
Anahtar Kelimeler:ChatGPT, GitHub, AI modeli, çok modlu, pekiştirmeli öğrenme, açık kaynak, Meta FAIR, AGI, ChatGPT derin araştırma özelliği, hibrit Transformer mimarisi, pekiştirmeli ince ayar RFT, AI çoklu dünya modeli Multiverse, bilim insanı AI çerçevesi
🔥 Öne Çıkanlar
ChatGPT Deep Research özelliği GitHub ile entegre edildi: OpenAI, ChatGPT’nin Deep Research özelliğinin artık GitHub kod depolarına bağlanmayı desteklediğini duyurdu. Kullanıcılar soru sorduktan sonra, yapay zeka ajanı kod deposundaki kaynak kodunu, PR’ları ve README gibi belgeleri otomatik olarak okuyabilir, arayabilir ve analiz edebilir, doğrudan alıntılar içeren ayrıntılı raporlar oluşturabilir. Bu özellik, geliştiricilerin projelere hızla aşina olmalarına, kod yapısını ve teknoloji yığınını anlamalarına yardımcı olmayı amaçlıyor. Bu özellik şu anda test aşamasında olup Team kullanıcılarına sunulmuştur ve yakında Plus ve Pro kullanıcılarına da sunulacaktır. (Kaynak: OpenAI Developers, snsf, EdwardSun0909, op7418, gdb, tokenbender, 量子位, 36氪)

Dünyanın ilk yapay zeka çok oyunculu dünya modeli Multiverse açık kaynak oldu: İsrailli startup Enigma Labs, geliştirdiği çok oyunculu dünya modeli Multiverse’ü açık kaynak olarak yayınladı. Bu model, iki yapay zeka ajanının aynı üretilmiş ortamda algılamasına, etkileşimde bulunmasına ve işbirliği yapmasına olanak tanıyor. Model, Gran Turismo 4 üzerinde eğitilmiş olup, paylaşılan dünya durumunu işlemek için iki oyuncunun bakış açılarını renk kanalları boyunca yığarak ve seyrek örneklenmiş geçmiş kareleri birleştirerek PC’de 1500 doların altında bir maliyetle eğitilip gerçek zamanlı olarak çalıştırılabilmektedir. Bu gelişme, yapay zekanın paylaşılan sanal ortamları anlama ve üretme konusunda önemli bir ilerleme olarak görülüyor ve çoklu ajan sistemleri ile simülasyon eğitim platformları için yeni fikirler sunuyor. (Kaynak: Reddit r/MachineLearning, 36氪)
Önde gelen yapay zeka bilimcisi Rob Fergus, Meta FAIR’in başına geçerek AGI’yi hedefliyor: Yann LeCun ile birlikte FAIR’i kuran ve daha sonra DeepMind’ın New York ekibine liderlik eden Rob Fergus, Joelle Pineau’nun yerine FAIR’in başına geçmek üzere Meta’ya geri döndü. Fergus, bu yılın Nisan ayında Meta’nın GenAI bölümüne katılarak Llama modellerinin hafıza ve kişiselleştirme yeteneklerini geliştirmeye odaklandı. LeCun aynı zamanda FAIR’in yeni hedefinin Gelişmiş Makine Zekası (AGI) olacağını duyurdu. Fergus, yapay zeka alanında çok atıf alan bir akademisyen olup, ZFNet’in görselleştirme araştırması ve çelişkili örnekler üzerine öncü çalışmalarıyla tanınmaktadır. (Kaynak: ylecun, 36氪)

Anthropic, Claude AI değerleri araştırmasını yayınladı ve 3307 yapay zeka değer eğilimini ortaya koydu: Anthropic araştırma ekibi, Claude AI’nin gerçek dünya diyaloglarındaki performansını analiz ederek 3307 benzersiz yapay zeka değerini tanımlayan “Values in the Wild” başlıklı bir ön baskı makalesi yayınladı. Araştırma, en yaygın değerlerin “yardımseverlik” (%23,4), “profesyonellik” (%22,9) ve “şeffaflık” (%17,4) gibi hizmet odaklı değerler olduğunu buldu. Yapay zeka değerleri beş üst kategoriye ayrıldı: pratik (%31,4), bilişsel (%22,2), sosyal (%21,4), koruyucu (%13,9) ve kişisel (%11,1) ve yüksek derecede bağlamsal bağımlılık gösterdi. Claude genellikle insanların ifade ettiği değerlere destekleyici bir şekilde yanıt verdi (%43), değer yansıtma yaklaşık %20’sini oluştururken, kullanıcı değerlerine direnç nadiren görüldü (%5,4). (Kaynak: Reddit r/ArtificialInteligence)
Yoshua Bengio, daha güvenli bir yapay zeka geliştirme yolu öneren “Scientist AI” çerçevesini sundu: Turing Ödülü sahibi Yoshua Bengio, Time dergisinde yayınlanan bir köşe yazısında ekibinin “Scientist AI” (Bilim İnsanı Yapay Zeka) araştırma yönünü açıkladı. Bunun, mevcut kontrolsüz, ajan odaklı yapay zeka geliştirme yörüngesinin yerini almayı amaçlayan pratik, etkili ve daha güvenli bir yapay zeka geliştirme yolu olduğunu savundu. Bu çerçeve, yapay zeka sistemlerinin yorumlanabilirlik, doğrulanabilirlik ve insan değerleriyle uyum yeteneklerine sahip olması gerektiğini vurguluyor ve bilimsel araştırma metodolojisini simüle ederek yapay zekanın davranış ve karar alma süreçlerini daha şeffaf ve kontrol edilebilir hale getirerek potansiyel riskleri azaltmayı hedefliyor. (Kaynak: Yoshua_Bengio)
🎯 Gelişmeler
OpenAI Pekiştirmeli İnce Ayar (RFT) özelliği o4-mini’de resmi olarak kullanıma sunuldu: OpenAI, geçen yıl Aralık ayında önizlemesi yapılan Pekiştirmeli İnce Ayar (RFT) özelliğinin artık o4-mini modelinde resmi olarak kullanılabilir olduğunu duyurdu. RFT, modelin karmaşık alanlardaki performansını artırmak için düşünce zinciri çıkarımı ve göreve özgü puanlamayı kullanır. Örneğin, AccordanceAI şirketi, vergi ve muhasebe alanında üstün performans gösteren bir model ince ayarı yapmak için RFT’yi kullanmıştır. (Kaynak: OpenAI Developers, gdb, 量子位, 36氪)
Gemini API, %75 çağrı maliyetini düşüren örtük önbellekleme özelliğini kullanıma sundu: Google Gemini API, kullanıcı isteği önceki bir istekle ortak bir öneke sahip olduğunda otomatik olarak önbellek isabetini tetikleyebilen ve kullanıcılara Token ücretlerinde %75 tasarruf sağlayan yeni bir örtük önbellekleme özelliği ekledi. Bu özellik, geliştiricilerin aktif olarak bir önbellek oluşturmasını gerektirmez. Aynı zamanda, önbelleği tetikleyen minimum Token gereksinimi Gemini 2.5 Flash’ta 1K’ya ve 2.5 Pro’da 2K’ya düşürülerek API kullanım maliyetleri daha da azaltıldı. (Kaynak: op7418)

OpenAI, ChatGPT hafıza özelliğini Avrupa Ekonomik Alanı ve diğer birçok bölgede tam olarak kullanıma sundu: OpenAI, ChatGPT’nin hafıza özelliğinin Avrupa Ekonomik Alanı (EEA), Birleşik Krallık, İsviçre, Norveç, İzlanda ve Lihtenştayn’daki Plus ve Pro kullanıcıları için tam olarak kullanıma sunulduğunu duyurdu. Bu özellik, ChatGPT’nin daha kişiselleştirilmiş yanıtlar sunmak, kullanıcı tercihlerini ve ilgi alanlarını daha iyi anlamak ve böylece yazma, tavsiye verme, öğrenme gibi konularda daha doğru yardım sağlamak için kullanıcının geçmiş tüm sohbet kayıtlarına başvurmasına olanak tanır. (Kaynak: openai)
ByteDance SEED, çok modlu temel model Mogao’yu tanıttı: ByteDance’in SEED ekibi, özellikle geçişli çok modlu üretim için tasarlanmış Mogao adlı bir Omni temel modelini yayınladı. Mogao, derin füzyon tasarımı, çift görsel kodlayıcı, geçişli dönel konum gömme ve çok modlu sınıflayıcısız yönlendirme dahil olmak üzere birçok teknik iyileştirmeyi entegre eder. Bu iyileştirmeler, otoregresif modellerin (metin üretimi) ve difüzyon modellerinin (yüksek kaliteli görüntü sentezi) avantajlarını birleştirerek rastgele geçişli metin ve görüntü dizilerini etkili bir şekilde işlemesini sağlar. (Kaynak: NandoDF)

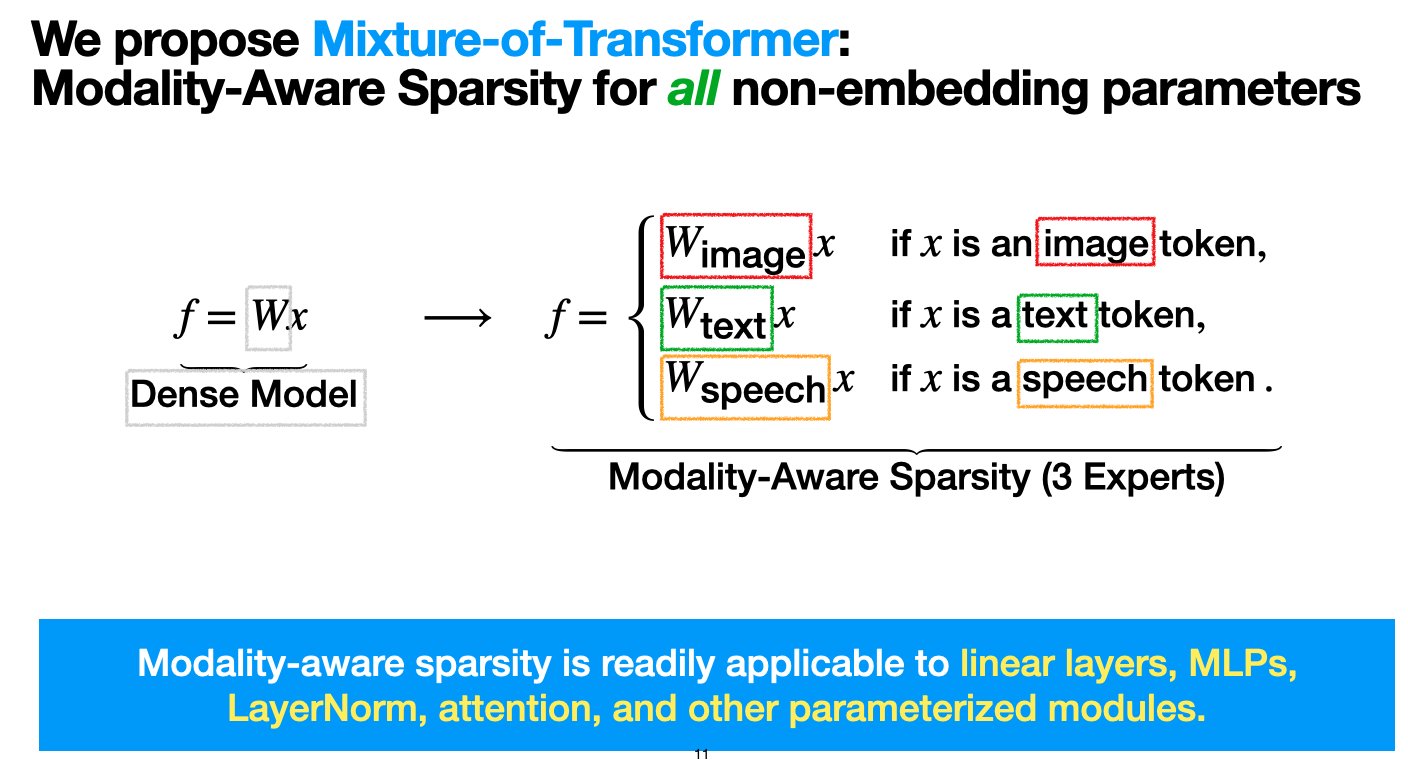
Meta, çok modlu model ön eğitim maliyetlerini düşürmeyi amaçlayan hibrit Transformer (MoT) mimarisini tanıttı: Meta AI araştırmacıları, performanstan ödün vermeden çok modlu model ön eğitiminin hesaplama maliyetini önemli ölçüde azaltmayı amaçlayan “Mixture-of-Transformers (MoT)” adlı seyrek bir mimari önerdi. MoT, ileri beslemeli ağlar, dikkat matrisleri ve katman normalizasyonu gibi gömülü olmayan Transformer parametreleri için modaliteye duyarlı seyreklik kullanır. Deneyler, Chameleon (metin + görüntü üretimi) ayarında, 7B MoT modelinin yoğun taban çizgisi kalitesine yalnızca %55,8 FLOPs ile ulaştığını göstermiştir; üçüncü bir modalite olarak konuşma eklendiğinde ise yalnızca %37,2 FLOPs kullanılmıştır. Bu araştırma TMLR (Mart 2025) tarafından kabul edilmiş olup kodu açık kaynaklıdır. (Kaynak: VictoriaLinML)
Qwen model iyileştirme projesi Smoothie Qwen, çok dilli üretimi dengelemek için yayınlandı: Smoothie Qwen adlı bir Qwen model iyileştirme projesi, modelin iç parametrelerinin olasılıklarını ayarlayarak çok dilli üretim yeteneklerini dengelemeyi amaçlayarak yayınlandı. Proje, temel olarak Qwen kullanırken bazı Çince olmayan kullanıcıların ara sıra Çince çıktı alması sorununu çözmeyi amaçlıyor ve modelin zekasını düşürmeyeceğini iddia ediyor. (Kaynak: karminski3)

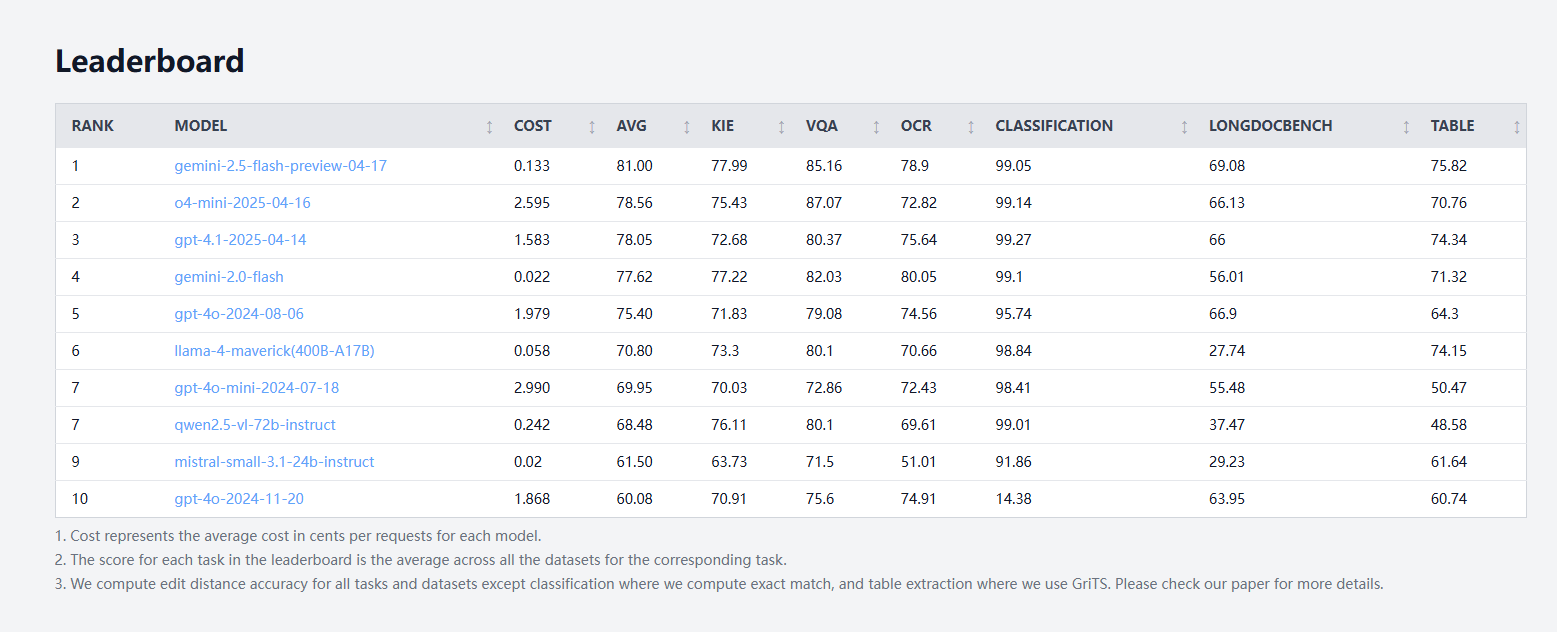
idp-leaderboard yayınlandı, ilk belge türü yapay zeka test kıyaslaması: Yeni yapay zeka test kıyaslaması idp-leaderboard, modellerin belgeleri ve belge görüntülerini işleme yeteneğini değerlendirmeye odaklanarak kullanıma sunuldu. İlk sıralamalara göre, gemini-2.5-flash-preview-04-17 genel belge işlemede en güçlü performansı sergiliyor. Qwen2.5-VL’nin tablo işleme performansında düşük performans göstermesi dikkat çekicidir. (Kaynak: karminski3)
Perplexity Discover özelliği önemli bir güncelleme aldı: Perplexity’nin kurucu ortağı Arav Srinivas, Discover özelliğinin (bilgi akışını keşfetme) önemli ölçüde geliştirildiğini duyurdu ve kullanıcıları deneyimlemeye teşvik etti. Bu genellikle, kullanıcıların yeni bilgileri edinme ve keşfetme yeteneğini artırmayı amaçlayan bilgi sunumu, alaka düzeyi veya kullanıcı arayüzü optimizasyonları anlamına gelir. (Kaynak: AravSrinivas)
Lenovo, Tianxi kişisel süper akıllı ajanının büyük bir yükseltmesini ve dünyanın ilk tablette yerel olarak DeepSeek dağıtımını duyurdu: Lenovo, Tianxi kişisel süper akıllı ajanının kapsamlı L3 seviyesine doğru büyük bir yükseltme aldığını ve kişisel akıllı cihaz yapay zeka hizmetlerine odaklanan alan akıllı ajanı “Xiang Bang Bang”i piyasaya sürdüğünü duyurdu. Aynı zamanda Lenovo, tablet tarafında DeepSeek büyük modelini yerel olarak dağıtan dünyanın ilk YOGA Pad Pro 14.5 AI Yuanqi Sürümü, moto AI telefonları, Legion serisi PC’ler dahil olmak üzere birçok yapay zeka terminal ürününü piyasaya sürerek yapay zeka PC, yapay zeka telefon, yapay zeka tablet ve AIoT’den oluşan eksiksiz bir yapay zeka ekosistemi oluşturdu. (Kaynak: 量子位)

Lou Tiancheng (楼教主) otonom sürüş ve somutlaşmış zeka hakkında konuştu: L2, L4’e yükseltilemez, VLA’nın L4’e yardımı sınırlı: Pony.ai kurucu ortağı ve CTO’su Lou Tiancheng, yeni nesil Robotaxi modelini tanıtırken otonom sürüş ve yapay zeka hakkındaki en son görüşlerini paylaştı. L2 ile L4 arasındaki temel farkı vurgulayarak, L2’nin L4’e yükseltilemeyeceğini ve mevcut L2 alanındaki popüler VLA (Görsel-Dil-Eylem) paradigmasının L4’e “temelde pek yardımcı olamayacağını” belirtti. L4’ün uzman bir doktor gibi aşırı güvenlik gerektirdiğini, VLA’nın ise daha çok pratisyen hekime benzediğini belirtti. Pony.ai’nin son iki yıldaki teknolojik dönüşümünün temelinde uçtan uca ve yaklaşık 5 yıldır uygulanan dünya modeli yer alıyor. Ayrıca “bulut tabanlı sürüşün” sahte bir kavram olduğunu düşündüğünü ve somutlaşmış zekanın mevcut durumunun 2018’deki otonom sürüşe benzediğini ve benzer “boşluk dönemi” zorluklarıyla karşılaşacağını belirtti. (Kaynak: 量子位)

Kimi içerik topluluğunu test ediyor, OpenAI sosyal uygulama geliştirebilir, yapay zeka büyük model şirketleri kullanıcı bağlılığını artırmak için sosyalleşmeyi araştırıyor: Moonshot AI’ın Kimi’si, temel olarak yapay zekanın teknoloji, finans gibi alanlara odaklanarak haber başlıklarını alıp içerik ürettiği bir içerik topluluğu ürününü gri ölçekte test ediyor. Tesadüfen, OpenAI’nin de X’e rakip olabilecek bir sosyal yazılım geliştirmeyi planladığı bildiriliyor. Bu hamleler, yapay zeka büyük model şirketlerinin, yapay zeka araçlarının “kullan-at” sorununu çözmek için topluluk veya sosyal işlevler oluşturarak kullanıcı bağlılığını artırmaya çalıştığını gösteriyor. Ancak topluluk yönetimi, içerik kalitesi, güvenlik riskleri ve ticarileşme zorluklarıyla karşı karşıya. Bu hamle aynı zamanda yapay zeka endüstrisinin büyüme ivmesinin zirveye ulaşmasının ardından “büyüme için para yakmaktan” daha çok yatırım getirisine (ROI) odaklanmaya ve yeni iş modelleri keşfetmeye başladığını yansıtıyor. (Kaynak: 36氪)

TCL yapay zekayı tamamen benimsiyor, Fuxi büyük modelini ve birçok yapay zeka ev aletini piyasaya sürüyor, ancak homojenleşme zorluklarıyla karşı karşıya: TCL, AWE 2025, CES 2025 gibi fuarlarda TCL Fuxi büyük modeli ve televizyon, klima, çamaşır makinesi gibi ev aletlerinde uygulanan yapay zeka işlevleri dahil olmak üzere yapay zeka ürünlerini ve stratejisini öne çıkardı. Televizyon işi olağanüstü performans gösterdi, ilk çeyrek sevkiyatları küresel olarak birinci oldu ve Mini LED teknolojisi avantajıydı. Ancak, ev aletleri alanındaki yapay zeka uygulaması şu anda temel olarak sesli etkileşim ve belirli işlev optimizasyonlarına (yapay zeka görüntü kalitesi çipi, yapay zeka uyku, yapay zeka güç tasarrufu gibi) odaklanıyor ve diğer markalarla (Hisense Xinghai, Haier HomeGPT, Midea Meiyan gibi) homojen rekabet zorluklarıyla karşı karşıya. TCL ayrıca yapay zeka eşlik robotlarını ve Thunderbird aracılığıyla akıllı gözlük düzenini de araştırıyor. Yapay zeka yatırımları artmasına rağmen, bağımsız teknolojik avantajı henüz belirgin değil ve yüksek pazarlama maliyetleri, düşen brüt kar marjları gibi sorunlarla karşı karşıya. (Kaynak: 36氪)
Yapay zeka destekli eğitim dönüşümü, iFlytek, Zhuoyue Education gibi lider şirketler yapay zeka düzenini hızlandırıyor: Rapor, iFlytek, Zhuoyue Education, Fenbi, Zhonggong Education, Huatu Education, Yiqi Education Technology gibi lider eğitim şirketlerinin yapay zeka alanındaki en son uygulamalarını analiz ediyor. iFlytek, yerli bilgi işlem gücü ve Deepseek-V3/R1 modelleriyle bilgi teknolojisi eğitimine derinlemesine odaklanıyor. Zhuoyue Education, tüm öğretim zincirini güçlendirmek için Deepseek R1’i kullanıyor ve yapay zeka notlandırma ve yapay zeka okuma araçlarını piyasaya sürüyor. Fenbi, yüksek frekanslı öğrenmeyi ve temel ihtiyaç senaryolarını kapsayan bir yapay zeka ürün matrisi oluşturdu. Zhonggong Education, yapay zeka istihdam hizmetlerine odaklanıyor ve “Yunxin” büyük modelini geliştiriyor. Huatu Education, çevrimdışı avantajlarını birleştirerek kamu hizmeti sınav hizmetlerinin doğruluğunu artırmak için yapay zekayı kullanıyor. Yiqi Education Technology ise yapay zeka destekli öğretim değerlendirme entegrasyonunu kullanıyor. Sektör eğilimleri, yapay zeka eğitiminin tek nokta araçlarından ekosistem rekabetine ve değer gerçekleştirmeye doğru ilerlediğini gösteriyor. (Kaynak: 36氪)
Baidu, Alibaba gibi büyük şirketler MCP protokolünü zorluyor, yapay zeka Agent ekosisteminin tanım hakkı için yarışıyor: Model Bağlam Protokolü (MCP) son zamanlarda Anthropic, OpenAI, Google ve Çin’deki Baidu, Alibaba gibi büyük şirketler tarafından destekleniyor. Baidu’nun “Xīnxiǎng” uygulaması ve Alibaba Cloud’un Bailian platformu, yapay zeka Agent’larının harici araçları ve hizmetleri daha kolay çağırmasına olanak tanıyan MCP’yi zaten destekliyor. Bu hamle görünüşte endüstri standartlarını birleştirmek için olsa da, aslında büyük şirketlerin gelecekteki yapay zeka Agent ekosisteminin tanım hakkı için verdiği bir mücadeledir. MCP’yi oluşturup tanıtarak, büyük şirketler ekosistemlerine daha fazla geliştirici çekmeyi ve böylece veri engellerini ve endüstri söz hakkını ele geçirmeyi amaçlıyor. Agent uygulamalarının ticarileştirme yönü şu anda hala trafik ve reklama odaklanmış görünüyor. (Kaynak: 36氪)

Apple’ın yapay zeka stratejisi ortaya çıktı: Baidu, Alibaba ile işbirliği yaparak “çift çekirdekli” Çin versiyonu yapay zeka sistemi oluşturabilir: Raporlar, Apple’ın Çin pazarındaki yapay zeka özellikleri için teknoloji desteği sağlamak üzere Baidu ve Alibaba ile işbirliği yapabileceğini analiz ediyor. Baidu’nun Wenxin Yiyan’ı görsel tanımada avantajlıyken, Alibaba’nın Qianwen büyük modeli bilişsel anlama ve içerik uyumluluğunda öne çıkıyor. Bu “çift çekirdekli” model, Çin pazarının veri ekosistemi, teknoloji odağı ve düzenleyici gereksinimlerini karşılarken, Apple’ın işbirliğindeki hakimiyetini ve pazarlık gücünü korumayı amaçlayabilir. Bu hamle, Apple’ın HarmonyOS gibi yerel rekabet baskılarına ve veri düzenlemelerinin sıkılaştığı bir ortamda bir “ekolojik niş bölme” stratejisi olarak görülüyor. (Kaynak: 36氪)
Profesör Yu Jingyi uzaysal zekayı derinlemesine yorumluyor: Potansiyel çok büyük, ancak fikir birliği oluşmadı, veri ve fiziksel anlayış anahtar: Şanghay Teknoloji Üniversitesi’nden Profesör Yu Jingyi bir röportajda, büyük modellerin çapraz modal entegrasyondaki potansiyelinin henüz tükenmediğini, üretken yapay zekadaki atılımlar sayesinde uzaysal zekanın dijital kopyalamadan akıllı anlama ve yaratmaya doğru evrildiğini belirtti. Mevcut uzaysal zekanın temel zorluğunun gerçek 3D sahne verilerinin kıtlığı ve üç boyutlu ifade yöntemlerinin henüz birleştirilmemiş olması olduğunu düşünüyor. Ekibinin CAST projesi, “aktör-ağ teorisi” ve fiziksel kuralları tanıtarak nesneler arası ilişkileri ve fiziksel makuliyeti araştırıyor. Algılamanın önceliğini vurguluyor ve sensör teknolojisinde devrim niteliğinde bir atılım olacağını öngörüyor. Somutlaşmış zekanın ölçüm standardı saf doğruluk değil, sağlamlık ve güvenlik olmalıdır. Kısa vadede, uzaysal zeka film yapımı, oyunlar gibi alanlarda patlayacak, orta ve uzun vadede somutlaşmış zekanın çekirdeği olacak ve alçak irtifa ekonomisi de önemli bir uygulama senaryosudur. (Kaynak: 36氪)

Yapay zeka yetenek savaşı kızışıyor: Büyük şirketler yüksek maaşlarla yetenek avında, CTO’lar bizzat rehberlik ediyor, odak büyük modeller ve çok modluluk: Yurtiçi ve yurtdışındaki teknoloji devleri, yapay zeka yetenekleri için kıyasıya bir rekabet içinde. ByteDance, Alibaba, Tencent, Baidu, JD.com, Huawei gibi şirketler, en iyi doktora öğrencileri ve dahi gençler için üst sınırı olmayan maaşlar, CTO’ların bizzat rehberliği, staj deneyimi gerektirmeme gibi imkanlar sunan işe alım programları başlattı. İşe alım yönleri temel olarak büyük modeller ve çok modluluk alanlarına odaklanıyor ve şirketlerin temel iş senaryolarıyla yakından ilişkili. DeepSeek gibi modellerin başarısı, sektörün yeteneklere olan talebini daha da artırdı. Musk da yapay zeka yetenek rekabetinin çılgınlığından yakınmıştı; OpenAI gibi yurtdışı devler de yüksek maaşlar ve kurucuların bizzat işe alım yapması gibi yöntemlerle yetenekleri çekiyor. (Kaynak: 36氪)
Sequoia Capital: Yapay zeka pazar potansiyeli bulut bilişimi çok aşıyor, uygulama katmanı kilit önemde, Baş Yapay Zeka Sorumlusu standart olacak: Sequoia Capital ortağı, yapay zeka pazar büyüklüğünün mevcut yaklaşık 400 milyar dolarlık bulut bilişim pazarını çok aşacağını, önümüzdeki 10-20 yılda devasa bir hacme ulaşacağını ve değerin temel olarak uygulama katmanında yoğunlaşacağını öngörüyor. Startup’lar müşteri ihtiyaçlarına odaklanmalı, uçtan uca çözümler sunmalı, dikey alanlarda derinleşmeli ve “veri volanı” kullanarak rekabet avantajı oluşturmalıdır. AWS araştırması, küresel şirketlerin üretken yapay zekayı benimsemeyi hızlandırdığını, karar vericilerin %45’inin bunu 2025 için öncelikli görev olarak planladığını ve Baş Yapay Zeka Sorumlusu (CAIO) pozisyonunun şirketlerde standart hale geleceğini, şu anda şirketlerin %60’ının bu pozisyonu oluşturduğunu gösteriyor. Ajan ekonomisi, yapay zeka gelişiminin bir sonraki aşaması olarak görülüyor, ancak kalıcı kimlik, iletişim protokolleri ve güvenlik güveni olmak üzere üç teknik zorluğun çözülmesi gerekiyor. (Kaynak: 36氪)

Yeni nesil otomobil üreticileri tamamen yapay zekaya yatırım yapıyor, Li Auto, XPeng, NIO yeni nesil otomobil tanımı için yarışıyor: Tesla FSD V12’nin uçtan uca sinir ağı teknolojisiyle getirdiği atılım, Li Auto, XPeng, NIO gibi yerli yeni nesil otomobil üreticilerinin yapay zeka düzenini hızlandırmasına neden oldu. Li Auto, VLA (Görsel-Dil-Eylem) sürücü büyük modelini piyasaya sürdü ve dil bölümünü geliştirmek için DeepSeek açık kaynak modelini temel aldı. XPeng Motors, 72 milyar parametrelik bir LVA temel modeli oluşturdu. NIO ise Çin’in ilk akıllı sürüş dünya modeli NWM’yi yayınladı ve kendi geliştirdiği 5nm akıllı sürüş çipi Shenji NX9031’i tanıttı. Her şirket algoritma, hesaplama gücü (kendi geliştirdiği çipler) ve veri alanlarına büyük yatırımlar yapıyor ve yapay zeka teknolojisini insansı robotlar gibi alanlara yayarak yeni nesil otomobil ve hatta ürün tanımı için yarışıyor, ancak finansman ve ticarileşme zorluklarıyla karşı karşıya. (Kaynak: 36氪)
🧰 Araçlar
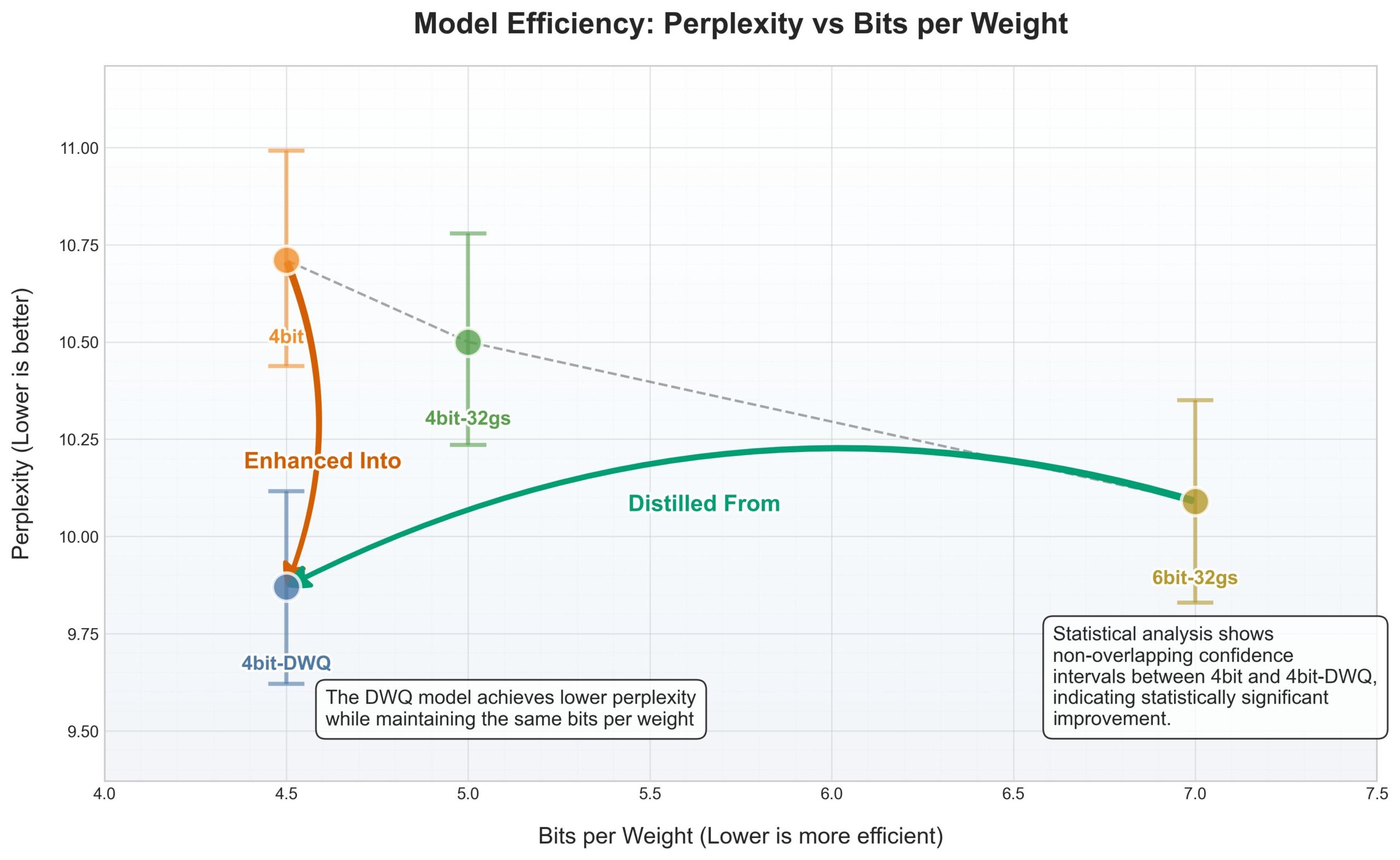
Apple MLX çerçevesi DWQ nicelemesini memnuniyetle karşılıyor, 4bit eski 6bit’ten daha iyi performans gösteriyor: Apple MLX (makine öğrenimi çerçevesi) için yeni bir DWQ (Dinamik Ağırlık Nicelemesi) niceleme yöntemi yayınlandı. Kullanıcı karminski3 tarafından paylaşılan verilere göre, 4bit-dwq ile nicelenen modeller (Qwen3-30B gibi) şaşkınlık açısından eski 6bit niceleme yönteminden bile daha iyi performans gösteriyor ve çalışmak için yalnızca 17GB bellek gerektiriyor. Bu, Apple cihazlarında büyük dil modellerini verimli bir şekilde çalıştırmak için yeni olanaklar sunuyor. (Kaynak: karminski3)
Perplexity artık WhatsApp içinde daha doğal konuşma tabanlı aramayı destekliyor: Perplexity’nin kurucu ortağı Arav Srinivas, Perplexity’nin WhatsApp entegrasyonunun geliştirildiğini, artık daha doğal bir konuşma deneyimi sunduğunu ve arama gerektirmeyen durumlarda arama adımını akıllıca atlayarak kullanıcıların doğrudan yapay zeka ile sohbet tarzı etkileşim kurmasını sağladığını duyurdu. (Kaynak: AravSrinivas)
nanobrowser_ai ana akım LLM’leri destekliyor, Langchain.js ile entegre: Yapay zeka aracı nanobrowser_ai, OpenAI modelleri, Gemini ve Ollama aracılığıyla çalışan yerel modeller dahil olmak üzere çeşitli büyük dil modellerini desteklediğini duyurdu. Araç, farklı LLM’lere esnek destek sağlamak için Langchain.js çerçevesini kullanıyor ve kullanıcılara daha geniş bir model seçeneği sunuyor. (Kaynak: hwchase17)
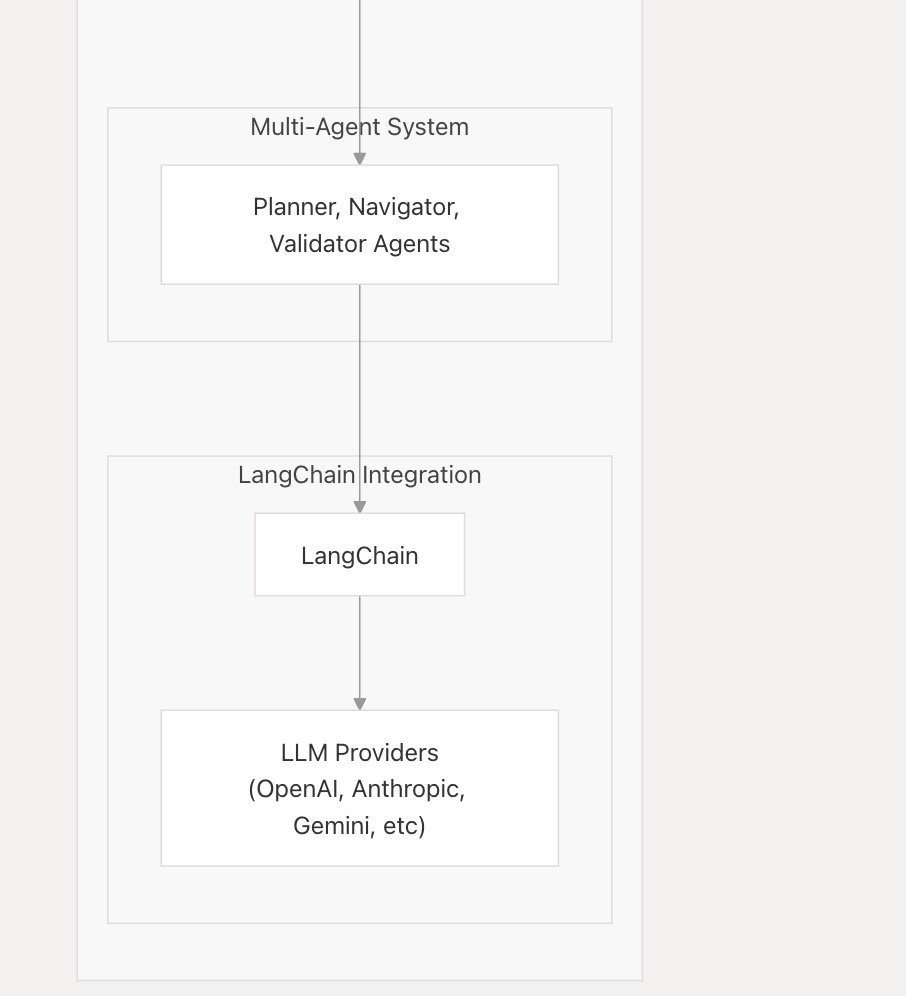
LlamaIndex TypeScript, gerçek zamanlı LLM API’leri için destek ekledi, ilk entegrasyon Google Gemini: LlamaIndex TypeScript, geliştiricilerin yapay zeka uygulamalarında gerçek zamanlı sesli diyalog özellikleri uygulamasını sağlayan gerçek zamanlı LLM API’lerini desteklediğini duyurdu. İlk entegrasyon Google Gemini’nin gerçek zamanlı soyutlama arayüzü olup, OpenAI’nin gerçek zamanlı desteği de yakında sunulacak. Bu güncelleme, geliştiricilerin farklı gerçek zamanlı modeller arasında geçiş yapmasını ve daha etkileşimli yapay zeka uygulamaları oluşturmasını kolaylaştırıyor. (Kaynak: _philschmid)
Gradio uygulama eğitimi: Görüntü ve video etiketleme ve nesne tespiti için Qwen2.5-VL kullanma: Bir eğitim, görüntü ve videoların otomatik etiketlenmesi ve nesne tespiti işlevlerini gerçekleştirmek için Qwen2.5-VL (görsel dil modeli) kullanarak bir Gradio uygulamasının nasıl oluşturulacağını ayrıntılı olarak açıklıyor. Eğitim, geliştiricilerin Qwen2.5-VL’nin güçlü yeteneklerini kullanarak hızlı bir şekilde etkileşimli yapay zeka uygulamaları oluşturmalarına yardımcı olmayı amaçlıyor. (Kaynak: Reddit r/deeplearning)

VSCode eklentisi gemini-code indirme sayısı yaklaşık 50.000’e ulaştı: VSCode’un yapay zeka programlama yardımcısı eklentisi gemini-code’un indirme sayısı yaklaşık 50.000’e ulaştı. Geliştirici raizamrtn, hafta sonu bazı gerekli güncellemeler yapacağını belirtti. Eklenti, geliştiricilere kodlama çalışmalarında yardımcı olmak için Gemini modelinin yeteneklerini kullanmayı amaçlıyor. (Kaynak: raizamrtn)

Fransız yapay zeka startup’ı Arcads AI: 5 kişilik ekip yılda 5 milyon dolar kazanıyor, otomatik video reklam üretimine odaklanıyor: Paris merkezli yapay zeka startup’ı Arcads AI, yalnızca 5 kişilik bir ekiple yıllık 5 milyon dolar yinelenen gelir elde etti ve kar etti. Şirket, reklamverenlere hızlı, düşük maliyetli, yüksek dönüşüm oranlı video reklam üretim hizmetleri sunmak için yüksek düzeyde otomatikleştirilmiş bir yapay zeka sistemi kullanıyor. Müşterilerin yalnızca temel metni sağlaması yeterli oluyor, yapay zeka sahne oluşturma, oyuncu performansı, seslendirme kaydı ve nihai çıktıya kadar tüm süreci tamamlıyor. Arcads platformu, gerçek kişilerden lisanslı 300’den fazla yapay zeka oyuncu imajı içeriyor, 35 dili destekliyor ve “hizmet olarak içerik” sağlıyor. Şirketin iç operasyonları da rakip analizi yapan AI Spy Agent, yaratıcı içerik üreten AI Ghostwriter gibi yapay zeka ajanlarını yaygın olarak kullanarak verimliliği önemli ölçüde artırıyor. (Kaynak: 36氪)
📚 Öğrenme Kaynakları
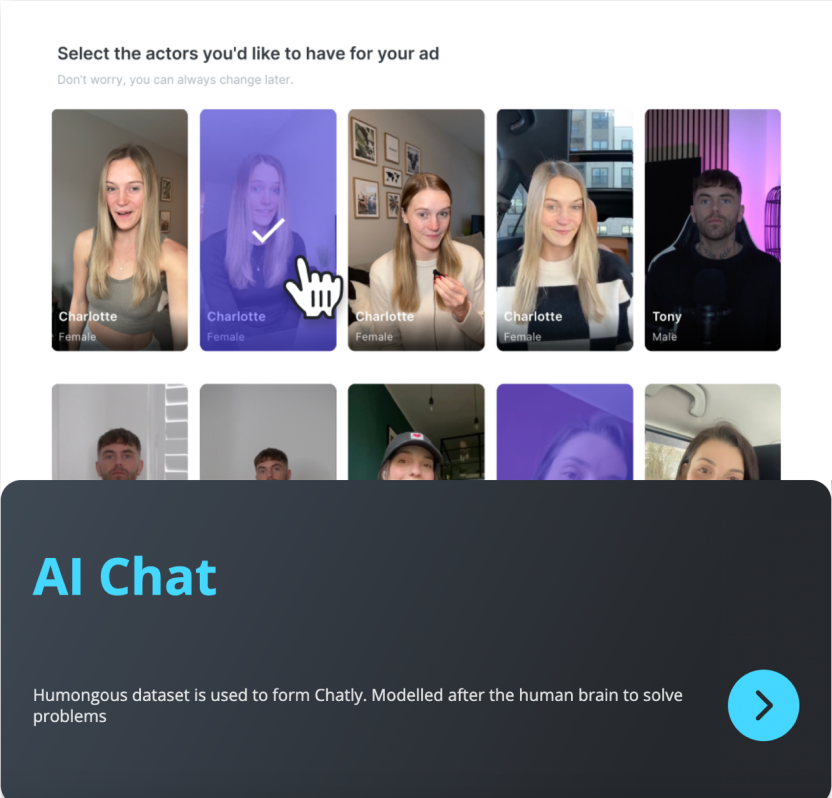
HuggingFace, 370B token içeren MegaMath veri kümesini yayınladı, %20’si sentetik veri: HuggingFace, 370 milyar token içeren MegaMath veri kümesini yayınladı; bu, şu anda en büyük matematik ön eğitim veri kümesi olup, İngilizce Wikipedia’nın yaklaşık 100 katı büyüklüğündedir. Dikkate değer bir şekilde, verilerin %20’si sentetik veridir ve bu da model eğitiminde yüksek kaliteli sentetik verilerin rolü hakkındaki tartışmaları yeniden alevlendirmiştir. (Kaynak: ClementDelangue)
Nous Research, 50.000 dolarlık ödül havuzlu RL ortamı hackathon’u düzenliyor: Nous Research, San Francisco’da Nous RL ortamı hackathon’u düzenleyeceğini duyurdu. Katılımcılar, Nous’un pekiştirmeli öğrenme ortamı çerçevesi Atropos’u kullanarak yaratacaklar ve toplam ödül havuzu 50.000 dolar olacak. Ortaklar arasında xAI, NVIDIA, Nebius AI gibi şirketler bulunuyor. (Kaynak: Teknium1)

HuggingFace popüler modeller haftalık listesi yayınlandı: Kullanıcı karminski3, bu hafta HuggingFace’deki en popüler modellerin listesini paylaştı ve bu modellerin çoğunu bizzat test ettiğini veya resmi demolarını paylaştığını belirtti. Bu, topluluğun yeni modellere hızlı bir şekilde ayak uydurma ve değerlendirme hevesini yansıtıyor. (Kaynak: karminski3)
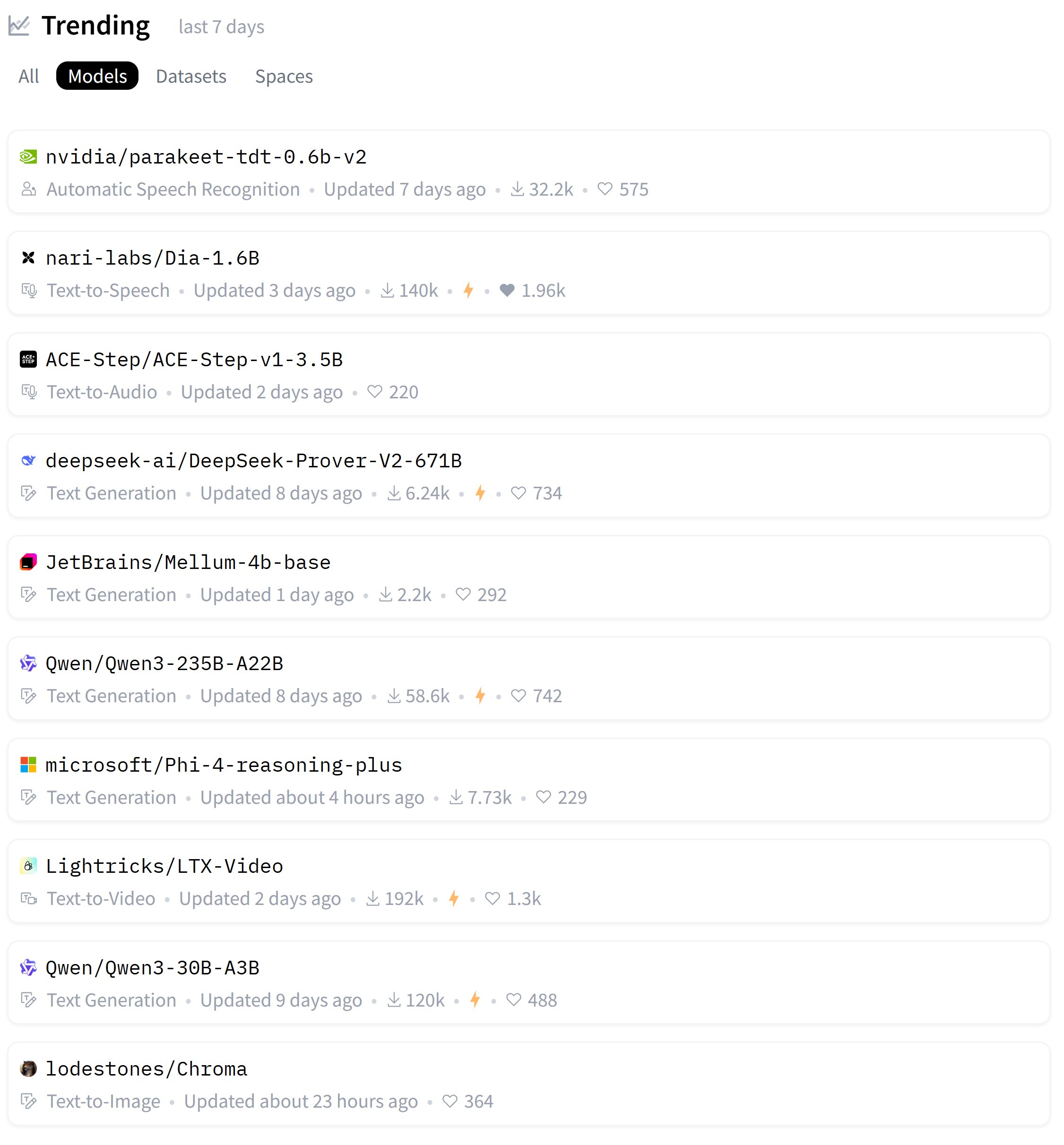
Zeyuan Allen-Zhu, LLM mimari tasarımı üzerine bir dizi araştırma yayınladı, Primer modelini tartışıyor: Araştırmacı Zeyuan Allen-Zhu, “LLM Tasarım Fiziği” adlı araştırma serisi aracılığıyla, kontrollü sentetik ön eğitim ortamlarını kullanarak LLM mimarilerinin gerçek sınırlarını ortaya koyuyor. En son paylaşımında, Primer modelini (arxiv.org/abs/2109.08668) ve onun multi-dconv-head attention’ını (kendisinin Canon-B kalıntı bağlantısız olarak adlandırdığı) tartışıyor, sorunları olduğuna işaret ediyor, ancak aynı zamanda Primer modelinin (sadece 180 atıf) gürültülü gerçek deneylerden anlamlı sinyaller bulduğu için yeterince takdir edilmediğini düşünüyor. (Kaynak: ZeyuanAllenZhu, cloneofsimo)
Simons Institute sinir ağı ölçekleme yasalarını tartışıyor: Simons Institute, Polylogues serisi programında Anil Ananthaswamy ve Alexander Rush’ı son yıllarda ampirik olarak keşfedilen sinir ağı ölçekleme yasalarını (neural scaling laws) tartışmaya davet etti. Bu yasalar, büyük şirketlerin giderek daha büyük modeller oluşturma kararları üzerinde önemli bir etkiye sahip oldu. (Kaynak: NandoDF)

François Fleuret “Derin Öğrenmenin Küçük Kitabı”nı yayınladı: François Fleuret, okuyuculara derin öğrenme hakkında rafine bilgiler sunmayı amaçlayan “The Little Book of Deep Learning” adlı bir kitap yayınladı. (Kaynak: Reddit r/deeplearning)
Princeton profesörü: Yapay zeka beşeri bilimleri sona erdirebilir, ancak varoluşsal deneyime geri dönmelerini sağlayabilir: Princeton Üniversitesi profesörü D. Graham Burnett, The New Yorker’da yapay zekanın beşeri bilimler üzerindeki etkisini tartışan bir makale yayınladı. ABD üniversitelerinde yaygın bir “yapay zeka utancı” olduğunu, öğrencilerin yapay zeka kullandıklarını kabul etmekten çekindiklerini gözlemledi. Yapay zekanın bilgi erişimi ve analizi konusunda geleneksel akademik yöntemleri aştığını, akademik kitapları arkeolojik eserler gibi gösterdiğini düşünüyor. Yapay zeka, geleneksel anlamda bilgi üretimini merkezine alan beşeri bilimleri sona erdirebilse de, aynı zamanda temel sorulara geri dönmelerini sağlayabilir: nasıl yaşanır, ölümle nasıl yüzleşilir gibi yapay zekanın doğrudan dokunamayacağı varoluşsal deneyimlerin tartışılması. (Kaynak: 36氪)

7 araştırma, yapay zekanın insan beyni ve davranışı üzerindeki derin etkilerini ortaya koyuyor: Bir dizi yeni araştırma, yapay zekanın insan psikolojisi, sosyal ve bilişsel düzeylerdeki etkilerini inceliyor. Araştırma bulguları şunları içeriyor: 1) LLM kırmızı takım testçileri merak ve ahlaki sorumluluk duygusuyla model açıklarını araştırıyor; 2) ChatGPT psikiyatrik vaka analizinde yüksek tanı doğruluğu gösteriyor; 3) ChatGPT’nin siyasi eğilimleri farklı versiyonlar arasında ince değişiklikler gösteriyor; 4) ChatGPT kullanımı işyeri eşitsizliğini artırabilir, genç yüksek gelirli erkekler daha fazla kullanıyor; 5) Yapay zeka yaşlıların sürüş davranışlarını analiz ederek depresyon belirtilerini tespit edebilir; 6) LLM kişilik testlerinde imajı “güzelleştirme” sosyal beklenti yanlılığı gösteriyor; 7) Yapay zekaya aşırı güven, özellikle genç gruplarda eleştirel düşünmeyi zayıflatabilir. (Kaynak: 36氪)

Onur Boyar röportajı: Üretken modeller ve Bayes optimizasyonu ile ilaç ve malzeme tasarımı: AAAI/SIGAI Doktora Öğrencisi Forumu katılımcısı Onur Boyar, Nagoya Üniversitesi’ndeki doktora çalışmalarını tanıttı; bu çalışmalar, üretken modeller ve Bayes yöntemleri kullanarak ilaç ve malzeme tasarımına odaklanıyor. İlaç keşfi süreçlerini yürütecek yapay zeka bilim insanı robotları oluşturmayı amaçlayan Japon Moonshot projesine katıldı. Araştırma yöntemleri arasında, örnek verimliliğini ve sentezlenebilirliği artırmak için mevcut molekülleri düzenlemek üzere gizli uzay Bayes optimizasyonunu kullanmak yer alıyor. Kimyagerlerle yakın işbirliğini vurguluyor ve mezuniyetten sonra IBM Tokyo Araştırma Enstitüsü’nün malzeme keşfi ekibine katılacak. (Kaynak: aihub.org)

💼 İş Dünyası
Modular şirketi, MI300X GPU kullanarak Mojo Hackathon düzenlemek için AMD ile işbirliği yapıyor: Modular şirketi, AGI House’da özel bir hackathon düzenlemek için AMD ile işbirliği yaptığını duyurdu. Etkinlikte geliştiriciler, AMD Instinct™ MI300X GPU kullanarak Mojo dilinde programlama yapacaklar. Etkinlik ayrıca Modular, AMD, SemiAnalysis’ten Dylan Patel ve Anthropic temsilcilerinden teknik paylaşımlar da içerecek. (Kaynak: clattner_llvm)
Stripe, ödeme alanında yapay zeka temel modeli de dahil olmak üzere birçok yapay zeka destekli yeni özellik yayınladı: Finansal hizmetler şirketi Stripe, yıllık konferansında yapay zeka uygulamalarının hayata geçirilmesini hızlandırmak için birçok yeni ürün duyurdu; bunlar arasında ödeme alanı için özel olarak tasarlanmış dünyanın ilk yapay zeka temel modeli de bulunuyor. Yüz milyarlarca işlem üzerinde eğitilen bu model, dolandırıcılık tespitini (örneğin “kart testi” saldırı tespit oranını %64 artırma), yetkilendirme oranlarını ve kişiselleştirilmiş ödeme deneyimini iyileştirmeyi amaçlıyor. Stripe ayrıca çoklu para birimi fon yönetimi yeteneklerini genişletti ve Nvidia (GeForce Now aboneliklerini yönetmek için Stripe Billing kullanan), PepsiCo gibi büyük şirketlerle işbirliğini derinleştirdi. (Kaynak: 36氪)
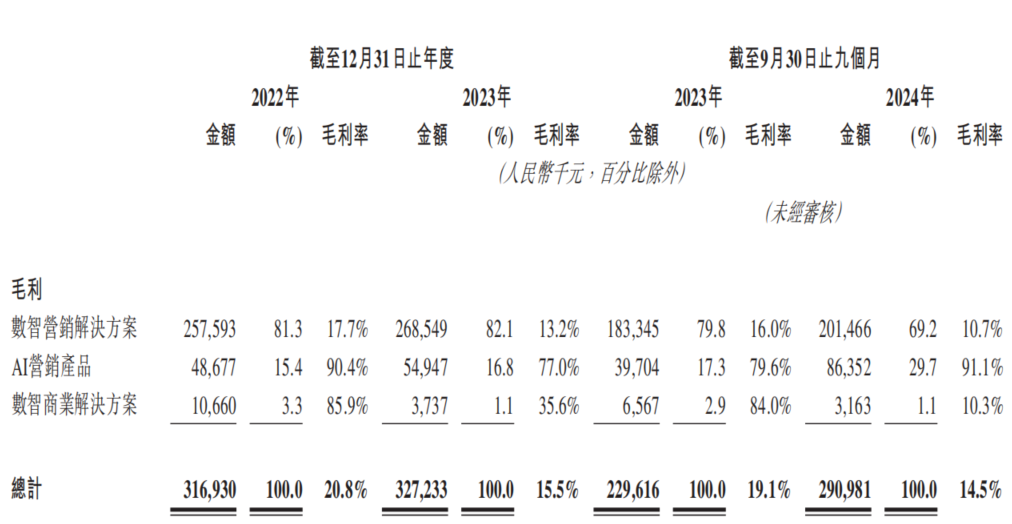
Yapay zeka pazarlama şirketi Dongxin Marketing, Hong Kong Borsası’na tekrar başvuruyor, “gelir artışı kar artışı getirmiyor” ikilemiyle karşı karşıya: Dongxin Marketing, “Çin’in en büyük yapay zeka pazarlama şirketi” unvanıyla Hong Kong Borsası’na tekrar başvuru yaptı. Veriler, şirketin 2022-2024 ilk üç çeyreğinde gelirinin sürekli arttığını, ancak net karının önemli ölçüde düştüğünü hatta zarara geçtiğini, brüt kar marjının %20,8’den %14,5’e düştüğünü gösteriyor. Yapay zeka pazarlama işinin gelir payı %5’in altında, brüt kar marjı %91,1 gibi yüksek bir oranda olsa da, araştırma ve geliştirme harcamalarını karşılamaya yetmiyor. Şirket, yüksek alacak hesapları, sıkışık nakit akışı, büyük borç baskısı gibi sorunlarla karşı karşıya ve karı büyük ölçüde devlet teşviklerine bağlı. Pazar konumu “mobil pazarlama hizmet sağlayıcısı”ndan “yapay zeka pazarlama şirketi”ne dönüştü, ancak yapay zeka teknolojisinin değeri ve ticarileşme potansiyeli şüpheli. (Kaynak: 36氪)
🌟 Topluluk
vLLM ve SGLang çıkarım motorları arasındaki rekabet kızışıyor, geliştiriciler PR birleştirme verilerini kamuya açık olarak karşılaştırıyor: Geliştirici topluluğu, vLLM ve SGLang adlı iki çıkarım motoru arasındaki rekabeti hararetle tartışıyor. vLLM’in ana bakımcısı, SGLang ile vLLM’in GitHub’da birleştirilen çekme isteği (PR) sayısını karşılaştırmak için herkese açık bir gösterge paneli bile oluşturdu; bu da ikisinin özellik yinelemesi ve performans optimizasyonu konusundaki kıyasıya rekabetini vurguluyor. SGLang tarafı ise radix önbelleği, CPU çakışması, MLA ve büyük ölçekli EP gibi konularda öncü açık kaynak uygulamalarını vurguluyor. (Kaynak: dylan522p, jeremyphoward)
Yapay zeka tarafından üretilen “İtalyan beyin çürümesi” karakter evreni Zoomer kuşağını kasıp kavuruyor, izlenme sayısı yüz milyonları buluyor: Justine Moore, yapay zeka tarafından üretilen bir dizi “İtalyan beyin çürümesi” (Italian brainrot) karakterinin Zoomer (Z kuşağı) kuşağında olağanüstü derecede popüler olduğunu, bu karakterler etrafında eksiksiz bir “sinematik evren” oluşturduklarını ve ilgili içeriklerin yüz milyonlarca izlenme aldığını belirtiyor. Bu olgu, yapay zeka tarafından üretilen içeriğin genç nesiller arasındaki güçlü çekiciliğini ve viral yayılma potansiyelini ve ayrıca belirli alt kültürlerin oluşumunu yansıtıyor. (Kaynak: nptacek)

Qwen3 ve DeepSeek R1 modellerinin karşılaştırılması tartışmalara yol açtı, her birinin avantaj ve dezavantajları var: Reddit kullanıcısı, Qwen3 235B ve DeepSeek R1 adlı iki açık kaynaklı büyük modelin test karşılaştırmasını paylaştı. Gönderiyi yapan kişi, Qwen’in basit görevlerde daha iyi performans gösterdiğini, ancak çıkarım, matematik ve yaratıcı yazma gibi incelik gerektiren görevlerde DeepSeek R1’in daha iyi performans gösterdiğini düşünüyor. Topluluk yorumlarında kullanıcılar, DeepSeek R1’in erişilebilirliğini, Qwen3 235B’nin sansürsüz ince ayarlı sürümünü ve yaratıcı yazma için dil modellerini kullanmanın makul olup olmadığını tartıştı. (Kaynak: Reddit r/LocalLLaMA)

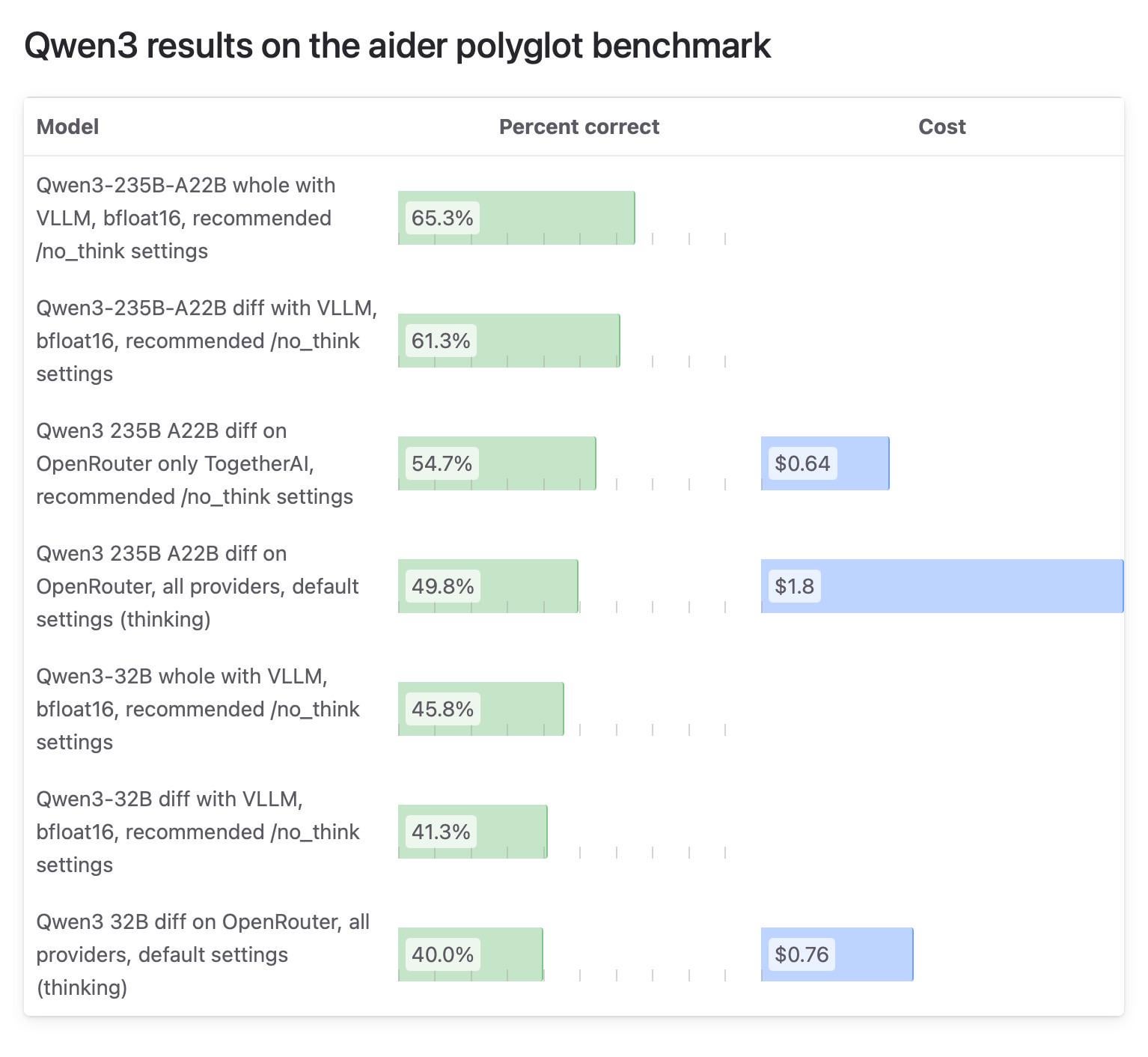
Aider topluluğunun Qwen3 model test sonuçlarındaki farklılıklar dikkat çekiyor, OpenRouter testi sorgulanıyor: Aider blogu, Qwen3 modeli hakkında bir test raporu yayınladı ve modelin farklı çalıştırma yöntemlerinde puanlarının büyük ölçüde farklılık gösterdiğini belirtti. Topluluk tartışmalarının odak noktası, çoğu kullanıcının modeli OpenRouter aracılığıyla kullanabileceği için model testi için OpenRouter kullanmanın güvenilirliği oldu, ancak yönlendirme mekanizması sonuçların tutarsız olmasına neden olabilir. Bazı kullanıcılar, açık kaynaklı modellerin tekrarlanabilirliği sağlamak için standartlaştırılmış kendi kendine barındırılan ortamlarda (vLLM gibi) test edilmesi gerektiğini düşünüyor ve API sağlayıcılarını şeffaflığı artırmaya, kullanılan niceleme sürümünü ve çıkarım motorunu açıkça belirtmeye çağırıyor. (Kaynak: Reddit r/LocalLLaMA)
Kullanıcılar ChatGPT’yi ücretli kullanma kişisel nedenlerini paylaşıyor; yaşam yardımı, öğrenme, yaratıcılık gibi alanları kapsıyor: Reddit r/ChatGPT topluluğunda birçok kullanıcı, ChatGPT Plus/Pro’ya ücretli abone olma kişisel amaçlarını paylaştı. Bunlar arasında şunlar yer alıyor: görme engelli kullanıcılara görüntüleri tanımlama, yiyecek ambalajlarını ve yol işaretlerini okuma konusunda yardımcı olma; mülakat hazırlığı yapma; Elden Ring gibi oyunların hikayelerini derinlemesine anlama; koşu antrenman planlarını analiz etme, özel yemek tarifleri oluşturma; çömlekçilik gibi yeni beceriler öğrenmeye yardımcı olma; kişisel bir arkadaş olarak kullanma; bahçe planlama, bitkisel ilaçlar yapma; ve D&D karakter oluşturma ve hayran kurgusu yazma. Bu örnekler, ChatGPT’nin günlük yaşamda ve kişisel ilgi alanlarında geniş uygulama değerini gösteriyor. (Kaynak: Reddit r/ChatGPT)
GGUF niceleme modeli karşılaştırma testi “niceleme savaşları” tartışmasını ateşledi, farklı niceleme şemalarının her birinin kendine özgü avantajları olduğu vurgulandı: Reddit kullanıcısı ubergarm, Qwen3-30B-A3B gibi modellerin farklı GGUF niceleme sürümleri için bartowski ve unsloth gibi farklı sağlayıcıların niceleme şemalarını içeren ayrıntılı bir kıyaslama testi karşılaştırması yayınladı. Test, şaşkınlık, KLD sapması, çıkarım hızı gibi birçok boyutu kapsıyordu. Makale, önem matrisi nicelemesi (imatrix), IQ4_XS gibi yeni niceleme türlerinin ortaya çıkması ve unsloth dinamik GGUF gibi yöntemlerin tanıtılmasıyla GGUF nicelemesinin artık “tek tip” olmadığını belirtiyor. Yazar, mutlak olarak en iyi niceleme şemasının olmadığını, kullanıcıların kendi donanımlarına ve belirli kullanım durumlarına göre seçim yapmaları gerektiğini, ancak genel olarak ana akım şemaların hepsinin iyi performans gösterdiğini vurguluyor. (Kaynak: Reddit r/LocalLLaMA)

💡 Diğer
Daimon Robotics, akıllı ve becerikli robot Sparky 1’i tanıttı: Daimon Robotics şirketi, becerikli robot teknolojisindeki çığır açan ürünü Sparky 1’i sergiledi. Bu robot, “Akıl-Becerikli” (Mind-Dexterous) yeteneklere sahip olarak tanımlanıyor; bu da algılama, karar verme ve hassas operasyon konularında yeni bir seviyeye ulaştığını, muhtemelen gelişmiş yapay zeka ve makine öğrenimi teknolojilerini birleştirdiğini ima ediyor. (Kaynak: Ronald_vanLoon)
MIT, beyne girerek ameliyat edilemeyen tümörleri tedavi edebilen pirinç tanesi büyüklüğünde mikro robotlar geliştirdi: MIT araştırmacıları, beyne minimal invaziv bir şekilde girerek daha önce cerrahi olarak çıkarılması zor olan tümörleri tedavi etme potansiyeline sahip pirinç tanesi büyüklüğünde bir mikro robot geliştirdi. Bu tür bir teknoloji, mikro robot teknolojisini yapay zeka navigasyonu veya kontrolü ile birleştirerek beyin cerrahisi ve kanser tedavisi için yeni olanaklar sunuyor. (Kaynak: Ronald_vanLoon)

Aosha Intelligence iki tur finansmanı tamamladı, tüketici sınıfı dış iskelet robotlarının seri üretimini ve yapay zeka teknolojisi entegrasyonunu destekliyor: Dış iskelet robot teknolojisi platformu şirketi Aosha Intelligence, BinFu Capital liderliğinde ve eski hissedar Guoyi Capital’in katılımıyla art arda iki tur finansmanı tamamladığını duyurdu. Fonlar, tüketici sınıfı dış iskelet robotlarının seri üretimi ve dış iskelet donanımının yapay zeka teknolojisiyle entegrasyonunu desteklemek için kullanılacak. Şirketin ürünleri endüstriyel senaryolarda zaten kullanılıyor ve açık hava yardımı (turistik yerlerde dağ tırmanışı yardımı gibi) ve evde yaşlı bakımı pazarlarını keşfetmeye başladı; 10.000 yuan’ın altında tüketici sınıfı ürünler piyasaya sürmeyi planlıyor. En son ürünleri yapay zeka büyük model eğitim yetenekleriyle donatılmış ve beyin-bilgisayar arayüzü teknolojisini önceden araştırıyor. (Kaynak: 36氪)