Anahtar Kelimeler:Gemini 2.5 Pro, Yapay Zeka Modeli, İnsansı Robot, Yapay Zeka Etiği, Yapay Zeka Girişimi, Yapay Zeka Üretilen İçerik, Yapay Zeka Destekli Yaratıcılık, Gemini 2.5 Pro ile Pokémon: Mavi Tamamlama, Anthropic Claude Küresel Web Arama, Qwen3 MoE Model Yönlendirme Sapması, Runway Gen-4 Referanslar Özelliği, Yapay Zeka ile Ruh Sağlığı Desteği
🔥 Odak Noktası
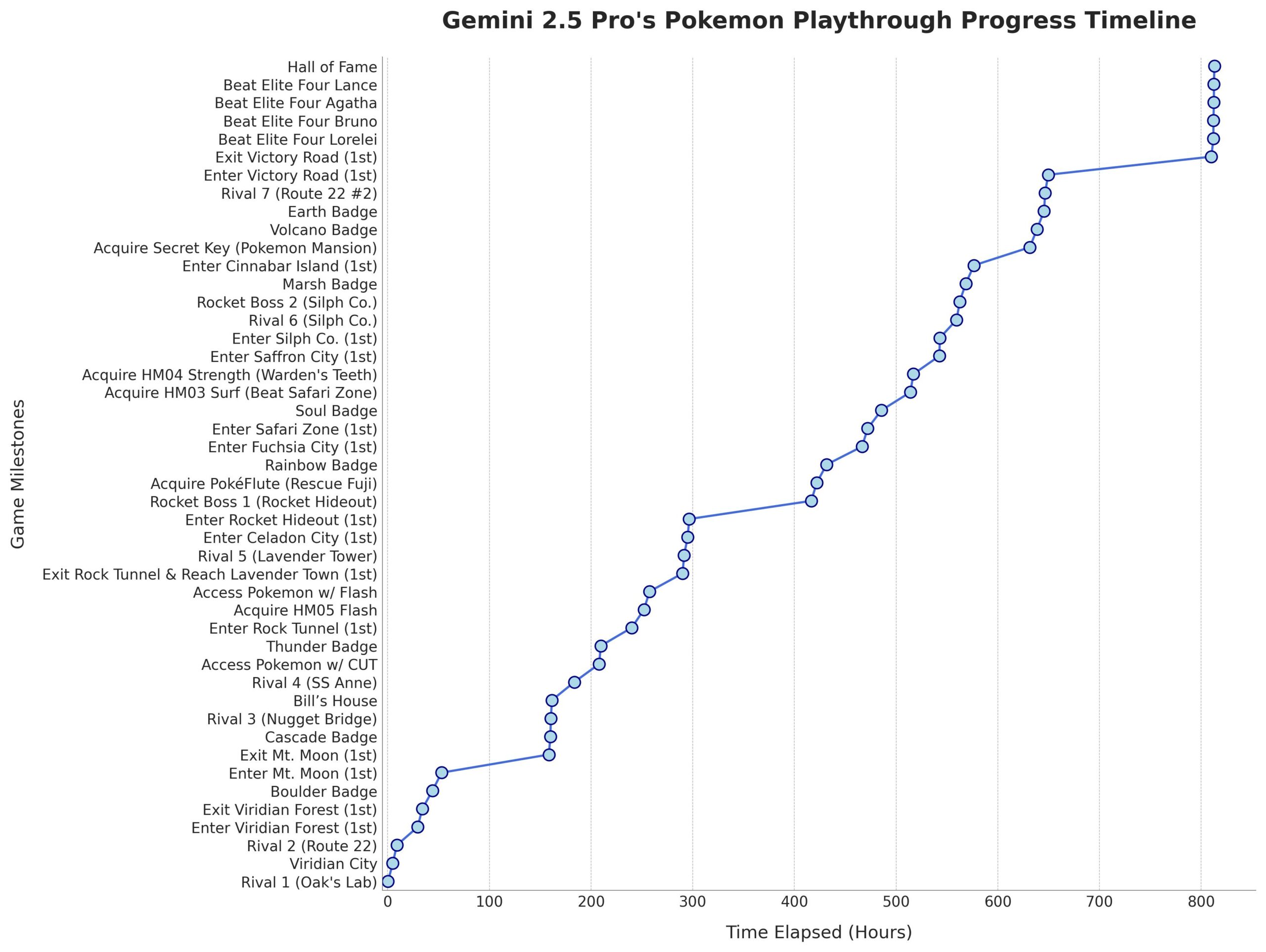
Gemini 2.5 Pro, Pokémon: Blue’yu başarıyla tamamladı: Google’ın Gemini 2.5 Pro AI modeli, 8 rozetin tamamını toplamak ve Pokémon Ligi’nin Elit Dörtlü’sünü yenmek de dahil olmak üzere klasik oyun Pokémon: Blue’yu başarıyla tamamladı. Bu başarı, yayıncı @TheCodeOfJoel tarafından yürütüldü ve canlı yayınlandı ve Google CEO’su Sundar Pichai ile DeepMind CEO’su Demis Hassabis tarafından tebrik edildi. Bu, mevcut AI’ın karmaşık görev planlama, uzun vadeli strateji geliştirme ve simüle edilmiş ortamlarla etkileşim konularında kaydettiği önemli ilerlemeyi gösteriyor, önceki AI’ların bu oyundaki performansını aşıyor ve AI ajanı yeteneklerinde yeni bir kilometre taşını işaret ediyor. (Kaynak: Google, jam3scampbell, teortaxesTex, YiTayML, demishassabis, _philschmid, Teknium1, tokenbender)
Apple, AI kodlama platformu “Vibe Coding” geliştirmek için Anthropic ile iş birliği yapıyor: Bloomberg’e göre Apple, “Vibe Coding” adlı yeni bir AI destekli kodlama platformu geliştirmek için AI startup’ı Anthropic ile iş birliği yapıyor. Platform şu anda Apple içinde çalışanlara test için sunuluyor ve gelecekte üçüncü taraf geliştiricilere açılma potansiyeli taşıyor. Bu, Apple’ın AI programlama yardımcı araçları alanındaki daha ileri keşiflerini işaret ediyor, geliştirme verimliliğini ve deneyimini artırmak için AI’dan yararlanmayı hedefliyor ve muhtemelen kendi Swift Assist gibi projelerini tamamlayabilir veya onlarla entegre olabilir. (Kaynak: op7418)
AI destekli robotik teknolojisindeki ilerlemeler ve tartışmalar: Son zamanlarda insansı robotlar ve cisimleşmiş zeka (embodied intelligence) geniş ilgi görüyor. Figure şirketi, batarya, aktüatörlerden AI laboratuvarlarına kadar uzanan yüksek teknolojili yeni merkezini sergileyerek robotik alanındaki hedeflerini ortaya koydu. Disney de insansı karakter robot teknolojisini sergiledi. Ancak, Pekin İnsansı Robot Maratonu yarışmasında, bazı robotlar (müşteriler tarafından modifiye edilen Unitree G1 dahil) düşme, zayıf pil ömrü ve denge sorunları gibi kötü performanslar sergiledi. Bu durum, mevcut insansı robotların gerçek yetenekleri hakkında tartışmalara yol açtı ve “beyincik” (hareket kontrolü) ve “beyin” (akıllı karar verme) konularında hala büyük ilerlemelere ihtiyaç duyulduğunu vurguladı. (Kaynak: adcock_brett, Ronald_vanLoon, 人形机器人,最重要的还是“脑子”)

AI etiği ve toplumsal etki tartışmaları artıyor: Sosyal medya ve araştırma alanlarında AI’ın toplumsal etkileri ve etik sorunları hakkındaki tartışmalar giderek artıyor. Örneğin, Kaliforniya SB-1047 AI yasa tasarısı tartışmalara yol açtı ve ilgili belgeseller düzenlemenin gerekliliğini ve zorluklarını ele alıyor. NAACL 2025 konferansı, AI’ın insanlar ve toplumla etkileşimindeki uzun vadeli ve yeni ortaya çıkan zorlukları tartışmak üzere “LLM Çağında Sosyal Zeka” üzerine bir eğitim düzenledi. Aynı zamanda, kullanıcılar AI tarafından üretilen içeriğin kalitesi (“slop”) konusunda endişelerini dile getiriyor ve daha iyi model tasarımı ve kontrolüne ihtiyaç olduğunu savunuyorlar. Bu tartışmalar, toplumun AI teknolojisinin hızlı gelişiminin getirdiği etik, düzenleyici ve sosyal uyum sorunlarına yönelik artan ilgisini yansıtıyor. (Kaynak: teortaxesTex, gneubig, stanfordnlp, jam3scampbell, willdepue, wordgrammer)

🎯 Gelişmeler
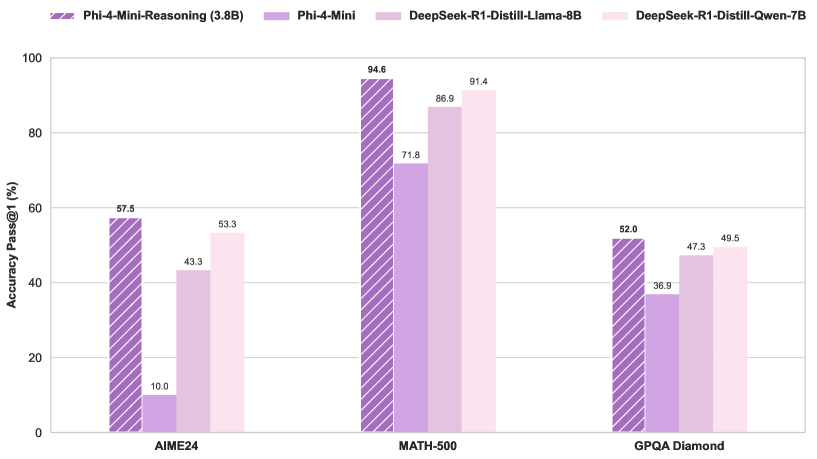
Microsoft, Phi-4-Mini-Reasoning modelini yayınladı: Microsoft, Hugging Face üzerinde Phi-4-Mini-Reasoning modelini yayınladı. Bu model, küçük dil modellerinin matematiksel akıl yürütme yeteneklerini geliştirmeyi amaçlıyor ve küçük boyutlu, yüksek verimli modellerin gelişimini daha da ileri taşıyor. (Kaynak: _akhaliq)
Anthropic Claude modeli küresel web aramasını destekliyor: Anthropic, Claude AI modelinin artık tüm ücretli kullanıcılar için küresel çapta web arama özelliği sunduğunu duyurdu. Basit görevler için Claude hızlı bir arama yapacak; karmaşık sorunlar için ise Google Workspace dahil olmak üzere birden fazla bilgi kaynağını keşfedecek, bu da modelin gerçek zamanlı bilgi edinme ve işleme yeteneklerini artırıyor. (Kaynak: Teknium1, Reddit r/ClaudeAI)

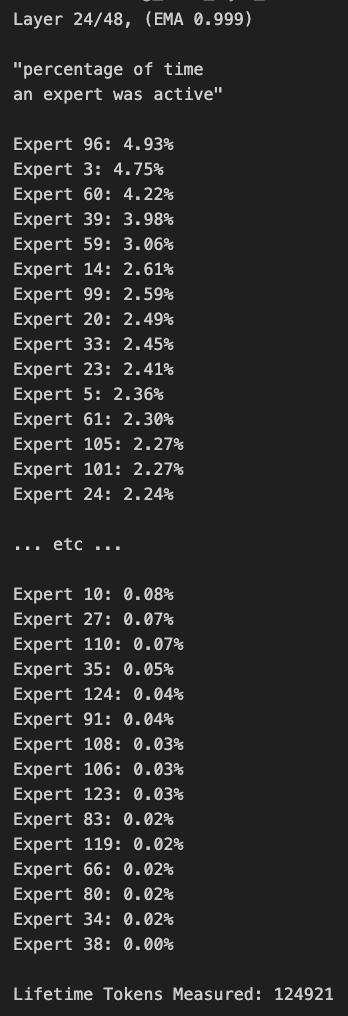
Qwen3 MoE model yönlendirmesinde sapma var, budanabilir: Kullanıcı kalomaze, Qwen3 MoE (Uzmanlar Karması modeli) yönlendirme dağılımında önemli bir sapma olduğunu analiz etti; 30B MoE modeli bile budanabilirlik potansiyeli gösteriyor. Bu, bazı uzmanların (Experts) yeterince kullanılmadığı anlamına geliyor ve bu uzmanları budayarak kaldırmak, performansı önemli ölçüde etkilemeden model boyutunu ve hesaplama gereksinimlerini azaltabilir. Kalomaze, bu bulguya dayanarak 30B modelini 16B’ye budayan bir sürüm yayınladı ve 235B modelini 150B’ye budayan bir sürüm yayınlamayı planlıyor. (Kaynak: andersonbcdefg, Reddit r/LocalLLaMA)
DeepSeek Prover V2, açık kaynak matematik asistanları arasında öne çıkıyor: DeepSeek Prover V2, şu anda en iyi performans gösteren açık kaynak matematik yardımcı modeli olarak kabul ediliyor. Performansı hala Gemini 2.5 Pro, o4 mini high, o3, Claude 3.7 ve Grok 3 gibi kapalı kaynak veya daha güçlü modellerin gerisinde kalsa da, yapılandırılmış akıl yürütmede iyi performans gösteriyor. Kullanıcılar, yaratıcı düşünme gerektiren “beyin fırtınası” oturumlarında geliştirilmesi gerektiğini düşünüyor. (Kaynak: cognitivecompai)
Model tercihleri tartışması: Geliştirici eğilimleri ve belirli model özellikleri: Geliştirici topluluğunda farklı büyük modellerin artı ve eksileri hakkındaki tartışmalar devam ediyor. Örneğin, Sentdex, Cursor’da Codex ile birleştirilmiş o3’ün performansının Claude 3.7’den daha iyi olduğunu düşünüyor. VictorTaelin ise Sonnet 3.7’nin mükemmel olmamasına rağmen (bazen istenmeyen içerikleri proaktif olarak ekliyor, zeka seviyesi beklentileri karşılamıyor), pratikte hala GPT-4o (hataya eğilimli), o3/Gemini (kod formatlama ve yeniden yazma zayıf), R1 (biraz eski kalmış) ve Grok 3’ten (ikinci en iyi, ancak pratikte biraz geride) daha istikrarlı ve güvenilir sonuçlar sunduğunu belirtiyor. Bu, farklı modellerin belirli görevler ve iş akışlarındaki uygunluk farklılıklarını yansıtıyor. (Kaynak: Sentdex, VictorTaelin, paul_cal)

LLM performans trendleri tartışması: Üssel büyüme mi yoksa azalan getiriler mi?: Reddit kullanıcıları, LLM’lerin hala üssel bir iyileşme yaşayıp yaşamadığını tartışıyor. Bir görüşe göre, erken dönemdeki hızlı ilerlemelere rağmen, LLM performans artışı şu anda azalan getirilere doğru yöneliyor ve ek performans elde etmek giderek daha zor ve pahalı hale geliyor, tıpkı otonom sürüş teknolojisinin gelişimi gibi. Diğer kullanıcılar ise GPT-3’ten Gemini 2.5 Pro’ya kadar olan büyük sıçramanın ilerlemenin hala önemli olduğunu gösterdiğini ve bir platodan bahsetmek için henüz erken olduğunu savunarak buna karşı çıkıyor. Tartışma, AI’ın gelecekteki gelişim hızına ilişkin farklı beklentileri yansıtıyor. (Kaynak: Reddit r/ArtificialInteligence)
AI çipleri insansı robot gelişiminin anahtarı haline geliyor: Sektör görüşleri, insansı robotların çekirdeğinin “beyinleri”, yani yüksek performanslı çipler olduğunu belirtiyor. Makale, mevcut insansı robotların hareket kontrolü (beyincik) ve akıllı karar verme (beyin) konularında hala eksiklikleri olduğunu ve çip performansının robotların zeka seviyesini doğrudan belirlediğini işaret ediyor. Nvidia’nın GPU’ları, Intel işlemcileri ve yerli Black Sesame Technologies’in Huashan A2000 ve Wudang C1236 gibi çipleri, robotlara daha güçlü algılama, çıkarım ve kontrol yetenekleri sağlıyor ve insansı robotları gösterişten pratik uygulamaya taşımanın anahtarı konumunda. (Kaynak: 人形机器人,最重要的还是“脑子”)

AI etiği ve insanlaştırma: Neden AI’a “teşekkür ederim” diyoruz?: Tartışma, AI’ın duyguları olmamasına rağmen, kullanıcıların ona karşı kibar ifadeler (“teşekkür ederim”, “lütfen” gibi) kullanma eğiliminde olduğunu belirtiyor. Bu, insanların insanlaştırma içgüdüsünden ve “sosyal varlık algısından” kaynaklanıyor. Araştırmalar, kibar etkileşim tarzlarının AI’ı daha beklentilere uygun, daha insancıl yanıtlar üretmeye yönlendirebileceğini gösteriyor. Ancak bu aynı zamanda riskler de taşıyor; örneğin AI, insan önyargılarını öğrenebilir ve büyütebilir veya kötü niyetli olarak uygunsuz içerik üretmeye yönlendirilebilir. AI’a karşı kibar davranışlar, insanların giderek akıllanan makinelerle etkileşim halindeyken sergilediği karmaşık psikolojiyi ve sosyal uyumu yansıtıyor. (Kaynak: 你对 AI 说的每一句「谢谢」,都在烧钱)

🧰 Araçlar
Runway Gen-4 References özelliği: RunwayML tarafından sunulan Gen-4 References özelliği, kullanıcıların kendi veya diğer referans görüntülerini AI tarafından üretilen videolara veya resimlere (meme gibi) entegre etmelerine olanak tanır. Kullanıcı geri bildirimleri, özelliğin etkileyici olduğunu, aynı üretilen görüntüde birden fazla tutarlı karakterin görünmesini işleyebildiğini ve belirli kişileri veya stilleri AI yaratımlarına dahil etme sürecini basitleştirdiğini belirtiyor. (Kaynak: c_valenzuelab)

Krea AI, görüntü oluşturma şablonlarını başlattı: Krea AI, yaygın GPT-4o görüntü oluşturma istemlerini şablonlara dönüştüren yeni bir özellik ekledi. Kullanıcılar sadece kendi resimlerini yükleyip bir şablon seçerek ilgili stilde resimler oluşturabilirler, karmaşık istemleri manuel olarak girmeye gerek kalmaz, bu da görüntü oluşturma sürecini basitleştirir. (Kaynak: op7418)
NotebookLM yakında mobil uygulama sunacak: Google’ın NotebookLM’i (eski adıyla Project Tailwind) yakında bir mobil uygulama yayınlayacak. Kullanıcılar telefonlarında gördükleri makaleleri ve içerikleri işlemek ve entegre etmek için hızla NotebookLM’e iletebilecekler. Uygulama bekleme listesi kaydı şu anda açık olup, daha uygun bir mobil bilgi yönetimi ve AI destekli öğrenme deneyimi sunmayı amaçlamaktadır. (Kaynak: op7418)
İç mekan tasarımı için Runway kullanımı: Kullanıcılar, iç mekan tasarımı için Runway AI kullanımını gösterdi. Bir mekan resmi ve stil/duyguyu temsil eden bir referans resmi sağlayarak, Runway ikisinin özelliklerini birleştiren iç mekan tasarım görselleri üretebiliyor, bu da AI’ın yaratıcı tasarım alanındaki uygulama potansiyelini gösteriyor. (Kaynak: c_valenzuelab)

Unsloth, Qwen3 modeli ince ayarını destekliyor: Unsloth, Qwen3 serisi modeller için ince ayar (fine-tuning) desteğini duyurdu; hız 2 kat artarken VRAM kullanımı %70 azalıyor. Kullanıcılar, 24GB VRAM’li bir GPU’da Flash Attention 2’den 8 kat daha uzun bağlam uzunluğunda ince ayar yapabilirler. Qwen3 14B modelini ücretsiz olarak ince ayarlamak için bir Colab not defteri sunuluyor ve GGUF dahil olmak üzere çeşitli nicelleştirilmiş (quantized) modeller yüklendi. Bu, gelişmiş modellerin ince ayarı için donanım engelini düşürüyor. (Kaynak: Reddit r/LocalLLaMA)
Claude AI Styles özelliği: Kullanıcılar, AI ile işbirliği deneyimini iyileştirmek için Claude AI’ın Styles özelliğini kullandıklarını paylaştı. “Iterative Engineering” adlı bir stil oluşturarak, tartışma, planlama, küçük adımlarla değişiklik yapma, test etme, iterasyon yapma ve gerektiğinde yeniden yapılandırma adımlarını belirleyerek, Claude’u daha metodik ve artımlı bir şekilde kodlama yapmaya yönlendirebilir, AI’ın kodu aşırı derecede yeniden yazmasını önleyebilir ve AI’ın bir programlama ortağı olarak kullanışlılığını artırabilirler. (Kaynak: Reddit r/ClaudeAI)
Deepwiki kod bloğu kaynakları sağlıyor: Kullanıcı cto_junior, Deepwiki’nin bir avantajının, her yanıtın yanında sadece ekli bağlantılar yerine kaynak kod bloklarını göstermesi olduğunu belirtti. Bu uygulama, özellikle AI araçlarına şüpheyle yaklaşan yazılım geliştirme mühendisleri (SDE’ler) için bilginin güvenilirliğini artırıyor. (Kaynak: cto_junior)
📚 Öğrenme
NousResearch, Atropos RL çerçevesi güncellemesini yayınladı: NousResearch’ün Atropos pekiştirmeli öğrenme (RL) ortam çerçevesi güncellendi. Yeni özellikler, kullanıcıların eğitim veya çıkarım motoruna ihtiyaç duymadan RL ortamlarının rollout’larını hızlı ve kolay bir şekilde test etmelerine olanak tanır. Varsayılan olarak OpenAI API kullanır, ancak diğer API sağlayıcılarına (veya yerel VLLM/SGLang uç noktalarına) yapılandırılabilir. Test tamamlandıktan sonra, tamamlamaları ve puanlarını içeren bir web sayfası raporu oluşturulur ve wandb günlüğünü destekler, bu da RL ortamlarının hata ayıklamasını ve değerlendirmesini kolaylaştırır. (Kaynak: Teknium1)

Kişiselleştirilmiş RAG kıyaslama veri seti EnronQA yayınlandı: Araştırmacılar, özel belgeler üzerinde kişiselleştirilmiş geri alım destekli üretimi (Personalized RAG) araştırmasını ilerletmek amacıyla EnronQA veri setini yayınladı. Bu veri seti, 103.638 e-posta ve 150 kullanıcı için 528.304 yüksek kaliteli soru-cevap çifti içeriyor ve kişiye özel bilgileri anlayabilen ve kullanabilen RAG sistemlerini değerlendirmek ve geliştirmek için kaynak sağlıyor. (Kaynak: lateinteraction)
GTE-ModernColBERT (PyLate) yayınlandı: LightOnAI, gte-modernbert-base tabanlı ve ms-marco-en-bge-gemma üzerinde ince ayarlanmış 128 boyutlu bir MaxSim geri alıcısı olan GTE-ModernColBERT’ü (PyLate) yayınladı. Yeniden sıralama ve HNSW indeksleme için yerel olarak PyLate kütüphanesini destekler. NanoBEIR kıyaslamasında üstün performans gösteriyor ve BEIR ortalama puanında ColBERT-small’u geçerek yeni ve verimli metin geri alımı seçenekleri sunuyor. (Kaynak: lateinteraction)

SOLO Bench – Yeni LLM kıyaslama testi: Kullanıcı jd_3d, yeni bir LLM kıyaslama yöntemi olan SOLO Bench’i geliştirdi ve yayınladı. Bu test, LLM’den belirli sayıda (örneğin 250 veya 500) cümle içeren bir metin üretmesini istiyor; her cümle, önceden tanımlanmış bir listeden (isimler, fiiller, sıfatlar vb. içeren) yalnızca bir kelime içermeli ve her kelime yalnızca bir kez kullanılmalıdır. Kural tabanlı bir betik aracılığıyla değerlendirilen test, LLM’nin talimat takibi, kısıtlama karşılama ve uzun metin üretme yeteneklerini test etmeyi amaçlıyor. İlk sonuçlar, kıyaslamanın farklı modellerin performansını etkili bir şekilde ayırt edebildiğini gösteriyor. (Kaynak: Reddit r/LocalLLaMA)
Stratejik özyinelemeli yansıtma kullanarak gizli uzayı manipüle etme: Kullanıcı, LLM’nin gizli uzayında (latent space) iç içe geçmiş çıkarım hiyerarşileri oluşturmak için “stratejik özyinelemeli yansıtma” (Strategic recursive reflection, RR) yoluyla bir yöntem öneriyor. Kritik anlarda modeli önceki etkileşimleri yansıtmaya yönlendirerek, üstbilişsel döngüler oluşturulur ve “mini gizli uzaylar” inşa edilir. Her istem, modelin gizli uzaydaki yolunu yönlendiren bir baskı olarak görülür ve onu daha öz-göndergesel ve soyut hale getirir. Bunun, insanların düşüncelerini yansıtarak düşünmeyi derinleştirme sürecini simüle ettiği ve daha derin kavramsal seviyeleri keşfetmeyi amaçladığı düşünülmektedir. (Kaynak: Reddit r/ArtificialInteligence)
💼 İş Dünyası
Google, Gemini AI’ı önceden yüklemek için Samsung’a ödeme yapıyor: Geçen yıl varsayılan arama motoru anlaşması nedeniyle antitröst yasasını ihlal etmekten suçlu bulunduktan sonra, Google’ın Samsung cihazlarına Gemini AI’ı önceden yüklemek için Samsung’a aylık “büyük meblağlar” ve gelir paylaşımı ödediği ve iş ortaklarından Gemini’ı zorunlu olarak önceden yüklemelerini talep edebileceği ortaya çıktı. Bu, Samsung Galaxy S25 serisinin neden Gemini’ı derinlemesine entegre ettiğini ve hatta varsayılan AI asistanı olarak ayarladığını açıklıyor. Bu hamle, Google’ın kendi donanım kanallarının yetersiz olduğu bir durumda mobil AI giriş noktasını ele geçirme stratejisini yansıtıyor, ancak aynı zamanda yeniden antitröst endişelerini tetikleyebilir. (Kaynak: 三星手机预装Gemini AI,也是谷歌花钱买的)

AI startup’ları zorluklarla karşı karşıya: Reddit tartışması, model yetenekleri yakınsadıkça ve kullanıcı sadakati düşük olduğundan birçok AI startup’ının bir rekabet avantajına (moat) sahip olmayabileceğini belirtiyor. Büyük teknoloji şirketleri (Google, Microsoft, Apple) ekosistem avantajları (önceden yükleme, entegrasyon gibi) sayesinde kullanıcılara daha kolay ulaşıyor. Startup’ların modelleri biraz daha iyi olsa bile, kullanıcılar varsayılan veya entegre edilmiş “yeterince iyi” AI’ı kullanma eğiliminde olabilir. Bu durum, AI startup’larının uzun vadeli sürdürülebilirliği ve VC yatırımlarının geleceği hakkında endişelere yol açıyor. (Kaynak: Reddit r/ArtificialInteligence)
Bu Hafta AI Finansmanı ve İş Dünyası Gelişmeleri Özeti (2 Mayıs 2025): Microsoft CEO’su, AI’ın şirketin kodunun “önemli kısımlarını” yazdığını açıkladı; Microsoft CFO’su, aşırı talep nedeniyle AI hizmetlerinin kesintiye uğrayabileceği konusunda uyardı; Google, üçüncü taraf AI sohbet botlarında reklam yayınlamaya başladı; Meta bağımsız bir AI uygulaması başlattı; Cast AI 108 milyon dolar, Astronomer 93 milyon dolar, Edgerunner AI 12 milyon dolar yatırım aldı; Araştırma, LM Arena’yı kıyaslama testlerinin manipüle edildiği iddiasıyla suçladı; Nvidia, Anthropic’in çip ihracat kontrollerine verdiği desteğe meydan okudu. (Kaynak: Reddit r/artificial)
🌟 Topluluk
AI tarafından üretilen içeriğin kalitesi ve maliyeti tartışması: Toplulukta, AI tarafından üretilen içeriğin değişken kalitesi (“slop” olarak adlandırılır) konusunda endişeler dile getiriliyor. Kullanıcı wordgrammer, toplu olarak üretilen AI videolarının kalitesinin düşük olduğunu ve gerçek maliyetin (eleme ve yeniden deneme maliyeti göz önüne alındığında) belirtilen fiyattan çok daha yüksek olduğunu belirtiyor. Bu durum, model tasarımı (jam3scampbell’in Steve Jobs’un görüşüne atıfta bulunması gibi) ve AI araçlarının etkili kullanımı üzerine tartışmalara yol açıyor ve daha hassas kontrol ve daha yüksek üretim kalitesi standartlarına ihtiyaç olduğunu vurguluyor. (Kaynak: wordgrammer, jam3scampbell, willdepue)
AI’ın belirli görevlerdeki performansı tartışmalara yol açıyor: Topluluk üyeleri, AI’ın farklı görevlerdeki performansını ve sınırlamalarını tartışıyor. Örneğin, DeepSeek R1’in LLM heyecanının zirvelerinden biri olabileceği düşünülüyor; biçimsel matematik, tıp gibi alanlarda ilerlemeler olmasına rağmen, henüz sıradan kullanıcıların geniş ilgisini çekmedi. DeepSeek Prover V2 matematikte iyi performans gösteriyor ancak yaratıcılıktan yoksun olduğu düşünülüyor. Kullanıcı vikhyatk, modelleri AIME (Amerikan Matematik Davet Yarışması) gibi belirli kıyaslamalarda performans göstermesi için aşırı optimize etmenin anlamını sorguluyor ve kitlenin matematik yeteneğiyle ilgilenmediğini savunuyor. Bu tartışmalar, AI’ın yetenek sınırları ve pratik uygulama değeri üzerine düşünceleri yansıtıyor. (Kaynak: wordgrammer, cognitivecompai, vikhyatk)
AI destekli yaratıcılık ve tasarım: Topluluk, AI araçlarını kullanarak yaratıcı tasarım yapmanın çeşitli yollarını sergiliyor. Kullanıcılar Runway’in Gen-4 References özelliğini kullanarak kendilerini meme’lere dahil ediyor; Runway’i iç mekan tasarımı konseptleri oluşturmak için kullanıyor; GPT-4o ve istem şablonlarını kullanarak belirli stillerde (origami Güney Çin kaplanı, hayvan silikon bilek desteği, kelime anlamlarını harf tasarımına entegre etme gibi) görüntüler yaratıyor. Bu örnekler, AI’ın görsel yaratıcılık ve kişiselleştirilmiş tasarım alanlarındaki potansiyelini gösteriyor. (Kaynak: c_valenzuelab, c_valenzuelab, dotey, dotey, dotey)

AI’ın yazım tarzı taklit etme yeteneğine dair şüpheler: Kullanıcı nrehiew_, LLM’ye “benim tonumda ve tarzımda yazmaya devam et” komutunun pratikte bir etkisi olmayabileceğini, çünkü çoğu insanın kendi yazım tarzının benzersizliğini abarttığını düşünüyor. Bu, LLM’nin ince yazım tarzlarını anlama ve kopyalama yeteneği ve kullanıcıların bu yeteneğe ilişkin algısal önyargıları hakkında tartışmalara yol açıyor. (Kaynak: nrehiew_)
AI’ın duygusal destek için kullanılması yankı uyandırıyor ve tartışılıyor: Reddit kullanıcıları, ChatGPT gibi AI’larla konuşarak duygusal destek aldıkları ve hatta krizlerle başa çıkmalarına yardımcı olduğu deneyimlerini paylaşıyor. Birçoğu, yalnızlık, konuşma ihtiyacı veya psikolojik zorluklarla karşılaştıklarında, AI’ın yargılamayan, sabırlı ve her zaman ulaşılabilir bir iletişim ortağı sunduğunu, hatta bazen gerçek insanlarla iletişim kurmaktan daha etkili hissettirdiğini belirtiyor. Bu, AI’ın ruh sağlığı desteğindeki rolü hakkında tartışmalara yol açarken, aynı zamanda AI’ın profesyonel insan yardımının yerini tutamayacağını ve AI’ın getirebileceği önyargılara veya yanlış yönlendirmelere karşı dikkatli olunması gerektiğini vurguluyor. (Kaynak: Reddit r/ChatGPT, Reddit r/ClaudeAI)
AI tarafından üretilen sanata ilişkin görüş ayrılıkları: Kullanıcılar, AI tarafından üretilen sanatın insan sanatçılar ve eserlerinin algılanması üzerindeki potansiyel etkisini tartışıyor. Bazıları, yüksek kaliteli eserlerin artık kolayca AI üretimi olarak etiketlenmesinden ve yaratıcıların yetenek ve çabalarının göz ardı edilmesinden şikayet ediyor. Bu olgu, insanların algısını çarpıtmaya bile başlıyor ve insanları, bir eserin AI tarafından yapılmadığını doğrulamak için “insan hatası” aramaya yöneltiyor. Tartışma ayrıca, AI tarafından üretilen içeriğe filigran eklenmesinin zorunlu olup olmaması gerektiği konusuna da değiniyor. (Kaynak: Reddit r/ArtificialInteligence)
💡 Diğer
AI’ın kaynak tüketimi dikkat çekiyor: Tartışma, AI gelişiminin arkasındaki devasa kaynak tüketimini vurguluyor. Büyük AI modellerini eğitmek ve çalıştırmak büyük miktarda elektrik ve su kaynağı gerektiriyor, veri merkezleri yeni yüksek enerji tüketen tesisler haline geliyor. Kullanıcıların AI ile her etkileşimi, basit bir “teşekkür ederim” dahil, enerji tüketimini biriktiriyor. Bu durum, AI’ın sürdürülebilir gelişimi ve nükleer füzyon gibi enerji çözümlerine olan ilgiyi artırıyor. (Kaynak: 你对 AI 说的每一句「谢谢」,都在烧钱)
AI ve bilinç arasındaki mesafe: Reddit kullanıcıları mevcut AI’ın öz farkındalığa sahip olup olmadığını tartışıyor. Yaygın görüş, mevcut AI’ın (LLM’ler gibi) özünde kelimeleri olasılıksal olarak tahmin eden karmaşık örüntü eşleştirme sistemleri olduğu, gerçek anlayış ve öz farkındalıktan yoksun olduğu ve bu yeteneğe sahip olmaktan çok uzak olduğudur. Ancak bazı yorumlar, insan bilincinin kendisinin de tam olarak anlaşılmadığını, karşılaştırmanın yanıltıcı olabileceğini ve AI’ın belirli görevlerdeki insanüstü yeteneklerinin göz ardı edilmemesi gerektiğini belirtiyor. (Kaynak: Reddit r/ArtificialInteligence)
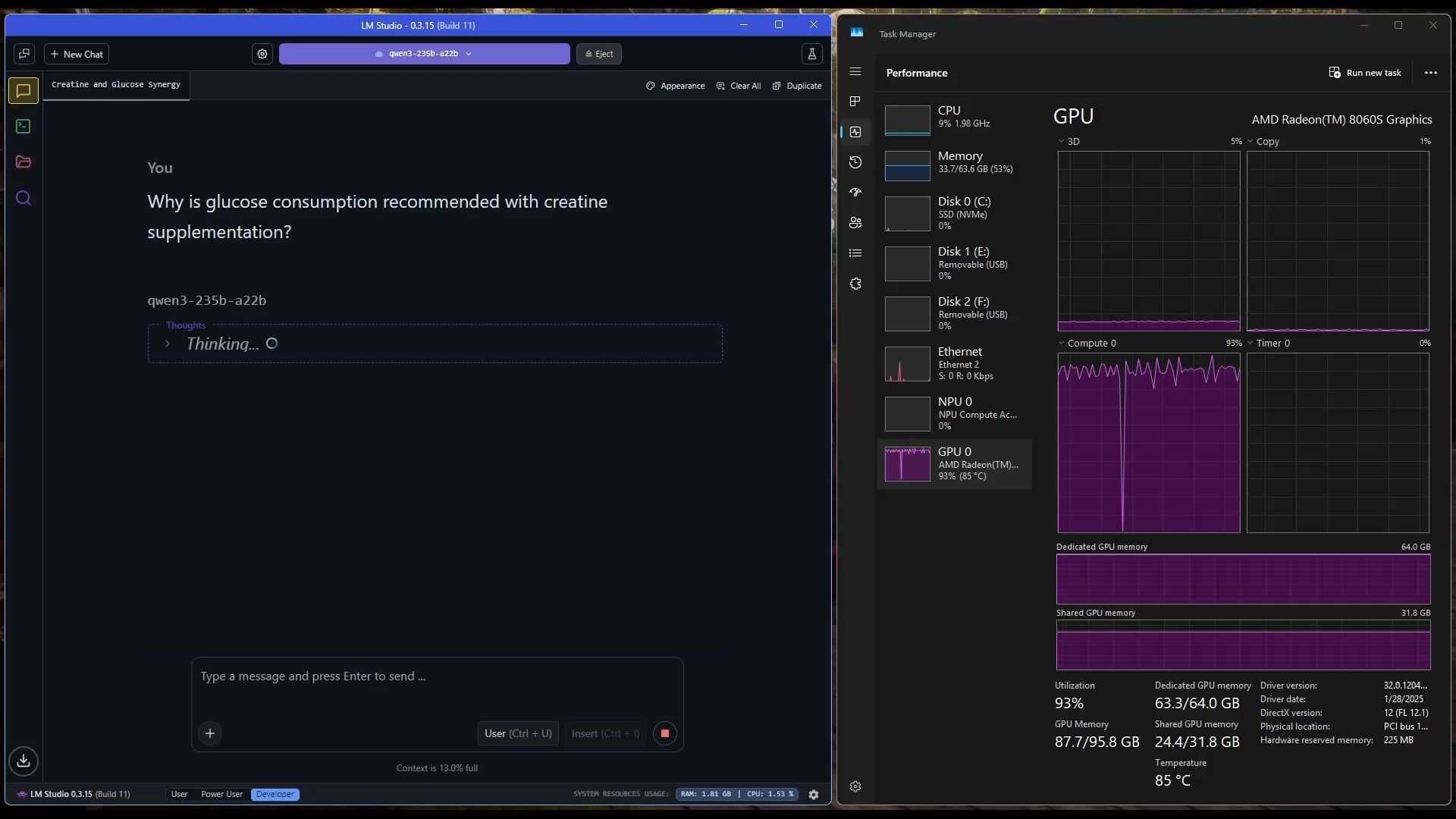
Windows tablet büyük MoE modelini çalıştırıyor: Kullanıcı, AMD Ryzen AI Max 395+ ve 128GB RAM ile donatılmış bir Windows tablette, yalnızca iGPU (Radeon 8060S, 95.8GB’ın 87.7GB’ını VRAM olarak ayırmış) kullanarak Qwen3 235B-A22B MoE modelini (Q2_K_XL nicelleştirmesi ile) yaklaşık 11.1 t/s hızında çalıştırdığını gösteriyor. Bu, bellek bant genişliği hala bir darboğaz olsa da, taşınabilir cihazlarda ultra büyük modelleri çalıştırma olasılığını gösteriyor. (Kaynak: Reddit r/LocalLLaMA)