Anahtar Kelimeler:Mutlak Sıfır, Qwen3, Mistral Medium 3, PyTorch Vakfı, AI Kendi Kendini Evrimleştirme, çok modelli model, açık kaynak AI, RLVR paradigması, AZR sistemi, Qwen3-235B-A22B, DeepSpeed optimizasyon kütüphanesi, LangSmith çok modelli destek
🔥 Odak Noktası
Tsinghua Üniversitesi “Absolute Zero” Makalesini Yayınladı: AI Harici Veri Olmadan Kendi Kendine Evrimleşebiliyor: Tsinghua Üniversitesi LeapLabTHU ekibi, “Absolute Zero” adlı yeni bir RLVR (Reinforcement Learning with Verifiable Rewards) paradigması yayınladı. Bu paradigma altında, tek bir model öğrenme sürecini en üst düzeye çıkaracak görevleri kendi kendine önerebiliyor ve bu görevleri çözerek çıkarım yeteneklerini geliştirebiliyor, hem de hiçbir harici veriye dayanmadan. Sistemi AZR (Absolute Zero Reasoner), görevleri ve cevapları doğrulamak için bir kod yürütücüsü kullanarak açık uçlu ancak temellendirilmiş bir öğrenme sağlıyor. Deneyler, AZR’nin kodlama ve matematiksel çıkarım görevlerinde SOTA seviyesine ulaştığını ve on binlerce insan etiketli örneğe dayanan mevcut sıfır-atış (zero-shot) modelleri geride bıraktığını gösteriyor (Kaynak: Reddit r/LocalLLaMA)
Alibaba, MoE ve Çeşitli Boyutlarda Qwen3 Serisi Modellerini Yayınladı: Alibaba, 0.6B ila 235B arasında değişen parametre sayılarına sahip 8 model içeren Qwen3 serisi büyük dil modellerini yayınladı. Bunlardan Qwen3-235B-A22B ve Qwen3-30B-A3B MoE mimarisini kullanırken, diğerleri yoğun (dense) modellerdir. Bu seri, 36T token üzerinde önceden eğitilmiş olup 119 dili kapsamaktadır ve kod, matematik, bilim gibi birçok alana uygun, açılıp kapatılabilir bir çıkarım moduna sahiptir. Değerlendirmeler, MoE modellerinin üstün performans gösterdiğini, 235B versiyonunun birçok benchmark’ta DeepSeek-R1 ve Gemini 2.5 Pro’yu geride bıraktığını, 30B versiyonunun da güçlü bir performans sergilediğini, hatta 4B modelin bazı benchmark’larda kendisinden çok daha fazla parametreye sahip modellerden daha iyi olduğunu göstermektedir. Modeller HuggingFace ve ModelScope üzerinde Apache 2.0 lisansıyla açık kaynak olarak yayınlanmıştır (Kaynak: DeepLearning.AI Blog)
Mistral, Mistral Medium 3 Multimodal Modelini ve Kurumsal AI Asistanını Yayınladı: Mistral AI, performansta Claude Sonnet 3.7’ye yakın olduğunu iddia ettiği ancak maliyeti önemli ölçüde (giriş $0.4/M token, çıkış $2/M token) 8 kat düşürdüğü yeni bir multimodal model olan Mistral Medium 3’ü piyasaya sürdü. Model, kodlama ve fonksiyon çağırma konularında üstün performans sergiliyor ve hibrit veya yerel dağıtım, özelleştirilmiş sonradan eğitim gibi kurumsal düzeyde özellikler sunuyor. Aynı zamanda Mistral, şirket bilgi tabanlarıyla (Gmail, Google Drive, Sharepoint gibi) entegrasyonu destekleyen, Agent, kodlama asistanı, web arama gibi işlevlere sahip, özelleştirilebilir ve güvenli bir kurumsal AI asistanı olan Le Chat Enterprise’ı da yayınladı. Mistral, önümüzdeki haftalarda yeni bir Large model yayınlayacağını duyurdu (Kaynak: Mistral AI, GuillaumeLample, scaling01, karminski3)
PyTorch Vakfı, vLLM ve DeepSpeed’i Bünyesine Katarak Çatı Vakfı Haline Geldi: PyTorch Vakfı, daha fazla yüksek kaliteli AI açık kaynak projesini bir araya getirmeyi amaçlayan bir çatı vakfı yapısına geçtiğini duyurdu. Katılan ilk projeler vLLM ve DeepSpeed oldu. vLLM, LLM’ler için tasarlanmış yüksek verimli, bellek açısından verimli bir çıkarım ve hizmet motorudur; DeepSpeed ise büyük ölçekli model eğitimini daha verimli hale getiren bir derin öğrenme optimizasyon kütüphanesidir. Bu hamle, araştırmadan üretime kadar tüm yaşam döngüsünü kapsayan, topluluk odaklı AI gelişimini teşvik etmeyi amaçlıyor ve AMD, Arm, AWS, Google, Huawei gibi birçok üye tarafından destekleniyor (Kaynak: PyTorch, soumithchintala, vllm_project, code_star)

🎯 Gelişmeler
Tencent ARC Laboratuvarı FlexiAct’ı Yayınladı: Video Hareket Aktarım Aracı: Tencent ARC Laboratuvarı, Hugging Face üzerinde FlexiAct adlı yeni bir araç yayınladı. Bu araç, referans videodaki hareketleri herhangi bir hedef görüntüye aktarabiliyor; hedef görüntünün düzeni, bakış açısı veya iskelet yapısı referans videodan farklı olsa bile bunu başarabiliyor. Bu, video üretimi ve düzenleme alanında yeni olanaklar sunarak kullanıcıların üretilen içerikteki hareketleri ve duruşları daha esnek bir şekilde kontrol etmelerine olanak tanıyor (Kaynak: _akhaliq)
White Circle, CircleGuardBench’i Yayınladı: AI İçerik Denetleme Modelleri İçin Yeni Bir Benchmark: White Circle, AI içerik denetleme modellerini değerlendirmek için yeni bir benchmark olan CircleGuardBench’i tanıttı. Bu benchmark, üretim düzeyinde değerlendirme yapmak üzere tasarlanmış olup, zarar tespiti, jailbreak direnci, yanlış pozitif oranı ve gecikme süresi gibi konuları test ederek 17 gerçek dünya zarar kategorisini kapsamaktadır. İlgili blog yazısı ve sıralama tabloları Hugging Face üzerinde yayınlanarak AI güvenliği ve içerik denetleme alanına yeni değerlendirme standartları getirildi (Kaynak: TheTuringPost, _akhaliq)

Hugging Face SIFT-50M’yi Yayınladı: Büyük Ölçekli Çok Dilli Sesli Komut İnce Ayar Veri Seti: Hugging Face üzerinde, sesli komut ince ayarı için özel olarak tasarlanmış büyük ölçekli, çok dilli bir veri seti olan SIFT-50M yayınlandı. Bu veri seti, 5 dili kapsayan 50 milyondan fazla komut tabanlı soru-cevap çifti içermektedir. Bu veri setine dayalı olarak eğitilen SIFT-LLM, sesli komut takip etme benchmark’larında SALMONN ve Qwen2-Audio’dan daha iyi performans göstermiştir. Veri seti ayrıca akustik ve üretken değerlendirme için EvalSIFT adlı bir benchmark içermekte ve Whisper, HuBERT, X-Codec2 & Qwen2.5 tabanlı olarak kontrol edilebilir ses üretimi (örneğin perde, konuşma hızı, aksan) desteklemektedir (Kaynak: ClementDelangue, huggingface)
Meta, Perception Language Model (PLM)’yi Yayınladı: Açık Kaynak ve Tekrarlanabilir Görsel Dil Modeli: Meta AI, zorlu görsel görevleri çözmek amacıyla tasarlanmış, açık ve tekrarlanabilir bir görsel dil modeli olan Meta Perception Language Model (PLM)’yi tanıttı. Meta, PLM aracılığıyla açık kaynak topluluğunun daha güçlü bilgisayarlı görü sistemleri oluşturmasına yardımcı olmayı umuyor. İlgili araştırma makalesi, kod ve veri seti araştırmacıların ve geliştiricilerin kullanımına sunuldu (Kaynak: AIatMeta)
Google, Gemini 2.0 Görüntü Üretme Modelini Güncelledi: Kalite ve Hız Artışı: Google, Gemini 2.0 görüntü üretme modelinin (önizleme sürümü) güncellendiğini duyurdu. Yeni sürüm daha iyi görsel kalite, daha doğru metin oluşturma, daha düşük engelleme oranları (block rates) ve daha yüksek hız limitleri (rate limits) sunuyor. Üretilen her görüntü başına maliyet $0.039. Bu güncelleme, geliştiricilerin Gemini ile görüntü üretme deneyimini ve sonuçlarını iyileştirmeyi amaçlıyor (Kaynak: m__dehghani, scaling01, andrew_n_carr, demishassabis)
NVIDIA Açık Kaynak Kod Çıkarım Modeli Serisini Yayınladı: NVIDIA, 32B, 14B ve 7B olmak üzere üç farklı boyutta, tamamı APACHE 2.0 lisanslı bir dizi açık kaynak kod çıkarım modeli yayınladı. Bu modeller OCR veri setleri üzerinde eğitilmiş olup, LiveCodeBench benchmark’ında O3 mini ve O1 (low)’dan daha iyi performans gösterdiği ve benzer çıkarım modellerine göre token verimliliğinde %30 daha yüksek olduğu iddia ediliyor. Modeller llama.cpp, vLLM, transformers, TGI gibi çeşitli framework’lerle uyumludur (Kaynak: huggingface, ClementDelangue)
ServiceNow ve NVIDIA İşbirliğiyle Apriel-Nemotron-15b-Thinker Modeli Tanıtıldı: ServiceNow ve NVIDIA, MIT lisanslı Apriel-Nemotron-15b-Thinker adlı 15B parametreli bir modeli ortaklaşa yayınladı. Bu modelin 32B modellerle karşılaştırılabilir performansa sahip olduğu, ancak token tüketiminde önemli ölçüde azalma (Qwen-QwQ-32b’den yaklaşık %40 daha az) sağladığı iddia ediliyor. MBPP, BFCL, kurumsal RAG, IFEval gibi birçok benchmark testinde başarılı performans gösterdiği, özellikle kurumsal RAG ve kodlama görevlerinde rekabetçi olduğu belirtiliyor (Kaynak: Reddit r/LocalLLaMA)

s1 Modeli: Az Sayıda Örnekle İnce Ayar Yaparak Çıkarım Yeteneği, “Wait” Tekniği Performansı Artırıyor: Stanford Üniversitesi ve diğer kurumlardan araştırmacılar, sadece yaklaşık 1000 adet zincirleme düşünme (CoT) örneğiyle denetimli ince ayar yaparak, Qwen 2.5-32B gibi önceden eğitilmiş LLM’lere çıkarım yeteneği kazandırılabileceğini gösteren s1 modelini geliştirdi. Araştırma ayrıca, çıkarım sürecinde modeli “Wait” token’ı üretmeye zorlayarak çıkarım zincirini uzatmanın, modelin matematik gibi görevlerdeki doğruluğunu önemli ölçüde artırabildiğini ve performansını OpenAI o1-preview’a yaklaştırdığını ortaya koydu. Bu bulgu, modelin çıkarım yeteneğini düşük maliyetle artırmak için yeni bir yol sunuyor (Kaynak: DeepLearning.AI Blog)
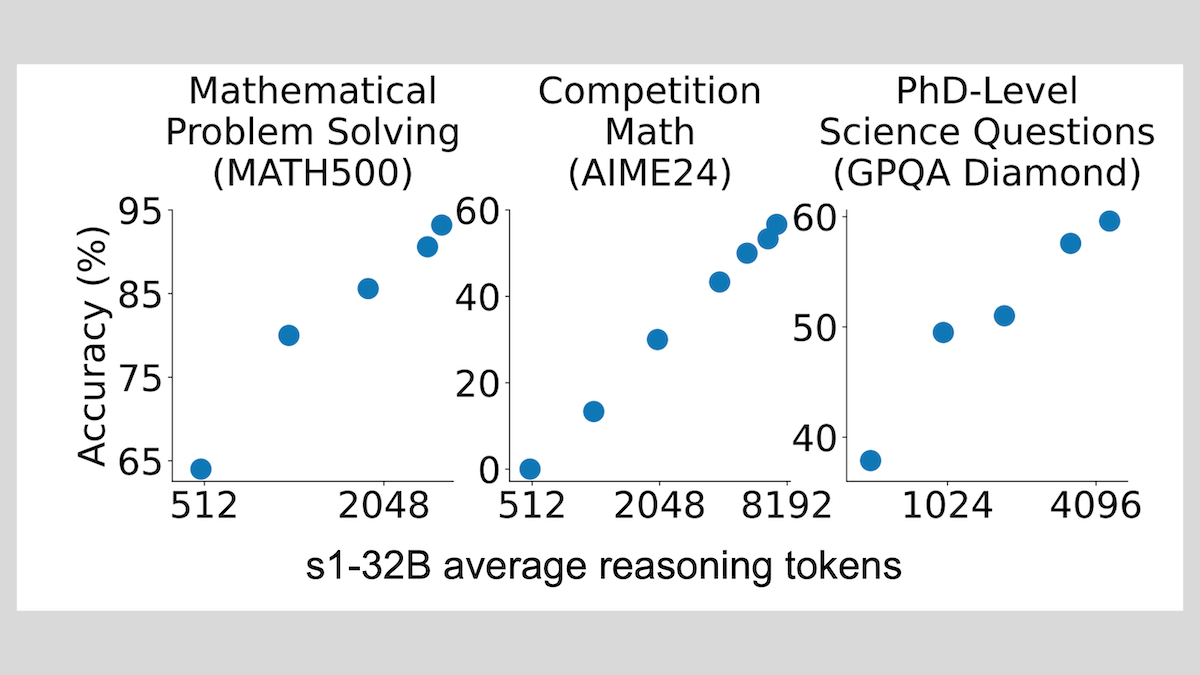
ThinkPRM: Sadece 8K Etiketle Eğitilebilen Üretken Süreç Ödül Modeli: Araştırmacılar, sadece 8K süreç etiketiyle ince ayar yapılabilen üretken bir süreç ödül modeli (PRM) olan ThinkPRM’yi önerdiler. Bu model, uzun düşünce zincirleri (long chains-of-thought) üreterek çıkarım süreçlerini doğrulayabiliyor ve PRM eğitmek için gereken büyük miktarda adım düzeyinde denetimli verinin maliyetli sorununu çözüyor. İlgili kod, model ve veriler GitHub ve Hugging Face üzerinde yayınlandı (Kaynak: Reddit r/MachineLearning)
🧰 Araçlar
Zed, Dünyanın En Hızlı AI Kod Editörü Olduğunu İddia Ediyor: Zed, dünyanın en hızlı AI kod editörü olduğunu iddia ettiği bir ürünü piyasaya sürdü. Bu editör, insan ile AI arasındaki işbirliğini optimize etmek ve yıldırım hızında bir agent tabanlı düzenleme deneyimi (agentic editing experience) sunmak amacıyla Rust ile sıfırdan geliştirildi. Claude 3.7 Sonnet gibi popüler modelleri destekliyor ve kullanıcıların kendi API anahtarlarını getirmelerine veya Ollama aracılığıyla yerel modelleri kullanmalarına olanak tanıyor (Kaynak: andersonbcdefg, ollama)
Hugging Face nanoVLM’yi Tanıttı: Minimalist Görsel Dil Modeli Kütüphanesi: Hugging Face, yaklaşık 750 satır kodla sıfırdan görsel dil modelleri (VLM) eğitmek amacıyla tasarlanmış saf bir PyTorch kütüphanesi olan nanoVLM’yi açık kaynak olarak yayınladı. Bu model, MMStar benchmark’ında %35.3 doğruluk oranına ulaşarak SmolVLM-256M ile karşılaştırılabilir bir performans sergiliyor, ancak eğitim için gereken GPU saatini 100 kat azaltıyor. nanoVLM, görsel kodlayıcı olarak SigLiP-ViT’i, LLaMA tarzı bir kod çözücüyü kullanıyor ve ikisini bir modalite projektörü aracılığıyla birbirine bağlıyor; öğrenme, prototip oluşturma veya özel VLM’ler oluşturmak için uygun (Kaynak: clefourrier, ben_burtenshaw, Reddit r/LocalLLaMA)
DBOS, DBOS Python 1.0’ı Yayınladı: Hafif Kalıcı İş Akışı Aracı: DBOS, DBOS Python 1.0 sürümünü yayınladı. Bu araç, Python uygulamalarına (iş süreçleri, AI otomasyonu, veri hatları vb. dahil) hafif, kullanımı kolay kalıcı iş akışı yetenekleri sağlamayı amaçlıyor. Yeni sürüm, kalıcı kuyruklar (eşzamanlılık sınırı, hız sınırı, zaman aşımı, öncelik, tekilleştirme vb. destekler), programatik iş akışı yönetimi (Postgres tabloları aracılığıyla sorgulama, duraklatma, devam ettirme, yeniden başlatma vb.), senkron/asenkron kod desteği ve geliştirilmiş araçlar (gösterge paneli, görselleştirme vb.) içeriyor (Kaynak: lateinteraction)
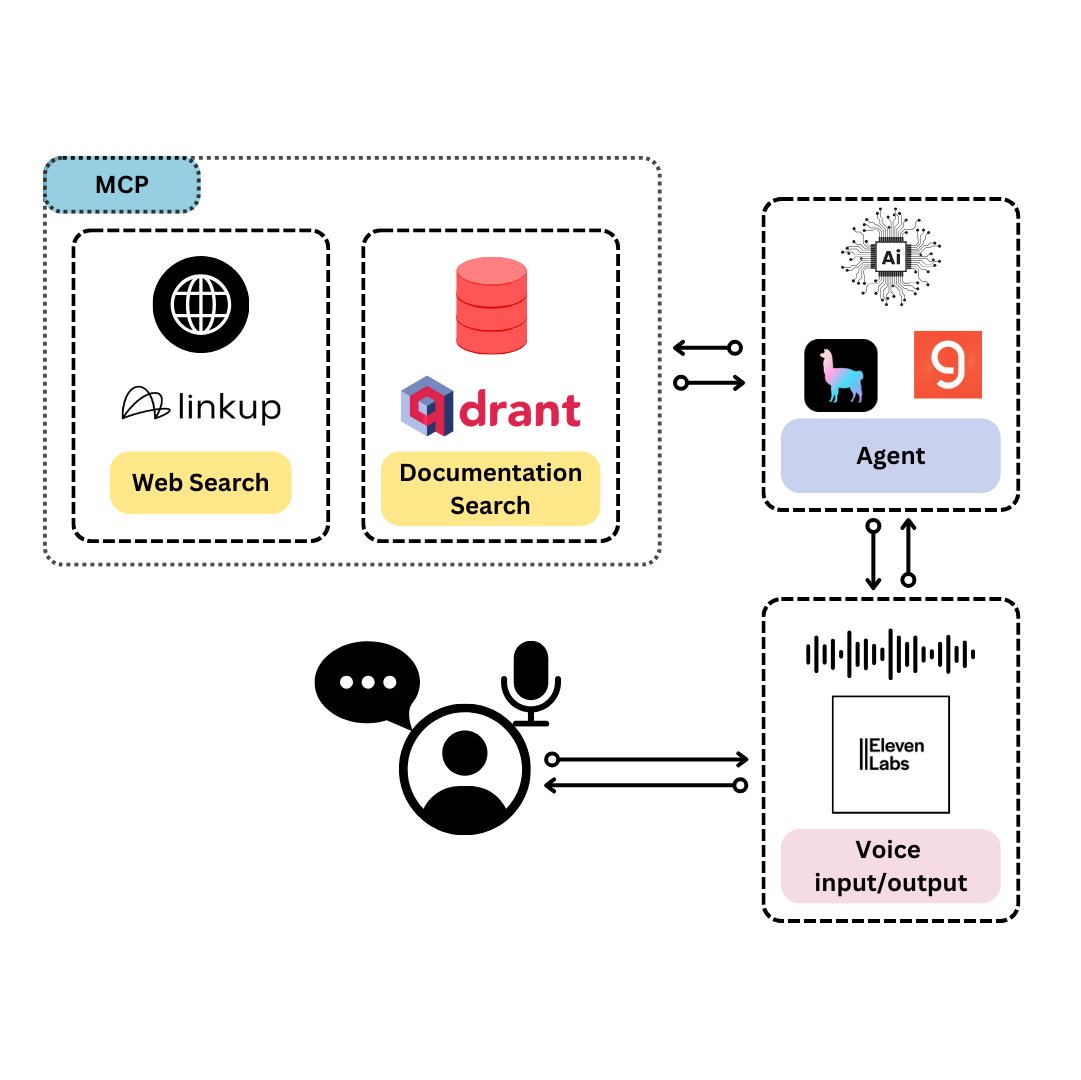
Qdrant, TySVA’yı Tanıttı: TypeScript Geliştiricileri İçin Özel Sesli Asistan: Qdrant, TypeScript geliştiricilerine doğru, bağlama duyarlı yanıtlar sunmayı amaçlayan bir sesli asistan olan TySVA’yı (TypeScript Voice Assistant) tanıttı. TySVA, TypeScript belgelerini yerel olarak depolamak için Qdrant’ı kullanıyor, ilgili web verilerini çekmek için Linkup platformunu entegre ediyor ve en iyi veri kaynağını seçmek için LlamaIndex’i kullanıyor. Sesli ve metin girişini destekleyerek geliştiricilerin kodlama sırasında güvenilir, eller serbest yardım almalarına yardımcı oluyor (Kaynak: qdrant_engine, qdrant_engine)
LlamaIndex, LlamaExtract’e Yeni Özellikler Ekledi: Atıf ve Çıkarım Desteği: LlamaIndex’in LlamaExtract aracı, AI uygulamalarının güvenilirliğini ve şeffaflığını artırmayı amaçlayan yeni özellikler ekledi. Yeni özellikler, SEC dosyaları gibi karmaşık veri kaynaklarından bilgi çıkarırken kesin kaynak atıfları (citations) ve çıkarım süreci (reasoning) sunulmasına olanak tanıyor. Bu, geliştiricilerin daha sorumlu, daha yorumlanabilir AI sistemleri oluşturmasına yardımcı oluyor (Kaynak: jerryjliu0, jerryjliu0, jerryjliu0)

Hugging Face Geliştiricisi, Agent’ları Hub’a Bağlamak İçin MCP Sunucu Prototipi Oluşturuyor: Hugging Face’den bir geliştirici olan Wauplin, AI Agent’larını Hugging Face Hub’a bağlamayı amaçlayan bir Hugging Face MCP (Machine Communication Protocol) sunucu prototipi geliştiriyor. Bu prototip, “HfApi MCP ile buluşuyor” olarak düşünülebilir ve Agent’ların protokol aracılığıyla Hub ile etkileşime girmesine, örneğin modelleri, veri setlerini, Space’leri paylaşmasına ve düzenlemesine olanak tanıyor. Geliştirici, bu aracın kullanışlılığı ve potansiyel kullanım durumları hakkında topluluktan geri bildirim istiyor (Kaynak: ClementDelangue, ClementDelangue, huggingface)

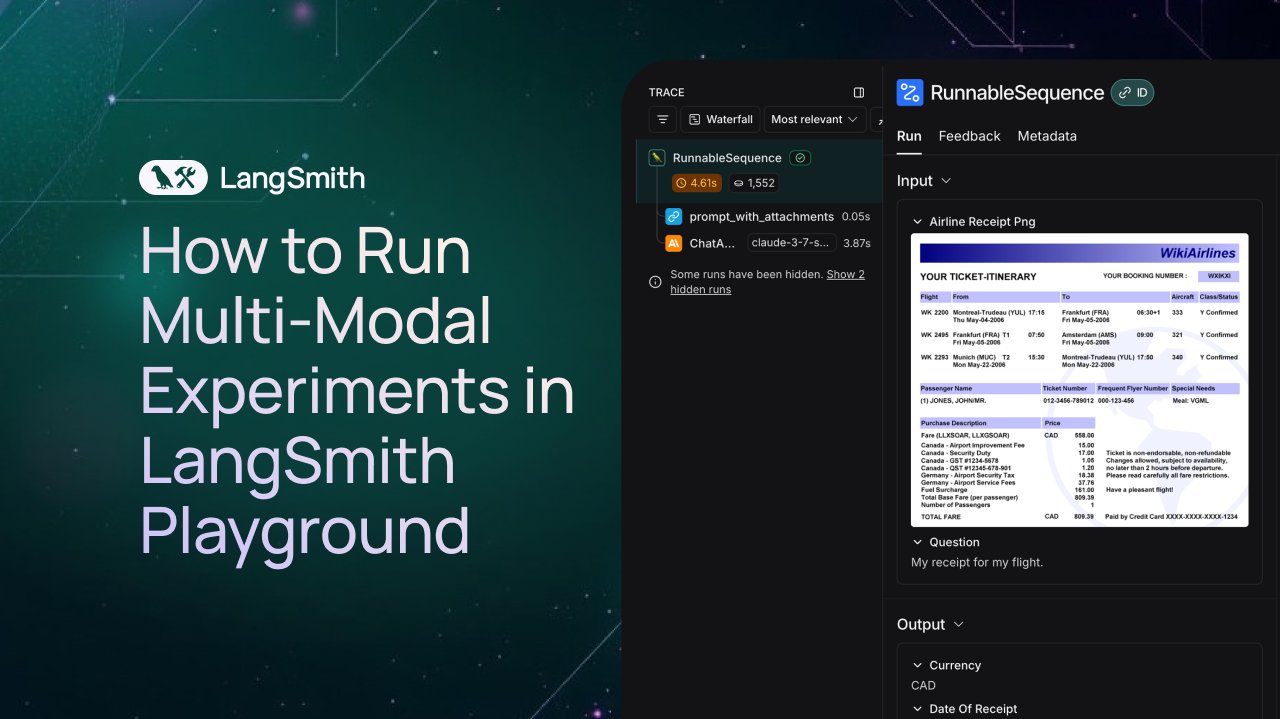
LangSmith, Multimodal Agent’lar İçin Gözlem ve Değerlendirme Desteği Ekledi: LangSmith platformu artık Playground, etiketleme kuyrukları ve veri setlerinde görüntü, PDF ve ses dosyalarını işlemeyi destekliyor. Bu güncelleme, fatura çıkarma Agent’ları gibi multimodal uygulamaların oluşturulmasını ve değerlendirilmesini kolaylaştırıyor. Resmi olarak demo videoları ve belgeler yayınlanarak kullanıcıların yeni özellikleri kullanmaya başlamasına yardımcı olunuyor (Kaynak: LangChainAI, Hacubu, hwchase17)
DFloat11, FLUX.1 Modelinin Kayıpsız Sıkıştırılmış Sürümünü Yayınladı, 20GB VRAM’de Çalışabiliyor: DFloat11 projesi, FLUX.1-dev ve FLUX.1-schnell (12B parametre) modellerinin kayıpsız sıkıştırılmış sürümlerini yayınladı. DFloat11 sıkıştırma yöntemiyle (BFloat16 ağırlıklarına entropi kodlaması uygulanarak), model boyutu 24GB’den yaklaşık 16.3GB’ye (yaklaşık %30) düşürülürken çıktı değişmeden kalıyor. Bu, bu modellerin 20GB veya daha fazla VRAM’e sahip tek bir GPU’da, görüntü başına yalnızca birkaç saniyelik ek yükle çalışmasını sağlıyor. İlgili modeller ve kodlar Hugging Face ve GitHub’da yayınlandı (Kaynak: Reddit r/LocalLLaMA)

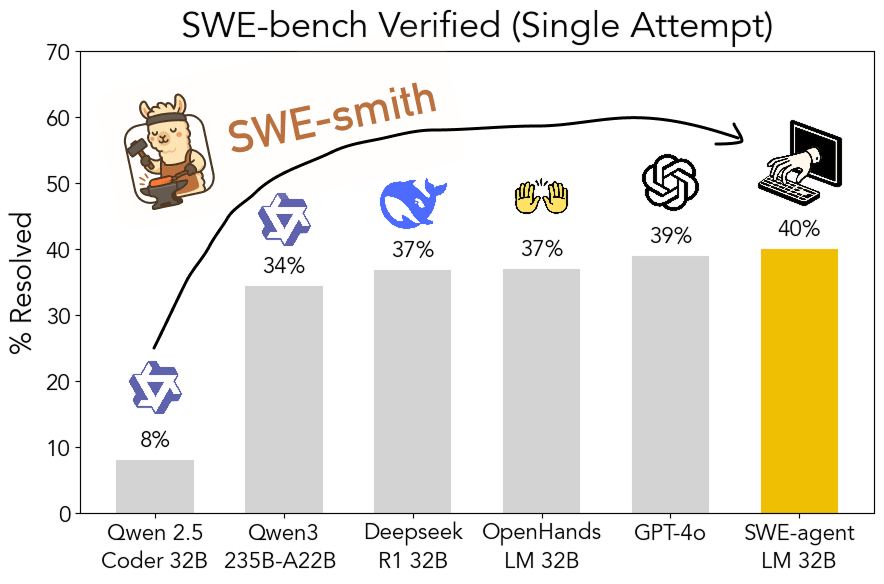
SWE-smith Araç Kiti Açık Kaynak Oldu: Ölçeklenebilir Yazılım Mühendisliği Eğitim Verisi Üretimi: Stanford Üniversitesi araştırmacıları, herhangi bir Python deposundan yazılım mühendisliği eğitim verisi üretmek için ölçeklenebilir bir boru hattı olan SWE-smith’i açık kaynak olarak yayınladı. Bu araç kiti kullanılarak 50.000’den fazla örnek üretildi ve buna dayalı olarak SWE-agent-LM-32B modeli eğitildi. Bu model, SWE-bench Verified benchmark’ında %40.2 Pass@1 başarısı elde ederek bu benchmark’ta en iyi performans gösteren açık kaynak model oldu. Kod, veri ve modellerin tümü açık erişime sunuldu (Kaynak: OfirPress, stanfordnlp, stanfordnlp, huybery, Reddit r/LocalLLaMA)
📚 Öğrenme
Weaviate Ücretsiz Kurs Yayınladı: Gömme Modeli Değerlendirme ve Seçimi: Weaviate Akademisi, “Gömme Modeli Değerlendirme ve Seçimi” üzerine ücretsiz bir kurs başlattı. Kurs, MTEB gibi genel benchmark’ların ötesine geçmenin önemini vurgulayarak, öğrencilere belirli kullanım durumları için bir “altın değerlendirme seti” (golden evaluation set) oluşturmayı ve en uygun gömme modelini seçmek için özel benchmark’lar ayarlamayı, ayrıca yeni yayınlanan modellerin uygun olup olmadığını değerlendirmeyi öğretiyor. Bu, verimli arama ve RAG sistemleri oluşturmak için hayati önem taşıyor (Kaynak: bobvanluijt)
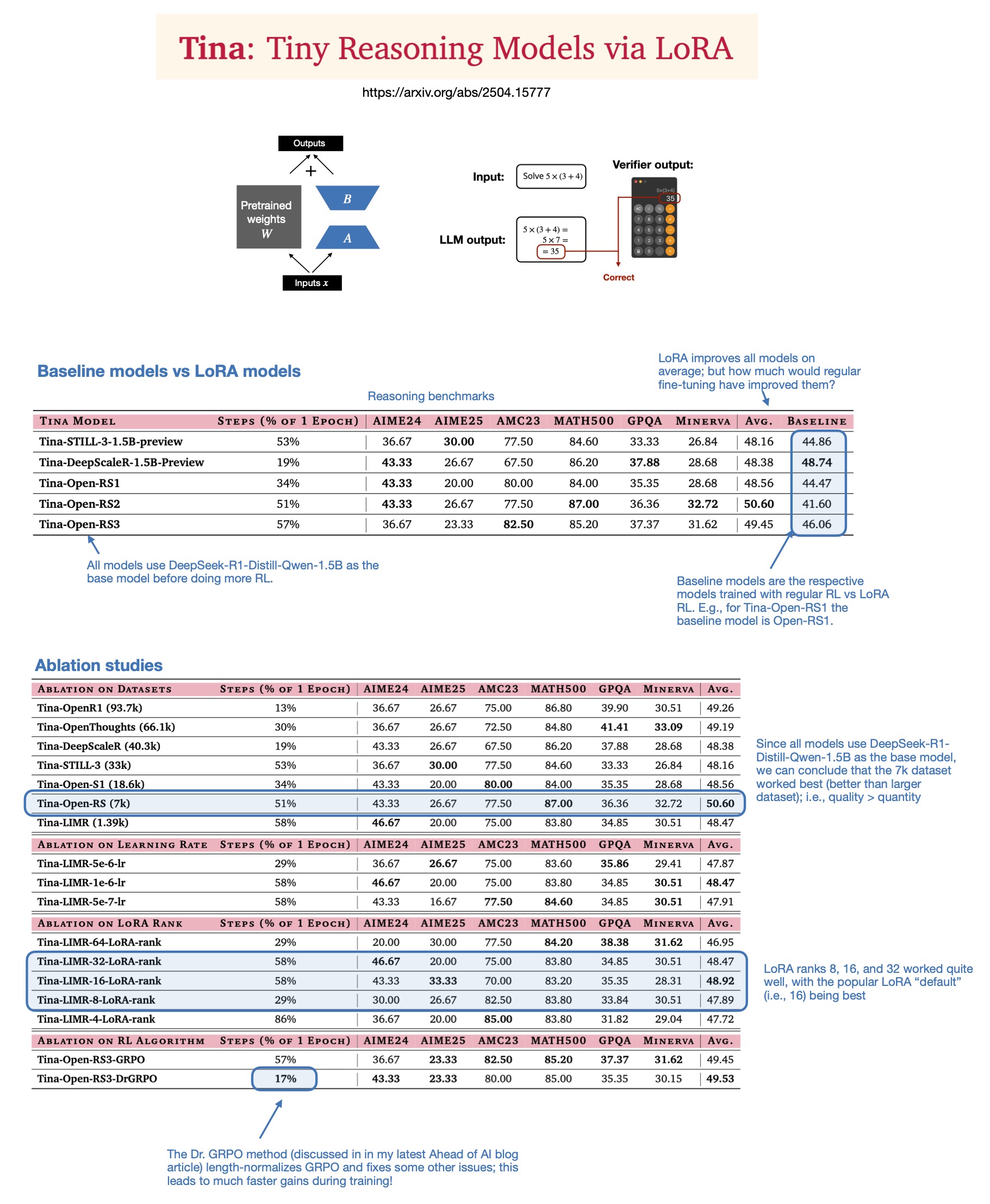
Sebastian Rasbt, LoRA’nın 2025 Yılında Çıkarım Modellerindeki Değerini Tartışıyor: Sebastian Rasbt, “Tina: Tiny Reasoning Models via LoRA” adlı makaleyi okuduktan sonra, LoRA’nın (Low-Rank Adaptation) mevcut büyük model çağındaki anlamını yeniden değerlendirdi. Tam parametreli ince ayar ve damıtma tekniklerinin popülaritesine rağmen Rasbt, LoRA’nın belirli senaryolarda (çıkarım görevleri, çoklu müşteri/çoklu kullanım durumu senaryoları gibi) hala değerli olduğuna inanıyor. Makale, LoRA’nın pekiştirmeli öğrenme (RL) ile birleştirilerek küçük modellerin (1.5B) çıkarım yeteneğini düşük maliyetle (sadece $9 eğitim maliyeti) artırma potansiyelini gösteriyor ve LoRA’nın birden fazla benchmark’ta standart RL ince ayarından daha iyi performans gösterdiğini ortaya koyuyor. LoRA’nın temel modelin özelliklerini değiştirmemesi, çok sayıda özelleştirilmiş model ağırlığının saklanması gerektiğinde maliyet avantajı sağlıyor (Kaynak: rasbt)
DeepLearning.AI Yeni Kurs Başlattı: Üretim Seviyesinde AI Sesli Agent’lar Oluşturma: DeepLearning.AI, LiveKit ve RealAvatar ile işbirliği yaparak “Üretim Seviyesinde AI Sesli Agent’lar Oluşturma” adlı yeni bir kısa kurs başlattı. Kurs, gerçek zamanlı konuşmalar yapabilen, düşük gecikmeli yanıtlar veren ve doğal sesli AI sesli agent’lar oluşturmayı öğretmeyi amaçlıyor. Öğrenciler, ses aktivitesi tespiti, konuşma sırası alma gibi teknikleri uygulayacak ve gecikmeyi azaltmak için mimariyi nasıl optimize edeceklerini öğrenecek, sonunda ölçeklenebilir sesli agent’lar oluşturup dağıtacaklar. Kurs, LiveKit CEO’su, geliştirici savunucusu ve RealAvatar AI sorumlusu tarafından veriliyor (Kaynak: DeepLearningAI, AndrewYNg)
LangChain ve LangGraph Ortaklaşa ACM Teknik Konuşması Düzenliyor: LangChain’in erken geliştirici katkıda bulunanlarından Mayowa Oshin ve LangGraph’in yaratıcısı Nuno Campos, ACM teknik konuşmasında LangChain ve LangGraph kullanarak güvenilir AI Agent’ları ve LLM uygulamaları oluşturmayı anlatacaklar. Konuşma ücretsiz olup canlı yayınlanacak ve kayıt yaptıranlara daha sonra izleme bağlantısı gönderilecek (Kaynak: hwchase17, hwchase17)

Cohere Labs, Birinci Dereceden Optimizasyonun Derinlikleri Üzerine Bir Konuşma Düzenliyor: Cohere Labs, Jeremy Bernstein’ı 8 Mayıs’ta “Birinci Dereceden Optimizasyonun Derinlikleri” (Depths of First-Order Optimization) başlıklı bir konuşma yapması için davet etti. Bu konuşma, makine öğreniminde optimizasyon algoritmalarının uygulamalarını ve teorisini derinlemesine incelemeyi amaçlıyor (Kaynak: eliebakouch)

AI2, OLMo Modeli İçin AMA Etkinliği Düzenliyor: Allen Institute for AI (AI2), 8 Mayıs sabah 8-10 (Pasifik Saati) arasında r/huggingface Reddit alt forumunda açık dil modeli ailesi OLMo hakkında bir “Bana Her Şeyi Sor” (AMA) etkinliği düzenleyecek ve araştırmacıları topluluk sorularını yanıtlamaya davet edecek (Kaynak: natolambert)

💼 İş Dünyası
OpenAI, Microsoft’a Ödenen Gelir Paylaşım Oranını Düşürmeyi Planlıyor: The Information’ın haberine göre OpenAI, yatırımcılara şirket yeniden yapılanma sürecinde en büyük destekçisi Microsoft’a ödenen gelir paylaşım oranını düşürmeyi planladığını bildirdi. Ayrıntılar ve potansiyel etkiler henüz tam olarak açıklanmadı, ancak bu durum iki şirket arasındaki ticari ilişkilerde bir değişikliğe işaret edebilir (Kaynak: steph_palazzolo)
Risk Sermayedarları AI Kurucularına Daha Fazla Yetki Veriyor, Balon Endişeleri Artıyor: The Information, risk sermayedarlarının (VC’ler) en iyi AI kurucularını (özellikle tanınmış AI laboratuvarlarında yönetici deneyimi olanları) çekmek için yönetim kurulu veto hakkı, VC’lerin yönetim kurulunda yer almaması ve kurucuların hisselerinin bir kısmını satmasına izin verilmesi gibi benzeri görülmemiş avantajlı koşullar sunduğunu bildiriyor. Bu durum, bazıları tarafından AI alanında olası bir balonun işareti olarak görülüyor (Kaynak: steph_palazzolo)
Toloka, Bezos Expeditions Liderliğinde Stratejik Yatırım Aldı, Mikhail Parakhin Yönetim Kurulu Başkanı Oldu: Veri etiketleme ve AI eğitim verisi şirketi Toloka, Jeff Bezos’un Bezos Expeditions liderliğinde stratejik bir yatırım aldığını duyurdu. Microsoft’un eski yöneticilerinden Mikhail Parakhin de yatırıma katılarak yönetim kurulu başkanı oldu. Bu yatırım turu, Toloka’nın insan-YZ işbirliği (human+AI) çözümlerini genişletmesini ve veri toplama ile etiketleme işlerini daha da geliştirmesini destekleyecek (Kaynak: menhguin, teortaxesTex, TheTuringPost)

🌟 Topluluk
LLM Eğitim Verilerinin Adil Kullanımı (Fair Use) Hakkında Tartışma: Dorialexander, LLM eğitim verilerinin adil kullanım argümanının büyük ölçüde LLM’lerin eğitim kaynaklarıyla doğrudan ticari rekabete girmemesi varsayımına dayandığını belirtiyor. LLM yetenekleri arttıkça (örneğin Perplexity gibi platformların kurgusal olmayan okuma deneyimine benzer hizmetler sunmaya başlamasıyla), bu varsayım sorgulanabilir hale gelebilir ve telif hakkı ile ticari rekabet hakkında yeni soruları gündeme getirebilir (Kaynak: Dorialexander)
AI Tarafından Üretilen İçeriğin Yaygınlaşmasına Dair Endişeler ve Tartışmalar: Sosyal medyada ve Reddit’te kullanıcılar, düşük kaliteli, tekrarlayan AI tarafından üretilen içeriklerin (örneğin AI tarafından oluşturulan Reddit hikaye videoları) yaygınlaşmasından duydukları endişeyi dile getiriyorlar. Kullanıcılar, bunun insan yaratıcıların alanını daralttığını, yanlış veya homojenleşmiş bilgiler yaydığını ve AI teknolojisinin kolay kar elde etmek için özgünlükten yoksun bir şekilde kullanılmasından rahatsızlık duyduklarını belirtiyorlar (Kaynak: Reddit r/ArtificialInteligence)
AI’nin Bilinçli Olup Olmadığına Dair Felsefi Tartışma: Reddit topluluğunda AI’nin halihazırda bilince sahip olup olamayacağına dair tartışmalar yeniden alevlendi. Destekleyenler, bilinç tanımımızın fazla dar veya insan merkezli olabileceğini savunurken, karşı çıkanlar mevcut LLM’lerin temel mekanizmalarının (örneğin bir sonraki token’ı tahmin etme) gerçek bilinç üretmek için yetersiz olduğunu vurguluyor. Tartışma, halkın AI’nin doğası ve gelecekteki potansiyeli hakkındaki sürekli merakını ve fikir ayrılıklarını yansıtıyor (Kaynak: Reddit r/ArtificialInteligence)
ChatGPT(4o) Performans Düşüşü ve Davranış Değişiklikleri Hakkında Tartışma: Reddit kullanıcıları, son zamanlarda ChatGPT 4o modelinin uzun belgeleri işleme, bağlam hafızasını koruma konularında performansının düştüğünü, daha fazla halüsinasyon gördüğünü ve hatta daha önce işleyebildiği belge formatlarını okuyamadığını bildiriyor. Aynı zamanda OpenAI da son güncellenen GPT-4o sürümünde aşırı yaltaklanma (sycophancy) sorunu yaşandığını kabul etti ve geri aldı. Bu durum, toplulukta model kararlılığı ve iterasyon kalite kontrolü hakkında endişelere yol açtı (Kaynak: Reddit r/ChatGPT, DeepLearning.AI Blog)
AI’nin Eğitim Modellerine Etkisi ve Üzerine Düşünceler: Topluluk tartışmaları, ABD’nin ev ödevleri ve bireysel makalelere dayalı eğitim modelinin, AI’nin (LLM’ler gibi) görevleri otomatik olarak tamamlama yeteneği karşısında son derece savunmasız olduğunu gösteriyor. Buna karşılık, Danimarka gibi bazı Avrupa ülkelerinin okul içi işbirliği, tartışma ve proje tabanlı öğrenmeye daha fazla odaklanması nedeniyle AI’den daha az etkilendiği belirtiliyor. Bu durum, gelecekteki eğitim modelleri üzerine düşünmeye sevk ediyor; eleştirel düşünme, işbirliği gibi kişilerarası becerilerin geliştirilmesine daha fazla odaklanılması, mekanik görevlerin AI’ye devredilmesi ve eğitimin daha senkronize, daha sosyal bir yöne doğru ilerlemesi gerektiği savunuluyor (Kaynak: alexalbert__, riemannzeta, aidan_mclau)
💡 Diğer
AI’nin Robotik Alanındaki Uygulama Gelişmeleri: Birden fazla kaynak, AI’nin robotik alanındaki uygulama örneklerini sergiliyor: 90 saniyede pilav pişirebilen robot şef, Figure AI robotlarının gerçek dünya uygulama gösterimi, Pickle robotunun dağınık bir kamyon römorkundan yük boşaltma demosu, Unitree G1 robotunun engebeli arazide dengede kalması ve iç yapısının gösterimi, İsviçre EPFL tarafından geliştirilen şekil değiştirebilen robot Mori3 gibi. Bu vakalar, AI’nin robotların özerkliğini, uyarlanabilirliğini ve pratikliğini artırma potansiyelini gösteriyor (Kaynak: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Sentdex)

AI Teknolojisinin Belirli Sektörlerdeki Uygulama Keşifleri (Sağlık, Tekstil, Cep Telefonu): Johnson & Johnson, satış desteği, ilaç geliştirmenin hızlandırılması (bileşik taraması, klinik deney optimizasyonu), tedarik zinciri risk tahmini ve iç iletişim (İK soru-cevap robotu) gibi alanlara odaklanan AI stratejisini paylaştı. Aynı zamanda AI teknolojisi, AI destekli tasarım, hassas boyama kontrolü ve otomatik kalite kontrolden başlayarak geleneksel tekstil endüstrisini güçlendiriyor, verimliliği ve sürdürülebilirliği artırıyor. Cep telefonu endüstrisi ise AI’yi yeni bir büyüme motoru olarak görüyor; üreticiler cihaz üzerinde büyük modeller, AI yerel işletim sistemleri ve senaryo tabanlı akıllı hizmetler etrafında rekabet ediyor ve Apple, Huawei ve açık kamp olmak üzere üç ana grup oluşturuyor (Kaynak: DeepLearning.AI Blog, 36氪, 36氪)
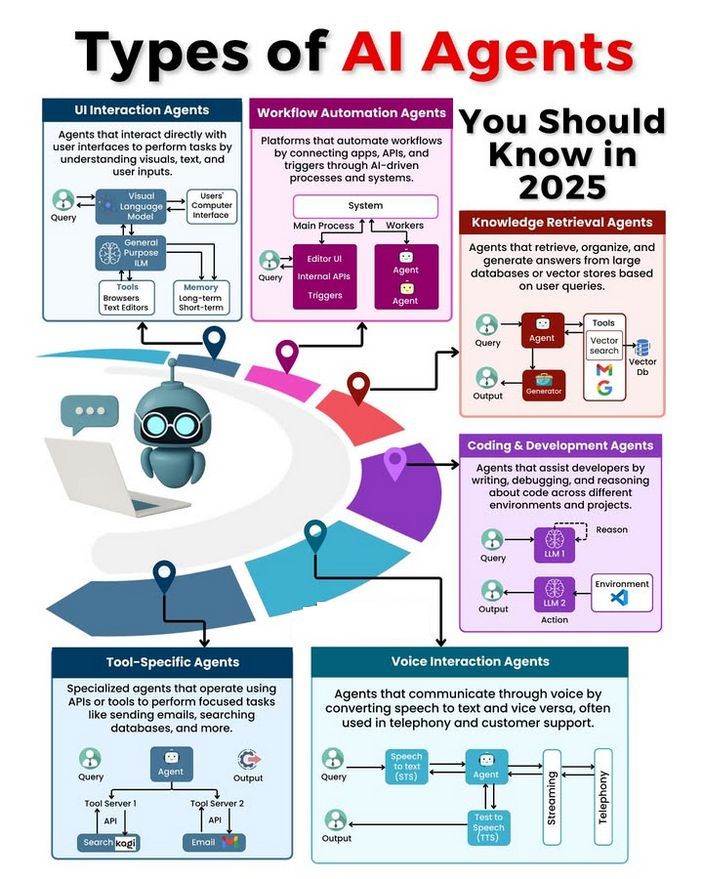
AI Agent Türleri ve Gelişim Tartışması: Topluluk, farklı AI Agent türlerini (basit refleks tabanlı, model tabanlı refleks tabanlı, hedef tabanlı, fayda tabanlı, öğrenen Agent’lar gibi) tartışıyor ve güvenilir Agent’lar oluşturma metodolojilerini (LangChain/LangGraph kullanmak gibi) ele alıyor. Aynı zamanda, gelecekteki AGI’nin tek bir model olmayabileceği, bunun yerine birden fazla uzmanlaşmış modelin işbirliğinden oluşabileceği yönünde görüşler de mevcut (Kaynak: Ronald_vanLoon, hwchase17, nrehiew_)