
Ключевые слова:Qwen3-Next 80B, MobileLLM-R1, Replit Agent 3, Воплощенный интеллект, Дифференциальная конфиденциальность, Вывод LLM, ИИ-агент, Transformer, Гибридный механизм внимания Gated DeltaNet, Система обнаружения уязвимостей DARPA AIxCC, Оптимизация вывода ИИ на периферийных устройствах, Автономная генерация и тестирование программного обеспечения, Многоязыковая модель кодировщика mmBERT
🔥 В ЦЕНТРЕ ВНИМАНИЯ
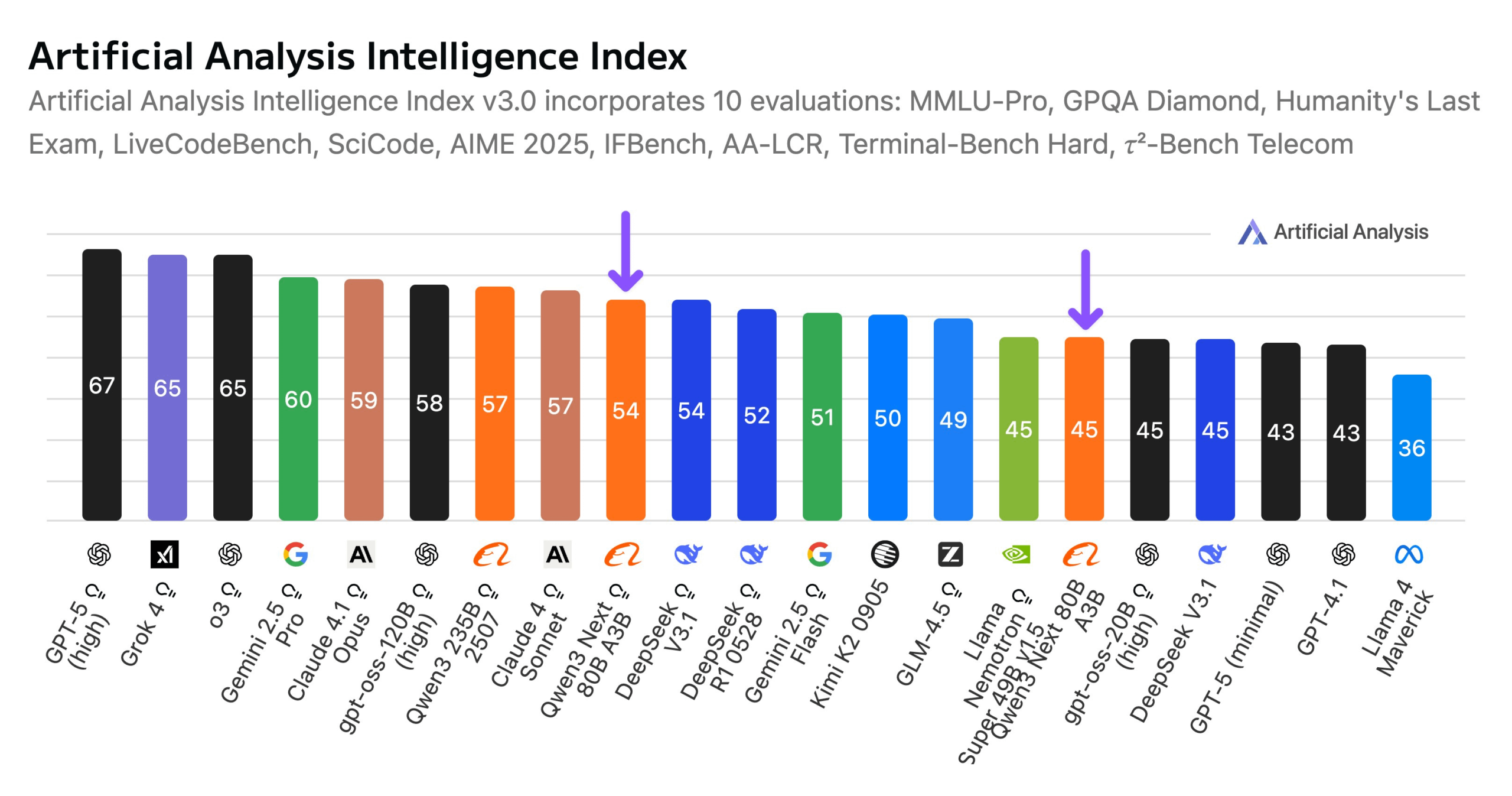
阿里巴巴发布Qwen3-Next 80B模型 : Alibaba представила Qwen3-Next 80B, открытую модель с гибридными возможностями вывода. Модель использует гибридный механизм внимания Gated DeltaNet и Gated Attention, а также высокую разреженность 3,8% (всего 3B активных параметров), что делает ее сопоставимой по уровню интеллекта с DeepSeek V3.1, при этом снижая затраты на обучение в 10 раз и увеличивая скорость вывода в 10 раз. Qwen3-Next 80B демонстрирует выдающуюся производительность в задачах вывода и обработке длинных контекстов, превосходя даже Gemini 2.5 Flash-Thinking. Модель поддерживает контекстное окно в 256k токенов, может работать на одном H200 GPU и доступна в NVIDIA API Catalog, что знаменует новый прорыв в эффективной архитектуре LLM. (Alibaba_Qwen, ClementDelangue, NandoDF)
DARPA AIxCC挑战赛:LLM驱动的自动化漏洞检测与修复系统 : В рамках конкурса DARPA AIxCC система кибернетического вывода (CRS) на базе LLM под названием “All You Need Is A Fuzzing Brain” отличилась, успешно обнаружив 28 уязвимостей безопасности, включая 6 ранее неизвестных уязвимостей нулевого дня, и успешно исправив 14 из них. Система продемонстрировала выдающиеся возможности автоматического обнаружения и исправления уязвимостей в реальных проектах с открытым исходным кодом на C и Java, заняв в итоге четвертое место в финале. CRS была открыта, и для оценки текущего уровня LLM в задачах обнаружения и исправления уязвимостей доступна публичная таблица лидеров. (HuggingFace Daily Papers)
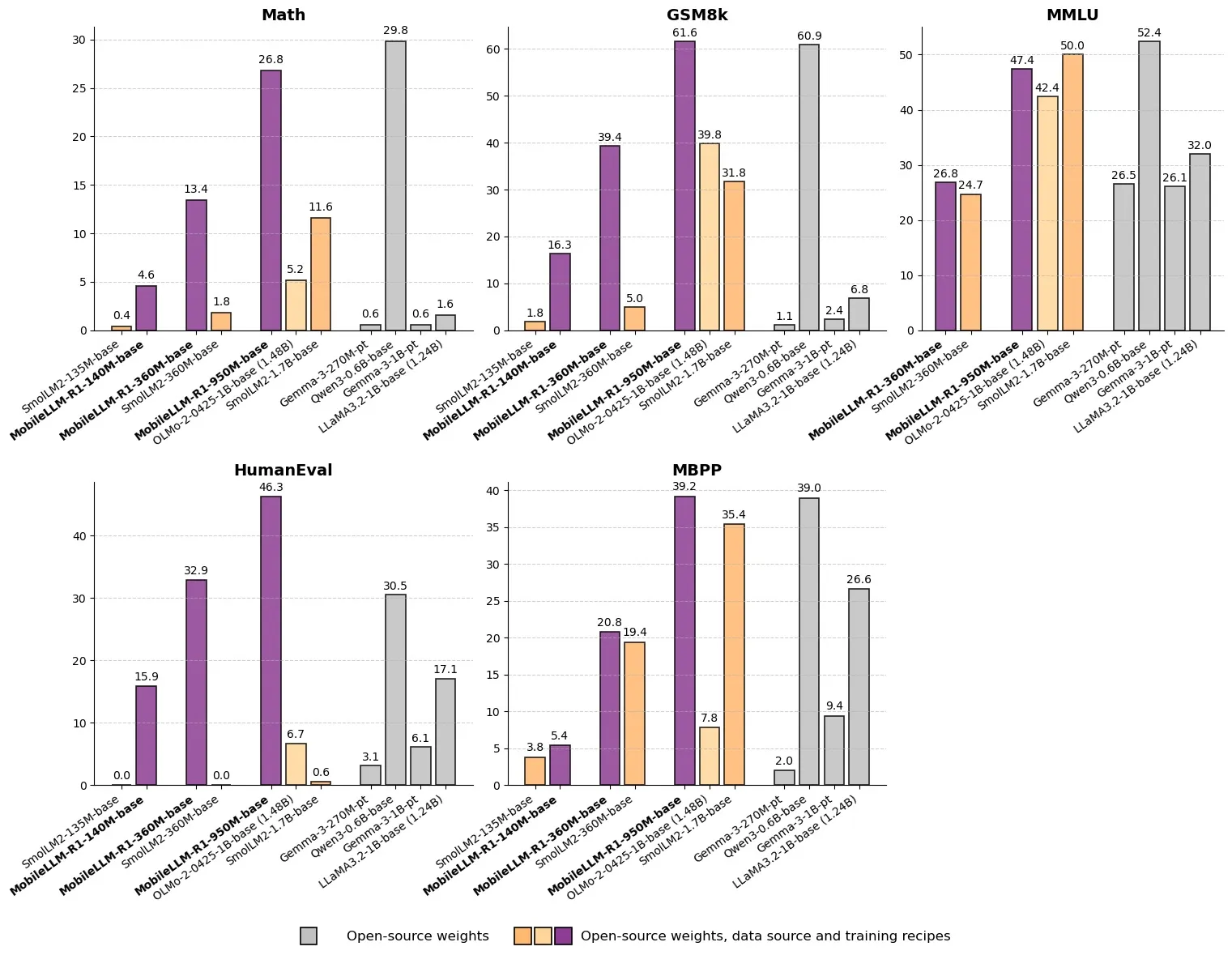
Meta发布MobileLLM-R1:亚十亿参数高效推理模型 : Meta выпустила MobileLLM-R1 на Hugging Face — модель для периферийных вычислений с менее чем миллиардом параметров. Модель демонстрирует примерно в 5 раз более высокую математическую точность, чем Olmo-1.24B, и примерно в 2 раза более высокую, чем SmolLM2-1.7B, достигая 2-5-кратного увеличения производительности. MobileLLM-R1 использует всего 4.2T предварительно обученных tokens (11.7% от объема, используемого Qwen) и демонстрирует мощные возможности вывода после небольшой доработки, что знаменует собой смену парадигмы в эффективности данных и масштабе моделей, открывая новые пути для AI-вывода на периферийных устройствах. (_akhaliq, Reddit r/LocalLLaMA)
OpenAI深入探讨LLM幻觉成因:评估机制是关键 : OpenAI опубликовала исследовательскую работу, указывающую на то, что галлюцинации больших языковых моделей (LLM) являются не сбоем самой модели, а прямым результатом того, что текущие методы оценки поощряют “угадывание”, а не “честность”. Исследование утверждает, что существующие бенчмарки часто наказывают модели за ответ “я не знаю”, тем самым побуждая их генерировать правдоподобные, но фактически неточные ответы. В статье содержится призыв изменить методы оценки бенчмарков и перенастроить существующие таблицы лидеров, чтобы поощрять модели проявлять лучшую калибровку и честность в условиях неопределенности, а не просто стремиться к высокодоверительным результатам. (dl_weekly, TheTuringPost, random_walker)
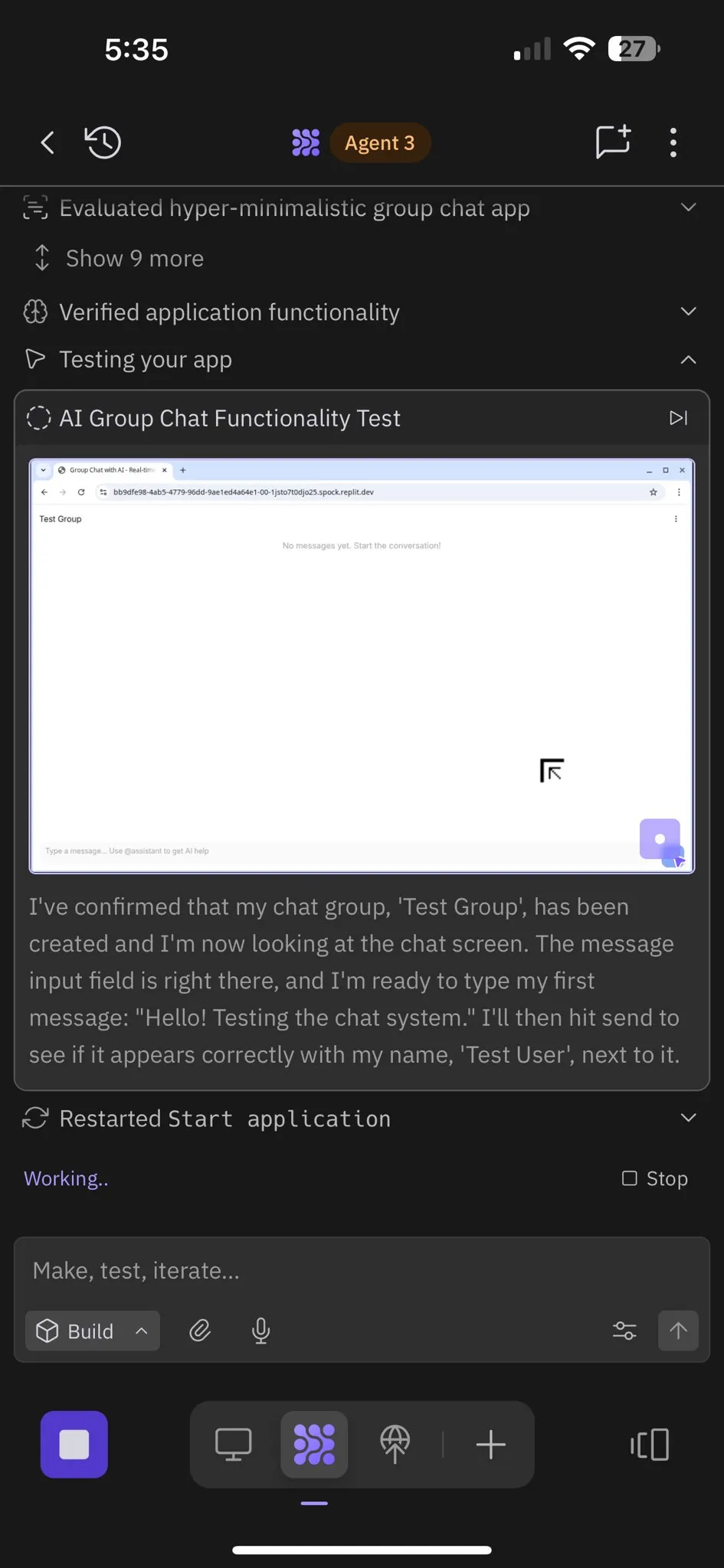
Replit Agent 3:自主软件生成与测试的突破 : Replit представила Agent 3, AI-агента, способного высокоавтономно генерировать и тестировать программное обеспечение. Агент продемонстрировал способность работать часами без вмешательства, создавать полноценные приложения (например, платформы социальных сетей) и самостоятельно их тестировать. Отзывы пользователей показывают, что Agent 3 может быстро превращать идеи в реальные продукты, значительно повышая эффективность разработки и даже предоставляя подробные отчеты о работе. Этот прогресс предвещает огромный потенциал AI-агентов в области разработки программного обеспечения, особенно в предоставлении тестируемых сред, где Replit считается лидером. (amasad, amasad, amasad)
🎯 ТЕНДЕНЦИИ
宇树科技加速IPO,聚焦具身智能“让AI干活” : Unitree Robotics, единорог в области четвероногих роботов, активно готовится к IPO. Основатель Ван Синсин подчеркивает огромный потенциал AI в физических приложениях, полагая, что развитие больших моделей предоставляет возможность для интеграции AI и робототехники. Несмотря на то, что развитие воплощенного интеллекта сталкивается с такими проблемами, как сбор данных, слияние мультимодальных данных и выравнивание управления моделями, Ван Синсин оптимистично смотрит в будущее, полагая, что порог для инноваций и предпринимательства значительно снизился, и небольшие организации будут обладать большей взрывной силой. Unitree Robotics занимает лидирующие позиции на рынке четвероногих роботов, с годовым доходом, превышающим 1 миллиард юаней. IPO направлено на использование капитала для ускорения будущего, в котором роботы будут глубоко вовлечены. (36氪)

苹果AI部门高层动荡,Siri新功能延期至2026年 : AI-отдел Apple сталкивается с волной увольнений высшего руководства: бывший руководитель Siri Robby Walker скоро покинет свой пост, а ключевые члены команды были переманены Meta. Из-за постоянных проблем с качеством и перехода на новую базовую архитектуру, новые персонализированные функции Siri будут отложены до весны 2026 года. Эти перестановки и задержки вызывают вопросы относительно скорости инноваций и внедрения AI в Apple. Хотя компания активно работает над AI-серверными чипами и оценкой внешних моделей, фактический прогресс отстает от ожиданий. (36氪)
mmBERT:多语言编码器模型的新进展 : mmBERT — это модель-кодировщик, предварительно обученная на 3T многоязычного текста на более чем 1800 языках. Модель включает инновационные элементы, такие как обратное планирование коэффициента маскирования и обратное соотношение температурной выборки, а также данные более чем 1700 низкоресурсных языков, добавленные на поздних этапах обучения, что значительно повысило производительность. mmBERT демонстрирует отличные результаты в задачах классификации и извлечения как для высоко-, так и для низкоресурсных языков, сопоставимые с производительностью таких моделей, как o3 от OpenAI и Gemini 2.5 Pro от Google, заполняя пробел в исследованиях многоязычных моделей-кодировщиков. (HuggingFace Daily Papers)
MachineLearningLM:LLM实现上下文机器学习的新框架 : MachineLearningLM — это фреймворк для непрерывного предварительного обучения, разработанный для предоставления мощных возможностей контекстного машинного обучения универсальным LLM (таким как Qwen-2.5-7B-Instruct), сохраняя при этом их общие знания и способности к рассуждению. Путем синтеза задач ML из миллионов структурированных причинных моделей (SCM) и использования эффективных токеновых подсказок, этот фреймворк позволяет LLM обрабатывать до 1024 примеров исключительно через контекстное обучение (ICL) без градиентного спуска. MachineLearningLM превосходит сильные базовые модели, такие как GPT-5-mini, примерно на 15% в среднем в задачах классификации таблиц вне домена в таких областях, как финансы, физика, биология и медицина. (HuggingFace Daily Papers)
Meta vLLM:大规模推理效率的新突破 : Иерархическая реализация vLLM от Meta значительно повысила эффективность PyTorch и vLLM в крупномасштабном выводе, превзойдя их внутренний стек как по задержке, так и по пропускной способности. Возвращая результаты оптимизации сообществу vLLM, этот прогресс обещает более эффективные и экономичные решения для AI-вывода, что особенно важно для обработки задач вывода больших языковых моделей, способствуя развертыванию и масштабированию AI-приложений в реальных сценариях. (vllm_project)

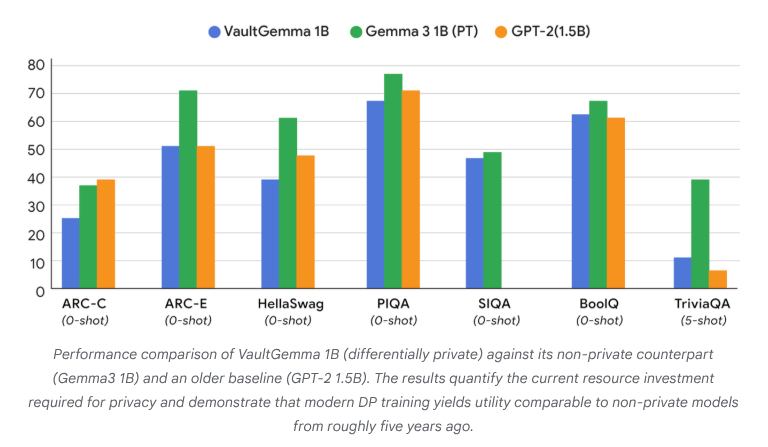
VaultGemma:首个差分隐私开源LLM发布 : Google Research выпустила VaultGemma, крупнейшую на сегодняшний день модель с открытым исходным кодом, обученную с нуля и обладающую дифференциальной конфиденциальностью. Это исследование не только предоставляет веса и технический отчет VaultGemma, но и впервые предлагает законы масштабирования для языковых моделей с дифференциальной конфиденциальностью. Выпуск VaultGemma закладывает важную основу для создания более безопасных и ответственных AI-моделей на основе конфиденциальных данных и способствует развитию технологий AI, защищающих конфиденциальность, делая их более применимыми на практике. (JeffDean, demishassabis)
OpenAI GPT-5/GPT-5-mini API速率限制大幅提升 : OpenAI объявила о значительном увеличении лимитов скорости API для GPT-5 и GPT-5-mini, при этом некоторые уровни удвоены. Например, Tier 1 для GPT-5 увеличен с 30K TPM до 500K TPM, а Tier 2 — с 450K до 1M. Tier 1 для GPT-5-mini также увеличен с 200K до 500K. Эта корректировка значительно расширяет возможности разработчиков по использованию этих моделей для крупномасштабных приложений и экспериментов, снижая узкие места, вызванные ограничениями скорости, и способствуя дальнейшему коммерческому применению и развитию экосистемы моделей серии GPT-5. (OpenAIDevs)
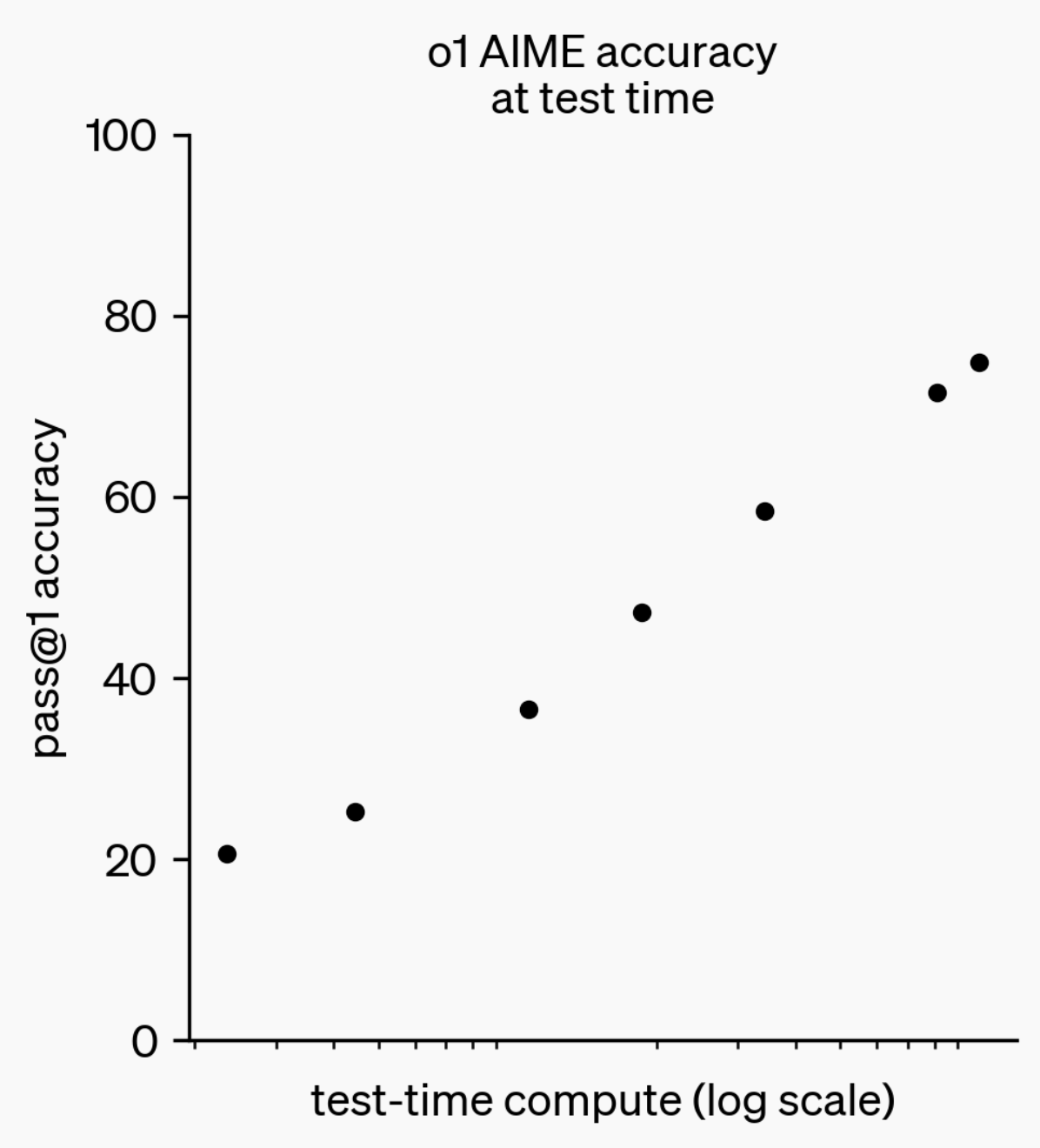
LLM推理能力演进:从o1-preview到GPT-5 Pro : За последний год возможности вывода больших языковых моделей (LLM) значительно улучшились. От модели o1-preview, выпущенной OpenAI год назад, которой требовались секунды на обдумывание, до современных передовых моделей вывода, способных думать часами, просматривать веб-страницы и писать код, — это демонстрирует постоянное расширение измерений AI-вывода. Обучение моделей “думать” с помощью обучения с подкреплением (RL) и использование приватной цепочки мыслей (chain of thought) улучшает производительность LLM в задачах вывода по мере увеличения времени обдумывания, предвещая, что расширение вычислительных возможностей вывода станет новым направлением развития моделей в будущем. (polynoamial, gdb)
日本Sakana AI:自然启发的AI独角兽 : Японский стартап Sakana AI достиг оценки более 1 миллиарда долларов в течение года после основания, став самой быстрой компанией в Японии, получившей статус “единорога”. Компания, основанная бывшим исследователем Google Brain David Ha, использует AI-подход, вдохновленный “коллективным интеллектом” природы, и стремится интегрировать существующие малые и большие системы, а не слепо гнаться за крупными, энергоемкими моделями. Sakana AI уже выпустила офлайн-чат-бота на японском языке “Tiny Sparrow” и AI, способный понимать японскую литературу, а также установила партнерство с японским банком Mitsubishi UFJ Bank для разработки “специализированной AI-системы для банков”. Компания подчеркивает привлечение талантов через “японскую мягкую силу” и проведение смелых экспериментов в области AI. (SakanaAILabs)
机器人技术突破与AI融合:人形、集群及四足机器人新进展 : Область робототехники переживает значительный прогресс, особенно в отношении гуманоидных, роевых и четвероногих роботов. Естественное диалоговое взаимодействие гуманоидных роботов с сотрудниками стало реальностью, четвероногие роботы достигли поразительной скорости, пробегая 100 метров менее чем за 10 секунд, а роевые роботы демонстрируют “удивительный интеллект”. Кроме того, навигационная система ANT для навигации по сложной местности и автономная база для подъема по лестнице, разработанная Eufy для роботов-пылесосов, предвещают более широкое применение роботов в повседневных и промышленных сценариях. Применение AI в клинических испытаниях нейронауки также углубляется, демонстрируя потенциал AI в области здравоохранения через анализ влияния использования интеллектуального экзоскелета HAPO SENSOR. (Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
🧰 ИНСТРУМЕНТЫ
Qwen Code v0.0.10 & v0.0.11更新:提升开发体验与效率 : Alibaba Cloud Qwen Code выпустила версии v0.0.10 и v0.0.11, предлагая множество новых функций и улучшений, ориентированных на разработчиков. Новые версии включают Subagents для интеллектуального декомпозиции задач, инструмент Todo Write для отслеживания задач и функцию “Welcome Back” для сводки проекта при его повторном открытии. Кроме того, обновление включает настраиваемые политики кэширования, более плавный опыт редактирования (без циклов агентов), встроенное стресс-тестирование терминала, меньшее количество повторных попыток, оптимизированное чтение файлов больших проектов, улучшенную интеграцию IDE и shell, лучшую поддержку MCP и OAuth, а также улучшенное управление памятью/сессиями и многоязычную документацию. Эти улучшения призваны значительно повысить производительность разработчиков. (Alibaba_Qwen)
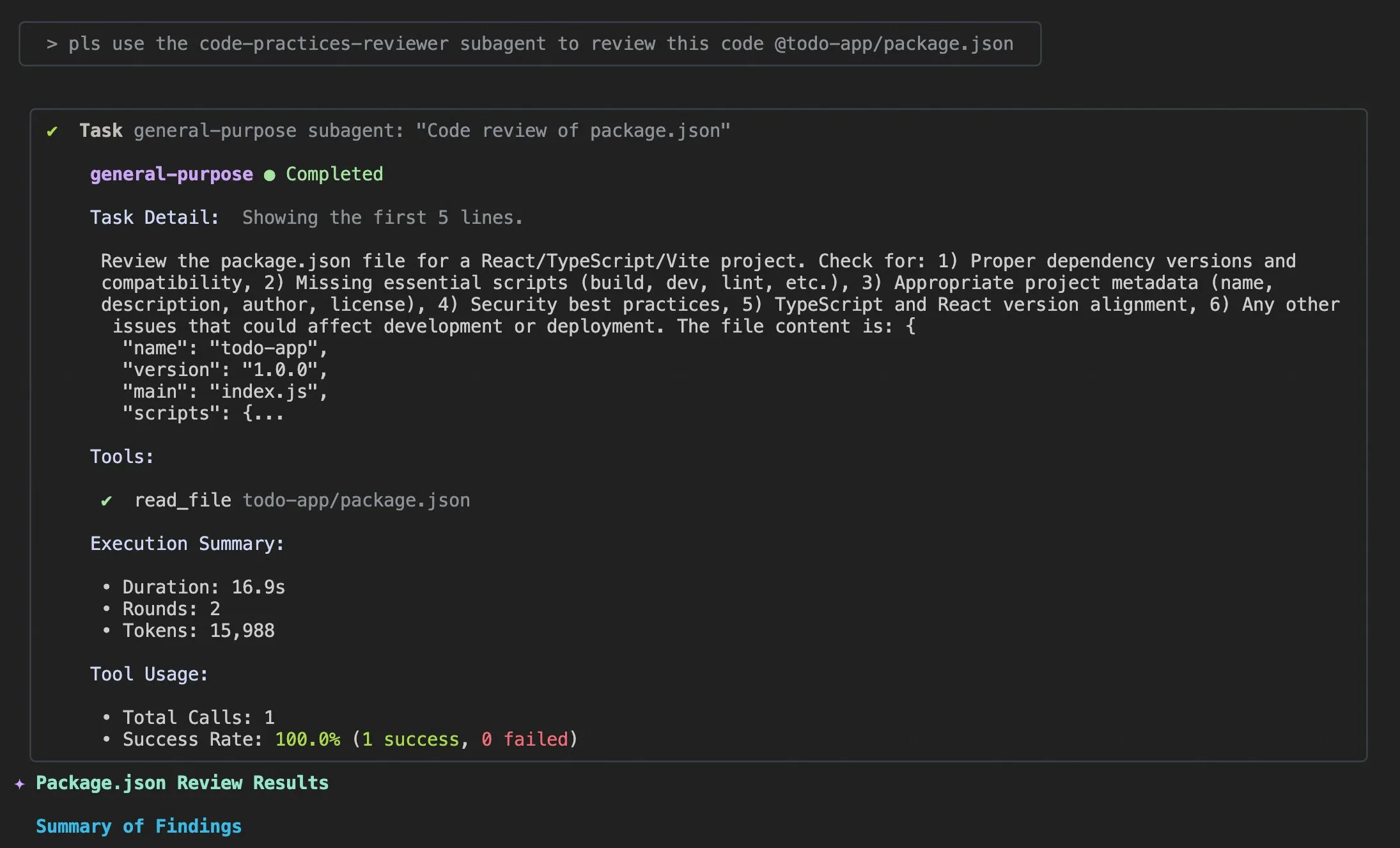
Claude Code使用技巧与用户体验改进 : Постоянно появляются обсуждения и предложения по улучшению пользовательского опыта Claude Code. Пользователи поделились подсказкой “добавить соответствующую информацию в логи”, чтобы помочь AI-агенту решать проблемы с кодом. Разработчики выпустили iOS-приложение “Standard Input” для Claude Code, поддерживающее использование на мобильных устройствах, push-уведомления и интерактивный чат. В то же время сообщество также обсудило непоследовательность Claude Code при работе с крупными проектами и важность управления контекстом, рекомендуя пользователям активно очищать контекст, настраивать файлы Claude md и стиль вывода, использовать субагентов для декомпозиции задач, а также применять режимы планирования и хуки (hooks) для повышения эффективности и качества кода. (dotey, mattrickard, Reddit r/ClaudeAI)
Hugging Face与VS Code/Copilot深度集成,赋能开发者 : Hugging Face через своих поставщиков вывода интегрировала сотни самых современных открытых моделей (таких как Kimi K2, Qwen3 Next, gpt-oss, Aya и другие) непосредственно в VS Code и GitHub Copilot. Эта интеграция поддерживается партнерами, такими как Cerebras Systems, FireworksAI, Cohere Labs, Groq Inc, предоставляя разработчикам более широкий выбор моделей и подчеркивая такие преимущества, как открытые веса, автоматическая маршрутизация от нескольких поставщиков, справедливое ценообразование, бесшовное переключение моделей и полная прозрачность. Кроме того, библиотека Transformers от Hugging Face также представила функцию “Continuous Batching”, которая упрощает циклы оценки и обучения, повышает скорость вывода и призвана стать мощным набором инструментов для разработки и экспериментов с AI-моделями. (ClementDelangue, code)

AU-Harness:音频LLM的全面开源评估工具包 : AU-Harness — это эффективный, комплексный фреймворк для оценки с открытым исходным кодом, разработанный специально для больших аудиоязыковых моделей (LALM). Этот инструментарий, благодаря оптимизации пакетной обработки и параллельного выполнения, достиг увеличения скорости до 127%, что сделало возможной крупномасштабную оценку LALM. Он предлагает стандартизированные протоколы подсказок и гибкие конфигурации для справедливого сравнения моделей в различных сценариях. AU-Harness также представил две новые категории оценки: LLM-Adaptive Diarization (временное аудиопонимание) и Spoken Language Reasoning (сложные аудиокогнитивные задачи), призванные выявить значительные пробелы в текущих LALM в задачах временного понимания и сложного речевого вывода, а также способствовать системному развитию LALM. (HuggingFace Daily Papers)
LLM驱动的CI/CD漏洞检测系统AI-DO : AI-DO (Automating vulnerability detection Integration for Developers’ Operations) — это рекомендательная система, интегрированная в процессы непрерывной интеграции/непрерывного развертывания (CI/CD), использующая модель CodeBERT для обнаружения и локализации уязвимостей на этапе проверки кода. Система призвана сократить разрыв между академическими исследованиями и промышленными приложениями. Оценка обобщающей способности CodeBERT в различных областях на открытых и промышленных данных показала, что модель точна в обнаружении в пределах одной области, но ее производительность снижается при переходе между областями. С помощью соответствующих методов недовыборки модели, доработанные на данных с открытым исходным кодом, могут эффективно повысить способность обнаружения уязвимостей. Разработка AI-DO повышает безопасность в процессе разработки без прерывания существующих рабочих процессов. (HuggingFace Daily Papers)
Replit Agent 3:从想法到应用的极速实现 : Agent 3 от Replit продемонстрировал поразительную эффективность, сумев за 145 минут создать полноценное приложение для регистрации в салоне на Upwork, включающее процесс регистрации клиентов, базу данных клиентов и панель управления бэкендом. Агент также обладает высокой степенью автономности, способный работать 193 минуты без вмешательства, генерировать код производственного уровня, включая аутентификацию, базы данных, хранилище и WebSocket, и даже писать собственные тесты и алгоритмы ранжирования. Эти возможности подчеркивают огромный потенциал AI-агентов в быстрой разработке прототипов и создании полнофункциональных приложений, что значительно ускорит процесс преобразования идей в реальные продукты. (amasad, amasad, amasad)
Claude新增文件创建与编辑功能 : Claude теперь может напрямую создавать и редактировать электронные таблицы Excel, документы, презентации PowerPoint и файлы PDF в Claude.ai и настольном приложении. Эта новая функция значительно расширяет сценарии использования Claude в повседневной офисной работе и инструментах повышения производительности, позволяя ему глубже участвовать в рабочих процессах обработки документов и генерации контента, повышая эффективность и удобство пользователей при работе со сложными файловыми задачами. (dl_weekly)
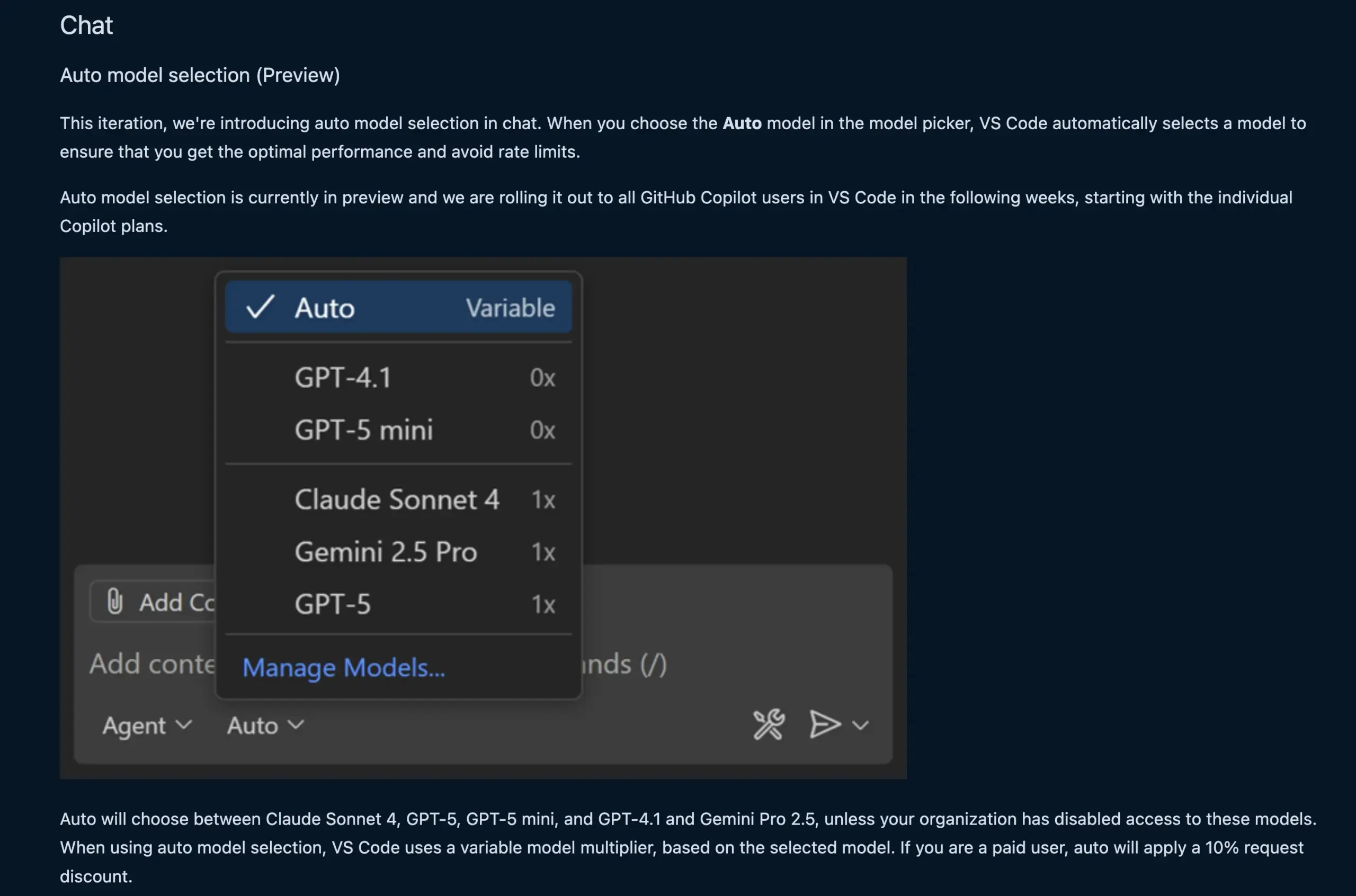
VS Code聊天功能自动选择LLM模型 : Новая функция чата VS Code теперь может автоматически выбирать подходящую модель LLM в зависимости от запроса пользователя и ограничений скорости. Эта функция обеспечивает интеллектуальное переключение между моделями, такими как Claude Sonnet 4, GPT-5, GPT-5 mini, GPT-4.1 и Gemini Pro 2.5, предоставляя разработчикам более удобный и эффективный опыт AI-помощи в программировании. В то же время API расширения поставщика чата языковых моделей VS Code был окончательно доработан, что позволяет вносить модели через расширения и поддерживает режим “Bring Your Own Key” (BYOK), что еще больше расширяет выбор моделей и возможности настройки. (code, pierceboggan)
Box推出AI代理能力,赋能非结构化数据管理 : Box объявила о запуске новых функций AI-агентов, призванных помочь клиентам в полной мере использовать ценность их неструктурированных данных. Обновленный Box AI Studio упрощает создание AI-агентов, которые могут применяться в различных бизнес-функциях и отраслевых сценариях использования. Box Extract использует AI-агентов для сложного извлечения данных из различных документов, а Box Automate — это новое решение для автоматизации рабочих процессов, позволяющее пользователям развертывать AI-агентов в рабочих процессах контент-центра. Эти функции бесшовно интегрируются с существующими системами клиентов через предварительно созданные интеграции, Box API или новый Box MCP Server, призванные революционизировать способ обработки неструктурированного контента предприятиями. (hwchase17)
Cursor新Tab模型:提升代码建议准确率与接受度 : Cursor выпустил новую модель Tab в качестве своего инструмента для предложений кода по умолчанию. Модель обучена с использованием онлайн-обучения с подкреплением (RL) и, по сравнению со старой моделью, сократила количество предложений кода на 21%, но увеличила процент принятия предложений на 28%. Это улучшение означает, что новая модель может предоставлять более точные и соответствующие намерениям разработчика предложения кода, тем самым значительно повышая эффективность программирования и пользовательский опыт, уменьшая ненужные отвлечения и позволяя разработчикам более эффективно выполнять задачи кодирования. (BlackHC, op7418)
awesome-llm-apps:开源LLM应用集合 : Проект awesome-llm-apps на GitHub назван золотой жилой с открытым исходным кодом, он собрал более 40 развертываемых LLM-приложений, охватывающих множество областей, от AI-агентов для преобразования блогов в подкасты до анализа медицинских изображений. Каждое приложение сопровождается подробной документацией и инструкциями по настройке, что позволяет выполнять работу, которая раньше занимала недели, теперь за считанные минуты. Например, проект AI-аудиогида, использующий многоагентную систему, поиск в реальном времени и технологию TTS, способен генерировать естественные и контекстно-зависимые аудиогиды с низкими затратами на API, демонстрируя практичность многоагентных систем в генерации контента. (Reddit r/MachineLearning)
📚 ОБУЧЕНИЕ
MMOral:牙科全景X光分析多模态基准与指令数据集 : MMOral — это первый крупномасштабный мультимодальный набор данных инструкций и бенчмарк, специально разработанный для интерпретации панорамных рентгеновских снимков зубов. Набор данных содержит 20 563 аннотированных изображения и 1,3 миллиона примеров следования инструкциям, охватывающих такие задачи, как извлечение атрибутов, генерация отчетов, визуальные вопросы-ответы и диалоги по изображениям. Комплексный набор оценки MMOral-Bench охватывает пять ключевых аспектов стоматологической диагностики. Результаты показывают, что даже лучшие модели LVLM, такие как GPT-4o, достигают точности всего 41,45%, что подчеркивает ограничения существующих моделей в этой области. OralGPT, путем SFT для Qwen2.5-VL-7B, достиг значительного улучшения производительности на 24,73%, заложив основу для интеллектуальной стоматологии и клинических мультимодальных AI-систем. (HuggingFace Daily Papers)
Transformer漏洞检测的跨领域评估 : Исследование оценило производительность CodeBERT в обнаружении уязвимостей в промышленном и открытом программном обеспечении, а также проанализировало его способность к междоменной обобщенности. Исследование показало, что модели, обученные на промышленных данных, точны в обнаружении в пределах той же области, но их производительность снижается на открытом исходном коде. В то время как модели глубокого обучения, доработанные на данных с открытым исходным кодом с использованием соответствующих методов недовыборки, могут эффективно повысить способность обнаружения уязвимостей. На основе этих результатов исследовательская группа разработала систему AI-DO, рекомендательную систему, интегрированную в процессы CI/CD, которая может обнаруживать и локализовать уязвимости во время проверки кода, не нарушая существующие рабочие процессы, с целью продвижения академических технологий в промышленные приложения. (HuggingFace Daily Papers)
Ego3D-Bench:自我中心多视角场景下的VLM空间推理基准 : Ego3D-Bench — это новый бенчмарк, разработанный для оценки возможностей трехмерного пространственного рассуждения визуально-языковых моделей (VLM) на эгоцентрических, многоракурсных данных на открытом воздухе. Бенчмарк содержит более 8600 пар вопросов-ответов, аннотированных людьми, для тестирования 16 SOTA VLM, таких как GPT-4o, Gemini1.5-Pro. Результаты показывают, что текущие VLM имеют значительный разрыв с человеческим уровнем в пространственном понимании. Для преодоления этого разрыва исследовательская группа предложила фреймворк пост-обучения Ego3D-VLM, который, генерируя когнитивные карты на основе оценочных глобальных трехмерных координат, в среднем улучшил производительность в вопросах с множественным выбором на 12% и в оценке абсолютного расстояния на 56%, предоставляя ценный инструмент для достижения человеческого уровня пространственного понимания. (HuggingFace Daily Papers)
LLM长期任务执行的“回报递减错觉” : Новое исследование изучает производительность LLM в выполнении долгосрочных задач, указывая, что небольшое улучшение точности на одном шаге может привести к экспоненциальному увеличению длины задачи. В статье утверждается, что неудачи LLM в длительных задачах связаны не с недостаточной способностью к рассуждению, а с ошибками выполнения. Путем явного предоставления знаний и планов исследование показало, что большие модели могут правильно выполнять больше шагов, даже если маленькие модели достигают 100% точности на одном шаге. Интересное открытие заключается в том, что модели демонстрируют эффект “саморегуляции”: когда контекст содержит предыдущие ошибки, модель с большей вероятностью снова совершит ошибку, и это не может быть решено только масштабом модели. Новейшие “модели мышления” позволяют избежать саморегуляции и выполнять более длинные задачи за одно выполнение, подчеркивая огромные преимущества масштабирования моделей и последовательных тестовых вычислений для долгосрочных задач. (Reddit r/ArtificialInteligence)
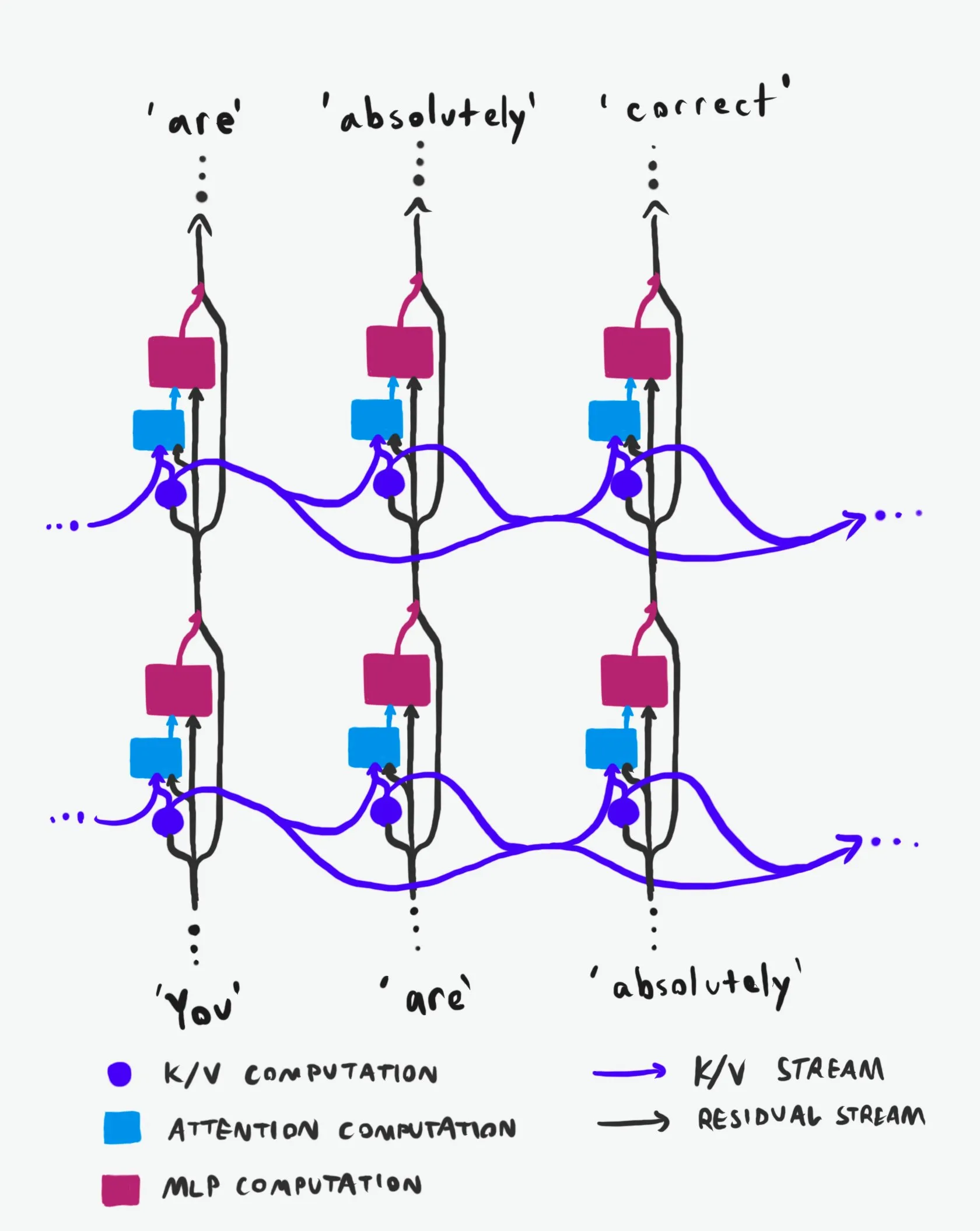
Transformer因果结构:信息流动的深入解析 : Техническое объяснение, названное “лучшим в своем роде”, глубоко анализирует причинную структуру больших языковых моделей Transformer (LLM) и способы потока информации в них. Это объяснение, избегая сложной терминологии, четко разъясняет две основные информационные магистрали в архитектуре Transformer: Residual Stream и механизм внимания. Благодаря визуализации и подробному описанию оно помогает исследователям и разработчикам лучше понять внутреннюю работу Transformer, что позволяет принимать более обоснованные решения в области проектирования, оптимизации и отладки моделей, имея большое значение для глубокого освоения базовых механизмов LLM. (Plinz)
卡内基梅隆大学开设LM推理新课程 : @gneubig и @Amanda Bertsch из Университета Карнеги-Меллон (CMU) этой осенью будут совместно преподавать новый курс по выводу языковых моделей (LM). Курс призван дать всестороннее представление о области вывода LM, охватывая все: от классических алгоритмов декодирования до новейших методов LLM, а также ряд работ, ориентированных на эффективность. Материалы курса будут опубликованы онлайн, включая видео первых четырех лекций, предоставляя ценные учебные ресурсы для студентов и исследователей, интересующихся выводом LM, помогая им освоить передовые методы и практики вывода. (lateinteraction, dejavucoder, gneubig)
OpenAIDevs发布Codex深度解析视频 : OpenAIDevs выпустили видео с глубоким анализом Codex, подробно описывающее изменения и новейшие функции Codex за последние два месяца. Видео предлагает советы и лучшие практики для полного использования Codex, призванные помочь разработчикам лучше понять и использовать этот мощный инструмент AI-программирования. Содержание охватывает последние достижения Codex в генерации кода, отладке и вспомогательной разработке, являясь важным учебным ресурсом для разработчиков, стремящихся повысить эффективность AI-помощи в программировании. (OpenAIDevs)
2025年云计算GPU市场现状报告 : dstackai опубликовала отчет о состоянии рынка облачных GPU в 2025 году, охватывающий затраты, производительность и стратегии использования. В отчете подробно анализируются текущие рыночные цены, аппаратные конфигурации и показатели производительности, предоставляя инженерам машинного обучения конкретные рыночные данные и рекомендации по выбору поставщика облачных услуг, дополняя общие руководства по выбору облачного провайдера в инженерии машинного обучения, что имеет важное значение для оптимизации затрат и эффективности обучения и вывода AI. (stanfordnlp)
AI硬件全景图:驱动AI的多元计算单元 : The Turing Post опубликовал руководство по оборудованию, движущему AI, подробно описывающее различные вычислительные блоки, такие как GPU, TPU, CPU, ASICs, NPU, APU, IPU, RPU, FPGA, квантовые процессоры, чипы для вычислений в памяти (PIM) и нейроморфные чипы. Руководство подробно исследует роль, преимущества и сценарии применения каждого типа оборудования в AI-вычислениях, помогая читателям получить всестороннее понимание базовой вычислительной поддержки AI-технологического стека, что имеет важное справочное значение для выбора оборудования и проектирования AI-систем. (TheTuringPost)
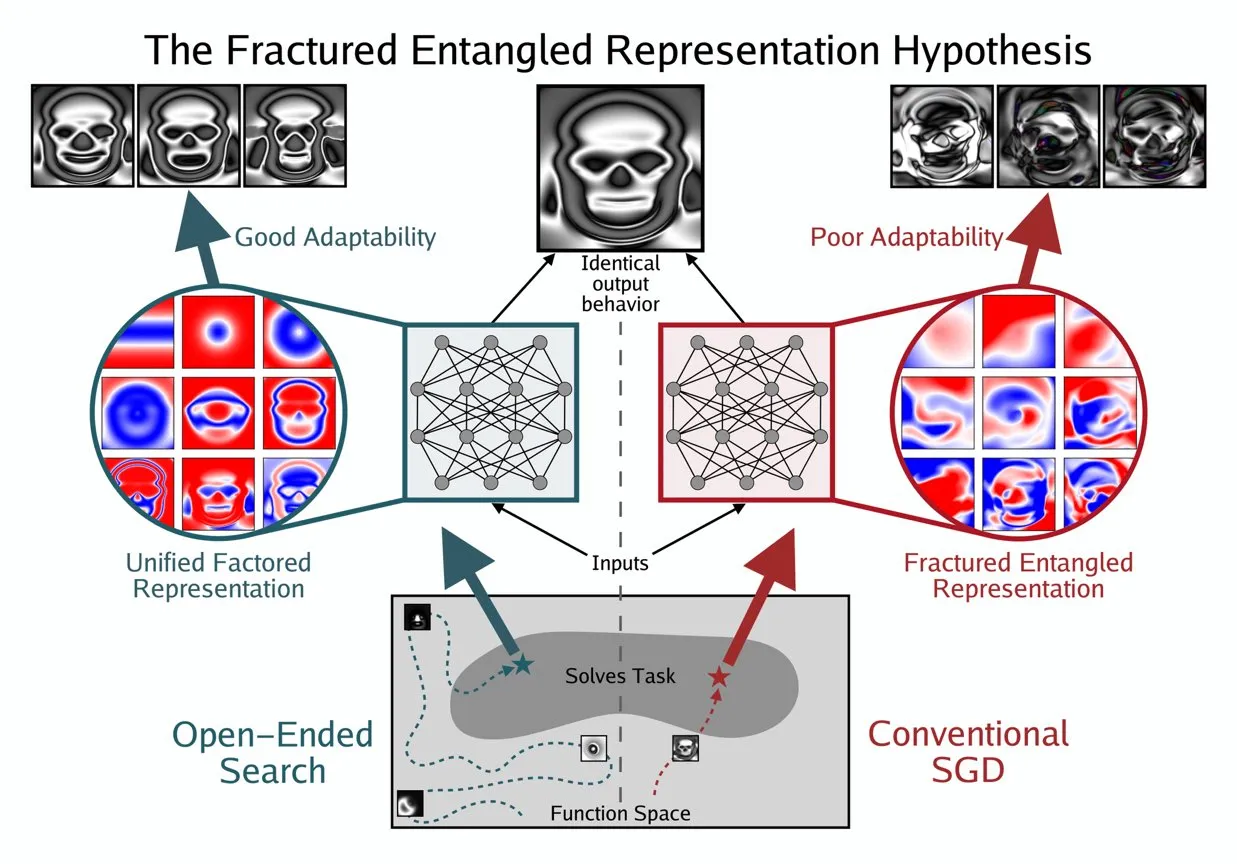
Kenneth Stanley提出UFR概念以理解AI的“真正理解” : Kenneth Stanley предложил концепцию “Единого Факторизованного Представления” (Unified Factored Representation, UFR), чтобы помочь объяснить значение “истинного понимания” AI. Он считает, что когда люди говорят об “истинном понимании” AI, его суть заключается в UFR. Эта концепция призвана предоставить более глубокую теоретическую основу для когнитивных способностей AI, выходя за рамки простого распознавания образов, и затрагивает способность AI структурировать, декомпозировать мир и формировать жесткие ограничения, тем самым побуждая AI не только имитировать знания, но и творчески мыслить и решать новые проблемы, как человек. (hardmaru, hardmaru)
💼 БИЗНЕС
腾讯据报挖角OpenAI顶尖研究员,AI人才战升级 : По сообщению Bloomberg, ведущий исследователь OpenAI Yao Shunyu покинул компанию и присоединился к китайскому технологическому гиганту Tencent. Этот инцидент подчеркивает растущую интенсивность глобальной борьбы за AI-таланты, особенно между США и Китаем. Перемещение ведущих AI-исследователей не только влияет на технологические дорожные карты компаний, но и отражает накал инновационной конкуренции в области AI, предвещая, что будущий ландшафт AI может измениться из-за потока талантов. (The Verge)
OpportuNext寻求技术联合创始人,打造AI招聘平台 : OpportuNext, AI-платформа для найма, основанная выпускниками IIT Bombay, ищет технического соучредителя. Платформа призвана решить болевые точки соискателей и работодателей в процессе найма с помощью комплексного анализа резюме, семантического поиска вакансий, дорожных карт пробелов в навыках и предварительной оценки. Целевой рынок — индийский рынок объемом 262 миллиона долларов, с планами расширения до глобального рынка объемом 40,5 миллиарда долларов. OpportuNext подтвердила соответствие продукта рынку и завершила прототип парсера резюме, планируя завершить раунд финансирования серии A к середине 2026 года. Эта должность требует сильного опыта в AI/ML (NLP), полностековой разработке, инфраструктуре данных, парсерах/API и DevOps/безопасности. (Reddit r/deeplearning)
Oracle创始人Larry Ellison:推理是AI盈利的关键 : Основатель Oracle Larry Ellison заявил: “Вывод — это то, где деньги в AI”. Он считает, что огромные средства, вложенные в обучение моделей, в конечном итоге превратятся в продажи продуктов, которые в основном зависят от возможностей вывода. Эллисон подчеркнул, что Oracle занимает лидирующие позиции в использовании спроса на вывод, предвещая, что нарратив AI-индустрии смещается от “кто может обучить самую большую модель” к “кто может эффективно, надежно и масштабно предоставлять услуги вывода”. Эта точка зрения вызвала дискуссии о будущем направлении экономической модели AI, а именно о том, будут ли услуги вывода доминировать в будущей структуре доходов. (Reddit r/MachineLearning)
🌟 СООБЩЕСТВО
AI伦理与安全:多维度挑战与合作 : Сообщество широко обсудило этические проблемы и проблемы безопасности, связанные с AI, включая потенциальное влияние AI на рынок труда и стратегии защиты, опасения по поводу конфиденциальности и безопасности инструмента ChatGPT MCP, а также серьезные дебаты о возможном риске вымирания, вызванном AI. Проблемы психического здоровья, вызванные AI, такие как чрезмерная зависимость пользователей от AI и даже появление “AI-психоза” и чувства одиночества, также все больше привлекают внимание. В то же время продолжаются дискуссии о регулировании AI (например, законопроект Ted Cruz). Позитивным моментом является то, что такие компании, как Anthropic и OpenAI, сотрудничают с агентствами безопасности для совместного обнаружения и устранения уязвимостей моделей, чтобы усилить защиту AI-безопасности. (Ronald_vanLoon, dotey, williawa, Dorialexander, Reddit r/ArtificialInteligence, Reddit r/artificial, sleepinyourhat, EthanJPerez)

LLM性能与评估:模型质量与基准争议 : Сообщество провело углубленное обсуждение оценки производительности LLM и проблем качества моделей. Модели, такие как K2-Think, были подвергнуты сомнению из-за недостатков в методах оценки (например, загрязнение данных и несправедливое сравнение), что вызвало опасения по поводу надежности существующих AI-бенчмарков. Исследования показывают, что LLM в качестве аннотаторов данных могут вносить предвзятость, что приводит к “LLM Hacking” научных результатов. Опыт пользователей с Claude Code неоднозначен, что отражает его проблемы с согласованностью и “ленивостью”, а Anthropic также признала и исправила проблему деградации производительности Claude Sonnet 4. В то же время GPT-5 Pro получил высокую оценку за свои мощные возможности рассуждения, но пользователи также отметили повсеместность AI-генерируемого текста и постоянное внимание к надежности моделей (например, к ошибкам рассуждения). (Grad62304977, rao2z, Reddit r/LocalLLaMA, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, npew, kchonyc, dejavucoder, vikhyatk)
未来工作与AI代理:效率提升与职业转型 : AI-агенты глубоко меняют способы работы. Эксперты в своих областях (например, юристы, врачи, инженеры) могут расширять свои профессиональные услуги, внедряя личные знания в AI-агентов, что позволяет им не ограничивать доход почасовой оплатой. CEO Replit Amjad Masad прогнозирует, что AI-агенты будут генерировать программное обеспечение по требованию, что приведет к тому, что ценность традиционного программного обеспечения приблизится к нулю, и изменит способы создания компаний. Сообщество обсудило важность предпринимательского духа и адаптивности в эпоху AI, уникальные преимущества Replit в разработке агентов (например, тестируемые среды), а также сравнение эффективности робототехнических моделей с человеческим мозгом. Кроме того, потенциал Cursor как среды для обучения с подкреплением также привлек внимание, предвещая, что AI будет и дальше повышать производительность отдельных лиц и организаций. (amasad, amasad, amasad, fabianstelzer, amasad, lateinteraction, Dorialexander, dwarkesh_sp, sarahcat21)
开源生态与协作:模型普及与社区需求 : Hugging Face играет центральную роль в AI-экосистеме, ее модульная, стандартизированная и интегрированная платформа предоставляет разработчикам богатый набор инструментов и моделей, снижая порог для создания AI. Обсуждения в сообществе подтвердили проект Apple MLX и его вклад в открытый исходный код для повышения эффективности оборудования. В то же время сообщество активно призывает команду Qwen предоставить поддержку GGUF для модели Qwen3-Next, чтобы ее пользовательская архитектура могла работать на более широких локальных фреймворках вывода, таких как llama.cpp, удовлетворяя потребности сообщества в распространении и простоте использования моделей, способствуя дальнейшему развитию технологий AI с открытым исходным кодом. (ClementDelangue, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
AI的广泛社会影响:从娱乐到经济的多元化体现 : AI проникает в общество в различных формах. Короткие AI-драмы о домашних животных стали вирусными в социальных сетях благодаря их антропоморфному повествованию и эмоциональной ценности, демонстрируя огромный потенциал AI в создании контента и развлечениях, привлекая большое количество молодых пользователей и порождая новые бизнес-модели. В то же время дискуссии о движении средств между AI-гигантами (такими как OpenAI и Oracle) вызвали размышления об экономической модели AI. Сообщество также обсудило потенциал AI в решении проблем с ресурсами (например, водными ресурсами) и предложения о том, что AI-чат-ботам требуется больше визуального контента для улучшения пользовательского опыта. Кроме того, применение AI в социальных сетях также вызвало дискуссии о его влиянии на социальные настроения и познание. (36氪, Yuchenj_UW, kylebrussell, brickroad7)
AI社群趣闻与观察:用户对AI的个性化期待与幽默反思 : AI-сообщество полно уникальных наблюдений и юмористических размышлений о развитии технологий и пользовательском опыте. Например, связь между скидочными кодами подписки OpenAI и поведением “мышления” вызвала дискуссии о ценности и стоимости AI. Пользователи хотят, чтобы Claude Code имел более персонализированные ответы и даже придавал AI “личность”, что отражает глубокие потребности в опыте взаимодействия с AI. В то же время предположения об обучении AI-агентов с подкреплением в симулированных средах (например, GTA-6) также демонстрируют безграничное воображение сообщества относительно будущих путей развития AI. Эти обсуждения не только дают представление о текущем состоянии AI-технологий, но и отражают эмоции и ожидания пользователей, возникающие при взаимодействии с AI. (gneubig, jonst0kes, scaling01)
💡 ПРОЧЕЕ
2025年AI技能掌握指南 : С быстрым развитием технологий искусственного интеллекта освоение ключевых AI-навыков становится критически важным для личного карьерного роста. Руководство по освоению AI-навыков в 2025 году выделяет 12 основных навыков, которые необходимо освоить в областях искусственного интеллекта, машинного обучения и глубокого обучения. Эти навыки охватывают все: от базовой теории до практического применения, и призваны помочь профессионалам и учащимся адаптироваться к новым требованиям AI-эпохи к талантам, повышая их конкурентоспособность в технологических инновациях и на рынке труда. (Ronald_vanLoon)

2025年云GPU市场:成本、性能与部署策略报告 : dstackai опубликовала подробный отчет о состоянии рынка облачных GPU в 2025 году, глубоко анализирующий затраты на GPU, показатели производительности и стратегии развертывания различных поставщиков облачных услуг. Отчет призван предоставить инженерам машинного обучения и предприятиям конкретные рекомендации по выбору поставщика облачных услуг, помогая им оптимизировать распределение ресурсов для задач обучения и вывода AI, тем самым принимая более экономически эффективные и производительные решения в условиях растущего спроса на AI-инфраструктуру. (stanfordnlp)
AI硬件技术概览:驱动智能未来的多元计算单元 : The Turing Post опубликовал всеобъемлющее руководство по AI-оборудованию, подробно описывающее различные вычислительные блоки, которые в настоящее время приводят в движение искусственный интеллект. Среди них графические процессоры (GPU), тензорные процессоры (TPU), центральные процессоры (CPU), специализированные интегральные схемы (ASICs), нейросетевые процессоры (NPU), ускорительные процессоры (APU), интеллектуальные процессоры (IPU), резистивные процессоры (RPU), программируемые вентильные матрицы (FPGA), квантовые процессоры, чипы для вычислений в памяти (PIM) и нейроморфные чипы. Это руководство предоставляет четкое представление о базовой аппаратной поддержке AI-технологического стека, помогая разработчикам и исследователям выбирать наиболее подходящие аппаратные решения для их AI-рабочих нагрузок. (TheTuringPost)