
Ключевые слова:OpenAI, o3-pro, Meta, Лаборатория суперинтеллекта, Mistral AI, Magistral, IBM, Квантовый компьютер, ценообразование o3-pro, инвестиции Scale AI, Magistral-Small-2506, Квантовый компьютер Starling, тестирование военного применения ИИ
🔥 В центре внимания
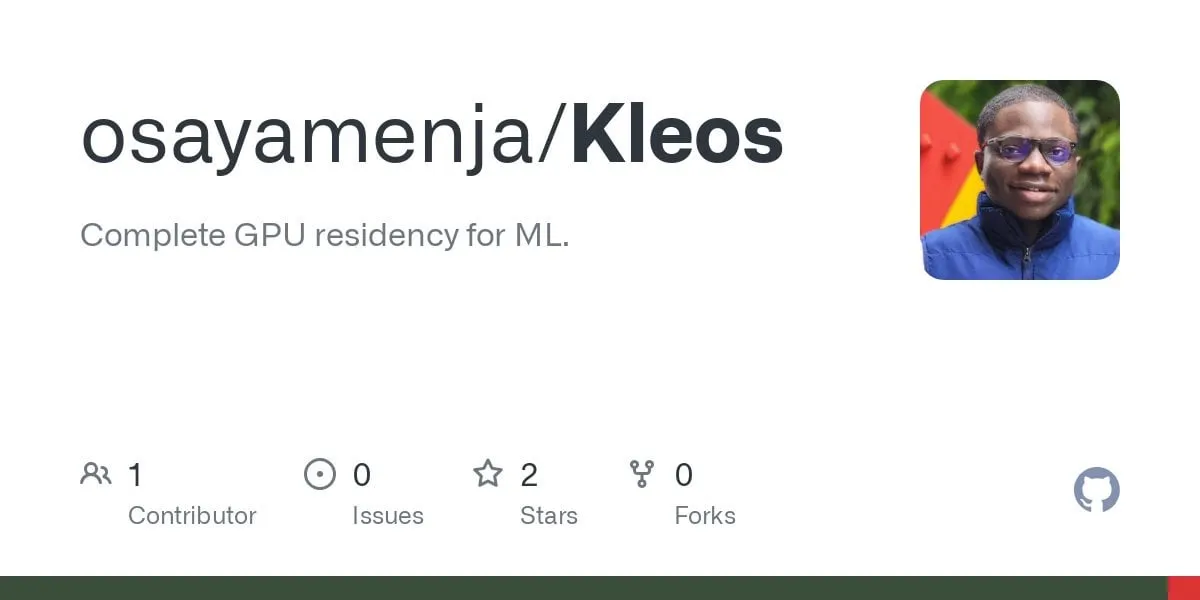
OpenAI выпустила o3-pro, заявленную как самую мощную модель в истории, и значительно снизила цены на o3: OpenAI официально представила свою самую мощную на сегодняшний день модель для логического вывода o3-pro, которая уже доступна пользователям ChatGPT Pro и Team, API также запущен одновременно. o3-pro превосходит предыдущие поколения в таких областях, как наука, образование, программирование, бизнес и помощь в написании текстов, поддерживает различные инструменты, включая веб-поиск, анализ файлов, визуальный ввод и программирование на Python. Стоимость составляет 20 долларов США за миллион входных токенов и 80 долларов США за миллион выходных токенов. В то же время цена на оригинальную модель o3 была значительно снижена на 80%, после корректировки цена составляет 2 доллара США за миллион входных токенов и 8 долларов США за миллион выходных токенов, что соответствует уровню GPT-4o. Этот шаг может спровоцировать ценовую войну на рынке AI-моделей и способствовать более глубокому применению AI в профессиональных областях, однако o3-pro также имеет ограничения, такие как более длительное время отклика и временное отсутствие поддержки временных диалогов. (Источник: OpenAI, sama, OpenAIDevs, scaling01, dotey)
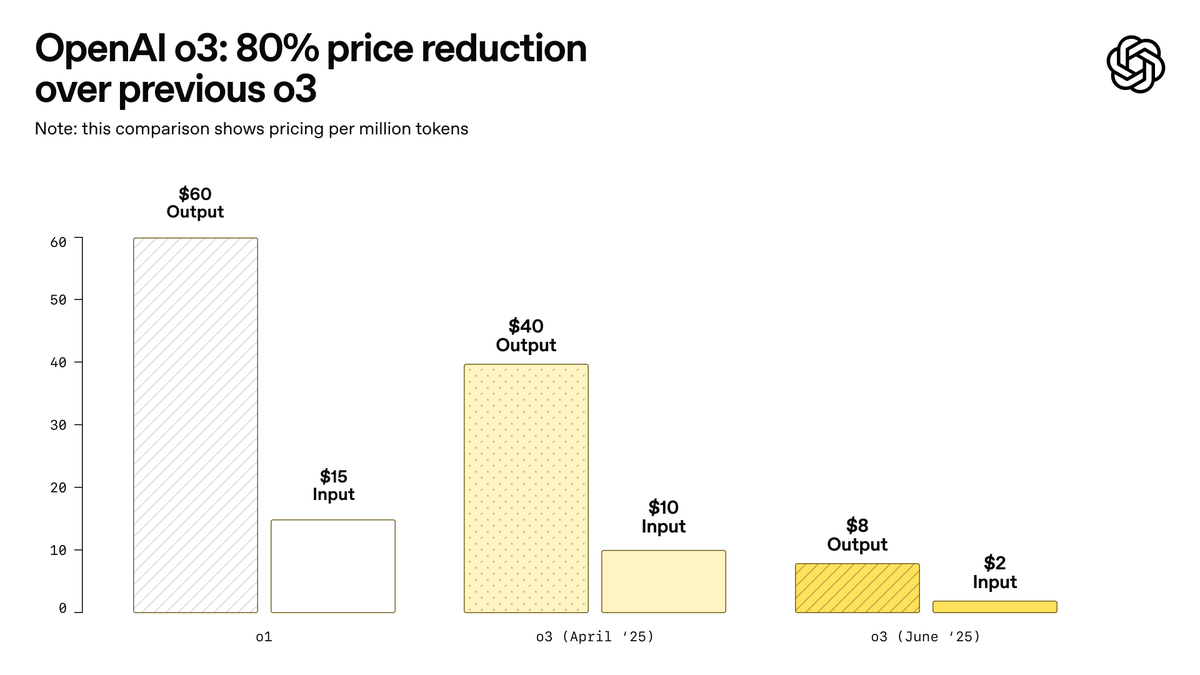
Meta создает «Лабораторию суперинтеллекта» и инвестирует значительные средства в Scale AI, стремясь восстановить конкурентоспособность в области AI: По сообщениям The New York Times и других источников, Meta Platforms реорганизует свое подразделение AI, создавая новую «Лабораторию суперинтеллекта», и планирует инвестировать более 14 миллиардов долларов США в приобретение 49% акций компании по разметке данных Scale AI. Сооснователь и CEO Scale AI Alexandr Wang присоединится к Meta и возглавит новую лабораторию. Этот шаг направлен на ускорение исследований и разработок в области общего искусственного интеллекта (AGI), повышение общей конкурентоспособности Meta в сфере AI, особенно в обработке высококачественных данных и привлечении ведущих специалистов. Это знаменует собой серьезную корректировку стратегии Meta в области AI, которая может оказать глубокое влияние на конкурентную среду в отрасли. (Источник: natolambert, kylebrussell, Yuchenj_UW, steph_palazzolo)

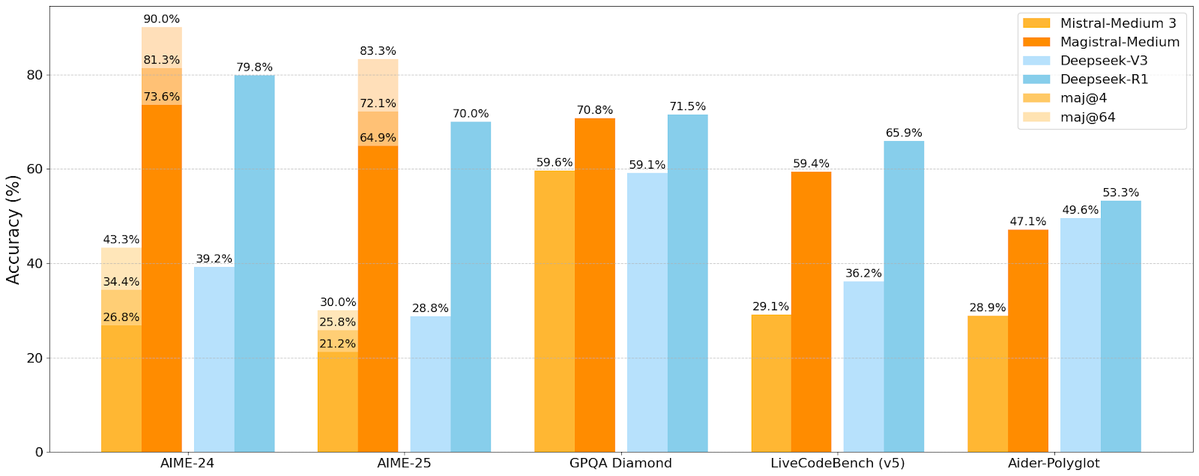
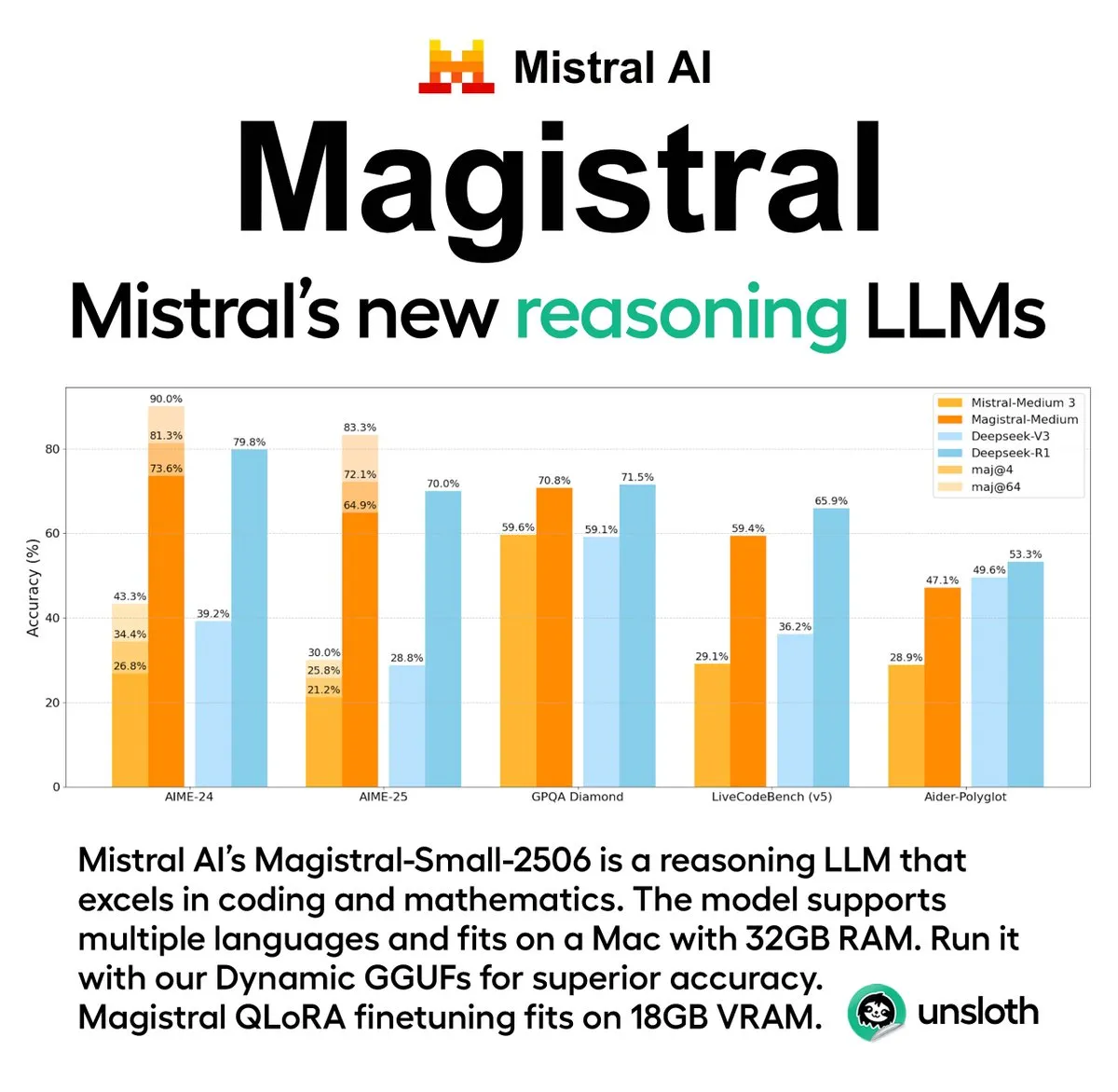
Mistral AI выпустила первую серию моделей для логического вывода Magistral, включающую версию с открытым исходным кодом: Французский стартап в области AI Mistral AI представил свою первую серию моделей, специально разработанных для логического вывода, — Magistral. Серия включает более мощную коммерческую модель с закрытым исходным кодом Magistral Medium и модель с открытым исходным кодом на 24 миллиарда параметров Magistral Small (Magistral-Small-2506), последняя выпущена под лицензией Apache 2.0. Эти модели демонстрируют выдающиеся результаты в математике, кодировании и многоязычном логическом выводе и нацелены на предоставление более прозрачных и специфичных для предметной области возможностей логического вывода. Утверждается, что скорость логического вывода Magistral Medium на платформе Le Chat в 10 раз выше, чем у конкурентов, в то время как Magistral Small предоставляет сообществу мощные возможности для локального запуска. (Источник: Mistral AI, jxmnop, karminski3)
IBM планирует построить к 2028 году крупномасштабный отказоустойчивый квантовый компьютер Starling: IBM обнародовала свою дорожную карту развития квантовых вычислений, планируя построить к 2028 году крупномасштабный отказоустойчивый квантовый компьютер под названием Starling и рассчитывая открыть к нему доступ пользователям через облачные сервисы в 2029 году. Ожидается, что система Starling будет содержать около 100 модулей и 200 логических кубитов, а основной целью является достижение эффективной коррекции ошибок, что является одной из самых больших технологических проблем в современной области квантовых вычислений. Машина будет использовать коды с низкой плотностью проверок на четность (LDPC) от IBM для коррекции ошибок и стремиться к реализации диагностики ошибок в реальном времени. В случае успеха это станет крупным прорывом в области квантовых вычислений, который может ускорить их применение в решении сложных задач в материаловедении, разработке лекарств и других областях. (Источник: MIT Technology Review)

🎯 Тренды
Достижения Apple в области AI на WWDC 2025 не смогли впечатлить разработчиков: Apple на WWDC 2025 представила множество обновлений, включая совершенно новый язык дизайна «жидкое стекло» и интеграцию ChatGPT в Xcode 26. Однако сообщество разработчиков в целом выразило мнение, что ее достижения в области искусственного интеллекта «не оправдали ожиданий». Хотя Apple впервые открыла разработчикам доступ к своим моделям AI для конечных устройств и представила фреймворк Foundation Models для упрощения интеграции функций AI, долгожданное обновление новой версии Siri может быть отложено до следующего года. Аналитик Го Минци отметил, что стратегия Apple в области AI занимает центральное место, но в технологическом плане значительных прорывов не наблюдается, и управление ожиданиями рынка становится ключевым фактором. Похоже, Apple больше сосредоточена на улучшении пользовательского интерфейса и функций операционной системы, а не на революционных инновациях в самих моделях AI. (Источник: MIT Technology Review, jonst0kes, rowancheung)
Пентагон сокращает штат управления по тестированию и оценке систем вооружений с AI: Министр обороны США Pete Hegseth объявил о сокращении штата Управления директора по оперативным испытаниям и оценке Министерства обороны (DOT&E) вдвое, с 94 до примерно 45 человек. Это управление отвечает за тестирование и оценку безопасности и эффективности систем вооружений и AI. Данная реорганизация направлена на «сокращение раздутой бюрократии и расточительных расходов, повышение боеспособности». Этот шаг вызвал обеспокоенность по поводу возможного влияния на тестирование безопасности и эффективности военных применений AI, особенно в контексте активной интеграции Пентагоном технологий AI (включая большие языковые модели) в различные военные системы. (Источник: MIT Technology Review)

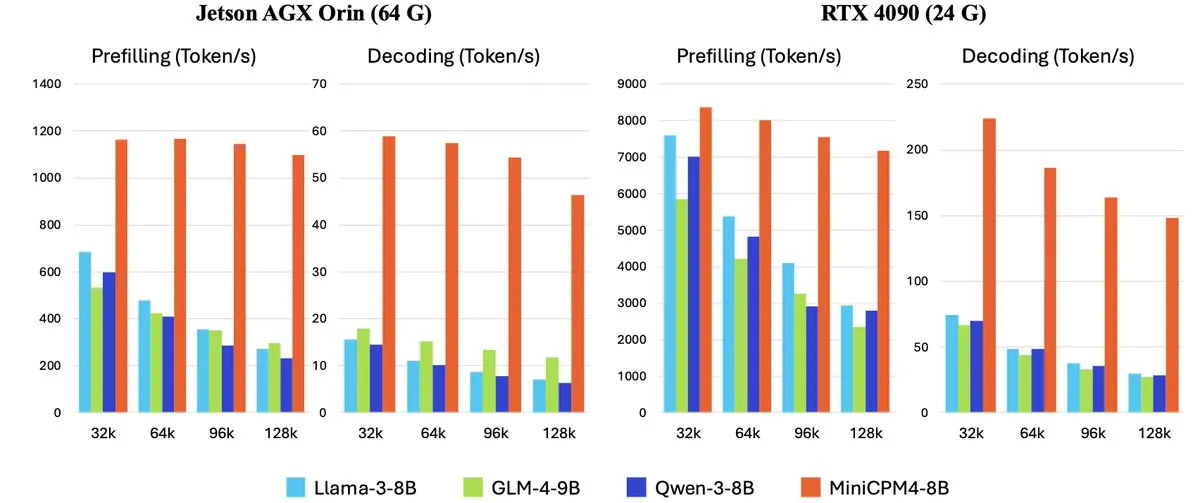
OpenBMB выпустила серию высокоэффективных больших языковых моделей для конечных устройств MiniCPM-4: OpenBMB (Mianbi Intelligence) представила серию моделей MiniCPM-4, специально разработанных для конечных устройств с целью достижения сверхвысокой эффективности работы. Серия включает MiniCPM4-0.5B, MiniCPM4-8B (флагманская модель), BitCPM4 (1-битная квантованная модель), MiniCPM4-Survey, специально предназначенную для генерации отчетов, и специализированную модель для MCP MiniCPM4-MCP. В техническом отчете подробно описывается их эффективная архитектура моделей (например, обучаемый механизм разреженного внимания InfLLM v2), эффективные алгоритмы обучения (например, Model Wind Tunnel 2.0) и методы обработки высококачественных обучающих данных. Эти модели теперь доступны для загрузки на Hugging Face. (Источник: _akhaliq, arankomatsuzaki, karminski3)
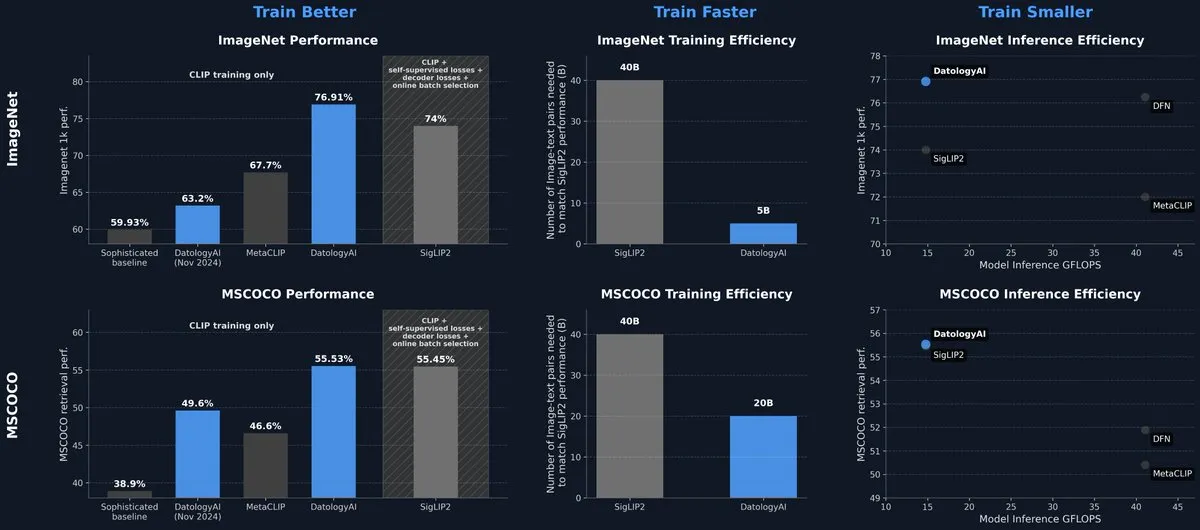
DatologyAI выпустила модель CLIP, достигшую уровня SOTA только за счет управления данными: DatologyAI продемонстрировала свои последние исследовательские достижения в мультимодальной области, добившись для своей модели CLIP ViT-B/32 точности 76,9% на ImageNet 1k за счет тщательного управления данными (data curation), а не инноваций в алгоритмах или архитектуре, превзойдя заявленные SigLIP2 74%. Этот метод также позволил в 8 раз повысить эффективность обучения и в 2 раза — эффективность логического вывода. Модель была опубликована в открытом доступе, что подчеркивает огромный потенциал высококачественных данных в повышении производительности моделей. (Источник: code_star, andersonbcdefg)
Krea AI выпустила свою первую собственную модель изображений Krea 1: Krea AI представила свою первую модель изображений Krea 1, которая отличается превосходным контролем эстетики и качеством изображений, обладает обширными знаниями в области искусства и поддерживает использование стилевых референсов и пользовательское обучение. Krea 1 нацелена на повышение реалистичности изображений, детализацию текстур и богатое стилевое разнообразие. В настоящее время Krea 1 открыта для бесплатного бета-тестирования, и пользователи могут испытать ее мощные возможности генерации изображений. (Источник: _akhaliq, op7418)
NVIDIA выпустила настраиваемую модель человекоподобного робота с открытым исходным кодом GR00T N1: NVIDIA представила GR00T N1, настраиваемую модель человекоподобного робота с открытым исходным кодом. Этот шаг направлен на содействие исследованиям и разработкам в области человекоподобных роботов, предоставляя разработчикам гибкую платформу для создания и экспериментирования с различными роботизированными приложениями. Ожидается, что открытый характер GR00T N1 привлечет более широкое участие сообщества, ускорив прогресс в технологиях человекоподобных роботов. (Источник: Ronald_vanLoon)
RoboBrain 2.0 выпустил мультимодальные модели роботов на 7B и 32B параметров: RoboBrain 2.0 выпустил свои мультимодальные модели роботов с 7 и 32 миллиардами параметров, нацеленные на улучшение способностей роботов в восприятии, мышлении и выполнении задач. Новые модели поддерживают интерактивное рассуждение, долгосрочное планирование, обратную связь с замкнутым контуром, точное пространственное восприятие (прогнозирование точек и ограничивающих рамок), временное восприятие (оценка будущих траекторий), а также рассуждение о сцене, достигаемое за счет построения и обновления структурированной памяти в реальном времени. Ожидается, что эти усовершенствования будут способствовать повышению уровня автономной работы и принятия решений роботами в сложных средах. (Источник: Reddit r/LocalLLaMA)
Kling AI поделится последними исследованиями в области моделей генерации видео на CVPR 2025: Pengfei Wan, руководитель отдела моделей генерации видео Kling AI, выступит с основным докладом на ведущей конференции по компьютерному зрению CVPR 2025 на тему «Введение в Kling и наши исследования более мощных моделей генерации видео». Вместе с экспертами из Google DeepMind и других организаций он обсудит последние прорывы и передовые достижения в технологии генерации видео. Это выступление подробно представит достижения Kling в продвижении технологий генерации видео. (Источник: Kling_ai)

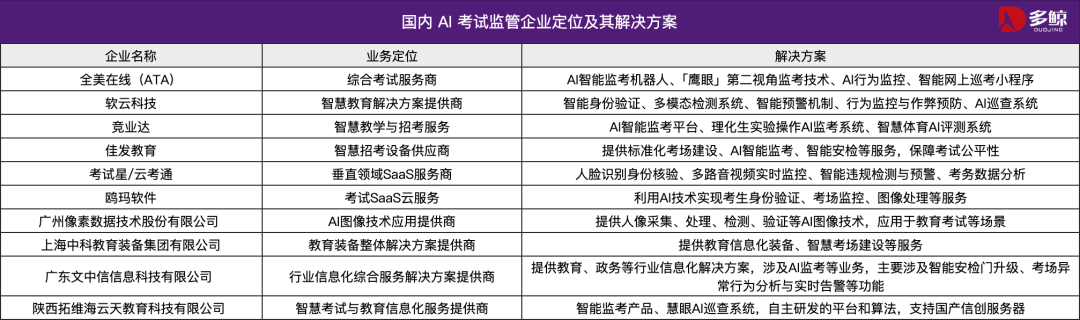
Технологии AI помогают на всекитайских вступительных экзаменах в вузы (Гаокао) 2025 года, во многих местах внедрены интеллектуальные системы контроля: На всекитайских вступительных экзаменах в вузы (Гаокао) 2025 года широко применяются интеллектуальные системы контроля на базе AI. В Тяньцзине, Цзянси, Хубэе, Янцзяне (провинция Гуандун) и других местах экзаменационные пункты полностью охвачены AI-наблюдением. Эти системы используют камеры 4K, отслеживание скелета, распознавание лиц, аудиомониторинг и другие технологии для выявления в реальном времени нарушений со стороны экзаменуемых, таких как преждевременное начало работы, передача предметов, перешептывание, аномальное отклонение взгляда и т. д., а также могут выдавать предупреждения. Эта мера направлена на повышение справедливости экзаменов и обеспечение дисциплины в аудиториях. Применение систем AI-наблюдения знаменует собой переход управления экзаменами в интеллектуальную эру и влечет за собой изменения в традиционных методах наблюдения. (Источник: 36氪)
Выпущена десктопная модель Gemma 3n с поддержкой кроссплатформенности и IoT-устройств: Google выпустила десктопную модель Gemma 3n, включающую версии с 2 и 4 миллиардами параметров, оптимизированные для настольных компьютеров (Mac/Windows/Linux) и устройств Интернета вещей (IoT). Модель работает на новой библиотеке LiteRT-LM, разработанной для обеспечения эффективной локальной работы. Разработчики могут ознакомиться с предварительной версией на Hugging Face и получить соответствующие ресурсы на GitHub, что будет способствовать дальнейшему применению легковесных AI-моделей на периферийных устройствах. (Источник: ClementDelangue, demishassabis)
🧰 Инструменты
Yutori AI представила Scouts: AI-агенты для мониторинга сети в реальном времени: Компания Yutori AI, основанная бывшим исследователем Meta AI, выпустила продукт в виде AI-агентов под названием Scouts. Scouts способны в реальном времени отслеживать информацию в интернете по заданным пользователем темам или ключевым словам и уведомлять пользователя при появлении соответствующего контента. Этот инструмент предназначен для помощи пользователям в отборе ценной для них информации из огромного потока сетевых данных, например, для отслеживания новостей в определенной области, рыночных тенденций, предложений по продуктам или даже дефицитных бронирований. Выпуск Scouts знаменует собой дальнейшее развитие инструментов персонализированного получения информации, превращая AI в цифровых «разведчиков» для пользователей. (Источник: DhruvBatraDB, krandiash, saranormous, JeffDean)
Replit представил новую функцию: преобразование дизайн-макетов из Figma и других платформ в функциональные приложения одним кликом: Replit выпустил функцию Replit Import, позволяющую пользователям напрямую импортировать дизайн-макеты с платформ Figma, Lovable, Bolt и других и преобразовывать их в работающие приложения. Эта функция призвана снизить порог входа в разработку, позволяя даже не программистам быстро воплощать дизайнерские идеи в реальность. Replit Import поддерживает сохранение точности дизайна и включает встроенное сканирование безопасности и управление ключами, а в сочетании с Replit Agent, базами данных, аутентификацией и хостинговыми сервисами позволяет создавать полнофункциональные приложения. (Источник: amasad, pirroh)
Hugging Face выпустила AISheets: объединение электронных таблиц с тысячами AI-моделей: Сооснователь Hugging Face Thomas Wolf анонсировал экспериментальный продукт AISheets, который объединяет простоту использования электронных таблиц с мощными возможностями тысяч AI-моделей с открытым исходным кодом (особенно LLM). Пользователи могут создавать, анализировать и автоматизировать задачи обработки данных в привычном интерфейсе электронных таблиц, используя AI-модели для получения аналитических выводов и автоматизации задач. Цель — предоставить новый, быстрый, простой и мощный способ анализа данных. (Источник: _akhaliq, clefourrier, ClementDelangue, huggingface)
LlamaIndex теперь поддерживает преобразование Agent в MCP-сервер для взаимодействия с моделями Claude и другими: LlamaIndex объявил о поддержке преобразования любого своего Agent в сервер по протоколу контекста модели (MCP). С помощью примеров кода и видео демонстрируется, как развернуть пользовательский рабочий процесс FidelityFundExtraction (для извлечения структурированных данных из сложных PDF) в качестве MCP-сервера и вызывать его из модели Claude. Эта функция призвана повысить уровень интеллектуализации инструментов, облегчить интеграцию с MCP-клиентами, такими как Claude Desktop и Cursor, и упростить процесс подключения существующих рабочих процессов к более широкой экосистеме AI. (Источник: jerryjliu0)
GPT Researcher интегрировал протокол контекста модели (MCP) от LangChain: GPT Researcher теперь использует адаптер протокола контекста модели (MCP) от LangChain для интеллектуального выбора инструментов и проведения исследований. Эта интеграция бесшовно объединяет MCP с функциями веб-поиска для всестороннего сбора данных. Пользователи могут ознакомиться с соответствующей документацией по интеграции, чтобы узнать, как настроить и использовать эту новую функцию для повышения эффективности и глубины исследований. (Источник: hwchase17)
Tesslate выпустила серию моделей генерации UI UIGEN-T3 с поддержкой различных размеров: Команда Tesslate представила серию моделей генерации UI UIGEN-T3, включающую различные масштабы параметров, такие как 32B, 14B, 8B и 4B. Эти модели специально разработаны для генерации UI-компонентов (таких как хлебные крошки, кнопки, карточки) и полного фронтенд-кода (например, страниц входа, дашбордов, чат-интерфейсов) с поддержкой Tailwind CSS. Модели доступны на Hugging Face и призваны помочь разработчикам быстро создавать пользовательские интерфейсы. Разработчики отмечают, что стандартное квантование значительно снижает качество моделей, и рекомендуют запускать их в BF16 или FP8 для достижения наилучших результатов. (Источник: Reddit r/LocalLLaMA)
Выпущена модель Doubao Podcast, генерирующая человекоподобные AI-подкасты в один клик: Volcano Engine выпустила модель Doubao Podcast, которая способна быстро генерировать подкасты с высокой степенью человекоподобия в диалоговом стиле на основе введенного пользователем текста (например, ссылки на статью или Prompt). Сгенерированное моделью аудио близко к человеческой речи по интонации, паузам и разговорным выражениям, и даже способно вести аргументированное обсуждение на основе контента. Эта технология основана на сквозной модели синтеза речи в реальном времени от команды речевых технологий ByteDance, реализующей прямое понимание и логический вывод на уровне речевой модальности. В настоящее время эта функция доступна в десктопной версии Doubao и в пространстве Kouzi, и призвана снизить порог входа в создание аудиоконтента, предоставляя эффективный и персонализированный способ получения информации. (Источник: 量子位)

Unsloth AI предоставила GGUF-квантованную версию Magistral-Small-2506: Для недавно выпущенной Mistral AI модели логического вывода Magistral-Small-2506, Unsloth AI предоставила GGUF-квантованную версию. Это позволяет пользователям запускать эту модель с 24 миллиардами параметров локально, например, на устройстве всего с 32 ГБ ОЗУ. Этот шаг снижает аппаратные требования для высокопроизводительных моделей логического вывода, облегчая более широкому кругу разработчиков и исследователей возможность опробовать и использовать модель Magistral в локальной среде. (Источник: ImazAngel)
📚 Обучение
Глубокий технический анализ архитектуры визуального ассистента LLaVA-1.5: LearnOpenCV опубликовал статью с глубоким техническим анализом архитектуры LLaVA-1.5. В статье подробно описывается, как LLaVA-1.5 создает передовых AI-визуальных ассистентов, включая ее прорывную технологию тонкой настройки визуальных инструкций (Visual Instruction Tuning) и наборы данных с открытым исходным кодом, изменившие область мультимодального AI. Это руководство имеет важную справочную ценность для инженеров и исследователей в области AI/ML, стремящихся понять принципы работы и методы обучения мультимодальных больших языковых моделей. (Источник: LearnOpenCV)
Опубликовано руководство для начинающих по машинному обучению для белков: DL Weekly поделился всеобъемлющим руководством по машинному обучению для белков, предназначенным для начинающих. Руководство охватывает основные типы данных, связанные с белками, модели глубокого обучения, вычислительные методы и фундаментальные биологические концепции, с целью помочь исследователям и разработчикам, интересующимся этой междисциплинарной областью, быстро освоиться. (Источник: dl_weekly)
Qdrant в сотрудничестве с DataTalksClub запускает бесплатный курс по RAG и векторному поиску: Qdrant объявил о сотрудничестве с DataTalksClub для проведения 10-недельного бесплатного онлайн-курса. Содержание курса включает генерацию с расширенным поиском (RAG), векторный поиск, гибридный поиск, методы оценки и практический сквозной проект. Эксперты Qdrant Kacper Łukawski и Daniel Wanderung будут лично вести занятия, чтобы помочь слушателям овладеть практическими навыками создания передовых AI-приложений. (Источник: qdrant_engine)
Подкаст Weaviate обсуждает структурированный вывод LLM и ограниченное декодирование: В последнем выпуске подкаста Weaviate приняли участие Will Kurt и Cameron Pfiffer из dottxt.ai, которые вместе с ведущим Connor Shorten обсудили проблему структурированного вывода больших языковых моделей (LLM). В программе подробно обсуждалось, как с помощью техник ограниченного декодирования обеспечить генерацию LLM надежных, предсказуемых результатов (например, валидный JSON, электронные письма, твиты и т.д.), а не просто проверку формата JSON. Они также представили инструмент с открытым исходным кодом Outlines и его применение в реальных AI-кейсах, а также перспективы влияния этой технологии на будущие AI-системы. (Источник: bobvanluijt)
Статья ACL2025NLP SynthesizeMe!: Генерация персонализированных подсказок из взаимодействия с пользователем: Статья “SynthesizeMe!” для конференции ACL 2025 NLP предлагает новый метод создания персонализированных пользовательских моделей на естественном языке путем анализа взаимодействия пользователя с AI (включая неявную и явную обратную связь). Метод сначала генерирует и проверяет процесс рассуждений, объясняющий предпочтения пользователя, затем на его основе обобщает синтетический портрет пользователя, отбирает информативные предыдущие взаимодействия пользователя и, наконец, создает персонализированные подсказки для конкретного пользователя с целью улучшения персонализированного моделирования вознаграждений и ответов LLM. DSPy также ретвитнул и упомянул это как отличный пример применения dspy.MIPROv2. (Источник: lateinteraction, stanfordnlp)
Новая статья исследует мониторинг и «разгон» LLM с масштабированием во время тестирования (Test-Time Scaling): Новая статья посвящена технологии масштабирования во время тестирования, используемой в таких моделях, как o3 и DeepSeek-R1. Эта технология позволяет LLM выполнять больше логических операций перед ответом, но пользователи часто не могут отслеживать внутренний прогресс или контролировать его. Исследователи предлагают раскрыть внутренние «часы» LLM и демонстрируют, как можно отслеживать процесс их рассуждений и «разгонять» его для ускорения. Это открывает новые перспективы для понимания и оптимизации эффективности больших моделей логического вывода. (Источник: arankomatsuzaki)

Статья предлагает CARTRIDGES: сжатие KV-кэша LLM с длинным контекстом посредством офлайн-самообучения: Исследователи из HazyResearch Стэнфордского университета предложили новый метод под названием CARTRIDGES, направленный на решение проблемы чрезмерного потребления памяти KV-кэшем в LLM с длинным контекстом. Метод использует механизм обучения во время тестирования в режиме «самообучения» для офлайн-тренировки меньшего KV-кэша (называемого cartridge) для хранения информации из документов. Это позволяет в среднем сократить объем памяти кэша в 39 раз и увеличить пиковую пропускную способность в 26 раз, сохраняя при этом производительность на задачах. Такой cartridge, обученный один раз, может повторно использоваться для запросов разных пользователей, предлагая новый подход к оптимизации обработки длинных контекстов. (Источник: gallabytes, simran_s_arora, stanfordnlp)

Новая статья Grafting: низкозатратное редактирование архитектуры предварительно обученных диффузионных Transformer: Исследователи из Стэнфордского университета предложили новый метод под названием Grafting для редактирования архитектуры предварительно обученных моделей диффузионных Transformer. Эта технология позволяет заменять механизмы внимания и другие вычислительные примитивы в модели новыми, затрачивая всего 2% от вычислительных ресурсов, необходимых для предварительного обучения. Это позволяет настраивать архитектуру модели при небольшом вычислительном бюджете, что имеет важное значение для исследования новых архитектур моделей и повышения эффективности существующих. (Источник: realDanFu, togethercompute)
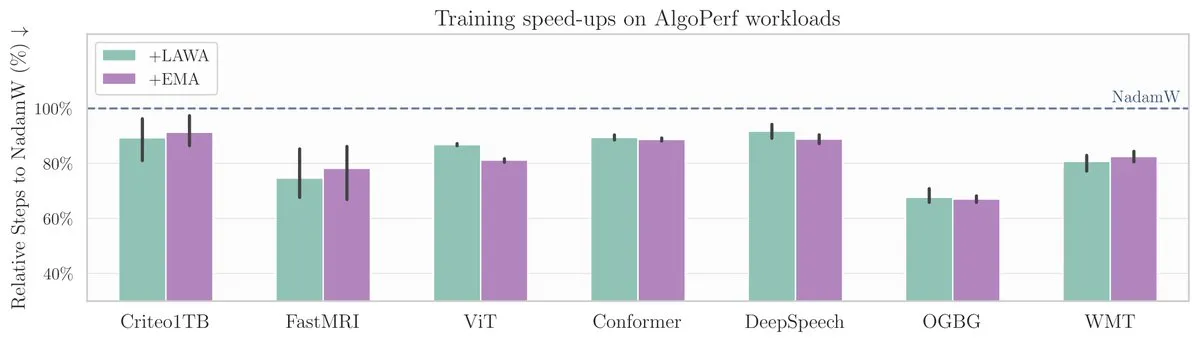
Новая статья ICML: метод усреднения контрольных точек ускоряет обучение моделей на бенчмарке AlgoPerf: В новой статье ICML исследуется применение классического метода усреднения контрольных точек (Averaging Checkpoints) для повышения скорости и производительности обучения моделей машинного обучения. Исследователи протестировали этот метод на AlgoPerf, структурированном и разнообразном бенчмарке для алгоритмов оптимизации, изучая его практическую пользу на различных задачах и предоставляя практические рекомендации для ускорения обучения моделей. (Источник: aaron_defazio)
Инструмент визуализации и объяснения Transformer с открытым исходным кодом: DL Weekly представил интерактивный инструмент визуализации, призванный помочь пользователям понять принципы работы моделей на основе архитектуры Transformer (таких как GPT). Инструмент наглядно демонстрирует внутренние механизмы модели, делая сложные концепции более доступными для понимания, и подходит для учащихся и исследователей, интересующихся моделями Transformer. Проект доступен на GitHub с открытым исходным кодом. (Источник: dl_weekly)
Чжэцзянский университет предложил InftyThink: сегментация и обобщение для достижения бесконечно глубокого логического вывода: Исследовательская группа из Чжэцзянского университета совместно с Пекинским университетом предложила новую парадигму логического вывода для больших моделей — InftyThink. Этот метод разбивает длинный логический вывод на несколько коротких сегментов и вводит обобщение между сегментами для связывания контекста, тем самым теоретически достигая бесконечно глубокого логического вывода при сохранении высокой пропускной способности генерации. Этот метод не требует корректировки структуры модели, совместим с существующими процессами предварительного обучения и тонкой настройки за счет реструктуризации обучающих данных в формат многоэтапного логического вывода. Эксперименты показали, что InftyThink может значительно улучшить производительность моделей на таких бенчмарках, как AIME24, и повысить пропускную способность генерации. (Источник: 量子位)

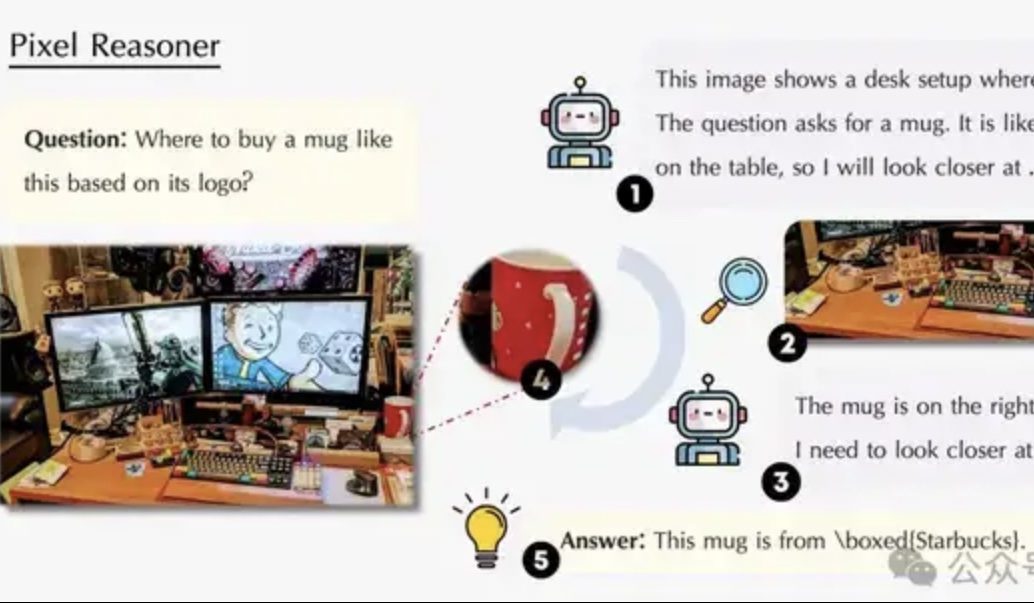
Статья исследует логический вывод в пиксельном пространстве: позволить VLM «использовать глаза и мозг» как люди: Исследовательская группа из Университета Ватерлоо, Гонконгского университета науки и технологий и Китайского научно-технического университета предложила парадигму «логического вывода в пиксельном пространстве» (Pixel-Space Reasoning), позволяющую визуально-языковым моделям (VLM) напрямую выполнять операции и рассуждения на уровне пикселей, такие как визуальное масштабирование, пространственно-временная маркировка и т.д., вместо того чтобы полагаться на текстовые токены в качестве посредника. С помощью схемы обучения с подкреплением, основанной на внутреннем любопытстве и внешнем стимулировании правильности, преодолевается «когнитивная инерция» модели. Pixel-Reasoner, построенный на базе Qwen2.5-VL-7B, продемонстрировал превосходные результаты на нескольких бенчмарках, таких как V*Bench, причем модель 7B превзошла по производительности GPT-4o. (Источник: 量子位)
DeepLearning.AI запускает пятый курс в рамках специализации по анализу данных: «Рассказывание историй с помощью данных»: DeepLearning.AI анонсировала пятый курс своей специализации по анализу данных под названием «Рассказывание историй с помощью данных» (Data Storytelling). Курс научит выбирать подходящие средства (дашборды, служебные записки, презентации) для представления результатов анализа, использовать Tableau для создания интерактивных дашбордов, согласовывать выводы с бизнес-целями и эффективно их коммуницировать, а также даст рекомендации по поиску работы. Подчеркивается важность рассказывания историй с помощью данных для повышения эффективности бизнеса и действенной передачи аналитических выводов. (Источник: DeepLearningAI)

Статья исследует влияние конфликта знаний на большие языковые модели: Новая статья систематически оценивает поведение больших языковых моделей (LLM) при столкновении с конфликтом между входными данными из контекста и параметризованными знаниями (т.е. внутренней «памятью» модели). Исследование показало, что конфликт знаний оказывает незначительное влияние на задачи, не зависящие от использования знаний; когда контекст соответствует параметризованным знаниям, модель работает лучше; даже при наличии инструкций модель не может полностью подавить внутренние знания; предоставление объяснений конфликта увеличивает зависимость модели от контекста. Эти выводы ставят под сомнение валидность оценок на основе моделей и подчеркивают необходимость учета проблемы конфликта знаний при развертывании LLM. (Источник: HuggingFace Daily Papers)
Статья CyberV: кибернетическая структура для масштабирования во время тестирования в задачах понимания видео: Для решения проблем вычислительных требований, робастности и точности, с которыми сталкиваются мультимодальные большие языковые модели (MLLM) при обработке длинных или сложных видео, исследователи предложили структуру CyberV. Эта структура, вдохновленная принципами кибернетики, переосмысливает видео MLLM как адаптивную систему, включающую систему логического вывода MLLM, датчики и контроллер. Датчики отслеживают прямой проход модели и собирают промежуточные интерпретации (например, дрейф внимания), а контроллер решает, когда и как запускать самокоррекцию и генерировать обратную связь. Эта адаптивная структура масштабирования во время тестирования не требует переобучения для улучшения существующих MLLM, и эксперименты показали, что она значительно повышает производительность таких моделей, как Qwen2.5-VL-7B, на бенчмарках типа VideoMMMU. (Источник: HuggingFace Daily Papers)
Статья предлагает LoRMA: низкоранговая мультипликативная адаптация для параметроэффективной тонкой настройки LLM: Для решения существующих проблем коллапса представлений и несбалансированной загрузки экспертов в методах параметроэффективной тонкой настройки (PEFT) на основе LoRA и MoE, исследователи предложили низкоранговую мультипликативную адаптацию (LoRMA). Этот метод изменяет способ обновления экспертов адаптера PEFT с аддитивного на более богатое матричное мультипликативное преобразование, используя эффективные операции перестановки и вводя стратегию расширения ранга для решения проблем вычислительной сложности и узких мест ранга. Эксперименты показали, что гетерогенный метод MoA (смесь адаптеров) превосходит гомогенный метод MoE-LoRA как по производительности, так и по параметрической эффективности. (Источник: Reddit r/MachineLearning)
Статья предлагает FlashDMoE: быстрая реализация распределенного MoE на одном ядре: Исследователи представили FlashDMoE, первую систему, которая полностью объединяет прямой проход распределенной смеси экспертов (MoE) в одно ядро CUDA. Написав объединенный слой с нуля на чистом CUDA, FlashDMoE достигает до 9-кратного увеличения использования GPU, 6-кратного снижения задержки и 4-кратного улучшения эффективности слабого масштабирования. Эта работа предлагает новые идеи и реализации для оптимизации эффективности логического вывода крупномасштабных моделей MoE. (Источник: Reddit r/MachineLearning)
💼 Бизнес
xAI и Polymarket сотрудничают для объединения рыночных прогнозов с аналитикой Grok: Компания xAI Илона Маска, занимающаяся искусственным интеллектом, объявила о партнерстве с децентрализованной платформой прогнозирования рынков Polymarket. Целью этого сотрудничества является объединение данных рыночных прогнозов Polymarket с данными X (ранее Twitter) и аналитическими возможностями Grok AI для создания «движка неопровержимой правды», который бы раскрывал факторы, формирующие мир. xAI заявила, что это только начало сотрудничества, и в будущем будет больше совместных проектов. (Источник: xai)
Компания по производству чипов для AI-вывода Groq получила инвестиционное обязательство в размере 1,5 млрд долларов от Саудовской Аравии, сосредоточившись на стратегии вертикальной интеграции: Компания по производству чипов для AI-вывода Groq объявила о получении инвестиционного обязательства в размере 1,5 млрд долларов от Саудовской Аравии для расширения масштабов поставок своей инфраструктуры AI-вывода на базе LPU (Language Processing Unit) в регионе. Groq, основанная одним из изобретателей TPU Jonathan Ross, специализируется на вычислениях для AI-вывода. Ее чипы LPU используют программируемую конвейерную архитектуру, где память и вычислительные блоки интегрированы на одном кристалле, что значительно повышает скорость доступа к данным и энергоэффективность. Groq не только продает чипы, но и предлагает кластеры GroqRack (частное облако/вычислительный центр AI) и облачную платформу GroqCloud (Tokens-as-a-Service), а также поддерживает основные модели с открытым исходным кодом, такие как Llama, DeepSeek, Qwen. Компания также разработала составную AI-систему Compound, повышающую ценность облачного AI-вывода. (Источник: 36氪)

Шэньчжэньская компания по производству интерактивных человекоподобных роботов «Digital China» завершила раунд ангельского+ финансирования на несколько десятков миллионов юаней: Digital China (Shenzhen) Technology Co., Ltd. недавно завершила раунд ангельского+ финансирования на несколько десятков миллионов юаней, эксклюзивным инвестором выступила Tongchuangweiye. Компания фокусируется на масштабном коммерческом применении роботов AGI. Ее основная продукция включает человекоподобного робота «Xia Lan», универсального человекоподобного робота «Xia Qi» и IP-серию роботов «Xing Xing Xia». Робот «Xia Lan» основан на прецизионной бионической технологии, способен имитировать подавляющее большинство человеческих выражений и обладает мультимодальными интерактивными возможностями. Компания уже получила заказы на несколько сотен миллионов юаней от ведущих ИКТ-производителей, региональных электросетевых компаний и других клиентов. (Источник: 36氪)

🌟 Сообщество
Sam Altman опубликовал пост в блоге «Нежная сингулярность», обсуждая постепенную революцию AI и будущее: CEO OpenAI Sam Altman опубликовал пост в блоге, в котором утверждает, что технологическая сингулярность происходит более плавно и «нежно», чем предполагалось, представляя собой непрерывный, экспоненциально ускоряющийся постепенный процесс. Он прогнозирует, что к 2025 году AI-агенты, способные самостоятельно выполнять сложную интеллектуальную работу (например, программирование), изменят индустрию программного обеспечения; к 2026 году могут появиться системы, способные делать совершенно новые научные открытия; а к 2027 году могут появиться роботы, способные выполнять задачи в реальном мире. Altman подчеркивает, что решение проблемы согласования AI и обеспечение всеобщего доступа к технологиям являются ключом к процветающему будущему. Он также сообщил, что выпуск первой модели OpenAI с открытыми весами будет отложен до конца лета, поскольку исследовательская группа добилась «неожиданно поразительных результатов». (Источник: dotey, scaling01, sama)
Сообщество активно обсуждает OpenAI o3-pro: мощная производительность, но высокая стоимость; снижение цен на o3 вызывает цепную реакцию: Выпуск OpenAI o3-pro и его высокая цена (80 долларов за миллион выходных токенов) стали предметом активного обсуждения в сообществе. Пользователи в целом признают его мощные возможности в сложных задачах логического вывода, программирования и т.д., но также выражают обеспокоенность по поводу скорости отклика и стоимости. Некоторые пользователи шутят, что простое приветствие «Hi» может стоить 80 долларов. В то же время значительное снижение цены на модель o3 на 80% рассматривается как возможный катализатор ценовой войны на рынке AI-моделей, конкурируя с GPT-4o и другими продуктами. В сообществе существуют разногласия относительно того, не «поглупела» ли модель o3 после снижения цены. Впоследствии OpenAI объявила об удвоении лимита использования o3 для пользователей ChatGPT Plus в ответ на запросы пользователей. (Источник: Yuchenj_UW, scaling01, imjaredz, kevinweil, dotey)
Высокие зарплаты Meta для привлечения талантов и инвестиции в организацию AI вызывают бурное обсуждение: Высокие компенсационные пакеты Meta для исследователей AI (по слухам, достигающие девятизначных сумм в долларах) вызвали обсуждение в сообществе. Nat Lambert отметил, что такая зарплата, возможно, могла бы профинансировать целый исследовательский институт размером с AI2, намекая на высокую стоимость привлечения ведущих специалистов. В сочетании с созданием Meta «Лаборатории суперинтеллекта» и крупными инвестициями в Scale AI, сообщество в целом считает, что Meta любой ценой стремится восстановить свою конкурентоспособность в области AI, но также обращает внимание на проблемы внутренней организационной политики и эффективности. Helen Toner, ретвитнув сообщение ChinaTalk, указала, что этот шаг Meta направлен на преодоление проблем внутренней политики и самомнения в организации. (Источник: natolambert, natolambert)
Новый стиль UI Apple на WWDC «жидкое стекло» вызвал дискуссии о дизайне и удобстве использования: Новый стиль дизайна UI «жидкое стекло» (Liquid Glass), представленный Apple на WWDC 2025, вызвал широкое обсуждение в сообществах разработчиков и дизайнеров. Некоторые считают его визуально новаторским, отражающим стремление Apple к исследованию 3D-интерфейсов. Однако такие ветераны, как ID_AA_Carmack (John Carmack), отметили, что полупрозрачные UI обычно имеют проблемы с удобством использования, легко создают визуальные помехи и низкую контрастность, что мешает чтению и работе. Они также упомянули, что Windows и Mac в прошлом уже пробовали подобные дизайны, но в конечном итоге скорректировали их из-за проблем с юзабилити. Приоритет пользовательского опыта (UX) над визуальными эффектами пользовательского интерфейса (UI) стал центральной темой обсуждения. (Источник: gfodor, ID_AA_Carmack, ReamBraden, dotey)
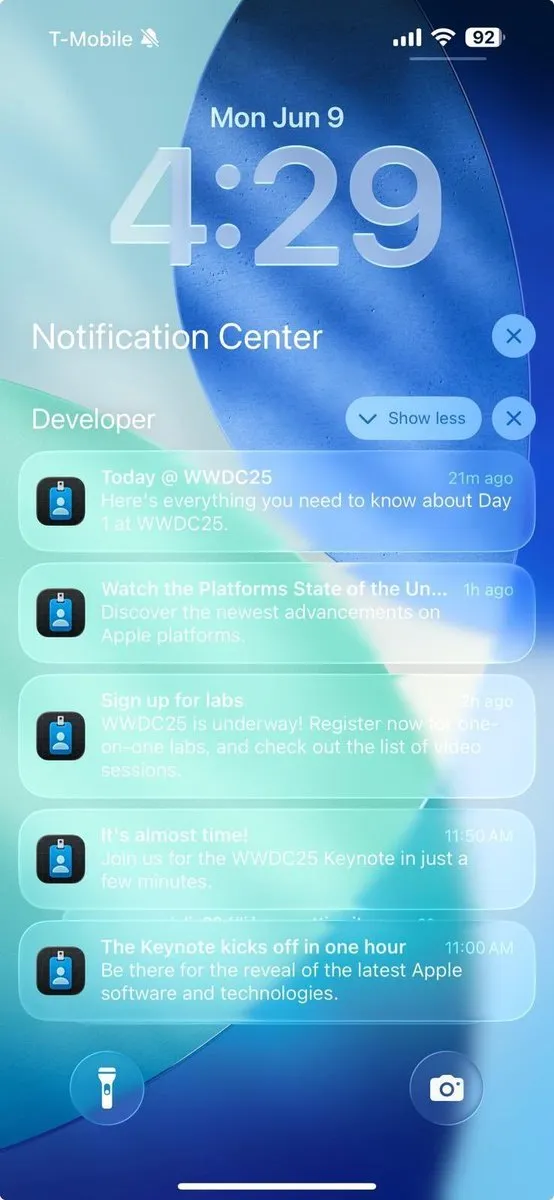
Практика программирования с помощью AI: гибкая итерация предпочтительнее одноразовой генерации: В социальных сетях dotey высказал мнение о наилучших практиках программирования с использованием AI (например, Claude Code). Он считает, что не следует применять подход одноразового предоставления полных требований для генерации AI огромного полуфабриката (модель водопада) или сначала генерировать несовершенный продукт, а затем оптимизировать его (аналогично третьему варианту на изображении), поскольку это затрудняет контроль качества и последующее обслуживание. Он выступает за применение модели гибкой итерации (аналогично первому варианту на изображении), при которой крупные проекты (например, ERP-системы) разбиваются на множество небольших, независимо стабильно работающих версий, разрабатываемых постепенно итеративно. Это обеспечивает полноту функциональности и контролируемость каждой версии, что соответствует лучшим практикам традиционной инженерии программного обеспечения. (Источник: dotey)
Mustafa Suleyman: Технологии AI эволюционируют от фиксированных и унифицированных к динамичным и персонализированным: Mustafa Suleyman, сооснователь Inflection AI и бывший сооснователь DeepMind, отметил, что традиционные технологии обычно являются фиксированными, унифицированными, «одноразмерными», в то время как современные технологии искусственного интеллекта демонстрируют динамичные, персонализированные и эмерджентные характеристики. Он считает, что это означает переход технологий от предоставления единственного повторяющегося результата к исследованию бесконечных путей возможностей, подчеркивая огромный потенциал AI в персонализированных услугах и творческих приложениях. (Источник: mustafasuleyman)
Perplexity AI столкнулась с проблемами инфраструктуры, CEO выступил с объяснениями: CEO Perplexity AI Arav Srinivas в социальных сетях ответил на вопросы пользователей о нестабильной работе сервиса, заявив, что из-за проблем с инфраструктурой пришлось для части трафика включить ухудшенный пользовательский опыт (degraded UX). Он подчеркнул, что данные пользователей (например, library или threads) не потеряны, и как только система стабилизируется, все функции будут восстановлены в полном объеме. Это отражает проблемы стабильности и масштабируемости инфраструктуры, с которыми сталкиваются AI-сервисы в процессе быстрого развития. (Источник: AravSrinivas)
Sergey Levine обсуждает различия в обучении языковых и видеомоделей: Профессор Калифорнийского университета в Беркли Sergey Levine в своей статье «Языковые модели в пещере Платона» поднимает глубокий вопрос: почему языковые модели так многому учатся, предсказывая следующее слово, в то время как видеомодели, предсказывая следующий кадр, учатся относительно мало? Он считает, что LLM, изучая «тени» человеческих знаний (текстовые данные), приобрели мощные способности к рассуждению, что больше похоже на «обратную инженерию» человеческого познания, чем на подлинное автономное исследование физического мира. Видеомодели непосредственно наблюдают физический мир, но в настоящее время уступают LLM в сложных рассуждениях. Он предполагает, что долгосрочной целью AI должно стать преодоление зависимости от «теней» человеческих знаний и достижение автономного исследования через непосредственное взаимодействие с физическим миром с помощью датчиков. (Источник: 36氪)
💡 Прочее
Обсуждение этики и сознания AI: может ли AI обладать настоящим сознанием?: MIT Technology Review обращает внимание на сложный вопрос сознания AI. В статье отмечается, что сознание AI — это не только интеллектуальная головоломка, но и вопрос, имеющий моральный вес. Ошибочная оценка сознания AI может привести к непреднамеренному порабощению разумных AI или к принесению в жертву благополучия людей ради неразумных машин. Исследовательское сообщество достигло прогресса в понимании природы сознания, и эти результаты могут послужить ориентиром для исследования и решения проблемы искусственного сознания. Это вызывает глубокие размышления о правах, ответственности AI и отношениях между человеком и машиной. (Источник: MIT Technology Review)
Лауреат премии Тьюринга Joseph Sifakis: современный AI не является истинным интеллектом, необходимо остерегаться смешения знаний и информации: Лауреат премии Тьюринга Joseph Sifakis в своих работах и интервью отмечает, что в современном обществе существует искаженное понимание AI, смешивающее накопление информации с творчеством и переоценивающее «интеллект» машин. Он считает, что настоящих интеллектуальных систем пока не существует, а реальное влияние AI на промышленность незначительно. AI не хватает понимания здравого смысла, его «интеллект» является продуктом статистических моделей, и ему трудно взвешивать ценности и риски в сложных социальных контекстах. Он подчеркивает, что ядром образования является развитие критического мышления и творческих способностей, а не передача знаний, и призывает к созданию глобальных стандартов применения AI, четкому определению границ ответственности, чтобы AI стал партнером, усиливающим человека, а не его заменой. (Источник: 36氪)
Реконструкция рекламной индустрии в эпоху AI: от генерации креативов до персонализированного размещения: Конференция Google I/O 2025 продемонстрировала, как AI глубоко реконструирует рекламную индустрию. Тенденции включают: 1) Автоматизация креатива с помощью AI: от изображений до сценариев видео — все может генерироваться AI, такие инструменты, как Veo 3, Imagen 4 и Flow, снижают порог для создания высококачественного контента. 2) Парадигма персонализации смещается от «тысячи лиц для тысячи людей» к «тысяче лиц для одного человека»: интеллектуальные AI-агенты могут активно понимать потребности пользователей и способствовать заключению сделок. 3) Границы между рекламой и контентом стираются: реклама напрямую интегрируется в результаты поиска, сгенерированные AI, становясь частью информации. Брендам необходимо создавать собственных интеллектуальных агентов, предоставлять услуги, ориентированные на AI, и придерживаться долгосрочной стратегии «единства бренда и эффективности», чтобы адаптироваться к изменениям. (Источник: 36氪)