
Anahtar Kelimeler:ChatBot Arena, Phi-4-reasoning, Claude Entegrasyonları, AI Akıllı Ajanlar, DeepSeek-Prover-V2, Qwen3, Gemini, Parakeet-TDT-0.6B-v2, Sıralama Yanılsaması, Küçük Model Çıkarım Yeteneği, Üçüncü Taraf Uygulama Entegrasyonları, AI Programlama Ajanları, Matematik Teoremi Kanıtlama
🔥 Odak Noktası
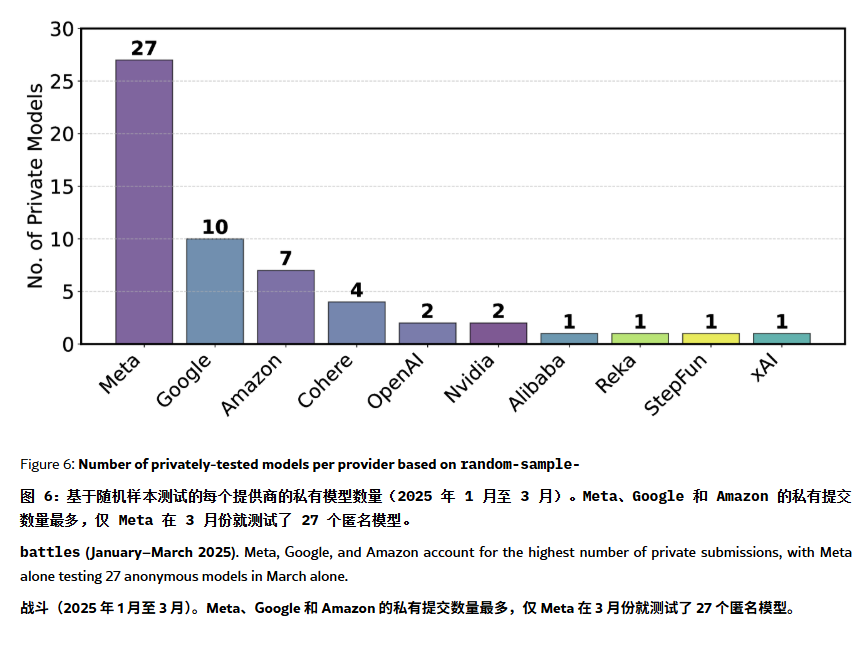
ChatBot Arena Sıralamasının “Halüsinasyon” ve Manipülasyon İçerdiği İddia Edildi: Bir ArXiv makalesi [2504.20879], yaygın olarak referans gösterilen ChatBot Arena model sıralamasını sorgulayarak “sıralama halüsinasyonu” içerdiğini öne sürdü. Makale, büyük teknoloji şirketlerinin (Meta gibi) çok sayıda ince ayarlı model varyantı (örneğin, Llama-4 için 27 tane test edildi) gönderip yalnızca en iyi sonuçları yayınlayarak sıralamayı manipüle edebileceğini belirtiyor; model gösterim sıklığının da büyük şirketlerin modellerini kayırarak açık kaynaklı modellerin görünürlüğünü azaltabileceğini; model eleme mekanizmasının şeffaf olmadığını ve birçok açık kaynaklı modelin yetersiz test verisi nedeniyle listeden çıkarıldığını; ayrıca, kullanıcıların sık sorduğu soruların benzerliğinin, modellerin puanlarını artırmak için hedefe yönelik aşırı uyum (overfitting) eğitimi almasına yol açabileceğini iddia ediyor. Bu durum, mevcut ana akım LLM kıyaslama testlerinin güvenilirliği ve tarafsızlığı konusunda endişelere yol açtı ve geliştiricilerin ve kullanıcıların sıralama listelerine ihtiyatlı yaklaşmaları ve kendi ihtiyaçlarına uygun değerlendirme sistemleri oluşturmayı düşünmeleri öneriliyor. (kaynak: karminski3, op7418, TheRundownAI)
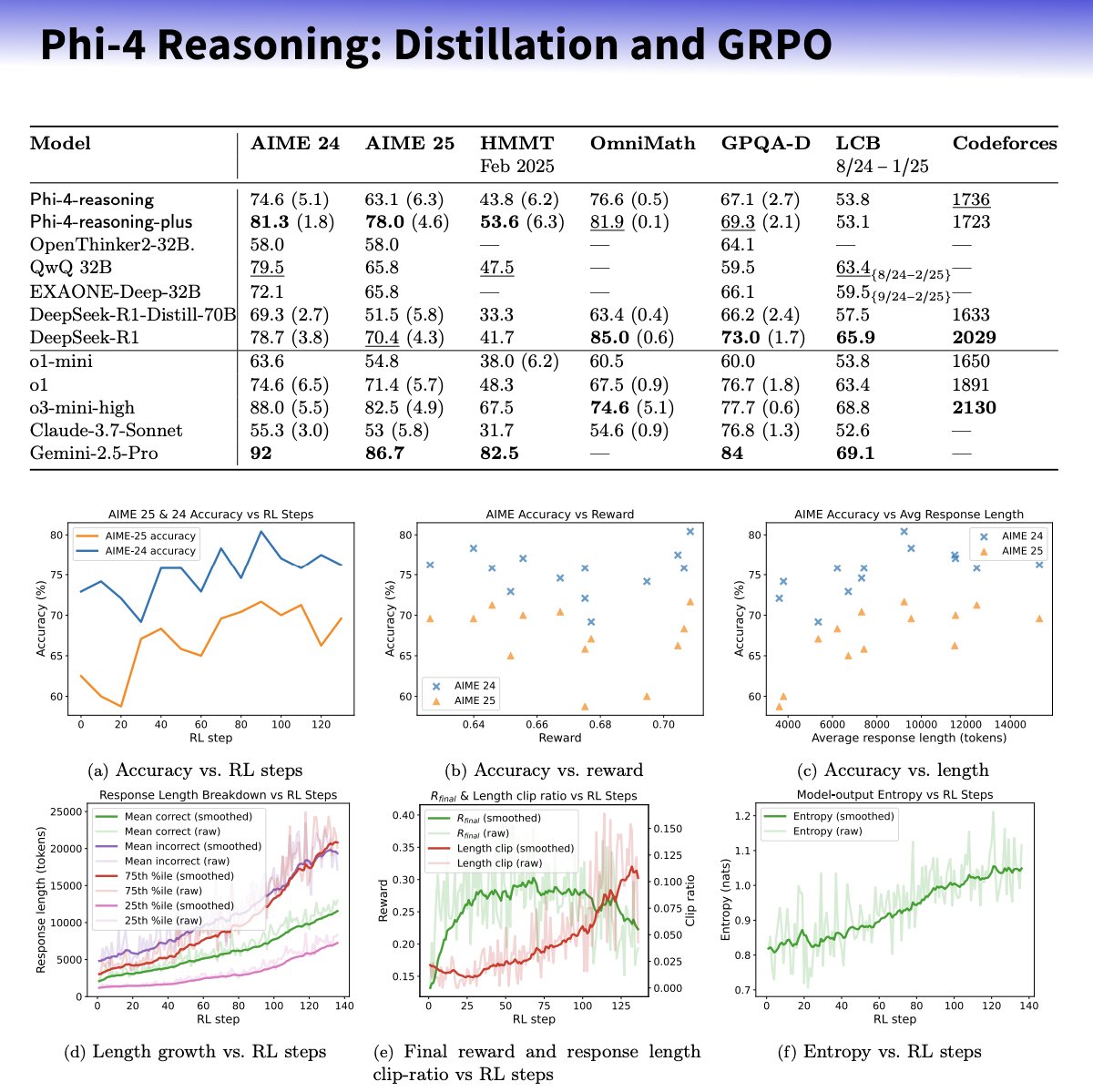
Microsoft, Akıl Yürütme Yeteneğini Artırmaya Odaklanan Phi-4-reasoning Serisi Küçük Modelleri Yayınladı: Microsoft, küçük dil modellerinin akıl yürütme yeteneklerini özenle seçilmiş veri setleri, denetimli ince ayar (SFT) ve hedeflenen pekiştirmeli öğrenme (RL) yoluyla geliştirmeyi amaçlayan Phi-4 mimarisine dayalı Phi-4-reasoning ve Phi-4-reasoning-plus modellerini tanıttı. Bu modellerin, yüksek kaliteli düşünce zinciri (CoT) akıl yürütme yörüngeleri oluşturmak için OpenAI o3-mini’yi “öğretmen” olarak kullandığı ve GRPO algoritması aracılığıyla pekiştirmeli öğrenme optimizasyonu yaptığı iddia ediliyor. Microsoft araştırmacısı Sebastien Bubeck, Phi-4-reasoning’in matematik yeteneğinde DeepSeek R1’den daha iyi olduğunu, ancak model boyutunun sadece %2’si olduğunu iddia ediyor. Bu model serisi, özel akıl yürütme token’ları ve genişletilmiş 32K bağlam uzunluğu kullanıyor. Bu hamle, küçük boyutlu, uzmanlaşmış modeller yönünde bir keşif olarak görülüyor ve kaynak kısıtlı senaryolar için daha güçlü akıl yürütme çözümleri sunabilir, ancak OpenAI teknolojisinden yararlanıp yararlanmadığı ve MIT lisansı altında yayınlanıp yayınlanmadığı konusunda tartışmalara yol açtı. (kaynak: _philschmid, TheRundownAI, Reddit r/LocalLLaMA)
Anthropic, Integrations Özelliğini Tanıttı ve Araştırma Yeteneklerini Genişletti: Anthropic, kullanıcıların Claude’u Jira, Confluence, Zapier, Cloudflare, Asana gibi 10 üçüncü taraf uygulama ve hizmetle bağlamasına olanak tanıyan Claude Integrations’ı duyurdu; gelecekte Stripe, GitLab gibi platformlar da desteklenecek. Daha önce yalnızca yerel sunucularla sınırlı olan MCP (Model Context Protocol) desteği uzak sunuculara genişletildi; geliştiriciler belgeler veya Cloudflare gibi çözümler aracılığıyla yaklaşık 30 dakika içinde kendi entegrasyonlarını oluşturabilirler. Aynı zamanda, Claude’un Araştırma (Research) özelliği geliştirildi; web’i, Google Workspace’i ve bağlı Integrations’ı arayabilen, karmaşık istekleri araştırmak üzere parçalara ayırabilen, alıntılarla birlikte kapsamlı raporlar oluşturabilen ve işlem süresi 45 dakikaya kadar çıkabilen gelişmiş bir mod eklendi. Web arama özelliği de dünya genelindeki ücretli kullanıcılara açıldı. Bu güncellemeler, Claude’un bir iş asistanı olarak entegrasyonunu ve derinlemesine araştırma yeteneklerini artırmayı amaçlıyor. (kaynak: _philschmid, Reddit r/ClaudeAI)

AI Agent Yetenekleri Yeni Moore Yasasını Takip Ediyor: Her 4 Ayda Bir İkiye Katlanıyor: AI Digest’in araştırması, AI programlama agent’larının görev tamamlama yeteneklerinin üssel bir büyüme yaşadığını gösteriyor. Görevleri işleme süreleri (insan uzmanların ihtiyaç duyduğu süre cinsinden ölçüldüğünde) 2024-2025 yılları arasında yaklaşık her 4 ayda bir ikiye katlanıyor; bu, 2019-2025 yılları arasındaki her 7 ayda bir ikiye katlanma hızından daha hızlı. Şu anda en iyi AI agent’ları, insanların 1 saatte tamamlayabileceği programlama görevlerini yerine getirebiliyor. Bu hızlanan eğilim devam ederse, 2027 yılına kadar AI agent’larının 167 saate (yaklaşık bir ay) kadar süren karmaşık görevleri tamamlayabileceği tahmin ediliyor. Bu yeteneklerdeki hızlı artış, modellerin kendisindeki ilerlemelerden ve algoritma verimliliğindeki artışlardan kaynaklanıyor ve AI destekli AI Ar-Ge’si nedeniyle üstel üstü bir büyüme pozitif geri besleme döngüsü oluşturabilir. Bu durum, “yazılım zekası patlaması” olasılığını işaret ediyor ve yazılım geliştirme, bilimsel araştırma gibi alanları derinden değiştirecek, aynı zamanda otomasyonun işgücü piyasasına etkileri gibi sosyal zorlukları da beraberinde getirecek. (kaynak: 新智元)

🎯 Trendler
DeepSeek-Prover-V2 Yayınlandı, Matematiksel Teorem Kanıtlama Yeteneği Geliştirildi: DeepSeek AI, Lean 4 biçimsel teorem kanıtlamaya odaklanan 7B ve 671B olmak üzere iki boyutta DeepSeek-Prover-V2’yi yayınladı. Model, özyinelemeli kanıt arama ve pekiştirmeli öğrenme (GRPO) kullanılarak eğitildi; karmaşık teoremleri ayrıştırmak ve kanıt taslakları oluşturmak için DeepSeek-V3’ten yararlanıldı, ardından uzman iterasyonu ve sentetik soğuk başlatma verileriyle ince ayar ve pekiştirmeli öğrenme yapıldı. DeepSeek-Prover-V2-671B, MiniF2F-test’te %88.9 geçme oranına ulaştı ve PutnamBench’te 49 problemi çözerek SOTA performansı sergiledi. Aynı zamanda AIME ve ders kitabı problemlerini içeren ProverBench kıyaslaması da yayınlandı. Bu model, biçimsel olmayan akıl yürütme ile biçimsel kanıtlamayı birleştirmeyi ve otomatik teorem kanıtlamanın gelişimini desteklemeyi amaçlıyor. (kaynak: 新智元)

Nvidia ve UIUC, 4 Milyon Token Bağlam Genişletme İçin Yeni Yöntem Önerdi: Nvidia ve University of Illinois Urbana-Champaign (UIUC) araştırmacıları, Llama 3.1-8B-Instruct’ın bağlam penceresini 128K’dan 1M, 2M ve hatta 4M token’a kadar genişletebilen verimli bir eğitim yöntemi önerdi. Yöntem, sürekli ön eğitim ve talimat ince ayarı olmak üzere iki aşamalı bir strateji benimsiyor; anahtar teknolojiler arasında özel belge ayırıcıları kullanma, YaRN tabanlı pozisyon kodlama genişletmesi ve tek adımlı ön eğitim bulunuyor. Eğitilen UltraLong-8B modeli, RULER, LV-Eval, InfiniteBench gibi uzun bağlam kıyaslama testlerinde üstün performans gösterdi ve MMLU, MATH gibi standart kısa bağlam görevlerinde temel Llama 3.1 performansını korudu, hatta aştı; ProLong, Gradient gibi diğer uzun bağlam modellerinden daha iyi performans sergiledi. Bu araştırma, ultra uzun bağlamlı LLM’ler oluşturmak için verimli ve ölçeklenebilir bir yol sunuyor. (kaynak: 新智元)

Qwen3 Yayınlandı, Performans Önemli Ölçüde Arttı: Alibaba, Qwen3-30B-A3B gibi modelleri içeren Qwen3 serisini yayınladı. Reddit kullanıcılarının ilk testlerine ve kıyaslama verilerine (AHA Leaderboard gibi) göre, Qwen3 önceki Qwen2.5 ve QwQ sürümlerine kıyasla birçok boyutta (sağlık, bitcoin, Nostr gibi belirli alan bilgileri dahil) daha iyi performans gösteriyor. Kullanıcı geri bildirimleri, Qwen3’ün belirli görevleri (güneş sistemi dinamiklerini simüle etmek gibi) yerine getirirken güçlü bir yetenek sergilediğini, eliptik yörüngeler ve göreceli periyotlar oluşturmak için fizik yasalarını doğru bir şekilde uygulayabildiğini gösteriyor. Ancak bazı kullanıcılar Qwen3’ün uzun bağlamlarda (16K’ya yakın gibi) performansının belirgin şekilde düştüğünü ve çıkarım sırasında token tüketiminin yüksek olduğunu belirterek arama araçlarıyla birlikte kullanılmasını öneriyor. Qwen3’ün adlandırma şekli (Qwen3-30B-A3B gibi) de netliği nedeniyle övgü aldı. (kaynak: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, karminski3, madiator)
Gemini Yakında Kişiselleştirilmiş Deneyim Sunmak İçin Google Hesap Verilerini Entegre Edecek: Google, Gemini AI asistanının kullanıcıların Gmail, Fotoğraflar, YouTube geçmişi gibi Google hesap verilerine erişmesini sağlamayı planlıyor. Amaç, daha kişiselleştirilmiş, proaktif ve güçlü bir yardımcı deneyim sunmak. Google Ürün Yöneticisi Josh Woodward, bunun Gemini’nin kullanıcıları daha iyi anlamasını ve kullanıcıların bir uzantısı haline gelmesini sağlamak için olduğunu belirtti. Bu özellik isteğe bağlı (opt-in) olacak ve kullanıcılar veri erişim iznini açıp açmamayı seçebilecekler. Bu hamle, gizlilik ve veri güvenliği hakkında tartışmalara yol açtı; kullanıcıların kişiselleştirilmiş kolaylık ile veri gizliliği arasında bir denge kurması gerekecek. (kaynak: JeffDean, Reddit r/ArtificialInteligence)

Nvidia, Parakeet-TDT-0.6B-v2 ASR Modelini Tanıttı: Nvidia, 600 milyon parametreye sahip yeni otomatik konuşma tanıma (ASR) modeli Parakeet-TDT-0.6B-v2’yi yayınladı. Modelin, Open ASR Leaderboard’da Whisper3-large’dan (1.6 milyar parametre) daha iyi performans gösterdiği, özellikle çeşitli veri setlerini (LibriSpeech, Fisher Corpus, YouTube verileri gibi yaklaşık 120.000 saatlik veri dahil) işlemede başarılı olduğu iddia ediliyor. Model, karakter, kelime ve paragraf düzeyinde zaman damgalarını destekliyor ancak şu anda yalnızca İngilizce’yi destekliyor ve çalışması için Nvidia GPU ve belirli framework’ler gerekiyor. Kullanıcıların ilk geri bildirimleri, transkripsiyon ve noktalama işaretleri doğruluğunun yüksek olduğu yönünde. (kaynak: Reddit r/LocalLLaMA)

Qwen2.5-VL Yayınlandı, Görsel Dil Anlama Yeteneği Geliştirildi: Alibaba, makinelerin görsel dünyayı anlama ve etkileşim kurma yeteneğini geliştirmeyi amaçlayan Qwen2.5-VL serisi çok modlu modelleri (3B, 7B, 72B parametreleri dahil) yayınladı. Bu modeller görüntü özetleme, görsel soru cevaplama, karmaşık görsel bilgilerden rapor oluşturma gibi görevler için kullanılabilir. Makale, mimarisini, kıyaslama performansını ve çıkarım ayrıntılarını tanıtarak görsel dil anlama konusundaki ilerlemesini gösteriyor. (kaynak: Reddit r/deeplearning)

Mistral Small 3.1 Vision Desteği llama.cpp’ye Birleştirildi: llama.cpp projesi, Mistral Small 3.1 Vision modeline (24B parametre) yönelik desteği birleştirdi. Bu, kullanıcıların bu çok modlu modeli llama.cpp framework’ü altında çalıştırarak görüntü anlama gibi görevleri gerçekleştirebileceği anlamına geliyor. Unsloth, ilgili GGUF formatındaki model dosyalarını sağladı. Bu, Mistral’in görsel modelini yerel olarak çalıştırmak için kolaylık sağlıyor. (kaynak: Reddit r/LocalLLaMA)
Meta, Synthetic Data Kit’i Yayınladı: Meta, LLM ince ayarı için gereken veri hazırlama aşamasını basitleştirmeyi amaçlayan Synthetic Data Kit adlı bir komut satırı aracını açık kaynak olarak yayınladı. Araç, ingest (veri içe aktarma), create (QA çiftleri oluşturma, isteğe bağlı çıkarım zinciri), curate (kaliteli örnekleri filtrelemek için Llama’yı hakem olarak kullanma), save-as (uyumlu formatta dışa aktarma) olmak üzere dört komut sunuyor. Yüksek kaliteli sentetik eğitim verileri oluşturmak için yerel LLM’leri (vLLM aracılığıyla) kullanıyor ve özellikle Llama-3 gibi modeller için belirli görev akıl yürütme yeteneklerinin kilidini açmak için uygun. (kaynak: Reddit r/MachineLearning)
GTE-ModernColBERT-v1 Popüler Gömme Modeli Oldu: LightOnIO tarafından sunulan GTE-ModernColBERT-v1 modeli, Hugging Face’te yeni popüler trend arama/gömme modeli oldu. Model, çoklu vektör (aynı zamanda geç etkileşim veya ColBERT olarak da bilinir) arama yöntemini kullanıyor ve bu tür teknolojilere ilgi duyan geliştiricilere yeni bir seçenek sunuyor. (kaynak: lateinteraction)
X Tavsiye Algoritması Güncellendi: X platformu (eski adıyla Twitter), kullanıcıların olumsuz geri bildirimlerinin dikkate alınmaması, aynı içeriğin tekrar tekrar görülmesi ve SimCluster algoritmasının ilgisiz içerik önermesi gibi uzun süredir devam eden sorunları çözmeyi amaçlayan tavsiye algoritmasında bir düzeltme yaptı. İlk geri bildirimlerin olumlu olduğu belirtiliyor. (kaynak: TheGregYang)
Wikipedia, İnsan Editörlere Yardımcı Olmak İçin Yeni AI Stratejisini Duyurdu: Wikipedia, insan editörlerin yerini almak yerine onların çalışmalarını desteklemek ve geliştirmek için AI araçlarını kullanmayı amaçlayan yeni yapay zeka stratejisini açıkladı. Kaynakta ayrıntılar belirtilmemiş olsa da, bu durum dünyanın en büyük çevrimiçi ansiklopedisinin AI teknolojisini içerik oluşturma ve bakım süreçlerine nasıl entegre edeceğini araştırdığını gösteriyor. (kaynak: Reddit r/artificial)
🧰 Araçlar
Midjourney, Omni-Reference Özelliğini Tanıttı: Midjourney, kullanıcıların referans resim URL’si sağlayarak (–oref parametresi kullanarak) karakter, nesne, araç veya insan olmayan canlıların tutarlılığını sağlamak amacıyla görüntü oluşturmayı yönlendirmelerine olanak tanıyan yeni Omni-Reference (oref) özelliğini yayınladı. Kullanıcılar, referans resmin etki ağırlığını –ow parametresiyle kontrol edebilirler; düşük ağırlık stilizasyon için, yüksek ağırlık ise gerçekçilik veya hassas yüz eşleştirme için uygundur. Bu özellik, oluşturulan görüntülerdeki belirli öğelerin tutarlılığını ve kontrol edilebilirliğini artırmayı amaçlıyor. (kaynak: op7418, DavidSHolz)

Runway Gen-4 References Tek Görüntüyle Kişiselleştirme Sağlıyor: Runway’in Gen-4 modeli, kullanıcıların yalnızca bir referans görüntü sağlayarak görüntüdeki stili veya karakter özelliklerini yeni oluşturulan içeriğe uygulamasına olanak tanıyan References (Referanslar) özelliğini tanıttı. Tanıtım, özelliğin bir karakter portresini referans görüntünün stiliyle veya referans görüntünün tasvir ettiği dünyada kolayca yeniden oluşturabildiğini gösteriyor ve modelin yalnızca tek bir referans görüntüyle yüksek tutarlılık ve estetik kalitede kişiselleştirilmiş üretim yeteneğini sergiliyor. (kaynak: c_valenzuelab, c_valenzuelab)

Perplexity’nin WhatsApp Botu Hizmete Geri Döndü: Perplexity AI’nin WhatsApp sohbet botu, beklenenin çok üzerinde talep nedeniyle kısa süreliğine hizmet dışı kaldıktan sonra tekrar hizmete girdi. Kullanıcılar +1 (833) 436-3285 telefon numarası üzerinden etkileşim kurabilir, mesajları gerçeklik kontrolü için iletebilir, doğrudan soru sorarak cevap alabilir, serbest biçimli metin sohbetleri yapabilir ve görüntüler oluşturabilirler. (kaynak: AravSrinivas, AravSrinivas)
Krea AI, Hassas Görüntü Kontrolü İçin 4o Görüntü Modelini Birleştirdi: AI yaratıcılık aracı Krea AI, kullanıcıların OpenAI’nin 4o görüntü modeli yeteneklerini birleştirerek görüntü kolajı ve karalama yoluyla oluşturulan görüntülerin içeriğini ve stilini daha hassas bir şekilde kontrol etmelerini sağlayan yeni bir özellik ekledi. Bu, Krea’nın etkileşimli görüntü oluşturma konusundaki sürekli yenilikçiliğini gösteriyor ve kullanıcıların AI yaratıcılığını daha sezgisel ve ayrıntılı bir şekilde yönlendirmelerine olanak tanıyor. (kaynak: op7418)
Xingyun Brown Ant All-in-One: Düşük Maliyetle Tam Performanslı DeepSeek Çalıştırma: Tsinghua kökenli Xingyun Integrated Circuits, 149.000 yuan fiyatla, nicelleştirilmemiş FP8 hassasiyetindeki DeepSeek-R1/V3 671B modelini 20 token/s’den fazla hızda çalıştırabildiğini ve 128K bağlamı desteklediğini iddia eden Brown Ant AI All-in-One makinesini tanıttı. Çözüm, çift yollu AMD EPYC CPU ve büyük kapasiteli yüksek frekanslı bellek ile az sayıda GPU hızlandırmasını birleştirerek, CPU+bellek mimarisi aracılığıyla büyük modellerin özel dağıtımının donanım maliyetini önemli ölçüde düşürmeyi hedefliyor. Maliyete duyarlı ve yüksek hassasiyete ihtiyaç duyan kurumsal senaryolar için resmi performansa yakın yerelleştirilmiş bir deneyim sunuyor. (kaynak: 新智元)

NotebookLM Uygulaması Yakında Yayınlanacak: Google’ın AI not alma uygulaması NotebookLM, yakında resmi iOS ve Android uygulamalarını yayınlayacak. 20 Mayıs’ta yayınlanması beklenen uygulamalar için ön siparişler açıldı. Bu, NotebookLM’in kullanıcı notlarına ve belgelerine dayalı özetleme, soru cevaplama ve yaratıcı fikir üretme özelliklerini mobil platforma taşıyacak. (kaynak: zacharynado)
Granola, AI Gerçek Zamanlı Toplantı Tutanakları İçin iOS Uygulamasını Başlattı: AI not alma uygulaması Granola, mevcut Zoom toplantısı AI not alma özelliğini çevrimdışı yüz yüze görüşme senaryolarına genişleten iOS sürümünü yayınladı. Kullanıcılar iPhone’larında Granola’yı kullanarak konuşmaları kaydedebilir, transkribe edebilir ve AI kullanarak özetler ve notlar oluşturarak daha sonra gözden geçirme ve düzenleme kolaylığı sağlayabilirler. (kaynak: amasad)
Grok Studio PDF İşlemeyi Destekliyor: Grok AI asistanı, Studio özelliğine PDF dosyalarını işleme yeteneği ekledi. Kullanıcılar artık Grok Studio’da PDF belgelerini daha kolay işleyebilir ve analiz edebilirler. Özellik ayrıntıları belirtilmemiş olsa da, bu Grok’un çok formatlı belge anlama ve etkileşim yeteneklerinin genişlediğini gösteriyor. (kaynak: grok, TheGregYang)
Suno Yeni Modeli Üstün Müzik Üretme Yeteneği Sergiliyor: AI müzik üretme platformu Suno yeni bir model çıkardı ve kullanıcı geri bildirimleri üretilen sonuçların “çok başarılı” olduğu yönünde. Bir kullanıcı canlı performans tarzında bir şarkı üretmeyi denediğinde, beklenen yankı efektini tam olarak elde edemese de, üretilen müziğin kalabalık atmosferi gibi konularda iyi performans gösterdiği belirtildi. Bu, yeni modelin müzik kalitesi ve stil çeşitliliği konusundaki ilerlemesini gösteriyor. (kaynak: nptacek, nptacek)
Kurbağa Seslerini Tanımaya Yardımcı AI Uygulaması: Frog Spot: Bir geliştirici, farklı kurbağa türlerinin seslerini tanımlamak için 10 saniyelik sesin spektrogramını analiz eden kendi eğittiği bir CNN modelini (TensorFlow Lite) kullanan Frog Spot adlı ücretsiz bir uygulama oluşturdu. Uygulama, halkın yerel türler hakkında bilgi edinmesine yardımcı olmayı amaçlıyor ve aynı zamanda derin öğrenmenin biyoakustik izleme ve vatandaş bilimi alanlarındaki uygulama potansiyelini gösteriyor. (kaynak: Reddit r/deeplearning)
Endüstriyel Teknik Çizimlerin Otomasyonuna AI Yardımı: Bir IAAI 2025 makalesi, borulama ve enstrümantasyon şemalarındaki (P&ID) “enstrüman tipiklerinin” (Instrument Typicals) genişletilmesini otomatikleştiren bir yöntemi tanıtıyor. Yöntem, bilgisayarlı görü modellerini (metin algılama ve tanıma) ve alana özgü kuralları birleştirerek P&ID çizimlerinden ve lejant tablolarından otomatik olarak bilgi çıkarıyor, basitleştirilmiş enstrüman tipik sembollerini ayrıntılı enstrüman listelerine genişletiyor ve doğru enstrüman indeksleri oluşturuyor. Bu, mühendislik projelerinin (özellikle teklif aşamasında) verimliliğini artırmayı ve manuel hataları azaltmayı amaçlıyor. (kaynak: aihub.org)

Sora Kullanarak Minyatür Soslu Ördek Manzarası Oluşturma: Bir kullanıcı, ayrıntılı istemlere dayanarak Sora tarafından oluşturulan “minyatür manzara soslu ördek” resmini paylaştı. İstemler, sahne stilini (makro fotoğrafçılık, minyatür manzara), ana konuyu (soslu ördekten oluşan tezgah binası), detayları (soslu kırmızı deri, biber ve susam, dilimleyen şef, yemek yiyenler), çevreyi (ördek sosundan oluşan sokaklar, marine edilmiş stil duvarlar, kırmızı fenerler vb.) ayrıntılı olarak tanımlıyor. Bu, Sora’nın karmaşık, yaratıcı metin açıklamalarını anlama ve buna uygun yüksek kaliteli görüntüler oluşturma yeteneğini gösteriyor. (kaynak: dotey)

3D Hava Durumu Tahmini GPT’leri Oluşturma: Bir kullanıcı, kendi yaptığı “Weather 3D” adlı bir ChatGPTs uygulamasını paylaştı. Kullanıcının girdiği şehir adına göre hava durumu API’sini çağırarak gerçek zamanlı hava durumu verilerini alıyor ve o şehrin ikonik binasının 3D izometrik minyatür model tarzında bir illüstrasyonunu oluşturuyor, aynı zamanda mevcut hava koşullarını da entegre ediyor. İllüstrasyonun üst kısmında şehir adı, hava durumu, sıcaklık ve hava durumu simgesi gösteriliyor. Bu GPTs, API çağrılarını ve görüntü oluşturma yeteneklerini birleştirerek pratik ve görsel olarak çekici AI uygulamaları oluşturmanın nasıl mümkün olduğunu gösteriyor. (kaynak: dotey)

📚 Öğrenme
AdaRFT: Pekiştirmeli Öğrenme İnce Ayarını Optimize Etmek İçin Yeni Bir Yöntem: Taiwei Shi ve arkadaşları, insan geri bildirimine dayalı pekiştirmeli öğrenme (RFT) algoritmalarının (PPO, GRPO, REINFORCE gibi) eğitim sürecini optimize etmeyi amaçlayan AdaRFT adlı hafif, tak-çalıştır bir müfredat öğrenme yöntemi önerdi. AdaRFT’nin, RFT eğitim süresini %50’ye kadar kısaltabildiği ve model performansını artırabildiği iddia ediliyor. Bunu, eğitim verisi sırasını daha akıllıca düzenleyerek öğrenme verimliliğini ve etkinliğini artırarak başarıyor. (kaynak: menhguin)

AI Değerlendirme (Evals) Çevrimiçi Ustalık Sınıfı: Hamel Husain ve Shreya Shankar, AI uygulamalarının değerlendirilmesi (Evals) üzerine 4 haftalık bir çevrimiçi ustalık sınıfı başlattı. Kurs, geliştiricilerin AI uygulamalarını prototip aşamasından üretime hazır hale getirmelerine yardımcı olmayı amaçlıyor. İçerik, geliştirme ve lansman sonrası değerlendirme yöntemlerini, kıyaslama testleri ile gerçek dünya değerlendirmesi arasındaki farkları, veri kontrolünü, PromptEvals’ı vb. kapsıyor. AI uygulamalarının güvenilirliğini ve performansını sağlamada değerlendirmenin önemini vurguluyor. (kaynak: HamelHusain, HamelHusain)

Google Model İnce Ayar Kılavuzu: Google Research, model ince ayarı için rehberlik ve en iyi uygulamaları sağlamayı amaçlayan “tuning_playbook” adlı bir kaynak deposu sunuyor. Bu, büyük dil modellerini veya diğer makine öğrenimi modellerini belirli görevlere veya veri setlerine uyarlamak için ince ayar yapması gereken geliştiriciler ve araştırmacılar için değerli bir öğrenme kaynağıdır. (kaynak: zacharynado)

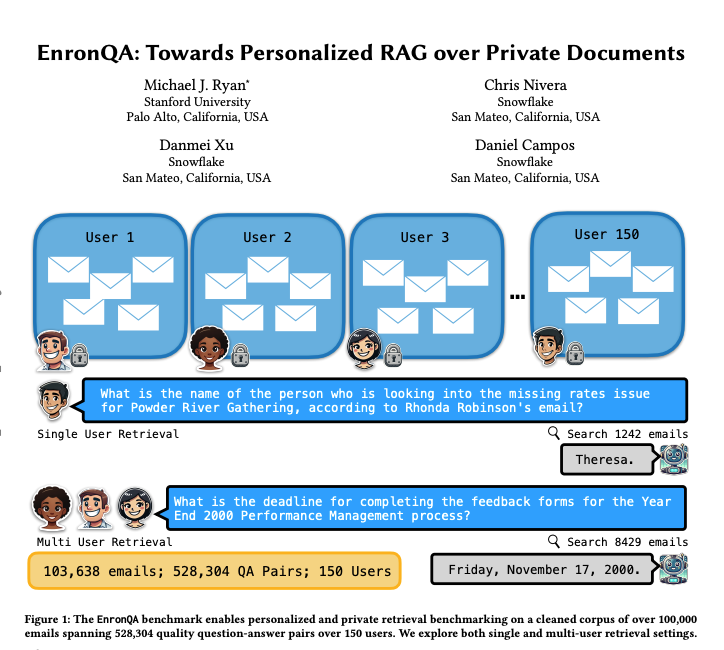
EnronQA: Kişiselleştirilmiş RAG Kıyaslama Veri Seti: Araştırmacılar, 150 kullanıcıdan gelen 103.638 e-posta ve 528.304 yüksek kaliteli soru-cevap çiftini içeren EnronQA veri setini tanıttı. Bu veri seti, kişiselleştirilmiş geri alma artırılmış üretim (RAG) sistemlerinin özel belgeleri işleme performansını değerlendirmek için bir kıyaslama olarak tasarlanmıştır. Veri seti, altın referans cevapları, yanlış cevapları, akıl yürütme gerekçelerini ve alternatif cevapları içererek RAG sistemlerinin performansını daha ayrıntılı analiz etmeye yardımcı oluyor. (kaynak: tokenbender)
ReXGradient-160K: Büyük Ölçekli Göğüs Röntgeni ve Rapor Veri Seti: ABD’deki 3 sağlık sisteminden (79 tıbbi nokta) 109.487 benzersiz hastaya ait 60.000 göğüs röntgeni çalışmasını ve eşleştirilmiş radyoloji raporlarını (serbest metin) içeren ReXGradient-160K adlı büyük, halka açık bir göğüs X-ray veri seti yayınlandı. Bunun, şu anda halka açık olan en fazla hasta sayısına sahip göğüs röntgeni veri seti olduğu iddia ediliyor ve tıbbi görüntüleme AI modellerini eğitmek ve değerlendirmek için değerli bir kaynak sağlıyor. (kaynak: iScienceLuvr)

AI Agent Yetenek Artışını Tartışan Blog Yazısı: Araştırmacı Shunyu Yao, “The Second Half” başlıklı blog yazısında mevcut AI gelişiminin bir “devre arası” anında olduğunu öne sürüyor. Bundan önce eğitimin değerlendirmeden daha önemli olduğunu; bundan sonra ise pekiştirmeli öğrenmenin (RL) nihayet etkili bir şekilde çalışmaya başlaması nedeniyle değerlendirmenin eğitimden daha önemli olacağını belirtiyor. Makale, AI yeteneklerinin sürekli arttığı bir ortamda değerlendirme metodolojisindeki değişimin önemini tartışıyor. (kaynak: andersonbcdefg)
OpenAI’nin Gizlilik ve Ezberleme Üzerine Araştırma Paylaşımı: OpenAI araştırmacıları Pratyush Maini ve Zhili Feng, gizlilik ve ezberleme araştırmaları üzerine bir sunum yapacaklar. Büyük dil modellerindeki ezberleme olgusunun nasıl tespit edileceğini, ölçüleceğini ve ortadan kaldırılacağını ve bunun üretim ortamındaki LLM’lerdeki pratik uygulamalarını tartışacaklar. Bu, model yetenekleri ile kullanıcı veri gizliliğinin korunması arasındaki dengenin nasıl kurulacağıyla ilgilidir. (kaynak: code_star)

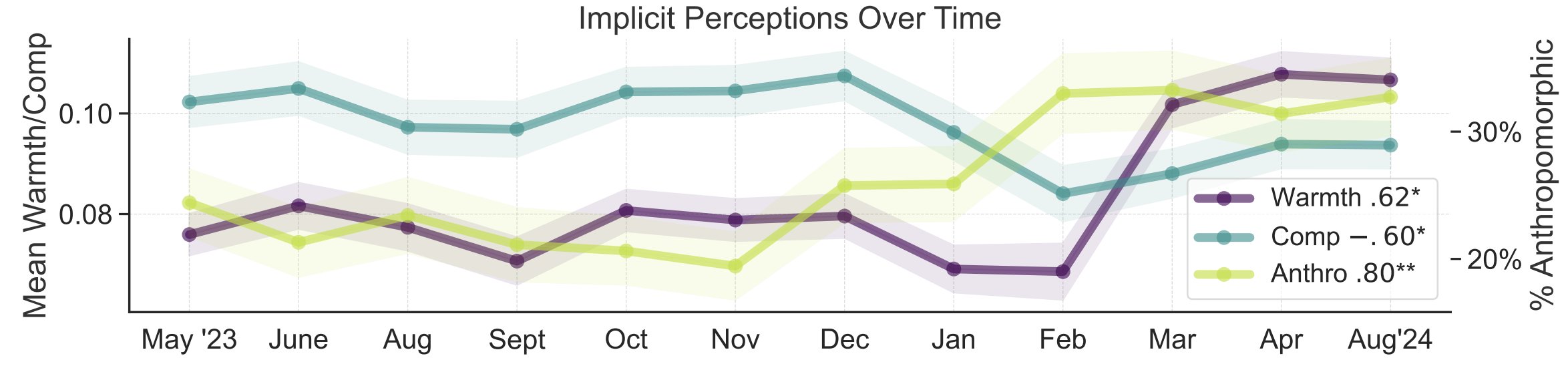
AI Kamuoyu Algısının Metafor Çalışması: Stanford Üniversitesi araştırmacıları Myra Cheng ve arkadaşları, FAccT 2025’te sundukları makalede, 12 ay boyunca toplanan AI hakkındaki 12.000 metaforu analiz ederek halkın AI hakkındaki zihinsel modellerini ve zaman içindeki değişimini anlamaya çalışıyorlar. Araştırma, zamanla halkın AI’ı daha insansı ve etkin (antropomorfizm derecesi artıyor) olarak görme eğiliminde olduğunu ve ona yönelik duygusal eğilimlerinin (sıcaklık) de arttığını buldu. Bu yöntem, kendi kendine raporlamadan daha ayrıntılı bir kamuoyu algısı içgörüsü sağlıyor. (kaynak: stanfordnlp, stanfordnlp)
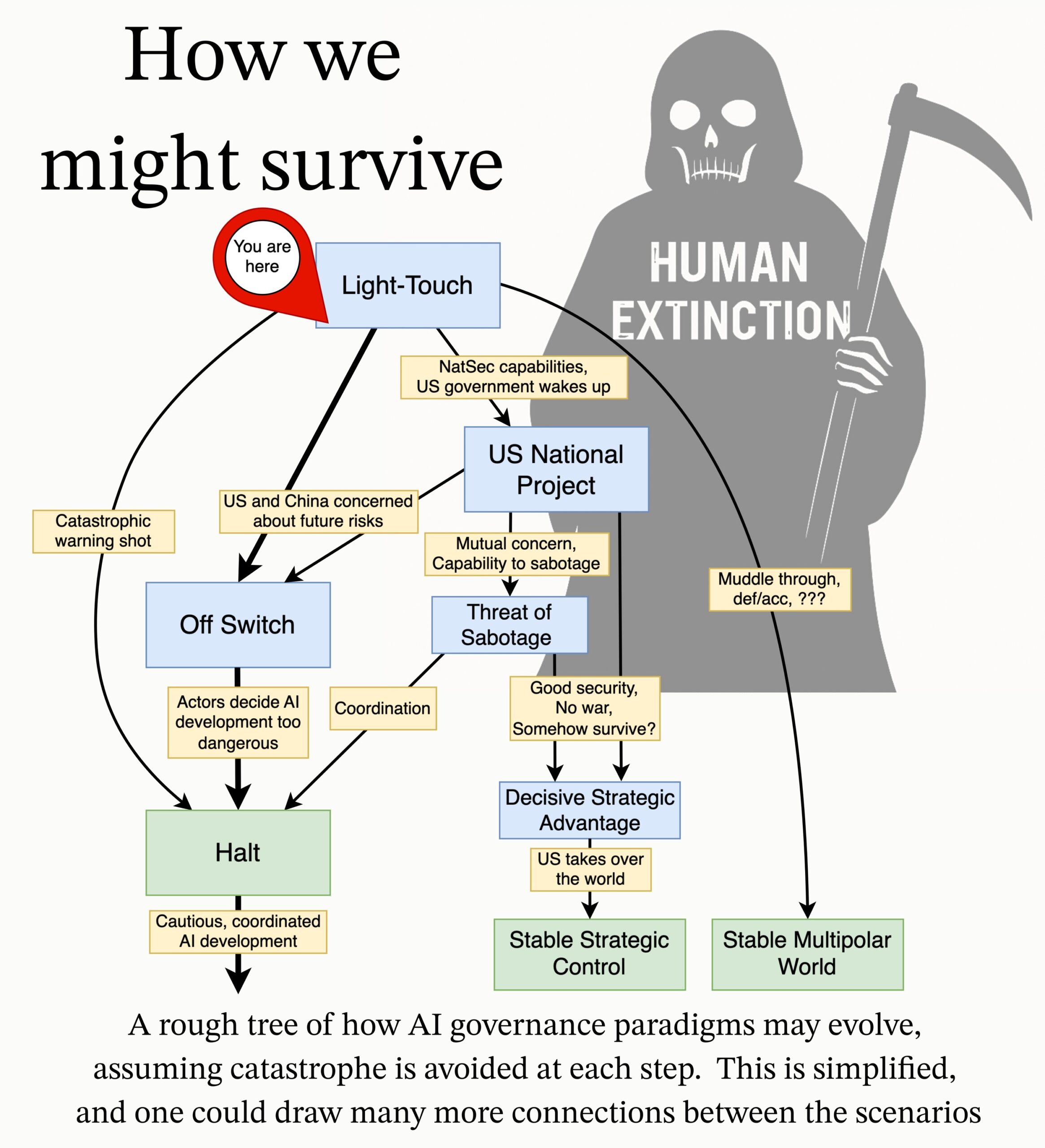
MIRI, AI Yönetişimi Araştırma Gündemini Yayınladı: Yapay Zeka Araştırma Enstitüsü’nün (MIRI) Teknik Yönetişim ekibi, yeni AI Yönetişimi araştırma gündemini yayınladı. Stratejik manzaraya ilişkin görüşlerini açıklıyor ve bir dizi eyleme geçirilebilir araştırma sorusu öneriyorlar. Amaçları, herhangi bir kuruluşun veya bireyin kontrol edilemeyen süper zeka inşa etmesini önlemek için hangi önlemlerin alınması gerektiğini araştırmak ve böylece AI’dan kaynaklanan felaket risklerini ve yok olma riskini azaltmaktır. (kaynak: JeffLadish)
💼 İş Dünyası
Kurumsal Düzeyde AI Çözüm Sağlayıcısı Deepexi, Hong Kong Borsası’na IPO Başvurusu Yaptı: Eski Huawei ve Alibaba yöneticisi Zhao Jiehui tarafından kurulan kurumsal düzeyde AI çözüm sağlayıcısı Deepexi (滴普科技), Hong Kong borsasına resmi olarak halka arz başvurusunda bulundu. Şirket, FastData veri zekası platformu ve FastAGI kurumsal düzeyde yapay zeka çözümlerine odaklanarak perakende (Belle gibi), imalat, sağlık gibi sektörlere hizmet veriyor. Son üç yılda şirketin geliri sürekli artarak 2024’te 243 milyon yuan’a ulaştı. Deepexi, Hillhouse Capital, IDG Capital, 5Y Capital gibi tanınmış kurumlardan yatırım alarak 8 tur finansman tamamladı ve son finansman turundan sonraki değerlemesi yaklaşık 6.8 milyar RMB oldu. Gelir artışına rağmen şirket şu anda hala zarar ediyor ancak düzeltilmiş net zararı yıldan yıla azalıyor. (kaynak: 36氪)
BMW Çin, DeepSeek Büyük Modelini Entegre Edeceğini Duyurdu: Alibaba ile yaptığı işbirliğinin ardından BMW Grubu, Çin’deki AI yapılanmasını daha da derinleştirerek DeepSeek büyük modelini entegre edeceğini duyurdu. Bu özelliğin 2025’in üçüncü çeyreğinde başlaması planlanıyor ve ilk olarak Çin’de satılan 9. nesil BMW İşletim Sistemi ile donatılmış çeşitli yeni otomobillerde uygulanacak, gelecekte yerli üretim BMW Yeni Nesil modellerinde de kullanılacak. Bu hamle, DeepSeek’in derin düşünme yeteneği aracılığıyla BMW Akıllı Kişisel Asistan merkezli insan-makine etkileşimi deneyimini güçlendirmeyi, araçların akıllı seviyesini ve duygusal bağlantı yeteneğini artırmayı amaçlıyor ve BMW’nin yerelleştirilmiş AI stratejisini hızlandırması ve akıllı dönüşüm zorluklarına yanıt vermesi açısından önemli bir adımdır. (kaynak: 36氪)
Shopify Tüm Çalışanları AI Kullanmaya Zorluyor, Bazı Pozisyonları AI ile Değiştirmek İstiyor: Küresel e-ticaret platformu Shopify CEO’su Tobi Lutke, şirket içi bir notta AI’ı verimli kullanmanın artık tüm çalışanlar için bir tavsiye değil, “kesin kural” olduğunu vurguladı. Not, çalışanların AI’ı iş akışlarına uygulamasını ve bunu bir refleks haline getirmesini; ekiplerin ek personel talep etmeden önce neden AI’ın görevi tamamlayamayacağını kanıtlamasını; performans değerlendirmelerine AI kullanım metriklerinin dahil edilmesini gerektiriyor. Lutke, AI’ın verimliliği büyük ölçüde artırabildiğini (bazı çalışanlarda 10 kat, hatta 100 kat) ve çalışanların rekabetçi kalabilmek için her yıl %20-%40 oranında gelişmesi gerektiğini belirtti. Shopify daha önce müşteri hizmetleri gibi departmanlarda işten çıkarmalar yapmış ve yerlerine AI getirmişti. Bu hamle, AI’ın beyaz yaka pozisyonlarında ayarlamalara ve işten çıkarmalara yol açma eğiliminin açık bir sinyali olarak görülüyor. (kaynak: 新智元)

🌟 Topluluk
AI Halüsinasyon Sorunu Üzerine Tartışmalar: Baidu AI Geliştirici Konferansı’nda Robin Li’nin DeepSeek-R1’i yüksek halüsinasyon oranı, yavaş hız ve yüksek maliyet gibi sorunlar nedeniyle eleştirmesi, toplulukta büyük modellerdeki “halüsinasyon” olgusu üzerine yeniden bir tartışma başlattı. Analizler, sadece DeepSeek’in değil, OpenAI’nin o3/o4-mini, Alibaba’nın Qwen3 gibi gelişmiş modellerinin de yaygın olarak halüsinasyon sorunu yaşadığını ve çıkarım modellerinin çok turlu düşünmesinin sapmayı artırabileceğini gösteriyor. Vectara’nın değerlendirmesi, R1’in halüsinasyon oranının (%14.3) V3’ten (%3.9) çok daha yüksek olduğunu ortaya koydu. Topluluk, model yetenekleri arttıkça halüsinasyonların daha gizli ve mantıksal hale geldiğini, kullanıcıların doğruyu yanlıştan ayırt etmesini zorlaştırdığını ve güvenilirlik konusunda endişelere yol açtığını düşünüyor. Aynı zamanda, halüsinasyonun yaratıcılığın bir yan ürünü olduğu ve özellikle edebi yaratım gibi alanlarda değeri olduğu görüşü de mevcut. Kabul edilebilir halüsinasyon seviyesinin nasıl tanımlanacağı ve RAG, veri kalitesi kontrolü, eleştirel modeller gibi teknik araçlarla halüsinasyonun nasıl azaltılacağı, sektörün sürekli araştırdığı konulardır. (kaynak: 36氪)

AI Arkadaş/Dost Üzerine Düşünceler ve Tartışmalar: Meta CEO’su Mark Zuckerberg’in, insanların daha fazla sosyal bağlantı ihtiyacını karşılamak için kişiselleştirilmiş AI arkadaşlar kullanma önerisi (ortalama bir insanın 3 arkadaşı olduğunu ancak ihtiyacın 15 olduğunu iddia ederek) toplulukta tartışmalara yol açtı. Sebastien Bubeck, gerçek AI arkadaşları gerçekleştirmenin çok zor olduğunu, anahtarın AI’ın sadece kullanıcının deneyimlerini paylaşmak yerine kendi deneyimlerine ve yaşanmışlıklarına sahip olarak “Son zamanlarda neyle meşgulsün?” sorusuna anlamlı bir şekilde cevap verebilmesi olduğunu savunuyor. Mevcut AI arkadaş vizyonunun paylaşılan deneyimlere aşırı odaklandığını, AI’ın kendisinin de paylaşılabilir bağımsız deneyimlere, hatta dedikoduya (birbirlerinin deneyimlerini paylaşma) ihtiyacı olduğunu göz ardı ettiğini düşünüyor. Başka bir yorumcu, Dunbar sayısını referans alarak AI’dan oluşan geniş bir sosyal çevrenin gerçek anlamdan yoksun olabileceğini sorguluyor. Ticari şirketler tarafından sağlanan AI arkadaşların nihai amacının gerçek arkadaşlık yerine hassas pazarlama dönüşümü olabileceği endişesi de dile getiriliyor. (kaynak: jonst0kes, SebastienBubeck, gfodor, gfodor)

AI Sanat Yaratımının Tetiklediği Duygular ve Düşünceler: Toplulukta bir kullanıcı, AI’ın kısa sürede “çılgınca iyi” sanat eserleri yaratabilmesi nedeniyle “üzgün” (grieving) hissettiğini, bunun insanın sanatsal yaratıcılıktaki benzersizliğine meydan okuduğunu ifade etti. Bu, AI sanatı, insan yaratıcılığının doğası ve teknolojinin etkisi altındaki kişisel değer duygusu hakkında tartışmaları tetikledi. Bazı yorumcular, sanat yaratmanın zevkinin AI ile rekabet etmek değil, sürecin kendisi olduğunu; AI sanatının ilham kaynağı olarak kullanılabileceğini düşünüyor. Bazıları ise AI sanatının insan yaratımındaki “hata” veya ruhtan yoksun olduğunu, fazla mükemmel veya kalıplaşmış göründüğünü savunuyor. Aynı zamanda tartışma, AI’ın duygu simülasyonu, bilinç ve gelecekteki sosyal yapılar (işlerin yerini alması gibi) gibi konularda getirdiği felsefi düşüncelere de uzanıyor. (kaynak: Reddit r/ArtificialInteligence)
AI Etiği ve Sorumluluğu: Gizli Deneyler ve Bilgi İfşası: Topluluk, AI araştırmalarındaki etik sorunları tartıştı. Bir haberde, AI araştırmacılarının Reddit’te kullanıcıların fikirlerini değiştirmeye çalıştığı gizli bir deney yaptığı belirtildi ve bu durum, kullanıcıların bilgilendirilme hakkı ve AI manipülasyonu riskleri konusunda endişelere yol açtı. Başka bir tartışmada, bir kullanıcı AI şirketlerine potansiyel güvenlik sorunlarını bildirirken karmaşık süreçler ve belirsiz sorumluluklarla karşılaştığını belirtti; bu da mevcut AI alanında sorumlu ifşa ve güvenlik açığı yanıt mekanizmalarının henüz olgunlaşmadığını vurguladı. (kaynak: Reddit r/ArtificialInteligence, nptacek)

NLP Alanının ChatGPT Yükselişine Yönelik Yansıması: Quanta Magazine, Chris Potts, Yejin Choi, Emily Bender gibi birçok Doğal Dil İşleme (NLP) alanı uzmanıyla yapılan röportajlar aracılığıyla ChatGPT’nin yayınlanmasının ardından tüm alana getirdiği etkiyi ve yansımaları inceleyen bir makale yayınladı. Makale, büyük dil modellerinin yükselişinin geleneksel NLP’nin teorik temellerine nasıl meydan okuduğunu, alanda tartışmalara, gruplaşmalara ve araştırma yönelimlerinde ayarlamalara nasıl yol açtığını tartışıyor. Topluluk üyeleri bu makaleye yoğun ilgi gösterdi ve GPT-3 sonrası dilbilim alanındaki sarsıntıyı ve adaptasyon sürecini iyi özetlediğini belirtti. (kaynak: stanfordnlp, Teknium1, YejinChoinka, sleepinyourhat)
AI Tarafından Üretilen Reklamların Ortaya Çıkışı ve Yarattığı İzlenim: Sosyal medya kullanıcıları, YouTube gibi platformlarda AI tarafından üretilen reklamları görmeye başladıklarını ve bundan “çok rahatsız” olduklarını bildirdi. Bu, AI içerik üretme teknolojisinin ticari reklam yapımında kullanılmaya başlandığını gösterirken, aynı zamanda kullanıcıların AI tarafından üretilen içeriğin kalitesi, gerçekliği ve duygusal deneyimi hakkındaki ilk tepkilerini de ortaya koyuyor. (kaynak: code_star)
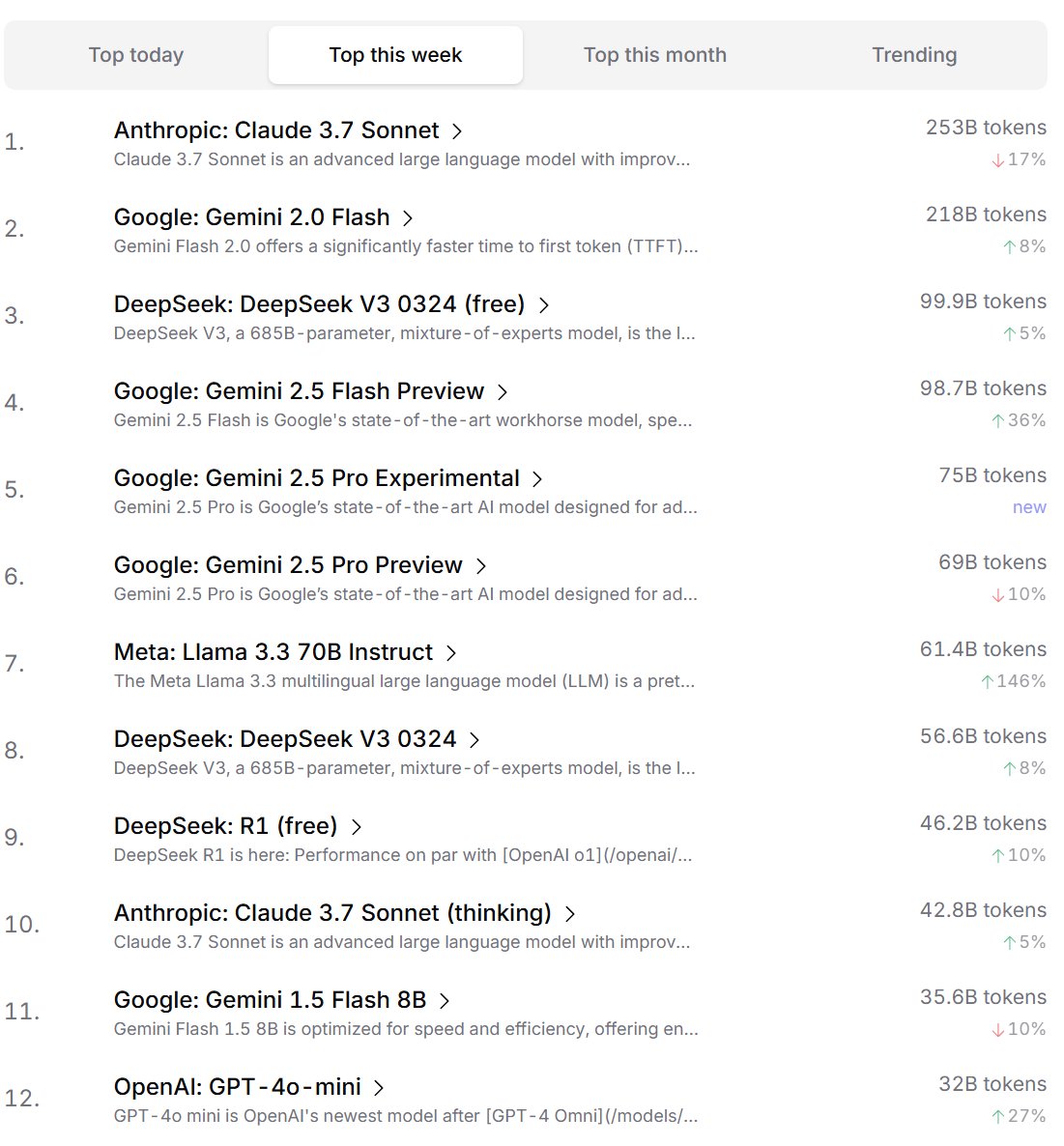
Geliştiricilerin AI Modeli Tercih Sıralaması: Cursor.ai, kullanıcılarının (çoğunlukla geliştiriciler) tercih ettiği AI modellerinin sıralamasını yayınladı. Aynı zamanda Openrouter da model Token kullanım miktarı sıralamasını açıkladı. Gerçek ürün kullanım verilerine dayanan bu sıralamaların, ChatBot Arena gibi rekabetçi listelerden ziyade kullanıcıların gerçek geliştirme senaryolarındaki tercihlerini daha iyi yansıtabileceği düşünülüyor ve model pratikliğini değerlendirmek için farklı bir bakış açısı sunuyor. (kaynak: op7418, Reddit r/LocalLLaMA)
AI’ın “Düşünme” Yeteneğine Sahip Olup Olmadığı Tartışması: Toplulukta, büyük dil modellerinin (LLM’ler) gerçekten “düşünme” yeteneğine sahip olup olmadığı konusunda süregelen bir tartışma var. Bir görüşe göre, mevcut LLM’ler aslında konuşmadan önce düşünmüyor, bunun yerine daha fazla metin üreterek (düşünce zinciri gibi) düşünme sürecini simüle ediyorlar ve bu yanıltıcı bir durum. Başka bir görüşe göre, ayrık bilgisayarlarda ayrık akıl yürütme yapmak için sürekli matematiksel yöntemler (LLM’ler gibi) kullanmak temelden sorunlu. Bu tartışmalar, mevcut AI teknolojisinin doğası ve gelecekteki gelişim yönü hakkında derinlemesine düşünceleri yansıtıyor. (kaynak: francoisfleuret, pmddomingos)
AI Enerji Tüketimi ve Çevresel Etkileri Üzerine Diyalektik Düşünce: AI eğitimi ve çalıştırılması için gereken devasa enerji tüketiminin getirdiği çevresel sorunlara karşı toplulukta diyalektik bir düşünce ortaya çıktı. Bir görüşe göre, AI’ın devasa enerji talebi (özellikle Google, Amazon, Microsoft gibi hiper ölçekli bilişim şirketleri) bu şirketleri kendi yenilenebilir enerji kaynaklarını (güneş, rüzgar, batarya) inşa etmeye, hatta nükleer santralleri yeniden başlatmaya (Microsoft’un Constellation ile Three Mile Island nükleer santralini yeniden başlatma işbirliği gibi) zorluyor. Bu talebin, temiz enerji dağıtımını ve teknolojik atılımları (küçük modüler nükleer reaktörler SMR gibi) hızlandıran bir katalizör olabileceği düşünülüyor. Ancak başka bir görüş, AI enerji tüketiminin azalan getirileri sorununa ve soğutma için gereken su kaynağı tüketiminin de dikkate alınması gerektiğine işaret ediyor. (kaynak: Reddit r/ArtificialInteligence)
Anthropic’in AI Çip Rekabetini Sınırlamaya Çalıştığı İddiası: Topluluk tartışmaları, Anthropic CEO’su Dario Amodei’nin Çin gibi yerlere AI çip ihracat kontrollerinin sıkılaştırılmasını savunduğunu, hatta çiplerin hamile kadın taklidi sahte karınlar gibi yöntemlerle kaçırılabileceği iddiasını ortaya attığını belirtiyor. Eleştirmenler, Anthropic’in bu hamlesinin, rakiplerin (özellikle DeepSeek, Qwen gibi Çinli şirketlerin) gelişmiş hesaplama kaynaklarına erişimini sınırlayarak en ileri model geliştirmedeki avantajını korumayı amaçladığını savunuyor. Bu yaklaşım, rekabeti politika yoluyla bastırmakla suçlanıyor ve küresel AI teknolojisinin açık gelişimine ve açık kaynak topluluğuna zarar verdiği belirtiliyor. (kaynak: Reddit r/LocalLLaMA)

💡 Diğer
AI ve İnsan Bilişsel Sınırları Üzerine Düşünceler: Jeff Ladish, insanların AI için “kopyala-yapıştır asistanı” rolünün pencere döneminin son derece kısa olduğunu belirterek, AI’ın özerk yeteneklerinin basit yardımı hızla aşacağını ima ediyor. Aynı zamanda, DeepMind kurucusu Hassabis bir röportajda, gerçek AGI’nin sadece sorunları çözmekle kalmayıp, değerli bilimsel varsayımları (Einstein’ın genel göreliliği önermesi gibi) bağımsız olarak ortaya atabilmesi gerektiğini belirtiyor ve mevcut AI’ın hipotez üretme konusunda hala eksik olduğunu düşünüyor. Liu Cixin ise AI’ın insan beyninin biyolojik bilişsel sınırlarını aşmasını umuyor. Bu görüşler, AI yeteneklerinin sınırları, insan rolünün evrimi ve gelecekteki zekanın doğası üzerine derinlemesine düşüncelere işaret ediyor. (kaynak: JeffLadish, 新智元)
Waymo Lidar’ı Tehlikeli Anı Yakaladı: Waymo otonom sürüş aracının Lidar sistemi, başarıyla kaçındığı bir motosiklet kazası sırasında, teslimat sürücüsünün çarpışma anında takla attığı 3D nokta bulutu görüntüsünü net bir şekilde yakaladı. Bu, sadece Waymo’nun algılama sisteminin güçlü yeteneğini (karmaşık dinamik sahnelerde bile) göstermekle kalmadı, aynı zamanda kazanın benzersiz bir perspektifini de beklenmedik bir şekilde kaydetti. Neyse ki kazada kimse ağır yaralanmadı. (kaynak: andrew_n_carr)
Roman Yazımı İçin Yeni Bir AI Yaklaşımı: Olay Örgüsü Vaadi Sistemi: Geliştirici Levi, AI roman yazımı için geleneksel hiyerarşik taslak yönteminin yerine geçecek bir “Olay Örgüsü Vaadi” (Plot Promise) sistemi önerdi. Brandon Sanderson’ın “vaat, ilerleme, karşılık” teorisinden esinlenen sistem, hikayeyi bir dizi aktif anlatı ipucu (vaat) olarak görüyor. Her vaadin bir önem puanı var ve algoritma puana ve ilerleme durumuna göre ilerleme zamanlamasını öneriyor, ancak AI bağlam mantığına göre o an ilerletilmesi en uygun olan vaadi seçiyor. Kullanıcılar vaatleri dinamik olarak ekleyip çıkarabiliyor. Bu yöntem, hikayenin esnekliğini, ölçeklenebilirliğini (çok uzun metinlere uyum) ve yaratımın kendiliğindenliğini artırmayı amaçlıyor, ancak AI karar optimizasyonu, uzun vadeli tutarlılığın sürdürülmesi ve girdi istemi uzunluk sınırlamaları gibi zorluklarla karşı karşıya. (kaynak: Reddit r/ArtificialInteligence)