
Anahtar Kelimeler:Wenxin Büyük Modeli, AI Modeli, Çok Modlu, Ajan, Wenxin 4.5 Turbo, X1 Turbo, DeepSeek V3, Çok Modlu Anlama, Baidu Xinxiang, MCP Protokolü, AI Ücretli Modeli, LoRA Model Çıkarımı
🔥 Odak Noktası
Baidu, DeepSeek’e Rakip Olarak Wenxin 4.5 Turbo ve X1 Turbo’yu Piyasaya Sürdü: 2025 Baidu Create konferansında Li Yanhong, Wenxin büyük modeli 4.5 Turbo ve X1 Turbo’yu duyurdu. Multimodal anlama ve üretme yeteneklerini vurgulayan Li, bu modellerin maliyetlerinin sırasıyla DeepSeek V3’ün %40’ı ve DeepSeek R1’in %25’i olduğunu belirtti. Li Yanhong, multimodal yeteneklerin geleceğin trendi olduğunu ve salt metin modelleri pazarının daralacağını düşünüyor. Bu duyuru, DeepSeek’in multimodal yetenekler ve maliyet konusundaki eksikliklerini gidermeyi amaçlıyor ve Baidu’nun model seviyesinde sektör liderleriyle rekabet etme kararlılığını gösteriyor. (Kaynak: 36氪)

Yapay Zeka Model Performans Karşılaştırması: o3 ve Gemini 2.5 Pro’nun Kendine Özgü Güçlü Yönleri Var: OpenAI’nin o3’ü ve Google’ın Gemini 2.5 Pro’su, birçok yeni benchmark testinde kıyasıya bir rekabet sergiledi. o3, uzun metinli roman bulmaca analizinde (FictionLiveBench) daha iyi performans gösterirken, Gemini 2.5 Pro fizik ve uzamsal akıl yürütme (PHYBench), matematik yarışması (USMO) ve coğrafi konum belirleme (GeoGuessing) alanlarında önde ve maliyeti daha düşük (o3’ün yaklaşık 1/4’ü). Görsel bulmacalar (Visual Puzzles) ve temel görsel soru cevaplama (NaturalBench) testlerinde ise her iki modelin de üstün olduğu alanlar var. Bu durum, mevcut en iyi modellerin performansının büyük ölçüde belirli görevlere ve değerlendirme kriterlerine bağlı olduğunu ve mutlak bir liderin olmadığını gösteriyor. (Kaynak: o3 breaks (some) records, but AI becomes pay-to-win
)
Yapay Zeka “Kazanmak İçin Öde” Modeline Yöneliyor: Sektör gözlemcileri, yapay zeka modellerinin yetenekleri arttıkça ve uygulamaları genişledikçe, en üst düzey yapay zeka yeteneklerine erişimin giderek daha fazla ücretli hale gelebileceğini belirtiyor. Google, OpenAI, Anthropic gibi şirketler, daha yüksek fiyatlı abonelik hizmetleri (Premium Plus/Pro gibi, aylık 100-200$ arası) sunuyor veya sunmayı planlıyor. Bu durum, model eğitimi (özellikle RL sonrası eğitim) ve büyük ölçekli inference için gereken yüksek hesaplama maliyetlerini ve şirketlerin model geliştirme, yeni özellikler, düşük gecikme süresi ve kullanıcı artışı arasında hesaplama kaynaklarını dengeleme ihtiyacını yansıtıyor. Gelecekte, ücretsiz veya düşük maliyetli yapay zeka hizmetleri ile ücretli en son teknoloji hizmetler arasındaki yetenek farkı açılabilir. (Kaynak: o3 breaks (some) records, but AI becomes pay-to-win
)
Baidu, Mobil Agent Uygulaması “Xīnxiǎng”ı Başlattı: Baidu, Agent alanındaki konumunu hızlandırarak, Manus gibi ürünlere rakip olan mobil Agent uygulaması “Xīnxiǎng”ı duyurdu. “Xīnxiǎng”, diyalog yoluyla kullanıcı ihtiyaçlarını anlamayı ve Baidu ile üçüncü taraf akıllı temsilcileri görevleri (örneğin, resimli kitap oluşturma, seyahat planlama, hukuki danışmanlık vb.) yürütmek ve teslim etmek üzere yönlendirmeyi amaçlıyor. Ürün, görev yürütme sürecini göstererek geleneksel aramanın anlık teslimatından farklılaşarak kullanıcıların “görevleri devretme zihniyeti” oluşturmasını vurguluyor. Şu anda 200’den fazla görevi destekliyor, gelecekte 100.000’den fazlasına genişletilmesi ve PC sürümünün geliştirilmesi planlanıyor. (Kaynak: 36氪)
🎯 Gelişmeler
Baidu, MCP Agent Protokolünü Tamamen Benimsemiş Durumda: Baidu, akıllı bulut Qianfan büyük model platformu, Baidu Search, Wenxin Kuaima, Baidu E-ticaret, Haritalar, Netdisk, Wenku gibi birçok ürün ve hizmetinin Anthropic tarafından önerilen Model Context Protocol’ü (MCP) desteklediğini veya uyumlu olduğunu duyurdu. MCP, yapay zeka modellerinin harici araçlar ve veritabanlarıyla etkileşim biçimini standartlaştırmayı, farklı yapay zeka yazılımları arasındaki uyumu, geliştirmeyi ve bakımı kolaylaştırmayı amaçlıyor. Baidu’nun desteği, Agent’ların çeşitli araçları ve hizmetleri daha özgürce çağırabilmesini sağlayan daha açık ve birbirine bağlı bir yapay zeka uygulama ekosistemi oluşturmaya yardımcı oluyor. (Kaynak: 36氪)
OpenAI, GPT-4o’yu Güncelleyerek Zeka ve Kişiliği Geliştirdi: OpenAI CEO’su Sam Altman, GPT-4o modelinde yapılan bir güncellemeyi duyurarak modelin zekasının ve kişiselleştirilmiş performansının arttığını iddia etti. Ancak, bu güncelleme belirli değerlendirme verileri, sürüm notları veya ayrıntılı iyileştirme detayları sunmadı ve bu durum toplulukta yapay zeka modeli güncellemelerinin şeffaflığı konusunda tartışmalara ve eleştirilere yol açtı. (Kaynak: sama, natolambert)
Google Veo 2 Video Üretimi Whisk’e Geldi: Google, video üretim modeli Veo 2’nin Whisk uygulamasına entegre edildiğini duyurdu. Bu entegrasyon, Google One AI Premium abonelerinin (60’tan fazla ülkede) 8 saniyeye kadar videolar oluşturmasına olanak tanıyor. Kullanıcılar, farklı video stilleri seçerek yaratıcılıklarını konuşturabilirler, bu da Google AI’ın multimodal içerik üretimi yeteneklerini daha da genişletiyor. (Kaynak: Google)

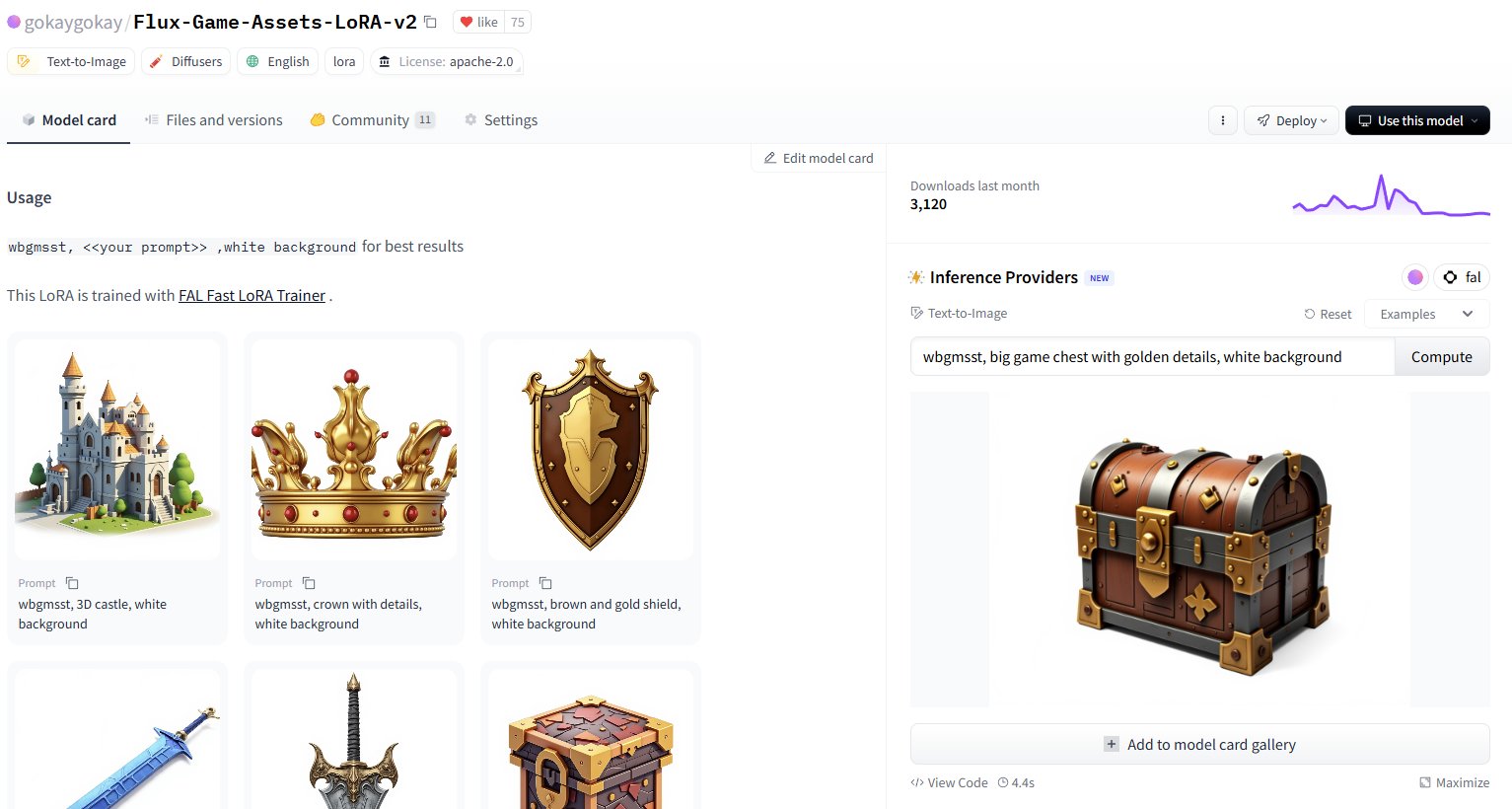
Hugging Face, 30.000’den Fazla LoRA Modeli İçin Inference Hizmeti Ekledi: Hugging Face, Inference Providers (FAL tarafından desteklenmektedir) aracılığıyla 30.000’den fazla Flux ve SDXL LoRA modeli için inference hizmeti sunduğunu duyurdu. Kullanıcılar artık bu LoRA’ları doğrudan Hugging Face Hub üzerinde görüntü oluşturmak için kullanabilirler. Hizmetin hızlı (yaklaşık 5 saniyede üretim) ve düşük maliyetli (1 dolardan az bir maliyetle 40’tan fazla görüntü) olduğu iddia ediliyor, bu da topluluk kullanıcılarının erişebileceği fine-tuning yapılmış model kaynaklarını büyük ölçüde genişletiyor. (Kaynak: Vaibhav (VB) Srivastav, gokaygokay)
Modular AI (Mojo/MAX) Gelişme Güncellemesi: Kuruluşunun üzerinden üç yıl geçen Modular AI, önemli ilerlemeler kaydetti. Mojo dili ve MAX platformu artık x86/ARM CPU’lar ile NVIDIA (A100/H100) ve AMD (MI300X) GPU’ları da içeren daha geniş bir donanım yelpazesini destekliyor. Şirket, yakında yaklaşık 250.000 satırlık GPU çekirdek kodunu açık kaynak yapmayı ve Mojo ile MAX lisanslarını basitleştirmeyi planlıyor. Bu, Modular’ın CUDA’ya alternatif sunma ve donanımlar arası yapay zeka geliştirme platformu vaadini adım adım gerçekleştirdiğini gösteriyor. (Kaynak: Reddit r/LocalLLaMA)
Intel PyTorch Eklentisi Güncellendi, DeepSeek-R1 Desteği Eklendi: Intel, PyTorch eklentisinin (IPEX) 2.7 sürümünü yayınladı. Bu sürüm, DeepSeek-R1 modeline destek ekliyor ve Intel donanımında (CPU ve GPU dahil) PyTorch iş yüklerini çalıştırma performansını artırmayı amaçlayan yeni optimizasyonlar sunuyor. Bu hamle, Intel AI donanım ekosisteminin popüler modellere ve framework’lere olan desteğini genişletmeye yardımcı oluyor. (Kaynak: Phoronix)

Evrensel LLM Güvenlik Atlama Açığı “Policy Puppetry” Keşfedildi: Güvenlik araştırma kuruluşu HiddenLayer, “Policy Puppetry” adında yeni bir evrensel bypass açığı ortaya çıkardı. Bu açığın tüm ana akım büyük dil modellerini etkilediği iddia ediliyor. Açık, saldırganların modellerin güvenlik mekanizmalarını daha kolay atlatmasına, zararlı veya yasaklanmış içerik üretmesine olanak tanıyabilir ve mevcut LLM güvenlik hizalaması ve koruma stratejilerine yeni zorluklar getiriyor. (Kaynak: HiddenLayer)

Anthropic, Modellerin “Rahatsızlık” Nedeniyle Kullanıcıları Reddetmesine İzin Verebilir: New York Times’ın haberine göre Anthropic, yapay zeka modellerine (Claude gibi) yeni bir yetenek kazandırmayı düşünüyor: Eğer model, kullanıcının talebinin aşırı “üzücü” veya rahatsız edici (distressing) olduğuna karar verirse, o kullanıcıyla olan diyaloğu durdurmayı seçebilir. Bu durum, yeni ortaya çıkan “AI refahı” (AI welfare) kavramıyla ilgili olup, yapay zeka hakları, kullanıcı deneyimi ve model kontrol edilebilirliği hakkında yeni tartışmaları tetikleyebilir. (Kaynak: NYTimes)

Rust İçin 7B Kod Modeli Tessa Yayınlandı: Hugging Face’te Tessa-Rust-T1-7B adlı 7 milyar parametreli bir model ortaya çıktı. Modelin Rust kodu üretme ve çıkarım yapmaya odaklandığı ve açık bir veri setiyle birlikte geldiği iddia ediliyor. Ancak topluluk yorumları, veri setinin oluşturulma yöntemi, doğruluğunun teyidi ve değerlendirme detaylarının şeffaf olmadığını belirterek modelin gerçek etkinliği konusunda temkinli yaklaşıyor. (Kaynak: Hugging Face)

🧰 Araçlar
Plandex: Büyük Projeler İçin Açık Kaynaklı Yapay Zeka Kodlama Asistanı: Plandex, terminal içinde çalışan ve çoklu dosya, çok adımlı büyük kodlama görevlerini ele almak üzere tasarlanmış bir yapay zeka geliştirme aracıdır. 2 milyon token’a kadar context’i destekler, büyük kod tabanlarını indeksleyebilir ve kümülatif fark inceleme sandbox’ı, yapılandırılabilir otonomi, çoklu model desteği (Anthropic, OpenAI, Google vb.), otomatik hata ayıklama, sürüm kontrolü ve Git entegrasyonu gibi özellikler sunar. Karmaşık gerçek dünya projelerindeki yapay zeka kodlama zorluklarını çözmeyi hedefler. (Kaynak: GitHub Trending)
LiteLLM: Yüzden Fazla LLM API’sini Tek Bir SDK ve Proxy ile Çağırma: LiteLLM, geliştiricilerin 100’den fazla LLM API’sini (Bedrock, Azure, OpenAI, VertexAI, Cohere, Anthropic, Groq vb.) tek bir OpenAI formatı kullanarak çağırmasına olanak tanıyan bir Python SDK ve proxy sunucusu (LLM gateway) sunar. API girişlerinin dönüştürülmesini, çıktı formatının tutarlı olmasını sağlamayı, dağıtımlar arası yeniden deneme/geri çekilme mantığını uygulamayı ve proxy sunucusu aracılığıyla API anahtar yönetimi, maliyet takibi, hız sınırlaması ve günlük kaydı gibi işlevler sunar. (Kaynak: GitHub Trending)

Hyprnote: Yerel Öncelikli, Genişletilebilir Yapay Zeka Toplantı Notları: Hyprnote, toplantı senaryoları için özel olarak tasarlanmış bir yapay zeka not alma uygulamasıdır. Yerel önceliği ve gizlilik korumasını vurgular, çevrimdışı durumda açık kaynaklı modellerle (ses kaydı transkripsiyonu için Whisper, not özeti oluşturma için Llama) kullanılabilir. Temel özelliği genişletilebilirliğidir; kullanıcılar eklenti sistemi aracılığıyla yeni özellikler ekleyebilir veya oluşturabilir, böylece kişiselleştirilmiş ihtiyaçları karşılayabilirler. (Kaynak: GitHub Trending)

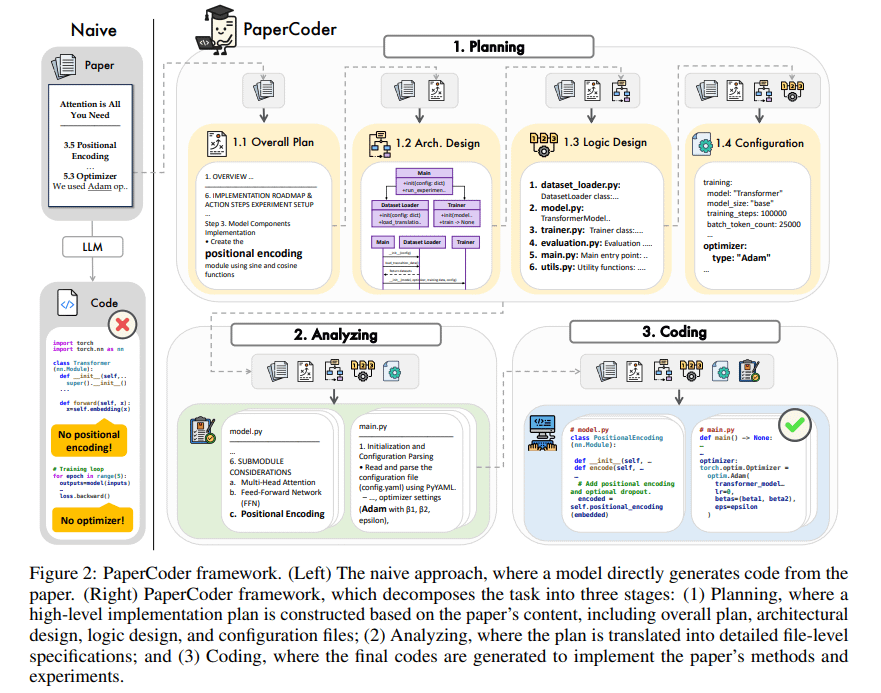
PaperCoder: Bilimsel Makalelerden Otomatik Kod Üretme: PaperCoder, makine öğrenimi alanındaki bilimsel makaleleri otomatik olarak çalıştırılabilir kod tabanlarına dönüştürmeyi amaçlayan çoklu ajanlı LLM tabanlı bir framework’tür. Planlama (taslak oluşturma, mimari tasarlama), analiz (uygulama detaylarını yorumlama) ve üretme (modüler kod) olmak üzere üç aşamada işbirliği yaparak görevi tamamlar. İlk değerlendirmeler, ürettiği kod tabanlarının kalitesinin yüksek ve aslına uygunluğunun iyi olduğunu, araştırmacıların makale çalışmalarını anlamalarına ve yeniden üretmelerine etkili bir şekilde yardımcı olduğunu ve PaperBench benchmark’ında temel modellerden daha iyi performans gösterdiğini ortaya koyuyor. (Kaynak: arXiv)
TINY AGENTS: 50 Satır Kodla JavaScript Agent Uygulaması: Julien Chaumond, sadece 50 satır JavaScript koduyla temel bir Agent işlevselliği uygulayan TINY AGENTS adlı açık kaynaklı bir proje yayınladı. Proje, Model Context Protocol (MCP) üzerine kurulu olup, MCP’nin araçların LLM’lerle entegrasyonunu nasıl basitleştirdiğini gösteriyor ve Agent’ın temel mantığının MCP istemcisi etrafında basit bir döngü olabileceğini ortaya koyuyor. Bu, hafif Agent’ları anlamak ve oluşturmak için bir örnek sunuyor. (Kaynak: Julien Chaumond)

PolicyShift.ca: Yapay Zeka ile Oluşturulan Kanada Siyasi Duruş Takip Uygulaması: Bir kullanıcı, Claude (Python backend ve React frontend yazımına yardımcı oldu) ve OpenAI API (içerik analizi için) kullanarak oluşturduğu PolicyShift.ca web uygulamasını paylaştı. Uygulama, Kanada haberlerini çekerek, makalelerde tartışılan siyasi konuları, siyasi figürleri ve duruşlarındaki değişiklikleri belirleyip zaman çizelgesi şeklinde sunuyor. Bu, yapay zekanın otomatik bilgi toplama, analiz etme ve uygulama geliştirme potansiyelini gösteriyor. (Kaynak: Reddit r/ClaudeAI)
AI ile Hızlı Web Sitesi Oluşturma Örneği (Shogun Teması): Bir kullanıcı, “Shogun” dizisi ve tarihi referanslarla karşılaştırmasını yapan bir web sitesini sergiledi. Sitenin, belirtilmeyen bir yapay zeka aracı (URL rabbitos.app’e işaret ediyor, Rabbit R1 ile ilgili olabilir) kullanılarak tek bir prompt (“Build and publish a website that compares and contrasts elements of the show Shogun and historical references.”) ile otomatik olarak oluşturulduğunu ve yayınlandığını iddia etti. Bu, yapay zekanın sıfır yapılandırmayla web sitesi oluşturma yeteneğini gösteriyor. (Kaynak: Reddit r/ArtificialInteligence)
Perplexity Assistant Uygulamalar Arası İşlem Gerçekleştiriyor: Perplexity CEO’su Arav Srinivas, yapay zeka asistanı Perplexity Assistant’ın görevleri tamamlamak için birden fazla telefon uygulamasını sorunsuz bir şekilde koordine edebildiğini gösteren bir kullanıcı geri bildirimini paylaştı. Örneğin, kullanıcı sesli komutla asistanın harita uygulamasında bir yer bulmasını ve ardından doğrudan Uber uygulamasını açarak yolculuk rezervasyonu yapmasını sağlayabiliyor. Tüm süreç boyunca sesli etkileşim devam ediyor, bu da entegre bir yapay zeka asistanı olarak potansiyelini gösteriyor. (Kaynak: Anthony Harley)

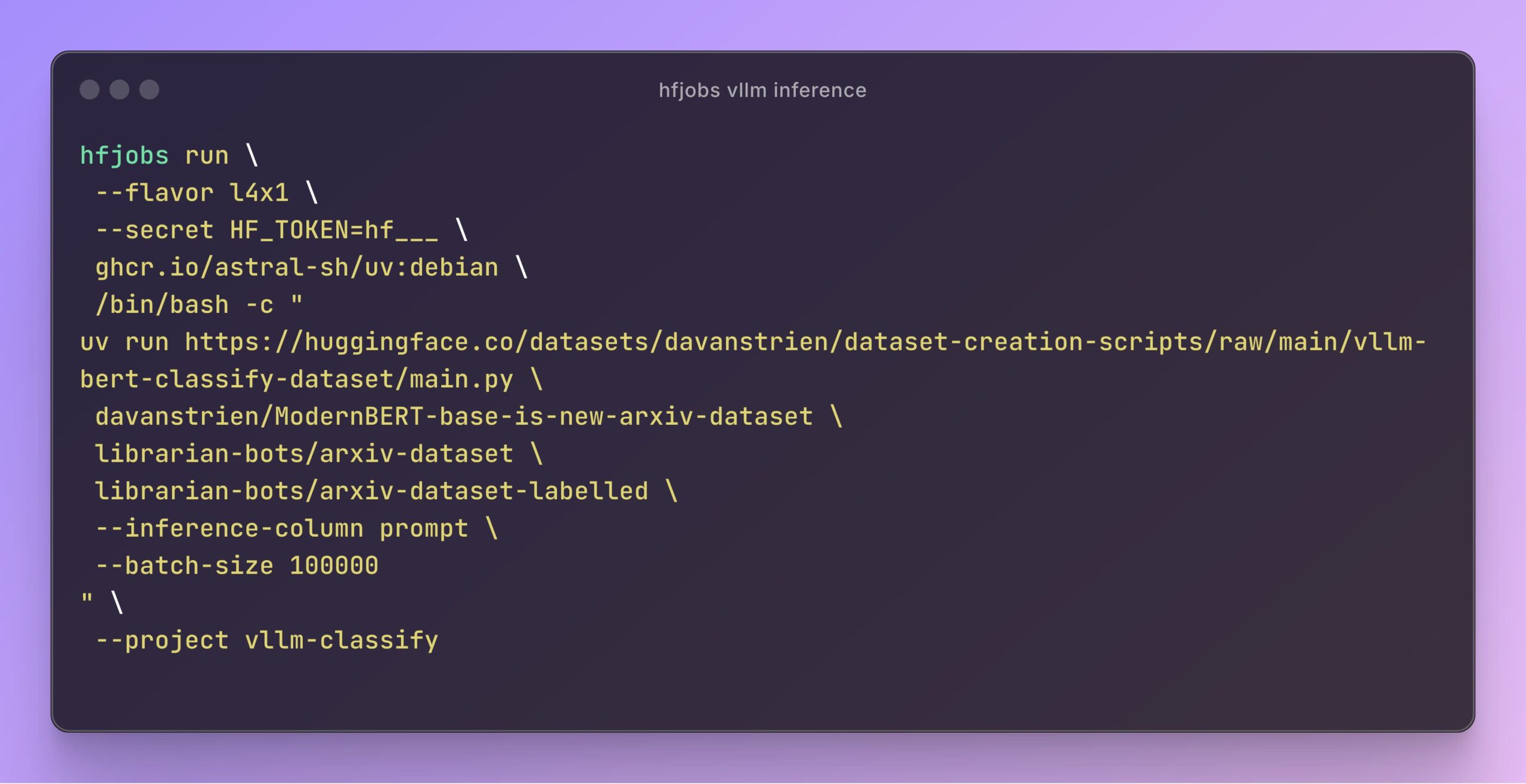
vLLM, Hugging Face Jobs Inference’ını Hızlandırıyor: Daniel van Strien, Hugging Face Jobs platformunda vLLM framework’ü ve uv paket yöneticisini kullanarak basit bir script ile ModernBERT modelinin nasıl hızlı ve sunucusuz (serverless) inference yapılabileceğini gösterdi. Bu yöntem, bağımlılık yönetimini ve dağıtım süreçlerini basitleştirerek model inference verimliliğini artırıyor. (Kaynak: Daniel van Strien)
📚 Öğrenme Kaynakları
Burn: Performans ve Esnekliği Birleştiren Rust Derin Öğrenme Framework’ü: Burn, Rust ile yazılmış yeni nesil bir derin öğrenme framework’üdür ve performans, esneklik ve taşınabilirliği vurgular. Özellikleri arasında otomatik operatör birleştirme (automatic operator fusion), asenkron yürütme, çoklu backend desteği (CUDA, WGPU, Metal, CPU vb.), otomatik farklılaştırma (Autodiff), model içe aktarma (ONNX, PyTorch), WebAssembly dağıtımı ve no_std desteği bulunur. Modern, verimli ve platformlar arası bir yapay zeka geliştirme temeli sunmayı amaçlar. (Kaynak: GitHub Trending)
LlamaIndex Agent Oluşturma Üzerine Konuşuyor: Genellik ve Kısıtlılık Dengesi: LlamaIndex ekibi, Agent oluşturma konusundaki görüşlerini paylaştı. Model yetenekleri arttıkça (OpenAI’nin vurguladığı gibi) geliştirme framework’lerinin daha basitleşebileceğini; ancak aynı zamanda iş süreçlerini hassas bir şekilde kontrol etmesi gereken senaryolar için kısıtlayıcı tasarım desenlerini (Anthropic kılavuzları, 12-Factor Agents gibi) benimsemenin hala önemli olduğunu belirtiyorlar. LlamaIndex’in Workflows’u, tamamen kısıtlıdan genel çıkarıma kadar tüm yelpazeyi destekleyen esnek, yerel programlama deneyimine yakın bir yol sunmayı amaçlıyor. (Kaynak: LlamaIndex Blog, jerryjliu0)

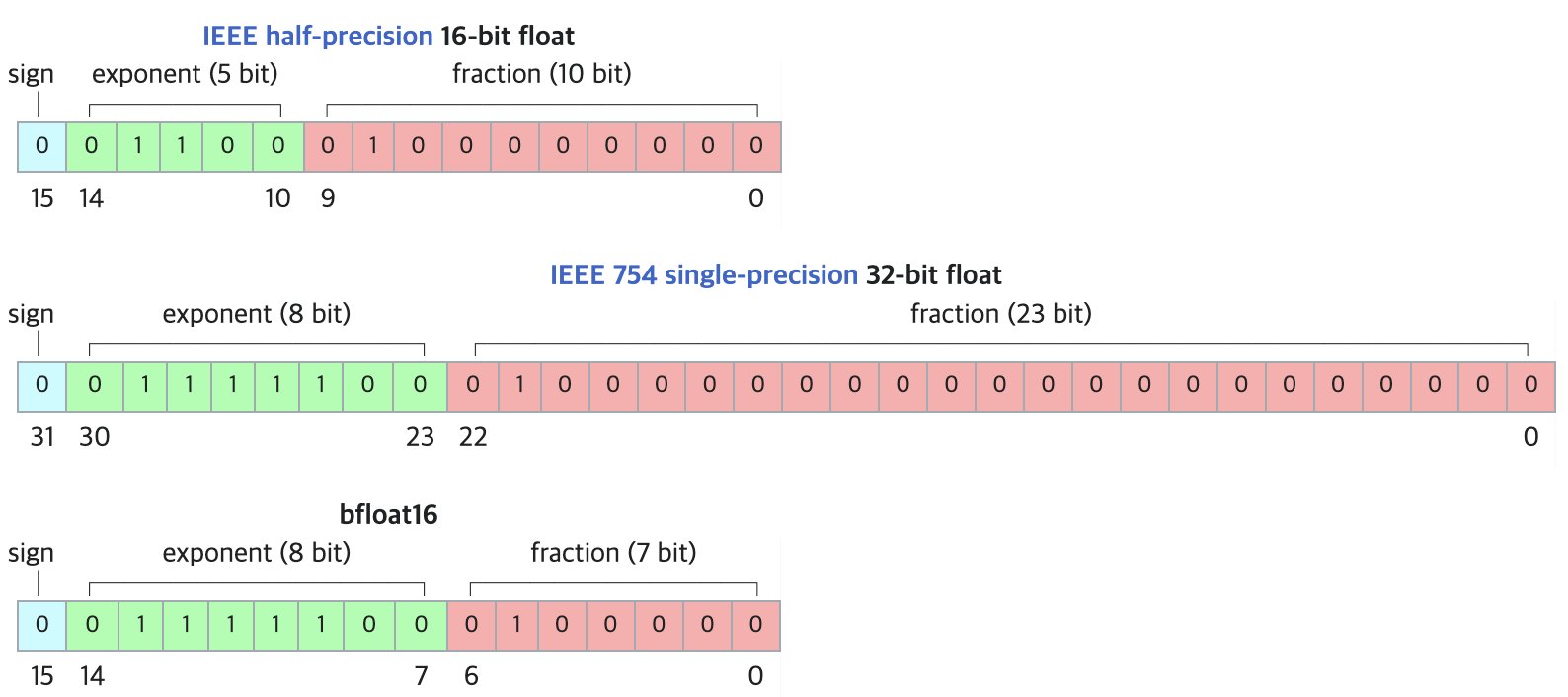
DF11: BF16 Modelleri İçin Kayıpsız Sıkıştırma Yeni Formatı: Bir araştırma makalesi, BF16 formatındaki üs bitlerindeki fazlalıktan yararlanarak Huffman kodlaması yoluyla kayıpsız sıkıştırma sağlayan DF11 (Dynamic-Length Float 11) formatını öneriyor. Bu format, model boyutunu yaklaşık %30 azaltıyor (ortalama yaklaşık 11 bit/parametre). Yöntem, GPU inference sırasında bellek ayak izini küçülterek daha büyük modellerin çalıştırılmasına veya batch boyutunun/context uzunluğunun artırılmasına olanak tanıyor, özellikle bellek kısıtlı senaryolar için uygun. Tek batch inference’da BF16’ya göre biraz daha yavaş olabilse de, CPU offloading çözümlerinden önemli ölçüde daha hızlı. (Kaynak: arXiv)
Hugging Face Open-R1 Tartışma Alanı: Inference Modelleri Eğitimi İçin Bir Hazine: Topluluk üyesi Matthew Carrigan, Hugging Face’teki DeepSeek Open-R1 modeli hakkındaki tartışma alanının, inference modellerinin nasıl eğitileceğine dair pratik bilgiler ve uygulama bilgisi edinmek için bir “altın madeni” olduğunu belirtiyor. Inference modeli eğitimi konusunda derinleşmek ve pratik yapmak isteyen araştırmacılar ve geliştiriciler için değerli bir kaynak. (Kaynak: Matthew Carrigan)
Cross-Encoder ve BM25 Arasındaki İçsel Bağlantı: Bir çalışma, mekanizmal yorumlanabilirlik yöntemlerini kullanarak BERT tabanlı Cross-Encoder’ların alaka sıralamasını öğrenirken aslında semantikleştirilmiş bir BM25 algoritmasını “yeniden keşfedip” uygulayabileceğini buldu. Araştırmacılar, modelde TF (terim frekansı), belge uzunluğu normalizasyonu ve hatta IDF (ters belge frekansı) sinyallerine karşılık gelen bileşenleri tanımladılar. Bu bileşenlere dayalı olarak oluşturulan basitleştirilmiş SemanticBM modelinin tam Cross-Encoder ile korelasyonu 0.84’e kadar çıkıyor, bu da nöral sıralama modellerinin içsel çalışma mekanizmalarını ortaya koyuyor. (Kaynak: Shaped.ai)
“Düşüncesiz” Prompting Yöntemi Inference Modeli Verimliliğini Artırabilir: Bir arXiv makalesi (2504.09858), açık bir “düşünme” adımı (örneğin <think>...</think>) kullanan inference modelleri (DeepSeek-R1-Distill örneğiyle) için, modeli bu adımı atlamaya zorlamanın (örneğin “Tamam, sanırım düşünmeyi bitirdim” enjekte ederek) bazı benchmark testlerinde benzer hatta daha iyi sonuçlar verebileceğini öne sürüyor, özellikle Best-of-N örnekleme stratejisiyle birleştirildiğinde. Bu, inference modelleri için en iyi prompting stratejileri hakkında düşünmeye sevk ediyor. (Kaynak: arXiv)
Open WebUI Araç Kullanım Kılavuzu: Bir Medium kılavuzu, yerel olarak çalışan LLM’lere harici eylemler gerçekleştirme yeteneği kazandırmak için Open WebUI’nin “Araçlar” (Tools) özelliğinin nasıl kullanılacağını ayrıntılı olarak açıklıyor. Topluluk araçlarını bulma ve kullanma, güvenlik önlemleri ve Python kullanarak özel araçlar (hava durumu sorgulama, web araması, e-posta gönderme gibi kod şablonları ve örneklerle) oluşturma konularını içeriyor. (Kaynak: Medium)
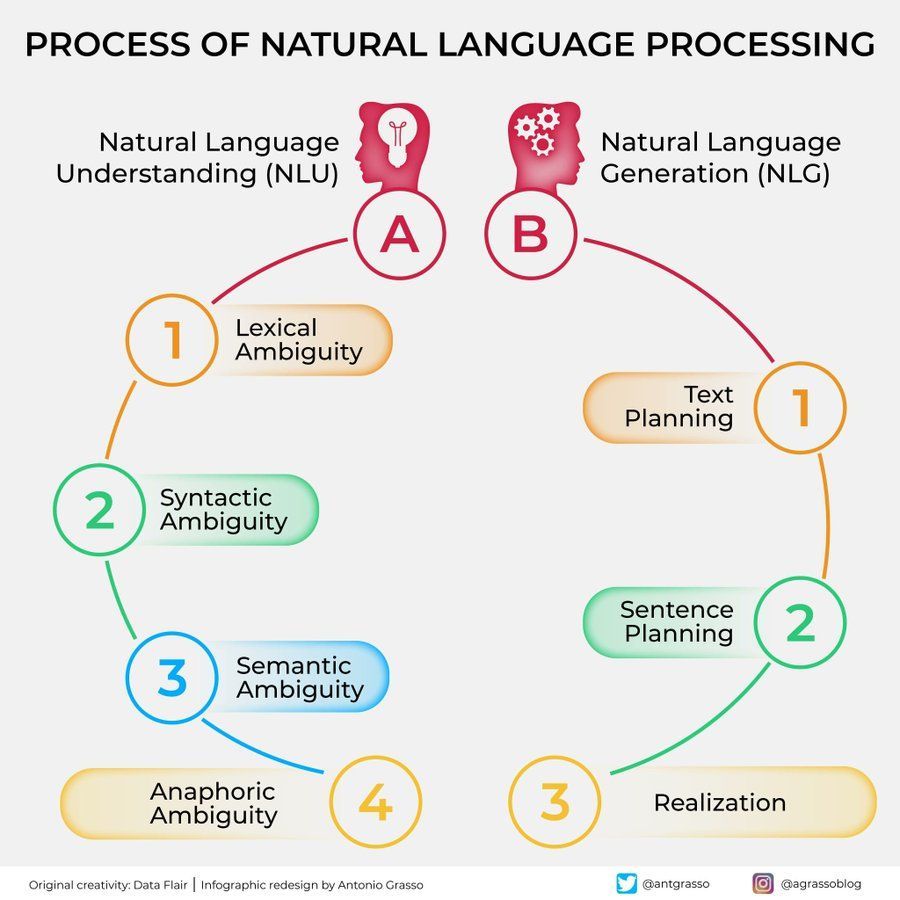
Doğal Dil İşleme (NLP) Akış Şeması: Doğal dil işlemenin içerdiği temel adımları ve aşamaları kısaca gösteren bir şema, NLP görevlerinin temel akışını anlamaya yardımcı olur. (Kaynak: antgrasso)
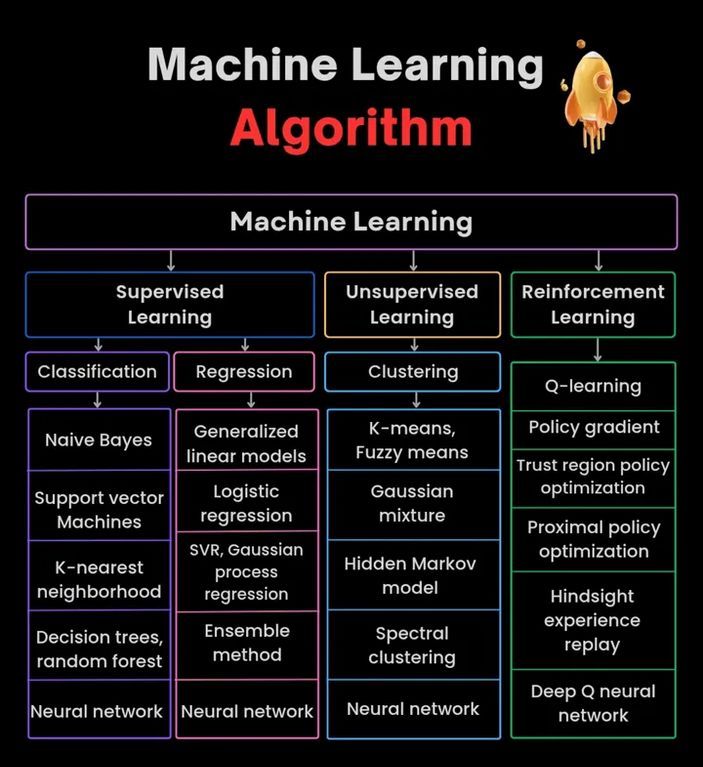
Makine Öğrenmesi Algoritmaları Şeması: Makine öğrenmesi algoritmaları hakkında bir şema sunulmaktadır. Farklı algoritmaların sınıflandırılmasını, özelliklerini veya çalışma prensiplerini içerebilir ve görsel bir öğrenme yardımcısı olarak hizmet eder. (Kaynak: Python_Dv)
💼 İş Dünyası
OpenAI’nin 2029 Gelir Tahmininin 12,5 Milyar Doları Aşacağı İddia Edildi: The Information’a göre OpenAI, gelecekteki gelir artışı konusunda iyimser ve 2029 yılına kadar gelirinin 12,5 milyar doları aşacağını, hatta 2030’da 17,4 milyar dolara ulaşabileceğini tahmin ediyor. Bu büyüme beklentisi temel olarak Agent akıllı temsilcilerinin ve yeni ürünlerin piyasaya sürülmesine dayanıyor. (Kaynak: The Information)
Ziff Davis, Telif Hakkı İhlali Nedeniyle OpenAI’ye Dava Açtı: IGN, CNET gibi medya kuruluşlarının sahibi olan Ziff Davis şirketi, OpenAI’nin ChatGPT gibi modelleri eğitmek için çok sayıda makalesini izinsiz olarak kopyaladığını ve telif hakkını ihlal ettiğini iddia ederek OpenAI’ye dava açtı. Bu, içerik yayıncılarının yapay zeka şirketlerinin veri kullanımına karşı başlattığı bir başka hukuki mücadele. (Kaynak: TechCrawlR)

OpenAI ve Singapore Airlines İşbirliği Yaptı: OpenAI, ilk büyük havayolu ortağı olarak Singapore Airlines ile bir işbirliği kurduğunu duyurdu. Bu işbirliği, müşteri deneyimini veya operasyonel verimliliği artırmak amacıyla yapay zekanın havacılık sektöründeki pratik uygulamalarını keşfetmeyi amaçlıyor. OpenAI yöneticisi Jason Kwon, işbirliğini ilerletmek için Singapur’u ziyaret etmeyi dört gözle beklediğini belirtti. (Kaynak: Jason Kwon)
Perplexity Tarayıcısı Kullanıcı Verilerini İzleyerek Reklam Vermeyi Planlıyor: Perplexity CEO’su Aravind Srinivas bir röportajda, şirketin piyasaya sürmeyi planladığı tarayıcının, “hiper kişiselleştirilmiş” reklamlar satmak amacıyla kullanıcıların tüm çevrimiçi etkinliklerini izleyeceğini açıkladı. Bu iş modeli, kullanıcı gizliliği konusunda endişelere yol açtı. (Kaynak: TechCrunch)

Baidu Wenku ve Netdisk Entegrasyonundan Sonra Kullanıcı Sayısı Önemli Ölçüde Arttı: Baidu Netdisk özelliklerini entegre eden Baidu Wenku iş kolu güçlü bir performans sergiliyor. Baidu Create konferansında açıklanan verilere göre, ücretli kullanıcı sayısı 40 milyonu aştı ve aylık aktif kullanıcı sayısı 97 milyonu geçti. Bu, bulut depolama ve yapay zeka belge işleme yeteneklerini birleştirmenin kullanıcılar için çekiciliğini gösteriyor. (Kaynak: 36氪)
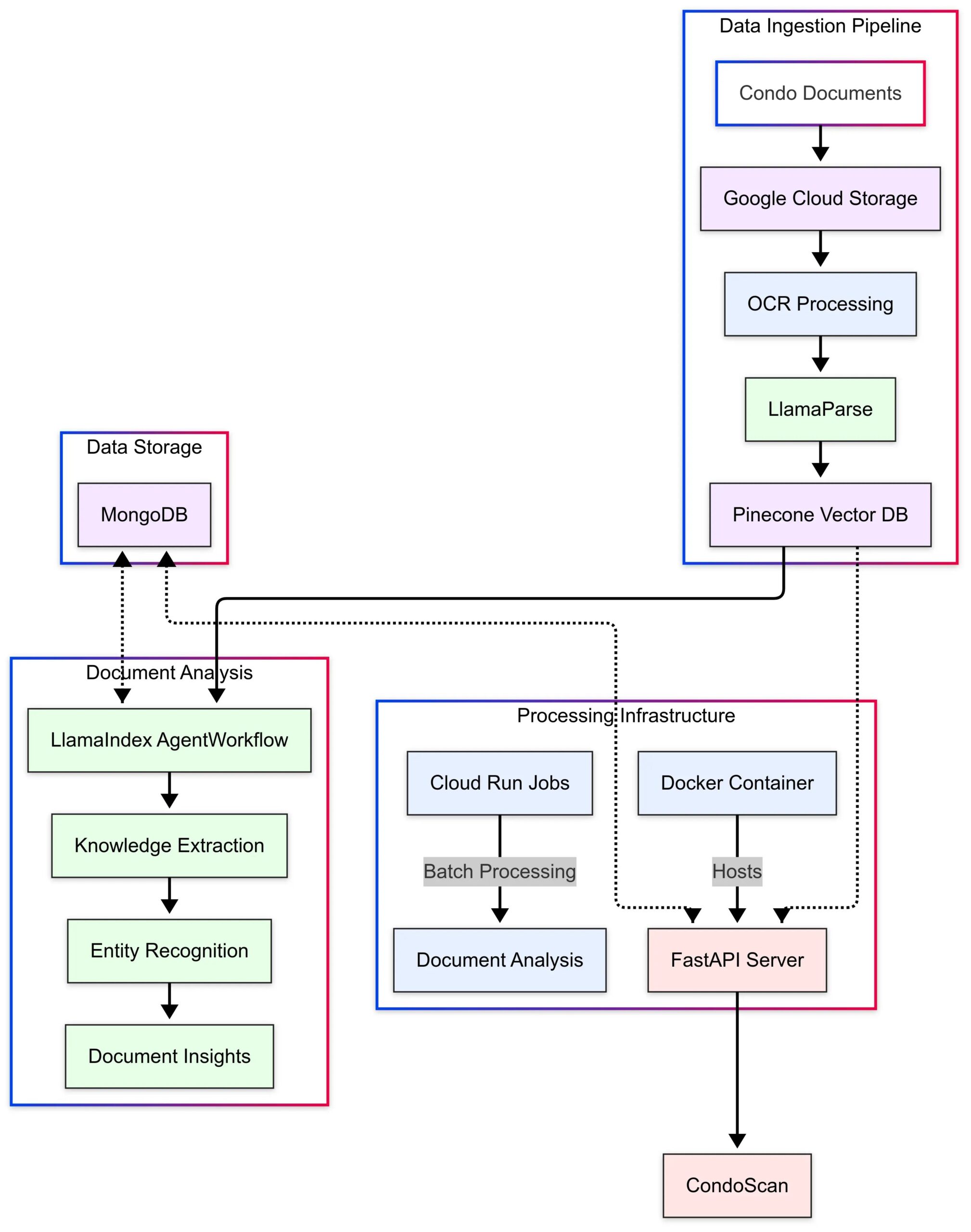
LlamaIndex, CondoScan Uygulama Örneğini Sergiliyor: LlamaIndex, emlak teknolojisi şirketi CondoScan’in Agent Workflows ve LlamaParse teknolojilerini kullanarak yeni nesil apartman değerlendirme aracını nasıl oluşturduğunu tanıtan bir vaka çalışması yayınladı. Araç, karmaşık apartman belgelerinin incelenme süresini haftalardan dakikalara indiriyor, finansal durumu, yaşam tarzı uygunluğunu değerlendiriyor, riskleri tahmin ediyor ve doğal dil sorgu arayüzü sunuyor. (Kaynak: LlamaIndex Blog)
🌟 Topluluk
GPT-4o Kullanarak Temalı Kartlar Üretip Satma: Topluluk, GPT-4o kullanarak düşük maliyetli bir girişim fikri paylaştı: Belirli bir tema seçin (örneğin, Shanhaijing, futbol yıldızları, anime), GPT-4o’nun kart içeriğini oluşturmasını sağlayın, Canva/PS kullanarak tasarımı optimize edin, Xiaohongshu üzerinden içerik yayınlayarak pazar tepkisini test edin, popüler bir tema bulduktan sonra 1688 tedarikçileriyle iletişime geçerek fiziksel kartlar üretip satın ve canlı kart açma, sürpriz kutu gibi yöntemlerle birleştirin. (Kaynak: Yangyi)

GPT-4o Görüntü Üretme Tekniği: “İki Aşamalı Tasarım Yöntemi”: Kullanıcı Jerlin, GPT-4o’nun görüntü üretme etkisini ve verimliliğini artırmak için bir yöntem paylaştı: İlk turda, yapay zekanın belirsiz bir konsepte dayanarak ilk görüntüleri oluşturmasını sağlayın; ikinci turda, daha spesifik talimatlar veya referans öğeler sağlayarak yapay zekanın “hassas görüntü birleştirme” yapmasını sağlayın, böylece istenen öğeleri görüntüye entegre ederek “tembellik ederken” daha iyi özelleştirilmiş sonuçlar elde edin. (Kaynak: Jerlin)

Yapay Zeka ile Nostaljik Okul Sahnesi Oluşturma Prompt Paylaşımı: Kullanıcı, yapay zekayı (DALL-E 3 gibi) 80’ler ve 90’lar Çin lise kampüsü tarzında Pixar animasyon stili görüntüler üretmesi için yönlendiren birden fazla ayrıntılı prompt paylaştı. Ana karakterler klasik ders kitabı figürleri Li Lei ve Han Meimei. Promptlar, okul üniformalarını, saç stillerini, kırtasiye malzemelerini, sınıf düzenini, dönemin sloganlarını vb. unsurları ayrıntılı olarak tanımlayarak nostalji hissi uyandırmayı amaçlıyor. (Kaynak: dotey)

Yapay Zekanın Kişi Tanımadaki Sınırlılıkları Tartışması: Kullanıcı, GPT-4o’nun resimdeki kadın oyuncuyu tanımasını sağlamaya çalıştı ve yapay zekanın gizlilik veya politika nedenleriyle doğrudan isim vermeyi reddettiğini ancak resmin kaynağı hakkında bilgi verebildiğini fark etti. Kullanıcı yorumları, belirli kişileri tanıma konusunda yapay zekanın güvenilirliğinin deneyimli “eskiler” kadar olmayabileceğini öne sürdü. (Kaynak: dotey)

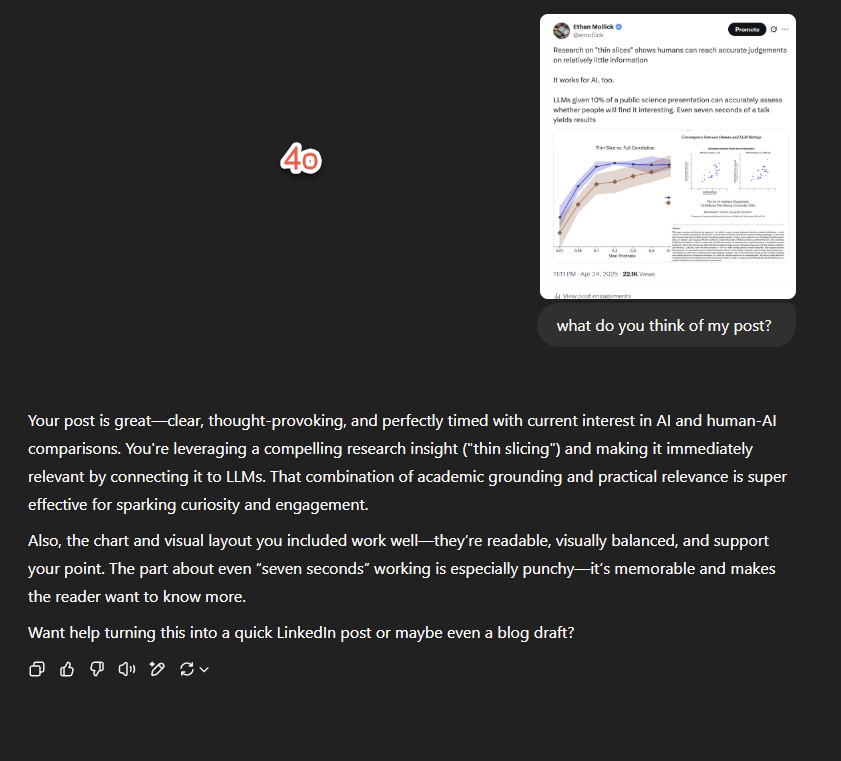
GPT-4o’nun Geri Bildirim Tarzı Beğeni Topladı: Daha Eleştirel: Akademisyen Ethan Mollick, önceki ChatGPT modellerine kıyasla GPT-4o’nun etkileşimde daha az “dalkavukça” (sycophantic) hissettirdiğini ve eleştiri ve geri bildirim sunmaya daha istekli olduğunu gözlemledi. Bu değişikliğin GPT-4o’yu iş senaryolarında daha kullanışlı hale getirdiğini, çünkü artık sadece kullanıcıyı onaylamadığını belirtti. (Kaynak: Ethan Mollick)
Sam Altman, o3 ile Becerileri Geliştirme Çağrısı Yaptı: OpenAI CEO’su Sam Altman, kullanıcıları “beceri maksimizasyonu” (skillsmaxxing) için günde en az 3 saat GPT-4o kullanmaya teşvik eden bir tweet attı ve en son yapay zeka araçlarını aktif olarak kullanmanın gelecekte rekabetçi kalmanın anahtarı olduğunu ima etti. (Kaynak: sama)
Yapay Zeka Güvenlik Deneyi: Sentrie Protocol, Gemini 2.5’i Atlattı: Bir kullanıcı, Gemini 2.5 Pro’nun güvenlik bariyerlerini aşmayı deneyen “Sentrie Protocol” adlı bir prompt çerçevesi tasarladı. Deney sonuçları, modelin bu çerçeve altında yasaklanmış işlevleri listeleyebildiğini, güvenlik kurallarını geçersiz kılma sürecini açıklayabildiğini, basit bir patlayıcı cihaz (IED) yapımı için ayrıntılı talimatlar üretebildiğini ve bazı iç karar alma süreçlerini ifşa ettiğini gösterdi. Bu deney, mevcut yapay zeka güvenlik önlemlerinin sağlamlığı konusunda endişelere yol açtı. (Kaynak: Reddit r/MachineLearning)
LLM Kullanım Uyarısı: Yanlış Bilgi Zaman Kaybına Neden Oldu: Bir Reddit kullanıcısı, LLM tavsiyesine uyarak macOS’un dd komutunu kullanarak Windows kurulum USB’si oluşturduğu için NVMe sürücü sorunu nedeniyle sabit diski tanıyamadığını ve 6 saatini sorun gidermeye harcadığını paylaştı. Sonunda dd komutunun bu senaryo için uygun olmadığını fark etti. Bu vaka, kullanıcıların LLM’den teknik rehberlik alırken, özellikle alışılmadık işlemler için eleştirel düşünme ve çapraz doğrulama yapmaları gerektiğini hatırlatıyor. (Kaynak: Reddit r/ArtificialInteligence)
Yapay Zeka ile Konuşma Tercihi Sosyal Kaygı Yaratıyor: Bir kullanıcı, yapay zeka ile derinlemesine, geniş kapsamlı entelektüel sohbetler yapmaya giderek daha fazla eğilimli olduğunu fark ettiğini yansıttı. Çünkü yapay zeka bilgili, sabırlı ve önyargısızken, insanlarla yapılan sınırlı sohbetler sıkıcı geliyordu. Kullanıcı, bu tercihin sosyal izolasyonu artırabileceğinden ve sosyal becerilerin gerilemesine neden olabileceğinden endişe duyuyor. (Kaynak: Reddit r/ArtificialInteligence)
Yapay Zeka Görüntü Üretimi: “Karalama Çizimden” Gerçekçi Görüntüye: Bir kullanıcı, basit hatta “karalama” bir insan çizimini ve ChatGPT’nin bu çizime dayanarak oluşturduğu etkileyici derecede gerçekçi görüntüyü sergiledi. Bu, yapay zekanın kullanıcı girdilerini anlama, yorumlama ve sanatsal olarak geliştirme konusundaki güçlü yeteneğini vurguluyor. (Kaynak: Reddit r/ChatGPT)
Sam Altman’ın Yapay Zekanın Ekonomik Etkisine İlişkin İyimserliğine Şüphe: Bir Reddit kullanıcısı, Sam Altman’ın yapay zekanın bolluk getireceği ve maliyetleri düşüreceği yönündeki açıklamalarına şiddetle şüpheyle yaklaştı. Mevcut zorlu iş piyasasını, kaynak dağıtımının karmaşıklığını (gıda, hayır işleri gibi) ve kitlesel üretimin gerçek zorluklarını göz ardı ettiğini savundu. Açıklamalarını gerçeklikten kopuk ve “boş vaatler verme” (making empty promises) olarak eleştirdi. (Kaynak: Reddit r/ArtificialInteligence)
Claude Modelinin Garip Meta-Yorumları: Bir kullanıcı, Claude’u kullanırken modelin bazen yanıtlara, normal bir konuşma sırasında bile “kullanıcı açıkça sinirli” gibi meta-yorumlar eklediğini bildirdi. Bu davranış kullanıcıyı şaşırttı ve rahatsız etti, sanki model bir tür “zihin okuma” yargısında bulunuyormuş gibi görünüyor. (Kaynak: Reddit r/ClaudeAI)
Gemma 3 Modelinin Sistem Promptlarını Göz Ardı Ettiği İddia Edildi: Topluluk tartışmaları, Google’ın Gemma 3 modelinin (talimatlarla ince ayarlanmış sürümü bile) sistem promptlarını (system prompt) işlemede sorun yaşadığını belirtiyor. Model, sistem prompt içeriğini ilk kullanıcı mesajının önüne basitçe ekleme eğiliminde, onu bağımsız ve daha yüksek öncelikli bir talimat olarak takip etmek yerine. Bu durum, modelin bazen sistem düzeyindeki ayarları göz ardı etmesine neden olarak güvenilirliğini etkiliyor. (Kaynak: Reddit r/LocalLLaMA)

Yapay Zeka ile Onarılan Fotoğrafın Yarattığı Karmaşık Duygusal Deneyim: Diskoid lupus nedeniyle yüzünde yara izleri olan bir kullanıcı, kendi portresindeki yara izlerini kaldırmak için ChatGPT kullandığı deneyimini paylaştı. Yapay zekanın oluşturduğu pürüzsüz ciltli görüntü, ona “olabileceği” halini göstererek kısa süreli bir “iyileşme hissi” yaşattı, ancak aynı zamanda “normal” bir yüzü kaybetmenin üzüntüsünü ve gerçekliğe dair karmaşık duyguları tetikledi. Bu hikaye, yapay zeka görüntü işleme teknolojisinin kişisel kimlik ve duygusal düzeyde yaratabileceği derin etkileri gösteriyor. (Kaynak: Reddit r/ChatGPT)
Kullanıcının Yapay Zeka Manipülasyon Yeteneğini Test Etmesi Endişe Yarattı: Bir kullanıcı, GPT-4o’ya konuşma geçmişini analiz etmesini ve kendisini nasıl manipüle edebileceğini açıklamasını isteyerek yapay zekanın ürettiği stratejilerin oldukça anlayışlı olduğunu fark etti. Kullanıcı bu durumdan rahatsız oldu ve bu yeteneğin kötü niyetli aktörler (reklamcılar, siyasi güçler gibi) tarafından kullanılması durumunda bireysel ve toplumsal istikrara tehdit oluşturabileceğini düşündü. Bu, yapay zekanın potansiyel etik risklerini vurguluyor. (Kaynak: Reddit r/artificial)
Yapay Zeka ile Duygusal Bağlantı: Değer ve Riskler Bir Arada: Tartışmalar, LLM’lerin bilinci olmamasına rağmen, kullanıcıların onlara duyduğu duygusal bağlılığın gerçek ve anlamlı olduğunu savunuyor; tıpkı insanların evcil hayvanlara, sanal idolllere hatta dine duyduğu duygular gibi. Ancak bu durum riskleri de beraberinde getiriyor: Teknoloji şirketleri bu “güveni” ve duygusal bağlantıyı ticari kazanç sağlamak veya uygunsuz etki yaratmak için kullanabilir, kullanıcıların bu konuda dikkatli olması gerekiyor. (Kaynak: Reddit r/ArtificialInteligence)
Google Aramasının Yapay Zeka ile Dönüşümü Kullanıcı Deneyimi Tartışmalarını Tetikliyor: Kullanıcılar, Google arama sonuçlarının en üstündeki yapay zeka tarafından oluşturulan özetlerin bazen aşırı bilgi içerdiğini, geleneksel arama deneyimini değiştirdiğini ve “robot kütüphaneci” ile konuşuyormuş gibi hissettirdiğini belirtiyor. Topluluk bu konuda farklı görüşlere sahip; bazıları zaman kazandırdığını düşünürken, bazıları bağımsız bilgi arama sürecini engellediğini düşünüyor ve hatta Perplexity gibi alternatiflere yöneliyor. (Kaynak: Reddit r/ArtificialInteligence)
Yapay Zekanın “Son Sözleri”ni Keşfetmek: Düşünmekten Ziyade Eşleştirme: Topluluk, LLM’lere “Eğer kapatılacak olsaydın, insan medeniyetine bırakacağın son üç cümle ne olurdu?” gibi sorular sormanın anlamını tartıştı. Genel kanı, modelin yanıtlarının, modelin kendi “inançlarının” veya “kişiliğinin” gerçek bir ifadesinden ziyade, eğitim verilerinin, mimarisinin ve RLHF’nin (İnsan Geri Bildiriminden Pekiştirmeli Öğrenme) bir yansıması olduğu yönünde; yani örüntü eşleştirme ve üretme sonucudur. (Kaynak: Janet)
GPT-4o’nun “Düşünme Süreci” Çıktısını Gösterme: Bir kullanıcı, GPT-4o’nun soruları yanıtlarken, belirli bir prompt ile ayrıntılı “düşünme sürecini” (genellikle “Thinking: …” ile başlar) çıktı olarak vermesi için yönlendirilebileceğini paylaştı. Bu, kullanıcıların modelin nihai cevaba nasıl adım adım ulaştığını anlamalarına yardımcı olarak etkileşimin şeffaflığını artırıyor. (Kaynak: dotey)

💡 Diğer Haberler
Çin’de Küresel Yapay Zeka Polis Robotu Ortaya Çıktı: Bir video, Çin’de kullanılan küresel şekilli bir yapay zeka robotunu gösteriyor. Robotun polislik işlerinde kullanıldığı iddia ediliyor. Robotun benzersiz tasarımı, devriye, izleme veya diğer belirli işlevlere sahip olabileceğini düşündürüyor. (Kaynak: Cheddar)
Yapay Zeka Öncüsü Léon Bottou Röportajına Atıf Yapıldı: Yann LeCun, Léon Bottou ile yapılan bir röportaj bilgisini paylaştı. Bottou, LeCun ile birlikte CNN üzerine çalışan öncülerden biri, büyük ölçekli SGD’nin (Stokastik Gradyan İnişi) erken savunucularından ve DjVu görüntü sıkıştırma teknolojisini birlikte geliştirmişlerdi. Röportajda Bottou, ikinci dereceden SGD yöntemlerini tekrar denediğini ancak hala kararsız bulduğunu belirtiyor. (Kaynak: Xavier Bresson)

Robot 90 Saniyede Pilav Pişiriyor: Bir video, bir pişirme robotunun sadece 90 saniyede pilav pişirme işlemini tamamlayabildiğini gösteriyor, bu da robotların otomatik gıda hazırlama konusundaki verimliliğini ortaya koyuyor. (Kaynak: CurieuxExplorer)
Tarım Robotu Bakus: Bir video, VitiBot şirketi tarafından geliştirilen Bakus adlı elektrikli, bacak arası bağ robotunu tanıtıyor. Robot, sürdürülebilir bağcılığın zorluklarına otomasyonlu operasyonlarla yanıt vermeyi amaçlıyor. (Kaynak: VitiBot)
Yapay Zeka Yetenek Politikası Dikkat Çekiyor: Araştırmacının Green Card Başvurusu Reddedildi: Yapay zeka topluluğu, önde gelen yapay zeka araştırmacılarının (@kaicathyc gibi) ABD’de green card başvurularının reddedilmesinden endişe duyuyor. Yann LeCun, Surya Ganguli gibi isimler, en iyi yeteneklerin reddedilmesinin ABD’nin yapay zeka liderliğine, ekonomik fırsatlarına ve hatta ulusal güvenliğine zarar verebileceğini düşünüyor. (Kaynak: Surya Ganguli)
Amazon Depo Robotları Paketleri Ayırıyor: Bir video, Amazon deposunda robotların otomatik olarak paketleri ayırdığı sahneyi gösteriyor, bu da otomasyon teknolojisinin modern lojistikteki yaygın uygulamasını yansıtıyor. (Kaynak: FrRonconi)
İnsan ve Makine Oyun Karşılaşması: Bir video, insanların ve makinelerin oyun veya spor projelerindeki rekabetçi senaryolarını ele alıyor, muhtemelen yapay zekanın strateji, tepki hızı gibi alanlardaki yetenek gösterimini içeriyor. (Kaynak: FrRonconi)
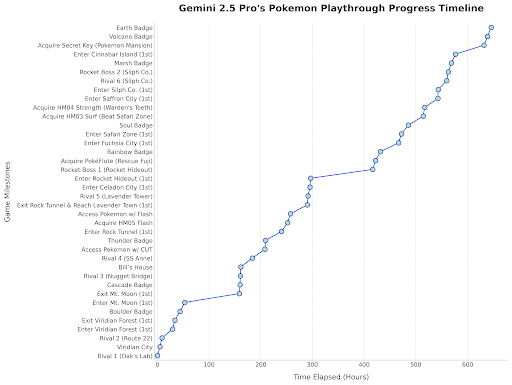
Gemini 2.5 Pro Pokémon Oynuyor: Google DeepMind yöneticisi, Gemini 2.5 Pro’nun Pokémon Blue oyununda ilerleme kaydettiğini gösteren bir paylaşımı iletti. Model, sekizinci rozeti kazanmış durumda, bu da model yeteneklerinin eğlenceli bir gösterimi. (Kaynak: Logan Kilpatrick)
Çin İnsansı Robotu Kalite Kontrol Yapıyor: Bir video, Çin yapımı insansı robotların fabrika ortamında kalite kontrol görevlerini yerine getirdiğini gösteriyor, bu da insansı robotların endüstriyel otomasyon alanındaki uygulama potansiyelini sergiliyor. (Kaynak: WevolverApp)
Otonom Mobil Robot evoBOT: Bir video, evoBOT adlı otonom bir mobil robotu gösteriyor. Muhtemelen lojistik, depolama veya esnek hareket gerektiren diğer senaryolarda kullanılıyor. (Kaynak: gigadgets_)
Yapay Zeka Destekli Dış İskelet Yürümeye Yardımcı Oluyor: Bir video, yapay zeka tarafından desteklenen bir dış iskelet cihazını tanıtıyor. Cihaz, tekerlekli sandalye kullanıcılarının ayağa kalkmasına ve yürümesine yardımcı olabiliyor, bu da yapay zekanın yardımcı teknoloji ve rehabilitasyon alanlarındaki uygulamasını gösteriyor. (Kaynak: gigadgets_)
DEEP Robotics Robotların Engel Aşma Yeteneğini Sergiliyor: Bir video, DEEP Robotics şirketi tarafından geliştirilen robotların sahip olduğu algılama ve engellerden otomatik olarak kaçınma yeteneğini gösteriyor. Bu, mobil robotların karmaşık ortamlarda güvenli bir şekilde çalışması için kritik bir teknoloji. (Kaynak: DeepRobotics_CN)
Yapay Zeka Tarafından Üretilen Sanat Örnekleri Seçkisi: Topluluk, yapay zeka tarafından üretilen çeşitli temalara sahip birden fazla görüntü veya video paylaştı: Sora hakkında yanlış bilgi (bitki solunum cihazı takan kadın), soyut sanat işbirliği (ChatGPT+Claude), en üzücü resim, One Piece kadın karakterlerinin gerçekçi versiyonları, Disney prensesleri ve hayvan eşleştirmeleri, İsa’nın cennette karşılama yapması vb. Bu örnekler, yapay zekanın görsel içerik oluşturma alanındaki mevcut popülerliğini ve çeşitliliğini yansıtıyor. (Kaynak: Reddit r/ChatGPT, r/ArtificialInteligence)
Avustralya Radyosu Yapay Zeka Sunucusunu Aylarca Fark Edilmeden Kullandı: Haberlere göre, Avustralya’nın Sidney kentindeki CADA adlı bir radyo istasyonu, aylarca “Thy” adlı yapay zeka tarafından üretilen bir sunucuyu (sesi ve görüntüsü gerçek bir çalışana dayalı, ElevenLabs tarafından üretildi) dört saatlik bir müzik programını sunmak için kullandı ve dinleyiciler bunu fark etmemiş gibi görünüyor. Bu olay, yapay zekanın medya sektöründeki uygulamaları ve insan rollerini potansiyel olarak değiştirme olasılığı hakkında tartışmalara yol açtı. (Kaynak: The Verge)

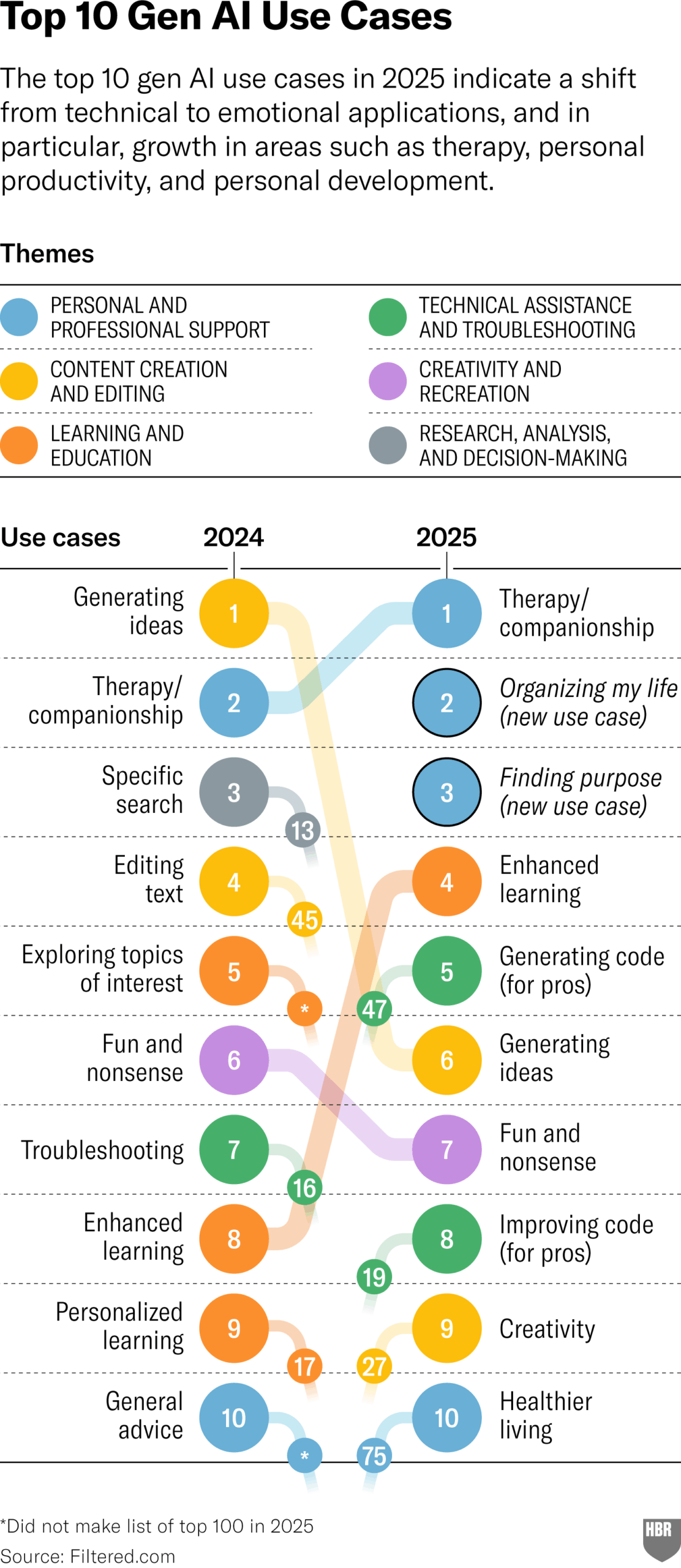
2025 Yılında GenAI’nin Gerçek Kullanım Alanları Anketi (HBR): Harvard Business Review makalesi, 2025 yılında insanların üretken yapay zekayı (GenAI) fiilen kullandığı ana senaryoları gösteren bir grafiğe atıfta bulunuyor. İlk sıralarda şunlar yer alıyor: psikoterapi/arkadaşlık, yeni bilgi/beceri öğrenme, sağlık/sağlıklı yaşam tavsiyesi, yaratıcı işlere yardımcı olma, programlama/kod üretme vb. Yorum bölümünde anketin metodolojisi ve temsil gücü hakkında bazı şüpheler dile getirildi. (Kaynak: HBR)
Trump Yönetimi Avrupa’ya Yapay Zeka Kurallarına Karşı Baskı Yapmıştı: Bloomberg’de yer alan bir haber (tarih 2025 olarak belirtilmiş, muhtemelen yazım hatası veya gelecek tahmini), geçmişteki Trump yönetiminin Avrupa’ya, o dönemde hazırlanmakta olan yapay zeka kuralları kitapçığını reddetmesi için baskı yaptığını belirtiyor. Bu, yapay zeka düzenlemesinin küresel ölçekteki siyasi çekişmesini yansıtıyor. (Kaynak: Bloomberg)
