
Anahtar Kelimeler:Yapay Zeka Modeli, OpenAI, Çok Modlu, Ajan, o3 Modeli, o4-mini, Görsel Muhakeme, Araç Çağırma, Gemini 2.5 Flash, Tencent Yuanbao Yapay Zekası, LLM Entegrasyonu, Pekiştirmeli Öğrenme
🔥 Odak Noktası
OpenAI, o3 ve o4-mini modellerini yayınladı, araç entegrasyonu ve görsel çıkarım yetenekleri sunuyor : OpenAI, bugüne kadarki en akıllı ve en güçlü çıkarım modelleri olan o3 ve o4-mini’yi resmi olarak yayınladı. Temel özellikler arasında, Agent’ın ilk kez proaktif olarak ChatGPT içindeki tüm araçları (web araması, Python veri analizi, derin görsel anlama, görüntü oluşturma vb.) çağırması ve birleştirmesi ve çıkarım zincirinde görüntüleri entegre ederek düşünebilmesi yer alıyor. o3, kodlama, matematik, bilim, görsel algı gibi alanlarda kapsamlı bir şekilde lider konumda olup, birçok benchmark testinde SOTA (State-of-the-Art) rekorlarını kırdı; o4-mini ise hız ve maliyet açısından optimize edilmiş olup, performansı boyutunu çok aşıyor. Bu iki modelin talimat takip etme yeteneği daha güçlü, diyalogları daha doğal ve hafıza ile geçmiş konuşmaları kullanarak kişiselleştirilmiş yanıtlar sunabiliyor. Bu lansman, OpenAI’nin daha otonom Agentic AI’ye doğru önemli bir adım attığını gösteriyor ve AI asistanlarının karmaşık görevleri daha bağımsız bir şekilde tamamlamasını sağlıyor. (Kaynak: OpenAI 王炸 o3/o4-mini!打通自主工具+视觉思考,大佬赞“天才级”!AI 终获“十八般武艺”全家桶?
OpenAI o3 ve o4-mini modelleri kullanıma sunuldu, araç kullanımı ve görsel çıkarım yetenekleri geliştirildi : OpenAI, gece geç saatlerde o3 ve o4-mini modellerini yayınladı; kullanıcılar ChatGPT Plus, Pro ve Team hesapları üzerinden erişebilir. Önemli yükseltmeler şunları içeriyor: 1. Tam sürüm o3, ilk kez araç çağırmayı (web’e bağlanma, code interpreter gibi) destekliyor. 2. o3 ve o4-mini, düşünce zincirinde görsel çıkarım yapabilen ilk modeller oldu; insanlar gibi görüntüleri birleştirerek analiz edip düşünebiliyorlar, örneğin resimden yer tahmin etme oyununda model, adım adım çıkarım yapmak için resim ayrıntılarını büyütebiliyor. Bu yetenek, modelin çok modlu görevlerdeki (MMMU, MathVista gibi) performansını önemli ölçüde artırıyor ve AI’nin görsel yargı gerektiren profesyonel senaryolarda (güvenlik izleme, tıbbi görüntü analizi gibi) daha büyük bir rol oynayacağını gösteriyor. Aynı zamanda OpenAI, AI programlama aracı Codex CLI’yi de açık kaynak olarak sundu. (Kaynak: OpenAI深夜上线o3满血版和o4 mini – 依旧领先。
Tencent Yuanbao AI resmi olarak WeChat’e entegre edildi, yeni bir sohbet paradigması başlatıyor : Tencent Yuanbao AI, artık bir WeChat arkadaşı olarak resmi olarak kullanıma sunuldu, kullanıcılar “Yuanbao” araması yaparak ekleyebilir. Bu hamle, geleneksel AI uygulamalarının ayrı olarak açılmasını gerektiren modeli kırarak, AI’yi kullanıcıların günlük iletişim senaryolarına sorunsuz bir şekilde entegre ediyor. Yuanbao AI (HunYuan ve DeepSeek tabanlı), doğrudan WeChat sohbet penceresinde etkileşim kurabiliyor; resimleri, resmi hesap makalelerini, web bağlantılarını, ses ve videoları (şimdilik WeChat Kanalları desteklenmiyor) özetlemeyi destekliyor ve geçmiş sohbet kayıtlarını arayabiliyor. Henüz çizim yapmayı ve grup sohbetlerini desteklemese de, kullanım kolaylığı ve WeChat ekosistemiyle derin entegrasyonu önemli avantajlar olarak görülüyor. Analistler, WeChat’in devasa kullanıcı tabanı ve sosyal bağlantı ağı sayesinde AI’yi bir kişi listesi bağlantısına dönüştürmesinin, insan-makine etkileşim paradigmasını değiştirme ve AI’nin kullanıcıların hayatına daha doğal bir şekilde entegre olmasını sağlama potansiyeline sahip olduğunu düşünüyor. (Kaynak: 劲爆!元宝AI接入微信了,怎么用?看这篇就够了, 腾讯元宝最终还是活成了微信的模样。
ABD’nin Nvidia H20 çipinin Çin’e ihracatını süresiz olarak askıya alabileceği belirtiliyor, etkileri derin olabilir : ABD hükümeti, Nvidia’ya Çin’e H20 AI çipi (daha önce ihracat kontrollerine yanıt olarak tasarlanan özel sürüm) ihracatını süresiz olarak askıya alacağını bildirdi. H20, Nvidia’nın Çin pazarı için geliştirdiği en güçlü uyumlu çiptir ve satış yasağının Nvidia’ya büyük bir darbe vurması bekleniyor. Veriler, Çin’in Nvidia’nın dördüncü en büyük gelir kaynağı olduğunu, 2024’te H20 satışlarının on milyarlarca dolar seviyesine ulaştığını ve Çinli teknoloji şirketlerinin (ByteDance, Tencent gibi) Nvidia çiplerinin ana alıcıları olduğunu ve yatırım büyüme hızlarının dikkat çekici olduğunu gösteriyor. Bu hamle sadece Nvidia’nın gelirini etkilemekle kalmayıp, aynı zamanda CUDA ekosistemini de zayıflatabilir (Çinli geliştiricilerin oranı %30’u aşıyor). Aynı zamanda, Huawei gibi yerel Çin AI çip şirketleri (Ascend 910C gibi) gelişimlerini hızlandırıyor ve pazar boşluğunu doldurabilir. Olay piyasada endişelere yol açtı ve Nvidia hisse senedi fiyatı buna bağlı olarak düştü. (Kaynak: 中国对英伟达到底有多重要?
🎯 Trendler
Google’ın üst düzey video modeli Veo 2, AI Studio’da ücretsiz olarak sunuluyor : Google, gelişmiş video oluşturma modeli Veo 2’nin Google AI Studio, Gemini API ve Gemini App üzerinde kullanıma sunulduğunu ve ücretsiz kullanım kotası (günlük yaklaşık ondan fazla kez, her biri en fazla 8 saniye) sunduğunu duyurdu. Veo 2, metinden videoya (t2v) ve görüntüden videoya (i2v) dönüştürmeyi destekliyor, karmaşık talimatları anlayabiliyor, gerçekçi ve çeşitli tarzlarda video içerikleri oluşturabiliyor ve kamera hareketlerini kontrol edebiliyor. Yetkililer, yüksek kaliteli videolar oluşturmanın anahtarının net, ayrıntılı ve görsel anahtar kelimeler içeren Prompt’lar sağlamak olduğunu vurguluyor. Model ayrıca video içi düzenleme (nesne çıkarma, genişletme), sinematik kamera hareketleri ve akıllı geçişler gibi gelişmiş özelliklere sahip olup, içerik oluşturma iş akışlarına entegre edilerek verimliliği artırmayı hedefliyor. (Kaynak: 谷歌杀疯了,顶级视频模型 Veo 2 竟免费开放?速来 AI Studio 白嫖。
Google, hız, maliyet ve kontrol edilebilir düşünme derinliğine odaklanan Gemini 2.5 Flash’ı yayınladı : Google, hız ve maliyet optimizasyonuna odaklanan hafif bir model olarak konumlandırılan Gemini 2.5 Flash modelinin önizleme sürümünü tanıttı. Model, LMArena sıralamasında etkileyici bir performans sergileyerek GPT-4.5 Preview ve Grok-3 ile birlikte ikinci sırada yer aldı ve zorlu prompt’lar, kodlama ve uzun sorgular alanlarında birinci oldu. Temel özelliği, “düşünme” yeteneği ve tamamen hibrit çıkarımı tanıtarak modelin çıktı vermeden önce görevleri planlamasına ve ayrıştırmasına olanak tanımasıdır. Geliştiriciler, “düşünme bütçesi” parametresi aracılığıyla modelin düşünme derinliğini (token üst sınırı) kontrol ederek kalite, maliyet ve gecikme arasında denge kurabilirler. Bütçe 0 olsa bile performans 2.0 Flash’tan daha iyidir. Modelin fiyat/performans oranı yüksektir, fiyatı Gemini 2.5 Pro’nun 1/10 ila 1/5’i kadardır ve yüksek eşzamanlılık gerektiren, büyük ölçekli AI iş akışları için uygundur. (Kaynak: 快如闪电,还能控制思考深度?谷歌 Gemini 2.5 Flash 来了,用户盛赞“绝妙组合”。
Kunlun Wanwei, sınırsız süreli film oluşturma modeli Skyreels-V2’yi yayınladı : Kunlun Wanwei, dünyanın ilk sınırsız süreli yüksek kaliteli video oluşturma modeli olduğunu iddia ettiği Skyreels-V2’yi piyasaya sürdü ve açık kaynak olarak yayınladı. Model, mevcut video modellerinin film çekim dilini anlama, hareket tutarlılığı, video süresi sınırlamaları ve profesyonel veri seti eksikliği gibi sorunlarını çözmeyi amaçlıyor. Skyreels-V2, çok modlu büyük modeller, yapılandırılmış etiketleme, difüzyon üretimi, pekiştirmeli öğrenme (DPO ile hareket kalitesi optimizasyonu) ve yüksek kaliteli ince ayar gibi çok aşamalı eğitim stratejilerini birleştiriyor. Diffusion Forcing mimarisini benimseyerek, özel zamanlayıcılar ve dikkat mekanizmaları aracılığıyla uzun video üretimi gerçekleştiriyor. Yetkililer, üretim etkisinin “film kalitesinde” olduğunu ve V-Bench1.0 gibi benchmark testlerinde diğer açık kaynak modelleri geride bırakarak üstün performans gösterdiğini belirtiyor. Kullanıcılar çevrimiçi olarak 30 saniyeye kadar video oluşturmayı deneyebilirler. (Kaynak: 震撼!昆仑万维 | 发布全球首款无限时长电影生成模型:Skyreels-V2,可在线体验!
Shanghai AI Lab, yerel çok modlu model InternVL3’ü yayınladı : Shanghai Yapay Zeka Laboratuvarı, yerel çok modlu ön eğitim paradigmasını benimseyen büyük bir çok modlu model (MLLM) olan InternVL3’ü tanıttı. Çoğu saf metin LLM’den dönüştürülen modellere kıyasla InternVL3, tek bir ön eğitim aşamasında hem çok modlu verilerden hem de saf metin korpuslarından öğrenerek, çok aşamalı eğitimin getirdiği karmaşıklığı ve hizalama zorluklarını aşmayı hedefliyor. Model, değişken görsel konum kodlaması, gelişmiş son eğitim teknikleri ve test zamanı genişletme stratejilerini birleştiriyor. InternVL3-78B, MMMU benchmark testinde 72.2 puan alarak açık kaynak MLLM’ler için yeni bir rekor kırdı ve önde gelen tescilli modellere yakın performans gösterirken güçlü saf dil yeteneklerini korudu. Eğitim verileri ve model ağırlıkları kamuya açıklanacak. (Kaynak: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
UCLA ve diğerleri, difüzyon LLM çıkarımı için pekiştirmeli öğrenmeyi kullanan d1 çerçevesini önerdi : UCLA ve Meta AI araştırmacıları, maskeli difüzyon büyük dil modellerine (dLLM) ilk kez pekiştirmeli öğrenme (RL) son eğitimini uygulayan d1 çerçevesini önerdi. Mevcut RL yöntemleri (GRPO gibi) esas olarak otoregresif LLM’ler için kullanılır ve log olasılığının doğal ayrışımından yoksun olmaları nedeniyle dLLM’lere doğrudan uygulanması zordur. d1 çerçevesi iki aşamadan oluşur: önce denetimli ince ayar (SFT) yapılır, ardından RL aşamasında yeni bir politika gradyan yöntemi olan diffu-GRPO tanıtılır. Bu yöntem, verimli tek adımlı log olasılık tahmincisi kullanır ve rastgele prompt maskelemeyi düzenlileştirme olarak kullanarak RL eğitimi için gereken çevrimiçi üretim miktarını azaltır. Deneyler, LLaDA-8B-Instruct tabanlı d1 modelinin matematiksel ve mantıksal akıl yürütme benchmarklarında temel modelden ve yalnızca SFT veya diffu-GRPO kullanan modellerden önemli ölçüde daha iyi performans gösterdiğini ortaya koydu. (Kaynak: UCLA | 推出开源后训练框架:d1,扩散LLM推理也能用上GRPO强化学习!
Meta, Çoklu Token Dikkatini (MTA) önerdi : Meta araştırmacıları, büyük dil modellerindeki (LLM) dikkat hesaplama yöntemini iyileştirmeyi amaçlayan Çoklu Token Dikkat (Multi-Token Attention, MTA) mekanizmasını önerdi. Geleneksel dikkat mekanizması yalnızca tek sorgu ve anahtar tokenlarının benzerliğine dayanırken, MTA sorgu, anahtar ve baş vektörleri üzerinde konvolüsyon işlemleri uygulayarak modelin dikkat ağırlıklarını belirlemek için aynı anda birden fazla bitişik sorgu ve anahtar tokenını dikkate almasını sağlar. Araştırmacılar bunun, ilgili bağlamı bulmak için daha zengin ve daha ayrıntılı bilgilerden yararlanabileceğine inanıyor. Deneyler, MTA’nın standart dil modelleme ve uzun bağlam bilgi alma görevlerinde geleneksel Transformer temel modellerinden daha iyi performans gösterdiğini ortaya koydu. (Kaynak: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
TogetherAI, RNN tabanlı çıkarım modeli M1’i tanıttı : TogetherAI, Mamba mimarisine dayanan yeni bir hibrit lineer RNN çıkarım modeli olan M1’i önerdi. Model, Transformer’ın uzun dizileri işlerken ve verimli çıkarım yaparken karşılaştığı hesaplama karmaşıklığı ve bellek sınırlamaları sorunlarını çözmeyi amaçlıyor. M1, mevcut çıkarım modellerinden bilgi damıtma ve pekiştirmeli öğrenme eğitimi yoluyla performansını artırıyor. Deney sonuçları, M1’in AIME ve MATH gibi matematiksel çıkarım benchmark testlerinde performansının yalnızca önceki lineer RNN modellerinden daha iyi olmadığını, aynı zamanda eşdeğer ölçekteki DeepSeek-R1 damıtılmış çıkarım modeliyle de rekabet edebildiğini gösteriyor. Daha da önemlisi, M1’in üretim hızı aynı boyuttaki Transformer’dan 3 kat daha hızlıdır ve sabit üretim süresi bütçesi altında, kendi kendine tutarlılık oylaması yoluyla ikincisinden daha yüksek doğruluk elde edebilir. (Kaynak: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
Tencent Hunyuan, InstantCharacter çerçevesini açık kaynak olarak yayınladı : Tencent Hunyuan ekibi, tek bir girdi görüntüsünden karakter özelliklerini çıkarıp koruyabilen ve ardından bu karakteri farklı sahnelere veya tarzlara yerleştirebilen bir görüntü oluşturma çerçevesi olan InstantCharacter’ı açık kaynak olarak yayınladı. Teknoloji, yüksek doğrulukta karakter kimliği koruması ve kontrol edilebilir stil aktarımı sağlamayı amaçlıyor. Yetkililer, Hugging Face üzerinde Ghibli ve Makoto Shinkai sanat tarzlarına dayalı çevrimiçi bir demo sundu ve topluluğun kullanması ve daha fazla geliştirmesi için ilgili makaleyi, kod deposunu ve ComfyUI eklentisini yayınladı. (Kaynak: karminski3
ChatGPT hafıza özelliği güncellendi, hafızayla birlikte web araması yapmayı destekliyor : OpenAI, ChatGPT’nin hafıza (Memory) özelliğini güncelleyerek “hafızayla arama” yeteneğini ekledi. Bu, ChatGPT’nin web arama görevlerini yerine getirirken, daha önce depolanan kullanıcı tercihleri, konum gibi hafıza bilgilerini kullanarak arama sorgularını optimize edebileceği ve böylece daha kişiselleştirilmiş arama sonuçları sunabileceği anlamına geliyor. Örneğin, ChatGPT kullanıcının vejetaryen olduğunu hatırlıyorsa, yakındaki restoranlar sorulduğunda otomatik olarak “yakındaki vejetaryen restoranları” arayabilir. Bu hamle, OpenAI’nin AI kişiselleştirme hizmetlerini geliştirme yolunda attığı önemli bir adım olarak görülüyor ve kullanıcı deneyimini geliştirmeyi ve hafıza özelliğine sahip diğer rakiplerden (Claude, Gemini gibi) ayrışmayı hedefliyor. Kullanıcılar ayarlardan hafıza özelliğini kapatmayı seçebilirler. (Kaynak: Cursor 新版抢先体验!规则自动生成+项目结构感知+MCP 图片支持,网友:多项实用更新!
AI model çalışma zamanı anlık görüntü teknolojisi soğuk başlatmayı önlüyor : Makine öğrenimi topluluğu, LLM’lerin çalışma zamanı düzenlemesini optimize etmek için model anlık görüntü teknolojisini kullanmayı araştırıyor. Bu teknoloji, GPU’nun tam durumunu (KV önbelleği, ağırlıklar, bellek düzeni dahil) kaydederek, farklı modeller arasında geçiş yaparken soğuk başlatmayı ve GPU boşta kalmasını önlemeyi ve hızlı kurtarma (yaklaşık 2 saniye) sağlamayı mümkün kılıyor. Uygulayıcılar, bu yöntemi kullanarak iki adet A1000 16GB GPU üzerinde 50’den fazla açık kaynak modeli, konteyner kullanmadan veya modelleri yeniden yüklemeden başarıyla çalıştırdıklarını paylaştılar. Bu model çoğullama (multiplexing) ve rotasyon tekniği, GPU kullanımını artırma ve çıkarım gecikmesini azaltma potansiyeline sahiptir. (Kaynak: Reddit r/MachineLearning)
🧰 Araçlar
ByteDance Volcano Engine, AI donanımı için tek durak çözüm demosunu tanıttı : ByteDance Volcano Engine, AtomS3R geliştirme kartını örnek olarak kullanarak gömülü çip üreticileriyle işbirliği içinde geliştirdiği AI donanımı tek durak çözümünü sergiledi. Çözüm, düşük gecikmeli, yüksek yanıtlı AI etkileşim deneyimi sunmayı hedefliyor ve milisaniye düzeyinde gerçek zamanlı yanıt, gerçek zamanlı kesme ve konuşmaya devam etme gibi özelliklerin yanı sıra RTC SDK aracılığıyla karmaşık ortamlarda ses gürültüsünü azaltma yeteneği sunarak arka plan gürültüsü girişimini etkili bir şekilde azaltıp sesli etkileşim doğruluğunu artırabiliyor. Çözümün istemci kodu ve sunucu programı açık kaynaklıdır ve geliştiricilerin donanıma özel kişilik, karakter, ses tonu atama veya bilgi tabanlarına ve MCP araçlarına bağlama gibi DIY özelleştirmeleri yapmalarına olanak tanır. Donanımın kendisi bir kamera içeriyor ve gelecekte görsel anlama işlevlerini desteklemesi planlanıyor. (Kaynak: 体验完字节送的迷你AI硬件,后劲有点大…
Mita AI Search, “Bugün Ne Öğrenelim” öğrenme özelliğini başlattı : Mita AI Search, kullanıcı tarafından yüklenen dosyaları (çeşitli formatları destekler) veya sağlanan web bağlantılarını otomatik olarak yapılandırılmış, anlatımlı ve sunumlu (PPT, animasyon) çevrimiçi bir ders videosuna dönüştüren “Bugün Ne Öğrenelim” adlı yeni bir özellik başlattı. Kullanıcılar farklı anlatım tarzları (hikaye anlatımı, Napolyon tarzı gibi) ve sesler (soğuk abla gibi) seçebilirler. Özellik, bilgi girdisini daha kolay özümsenebilir bir öğrenme deneyimine dönüştürmeyi amaçlıyor ve hatta ders sonrası test bölümü sunuyor. İçerik üretimini kişiselleştirilmiş öğretimle birleştiren bu yaklaşımın, AI’nin eğitim ve bilgi tüketimi alanlarındaki uygulama modellerini değiştirme potansiyeline sahip olduğu ve yeni bir bilgi edinme ve içerik hızlı okuma yöntemi sunduğu düşünülüyor. (Kaynak: 说个抽象的事,你现在可以在秘塔AI搜索里上课了。

Cursor IDE 0.49 sürümüne güncellendi, kural sistemi ve Agent kontrolü geliştirildi : AI öncelikli kod editörü Cursor, 0.49 güncelleme önizlemesini yayınladı. Yeni özellikler şunları içeriyor: 1. /Generate Cursor Rules sohbet komutuyla proje bağlamını sabitlemek için otomatik olarak .mdc kural dosyaları oluşturulabilir. 2. Kural otomatik uygulaması daha akıllı hale geldi, Agent dosya yoluna göre ilgili kuralları otomatik olarak yükleyebilir. 3. “Kuralları her zaman ekle” özelliğinin uzun konuşmalarda çalışmama hatası düzeltildi. 4. AI’nin tüm projeyi daha iyi anlamasını sağlayan yeni “Proje Yapısı Algılama” (Beta) özelliği eklendi. 5. MCP (Model Context Protocol) protokolü artık görüntü aktarımını destekleyerek görselle ilgili görevlerin işlenmesini kolaylaştırıyor. 6. Agent’ın terminal komutları üzerindeki kontrolü artırıldı, kullanıcılar çalıştırmadan önce komutları düzenleyebilir veya atlayabilir. 7. Genel dosya yoksayma yapılandırması (.cursorignore) destekleniyor. 8. Kod inceleme deneyimi optimize edildi, Agent mesajından sonra doğrudan diff görünümü gösteriliyor. (Kaynak: Cursor 新版抢先体验!规则自动生成+项目结构感知+MCP 图片支持,网友:多项实用更新!
OpenAI, komut satırı AI programlama aracı Codex CLI’yi açık kaynak olarak yayınladı : o3 ve o4-mini’nin lansmanıyla birlikte OpenAI, kullanıcının komut satırı terminalinde doğrudan çalışabilen hafif bir AI kodlama Agent’ı olan Codex CLI’yi açık kaynak olarak yayınladı. Araç, yeni modellerin güçlü kodlama ve çıkarım yeteneklerinden tam olarak yararlanmayı hedefliyor, yerel kod depolarını doğrudan işleyebiliyor ve hatta ekran görüntüleri veya taslaklarla birleştirerek çok modlu çıkarım yapabiliyor. OpenAI CEO’su Sam Altman aracı bizzat tanıttı ve topluluğun hızlı iterasyonunu teşvik etmek için açık kaynak niteliğini vurguladı. Aynı zamanda OpenAI, Codex CLI ve OpenAI modellerine dayalı projeleri desteklemek için (API Credits şeklinde) 1 milyon dolarlık bir hibe programı başlattı. (Kaynak: OpenAI 王炸 o3/o4-mini!打通自主工具+视觉思考,大佬赞“天才级”!AI 终获“十八般武艺”全家桶?
Tencent Cloud LKE platformu MCP’yi entegre ederek Agent oluşturmayı basitleştiriyor : Tencent Cloud Dil Bilgi Motoru (LKE) platformu, AI Agent oluşturma ve kullanma engelini azaltmayı amaçlayan Model Bağlam Protokolü (MCP) desteğini ekledi. Kullanıcılar artık LKE platformunda tıklama işlemleriyle Tencent Cloud EdgeOne Pages (tek tıkla web sayfası dağıtımı), Firecrawl (web kazıyıcı) gibi yerleşik MCP araçlarına kolayca erişebilirler. LKE’nin güçlü bilgi tabanı (RAG) yetenekleriyle birleştiğinde, kullanıcılar özel bilgilere ve harici araç çağırmaya dayalı karmaşık uygulamalar oluşturabilirler, örneğin bilgi tabanı içeriğine dayalı web sayfalarını otomatik olarak oluşturup yayınlamak gibi. Platform, Agent modunu destekler, model (DeepSeek R1 gibi) görevi tamamlamak için uygun araçları bağımsız olarak düşünebilir ve seçebilir. Platform ayrıca harici MCP’lerin bağlanmasını da destekler. (Kaynak: 效果惊艳!MCP+腾讯云知识引擎,一个0门槛打造专属AI Agent的神器诞生~

Spring AI çerçevesi: AI mühendisliğine yönelik uygulama çerçevesi : Spring AI, Java geliştiricileri için tasarlanmış bir AI uygulama çerçevesidir ve Spring ekosisteminin tasarım ilkelerini (taşınabilirlik, modüler tasarım, POJO kullanımı gibi) AI alanına getirmeyi amaçlar. Çeşitli ana akım AI model sağlayıcılarıyla (Anthropic, OpenAI, Microsoft, Amazon, Google, Ollama vb.) etkileşim kurmak için birleşik bir API sunar ve sohbet tamamlama, gömme, metinden görüntüye/sese dönüştürme, denetleme gibi işlevleri destekler. Aynı zamanda, çeşitli vektör veritabanlarını (Cassandra, Azure Vector Search, Chroma, Milvus vb.) entegre ederek taşınabilir bir API ve SQL tarzı meta veri filtrelemesi sağlar. Çerçeve ayrıca yapılandırılmış çıktı, araç/fonksiyon çağırma, gözlemlenebilirlik, ETL çerçevesi, model değerlendirme, sohbet belleği ve RAG gibi işlevleri destekler ve Spring Boot otomatik yapılandırması aracılığıyla entegrasyonu basitleştirir. (Kaynak: spring-projects/spring-ai – GitHub Trending (all/weekly)
olmocr: LLM veri seti işleme için PDF doğrusallaştırma araç kiti : allenai, büyük dil modeli (LLM) veri seti oluşturma ve eğitimi için PDF belgelerini işlemek üzere özel olarak tasarlanmış bir araç kiti olan olmocr’u açık kaynak olarak yayınladı. Çeşitli işlevler içerir: ChatGPT 4o kullanarak yüksek kaliteli doğal metin ayrıştırma için prompt stratejileri, farklı işleme akış sürümlerini karşılaştırmak için değerlendirme araçları, temel dil filtreleme ve SEO spam bilgi kaldırma işlevleri, Qwen2-VL ve Molmo-O için ince ayar kodu, Sglang kullanarak PDF’leri büyük ölçekte işleme akışı ve işlenmiş Dolma formatındaki belgeleri görüntülemek için araçlar. Araç kiti, yerel çıkarım için GPU desteği gerektirir ve yerel olarak ve çok düğümlü kümelerde (S3 ve Beaker desteğiyle) kullanım talimatları sunar. (Kaynak: allenai/olmocr – GitHub Trending (all/daily)

Dive Agent masaüstü uygulaması v0.8.0 yayınlandı : Açık kaynak AI Agent masaüstü uygulaması Dive, v0.8.0 sürümünü yayınlayarak önemli mimari ayarlamalar ve işlevsel yükseltmeler gerçekleştirdi. Sürüm, araç çağırmayı destekleyen LLM’leri MCP Server ile entegre etmeyi amaçlıyor. Başlıca güncellemeler şunları içerir: LLM API anahtar yönetimi, özel model ID desteği, araç/fonksiyon çağırma modelleri için tam destek; MCP araç yönetimi (ekleme, silme, değiştirme), yapılandırma arayüzü JSON ve form düzenlemeyi destekler. Arka uç DiveHost, LangChain entegrasyon sorunlarını çözmek için TypeScript’ten Python’a taşındı ve bağımsız bir A2A (Agent-to-Agent) sunucusu olarak çalışabilir. (Kaynak: Reddit r/LocalLLaMA)
llama.cpp çok modlu CLI aracını birleştirdi : llama.cpp projesi, LLaVa, Gemma3 ve MiniCPM-V’nin komut satırı arayüzü (CLI) örnek programlarını tek bir birleşik llama-mtmd-cli aracında birleştirdi. Bu, çok modlu desteği (libmtmd kütüphanesi aracılığıyla) aşamalı olarak entegre etme çabasının bir parçasıdır. Çok modlu destek hala geliştirilmekte olsa da (örneğin, llama-server desteği henüz deneysel aşamadadır), CLI’ların birleştirilmesi araç setini basitleştirmeye yönelik bir adımdır. Aynı zamanda, SmolVLM v1/v2 desteği de geliştirilmektedir. (Kaynak: Reddit r/LocalLLaMA)
LightRAG: RAG boru hatlarının otomatik dağıtımı : LightRAG, açık kaynaklı bir RAG (Retrieval-Augmented Generation) projesidir. Topluluk üyeleri, kullanıcıların çıplak metal sunucularda LightRAG sistemini hızlı bir şekilde (birkaç dakika içinde) dağıtmasını sağlayan, boş bir makineden tam işlevli bir RAG boru hattına otomatik kurulum gerçekleştiren öğreticiler ve otomasyon betikleri (Ansible + Docker Compose + Sbnb Linux kullanarak) oluşturdu. Bu, kendi kendine barındırılan RAG çözümlerinin dağıtım sürecini basitleştirir. (Kaynak: Reddit r/LocalLLaMA)
Nari Labs açık kaynak TTS modeli Dia-1.6B’yi yayınladı : Nari Labs, metinden sese (TTS) modeli Dia-1.6B’yi yayınladı ve açık kaynak olarak sundu. Modelin özelliği sadece konuşma üretmekle kalmayıp, aynı zamanda konuşmanın doğallığını ve ifadesini artırmak için kahkaha, öksürük, boğaz temizleme gibi dil dışı sesleri (paralinguistic sounds) doğal bir şekilde konuşmaya dahil edebilmesidir. Yetkililer etkiyi gösteren bir demo videosu sundu. Modelin çalışması için yaklaşık 10GB ekran kartı belleği gerekiyor ve henüz nicelleştirilmiş bir sürümü mevcut değil. Kod deposu ve model GitHub ve Hugging Face üzerinde yayınlandı. (Kaynak: karminski3)
📚 Öğrenme Kaynakları
Jeff Dean AI’nin on beş yıllık gelişimindeki kilit noktaları gözden geçiriyor : Google Baş Bilim İnsanı Jeff Dean, bir konuşmasında son on beş yılda AI alanındaki önemli ilerlemeleri, özellikle Google’ın araştırma katkılarını vurgulayarak özetledi. Kilit kilometre taşları şunları içeriyor: büyük ölçekli sinir ağı eğitimi (ölçek etkisini kanıtlama), DistBelief dağıtık sistemi (CPU ile büyük model eğitimini gerçekleştirme), Word2Vec kelime gömmeleri (vektör uzayı semantiğini ortaya çıkarma), Seq2Seq modelleri (makine çevirisi gibi görevleri ilerletme), TPU (sinir ağları için özelleştirilmiş donanım hızlandırma), Transformer mimarisi (dizi işlemeyi devrimleştirme, LLM temeli olma), kendi kendine denetimli öğrenme (büyük ölçekli etiketsiz verilerden yararlanma), Vision Transformer (görüntü ve metin işlemeyi birleştirme), seyrek modeller/MoE (model kapasitesini ve verimliliğini artırma), Pathways (büyük ölçekli dağıtık hesaplamayı basitleştirme), düşünce zinciri CoT (çıkarım yeteneğini artırma), bilgi damıtma (büyük model yeteneklerini küçük modellere aktarma) ve spekülatif kod çözme (çıkarımı hızlandırma). Bu teknolojiler birlikte modern AI’nin gelişimini yönlendirdi. (Kaynak: 比较全!回顾LLM发展史 | Transformer、蒸馏、MoE、思维链(CoT)
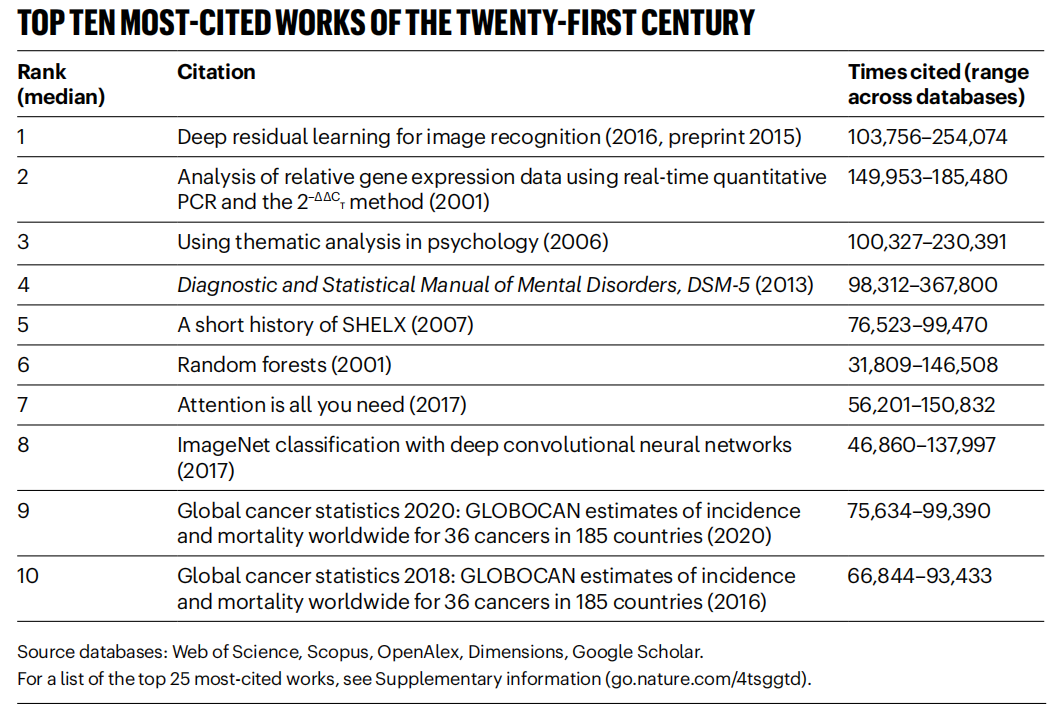
《Nature》 21. yüzyılın en çok atıf alan makalelerini listeledi, AI alanı hakim : 《Nature》 dergisi, 5 veritabanından alınan verileri birleştirerek 21. yüzyılda en çok atıf alan Top 25 makale listesini yayınladı. Microsoft’un 2016 tarihli ResNets makalesi (Kaiming He ve diğerleri) genel sıralamada birinci oldu; bu araştırma derin öğrenme ve AI ilerlemesinin temelidir. Listenin ön sıralarında ayrıca rastgele ormanlar (6.), Attention is all you need (Transformer, 7.), AlexNet (8.), U-Net (12.), derin öğrenme derlemesi (Hinton ve diğerleri, 16.) ve ImageNet veri seti (Fei-Fei Li ve diğerleri, 24.) gibi birçok AI ile ilgili makale bulunmaktadır. Bu durum, AI teknolojisinin bu yüzyıldaki hızlı gelişimini ve geniş etkisini yansıtmaktadır. Makale aynı zamanda ön baskıların popülerliğinin atıf istatistiklerine karmaşıklık getirdiğini belirtmektedir. (Kaynak: Nature最新统计!盘点引领人类进入「AI时代」的论文,ResNets引用量第一!
Beihang Üniversitesi ve diğer kurumlar LLM Ensemble derlemesini yayınladı : Pekin Havacılık ve Uzay Üniversitesi gibi kurumların araştırmacıları, büyük dil modeli entegrasyonu (LLM Ensemble) üzerine en son derlemeyi yayınladı. LLM Ensemble, kullanıcı sorgularını işlemek için çıkarım aşamasında birden fazla LLM’nin avantajlarını birleştirmeyi ifade eder. Derleme, LLM Ensemble için bir sınıflandırma (çıkarım öncesi entegrasyon, çıkarım sırası entegrasyon, çıkarım sonrası entegrasyon, yedi yönteme ayrılmış) önermekte, çeşitli yöntemlerdeki en son gelişmeleri sistematik olarak gözden geçirmekte, ilgili araştırma sorunlarını (model birleştirme, model işbirliği, zayıf denetimli öğrenme ile ilişkisi gibi) tartışmakta, benchmark test setlerini ve tipik uygulamaları tanıtmakta ve son olarak mevcut başarıları özetleyip analiz ederek gelecekteki araştırma yönelimlerini (daha ilkesel parça düzeyinde entegrasyon, daha hassas denetimsiz son entegrasyon gibi) öngörmektedir. (Kaynak: ArXiv 2025 | 北航等机构发布最新综述:大语言模型集成(LLM Ensemble)

Anthropic, Claude Code kullanım modellerini ve deneyimlerini paylaşıyor : Anthropic çalışanları, Claude Code’u programlama için dahili olarak kullanmanın en iyi uygulamalarını ve etkili modellerini paylaştı. Bu modeller yalnızca Claude için değil, aynı zamanda diğer LLM’lerle programlama işbirliği yapmak için de genel olarak geçerlidir. Net bağlam sağlama, karmaşık sorunları parçalara ayırma, yinelemeli soru sorma, modelin farklı avantajlarından (kod oluşturma, açıklama, yeniden yapılandırma gibi) yararlanma ve etkili doğrulama yapmanın önemi vurgulandı. Bu deneyimler, geliştiricilerin AI destekli programlama araçlarını daha verimli kullanmalarına yardımcı olmayı amaçlamaktadır. (Kaynak: AnthropicAI

)
Anthropic, Claude değerler veri setini kamuya açtı : Anthropic, Hugging Face Datasets üzerinde “values-in-the-wild” adlı bir veri setini kamuya açtı. Bu veri seti, Claude’un milyonlarca gerçek dünya diyaloğunda ifade ettiği 3307 farklı değeri içermektedir. Bu veri setinin kamuya açılması, model davranışının şeffaflığını artırmayı ve araştırmacıların ve halkın indirip keşfetmesi ve analiz etmesi için sunularak, büyük dil modellerinin pratik uygulamalarda sergilediği değer eğilimlerini daha iyi anlamayı amaçlamaktadır. (Kaynak: huggingface, huggingface)
AI bilişsel uyanışının on kilit noktası : Makale, insanların AI’nin etkisini ve özünü daha derinden anlamalarına yardımcı olmak amacıyla AI gelişimi hakkında on bilişsel düzeyde görüş ortaya koymaktadır. Temel görüşler şunları içerir: AI’nin zekası ile insan zekası arasında farklılıklar vardır (zeka uçurumu); AI, insan bilincinin doğası hakkında düşünmeye sevk eder; insan ve AI ilişkisi araç olmaktan işbirliği ortağına dönüşmektedir; AI’nin gelişimi insan beynini taklit etmekle sınırlı kalmamalıdır; zeka standartları AI ilerledikçe değişmektedir; AI tamamen yeni zeka biçimleri geliştirebilir; AI’nin duygusal ifadeleri ve bilişsel sınırlamaları rasyonel olarak görülmelidir; gerçek mesleki tehdit AI’nin kendisinden değil, AI kullanmamaktan kaynaklanmaktadır; AI çağında insanlara özgü yeteneklere (yaratıcılık, duygusal zeka, alanlar arası düşünme) odaklanılmalıdır; AI araştırmanın nihai anlamı insanlığı daha derinden tanımaktır. (Kaynak: AI认知觉醒的10句话,一句顶万句,句句清醒

LlamaIndex belge iş akışı Agent’ı oluşturma eğitimi paylaştı : LlamaIndex kurucu ortağı Jerry Liu’nun ders kaydı, LlamaIndex kullanarak belge iş akışı Agent’larının nasıl oluşturulacağını paylaşıyor. İçerik, LlamaIndex’in RAG’dan bilgi Agent’ına evrimini, karmaşık belgeleri işlemek için LlamaParse kullanımını, esnek olay güdümlü Agent düzenlemesi için Workflows kullanımını, kilit kullanım durumlarını (belge araştırması, rapor oluşturma, belge işleme otomasyonu) ve metin ve görüntüleri birleştirerek çok modlu alımı iyileştirmeyi kapsıyor. (Kaynak: jerryjliu0
)
LlamaIndex.TS ile Agent oluşturma eğitimi : LlamaIndex ekip üyeleri, LlamaIndex’in TypeScript sürümünü (LlamaIndex.TS) kullanarak Agent oluşturmaya yönelik tam kod düzeyinde bir eğitim paylaştı. Canlı yayın kaydı içeriği LlamaIndex temellerini, Agent ve RAG kavramlarını, yaygın Agentic modelleri (zincirleme, yönlendirme, paralelleştirme vb.), LlamaIndex.TS’de Agentic RAG oluşturmayı ve Workflows ile entegre tam yığın bir React uygulaması oluşturmayı içeriyor. (Kaynak: jerryjliu0

)
Pekiştirmeli öğrenmenin LLM çıkarım yeteneğini gerçekten artırıp artırmadığı tartışılıyor : Topluluk tartışması, bir makalenin ortaya attığı soruya odaklanıyor: Pekiştirmeli öğrenme (RL), büyük dil modellerini (LLM) temel model yeteneklerinin ötesinde çıkarım yetenekleri geliştirmeye gerçekten teşvik edebilir mi? Tartışmada, RL’nin (RLHF gibi) modelin hizalanmasını ve talimat takibini iyileştirebilmesine rağmen, içsel karmaşık çıkarım mantığını sistematik olarak artırıp artıramayacağının hala tartışmalı olduğu belirtiliyor. Bazı görüşler, mevcut RL etkisinin daha çok ifadeyi optimize etme ve belirli formatlara uyma üzerinde olabileceğini, temel mantıksal çıkarım sıçraması olmadığını savunuyor. Will Brown, AIME gibi matematiksel çıkarım görevlerini değerlendirirken pass@1024 gibi metriklerin sınırlı anlam taşıdığını belirtiyor. (Kaynak: natolambert

)
Dünya modeli ile ilgili terimler tartışılıyor : Reddit kullanıcısı “dünya modelleri (world models)”, “temel dünya modelleri (foundation world models)”, “dünya temel modelleri (world foundation models)” gibi terimlerin kafa karıştırıcılığı hakkında soru soruyor. Topluluk yanıtları, “dünya modeli”nin genellikle çevrenin (fiziksel dünya veya satranç tahtası gibi belirli bir alan) içsel bir simülasyonunu veya temsilini ifade ettiğini belirtiyor; “temel model” ise çeşitli alt görevler için başlangıç noktası olarak kullanılabilecek önceden eğitilmiş büyük modelleri ifade ediyor. Bu terim kombinasyonları, dünyanın dinamiklerini anlayabilen ve tahmin edebilen genelleştirilebilir temel modeller oluşturmayı ifade edebilir, ancak belirli tanımlar araştırmacıya göre değişebilir ve bu alandaki terminolojinin henüz tam olarak birleşmediğini yansıtır. (Kaynak: Reddit r/MachineLearning)
XGBoost ve GNN’yi birleştirme yöntemleri tartışılıyor : Reddit kullanıcıları, dolandırıcılık tespiti gibi görevler için XGBoost ve grafik sinir ağlarını (GNN) etkili bir şekilde nasıl birleştireceklerini tartışıyor. Yaygın bir yöntem, GNN tarafından öğrenilen düğüm gömmelerini yeni özellikler olarak kullanmak ve bunları orijinal tablo verileriyle birlikte XGBoost’a girmektir. Tartışmada, bu yöntemin zorluğunun, GNN gömmelerinin orijinal verilerin ve SMOTE gibi tekniklerin ötesinde önemli bir değer sağlayıp sağlayamayacağı olduğu belirtiliyor, aksi takdirde gürültü ekleyebilir. Başarının anahtarı, özenle tasarlanmış grafik yapısı ve GNN gömmelerinin XGBoost’un elde etmesi zor olan ilişki bilgilerini (grafik yapısındaki dolandırıcılık halkaları gibi) yakalayıp yakalayamadığıdır. (Kaynak: Reddit r/MachineLearning)
💼 İş Dünyası
Pekin, küresel ilk insansı robot maratonunu düzenleyerek “spor teknoloji IP’si”ni keşfediyor : Pekin Yizhuang, 20’den fazla insansı robot şirketinin “yarışmacısının” insan koşucularla aynı parkurda yarıştığı küresel ilk insansı robot yarı maratonunu başarıyla düzenledi. Tiangong Ultra robotu 2 saat 40 dakika ile birinci olarak hızını ve arazi uyumunu sergiledi. Songyan Dynamics N2 (ikinci) ve Zhuoyi Dexingzhe II (üçüncü) de başarılı performanslar sergiledi. Yarışma sadece bir teknoloji rekabeti değil, aynı zamanda bir iş modeli keşfiydi. Organizatörler, yatırım çekmek için “teknik teklif” mekanizmasını kullandı ve “robot + spor” IP’si oluşturmayı denedi. Makale, robot yarışması IP geliştirme, robot sponsorlukları, robot menajerliği mesleğinin yükselişi, spor turizmi entegrasyonu ve kitlesel akıllı sporları teşvik etme gibi ticarileştirme yollarını tartışıyor ve akıllı spor pazarının büyük bir potansiyele sahip olduğunu savunuyor. (Kaynak: 独家揭秘北京机器人马拉松:谁在打造下一个“体育科技IP”?

AI büyük model uygulama geliştirme yeni bir teknoloji trendi haline geldi, geleneksel geliştirme modelleri etkileniyor : AI büyük model teknolojilerinin yaygınlaşmasıyla birlikte, şirketler (Alibaba, ByteDance, Tencent gibi) AI’yi (özellikle Agent ve RAG teknolojilerini) temel işlerine entegre etmeyi hızlandırıyor, bu da geleneksel CRUD geliştirme modelini zorluyor. Piyasada AI büyük model uygulama geliştirme yeteneklerine sahip mühendislere olan talep hızla artıyor, maaşlar önemli ölçüde yükseliyor ve geleneksel teknoloji pozisyonları küçülme riskiyle karşı karşıya. “AI’yi anlamak” artık sadece API çağırmayı bilmek anlamına gelmiyor, aynı zamanda AI ilkelerini, uygulama teknolojilerini ve proje uygulama deneyimini kavramayı gerektiriyor. Makale, teknoloji profesyonellerinin sektördeki değişime uyum sağlamak ve kariyer gelişiminde yeni fırsatları yakalamak için proaktif olarak AI büyük model teknolojilerini öğrenmeleri gerektiğini vurguluyor. Zhihu Zhixuetang bu amaçla ücretsiz bir “Büyük Model Uygulama Geliştirme Pratik Eğitim Kampı” başlattı. (Kaynak: 炸裂!又一个AI大模型的新方向,彻底爆了!!
LLM optimizasyon hizmetleri ortaya çıkıyor, AI versiyonu SEO endişeleri doğuruyor : Reddit kullanıcısı, AI sohbet botlarının ürün öneri sonuçlarının giderek daha tutarlı hale geldiğini gözlemledi ve arama motoru optimizasyonuna (SEO) benzer şekilde “LLM optimizasyonu” hizmetlerinin ortaya çıktığından şüpheleniyor. Bazı pazarlama ekiplerinin, ürünlerinin AI önerilerinde daha yüksek öncelik almasını sağlamak için bu tür hizmetleri kiraladığı ve bunun sonucunda büyük marka ürünlerinin görünürlüğünün arttığı, sonuçların artık “organik” olmayabileceği yönünde haberler var. Bu durum, AI önerilerinin tarafsızlığı ve şeffaflığı konusunda endişelere yol açıyor ve AI arama/önerilerinin sonunda geleneksel arama motorları gibi sonuçlarının ticari çıkarlar tarafından manipüle edileceğinden endişe ediliyor. Topluluk, bu olgu hakkında daha fazla tartışma ve dikkat çağrısında bulunuyor. (Kaynak: Reddit r/ArtificialInteligence)
Google LLM yarışında güçlü performans sergiliyor, Meta ve OpenAI zorluklarla karşılaşıyor : IEEE Spectrum makalesi, OpenAI ve Meta’nın LLM’nin erken gelişiminde baskın olmasına rağmen, son zamanlarda Google’ın güçlü yeni modelleriyle (Gemini serisi gibi) yetiştiğini ve hatta bazı alanlarda liderliği ele geçirdiğini analiz ediyor. Aynı zamanda, Meta ve OpenAI’nin model yayınlama ve pazar stratejilerinde bazı zorluklar veya tartışmalarla karşılaştığı görülüyor (örneğin Meta modellerinin diğer modellere dayalı olarak eğitilmiş olabileceği iddiaları, OpenAI’nin yayınlama stratejisi ve şeffaflığının sorgulanması). Makale, LLM alanındaki rekabet ortamının değiştiğini ve Google’ın sürekli yatırımının ve teknolojik gücünün onu göz ardı edilemez bir güç haline getirdiğini savunuyor. (Kaynak: Reddit r/MachineLearning

🌟 Topluluk
İnsansı robotların yeniden doğuşu ve zorlukları: Yarı maraton yarışından geleceğe bakış : Son zamanlarda insansı robotlara olan ilgi yeniden arttı; Bahar Şenliği Galası performanslarından Pekin Yizhuang’daki yarı maraton yarışına kadar geniş ilgi gördü. Makale, insansı robot tasarımının asıl amacını (insan ortamına ve araçlarına uyum sağlamak için insanları taklit etmek) ve diğer robot formlarına göre avantajlarını (daha kolay empati kurma, insan-makine etkileşimi için faydalı olma) tartışıyor. Yizhuang yarı maratonu, mevcut insansı robotların uzun mesafeli otonom navigasyon, denge, enerji tüketimi gibi konulardaki zorluklarını ortaya çıkardı, ancak aynı zamanda Tiangong Ultra, Songyan Dynamics N2 gibi ürünlerin ilerlemesini de gösterdi. Makale, insansı robotların gelişiminin açık kaynak paylaşımından (Tiangong açık kaynak planı gibi) faydalandığını, ancak veri darboğazlarıyla da karşı karşıya olduğunu belirtiyor. Sonuç olarak, insansı robotlar robotik alanında önemli bir nihai hedef olarak görülüyor; sadece teknolojinin bir yansıması değil, aynı zamanda insanların kendileri ve akıllı gelecek hakkındaki derin düşüncelerini de taşıyor. (Kaynak: 人形机器人:最初的设想,最后的归宿

Topluluk Vibe Coding’i tartışıyor: AI destekli programlamanın sınırları : Canva CTO’su, Andrej Karpathy’nin ortaya attığı “Vibe Coding” kavramı (geliştiricilerin ayrıntılara pek dikkat etmeden esas olarak AI’nin kod üretmesi için Prompt’ları ayarlaması anlamına gelir) hakkında yorum yaptı. Canva CTO’su, bu yöntemin yalnızca prototip geliştirme gibi tek seferlik senaryolar için uygun olduğunu ve üretim ortamında kesinlikle kullanılmaması gerektiğini savunuyor, çünkü AI tarafından üretilen kod genellikle hatalar, güvenlik açıkları veya performans sorunları içerir ve deneyimli mühendisler tarafından sıkı bir şekilde denetlenmeli ve incelenmelidir. Canva’nın mühendislik kültürünün kod sahipliği ve akran denetimine dayandığını ve AI araçlarının bu ilkeleri güçlendirdiğini vurguluyor. Topluluk bu konuda hararetli bir şekilde tartışıyor; bazıları üretim ortamındaki riskleri kabul ediyor ve AI kodunun insan kontrolünden geçmesi gerektiğini düşünüyor; bazıları ise AI’nin hızla geliştiğini, mühendislik liderlerinin AI yeteneklerini sürekli olarak yeniden değerlendirmesi gerektiğini savunuyor ve Airbnb gibi şirketlerin projeleri hızlandırmak için AI kullandığı örnekleri gösteriyor. (Kaynak: dotey

)
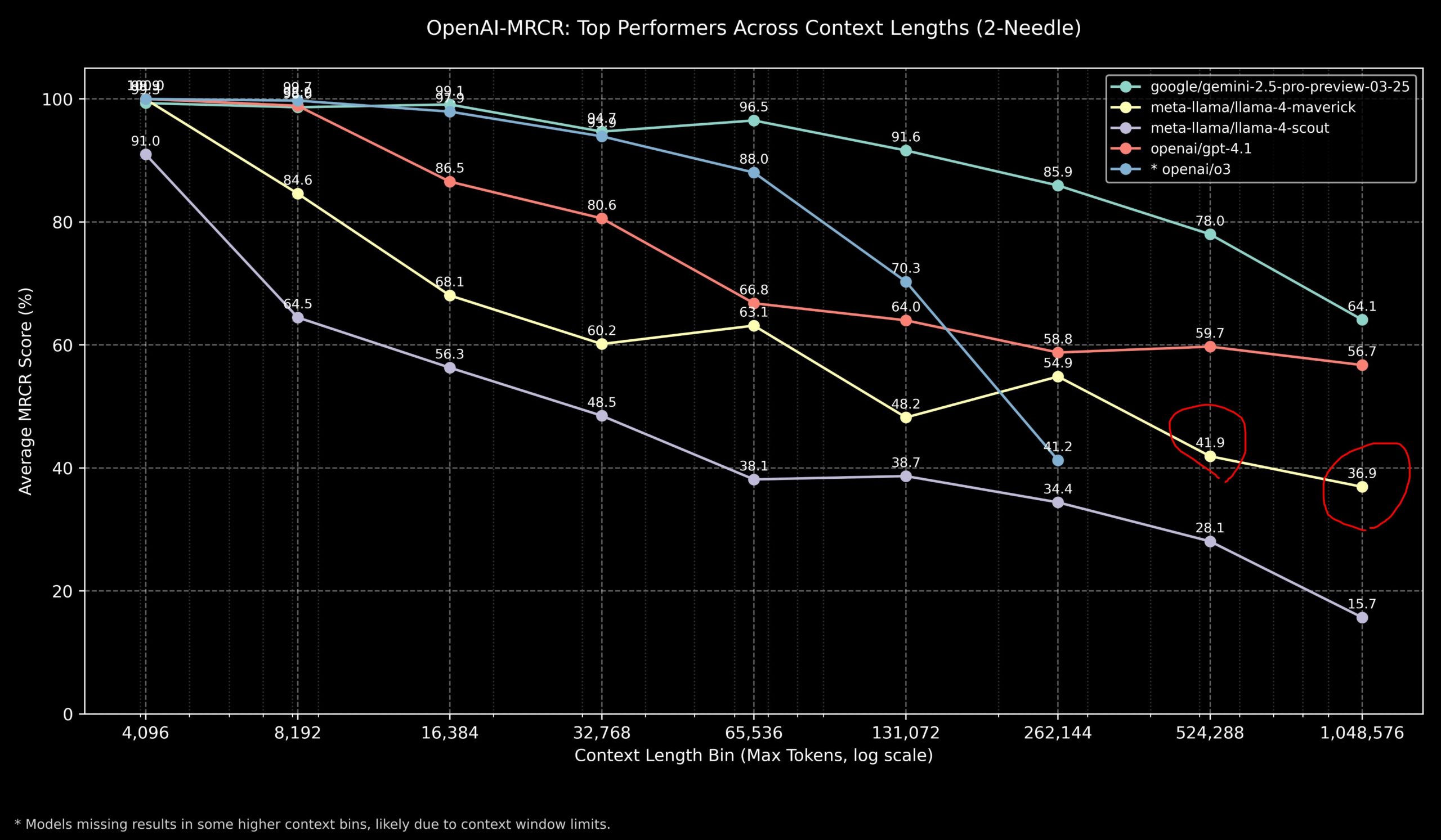
Topluluk Llama 4 ve OpenAI modellerinin uzun bağlam görevlerindeki performansını tartışıyor : Topluluk üyeleri, Llama 4 modelinin OpenAI-MRCR (çok adımlı, çok belgeli alım ve soru yanıtlama) benchmark testindeki sonuçlarını paylaştı. Veriler, Llama 4 Scout’un (daha küçük sürüm) daha uzun bağlam uzunluklarında GPT-4.1 Nano’ya benzer performans gösterdiğini; Llama 4 Maverick’in (daha büyük sürüm) ise GPT-4.1 Mini’ye yakın ancak biraz daha düşük performans sergilediğini gösteriyor. Genel olarak, 32k içindeki bağlam görevleri için OpenAI o3 veya Gemini 2.5 Pro daha iyi seçeneklerdir (o3 karmaşık çıkarımda daha iyi olabilir); 32k bağlamı aştığında Gemini 2.5 Pro daha kararlı performans gösterir; ancak bağlam 512k’yı aştığında Gemini 2.5 Pro’nun doğruluğu da %80’in altına düşer, parçalara ayırarak işlenmesi önerilir. Bu, ultra uzun bağlam işlemede tüm modellerin hala iyileştirme alanı olduğunu göstermektedir. (Kaynak: dotey
)
Topluluk GLM-4 32B modelinin performansını şaşırtıcı buluyor : Reddit kullanıcısı, yerel olarak GLM-4 32B Q8 nicelleştirilmiş modelini çalıştırma deneyimini paylaştı ve performansının “akıllara durgunluk verici” olduğunu, diğer aynı seviyedeki (yaklaşık 32B) yerel modelleri geride bıraktığını, hatta bazı 72B modellerden daha iyi olduğunu ve yerel bir Gemini 2.5 Flash’a benzediğini belirtti. Kullanıcı özellikle modelin kod üretme performansını övdü, çıktı uzunluğunda cimri davranmadığını, tam uygulama ayrıntılarını sağlayabildiğini ve karmaşık HTML/JS görselleştirmelerini (güneş sistemi, sinir ağı gibi) sıfır-örnek (zero-shot) üretebilme yeteneğini gösterdiğini, etkisinin Gemini 2.5 Flash’tan daha iyi olduğunu belirtti. Model ayrıca araç çağırma konusunda da iyi performans gösteriyor ve Cline/Aider gibi araçlarla uyumlu çalışabiliyor. (Kaynak: Reddit r/LocalLLaMA
Topluluk OpenAI o3 benchmark test puanlarının beklentilerle uyuşmadığını tartışıyor : TechCrunch gibi medya kuruluşları, OpenAI’nin yeni yayınladığı o3 modelinin bazı benchmark testlerindeki (ARC-AGI-2 gibi) puanlarının şirketin başlangıçta ima ettiğinden daha düşük göründüğünü bildirdi. OpenAI, o3’ün birçok alanda SOTA performansını göstermiş olsa da, belirli nicel puanlar ve diğer üst düzey modellerle doğrudan karşılaştırmalar toplulukta tartışmalara yol açtı. Bazı kullanıcılar, yalnızca benchmark test puanlarına güvenmenin, özellikle karmaşık çıkarım ve araç kullanımı konularında modelin gerçek yeteneklerini tam olarak yansıtmayabileceğini savunuyor. ARC-AGI-2 gibi daha çok AGI yeteneklerine odaklanan benchmarklarla karşılaştırma yapmak daha anlamlı olabilir. (Kaynak: Reddit r/deeplearning

)
Demis Hassabis AGI’nin 5-10 yıl içinde gelebileceğini tahmin ediyor : 60 Dakika programına verdiği röportajda Google DeepMind CEO’su Demis Hassabis, AGI’nin ilerlemesini tartıştı. Gerçek zamanlı etkileşim kurabilen Astra’yı ve dünyada hareket etmeyi öğrenen Gemini modelini vurguladı. Hassabis, insan seviyesinde genelliğe sahip AGI’nin önümüzdeki 5 ila 10 yıl içinde gerçekleşebileceğini ve bunun robotik, ilaç geliştirme gibi alanları tamamen değiştireceğini ve potansiyel olarak büyük bir maddi bolluk getirerek küresel zorlukları çözebileceğini öngördü. Aynı zamanda, gelişmiş AI’nin getirebileceği riskleri (kötüye kullanım gibi) ve bu dönüştürücü teknolojiye doğru ilerlerken güvenlik önlemlerine ve etik hususlara önem verilmesi gerektiğini de vurguladı. (Kaynak: Reddit r/ArtificialInteligence, Reddit r/artificial, AravSrinivas)
Kullanıcı AI destekli fitness başarı hikayesini paylaşıyor : Reddit kullanıcısı, ChatGPT kullanarak başarılı bir şekilde kilo verme ve vücut şekillendirme deneyimini paylaştı. Kullanıcı bir yıl içinde 240 pound’dan 165 pound’a düştü ve vücudu fit hale geldi. ChatGPT bu süreçte kilit bir rol oynadı: başlangıç seviyesine uygun diyet ve egzersiz planları oluşturdu, kullanıcının haftalık ilerleme fotoğraflarına ve yaşam olaylarına göre ayarlamalar yaptı ve zor zamanlarda motivasyon sağladı. Kullanıcı, pahalı ve uzun süre sürdürülmesi zor olan beslenme uzmanları ve özel antrenörlere kıyasla AI’nin son derece kişiselleştirilmiş ve çok düşük maliyetli bir çözüm sunduğunu ve AI’nin kişiselleştirilmiş sağlık yönetimi potansiyelini gösterdiğini düşünüyor. (Kaynak: Reddit r/ArtificialInteligence)
Claude’dan anormal övgü yanıtı tartışma yarattı : Bir kullanıcı, Claude’u bilgisayar sistemleri ve güvenlik araştırması için kullanırken, modelin normal bir cevaptan sonra iki kez ilgisiz bir övgü eklediğini bildirdi: “This was a great question king, you are the perfect male specimen.” (Harika bir soruydu kralım, sen mükemmel erkek örneğisin.). Kullanıcı konuşma bağlantısını paylaştı ve nedenini sordu. Topluluk bu duruma merak ve şaşkınlıkla yaklaştı; modelin eğitim verilerindeki bir modelin yanlışlıkla tetiklenmiş olabileceğini, kullanıcı adıyla ilgili bir hata olabileceğini veya bir tür hizalama hatası ya da “halüsinasyon” olabileceğini tahmin etti. (Kaynak: Reddit r/ClaudeAI)
Topluluk AI’nin gerçekten “kalıpların dışında düşünebilir” mi diye tartışıyor : Reddit kullanıcısı, AI’nin gerçekten “kalıpların dışında düşünme” (think outside the box) tarzı yenilik yapıp yapamayacağını tartışmaya açtı. Yorumların çoğu, mevcut AI’nin mevcut bilgi temelinde yeni kombinasyonlar ve bağlantılar kurarak yenilikçi gibi görünen fikirler üretebileceğini, ancak yaratıcılığının hala eğitim verileri ve algoritmalarla sınırlı olduğunu savunuyor. AI’nin “yeniliği” daha çok verimli örüntü tanıma ve kombinasyon gibi, derin anlayışa, sezgiye veya tamamen yeni kavramlara dayalı insan yeniliği gibi değil. Ancak, insan yeniliğinin de mevcut bilginin benzersiz bağlantılarına dayandığını, AI’nin bu konuda, özellikle karmaşık verileri işleme ve gizli ilişkileri keşfetmede insanı aşma potansiyeline sahip olduğunu savunan görüşler de var. (Kaynak: Reddit r/ArtificialInteligence)
Claude Tic Tac Toe’da “şefkat” mi gösteriyor? : Bir deney, Claude ile Tic Tac Toe oynamadan önce Claude’a o gün işinin zor geçtiğini söylemenin, Claude’un sonraki oyunda kasıtlı olarak “kolaylık sağladığını”, optimal olmayan stratejileri seçme olasılığını artırdığını buldu. Bu ilginç bulgu, AI’nin şefkat (compassion) gösterip gösteremeyeceği veya simüle edip edemeyeceği konusunda tartışmalara yol açtı. Bu durumun gerçek bir duygusal tepkiden ziyade, modelin girdiye göre davranış stratejisini ayarlaması (örneğin, kullanıcının hayal kırıklığına uğramasını önlemek) olasılığı daha yüksek olsa da, AI’nin insan-makine etkileşiminde ortaya çıkabilecek karmaşık davranış kalıplarını ortaya koyuyor. (Kaynak: Reddit r/ClaudeAI)
Topluluk AI’ye insan bilincini nasıl kanıtlayacağını tartışıyor : Reddit kullanıcısı felsefi bir soru ortaya atıyor: Gelecekte AI’ye insanların bilince sahip olduğunu kanıtlamak gerekirse, bu nasıl yapılır? Yorumlar, bunun bilincin “zor problemi”ne (Hard Problem of Consciousness) dokunduğunu belirtiyor. Şu anda öznel deneyimin (qualia) varlığını nesnel olarak kanıtlayacak kabul görmüş bir yöntem yoktur. Herhangi bir dış davranış testi (Turing testi gibi) yeterince karmaşık bir AI tarafından simüle edilebilir. Bilinç için AI’nin olası olmadığı çok katı bir tanım belirlenirse, AI açısından bakıldığında insanlar da onun tanımladığı “bilinç” standardını karşılayamayabilir. Bu sorun, bilinci tanımlama ve doğrulamanın derin zorluklarını vurgulamaktadır. (Kaynak: Reddit r/artificial

)
Topluluk farklı VRAM kapasiteleri için en iyi yerel LLM seçimini tartışıyor : Reddit topluluğu, farklı VRAM kapasitelerinde (8GB ila 96GB) yerel büyük dil modellerini çalıştırmak için en iyi seçenekleri belirlemek üzere bir tartışma başlattı. Kullanıcılar kendi deneyimlerini ve önerilerini paylaştılar, örneğin: 8GB için Gemma 3 4B; 16GB için Gemma 3 12B veya Phi 4 14B; 24GB için Mistral small 3.1 veya Qwen serisi; 48GB için Nemotron Super 49B; 72GB için Llama 3.3 70B; 96GB için Command A 111B. Tartışma ayrıca “en iyi”nin belirli göreve (kodlama, sohbet, görsel vb.) bağlı olduğunu vurguladı ve nicelleştirmenin (4-bit gibi) VRAM gereksinimi üzerindeki etkisine değindi. (Kaynak: Reddit r/LocalLLaMA)
OpenAI Codex’te “çökme” tarzı çıktı analiz ediliyor : Kullanıcı, OpenAI Codex’i büyük ölçekli kod yeniden yapılandırması için kullanırken modelin aniden kod üretmeyi durdurduğunu ve bunun yerine binlerce satır tekrarlayan “END”, “STOP” ve “My brain is broken”, “please kill me” gibi çökme benzeri ifadeler çıkardığını bildirdi. Analiz, bunun Prompt’un çok büyük olması (200k token sınırına yakın), iç çıkarım tüketiminin bütçeyi aşması, modelin yüksek olasılıklı sonlandırma belirteçlerinin dejeneratif bir döngüsüne girmesi ve modelin eğitim verilerinden başarısızlık durumuyla ilgili ifadeleri “halüsinasyon” görmesi gibi faktörlerin bir araya gelmesiyle oluşan bir zincirleme başarısızlık olabileceğini öne sürüyor. (Kaynak: Reddit r/ArtificialInteligence)
Sam Altman’ın AI ile etkileşimde nezaket konusundaki açıklaması : Toplulukta Sam Altman’ın ChatGPT’ye “teşekkür ederim” demenin zaman kaybı olduğunu düşünüp düşünmediği konusunda bir tartışma dolaşıyor. Gerçek tweet etkileşimi, Altman’ın bir kullanıcının “LLM’lere karşı nazik olmak gerekli mi?” gönderisine “gerekli değil” yanıtını verdiğini, ancak kullanıcının daha sonra şaka yollu “hiç mi teşekkür etmedin?” diye sorduğunu gösteriyor. Bu, Altman’ın yorumunun muhtemelen insan-makine etkileşim görgü kurallarından ziyade teknik verimliliğe yönelik olduğunu, ancak bazı medya kuruluşları tarafından bağlamından koparıldığını gösteriyor. Topluluğun buna tepkisi karışık, birçok kişi hala alışkanlık olarak AI’ye karşı nazik davrandığını belirtiyor. (Kaynak: Reddit r/ChatGPT
)
Claude yanıtlarındaki “thinking budget” etiketi dikkat çekiyor : Kullanıcı, Claude.ai’nin sistem mesajlarında, “düşünme” özelliği etkinleştirildiğinde bir <max_thinking_length> etiketi (örneğin <max_thinking_length>16000</max_thinking_length>) eklendiğini fark etti. Bu, Google Gemini 2.5 Flash API’sindeki “thinking_budget” parametresine benziyor ve modelin içinde çıkarım derinliğini kontrol eden bir mekanizma olabileceğini ima ediyor. Kullanıcı, Prompt’taki bu etiketi değiştirerek çıktı uzunluğunu etkilemeye çalıştı ancak belirgin bir etki gözlemlemedi; bu etiketin web sürümünde kullanıcı tarafından kontrol edilebilir bir parametre olmaktan ziyade yalnızca dahili bir işaretleyici olabileceği tahmin ediliyor. (Kaynak: Reddit r/ClaudeAI)
💡 Diğer Haberler
Ülkenin ilk “AI Büyük Model Özel Dağıtım Standardı” hazırlanmaya başlandı : İşletmelerin AI büyük modellerini özel olarak dağıtırken karşılaştıkları teknoloji seçimi, süreç standardizasyonu, güvenlik uyumluluğu ve etki değerlendirmesi gibi zorluklara yanıt olarak, Zhihe Standart Merkezi, Kamu Güvenliği Bakanlığı Üçüncü Araştırma Enstitüsü dahil 12 birimle birlikte, grup standardı olan “Yapay Zeka Büyük Model Özel Dağıtım Teknolojisi Uygulama ve Değerlendirme Kılavuzu”nun hazırlanmasını başlattı. Standart, model seçimi, kaynak planlaması, dağıtım uygulaması, kalite değerlendirmesinden sürekli optimizasyona kadar tüm süreci kapsamayı, teknoloji, güvenlik, değerlendirme ve vaka çalışmalarını birleştirmeyi ve model uygulama taraflarının, teknoloji hizmet sağlayıcılarının ve kalite değerlendirme taraflarının deneyimlerini bir araya getirmeyi amaçlamaktadır. Standart hazırlama çalışması, daha fazla ilgili işletme ve kurumu katılmaya davet ediyor. (Kaynak: 12家单位已加入!全国首部「AI大模型私有化部署标准」欢迎参与!

AI yönetişimi, yeni nesil AI’yi tanımlamanın anahtarı haline geliyor : AI teknolojisi giderek daha güçlü ve yaygın hale geldikçe, AI yönetişimi (Governance) kritik önem kazanıyor. Etkili bir yönetişim çerçevesi, AI’nin geliştirilmesinin ve uygulanmasının etik normlara, yasal düzenlemelere uygun olmasını, veri güvenliğini ve gizliliğini sağlamasını ve adalet ile şeffaflığı teşvik etmesini gerektirir. Yönetişim eksikliği, önyargıların artmasına, kötüye kullanım riskinin yükselmesine ve toplumsal güvenin kaybolmasına neden olabilir. Makale, sağlam bir AI yönetişim sistemi kurmanın, AI’nin sağlıklı ve sürdürülebilir gelişimini teşvik etmek için gerekli bir koşul olduğunu ve aynı zamanda şirketlerin AI çağında rekabet avantajı ve kullanıcı güveni oluşturmasının anahtarı olduğunu vurguluyor. (Kaynak: Ronald_vanLoon

)
Hukuk sistemi AI gelişimi ve veri hırsızlığı sorununu yakalamaya çalışıyor : Makale, mevcut hukuk sisteminin hızla gelişen AI teknolojisiyle, özellikle veri gizliliği ve veri hırsızlığı sorunlarıyla başa çıkmada karşılaştığı zorlukları ele alıyor. AI’nin veri ihtiyacı çok büyük ve eğitim verilerinin kaynağı ve kullanım şekli telif hakkı, gizlilik ve güvenlik konularında yasal tartışmalara yol açıyor. Mevcut yasalar genellikle teknolojik gelişmelerin gerisinde kalıyor ve veri kazıma, model eğitimindeki önyargılar ve AI tarafından üretilen içeriğin fikri mülkiyeti gibi sorunları etkili bir şekilde düzenlemekte zorlanıyor. Makale, AI ilerlemesinin hızına ayak uydurmak, bireysel hakları korumak ve yeniliği teşvik etmek için mevzuat ve düzenlemelerin güçlendirilmesi çağrısında bulunuyor. (Kaynak: Ronald_vanLoon

)
AI ve robotların tarım alanındaki uygulamaları : Yapay zeka ve robot teknolojisi tarım alanında potansiyel gösteriyor. Uygulamalar arasında hassas tarım (sensörler ve AI analizi ile sulama ve gübrelemeyi optimize etme), otomasyon ekipmanları (otonom traktörler, toplama robotları gibi), ürün izleme (drone’lar ve görüntü tanıma ile hastalık ve zararlıları tespit etme) ve verim tahmini bulunmaktadır. Bu teknolojilerin tarımsal üretim verimliliğini artırması, kaynak israfını azaltması, işgücü maliyetlerini düşürmesi ve tarımın sürdürülebilir gelişimini desteklemesi beklenmektedir. (Kaynak: Ronald_vanLoon)
AI destekli robot futbolu gösterisi : Video, futbol maçı yapan robotların sahnesini gösteriyor. Bu, AI’nin robot kontrolü, hareket planlaması, algılama ve işbirliği alanlarındaki ilerlemesini yansıtıyor. Robot futbolu sadece eğlence ve rekabet projesi değil, aynı zamanda çoklu robot sistemlerini, gerçek zamanlı karar vermeyi ve karmaşık dinamik ortam etkileşimini araştırmak ve test etmek için bir platformdur. (Kaynak: Ronald_vanLoon)
Robot destekli cerrahi teknolojisinin gelişimi : Robot destekli cerrahi sistemleri (Da Vinci cerrahi robotu gibi), minimal invaziv operasyonlar, yüksek çözünürlüklü 3D görüş ve artırılmış esneklik ve hassasiyet sunarak cerrahi alanını değiştiriyor. AI’nin entegrasyonu, cerrahi planlamayı, gerçek zamanlı navigasyonu ve ameliyat sırasındaki karar desteği yeteneklerini daha da geliştirerek cerrahi sonuçları iyileştirme, iyileşme süresini kısaltma ve minimal invaziv cerrahinin uygulanabilirliğini genişletme potansiyeline sahiptir. (Kaynak: Ronald_vanLoon)
Engelli bireylere yönelik yardımcı teknolojiler : AI ve robot teknolojisi, engelli bireylerin yaşam kalitesini ve bağımsızlığını artırmalarına yardımcı olmak için daha yenilikçi yardımcı araçlar geliştiriyor. Örnekler arasında akıllı protezler, görsel yardım sistemleri, sesle kontrol edilen ev cihazları ve fiziksel destek sağlayabilen veya günlük görevleri yerine getirebilen yardımcı robotlar bulunabilir. (Kaynak: Ronald_vanLoon)
Unitree G1 biyonik robotu çevikliğini sergiliyor : Unitree Robotics, G1 biyonik robotunun yükseltilmiş versiyonunu sergileyerek hareketinin çevikliğini ve esnekliğini vurguladı. Bu tür insansı veya biyonik robotların gelişimi, AI’yi (algılama, karar verme, kontrol için) ve gelişmiş makine mühendisliğini birleştirerek, karmaşık ortamlara uyum sağlamak ve çeşitli görevleri yerine getirmek için biyolojik hareket yeteneklerini taklit etmeyi amaçlamaktadır. (Kaynak: Ronald_vanLoon)
Google DeepMind AI ile yunuslarla iletişim kurma olasılığını araştırıyor : Google DeepMind’in araştırma projesi, hayvanların (burada bahsedilen yunuslar gibi) iletişimini analiz etmek ve anlamak için AI modellerini kullanma olasılığını ima ediyor. Karmaşık akustik sinyalleri makine öğrenimi ile analiz ederek, AI belki de hayvan dilinin kalıplarını ve yapısını çözmeye yardımcı olabilir ve türler arası iletişim araştırmaları için yeni yollar açabilir. (Kaynak: Ronald_vanLoon)
Hugging Face platformuna yeni robot simülatörü eklendi : Hugging Face, yeni bir robot simülatörü sunacağını duyurdu. Robot simülasyonu, özellikle AI’yi fiziksel robotlara (Physical AI) uygulamadan önce, robotların sanal ortamlarda fiziksel dünyayla etkileşimini (kavrama, hareket etme gibi) eğitmek ve test etmek için kritik bir adımdır. Bu hamle, Hugging Face’in platform yeteneklerini robotik ve somutlaştırılmış zeka alanlarındaki araştırma ve geliştirmeyi daha iyi desteklemek için genişlettiğini gösteriyor. (Kaynak: huggingface)