiyelinden, 2025’in AI ajanlarının parlayacağı bir yıl olacağından bahsetti ve kodlamanın model işleyişini ve API çağrılarını yönlendiren çekirdek olacağını düşündüğünü belirtti. (Kaynak: 36氪, 量子位)

Karminski3, Qwen3-30B topluluk modifiyeli sürümünü paylaştı, aktif uzman sayısı iki katına çıktı: Geliştirici topluluğu Qwen3 modelinde değişiklikler yaparak Qwen3-30B-A6B-16-Extreme sürümünü yayınladı. Model parametrelerini değiştirerek aktif uzman sayısını A3B’den A6B’ye çıkardılar; bunun kaliteyi hafifçe artırdığı ancak üretim hızını yavaşlattığı iddia ediliyor. Kullanıcılar ayrıca llama.cpp’nin çalışma parametrelerini --override-kv http://qwen3moe.expert_used_count=int:24 olarak değiştirerek benzer bir etki elde edebilir veya Qwen3-235B-A22B’nin aktif miktarını azaltarak hızı artırmak için ters işlemi yapabilirler. (Kaynak: karminski3)

🧰 Araçlar
OpenMemory MCP yayınlandı: Yerel olarak çalışan paylaşımlı bellek sistemi, birçok AI aracını birbirine bağlıyor: mem0ai ekibi, açık model bağlam protokolüne (MCP) dayalı olarak oluşturulmuş özel bir bellek sunucusu olan OpenMemory MCP’yi tanıttı. %100 yerel çalışmayı destekliyor ve mevcut AI araçları (Cursor, Claude Desktop, Windsurf, Cline gibi) arasındaki bağlam bilgilerinin paylaşılmaması ve oturum sona erdiğinde belleğin kaybolması sorununu çözmeyi amaçlıyor. Kullanıcı verileri yerel olarak depolanarak gizlilik güvenliği sağlanıyor. OpenMemory MCP, standartlaştırılmış bellek işlemleri API’si (ekleme, silme, sorgulama, değiştirme) sunuyor ve kullanıcıların belleği ve istemci erişim izinlerini yönetmesi için merkezi bir gösterge panosuna sahip; Docker ile dağıtımı basitleştiriyor. (Kaynak: 36氪, AI进修生)

LangChain, LangGraph platformunun resmi sürümünü ve AI ajan geliştirme ile gözlemlenebilirliği güçlendiren birçok güncellemeyi duyurdu: LangChain, Interrupt konferansında, uzun süreli, durum bilgisi olan AI ajan iş akışlarını oluşturmak ve yönetmek için özel olarak tasarlanmış LangGraph platformunun genel kullanıma (GA) sunulduğunu duyurdu. Platform, tek tıklamayla dağıtım, yatay ölçeklendirme ve bellek, insan-makine etkileşimi (HIL), diyalog geçmişi gibi API’leri destekliyor. Aynı zamanda yayınlanan LangGraph Studio V2, bir ajan IDE’si olarak yerel çalıştırmayı, yapılandırmayı doğrudan düzenlemeyi, Playground entegrasyonunu destekliyor ve üretim ortamı izleme verilerini çekerek yerel hata ayıklama yapabiliyor. Ayrıca LangChain, açık kaynaklı kodsuz ajan oluşturma platformu Open Agent Platform’u (OAP) başlattı ve LangSmith’in araç çağırma ve izleme konularındaki ajan gözlemlenebilirliğini geliştirdi. (Kaynak: LangChainAI, hwchase17)
PatronusAI, diğer AI ajanlarını değerlendirip onarabilen bir AI ajanı olan Percival’ı yayınladı: PatronusAI, diğer AI ajanlarının hatalarını değerlendirip otomatik olarak onarabilen ilk AI ajanı olduğunu iddia ettiği Percival’ı tanıttı. Percival, yalnızca ajan izleme kayıtlarındaki arızaları tespit etmekle kalmıyor, aynı zamanda onarım önerileri de sunuyor. GAIA ve SWE-Bench insan tarafından etiketlenmiş hataları içeren TRAIL veri kümesinde Percival’ın performansının SOTA LLM’lerden 2.9 kat daha iyi olduğu iddia ediliyor. İşlevleri arasında ajan istemi onarım çözümlerini otomatik olarak önerme, 20’den fazla ajan arıza türünü (araç kullanımı, planlama koordinasyonu, alana özgü hatalar vb. dahil) yakalama ve manuel hata ayıklama süresini saatlerden 1 dakikanın altına indirme yer alıyor. (Kaynak: rebeccatqian, basetenco)
PyWxDump: WeChat bilgi alma ve dışa aktarma aracı, AI eğitimini destekler: PyWxDump, WeChat hesap bilgilerini (takma ad, hesap, telefon, e-posta, veritabanı anahtarı) almak, veritabanının şifresini çözmek, sohbet kayıtlarını yerel olarak görüntülemek ve sohbet kayıtlarını AI eğitimi, otomatik yanıtlar gibi senaryolar için CSV, HTML gibi formatlarda dışa aktarmak için kullanılan bir Python aracıdır. Araç, çoklu hesap bilgisi alımını ve tüm WeChat sürümlerini destekler ve sohbet kayıtlarını görüntülemek için bir web arayüzü sunar. (Kaynak: GitHub Trending)

Airweave: AI ajanlarının herhangi bir uygulamayı aramasını sağlayan, MCP protokolüyle uyumlu bir araç: Airweave, AI ajanlarının herhangi bir uygulamanın içeriğini anlamsal olarak aramasını sağlamak için tasarlanmış bir araçtır. Model bağlam protokolü (MCP) ile uyumludur ve çeşitli uygulamaları, veritabanlarını veya API’leri sorunsuz bir şekilde bağlayarak içeriklerini ajanların kullanabileceği bilgiye dönüştürebilir. Başlıca işlevleri arasında veri senkronizasyonu, varlık çıkarma ve dönüştürme, çok kiracılı mimari, artımlı güncellemeler, anlamsal arama ve sürüm kontrolü bulunur. (Kaynak: GitHub Trending)

iFLYTEK, viaim AI beyniyle donatılmış yeni nesil AI kulaklıkları iFLYBUDS Pro3 ve Air2’yi piyasaya sürdü: Future Intelligence, her ikisi de yeni viaim AI beyniyle donatılmış iFLYTEK AI konferans kulaklıkları iFLYBUDS Pro3 ve iFLYBUDS Air2’yi piyasaya sürdü. viaim, kişisel iş ofisleri için tasarlanmış bir AI ajanı olup, uçtan uca akıllı algılama işleme, akıllı Agent işbirlikçi çıkarım, gerçek zamanlı çok modlu yetenekler ve veri güvenliği gizlilik koruması olmak üzere dört temel modülü entegre eder. Kulaklıklar, kolay kayıt (çağrı, yerinde, ses/video kaydı), AI asistanı (otomatik başlık özeti oluşturma, hedefe yönelik sorular sorma), çok dilli çeviri (32 dil, eş zamanlı çeviri dinleme, yüz yüze çeviri, çağrı çevirisi) gibi işlevleri destekler ve ses kalitesi ile takma konforunu artırır. (Kaynak: WeChat)

KoboldCpp Smart Launcher yayınlandı: LLM performansını optimize eden Tensor Offload otomatik ayarlama aracı: KoboldCpp Smart Launcher adlı bir GUI ve CLI aracı yayınlandı. Bu araç, kullanıcıların yerel olarak LLM çalıştırırken KoboldCpp için en iyi Tensor Offload stratejisini otomatik olarak bulmalarına yardımcı olmayı amaçlıyor. Tensörleri CPU ve GPU arasında tüm katmanlar yerine daha ince taneli bir şekilde dağıtarak, aracın VRAM gereksinimlerini artırmadan üretim hızını iki katından fazla artırdığı iddia ediliyor. Örneğin, QwQ Merge’in 12GB VRAM GPU’daki hızı 3.95 t/s’den 10.61 t/s’ye yükseldi. (Kaynak: Reddit r/LocalLLaMA)
OpenBMB, AgentCPM-GUI’yi açık kaynak olarak yayınladı: Çince için optimize edilmiş ilk cihaz üstü GUI ajanı: OpenBMB ekibi, Çince uygulamalar için özel olarak optimize edilmiş ilk cihaz üstü GUI (grafik kullanıcı arayüzü) ajanı olan AgentCPM-GUI’yi açık kaynak olarak yayınladı. Bu ajan, takviyeli ince ayar (RFT) ile çıkarım yeteneklerini geliştirdi, kompakt bir eylem alanı tasarımı benimsedi ve Çince ortamında çeşitli uygulamaları çalıştırma kullanıcı deneyimini iyileştirmeyi amaçlayan yüksek kaliteli GUI yerleştirme (grounding) yeteneğine sahip. (Kaynak: Reddit r/LocalLLaMA)
MAESTRO: Çoklu ajan işbirliğini ve özel LLM’leri destekleyen, yerel öncelikli bir AI araştırma uygulaması: MAESTRO (Multi-Agent Execution System & Tool-driven Research Orchestrator), yerel kontrol ve yetenekleri vurgulayan yeni yayınlanmış bir AI güdümlü araştırma uygulamasıdır. Belge çıkarma, güçlü RAG süreçleri ve karmaşık araştırma sorunlarını ele alabilen çoklu ajan sistemleri (planlama, araştırma, yansıtma, yazma) dahil olmak üzere modüler bir çerçeve sunar. Kullanıcılar, Streamlit Web UI veya CLI aracılığıyla etkileşimde bulunabilir, kendi belge kümelerini ve seçtikleri yerel veya API LLM’lerini kullanabilirler. (Kaynak: Reddit r/LocalLLaMA)
Contextual AI, RAG için optimize edilmiş bir belge ayrıştırıcısı yayınladı: Contextual AI, özellikle geri alma artırılmış üretim (RAG) sistemleri için tasarlanmış yeni bir belge ayrıştırıcısı yayınladı. Bu araç, görsel, OCR ve görsel dil modellerini birleştirerek karmaşık yapılandırılmamış belgelerin yüksek doğrulukta ayrıştırılmasını sağlamayı, belge hiyerarşik yapısını korumayı, tablolar, grafikler ve şekiller gibi karmaşık modaliteleri işlemeyi ve kullanıcı denetimi için sınırlayıcı kutular ve güvenirlik skorları sunmayı amaçlar, böylece RAG sistemlerinde ayrıştırma hatalarından kaynaklanan bağlam eksikliğini ve halüsinasyonları azaltır. (Kaynak: douwekiela)
Gradio’ya ImageEditor geri alma/yineleme özelliği eklendi: Gradio’nun ImageEditor bileşenine artık geri alma (undo) ve yineleme (redo) düğmeleri eklendi. Bu, kullanıcılara profesyonel ücretli uygulamalara benzer Python görüntü düzenleme işlevleri sunarak etkileşimi ve kullanım kolaylığını artırıyor. (Kaynak: _akhaliq)
RunwayML, sıfır-örnek malzeme, kıyafet, mekan ve poz testi desteği sunan References yeni özelliğini tanıttı: RunwayML’in References özelliği güncellendi. Kullanıcılar artık geleneksel 3D malzeme küresi önizleme görüntülerini girdi olarak kullanarak malzemelerini herhangi bir nesneye uygulayabilir, böylece sıfır-örnek malzeme transferi ve görselleştirme gerçekleştirebilirler. Ayrıca, yeni özellik kıyafet, mekan ve karakter pozları için sıfır-örnek testleri de destekleyerek yaratıcı üretim ve hızlı prototipleme olanaklarını genişletiyor. (Kaynak: c_valenzuelab, c_valenzuelab)

Mita AI, “Bugün Ne Öğrenelim” özelliğini başlattı, AI destekli yapılandırılmış öğrenme: Mita AI, “Bugün Ne Öğrenelim” adlı yeni bir özellik başlattı. Bu özellik, AI’ı bilgi alma ve belge işleme yardımcısı rolünden, aktif olarak rehberlik edebilen ve öğretebilen bir “AI öğretmeni” rolüne dönüştürmeyi amaçlıyor. Kullanıcılar materyal yükledikten veya aradıktan sonra, bu özellik otomatik olarak sistematik, yapılandırılmış video dersleri ve PPT sunumları oluşturarak kullanıcıların bilgi noktalarını düzenlemesine yardımcı oluyor ve kullanıcı seviyesine göre farklı anlatım derinlikleri (başlangıç/uzman) ve stilleri (hikaye anlatımı/huysuz ihtiyar vb.) seçmeyi destekliyor. Ayrıca, ders sırasında soru sorma ve ders sonrası test imkanı da sunuyor. (Kaynak: WeChat)

📚 Öğrenme Kaynakları
Andrew Ng ve Anthropic, yeni bir kurs başlattı: MCP ile Zengin Bağlamlı AI Uygulamaları Oluşturma: Andrew Ng’nin DeepLearning.AI’ı, Anthropic ile işbirliği yaparak “MCP: Build Rich-Context AI Apps with Anthropic” adlı yeni bir kurs başlattı. Kursu, Anthropic Teknik Eğitim Müdürü Elie Schoppik veriyor. Kurs, LLM’lerin harici araçlara, verilere ve istemlere erişimini standartlaştırmayı amaçlayan açık bir protokol olan Model Bağlam Protokolü’ne (MCP) odaklanıyor. Katılımcılar, MCP’nin temel mimarisini öğrenecek, MCP uyumlu sohbet robotları oluşturacak, MCP sunucuları kurup dağıtacak ve bunları Claude destekli uygulamalara ve diğer üçüncü taraf sunuculara bağlayarak zengin bağlamlı AI uygulamalarının geliştirilmesini basitleştirecekler. (Kaynak: AndrewYNg, DeepLearningAI)
FlashInfer: MLSys 2025 En İyi Makale, verimli ve özelleştirilebilir LLM çıkarım dikkat motoru: Washington Üniversitesi’nden Zihao Ye, NVIDIA, OctoAI’den Tianqi Chen ve diğerlerinin işbirliğiyle geliştirilen FlashInfer projesi, MLSys 2025 En İyi Makale ödülünü kazandı. FlashInfer, LLM çıkarım hizmetleri için optimize edilmiş, verimli ve özelleştirilebilir bir dikkat motorudur. Bellek erişimini optimize ederek (KV önbelleğini işlemek için blok seyrek formatı ve birleştirilebilir formatlar kullanarak), JIT derlemesine dayalı esnek dikkat hesaplama şablonları sunarak ve yük dengelemeli görev zamanlama mekanizması getirerek LLM çıkarım performansını önemli ölçüde artırır ve vLLM, SGLang gibi projelere entegre edilmiştir. (Kaynak: 机器之心)
ICML 2025 Makalesi: Veri işleme perspektifinden Graf İstemleme (Graph Prompting) için teorik analiz: Hong Kong Çin Üniversitesi’nden Wang Qunzhong, Dr. Sun Xiangguo ve Prof. Cheng Hong, ICML 2025’te yayınlanan bir makalede, graf istemlemenin etkinliği için “veri işleme” perspektifinden ilk kez sistematik bir teorik çerçeve sundular. Araştırma, “köprü grafiği” kavramını tanıtarak, graf istemleme mekanizmasının teorik olarak giriş grafiği verileri üzerinde belirli bir işlem yapmaya eşdeğer olduğunu ve böylece önceden eğitilmiş modelin yeni görevlere uyum sağlamak için doğru şekilde işlemesini sağladığını kanıtlıyor. Makale, hata üst sınırlarını türetiyor, hata kaynaklarını ve kontrol edilebilirliğini analiz ediyor ve hata dağılımını modelleyerek graf istemlemenin tasarımı ve uygulaması için teorik bir temel sağlıyor. (Kaynak: WeChat)
ICML 2025 Makalesi: Model çökmesini önlemek için Token düzeyinde düzenleme ile sentetik metin verileri oluşturma: Shanghai Jiao Tong Üniversitesi ve diğer kurumların araştırma ekibi, ICML 2025’te yayınlanan bir makalede, sentetik verilerin “model çökmesine” neden olma sorununu ele aldı ve “Token-Level Editing” adlı bir veri üretim stratejisi önerdi. Bu yöntem, tamamen yeni metinler üretmek yerine, gerçek veriler üzerinde modelin “aşırı güvendiği” Token’ları mikro düzenlemelerle değiştirerek, daha kararlı bir yapıya ve daha iyi genelleme yeteneğine sahip yarı sentetik veriler oluşturmayı amaçlar. Teorik analiz, bu yöntemin test hatasını etkili bir şekilde sınırlayabildiğini ve model performansının iterasyon turları arttıkça çökmesini önleyebildiğini göstermektedir. Deneyler, ön eğitim, sürekli ön eğitim ve denetimli ince ayar aşamalarında bu yöntemin etkinliğini doğrulamıştır. (Kaynak: WeChat)

ICML 2025 Makalesi: OmniAudio, 360° panoramik videodan 3D uzamsal ses üretimi: OmniAudio ekibi, ICML 2025’te 360° panoramik videodan doğrudan birinci dereceden ambisonik (FOA) uzamsal ses üreten bir teknolojiyi sergiledi. Veri kıtlığı sorununu çözmek için ekip, Sphere360 (100.000’den fazla klip, 288 saat) adlı büyük ölçekli bir 360V2SA veri kümesi oluşturdu. OmniAudio iki aşamalı bir eğitim kullanır: önce normal stereo sesi sahte FOA’ya dönüştürerek kendi kendine denetimli kaba-ince akış eşleştirme ön eğitimi, ardından gerçek FOA ile ince ayar; daha sonra küresel ve yerel perspektif özelliklerini çıkarmak ve yüksek sadakatli, yönü doğru uzamsal ses üretmek için çift dallı bir video kodlayıcı ile denetimli ince ayar. (Kaynak: 量子位)

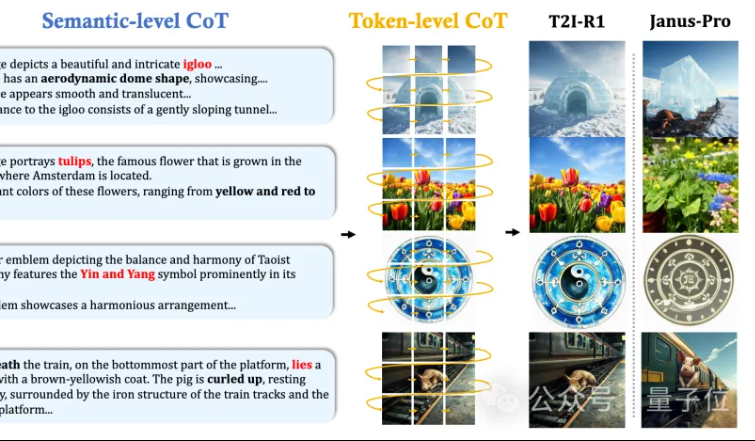
Hong Kong Çin Üniversitesi MMLab, T2I-R1’i önerdi: Metinden görüntüye üretim için çift katmanlı CoT çıkarımı ve takviyeli öğrenme: Hong Kong Çin Üniversitesi MMLab ekibi, takviyeli öğrenmeye dayalı ilk çıkarım artırılmış metinden görüntüye üretim modeli olan T2I-R1’i yayınladı. Bu model, yenilikçi bir şekilde çift katmanlı düşünce zinciri (CoT) çıkarım çerçevesi öneriyor: Semantic-CoT (metin çıkarımı, görüntünün küresel yapısını planlama) ve Token-CoT (görüntü Token’larının blok blok üretimi, alt düzey ayrıntılara odaklanma). BiCoT-GRPO takviyeli öğrenme yöntemi aracılığıyla, bu iki CoT katmanı, ek bir modele ihtiyaç duymadan birleşik bir LMM’de (Janus-Pro) eş zamanlı olarak optimize edilir. Ödül modeli, değerlendirmenin güvenilirliğini sağlamak ve aşırı uyumu önlemek için birden fazla görsel uzman modelinin entegrasyonunu kullanır. Deneyler, T2I-R1’in kullanıcı niyetini daha iyi anlayabildiğini, beklentilere daha uygun görüntüler üretebildiğini ve T2I-CompBench ile WISE kriterlerinde temel modellerden önemli ölçüde daha iyi performans gösterdiğini ortaya koydu. (Kaynak: 量子位, WeChat)
OpenAI, hafif dil modeli değerlendirme kütüphanesi simple-evals’ı yayınladı: OpenAI, en son model sürümlerinin doğruluk verilerini şeffaflaştırmak amacıyla dil modellerini değerlendirmek için hafif bir kütüphane olan simple-evals’ı açık kaynak olarak yayınladı. Kütüphane, sıfır-örnek, düşünce zinciri (chain-of-thought) değerlendirme ayarlarını vurguluyor ve MMLU, MATH, GPQA gibi birçok kriterde OpenAI’nin kendi modelleri (o3, o4-mini, GPT-4.1, GPT-4o gibi) ile diğer başlıca modellerin (Claude 3.5, Llama 3.1, Grok 2, Gemini 1.5 gibi) ayrıntılı model performansı karşılaştırmalarını sunuyor. (Kaynak: GitHub Trending)
LLM Engineer’s Handbook Korece sürümü yayınlandı: Maxime Labonne’un “LLM Mühendisinin El Kitabı” artık Woocheol Cho tarafından çevrilen Korece sürümüyle mevcut. El kitabının Rusça, Çince, Lehçe gibi daha fazla dildeki sürümleri de yakında yayınlanacak ve küresel LLM geliştiricilerine öğrenme kaynakları sunacak. (Kaynak: maximelabonne)

ICML 2025 Ses için Makine Öğrenimi Çalıştayı ML4Audio duyuruldu: Popüler Ses için Makine Öğrenimi Çalıştayı (ML for Audio), Vancouver’da düzenlenecek ICML 2025 sırasında, 19 Temmuz Cumartesi günü geri dönecek. Çalıştayda Dan Ellis, Albert Gu, Jesse Engel, Laura Laurenti ve Pratyusha Rakshit gibi tanınmış akademisyenler konuşma yapacak. Makale gönderim son tarihi 23 Mayıs. (Kaynak: sedielem)
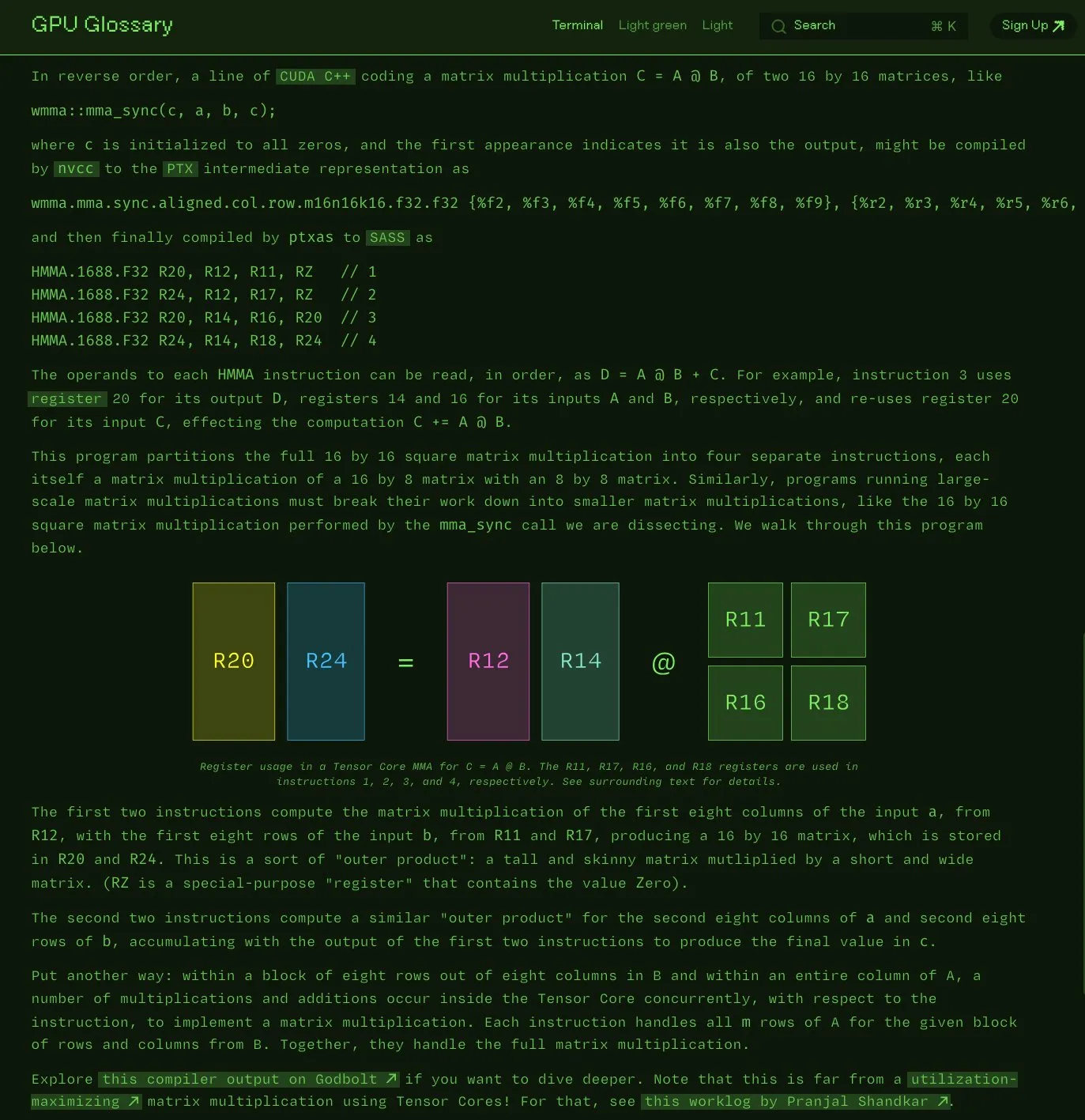
Charles Frye, GPU terimler sözlüğünü açık kaynak olarak yayınladı: Charles Frye, yazdığı GPU terimler sözlüğünün (GPU Glossary) artık açık kaynak olduğunu duyurdu. Bu terimler sözlüğü, GPU donanımı ve programlamayla ilgili kavramları anlamaya yardımcı olmayı amaçlıyor ve son olarak Tensor Core’un basit matris çarpma-toplama (mma) işlemini yürüten SASS komutlarının ayrıştırılması hakkında güncellendi. Proje GitHub’da barındırılıyor ve tamamlanması gereken bazı görevleri listeliyor. (Kaynak: charles_irl)
OpenAI, GPT-4.1 için istem mühendisliği kılavuzunu yayınladı, yapılandırılmış ve net talimatları vurguladı: OpenAI, kullanıcıların özellikle yapılandırılmış çıktı, çıkarım, araç kullanımı ve ajan tabanlı uygulamalar gerektiren durumlarda istemleri daha etkili bir şekilde oluşturmalarına yardımcı olmak amacıyla GPT-4.1 için bir istem mühendisliği kılavuzu yayınladı. Kılavuz, rol ve hedeflerin net bir şekilde belirlenmesini, net talimatların (ton, format, sınırlar dahil) verilmesini, isteğe bağlı alt talimatları, adım adım çıkarım/planlamayı, çıktı formatının hassas bir şekilde tanımlanmasını ve örneklerin kullanılmasının önemini vurguluyor ve önemli talimatları vurgulama, Markdown veya XML kullanarak girdiyi yapılandırma gibi bazı pratik ipuçları sunuyor. (Kaynak: Reddit r/MachineLearning)

Kaggle ve Hugging Face işbirliğini derinleştirerek model çağırma ve keşfini basitleştiriyor: Kaggle, Hugging Face ile işbirliğini güçlendirdiğini duyurdu. Kullanıcılar artık doğrudan Kaggle Notebooks’ta Hugging Face modellerini başlatabilir, ilgili açık kaynak kod örneklerini keşfedebilir ve iki platform arasında sorunsuz bir şekilde gezinebilirler. Bu entegrasyon, modellerin erişilebilirliğini genişletmeyi ve Kaggle kullanıcılarının Hugging Face ekosistemindeki model kaynaklarından daha kolay yararlanmasını sağlamayı amaçlıyor. (Kaynak: huggingface)
FedRAG: RAG sistemlerinin ince ayarı için açık kaynaklı bir çerçeve, federal öğrenmeyi destekliyor: Vector Institute araştırmacıları, geri alma artırılmış üretim (RAG) sistemlerinin ince ayarını basitleştirmeyi amaçlayan açık kaynaklı bir çerçeve olan FedRAG’ı tanıttı. Bu çerçeve, yalnızca tipik merkezi eğitimi desteklemekle kalmıyor, aynı zamanda dağıtılmış veri kümeleri üzerinde eğitim ihtiyacına uyum sağlamak için özel olarak bir federal öğrenme mimarisi sunuyor. FedRAG, PyTorch ve Hugging Face ekosistemiyle uyumludur, bilgi tabanı depolaması olarak Qdrant kullanımını destekler ve LlamaIndex’e köprü kurulabilir. (Kaynak: nerdai)

💼 İş Dünyası
Cursor’ın ana şirketi Anysphere, iki yılda 200 milyon dolar ARR’ye ulaştı, değerlemesi 9 milyar dolara fırladı: Sadece 25 yaşındaki MIT terk Michael Truell liderliğindeki Anysphere şirketi, AI kod editörü Cursor ile pazarlama yapmadan iki yıl içinde 200 milyon dolar yıllık yinelenen gelire (ARR) ulaştı ve şirket değerlemesi hızla 9 milyar dolara yükseldi. Cursor, AI’ı geliştirme süreçlerine derinlemesine entegre ederek yazılım geliştirme paradigmasını yeniden şekillendirdi, bireysel geliştiricilere hizmet vermeye odaklandı ve dünya çapındaki geliştiricilerden geniş çapta tanınırlık ve ağızdan ağıza yayılma elde etti. Thrive Capital, son finansman turuna liderlik etti. (Kaynak: 36氪)

Databricks, Serverless Postgres şirketi Neon’u satın alacağını duyurdu: Databricks, geliştirici odaklı Serverless Postgres şirketi Neon’u satın almayı kabul etti. Neon, hız, elastik ölçeklendirme ve geliştiriciler ile AI ajanları için çekici olan dallanma ve çatallanma (branching and forking) özellikleri sunan yenilikçi veritabanı mimarisiyle tanınıyor. Bu satın alma, geliştiriciler ve AI ajanları için açık, Serverless bir veritabanı temeli oluşturmayı amaçlıyor. (Kaynak: jefrankle, matei_zaharia)
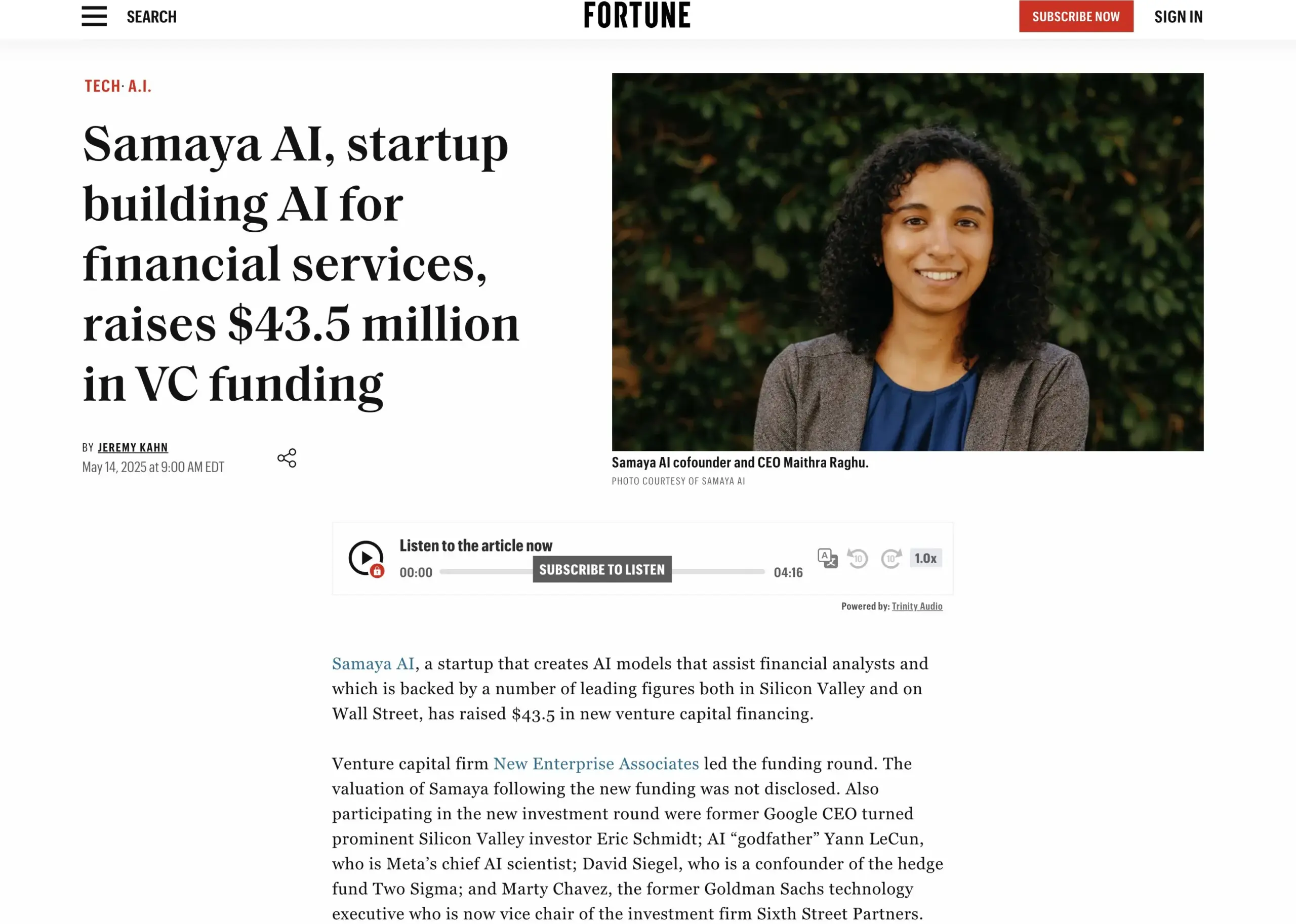
AI finansal hizmetler girişimi Samaya AI, 43,5 milyon dolar finansman sağladı: Samaya AI, bilgi çalışmasını ölçekli bir şekilde dönüştürmeyi amaçlayan finansal hizmetler için uzman AI ajanları oluşturmak üzere NEA liderliğinde 43,5 milyon dolar finansman sağladığını duyurdu. Şirket 2022’de kuruldu ve karmaşık finansal iş akışları için özel AI çözümleri oluşturmaya odaklanıyor. Kendi geliştirdiği LLM tabanlı uzman AI ajanları, Morgan Stanley gibi üst düzey kurumlarda binlerce kullanıcı tarafından durum tespiti, ekonomik modelleme ve karar destek gibi senaryolarda kullanılıyor ve hassasiyet, şeffaflık ve halüsinasyonsuzluğu vurguluyor. (Kaynak: maithra_raghu)
🌟 Topluluk
AI yazılım mühendislerinin yerini alacak mı? Topluluk, beceri geliştirmenin gerekliliğini hararetle tartışıyor: Sosyal medyada AI’ın yazılım mühendislerinin yerini alıp almayacağı konusu yeniden tartışılıyor. Genel kanı, AI’ın yazılım mühendislerini tamamen ortadan kaldırmayacağı yönünde, çünkü yazılım geliştirme sadece kod yazmaktan çok daha fazlasını içeriyor. Ancak, temel olarak tekrarlayan kodlama işleriyle uğraşan, sistemin bütününü anlamaktan yoksun “kod maymunları” (code monkeys), becerilerini geliştiremez, sistem mimarisini ve karmaşık problem çözmeyi derinlemesine anlayamazlarsa, AI destekli araçlar tarafından yerlerinden edilme riskiyle karşı karşıyalar. (Kaynak: cto_junior, cto_junior)
AI Agent’in Geleceği: Fırsatlar ve Zorluklar Bir Arada, Sektör Liderleri Potansiyelini Olumlu Değerlendiriyor: OpenAI CEO’su Altman, 2025’in AI Agent’lerinin parlayacağı ve gerçek işlere daha fazla dahil olacağı bir yıl olacağını öngörüyor. Liu Zhiyi de röportajında, Agent’in pasif araçlardan aktif yürütme sistemlerine dönüştüğünü, gelişiminin temel modellerdeki ilerlemelere ve fiziksel dünyayla etkileşim yeteneğine bağlı olduğunu vurguladı. Şu anda Agent’ler yanıt hızı, halüsinasyon kontrolü gibi konularda hala eksikliklere sahip olsa da, görevleri otonom olarak yürütme ve büyük modellerin öğrenmesine yardımcı olma yetenekleri geniş çapta olumlu karşılanıyor ve akıllı müşteri hizmetleri, finansal danışmanlık gibi alanlarda uygulanmaya başlandı. (Kaynak: 36氪, 量子位)

Perplexity AI, PayPal ve Venmo ile işbirliği yaparak e-ticaret ve seyahat ödemelerini entegre ediyor: Perplexity AI, platformundaki e-ticaret alışverişleri, seyahat rezervasyonları ile sesli asistanı ve yakında çıkacak olan tarayıcısı Comet’te ödeme işlevlerini entegre etmek için PayPal ve Venmo ile işbirliği yapacağını duyurdu. Bu hamle, göz atma, arama, seçme ve güvenli ödeme süreçlerini basitleştirerek kullanıcı deneyimini iyileştirmeyi amaçlıyor. (Kaynak: AravSrinivas, perplexity_ai)
AI model değerlendirmesi üzerine tartışma: IFEval ve ChartQA dikkat çekiyor, eğitim verisi kirliliğine karşı dikkatli olunmalı: Topluluk tartışmalarında, IFEval basit ama zekice tasarımı nedeniyle en iyi talimat takip değerlendirme kriterlerinden biri olarak kabul ediliyor. Aynı zamanda, bazı kullanıcılar ChartQA test verilerinde gürültü, belirsiz cevaplar ve tutarsızlıklar gibi sorunlar olduğunu ve bunun kullanımdan kaldırılması gerekebileceğini belirtiyor. Vikhyatk, kriter testlerinde yüksek doğruluk iddia eden birçok modelin eğitim verisi kirliliği sorunu olabileceği ve bunun fark edilmeyebileceği konusunda uyarıyor. (Kaynak: clefourrier, vikhyatk)

AI tarafından üretilen içeriklerin telif hakkı ve etiği dikkat çekiyor: Audible AI anlatıcı kullanmayı planlıyor, AI tarafından üretilen karakterlerin çevrimiçi arkadaşlıkta kullanılması endişe yaratıyor: Audible, sesli kitaplar üretmek için AI tarafından üretilen anlatıcılar kullanmayı planladığını duyurdu ve bunun “daha fazla hikayeyi hayata geçirmeyi” amaçladığını belirtti; bu durum AI’ın yaratıcı endüstrilerdeki uygulamaları hakkında tartışmalara yol açtı. Öte yandan, Reddit’te bir kullanıcı, annesinin bir tanışma sitesinde AI tarafından üretilmiş gibi görünen “gerçek erkek” imajlarıyla etkileşimde bulunduğunu ve aldatılmasından endişe ettiğini paylaştı. Bu, AI tarafından üretilen içeriklerin gerçeklik, duygusal manipülasyon ve dolandırıcılık konularındaki potansiyel risklerini vurguluyor. (Kaynak: Reddit r/artificial, Reddit r/ArtificialInteligence)

💡 Diğer
Çinli şirket “Star Computing”, ilk 12 uzay hesaplama uydusunu başarıyla fırlatarak uzay tabanlı hesaplama gücünde yeni bir çağ başlattı: Guoxing Aerospace liderliğindeki “Star Computing” (Yıldız Hesaplama) planı, ilk 12 hesaplama uydusunu başarıyla uzaya göndererek dünyanın ilk uzay hesaplama takımyıldızını oluşturdu. Her uydu, uzayda hesaplama ve bağlantı yeteneğine sahip olup, tek bir uydunun hesaplama kapasitesi T-seviyesinden P-seviyesine yükseltildi. İlk fırlatılan takımyıldızın yörüngedeki hesaplama gücü 5 POPS’a ulaşıyor ve uydular arası lazer iletişimi hızı 100 Gbps’ye kadar çıkıyor. Bu girişim, yer tabanlı hesaplama gücünün büyük enerji tüketimi ve ısı dağıtımı zorlukları gibi sorunları çözmeyi ve derin uzay keşif verilerinin yörüngede gerçek zamanlı işlenmesini destekleyerek “gökyüzü verisi, gökyüzü hesaplaması”nı gerçekleştirmeyi amaçlıyor. Gelecekte, büyük bir uzay hesaplama ağı oluşturmak için 2800 uydu fırlatılması planlanıyor. (Kaynak: 量子位)

NVIDIA yıllık değerlendirmesini yayınladı, AI’ın yeni endüstri devriminin çekirdeği olduğunu ve zekanın ürün olduğunu vurguladı: NVIDIA, yıllık değerlendirmesinde dünyanın yeni bir endüstri devrimine girdiğini ve temel ürününün “zeka” olduğunu belirtti. NVIDIA, zeka altyapısı oluşturmaya ve hesaplamayı çeşitli endüstrilerin gelişimini yönlendiren üretken bir güce dönüştürmeye kendini adamıştır. (Kaynak: nvidia)

NBA, Kuaishou Kling AI ile işbirliği yaparak “Curry’nin Çocukluk Smaçı” adlı AI kısa filmini yayınladı: NBA, Kuaishou’nun Sora benzeri metinden video üreten büyük modeli Kling AI ile işbirliği yaparak AI TALK tarafından “Childhood Curry’s Dunk” adlı bir AI kısa filmi üretti. Film, Kling AI kullanarak Curry’nin “zaman yolculuğu” smaç sahnesini yeniden canlandırmaya çalışıyor ve NBA playofflarına destek veriyor. Filmde Barkley, O’Neal ve Jokic’in özel konuk oyuncu olarak yer aldığı belirtiliyor. (Kaynak: TomLikesRobots)