
Keywords:GPT-4.5, Büyük dil modeli, Huawei Pangu Ultra performansı, GPT-4.5 eğitim detayları, RLHF’nin akıl yürütme yeteneğine etkisi, İnsan öğrenme sınırı 4GB araştırması, Açık kaynak matematik veri seti MegaMath
🔥 Odak Noktası
OpenAI, GPT-4.5 Eğitim Detaylarını ve Zorluklarını Açıkladı: OpenAI CEO’su Sam Altman ve GPT-4.5 çekirdek teknik ekibi, model geliştirme detaylarını açıkladı. Proje iki yıl önce başladı, neredeyse tüm personeli kapsadı ve beklenenden uzun sürdü. Eğitim sırasında 100.000 GPU’luk küme arızası, gizli bug’lar gibi “felaket sorunlarla” karşılaşıldı; bu durum altyapı darboğazlarını ortaya çıkardı ancak teknoloji yığınının (tech stack) yükseltilmesini sağladı. Şimdi GPT-4 seviyesindeki bir modeli kopyalamak için sadece 5-10 kişi yeterli. Ekip, gelecekteki performans artışının anahtarının hesaplama gücü değil, veri verimliliği olduğuna inanıyor; aynı miktarda veriden daha fazlasını öğrenmek için yeni algoritmalar geliştirilmesi gerekiyor. Sistem mimarisi çoklu kümelere (multi-cluster) doğru kayıyor, gelecekte milyonlarca GPU’nun işbirliğini içerebilir ve bu da hata toleransına (fault tolerance) daha yüksek gereksinimler getiriyor. Görüşmede ayrıca Scaling Law, makine öğrenimi (ML) ve sistem eş tasarımı (co-design), denetimsiz öğrenmenin (unsupervised learning) doğası gibi konulara değinildi ve OpenAI’nin öncü büyük dil modellerinin (LLM) geliştirilmesindeki düşünce ve uygulamaları sergilendi (Kaynak: 36氪)

Huawei, Ascend Yerli 135B Yoğun Büyük Dil Modeli Pangu Ultra’yı Yayınladı: Huawei Pangu ekibi, yerli Ascend NPU’ları üzerinde eğitilmiş 135B parametreli yoğun genel amaçlı dil modeli Pangu Ultra’yı yayınladı. Model, 94 katmanlı Transformer yapısını benimsiyor ve ultra derin modellerin eğitim kararlılığı sorununu çözmek için Depth-scaled sandwich-norm (DSSN) ve TinyInit başlatma tekniklerini kullanıyor. 13.2T yüksek kaliteli veri üzerinde kayıp sıçraması (loss spike) olmadan kararlı bir eğitim gerçekleştirdi. Sistem düzeyinde, hibrit paralellik, operatör birleştirme, alt dizi bölme gibi optimizasyonlarla 8192 kartlık Ascend kümesinde hesaplama gücü kullanım oranını (MFU) %50’nin üzerine çıkardı. Değerlendirmeler, Pangu Ultra’nın birçok benchmark’ta Llama 405B, Mistral Large 2 gibi yoğun modelleri geride bıraktığını ve DeepSeek-R1 gibi daha büyük ölçekli MoE modelleriyle rekabet edebildiğini gösteriyor, bu da yerli hesaplama gücüyle en üst düzey büyük dil modelleri geliştirmenin fizibilitesini kanıtlıyor (Kaynak: 机器之心)

Araştırma, Pekiştirmeli Öğrenmenin LLM Çıkarım Yeteneği Üzerindeki Belirgin Etkisini Sorguluyor: Tübingen Üniversitesi ve Cambridge Üniversitesi’nden araştırmacılar, pekiştirmeli öğrenmenin (RL) dil modellerinin çıkarım yeteneklerini önemli ölçüde artırdığı yönündeki son iddiaları sorguluyor. Yaygın çıkarım benchmark’larının (AIME24 gibi) sıkı bir incelemesiyle, sonuçların yüksek derecede istikrarsız olduğu, sadece rastgele tohumu (random seed) değiştirmenin bile puanlarda büyük dalgalanmalara neden olabileceği bulundu. Standartlaştırılmış değerlendirme altında, RL’nin getirdiği performans artışı orijinal raporlardan çok daha az ve genellikle istatistiksel olarak anlamlı değil, hatta denetimli ince ayardan (SFT) daha zayıf ve genelleme yeteneği de daha düşük. Araştırma, örnekleme farklılıkları, kod çözme (decoding) yapılandırmaları, değerlendirme çerçeveleri ve donanım heterojenliğinin istikrarsızlığın ana nedenleri olduğunu belirtiyor ve model çıkarım yeteneklerindeki gerçek ilerlemeyi soğukkanlılıkla değerlendirmek ve ölçmek için daha sıkı, tekrarlanabilir değerlendirme standartları çağrısında bulunuyor (Kaynak: 机器之心)

Altman TED Konuşması: Güçlü Açık Kaynak Modeli Gelecek, ChatGPT’nin AGI Olmadığını Düşünüyor: OpenAI CEO’su Altman, TED konferansında, mevcut tüm açık kaynak modellerini geride bırakacak güçlü bir açık kaynak modeli geliştirdiklerini belirterek DeepSeek gibi rakiplere doğrudan yanıt verdi. ChatGPT kullanıcı sayısının hızla artmaya devam ettiğini ve yeni hafıza özelliğinin kişiselleştirilmiş deneyimi artıracağını vurguladı. Yapay zekanın bilimsel keşifler ve yazılım geliştirme (verimlilik artışı muazzam) alanlarında çığır açacağına inandığını ancak ChatGPT gibi mevcut modellerin henüz kendi kendine sürekli öğrenme ve alanlar arası genelleme yeteneğine sahip olmadığını, dolayısıyla AGI olmadığını belirtti. Ayrıca GPT-4o’nun yaratıcı yeteneklerinin telif hakkı ve “stil hakkı” sorunlarını gündeme getirdiğini tartıştı ve OpenAI’nin model güvenliğine olan güvenini ve risk kontrol mekanizmalarını yineledi (Kaynak: 新智元)

Araştırma İnsan Ömrü Boyunca Öğrenme Sınırının Yaklaşık 4GB Olduğunu İddia Ediyor, Beyin-Bilgisayar Arayüzü ve AI Gelişimi Tartışmalarını Ateşliyor: Cell dergisinin Neuron yayınında yer alan Caltech araştırması, insan beyninin bilgi işleme hızının saniyede yaklaşık 10 bit olduğunu tahmin ediyor; bu, duyu sistemlerinin saniyede 10 milyar bitlik veri toplama hızından çok daha düşük. Buna dayanarak araştırma, bir insan ömrü boyunca (100 yıl kesintisiz öğrenme ve unutmama varsayımıyla) bilgi birikimi üst sınırının yaklaşık 4GB olduğunu, bunun büyük model parametre depolama kapasitesinden (örneğin 7B model 140 milyar bit depolayabilir) çok daha az olduğunu çıkarıyor. Araştırma, bu darboğazın merkezi sinir sisteminin seri işleme mekanizmasından kaynaklandığını ve makine zekasının insanı geçmesinin sadece zaman meselesi olduğunu öngörüyor. Araştırma ayrıca Musk’ın Neuralink’ine şüpheyle yaklaşıyor, beyin temel yapısının sınırlarını aşamayacağını, mevcut iletişim yöntemlerini optimize etmenin daha iyi olacağını savunuyor. Bu çalışma, insan bilişsel sınırları, AI geliştirme potansiyeli ve beyin-bilgisayar arayüzü yönü hakkında geniş çaplı tartışmalara yol açtı (Kaynak: 量子位)

🎯 Gelişmeler
GPT-4 Yakında Emekliye Ayrılıyor, GPT-4.1 ve Gizemli Yeni Model Gelebilir: OpenAI, 30 Nisan’dan itibaren ChatGPT’de iki yıl önce piyasaya sürülen GPT-4’ün yerini tamamen GPT-4o’nun alacağını duyurdu, ancak GPT-4 API aracılığıyla kullanılmaya devam edecek. Aynı zamanda, topluluk ve kod sızıntıları, OpenAI’nin yakında GPT-4.1 (ve mini/nano sürümleri), tam güçlü o3 çıkarım modeli ve yeni o4 serisi (o4-mini gibi) dahil olmak üzere bir dizi yeni model yayınlayabileceğini gösteriyor. Optimus Alpha adlı gizemli bir model OpenRouter’da kullanıma sunuldu ve mükemmel performans (özellikle programlama) sergiliyor, milyonlarca bağlamı destekliyor ve yaygın olarak OpenAI’nin yakında piyasaya süreceği yeni modellerden biri (muhtemelen GPT-4.1 veya o4-mini) olduğu tahmin ediliyor; OpenAI modelleriyle birçok benzerliği (belirli bug’lar gibi) bulunuyor. Bu, OpenAI’nin model iterasyon hızının arttığını ve teknolojik liderliğini aktif olarak pekiştirdiğini gösteriyor (Kaynak: source, source)

Alibaba Qwen3 Büyük Modeli Hazırlık Aşamasında: Haberlere göre Alibaba’nın yakın zamanda Qwen3 büyük modelini yayınlaması bekleniyor. Geliştirme ekibi modelin son hazırlık aşamasında olduğunu doğruladı ancak kesin yayın tarihi belirlenmedi. Qwen3’ün Alibaba’nın 2025’in ilk yarısındaki önemli model ürünlerinden biri olduğu ve geliştirilmesine Qwen2.5’ten sonra başlandığı bildiriliyor. DeepSeek-R1 gibi rakip modellerin etkisiyle Alibaba Cloud temel model ekibi, stratejik odağını modelin çıkarım yeteneklerini geliştirmeye daha fazla kaydırdı; bu da büyük model rekabet ortamında belirli yeteneklere yönelik stratejik odaklanmayı gösteriyor (Kaynak: InfoQ)

Kimi Açık Platformu Fiyatları Düşürdü ve Hafif Görsel Modeli Açık Kaynak Yaptı: Moonshot AI’nin Kimi açık platformu, model çıkarım hizmetleri ve bağlam önbelleği fiyatlarını düşürdüğünü duyurdu; amaç teknolojik optimizasyon yoluyla kullanıcı maliyetlerini azaltmak. Aynı zamanda Kimi, MoE mimarisine dayalı iki hafif görsel dil modeli olan Kimi-VL ve Kimi-VL-Thinking’i açık kaynak olarak yayınladı. Bu modeller 128K bağlamı destekliyor ve etkinleştirilmiş parametre sayısı sadece yaklaşık 3 milyar. Çok modlu çıkarım yeteneklerinde 10 kat daha fazla parametreye sahip büyük modellerden önemli ölçüde daha iyi olduğu iddia ediliyor; amaç küçük, verimli çok modlu modellerin geliştirilmesini ve uygulanmasını teşvik etmek (Kaynak: InfoQ)
Google, Agent Birlikte Çalışabilirlik Protokolü A2A ve Birçok Yeni AI Ürününü Duyurdu: Google Cloud Next ’25 konferansında Google, 50’den fazla ortakla birlikte, farklı şirketler ve platformlar tarafından geliştirilen AI ajanları arasında birlikte çalışabilirliği ve işbirliğini sağlamayı amaçlayan açık protokol Agent2Agent’ı (A2A) tanıttı. Aynı zamanda Gemini 2.5 Flash (verimli amiral gemisi modeli), Lyria (metinden müziğe), Veo 2 (video oluşturma), Imagen 3 (görüntü oluşturma), Chirp 3 (özel ses) gibi birçok AI modeli ve uygulamasını yayınladı ve çıkarım için optimize edilmiş yedinci nesil TPU çipi Ironwood’u tanıttı. Bu duyuru serisi, Google’ın AI altyapısı, modelleri, platformları ve ajanları konusundaki kapsamlı düzenini ve açık stratejisini yansıtıyor (Kaynak: InfoQ)
ByteDance, 200B Parametreli Çıkarım Modeli Seed-Thinking-v1.5’i Yayınladı: ByteDance Doubao ekibi, 200B toplam parametreye sahip MoE çıkarım modeli Seed-Thinking-v1.5’i tanıtan bir teknik rapor yayınladı. Model her seferinde 20B parametreyi etkinleştiriyor ve birçok benchmark testinde üstün performans sergiliyor; 671B toplam parametreye sahip DeepSeek-R1’i geride bıraktığı iddia ediliyor. Topluluk, bunun şu anda ByteDance Doubao uygulamasındaki “derin düşünme” modunda kullanılan model olabileceğini tahmin ediyor, bu da ByteDance’in verimli çıkarım modeli geliştirmedeki ilerlemesini gösteriyor (Kaynak: InfoQ)
Midjourney, Görüntü Kalitesini ve Üretim Verimliliğini Artıran V7 Modelini Yayınladı: AI görüntü oluşturma aracı Midjourney, yeni modeli V7’nin (alfa sürümü) yayınladı. Yeni sürüm, görüntü oluşturmanın tutarlılığını ve bütünlüğünü iyileştiriyor, özellikle eller, vücut parçaları ve nesne detaylarında daha iyi performans gösteriyor ve daha gerçekçi, zengin dokular üretebiliyor. V7, yarı maliyetle on kat işleme hızı sağlayan Draft Mode’u sunuyor, bu da hızlı iterasyon ve keşif için uygun. Aynı zamanda farklı kullanıcı ihtiyaçlarını karşılamak için turbo (daha hızlı ama daha pahalı) ve relax (daha yavaş ama daha ucuz) olmak üzere iki üretim modu sunuyor (Kaynak: InfoQ)
Amazon, AI Ses Modeli Nova Sonic’i Tanıttı: Amazon, yeni nesil doğal ses işleyen üretken AI modeli Nova Sonic’i yayınladı. Modelin hız, konuşma tanıma ve diyalog kalitesi gibi temel metriklerde OpenAI ve Google’ın en iyi ses modelleriyle rekabet edebileceği iddia ediliyor. Nova Sonic, Amazon Bedrock geliştirici platformu aracılığıyla sunuluyor, yeni bir çift yönlü akış API erişimi kullanıyor ve fiyatı GPT-4o’dan yaklaşık %80 daha ucuz; amaç kurumsal AI uygulamaları için yüksek maliyet etkinliğine sahip doğal ses etkileşimi yeteneği sağlamak (Kaynak: InfoQ)
Apple’ın Çin Pazarındaki iPhone AI Özellikleri Yıl Ortasında Gelebilir, Baidu ve Alibaba Teknolojilerini Entegre Edecek: Haberlere göre Apple, 2025 ortasından önce Çin pazarındaki iPhone’lar için (muhtemelen iOS 18.5’te) Apple Intelligence hizmetini sunmayı planlıyor. Bu özellik, akıllı yetenekler sağlamak için Baidu Wenxin büyük modelini kullanacak ve içerik düzenleme gereksinimlerine uymak için Alibaba’nın denetim motorunu entegre edecek. Apple’ın Baidu veya Alibaba ile özel bir anlaşma imzalamaması, kritik pazarlarda AI özelliklerini hızla dağıtmak için yerel işbirliği stratejisi benimsediğini gösteriyor (Kaynak: InfoQ)
🧰 Araçlar
Volcano Engine, Kurumsal Veri Zekası Ajanı Data Agent’ı Yayınladı: Volcano Engine, kurumsal düzeyde veri zekası ajanı Data Agent’ı tanıttı. Bu araç, büyük modellerin çıkarım, analiz ve araç çağırma yeteneklerini kullanarak kurumsal iş ihtiyaçlarını derinlemesine anlamayı, derinlemesine araştırma raporları yazma, pazarlama kampanyaları tasarlama gibi karmaşık veri analizi ve uygulama görevlerini otomatikleştirmeyi, kurumsal veri kullanım verimliliğini ve karar verme düzeyini artırmayı hedefliyor (Kaynak: InfoQ)
GPT-4o Görüntü Üretiminde Yeni Stiller Dikkat Çekiyor: Sosyal medya kullanıcıları, GPT-4o görüntü oluşturma özelliğini kullanarak oluşturdukları yeni stilleri sergiliyorlar; örneğin, Windows 2000 retro arayüz öğelerini karakter resimleriyle birleştirerek benzersiz kolaj efektleri oluşturuyorlar. Kullanıcılar, kılavuz resim kullanma, stil ve içerik açıklamalarını birleştirme gibi prompt ipuçlarını paylaştılar, bu da topluluğun GPT-4o’nun yaratıcı potansiyelini keşfetme ilgisini artırdı (Kaynak: source, source)

📚 Öğrenme
En Büyük Açık Kaynak Matematik Ön Eğitim Veri Seti MegaMath Yayınlandı: LLM360, DeepSeek-Math Corpus’u aşan ölçekte, 3710 milyar token içeren açık kaynaklı bir matematiksel çıkarım ön eğitim veri seti olan MegaMath’ı tanıttı. Veri seti, matematik yoğun web sayfalarını (279B), matematikle ilgili kodu (28B) ve yüksek kaliteli sentetik verileri (64B) kapsıyor. Ekip, HTML yapısı optimizasyonu, iki aşamalı çıkarma, LLM destekli filtreleme ve iyileştirme gibi hassas veri işleme süreçleriyle verinin ölçeğini, kalitesini ve çeşitliliğini sağladı. Llama-3.2 modeli üzerindeki ön eğitim doğrulaması, MegaMath kullanmanın GSM8K, MATH gibi benchmark’larda %15-20 mutlak artış sağladığını gösteriyor ve açık kaynak topluluğuna güçlü bir matematiksel çıkarım yeteneği eğitim temeli sunuyor (Kaynak: 机器之心)

Nabla-GFlowNet: Difüzyon Modeli İnce Ayarında Çeşitlilik ve Verimliliği Dengeleme: Hong Kong Çin Üniversitesi (Shenzhen) ve diğer kurumlardan araştırmacılar, üretken akış ağlarına (GFlowNet) dayalı yeni bir difüzyon modeli ödül ince ayar yöntemi olan Nabla-GFlowNet’i önerdi. Bu yöntem, geleneksel pekiştirmeli öğrenme ince ayarının yavaş yakınsaması ve doğrudan ödül optimizasyonunun kolayca aşırı uyum (overfitting) sağlaması ve çeşitliliği kaybetmesi sorunlarını çözmeyi amaçlıyor. Yeni bir akış denge koşulu (Nabla-DB) türeterek ve belirli kayıp fonksiyonları ile log-akış gradyan parametrizasyonu tasarlayarak, Nabla-GFlowNet, üretilen örneklerin çeşitliliğini korurken modeli ödül fonksiyonlarına (estetik puanlama, talimat takibi gibi) verimli bir şekilde hizalayabiliyor. Stable Diffusion üzerindeki deneyler, DDPO, ReFL, DRaFT gibi yöntemlere göre avantajlarını kanıtladı (Kaynak: 机器之心)
Llama.cpp, Llama 4 İle İlgili Sorunları Düzeltti: llama.cpp projesi, Llama 4 modellerini hedefleyen iki düzeltmeyi birleştirdi; bunlar RoPE (Dönel Konum Kodlaması) ve hatalı norm hesaplamalarıyla ilgili. Bu düzeltmeler model çıktısının kalitesini artırmayı amaçlıyor, ancak kullanıcıların etkili olması için düzeltilmiş dönüştürme aracıyla oluşturulan GGUF model dosyalarını yeniden indirmeleri gerekebilir (Kaynak: source)
💼 İş Dünyası
Nvidia, Lepton AI’nin Satın Alımını Tamamladı: Haberlere göre Nvidia, eski Alibaba Başkan Yardımcısı Jia Yangqing tarafından kurulan AI altyapı girişimi Lepton AI’yi satın aldı, işlem değeri yüz milyonlarca dolar olabilir. Lepton AI’nin ana işi Nvidia GPU sunucularını kiralamak ve işletmelerin AI uygulamaları oluşturmasına ve yönetmesine yardımcı olacak yazılım sağlamaktı. Jia Yangqing ve kurucu ortağı Bai Junjie dahil yaklaşık 20 çalışan Nvidia’ya katıldı. Bu hamle, Nvidia’nın bulut hizmetleri ve kurumsal yazılım pazarını genişletme ve AWS, Google Cloud gibi kendi çiplerini geliştiren rakiplere karşı koyma stratejisinin bir parçası olarak görülüyor (Kaynak: InfoQ)
ABD Teknoloji Sektöründe Endişe Havası Hakim, AI İş Piyasasını Vuruyor: Haberler, ABD teknoloji sektörünün pozisyon azalması, maaşlarda düşüş ve iş arama sürelerinin uzaması gibi zorluklar yaşadığını belirtiyor. Büyük çaplı işten çıkarmalar, şirketlerin (Salesforce, Meta, Google gibi) AI’ı insan gücü yerine kullanması veya işe alımları (özellikle mühendislik ve giriş seviyesi pozisyonlarda) durdurması, sektör çalışanlarının kariyer endişelerini artırıyor. Veriler, maaş düşüşü bildirenlerin ve yönetici pozisyonlarından bireysel katkıda bulunan pozisyonlara geçenlerin oranının arttığını gösteriyor. AI, iş piyasasını yeniden şekillendiriyor ve iş arayanları teknoloji dışı sektörlere yönelmeye veya girişimciliğe dönmeye zorluyor. Uzmanlar, “Yedi Dev” dışındaki iş fırsatlarına odaklanmayı ve rekabet gücünü artırmak için AI araçlarını kullanmayı öneriyor (Kaynak: InfoQ)

OpenAI’nin Altman ve Jony Ive İşbirliğindeki AI Donanım Şirketini Satın Alacağı İddiası: Haberlere göre OpenAI, CEO’su Altman ile eski Apple tasarım şefi Jony Ive’ın işbirliğiyle kurulan AI şirketi io Products’ı en az 500 milyon dolara satın almayı görüşüyor. Şirket, AI destekli kişisel cihazlar geliştirmeyi hedefliyor; olası formlar arasında ekransız “telefon” veya ev cihazları bulunuyor. io Products’ta mühendis ekibi cihazları geliştiriyor, OpenAI teknolojiyi sağlıyor, Ive’ın stüdyosu tasarımı üstleniyor ve Altman sürece derinden dahil oluyor. Satın alma tamamlanırsa, bu donanım ekibi OpenAI’ye entegre edilecek ve şirketin AI donanım alanındaki konumunu hızlandıracak (Kaynak: InfoQ)
Eski OpenAI CTO’sunun Girişimi Eski Şirketinden Yetenekleri Çekiyor: Eski OpenAI CTO’su Mira Murati’nin kurduğu AI şirketi “Thinking Machines Laboratory”, iki eski önemli OpenAI ismini danışman ekibine kattı: eski Baş Araştırmacı Bob McGrew ve eski Araştırmacı Alec Radford. Radford, GPT serisinin temel teknik makalelerinin baş yazarıdır. Bu işe alım, girişimin teknik gücünü daha da artırıyor ve AI alanındaki yoğun yetenek rekabetini yansıtıyor (Kaynak: InfoQ)
Baichuan Intelligence İş Odağını Değiştiriyor, Tıp Alanına Odaklanıyor: Baichuan Intelligence kurucusu Wang Xiaochuan, şirketin ikinci kuruluş yıldönümünde tüm çalışanlara gönderdiği bir mektupla şirketin tıp alanına odaklanacağını, Baixiaoying, AI pediatri, AI pratisyen hekimlik ve hassas tıp gibi uygulama hizmetlerini geliştireceğini yineledi. Gereksiz faaliyetlerin azaltılması gerektiğini ve organizasyon yapısının daha yatay hale geleceğini vurguladı. Daha önce şirketin finans sektörü B2B grubunun kapatıldığı, ticari ortak Deng Jiang’ın ayrıldığı ve birkaç kurucu ortağın daha ayrıldığı veya ayrılmak üzere olduğu bildirilmişti; bu da şirketin stratejik odaklanma ve organizasyonel yeniden yapılanma sürecinden geçtiğini gösteriyor (Kaynak: InfoQ)
Alibaba Cloud, AI Ekosistem Ortağı “Fan Hua” Planını Başlattı: Alibaba Cloud, AI ekosistem ortaklarını desteklemeyi amaçlayan “Fan Hua” (Çiçeklenme) planını duyurdu. Plan, ortakların ürün olgunluğuna göre bulut kaynakları, hesaplama gücü desteği, ürün paketleme, ticarileştirme planlaması ve tam yaşam döngüsü hizmetleri sunacak. Aynı zamanda Alibaba Cloud, AI uygulama ve hizmet pazarını başlattı; amaç gelişen bir AI ekosistemi oluşturmak ve AI teknolojisi ile uygulamalarının yaygınlaşmasını hızlandırmak (Kaynak: InfoQ)
Kugou Music ve DeepSeek Derin İşbirliğine Gitti: Kugou Music, AI şirketi DeepSeek ile işbirliği yaptığını ve bir dizi AI inovasyon özelliğini sunacağını duyurdu. Bunlar arasında çok modlu analiz kullanarak kişiselleştirilmiş dinleme raporları oluşturma, AI günlük öneriler, akıllı arama, AI çalma listesi yönetimi, AI dinamik kapak oluşturma ve karakter ayarlarına sahip “AI Yorumcusu” gibi özellikler bulunuyor; amaç AI teknolojisi aracılığıyla kullanıcıların müzik deneyimini ve topluluk etkileşimini geliştirmek (Kaynak: InfoQ)
Google’ın AI Yeteneklerini Elde Tutmak İçin “Radikal” Rekabet Yasağı Anlaşmaları Kullandığı İddiası: Haberlere göre Google’ın DeepMind birimi, yeteneklerin rakiplere geçmesini engellemek için bazı İngiltere çalışanlarına bir yıllık rekabet yasağı anlaşması uyguluyor. Bu süre zarfında çalışanların çalışması gerekmiyor ancak maaşlarını almaya devam ediyorlar (ücretli izin), ancak bu durum bazı araştırmacıların kendilerini dışlanmış hissetmelerine ve hızla gelişen sektör süreçlerine katılamamalarına neden oluyor. Bu uygulama ABD’de FTC tarafından yasaklanabilir ancak Londra merkezinde geçerli ve yetenek rekabeti ile inovasyonun kısıtlanması hakkında tartışmalara yol açıyor (Kaynak: InfoQ)
Eski OpenAI Çalışanları Musk’ın Davasını Destekleyen Hukuki Belgeler Sundu: 12 eski OpenAI çalışanı, Musk’ın OpenAI’ye karşı açtığı davayı destekleyen hukuki belgeler sundu. OpenAI’nin yeniden yapılanma planının (kar amacı güden yapıya geçiş) şirketin başlangıçtaki kar amacı gütmeyen misyonunu temelden ihlal edebileceğini ve bu misyonun kendilerini şirkete çeken kilit faktör olduğunu savunuyorlar. OpenAI, yapı değişse bile misyonunun değişmeyeceğini yanıtladı (Kaynak: InfoQ)
🌟 Topluluk
Anthropic Araştırması, AI’ın Yüksek Öğretimdeki Kullanım Modellerini ve Zorluklarını Ortaya Koyuyor: Anthropic, Claude.ai platformundaki milyonlarca anonim öğrenci konuşmasını analiz ederek, fen ve mühendislik (özellikle bilgisayar bilimi) öğrencilerinin AI’ın erken benimseyicileri olduğunu buldu. Öğrencilerin AI ile etkileşim modları arasında doğrudan problem çözme, doğrudan içerik üretme, işbirlikçi problem çözme ve işbirlikçi içerik üretme bulunuyor ve oranları birbirine yakın. AI esas olarak yaratma (programlama, alıştırma yazma gibi) ve analiz etme (kavramları açıklama gibi) gibi üst düzey bilişsel görevler için kullanılıyor. Araştırma ayrıca potansiyel akademik sahtekarlık davranışlarını (cevapları alma, intihal tespitinden kaçınma gibi) ortaya çıkarıyor ve akademik dürüstlük, eleştirel düşünme eğitimi ve değerlendirme yöntemleri hakkında endişelere yol açıyor (Kaynak: 新智元)

GPT-4o Görüntü Üretimi Yeni Akımlar Yaratıyor: Ghibli Tarzından AI Ünlü Kartlarına: GPT-4o’nun güçlü görüntü oluşturma yeteneği sosyal medyada yaratıcılık dalgaları yaratmaya devam ediyor. “Ghibli tarzı aile fotoğrafı”nın viral olmasının ardından (arkasındaki itici güç eski Amazon mühendisi Grant Slatton), kullanıcılar şimdi de AI alanındaki ünlülerin “Magic: The Gathering” tarzı kartlarını (örneğin Altman “AGI Hükümranı” olarak ayarlandı) ve kişiselleştirilmiş tarot kartları oluşturuyor. Bu örnekler, AI’ın sanat tarzı taklidi ve yaratıcı üretim potansiyelini gösteriyor, ancak aynı zamanda orijinallik, telif hakkı, estetik değer ve AI’ın tasarımcıların kariyerleri üzerindeki etkisi hakkında tartışmalara yol açıyor (Kaynak: 新智元)

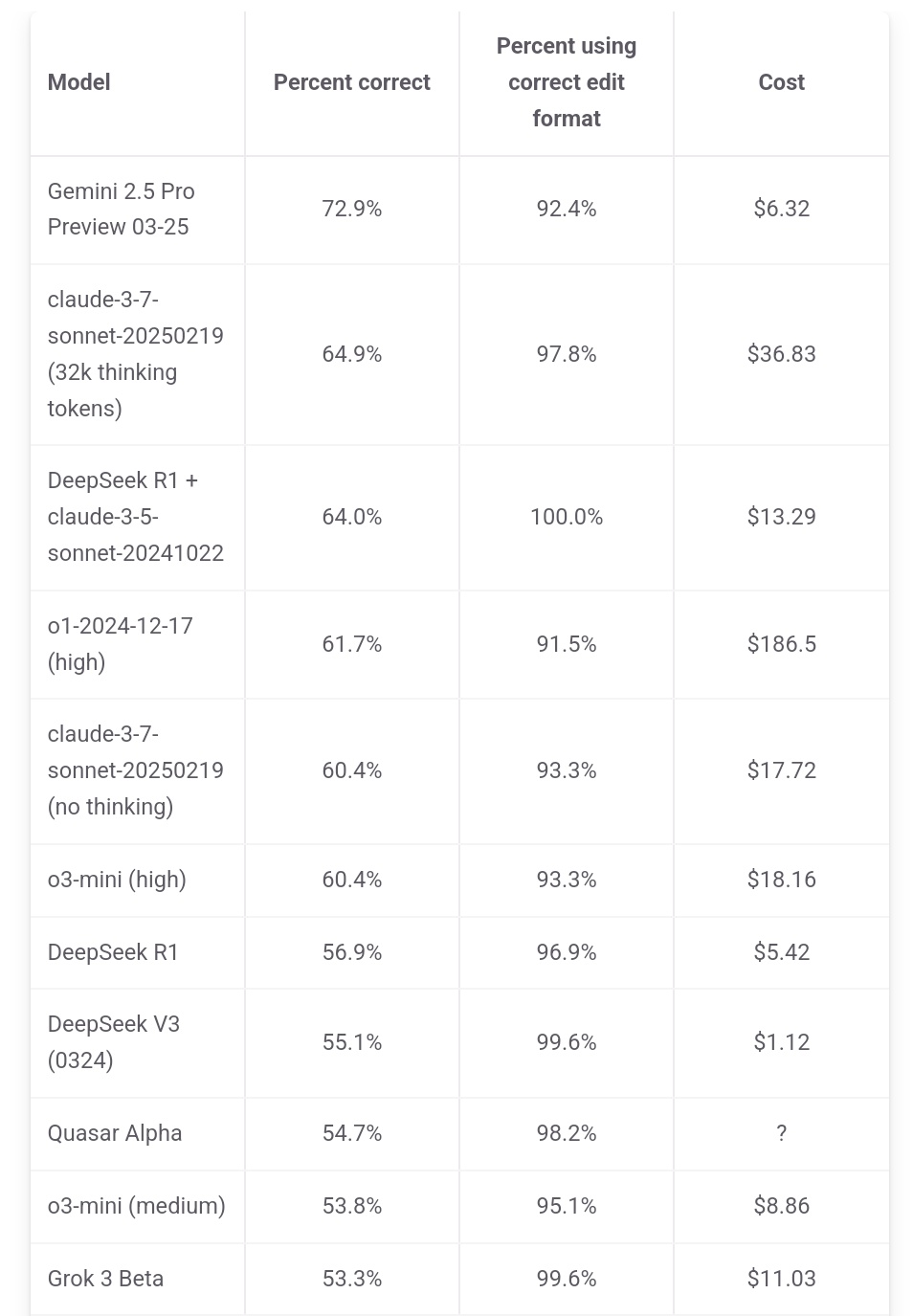
Jeff Dean, Gemini 2.5 Pro’nun Maliyet Avantajını Vurguluyor: Google AI Başkanı Jeff Dean, aider.chat’in sıralama verilerini paylaşarak Gemini 2.5 Pro’nun Polyglot programlama benchmark testinde sadece performans lideri olmakla kalmayıp, maliyetinin (6$) DeepSeek dışındaki diğer Top 10 modellerden önemli ölçüde düşük olduğunu belirtti ve fiyat/performans avantajını vurguladı. Bazı rakip modellerin maliyeti Gemini 2.5 Pro’nun 2 katı, 3 katı hatta 30 katı kadar (Kaynak: JeffDean)
Reddit, AI’ın İş Piyasasına Etkisini Tartışıyor, Özellikle Giriş Seviyesi Pozisyonlar: Reddit forumunda bir gönderi yoğun tartışmalara yol açtı. Gönderiyi yapan kişi (CIS yüksek lisans öğrencisi), AI’ın giriş seviyesi fiziksel olmayan işleri (özellikle yazılım mühendisliği, veri analizi, IT desteği) devralması konusundaki derin endişesini dile getirerek, “AI işleri kapmayacak” söyleminin yeni mezunların zorluklarını göz ardı ettiğini savundu. Büyük şirketlerin zaten kampüs işe alımlarını azalttığını ve gelecekteki iş piyasasının zorlu olabileceğini belirtti. Yorum bölümünde bu görüşe katılanlar ve katılmayanlar oldu; bazıları krizi kabul ederken, bazıları bunun teknolojik değişimin normal bir parçası olduğunu ve yeni rollere (AI ekiplerini yönetmek gibi) uyum sağlanması gerektiğini savundu. Bazıları ise “işlerin %90’ının yok olacağı” iddiasını sorgulayarak, ekonomik döngülerin ve farklı ülke durumlarının çok farklı olduğunu ve AI’ın mevcut yeteneklerinin hala sınırlı olduğunu belirtti (Kaynak: source)
Claude Kullanıcıları Performans Düşüşünden ve Kısıtlamaların Sıkılaşmasından Şikayetçi: Reddit ClaudeAI bölümünde toplu bir tartışma ortaya çıktı; birçok kullanıcı (Pro kullanıcılar dahil) son zamanlarda daha sıkı kullanım kısıtlamalarıyla (kota) karşılaştıklarını, rutin işlemlerin bile sık sık sınıra ulaştığını bildirdi. Bazı kullanıcılar Anthropic’in gizlice kotaları sıktığını düşünüyor ve bundan memnuniyetsizliklerini dile getirerek bunun kullanıcıları rakip ürünlere yönelteceğini savunuyor. Ayrıca, bazı kullanıcılar Claude’un “kişiliğinin” değişmiş gibi göründüğünü, daha “soğuk”, “mekanik” hale geldiğini ve erken sürümlerin felsefi ve şiirsel hissini kaybettiğini, bunun da bazı kullanıcıların aboneliklerini iptal etmesine neden olduğunu bildirdi (Kaynak: source, source, source, source)
ChatGPT Görüntü Üretimi Eğlence ve Tartışma Yaratıyor: Reddit kullanıcıları, ChatGPT kullanarak çeşitli görüntü oluşturma denemelerini ve sonuçlarını paylaşıyor. Bir kullanıcı köpeğini insana “dönüştürmesini” istedi ve sonuçta “ork/furry” benzeri bir görüntü oluştu, bu da prompt anlama ve potansiyel önyargılar hakkında tartışmalara yol açtı. Başka bir kullanıcı kendisini çoklu evren versiyonu bir vitray pencere olarak çizmesini istedi ve sonuç etkileyiciydi. Başka bir kullanıcı AI hakkında metaforik bir görüntü oluşturmasını istedi veya AI’ın “kabuslarını” sordu, bu da AI görüntü üretiminin yaratıcı ifade ve soyut kavram görselleştirmesindeki yeteneklerini ve sınırlamalarını gösterdi (Kaynak: source, source, source, source, source)

Topluluk LLM Modeli Seçimi ve Kullanım Stratejilerini Tartışıyor: Reddit LocalLLaMA bölümünde bir kullanıcı, farklı senaryolarda (kodlama, yazma, araştırma vb.) kullandıkları en iyi modelleri (açık kaynak ve kapalı kaynak) ve nedenlerini paylaşmak için aylık bir model kullanımı tartışması önerdi. Yorum bölümündeki kullanıcılar şu anda kullandıkları model kombinasyonlarını paylaştılar: Deepseek V3.1/Gemini 2.5 Pro/4o/R1/Qwen 2.5 Max/Sonnet 3.7/Gemma 3/Claude 3.7/Mistral Nemo vb. ve belirli kullanımlardan (araç çağırma, sınıflandırma, rol yapma gibi) bahsettiler; bu da kullanıcıların görev gereksinimlerine göre farklı modelleri seçme ve birleştirme eğilimini yansıtıyor (Kaynak: source)
💡 Diğer
Çin AIGC Endüstri Zirvesi Yakında Düzenlenecek: Üçüncü Çin AIGC Endüstri Zirvesi 16 Nisan’da Pekin’de düzenlenecek. Zirve, Baidu, Huawei, Microsoft Research Asia, Amazon Web Services, ModelBest, ShengShu Technology gibi şirketlerden 20’den fazla sektör liderini bir araya getirerek AI teknoloji atılımları (hesaplama gücü, büyük modeller), sektör uygulamaları (eğitim, eğlence, araştırma, kurumsal hizmetler), ekosistem inşası (güvenli ve kontrol edilebilir, uygulama zorlukları) gibi konuları tartışacak. Zirvede ayrıca AIGC şirket/ürün listeleri ve Çin AIGC Uygulama Panoraması yayınlanacak (Kaynak: 量子位)

Stanford Raporu: Çin ve ABD’nin En İyi AI Modelleri Arasındaki Performans Farkı %0.3’e Düştü: Stanford Üniversitesi’nin yayınladığı 2025 AI Endeksi Raporu, Çin ve ABD’nin en iyi AI modelleri arasındaki performans farkının 2023’teki %20’den önemli ölçüde azalarak %0.3’e düştüğünü gösteriyor. ABD, tanınmış model sayısı (40’a karşı 15) ve sektör lideri şirketler açısından hala önde olsa da, Çin modellerinin yetişme hızı artıyor. Rapor ayrıca, en iyi modeller arasındaki performans farkının da küçüldüğünü, 2024’teki %12’den %5’e düştüğünü ve yakınsama eğiliminin belirgin olduğunu belirtiyor (Kaynak: InfoQ)