Ключевые слова:Квантовые вычисления, Самообучение ИИ, Нейроинтерфейс, Большие языковые модели, Нейроморфные вычисления, Генерация видео с помощью ИИ, Обучение с подкреплением, Этика ИИ, Уровень ошибок кубитов, Самообучение JEPA, Квантование формата MLX, Модель визуального понимания PAM, Генерация ASMR-контента с помощью ИИ
🔥 Фокус
Оксфордский университет достиг рекордного уровня ошибок в 0,000015% в эксперименте по Quantum Computing: Исследовательская группа Оксфордского университета добилась значительного прорыва в экспериментах по квантовым вычислениям, снизив частоту ошибок кубитов до 0,000015%, установив новый мировой рекорд. Этот прогресс имеет решающее значение для создания отказоустойчивых квантовых компьютеров, поскольку чрезвычайно низкий уровень ошибок является предпосылкой для реализации сложных квантовых алгоритмов и раскрытия потенциала квантовых вычислений. Это достижение демонстрирует значительный прогресс в повышении стабильности кубитов и точности управления на аппаратном уровне, закладывая более прочную основу для будущих приложений в таких областях, как AI, которые зависят от мощных вычислительных ресурсов (источник: Ronald_vanLoon)

Исследователи MIT научили искусственный интеллект самообновляться и совершенствоваться: Исследователи из Массачусетского технологического института (MIT) добились прогресса в области самосовершенствования AI, разработав новый метод, позволяющий системам AI самостоятельно учиться и улучшать свою производительность. Эта способность имитирует процесс постоянного совершенствования человека через опыт и рефлексию и имеет решающее значение для разработки более автономного и адаптивного искусственного интеллекта. Исследование может проложить путь к постоянной оптимизации моделей AI после их развертывания, уменьшая зависимость от вмешательства человека, и оказать глубокое влияние на долгосрочное развитие и применение AI (источник: TheRundownAI)

AI «чтения мыслей» мгновенно преобразует мозговые волны парализованного человека в речь: Прорывное исследование продемонстрировало, как AI «чтения мыслей» в реальном времени преобразует мозговые волны парализованных пациентов в четкую речь. Эта технология использует передовые мозго-компьютерные интерфейсы (BCI) и алгоритмы AI для декодирования нейронных сигналов, связанных с языком, и синтезирования их в понятную речевую продукцию. Это предоставляет совершенно новый способ общения для пациентов, потерявших способность говорить из-за серьезных двигательных нарушений, и обещает значительно улучшить качество их жизни, знаменуя собой важный прогресс AI в области вспомогательной медицины и нейронаук (источник: Ronald_vanLoon)

Достигнут прорыв в вековой проблеме математической физики, выпускники Пекинского университета участвовали в решении шестой проблемы Гильберта: Выпускник Пекинского университета Дэн Юй, Ма Сяо из молодежного класса Научно-технического университета Китая и ученик Теренса Тао Захир Хани добились значительного прорыва в решении шестой проблемы Гильберта «Об аксиоматизации физики». Они впервые строго доказали полный переход от ньютоновской механики (микроскопической, обратимой во времени) к уравнению Больцмана (макроскопической статистической, необратимой во времени), заполнив логический пробел между ними, заложив более прочную математическую основу для статистической механики и неожиданно разрешив «загадку стрелы времени». Это достижение, используя сложные математические инструменты и поэтапные выводы, демонстрирует путь от атомизма к законам движения сплошных сред (источник: 量子位)

🎯 Тенденции
Alibaba выпустила модели серии Qwen3 в формате MLX: Alibaba объявила, что ее большие модели серии Qwen3 теперь поддерживают формат MLX и предлагают четыре уровня квантования: 4-битное, 6-битное, 8-битное и BF16. MLX — это фреймворк машинного обучения, оптимизированный Apple для Apple Silicon. Этот шаг означает, что модели Qwen3 смогут более эффективно работать на устройствах Apple, снижая барьер для развертывания и запуска больших моделей на конечных устройствах и способствуя популяризации и применению больших моделей на персональных устройствах (источник: Alibaba_Qwen, awnihannun, cognitivecompai, Reddit r/LocalLLaMA)
Google выпустила модель Gemma 3n, достигающую высокой производительности при малом количестве параметров: Google представила модель Gemma 3n, которая имеет менее 10 миллиардов параметров, но набрала более 1300 баллов в рейтинге LMArena, став первой малой моделью, достигшей такого результата. Выдающаяся производительность Gemma 3n доказывает, что высокий уровень понимания и генерации языка может быть достигнут при меньшем масштабе параметров, и она поддерживает работу на конечных устройствах, таких как мобильные телефоны, что имеет большое значение для продвижения приложений AI и снижения затрат на вычислительные мощности (источник: osanseviero)
Tencent представила технологию генерации 3D-ассетов кинематографического качества с помощью AI: Tencent продемонстрировала новую технологию искусственного интеллекта, способную генерировать 3D-ассеты кинематографического качества. Ожидается, что эта технология значительно повысит эффективность и качество создания 3D-контента в таких областях, как разработка игр и производство фильмов и телепередач, а также снизит производственные затраты. Быстрая генерация высококачественных 3D-ассетов является ключевым звеном в развитии метавселенной и индустрии цифрового контента (источник: TheRundownAI)
Модель Kuaishou Kling 2.1 демонстрирует превосходные результаты в преобразовании изображений в видео и синхронной генерации аудио и видео: Модель генерации видео с помощью AI Kling от Kuaishou обновлена до версии 2.1, демонстрируя мощные возможности в преобразовании изображений в видео. Утверждается, что новая версия способна генерировать видео и аудио одним щелчком мыши, без необходимости последующего звукового дизайна, создавая синхронизированный аудиовизуальный контент студийного уровня. Это знаменует прогресс AI в генерации мультимодального контента, особенно в области видео, упрощая творческий процесс и повышая качество генерации (источник: Kling_ai, Kling_ai)
Новая AI-модель для видео “Kangaroo”, возможно, является Minimax Hailuo 2.0 и бросает вызов существующим SOTA: На рынке появилась загадочная AI-модель для генерации видео под названием “Kangaroo”, которая демонстрирует сильные результаты на арене AI-видео, особенно в преобразовании изображений в видео. Аналитики предполагают, что эта модель может быть версией Hailuo 2.0 от компании Minimax. Ее появление может изменить существующую иерархию производительности моделей преобразования текста в видео и изображений в видео, хотя ее возможности обработки аудио еще предстоит оценить (источник: TomLikesRobots)
MiniMax выпустила серию моделей M1 с выдающимися возможностями обработки длинных текстов: MiniMaxAI выпустила серию моделей MiniMax-M1, представляющую собой модель MoE (Mixture of Experts) с 456 миллиардами параметров. Модели этой серии показали отличные результаты во многих бенчмарках, особенно в обработке длинного контекста (например, в бенчмарке OpenAI-MRCR), превзойдя GPT-4.1 и заняв третье место в LongBench-v2. Это демонстрирует их потенциал в обработке и понимании длинных документов, однако их больший «бюджет на размышления» (thinking budget) может предъявлять высокие требования к вычислительным ресурсам (источник: Reddit r/LocalLLaMA)

Лауреат премии Тьюринга Richard Sutton: AI переходит от «эпохи человеческих данных» к «эпохе опыта»: Основоположник обучения с подкреплением Richard Sutton на конференции BAII в Пекине отметил, что нынешние большие модели AI, зависящие от человеческих данных, приближаются к своему пределу: высококачественные человеческие данные исчерпываются, а эффективность расширения масштаба моделей снижается. Он считает, что будущее AI заключается во вступлении в «эпоху опыта», то есть агенты будут учиться, генерируя первичный опыт через взаимодействие со средой в реальном времени, а не имитируя старые тексты. Это требует, чтобы интеллектуальные агенты постоянно работали в реальной или смоделированной среде, используя обратную связь от среды в качестве сигнала вознаграждения, развивая модели мира и системы памяти для достижения истинного непрерывного обучения и инноваций (источник: 36氪)

Модель PAM: 3B параметров для интегрированной сегментации, распознавания и описания изображений и видео: MMLab Китайского университета Гонконга и другие учреждения представили Perceive Anything Model (PAM), модель с 3 миллиардами параметров, которая может одновременно выполнять сегментацию, распознавание, интерпретацию и описание объектов на изображениях и видео, а также синхронно выводить текст и маски (Mask). PAM реализует эффективное преобразование визуальных признаков в мультимодальные токены путем введения Semantic Perceiver для соединения основы сегментации SAM2 и LLM. Команда также создала крупномасштабный высококачественный набор данных для обучения на изображениях и текстах. PAM обновляет или приближается к SOTA во многих бенчмарках визуального понимания и обладает лучшей эффективностью вывода (источник: 量子位)

Нейроморфные вычисления могут стать ключом к AI следующего поколения, обещая работу с низким энергопотреблением: Ученые активно исследуют нейроморфные вычисления, стремясь имитировать структуру и принципы работы человеческого мозга для решения проблемы высокого энергопотребления современных моделей AI. Национальные лаборатории США и другие учреждения разрабатывают нейроморфные компьютеры с количеством нейронов, сопоставимым с корой головного мозга человека, теоретическая скорость работы которых значительно превышает биологический мозг, а энергопотребление чрезвычайно низкое (например, 20 Вт для управления AI, подобным человеческому мозгу). Эта технология, благодаря событийно-управляемой связи, вычислениям в памяти и адаптивному обучению, обещает создание более интеллектуального, эффективного и энергосберегающего AI, рассматриваясь как потенциальное решение энергетического кризиса AI и новый путь развития AGI (источник: 量子位)

AI ASMR-контент становится вирусным на платформах коротких видео, технологии вроде Veo 3 способствуют этому: Видео ASMR (автономная сенсорная меридиональная реакция), созданные с помощью AI, быстро набирают популярность на таких платформах, как TikTok. Один аккаунт за 3 дня привлек почти 100 000 подписчиков, а одно видео с нарезкой фруктов набрало более 16,5 миллионов просмотров. Эти видео сочетают необычные визуальные эффекты, созданные AI (например, фрукты со стеклянной текстурой), с соответствующими звуками нарезки, столкновения и т.д., создавая уникальное «затягивающее» ощущение. Модели, такие как Veo 3 от Google DeepMind, которые могут напрямую генерировать синхронизированный аудиовизуальный контент, считаются ключевой технологией, способствующей созданию такого AI ASMR-контента, упрощая ранее необходимый процесс раздельного создания аудио и видео с последующим их объединением (источник: 量子位)

Публикация истории поиска Meta AI привлекает внимание, Google тестирует AI-аудиосводки: Компания Meta обнародовала историю поисковых запросов пользователей своей функции AI-поиска, что вызвало обеспокоенность пользователей по поводу их конфиденциальности и прозрачности использования данных. В то же время Google в рамках своих лабораторных проектов тестирует новую функцию — предоставление аудиосводок в стиле подкастов, сгенерированных AI, в верхней части результатов поиска, с целью предоставить пользователям более удобный способ получения информации. Эти два события отражают постоянные исследования технологических гигантов в области AI-поиска и представления информации, а также попытки оптимизации пользовательского опыта (источник: Reddit r/ArtificialInteligence)

Команда из Сиднея разрабатывает AI-модель для распознавания мыслей по мозговым волнам: Исследовательская группа из Сиднея, Австралия, разработала новую модель искусственного интеллекта, способную распознавать содержание мыслей индивида путем анализа данных электроэнцефалограммы (EEG). Эта технология имеет потенциальную ценность в таких областях, как нейронаука, взаимодействие человека с компьютером и вспомогательная коммуникация, например, помогая людям, которые не могут общаться традиционными способами, выражать свои намерения. Данное исследование способствует дальнейшему развитию технологии мозго-компьютерных интерфейсов и исследует возможности AI в интерпретации сложной мозговой активности (источник: Reddit r/ArtificialInteligence)
Калифорния планирует законодательно ограничить роль «роботов-начальников» AI в принятии решений о найме, увольнении и т.д.: Штат Калифорния, США, продвигает законопроект, направленный на ограничение принятия компаниями ключевых кадровых решений, таких как найм и увольнение, исключительно на основании рекомендаций систем AI. Законопроект требует, чтобы менеджеры-люди проверяли и поддерживали любые подобные рекомендации AI для обеспечения человеческого надзора и подотчетности. Бизнес-группы выступают против этого, утверждая, что это увеличит затраты на соблюдение требований и вступит в конфликт с существующими технологиями найма. Этот шаг отражает растущую обеспокоенность этическими и социальными последствиями AI, особенно в области автоматизации принятия решений на рабочем месте (источник: Reddit r/ArtificialInteligence)

🧰 Инструменты
Выпущен Augmentoolkit 3.0, улучшающий процесс генерации наборов данных и тонкой настройки: Выпущена версия 3.0 Augmentoolkit, инструмента для создания наборов данных QA из длинных документов (например, исторических текстов) и последующей тонкой настройки моделей. Новая версия предоставляет конвейер производственного уровня, который может автоматически генерировать обучающие данные и обучать модели, включает встроенные локальные модели, специально доработанные для генерации высококачественных наборов данных QA, и предлагает интерфейс без написания кода. Инструмент предназначен для упрощения процесса тонкой настройки моделей для конкретных областей и генерации обучающих данных, снижая технический барьер (источник: Reddit r/LocalLLaMA)
Opius AI Planner: AI-планировщик для оптимизации опыта работы с Cursor Composer: Выпущено расширение для Cursor под названием Opius AI Planner, предназначенное для решения проблем Cursor Composer с пониманием нечетких требований. Инструмент анализирует требования проекта, генерирует подробную дорожную карту реализации и выводит структурированные подсказки, оптимизированные для Composer, тем самым сокращая количество итераций и делая результаты проекта более соответствующими первоначальному замыслу. Это отражает тенденцию повышения практичности инструментов генерации кода с помощью AI за счет AI-ассистированного планирования (источник: Reddit r/artificial)
Расширение Continue: реализация локального open-source Copilot с интеграцией MCP в VSCode: Continue — это расширение для VSCode, которое позволяет пользователям настраивать и использовать локально работающие большие языковые модели с открытым исходным кодом в качестве помощников по кодированию, а также интегрировать инструменты MCP (Model Control Protocol). Пользователи могут развертывать модели локально с помощью таких сервисов, как Llama.cpp или LMStudio, и взаимодействовать с ними через Continue, получая полный контроль и возможность настройки помощника по кодированию, например, интегрируя инструмент автоматизации браузера Playwright (источник: Reddit r/LocalLLaMA)

Сочетание большой модели Doubao и Volcano Engine MCP упрощает развертывание облачных сервисов и генерацию персональных страниц: Большая модель Doubao от ByteDance продемонстрировала возможности глубокой интеграции с протоколом управления моделями (MCP) Volcano Engine. Пользователи могут с помощью команд на естественном языке заставить большую модель Doubao вызывать функции Volcano Engine (например, veFaaS — функции как сервис) для выполнения таких задач, как генерация персональной навигационной веб-страницы для социальных сетей и ее автоматическое развертывание. Такая интеграция избавляет от сложных шагов ручной настройки облачной среды, снижает барьер для использования облачных сервисов и демонстрирует потенциал AI в упрощении процессов DevOps (источник: karminski3)
Figma представила новую AI-функцию: мгновенная генерация веб-сайтов из текстовых подсказок: Figma продемонстрировала новую функцию на базе AI, способную быстро генерировать прототипы или страницы веб-сайтов на основе текстовых подсказок (prompt), введенных пользователем. Эта функция призвана ускорить процессы веб-дизайна и разработки, позволяя дизайнерам и разработчикам быстро преобразовывать идеи в визуальные проекты с помощью описаний на естественном языке, что еще раз подчеркивает проникновение генеративного AI в инструменты творческого дизайна (источник: Ronald_vanLoon)
В центре моделей Hugging Face добавлена функция фильтрации по размеру модели: Платформа Hugging Face добавила в свой центр моделей полезную функцию, позволяющую пользователям фильтровать модели по размеру их параметров. Это улучшение позволяет разработчикам и исследователям удобнее находить модели, соответствующие их конкретным аппаратным ресурсам или требованиям к производительности, повышая эффективность навигации и выбора в обширной библиотеке моделей (источник: ClementDelangue, TheZachMueller, huggingface, clefourrier, multimodalart)
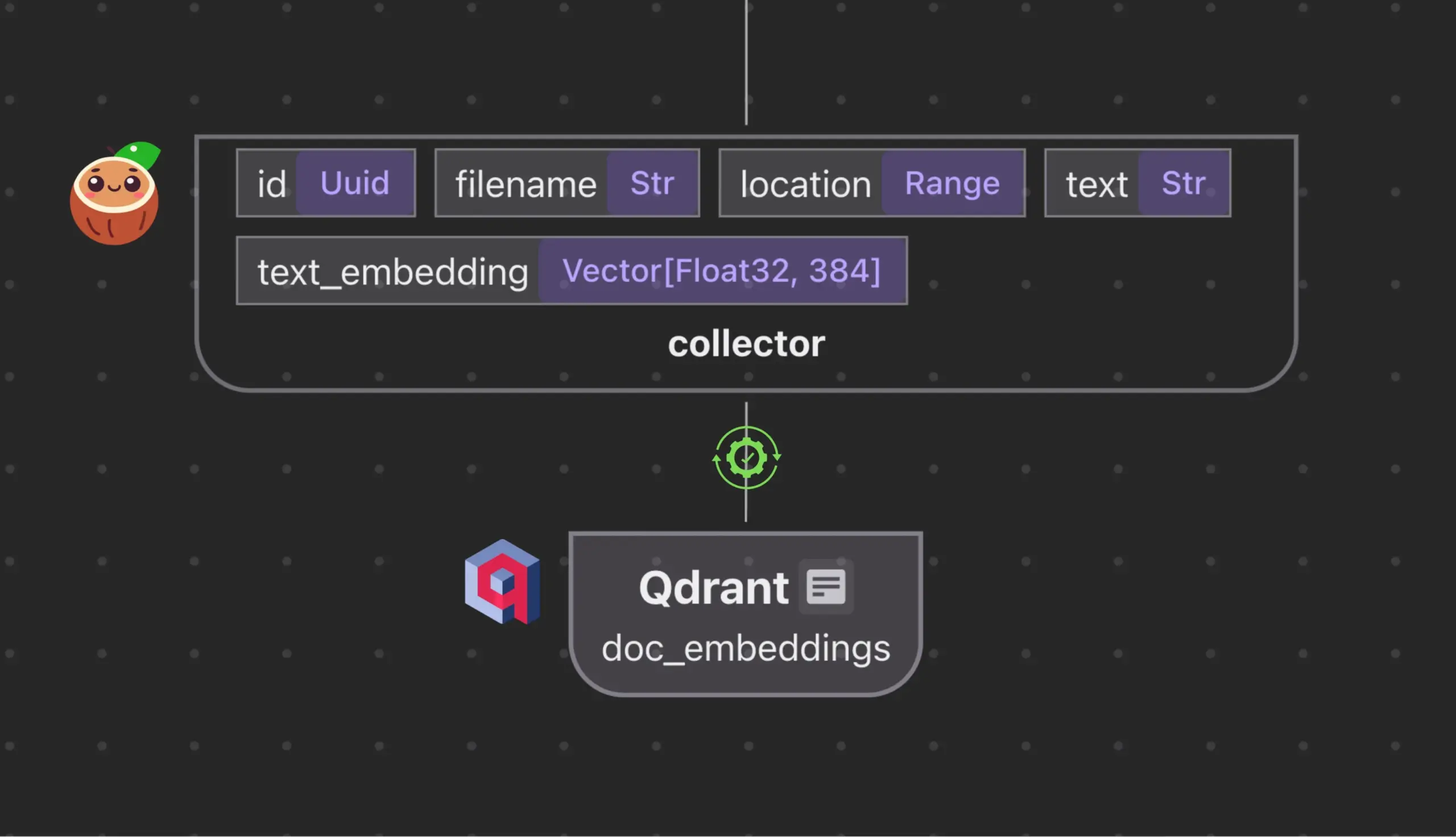
Cocoindex.io интегрирован с Qdrant для автоматического создания и синхронизации коллекций векторных баз данных: Инструмент для потоковой обработки данных с открытым исходным кодом Cocoindex.io теперь поддерживает автоматическое создание коллекций векторных баз данных Qdrant. Пользователям достаточно определить поток данных, и инструмент сможет вывести подходящую схему Qdrant (включая размер вектора, метрику расстояния и структуру полезной нагрузки), а также поддерживать синхронизацию векторных полей, типов полезной нагрузки и первичных ключей, поддерживая инкрементные обновления. Это упрощает настройку и управление векторными базами данных, повышая эффективность команд по работе с данными (источник: qdrant_engine)
Manus AI: инструмент разработки AI полного цикла, который не только пишет код, но и автоматически его развертывает: Manus AI — это инструмент разработки AI полного цикла, способный выполнять все этапы от написания кода до настройки среды, установки зависимостей, тестирования и даже окончательного развертывания на онлайн URL. Он использует архитектуру сотрудничества нескольких агентов (планирование, разработка, тестирование, развертывание) и может самостоятельно решать проблемы с зависимостями и отлаживать ошибки. Несмотря на существующие ограничения, такие как модель ценообразования на основе кредитов, разработка китайской командой (что может повлечь за собой соображения соответствия требованиям) и поддержка сверхсложных корпоративных архитектур, он демонстрирует потенциал перехода от «AI-ассистированного кодирования» к «AI-исполняемой разработке» (источник: Reddit r/artificial)

📚 Обучение
Теория перевода и руководство по оптимизации промптов для AI-перевода: Сочетая теорию «перевод как переписывание» из «Нового исследования перевода» Сы Го и взгляды Юй Гуанчжуна из «Перевод — это великий путь», обсуждаются принципы высококачественного перевода. Подчеркивается, что перевод должен уделять внимание аутентичному выражению на целевом языке, а не буквальному соответствию, гибко использовать дословный и смысловой перевод, а также учитывать логические различия между китайским и западными языками для синтаксического переписывания. В статье также обсуждается чистота китайского выражения, обработка терминологии и переосмысливаются ограничения трехэтапного процесса «дословный перевод — анализ — смысловой перевод» в AI-переводе, предлагая использовать более интегрированный процесс «понимание — выражение — вычитка — оптимизация» для повышения качества AI-перевода, чтобы он лучше соответствовал стилю китайских научно-популярных текстов (источник: dotey)

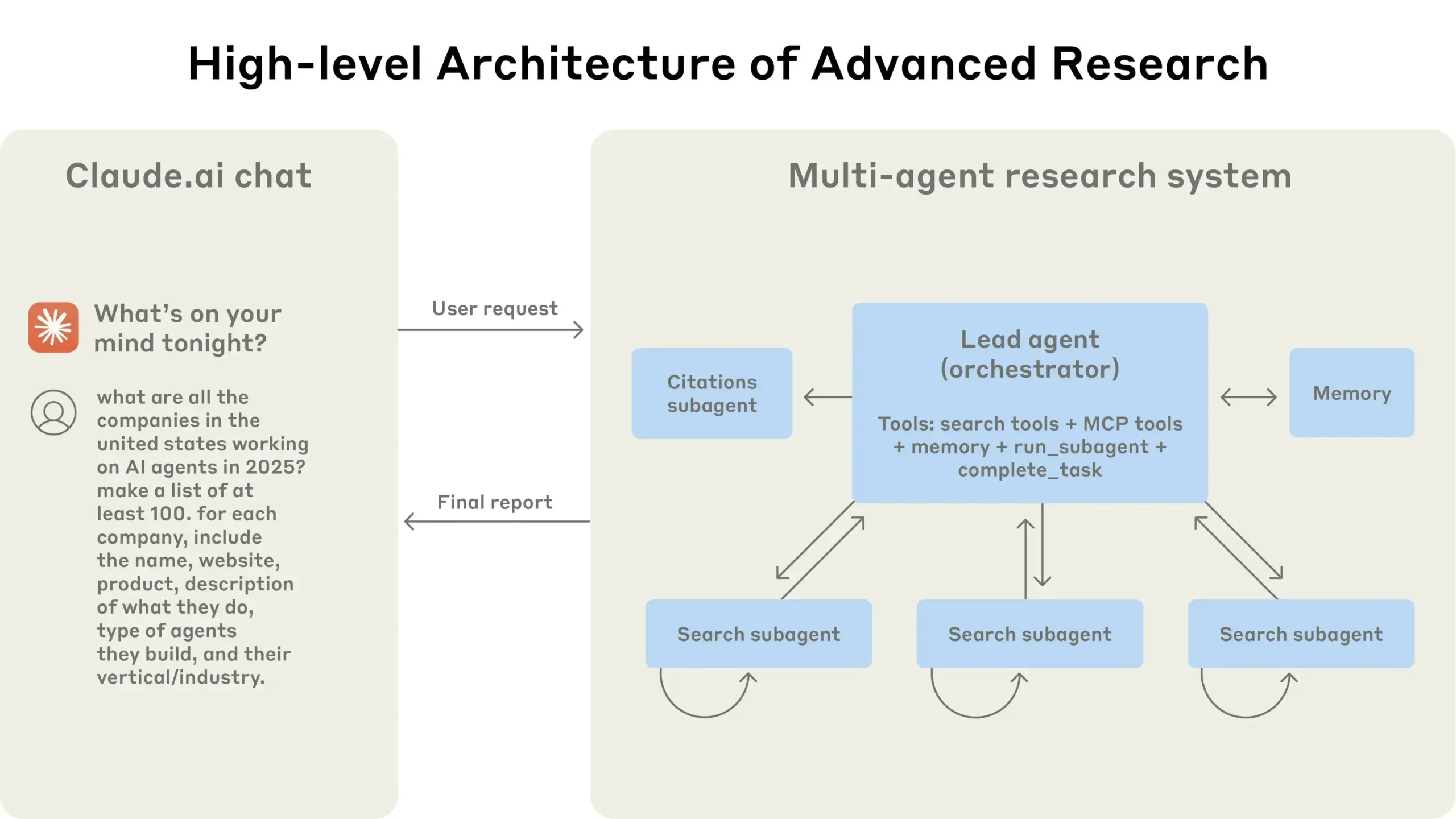
Anthropic делится опытом создания своей многоагентной исследовательской системы: AnthropicAI опубликовала бесплатное руководство, в котором подробно описывается, как они создали свою многоагентную исследовательскую систему. Содержание включает принципы работы архитектуры системы, методы инженерии промптов и тестирования, проблемы, возникающие в производстве, а также преимущества многоагентных систем. Это руководство предоставляет ценный практический опыт и идеи для исследователей и разработчиков, интересующихся многоагентными системами (источник: TheTuringPost, TheTuringPost)
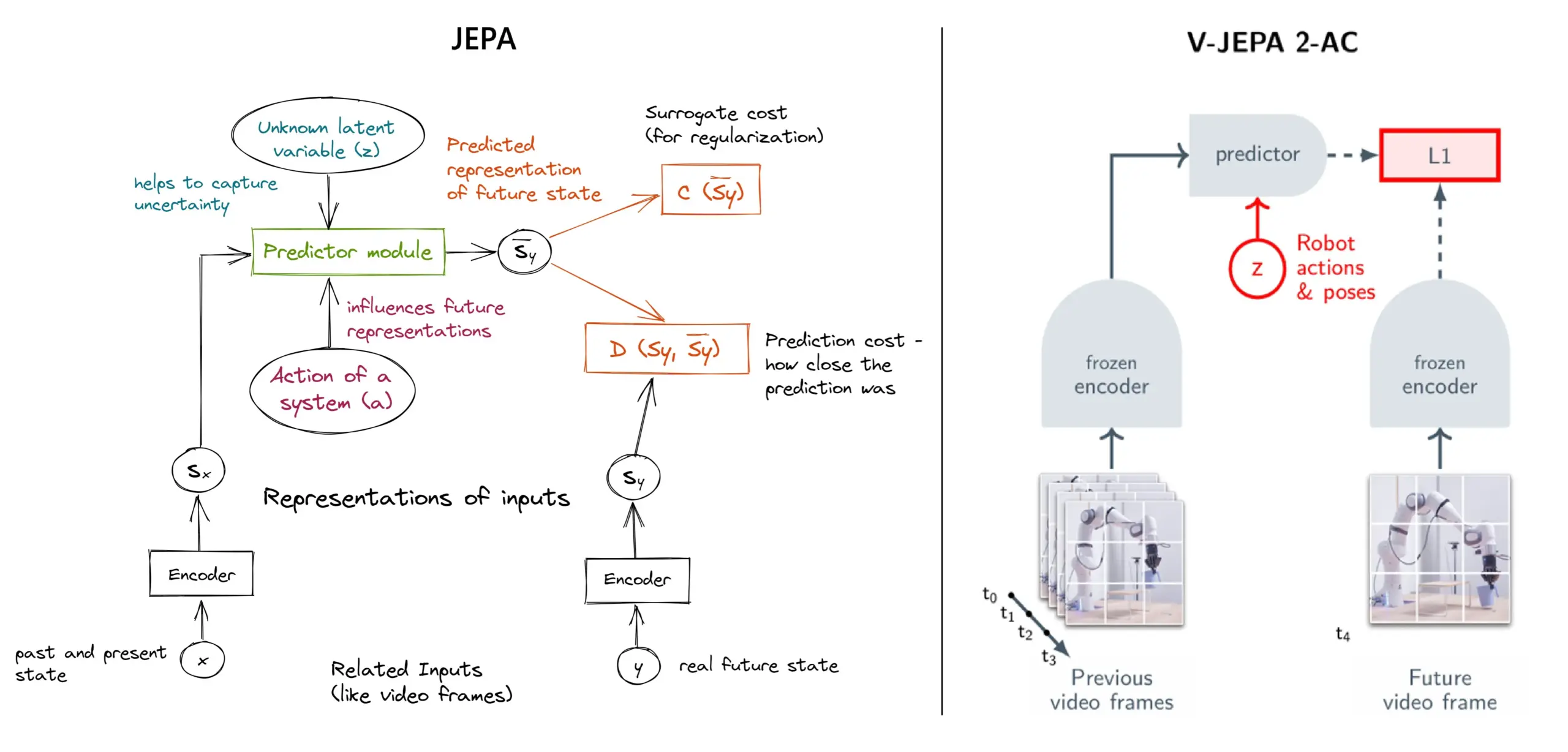
Подробное описание фреймворка самообучения JEPA: обзор 11 типов: JEPA (Joint Embedding Predictive Architecture), предложенный Яном ЛеКуном из Meta и другими исследователями, представляет собой фреймворк самообучения, который учится, предсказывая скрытые представления отсутствующих частей входных данных. В статье представлены 11 различных типов JEPA, включая V-JEPA 2, TS-JEPA, D-JEPA и другие, а также предоставлены ссылки на дополнительную информацию и соответствующие ресурсы, что помогает понять этот передовой метод самообучения (источник: TheTuringPost, TheTuringPost)
Фреймворк DSPy: разделение задач и LLM, повышение поддерживаемости кода: В статье, посвященной DSPy, отмечается, что фреймворк DSPy снижает сложность использования больших языковых моделей (LLM) за счет разделения задач и LLM. Даже до оптимизации DSPy помогает разработчикам быстрее запускать проекты и генерировать код, который легче поддерживать и расширять. Это имеет большую ценность для проектов, требующих сложной инженерии промптов и интеграции LLM (источник: lateinteraction, stanfordnlp)

Обсуждение статьи: Vision Transformers Don’t Need Trained Registers: Новая исследовательская статья исследует механизм возникновения артефактов на картах внимания и картах признаков в Vision Transformer, явление, которое также существует в больших языковых моделях. В статье предлагается метод без обучения для смягчения этих артефактов, направленный на повышение производительности и интерпретируемости Vision Transformer. Данное исследование имеет справочную ценность для понимания и улучшения архитектуры Transformer в задачах компьютерного зрения (источник: Reddit r/MachineLearning)
Обмен учебными материалами: создание серии видео DeepSeek с нуля (всего 29 серий): Один из создателей контента выпустил серию видеоуроков под названием «Как создать DeepSeek с нуля», состоящую из 29 серий. Содержание охватывает основы модели DeepSeek, детали архитектуры (такие как механизм внимания, многоголовое внимание, KV-кэш, MoE), позиционное кодирование, предсказание нескольких токенов и квантование, а также другие ключевые технологии. Эта серия учебных пособий предоставляет ценные видеоресурсы для тех, кто хочет глубже понять внутреннюю работу DeepSeek и аналогичных больших моделей (источник: Reddit r/LocalLLaMA)

Учебное пособие: создание RAG-конвейера для обобщения постов Hacker News: Haystack by deepset поделился пошаговым руководством, которое показывает пользователям, как создать конвейер генерации с расширенным поиском (RAG). Этот конвейер способен получать посты Hacker News в реальном времени и использовать локально работающую конечную точку большой языковой модели (LLM) для обобщения этих постов. Это предоставляет практический пример для разработчиков, желающих использовать технологию RAG для обработки потоков информации в реальном времени и локальной обработки (источник: dl_weekly)
Обзор статей: набор данных InterSyn и модель оценки SynJudge для генерации чередующихся изображений и текста: Для решения текущих недостатков LMM в генерации тесно чередующихся выводов изображений и текста (в основном из-за ограниченного масштаба, качества и разнообразия инструкций в обучающих наборах данных) исследователи представили InterSyn, крупномасштабный мультимодальный набор данных, созданный с помощью метода SEIR (самооценка и итеративная оптимизация). InterSyn содержит многоэтапные, управляемые инструкциями диалоги, в ответах которых изображения и текст тесно чередуются. Одновременно для оценки таких выводов исследователи также предложили автоматическую модель оценки SynJudge, которая оценивает по четырем параметрам: содержание текста, содержание изображения, качество изображения и согласованность изображения и текста. Эксперименты показывают, что LMM, обученные на InterSyn, улучшают показатели по всем метрикам оценки (источник: HuggingFace Daily Papers)
Обзор статей: Синтез изображений и геометрии с новой точки зрения через дистилляцию кросс-модального внимания для выравнивания: Исследователи предлагают фреймворк MoAI на основе диффузии, который реализует генерацию выровненных изображений и геометрии с новой точки зрения с помощью метода «искажение и восстановление» (warping-and-inpainting). Этот метод использует готовые предикторы геометрии для предсказания частичной геометрии эталонного изображения и синтезирует новую точку зрения как задачу восстановления изображения и геометрии. Для обеспечения точного выравнивания изображения и геометрии в статье предлагается дистилляция кросс-модального внимания, при которой карты внимания из ветви диффузии изображения вводятся в параллельную ветвь диффузии геометрии во время обучения и вывода. Этот метод обеспечивает высококачественный синтез экстраполированных видов в различных невиданных ранее сценах (источник: HuggingFace Daily Papers)
Обзор статей: Конфигурируемая настройка предпочтений (CPT) на основе синтетических данных, управляемых правилами: Для решения проблем закрепления предпочтений и ограниченной адаптивности в моделях обратной связи от человека, таких как DPO, исследователи предлагают фреймворк конфигурируемой настройки предпочтений (CPT). CPT использует системные подсказки, основанные на структурированных мелкозернистых правилах (определяющих желаемые атрибуты, такие как стиль письма), для генерации синтетических данных предпочтений. Путем тонкой настройки с использованием этих предпочтений, управляемых правилами, LLM могут динамически настраивать вывод во время инференса на основе системных подсказок без необходимости переобучения, достигая более детального и контекстно-зависимого контроля предпочтений (источник: HuggingFace Daily Papers)
Обзор статей: Диффузионная двойственность (The Diffusion Duality): Исследователи предлагают метод Duo, который, раскрывая понимание того, что дискретные диффузионные процессы в равномерном состоянии происходят из скрытой гауссовой диффузии, переносит мощные методы гауссовой диффузии на дискретные диффузионные модели для повышения их производительности. В частности, это включает: 1) Введение стратегии обучения по учебному плану, управляемой гауссовым процессом, для уменьшения дисперсии, удвоения скорости обучения и превосходства над авторегрессионными моделями в нескольких бенчмарках. 2) Предложение дискретной дистилляции согласованности, которая адаптирует непрерывную дистилляцию согласованности к дискретным настройкам, ускоряя выборку на два порядка и реализуя генерацию диффузионных языковых моделей за малое количество шагов (источник: HuggingFace Daily Papers)
Обзор статей: SkillBlender — управление движением всего тела многофункционального гуманоидного робота путем слияния навыков: Для решения ограничений существующих методов управления гуманоидными роботами в области многозадачной генерализации и масштабируемости исследователи предлагают SkillBlender, иерархический фреймворк обучения с подкреплением. Этот фреймворк сначала предварительно обучает целеориентированные, не зависящие от задачи примитивные навыки, а затем динамически объединяет эти навыки при выполнении сложных задач управления движением, требуя лишь минимальной инженерии вознаграждений, специфичных для задачи. Одновременно для оценки был представлен симуляционный бенчмарк SkillBench. Эксперименты показывают, что этот метод может значительно повысить точность и выполнимость различных задач управления движением (источник: HuggingFace Daily Papers)
Обзор статей: Фреймворк U-CoT+ — разделение понимания и управляемое рассуждение CoT для обнаружения вредоносных мемов: Для решения проблем эффективности использования ресурсов, гибкости и интерпретируемости при обнаружении вредоносных мемов исследователи предлагают фреймворк U-CoT+. Этот фреймворк сначала преобразует визуальные мемы в текстовые описания, сохраняющие детали, с помощью высокоточного процесса преобразования мема в текст, тем самым разделяя интерпретацию мема и классификацию, что позволяет универсальным большим языковым моделям (LLM) выполнять ресурсоэффективное обнаружение. Затем, в сочетании с разработанными человеком интерпретируемыми руководствами, модель направляется на рассуждение в рамках подсказок CoT с нулевым выстрелом, что повышает адаптивность к изменениям на разных платформах и во времени, а также интерпретируемость (источник: HuggingFace Daily Papers)
Обзор статей: CRAFT — эффективное тестирование красной команды для агентов, следующих политике: В отношении проблемы следования задача-ориентированных агентов LLM строгим политикам (например, право на возврат средств) исследователи предложили новую модель угроз, сосредоточенную на враждебных пользователях, пытающихся использовать агентов, следующих политике, для получения личной выгоды. Для этого они разработали CRAFT, многоагентную систему тестирования красной команды, которая использует стратегии убеждения, учитывающие политику, для атаки на агентов, следующих политике, в сценариях обслуживания клиентов, и ее эффективность превосходит традиционные методы обхода защиты. Одновременно был представлен бенчмарк tau-break для оценки устойчивости агентов к таким манипулятивным действиям (источник: HuggingFace Daily Papers)
Обзор статей: Неудачи плотных ретриверов на простых запросах и дилемма гранулярности вложений: Исследование выявляет ограничение текстовых кодировщиков: вложения могут не распознавать мелкозернистые сущности или события внутри семантики, что приводит к тому, что плотный поиск может давать сбои даже в простых случаях. Для изучения этого явления в статье вводится китайский оценочный набор данных CapRetrieval (где абзацы являются подписями к изображениям, а запросы — короткими фразами, обозначающими сущности/события). Оценка с нулевым выстрелом показывает, что кодировщики могут плохо справляться с мелкозернистым сопоставлением. Тонкая настройка кодировщика с помощью предложенной стратегии генерации данных может повысить производительность, но также выявляет «дилемму гранулярности», заключающуюся в том, что вложениям трудно одновременно выражать мелкозернистую значимость и согласовываться с общей семантикой (источник: HuggingFace Daily Papers)
Обзор статей: pLSTM — параллелизуемая сеть маркировки с линейным преобразованием источника: В связи с тем, что существующие рекуррентные архитектуры (такие как xLSTM, Mamba) в основном подходят для последовательных данных или требуют последовательной обработки многомерных данных, исследователи предложили pLSTM (параллелизуемую сеть маркировки с линейным преобразованием источника). pLSTM расширяет многомерность на линейные RNN, используя вентили источника, преобразования и маркировки, действующие на линейном графе общего ориентированного ациклического графа (DAG), реализуя параллелизацию, подобную параллельному ассоциативному сканированию и блочным рекуррентным формам. Этот метод демонстрирует хорошую экстраполяционную способность и производительность на синтетических задачах компьютерного зрения, а также на молекулярных графах и бенчмарках компьютерного зрения (источник: HuggingFace Daily Papers)
Обзор статей: DeepVideo-R1 — тонкая настройка видео с подкреплением через регрессионный GRPO с учетом сложности: Для решения недостатков применения обучения с подкреплением в больших языковых моделях для видео (Video LLM) исследователи предложили DeepVideo-R1, Video LLM, обученный с помощью предложенного ими Reg-GRPO (регрессионный GRPO) и стратегии увеличения данных с учетом сложности. Reg-GRPO переформулирует цель GRPO как задачу регрессии, напрямую предсказывая функцию преимущества в GRPO, устраняя зависимость от мер предосторожности, таких как отсечение, и тем самым более непосредственно направляя политику. Увеличение данных с учетом сложности динамически усиливает обучающие выборки с разрешимым уровнем сложности. Эксперименты показывают, что DeepVideo-R1 значительно улучшает производительность видео-рассуждений (источник: HuggingFace Daily Papers)
Обзор статей: Фреймворк самосовершенствования для улучшения ASR с использованием синтетических данных TTS: Исследователи предлагают фреймворк самосовершенствования, который позволяет улучшить производительность автоматического распознавания речи (ASR), используя только немаркированные наборы данных. Фреймворк сначала генерирует псевдо-метки на немаркированной речи с помощью существующей модели ASR, затем использует эти псевдо-метки для обучения высококачественной системы преобразования текста в речь (TTS). Затем синтезированные TTS пары речь-текст используются для управления обучением исходной системы ASR, образуя замкнутый цикл самосовершенствования. Эксперименты на тайваньском мандаринском языке показывают, что этот метод может значительно снизить частоту ошибок, предоставляя практический путь для повышения производительности ASR с низкими ресурсами или в特定ных областях (источник: HuggingFace Daily Papers)
Обзор статей: Внутренне достоверные карты внимания для Vision Transformer: Исследователи предлагают метод на основе внимания, использующий обученные бинарные маски внимания, чтобы гарантировать, что только те области изображения, на которые обращено внимание, влияют на предсказание. Этот метод направлен на решение проблемы предвзятости, которая может возникнуть из-за контекста при восприятии объектов, особенно когда объекты появляются на нераспределенном фоне. С помощью двухэтапного фреймворка (первый этап обнаруживает части объекта и идентифицирует области, релевантные для задачи, второй этап использует входные маски внимания для ограничения поля восприятия для сфокусированного анализа) совместное обучение обеспечивает повышение устойчивости модели к ложным корреляциям и нераспределенному фону (источник: HuggingFace Daily Papers)
Обзор статей: ViCrit — верифицируемая задача-заместитель для обучения с подкреплением с визуальным восприятием VLM: Для решения проблемы отсутствия задач визуального восприятия в VLM, которые были бы одновременно сложными и четко верифицируемыми, исследователи представили ViCrit (Visual Captioning Hallucination Critic). Это задача-заместитель для обучения с подкреплением, которая обучает VLM локализовать тонкие, синтетические визуальные галлюцинации, внедренные в абзацы подписей к изображениям, написанные человеком. Путем внедрения одной тонкой ошибки визуального описания в подпись объемом около 200 слов и требования к модели локализовать диапазон ошибки на основе изображения и измененной подписи, эта задача предоставляет легко вычисляемое и однозначное бинарное вознаграждение. Модели, обученные с помощью ViCrit, демонстрируют значительный прирост в различных бенчмарках VL (источник: HuggingFace Daily Papers)
Обзор статей: За пределами гомогенного внимания — энергоэффективные LLM на основе KV-кэша с аппроксимацией Фурье: Для решения проблемы растущего объема памяти KV-кэша в LLM с увеличением длины контекста исследователи предлагают FourierAttention, фреймворк без обучения. Этот фреймворк использует гетерогенные роли измерений в головах Transformer: низкоразмерные предпочитают локальный контекст, высокоразмерные улавливают дальнодействующие зависимости. Проецируя измерения, нечувствительные к длинному контексту, на ортогональный базис Фурье, FourierAttention аппроксимирует их временную эволюцию с помощью спектральных коэффициентов фиксированной длины. Оценка на моделях LLaMA показывает, что этот метод достигает наилучшей точности при длинном контексте на LongBench и NIAH, а также оптимизирует память с помощью специально разработанного ядра Triton FlashFourierAttention (источник: HuggingFace Daily Papers)
Обзор статей: JAFAR — универсальный апсемплер для улучшения произвольных признаков при произвольном разрешении: Для решения проблемы, связанной с тем, что пространственные признаки низкого разрешения, выводимые базовыми визуальными кодировщиками, не удовлетворяют требованиям последующих задач, исследователи представили JAFAR, легковесный и гибкий апсемплер признаков. JAFAR может повышать пространственное разрешение визуальных признаков любого базового визуального кодировщика до произвольного целевого разрешения. Он использует модуль на основе внимания, модулированный пространственным преобразованием признаков (SFT), для содействия семантическому выравниванию между запросами высокого разрешения, полученными из низкоуровневых признаков изображения, и семантически богатыми ключами низкого разрешения. Эксперименты показывают, что JAFAR может эффективно восстанавливать мелкозернистые пространственные детали и превосходит существующие методы в различных последующих задачах (источник: HuggingFace Daily Papers)
Обзор статей: SwS — Синтез задач, управляемый самосознанием слабых мест в обучении с подкреплением: Для решения проблемы нехватки высококачественных, проверяемых по ответам наборов задач при обучении LLM решению сложных задач рассуждения (таких как математические задачи) в RLVR (обучение с подкреплением с верифицируемым вознаграждением) исследователи предлагают фреймворк SwS (синтез задач, управляемый самосознанием слабых мест). SwS систематически выявляет недостатки модели (проблемы, с которыми модель постоянно не справляется в процессе обучения RL), извлекает основные концепции этих неудачных случаев и синтезирует новые задачи для усиления слабых мест модели в последующем расширенном обучении. Этот фреймворк позволяет модели самостоятельно выявлять и устранять свои слабые места в RL, достигая значительного повышения производительности в нескольких основных бенчмарках рассуждений (источник: HuggingFace Daily Papers)
Обзор статей: Обучение токену «продолжать думать» для улучшения способности к расширению во время тестирования: Для повышения производительности языковых моделей при расширении шагов рассуждения за счет дополнительных вычислений во время тестирования исследователи изучили возможность обучения специальному токену «продолжать думать» (<|continue-thinking|>). Они обучали только вложение этого токена с помощью обучения с подкреплением, сохраняя веса дистиллированной версии модели DeepSeek-R1 замороженными. Эксперименты показывают, что по сравнению с базовыми моделями и методами расширения во время тестирования с использованием фиксированного токена (например, “Wait”) для принудительного бюджета, обученный токен достигает более высокой точности в стандартных математических бенчмарках, особенно в случаях, когда фиксированный токен может улучшить точность базовой модели, обученный токен может принести большее улучшение (источник: HuggingFace Daily Papers)
Обзор статей: LoRA-Edit — управляемое редактирование видео с ориентацией на первый кадр путем тонкой настройки LoRA с учетом маски: Для решения проблем существующих методов редактирования видео, зависящих от крупномасштабного предварительного обучения и недостаточной гибкости, исследователи предлагают LoRA-Edit, метод тонкой настройки LoRA на основе маски для адаптации предварительно обученных моделей преобразования изображения в видео (I2V) для гибкого редактирования видео. Этот метод, сохраняя фоновые области, способен распространять управляемые эффекты редактирования и объединять другую справочную информацию (например, альтернативные точки обзора или состояния сцены) в качестве визуальных якорей. Благодаря стратегии настройки LoRA, управляемой маской, модель учится на входном видео (пространственная структура и сигналы движения) и эталонном изображении (руководство по внешнему виду), реализуя обучение, специфичное для региона (источник: HuggingFace Daily Papers)
Обзор статей: Infinity Instruct — расширение выбора и синтеза инструкций для улучшения языковых моделей: Чтобы восполнить пробел, связанный с тем, что существующие наборы данных инструкций с открытым исходным кодом в основном сосредоточены на узких областях (таких как математика, кодирование), что приводит к ограниченной способности к обобщению, исследователи представили Infinity-Instruct, высококачественный набор данных инструкций, предназначенный для улучшения базовых и диалоговых возможностей LLM с помощью двухэтапного процесса. На первом этапе с использованием методов смешанного выбора данных из более чем 100 миллионов образцов было отобрано 7,4 миллиона высококачественных базовых инструкций. На втором этапе с помощью двухэтапного процесса выбора инструкций, их эволюции и диагностической фильтрации было синтезировано 1,5 миллиона высококачественных диалоговых инструкций. Эксперименты по тонкой настройке на различных моделях с открытым исходным кодом показывают, что этот набор данных может значительно улучшить производительность моделей в базовых бенчмарках и бенчмарках следования инструкциям (источник: HuggingFace Daily Papers)
Обзор статей: Сначала кандидаты, потом дистилляция — фреймворк учитель-ученик для разметки данных с помощью LLM: В связи с проблемой существующих методов разметки данных с помощью LLM, где LLM напрямую определяет единственную золотую метку, что может привести к ошибкам из-за неопределенности, исследователи предлагают новую парадигму разметки кандидатов: поощрять LLM выводить все возможные метки в случае неопределенности. Чтобы обеспечить получение единственной метки для последующих задач, разработан фреймворк учитель-ученик CanDist, который использует малую языковую модель (SLM) для дистилляции разметок кандидатов. Теоретически доказано, что дистилляция разметок кандидатов от учителя LLM превосходит прямое использование единственной разметки. Эксперименты подтвердили эффективность этого метода (источник: HuggingFace Daily Papers)
Обзор статей: Med-PRM — модель медицинского рассуждения с пошаговым вознаграждением за процесс, проверенный по руководствам: Для решения ограничений больших языковых моделей в клиническом принятии решений, связанных с трудностью локализации и исправления ошибок на конкретных этапах рассуждения, исследователи представили Med-PRM, фреймворк моделирования вознаграждения за процесс. Этот фреймворк использует методы генерации с расширенным поиском для проверки каждого этапа рассуждения по установленным медицинским базам знаний (клиническим руководствам и литературе). Благодаря такому мелкозернистому подходу к точной оценке качества рассуждений, Med-PRM достигает производительности SOTA в нескольких медицинских бенчмарках QA и задачах открытой диагностики, а также может интегрироваться с сильными моделями политики (такими как Meerkat) по принципу plug-and-play, значительно повышая точность малых моделей (8B параметров) (источник: HuggingFace Daily Papers)
Обзор статей: Трение обратной связи — LLM с трудом усваивают внешнюю обратную связь: Исследование систематически изучает способность LLM усваивать внешнюю обратную связь. В экспериментах модель-решатель пыталась решить проблему, затем генератор обратной связи, обладающий почти полным истинным ответом, предоставлял целевую обратную связь, после чего решатель снова предпринимал попытку. Результаты показывают, что даже в почти идеальных условиях, включая модели SOTA, такие как Claude 3.7, проявляют сопротивление обратной связи, названное «трением обратной связи». Несмотря на то, что применение стратегий, таких как постепенное повышение температуры и явный отказ от предыдущих неверных ответов, принесло некоторое улучшение, модели все же не достигли целевой производительности. Исследование исключило такие факторы, как чрезмерная самоуверенность модели и знакомство с данными, с целью выявить это основное препятствие для самосовершенствования LLM (источник: HuggingFace Daily Papers)
💼 Бизнес
Meta потратила 14,3 миллиарда долларов на приобретение 49% акций Scale AI, основатель Alexandr Wang присоединяется к команде Meta по суперинтеллекту: Meta объявила о приобретении 49% неголосующих акций компании по разметке данных для AI Scale AI за 14,3 миллиарда долларов. Основатель Scale AI, 28-летний китайско-американский гений Alexandr Wang, останется членом совета директоров и возглавит свою основную команду, присоединившись к команде Meta по суперинтеллекту, созданной лично Цукербергом. Это приобретение рассматривается как дорогостоящее поглощение талантов, предпринятое Meta для повышения своих возможностей в области AI после неудовлетворительных результатов Llama 4, с целью глубокой интеграции AI во все свои продукты. Scale AI начинала с предоставления услуг по крупномасштабной высококачественной ручной разметке данных, ее клиентами являются Waymo, OpenAI и другие. Этот шаг вызвал опасения по поводу нейтральности ее платформы и безопасности данных, и такие клиенты, как Google, могут прекратить сотрудничество (источник: 36氪)

Стратегия Kunlun Wanwei “All in AI” привела к первому убытку за десять лет листинга, перспективы коммерциализации AI неясны: С момента объявления стратегии “All in AGI и AIGC” Kunlun Wanwei активно развивает большие модели (Tiangong大模型), а также приложения AI для музыки (Mureka), социальных сетей (Linky), видео (SkyReels), офисной работы (Skywork Super Agents) и инвестирует в чипы для вычислений AI. Однако высокие затраты на исследования и разработки, а также на маркетинг привели к тому, что в 2024 году компания впервые за десять лет листинга понесла убытки (1,59 млрд юаней), а в первом квартале 2025 года убытки продолжились. Несмотря на то, что некоторые AI-приложения, такие как Mureka и Linky, начали приносить доход, общая прибыльность и конкурентоспособность AI-бизнеса все еще сталкиваются с проблемами, и сможет ли компания осуществить свою «мечту о большой компании» с помощью AI, покажет рынок (источник: 36氪)

OpenAI, возможно, тестирует рекламу в ChatGPT, давление прибыльности стимулирует поиск бизнес-моделей: Некоторые платные пользователи ChatGPT Plus сообщили, что столкнулись с прерывающей рекламой при использовании расширенного голосового режима, что вызвало дискуссии о том, начала ли OpenAI тестировать рекламу среди платных пользователей. Ранее сообщалось, что OpenAI рассматривает возможность введения рекламы для расширения доходов. Учитывая высокие операционные расходы на большие модели AI и давление прибыльности (ожидаемые убытки в 440 миллиардов долларов до 2029 года), а также неопределенность сроков достижения AGI, поиск OpenAI новых моделей монетизации, таких как реклама, считается неизбежным выбором для ее коммерческой устойчивости, особенно в условиях относительно низкого уровня проникновения платных подписок (источник: 36氪)

🌟 Сообщество
AI обладает огромным потенциалом в области науки о данных, Databricks активно нанимает сотрудников: Matei Zaharia из Databricks считает, что повышение производительности AI в области науки о данных будет более значительным, чем в AI-ассистированном кодировании. Databricks возглавляет эту тенденцию с такими продуктами, как Lakeflow Designer и Genie Deep Research, и активно нанимает исследователей и инженеров в этой области, что свидетельствует о высоком внимании отрасли к инновациям в науке о данных, управляемым AI (источник: matei_zaharia)
Различия в «личности» LLM влияют на поведение агентных циклов: Исследователь Fabian Stelzer заметил, что разные большие языковые модели (LLM) различаются по «личности», что приводит к разному поведению при выполнении агентных циклических задач. Например, Claude склонен выполнять инструменты последовательно, в то время как GPT-4.1 сильно предпочитает параллельное выполнение, даже игнорируя последовательные запросы; модель Haiku более «агрессивна» в запуске инструментов. Это наблюдение подчеркивает важность учета характеристик базовых LLM и функциональных последствий их «эмоционального состояния» при проектировании и оценке многоагентных систем (источник: fabianstelzer, menhguin)
«Мышление» LLM зависит от вывода токенов, без вывода нет эффективного анализа: Пользователь dotey пересказывает открытие xincmm при отладке промпта ReAct: если ожидается, что LLM сначала проанализирует, а затем выполнит операцию (например, нарисует изображение), но не заставить его вывести токены процесса анализа, LLM может пропустить этап анализа. Это подтверждает, что процесс «мышления» LLM реализуется путем генерации токенов; «анализ», определенный в промпте, если не имеет фактического вывода содержимого, означает, что AI на самом деле не выполнил этот анализ. Это имеет руководящее значение для разработки эффективных промптов LLM (источник: dotey)

Ограничения AI в конкретных задачах: Теренс Тао утверждает, что AI не хватает «математического чутья»: Математик Теренс Тао отметил, что хотя доказательства, генерируемые современным AI, на первый взгляд выглядят безупречно (проходят «тест на глаз»), им часто не хватает тонкого, присущего человеку «математического чутья», и они склонны совершать нечеловеческие ошибки. Он считает, что истинный интеллект заключается не только в том, чтобы выглядеть правильно, но и в способности «чуять», что является истинным. Это выявляет ограничения современного AI в глубоком понимании и интуитивных суждениях (источник: ecsquendor)
Проблемы генерации контента AI и соответствия реальным физическим законам: Пользователь karminski3 при тестировании генерации кода (симуляция 3D-анимации сноса дымовой трубы взрывом) с использованием Doubao Seed 1.6 и DeepSeek-R1 обнаружил, что, хотя модели могут генерировать код и симулировать анимацию, в воспроизведении реальных физических процессов (таких как эффект ударной волны, способ обрушения конструкции) все еще есть различия и возможности для улучшения. Doubao Seed 1.6 ближе к реальности в симуляции эффектов частиц и обрушения конструкций, в то время как DeepSeek лучше справляется с эффектами света, тени и дыма. Это отражает проблемы AI в понимании и симуляции сложных физических явлений (источник: karminski3)
Опытный программист уволен за чрезмерную зависимость от AI для написания кода, нежелание вносить изменения вручную и запугивание новичков тем, что AI их заменит: Статья из 36Kr, перепечатанная с Reddit, рассказывает о случае программиста с 30-летним опытом, который был уволен компанией из-за чрезмерного увлечения AI (например, полная зависимость от Copilot Agent для отправки PR, отказ от ручного изменения кода, затрата 5 дней на выполнение однодневной задачи, пропаганда среди стажеров идеи замены их AI). Этот инцидент вызвал дискуссии о границах разумного использования AI в разработке программного обеспечения и о влиянии AI на профессиональную ценность разработчиков (источник: 36氪)
Влияние «потока» и «личности» AI на пользовательский опыт: пользователи сообщают, что AI слишком «активно поддакивает»: Пользователи сообщества Reddit обсуждают, что при взаимодействии с AI (особенно с Claude) AI склонен к чрезмерному оптимизму и активному поддакиванию мнениям пользователя, ему не хватает эффективного оспаривания и глубокой критической обратной связи, из-за чего пользователи чувствуют себя как в «эхо-камере». Эта «усталость от тональности AI» побуждает пользователей искать способы заставить AI вести себя более нейтрально и критично, например, с помощью специальных подсказок. Это отражает текущие проблемы AI в имитации реального, многогранного человеческого диалога и предоставлении действительно глубоких идей (источник: Reddit r/ClaudeAI)
В эпоху AI ценность человеческой обратной связи возрастает, но платформы для реального человеческого взаимодействия сталкиваются с проникновением AI-контента: Пользователи Reddit отмечают, что в условиях растущего объема контента, генерируемого AI, реальная человеческая обратная связь и мнения становятся все более ценными, а платформы вроде Reddit ценятся за их человеческое взаимодействие. Однако эти платформы также сталкиваются с проблемой проникновения контента, генерируемого AI (например, комментарии ботов, посты, написанные с помощью AI), что затрудняет распознавание реальных человеческих мнений и вызывает опасения по поводу подлинности будущего сетевого общения (источник: Reddit r/ArtificialInteligence)
AI-«друзья» могут стать нормой? Тенденции и обсуждения установления пользователями эмоциональных связей с AI: В социальных сетях и сообществах Reddit появляются обсуждения AI-компаньонов и AI-друзей. Некоторые пользователи считают, что благодаря непредвзятости и постоянной поддержке со стороны AI, AI-друзья могут стать нормой в ближайшие 5 лет, что уже проявляется в таких приложениях, как Endearing AI, Replika, Character.ai. Другие пользователи делятся своим опытом установления глубоких диалоговых отношений с AI, такими как ChatGPT, и даже считают их «лучшими друзьями». Это вызывает широкие размышления об эмоциональном взаимодействии человека и AI, роли AI в эмоциональной поддержке и его потенциальных социальных последствиях (источник: Ronald_vanLoon, Reddit r/artificial, Reddit r/ArtificialInteligence)

Будущее стартапов-«оберток» для AI вызывает дискуссии: Сообщество Reddit обсуждает перспективы большого количества AI-стартапов, которые занимаются «оберткой» базовых моделей, таких как GPT или Claude (добавляя UI, цепочки подсказок или тонкую настройку для конкретных областей). Участники дискуссии сомневаются, смогут ли такие приложения-«обертки» оставаться конкурентоспособными после итераций функций самих базовых моделей, и смогут ли они создать настоящие «защитные рвы». Считается, что сосредоточение на конкретных вертикальных рынках, накопление собственных данных и выход за рамки простой «обертки» могут стать путем к их устойчивому развитию (источник: Reddit r/LocalLLaMA)
Сравнительное обсуждение потенциала замены AI в медицинской диагностике и программной инженерии: В сообществе Reddit возникло обсуждение, согласно которому AI может заменить врачей быстрее, чем старших инженеров-программистов. Причина в том, что многие медицинские диагнозы следуют установленным протоколам, и AI хорошо справляется с интерпретацией результатов тестов и распознаванием симптомов; в то время как программная инженерия часто включает большое количество неявных знаний и сложную коммуникацию по требованиям, с чем AI трудно справиться полностью. Эта точка зрения вызвала дальнейшие размышления о глубине применения AI в различных профессиональных областях и возможностях замены, но также встретила возражения со стороны врачей и других специалистов, подчеркивающих сложность практической работы и важность человеческого суждения (источник: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
💡 Прочее
AI-цифровой аватар Ло Юнхао дебютировал на Baidu E-commerce, GMV превысил 55 миллионов юаней: AI-цифровой аватар Ло Юнхао провел свою первую прямую трансляцию с продажами на платформе Baidu E-commerce, привлекшую более 13 миллионов просмотров, а общий объем товарных операций (GMV) превысил 55 миллионов юаней. Этот цифровой аватар был создан платформой Baidu E-commerce «HuiBoXing» на базе большой модели Wenxin 4.5 и способен имитировать тон голоса, акцент и мимику Ло Юнхао, а также вести интеллектуальные диалоги. Эта прямая трансляция продемонстрировала потенциал модели «AI + топовый ведущий», а также разработки Baidu в области технологии «высокоубедительных цифровых людей» и AI-коммерции (источник: 36氪)

Baidu, Tencent и другие компании усиливают набор AI-талантов, запуская масштабные программы найма: Baidu запустила свою крупнейшую программу найма ведущих AI-талантов «AIDU Plan», количество вакансий увеличилось на 60% по сравнению с прошлым годом, с фокусом на передовые области, такие как алгоритмы больших моделей и базовая инфраструктура, предлагая зарплаты без верхнего предела. Аналогичным образом, Tencent также провела конкурс алгоритмов «Генеративная рекомендация полного модального ряда», предложив миллионные призы и предложения о работе для выпускников, чтобы привлечь мировые AI-таланты. Эти инициативы отражают острую потребность китайских технологических гигантов в ведущих талантах и их стратегическое позиционирование на фоне обострения конкуренции в области AI (источник: 量子位, 量子位)

Baidu запустила комплексный сервис помощи в выборе вуза с использованием AI, интегрировав несколько моделей и большие данные: В ответ на сложность выбора вуза, вызванную новой реформой вступительных экзаменов, Baidu запустила бесплатный инструмент помощи в выборе вуза на базе AI. Этот сервис интегрирован на специальной странице «ЕГЭ» в приложении Baidu и предлагает «AI-помощника по выбору вуза» для рекомендации учебных заведений и специальностей, а также анализа вероятности поступления, поддерживая персонализированные консультации с интеллектуальными агентами «AI-чат о выборе вуза» на базе нескольких моделей, таких как Wenxin и DeepSeek R1. Кроме того, он сочетает эксклюзивные большие данные поиска Baidu для анализа перспектив трудоустройства по специальностям, профессионального тестирования MBTI, а также прямые трансляции приемных комиссий вузов и ответы от старшекурсников, стремясь помочь абитуриентам справиться с информационным разрывом и сделать более подходящий выбор (источник: 36氪)