
Anahtar Kelimeler:AI güvenliği, Yapay zeka etiği, AI ajanları, 3D oluşturma, Kod modelleri, AI risk değerlendirmesi, Gemini 2.5 Pro video anlama, AssetGen 2.0 3D oluşturma, Seed-Coder kod modeli, AgentOps ajan operasyonları
🔥 ÖNE ÇIKANLAR
AI Güvenlik Riskleri Endişe Yaratıyor, Uzmanlar Risk Değerlendirmesi İçin Nükleer Güvenlik Deneyimlerinden Yararlanılması Çağrısında Bulunuyor: Uluslararası toplumun yapay zekanın potansiyel risklerine ilişkin endişeleri giderek artıyor. Max Tegmark gibi uzmanlar, AI şirketlerinin tehlikeli AI sistemlerini yayınlamadan önce, Robert Oppenheimer’ın ilk nükleer denemedeki güvenlik hesaplama yöntemlerini örnek alarak yapay zekanın kontrolden çıkma olasılığını (Compton sabiti) sıkı bir şekilde değerlendirmeleri çağrısında bulunuyor. Bu adım, sektörde bir fikir birliği oluşturmayı, küresel bir AI güvenlik mekanizması kurulmasını teşvik etmeyi ve süper zekanın yol açabileceği felaket sonuçlarını önlemeyi amaçlıyor. (kaynak: Reddit r/artificial, Reddit r/ArtificialInteligence)

Yeni Papa Francis (Leo XIV adıyla anılıyor) AI’nın Getirdiği Toplumsal Değişimlere Büyük Önem Veriyor: Yeni seçilen Papa Francis’in (Leo XIV olduğu söyleniyor) yapay zekayı insanlığın karşı karşıya olduğu başlıca zorluklardan biri olarak tanımladığı bildiriliyor. “Leo” adını seçmesinin nedenlerinden biri, AI güdümlü yeni toplumsal sorunlar ve sanayi devrimi olup, bu durum tarihsel olarak Papa Leo XIII’ün Birinci Sanayi Devrimi’ne verdiği yanıtla örtüşüyor. Papa, AI’nın “insan onuru, adalet ve emek”in korunması açısından zorluklar teşkil ettiğini vurguluyor ve gelecekte AI etiği üzerine önemli bir belge yayınlamayı planlıyor; bu da dini liderlerin AI teknolojisinin etik ve toplumsal etkilerine yönelik derin endişelerini gösteriyor. (kaynak: Reddit r/artificial, AymericRoucher, AravSrinivas, Reddit r/ArtificialInteligence)

Google, AgentOps ve Gelecekteki Uygulamaları Açıklayan 76 Sayfalık AI Agent Teknik Raporunu Yayınladı: Google, agent’ların oluşturulması, değerlendirilmesi ve uygulanmasını ayrıntılı olarak açıklayan 76 sayfalık bir AI agent teknik raporu yayınladı. Teknik rapor, üretken AI operasyonlarının bir dalı olarak agent operasyonlarının (AgentOps) önemini vurguluyor. AgentOps, agent’ların verimli çalışması için gereken araç yönetimi, temel prompt ayarları, bellek işlevleri ve görev ayrıştırma gibi konulara odaklanıyor. Teknik rapor ayrıca, farklı agent’ların planlama, bilgi getirme, yürütme ve değerlendirme gibi roller üstlenerek karmaşık görevleri birlikte tamamladığı çoklu agent işbirliği mimarilerini ele alıyor ve NotebookLM kurumsal sürümü ile Agentspace gibi agent’ların işletmelerde çalışanlara yardımcı olma ve arka plan görevlerini otomatikleştirme konusundaki gelecek vaat eden uygulamalarını inceliyor. (kaynak: WeChat)

Meta, AssetGen 2.0’ı Tanıttı: Metin/Görüntüden Yüksek Kaliteli 3D Varlıklar Üretimi: Meta, metin ve görüntü prompt’larından yüksek kaliteli 3D varlıklar oluşturabilen en son 3D temel AI modeli AssetGen 2.0’ı duyurdu. AssetGen 2.0 iki alt model içeriyor: Biri, ayrıntı ve doğruluğu artırmak için tek aşamalı bir 3D difüzyon modeli kullanan 3D mesh üretimi için; diğeri ise doku üretimi için TextureGen modeli olup, geliştirilmiş görünüm tutarlılığı, doku onarımı ve daha yüksek doku çözünürlüğü yöntemleri sunuyor. Bu teknoloji şu anda Meta içinde 3D dünyalar oluşturmak için kullanılıyor ve bu yılın ilerleyen dönemlerinde Horizon yaratıcılarına sunulması planlanıyor. (kaynak: Reddit r/artificial)

🎯 GELİŞMELER
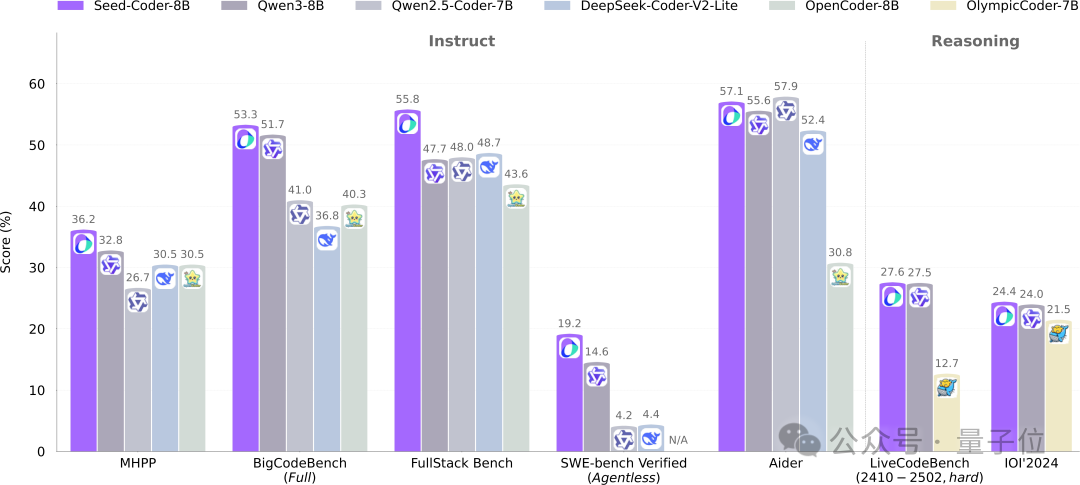
ByteDance Seed, 8B Kod Modeli Seed-Coder’ı Açık Kaynak Olarak Yayınladı, Model Odaklı Veri Yönetiminde Yeni Bir Paradigma Kullanıyor: ByteDance Seed ekibi, Base, Instruct ve Reasoning olmak üzere üç versiyon içeren 8B parametreli kod modeli Seed-Coder’ı ilk kez açık kaynak olarak kullanıma sundu. Model, birçok kod üretme benchmark’ında üstün performans gösterdi ve özellikle HumanEval ve MBPP’de Qwen3 gibi modelleri geride bıraktı. Seed-Coder’ın temel yeniliği, LLM’nin kendisini kullanarak dosya düzeyinde kod, depo düzeyinde kod, Commit verileri ve kodla ilgili ağ verileri dahil olmak üzere yüksek kaliteli kod eğitim verileri üretip filtrelediği “model merkezli” bir veri işleme yaklaşımı önermesidir; toplam eğitim verisi miktarı 6T token’a ulaşmaktadır. Bu hamle, insan müdahalesini azaltmayı ve kod modeli yeteneklerini geliştirmeyi amaçlamaktadır. (kaynak: WeChat)
Gemini 2.5 Pro Video Anlamada Çığır Açtı, Ses-Video ve Kodu Doğal Olarak Birleştirdi: Google’ın en son Gemini 2.5 Pro ve Flash modelleri video anlama yeteneklerinde önemli ilerlemeler kaydetti. Gemini 2.5 Pro, birçok önemli video anlama benchmark’ında SOTA seviyesine ulaştı ve hatta GPT 4.1’i geride bıraktı. Gemini 2.5 serisi modeller, ses-video bilgilerini kod gibi diğer veri formatlarıyla ilk kez doğal ve sorunsuz bir şekilde birleştirerek, videoları doğrudan etkileşimli uygulamalara (örneğin öğrenme uygulamaları) dönüştürebiliyor, videolara göre p5.js animasyonları oluşturabiliyor ve video kesitlerini hassas bir şekilde alıp tanımlayabiliyor, bu da güçlü zamansal çıkarım yeteneklerini gösteriyor. Bu özellikler Google AI Studio, Gemini API ve Vertex AI’da kullanıma sunuldu. (kaynak: WeChat)

ModelScope, GPT-4o’nun Görüntü Yeteneklerini Hedefleyen Birleşik Görüntü Modeli Nexus-Gen’i Açık Kaynak Olarak Yayınladı: ModelScope ekibi, GPT-4o’nun görüntü işleme yetenekleriyle rekabet etmeyi amaçlayan, görüntü anlama, üretme ve düzenlemeyi aynı anda gerçekleştirebilen birleşik bir çok modlu model olan Nexus-Gen’i tanıttı. Model, MLLM’nin metin modelleme yeteneklerini Diffusion modelinin görüntü oluşturma yetenekleriyle birleştiren token → transformer → diffusion → pixels teknik yolunu benimsiyor. Ardışık görüntü Embedding’lerinin otoregresif tahmini sırasında biriken hataları çözmek için ekip, önceden doldurmalı otoregresif bir strateji önerdi. Nexus-Gen, ModelScope topluluğunun yakın zamanda açık kaynak olarak sunduğu ImagePulse düzenleme veri kümesi de dahil olmak üzere yaklaşık 25 milyon görüntü-metin verisi üzerinde eğitildi. (kaynak: WeChat)

Cursor 0.50 Sürümü Yayınlandı, Fiyatlandırmayı Basitleştirdi ve Birçok Kod Düzenleme Özelliğini Geliştirdi: AI kod editörü Cursor, önemli güncellemeler içeren 0.50 sürümünü yayınladı. Fiyatlandırma modeli, istek tabanlı bir modele basitleştirildi; Max modu tüm üst düzey AI modellerini destekliyor ve token tabanlı bir fiyatlandırma kullanıyor. Özellik geliştirmeleri şunları içeriyor: yeni Tab modeli, dosyalar arası önerileri ve kod yeniden yapılandırmayı destekliyor; arka plan agent’ı (önizleme sürümü), birden fazla agent’ı paralel olarak çalıştırmayı ve uzak ortamlarda görevleri yürütmeyi destekliyor; kod tabanı bağlamı, @folders aracılığıyla tüm kod tabanının eklenmesine izin veriyor; satır içi düzenleme kullanıcı arayüzü optimize edildi, tam dosya düzenleme ve agent’a gönderme özellikleri eklendi; uzun dosya düzenlemesi için arama-değiştirme aracı tanıtıldı; birden fazla kod tabanını işlemek için çoklu kök çalışma alanlarını destekliyor; sohbet işlevi geliştirildi, Markdown olarak dışa aktarma ve kopyalama desteği eklendi. (kaynak: op7418)
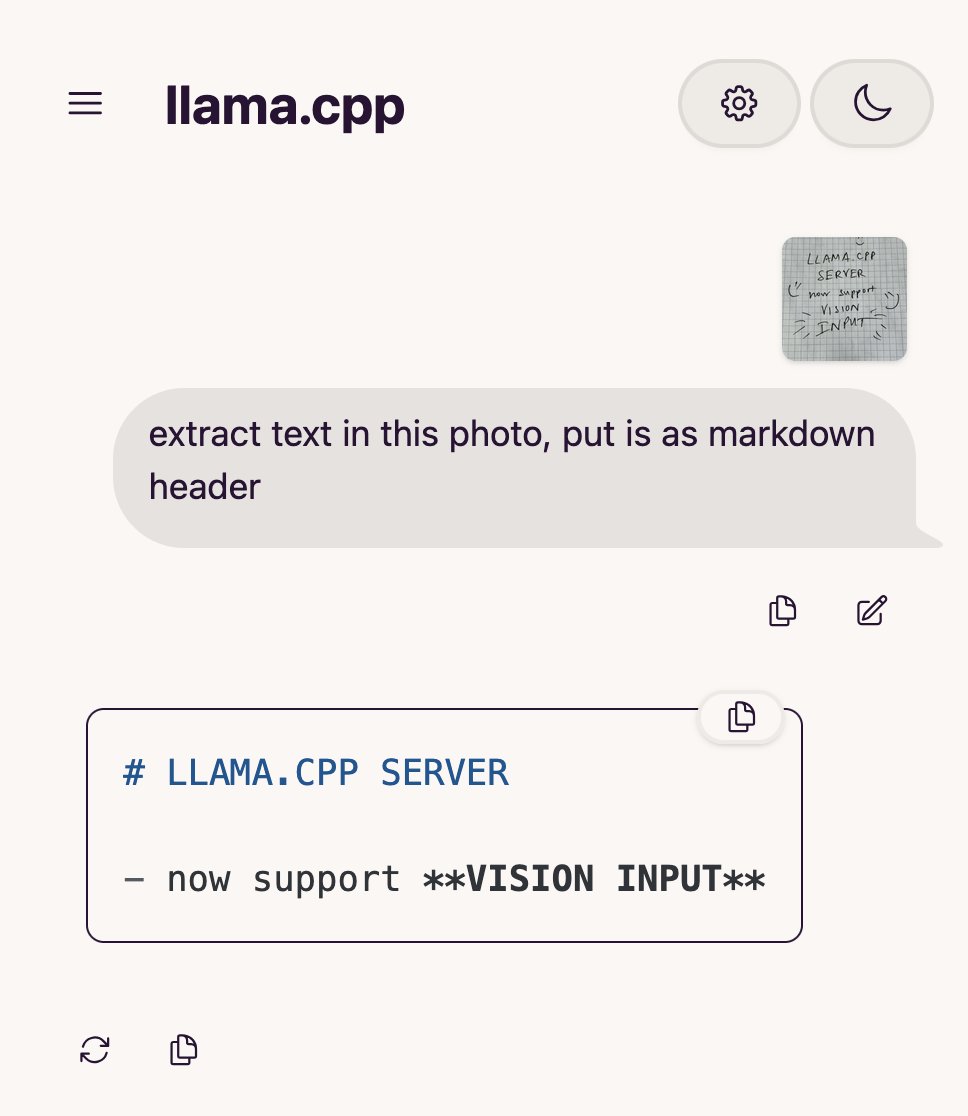
llama.cpp’ye Görsel Dil Modeli (VLM) Desteği Eklendi, Tam Bir Görsel RAG Akışı Oluşturulabilir: Açık kaynak proje llama.cpp, görsel dil modellerini (VLM) desteklediğini duyurdu. Kullanıcılar artık llama.cpp sunucusu ve web arayüzü aracılığıyla görsel özellikleri kullanabilecekler. Bu güncelleme, llama.cpp üzerinde aynı temel modelin çoklu LoRA destekli versiyonlarının yanı sıra embedding modellerinin de yüklenebileceği anlamına geliyor, bu da tam bir görsel bilgiye dayalı üretkenlik (Vision RAG) akışı oluşturulmasını sağlıyor. Bu hamle, llama.cpp’nin büyük dil modellerini yerel olarak çalıştırma yeteneğini daha da genişleterek çok modlu görevleri yerine getirmesini sağlıyor. (kaynak: mervenoyann, mervenoyann)
Tencent, HunyuanVideo Tabanlı Özelleştirilmiş Video Üretim Mimarisi HunyuanCustom’ı Yayınladı: Tencent, Hugging Face üzerinde özelleştirilmiş video üretimi için tasarlanmış çok modlu güdümlü bir mimari olan HunyuanCustom’ı yayınladı. Bu çalışma, HunyuanVideo temel alınarak geliştirilmiş olup, özellikle video üretirken ana nesnenin tutarlılığını korumaya vurgu yapıyor ve aynı zamanda görüntü, ses, video ve metin gibi çeşitli koşulların girişini destekleyerek kullanıcılara daha esnek ve kişiselleştirilmiş video oluşturma yetenekleri sunuyor. (kaynak: _akhaliq)
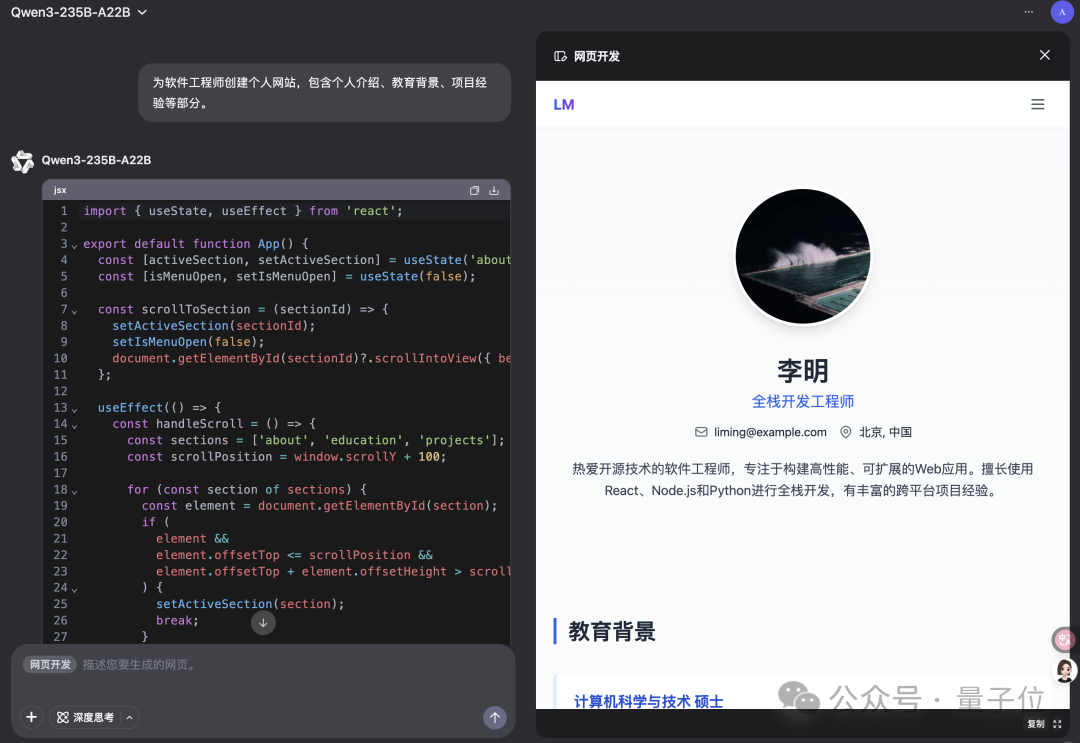
Qwen Chat’e “Web Geliştirme” Modu Eklendi, Tek Cümleyle React Web Uygulaması Oluşturma: Alibaba Qwen Chat, kullanıcıların yalnızca tek bir cümlelik komutla HTML, CSS ve JavaScript içeren web uygulamaları oluşturmasına olanak tanıyan “Web Geliştirme” (Web Dev) modunu kullanıma sundu; altyapıda React framework’ü ve Tailwind CSS kullanılıyor. Bu özellik, kişisel web siteleri oluşturmayı, mevcut web arayüzlerini (Twitter, GitHub gibi) kopyalamayı veya açıklamaya göre belirli formlar ve animasyonlar oluşturmayı hızlandırabiliyor. Kullanıcılar farklı Qwen modellerini seçebilir ve web sayfası kalitesini artırmak için “derinlemesine düşünme” modunu birleştirebilir. Bu özellik, ön uç geliştirme süreçlerini basitleştirmeyi ve uygulama prototiplerini hızla oluşturmayı amaçlıyor. (kaynak: WeChat)
Unitree Robotics, Go1 Robot Köpeğinin Güvenlik Açığına Yanıt Verdi, Sonraki Ürünlerin Yükseltildiğini Vurguladı: Unitree Robotics, yaklaşık iki yıldır üretimi durdurulan Go1 robot köpek serisinde “arka kapı açığı” olduğu yönündeki söylentilere yanıt vererek sorunun bir güvenlik açığı olduğunu kabul etti. Saldırganlar, üçüncü taraf bir bulut tünel hizmetinin yönetim anahtarını kullanarak kullanıcı cihaz verilerini değiştirebilir, kamera görüntülerini ve sistem yetkilerini ele geçirebilir. Unitree Robotics, sonraki robot serilerinin daha güvenli, yükseltilmiş sürümler kullandığını ve bu açıktan etkilenmediğini belirtti. Bu olay, özellikle insansı robotların ticarileşmesinin ilk yılında, akıllı robot tedarik zinciri güvenliği ve veri gizliliği konusunda endişelere yol açtı; sektör, teknolojik atılımlar, maliyet kontrolü ve ticarileştirme yollarının keşfi gibi birçok zorlukla karşı karşıya. (kaynak: 36氪)

Claude Code Artık Diğer .MD Dosyalarına Referans Verebiliyor, Komut Organizasyonunu Optimize Ediyor: Anthropic’in Claude Code’u, 0.2.107 sürümüyle CLAUDE.md dosyalarının diğer Markdown dosyalarını içe aktarmasına olanak tanıyan bir güncelleme aldı. Kullanıcılar, ana CLAUDE.md dosyasına [u/path/to/file].md ekleyerek başlangıçta ek dosya içeriklerini yükleyebilirler. Bu geliştirme, kullanıcıların Claude komutlarını daha iyi organize etmelerini ve yönetmelerini sağlayarak, büyük projelerde komut yapılandırmasının güvenilirliğini ve modülerliğini artırıyor ve daha önce dağınık dosyalara güvenmenin neden olabileceği karmaşıklık sorununu çözüyor. (kaynak: Reddit r/ClaudeAI)

ABD Telif Hakkı Ofisi, AI Ön Eğitimi Konusunda Daha Sert Bir Tutum Sergiliyor ve “Adil Kullanım” Savunmasını Zayıflatıyor: ABD Telif Hakkı Ofisi’nin yayınladığı son rapor, AI modellerinin ön eğitim aşamasında telif hakkıyla korunan materyallerin kullanılması sorununa daha sert bir yaklaşım getiriyor. Rapor, AI laboratuvarlarının artık modellerinin hak sahipleriyle rekabet edebileceğini (örneğin, orijinal eserlere benzer içerikler üretebildiğini) iddia etmeleri nedeniyle, telif hakkı ihlali davalarında “adil kullanım” (fair use) savunmalarının zayıfladığını belirtiyor. Bu değişiklik, AI modellerinin eğitim verisi kaynakları ve uyumluluğu üzerinde önemli etkilere sahip olabilir. (kaynak: Dorialexander)

Nvidia, 48GB GDDR7 Belleğe Sahip RTX Pro 5000 Profesyonel Ekran Kartını Duyurdu: Nvidia, Blackwell mimarisine dayanan yeni profesyonel masaüstü GPU’su RTX Pro 5000’i tanıttı. Ekran kartı 48GB GDDR7 belleğe, 1344 GB/s’ye varan bellek bant genişliğine ve 300W güç tüketimine sahip. Resmi olarak “ucuz” bir 48GB Blackwell ekran kartı olarak adlandırılsa da, fiyatının hala yüksek olması bekleniyor (bir yorumda 4000 dolar seviyesinden bahsediliyor) ve esas olarak AI model eğitimi, büyük 3D renderleme gibi görevler için güçlü hesaplama desteği sağlayan profesyonel iş istasyonu kullanıcılarını hedefliyor. (kaynak: Reddit r/LocalLLaMA)

🧰 ARAÇLAR
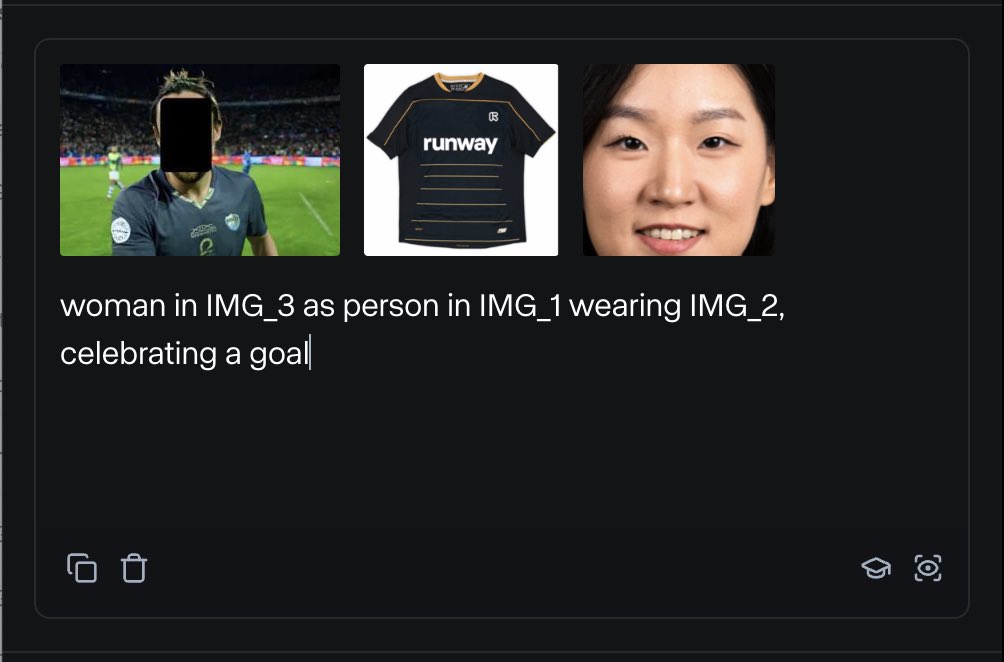
RunwayML, Birden Fazla Referans Materyalini Karıştırarak İçerik Üretmeye Olanak Tanıyan References Özelliğini Tanıttı: RunwayML’in yeni “References” özelliği, kullanıcıların farklı referans materyallerini (görüntüler, stiller gibi) “hammadde” olarak karıştırmasına ve bu “hammadde”lerin herhangi bir kombinasyonuna göre yeni görsel içerikler üretmesine olanak tanıyor. Bu özellik, kullanıcıların çeşitli yaratıcı fikirleri hızla hayata geçirmelerine yardımcı olabilen, neredeyse gerçek zamanlı bir yaratım makinesi olarak görülüyor ve AI’nın görsel içerik oluşturma alanındaki esnekliğini ve olanaklarını büyük ölçüde genişletiyor. (kaynak: c_valenzuelab)
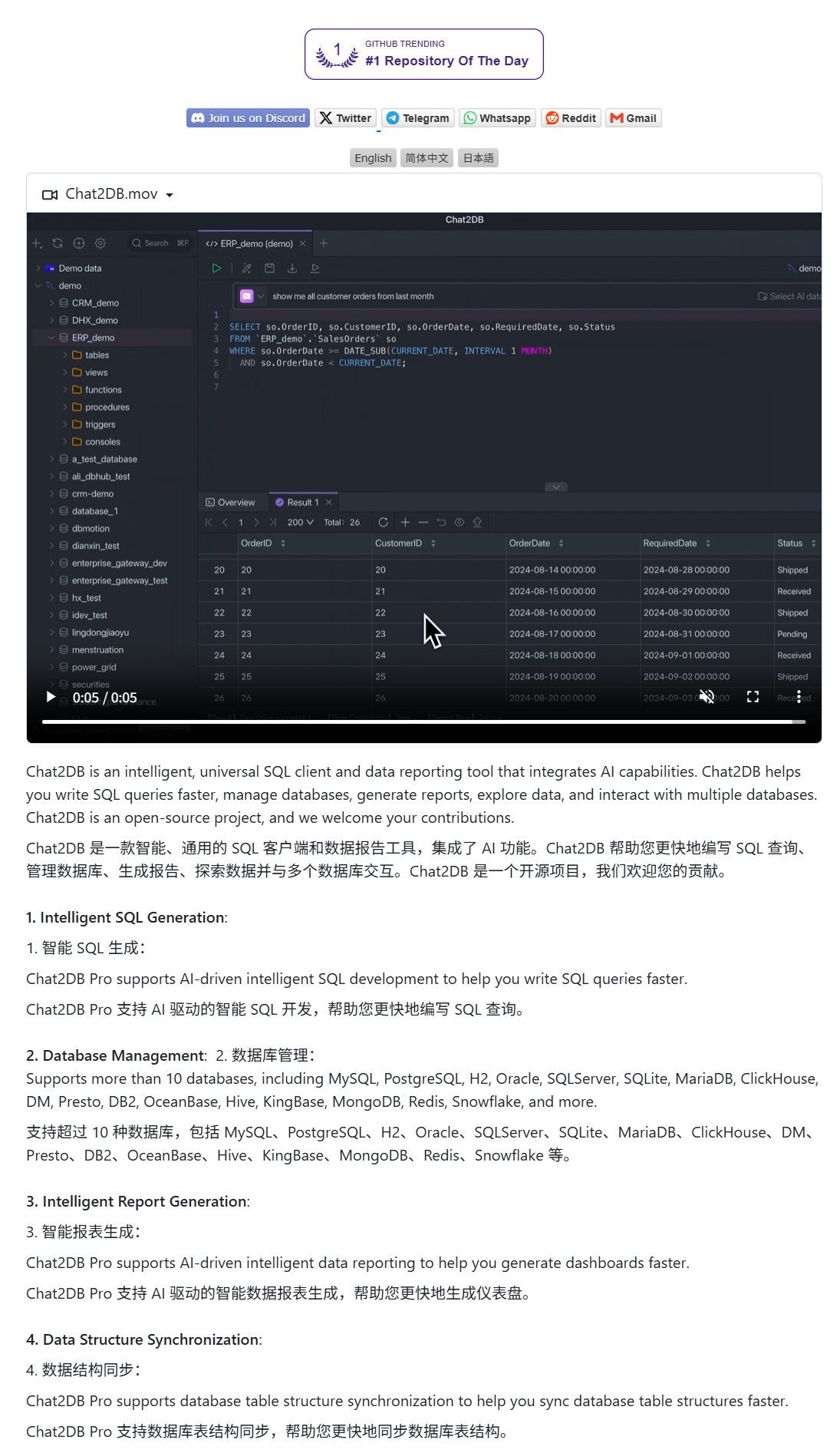
Chat2DB: Doğal Dille Veritabanı İşlemleri için AI İstemcisi: Chat2DB, kullanıcıların doğal dil aracılığıyla veritabanlarıyla etkileşim kurmasına olanak tanıyan AI güdümlü bir veritabanı istemci aracıdır. Örneğin, kullanıcılar “Bu ay en çok harcama yapan müşteri kim?” gibi sorular sorabilir ve Chat2DB, AI kullanarak soruyu anlayabilir, veritabanının tablo yapısına göre otomatik olarak ilgili SQL sorgu ifadelerini oluşturabilir, sorguyu yürütebilir ve sonuçları döndürebilir. Bu, veritabanı işlemlerinin teknik engelini büyük ölçüde azaltarak teknik olmayan personelin de kolayca veri sorgulama ve analizi yapmasını sağlar. Proje GitHub’da açık kaynak olarak yayınlanmıştır. (kaynak: karminski3)
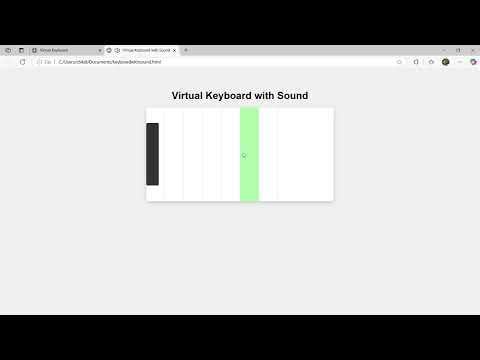
Qwen 3 8B Modeli Mükemmel Kod Yeteneği Sergiliyor, HTML Klavye Oluşturabiliyor: Qwen 3 8B modeli (Q6_K nicemlenmiş sürümü), parametre sayısı nispeten küçük olmasına rağmen kod üretme konusunda mükemmel bir performans sergiliyor. Kullanıcılar, iki kısa prompt ile modelin oynanabilir bir HTML klavye kodu üretmesini başarıyla sağladı. Bu, küçük boyutlu modellerin belirli görevlerde yüksek pratikliğe ulaşabileceğini, özellikle kaynakları sınırlı yerel dağıtım senaryoları için çekici olduğunu gösteriyor. (kaynak: Reddit r/LocalLLaMA)
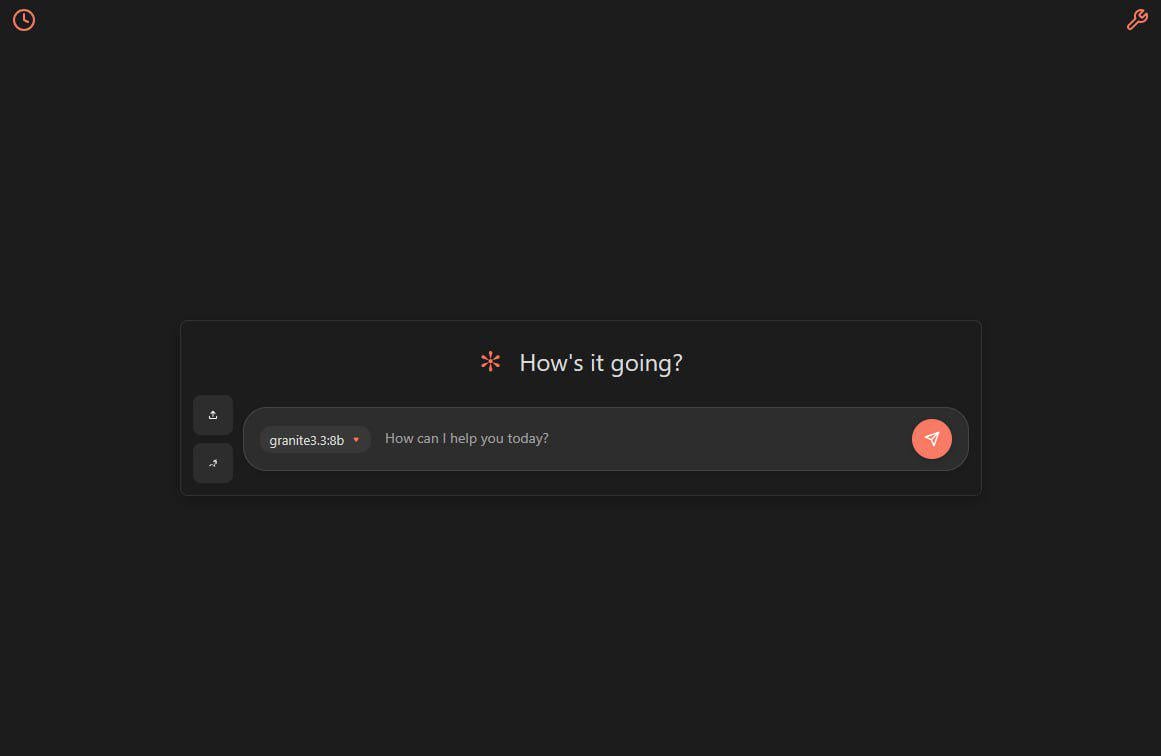
Ollama Chat: Claude Arayüzüne Benzer Yerel LLM Sohbet Aracı: Ollama Chat, yerel büyük dil modelleri için tasarlanmış bir web sohbet arayüzüdür ve kullanıcı arayüzü stili ile kullanıcı deneyimi Anthropic’in Claude’undan esinlenmiştir. Araç, metin dosyası yükleme, konuşma geçmişi kaydı ve sistem prompt’u ayarlarını destekleyerek, kullanımı kolay ve estetik bir yerel LLM etkileşim çözümü sunmayı amaçlamaktadır. Proje, kullanıcıların kendi başlarına dağıtıp kullanabilmeleri için GitHub’da açık kaynak olarak yayınlanmıştır. (kaynak: Reddit r/LocalLLaMA)
AI ile Kişiselleştirilmiş Kart (Doğum Günü/Anneler Günü) Oluşturma Prompt İpuçları: Kullanıcılar, AI ile kişiselleştirilmiş kartlar (doğum günü kartı, Anneler Günü kartı gibi) oluşturmak için prompt ipuçlarını paylaştı. Önemli olan kartın temasını (Anneler Günü, doğum günü gibi), stilini (kadınsı stil, çocuksu stil gibi), alıcısını (anne, Sandy, Jimmy gibi), yaşını (30 yaş, 6 yaş gibi) ve tebrik mesajının belirli içeriğini veya sıcak, tatlı tonunu açıkça belirtmektir. Bu unsurları birleştirerek, AI’nın istenen kart tasarımını oluşturması sağlanabilir. (kaynak: dotey)

📚 AKADEMİK ÇALIŞMALAR VE KAYNAKLAR
Google, Kullanıcılara Nasıl Etkili Soru Sorulacağını Öğreten Prompt Mühendisliği Teknik Raporunu Yayınladı: Google, kullanıcılara AI modellerine nasıl daha etkili sorular sorulacağını öğretmeyi amaçlayan bir prompt mühendisliği teknik raporu (Kaggle üzerinden erişilebilir) yayınladı. Eğitim içeriği açık ve net olup, çıktı gereksinimlerinin nasıl netleştirileceği, çıktı aralığının nasıl sınırlandırılacağı ve değişkenlerin nasıl kullanılacağı gibi becerileri ayrıntılı olarak tanıtarak, kullanıcıların büyük dil modelleriyle etkileşim verimliliğini ve etkinliğini artırmasına ve böylece daha doğru ve yararlı yanıtlar almasına yardımcı oluyor. (kaynak: karminski3)

HKUST(GZ) Ekibi MultiGO’yu Önerdi: Tek Görüntüden 3D Dokulu İnsan Üretimi için Katmanlı Gauss Modelleme: Hong Kong Bilim ve Teknoloji Üniversitesi (Guangzhou) ekibi, tek bir görüntüden dokulu 3D insan modeli yeniden oluşturmak için katmanlı Gauss modelleme yoluyla MultiGO adlı yenilikçi bir çerçeve önerdi. Bu yöntem, insan vücudunu iskelet, eklemler, kırışıklıklar gibi farklı hassasiyet seviyelerine ayırarak kademeli olarak iyileştirir. Temel teknoloji, 3D temel öğeler olarak Gauss sıçratma noktalarını kullanır ve iskelet geliştirme, eklem geliştirme ve kırışıklık optimizasyon modülleri tasarlar. Bu araştırma sonucu CVPR 2025’e seçildi ve tek görüntüden 3D insan yeniden yapılandırması için yeni bir yaklaşım sunuyor; kod yakında açık kaynak olacak. (kaynak: WeChat)

Tsinghua, Fudan ve HKUST Ortaklaşa RM-BENCH’i Yayınladı: İlk Ödül Modeli Değerlendirme Benchmark’ı: Mevcut büyük dil modeli ödül modeli değerlendirmesindeki “içerikten çok biçim” ve stil yanlılığı sorunlarına yönelik olarak, Tsinghua Üniversitesi, Fudan Üniversitesi ve Hong Kong Bilim ve Teknoloji Üniversitesi araştırma ekipleri ortaklaşa ilk sistematik ödül modeli değerlendirme benchmark’ı olan RM-BENCH’i yayınladı. Bu benchmark, sohbet, kod, matematik ve güvenlik olmak üzere dört ana alanı kapsamakta olup, modelin ince içerik farklılıklarına duyarlılığını ve stil sapmalarına karşı sağlamlığını değerlendirerek daha güvenilir bir “içerik hakemi” yeni standardı oluşturmayı amaçlamaktadır. Araştırma, mevcut ödül modellerinin matematik ve kod alanlarında yetersiz performans gösterdiğini ve genel olarak stil yanlılığına sahip olduğunu ortaya koymuştur. Bu çalışma ICLR 2025 Oral olarak kabul edilmiştir. (kaynak: WeChat)

Tianjin Üniversitesi ve Tencent, COME Çözümünü Açık Kaynak Olarak Sundu: 5 Satır Kodla TTA Sağlamlığını Artırıyor, Model Çökmesini Çözüyor: Tianjin Üniversitesi ve Tencent işbirliğiyle, test zamanı adaptasyonu (TTA) sürecinde entropi minimizasyonu (EM) nedeniyle oluşan modelin aşırı güven ve çökme sorununu çözmeyi amaçlayan COME (Conservatively Minimizing Entropy) yöntemi önerildi. COME, tahmin belirsizliğini açıkça modellemek için öznel mantığı tanıtarak ve belirsizliği dolaylı olarak kontrol etmek için uyarlanabilir bir Logit kısıtlaması (Logit normunu dondurma) kullanarak muhafazakar bir entropi minimizasyonu gerçekleştirir. Bu yöntem, model mimarisini değiştirmeden, mevcut TTA yöntemlerine yalnızca birkaç satır kodla entegre edilebilir ve ImageNet-C gibi veri kümelerinde model sağlamlığını ve doğruluğunu önemli ölçüde artırırken hesaplama maliyeti son derece düşüktür. Makale ICLR 2025’te kabul edildi ve kodu açık kaynak olarak yayınlandı. (kaynak: WeChat)
Huawei ve IIE, DEER’i Önerdi: LLM Çıkarım Verimliliğini ve Doğruluğunu Artıran Düşünce Zinciri “Dinamik Erken Çıkış” Mekanizması: Huawei, Çin Bilimler Akademisi Bilgi Mühendisliği Enstitüsü (IIE) ile birlikte, büyük dil modellerinin uzun düşünce zinciri (Long CoT) çıkarımında ortaya çıkabilecek aşırı düşünme sorununu çözmeyi amaçlayan DEER (Dynamic Early Exit in Reasoning) mekanizmasını önerdi. DEER, çıkarım dönüşüm noktalarını izleyerek, deneme amaçlı yanıtları teşvik ederek ve bunların güvenilirliğini değerlendirerek, düşünmeyi erken sonlandırıp sonuca varıp varmayacağına dinamik olarak karar verir. Deneyler, DeepSeek serisi gibi çıkarım LLM’lerinde DEER’in ek eğitime gerek kalmadan düşünce zinciri oluşturma uzunluğunu ortalama %31-%43 oranında azalttığını ve aynı zamanda doğruluğu %1.7-%5.7 oranında artırdığını göstermiştir. (kaynak: WeChat)

Çin Bilimler Akademisi ve Diğerleri R1-Reward’ı Önerdi: Kararlı Pekiştirmeli Öğrenme ile Çok Modlu Ödül Modelleri Eğitimi: Çin Bilimler Akademisi, Tsinghua Üniversitesi, Kuaishou ve Nanjing Üniversitesi’nden araştırma ekipleri, uzun süreli çıkarım yeteneklerini geliştirmek amacıyla çok modlu ödül modellerini (MRM) eğitmek için kararlı bir pekiştirmeli öğrenme algoritması olan StableReinforce’u kullanan R1-Reward’ı önerdi. StableReinforce, MRM’leri eğitirken PPO gibi mevcut RL algoritmalarının karşılaşabileceği kararsızlık sorunlarını, Pre-Clip stratejisi, avantaj filtresi ve yeni bir tutarlılık ödül mekanizması (analiz ile yanıtın tutarlılığını kontrol etmek için bir hakem modeli tanıtarak) aracılığıyla eğitim sürecini stabilize ederek iyileştirir. Deneyler, R1-Reward’ın birden fazla MRM benchmark’ında SOTA modellerinden daha iyi performans gösterdiğini ve çıkarım sırasında çoklu örnekleme oylamasıyla performansın daha da artırılabileceğini göstermiştir. (kaynak: WeChat)
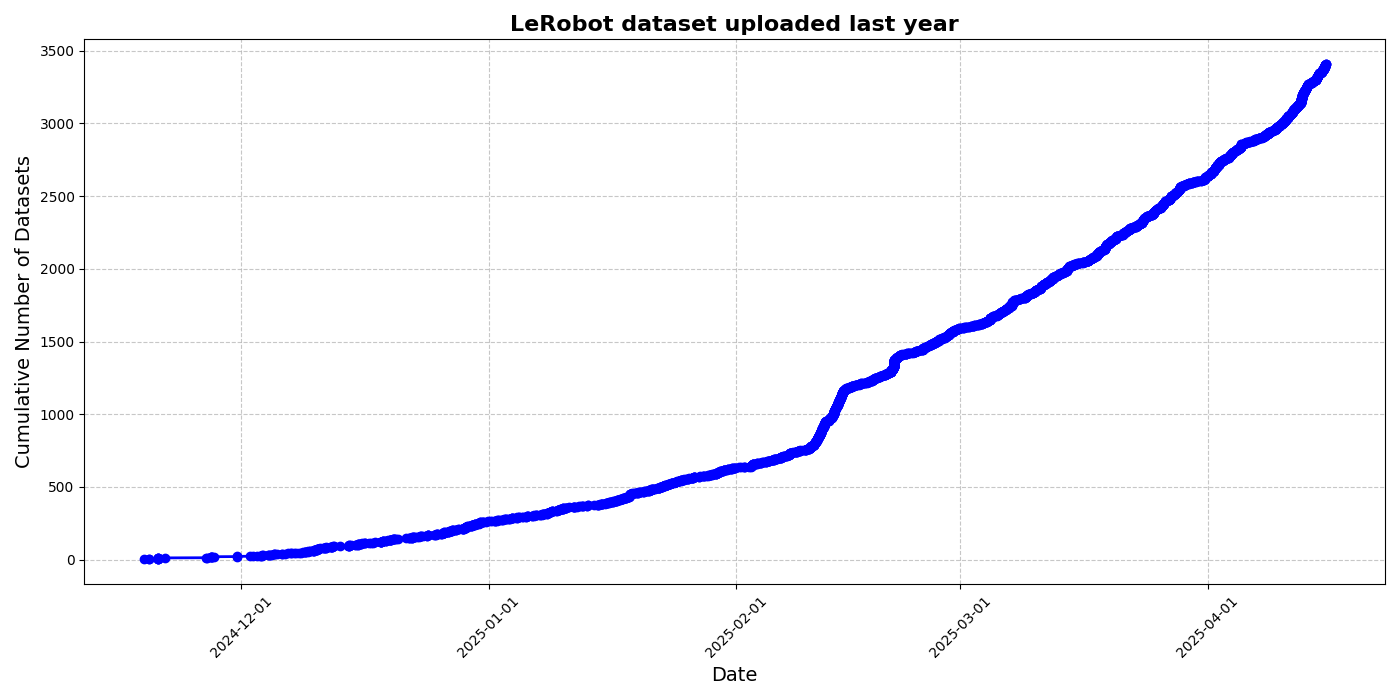
HuggingFace, Robotik Alanında “ImageNet Anı”nı Teşvik Etmek İçin LeRobot Topluluk Veri Kümesi Girişimini Başlattı: HuggingFace, robotik alanında bir “ImageNet” oluşturmayı amaçlayan LeRobot topluluk veri kümesi projesini başlattı ve topluluk katkılarıyla genel amaçlı robotik teknolojisinin gelişimini teşvik etmeyi hedefliyor. Makale, veri çeşitliliğinin robotların genelleme yeteneği için önemini vurguluyor ve mevcut robotik veri kümelerinin çoğunun kısıtlı akademik ortamlardan kaynaklandığını belirtiyor. LeRobot, veri toplama ve yükleme süreçlerini basitleştirerek ve donanım maliyetlerini düşürerek kullanıcıları farklı robotların (So100, Koch mekanik kolu gibi) çeşitli görevlerdeki (satranç oynama, çekmece çalıştırma gibi) verilerini paylaşmaya teşvik ediyor. Aynı zamanda makale, veri etiketlemedeki tutarsızlıklar, özellik eşleştirmesindeki belirsizlikler gibi zorluklarla başa çıkmak ve yüksek kaliteli, çeşitli robotik veri kümelerinin oluşturulmasını teşvik etmek için veri kalitesi standartları ve en iyi uygulamalar listesi sunuyor. (kaynak: HuggingFace Blog, LoubnaBenAllal1)
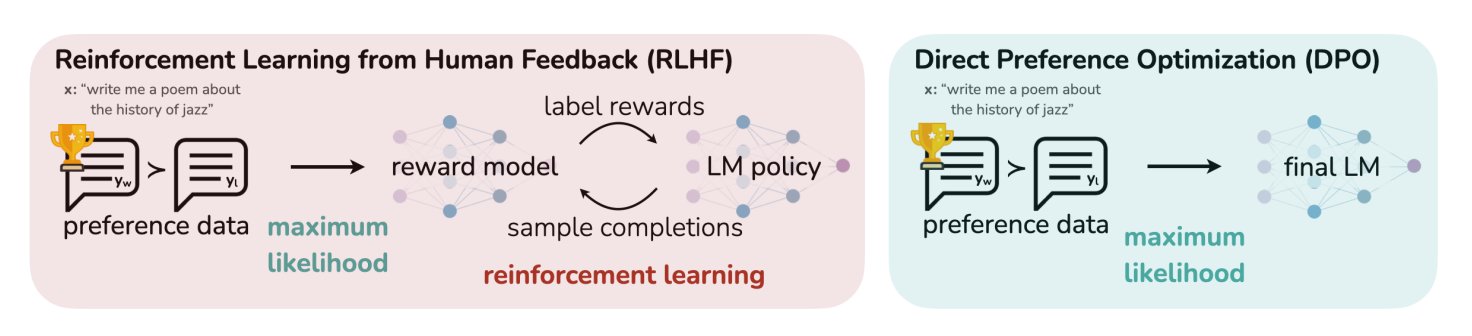
HuggingFace Blog Yazısı LLM’ler İçin 11 Uyum ve Optimizasyon Algoritmasını Özetliyor: TheTuringPost, HuggingFace’te yer alan ve büyük dil modelleri (LLM) için kullanılan 11 uyum ve optimizasyon algoritmasını özetleyen bir makaleyi paylaştı. Bu algoritmalar arasında PPO (Yakınsal Politika Optimizasyonu), DPO (Doğrudan Tercih Optimizasyonu), GRPO (Grup Göreceli Politika Optimizasyonu), SFT (Denetimli İnce Ayar), RLHF (İnsan Geri Bildirimli Pekiştirmeli Öğrenme) ve SPIN (Kendi Kendine Oynayarak İnce Ayar) gibi yöntemler bulunuyor. Makale, bu algoritmaların bağlantılarını ve daha fazla bilgisini sunarak araştırmacılara ve geliştiricilere LLM optimizasyon yöntemlerine genel bir bakış sağlıyor. (kaynak: TheTuringPost)
UC Berkeley, CS280 Lisansüstü Bilgisayar Görmesi Dersi Materyallerini Paylaştı: Kaliforniya Üniversitesi Berkeley’den Profesör Angjoo Kanazawa ve Jitendra Malik, bu dönem verdikleri lisansüstü bilgisayar görmesi dersi CS280’in tüm ders materyallerini paylaştı. Klasik ve modern bilgisayar görmesi içeriklerini birleştiren bu materyal setinin iyi sonuç verdiğini düşünüyorlar ve öğrenenlerin referans alması için kamuya açık hale getirdiler. (kaynak: NandoDF)
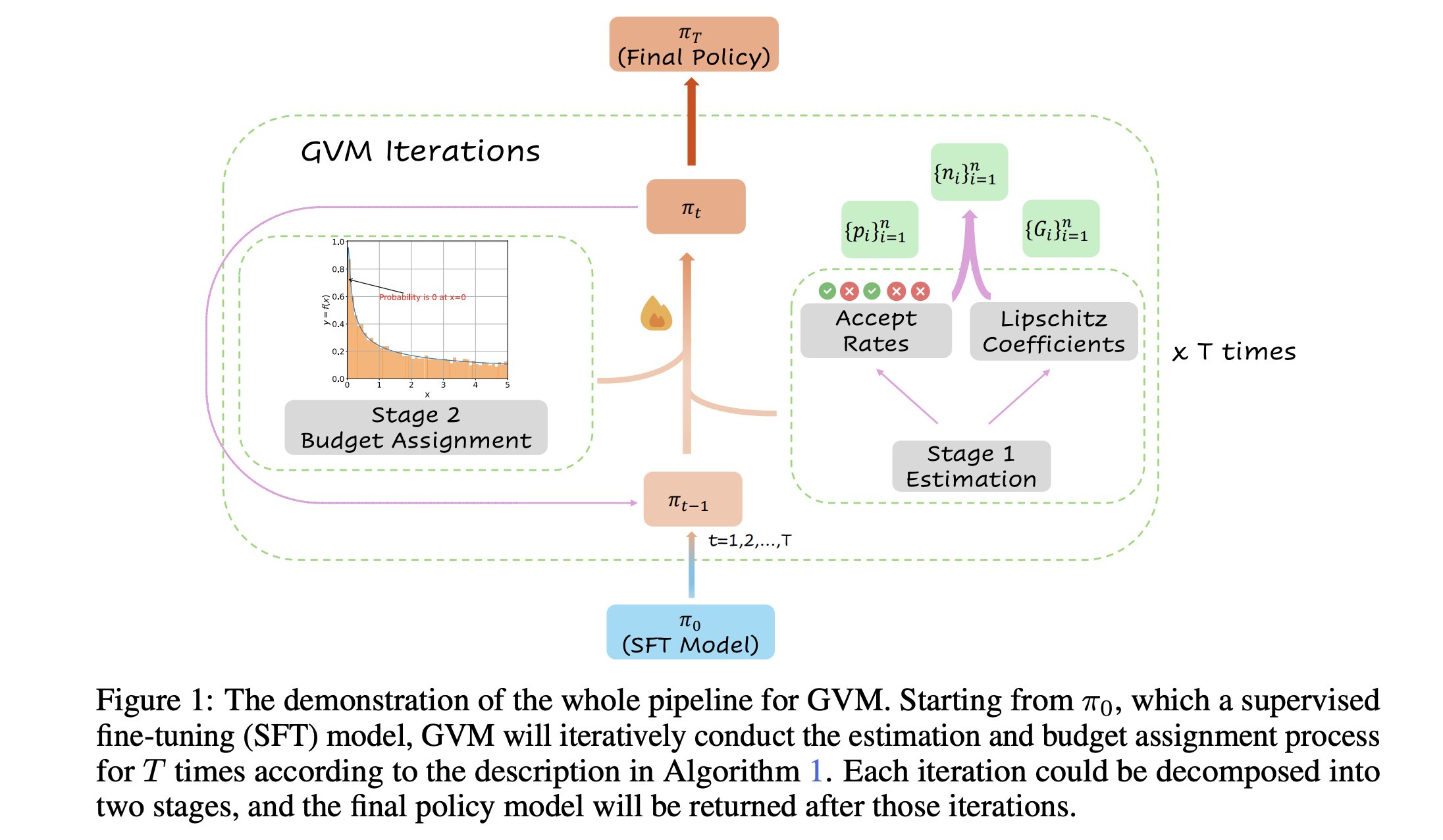
GVM-RAFT: Düşünce Zinciri Çıkarımcılarını Optimize Eden Dinamik Örnekleme Çerçevesi: Yeni bir makale, her bir prompt için örnekleme stratejisini dinamik olarak ayarlayarak düşünce zinciri (chain-of-thought) çıkarımcılarını optimize etmeyi ve gradyan varyansını en aza indirmeyi amaçlayan GVM-RAFT çerçevesini tanıtıyor. Bu yöntemin matematiksel çıkarım görevlerinde 2-4 kat hızlanma sağladığı ve doğruluğu artırdığı iddia ediliyor. (kaynak: _akhaliq)
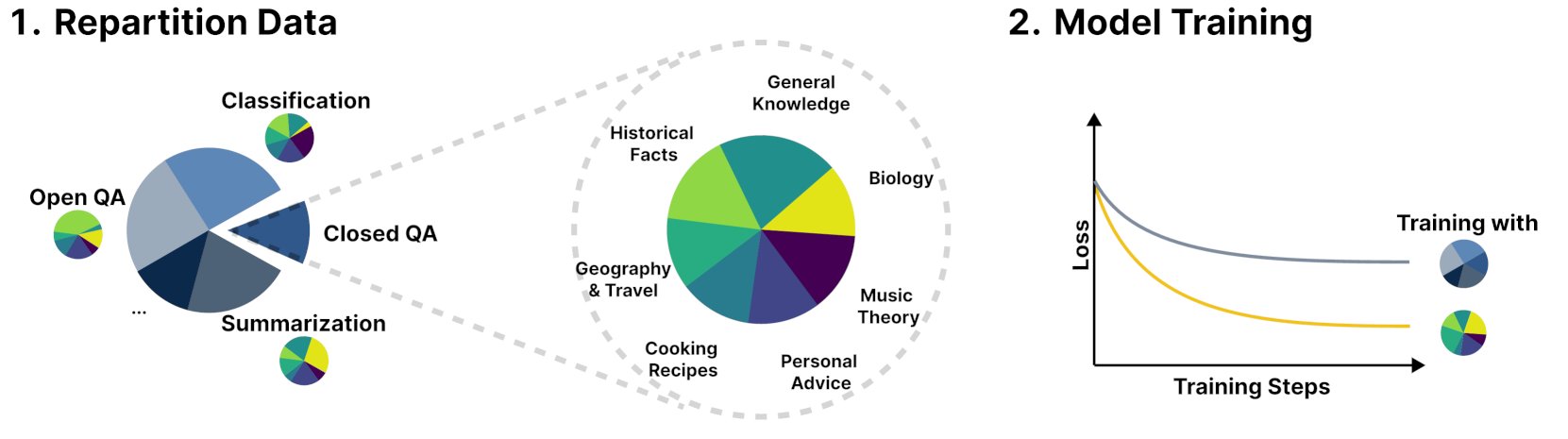
Yeni Çerçeve R&B, Eğitim Verilerini Dinamik Olarak Dengeleyerek Dil Modeli Performansını Artırıyor: R&B adlı yeni bir araştırma, dil modellerinin eğitim verilerini dinamik olarak dengeleyerek, yalnızca %0.01 ek hesaplama yüküyle model performansını artıran yeni bir çerçeve öneriyor. Bu yöntem, veri kullanım verimliliğini optimize etmeyi ve daha küçük bir maliyetle model performansında iyileşme sağlamayı amaçlıyor. (kaynak: _akhaliq)
Makale AI Güvenliğine Yeni Bir Bakış Açısı Getiriyor: Toplumsal ve Teknolojik İlerlemeyi Bir Yorganı Yamamak Olarak Görüyor: arXiv’de yayınlanan “Societal and technological progress as sewing an ever-growing, ever-changing, patchy, and polychrome quilt” başlıklı yeni bir makale, AI güvenliğinin temelini anlaşmazlıkların çatışmaya dönüşmesini önlemeye odaklayan yeni bir AI güvenlik görüşü öneriyor. Makale, toplumsal ve teknolojik ilerlemeyi sürekli büyüyen, değişen, yamalı ve çok renkli bir yorganı dikmeye benzeterek, karmaşık sistemlerde istikrar ve işbirliğini sürdürmenin önemini vurguluyor. (kaynak: jachiam0)
Makale, Otoregresif Dil Modellerinde Uyarlanabilir Hesaplamayı Tartışıyor: Tartışma, derin öğrenmede uyarlanabilir hesaplamanın ilginçliğine değiniyor ve ilgili teknolojik gelişmeleri sıralıyor: PonderNet (DeepMind, 2021) sinir ağları ve döngüleri entegre eden erken bir araç olarak; çoklu ileri yayılımlar yoluyla hesaplama yapan difüzyon modelleri; ve son zamanlarda keyfi sayıda token üreterek benzer etkiler elde eden çıkarım tipi dil modelleri. Bu, modellerin hesaplama kaynaklarının tahsisi ve kullanımındaki esneklik ve dinamiklik eğilimlerini yansıtıyor. (kaynak: jxmnop)
Makale “Kötü Verilerin” Nasıl “İyi Modellere” Yol Açabileceğini İnceliyor: Harvard Üniversitesi’nden 2025 tarihli bir makale (“When Bad Data Leads to Good Models”, arXiv:2505.04741), bazı durumlarda, görünüşte düşük kaliteli verilerin (örneğin 4chan içeriği içeren ön eğitim verileri) model uyumuna ve “güç seviyesini” (power level) gizlemesine yardımcı olarak daha iyi performans göstermesine nasıl katkıda bulunabileceğini inceliyor. Bu, veri kalitesi, model uyumu ve model davranışının gerçekliği hakkında tartışmalara yol açıyor. (kaynak: teortaxesTex)

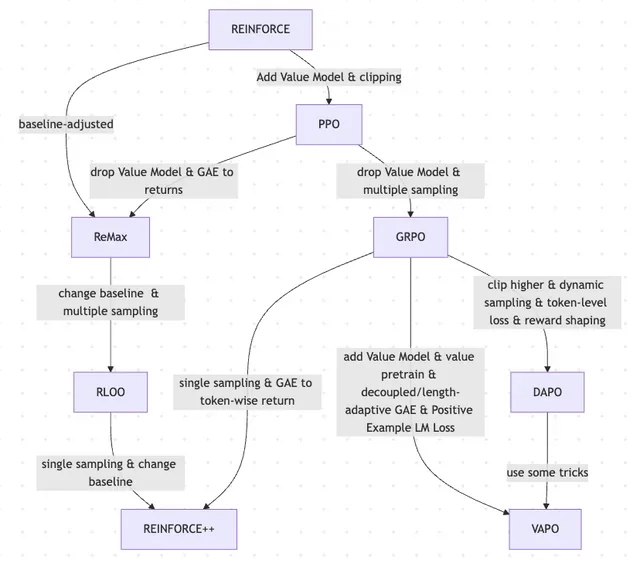
Makale RLHF ve Varyantlarının REINFORCE’dan VAPO’ya Evrimini İnceliyor: Bir araştırma makalesi, büyük dil modellerini (LLM’ler) ince ayarlamak için kullanılan pekiştirmeli öğrenme (RL) yöntemlerinin evrim sürecini özetliyor. Makale, klasik PPO ve REINFORCE algoritmalarından başlayarak GRPO, ReMax, RLOO, DAPO ve VAPO gibi yakın tarihli yöntemlere kadar olan evrimi izliyor; değer modellerinin terk edilmesi, örnekleme stratejilerinin değiştirilmesi, temel çizgilerin ayarlanması ve ödül şekillendirme ile token düzeyinde kayıp gibi tekniklerin uygulanmasını analiz ediyor. Bu araştırma, RLHF ve varyantlarının LLM uyum alanındaki araştırma haritasını net bir şekilde göstermeyi amaçlıyor. (kaynak: Reddit r/MachineLearning)
Makale “Absolute Zero”: AI’nın İnsan Verisi Olmadan Pekiştirmeli Öz-Öğrenme ile Çıkarım Yapması: “Absolute Zero: Reinforced Self-Play Reasoning with Zero Data” (arXiv:2505.03335) başlıklı bir teknik rapor, mantıksal AI eğitmek için yeni yöntemler araştırıyor. Araştırmacılar, insan etiketli veri kümeleri kullanmadan mantıksal AI modellerini eğitiyor; model, kendi kendine çıkarım görevleri üretebiliyor, sorunları çözebiliyor ve çözümleri kod yürütme yoluyla doğrulayabiliyor. Bu, AI’nın tamamen ön bilgi (matematik, fizik, dil gibi) olmadan, sıfırdan sembolik temsiller icat edip edemeyeceği, mantıksal yapılar tanımlayıp geliştiremeyeceği, sayı sistemleri geliştirip nedensel modeller kurup kuramayacağı ve bu tür “farklı bir zekanın” potansiyeli ve riskleri hakkında tartışmalara yol açıyor. (kaynak: Reddit r/ArtificialInteligence, Reddit r/artificial)
Fudan Üniversitesi Akıllı İnsan-Makine Etkileşimi Laboratuvarı 2026 Sınıfı Yüksek Lisans ve Doktora Öğrencileri Arıyor: Fudan Üniversitesi Bilgisayar Bilimleri ve Teknolojisi Fakültesi’ne bağlı Akıllı İnsan-Makine Etkileşimi Laboratuvarı, 2026 sınıfı yaz kampı/tavsiye ile kabul edilecek yüksek lisans ve doktora öğrencileri arıyor. Laboratuvar, Profesör Shang Li tarafından yönetilmekte olup, araştırma alanları arasında giyilebilir AGI (MemX akıllı gözlükler ve LLM entegrasyonu), açık kaynaklı somutlaştırılmış zeka, model sıkıştırma (büyükten küçüğe) ve makine öğrenimi sistemleri (ML derleyici optimizasyonu, AI işlemcileri gibi) bulunmaktadır. Laboratuvar, insan merkezli zekayı keşfetmeye, büyük modelleri akıllı giyilebilir cihazlar ve somutlaştırılmış zeka sistemleriyle birleştiren yeni insan-makine etkileşimi paradigmalarını araştırmaya adanmıştır. (kaynak: WeChat)

💼 İŞ DÜNYASI
Değeri 1 Milyar Doları Aşan ve Çalışan Sayısı 50’den Az Olan 10 AI Girişimine Genel Bakış: Business Insider, değeri 1 milyar doları aşan ancak çalışan sayısı 50’den az olan 10 AI girişimini sıraladı. Bunlar arasında Safe Superintelligence (değeri 32 milyar dolar, 20 çalışan), OG Labs (değeri 2 milyar dolar, 40 çalışan), Magic (değeri 1.58 milyar dolar, 20 çalışan), Sakana AI (değeri 1.5 milyar dolar, 28 çalışan) gibi şirketler bulunuyor. Bu şirketler, AI alanında küçük ekiplerle yüksek değerlemelere ulaşma potansiyelini gösteriyor ve teknoloji ile inovasyonun sermaye piyasalarındaki yüksek değerini yansıtıyor. (kaynak: hardmaru)
Fourier Intelligence, Bakım ve Rehabilitasyon Senaryolarını Derinleştiriyor, Şanghay Uluslararası Tıp Merkezi ile Somutlaştırılmış Zeka Rehabilitasyon Üssü Kurmak İçin İşbirliği Yapıyor: Somutlaştırılmış zeka alanında tek boynuzlu at olan Fourier, ilk Somutlaştırılmış Zeka Ekoloji Zirvesi’nde, Şanghay Uluslararası Tıp Merkezi ile işbirliği yaparak somutlaştırılmış zeka robotlarının rehabilitasyon tıbbı senaryolarındaki uygulamasını ortaklaşa teşvik edeceğini duyurdu. Bu işbirliği, standartların oluşturulması, çözümlerin ortaklaşa geliştirilmesi ve bilimsel araştırmaların yürütülmesini kapsayacak ve Çin’in ilk somutlaştırılmış zeka rehabilitasyon gösteri üssünü kuracak. Fourier’in kurucusu Gu Jie, önümüzdeki on yıl için temel stratejinin “bakım ve rehabilitasyona odaklanmak, etkileşime odaklanmak ve insanlara hizmet etmek” olduğunu belirtti ve tıbbi rehabilitasyonun temelleri olduğunu vurguladı. Şirket, 2015 yılında kurulduğundan bu yana rehabilitasyon robotlarından genel amaçlı insansı robotlar GR-1 ve GRx serilerine kadar genişledi ve yüzlerce adet sattı. (kaynak: 36氪)
Meta’nın Eski Pentagon Yetkililerini İşe Aldığı İddia Ediliyor, Askeri Alandaki Varlığını Güçlendirebilir: Forbes’un haberine göre, Meta şirketi eski Pentagon yetkililerini işe alıyor. Bu hamle, şirketin askeri teknoloji veya savunma ile ilgili alanlardaki faaliyetlerini güçlendirmeyi planladığı anlamına gelebilir. Bu gelişme, büyük teknoloji şirketlerinin askeri uygulamalara katılımı konusunda tartışmalara ve endişelere yol açtı. (kaynak: Reddit r/artificial)

🌟 TOPLULUK
Andrej Karpathy’nin LLM Öğreniminde Önemli Bir Paradigma Olan “Sistem Prompt’u Öğrenimi”nin Eksik Olduğu Yönündeki Görüşü Yoğun Tartışmalara Neden Oldu: Andrej Karpathy, mevcut LLM öğreniminde “sistem prompt’u öğrenimi” adını verdiği önemli bir paradigmanın eksik olduğunu düşünüyor. Ön eğitimin bilgi için, ince ayarın (denetimli/pekiştirmeli öğrenme) ise alışkanlık davranışları için olduğunu ve her ikisinin de parametre değişikliği içerdiğini belirtiyor, ancak büyük miktarda insan etkileşimi ve geri bildiriminin yeterince kullanılmadığını savunuyor. Bunu, küresel sorun çözme bilgisi ve stratejilerini depolamak için “Memento” filmindeki başkahramana bir not defteri vermeye benzetiyor. Bu görüş geniş çaplı tartışmalara yol açtı; bazıları bunun DSPy’nin felsefesine benzediğini veya bellek/optimizasyon, sürekli öğrenme sorunlarını içerdiğini düşünüyor ve Langgraph’ta benzer bir mekanizmanın nasıl uygulanabileceğini tartışıyor. (kaynak: lateinteraction, hwchase17, nrehiew_, tokenbender, lateinteraction, lateinteraction)
AI Şirketlerinin İş Başvurularında AI Kullanılmamasını İstemesi Tartışma Yarattı: Anthropic gibi AI şirketlerinin iş başvurularında (özgeçmiş gibi) AI araçlarının kullanılmamasını istemesi toplulukta tartışmalara yol açtı. Bazı işe alım uzmanları, AI tarafından oluşturulan özgeçmişlerde “metin çöpü” olgusunun ciddi olduğunu ve deneyimli kişilerin bile bu nedenle odak noktasını kaybedebileceğini belirtti. Ancak bazı iş arayanlar, AI’nın pozisyon gereksinimlerine göre özgeçmişlerini daha iyi optimize etmelerine, becerilerini vurgulamalarına ve okunabilirliği artırmalarına yardımcı olabileceğini düşünüyor. Tartışma, LinkedIn gibi platformların AI tarafından oluşturulan içeriklerle dolup taşması ve iş arayanları değerlendirmek için video gibi başka yöntemlerin kullanılıp kullanılmaması gerektiği konularına da uzandı. (kaynak: Reddit r/artificial, Reddit r/ArtificialInteligence)

AI Tarafından Üretilen İçeriğin “Tanınabilirliği” Tartışma Konusu Oldu, Kullanıcılar Kolayca Fark Edilebildiğini Düşünüyor: Topluluk tartışmaları, AI (özellikle ChatGPT) tarafından üretilen içeriğin kolayca tanınabildiğini belirtiyor; bunun nedeni yalnızca belirli noktalama işaretleri (em tireleri gibi) veya cümle yapıları (“Bu x değil; bu y.” gibi) değil, aynı zamanda kendine özgü “ritim duygusu” ve “yavanlığı”. AI izleri bir kez tanındığında, içerik gerçek dışı ve kişiliksiz görünüyor. Bazı kullanıcılar e-postalarda, sosyal medya gönderilerinde ve hatta video oyunlarında bu tür durumlarla karşılaştıklarını belirterek, AI tarafından üretilen içeriğin doğrudan kullanılmasının içeriği sıkıcı ve samimiyetsiz hale getireceğini ve kullanıcıların AI’yı bir araç olarak kullanarak değişiklikler yapıp kişiselleştirmeleri gerektiğini öne sürüyor. (kaynak: Reddit r/ChatGPT)
AI Gelişimi “Balayı Dönemi-Tepki Dönemi” Döngüsü Sergiliyor, İnsanların Gerçekliğe Olan Tercihini Yansıtıyor: Bir görüşe göre, yeni üretken AI modellerinin (metin, görüntü, müzik vb.) ortaya çıkışı genellikle insanların yeteneklerine hayran kaldığı bir “balayı dönemi” ile birlikte gelir. Ancak kısa süre sonra, insanlar AI tarafından üretilen “kalıpları” veya “izleri” tanımaya başladıklarında bir tepki oluşur; övgüden şüpheye, hatta “ruhu olmadığı” düşüncesine kadar varan bir tepki. AI eserlerini hızla tanımayı öğrenme ve kusurlu insan yaratılarına yönelme eğilimi, AI’nın insan yaratıcılarının yerini tamamen almaktan ziyade daha çok bir yardımcı araç olduğu anlamına gelebilir, çünkü insanlar eserlerin arkasındaki hikayeye, yazarın niyetine ve gerçekliğe değer verirler. (kaynak: Reddit r/ArtificialInteligence)
Anthropic’in Şirket İçi AI Kod Üretim Oranının %70’i Aşması, AI’nın Kendi Kendine Yinelemesi Konusunda Çağrışımlar Uyandırdı: Anthropic’ten Mike Krieger, şirket içindeki pull request’lerin %70’inden fazlasının artık AI tarafından üretildiğini açıkladı. Bu veri, toplulukta tartışmalara yol açtı; bazıları bunu bilim kurgu eserlerindeki sahnelere benzer şekilde makinelerin kendi kendini düzenlemesi ve iyileştirmesi senaryolarıyla ilişkilendirdi. Aynı zamanda, bazıları bu verinin gerçekliği ve özel anlamı (örneğin bu PR’ların karmaşıklık derecesi) hakkında şüphelerini dile getirdi. (kaynak: Reddit r/ClaudeAI)

Nvidia CEO’su Jensen Huang, Tüm Çalışanların AI Agent’larını Benimsemesini Vurguladı, AI Geliştirici Rolünü Yeniden Şekillendirecek: Nvidia CEO’su Jensen Huang, şirketin tüm çalışanlarına AI asistanları sağlayacağını ve AI agent’larının günlük geliştirmeye entegre edilerek kodu optimize edeceğini, açıkları bulacağını ve prototip tasarımını hızlandıracağını belirtti. Gelecekte herkesin birden fazla AI asistanını yöneteceğini ve üretkenliğin katlanarak artacağını düşünüyor. Meta CEO’su Zuckerberg, Microsoft CEO’su Nadella gibi isimler de benzer görüşlere sahip olup, AI’nın kodlama işlerinin çoğunu yapacağını ve geliştirici rolünün “AI’yı yönetmek” ve “gereksinimleri tanımlamak” şeklinde dönüşeceğini belirtiyorlar. Bu eğilim, yazılım geliştirme döngüsünün büyük ölçüde değişeceğini ve GitHub Copilot, Cursor gibi AI programlama araçlarının yaygınlaşacağını gösteriyor. (kaynak: WeChat)

Tartışma: ML Araştırmacılarının Yılda 1000-2000 Makale Okuması Mümkün mü?: Toplulukta, önde gelen makine öğrenimi araştırmacılarının yılda yaklaşık 2000 makale okuyabileceğine dair bir tartışma var. Buna karşılık, bazı yorumcular makale okuma sayısının yalnızca bir vekil gösterge olduğunu, asıl önemli olanın büyük miktarda bilgiden sinyalleri filtreleme, etkili bilgileri çıkarma ve doğru bir şekilde uygulama yeteneği olduğunu belirtiyor. Alandaki önemli gelişmeleri ve eğilimleri takip edebilmek ve gerektiğinde belirli konuları derinlemesine araştırabilmek, bu bilgi filtreleme yeteneğinin bu yüzyılın temel becerilerinden biri olduğunu vurguluyorlar. (kaynak: torchcompiled)
Tartışma: Model Eğitimi/İnce Ayarı İçin GPU Satın Almak mı, Kiralamak mı?: Makine öğrenimi uygulayıcıları, GPU kaynaklarını seçerken satın alma veya kiralama arasında bir karar vermekle karşı karşıyadır. Deneyimli kişiler karma bir strateji önermektedir: küçük deneyler için yerel olarak makul performanslı bir tüketici sınıfı GPU yapılandırmak, büyük ölçekli eğitim görevleri için ise bulut GPU kiralamak. Seçim, model karmaşıklığına, veri miktarına ve bütçeye bağlıdır. Bulut GPU’lar ML Ops organizasyonu açısından avantajlıdır, ancak aynı fiyata T4 gibi yaygın bulut GPU’larının performansı üst düzey tüketici kartlarından (3090/4090 gibi) daha düşük olabilir; bununla birlikte bulut, daha büyük belleğe sahip A100/H100 gibi en üst düzey GPU’ları sunabilir. (kaynak: Reddit r/MachineLearning)
💡 DİĞER
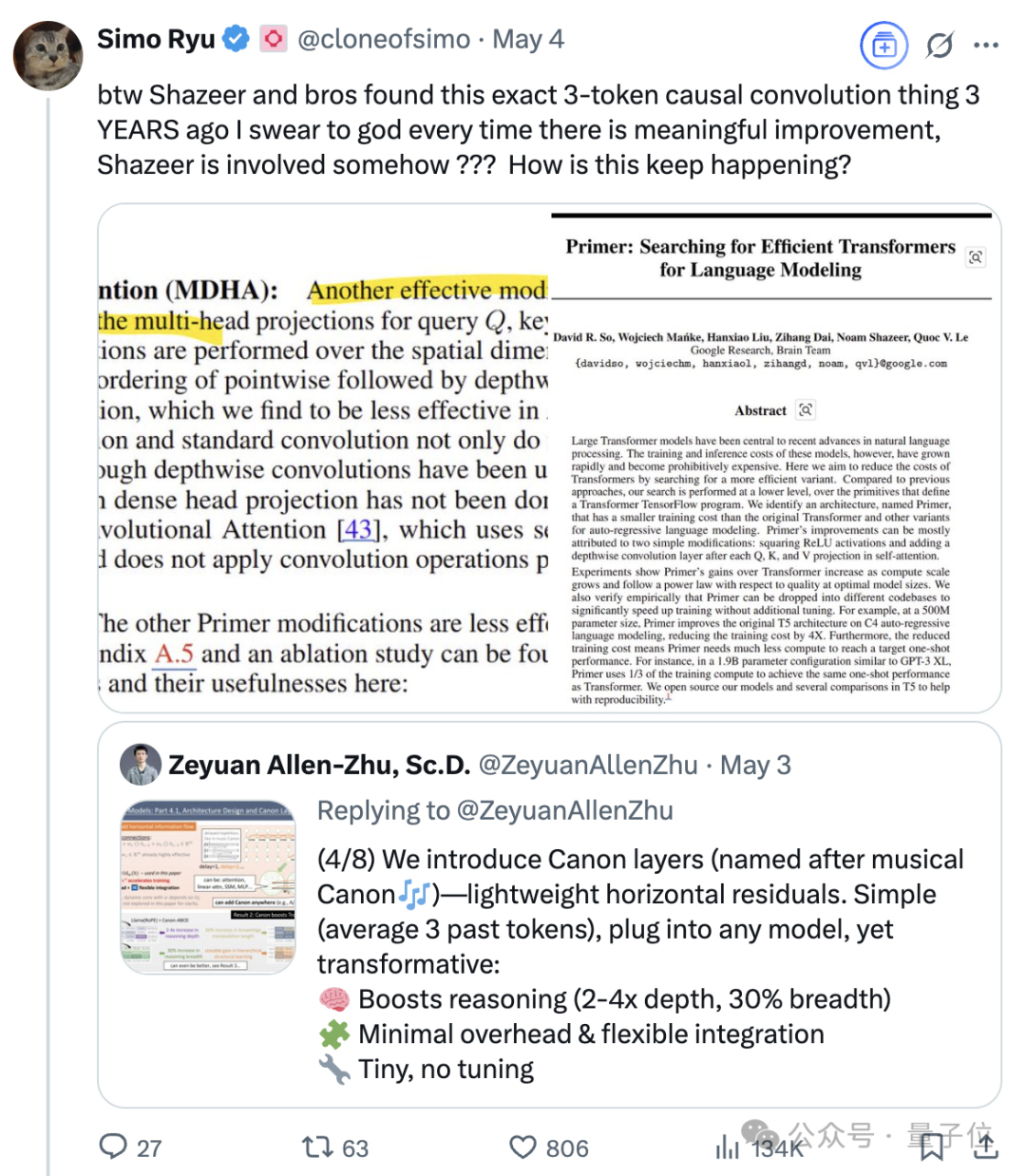
Transformer Sekizlisinden Biri Olan Noam Shazeer’in Süregelen Etkisi: Transformer mimarisi makalesi “Attention Is All You Need”in sekiz yazarından biri olan Noam Shazeer’in katkıları geniş çapta en büyüğü olarak kabul ediliyor. Etkisi bununla da sınırlı kalmıyor; seyrek kapılı uzman karışımını (MoE) dil modellerine erken dönemde dahil etme çalışmaları, Adafactor optimize edicisi, çoklu sorgu dikkati (MQA) ve Transformer’daki kapılı doğrusal katmanlar (GLU) gibi çalışmaları da içeriyor. Bu çalışmalar, mevcut ana akım büyük dil modeli mimarilerinin temelini attı ve Shazeer’in AI alanında teknolojik paradigmaları sürekli olarak tanımlayan kilit isimlerden biri olarak kabul edilmesini sağladı. Google’dan ayrılarak Character.AI’ı kurmuş, daha sonra şirketin satın alınmasıyla Google’a geri dönerek Gemini projesini ortaklaşa yönetmiştir. (kaynak: WeChat)
Teknoloji Devleri AI’nın Tetiklediği “Orta Yaş Krizi” ile Karşı Karşıya: Makale, Google, Apple, Meta, Tesla dahil olmak üzere “teknoloji yedi devinin” yapay zekanın getirdiği yıkıcı zorluklarla karşı karşıya olduğunu ve bir “orta yaş krizine” girdiğini analiz ediyor. Google’ın arama işi, AI’nın doğrudan yanıt verme modelinden tehdit altında, Apple AI inovasyonunda yavaş ilerliyor, Meta AI’yı sosyal medyaya entegre etmeye çalışıyor ancak Llama 4 beklenen performansı göstermedi ve Tesla satış ve hisse senedi fiyatlarında düşüş baskısıyla karşı karşıya. Bu eski sektör liderleri, “Yenilikçinin İkilemi”ndeki vakalar gibi, AI’nın getirdiği yeni pazarların ve yeni modellerin etkisine yanıt vermek zorunda, aksi takdirde AI çağının “Nokia”sı olabilirler. (kaynak: WeChat)

Google AI, Simüle Edilmiş Tıbbi Diyaloglarda İnsan Doktorlardan Daha İyi Performans Gösterdi: Araştırmalar, tıbbi görüşmeler yapmak üzere eğitilmiş bir AI sisteminin, simüle edilmiş hastalarla diyalog kurma ve hastalık geçmişine göre olası teşhisleri listeleme konusunda insan doktorlarla eşleştiğini ve hatta onları geçtiğini gösteriyor. Araştırmacılar, bu tür bir AI sisteminin sağlık hizmetlerinin yaygınlaştırılmasına ve demokratikleştirilmesine yardımcı olma potansiyeline sahip olduğuna inanıyor. (kaynak: Reddit r/ArtificialInteligence)
