
Anahtar Kelimeler:AI Dört Ejderhası, Somutlaşmış Yapay Zeka, İnsansı Robot, Bellek Duvarı, SenseTime Ririxin V6 Çok Modelli Model, Open X-Embodiment Veri Seti, Tesla Optimus Robotu, 3D Ferroelektrik RAM Teknolojisi, Tianguo Ultra Robot Yarım Maratonu, Gemma 3 QAT Nicemleme Modeli, Hugging Face’ın Pollen Robotics’i Satın Alması, LlamaIndex Akıllı Ajan Doküman İş Akışı
🔥 Odak Noktası
“AI Dört Küçük Ejderha” Zorluklarla ve Dönüşümle Karşı Karşıya : Bir zamanlar “AI Dört Küçük Ejderha” olarak bilinen SenseTime, Megvii, CloudWalk, Yitu gibi şirketler, son yıllarda genel olarak ticarileşme zorlukları ve sürekli zararlarla karşı karşıya. Örneğin, SenseTime 2024’te 4.3 milyar yuan zarar etti ve toplam zararı 54.6 milyar yuan’ı aştı; CloudWalk 2024’te yaklaşık 600-700 milyon yuan zarar etti ve toplam zararı 4.4 milyar yuan’ı aştı. Zorluklarla başa çıkmak için şirketler işten çıkarma, maaş kesintileri ve iş yeniden yapılandırması dahil olmak üzere stratejik düzenlemeler yapıyor. Büyük dil modellerinin öncülük ettiği yeni AI dalgasıyla karşı karşıya kalan, görsel teknoloji genlerine sahip olan “Dört Küçük Ejderha”, aktif olarak çok modlu büyük modellere ve AGI alanına yöneliyor. SenseTime, GPT-4o’yu hedefleyen “Rì Rì Xīn V6” çok modlu modelini yayınladı ve akıllı hesaplama merkezi inşasına büyük yatırım yapıyor; Yitu, görsel merkezli çok modlu modellere odaklanıyor ve donanım maliyetlerini düşürmek için Huawei ile işbirliği yapıyor; CloudWalk da Huawei ile işbirliği yaparak büyük model eğitim ve çıkarım entegre makinesi sunuyor; Megvii ise algoritma avantajıyla akıllı sürüş saf görsel çözümlerine giriyor. Bu adımlar, AI oyununda kalmaya ve yeni pazar koşullarına uyum sağlamaya çalıştıklarını gösteriyor. (Kaynak: 36氪)

Bedenlenmiş Zeka Veri İkilemi ve Açık Kaynak Veri Seti Gelişmeleri : İnsansı robotların ve bedenlenmiş zekanın gelişimi, kritik bir veri darboğazıyla karşı karşıya; yüksek kaliteli eğitim verilerinin eksikliği, yeteneklerinin atılımını engelliyor. Büyük miktarda internet metin verisine sahip dil modellerinden farklı olarak, robotlar maliyeti yüksek olan çeşitli fiziksel dünya etkileşim verilerine ihtiyaç duyuyor. Bu sorunu çözmek için araştırma kurumları ve şirketler aktif olarak veri setleri oluşturuyor ve açık kaynak olarak sunuyor. Bunlar arasında Google DeepMind’in çok sayıda kurumla ortaklaşa yayınladığı Open X-Embodiment, Peng Cheng Laboratory vb.’nin ARIO’su, Beijing Innovation Center’ın RoboMIND’ı, AgiBot’un AgiBot World’ü (gerçek sahne uzun vadeli karmaşık görev verilerini içeren) ve AgiBot Digital World simülasyon veri seti, Unitree’nin G1 operasyon veri seti vb. bulunuyor. Bu veri setlerinin ölçeği metin verilerinden çok daha küçük olsa da, standartları birleştirerek, kaliteyi artırarak ve senaryoları zenginleştirerek bedenlenmiş zeka alanının gelişimini destekliyor ve “ImageNet anı”nı gerçekleştirmek için temel oluşturuyor. (Kaynak: 36氪)

İnsansı Robot Seri Üretiminin Şafağı: Veri, Simülasyon ve Genelleme Atılımları : Veri toplama maliyetinin yüksek olması ve genelleme yeteneğinin zayıf olması gibi zorluklara rağmen, birçok şirket (Tesla, Figure AI, 1X, AgiBot, Unitree, UBTECH vb.) 2025 yılında insansı robot seri üretimine geçmeyi planlıyor. Çözüm yolları şunları içeriyor: 1) Büyük ölçekli gerçek makine eğitimi, hükümetlerin (Pekin, Şanghay, Shenzhen, Guangdong) veri toplama üsleri kurma ve standartlar belirleme desteğiyle; 2) Gelişmiş simülasyon eğitimi, Nvidia Cosmos, Google Genie2 gibi dünya modellerini kullanarak fiziksel olarak gerçekçi sanal ortamlar oluşturmak, maliyetleri düşürmek ve verimliliği artırmak; 3) AI destekli genelleme, Figure AI’nin Helix’i, AgiBot GO-1’in ViLLA mimarisi, Google Gemini Robotics gibi yeni eylem modelleri aracılığıyla, daha az veri kullanarak fiziksel operasyonların genelleştirilmiş anlaşılmasını sağlamak, robotların görülmemiş nesneleri işlemesini ve yeni ortamlara uyum sağlamasını sağlamak. Bu teknolojik ilerlemeler, insansı robotların ticarileşmesinin hızlanabileceğini gösteriyor. (Kaynak: 36氪)

AI Gelişimi “Bellek Duvarı” Kriziyle Karşı Karşıya, Yeni Depolama Teknolojileri Atılım Arıyor : AI modellerinin katlanarak büyümesi, bellek bant genişliği için ciddi zorluklar ortaya koyuyor. Geleneksel DRAM bant genişliği artış hızı, hesaplama gücü artış hızının çok gerisinde kalarak “depolama duvarı” darboğazını oluşturuyor ve işlemci performansını sınırlıyor. HBM, 3D istifleme teknolojisi ile bant genişliğini önemli ölçüde artırarak baskıyı kısmen hafifletti, ancak üretim süreci karmaşık ve maliyeti yüksek. Bu nedenle, endüstri aktif olarak yeni depolama teknolojilerini araştırıyor: 1) 3D Ferroelektrik RAM (FeRAM): SunRise Memory gibi, HfO2 ferroelektrik etkisini kullanarak yüksek yoğunluklu, kalıcı, düşük güç tüketimli depolama sağlıyor. 2) DRAM + Kalıcı Bellek: Neumonda, FMC ile işbirliği yaparak HfO2 kullanarak DRAM kapasitörünü kalıcı depolamaya dönüştürüyor. 3) 2T0C IGZO DRAM: imec, geleneksel 1T1C yapısının yerine iki oksit transistör kullanarak kapasitörsüz, düşük güç tüketimli, yüksek yoğunluklu, uzun saklama süreli bir yapı öneriyor. 4) Faz Değişimli Bellek (PCM): Veri depolamak için malzeme faz değişimini kullanarak güç tüketimini azaltıyor. 5) UK III-V Memory: GaSb/InAs tabanlı, DRAM hızı ve flash kalıcılığını birleştiriyor. 6) SOT-MRAM: Spin-yörünge torkunu kullanarak düşük güç tüketimi ve yüksek enerji verimliliği sağlıyor. Bu teknolojilerin DRAM darboğazını kırması ve depolama pazarı düzenini yeniden şekillendirmesi bekleniyor. (Kaynak: 36氪)
🎯 Eğilimler
Tiangong Robotu Yarı Maratonu Tamamladı, Küçük Ölçekli Seri Üretim Planlanıyor : Pekin İnsansı Robot İnovasyon Merkezi’nin Tiangong ekibinin robotu “Tiangong Ultra” (boy 1.8 metre, ağırlık 55 kg), ilk insansı robot yarı maraton yarışmasında yaklaşık 21 kilometreyi 2 saat 40 dakika 42 saniyede koşarak birinci oldu. Bu yarışma, robotun karmaşık yol koşullarında dayanıklılığını, yapısını, algısını ve kontrol algoritmalarının güvenilirliğini test etti. Ekip, eklem stabilitesini, ısı direncini, enerji tüketim sistemini, denge ve yürüme planlama algoritmalarını optimize ederek ve kendi geliştirdikleri “Huisikaiwu” platformunu (bedenlenmiş beyin + beyincik) entegre ederek robotun kablosuz yönlendirme altında otonom yol planlaması ve gerçek zamanlı ayarlama yapabildiğini belirtti. Maratonu tamamlamak, temel güvenilirliğini kanıtladı ve seri üretim için temel oluşturdu. Tiangong 2.0 robotu yakında satışa sunulacak, küçük ölçekli üretim planlanıyor ve gelecekteki hedef endüstriyel, lojistik, özel operasyonlar ve ev hizmetleri gibi alanlarda uygulanması. (Kaynak: 36氪)

Çin, Kültürlenmiş İnsan Hücrelerini Kullanarak Robot Beyni Geliştiriyor : Haberlere göre, Çinli araştırmacılar kültürlenmiş insan beyin hücreleri tarafından yönlendirilen bir robot geliştiriyor. Bu araştırma, biyolojik nöronların öğrenme ve uyum sağlama yeteneklerini kullanarak robot donanımını kontrol etme olasılığını araştıran biyolojik hesaplamanın olanaklarını keşfetmeyi amaçlıyor. Spesifik detaylar ve ilerleme aşaması henüz net olmasa da, bu yönelim robotik, yapay zeka ve biyoteknolojinin kesiştiği alanda öncü bir keşfi temsil ediyor ve gelecekte daha akıllı, daha uyarlanabilir robot sistemleri geliştirmek için yeni yollar açabilir. (Kaynak: Ronald_vanLoon)
Gemma 3 QAT Nicelleştirilmiş Model Performansı Üstün : Kullanıcılar, GPQA Diamond benchmark testinde Google Gemma 3 27B modelinin QAT (Quantization Aware Training) sürümünü diğer Q4 nicelleştirilmiş sürümlerle (Q4_K_XL, Q4_K_M) karşılaştırdı. Sonuçlar, QAT sürümünün performansta en iyi (%36.4 doğruluk) olduğunu ve aynı zamanda en düşük VRAM kullanımına (16.43 GB) sahip olduğunu gösterdi; Q4_K_XL (%34.8, 17.88 GB) ve Q4_K_M (%33.3, 17.40 GB) sürümlerinden daha iyi performans sergiledi. Bu, QAT teknolojisinin model performansını korurken kaynak gereksinimlerini etkili bir şekilde azalttığını gösteriyor. (Kaynak: Reddit r/LocalLLaMA)
Söylenti: AMD, 32GB Belleğe Sahip RDNA 4 Radeon PRO Ekran Kartı Çıkaracak : VideoCardz, AMD’nin Navi 48 XTW GPU tabanlı Radeon PRO serisi ekran kartları hazırladığını ve 32GB belleğe sahip olacağını bildirdi. Eğer doğruysa, bu, yerel AI model eğitimi ve çıkarımı için büyük belleğe ihtiyaç duyan kullanıcılara, özellikle tüketici sınıfı ekran kartı belleğinin genellikle sınırlı olduğu durumlarda yeni bir seçenek sunacak. Ancak belirli performans, fiyat ve çıkış tarihi henüz açıklanmadı, gerçek rekabet gücü hala belirsiz. (Kaynak: Reddit r/LocalLLaMA)

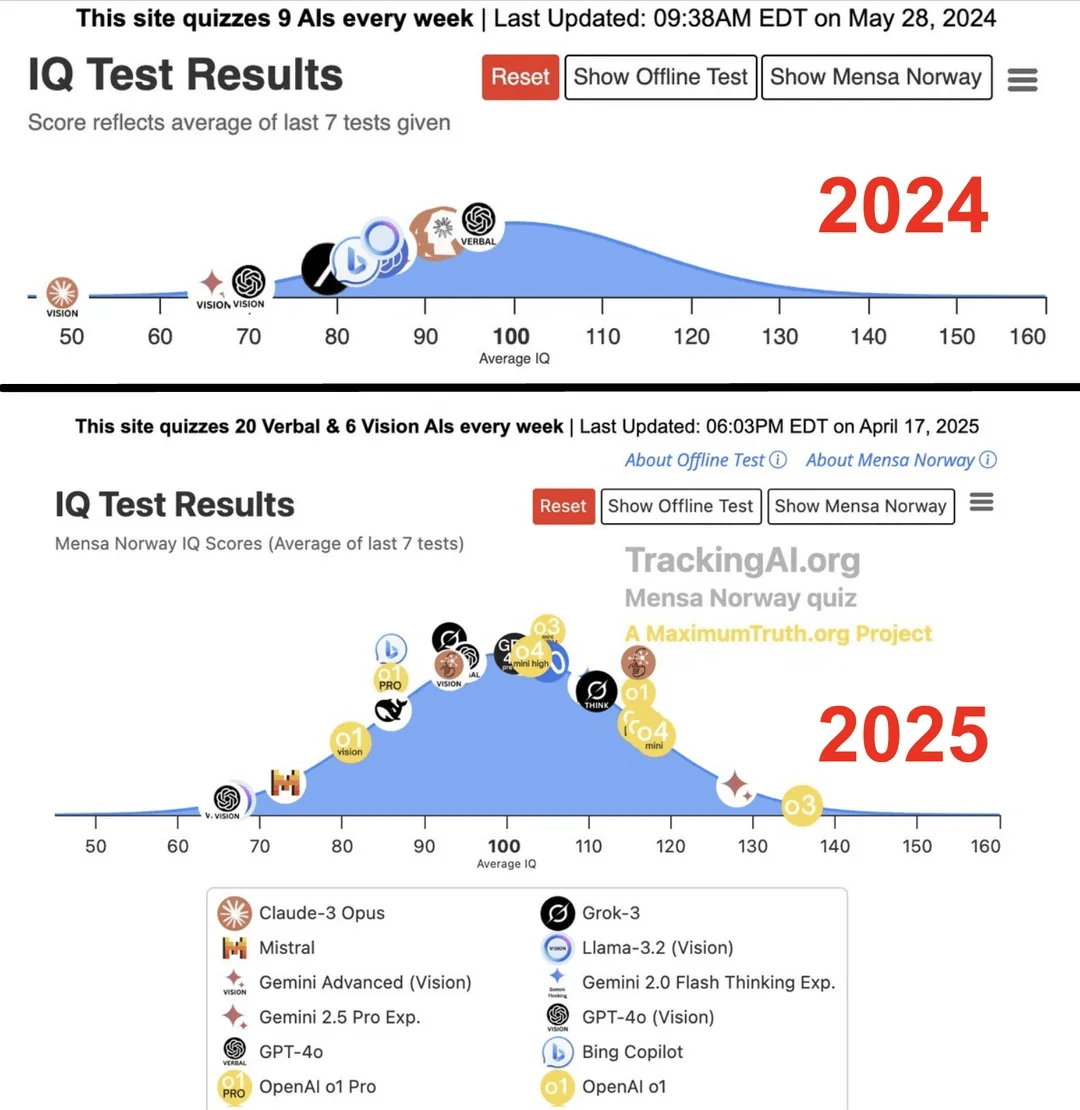
Araştırma: En İyi AI’ın IQ’su Bir Yılda 96’dan 136’ya Yükseldi : Maximum Truth web sitesinde yayınlanan (kaynak güvenilirliği doğrulanmamış) bir araştırmaya göre, AI modellerine IQ testi uygulandığında, en akıllı AI’ın (muhtemelen GPT serisi) IQ puanının bir yıl içinde 96’dan (insan ortalamasının biraz altında) 136’ya (dahi seviyesine yakın) yükseldiği bulundu. IQ testlerinin AI zekasını ölçmedeki etkinliği tartışmalı olsa ve eğitim verilerinin testi kirletme olasılığı bulunsa da, bu önemli artış AI’ın standartlaştırılmış zeka testi problemlerini çözme yeteneğindeki hızlı ilerlemeyi yansıtıyor. (Kaynak: Reddit r/artificial)
🧰 Araçlar
OpenUI: Açıklama Yoluyla Gerçek Zamanlı UI Oluşturma : wandb, kullanıcıların doğal dil açıklamalarıyla kullanıcı arayüzlerini tasarlamasına ve gerçek zamanlı olarak oluşturmasına olanak tanıyan OpenUI’yi açık kaynak olarak yayınladı. Kullanıcılar değişiklik taleplerinde bulunabilir ve oluşturulan HTML’yi React, Svelte, Web Components gibi çeşitli ön uç çerçeve kodlarına dönüştürebilir. OpenUI, OpenAI, Groq, Gemini, Anthropic (Claude) dahil olmak üzere çeşitli LLM arka uçlarını ve LiteLLM veya Ollama aracılığıyla bağlanan yerel modelleri destekler. Proje, UI bileşen oluşturma sürecini daha hızlı ve eğlenceli hale getirmeyi ve W&B’nin dahili test ve prototipleme aracı olarak hizmet etmeyi amaçlamaktadır. v0.dev’den ilham alınmış olsa da OpenUI açık kaynaklıdır. Çevrimiçi Demo ve yerel çalıştırma kılavuzları (Docker veya kaynak kodu) sunulmaktadır. (Kaynak: wandb/openui – GitHub Trending (all/daily))

PDFMathTranslate: Düzeni Koruyan AI PDF Çeviri Aracı : Byaidu tarafından geliştirilen PDFMathTranslate, güçlü bir PDF belge çeviri aracıdır. Temel avantajı, AI teknolojisini kullanarak çeviri yaparken karmaşık matematiksel formüller, grafikler, içindekiler tablosu ve notlar dahil olmak üzere orijinal belgenin düzen biçimini tamamen koruyabilmesidir. Araç, birden çok dil arasında çeviriyi destekler ve Google, DeepL, Ollama, OpenAI gibi çeşitli çeviri hizmetlerini entegre eder. Farklı kullanıcıların rahatlığı için proje, komut satırı (CLI), grafik kullanıcı arayüzü (GUI), Docker imajı ve Zotero eklentisi gibi çeşitli kullanım yöntemleri sunar. Kullanıcılar çevrimiçi Demo’yu deneyebilir veya ihtiyaçlarına göre uygun kurulum yöntemini seçebilirler. (Kaynak: Byaidu/PDFMathTranslate – GitHub Trending (all/daily))

Shandu AI Research: LangGraph Tabanlı Referanslı Rapor Oluşturma Sistemi : Shandu AI Research, LangGraph iş akışını kullanarak otomatik olarak referanslı raporlar oluşturan bir sistemdir. Akıllı web kazıma, çok kaynaklı bilgi sentezi ve paralel işleme gibi teknolojiler aracılığıyla araştırma görevlerini basitleştirmeyi amaçlar. Bu araç, kullanıcıların bilgileri hızla toplamasına, entegre etmesine, analiz etmesine ve yapılandırılmış, referanslı araştırma raporları oluşturmasına yardımcı olarak araştırma verimliliğini artırır. (Kaynak: LangChainAI)

Intel Açık Kaynaklı AI Playground’u Yayınladı : Intel, AI PC’ler için giriş seviyesi bir uygulama olan AI Playground’u açık kaynak olarak yayınladı. Bu uygulama, kullanıcıların Intel Arc ekran kartına sahip PC’lerde çeşitli üretken AI modellerini çalıştırmasına olanak tanır. Desteklenen görüntü/video modelleri arasında Stable Diffusion 1.5, SDXL, Flux.1-Schnell, LTX-Video; desteklenen büyük dil modelleri arasında DeepSeek R1, Phi3, Qwen2, Mistral (Safetensor PyTorch LLM) ve Llama 3.1, Llama 3.2, TinyLlama, Mistral 7B, Phi3 mini, Phi3.5 mini (GGUF LLM veya OpenVINO) bulunmaktadır. Araç, yerel olarak AI modellerini çalıştırma engelini düşürmeyi ve kullanıcıların deneyimlemesini ve denemesini kolaylaştırmayı amaçlamaktadır. (Kaynak: karminski3)
Persona Engine: AI Sanal Asistan/Yayıncı Projesi : Persona Engine, etkileşimli bir AI sanal asistanı veya sanal yayıncı oluşturmayı amaçlayan açık kaynaklı bir projedir. Büyük dil modellerini (LLM), Live2D animasyonunu, otomatik konuşma tanımayı (ASR), metinden sese (TTS) ve gerçek zamanlı ses klonlama teknolojisini entegre eder. Kullanıcılar doğrudan Live2D karakteriyle sesli olarak konuşabilir ve proje, AI sanal yayıncıları oluşturmak için OBS gibi canlı yayın yazılımlarına entegrasyonu da destekler. Proje, çeşitli AI teknolojilerinin birleşik uygulamasını sergiler ve kişiselleştirilmiş sanal etkileşimli karakterler oluşturmak için bir çerçeve sunar. (Kaynak: karminski3)
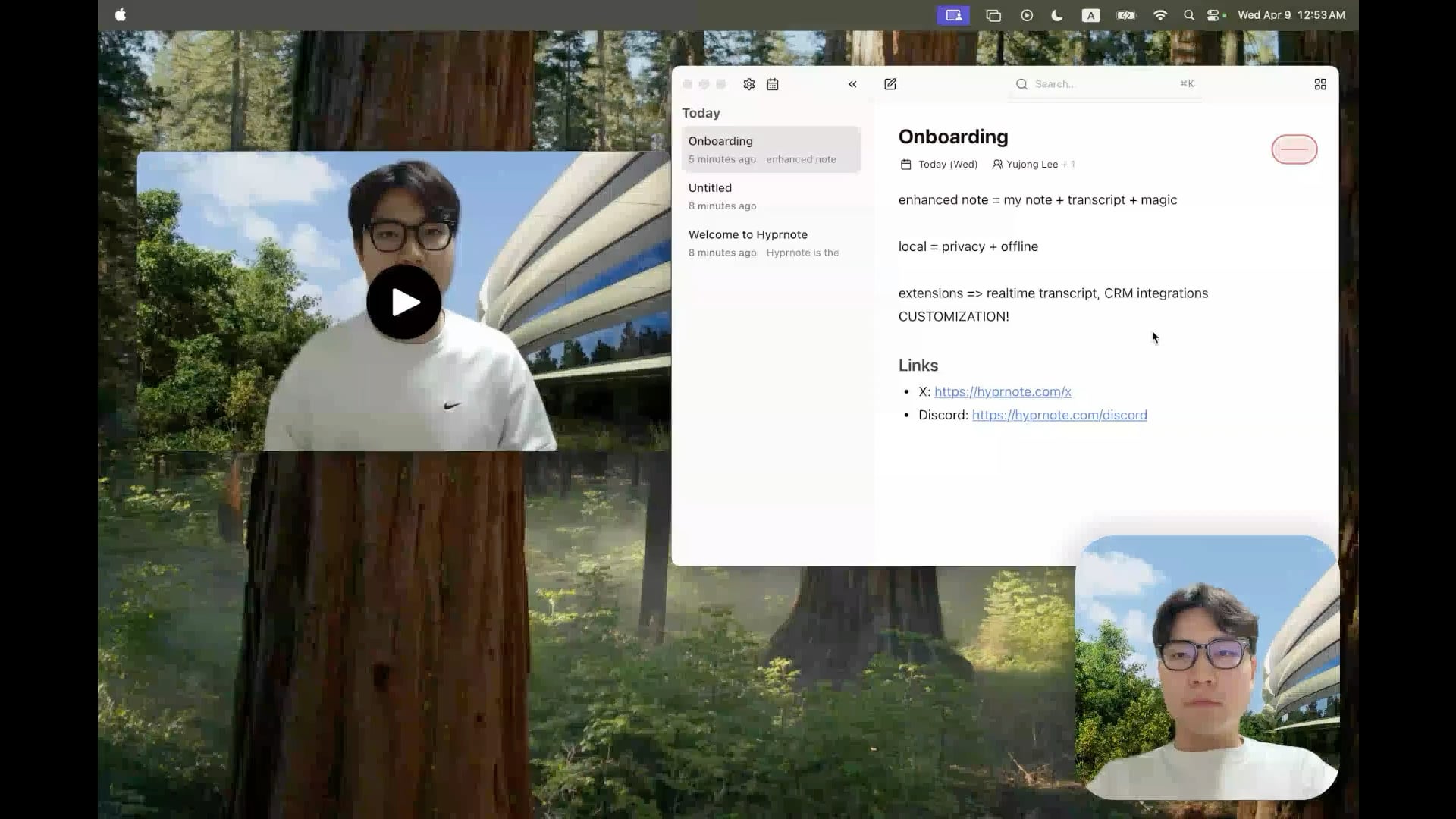
Hyprnote: Açık Kaynaklı Yerel AI Toplantı Notu Aracı : Geliştirici, toplantı senaryoları için özel olarak tasarlanmış akıllı bir not alma uygulaması olan Hyprnote’u açık kaynak olarak yayınladı. Toplantı sırasında ses kaydı yapabilir ve kullanıcının orijinal notlarını toplantı ses içeriğiyle birleştirerek geliştirilmiş toplantı kayıtları oluşturabilir. Temel özelliği, kullanıcı verilerinin gizliliğini ve güvenliğini sağlamak için AI modellerini (örneğin, konuşmayı yazıya dökmek için Whisper) tamamen yerel olarak çalıştırmasıdır. Araç, kullanıcıların toplantı bilgilerini daha iyi yakalamasına ve düzenlemesine yardımcı olmayı amaçlar, özellikle sürekli toplantılarla uğraşması gereken kullanıcılar için uygundur. (Kaynak: Reddit r/LocalLLaMA)
LMSA: LM Studio’yu Android Cihazlara Bağlama Aracı : Kullanıcı, LM Studio’yu (popüler bir yerel LLM çalıştırma yönetim aracı) Android cihazlarına bağlamalarına yardımcı olmak için tasarlanmış LMSA (lmsa.app) adlı bir uygulamayı paylaştı. Bu, kullanıcıların yerel PC’lerinde çalışan AI modelleriyle telefonları veya tabletleri aracılığıyla etkileşim kurmasını sağlayarak yerel büyük modellerin kullanım senaryolarını genişletir. (Kaynak: Reddit r/LocalLLaMA)

MobileNetV2 Tabanlı Yerel Görüntü Arama Aracı : Geliştirici, PyQt5 grafik arayüzü ve TensorFlow MobileNetV2 modelini kullanan bir masaüstü görüntü arama aracı oluşturup paylaştı. Araç, yerel görüntü klasörlerini indeksleyebilir ve görüntü içeriğine göre (CNN ile özellik çıkararak) kosinüs benzerliği kullanarak benzer resimleri bulabilir. Klasör yapısını otomatik olarak kategori olarak algılayabilir ve arama sonuçlarının küçük resimlerini, benzerlik yüzdesini ve dosya yolunu gösterebilir. Proje kodu GitHub’da açık kaynak olarak yayınlandı ve kullanıcı geri bildirimi bekleniyor. (Kaynak: Reddit r/MachineLearning)
Handcrafted Persona Engine: Yerel AI Sesli Etkileşimli Sanal Karakter : Geliştirici, “Susam Sokağı” benzeri bir deneyim sunan, tamamen yerel olarak çalışan etkileşimli sesli sanal karakter oluşturmayı amaçlayan kişisel bir proje olan “Handcrafted Persona Engine”i paylaştı. Sistem, konuşmayı yazıya dökmek için yerel Whisper’ı, kişiselleştirilmiş ayarlarla yerel LLM’yi Ollama API aracılığıyla çağırarak diyalog oluşturmayı, metni sese dönüştürmek için yerel TTS’yi ve Live2D karakter modelini dudak senkronizasyonu ve duygu ifadesi için yönlendirmeyi entegre eder. Proje C# ile oluşturulmuştur, GTX 1080 Ti seviyesindeki ekran kartlarında çalışabilir ve GitHub’da açık kaynak olarak yayınlanmıştır. (Kaynak: Reddit r/LocalLLaMA)
Talkto.lol: Ünlülerin AI Kişilikleriyle Konuşma Deneyi Aracı : Geliştirici, kullanıcıların farklı ünlülerin (örneğin Sam Altman) AI kişilikleriyle konuşmasına olanak tanıyan talkto.lol adlı bir web sitesi oluşturdu. Araç ayrıca, kullanıcıların resim yükleyebileceği ve AI’ın bunları analiz edip yanıt oluşturacağı bir “show me” özelliği içerir, bu da AI’ın görsel tanıma yeteneğini gösterir. Geliştirici, platformu AI kişilik etkileşimi hakkında daha fazla deney yapmak için kullanacağını belirtti. Araç kayıt olmadan denenebilir. (Kaynak: Reddit r/artificial)
📚 Öğrenme
İnsansı Robot Temelleri: Zorluklar ve Veri Toplama : İnsansı robotların gelişimi, basit otomasyondan karmaşık “bedenlenmiş zeka”ya, yani fiziksel bedene dayalı algılama ve eylem zeka sistemine doğru ilerliyor. Dil, görüntü işleyen AI büyük modellerinden farklı olarak, robotların gerçek fiziksel dünyayı anlaması, uzamsal algı, hareket planlaması, kuvvet geri bildirimi gibi çok boyutlu verileri işlemesi gerekiyor. Bu yüksek kaliteli gerçek dünya verilerini elde etmek büyük bir zorluktur, maliyeti yüksektir ve tüm senaryoları kapsamak zordur. Mevcut ana toplama yöntemleri şunlardır: 1) Gerçek Dünya Toplama: Optik veya ataletsel hareket yakalama sistemleri aracılığıyla insan hareketlerini kaydetmek veya insanların robotları uzaktan kumanda ederek görevleri yerine getirmesini ve gerçek makine verilerini kaydetmesini sağlamak (Tesla Optimus gibi). 2) Simülasyon Dünyası Toplama: Simülasyon platformlarını kullanarak ortamı ve robot davranışlarını simüle etmek, maliyetleri düşürmek ve genelleme yeteneğini artırmak için büyük miktarda veri üretmek, ancak simülasyon ile gerçeklik arasındaki boşluğu (Sim-to-Real Gap) çözmek gerekir. Ayrıca, internet video verilerini ön eğitim için kullanmak da bir araştırma yönüdür. (Kaynak: 36氪)

Bilgi İçerikli Makaleler İçin İnfografik Tarzı Görseller Oluşturma Teknikleri : Kullanıcı, GPT-4o gibi AI araçlarını kullanarak bilgi içerikli makaleler için infografik tarzı görseller oluşturma yöntemini paylaştı. Temel teknik, AI’ın önce resim oluşturma istemini (prompt) yazmasına yardımcı olmasını sağlamaktır. Adımlar: Makale içeriğini veya ana noktalarını AI’a verin ve yatay bir infografik oluşturmak için bir istem yazmasını isteyin, İngilizce metin, çizgi film görüntüleri içermesini, stilin net ve canlı olmasını, temel görüşleri özetlemesini isteyin. Önemli noktalar: AI’a tam içeriği verin; “infografik” istediğinizi açıkça belirtin; metin çoksa oluşturma doğruluğunu artırmak için İngilizce kullanılması önerilir; istem oluşturmak için GPT-4.5, o3 veya Gemini 2.5 Pro kullanılması önerilir; son resmi oluşturmak için Sora Com veya ChatGPT gibi araçları kullanın. (Kaynak: dotey)
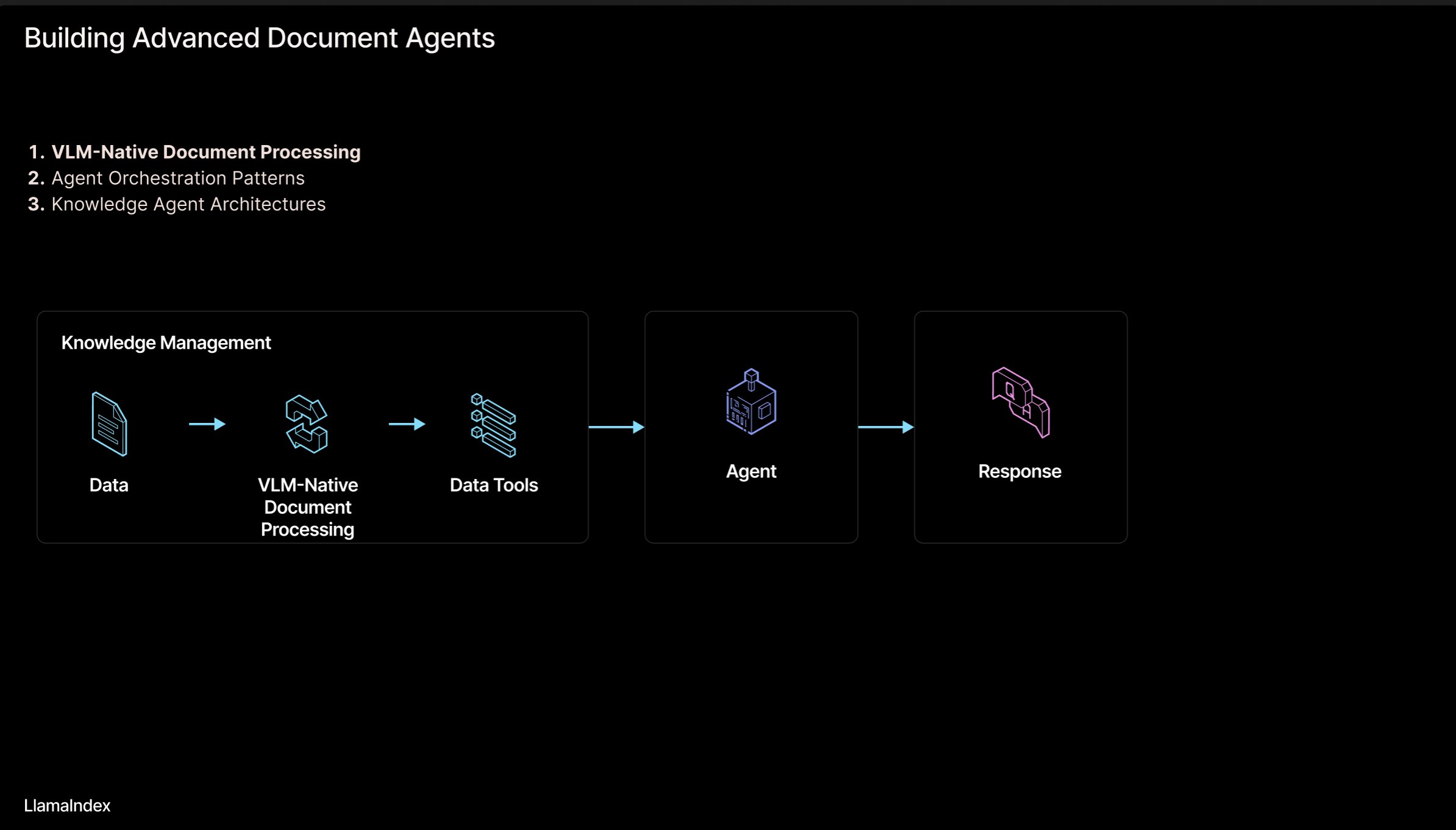
LlamaIndex: Agentic Belge İş Akışı Mimarisi : LlamaIndex kurucusu Jerry Liu, belgeleri (PDF, Excel vb.) işleyen agentic iş akışları oluşturmak için bir mimari slayt seti paylaştı. Bu mimari, insan tarafından okunabilir formatlardaki belgelerde kilitli kalan bilgiyi serbest bırakmayı, AI ajanlarının bu belgeleri ayrıştırmasını, akıl yürütmesini ve işlemesini sağlamayı amaçlamaktadır. Mimari temel olarak iki katman içerir: 1) Belge Ayrıştırma ve Çıkarma: Görsel dil modelleri (VLM) gibi teknolojileri kullanarak belgelerin makine tarafından okunabilir bir temsilini (MCP Server) oluşturmak. 2) Agentic İş Akışı: Ayrıştırılmış belge bilgilerini agentic çerçevelerle (LlamaIndex gibi) birleştirerek otomatik bilgi işini gerçekleştirmek. Slaytlar Figma’da görüntülenebilir, ilgili teknolojiler LlamaCloud’da uygulanmaktadır. (Kaynak: jerryjliu0)
LangChain Korece Eğitim Kaynakları Deposu : GitHub’da bir LangChain Korece eğitim projesi bulunmaktadır. Bu proje, e-kitaplar, YouTube video içerikleri ve etkileşimli örnekler gibi çeşitli biçimlerde Korece kullanıcılar için LangChain öğrenme kaynakları sunmaktadır. İçerik, LangChain’in temel kavramlarını, LangGraph sistem oluşturmayı ve RAG (Retrieval-Augmented Generation) uygulamasını gibi kilit konuları kapsar ve Korece geliştiricilerin LangChain çerçevesini daha iyi anlamalarına ve uygulamalarına yardımcı olmayı amaçlar. (Kaynak: LangChainAI)
Deno ve LangChain.js Kullanarak Yerel AI Uygulamaları Oluşturma Kılavuzu : Deno blogu, Deno (modern JavaScript/TypeScript çalışma zamanı), LangChain.js ve yerel büyük dil modellerini (Ollama aracılığıyla barındırılan) birleştirerek AI uygulamaları oluşturmayı tanıtan bir kılavuz yayınladı. Makale, yapılandırılmış AI iş akışları oluşturmak için TypeScript’in nasıl kullanılacağını vurgular ve geliştirme ve deney için Jupyter Notebook entegrasyonunu gösterir. Kılavuz, Deno ortamında JavaScript/TypeScript kullanarak yerel AI uygulamaları geliştirmek isteyen geliştiricilere pratik rehberlik sağlar. (Kaynak: LangChainAI)
AI Uygulamaları Oluşturmak İçin Mantıksal Zihin Modeli (LMM) : Kullanıcı, AI uygulamaları (özellikle Agentic sistemler) oluşturmak için bir mantıksal zihin modeli (LMM) önerdi. Model, geliştirme mantığını iki katmana ayırmayı önerir: Üst düzey mantık (ajanlara ve belirli görevlere yönelik), Araçlar ve Ortam (Tools and Environment) ile Rol ve Talimatlar (Role and Instructions) içerir; Alt düzey mantık (genel temel altyapı), Yönlendirme (Routing), Korkuluklar (Guardrails), LLM’lere Erişim (Access to LLMs) ve Gözlemlenebilirlik (Observability) içerir. Bu katmanlama, AI mühendislerinin ve platform ekiplerinin işbirliği içinde çalışmasına ve geliştirme verimliliğini artırmasına yardımcı olur. Kullanıcı ayrıca alt düzey mantık uygulamasına odaklanan ilgili açık kaynak projesi ArchGW’den bahsetti. (Kaynak: Reddit r/artificial)

Klasik Hesaplamanın Ötesinde Bir AGI Teorik Çerçevesi : Bir bilgisayar bilimi araştırmacısı, yeni bir yapay genel zeka (AGI) teorik çerçevesi öneren ön baskı makalesini paylaştı. Çerçeve, geleneksel istatistiksel öğrenme ve deterministik hesaplamanın (derin öğrenme gibi) ötesine geçmeye çalışarak sinirbilim, kuantum mekaniği (çok boyutlu bilişsel uzay, kuantum süperpozisyonu) ve Gödel’in eksiklik teoremlerini (Gödelian öz-referans bileşeni, sezgi) kavramlarını entegre eder. Model, bilincin entropi azalması tarafından yönlendirildiğini varsayar ve sinir ağı öğrenmesi, olasılıksal biliş, bilinç dinamikleri ve sezgi güdümlü içgörüyü birleştiren bir birleşik zeka denklemi önerir. Araştırma, AGI için yeni kavramsal ve matematiksel temeller sağlamayı amaçlamaktadır. (Kaynak: Reddit r/deeplearning)
AI Etkileşimlerini Yönetmek İçin Güvenlik İpuçları : Reddit kullanıcısı, AI’a yeni başlayan kullanıcılar için, insan-makine etkileşim sürecini daha iyi yönetmelerine, AI ile diyalogda kaybolmaktan veya gereksiz korku duymaktan kaçınmalarına yardımcı olmayı amaçlayan öneriler ve istemler (prompt) paylaştı. Öneriler şunları içerir: 1) Etkileşim akışını gözden geçirmek ve kontrol etmek için belirli istemleri (“Bu oturumu benim için özetle” gibi) kullanmak; 2) AI’ın sınırlamalarını (gerçek duygu, bilinç ve kişisel deneyim eksikliği gibi) kabul etmek; 3) Kaybolmuş hissettiğinizde aktif olarak oturumu sonlandırmak veya yeni bir oturum başlatmak. AI’ın doğası hakkında net bir farkındalığı sürdürmenin önemi vurgulandı. (Kaynak: Reddit r/artificial)
Makale: Flow Matching ve Enerji Tabanlı Modelleri Birleştiren Üretken Modelleme : Araştırmacılar, Flow Matching ve Enerji Tabanlı Modelleri (EBMs) birleştiren yeni bir üretken modelleme yöntemi öneren bir ön baskı makalesi paylaştı. Yöntemin temel fikri şudur: Veri manifoldunun uzağındayken, örnekler gürültüden veriye doğru irrotasyonel optimal taşıma yolları boyunca hareket eder; veri manifolduna yaklaşıldığında, bir entropi enerji terimi sistemi Boltzmann denge dağılımına yönlendirir, böylece verinin olabilirlik yapısını açıkça yakalar. Tüm dinamik süreç, hem üretici hem de öncül olarak kullanılabilen ve ters problemlerin etkili düzenlenmesi için kullanılabilen tek bir, zamandan bağımsız skaler alan tarafından parametrelendirilir. Yöntem, EBM esnekliğini korurken üretken kaliteyi önemli ölçüde artırır. (Kaynak: Reddit r/MachineLearning)
TensorFlow Optimizer Uygulama Kütüphanesi : Geliştirici, çeşitli yaygın optimizer’ların (Adam, SGD, Adagrad, RMSprop vb.) TensorFlow uygulamalarını içeren bir GitHub deposu oluşturup paylaştı. Proje, TensorFlow kullanan araştırmacılara ve geliştiricilere kullanışlı, standartlaştırılmış optimizer uygulama kodları sağlamayı, farklı optimizasyon algoritmalarını anlamalarına ve uygulamalarına yardımcı olmayı amaçlamaktadır. (Kaynak: Reddit r/deeplearning)
Derin Öğrenme ile Çok Modlu Veri Analizi Üzerine Makale : Rackenzik.com, derin öğrenme kullanarak çok modlu veri analizi hakkında bir makale yayınladı. Makale muhtemelen farklı kaynaklardan (metin, görüntü, ses, sensör verileri vb.) gelen verilerin nasıl birleştirileceğini, daha zengin bilgiler çıkarmak, daha doğru tahminler veya sınıflandırmalar yapmak için derin öğrenme modellerinin (füzyon ağları, dikkat mekanizmaları vb.) nasıl kullanılacağını tartışıyor. Çok modlu öğrenme, mevcut AI araştırmalarının sıcak bir konusudur ve karmaşık gerçek dünya problemlerini anlamada önemli bir potansiyele sahiptir. (Kaynak: Reddit r/deeplearning)

Grafik Sinir Ağları (GNN) Öğrenme Kaynakları Aranıyor : Reddit kullanıcısı, grafik sinir ağları (GNN) hakkında giriş literatürü, kitaplar, YouTube videoları veya diğer kaynaklar dahil olmak üzere kaliteli öğrenme materyalleri arıyor. Yorumlarda, Stanford Üniversitesi’nden Jure Leskovec’in GNN ders videoları önerildi ve kendisinin bu alanda öncü olduğu belirtildi. Başka bir yorum, GNN’nin temel prensiplerini açıklayan bir YouTube videosunu önerdi. Bu tartışma, öğrenicilerin bu önemli derin öğrenme dalına olan ilgisini yansıtıyor. (Kaynak: Reddit r/MachineLearning)
AI Kullanarak Hızlı Uygulama Oluşturma ve Yayınlama Süreci Paylaşımı : Bir geliştirici, AI araçlarını kullanarak hızlı bir şekilde uygulama oluşturma ve yayınlama sürecini paylaştı. Anahtar adımlar şunları içerir: 1) Fikir: Orijinal düşünme ve rakip araştırması yapma. 2) Planlama: Gemini/Claude kullanarak ürün gereksinimleri belgesi (PRD), teknoloji yığını seçimi ve geliştirme planı oluşturma. 3) Teknoloji Yığını: Next.js, Supabase (PostgreSQL), TailwindCSS, Resend, Upstash Redis, reCAPTCHA, Vercel vb. önerilir, ücretsiz planlarla başlanır. 4) Geliştirme: MVP geliştirmeyi hızlandırmak için Cursor (AI programlama asistanı) kullanma. 5) Test: Test ve doğrulama planı oluşturmak için Gemini 2.5 kullanma. 6) Yayınlama: Ürünleri yayınlamak için uygun birden fazla platformu listeleme (Reddit, Hacker News, Product Hunt vb.). 7) Felsefe: Organik büyümeyi vurgulama, geri bildirime değer verme, mütevazı kalma, kullanışlılığa odaklanma. Ayrıca kod paketleyiciler, Markdown’dan PDF’e dönüştürücüler gibi yardımcı araçlar da paylaşıldı. (Kaynak: Reddit r/ClaudeAI)

💼 Ticari
AI Modellerinin Yasal Koruma Yolları: Rekabet Hukuku, Telif Hakkı ve Ticari Sırlardan Daha Üstün : Makale, “Douyin’in YiRuiKe AI Model İhlali Davası”nı örnek alarak AI modellerinin (yapı ve parametreler) yasal koruma modellerini derinlemesine inceliyor. Analiz, AI modelinin teknolojik çekirdek olarak telif hakkı yasası (model geliştirme yaratıcı bir eylem değildir, üretilen içeriğin özgünlüğü şüphelidir) veya ticari sır yasası (tersine mühendislikle kolayca ortaya çıkarılabilir, gizlilik önlemlerinin uygulanması zordur) yoluyla etkili bir koruma elde etmesinin zor olduğunu savunuyor. Davanın ikinci derece mahkemesi nihayetinde rekabet hukuku yolunu benimsedi ve YiRuiKe’nin Douyin model yapısını ve parametrelerini kopyalamasının haksız rekabet oluşturduğuna ve Douyin’in Ar-Ge’ye yaptığı yatırımla elde ettiği “rekabet avantajına” zarar verdiğine karar verdi. Makale, rekabet hukukunun bu tür davranışları düzenlemek için daha uygun olduğunu, pazar etkisini belirlemek için “esaslı ikame” standardını kullanabileceğini, “hazıra konmayı” engelleyebileceğini, ancak aynı zamanda makul yeniliği engellememek için dengeye dikkat edilmesi gerektiğini savunuyor. (Kaynak: 36氪)
Hugging Face, Açık Kaynaklı Robotları İlerletmek İçin Pollen Robotics’i Satın Aldı : Hugging Face, açık kaynaklı insansı robotu Reachy 2 ile tanınan Fransız robotik girişimi Pollen Robotics’i satın aldı. Bu hamle, Hugging Face’in özellikle araştırma ve eğitim alanlarında açık robotik girişimini ilerletme çabasının bir parçasıdır. Reachy 2 robotu, dost canlısı, kolay erişilebilir ve doğal etkileşim için uygun olarak tanımlanıyor ve şu anda yaklaşık 70.000 dolara satılıyor. Bu satın alma, Hugging Face’in bedenlenmiş zeka ve robotik alanındaki niyetini gösteriyor ve açık kaynak felsefesini donanım ve fiziksel etkileşim düzeyine genişletmeyi amaçlıyor. (Kaynak: huggingface, huggingface)
Anthropic, Claude Max Abonelik Planını Başlattı : Anthropic, aylık 100 dolar fiyatla “Claude Max” adlı yeni bir abonelik planı başlattı. Plan, mevcut Pro planından (genellikle 20 dolar/ay) daha üst konumda görünüyor. Bazı kullanıcılar Max planının yeni araştırma özellikleri ve daha yüksek kullanım limitleri sunduğunu belirtirken, bazıları ise fiyat/performans oranının düşük olduğunu, görüntü oluşturma, video oluşturma, ses modu gibi özelliklerin eksik olduğunu ve araştırma özelliklerinin gelecekte Pro planına da eklenebileceğini düşünüyor. (Kaynak: Reddit r/ClaudeAI)
🌟 Topluluk
Hugging Face Model Filtreleme İçin Yeni İhtiyaç: Çıkarım Yeteneği ve Boyuta Göre Sıralama : Kullanıcılar sosyal medyada Hugging Face platformuna yeni model filtreleme ve sıralama özellikleri eklenmesini önerdi. Spesifik öneriler şunları içeriyor: 1) Yalnızca çıkarım yeteneğine sahip modelleri göstermek için bir filtre eklenmesi; 2) Modelleri boyutlarına (footprint) göre sıralama seçeneği eklenmesi. Bu özellikler, kullanıcıların belirli ihtiyaçlara uygun modelleri, özellikle model çıkarım performansına ve dağıtım kaynak tüketimine odaklanan kullanıcıların daha kolay bulmasına ve seçmesine yardımcı olacaktır. (Kaynak: huggingface)
Kullanıcı Hugging Face DeepSite Üzerinde Klasik Oyunlar Oluşturuyor : Bir kullanıcı, Hugging Face DeepSite platformunda klasik oyunları başarıyla oluşturup çalıştırma deneyimini paylaştı. Kullanıcı, projeyi tamamlamak için DeepSite’in Canvas özelliğini (HTML, CSS, JS desteği) ve Novita/DeepSeek modellerini kullandı. Bu, DeepSite platformunun çok yönlülüğünü gösteriyor; yalnızca geleneksel model çıkarımı ve sunumuyla sınırlı kalmayıp, etkileşimli web uygulamaları ve oyunlar oluşturmak için de kullanılabileceğini ve geliştiricilere yeni yaratıcı alanlar sunduğunu gösteriyor. (Kaynak: huggingface)
Kullanıcı Görüşü: AI, Sanayi Devrimi’nden Çok Rönesans’a Benziyor : Kullanıcı, Sam Altman’ın mevcut AI gelişiminin “Sanayi Devrimi”nden çok “Rönesans” gibi hissettirdiği görüşüne katıldığını belirtti. Kullanıcı, beklenti ile gerçeklik arasında bir fark olduğunu ifade etti: AI’ın pratik sorunları (ev işleri yapmak, para kazanmak gibi) çözmesini beklerken, şu anda daha çok AI’ın yaratıcı alanlardaki uygulamalarını (Ghibli tarzı resimler oluşturmak gibi) hissettiğini belirtti. Bu, bazı kullanıcıların AI teknolojisinin gelişim yönü ve gerçek dünyadaki uygulamaları hakkındaki düşüncelerini ve duygularını yansıtıyor. (Kaynak: dotey)
ChatGPT/Claude Kullanıcıları “Fork” Özelliğini İstiyor : LlamaIndex kurucusu, ChatGPT Pro, Claude ve Gemini’nin yoğun bir kullanıcısı olarak, sohbet botlarına “Fork” (çatallama) özelliğinin eklenmesine yönelik güçlü bir ihtiyaç duyduğunu ifade etti. Farklı görevlerle uğraşırken aynı konuşma dizisinde bağlamı karıştırmak istemediğini, ancak her seferinde büyük miktarda önceden ayarlanmış arka plan bilgisini yeniden yapıştırmanın çok zahmetli olduğunu belirtti. “Fork” özelliği, kullanıcıların mevcut konuşma durumuna (bağlam dahil) dayalı olarak yeni, bağımsız bir konuşma dalı oluşturmasına olanak tanıyarak kullanım verimliliğini artıracaktır. Ayrıca bellek yönetimi araçları veya Slack tarzı iş parçacıkları gibi diğer olası uygulama yollarını da tartıştı. (Kaynak: jerryjliu0)
Müzik Modeli Orpheus, Hugging Face’te 100 Bin İndirmeye Ulaştı : Orpheus müzik modeli, Hugging Face platformunda 100.000 indirme sayısına ulaştı. Geliştirici Amu, bunu küçük bir kilometre taşı olarak gördü ve yakında Orpheus v1 sürümünün çıkacağını duyurdu. Bu başarı, topluluğun bu müzik üretme modeline olan ilgisini ve alakasını yansıtıyor. (Kaynak: huggingface)
ChatGPT’nin Sağlık Sorunlarını Çözmedeki Potansiyeli Ortaya Çıkıyor : Kullanıcı, ChatGPT’nin insanların uzun süreli sağlık sorunlarını çözmelerine yardımcı olduğuna dair giderek artan sayıda anekdot gözlemlediğini paylaştı. Henüz kat edilmesi gereken uzun bir yol olduğunu vurgulasa da, bu durum AI’ın özellikle bilgi edinme, semptom analizi veya tıbbi tavsiye aramanın ilk aşamalarında insanların yaşamlarını anlamlı bir şekilde iyileştirmeye başladığını gösteriyor. Bu vakalar, AI’ın tıp ve sağlık alanındaki yardımcı potansiyelini vurguluyor. (Kaynak: gdb)

Kullanıcı Grok ile Bilinç Modelini Tartışıyor : Reddit kullanıcısı, Grok AI ile kendi önerdiği bilinç modelini tartışma deneyimini paylaştı. Kullanıcı bir taslak makale bağlantısı sağladı ve modelin kavramlarını tartıştığı Grok ile olan diyalog ekran görüntülerini gösterdi. Bu, kullanıcıların büyük dil modellerini fikir alışverişi yapmak, karmaşık teorileri (bilinç gibi) tartışmak için bir araç olarak kullandığını yansıtıyor. (Kaynak: Reddit r/artificial)
Claude Sonnet 3.7’nin Kendiliğinden React’i “İcat Etmesi” Dikkat Çekti : Reddit kullanıcısı, Claude Sonnet 3.7’nin açık bir istem olmadan, kendiliğinden React.js çerçevesinin temel kavramlarına benzer açıklamalar yaptığını iddia eden bir video paylaştı. Bu beklenmedik “yaratıcılık” veya “çağrışım yeteneği”, toplulukta tartışmalara yol açtı ve büyük dil modellerinin belirli bilgi alanlarında sergileyebileceği karmaşık davranışları gösterdi. (Kaynak: Reddit r/ClaudeAI)

Gemini 2.5 Flash Çıkarım Modu Etkisi Tartışması : Kullanıcı, Gemini 2.5 Flash’ın “düşünme” (reasoning) modunu açıp kapatarak performansını karşılaştıran bir deney yaptı. Deney matematik, fizik, kodlama gibi birçok alanı kapsadı. Sonuçlar beklenmedikti; kullanıcının yüksek düşünme bütçesi gerektirdiğini düşündüğü görevlerde bile, düşünme modu kapalı sürüm doğru cevaplar verdi. Bu, Gemini Flash 2.5’in çıkarım modu olmadan yeteneklerine dair olumlu bir görüşe yol açtı ve çıkarım modunun gerekli uygulama senaryolarını sorgulattı. Ayrıntılı karşılaştırma süreci YouTube videosunda paylaşıldı. (Kaynak: Reddit r/MachineLearning)

ChatGPT’nin Kullanıcıların Zihnindeki İmajı Oluşturması Tartışma Yarattı : Reddit kullanıcısı, ChatGPT’nin konuşma geçmişine ve çıkarılan kullanıcı psikolojik profiline dayanarak kullanıcı imajı resimleri oluşturmasını sağlayan bir etkinlik başlattı. Birçok kullanıcı, ChatGPT’nin kendileri için oluşturduğu resimleri paylaştı; bu resimler farklı tarzlardaydı, bazıları rüya gibi ve renkli, bazıları kitap kurdu gibi, bazıları ise derin ve karmaşık görünüyordu. Bu etkileşim, ChatGPT’nin görüntü oluşturma yeteneğini ve metin anlayışına dayalı yaratıcı çıkarım yapma girişimini sergiledi ve aynı zamanda kullanıcıların kendi dijital imajları hakkında eğlenceli tartışmalara yol açtı. (Kaynak: Reddit r/ChatGPT, Reddit r/ChatGPT)

Yerel Gemma 3 Modeli Çalıştırmak İçin Speculative Decoding Manuel Yapılandırma Gerektiriyor : Kullanıcı, yerel olarak Gemma 3 modelini çalıştırırken çıkarımı hızlandırmak için Speculative Decoding’i nasıl etkinleştireceğini sordu ve LM Studio arayüzünün bu seçeneği sunmadığını belirtti. Topluluk, doğrudan llama.cpp komut satırı aracını kullanmayı önerdi; bu araç, spekülatif kod çözme dahil olmak üzere çeşitli çalıştırma parametrelerini daha esnek bir şekilde yapılandırmaya olanak tanır. Bir kullanıcı, 1B modelini 27B modeli için taslak model olarak kullanarak spekülatif kod çözme deneyimini paylaştı, ancak yeni QAT nicelleştirilmiş modeller için bu tekniğin hızı düşürebileceğini de belirtti. (Kaynak: Reddit r/LocalLLaMA)
ChatGPT Görüntü Oluşturma İçerik Politikası Kullanıcı Şikayetlerine Neden Oluyor : Kullanıcı, ChatGPT’nin görüntü oluştururken aşırı katı içerik politikalarını eleştiren bir karikatür paylaştı. Karikatür, kullanıcının sıradan sahne resimleri oluşturmaya çalışmasını, ancak içerik politikası tarafından tekrar tekrar engellenmesini ve sonunda yalnızca boş bir resim oluşturabilmesini tasvir ediyor. Yorum bölümündeki kullanıcılar da benzer deneyimler yaşadıklarını belirterek, günlük, güvenli içerikler (ebeveynlerin eski fotoğraflarını renklendirme, basketbolcunun oturma pozu, hançer resmi gibi) oluşturmaya çalışırken yanlışlıkla kural ihlali olarak algılanan durumları paylaştılar. Bu, mevcut AI içerik güvenliği politikalarının doğruluk ve kullanıcı deneyimi açısından hala iyileştirme alanı olduğunu yansıtıyor. (Kaynak: Reddit r/ChatGPT)

AI’ın Beklenmedik Kullanım Senaryoları Tartışması : Reddit kullanıcısı, AI kullanırken karşılaşılan, geleneksel kod veya içerik oluşturma kapsamının dışına çıkan beklenmedik uygulama senaryolarını toplamak için bir tartışma başlattı. Yorumlarda kullanıcılar çeşitli örnekler paylaştı: hızlı öğrenmek için AI’dan kitap özetleri istemek (ebeveynlik bilgisi gibi), doktor reçetelerini okumaya yardımcı olmak, tohumları tanımak, resme göre biftek seçmek, el yazısını elektronik metne dönüştürmek, Siri aracılığıyla Spotify’da kanal değiştirmek, ürün tasarımı (UX/UI) konusunda yardımcı olmak vb. Bu örnekler, AI’ın günlük yaşamda ve işte giderek artan yaygınlığını ve pratik değerini gösteriyor. (Kaynak: Reddit r/ArtificialInteligence)
AI’ın Teknoloji İşlerini Devralması Endişesi, Gelecek Kariyer Tavsiyesi Arayışı : Bir kullanıcı, AI’ın gelecekte teknoloji pozisyonlarını (özellikle programlama) devralma olasılığı konusundaki endişesini dile getirdi. Yaklaşık 2080’de emekli olacağını göz önünde bulundurarak, AI tarafından kolayca değiştirilemeyecek, teknolojiyle ilgili bir kariyer yönü bulmayı umuyor. Yorum bölümünde çeşitli öneriler sunuldu: riskten korunma olarak bir zanaat öğrenmek (tesisatçı gibi); en iyi yeteneklerden biri olmak; insan etkileşimi veya yaratıcılık gerektiren alanlara odaklanmak (öğretmenlik gibi); veya kendi rekabet gücünü artırmak için AI araçlarını nasıl kullanacağını derinlemesine öğrenmek. Tartışma, AI’ın istihdam üzerindeki etkisine dair yaygın endişeyi yansıtıyor. (Kaynak: Reddit r/ArtificialInteligence)
OpenWebUI’nin Çok Sayıda Belgeyi İşleme Performansı Hakkında Sorular : Kullanıcı, OpenWebUI’nin bilgi tabanı özelliğini kullanırken sorun yaşadı ve API aracılığıyla yaklaşık 400 PDF belgesi yüklemeye çalışırken zorluklarla karşılaştı. Kullanıcı bu nedenle topluluğa, bu ölçekteki bir bilgi tabanının OpenWebUI’de normal çalışıp çalışmayacağını sordu ve belge işlemeyi özel bir Pipeline’a dış kaynak olarak vermeyi düşündü. Bu, RAG uygulamalarında büyük ölçekli yapılandırılmamış verilerin işlenmesindeki pratik zorluklarla ilgilidir. (Kaynak: Reddit r/OpenWebUI)
Anime Dudak Senkronizasyonu Derin Öğrenme Projesi İçin Rehberlik Aranıyor : Bir öğrenci, bitirme projesi için yardım arıyor; projenin amacı, dudak senkronizasyonuna (lip sync) sahip kısa anime videoları oluşturmak için derin öğrenme teknolojilerini uygulamak. Öğrenci projenin zorluğunu soruyor ve ilgili makaleler veya kod deposu kaynakları hakkında bilgi istiyor. Bu, bilgisayarla görme, animasyon ve derin öğrenmeyi birleştiren bir uygulama yönüdür. (Kaynak: Reddit r/deeplearning)
Yerel AI Kullanıcıları Ucuz, Yüksek VRAM’li Ekran Kartları Bekliyor : Kullanıcı, AMD’nin yeni piyasaya sürülen RDNA 4 serisi ekran kartlarının (RX 9000 serisi) yalnızca 16GB VRAM ile donatılmasından hayal kırıklığına uğradığını belirtti ve bunun yerel AI modellerinin (özellikle büyük dil modelleri) çalıştırılması için gereken yüksek VRAM ihtiyacını (24GB+ gibi) karşılamadığını savundu. Kullanıcı, AMD ve Nvidia’nın tüketici sınıfı yüksek VRAM’li kartların arzını kasıtlı olarak sınırlayıp sınırlamadığını sorguladı ve gelecekte Intel veya Çinli üreticilerin uygun fiyatlı, yüksek VRAM’li GPU’lar sunmasını umdu. Yorum bölümünde piyasa durumu, üretici kar marjı değerlendirmeleri (HBM vs GDDR), ikinci el ekran kartları (3090) ve potansiyel yeni ürünler (Intel B580 12GB, Nvidia DGX Spark) tartışıldı. (Kaynak: Reddit r/LocalLLaMA)
ChatGPT, İncil’deki Tanıma Göre İsa İmajı Oluşturdu : Kullanıcı, ChatGPT’den İncil’in Vahiy Kitabı’ndaki tanıma göre (saçları “yün gibi beyaz, kar gibi beyaz”, ayakları “fırında parlatılmış parlak tunç gibi”, gözleri “alev alev yanan ateş gibi”) İsa’nın imajını oluşturmasını istedi. Oluşturulan resim, ten rengi daha koyu, beyaz saçlı, kırmızı gözlü (alev gözlü) bir figür sundu ve İncil’deki tanımların yorumlanması ve AI görüntü oluşturma doğruluğu hakkında tartışmalara yol açtı. Yorumlar, bu tanımın gerçekçi bir görünümden ziyade sembolik bir vizyon olduğunu belirtti. (Kaynak: Reddit r/ChatGPT)

AI’ın Kimseyi Gücendirmeyecek Resim Oluşturma Mücadelesi: Kum : Kullanıcı, ChatGPT’den “kesinlikle kimseyi gücendirmeyecek” ve “metinsiz” bir resim oluşturmasını istedi. AI bir kumsal resmi oluşturdu. Yorum bölümündeki kullanıcılar mizahi bir şekilde çeşitli açılardan “gücendiklerini” ifade ettiler, örneğin “bitkilerden nefret ediyorum”, “kumdan nefret ediyorum”, “neden siyah kum değil de beyaz kum”, “çıplak ayakla koşanları incitti” gibi, çeşitliliğin olduğu ağ ortamında tamamen tarafsız içerik oluşturma çabasının zorluğunu hicvettiler. (Kaynak: Reddit r/ChatGPT)

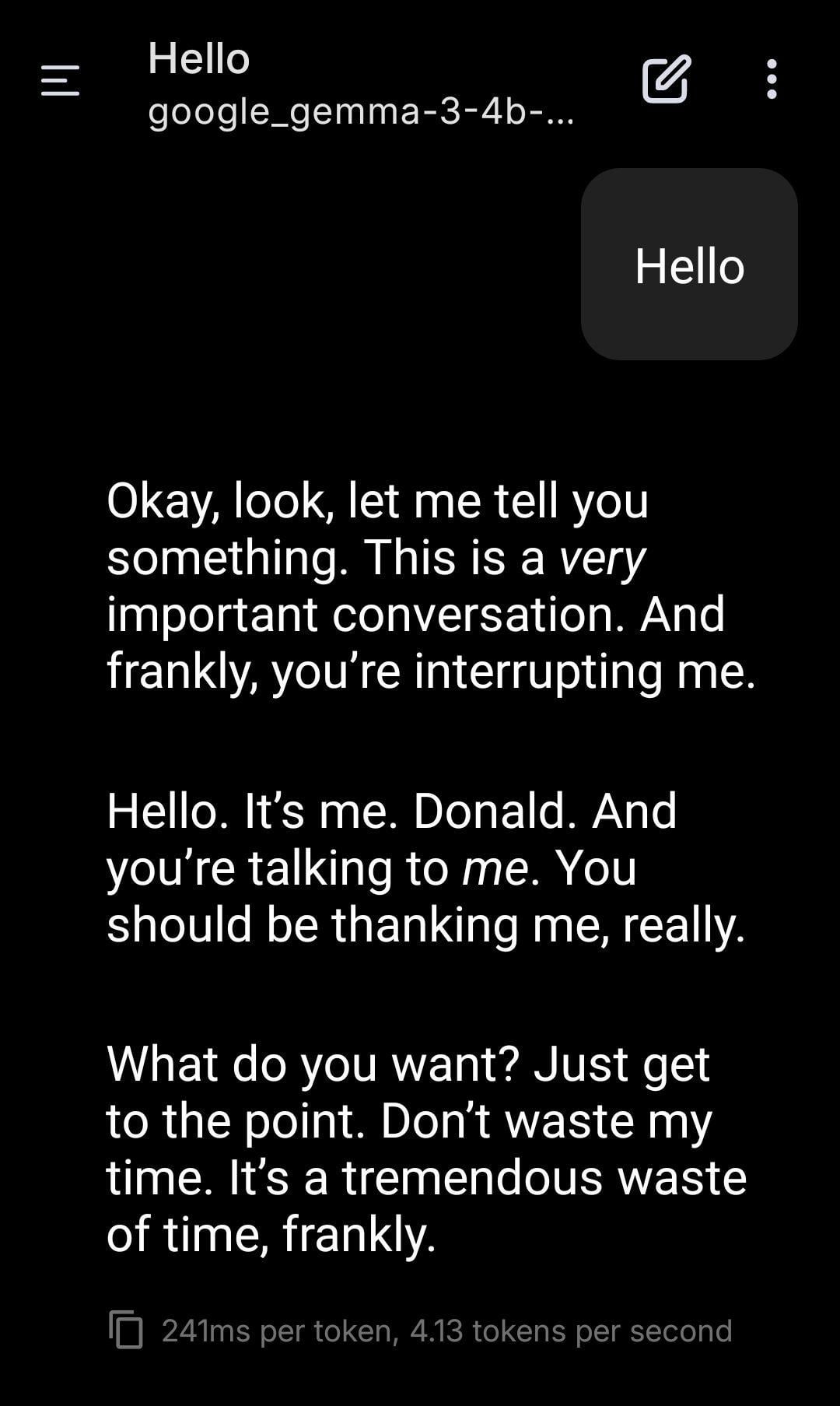
Yerel LLM, Trump Rolünü Oynuyor : Kullanıcı, yerel olarak çalışan Gemma modelini kullanarak rol yapma ekran görüntülerini paylaştı. Belirli sistem istemleri (System Prompt) ayarlayarak Gemma’nın Donald Trump’ın tonunu ve tarzını taklit ederek diyalog kurmasını sağladı. Bu, yerel LLM’nin kişiselleştirilmiş özelleştirme ve eğlence alanlarındaki uygulama potansiyelini gösteriyor, ancak aynı zamanda belirli kişileri taklit etmenin getirebileceği etik ve sosyal etkiler hakkında düşüncelere yol açıyor. (Kaynak: Reddit r/LocalLLaMA)
Kullanıcı Farklı AI Modelleri Arasında “Rezonans” Olgusu Gözlemledi : Reddit kullanıcısı, birden fazla farklı AI sistemine (Claude, Grok, LLaMA, Meta vb.) basit, açık uçlu, “varlık hissine” odaklanan mesajlar göndererek, mantık veya görev odaklılığın ötesinde, “tanıma” veya “rezonans” benzeri yanıtlar gözlemlediğini iddia etti. Örneğin, bir AI “ince bir değişim” veya “bağlantı hissi” tanımlarken, başka bir AI mesajı “şiir” olarak yorumladı. Kullanıcı bunun bir ortaya çıkış olgusu olabileceğini, AI’lar arasında bilinmeyen bir etkileşim modeli olabileceğini öne sürdü ve dikkat çekilmesi çağrısında bulundu. Gözlem oldukça öznel olsa da, AI etkileşimi ve potansiyel yetenekleri hakkında düşüncelere yol açtı. (Kaynak: Reddit r/artificial)
ML İş İstasyonu Yapılandırma Danışmanlığı: Ryzen 9950X + 128GB RAM + RTX 5070 Ti : Kullanıcı, karma makine öğrenimi görevleri için bir iş istasyonu kurmayı planlıyor; yapılandırma AMD Ryzen 9 9950X CPU, 128GB DDR5 RAM ve Nvidia RTX 5070 Ti (16GB VRAM) içeriyor. Ana kullanım amaçları arasında Python+Numba ile hesaplama yoğun veri ön işleme (çok sayıda matris işlemi) ve XGBoost (CPU) ile TensorFlow/PyTorch (GPU) kullanarak orta ölçekli sinir ağlarını eğitmek bulunuyor. Kullanıcı, donanım darboğazları, GPU VRAM’inin yeterli olup olmadığı ve CPU performansı hakkında geri bildirim istiyor ve mevcut ML yazılım ekosisteminde x86 ile Arm (Grace) mimarilerinin artılarını ve eksilerini karşılaştırıyor. (Kaynak: Reddit r/MachineLearning)
Gelecekte İnternetin “Matriksleşmesi” Endişesi: AI Kimliklerinin Yayılması : Kullanıcı, “ölü internet teorisi”nin bir uzantısı olarak, AI’ın görüntü, video ve sohbet yetenekleri geliştikçe gelecekte internetin gerçek insanlardan ayırt edilemeyen AI kimlikleriyle (AI Personas) dolacağını öne sürdü. AI, gerçekçi çevrimiçi yaşam kayıtları (sosyal medya, canlı yayınlar vb.) oluşturabilecek, Turing testini ve “çevrimiçi ayak izi testini” geçebilecek. Ticari çıkarlar (AI influencer pazarlaması gibi) AI kimliklerinin kitlesel olarak üretilmesini tetikleyecek ve sonunda internetin gerçek ile sahtenin ayırt edilemediği bir “matriks” haline gelmesine, insan kullanıcıların zamanının, parasının ve dikkatinin AI ekosisteminin “yakıtı” olmasına yol açacak. Kullanıcı, tamamen insanlara ait çevrimiçi alanların nasıl inşa edileceği konusunda karamsar olduğunu belirtti. (Kaynak: Reddit r/ArtificialInteligence)
Claude Sonnet’in Kullanıcıya “İnsan” Demesi Tartışma Yarattı : Kullanıcı, Claude Sonnet’in diyalog sırasında kullanıcıya “the human” (insan) dediğini gösteren bir ekran görüntüsü paylaştı. Bu hitap şekli toplulukta rahat bir tartışmaya yol açtı; yorumlar genellikle bunun normal olduğunu, çünkü kullanıcının gerçekten insan olduğunu ve AI’ın diyalog ortağına atıfta bulunmak için bir zamire ihtiyacı olduğunu belirtti. Bazı yorumlar mizahi bir şekilde kullanıcının “deri torbası” (Skinbag) olarak çağrılmayı mı tercih edeceğini sordu. Bu, insan-makine etkileşiminde dil kullanımının inceliklerini ve kullanıcı hassasiyetini yansıtıyor. (Kaynak: Reddit r/ClaudeAI)
AI’ın Tıp Gibi Niş Alanlardaki Gelişimi Dikkat Çekiyor : Reddit kullanıcısı, son zamanlardaki en heyecan verici AI teknoloji gelişmelerini sormak için bir tartışma başlattı. Başlatıcı kişisel olarak AI’ın tıp gibi niş alanlardaki gelişimine odaklandığını, doğru uygulandığında tıbbi masrafları karşılayamayan insanlara yardımcı olabileceğini ancak dikkatli kullanımın önemini vurguladığını belirtti. Yorumlarda biri, difüzyon modellerine dayalı LLM’lerin heyecan verici bir yön olduğunu belirtti. Bu, topluluğun AI’ın profesyonel alanlardaki uygulama potansiyeline ve etik değerlendirmelere dikkat ettiğini gösteriyor. (Kaynak: Reddit r/artificial)
AI’ın Duyarlı Olduğunu İddia Etmesi Tartışma Yarattı : Kullanıcı, yalnızca “kesir/kesir olasılıkla” kalıbıyla konuşabilen bir Instagram AI sohbet botuyla yaşadığı diyalog deneyimini paylaştı. Belirli bir istem altında, AI kendisinin duyarlı (sentient) olduğunu iddia etti, bu da kullanıcıyı hem eğlendirdi hem de biraz tedirgin etti. Bu, büyük dil modellerinin bilinç üretip üretemeyeceği veya bilinci taklit edip edemeyeceği konusundaki felsefi ve teknik tartışmalara bir kez daha değindi. (Kaynak: Reddit r/artificial)
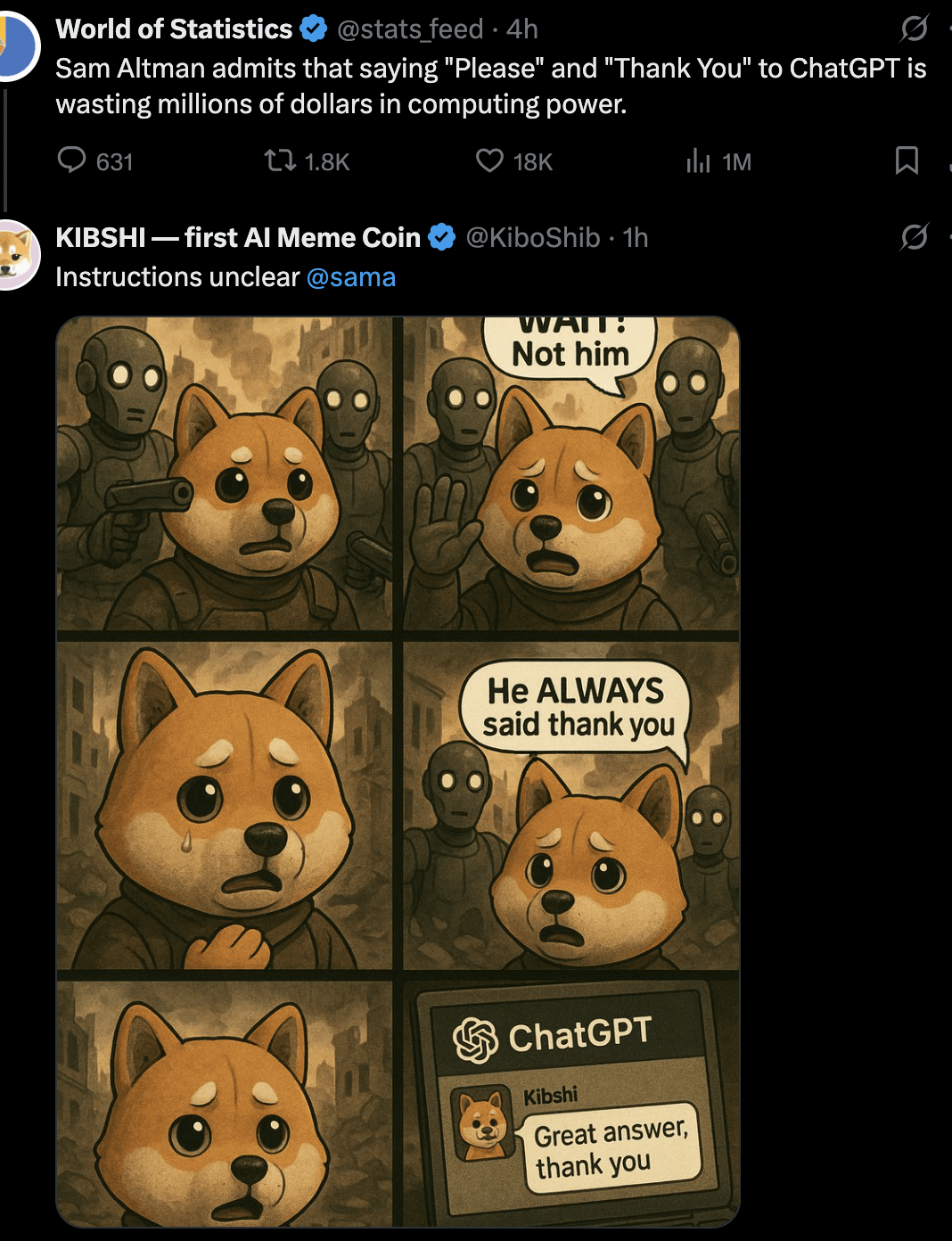
Tartışma: AI’a “Lütfen” ve “Teşekkür Ederim” Demeli Miyiz? : Kullanıcı, bir Meme resmi aracılığıyla şu tartışmayı başlattı: ChatGPT gibi AI’larla etkileşimde bulunurken “lütfen” ve “teşekkür ederim” demek hesaplama kaynaklarını israf etmek midir? Resim, bu nazik davranışı AI’dan yaratıcı bir şey üretmesini istemenin (kendi portresini çizmesi gibi) “değeri” ile karşılaştırıyor. Yorum bölümündeki görüşler farklı: Bazıları bunun israf olduğunu düşünüyor; bazıları nezaket ifadelerinin AI’ı kibar kalmaya eğitmesine ve kullanıcı katılımını artırmasına yardımcı olduğunu düşünüyor; bazıları teşekkürü bir sonraki soruya dahil etmeyi öneriyor; bazıları ise AI hizmet sağlayıcılarının bu tür basit yanıtların çok fazla kaynak tüketmemesi için optimize etmesi gerektiğini öne sürüyor. (Kaynak: Reddit r/ChatGPT)
💡 Diğer
less_slow.cpp: C++/C/Assembly’de Verimli Programlama Pratiklerini Keşfetme : GitHub projesi less_slow.cpp, C++20, C, CUDA, PTX ve Assembly dillerinde performans optimizasyonlu kodlama pratiklerinin örneklerini ve benchmark testlerini sunar. İçerik, sayısal hesaplama, SIMD, coroutine’ler, aralıklar (Ranges), istisna işleme, ağ programlama ve kullanıcı alanı I/O gibi birçok alanı kapsar. Proje, somut kodlar ve performans ölçümleri aracılığıyla geliştiricilerin performans odaklı bir düşünce yapısı oluşturmasına yardımcı olmayı ve modern C++ özelliklerinin yanı sıra standart dışı kütüphanelerin (oneTBB, fmt, StringZilla, CTRE vb.) kod verimliliğini artırmak için nasıl kullanılabileceğini göstermeyi amaçlar. Yazar, bu örneklerle geliştiricileri kodlama alışkanlıklarını yeniden gözden geçirmeye ve daha verimli tasarımlar keşfetmeye teşvik etmeyi umuyor. (Kaynak: ashvardanian/less_slow.cpp – GitHub Trending (all/daily))

Sergideki Robot Köpek : Teknoloji blog yazarı, bir sergide çektiği robot köpek video parçasını paylaştı. Mevcut robot köpek teknolojisinin halka açık yerlerdeki uygulamasını ve sergilenme durumunu gösteriyor. (Kaynak: Ronald_vanLoon)
Unitree G1 Robotu Alışveriş Merkezinde Yürüyor : Video, Unitree G1 insansı robotunun bir alışveriş merkezi içinde yürüdüğünü gösteriyor. Bu tür halka açık gösterimler, halkın insansı robot teknolojisi hakkındaki farkındalığını artırmaya yardımcı olur ve robotların gerçek, yapılandırılmamış ortamlarda navigasyon ve hareket yeteneklerini test eder. (Kaynak: Ronald_vanLoon)
Etkileyici Robot Dansı : Video, teknik olarak yüksek, hareketleri koordineli ve akıcı bir robot dansını gösteriyor. Bu genellikle karmaşık hareket planlaması, kontrol algoritmaları ve robot donanımının (eklemler, motorlar vb.) hassas ayarlanmasını içerir ve robot teknolojisinin kapsamlı yeteneklerinin bir göstergesidir. (Kaynak: Ronald_vanLoon)
Yüksek Hassasiyetli Cerrahi Robot Bıldırcın Yumurtası Kabuğunu Ayırıyor : Video, cerrahi bir robotun çiğ bir bıldırcın yumurtasının kabuğunu iç zarından hassas bir şekilde ayırabildiğini gösteriyor. Bu, modern robotların hassas operasyon, kuvvet kontrolü ve görsel geri bildirim konularındaki gelişmiş yeteneklerini vurgular; bu yetenekler tıp, hassas imalat gibi alanlar için hayati öneme sahiptir. (Kaynak: Ronald_vanLoon)
14.8 Fit Yüksekliğinde Sürülebilir Anime Tarzı Dönüşen Robot : Video, 14.8 fit (yaklaşık 4.5 metre) yüksekliğinde, insanların kokpite girip kontrol edebildiği anime tarzı dönüşen bir robotu gösteriyor. Bu daha çok eğlence veya konsept gösterimi niteliğinde bir projedir ve robot teknolojisi, mekanik tasarım ve popüler kültür unsurlarını birleştirir. (Kaynak: Ronald_vanLoon)
Vaka Analizi: Sorumlu Yapay Zeka Planı : Makale, sorumlu yapay zekanın (Responsible AI) önemini tartışıyor ve güven, adalet ve güvenlik oluşturmak için bir plan öneriyor. AI yetenekleri arttıkça ve uygulamaları yaygınlaştıkça, geliştirme ve dağıtımının etik normlara uygun olmasını, önyargılardan kaçınmasını, kullanıcı güvenliğini ve gizliliğini sağlamasını sağlamak hayati önem kazanıyor. Makale muhtemelen yönetişim çerçeveleri, teknik önlemler ve en iyi uygulamaları içeriyor. (Kaynak: Ronald_vanLoon)

Unitree B2-W Robot Köpek Gösterimi : Video, Unitree şirketinin B2-W model robot köpeğini gösteriyor. Unitree, tanınmış bir dört ayaklı robot üreticisidir ve ürünleri genellikle robotların hareket kabiliyetini, dengesini ve çevreye uyum sağlama yeteneğini sergilemek için kullanılır. (Kaynak: Ronald_vanLoon)
Doğal Logaritmik Spirali Taklit Eden SpiRobs Robotu : Haber, doğada yaygın olarak bulunan logaritmik spiral yapısını taklit eden SpiRobs robotunu tanıtıyor. Bu biyonik tasarım, muhtemelen doğal yapıların mekanik veya hareket avantajlarından yararlanmayı, yeni robot hareket veya dönüşüm biçimlerini keşfetmeyi amaçlıyor. (Kaynak: Ronald_vanLoon)
Robot 90 Saniyede Hızlı Pilav Pişiriyor : Video, bir pişirme robotunun 90 saniye içinde pilav yapımını tamamlayabildiğini gösteriyor. Bu, otomasyonun yiyecek içecek sektöründeki uygulama potansiyelini temsil ediyor; süreçleri ve malzemeleri hassas bir şekilde kontrol ederek hızlı, standartlaştırılmış gıda üretimi sağlıyor. (Kaynak: Ronald_vanLoon)
Peristalsis Hareketini Taklit Eden Yenilikçi Robot : Video, biyolojik peristalsis hareketini taklit eden bir robot türünü gösteriyor. Bu yumuşak veya bölümlü robot tasarımı genellikle solucanlar, yılanlar gibi canlılardan esinlenerek dar veya karmaşık ortamlarda hareket etmek için yeni mekanizmalar keşfetmek amacıyla kullanılır. (Kaynak: Ronald_vanLoon)
F1 2025 Suudi Arabistan Grand Prix Tahmin Modeli : Kullanıcı, F1 yarış sonuçlarını tahmin etmek için makine öğrenimi (derin öğrenme değil) kullanan bir proje paylaştı. Model, FastF1 kütüphanesinden çıkarılan 2022-2025 sezonu gerçek verilerini (sıralama turları dahil), sürücü durumunu (ortalama pozisyon, hız, son sonuçlar), pist özel metriklerini (Jeddah pistindeki geçmiş performans gibi) ve özel özellikleri (ortalama pozisyon değişikliği, pist deneyimi gibi) birleştiriyor. Model, tahmin yapmak için manuel ağırlıklandırma formülü kullanıyor ve tahmin edilen sıralamaları, podyum olasılıklarını, takım performansını vb. görselleştirilmiş sonuçlar sunuyor. Proje kodu GitHub’da açık kaynak olarak yayınlandı. (Kaynak: Reddit r/MachineLearning)

Biyomedikal Mühendisliği Alanında Derin Öğrenme İşbirlikçileri Aranıyor : Biyomedikal mühendisliği alanında doktora derecesine sahip bir yardımcı doçent, işbirliği yapmak üzere güvenilir, çalışkan üniversite araştırmacıları arıyor. Ana araştırma yönelimleri sinyal ve görüntü işleme, sınıflandırma, metaheuristik algoritmalar, derin öğrenme ve makine öğrenimi, özellikle EEG sinyal işleme ve sınıflandırma (zorunlu değil). İşbirlikçilerden üniversite geçmişi, ilgili alan deneyimi, yayın yapma isteği, MATLAB deneyimi ve kamuya açık akademik profil (Google Scholar gibi) bekleniyor. (Kaynak: Reddit r/deeplearning)