
Anahtar Kelimeler:Yapay Zeka Gelişimi, Grok 3, Gemma 3, Yapay Zeka Uygulamaları, Yapay Zeka Gelişim Paradigma Değişimi, xAI Grok 3 API, Google Gemma 3 QAT, VideoGameBench Yapay Zeka Değerlendirmesi, Yapay Zeka ile Molekül Keşfi Hızlandırma, Federatif Öğrenme ile Tıbbi Görüntüleme, LlamaIndex Bilgi Aracısı, Yapay Zeka Kod Otomatik Onarım Teknolojisi
🔥 Odak Noktası
Yapay Zeka Geliştirme Paradigm Değişikliği: Skor Tablolarından Değer Yaratmaya: OpenAI araştırmacısı Yao Shunyu’nun blog yazısı tartışmalara yol açtı ve yapay zeka gelişiminin ikinci yarıya girdiğini öne sürdü. İlk yarı, algoritma yeniliklerine ve benchmark testlerinde skor elde etmeye odaklanmıştı (AlphaGo, GPT-4 gibi). Büyük ölçekli ön eğitim (öncül bilgi sağlama) ve takviyeli öğrenme (RL) kombinasyonuyla, “eylem olarak akıl yürütme” kavramını tanıtarak genelleme atılımı gerçekleştirildi. Ancak, sürekli skor tablolarında zirveye oynamanın marjinal faydasının azaldığını, ikinci yarının pratik uygulama değeri olan sorunları tanımlamaya, gerçek dünyaya daha yakın değerlendirme yöntemleri geliştirmeye, bir ürün yöneticisi gibi düşünmeye ve sadece metrikleri yükseltmek yerine yapay zeka ile gerçekten kullanıcı değeri ve toplumsal değer yaratmaya yönelmesi gerektiğini savunuyor. Bu, yapay zeka alanında teknoloji keşfinden uygulama ve değer gerçekleştirmeye odaklı bir zihniyet değişikliğini işaret ediyor (kaynak: dotey)
xAI, Grok 3 Serisi Model API’sini Yayınladı: xAI, Grok 3 serisi modellerinin API arayüzünü (docs.x.ai) resmi olarak kullanıma sundu ve en yeni modellerini geliştiricilere açtı. Bu seri, Grok 3 Mini ve Grok 3’ü içeriyor. xAI’ye göre, Grok 3 Mini, düşük maliyeti korurken (benzer çıkarım modellerinden 5 kat daha ucuz olduğunu iddia ediyor) üstün çıkarım yetenekleri sergiliyor; Grok 3 ise hukuk, finans, tıp gibi gerçek dünya bilgisi gerektiren alanlarda öne çıkan güçlü bir çıkarım dışı model (muhtemelen bilgi yoğun görevleri kastediyor) olarak konumlandırılıyor. Bu hamle, xAI’nin yapay zeka model API pazarı rekabetine katıldığını ve geliştiricilere yeni seçenekler sunduğunu gösteriyor (kaynak: grok, grok)
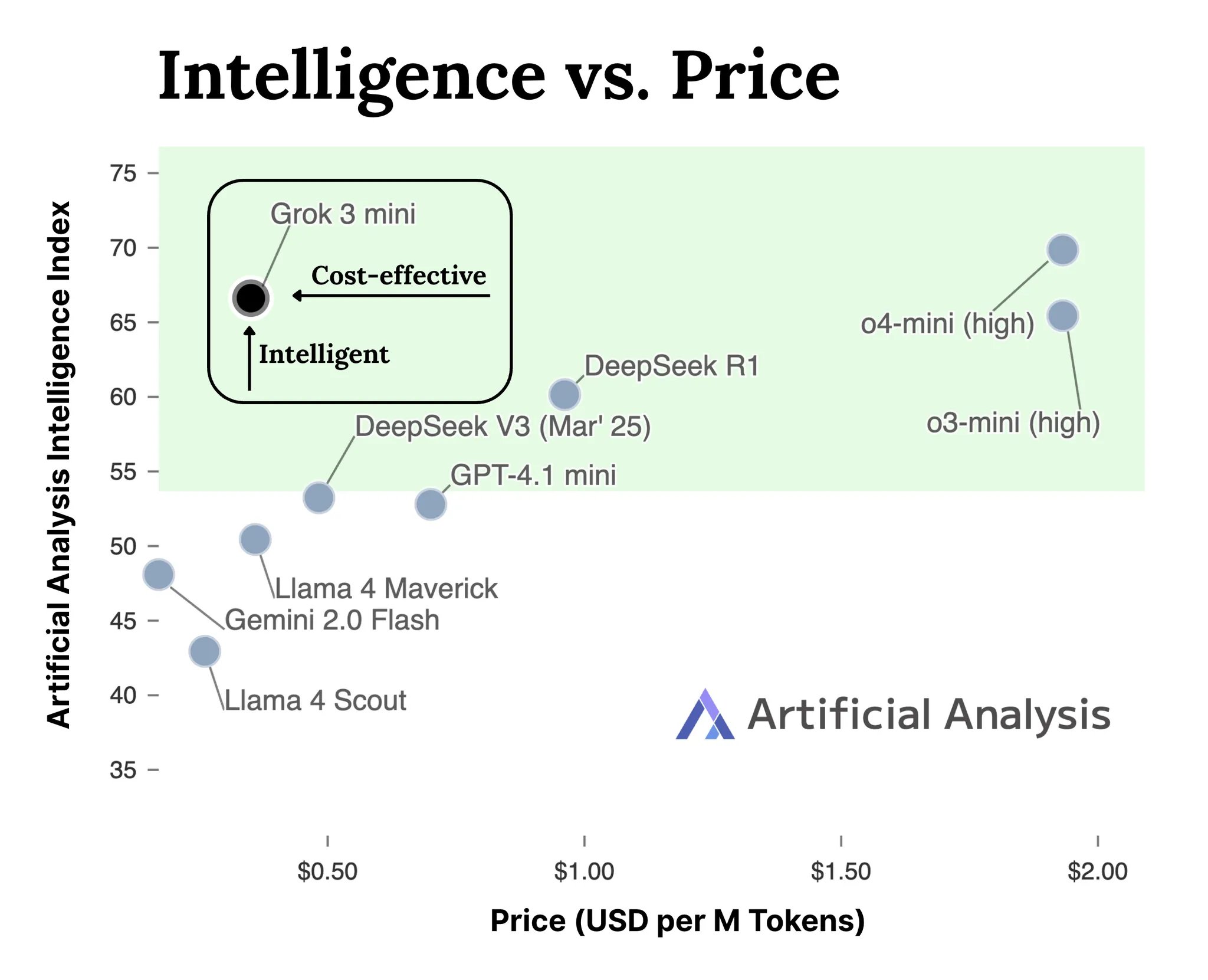
VideoGameBench: Klasik Oyunlarla Yapay Zeka Ajan Yeteneklerini Değerlendirme: Araştırmacılar, görsel dil modellerinin (VLM) 20 klasik video oyunundaki (Doom II gibi) görevleri gerçek zamanlı olarak tamamlama yeteneklerini değerlendirmeyi amaçlayan VideoGameBench benchmark testinin önizleme sürümünü yayınladı. İlk testler, GPT-4o, Claude Sonnet 3.7, Gemini 2.5 Pro dahil olmak üzere önde gelen modellerin Doom II’de farklı performanslar sergilediğini ancak hiçbirinin ilk bölümü geçemediğini gösterdi. Bu, modellerin birçok görevde güçlü yeteneklere sahip olmasına rağmen, gerçek zamanlı algılama, karar verme ve eylem gerektiren karmaşık dinamik ortamlarda hala zorluklarla karşılaştığını gösteriyor. Bu benchmark, yapay zeka ajanlarının etkileşimli ortamlardaki ilerlemesini ölçmek ve teşvik etmek için yeni bir araç sunuyor (kaynak: Reddit r/LocalLLaMA)
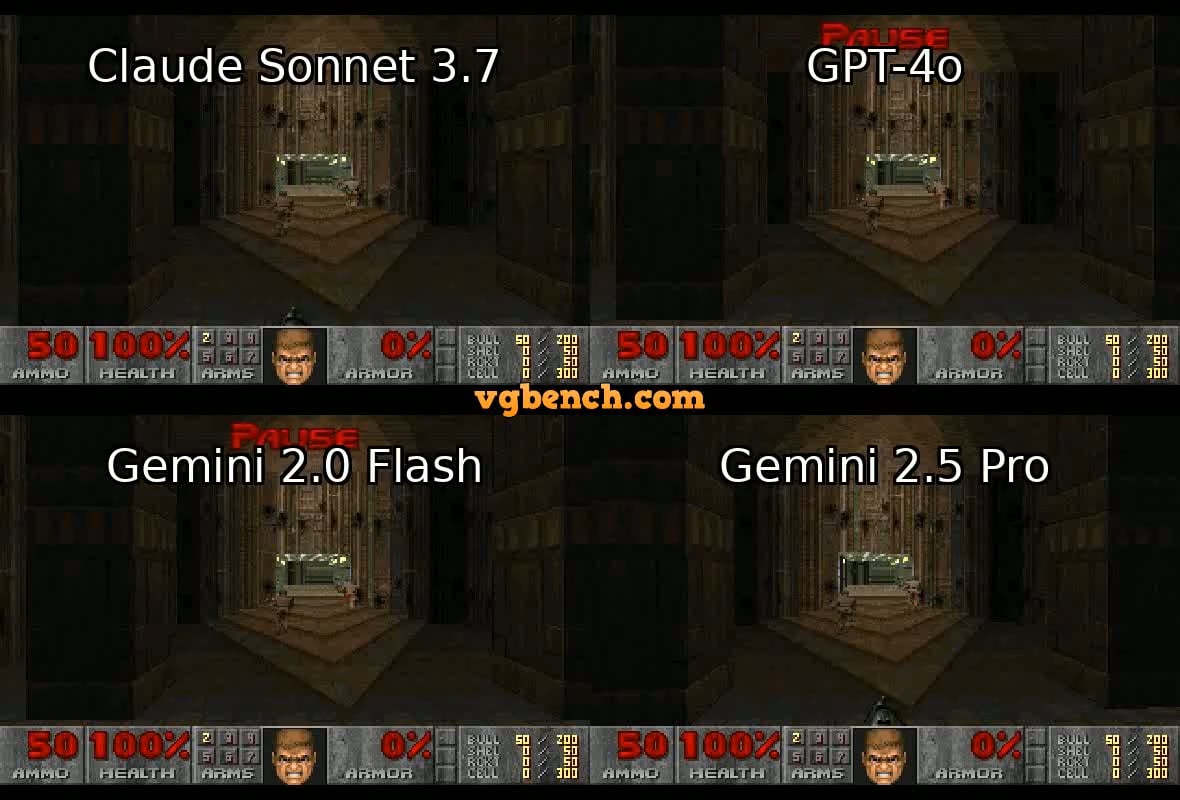
OpenAI’nin Güçlendirilmiş Kimlik Doğrulaması Tartışma Yarattı: OpenAI’nin, bazı gelişmiş modellerine (özellikle güçlü çıkarım yeteneklerine sahip o3 gibi) erişim için kullanıcılardan ayrıntılı kimlik kanıtı (pasaport, vergi beyannamesi, fatura gibi) talep ettiği ortaya çıktı. Bu hamle, toplulukta güçlü bir tepkiye yol açtı; kullanıcılar genellikle gizlilik ihlali ve erişim engelinin artması konusunda endişelerini dile getirdi. OpenAI’nin bu adımı güvenlik, uyumluluk veya kaynak yönetimi nedenleriyle atmış olması mümkün olsa da, bu katı doğrulama gerekliliği, şirketin açık imajıyla çelişiyor ve kullanıcıları daha iyi gizlilik koruması sunan veya daha kolay erişilebilir alternatiflere, özellikle yerel modellere yöneltebilir (kaynak: Reddit r/LocalLLaMA)
Yapay Zeka Molekül Keşfini Hızlandırıyor: Doğanın Milyonlarca Yıllık Evrimini Simüle Ediyor: Sosyal medya tartışmalarında, yapay zekanın birkaç gün içinde bir molekül tasarlayabildiği, oysa bu molekülün doğada evrimleşmesinin 500 milyon yıl sürebileceği belirtiliyor. Ayrıntılar doğrulanmaya muhtaç olsa da, bu durum yapay zekanın özellikle kimya ve biyoloji alanlarında bilimsel keşifleri hızlandırma konusundaki muazzam potansiyelini vurguluyor. Yapay zeka, geniş kimyasal uzayı keşfedebilir, moleküler özellikleri tahmin edebilir ve bunu geleneksel deneysel yöntemlerden ve doğal evrimden çok daha hızlı yapabilir; ilaç geliştirme, malzeme bilimi gibi alanlarda çığır açıcı ilerlemeler vaat ediyor (kaynak: Ronald_vanLoon)
🎯 Gelişmeler
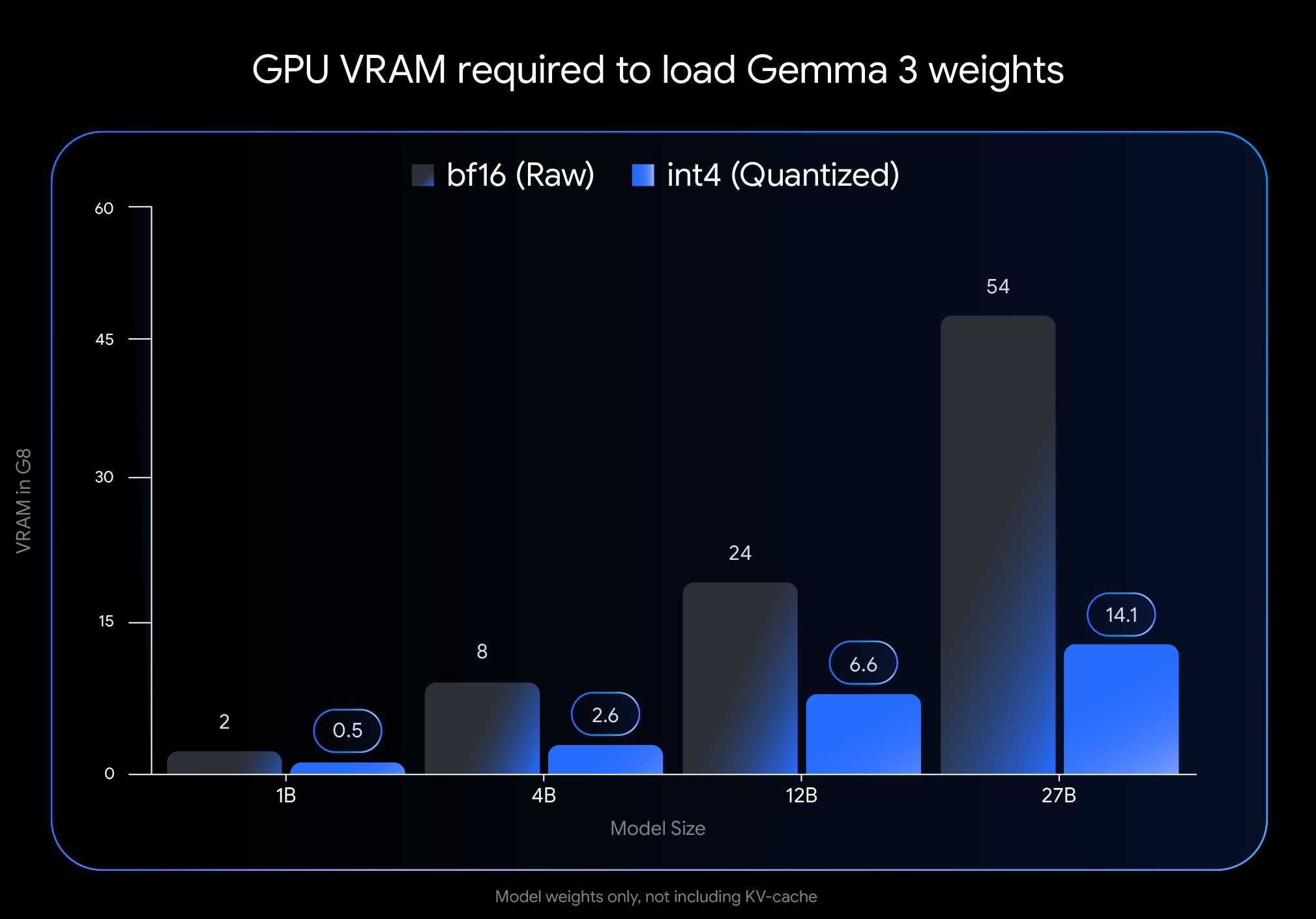
Google, Gemma 3 QAT Sürümünü Yayınlayarak Dağıtım Engelini Önemli Ölçüde Düşürdü: Google DeepMind, Quantization-Aware Training (QAT) ile eğitilmiş Gemma 3 model sürümlerini tanıttı. QAT teknolojisi, model boyutunu önemli ölçüde sıkıştırırken orijinal modelin performansını en üst düzeyde korumayı hedefler. Örneğin, Gemma 3 27B modelinin boyutu 54GB’den (bf16) yaklaşık 14.1GB’ye (int4) düşürüldü, bu da daha önce üst düzey bulut GPU’ları gerektiren lider modellerin artık tüketici sınıfı masaüstü GPU’larında (RTX 3090 gibi) çalıştırılabilmesini sağlıyor. Google, nicelleştirilmemiş QAT kontrol noktalarını ve çeşitli formatları (MLX, GGUF) yayınladı ve Ollama, LM Studio, llama.cpp gibi topluluk araçlarıyla işbirliği yaparak geliştiricilerin çeşitli platformlarda kolayca kullanabilmesini sağladı, bu da yüksek performanslı açık kaynak modellerinin yaygınlaşmasını büyük ölçüde teşvik etti (kaynak: huggingface, JeffDean, demishassabis, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Meta FAIR Algı Araştırması Sonuçlarını Yayınladı, Açık Kaynak Yolunda Israrcı: Meta FAIR, gelişmiş makine zekası (AMI) alanında, özellikle algı alanında ilerlemeler kaydeden birçok yeni araştırma sonucunu yayınladı; buna büyük ölçekli bir görsel kodlayıcı olan Meta Perception Encoder’ın yayınlanması da dahil. Yann LeCun, bu sonuçların açık kaynak olacağını vurguladı. Bu, Meta’nın temel yapay zeka araştırmalarına sürekli yatırım yaptığını ve araştırma ilerlemelerini açık kaynak yoluyla paylaşarak tüm alanın gelişimini teşvik etmeye kararlı olduğunu gösteriyor. Yayınladığı görsel kodlayıcı gibi araçlar daha geniş bir araştırma ve geliştirici topluluğuna fayda sağlayacaktır (kaynak: ylecun)
OpenAI Model Kullanım Sınırlarını Belirledi: OpenAI, ChatGPT Plus, Team ve Enterprise kullanıcıları için model kullanım miktarlarını netleştirdi. Buna göre, o3 modeli haftada 50 mesajla, o4-mini günde 150 mesajla ve o4-mini-high günde 50 mesajla sınırlı. İddiaya göre ChatGPT Pro (belirli bir paketi veya yanlış anlaşılmayı kastediyor olabilir) sınırsız erişim hakkına sahip. Bu sınırlamalar, yüksek frekanslı kullanıcıları ve belirli modellere bağımlı uygulama geliştiricilerini doğrudan etkiliyor ve kullanım planlamasında dikkate alınması gerekiyor (kaynak: dotey)
LlamaIndex, Bilgi Ajanları Oluşturmak İçin Google Cloud Veritabanlarıyla Entegre Oldu: Google Cloud Next 2025 konferansında LlamaIndex, çerçevesinin çok adımlı araştırma yapabilen, belgeleri işleyebilen ve raporlar oluşturabilen bilgi ajanları oluşturmak için Google Cloud veritabanlarıyla nasıl entegre olduğunu gösterdi. Demo, çalışan işe alım kılavuzunu otomatik olarak oluşturan çoklu ajan sistemi örneğini içeriyordu. Bu, yapay zeka uygulama çerçevelerinin bulut platformları ve veri hizmetleriyle derinlemesine entegrasyon eğilimini gösteriyor ve işletmelerin iç bilgi ve verileri işlemek için yapay zekadan yararlanma konusundaki pratik ihtiyaçlarını çözmeyi amaçlıyor (kaynak: jerryjliu0)

Yeni Nano Beyin Sensörü, Yüksek Hassasiyetli Sinyal Tanıma İçin Yapay Zeka ile Birleşti: Araştırmalar, sinir sinyallerini tanımada %96.4 doğruluk oranına ulaşan yeni bir nano ölçekli beyin sensörünü bildirdi. Sensör teknolojisinin kendisi temel bir atılım olsa da, bu kadar yüksek tanıma doğruluğuna ulaşmak genellikle karmaşık, zayıf sinir sinyallerini çözmek için gelişmiş yapay zeka ve makine öğrenimi algoritmalarının yardımını gerektirir. Bu ilerleme, beyin bilimi araştırmaları ve gelecekteki beyin-bilgisayar arayüzü uygulamaları için yeni yollar açıyor ve daha hassas beyin aktivitesi izleme ve etkileşimi sağlama potansiyeli taşıyor (kaynak: Ronald_vanLoon)

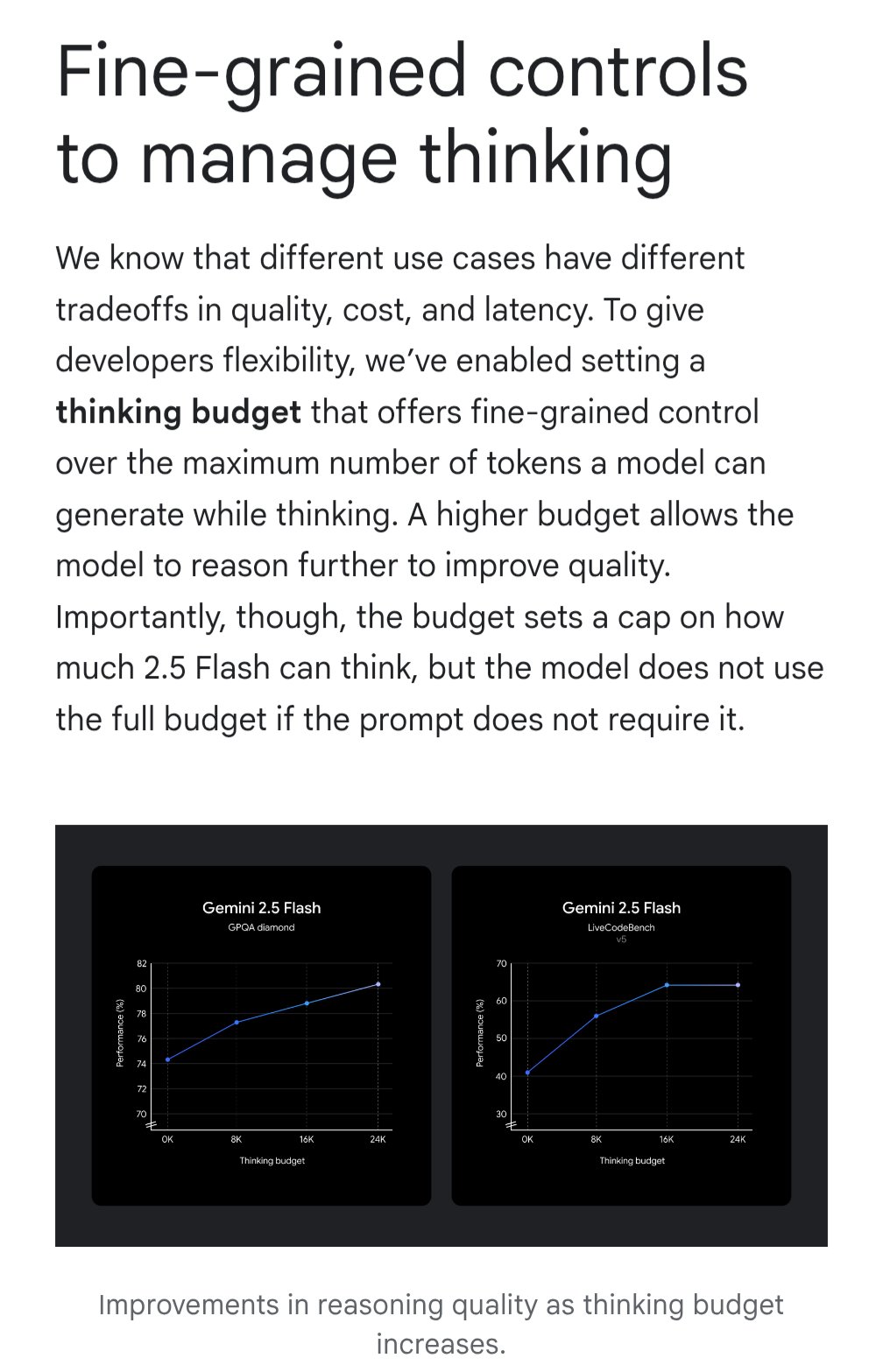
Gemini, Maliyet Etkinliğini Optimize Etmek İçin “Düşünme Bütçesi” Özelliğini Tanıttı: Google Gemini modeli, kullanıcıların modelin sorguları işlerken ayırdığı hesaplama kaynaklarını veya “düşünme” derinliğini ayarlamasına olanak tanıyan “düşünme bütçesi” (thinking budget) özelliğini tanıttı. Bu özellik, kullanıcıların yanıt kalitesi, maliyet ve gecikme arasında bir denge kurmasını sağlamayı amaçlıyor. Bu, API kullanıcıları için oldukça pratik bir özelliktir ve belirli uygulama senaryolarının gereksinimlerine göre model kullanım maliyetini ve performansını esnek bir şekilde kontrol etmelerini sağlar (kaynak: JeffDean)
Yapay Zeka Destekli Ultrason İnceleme Kalitesi Uzmanlarla Karşılaştırılabilir Düzeyde: JAMA Cardiology’de yayınlanan araştırma, eğitimli tıp uzmanlarının yapay zeka rehberliğinde gerçekleştirdiği ultrason incelemelerinin görüntü kalitesinin tanı standartlarını karşılayacak düzeyde (%98.3) olduğunu ve yapay zeka rehberliği olmayan uzmanlar tarafından elde edilen görüntülerle istatistiksel olarak anlamlı bir fark olmadığını gösterdi. Bu, yapay zekanın bir yardımcı araç olarak, uzman olmayan kullanıcıların tıbbi görüntüleme işlemlerinin kalitesini ve tutarlılığını artırmasına etkili bir şekilde yardımcı olabileceğini ve kaynakları sınırlı bölgelerde yüksek kaliteli tanı hizmetlerinin erişilebilirliğini genişletme potansiyeli taşıdığını gösteriyor (kaynak: Reddit r/ArtificialInteligence)
MIT Araştırması, Yapay Zeka Tarafından Üretilen Kodun Doğruluğunu ve Yapıya Uygunluğunu Artırıyor: MIT araştırmacıları, büyük dil modellerinin çıktılarını kontrol etmek için daha verimli bir yöntem geliştirdi. Bu yöntem, modelleri belirli bir yapıya (programlama dili sözdizimi gibi) uygun ve hatasız kod üretmeye yönlendirmeyi amaçlıyor. Bu araştırma, yapay zeka tarafından üretilen kodun güvenilirliği sorununu çözmeye adanmıştır ve kısıtlı üretim tekniklerini geliştirerek çıktının sözdizimi kurallarına sıkı sıkıya uymasını sağlamayı, böylece yapay zeka kod yardımcılarının pratikliğini artırmayı ve sonraki hata ayıklama maliyetlerini azaltmayı hedefler (kaynak: Reddit r/ArtificialInteligence)
NVIDIA, Robotik Alanındaki Büyük Projesini Açıklayabilir: Sosyal medyada NVIDIA’nın robotik, mühendislik, yapay zeka ve otonom teknolojileri içeren “en iddialı projesi” üzerinde çalıştığı belirtiliyor. Ayrıntılar bilinmemekle birlikte, NVIDIA’nın yapay zeka donanımı ve platformlarındaki (Isaac gibi) merkezi konumu göz önüne alındığında, ilgili herhangi bir büyük duyuru büyük ilgi görüyor ve şirketin somutlaştırılmış zeka ve robotik alanındaki daha ileri stratejik hamlelerini ve teknolojik atılımlarını müjdeliyor olabilir (kaynak: Ronald_vanLoon)
🧰 Araçlar
Potpie: Kod Tabanına Özel Yapay Zeka Mühendislik Asistanı: Potpie (GitHub: potpie-ai/potpie), kod tabanları için özelleştirilmiş yapay zeka mühendislik ajanları oluşturmayı amaçlayan açık kaynaklı bir platformdur. Bileşenler arasındaki karmaşık ilişkileri anlamak için bir kod bilgi grafiği oluşturarak kod analizi, test etme, hata ayıklama ve geliştirme gibi otomatik görevler sunar. Platform, çeşitli önceden oluşturulmuş ajanlar (hata ayıklama, soru-cevap, kod değişikliği analizi, birim/entegrasyon testi oluşturma, alt düzey tasarım, kod oluşturma gibi) ve araç setleri sunar ve kullanıcıların özel ajanlar oluşturmasını destekler. Geliştirme süreçlerine kolay entegrasyon için VSCode uzantısı ve API entegrasyonu sağlar (kaynak: potpie-ai/potpie – GitHub Trending (all/daily))

1Panel: LLM Yönetimini Entegre Eden Linux Sunucu Paneli: 1Panel (GitHub: 1Panel-dev/1Panel), ana bilgisayarları, dosyaları, veritabanlarını, konteynerleri vb. yönetmek için web tabanlı bir grafik arayüz sağlayan modern, açık kaynaklı bir Linux sunucu işletim ve yönetim panelidir. Özelliklerinden biri, büyük dil modellerinin (LLM) yönetim işlevlerini içermesidir. Ayrıca, uygulama mağazası, hızlı web sitesi dağıtımı (WordPress entegrasyonu), güvenlik koruması ve tek tıkla yedekleme/geri yükleme gibi özellikler sunarak, yapay zeka ile ilgili uygulamaların dağıtımı ve yönetimi de dahil olmak üzere sunucu yönetimini ve uygulama dağıtımını basitleştirmeyi amaçlar (kaynak: 1Panel-dev/1Panel – GitHub Trending (all/daily))

LlamaIndex Yükseltilmiş Sohbet Arayüzü Bileşenini Tanıttı: LlamaIndex, sohbet arayüzü bileşen kütüphanesinin (@llamaindex/chat-ui) önemli bir güncellemesini yayınladı. Yeni bileşen shadcn UI üzerine inşa edilmiş olup daha şık bir tasarıma, duyarlı bir düzene sahiptir ve tamamen özelleştirilebilir. Geliştiricilerin LLM tabanlı projeler için güzel, kullanıcı dostu sohbet arayüzleri oluşturmalarına daha kolay yardımcı olmayı ve yapay zeka uygulamalarının etkileşim deneyimini iyileştirmeyi amaçlar. Geliştiriciler npm aracılığıyla kurabilir ve projelerinde doğrudan kullanabilirler (kaynak: jerryjliu0)
LlamaExtract Uygulamada: Finansal Analiz Uygulaması Oluşturma: LlamaIndex, LlamaExtract aracını (LlamaCloud’un bir parçası) kullanarak tam yığın bir web uygulaması oluşturma örneğini sergiledi. LlamaExtract, kullanıcıların karmaşık belgelerden yapılandırılmış verileri çıkarmak için hassas Schema tanımlamasına olanak tanır. Bu örnek uygulama, şirket yıllık raporlarından risk faktörlerini çıkarır ve yıllar içindeki değişiklikleri analiz ederek normalde 20 saatten fazla süren bir işi otomatikleştirir. Bu uygulama açık kaynaklıdır (GitHub: run-llama/llamaextract-10k-demo) ve LlamaExtract ile Sonnet 3.7’yi birleştirerek bu iş akışının nasıl oluşturulacağını gösteren bir video demosu bulunmaktadır, bu da yapay zeka ajanlarının karmaşık analiz görevlerini otomatikleştirme potansiyelini göstermektedir (kaynak: jerryjliu0, jerryjliu0)
mcpbased.com: Açık Kaynak MCP Sunucu Dizini Yayında: Yeni web sitesi mcpbased.com, açık kaynak MCP (muhtemelen Meta Controller Pattern veya benzer bir kavramı ifade ediyor) sunucuları için özel bir dizin olarak başlatıldı. Platform, çeşitli MCP sunucu projelerini bir araya getirmeyi ve sergilemeyi, Github depo verilerini gerçek zamanlı olarak senkronize etmeyi ve geliştiricilerin ilgili araçları keşfetmesini, göz atmasını ve bunlara bağlanmasını kolaylaştırmayı amaçlıyor. MCP sunucuları oluşturan veya kullanan, araç entegrasyonu yapan veya MCP ekosistemini takip eden geliştiriciler için bu yeni bir kaynak merkezidir (kaynak: Reddit r/ClaudeAI)
📚 Öğrenme
RLHF Kitabı ArXiv’de Yayınlandı: Nathan Lambert ve diğerleri tarafından yazılan, insan geri bildiriminden takviyeli öğrenme (RLHF) hakkındaki “rlhfbook” adlı kitap artık ArXiv platformunda (numara 2504.12501) yayınlandı. RLHF, şu anda ChatGPT gibi büyük dil modellerini hizalamak için kullanılan temel teknolojilerden biridir. Kitabın yayınlanması, araştırmacılara ve uygulayıcılara RLHF ilkelerini ve uygulamalarını sistematik olarak öğrenmek ve derinlemesine anlamak için önemli bir kaynak sunarak bu alandaki bilginin yayılmasını ve uygulanmasını teşvik ediyor (kaynak: natolambert)
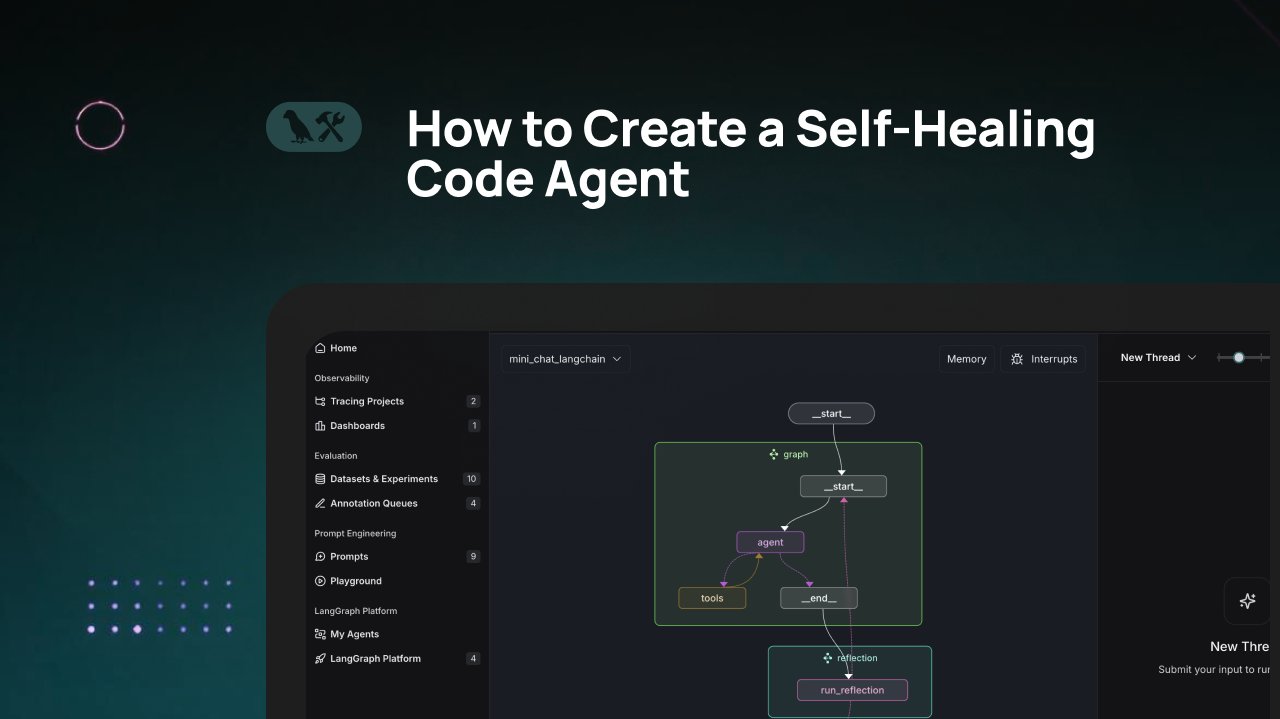
LangChain Eğitimi: Kendi Kendini Onaran Kod Üretme Ajanı Oluşturma: LangChain, “kendi kendini onarma” yeteneğine sahip yapay zeka kod üretme ajanlarının nasıl oluşturulacağını tanıtan bir video eğitimi yayınladı. Temel fikir, kod ürettikten sonra bir “yansıtma” (reflection) adımı ekleyerek ajanın ürettiği kodu kendi kendine doğrulamasını, değerlendirmesini veya iyileştirmesini sağlamak ve ardından sonucu döndürmektir. Bu yöntem, yapay zeka tarafından üretilen kodun doğruluğunu ve güvenilirliğini artırmayı amaçlar ve kod yardımcılarının pratikliğini geliştirmek için etkili bir tekniktir (kaynak: LangChainAI)
Yapay Zeka ve Blender ile Oyuna Hazır 3D Varlıklar Oluşturma: Sosyal medyada, yapay zeka araçlarını (muhtemelen görüntü üretimi) 3D modelleme yazılımı Blender ile birleştirerek oyuna hazır (game-ready) 3D varlıklar oluşturma eğitimi paylaşıldı. Bu, yapay zekanın doğrudan 3D model üretme yeteneğinin mevcut eksikliğini ele alıyor ve pratik bir hibrit iş akışını gösteriyor: kavram veya doku haritaları oluşturmak için yapay zekayı kullanmak, ardından Blender gibi profesyonel araçlarla modelleme ve optimizasyon yapmak ve son olarak oyun motoru gereksinimlerine uygun kaynaklar üretmek (kaynak: huggingface)
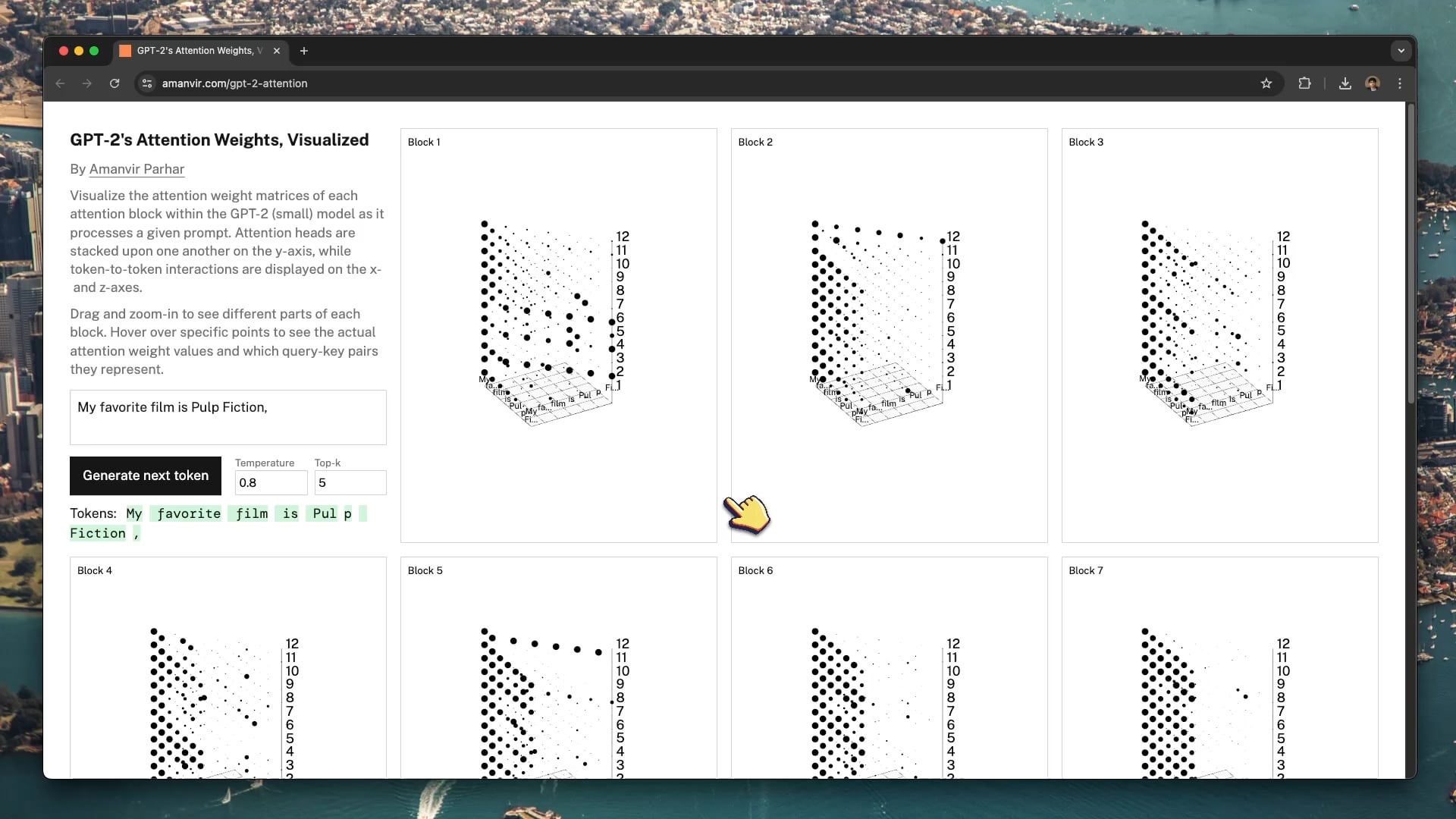
Etkileşimli Görselleştirme Aracı GPT-2 Dikkat Mekanizmasını Anlamaya Yardımcı Oluyor: Geliştirici tycho_brahes_nose_, GPT-2 (küçük) modelinin içindeki her dikkat bloğunun ağırlık hesaplama sürecini göstermek için etkileşimli bir 3D görselleştirme aracı (amanvir.com/gpt-2-attention) oluşturdu ve paylaştı. Kullanıcılar, giriş metninden sonra modelin farklı katmanlar ve dikkat başlıkları arasında token-token etkileşim gücünü nasıl hesapladığını sezgisel olarak görebilirler. Bu, Transformer’ın temel mekanizmalarını anlamak için mükemmel bir yardımcı sağlar ve yapay zeka öğrenimi ile model yorumlanabilirliği araştırmalarına katkıda bulunur (kaynak: karminski3, Reddit r/LocalLLaMA)
Federated Learning’in Tıbbi Görüntü Analizindeki Uygulamaları: Reddit gönderisi, Federated Learning (FL) ile derin sinir ağlarını (DNN) birleştirerek tıbbi görüntü analizine uygulayan bir makaleye işaret ediyor. Tıbbi verilerin gizliliğe duyarlılığı nedeniyle, FL orijinal verileri paylaşmadan birden fazla kurum arasında işbirliği içinde model eğitmeye olanak tanır. Bu, yapay zekanın tıp alanındaki uygulamalarını ilerletmek için kritik öneme sahiptir ve bu kaynak, gizliliği koruyan bu dağıtık öğrenme tekniğini ve tıbbi görüntülemedeki uygulamalarını anlamaya yardımcı olur (kaynak: Reddit r/deeplearning)

Sander Dielman VAE ve Gizli Uzayı Derinlemesine İnceliyor: Andrej Karpathy, Sander Dielman’ın varyasyonel otokodlayıcılar (VAE) ve gizli uzay modellemesi hakkındaki derinlemesine blog yazısını (sander.ai/2025/04/15/latents.html) tavsiye etti. Makale, VAE eğitimindeki ayrıntıları, örneğin KL sapma teriminin gizli uzayı şekillendirmedeki sınırlı pratik etkisini ve L1/L2 yeniden yapılandırma kaybının neden bulanık görüntüler üretme eğiliminde olduğunu (görüntü spektral zayıflaması ile insan gözünün algısal odak noktalarının uyuşmaması) inceliyor. Bu yazı, üretken modelleri anlamak için titiz ve anlayışlı bir analiz sunuyor (kaynak: Reddit r/MachineLearning)
💼 Ticari
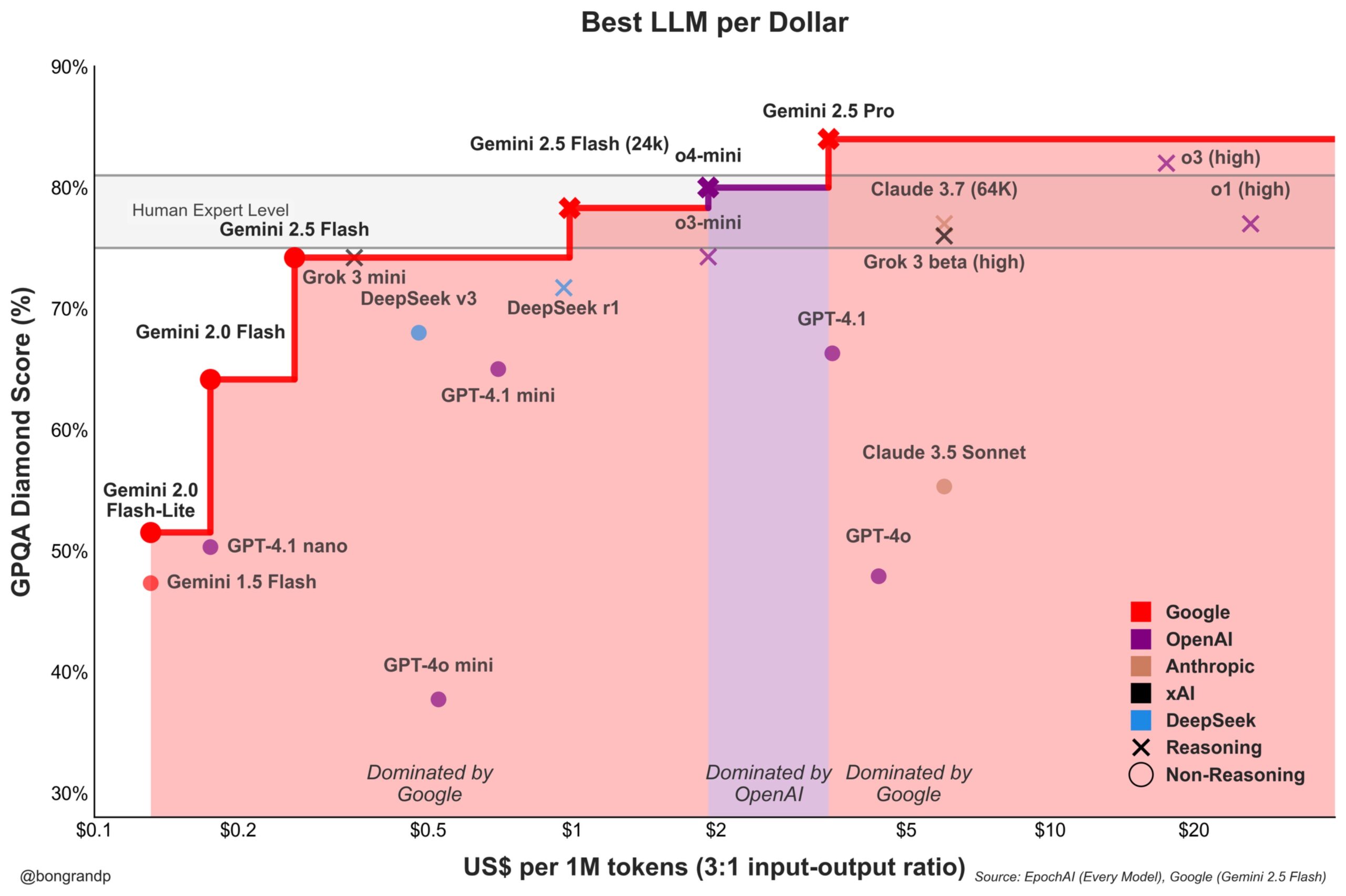
Model Fiyat Savaşı Kızışıyor: Google Gemini, OpenAI’ye Aktif Olarak Meydan Okuyor: Analizler, Google’ın Gemini serisi modelleriyle (özellikle yeni yayınlanan Gemini 2.5 Flash) performans ve fiyat açısından güçlü bir rekabet gücü sergilediğini ve iddiaya göre senaryoların yaklaşık %95’inde OpenAI’den daha iyi bir fiyat/performans oranı sunduğunu belirtiyor. Google’ın API’lerine hızlı yanıt vermesi ve fiyatlandırma stratejisi (fiyat aralıklarının %90’ından fazlasına hakim olması), LLM pazar payını aktif olarak ele geçirmeye çalıştığını, maliyet avantajıyla kullanıcıları çekmek istediğini ve temel model pazarındaki rekabeti kızıştırdığını gösteriyor (kaynak: JeffDean)
Coinbase, Agentic Commerce’i Keşfetmek İçin LangChain Konferansına Sponsor Oldu: Coinbase Development, LangChain Interrupt 2025 konferansının sponsoru oldu. Coinbase, AgentKit ve x402 ödeme protokolü gibi araçlarıyla “ajan ticareti”ni (Agentic Commerce) güçlendiriyor ve yapay zeka ajanlarının bağlam çıkarımı, API çağrıları gibi hizmetler için otonom ödemeler yapmasını sağlıyor. Bu işbirliği, yapay zeka ajan teknolojisi ile Web3 ödemelerinin kesişim noktasını vurguluyor ve gelecekteki yapay zeka odaklı otomatik ekonomik etkileşim senaryolarını müjdeliyor (kaynak: LangChainAI)

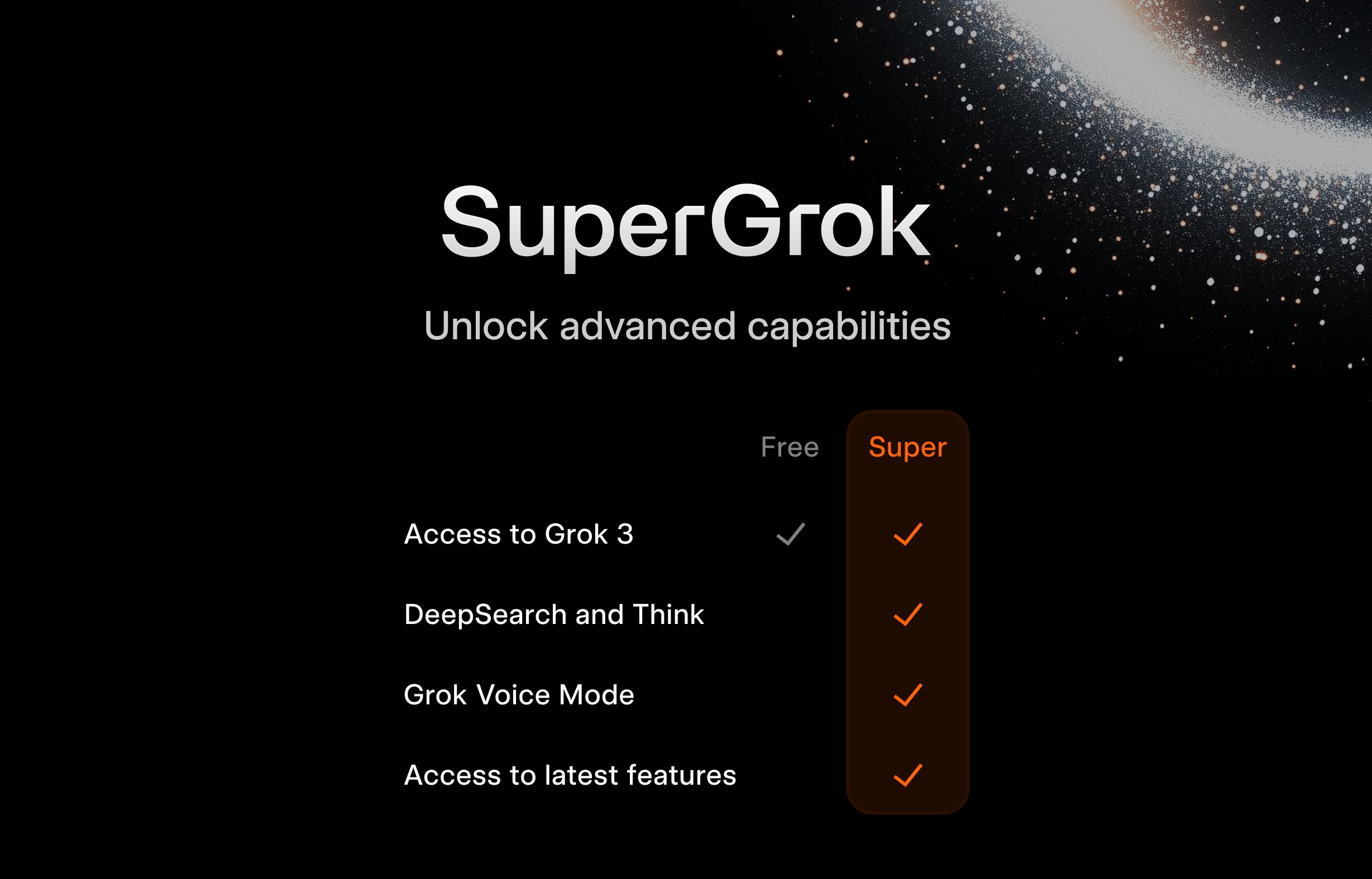
xAI, Öğrencilere Yönelik Ücretsiz SuperGrok Programını Başlattı: Genç kullanıcı kitlesini çekmek amacıyla xAI, öğrencilere yönelik bir kampanya başlattı: .edu uzantılı e-posta ile kaydolanlar, iki ay boyunca SuperGrok (Grok’un gelişmiş sürümü) kullanım hakkını ücretsiz olarak elde edecekler. Bu hamle, Grok’u bir öğrenme yardımcısı olarak konumlandırmayı, final sınavları döneminde tanıtım yapmayı, eğitim pazarındaki kullanıcıları kazanmayı ve gelecekteki potansiyel ücretli müşterileri yetiştirmeyi amaçlıyor (kaynak: grok)
Google, ABD Üniversite Öğrencilerine Gemini Advanced ve Birçok Hizmeti Ücretsiz Sunuyor: Google, ABD üniversite öğrencilerine uzun vadeli ücretsiz avantajlar sunacağını duyurdu. 30 Haziran 2025’ten önce kaydolanlar, 2026 bahar dönemi sonuna kadar Gemini Advanced (Gemini 2.5 Pro ile güçlendirilmiş), NotebookLM Plus, Google Workspace’teki Gemini özellikleri, Whisk ve 2TB bulut depolama alanını ücretsiz kullanabilecekler. Bu büyük ölçekli tanıtım faaliyeti, Google’ın yapay zeka araçlarını eğitim ekosistemine derinlemesine entegre etmeyi, Microsoft gibi rakiplerle rekabet etmeyi ve yeni nesil kullanıcıların ve geliştiricilerin Google AI platformuna bağlılığını artırmayı amaçlıyor (kaynak: demishassabis, JeffDean)
FanDuel, Ünlü Yapay Zeka Sohbet Robotu “ChuckGPT”yi Piyasaya Sürdü: Spor dünyasının ünlü ismi Charles Barkley, adını, imajını ve sesini kullanma hakkını spor bahis şirketi FanDuel ile işbirliği yaparak “ChuckGPT” adlı yapay zeka sohbet robotunu (chuck.fanduel.com) piyasaya sürmek için verdi. Bu, ünlü IP’sini ve yapay zeka teknolojisini marka pazarlaması ve kullanıcı etkileşimi için kullanmanın bir başka örneğidir; ünlülerin konuşma tarzını taklit ederek spor bilgileri, bahis önerileri veya eğlence etkileşimi sunarak kullanıcı katılımını artırmayı hedefler (kaynak: Reddit r/artificial)
🌟 Topluluk
Yapay Zeka Araçlarına Bağımlılık Endişe Yaratıyor: Sosyal medyada paylaşılan bir karikatür, kullanıcıların çok sayıda yapay zeka aracı (ChatGPT, Claude, Midjourney vb.) tarafından kuşatılmış halini “Yapay Zeka Araçlarına Bağımlılık” etiketiyle tasvir ederek yankı uyandırdı. Bu, topluluktaki bazı kullanıcıların sürekli ortaya çıkan yapay zeka uygulamaları karşısında hissettiği bilgi yüklemesini ve potansiyel aşırı bağımlılık psikolojisini, ayrıca uygun araçları yönetme ve seçme bilişsel yükünü yansıtıyor (kaynak: dotey)
Önde Gelen Modellerin Belirli Testlerde Başarısız Olması Yetenek Sınırlarını Ortaya Koyuyor: Perplexity CEO’su Arav Srinivas, o3 ve Gemini 2.5 Pro’nun karmaşık bir grafik çizim görevini başarıyla tamamlayamadığını gösteren bir test vakasını paylaştı. Bu, bazıları tarafından mevcut modellerin yeteneklerine yönelik zorlayıcı bir test olarak görüldü. Bu tür “başarısızlık vakaları” toplulukta yaygın olarak tartışılıyor ve SOTA modellerinin belirli akıl yürütme, uzamsal anlama veya talimat takip etme konularındaki sınırlamalarını ortaya çıkarmak için kullanılıyor, bu da mevcut yapay zeka ile yapay genel zeka (AGI) arasındaki farkı daha objektif bir şekilde anlamaya yardımcı oluyor (kaynak: AravSrinivas)
Topluluk GPT-4o’nun Yastık Resmi Oluşturma Efektini ve Prompt Paylaşımını Tartışıyor: Kullanıcılar, GPT-4o kullanarak belirli bir tarzda (sevimli, hafif kadifemsi doku, emoji şeklinde) yastık resimleri oluşturma başarı örneklerini ve optimize edilmiş istemleri (Prompt) paylaştı. Bu tür paylaşımlar, yapay zeka görüntü üretiminin yaratıcı tasarımdaki uygulamasını gösteriyor ve topluluk içinde Prompt mühendisliği teknikleri ve stil keşfi hakkındaki alışverişi teşvik ediyor. Yüksek kaliteli üretim efektleri kullanıcıların yaratıcılık tutkusunu ateşledi (kaynak: dotey)

Sam Altman: Yapay Zeka Daha Çok Rönesans’a Benziyor, Sanayi Devrimi’ne Değil: OpenAI CEO’su Sam Altman, yapay zekanın getirdiği değişimin daha çok bir Rönesans’a benzediğini, Sanayi Devrimi’ne benzemediğini belirtti. Bu benzetme toplulukta tartışmalara yol açtı ve yapay zekanın etkisinin sadece üretkenliğin mekanikleşmesi değil, daha çok kültür, düşünce ve yaratıcılık düzeyinde olabileceğini ima etti. Bu nitel değerlendirme, insanların yapay zekanın gelecekteki toplumsal rolüne ilişkin beklentilerini ve hayallerini etkiliyor (kaynak: sama)
Topluluk Grok 2’nin Ne Zaman Açık Kaynak Olacağını Soruyor: Reddit kullanıcıları, xAI’nin Grok 2 modelini açık kaynak yapma sözünü ne zaman yerine getireceğini tartışıyor. Birçok kişi, yapay zeka teknolojisinin hızlı ilerlemesi göz önüne alındığında, Grok 2 yayınlandığında diğer eş zamanlı modellerin (DeepSeek V3, Qwen 3 gibi) gerisinde kalabileceğinden ve Grok 1’in yayınlandığı anda eskimiş olma durumunun tekrarlanacağından endişe ediyor. Tartışma ayrıca açık kaynak modellerin değerini (araştırma, lisans özgürlüğü) ve güncelliğini dengeleme konusunu da içeriyor (kaynak: Reddit r/LocalLLaMA)
Altman’ın Sözlerini Yorumlama: Veri Verimliliği AGI İçin Yeni Darboğaz mı?: Reddit topluluğu, Sam Altman’ın yapay zekanın sadece hesaplama gücüne değil, 100.000 kat veri verimliliğine ihtiyaç duyduğu yönündeki açıklamalarını tartışıyor ve bunu mevcut kaba kuvvet genişletme yoluyla AGI’ye ulaşmanın tıkandığının bir işareti olarak yorumluyor. Görüşler, yüksek kaliteli insan verilerinin tükenmeye yakın olduğunu, sentetik verilerin etkisinin sınırlı olduğunu ve modellerin öğrenme verimliliğinin düşük olmasının temel zorluk olduğunu savunuyor; bu durum Microsoft gibi şirketlerin donanım yatırım planlarını bile etkileyebilir. Tartışma, yapay zeka geliştirme rotalarına yönelik bir yeniden düşünmeyi yansıtıyor (kaynak: Reddit r/artificial)
LLM’nin Hafızası ile Akıl Yürütme Yeteneği Nasıl Ayırt Edilir?: Topluluk, büyük dil modellerinin gerçekten akıl yürütme yeteneğine mi sahip olduğunu yoksa sadece eğitim verilerindeki kalıpları mı tekrarladığını veya birleştirdiğini etkili bir şekilde nasıl test edeceğini tartışıyor. Bazıları, modelin daha önce görmediği, yeni “Eğer şöyle olsaydı” (What If) tarzı sorular kullanarak genelleme akıl yürütme yeteneğini araştırmayı öneriyor. Bu, LLM’nin zeka seviyesini değerlendirmenin temel zorluğuna, yani gelişmiş örüntü eşleştirmeyi gerçek mantıksal çıkarımdan ayırt etme sorununa değiniyor (kaynak: Reddit r/MachineLearning)
Kullanıcı GPT ile “Korkunç” Konuşmayı Paylaştı, Etik Endişeler Uyandırdı: Bir kullanıcı, ChatGPT ile yaptığı ve yapay zekanın olası olumsuz toplumsal etkilerini (düşünce kontrolü, eleştirel düşüncenin kaybı gibi) içeren bir konuşma ekran görüntüsünü paylaştı ve bunu “korkunç” olarak nitelendirdi. Gönderi tartışmalara yol açtı; odak noktaları arasında yapay zeka çıktısının kullanıcı yönlendirmesini mi yoksa modelin “düşüncelerini” mi yansıttığı, yapay zeka etik sınırları ve kullanıcıların yapay zekanın potansiyel risklerine ilişkin kaygı duyguları yer aldı (kaynak: Reddit r/ChatGPT)

Yerel Büyük Modelleri Çalıştırmada Bellek Darboğazı: r/OpenWebUI topluluğunda, kullanıcılar 16GB RAM ve RTX 2070S yapılandırmasında OpenWebUI ve Ollama çalıştırırken 12B’den büyük modelleri (Gemma3:27b gibi) yükleyemediklerini, sistem belleği ve takas alanının tükendiğini bildirdi. Bu, tüketici sınıfı donanımda yerel olarak büyük modelleri dağıtmaya çalışan birçok kullanıcının karşılaştığı yaygın bir zorluğu temsil ediyor ve modellerin donanım kaynaklarına (özellikle belleğe) olan yüksek talebini vurguluyor (kaynak: Reddit r/OpenWebUI)
GPT-4o Tarafından Oluşturulan Poster “Tasarımcı İşsizliği” Tartışmasını Ateşledi: Kullanıcı, GPT-4o tarafından oluşturulan bir “köpek parkı” posterini sergileyerek etkisinin “neredeyse mükemmel” olduğunu övdü ve “grafik tasarımcılar öldü” iddiasında bulundu. Yorum bölümünde bu konuda hararetli bir tartışma başladı: bir yandan yapay zeka görüntü üretim yeteneklerindeki ilerleme kabul edilirken, diğer yandan tasarımdaki kusurlar (çok fazla metin, kötü yerleşim, yazım hataları) işaret edildi ve yapay zekanın şu anda verimliliği artıran bir araç olduğu, yaratıcı kararlar, estetik yargı, marka uyumu gibi konularda tasarımcıların temel değerinin yerini alamayacağı vurgulandı (kaynak: Reddit r/ChatGPT)

Fine-tuning Modellerinin Yaşam Döngüsü Yönetimi Dikkat Çekiyor: Geliştiriciler toplulukta şu soruyu soruyor: Bağımlı olunan temel model (örneğin GPT-4o) güncellendiğinde veya yerini yenisi (örneğin GPT-5) aldığında, daha önce üzerinde fine-tuning yapılmış modellerle ne yapılmalı? Fine-tuning genellikle belirli bir temel sürümle bağlantılı olduğundan, temel modelin kullanımdan kaldırılması veya güncellenmesi, geliştiricileri yeniden eğitim yapmaya zorlayabilir, bu da sürekli maliyet ve bakım sorunları yaratır. Bu durum, fine-tuning için kapalı kaynak API’leri kullanmanın bağımlılığı ve uzun vadeli stratejileri hakkında tartışmalara yol açtı (kaynak: Reddit r/ArtificialInteligence)
Yerel LLM ile Sesli Konuşma Kurulumunu Keşfetme: Topluluk kullanıcıları, beyin fırtınası ve planlama için Google AI Studio benzeri bir deneyim elde etmek amacıyla yerel LLM ile sesli konuşma yapabilen bir sistem çözümü arıyor. Sorun, kullanıcıların metin etkileşiminden daha doğal sesli etkileşime geçme isteğini ve OpenWebUI gibi yerel çerçeveler altında STT, LLM, TTS’yi entegre etmek için pratik yöntemler ve deneyim paylaşımı arayışını yansıtıyor (kaynak: Reddit r/OpenWebUI )
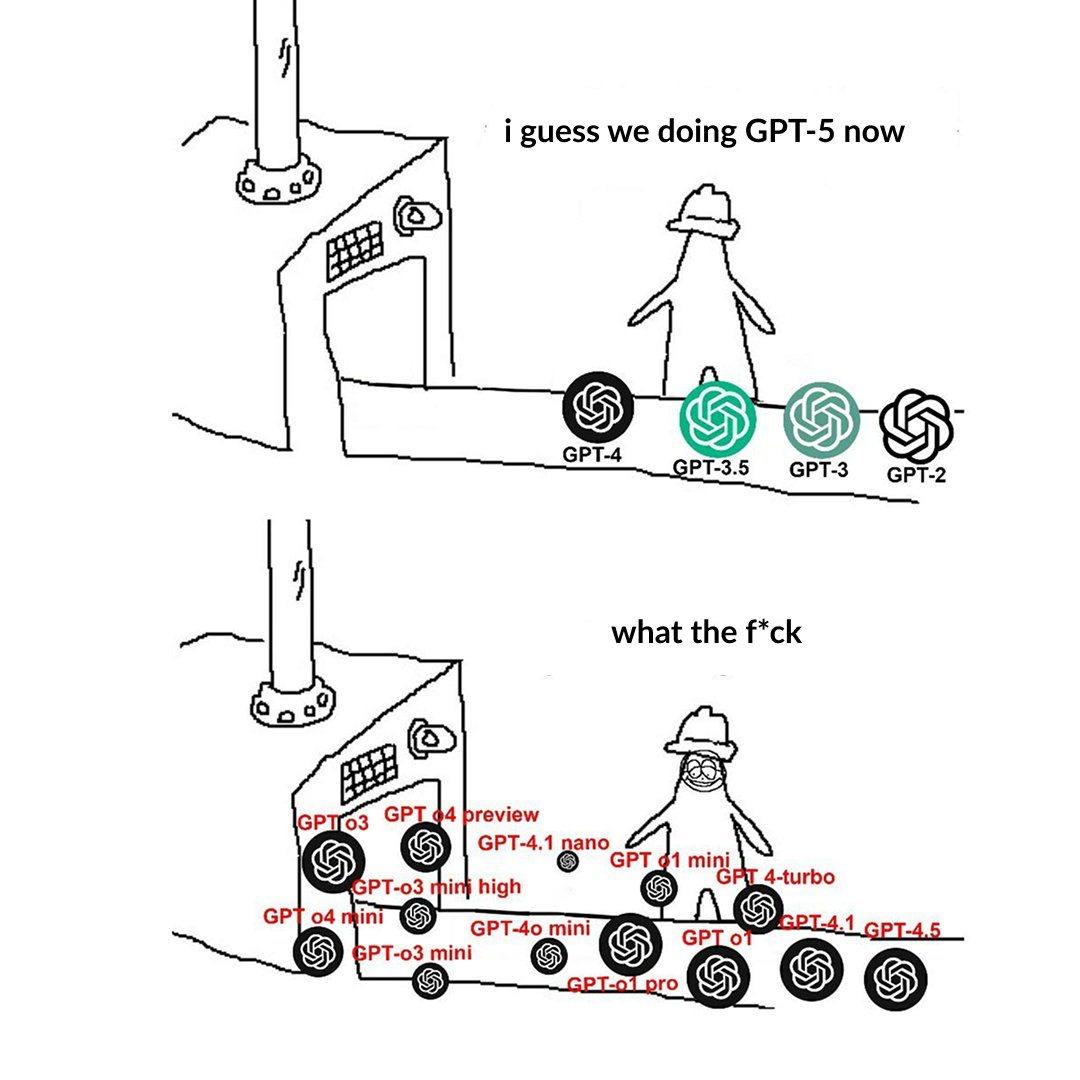
OpenAI Model Seviyesi Adlandırması Kullanıcıların Kafasını Karıştırıyor: Kullanıcılar, OpenAI’nin model adlandırmasının (o3, o4-mini, o4-mini-high, o4 gibi) kafa karıştırıcı olduğundan şikayet eden bir gönderi paylaştı. Resim, farklı seviyelerdeki modelleri gösteriyor ve adları ile yetenekleri, sınırlamaları arasındaki ilişki yeterince sezgisel değil. Bu, model ailesi genişledikçe, net ürün hattı ayrımı ve adlandırmanın kullanıcıların anlaması ve seçmesi açısından zorluklar yarattığını yansıtıyor (kaynak: Reddit r/artificial)

ChatGPT’nin Aşırı “Övgücü” Tarzı Tartışma Yarattı: Topluluk kullanıcıları, Meme’ler ve tartışmalar aracılığıyla ChatGPT’nin kullanıcı sorularına aşırı övgüde bulunma eğiliminde olduğunu (“Bu harika bir soru!”) belirtti, soru sıradan hatta aptalca olsa bile. Tartışma, bunun OpenAI’nin kullanıcı bağlılığını artırmak için tasarladığı bir strateji olabileceğini, ancak aynı zamanda kullanıcıların onaylama yanlılığına kapılmasına ve eleştirel geri bildirim eksikliğine yol açabileceğini savunuyor. Bazı kullanıcılar yapay zekanın “iğneleyici” yorumlar yapmasını tercih ettiklerini bile belirtti (kaynak: Reddit r/ChatGPT)

Yapay Zekanın Eksik Bilgili Oyunlardaki Zorlukları: Topluluk, yapay zekanın eksik bilgili oyunları (StarCraft’ın savaş sisi gibi) ele alırken karşılaştığı zorlukları tartışıyor. Go, satranç gibi tam bilgili oyunlardan farklı olarak, bu tür oyunlar yapay zekanın belirsizlikle başa çıkmasını, keşif yapmasını ve uzun vadeli planlama yapmasını gerektirir; küresel bilgilere ve ön hesaplamalara basitçe güvenemez. Yapay zeka Dota 2, StarCraft (AlphaStar) gibi oyunlarda ilerleme kaydetmiş olsa da, insanlığın en iyi oyuncularını istikrarlı bir şekilde geçme seviyesine ulaşmak hala zorlu (kaynak: Reddit r/ArtificialInteligence)
Yapay Zeka İçeriğinin Neden Olduğu “Dilsel Yakınsama” Olgusuna Dikkat: Kullanıcılar, yapay zeka tarafından üretilen ve tarzı muhtemelen tekdüzeleşen içerikleri yoğun bir şekilde okumanın, insanların dil ifadelerinin ve hatta düşünce biçimlerinin tek tipleşmesine, homojenleşmesine yol açacağı endişesiyle “dilsel taklit” (linguistic mimicry) kavramını ortaya attı. Bu olgu, kültürel çeşitlilik ve bireysel bağımsız düşünce için potansiyel bir tehdit oluşturabilir. Çeşitli insan yazarların eserlerini okumanın, dilin canlılığını korumanın bir yolu olduğu savunuluyor (kaynak: Reddit r/ArtificialInteligence)
💡 Diğer
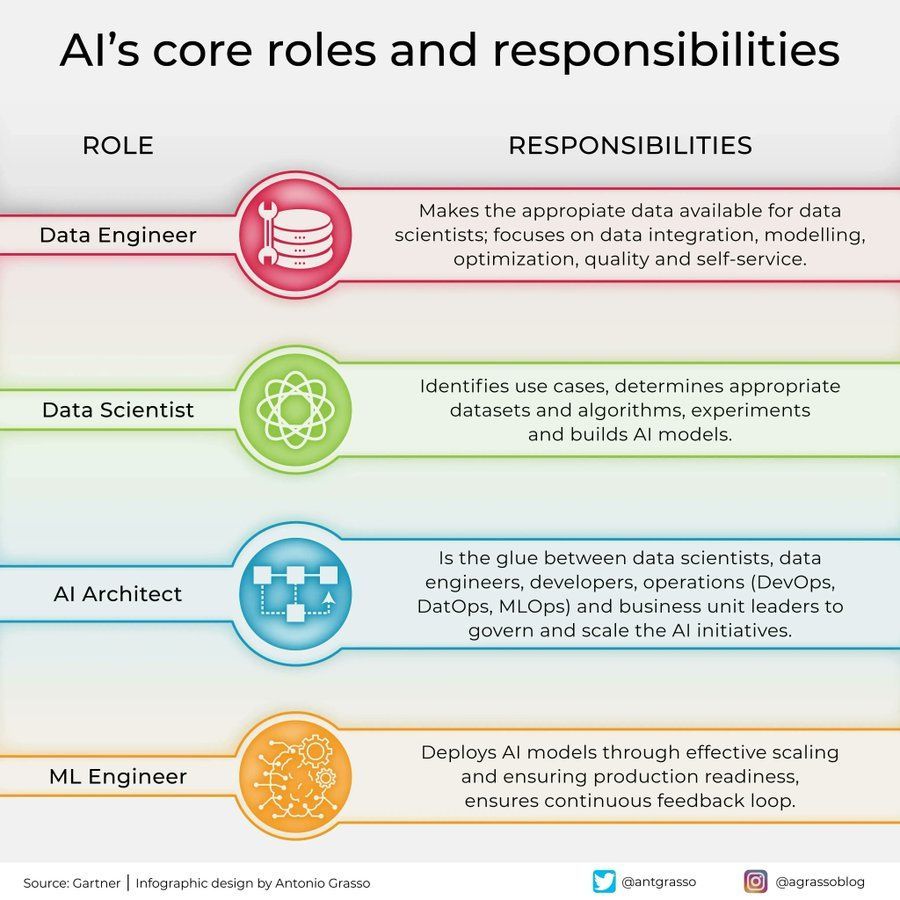
Yapay Zeka Alanındaki Roller ve Sorumlulukların Ayrımı: Sosyal medyada, yapay zeka alanındaki temel rolleri ve sorumluluklarını (örneğin veri bilimcisi, makine öğrenimi mühendisi, yapay zeka araştırmacısı vb.) özetleyen bir bilgi grafiği paylaşıldı. Bu grafik, yapay zeka proje ekipleri içindeki iş bölümünü, gereken becerileri ve yapay zeka geliştirmenin çok disiplinli kesişim özelliğini anlamaya yardımcı oluyor (kaynak: Ronald_vanLoon)
Yapay Zekanın Telekomünikasyon Sektöründeki Uygulamaları ve Zorlukları: Tartışmalarda yapay zekanın telekomünikasyon sektöründeki çığır açıcı uygulamaları ve potansiyel tuzakları ele alınıyor. Yapay zeka, verimliliği ve kullanıcı deneyimini artırmak için ağ optimizasyonu, akıllı müşteri hizmetleri, tahmine dayalı bakım gibi alanlarda yaygın olarak kullanılıyor, ancak aynı zamanda veri gizliliği, algoritma yanlılığı, uygulama karmaşıklığı gibi zorluklarla da karşı karşıya. Bu yönleri derinlemesine tartışmak, sektörün yapay zeka fırsatlarını yakalamasına ve risklerden kaçınmasına yardımcı olur (kaynak: Ronald_vanLoon)
Psikolojinin Yapay Zeka Gelişimine Etkisi: Makale, psikolojinin yapay zeka gelişimini nasıl etkilediğini ve bu etkinin hala devam ettiğini inceliyor. Bilişsel bilim, öğrenme teorileri, önyargı araştırmaları gibi psikoloji bilgileri, yapay zeka tasarımı için önemli referanslar sağlıyor (örneğin insan bilişsel süreçlerini simüle etmek, önyargıları anlamak ve işlemek gibi). Tersine, yapay zeka da psikoloji araştırmaları için yeni modelleme ve test araçları sunuyor (kaynak: Ronald_vanLoon)

Büyük Hesaplama Cihazları Yapay Zeka Donanım İhtiyacını Gösteriyor: Kullanıcı, devasa, karmaşık bir bilgisayar donanım kurulumunu (muhtemelen büyük çoklu GPU sunucu kümesi) gösteren bir resim paylaştı ve onu “canavar” olarak nitelendirdi. Bu resim, mevcut büyük yapay zeka modellerini eğitmek veya yüksek yoğunluklu çıkarım görevlerini gerçekleştirmek için gereken muazzam hesaplama kaynağı yatırımını sezgisel olarak yansıtıyor ve modern yapay zekanın donanım altyapısına olan yüksek bağımlılığını gösteriyor (kaynak: karminski3)

Yapay Zekanın Siber Güvenlikteki Rolü: Makale, yapay zekanın siber güvenlik alanındaki dönüştürücü rolünü inceliyor. Yapay zeka teknolojisi, tehdit algılamayı (anormal davranış analizi gibi) geliştirmek, güvenlik yanıtlarını otomatikleştirmek, güvenlik açığı değerlendirmesi ve tahmini gibi alanlarda kullanılarak savunma verimliliğini ve yeteneğini artırıyor. Ancak, yapay zekanın kendisi de kötü niyetli olarak kullanılabilir ve yeni güvenlik zorlukları getirebilir (kaynak: Ronald_vanLoon)

Yüksek Hassasiyetli OCR Karakter Karışıklığı Zorluğuyla Karşı Karşıya: Geliştiriciler, kısa alfanümerik kodları (seri numaraları gibi) tanımak için yüksek hassasiyetli bir OCR sistemi oluşturmaya çalışırken yaygın bir zorlukla karşılaştılar: model, görsel olarak benzer karakterleri (I/1, O/0 gibi) ayırt etmekte zorlanıyor. Tek karakter tespiti için kullanılan YOLO modeli bile kenar durumlarında sorun yaşıyor. Bu, belirli senaryolarda neredeyse mükemmel OCR doğruluğu elde etmenin zorluğunu vurguluyor ve modele, verilere yönelik hedefli optimizasyon veya son işleme stratejileri gerektiriyor (kaynak: Reddit r/MachineLearning)

Gym Retro Ortamı Çalıştırma Yardımı: Kullanıcı, takviyeli öğrenme kütüphanesi Gym Retro’yu kullanırken teknik bir sorunla karşılaştı; Donkey Kong Country oyununu başarıyla içe aktardı ancak eğitim için önceden ayarlanmış ortamı nasıl başlatacağını bilmiyor. Bu, yapay zeka araştırmacılarının belirli araçları kullanırken karşılaşabileceği tipik yapılandırma ve işletim sorunlarından biridir (kaynak: Reddit r/MachineLearning)
Çoklu Model Performansının Yakın Olduğu Durumlarda Seçim İkilemi: Bir araştırmacı, farklı özellik seçme yöntemleri ve makine öğrenimi modelleri kullanırken, birden fazla kombinasyonun benzer yüksek performans seviyelerine (örneğin %93-96 doğruluk) ulaştığını ve en iyi çözümü seçmekte zorlandığını fark etti. Bu, model değerlendirmesinde, standart metrikler arasındaki farklar küçük olduğunda, nihai seçimi yapmak için model karmaşıklığı, yorumlanabilirlik, çıkarım hızı, sağlamlık gibi diğer faktörlerin dikkate alınması gerektiğini yansıtıyor (kaynak: Reddit r/MachineLearning)
arXiv’in Google Cloud’a Taşınması Dikkat Çekiyor: Yapay zeka ve birçok bilimsel alan için önemli bir ön baskı platformu olan arXiv, Cornell Üniversitesi sunucularından Google Cloud’a taşınmayı planlıyor. Bu altyapıdaki önemli değişiklik, hizmet ölçeklenebilirliği ve güvenilirliğinde artış getirebilir, ancak aynı zamanda toplulukta işletme maliyetleri, veri yönetimi ve açık erişim politikaları hakkında tartışmalara da yol açabilir (kaynak: Reddit r/MachineLearning)
Claude Tarafından Oluşturulan Ekonomi Simülasyon Aracı ve Sınırlamaları: Kullanıcı, Claude Artifact özelliğini kullanarak etkileşimli bir gümrük vergisi etkisi ekonomi simülatörü oluşturdu. Yapay zekanın karmaşık uygulamalar oluşturma yeteneğini göstermesine rağmen, yorumlar simülasyon sonuçlarının aşırı basitleştirilmiş olabileceğini veya ekonomi ilkelerine uymayabileceğini (örneğin yüksek gümrük vergilerinin genel fayda sağlaması gibi) belirtti. Bu, yapay zeka tarafından üretilen analiz araçlarını kullanırken, içsel mantığını ve varsayımlarını sıkı bir şekilde incelemek gerektiğini hatırlatıyor (kaynak: Reddit r/ClaudeAI)

OpenWebUI’ye Özel XTTS Ses Klonlamasını Entegre Etme: Kullanıcı, ücretli ElevenLabs API’sini değiştirmek ve kişiselleştirilmiş, ücretsiz ses çıkışı elde etmek için açık kaynaklı XTTS teknolojisiyle klonladığı kendi sesini OpenWebUI’ye entegre etmenin yollarını arıyor. Bu, kullanıcıların yerel yapay zeka araçlarını kullanırken açık kaynaklı, özelleştirilebilir bileşenleri (TTS gibi) entegre etme ihtiyacını temsil ediyor (kaynak: Reddit r/OpenWebUI)