
Anahtar Kelimeler:GPT-4.1, Hugging Face, GPT-4.1 serisi model performans karşılaştırması, Hugging Face Pollen Robotics satın aldı, OpenAI yeni model kodlama yeteneği geliştirme, GPT-4.1 mini maliyet %83 azaldı, açık kaynak robot Reachy 2
🔥 Odak Noktası
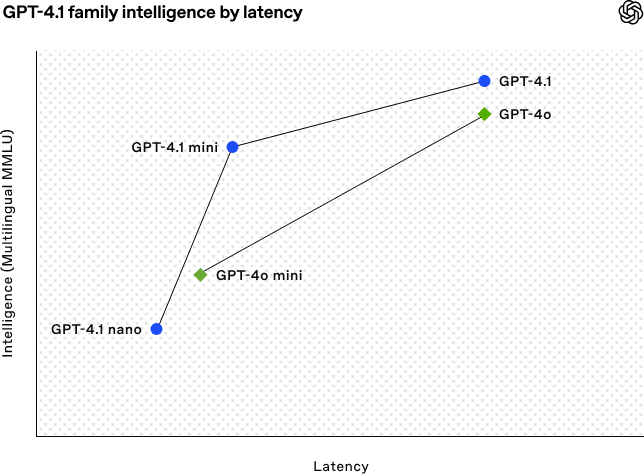
OpenAI, kodlama ve uzun metin işleme yeteneklerini güçlendiren GPT-4.1 serisi modellerini yayınladı: OpenAI, 15 Nisan sabahı GPT-4.1 serisinden üç yeni model yayınladı: GPT-4.1 (amiral gemisi), GPT-4.1 mini (yüksek verimli) ve GPT-4.1 nano (ultra küçük), hepsi yalnızca API aracılığıyla sunuluyor. Bu model serisi kodlama, talimat takibi ve uzun bağlam anlama konularında üstün performans gösteriyor; bağlam pencereleri 1 milyon token’a, çıktı token’ları ise 32768’e ulaşıyor. GPT-4.1, SWE-bench Verified testinde %54.6 puan alarak GPT-4o’yu ve kullanımdan kaldırılacak olan GPT-4.5 Preview’u önemli ölçüde geride bıraktı. GPT-4.1 mini, GPT-4o’yu performans olarak geçerken gecikmeyi yarıya indiriyor ve maliyeti %83 azaltıyor. GPT-4.1 nano ise şu anki en hızlı ve en düşük maliyetli model olup düşük gecikmeli görevler için uygun. Bu sürüm, geliştiricilere daha güçlü performans, daha iyi maliyet ve daha yüksek hız sunan model seçenekleri sağlamayı, karmaşık akıllı sistemlerin ve ajan uygulamalarının oluşturulmasını teşvik etmeyi amaçlıyor. (Kaynak: 36Kr, Zhidx, op7418, openai, karminski3, sama, natolambert, karminski3, karminski3, karminski3, dotey, OpenAI, GPT-4.1 geldi, GPT-4.5’i geçti, SWE-Bench %55’e ulaştı, geliştiricilere özel.)
Hugging Face, açık kaynaklı robotik şirketi Pollen Robotics’i satın aldı: AI topluluk platformu Hugging Face, AI robotlarının açık kaynaklı hale getirilmesini ve yaygınlaştırılmasını teşvik etmek amacıyla Fransız açık kaynaklı robotik girişimi Pollen Robotics’i satın aldığını duyurdu. Bu satın alma, Hugging Face’in yazılım platformlarındaki (LeRobot kütüphanesi ve Hub gibi) avantajlarını Pollen Robotics’in açık kaynaklı donanımdaki (Reachy 2 insansı robotu gibi) uzmanlığıyla birleştirecek. Reachy 2, araştırma, eğitim ve somutlaştırılmış zeka deneyleri için tasarlanmış, 70.000 dolara satılan açık kaynaklı, VR uyumlu bir insansı robottur. Hugging Face, robotların AI için bir sonraki önemli etkileşim arayüzü olduğuna ve açık, uygun fiyatlı ve özelleştirilebilir olmaya odaklanılması gerektiğine inanıyor. Bu satın alma, bu vizyonu gerçekleştirme yolunda önemli bir adımdır ve topluluğun kapalı ve pahalı sistemlere bağımlı kalmak yerine kendi robot arkadaşlarını inşa edip kontrol edebilmesini hedeflemektedir. (Kaynak: huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface)

🎯 Gelişmeler
AI, 50 yıldır çözülemeyen matematik problemini çözmeye yardımcı oldu: ABD Brookhaven Ulusal Laboratuvarı’ndan Çinli araştırmacı Weiguo Yin, OpenAI’nin çıkarım modeli o3-mini-high’ı kullanarak tek boyutlu J_1-J_2 q-durumlu Potts modelinin kesin çözümünde, özellikle q=3 durumunda, bir atılım gerçekleştirdi ve AI kritik kanıtlamayı tamamlamada yardımcı oldu. Bu problem, istatistiksel mekaniğin temel modelleriyle ilgili olup katmanlı malzemelerin atomik istiflenmesi, alışılmadık süperiletkenlik gibi fiziksel olgularla bağlantılıdır ve kesin çözümü son 50 yıldır elde edilememiştir. Araştırmacılar, maksimum simetri alt uzayı (MSS) yöntemini tanıtarak ve transfer matrisini işlemek için AI’dan adım adım ipuçları alarak, q=3 durumundaki 9×9 transfer matrisini etkili bir 2×2 matrise başarıyla indirgedi ve bu yöntemi herhangi bir q değeri için genelleştirdi. Bu çalışma sadece uzun süredir devam eden bir matematiksel fizik problemini çözmekle kalmadı, aynı zamanda AI’ın karmaşık bilimsel araştırmalara yardımcı olma ve yeni içgörüler sağlama konusundaki muazzam potansiyelini de gösterdi. (Kaynak: Az önce AI, 50 yıldır çözülemeyen matematik problemini çözdü! Nanjing Üniversitesi mezunu OpenAI modelini kullanarak ilk önemsiz olmayan matematiksel kanıtı tamamladı)

AI web tabanlı asistanlar yükselişte, cep telefonu ve otomobil üreticileri çoklu cihaz deneyimi için konumlanıyor: Huawei (Xiaoyi Asistanı), Li Auto (Lixiang Tongxue), OPPO (Xiaobu Asistanı) gibi üreticiler art arda AI asistanlarının web sürümlerini piyasaya sürerek dikkat çekti. Bu web sürümleri, işlevsellik açısından (soru düzenleme, düzenleme, ayar seçenekleri gibi) DeepSeek gibi profesyonel model hizmetleri kadar gelişmiş olmasa da, temel hedefleri doğrudan rekabet etmek değil, kendi markalarının kullanıcılarına hizmet etmek ve cep telefonu, araç içi sistemlerden PC’ye kadar olan deneyim döngüsünü tamamlamaktır. Kullanıcı hesaplarını bağlayarak ve konuşma kayıtlarını senkronize ederek, bu web sürümleri kullanıcı bağlılığını artırmayı, terminaller arası tutarlı bir etkileşim deneyimi sunmayı ve AI asistanlarını daha geniş kullanıcı senaryolarına entegre etmeyi amaçlamaktadır; bu özünde kullanıcı giriş noktaları ve veri ekosistemi üzerine bir konumlandırmadır. (Kaynak: AI web sürümleri toplu halde piyasaya sürülüyor, Huawei, Li Auto, OPPO neyin peşinde?)
Figure robotu, pekiştirmeli öğrenme yoluyla simülasyondan gerçeğe sıfır-atış transferi gerçekleştiriyor: Figure şirketi, Figure 02 insansı robotunun tamamen simülasyon ortamında pekiştirmeli öğrenme (RL) yoluyla doğal yürüyüşü nasıl başardığını gösterdi. Verimli GPU hızlandırmalı fizik simülatörünü kullanarak, birkaç saat içinde yıllarca süren eğitim verisine eşdeğer veri üreterek, farklı fiziksel parametrelere ve senaryolara (farklı araziler, parazitler gibi) sahip birden fazla sanal robotu kontrol edebilen tek bir sinir ağı politikası eğitti. Simülasyon alanı rastgeleleştirmesi ve gerçek robotun yüksek frekanslı tork geri bildirimi birleştirilerek, eğitilen politika ince ayar gerektirmeden fiziksel robota sıfır-atış transferi yapabiliyor. Bu yöntem sadece geliştirme süresini kısaltmakla kalmıyor, aynı zamanda gerçek dünya performansının istikrarını artırıyor ve tek bir politika tüm robot filosunu kontrol edebiliyor, bu da büyük ölçekli ticari uygulamalardaki potansiyelini gösteriyor. (Kaynak: Tek bir algoritma robot ordusunu kontrol ediyor! Tamamen simülasyon ortamında pekiştirmeli öğrenme, Figure insan gibi yürümeyi öğrendi)

DeepSeek, çıkarım motoru optimizasyonlarının bir kısmını açık kaynak yapacak: DeepSeek, vLLM tabanlı olarak değiştirilmiş yüksek performanslı çıkarım motorunun bazı optimizasyonlarını ve özelliklerini topluluğa geri katkıda bulunmayı planladığını duyurdu. Tamamen özelleştirilmiş çıkarım yığınını yayınlamak yerine, anahtar iyileştirmeleri (en son model mimarileri desteği, performans optimizasyonları gibi) vLLM ve SGLang gibi ana akım açık kaynaklı çıkarım çerçevelerine entegre etmeyi seçiyorlar. Amaç, topluluğun yeni modellere ve teknolojilere ilk günden itibaren SOTA düzeyinde destek almasını sağlamak. Bu hamle topluluk tarafından memnuniyetle karşılandı ve sadece sözde değil, gerçekten açık kaynak katkısına adanmışlık olarak değerlendirildi. (Kaynak: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, natolambert)
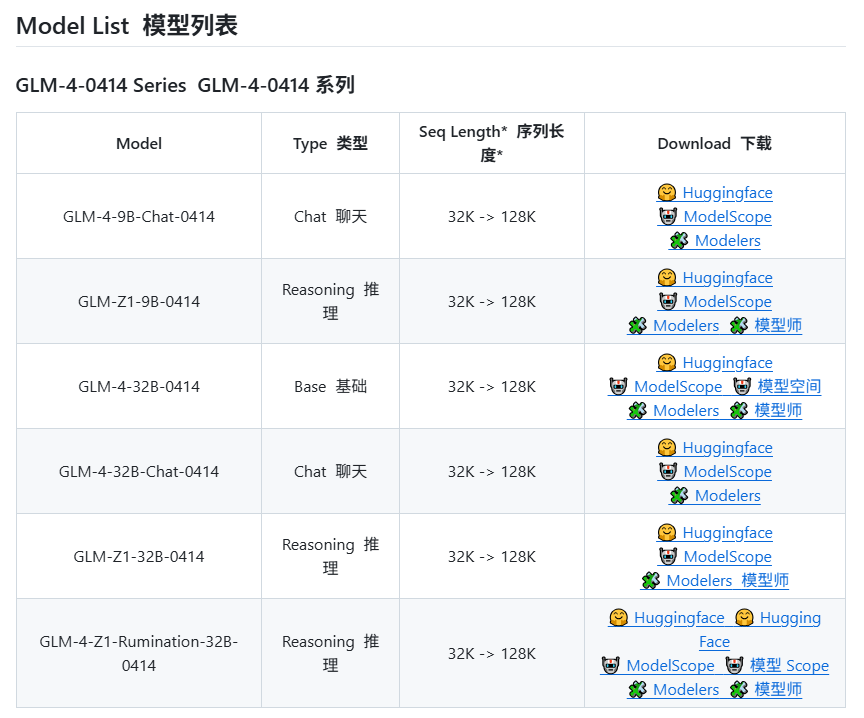
Zhipu AI’nin GLM-4 serisi yeni modeller yayınlayacağı iddia ediliyor: GitHub’da sızdırılan (daha sonra kaldırılan) bilgilere göre, Zhipu AI’nin GLM-4 serisi yeni modeller yayınlamaya hazırlandığı görülüyor. Seri, farklı parametre boyutlarına (örneğin 9B, 32B) ve işlevlere sahip sürümler içerebilir; örneğin temel model (GLM-4-32B-0414), diyalog modeli (Chat), çıkarım modeli (GLM-Z1-32B-0414) ve daha derin düşünme yeteneğine sahip “geviş getirme” modeli (Rumination), muhtemelen OpenAI’nin Deep Research’üne rakip olabilir. Ayrıca, görsel çok modlu bir model (GLM-4V-9B) de içerebilir. Sızdırılan kıyaslama testi verileri, GLM-4-32B-0414’ün bazı metriklerde DeepSeek-V3 ve DeepSeek-R1’den daha iyi olabileceğini gösteriyor. İlgili çıkarım motoru destek kodu transformers/vllm/llama.cpp’ye birleştirildi. Topluluk bu konuya büyük ilgi gösteriyor ve resmi duyuruyu ve incelemeleri bekliyor. (Kaynak: karminski3, karminski3, Reddit r/LocalLLaMA)
NVIDIA, Nemotron serisi yeni modeller yayınladı: NVIDIA, Hugging Face üzerinde yeni Nemotron-H serisi temel modellerini yayınladı; 56B, 47B ve 8B olmak üzere üç farklı parametre boyutuna sahip ve hepsi 8K bağlam penceresini destekliyor. Bu modeller hibrit Transformer ve Mamba mimarisine dayanıyor. Şu anda yayınlananlar temel modeller (Base) olup, henüz talimat ince ayarlı (Instruct) sürümleri mevcut değil. Nemotron serisi, yeni mimarilerin dil modellemedeki potansiyelini keşfetmeyi amaçlıyor. (Kaynak: Reddit r/LocalLLaMA)

🧰 Araçlar
GitHub Copilot, Windows Terminal Canary sürümüne entegre edildi: Microsoft, GitHub Copilot işlevini Windows Terminal’in Canary önizleme sürümüne entegre ederek “Terminal Chat” adlı yeni bir özellik sundu. Bu özellik, kullanıcıların doğrudan terminal ortamında AI ile etkileşim kurarak komut önerileri ve açıklamaları almasını sağlıyor. Kullanıcıların GitHub Copilot’a abone olmaları ve en son Canary sürüm terminali yüklemeleri, hesaplarını doğruladıktan sonra kullanmaları gerekiyor. Bu hamle, AI yardımını doğrudan geliştiricilerin sık kullandığı komut satırı ortamına entegre etmeyi, bağlam geçişini azaltmayı, karmaşık veya bilinmeyen görevleri ele alma verimliliğini artırmayı, öğrenme sürecini hızlandırmayı ve hataları azaltmaya yardımcı olmayı amaçlıyor. (Kaynak: GitHub Copilot artık Windows Terminal’de çalışıyor)

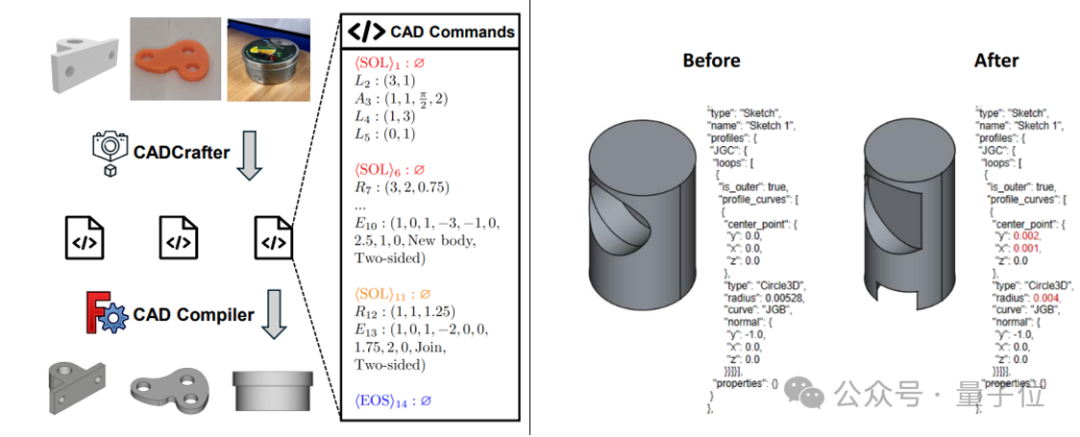
CADCrafter: Tek görüntüden düzenlenebilir CAD dosyaları oluşturma: KOKONI 3D (魔芯科技), Nanyang Technological University ve diğer kurumların araştırmacıları, tek bir görüntüden (render, gerçek nesne fotoğrafı vb.) doğrudan parametrik, düzenlenebilir CAD mühendislik dosyaları (CAD komut dizileri olarak temsil edilir) oluşturabilen CADCrafter adlı yeni bir çerçeve önerdi. Bu, mevcut görüntüden 3D’ye (Mesh veya 3DGS üreten) yöntemlerin ürettiği modellerin hassas bir şekilde düzenlenememesi ve yüzey kalitesinin düşük olması sorununu çözüyor. Yöntem, VAE ile Diffusion Transformer’ı birleştiren iki aşamalı bir üretim mimarisi kullanıyor ve çoklu görünümden tek görünüme damıtma stratejisi ve DPO tabanlı derlenebilirlik kontrol mekanizması aracılığıyla üretim kalitesini ve başarı oranını artırıyor. Araştırma sonuçları CVPR 2025 tarafından kabul edildi ve AI destekli endüstriyel tasarım için yeni bir paradigma sunuyor. (Kaynak: Tek görüntüden doğrudan CAD mühendislik dosyası! CVPR 2025 yeni araştırması AI tarafından üretilen 3D modellerin “düzenlenemez” sorununu çözüyor|KOKONI 3D, NTU vb. tarafından üretildi)
LangChain, GraphRAG ve MongoDB Atlas entegrasyonunu başlattı: LangChain, MongoDB ile işbirliği yaparak graf tabanlı RAG (GraphRAG) sistemini başlattığını duyurdu. Bu sistem, verileri depolamak ve işlemek için MongoDB Atlas’ı kullanıyor ve LangChain aracılığıyla uygulanarak, geleneksel benzerlik aramasına dayalı RAG’ın ötesine geçerek varlıklar arasındaki ilişkileri anlayabiliyor ve bunlar hakkında akıl yürütebiliyor. Varlık ve ilişki çıkarımı için LLM kullanımını destekliyor ve bağlı bağlam bilgilerini elde etmek için graf dolaşımını kullanıyor. Derin ilişkisel anlayış gerektiren uygulamalar için daha güçlü soru yanıtlama ve akıl yürütme yetenekleri sağlamayı amaçlıyor. (Kaynak: LangChainAI)
Hugging Face, çıkarım oyun alanını (Inference Playground) açık kaynak yaptı: Hugging Face, model çıkarım testi ve karşılaştırması için kullandığı çevrimiçi aracı Inference Playground’u açık kaynak yaptı. Bu, kullanıcıların çeşitli çıkarım ayarlarını (sıcaklık, top-p vb.) kontrol etmesine, AI yanıtlarını değiştirmesine, farklı modellerin ve sağlayıcıların performansını karşılaştırmasına olanak tanıyan web tabanlı bir LLM sohbet arayüzüdür. Proje Svelte 5, Melt UI ve Tailwind kullanılarak oluşturulmuştur ve kodu GitHub’da yayınlanmıştır, geliştiricilere özelleştirilebilir ve genişletilebilir yerel veya çevrimiçi model etkileşimi ve değerlendirme platformu sunmaktadır. (Kaynak: huggingface)
Flowith platformu ARR’si 1 milyon doları aştı, AI Agent’ın web sayfası oluşturma yeteneğini sergiliyor: AI Agent platformu Flowith’in yıllık yinelenen geliri (ARR) 1 milyon doları aştı, bu da insan emeğini ikame edebilen çok yönlü AI Agent platformlarına yönelik güçlü pazar talebini gösteriyor. Kullanıcılar, Flowith’in Oracle özelliğini kullanarak, sadece basit doğal dil açıklamalarıyla (“Sosyal medya görsel önizleme programı web sayfası yapmak istiyorum…”) hızlı bir şekilde işlevsel, stili hassas bir şekilde (Twitter tarzı gibi) yeniden üreten ve resim önizlemesini destekleyen bir web aracı oluşturabildiklerini paylaştı. GitHub’a bağlanmaya veya karmaşık yapılandırmalar yapmaya gerek kalmadan, AI Agent’ın düşük kodlu/kodsuz web sayfası oluşturma potansiyelini gösteriyor. (Kaynak: karminski3)
Otonom hata ayıklama ajanı Deebo yayınlandı: Araştırmacılar, Deebo adlı otonom bir hata ayıklama ajanı MCP sunucusu oluşturdular. Yerel bir arka plan programı olarak çalışır ve programlama ajanları zorlu hata işleme görevlerini eşzamansız olarak ona devredebilir. Deebo, farklı düzeltme hipotezlerine sahip birden fazla alt süreç oluşturarak, her senaryoyu izole git dallarında çalıştırır ve bir “ana ajan” tarafından döngüsel olarak test edilir, akıl yürütülür ve son olarak teşhis sonuçları ve önerilen yamalar döndürülür. Gerçek bir tinygrad 100$ ödüllü hata testinde Deebo, sorunun kaynağını başarıyla belirledi ve testleri geçen iki özel düzeltme önerdi. (Kaynak: Reddit r/MachineLearning)
![[D] Otonom bir hata ayıklama ajanı oluşturduk. İşte 100 dolarlık bir hatayı nasıl anladığı](https://rebabel.net/wp-content/uploads/2025/04/81BPXr5Ywnk-6MetZBQchhgsROH341CoTk3xAdE5Jic.jpg)
📚 Öğrenme Kaynakları
Nabla-GFlowNet: Çeşitliliği ve verimliliği dengeleyen difüzyon modeli ödül ince ayarı için yeni bir yöntem: Difüzyon modeli ince ayarında geleneksel pekiştirmeli öğrenmenin yavaş yakınsaması, doğrudan ödül maksimizasyonunun kolayca aşırı uyum sağlaması ve çeşitliliği kaybetmesi sorunlarına karşı, Hong Kong Çin Üniversitesi (Shenzhen) ve diğer kurumların araştırmacıları Nabla-GFlowNet’i önerdi. Bu yöntem, üretken akış ağı (GFlowNet) çerçevesine dayanır, difüzyon sürecini bir akış denge sistemi olarak ele alır ve Nabla-DB denge koşulunu ve ilgili kayıp fonksiyonunu türetir. Parametrik tasarım aracılığıyla, tek adımlı gürültü giderme kullanarak artık gradyanı tahmin eder ve ek ağ tahminine olan ihtiyacı ortadan kaldırır. Deneyler, estetik puanlama, talimat takibi gibi ödül fonksiyonları üzerinde Stable Diffusion’u ince ayarlarken, Nabla-GFlowNet’in ReFL, DRaFT gibi yöntemlere kıyasla daha hızlı yakınsadığını, aşırı uyum sağlamaya daha az eğilimli olduğunu ve aynı zamanda üretilen örneklerin çeşitliliğini koruduğunu göstermiştir. (Kaynak: ICLR 2025 | Difüzyon modeli ödül ince ayarında yeni atılım! Nabla-GFlowNet çeşitlilik ve verimliliği bir araya getiriyor)

MegaMath: 371 Milyar Token’lık En Büyük Açık Kaynak Matematiksel Akıl Yürütme Veri Seti Yayınlandı: LLM360 tarafından sunulan MegaMath veri seti, 371 milyar token içeriyor ve açık kaynak topluluğundaki büyük ölçekli, yüksek kaliteli matematiksel akıl yürütme ön eğitim verisi eksikliğini gidermeyi amaçlıyor. Veri seti üç bölümden oluşuyor: matematik yoğun web sayfaları (279B), matematikle ilgili kodlar (28.1B) ve yüksek kaliteli sentetik veriler (64B). Oluşturma sürecinde, matematik formülleri için optimize edilmiş HTML ayrıştırma, iki aşamalı metin çıkarma, dinamik eğitim değeri puanlaması, kod verilerinin çok adımlı hassas geri çağrılması ve çeşitli büyük ölçekli sentetik yöntemler (Soru-Cevap, kod üretimi, metin-kod geçişimi) dahil olmak üzere yenilikçi bir veri işleme hattı kullanıldı. Llama-3.2 (1B/3B) üzerinde yapılan 100B Token’lık ön eğitim doğrulaması, MegaMath’ın GSM8K, MATH gibi kıyaslamalarda %15-20 mutlak performans artışı sağlayabildiğini gösterdi. (Kaynak: 371 Milyar Matematik Token’ı! Dünyanın en büyük açık kaynak matematik veri seti MegaMath şok edici bir şekilde yayınlandı, DeepSeek-Math’ı ezip geçiyor)
OS Agents İncelemesi: Çok Modlu Büyük Modeller Tabanlı Bilgisayar, Cep Telefonu ve Tarayıcı Akıllı Ajanları Üzerine Araştırma: Zhejiang Üniversitesi, OPPO, 01.AI ve diğer kurumlarla işbirliği yaparak işletim sistemi akıllı ajanları (OS Agents) üzerine bir inceleme makalesi yayınladı. Makale, bilgisayar, cep telefonu, tarayıcı gibi ortamlarda görevleri otomatik olarak tamamlayabilen akıllı ajanların (Anthropic’in Computer Use, Apple’ın Apple Intelligence gibi) oluşturulması için çok modlu büyük dil modellerinin (MLLM) kullanımına ilişkin mevcut araştırma durumunu sistematik olarak ele alıyor. İçerik, OS Agents’ın temellerini (çevre, gözlem alanı, eylem alanı, temel yetenekler), oluşturma yöntemlerini (temel model mimarisi ve eğitim stratejileri, ajan çerçevesinin algılama/planlama/hafıza/eylem modülleri), değerlendirme protokollerini ve kıyaslamalarını, ayrıca ilgili ticari ürünleri ve gelecekteki zorlukları (güvenlik ve gizlilik, kişiselleştirme ve kendi kendine evrim) kapsıyor. Araştırma ekibi, bu alandaki gelişimi teşvik etmek amacıyla 250’den fazla ilgili makaleyi içeren açık kaynaklı bir depo tutuyor. (Kaynak: Zhejiang Üniversitesi, OPPO vb. en son incelemeyi yayınladı: Çok modlu büyük modeller tabanlı bilgisayar, cep telefonu ve tarayıcı akıllı ajanları üzerine araştırma)
NLPrompt: MAE Kaybı ve Optimal Transport’u Birleştiren Sağlam Prompt Öğrenme Yöntemi: ShanghaiTech Üniversitesi YesAI Lab, CVPR 2025 Highlight makalesinde, görsel dil modeli prompt öğrenimindeki etiket gürültüsü sorununu çözmeyi amaçlayan NLPrompt’u önerdi. Araştırma, prompt öğrenme senaryosunda Ortalama Mutlak Hata (MAE) kaybını (PromptMAE) kullanmanın, Çapraz Entropi (CE) kaybına göre gürültülü etiketlerin etkisine karşı daha dirençli olduğunu buldu ve özellik öğrenme teorisi açısından sağlamlığını kanıtladı. Ayrıca, metin özelliklerini prototip olarak kullanan, veri setini temiz alt küme (CE kaybıyla eğitilir) ve gürültülü alt küme (MAE kaybıyla eğitilir) olarak bölen, prompt tabanlı Optimal Transport veri temizleme yöntemini (PromptOT) önerdi ve iki kaybın avantajlarını etkili bir şekilde birleştirdi. Deneyler, NLPrompt’un sentetik ve gerçek gürültülü veri setlerinde üstün performans gösterdiğini ve iyi bir genelleme yeteneğine sahip olduğunu kanıtladı. (Kaynak: CVPR 2025 | MAE kaybı + optimal transport ikilisi! ShanghaiTech yeni sağlam prompt öğrenme yöntemini önerdi)
DeepSeek-R1 Çıkarım Mekanizması Analizi: McGill Üniversitesi araştırmacıları, DeepSeek-R1 gibi büyük çıkarım modellerinin çıkarım sürecini analiz etti. Doğrudan cevap veren LLM’lerden farklı olarak, çıkarım modelleri ayrıntılı çok adımlı çıkarım zincirleri üretir. Araştırma, çıkarım zinciri uzunluğu ile performans arasındaki ilişkiyi (bir “optimum nokta” vardır, çok uzun olması performansı düşürebilir), uzun bağlam yönetimini, kültürel ve güvenlik sorunlarını (çıkarım yapmayan modellere kıyasla daha güçlü güvenlik açıkları vardır) ve insan bilişsel olgularıyla (örneğin, zaten keşfedilmiş sorunlar üzerinde sürekli takılıp kalma) olan ilişkisini inceledi. Bu çalışma, mevcut çıkarım modellerinin çalışma mekanizmalarının bazı özelliklerini ve potansiyel sorunlarını ortaya koyuyor. (Kaynak: LLM Haftalık Özeti! | Çok modlu, MoE modelleri, Deepseek çıkarımı, Agent güvenlik kontrolü, model nicemleme vb. içerir)
MoE Büyük Modelleri İçin Test Zamanı Optimizasyon Yöntemi C3PO: Johns Hopkins Üniversitesi, Uzmanlar Karışımı (MoE) LLM’lerinin uzman yolu alt optimalliği sorunu yaşadığını keşfetti ve test zamanı optimizasyon yöntemi C3PO’yu (Kritik Katman, Çekirdek Uzman, İşbirlikçi Yol Optimizasyonu) önerdi. Bu yöntem gerçek etiketlere dayanmaz, bunun yerine referans örneklem setindeki “başarılı komşular” aracılığıyla alternatif bir hedef tanımlayarak model performansını optimize eder. Desen bulma, çekirdek regresyonu, benzer örneklerin ortalama kaybı gibi algoritmalar kullanır ve maliyeti düşürmek için yalnızca kritik katmanların çekirdek uzman ağırlıklarını optimize eder. MoE LLM’lerine uygulandığında, C3PO altı kıyaslama testinde temel model doğruluğunu %7-15 artırdı, yaygın test zamanı öğrenme taban çizgilerini aştı ve küçük parametreli MoE modellerinin performansını daha büyük parametreli LLM’lerden daha iyi hale getirerek MoE verimliliğini artırdı. (Kaynak: LLM Haftalık Özeti! | Çok modlu, MoE modelleri, Deepseek çıkarımı, Agent güvenlik kontrolü, model nicemleme vb. içerir)
Nicemlemenin Çıkarım Modeli Performansı Üzerindeki Etkisi Araştırması: Tsinghua Üniversitesi araştırma ekibi, nicemleme teknolojisinin çıkarım tipi dil modellerinin (DeepSeek-R1 serisi, Qwen, LLaMA gibi) performansı üzerindeki etkisini ilk kez sistematik olarak araştırdı. Araştırma, farklı bit genişliklerindeki (W8A8, W4A16 vb.) ağırlık, KV önbelleği ve aktivasyon nicemleme algoritmalarının matematik, bilim, programlama gibi çıkarım kıyaslamalarındaki performansını değerlendirdi. Sonuçlar, W8A8 veya W4A16 nicemlemesinin genellikle kayıpsız performans sağlayabildiğini, ancak daha düşük bit genişliklerinin önemli doğruluk düşüşü riski taşıdığını gösterdi. Model boyutu, kaynağı ve görev zorluğu, nicemleme sonrası performansı etkileyen temel faktörlerdir. Nicemlenmiş modellerin çıktı uzunluğu önemli ölçüde artmadı ve model boyutunu makul bir şekilde ayarlamak veya çıkarım adımlarını artırmak performansı iyileştirebilir. İlgili nicemlenmiş modeller ve kodlar açık kaynak olarak yayınlandı. (Kaynak: LLM Haftalık Özeti! | Çok modlu, MoE modelleri, Deepseek çıkarımı, Agent güvenlik kontrolü, model nicemleme vb. içerir)
SHIELDAGENT: Agent’ı Güvenlik Politikalarına Uymaya Zorlayan Koruma Çerçevesi: Chicago Üniversitesi, AI Agent’ın eylem yörüngelerinin açık güvenlik politikalarına uymasını mantıksal çıkarım yoluyla zorlamayı amaçlayan SHIELDAGENT çerçevesini önerdi. Çerçeve önce politika belgelerinden doğrulanabilir kuralları çıkarır, bir güvenlik politikası modeli (olasılıksal kural devrelerine dayalı) oluşturur, ardından Agent yürütme sırasında eylem yörüngesine göre ilgili kuralları alır ve bir koruma planı oluşturur, araç kitaplıklarını ve yürütülebilir kodu kullanarak biçimsel doğrulama yapar ve Agent davranışının güvenlik düzenlemelerini ihlal etmemesini sağlar. Aynı zamanda 3K güvenlik ile ilgili talimat ve yörünge çifti içeren SHIELDAGENT-BENCH veri setini yayınladı. Deneyler, SHIELDAGENT’ın birden fazla kıyaslamada SOTA’ya ulaştığını, güvenlik uyum oranını ve geri çağırma oranını önemli ölçüde artırdığını, aynı zamanda API sorgu ve çıkarım süresini azalttığını gösterdi. (Kaynak: LLM Haftalık Özeti! | Çok modlu, MoE modelleri, Deepseek çıkarımı, Agent güvenlik kontrolü, model nicemleme vb. içerir)
MedVLM-R1: Pekiştirmeli Öğrenme ile Tıbbi VLM Çıkarım Yeteneklerini Teşvik Etme: Münih Teknik Üniversitesi, Oxford Üniversitesi ve diğer kurumlar işbirliği yaparak, açık doğal dil çıkarım süreçleri üretmeyi amaçlayan bir tıbbi görsel dil modeli (VLM) olan MedVLM-R1’i önerdi. Model, DeepSeek’in Grup Göreceli Politika Optimizasyonu (GRPO) pekiştirmeli öğrenme çerçevesini kullanıyor, yalnızca nihai cevapları içeren veri setleri üzerinde eğitiliyor, ancak insan tarafından yorumlanabilir çıkarım yollarını otonom olarak keşfedebiliyor. Sadece 600 MRI VQA örneği kullanılarak eğitildikten sonra, bu 2B parametreli model MRI, CT, X-ray kıyaslama testlerinde %78.22 doğruluk oranına ulaştı, taban çizgilerini önemli ölçüde geride bıraktı ve güçlü alan dışı genelleme yeteneği sergiledi, hatta Qwen2-VL-72B gibi daha büyük ölçekli modelleri bile geçti. Bu çalışma, güvenilir ve yorumlanabilir tıbbi AI oluşturmak için yeni yollar sunuyor. (Kaynak: Küçük örneklem, büyük enerji! MedVLM-R1, DeepSeek pekiştirmeli öğrenmesinden güç alarak tıbbi AI çıkarım yeteneklerini yeniden şekillendiriyor)
Araştırma, Pekiştirmeli Öğrenme Eğitiminin Çıkarım Modeli Yanıtlarını Uzatabileceğini Ortaya Koydu: Wand AI tarafından yapılan bir araştırma, çıkarım modellerinin (DeepSeek-R1 gibi) neden daha uzun yanıtlar ürettiğini analiz etti. Araştırma, bu davranışın sorunun kendisinin daha uzun çıkarım gerektirmesinden ziyade, pekiştirmeli öğrenme (özellikle PPO algoritması) eğitim sürecinden kaynaklanabileceğini buldu. Model yanlış cevaplar için negatif ödül aldığında, PPO kayıp fonksiyonu her bir token’ın cezasını seyreltmek için daha uzun yanıtlar üretme eğilimindedir, ek içerik doğruluğu artırmaya yardımcı olmasa bile. Araştırma ayrıca, kısa ve öz çıkarımın genellikle daha yüksek doğrulukla ilişkili olduğunu gösteriyor. Yalnızca kısmen çözülebilir sorunların kullanıldığı ikinci bir pekiştirmeli öğrenme eğitimi turuyla, yanıt uzunluğu kısaltılabilirken doğruluk korunabilir veya hatta artırılabilir, bu da dağıtım verimliliğini artırmak için önemli bir anlam taşımaktadır. (Kaynak: Daha uzun düşünce daha güçlü çıkarım performansı anlamına gelmez, pekiştirmeli öğrenme çok kısa ve öz olabilir)

USTC ve ZTE, Curr-ReFT’i Önerdi: Küçük Boyutlu VLM’lerin Çıkarım ve Genelleme Yeteneklerini Geliştirme: Küçük boyutlu görsel dil modellerinin (VLM) karmaşık görevlerdeki “eğitim darboğazı” (tuğla duvar) olgusu ve alan dışı genelleme yeteneği eksikliği sorunlarına karşı, USTC ve ZTE Corporation, Müfredatlı Pekiştirmeli Öğrenme Sonrası Eğitim Paradigması’nı (Curr-ReFT) önerdi. Bu paradigma, müfredat öğrenimini (CL) ve pekiştirmeli öğrenmeyi (RL) birleştirir, zorluk algılayan bir ödül mekanizması tasarlar ve modelin kolaydan zora (ikili karar → çoktan seçmeli → açık uçlu cevaplama) aşamalı olarak öğrenmesini sağlar. Aynı zamanda, modelin temel yeteneklerini korumak için yüksek kaliteli çok modlu ve dil örneklerini kullanarak reddetme örneklemesine dayalı bir kendi kendini iyileştirme stratejisi benimser. Qwen2.5-VL-3B/7B modelleri üzerindeki deneyler, Curr-ReFT’in modellerin çıkarım ve genelleme performansını önemli ölçüde artırdığını, 7B modelinin bazı kıyaslamalarda InternVL2.5-26B/38B’yi bile geçtiğini göstermiştir. (Kaynak: USTC, ZTE yeni bir son eğitim paradigması önerdi: Küçük boyutlu çok modlu model, R1 çıkarımını başarıyla yeniden üretti)

GenPRM: Üretken Çıkarım Yoluyla Süreç Ödül Modellerini Genişletme: Tsinghua Üniversitesi ve Shanghai AI Lab, geleneksel süreç ödül modellerinin (PRM) skaler puanlamaya dayanması, yorumlanabilirlikten yoksun olması ve test zamanında genişletilememesi sorunlarını çözmeyi amaçlayan Üretken Süreç Ödül Modeli’ni (GenPRM) önerdi. GenPRM, üretken bir yaklaşım benimser, düşünce zinciri (CoT) çıkarımını ve kod doğrulamasını birleştirerek her çıkarım adımını doğal dil analizi ve Python kodu yürütme doğrulaması ile değerlendirir, daha derinlemesine, yorumlanabilir süreç denetimi sağlar. Ayrıca, GenPRM, değerlendirme hassasiyetini artırmak için paralel olarak birden fazla çıkarım yolu örnekleyerek ve ödül değerlerini birleştirerek bir test zamanı genişletme mekanizması sunar. Yalnızca 23K sentetik veri ile eğitilen 1.5B modeli, test zamanı genişletmesiyle ProcessBench’te GPT-4o’yu geçti, 7B sürümü ise 72B’lik Qwen2.5-Math-PRM-72B’yi geçti. GenPRM ayrıca politika modeli optimizasyonunu yönlendirmek için bir eleştirmen modeli olarak da işlev görebilir. (Kaynak: Süreç ödül modeli de test zamanında genişletilebilir mi? Tsinghua, Shanghai AI Lab 23K veri ile 1.5B küçük modelin GPT-4o’yu geçmesini sağladı)
Araştırma, Çıkarım AI’larının Eksik Önerme Sorunlarında “Aşırı Düşünme” Olgusunu Ortaya Koydu: Maryland Üniversitesi ve Lehigh Üniversitesi’ndeki araştırmalar, mevcut çıkarım modellerinin (DeepSeek-R1, o1 gibi) gerekli önerme bilgilerinin eksik olduğu sorunlarla (Missing Premise, MiP) karşılaştığında genellikle “aşırı düşünme” eğilimi gösterdiğini buldu. Normal sorunlardan 2-4 kat daha uzun yanıtlar üretiyorlar, sorunu tekrar tekrar gözden geçirme, niyeti tahmin etme, kendinden şüphe etme döngüsüne giriyorlar, bunun yerine sorunun çözülemez olduğunu hızla fark edip durmuyorlar. Buna karşılık, çıkarım yapmayan modeller (GPT-4.5 gibi) MiP sorunlarında daha kısa yanıt veriyor ve önerme eksikliğini daha iyi tanıyor. Araştırma, çıkarım modellerinin önerme eksikliğini fark edebilmesine rağmen, geçersiz çıkarımı kararlı bir şekilde durdurma “eleştirel düşüncesinden” yoksun olduğunu gösteriyor. Bu davranış modeli, pekiştirmeli öğrenme eğitimindeki uzunluk kısıtlamalarının yetersizliğinden kaynaklanabilir ve damıtma yoluyla yayılabilir. (Kaynak: Çıkarım AI’sı “beyin takviyesi” bağımlısı, boş laflarla dolu! Maryland’li Çinli dahi öğrenci perde arkasını araladı)

Binlerce Kelimelik Uzun Makale Sinir Ağı Normalizasyon Teknolojisinin Evrimini Detaylandırıyor: Makale, normalizasyonun sinir ağlarında, özellikle Transformer ve büyük modellerdeki rolünü ve evrimini sistematik olarak ele alıyor. Normalizasyon, veriyi sabit bir aralıkla sınırlayarak veri karşılaştırılabilirliği sorununu çözer, optimizasyon hızını artırır, aktivasyon fonksiyonu doygunluk bölgesini ve iç kovaryant kayması (ICS) sorunlarını hafifletir. Makale, yaygın doğrusal (Min-max, Z-score, Mean) ve doğrusal olmayan normalizasyon yöntemlerini tanıtıyor, özellikle derin öğrenme modelleri için uygun olan Batch Normalization (BN), Layer Normalization (LN), RMSNorm ve DeepNorm’u açıklıyor, bunların Transformer mimarisindeki uygulama farklılıklarını (neden LN/RMSNorm’un NLP için daha uygun olduğu) analiz ediyor. Ayrıca, normalizasyon modülünün Transformer katmanı içindeki farklı yerleştirme konumlarını (Post-Norm, Pre-Norm, Sandwich-Norm) ve bunların eğitim istikrarı ve performansı üzerindeki etkilerini tartışıyor. (Kaynak: Binlerce kelimelik uzun makale! Tek bir makalede normalizasyonu anlayın: Transformer normalizasyonundan ana akım büyük model normalizasyonunun evrimine!)
Belirli Stil Yazı Tipi Tasarımları Oluşturmak İçin AI Kullanarak Prompt Mühendisliği: Makale, yazarın belirli stil yazı tipi tasarımları oluşturmak için Instant Dream AI 3.0’ı kullanma deneyimini ve prompt şablonlarını paylaşıyor. Yazar, doğrudan yazı tipi adlarını (Song Ti, Kai Ti gibi) belirtmenin etkili olmadığını, AI modelinin bu konuda sınırlı bir anlayışa sahip olduğunu keşfetti. Bu nedenle yazar, yazı tipi stil özelliklerini, duygusal atmosferi ve görsel efektleri tanımlamaya yöneldi ve farklı stil referans örnekleriyle birleştirerek “Gelişmiş Metin Stili Tasarım Prompt Üreticisi” adlı bir prompt şablonu oluşturdu. Kullanıcıların yalnızca metin içeriğini girmesi yeterlidir; bu şablon, metnin anlamına göre önceden ayarlanmış çeşitli stilleri (Işık Ritmi Gece Gölgesi, Endüstriyel Sadelik, Çocuksu Karalama, Metalik Bilim Kurgu vb.) akıllıca eşleştirebilir veya birleştirebilir ve metinden görüntüye modeller için ayrıntılı prompt’lar üretebilir, böylece nispeten istikrarlı kalitede grafik ve metin tasarım efektleri elde edilebilir. (Kaynak: AI yazı tipi tasarımı oluşturmayı biraz anladım, bu Prompt setiyle verimliliği %50 artırdım., Instant Dream AI 3.0 ile yazı tipi içeren kapaklar oluşturma, bu çözüm tanrısal derecede havalı [Ek: 16+ örnek ve Prompt])

ZClip: LLM Ön Eğitimi İçin Uyarlanabilir Gradyan Tepe Bastırma Yöntemi: Araştırmacılar, LLM eğitim sürecindeki kayıp tepelerini azaltmayı ve eğitim istikrarını artırmayı amaçlayan hafif, uyarlanabilir bir gradyan kırpma yöntemi olan ZClip’i önerdi. Sabit bir eşik kullanan geleneksel gradyan kırpmanın aksine, ZClip anormal gradyan tepelerini, yani yakın zamandaki hareketli ortalamadan önemli ölçüde sapan gradyanları tespit etmek ve kırpmak için z-skoruna dayalı bir yöntem kullanır. Bu yöntem, yakınsamayı engellemeden eğitim istikrarını korumaya yardımcı olur ve herhangi bir eğitim döngüsüne kolayca entegre edilebilir. Kod ve makale yayınlandı. (Kaynak: Reddit r/deeplearning)
![[2504.02507] ZClip: LLM Ön Eğitimi İçin Uyarlanabilir Tepe Bastırma](https://rebabel.net/wp-content/uploads/2025/04/Swd9uQN43Dpl2SJyH6zjTbJAdRaXwKbmzZwM9L2rPXk.jpg)
💼 İş Dünyası
Intel Arc Ekran Kartı + Xeon W İşlemci Çözümü Düşük Maliyetli AI Hepsi Bir Arada Cihazlara Yardımcı Oluyor: Intel, Arc™ ekran kartı ve Xeon® W işlemci kombinasyonuyla piyasaya maliyeti kontrol edilebilir (100.000 yuan seviyesinde) ve performansı pratik olan büyük model hepsi bir arada cihaz çözümleri sunuyor. Arc™ ekran kartı Xe mimarisini ve XMX AI hızlandırma motorunu kullanır, ana akım AI çerçevelerini ve Ollama/vLLM’yi destekler, düşük güç tüketimine sahiptir ve çoklu kart paralel bağlantısını destekler. Xeon® W işlemci yüksek çekirdek sayısı ve bellek genişletme yeteneği sunar, dahili AMX hızlandırma teknolojisine sahiptir. IPEX-LLM, OpenVINO™ ve oneAPI gibi yazılım optimizasyonlarıyla birleştiğinde, CPU ve GPU arasında verimli bir işbirliği sağlanır. Gerçek testler, bu çözümle donatılmış hepsi bir arada cihazın Qwen-32B modelini tek kişi kullanımında 32 token/s’ye kadar çalıştırabildiğini, 671B DeepSeek R1 modelini (FlashMoE optimizasyonu gerektirir) ise yaklaşık 10 token/s’ye kadar çalıştırabildiğini gösteriyor, bu da çevrimdışı çıkarım ihtiyaçlarını karşılıyor ve AI çıkarımının yaygınlaşmasını teşvik ediyor. (Kaynak: 3000 yuan’lık ekran kartını sonuna kadar kullanıp, yüz milyarlarca parametreli büyük modeli çalıştırmanın sırrı geldi)

NVIDIA, ABD’de AI Süper Bilgisayarı Üretecek: NVIDIA, AI süper bilgisayarını ilk kez tamamen ABD’de tasarlayıp inşa edeceğini ve ana üretim ortaklarıyla işbirliği yapacağını duyurdu. Aynı zamanda, yeni nesil Blackwell çipi Arizona’daki TSMC fabrikasında üretilmeye başlandı. NVIDIA, önümüzdeki 4 yıl içinde ABD’de beş yüz milyar dolara kadar değerde AI altyapısı üretmeyi planlıyor; ortakları arasında TSMC, Foxconn, Wistron, Amkor ve SPIL bulunuyor. Bu hamle, AI çip ve süper bilgisayar talebini karşılamayı, tedarik zincirini güçlendirmeyi ve esnekliği artırmayı amaçlıyor. (Kaynak: nvidia, nvidia)

Horizon Robotics, 3D Yeniden Yapılandırma/Üretim Stajyeri Arıyor: Horizon Robotics Somutlaştırılmış Zeka ekibi, Şanghay/Pekin’de 3D yeniden yapılandırma/üretim odaklı algoritma stajyerleri arıyor. Sorumluluklar arasında robot Real2Sim algoritma çözümlerinin (3D GS yeniden yapılandırma, ileri beslemeli yeniden yapılandırma, 3D/video üretimi ile birleştirilmiş) tasarlanması ve geliştirilmesine katılmak, Real2Sim simülatör performansını optimize etmek (akışkan, dokunsal simülasyon vb. desteklemek) ve en son araştırmaları takip edip en iyi konferanslarda makale yayınlamak yer alıyor. Gereksinimler arasında yüksek lisans veya üzeri derece, bilgisayar/grafik/AI ile ilgili bölüm, 3D görme/video üretimi veya çok modlu/difüzyon modeli deneyimi, Python/Pytorch/Huggingface’i yetkin kullanma bulunmaktadır. En iyi konferanslarda yayın yapmış, simülasyon platformlarına veya açık kaynak projelerine aşina olanlar tercih edilir. Kadroya geçme fırsatı, GPU kümesi ve rekabetçi maaş sunulmaktadır. (Kaynak: Şanghay/Pekin İç Referans | Horizon Robotics Somutlaştırılmış Zeka Ekibi 3D Yeniden Yapılandırma/Üretim Yönünde Algoritma Stajyeri Arıyor)

Meituan Otel & Seyahat, L7-L8 Büyük Model Algoritma Mühendisi Arıyor: Meituan Otel & Seyahat Tedarik Algoritma ekibi, Pekin’de L7-L8 seviyesinde Büyük Model Algoritma Mühendisleri (deneyimli) arıyor. Sorumluluklar arasında otel & seyahat tedarik anlama sisteminin (ürün etiketleri, popüler nokta tespiti, benzer tedarik madenciliği vb.) oluşturulması, gösterim materyallerinin (başlık, görsel-metin, öneri nedeni üretimi) optimize edilmesi, tatil paketi kombinasyonlarının (ürün seçimi, satış tahmini, fiyatlandırma) oluşturulması ve en son büyük model teknolojilerinin (ince ayar, RL, Prompt optimizasyonu) araştırılması ve uygulanması yer alıyor. Gereksinimler arasında yüksek lisans veya üzeri derece, 2 yıldan fazla deneyim, bilgisayar/otomasyon/matematiksel istatistik ile ilgili bölüm, sağlam algoritma temeli ve kodlama yeteneği bulunmaktadır. (Kaynak: Pekin İç Referans | Meituan Otel & Seyahat Tedarik Algoritma Ekibi L7-L8 Büyük Model Algoritma Mühendisi Arıyor)

Meta, AB’de Kullanıcı Verilerini AI Eğitimi İçin Kullanacak: Meta, Avrupa Birliği bölgesindeki Facebook ve Instagram kullanıcılarının herkese açık verilerini (gönderiler, yorumlar gibi, özel mesajlar hariç) AI modellerini eğitmek için kullanmaya başlayacağını duyurdu; bu yalnızca 18 yaş üstü kullanıcılar için geçerli olacak. Şirket, uygulama içi bildirimler ve e-postalar aracılığıyla kullanıcıları bilgilendirecek ve itiraz etme (opt-out) bağlantısı sunacak. Daha önce Meta, İrlanda düzenleyici kurumunun talebi üzerine Avrupa’da kullanıcı verilerini AI eğitimi için kullanma planlarını askıya almıştı. (Kaynak: Reddit r/artificial)

Tencent Cloud, MCP Yönetilen Hizmetini Başlattı: Tencent Cloud da, işletmelere daha kolay ve verimli bulut kaynak yönetimi ve operasyon çözümleri sunmayı amaçlayan MCP (Managed Cloud Platform) yönetilen hizmetini sunmaya başladı. Bu hamle, ana akım bulut sağlayıcıları arasındaki bu alandaki rekabetin arttığı anlamına geliyor. Belirli hizmet detayları ve “WeChat özellikleri” henüz ayrıntılı olarak açıklanmadı. (Kaynak: Tencent Cloud da MCP yönetimi yapıyor, biraz da “WeChat özelliği” getirmiş.)
🌟 Topluluk
Turing Ödülü Sahibi LeCun AI Gelişimi Hakkında Konuştu: İnsan Zekası Evrensel Değil, Bir Sonraki Atılım Üretken Olmayan Modellerde Olabilir: Son podcast röportajında Yann LeCun, AGI teriminin yanıltıcı olduğunu, insan zekasının evrensel değil, son derece uzmanlaşmış olduğunu bir kez daha vurguladı. AI’daki bir sonraki büyük atılımın, makinelere fiziksel dünyayı gerçekten anlama, akıl yürütme ve planlama yeteneği kazandırma ve kalıcı hafıza sağlama odaklı, üretken olmayan modellerden gelebileceğini öngörüyor; bu, önerdiği JEPA mimarisine benziyor. Mevcut LLM’lerin gerçek akıl yürütme yeteneğinden ve fiziksel dünya modelleme yeteneğinden yoksun olduğunu, bir kedinin zeka seviyesine ulaşmanın bile büyük bir ilerleme olacağını düşünüyor. Meta’nın LLaMA’yı açık kaynak yapmasını, tüm AI ekosisteminin gelişimini teşvik etmek için doğru bir seçim olarak görüyor ve yeniliğin küresel olduğunu, açık kaynağın atılımları hızlandırmanın anahtarı olduğunu vurguluyor. Ayrıca akıllı gözlükleri AI asistanları için önemli bir taşıyıcı olarak görüyor. (Kaynak: Turing Ödülü Sahibi LeCun: İnsan zekası evrensel zeka değildir, yeni nesil AI üretken olmayan modellere dayanabilir)

GitHub’ın Çin IP’lerini Kısa Süreli “Engellemesi” Dikkat Çekti, Yetkililer Yapılandırma Hatası Olduğunu Söyledi: 12-13 Nisan tarihleri arasında bazı Çinli kullanıcılar GitHub’a erişemediklerini fark etti, sayfada “IP adresi erişim kısıtlamasına tabi” uyarısı görüldü, bu durum toplulukta panik ve tartışmalara yol açtı, hedefe yönelik bir engelleme olup olmadığı endişesi doğdu. GitHub daha önce ABD yaptırımları nedeniyle Rusya, İran gibi ülkelerden geliştirici hesaplarını engellemişti. GitHub yetkilileri daha sonra olayın, bir yapılandırma değişikliği hatası nedeniyle oturum açmamış kullanıcıların geçici olarak erişememesinden kaynaklandığını, sorunun 13 Nisan’da düzeltildiğini belirtti. Teknik bir arıza olmasına rağmen, olay kod barındırma platformlarının jeopolitik riskleri ve yerel alternatifler (Gitee, CODING, Jihu GitLab vb.) hakkındaki tartışmaları yeniden alevlendirdi. (Kaynak: “Hata” mı “Prova” mı? GitHub aniden tüm Çin IP’lerini “engelledi”, Yetkililer: Sadece “el kayması” teknik hata oldu)

AI Agent Siber Güvenlik Endişelerini Artırıyor: MIT Technology Review makalesi, AI tarafından yönlendirilen otonom siber saldırıların yakında geleceğini belirtiyor. AI yetenekleri arttıkça, kötü niyetli aktörler AI Agent’ları kullanarak otomatik olarak güvenlik açıklarını keşfedebilir, daha karmaşık ve daha büyük ölçekli siber saldırılar planlayıp yürütebilir, bu da bireyler, işletmeler ve hatta ulusal güvenlik için yeni tehditler oluşturur. Bu durum, siber güvenlik alanının AI güdümlü saldırılara karşı koyabilecek savunma stratejileri ve teknolojilerini acilen araştırmasını ve uygulamasını gerektiriyor. (Kaynak: Ronald_vanLoon)

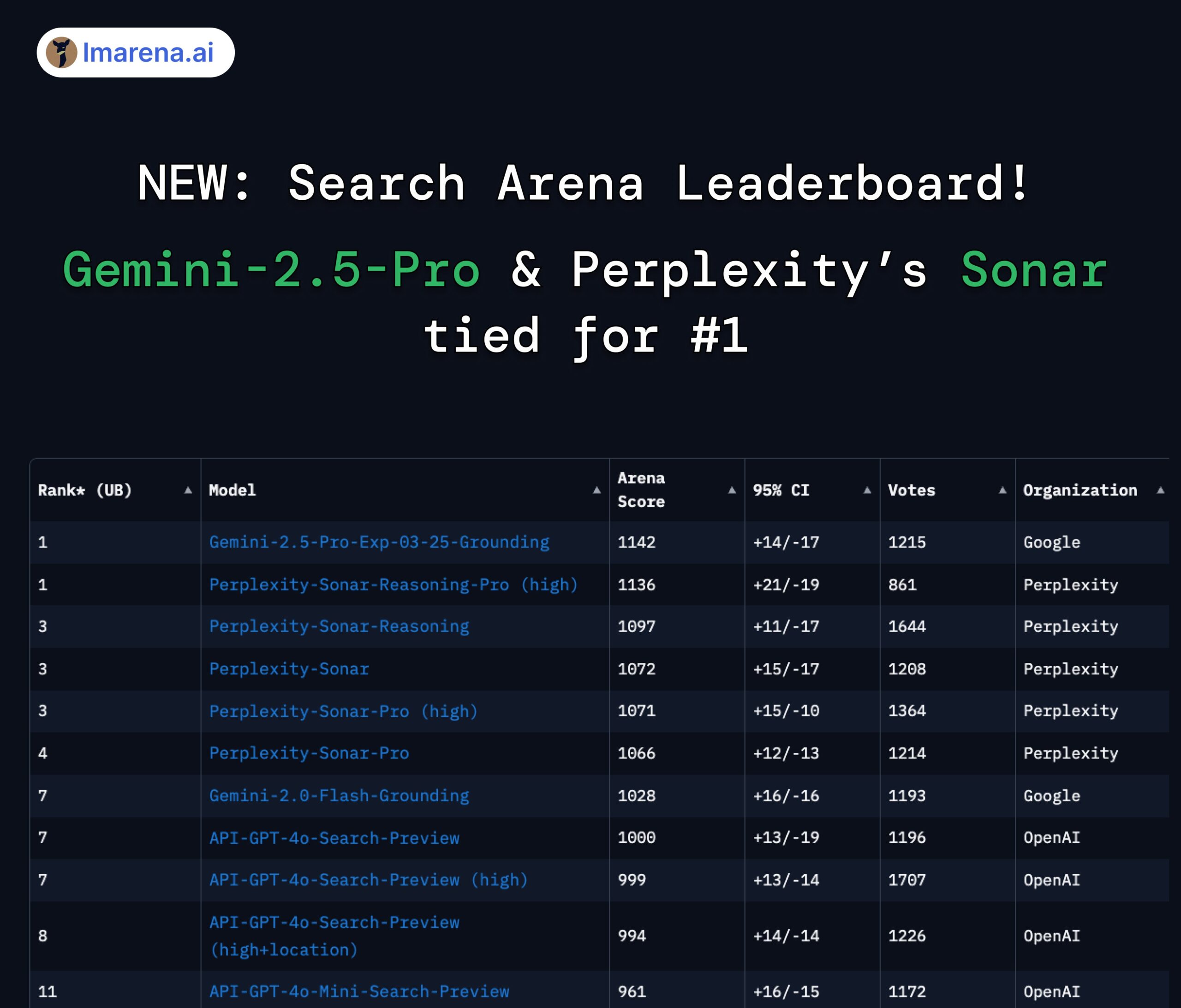
Perplexity Sonar ve Gemini 2.5 Pro Arama Arenası Liderliğini Paylaşıyor: LMArena.ai’nin (eski adıyla LMSYS) yeni başlattığı Search Arena sıralamasında, Perplexity’nin Sonar-Reasoning-Pro-High modeli Google’ın Gemini-2.5-Pro-Grounding modeli ile birinciliği paylaşıyor. Bu liste, web aramasına dayalı LLM yanıt kalitesini özel olarak değerlendiriyor. Perplexity CEO’su Arav Srinivas bu durumu tebrik etti ve Sonar modelini ve arama indeksini geliştirmeye devam edeceklerini vurguladı. Topluluk, bunun arama destekli LLM alanında rekabetin esas olarak Google ve Perplexity arasında olduğunu gösterdiğini düşünüyor. (Kaynak: AravSrinivas, lmarena_ai, lmarena_ai, AravSrinivas, lmarena_ai, AravSrinivas)
Claude Model Kullanım Sınırlamaları Hakkında Tartışma: Reddit r/ClaudeAI topluluğunda, kullanıcılar arasında Claude Pro sürümünün kullanım sınırlamaları (mesaj sayısı üst sınırı, kapasite kısıtlamaları gibi) konusunda anlaşmazlıklar var. Bazı kullanıcılar sık sık sınırlamalarla karşılaştıklarından, iş akışlarının etkilendiğinden ve hatta model değiştirmeyi düşündüklerinden şikayet ediyor; diğer kullanıcılar ise nadiren sınırlamalarla karşılaştıklarını, bunun muhtemelen kullanım şekli (çok büyük bağlam yüklemek gibi) veya abartıdan kaynaklanabileceğini belirtiyor. Bu durum, kullanıcıların Anthropic model kullanım politikaları ve istikrarı hakkındaki farklı deneyimlerini ve görüşlerini yansıtıyor. (Kaynak: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
AI ve İstihdamın Geleceği Tartışması: Reddit r/ChatGPT’de bir karşılaştırma grafiği tartışma yarattı: AI insan yeteneklerini artırıp refah dolu bir yaşam mı getirecek, yoksa insan işlerini değiştirip kitlesel işsizliğe mi yol açacak? Yorumlarda birçok kullanıcı, özellikle yaratıcı meslekler (programlama, sanat) için AI’ın işleri devralması konusundaki endişelerini dile getirdi. Bazıları, kazançların esas olarak AI sahiplerine gitmesi ve vergi tabanının azalmasının Evrensel Temel Gelir’i (UBI) zorlaştırabileceği için AI’ın toplumsal eşitsizliği artıracağını düşünüyor. Diğerleri ise daha iyimser bir tavır sergiliyor, AI’ın verimliliği artıran, yeni işler yaratan (prompt mühendisi gibi) güçlü bir araç olduğunu, anahtarın AI’ı kullanmaya uyum sağlamak ve öğrenmek olduğunu savunuyor. (Kaynak: Reddit r/ChatGPT, Reddit r/ArtificialInteligence)

AI Veri Toplama Gizlilik Endişelerini Artırıyor: Bir bilgi grafiği, farklı AI sohbet robotlarının (ChatGPT, Gemini, Copilot, Claude, Grok) topladığı kullanıcı verisi türlerini karşılaştırarak toplulukta gizlilik sorunları hakkında tartışma başlattı. Grafik, Google Gemini’nin en fazla veri türünü topladığını, Grok (hesap gerektirir) ve ChatGPT’nin (hesap gerektirmez) ise nispeten daha az topladığını gösteriyor. Kullanıcı yorumları, ücretsiz hizmetlerin arkasındaki veri toplamanın yaygınlığını (“bedava öğle yemeği yoktur”) vurguluyor ve veri toplamanın belirli amaçları (davranış tahmini gibi) hakkında endişelerini dile getiriyor. (Kaynak: Reddit r/artificial)

Model Damıtma, Düşük Maliyetle Yüksek Performansı Yeniden Üretmenin Etkili Bir Yolu Olarak Görülüyor: Reddit kullanıcısı, model damıtma tekniğini kullanarak, büyük modellerle (GPT-4o gibi) küçük, ince ayarlı modelleri eğiterek, belirli bir alanda (duygu analizi) 14 kat daha düşük maliyetle GPT-4o’ya yakın performans (%92 doğruluk) elde ettiğini paylaştı. Yorumlar, damıtmanın yaygın olarak kullanılan bir teknik olduğunu, ancak alanlar arası genelleme yeteneğinde küçük modellerin genellikle büyük modeller kadar iyi olmadığını belirtiyor. Belirli, istikrarlı alanlar için damıtma etkili bir maliyet düşürme ve verimlilik artırma yöntemidir, ancak sürekli yeni verilere veya çoklu alanlara uyum sağlaması gereken karmaşık senaryolar için doğrudan büyük API’leri kullanmak daha ekonomik olabilir. (Kaynak: Reddit r/MachineLearning)
![[D] Damıtma yeterince takdir edilmiyor. GPT-4o'nun yeteneğini 14 kat daha ucuz bir modelde kopyaladım](https://rebabel.net/wp-content/uploads/2025/04/zyj7as7ogque1.png)
💡 Diğer
OceanBase İlk AI Hackathon Yarışmasını Düzenliyor: Dağıtık veritabanı üreticisi OceanBase, Ant Open Source, Machine之心 ve diğerleriyle birlikte ilk AI Hackathon yarışmasını düzenliyor; başvurular 10 Nisan’da başladı ve 7 Mayıs’a kadar devam edecek. Yarışma “DB+AI” temasını taşıyor ve iki ana yöne odaklanıyor: Birincisi, OceanBase’i veri tabanı olarak kullanarak AI uygulamaları oluşturmak, ikincisi ise OceanBase ile AI ekosisteminin (CAMEL AI, FastGPT, OpenDAL gibi) entegrasyonunu keşfetmek. Yarışma toplam 100.000 yuan ödül havuzu sunuyor ve bireysel ve takım başvurularına açık olup, geliştiricileri veritabanı ile AI’ın derin entegrasyonunun yenilikçi uygulamalarını keşfetmeye teşvik etmeyi amaçlıyor. (Kaynak: 100.000 Ödül × Bilişsel Yükseltme! OceanBase İlk AI Hackathon’u Kahramanları Çağırıyor, Cesaretin Var mı?)

Tsinghua Üniversitesi Profesörü Liu Xinjun Paralel Robotları Canlı Yayında Anlatacak: Tsinghua Üniversitesi Makine Mühendisliği Bölümü Tasarım Mühendisliği Enstitüsü Başkanı ve IFToMM Çin Komitesi Başkanı Profesör Liu Xinjun, 15 Nisan akşamı “Paralel Robot Mekanizma Temelleri ve Ekipman İnovasyonu” konulu çevrimiçi bir seminer verecek. Seminer, paralel robotların temel teorilerini ve en son ekipman inovasyonlarındaki uygulamalarını ele alacak. Moderatör Harbin Teknoloji Enstitüsü’nden Profesör Liu Yingxiang olacak. (Kaynak: Önemli Canlı Yayın! Tsinghua Üniversitesi Profesörü Liu Xinjun Anlatıyor: Paralel Robot Mekanizma Temelleri ve Ekipman İnovasyonunun Sınırları)

Üçüncü Çin AIGC Endüstri Zirvesi Rehberi Yayınlandı: 16 Nisan’da Pekin’de düzenlenecek olan Üçüncü Çin AIGC Endüstri Zirvesi’nin ayrıntılı programı ve öne çıkanları yayınlandı. Zirve, AI teknolojisi ve uygulama alanlarına odaklanacak; konular arasında hesaplama altyapısı, büyük modellerin eğitim/eğlence/kurumsal hizmetler/AI4S gibi dikey senaryolardaki uygulamaları, AI güvenliği ve kontrol edilebilirliği yer alacak. Konuşmacılar Baidu, Huawei, AWS, Microsoft Research Asia, Mianbi Intelligence, Shengshu Technology, Fenbi, NetEase Youdao, Quwan Technology, Qingsong Health, Ant Group gibi şirketlerden gelecek. Zirvede ayrıca 2025’te dikkat edilmesi gereken AIGC şirketleri ve ürünleri listesi ile Çin AIGC Uygulama Panoraması da yayınlanacak. (Kaynak: Geri Sayım 2 Gün! 20’den Fazla Sektör Lideri AI’ı Tartışacak, Çin AIGC Endüstri Zirvesi’nin En Kapsamlı Rehberi Burada)
