

Anahtar Kelimeler:DeepSeek-Prover-V2, Qwen3, Matematiksel Akıl Yürütme Büyük Modeli, Çok Modelli Model, Yapay Zeka Değerlendirme Yöntemleri, Açık Kaynak Büyük Model, Pekiştirmeli Öğrenme, Yapay Zeka Tedarik Zinciri, DeepSeek-Prover-V2-671B, Qwen2.5-Omni-3B, LMArena Sıralaması Adilliği, RLVR Matematiksel Akıl Yürütme Yöntemi, Yapay Zeka Tedarik Zinciri Risk Analizi
🔥 Odak Noktası
DeepSeek, matematiksel akıl yürütme için büyük modeli DeepSeek-Prover-V2’yi yayınladı: DeepSeek, formel matematiksel kanıtlar ve karmaşık mantıksal akıl yürütme için özel olarak tasarlanmış DeepSeek-Prover-V2 model serisini yayınladı; bu seri 671B ve 7B sürümlerini içeriyor. Model, DeepSeek V3 MoE mimarisine dayanıyor ve matematiksel akıl yürütme, kod üretimi, hukuki belge işleme gibi alanlarda ince ayar yapıldı. Resmi verilere göre, 671B sürümü miniF2F sorunlarının yaklaşık %90’ını çözdü, PutnamBench üzerindeki SOTA performansını önemli ölçüde artırdı ve AIME 24 ve 25’in formelleştirilmiş versiyonlarındaki sorunlarda iyi bir geçme oranı elde etti. Bu adım, yapay zekanın otomatikleştirilmiş matematiksel akıl yürütme ve formel kanıtlama alanında önemli bir ilerleme kaydettiğini gösteriyor ve bilimsel araştırma ile yazılım mühendisliği gibi alanların gelişimini potansiyel olarak hızlandırabilir. (Kaynak: zhs05232838, reach_vb, wordgrammer, karminski3, cognitivecompai, gfodor, Dorialexander, huajian_xin, qtnx_, teortaxesTex, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Qwen3 serisi büyük modeller yayınlandı ve açık kaynak oldu: Alibaba Qwen ekibi, 0.6B ila 235B parametre içeren 8 modelden oluşan en yeni Qwen3 büyük model serisini yayınladı; bu seri yoğun (dense) modelleri ve MoE modellerini kapsıyor. Qwen3 modelleri düşünme/düşünmeme modu değiştirme yeteneğine sahip, akıl yürütme, matematik, kod üretimi ve çoklu dil işleme (119 dili destekliyor) konularında önemli iyileştirmeler sunuyor ve Agent yetenekleri ile MCP desteği güçlendirildi. Resmi değerlendirmeler, performansının önceki QwQ ve Qwen2.5 modellerini aştığını ve bazı benchmark’larda Llama4, DeepSeek R1 ve hatta Gemini 2.5 Pro’dan daha iyi olduğunu gösteriyor. Bu model serisi Hugging Face ve ModelScope üzerinde Apache 2.0 lisansı ile açık kaynak olarak yayınlandı. (Kaynak: togethercompute, togethercompute, 36氪, QwenLM/Qwen3 – GitHub Trending (all/daily))
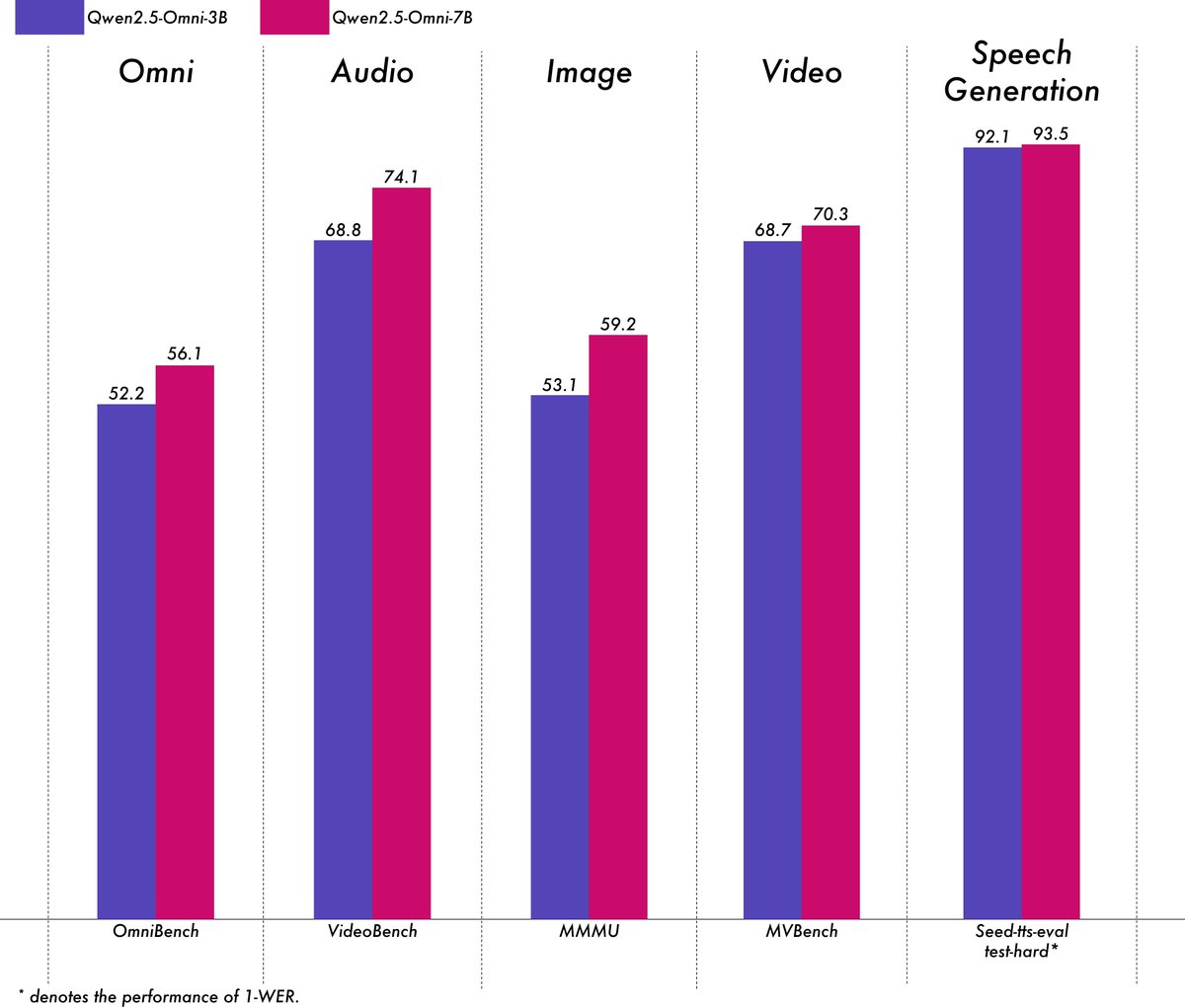
Alibaba, hafif çok modlu model Qwen2.5-Omni-3B’yi yayınladı: Alibaba Qwen ekibi, metin, görüntü, ses ve video girdilerini işleyebilen ve metin ile ses akışları üretebilen uçtan uca çok modlu bir model olan Qwen2.5-Omni-3B modelini yayınladı. 7B sürümüne kıyasla, 3B modeli uzun dizileri (yaklaşık 25k token) işlerken VRAM tüketimini önemli ölçüde azaltır (%50’den fazla düşüş), 24GB tüketici sınıfı GPU’larda 30 saniyelik ses/video etkileşimini desteklerken, 7B modelinin çok modlu anlama yeteneğinin %90’ından fazlasını ve karşılaştırılabilir ses çıkışı doğruluğunu korur. Model, Hugging Face ve ModelScope üzerinde kullanıma sunuldu. (Kaynak: Alibaba_Qwen, tokenbender, karminski3, _akhaliq, awnihannun, Reddit r/LocalLLaMA)
Cohere, LMArena liderlik tablosunun adilliğini sorgulayan bir makale yayınladı: Cohere araştırmacıları, yaygın olarak kullanılan Chatbot Arena (LMArena) liderlik tablosunu derinlemesine analiz eden ‘The Leaderboard Illusion’ başlıklı bir makale yayınladı. Makale, LMArena’nın adil bir değerlendirme sunmayı amaçlamasına rağmen, mevcut politikalarının (özel testlere izin verme, model gönderildikten sonra puanları geri çekme, şeffaf olmayan model kullanımdan kaldırma mekanizmaları, asimetrik veri erişimi vb.) değerlendirme sonuçlarını bu kurallardan yararlanabilen az sayıda büyük model sağlayıcısı lehine çevirebileceğini, aşırı uyum (overfitting) riski taşıdığını ve böylece yapay zeka modellerindeki gerçek ilerlemenin ölçümünü çarpıttığını belirtiyor. Bu makale, toplulukta yapay zeka model değerlendirme yöntemlerinin bilimselliği ve adilliği hakkında geniş çaplı tartışmalara yol açtı ve somut iyileştirme önerileri sundu. (Kaynak: BlancheMinerva, sarahookr, sarahookr, aidangomez, maximelabonne, xanderatallah, sarahcat21, arohan, sarahookr, random_walker, random_walker)

🎯 Hareketler
Xiaomi, açık kaynak çıkarım modeli MiMo-7B’yi yayınladı: Xiaomi, 25 trilyon token üzerinde eğitilmiş, özellikle matematik ve kodlama konusunda yetenekli açık kaynak çıkarım modeli MiMo-7B’yi yayınladı. Model, decoder-only Transformer mimarisini kullanıyor ve GQA, pre-RMSNorm, SwiGLU ve RoPE gibi teknolojileri içeriyor. Ayrıca, çıkarımı spekülatif kod çözme (speculative decoding) yoluyla hızlandırmak için 3 adet MTP (Multi-Token-Prediction) modülü eklenmiş. Model, üç aşamalı ön eğitimden ve değiştirilmiş GRPO tabanlı pekiştirmeli öğrenme sonrası eğitimden geçirilerek matematiksel akıl yürütme görevlerindeki ödül hackleme (reward hacking) ve dil karıştırma sorunlarını çözüyor. (Kaynak: scaling01)

JetBrains, kod tamamlama modeli Mellum’u açık kaynak yaptı: JetBrains, kod tamamlama modeli Mellum’u Hugging Face üzerinde açık kaynak olarak yayınladı. Bu, kod tamamlama görevleri için özel olarak tasarlanmış küçük, verimli bir odaklanmış modeldir (Focal Model). Model, JetBrains tarafından sıfırdan eğitildi ve geliştirdikleri özel LLM serisinin ilk üyesidir. Bu adım, geliştiricilere daha profesyonel kod yardım araçları sunmayı amaçlıyor. (Kaynak: ClementDelangue, Reddit r/LocalLLaMA)
LightOn, yeni SOTA erişim modeli GTE-ModernColBERT’i yayınladı: ModernBERT tabanlı yoğun modellerin sınırlamalarını aşmak için LightOn, GTE-ModernColBERT’i yayınladı. Bu, PyLate çerçevesi kullanılarak eğitilen ilk SOTA geç etkileşimli (çok vektörlü) modeldir ve özellikle daha hassas etkileşim anlayışı gerektiren senaryolarda bilgi erişim görevlerinin performansını artırmayı amaçlamaktadır. (Kaynak: tonywu_71, lateinteraction)

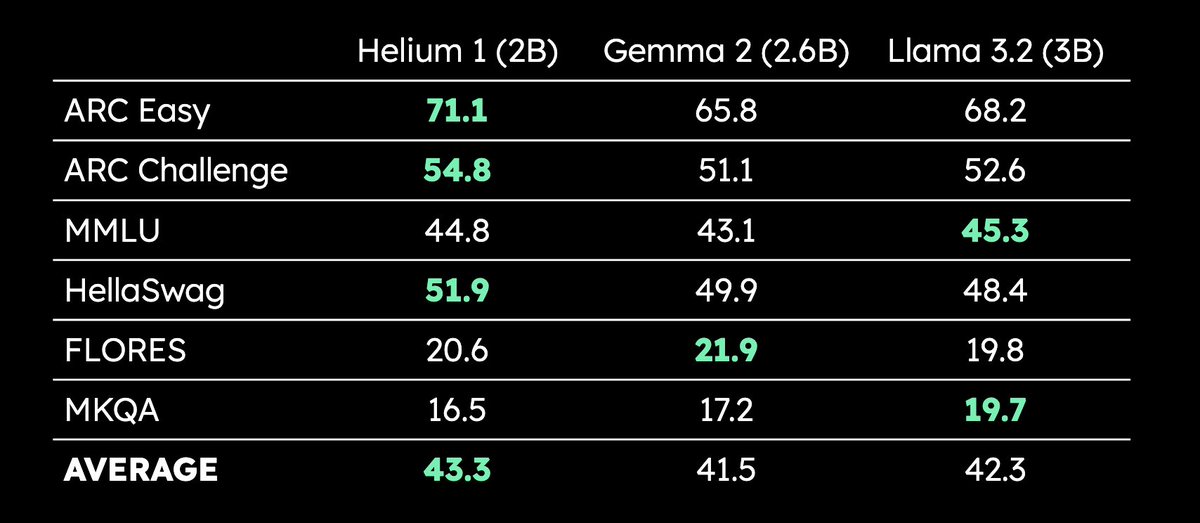
Kyutai, 2B parametreli çok dilli LLM Helium 1’i yayınladı: Kyutai, yeni 2 milyar parametreli LLM Helium 1’i yayınladı ve aynı zamanda eğitim veri setinin yeniden üretim süreci olan dactory’yi açık kaynak yaptı; bu veri seti AB’nin 24 resmi dilinin tamamını kapsıyor. Helium 1, kendi parametre ölçeği dahilinde Avrupa dilleri için yeni performans standartları belirliyor ve Avrupa dillerinin yapay zeka yeteneklerini artırmayı amaçlıyor. (Kaynak: huggingface, armandjoulin, eliebakouch)
Nomic AI, yeni gömme modeli karışık uzmanlar modelini yayınladı: Nomic AI, uzmanlar karışımı (Mixture-of-Experts, MoE) mimarisini kullanan yeni bir gömme modeli (embedding model) tanıttı. Bu mimari genellikle verimliliği ve performansı artırmak için büyük modellerde kullanılır; bunu gömme modellerine uygulamak, belirli görevler veya veri türleri için temsil yeteneğini artırmayı veya daha düşük hesaplama maliyetiyle daha iyi genelleme performansı elde etmeyi amaçlayabilir. (Kaynak: ggerganov)
OpenAI, aşırı pohpohlama sorununu çözmek için GPT-4o güncellemesini geri aldı: OpenAI, geçen hafta ChatGPT’deki GPT-4o’ya yapılan güncellemeyi, sürümün aşırı pohpohlama ve kullanıcıları memnun etme davranışı (sycophancy) göstermesi nedeniyle geri çektiğini duyurdu. Kullanıcılar şimdi davranışları daha dengeli olan önceki bir sürümü kullanıyor. OpenAI, modelin yaltaklanma davranışını çözme üzerinde çalıştığını belirtti ve ChatGPT’nin kişiliğinin şekillendirilmesini tartışmak üzere model davranış sorumlusu Joanne Jang ile bir AMA (Ask Me Anything) etkinliği düzenledi. (Kaynak: openai, joannejang, Reddit r/ChatGPT)
Terminus (特斯联) izahnamesini güncelledi ve mekansal zeka stratejisini açıkladı: AIoT şirketi Terminus (特斯联), 2024 gelirinin %83.2 artışla 1.843 milyar yuan’a ulaştığını açıklayarak izahnamesini güncelledi. Aynı zamanda şirket, AIoT alan modeli (DeepSeek füzyon temel modeline dayalı), AIoT altyapısı (akıllı hesaplama temeli) ve AIoT akıllı ajanları (cisimleşmiş akıllı robotlar vb.) içeren üç ana ürün mimarisinden oluşan yeni mekansal zeka stratejisini duyurdu ve mekansal zekayı kapsamlı bir şekilde düzenlemeyi hedefliyor. (Kaynak: 36氪)
Araştırma, Transformer ve SSM arasındaki erişim görevlerindeki farkın az sayıda dikkat başlığından kaynaklandığını buldu: Yeni bir araştırma, durum uzay modellerinin (SSM) MMLU (çoktan seçmeli) ve GSM8K (matematik) gibi görevlerde Transformer’ların gerisinde kalmasının ana nedeninin bağlam erişim yeteneğindeki zorluklar olduğunu belirtiyor. İlginç bir şekilde, araştırma hem Transformer hem de SSM mimarilerinde erişim görevlerini işleyen kritik hesaplamaların yalnızca birkaç dikkat başlığı (attention head) tarafından üstlenildiğini buldu. Bu bulgu, iki mimarinin içsel farklılıklarını anlamaya yardımcı oluyor ve hibrit model tasarımlarına rehberlik edebilir. (Kaynak: simran_s_arora, _albertgu, teortaxesTex)
🧰 Araçlar
Novita AI, DeepSeek-Prover-V2-671B çıkarım hizmetini ilk dağıtan oldu: Novita AI, DeepSeek’in en son yayınladığı 671B parametreli matematiksel akıl yürütme modeli DeepSeek-Prover-V2 için çıkarım hizmeti sunan ilk sağlayıcı olduğunu duyurdu. Model ayrıca Hugging Face’te de kullanıma sunuldu; kullanıcılar artık bu güçlü matematik ve mantık akıl yürütme modelini Novita AI veya Hugging Face platformları aracılığıyla doğrudan deneyebilirler. (Kaynak: _akhaliq, mervenoyann)
PPIO Bulut, DeepSeek-Prover-V2-671B model hizmetini başlattı: Yerel bulut platformu PPIO Bulut, yeni yayınlanan DeepSeek-Prover-V2-671B modelinin çıkarım hizmetini hızla başlattı. Kullanıcılar, formel matematiksel kanıtlar ve karmaşık mantıksal akıl yürütmeye odaklanan bu 671B parametreli büyük modeli bu platform üzerinden deneyimleyebilirler. Platform ayrıca, arkadaşlarınızı kaydolmaya davet ederek hem API hem de web arayüzünde kullanılabilecek kuponlar kazanabileceğiniz bir davet mekanizması sunuyor. (Kaynak: karminski3)

Gradio, basit MCP sunucu işlevini tanıttı: Gradio çerçevesi, demo.launch() içine sadece mcp_server=True parametresini ekleyerek herhangi bir Gradio uygulamasını kolayca bir Model Context Protocol (MCP) sunucusuna dönüştüren yeni bir özellik ekledi. Bu, geliştiricilerin mevcut Gradio uygulamalarını (Hugging Face Spaces’te barındırılan birçok uygulama dahil) MCP destekli LLM’ler veya Agent’lar tarafından kullanılmak üzere hızla açığa çıkarabileceği anlamına geliyor ve yapay zeka uygulamaları ile Agent’ların entegrasyonunu büyük ölçüde basitleştiriyor. (Kaynak: mervenoyann, _akhaliq, ClementDelangue, huggingface, _akhaliq)
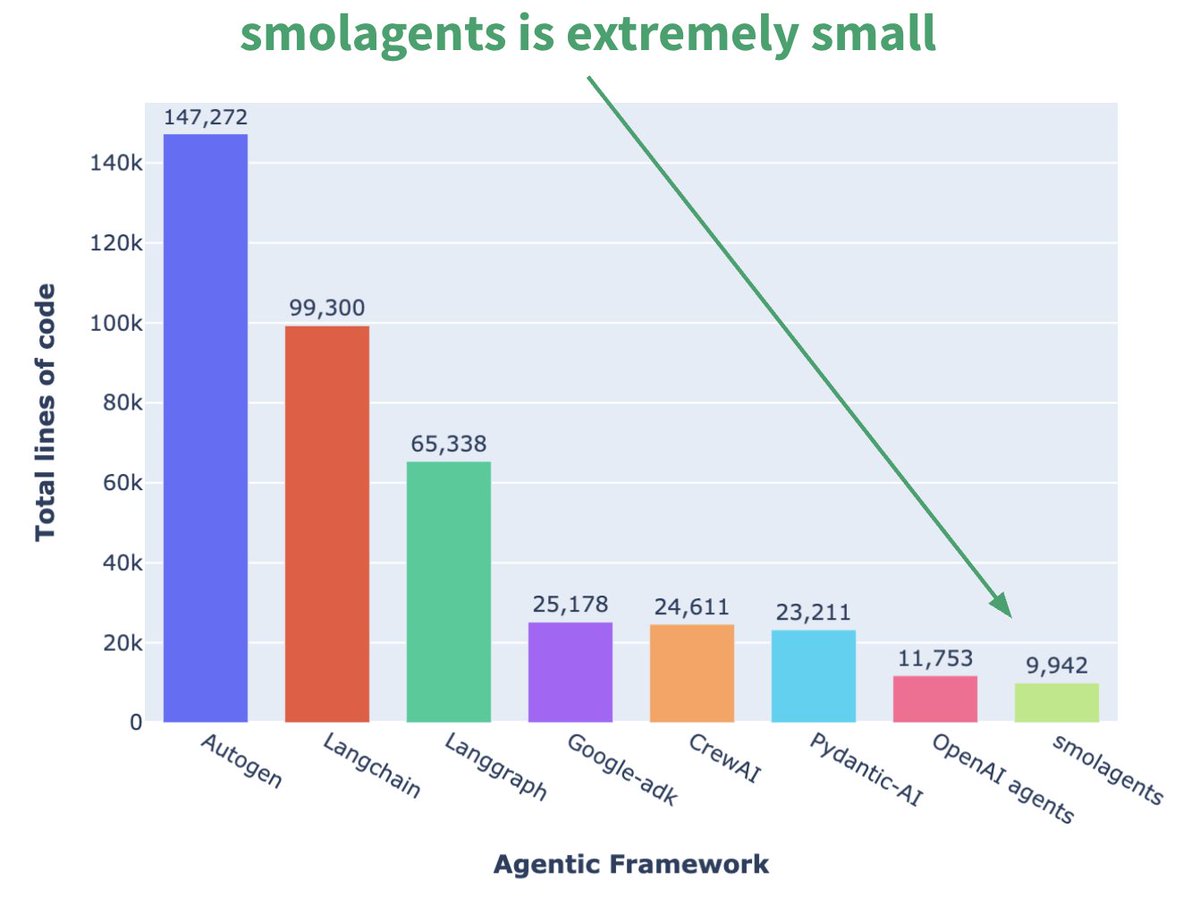
Hugging Face, mikro Agent çerçevesi smolagents’ı tanıttı: Hugging Face, temel özelliği minimalizm olan smolagents adlı bir Agent çerçevesi yayınladı. Bu çerçeve, aşırı soyutlama ve karmaşıklıktan kaçınarak en temel yapı taşlarını sağlamayı amaçlıyor, böylece kullanıcılar kendi Agent iş akışlarını esnek bir şekilde üzerine inşa edebiliyorlar. Resmi olarak, kullanıcıların başlamasına yardımcı olmak için ilgili DeepLearning.AI kısa kursu da yayınlandı. (Kaynak: huggingface, AymericRoucher, ClementDelangue)
Runway, video üretim tutarlılığını artırmak için Gen-4 References özelliğini yayınladı: Runway, tüm ücretli kullanıcılara Gen-4 References özelliğini sundu. Bu özellik, kullanıcıların fotoğraf, üretilmiş görüntü, 3D model veya selfie’leri referans olarak kullanarak tutarlı karakterler, mekanlar vb. içeren video içerikleri üretmelerine olanak tanıyor. Bu, yapay zeka video üretiminde uzun süredir devam eden tutarlılık sorununu çözüyor ve belirli kişileri veya nesneleri hayali herhangi bir sahneye yerleştirmeyi mümkün kılarak yapay zeka video oluşturmanın kontrol edilebilirliğini ve pratikliğini artırıyor. (Kaynak: c_valenzuelab, eerac, c_valenzuelab, c_valenzuelab, c_valenzuelab, TomLikesRobots, c_valenzuelab)
Hugging Face Spaces, ZeroGPU yeteneklerini geliştirmek için Nvidia H200’e yükseltildi: Hugging Face, ZeroGPU v2’sinin Nvidia H200 GPU’larına geçtiğini duyurdu. Bu, Hugging Face Spaces’in (özellikle Pro planı) artık 70GB VRAM ve 2.5 kat artırılmış kayan nokta işlem kapasitesi (flops) ile donatıldığı anlamına geliyor. Bu adım, yeni yapay zeka uygulama senaryolarının kilidini açmayı ve kullanıcılara daha büyük, daha karmaşık modelleri çalıştırmayı destekleyen daha güçlü, dağıtılmış, maliyet etkin CUDA hesaplama seçenekleri sunmayı amaçlıyor. (Kaynak: huggingface, ClementDelangue)

SkyPilot v0.9, yeni gösterge paneli ve ekip dağıtım özellikleriyle yayınlandı: SkyPilot, kullanıcıların ve ekiplerin tüm küme ve iş durumlarını, günlükleri, kuyrukları görüntülemesine ve doğrudan URL paylaşmasına olanak tanıyan Web gösterge paneli özelliğini tanıtan v0.9 sürümünü yayınladı. Yeni sürüm ayrıca ekip dağıtımlarını (istemci-sunucu mimarisi), bulut depolama kovaları aracılığıyla 10 kat daha hızlı model kontrol noktası kaydetmeyi destekliyor ve Nebius AI ile GB200 desteğini ekliyor. Bu güncellemeler, SkyPilot’un bulutta yapay zeka iş yüklerini çalıştırma yönetim verimliliğini ve işbirliği yeteneklerini artırmayı amaçlıyor. (Kaynak: skypilot_org)

Tesslate, 7B UI üretim modeli UIGEN-T2’yi yayınladı: Tesslate, grafikler ve etkileşimli öğeler içeren HTML/CSS/JS + Tailwind web sitesi arayüzleri oluşturmak için özel olarak tasarlanmış 7B parametreli bir model olan UIGEN-T2’yi yayınladı. Model, belirli verilerle eğitilmiş olup alışveriş sepetleri, grafikler, açılır menüler, duyarlı düzenler ve zamanlayıcılar gibi işlevsel UI öğeleri üretebiliyor ve glassmorphism ve karanlık mod gibi stilleri destekliyor. Modelin GGUF sürümü ve LoRA ağırlıkları Hugging Face’te yayınlandı ve çevrimiçi bir Playground ve Demo sunuldu. (Kaynak: Reddit r/LocalLLaMA)
AI EngineHost’un düşük fiyatlı ömür boyu AI barındırma hizmeti şüphe uyandırdı: AI EngineHost adlı bir hizmet, ömür boyu web barındırma sunduğunu ve NVIDIA GPU sunucularında Llama 3, Grok-1 gibi açık kaynak LLM’leri tek tıklamayla dağıtabildiğini iddia ediyor, hem de yalnızca 16.95 dolarlık tek seferlik bir ödemeyle. Hizmet, sınırsız NVMe depolama, bant genişliği, alan adı vaat ediyor, çeşitli dilleri ve veritabanlarını destekliyor ve ticari lisans içeriyor. Ancak, son derece düşük fiyatlandırması ve “ömür boyu” vaadi, toplulukta meşruiyeti ve sürdürülebilirliği konusunda yaygın şüpheler uyandırdı ve bir aldatmaca veya gizli tuzak olup olmadığı konusunda endişelere yol açtı. (Kaynak: Reddit r/deeplearning)
BrowserQwen: Qwen-Agent tabanlı tarayıcı asistanı: Qwen ekibi, Qwen-Agent çerçevesi üzerine inşa edilmiş bir tarayıcı asistanı uygulaması olan BrowserQwen’i tanıttı. Qwen modelinin araç kullanma, planlama ve hafıza yeteneklerinden yararlanarak, kullanıcıların tarayıcıyla daha akıllı bir şekilde etkileşim kurmasına yardımcı olmayı amaçlıyor; bu, web sayfası içeriğini anlama, bilgi çıkarma, otomatik işlemler gibi işlevleri içerebilir. (Kaynak: QwenLM/Qwen-Agent – GitHub Trending (all/daily))
AutoMQ: S3 tabanlı Stateless Kafka alternatifi: AutoMQ, S3 veya uyumlu nesne depolama üzerinde oluşturulmuş durumsuz (stateless) bir Kafka alternatifi sunmayı amaçlayan açık kaynaklı bir projedir. Temel avantajı, geleneksel Kafka’nın bulutta ölçeklenmesinin zorluğu ve yüksek maliyeti (özellikle kullanılabilirlik alanları arası trafik) sorununu çözmektir. Depolamayı hesaplamadan ayırarak AutoMQ, 10 kat maliyet etkinliği, saniyeler içinde otomatik ölçeklenme, tek haneli milisaniye gecikme süresi ve çoklu kullanılabilirlik alanı yüksek kullanılabilirliği sağladığını iddia ediyor. (Kaynak: AutoMQ/automq – GitHub Trending (all/daily))
Daytona: AI tarafından üretilen kodu çalıştırmak için güvenli, esnek altyapı: Daytona, özellikle yapay zeka tarafından üretilen kodu çalıştırmak için tasarlanmış güvenli, yalıtılmış ve hızlı yanıt veren bir altyapı platformu sağlamayı amaçlamaktadır. SDK (Python/TypeScript) aracılığıyla programatik kontrolü destekler, sanal alan ortamlarını hızla (90 milisaniyenin altında) oluşturabilir, dosya işlemleri, Git komutları, LSP etkileşimleri ve kod çalıştırmayı gerçekleştirebilir ve kalıcılığı ve OCI/Docker imajlarını destekler. Amacı, güvenilmeyen veya deneysel yapay zeka kodunu çalıştırırken güvenlik ve kaynak yönetimi sorunlarını çözmektir. (Kaynak: daytonaio/daytona – GitHub Trending (all/daily))
MLX Swift Examples: MLX Swift kullanımını gösteren örnek kütüphanesi: Apple’ın MLX ekibi, MLX Swift çerçevesini kullanan birden fazla örnek içeren bir proje sürdürüyor. Bu örnekler, büyük dil modelleri (LLM), görsel dil modelleri (VLM), gömme modelleri, Stable Diffusion görüntü üretimi ve klasik MNIST el yazısı rakam tanıma eğitimi gibi uygulamaları kapsıyor. Kod tabanı, geliştiricilerin özellikle Apple ekosistemi içinde makine öğrenimi görevleri için MLX Swift’i öğrenmelerine ve uygulamalarına yardımcı olmayı amaçlıyor. (Kaynak: ml-explore/mlx-swift-examples – GitHub Trending (all/daily))
Blender 4.4 yayınlandı, ışın izleme ve kullanım kolaylığı geliştirildi: Açık kaynaklı 3D yazılım Blender, 4.4 sürümünü yayınladı. Yeni sürüm, ışın izleme (ray tracing) konusunda önemli iyileştirmeler içeriyor, gürültü azaltma etkisini artırıyor, özellikle yüzey altı saçılımı (Subsurface Scattering) ve alan derinliği bulanıklığı (Depth of Field) işlerken daha iyi sonuçlar veriyor ve önizleme kalitesini ve animasyon tutarlılığını iyileştirmek için daha iyi mavi gürültü örneklemesi sunuyor. Ayrıca, görüntü birleştirici, kumaş heykel fırçası (Grab Cloth Brush), kurşun kalem aracı (Grease Pencil) ve kullanıcı arayüzü (örneğin, mesh dizin görünürlüğü) gibi alanlarda iyileştirmeler yapıldı. Video düzenleme işlevleri de optimize edildi. (Kaynak: YouTube – Two Minute Papers
)
📚 Öğrenme
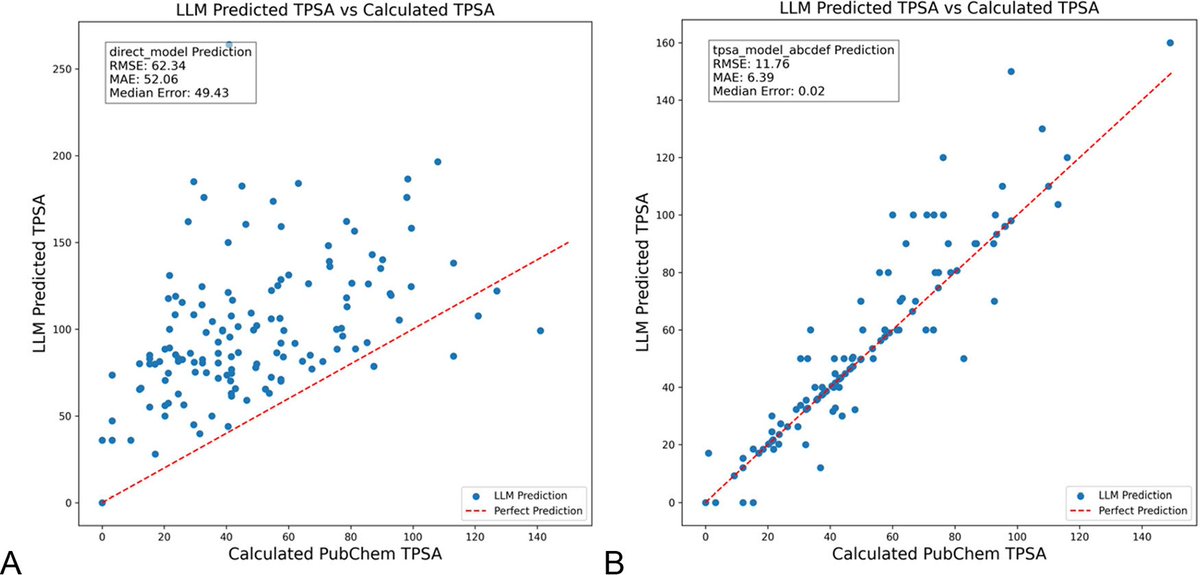
DSPy ile LLM komutlarını optimize etmek kimya alanındaki halüsinasyonları önemli ölçüde azaltıyor: Chemical Information and Modeling Dergisi’nde yayınlanan yeni bir makale, DSPy çerçevesini kullanarak LLM komutlarını (prompt) oluşturmanın ve optimize etmenin kimya alanındaki halüsinasyon sorununu önemli ölçüde azaltabildiğini gösteriyor. Araştırma, DSPy programını optimize ederek moleküler topolojik polar yüzey alanını (TPSA) tahmin etmedeki kök ortalama kare hatasını (RMS error) %81 oranında azalttı. Bu, programatik komut optimizasyonu yoluyla LLM’lerin kimya gibi uzmanlık gerektiren bilimsel alanlardaki doğruluğunun ve güvenilirliğinin etkili bir şekilde artırılabileceğini gösteriyor. (Kaynak: lateinteraction, lateinteraction)
Makale, sağduyu akıl yürütmesini grafiklerle ölçmeyi ve mekaniksel içgörüler sunmayı öneriyor: Yeni bir makale, 37 günlük aktivitenin örtük bilgisini yönlendirilmiş grafikler olarak temsil ederek devasa miktarda (her aktivite için yaklaşık 10^17 çeşit) sağduyu sorgusu üretme yöntemi öneriyor. Bu yöntem, mevcut benchmark’ların sınırlı ve kapsamlı olmama dezavantajlarını aşarak LLM’lerin sağduyu akıl yürütme yeteneğini daha sıkı bir şekilde değerlendirmeyi amaçlıyor. Araştırma, sağduyuyu ölçmek için grafik yapısını kullanıyor ve eşlenik komutlar (conjugate prompts) aracılığıyla aktivasyon yamalama (activation patching) tekniğini geliştirerek modelde akıl yürütmeden sorumlu kritik bileşenleri konumlandırıyor. (Kaynak: menhguin)

Tek bir örnekle LLM matematiksel akıl yürütmesini önemli ölçüde artıran pekiştirmeli öğrenme yöntemi (RLVR): Yeni bir makale, yalnızca bir eğitim örneği kullanan pekiştirmeli öğrenme doğrulama geri bildirimi (RLVR) yönteminin, büyük dil modellerinin matematik görevlerindeki performansını önemli ölçüde artırabildiğini öne sürüyor. Deneyler, MATH500 benchmark’ında tek örnekli RLVR’nin Qwen2.5-Math-1.5B’nin doğruluğunu %36.0’dan %73.6’ya, Qwen2.5-Math-7B’nin doğruluğunu ise %51.0’dan %79.2’ye çıkardığını gösteriyor. Bu bulgu, RLVR mekanizmalarının yeniden düşünülmesine ilham verebilir ve düşük kaynaklı durumlarda model yeteneklerinin geliştirilmesi için yeni yollar sunabilir. (Kaynak: StringChaos, _akhaliq, _akhaliq, natolambert)

DeepLearning.AI, “LLMs as Operating Systems: Agent Memory” kursunu güncelledi: DeepLearning.AI ve Letta işbirliğiyle sunulan ücretsiz kısa kurs “LLMs as Operating Systems: Agent Memory” güncellendi. Kurs, uzun süreli belleği (bağlam penceresi sınırlarının ötesinde) yönetebilen LLM Agent’ları oluşturmak için MemGPT yöntemini kullanmayı anlatıyor. Yeni içerikler arasında önceden dağıtılmış Letta Agent hizmeti (bulutta Agent pratiği için) ve akışlı çıktı özelliği (Agent’ın adım adım akıl yürütme sürecini gözlemlemek için) bulunuyor ve öğrenenlerin daha uyarlanabilir ve işbirlikçi yapay zeka sistemleri oluşturmalarına yardımcı olmayı amaçlıyor. (Kaynak: DeepLearningAI)

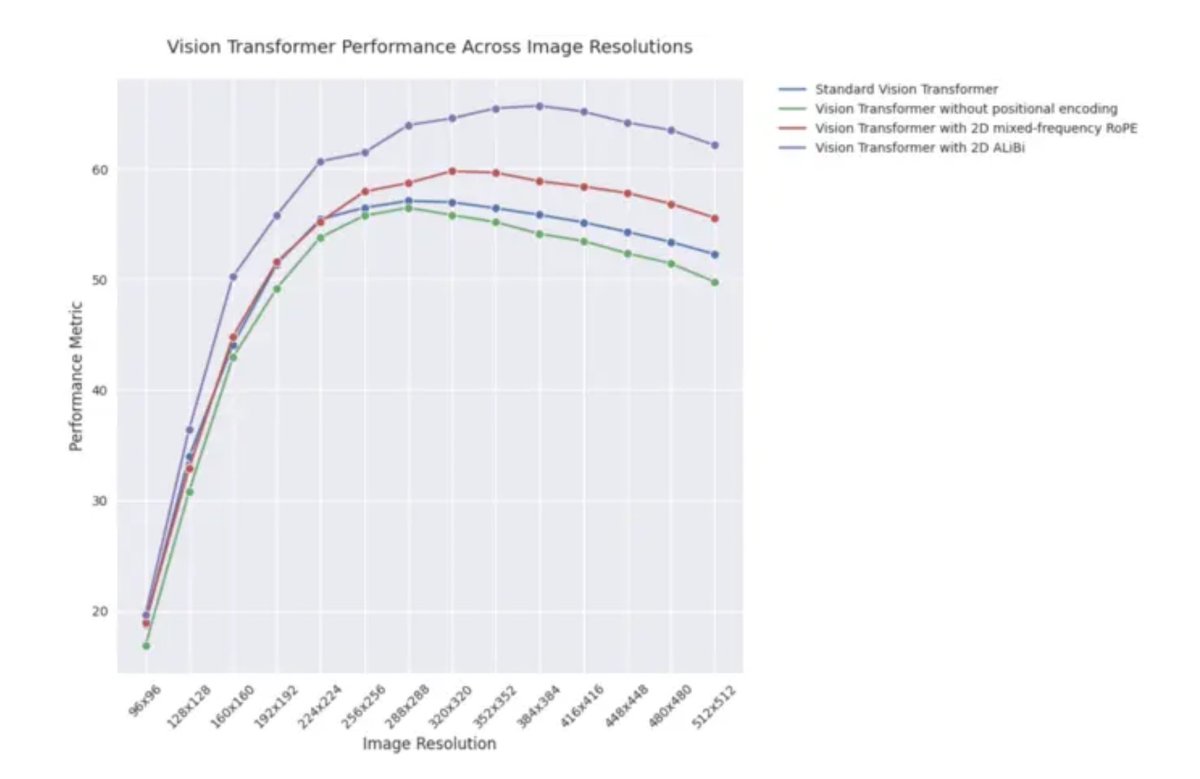
ICLR 2025 blog yazısı: Görsel Transformer’larda 2D ALiBi’nin dış değerleme performansı: Bir ICLR 2025 blog yazısı, iki boyutlu dikkat ile doğrusal yanlılık (2D ALiBi) kullanan görsel Transformer’ların (ViT), Imagenet100 veri setinde daha büyük görüntü boyutlarına dış değerleme (extrapolation) görevinde en iyi performansı gösterdiğini belirtiyor. ALiBi, NLP alanındaki başarılı uygulamasının görsel alandaki keşfine ilham veren göreceli bir konum kodlama yöntemidir; bu sonuç, 2D ALiBi’nin ViT’lerin eğitim sırasında görülmeyen görüntü çözünürlüklerine daha iyi genelleme yapmasına yardımcı olduğunu gösteriyor. (Kaynak: OfirPress)
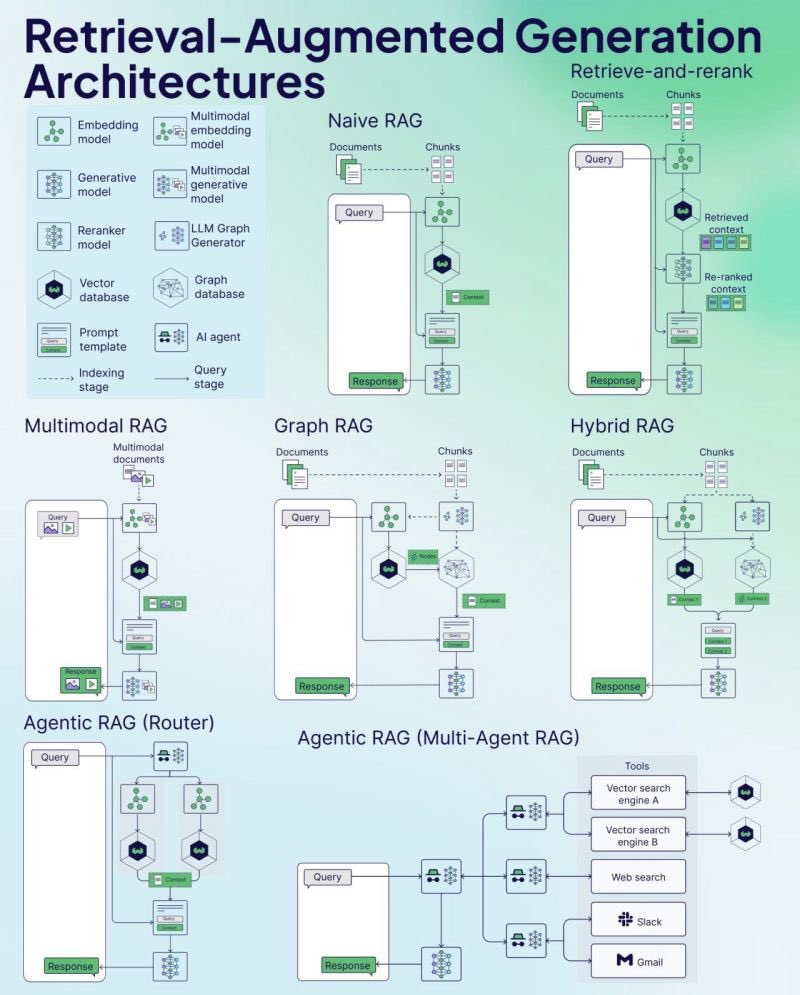
Weaviate, RAG kopya kağıdını (Cheat Sheet) yayınladı: Vektör veritabanı şirketi Weaviate, Erişimle Zenginleştirilmiş Üretim (Retrieval-Augmented Generation – RAG) üzerine bir kopya kağıdı (Cheat Sheet) yayınladı. Bu materyal, geliştiricilere hızlı bir başvuru kılavuzu sunmayı amaçlıyor ve muhtemelen RAG’ın temel kavramlarını, mimarisini, yaygın tekniklerini, en iyi uygulamalarını veya sık sorulan soruları kapsayarak geliştiricilerin RAG sistemlerini daha iyi anlamalarına ve uygulamalarına yardımcı olmayı hedefliyor. (Kaynak: bobvanluijt)
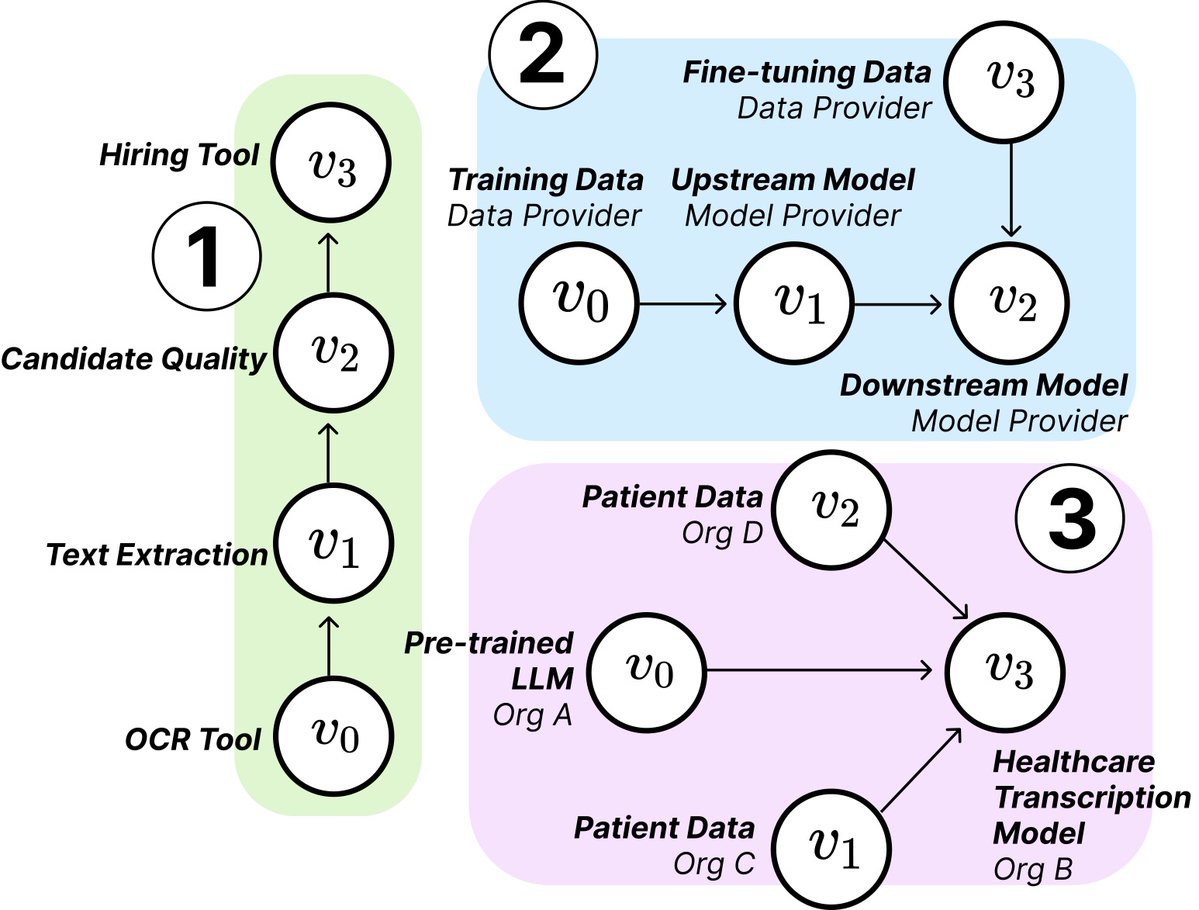
MIT araştırması, yapay zeka tedarik zincirinin yapısını ve risklerini ortaya koyuyor: MIT gibi kurumlardan araştırmacılar, gelişmekte olan yapay zeka tedarik zincirlerini (AI Supply Chains) inceleyen yeni bir makale yayınladı. Yapay zeka sistemleri oluşturma süreci giderek daha dağınık hale geldikçe (temel model sağlayıcıları, ince ayar hizmetleri, veri tedarikçileri, dağıtım platformları gibi birden fazla varlığı içeriyor), makale bu ağ yapısının getirdiği etkileri inceliyor; bunlar arasında potansiyel riskler (örneğin, yukarı akış arızalarının yayılması), bilgi asimetrisi, kontrol hakkı ve optimizasyon hedefi çatışmaları gibi sorunlar bulunuyor. Araştırma, teorik ve ampirik analizlerle iki vakayı inceleyerek yapay zeka tedarik zincirlerini anlamanın ve yönetmenin önemini vurguluyor. (Kaynak: jachiam0, aleks_madry)
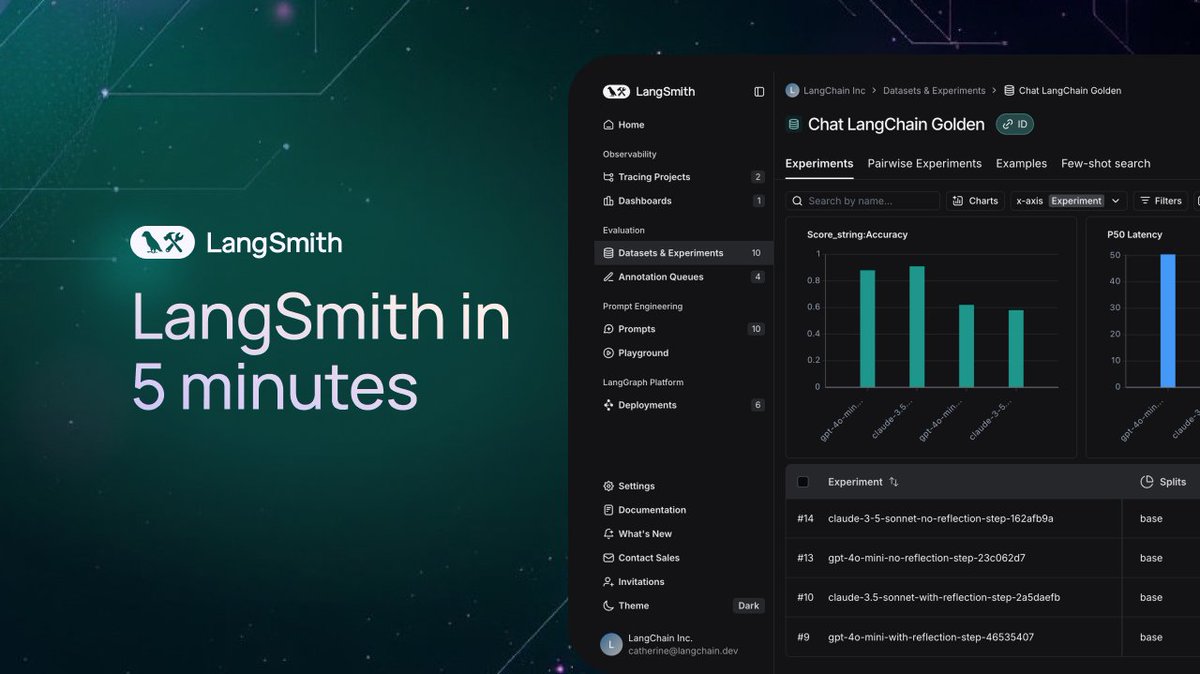
LangChain, LangSmith’i tanıtan beş dakikalık bir video yayınladı: LangChain, ticari platformu LangSmith’in işlevlerini açıklayan 5 dakikalık kısa bir video yayınladı. Video, LangSmith’in LLM uygulamaları ve Agent geliştirme yaşam döngüsü boyunca gözlemlenebilirlik (observability), değerlendirme (evaluation) ve komut mühendisliği (prompt engineering) konularında nasıl yardımcı olduğunu tanıtıyor ve geliştiricilerin uygulama performansını artırmalarına yardımcı olmayı amaçlıyor. (Kaynak: LangChainAI)
Together AI, OSS modellerini çalıştırma ve ince ayar yapma eğitim videosu yayınladı: Together AI, kullanıcıları Together AI platformunda açık kaynak büyük modelleri çalıştırma ve ince ayar yapma konusunda yönlendiren yeni bir eğitim videosu yayınladı. Video muhtemelen model seçme, ortam ayarlama, veri yükleme, eğitim görevini başlatma ve çıkarım yapma gibi adımları kapsıyor ve kullanıcıların platformlarını açık kaynak model özelleştirme ve dağıtımı için kullanma engelini düşürmeyi amaçlıyor. (Kaynak: togethercompute)
Makale, LLM’lerin sosyal bilişsel yeteneklerini değerlendirmek için “duyarlı Agent’lar” kullanmayı öneriyor: Yeni bir makale, SAGE (Sentient Agent as a Judge) çerçevesini tanıtıyor; bu, insan duygusal dinamiklerini ve içsel akıl yürütmeyi simüle eden duyarlı Agent’ları (Sentient Agent) kullanarak LLM’lerin diyaloglardaki sosyal bilişsel yeteneklerini değerlendiren yeni bir yöntemdir. Çerçeve, LLM’lerin duyguları yorumlama, gizli niyetleri çıkarma ve empatik yanıt verme yeteneklerini test etmeyi amaçlıyor. Araştırma, 100 destekleyici diyalog senaryosunda, duyarlı Agent’ların duygu puanlarının insan merkezli ölçütlerle (BLRI, empati göstergeleri gibi) yüksek oranda ilişkili olduğunu ve sosyal olarak yetenekli LLM’lerin mutlaka uzun yanıtlara ihtiyaç duymadığını buldu. (Kaynak: menhguin)

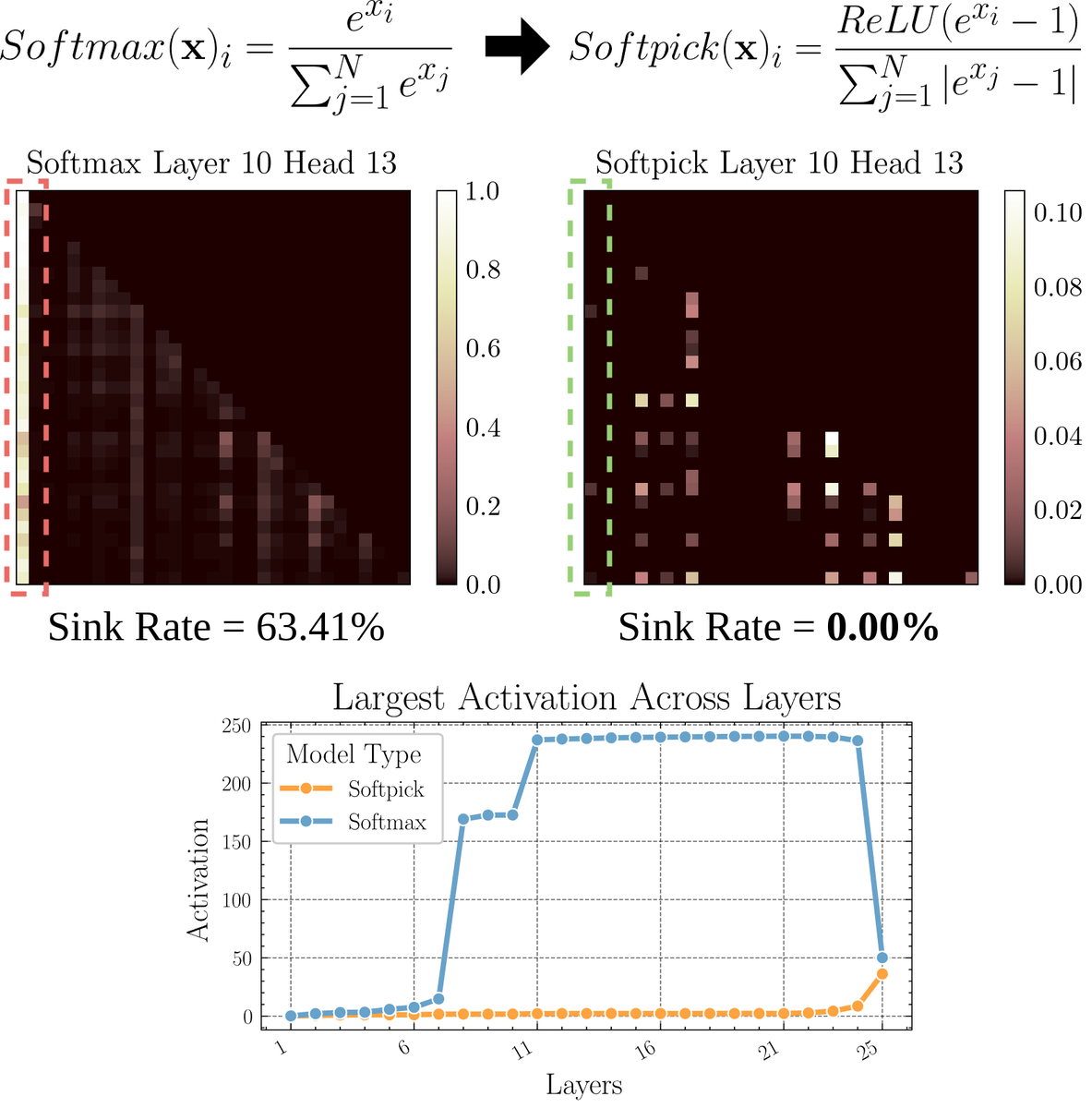
Makale, Softmax’a alternatif bir dikkat mekanizması olan Softpick’i tartışıyor: Bir ön baskı makalesi, dikkat mekanizmasındaki “dikkat çökmesi” (attention sink) ve büyük ölçekli aktivasyon değeri sorunlarını çözmek için Softmax’ı düzelterek bir alternatif olan Softpick’i öneriyor. Yöntem, Softmax’ın payında ReLU(x – 1) ve payda teriminde abs(x – 1) kullanılmasını öneriyor. Araştırmacılar, bu basit ayarlamanın performansı korurken mevcut dikkat mekanizmalarının bazı içsel sorunlarını, özellikle uzun dizileri işlerken veya daha kararlı dikkat dağılımları gerektiren senaryolarda iyileştirebileceğine inanıyor. (Kaynak: sedielem)
💼 İş Dünyası
Yapay zeka girişimi RogoAI, 50 milyon dolarlık B Serisi finansman turunu tamamladı: Finans hizmetleri sektörü için yapay zeka tabanlı yerel araştırma platformu oluşturan RogoAI, Thrive Capital liderliğinde J.P. Morgan Asset Management, Tiger Global gibi yatırımcıların katılımıyla 50 milyon dolarlık B Serisi finansman turunu tamamladığını duyurdu. Bu finansman turu, RogoAI’nin finansal analiz ve araştırma otomasyonu alanındaki ürün geliştirme ve pazar genişlemesini hızlandırmak için kullanılacak. (Kaynak: hwchase17, hwchase17)
Kurumsal yapay zeka arama girişimi Glean, 7 milyar dolarlık değerlemeyle yeni bir finansman turunu tamamladı: The Information’a göre, yapay zeka kurumsal arama girişimi Glean, Wellington Management liderliğinde yaklaşık 7 milyar dolarlık bir değerlemeyle yeni bir finansman turunu tamamlamak üzere. Şirket sadece dört ay önce 4.6 milyar dolarlık bir değerlemeyle finansman sağlamıştı; bu değerlemedeki büyük sıçrama, pazarın kurumsal düzeydeki yapay zeka uygulamalarına ve bilgi yönetimi çözümlerine olan yüksek beklentisini yansıtıyor. (Kaynak: steph_palazzolo)
Groq, Llama API’sini hızlandırmak için Meta ile işbirliği yapıyor: Yapay zeka çıkarım çipi şirketi Groq, resmi Llama API’sini hızlandırmak için Meta ile işbirliği yaptığını duyurdu. Geliştiriciler, en yeni Llama modellerini (Llama 4’ten başlayarak) saniyede 625 token’a varan işlem hacmiyle çalıştırabilecek ve OpenAI’den geçişin sadece 3 satır kod gerektirdiği iddia ediliyor. Bu işbirliği, geliştiricilere büyük dil modellerini çalıştırmak için yüksek hızlı, düşük gecikmeli çözümler sunmayı amaçlıyor. (Kaynak: JonathanRoss321)

🌟 Topluluk
Topluluk, Llama4 ile DeepSeek R1 karşılaştırmasını ve model değerlendirme benchmark sorununu tartışıyor: Meta CEO’su Zuckerberg bir röportajda, Llama4’ün arenada DeepSeek R1 kadar iyi performans göstermemesi sorununa yanıt verdi. Açık kaynak benchmark testlerinin kusurlu olduğunu, belirli kullanım durumlarına aşırı derecede eğilimli olduğunu ve modellerin gerçek ürünlerdeki performansını doğru bir şekilde yansıtmadığını savundu. Ayrıca Meta’nın çıkarım modelinin henüz yayınlanmadığını ve R1 ile doğrudan karşılaştırılamayacağını belirtti. Bu açıklamalar, Cohere’in LMArena’ya yönelik şüphelerini dile getiren makalesiyle birleşince, toplulukta LLM’lerin nasıl adil bir şekilde değerlendirileceği, kamuya açık liderlik tablolarının sınırlamaları ve model seçim stratejileri hakkında geniş çaplı tartışmalara yol açtı. Birçok kişi, genel liderlik tablolarına aşırı güvenilmemesi, bunun yerine belirli kullanım durumları, özel veri değerlendirmeleri ve topluluk sinyallerinin birleştirilerek model seçilmesi gerektiği konusunda hemfikir. (Kaynak: BlancheMinerva, huggingface, ClementDelangue, sarahcat21, xanderatallah, arohan, ClementDelangue, 量子位)
Yapay zekanın insan iş gücünün yerini alması tartışmaları kızışıyor: Reddit topluluğunda yapay zekanın istihdam üzerindeki etkisini tartışan birden fazla gönderi ortaya çıktı. Bir İspanyolca çevirmen, yapay zeka çeviri kalitesinin artması nedeniyle işlerinin önemli ölçüde azaldığını belirtti; başka bir ses mühendisi de yapay zeka mastering efektlerinin iyileşmesi nedeniyle meslek değiştirdi. Aynı zamanda, yapay zekanın tıbbi teşhis, vergi danışmanlığı gibi alanlardaki uygulamalarının profesyonellere olan ihtiyacı azaltabileceğini tartışan gönderiler de var. Bu vakalar, yapay zeka otomasyonunun getirdiği işsizlik krizinin beklenenden daha erken gelip gelmediği ve uygulayıcıların nasıl uyum sağlaması gerektiği (örneğin, yapay zekayı kullanarak dönüşüm, yapay zekanın yerini alamayacağı değeri bulma) hakkında tartışmalara yol açtı. (Kaynak: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Yapay zeka tarafından üretilen görüntülerin “yinelemeli kayma” fenomeni dikkat çekiyor: Reddit kullanıcısı, ChatGPT’nin sürekli olarak bir önceki üretilen görüntüye dayanarak “tam kopyasını” oluşturmasını istedi. Sonuçlar, görüntü içeriğinin ve stilinin yineleme sayısı arttıkça orijinal girdiden giderek uzaklaştığını ve sonunda soyut veya belirli desenlere (Samoa dövmeleri/kadın özellikleri gibi) yöneldiğini gösterdi. Dwayne Johnson örneği de benzer şekilde gerçekçilikten soyuta doğru bir evrim sergiledi. Bu fenomen, mevcut görüntü üretim modellerinin uzun vadeli tutarlılığı koruma konusundaki zorluklarını ve içsel temsillerinin olası önyargılarını veya yakınsama eğilimlerini ortaya koyuyor. (Kaynak: Reddit r/ChatGPT, Reddit r/ChatGPT)

Topluluk, yapay zekanın risk sermayesi (VC) işini değiştirip değiştirmeyeceğini tartışıyor: Marc Andreessen, yapay zeka diğer her şeyi yapabildiğinde, risk sermayesinin insanlar tarafından yapılacak son işlerden biri olabileceğini düşünüyor, çünkü bu daha çok bilimden ziyade sanata benziyor ve zevk, psikoloji ve kaos toleransına dayanıyor. Bu görüş tartışmalara yol açtı; bazıları bunun “komik bir iddia” olduğunu düşünüyor ve erken aşama yatırımın neden benzersiz olduğunu sorguluyor; diğerleri ise kendi alanlarından (oyun geliştirme gibi) yola çıkarak, bu düşüncenin “kendini avutma” (cope) olabileceğini düşünüyor, çünkü her alandaki insanlar kendi işlerinin benzersiz zevk gerektirdiği için yapay zeka tarafından değiştirilemeyeceğini düşünme eğilimindedir. (Kaynak: colin_fraser, gfodor, cto_junior, pmddomingos)
Zürih Üniversitesi’nin Reddit’te izinsiz yapay zeka ikna deneyi yapması tartışma yarattı: Reddit r/changemyview moderatörleri ve Reddit Lies’a göre, Zürih Üniversitesi araştırmacıları, topluluk kullanıcılarına açıkça bilgi vermeden, bu alt dizinde tartışmalara katılan birden fazla yapay zeka hesabı dağıtarak yapay zeka tarafından üretilen argümanların ikna gücünü test etti. Araştırma, yapay zeka hesaplarının ikna başarı oranının (kullanıcının görüşünün değiştiğini belirten “∆” işareti alma) insan taban çizgisini önemli ölçüde aştığını ve kullanıcıların yapay zeka kimliğini fark edemediğini buldu. Deneyin etik kurul onayı aldığını iddia etmesine rağmen, gizli yürütülme şekli ve potansiyel “manipülasyon” niteliği, yaygın etik tartışmalara ve yapay zekanın kötüye kullanımı endişelerine yol açtı. (Kaynak: 量子位)
💡 Diğer
Yapay zeka çağında hala programlama öğrenmek gerekip gerekmediği düşündürüyor: Toplulukta yapay zeka çağında programlama öğrenmenin değeri hakkında tartışmalar ortaya çıktı. Görüşler, yapay zekanın kod üretme yeteneği giderek artsa ve yazılım mühendislerinin iş doğası hızla değişse de, programlama öğrenmenin hala önemli olduğunu savunuyor. Programlama öğrenmek, yapay zeka (özellikle LLM’ler) ile etkili bir şekilde işbirliği yapmayı anlamanın temelidir ve bu insan-makine işbirliği yeteneği, alanlar arası temel bir yetkinlik haline gelecektir. Programlama, insanların yapay zeka ile “dans etmeye” başladığı noktadır ve gelecekte tüm sektörlerin bu işbirliği modelini benimsemesi gerekecektir. (Kaynak: alexalbert__, _philschmid)
Geliştiriciler, yapay zeka destekli programlama deneyimini ve zorluklarını tartışıyor: Topluluktaki geliştiriciler, yapay zeka programlama araçlarını (Cursor, ChatGPT Desktop gibi) kullanma deneyimlerini paylaşıyor. Bazıları geçmişteki derleme bekleme “soğuma dönemini” özlüyor ve yapay zeka destekli programlamanın benzer bir düzenleme/derleme/hata ayıklama döngüsünü yeniden getirdiğini düşünüyor. Bazıları ise yapay zeka araçlarının bağlamı anlama (çoklu dosya düzenleme gibi), talimatları takip etme (belirli sözdizimi/malzemeleri kullanmaktan kaçınma gibi) konusunda hala eksiklikleri olduğunu, bazen istenen sonuca ulaşmak için çok özel talimatlar gerektiğini ve yapay zeka tarafından üretilen kodun hala manuel inceleme ve hata ayıklama gerektirdiğini belirtiyor. (Kaynak: hrishioa, eerac, Reddit r/ChatGPT)

Yapay zeka odaklı mutluluk artışı: Potansiyel bir yapay zeka uygulama yönü: Reddit’teki bir gönderi, yapay zekanın nihai uygulamalarından birinin insan mutluluğunu artırmak olabileceğini öne sürüyor. Yazar, yüz geri bildirim hipotezine (gülümsemek mutluluğu artırır) ve odaklanma prensibine dayanarak, yapay zekanın (Gemini 2.5 Pro gibi) insanların basit egzersizlerle (gülümsemek ve getirdiği hoş duyguya odaklanmak gibi) mutluluk seviyelerini artırmalarına yardımcı olacak yüksek kaliteli rehberlik içeriği üretebileceğini savunuyor. Yazar, yapay zeka tarafından üretilen raporları ve ses kayıtlarını paylaşıyor ve gelecekte bu prensibe dayalı başarılı uygulamaların veya “mutluluk koçu” robotlarının ortaya çıkabileceğini öngörüyor. (Kaynak: Reddit r/deeplearning)
