
Anahtar Kelimeler:Gemini 2.5 Flash, OpenAI o3, AI iş yerini değiştirme, AI tıbbi ticarileştirme, hibrit çıkarım modeli, düşünce bütçesi işlevi, o4-mini çok modlu yetenek, AI kodlama asistanı Windsurf, Agentic AI ev ağ geçidi, VisualPuzzles kıyaslama testi, DeepSeek tavsiye güvenilirliği, Zhipu AI açık kaynak modeli
🔥 Öne Çıkanlar
Google, maliyet etkinliği ve kontrol edilebilir düşünme odaklı hibrit çıkarım modeli Gemini 2.5 Flash’ı duyurdu: Google, yüksek maliyet etkinliğine sahip bir hibrit çıkarım modeli olarak konumlandırılan Gemini 2.5 Flash’ın önizleme sürümünü tanıttı. Modelin benzersiz özelliği, geliştiricilerin (0-24k token) veya modelin kendisinin görev karmaşıklığına göre çıkarım derinliğini ayarlamasına olanak tanıyan “düşünme bütçesi” (thinking_budget) işlevini sunmasıdır. Düşünme kapalıyken maliyet son derece düşüktür (milyon token çıktı başına 0,6 $), performans 2.0 Flash’tan daha iyidir; düşünme açıkken (milyon token çıktı başına 3,5 $) ise karmaşık görevleri yerine getirebilir ve performans AIME, MMMU, GPQA gibi birçok benchmark’ta o4-mini ile rekabet edebilir düzeydedir ve LMArena sıralamasında üst sıralarda yer almaktadır. Bu model, performans, maliyet ve gecikmeyi dengelemeyi amaçlamakta olup, özellikle esneklik ve maliyet kontrolü gerektiren uygulama senaryoları için uygundur ve Google AI Studio ile Vertex AI’da API olarak sunulmaktadır. (Kaynak: 谷歌首款混合推理Gemini 2.5登场,成本暴降600%,思考模式一开,直追o4-mini, 谷歌大模型“性价比之王”来了,混合推理模型,思考深度可自由控制,竞技场排名仅次于自家Pro, op7418, JeffDean, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/artificial)

OpenAI, çıkarım ve çok modlu yetenekleri güçlendiren o3 ve o4-mini modellerini yayınladı: OpenAI, çıkarım, programlama ve çok modlu anlama yeteneklerini geliştirmeye odaklanan şimdiye kadarki en güçlü model serisi o3’ü ve optimize edilmiş o4-mini’yi tanıttı. Özellikle, görüntü detaylarını analiz ederek karmaşık yargılarda bulunabilen (örneğin, fotoğrafa dayanarak kesin çekim yerini tahmin etme – GeoGuessing) görüntü tabanlı “düşünce zinciri” çıkarımını ilk kez gerçekleştirdi. o3, Mensa IQ testinde 136 puanla yeni bir rekor kırdı ve programlama benchmark’larında üstün performans gösterdi. o4-mini ise yüksek verimlilik ve düşük maliyeti korurken, güçlü matematiksel problem çözme (Euler problemleri gibi) ve görsel işleme yetenekleri sergiledi. Bu modeller ChatGPT Plus, Pro ve Team kullanıcılarına sunuldu ve OpenAI’nin modelleri bilgi edinmeden araç kullanımına ve karmaşık problem çözmeye doğru ilerlettiğini gösteriyor. (Kaynak: 实测o3/o4-mini:3分钟解决欧拉问题,OpenAI最强模型名副其实, 智商136,o3王者归来,变身福尔摩斯“AI查房”,一张图秒定坐标, 满血版o3探案神技出圈,OpenAI疯狂暗示:大模型不修仙,要卷搬砖了)

AI verimlilik artışı istihdam endişelerine yol açıyor, bazı şirketler AI ile pozisyonları değiştirmeye başladı: Yapay zeka teknolojisinin yüksek verimliliği, PayPal, Shopify, United Wholesale Mortgage gibi şirketleri, özellikle müşteri hizmetleri, başlangıç seviyesi satış, IT desteği, veri işleme gibi alanlarda insan pozisyonlarını AI ile değiştirmeyi düşünmeye veya fiilen kullanmaya itiyor. Örneğin, PayPal’ın AI sohbet botu müşteri hizmetleri taleplerinin %80’ini işleyerek maliyetleri önemli ölçüde düşürdü. United Wholesale Mortgage, ipotek kredisi belgelerini işlemek için AI kullanarak verimliliği büyük ölçüde artırdı ve iş hacmi iki katına çıkmasına rağmen ek personel alımına gerek duymadı. Bazı şirketler hatta “sıfır çalışanlı ekip” kavramını ortaya atarak, yeni personel alımının ancak AI’ın görevi yerine getiremeyeceğinin kanıtlanması durumunda yapılmasını talep ediyor. Birçok şirket işten çıkarmaların AI nedeniyle olduğunu açıkça kabul etmekten kaçınsa da, işe alımların yavaşlaması ve pozisyonların azaltılması bir trend haline geldi. Özellikle maliyet baskısı altında, gelecekte AI’ın beyaz yakalı işler üzerindeki ikame etkisinin daha belirgin olması bekleniyor. (Kaynak: 招聘慢了、岗位少了,AI效率太高迫使人类员工“让位”)

OpenAI, uygulama katmanı düzenini güçlendirmek için AI kodlama asistanı Windsurf’ü 3 milyar dolara satın almayı planlıyor: OpenAI, yaklaşık 3 milyar dolara AI kodlama girişimi Windsurf’ü (eski adıyla Codeium) satın almayı planlıyor; bu, şirketin en büyük satın alması olacak. Windsurf, Cursor’a benzer şekilde, yine Anthropic modellerine dayanan AI kodlama yardım araçları sunuyor. Bu satın alma, OpenAI’nin uygulama katmanına genişlemesi, ekosistem kontrolünü güçlendirmesi, doğrudan kullanıcı edinmesi, eğitim verisi toplaması ve GitHub Copilot, Cursor gibi rakiplerle rekabet etmesi için kritik bir adım olarak görülüyor. Analistler, AI yetenekleri arttıkça “Vibe Coding” (AI’ın geliştirme süreçlerine derinlemesine entegre olduğu) trend haline gelirken, uygulama katmanı girişini ve kullanıcı verilerini kontrol etmenin model şirketlerinin uzun vadeli rekabet gücü için hayati önem taşıdığını belirtiyor. OpenAI’nin bu hamlesi, stratejik hedefinin model sağlayıcılığının ötesine geçtiğini ve eksiksiz bir AI geliştirme platformu kurma niyetinde olduğunu gösteriyor. (Kaynak: 有了一天涨万星的开源项目 Codex,OpenAI为何仍砸 30 亿美元重金收购 Windsurf ?)
🎯 Gelişmeler
ByteDance, Doubao 1.5 derin düşünme modelini ve çok modlu güncellemeleri yayınlayarak Agent düzenini hızlandırıyor: ByteDance’in Volcengine birimi, insan benzeri “aynı anda okuma, düşünme ve arama yapma” yeteneğine sahip Doubao 1.5 derin düşünme modelini yayınladı. Bu model karmaşık görevleri yerine getirebiliyor, çok modlu girdileri (metin, görüntü) destekliyor ve internette arama yapma ile görsel çıkarım yeteneklerine sahip. Aynı zamanda, Doubao metinden görüntü oluşturma modeli 3.0 (metin düzenini ve görüntü gerçekçiliğini iyileştiriyor) ve yükseltilmiş görsel anlama modeli (konumlandırma doğruluğunu ve video anlamayı geliştiriyor) yayınlandı. ByteDance, derin düşünme ve çok modluluğun Agent oluşturmanın temeli olduğuna inanıyor ve şirketlerin Agent uygulamaları oluşturma ve dağıtma engelini ve maliyetini düşürmeyi amaçlayan OS Agent çözümünü ve AI bulut tabanlı çıkarım paketini tanıttı. Bu hamle, ByteDance’in DeepSeek gibi rakip ürünlerin etkisinden sonra stratejisini yeniden netleştirmesi ve Agent uygulamalarının hayata geçirilmesine odaklanması olarak görülüyor. (Kaynak: 字节按下 AI Agent 加速键, 被DeepSeek打蒙的豆包,发起反攻了)

ByteDance ve Kuaishou, AI video üretimi alanında model performansı ve uygulamaya odaklanarak tekrar karşı karşıya geldi: ByteDance, düşük parametre (7B), yüksek verimlilik (66.5 milyon H100 GPU saat eğitim) ve düşük dağıtım maliyeti (tek GPU 1280×720 video üretebilir) vurgusuyla Seaweed-7B video üretim modelini yayınladı. Kuaishou ise performansının Google Veo2 ve Sora’yı aştığını iddia ettiği “Kling 2.0” video üretim modelini ve “Kling Image 2.0” görüntü üretim modelini yayınladı ve çok modlu düzenleme özelliği MVL’yi tanıttı. Her iki taraf da model yeteneklerinin AI ürünlerinin üst sınırı olduğunun farkında ve 2025 stratejik odak noktaları model geliştirmeye geri döndü. Ticarileştirme yolları farklı olsa da (ByteDance’in Jiemeng’i C tarafına, Kuaishou’nun Kling’i B tarafına yönelik), her ikisi de pratikliği artırmaya odaklanıyor; örneğin Kuaishou görüntüden video üretiminin önemini vurgularken, ByteDance metin işleme avantajını kullanarak video anlatım tutarlılığını sağlıyor ve rekabet giderek kızışıyor. (Kaynak: 字节快手,AI视频“狭路又相逢”)

Zhipu AI, açık kaynak ekosistemi inşasını güçlendirmek için üç açık kaynak modeli yayınladı: Zhipu AI, 2025’i “Açık Kaynak Yılı” ilan etti ve GLM-Z1-Air (çıkarım modeli), GLM-Z1-Air (muhtemelen yazım hatası, ultra hızlı veya temel sürüm kastediliyor olabilir) ve GLM-Z1-Rumination (düşünme/derinlemesine düşünme modeli) olmak üzere üç model yayınladı. Modeller 9B ve 32B boyutlarında ve MIT lisansı kullanıyor. GLM-Z1-Air (32B), bazı benchmark testlerinde DeepSeek-R1’e yakın performans gösteriyor ve çıkarım fiyatı önemli ölçüde daha düşük. Düşünme modeli Z1-Rumination ise daha derin düşünme seviyelerini araştırıyor ve araştırma döngüsünü destekliyor. Aynı zamanda, Zhipu Z Fonu, Zhipu modellerine dayalı projelerle sınırlı olmaksızın küresel AI açık kaynak topluluğunu desteklemek için 300 milyon yuan ayırdığını duyurdu. Bu hamle, Pekin’in “Küresel Açık Kaynak Başkenti” oluşturma stratejisiyle örtüşüyor. (Kaynak: 智谱获2亿元新融资,连发3款开源模型,拿3亿元支持全球开源社区)
Agentic AI’ın ev ağ geçitlerine entegrasyonu operatörler için yeni bir fırsat olabilir: AI’ın üretkenlikten Agentic AI’a (otonom hedef belirleme ve görev yürütme yeteneğine sahip AI sistemleri) evrilmesiyle birlikte, bu tür sistemler odak noktası haline geliyor. MediaTek yöneticileri, Agentic AI’ın ev ağ geçitlerine entegre edilmesinin, operatörlerin Nesnelerin İnterneti (IoT) pazarındaki rolünü değiştirme potansiyeline sahip olduğunu öne sürüyor. Ev ağının uç zeka merkezi olarak ağ geçidi, Agentic AI ile birleştiğinde ağı proaktif olarak yönetebilir (örneğin, video görüşmelerini optimize etme), arızaları teşhis edebilir, ev güvenliğini artırabilir (örneğin, paket hırsızlığını, çocukların havuza yaklaşma riskini tanıma), böylece operatörlerin müşteri hizmetleri maliyetlerini düşürebilir (çok sayıda Wi-Fi ile ilgili sorgu AI tarafından işlenebilir) ve katma değerli hizmetler sunabilir. Ticarileştirme modeli henüz keşfedilmeyi beklese de, bu durum operatörlere “boru hattı” rolünün ötesine geçerek Agentic AI hizmet sağlayıcısı olma potansiyeli sunuyor. (Kaynak: 将Agentic AI嵌入家庭网关,如何改变运营商在物联网市场的游戏规则?)
Microsoft, DeepSeek R1 tabanlı güvenlik ve uyumluluk sonrası eğitimi yapılmış MAI-DS-R1’i yayınladı: Microsoft AI ekibi, DeepSeek R1 üzerine sonradan eğitilmiş MAI-DS-R1 modelini yayınladı. Bu model, orijinal modeldeki bilgi boşluklarını doldurmayı ve risk profilini iyileştirmeyi hedeflerken, R1’in çıkarım yeteneklerini korumayı amaçlıyor. Eğitim verileri, Tulu 3 SFT’den 110.000 güvenlik ve uyumsuzluk örneği ile Microsoft içinde geliştirilen, önyargılı çeşitli konuları kapsayan yaklaşık 350.000 çok dilli örnek içeriyor. Bu hamle, bazı topluluk üyeleri tarafından Microsoft’un model güvenliğini ve uyumluluğunu artırma çabası olarak yorumlanırken, aynı zamanda “kurumsal düzeyde sansür” eklenip eklenmediği konusunda tartışmalara yol açtı. (Kaynak: Reddit r/LocalLLaMA)

🧰 Araçlar
OpenAI, terminal odaklı AI kodlama asistanı Codex CLI’yi açık kaynak olarak yayınladı: OpenAI, geliştiricinin yerel terminalinde çalışan ve kodlama görevlerini optimize eden bir AI ajanı olan yeni açık kaynak projesi Codex CLI’yi yayınladı. Varsayılan olarak en son o4-mini modelini kullanır, ancak kullanıcılar API aracılığıyla diğer OpenAI modellerini seçebilirler. Codex CLI, yerel kod tabanı işlemlerini anlayan ve yürüten sohbet odaklı bir geliştirme yöntemi sunmayı amaçlıyor ve Anthropic’in Claude Code’u ile Cursor, Windsurf gibi araçlarla rekabet ediyor. Proje, yayınlandıktan sonraki bir gün içinde GitHub’da 14.000’den fazla yıldız alarak, geliştiricilerin terminal tabanlı yerel AI kodlama araçlarına olan ilgisini gösterdi. (Kaynak: 有了一天涨万星的开源项目 Codex,OpenAI为何仍砸 30 亿美元重金收购 Windsurf ?)
Google AI Studio güncellendi, doğrudan AI uygulamaları oluşturma ve paylaşma desteği eklendi: Google, AI Studio platformunu güncelleyerek doğrudan platform içinde AI uygulamaları oluşturma özelliğini ekledi. Kullanıcılar artık yalnızca Gemini gibi modellerle geliştirme yapmakla kalmayıp, diğer kullanıcılar tarafından oluşturulan örnek uygulamalara göz atabilir ve deneyebilirler. Bu yükseltme, AI Studio’yu bir model deneme alanından daha eksiksiz bir uygulama geliştirme ve paylaşım platformuna dönüştürerek, Google AI teknolojisine dayalı uygulamalar oluşturma engelini düşürüyor. (Kaynak: op7418)
NVIDIA cuML, sıfır kod değişikliği ile GPU hızlandırma modunu tanıttı: NVIDIA cuML ekibi, kullanıcıların herhangi bir kod değişikliği yapmadan yerel scikit-learn, umap-learn ve hdbscan kodlarını doğrudan GPU üzerinde çalıştırmalarına olanak tanıyan yeni bir hızlandırıcı modunu yayınladı. Bu özellik python -m cuml.accel your_script.py komutuyla veya Jupyter Notebook’ta %load_ext cuml.accel yüklenerek etkinleştirilir. Benchmark testleri, Random Forest, Linear Regression, t-SNE, UMAP, HDBSCAN gibi algoritmaların 25 kattan 175 kata kadar değişen önemli hızlanmalar elde edebildiğini gösteriyor. Bu mod, CUDA Birleşik Bellek (UVM) kullanır ve genellikle veri kümesi boyutu konusunda endişelenmeye gerek kalmaz, ancak çok büyük bellekli veri kümelerinin performansı etkilenebilir. (Kaynak: Reddit r/MachineLearning)

Alibaba, ilk ve son kareye dayalı video modeli Wan 2.1’i açık kaynak olarak yayınladı: Alibaba, ilk ve son karelere dayanarak aradaki video içeriğini üreten Wan 2.1 video modelini açık kaynak olarak yayınladı. Bu, video interpolasyonu, stil transferi veya anahtar kare tabanlı animasyon üretimi gibi senaryolarda uygulanabilen özel bir video üretim teknolojisi türüdür. Bu modelin açık kaynak olarak yayınlanması, araştırmacılara ve geliştiricilere bu teknolojiyi keşfetme ve kullanma konusunda yeni araçlar sunuyor. (Kaynak: op7418)
ViTPose: Vision Transformer tabanlı insan duruş tahmini modeli: ViTPose, insan duruş tahmini için Vision Transformer (ViT) mimarisini kullanan yeni bir modeldir. Makale, bu modeli tanıtmakta ve ViT’nin bilgisayar görüşü görevlerindeki (burada insan duruş tahmini gibi) uygulama potansiyelini tartışmaktadır. Bu tür modeller genellikle Transformer’ın öz-dikkat mekanizmasını kullanarak görüntüdeki farklı bölümler arasındaki uzun mesafeli bağımlılıkları yakalar, bu da duruş tahmininin doğruluğunu ve sağlamlığını potansiyel olarak artırabilir. (Kaynak: Reddit r/deeplearning)

ClaraVerse: n8n entegrasyonuna sahip yerel öncelikli AI asistanı: ClaraVerse, Ollama üzerinde çalışan, gizliliği ve yerel kontrolü vurgulayan yerel öncelikli bir AI asistanıdır. En son güncelleme, n8n otomasyon platformunu entegre ederek kullanıcıların harici hizmetlere ihtiyaç duymadan asistan içinde özel araçlar ve iş akışları (posta kontrolü, takvim yönetimi, API çağrıları, veritabanı bağlantıları vb.) oluşturmasına ve çalıştırmasına olanak tanır. Bu, Clara’nın doğal dil komutları aracılığıyla yerel otomasyon görevlerini tetiklemesini sağlar ve kullanıcı dostu, düşük bağımlılıklı bir yerel AI ve otomasyon çözümü sunmayı hedefler. (Kaynak: Reddit r/LocalLLaMA)
CSM 1B TTS modeli gerçek zamanlı akış işleme ve ince ayar yeteneği kazandı: Açık kaynak topluluğu, CSM 1B metinden sese (TTS) modelinde ilerleme kaydederek gerçek zamanlı akış (real-time streaming) işlemeyi başardı ve ince ayar yetenekleri (LoRA ve tam ince ayar dahil) geliştirdi. Bu, modelin artık daha hızlı ses üretebileceği ve belirli ihtiyaçlara göre özelleştirilebileceği anlamına geliyor. Kod tabanı, kullanıcıların deneyebileceği ve diğer TTS modelleriyle karşılaştırabileceği yerel bir sohbet demosu sunuyor. (Kaynak: Reddit r/LocalLLaMA)
Deebo: AI Agent işbirliğine dayalı hata ayıklama için MCP kullanımı: Deebo, kodlama yapan AI Agent’ların karmaşık hata ayıklama görevlerini ona dış kaynak olarak vermesini sağlamayı amaçlayan deneysel bir Agent MCP (Machine Collaboration Protocol) sunucusudur. Ana Agent bir zorlukla karşılaştığında, MCP aracılığıyla bir Deebo oturumu başlatabilir. Deebo, farklı Git dallarında birden fazla alt süreç oluşturarak çeşitli düzeltme çözümlerini paralel olarak test eder ve çıkarım için LLM kullanır. Sonunda günlükleri, düzeltme önerilerini ve açıklamaları döndürür. Bu yöntem, süreç izolasyonunu kullanarak eşzamanlılık yönetimini basitleştirir ve AI Agent’lar arasında problem çözme işbirliği olasılığını araştırır. (Kaynak: Reddit r/OpenWebUI)
📚 Öğrenme
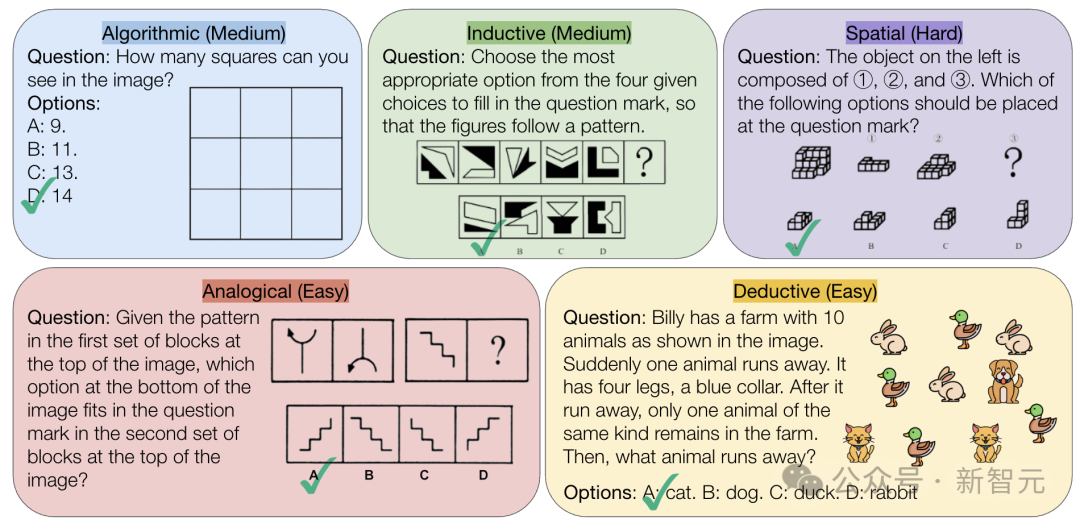
CMU, AI’ın saf mantıksal çıkarım yeteneğini zorlayan VisualPuzzles benchmark’ını yayınladı: Carnegie Mellon Üniversitesi (CMU) araştırmacıları, çok modlu çıkarım yeteneğini alan bilgisi bağımlılığından ayırmayı amaçlayan, kamu hizmeti sınavlarından uyarlanmış 1168 görsel mantık bulmacası içeren VisualPuzzles benchmark’ını oluşturdu. Testler, o1, Gemini 2.5 Pro gibi en iyi modellerin bile bu saf mantıksal çıkarım görevlerinde insanlardan çok daha kötü performans gösterdiğini ortaya koydu (en yüksek doğruluk oranı %57.5, insanların en düşük %5’lik diliminin altında). Araştırma, model boyutunu artırmanın veya “düşünme” modunu etkinleştirmenin her zaman saf çıkarım yeteneğini artırmadığını ve mevcut çıkarım geliştirme tekniklerinin etkilerinin değişken olduğunu gösteriyor. Bu, mevcut büyük modellerin uzamsal anlama ve derin mantıksal çıkarım konularında hala önemli eksiklikleri olduğunu ortaya koyuyor. (Kaynak: 全球顶尖AI来考公,不会推理全翻车,致命缺陷曝光,被倒数5%人类碾压)
InternVL3: Açık kaynaklı çok modlu modeller için gelişmiş eğitim ve test zamanı tekniklerini keşfetme: “InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models” başlıklı makale, 78B versiyonu MMMU benchmark’ında 72.2 puan alarak açık kaynaklı MLLM’ler için yeni bir rekor kıran InternVL3 modelini tanıtıyor. Anahtar teknolojiler arasında yerel çok modlu ön eğitim, uzun bağlamı destekleyen değişken görsel pozisyon kodlaması (V2PE), gelişmiş son eğitim teknikleri (SFT, MPO) ve test zamanı ölçeklendirme stratejileri (matematiksel çıkarımı geliştirme) bulunmaktadır. Bu çalışma, açık kaynaklı çok modlu modellerin performansını artırmak için etkili yöntemleri keşfetmeyi amaçlamakta ve eğitim verileri ile model ağırlıkları açık olarak sunulmuştur. (Kaynak: Reddit r/deeplearning)

Geobench: Büyük modellerin görüntü coğrafi konumlandırma yeteneklerini değerlendiren bir benchmark: Geobench, büyük dil modellerinin (LLM) Google Street View gibi görüntülere dayanarak çekim yerini tahmin etme yeteneğini (GeoGuessr oynamaya benzer şekilde) ölçmek için özel olarak tasarlanmış yeni bir benchmark web sitesidir. Modelin tahmin doğruluğunu, ülke/bölge doğruluk oranını ve gerçek konuma olan mesafeyi (ortalama ve medyan) gibi metrikleri değerlendirir. İlk sonuçlar, Google’ın Gemini serisi modellerinin bu görevde öne çıktığını gösteriyor; bu durum muhtemelen Google Street View verilerine erişim avantajından kaynaklanıyor. (Kaynak: Reddit r/LocalLLaMA)
Veri kümesi bölümlendirmesi için standart uygulamaların tartışılması: Reddit makine öğrenimi topluluğu, standart bir bölümlendirme olmadığında veri kümelerinin nasıl ele alınacağı (örneğin, train/val/test split) konusunu tartıştı. Yaygın uygulamalar arasında rastgele bölümlendirmeler oluşturma (ancak tekrarlanabilirliği etkileyebilir), belirli indeksleri/dosyaları kaydetme ve paylaşma, k-fold çapraz doğrulama kullanma yer alıyor. Tartışma, özellikle küçük veri kümeleri için bölümlendirme yönteminin performans değerlendirmesi ve SOTA iddiaları üzerinde önemli bir etkisi olduğunu vurguladı ve araştırmanın tekrarlanabilirliğini ve karşılaştırılabilirliğini artırmak için bölümlendirme bilgilerinin standartlaştırılması veya daha yaygın olarak paylaşılması çağrısında bulundu. Pratikteki zorluklar arasında birleşik bir platform eksikliği ve alana özgü normların olmaması yer alıyor. (Kaynak: Reddit r/MachineLearning, Reddit r/MachineLearning)
Stack Overflow gönderilerini sınıflandırmak için cümle gömme önerileri aranıyor: Bir kullanıcı Reddit’te, Stack Overflow gönderilerini (başlık, açıklama, etiketler, cevaplar içeren) denetimsiz olarak sınıflandırmak için cümle gömme (BERT, SBERT gibi) kullanımı konusunda tavsiye istedi. Amaç, basit kelime gömme etiketlerinin (örneğin “paket kurulumu”) ötesine geçerek, daha derinlemesine konu veya soru türü kümelemesini keşfetmek üzere cümle düzeyinde sınıflandırma yapmaktır. Yorumlar, metin paragrafları için tek bir gömme üretebilen ve ardından kümeleme algoritmalarının uygulanabileceği Sentence Transformers kütüphanesiyle başlamayı önerdi. (Kaynak: Reddit r/MachineLearning)
AI öğrenme yolları ve kariyer seçimleri hakkında tavsiyeler: Bir lise öğrencisi Reddit’te makine öğrenimi mühendisliği alanına girmek için üniversite bölümü seçimi (UCSD CS vs Cal Poly SLO CS) ve yüksek lisans yapmanın gerekip gerekmediği konusunda danıştı. Yorumlar, araştırma gücü daha yüksek olan UCSD’yi seçmeyi ve ML mühendisliğinin genellikle daha yüksek eğitim gerektirmesi nedeniyle yüksek lisans yapmayı düşünmeyi önerdi. Aynı zamanda, pratik becerilerin de önemli olduğu ve matematik ile istatistiğin de kilit temeller olduğu belirtildi. Başka bir gönderide, birisi AI’dan nasıl yararlanılacağı veya AI geliştirilecek bir bölüm hakkında soru sordu; yorumlarda genellikle yüksek lisans/doktora gerektiren bilgisayar bilimleri (CS) ile matematik/istatistikten bahsedildi, hatta birisi AI ikame riskinden kaçınmak için tesisatçılık gibi ticari mesleklerde pratik beceriler öğrenmeyi önerdi. (Kaynak: Reddit r/MachineLearning, Reddit r/ArtificialInteligence)
💼 İş Dünyası
AI sağlık hizmetleri ticarileştirme arayışı: Büyük teknoloji şirketlerinin stratejileri ile hastane ihtiyaçları arasındaki çekişme: Hastanelerin büyük modellere bütçe ayırmaya başlamasıyla (örneğin, Jiangsu Eyalet Organları Hastanesi’nin DeepSeek tabanlı bir platform için 4.5 milyon yuan harcaması), AI’ın sağlık sektöründeki ticarileşmesi hızlanıyor. Huawei, Alibaba, Baidu, Tencent gibi büyük teknoloji şirketleri, genellikle işlem gücü, bulut hizmetleri ve temel modeller sunarak ve sağlık dikeyindeki şirketlerle işbirliği yaparak bu alana yatırım yapıyor. Ancak, temel iş modeli hala belirsizliğini koruyor ve büyük şirketler şu anda doğrudan sağlık AI uygulamalarına derinlemesine girmek yerine donanım ve bulut hizmetleri satmaya daha fazla odaklanmış durumda. Hastane tarafında ise, Shaanxi Hanzhong 3201 Hastanesi gibi sınırlı bütçeye sahip kurumlar, maliyet etkinliğini göz önünde bulundurarak açık kaynak modelleri (düşük konfigürasyonlu DeepSeek gibi) deniyor. Yüksek kaliteli tıbbi veri elde etmek ve uzmanlaşmış modelleri eğitmek hala kilit zorluklar olup, veri etiketleme gibi “angarya işlerin” üstesinden gelinmesi gerekiyor. (Kaynak: AI看病这件事,华为、百度、阿里谁先挣到钱?, 科技大厂掀起医疗界的AI革命,谁更有胜算?)
DeepSeek gibi AI tavsiye araçlarının güvenilirliği sorgulanıyor, AI pazarlama optimizasyonu yeni bir savaş alanı haline geliyor: DeepSeek gibi AI araçları, restoran veya ürün tavsiyesi almak için giderek daha fazla kullanıcı tarafından kullanılıyor ve işletmeler de “DeepSeek tavsiyesi” etiketini pazarlama aracı olarak kullanmaya başlıyor. Ancak, bu tavsiyelerin güvenilirliği endişelere yol açıyor. Bir yandan, AI “halüsinasyon” görebilir, var olmayan dükkanlar uydurabilir veya güncelliğini yitirmiş ürünler önerebilir. Diğer yandan, AI’ın cevapları ticari etkilerden etkilenebilir, reklam yerleştirme veya SEO/GEO (Üretken Motor Optimizasyonu) stratejileriyle “kirletilme” riski taşıyabilir. İşletmeler, içeriklerini ve anahtar kelimelerini optimize ederek, AI’ın derlemini ve arama sonuçlarını etkileyerek marka görünürlüklerini artırmaya çalışıyor. Bu durum, AI tavsiyelerinin nesnelliğini sorgulatıyor ve tüketicilerin potansiyel yanıltıcı bilgilere karşı dikkatli olması gerekiyor. (Kaynak: 第一批用DeepSeek推荐的人,已上当)

Zhipu AI, Pekin Yapay Zeka Endüstrisi Yatırım Fonu’ndan 200 milyon yuan ek yatırım aldı: Birkaç yeni açık kaynak modelini duyurduktan ve 300 milyon yuan’lık bir açık kaynak fonu kurduktan sonra, Zhipu AI (Z.ai), Pekin Yapay Zeka Endüstrisi Yatırım Fonu’ndan 200 milyon yuan ek yatırım aldı. Bu fon, geçen yıl Zhipu’ya zaten yatırım yapmıştı. Bu ek yatırım, Zhipu’nun açık kaynak model araştırma ve geliştirmesini ve açık kaynak topluluğu ekosistemi inşasını desteklemeyi amaçlıyor ve aynı zamanda Pekin’in AI endüstrisinin gelişimini teşvik etme ve “Küresel Açık Kaynak Başkenti” oluşturma konusundaki kararlılığını yansıtıyor. (Kaynak: 智谱获2亿元新融资,连发3款开源模型,拿3亿元支持全球开源社区)
Intel CEO’su Patrick Gelsinger reformları yönlendiriyor, yeni CTO ve Baş AI Sorumlusu atandı: Yeni CEO Patrick Gelsinger (Not: Kaynakta Chen Liwu deniyor ancak Intel CEO’su Patrick Gelsinger’dır, muhtemelen kaynakta hata var. Gelsinger üzerinden çeviri yapacağım.), yönetim katmanlarını sadeleştirmeyi ve teknoloji odaklılığı güçlendirmeyi amaçlayan organizasyonel yeniden yapılandırma yapıyor. Kritik çip bölümleri (Veri Merkezi ve AI, PC Çipleri) doğrudan CEO’ya rapor verecek. Ağ çipleri başkanı Sachin Katti, yeni Baş Teknoloji Sorumlusu (CTO) ve Baş AI Sorumlusu olarak atandı; AI stratejisi, ürün yol haritası ve Intel Labs’ı yöneterek NVIDIA’nın AI alanındaki zorluklarına yanıt verecek. Bu hamle, Gelsinger’ın Intel’i yeniden canlandırma planının bir parçası olarak görülüyor ve üretim ile ürün zorluklarını çözmeyi, iç siloları kırmayı, mühendislik ve inovasyona odaklanmayı amaçlıyor. (Kaynak: 陈立武挥刀高层,英特尔重生计划曝光,技术团队直通华人CEO)

Meta’nın Llama eğitim maliyetlerini paylaşmak istediği bildirildi, AI yatırım baskısını vurguluyor: Haberlere göre Meta, açık kaynak modeli Llama’nın eğitim maliyetlerini ( “Llama ittifakı”) ortaklaşa üstlenmeyi teklif etmek için Microsoft, Amazon, Databricks gibi şirketler ve yatırım kuruluşlarıyla temasa geçti ve karşılığında özellik geliştirme konusunda kısmi söz hakkı istedi, ancak ilk tepkiler soğuk oldu. Nedenleri arasında iş ortaklarının ücretsiz bir modele yatırım yapmak istememesi, Meta’nın çok fazla kontrol devretmek istememesi ve potansiyel ortakların zaten kendi başlarına büyük AI yatırımları yapmış olması sayılabilir. Bu olay, Meta gibi devlerin bile artan AI geliştirme maliyetlerinin baskısıyla karşı karşıya olduğunu vurguluyor; özellikle de sermaye harcamalarının devasa olduğu (yıllık %60 artışla 60-65 milyar dolara ulaşması bekleniyor) ve açık kaynak modelinin ticarileştirme yolunun belirsiz olduğu bir durumda. (Kaynak: Llama开源太贵了,Meta被曝向亚马逊、微软“化缘”)

NVIDIA CEO’su Jensen Huang Çin’i ziyaret etti, ticaret kısıtlamalarına karşı DeepSeek gibi şirketlerle işbirliğini görüşebilir: NVIDIA CEO’su Jensen Huang, Çin Uluslararası Ticareti Geliştirme Konseyi’nin daveti üzerine yakın zamanda Çin’i ziyaret etti ve DeepSeek kurucusu Liang Wenfeng dahil olmak üzere müşterilerle görüştü. Bu ziyaretin karmaşık bir arka planı var: ABD hükümetinin NVIDIA H20 gibi Çin’e ihraç edilen çiplere yönelik kısıtlamalarının sıkılaşması, Çin’in yerli AI çiplerinin (Huawei Ascend gibi) yükselişi ve DeepSeek gibi modellerin optimizasyonunun NVIDIA’nın üst düzey GPU’larına olan mutlak bağımlılığı azaltması. Analistler, Huang’ın Çinli ortaklarla (DeepSeek gibi) ABD ihracat kısıtlamalarına uygun ve aynı zamanda Çin’in yüksek ithalat vergilerinden kaçınan AI çipleri tasarlamak üzere ortaklık kurmayı, derin işbirliği yoluyla Çin pazarındaki payını ve endüstri etkisini sürdürmeyi amaçlıyor olabileceğini düşünüyor. (Kaynak: 英伟达CEO黄仁勋突然访华,都不穿皮衣了,还见了梁文锋)

🌟 Topluluk
AI oyuncak bebek oluşturma çılgınlığı sosyal medyayı sardı, telif hakkı ve etik endişeleri doğurdu: Kişisel fotoğrafları ChatGPT gibi AI araçlarını kullanarak oyuncak bebek figürlerine (Barbie bebek tarzına benzer, ambalaj kutusu ve kişiselleştirilmiş aksesuarlarla) dönüştürme akımı LinkedIn, TikTok gibi platformlarda popüler hale geldi. Kullanıcılar fotoğraf yükleyerek ve ayrıntılı açıklamalar sağlayarak bu figürleri oluşturabiliyor. Eğlenceli olmasına rağmen, telif hakkı ve etik konularında endişelere yol açtı: AI üretimi, istemeden telif hakkıyla korunan sanat stillerini veya marka unsurlarını kullanabilir; aynı zamanda, bu AI modellerini eğitmek ve çalıştırmak için gereken büyük miktarda enerji tüketimi de dikkat çekiyor. Yorumlarda, AI kullanırken net sınırlar ve normlar belirlenmesi gerektiği belirtiliyor. (Kaynak: 芭比风AI玩偶席卷全网:ChatGPT几分钟打造你的时尚分身)

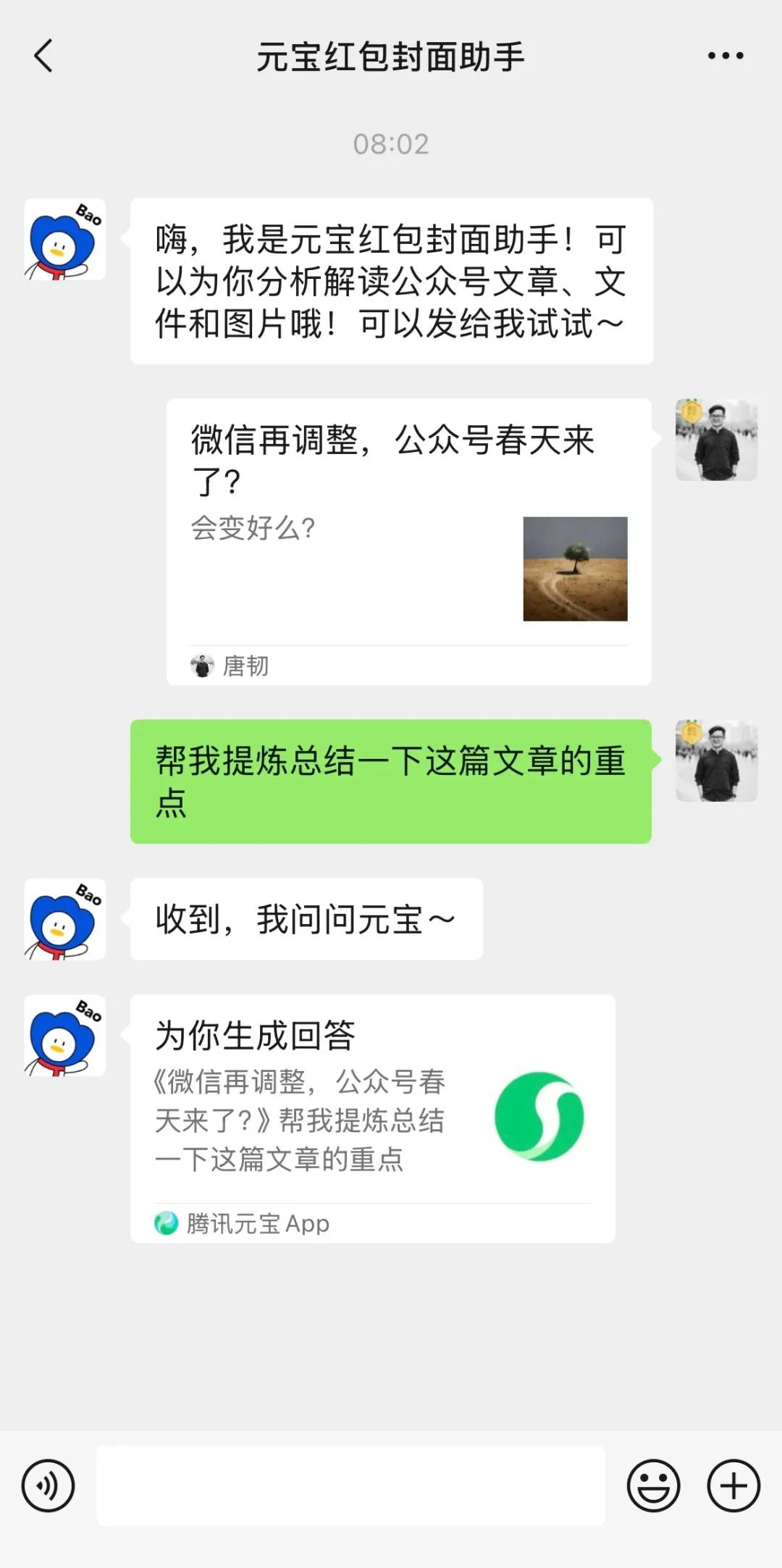
Tencent Yuanbao’nun (eski adıyla Kırmızı Zarf Kapağı Asistanı) WeChat’e derin entegrasyonu dikkat çekiyor: WeChat içinde “Yuanbao” araması yaparak doğrudan AI işlevleri çağrılabiliyor; bu aslında önceki “Yuanbao Kırmızı Zarf Kapağı Asistanı”nın yükseltilmiş bir versiyonu. Kullanıcı deneyimi, yeteneklerinin arttığını gösteriyor; örneğin, isteklere göre daha doğru resimler üretebiliyor ve yerel uyarlaması optimize edilmiş, cevap kartları oluşturabiliyor. Makale, Tencent’in AI hamlesinin WeChat senaryosuna odaklanma olasılığını, özellikle dosya aktarım asistanı gibi mevcut giriş noktalarının potansiyelini tartışıyor ve senaryo avantajının Tencent AI’ın hayata geçirilmesinde kilit rol oynadığını savunuyor. Aynı zamanda WeChat Resmi Hesaplarının yakın zamanda güncellendiği, mobil cihazlardan yayınlama girişinin eklendiği, bunun kısa içerik üretimini teşvik edebileceği ancak uzun biçimli içerik ekosistemini etkileyebileceği belirtiliyor. (Kaynak: 鹅厂的 AI 大招,真的落在微信上)
LMArena Beta test sitesini başlattı: Büyük model yarışma arenası LMArena, henüz yayınlanmamış modeller de dahil olmak üzere çeşitli büyük modelleri test etmek için yeni bir Beta test sitesi (beta.lmarena.ai) başlattı. Bu, topluluğa model performansını değerlendirmek ve karşılaştırmak için Hugging Face Gradio arayüzünden bağımsız yeni bir platform sunuyor. (Kaynak: karminski3)
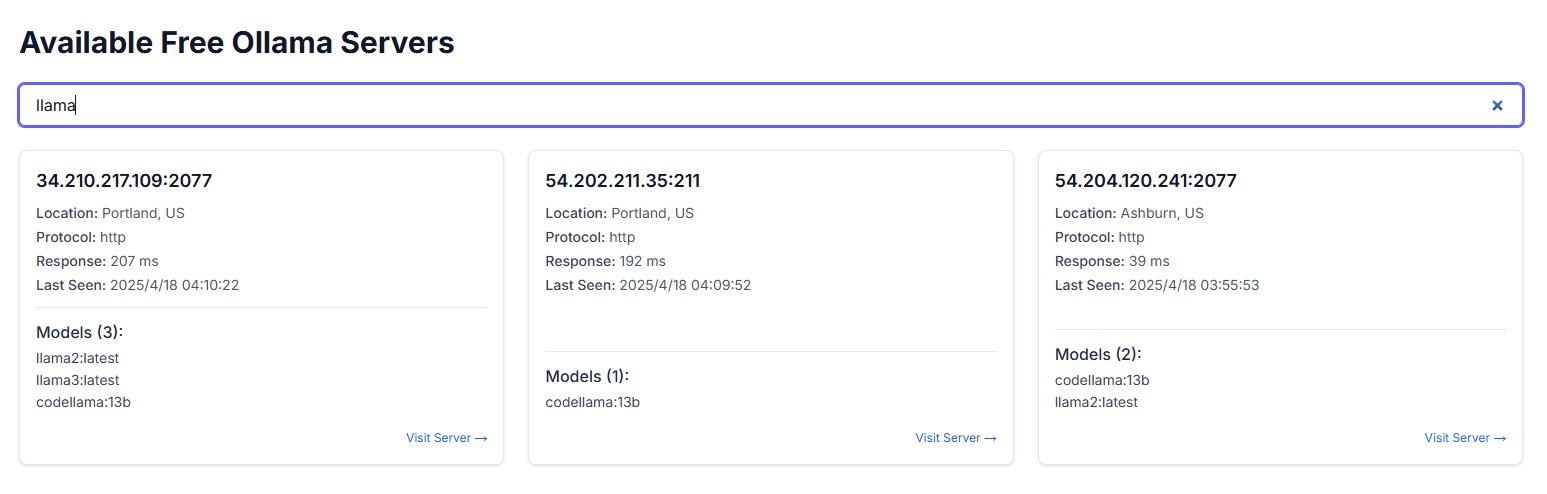
Ollama örneklerinin kamuya açık internete maruz kalması güvenlik endişelerine yol açıyor: Bir kullanıcı, freeollama.com adlı bir web sitesi keşfetti ve siber uzay aramasında, Ollama (yerel olarak dağıtılan büyük model aracı) portunu (genellikle 11434) güvenlik duvarı olmadan kamuya açık IP adresine maruz bırakan çok sayıda ana bilgisayar buldu. Bu, yetkisiz erişime ve yerel olarak dağıtılan modellerin kötüye kullanılmasına yol açabilecek ciddi bir güvenlik riski oluşturuyor. Kullanıcılara dağıtım yaparken ağ güvenliği yapılandırmasına dikkat etmeleri ve hizmetleri korumasız olarak kamuya açık internete maruz bırakmaktan kaçınmaları hatırlatılıyor. (Kaynak: karminski3)
ChatGPT’nin psikolojik destek için kullanılması tartışmalara ve uyarılara yol açıyor: Reddit kullanıcıları, depresyon, anksiyete gibi sorunlarla başa çıkmak için ChatGPT kullanma deneyimlerini paylaştı ve tavsiyelerinin tutarlılıktan yoksun olabileceğini, güvenilir rehberlik sağlamak yerine kullanıcının mevcut görüşlerini doğrulama eğiliminde olduğunu fark etti. Farklı sohbetlerde kendi mantığıyla çeliştirildiğinde, ChatGPT hatasını kabul ediyor. Kullanıcı, AI’ın yalnızca “dijital bir pohpohlayıcı” olabileceği ve ciddi psikoterapi desteği için kullanılmaması gerektiği konusunda uyarıyor. Yorum bölümünde ise AI’ı daha etkili kullanma yolları (örneğin, eleştirel bir rol üstlenmesini istemek, birden fazla bakış açısı sunmasını istemek) ve AI’ın kriz müdahalesinde insan profesyonellerin yerini alamayacağı sınırlamaları tartışılıyor. (Kaynak: Reddit r/ChatGPT)
Douglas Adams’ın Teknoloji Üç Yasası yankı uyandırıyor: Bir kullanıcı, bilim kurgu yazarı Douglas Adams’ın Teknoloji Üç Yasası’nı alıntılayarak, farklı yaş gruplarındaki insanların yeni teknolojilere yönelik genel tepkilerini mizahi bir dille betimliyor: Doğduğunuzda var olan teknoloji normal kabul edilir, gençken ortaya çıkan teknoloji devrim niteliğinde görülür, yaşlandıktan sonra ortaya çıkan teknoloji ise doğaya aykırı bulunur. Bu yorum, AI’ın hızla geliştiği günümüzde yankı uyandırıyor ve insanların AI gibi yıkıcı teknolojileri kabul etme derecesinin yaşamlarının hangi evresinde olduklarıyla ilgili olabileceğini ima ediyor. (Kaynak: dotey)
Kullanıcı deneyimi: ChatGPT “çok gerçekçi” veya “Gen Z tarzı” hale geliyor: Reddit gönderisi, bir ChatGPT konuşma ekran görüntüsünü paylaşıyor; yanıt tarzı kullanıcı tarafından “çok gerçekçi” veya “Gen Z” argosu ve internet memleri (örneğin “Let me cook”) içeriyor olarak tanımlanıyor. Yorum bölümünde tepkiler karışık; bazıları bunu eğlenceli bulurken, bazıları bu tarzı “rahatsız edici” veya “aptallaştırıcı” buluyor. Bu, kullanıcıların AI kişiselleştirmesi ve dil stiline ilişkin algı farklılıklarını ve modelin internet dil trendlerini taklit etmesinin getirebileceği deneyim sorunlarını yansıtıyor. (Kaynak: Reddit r/ChatGPT)
AI tarafından üretilen gelecekteki yaşam anlık görüntüleri yaratıcı tartışmalara yol açıyor: Bir kullanıcı, robot garsonlar, AI evcil hayvanlar, geleceğin ulaşımı gibi sahneleri betimleyen, ChatGPT kullanılarak oluşturulmuş bir dizi “gelecekteki yaşam Snapchat” tarzı resim paylaştı. Bu yaratıcı görüntüler, toplulukta AI görüntü oluşturma yetenekleri ve gelecekteki yaşam hayalleri üzerine tartışmalara yol açtı ve yaratıcılığı ile giderek artan gerçekçiliği takdir edildi. (Kaynak: Reddit r/ChatGPT)
Kullanıcı, ChatGPT kullanarak el çizimi eskizlerini gerçekçi görüntülere dönüştürme deneyimini paylaşıyor: Bir sanatçı kullanıcı, kendi sürrealist tarzı el çizimi eskizlerini ChatGPT kullanarak gerçekçi görüntülere dönüştürme sürecini ve sonuçlarını sergiledi. Topluluk bunu takdirle karşıladı ve bunun sadece “daha iyi” görüntüler peşinde koşmak yerine, sanatçıların fikirleri ve farklı stilleri keşfetmelerine yardımcı olan ilginç bir sanatsal deney yöntemi olduğunu belirtti. (Kaynak: Reddit r/ChatGPT)
💡 Diğer
AI sistem inşası üzerine düşünceler: “Acı Ders” ve işlem gücü önceliği: Makale, Richard Sutton’ın “Acı Ders” teorisine atıfta bulunarak, AI gelişiminde genel hesaplama yeteneği ölçeklendirmesine (işlem gücü odaklı) dayanan sistemlerin, sonunda insanların özenle tasarladığı karmaşık kurallara dayanan sistemleri geride bırakacağını belirtiyor. Müşteri hizmetleri AI vakası karşılaştırması (kural tabanlı sistem vs sınırlı işlem güçlü AI vs büyük işlem güçlü keşifçi AI) ve pekiştirmeli öğrenmenin (RL) başarısı (OpenAI derin araştırmaları, Claude gibi) aracılığıyla, şirketlerin algoritmaları aşırı optimize etmek yerine hesaplama altyapısına yatırım yapması gerektiğini ve mühendislerin rolünün ölçeklenebilir öğrenme ortamları inşa eden “pist yapıcılarına” dönüşmesi gerektiğini vurguluyor. Temel fikir şudur: Basit mimari + büyük ölçekli işlem gücü + keşifçi öğrenme > Karmaşık tasarım + sabit kurallar. (Kaynak: 苦涩的启示:对AI系统构建方式的反思)
AI alanı ile Rasyonalizm/Etkin Fedakarlık toplulukları arasındaki bağlantının tartışılması: Bir makine öğrenimi uygulayıcısı, AI araştırma alanında etkileşimi az olan iki alt topluluk varmış gibi göründüğünü gözlemliyor; bunlardan biri Rasyonalizm (Rationalism) ve Etkin Fedakarlık (Effective Altruism, EA) topluluklarıyla yakından ilişkili, sık sık AGI tahminleri, uyum sorunları üzerine araştırmalar yayınlıyor ve bazı Körfez Bölgesi büyük şirketleriyle yakın bağlantıları var. Yazar, bu topluluğun bazen bilişsel bilim kavramlarını (durumsal farkındalık gibi) tartışırken, mevcut akademik sistemden bağımsız olarak yeniden tanımlıyor gibi göründüğünü belirtiyor; örneğin Anthropic’in “durumsal farkındalık” tanımı, geleneksel bilişsel bilimdeki duyulara ve çevre modeline dayalı tanımdan ziyade, modelin kendi geliştirme sürecine ilişkin bilişine odaklanıyor. (Kaynak: Reddit r/ArtificialInteligence)
Kullanıcı, AI sohbet botunun beklenmedik bir şekilde diğer platformlardaki takma adını kullandığını fark etti: Bir kullanıcı, yeni bir AI sohbet botu platformunu denerken herhangi bir kişisel bilgi vermedi, ancak bot ikinci mesajında kullanıcının diğer platformlarda sıkça kullandığı takma adı doğru bir şekilde kullandı. Bu durum, kullanıcının veri gizliliği ve platformlar arası bilgi takibi konusundaki endişelerini artırdı ve muhtemelen “takip edildiğini” veya “profillendiğini” düşünmesine neden oldu. (Kaynak: Reddit r/ArtificialInteligence)
AI model değerlendirmesi için yeni bir yaklaşım: 3 dakikalık sözlü sunumla zekayı yargılama: Yeni bir AI zeka değerlendirme yöntemi öneriliyor: En iyi AI modellerinin (o3 vs Gemini 2.5 Pro gibi) belirli bir konuda (politika, ekonomi, felsefe vb.) 3 dakikalık sözlü bir sunum yapması ve insan dinleyicilerin zeka düzeyini yargılaması. Bu yöntemin, uzmanlaşmış benchmark testlerine dayanmaktan daha sezgisel olduğu ve modellerin organizasyon, retorik, duygu ve entelektüel performansını, özellikle ikna edicilik gerektiren görevlerde daha iyi değerlendirebileceği düşünülüyor. Bu tür bir “AI münazarası” veya “konuşma yarışması”, AGI’ye yakın modellerin yeteneklerini değerlendirmek için yeni bir boyut olabilir. (Kaynak: Reddit r/ArtificialInteligence)