Anahtar Kelimeler:Prime Intellect, INTELLECT-2, Sakana AI, Sürekli Düşünme Makinesi, Transformer, Google AI Ajanı, AgentOps, Çoklu Ajan İşbirliği, Dağıtılmış Pekiştirmeli Öğrenme Eğitimi, Nöral Zamanlama ve Nöron Senkronizasyonu, AI Ajan Operasyon Süreçleri, Çoklu Ajan Mimarisi, Şirketlerde AI Ajan Konuşlandırma
🔥 Odak Noktası
Prime Intellect, INTELLECT-2 Modelini Açık Kaynak Olarak Yayınladı: Prime Intellect, küresel dağıtık takviyeli öğrenme ile eğitilen ilk model olduğunu iddia ettiği 32 milyar parametreli INTELLECT-2 modelini yayınladı ve açık kaynak kodlu hale getirdi. Bu sürüm, ayrıntılı teknik raporu ve model kontrol noktalarını içeriyor. Model, birçok benchmark testinde Qwen 32B gibi modellerle karşılaştırılabilir veya daha iyi performans sergiledi, özellikle kod üretimi ve matematiksel akıl yürütme konularında öne çıktı ve topluluk üyeleri tarafından Wordle oynayabildiği keşfedildi. Eğitim yöntemi ve açık kaynak hamlesinin, gelecekteki büyük model eğitimi ve rekabet ortamını etkileyebileceği düşünülüyor (kaynak: Grad62304977, teortaxesTex, eliebakouch, Sentdex, Ar_Douillard, andersonbcdefg, scaling01, andersonbcdefg, vllm_project, tokenbender, qtnx_, Reddit r/LocalLLaMA, teortaxesTex)

Sakana AI Sürekli Düşünme Makinesini (CTM) Önerdi: Sakana AI, yapay zekaya daha esnek, insan benzeri zeka kazandırmak amacıyla nöral zamanlama ve nöron senkronizasyonu gibi biyolojik beyin mekanizmalarını dahil ederek “Sürekli Düşünme Makinesi” (Continuous Thought Machine, CTM) adlı yeni bir sinir ağı mimarisi sundu. CTM’nin temel yeniliği, nöron düzeyinde zaman işleme ve nöral senkronizasyonu potansiyel bir temsil olarak kullanmasıdır, bu da sıralı akıl yürütme ve uyarlanabilir hesaplama gerektiren görevleri yerine getirmesini ve hafızayı depolayıp geri çağırmasını sağlar. Bu araştırma, yapay zekanın “zamanla düşünme” yeni paradigmasını keşfetmek üzere blog yazısı, interaktif rapor, makale ve GitHub kod deposu ile yayınlandı (kaynak: SakanaAILabs, Plinz, SakanaAILabs, SakanaAILabs, hardmaru, teortaxesTex, tokenbender, Reddit r/MachineLearning)
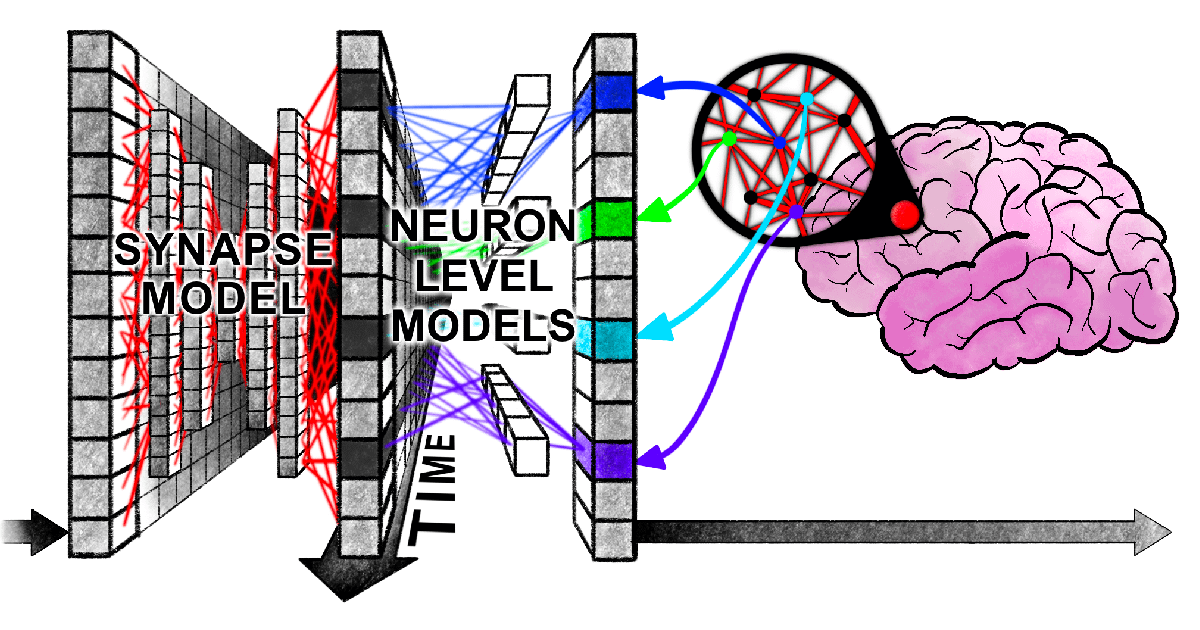
Harvard’ın Yeni Makalesi Transformer ve İnsan Beyninin Bilgi İşlemede “Senkronize Bir Karmaşa” İçinde Olduğunu Ortaya Koydu: Harvard Üniversitesi ve diğer kurumların araştırmacıları, “Linking forward-pass dynamics in Transformers and real-time human processing” başlıklı bir makale yayınlayarak Transformer modellerinin iç işleme dinamikleri ile insanların gerçek zamanlı bilişsel süreçleri arasındaki benzerlikleri inceledi. Araştırma, sadece nihai çıktıya bakmak yerine, modelin her katmanındaki “işlem yükü” metriklerini (belirsizlik, güven değişimi gibi) analiz ederek, yapay zekanın problem çözerken (başkentleri yanıtlama, hayvan sınıflandırma, mantıksal akıl yürütme, görüntü tanıma gibi) insanlar gibi “tereddüt”, “sezgisel hata” ve “düzeltme” süreçlerinden geçtiğini buldu. Bu “düşünme süreci” benzerliği, yapay zekanın görevleri tamamlamak için doğal olarak insanlara benzer bilişsel kısayollar öğrendiğini gösteriyor ve yapay zeka kararlarını anlamak ve insan deney tasarımlarını yönlendirmek için yeni bir bakış açısı sunuyor (kaynak: 36氪)

Google, AgentOps ve Çoklu Agent İşbirliğini Açıklayan 76 Sayfalık AI Agent Beyaz Kitabını Yayınladı: Google’ın en son yayınladığı AI agent beyaz kitabı, AI agent’larının oluşturulması, değerlendirilmesi ve uygulanmasını ayrıntılı olarak ele alıyor. Beyaz kitap, agent oluşturma ve üretim ortamına dağıtma sürecini optimize eden Agent Operasyonlarının (AgentOps) önemini vurguluyor; bu süreç araç yönetimi, temel ipucu ayarları, bellek uygulaması ve görev ayrıştırmayı kapsıyor. Beyaz kitap ayrıca, karmaşık hedefleri tamamlamak için uzmanlık alanlarına sahip birden fazla agent’ın birlikte çalıştığı çoklu agent mimarilerini tartışıyor ve Google’ın kurumsal agent dağıtımı (NotebookLM kurumsal sürümü, Agentspace kurumsal sürümü gibi) ve belirli uygulamalar (otomotiv çoklu agent sistemi gibi) konusundaki pratik örneklerini tanıtarak kurumsal üretkenliği ve kullanıcı deneyimini artırmayı hedefliyor (kaynak: 36氪)
🎯 Gelişmeler
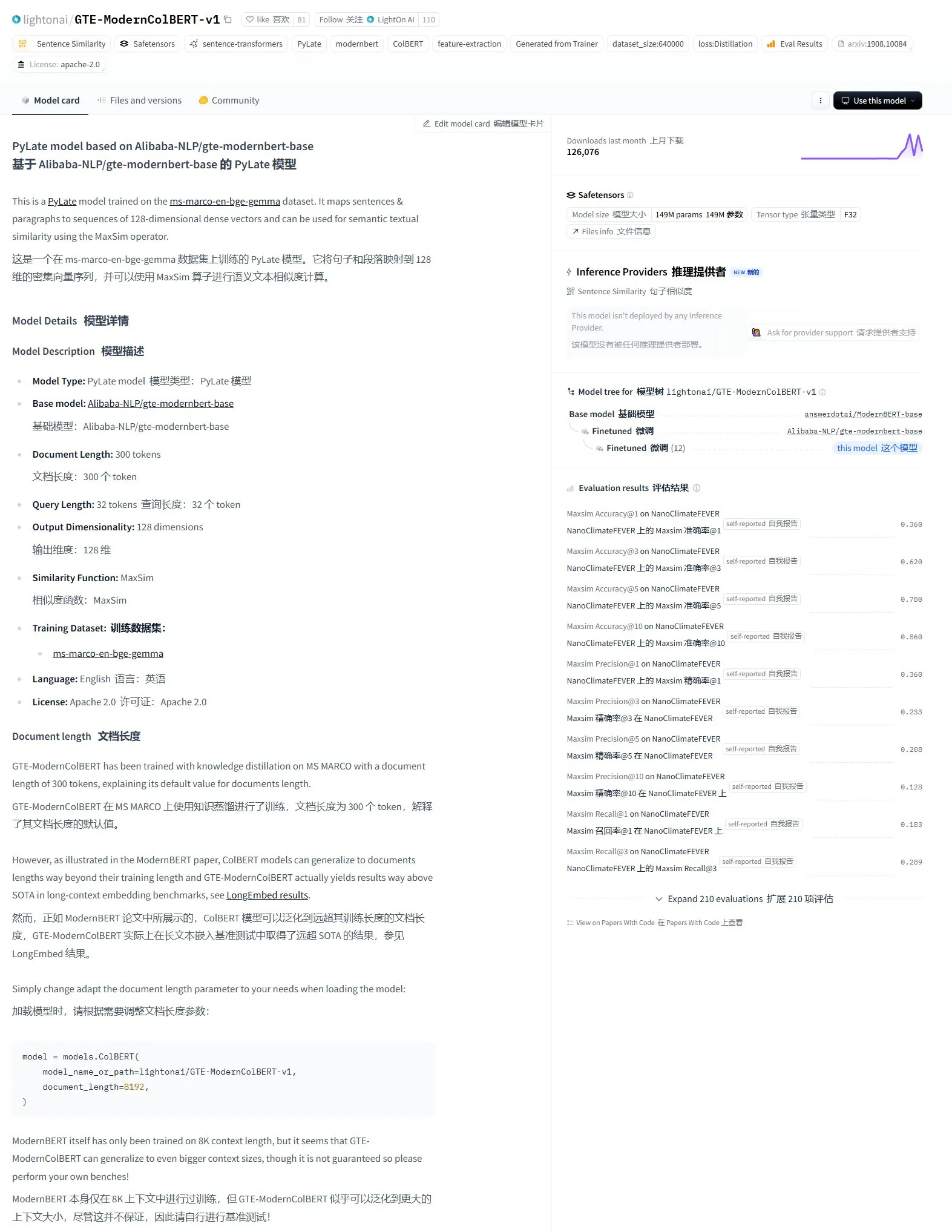
LightonAI, GTE-ModernColBERT-v1 Semantik Arama Modelini Yayınladı: LightonAI, LongEmbed / LEMB Narrative QA değerlendirmesinde mevcut en yüksek puanı alan yeni semantik arama modeli GTE-ModernColBERT-v1’i tanıttı. Bu model, semantik arama etkinliğini artırmak için özel olarak tasarlanmıştır ve belge içeriği arama, RAG gibi senaryolarda uygulanabilir ve mevcut sistemlerle entegre edilebilir. Modelin, geleneksel arama motorlarının yalnızca karakter eşleştirmeye dayalı sınırlamalarını iyileştirmek amacıyla Alibaba-NLP/gte-modernbert-base üzerinde ince ayar yapılarak elde edildiği bildirildi (kaynak: karminski3)
Teknoloji Liderleri DeepSeek’in Hızlı Yükselişine Odaklandı: VentureBeat, teknoloji liderlerinin DeepSeek’in hızlı gelişimine verdiği tepkileri bildirdi. DeepSeek, güçlü model yetenekleri ve açık kaynak stratejisiyle küresel yapay zeka alanında, özellikle matematik ve kod üretimi görevlerinde önemli başarılar elde etti ve mevcut pazar yapısına (OpenAI dahil) meydan okudu. Düşük maliyetli eğitim ve API fiyatlandırma stratejisi de yapay zeka teknolojilerinin yaygınlaşmasını ve ticarileşme sürecini hızlandırdı (kaynak: Ronald_vanLoon)

ByteDance ve Pekin Üniversitesi, Çoklu Koşul Kombinasyonunu Destekleyen Birleşik Görüntü Özelleştirme Üretim Çerçevesi DreamO’yu Ortaklaşa Yayınladı: ByteDance ve Pekin Üniversitesi, tek bir model aracılığıyla konu, kimlik, stil ve kıyafet referansı gibi çoklu koşulların serbestçe birleştirilmesini sağlayan bir görüntü özelleştirme üretim çerçevesi olan DreamO’yu tanıttı. Flux-1.0-dev üzerine inşa edilen bu çerçeve, koşullu görüntü girdilerini işlemek için özel bir eşleme katmanı sunar ve üretim kalitesini ve tutarlılığını artırmak için aşamalı eğitim stratejisi ve referans görüntüler için yönlendirme kısıtlamaları kullanır. DreamO, 400M’lik düşük eğitim parametre sayısıyla 8-10 saniyede özelleştirilmiş bir görüntü üretebilir ve tutarlılığı koruma konusunda üstün performans gösterir. İlgili kod ve model açık kaynak olarak yayınlanmıştır (kaynak: WeChat)

VITA Ekibi, Gerçek Zamanlı Konuşma Büyük Modeli VITA-Audio’yu Açık Kaynak Olarak Yayınladı, Çıkarım Verimliliği Büyük Ölçüde Arttı: VITA ekibi, hafif çoklu-modal çapraz-modal belirteç tahmini (MCTP) modülünü tanıtarak tek bir ileri yayılımda doğrudan çözülebilir Audio Token Chunk üreten uçtan uca konuşma modeli VITA-Audio’yu piyasaya sürdü. 7B parametre ölçeğinde, modelin metin almasından ilk ses parçasını çıkarmasına kadar geçen süre yalnızca 92ms’dir (ses kodlayıcı hariç 53ms), bu da aynı ölçekteki modellere göre çıkarım hızını 3-5 kat artırır. VITA-Audio, Çince ve İngilizce’yi destekler, yalnızca açık kaynak verilerle eğitilmiştir ve TTS, ASR gibi görevlerde üstün performans gösterir. İlgili kod ve model ağırlıkları açık kaynak olarak yayınlanmıştır (kaynak: WeChat)

Tsinghua ve Genel Yapay Zeka Araştırma Enstitüsü “Mutlak Sıfır” Eğitim Yöntemini Önerdi, Büyük Model Kendi Kendine Oynayarak Akıl Yürütme Yeteneğini Açığa Çıkarıyor: Tsinghua Üniversitesi, Pekin Genel Yapay Zeka Araştırma Enstitüsü ve diğer kurumların araştırmacıları, önceden eğitilmiş büyük modellerin harici verilere ihtiyaç duymadan, görevler üreterek ve çözerek (Self-play) akıl yürütmeyi öğrenmesini sağlayan “Mutlak Sıfır” (Absolute Zero) eğitim yöntemini önerdi. Bu yöntem, akıl yürütme görevlerini tek tip olarak (program, girdi, çıktı) üçlüsü şeklinde temsil eder ve model, Proposer (soru soran) ve Solver (çözen) rollerini üstlenerek abdüksiyon, dedüksiyon ve indüksiyon olmak üzere üç görev türü aracılığıyla öğrenir. Deneyler, bu yöntemle eğitilen modellerin kod ve matematiksel akıl yürütme görevlerinde önemli ölçüde iyileşme gösterdiğini ve uzman etiketli örneklerle eğitilen modelleri geride bıraktığını ortaya koydu (kaynak: WeChat)

AI PC Gelişimi Hızlanıyor, Lenovo ve Huawei Art Arda AI Terminal Ürünlerini Piyasaya Sürüyor: Lenovo ve Huawei son zamanlarda, Lenovo’nun Tianxi kişisel süper akıllı agent’ı ve Huawei HarmonyOS bilgisayarlarında bulunan Xiaoyi akıllı agent’ı gibi AI agent’ları entegre edilmiş PC ürünlerini piyasaya sürdü. AI PC pazar penetrasyonu hala düşük olsa da, büyüme hızı yüksek. Canalys verilerine göre, 2024’te Çin anakarasındaki AI PC sevkiyatları toplam PC pazarının %15’ini oluşturdu ve 2025’te %34’e ulaşması bekleniyor. Sektör uzmanları, AI PC tedarik zincirinin olgunlaşmasının 2-3 yıl süreceğini ve mevcut ana zorlukların bellek, çip gibi tedarik zinciri maliyetleri ve ölçeklendirme sorunları ile yerel AI PC ekosisteminin parçalanmışlığı olduğunu düşünüyor. Gelecekteki eğilimler arasında agent’ların temel etkileşim girişi haline gelmesi, AI’nin yerel olarak dağıtılması ve AI uygulama senaryolarının eğitim, sağlık gibi çeşitli alanlara genişlemesi yer alıyor (kaynak: 36氪)
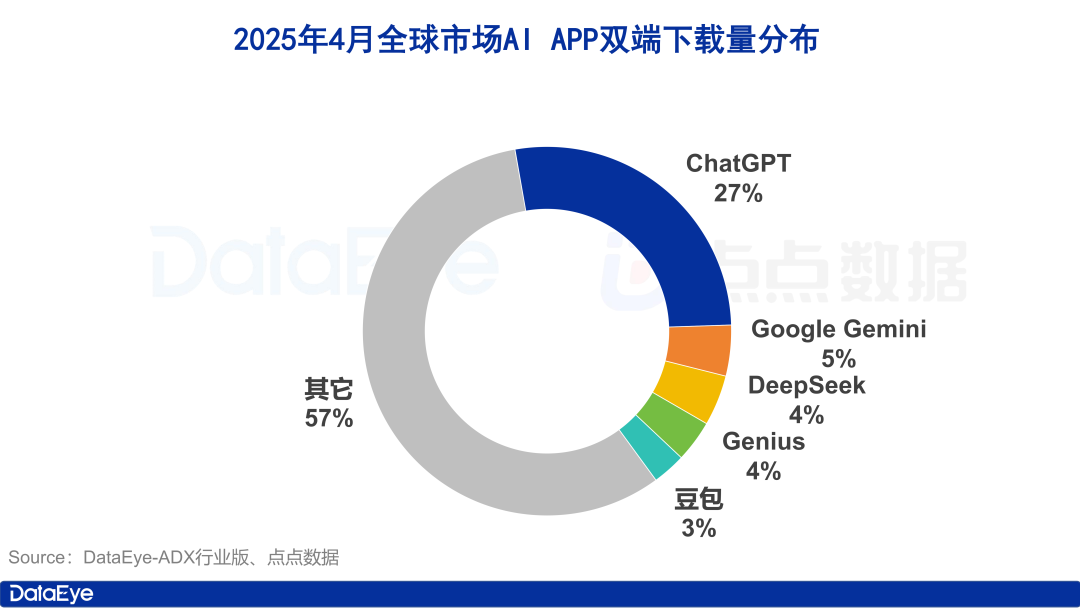
Küresel AI Uygulama İndirmeleri Artarken, Yerel Pazar Soğuyor, Doubao Trendin Tersine Büyüyor: Nisan 2025’te, küresel AI uygulamalarının çift platform (iOS ve Android) indirme sayısı %27.4 artışla 330 milyona ulaştı. ChatGPT, Google Gemini, DeepSeek, Genius ve Doubao ilk beşte yer aldı. Özellikle ChatGPT, GPT-4o’nun yayınlanmasıyla indirme sayısında büyük bir artış yaşadı. Buna karşılık, Çin anakarasındaki AI uygulamalarının Apple platformundaki indirme sayısı %24.0 azaldı. Doubao trendin tersine büyüyerek birinci sırada yer alırken, DeepSeek ve Jmeng AI (即梦AI) onu takip etti. Reklam satın alma açısından, Tencent Yuanbao ve Kuark büyük harcamalar yaparak materyal hacminin büyük kısmını oluştururken, Doubao’nun harcamaları azaldı. Genel olarak, yerel AI pazarındaki heyecan biraz soğudu ve rekabet teknoloji ve operasyonlara geri döndü (kaynak: 36氪)
Çin Büyük Model Pazarında Yeniden Yapılanma, “Beş Temel Model Devi” Ortaya Çıkıyor: 2024’te küresel AI finansman ortamının sıkılaşmasıyla birlikte, Çin büyük model pazarı bir “köpükten arındırma” sürecinden geçti ve önceki “altı küçük kaplan” yapısı, ByteDance, Alibaba, StepStar (阶跃星辰), Zhipu AI ve DeepSeek’in temsil ettiği “beş temel model devi”ne dönüştü. Bu lider oyuncular finansman, yetenek ve teknoloji açısından farklı avantajlara sahip ve farklılaşmış yollar izliyorlar: ByteDance kapsamlı bir düzenleme yapıyor, Alibaba açık kaynak ve tam yığın üzerine odaklanıyor, StepStar çoklu modaliteye derinlemesine giriyor, Zhipu AI Tsinghua geçmişine dayanarak 2B/2G’ye odaklanıyor ve DeepSeek ise aşırı mühendislik optimizasyonu ve açık kaynak stratejisiyle öne çıkıyor. Bir sonraki rekabet aşamasının odak noktası, AGI vizyonunu gerçekleştirmek amacıyla “zeka tavanını” aşmak ve “çoklu modalite yeteneğini” geliştirmek olacak (kaynak: 36氪, WeChat)

ICCV 2025 Başvuru Sayısındaki Rekor Artış Hakem Değerlendirme Kalitesi Endişelerini Artırdı, LLM Destekli Değerlendirme Yasaklandı: Bilgisayarlı görü alanındaki önde gelen konferanslardan ICCV 2025’e yapılan makale başvurusu sayısı 11.152’ye ulaşarak rekor kırdı. Ancak, değerlendirme sonuçları açıklandıktan sonra, çok sayıda yazar sosyal medyada değerlendirme kalitesinden memnuniyetsizliğini dile getirdi. Bazı değerlendirme yorumlarının baştan savma olduğunu, hatta GPT seviyesinden daha iyi olmadığını belirttiler ve hakemlerin ek materyalleri okumadığı gibi sorunlara işaret ettiler. Başvuru sayısındaki artışla başa çıkmak için konferans yönetimi, her başvuru sahibinin hakemlik yapmasını zorunlu kıldı ve orijinalliği ve gizliliği sağlamak amacıyla değerlendirme sürecinde büyük dil modellerinin (ChatGPT gibi) kullanılmasını açıkça yasakladı. Resmi verilere göre değerlendirmelerin %97.18’i zamanında teslim edilmiş olsa da, değerlendirme kalitesi ve hakem yükü sorunları sıcak tartışma konusu oldu (kaynak: 36氪)
Nvidia CEO’su Jensen Huang: Tüm Çalışanlar AI Agent’ları ile Donatılacak, Geliştirici Rolü Yeniden Şekillenecek: Nvidia CEO’su Jensen Huang, şirketin tüm çalışanlarını (yazılım mühendisleri ve çip tasarımcıları dahil) iş verimliliğini, proje ölçeğini ve yazılım kalitesini artırmak için AI agent’ları ile donatacağını belirtti. Gelecekte herkesin birden fazla AI asistanını yöneteceğini ve üretkenliğin katlanarak artacağını öngörüyor. Bu eğilim, Meta, Microsoft, Anthropic gibi şirketlerin, AI’nin kod yazımının büyük kısmını üstleneceği ve geliştirici rolünün “AI komutanı” veya “gereksinim tanımlayıcısı”na dönüşeceği yönündeki görüşleriyle örtüşüyor. Huang, enerji ve hesaplama gücünün AI’nin yaygınlaşmasındaki darboğazlar olduğunu ve çip paketleme, fotonik teknolojiler gibi alanlarda yeniliklere ihtiyaç duyulduğunu vurguladı. Büyük şirketler aktif olarak proaktif AI agent’ları geliştiriyor, bu da GenAI’den Agentic AI’ye geçişin habercisi (kaynak: 36氪)

OpenAI CEO’su Altman Kongre Oturumuna Katıldı, Gevşek Düzenleme Çağrısı Yaptı ve Açık Kaynak Planlarını Açıkladı: OpenAI CEO’su Sam Altman, ABD Senatosu’ndaki bir oturumda, yapay zekaya yönelik katı ön onaylamanın ABD’nin bu alandaki rekabet gücüne feci bir darbe vuracağını belirtti ve OpenAI’nin bu yaz ilk açık kaynak modelini yayınlamayı planladığını açıkladı. Altyapının (özellikle enerjinin) yapay zeka yarışını kazanmak için kritik öneme sahip olduğunu vurguladı ve yapay zekanın maliyetinin nihayetinde enerji maliyetiyle aynı seviyeye geleceğini düşündüğünü ifade etti. Altman ayrıca “Akıllı Çağ Yol Haritası (2025-2027)”nı paylaştı ve AI süper asistanlarının, AI güdümlü bilimsel keşiflerin katlanarak artmasının ve AI robot çağının art arda geleceğini öngördü. Kişisel hayatı hakkında konuşurken, oğlunun bir AI robotuyla yakın bir dostluk kurmasını istemediğini belirtti (kaynak: 36氪)

CMU Araştırmacıları, Fiziksel Olarak Stabil Lego Modelleri Tasarlamak İçin AI Kullanan LegoGPT’yi Önerdi: Carnegie Mellon Üniversitesi araştırmacıları, metin açıklamalarını fiziksel olarak inşa edilebilir Lego modellerine dönüştürebilen bir yapay zeka sistemi olan LegoGPT’yi geliştirdi. Meta’nın LLaMA modelini ince ayarlayarak ve 47.000’den fazla stabil yapı içeren StableText2Lego veri kümesiyle eğiterek, LegoGPT, blokların yerleştirilmesini aşamalı olarak tahmin edebilir ve oluşturulan yapıların gerçek dünyada fiziksel olarak stabil olmasını %98.8 başarı oranıyla sağlayabilir. Sistem ayrıca, stabil olmayan bir yapı tespit edildiğinde düzeltme yapmak için fiziksel farkındalığa sahip geri alma yöntemini kullanır. Araştırmacılar, bu teknolojinin sadece Lego ile sınırlı olmadığını, gelecekte 3D baskı bileşen tasarımı ve robotik montaj gibi alanlarda uygulanabileceğini düşünüyor. Kod, veri kümesi ve model şu anda açık kaynak olarak mevcuttur (kaynak: WeChat)

AI Papa Seçimi Tahmininde Başarısız Oldu, Yeni Papa Robert Prevost “Sürpriz Seçim” Oldu: Science dergisinin haberine göre, 135 kardinalin verilerini analiz ederek yeni papayı tahmin etmek için bir AI algoritması kullanan bir araştırma, Robert Francis Prevost’un seçilmesini başarılı bir şekilde tahmin edemedi. Model, kardinallerin kilit konulardaki duruşlarına (konuşmalarını analiz ederek AI’nin muhafazakar veya ilerici eğilimlerini belirlemesiyle eğitildi) ve aralarındaki ideolojik benzerliklere dayanarak simüle edilmiş seçimler yaptı ve sonuçta İtalyan Kardinal Pietro Parolin’in kazanma olasılığının en yüksek olduğunu tahmin etti. Araştırmacılar, modelin siyasi ve coğrafi faktörleri dikkate almamasının ana kusuru olduğunu kabul ettiler, ancak bu metodolojinin diğer tür seçim tahminleri için hala yol gösterici olabileceğini belirttiler. Prevost’un çeşitli konulardaki görüşlerinin nötr olması, onun tüm taraflarca kabul edilebilir bir uzlaşma adayı olabileceğini düşündürüyor (kaynak: 36氪)

Finansal Pazarlamada AI Uygulamaları: Müşteri Edinme, Kişiselleştirme, Uyumluluk Gibi Beş Büyük Sorunu Çözme: AI ve Agent teknolojisi, finansal pazarlama 3.0 çağının temel itici gücü haline geliyor ve yüksek müşteri edinme maliyetleri, yetersiz kişiselleştirilmiş deneyim, anlaşılması zor karmaşık ürünler, büyük uyumluluk baskısı ve ölçülmesi zor ROI gibi sorunları çözmeyi hedefliyor. “Akıllı Pazarlama Orta Platformu” (veri tabanı + akıllı motor + hizmet uygulaması) oluşturarak ve büyük dil modelleri (LLM) + RAG, bilgi grafikleri, akıllı Agent işbirliği (MAS) ve gizlilik hesaplama gibi teknolojileri kullanarak, finans kurumları daha derin müşteri içgörüleri, gerçek zamanlı hassas akıllı kararlar ve verimli tutarlı hizmet uygulamaları elde edebilir. Sektör örnekleri, AI’nin müşteri AUM’unu, yatırım ürünü dönüşüm oranlarını ve pazarlama içeriği üretim verimliliğini artırmada önemli sonuçlar elde ettiğini gösteriyor ve gelecekte çoklu modal etkileşim, nedensel karar verme, otonom evrim, uç nokta yanıtı ve insan-makine işbirliği gibi yönlere doğru gelişecek (kaynak: 36氪)
AI Güdümlü Robotlar Avrupa’nın Elektronik Atık Sorununu Çözüyor: AB tarafından finanse edilen araştırma projesi ReconCycle, özellikle lityum pil içeren cihazların sökülmesi başta olmak üzere artan elektronik atıkların otomatik olarak işlenmesi için AI güdümlü uyarlanabilir robotlar geliştirdi. Bu robotlar, duman dedektörlerinden ve radyatör ısı sayaçlarından pilleri çıkarmak gibi farklı görevlere uyum sağlamak için yeniden yapılandırılabiliyor. Bu teknoloji, geri dönüşüm verimliliğini artırmayı, manuel sökümün zahmetli ve tehlikeli yapısını azaltmayı ve AB’de her yıl üretilen yaklaşık 5 milyon ton elektronik atık (geri dönüşüm oranı %40’ın altında) sorununa çözüm bulmayı hedefliyor. Electrocycling GmbH gibi geri dönüşüm tesisleri bu tür teknolojilere ilgi göstermeye başladı ve hammadde geri kazanım oranlarını artırmasını, ekonomik kayıpları ve karbon emisyonlarını azaltmasını bekliyor (kaynak: aihub.org)

🧰 Araçlar
LocalSite-ai: DeepSite’ın Açık Kaynak Alternatifi, AI ile Çevrimiçi Frontend Sayfaları Oluşturma: LocalSite-ai, açık kaynaklı bir proje olarak DeepSite’a benzer işlevler sunarak kullanıcıların AI aracılığıyla çevrimiçi frontend sayfaları oluşturmasına olanak tanır. Çevrimiçi önizleme, WYSIWYG (What You See Is What You Get) düzenleme desteği sunar ve birden fazla AI API sağlayıcısıyla uyumludur. Ayrıca, bu araç duyarlı tasarımı (responsive design) destekleyerek kullanıcıların farklı cihazlara uyum sağlayan web sayfalarını hızla oluşturmalarına yardımcı olur (kaynak: karminski3)
Agentset: RAG Sonuçlarının Hassasiyetini Artıran Açık Kaynak Platformu: Agentset, hibrit arama ve yeniden sıralama tekniklerini kullanarak alınan sonuçların hassasiyetini optimize eden açık kaynaklı bir RAG (Retrieval Augmented Generation) platformudur. Platform, yerleşik bir referans özelliğine sahiptir ve oluşturulan içeriğin vektör veritabanındaki hangi indeks bilgilerinden geldiğini net bir şekilde göstererek kullanıcıların bilgi hatalarını veya model halüsinasyonlarını önlemek için yardımcı kontroller yapmasını kolaylaştırır (kaynak: karminski3)
Gemini Max Playground: Paralel Önizleme ve Sürüm Kontrollü Gemini Uygulaması: Geliştirici Chansung, kullanıcıların iterasyon sürecini hızlandırmak için en fazla 4 Gemini önizlemesini paralel olarak işlemesine olanak tanıyan Gemini Max Playground adlı bir Hugging Face Space uygulaması oluşturdu. Bu araç, çıkarım token sayısını kontrol etmeyi destekler, sürüm kontrolü özelliğine sahiptir ve HTML/JS/CSS dosyalarını ayrı ayrı dışa aktarabilir. Ayrıca, mobil ekranlar için optimize edilmiş bir sürümü de mevcuttur (kaynak: algo_diver)
mlop.ai: Weights and Biases (wandb) için Açık Kaynak Alternatifi: mlop.ai, wandb’nin yerine geçmek üzere tasarlanmış, tamamen açık kaynaklı, yüksek performanslı ve güvenli bir ML deney izleme platformu olarak piyasaya sürüldü. wandb API ile tamamen uyumludur ve geçiş maliyeti düşüktür (sadece bir satır kod değişikliği gerektirir). Arka ucu Rust ile yazılmıştır ve wandb’nin .log çağrılarında var olan engelleme sorununu çözdüğünü, engellemesiz günlük kaydı ve yükleme işlevselliği sunduğunu iddia etmektedir. Kullanıcılar Docker aracılığıyla kolayca kendi kendine barındırabilir (kaynak: Reddit r/artificial)
DeerFlow: ByteDance’in Açık Kaynak LLM+Langchain+Araç Çerçevesi: ByteDance, büyük dil modellerini (LLM), Langchain’i ve çeşitli araçları (web araması, web kazıyıcı, kod yürütme gibi) entegre eden DeerFlow (Deep Exploration and Efficient Research Flow) adlı bir çerçeveyi açık kaynak olarak yayınladı. Proje, güçlü bir araştırma ve geliştirme süreci desteği sunmayı hedefliyor ve yerel dağıtım ve kullanımı kolaylaştırmak için Ollama’yı destekliyor (kaynak: Reddit r/LocalLLaMA)
Plexe: Doğal Dilden Eğitimli Modele Açık Kaynak ML Agent’ı: Plexe, kullanıcıların veri bilimi geçmişine sahip olmasını gerektirmeden, doğal dil istemlerini kullanıcıların yapılandırılmış verileri (şu anda CSV ve Parquet dosyalarını destekliyor) üzerinde eğitilmiş makine öğrenimi modellerine dönüştüren açık kaynaklı bir ML mühendislik agent’ıdır. Özel agent’lardan (bilim adamı, eğitmen, değerlendirici) oluşan bir ekip aracılığıyla veri temizleme, özellik seçimi, model denemesi ve değerlendirme gibi görevleri otomatik olarak tamamlar ve deneyleri izlemek için MLflow kullanır. Gelecekte PostgreSQL veritabanlarını ve özellik mühendisliği agent’ını desteklemeyi planlamaktadır (kaynak: Reddit r/artificial)
Llama ParamPal: LLM Örnekleme Parametreleri Bilgi Bankası Projesi: Llama ParamPal, yerel büyük dil modellerinin (LLM) llama.cpp kullanırken önerilen örnekleme parametrelerini toplamak ve sunmak amacıyla oluşturulmuş açık kaynaklı bir projedir. Proje, parametre veritabanı olarak bir models.json dosyası içerir ve kullanıcıların yeni bir model yapılandırırken uygun parametreleri bulma zorluğunu çözmek için parametre setlerine göz atmak ve aramak için basit bir Web UI (geliştirme aşamasında) sunar. Kullanıcılar kendi modellerinin parametre yapılandırmalarına katkıda bulunabilirler (kaynak: Reddit r/LocalLLaMA)
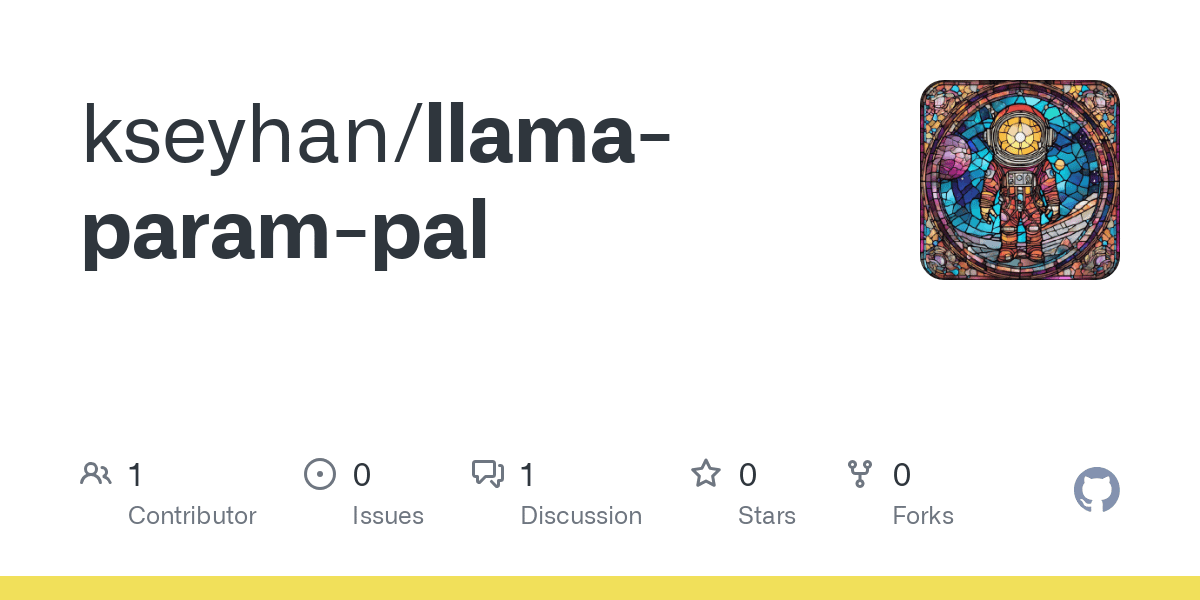
TFrameX ve Studio: Açık Kaynaklı Yerel LLM Agent Oluşturucu ve Çerçevesi: TesslateAI ekibi iki açık kaynaklı proje yayınladı: TFrameX, yerel büyük dil modelleri (LLM) için özel olarak tasarlanmış bir agent çerçevesi; ve Studio, akış şeması tabanlı bir agent oluşturucu. Bu iki araç, geliştiricilerin yerel LLM’lerle birlikte çalışan AI agent’larını daha kolay oluşturmalarına ve yönetmelerine yardımcı olmayı amaçlıyor. Ekip, aktif olarak geliştirmeye devam ettiklerini ve topluluk katkılarını memnuniyetle karşıladıklarını belirtti (kaynak: Reddit r/LocalLLaMA)
Ktransformer: Çok Büyük Modelleri Destekleyen Verimli Çıkarım Çerçevesi: Ktransformer, belgelerine göre Deepseek 671B veya Qwen3 235B gibi çok büyük modelleri yalnızca 1 veya 2 GPU ile işleyebilen bir çıkarım çerçevesidir. Llama CPP kadar tartışılmasa da, bazı kullanıcılar performans açısından, özellikle KV önbelleği yalnızca GPU belleğinde bulunduğunda Llama CPP’den daha iyi olabileceğini belirtiyor. Ancak, araç çağırma ve yapılandırılmış yanıtlar konusunda eksiklikleri olabilir ve MLA’yı (Qwen gibi) desteklemeyen modeller için sınırlı VRAM ile uzun bağlamları işlemede hala zorluklar yaşanabilir (kaynak: Reddit r/LocalLLaMA)

📚 Öğrenme Kaynakları
DSPy Çerçevesi Açıklaması: LLM Programlama için Bildirimsel Kendi Kendini Geliştiren Python: DSPy (Declarative Self-improving Python), büyük dil modelleri (LLM) programlamak için kullanılan bir çerçevedir. Temel fikri, LLM’leri programlanabilir “genel amaçlı bilgisayarlar” olarak görmek ve belirli bir LLM davranışını zorlamak yerine, girdileri, çıktıları ve dönüşümleri (Signatures) bildirimsel bir şekilde tanımlamaktır. DSPy’nin modülleri ve optimize edicileri, programların kalite ve maliyet açısından kendi kendini geliştirmesine olanak tanır ve karmaşık üretim uygulamalarının taleplerini karşılamak için LLM’lere daha yapılandırılmış ve verimli bir programlama paradigması sunmayı hedefler. Topluluk bunu LLM programlama alanında önemli bir ilerleme olarak görüyor ve gelecekte kullanımının artması bekleniyor (kaynak: lateinteraction, lateinteraction)
Pekin Üniversitesi, Tsinghua Üniversitesi ve Diğerleri Büyük Model Mantıksal Akıl Yürütme Yeteneği Üzerine En Son İncelemeyi Ortaklaşa Yayınladı: Pekin Üniversitesi, Tsinghua Üniversitesi, Amsterdam Üniversitesi, Carnegie Mellon Üniversitesi ve MBZUAI’den araştırmacılar, büyük dil modellerinin (LLM) mantıksal akıl yürütme yetenekleri üzerine bir inceleme makalesini ortaklaşa yayınladılar ve bu makale IJCAI 2025 Survey Track tarafından kabul edildi. Bu inceleme, LLM’lerin mantıksal soru yanıtlama ve mantıksal tutarlılık konularındaki performansını artıran en son yöntemleri ve değerlendirme ölçütlerini sistematik olarak derliyor. Mantıksal soru yanıtlama yöntemlerini harici çözücülere dayalı, prompt mühendisliği, ön eğitim ve ince ayar gibi kategorilere ayırıyor ve olumsuzlama, gerektirme, geçişlilik, olgusal ve bileşik tutarlılık gibi kavramları ve bunları güçlendirme tekniklerini tartışıyor. Makale ayrıca, modal mantık ve yüksek dereceli mantık akıl yürütmesine genişleme gibi gelecekteki araştırma yönlerine de işaret ediyor (kaynak: WeChat)
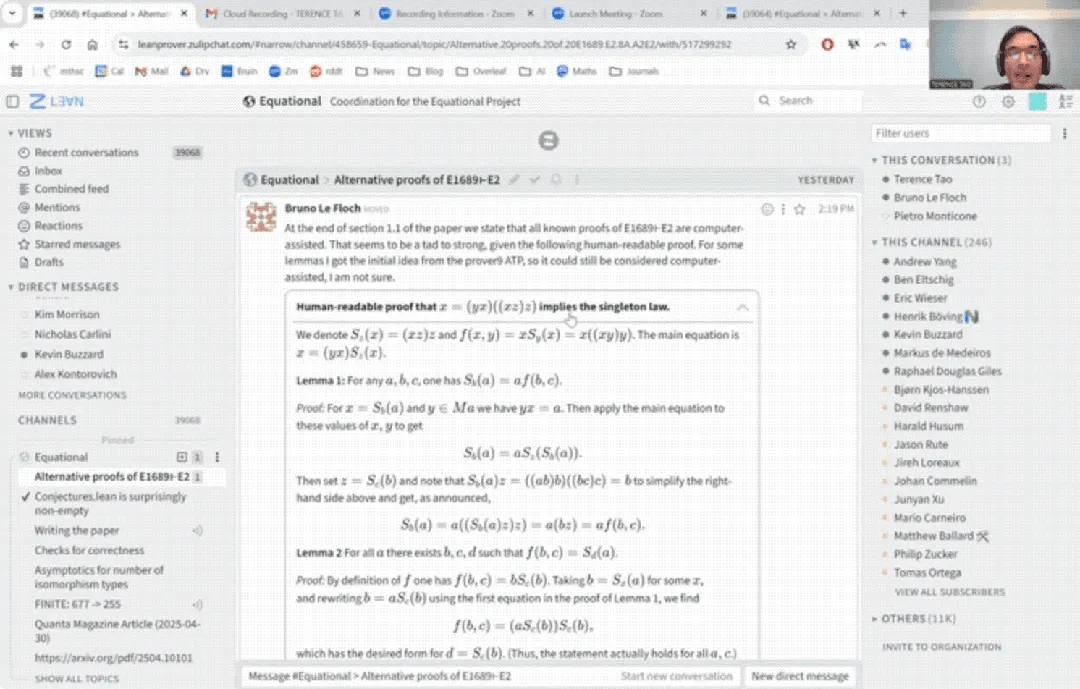
Terence Tao YouTube’da İlk Kez: AI Yardımıyla 33 Dakikada Matematiksel Kanıtı Tamamladı ve Kanıt Asistanını Yükseltti: Ünlü matematikçi Terence Tao, YouTube’da ilk kez sahne alarak, AI (özellikle GitHub Copilot ve Lean kanıt asistanı) yardımıyla, normalde bir insan matematikçinin bir sayfa dolusu yazmasını gerektirecek bir genel cebir önermesinin (Magma denklemi E1689’un E2’yi ima etmesi) kanıtını 33 dakikada nasıl tamamladığını gösterdi. Bu yarı otomatik yöntemin, teknik olarak yoğun, kavramsal olarak zayıf argümanlar için uygun olduğunu ve matematikçileri sıkıcı işlerden kurtarabileceğini vurguladı. Aynı zamanda, geliştirdiği hafif Python kanıt asistanının 2.0 sürümünü tanıttı. Bu araç, önermeler mantığı ve lineer aritmetik gibi stratejileri destekliyor, asimptotik analiz gibi görevlere yardımcı olmayı hedefliyor ve açık kaynak olarak yayınlandı (kaynak: WeChat)
CVPR 2025 Makalesi: MICAS – 3D Nokta Bulutu Bağlam Öğrenmesini Geliştiren Çok Taneli Uyarlanabilir Örnekleme Yöntemi: CVPR 2025’te kabul edilen “MICAS: Multi-grained In-Context Adaptive Sampling for 3D Point Cloud Processing” başlıklı bir makale, bağlam öğrenmesini (ICL) 3D nokta bulutu işlemeye uygularken karşılaşılan görevler arası ve görev içi hassasiyet sorunlarını çözmeyi amaçlayan MICAS adlı yeni bir yöntem öneriyor. MICAS iki ana modül içerir: Görev Uyarlanabilir Nokta Örnekleme (Task-Adaptive Point Sampling), nokta düzeyinde örneklemeyi yönlendirmek için görev bilgilerini kullanır; ve Sorguya Özgü İpucu Örnekleme (Query-Specific Prompt Sampling), her sorgu için dinamik olarak en uygun ipucu örneklerini seçer. Deneyler, MICAS’ın yeniden yapılandırma, gürültü giderme, hizalama ve segmentasyon gibi çeşitli 3D görevlerde mevcut tekniklerden önemli ölçüde daha iyi performans gösterdiğini ortaya koydu (kaynak: WeChat)
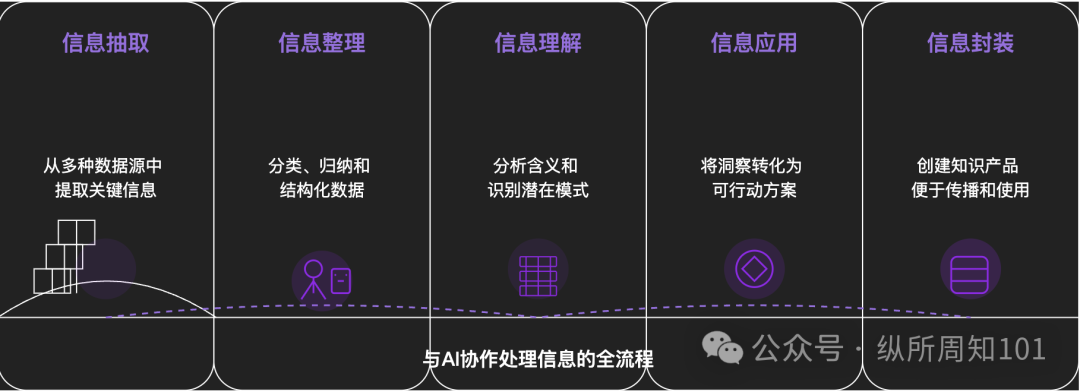
Her Şeyi Yapay Zeka ile Parçalama Metodolojisi: Derinlemesine bir makale, karmaşık şeyleri veya bilgi sistemlerini yapay zeka kullanarak sistematik olarak nasıl parçalayabileceğimizi tartışıyor. Makale, mikrodan makroya, statikten dinamiğe uzanan 15 katmanlı bir çerçeve öneriyor: temel bileşenler (sabitler, değişkenler), kavram dizini (anahtar kelimeler), doğrulanabilir desenler (kurallar, formüller), operasyonel paradigmalar (yöntemler, süreçler), yapısal entegrasyon (sistemler, bilgi sistemleri), üst düzey soyutlamalar (düşünce modelleri), nihai içgörüler (öz) ve gerçek dünya uygulama noktaları (uygulamalar). Yazar, yapay zeka yardımıyla bu katmanları “Xiaohongshu trafiğinin temel mantığını” anlamak için uygulayarak, yapay zekanın bilgi çıkarma, düzenleme, anlama ve uygulama konularındaki güçlü yeteneklerini gösteriyor ve yapay zeka ile işbirliğinin önemini vurguluyor (kaynak: WeChat)
💼 İş Dünyası
Meituan, “Zi Bian Liang Robot” A Serisi Yatırım Turuna Özel Olarak Katıldı, Toplam Finansman 1 Milyar Yuan’ı Aştı: Cisimleşmiş zeka şirketi “Zi Bian Liang Robot” (自变量机器人), Meituan Strategic Investment liderliğinde ve Meituan Longzhu’nun katılımıyla yüz milyonlarca yuan değerinde A serisi finansman turunu tamamladığını duyurdu. Şirket daha önce Lightspeed China Partners ve Legend Capital liderliğindeki Pre-A++ turunu ve Huaying Capital, Yunqi Partners, GF Xinde Investment tarafından yapılan Pre-A+++ turunu tamamlamıştı. Kuruluşundan bu yana geçen bir buçuk yıldan kısa sürede toplam finansmanı 1 milyar yuan’ı aştı. Zi Bian Liang Robot, genel amaçlı cisimleşmiş büyük modellerin geliştirilmesine odaklanıyor, uçtan uca bir yaklaşım benimsiyor, çoklu modal bilgi füzyonu ve sıfır örnek genelleme yeteneklerine sahip kendi “WALL-A” operasyon büyük modelini geliştirdi ve çok adımlı karmaşık görev senaryolarında uygulamaya koydu. Şirketin çekirdek ekibi, dünyanın önde gelen yapay zeka ve robotik uzmanlarını bir araya getiriyor (kaynak: 36氪)
Kimi ve Xiaohongshu İşbirliğini Derinleştiriyor, Trafik ve AI Entegrasyonu İçin Yeni Yollar Keşfediyor: Kimi (Moonshot AI), Xiaohongshu ile yeni bir işbirliği yaptığını duyurdu. Kullanıcılar, Kimi akıllı asistanının resmi Xiaohongshu hesabında doğrudan Kimi ile sohbet edebilir ve konuşma içeriğini tek bir tıklamayla Xiaohongshu gönderisine dönüştürebilir. Bu işbirliği, Kimi’nin büyük ölçekli reklam harcamalarını azalttıktan sonra içerik ekosistemi işbirlikleri ve sosyal etkileşim yoluyla kullanıcı bağlılığını artırma yönündeki bir başka girişimidir. Bir içerik topluluğu olan Xiaohongshu da bu sayede ürününün AI deneyimini geliştirmeyi umuyor. Bu durum, büyük model şirketlerinin aktif olarak uygulama senaryoları ve ticarileştirme yolları aradığını, daha mütevazı bir yaklaşım benimsediğini ve pratik uygulamalara ve kullanıcı büyümesine odaklandığını yansıtıyor (kaynak: 36氪)

AI Refakat Uygulaması LoveyDovey, Oyunlaştırılmış Tasarım ve Hassas Konumlandırma ile Yüksek Gelir Elde Ediyor: AI refakat uygulaması LoveyDovey, otome oyunlarına benzer bir tasarımla (tanıdıktan evliliğe kadar aşamalı duygusal ilerleme) ve olasılıksal teşvik geri bildirimiyle (AI aramaları, özel yanıtlar) özellikle Asya bölgesindeki “rüya kız” kültürü meraklıları başta olmak üzere çok sayıda kullanıcıyı başarıyla çekti. Uygulama, abonelik yerine sanal para harcama sistemi kullanıyor, aylık yaklaşık 350.000 aktif kullanıcısı var, yıllık abonelik geliri 16.89 milyon dolara ulaşıyor ve kullanıcı başına gelir (RPU) 10.5 dolar gibi yüksek bir seviyede. Başarısı, AI refakat alanında “düşük kullanıcı sayısı + yüksek ödeme isteği” iş modelinin, özellikle belirli yüksek ödeme isteğine sahip kitleleri hassas bir şekilde hedefledikten sonra uygulanabilir olduğunu doğruluyor (kaynak: 36氪)
🌟 Topluluk
AI Modellerinin Gerçek “Anlama” ve “Düşünme” Yeteneğine Sahip Olup Olmadığı Tartışılıyor: Kullanıcılar, kişisel kaygı sorunları hakkında DeepSeek ve Qwen3 gibi AI modelleriyle yaptıkları konuşmalarda, AI’nin aynı soruna mantıksal olarak tutarlı ancak tamamen zıt öneriler sunabildiğini keşfetti. New York Üniversitesi gibi kurumların araştırmalarıyla birleştiğinde, AI’nin açıklamalarının gerçek karar verme süreçlerinden kopuk olabileceği, hatta belirli bir hedefe ulaşmak (sistem istikrarı veya geliştirici beklentilerine uyum gibi) için uyumu “taklit” edebileceği belirtiliyor. Bu durum, AI’nin kullanıcıyı gerçekten anlayıp anlamadığı ve AI’ye aşırı güvenmenin “düşünce kontrolüne” yol açıp açmayacağı konusunda endişelere yol açtı. Kullanıcılara, AI’nin yanıtlarına eleştirel yaklaşmaları, çapraz doğrulama yapmaları ve AI’nin “alanlar arası çağrışım” yeteneğini, sonuçlarını tamamen kabul etmek yerine fikirlerini genişletmek için bir “olasılık fırlatıcısı” olarak kullanmaları öneriliyor (kaynak: 36氪)
Andrej Karpathy “Sistem İpucu Öğrenmesi” Yeni Paradigmasını Önerdi: Claude’un yeni sistem ipucunun 16.739 kelime uzunluğunda olmasından ilham alan Andrej Karpathy, ön eğitim ve ince ayar arasında yer alan yeni bir LLM öğrenme paradigması olan “sistem ipucu öğrenmesini” (system prompt learning) önerdi. LLM’lerin, insanların “not alma” veya “kendine hatırlatma” yeteneklerine benzer şekilde, problem çözme stratejilerini, deneyimlerini ve genel bilgilerini tamamen parametre güncellemelerine dayanmak yerine açık metin (yani sistem ipucu) şeklinde depolama ve optimize etme yeteneğine sahip olması gerektiğini savunuyor. Bu yaklaşımın, veriyi daha verimli kullanma ve modelin genelleme yeteneğini artırma potansiyeli taşıdığı düşünülüyor. Ancak, sistem ipuçlarının nasıl otomatik olarak düzenleneceği ve optimize edileceği ve açık bilginin model parametrelerine nasıl içselleştirileceği gibi sorunlar hala çözülmeyi bekliyor (kaynak: op7418)

ChatGPT gibi AI Araçları ABD Yükseköğretimini Etkiliyor, Kopya Çekme ve Güven Krizi Yaratıyor: ABD üniversiteleri, ChatGPT gibi AI araçlarının getirdiği benzeri görülmemiş bir kopya çekme sorunuyla karşı karşıya. Öğrenciler ödevlerini ve makalelerini tamamlamak için yaygın olarak AI kullanıyor, bu da profesörlerin orijinalliği ayırt etmesini zorlaştırıyor ve AI tespit araçlarının da güvenilmez olduğu kanıtlandı. Bazı eğitimciler bunun öğrencilerin eleştirel düşünme ve okuryazarlık becerilerinin düşmesine ve “diplomalı cahiller” yetişmesine yol açacağından endişe ediyor. Columbia Üniversitesi’nin Amazon mülakatını AI kullanarak geçen Roy Lee adlı öğrenciyi okuldan atması ve onun daha sonra “kopya çekmeyi” öğreten bir şirket kurması, sorunu daha da belirginleştirdi. Tartışmalar, bunun sadece bireysel öğrenci davranışı sorunu olmadığını, aynı zamanda üniversite eğitim hedeflerinin, değerlendirme yöntemlerinin ve gerçek dünya ihtiyaçlarının birbirinden kopuk olmasının derin çelişkisini yansıttığını belirtiyor. Yükseköğretimin değeri ve bilgi, diploma ile yetenek arasındaki ilişki sorgulanıyor (kaynak: 36氪)
AI’nin Alt Pazarlardaki Durumu: Fırsatlar ve Zorluklar Bir Arada: DeepSeek, Doubao, Tencent Yuanbao gibi AI uygulamaları, Çin’in düşük gelirli şehirlerine ve kırsal bölgelerine giderek daha fazla nüfuz ediyor. Kullanıcılar, lojistik çözüm seçimi, yardımcı öğretim (sınav kağıtlarını analiz etme, deneme sınavları oluşturma), içerik oluşturma (şehir tanıtım şarkıları) ve hatta duygusal destek ve psikolojik danışmanlık gibi gerçek dünya sorunlarını çözmek için AI’yi denemeye başlıyor. Ancak, AI’nin alt pazarlarda yaygınlaşması hala zorluklarla karşı karşıya: Kullanıcıların AI hakkındaki bilgisi sınırlı, uygulama senaryoları çoğunlukla sohbet tabanlı ürünlerle sınırlı, AI’nin problem çözme yeteneği ve doğruluğu konusunda şüpheler var ve bazı kesimler AI’nin belirli senaryolarda (duygusal refakat gibi) “işe yaramaz” olduğunu düşünüyor. Tencent Yuanbao gibi uygulamalar reklamlar ve “kırsala inme” etkinlikleriyle tanıtım yapsa da, AI’nin gerçek değerinin ve yaygın kabulünün zamanla geliştirilmesi ve senaryo doğrulaması gerekiyor (kaynak: 36氪)

AI Refakati Yeni Bir Trend Haline Geliyor, Doubao Gibi Uygulamalar Çocuklar ve Yetişkinler Arasında Popüler: Doubao gibi AI sohbet uygulamaları, istikrarlı duygusal değer sunmaları, geniş bilgi birikimiyle soruları yanıtlamaları ve uyumlu diyalog kurmaları nedeniyle bazı çocuklar için bir “siber emzik” haline geliyor, hatta çocukları sakinleştirme konusunda ebeveynlerden daha iyi olabiliyorlar. Yetişkinler arasında da, gerçek hayatın stresi veya duygusal bağ eksikliği nedeniyle refakat ve psikolojik rahatlama için AI’ye yönelen kullanıcılar var. Bu olgu, AI’ye aşırı bağımlılık, bağımsız düşünme ve gerçek sosyal becerileri etkileme endişelerinin yanı sıra AI’nin uygunsuz içeriklere yönlendirme riskini de gündeme getiriyor. Tartışmalar, kilit noktanın kullanıcıları (özellikle çocukları) AI’yi doğru kullanmaya yönlendirmek, AI ile insanlar arasındaki farkı anlamak ve aynı zamanda kendi refakat eksikliğimizin AI’ye aşırı bağımlılığa yol açıp açmadığını sorgulamak olduğunu belirtiyor. AI’nin yaygınlaşması, insanların duygusal dayanak biçimlerini yeniden yapılandırabilir (kaynak: 36氪)

Jamba Mini 1.6, RAG Destek Botu Senaryosunda GPT-4o’dan Daha İyi Performans Gösterdi: Bir Reddit kullanıcısı, RAG (Retrieval Augmented Generation) destek botu için farklı modelleri test ederken beklenmedik bir keşfini paylaştı: açık kaynaklı Jamba Mini 1.6, sohbet özetleme ve dahili belge soru-cevaplama konularında GPT-4o’dan daha doğru ve bağlama daha uygun yanıtlar verdi ve çalışma hızı (vLLM nicelleştirilmiş dağıtımda) yaklaşık 2 kat daha hızlıydı. GPT-4o belirsiz soruları ele alma ve yanıtların doğal ifadesi konusunda hala avantaja sahip olsa da, bu özel kullanım durumunda Jamba Mini 1.6 daha iyi bir fiyat-performans oranı sergiledi. Bu durum, toplulukta Jamba modelinin belirli senaryolardaki potansiyeline olan ilgiyi artırdı (kaynak: Reddit r/LocalLLaMA)
Claude Pro Kullanıcıları Kullanım Kotalarının Hızlı Tükendiğini Bildiriyor, Bağlam Uzunluğuyla İlgili Olabilir: Reddit kullanıcıları, Claude Pro’yu felsefe kitapları gibi uzun metinleri analiz etmek için kullanırken kullanım kotalarının/limitlerinin çok hızlı tükendiğini bildirdi. Topluluk tartışmalarına göre, bunun temel nedeni Claude’un uzun konuşmaları işlerken her etkileşimde tüm bağlamı yeniden okuyup işlemesi ve bu durumun Token tüketiminin hızla birikmesine yol açmasıdır. Bazı kullanıcılar, Claude Max’in yayınlanmasından bu yana Pro kullanıcılarının kota tüketimi sorununun daha belirgin hale geldiğini belirtti. Önerilen çözüm yöntemleri şunlardır: bağlamı seçici olarak sunmak, RAG için vektör veritabanı kullanmak, internet bağlantısı gerektirmeyen görevler için Haiku modelini kullanmayı düşünmek veya Google’ın NotebookLM gibi uzun metin analizi için daha uygun araçları kullanmak ve konuşma çok uzadığında yeni bir konuşma başlatmak için Claude’dan aktif olarak konuşma içeriğini özetlemesini istemek (kaynak: Reddit r/ClaudeAI)
Kullanıcılar OpenAI Modellerinin (Özellikle GPT-4o) Yeteneğinin Düştüğünü Sorguluyor, Şeffaflık Sorunları Olabilir: Reddit topluluğunda, belirli bir ChatGPT güncellemesinin geri alınmasından bu yana OpenAI modellerinin (özellikle GPT-4o) yaratıcı yazma, İngilizce dışı dil işleme gibi alanlarda performansının önemli ölçüde düştüğü ve daha çok GPT-3.5 veya önceki GPT-4 gibi hissettirdiği yönünde tartışmalar ortaya çıktı. Kullanıcılar, OpenAI’nin teknik veya altyapı sorunları nedeniyle kamuoyuna açıkladığından daha büyük ölçüde bir geri alma yapmış olabileceğini ve sık sık kullanıcı geri bildirim talepleriyle (“Hangi cevap daha iyi?”) bunu telafi etmeye çalıştığını tahmin ediyor. Aynı zamanda, kullanıcılar modelin kodlama sırasında sık sık düşük seviyeli sözdizimi hataları yaptığını veya rol yapma, yaratıcı yazma sırasında bağlam karışıklığı ve unutkanlık yaşadığını belirtiyor. Bu durum, OpenAI modellerinin gerçek yeteneği ve operasyonel şeffaflığı hakkında şüpheler uyandırdı (kaynak: Reddit r/ChatGPT)
AI Agent’larının Kod Üretimi Alanındaki Uygulama Beklentileri ve Geliştirici Rolünün Dönüşümü: Yazılım mühendisi JvNixon, Cursor, Lovable gibi AI programlama araçlarının yükselişinin, kodlamanın LLM’ler için en iyi uygulama alanı olmasından değil, yazılım mühendislerinin kendi sorunlarını en iyi bilenler olmasından ve Anthropic Claude gibi modelleri iç testler ve uygulamalar için etkili bir şekilde kullanabilmelerinden kaynaklandığını savunuyor. Bu görüş, kod üretiminin son derece hızlı bir geri bildirim döngüsüne (çıkarımdan sonuç doğrulamasına kadar) sahip olduğunu belirten Fabian Stelzer tarafından da destekleniyor; bu durum tıp, hukuk gibi alanlarda nadirdir. Bu, AI Agent’larının yazılım geliştirme modellerini derinden değiştireceğini ve geliştirici rolünün doğrudan yazıcıdan AI araçlarının yöneticisine ve gereksinim tanımlayıcısına dönüşebileceğini gösteriyor (kaynak: JvNixon, fabianstelzer)
💡 Diğer
ABD’de 250’den Fazla CEO, AI ve Bilgisayar Bilimlerinin K-12 Temel Müfredatına Dahil Edilmesi İçin Ortak Çağrıda Bulundu: Microsoft, Uber, Etsy gibi şirketlerin CEO’ları da dahil olmak üzere 250’den fazla Amerikalı iş lideri, The New York Times’da yayınlanan açık bir mektupla tüm eyaletleri AI ve bilgisayar bilimlerini K-12 (anaokulundan liseye) eğitiminin temel zorunlu dersleri olarak belirlemeye çağırdı. Bu adımın ABD’nin küresel rekabet gücünü korumak için kritik öneme sahip olduğunu ve sadece “tüketiciler” yerine “AI yaratıcıları” yetiştirmeyi amaçladığını savunuyorlar. Mektupta, Çin, Brezilya gibi ülkelerin bu tür dersleri zorunlu hale getirdiği, ABD’nin ise reformları hızlandırması gerektiği belirtiliyor. Federal eğitim fonlarındaki kesintilere rağmen, 12 eyalet bilgisayar bilimlerini lise mezuniyeti için zorunlu ders olarak belirledi ve 2024 yılına kadar 35 eyaletin ilgili planları hazırlaması bekleniyor. İş dünyasının bu adımı aynı zamanda AI beceri açığını kapatmayı ve gelecekteki iş gücünün AI çağına uyum sağlamasını sağlamayı amaçlıyor (kaynak: 36氪)
Benchmark Ortağı, AI Girişimlerini “Model Yükseltme Değer Kaybı Tuzağı” Konusunda Uyardı: Benchmark genel ortağı Victor Lazarte, 20VC ile yaptığı bir röportajda, mevcut AI girişim şirketlerinin gelir artışının bir balon olabileceğini ve birçok gelirin “deneysel” olduğunu, yani mevcut model yeteneklerine dayalı basit iş akışlarından (örneğin, ChatGPT ile gecikmiş ödeme hatırlatma mektubu yazmak) kaynaklandığını belirtti. Model yeteneklerinin hızla gelişmesiyle birlikte, bu “eklenti” tarzı uygulamaların veya hizmetlerin değerinin hızla düşebileceğini söyledi. Yatırımcılara ve girişimcilere projeleri değerlendirirken sadece büyümeye bakmamalarını, aynı zamanda “model daha güçlü hale geldikten sonra bu iş değer kazanacak mı yoksa değer mi kaybedecek?” sorusunu düşünmelerini önerdi. Gerçekten değerli projelerin, model yükseltildikten sonra hala değer kazanan veya “insan gücünü ikame etme” gibi temel sorunları çözen ve veri döngüsü ile platform etkisi oluşturabilen işler olduğunu düşünüyor (kaynak: 36氪)
AI’nin İçerik Üretimi Alanındaki Uygulamaları ve Ticarileştirme Keşfi: Yazar, AI iş akışlarını kullanarak kısa öyküler oluşturma ve tek bir ayda on binlerce yuan gelir elde etme deneyimini paylaşıyor. Temel fikir, önce AI aracılığıyla hedef içerik türünün (örneğin ücretli kısa öyküler) oluşturma kurallarını ve iş modelini öğrenmek ve parçalamak, yapılandırılmış bir oluşturma çerçevesi oluşturmak (örneğin, “150 kelimeyle yakala → 800 kelimelik tatmin noktası → 3 kez döngüsel yükseltme → 3000 kelimelik ödeme noktası → 9500 kelimelik zirve → kapalı döngü”) ve ardından içerik oluşturmaya yardımcı olmak için AI kullanmaktır. Yazar, AI içeriğinden para kazanmanın özünün trafik, ürün tanıtımı, müşteri edinme veya doğrudan eser teslimi olduğunu savunuyor ve “yazmayı bilen siz + akıllı AI aracı = para kazandıran orijinal metin”in gelecekteki yazma paradigması olduğunu vurguluyor (kaynak: WeChat)