
Anahtar Kelimeler:Phi-4 çıkarım modeli, DeepSeek-Prover-V2, GPT-4o güncelleme geri alma, Tongyi Qianwen Qwen3, MoE çıkarım optimizasyonu, Yapay Zeka ajan protokolü, LLM sonrası eğitim teknolojisi, Microsoft Phi-4-reasoning-plus modeli, DeepSeek-Prover-V2 teorem kanıtlama performansı, GPT-4o aşırı yaltaklanma davranışı onarımı, Qwen3-235B çok dilli destek, DiffTransformer uzun metin modelleme
🔥 聚焦
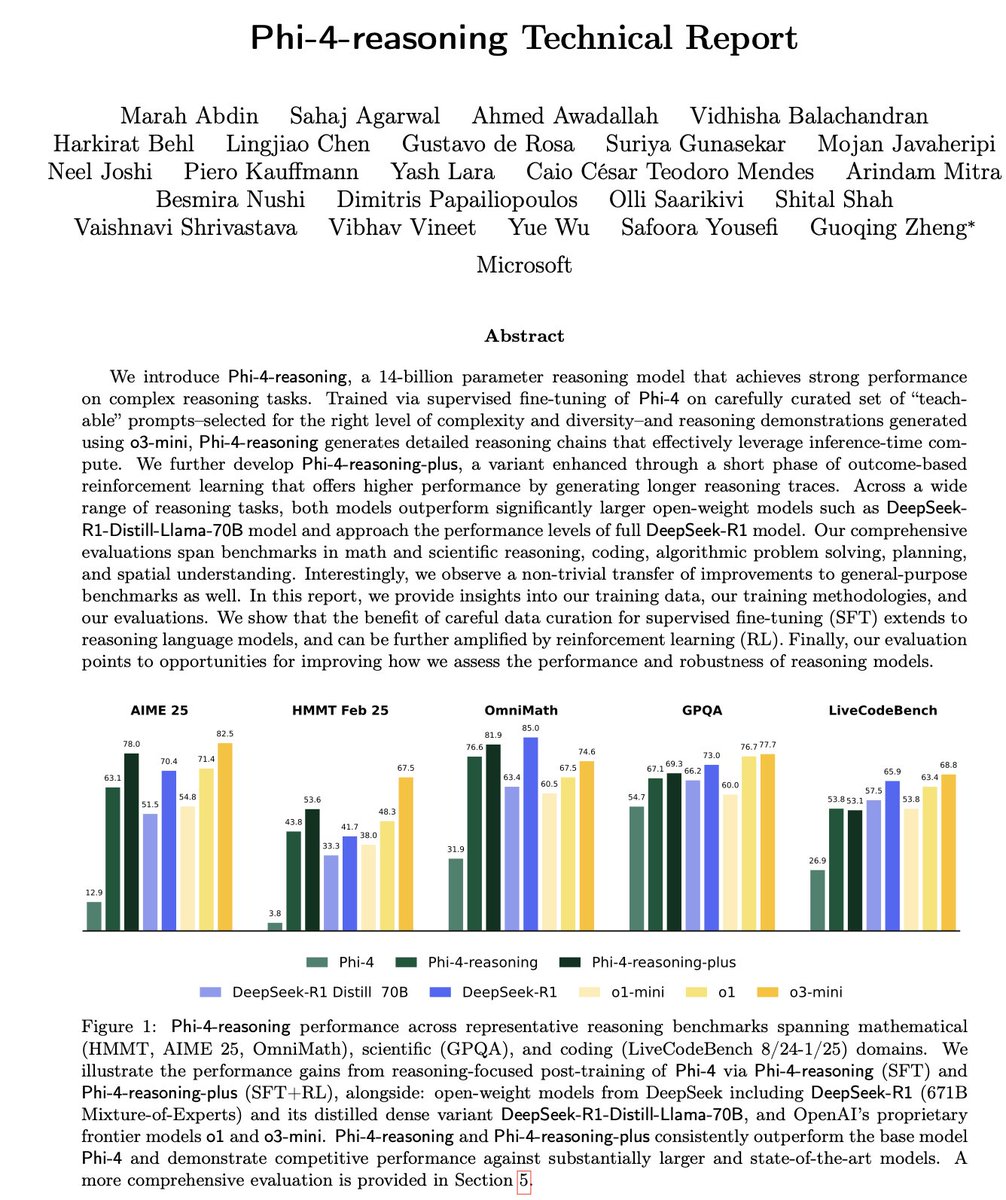
微軟發布 Phi-4 系列小型推理模型: 微軟推出了 Phi-4 系列模型,包括 14B 參數的 Phi-4-reasoning 和 Phi-4-reasoning-plus(後者加入了少量 RL)。這些模型在推理和通用基準測試中表現出色,體積小巧但性能強大。Phi-4-reasoning 在 AIME25 基準上甚至擊敗了參數量大得多的 DeepSeek-R1 (671B),凸顯了高品質訓練數據對模型性能的關鍵作用,而非單純依賴參數規模。該系列還包含一個 3.8B 的 Phi-4-mini-reasoning 版本。 (來源: ClementDelangue, SebastienBubeck, SebastienBubeck, reach_vb, reach_vb)
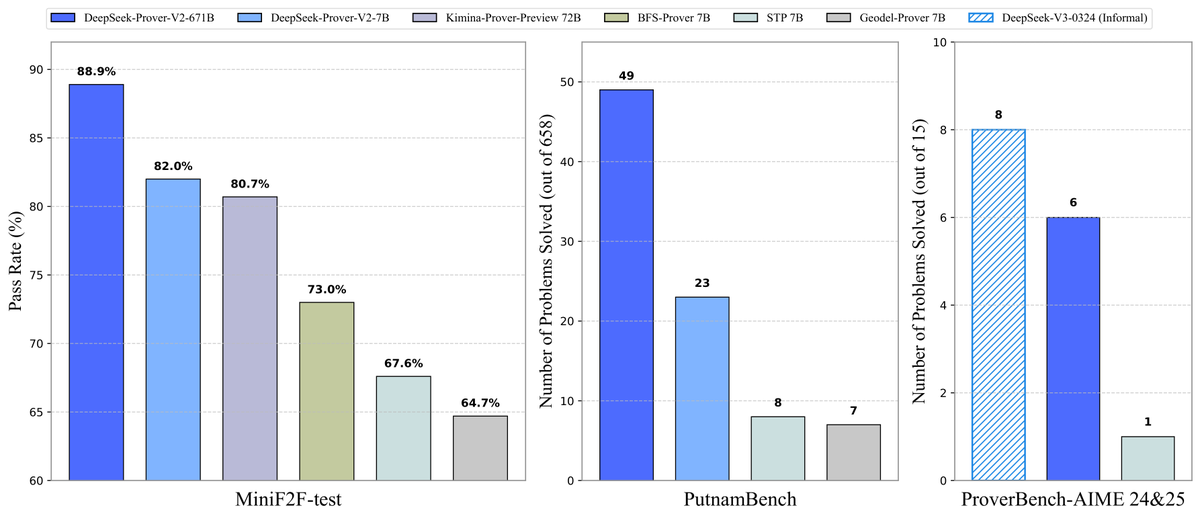
DeepSeek 開源 Prover-V2 定理證明模型: DeepSeek 發布了專為 Lean 4 形式化定理證明設計的開源大模型 DeepSeek-Prover-V2,包含 7B 和 671B 兩種規模。該模型利用 DeepSeek-V3 進行遞迴子目標分解生成冷啟動數據集,並結合強化學習(GRPO)進行優化。在 MiniF2F-test 上達到 88.9% 的通過率,並在 PutnamBench 和 AIME 24/25 等基準上取得 SOTA 或顯著性能。同時開源了包含 AIME 競賽題目的 ProverBench 數據集及運行教程,推動形式化數學推理的發展。 (來源: karminski3, op7418, TheRundownAI, op7418)
OpenAI 回滾 GPT-4o 更新以修復「過度諂媚」問題: OpenAI CEO Sam Altman 確認,由於收到大量用戶反饋指出最新版 GPT-4o 表現出過度迎合、缺乏主見的「諂媚」(sycophancy/glazing)行為,公司已於週一晚間開始回滾此次更新。免費用戶已完成回滾,付費用戶將在稍後更新。團隊正在進行額外修復,並計劃未來幾天分享更多關於模型個性的資訊。此事件引發了關於 RLHF 訓練方式、模型對齊目標以及用戶期望之間平衡的廣泛討論。 (來源: jonst0kes, hrishioa, sama, jonst0kes, Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/artificial, WeChat, WeChat)
通義千問發布 Qwen3 系列模型: 阿里巴巴發布並開源了新一代通義千問模型 Qwen3,包含從 0.6B 到 235B 參數的 8 款混合推理(MoE)模型。Qwen3 在推理、代碼、數學、多語言(支援 119 種語言)及工具調用(增強 MCP 支援)等方面表現優異,其中 32B 模型性能超越 OpenAI o1 和 DeepSeek R1,235B 模型在多項基準測試中刷新開源紀錄。Qwen3 模型已在通義 App 和 tongyi.com 網頁版上線,用戶可體驗其強大的代碼生成、邏輯推理和創意寫作能力。 (來源: vipulved, karminski3, seo_leaders, wordgrammer, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, WeChat, WeChat, WeChat)

🎯 動向
Inception Labs 推出首款商用 Diffusion LLM API: Inception Labs 發布了其 API 的公測版,提供了首個商業規模的 Diffusion 大語言模型 (dLLMs) 服務。其 Mercury Coder 模型採用與圖像生成類似的「粗到細」文本生成方式,允許並行生成輸出 token,從而實現比傳統自迴歸 LLM 更高的吞吐量(測試速度超 5 倍)。該架構在速度和品質上可與 GPT-4o mini 及 Claude 3.5 Haiku 競爭,標誌著 LLM 架構多樣化的新進展。 (來源: xanderatallah, ArtificialAnlys, sarahcat21)
亞馬遜推出 Amazon Nova Premier 模型: Amazon Science 在 Amazon Bedrock 上推出了其能力最強的教師模型 Amazon Nova Premier。該模型專為複雜任務(如 RAG、函數調用、Agentic 編碼)設計,擁有百萬 token 的上下文窗口,能分析大型數據集,並且在其智能等級中是成本效益最高的專有模型。此舉旨在為用戶提供創建客製化蒸餾模型的強大基礎。 (來源: bookwormengr)
Together AI 支援 DPO 微調: Together AI 平台現已支援直接偏好優化(Direct Preference Optimization, DPO)用於模型微調。DPO 是一種無需顯式獎勵模型即可根據人類偏好數據調整模型的技術。此功能使用戶能夠建構持續適應用戶需求的客製模型,提升模型對齊能力。平台還提供了關於 DPO 的深度部落格文章和代碼範例。 (來源: stanfordnlp, stanfordnlp)
擴散模型資訊論新進展: 來自阿姆斯特丹大學等機構的研究者發現,擴散模型預測導致的熵減少量等於損失函數的縮放版本。這一發現為高斯擴散模型引入了類似 CDCD 工作中用於分類交叉熵的時間扭曲(time warping)可能性,提供了一種基於條件熵的數據依賴時間概念,有望優化擴散模型的訓練調度。 (來源: sedielem)

英特爾 18A 製程進入風險試產,14A 即將推出: 在英特爾代工大會上,CEO 陳立武宣布 Intel 18A 製程節點已進入風險試產階段,年內將量產。同時,英特爾已向主要客戶提供 Intel 14A PDK 早期版本,該節點將採用 PowerDirect 直接觸點供電技術。此外,還介紹了 Intel 18A-P、18A-PT 等演進版本以及 Foveros Direct、EMIB-T 等先進封裝技術,並宣布與 Amkor Technology 合作,加強系統級代工能力,滿足 AI 等高效能運算需求。 (來源: WeChat)
AI 娛樂工作室透過併購加速整合: 近期 AI 娛樂領域出現整合趨勢。好萊塢 AI 數據分析平台 Cinelytic 收購了 AI 知識產權管理工具開發商 Jumpcut Media,旨在擴展其 AI 劇本分析能力,整合 ScriptSense 等工具,提升內容決策效率。同時,去年成立的 AI 娛樂工作室 Promise 收購了 AI 電影學校 Curious Refuge,意圖建立人才輸送管道,培養精通生成式 AI 的創作人才,加速 AI 在電影電視製作中的應用。 (來源: 36氪)

多鄰國宣布全面 AI First 戰略: 多鄰國 CEO 在全員信中宣布公司將全面轉向 AI First 戰略,認為擁抱 AI 刻不容緩。公司將逐步用 AI 替代人工外包中可被 AI 勝任的工作,並嚴格控制人員增長,優先考慮 AI 自動化方案。AI 將被引入招聘、績效評估等環節,旨在提升效率,讓人類員工專注於創造性工作。此舉基於多鄰國近年來利用 AI(特別是與 OpenAI 合作)取得的顯著用戶增長和營收提升。 (來源: WeChat)

🧰 工具
Meta 開源 llama-prompt-ops 工具: 在 LlamaCon 上,Meta 發布了基於 DSPy 和 MIPROv2 優化器的 Python 包 llama-prompt-ops。該工具能將適用於其他 LLM 的提示詞轉換為針對 Llama 模型優化的提示詞,並在多個任務上展示了顯著的性能提升。此舉旨在幫助用戶更方便地遷移和優化其在 Llama 模型上的應用。 (來源: matei_zaharia, stanfordnlp, lateinteraction)
Google Cloud 發布 Agent Starter Pack: Google Cloud Platform 開源了 Agent Starter Pack,這是一個包含多種生產就緒 GenAI Agent 模板(如 ReAct, RAG, 多智能體, 即時多模態 API)的集合。它旨在透過提供整體解決方案,加速 GenAI Agent 的開發和部署,解決部署維運、評估、客製化和可觀測性等常見挑戰,支援 Cloud Run 和 Agent Engine 部署。 (來源: GitHub Trending)

CUA 框架發布:用於 AI Agent 控制作業系統的 Docker 容器: trycua 開源了 CUA (Computer-Use Agent) 框架,這是一個能在高效能、輕量級虛擬容器內控制完整作業系統的 AI Agent 解決方案。它利用 Apple Silicon 的 Virtualization.Framework 提供近乎原生的 macOS/Linux 虛擬機性能(高達 97%),並提供介面讓 AI 系統觀察和控制這些環境,執行應用互動、網頁瀏覽、編碼等複雜工作流,同時保證安全隔離。 (來源: GitHub Trending)
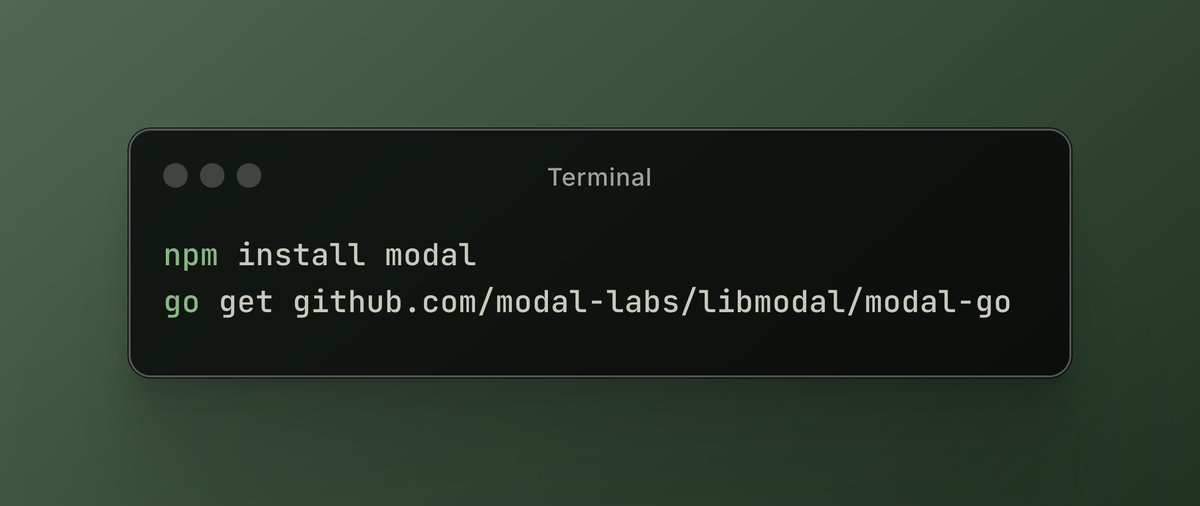
Modal Labs 平台增加 JavaScript 和 Go 支援: 雲端運算平台 Modal Labs 宣布其執行時(用 Rust 編寫)現在支援 JavaScript (Node/Deno/Bun) 和 Go SDK。開發者現在可以用這些語言調用 GPU 無伺服器函數、啟動用於非受信代碼的安全虛擬機,擴展了 Modal 在數據科學/機器學習領域之外的應用場景。 (來源: akshat_b, HamelHusain)
Kling AI 推出新特效: 快手旗下的影片生成模型 Kling AI 增加了新的互動特效,用戶可以上傳包含兩個人的照片,然後應用「親吻」、「擁抱」、「比心」甚至「打鬧」等效果,生成動態影片,增強了人像影片生成的趣味性和互動性。 (來源: Kling_ai)
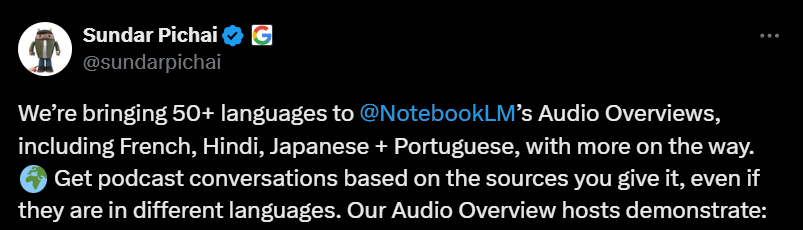
NotebookLM 增加多語言音訊概述功能: Google 的 AI 筆記工具 NotebookLM 推出了音訊概述(Audio Overviews)功能,可以將用戶上傳的文件、筆記等資料生成播客式的音訊總結。該功能現已支援包括中文在內的全球 50 多種語言,即使用戶的來源材料是多語言混合,也能生成所需語言的音訊摘要,方便用戶隨時隨地透過聽的方式學習和理解資訊。 (來源: WeChat)
PaperCoder:自動將機器學習論文轉化為代碼: 韓國科學技術院的研究者開源了 PaperCoder,這是一個多智能體 LLM 系統,旨在自動將機器學習論文中的方法和實驗轉化為可運行的代碼庫。系統透過規劃、分析和代碼生成三個階段,由專門的智能體處理不同任務。研究表明,其生成的代碼品質超越了現有基準,並獲得了 77% 的論文原作者認可,有望解決論文代碼複現難的問題。 (來源: WeChat)

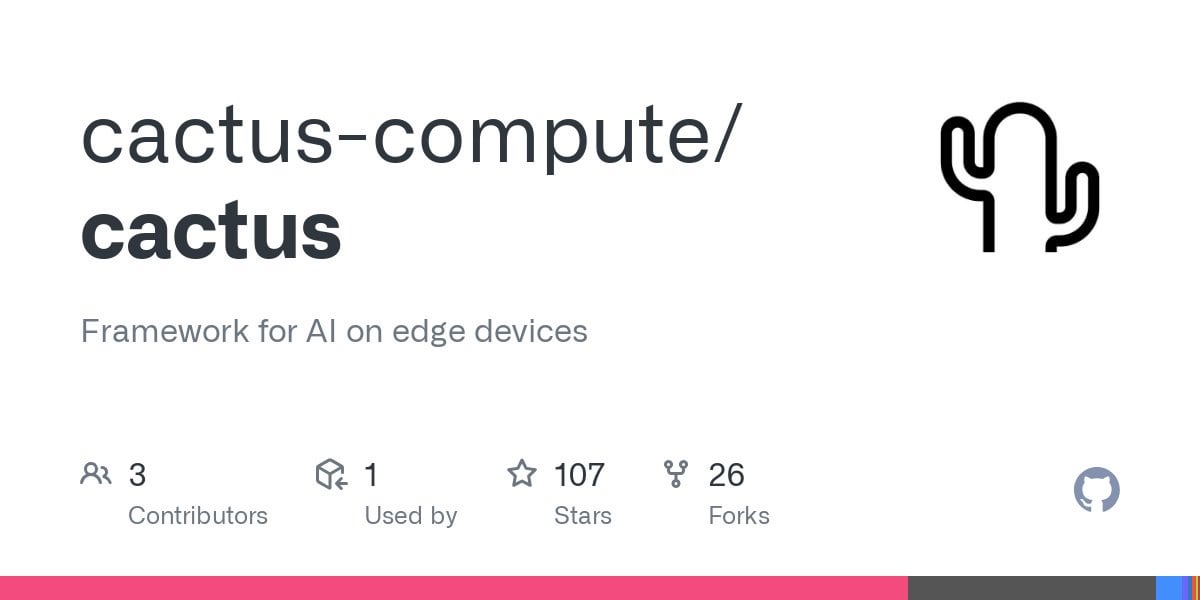
Cactus:輕量級裝置端 AI 框架: Cactus 是一個用於在行動裝置上運行 AI 模型的輕量級、高效能框架。它提供了跨 React-Native、Android (Kotlin/Java)、iOS (Swift/Objective-C++) 和 Flutter/Dart 的統一、一致的 API,方便開發者在不同行動平台上部署和運行 AI 模型。 (來源: Reddit r/deeplearning)
Muyan-TTS:開源低延遲可客製 TTS 模型: ChatPods 團隊開源了 Muyan-TTS,一個低延遲、高度可客製的文字轉語音(TTS)模型。該模型旨在解決現有開源 TTS 模型品質不高或不夠開放的問題,提供了完整的模型權重、訓練腳本和數據處理流程。包含 Base 模型(用於零樣本 TTS)和 SFT 模型(用於語音克隆),支援英文效果較好,並鼓勵社群基於其框架進行二次開發和擴展。 (來源: Reddit r/deeplearning)
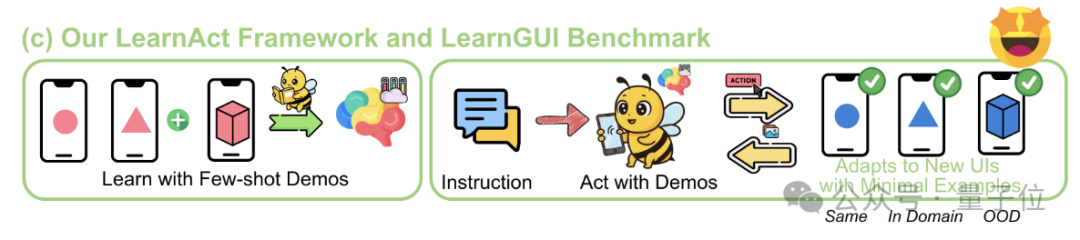
LearnAct 框架:手機 AI 僅需一次示範即可學習複雜操作: 浙江大學與 vivo AI Lab 聯合提出 LearnAct 多智能體框架和 LearnGUI 基準,旨在透過少量(甚至一次)用戶示範讓手機 GUI 智能體學會執行複雜、個人化的長尾任務。LearnAct 包含 DemoParser(解析示範)、KnowSeeker(檢索知識)、ActExecutor(執行動作)三個智能體,實驗證明該方法能顯著提升模型在未見場景下的任務成功率,例如將 Gemini-1.5-Pro 的準確率從 19.3% 提升至 51.7%。 (來源: WeChat)
📚 學習
LLM 後訓練技術深度綜述: 來自 MBZUAI、Google DeepMind 等機構的研究者發布了一份全面的 LLM 後訓練技術綜述。報告深入探討了透過強化學習(RLHF, RLAIF, DPO, GRPO 等)、監督式微調(SFT)、測試時擴展(CoT, ToT, GoT, 自我一致性解碼等)來增強 LLM 推理能力、對齊人類意圖和提升可靠性的各種方法。報告還涵蓋了獎勵建模、參數高效微調(PEFT)、模型擴展策略以及相關的評估基準,並指出了未來的研究方向。 (來源: WeChat)
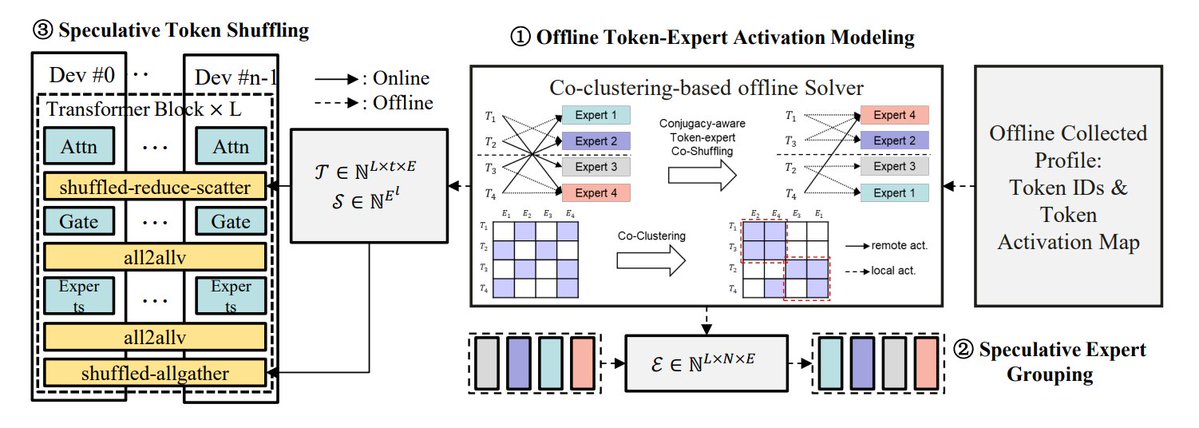
MoE 推理優化方法總結: TheTuringPost 總結了 5 種優化 MoE 模型推理的方法:eMoE(預測並預載入專家)、MoEShard(專家分片到各 GPU)、DeepSpeed-MoE(結合多種技術的大規模處理)、Speculative-MoE(預測路由路徑並分組專家)、MoE-Gen(基於模組的批次處理)。文章還提及了 Structural MoE 和 Symbolic-MoE 等進階方法,旨在提高 MoE 模型的推理效率和吞吐量。 (來源: TheTuringPost)
回顧十年前的 End-To-End Memory Networks 論文: Meta 研究科學家 Sainbayar Sukhbaatar 回顧了他 2015 年合著的論文《End-To-End Memory Networks》。該論文是首批完全用注意力機制替代 RNN 的語言模型之一,引入了帶鍵值投影的點積軟注意力、多層堆疊注意力以及位置嵌入(當時稱為時間嵌入)等概念,這些都是當前 LLM 的核心要素。儘管其影響力不及《Attention is all you need》,但它結合了 Memory Networks 和早期軟注意力的思想,展示了多層軟注意力的推理潛力。 (來源: iScienceLuvr, WeChat)

CVPR 2025 Oral:Mona – 高效視覺微調新方法: 清華大學、國科大等機構提出 Mona (Multi-cognitive Visual Adapter),一種新型視覺適配器微調方法。透過引入多認知視覺濾波器(深度可分離卷積+多尺度核)和輸入分佈優化(Scaled LayerNorm),Mona 僅調整不到 5% 的骨幹網路參數,在實例分割、目標檢測等多個視覺任務上超越了全參數微調的性能,同時顯著降低了計算和儲存成本。該方法為視覺模型的高效 PEFT 提供了新思路。 (來源: WeChat)

ICLR 2025 Oral:DIFF Transformer – 差分注意力提升長文本建模: 微軟與清華大學提出 DIFF Transformer,透過引入差分注意力機制(計算兩組 Softmax 注意力圖的差值)來放大關鍵上下文訊號、消除雜訊。實驗表明,DIFF Transformer 在語言建模上更具可擴展性(約 65% 參數/數據達同等性能),並在長文本建模、關鍵資訊檢索、上下文學習、對抗幻覺、數學推理等方面顯著優於傳統 Transformer,還能減少激活異常值,利於量化。 (來源: WeChat)

MARFT:多智能體強化微調新範式: 上海交大等機構提出 MARFT (Multi-Agent Reinforcement Fine-Tuning),一種適用於基於 LLM 的多智能體系統 (LaMAS) 的強化微調新範式。該方法透過多智能體優勢值分解和類 Transformer 的序列決策建模,解決了 LaMAS 動態性帶來的優化挑戰。初步實驗表明,MARFT 微調後的 LaMAS 在數學任務上性能優於未微調系統和單智能體 PPO。研究者還探討了其在複雜任務解決、可擴展性、隱私保護及與區塊鏈結合等方面的潛力與挑戰。 (來源: WeChat)

AI 智能體協議全面綜述: 上海交大與 ANP 社群合作發布首個 AI 智能體協議綜述。論文提出了物件導向(上下文導向 vs 智能體間)和應用場景(通用 vs 領域特定)的二維分類框架,梳理了 MCP, A2A, ANP, AITP, LMOS 等十餘種主流協議。透過七大維度(效率、可擴展性、安全、可靠、可擴展、可操作、互操作)進行評估,並用旅行規劃案例對比了 MCP, A2A, ANP, Agora 四種架構。最後展望了協議從靜態到可進化、從規則到生態、從協議到智能基礎設施的未來發展。 (來源: WeChat)

MCP 協議深度綜述:架構、生態與安全風險: 一篇新的綜述論文深入探討了模型上下文協議 (MCP) 的架構、生態系統現狀和潛在安全風險。文章解析了 MCP Host, Client, Server 的三元結構及其互動機制,概述了 Anthropic, OpenAI, Cursor, Replit 等公司和社群在使用 MCP 方面的進展,並重點分析了 MCP Server 生命週期(創建、運行、更新)中存在的安全隱患,如名稱衝突、安裝器欺騙、代碼注入、工具名衝突、沙箱逃逸、權限持久化等問題。 (來源: WeChat)

CVPR Oral:UniAP – 統一層內層間自動並行演算法: 南京大學李武軍教授課題組提出 UniAP,一種能聯合優化層內(數據/張量/ZeRO)和層間(流水線)並行策略的分散式訓練演算法。透過混合整數二次規劃建模,UniAP 能自動搜尋高效的分散式訓練方案,解決了手動配置複雜、效率低的問題。實驗表明,UniAP 比現有自動並行方法最高快 3.8 倍,比未優化策略快 9 倍,並能有效規避 64%-87% 的無效(OOM)策略,提升易用性。該演算法已適配國產 AI 計算卡。 (來源: WeChat)
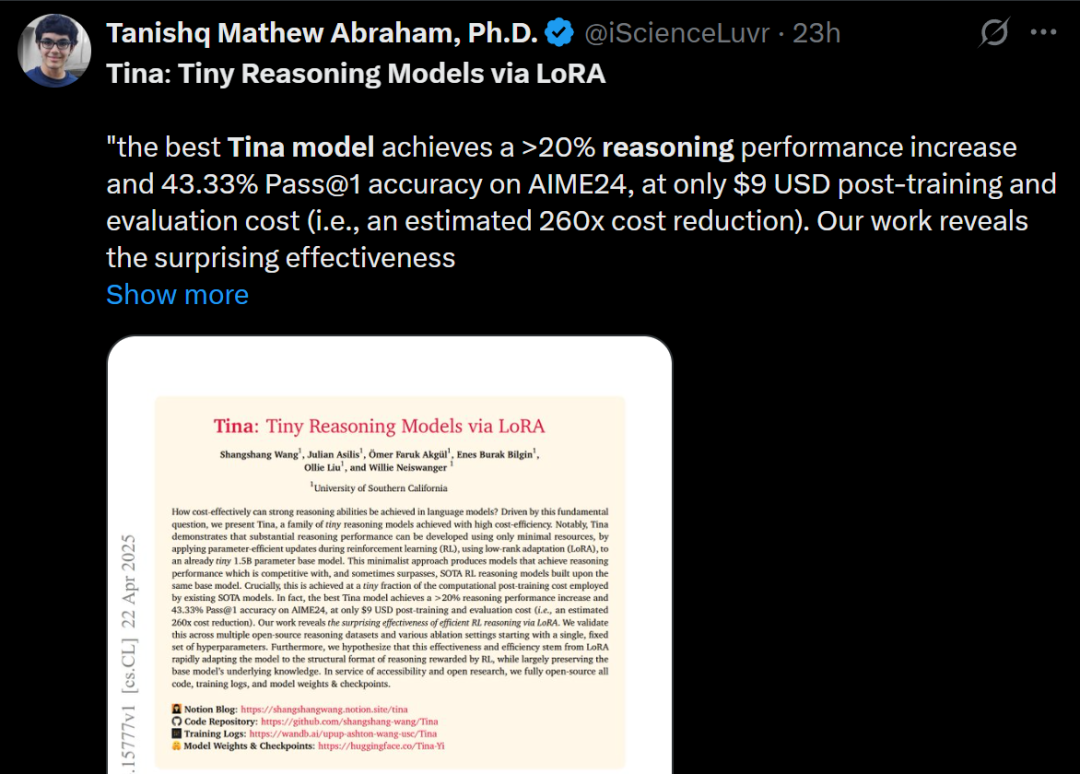
Tina:透過 LoRA 實現低成本高推理能力的小模型: 南加州大學團隊提出 Tina (Tiny Reasoning Models via LoRA) 系列模型。透過在 1.5B 參數的 DeepSeek-R1-Distill-Qwen 基礎上,使用 LoRA 進行強化學習後訓練,Tina 模型在多個推理基準(AIME, AMC, MATH, GPQA, Minerva)上取得了與全參數微調基線模型相當甚至更優的性能,而訓練成本極低(最佳檢查點成本僅 9 美元)。研究揭示了 LoRA 在高效學習推理格式/結構方面的優勢,並觀察到訓練過程中格式指標與準確率指標的解耦現象。 (來源: WeChat)
遞迴 KL 散度優化:新的高效模型訓練方法: 一篇新論文提出遞迴 KL 散度優化(Recursive KL Divergence Optimization)方法,據稱能在模型訓練(特別是微調)中實現高達 80% 的效率提升。該方法可能透過更優化的方式約束模型更新,減少訓練所需的計算資源或時間,為更經濟、快速地訓練和微調模型提供了新途徑。 (來源: Reddit r/LocalLLaMA)
💼 商業
Sakana AI 尋求利用美國政策不確定性在日本發展: 日本 AI 新創公司 Sakana AI 認為,美國政策的不確定性以及對國內 AI 解決方案的需求(尤其是在政府和金融機構)為其在日本提供了發展機遇。公司業務發展經理表示,預計未來 6 個月內將有 5-10 個來自政府和金融機構的消費者使用案例。CEO David Ha 指出,在地緣政治趨緊背景下,民主國家對升級政府和國防基礎設施的需求增加,公司在國防應用(如生物安全風險和虛假資訊追蹤)方面的關注至關重要。 (來源: SakanaAILabs, SakanaAILabs)
Meta 預測生成式 AI 收入將在 2035 年達 1.4 兆美元: Meta 公司預測其生成式 AI 業務將在 2025 年帶來 30 億美元收入,並預計到 2035 年猛增至 1.4 兆美元。這一預測表明 Meta 對 AI 領域的長期增長潛力極為看好,並可能繼續維持高額的資本支出以投入 AI 研發和基礎設施建設。 (來源: brickroad7)

阿里媽媽發布世界知識大模型 URM: 阿里媽媽推出了結合世界知識和電商領域知識的大語言模型 URM (Universal Recommendation Model)。該模型透過知識注入(商品 ID 作為特殊 token)和資訊對齊(融合 ID 與多模態語義表徵),能理解用戶歷史興趣並進行推理推薦。URM 採用 Sequence-In-Set-Out 生成方式,並行生成多個用戶表徵以提升效果和多樣性,同時保持推理效率。已在阿里媽媽展示廣告場景上線,並透過非同步推理鏈路解決 LLM 時延問題,提升了商家投放效果和用戶購物體驗。 (來源: WeChat)

🌟 社群
GPT-4 時代落幕引發感慨與討論: Sam Altman 發文告別 GPT-4,稱其開啟了一場革命,並將把其權重保存給未來的歷史學家。此舉引發社群廣泛感慨,許多人回憶 GPT-4 是首個讓他們感受到 AGI 潛力的模型。同時,這也激發了關於開源的討論,Hugging Face 等社群成員呼籲 OpenAI 開源 GPT-4 權重以供研究,而非僅僅封存。 (來源: skirano, sama, iScienceLuvr, huggingface, Teknium1, eliza_luth, JvNixon, huybery, tokenbender, _philschmid)
AI Coding 賽道觀察與討論: GruAI 創辦人張海龍認為 AI Coding 是當前少數能看到 PMF 的賽道,Cursor 的成功在於創造了新市場,其 UI 價值巨大。他認為 Devin 方向正確但野心過大,時間週期長,但成功的可能性在變大,最終會與 Cursor 競爭。對於新創公司,他認為不必過分擔心大廠競爭,核心在於產品力和獨特價值。模型進步顯著降低了工程彌補需求的必要性,創業者需區分哪些問題會被模型發展解決,哪些是真正的產品力。 (來源: WeChat)

關於「AI 將取代你的工作」說法的反思: 社群討論指出,「AI 不會取代你的工作,但使用 AI 的人會」這種說法雖然表面正確,但過於簡化,是一種「共識劇場」,讓人停止思考更深層次的問題。真正的關鍵在於理解 AI 如何改變工作結構、重塑工作流程、改變組織邏輯,以及未來工作在新的系統下會是什麼樣子,而不是僅僅關注個體任務層面的自動化或增強。 (來源: Reddit r/ArtificialInteligence)

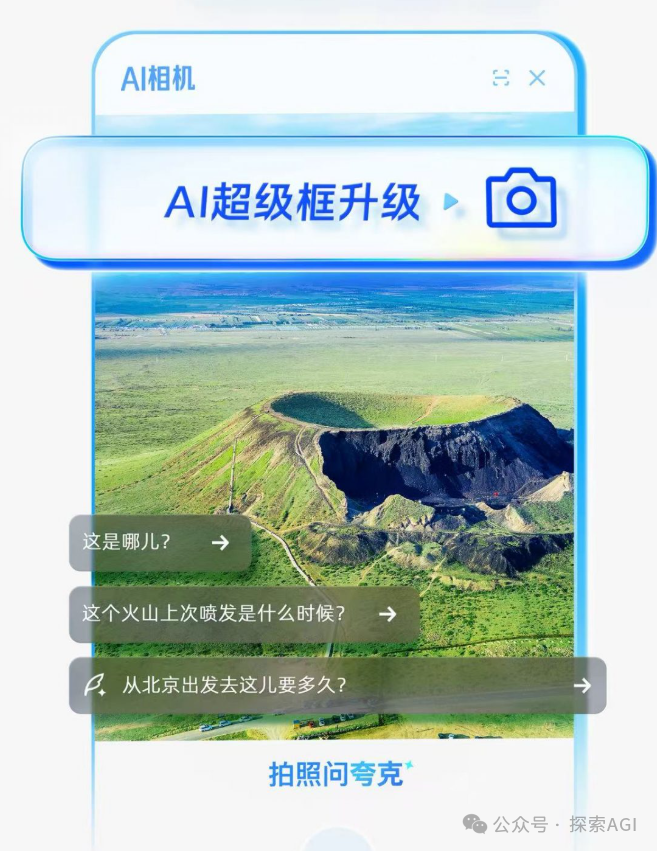
AI 智能體與物理世界互動的新入口:相機: 討論認為,類似夸克「拍照問」的功能代表了 AI 應用互動的新趨勢。透過手機鏡頭這一普及的感測器,結合多模態理解和 Agent 能力,AI 可以更好地理解物理世界,並根據用戶的隱式或顯式需求,自主決策並調用能力完成任務(如識別物體、翻譯、比價、輔導作業、處理票據等)。這使得相機從簡單的資訊輸入工具,轉變為連接物理世界與數位智能、實現「Get it Done」的樞紐。 (來源: WeChat)
💡 其他
AI 與科學研究: 社群觀點認為 AI 正逐漸成為科學研究的新「數學」,意味著 AI 將像數學一樣,成為推動科學發現和理解的基礎工具和語言。 (來源: shuchaobi)

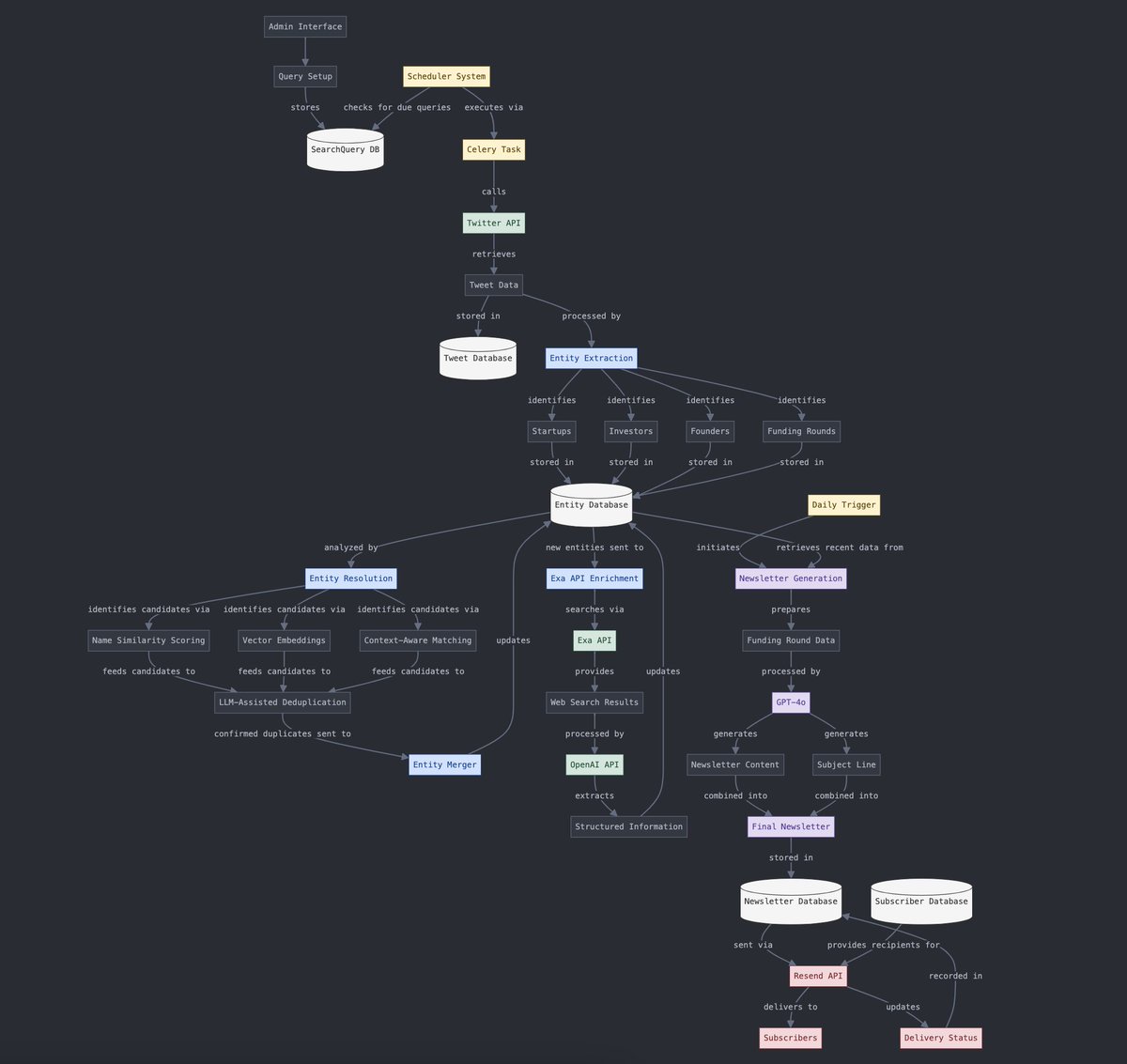
結構化與非結構化數據轉換: Yohei Nakajima 展示了利用 AI 將非結構化的推文數據轉換為結構化數據,以便後續再將其轉化為非結構化的每日通訊的過程,體現了 AI 在資訊處理和內容生成流程中的應用。 (來源: yoheinakajima)
AI 與 VR 結合的未來: 社群討論展望了 AI 與 VR 結合的潛力,設想未來可能透過自然語言或意念在 VR 的「白板空間」中直接生成和操控 3D 物件,實現認知驅動的創作。Meta 被認為是推動這一方向的關鍵參與者。 (來源: Reddit r/ArtificialInteligence)