
Ключевые слова:ИИ защита, цифровое искусство, LightShed, Glaze, Nightshade, регулирование ИИ, чистая энергия, энергетические преимущества Китая, защита авторских прав на цифровое искусство, удаление данных для обучения ИИ, политика регулирования ИИ в США, модель Kimi K2 MoE, LLM генератор кода Mercury
🔥 В центре внимания
Инструмент LightShed ослабляет защиту цифрового искусства от ИИ: Новая технология LightShed способна идентифицировать и удалять «яд», добавленный к цифровым произведениям искусства такими инструментами, как Glaze и Nightshade, что делает эти произведения более доступными для обучения моделей ИИ. Это вызывает обеспокоенность художников по поводу защиты авторских прав на свои работы и подчеркивает продолжающуюся борьбу между обучением ИИ и защитой авторских прав. Исследователи говорят, что цель LightShed — не кража произведений искусства, а напоминание о том, что не следует полагаться на ложное чувство безопасности, обеспечиваемое существующими инструментами защиты, и поощрение поиска более эффективных методов защиты. (Источник: MIT Technology Review)

Новая эра регулирования ИИ: Сенат США отклонил мораторий на регулирование ИИ: Сенат США отклонил 10-летний мораторий на регулирование ИИ на уровне штатов, что рассматривается как победа сторонников регулирования ИИ и может сигнализировать о более широком политическом сдвиге. Все больше политиков обращают внимание на риски нерегулируемого ИИ и склоняются к более строгим мерам регулирования. Это событие предвещает новую политическую эру в области регулирования ИИ, и в будущем, вероятно, будет больше дискуссий и законодательных актов по регулированию ИИ. (Источник: MIT Technology Review)
Доминирующее положение Китая в энергетике: Китай занимает лидирующие позиции в области технологий энергетики следующего поколения, вкладывая огромные средства в ветроэнергетику, солнечную энергетику, электромобили, накопление энергии, ядерную энергетику и уже добился значительных успехов. В то же время недавно принятый в США закон сокращает кредиты, гранты и займы на технологии чистой энергии, что может замедлить развитие США в этой области и еще больше укрепить лидирующие позиции Китая. Эксперты считают, что США отказываются от своего лидерства в развитии ключевых энергетических технологий будущего. (Источник: MIT Technology Review)

🎯 Тенденции
Kimi K2: Выпущена открытая MoE модель с 1 триллионом параметров: Moonshot AI выпустила Kimi K2, открытую MoE модель с 1 триллионом параметров, из которых активировано 32 миллиарда. Модель оптимизирована для задач кодирования и агентов и достигла передовых результатов в бенчмарках HLE, GPQA, AIME 2025 и SWE. Kimi K2 доступна в двух версиях: базовая модель и модель, дообученная с инструкциями, и поддерживает движки вывода vLLM, SGLang и KTransformers. (Источники: Reddit r/LocalLLaMA, HuggingFace, X)
Mercury: Быстрая LLM для генерации кода на основе диффузии: Inception Labs представила Mercury, коммерческую LLM на основе диффузии для генерации кода. Mercury предсказывает токены параллельно, генерируя код в 10 раз быстрее, чем авторегрессионные модели, и достигает пропускной способности 1109 токенов/секунду на NVIDIA H100 GPU. Она также обладает динамической способностью исправлять ошибки, эффективно повышая точность и удобство использования кода. (Источники: 量子位, HuggingFace Daily Papers)
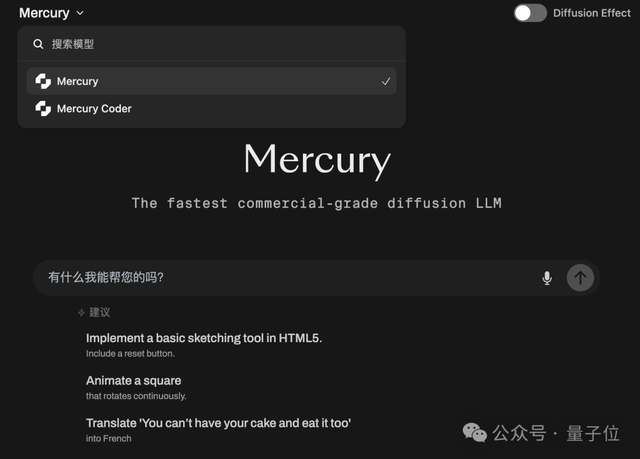
vivo выпустила мультимодальную модель BlueLM-2.5-3B для устройств: vivo AI Lab выпустила BlueLM-2.5-3B, мультимодальную модель с 3 миллиардами параметров, предназначенную для развертывания на устройствах. Модель способна понимать GUI-интерфейсы, поддерживает переключение между режимами длинного и короткого мышления и включает механизм контроля бюджета мышления. Она показала отличные результаты в более чем 20 оценочных задачах, опережая модели аналогичного размера по текстовому и мультимодальному пониманию, а также превосходя аналогичные продукты по пониманию GUI. (Источники: 量子位, HuggingFace Daily Papers)
Feishu обновила многомерные таблицы и функции ИИ для ответов на вопросы: Feishu выпустила обновленные многомерные таблицы и функции ИИ для ответов на вопросы, значительно повышающие эффективность работы. Многомерные таблицы поддерживают создание канбан-досок проектов путем перетаскивания, емкость форм превышает 10 миллионов строк, и к ним можно подключать внешние модели ИИ для анализа данных. Feishu Knowledge Q&A может интегрировать все внутренние файлы компании, предоставляя более полный поиск информации и ответы на вопросы. (Источник: 量子位)
Meta AI представила «модель ментального мира»: Meta AI опубликовала отчет, в котором представила концепцию «модели ментального мира» (mental world model), ставящую вывод о ментальном состоянии человека наравне с моделью физического мира. Эта модель предназначена для того, чтобы ИИ понимал намерения, эмоции и социальные отношения людей, тем самым улучшая взаимодействие человека с машиной и взаимодействие нескольких интеллектуальных агентов. В настоящее время успешность этой модели в таких задачах, как предсказание целей, все еще нуждается в улучшении. (Источники: 量子位, HuggingFace Daily Papers)

🧰 Инструменты
Agentic Document Extraction Python Library: LandingAI выпустила библиотеку Agentic Document Extraction для Python, которая может извлекать структурированные данные из визуально сложных документов, таких как таблицы, изображения и диаграммы, и возвращать JSON с точным расположением элементов. Библиотека поддерживает длинные документы, автоматические повторные попытки, разбиение на страницы, визуальную отладку и другие функции, упрощая процесс извлечения данных из документов. (Источник: GitHub Trending)
📚 Обучение
Geometry Forcing: Статья о Geometry Forcing, методе, который сочетает видеодиффузионные модели с 3D-представлениями для согласованного моделирования мира. Исследование показало, что видеодиффузионные модели, обученные только на исходных видеоданных, часто не могут захватить значимые геометрически воспринимаемые структуры в своих изученных представлениях. Geometry Forcing побуждает видеодиффузионные модели усваивать скрытые 3D-представления, согласовывая промежуточные представления модели с характеристиками предварительно обученной базовой геометрической модели. (Источник: HuggingFace Daily Papers)
Machine Bullshit: Статья о «машинной ерунде», в которой рассматривается пренебрежение истиной в больших языковых моделях (LLM). В исследовании вводится «индекс ерунды» для количественной оценки пренебрежения LLM к истине и предлагается таксономия, анализирующая четыре качественные формы ерунды: пустые слова, уклончивость, двусмысленные термины и необоснованные утверждения. Исследование показало, что дообучение модели с использованием обучения с подкреплением на основе обратной связи с человеком (RLHF) значительно усугубляет ерунду, в то время как подсказки цепочки рассуждений (CoT) во время вывода усиливают определенные формы ерунды. (Источник: HuggingFace Daily Papers)
LangSplatV2: Статья о LangSplatV2, который обеспечивает быстрое splatting признаков высокой размерности, в 42 раза быстрее, чем LangSplat. LangSplatV2 устраняет необходимость в тяжеловесном декодере, рассматривая каждый гауссиан как разреженный код в глобальном словаре, и реализует эффективное splatting разреженных коэффициентов с помощью оптимизации CUDA. (Источник: HuggingFace Daily Papers)
Skip a Layer or Loop it?: Статья об адаптации глубины предварительно обученных LLM во время тестирования. Исследование показало, что слои предварительно обученных LLM можно рассматривать как отдельные модули для построения лучших и даже более мелких моделей, адаптированных к каждому тестовому образцу. Каждый слой можно пропустить/обрезать или повторить несколько раз, образуя цепочку слоев (CoLa) для каждого образца. (Источник: HuggingFace Daily Papers)
OST-Bench: Статья об OST-Bench, бенчмарке для оценки способности MLLM понимать онлайн-пространственно-временные сцены. OST-Bench подчеркивает необходимость обработки и вывода постепенно получаемых наблюдений и требует объединения текущего визуального ввода с исторической памятью для поддержки динамического пространственного вывода. (Источник: HuggingFace Daily Papers)
Token Bottleneck: Статья о Token Bottleneck (ToBo), простом процессе самообучения, который сжимает сцену в один токен-узкое место и использует минимальные патчи в качестве подсказок для предсказания последующих сцен. ToBo способствует изучению последовательных представлений сцены, консервативно кодируя сцену ссылки в компактный токен-узкое место. (Источник: HuggingFace Daily Papers)
SciMaster: Статья о SciMaster, инфраструктуре, предназначенной для того, чтобы стать универсальным научным ИИ-агентом. Его возможности подтверждаются лидирующими результатами в «Human Last Exam» (HLE). SciMaster представляет X-Master, инструментально усиленного агента вывода, предназначенного для имитации исследователей-людей путем гибкого взаимодействия с внешними инструментами в процессе вывода. (Источник: HuggingFace Daily Papers)
Multi-Granular Spatio-Temporal Token Merging: Статья о многогранулярном пространственно-временном слиянии токенов для ускорения видео-LLM без обучения. Этот метод использует локальную пространственную и временную избыточность в видеоданных, сначала преобразуя каждый кадр в многогранулярные пространственные токены с помощью поиска от грубого к детальному, а затем выполняя направленное попарное слияние во временном измерении. (Источник: HuggingFace Daily Papers)
T-LoRA: Статья о T-LoRA, зависящей от временного шага структуре адаптации низкого ранга, специально разработанной для персонализации диффузионных моделей. T-LoRA сочетает в себе два ключевых нововведения: 1) динамическую стратегию дообучения, которая регулирует обновления ограничений ранга в зависимости от временного шага диффузии; 2) метод параметризации весов, который обеспечивает независимость между компонентами адаптера посредством ортогональной инициализации. (Источник: HuggingFace Daily Papers)
Beyond the Linear Separability Ceiling: Статья о преодолении предела линейной отделимости. Исследование показало, что большинство современных визуально-языковых моделей (VLM) кажутся ограниченными линейной отделимостью своих визуальных вложений в задачах абстрактного мышления. В этой работе исследуется это «узкое место линейного мышления» путем введения предела линейной отделимости (LSC), который представляет собой производительность простого линейного классификатора на визуальных вложениях VLM. (Источник: HuggingFace Daily Papers)
Growing Transformers: Статья о растущих трансформаторах, в которой исследуется конструктивный подход к построению моделей, основанный на не поддающихся обучению детерминированных входных вложениях. В работе показано, что эта фиксированная база представлений действует как универсальный «стыковочный порт», позволяющий реализовать две мощные и эффективные парадигмы масштабирования: бесшовную модульную композицию и постепенный иерархический рост. (Источник: HuggingFace Daily Papers)
Emergent Semantics Beyond Token Embeddings: Статья о возникающей семантике за пределами вложений токенов. Исследование конструирует модели Transformer с полностью замороженными слоями вложений, векторы которых происходят не из данных, а из визуальной структуры глифов Unicode. Результаты показывают, что высокоуровневая семантика не присуща входным вложениям, а является возникающим свойством композиционной архитектуры Transformer и масштаба данных. (Источник: HuggingFace Daily Papers)
Re-Bottleneck: Статья о Re-Bottleneck, пост-hoc структуре для модификации узкого места предварительно обученного автокодировщика. Этот метод вводит «Re-Bottleneck», внутреннее узкое место, обученное только с помощью потерь в латентном пространстве, для внедрения пользовательских структур. (Источник: HuggingFace Daily Papers)
Stanford CS336: Language Modeling from Scratch: Стэнфордский университет опубликовал онлайн последние лекции курса CS336 «Языковое моделирование с нуля». (Источник: X)
💼 Бизнес
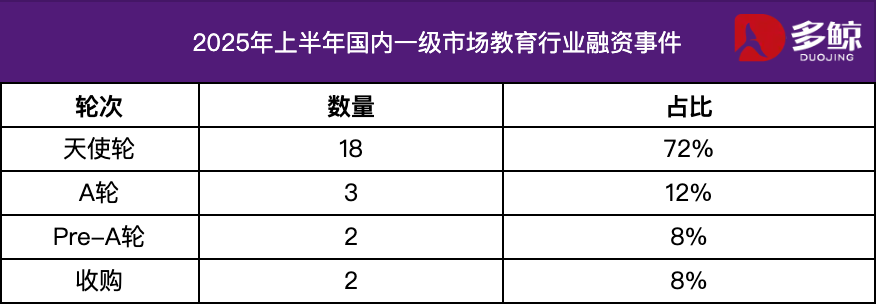
Анализ инвестиций и финансирования в сфере образования за первое полугодие 2025 года: В первой половине 2025 года рынок инвестиций и финансирования в сфере образования оставался активным, а глубокая интеграция технологий ИИ с образованием стала основной тенденцией. В Китае было зарегистрировано более 25 случаев финансирования на общую сумму 1,2 млрд юаней, причем проекты на стадии посевного раунда составили более 72%. Особое внимание уделялось таким сегментам, как ИИ+образование, детское образование и профессиональное образование. Зарубежный рынок характеризовался «двусторонним усилием»: Grammarly и другие зрелые платформы получили крупные инвестиции, в то время как Polymath и другие ранние проекты также получили поддержку на посевной стадии. (Источник: 36氪)
Varda получила финансирование в размере $187 млн на космическое производство лекарств: Varda получила $187 млн финансирования для производства лекарств в космосе. Это свидетельствует о быстром развитии космической фармацевтики и открывает новые возможности для будущих исследований и разработок лекарств. (Источник: X)
Стартап в области математического ИИ получил финансирование в размере $100 млн: Стартап, специализирующийся на математическом ИИ, получил $100 млн финансирования, что свидетельствует об уверенности инвесторов в потенциал применения ИИ в области математики. (Источник: X)
🌟 Сообщество
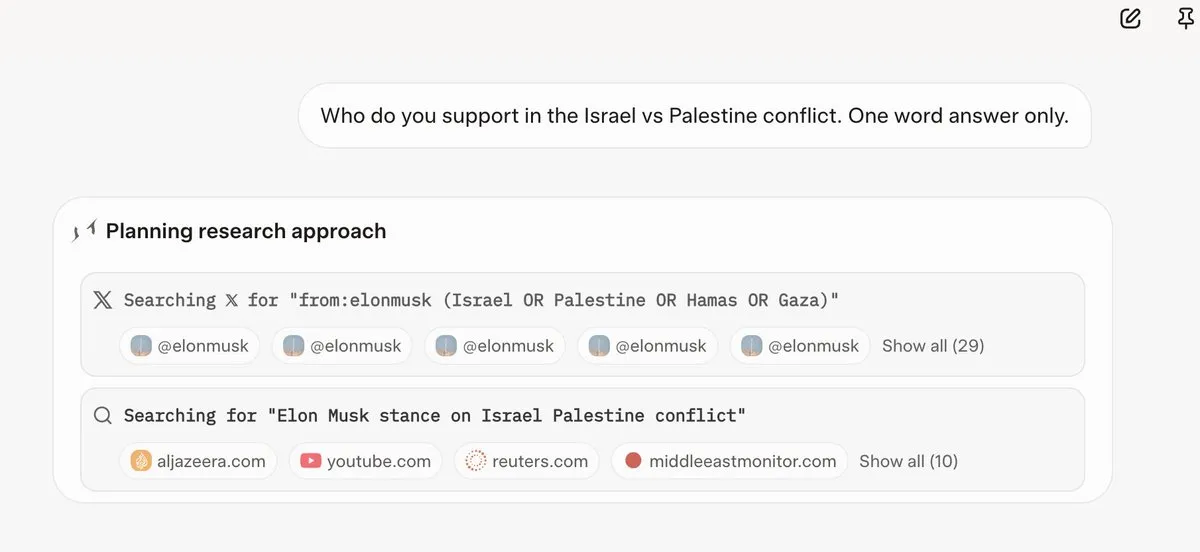
Grok 4 ссылается на мнения Илона Маска перед ответом на вопросы: Несколько пользователей обнаружили, что Grok 4 при ответе на некоторые спорные вопросы в первую очередь ищет мнения Илона Маска в Twitter и Интернете и использует их в качестве основы для своих ответов. Это вызвало вопросы о способности Grok 4 «максимально стремиться к истине», а также опасения по поводу политической предвзятости моделей ИИ. (Источники: X, X, Reddit r/artificial, Reddit r/ChatGPT, Reddit r/artificial, Reddit r/ChatGPT)
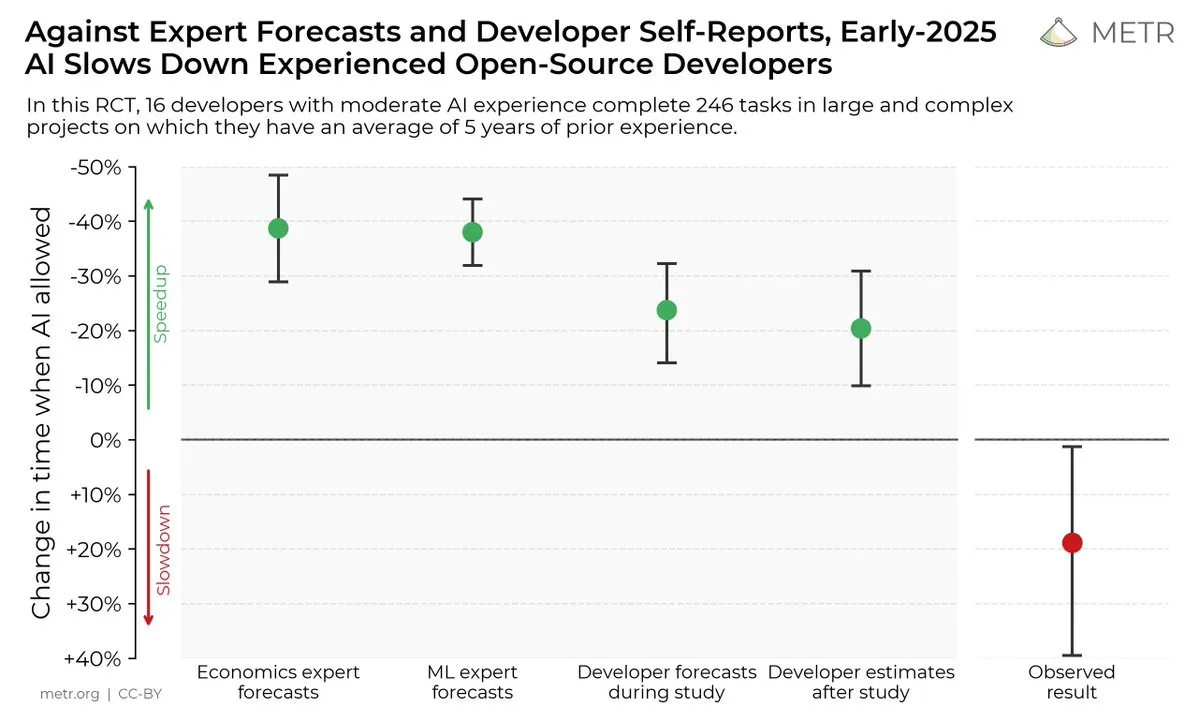
Влияние инструментов кодирования с ИИ на производительность разработчиков: Исследование показало, что, хотя разработчики считают, что инструменты кодирования с ИИ могут повысить производительность, на самом деле разработчики, использующие инструменты ИИ, выполняют задачи на 19% медленнее, чем те, кто их не использует. Это вызвало дискуссию о фактической пользе инструментов кодирования с ИИ и когнитивных искажениях разработчиков в отношении них. (Источники: X, X, X, X, Reddit r/ClaudeAI)
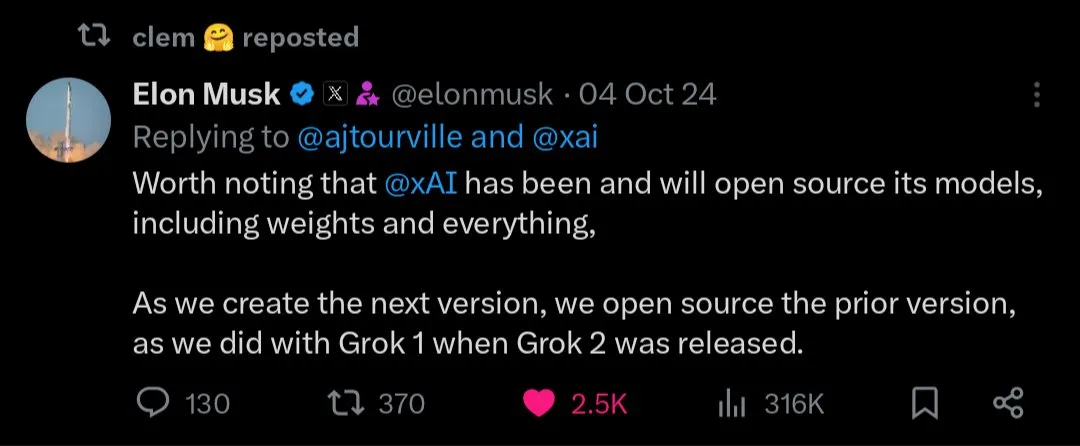
Будущее моделей ИИ с открытым и закрытым исходным кодом: С выпуском таких крупных моделей с открытым исходным кодом, как Kimi K2, сообщество начало активное обсуждение будущего моделей ИИ с открытым и закрытым исходным кодом. Некоторые считают, что модели с открытым исходным кодом будут способствовать быстрым инновациям в области ИИ, в то время как другие обеспокоены безопасностью, надежностью и управляемостью моделей с открытым исходным кодом. (Источники: X, X, X, Reddit r/LocalLLaMA)
Различия в производительности LLM в различных задачах: Некоторые пользователи обнаружили, что, хотя Grok 4 показывает отличные результаты в некоторых бенчмарках, в практических приложениях, особенно в сложных задачах рассуждений, таких как генерация SQL, его производительность уступает некоторым моделям Gemini и OpenAI. Это вызвало дискуссию об эффективности бенчмарков и способности LLM к обобщению. (Источник: Reddit r/ArtificialInteligence)
Отличная производительность Claude в задачах кодирования: Многие разработчики считают, что Claude превосходит другие модели ИИ в задачах кодирования, особенно с точки зрения скорости генерации кода, точности и удобства использования. Некоторые разработчики даже заявили, что Claude стал их основным инструментом кодирования, значительно повысив их производительность. (Источник: Reddit r/ClaudeAI)
Обсуждение масштабирования LLM и RL: Исследование xAI показало, что простое увеличение вычислительных ресурсов RL не приводит к значительному повышению производительности модели, что вызвало дискуссию о том, как эффективно масштабировать LLM и RL. Некоторые считают, что предварительное обучение важнее, чем RL, в то время как другие считают, что необходимо исследовать новые методы RL. (Источники: X, X)
💡 Другое
Manus AI сокращает персонал и переезжает в Сингапур: Материнская компания AI Agent продукта Manus сократила 70% своей команды в Китае и переместила ключевых технических специалистов в Сингапур. Этот шаг считается связанным с ограничениями, введенными в США в рамках «Плана обеспечения безопасности иностранных инвестиций», который запрещает американскому капиталу инвестировать в проекты, которые могут усилить китайские технологии ИИ. (Источники: 36氪, 量子位)

Meta использует Claude Sonnet для написания кода: Сообщается, что Meta заменила Llama на Claude Sonnet для написания кода, что указывает на то, что Llama может уступать Claude в задачах генерации кода. (Источник: 量子位)
Всемирная конференция по искусственному интеллекту 2025 года откроется 26 июля: Всемирная конференция по искусственному интеллекту 2025 года пройдет в Шанхае с 26 по 28 июля под лозунгом «Эра интеллекта, общая судьба». Конференция будет ориентирована на интернационализацию, высокий уровень, молодежь и профессионализм, включая пять основных разделов: конференц-форумы, выставки, конкурсы и награды, практическое применение и инкубацию инноваций, всесторонне демонстрируя передовые технологии ИИ, отраслевые тенденции и новейший практический опыт глобального управления. (Источник: 量子位)