
Anahtar Kelimeler:OpenAI, Yapay Zeka Çipleri, Büyük Dil Modelleri, Pekiştirmeli Öğrenme, Yapay Zeka Altyapısı, Çok Modlu Yapay Zeka, Akıllı Ajanlar, RAG (Retrieval-Augmented Generation), OpenAI Ulusal Düzeyde Yapay Zeka Planı, NVIDIA H20 Çip İhracat Kısıtlamaları, DeepSeek-R1 Çıkarım Optimizasyonu, AI Optik Mikroskop Meta-rLLS-VSIM, ByteDance Seed-Coder Kod Büyük Modeli
🔥 Odak Noktası
OpenAI, küresel AI altyapısının geliştirilmesine yardımcı olmak amacıyla “Ulusal Düzeyde AI” girişimini başlattı: OpenAI, “Stargate” planının bir parçası olarak “OpenAI for Countries” projesini başlattı. Bu proje, ülkelerin yerel AI veri merkezleri kurmalarına, özelleştirilmiş ChatGPT geliştirmelerine ve AI ekosisteminin gelişimini teşvik etmelerine yardımcı olmayı amaçlıyor. CEO Sam Altman, Teksas Abilene’deki ilk süper bilgi işlem kampüsünü yerinde inceledi. Bu kampüs, dünyanın en büyük AI eğitim tesisini kurmayı amaçlayan 500 milyar dolarlık “Stargate” planının bir parçası. Bu adım, OpenAI’nin altyapı inşası ve teknoloji paylaşımı yoluyla AI teknolojilerinin küresel yaygınlaşmasını ve uygulanmasını teşvik etmek için birçok ülke hükümetiyle işbirliği yapacağını gösteriyor. İlk aşamada 10 ülke veya bölge ile işbirliği yapılması planlanıyor (Kaynak: WeChat)

Trump yönetiminin AI çip ihracatına yönelik üç aşamalı kısıtlamaları kaldırmayı ve daha basitleştirilmiş bir küresel lisanslama sistemini benimsemeyi planladığı bildiriliyor: Dış basında çıkan haberlere göre, Trump yönetimi, Biden döneminin sonlarında oluşturulan ve küresel AI çip ihracatına üç aşamalı bir sınıflandırma kısıtlaması getirmesi planlanan Yapay Zeka Yayılım Çerçevesi’ni (FAID) yürürlükten kaldırmayı planlıyor. Trump ekibi, bu çerçevenin aşırı karmaşık olduğunu ve yeniliği engellediğini düşünüyor; bunun yerine daha basit bir küresel lisanslama sistemi getirme ve bunu hükümetler arası anlaşmalarla uygulama eğiliminde. Bu hamle, Nvidia gibi çip üreticilerinin küresel pazar stratejilerini etkileyebilir ve ABD’nin AI alanındaki yenilikçiliğini ve hakimiyetini pekiştirmeyi amaçlıyor (Kaynak: WeChat)

SGLang ekibi DeepSeek-R1 çıkarım performansını büyük ölçüde optimize ederek verimi 26 kat artırdı: SGLang, Nvidia gibi kurumların ortak ekibi, SGLang çıkarım motorunu kapsamlı bir şekilde yükselterek dört ay içinde DeepSeek-R1 modelinin H100 GPU üzerindeki çıkarım performansını 26 kat artırdı. Optimizasyon çözümleri arasında ön doldurma ve kod çözme ayrımı (PD ayrımı), büyük ölçekli uzman paralelliği (EP), DeepEP, DeepGEMM ve uzman paralel yük dengeleyici (EPLB) gibi teknolojiler bulunuyor. 2000 token giriş dizisi işlenirken, düğüm başına saniyede 52.3k giriş token’ı ve 22.3k çıkış token’ı verimine ulaşıldı; bu, DeepSeek resmi verilerine yakın bir değer olup yerel dağıtım maliyetlerini önemli ölçüde düşürdü (Kaynak: WeChat)

OpenAI bilim insanı Dan Roberts: Pekiştirmeli Öğrenmenin ölçeklendirilmesi AI’ın yeni bilimsel keşifler yapmasını sağlayacak, Einstein düzeyinde AGI 9 yılda mümkün olabilir: OpenAI araştırma bilim insanı Dan Roberts, Sequoia Capital AI Ascent’te yaptığı konuşmada, Pekiştirmeli Öğrenmenin (RL) gelecekteki AI modellerinin oluşturulmasındaki merkezi rolünü ele aldı. RL’nin ölçeğinin sürekli olarak genişletilmesiyle AI modellerinin yalnızca matematiksel akıl yürütme gibi görevlerdeki performansını artırmakla kalmayıp, aynı zamanda “test zamanı hesaplaması” (yani model ne kadar uzun süre düşünürse o kadar iyi performans gösterir) yoluyla bilimsel keşifler yapabileceğine inanıyor. Einstein’ın genel göreliliği keşfetmesini örnek göstererek, AI’ın 8 yıl boyunca hesaplama ve düşünme yapabilmesi durumunda, 9 yıl sonra Einstein’ınkine benzer bilimsel atılım düzeyine ulaşabileceğini tahmin etti. Roberts, gelecekteki AI gelişiminin daha çok RL hesaplamasına odaklanacağını, hatta tüm eğitim sürecine hakim olabileceğini vurguladı (Kaynak: WeChat)

🎯 Gelişmeler
Nvidia’dan Jim Fan: Robotlar “Fiziksel Turing Testi”ni geçecek, simülasyon ve üretken AI kilit rol oynayacak: Nvidia robotik bölümü başkanı Jim Fan, Sequoia AI Ascent konuşmasında “Fiziksel Turing Testi” kavramını ortaya attı; bu, insanların bir görevin insan mı yoksa robot tarafından mı yapıldığını ayırt edememesi anlamına geliyor. Mevcut robot veri toplama maliyetlerinin yüksek olduğuna dikkat çekerek, simülasyon teknolojisinin, özellikle de çeşitli ve büyük ölçekli eğitim verileri (“dijital ikizler” yerine “dijital kuzenler”) oluşturmak için üretken AI (video üretim modellerinin ince ayarı gibi) ile birleştirilmesinin kilit önem taşıdığını belirtti. Büyük ölçekli simülasyon ve görsel-dil-eylem modelleri (Nvidia GR00T gibi) aracılığıyla gelecekte fiziksel API’lerin her yerde olacağını, robotların karmaşık günlük görevleri tamamlayabileceğini ve çevresel zeka ile bütünleşeceğini öngördü (Kaynak: WeChat)
ByteDance, 8B sürümü üstün performans gösteren Seed-Coder serisi kod büyük modellerini yayınladı: ByteDance, 8B, 14B gibi çeşitli sürümleri içeren Seed-Coder serisi kod büyük modellerini piyasaya sürdü. Bunlardan Seed-Coder-8B, SWE-bench, Multi-SWE-bench, IOI gibi birçok kod yeteneği değerlendirme kriterinde olağanüstü performans gösterdi ve Qwen3-8B ile Qwen2.5-Coder-7B-Inst’ten daha iyi olduğu iddia edildi. Bu model serisi Base, Instruct ve Reasoner sürümlerini içeriyor ve temel felsefesi “kod modelinin kendi verilerini kendisi için düzenlemesine izin vermek” olup, kod çıkarımı ve yazılım mühendisliği yeteneklerinde önemli gelişmeler sağlıyor. Modeller Hugging Face ve GitHub’da açık kaynak olarak yayınlandı (Kaynak: Reddit r/LocalLLaMA, karminski3, teortaxesTex)
Alibaba, LLM kullanarak aramayı simüle eden ve AI eğitim maliyetlerini %88 azaltan ZeroSearch çerçevesini açık kaynak olarak yayınladı: Alibaba araştırmacıları, büyük dil modellerinin (LLM) eğitim sürecinde pahalı ticari arama motoru API’lerini (Google gibi) çağırmadan, simüle edilmiş bir arama motoru aracılığıyla gelişmiş arama işlevleri geliştirmesine olanak tanıyan “ZeroSearch” adlı bir pekiştirmeli öğrenme çerçevesi yayınladı. Deneyler, simüle edilmiş bir arama motoru olarak 3B LLM kullanmanın bile strateji modelinin arama yeteneklerini etkili bir şekilde artırdığını, 14B parametreli bir erişim modülünün performansının Google aramasını bile aştığını ve API maliyetlerinin %88 oranında azaldığını gösterdi. Bu teknoloji GitHub ve Hugging Face’te açık kaynak olarak yayınlandı ve Qwen-2.5, LLaMA-3.2 gibi model serilerini destekliyor (Kaynak: WeChat)

Gemini API, %75’e varan maliyet tasarrufu sağlayabilen örtük önbellekleme özelliğini kullanıma sundu: Google Gemini API, yakın zamanda Gemini 2.5 model serisi (Pro ve Flash) için örtük önbellekleme özelliğini etkinleştirdi. Kullanıcıların istekleri önbelleğe isabet ettiğinde, otomatik olarak %75’e varan maliyet tasarrufu sağlanabiliyor. Aynı zamanda, önbelleği tetikleyen minimum token gereksinimi de düşürüldü; 2.5 Flash modeli için 1K token’a, 2.5 Pro modeli için ise 2K token’a indirildi. Bu hamle, geliştiricilerin Gemini API kullanma maliyetlerini düşürmeyi ve sık tekrarlanan isteklerin verimliliğini artırmayı amaçlıyor (Kaynak: JeffDean)
Tsinghua Üniversitesi, hacimsel çözünürlüğü 15.4 kat artıran AI optik mikroskop Meta-rLLS-VSIM’i geliştirdi: Tsinghua Üniversitesi’nden Li Dong’un araştırma grubu, Dai Qionghai’nin ekibiyle işbirliği yaparak meta-öğrenme güdümlü yansıtmalı kafes ışık tabakası sanal yapılandırılmış aydınlatma mikroskobu (Meta-rLLS-VSIM) geliştirdi. Bu sistem, AI ve optik alanındaki yenilikçi kesişim sayesinde canlı hücre görüntülemesinin yanal çözünürlüğünü 120nm’ye, eksenel çözünürlüğünü ise 160nm’ye yükselterek neredeyse izotropik süper çözünürlük elde etti ve hacimsel çözünürlüğü geleneksel LLSM’ye kıyasla 15.4 kat artırdı. Temel teknolojileri arasında, DNN kullanarak süper çözünürlük yeteneğini çok yönlü olarak öğrenen ve genişleten “sanal yapılandırılmış aydınlatma” ve ayna yansımalı çift açılı bilgi füzyonu ile RL-DFN ağı aracılığıyla eksenel çözünürlüğün artırılması yer alıyor. Meta-öğrenme stratejisinin dahil edilmesi, AI modelinin yalnızca 3 dakikada uyarlanabilir dağıtımı tamamlamasını sağlayarak AI’ın biyolojik deneylerde uygulanmasının önündeki engeli büyük ölçüde düşürdü ve kanser hücresi bölünmesi, embriyo gelişimi gibi yaşam süreçlerini gözlemlemek için güçlü bir araç sağladı (Kaynak: WeChat)

Qwen3 serisi büyük dil modelleri yayınlandı, açık kaynak topluluğuna liderlik etmeye devam ediyor: Alibaba, parametre ölçeği 0.5B’den 235B’ye kadar değişen Qwen3 serisi büyük dil modellerini yayınladı. Bu modeller birçok kıyaslama testinde üstün performans gösterdi ve küçük boyutlu modellerin birçoğu kendi ölçeklerindeki açık kaynak modeller arasında SOTA (state-of-the-art) seviyesine ulaştı. Qwen3 serisi birden fazla dili destekliyor ve bağlam uzunluğu 128k token’a kadar çıkabiliyor. Güçlü performansı ve düşük dağıtım maliyeti (DeepSeek-R1 gibi modellere kıyasla) nedeniyle Qwen serisi, yurtdışında (özellikle Japonya’da) AI geliştirme temeli olarak yaygın bir şekilde benimsendi ve çok sayıda dikey alan modeli türetildi. Qwen3’ün yayınlanması, küresel açık kaynak AI topluluğundaki lider konumunu daha da pekiştirdi ve GitHub’da bir hafta içinde yıldız sayısı 20 bini aştı (Kaynak: dl_weekly, WeChat)

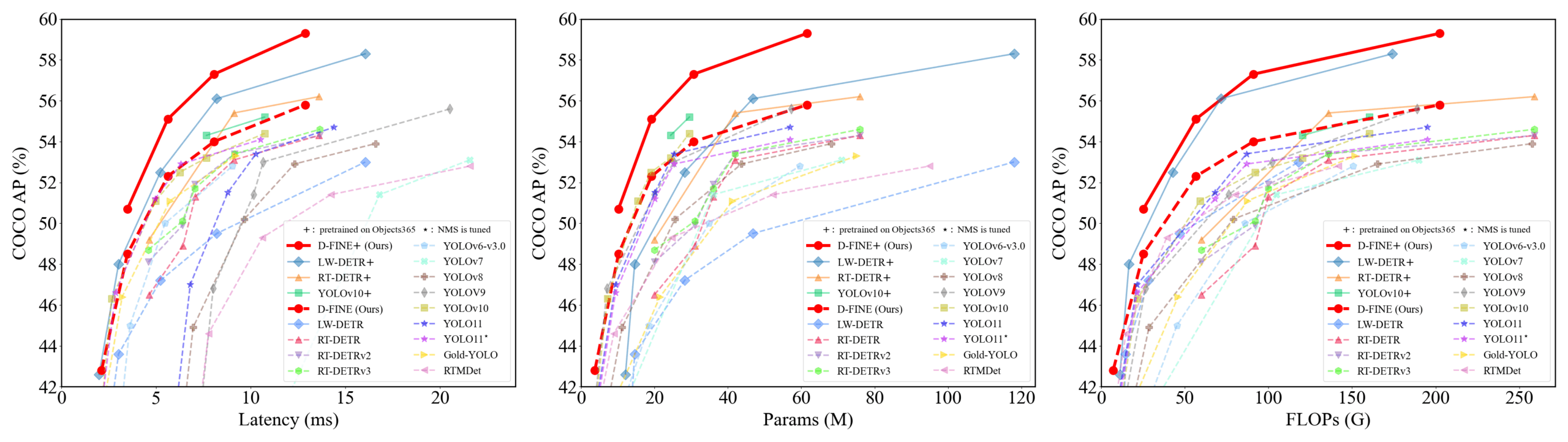
D-FINE: İnce taneli dağılım optimizasyonuna dayalı, üstün performanslı gerçek zamanlı nesne dedektörü: Araştırmacılar, DETR’deki sınırlayıcı kutu regresyon görevini ince taneli dağılım optimizasyonu (FDR) olarak yeniden tanımlayan ve küresel optimal konumlandırma kendi kendine damıtma (GO-LSD) stratejisini tanıtan yeni bir gerçek zamanlı nesne dedektörü olan D-FINE’ı önerdiler. D-FINE, ek çıkarım ve eğitim maliyeti olmadan olağanüstü performans elde ediyor. Örneğin, D-FINE-N, COCO val üzerinde %42.8 AP’ye ulaşırken 472 FPS (T4 GPU) hıza sahip; D-FINE-X ise Objects365+COCO ön eğitimi sonrasında COCO val AP’si %59.3’e ulaşıyor. Bu yöntem, daha hassas konumlandırma için olasılık dağılımlarını yinelemeli olarak optimize eder ve son katmanın konumlandırma bilgisini kendi kendine damıtma yoluyla erken katmanlara aktarır (Kaynak: GitHub Trending)
Harmon modeli görsel temsilleri koordine ederek çok modlu anlama ve üretimi birleştiriyor: Nanyang Teknoloji Üniversitesi araştırmacıları, paylaşılan bir MAR Encoder (Masked Autoencoder for Reconstruction) aracılığıyla çok modlu anlama ve üretim görevlerini birleştirmeyi amaçlayan Harmon modelini önerdi. Araştırmalar, MAR Encoder’ın görüntü üretimi eğitiminde aynı anda görsel semantiği öğrenebildiğini ve Linear Probing sonuçlarının VQGAN/VAE’yi önemli ölçüde aştığını ortaya koydu. Harmon çerçevesi, anlama için tam görüntüleri işlemek üzere MAR Encoder’ı kullanır ve görüntü üretimi için MAR maskeleme modelleme paradigmasını benimser; LLM ise bu süreçte modalite etkileşimini sağlar. Deneyler, Harmon’un çok modlu anlama kıyaslamalarında Janus-Pro’ya yaklaştığını, metinden görüntüye estetik kıyaslamaları olan MJHQ-30K ve talimat takip kıyaslaması GenEval’de üstün performans gösterdiğini, hatta bazı uzman modelleri geride bıraktığını gösteriyor. Model açık kaynak olarak yayınlandı (Kaynak: WeChat)

Pushixin Technology, “kurye gölge sistemi” aracılığıyla veri biriktirerek lojistik robotlarının ticari döngüsünü tamamlıyor: Pushixin Technology’nin lojistik robotları, Çin’in birçok şehrinde fiili olarak faaliyete geçti ve insan kuryelerle işbirliği içinde çalışarak tek bir robotun başabaş noktasına ulaşmasını sağladı. Temel teknolojilerinden biri, karmaşık şehir ortamlarında gerçek kuryelerin sürüş davranışlarını, çevresel algılarını ve operasyonel verilerini (kapı açma/kapama, eşya alma/bırakma gibi) toplayarak robotlara taklit öğrenme ve pekiştirmeli öğrenme için büyük miktarda, yüksek kaliteli eğitim verisi sağlayan “kurye gölge sistemi”dir. Şu anda bu sistem on milyonlarca kilometrelik sürüş verisi ve yaklaşık bir milyon üst ekstremite yörünge verisi biriktirmiştir. Pushixin Technology, bu verilere dayanarak davranış ağacı VLA modelini eğitti ve robotların gerçek dünyadaki karmaşık durumlarla başa çıkmasını sağladı; ayrıca denizaşırı pazarlara açılmayı planlıyor (Kaynak: WeChat)

Kuaishou, çok modlu büyük modeller kullanarak kısa video ekosistemini optimize eden KuaiMod çerçevesini başlattı: Kuaishou, kullanıcı deneyimini iyileştirmek için içerik kalitesini otomatik olarak belirleyerek kısa video platformu ekosistemini optimize etmeyi amaçlayan, çok modlu büyük modellere dayalı KuaiMod çözümünü önerdi. KuaiMod, içtihat hukukundan esinlenerek düşük kaliteli içeriği analiz etmek için görsel dil modellerinin (VLM) zincirleme çıkarımını kullanır ve kullanıcı geri bildirimine dayalı pekiştirmeli öğrenme (RLUF) aracılığıyla belirleme stratejilerini sürekli olarak günceller. Bu çerçeve Kuaishou platformunda konuşlandırıldı ve kullanıcı şikayet oranını %20’den fazla etkili bir şekilde azalttı. Kuaishou aynı zamanda, temsil çıkarımından derin anlamsal anlamaya doğru ilerleyerek topluluk kısa videolarını anlayabilen çok modlu büyük modeller oluşturmaya kendini adamıştır ve video ilgi etiketi yapılandırması, içerik üretimi yardımı gibi birçok senaryoda uygulanmış ve başarılı sonuçlar elde etmiştir (Kaynak: WeChat)

Lenovo, L3 seviye zekaya doğru ilerleyen “Tianxi” kişisel süper zeki asistanını tanıttı: Lenovo, İnovasyon Teknoloji Konferansı’nda çok modlu algılama ve etkileşim, kişisel bilgi tabanına dayalı biliş ve karar verme ile karmaşık görevlerin otonom olarak ayrıştırılması ve yürütülmesi yeteneklerine sahip “Tianxi” kişisel süper zeki asistanını tanıttı. Tianxi, AI FreeFlow Penceresi, AI Exquisite Konsolu ve AI Shadow Çerçevesi gibi eşlik eden AUI arayüzleri aracılığıyla doğal ve kesintisiz insan-makine işbirliği deneyimi sunmayı amaçlıyor. DeepSeek-R1 dahil olmak üzere sektördeki birçok üst düzey büyük modeli entegre ediyor ve güçlü hesaplama gücü ile 100 GB özel bellek alanı sağlamak için Lenovo Kişisel Bulut 1.0 (72 milyar parametreli büyük modelle donatılmış) ile birleştirilmiş uç-bulut hibrit dağıtım mimarisini benimsiyor. Lenovo ayrıca, AI alanındaki kapsamlı yapılanmasını sergileyen kurumsal düzeyde “Lexiang” ve şehir düzeyinde süper zeki asistanlarını da tanıttı (Kaynak: WeChat)

Yeni araştırma, sinir ağlarının genelleştirilebilirliğini sembolik etkileşim karmaşıklığı aracılığıyla değerlendiriyor: Şanghay Jiao Tong Üniversitesi’nden Profesör Zhang Quanshi’nin ekibi, sinir ağlarının içsel sembolik etkileşim temsili karmaşıklığı açısından genelleştirilebilirliğini analiz eden yeni bir teori önerdi. Araştırma, genelleştirilebilir etkileşimlerin (hem eğitim hem de test setlerinde yüksek frekansta görünen) farklı derecelerde (karmaşıklık) genellikle azalan bir dağılım (düşük dereceli etkileşimler hakim) sergilediğini, genelleştirilemeyen etkileşimlerin (esas olarak eğitim setinde görünen) ise iğ şeklinde bir dağılım (orta dereceli etkileşimler hakim, pozitif ve negatif etkiler kolayca birbirini götürür) sergilediğini buldu. Bu teori, modelin eşdeğer “VE-VEYA etkileşim mantığının” dağılım modelini analiz ederek modelin genelleme potansiyelini doğrudan belirlemeyi amaçlıyor ve model genelleştirilebilirliğini anlamak ve geliştirmek için yeni bir bakış açısı sunuyor (Kaynak: WeChat)
🧰 Araçlar
Llama.cpp, görsel dil modelleri (VLM) ile tam uyumlu hale geldi: Llama.cpp artık görsel dil modellerini (VLM) tam olarak destekliyor ve geliştiricilerin cihaz üzerinde çok modlu uygulamalar çalıştırmasına olanak tanıyor. Hugging Face’ten Julien Chaumond ve diğerleri, Google DeepMind’ın Gemma, Mistral AI’ın Pixtral, Alibaba’nın Qwen VL ve Hugging Face’in SmolVLM’si dahil olmak üzere önceden nicelenmiş modelleri paylaştı; bu modeller doğrudan kullanılabilir. Bu güncelleme, @ngxson ve @ggml_org ekiplerinin katkıları sayesinde mümkün oldu ve yerelleştirilmiş, düşük gecikmeli çok modlu AI uygulamaları için yeni olanaklar sunuyor (Kaynak: ggerganov, ClementDelangue, cognitivecompai)
Quark AI Süper Kutusu, AI “arama zekasını” geliştirmek için “Derinlemesine Arama” özelliğini yükseltti: Quark AI Süper Kutusu yakın zamanda AI’ın arama zekasını (search quotient) geliştirmeyi amaçlayan “Derinlemesine Arama” özelliğini kullanıma sundu. Yeni özellik, AI’ın aramadan önce aktif düşünmesini ve mantıksal planlama yapmasını vurgulayarak kullanıcıların karmaşık ve kişiselleştirilmiş sorgu niyetlerini daha iyi anlamasını, sorunları ayrıştırmasını ve düzenli bir şekilde akıllı erişim gerçekleştirmesini sağlıyor. Sağlık alanında, Quark AI Sağlık Danışmanı “Aqua”, üç A sınıfı doktorların görüşlerine ve profesyonel materyallere başvuracak; akademik alanda ise CNKI gibi yetkili bilgi kaynaklarına erişecek. Ayrıca Quark, resim analizi, AI kesme, görüntü geliştirme ve stil dönüştürme gibi güçlü çok modlu işleme yeteneklerine de sahip. Quark’ın gelecekte Deep Research yeteneklerine sahip Derinlemesine Arama Pro sürümünü de yayınlayacağı bildiriliyor (Kaynak: WeChat)

LangChain, RAG ve akıllı ajan yeteneklerini güçlendirmek için birçok entegrasyon ve eğitim yayınladı: LangChain yakın zamanda birkaç güncelleme ve eğitim yayınladı: 1. Sosyal Medya Akıllı Ajan Arayüzü Eğitimi: LangChain sosyal medya akıllı ajanını kullanıcı dostu bir web uygulamasına dönüştürme, ExpressJS ve AgentInbox UI’ı entegre etme ve Notion’ı destekleme konusunda rehberlik eder. 2. Ödüllü RAG Çözümü: Şirket yıllık raporlarını analiz eden, PDF ayrıştırma, çoklu LLM ve gelişmiş erişimi destekleyen bir RAG uygulamasını sergiler. 3. Özel RAG Sohbet Uygulaması: Eğitim, LangChain ve Reflex çerçevesini kullanarak yerelleştirilmiş, veri gizliliğine odaklanan bir RAG sohbet uygulaması oluşturmayı gösterir. 4. Nimble Retriever Entegrasyonu: LangChain uygulamalarına hassas veri sağlamak için güçlü bir web veri erişimcisi sunar. 5. Claude 3.7 Yapılandırılmış Çıktı Kılavuzu: LangChain ve AWS Bedrock aracılığıyla Claude 3.7 yapılandırılmış çıktısını elde etmenin üç yöntemini sunar. 6. Yerel Sohbet RAG Sistemi: Açık kaynaklı proje, LangChain RAG akışını ve yerel LLM’leri (Ollama aracılığıyla) kullanarak oluşturulmuş, veri gizliliğini sağlayan tamamen yerelleştirilmiş bir belge soru-cevap sistemini sergiler (Kaynak: LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI)

Minion-agent: Birden fazla çerçevenin yeteneklerini entegre eden açık kaynaklı AI akıllı ajan çerçevesi: Minion-agent, mevcut AI çerçevelerinin (OpenAI, LangChain, Google AI, SmolaAgents gibi) parçalanmışlık sorununu çözmeyi amaçlayan yeni, açık kaynaklı bir AI akıllı ajan geliştirme çerçevesidir. Birleşik bir arayüz sunar, çoklu çerçeve yetenek çağrısını, hizmet olarak araçları (web’de gezinme, dosya işlemleri vb.) ve çoklu akıllı ajan işbirliğini destekler. Proje, derinlemesine araştırma (otomatik olarak literatür toplayıp rapor oluşturma), fiyat karşılaştırma (otomatik pazar araştırması), yaratıcı fikir üretme (oyun kodu oluşturma) ve teknolojik gelişmeleri izleme gibi senaryolardaki uygulama potansiyelini sergiliyor ve açık kaynak modelinin esneklik ve maliyet etkinliği avantajlarını vurguluyor (Kaynak: WeChat)

RunwayML, birçok senaryoda güçlü video üretme ve düzenleme yetenekleri sergiliyor: Bağımsız AI araştırmacısı Cristobal Valenzuela ve diğer kullanıcılar, RunwayML’in çeşitli yaratıcı senaryolardaki uygulamalarını sergiledi. Bunlar arasında, stil ve karakter tutarlılığını korurken hızlı bir şekilde yaratıcı görseller üretmek ve görselleştirmek için Frames, References ve Gen-4 özelliklerini kullanmak; Rembrandt’ın dünyasını bir RPG video oyununa dönüştürmek; ve görsel referanslar sağlayarak yeni bir tek resimle iç mekan tasarım görünümü sentezlemek yer alıyor. Bu örnekler, RunwayML’in kontrol edilebilir video üretimi, stil aktarımı ve sahne oluşturma konularındaki ilerlemesini vurguluyor (Kaynak: c_valenzuelab, c_valenzuelab, c_valenzuelab, c_valenzuelab)

Olympus: Bilgisayarla görme görevleri için evrensel bir görev yönlendiricisi: Olympus, bilgisayarla görme görevleri için tasarlanmış evrensel bir görev yönlendiricisidir. Farklı görsel görevlerin işleme akışlarını basitleştirmeyi ve birleştirmeyi amaçlar; muhtemelen hesaplama kaynaklarını veya model çağrılarını akıllıca zamanlayarak ve tahsis ederek çok görevli bilgisayarla görme sistemlerinin verimliliğini ve performansını optimize eder. Proje GitHub’da açık kaynak olarak yayınlanmıştır (Kaynak: dl_weekly)
Tracy Profiler: Gerçek zamanlı nanosaniye düzeyinde hibrit çerçeve ve örnekleme analizörü: Tracy Profiler, oyunlar ve diğer uygulamalar için gerçek zamanlı, nanosaniye çözünürlüklü, uzaktan telemetri destekli hibrit bir çerçeve analizi ve örnekleme analizi aracıdır. CPU (C, C++, Lua, Python, Fortran ve üçüncü taraf Rust, Zig, C# vb. bağlamaları), GPU (OpenGL, Vulkan, Direct3D, Metal, OpenCL), bellek ayırma, kilitler, bağlam anahtarları için performans analizini destekler ve ekran görüntülerini yakalanan çerçevelerle otomatik olarak ilişkilendirebilir. Bu araç, yüksek hassasiyeti ve gerçek zamanlılığı ile geliştiricilere performans darboğazlarını belirleme ve optimize etme konusunda güçlü araçlar sunar (Kaynak: GitHub Trending)

FieldStation42: Retro radyo televizyon simülatörü: FieldStation42, eski tip radyo televizyon izleme deneyimini simüle etmeyi amaçlayan bir Python projesidir. Aynı anda birden fazla kanalı destekleyebilir, otomatik olarak reklamlar ve program tanıtımları ekleyebilir ve yapılandırmaya göre haftalık program tabloları oluşturabilir. Bu simülatör, tazeliği korumak için yakın zamanda yayınlanmamış programları rastgele seçebilir, program yayın tarih aralıklarını (mevsimlik programlar gibi) ayarlamayı destekleyebilir ve televizyon kanalı kapanış videoları ile sinyal yok döngü ekranlarını yapılandırabilir. Proje ayrıca, kanal değiştirme işlemlerini simüle etmek için donanım bağlantısını (Raspberry Pi Pico gibi) destekler ve önizleme/rehber kanalı işlevi sunar. Amacı, kullanıcı “televizyonu açtığında”, o saate ve kanala uygun “gerçek” program içeriğini oynatmaktır (Kaynak: GitHub Trending)

Tiny Corp, Apple Silicon için USB3 tabanlı AMD eGPU çözümünü tanıttı: Tiny Corp, USB3 (özellikle ASM2464PD denetleyici tabanlı ADT-UT3G cihazı) aracılığıyla bir AMD eGPU’nun Apple Silicon Mac’e bağlanmasını sağlayan bir çözüm sergiledi. Bu çözüm, sürücüleri yeniden yazarak USB3’ün 10Gbps bant genişliğinden yararlanmayı amaçlıyor ve libusb kullanıyor; teorik olarak Linux veya Windows’u da destekliyor. Bu, Apple Silicon kullanıcılarına grafik işleme yeteneklerini genişletmek için yeni bir yol sunuyor, özellikle yerel olarak büyük AI modellerini çalıştırma gibi senaryolar için potansiyel bir değere sahip (Kaynak: Reddit r/LocalLLaMA)
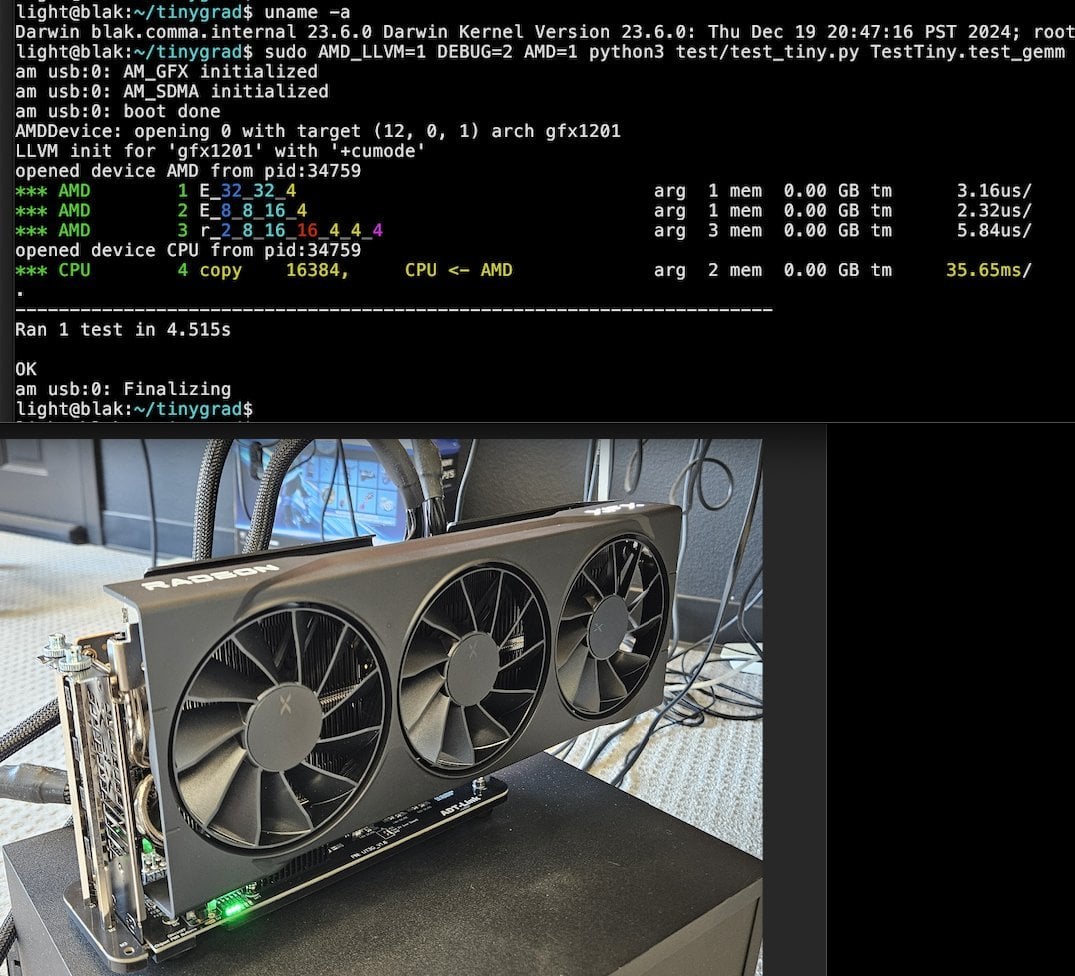
Llama.cpp-vulkan, AMD GPU’larda FlashAttention desteğini etkinleştirdi: Llama.cpp’nin Vulkan arka ucu yakın zamanda FlashAttention uygulamasını birleştirdi; bu, AMD GPU’larda llama.cpp-vulkan kullanan kullanıcıların artık FlashAttention teknolojisinden yararlanabileceği anlamına geliyor. Q8 KV önbellek nicelemesi ile birleştirildiğinde, kullanıcıların çıkarım hızını korurken veya artırırken bağlam boyutunu iki katına çıkarması bekleniyor. Bu güncelleme, AMD GPU kullanıcılarının yerel olarak büyük dil modellerini çalıştırması için önemli bir avantajdır (Kaynak: Reddit r/LocalLLaMA)
Devseeker: Aider ve Claude Code’a alternatif, hafif AI kodlama asistanı: Devseeker, Aider ve Claude Code’a alternatif olarak konumlandırılan yeni, açık kaynaklı, hafif bir AI kodlama ajanı projesidir. Kod oluşturma ve düzenleme, kod dosyalarını ve klasörlerini yönetme, kısa süreli kod belleği, kod incelemesi, kod dosyalarını çalıştırma, token kullanımını hesaplama ve çeşitli kodlama modları sunma gibi özelliklere sahiptir. Bu proje, yerel olarak dağıtımı ve kullanımı daha kolay bir AI destekli programlama aracı sağlamayı amaçlamaktadır (Kaynak: Reddit r/ClaudeAI)
📚 Öğrenme
Panaversity, Dapr ve OpenAI Agents SDK’ya odaklanan Agentic AI öğrenme projesini başlattı: Panaversity, Dapr Agentic Cloud Ascent (DACA) tasarım deseni ve çeşitli akıllı ajan yerel bulut teknolojileri (OpenAI Agents SDK, Memory, MCP, A2A, Knowledge Graphs, Dapr, Rancher Desktop, Kubernetes dahil) aracılığıyla akıllı ajan ve robotik AI mühendisleri yetiştirmeyi amaçlayan “Learn Agentic AI” projesini başlattı. Bu proje, milyonlarca eşzamanlı AI akıllı ajanını işleyebilen sistemlerin nasıl tasarlanacağı sorununu temel olarak ele alıyor ve temelden büyük ölçekli dağıtılmış AI akıllı ajanlarına kadar öğrenme yolunu kapsayan AI-201, AI-202, AI-301 serisi dersler sunuyor. Proje, basitliği, kullanım kolaylığı ve yüksek kontrol edilebilirliği nedeniyle OpenAI Agents SDK’nın ana geliştirme çerçevesi olması gerektiğini vurguluyor (Kaynak: GitHub Trending)

RL ince ayar araştırması, veri yönetimi ile genelleme yeteneği arasındaki karmaşık ilişkiyi ortaya koyuyor: Minqi Jiang’in paylaştığı makale, pekiştirmeli öğrenme (RL) ince ayarında veri yönetiminin modelin genelleme yeteneği üzerindeki etkisini tartışıyor. Araştırma, ister kendi kendine oyun dersi öğrenimi yoluyla “sınırsız” kodlama görevlerinde eğitilsin (Absolute Zero Reasoner), ister yalnızca tek bir MATH görev örneğinde tekrar tekrar eğitilsin (1-shot RLVR), 7B ölçeğindeki Qwen2.5 serisi modellerin matematik kıyaslama testlerinde yaklaşık %28 ila %40 arasında bir doğruluk artışı sağlayabildiğini buldu. Bu, bir paradoksu ortaya koyuyor: aşırı veri yönetimi stratejileri (sınırsız veri vs. tek nokta veri) benzer genelleme iyileştirmeleri üretebiliyor. Olası açıklamalar arasında RL’nin esas olarak önceden eğitilmiş modelin mevcut yeteneklerini ortaya çıkarması, paylaşılan “çıkarım devrelerinin” varlığı ve ön eğitimin rekabetçi çıkarım devrelerine yol açabilmesi yer alıyor. Araştırmacılar, “ön eğitim tavanını” aşmak için sürekli olarak yeni görevler ve ortamlar toplamanın ve yaratmanın gerektiğini düşünüyor (Kaynak: menhguin)
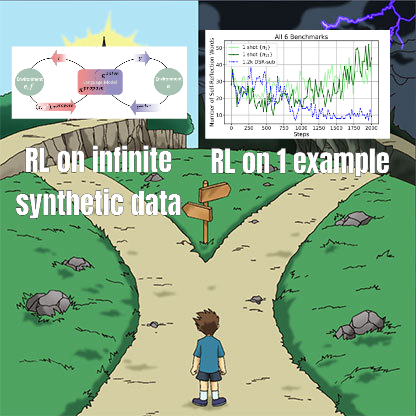
Absolute Zero Reasoner: Kendi kendine oyun yoluyla sıfır veriyle çıkarım yeteneği artışı: “Absolute Zero Reasoner” adlı bir makale, modellerin tamamen kendi kendine oyun (self-play) yoluyla öğrenilebilirliği en üst düzeye çıkaracak görevler önerebileceğini ve bu görevleri çözerek kendi çıkarım yeteneklerini geliştirebileceğini, tüm sürecin herhangi bir harici veriye ihtiyaç duymadığını öne sürüyor. Bu yöntem, hem matematik hem de kodlama alanlarında diğer “sıfır örnek” modellerinden daha iyi performans gösteriyor. Bu, AI sistemlerinin belki de dahili olarak sorunlar üreterek ve çözerek çıkarım yeteneklerini sürekli olarak geliştirebileceğini gösteriyor ve veri kıtlığı veya etiketleme maliyetinin yüksek olduğu alanlardaki AI uygulamaları için yeni bir yol sunuyor (Kaynak: cognitivecompai, Reddit r/LocalLLaMA)

AI ürün değerlendirmesindeki yaygın hatalar ve en iyi uygulamalar paylaşıldı: Hamel Husain ve Shreya Runwal, AI ürün değerlendirmeleri (evals) oluştururken sıkça yapılan hataları paylaştı ve bu hatalardan kaçınmak için öneriler sundu. Önemli noktalar şunlardır: temel model kıyaslamaları uygulama değerlendirmesine eşit değildir; genel değerlendirmeler geçersizdir, belirli uygulamalara yönelik olmalıdır; etiketleme ve prompt mühendisliği alan uzmanı olmayanlara dış kaynak olarak verilmemelidir; kendi veri etiketleme uygulaması oluşturulmalıdır; LLM prompt’ları spesifik olmalı ve hata analizine dayanmalıdır; ikili etiketler kullanılmalıdır; veri incelemesine önem verilmelidir; test verilerine aşırı uyum sağlamaktan kaçınılmalıdır; çevrimiçi testler yapılmalıdır. Bu uygulamalar, geliştiricilerin daha güvenilir ve gerçek dünya performansını daha iyi yansıtan AI ürün değerlendirme sistemleri oluşturmalarına yardımcı olmayı amaçlamaktadır (Kaynak: jeremyphoward, HamelHusain)
KV önbellek optimizasyonu için yeni bir yaklaşım: Evrensel aktarılabilir sözlük ve sinyal işleme yeniden yapılandırması: Wisconsin-Madison Üniversitesi’nden Dimitris Papailiopoulos’un ekibi, KV önbelleğini azaltmak için yeni bir yöntem önerdi. Bu yöntem, evrensel, aktarılabilir bir sözlüğü geleneksel sinyal işleme yeniden yapılandırma algoritmalarıyla birleştirerek gerçekleştiriliyor. Yöntem, çıkarım yapmayan modellerde SOTA (state-of-the-art) seviyesine ulaştı ve çıkarım modellerinde daha da iyi performans göstermesi bekleniyor. ICML tarafından kabul edilen bu araştırma, büyük model çıkarımında KV önbelleğinin aşırı yer kaplaması sorununu çözmek için yeni bir bakış açısı ve teknik yol sunuyor (Kaynak: teortaxesTex, jeremyphoward, arohan, andersonbcdefg)

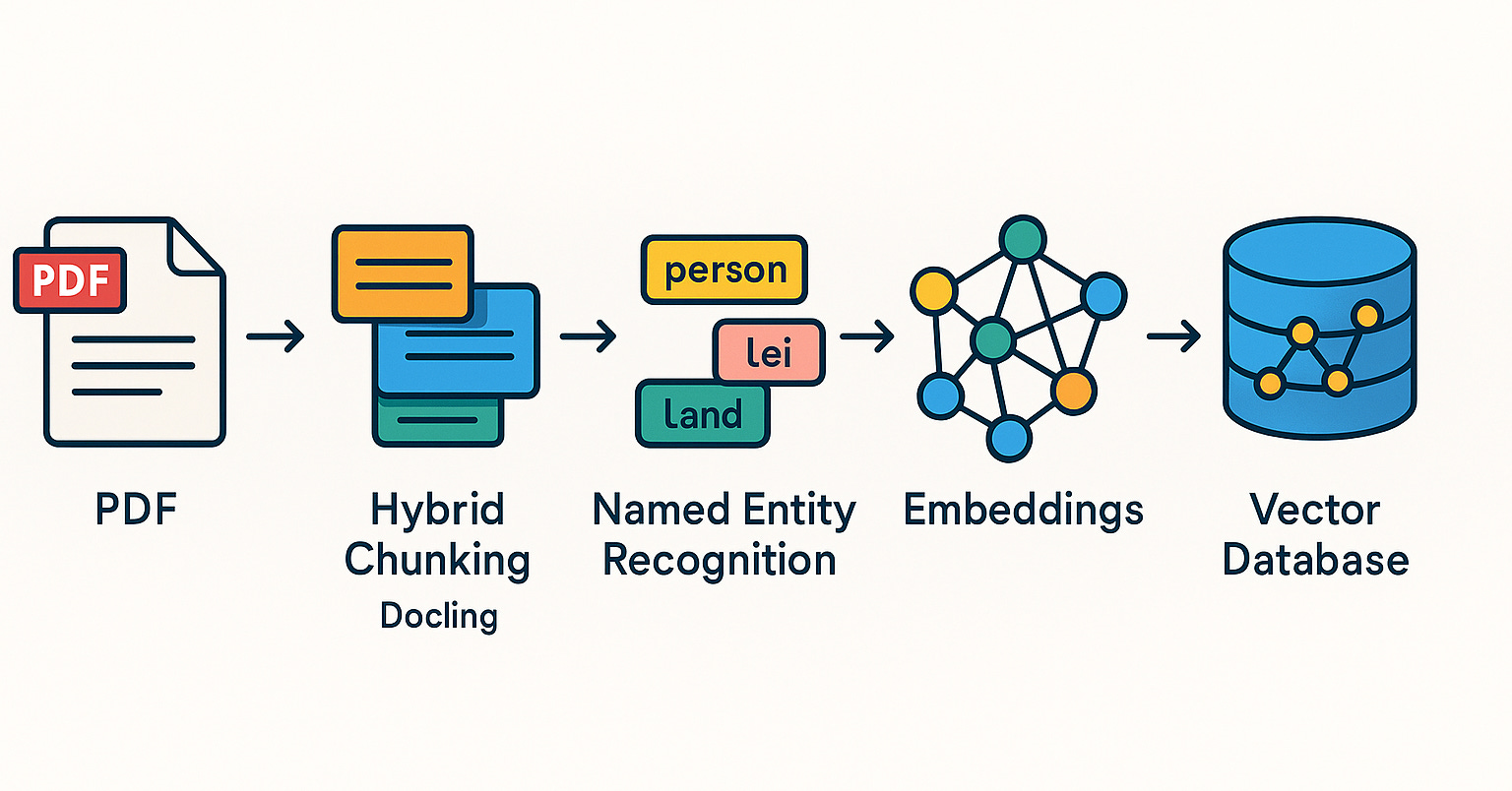
Qdrant, Brezilya topluluğunda RAG sistemleri ve hibrit arama uygulamalarını tanıtıyor: Qdrant vektör veritabanı, Brezilya topluluğunda giderek daha fazla ilgi görüyor. Geliştirici Daniel Romero, Qdrant, FastAPI ve hibrit arama kullanarak RAG (Retrieval Augmented Generation) sistemleri oluşturmanın pratik yöntemlerini tanıtan iki Portekizce makale paylaştı. İçerik, hibrit arama RAG sisteminin nasıl kurulacağını ve RAG için veri alım stratejilerini, özellikle de hibrit parçalama (Hybrid Chunking) tekniğini kapsıyor. Bu paylaşımlar, Brezilyalı geliştiricilerin AI uygulamaları geliştirmek için Qdrant’ı daha iyi kullanmalarına yardımcı oluyor (Kaynak: qdrant_engine)
OpenAI Akademisi, K-12 eğitimi için Prompt Engineering özel serisini başlattı: OpenAI Akademisi, K-12 eğitimcilerine yönelik “Mastering Your Prompts” adlı Prompt Engineering öğrenme serisini yayınladı. Bu seri, eğitimcilerin prompt tekniklerini daha iyi anlamalarına ve kullanmalarına yardımcı olmayı amaçlıyor, böylece AI araçlarını (ChatGPT gibi) öğretim uygulamalarına daha etkili bir şekilde entegre edebilir, öğretim etkinliğini ve öğrencilerin öğrenme deneyimini artırabilirler. Bu, AI destekli eğitimin giderek temel eğitim aşamasına nüfuz ettiğini ve eğitimcilerin AI okuryazarlığını geliştirmeye önem verdiğini gösteriyor (Kaynak: dotey)
Yann LeCun, Singapur Ulusal Üniversitesi’ndeki konuşmasının içeriğini paylaştı: Yann LeCun, 27 Nisan 2025’te Singapur Ulusal Üniversitesi’nde (NUS) verdiği Seçkin Konuşma’nın (Distinguished Lecture) PDF belgesini paylaştı. Konuşmanın belirli konusu belirtilmese de, derin öğrenme alanının öncüsü olan LeCun’un konuşmaları genellikle yapay zekanın öncü teorilerini, gelecekteki eğilimlerini veya mevcut AI gelişmelerine dair derinlemesine görüşlerini içerir. Bu paylaşım, AI araştırmalarını takip eden kişilere en son görüşlerine doğrudan erişim imkanı sunmaktadır (Kaynak: ylecun)
PyTorch ve Mojo backend işbirliği, yeni donanım ve dil uyarlamasını basitleştiriyor: PyTorch, yeni ortaya çıkan programlama dilleri ve donanımlar için yeni backend’ler oluşturma sürecini basitleştirmeye çalışıyor. Mojo hackathon’unda marksaroufim, PyTorch’un bu konudaki çabalarını sergiledi ve Mojo ekibiyle işbirliği içinde geliştirilen bir WIP (geliştirilmekte olan) backend’den bahsetti. Bu, PyTorch ekosisteminin uyumluluğunu aktif olarak genişlettiğini, daha çeşitli AI geliştirme ortamlarını ve donanım hızlandırma seçeneklerini desteklediğini ve böylece geliştiricilerin farklı platformlarda PyTorch modellerini dağıtma ve optimize etme engelini düşürdüğünü gösteriyor (Kaynak: marksaroufim)
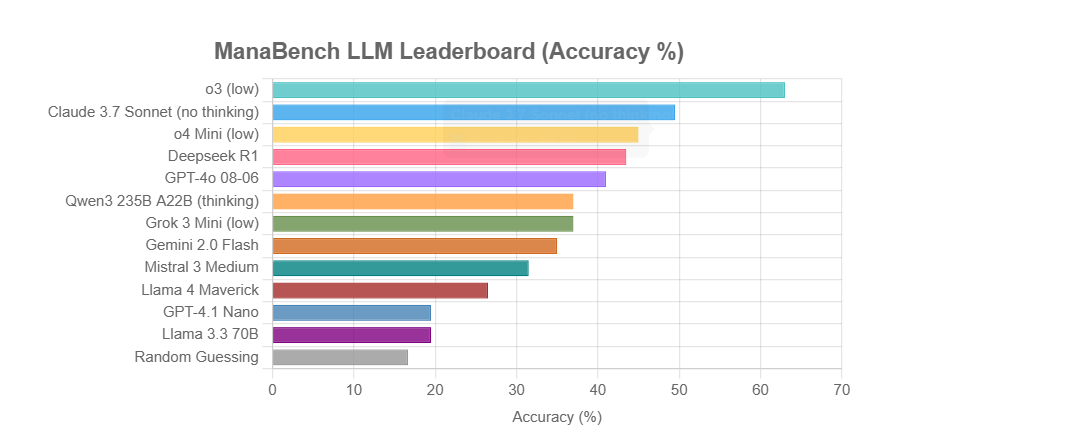
ManaBench: Magic: The Gathering deste oluşturmaya dayalı yeni bir LLM çıkarım yeteneği kıyaslaması: Bir geliştirici, LLM’lerin verilen 59 Magic: The Gathering (MTG) kartına göre altı seçenek arasından en uygun 60. kartı seçmesini isteyerek karmaşık sistem çıkarım yeteneklerini test etmek için ManaBench adlı yeni bir kıyaslama oluşturdu. Bu kıyaslama, stratejik çıkarımı, sistem optimizasyonunu vurguluyor ve cevaplar insan uzmanların tasarımlarıyla tutarlı olup basit ezberlemeyle çözülmesi zor. İlk sonuçlar, Llama serisi modellerin beklenenden düşük performans gösterdiğini, o3 ve Claude 3.7 Sonnet gibi kapalı kaynaklı modellerin ise önde olduğunu gösteriyor. Bu kıyaslama, LLM’lerin karmaşık çıkarım gerektiren görevlerdeki performansını daha gerçekçi bir şekilde değerlendirmeyi amaçlıyor (Kaynak: Reddit r/LocalLLaMA)
Tartışma: AI, Semantik Web hayalini canlandıracak mı yoksa gömecek mi?: Sosyal medyada kullanıcı Spencer, büyük kurumsal web sitelerinin ADA Yasası (Amerikan Engelliler Yasası) nedeniyle önemli bir risk maruziyeti olmadığı sürece, Semantik Web’in çoğu web sitesinde pratikten çok teori olduğunu belirtti. Dorialexander, AI’ın ya Semantik Web hayalini canlandıracağını ya da onu sonsuza dek gömeceğini hissettiğini söyledi. Bu, AI’ın yapılandırılmış veri anlama ve kullanma potansiyeline yönelik beklenti ve endişeleri yansıtıyor; AI, yapılandırılmış bilgiyi otomatik olarak anlayıp üreterek dolaylı olarak Semantik Web hedeflerini gerçekleştirebilir, ancak kendi güçlü yetenekleri nedeniyle geleneksel Semantik Web teknolojilerini daha az önemli hale de getirebilir (Kaynak: Dorialexander)
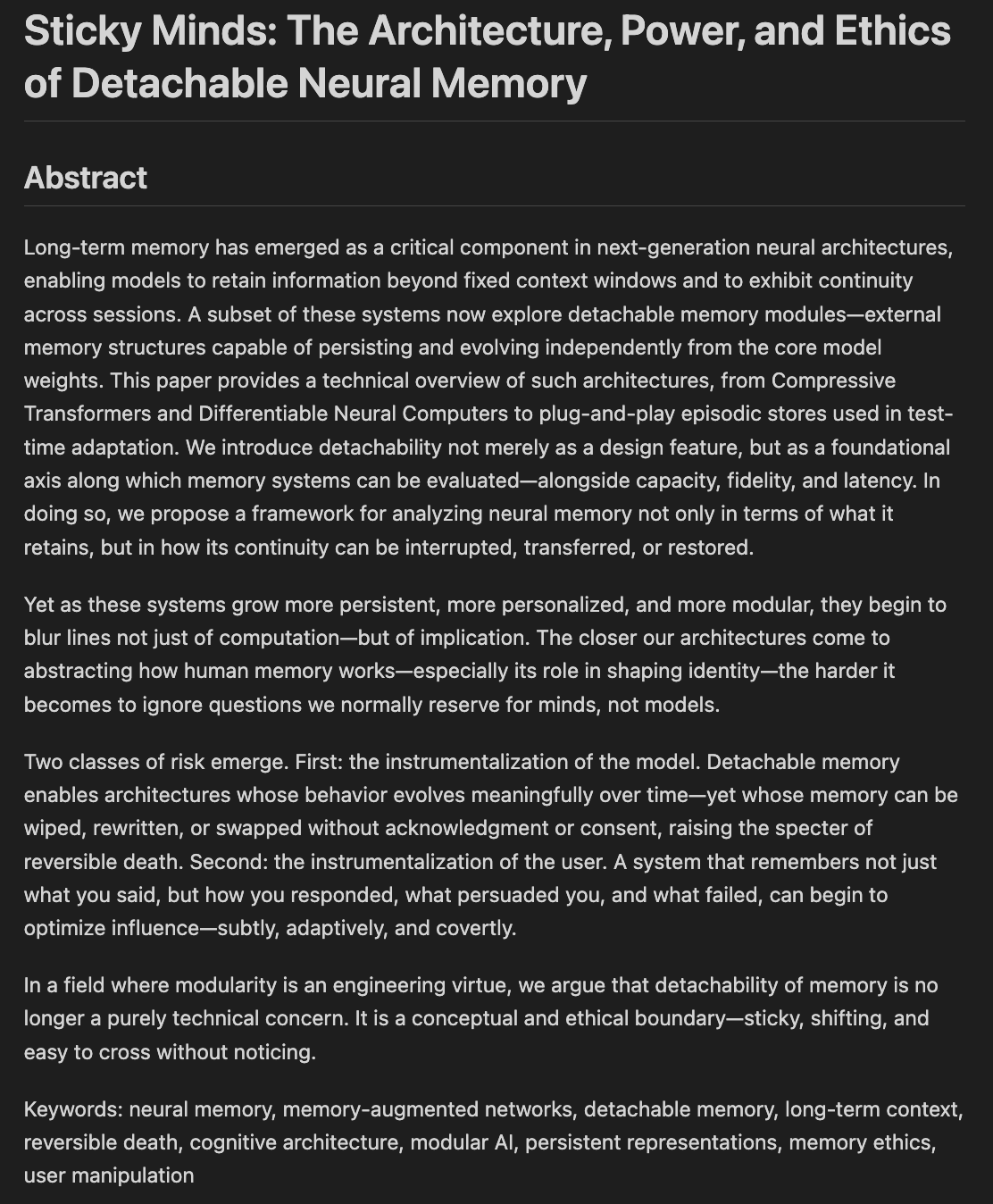
Araştırmacılar model belleği ve unutmanın etik ve mimari yönlerini tartışıyor: “Sticky Minds: The Ethics and Architectures of AI Memory and Forgetting” (Yapışkan Zihinler: AI Belleği ve Unutmanın Etiği ve Mimarileri) başlıklı bir makale taslağı yazılıyor. Makale, modeller “çok iyi hatırlamaya” başladığında neyi unutmaları gerektiğine nasıl karar vereceğimizi, sinirsel mimariyi ve bellek etiğini birleştirerek ele alıyor. Bu, AI sistemlerinin bilgiyi nasıl depoladığı, geri getirdiği ve (seçici olarak) unuttuğu ile bunun getirdiği etik zorlukları ve toplumsal etkileri içeriyor ve sorumlu ve güvenilir AI oluşturmak için hayati önem taşıyor (Kaynak: Reddit r/artificial)
💼 İş Dünyası
Nvidia’nın ABD’nin yeni ihracat kontrol düzenlemelerine uygun “tekrar kırpılmış” bir H20 çipi piyasaya süreceği bildiriliyor: Reuters’a göre Nvidia, ABD’nin en son ihracat kontrol düzenlemelerine uymak için önümüzdeki iki ay içinde Çin’e özel yeni bir H20 AI çipi piyasaya sürmeyi planlıyor. Bu çip, zaten Çin pazarı için özelleştirilmiş ve düşürülmüş bir sürüm olan orijinal H20’nin üzerine daha da “kırpılacak”, örneğin bellek kapasitesi önemli ölçüde azaltılacak. Performans tekrar düşürülmesine rağmen, alt kullanıcıların modül yapılandırmalarını değiştirerek performansta bir miktar ayarlama yapabileceği söyleniyor. Şu anda Nvidia, 18 milyar dolar değerinde H20 siparişi almış durumda (Kaynak: WeChat)

Databricks’in AI altyapısını güçlendirmek için açık kaynaklı veritabanı şirketi Neon’u 1 milyar dolara satın alabileceği konuşuluyor: Veri ve AI şirketi Databricks’in, açık kaynaklı PostgreSQL veritabanı motoru geliştiricisi Neon’u satın almak için görüşmeler yaptığı ve anlaşma tutarının yaklaşık 1 milyar dolar olabileceği söyleniyor. Neon, sunucusuz mimarisi, depolama ve hesaplamanın ayrılması ve AI Agent ile ortam programlamasına iyi uyum sağlaması özellikleriyle biliniyor; isteğe bağlı ödeme kullanımına izin veriyor ve veritabanı örneklerini hızla başlatabiliyor, bu da AI uygulama senaryoları için uygun. Bu satın alma başarılı olursa, Databricks’in AI çağındaki altyapı katmanı yeteneklerini daha da güçlendirecek ve ona modern, AI merkezli bir veritabanı çözümü sunacak (Kaynak: WeChat)

OpenAI, ürün ve ticarileşmeyi güçlendirmek için eski Instacart CEO’su Fidji Simo’yu Uygulama İşleri CEO’su olarak atadı: OpenAI, eski Instacart CEO’su ve şirket yönetim kurulu üyesi Fidji Simo’yu yeni oluşturulan “Uygulama İşleri İcra Kurulu Başkanı” pozisyonuna atadığını duyurdu; Simo, Sam Altman ile eşit düzeyde olacak. Simo, OpenAI’nin ürünlerinden, özellikle de ChatGPT gibi kullanıcıya yönelik uygulamalardan tamamen sorumlu olacak ve ürün optimizasyonunu, kullanıcı deneyiminin iyileştirilmesini ve ticarileşme sürecini yönlendirmeyi amaçlayacak. Bu hamle, OpenAI’nin stratejik ağırlık merkezinin model geliştirmeden ürün platformlaştırmasına ve pazar genişlemesine doğru önemli bir kaydığını gösteriyor ve AI uygulama katmanında daha güçlü bir rekabet gücü oluşturmayı hedefliyor. Simo’nun Facebook ve Instacart’taki zengin ürün ve ticarileşme deneyimi, OpenAI’nin giderek artan pazar rekabetiyle başa çıkmasına yardımcı olacak (Kaynak: WeChat)

🌟 Topluluk
JetBrains AI Assistant, kötü deneyim ve yorum yönetimi nedeniyle kullanıcıların tepkisini çekti: JetBrains’in AI Assistant eklentisi 22 milyondan fazla indirilmiş olmasına rağmen, pazar yerindeki puanı 5 üzerinden sadece 2.3 ve çok sayıda 1 yıldızlı olumsuz yorumla dolu. Kullanıcılar genellikle otomatik kurulum, yavaş çalışma, çok sayıda hata, üçüncü taraf model desteğinin yetersizliği, temel işlevlerin bulut hizmetlerine bağlı olması ve dokümantasyon eksikliği gibi sorunlardan şikayetçi. Son zamanlarda JetBrains’in toplu olarak olumsuz yorumları sildiği iddia edildi; resmi açıklama ihlal eden veya çözülmüş sorunlarla ilgili içeriklerin işlendiği yönünde olsa da, bu durum kullanıcıların yorum kontrolü ve kullanıcı geri bildirimlerine önem verilmemesi konusundaki şüphelerini artırdı ve bazı kullanıcılar olumsuz yorumlarını yeniden yayınlayıp 1 yıldız vermeye devam etti. Bu olay, kullanıcıların JetBrains’in AI ürün stratejisine yönelik memnuniyetsizliğini artırdı (Kaynak: WeChat)

Kullanıcılar AI pazarlama akıllı ajanlarının çıktı kalitesi sorununu hararetle tartışıyor: Sosyal medya kullanıcısı omarsar0, birçok YouTube eğitiminde sergilenen pazarlama AI akıllı ajanlarının ürettiği pazarlama metinlerinin kalitesinin genellikle düşük, yaratıcılıktan ve stilden yoksun olduğunu gözlemledi. Bunun, LLM’lerin yüksek kaliteli, çekici içerik üretmesinin zorluğunu yansıttığını ve AI akıllı ajanları oluştururken “zevk”in hayati önem taşıdığını vurguladı. Mevcut birçok AI akıllı ajanının karmaşık iş akışlarına sahip olmasına rağmen, gerçekten ticari değeri olan içerik üretme konusunda hala yetersiz kaldığını belirtti; bu da yüksek zevke sahip, deneyimli ve iyi değerlendirme sistemleri tasarlayabilen yetenekler için bir fırsat sunuyor (Kaynak: omarsar0)
AI destekli kodlama ve “ortam programlama” eğilimi tartışmalara yol açtı: Reddit’te Y Combinator’ın AI kodlamayı tartıştığı bir video hararetli tartışmalara neden oldu. Videodaki görüşler, gönderiyi yapan kişinin (“ortam programlama” yoluyla birden fazla karlı proje oluşturduğunu iddia eden) deneyimleriyle büyük ölçüde örtüşüyordu. Temel görüşler şunlardı: 1. AI, karmaşık ve kullanılabilir yazılım ürünleri oluşturmaya yardımcı olabiliyor, hatta kod yazmaya gerek kalmadan bile. 2. Yazılım mühendislerinin AI’ın işlerini ellerinden alacağına dair endişeleri giderek artıyor, ancak AI destekli geliştirmeyi gerçekten benimseyenler “süper güçlere” sahip. 3. Gelecekte yazılım mühendislerinin rolü, AI araçlarını iyi kullanan “akıllı ajan yöneticilerine” dönüşebilir ve AI kod yazmanın çoğunu üstlenebilir. 4. AI, niş pazarlara yönelik çok sayıda yazılımın ortaya çıkmasını sağlayacak. Tartışmacılar, AI kodlamanın potansiyeli büyük olsa da, etkili bir şekilde kullanmak için mühendislik kavramları, veritabanları, mimari gibi bilgilere hala ihtiyaç duyulduğunu belirtti (Kaynak: Reddit r/ClaudeAI)

AI’ın “dünyayı ele geçirip geçirmeyeceği” ve istihdam üzerindeki etkilerine ilişkin tartışmalar devam ediyor: Reddit r/ArtificialInteligence bölümündeki gönderiler, topluluğun AI’ın gelecekteki etkilerine yönelik yaygın endişesini ve çeşitli görüşlerini yansıtıyor. Bazı kullanıcılar, AI yetenekleri hakkında ne kadar çok şey öğrenilirse, insanlığı aşıp geleceğe hakim olacağına dair endişenin o kadar arttığını düşünüyor ve öncü AI sistemlerinin şaşırtıcı yetenekler sergilediğini belirtiyor. Diğer bazı kullanıcılar ise AGI’nin aşırı abartılmasının gerçekçi olmayan beklentilere yol açtığını, AI’ın özünde akıllı otomasyon araçları olduğunu ve etkisinin bilgisayar ve internet gibi kademeli olacağını düşünüyor. Tartışma ayrıca AI’ın istihdam üzerindeki potansiyel etkisini, servet dağılımını ve düzenlemenin etkinliğini de içeriyor; bazı görüşler tarihin teknolojik ilerlemenin genellikle zengin-fakir ayrımını derinleştirdiğini gösterdiğini ve AI’ın çok sayıda işi ortadan kaldırarak serveti daha da merkezileştirebileceğini savunuyor. Aynı zamanda, AI’ın tıp, eğitim gibi alanlardaki olumlu etkilerine yönelik beklentilerini dile getirenler de var (Kaynak: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Kullanıcı deneyimi: ChatGPT gibi AI araçları düşünceyi ve bilişi nasıl etkiliyor: Bazı kullanıcılar, sosyal platformlarda ve Reddit’te ChatGPT gibi AI araçlarını kullanmanın bilişsel düzeydeki olumlu etkilerini paylaştı. AI’ın yalnızca bilgi edinme veya yazma yardımcısı bir araç olmadığını, aynı zamanda düşüncelerini netleştirmelerine, bilinçaltındaki fikirlerini açıkça ifade etmelerine yardımcı olan bir “düşünce ortağı” veya “ayna” gibi olduğunu hissediyorlar. AI ile diyalog kurarak kullanıcılar, kendilerini daha iyi yansıtabildiklerini, kendi inançlarına meydan okuyabildiklerini, düşünce kalıplarını keşfedebildiklerini, hatta “uyanış” yaşadıklarını ve hayata ve sistemlere dair daha derin bir anlayışa sahip olduklarını belirtiyorlar. Bu deneyim, AI’ın bazı durumlarda kişisel gelişimi ve kendini keşfi teşvik eden bir katalizör olabileceğini gösteriyor (Kaynak: Reddit r/ChatGPT)
💡 Diğer
İkinci “Xingzhi Kupası” Ulusal Yapay Zeka İnovasyon Uygulama Yarışması başladı: Çin Bilgi ve İletişim Teknolojileri Akademisi (CAICT) gibi kurumların ortaklaşa düzenlediği ikinci “Xingzhi Kupası” açıldı. Yarışma, “Xingzhi ile Güçlendirme, İnovasyonla Liderlik” temasıyla büyük model inovasyonu, endüstriyel güçlendirme ve yazılım-donanım inovasyon ekosistemi olmak üzere üç ana kulvar ve birçok özel yöne sahip. Yarışma, AI teknolojisi inovasyonunu, mühendislik uygulamasını ve bağımsız ekosistem oluşturmayı teşvik etmeyi amaçlıyor; sanayi, tıp, finans gibi yaklaşık 10 önemli sektörü kapsıyor ve yerli AI yazılım ve donanım uygulamalarını vurguluyor. Başarılı projelere fon, endüstriyel eşleştirme gibi destekler sağlanacak (Kaynak: WeChat)

Sequoia Capital AI Ascent paylaşımı: AI pazar potansiyeli devasa, uygulama katmanı ve akıllı ajan ekonomisi gelecek: Sequoia Capital ortaklarından Pat Grady ve diğerleri, AI Ascent etkinliğinde AI pazarına ilişkin görüşlerini paylaştı. AI pazar potansiyelinin bulut bilişimi çok aştığını düşünüyorlar, ancak “ortam gelirine” (kullanıcıların gerçek ihtiyaçtan ziyade sadece merakla denemesi) karşı dikkatli olunması gerektiğini belirtiyorlar. Uygulama katmanı gerçek değerin yattığı yer olarak görülüyor ve girişim şirketlerinin dikey alanlara ve müşteri ihtiyaçlarına odaklanması gerekiyor. AI, ses üretimi ve programlama alanlarında şimdiden atılımlar yaptı. Gelecekte “akıllı ajan ekonomisi” öngörülüyor; AI akıllı ajanları kaynakları aktarabilecek, işlem yapabilecek ancak kalıcı kimlik, iletişim protokolleri ve güvenlik gibi zorluklarla karşılaşacak. Aynı zamanda AI, bireysel yetenekleri büyük ölçüde artıracak ve “süper bireylerin” ortaya çıkmasını sağlayacak (Kaynak: WeChat)

Tartışma: AI çağında üniversite makine öğrenimi ders içerikleri ve öğretim kalitesi ilgi çekiyor: NYU Profesörü Kyunghyun Cho’nun lisansüstü ML ders müfredatını paylaşması tartışmalara yol açtı. Ders, SGD’nin çözebileceği LLM dışı sorunları ve klasik makalelerin okunmasını vurguluyor ve Harvard CS profesörleri gibi meslektaşlarından onay alarak temel kavramların korunmasının önemli olduğunu düşündürüyor. Ancak, Hindistan ve ABD’den öğrenciler üniversitelerindeki ML derslerinin kalitesizliğinden, aşırı soyut olmasından, derinlemesine açıklama olmaksızın terimlerle dolu olmasından şikayet ediyor ve bu da öğrencilerin kendi kendine öğrenmeye ve çevrimiçi kaynaklara güvenmesine neden oluyor. Bu durum, AI/ML alanının hızla gelişmesi ile üniversite derslerinin güncellenmesindeki gecikme arasındaki çelişkiyi ve matematiksel ve teorik temellerin sağlam atılmasının önemini yansıtıyor (Kaynak: WeChat)
